
METHODS FOR CONSTRUCTING AND DECODING BLOCK ...
226
METHODS FOR CONSTRUCTING AND DECODING BLOCK ERROR-CORRECTING CODES By Abdullah Abdulmutlib Hashim, B.Sc. (Eng.), M.Sc. July, 1974 A thesis submitted for the degree of Doctor of Philosophy of the University of London and for . the Diploma of Imperial College Electrical Engineering Department, Imperial College of Science and Technology, London, S. W. 7.
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of METHODS FOR CONSTRUCTING AND DECODING BLOCK ...

METHODS FOR CONSTRUCTING AND DECODING BLOCK
ERROR-CORRECTING CODES
By
Abdullah Abdulmutlib Hashim, B.Sc. (Eng.), M.Sc.
July, 1974
A thesis submitted for the degree of Doctor
of Philosophy of the University of London
and for. the Diploma of Imperial College
Electrical Engineering Department,
Imperial College of Science and Technology,
London, S. W. 7.

ABSTRACT
This thesis contains the results of an investigation
into that branch of algebraic coding theory which is concerned
with linear block error-correcting codes. The classical problems
of coding theory are: firstly, the discovery of "good" codes,
where "good" is used with reference to optimality of the code's
rate and error-correcting capability; and secondly, the ease
with which the encoding and decoding of codes may be carried
out. This thesis considers both these problems and as a result
of several new procedures which are introduced for constructing
and decoding these codes, a large number of new codes are
presented, many of these being "good" codes.
A computerised search procedure based on certain
properties of the parity-check matrix of block codes is described
which yields new "good" codes. Also, by employing a sub-set of
Walsh functions to construct the parity-check matrix, a class
of binary codes is obtained which can be decoded by a simple
one-step majority decoding algorithm. Another possibility for
finding new codes is brought about by a mathematical analysis
of the concept of anticodes which yields a new systematic
procedure for their generation. A fourth procedure, concerned
with the modification of existing codes by puncturing and
lengthening, is shown to produce other new families of codes,
the decoding procedures for which are outlined.
A description of an important new class of codes is
given, referred to here as "nested codes". The codes of this
class cover a wide range of rate and error-correcting capability,
and possess a useful mathematical structure in that their
syndromes corresponding to errors in the information digits
of the codeword are themselves codewords of another code
having the same properties. These nested codes are found to
be decodable by a very simple decoding algorithm which results
2.

in the decoder complexity increasing only linearly with the
code length and number of errors that may be corrected.
Moreover, the decoder is shown to be capable of correcting
some errors with weight greater than the error-correcting
capability of the code.
The properties of the parity-check matrix of codes
used for compound channels have also been found to yield a
computerised search procedure for finding new codes capable
of correcting either both random and burst errors or multi-
burst errors. A considerable number of codes have been found
by this procedure which are capable of correcting errors of
this type. Moreover, the techniques and methods of constr-
ucting nested codes have been modified to establish a new
class of burst-and-random-error correcting codes. Codes of
this class and their decoding algorithm have been found to
exhibit the same properties as nested codes.
Finally, the lower bounds on minimum-Hamming distance
for linear block codes are examined. It is shown that the
Varshamov-Gilbert bound may possibly be improved. Furthermore,
a lower bound on the maximum-Haunaing distance of linear anti-
codes is presented.
3.

ACKNOWLEDGEMENTS
I should like to express my grateful thanks to Dr.
A.G. Constantinides for his supervision, guidance and constant
encouragement during the course of this research; his
suggestions and many contributions are also much appreciated.
The work reported in this thesis has benefited in
many ways from the numerous discussions that I have had with
several persons, most notable among whom are Professor E.C.
Cherry of Imperial College; Dr. V.N. Nomokonov of the Leningrad
Institute of Technology, U.S.S.R.; Professor G. Longo of the
University of Trieste, Italy; Dr. P.G. Farrell of the University
of Kent, U.K.; Mrs. Z. Chiba of the GEC Hirst Research Centre,
U.K.; Dr. D.J. Goodman of the Bell Laboratories, U.S.A.;
Professor D.A. Bell of the University of Hull, U.K.; and my
colleague Mike Buckley who also reviewed the manuscript and
supplied many detailed corrections.
Thanks are also due to Messrs. P. Beevor, L.C.
Stenning, I. Colyer and R. Howie for the time they spent in
checking through the manuscript.
The help and encouragement of my colleagues Nelson
Esteves, Jide Olaniyan, Michael Lai and Majid Ahmadi has also
been very much appieciated.
Finally, I should like to express my gratitude to
Professor J. Brown for offering me the post of academic
visitor and providing research facilities at Imperial College;
to Baghdad University, College of Engineering Technology, for
allowing study leave for the period of this research; to
Miss Shelagh Jenkins for her impeccable typing of the manu-
script; and to my family and friends without whose help this
work would never have been accomplished.
4.

CONTENTS
Page
ABSTRACT 2
ACKNOWLEDGEMENTS 4
CONTENTS 5
LIST OF SYMBOLS AND ABBREVIATIONS 9
SECTION 1 INTRODUCTION
12
SECTION 2 FUNDAMENTALS OF CODING THEORY 17
2.1 The Analysis of Linear Block Codes 18
2.2 The Construction of Linear Block Codes 23
2.2.1 Repetition Codes 24
2.2.2 Hamming Codes 24
2.2.3 Golay Codes 24
2.2.4 Circulants Codes 25
2.2.5 Optimum Codes 25
2.2.6 Quasi-Perfect Codes 26
2.2.7 Reed-Muller Codes 27
2.2.8 Concatenated Codes 27
2.2.9 Cyclic Codes 28
2.2.10 The BCH Codes 30
2.2.11 Goppa Codes 31
2.2.12 Justesen Codes 32
2.3 Decoding of Linear Block Codes 33
2.3.1 Syndrome Decoding 33
2.3.2 Decoding of Binary Cyclic Codes 35
2.3.3 Error-Trapping for Binary Cyclic Codes 38
2.3.4 Majority Logic Decoding Algorithms 40
2.3.5 Decoding of BCH Codes 42
2.4 Minimum-Distance Bounds for Binary Linear
Codes 46
5.

Page
SECTION 3 NOVEL PROCEDURES FOR CONSTRUCTING
LINEAR BLOCK CODES 51
3.1 A Computerised Search for Linear Codes 52
3.2 Application of Walsh Functions in
constructing Linear Block Codes 60
3.2.1 Code Construction and Decoding 63
3.2.2 Remarks 65
3.3 Application of the Concept of Anticodes 67
3.3.1 Matrix Description of Linear 68
Anticodes
3.3.2 A Systematic Procedure of 70
generating Linear Anticodes
3.4 Two Procedures of Linear Block Code 71
Modification
3.4.1 Introduction 71
3.4.2 Linear Block Code Puncturing 74
Procedures
3.4.3 Encoding and Decoding of the 78
Punctured Codes
3.4.4 A Technique for Lengthening 79
Linear Block Codes
SECTION 4 A NEW CLASS OF NESTED LINEAR BLOCK CODES
AND THEIR NESTED DECODING ALGORITHM 88
4.1 Introduction 89
4.2 The Construction of Nested Codes 89
4.2.1 Double Error-Correcting Nested Codes 95
4.2.2 Multiple Error-Correcting Nested
Codes 98
4.3 The Nested Decoding Algorithm 102
6.

Page
115
4.4 Features and Merits of the Nested
Decoding Algorithm
4.4.1
The Capability of Correcting
Pattern of Errors of Weight
greater than t.
4.4.2
The Complexity of the Nested
Decoder.
115
118
SECTION 5 LINEAR BLOCK CODES FOR NON-INDEPENDENT
ERRORS 121
5.1 Introduction 122
5.2 Block Codes for Non-Independent Errors,
Definition and Construction 124
5.3 Single-Burst-Error-Correcting Codes 131
5.4 Burst-and-Random-Error-Correcting Codes 138
5.5 Multiple-Burst-Error-Correcting Codes 152
SECTION 6 BOUNDS ON THE HAMMING DISTANCE OF LINEAR
CODES AND ANTICODES 157
6.1 Introduction 158
6.2 An Improvement on the Varshamov-Gilbert
Lower Bound on the Minimum Hamming Distance
of Linear Block Codes 160
6.3 The Weight Distribution of Linear Binary
Codes 165
6.4 Maximum Distance Bounds for Linear
Anticodes 171
SECTION 7 SUMMARY OF CONTRIBUTIONS AND SUGGESTIONS
FOR FURTHER RESEARCH 175
7.1 Summary of Contributions 176
7.2 Suggestions for Further Research 181
7.

Page
APPENDIX 1
Mathematical Background
186
APPENDIX 2
Computer Programmes 193
REFERENCES 204
8.

LIST OF SYMBOLS AND ABBREVIATIONS
Matrix X.
Transpose of the matrix EX]. txil Set x1, x2, •' xn (n is given in the text).
C, v011 Membership: v is an element of set fyl.
C,t1J1CV1 Membership: N1 is a sub-set of [V1.
)(11)(x) Set of all x that satisfy the condition P(x).
1:1
'1' Number of combinations of i out of n.
d Haunting distance of a code.
d(v,u) Hamming distance between two vectors v and u.
An error pattern.
Generator matrix of an (n,k) linear code.
GF(q) Galois field of q elements.
GF(Pn) Galois field of order Pn. •
[eJ CG]
g(x)
CH] DK]
K
Generator polynomial of cyclic code.
Parity-check matrix of an (n,k) linear code.
Identity matrix of order K.
Generator matrix of (m,k) linear anticode.
Number of information (data) digits in a block codeword.
(ICK1) First code of constructing an (n,k) nested code.
D.]
A parity-check matrix of linear anticode.
m Anticode length.
(m,k,6) A linear anticode of maximum Hamming distance
n Length of linear code.
9.

(n,k,d) A linear code that has a minimum Hamming distance d.
(n-k,k-k1) Second code of constructing an (n,k) nested code.
(n,k,t) A linear code capable of correcting t-random errors.
(n;k;t) A nest of t nested codes, corresponding to an (n,k)
nested code.
(nt,kt) The inner code of a nest of an (n,k,t) nested code.
q Number of code symbols.
r Number of parity-check digits in a block code.
R Code rate.
LSD Syndrome matrix.
Vn A vector space of dimension n.
V A subspace of the vector space Vn, used to indicate
the linear (n,k) block code .
V' A null space of subspace V.
w Weight of a codeword.
w(v) The Hamming weight of a vector v.
b Maximum distance of anticode.
BCH Bose-Chaudhuri-Hocquenghem code.
QLC Quasi-linear combinations.
B & R Burst-and-random.
tviveQLC(ni)(q-1)9 The set of vectors resulting from the quasi-
linear combinations of every i columns of a
parity-check matrix of an (n,k) block code
over a field of q. elements.
The largest integer, smaller than or equal to d/2. •
10.

EH/c] A matrix formed by placing the elements of matrix Da on the left and the elements of matrix EC] on the right.
A matrix formed by placing the elements of matrix CH] on the top and the elements of matrix [C] on the bottom.
II.

1. INTRODUCTION
12.

1. INTRODUCTION
During the last ten years the field of coding theory
has been extensively investigated and the original concepts put
forward in the early 1950's by Shannon, Hamming and others have
been expanded and developed. A considerable amount of material
has been published during this period in the form of research
reports and papers and several excellent textbooks have appeared
presenting, in a tutorial manner, the fundamentals underlying
coding theory and the recent discoveries in this subject. The
books of Berlekamp(3), Lin(5), Van Lint(6)
and Peterson and
Weldon() between them provide a comprehensive coverage of
algebraic coding theory, and summarize most of the work published
in the field during the last three decades, while other books
such as Massey(9) and Forney(10) have considered in detail
specific aspects of coding theory. Texts on general communic-
ation such as Lucky, Salz, and Weldon(1l), Gallager(12)
, and
Stiffler(13) have also devoted a great deal of space to the
problems of this field. Work in coding theory may therefore
be considered to be well advanced and the concepts and approach
to its problems to be well established. Some authorities such
as Wolf(1) and Chien(2) have consequently referred to the subject
as having reached a stage of maturity.
The remaining problems in the field can still, however,
be considered to be:
(a) Finding "good" codes:-
In spite of the fact that there are many known classes
of codes (such as Reed-Muller(25,26), Bose-Chaudhuri-Hocquenghem
(23,24), and Quadratic Residue(3,7) codes) the problem of
constructing arbitrarily long codes which meet or even come
close to the Varshamov-Gilbert(60,27) lower bound is an
important one, and is as yet unsolired except for codes with
rates of approximately 0 or 1.
13.

Justesen(59) in 1972 presented a class of codes air
any rate, whose ratio of minimum distance to block length
approaches a nonzero limit as the block length increases.
However, this limit is typically (.t rate 1/2) about 20 percent
of the Varshamov-Gilbert bound on achievable distance. The
class of Justesen codes is the only known class of asymptotically
good algebraic codes.
The gap between the.rates of known code and theoretically
achievable rates is still very wide, even for codes with moderate
length.
Since the early 1950's most of the effort in coding
theory has been directed towards constructing random-error-
correcting codes. The problems of treating burst-and-random-
error-correcting codes are, however, more complicated and have
still received considerably less attention.
(b) Finding practical decoding techniques:-
The most important known decoding algorithms are the
Viterbi(132-136) algorithm for maximum likelihood decoding of
convolutional codes, the Berlekamp(3) decoding algorithm for
BCH codes, and the majority logic decoding algorithm
Each of these decoding algorithms has unfortunately some severe
inherent limitations due to either the complexity of decoding
or its very restricted applicability. Other known decoding
algorithms (such as error-trapping techniques, and the Meggit(72'
73) decoding algorithm for cyclic codes) are simply implementable
for short codes but for long and high rate codes with large
error-correcting capabilities they are ineffective and impractical.
Under these circumstances a need exists for easily implementable
decoding algorithms.
14.

The solutions to the above classical problems have
been sought in two basic ways:
(1) Algebraic School (Hamming(30), Slepian(19), Reed-
Muller(25), Bose-Chaudhuri(23'24), ....). Here the approaches
are:-
(a) to find mathematical structures that yield
codes with desirable metric properties,
(b) to find specific encoding and decoding algorithms
that exploit the mathematical structure of the code.
(2) Probabilistic School (Shannon(103,104), Wozencraft(137,130
Gallager(12), Fano(139,140),...). Here the approaches are:-
(a) to find code ensembles with- good average
properties,
(b) to find encoding and decoding procedures applic-
able to the entire ensemble.
Our main concern in this thesis will be with that
branch of the algebraic school which is concerned with linear
block error-correcting codes. In Section 3 of this thesis the
problems of constructing and decoding block codes are
considered and several new procedures are introduced. The
problems of decoder complexity of block codes are investigated
in a detailed manner in Section 4 and a new class of codes is
described, which have been _ named "nested codes". The
codes of this class cover a wide range of rates and error-
correcting capabilities and possess a useful mathematical
structure which leads to a simple decoding algorithm whose
complexity increases only linearly with the code length and
number of errors that may be corrected. Moreover, the decoder
is shown to be capable of correcting some errors with weight
greater than the error-correcting capability of the code.
15.

Those techniques and methods introduced in Sections
3 and 4 are modified in Section 5 to enable the construction
and decoding of either random-and-burst or multiple-burst-
error-correcting codes. A number of codes are included as
examples of these procedures. In addition, a new class of
burst-and-random-error-correcting codes is introduced. Codes
of this class and their decoding algorithm are found to exhibit
the same properties as the nested codes introduced in Section 4.
In Section 6 the lower bounds on minimum Hamming
distances for linear block codes are examined. It is shown
that the Varshamov-Gilbert bound may possibly be improved.
Furthermore, a lower bound on the maximum Hamming distances of
linear anticodes is presented.
In view of the large volume of material that has been
published reviewing the fundamentals and concepts of coding
theory, it is felt that this thesis need not contain an
extensive introduction along these lines. However, a brief
review of those concepts of the field which are relevant to the
work of this thesis will be given. Section 2 therefore
contains a description of the classical techniques for the
construction, analysis, and implementation of linear block
codes and gives a brief outline of the bounds which are
eommonly applied to their performance. Other aspects of the
subjects which will be useful in the mathematical formulations
employed in the main body of the thesis are also outlined.
16.

♦ 2. FUNDAMENTALS OF CODING THEORY
2.1 The analysis of Linear Block Codes.
2.2 The Construction of Linear Block Codes.
2.3 Decoding of Linear Block Codes.
2.4 Minimum-Distance Bounds for Binary Linear Codes.
17.

2.1 THE ANALYSIS OF LINEAR BLOCK CODES
An (n,k) linear block code comprises a block of k
information digits and r=n-k redundant (or parity-check) digits.
It is a collection of M=qk distinct vectors called codewords.
Each codeword is an n-tuple vector of the vector space Vn over
a field F of q elements. A set of M such n-tuple vectors,
denoted by V, is a linear code, if and only if, it forms a
subspace of the vector space V over the field F of all qn (5) n
The rate of the code, R, is defined as(3):
R = (log M)/n = kin
For binary codes, q=2, while for nonbinary codes the
integer q>2. Usually q is chosen to be a prime number or a
prime raised to an integral power. If a set of the basis
vectors of the subspace V are considered as the rows of a k-by-n
matrix EC] then this matrix [G] is called the generator matrix of the code V. The reduced echelon form of the matrix DI generates the systematic form of the code. Its first k columns
make up a k-by-k identity matrix DO, whereas the remaining
(n-k) columns form a k-by-(n-k) arbitrary matrix [b].
n-tuples
VIM •
1- 0' . : : 0 b1,1 b1,2
. . .
b1,(n-k)
0 1 . . . 0 b2,1 b2,2 • •
. b2,(n-k)
• • • •
• • • • •
• • •
0 0 . . . 1 bk,1 bk,2 .' bk,(n-k)
EGKIkl bj=
A set of basis vectors from the null space V' of the
subspace V can be considered as the rows of a parity-check
matrix [H]. The reduced echelon form of [H] is an (n-k)-by-n
18.

matrix, the first k columns of which made up an (n-k)-by-k
matrix, and the remaining (n-k) columns an (n-k)-by-(n-k)
identity matrix The (n-k)-by-k matrix can be expressed
in terms of the negative transpose of the arbitrary matrix E].
DO= E-bT In-kJ
-b1,1 -b2,1 . . . .-bk,1 -b1,2 -b2,2 -bk,2
1 0 0
0 1 0
•
• •
-b1,(n-k) -b2,(n-k)* '-bk,(n-k) 0 0 ... 1
The parity-check matrix of a code can itself be a
generator matrix generating the so-called dual of the code
generated by EG-1 (7)
Since V is a rowspace of matrix [GJ, and V' is a
rowspace of matrix Da and a null space of V, an n-tuple
vector v is in V if and only if it is orthogonal to every row
of DO. That is to say, v[HT:1= 0
The above equation holds for every vector v4EV, and therefore
it follows that(7);
EG3 DT] = 0 As a consequence of the above results, for any n-tuple e that
is not a codeword(10;
e DT.3 0
The (n-k)-tuple vector (s) is referred to as the syndrome of
the n-tuple vector e.
The Hamming weight of a codeword vector is equal to
the number of non zero elements in that codeword vector.
19.

The weight distribution of a code is a list containing
the number of codewords of each possible weight (0,1,2,...,n).
The minimum weight of a code is the integer equal to
the smallest nonzero weight of a codeword in the code(3).
The Hamming distance between two n-tuple vectors is
equal to the number of components in which these vectors differ.
For linear codes, since the distance between any two codewords is
equal to the weight of another codeword in the the code, the
minimum Hamming distance in any (n,k) linear code therefore
coincides with the minimum Hamming weight of the nonzero
codewords.
The measure of minimum Halauting distance of a code drain man
provides important information regarding the capability of the
code to detect or correct random errors (or both)().
The codewords of a linear code are all the solutions to
a set of (n-k) homogeneous linear equations, called generalized
parity-check equations(). The coefficients of these equations
are elements from the appropriate field F. This implies that a
vector v of Hamming weight w, specifies a linearly dependent
set of w columns of the parity-check matrix DI conversely a
linear combination of w columns of [HJ resulting in the zero
vector, specifies a codeword v of weight w. It follows that
the (n,k) linear code V that has parity-check matrix [HJ will
correct all errors of weight t or less, if and only if every
2t columns from [HJ are linearly independent(7); and in any
(n,k) code the minimum Hamming distance is the number of
columns of [HJ in the smallest linearly dependent set.
Linear block codes, the class of codes with which
this thesis is exclusively concerned, form algebraic groups.
The mathematical decomposition of these groups as proposed by
Slepian(19)
is usually referred to' as the standard array. For
20.

an (n,k) linear code, the standard array is constructed by means
of the following procedure.
Place the M codeword vectors of the code in a row with
the zero vector as the leftmost element. From the remaining
(qn-qk) n-tuples, choose any n-tuple, e, and place it under the
zero codeword vector as the leader of the new row. The row is
then completed by placing under each codeword vector of the
first row its sum with e. This procedure is repeated until all
the qn-k rows of the array have been constructed. The set of
elements in a row of this array is called a left coset, and the
element appearing in the first column is called the coset leader.
No two n-tuples formed by the above process of adding different
codewords v1 and v2 to e can be identical because if (e+v1)=(e+v2),
then v1=v2' which is impossible. All the n-tuples of a left coset
have the same syndrome as the coset leader e since(5):
(e v) DT] e :HT]
Then, since every left coset has one syndrome and since
there are qn-k coset leaders, the left cosets are disjoint ().
A perfect linear block code is_defined as a linear code
that for some t has all patterns of weight t or less, and no
others, as coset leaders(5). Consider an (n,k) linear code over
GF(q). Each of these (n-k)-tuples indicates a particular error
pattern, including the no error pattern.
TherefEre in such a case the code can correct up to:
) (q - 1)
1=1 . . error patterns, and hence for a perfect code we must have ():
qn-k
(q - 1)i 1=1
Some examples of known perfect codes are as follows;
repetitive codes, the Hamming drain = 3 codes over any field;
21.

the two Golay codes (11,6), dmin = 5 code over GF(3), and
the(23,12)drain =7 code over GF(2).,. Van Lint(20) proved
that no other perfect codes exist over GF(Pa) for any a and P<:(d min - 1)/2, and Tietavainen
(21)(22) completed the
proof for P2>(dmin - 1)/2.
A quasi-perfect linear block code is defined as
a linear code for which some t has all coset leader patterns
of weight t or less, some of weight t+1, and none of greater
weight. In view of the previous arguments it can be seen that
a quasi-perfect code with elements from GF(q) is a block code
whose parameters satisfy the conditions
t+l
E(nixq _ i)i qn-k t
1=1 1=1
Note:
It is perhaps useful at this point to make a
distinction between good codes and optimum codes. In
general, a good code is that code which has the largest
number of information symbols for given values of code
length and minimum distance. On the other hand, an
optimum binary code is defined as the binary group code
for the binary symmetric channel, its probability of
error being as small as for any group code with the same
value of n, and k.
22.

2.2 THE CONSTRUCTION OF LINEAR BLOCK CODES
The major part of research effort in coding theory
has been directed towards finding ways and means of constructing
codes of high rates which exhibit a considerable mathematical
structure. The reason for the emphasis on the mathematical
structure is that it forms a basis for very simple coding and
decoding procedures. Because of this, most of the research in
block codes has been concentrated on a subclass of linear codes
known as cyclic codes, as is seen from the fact that the best
codes discovered during the past decade are cyclic. Bose-Chaudhuri-
Hocquenghem (BCH) code(23,24), quadratic residue (QR) codes (3,7)
(25' 26)
and shortened Reed-Muller (RM) codes are all cyclic.
However, it has been felt that the greater the mathematical
structure that a class or family of codes exhibits, the further
these codes are from the Varshamov(60) Gilbert(27) lower bound
on minimum Hamming distance; this is particularly so for large
values of n. Berlekamp(28) has recently shown that for BCH
codes we have for n tending to infinity:
d-f-1-(2nln R-1)/logILI
which is evidently an undesirable property. It is not yet
known, however, whether long cyclic codes are equally bad.
Kasami(29) has shown that good linear codes cannot be too
symmetric. This he achieved by showing that any code with given
d/n, which is invariant under the affine group, must have a rate
R tending to zero as n tends to infinity (this includes BCH
codes).
In this section a brief review is given of those
procedures for constructing codes that have led to some of the
best known linear block codes.
23.

2.2.1 Repetition Codes
This is the simplest example of binary codes. A
repetition code has one information digit and an arbitrary
number(r)of check digits. The value of each check digit is
identical to the value of the information digit. It is evident
that this class of codes is capable of correcting up to r/2
random errors. Repetition codes are perfect, and have the
lowest rate and the highest error-correcting capabilities.
2.2.2 Hamming Codes
Hamming(30) presented a class of perfect single-error-
correcting binary group codes, described through the parity-
check matrix. The columns of the parity-check matrix are all
the possible m-tuple vectors of the vector space Vm over the
field F of two elements. Since all columns of the H-matrix
are distinct and non zero, the null space of this matrix has
minimum weight 3 and is capable of correcting all patterns of
not more than one error. The code has m parity-check symbols,
and each code vector has a length of 2m - 1 and therefore 2m - 1-
m information symbols. A double-error--detecting and single-
error correcting Hamming code is obtained by adding an overall
parity check to a single-error-correcting Hamming code. This
code has the following parameters: n = 2m - 1, n-k = m+1, and
t = 1. The cyclic version of Hamming codes was recently
reported in references (8), (32), (33), (34) and (35).
2.2.3 Golay Codes
Golay(31) presented the only known multiple error-
correcting binary perfect code which is capable of correcting
up to three random errors. This code, (23,12), is cyclic
with many interesting properties,'as will be discussed later.
24.

C
The generator polynomial of this code is either:
L(x) = 4. x2 4_ x4 4 x5 .1. x6 4. x10 4 xll
4 x7 4. x9 4 x11 4x) = 1 + x + x5 + x6
Both gi(x) and g2(x) are factors of x23+1. The (24,12)
extended Golay codes have many important combinatorial properties
which have been studied by many authors (references (37), (38)
and (39)).
2.3.4 Circulants Codes
Leech(46) showed that the generator matrix of the
(23,12) Golay code can be written as:
1
where EC] is a circulant matrix, that is, each row is a cyclic shift of the previous row by one place. Karlin(47 '48) found a
large number of binary codes generated by circulants. Pless(49,50)
used the same properties of the circulant matrix to find some
new codes over GF(3),
2.2.5 Optimum Codes
A binary group code is called optimum for the binary
symmetric channel if its probability of error is as small as
for any group code with the same total number of symbols and
the same number of information symbols(7). Fontaine and
Peterson(56) presented a computer search procedure to find new
optimum linear block codes. The procedure was used to obtain
initially as good a code as possible and then to find all other
codes which have a smaller probability of error. Some of the
25.

new codes were also given. Tokura, Taniguchi and Kasami(53)
also found some new codes by using, a so called, systematic
computer search procedure for finding optimum error-correcting
linear block codes.
2.2.6 Quasi-Perfect Codes
The definition of the quasi-perfect code is given in
Section 2.2. The importance of such codes lies in the fact that
quasi-perfect codes by definition are optimum codes. Moreover,
Bose and Kuebler(81) were able to make limited progress in
finding optimum codes. They considered a code optimum if it
would correct all errors of weight t or less, with t as great
as possible, and would correct as many errors as possible of
weight t +1.
Wagner(51)(52) used the properties of the parity-check
matrix of binary linear codes to derive quasi-perfect codes. The
properties he employed are as follows:
1. Every 2t distinct colums from EEO are linearly
independent.
2. The set of colums from [HJ is (t+2) relatively
maximal in the space of all 2n-k possible columns. The
term "relatively maximal" is explained as follows. A
set 1A1 of vectors in a vector space S is called r-
relatively maximal in S, if every set of r-distinct
vectors from {Al is linearly independent and if every
vector ve:S is equal to a linear combination of r-1 vectors
from [Al (zero coefficients allowed). By computer search
using the above condition, many quasi-perfect codes were
found.
26.

2.2.7 Reed-Muller Codes
2m-r. The code is generated by a matrix EG: of k linearly d =2 min
independent rows. The first row is a vector vo whose 2m
components are all l's and m rows consisting of the vectors v1,
v2' .., vm of the characteristics illustrated for m=3 below.
The remaining k-m-1 rows are the modulo-2 product of the linear
combinations of every r vectors v1, v2, V.
vo 1 1 1 1 1 1 1 1
v1 0 0 0 0 1 1 1 1
v2 0 0 1 1 0 0 1 1
v3 0 1 0 1 0 1 0 1
Reed-Muller codes are equivalent to cyclic codes with
an overall parity check.
2.2.8 Concatenated Codes
Elias(61) presented the principle of the product of
two codes (n1, k1, d1) and (n2, k2, d2) to ) -t-o obtain a more
powerful (n1n2, k1k2, d1d2) code. The construction of product
codes may be best described by its codeword array. The inform-
ation digits k1k2 of the (n1n2, k1k2) code are placed in array
of k2 rows and k1 columns, the rows are extended by n1-k1 parity check digits, according to the encoding rules of the
(n1,
k1) code; the columns are extended by n2-k2 parity check
digits according to the encoding rules of the (n2, k2) code;
this is illustrated on the following page.
The resulting product codes are linear codes. Goldberg (15,62) showed by using new augmentation techniques that new
codewords may be added to a given product code while the
minimum distance is kept fixed.
Reed-Muller codes(25,26) are a class of binary group
codes with the following parameters. For any m and r <m there
is a Reed-Muller code for which, n= 2m, k = 1 + (m) + (2) + + (m) 1
27.

Checks
on
Rows
1
Information
Digits
Checks on
Columns
Checks on
Checks
The concatenated codes were presented by Forney(10)
In that procedure two codes are used, one called inner (n1,k1)
code with symbols from GF(q), and the other outer (n2,k2) code
with symbols from GF(qk ). The codewords of the concatenated
(n2n1, k2k1) codes are coded in two steps. First, the k1k2 information digits are divided into k2 bytes of k1 symbols.
These k2 bytes are encoded according to the rules for the outer
code. Second, each k1-digit byte is encoded into a code vector
in the inner code, resulting in a string of n2 code vectors of
the inner code, and hence a total of n2n1 digits.
2.2.9 Cyclic Codes
The study of general cyclic codes has been done
firstly by Prange(36) and references (3), (5), (7) and (8)
contain excellent expositions of these codes. Here we give
below a short exposition of cyclic codes and their salient
properties. Let T denote the cyclic operator for n-tuples, i.e.,
TCX .x x ,....,x 0- l' n-1 n-1' n-2]
A linear block code is said to be cyclic if the cyclic shift
Tx of every codeword x is again a.codeword. The components
•
28.

of an n-tuple codeword are treated as coefficients of a poly-
nomial as follows: n-1
a = E ao,ai, • .• a(x)
1=0
Ta =n-1Ya0' ...,an-2:] x a(x) an-1(xn- 1)
The structural properties of cyclic codes can be summarized as
follows. An (n,k) cyclic code over GF(q) is characterized by
a unique monic polynomial of degree n-k, called the generator
polynomial g(x) over GF(q), such that an n-tuple a=Ca 0 a' l' • • • ...,a11-1
is a codeword, if and only if, a(x) = a0+a1x +
+ an-lxn-1 is a multiple of g(x). Moreover, g(x) divides
(xn- 1). The set of codewords is the row spaces of the matrix
g0 gl g2 • gn-k-1 1 0 . . . 0
0 g0 g1 • . gn-k-2 gn-k-11. . . 0 G
.1.11111
o. . . 0 go g1
gn-k-1 1
The parity check matrix may be chosen as
1 hk-1 hk-2 . . . . h1 h0 0 0
0 1. . . . . h2 hl 0 h0
•
• 0 1 hk-1 h2 "- hi
where h(x)=(xn-3.)/g(x)=h0+11ix+ • • • • + hk_ix x k •
Conversely every monic polynomial g(x) which divides xn- 1
generates such an (n,k) cyclic code. The row space of the
parity-check matrix H of an (n,k) cyclic code is also a
cyclic code.
29.

An irreducible polynomial P(x) over GF(q) is said to
be primitive if its roots are primitive elements of GF(qm)
where m is the degree of P(x). This is fully equivalent to the
statement that the least integer n such that P(x) divides Kn - 1
is n = qm - 1 since this n is the multiplicative order of the
roots of P(x).
If g(x)= TT P.(x) is a product of distinct monic TT
irreducible polynomials over GF(q), then the cyclic code
generated by g(x) has length n equal to the least common multiple
of (m1, m2,
m/)wherem.is the multiplicative order of the
roots of P.(x), i.e. the least integer such that P.(x) divides
X
A cyclic code over GF(q) is called irreducible if its
check polynomial h(x) is irreducible over GF(q). The above
general properties of cyclic codes have been used to discover
many new codes during the last few years (see bibliography).
An (mn0, mk0 ) linear code is said to be quasicyclic
with basic block length n0 if every cyclic
by nn digits yields another codeword(54)
`' Weldon(55) gave a short computer generated
quasicyclic codes of rate 1/2. They also showed that there
exist a very long quasicyclic codes which meet the Gilbert bound.
Z. 2. 10 11-12Bose-cbudhuri-lcc 1...g isLLch2rri Codes
The BCH(23)'(24) codes are first of three of the most
important classes of linear codes discovered to date. These
codes are cyclic codes and are most conveniently described in
terms of the roots of g(x). Let q be a prime power, m be the
order of q modulo n, and 01 be a primitive nth root of unity in
GF(qm). Then the BCH code of length n, designed for a distance
d = dBCH and having its symbols from GF(q), will have the
parity-check matrix, [H3 below:
30. •
shift of a codeword
Chen, Peterson and
list of the best

EH] =
1 •
•
r
1
a
•
•
ad-1
a.2
oc4
ce(d-1)
CE 1-1 a2(n-1)
a(d-1)(n-1)
If n.= qn- 1 the code is called primitive and the BCH
bound of any such code has actual minimum distance
dmin. > dBCH
BCH codes have been the subject of much study owing
to their great generality. Berlekamp(3) gives an excellent
exposition of these codes. Kasami and Tokura(4o) showed that
there are binary primitive BCH codes of length n= 2m - 1 for
which dmin> dBcH. Extended binary BCH codes have also been
studied (references (41), (42), (43), (44) and (45)).
2.2.11 Goppa Codes
Goppa(57),(58) presents a new class of codes (see also
reference (82)). This class of codes is considered to be the
second of the three most important classes of linear codes
discovered to date. These codes are in general noncyclic. The
only cyclic codes in the class are the BCH codes. The basic
principles involved in the construction of this class of codes
are as follows:
Let integers m,t be given satisfying 3$;;m<i2m. Let:
Z = zeGF(2mt)I degree of minimal polynomial of
z is mtl
and let 0. be a primitive element of GF(2m). Then for any zaZ
the binary Goppa code (m,t,z) is the (n= 2m, k2m -mt) code
with the mt x 2m parity check matrix:
31.

1 1 1 [H] = 0 'z-1' z-Ot''''' z Wm-3
Goppa has shown that the minimum distance of (m,t,z) is
(i) at least 2t+ 1 for all zEZ, (ii) equal to that given by the
Gilbert bound for some zeZ. Unfortunately it is not as yet
known how to choose z4aZ so as to make this happen.
2.2.12 Justesen Codes
Justesen(59)
presented a constructive sequence of binary
codes for any rate R, 0<R<1, such that the minimum distance d is
given by:
— (1- r-1R) H
-1(1 - r) >0
Hence the codes are asymptotically good, when r is at its maximum
value of 1/2 and the corresponding rates in general given byl- 2
R = 1 + lo 1 - H-1(1- r)]
H(x) = -x log2 x-(1 - x)log2(1 - x) is the binary entropy
function.
The construction of these codes is based on Forney's(10)
concept of concatenated codes in which the m information digits
of an inner binary code are treated as single digits of an outer
Reed-Solomon(59) code over GF(2m), by generalizing the concept to
allow variation of the inner code. The inner codes are given by
a simple algebraic description and are shown to be equivalent to
the 2m - 1 distinct codes in the ensemble of randomly shifted
codes described by Massey(9) and attributed to Wozencraft.
Justesen codes are considered as the third of three most
important classes of linear codes. Justesen codes are the only known
asymptotically good codes; however, the ratio of minimum distance
to block length approaches a nonzero limit as the block length
increases, which is typically (at rate 1/2) about 20 percent of
the Gilbert bound on achievable distance.
• 32.

2.3 DECODING OF LINEAR BLOCK CODES
The construction of sufficiently simple error-correcting
devices is an important problem of the application of correcting
codes in data systems. The use of the algebraic features of some
classes of codes has opened up interesting possibilities in this
direction.
In this section we consider the principles involved in
the decoding of those classes of codes discussed in Section 2.2
and also the complexity of the associated decoding algorithms.
Most of these decoding algorithms are suitable for decoding
short random error-correcting codes. However, when they are
applied to long and high rate codes with large error-correcting
capabilities they become very ineffective and impractical.
There exist, however, two known methods for decoding long
random error-correcting codes that belong to the BCH class and
the class of majority logic decodable codes. Both of these
decoding algorithms have inherent limitations in that the
complexity of decoding is far from simple. We shall now
consider several decoding procedures that are in existence and
are applicable to the important classes of codes mentioned in
previous section. The complexity of decoding is generally
measured by the number of operations required for decoding a
single information symbol. The number of operations required
for decoding is the average number of times a sequence of
symbols at the channel output must be compared with code
combinations at the channel input to decode one information
symbol.
2.3.1 Syndrome Decoding
Basically all decoding algorithms of linear block codes
are syndrome decoding in nature. We have defined in Section 2.2
33.

the (n-k)-tuple syndrome vector s for a received n-tuple vector
r as:
s = Es1' s2, °°'" sn-0=0 i=[ri, r, rn=1 DT]
For a given r, we say that an error pattern em is a valid error
pattern if r - em is a codeword; this implies that there is some
codeword vm such that vm +em =r. However, there are qk distinct
s = (vm+em) [HT] = vM :HT] em DT] = em [HT] ; since v
EHTD = O.
The syndrome is independent of the codeword transmitted
but depends only on the channel error sequence. Thus every valid
error pattern is a solution of the syndrome equation;
s = e DJ.]
Since the set of qk valid error patterns is exactly
the set of solutions of the syndrome equation s = e BIT] / we see that a decoder which decodes r into r- e, where e is (one of)
the solution(s) of s=eHT that maximizes Pn(e), is a maximum
likelihood decoder for an algebraically additive channel*. This
follows from the fact that P(r/v)=Pn(e) so that v=y- e
maximizes P(r/v). The above can be summarized as follows: For
a given syndrome s, the qk solution of s=eH
T are the qk valid
error patterns. A maximum likelihood decoding rule for an
algebraically additive channel is to decode r into v=r- e
where e is the solution of s = eHT which maximizes Pn(e).
A channel is said to be algebraically additive if P(r/v)
depends only on e=r-v, i.e., P(r/v)=Pn(e) where Pn is
the probability distribution for error patterns.
codewords and hence there are exactly qk valid error patterns
for each possible r. Equation (2.4.1) can be rewritten as
follows:
• 34.

The syndrome decoding of linear block codes, therefore,
consists of three basic steps:
1) Calculation of syndrome of the received vector.
2) Identification of the correctable error pattern that
corresponds to the syndrome calculated in step 1.
3) Correction of the errors.
In general, step 2 is the most complex part of the
decoder to implement. This is because step 2 involves a one-to-
one mapping between the syndrome and the large number of qn-k - 1
correctable error patterns.
Most of the well known procedures of decoding employ
the algebraic structure of the code to simplify the implementation
of step 2. Some of the methods used are described briefly below.
2.3.2 Decoding of Binary Cyclic Codes
We have seen in Section 2.2 that a cyclic code is
defined in terms of a generator polynomial g(x) of degree n-k.
A polynomial of degree less than n is a code polynomial, if
and only if it is divisible by the generator polynomial g(x).
To encode a message polynomial m(x), we divide xn-k
m(x) by g(x)
and then add the remainder r(x) resulting from this division to
xn-km(x) to form the code polynomial F(x). That is,
xn-km(x) = g(x) q(x) + r(x).
where g(x) is the quotient and r(x) the remainder resulting from
dividing xn-km(x) by g(x). Since in modulo two arithmetic,
addition and subtraction are the same, we have,
F(x) = xn-km(x) + r(x) = q(x) g(x)
which is a multiple of g(x) and, hence, a code polynomial.
Furthermore, r(x) has degree less than n-k, and xn-km(x) has
35.

zero coefficients in the n-k low-order terms. Thus the k
highest-order coefficients of F(x) are the coefficients of r(x),
and these are the check symbols.
An encoded message containing errors can be represented
by:
H(x) = F(x) + e(x)
where F(x) is the correct encoded message and e(x) is a poly-
nomial which has a nonzero term in each erroneous position.
Because the addition is modulo two, F(x)+e(x) is the true
encoded message with the erroneous positions altered. If the
received message H(x) is not divisible by g(x), then clearly an
error has occurred. If, on the other hand, H(x) is divisible
by g(x), then H(x) is a code polynomial and we must accept it
as the one which was transmitted, even though errors may have
occurred. Therefore, an error pattern e(x) is detectable if and
only if it is not evenly divisible by g(x).
To detect errors, we divide the received, possibly
erroneous, message H(x) by g(x) and test the remainder s(x).
If the remainder is nonzero, an error has been detected. If
the remainder is zero, either no error or an undetectable error
has occurred. The syndrome of any linear block code is obtained
by taking the modulo-2 sum of the received parity check digits
with the parity check digits calculated from the received
information digits. Therefore the remainder's(x) resulting
from dividing the received vector H(x) by the generator poly-
nomial g(x) is the syndrome of H(x), i.e.:
H(x) = p(x) g(x) + s(x)
Therefore encoding and syndrome calculation can be accomplished
by a division circuit used to calculate the remainder of the
division. The hardware to implement this algorithm is a shift
36.
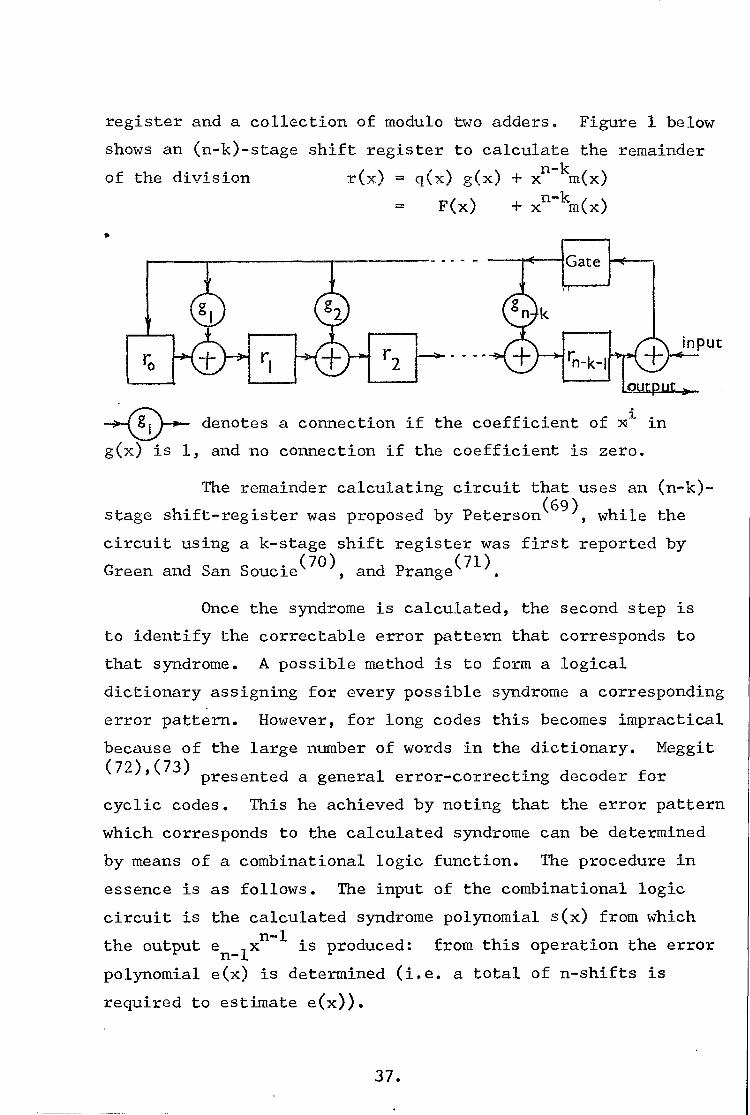
register and a collection of modulo two adders. Figure 1 below
shows an (n-k)-stage shift register to calculate the remainder
of the division r(x) = q(x) g(x) + xn-k
m(x)
F(x) + xn-km
(x)
•
denotes a connection if the coefficient of xi in
g(x) is 1, and no connection if the coefficient is zero.
The remainder calculating circuit that uses an (n-k)-
stage shift-register was proposed by Peterson(69), while the
circuit using a k-stage shift register was first reported by
Green and San Soucie(70), and Prange(71)
Once the syndrome is calculated, the second step is
to identify the correctable error pattern that corresponds to
that syndrome. A possible method is to form a logical
dictionary assigning for every possible syndrome a corresponding
error pattern. However, for long codes this becomes impractical
because of the large number of words in the dictionary. Meggit (72),(73) presented a general error-correcting decoder for
cyclic codes. This he achieved by noting that the error pattern
which corresponds to the calculated syndrome can be determined
by means of a combinational logic function. The procedure in
essence is as follows. The input of the combinational logic
circuit is the calculated syndrome polynomial s(x) from which
the output en-1xn-1 is produced: from this operation the error
polynomial e(x) is determined (i.e. a total of n-shifts is
required to estimate e(x)).
37.

Whether Meggitt decoder is a "practical" decoder for
a cyclic code depends entirely on the complexity of the logical
circuit, Generally, if only t or fewer errors are to be
corrected, where t is about 3 or less, the decoder is much
easier to implement than the corresponding BCH decoder. (The
BCH decoder will be discussed in a later section.)
2.3.3 Error-Trapping for Binary Cyclic Codes
This process is based on the simplification of the
following equation:
H(x) = p(x) g(x) + s(x)
which is simplified to:
s(x) = F(x) + e(x) + p(x) g(x)
We can see from the above that since the code polynomial F(x)
is divisible by the generator polynomial g(x) the remainder of
dividing s(x) by g(x) is entirely due to the error polynomial
e(x). We can also see that the syndrome polynomial is identical
to the error pattern polynomial by noting that the above
equation can be written as:
s(x) = e(x) + B(x) g(x)
where B(x) is the quotient of dividing e(x) by g(x). If the
error polynomial is of degree (n-k-1) or less, then B(x) = 0
due to the fact that g(x) is a polynomial of degree (n-k).
Hence it follows from the above equation that:
s(x) = e(x)
This implies that the syndrome is identical to the
error pattern if the errors are confined to the check digits
only. Note that the weight of the syndrome is t or less if
the correctable error pattern is confined to the check digits
38.

only, and the weight is greater than t if the correctable error
pattern is not confined to the check digits.
From the above results one is led to a simple decoding
algorithm for cyclic codes: for example, Mitchell(74),(75)
Rudolph(76) and MacWilliams(77) have described the operation of
the decoder, which can be summarised thus:-
•
(i) Calculate the syndrome s(x) by dividing the received
polynomial by the generator polynomial and retaining the remainder.
(ii) Test if the syndrome is of weight t or less in which
case the error pattern is identical to the syndrome polynomial.
(iii) If the weight of the syndrome is greater than t
shift the received polynomial H(x) by one position xfH(x)1 and
repeat the above steps. This procedure is repeated until the
weight of the new syndrome is t or less. If this cannot be
achieved having gone through the entire number of shifts, the
error cannot be corrected.
It can be seen, therefore, that the error-trapping
decoding procedure is very effective for decoding single error-
correcting codes. However, when it is applied to multiple
error-correcting codes, it becomes very ineffective and much
error-correcting capability is lost. This is because all
errors that occur at positions of (n-k) or greater digits
apart cannot possibly be corrected.
A modification to the above error-trapping procedure
was introduced by Kasami78) in which he made the error-trapping
technique effective for some multiple error-correcting codes.
The principle of the modification is as follows. A set of
polynomials tQi(x)I of degree k-1 or less is chosen such that
for any error pattern e(x) of weight t or less, there is one
polynornialQ.WinthesetforwhichxrQi(x) agrees with e(x)
39.-

or a cyclic shift of e(x) in its k information positions. Let
qi(x) be the parity sequence associated with the information
sequence. Ql(x). We recall that the syndrome is the sum of
the noise sequence in the information positions. Thus, adding
q.(x) to the syndrome s(x) gives the error pattern in the
parityplaceswhenxrQ.(x) coincides with xr+i
e(x) in the
information positions. Since the code has a minimum distance of
at least 2t+ 1, this coincidence can be detected uniquely by the
inequality:
wEsi(x)+qi(x)] t v&i(x)..]
Then the original error pattern e(x) is given by:
e(x) = )ck-i(s.(x) q.(x). Qi(x)) (Mod xn- 1)
Kasami shows that such a set of tQi(x) polynomials
can be found for some cyclic codes and gave the set of polynomials
required for the cyclic Golay code, the Bose-Chaudhuri (63,45),
(31,16), (31,11) codes and the (41,21) cyclic codes.
2.3,4 Majority Logic Decoding Algorithm
In this section we consider the majority principle of
decoding cyclic and non cyclic linear block codes, which often
enables a simple solution of the problem of correcting multiple
errors to be found. This type of decoding is based on the
possibility, that for certain cyclic and non cyclic codes, the
value of any one symbol of a codeword may be expressed by
several independent methods as a linear combination of other
symbols. Independence of the methods is understood in the
sense that no two expressions depend on the same symbols.
A single distortion can change only one expression, two
distortions can change not more than two expressions, etc.,
t distortions, therefore, can change not more than t
expressions. For correct decoding of the symbol it is then
40.

sufficient to have 2t + 1 independent expressions defining the
given symbol in terms of all the remainder and the decision as
to the definite symbol to be transmitted is taken from the
majority of the meanings given by each individual expression.
The possibility of using the principle of decision
by the majority (majority principle) for decoding cyclic codes
was first indicated by Green and San Soucie(79) using the
example of the (15,4) code with a Hanudng distance of 8.
Reed(26) used this principle for decoding noncyclic Killer codes(25)
Massey(9) unified the theory of majority logic decoding which is
outlined below.
Let e= e0' e1, •' en-1 be an error pattern, for
the syndrome of which is given by:
s = s s s 0' 1, 2' sn-k-1 = eH
T
where:
s = e0 0
S1 = e1
en-k +.7.:74-13k1 e
n-1
en-k 1-****4-Pk2 en-1
sn-k-1
= en-k-1 4V1,(n-k) en-k —4-21k,(n-k)en-1
Consider a check sum A of the syndrome bits defined as:
A = a0 s0
+ alsl + . . . . +
an-k-1 sn-k-1
= b0 e0
+ blel + . . . . + b
n-1 en-1
where d.1 =1 or 0 and b. = 1 or 0. A parity check A.1 will be said
to check an error digit ei if ei appears in the summation given
by A with a nonzero coefficient. A set tAl of parity checks is
said to be orthogonal on em if each Ai checks em but no other
error bit is checked by more than one Ai. Each parity check in
an orthogonal set thus provides an independent estimate of em
41.

when the noise bits are statistically independent. If, then,
there are 2t parity-check sums orthogonal on em, m=n.-k, n-k+l,..
.., n-1, the value of the error digit em is given as the value
assumed by a clear majority of the parity check sums orthogonal
on em. A code with minimum distance d is said to be completely
orthogonizable in one step if and only if it is possible to form J=d-1
parity-check sums orthogonal on every error digit. A set of J
parity-check sums Al, A2, ..., Aj is said to be orthogonal on
the setiEif and only if: (1) every error digit eit in E is
checkedbyeverychecksumA.for j= 1, 2, J, and (2) no
other error digit is checked by more than one check sum. The
process of estimating sums from sums of larger size is called
orthogonalization. The orthogonalization process continues
until a set of J or more parity-check sums, orthogonal on every
error digit, are obtained. A code is said to be L-step orthogon-
izable (or L-step majority-logic decodable) if L steps of
orthogonalization are required to make a decoding decision on
every error digit.
The majority method of decoding is appreciably simpler
and more reliable than the decoding scheme of Peterson(80)
or
the decoding algorithm of Berlekamp(3) for Bose-Chaudhuri codes.
The deficiency of this method is that, in all the cases
considered, cyclic codes with majority decoding schemes are no
better in correcting capability than the corresponding (n,k)
Bose-Chaudhuri codes. Nevertheless, because of the simplicity
of the decoding devices, codes with majority decoding schemes
are in many cases more effective than other schemes.
2.3.5 Decodin of BCH Codes
For the purpose of decoding BCH codes(69)
we note
that v(x) is a codeword polynomial of an (n,k,t) BCH code with
42.

ti
abeing a primitive nth root of unity in GF(2m) if and only if
al, i = 1, 2, ..., 2t are roots of:
v(x) = v0 +v
lx+v2x2 + +vn-1x
ri-1
Let the received polynomial be denoted by r(x), and
let it be corrupted by the noise polynomial e(x), i.e.:
r(x) = e(x) + v(x)
Ifwesubstitutetherootsa_of the code in r(x) we obtain:
s1 = e(0) + v(0) s2 = e(a2)+v(a2)
s3 = •e(CC3)+v(0C-3)
s 2t
e( a2t + v( ( t)
Since Ce", i = 1, 2, ..., 2t are roots of v(x), the v(4),
i = 1, 2, ..., 2t, are all equal to zero.
The vector s = s1, s2, s2t is defined(80) to be
the syndrome of the code.
If the received polynomial r(x) has errors in the
positions ji, j,`„ z5." <,t, the syndrome si, i = 1, 2, ...,2t
will be given by(6,9) :
si = (aik )1
Z=1 Any error correction procedure therefore will involve
the simultaneous solution of the set of the 2t equations given
in the above summation.
Peterson(80) presented an algorithm to facilitate the
above process of decoding. Several authors suggested various
improvements to this basic algorithm(81-85). We outline below
•
•
43.

one of the procedures which is a well known modification of
the Peterson algorithm, the simplest to date. We start by
defining the error location polynomial in the form(80)
a(x) = n (1 4- 0)2, x) 2.=1
where the roots of a(x) are the inverses of the error location
positions. The polynomial a(x) can be determined for the
received polynomial r(x) by completing the table below(3)'(8)&(5)
V
-% 2
o
a(11)(x)
1
1
dp 1
s 0
211414
-1
0
1 2
t
where the l)th row is given by:
(1) if dti = 0, the a(11-1)(x) = a(1)(x), or
(ii) if dµ # 0, find another two preceding the p, say.the pth, such that the number 2p - 2p in the last column is as large
as possible and dpi0. Then:
a(11+1) (x) = a( (x) dpdp-1 x2 (11-p) a( p ) (x)
In either case, 2 +1 is exactly the degree of a
("1)(x), and
11
d = s + al 2p (11+1)s + a2(1+1)s2
41+1 s 2 1-1 +3 - 12, µ+1
Therefore a(x) is given by a(t)(x), and hence the
roots of a(x) may be calculated to locate the errors.
At this point it might be well to point out that
finding a simple way to extend the BCH decoding algorithm to
+ a (1/41)
44.

•
- correct t:>
d1--f— errors is an important, but unsolved, problem.
The complexity of the decoder increases linearly
with the block length of the code and also with the square
of errors to be corrected. The implementation of the decoder
needs a special-purpose computer to carry out the computation
in GF(2m). Lin(5) estimates roughly that 127,000 [isec. of
computing time are needed to carry the required calculation for
each received block of (127,92) BCH code capable of correcting
5 errors, whereas 190,000 psec. are needed for (1023,923) BCH
code capable of correcting 10 errors.
Although BCH codes have in some sense very desirable
attributes (i.e. they encompass a very large class of codes of
various rates and error-correcting capabilities), they become
impracticable for large n due to the increasing complexity of
the decoder hardware and the long computation time needed
for the decoding of each block.
45.

2.4 MINIMUM-DISTANCE BOUNDS FOR BINARY LINEAR CODES
For a binary symmetric channel *(BSC), an (n,k) linear
block code V of minimum Hamming distance d can correct t random
errors if and only if d.3.2t+1; for a code that corrects t errors A t
and detects random errors, we have dt+Z+1(. This can be
justified as follows. Consider a received vector r corrupted
by an error vector of weight t or less. If t=',] d-71—, then the
received vector r is closer to the actual transmitted code
vector r than to any other code vector U. Thus, the decoder
will make a correct decoding and hence the error will be
corrected. However, the decoder cannot correct all the error
patterns of e errors, where e > t+1, for there is at least one case for which an error pattern of P. errors results in a
received vector which is closer to an incorrect code vector
than to the transmitted one. In this case the decoder can
detect Q < d-1 errors, due to the fact that no error pattern of
weight (d-1) or less will alter the transmitted code vector into
another [code vector. On the other hand, the decoder may not
detect an error pattern of Q errors fora > d since there is at
least one case of the random error pattern of Q errors that may
result in a received vector coincident with one of the codeword
vectors in the subspace V.
The maximum minimum-Hamming distance dmax of all
binary linear codes of fixed n and k, is therefore a critical
parameter in the evaluation of coding as a method of error
control. Thus to determine the ultimate capabilities and
limitations of error-correcting codes it is necessary to study
upper and lower bounds on d. The upper bound on d is defined
as the absolute theoretical maximum value of d for given values
BSC is that channel which has an equal, small probability
of changing a 0 to a 1• and a 1 to 0 (called the memory
less binary symmetric channel), and maximum likelihood
decoding . 46.

of n and k, and it is said to be "good" if it is the nearest to
the best lower bound.
s
The lower bound is defined as the upper
bound on d for those codes which can be shown to exist, and is
said to be "good" if it is nearest to the best upper bound. A
number of upper and lower bounds have been reported in the
literature. Most of these are based either on the well-known
sphere-packing argument introduced by Hamming(30),(27), the
"average distance" approach of Plotkin(63),(64)
, or a combination
of these(65)
. The Hamming upper bound(30) which is based on the
sphere-packing argument (given in Section 2.2 under the definition
of perfect codes) yields the following results. For any (n,k)
block code with minimum distance 2t+ 1 or greater, the number
of check digits (n-k) is such that: t
(q-1)1 (7)
i=0 For binary codes and large values of n the bound
approaches a simple asymptotic form that can be easily evaluated
numerically using the following inequalities(8),(83)
In\ = Tf n\ ■ii
i=0 i=n-t
n ( iia ) x- X n µ-µn
i=Xn where X2>1- and p.= 1-X.
Therefore the asymptotic form of Hamming's upper bound
is given by: -(n-t) -t
2n-k
/ ( IT. ) n
On the other hand, the Plotkifniper bound is based on the fact
that the minim= weight of a codeword in an (n,k) linear code
is at most as large as the average weight of the code. Thus the
47.

•
•
average codeword weight of an (n,k) linear block code can be
found by arranging the code vectors as rows of a matrix, where
each field element appears qk-1 times in each column. There-
fore, the number of non-zero elements in each column is
(q-1)qk-1, and since there are n columns,(will be)the sum of
the weights of all codewords in the code4q-1)qk-1
. It follows
therefore that the average weight of an (n,k) code over a field
of q elements is nqk-1
(q-1)/(qk- 1) bearing in mind that there
are qk - 1 non-zero code vectors, Hence the asymptotic form of
Plotkin's bound becomes:
d q
However, the maximum number of codewords possible,
B(n,d), in a linear code of length n with minimum weight, d,
if n>d,is such that B(n,d) -1::: qB(n-1,d). Then it can be shown()
that if n;“qd-1)/(q-1), the number of check symbols required to
achieve minimum weight d in an n-symbol linear block code is at
least equal to
Dqd-1)/(q-0] - 1 - logqd
which in the asymptotic form for binary codes becomes:
n k .3?2d-2 log2d
1 - k > 2d - - liogd n n n n 2
Hence the rate is given by R = n <1 -
Elias obtained another upper bound on the minimum
Hamming distance, by employing the concepts used in both the
Plotkin and Hamming bounds(3). In this case for large n the
bound is tighter than either the Hamming or Plotkin bounds.
For the binary case the Elias bound is given by:
-11.)(0T) d 2t(1 -
where t is any integer such that:
• 48.

T, (3) > 2n-k
j=0
and k is the smllest integer for which
k ( ())/2n-k
J-0
The Elias bound is an important upper bound since it
is the nearest known to the Varshamov-Gilbert lower bound. The
Varshamov-Gilbert bound was proposed by Varshamov(60) and is in
fact a refinement of a bound proposed by Gilbert(27). The same
bound was also found by Sacks(66)
. The Varshamov-Gilbert lower
bound on d is given by: d-2
(1) (q-1)1 qr i=0
For the binary case this bound can be simplified by
using the inequalities given in (2.2.2) and (2.2.3) and assuming
n to be very large. Hence the asymptotic form in this case
becomes:
2n-k tn-d+2\-(n-d+2)
d -(d-2) 2 (-) n I
For small values of n the numerical evaluations of-
the bound may require a large and tedious amount of computation.
However, the minimum distances of a number of well-known codes
such as the BCH, Hamaing and Srivastava codes also provide a
lower bound on the minimum Hamming distance. These difficulties,
the complexity of some of the bounds previously mentioned, and
the continued appearance of new codes and code construction
techniques have prompted Calabi and Myrvaagnes(67)
to compile
a table of upper and lower bounds on d. In May 1973 Helgert
and Stinaff(68) expanded the Calabi and Myrvaagnes table for
1<n<127, 1<k<n. This table is considered very important
and we shall refer to it throughout the thesis. This is due
to two main reasons, the first being that the table is based
49.

on all the information available to date, and the second reason
is that the table compiled the best results obtained from the
best known codes together with the bounds obtained by combining
codes with other codes according to certain rules of construction.
Or their generator and parity-check matrices can be increased
or decreased in size by adding or omitting certain rows and
columns, and the minimum distances of the codes thus obtained
can be related to the minimum distance of the original code.
The combination of these codes has the following properties:
(I) dmax(n,n) = 1; dmax(n,l) = n.
(ii) If dmax
(n,k) = 2t + 1, then
d x(n+1,k) = 2t + 2.
ma
(iii) d x(n+1,k)4C 1 + dmax
(n,k). ma
(iv) d x (n+1, k+1)< drrtax (n,k). ma
(v) dmax(n + n2k) dmax
(n1
k) + dmax(n2 ' k)
50.

3. NOVEL PROCEDURES FOR CONSTRUCTING
LINEAR BLOCK CODES
3.1 A Computerised Search for Linear Codes.
3.2 Application of Walsh Functions in
constructing Linear Block Codes.
3.3 Application of the Concept of Anticodes.
3.4 Two Procedures of Linear Block Code
Modification
(1) Code Puncturing.
(2) Code Lengthening.
51.

3.1 A COMPUTERISED SEARCH FOR LINEAR CODES
A linear block (n,k,t) error-correcting code(3W)
• ' comprises qk distinct codewords (q being the number of symbols
per sign and for binary codes q = 2), which form a subspace V
of the vector space Vn over the field F of q elements. The
basis vectors of the subspace V can be considered to be the
rows of a matrix ECC,called the generator matrix of V. The
basis vectors of the null space V' of the subspace V can be
considered as the rows of the parity check matrix Da. Since V'
is the row space of [HJ and the null space of V, a vector v is
in V if and only if it is orthogonal to every row of CH]. It
follows that for each codeword of Hamming weight W, there is a
linear dependence relation between W columns of DO, and
conversely, for each linear dependence relation involving W
columns of H, there is a codeword of weight U.)0).
Lemma 3.1:
If an (n,k) code V has a parity-check matrix Ildj,
then V will correct all errors of weight t or less if, and only
if, every 2t columns from H are linearly independent(7).
Theorem 3.1:
Let a subset U of n vectors in a vector space Vn-k be
formed over a field F of q elements, and let U contain at least
one set of the basis vectors of Vn_k. A parity-check matrix Eta
can then be produced such that its n columns are the vectors in
U. The (n,k) linear code corresponding to this matrix will
correct t random errors if, and only if, all linear combinations
of every t vectors in U give unique non-zero vectors in Vn_k.
Proof:
Since the set U contains at least one set of the basis
vectors of the vector space Vn_k, then the parity-check matrix
52.

•
Elij whose columns are the vectors of U, has a rank equal to its dimension. All the (n-k) rows of E11 are thus linearly
independent. Now consider 2t vectors of the set U. Let these
2t vectors form two sets U1 and U
2 of t vectors each. The
linear combination of all vectors of U1 form a set S
1 of qt
unique vectors. Similarly set S2 corresponds to the linear
combinations of all vectors of U2. Since S1 contains all the
vectors which are the linear combinations of the vectors (u1, u2,..
ut) EUl'
it follows that if a vector s is in S1, then all
vectors of the scalar product (as) are in S1 also, where a =
1, 2, ..., q-1. This implies that the modulo-q addition of any
vector in S1 with any vector in S2
is a non-zero vector, and
therefore every 2t vectors of U are linearly independent. As a
consequence of this, every 2t columns of the parity-check
matrix EH] are linearly independent and hence the corresponding (n,k) code can correct up to t random errors.
Using the above characteristics of the parity-check
matrix, a computer search is developed to find one code at a
time for a given number of parity-check digits and a given
error correcting capability t. The computer search follows
the following steps:
1) Read the given Da matrix. 2) Cross out the (n-k)-tuple vectors resulting from all
the linear combinations of t columns of the EH: matrix. 3) Take the vectors of the vector space Vn_k in turn,
starting with the all zero vector and ending with the
all one vector.
4) Test each vector for uniqueness. If not unique,
start again at step 3 with the next vector.
5) Test for uniqueness of all t linear combinations of
the vector with the columns of the DC matrix. If
53. •

any vector of the resultant linear combination is
not unique, start again at step 3 with the next vector.
6) Cross out the vector and all the t linear combinations
of step 5.
7) Increase the size of the DO matrix by one column by
adding the vector to theHmatrix.
8) Continue the search again starting from step 3 until
all vectors in Vn-k have been tested.
Appendix 2 contains a typical computer programme to
find a new binary code for error correcting capability t=3 and
the number of parity-check digits rr.:15. In this programme, the
parity-check matrix of the Karlin(47) (30,16,3) code, with a
dummy parity-check digit was used as a starting matrix. All
programmes are written in Fortran IV and were executed on the
London University computer CDC 7600.
Using the above search the following results have been
obtained as in table 3.1.1.
For t = 5, m = n-k = 19, and taking the 19th order
identity matrix as the starting matrix, a (26,7,5) code was
found. The best linear block code corresponding to the largest
previously known value of k for t = 5, and m = 19 was (25,6,5)(7).
For t = 4, m = 17, 18, 19 and 22, the mth order
identity matrix is taken as the starting [HJ matrix. The
following codes were found: (26,9,4), (30,12,4), (34,15,4) and
(47,25,4). For these values of t and m the previously best
known linear block codes were (23,6,4)(7), (25,7,4)(7), (30,11,4)(7)
and (46,24,4)(7).
For t = 3, m = 15, the parity-check matrix of the
Karlin(47) (30,16,3) code, with a dummy parity digit, was used
54.

as a starting matrix. A (34,19,3) code was found. The largest
previously known value of K for t = 3, and m = 15 is given by
the (32,17,3)(57) code.
For t = 3, and m = 19 and 20, starting with the mth
order identity matrix as the starting matrix, a (72,53,3) code,
and a (86,66,3) code were found. The best codes corresponding
to the largest known values of K for t = 3, and m = 19 and 20
respectively were previously (70,51,3) and (83,63,3)(84)
Finally, for t = 2, m = 11 and 13, and starting with
the mth order identity matrix as theKmatrix, the following
codes are found: (41,30,2), and (71,58,2). For these values
of t and m the previously best known linear block codes were
(39,28,2)(51), and (70,57,2)().
Using the above search 10 new good binary codes were
found plus the 10 even Hatmaing distance versions of the newly
found codes.
Owing to the limitations of computer memory and time,
the above results represent the limit of application of the
search procedure.
Table 3.1.2 gives the parameters (n,k,d) and the
first k columns of the NI matrix of twenty-six codes found by the above computerised search procedure. All codes listed in
this table are as good as the best previously known codes of
identical Hamming distance and the same number of parity-check
digits. Note that the columns of the EHJ matrix in both tables
(tables 3.1.1 and 3.1.2) are given in Octal, where the first
digit of the columns is taken to designate the least significant
digit of the Octal number.
55.

minimum
d : Helgert minimum
dL : Helgert
TABLE 3.1.1 TWENTY NEW GOOD CODES FOUND BY COMPUTERISED SEARCH
n : Code length.
k : Number of information digits.
d : Hamming distance.
and Russell(1) lower Hamming distance.
and Russell(1) upper Hamming distance.
bounds on
bounds on
d dL dU The first K columns of Do matrix in Octal. 26 7 11 11 11 1777 76037 316343 526554 653265 1132671 1255316
27 7 12 12 12 As above with addition of overall parity check digit
26 9 9 8 10 377 7417 31463 52525 65252 113152 213630 263723 306136
27 9 10 9 10 As above with addition of overall parity checkdigit
30 12 9 8 10 All columns of code (26,9) plus: 416246 520155 724616
31 12 10 9 10 As above with addition of overall parity check digit
34 15 9 8 10 All columns of code (30,12) plus: 1023305 1441516 1777651
35 15 10 9 11 As above with additionof overall parity check digit
47 25 9 8 12 All columns of code (30,12) plus: 1023305 1347214 2027151 2457261 3166444 4055666 4632577 5251417 7514712 10057307 11414574 12345175 17170103
48 25 10 9 12 As above with additionof overall parity check digit
34 19 7 7 8 23642 7504 7211 36422 35044 32111 24233 10447 21117 2236 4475 11172 22364 4750 11721 37777 40343 42507 56016
35 19 8 8 8 As above with additionof overall parity check digit
72 7 6 8 All columns of code (55,38) plus: 414510 425201 431744 612665 622311 657104 667425 1014517 1025230 1031772 1206630 1236343 1243167 1273441 1404303
73 53 8 7 8 As above with additionof overall parity check digit
86 66 7 6 8 All columns of code (72,38) plus: 2014523 225217 2031761 2317101 2327413 2352645 2362302 2407003 3106403 3400062 3431735 3733415 3776332
87 66 8 7 8 As above with additionof overall parity checkdigit
41 30 5 4 6 17 63 125 152 226 253 333 355 367 427 455 511 647 1031 1113 1214 1343 1562 1660 1710 1723 2034 2045 2203 2432 2563 3060 3102 3465 3611
42 30 6 5 6 As above with additionof overall parity checkdigit
56.

*
TABLE 3.1.1 Continued.
6 12543 15172 13115 16445 17131 17440 3220 1750 10347 14270 3066 4267 12220 5110 2444 521 14342 13353 15676 2633 4433 5073 12726 5353 12676 2573- 11166 12116 5047 12730 5354 10602 4301 15206 6503 12505 16747 17070 3626 1713 5122 2451 11137 11745 14471 16127 777 10064 2025 16012 7005 16510 7244 1661 10423 6071 13327 3374
6 As above with addition of overall parity check digit
I
n k d dL dU 71 58 5 5
72 58 6 5
57.
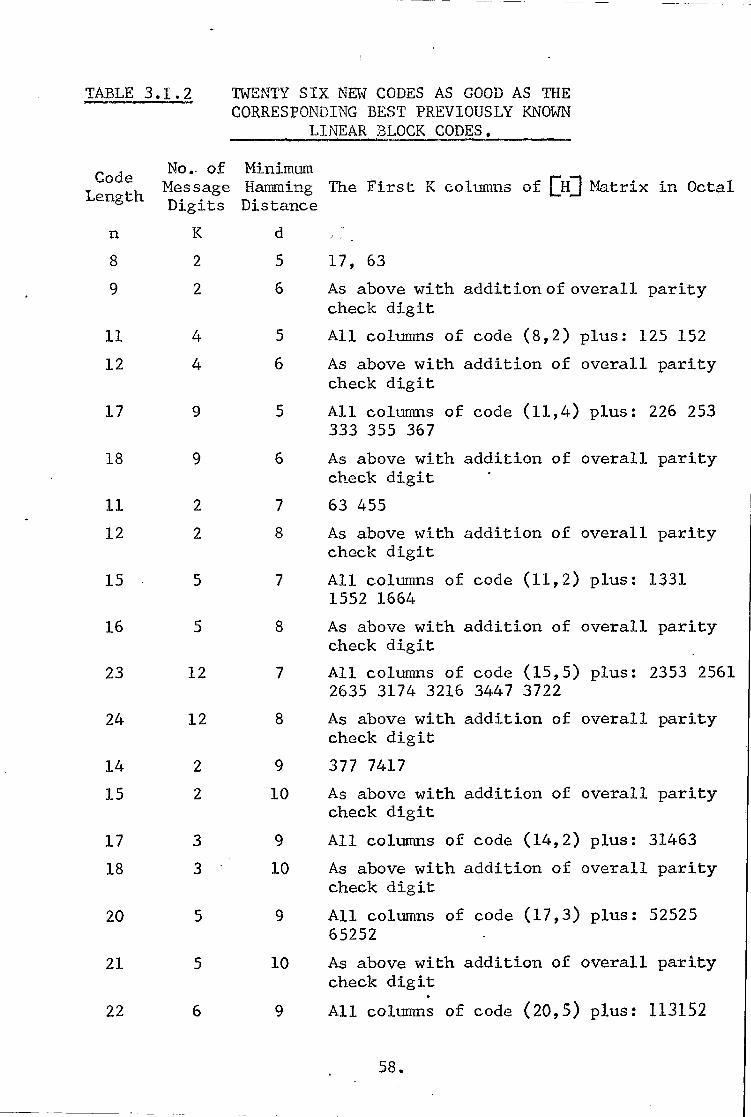
TABLE 3.1.2
TWENTY SIX NEW CODES AS GOOD AS THE CORRESPONDING BEST PREVIOUSLY KNOWN
LINEAR BLOCK CODES.
Code No.- of Minimum
Length Message Hamming The First K columns of [H] Matrix in Octal Digits Distance
n K d
8 2 5 17, 63
9 2 6 As above with addition of overall parity check digit
11 4 5 All columns of code (8,2) plus: 125 152
12 4 6 As above with addition of overall parity check digit
17 9 5 All columns of code (11,4) plus: 226 253 333 355 367
18 9 6 As above with addition of overall parity check digit
11 2 7 63 455
12 2 8 As above with addition of overall parity check digit
15 5 7 All columns of code (11,2) plus: 1331 1552 1664
16 5 8 As above with addition of overall parity check digit
23 12 7 All columns of code (15,5) plus: 2353 2561 2635 3174 3216 3447 3722
24 12 8 As above with addition of overall parity check digit
14 2 9 377 7417
15 2 10 As above with addition of overall parity check digit
17 3 9 All columns of code (14,2) plus: 31463
18 3 10 As above with addition of overall parity check digit
20 5 9 All columns of code (17,3) plus: 52525 65252
21 5 10 As above with addition of overall parity check digit
22 6 9 All columns of code (20,5) plus: 113152
58.

TABLE 3.1.2 Continued.
Code Length
No. of Minimum Message Hamming The First K Columns of CH] Matrix in Octal Digits Distance
n K d
23 6 10 As above with addition of overall parity check digit
17 2 11 1777 76037
18 2 12 As above with addition of overall parity check digit.
20 3 11 All columns of code (17,2) plus: 316343
21 3 12 As above with addition of overall parity check digit
23 5 11 All columns of code (21,3) plus: 526554 653265
24 5
12 As above with addition of overall parity check digit
59.

3.2 APPLICATION OF WALSH FUNCTIONS IN CONSTRUCTING LINEAR BLOCK CODES
Lemma 3.2:
If the result of multiplying together two Walsh
functions, Wal(h,9), where Wal(h,e) = Whl' Wh2"." WhL' Wij = amd Wal(k,9), is transformed by replacing all the positive
elements by 0's and the negative elements by l's, then the
subsequent product is identical to that produced by similarly
transforming the original functions and then performing a simple
modulo-2 addition.
Proof:
Since the Walsh functions 1Wal(i,9)1i = 1,2, ...,
(2j- 1), j = 1,2,3, ..., etc.1 form an Abelian group with
respect to multiplication, then the product of two Walsh
functions yields another Walsh function in the group
Wal(h,9) Wa14,9) = Wal(r,9)
where the value of r is equal to the modulo-2 sum of h and(85)
r = h + t
th The j element of Wal(r,9) is given by:
W = W x W . rj hj zj
The multiplication rules are given below:
X +1 -1
+1 +1 -1 -1 -1 +1
The above table is identical to modulo-2 addition, when +1's
are replaced by 0's and -1's are replaced by l's, as shown
below:
60.

Further details of the algebra of Walsh functions can be found
in Harmuth(85)
Theorem 3.2:
If the parity-check matrix EH] of an (n,k) systematic linear binary code, has the first k columns given by the subset
of the Walsh functions of length L, [Walsh, 9) I h = 2J-1, j = 1, 2,3,...,k J, then the code is capable of correcting t = L/4 random errors.
Proof:
Consider the subset V" of k vectors, of the vector
space Vk, such that each vector vEV" corresponds to the binary
representation of the number h = 2j -1, j = 1,2, thooyko This
subset is given below:
h = 1 , 0 0 0 0 0 0 1 i = 1 •
3 0 0 0 0 0 1 1 2
7 0 0 0 0 1 1 1 3
. • •
• . • .
. . . . • •
. • • • . • • . 2k-1 1 1 1 1111 k
It is apparent from the above array that the vectors vEV" are
linearly independent. Now consider the Abelian group of the
Walsh functions fWal(i,(41) 1 1=0,1,2,3,••,(2k_ 1)3 of length L = C2k where C = 1,2,...,etc. Since the vectors v in V" are
linearly independent, it follows from the one to one relationship
between the vectors v and the decimal numbers h that the subset
of tWal(h,9)i where fWal(h,0) (=IWal(1,0i has k linear
61.

independent members which form a basis for the group [Wal(i,9)3.
Since the weight of every Walsh function in the Abelian group
Wal(i,9) is L/2, it follows that every Walsh function resulting
from the linear combination of the members of the subset .XAla.1(h,9)1
are linearly independent of every (L/2)-1 of the remaining (n-k)
columns of the reduced echelon form of the Epli matrix. Hence every L/2 columns of the DC matrix are linearly independent
and according to lemma 3.2, t = (L/2)/2 = L/4 random errors can
be corrected. This completes the proof.
As an example, first consider an (n,k) linear binary
code of k = 2, where the first 2 columns of the [H] matrix are
given by Wal(1,9) and Wal(3,9). Let the length of the Walsh
functions be L = C.2k = 8, whence C = 2, and n-k = L = 8.
From theorem 3.3, the code will correct t = L/4 = 2
random errors. The parity check matrix is given by:
Wal(1,9)
1 0 1 0 0 0 0 0-
1 0 0 loo 0 f o 0
1 1 0 0 1 0 U n o 0
1 1 0 0 0 1 0 4 0 0
0 0 0 0 0 0
ol0000 0 0 1 0
Wal(3,9) Truncated columns
It can be seen that the fifth and sixth digit of Wal(1,9) and
Wal(3,9) are zero, and therefore they can be truncated with no
effect on the error correcting capabilities of the code. Thus
the code has a length n of 8 digits, k = 2, and the minimum
Hamming distance d is 5. The Helgert and Stinaff upper bound
=
Truncated rows
62.

for this code is 5. The truncation of some rows and consequently
all zero columns of the [H] matrix can be generalised by the
following corollary.
Corollary 3.2:
The truncation of the rows, 2 --F 1, 2, ... —+C, 2 ' 2 C = L/2k, and the consequent removal of the C all zero columns
of the parity-check matrix of any (n,k,t) linear binary code
derived by applying theorem 2.1, does not alter the error
correcting capabilities of the code.
Proof:
The Walsh functions of the subset tWal(h,9)1 h= 2' - 1,
j=1,2,...,k1 are all square waves of frequency equal to j Hz and
period L/2j. The minimum period therefore C=L/2k. Since the
Abelian group of Walsh functionstWal(i,9)1 i = 0,1,2,...,(2k-1)}
forms an: orthogonal square matrix of rows IWal(i,9)1 i = 0,1,2,
...,(2k-1)1 and columns of fWal(1,01, with Wal(0,9) appearing
at the mid columns, it follows that all 24- 1, 124 + 2, 2 + C
digits of Wal(1,9), Wal(1,9)EfWal(h,9)111 = 23-1, j = 1,2,...,k1
must be zero. Therefore the truncation of the corresponding C
rows and the consequent removal of the C all zero columns from
the parity-check matrix does not alter the error correcting
capabilities of the (n,k,t) code.
3.2.1 Code Construction and Decoding
Using theorem 3.2 and corollary 3.2, a class of linear
binary codes may be constructed by following steps given below:
i) fix the value of k.
ii) the length L of the Walsh functions to be used is
given by L = C.2k where C = 1,2,3,..., etc:, and must
always be a multiple of 4.
iii) The first k columns of the required parity-check
matrix are given by the subset of Walsh functions
1Wal(h,9)lh = 2j-1, j = 1,2,...,ki.
63.

iv) the error correcting capability of such a code is
given by: t = C.2k-2.
v) finally, truncate the appropriate C digits from each
function in the subset 1Wal(h,4
Table 3.2 shows some codes of this class for k'5-C10.
All (n,k) codes in this class can be decoded by a one
step majority logic algorithm. This can be seen as follows; the
parity-check matrix of the given (n,k) code can be arranged in
the following form:
[ 1
0 0 W1,1 W1,3 W1,(2k-1)
0 1 0 W2,1
W2,3 W2,(2k-1) • •
Da = . . . . . .
• .
• •
Let e = 0' 1, .' el, en-1] be an error pattern. The syndrome corresponding to e is given by:
S = e
=, 0, s 1 s2, sn-k-1]
where,
so = eo + W1,1
en-k + + W1,(2
k-1) en-1
s1 = el
+ W2!1 en-k + + W2'(2
k-1) en-1
8n-k-1= e
n-k-1 + W(L-C),1 en-k
+ + W(L-C1(2k-1) en-1
Consider a check sum A of the syndrome bits:
A = a0 s0 + alsl
+ + an-k-1 sn-k-1
= b0 e0 + blel
+ + bn-1 en-1
where ,a. = 1 or 0, and b1 = 1 or 0. ,A parity check Al will be
said to check an error digitej if e appears in the summation
• • •
•
0 0 1 w(L-C),1
W(L-C),3 w
(L-C),(2/j)
64.

3 0 0 0 1 1 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 7 0 0 1 1 1 0 0 0 0 1 1 1 1 0 0 0 0 1 l 1 1 0 0 0 0 1 1 1 1 0 0 0 0 1 1 1 1
15 0 1 1 1 1 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 l 0 0 1 1 0 0 1 1 311 1 1 1 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 00 1 0 1 0 1 0 1 0 1 0 1
given by Ai with a non-zero coefficient. A set 1.A1 of parity
checks is said to be orthogonal on em if each Ai checks em but
no other error bit is checked by more than one Ai. Each parity
check in an orthogonal set thus provides an independent estimate
of em when the noise bits are statistically independent. If then
there are 2t parity-check sums orthogonal on em, m = n-k, n-k+l,
..., n-1, the value of the error digit em is given as the value
assumed by a clear majority of the parity-check sums orthogonal
on em(7). It is apparent from the characteristics of the subset
tWal(h,G)) as given in tabular form below, that there is a
unique syndrome check digit for each information noise digit.
The functions of the subset tWal(h,9)lh = 2j-1, j = 1,
2, k, k = 5} h are given in decimal and binary notation
below: sib, checks en-1
h so, checks en—k o si ,7);/checks en-2 T7/r)111111111111111110000000000000000
Trunc'tedt sl, checks en-3 s 23 'checks en-4 Column s checks the first information noise digit en-k, and sr,
r0 = -2- +C.2k-m-1, checks the mth, m = 2,3, ..., k, information
noise digit, en-k+m-1. Since the subset {Wal(h,9)Ih = 2j-1,
j = 1,2, ..., kl has a minimum weight of 2t, 2t parity-check
sums orthogonal on each information digit can be formed, and
therefore all codes of this class are completely orthogonisable
in one step.
3.2.2 Remarks
From the above theory and results, we can make the
following remarks.
i) The rows corresponding to 7 + 1, 7 + 2, ..., Ti+ p of the parity-check matrix of any (n,k,d) code of the proposed
65.

•
class, may be deleted; L being the length of the Walsh functions used for the construction of the parity-check matrix. The
punctured code which is produced from such an operation may have
a minimum Hamming distance of d - if p is an even multiple of
the duration of Wal(2k - 1, 9) and if p<27.
The correctness of the procedure given in the above
remark can be shown by considering the Walsh functions matrix
fWal(i,9)1i = 0,1,2, (2k - 1)1 of length L. If the
columns 7 + 1, 7 + 2, ..., 7 + p of the matrix have been deleted the minimum weight of the matrix will be reduced at most by p/2,
providing p is an even multiple of the duration C of the last
row in the matrix Wal(2k-1, 9), and p<217. This can be seen
clearly if we state the fact that the deleted columns of the
matrix are Wal(1,9), Wal(2,9), ..., and Wal(P/C,9). Therefore
the resulting code corresponds to the punctured Walsh function
matrix has a minimum Hamming distance d - P/2. See the proof
of theorem 3.2.
ii) For the case corresponding to k = 1, the codes given
in this paper are repetitive and therefore perfect.
iii) Consider the (n,k,t) codes of the proposed class of
C = 1, where one of the columns of the parity-check matrix EH] is Wal(2k-1,9), which is a square wave of frequency kHz., and
duration one bit. If the complement of Wal(0,8) with the 2 —+ 1
bit is deleted, (Wal*(0,9)) is taken as the column of the EH] matrix of the code, then this column of weight (L-1) is
linearly independent of all the members of the truncated subset
of the Walsh functions fWal(h,O)In = 21-1, j = 1,2, ..., kl.
Moreover, the resulting vectors formed by this linear combination
are of weight 2t or 2t-1 and hence the required conditions of
Lemma 3.1 are satisfied. For example, the codes (n,k,d) of
Table 3.3, (5,2,3), (10,3,5), (19,4,9), (36,5,17), (69,6,3),
(134,7,65), (263,8,12), (520,9,257) and (1033,10,513), can
• 66.

therefore be modified as above to (6,3,3), (11,4,5), (20,5,9),
(37,6,17), (70,7,33), (135,8,65), (264,9,129), (521,10,257) and
(1034,11,513) respectively.
iv) The codes of the proposed class are of low rate and
as n increases to very large values the rate kin tends to zero
and the ratio d/2n tends to 0.25. The method of deriving this
class of codes may be extended to derive a new class of codes
of higher rate and useful characteristics for decoding. Work
in this direction is under way and it is hoped will appear in
future publications. (see section 4)
3.3 APPLICATION OF THE CONCEPT OF ANTICODES
A linear block (m,k,5) anticode over a Galois field
GF(q), forms an array of 2k rows and m columns in which each of
the m columns is some linear combination, (modulo-q), of the
first k, (1c-c.m), columns of the array(86). The anticode has a maximum distance, b, if the distance between any two rows of
the anticode array is less than or equal to 6, and since any
linear anticode forms an algebraic group over GF(q), then 6 is
equal to the maximum weight max of the rows of the array(3).
An anticode is good if it exhibits the least 6 for given m and
k; and said to be non-repetitive if no two columns of the anti-
code array are identical.
Farrell(14,86) was the first to introduce the concept
of anticodes. He suggested that for every good non-repetitive
(m,k,o) anticode,there exists an (n,k,d) good or nearly good
non-repetitive linear code which can be coistructed simply by
deleting the given anticode array from the appropriate m-sequence
code array.
The m-sequence code array is a qk by q
k-1 matrix in
which the first k columns are the information columns, and
each of the remaining qk-1-k columns is some distinct, linear
67.

combination (modulo-q) of the information columns(14)
. The
array can be partitioned into two parts, with one part
consisting of the codewords of a linear non-repetitive (n,k,d)
code, and the other the corresponding (m,k,6) anticode words.
This implies that:
m + n = qk - 1
Since the m-sequence codes are equi-distance codes(3)
of distance equal to qk-1, it follows that:
d + 6 = qk - 1
The object behind this section is the formulation of
a mathematical description of linear anticodes from which a
systematic procedure for the generation of anticodes is estab-
lished.
3.3.1 Matrix Description of Linear Anticodes*
Since an (m,k,15) linear anticode forms an algebraic
group under modulo-q addition", (q being the number of symbols
per sign), then an (m,k,o) linear anticode forms a subspace U
of the vector space Um over GF(q). If a set of the basis
vectors of the subspace U are considered as the rows of a
(k-by-m) matrix DJ, then matrix Di is called the generator matrix of the anticode U. The reduced echelon form of the
matrix [4..] has the form(3): - C Ik b 3 (1)
The matrix Elk] is the identity matrix of order k,
and E] is an arbitrary b-by-(m-k) matrix. The null space U'
of U is a subspace of the vector space Vm(3). A set of basis
vectors from the null space U' of the subspace U can be
considered as the rows of a (m-k)-by-m matrix [Q, the EL]
Since linear anticodes form algebraic groups, their matrix description is similar to that of group codes. The reader is referred to references (3) and (7).
68.

matrix is called the generator matrix of the null space U' or
the parity-check matrix of U. The reduced echelon form of L
has the form(3):
EL: = E-brr lin_k] (2)
where the matrix E-13T] is the transpose of the arbitrary matrix
[-b], and is the identity matrix of the order (m-k).
The parity-check matrix of an anticode can itself be a generator
matrix which generates the dual anticode of the anticode
generated by EC . For simplicity, let us introduce the term "quasi-
linear independence". The r-tuple vectors rl, r2, ri
over GF(q) are quasi-linearly independent if the modulo-q
addition of the scalar products, airi +a2r2+ airi does not
equal zero when the scalars (a., j= 1,2,...,1) may take any
values of the non-zero elements in GF(q). Since there are (q-1)
non-zero elements in GF(q) then the quasi-linear combinations
of the above vectors may have (q-1)1 combination sums, each sum
, resulting in an r-tuple vector over GF(q). If the vectors are
not quasi-linearly independent over GF(q), they are linearly.
dependent over GF(q).
From the above we have the following,
Theorem:
For any (m,k) linear anticode U over GF(q), which
has a parity-check matrix [(], U will have a maximum distance
6 or greater if and only if every combination of 6+i, i = 1,2,
..., m-6, columns of [1.] are quasi-linearly independent.
Proof:
Suppose that some m-tuple vector u, u(311, has a
weight of 6+i, 1=a4;m-O. Since U is a row-space of Ea, and U' is a row-space of [1] and a null space of U, an m-tuple vector such as u is in U if and only if it is orthogonal to
69.

every row of El]. That is to say:
uT
= °
Since u has a weight of 6+i, this specifies a
linearly dependent set of 6+i columns of [i] . Conversely the modulo-q addition of 5+i columns of EL] is equal to the zero vector which contradicts the conditions of the theorem. There-
fore, we conclude that for the condition of the theorem to be
fulfilled there must be no m-tuple vector in U of weight
greater than 6.
3.3.2 A S stematic Procedure of Generatin Linear Anticodes
Consideration of the above theorem suggests the
following systematic procedure for the construction of an
(m,k,6) anticode over GF(q) for given values of 6 and (m-k). The
columns of the [U matrix can be determined as follows: start
with the identity matrix of order (m-k). The (m-k+1)th column
is chosen arbitrarily from the vector space Vm_k over GF(q),
subject only to the condition that the chosen column must not
be the inverse of any of the vectors obtained from the quasi-
linear combinations of every 6+1, i = 0,1,...,(m-k) of the
previously chosen columns. The inverse of a vector r over
GF(q) is that vector which when added (modulo-q) to r results in th a zero vector. Similarly the j column is chosen so that it is
different from the inverse of any of the vectors obtained from
the quasi-linear combinations of every 6+i, i = 0,1,...,j-1 of
the previously chosen columns. This method of generation
guarantees the required independence of columns specified in
the theorem. As long as the set of all these inverse vectors
does not include all the (m-k)-tuple vectors, another column
can be added. This process of building up the L-matrix will,
therefore, continue until all the (m-k)-tuple vectors are
exhausted. The anticode is the null space of this (m-k)-by-m
matrix IX] .
70.

Using the properties of the parity-check matrix EL: for linear anticodes established above, a computerised search procedure
for new binary linear anticodes can be developed to generate
new anticodes. Such new anticodes may in turn lead to new
linear block codes.
3. TWO PROCEDURES OF LINEAR BLOCK CODE MODIFICATION
3.4.1 Introduction
In a communication system employing coding as a means
of error correction or detection, the usual constraint on the
choice of linear block code for use in such a system is that the
block length n or the number of information digits k must take
some specific value. Any arbitrary value of k or n may be
achieved in principle by some appropriate procedure whereby an
already existing code may be modified to have the desired value
of k or n.
The techniques by which codes may be modified to
generate new codes can be grouped into six basic categories.
These techniques in the past have been referred to in a variety
of ways: Berlekamp(3), however, adopted a unified approach and
classified them under the headings of extension, lengthening,
puncturing, shortening, augmentation and expurgation.
The first of these methods, code extension, involves
the annexation of extra check digits to the code. An example
of this technique is the construction of even Hamming distance
codes by annexing an overall parity-check digit to the approp-
riate linear block codes of odd Hamming distance. Another useful
example of code extension is given by Andryanov and Saskovets(87),
in which BCH codes are extended by annexing a number of parity
check digits in such a way that the minimum Hamming distance of
the given code is improved by at least a factor of 2.
71.

A second technique, puncturing, involves deleting
check digits from the code. In general, if one punctures p
digits from a linear binary code of length n and minimum
Hamming distance d, then the punctured code may have a minimum
distance as low as d-p(3). However, Solomon and Stiffler(88)
derived some good linear codes by puncturing subspaces of a
maximal-length shift-register code. If j subspaces, each with
corresponding dimensions 21, where i = 1,2,...,j, are punctured
from a maximal-length shift-register code of length n and
minimum Hamming distance d, then the newly formed code has a
length of En - (2Qi_1X] and a minimum Hamming distance
1=1 2..-1 given by [d - t (2 1 ).j. Farrell(86) generalised the Solomon
i-1 and Stiffler puncturing procedure by introducing the concept of
anticodes. Farrell establishes that for every good non-repetitive
anticode there exists a good or nearly good non-repetitive linear
code which can be constructed simply by deleting the given anti-
code array from the appropriate maximal-sequence code array.
The third method can be described as code augmentation(3)
If new codewords are added to a code, then the code is said to
be augmented. The effect of this operation is to increase the
rate, while maintaining the block length constant. Goldberg(90)
proposed an augmentation technique in which he improves the rates
of a few existing codes, while maintaining the minimum Hamming
distance constant:
A fourth procedure entails the expurgation of code-
words from the code. The expurgated codes thus formed always
have a rate lower than the original code but may have an increased
minimum distance. The most common expurgated code is the one
expurgated by g(x)(x-1). In the binary case, the codeword of
this expurgated code are the even-weight codewords of the
original code(3)
72.

Lengthening codes by the annexation of more message
digits constitutes a fifth procedure by which codes may be
modified. The resulting lengthened codes have higher rates
than the original code, but, as a consequence, the minimum
Hamming distance may be decreased. The technique of lengthening
has not yet been used in algebraic coding theory in any non-
trivial way(3).
The last technique of code modification is the short-
ening of codes by omitting message digits. These resulting
codes have a rate lower than the original code and the minimum
distance in general does not alter. In practice this technique is
often used for cyclic codes to achieve simplicity of implementation
Davida and Reddy(91) proposed a code modification
procedure which was based on a combination of puncturing columns
and rows from the parity-check matrix of an (n,k,d) linear block
code in such a way that the resulting punctured code has a 1+ minimum distance of dT —. The new modified t-error-detecting code,
- where t= d21-, is used for communication over a noisy channel. When
t or less errors are detected, a single request is made via a
feedback channel for transmission of the punctured parity check
digits to enable the decoder to correct t or less errors. This
method of puncturing codes is not applicable to all (n,k) linear
codes. However, it is shown that the following families of
codes may be punctured by the above suggested procedure:
Single-error-correcting Hamming codes(30), Reed-Solomon codes
(50)
the Golay (23,12) code(31), and a class of extended BCH codes
(Davida(93)).
The object of this section is to introduce two technique
of code modification which are extensions of the above discussed
procedures. These techniques lead to some new codes of high
rate.
• 73.

•
3.4.2 Linear Block Code Puncturing Procedures
A linear (n,k) error-correcting code is a set of qk
n-tuples that forms a subspace V of the vector space Vn over a
field of q elements. The code can be described in terms of a
k-by-n generator matrix a], whose rows are linearly independent
and form a basis for the code. For a systematic code, the
generator matrix [G] has the form given by:
. 1 bk,1 bk,2 .. .. .
.
.
.
. bk,(n-k)
•
.
[ .
.
.
. . 0 b1,1 b1,2 b1,(n-k)— •
. 0 b2,1
b2,2 . b2,(n-k)
0
.
.
•
. .
.
.
.
0 .
DJ = lo.
1 .
.
.0
.
where EIk is the identity matrix of order k and Chi is an arbitrary k-by-(n-k) matrix.
The null space of [CO, VI is a set of qn-k n-tuples
which is generated by an (n-k)-by-n parity check matrix pa,
whose rows are linearly independent and form a basis for v's
The null space V in its own right forms a linear (n,n-k) code
referred to as the dual of the (n,k) code V. The weight
distribution of the dual code is a function of the weight
distribution of the original code. The form of this function
is governed by the MacWilliams(94) identities.
The parity check matrix DJ of a systematic code is
always of the form:
-b1,1 -b2,1 . .
- -b1,2 -b2,2 . .
. .
. -bk,1 1 0 . .
• -bk,2 0 1. .
. • •
Eg3 = E:1::9Q . . • • .
-b1,(n-k) -b2,(n-k) -bk,(n-k 0 0 1
• .
74.

41
where C-1311 is the negative transpose of the matrix El)] , and
[In-kI is the identity matrix of the order (n-k).
A linear (n,k) code is saidtohaveaminimum Hamming
distance d if and only if every d-1 columns of its parity-check
matrix EH] are linearly independent(13)
It follows from the above description of linear block
codes that if one punctures any number of columns of the parity-
check matrix [H] of an (n,k) code, then the resulting punctured
matrix retains the same column independence. The row independ-
ence, however, may be altered unless the punctured columns are
carefully chosen.
ith Now consider the case of deleting the . row of the
parity-check matrix Ea and all the corresponding columns which contain a non-zero element in the i
th position. Since all the
columns of the original [0 matrix which have not been deleted
have a zero element in the ith position, the conditions for
column independence in the newly formed punctured matrix EH''.] are identical to those in the original Eta matrix. And since
only one column in the identity matrix EIn_kj of the NI matrix has a non-zero element in the ith position, then all n-k-1 rows
of the punctured matrix LW] are linearly independent.
ith Let the . row of the matrix have a weight y;
then the punctured (n-y, k-y+1) code, which is the null space
of the punctured (n-y)-by-(n-k-1) matrix [HI], has a minimum
distance identical to that of the original (n,k) code.
In general, if the J1, J2, ...., Jx rows (where J
J2, ...., Jx are the row location numbers) are deleted from the
parity-check matrix of an (n,k,d) code together with all the
corresponding y columns containing at least one non-zero
element at the position Jl, J2, ...., Jx, then the resulting
75. "

matrix DV] has (n-k-x) linearly independent rows and (n-y) columns having an independence identical to that of the
original Ell:1 matrix. The null space of the punctured parity matrix EH'] forms an (n-y, k+x-y, d) linear block code.
For example, consider the parity-check matrix al] of a three error correcting (15,5) binary BCH code, with a
generator polynomial:
g(x) 1 + x + x2 4. x4 .4. x5 x8 x 10
The parity-check matrix as is given by:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
ELO =
1 0 1 0 1 1 0 0 0 0 0 0 0 0 0 1
1 1 1 1 1 0 1 0 0 0 0 0 0 0 0 2
1 1 0 1 0 0 0 1 0 0 0 0 0 0 0 3
0 1 1 0 1 0 0 0 1 0 0 0 0 0 0 4
1 0 0 1 1 0 0 0 0 1 0 0 0 0 0 5
1 1 1 0 0 0 0 0 0 0 1 0 0 0 0 6
0 1 1 1 0 0 0 0 0 0) 0 1 0 0 0 7
0 0 1 1 1 0 0 0 0 0 0 0 1 0 0 8
1 0 1 1 0 0 0 0 0 0 0 0 0 1 0 9
0 1 0 1 1 0 0 0 0 0 0 0 0 0 1 10
The punctured code may be generated by deleting
columns 1, 3, 5 and 6. This will leave row 1 with all zeroes,
which in turn can be deleted. The newly formed punctured matrix
0-111 is thus:
1 1 1 0 0 0 0 0 0 0 0
1 1 0 1 0 0 0 0 0 0 0
1 0 0 0 1 0 0 0 0 0 0
0 1 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0
1 1 0 0 0 0 0 1 0 0 0
0 1 0 0 0 0 0 0 1 0 0
0 1 0 0 0 0 0 0 0 1 0
1 1 0 0 0 0 0 0 0 0
76.
Cr] =

The null space of EH'j is a linear systematic (11,2)
code with a minimum Hamming distance of 7. Note that the Helgert
and Stinaff(68)
upper bound on d for an (11,2) code is 7.
The rate of the newly found punctured code will be
highest when the weight of the deleted row is lowest. Since
the rows of the parity-check matrix [1J are codewords of the
(n,n-k) dual of the original (n,k) code, the lowest weight y
of those rows cannot be less than the minimum Hamming distance
of the (n,n-k) dual code.
This provides a bound on the lowest number of columns
of the matrix DO that must be deleted to form a new punctured
code.
Binary BCH codes of length 255 and 511, and of
various error-correcting capabilities ranging from 6 to 14
random errors were punctured in accordance with the above
procedure and the best punctured codes were computed in each
case. From these codes listed in Table 3.5.1 seventeen were
found to be better than the best previously known codes of
identical Hamming distance and the same number of parity check
digits. For ease of comparison the parameters (n,k,d) of the
original and the resulting punctured codes are tabulated in=
Table 3.5.1 side by side with those of the best previously
known codes. These parameters are taken from a table of binary
codes of highest known rate published in 1972 by Sloane(15)
Appendix 2 contains a typical computer programme to
generate the [U] matrix of a given (n,k) BCH code and to
determine the row of the generated Da matrix which has the lowest weight. Then the punctured code parity check matrix
is printed out.
77.
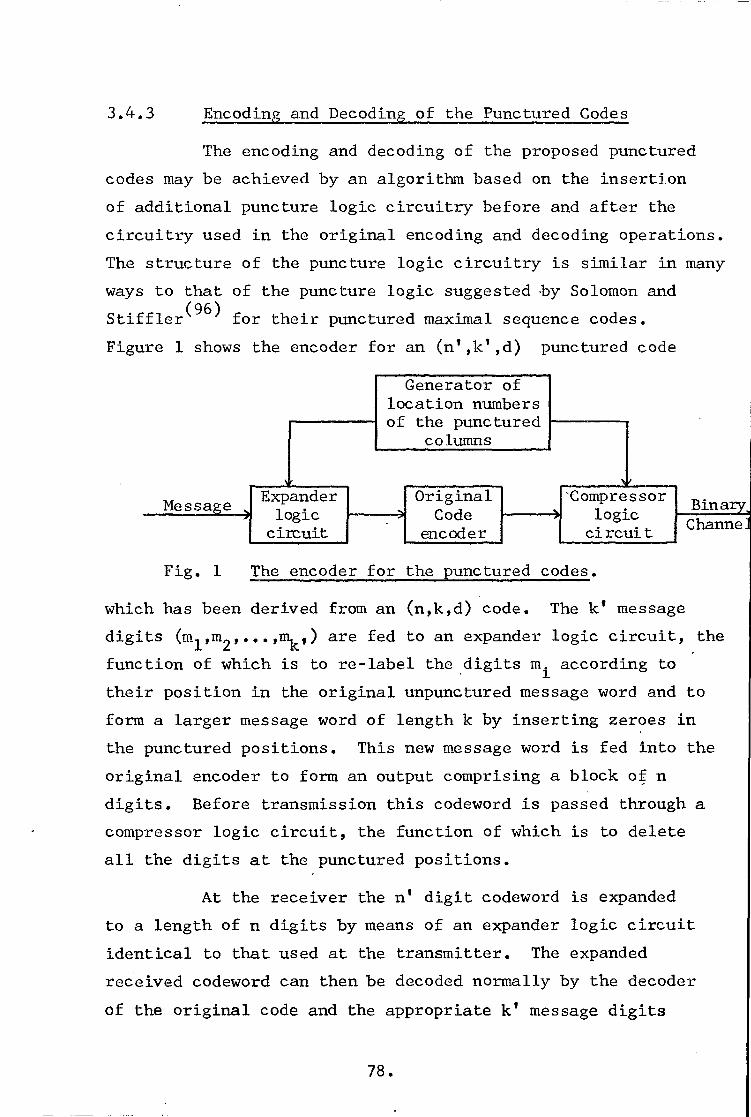
Message Expander logic circuit
3.4.3 Encoding and Decoding of the Punctured Codes
The encoding and decoding of the proposed punctured
codes may be achieved by an algorithm based on the insertion
of additional puncture logic circuitry before and after the
circuitry used in the original encoding and decoding operations.
The structure of the puncture logic circuitry is similar in many
ways to that of the puncture logic suggested by Solomon and
Stiffler(96)
for their punctured maximal sequence codes.
Figure 1 shows the encoder for an (n',k',d) punctured code
Generator of location numbers of the punctured
columns
Original Code
encoder
`Compressor logic circuit
Binary, Channel
Fig. 1 The encoder for the punctured codes.
which has been derived from an (n,k,d) code. The k' message
digits (ml,m2,...,mk,) are fed to an expander logic circuit, the
function of which is to re-label the digits mi according to
their position in the original unpunctured message word and to
form a larger message word of length k by inserting zeroes in
the punctured positions. This new message word is fed into the
original encoder to form an output comprising a block of n
digits. Before transmission this codeword is passed through a
compressor logic circuit, the function of which is to delete
all the digits at the punctured positions.
At the receiver the n' digit codeword is expanded
to a length of n digits by means of an expander logic circuit
identical to that used at the transmitter. The expanded
received codeword can then be decoded normally by the decoder
of the original code and the appropriate k' message digits
78.

recovered by passing the output of the original code decoder
Generator of location numbers of the punctured
columns
Message
kl
Received
Expander logic
circuit -->
Original Code
decoder
Compressor logic
circuit Codeword
Fig. 2 The Decoder for the Punctured Codes.
through a compressor logic circuit identical to that used at
the transmitter. This operation is illustrated in Figure 2.
3.4.4 A Technique for Lengthening Linear Block Codes
The parity-check matrix [H] of an (n,k,t) linear
block code V consists of n columns, each column being an (n-k)-
tuple vector of the vector space Vn_k. The code can be
lengthened by one information digit while still retaining its
error-correcting capability, if and only if there exists a
vector v in Vn-k which is linearly independent of every (2t-1)
columns of D-]. This vector v can then be considered as a new
additional column of Da. Most of the best known codes, however,
cannot be lengthened in this manner because there is no vector v,
v€1.7n-k which satisfies the required conditions of independence.
The lengthening of linear block codes may be viewed in
a different way. Consider the D:1 matrix of an (n,k,t) linear code, where Di is given by:
aaT
I -111_0
Each column of the E-bT1 matrix is identical to the syndrome
vector which is obtained when an error occurs in the information
digits at that column position. Similarly each column of the
identity matrix Eln-k 3 is identical to the syndrome vector
79.

corresponding to an error occurring in the parity-check digit
at that column position. This implies that the code is capable
of correcting t random errors if and only if the linear
combinations of every t column vectors in Di] give unique
nonzero vectors in Vn-k
(89). Consequently it can be lengthened
by one information digit if there exists a vector v in Vn_k
such that all the linear combinations of v with (t-1) columns
of Eu] give unique nonzero vectors in Vn-k.
Let us consider a vector u1 in the vector space Vn-k such that all the linear combinations of u-1 with (t-1) columns
of the E-bril matrix give unique nonzero vectors in Vn-k.
Similarly all the linear combinations of ul with (s-1) of the
remaining columns of DJ yield additional unique nonzero
vectors in Vn-k'
where s is an integer such that 1<s<t. Now
let us construct a parity-check matrix Dqj such that:
3 uTIH] C T bT I I 1 E-1 - u I1 -
The null space of matrix [H1] is an (n+1, k+1) code.
Since alf the linear combinations of the t columns of [HI]
which contain at least one column of matrix E-brr] give a
unique nonzero vector in Vil-k and since all the linear
combinations of s columns of Di3 give unique vectors, it
follows that every 2t columns of [a1] containing at least one
column of E-hT] are linearly independent and similarly every
2s columns of cy1 3 are linearly independent(89). This implies
- that the (n+1, k+1) linear code is capable of correcting t
random errors or less if at least one of these occurs in the
block of k message digits and s random errors or less if none
of the'errors occur in any of the k message digits.
The (n+1, k+1) code can be lengthened further by
finding another vector u2 in the vector space Vn_k which is
subjected to the same independence conditions with respect to
80.

matrix EH1 as exist between vector u1 and matrix D]. This - procedure for building up the lengthened code may be continued
until the maximum possible number of vectors u , u fL 1 -2' le
are found. The newly constructed Dk':I matrix is therefore given by:
T D]
rie
T. T T 1 1121111 I I In-k]
And thus the null space of [pic,] is the lengthened
(n+k', k+k', t and s) code, where t and s indicate that the
code is capable of correcting t random errors or less if at
least one of these occurs in the first block of k information
digits and s random errors or less if none of the errors occur
in any of the k message digits.
For example, consider the lengthening of the two-
error correcting (15,7) BCH code. The Do matrix of this code is:
1 0 1 0 0 0 1 0 0 0 0 0 0 0
0 1 1 0 1 0 0 0 1 0 0 0 0 0 0
0 0 1 1 0 1 0 0 0 1 0 0 0 0 0
0 0 0 1 1 0 1 0 0 0 1 0 0 0 0
1 1 0 1 1 1 0 0 0 0 0 1 0 0 0
0 1 1 0 1 1 1 0 0 0 0 0 1 0 0
1 1 1 0 0 1 1 0 0 0 0 0 0 1 0
1 0 1 0 0 0 1 0 0 0 0 0 0 0 1
A computer search used to find all possible vectors
of the vector space V8 which satisfy the condition set by the
lengthening procedure; s was taken to be 1. Four vectors were
found. The Eti4 matrix of the lengthened code (15+4, 7+4, 2
and 1) has the form given below:
81.

k—Ds-TsJ * Ca3 )1
0 0 0 0 0 0 0 1
E11 4]
S
r
0 1 1 1 1 1 0 1 0 0 0 1 0 0 0 0 0 0 1 0 1 I 0 1 1 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 1 0 1 0 0 0 1 0 0 0 0 1 1 0 1 0 0 0 1 1 0 1 0 0 0 1 0 0 0 0 0 0 0 1 1 0 1 1 1 0 0 0 0 0 1 0 0 0 0 0 0 0 1 1 0 1 1 1 0 0 0 0 0 1 0 0 0 0 0 1 1 1 0 0 I 1 0 0 0 0 0 0 1 1 1 1 0 1 0 1 0 0 0 1 0 0 0 0 0 0 0
Five linear codes with the highest rate for given
block length and error-correcting capability were lengthened
in accordance with the above procedure. The parameters (n,k,t)
of these codes are listed in Table 3.4.4 together with the
parameters (n+k', k+k', t and s) of the modified codes. The
first k columns of the parity check matrix of each original
code are also tabulated in Octal, where the first digit in
each column designates the least significant digits of the
Octal number. In the last column of the table the new columns
are given also in Octal.
Appendix 2 contains a typical computer programme to
determine all possible vectors of the vector space Vn_k which
satisfy the conditions set by the lengthening procedure for a
given (n,k) linear block code.
82.
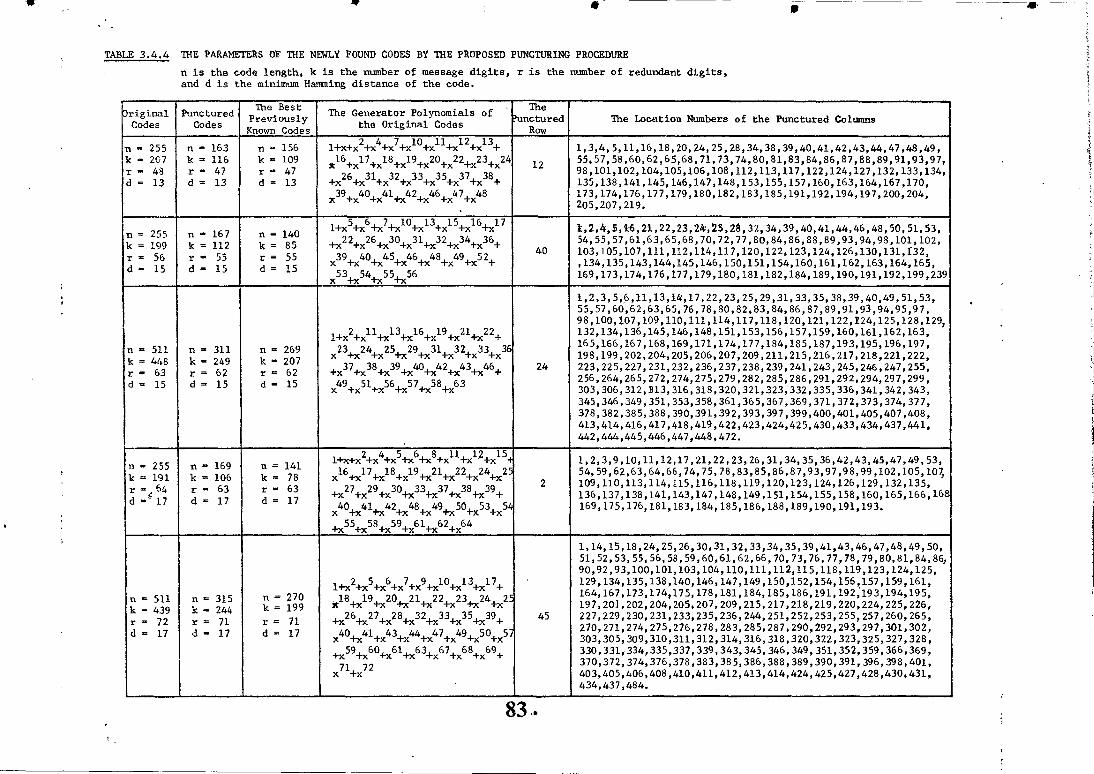
TABLE 3.4.4 THE PARAMETERS OF THE NEWLY FOUND CODES BY THE PROPOSED PUNCTURING PROCEDURE
n is the code length, k is the number of message digits, r is the number of redundant digits, and d is the minimum Hamming distance of the code.
3riginal Codes
Punctured Codes
The Best previously
Known Codes the Original Codes
The Generator Polynomials of , The
• .uncturea Row
The Location Numbers of the Punctured Columns
n = 255 k - 207 r = 48 d = 13
n = 163 k = 116 r = 47 d = 13
n = 156 k - 109 r = 47 d = 13
1+x+x2+x4+x7+x10+x1141(12+x13+ 16 17 18 19 20 22 23 24 x +x +x +x +x +x +x +x
+x26 +x31 +x32 +x33 +x35 +x37 +x38+
39+x 40+x 41+x 42+x 46+x 47+x 48 x •
12
1,3,4,5,11,16,18,20,24,25,28,34,38,39,40,41,42,43,44,47,48,49, 55,57,58,60,62,65,68,71,73,74,80,81,83,84,86,87,88,89,91,93,97, 98,101,102,104,105,106,108,112,113,117,122,124,127,132,133,134, 135,138,141,145,146,147,148,153,155,157,160,163,164,167,170, 173,174,176,177,179,180,182,183,185,191,192,194,197,200,204, 205,207,219.
n = 255 k = 199 r = 56 d = 15
n = 167 k = 112 r = 55 d = 15
n = 140 k = 85 r = 55 d = 15
5 7 10 13 15 16 17 1+x +x +x +x +x +x +x +x
22 26 30 31 32 34 36 +x +x +x +x +x +x +x + 39 40 45 46 48 49 52 x +x +x +x +x +x +x +
x5354
+x55+x56
40
1,2,4,5,16,21,22,23,24,25,2S,32,34,39,40,41,44,46,48,50,51,53, 54,55,57,61,63,65,68,70,72,77,80,84,86,88,89,93,94,98,101,102, 103,105,107,111,112,114,117,120,122,123,124,126,130,131,132, ,134,135,143,144,145,146,150,151,154,160,161,162,163,164,165, 169,173,174,176,177,179,180,181,182,184,189,190,191,192,199,239
n = 511 k = 448 r = 63 d = 15
n = 311 k - 249 r = 62 d = 15
= n 269 k = 207 r = 62 d = 15
2+x + 11 13+x 16+x 19+x 21+x 22+
1+x x
23 24 25 29 31 32 33 36 x +x +x +x +x +x +x +x
+x 37+x 38+x 39+x 40+x 42+x 43+x 46+
x49+x
51+x56+x57+x58+x63
•
24
1,2,3,5,6,11,13,14,17,22,23,25,29,31,33,35,38,39,40,49,51,53, 55,57,60,62,63,65,76,78,80,82,83,84,86,87,89,91,93,94,95,97, 98,100,107,109,110,111,114,117,118,120,121,122J24,125,128,129, 132,134,136,145,146,148,151,153,156,157,159,160,161,162,163, 165,166,167,168,169,171,174,177,184,185,187,193,195,196,197, 198,199,202,204,205,206,207,209,211,215,216,217,218,221,222, 223,225,227,231,232,236,237,238,239,241,243,245,246,247,255, 256,264,265,272,274,275,279,282,285,286,291,292,294,297,299, 303,306,312,313,316,318,320,321,323,332,335,336,341,342,343, 345,346,349,351,353,358,361,365,367,369,371,372,373,374,377, 378,382,385,388,390,391,392,393,397,399,400,401,405,407,408, 413,414,416,417,418,419,422,423,424,425,430,433,434,437,441, 442,444,445,446,447,448,472.
n = 255 = k 191
r =464 d = 17
n = 169 k = 106
d r = 63 = 17
n = 141 k = 78 r = 63 d = 17
1+x+x2+x4+x5+x6+x8+x11+x12+x15+
16+x 17+x
18+x
19+x
21+x
22+x 24+x 25 x 27 29 30 33 37 38 39 +x +x +x +x +x +x +x + 40+x 41+x 42+x 48+x 49+x 50
+x 53+x 54 x
+x55+x58+x59+x61+x62+x64
2
1,2,3,9,10,11,12,17,21,22,23,26,31,34,35,36,42,43,45,47,49,53, 54,59,62,63,64,66,74,75,78,83,85,86,87,93,97,98,99,102,105,107, 109,110,113,114,115,116,118,119,120,123,124,126,129,132,135, 136,137,138,141,143,147,148,149,151,154,155,158,160,165,166,16: 169,175,176,181,183,184,185,186,188,189,190,191,193.
n = 511 k = 439 r = 72 d = 17
n = 315 k = 244 r = 71 = d 17
n = 270 k = 199
r = 71 d = 17
1+x2+x5+x6+x7+x9+x10+x13+x17+ 18 19 20 21 22 23 24 25 X +x +x +x +x +x +x +x 26+x 27+x
28+x 32+x 33+x 35+x 39+ +x 40 41 43 44 47 49 50 57 x +x +x +x +x +x +x +x
+x 59+x 60+x+ 61 63+x 67+x 68+x 69+ x
x71+x72
•
45
1,14,15,18,24,25,26,30,31,32,33,34,35,39,41,43,46,47,48,49,50, 51,52,53,55,56,58,59,60,61,62,66,70,73,76,77,78,79,80,81,84,86, 90,92,93,100,101,103,104,110,111,112,115,118,119,123,124,125, 129,134,135,138,140,146,147,149,150,152,154,156,157,159,161, 164,167,173,174,175,178,181,184,185,186,191,192,193,194,195, 197,201,202,204,205,207,209,215,217,218,219,220,224,225,226, 227,229,230,231,233,235,236,244,251,252,253,255,257,260,265, 270,271,274,275,276,278,283,285,287,290,292,293,297,301,302, 303,305,309,310,311,312,314,316,318,320,322,323,325,327,328, 330,331,334,335,337,339,343,345,346,349,351,352,359,366,369, 370,372,374,376,378,383,385,386,388,389,390,391,396,398,401, 403,405,406,408,410,411,412,413,414,424,425,427,428,430,431, 434,437,484.
w
83 .
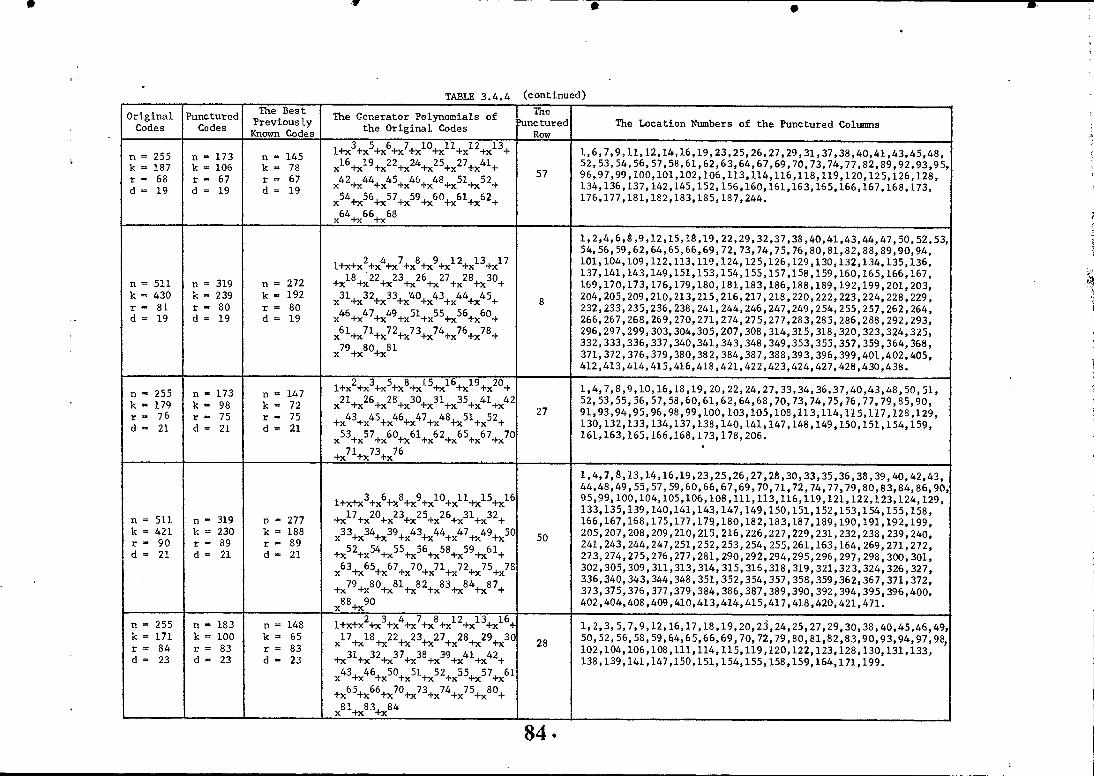
TABLE 3.4.4 (continued)
Original Codes
Punctured Codes
e Best PreTh
Y viousl Known Codes
The Generator Polynomials of 1
the Original Codes
e -3unct
Thured
Row The Location Numbers of the Punctured Columns
n = 255 k = 187 r 68 d = 19
n = 173 k = 106 r = 67 d = 19
n = 145 k = 78 r = 67 d = 19
1+x3+x5+x6+x7+x10+x11+x12+x13+ 16 19 22 24 25 27 41 x +x +x +x +x +x +x + 42 44 45 46 48 51 52 x +x +x +x +x +x +x + 54+x 56+x 57+x 59+x 60+x 61+x62+ x
x64+x66+x68
57
1,6,7,9,11,12,14,16,19,23,25,26,27,29,31,37,38,40,41,43,45,48, 52,53,54,56,57,58,61,62,63,64,67,69,70,73,74,77,82,89,92,93,95, 96,97,99,100,101,102,106,113,114,116,118,119,120,125,126,128, 134,136,137,142,145,152,156,160,161,163,165,166,167,168,173, 176,177,181,182,183,185,187,244.
n = 511 k = 430 r = 81 d = 19
n = 319 k = 239 r = 80 d = 19
n = 272 k = 192 r = 80 d = 19
1+x+x2+x4+x7+x8+x9+x12+x13+x17
18 22 23 26 27 28 30 +x +x +x +x +x +x +x + 31 32 33 40 43 44 45 x +x +x +x +x +x +x +
x46
+x47
+x49
+x51
+x55
+x56
+x60
+ 61 71 72 73 74 76 78 x +x +x +x +x +x +x +
x79+x80+x81
8
1,2,4,6,8,9,12,15,18,19,22,29,32,37,38,40,41,43,44,47,50,52,53, 54,56,59,62,64,65,66,69,72,73,74,75,76,80,81,82,88,89,90,94, 101,104,109,112,113,119,124,125,126,129,130,132,134,135,136, 137,141,143,149,151,153,154,155,157,158,159,160,165,166,167, 169,170,173,176,179,180,181,183,186,188,189,192,199,201,203, 204,205,209,210,213,215,216,217,218,220,222,223,224,228,229, 232,233,235,236,238,241,244,246,247,249,254,255,257,262,264, 266,267,268,269,270,271,274,275,277,283,285,286,288,292,293, 296,297,299,303,304,305,207,308,314,315,318,320,323,324,325, 332,333,336,337,340,341,343,348,349,353,355,357,359,364,368, 371,372,376,379,380,382,384,387,388,393,396,399,401,402,405, 412,413,414,415,416,418,421,422,423,424,427,428,430,438.
n = 255 k = 179 r - 76 d = 21
n - 173 k = 98 r = 75 d = 21
n = 147 k = 72 r = 75 d = 21
1+x2+x3+x5+x8+x15+x16+x19+x20+
21+x
26+x
28+x 30+x 31+x
35+x 41+x 42 x
43 45 46 47 48 51 52 +x +x +x +x +x +x +x + 53+x 57+x 60+x
61+x 62+x 65
+x 67+x 70 x
+x71+x73+x76
27
1,4,7,8,9,10,16,18,19,20,22,24,27,33,34,3637,40,43,48,50,51 , , 52,53,55,56,57,58,60,61,62,64,68,70,73,74,75,76,77,79,85,90, 91,93,94,95,96,98,99,100,103,105,108,113,114,115,117,128,129, 130,132,133,134,137,138,140,141,147,148,149,150,151,154,159, 161,163,165,166,168,173,178,206.
•
n = 511 k = 421 r - 90 d = 21
n = 319 k = 230 r = 89 d = 21
n = 277 k = 188 r = 89 d = 21
1+x+x3+x6+x8+x9+x10+x11
-Ic15+x16
17 20 23 25 26 31 32 +x +x +x +x +x +x +x + 50 x 33+x 34+x 39+x 43+x 44+x 47+x 49+x
52 54 55 56 58 59 61 +x +x +x +x +x +x +x + 63+x 65+x 67+x 70+x 71+x 72+x 75+x
78 x 79 80 81 82 83 84 87 +x +x +x +x +x +x +x +
x88+x90
50
1,4,7,8,13,14,16,19,23,25,26,27,28,30,33,35,36,38,39,40,42,43, 44,48,49,55,57,59,60,66,67,69,70,71,72,74,77,79,80,83,84,86,90, 95,99,100,104,105,106,108,111,113,116,119,121,122,123,124,129, 133,135,139,140,141,143,147,149,150,151,152,153,154,155,158, 166,167,168,175,177,179,180,182,183,187,189,190,191,192,199, 205,207,208,209,210,215,216,226,227,229,231,232,238,239,240, 241,243,244,247,251,252,253,254,255,261,163,164,269,271,272, 273,274,275,276,277,281,290,292,294,295,296,297,298,300,301, 302,305,309,311,313,314,315,316,318,319,321,323,324,326,327, 336,340,343,344,348,351,352,354,357,358,359,362,367,371,372, 373,375,376,377,379,384,386,387,389,390,392,394,395,396,400, 402,404,408,409,410,413,414,415,417,418,420,421,471.
n = 255 k = 171 r = 84 d = 23
n = 183 k = 100 • r = 83 d = 23
n = 148 k = 65 r = 83 d = 23
1+x+x2+x3+x4+x7+x8+x12+x13+x16+
17 18 22 23 27 28 29 30 x +x +x +x +x +x +x +x 31 32 37 38 39 41 42 +x +x +x +x +x +x +x + 43 46 50+x 51+x +x55 +x57 +x
52 55 57 61 x43 +x46 +x 65 66 70 73 74 75 80 +x +x +x +x +x +x +x +
x81+x83+x84
28
1,2,3,5,7,9,12,16,17,18,19,20,23,24,25,27,29,30,38,40,45,46,49, 50,52,56,58,59,64,65,66,69,70,72,79,80,81,82,83,90,93,94,97,98, 102,104,106,108,111,114,115,119,120,122,123,128,130,131,133, 138,139,141,147,150,151,154,155,158,159,164,171,199.
84 •

• 0
TABLE 3.4.4 (continued)
Original Codes
Punctured Codes
e Best PreThviously Known Codes
The Generator Polynomials of the Original Codes
e ' nct
Thured
Row The Location Numbers of the Punctured Columns
n = 511 k = 412 r = 99 d = 23
n = 319 k = 221 r = 98 d = 23
n = 278 k = 180 r = 98 d = 23
1+x6+x9+x10+x
11+x14+x15+x18+
19+x 20+x 22+x
23+x 24
+x 25+x 26+ x 27 28 30 31 32 33 37 x +x +x +x +x +x +x + 38 39 42 43 46 48 51 x +x +x +x +x +x +x +
x52 +x53 +x54 +x56 +x60 +x61 +x66
+ 71+x 74+x 76+x 77+x 78+x 84+x 85+ x 87 89 90 91 92 93 94 x +x +x +c +x +x +x +
x96+x97+x99
19
1,3,7,8,10,11,12,13,15,17,18,19,21,22,25,27,29,31,32,34,35,36, 38,39,40,42,44,45,47,48,49,51,54,56,59,60,61,62,65,69,72,75,76, 77,78,82,84,85,86,87,92,96,97,98,105,106,108,110,111,115,117, 119,120,123,124,125,128,130,134,140,141,144,145,148,149,150, 157,162,165,168,171,175,177,178,184,185,186,188,189,191,192, 195,197,199,200,207,213,215,219,220,221,224,226,230,231,235, 238,239,240,242,243,244,245,248,250,253,255,257,262,263,267, 268,270,272,278,282,284,288,289,291,293,294,301,302,304,308, 309,311,317,318,320,323,324,325,326,328,329,333,334,335,336, 337,341,345,350,352,355,357,358,359,361,362,363,364,366,367, 369,370,373,374,375,378,380,382,385,390,391,393,394,396,397, 399,400,402,403,404,407,408,409,411,412,431.
n = 255 k = 163 r = 92 d = 25
n = 181 k = 90 r = 91 d = 25
n = 149 k = 58 r = 91 d - 25
1+x7 +x
8 +x11 +x12 +x15 +x17 +x
20 +x22 24 25 26 29 30 31 32
+x +x +x +x +x +x +x +
x33 +x35 +x36 +x39 +x41
+x42
+x44 +x46
52 53 54 56 S7 58 59+ 6
+x +x +x +x +x +x +x x 69+x +x72 +x74 +x75 +x80 +x 71 72 74 75 80 87+x 89 x
+x90+x91+x92
26
1,3,4,7,9,13,14,16,19,22,27,28,32,33,34,36,37,38,40,42,44,46, 47,48,49,52,53,54,55,57,59,61,64,65,72,73,74,75,82,83,85,86,88, 95,101,102,103,107,110,116,118,120,123,125,126,127,130,133,137, 138,140,147,148,150,151,152,154,155,157,158,159,160,163,189.
n = 511 k = 403 r = 108 d = 25
n = 327 k = 220 r = 107 d = 25
n = 279 k = 172 r = 107 d = 25.:
1+x3+x5+x7+x8+x
9+x
10+x16+x18+
21+x
23+x
25+x
26+x
29+x 31
+x 33+x 34 x 35 36 37 38 39 41 43
+x +x +x +x +x +x +x +
x 44+x 46+x 47+x 49+x 51+x 52+x 53+x 55
58 59 60 61 62 63 66 +x +x +x +x +x +x +x +
x 69+x 70+x 72+x 73+x 74+x 75+x 77+x 79
80 81 82 87 88 91 92 +x +x +x +x +x +x +x + 93+x 94+x 98+x 99+x 100+x 102+x 103 x
x104+x105+x
107+x108
10
1,3,7,10,13,15,16,17,19,25,28,29,31,35,38,40,43,44,45,50,52, 57,58,59,60,67,69,70,71,73,80,83,86,87,89,91,92,93,94,95,96,7,98 99,100,102,104,105,110',112,117,119,121,123,124,125,126,129,130, 131,132,133,134,137,138,139,140,145,148,149,152,155,157,260, 163,166,168,171,173,174,177,179,182,183,185,187,192,194,196, 199,201,202,203,204,209,213, 214,215,216,217,223,225,227, 230,232,243,246,247,248,249,252,256,257,261,262,268,269,273, 274,275,276,277,282,289,290,291,295,298,303,304,305,308,310, 311,313,315,317,319,321,322,326,327,328,331,336,1340,343,345, 346,347,348,349,350,354,355,356,357,362,364,365,366,367,371, 373,374,375,377,378,380,381,382,383,384,386,387,388,389,390, 394,396,398,400,403,413.
n = 255 k = 155 r = 100 d = 27
n = 187 k = 88 r = 99 d = 27
n = 165 k = 66 r = 99 d = 27
1+x+x3+x4+x7+x8+x
9+x10+x11+x12
13 14 16 17, 20 22 23 26 x +x +x +x +x +x +x +x
28 29 33 35 37 40 42 +x +x +x +x +x +x +x + 43 44 45 47 48 54 56 58 x +x +x +x +x +x +x +x
59 61 62 63 64 65 71 +x +x +x +x +x +x +x + 72 74 81 82+x 84+x
87+x 89+x 90 x72 +x74 +x +x 91 92 93 95 96 97 98 +x +x +x +x +x +x +x +
x99+x100
8
1,2,4,6,10,11,12,16,20,22,24,28,33,36,37,39,40,41,45,47,49,50, 52,53,56,58,59,63,66,68,69,74,79M,81,83,86,87,89,92,94,100, 104,108,109,112,113,119,123,125,127,131,134,135,139,141,143, 144,145,146,147,148,150,151,152,153,155,163.
85 .
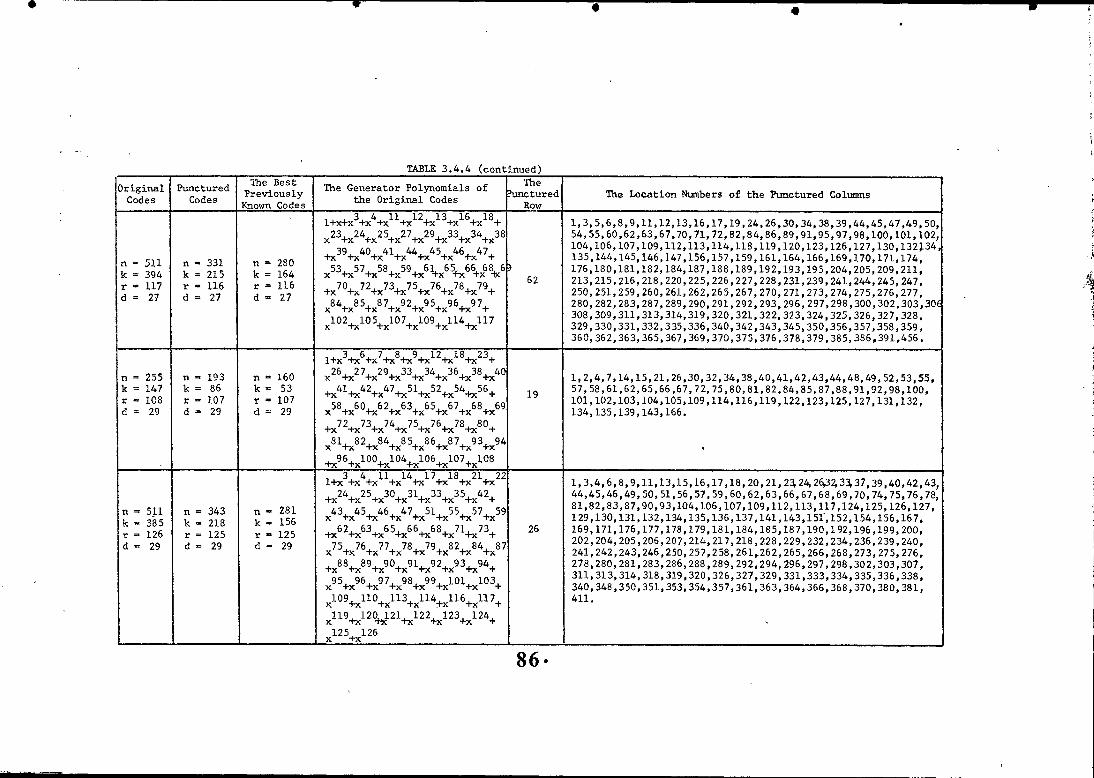
TABLE 3.4.4 (continued)
Original Codes
Punctured Codes
e Best PreThviously Known Codes
The Generator Polynomials of the Original Codes
e Punct
Thured
Row The Location numbers of the Punctured Columns
n = 511 k = 394 r = 117 d = 27
n = 331 k = 215 r = 116 = d 27
n = 280 k = 164 r = 116 d = 27
1+x+x3+x4+x
11+x12+x13+x16+x18+
23+x 24+x 25+x 27+x 29+x 33+x 34+x 38 x 39 40 41 44 45 46 47 +x +x +x +x +x +x +x + 53+x 57+x 58+x
59+x 61+x 65+x 66+x iK
68 69 x 70 72 73 75 76 78 79 +x +x +x +x +x +x +x + 84+x 85+x 87+x 92+x 95+x 96+x 97+ x
x102
+x105
+x107+x109
+x114
+x117
62
1,3,5,6,8,9,11,12,13,16,17,19,24,26,30,34,38,39,44,45,47,49,50, 54,55,60,62,63,67,70,71,72,82,84,86,89,91,95,97,98,100,101,102, 104,106,107,109,112,113,114,118,119,120,123,126,127,130,132p4, 135,144,145,146,147,156,157,159,161,164,166,169,170,171,174, 176,180,181,182,184,187,188,189,192,193,195,204,205,209,211, 213,215,216,218,220,225,226,227,228,231,239,241,244,245,247, 250,251,259,260,261,262,265,267,270,271,273,274,275,276,277, 280,282,283,287,289,290,291,292,293,296,297,298,300,302,303,306 308,309,311,313,314,319,320,321,322,323,324,325,326,327,328, 329,330,331,332,335,336,340,342,343,345,350,356,357,358,359, 360,362,363,365,367,369,370,375,376,378,379,385,386,391,456.
n = 255 k = 147 r = 108 d = 29
n = 193 k = 86 r = 107 d = 29
n = 160 k = 53 r = 107 d = 29
1+x3+x6+x7+x8+x9+x12+x18+x23+
8 x26 +x27 +x29 +x33 +x34 +x36 +x3 +x40
+x 41+x 42+x 47+x 51+x 52+x 54+x 56+ 58 60 62 63 65 67 68 69 x +x +x +x +x +x +x +x 72 73 74 75 76 78 80
+x +x +x +x +x +x +x + 81+x +x 82 84+x 85+x 86+x 87+x 93+x 94 x
+x96+x100+x104+x106+x107+x108
19
1,2,4,7,14,15,21,26,30,32,34,38,40,41,42,43,44,48,49,52,53,55, 57,58,61,62,65,66,67,72,75,80,81,82,84,85,87,88,91,92,98,100, 101,102,103,104,105,109,114,116,119,122,123,125,127,131,132, 134,135,139,143,166.
.
n = 511 k = 385 r = 126 d = 29
n = 343 k = 218 r = 125 d = 29
n = 281 k - 156 r = 125 d - 29
3 4 11 14 17 18 21 22 1+x +x +x +x +x +x +x +x 24+x
25+x 30+x 31+x 33
+x 35+x 42+ +x 43 45 46 47 51 55 57 59 x +x +x +x +x +x +x +x 62+x 63+x 65+x 66+x 68+x 71+x 73+ +x
75 76 77 78 79 82 84 87 x +x +x +x +x +x +x +x 88+x 89+x 90+x 91+x 92+x 93+x94+ +x 95 96 97 98 99 101 103 x +x +x +x +x +x +x +
x109+x110
+x113+x114
+x116+x117
+ 119 120 121 122 123 124
x125-1-x126
x +x 4tt +X +x +x
+
26
411.
1,3,4,6,8,9,11,13,15,16,17,18,20,21,23,24,26,32,3137,39,40,42,43, 44,45,46,49,50,51,56,57,59,60,62,63,66,67,68,69,70,74,75,76,78, 81,82,83,87,90,93,104,106,107,109,112,113,117,124,125,126,127, 129,130,131,132,134,135,136,137,141,143,151,152,154,156,167, 169,171,176,177,178,179,181,184,185,187,190,192,196,199,200, 202,204,205,206,207,214,217,218,228,229,232,234,236,239,240, 241,242,243,246,250,257,258,261,262,265,266,268,273,275,276, 278,280,281,283,286,288,289,292,294,296,297,298,302,303,307, 311,313,314,318,319,320,326,327,329,331,333,334,335,336,338, 340,348,350,351,353,354,357,361,363,364,366,368,370,380,381,
86.

•
TABLE 3.4.4 THE PARAMETERS OF THE NEWLY FOUND CODES GENERATED BY THE PROPOSED LENGTHENING PROCEDURE
n is the code length, kr is the number of message digits, t is the error-correcting capability of the first k message digits, and s is the error-correcting capability of the annexed k message digits.
Original Codes
(n,k,t) (n+k',k+k',t
Lengthened Codes
&- s) The first k columns of CA in Octal The new k' columns in Octal
7, 1, 2 17, 1 + 10, 2 & 1 17. 23,25,26,43,45,46,61,62,64,70.
12, 4, 2 20, 4 + 8, 2 & 1 17,63,25,152. 26,203,205,206,221,222,224,230.
14, 6, 2 20, 6 + 6, 2 & 1 17,63,125,152,226,253. 114,214,314,310,320,340.
15, 7, 2 19, 7 + 4, 2 & 1 321,163,346,35,72,164,350. 13,203,211,212.
18, 9, 2 25, 9 + 7, 2 & 1 17,63,125,152,226,253,333,355,367. 403,405,406,421,422,424,430.

4. A NEW CLASS OF NESTED LINEAR BLOCK CODES AND THEIR NESTED DECODING ALGORITHM
4.1 Introduction.
4.2 The Construction of Nested Codes.
4.3 The Nested Decoding Algorithm.
4.4 Features and Merits of the Nested
Decoding Algorithm.
88.

4.1
INTRODUCTION
A large volume of research in coding theory has
concentrated on searching for codes that have sufficiently well
defined mathematical structures so as to facilitate their encoding
and decoding with equipment of moderate complexity and cost. In
general the overall objective of the effort is to incorporate
the ideas of Shannon(103-4) into the design of engineering
systems in such a way that the improvement in performance
justifies the extra cost and complexity(1). Since Berlekamps(3)
decoding algorithm for BCH codes, (the complexity of which
increases as the square of the number of errors to be corrected),
no major work has been published on the subject of simplifying
the complexity of the necessary decoding procedures for linear
block codes.
In this section a new class of multiple error-correcting
linear block codes is introduced. The codes of this class,
referred to as nested codes, cover a wide range of code lengths
and rates. An (n,k) linear block code is said to be a nested
code if and only if its syndrome, corresponding to errors in the
k information digits, are codewords of either a nested or a
Hamming code.
The decoding algorithm of a nested code, referred to as
the nested decoding algorithm, is shown to be very simple, its
complexity increasing only linearly with code length and error-
correcting capability. The essence of this algorithm is as
follows:-
Consider an (n1, k1, t) nested code. Its syndromes,
corresponding to errors in the kl information digits, are code-
words of a second(n1-k1, k2, t-1) nested code. In addition, the
syndromes of this second nested code, corresponding to errors in
89.

the k2 information digits, are codewords of a third (n1-k1-k2'k3' t-2) nested code. This process of building up a nest of codes
may be continued until the (t-1)th nested code. Its syndromes,
corresponding to errors in the kt-1 information digits, are
codewords of an (ni-ki-k2-....-kt_i, kt, t-(t-1)) single error-
correcting Hamming code. It follows that there is a nest of t
syndromes for every codeword of an (n1, kl, t) nested code
corrupted by noise. And for every (n,k,t) nested code there is
a corresponding nest, referred to as the (n;k;t) nest, of t
codes. The (n,k,t) code forms the outer code of the nest, whilst
the Hamming code forms the inner code. The other (t-2) codes are
obviously nested codes.
ith syndrome of the nest is calculated according to the
i th
parity-
check equations of the (n1-k1-...-k.1-1' k.,t+l-i) nested
code of the(nl' .k1 ;0 nest.
. A codeword vector of an (n k t) l' J' nested code corrupted by noise
nl-tuple I - 1 nf 1 k1 I k vector I 1
I Syndrome Corresponding nested code n2-tuple I I k0 1st (n1, k1, t) vector 1'
I
vector I n-tuple
I I i ka] ' 2nd (n1-k1, k2, t) v
1 .
I nt-tuple 7-6 I vector (n
t-1' kt-1'2)
nt+1-tuple tth vector LI (nt, kt)
Figure 4.1. THE SYNDROMES NEST OF AN n1 -TUPLE VECTOR.
Figure 4.1. shows a nest of an nctuple vestor. The
90.

The (t-1)th syndrome of the above nest may be an
nt-tuple vector which forms a codeword, corrupted by noise,
of an (nt' kt) double error-detecting and single error-correcting
cyclic Hamming code (or shortened version of it) which is
very easily decodable particularly by error trapping techniques.
This implies that all the first nt digits of the original code
can be easily cleared of errors. It is also shown that the
remaining (n1 -nt) digits of the corrupted codeword v can be
cleared of errors as easily as the first nt digits by using
the nested characteristics of the other codes of the (n •k • t)
nest.
91.

4.2 THE CONSTRUCTION OF NESTED CODES
An (n,k) linear block code is by definition a sub-
space V of the vector space Vn over a field of q elements.
The code V is a rowspace of its generator matrix Ed], whose k rows are the basis vectors of V. For a systematic code, the
generator matrix EGD has the form given by:
CG] = [Ikib] where DIJ is the identity matrix of order k and Lb] is an arbitrary k-by-(n-k) matrix.
The null space of DI VI , is a set of qn-k n-tuples,
which is generated by an (n-k)-by-n parity check matrix 1.7A, whose rows are linearly independent and form a basis for V'.
The reduced echelon form of [H] is given by:
CH] = E-bT 11.11_0 The reduced echelon form of the parity-check matrix
[H] of an (n,k) nested code may be constructed by using two
known error-correcting codes (see Figure 4.2.1), the first being
an (ni, kl) linear block code or nested code, and the second an
(n2, k2) nested code. The procedure of construction can be
described in the following steps:-
- ki
Da k2=n1-k1
The parity-check matrix of the first (n1,1(1) linear block code
EIn_kj CHID = E-bT, I ini__1(i] Parity-check digits generated byl the second (n2,k2) nested code.
k
2=11-
.NC
Figure 4.2.1 THE CONSTRUCTION or THE PARITY-CHECK MATRIX OF AN (n, k) NESTED CODE
k=n1
>n-
92.

•
(i) The last (n-k) columns of the DI:1 matrix form an identity matrix of order (n-k), [In_k] •
(ii) The first k columns of the first (nl-k1) rows of the
parity check matrix [H], form the parity-check matrix [H1] of the first (ni,ki) linear block code (i.e. ni = k).
(iii) Take each of the columns of the [H1] matrix as a block of k2 information digits of the second (n
2,k2) nested
code, (i.e. k2 = n1-k1), and then generate the corresponding
n2-k2 parity check digits of the second (n2,k2) code to form
the remaining (n-k)-(nl-k1) digits of each of the first k
columns of the pci matrix (i.e. n2 = n-k).
The null space of the constructed parity-check matrix
Da is an (n,k) nested code. The validity of this statement
can be shown by the following argument.
Since each of the k columns of the Da matrix is a codeword of the second (n2,k2) nested code, and since (n2,k2)
is a linear code (i.e. the modulo-q addition of any two code-
words of the code is also a codeword of the code), the (n-k)-.
tuple vectors resulting from the linear combination of the
first k columns of the EH] matrix are therefore codewords of the (n2, k2
) nested-code. Now consider the syndromes which
correspond to errors in the k information digits of an (n,k)
Linear block code. These syndromes are (n-k)-tuple vectors
resulting from the linear combination of the first k columns
of the parity-check matrix or conversely they are codewords
of the (n2, k2) nested code. The resulting (n,k) linear block
code is therefore, by definition, a nested code.
The Hamming distance of the resulting (n,k) nested
code is determined by the following:
93.

Lemitia 4.2.1
A block code that is the null space of a matrix [H]
has a minimum Hamming distance, d, if and only if the linear
combination of every (d-1) columns of the [H] matrix is linearly
independent ()
Theorem 4.2.1
An (n,k) nested code derived from two codes, the
first being a (k, k1) block code and the second a (n-k, k-k1)
nested code, has an odd minimum Hamming distance, d, if the
minimum Hamming distances of the first and second codes are d
and d-1 respectively.
Proof:
Consider the parity-check matrix Era of the (n, k)
nested code which is given by:
[H] = E.-13TI/n_k3
The first (k-k1) digits of each column of E-1311 matrix
is a column of the parity-check matrix [H1] of the (k,k1) block
code. Since the (k,k1) block code has a maximum Hamming distance,
d, it follows that the linear combination of every d-f column of
[-bill is linearly independent.
The vectors resulting from these linear combinations
are codewords of the (n-k, k-k1) nested code and they are all
non-zero vectors. Since the minimum Hamming distance of the
(n-k, k-k1) nested code is d-1, the minimum weight of these
vectors is d-1. It follows that the vectors resulting from
the linear combination of every (d-1) columns of the E.-01
matrix are linearly independent of every (d-2) columns of the
identity matrix Hence every d-1 columns of the [H]
• 94.

1 1 1 0 1
1 1 0 1 0
1 0 1 0 0
1 0 0 1 0
0 1 1 0 0
0 1 0 1 0
0 0 1 1 0
DO
matrix are linearly independent and according to Lemma 4.2.1
the minimum Hamming distance of the (n,k) nested code is d.
This completes the proof.
4.2.1 Double error-correcting nested codes
An (n,k) nested code, of minimum Hamming distance
equal to five, may be constructed by using for the first code
the best known block error-correcting code for a given number
of parity-check digits and with a minimum Hamming distance
equal to five and an appropriate double error-correcting and
single error-correcting Hamming code or its shortened version
as the second code.
For example, consider the construction of a nested
binary code from the (11,4) Slepian(105) block code of minimum
Hamming distance equal to five, and the shortened double-error
detecting and single error-correcting (12,7) Hamming code.
The parity-check matrix of the derived (23,11) nested code may
be constructed as follows:-
The [H1:1 matrix of the Slepian (11,4) double error-
correcting code is given by:-
0 0 0 0 0 0
1 0 0 0 0 0
0 1 0 0 0 0
0 0 1 0 0 0
0 0 0 1 0 0
0 0 0 0 1 0
0 0 0 0 0 0
The generator polynomial of the (12,7) shortened
Hamming code () is given by:-
95.

g(x) = x5 + x4 + x2 + 1.
The codeword of the (12,7) code corresponding_to the
information given by the seven digits of the first column of the
Ey1:1 matrix of Slepian code is:- x11
+ x10 + x
9 +x8 + x
2 + x
The eleven codewords corresponding to the information
pattern given by the eleven columns of the Slepian code EHJj matrix may be determined in a similar manner. The parity-check
matrix [H] of the (23,11) nested code is given by the eleven
columns which are identical to the calculated codewords of the
(12,7) code and the 12th order identity matrix EI12D. The EH3 matrix therefore has the form:
MN/
1 1 1 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1101010 0 0 0 0 010 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0110 0 0 0 010 0 0 0 0 010 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 010100110110 0 0 0 0 0 010 0 0 0 0 1 1 1 1 0 1 0 1 1 0. 0 0 0 0 0 0 0 0 1 0 0 0 1 1 0 0 1 1 0 1 0 1 1 0 0 0 0 0 0 0 0 0 1 0 0
1 0 0 1 1 1 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 1 0
2 1 1 1 o 1 1 o 1 1 1 o 0 o o o o o o o o o
Table4.2.1provides a list of double error-correcting
nested codes derived from the best previously known binary
(n,k) block codes of parity-check digits from five to twenty
digits. The parameters and the generator polynomial of the
required double error-deteCting and single error-correcting
Hamming code are also tabulated.
96.
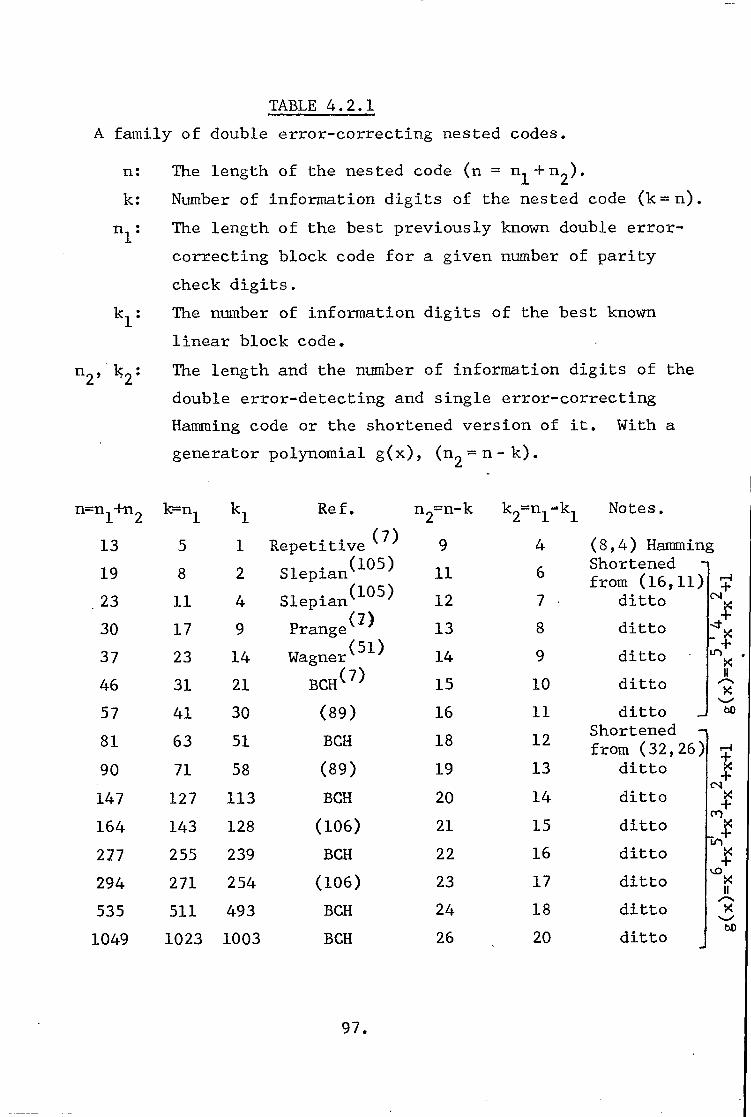
n=n1+n2 k=n1 k1 Ref. n2=n-k k2=n1
13 5 1 Repetitive (7) 9 4
19 8 2 Slepian(105) 11 6
23 11 4 Slepian(105) 12 7
30 17 9 Prange(7) 13 8
37 23 14 Wagner(51) 14 9
46 31 21 BCH(7) 15 10
57 41 30 (89) 16 11
81 63 51 BCH 18 12
90 71 58 (89) 19 13
147 127 113 BCH 20 14
164 143 128 (106) 21 15
277 255 239 BCH 22 16
294 271 254 (106) 23 17
535 511 493 BCH 24 18
1049 1023 1003 BCH 26 20
Notes.
(8,4) Hamming Shortened -from (16,11)
ditto
ditto
ditto Shortened from (32,26)
ditto
ditto
ditto
ditto
ditto
ditto
ditto
ditto
ditto
TABLE 4.2.1
A family of double error-correcting nested codes.
n: The length of the nested code (n = n1+n2).
k: Number of information digits of the nested code (k=n).
n1: The length of the best previously known double error-
correcting block code for a given number of parity
check digits.
k1: The number of information digits of the best known
linear block code.
The length and the number of information digits of the
double error-detecting and single error-correcting
Hamming code or the shortened version of it. With a
generator polynomial g(x), (n2=n-k).
97.

4. 2 . 2 Multi le error-correcting nestecicacies
An (n,k) nested code capable of correcting t random
errors or less (where t>2) may be constructed by using the
best previously known block codes of the required number of
parity check digits and also capable of correcting t random
• errors. The second code is the appropriate t-detecting and
(t-1)-correcting nested code.
Table 4.2.2 provides a list of three-error-correcting
nested codes. The first group of codes contains the best
previously known block codes capable of correcting three errors,
and the second group os codes are the nested codes of Table 4.2.1
or their shortened version with the addition of an overall parity-
check digit to each of them.
Similarly, the parameters of the nested codes capable
of correcting four random errors are calculated and then
tabulated in Table 4.2.3. The parameters of those capable of
correcting five errors are tabulated in Table 4.2.4.
This procedure can be applied to generate nested
codes for various values of rates and error-correcting
capabilities.
98.

TABLE 4.2.2
A family of three-error correcting nested codes.
Notations are similar to those of Table 4.2.1.
(n1k1)
(n2k2)
The best previously known three-error correcting block codes.
Three-error detecting and double-error correcting nested codes of Table 4.2.1 with the addition of an overall parity-check digit.
n=n1+n2 k=n1 k1 Ref. _ n2 k2=n1-k1 Notes
24 7 1 Repetitive () 18 6 From (19,8)°
33 11 2 Slepian (105) 22 9)
38 15 5 BCH 23 10) Short (24,11)
47 23 12 Golay(7) 24 11 From (23,11)
58 30 16 Karlin(47) 28 14) Short (31,17)
63 34 19 (89) 29 15)
96 63 45 BCH 33 18) 106 121
72 86
53 66
(89) (89)
34 35
19) 20)
Short (38,23)
163 127 106 BCH 36 21)
181 143 120 (106) 38 23 From (37,23)
298 255 231 BCH 43 24) 331 287 261 (106) 44 26) Short (47,31) 556 511 484 BCH 45 27) From (46,31) 1069 1023 993 BCH 46 30)
99.
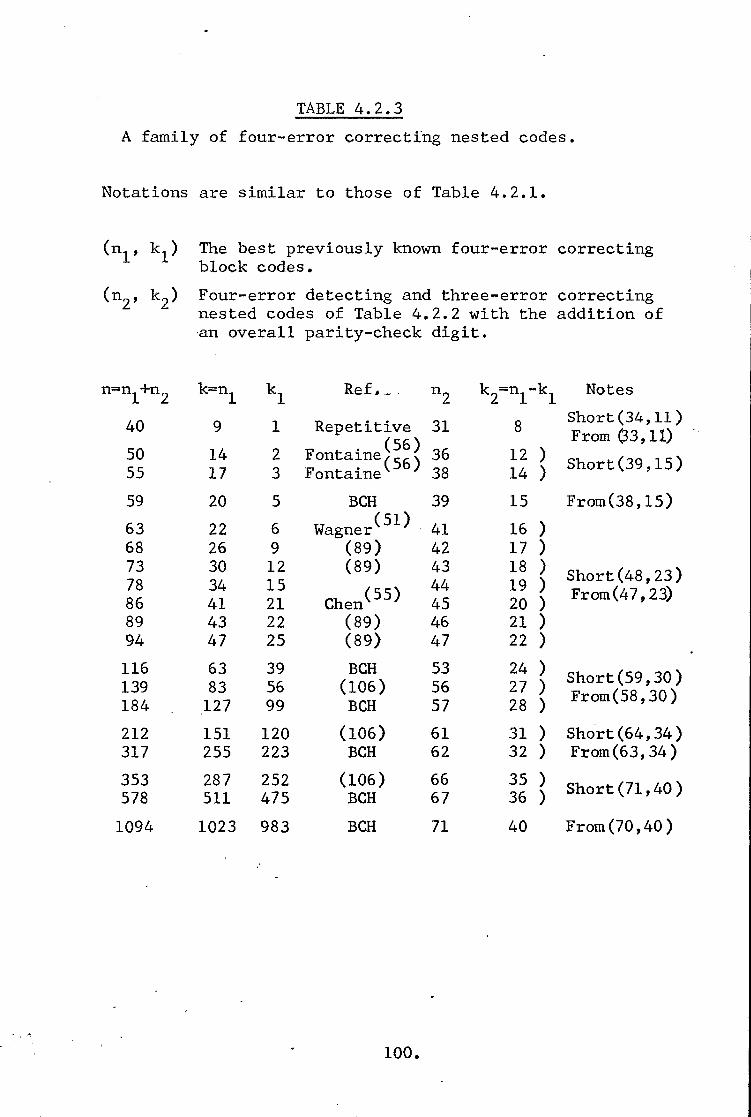
TABLE 4.2.3
A family of four-error correcting nested codes.
Notations are similar to those of Table 4.2.1.
(n1, k1) The best previously known four-error correcting block codes.
(n2, k2) Four-error detecting and three-error correcting nested codes of Table 4.2.2 with the addition of an overall parity-check digit.
n=n1-f-n.2
40
50 55
59
63 68 73 78 86 89 94
116 139 184
212 317
353 578
1094
k=n1
9
14 17
20
22 26 30 34 41 43 47
63 83 127
151 255
287 511
1023
k1
1
2 3
5
6 9 12 15 21 22 25
39 56 99
120 223
252 475
983
Ref._
Repetitive
Fontaine(56) (56) Fontaine
BCH
Wagner(51) (89) (89)
Chen (89) (89)
BCH (106) BCH
(106) BCH
(106) BCH
BCH
n2
31
36 38
39
41 42 43 44
46 47
53 56 57
61 62
66 67
71
45 45
k2=n1-k1
8
12 ) 14 )
15
16 ) 17 ) 18 ) 19 ) 20 ) 21 ) 22 )
24 ) 27 ) 28 )
31 ) 32 )
35 ) 36 )
40
Notes
Short (34,11) From (33,11)
Short(39,15)
From(38,15)
Short(48,23) From(47,23)
Short(59,30) From (58,30)
Short(64,34) From(63,34)
Short(71,40)
From(70,40)
100.
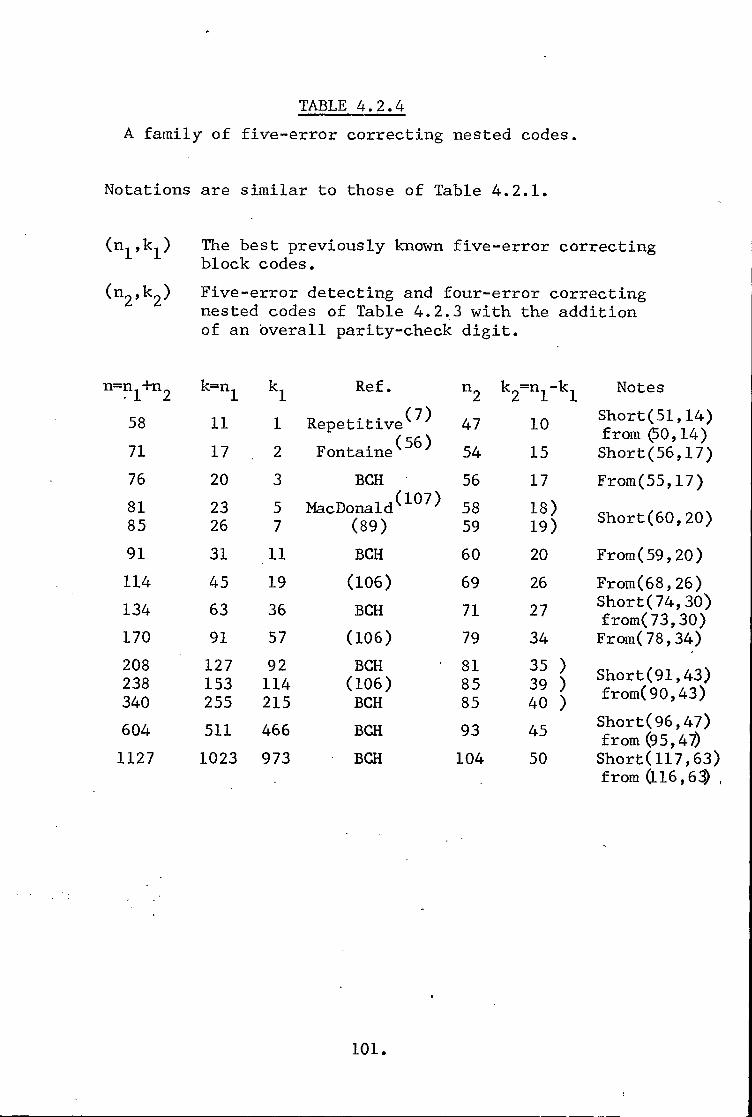
Short(51,14) from (50,14)
15 Short(56,17)
17 From(55,17)
Short(60,20)
20 From(59,20)
26 From(68,26) Short(74,30) from(73,30)
34 From(78,34)
35 ) 39 ) 40 )
45
10
18) 19)
27
Short(91,43) from(90,43)
Short(96,47) from (95,47)
50 Short(117,63) from (116,61) ,
•
TABLE 4.2.4
A family of five-error correcting nested codes.
Notations are similar to those of Table 4.2.1.
(nk1) The best previously known five-error correcting block codes.
(n2,k2) Five-error detecting and four-error correcting nested codes of Table 4.2.3 with the addition of an overall parity-check digit.
n=n +n 1 2
k=n1 k1 Ref. n
2 k2=n1-k1 Notes
58 11 1 Repetitive(7) 47
71 17 2 Fontaine(56) 54
76 20
3 BCH 56
81 23
5 MacDonald(107) 58 85 26
7 (89) 59
91 31 11
BCH
60
114 45 19
(106)
69
134 63 36
BCH
71
170 91 57
(106)
79
208 127 92
BCH
' 81 238 153 114 (106)
85
340 255 215
BCH
85
604 511 466
BCH
93
1127 1023 973
BCH
104
101.

4.3 THE NESTED DECODING ALGORITHM
We shall now examine the decoding procedure for the
previously proposed nested codes. For this purpose consider an
(n,k,d) nested code over a field of q elements derived from an
(k, k1, d) block code and (n-k,
k-k1, d-1) nested code.
The parity-check matrix [H1] of the (k, kl, d) block
code can be arranged in the following form:
1 0 0 0 . . . 0 al,r+1 a1,r+2 a1,r+3 • . . al,k 0 1 0 0 . . . 0 a2,r+1 a2,r+2 ,a2,r+3 • • ' a2,k 0 0 1 0 . . . 0 a3,r+1 a3,r+2 a3,r+3 • • . a3,k • .
[Hi] • • •
• . •
• • • •
0 0 0 0 . . . 1 ar,r+1 ar,r+2 ar,r+3 • . . ar,k
wherer=k-kl anda..ij may have any value of the q-elements of
the field.
Let the parity-check digits of a codeword in the
(n-k, k-k1, d-1) nested code corresponding to the information
digits given by the ith column of [Hi] matrix, al,i a2,1 a3,1
.. ar,i, be given by the digits Cr+1,i Cr+2,i Cr+3, i Cn-k,i'
Thus the parity-check matrix of the (n,k,d) nested code can be
arranged in the following form:-
1 0 0 1 0 0 . • . 0 0 0 0 0 0
• 0 0
0 0 1
0 0 0
0
0 . . 0 . . 0 . .
0 . . 0 . 0 .
0 .
. 0 1 0 0 0 . . .
. 0 0 _ 1 0 0 . . .
. 0 0 0 1 0 . . . . .
• •
• •
. 0 0 0 0 0 • • • . . 0 .
Cr+1,1Cr+1,2 Cr+1,3 cr+1,4 "
. . 0 . Cr+Z1Cr+2,2 Cr+2,3 Cr+2,4 ' ' . .
• •
. . . . 1 . . .
Cn-k,1%-k,2cn-k,3Cn-k,4 •
0 a a1,r+1 a1,r+2 1,r+3 ' • a a 0 2,r+1 a2,r+2 2,r+3 • •
0 a3,r+1 a3,r+2 a3,r+3 ' •
• 1 ar,r+1 ar,r+2 ar,r+3 • • C • Cr+1,r Cr+1,r+1 cr+1,r+2 Cr+1,r+3 • . Cr+2,r Cr+2,r+1 r+2,r+2 Cr+2,r+3 •
. Cn -k,r cn-k,r+1 cn-k,r+2 Cn-k,r+3 •
• al,k • a2,k • a3,k
• ' • ar,k • r+1 k . C ' r+2,k .
. Cn-k,k
=141 11 ] n- C . Irk]
2 [..1 ---- n-k C
102 .

•
1
Let e = [el e3 e ] be an error pattern. The digits (e 1 2 3 .•. n 1, e2 ... en-k) e •.. e are parity error digits and en-k+1' en-k+2' n are information error digits. The syndrome corresponding to
error pattern e is:
ss 1 2 s3 sn-kJ
= [eJ COI The above equation yields the following syndrome bits:
s1=e1
+dn-k+1 +a1,r+1en-k+r+1+...+a1,k en
s2= e2 en-k+2 +a2,r+1en-k+r+1+...+a2,k en s3= e3 en-k+3 -F - 4...+a a3,r+1en-k+r+1 3,k en
sr- er
en-k+r+ar,r+1en-k+r+1+...+ar,k en
e ...+ Sr+1= r+1 +Cr+1,1en-k+1+ Cr+1,ken
e Sr+2 r+2 ... +Cr+2,1en-k+1+ 1-Cr+2,ken
• •
en -k,1e+ ...+ Sn-k= n-k+1 n-k Cn-k,ken
Each bit of the syndrome is a modulo-q addition of certain error
digits given by one of the above (n-k)-syndrome equations.
However, if the information digits are free of errors (i.e.
= en-k+1 en-k+2 = = en = 0) then the (n-k)-tuple vector s is
given by:
s = Eel e2 e3 . . . en-k] This implies that the syndrome vector s is identical to the error
pattern e or conversely, for a t-error correcting code, the
syndrome vector which corresponds to.a pattern of t errors or
103.

less in the parity check digits is of weight t or less. Then,
any other syndrome vector corresponding to other correctable
errors pattern is of weight greater than t.
Since the (n-k) rows of the Da matrix are linearly
independent, the (n-k) syndrome-equations are also linearly
independent. This suggests that if the code rate is 50% or •
less (i.e. the number of information error digits is less than
or equal to the total number of syndrome equations), and if
the parity check digits are free of errors (i.e. el = e2 = e3 = .
= en-k = 0), the numerical values of the information error
digits, en-k+1 en-k+2
en, correspond to the solution of k
of the (n-k) syndrome equations.
Theorem 4.3.1
In an (n,k) nested code over a field of q elements,
which is capable of correcting t-random errors and derived from
two codes, the first a (k, kl, d) block code, and the second an
(n-k, k-k1, d-1) nested code, no syndrome which corresponds to
t errors or less and involves at least one of the parity check
digits is a codeword of the (n-k, k-kl, d-1) nested code.
Proof
Consider a syndrome vector, s, of the (n,k) nested
code, which corresponds to j errors (where j<t), so that (j-i)
errors are in the k information digits (where 1<i<j), and the
remaining i errors are in the parity check digits.
Let the syndrome vector corresponding to the (j-i)
errors in the information digits be sl and that corresponding to
the i-errors in the parity check digits be s2. Thus s is given
by:
s = s1
+ s2 (modulo-q addition)
104.

The above equality indicates that the Hamming
distance between s and s1 (d(s,s1)) is equal to the Hamming
weight of s2, w(s„,L) , i.e.
d(s,s1) = w(s2)
However, the vector s2 is identical to the vector corresponding
to errors in the parity check digits. This implies that:
w(s2) = i
and thus:
w(s2 ) C t
and therefor
d(s,s1) t 4; d21
Since the vector s is by definition a codeword of the
(n-k, k-k1, d-1) nested code and since the minimum Hamming
distance between any two codewords in the (n-k, k-kl, d-1) nested
code is d-1, the vector s is therefore not a codeword of the
(n-k, k-k1, d-1) nested code. This completes the proof.
Corollary 4.3.1
In an (n,k,d) nested code over a field of q-elements,
which is capable of-correcting t-random errors and is derived
from two codes, the first being a (k,kl,d) block code and the
second a (n-k, k-k1,
d-1) nested code, the syndrome of the (n-k,
k-k1,
d-1) nested code for an (n-k)-tuple vector, given by a
syndrome corresponding to t errors or less in the (n,k,d)
nested code, will correspond to errors in the parity check digits.
Proof
Since the syndromes of the (n,k,d) nested code
corresponding to errors in the k information digits are codewords
105.

of the (n-k, k-k1, d-1) nested code, the proof of the corollary
becomes self evident.
From the above argument the principles of the nested
decoding algorithm follow immediately for codes of rate less
than or equal to 50%. The decoder generates a nest of t syndromes
for the received vector (see Figure 4.1) which leads to a simple
operation for clearing the errors from the parity check digits.
As a result of this, the errors in the information digits can be
corrected by a solution of the syndrome equations.
Consider the nested decoding algorithm of an (ni,ki,t)
nested code. If all nested codes of the (n • k • t) nest are of
rate less than or equal to 50%, then the operation of this
decoder can be described in the following steps:
(1) Calculate the syndrome, s, corresponding to the
received vector, u, according to the syndrome-equations of the
first nested-code of the (n1, k1, t) nest:
s = 11[1-11] = V DT] e EHT3 e DiT3
where v is the transmitted vector and e is the error pattern
vector.
If the syndrome vector is zero, the decoder assumes
that no error has occurred and no correction is necessary.
If the syndrome is not zero, the decoder performs
the following tests:-
(a) If the weight, w(s), of the syndrome vector is less
than or equal to t, the decoder assumes that all errors
are confined to the parity-check digits and no correction
is necessary.
(b) If w(s)>t, the decoder proceeds to the second step.
106.

(2) The syndrome of the previous step is considered as a
received vector for the next code down the nest (see Figure 4.1.1)
and its corresponding syndrome is calculated according to the
syndrome-equations of this code.
If the calculated syndrome is zero, the decoder
proceeds to step (3); otherwise the following operations are
performed:-
(a) If the weight of the calculated syndrome vector is
less than or equal to the error-correcting capability of
this code, the decoder assumes that the error pattern in
the first L digits of the received vector is identical to
the calculated syndrome, the dimension of the calculated
syndrome vector being L.
The inverse of the calculated syndrome is added to itself
to the first L digits of the received vector u, and to all
the previously calculated syndromes. The decoder then
proceeds to step (3).
(b) If the weight of this syndrome is greater than the
error-correcting capability of this code, and if the code
is not an (nt, kt) Hamming code, the above procedure is
repeated starting with step (2).
(c) If the code IA the (nt' kt) code, the errors in the
first nt digits of the received vector are determined by
using an appropriate decoding algorithm of Hamming codes.
The inverse of the determined error vector is added
to the first nt digits of vector u and to the first nt
digits of all previously calculated syndromes. The decoder
then proceeds to step (3).
(3)
Assume that the code undergoing processing in the
previous operation is the (ni, ki, t-i+l) nested code, i.e. the
107.

.th code of the nest (see Figure 4.1. ). Since the calculated
syndrome of the ni-tuple vector of the previous operation is
found to be zero or made to be zero, the decoder assumes that
the first n. digits of the resulting processed received vector
u are free of errors. This implies that the errors in the
ni-l -tuple vector are now confined to the Ri-1 information
digits. These errors are assumed to be a solution of the
syndrome equations of the (i-1)th code of the nest (ni_i, ki_1,
t-i).
The inverse of the error pattern in the ni_1-tuple
vector is then added to the-tuple vector, to the first ni-1 ni-1
digits of the received vector, and to all the previously found
syndromes of the nest.
If the (i-1)th
code is not the outer code of the nest,
the decoding procedure, starting with step (3), is repeated.
Figure 4.3.1 gives a flow chart of the above basic
nested decoder.
However, to decode an (n,k) nested code of rate'
greater than 50%, some particular code properties are required.
The characteristics of these properties are as follows:-
Consider the syndrome equations of an (n,k) nested
code constructed from the codes (k,ki) and (n-k, k-k1) respect-
ively. If the first r parity check digits are free of errors,
(i.e. el = e2 = = er = 0), the first r bits of the syndrome
vector, s, are therefore given by:-
s1 =en-k+1
s2= en-k+2
S3= e
n-k+3
+ . . . + a1,r+1 en-k+r+1 + a1,k en
+ a2,r+1
en-k+r+1 • • • a2,k
en
. . . + a3,k
en
+ a3,r+1'
en-k+r+1 +
sr= . . . en-k+r + ar r+1 en-k+r+1 +
+ ar,k en
1.08.
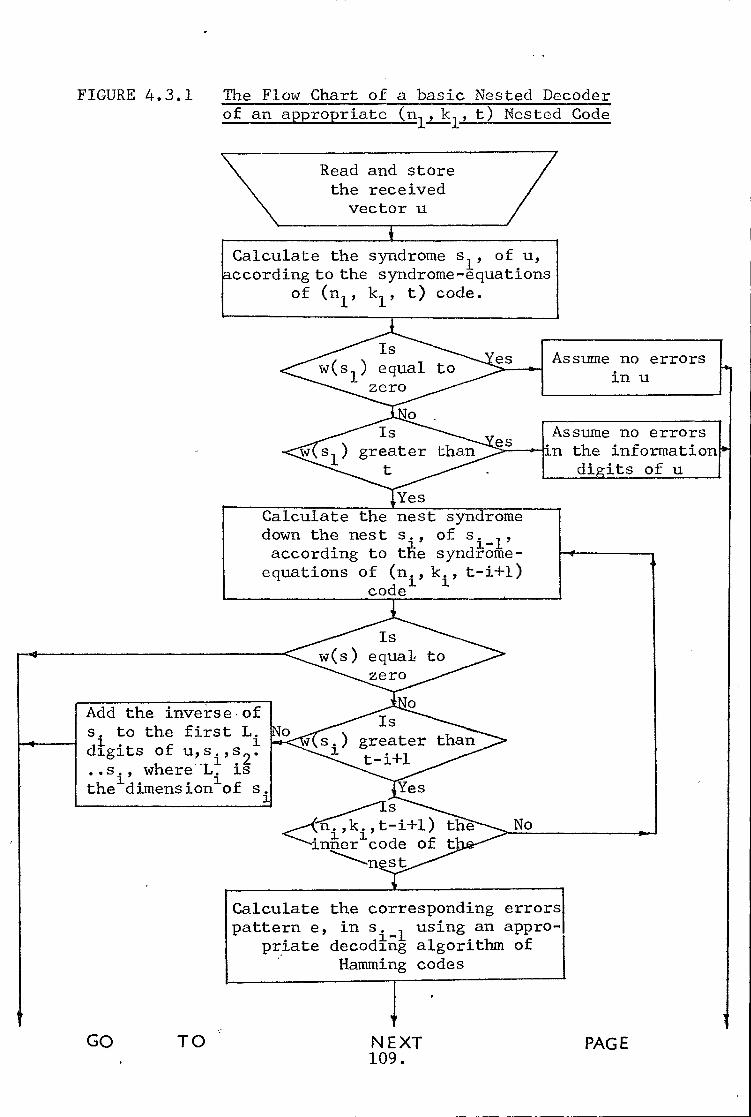
GO TO PAG E NEXT 109.
Calculate the syndrome sl, of u, according to the syndrome-equations
of (n1, k1,
t) code.
Is w(s1) equal to
zero
Assume no errors in u
Assume no errors in the information
di:its of u
Yes Calculate the nest syndrome down the nest s., of si_i, according to tke syndrome-equations of (ni, ki, t-i+l)
code
Is w(s) equal to
zero
Add the inverse.of s. to the first L. 1 digits of uls.1,s . 2 ..s., where -L. is the
1 dimensionlof s.
I.,k.,t-i+1) the 1 inner
1 code of t
Yes
Calculate the corresponding errors pattern e, in si-1 using an appro-
priate decoding algorithm of Hamming codes
FIGURE 4.3.1 The Flow Chart of a basic Nested Decoder of an appropriate (n1.11, t) Nested Code
Read and store the received vector u

Calculate e' as a solution to the syndrome-equations of (n.
1 ,k.
1, t-i+l) code
-
Add the inverse of e' to the first digits of u'ss2'
..., and si 2
Consider the nest code up the nest (ie reduce i by 1)
Yes
Is n.1 ' k. t-i+l) th outer i-1 , code of the
nest
Add the inverse of e to the first L
1-1 digits of us
1,s2'
...., and s . i-1
Assume the errors pattern e is confined to the last (
- )digits of s -Li-1 i-2
Assume the decoded received vector is identical to the
transmitted vector
110.

where r = k-k1.
These equations are in fact the syndrome equations of
the (k,k1) block code. A possible approach for decoding is
therefore: if the (k,k1) block code is itself a decodable
nested code, the numerical evaluation of the information error
digits (en_k+i, en-k+2,
..., en) can be determined by decoding
the (k,k1) nested code after clearing all errors from the first
r parity check digits of the (n,k) code.
In general an (n,k) nested code is decodable, if it
exhibits one of the following properties:-
(1) The rates of all the codes of the (n;k) nest, other
than the inner code, are less than or equal to 50%.
In this case, the basic decoder is as explained above.
(2) The rate of the (n,k) nested code is greater than 50%.
However, all other codes of the (n,k) nest are of rate less than
or equal to 50% except for that of the inner code, and the (k,k1)
code is itself a decodable nested code.
The decoder first clears the errors in the parity check
digits of the (n,k) code and then proceeds to decode the (k,k1)
nested code.,
(3) The second code of the (n,k) nest and the (k,k1) code
are both decodable nested codes.
These properties are the generalised form of (2).
(4) The first r parity check digits of the (n,k) nested
code are decodable (i.e. the jth code of the (n,k) nest, (ni,kj),
whose length n. is a decodable nested code) and the 3
(k,k1) is a decodable nested code.
(5) Both second codes of the (n,k) nest and the (k,k1) nest

are decodable nested codes, where k is less than or equal to
(n k1).
The decoder in this case first clears the errors from
the parity check digits of the (n,k) code (e e2' ...,
en-k)
and then proceeds to clear the errors in the parity check digits
of (k,k1) code (en-k+1' en-k+2'' en-k+r)• The remaining
information error digits are, therefore, a solution of the (n-k)
syndrome equations.
An (n,k) decodable nested code can, therefore, be
constructed in a variety of ways, so as to exhibit any one of
the five properties. These many possible ways of construction
lead to a wide range of code rates and error-correcting
capabilities.
Table 4.3.1 provides a list of examples of decodable
nested codes with rates greater than 50% and of various error-
correcting capabilities.
112.

TABLE 4.3.1 Some examples of decodable binary nested codes of rate greater than 50%
Decodable nested code.
Rate of the above code.
The first nested code for constructing the (n, k, d) nested code.
(n-k,k-ki,d-1)
(n, k, d) R in %
The second code of constructing the (n, k, d) nested code.
(k, k1, d) (n-k,k-ki,d-1) Notes
26, 13,5 50.0 13, 5,5 13, 8,4 Shortened from (16,11,4) Hamming code.
35, 19,5 54.2 19, 8,5 16, 11,4 Hamming code. 41, 23,5 56.0 23, 11,5 18, 12,4 Short Hamming (32,26,4) 49, 30,5 61.2 30, 17,5 19, 13,4 ditto 74, 49,5 66.2 49, 30,5 25, 19,4 ditto 105, 74,5 70.4 74, 49,5 31, 25,4 ditto 142, 105,5 73.9 105, 74,5 37, 31,4 ditto (64,57,4) 186, 142,5 76.3 142, 105,5 44, 37,4 ditto 237, 186,5 78.4 186, 142,5 51, 44,4 ditto 295, 237,5 80.3 237, 186,5 58, 51,4 ditto 361, 295,5 81.7 295, 237,5 66, 58,4 ditto (128,120,4) 435, 361,5 82.9 361, 295,5 74, 66,4 ditto 517, 435,5 84.1 435, 361,5 82, 74,4 ditto 607, 517,5 85.1 517, 435,5 90, 82,4 ditto 705, 607,5 86.0 607, 517,5 98, 90,4 ditto 811, 705,5. '86.9 705, 607,5 106, 98,4 ditto 925, 811,5 87.6 811, 705,5 114,106,4 ditto 1047, 925,5 88.3 925, 811,5 122,114,4 ditto 1178,1047,5 88.8 1047, 925,5 131,122,4 ditto (256,247,4) 1318,1178,5 89.3 1178,1047,5 140,131,4 ditto 1467,1318,5 89.8 1318,1178,5 149,140,4 ditto 1625,1467,5 90.2 1467,1318,5 158,149,4 ditto 1792,1625,5 90.6 1625,1467,5 167,158,4 ditto 1968,1792,5 91.0 1792,1625,5 176,167,4 ditto 2153,1968,5 91.4 1968,1792,5 185,176,4 ditto 2347,2153,5 91.7 2153,1968,5 194,185,4 ditto 2550,2347,5 92.0 2347,2153,5 203,194,4 ditto 2762,2550,5 92.3 2550,2347,5 212,203,4 ditto 2987,2762,5 92.5 2762,2550,5 221,212,4 ditto 3213,2983,5 92.8 2983,2762,5 230,221,4 ditto 3452,3213,5 93.0 3213,2983,5 239,230,4 ditto
113.
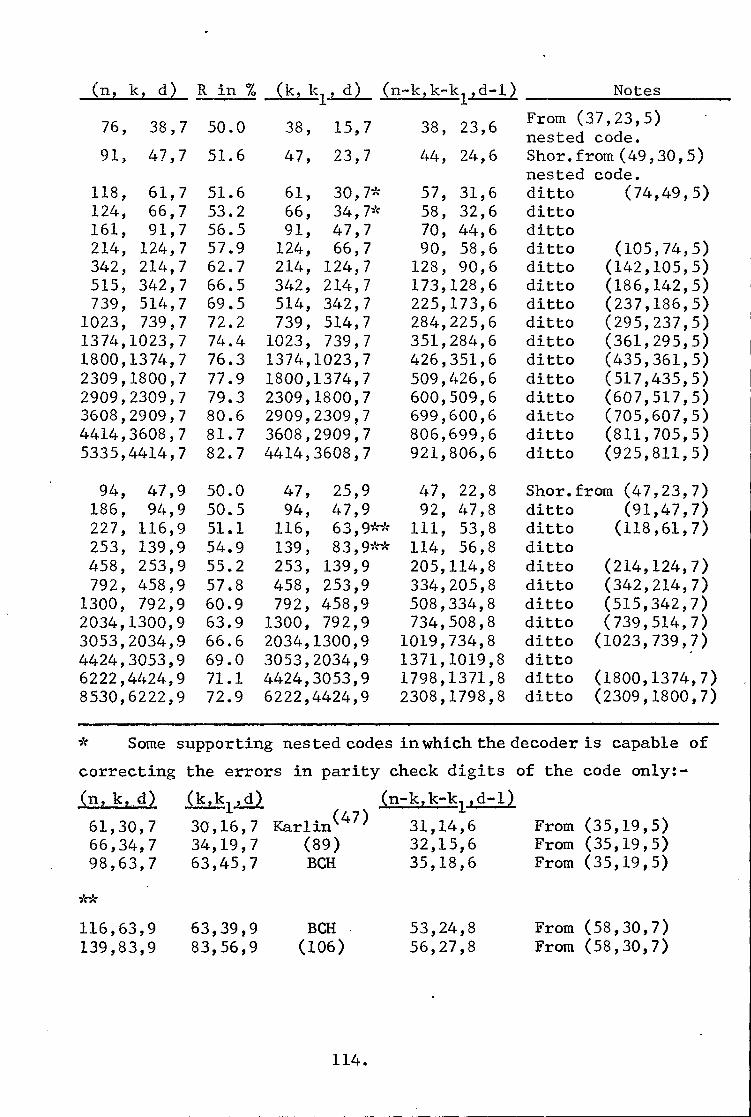
(n, k, d) R in % (k, k1 (n-k k-k ,d-1)
76, 38,7 50.0 38, 15,7 38, 23,6 91, 47,7 51.6 47, 23,7 44, 24,6
118, 61,7 51.6 61, 30,7* 57, 31,6 124, 66,7 53.2 66, 34,7* 58, 32,6 161, 91,7 56.5 91, 47,7 70, 44,6 214, 124,7 57.9 124, 66,7 90, 58,6 342, 214,7 62.7 214, 124,7 128, 90,6 515, 342,7 66.5 342, 214,7 173,128,6 739, 514,7 69.5 514, 342,7 225,173,6
1023, 739,7 72.2 739, 514,7 284,225,6 1374,1023,7 74.4 1023, 739,7 351,284,6 1800,1374,7 76.3 1374,1023,7 426,351,6 2309,1800,7 77.9 1800,1374,7 509,426,6 2909,2309,7 79.3 2309,1800,7 600,509,6 3608,2909,7 80.6 2909,2309,7 699,600,6 4414,3608,7 81.7 3608,2909,7 806,699,6 5335,4414,7 82.7 4414,3608,7 921,806,6
94, 47,9 50.0 47, 25,9 47, 22,8 186, 94,9 50.5 94, 47,9 92, 47,8 227, 116,9 51.1 116, 63,9** 111, 53,8 253, 139,9 54.9 139, 83,9** 114, 56,8 458, 253,9 55.2 253, 139,9 205,114,8 792, 458,9 57.8 458, 253,9 334,205,8
1300, 792,9 60.9 792, 458,9 508,334,8 2034,1300,9 63.9 1300, 792,9 734,508,8 3053,2034,9 66.6 2034,1300,9 1019,734,8 4424,3053,9 69.0 3053,2034,9 1371,1019,8 6222,4424,9 71.1 4424,3053,9 1798,1371,8 8530,6222,9 72.9 6222,4424,9 2308,1798,8
Notes
From (37,23,5) nested code. Shor.from (49,30,5) nested code. ditto (74,49,5) ditto ditto ditto (105,74,5) ditto (142,105,5) ditto (186,142,5) ditto (237,186,5) ditto (295,237,5) ditto (361,295,5) ditto (435,361,5) ditto (517,435,5) ditto (607,517,5) ditto (705,607,5) ditto (811,705,5) ditto (925,811,5)
Shor.from (47,23,7) ditto (91,47,7) ditto (118,61,7) ditto ditto (214,124,7) ditto (342,214,7) ditto (515,342,7) ditto (739,514,7) ditto (1023,739,7) ditto ditto (1800,1374,7) ditto (2309,1800,7)
j. Some supporting nested codes in which the decoder is capable of
correcting the errors in parity check digits of the code only:- (n,k,c1) (k,k1211 (n-k k-k d-1) it
61,30,7 30,16,7 Karlin( 31,14,6 47) From (35,19,5) 66,34,7 34,19,7 (89) 32,15,6 From (35,19,5) 98,63,7 63,45,7 BCH 35,18,6 From (35,19,5)
** o% Aft
116,63,9 63,39,9 BCH 53,24,8 From (58,30,7) 139,83,9 83,56,9 (106) 56,27,8 From (58,30,7)
114.

4.4 FEATURES AND MERITS OF THE NESTED DECODING ALGORITHM
The main two features of the nested decoding algorithm
are as follows:-
4.4.1 The capability of correcting pattern of errors of weight greater than t
Theorem 4.4.1
The decoder of an (n,k,t) nested code which is
constructed to fulfil the conditions of decodable nested codes
given in (1) is capable of correcting any pattern of errors of
weight greater than t if the pattern of errors exhibits the
following properties:-
(1) The pattern of errors is a coset leader of the
• standard array of the (n,k,t) code.
(2) The number of errors in the parity check digits is
less than t.
(3) The pattern of errors in the remaining k information
digits is also a coset leader of the standard array of the code.
Proof
Consider a pattern of errors e (where e = Ce/e2e3...enj)
which fulfils the conditions of the above theorem. Let the
n-tuple vector em where em ... en be = E0 0 0 .•• en-k+1en-k+2 n
J, the pattern of errors in the information digits and let the
n-tuple vector ep where ep = [ele2 en-k 0 0 ... 0:1 be the
pattern of errors in the parity check digits.
Since e is of weight less than t, it is therefore a
coset leader of the (n,k,t) nested code and since all the errors
of e are in the parity check digits, it follows that the
syndrome, s , corresponding to e , is identical to the first
(n-k)-digits of e , i.e.
• 115.

•
s = Ee le2e3 en-kJ
Since the n-tuple vector e is a coset leader and of
weight greater than t, the syndrome s corresponding to e is a
unique nonzero (n-k)-tuple vector of weight greater than t and
given by:
s = e [HT]
where EHT3 is the transpose of the parity-check matrix of the (n,k,t) nested code.
Let the syndrome vector corresponding to errors in
the information digits em be S. Thus the syndrome vector s
is given by:
s = sp + sm ep CHT3 + ern CHT3 The first operation of the nested decoder is the
calculation of s. Since s is of weight greater than t, the
decoder then proceeds to calculate the syndrome vector s1 corresponding to the vector s according to the syndrome
equations of the (n-k, k-kl, t-1) nested code. This code is
obviously the second code of the (n; k; t) nest. Let the
parity-check matrix of the (n-k, k-kl, t-1) nested code be
. Then sl is given by:
si =sEHT2j=(sp +sm) 2 EHTJ= sp 2 DIT3+ sm 2 DT]
Since sm is a codeword of the (n-k, k-k1,
t-1) nested
code we have:
s DITJ m 2 = 0, and therefore
s1 = sp CHTJ = Ee1 e2 e3 ... e n- 0 [H2]
However, since the weight of the error vector Eele2e3 ... en_k]
is less than or equal to the error correcting capability (t-1)
116.

of the (n-k, k-k1, t-1) nested code, the error pattern, e ,
can be corrected by the nested decoder*.
Since em is a coset leader, the remaining information
error digits Cell _k4.1 en-k+2 ej can be determined as a
solution of the syndrome equations of the (n,k,t) nested code.
This completes the proof.
Corollary 4.4.1
The decoder of an (n,k,t) nested code, which has the
properties given in one of the conditions of (2), (3) or (4) of
constructing decodable nested codes, is capable of correcting
any pattern of errors of weight greater than t, if the pattern
of errors exhibits the following properties:-
(1) The pattern of errors is a coset leader of the standard
array of the (n,k,t) code.
(2) The pattern of errors in the parity-check digits is
a coset leader of the (n,k,t) code and is decodable by the
decoder of the second code of the (n;k;t) nest.
(3) The pattern of errors is in the k information digits,
is a coset leader of the standard array of the (n,k,t) code and
is decodable by the.(k, kl, t) nested code.
It is interesting to note that since (n-k, t-1)
is itself a nested code, it is capable of correcting some
patterns of errors of weight greater than (t-1). This
suggests that the second condition of Theorem 4.4.1 may be
restated in a more general form as follows:-
"(2) The pattern of errors in the parity-check
digits is a coset leader of the (n,k,t) code and
is decodable by the decoder of the second code
of the (n;k;t) nest."
117.

S
Corollary 4.4.2
The decoder of an (n,k,t) nested code which is constr-
ucted to fulfil the conditions of decodable nested codes given
in (5) is capable of correcting some pattern of errors of
weight greater than t, if the pattern of errors exhibits the
following properties:-
(1) The pattern of errors fulfils the first two conditions
set by Corollary 4.4.1, and
(2) The pattern of errors in the information digits is a
coset leader of the (n,k,t) code and the first (k-k1) digits
(i.e. en-k+1 en-k+2 en_ki) are decodabie by the second code
of the (k; kl; t) nest.
It has been established by the above theorem and two
corollaries that the nested decoding algorithm is capable of
correcting some of the correctable pattern of errors* of weight -
greater than t (where t = d21). The importance of this feature
is realized from the fact that most known decoding algorithms
of known classes of codes are not capable of correcting errors
of weight greater than t. It is also of interest to note that
finding a simple way to extending Berlekamp's decoding
algorithm for BCH codes, so as to enable the decoder to
correct the correctable errors of weight greater than t, is an
important but as yet unsolved problem.
4.4.2 The complexity of the nested decoder
The complexity of decoding is generally measured by
the number of operations required for decoding a single
*
A correctable pattern of errors is one that is a coset
leader of the standard array of the given code. Since
there are 2n-k
-1 nonzero coset leaders, the number of
. correctable patterns of errors if therefore equal to
2n-k
-1.
118.

information digit.
The number of operations required for decoding a
sequence of n digits at the output of a channel using an
(n,k,t) nested code may be tabulated as follows:-
(1) The calculation of a nest of t syndrome vectors:-
The dimension of the first vector is (n-k) whilst
the dimension of other vectors of the nest approximately
decreases exponentially with their positions down the nest. The
calculation of such syndromes requires the evaluation of each
of the individual syndrome bits. Each bit of a syndrome in the
nest is a modulo-q addition of certain digits of the syndrome
directly above it in the nest and is determined by the syndrome
equations of the corresponding code of the (n;k;t) nest.
Syndrome calculations therefore involve a number of modulo-q
additions (for binary codes modulo-q adders are simply
exclusive-OR gates). The number is equal to the total
dimension of the t syndromes, which increases linearly with
code length and t.
(2) The syndromes weighting:-
Each of the calculated syndromes in the above operation
is tested as to whether its weight is greater than, equal to or
less than the error-correcting capability of the corresponding
code of the (n;k;t) nest. The number of operations obviously
depends only on the number of the syndromes under test.
(3) The decoding of the inner code, (Hamming code), of the (n; k; t) nest:-
The number of operations required in this decoding
process depends entirely on the code length and increases
linearly with it.
119.

(4) The decoding of the corresponding information
error d* its of all codes other than the outer code of the
(n; k; t) nest:-
Since each information error digit of these codes is
a modulo-q addition of certain parity check digits of the
individual code, the operation required in this process
involves a number of modulo-q adders. The number of these
adders is equal to the total number of information digits of
these codes, which is a linear function of the (n,k,t) code
length and t.
(5) Decoding the information error digits of the
(n,k,t) nested codes:-
This stage involves, for most decodable nested codes,
the repetition of the above operation for the corresponding
first code of the construction, (n,k,t) nested code.
From the above it may be concluded that the average
number of operations required to decode one symbol of the
received sequence of a digits, is a linear function of the code
length, n, and the error correcting capability t.
Finally, it is worth noting that the decoding procedure
does not require any operation which consumes computation time,
such as filling a table of information or the mathematical
operation in GF(p°). The time required for nested decoding of
an (n,k,t) nested code is therefore approximately equal to 2t
multiplied by the transit time of the modulo-q adders.
120.

• 5. LINEAR BLOCK CODES FOR NON-INDEPENDENT ERRORS
5.1 Introduction.
5.2 Block Codes for Non-independent errors,
Definition and Construction.
5.3 Single-Burst-Error-Correcting Codes.
5.4 Burst-and-Random-Error-Correcting Codes.
5.5 Multiple-Burst-Error-Correcting Codes.
121.

5.1 INTRODUCTION
Previous sections of this thesis have been mainly
concerned with the construction and decoding of block codes
capable of correcting independent (random) errors. However,
in many communication channels, noise disturbances tend to
occur in a (single) burst and in many instances these noise
disturbances cause the errors to cluster in the form of low-
density bursts. For example, on telephone lines, lightning or
man-made electrical disturbances frequently affect several
adjacent transmitted digits. Moreover, in many digital systems
for data transmission (and particularly data storage), distur-
bances of a burst nature and those of random nature are both
present. The burst errors are mainly due.to impulsive distur-
bances or spot imperfections in the storage media, whilst the
random noise may be largely due to circuit noise or noise from
the environment. Under these circumstances, it is not efficient
to use either random error-correcting codes or codes for
correcting (single) burst errors. A need therefore exists for
classes of codes that are capable of correcting either multiple-
bursts of errors or random-and-burst errors. In the literature
on error-correcting codes, there has been a good deal of attention
given to the correction of a (single) burst of errors(3,5,7,108-118)
However, the literature concerned with the correction of either
random-and-burst errors or multiple bursts of errors is
comparatively more limited.
The most effective method of constructing either random-
and-burst or multiple-burst-error-correcting codes is the inter-
lacing of a t random error-correcting (n,k) code with itself,
times; an (n9, kZ) code, capable of correcting any combination
of t bursts of length Q or less, is then obtained. Other attempts (
to construct such codes are given in the literature-5'7,119-130)
122.

However, in many of these cases, the derived codes for correcting
short length of bursts are of extremely large length; as was the
case with the codes found by Bahl and Chien(119), Wolf(120), and
Chien and Spencer(121)
In this section an investigation of other methods of
generating codes (capable of correcting either random-and-burst
errors or multiburst errors) is given in detail. The ideas and
techniques proposed in the previous sections of this thesis are
modified to construct such codes. A considerable number of such
codes have been found by these modified techniques.
123.

5.2 BLOCK CODES FOR NON-INDEPENDENT ERRORS DEFINITION AND CONSTRUCTION
A burst of length t is defined as a vector whose non-
zero components are confined to t consecutive digit positions,
the first and last of which are non-zero(5).
An (n,k) linear block code is said to be an i-burst
error-correcting code, if it is capable of correcting all n-tuple
error vectors of a set [Ph which contain all burst errors of
length t or less (not all bursts of length t+1).
Definition 5.2.1
An (n,k) linear block code V, over a field of q
elements, is capable of correcting a set of errors [P], if and
only if all elements of {P1 are coset leaders of a standard
' array of V(131)
Lemma 5.2.1
An (n,k) linear block code V, over a field of q
elements, is capable of correcting a set of errors tP) if and
only if (e1-e2) in V and (e1 and e2 etpi ) implies el equals e2.
Proof
Consider two n-tuple vectors el and e2 in the set [Ps.
Since the (n,k) code is capable of correcting all vectors in the
set .1211, the n-tuple vectors el and e2 are, according to
definition 5.2.1, coset leaders.
Suppose that (el-e2) is a code vector (say V). Thus
el-e2 equals V or conversely el equals VA-e2. That is, el is
in the coset whose leader is e2, which contradicts the constr-
uction rule of a standard array of the code V, that the coset
leader e1 should be previously unused. Therefore it may be
124.

concluded that for e1 not equal to e2, e1 - e2 does not equal v,
otherwise e1 equals e2. This completes the proof.
From Lemma 5.2.1 it follows that for an (n,k) block
code (that is, the null space of a matrix Ho to correct a set
of E error vectors [131, it is necessary and sufficient that no
code vector consists of the sum of two error vectors el and e2,
where e1and e
2 elpi; consequently, it is necessary and
sufficient that for any two vectors in fP3 such as e1 and e2,
the following inequality holds:
Eel + e2 [HT] 0
The generalised form of the Hamming upper bound on the
number of information digits for a linear code that is capable
of correcting a set of E errors €P1, may be obtained by using
Definition 5.2.1 as follows:
Lemma 5.2.2
For an (n,k) block code V over a field of q elements
(capable of correcting a set of E errors [Ps), the largest value
of k is bounded by:
qn-k > E.
Proof
Since the code is capable of correcting all E error
vectors of set fP), all error vectors in tP1 by definition must
be coset leaders. Thus the number of error vectors of {PI must
be no greater than the total number of cosets. That is:
qn-k > E.
This completes the proof.
The generalised form of the Varshamov-Gilbert bound,
for an (n,k) block code capable of correcting a set of E
125.

error vectors 1:1, follows from the fact that the parity check matrix [H] for the code may be constructed in such a way that
the chosen columns of [H] satisfy the inequality:
Ee. e .J DTI 0 for all values of i, i = 1, 2, 3, E, and j, j = 1, 2, 3, .
E, where e. and ej G[P'. Thus the worst conceivable case 1
would be for each Lei ej [HT] to result in a unique non-zero vector of the vector space The total number of these
vectors is therefore bounded by qn-k
, including all the zero
vectors for the no error case.
The above properties of the parity-check matrix of
an (n,k) block code capable of correcting non-independent
errors, may be viewed in a slightly different, but nevertheless
useful way, as follows:-
Theorem 5.2.1
An (n,k) linear block code that is the null space of
a matrix [HD is capable of correcting a set of errors (P1 if and only if for every e in f131, the matrix product e[HT3results in a unique non-zero vector in the vector space Vn-k.
Proof
Let e be an error vector in [Ps. The syndrome
corresponding to e is given by:
s = e [HT].
Since the syndrome of any error vector e, eCiP1, is
unique, and since all the vectors of a coset have the same
syndrome, no two error vectors (el, e2) in {Pi are therefore
in the same coset. This implies that every error vector
e, e (Pi, is a coset leader and according to Definition 5.2.1,
126.

the code is capable of correcting all error vectors in {P.I.
This completes the proof.
An (n,k) block code may also be constructed by using
the construction procedure for nested codes, described in
Section 4.2, in such a way that the first and second codes of
construction are linear block codes. The error-correcting
capability of the newly derived code is determined by the
following theorem:-
Theorem 5.2.2
An (n,k) block code constructed in accordance with
the construction rules for nested codes (using two block codes
for construction) is capable of correcting a set of errors tP1,
if the first code of construction is capable of correcting all
patterns of errors in the k information digits corresponding
to the error vectors of fP1 and the second code is capable of
correcting all patterns of errors in the (n-k) parity check
digits corresponding to the error vectors of (Pi.*
Proof
The parity check matrix [H] of the (n,k) code is given
In-k = E.-13 lin_k]
where [H1J is the parity check matrix of the first (k,ki) code of
Since the (n,k) code is constructed in accordance with the construction rules of nested codes, it follows (see Section 4 of this thesis) that the syndromes corresponding to the correctable error patterns in the information digits are codewords of the second code of construction (i.e. the (n-k, k-k1 ) code), and moreover all other syndromes corresp-onding tocorrectable error patterns involving at least one error in the parity check digits are not codewords of the (n-k, k-k
1) code. The correctness of these statements can also be seen as a consequence of the proof of the theorem.
•
*
by:
=
127.

construction, Dn_kj is an identity matrix of, dimension (n-k)
and Ed.] is that matrix in which each of its (k) columns are
formed by the parity check digits of a codeword (in the second
(n-k, k-k1) code of construction) corresponding to the inform-
ation digits given by the appropriate column of DJ] matrix.
Let e = E.e1 e2 en] be an error vector in P .
Let ei = Eel e2 ek 0 0 ... 0] be the error pattern of e
that is confined to the first k digits of the received vector
and let ep = 0 ... 0 ek+l ek+2 • enJ be the error pattern
of e that is confined to the remaining (n-k) digits.
The syndrome vector s corresponding to e is given by:
TT
e = e DT 11 I C
] = (e. +e p) [.1
In-kT T T
=E e2 ek o o [1111C + CO 0 ... 0 ek+1
T
Ti c T In-k
ek+2 en.„ n-k
= 1 e2 ... D 1 ek] T I CT] Eek+1 ek+2 . . . e] n-j]
= e.' T lcT 3 + e' 1
wheree.'= [el e2 ekJ and e = E.ek+1 ek+2 '" er]
Since the first k columns of CH] matrix are code vectors of the (n-k, k-k1) block code, the matrix product e., [HTicT] therefore results in a code vector of the (n-k,
k-k1) code, say v. Thus s = v + ep
Since the first (k-k1) digits of each column of [-bT]
matrix is a column of the parity check matrix [H1] of the (k,k1)
128.

block code, and since the block code is capable of correcting
all the patterns of errors in the k information digits corr-
esponding to e, e 0)1, it follows that for every pattern of
errors such as e., there is a corresponding unique nonzero
syndrome vector (v) in the (n-k, k-k1) code. Thus s equals v
fore' = 0.
Suppose that the syndrome s (where s = v + e e 0)
is a code vector u in the (n-k, k-k1) code; thus u equals v+e 1.
That is, e ' is also a code vector of the (n-k, k-k1); ). this
implies e ' is not a correctable error pattern, contradicting
the condition of the theorem that the (n-k, k-k1) code is
capable of correcting all patterns of errors in the parity
check digits corresponding to e, eel.pi. Therefore it may be
concluded that s is not a code vector of (n-k, k-k1) code unless
e = 0.
Now suppose that the syndrome s (s = v+e ') is equal
to some other syndrome vector si, corresponding to an error
pattern ,
e.3 where e,(3tPl. Let si be given by v.
3 + e.', where
v.3 issomecodevectorofthe(n-k,k-kdcodeande.'is that
errorpatternofe.3 confined to the last (n-k) digits. Thus
v + e ' equals v. +e.'. That is, e.' and e ' are in the same J 3
coset of a standard array of the (n-k, k-k1) code contradicting
the condition of the theorem that the (n-k, k-k1) code is
capable of correcting all patterns of errors in the parity check
digits,suchase'ande.3'. It may be concluded therefore that
s does not equalsj . This implies that for every error pattern
e, where e G [Ps, there is a corresponding unique syndrome and according to Theorem 5.2.1, the (n,k) code is capable of
correcting all patterns of errors in the set {P3. This completes
the proof.
129.

From the above arguments, two methods for constructing
block codes to correct the required set of errors tPi, approp-
riate for the given channel characteristics are suggested. The
first makes use of Theorem 5.2.1 to establish a computerised
search procedure for new codes. However, this method is limited
by the computer core size, computation time or both these
factors. The second method is based on the modification of the
principles used for constructing a nested code for random errors
as given in Theorem 5.2.2.
130.

5.3 SINGLE-BURST-ERROR-CORRECTING CODES
From Theorem 5.2.1 the following corollary follows
immediately:-
Corollary 5.2.1.1
An (n,k) block code V, that is the null space of a
matrix E], is capable of correcting a burst of length 2, or
less, if and only if the linear combinations of every g
adjacent columns of the Efij matrix result in unique nonzero
(n-k)-tuple vectors.
This corollary suggests a computerised search procedure
for single-burst error-correcting codes. A computer search
progrannue is developed to find such codes for a given number of
parity check digits and given burst length 2. . The search
follows the following steps:-
(1) Read the identity matrix Ein_k] of dimension (n-k).
(2) Cross out the (n-k)-tuple vector of the linear
combinations of every adjacent columns of the [H] matrix
from the set of qn-k-1 non-zero vectors of the vector space
Vn-le
(3) Take.the vectors of the vector space Vn_k in turn,
starting with the all-zero vector and ending with the all
q vector,
(4) Test the vector(chosen in step (3))for uniqueness,
if it is not unique, start again at step (3).
(5) Perform the linear combination of the vector(under
test)with the last - 1) columns of the Da matrix and
test the resulting vectors from this linear combination for
uniqueness - if any of these vectors is not unique, start
again at step (3).
131.

(6) Cross out the vector resulting from the last
performed linear combination.
(7) Increase the size of the Da matrix by one column,
by adding the vector to the CH: matrix. (8) Continue the search again, starting from step (3),
until all vectors in Via-k have been tested.
Table 5.3.1 gives some examples of the single-burst-
error-correcting codes that were found by the above search
procedure. However, the search was not carried out extensively
due to the fact that there is a large range of cyclic codes with
a minimum or near-minimum redundancy; moreover, the codes are
capable of correcting burst errors of various lengths
Furthermore, there exists a simply implemnted decoding procedure
(error trapping techniques for cyclic codes) that is applicable
to all of these codes. Thus Peterson(7) suggests, from an
engineering viewpoint, that the problem of designing burst-
correcting codes and decoders appears to be solved. However,
the general decoder for these codes is capable of correcting
only the specified 2 burst errors or less and moreover that for
certain range of code parameters the choice of codes is limited.
To decode some of the remaining correctable error patterns and
to widen the range of choice of single burst error correcting
codes, the following corollary (which follows from Theorem 5.2.1)
provides a basis for constructing single burst codes, from other
best known codes. The decoder complexity for such codes is
slightly greater than that of the decoder of the original codes.
Corollary 5.2.2.1
An (n,k) block code constructed in accordance with
the construction rules of nested codes, using two block codes
for construction, is capable of correcting any burst of length
132.

2 or less, if both codes of the construction are .t-burst-error-
correcting codes.
For example, consider the construction of (40,27)
single-burst-error-correcting block code, capable of correcting
a burst of three errors or less from two other block codes. The
first is a (27,20) shortened cyclic code capable of correcting
a burst of three errors or less and the second a (13,7) shortened
cyclic code also capable of correcting a burst of three errors or
less. The generator polynomial, g1(x), of the (27,20) code is
given by(7) :
gi(x) = x7 + x6 + x3 + 1.
Thus the parity check matrix, [HI], is given by:-
EH 3. 011001111010010101110001000 010110001100101111000000100 101011000110010111100000010 110101100011001011110000001
The generator polynomial, g2(x), of the (13,7) code is
given by(7):
g2(x) = x6 + x5 + x4 + x3 + 1
Determine the 6-by-27 matrix DO, whose columns are defined as the parity check digits of a set of 27 codewords in
the (13,7) code. Each of these codewords corresponds to those
information digits given by the appropriate column of EHij matrix. Thus matrix [CD is given by:
1 1 1 0 1 0 1 1 0 0 0 1 1 0 0 1 0 1 1 1 1 0 0 0 0 0 0 1 0 0 1 1 1 1 0 1 0 0 1 0 1 0 1 1 1 0 0 0 1 0 0 0 0 0 1 1 0 0 1 1 1 1 0 1 0 0 1 0 1 0 I 1 1 0 0 0 1 0 0 0 0
Cc]=
Nam. ••■•■
1 1 1 0 0 0 0 0 0 1 0 0 1 0 0 0 1 0 1 0 0 1 1 1 0 0 1 0 0 0 1 0 0 0 0 0 1 1 0 1 1 0 0 1 1 1 1 0 1 0 0 1 0 1 0 1 1 0 1 0 0 0 0 1 1 1 1 1 1 0 1 1 0 1 1 1 0 1 0 1 1 1 1 0 1 0 1 0 0 0 1 1 1 0 1 1 1 1 1 0 0 1 0 0 1 1 0 0 1 0 0 0 0 0 0 1 0 0 1 0.0 0 1 0 1 0 0 1 1 1 0 0 1 1 0 1 0 0 0 0 0 0 1 0 0 1 0 0 0 1 0 1 0 0 1 1 1 0 0 1 1_
133.

The parity check matrix Eta of the newly derived
(40,27) code is therefore given by:-
Da Dll I I13
A wide range of Z-burst-error-correcting codes may be
derived (by the above procedure) from various lengths and rates.
If both codes of construction (k,k1) and (n-k, k-k1)
have a simply implemented decoding procedure, the derived (n,k)
P-burst-error-correcting code may, therefore, be decoded simply
by the following steps:
1) Calculate the symdrome (s) which corresponds to the
received vector (u), according to the syndrome equations of the
(n,k) code. If the calculated syndrome s is zero, the decoder
assumes that no errors occurred in u, otherwise it proceeds to
step (2).
2) Assume the syndrome vector s, as a received vector for
the (n-k, k-k1) code and the corresponding error pattern e
(where e ' =[ek+l ek+2 ... en.] ), may be determined by using the
appropriate decoding procedure for the (n-k, k-k1) code. Add
the inverse of e ' to s and to the parity check digits of u.
3) Assume that the remaining errors e1' (where e1' =
[e1 e2 ... %Dare confined to the k information digits. The
syndrome vector of the (k,k1) code is assumed to be identical
tothefirst(k-kddigitsofs.Thene.'may, therefore, be
determined by using the appropriate decoding procedure for the
(k,k1) code.
The complexity of this decoder is approximately equal
to the sum of the complexities of both decoders of the (k,k1)
and the (n-k,k-k1) codes. However, this decoder exhibits some
of the characteristics of the nested decoders; that is, the
decoder is capable of correcting some of the correctable random
errors and burst-errors of length greater than Q. This charac-
teristic for some applications of error-correcting codes may be
considered as the major factor in the choice of codes. 134.

Add the inverse of e.' to the first (k) digits of u.
(\
Assume the decoded received vector is identical to the transmitted vector
A
•
FIGURE 5.3.1 The flow chart of the decoder of an (n,k) block code (capable of correcting a set of errors {PP) constructed in accordance with the construction rules of the nested codes. Both codes of the construction have simply implemented decoding procedure and are capable of correcting the set of errors (Pi.
\\\\\
Receive and store the received vector, u.
Calculate the syndrome s, of u, according to the syndrome equations of the (n,k) code
Consider s as a received vector to the (n-k,k-k
1) second code of the construction
Determine the error vector e by using the appropriate decoder
of the (n-k,k-k1) code
Add the inverse of e to s and to the last (n-k) dgits of u
Consider the first (k-k1) digit of s as a syndrome vector to the
(k,ki) code
Determine the error vector e.' by using the appropriate decoder
of the (k,k1) second code of the construction.
135.

TABLE 5.3.1
Some Single-Burst- -Error-Correcting-
Codes obtained by the described Computer Search.
• NUMBER OF
CODE INFORMATION THE FIRST K COLUMNS OF THE PARITY-CHECK LENGTH DIGITS (k) MATRIX EH] IN OCTAL
CODES CAPABLE OF CORRECTING SINGLE BURST OF LENGTH TWO OR LESS
7 3 13,5,17.
15 10 26,13,22,11,32,16,21,15,12,5.
30 24 56,26,53,36,74,51,23,64,43,24,62,35,44, 22,77,61,33,50,41,32,21,15,12,5.
62 55 144,36,130,51,145,72,110,45,150,104,71,44, 143,135,160,47,173,103,74,43,117,33,56,167, 142,125,102,120,133,64,136,42,24,163,75, 123,141,53,122,52,101,77,166,105,61,50,16, 41,32,113,21,15,12,5,26.
126 118 330,217,162,354,272,224,46,372,301,27,331, 250,225,207,147,114,103,71,55,23,16,52,201, 156,244,54,216,131,204,163,72,141,202,66, 122,175,305,67,256,120,303,154,117,34,302, 101,212,77,132,61,227,322,346,125,11,344,170, 211,65,374,50,166,373,205,124,314,151,42, 104,371,226,41,160,32,102,206,116,62,213,21, 51,356,214,155,222,173,107,235,350,15,12, 243,266,255,360,5,110,276,233,171,112,333, 26,247,167,220,363,137,31,337,47,364,36,244 13,273,164,237.
250
241
CODES CAPABLE OF CORRECTING SINGLE BURST OF LENGTH THREE ERRORS OR LESS
7 3 13,5,17.
15 10 26,13,22,11,32,16,21,15,12,5.
30 • 24 56,26,53,36,74,51,23,64,43,24,62,35,44,22, 77,61,33,50,41,32,21,15,12,5.
62 55 144,36,130,51,145,72,110,45,150,104,71,44, 143,135,160,47,173,103,74,43,117,33,56, 167,142,125,102,120,133,64,136,42,24,163, 75,123,141,53,122,52,101,77,166,105,61,50, 16,41,32,113,21,15,12,5,26.
136.

126 118 *
253 144 *
507 497 *
Codes obtained using the described computer search
procedure but not included here due to their being
inordinately long.
137. /

5.4 BURST-OR-RANDOM-ERROR-CORRECTING CODES
From Theorem 5.2.1 the following corollary follows
immediately: -
Corollary 5.2.1.2
An (n,k) block code, V, that is the null space of a
matrix EHJ, is capable of correcting t random errors or less,
or a burst of length Q or less, if and only if the linear
combinations of every t columns and every Q adjacent columns of
the D-1:1 matrix result in unique nonzero vectors of the vector space
This corollary suggests a computerised search proced-
ure for burst-or.-random error-correcting codes. A computer
search programme is developed to find such codes for given
numbers of parity-check digits and given values of t and P.
This programme is simply the synthesis of the previously developed
programmes, the first being the search programme developed in
Section 3 of this thesis for finding some new random error-
correcting codes and the second the search programme developed
in the last chapter for finding single-burst-error-correcting
codes.
Table 5.4.1 provides a list of the codes obtained by
the above computerised search; the codes length (n) and the
number of information digits (k) are tabulated together with the
columnS (in Octal) of the determined EH] matrix. The techniques employed in constructing and decoding
random-error-correcting nested codes can be modified slightly
to construct a wide class of nested burst- or -random error-
correcting codes. Codes of this class are simply decodable by
the nested decoding algorithm described in Section 4 of this
thesis, and cover a wide range of code rates and error-
correcting capabilities. Buv.st - ar ) - damcJo,m . _ C ov.ve c 6'7 Cale, = 9.vit -
)
138.

An (n,k) linear block code is said to be a nested
burst-.or:-random (B C)R) error-correcting code if and only if
its syndromes, corresponding to errors in the information
digits, are codewords of either a nested B UR code or a single
burst-error-correcting code. The inner code of the nest of
such an (n,k) nested code is usually a cyclic (or shortened
cyclic) single-burst-error correcting code.
The reduced echelon form of the parity-check matrix Dij
ofan(n,k)nestedBOR code may be constructed by using the
construction procedure of random error-correcting codes
described in Section 4.
The error-correcting capability of a nested BO R
code is given by the following corollary which follows from
Theorem 5.2.2:-
Corollary 5.2.2.2
An (n,k) nested B C)R code is capable of correcting
t random errors or less, or any burst of length for less, if
both codes of the construction are 2-burst error-correcting
codes, the first having a minimum Hamming distance equal to
(2t+ 1) and the second a minimum Hamming distance equal to 2t.
Proof
In accordance with Corollary 5.2.2.1, the (n,k) nested
B"OR code is capable of correcting a burst of length 2,, due to
the fact that both codes of the construction are capable of
constructing any burst of length 2, or less.
Since the first and second codes of the construction
are of minimum Hamming distance, equal to (2t+ 1) and 2t
respectively, the (n,k) code is therefore (according to Theorem
4.2.1 of Section 4) capable of correcting any random errors of
weight t or less. This completes the proof.
139.

An (n,k) nested double random-or-single 2--burst
error-correcting code may be constructed by using, for the
first code, the best known double random-_on-single 2.-burst
error-correcting block code for the given number of parity-
check digits and an appropriate cyclic (or shortened cyclic)
single 2.-burst error-correcting code. An overall parity check
digit may be added to the single 2--burst error correcting
cyclic code to increase its minimum Hamming distance to four.
For example, consider the construction of a nested
binary double-random- or-single Q.-burst error-correcting code
from two other block codes. Let the first code of the
construction be a (21,12) block code of Table 5.4.1 capable of
correcting two random errors or less or a burst of length
three or less. The parity check matrix EH1] of this code is
given by:-
111110 0 0 0 0 0 010 0 0 0 0 0 0 0 110 0 01110 0 0 0 010 0 0 0 0 0 0 00100100110 0 0 010 0 0 0 0 0 110100101010 0 0 010 0 0 0 0
EH13= 1 0 0 0 1 0 0 1 1 0 0 1 0 0 0 0 1 0 0 0 0 010001100111000001000 1 0 1 1 1 1 0 1 1 1 1 0 0 0 0 0 0 0 1 0 0 0 0 1 1 0 0 1 1 0 1 0 1 0 0 0 0 0 0 0 1 0
_0 1 0 1 1 0 0 0 1 1 1 1 0 0 0 0 0 0 0 0 1_
The number of information digits of the second code
must be equal to the number of redundant digits of the second
code (i.e. k-k1=9). The second code must be capable of
correcting a burst of three errors or less and of minimum
Hamming distance equal to four. The (15,9) cyclic single 3-
burst-error-correcting code of the generator polynomial(7)
(g(x) = x6 + x5 + x4 + x3 + 1) can therefore be used as the
second code of the construction by adding an overall parity
check digit to increase its minimum Hamming distance to four.
140.

The columns of matrix Ec:1 may therefore be determined by forming the parity check digits of those codewords of the
even Hamming distance (16,9) code, whose information digits are
given by the columns of the [I1] matrix. Thus the matrix [C] is given by:
-I 0 1 1 1 1 0 1 1 1 1 1 1 0 0 1 1 1 0 0 1- 1 0 0 010 0 0 1 11111 010 010 1 0 1 1 0 0 1 0 0 1 1 1 1 1 1 1 1 0 1 0 1 1
[C]=011000000001111001100 0 0 1 1 1 1 1 1 1 0 0 1 0 1 1 1 0 0 1 1 0 0 0 01010 0 0 0 01001110011 1 1 0 0 1 0 1 0 1 0 1 0 1 1 1 0 1 0 0 0 1
The parity check matrix Da of the derived (37,21)
nested B 0 R code is therefore given by:-
1.111
DO[ I 1 6] In a similar manner, t-random errors-or -single c--burst
error-correcting nested codes may be constructed by using the
best known t-random errors-or_-single t-burst error-correcting
block codes for the first code of the construction and the
derived (t-1)-random errors- or-single-burst error-correcting
nested codes for the second code of the construction.
The basic principles and techniques of the nested
decoding algorithm for the nested B C) R codes are identical to
the nested decoding algorithm for random error-correcting nested
codes described in Sub-section 4.3. However, the two nested
decoders differ only in that the decocer of the inner code of
the latter decoder (as previously explained) is the error-trapping
decoder for the single-error-correcting Hatmaing code, whilst in
the case of the B 0 R nested decoder, the decoder of the inner
code is obviously the error-trapping decoder of the single-
burst-error-correcting cyclic codes.
ARM 1111•1116
141.

All nested B C) R codes which exhibit one of the
properties of decodable nested codes given in Chapter 4.3,
are decodable by the nested B C)R decoder. Table 5.4.2
gives the parameters of some decodable B C) R nested codes.
It may be useful to emphasize at this stage that the
features and merits of the B C)R nested decoder are identical
to those of the random-error nested decoder.
142.

TABLE 5.4.1
Some burst-asi-random-error-correcting codes found by computer search.
CODE NUMBER OF LENGTH INFORMATION
(n) DIGITS (k) THE COLUMNS OF THE PARITY CHECK MATRIX [HD IN OCTAL
Codes capable of correcting two random errors or less,or a burst of length three or less.
8 2 55,33,40,20,10,4,2,1.
11 4 165,117,55,33,100,40,20,10,4,2,1.
18 8 252,343,321,235,165,117,55,33,200,100,40,20,10,4,2,1.
21 12 664,651,506,447,425,314,252,226,165,117,55,33,400,200,100,40,20,10,4,2,1.
29 19 1637,1504,1363,1324,1205,1043,1035,736,611,577,446,425,314,252,226,165,117,55,33,1000, 400,200,100,40,20,10,4,2,1.
37 26 3474,3353,2640,2217,2144,2135,2036,1637,1504,1363,3124,1205,1043,1035,736,611,577,446, 425,314,252,226,165,117,55,33,2000,1000,400,200,100,40,20,10,4,2,1.
51 39 7744,7414,6517,6343,6213,5634,5471,4462,4237,4170,4112,4053,3771,3552,3017,2461,2267, 2162,2103,2036,1637,1504,1363,1324,1205,1043,1035,736,611,577,446,425,314,252,226,165, 117,55,33,4000,2000,1000,400,200,100,40,20,10,4,2,1.
68 55 17305,17073,15042,14745,13715,13125,12743,12675,12432,11203,10624,10506,10277,10174, 10105,10056,7744,7414,6517,6343,6213,5634,5471,4462,4237,4170,4112,4053,3771,3552, 3017,2461,2267,2162,2103,2036,1637,1504,1363,1324,1205,1043,1035,736,611,577,446,425, 314,252,226,165,117,55,33,10000,4000,2000,1000,400,200,100,40,20,10,4,2,1.
89 75 36147,35251,34773,34030,31531,30747,26362,25004,23214,23124,22722,22152,21656,21632, 21507,20753,20454,20260,20126,20077,17305,17073,15042,14745,13715,13125,12743,12675, 12432,11203,10624,10506,10277,10174,10105,10056,7744,7414,6517,6343,6213,5634,5471, 4462,4237,4170,4112,4053,3771,3552,3017,2461,2267,2162,2103,2036,1637,1504,1363,1324, 1205,1043,1035,736,611,577,446,425,314,252,226,165,117,55,33,20000,10000,4000,2000, 1000,400,200,100,40,20,10,4,2,1.
119 104 77701,76555,75720,73635,70564,67670,65310,63534,62337,60726,57361,54202,53441,53046, 52100,50455,47735,47241,45055,44443,44027,42714,42013,41531,41011,40604,40516,40126, 40077,36550,35463,35335,35037,31402,30330,26251,24641,24072,23554,23207,22447,22355, 21301,21116,21052,20627,20415,20306,20064,17305,17073,15042,14745,13715,13125,12743, 12675,12432,11203,10624,10506,10277;10174,10105,10056,7744,7414,6517,5343,6213,5634, 5471,4462,4237,4170,4112,4053,3771,3552,3017,2461,2267,2162,2103,2036,1637,1504,1363, 1324,1205,1043,1035,736,611,577,446,425,314,252,226,165,117,55,33,40000,20000,10000, 4000,2000,1000,400,200,100,40,20,10,4,2,1.
153 137
201 184
261 243
341 322
444 424
572 551
Codes capable of correcting two random errors or less, or a burst of length four or less.
12 4 255,177,125,63,200,100,40,20,10,4,2,1.
17 8 603,571,507,445,227,177025,63,400,200,100,40,20,4,2,1.
25 15 1735,1664,1421,1215,1153,1045,1037,603.507,455,433,227,177,125,63,1000,400,200,100, 40,20,10,4,2,1.
34 23 3251,3742,3065,2735,2554,2416,2213,2145,2037,1661,1515,1222,1113,1047,1035,603,507, 455,433,227,177,125,63,2000,1000,400,200,100,40,20,10,4,2,1.
47 35 7763,7430,7253,6710,6202,6075,5236,4715,4233,4174,4123,4045,3521,3303,3052,2416, 2270,2153,2122,2037,1772,1631,1566,1217,1106,1047,1035,603,507,455,433,227,177,125, 63,4000,2000,1000,400,200,100,40,20,10,4,2,1.
62 49 16656,16120,15172,14425,13701,13205,13162,12107,13607,11027,10677,10443,10310,10233, 10051,7641,7512,7060,6413,6243,5467,5151,4611,4462,4206,4113,4045,3367,2524,2346,2270, 2153,2122,2037,1772,1631,1566,1217,1106,1047,1035,603,507,455,433,227,177,125,63, 10000,4000,2000,1000,400,200,100,40,20,10,4,2,1.
143.

TABLE 5.4.1 (continued)
CODE NUMBER OF LENGTH INFORMATION (n) DIGITS (k)
THE COLUMNS OF THE PARITY CHECK MATRIX [NJ IN OCTAL
Codes capable of correcting two random errors or less, or a burst of length four or less. (Continued).
85 71 34472,25746,37612,35360,34617,32074,31630,3]342,30241,26454,26174,24325,23423,22477, 22324,22013,21734,21556,21064,20425,20205,20112,20057,17130,16067,15271,14762,14214, 13616,12443,12375,11432,11222,10712,10272,10162,10117,10053,7307,6754,6620,6043,5467, 5151,4611,4462,4206,4113,4045,3367,2524,2346,2270,2153,2122,2037,1772,1631,1566,1217, 1106,1047,1035,603,507,455,433,227,177,125,63,20000,10000,4000,2000,1000,400,200,100, 40,20,10,4,2,1.
111
96 65663,76211,75617,74470,72351, 70005,64302,63077,61651,61361,56301,55112,54637,52716, 51750,50424,47777,47013,44335, 44166,42700,42416,41375,41214,41041,40306,40205,40057, 36734,32436,31071,30721,27621, 27135,25744,25460,25276,24073,23033,22417,22330,22222, 21150,20412,20242,20234,20051, 17333,17242,16424,15777,14320,14023,13616,12443,12375, 11432,11222,10712,10272,10162, 10117,10053,7307,6754,6620,6043,5467,5151,4611,4406,4206, 4113,4045,3367,2524,2346,2270, 2153,2122,2037,1772,1631,1566,1217,1106,1047,1035,603, 507,455,433,227,177,125,40000, 20000,10000,4000,2000,1000,400,200,100,40,20,10,4,2,1.
148
132
193
176
255
237
334
315
430
410
558
537
729
707
Codes capable of correcting two random errors or less, or a burst of length five or less.
15 5 1077,467,357,245,143,1000,400,200,100,40,20,10,4,2,1.
25 14 3533,1666,3232,3017,2576,2246,2211,2107,2065,1061,447,357,245,143,2000,1000,400,200, 100,40,20,10,4,2,1.
35 23 1127,7232,6621,6033,5650,5031,4413,4351,4207,4063,3724,3322,3017,2414,2246,2211,2107, 2065,1061,447,357,245,143,4000,2000,1000,400,200,100,40,20,10,4,2,1.
50 37 17511,16437,16234,16130,15565,14517,14362,12727,12564,11326,11074,11013,10424,10242, 10133,10065,7471,6174,6041,5714,5031,4415,4226,4105,4057,3763,3014,2403,2207,2162, 2115,2053,1061,447,357,245,143,10000,4000,2000,1000,400,200,100,40,20,10,4,2,1.
69 55 37566,33156,31441,31334,30136,26755,26266,25766,24121,23705,22017,21250,21045,20465, 20232,20111,20063,17141,16406,15475,14661,14546,14423,13062,12733,12427,12124,11007, 10473,10221,10122,10057,7005,6660,6031,5320,5104,5033,4437,4222,4176,4107,4055,3763, 3014,2403,2202,2162,2115,2053,1061,447,357,245,143,20000,10000,4000,2000,1000,400, 200,40,20,10,4,2,1.
96 81 74751,75532,71274,66607,65425,63662,61556,60130,56155,55535,55410,51214,51177,50601,50064 46133,45441,445U,44012,43204,43066,40550,40327,40276,40065,37226,35641,34042,33510, 33261,32503,30250,24211,23521,23044,22610,22017,21703,21567,21255,20405,20232,20111, 20063,17762,16347,15627,14474,13367,12544,12220,11307,11154,11011,10432,10215,10122, 10057,7005,6660,6031,5320,5104,5033,4437,4222,4176,4107,4055,3763,3014,2403,2207, 2162,2115,2053,1061,447,357,245,143,40000,20000,10000,4000,2000,1000,400,200,100,40, 20,10,4,2,1.
132
116
175
158
237
219
314
295
414
394
538
517
144 .

TABLE 5.4.1 (continued
CODE NUMBER OF LENGTH INFORMATION
THE COLUMNS OF THE PARITY CHECK MATRIX [HJ IN OCTAL.
(n) DIGITS (k)
Codes capable of correcting two random errors or less, or a burst of length six or less.
18 6 4141,2137,1127,717,505,303,4000,2000,1000,400,200,100,40,20,10,4,2,1.
31 18 17346,16017,15165,14722,14003,12245,12027,11011,10423,10352,10207,10125,4141,2121, 1107,717,505,303,10000,4000,2000,1000,400,200,100,40,20,10,4,2,1.
49 35 26757,35304,33732,31522,30573,27140,26470,25032,24376,24227,24031,22016,21053,20467, 20306,20251,20123,16006,15033,14647,14270,14166,14003,12013,11011,10423,10352,10207, 10125,4141,2121,1107,717,505,303,20000,10000,4000,02000,1000,400,200,100,40,20,10,4,2,1.
72 57 35756,77165,75211,70120,67525,65042,64700,62147,61217,60044,56675,55364,54351,52510, 50526,45414,45370,44272,44035,42552,41665,41161,41030,40251,40123,34743,34255,30065, 26416,25066,24422,24333,24150,24015,22053,21031,20421,20342,20117,16337,16005,15061, 14460,14011,12230,12003,11006,10423,10352,10207,10125,4141,2121,1107,717,505,303, 40000,20000,10000,4000,2000,1000,400,200,100,40,20,10,4,2,1.
104 88 70512,174412,155512,124476,176470,170732,167317,164533,153043,151731,144247,142436, 142205,141350,140132,130547,126267,125515,123006,122275,121033,117256,111154,110603, 110425,110321,104017,102047,101034,100567,100253,100125,71667,65252,62620,61062,60714, 60375,57736,55131,50541,50073,47562,45706,44457,44316,44031,42126,41153,41046,40435, 40241,40123,37142,34721,32716,32671,30143,27244,26112,24462,24255,24030,23445,22063, 21067,20366,20225,20117,16506,16021,15026,14670,14212,14134,14005,12042,11003,10407, 10322,10215,10113,4141,2121,1107,717,505,303,100000,40000,20000,10000,4000,2000,1000, 400,200,100,40,20,10,4,2,1.
147 130
203 185
275 256
377 357
Codes capable of correcting two random errors or less, or a burst of length seven or less.
21 7 2031,10241,4237,2227,1617,1205,603,20000,10000,4000,2000,1000,400,200,100,40,20,10,4,2,1.
43 28 47266,33653,24647,22066,21135,70636,70324,70061,64042,62121,61117,60514,60276,60013, 50102,44027,42011,41023,40652,40407,40225,20301,10241,4221,2207,1617,1205,603,40000, 20000,10000,4000,2000,1000,400,200,100,40,20,10,4,2,1.
67 51 146075,132575,37036,36272,172240,170154,165516,155714,150222,143341,140654,140045, 135144,134512,130165,122035,120521,120030,115056,114132,110152;106234,105273,104702 104431,104017,100227,72003,70077,65663,65522,64005,60021,52120,51564,50770,50515,50006, 44013,42011,41023,40652,40407,40225,20301,10241,4221,2207,1617,1205,603,100000,400001 20000,10000,4000,2000,1000,400,200,100,40,20,10,4,2,1.
101 84
153 135
220 201
307 287
422 401
Codes capable of correcting three random errors or less, or a burst of length four or less.
9 1 267,200,100,40,20,10,4,2,1.
11 2 533,400,**.
14 4 1706,1455,1000,**.
16 5 2476,2000,**.
22 10 7262,6730,6071,5143,4315,4000,**.
25 12 11073,10336,10000,**.
28 14 32027,21534,20000,**.
33 18 74506,62702,53035,40652,40000,**.
39 23 152601,135555,123230,115352,102255,100000,**.
145.

TABLE 5.4.1 (continued)
CODE NUMBER OF LENGTH INFORMATION (n) DIGITS (k)
THE COLUMNS OF THE PARITY CHECK MATRIX Da IN OCTAL.
Codes capable of correcting three random errors or less, or a burst of length four or less. (continued)
45 28 340521,323426,235563,221157,202356,200000,**.
53 35 716576,651257,544232,450417,431624,415321,403547,400000,**.
62 43 151040201361322,1350046,1222051,1127734,1041665,1015607,1003715,1000000,**.
Ilk 73 53 3657453,3231643,3074272,2747671,2435207,2263136,2240516,2140262,2030352,2006341, 2000000,**.
86 65 7776040,7154337,6126444,5422412,5307523,4664522,4530504,4470606,4240323,4057207, 4022122,4010711,4000000,**.
Codes capable of correcting four random errors or less or a burst of length five or less.
11 1 1357,1000,400,200,100,40,20,10,4,2,1.
14 2 6467,4000,2000,**.
17 3 30533,20000,10000,**.
20 5 65542,52235,40000,**.
22 6 112750,1000000,**.
26 9 363666,304572,213524,200000,**.
• 29 11 524747,415436,400000,**.
di 33 14 1623671,1167061,1017641,1000000,**.
37 17 3444515,2251767,2024774,2000000,**.
42 21 7377137,4662710,4510463,4046345,4000000,**.
Codes capable of correcting five random errors or less, or a burst of length six or less.
13 1 5737,4000,2000,1000,400,200,100,40,20,10,4,2,1.
17 2 72157,40000,20000,10000,**.
20 3 322663,200000,100000,**.
23 5 654465,513274,400000,**.
26 7 1274703,1131565,1000000,**.
28 8 2427161,2000000,**.
32 11 7614452,6036427,4470632,4000000,**.
Codes obtained using the described computer search procedure but not included here due to
their being inordinately long.
* *
Plus the columns of the parity check matrix of the above code.
146 .
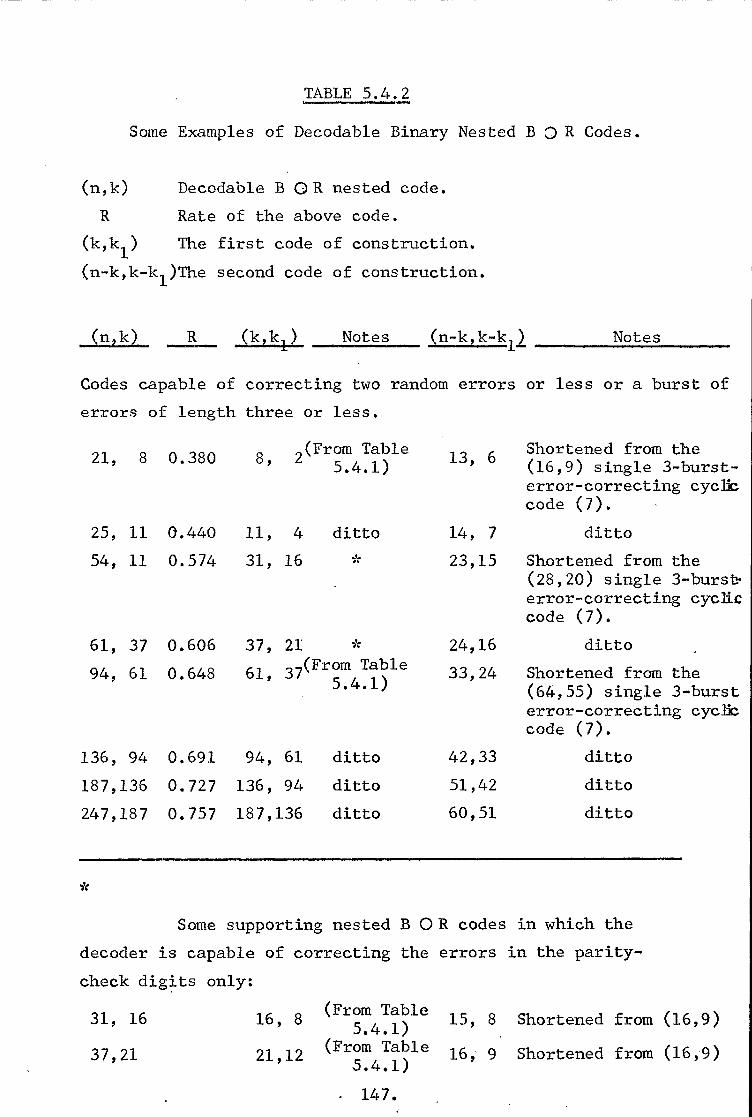
TABLE 5.4.2
Some Examples of Decodable Binary Nested B OR Codes.
(n,k) Decodable B C)R nested code.
R Rate of the above code.
(k,k1) The first code of construction.
(n-k,k-k1)The second code of construction.
(n,k)
(k, k1) Notes ( -k,k-k1 Notes
Codes capable of correcting two random errors or less or a burst of
errors of length three or less.
Shortened from the (16,9) single 3-burst-error-correcting cyclic code (7).
ditto
21, 8 0.380 8 2(From Table 5.4.1) 13, 6
25, 11 0.440 11, 4 ditto
14, 7
54, 11 0.574 31, 16
61, 37 0.606 37, 21
94, 61 0.648 61, 37(From Table 5.4.1)
136, 94 0.691 94, 61 ditto
187,136 0.727 136, 94 ditto
247,187 0.757 187,136 ditto
23,15 Shortened from the (28,20) single 3-burs& error-correcting cyclic code (7).
24,16
ditto
33,24 Shortened from the (64,55) single 3-burst error-correcting cyclic code (7).
42,33 ditto
51,42 ditto
60,51 ditto
Some supporting nested B C)R codes in which the
decoder is capable of correcting the errors in the parity-
check digits only:
31, 16 16, 8 (From Table 15, 8 Shortened from (16,9) 5.4.1)
37,21 21,12 (From Table 16,' 9 Shortened from (16,'9) 5.4.1)
147.
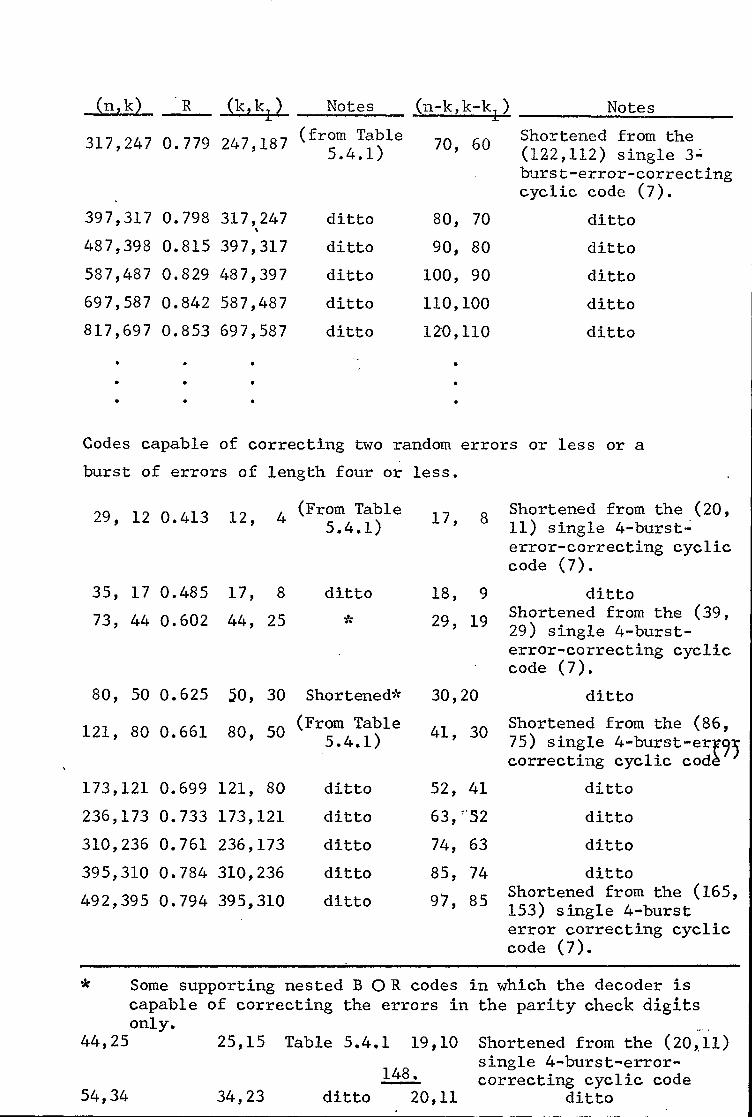
Shortened from the (20, 11) single 4-burst-error-correcting cyclic code (7).
18, 9 ditto Shortened from the (39, 29) single 4-burst-error-correcting cyclic code (7).
ditto
Shortened from the (86, 75) single 4-burst-erF9N correcting cyclic code. '
ditto
ditto
ditto
ditto Shortened from the (165, 153) single 4-burst error correcting cyclic code (7).
17, 8
29, 19
30,20
41, 30
52, 41
63,r52
74, 63
85, 74
97, 85
R (k,ki) Notes n-k,k-k1) Notes
317,247 0.779 247,187 (from Table 5.4.1) 70, 60 Shortened from the
(122,112) single 3-; burst-error-correcting cyclic code (7).
397,317 0.798 317,247 ditto 80, 70 ditto
487,398 0.815 397,317 ditto 90, 80 ditto
587,487 0.829 487,397 ditto 100, 90 ditto
697,587 0.842 587,487 ditto 110,100 ditto
817,697 0.853 697,587 ditto
•
120,110 ditto
.
• • • •
Codes capable of correcting two random errors or less or a
burst of errors of length four or less.
29, 12 0.413 12, 4 (From Table 5.4.1)
35, 17 0.485 17, 8 ditto
73, 44 0.602 44, 25
80, 50 0.625 50, 30 Shortened*
121, 80 0.661 80, 50 (From Table 5.4.1)
173,121 0.699 121, 80 ditto
236,173 0.733 173,121 ditto
310,236 0.761 236,173 ditto
395,310 0.784 310,236 ditto
492,395 0.794 395,310 ditto
Some supporting nested B C)R codes in which the decoder is capable of correcting the errors in the parity check digits only.
44,25 25,15 Table 5.4.1 19,10 Shortened from the (20,11) single 4-burst-error-
148. correcting cyclic code
54,34 34,23 ditto 20,11 ditto
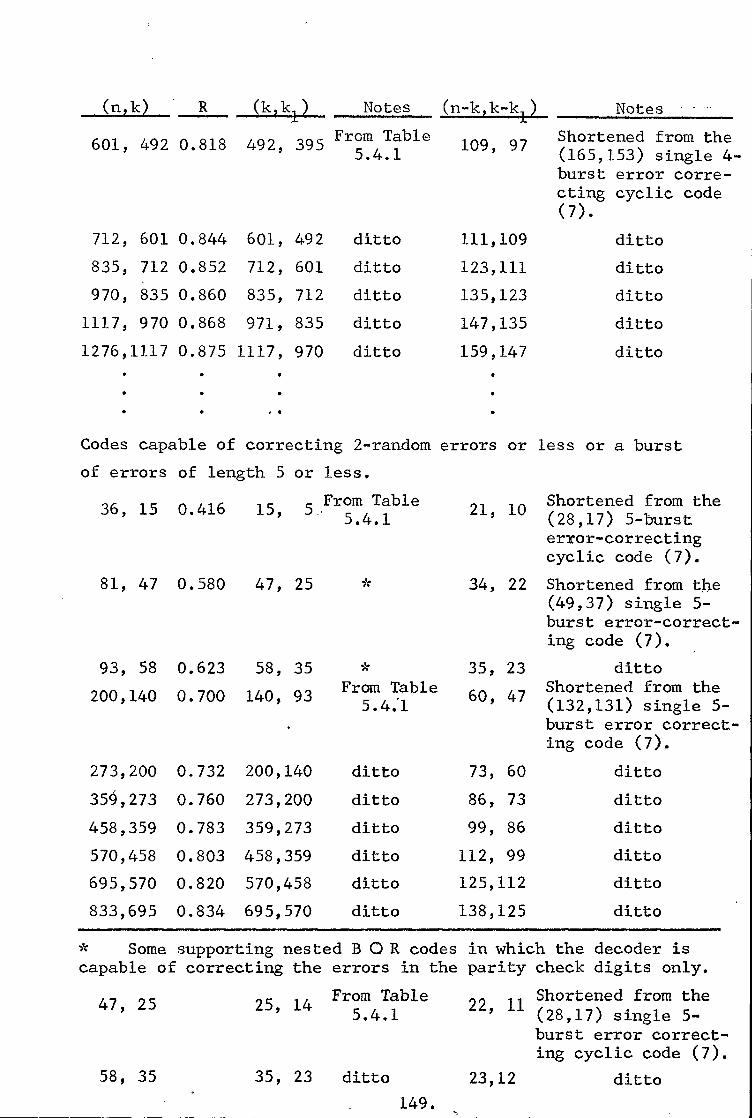
(n,k) R (k,k1) Notes
601, 492 0.818 492, 395 From Table 5.4.1
712, 601 0.844
835, 712 0.852
970, 835 0.860
1117, 970 0.868
1276,1117 0.875
•
n-k, kl) Notes
109, 97 Shortened from the (165,153) single 4-burst error corre-cting cyclic code (7).
601, 492 ditto 111,109 ditto
712, 601 ditto 123,111 ditto
835, 712 ditto 135,123 ditto
971, 835 ditto 147,135 ditto
1117, 970 ditto 159,147 ditto
•
• •
Codes capable of correcting 2-random errors or less or a burst
of errors of length 5 or less.
36, 15
81, 47
93, 58
200,140
273,200
359,273
458,359
570,458
695,570
833,695
0.416
0.580
0.623
0.700
0.732
0.760
0.783
0.803
0.820
0.834
15, 5 From Table 5.4.1
47, 25
58, 35
140, 93 From Table 5.4.1
200,140 ditto
273,200 ditto
359,273 ditto
458,359 ditto
570,458 ditto
695,570 ditto
21, 10
34, 22
35, 23
60, 47
73, 60
86, 73
99, 86
112, 99
125,112
138,125
Shortened from the (28,17) 5-burst error-correcting cyclic code (7).
Shortened from the (49,37) single 5-burst error-correct-ing code (7).
ditto Shortened from the (132,131) single 5-burst error correct-ing code (7).
ditto
ditto
ditto
ditto
ditto
ditto
Some supporting nested B C)R codes in which the decoder is capable of correcting the errors in the parity check digits only.
47,
58,
25
35
25,
35,
14
23
From Table 5.4.1
ditto
' 11
23,12
22, 11 from the
(28,17) single 5-burst error correct-ing cyclic code (7).
ditto 149.

(n,k) "R (k k ) ---2--±- Notes (n-k,k-k1) Notes
Codes capable of correcting 2-random errors or less or a burst of
errors of length six or less.
43, 18
97, 51
109 68 ,
0.418
0.525
0.623
18, 6 From Table 25, 12 5.4.1
57, 31 40, 26
68,41 Shortened* 41 27 from (76,49) '
Shortened from the (35, 22) single 6-burst-erTo\-- correcting cyclic cod ?)
Shortened from the (68, 54) single 6-burst-ero;..- correcting cyclic codI
ditto
192,109 0.567 109, 68 From Table 5.4.1 83, 68 Shortened from the (170,
155) single 6-burst-erra correcting cyclic code.
290,192 0.662 192,109 ditto 98, 83 ditto
403,290 0.719 290,192 ditto 113, 98 ditto
531,403 0.758 403,290 ditto 128,113 ditto
674,531 0.787 531,403 ditto 143,128 ditto
832,674 0.810 674,531 ditto 158,143 ditto
Codes capable of correcting 2-random errors or less or a burst
of errors of length seven or less.
50, 21
119, 73
181,119
259,181
353,259
0.420
0.613
0.657
0.698
0.733
21, 7 From Table
5.4.1
73, 43
119, 73 From Table 5.4.1
181,119 ditto
259,181 ditto
29,
46,
62,
78,
94,
14
30
46
62
78
Shortened from the (39,24) single 7-burst-error- (7) correcting cyclic code":.
Shortened from the (104, 88) single 7-burst-error-correcting cyclic code.
ditto
ditto
ditto
* Some supporting nested B C) R codes in which the decoder is
capable of correcting the errors in the parity check digits only.
57, 31 31 18 From Table 26 11 Shortened from the (35,22) , ,
5.4.1 single 6-burst error- (7) . correcting cyclic code
49, 35 Ditto 27,14 ditto
43, 28 Ditto 30,15 Shortened from the (39,24)
single 7-burst error- (7) correcting cyclic code 1.
76, 49
73, 43
150.

1
(n,k) R (k,k1) Notes (n-k,k-k1) Notes
Codes capa ble of correcting 3-random errors or less or a burst
of errors of length four or less.
35, 9
38, 11
42, 14
45, 16
52, 22
57, 25
61, 28
67, 33
139, 74
147, 81
180, 101
191, 111
204, 123
230, 137
376, 230
586, 376
871, 586
1242, 871
1711,1242
0.257
0.289
0.333
0.355
0.423
0.438
0.459
0.492
0.532
0.551
0.561
0.581
0.602
0.595
0.611
0.641
0.672
0.7012
0.725
• •
9 ,
11,
14,
16,
22,
25,
28,
33,
74,
81,
101,
111,
123,
137,
230,
376,
586,
871,
1242,
•
1 From Table 5.4.1
2 ditto
4 ditto
5 ditto
10 ditto
12 ditto
14 ditto
18 ditto
39
45
53
62
73
86 137 From Table
5.4.1
230 ditto
376 ditto
586 ditto
871 ditto
26, 8
27, 9
28, 10
29, 11
30, 12
32, 13
33, 14
34, 15
65, 35
66, 36
79, 48
80, 49
81, 50
93, 51
146, 93
210,146
285,210
371,285
469,371
•
Shortened from (30,12) of this table.
ditto
ditto
ditto
ditto Shortened from (36,17) of this table.
ditto
ditto Shortened from (74,44) of this table.
ditto
Shortened from (81,50)
ditto
ditto
Shortened from (122,80)
Shortened from(174,120
Shortened from( 237,171
Shortened from(311,23)
Shortened fr om( 396,31.0)
Shortened from(493,395)
Some supporting nested B 0 R codes in which the decoder is
capable of correcting the errors in the parity check digits only.
74,39
81,45
101,53
111,62 123,73 137,86
From Table 39,23 5.4.1
45,28 ditto
53,35 ditto
62,43 ditto
73,53 ditto
86,65 ditto
35,16
36,17
48,18
49,19 50,20 51,21
Shortened from (36,17) of this table.
ditto Shortened from (74,44) of this table.
ditto ditto ditto
151.

5.5 MULTIPLE-BURST-ERROR-CORRECTING CODES
The corollaries of Chapter 5.4 may be modified for
multiple-burst-error-correcting codes as follows:
Corollary 5.2.1.3
An (n,k) block code V, that is the null space of a
matrix [H], is capable of correcting b bursts of errors or less
of length t or less, if and only if the linear combinations of
every combination of b or less sets of 2, adjacent columns of the
Da matrix result in unique nonzero vectors of the vector space
Vn-k.
A computer programme is developed, in accordance with
the above corollary, for finding multiple-burst-error-correcting
codes for a given number of parity check digits and given values
of b and Q. The programme follows the same steps as the
programme given in Chapter 5.3 for finding single burst error
correcting codes. However, it differs in the type of linear
combinations of steps (4) and (5); in this case the computerised
search performed the linear combinations of every combination
of b or less sets of 2 adjacent columns of the [H] matrix and
the resulting vector is tested for uniqueness. Table 5.5.1
supplies a list of some of these codes. The code lengths and
number of information digits are given, together with the
Octal equivalent of the columns of the determined parity check
matrix.
The conditions of constructing multiple-burst-error-
correcting codes (exhibiting some of the characteristics of
nested codes) are given by the following corollary which
follows from Theorem 5.2.2:-
• 152.

Corollary 5.2.2.3
An (n,k) block code, constructed in accordance with
the construction rules of nested codes using two block codes
for construction, is capable of correcting b bursts of error
or less of length 2 or less, if both codes of construction
are capable of correcting b bursts of errors or less of length
2, or less.
For example, consider the construction of a block
code capable of correcting double bursts of length two or less
from two other block codes of Table 5.5.1 ; the first code of
construction being the (41,27) code and the second code of
construction the (27,14) shortened code from the (30,17) code
of Table 5.5.1.
The parity check matrix EHij of the (41,27) is given by:
-110110 0 111110 0 0 0 0 0 0 0 0 0 0 0 00 010 0 0 0 0 0 0 0 0 0 0 0 0 1011010110 0 011110 0 0 0 0 0 0 0 0 0 0 010 0 0 0 0 0 0'0 0 0 00 1010 0 0110 10 0110 011110 0 0 0 0 0 0 0 0 10 0 0 0 0 0 0 0 0 0 0 10110 010 0 01010 10110 0110 0 0 0 0 0 0 010 0 0 0 0 0 0 0 0 0 O1010100001000001010001100000001000000000 10100111000001000000101010000000100000000
Eig. 0 0 0110 0110 101010 010 010 0 0 010 0 0 0 0 0 0 10 0 0 0 0 0 0 11110 011110 01 0 0 0 0 0 101010 0 01 0 0 0 0 0 0 010 0 0 0 0 0 O0100000110001110101000101000000000100000 O11101010101010 0 0110 010 01010 0 0 0 0 0 0 0 010 0 0 0 11101101010110 01110 0 1101010 0 0 0 0 0 0 0 0 0 010 0 0 O 0101110 0111110 01011111 010 10 0 0 0 0 0 0 0 0 0 010 0 110 010 0 110 011111111010 10 110 0 0 0 00 0 0 0 0 0 0 010
_0 11 0 0 01011 010 0 01110111111010 0 0 0 0 0 0 0 0 0 0 0 01
The parity check matrix EH23 of the (27,14) code is
given by:
1 1 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 1 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 1 0 0 1 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 1 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 1 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 1 0 0 1 0 0 1 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0
[112j= 1 0 0 0 0 1 0 1 0 1 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 1 0 1 0 1 0 0 0 1 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 1 0 0 1 0 0 1 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 1 1 0 0 1 1 0 1 0 i 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 1 0 1 1 1 1 1 0 1 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 01111101010110 0 0 0 0 0 0 0 0 0 0 010 0 1 1 1 0 1 1 1 1 1 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1
153.

Using the above [-12:1 matrix, the parity-check equations
of the (27,14) code may be determined. Thus the 41 columns
of the matrix EC] are formed by the parity check digits of
those 41 codewords of the (27,14) code whose information
digits given by the columns of the [HI] matrix.
If 2: is the generator matrix of the (27,14) code,
the [C] matrix is therefore given by:
Ec3 = [Hi] EG2] The parity check matrix [H] of the derived (68,41)
code is therefore given by:
[1.11
= n-j
It has been established in Chapter 5.3 that if both
codes used for constructing (41,27) and (27,14) have a simply
implemented decoding logic, the derived (68,41) code can be
decoded simply by following the steps of the decoder suggested
for single-burst-error-correcting codes (see Chapter 5.3).
154.

TABLE 5.5.1
Some multiple-burst-error-correcting-codes found by
computer search capable of correcting double bursts
of length two or less
CODE NUMBER OF THE FIRST K COLUMNS OF THE PARITY CHECK LENGTH INFORMATION MATRIX [H] IN OCTAL (n) DIGITS (k)
10 2 252,125.
15 5 1507,1051,427,252,125.
19 8 1244,3155,2037,1507,1051,427,252,125.
23 11 7021,6265,5130,4053,2717,2035,1507,1051,427, 252,125.
30 17 12513,11147,4477,14705,12242,10053,7017,6273, 5126,4045,2717,2035,1507,1051,427,252,125.
41 27 36512,21133,16575,33320,20216,11434,6505, 34732,30343,24175,23204,20037,16316,14466, 12242,10053,7017,6273,5126,4045,2717,2035, 1507,1051,427,252,125.
50 35 66246,43451,24404,62557,53143,41157,33547, 21132,10734,70464,60117,57423,50005,45325, 40047,34732,30343,24175,23204,20037,16316, 14466,12242,10053,7017,6273,5126,4045,2717, 2035,1507,1051,427,252,125.
66 50 121714,57324,143625,112721,42165,145534, 102066,75130,46223,142232„125402,100346, 61603,40731,24404,16022,175540,160363,151652, 140151,131536,120043,111234,100172,70420, 60117,57423,50005,45325,40047,34732,30343, 24175,23204,20037,16316,14466,12242,10053, 7017,6273,5126,4045,2717,2035,1507,1051,427, 252,125.
86 69 206343,72374,342016,216424,143421,313247, 246146,207204,125035,303027,225250,201747, 106533,50515,346454,301432,271535,242372, 200631,165712,124701, 101171,65453,42605,23442, 361242,340141,321715,300153,260550,240070, 237763,22000,216050,200172,173502,1602471, 152614,140217,131512,120067,111210,100055, 70420,60117,57423,50005,45325,40047,34732, 30343,24175,23204,20037,16316,14466,12242, 10053,7017,6273,5126,4045,2717,2035,1507,1051, 427,252,125.
155.

(n) (k) THE FIRST K COLUMNS OF THE PARITY CHECK MATRIX EH] IN OCTAL
110 92 764103,615115,427116,215004,646732,412015, 247634,613171,526221,410717,205735,106311, 724642,602515,511221,403775,315540,271204, 204050,126130,73334,756026,704273,600474, 552071,501202,444444,401150,353612,305112, 242641,201013,144474,102401,42164,741036, 700335,640266,635753,600133,573051,540407, 525147,500037,463524,440315,422345,400056, 360702,341171,320523,300245,260355,240123, 236504,220426,217603,200071,173502,160271, 152614,140217,131512,120067,111210,100055; 70420,60117,57423,50005,45325,40047,34732,30343, 24175,23204,20037,16316,14466,12242,10053, 7017,6273,5126,4045,2717,2035,1507,1051, 427,252,125.
140 121 1116163,555373,1622251,1265300,1034564, 550104,1426121,1010434,530357,1455417,1325333, 1017251,503140,235012,1750660,1401217,1232241, 1005566,647331,411761,240554,1621660,1403747, 1376227,1216705,1003043,604766,401542,264231, 155065,1733253,1602472,1511165,1401074,1317223, 1201273,1115723,1000616,761375,710062,603666, 504524,400443,312143,275252,201016,114654, 53103,1767006,1700432,1654740,1600233,1546256, 1500353,1444523,1400136,1344544,1300210,1243755, 1200066 , 1142712,1100113,1042044,1000172,741204, 700106,675107,640767,600174,573046,540347, 525142,500032,463653,440062,422345,400056, 360702,341171,320523,300245,260355,240123, 236504,220426,217603,200071,173502,160271, 152614,140217,131512,120067,11210,100055,70420, 60117,57423,50005,45325,40047,34732,30343, 24175,23204,20037,16316,14466,12242,10053, 7017,6273,5126,4045,2717,2035,1507,1051,427, 252,125.
156.

6. BOUNDS ON THE HAMMING DISTANCE OF LINEAR CODES AND ANTICODES
6.1 Introduction.
6.2 An Improvement on the Varshamov-Gilbert Lower
Bound on the minimum Hamming Distance of
Linear Block Codes.
6.3 The Weight Distribution of Linear Binary Codes.
6.4 Maximum Hamming Distance Bounds for Linear
Anticodes.
•
157.

6.1 INTRODUCTION
An upper bound on the minimum Hamming distance d (of
an (n,k) linear block code V over the Galois field of q elements
GF(q)) is defined as the absolute theoretical maximum value d
can take for any arbitrary code length (n) and number of message
digits (k). The upper bound is said to be "good" if it is close
to the best lower bound. A lower bound on d is defined, for
arbitrary values of n and k, as the largest value of d
associated with any code which can be shown to exist, having
the value of n and k. The lower bound is said to be "good" if it
is close to the best upper bound.
A number of upper and lower bounds have been reported
in the literature. Most of these are based either on the well-
known sphere-packing argument introduced by Hamming(30,27), the
average distance" approach of Plotkin(63' 64) , or a combination
of these(65)
. The values of d for a number of well-known codes,
such as the Hamming(30)
, BCH(3,7), Goppa(57,58,82) and 84)
Srivastara (3, codes, also provide'a lower bound on d(67,68)
The Varshamov-Gilbert bound was proposed by Varshamov(60)
and is in fact a refinement of a bound proposed by Gilbert(27)
The same bound was also found by Sacks(66)
from a consideration
of the characteristics of the parity-check matrix EH] of the code. Sacks shows that since the minimum Hamming distance of an (n,k)
linear code is d, if and only if every (d-1) columns of matrix
Da are linearly independent(3), the following systematic
procedure for constructing an (n,k) code with r-parity check
symbols and minimum distance (d) follows immediately:-
1) The first column of the EH] matrix is chosen arbitrarily
from the vector space Vr, subject only to the condition that it
is not a null vector.
158.

2) The second column is chosen so that it is different
from all multiples of the first column and the null vector.
3) The third column is chosen to be different from the
null vectors, and from the linear combination of the first two
columns.
4) The remaining columns are then chosen such that they
are different from the null vector and from all possible linear
combinations of the previously chosen columns.
This method of generation guarantees the required
independence of the columns. The method cannot be successfully
completed unless r is sufficiently large. To find the minimum
value of r, the worst possible outcome of making n arbitrary
choices for the columns of [lj] is considered. The outcome is such
that all the entries in the nth stage are distinct and then to
ensure success in the face of this worst outcome, qr need only be
greater than the total number of entries in the nth stage (q
being equal to 2 for the binary case). The smallest integer (r),
that satisfies the following equation, is thus the Varshamov-
Gilbert lower bound on d.
d-2
(q-1)1 = qr i=d
(6.1)
The object of this section is to introduce a possible
improvement on the above bound by showing that the number of
distinct vectors, resulting from the linear combination of all
d-2 columns of the Da matrix, are much less than the summation
in equation (6.1).
An expression for the largest possible number of these
distinct vectors (for any (n,k) group codes) is proposed and a
tighter bound is therefore obtained.
159.

6.2 AN IMPROVEMENT ON THE VARSHAMOV-GILBERT LOWER BOUND ON THE MINIMUM HAMMING DISTANCE OF LINEAR BLOCK CODES
Let an (n,k) group code V over GF(q) have a parity
check matrix Dd.]; then a vector v of the vector space Vn is a
codeword (i.e. v EV) if and only if it is orthogonal to every
row of Da. That is(7)
[HTJ = 0 (6.2)
This implies that any vectory (ve_V) of weight w, specifies a
linearly dependent set of w columns of the Efa matrix, or
conversely a linear combination of w columns of DI resulting
in the zero vector, establishes the existence of a codeword v
of weight w(7).
It is convenient here to employ the term "quasi-linear
independence" introduced in Section 3.4.1. The r-tuple vectors
rl, r2, ri over GF(q) are quasi-linearly independent if the
vectors, formed by modulo-q addition of the scalar products
(a1r1 + a2r2 + + air.) are all nonzero vectors, where a.
may be any one of the nonzero elements of GF(q). Since there are
(q-1) nonzero elements in GF(q), the quasi-linear combinations
(QLC) of the above vectors may have (q-1)1 combinational sums,
each sum resulting in a nonzero r-tuple vector over GF(q). It
follows that if the vectors are not quasi-linearly independent
over GF(q) they must be linearly dependent over the field.
The numerical value of the Varshamov-Gilbert bound,
given by equation (6.1), may be rewritten as follows:
1 + (ni)(q.4)+ (2)(q-1)2+ ...+(dn3)(q...i)d-3
(d1.12)(q-1)d-2 qn-k (6.3)
We may say therefore that since elLrepresents the total number
of the quasi-linear combinations of one, two, ..., and (d-2)
columns of the EH: matrix, the bound assumes that all the vectors resulting from these combinations are distinct.
160.

Now let us consider a codeword vector v of weight d,
which has nonzero elements at the positions p1, p2, Pd* It follows from equation (6.2) that the modulo-q addition of the
scalar products of these nonzero elements with the corresponding
pi, p2, ..., and pd columns of the Ea matrix, results in a zero vector. Let the set of these d scalar products, say [C), be
divided into two sub-sets tA} and -Pl. Moreover, let the
modulo-q addition of the members of sub-set [Al result in an
r-tuple vector a and similarly the members of a sub-set
result in a vectot b. Then
a + b = 0 (6.4)
This equality indicates that a is the inverse vector of b and
vice versa. If the sub-set has two members, then the vector
a must be a vector in the set of vectors resulting from the
quasi-linear combination of every two columns of the DO matrix (denoted by OT IV GQLC(2)(q-1)2 ). And, since the inverse of a vector a is equal to the scalar product ((q-1).a) it follows
that the vector b is one of the vectors resulting from the
quasi-linear combinations of every two columns of DJ (i.e.
b I v eQLC(ni)(q-1)2 } ). However, the vector b is in the set
[v y +v GQLC( q-2 )(q-1)ad-1- 21 5, which suggests that vector b is not distinct. Similarly all the multiples of vector b, g.b, (whetrie
g is any nonzero element of GF(q)) are in the set iviveQu(d_ 2 ). (q-1)d-21 5 and since g.a + g.b = 0, according to the above
argument, the (q-1) multiples of vector b are not distinct.
Since set [C has d members, it can be divided, in
two sub-sets 1A1 and [BI of two members and (d-2) members
respectively, in many ways. The number of these combinations is
equal to (E21). Consequently, the corresponding number of non-
distinct vectors in the set tvivGQLC(dn...2)(q-1)d-21, for every
codeword of weight d, is given by:
161.

((2)(q-1).
Moreover, the sub-set tAl may also have 3, 4, ... or j members
and consequently the sub-set f13.1 may have (d-3), (d-4) .... or
d-j members. If j is less than half the number of members of
the set (C1, then all possible combinations of 3, 4,..., j
members out of d members of set IC) (used to form the sub-set {Aj)
are different from all the corresponding combinations forming
the sub-set 1131. Each of these ways of dividing set {C1
corresponds to a non-distinct vector in one of the sets
[Nr v- QLC(dn2)(q-1)d-2 tv I v GQLC(d n3 )(q-1)d-31
non-distinct vectors, for every codeword of weight d, is given (d+7)/2)(q-1)
(d+1)/21 [v I v G QLC( The total number of these
by:-- rd-
21
(6.5)
In general every codeword of weight w, where d<w<d-2-Ft, t =
r-21-1 (q-1) (1) (6.6)
i=w-d+2
n d-22 non distinct vectors in the sets [viveQLC(d2)(q-1) 3,
{v I v GQLC(dn3)(q-1)(1-31,..., fv i v GQI,c((d÷i)/2)(q-1)(d+1)/21
Since the linear combinations of every t columns of the EH]
matrix give unique nonzero vectors in the vector space Vr(89)
no two codewords of weight w (where d<w<t+d-2) suggest the
same non distinct vectors.
means the largest integer, smaller or equal to 2 d-1
(d-1)/2, i.e. 1-- 2 — t.the number of random errors the
code can correct.
, suggests the existence of: Fdi 2
162.

The total number of these vectors may be computed as
follows:-
Let the minimum number of codewords in an (n,k,d)
linear code of weight w be fw; then the whole computation of
these non-distinct vectors may be tabulated in the following
table:-
- The minimum CODEWORD number of WEIGHT codewords of
weight w.
Number of non-distinct vectors in the linear combinations of (d-2) columns of the DJ, matrix, corresponding to sub-sets [Al and tBi of "i" members and (w-i) members respectively.
i = 2 3 4
fd(q -1)
d+1
fd+1
fd-Ei (q-1) [ d+2
fd+2 fd+2(c1-1) [
• •
d-2 d-1 2 fd-24e1 &1-5(c1-1) [I 2
The total summation is then given by:
d-2fd-1 2 2
(q-1)y--; (7) w=d i=w-d+2
(6.7)
The subtraction of the total number of non-distinct
vectors of equation (6.7), from the summation of equation (6.1),
w fw
d
fd
163.
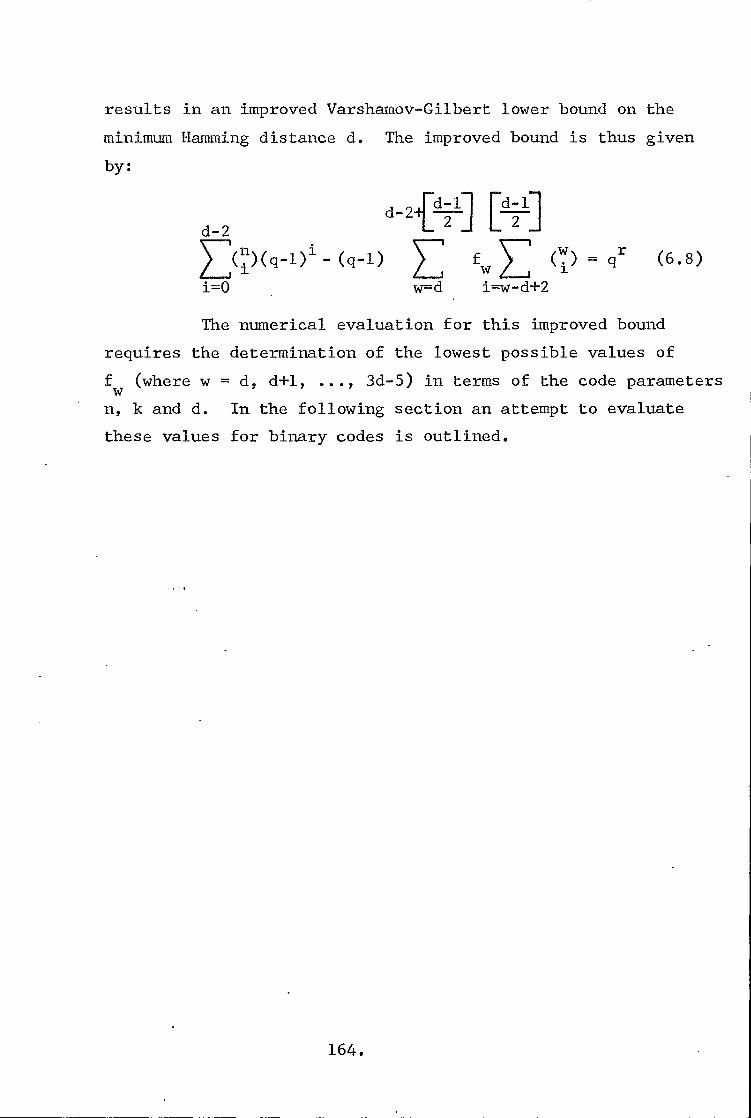
results in an improved Varshamov-Gilbert lower bound on the
minimum Hamming distance d. The improved bound is thus given
by:
d-2 d-1 Ed-11 2
2
T()(1) -(q-1) n i (7) = qr (6.8)
i=0 w=d i=w-d+2
The numerical evaluation for this improved bound
requires the determination of the lowest possible values of
fw (where w = d, d+1, 3d-5) in terms of the code parameters
n, k and d. In the following section an attempt to evaluate
these values for binary codes is outlined.
d-2
164.

6.3 THE WEIGHT DISTRIBUTION OF LINEAR BINARY CODES
The 2k codewords of an (n,k) binary block code can
be tabulated as the rows of an nk xn matrix; this matrix being
referred to as the code array. The first k columns of the
binary array are the k information columns, and each of the
remaining (n-k) check (redundant) columns is some linear
(modulo-2) combination of the k information columns.
Consider the code array of an (n,k) binary block code
arranged as follows:-
The codeworcb of the upper half of the array are
tabulated in a sequence that corresponds to the decimal value
(from 2k-1 up to 2k - 1) of the k binary information digits of
each codeword. The codewords of the lower half of the array
are tabulated in a sequence that corresponds to the decimal
value (in the range 0 to (2k-1 - 1) of the k information digits
(as shown on the next page).
If all zero elements of the first k columns of this
array are replaced by +1's and the 1 elements by -1's, then the
resulting columns form the k functions of Rademacher(85). Walsh
functions are usually defined by products of Rademacher functions (86)
. This definition, however, does not yield the Walsh
functions ordered by the number of sign changes as does the
difference equation*. Rademacher functions correspond to the
The Walsh functions Wal(j,9) may be defined by the
following difference equation(85).
.
Wal(2j+p,9)= (-1)1-3/71+P(walE),2(94fl+(-1)-14-1Walp,2(9 44
p=0 or 1; j= 0, 1, 2, ...; Wal(0,9)=1 for 4.-5Z9<-2;
`Wal(0,9)= 0 for 9
r)/21 means the largest integer smaller than or equal to Tie
165.

Redundant Digits
0 0
1 • • • . . • 1
1 1
0 0
0 1
1 0
• •
• •
• •
• '2k
Decimal Value of Information Digits Information Digits
2kT1 + 0 1 0 0 0 •
2k-1 + 1 1 0 0 1
2k-1 + 2 1 0 1 0
2k-1 + 3 1 0 1 1
2k-1 + 4 1 1 0 0
2k-1 + 5 1 1 0 1
• . • •
• . • •
• • • •
• • . •
k 2 - 1 1 1 1 1
0 0 0 0 0
1 0 0 0 1
2 0 0 1 0
3 0 0 1 1
4 0 1 0 0
5 0 1 0 1
1 1
0 0
1 1
1 1
0 0
1 1
0 0
2 k 1
• • • • 4
• • • • •
• • • • •
• • • • •
0 1 1 1 0
>4
n
166.

O ave.
functions Wal(1,9), Wal(3,9), Wal(7,9), It should be
noted that the result of multiplying together two Walsh functions,
when transformed by replacing all the positive elements by 0's
and the negative elements by l's, is identical to that produced
by similarly transforming the original functions and performing
a simple modulo-2 addition(97). Since all the redundant digits
of any (n,k) linear code are a consequence of the modulo-2
addition of some of the k information digits, it follows that
all the n columns of the above array are Walsh functions.
Every Walsh function has equal numbers of l's and 0's and hence
the columns of any code array will have equal l's and 0's;
therefore the total number of l's in the array is equal to
(n.2k-1). Since there are 2
k - 1 nonzero codewords in V, the
average weight of codewords in V is given by:*
n.2k-1
Wave.
2-1 (6.9)
Now consider an (n,k) linear code (V) of minimum
Hamming distance (d) equal to average weight (Wave.). Since the
minimum Hamming distance a of any (n,k) linear code is equal to
the minimum weight(7), (i.e. in the case of the code under
considerationMd=Wrian.= W ), it follows that as d tends
to Wave.
the maximum weight of M' codewords of V will be equal
to the minimum weight. Therefore the code V is an equidistance
code with all its 2k 1 nonzero codewords of weight
Wave., where
Wave. =n.2k-1
/(2k - 1). For large values of k, Wave.
tends to
n/2. The weight distribution of V is shown diagrammatically below. k 2 -1
fw
The same results may be obtsline identities, see also Peterson(?
167.
by using Pless(100)
page 70.
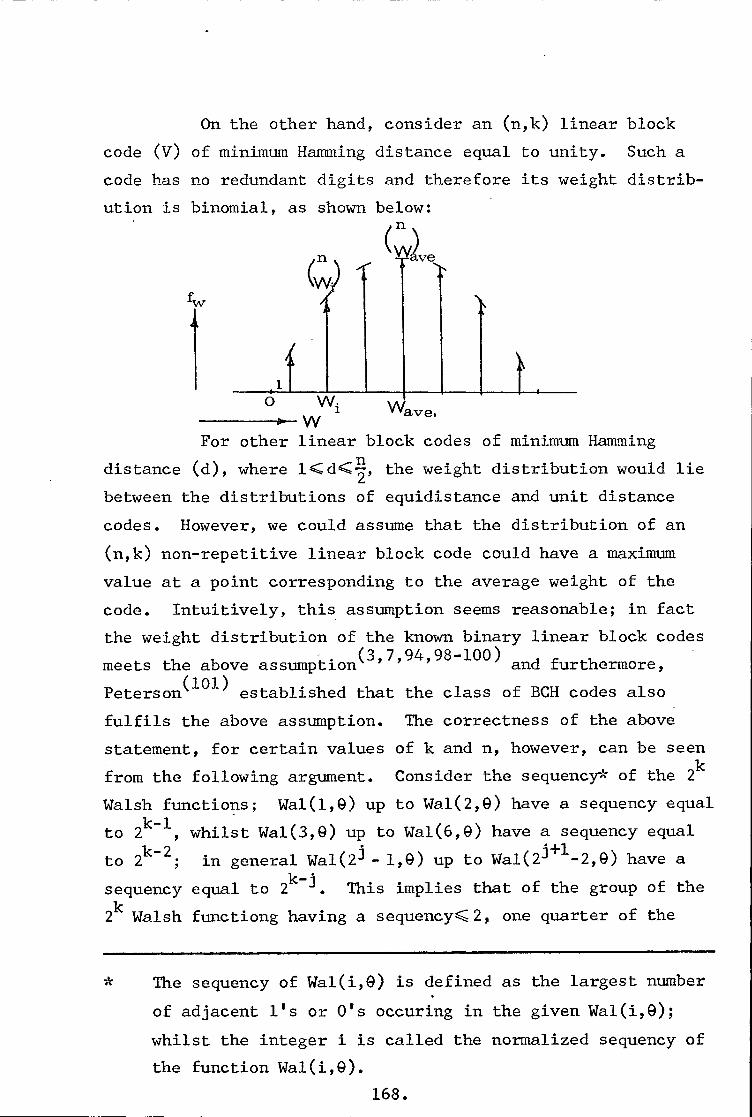
2ve
1
On the other hand, consider an (n,k) linear block
code (V) of minimum Hamming distance equal to unity. Such a
code has no redundant digits and therefore its weight distrib-
ution is binomial, as shown below:
0 W. VV
Wave,
For other linear block codes of minimum Hamming
distance (d), where 1<d<-1:1- 2' the weight distribution would lie
between the distributions of equidistance and unit distance
codes. However, we could assume that the distribution of an
(n,k) non-repetitive linear block code could have a maximum
value at a point corresponding to the average weight of the
code. Intuitively, this assumption seems reasonable; in fact
the weight distribution of the known binary linear block codes
meets the above assumption(3,7,94,98-100) and furthermore,
Peterson(101) established that the class of BCH codes also
fulfils the above assumption. The correctness of the above
statement, for certain values of k and n, however, can be seen
from the following argument. Consider the sequency* of the 2k
Walsh functions; Wal(1,9) up to Wal(2,9) have a sequency equal
to 2k-1, whilst Wal(3,9) up to Wal(6,0) have a sequency equal
to in in general Wal(2j - 1,9) up to Wal(234-1-2,9) have a
sequency equal to 2k 3. This implies that of the group of the
2k Walsh functiong having a sequency2, one quarter of the
The sequency of Wal(i,9) is defined as the largest number
of adjacent l's or 0's occuring in the given Wal(i,9);
whilst the integer i is called the normalized sequency of
the function Wal(i,9).
168.

functions of the group have a sequency<4, and in general,
the (20th part of the Walsh functions of the group have a
sequency <C23, such that only one Walsh function has a sequency
equal to 2k. Since the code array of an (n,k) code may be
arranged in such a way that each column of the array represents
a Walsh function and if the (n,k) code is non-repetitive, then
each row of the array forms a part of a distinct Walsh function.
This suggests that if n is not negligible compared with 2k, then
half of the rows of the (n,k) code array have a sequency <2,
one quarter of the rows have a sequency <4, ki rows have a
sequency of 2j and two rows may have a sequency of n. Then
since the largest number of codewords has a weight equal to the
average value, it follows that the weight distribution of an
(n,k) non-repetitive linear block code may have a maximum value
at a point corresponding to the average weight of the code.
The proposed improvement on the Varshamov-Gilbert
lower bound on d for linear block codes may be evaluated for
codes, fulfilling the above assumptions, as follows:-
(i) Assume that the minimum number of codewords of
weight (w) where d <w< wave in an (n,k,d) linear code,
is as low as zero; and
(ii) the minimum number of codewords of average weight
(fwave) tends to the average value of fw. The correct-
ness of this statement can be seen from the fact that
since fwave
is the maximum value for fw, (where w = 1, 2,
n), then the lowest value of fwave cannot be less
than the average value of fw. That is:
2k
1 fwave.
(6.10)
where Z is the total number of the non-zero fw and in
general Z‹.;:n-d. However, for an (n,k) code with even
169.

Hamming distance d, derived from an (n-1,k) code with
odd Hamming distance (d-1) by annexing an overall
parity check digit, fw, equal to zero for w odd and
therefore:
Z <
(6.11)
Using equations (6.1), (6.8) and (6.10), the Varshamov-Gilbert
bound and its improvement may be evaluated. The improvement
is found to be significant for n<10. However, as the code
length increases, the numerical evaluation of the proposed:
improvement using the above suggested bound on the lowest
value of fwave is found to be negligible. Nevertheless, the
proposed improvement can be of great importance if a tighter
bound on the lowest values of fw (where d<w<d-2 + 2 ) is
known.
In spite of the fact that a considerable amount of
research has been devoted to the study of weight distribution
of linear block codes, no work has been done to study the
bounds on the weight distribution (fw).
170.

6.4 MAXIMUM HAMMING DISTANCE BOUNDS FOR LINEAR ANTICODES
In Section 3.4.2 a systematic procedure for the
construction of an (m,k,6) anticode over GF(q) for given values
of 6 and (m-k) has been proposed. Thr procedure is based on
the characteristics of the parity-check matrix EL: of the anti-code. It has been established that the maximum Hamming distance
of an (m,k) anticode is 6, if and only if all combinations of
6+i, i = 1, 2, ..., m-6 columns of EL: are quasi-linearly independent. From this the following procedure for constructing
the m columns of the ELImatrix is formulated as follows:-
(1) The first (m-k) columns of EL:1 matrix form an identity matrix of order (m-k).
(2) The (m-k+1)th column is chosen arbitrarily from the
vector space (Vm_k) over GF(q), subject only to the condition
that the chosen column must not be the inverse of any of the
vectors obtained from the quasi-linear combinations of every
6+1, i = 0, 1, (m-k) of the previously chosen columns.
(3) The remaining columns are chosen so that they are
different from the inverse of any of the vectors obtained from
the quasi-linear combinations of every 6+1, i = 0, 1 ... of
the previously chosen columns.
This method of generation guarantees the required
independence of the columns. The method cannot be completed
successfully unless (m-k) is sufficiently large. To find the
minimum value of (m-k), consider the worst possible case for
an arbitrary choice of columns of the ELD matrix, viz., the inverses of all the vectors of the quasi-linear combinations
might be distinct. Since the inverse vectors of the quasi-
linear combinations of the mth stage include all these vectors
in the previous stages, then to ensure success in the face of
171.

•
•
this worst case, the number of qm-k vectors of the vector space
Vi-k need only be greater than or equal to the total number of
inverses of all vectors of the quasi-linear combinations of the
last stage plus a vector for the last chosen column. That is,
if:
qm-k!l+ )(c1-65 +(rac-1)(q-1)
6+1 + • •• (m-1).c1-1) 0+1
m m-1 , .111-1
(6.12)
there exists an anticode with m digits and minimum-maximum
Hamming distance (5). Now let m be the largest value of m for
which inequality (6.12) holds. Then an (m,k) anticode with
minimum-maximum distance (5) exists which satisfies the
inequality:
(7.1)(q-1)i (6.13)
This provides a lower bound on the minimum-maximum
Hamming distance obtainable with an (m,k) anticode.
For large m, asymptotic results for binary anticodes
may be obtained using the following inequalities:
n
. ‹; (X)-Xn (0-1111 (6.14)
i= n
providing X >k, where 1.1= 1 -X. (See Peterson(7), page 468.)
(6.15)
Taking the logarithm of both sides, assuming 2m-k%>1,
and dividing by m, we obtain:
6 1 - k6 log2 m dl) - (1 -m) —) log2 (1 -b-) (6.16)
m m
This lower bound is plotted below. Note that the
shape of this bound is the mirror image of Varshamov and
Gilbert's(60,27) lower bound for linear block codes of minimum
distance (d), where d is replaced by 6 and m by n.
qm-k 1 +
Inequality (6.14) becomes:
2m-k - 1 ‹_ (5/m)-6 (114)-(m-6)
172.

An upper bound on the minimum-maximum distance of
anticodes may be established by using the Plotkin(63) principle
of "average distance". That is, the minimum weight of a code-
word in an (n,k) linear code is at most as large as the average
weight of the code. Due to the similarities between linear
codes and linear anticodes, it follows that the Plotkin(63)
average distance bound is also true for linear anticodes, and
that it is true to say that the maximum weight of an anticode-
word in an (m,k) linear anticode is never smaller than the
average weight of the anticode.
Consider the array of an (m,k) linear anticode over
GF(q). Since each field element appears qk-1 times in each
column(14)(86), the number of non-zero elements in each column
is (q-1)qk-1
, and since there are m columns, the sum of the
weights of all anticodewords in the anticode is m(q-1)qk-1
Also, since there are qk-1 non-zero anticode words, it follows
that the average weight of an (m,k) anticode over GF(q) is
mqk-1(q-1)/(qk-1). This is also found by Farrell(102) in
unpublished work. The asymptotic form of the Plotkin bound
on 6 for linear anticodes is given by:
6 < m/q (6.17)
For the binary case, this bound is plotted below.
173.
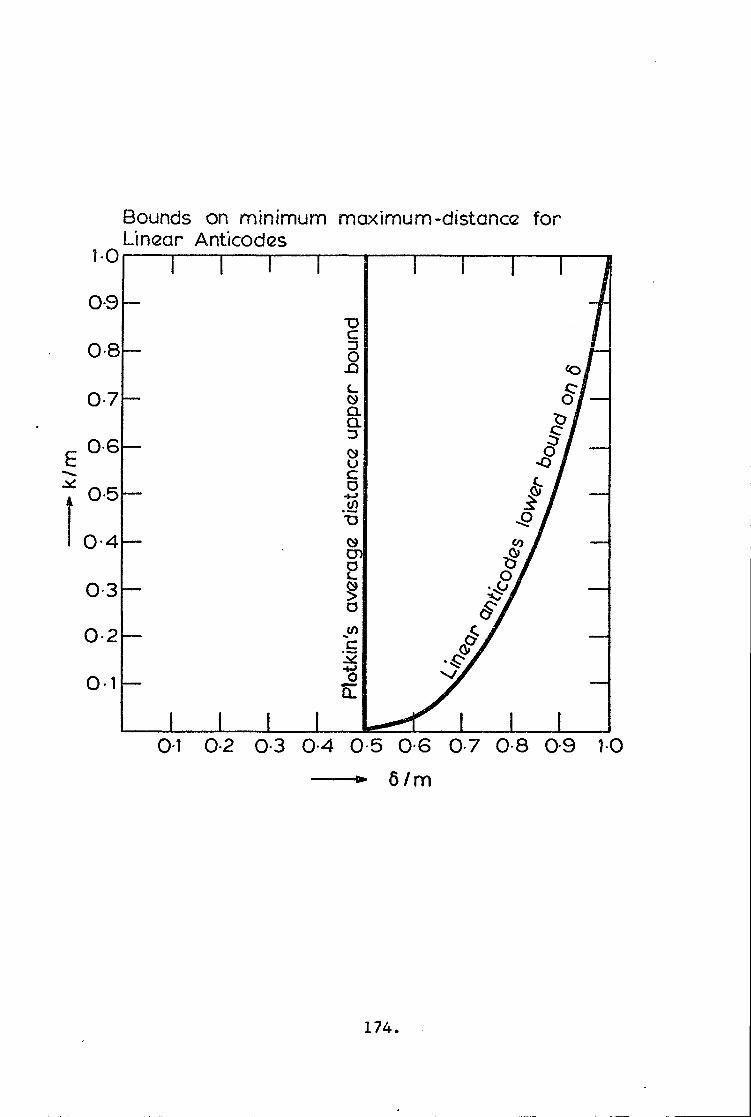
0.9
0-8—
0.7
0.6
"f • 0-5
I 0.4
0.3
0.2
0.1
0
0 • 0
Ac c
o •
istan
ce u
p per
bou
nd
•■•••••••1
.1011.1101.1•M
•■•••••■1
Bounds on minimum maximum-distance for Linear Anticodes
1 1 1 1 1 1 al 0.2 0.3 0.4 0.5 0.6 0.7 0-8 09 1.0
6 /rn
174.

7. SUMMARY OF CONTRIBUTIONS AND SUGGESTIONS FOR FURTHER RESEARCH
7.1 Summary of Contributions.
7.2 Suggestions for Further Research.
175.

7.1 SUMMARY OF CONTRIBUTIONS
In this section the original aspects of the work
contained in the thesis are summarized. These may be listed
as follows:-
(1) Asomputerised search for linear codes: Certain
properties of the parity-check matrix Da of (n,k) linear codes have been used to establish a computerised search procedure for
new binary linear codes. Of the new error-correcting codes
found by this procedure, two codes are capable of correcting up
to two errors, three codes up to three errors, four codes up to
four errors, and one code up to five errors. Two meet the lower
bound given by Helgert and Stinaff(68)
, and seven codes in fact
exceed it. In addition, one meets the upper bound. Of the even
Hamming distance versions of these codes, eight meet the upper
bound, and the remaining two exceed the lower bound. Moreover,
the following codes have been found whose parameters (n,k,d)
are as good as those of best previously known codes of identical
Haunting distances and the same number of parity-check digits.
These are three codes capable of correcting two random errors,
three codes up to three errors, four codes up to four errors
and three codes up to five errors. Corresponding to these
there are thirteen more codes having even Haunting distance.
(2) Applications of Walsh functions in constructin linear
block codes: A class of algebraic linear codes has been intro-
duced in which the parity-check matrix of the code is
constructed by using a sub-set of the Abelian group of Walsh
functions. These codes meet the Helgert and Stinaff upper
bounds on minimum Hamming distance and all the codes of this
class are easily decodable by a one step majority-logic algorithm.
176.

(3) Aulication of the concept of anticodes: A math-
ematical analysis of linear anticodes has been established
from which a systematic procedure for generation of such anti-
codes is proposed.
(4) Two procedures of linear block code modification:
(a) Code puncturing.
(b) Code lengthening.
Two procedures for modifying linear block error-
correcting codes have been suggested. The first is based on
the deletion of x rows and y columns from the parity-check
matrix of a given (n,k) code in such a way that the minimum
Hamming distance of the resulting (n-y, k+x-y) code remains
equal to that of the original. It has been shown that if x is
unity, then y may be as low as the minimum Hamming distance of
the (n, n-k) dual of the original (n,k) code. This procedure
of deleting rows and columns when applied to the known linear
binary block code yields a family of codes, some of which have
better rates than those of the best previously known codes of
identical Hamming distance and the same number of parity-check
digits. Seventeen examples of such new codes have been given.
It has also been shown that, apart from appropriate slight
modification, the coding and decoding algorithm for this family
of modified codes are similar to those of the original code.
The second proposed procedure of code modification
entails lengthening the original (n,k) linear block code by
annexing k' message digits. If the original code is capable
of correcting t random errors or less, then the resulting
modified (n+k', k+k') code has a rate higher than that of the
original (n,k) code. Moreover, its error-correcting capability
177.

is such that it will correct t random errors or less if at
least one of these occurs in the block of k message digits
and s random errors or less, where 14;s<t, if none of the
errors occur in any of the k message digits. Five examples
of such codes have been given.
(5) A new class of nested codes and their decoding
algorithm: A new class of multiple error-correcting linear
block codes has been introduced. The codes of this class,
referred to as nested codes, cover a wide range of code length
and rates. The parity-check matrix of such an (n,k) nested
code is derived by the construction of a nest of parity-check
matrices of previously known linear block codes. Although
the rates of the resulting nested codes are not optimum, these
codes exhibit, nevertheless, some useful properties and a well
defined mathematical structure which leads to a simple decoding
algorithm. This algorithm, referred to as the nested decoding
algorithm, makes use of the fact that the syndromes of the
nested codes, corresponding to patterns of errors in the
information digits, are codewords of another nested code. Thus,
the calculated syndrome of the corrupted received codewords
gives rise to a nest of error-correcting codes. This unique
characteristic results in the complexity of the decoder
increasing only linearly with the code length and error-
correcting capability. Moreover, the nested decoder has been
shown to be capable of correcting some of the errors of weight
greater than the number of errors, t, to be corrected.
(6) Block codes for non-independent errors: A computerised
search procedure based on certain properties of the parity-check
matrix of those block codes capable of correcting non-independent
errors has been described which yields a considerable number of
178.

codes that are capable of correcting burst, burst-and-random,
and multiple-burst-errors. These new codes were used,
together with other known block codes for compound channels,
to construct a new class of burst-and-random-error correcting
codes. It was shown that this class of code exhibits the
properties of the nested codes, i.e. the syndromes corresponding
to errors in the information digits are codewords of other
nested codes. Moreover, it was also established that codes
of this class are decodable by a simply implementable decoding
algorithm, the decoder for which exhibits the same features
and merits as the random-error nested decoder.
Finally, in Section 6 a lower bound on the minimum
Hamming distance (d) for linear block codes and a lower bound
on the maximum Haulaing distance (6) for linear anticodes has
been introduced. Moreover, the Plotkin upper bound on d for
linear block codes has been modified to establish an upper
bound on 6 for linear anticodes. These new bounds are:
(7) A possible improvement on the Varshamov-Gilbert
lower bound on the minimum Hamming distance of linear block
codes:
The improved bound is based on the assumption that,
for an (n,k) group code, the number of distinct vectors
resulting from the linear combination of every (d-2) columns
of the parity check matrix is much less than the total number
of vectors generated from such linear combinations. An
expression for the largest possible number of distinct vectors
obtainable from any (n,k) group code can therefore be
introduced and shown to be a function of the weight distribution
of the code. It has been demonstrated that this functions could
lead to a considerable improvement on the Varshamov-Gilbert
bound for certain ranges of n and k.
179.

(8)
Maximum Hammin distance bounds for linear anticodes:
The mathematical analysis of linear anticodes given
in Section 3.4.1 and the systematic procedure of generating
linear anticodes proposed in Section 3.4.2 have both been used
to obtain a lower bound on the maximum Hauaiiing distance , 6,
of linear anticodes. For the case of binary anticodes, the
asymptotic form of this bound has been established. In
addition, the Plotkin principle of "average distance" yields
an upper bound on 6 for linear anticodes.
180.

e
7.2 SUGGESTIONS FOR FURTHER RESEARCH
The various possibilities which appear to deserve
consideration are discussed below:
(1) In Section 3.4.2, a systematic procedure has been
introduced for generating linear anticodes. This procedure
may be used as a basis for a computerized search for "good"
anticodes and these anticodes in turn may lead to other new
families of linear block codes.
(2) The measure of complexity for a given decoder is
still not a rigorously defined concept. Research is therefore
needed to evaluate numerically the complexity of the Berlekamp
decoding algorithm for BCH codes, the majority logic decoding
algorithm for cyclic codes, and the nested decoding algorithm
for nested codes, in terms of:
0 The number of operations needed for decoding a single
information digit.
ii) The total time required for these operations.
iii) The complexity of the hardware circuitry; that is,
the number of components needed and the resulting wiring
complexity.
iv) The overall cost evaluation.
The outcome of such research of course would be very
beneficial from an engineering point of view.
(3) In Section 4 the nested decoding algorithm has been
introduced. This is capable of correcting some errors of
weight greater than the error-correcting capability of the
nested code. In consequence, the following questions arise:-
(a) What are the effects of this property of the nested
decoder on the average probability of error?
181.

(b) What characteristics of a nested code give the lowest
probability of error?
(c) What are the relationships between the probability of
error of a given nested code and that of the codes of the
construction?
(4) In Section 5 two computerised search procedures have
been introduced to search for burst-and-random and multiple-
burst-error-correcting codes, the results of these being given
in Tables 5.4.1 and Table 5.5.1 respectively. However, these
searches are not exhaustive and the computer limits have not
yet been reached. More codes therefore may be found by
extending the proposed computer searches.
Enlarging Table 5.4.1 is of particular importance due
to the fact that the extension of the nested burst-and-random-error-
correcting codes (of Section 5) depends on the existence of
such a table of codes.
(5) In Section 6 an improvement on the Varsh2mov-Gilbert
lower bound on the minimum Hauaing distance of linear codes has
been introduced. This improvement was found to be a function
of the weight enumerator (fw) of the codes. In spite of the
fact that a considerable amount of research has been devoted
to the study of weight enumerators, no work has, however, been
published to study the "lower bound" on these enumerators;
"lower bound" theory being used here with reference to the -
lowest possible value of fw for the (n,k) linear code. Research
is therefore needed to examine and suggest such a bound. A
lower bound on fw
may lead to a considerable improvement on the
Varshamov-Gilbert bound on d.
(6) In the last few years, due to the increasing applic-
ations for non-binary codes, a great deal of attention has been
devoted to this subject (see references 141 and 142).
182.

Since the problems introduced in Sections 3, 4 and 5
of this thesis have been formulated in a generalized manner,
that is, the codes are considered over a field of q elements,
the techniques and methods given in these sections may
consequently be used to construct and decode non-binary codes.
The immediate and reasonable suggestions for further research
on this subject apppear to be as follows:
(a) A computer programme may be developed along the lines
of the computerised search procedure described in Sections 3
and 5. The resulting computer search will then lead to new
families of non-binary, random, burst, burst-and-random, and
multiple-burst-error-correcting codes.
(b) The codes found by the technique described above may
also be used together with other known non-binary codes to
construct new classes of non-binary simply decodable nested
codes.
(7) Disjoint Codes:
Consider an (n,k1,t) linear block code V over a field
of q elements. Assume that there exists an (n,k2) linear block
code U over the same field, such that it is disjoint with V;
that is, no non-zerp vector in V is in U and therefore the
intersection between V and U is equal to zero vector. If the
minimum Hamming distance of U is equal to or greater than unity,
the error-correcting capability (t) of V may be increased to
any value by annexing more parity-check digits to V as follows:
(1) Add an overall parity check digit (in the usual
manner) to V to increase its Hamming distance by one. The
resulting annexed code will therefore have an even Hamming
distance.
(2) Add (n-k2) redundant digits to each code vector
of V such that the annexed (n-k2) digits of any code
183.

vector of V (say v) are those digits of the syndrome
vector of U corresponding to the code vector v. Since
none of the code vectors of V are in U, the syndromes of
U corresponding to the n-tuple vectors of V must there-
fore be non-zero vectors. Thus the weight of each
annexed code vector must have been increased by at least
one.
The newly annexed (2n- k2+ 1, kl) code is therefore
capable of correcting (t+ 1) random errors or less. This error-
correcting capability can be increased by another one by again
adding an overall parity check digit, this time to the newly
formed code and the same set of (n-k2) redundant digits as was
added in step (2). This procedure can be repeated indefinitely
to achieve any arbitrary error-correcting capability.
If (n-k2) is much less than k1, the above method
should yield families of asymptotically or nearly asymptotically
good codes. Research devoted to finding codes such as U, which
are disjoint with single-error-correcting Hamming codes, would
therefore be very fruitful.
Consider now the case where the codes V and U are not
disjoint and let the intersection between them be a subspace Z.
If Z is capable of Correcting (t+j) random errors or less, the
procedure described above may be repeated j times to generate
((j +1)n- jk2+j, kl) block code cap able of correcting (t+j)
random errors or less. Consequently the search for subspaces
which satisfy the properties of Z and which could be used to
generate new annexed codes should prove to be a profitable line
of research.
It is appropriate to mention that Andryanov and
Saskovets's(87) procedure for annexing BCH codes can be
considered as a special case of the latter described idea.
184.

Finally, the classical problems of coding theory as
outlined in Section 1 still remain as the main source of
stimulation for research work in this field. Although these
problems have been recognised now for many years and much
classical work has been produced in an attempt to find solutions,
the main questions still remain unanswered. Coding theory has
reached maturity but this maturity does not preclude future
research in this field from being any less scientifically
rewarding than it has been in the past.
185.

APPENDIX 1 -
Mathematical Background
The purpose of this appendix is .to list some mathem-
atical definitions of the terms used in this thesis. All
definitions are taken from standard text-books, such as
references (3), (5) and (7) and others dealing witn algebra
(e.g. references (16), (17) and (18)).
Set:
A set S is a well-defined collection of entities.
Null Set:
A null (empty) set is that set with no elements.
Binary Operation:
A binary operation represented by ,*, on a set is a
rule which assigns to each ordered pair of elements of the set
some element of the set.
Commutative and Associative Binary Operation:
A binary operation * on a set is cotiauutative if and
only if a*b=b*a for all a,b € S. The operation * is associative
if and only if (a*b)*c= a*(b*c) for all a,b,c S.
Group:
A group G is a set G, together with a binary operation
* on G, such that the following axioms are satisfied:
i) The binary operation * is associative.
ii) There is an element e in G such that e*x=x*e = x
for all xeG. This element e is the identity element for
* on G.
186.

iii) For each a in G, there is an element a' in G with the property that a`lra=a*a t = e. The element a' is the inverse of a with respect to *.
Note: The group G is closed under the operation *, since by the definition of a binary operation on G, (a*b)GG.
* Abelian Group:
A group is Abelian if its binary operation * is colianutative.
Subset:
A set B is a subset of set A, if every element of
B is in A.
Improper Subset:
If A is any set, then 0 and A are improper subsets of
A. Any other subset of A is a proper subset of A.
Subgroul:
A group H is a subgroup of G, if H is a subset of
group G such that the binary operation of G is closed with
respect to H, and if H is itself a group under this binary
operation.
Improper Subgroup:
If G is a group, then G and "e" are improper subgroups
of G. All other subgroups are proper subgroups.
Cyclic Subgroup:
If H is a subgroup of G and is the smallest subgroup
of G which contains the element a, aeG such that,
H = {- n/x = an, n(3A1
H is the cyclic subgroup of G generated by a.
187.

Cyclic Grou :
An element a of a group G generates G and is a
generator for G if<a>= G. A group G is cyclic if there is some
element a in G which generates G.
Ring:
A ring R is a set R together with two binary operations
to be known as addition and multiplication defined on R such that
the following axioms are satisfied:
i) <R, +:> is an Abelian group.
ii) Multiplication is associative.
iii) For all a,b,c(;11, the left distributive law,
a(b+c) = (ab) + (ac), and the right distributive law:
(a+b)c = (ac) + (bc), hold.
Field:
A field is an Abelian group under two binary operations,
multiplication as well as•addition.
Vector Space:
A vector space consists of an Abelian group V under
addition of elements called vectors, and a field F of scalar
elements satisfying the following axioms:
(A) To every pair, a and x, where cc. is a scalar in F and
x is a vector in V, there corresponds a vector ax in V,
called the product of 0. and x, in such a way that:
i) multiplication by scalars is associative,
a(Px) = (a0)x, and,
ii) lx = x for every vector x.
(B) i) Multiplication by scalars is distributive with
respect to vector addition, OC(x+y) = Ctn + C(y, and
188.

ii) multiplication by vectors is distributive
with respect to scalar addition, (a+ 13)x= ax+ Px.
The relation between a vector space v and the under-
lying field F is usually described by saying that V is a vector
space over field F.
Subspace:
Let V be a vector space over F. The vectors in a
subset S = fa. I ie 1i of V is called a subspace if, (i) the all-zero vector in S and, (ii) the sum of any two vectors in S is
also in S, i.e., the set of all linear combinations of subset S
of V is a subspace of V.
Definition (17) Linear independence and linear
dependence: the vectors in a subset S = fail iGij of a vector space V over a field F are linearly independent over F if n
T1ij a.ai0forscalarsa.j= 1, 2, ..., n, not all zero. I. J
j,
j=1 If the vectors are not linearly independent over F, they are
linearly dependent over F.
Span a Vector Space:
Let V be a vector space over F. The vectors in a
subsets=fa.lif3I1 of V span (or generate) v if for every REV,
we have:
13= alail + ct 2 ai2 + + an ain
for some a. e F and a. 3 . G S, j = 1, , n. A vector 1 is a linear combination of the a... 13
Dimension:
a. a,13..
=1
In any space, the number of linearly independent
vectors that span the space is called the dimension of the
space. A vector space V over a field F is finite dimensional
189.
I

if there is a finite subset of V whose vectors span v.
Basis:
If V is a vector space over a field F, the vectors
in a subset f3= {: . 1.613 of V form a basis for V over F if
they span V and are linearly independent. It follows that if V
is a k-dimensional vector space, any set of k linearly independent
vectors in V is a basis for V.
Inner Product and Ortho:onal Vectors:
If a= E a1, a2' .. an] and p. £ I1, p2... on] are two vectors of vector space V over field F, , V, and their
inner product defined to be the scalar:
a43 = al P l a2 P2 + a Pri; the inner product is commutative and associative:
a. p 13. a and that )5.( + p). )s.c1L + ?5.p
a and 13E v. The two vectors a and p , are said to be ortho-
gonal if their inner product is zero.
Transpose Matrix:
The transpose of a'matrix is that matrix of order
n x m obtained by interchanging the rows and columns of an m x n
matrix A is called the "TRANSPOSE" of A and is denoted by AT.
Symmetric Matrix:
Symmetric matrix is a square matrix A such that AT=A.
Matrix Overfield:
When all of the elements of a matrix A are in a field
F, it is called matrix A over field F.
190.

Row Space:
Let tGi an "k x n" matrix over field "F" if the rows k
are less than the columns n, and are linearly independent, then
all linear combinations of rows of G form a k-dimensional subspace
of the vector space Vn over field F, which is called the row space
of G.
Row Rank Column Rank and Matrix Rank:
The dimension of the row space is called the row rank.
Similarly, the set of all linear combinations of column vectors
of the matrix forms the column space, whose dimension is called
the column ranks, it can be shown that row rank equals column
rank; this value is referred to as the rank of the matrix.
Echelon Canonical form of a Matrix:
The Echelon Canonical form of a matrix is a standard
simplified form of a matrix which has the following properties:
i) Every leading term of a non zero row is 1.
ii) Every column containing such a leading term has all
its other entries zero.
iii) The leading term of any row is to the right of the
leading term in every preceding row. All zero rows are
below all nonzero rows.
The Dimension of Echelon Canonical Form Matrix:
If A is a matrix in echelon canonical form, then the
nonzero rows of A are linearly independent, and thus the number
of nonzero rows is the dimension of the row space. There is
only one matrix in echelon canonical form for any given row
space.
191.

•
Nonsingular
A nonsingular matrix is a square matrix with all rows
linearly independent. The echelon canonical form of a non-
singular matrix is an identity matrix I.
Null Space:
Let V be a vector space over F, of n-tuples. The
vectors in a subset S =fa. iGI1 of V is called the null space of a subset u =. ell of V, if all vectors of S are 011 orthogonal to all vectors of u.
A Null Space of a Matrix:
For any k x n matrix G with k linearly independent
rows, there exists an (n-k) x n matrix H with (n-k) linearly
dependent rows and any vector v in the row space of G is
orthogonal to all the rows of H. The row space of G is the
null space of H or vice versa.
192.

APPENDIX 2
Computer Programmes:
Programme 1 is a computer search for a new binary
linear block code according to the procedure proposed in
Section 3.2, where t and r are given to be 3 and 15 respectively.
The starting parity-check matrix is. given by Karlin(47)
:
(30,16,3) code EH] matrix with an extra dummy parity-check digit.
Programme 2 is written to generate the parity-check
matrix [H] of (255,187,19) BCH code and to determine the lowest
weight of this [H] matrix.
Programme 3 is written to determine all possible
vectors of the vector space Vn-k which satisfy the condition
set by the lengthening procedure proposed in Section 3.5.4.
The code before lengthening in this programme has the parameters
(7,1,2).
All programmes are written in FORTRAN IV and executed
on London University computer CDC 7600.
193.

PROGRAMME
CODE
DIMENSION IC(40),MT(780),IP(22),II(15),IS(60),NC(547),ME(9880) COMMON IC,MT,IP,II,IS,LC I IIND,NO,LR,L1,L2,L3,L4,L5,J,K,NOP,L11, 1L22,LIS,LE,NC,ME
INTEGER SHIFT LC = 31 LIS = 32767 NP = 15 DO 100 I = 1,60 ND = I - 1 IS(I) = SHIFT(1,ND)
100 CONTINUE DO 200 I = 1,547 NC(I) = 0
200 CONTINUE DO 196 I=1,NP IC(I) = IS(I)
196 CONTINUE READ (5,1000) (IC(I),I=16,LC)
1000 FORMAT (1605) WRITE (6,4000) LC
4000 FORMAT (26H1 (THE INPUT DATA FOR LC=,13) DO 156 I=1,LC DO 951 J=1,NP IP(J) = IC(I).AND.IS(J) IF(IP(J).NE.0) IP(J) = 1
951 CONTINUE WRITE (6,5000) II IC(I),IC(I),(IP(J),J=1,NP)
5000 FORMAT (5X,13,18,2X,08,2X,15I4) 156 CONTINUE
LR = 0 LE = 0 • DO 300 I=1,LC Ll = (IC(I)-1)/60 L2 = IC(I) L1*60 LI = L1 + 1 NX = NC(L1).AND.IS(L2) IF (NX.NE.0) WRITE (6,2233) IC(I)
2233 FORMAT (31H0 THERE IS AN ERROR AT IC(I),I8) NC(L1) = NC(L1).O.IS(L2) L3 = I + 1 IF (L3.GT.LC) GO TO 300 DO 310 J=L3,LC LR = LR + I MT(LR) = L1 = (MT(LR)-1)/60 L2 = MT(LR) = L1*60 LI = LI + 1
194.

NX = NC(L1).AND.IS(L2) IF(NX.NE.0) WRITE (6,2233) IC(I) NC(L1) = NC(L1).0.IS(L2) L4 = J + 1 IF (L4.GT.LC) GO TO 310 DO 320 K=L4,LC LE = LE + 1 ME(LE) = .N.MT(LR).A.IC(K).0.MT(LR).A..N.IC(K) Ll = (ME(LE)-1)/60 L2 = ME(LE) = L1*60 Ll = Ll + 1 NX = NC(L1).AND.IS(L2) IF (NX.NE.0) WRITE (6,2233) IC(1) NC(L1) = NC(L1).0.IS(L2)
320 CONTINUE 310 CONTINUE 300 CONTINUE
NOP = 33 L2 = LC - 24 J = L2 - 1 II(L2) = 1 DO 357 I=1,J II(I) = IC(25+1)
357 CONTINUE 40 DO 400 L1=L2,15
L3 = 25 + Ll 30 L = II(L1)
CALL TEST IF (LC.LT.L3) GO TO 10 IF (LC.EQ.NOP) CALL OUTPUT II (L1+1) = II(L1) + 1 IF (II(L1+1).GT.LIS) GO TO 20 GO TO 400
10 LL(L1) = II(L1) + 1 IF (II(L1).GT.LIS) GO TO 20 GO TO 30
400 CONTINUE GO TO 60
20 L4 = L3 - 1 IF (L4.EQ.25) GO TO 60 DO 500 J=L4,LC L11=IC(J)-1)/60 L22=IC(J) - L11*60 L11=L11 + 1 NC(L11) = NC(L11).A..N.IS(L22)
500 CONTINUE LC = L4 - 1 L5 = LC*(LC-1)/2 + 1 DO 600 J=L5,LR
195.

L11 = MT(J)-1)/60 L22 = MT(J) - L11*60 L11 = L11 + 1 NC(L11) = NC(L11).A..N.IS(L22)
600 CONTINUE LR = L5 - 1 L5 = LR*(LC-2)/3 + 1 DO 700 J=L5,LE L11 = (ME(J)-1)/60 L22 = ME(J) L11*60 L11 = L11 + 1 NC(L11) = NC(L11).A..N.IS(L22)
700 CONTINUE LE = L5 - 1 L2 = L3 - 26 II(L2) = II(L2) + 1 GO TO 40
60 CALL OUTPUT STOP END
196.

SUBROUTINE TEST DIMENSION IC(40),MT(780),IP(22),I1(14),IS(60),NC(547),ME(9880) COMMON IC,MI,IP,II,IS,LC,I,ND,NO,LR,L1,L2,L3,L4,L5,J,K,NOP,
1L11,L22,LIS,LE,NC,ME
L11 = (1-1)/60 L22 = I = L11*60 L11 = L11 + 1 NO = NC(L11).A.IS(L22) IF (NO.NE.0) RETURN DO 100 J=1,LC • ND = L11 = (ND-1)/60 L22 = ND - L11*60 L11 = L11 + 1 NO = NC(L11).A.IS(L22) IF (NO.NE.0) RETURN
100 CONTINUE DO 200 J=1,LR ND = L11 = (ND-1)/60 L22 = ND = L11*60 L11 = L11 + 1 NO = NC(L11).A.IS(L22) IF (NO.NE.0) RETURN
200 CONTINUE DO 300 J=1,LR LE = LE + 1 ME(LE) = L11 = (ME(LE)-1)/60 L22 = ME(LE) L11*60 L11 = L11 + 1 NC(L11) = NC(L11).O.IS(L22)
300 CONTINUE DO 400 J=1,LC LR = LR + 1 MT(LR) = .N.IC(J).A.I.O.IC(J).A..N.I L11 = (MT(LR)-1)/60 L22 = MT(LR) - L11*60 LII = L11 + 1 NC(L11) = NC(L11).0.IS(L22)
400 CONTINUE LC = LC + I IC(LC) = L11 = (1-1)/60 L22 = I - L11*60 L11 = L11 + 1 NC(L11) = NC(L11).0.IS(L22) CALL SECOND (T)
197.

IF (T.GT.1180.0) GO TO 17 RETURN
17 WRITE (6,3300) 3300 FORMAT (1H0 / 27H0 LC II(1 )
WRITE (6,1020) LC,(II(JI),JI=1,L1) 1020 FORMAT (5H0 , 1116)
STOP END
SUBROUTINE OUTPUT
SUBROUTINE OUTPUT DIMENSION IC(40),MT(780),IP(22),11(15),IS(60),NC(547)-IME(9880) COMMON IC,MT,IP,II,IS,LC,I,ND,NOILR,L1,L2,L3,L4,L5,J,KI NOP,L11,
1 L22,LIS,LE,NC,ME NOP = NOP + 1 WRITE (6,1000) LC,LR,LE
1000 FORMAT (38H0 THE TOTAL NUMBER OF CODEWORDS IS ,17 / 48H0 THE 1 TOTAL NUMBER OF COMBINATION IN TWOS IS ,18 / 52H0 THE TOTAL 2 NUMBER OF COMBINATIONS IN THREES IS ,18) DO 100 J=1,LC DO 200 N0=1,22 IP(NO) = IC(J).A.IS(NO) IF (IP(NO).GT.0) IP(N)=1
200 CONTINUE WRITE (6,2000) J,IC(J),IC(J),(IP(NO),N0=1,22)
2000 FORMAT (5H0 ,IB„18,2X,08,2X,2214) 100 CONTINUE
RETURN END
198.

PROGRAMME 2
PROGRAM CODE (INPUT,OUTPUT,TAPE5=INPUT,TAPE6=OUTPUT) DIMENSION IP(100),NU(100),IM(100),IS(100) INTEGER SHIFT N = 255 K = 187 NT = 9 M = N K Ll = M - 1 DO 200 1=1,100 IP(I) = 0 NU(1) = 0 J = L 1 IS(I) = SHIFT(1,J)
200 CONTINUE I = 57 WRITE (6,5000) I
5000 FORMAT (31HO THE POSITIONS OF ZEROS ARE / 10X,I5) DO 310 J=11M NU(J) = NU(J) + 1
310 CONTINUE DO 400 I-1,K DO 410 J=1,M IP(J) = 0
410 CONTINUE DO 420 J=I1K IF (J.EQ.1) GO TO 10 KON = IP(M)
20 IF (KON.EQ.I) GO TO 30 DO 430 L=1,L1 IP(M+1-0 = IP(M-L)
430 CONTINUE IP(1) = 0 GO TO 420
30 DO 440 L=2,M IM(L) = .NOT.IP(L-1) IM(L) = IM(L).AND.1
440 CONTINUE IM(1) = 1 DO 450 L=1,L1 IP(M+1-L) = IP(M-L)
450 CONTINUE IP(1) = IM(1) IP(4) = IM(4) IP(6) = IM(6) IP(7) = IM(7) IP(8) = IM(8) IP(11) = IM(11) IP(12) = IM(12) IP(13) = IM(13)
199.

IP(14) = IM(14) IP(17) = IM(17) IP(20) = IM(20) IP(23) = IM(23) IP(25) = IM(25) IP(26) = IM(26) IP(28) = IM(28) IP(42) = IM(42) IP(43) = IM(43) IP(45) = IM(45) IP(46) = IM(46) IP(47) = IM(47) IP(49) = IM(49) IP(52) = IM(52) IP(53) = IP(53) IP(55) = 114(55) IP(57) = IM(57) IP(58) = IM(58) IP(60) = IM(60) IP(61) = IM(61) IP(62) = IM(62) IP(63) = IM(63) IP(65) = IM(65) IP(67) = IM(67) GO TO 420
10 KON = .NOT.IP(M) KON = KON.AND.1 GO TO 20
420 CONTINUE DO 460 J=1,M IF (IP(J).EQ.0) GO TO 460 NU(J) = NU(J) + 1
460 CONTINUE IF (IP(57).EQ.1) WRITE (6,6000) I
6000 FORMAT (10X,I5) 400 CONTINUE
WRITE (6,1000) N,K,M,NT 1000 FORMAT (42H1 THE PARITY CHECK MATRIX H OF BCH CODE / 18H0
1CODE LENGTH IS,I6 / 29H0 NUMBER OF MESSAGE BITS IS,I6 / 31H0 2NUMBER OF PARITY CHECKS IS ,I6 / 34H0 ERROR CORRECTING 3CAPABILITY T=3,I2 / 5H0 ) WRITE (6,3000) (NU(J),J=1,M)
3000 FORMAT (4(5H0 ,30I4 / )) STOP END
200.

PROGRAMME 3
PROGRAM OCDEXPN(INPUT,OUTPUT,TAPE5=INPUT,TAPE6=OUTPUT) DIMENSION IS(60),IC(520),NC(1093),NR(1093),IP(18),IM(18) INTEGER SHIFT DO 114 L=1,60 J = I - 1 IS(I) = SHIFT(1,J)
114 CONTINUE N = 6 LC = 7 DO 109 I=1,6 IC(I) = IS(I)
109 CONTINUE IC(7) = 15 NT = 2
70 NN = LC JI = NN + 1 KK = NN - N MLC = N + 1 LIS = 2**N - 1 WRITE (6,2000) NN,KK,NT
2000 FORMAT (33H1 THE CODE EXPANSION TECHNIQUES / 30 HO THE lORIGINAL CODE LENGTH IS,I3 / 36H0 NUMBER OF INFORMATION 2DIGITS IS,I3 / 34H0 ERROR CORRECTING CAPABILITY 18,13 #54H0 3THE COLUMNS OFTHE PARITY CHECK MATRIX IS GIVEN BY) DO 110 L=1,LC DO 120 J=1,N IP(J) = IC(I).AND.IS(J) IF(IP(J).GT.0) IP(J)=1
120 CONTINUE-: WRITE (6,3000) I,IC(I),IC(I),(IP(J),J=1,N)
110 CONTINUE DO 200 1=1,1093 NR(I) = 0 NC(I) = 0
200 CONTINUE = 0
J = 0 DO 300 I=1,LC LF = (IC(I)-1)/60 LS = IC(I) - LF*60 LF = LF + 1 NE = NC(LF).AND.IS(LS) IF(NE.NE.0) WRITE (6,1234) I,J NC(LF) = NC(LF).0R.IS(LS) NR(LF) = NR(LF).OR.IS(LS) JJ = I+ 1 IF (JJ.GT.LC) GO TO 300 DO 310 J=JJ,LC
201.

ND = .NOT.IC(I).AND.IC(J).0R.IC(I).AND..NOT.IC(J) LF = (ND-1)/60 LS = ND - LF*60 LF = LF + 1 NE = NC(LF).AND.IS(LS) IF(NE.NE.0) WRITE (6,1234) I,J NC(LF) = NC(LF).OR.IS(LS) IF (I.GT.N.OR.J.GT.N) NR(LF) = NR(LF).OR.IS(LS)
1234 FORMAT (36H THERE IS AN ERROR IN THE DATE AT,2I4) 310 CONTINUE 300 CONTINUE
WRITE (6,1111) 1111 FORMAT (105H0 THE EXPANDED COLUMNS TO CORRECT ONE ERROR AND
1SOME OF THE TWO ERRORS AND DETECTING OTHER ERRORS / 4H0 ) DO 400 I=1,LIS LF = (I-1)/60 LS = I - LF*60 LF = LF + 1 NE = NC(LF).AND.IS(LS) IF (NE.NE.0) GO TO 400 KL = 0 DO 410 J=1,N ND = I.AND.IS(J) IF(ND.NE.0) KL = KL + 1 IF (KL.GT.3) GO TO 400
410 CONTINUE IF (KL.LT.3) GO TO 400 DO 415 J=1,N ND = .NOT.IC(J).AND.I.OR.IC(J).AND..NOT.I LF = (ND - 1) / 60 LS = ND - LF*60 LF = LF + 1 NE = NR(LF).AND.IS(LS) IF (NE.NE.0) GO TO 400
415 CONTINUE DO 420 J=MLC,NN ND = .NOT.IC(J).AND.I.OR.IC(J).AND..NOT.I LF = (ND-1)/60 LS = ND - LF*60 LF = LF + 1 NE = NC(LF).AND.IS(LS) IF (NE.NE.0) GO TO 400
420 CONTINUE LF (LC.LT.JI) GO TO 15 DO 425 J=JI,LC ND=.NOT.IC(J).AND.I.OR.IC(J).AND..NOT.I LF = (ND - 1) / 60 LS = ND - LF*60 LF = LF + 1
• 202.

NE = NR(LF).AND.IS(LS) IF (NE.NE.0) GO TO 400
425 CONTINUE 15 DO 510 J=1,N
ND = .NOT.IC(J).AND.I.OR.IC(J).AND..NOT.I LF = (ND - 1) / 60 LS = ND - LF*60 LF = LF + 1 NC(LF) = NC(LF).0R.IS(LS)
510 CONTINUE DO 520 J=MLC,NN ND = .NOT.IC(J).AND.I.OR.IC(J).AND..NOT.I LF = (ND - 1) / 60 LS = ND - LF*60 LF = LF + 1 NC(LF) = NC(LF).OROIS(LS) NR(LF) = NR(LF).OR.IS(LS)
520 CONTINUE IF (LC.LT.JI) GO TO 16 DO 530 J=JI,LC ND = .NOT.IC(J).AND.I.OR.IC(J).AND..NOT.I LF = (ND - 1) / 60 LS = ND - LF*60 LF = LF + 1 NC(LF) = NC(LF).OR.IS(LS)
530 CONTINUE 16 LC = LC + 1
IC(LC) = I LF = (I-1)/60 LS = I - LF*60 LF = LF + 1 NC(LF) = NC(LF).0R.IS(LS) NR(LF) = NR(LF).OROIS(LS) DO 610 J=1,N IP(J) = I.ANDOIS(J) IF (IP(J).GT.0) IP(J) = 1
610 CONTINUE WRITE (6,3000)LC9J9I,(IP(J),J=1,N)
3000 FORMAT (5X,I3,I9,4X,07,2014) 400 CONTINUE
STOP END
203.

REFERENCES
1. WOLF, J.K.
"A Survey of Coding Theory: 1967-1972",
IEEE Transactions on Information Theory, Vol. IT-19,
No. 4, pp. 381-389, July 1973.
,2. CHIEN, R.T.
"Review of Algebraic Coding Theory",
IEEE Transaction on Information Theory (Book Rev.),
Vil. IT-15, pp. 509-510, July 1969.
3. BERLEKAMP, E.R.
"Algebraic Coding Theory",
McGraw-Hill Book Company, New York, 1968.
4. MANN, H.B., Ed.
"Error-Correcting Codes",
Wiley Book Inc., New York, 1968.
5. LIN,S.
"An Introduction to Error-Correcting Codes",
Prentice-Hall, Inc., Englewood Cliffs, 1970.
6. VAN LINT, J.H.
"Coding Theory",
Springer, Berlin, Germany, 1971.
7. PETERSON, W.W. and E.J. WELDON, JR.
"Error-Correcting Codes",
The M.I.T. Press, Cambridge, 1972, Second Edition.
8. PETERSON, W.W.
"Error-Correcting Codes",
First Edition, M.I.T. Press, Cambridge, Mass., 1961.
9. MASSEY, J.L.
"Threshold Decoding",
The M.I.T. Press, Cambridge, Mass., 1963.
204.

10. FORNEY, G.D., JR.
"Concatenated Codes",
The M.I.T. Press, Cambridge, Mass., 1966.
11. LUCKY, R.W., SALZ J., and E.J. WELDON, JR.
"Principles of Data Communication",
McGraw-Hill Book Co., New York 1968.
12. GALLAGER, R.G.
"Information Theory and Reliable Communication",
John Wiley & Sons Inc., New York, 1968.
13. STIFFLER, J.J.
"Theory of Synchronous Communications",
Englewood Cliffs, Prentice Hall, 1971.
14. FARRELL, P.G.
"Coding for Noisy Data Links",
A dissertation submitted for the degree of Doctor of
Philosophy of the University of Cambridge, England, 1969
15. GOLDBERG, M.
"Easily Decoded Error-Correcting Codes and Techniques
for their Generation",
A thesis submitted for the degree of Doctor of Philosophy
in the Faculty of Engineering, University of London, Imperial
College, England, 1971.
16. HALMOS, P.R.
"Finite-Dimensional Vector Spaces",
Van-Nostrand.
17. FRALEIGH, J.B.
"A First Course in Abstract Algebra",
Addison-Wesley.
18. BIRKHOFF, G. and MACLANE
"A Survey of Modern Algebra";
The MacMillan Co.
205.

19. SLEPIAN, D.
"A Class of Binary Signalling Alphabets",
The Bell System Technical Journal, Vol. 35, pp. 203-234,
January 1956.
20. VAN LINT, J.H.
"Nonexistence Theorems for perfect Error-Correcting Codes",
in 'Computers in Algebra and Number Theory', SIAM-AMS Proc.,
Vol. 45, G. Birkhoff and M. Hall, Jr., Eds., 1970, pp. 1189-96.
21. TIETKVRINEN, A.
"On the Nonexistence of Perfect Codes over Finite Fields",
SIAM J. Appl. Math., Vol. 24, pp. 88-96, January 1973.
22. TIETRVRINEN, A. and A. PERKO
"There are No Unknown Perfect Binary Codes",
Ann. Univ. Turki, Ser. AI 148, 1971, pp. 3-10.
23. BOSE, R.C. and D.K. RAY-CHAUDHURI
"On a Class of Error-Correcting Binary Group Codes",
Information and Control, Vol. 3, 1960, 68-79, 279-290.
24. HOCQUENGHEM, A
"Codes correcteurs d'erreurs",
Chiffres, 2, 1959, pp. 147-156.
25. MULLER, D.E.
"Application of Boolean Algebra to Switching Circuit
Design and Error Detection",
IRE Trans., Electronic Computers, EC3, 1954, pp. 6-12.
26. REED, I.S.
"A Class of Multiple-Error-Correcting Codes and the
Decoding Scheme",
IEEE Transactions on Information Theory, Vol. 4, 1954,
pp. 38-49.
206.

27. GILBERT, E.N.
"A Comparison of Signalling Alphabets",
Bell System Technical Journal, Vol. 31, 1952, pp. 504-522.
28. BERLEKAMP, E.R.
"Long primitive binary BCH Codes have Distance d 2n/nR-1/
log n ...",
IEEE Transactions on Information Theory, Vol. 18, 1972,
pp. 415-426.
29. KASAMI., T.
"An Upper Bound on Kin for Affine-invariant Codes with
Fixed din",
IEEE Transactions on Information Theory, Vol. 15, 1959,
pp. 174-176.
30. HAMMING, R.W.
"Error-Detecting and Error-Correcting Codes",
Bell Systems Journal, Vol. 29, pp. 147-160, April 1950.
31. GOLAY, M.J.E.
"Notes on Digital Coding",
Proc. IRE, 37, p. 657, June 1949.
32. STERN, T.E. and B. FRIEDLAND
"Application of Modular Sequential Circuits to Single-Error-
Correcting P-nary Codes",
IRE Trans. on Information Theory, IT-5, pp. 114-123,
September 1959.
33. ABRAMSON, N.M.
"A Class of Systematic Codes for Non-Independent Errors",
IRE Trans. on Information Theory, IT-5, pp. 150-157,
December 1959,
34. ABRAMSON, N.M.
"A Note 9n Single-Error-Correcting Binary Codes",
IRE Transaction on Information Theory, IT-6, pp. 502-503, September 1960.
207.

35. ELSPAS, B.
"A Note on P-nary Adjacent-Error-Correcting Codes",
IRE Trans. on Information Theory, IT-6, pp. 13-15,
March 1960.
36. PRANGE, E.
"Cyclic Error-Correcting Codes in Two Symbols",
AFCRC-TN-57-103, Air Force Cambridge Research Laboratories,
Cambridge, Massachussetts, September 1957.
37. LEECH, J.
"Some Sphere Packings in Higher Space",
Can. J. Math., 19, 1967, pp. 251-267.
38. PLESS, V.S.
"On the Uniqueness of the Golay Codes",
Journal of Combinatorial Theory, 5, 1958, pp. 215-228.
39. LEECH, J. and N.J.A. SLOANE
"Sphere Packing and Error-Correcting Codes",
Can. J. Math., 23, 1971, pp. 718-745.
40. KASAMI, T. and TOKURA
"Some Remarks on BCH Bounds and Minimum Weights of
Binary Primitive BCH Codes",
IEEE Transactipns on Information Theory, IT-15,
1959, pp. 408-413.
41. BERLEKAMP, E.R.
"The Weight Enumerators for Certain Subcodes of the
Second Order Binary Reed-Muller Codes",
Information and Control, Vol. 17, 1970, pp. 485-500.
42. SIDEL'NIKOV, V.M.
"Weight Spectra of Binary Bose-Chaudhuri-Hocquenghem Codes",
Probl. Peredaci Inform., 7, 1971, pp. 14-22 (in Russian).
43. WOLF, J.K.
"Adding two Information Symbols to Certain Nonbinary -
BCH Codes and some Applications",
Bell System Technical Journal, Vol. 48, 1969, pp. 2405-2424. 208.

44. ASSMUS, E.F. JR. and H.F. MATTSON, JR.
"New 5-designs",
Journal of Combinatorial Theory, Vol. 6, 1969, pp. 122-151.
45. WOLF, J.K.
"Nonbinary Random Error-Correcting Codes",
IEEE Trans. on Information Theory, IT-16, 1970, pp. 236-237.
46. LEECH, J.
"Some Sphere Packings in Higher Space",
Can. J. Math., 16, 1964, pp. 657-682.
47. KARLIN, M.
"New Binary Coding Results by Circulants",
IEEE Trans. on Inf. Theory, Vol. 15, 1969, pp. 81-92.
48. KARLIN, M.
"Decoding of Circulant Codes",
IEEE Trans. on Inf. Theory, Vol. 16, 1970, pp. 797-802.
49. PLESS, V.S.
"On a New Family of Symmetry Codes Related New Five-Designs",
Bull. Am. Math. Soc., 75, 1969, pp. 1339-1342.
50. PLESS, V.S.
"Symmetry Codes over GF(3) and New Five-Designs",
Journal of Combinatorial Theory, Vol. 12, 1972, pp. 119-142.
51. WAGNER, T.J.
"A Search Technique for Quasi-Perfect Codes",
Information and Control, 9, pp. 94-99, 1966.
52. WAGNER, T.J.
"Some Additional Quasi-Perfect Codes",
Information and Control, 10, p. 334, 1967.
53. TOKURA, N., TANIGUCHI, K. and T.K. KASAMI
"A Search Procedure for Finding Optimum Group Codes
for the binary symmetric channel",
IEEE Trans. on Inf. Theory, Vol. LT-13, No. 4, October 1967.
209.

54. TOWNSEND, R.L. and E.J. WELDON, JR.
"Self-Orthogonal Quasi-Cyclic Codes",
IEEE Trans., 13, (April 1967), pp. 183-195.
55. CHEN, C.L., PETERSON, W.W. and WELDON, E.J., JR.
"Some Results on Quasi-Cyclic Codes",
Information and Control, 15, pp. 407-423.
56. FONTAINE,,A.B. and W.W. PETERSON
"Group Code Equivalence and Optimum Codes",
IRE Trans., IT-5, Special Supplement, pp. 60-70, 1959.
57. GOPPA, V.D.
"A New Class of Linear Correcting Codes",
Probl. peredach. Inform., Vol. 6, pp. 24-30, 1970 (in Russian).
58. GOPPA,,V.D.
"Rational representation of Codes and (L,g) Codes",
Probl. peredach. Inform., Vol. 7, pp. 41-49, 1971.
59. REED, I.S. and G. SOLOMON
"Polynomial Codes over Certain Finite Fields",
J. Soc. Ind. Appl. Math., Vol. 8, pp. 300-304, 1960.
60. VARSHAMOV, R.P.
"Estimate of the Number of Signals in Error-Correcting Codes",
Dokl. Akad. Nauk. SSSR, Vol. 117, pp. 739-741, 1957.
61. ELIAS, P.
"Error-Free Coding",
IRE Trans., PG IT-4, pp. 29-37, 1954.
62. GOLDBERG, M.
”Augmentation Techniques for a Class of Product Codes",
IEEE Trans. Inform. Theory, Vol. IT-11, pp. 3-18, January 1965.
63. PLOTKIN, M.
"Binary Codes with Specified Minimum Distance",
IEEE Trans. Inform. Theory, Vol. IT-6, pp. 445-450, Sept.1960.
210.

64. GRIESMER, J.H.
"A Bound for Error-Correcting Codes",
IBM Journal Res. Develop., Vol. 4, pp. 532-542, 1960.
65. WYNER, A.D.
"Capability of Bounded Discrepancy Decoding",
Bell System Technical Journal, Vol. 44, pp. 1061-1122, 1965.
66. SACKS, G.E.
"Multiple Error Correction by Means of Parity Checks",
IRE Trans., IT-4, pp. 145-147, 1958.
67. CALABI, L. and E. MYRVAAGNES
"On the Minimal Weight of Binary Group Codes",
IEEE Trans. Inform. Theory (Corresp.), Vol. IT-10,
pp. 385-387, October 1964.
68. HELGERT, H.J. and STINAFF, R.D.
"Minimum-Distance Bounds for Binary Linear Codes",
IEEE Trans. on Inf. Theory, Vol. IT-19, No. 3, May 1973.
69. PETERSON, W.W.
"Encoding and Error-Correction Procedures for the Bose.-
Chaudhuri Codes",
IRE Trans., IT-6, pp. 459-470, 1960.
70. GREEN, J.H. and R.L. SAN SOUCIE
"An Error-Correcting Encoder and Decoder of high Efficiency",
, Proc. IRE., 46, pp. 1741-1744, 1958.
71. PRANGE, E.
"Some Cyclic Error-Correcting Codes with simple Decoding
Algorithms",
AFCRC-TN-58-156, Air Force Cambridge Research Centre,
Bedford, Mass., April 1958.
72. MEGGITT, J.E.
"Error-Correcting Codes and their Implementation",
IRE Trans. on Information Theory IT-7, pp. 232-244, Oct.1961.
211.

73. MEGGITT, J.E.
"Error-Correcting Codes for correcting Bursts of Errors",
IBM J. Research Develop., 4, pp. 329-334, July 1960.
74. MITCHELL, M.E.
"Error-Trap Decoding of Cyclic Codes",
G.E. Report No. 62MCD3, General Electric Military
Communications Department, Oklahoma City, Oklahoma,
December 1962.
75. MITCHELL, M.E. et al.
"Coding and Decoding Operations Research",
G.E. Advanced Electronics Final Report on Contract AF19(604)-
6183, Air Force Cambridge Research Labs., Cambridge, Mass,
1960.
76. RUDOLPH, L. and M.E. MITCHELL
"Implementation of Decoders for Cyclic Codes",
IEEE Trans. on Information Theory, IT-10, pp. 259-260,
July 1964.
77. MAC WILLIAMS, F.J.
"Permutation Decoding of Systematic Codes",
Bell System Tech. J., 43, pp. 485-505, 1964.
78. KASAMI, T. °
"A Decoding Procedure for Multiple-Error-Correcting
Cyclic Codes",
IEEE Trans. on Information Theory, IT-10, pp. 134-139,
April 1964.
79. GREEN, I.H. and R.L. SAN SOUCIE
"An _Error Correcting Encoder and Decoder of High Efficiency",
Proc. IRE, 46, 10, pp. 1741-1744, 1958.
80. PETERSON, W.W.
"Encoding and Error-Correction Procedures for the Bose-
Chaudhuri Codes",
IRE Trans. on Inform. Theory, IT-6, pp. 459-470, 1960.
212.

81. BOSE, R.C. and R.R. KUBLER, JR.
"On the Construction of a Class
Signalling Codes",
Technical Report, University of
N.C. (May 1958).
of Error Correcting Binary
North Carolina, Chapel Hill,
82. BERLEKAMP, E.R.
"Goppa Codes",
IEEE Transactions on Information Theort, Vol. IT-19, No. 5,
September 1973.
83. SHANNON, C.E. and W. WEAVER
"The Mathematical Theory of Communication",
ILLINI Books 1949.
84. HELGERT, H.J.
"Srivasava Codes",
IEEE Trans. on Inf. Theory, Vol. IT-18, 1972, pp. 292-297.
85. HARMUTH, F.
"Transmission of Information by Orthogonal Function",
Spriger-Verlag Book Co., 1971.
86. FARRELL, P.G.
"Linear Binary Anticodes",
Electronics Letters, Vol. 6, No. 13, June 1970.
87. ANDRYANOV, V.I. and V.N. SASKOVETS
"Decycling Codes",
Akad. Nauk. Ukr. SSR, Kibernetika, pt. 1, 1966.
88. SOLOMON, G. and J.J. STIFFLER
"Algebraically Punctured Cyclic Codes",
Information and Control, 8, pp. 1970-1979, 1965.
89. HASHIM, A.A. and A.G. Constantinides
"Some New Results on Binary Linear Block Codes",
Electronics Letters, Vol. 10, No. 3, February 1974.
213.

90. GOLDBERG, M.
"Augmentation Techniques for a Class of Product Codes",
IEEE Transactions on Information Theory, Vol. IT-19,
No. 5, 1973.
91. DAVIDA, G.I. and S.M. REDDY
"Forward-Error Correction with Decision Feedback",
Information and Control, 21, pp. 117113, 1972.
92. ROBINSON, J.P.
"Punctured Uniform Codes",
IEEE Trans: Inform. Theory, IT-15, pp. 149-152, 1969.
93. DAVIDA, G.I.
"Multiple Extension of the Minimum Distance of BCH Codes",
Proceedings of the Eighth Annual Allerton Conference on
Circuit and System Theory, 1970.
94. MACWILLIAMS, F.J.
"A Theory on the Distribution of Weights in a Systematic
Code",
Bell System Tech. J., 42, pp. 79-94, 1963.
95. SLOANE, N.J.A.
"A Survey of Constructive Coding Theory and a Table of
Binary Codes of Highest Known Rate",
Discrete Mathematics, Vol. 3, pp. 265-294, 1972.
96. SOLOMON, G. and J.J. STIFFLER
"Punctured Systematic Cyclic Codes",
IEEE Intern. Cony. Record, Part 1, pp. 128-129, 1964.
97. HASHIM, A.A. & A.G. CONSTANTINIDES
"A Class of Linear ,Binary Codes",
Proceedings of IEE., July 1974.
98. GOETHALS, J.M.
"Algebraic Structure and Weight Distribution of Binary
Cyclic Codes",
MBLE Res. Lab. (Belgium) Report, R37, 1965.
214.

99. GOETHALS, J.M.
"Analysis of Weight Distribution in Binary Cyclic Codes",
IEEE Trans. Inform. Theory, IT-12, pp. 401-402, 1966.
100. PLESS, V.
"Power Moment Identities on Weight Distributions in Error
Correcting Codes",
Inform. Control, 6, pp. 147-152, 1963.
101. PETERSON, W.W.
"On the Weight Structure and Symmetry of BCH Codes",
Journal of the Institute of Electrical Communication
Engineers, Japan, 50, pp. 1183-1190, 1967.
102. FARRELL, P.G.
Personal Communication.
103. SHANNON, C.E.
”A Mathematical Theory of Communication" ,
Bell System Tech. J., 27, pp. 379-423, 623-656, 1948.
104. SHANNON, C.C. and W. WEAVER
"The Mathematical Theory of Communication",
The University of, Illinois Press, Urbana 1962.
105. SLEPIAN, D.
"A Note on Two Binary Signaling Alphabets",
IRE Trans., IT-2, pp. 84-86, 1956.
106. HASHIM, A.A.
"New Families of Error Correcting Codes Generated by
Modification of Other Linear Binary Block Codes",
To appear in the Proceedings of IEE.
107. MACDONALD, J.E.
"Design Method for Maximum Minimum-Distance Error
Correcting Codes",
IBM J. Research Develop., 4, pp. 43-57, 1960.
215.

108. REIGER, S.H.
"Codes for the Correction of 'Clustered'Errors"
IRE Trans. on Inform. Theory, IT-6, pp. 16-21, March 1960.
109. ABRAMSON, N.M.
"A Class of Systematic Codes for Non-Independent Errors",
IRE Trans. on Inform. Theory, IT-5, pp. 150-157, December 195
110. FIRE, P.
"A Class of Multiple-Error-Correcting Binary Codes for
Non-Independent Errors",
Sylvania Report RSL-E-2, Sylvania Electronic Defense
Laboratory, Reconnaissance Systems Division, Mountain View,
California, March 1959.
111. ELSPAS, B. and R.A. SHORT
"A Note on Optimum Burst-Error-Correcting Codes",
IRE Trans. on Inform. Theory, IT-8, pp. 39-42, January 1962.
112. ABRAMSON, N.M.
"Error Correcting Codes from Linear Sequential Networks",
Proc. 4th London Symposium on Information Theory, C. Cherry,
Ed., Butterworths, Washington, D.C., 1961.
113. FOULK, C.R.
"Some Properties of Maximally-Efficient Cyclic Burst-
Correcting Codes and Results of a Computer Search for
such Codes",
File No. 375, Digital Computer Lab., University of Illinois,
Urbana, Illinois, June 12, 1961.
114. GROSS, A.J.
"Binary Group Codes which correct in Bursts of Three or
less for Odd Redundancy",
IRE Trans. on Information Theory, IT-8, pp.'356-359,
October 1962.
216.

115. GROSS, A.J.
"A Note on Some Binary Group Codes which Correct Errors
in Bursts of Four or Less",
IRE Trans. on Inform. Theory, IT-8, p. 384, October 1962.
116. KASAMI, T.
"Optimum. Shortened Cyclic Codes for Burst-Error-Correction",
IEEE Trans. on Inform. Theory, IT-9, pp. 105-109, April 1963.
117. KASAMI, T. and S. MATOBA
"Some Efficient Shortened Cyclic Codes for Burst-Error-
Correction",
IEEE Trans. on Inform. Theory, IT-10, pp. 252-253, July 1964.
118. MELAS, C.M.
"A New Group of Codes for Correction of Dependent Errors
in Data Transmission",
IBM J. Research Develop., 4, pp. 58-64, January 1960.
119. BAHL, L.R. and R.T. CHIEN
"Single-and-Multiple-Burst-Correcting Properties of a
Class of Cyclic Product Codes",
IEEE Trans. Inform. Theory, Vol. IT-17, pp. 594-600,
September 1971.
120. WOLF, J.K.
"On Codes Derivable from the Tensor Product of Check
Matrices",
IEEE Trans. Inform. Theory, Vol. IT-11, pp. 281-284,
April 1965.
121. CHIEN, R.T. and W.N.G. SPENCER
"Dual Product Codes for Correction of Multiple Low-Density
Burst Errors",
IEEE Trans. on Inform. Theory, Vol. IT-19, No. 5,
September 1973.
217.

122. BAHL, L. and R.T. CHIEN
"A Class of Multiple-Burst-Error-Correcting Codes",
Presented at the IEEE International Symposium on
Information Theory, Ellenville, New York, 1969.
123. HSU, H.T., T. KASAMI and R.T. CHIEN
"Error-Correcting Codes for a Compound Channel",
IEEE Trans. on Inform. Theory, IT-14, pp. 135-139,
January 1968.
124. POSNER, W.
"Simultaneous Error-Correction and Burst-Error Detection
Binary Linear Cyclic Codes",
J. Soc. Indust. Appl. Math., 13, pp. 1087-1095, Dec. 1965.
125. STONE, J.J.
"Multiple Burst Error Correction",
Information and Control, 4, pp. 324-331, March 1961.
126. TONG, S.Y.
"Burst Trapping Techniques for a Compound Channel",
Bell Telephone Labs. Tech. Memo., 1968.
127. TAVARES, S.E. and S.G.S. SHIVA
"Detecting and Correcting Multiple Bursts for Binary
Cyclic Codes",
IEEE Trans. on Inform. Theory, IT-16, 1970.
128. MANDELBAUM, D.M.
"Some Classes of Multiple-Burst-Error-Correcting Codes
using Threshold Decoding",
IEEE Trans. Inform. Theory, Vol. IT-18, pp. 285-292,
March 1972.
129. BURTON, H.O. and E.J. WELDON
"Cyclic Product Codes",
IEEE Trans. Inform. Theory, Vol. IT-11, pp. 433-439,
July 1969.
218.

130. SHIVA, S.G.S. and C.L. SHENG
"Multiple Solid Burst Error Correcting Binary Codes",
IEEE Trans. Inform. Theory (Corresp.), Vol. IT-15,
pp. 188-189, January 1969.
131. SLEPIAN, D.
"Some Further Theory of Group Codes",
Bell Syst. Tech. J., Vol. 39, pp. 1219-1252, September 1960.
132. VITERBI, A.J.
"Error Bounds for Convolutional Codes and an Asymptotically
Optimum Decoding Algorithm",
IEEE Trans. Inform. Theory, Vol. IT-13, pp. 260-269,
April 1967.
133. FORNEY, G.D., Jr.
"The Viterbi Algorithm",
Proc. IEEE, Vol. 61, pp. 268-278, March 1973.
134. FORNEY, G.D., Jr.
"A Review of Random Tree Codes",
In Final Report on a Coding System Design for Advanced
Solar Missions, Appendix A, (No. N68-16388), 1967.
135. VITERBI, A.J. and J.P. ODENWALDER,
"Further Results on Optimal Decoding of Convolutional Codes",
IEEE Trans. Inform. Theory (Corresp.), Vol. IT-15,
pp. 732-734, November 1969.
136. OMURA, J.K.
"On the Viterbi Decoding Algorithm",
IEEE Trans. Inform. Theory (Corresp.), Vol. IT-15,
pp. 177-179, January 1969.
137. WOZENCRAFT, J.M. and I.M. JACOBS
"Principles of Communication Engineering",
John Wiley & Sons, Inc., Second Printing, 1967.
219.

138. WOZENCRAFT, J.M. and R.S. KENNEDY
"Modulation and Demodulation for Probabilistic Coding",
IEEE Trans. Inform. Theory, IT-12, pp. 291-297, July 1966.
139. FANO, R.M.
"Transmission of Information",
The M.I.T. Press and John Wiley & Sons, Inc., 1961.
140. FANO, R.M.
"A Heuristic Discussion of Probabilistic Decoding",
IEEE Trans., IT-9, No. 2, pp. 64-73, 1963.
141. MASSEY, J.L.
"Coding and Modulation in Digital Communications",
The Proceedings of the International Zurich Seminar
on Digital Communications, E2, pp. 1-4, March 1974.
142. BELL, D.A.
"Some Quaternary Codes",
The Proceedings of the Conference on Digital Processing
of Signals in Communications, University of Technology,
Loughborough, pp. 409-420, April 1972.
143. HASHIM, A.A. and A.G.,CONSTANTINIDES
"Digital Code Division Multiplexing",
The Proceedings of the International Zurich Seminar on
Digital Communications, Zurich, pp. F5, 1-5, March 1974.
220.

DIGITAL CODE DIVISION MULTIPLEXING Mr. A.A. Hashim, B.Sc. (Eng.), M.Sc.
Dr. A.G. Constantinides, B.Sc. (Eng.), Ph.D. Imperial College of Science and Technology
London, England.
Summary
The theory of Code-Division-Multiplexing is developed in this paper. The development of this theory is effected on the inter-pretation of the system in terms of the concept of code-division tree based on the amplitude distribution of code-words at the output of the multiplexer. It is shown that in the Digital-Majority-Logic-Multiplexing system the length L of the codeword carriers is equal to the number of channels n for n=3 and 7 only. For all other values of n, the length L is considerably greater than n.
In addition to the above, a method of multiplexing is proposed, designated as Time-Code-Division-Multiplexing (TCDM) which is based on the combination of Time-Division-Multiplexing (TDM) and Code-Div-ision-Multiplexing (CDM). The binary input data in TCDM is modulated onto codewords of three levels, i.e. of levels +1, 0, and -1. A majority-logic gate forms the transmitted binary signal from the modulated codewords. Detection is achieved by correlating the received binary signal with the appropriate locally generated three-levelled codewords. Such a system has the advantages of both TDM and CDM systems in the sense that the length of the codewords is equal to the number of channels. It is necessary, how-ever, to have the total number of channels in the system a multiple of 3 or 7. Auto-matic random and effective burst error correcting capability at the multiplexer is one of the desirable features of TCDM. Moreover, there exists a tradeoff between the number of channels in use at any one time and the error correcting capabilities of the system
1. Introduction
The basic n-channel CDM system is founded on the orthogonality of the re-channel carriers (1) and (2). The input binary data di=1 or -1 is modulated onto
periodic binary orthogonal codewords W.= w. 1 , w.2' —.. Iw.L' wherewii =1 or -1 11 is the j-th element of the i-th codeword carrier. The modulated binary codeword is summed algebraically to form a multi-level transmitter signal S = s , s2,
2' ''''' sL' the elements of which are given by n
s. i = E1 j d.w. (1) = 1 i
At the receiver, the incoming signal is correlated with the orthogonal codeword carriers. Assuming a noise free channel the correlator output for the k-th channel Rk is given by
R = E sw (2) j k j=1 kj On substituting equation (1) into equation (2) and no ing the orthogonality of the carriers ( wk.wi.=L for k=i otherwise the sum is zero), equation (2) may be rewritten in the form
Rk = L dk (3)
Thus Rk has an amplitude which is L times greater than that of the k-th channel
data dk.
A modification of the basic CDM system has been proposed in (3), which is referred to as Boolean-Function Multiplexing, where-by the transmitter signal S of the CDM system before transmission is passed through a majority-logic function generator the output of which St
= stl, st2,...pstL is binary. The elements of St are given by
St. = Sgn1=1
d.w..) (4) ij At the receiver, the correlator output
for the k-th channel is given by:
Rtk
= sgn ( E S .) (5) j=1 tJ kJ
Moreover, it has been shown that the crosstalk between channels is zero when(3):
i) The codewords form an algebraic group and L = 2n, or
ii) The codewords are the first n time-shifts of a pseudorandom binary
1974 ZURICH SEMINAR F5 (1)

sequence of length L = 2n - 1.
If the system parameters are chosen corr-ectly and the errors in the received signal do not exceed the permitted level, then Sgn(Rt0=dk and the channels are separated correctly.
The error-correcting capability of the system is characterised by the minimum "Reassurance" defined as
L r =d ( 2: s oa ) =d R (6) min k j=1 tj kj min k tk(min) The reassurance of a system must remain
positive for correct separation of all channels. The minimum reassurance is equivalent to the minimum Hamming distance of an error correcting code. The number of random errors t that can be corrected by the system is given by
t = (rmin
- 1)/2 (7)
In (4), (5) and (6) a Digital Majority-logic Multiplexing system is developed which is based on the Boolean-function multiplexing system of (3). By suitable computer search the authors of the above papers propose several sets of suitable codeword carriers that give minimum reass-,'rance of unity for the case when the number of channels is equal to the length of the codewords. These are,
i) All shifts of length n=L=3 and n=L=7 of maximal length sequences, and
ii) the three truncated Walsh functions Wal(1,8), Wal(2,9) and Wal(309) with the first character omitted in each case, and the seven truncated Walsh functions Wal(1,9), Wal(2,9), ....,Wal(7,9).
It appears that the Digital-Majority-logic multiplexing system has inherent limitations. These limitations relate to the type of sets of codeword carriers and to the maximum number of channels which can be multiplexed without errors occurring. We offer in this paper a theoretical basis for the understanding of these limitations. Furthermore, we propose a new system, developed from these theoretical consider-ations, which overcomes the limitations and increases the advantages of digital multiplexing.
2. CDM System Analysis
Consider a basic n-channel CDM system of n=23-1, j is a positive integer. Let the n rows of the orthogonal Hadamard matrix of length L=23 (the first row being omitted) be used as the n codewords carrier. The Hadamard matrix of seven rows and eight columns is given below:
If all the n input binary data are +1, i.e. di=+1, i=1,2,....,n, then the L digit multi-level transmitter signal S, which is formed by the algebraic sum of the n modulated carrier codewords, contains one digit of amplitude level n, and n digits of amplitude level -1. Now, if the j-th row is replaced by its binary complement, i.e. di -=-1, then S contains one digit of level (n-2), (L/2)-1 digits of level -3 and L/2 digit of level 1. This follows from the fact that all two rows of Hadamard matrix have equal numbers of +1's and -1's. As the Hadamard matrix is orthogonal, then, if the j-th and k-th rows are replaced by their complements, i.e. d7•=dk=-1, S contains one digit of amplitude level (n-4), (L/4)-1 digits of amplitude level 3, and (2(L/4)) digits of amplitude level -1, provided that the number of channels with -1 information is less than L/4.
On this basis a code division tree can be easily constructed as can be seen in Fig. 1. Taking any node in the tree at a given amplitude level a, two branches (left and right) lead to two further nodes whose amplitude levels are respectively (a-2) and (a+2). Each amplitude level occurs ((n+1)/21) times if it lies to the right of the dotted line in Fig. 1 and ((n+1)/22,1.1 times if it lies to the left, i being the number of levels down the tree from the initial level of node -1. To complete the representation of S, an amplitude level of (n-2i) is added to the i-th level of the tree. Obviously the code division tree is applicable to any set of binary orthogonal
F5 (2)

NUMBER OF EVENTS (i) Nodes No.
0
1
2
3
-3
NUMBER OF EVENTS
n+ 1 - 1 I
n+1
2i 2i
n-8 A A A A 10, -\\ - - - - - - - - 3 - 3 4
n- 3 A \ 3 \AAA/V\ AA 5 -7 - -7 -3 -3 -7 - -3 -3 1 1 5-7 -3 -3 -3 1 5-3 1 1 1 5 5 9
Fig. 1 Code-Division Tree
functions which form a matrix of columns having equal numbers of +1's and -1's (excluding the first column) as for example, the set of codewords formed by the n phase shift of maximal pseudo-random binary sequence of length n, with +1 added at the beginning of each row.The transmitter signal S has 2n unique codewords. The frequency of occurrence of the modules of amplitude levels in each codeword is identical to the frequency of one of the first L/4 code division tree levels, if L/4 c log2L.
However, if log2L > L/4, the first (l+log2L) levels represent the frequency distribution of E 2Cin code,,,ove6.
i=log2L
The frequency distribution of the mod-ulus of the amplitude level of codewords of the correlator output at the receiver is identical to S. However, the amplitude level signs may take any pattern so that the algebraic sum of all (L) digits of the codeword yield a reassurance of value +L. The sign patterns of the digits which have maximum number of amplitude level 1 with opposite sign to the channel information and maximum number of high amplitude level with identical sign to channel information give minimum reassurance in the CDM system using majority techniques. The minimum reassurance was calculated for all the levels of the tree when L/4 4C- log2L. For
L/4 > log2L, the minimum reassurance assumed to occur at least once in the distribution
n n i=lo
Eg2L C. /2n-1 of the total 2n unique
codewords of the correlator output. The value of reassurance for different values of n were found to be:
L 4 8 16 32 64 128 256 512 1024 2048
n 3 7 15 31 63 127 255 511 1023 2047
R 2 2 -2 -6 -18 -38 -82 -166 -388 -678
From the above results, it can be seen that the CDM system, using majority-logic techniques, works only when L=4 and 8, n=3 and 7. The rows can be truncated by 1, so that at the worst possible case the minimum reassurance reduces to 1. It is also clear that the CDM system using majority techniques breaks down for L=n or n+1 at n>7. In the following section a system which makes use of the codewords L=n=3 and L=n=7 was designed to achieve the value of L=n for large number of channels.
3. TCDM System
Let H21 denote the second order TCDM matrix of first degree, given by:
1974 ZURICH SEMINAR F5 (3)

Li 1
• H21 0
The second order TCDM matrix of second degree is defined by the Kronecker products of H21 with itself, which yields:
H22
= —H21 H21..]
H21 -H21 = 0 [4.1
+1 0
0 +1 0 +1
+1 0 -1 0
+1 0 -1
The i-th order TCDM matrix of the first degree, Hil, is a square matrix of i rows and columns. The i-th order TCDM matrix of the k-th degree, Hik, is a square matrix of (ix2k-1) rows and columns, which is formed by the Kronecker products of Hi(k-1) with itself.
Consider a CDM system using a set of codewords given by higher degree TCDM matrix Hik with the first i's rows omitted; the transmitter signal S has a frequency distr-ibution of the modulud of the amplitude level given by the first L/4k code division tree levels providing the degree of the matrix is less than 6. Tice reason for this is that higher degree i-th order TCDM matrices are orthogonal matrices with columns of equal +1's and -1's excluding the first i columns.
Now consider a COM system which uses a set of codewords given by the third degree, i-th order TCDM matrix with the first i's rows omitted. The signal S has frequency distribution of the amplitude levels identical to the CDM system using a Hadamard matrix of three rows and four columns. Therefore a CDM system using majority techniques can employ a set of codewords given by the third degree i-th order TCDM matrix with first and last i rows and columns omitted respectively so as to achieve a minimum reassurance of +1 when L=n=3i where i=2,3
Similarly a CDM system using majority techniques employing a set of codewords given by fourth degree i-th order TCDM matrix with first and last i rows and columns omitted (called TCDM system) will achieve minimum reassurance of +1, when L=n=7i, where i=2,3,....
Computer programmes were written to simulate a TCDM system for L=n=6,9,12,14 and 15 bits. The results were found to
agree with the above analysis, which gave a minimum reassurance of +1.
Error correcting capabilities
Consider a TCDM system using a set of codewords given by the fourth order TCDM matrix of the third degree, with the first four rows omitted (matrix dimension (12x16), L=16, n=12). When the system is operating to maximum capacity, the 12 rows of the matrix provide carrier codewords for 12 channels. Such a system will have a reassurance of 2. When fewer channels are being used, the required number of codewords is generated by a specific linear addition of some of the rows in the matrix to form new codewords. The number of new codewords generated is equal to the number of channels in use. The rows to be added are chosen such that the resultant codewords are still in the tertiary form, i.e. contain only +1, 0, or -1 levels. The reassurance for channels having carrier codewords formed from linear summation of m rows obviously has the magnitude of 2m. The reassurance distribution in the channels was tabulated in Table (1).
A binary error in the received signal in the worst case will cause the reassurance to be reduced by 2. The number of random binary errors t which can be corrected and the number t of errors that can be detected for a given reassurance r, is given by:
t + t = r - 1
Since the carrier in each channel is made up of information digits interlaced with additional zeros in such a way that between each information digit and the next (i) zeros are added, where i is the order of the TCDM matrix, the TCDM system is capable of correcting ((r-1)/2) bursts of length i or less, where r is the reassurance of the system.
F5 (4)

Number of channels in use
n = 12
Carrier codewords used for each channel, number indicates the number of the rows
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12
R= 2
12
R = 4 R = 6 R = 8
11 1+2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 10 1
10 1+2, 3+4, 5, 6, 7, 8, 9, 10, 11, 12 8 2
9 1+2, 3+4, 5+6, 7, 8, 9, 10, 11, 12 6 3
8 1+2. 3+4, 5+6, 7+8, 9, 10, 11, 12 4 4
7 1+2, 3+4, 5+6, 7+8, 9+10, 11, 12 2 5
6 1+2, 3+4, 5+6, 7+8, 9+10, 11+12 6
5 1+2+3+4, 5+6, 7+8, 9+10, 11+12 4 1 1+2+3, 4+5+6, 7+8, 9+10, 11+12 or 3 2
4 1+2+3+4, 5+6+7+8, 9+10, 11, 12 2 2 1+2+3, 4+5+6, 7+8+9, 10+11+12 or 4
3 1+2+3+4, 5+6+7+8, 9+10+11+12 3
Table 1 Number of channels with reassurance
References
1. Harmuth, H.F.: "Transmission of inform-ation by orthogonal functions". (Springer, 1970, 2nd. edition).
2. Judge, W.J.: "Multiplexing using quasi-orthogonal binary functions", Trans. Amer. Inst. Elect. Engineers, 1962, 81, part 1, pp. 81-83.
3. Titsworth, R.C.: "A Boolean-function-multiplexed-telemetry data system", IEEE Trans., 1963, SET-9, pp. 42-45.
4. Gordon, J.A. and Barrett, R.: "Correlation-recovered adaptive majority multiplexing", Proc. IEE, Vol. 118, No. 3/4, March/April 1971, pp. 417-422.
5. Gordon, J.A. and Barrett, R.: "On Coordinate Transformations and Digital Majority Multiplexing", Symp. Theory and Applications of Walsh Functions, Hatfield, June 1971.
6. Gordon, J.A. and Barrett, R.: "Digital Majority Logic-Multiplexer using Walsh Functions", IEEE Trans.,.1971, EMC-13, Special Edition on Walsh Function, Symp., Washington 1971.
1974 ZURICH SEMINAR F5 (5)

Paper Included HASHIM, A. A. and A.G. CONSTANTINIDES "Digital Code Division Multiplexing" The proceedings of the International Zurich Seminar on Digital Communications, Zurich, March 1974.




















