Machine learning for neural decoding - arXiv
35
Machine learning for neural decoding Joshua I. Glaser 1,2,6,8,9* , Ari S. Benjamin 6 , Raeed H. Chowdhury 3,4 , Matthew G. Perich 3,4 , Lee E. Miller 2-4 , and Konrad P. Kording 2-7 1. Interdepartmental Neuroscience Program, Northwestern University, Chicago, IL, USA 2. Department of Physical Medicine and Rehabilitation, Northwestern University and Shirley Ryan Ability Lab, Chicago, IL, USA 3. Department of Physiology, Northwestern University, Chicago, IL, USA 4. Department of Biomedical Engineering, Northwestern University, Chicago, IL, USA 5. Department of Applied Mathematics, Northwestern University, Chicago, IL, USA 6. Department of Bioengineering, University of Pennsylvania, Philadelphia, IL, USA 7. Department of Neuroscience, University of Pennsylvania, Philadelphia, IL, USA 8. Department of Statistics, Columbia University, New York, NY, USA 9. Zuckerman Mind Brain Behavior Institute, Columbia University, New York, NY, USA * Contact: [email protected] Abstract Despite rapid advances in machine learning tools, the majority of neural decoding approaches still use traditional methods. Modern machine learning tools, which are versatile and easy to use, have the potential to significantly improve decoding performance. This tutorial describes how to effectively apply these algorithms for typical decoding problems. We provide descriptions, best practices, and code for applying common machine learning methods, including neural networks and gradient boosting. We also provide detailed comparisons of the performance of various methods at the task of decoding spiking activity in motor cortex, somatosensory cortex, and hippocampus. Modern methods, particularly neural networks and ensembles, significantly outperform traditional approaches, such as Wiener and Kalman filters. Improving the performance of neural decoding algorithms allows neuroscientists to better understand the information contained in a neural population and can help advance engineering applications such as brain machine interfaces. Introduction Neural decoding uses activity recorded from the brain to make predictions about variables in the outside world. For example, researchers predict movements based on activity in motor cortex (Serruya et al., 2002; Ethier et al., 2012), decisions based on activity in prefrontal and parietal cortices (Baeg et al., 2003; Ibos and Freedman, 2017), and spatial locations based on activity in the hippocampus (Zhang et al., 1998; Davidson et al., 2009). These decoding predictions can be used to control devices (e.g., a robotic limb), or to better understand how areas of the brain relate to the outside world. Decoding is a central tool in neural engineering and for neural data analysis. In essence, neural decoding is a regression (or classification) problem relating neural signals to particular variables. When framing the problem in this way, it is apparent that there is a wide range of methods that one could apply. However, despite the recent advances in machine learning (ML) techniques for regression, it is still common to decode activity with traditional methods such as linear regression. Using modern ML tools for neural decoding has the potential to boost performance significantly and might allow deeper insights into neural function. This tutorial is designed to help readers start applying standard ML methods for decoding. We describe when one should (or should not) use ML for decoding, how to choose an ML method, and
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of Machine learning for neural decoding - arXiv

Machinelearningforneuraldecoding
JoshuaI.Glaser1,2,6,8,9*,AriS.Benjamin6,RaeedH.Chowdhury3,4,MatthewG.Perich3,4,LeeE.Miller2-4,andKonradP.Kording2-7
1. InterdepartmentalNeuroscienceProgram,NorthwesternUniversity,Chicago,IL,USA2. DepartmentofPhysicalMedicineandRehabilitation,NorthwesternUniversityandShirleyRyanAbilityLab,Chicago,IL,USA3. DepartmentofPhysiology,NorthwesternUniversity,Chicago,IL,USA4. DepartmentofBiomedicalEngineering,NorthwesternUniversity,Chicago,IL,USA5. DepartmentofAppliedMathematics,NorthwesternUniversity,Chicago,IL,USA6. DepartmentofBioengineering,UniversityofPennsylvania,Philadelphia,IL,USA7. DepartmentofNeuroscience,UniversityofPennsylvania,Philadelphia,IL,USA8. DepartmentofStatistics,ColumbiaUniversity,NewYork,NY,USA9. ZuckermanMindBrainBehaviorInstitute,ColumbiaUniversity,NewYork,NY,USA*Contact:[email protected]
AbstractDespiterapidadvancesinmachinelearningtools,themajorityofneuraldecodingapproachesstillusetraditionalmethods.Modernmachinelearningtools,whichareversatileandeasytouse,havethe potential to significantly improve decoding performance. This tutorial describes how toeffectively apply these algorithms for typical decoding problems. We provide descriptions, bestpractices,andcodeforapplyingcommonmachinelearningmethods,includingneuralnetworksandgradientboosting.Wealsoprovidedetailedcomparisonsoftheperformanceofvariousmethodsatthe task of decoding spiking activity in motor cortex, somatosensory cortex, and hippocampus.Modernmethods,particularlyneuralnetworksandensembles,significantlyoutperformtraditionalapproaches, such as Wiener and Kalman filters. Improving the performance of neural decodingalgorithms allows neuroscientists to better understand the information contained in a neuralpopulationandcanhelpadvanceengineeringapplicationssuchasbrainmachineinterfaces.IntroductionNeuraldecodingusesactivityrecordedfromthebraintomakepredictionsaboutvariables intheoutside world. For example, researchers predict movements based on activity in motor cortex(Serruya et al., 2002; Ethier et al., 2012), decisions based on activity in prefrontal and parietalcortices(Baegetal.,2003;IbosandFreedman,2017),andspatiallocationsbasedonactivityinthehippocampus(Zhangetal.,1998;Davidsonetal.,2009).Thesedecodingpredictionscanbeusedtocontroldevices(e.g.,arobotic limb),or tobetterunderstandhowareasof thebrainrelate to theoutsideworld.Decodingisacentraltoolinneuralengineeringandforneuraldataanalysis.In essence, neural decoding is a regression (or classification) problem relating neural signals toparticularvariables.Whenframingtheprobleminthisway,itisapparentthatthereisawiderangeofmethodsthatonecouldapply.However,despitetherecentadvances inmachine learning(ML)techniques for regression, it is still common to decode activitywith traditionalmethods such aslinear regression. Using modern ML tools for neural decoding has the potential to boostperformancesignificantlyandmightallowdeeperinsightsintoneuralfunction.This tutorial is designed to help readers start applying standardMLmethods for decoding.Wedescribewhenoneshould(orshouldnot)useMLfordecoding,howtochooseanMLmethod,and

bestpractices suchas cross-validationandhyperparameteroptimization.Weprovidecompanioncode thatmakes itpossible to implementavarietyofdecodingmethodsquickly.Using thissamecode,wedemonstrateherethatMLmethodsoutperformtraditionaldecodingmethods.Inexampledatasets of recordings from monkey motor cortex, monkey somatosensory cortex, and rathippocampus,modernMLmethods showed the highest accuracy decoding of availablemethods.Using our code and this tutorial, readers can achieve these performance improvements on theirowndata.MaterialsandMethodsInthissection,weprovide1)generalbackgroundaboutdecoding,includingwhentousemachinelearning(ML)fordecodingandconsiderationsforchoosingadecodingmethod;2)thepracticalimplementationdetailsofusingMLfordecoding,includingdataformatting,propermodeltesting,andhyperparameteroptimization;and3)methodsthatweusetocompareMLtechniquesintheResultssection,includingdescriptionsofthespecificMLtechniqueswecompareanddatasetsweuse.WhentousemachinelearningfordecodingMachinelearningismosthelpfulwhenthecentralresearchaimistoobtaingreaterpredictiveperformance.Thisisinpartbecauseofthegeneralsuccessofmachinelearningfornonlinearproblems(Heetal.,2015;LeCunetal.,2015;Silveretal.,2016).WewilldemonstratethislaterinthistutorialinResults.Therearemultipleseparateresearchaimsfordecodingthatbenefitfromimprovedpredictiveperformance,includingengineeringapplicationsand,ifusedcarefully,understandingneuralactivity(Glaseretal.,2019).EngineeringapplicationsDecodingisoftenusedinengineeringcontexts,suchasforbrainmachineinterfaces(BMIs),wheresignalsfrommotorcortexareusedtocontrolcomputercursors(Serruyaetal.,2002),roboticarms(Collinger et al., 2013), and muscles (Ethier et al., 2012). When the primary aim of theseengineeringapplicationsistoimprovepredictiveaccuracy,MLshouldgenerallybebeneficial.UnderstandingwhatinformationiscontainedinneuralactivityDecodingisalsoanimportanttoolforunderstandinghowneuralsignalsrelatetotheoutsideworld.It can be used to determine how much information neural activity contains about an externalvariable (e.g., sensation or movement) (Hung et al., 2005; Raposo et al., 2014; Rich andWallis,2016),andhowthisinformationdiffersacrossbrainareas(Quirogaetal.,2006;Hernándezetal.,2010;vanderMeeretal.,2010),experimentalconditions(Deklevaetal.,2016;Glaseretal.,2018),anddiseasestates(Weygandtetal.,2012).Whenthegoalistodeterminehowmuchinformationaneuralpopulationhasaboutanexternalvariable,regardlessof theformofthat information, thenusing ML will generally be beneficial. However, when the goal is to determine how a neuralpopulation processes that information, or to obtain an interpretable description of how thatinformationisrepresented,oneshouldexercisecarewithML,aswedescribeinthenextsection.BenchmarkingforsimplerdecodingmodelsDecoders can also be used to understand the form of themapping between neural activity andvariablesintheoutsideworld(Paganetal.,2016;Naufeletal.,2018).Thatis,ifresearchersaimtotest if the mapping from neural activity to behavior/stimuli (the “neural code”) has a certainstructure,theycandevelopa“hypothesis-drivendecoder”withaspecificform.Ifthatdecodercanpredict taskvariableswithsomearbitraryaccuracy level, this issometimesheldasevidencethat

informationwithinneuralactivityindeedhasthehypothesizedstructure.However,itisimportanttoknowhowwellahypothesis-drivendecoderperformsrelativetowhatispossible.ThisiswheremodernMLmethodscanbeofuse.IfamethoddesignedtotestahypothesisdecodesactivitymuchworsethanMLmethods,thenaresearcherknowsthattheirhypothesislikelymisseskeyaspectsoftheneuralcode.Hypothesis-drivendecodersshouldthusalwaysbecomparedagainstagood-faithefforttomaximizeperformanceaccuracywithagoodmachinelearningapproach.CautionininterpretingmachinelearningmodelsofdecodingUnderstandinghowinformationinneuralactivityrelatestoexternalvariablesItistemptingtoinvestigatehowanMLdecoder,oncefittoneuraldata,transformsneuralactivitytoexternalvariables.Thismaybeespeciallytemptingif theMLmodelresemblesneural function,such as in a neural network decoder. Still, high predictive performance is not evidence thattransformations occurringwithin theML decoder are the same, or even similar to, those in thebrain.Ingeneral,andunlikehypothesis-drivendecoders,themathematicaltransformationsofmostMLdecodersarehardtointerpretandthemselvesarenotmeanttorepresentanyspecificbiologicalvariable.SomerecenteffortshavestartedtoinvestigatehowMLmodelsmightbeinterpretedoncefit todata(Ribeiroetal.,2016;Olahetal.,2018;Cranmeretal.,2020).However,usersshouldbecautiousthatthisisanactiveresearchareaandthat,ingeneral,MLmethodsarenotdesignedformechanisticinterpretation.UnderstandingwhatinformationiscontainedinneuralactivityItisimportanttobecarefulwiththescientificinterpretationofdecodingresults,bothforMLandother models (Weichwald et al., 2015). Decoding can tell us how much information a neuralpopulation has about a variableX. However, high decoding accuracy does notmean that a brainareaisdirectlyinvolvedinprocessingX,orthatXisthepurposeofthebrainarea(Wuetal.,2020).Forexample,withapowerfuldecoder, itcouldbepossibletoaccuratelyclassify imagesbasedonrecordings from the retina, since the retinahas informationaboutall visual space.However, thisdoesnotmeanthattheprimarypurposeoftheretinaisimageclassification.Moreover,eveniftheneural signal temporally precedes the external variable, it does not necessarily mean that it iscausallyinvolved(Weichwaldetal.,2015).Forexample,movement-relatedinformationcouldreachsomatosensorycortexpriortomovementduetoanefferencecopyfrommotorcortex,ratherthansomatosensory cortex being responsible formovement generation. Researchers should constraininterpretationstoaddresstheinformationinneuralpopulationsaboutvariablesofinterest,butnotusethisasevidenceforareas’rolesorpurpose.Onamoretechnicallevel,therearesomedecodersthatwillnotdirectlytelluswhatinformationiscontained in the neural population. As described more in the following section, some neuraldecodersincorporatepriorinformation,e.g.incorporatingtheoverallprobabilityofbeinginagivenlocationwhendecodingfromhippocampalplacecells(Zhangetal.,1998).Ifadecoderusespriorinformationabout thedecodedvariable, then the finaldecodedvariableswillnotonlyreflect theinformationcontainedintheneuralpopulation,butwillalsoreflectthepriorinformation-thetwowillbeentangled(KriegeskorteandDouglas,2019).WhatdecodershouldIusetoimprovepredictiveperformance?Dependingontherecordingmethod,location,andvariablesofinterest,differentdecodingmethodsmay be most effective. Neural networks, gradient boosted trees, support vector machines, and

linearmethods are among thedozens of potential candidates. Eachmakesdifferent assumptionsabout how inputs relate to outputs.Wewill describe a number of specificmethods suitable forneuraldecodinglaterinthistutorial.Ultimately,werecommendtestingmultiplemethods,perhapsstartingwith themethodswehave found toworkbest forourdemonstrationdatasets. Still, it isimportanttohaveageneralunderstandingofdifferencesbetweenmethods.DifferentmethodsmakedifferentimplicitassumptionsaboutthedataThere is no such thing as a method that makes no assumptions. This idea derives from a keytheoremintheMLliteraturecalledthe“NoFreeLunch”theorem,whichessentiallystatesthatnoalgorithmwilloutperformallothersoneveryproblem(WolpertandMacready,1997).Thefactthatsome algorithms performbetter than others in practicemeans that their assumptions about thedataarebetter.Theknowledgethatallmethodsmakeassumptionstovaryingdegreescanhelponebeintentionalaboutchoosingadecoder.Theassumptionsofsomemethodsareveryclear.Regularized(ridge,orL2) linearregression, forexample,makesthree: thechange intheoutputs isassumedtobeproportionatetothechange inthe inputs, any additional noise on the outputs is assumed to beGaussian noise (implied by themean-squared error), and the regression coefficients are assumed to pull from a Gaussiandistribution(HoerlandKennard,1970;Bishop,2006).Formorecomplicatedmethods likeneuralnetworks,theassumptionsaremorecomplicated(andstillunderdebate,e.g.(Aroraetal.,2019))butstillexist.Onecrucial assumption that isbuilt intodecoders is the formof the input/output relation. Somemethods, e.g. linear regression or a Kalman filter, assume thismapping has a fixed linear form.Others,e.g.neuralnetworks,allowthismappingtohaveaflexiblenonlinearform.Inthescenariothatthemappingistrulylinear,makingthislinearassumptionwillbebeneficial;itwillbepossibletoaccuratelylearnthedecoderwhenthereislessdataormorenoise(Hastieetal.,2009).However,if the neural activity relates nonlinearly to the task variable, then it can be beneficial to have adecoderthat isrelativelyagnosticabouttheoverall input/outputrelationship, inthesensethat itcanexpressmanydifferenttypesofrelationships.A challenge of choosing a model that is highly expressive or complex is the phenomenon of“overfitting”,inwhichthemodellearnscomponentsofthenoisethatareuniquetothedatathatthemodel is trained on, but which do not generalize to any independent test data. To combatoverfitting, one can choose a simpler algorithm that is less likely to learn to model this noise.Alternatively,onecanapplyregularization,whichessentiallypenalizesthecomplexityofamodel.This effectively reduces the expressivity of a model, while still allowing it to have many freeparameters(Friedmanetal.,2001).Regularizationisanimportantwaytoincludetheassumptionthattheinput/outputrelationshipisnotarbitrarilycomplex.Additionally, for someneuraldecodingproblems, it ispossible to incorporateassumptionsabouttheoutputbeingpredicted.Forexample,letussayweareestimatingthekinematicsofamovementfromneuralactivity.TheKalmanfilter,whichisfrequentlyusedformovementdecoding(Wuetal.,2003;WuandHatsopoulos,2008;Giljaetal.,2012),usestheadditionalinformationthatmovementkinematicstransitionovertimeinasmoothandorderlymanner.TherearealsoBayesiandecodersthat can incorporate prior beliefs about the decoded variables. For example, the Naive Bayesdecoder,which is frequently used for position decoding fromhippocampal activity (Zhang et al.,1998;Barbierietal.,2005;Kloostermanetal.,2013),cantakeintoaccountpriorinformationabout

theprobabilitydistributionofpositions.Decoderswithtaskknowledgebuiltinareconstrainedintermsoftheirsolutions,whichcanbehelpful,providedthisknowledgeiscorrect.Maximumlikelihoodestimatesvs.posteriordistributionsDifferentclassesofmethodsalsoprovidedifferenttypesofestimates.Typically,machinelearningalgorithmsprovidemaximumlikelihoodestimatesofthedecodedvariable.Thatis,thereisasinglepointestimateforthevalueofthedecodedvariable,whichistheestimatethatismostlikelytobetrue. Unlike the typical use of machine learning algorithms, Bayesian decoding provides aprobabilitydistributionoverallpossibilitiesforthedecodedoutputs(the“posterior”distribution),thus also providing information about the uncertainty of the estimate (Bishop, 2006). Themaximumlikelihoodestimateisthepeakoftheposteriordistributionwhenthepriordistributionisuniform.EnsemblemethodsIt is important to note that the user does not need to choose a single model. One can usuallyimproveon theperformanceofanysinglemodelbycombiningmultiplemodels, creatingwhat iscalledan“ensemble”.Ensemblescanbesimpleaveragesoftheoutputsofmanymodels,ortheycanbe more complex combinations. Weighted averages are common, which one can imagine as asecond-tier linear model that takes the outputs of the first-tier models as inputs (sometimesreferred to as a super learner). In principle, one can use anymethod as the second-tier model.Third-andfourth-tiermodelsareuncommonbutimaginable.ManysuccessfulMLmethodsare,attheircore,ensembles(LiawandWiener,2002).InMLcompetitionsiteslikeKaggle(Kaggle,2020),mostwinningsolutionsarecomplicatedensembles.UnderwhichconditionswillMLtechniquesimprovedecodingperformance?WhetherMLwilloutperformothermethodsdependsonmanyfactors.Theformoftheunderlyingneuralcode,thelengthoftherecordingsession,andthelevelofnoisewillallaffectthepredictiveaccuracyofdifferentmethodstodifferentdegrees.There isnowaytoknowaheadof timewhichmethodwillperformthebest,andwerecommendcreatingapipelinetoquicklytestandcomparemany ML and simpler regression methods. For typical decoding situations, however, we expectcertainmodernMLmethods to performbetter than simplermethods. In the demonstration thatfollowsinResults,weshowthatthisistrueacrossthreedatasetsandawiderangeofvariablesliketrainingdatalength,numberofneurons,binsize,andhyperparameters.Apracticalguide(“thenittygritty”)forusingmachinelearningfordecodingInanydecodingproblem,onehasneuralactivityfrommultiplesourcesthatisrecordedforaperiodoftime.Whilewefocushereonspikingneurons,thesamemethodscouldbeusedwithotherformsofneuraldata,suchastheBOLDsignalinfMRI,orthepowerinparticularfrequencybandsoflocalfield potential (LFP) or electroencephalography (EEG) signals.Whenwe decode from the neuraldata,whateverthesource,wewouldliketopredictthevaluesofrecordedoutputs(Fig.1a).Dataformatting/preprocessingfordecodingPreparingforregressionvs.classificationDepending on the task, the desired output can be variables that are continuous (e.g., velocity orposition),ordiscrete(e.g.,choices). Inthefirstcasethedecoderwillperformregression,whileinthesecondcaseitwillperformclassification.InourPythonpackage,decoderclassesarelabeledtoreflectthisdivision.

Inthedataprocessingstep,takenotewhetherapredictionisdesiredcontinuouslyintime,oronlyat the end of each trial. In this tutorial, we focus on situations in which a prediction is desiredcontinuouslyintime.However,manyclassificationsituationsrequireonlyonepredictionpertrial(e.g.,whenmakingasinglechoicepertrial).Ifthisisthecase,thedatamustbepreparedsuchthatmanytimepointsinasingletrialaremappedtoasingleoutput.TimebinningdividescontinuousdataintodiscretechunksAnumberofimportantdecisionsarisefromthebasicproblemthattimeiscontinuouslyrecorded,but decoding methods generally require discrete data for their inputs (and, in the continual-predictionsituation,theiroutputs).Atypicalsolutionistodivideboththeinputsandoutputsintodiscrete timebins.Thesebinsusually contain the average input or output over a small chunkoftime,butcouldalsocontaintheminimum,maximum,ortheregularsamplingofanyinterpolationmethodfittothedata.When predictions are desired continuously in time, one needs to decide upon the temporalresolution,R, fordecoding.Thatis,dowewanttomakeapredictionevery50ms,100ms,etc?Weneed to put the input and output into bins of length R (Fig. 1a). It is common (although notnecessary)tousethesamebinsizefortheneuraldataandoutputdata,andwedosohere.Thus,ifTis the lengthof therecording,wewillhaveapproximatelyT/R totaldatapointsofneuralactivityandoutputs.Next,weneed to choose the timeperiodofneural activityused topredict a givenoutput. In thesimplestcase,theactivityfromallneuronsinagiventimebinwouldbeusedtopredicttheoutputin that same timebin.However, it is often the case thatwewant theneuraldata toprecede theoutput (e.g., in the case ofmakingmovements) or follow the decoder output (e.g., in the case ofinferringthecauseofasensation).Plus,weoftenwanttouseneuraldatafrommorethanonebin(e.g.,using500msofprecedingneuraldatatopredictamovementinthecurrent50msbin).Inthefollowing,weusethenomenclaturethatBtimebinsofneuralactivityarebeingusedtopredictagivenoutput.Forexample,ifweusethreebinsprecedingtheoutputandoneconcurrentbin,thenB=4(Fig.1a).Notethatwhenmultiplebinsofneuraldataareusedtopredictanoutput(B>1),thenoverlapping neural data will be used to predict different output times (Fig. 1a), making themstatisticallydependent.Whenmultiplebinsofneuraldataareusedtopredictanoutput,thenwewillneedtoexcludesomeoutput bins. For instance, if we are using one bin of neural data preceding the output, thenwecannotpredictthefirstoutputbin,andifweareusingonebinofneuraldatafollowingtheoutput,thenwecannotpredictthefinaloutputbin(Fig.1a).Thus,wewillbepredictingKtotaloutputbins,whereKislessthanthetotalnumberofbins(T/R).Tosummarize,ourdecoderswillbepredictingeachoftheseKoutputsusingBsurroundingbinsofactivityfromNneurons.TheformatoftheinputdatadependsontheformofthedecoderNon-recurrentdecoders:Formost standard regressionmethods, thedecoderhasnopersistentinternalstateormemory.InthiscaseNxBfeatures(thefiringratesofeachneuronineachrelevanttime bin) are used to predict each output (Fig. 1b). The inputmatrix of covariates,X, hasN xBcolumns(oneforeachfeature)andKrows(correspondingtoeachoutputbeingpredicted).Ifthereisasingleoutputthatisbeingpredicted,itcanbeputinavector,Y,oflengthK.Notethatformanydecoders,iftherearemultipleoutputs,eachisindependentlydecoded.Ifmultipleoutputsarebeingsimultaneouslypredicted,whichcanoccurwithneuralnetworkdecoders,theoutputscanbeputinamatrixY,thathasKrowsanddcolumns,wheredisthenumberofoutputsbeingpredicted.Since

this is the format of a standard regression problem, many regression methods can easily besubstitutedforoneanotheroncethedatahasbeenpreparedinthisway.Recurrent neural network decoders: When using recurrent neural networks (RNNs) fordecoding, we need to put the inputs in a different format. Recurrent neural networks explicitlymodel temporal transitions across timewith apersistent internal state, called the “hidden state”(Fig.1c).Ateach timeof theB timebins, thehiddenstate isadjustedasa functionofboth theNfeatures(thefiringratesofallneuronsinthattimebin)andthehiddenstateattheprevioustimebin(Fig.1c).Notethatanalternativewaytoviewthismodelisthatthehiddenstatefeedsbackonitself(acrosstimepoints).AftertransitioningthroughallBbins,thehiddenstateinthisfinalbinisusedtopredicttheoutput.InthiswayanRNNdecodercanintegratetheeffectofneuralinputsoveran extended period of time. For use in this type of decoder, the input can be formatted as a 3-dimensionaltensorofsizeKxNxB(Fig.1c).Thatis,foreachrow(correspondingtooneoftheKoutputbinstobepredicted),therewillbeNfeatures(2ndtensordimension)overBbins(3rdtensordimension)usedforprediction.Withinthis format,differenttypesofRNNs, includingthosemoresophisticatedthanthestandardRNNshowninFig.1c,canbeeasilyswitchedforoneanother.

Figure 1: Decoding Schematic a) To decode (predict) the output in a given time bin, we used the firing rates of all N neurons in B time bins. In

this schematic, N=4 and B=4 (three bins preceding the output and one concurrent bin). As an example, preceding bins of neural activity could be useful for predicting upcoming movements and following bins of neural activity could be useful for predicting preceding sensory information. Here, we show a single output being predicted. b) For non-recurrent decoders (Wiener Filter, Wiener Cascade, Support Vector Regression, XGBoost, and Feedforward Neural Network in our subsequent demonstration), this is a standard machine learning regression problem where N x B features (the firing rates of each neuron in each relevant time bin) are used to predict the output. c) To predict outputs with recurrent decoders (simple recurrent neural network, GRUs, LSTMs in our subsequent demonstration) we used N features, with temporal connections across B bins. A schematic of a recurrent neural network predicting a single output is on the right. Note that an alternative way to view this model is that the hidden state feeds back on itself (across time points).
ApplyingmachinelearningThe typical process of applying ML to data involves testing several methods and seeing whichworksbest.Somemethodsmaybeexpectedtoworkbetterorworsedependingonthestructureofthedata,andinthenextpartofthistutorialweprovideademonstrationofwhichmethodsworkbestfortypicalneuralspikingdatasets.Thatsaid,applyingMLisunavoidablyaniterativeprocess,andforthisreasonwebeginwiththeproperwaytochooseamongmanymethods.Itisparticularlyimportanttoconsiderhowtoavoidoverfittingourdataduringthisiterativeprocess.Comparemethodperformanceusingcross-validationGiven two (ormore)methods, theML practitionermust have a principledway to decidewhichmethodisbest.Itiscrucialtotestthedecoderperformanceonaseparate,held-outdatasetthatthedecoderdidnotseeduringtraining(Fig.2a).This isbecauseadecodertypicallywilloverfit to itstraining data. That is, itwill learn to predict outputs using idiosyncratic information about eachdatapointinthetrainingset,suchasnoise,ratherthantheaspectsthataregeneraltothedata.Anoverfit algorithm will describe the training data well but will not be able to provide goodpredictionsonnewdatasets.Forthisreason,thepropermetrictochoosebetweenmethodsistheperformance on held-out data, meaning that the available data should be split into separate“training”and“testing”datasets.Inpractice,thiswillreducetheamountoftrainingdataavailable.Inordertoefficientlyuseallofthedata,itiscommontoperformcross-validation(Fig.2b).In10-foldcross-validation,forexample,thedatasetissplitinto10sets.Thedecoderistrainedon9ofthesets,andperformanceistestedonthefinalset.Thisisdone10timesinarotatingfashion,sothateachsetistestedonce.Theperformanceonalltestsetsisgenerallyaveragedtogethertodeterminetheoverallperformance.Whenpublishingabouttheperformanceofamethod, it is importanttoshowtheperformanceonheld-out data thatwas additionally not used to select betweenmethods (Fig. 2c). Randomnoisemayleadsomemethodstoperformbetterthanothers,anditispossibletofooloneselfandothersby testingagreatnumberofmethodsandchoosing thebest. In fact,onecanentirelyoverfit toatestingdatasetsimplybyusingthetestperformancetoselectthebestmethod,evenifnomethodistrainedonthatdataexplicitly.Practitionersoftenmakethedistinctionbetweenthe“training”data,the “validation”data (which is used to select betweenmethods) and the “testing” data (which isused toevaluate the trueperformance).This three-waysplitofdata complicates cross-validationsomewhat(Fig.2b).Itispossibletofirstcreateaseparatetestingset,thenchooseamongmethodson theremainingdatausingcross-validation.Alternatively, formaximumdataefficiency,onecaniterativelyrotatewhichsplitisthetestingset,andthusperformatwo-tiernestedcross-validation.

HyperparameteroptimizationWhen fitting any singlemethod, oneusuallyhas to additionally choose a set ofhyperparameters.Theseareparametersthatrelatetothedesignofthedecoderitselfandshouldnotbeconfusedwiththe ‘normal’ parameters that are fit during optimization, e.g., the weights that are fit in linearregression. For example, neural networks can be designed to have any number of hidden units.Thus, theuserneeds toset thenumberofhiddenunits (thehyperparameter)before training thedecoder.Oftendecodershavemultiplehyperparameters,anddifferenthyperparametervaluescansometimes lead to greatly different performance. Thus, it is important to choose a decoder’shyperparameterscarefully.Whenusingadecoderthathashyperparameters,oneshouldtakethefollowingsteps.First,alwayssplit thedata into threeseparatesets (trainingset, testingset,andvalidationset),perhapsusingnestedcross-validation(Fig.2b).Next,iteratethroughalargenumberofhyperparametersettingsand choose thebestbasedonvalidation setperformance. Simplemethods for searching throughhyperparametersareagridsearch(i.e.,samplingvaluesevenly)andrandomsearch(BergstraandBengio, 2012). There are also more efficient methods (e.g., (Snoek et al., 2012; Bergstra et al.,2013)) that can intelligently search through hyperparameters based on the performance ofpreviouslytestedhyperparameters.Thebestperforminghyperparameterandmethodcombination(onthevalidationset)willbethefinalmethod,unlessoneiscombiningmultiplemethodsintoanensemble.

Figure 2. Schematic of cross-validation a) After training a decoder on some data (green), we would like to know how well it performs on held-out data that we do not have access to (red). b) Left: By splitting the data we have into test (orange) and train (green) segments, we can approximate the performance on held-out data. In k-fold cross-validation, we re-train the decoder k times, and each time rotate which parts of the data are the test or train data. The average test set performance approximates the performance on held-out data. Right: If we want to select among many models, we cannot maximize the performance on the same data we will report as a score. (This is very similar to “p-hacking” statistical significance.) Instead we maximize performance on “validation” data (blue), and again rotate through the available data. c) All failure modes are ways in which a researcher lets information from the test set “leak” into the training algorithm. This happens if you explicitly train on the test data (top), or use any statistics of the test data to modify the train data before fitting (middle), or select your models or hyperparameters based on the performance on the test data (bottom).
MethodsforourdecodingcomparisonsanddemonstrationsInthissection,wedemonstratetheusageofourcodepackageandshowwhichofitsmethodsworkbetterthantraditionalmethodsforseveralneuraldatasets.CodeaccessibilityWehavepreparedaPythonpackagethatimplementsthemachinelearningpipelinefordecodingproblems.Itisavailableathttps://github.com/KordingLab/Neural_Decoding,anditincludescodetocorrectlyformattheneuralandoutputdatafordecoding,toimplementmanydifferentdecodersforbothregressionandclassification,andtooptimizetheirhyperparameters.Specificdecoders:The following decoders are available in our package, andwe demonstrate their performance onexampledatasetsbelow.Weincludedbothhistoricallineartechniques(e.g.,theWienerfilter)andmodernML techniques (e.g.,neuralnetworksandensemblesof techniques).Additionaldetailsofthe methods, including equations and hyperparameter information, can be found in a table inExtendedData(Figure4-3).WienerFilter:TheWienerfilterusesmultiplelinearregressiontopredicttheoutputfrommultipletimebinsofallneurons’spikes(Carmenaetal.,2003).Thatis,theoutputisassumedtobealinearmappingofthenumberofspikesintherelevanttimebinsfromeveryneuron(Fig.1a,b).Wiener Cascade: The Wiener cascade (also known as a linear-nonlinear model) fits a linearregression(theWienerfilter)followedbyafittedstaticnonlinearity(e.g.,(Pohlmeyeretal.,2007)).Thisallowsforanonlinearinput-outputrelationshipandassumesthatthisnonlinearityispurelyafunctionofthelinearoutput.Thus,thereisnononlinearmixingofinputfeatureswhenmakingtheprediction.Thedefaultnonlinearcomponentisapolynomialwithdegreethatcanbedeterminedonavalidationset.Support Vector Regression: In support vector regression (SVR) (Smola and Schölkopf, 2004;ChangandLin,2011), the inputsareprojected intoahigher-dimensionalspaceusinganonlinearkernel,andthen linearlymappedfromthisspaceto theoutput tominimizeanobjective function(SmolaandSchölkopf,2004;ChangandLin,2011).Thatis,theinput/outputmappingisassumedtononlinear,butisconstrainedbythekernelbeingused(itisnotcompletelyflexible).Inourtoolbox,thedefaultkernelisaradialbasisfunction.XGBoost:XGBoost(ExtremeGradientBoosting)(ChenandGuestrin,2016)isanimplementationofgradient boosted trees (Natekin and Knoll, 2013; Chen, 2014). Tree-basedmethods sequentially

split the inputspace intomanydiscreteparts (visualizedasbranchesona tree foreachsplit), inordertoassigneachfinal“leaf”(aportionofinputspacethatisnotsplitanymore)avalueinoutputspace(Breiman,2017).XGBoostfitsmanyregressiontrees,whicharetreesthatpredictcontinuousoutputvalues.“Gradientboosting”referstofittingeachsubsequentregressiontreetotheresidualsofthepreviousfit.Thismethodassumesflexiblenonlinearinput/outputmappings.FeedforwardNeuralNetwork:Afeedforwardneuralnet(Rosenblatt,1961;Goodfellowetal.,2016)connects the inputs to sequential layers of hidden units,which then connect to the output. Eachlayerconnectstothenext(e.g.,theinputlayertothefirsthiddenlayer,orthefirsttosecondhiddenlayers) via linearmappings followedbynonlinearities.Note that theWiener cascade is a specialcaseofaneuralnetworkwithnohiddenlayers. Feedforwardneuralnetworksalsoallowflexiblenonlinearinput/outputmappings.SimpleRNN:Inastandardrecurrentneuralnetwork(RNN)(Rumelhartetal.,1986;Goodfellowetal.,2016), the hidden state is a linear combination of the inputs and the previous hidden state. Thishiddenstate is then run throughanoutputnonlinearity, and linearlymapped to theoutput.Likefeedforwardneuralnetworks,RNNsallowflexiblenonlinearinput/outputmappings.Additionally,unlike feedforwardneural networks, RNNs allow temporal changes in the system to bemodeledexplicitly.GatedRecurrentUnit:Gatedrecurrentunits(GRUs)(Choetal.,2014;Goodfellowetal.,2016)areamorecomplextypeofrecurrentneuralnetwork. Ithasgatedunits,whichdeterminehowmuchinformationcanflowthroughvariouspartsofthenetwork.Inpractice,thesegatedunitsallowforbetterlearningoflong-termdependencies.LongShortTermMemoryNetwork:LiketheGRU,thelongshorttermmemory(LSTM)network(HochreiterandSchmidhuber,1997;Goodfellowetal.,2016) isamorecomplexrecurrentneuralnetworkwithgatedunits that further improve thecaptureof long-termdependencies.TheLSTMhasmoreparametersthantheGRU.KalmanFilter:OurKalmanfilterforneuraldecodingwasbasedon(Wuetal.,2003).IntheKalmanfilter, thehidden state at time t is a linear functionof thehidden state at time t-1, plus amatrixcharacterizing the uncertainty. For neural decoding, the hidden state is the kinematics (x and ycomponents of position, velocity, and acceleration), which we aim to estimate. Note that eventhoughweonlyaimtopredictpositionorvelocity,allkinematicsareincludedbecausethisallowsforbetterprediction.Kalmanfiltersassumethatboththeinput/outputmappingandthetransitionsinkinematicsovertimearelinear.Naïve Bayes: The Naïve Bayes decoder is a type of Bayesian decoder that determines theprobabilities of different outcomes, and it then predicts the most probable. Briefly, it fits anencodingmodeltoeachneuron,makesconditionalindependenceassumptionsaboutneurons,andthenusesBayes’ rule to create a decodingmodel from the encodingmodels. Thus, the effects ofindividual neurons are combined linearly. This probabilistic framework can incorporate priorinformation about the output variables, including theprobabilities of their transitions over time.WeusedaNaïveBayesdecodersimilartotheoneimplementedin(Zhangetal.,1998).Inthecomparisonsbelow,wealsodemonstrateanensemblemethod.WecombinedthepredictionsfromalldecodersexcepttheKalmanfilterandNaïveBayesdecoders(whichhavedifferentformats)usingafeedforwardneuralnetwork.Thatis,theeightmethods’predictionswereprovidedasinputintoafeedforwardneuralnetworkthatwetrainedtopredictthetrueoutput.DemonstrationdatasetsWefirstexaminedwhichofseveraldecodingmethodsperformedthebestacrossthreedatasetsfrommotorcortex,somatosensorycortex,andhippocampus.AlldatasetsarelinkedfromourGitHubrepository:https://github.com/KordingLab/Neural_Decoding.

.In the task for decoding frommotor cortex,monkeysmoved amanipulandum that controlled acursoronascreen(Glaseretal.,2018),andweaimedtodecodethexandyvelocityofthecursor.Detailsofthetaskcanbefoundin(Glaseretal.,2018).The21minuterecordingfrommotorcortexcontained164neurons.Themeanandmedianfiringrates,respectively,were6.7and3.4spikes/sec.Datawereputinto50msbins.Weused700msofneuralactivity(theconcurrentbinand13binsbefore)topredictthecurrentmovementvelocity.Thesametaskwasusedintherecordingfromsomatosensorycortex(Benjaminetal.,2018).Therecording fromS1was51minutesandcontained52neurons.Themeanandmedian firingrates,respectively, were 9.3 and 6.3 spikes / sec. Data were put into 50 ms bins. We used 650 mssurroundingthemovement(theconcurrentbin,6binsbefore,and6binsafter).In the task for decoding from hippocampus, rats chased rewards on a platform (Mizuseki et al.,2009b; Mizuseki et al., 2009a), and we aimed to decode the rat’s x and y position. From thisrecording,we used 46 neurons over a time period of 75minutes. These neurons hadmean andmedianfiringratesof1.7and0.2spikes/sec,respectively.Datawereput into200msbins. Weused2secondsofsurroundingneuralactivity(theconcurrentbin,4binsbefore,and5binsafter)topredictthecurrentposition.NotethatthebinsusedfordecodingdifferedinalltasksfortheKalmanfilterandNaïveBayesdecoders(seeExtendedDataFigure4-3foradditionaldetails).All datasets,which have been used in prior publications (Mizuseki et al., 2009b;Mizuseki et al.,2009a; Benjamin et al., 2018; Glaser et al., 2018), were collected with approval from theInstitutionalAnimalCareandUseCommitteesoftheappropriateinstitutions.DemonstrationanalysismethodsScoringMetric:To determine the goodness of fit, we used𝑅! = 1− !!!!! !!
!!!! !!, where𝑦! are the
predictedvalues,𝑦! arethetruevaluesand𝑦isthemeanvalue.ThisformulationofR2(Serruyaetal.,2003;Faggetal.,2009)(whichisthefractionofvarianceaccountedfor,ratherthanthesquaredPearson’scorrelationcoefficient)canbenegativeonthetestsetduetooverfittingonthetrainingset.ThereportedR2valuesaretheaverageacrossthexandycomponentsofvelocityorposition.Preprocessing:Thetrainingoutputwaszero-centered(meansubtracted),exceptinsupportvectorregression,wheretheoutputwasnormalized(z-scored),whichhelpedalgorithmperformance.Thetraining input was z-scored for all methods. The validation/testing inputs and outputs werepreprocessedusingthepreprocessingparametersfromthetrainingset.Cross-validation:When determining the R2 for every method (Fig. 3), we used 10-fold cross-validation.Foreachfold,wesplitthedataintoatrainingset(80%ofdata),acontiguousvalidationset(10%ofdata),andacontiguoustestingset(10%ofdata).Foreachfold,decodersweretrainedtominimize themean squared error between the predicted and true velocities/positions of thetrainingdata.WefoundthealgorithmhyperparametersthatledtothehighestR2onthevalidationsetusingBayesianoptimization(Snoeketal.,2012).Thatis,wefitmanymodelsonthetrainingsetwith different hyperparameters and calculated the R2 on the validation set. Then, using thehyperparametersthatledtothehighestvalidationsetR2,wecalculatedtheR2valueonthetestingset.ErrorbarsonthetestsetR2valueswerecomputedacrosscross-validationfolds.Becausethetraining sets on different folds were overlapping, computing the SEM as 𝜎/ 𝐽 (where 𝜎 is thestandarddeviationand J is thenumberof folds)wouldhaveunderestimatedthesizeof theerror

bars(NadeauandBengio,2000).WethuscalculatedtheSEMas𝜎 ∗ !!+ !
!!!(NadeauandBengio,
2000),whichtakesintoaccountthattheestimatesacrossfoldsarenotindependent.Bootstrapping:Whendetermininghowperformancescaledasafunctionofdatasize(Fig.5),weusedsingletestandvalidationsets,andvariedtheamountsoftrainingdatathatdirectlyprecededthevalidationset.Wedidnotdothison10cross-validation foldsdueto longrun-times.Thetestandvalidationsetswere5minuteslongformotorandsomatosensorycortices,and7.5minutesforhippocampus.Toget errorbars,we resampled from the test set.Becauseof thehigh correlationbetween temporally adjacent samples, we didn’t resample randomly from all examples (whichwould createhighly correlated resamples). Instead,we separated the test set into20 temporallydistinctsubsets,S1-S20(i.e.,S1isfromt=1tot=T/20,S2isfromt=T/20tot=2T/20,etc.,whereTisthe end time), to ensure that the subsetsweremore nearly independent of each other.We thenresampled combinations of these 20 subsets (e.g., S5, S13, … S2) 1000 times to get confidenceintervalsofR2values.ResultsWeinvestigatedhowthechoiceofmachinelearningtechniqueaffectsdecodingperformanceusinga number of common machine learning methods that are included in our code package. Theseranged from historical linear techniques (e.g., the Wiener filter) to modern machine learningtechniques (e.g., neural networks and ensembles of techniques). We tested the performance ofthesetechniquesacrossdatasetsfrommotorcortex,somatosensorycortex,andhippocampus.PerformancecomparisonIn order to get a qualitative impression of the performance, we first plotted the output of eachdecodingmethod foreachof the threedatasets (Fig.3). In theseexamples, themodernmethods,such as the LSTM and ensemble, appeared to outperform traditional methods. We nextquantitativelycompared themethods’performances,using themetricofR2onheld-out test sets.These results confirmed our qualitative findings (Fig. 4). In particular, neural networks and theensemble led to the best performance, while the Wiener or Kalman Filter led to the worstperformance. In fact, the LSTMdecoder explained over 40%of the unexplained variance from aWiener filter (R2’s of 0.88, 0.86, 0.62 vs. 0.78, 0.75, 0.35). Interestingly, while the Naïve Bayesdecoderperformedrelativelywellwhenpredictingpositioninthehippocampusdataset(meanR2just slightly less than the neural networks), it performed very poorly when predicting handvelocities in the other two datasets. Another interesting finding is that the feedforward neuralnetworkdidalmostaswellastheLSTMinallbrainareas.Acrosscases,theensemblemethodaddeda reliable, but small increase to the explained variance. Overall, modern ML methods led tosignificantincreasesinpredictivepower.

Figure 3: Example Decoder Results Example decoding results from motor cortex (left), somatosensory cortex (middle), and hippocampus (right), for all eleven methods (top to bottom). Ground truth traces are in black, while decoder results are in various colors.

Figure 4: Decoder Result Summary R2 values are reported for all decoders (different colors) for each brain area (top to bottom). Error bars represent the mean +/- SEM across cross-validation folds. X’s represent the R2 values of each cross-validation fold. The NB decoder had mean R2 values of 0.26 and 0.36 (below the minimum y-axis value) for the motor and somatosensory cortex datasets, respectively. Note the different y-axis limits for the hippocampus dataset in this and all subsequent figures. In Extended Data, we include the accuracy for multiple versions of the Kalman filter (Figure 4-1), accuracy for multiple bin sizes (Figure 4-2), and a table with further details of all these methods (Figure 4-3).

ConcernsaboutlimiteddatafordecodingWechosearepresentativesubsetofthetenmethodstopursuefurtherquestionsaboutparticularaspectsofneuraldataanalysis: thefeedforwardneuralnetworkandLSTM(twoeffectivemodernmethods),alongwiththeWienerandKalmanfilters(twotraditionalmethodsinwidespreaduse).The improved predictive performance of the modern methods is likely due to their greatercomplexity. However, this greater complexity may make these methods unsuitable for smalleramountsofdata.Thus,wetestedperformancewithvaryingamountsoftrainingdata.Withonly2minutesofdataformotorandsomatosensorycortices,and15minutesofhippocampusdata,bothmodernmethodsoutperformedbothtraditionalmethods(Fig.5a,ExtendedDataFig.5-1). Whendecreasing the amount of training data further, to only 1 minute for motor and somatosensorycortices and 7.5 minutes for hippocampus data, the Kalman filter performance was sometimescomparable to the modern methods, but the modern methods significantly outperformed theWiener Filter (Fig. 5a). Thus, even for limited recording times, modern ML methods can yieldsignificantgainsindecodingperformance.Besides limited recording times, neural data is often limited in thenumberof recordedneurons.Thus,wecomparedmethodsusingasubsetofonly10neurons.Formotorandsomatosensorydata,despite a general decrease in performance for all decoding methods, the modern methodssignificantly outperformed the traditional methods (Fig. 5b). For the hippocampus dataset, nomethodpredictedwell (meanR2<0.25)withonly10neurons.This is likelybecause10sparselyfiring neurons (median firing of HC neurons was ~0.2 spikes / sec) did not contain enoughinformationabouttheentirespaceofpositions.However,inmostscenarios,withlimitedneuronsandforlimitedrecordedtimes,modernMLmethodscanbeadvantageous.

Figure 5: Decoder results with limited data (A) Testing the effects of limited training data. Using varying amounts of training data, we trained two traditional methods (Wiener filter and Kalman filter), and two modern methods (feedforward neural network and LSTM). R2 values are reported for these decoders (different colors) for each brain area (top to bottom). Error bars are 68% confidence intervals (meant to approximate the SEM) produced via bootstrapping, as we used a single test set. Values with negative R2s were not shown. (B) Testing the effects of few neurons. Using only 10 neurons, we

trained two traditional methods (Wiener filter and Kalman filter), and two modern methods (feedforward neural network and LSTM). We used the same testing set as in panel A, and the largest training set from panel A. R2 values are reported for these decoders for each brain area. Error bars represent the mean +/- SEM of multiple repetitions with different subsets of 10 neurons. X’s represent the R2 values of each repetition. Note that the y-axis limits are different in panels A and B. In Extended Data, we provide examples of the decoder predictions for each of these methods (Figure 5-1).
Concernsaboutrun-timeWhile modern ML methods lead to improved performance, it is important to know that thesesophisticateddecodingmodelscanbetrainedinareasonableamountoftime.Togetafeelingforthetypicaltimescale,considerthatwhenrunningourdemonstrationdataonadesktopcomputerusing only CPUs, it took less than 1 second to fit a Wiener filter, less than 10 seconds to fit afeedforwardneural,andlessthan8minutestofitanLSTM.(Thiswasfor30minutesofdata,using10timebinsofneuralactivityforeachprediction,and50neurons.)Inpractice,thesemodelswillneed to be fit tens to hundreds of times when incorporating hyperparameter optimization andcross-validation.As a concrete example, let us say thatwe are doing5-fold cross-validation, andhyperparameteroptimization requires50 iterationsper cross-validation fold. In that case, fittingtheLSTMwouldtakeabout30hours,andfittingthefeedforwardneuralnetwouldtakelessthan1hour. Note that variations in hardware and software implementations can drastically changeruntime,andmodernGPUscanoften increasespeedsapproximately10-fold.Thus,whilemodernmethodsdo takesignificantly longer to train (andmayrequirerunningovernightwithoutGPUs),thatshouldbemanageableformostofflineapplications.ConcernsaboutrobustnesstohyperparametersAll our previous results used hyperparameter optimization. While we strongly encourage athorough hyperparameter optimization, a user with limited time might just do a limitedhyperparameter search. Thus, it is helpful to know how sensitive results may be to varyinghyperparameters.Wetestedtheperformanceofthefeedforwardneuralnetworkwhilevaryingtwohyperparameters: thenumberofunitsandthedropoutrate(aregularizationhyperparameterforneuralnetworks).Weheldthethirdhyperparameterinourcodepackage,thenumberoftrainingepochs,constantat10.Wefoundthattheperformanceoftheneuralnetworkwasgenerallyrobustto large changes in the hyperparameters (Fig. 6). As an example, for the somatosensory cortexdataset,thepeakperformanceoftheneuralnetworkwasR2=0.86with1000unitsand0dropout,andvirtuallythesame(R2=0.84)with300unitsand30%dropout.Evenwhenusinglimiteddata,neuralnetworkperformancewasrobust tohyperparameterchanges.For instance,whentrainingthe somatosensory cortex dataset with 1 minute of training data, the peak performance wasR2=0.77with700unitsand20%dropout.Anetworkwith300unitsand30%dropouthadR2=0.75.Notethatthehippocampusdataset,inparticularwhenusinglimitedtrainingdata,didhavegreatervariability, emphasizing the importance of hyperparameter optimization on sparse datasets.However, for most datasets, researchers should not be concerned that slightly non-optimalhyperparameterswillleadtolargelydegradedperformance.

Figure 6: Sensitivity of neural network results to hyperparameter selection In a feedforward neural network, we varied the number of hidden units per layer (in increments of 100) and the proportion of dropout (in increments of 0.1), and evaluated the decoder’s performance on all three datasets (top to bottom). The neural network had two hidden layers, each with the same number of hidden units. The number of training epochs was kept constant at 10. The colors show the R2 on the test set, and each panel’s colors were put in the range: [maximum R2 – 0.2 , maximum R2]. a) We used a large amount of training data (the maximum amount used in Fig. 5a), which was 10, 20, and 37.5 minutes of data for the motor cortex, somatosensory cortex, and hippocampus datasets, respectively. b) Same results for a limited amount of training data: 1, 1, and 15 minutes of data for the motor cortex, somatosensory cortex, and hippocampus datasets, respectively.

DiscussionHerewehaveprovidedatutorial,codepackage,anddemonstrationsoftheuseofmachinelearningforneuraldecoding.Ourcomparisons,whichweremadeusingthecodewehavepublishedonline,show that machine learning works well on typical neural decoding datasets, outperformingtraditional decoding methods. In our demonstration, we decoded continuous-valued variables.However,thesesamemethodscanbeusedforclassificationtasks,whichoftenuseclassicdecoderssuch as logistic regression and support vector machines. Our available code also includesclassificationmethods.We find it particularly interesting that theneural networkmethodsworked sowellwith limiteddata, counter to the common perception. We believe the explanation is simply the size of thenetworks. For instance, our networks have on the order of 105 parameters, while commonnetworks for image classification (e.g., (Krizhevsky et al., 2012)) can have on the order of 108parameters.Thus, thesmallersizeofournetworks(hundredsofhiddenunits)mayhaveallowedforexcellentpredictionwithlimiteddata(Zhangetal.,2016).Moreover,thefactthatthetasksweused had a low-dimensional structure, and therefore the neural data was also likely lowdimensional(Gaoetal.,2017),mightallowhighdecodingperformancewithlimiteddata.In order to find the best hyperparameters for the decoding algorithms, we used a Bayesianoptimizationroutine(Snoeketal.,2012) tosearchthehyperparameterspace(seeDemonstrationMethods).Still, it ispossiblethat, forsomeofthedecodingalgorithms,thehyperparameterswerenonoptimal,whichwouldhaveloweredoverallaccuracy.Moreover,forseveralmethods,wedidnotattempt to optimize all the hyperparameters. We did this in order to simplify the use of themethods, decrease computational runtime during hyperparameter optimization, and becauseoptimizing additional hyperparameters (beyond default values) did not appear to improveaccuracy.Forexample,fortheneuralnetsweuseddropoutbutnotL1orL2regularization,andforXGBoostweoptimized lessthanhalf theavailablehyperparametersdesignedtoavoidoverfitting.While our preliminary testing with additional hyperparameters did not appear to change theresultssignificantly,itispossiblethatsomemethodsdidnotachieveoptimalperformance.Wehavedecodedfromspikingdata,butitispossiblethattheproblemofdecodingfromotherdatamodalities is different. One main driver of a difference may be the distinct levels of noise. Forexample, fMRI signals have far higher noise levels than spikes. As the noise level goes up, lineartechniques become more appropriate, which may ultimately lead to a situation where thetraditional linear techniques become superior. Applying the same analyses we did here acrossdifferentdatamodalitiesisanimportantnextstep.Allourdecodingwasdone“offline,”meaning that thedecodingoccurredafter therecording,andwasnotpartofacontrolloop.Thistypeofdecodingisusefulfordetermininghowinformationinabrain area relates to an external variable. However, for engineering applications such as BMIs(Nicolas-Alonso and Gomez-Gil, 2012; Kao et al., 2014), the goal is to decode information (e.g.,predictmovements) in real time. Our results heremay not apply as directly to online decodingsituations,sincethesubjectisultimatelyabletoadapttoimperfectionsinthedecoder.Inthatcase,evenrelativelylargedecoderperformancedifferencesmaybeirrelevant.Plus,thereareadditionalchallenges inonlineapplications, suchasnon-stationary inputs (e.g.,due toelectrodesshifting inthebrain)(WuandHatsopoulos,2008;Sussilloetal.,2016;Farshchianetal.,2018).Finally,onlineapplications are concerned with computational runtime, which we have only briefly addressed

here. In the future, it would be valuable to test modern techniques for decoding in onlineapplications(asin(Sussilloetal.,2012;Sussilloetal.,2016)).Finally,wewanttobrieflymentiontheconceptoffeatureimportance,whichourtutorialhasnotaddressed.Featureimportancereferstothedeterminationofwhichinputsmostaffectamachinelearningmodel’spredictions.Fordecoding,featureimportancemethodscouldbeusedtoaskwhichneuronsareimportantformakingthepredictions,orifmultiplebrainareasareinputintothedecoder,whichofthesebrainregionsmatter.Threecommon,straightforwardapproachesthatwewouldrecommendare1)tobuildseparatedecoderswithindividualfeaturestotestthosefeatures’predictiveabilities;2)leave-one-feature-out,inwhichthedecoderisfitwhileleavingoutafeature,inordertoevaluatehowremovingthatfeaturedecreasespredictionperformance;and3)permutationfeatureimportance,inwhichafterfittingthedecoder,afeature’svaluesareshuffledtodeterminehowmuchpredictionperformancedecreases.(Molnar,2018;Dankersetal.,2020)providemoredetailsontheseapproaches,and(Molnar,2018)describesothercommonfeatureimportancemethodsinthemachinelearningliterature.ThesemethodscanfacilitatesomeunderstandingofneuralactivityevenwhentheMLdecoderisquitecomplex.ConclusionMachinelearningisrelativelystraightforwardtoapplyandcangreatlyimprovetheperformanceofneuraldecoding.Itsprincipleadvantageisthatmanyfewerassumptionsneedtobemadeaboutthestructureof theneural activity and thedecodedvariables.Bestpractices like testingonheld-outdata,perhapsviacrossvalidation,arecrucialtotheMLpipelineandarecriticalforanyapplication.ThePythonpackagethataccompaniesthistutorialisdesignedtoguidebothbestpracticesandthedeployment of specific ML algorithms, and we expect it will be useful in improving decodingperformance for new datasets. Our hunch is that it will be hard for specialized algorithms (e.g.(Corbettetal.,2010;Kaoetal.,2017))tocompetewiththestandardalgorithmsdevelopedbythemachinelearningcommunity.AcknowledgementsWewould like to thank Pavan Ramkumar for helpwith code development. For funding, JGwassupportedbyNIHF31EY025532andNIHT32HD057845,NSFNeuroNexAwardDBI-1707398,andtheGatsbyCharitableFoundation.ABwassupportedbyNIHMH103910.MPwassupportedbyNIHF31 NS092356 and NIH T32 HD07418. RC was supported by NIH R01 NS095251 and DGE-1324585.LMwassupportedbyNIHR01NS074044andNIHR01NS095251.KKwassupportedbyNIHR01NS074044,NIHR01NS063399andNIHR01EY021579.

References
AroraS,CohenN,HuW,LuoY(2019) Implicitregularization indeepmatrix factorization. In:Advances inNeuralInformationProcessingSystems,pp7411-7422.
BaegE,KimY,HuhK,Mook-JungI,KimH,JungM(2003)Dynamicsofpopulationcodeforworkingmemoryintheprefrontalcortex.Neuron40:177-188.
Barbieri R, Wilson MA, Frank LM, Brown EN (2005) An analysis of hippocampal spatio-temporalrepresentationsusingaBayesianalgorithmforneuralspiketraindecoding.IEEETransNeuralSystRehabilEng13:131-136.
Benjamin AS, Fernandes H, Tomlinson T, Ramkumar P, VerSteeg C, Chowdhury R, Miller LE, Kording K(2018) Modern machine learning as a benchmark for fitting neural responses. Front ComputNeurosci12:56.
BergstraJ,BengioY(2012)Randomsearchforhyper-parameteroptimization.JournalofMachineLearningResearch13:281-305.
Bergstra J, Yamins D, Cox DD (2013)Making a science ofmodel search: Hyperparameter optimization inhundredsofdimensionsforvisionarchitectures.
BishopCM(2006)Patternrecognitionandmachinelearning:springer.BreimanL(2017)Classificationandregressiontrees:Routledge.CarmenaJM,LebedevMA,CristRE,O'DohertyJE,SantucciDM,DimitrovDF,PatilPG,HenriquezCS,Nicolelis
MA (2003) Learning to control a brain–machine interface for reaching and grasping by primates.PLoSBiol1.
ChangC-C,LinC-J (2011)LIBSVM:a library forsupportvectormachines.ACMTransactionson IntelligentSystemsandTechnology(TIST)2:27.
ChenT(2014)Introductiontoboostedtrees.UniversityofWashingtonComputerScience22:115.Chen T, Guestrin C (2016) Xgboost: A scalable tree boosting system. In: Proceedings of the 22Nd ACM
SIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining,pp785-794:ACM.Cho K, Van Merriënboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, Bengio Y (2014) Learning
phrase representations using RNN encoder-decoder for statistical machine translation. arXivpreprintarXiv:14061078.
CholletF(2015)Keras.In.Collinger JL, Wodlinger B, Downey JE, Wang W, Tyler-Kabara EC, Weber DJ, McMorland AJ, Velliste M,
BoningerML,SchwartzAB(2013)High-performanceneuroprostheticcontrolbyanindividualwithtetraplegia.TheLancet381:557-564.
CorbettE,PerreaultE,KoerdingK(2010)Mixtureoftime-warpedtrajectorymodelsformovementdecoding.In:AdvancesinNeuralInformationProcessingSystems,pp433-441.
CranmerM,Sanchez-GonzalezA,BattagliaP,XuR,CranmerK,SpergelD,HoS(2020)DiscoveringSymbolicModelsfromDeepLearningwithInductiveBiases.arXivpreprintarXiv:200611287.
DankersC,KronsederV,WagnerM,CasalicchioG(2020)IntroductiontoFeatureImportance.In:LimitationsofMLInterpretability.
DavidsonTJ,KloostermanF,WilsonMA(2009)Hippocampalreplayofextendedexperience.Neuron63:497-507.
DeklevaBM,RamkumarP,WandaPA,KordingKP,MillerLE(2016)Uncertaintyleadstopersistenteffectsonreachrepresentationsindorsalpremotorcortex.eLife5:e14316.
Ethier C, Oby ER, Bauman MJ, Miller LE (2012) Restoration of grasp following paralysis through brain-controlledstimulationofmuscles.Nature485:368-371.
FaggAH,OjakangasGW,MillerLE,HatsopoulosNG(2009)Kinetictrajectorydecodingusingmotorcorticalensembles.IEEETransNeuralSystRehabilEng17:487-496.
FarshchianA,GallegoJA,CohenJP,BengioY,MillerLE,SollaSA(2018)AdversarialDomainAdaptationforStableBrain-MachineInterfaces.arXivpreprintarXiv:181000045.
Friedman J,HastieT,TibshiraniR (2001)The elements of statistical learning: Springer series in statisticsNewYork.
GaoP,TrautmannE,ByronMY,SanthanamG,RyuS,ShenoyK,GanguliS(2017)Atheoryofmultineuronaldimensionality,dynamicsandmeasurement.bioRxiv:214262.

GiljaV,NuyujukianP,ChestekCA,CunninghamJP,ByronMY,FanJM,ChurchlandMM,KaufmanMT,KaoJC,Ryu SI (2012) A high-performance neural prosthesis enabled by control algorithm design. NatNeurosci15:1752.
GlaserJI,BenjaminAS,FarhoodiR,KordingKP(2019)Therolesofsupervisedmachinelearninginsystemsneuroscience.ProgNeurobiol.
GlaserJI,PerichMG,RamkumarP,MillerLE,KordingKP(2018)Populationcodingofconditionalprobabilitydistributionsindorsalpremotorcortex.NatureCommunications9:1788.
GlorotX,BordesA,BengioY(2011)Deepsparserectifierneuralnetworks.In:ProceedingsoftheFourteenthInternationalConferenceonArtificialIntelligenceandStatistics,pp315-323.
GoodfellowI,BengioY,CourvilleA(2016)Deeplearning:MITpress.HastieT,TibshiraniR, Friedman J (2009)Theelementsof statistical learning:datamining, inference, and
prediction:SpringerScience&BusinessMedia.HeK,ZhangX,RenS, Sun J (2015)DelvingDeep intoRectifiers:SurpassingHuman-LevelPerformanceon
ImageNetClassification.In:2015IEEEInternationalConferenceonComputerVision(ICCV).Hernández A, Nácher V, Luna R, Zainos A, Lemus L, Alvarez M, Vázquez Y, Camarillo L, Romo R (2010)
Decodingaperceptualdecisionprocessacrosscortex.Neuron66:300-314.HochreiterS,SchmidhuberJ(1997)Longshort-termmemory.NeuralComput9:1735-1780.Hoerl AE, Kennard RW (1970) Ridge regression: Biased estimation for nonorthogonal problems.
Technometrics12:55-67.Hung CP, Kreiman G, Poggio T, DiCarlo JJ (2005) Fast readout of object identity from macaque inferior
temporalcortex.Science310:863-866.IbosG,FreedmanDJ(2017)Sequentialsensoryanddecisionprocessinginposteriorparietalcortex.eLife6.Kaggle(2020)Kaggle.In.KaoJC,NuyujukianP,RyuSI,ShenoyKV(2017)Ahigh-performanceneuralprosthesisincorporatingdiscrete
stateselectionwithhiddenMarkovmodels.IEEETransBiomedEng64:935-945.KaoJC,StaviskySD,SussilloD,NuyujukianP,ShenoyKV(2014)Informationsystemsopportunitiesinbrain–
machineinterfacedecoders.ProceedingsoftheIEEE102:666-682.KingmaD,BaJ(2014)Adam:Amethodforstochasticoptimization.arXivpreprintarXiv:14126980.KloostermanF, Layton SP, Chen Z,WilsonMA (2013)Bayesian decoding using unsorted spikes in the rat
hippocampus.JNeurophysiol111:217-227.Kriegeskorte N, Douglas PK (2019) Interpreting encoding and decoding models. Curr Opin Neurobiol
55:167-179.Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural
networks.In:Advancesinneuralinformationprocessingsystems,pp1097-1105.LeCunY,BengioY,HintonG(2015)Deeplearning.Nature521:436-444.LiawA,WienerM(2002)ClassificationandregressionbyrandomForest.Rnews2:18-22.MizusekiK,SirotaA,PastalkovaE,BuzsákiG(2009a)Multi-unitrecordingsfromtherathippocampusmade
duringopenfieldforaging.MizusekiK,SirotaA,PastalkovaE,BuzsákiG(2009b)Thetaoscillationsprovidetemporalwindowsforlocal
circuitcomputationintheentorhinal-hippocampalloop.Neuron64:267-280.Molnar C (2018) A guide for making black box models explainable. URL:
https://christophmgithubio/interpretable-ml-book.Nadeau C, Bengio Y (2000) Inference for the generalization error. In: Advances in neural information
processingsystems,pp307-313.NatekinA,KnollA(2013)Gradientboostingmachines,atutorial.FrontNeurorobot7:21.Naufel S, Glaser JI, Kording KP, Perreault EJ, Miller LE (2018) Amuscle-activity-dependent gain between
motorcortexandEMG.JNeurophysiol121:61-73.Nicolas-AlonsoLF,Gomez-GilJ(2012)Braincomputerinterfaces,areview.Sensors12:1211-1279.OlahC(2015)UnderstandingLSTMNetworks.In.OlahC,SatyanarayanA, JohnsonI,CarterS,SchubertL,YeK,MordvintsevA(2018)Thebuildingblocksof
interpretability.Distill3:e10.PaganM,SimoncelliEP,RustNC(2016)Neuralquadraticdiscriminantanalysis:NonlineardecodingwithV1-
likecomputation.NeuralComput28:2291-2319.

Park IM, Archer EW, Priebe N, Pillow JW (2013) Spectral methods for neural characterization usinggeneralizedquadraticmodels.In:Advancesinneuralinformationprocessingsystems,pp2454-2462.
PohlmeyerEA,SollaSA,PerreaultEJ,MillerLE(2007)Predictionofupperlimbmuscleactivityfrommotorcorticaldischargeduringreaching.Journalofneuralengineering4:369.
QuirogaRQ,SnyderLH,BatistaAP,CuiH,AndersenRA(2006)Movementintentionisbetterpredictedthanattentionintheposteriorparietalcortex.JNeurosci26:3615-3620.
Raposo D, Kaufman MT, Churchland AK (2014) A category-free neural population supports evolvingdemandsduringdecision-making.NatNeurosci17:1784-1792.
RibeiroMT,SinghS,GuestrinC(2016)"WhyshouldItrustyou?"Explainingthepredictionsofanyclassifier.In:Proceedingsofthe22ndACMSIGKDDinternationalconferenceonknowledgediscoveryanddatamining,pp1135-1144.
RichEL,WallisJD(2016)Decodingsubjectivedecisionsfromorbitofrontalcortex.NatNeurosci19:973-980.Rosenblatt F (1961) Principles of neurodynamics. perceptrons and the theory of brain mechanisms. In:
CornellAeronauticalLabIncBuffaloNY.RumelhartDE,HintonGE,WilliamsRJ(1986)Learningrepresentationsbyback-propagatingerrors.Nature
323:533-536.Serruya M, Hatsopoulos N, Fellows M, Paninski L, Donoghue J (2003) Robustness of neuroprosthetic
decodingalgorithms.BiolCybern88:219-228.SerruyaMD,HatsopoulosNG,PaninskiL,FellowsMR,DonoghueJP(2002)Brain-machineinterface:Instant
neuralcontrolofamovementsignal.Nature416:141-142.Silver D, Huang A, Maddison CJ, Guez A, Sifre L, van den Driessche G, Schrittwieser J, Antonoglou I,
PanneershelvamV,LanctotM,DielemanS,GreweD,NhamJ,KalchbrennerN,SutskeverI,LillicrapT,LeachM,KavukcuogluK,GraepelT,HassabisD(2016)MasteringthegameofGowithdeepneuralnetworksandtreesearch.Nature529:484-489.
SmolaAJ,SchölkopfB(2004)Atutorialonsupportvectorregression.Statisticsandcomputing14:199-222.SnoekJ,LarochelleH,AdamsRP(2012)Practicalbayesianoptimizationofmachinelearningalgorithms.In:
Advancesinneuralinformationprocessingsystems,pp2951-2959.SussilloD,StaviskySD,KaoJC,RyuSI,ShenoyKV(2016)Makingbrain–machineinterfacesrobusttofuture
neuralvariability.Naturecommunications7:13749.SussilloD,NuyujukianP,FanJM,KaoJC,StaviskySD,RyuS,ShenoyK(2012)Arecurrentneuralnetworkfor
closed-loopintracorticalbrain–machineinterfacedecoders.Journalofneuralengineering9:026027.TielemanT,HintonG (2012)Lecture6.5-RmsProp:Divide thegradientbya runningaverageof its recent
magnitude.COURSERA:NeuralNetworksforMachineLearning.van derMeerMA, JohnsonA, Schmitzer-Torbert NC, Redish AD (2010) Triple dissociation of information
processingindorsalstriatum,ventralstriatum,andhippocampusonalearnedspatialdecisiontask.Neuron67:25-32.
Weichwald S, Meyer T, Özdenizci O, Schölkopf B, Ball T, Grosse-WentrupM (2015) Causal interpretationrulesforencodinganddecodingmodelsinneuroimaging.Neuroimage110:48-59.
WeygandtM,BleckerCR,SchäferA,HackmackK,HaynesJ-D,VaitlD,StarkR,SchienleA(2012)fMRIpatternrecognitioninobsessive–compulsivedisorder.Neuroimage60:1186-1193.
Wolpert DH, Macready WG (1997) No free lunch theorems for optimization. IEEE transactions onevolutionarycomputation1:67-82.
WuW,HatsopoulosNG (2008)Real-time decoding of nonstationary neural activity inmotor cortex. IEEETransNeuralSystRehabilEng16:213-222.
WuW, BlackMJ, Gao Y, SerruyaM, Shaikhouni A, Donoghue J, Bienenstock E (2003) Neural decoding ofcursormotionusingaKalmanfilter.In:Advancesinneuralinformationprocessingsystems,pp133-140.
WuZ,Litwin-KumarA,ShamashP,TaylorA,AxelR,ShadlenMN(2020)Context-dependentdecisionmakinginapremotorcircuit.Neuron.
Zhang C, Bengio S, Hardt M, Recht B, Vinyals O (2016) Understanding deep learning requires rethinkinggeneralization.arXivpreprintarXiv:161103530.

Zhang K, Ginzburg I, McNaughton BL, Sejnowski TJ (1998) Interpreting neuronal population activity byreconstruction: unified framework with application to hippocampal place cells. J Neurophysiol79:1017-1044.

ExtendedData
Figure 4-1. Kalman Filter Versions R2 values are reported for different versions of the Kalman Filter for each brain area (top to bottom). On the left (in bluish gray), the Kalman Filter is implemented as in (Wu et al., 2003). On the right (in cyan), the Kalman Filter is implemented with an extra parameter that scales the noise matrix associated with the transition in kinematic states (see Demonstration Methods). This version with the extra parameter is the one used in the main text. Error bars represent the mean +/- SEM across cross-validation folds. X’s represent the R2 values of each cross-validation fold. Note the different y-axis limits for the hippocampus dataset.

Figure 4-2: Decoder results with different bin sizes As different decoding applications may require different temporal resolutions, we tested a subset of methods with varying bin sizes. We trained two traditional methods (Wiener filter and Kalman filter), and two modern methods (feedforward neural network and LSTM). We used the same testing set as in Fig. 5, and the largest training set from Fig. 5. R2 values are reported for these decoders (different colors) for each brain area (top to bottom). Error bars are 68% confidence intervals (meant to approximate the SEM) produced via bootstrapping, as we used a single test set. Modern machine learning methods remained advantageous regardless of the temporal resolution.

Note that for this figure, we used a slightly different amount of neural data than in other analyses, in order to have a quantity that was divisible by many bin sizes. In this case, for motor cortex, we used 600 ms of neural activity prior to and including the current bin. For somatosensory cortex, we used 600 ms of neural activity centered on the current bin. For hippocampus, we used 2 seconds of neural activity, centered on the current bin.
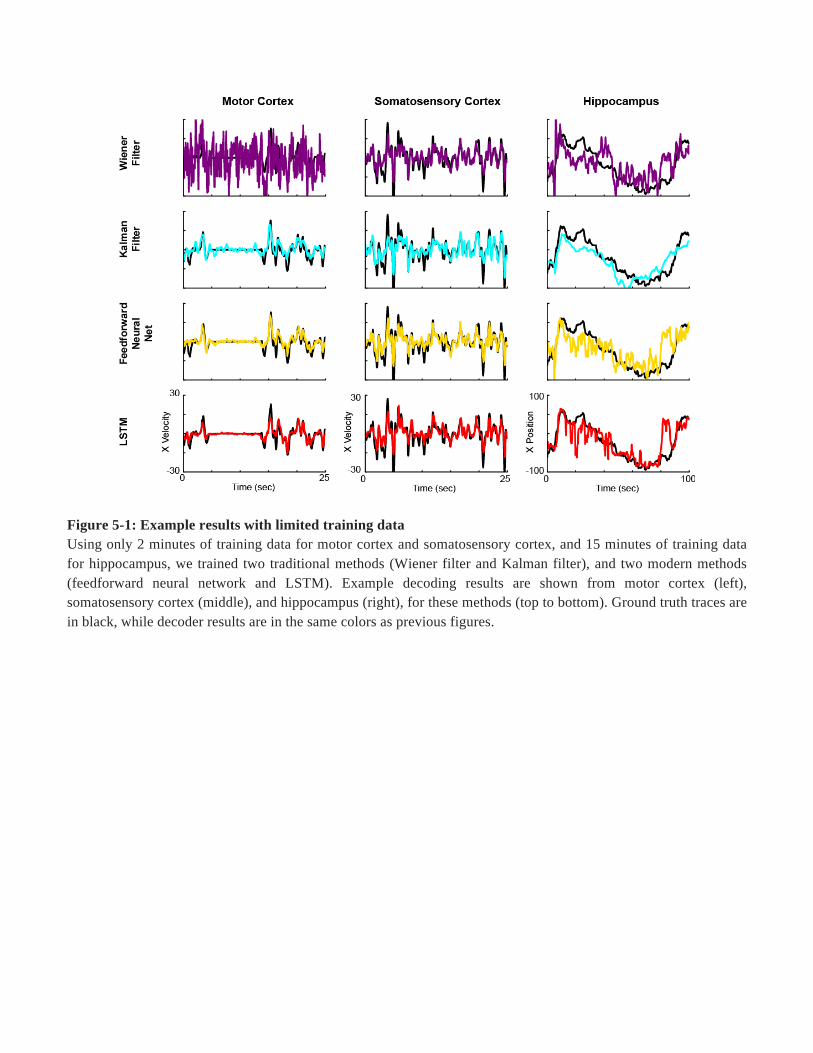
Figure 5-1: Example results with limited training data Using only 2 minutes of training data for motor cortex and somatosensory cortex, and 15 minutes of training data for hippocampus, we trained two traditional methods (Wiener filter and Kalman filter), and two modern methods (feedforward neural network and LSTM). Example decoding results are shown from motor cortex (left), somatosensory cortex (middle), and hippocampus (right), for these methods (top to bottom). Ground truth traces are in black, while decoder results are in the same colors as previous figures.

Method Equations,details,andhyperparametersGeneralinformation
For all themethods below,we describeour particular uses, which are available in ourcodepackageandareusedinthedecodingdemonstrationsweshowinResults.LetXbetheinputmatrixofcovariatesandletYbetheoutputthatisbeingpredicted.Yiseitheravectorormatrixdependingonwhethertheoutputs(e.g.xandycomponentsofvelocity)arepredictedsimultaneously.Also,notethatforourdemonstrations, forallmethodsbelow,thenoiseoftheoutputisassumedtobenormallydistributed.
WienerFilter Decoder predictions have the form 𝒀 = 𝜽𝑿, where 𝜽 is fit according to maximumlikelihoodestimation.Hyperparameters:None
WienerCascade Decoder predictions have the form 𝒀 = 𝛽! + 𝛽!𝒁! +⋯+ 𝛽!𝒁!, where 𝒁 = 𝜽𝑿. Theparameters𝜽andthe𝛽’sarefititerativelyaccordingtomaximumlikelihoodestimation.Hyperparameters:Degreeofthepolynomialusedforthenonlinearity,n.
SVR Tutorials havepreviouslybeenwrittenon thedetails of support vector regression andhow they are optimized (Smola and Schölkopf, 2004). Here, we provide a very shortmathematicalsummary.InnonlinearSVR:
𝒀 = (𝛼! − 𝛼!∗)𝑘(𝑿𝒊,𝑿)!
!!!
+ 𝑏
whereirepresentsthedatapoint.kisthekernelfunction,whichallowsforthenonlineartransformation.Weusedaradialbasisfunctionkernel:
𝑘 𝒙′, 𝒙 = exp −𝒙′ − 𝒙 𝟐
𝝈𝟐
Theparameters𝛼! and 𝛼!∗ are constrained to be in the range [0,𝐶] in the optimizationproblem,whereCisahyperparameterthatcanbeunderstoodasbeinginverselyrelatedtoregularizationstrength.Hyperparameters:Penaltyoftheerrorterm(C),maximumnumberofiterations
XGBoost Ingradient-boostedtreemethods(whichXGBoostisanimplementationof),amappingislearnedusinga collectionof regression trees. Trainingan individual regression tree isaccomplishedbysequentiallysplittingtheinputspace,andassigninganoutputvaluetoeachfinalpartitionoftheinputspace(see(Breiman,2017)forfurtherdescription).Let𝑓! be the input/output mapping of regression tree i. The final decoder, which combinesacrossNregressiontrees,willhavetheform:
𝒀 = 𝑓!(𝑿)!
!!!
TotraintheXGBoostdecoder,regressiontreesaretrainedsequentially.Thefirsttreeistrained tominimize the loss functionwhich here is 𝒀 − 𝑓!𝑿 𝟐
𝟐 + 𝛺(𝑓!), where𝛺 is aregularizationfunction.Thesecondtreeisthentrainedtopredicttheresidualofthefirsttree’s predictions. That is, we optimize 𝑓! to minimize 𝒀 − 𝑓!𝑿 − 𝑓!𝑿 𝟐
𝟐 + 𝛺(𝑓!).Successive trees continue to be optimized to predict the remaining residual. Seehttps://xgboost.readthedocs.io/en/latest/tutorials/model.html for a more in-depthtutorialdescription.

Hyperparameters:Maximumdepthofeachregressiontree,numberoftrees,learningrateFeedforwardNeuralNet
Wecreateda fullyconnected(dense) feedforwardneuralnetworkwith2hidden layersand rectified linear unit (“ReLU”) (Glorot et al., 2011) activations after each hiddenlayer.Werequiredthenumberofhiddenunitsineachlayertobethesame.Thiscanbewrittenas:
𝑯𝟏 = ReLU(𝑾𝟏𝑿 + 𝒃𝟏)𝑯𝟐 = ReLU(𝑾𝟐𝑿 + 𝒃𝟐)
𝒀 = 𝑾𝟑𝑯𝟐 + 𝒃𝟑We used the Adam algorithm (Kingma andBa, 2014) as the optimization routine tosolve for all𝑾’s and 𝒃’s. We used the Keras library (Chollet, 2015) for all neuralnetworkimplementations.Thisneuralnetwork,andallneuralnetworksbelowhadtwooutputunits.Thatis,thesamenetworkpredictedthexandycomponents(ofpositionorvelocity)together,ratherthanseparately.Hyperparameters:Number of units (dimensionality of𝑯𝟏 and𝑯𝟐), amount of dropoutduringtraining,numberoftrainingepochs
SimpleRNN Decoderpredictionshavetheform:
𝑯𝒕 = ReLU(𝑼𝑿𝒕 +𝑾𝑯𝒕!𝟏 + 𝒃)𝒀𝒕 = 𝑽𝑯𝒕 + 𝒄
NotethatweusedtheReLUnonlinearityasopposedtothe“tanh”nonlinearity,whichismore common in RNNs, as this improved performance.We used RMSprop (TielemanandHinton,2012)astheoptimizationroutine.Hyperparameters: Number of units (dimensionality of 𝑯), amount of dropout duringtraining,numberoftrainingepochs
GRUs Here,wemix notation from (Goodfellow et al., 2016) and (Olah, 2015),which provideexcellent descriptions of the method. The GRU has two gates, which control thetransmission of information through the network. The “update” and “reset” gates areparameterizedasfollows:Updategate:𝒛𝒕 = σ(𝑼𝒛𝑿𝒕 +𝑾𝒛𝑯𝒕!𝟏 + 𝒃𝒛)Resetgate:𝒓𝒕 = σ(𝑼𝒓𝑿𝒕 +𝑾𝒓𝑯𝒕!𝟏 + 𝒃𝒓)Atemporaryhiddenstateiscalculatedas:
𝒉𝒕 = tanh(𝑼𝒉𝑿𝒕 + 𝒓𝒕 ∗𝑾𝒉𝑯𝒕!𝟏 + 𝒃𝒄)In this calculation, the reset gate controls what information from the previous hiddenstate is in this proposed new hidden state. Note that the ∗ symbol denotes anelementwise (byneural networkunit)multiplication. To calculate thehidden state,weuse the update gate to controlwhat information flows from the previous hidden stateversuswhatisupdatedfromthetemporarystate:
𝒉𝒕 = (𝟏 − 𝒛𝒕) ∗ 𝒉𝒕!𝟏 + 𝒛𝒕 ∗ 𝒉𝒕Finally,asinthestandardRNN:
𝒀𝒕 = 𝑽𝑯𝒕 + 𝒄WeusedRMSprop(TielemanandHinton,2012)astheoptimizationroutine.

Hyperparameters: Number of units (dimensionality of 𝑯), amount of dropout duringtraining,numberoftrainingepochs.
LSTM Asabove,wemixnotationfrom(Goodfellowetal.,2016)and(Olah,2015),whichprovideexcellent descriptions of the method. The LSTM has three gates, which control thetransmission of information through the network. The “forget”, “input”, and “output”gatesareparameterizedasfollows:
𝒇𝒕 = σ(𝑼𝒇𝑿𝒕 +𝑾𝒇𝑯𝒕!𝟏 + 𝒃𝒇)𝒊𝒕 = σ(𝑼𝒊𝑿𝒕 +𝑾𝒊𝑯𝒕!𝟏 + 𝒃𝒊)𝒐𝒕 = σ(𝑼𝒐𝑿𝒕 +𝑾𝒐𝑯𝒕!𝟏 + 𝒃𝒐)
TheLSTMhasacellstate,𝑪𝒕,thatcarriesinformationacrosstime.Wecancalculate𝑪𝒕,as:
𝑪𝒕 = tanh(𝑼𝒄𝑿𝒕 +𝑾𝒄𝑯𝒕!𝟏 + 𝒃𝒄)𝑪𝒕 = 𝒇𝒕 ∗ 𝑪𝒕!𝟏 + 𝒊𝒕 ∗ 𝑪𝒕
where𝑪𝒕 isa temporarycellstate, thatbecomespartof thecellstatedependingontheinput gate, 𝒊𝒕. Additionally, the previous time point’s cell state is carried throughdepending on the forget gate, 𝒇𝒕. Note that the ∗ symbol denotes an elementwise (byneuralnetworkunit)multiplication.Thehiddenstateofthenetworkisanoutput-gatedversionofthecellstate:
𝑯𝒕 = 𝒐𝒕 ∗ tanh (𝑪𝒕)Finally,asinthestandardRNN:
𝒀𝒕 = 𝑽𝑯𝒕 + 𝒄WeusedRMSprop(TielemanandHinton,2012)astheoptimizationroutine.Hyperparameters: Number of units (dimensionality of 𝑯), amount of dropout duringtraining,numberoftrainingepochs
KalmanFilter InthestandardKalmanFilter,
𝒚! = 𝑨𝒚!!! + 𝒘where 𝒚!and𝒚!!!are6x1vectorsreflectingkinematicvariables(notjustthevelocityorpositionbeingpredicting),andwissampledfromanormaldistribution,N(0,W),withmean0andcovarianceW.
𝒙!∗ = 𝑯𝒚! + 𝒒where 𝒙!∗istheneuralactivityattime𝑡∗,andqissampledfromanormaldistribution,N(0,Q). Note thatwe allowed a lag between the neural data and predicted kinematics,whichiswhyweuset*forthetimeoftheneuralactivity.During training,A,H,W, andQ are empirically fit on the training set usingmaximumlikelihoodestimation.Whenmakingpredictions,toupdatetheestimatedhiddenstateatagiventimepoint,theupdatesderivedfromthecurrentmeasurementandtheprevioushidden states are combined. During this combination, the noisematrices give a higherweighttothelessuncertaininformation.See(Wuetal.,2003)orourcodefortheupdateequations(notethatxandyhavedifferentnotationin(Wuetal.,2003)).Wehadonehyperparameterwhichdifferedfromthestandardimplementation(Wuetal.,

2003).Wedividedthenoisematrixassociatedwiththetransitioninkinematicstates,W,by the hyperparameter scalar C, which allowed weighting the neural evidence andkinematic transitions differently. The rationale for this addition is that neurons havetemporalcorrelations,whichmakeitdesirabletohaveaparameterthatallowschangingtheweight of the newneural evidence. The introduction of this parametermade a bigdifferenceforthehippocampusdataset(ExtendedDataFig.4-1).Hyperparameters:Candthelagbetweentheneuraldataandpredictedkinematics.
NaïveBayes WeusedaNaïveBayesdecodersimilar to theone implemented in(Zhangetal.,1998).Wefirstfitanencodingmodel(tuningcurve)usingtheoutputvariables.Letfi(s)bethevalue of the tuning curve (the expected number of spikes) for neuron i at the outputvariabless.Notethatsisavectorcontainingthetwooutputvariableswearepredicting(x andypositions/velocities). We assume thenumberof recorded spikes in the givenbin,ri,isgeneratedfromthetuningcurvewithPoissonstatistics:
𝑃 𝑟! 𝒔 =exp [−𝑓!(𝒔)]𝑓!(𝒔)!!
𝑟!!
We also assume that all theneurons’ spike counts are conditionally independent giventheoutputvariables,sothat:
𝑃 𝒓 𝑠 ∝ 𝑃 𝑟! 𝑠!
wherer isavectorwiththespikecountsofallneurons.Bayes’rulecanthenbeusedtodeterminethelikelihoodoftheoutputvariablesgiventhespikecountsofallneurons:
𝑃 𝒔 𝒓 ∝ 𝑃 𝒓 𝒔 𝑃(𝒔)whereP(s)istheprobabilitydistributionoftheoutputvariables.Tohelpwithtemporalcontinuity of decoding, we want our probabilistic model to include how the outputvariables at one time step depend on the output variables at the previous time step:𝑃 𝒔! 𝒔!!! .Thus,wecanmoregenerallywrite,usingBayes’ruleasbefore:
𝑃 𝒔! 𝒓!∗, 𝒔!!! ∝ 𝑃 𝒓!∗ 𝒔! 𝑃 𝒔!!! 𝒔! 𝑃 𝒔! Notethatweuse𝒓!∗ratherthan𝒓!becauseweuseneuralresponsesfrommultipletimebinstopredictthecurrentoutputvariables.Theaboveformulaassumesthat𝒓!∗and𝒔!!!are independent, conditioned on 𝒔! . The final decoded stimulus in a time bin is:argmax𝒔! 𝑃 𝒔! 𝒓!∗, 𝒔!!! .𝑃 𝒔!!! 𝒔! was determined as follows. LetΔ𝒔be the Euclidean distance in s from onetime step to the next. We fit 𝑃(Δ𝒔) as a Gaussian using data from the training set.𝑃 𝒔!!! 𝒔! wasapproximatedas𝑃(Δ𝒔!).Thatis,theprobabilityofgoingfromoneoutputstatetoanotherwasonlybasedonthedistancebetweentheoutputstates,nottheoutputstateitself.Additionally,including𝑃 𝒔 basedonthedistributionofoutputvariablesinthetrainingset did not improve performance on the validation set. This could be because theprobability distribution differed between the training and validation/testing sets, orbecause the distribution of output variables was approximately uniform in our tasks.Thus,wesimplyusedauniformprior.

In our calculations, we discretize s into a 100 x 100 grid going from theminimum tomaximumoftheoutputvariables.Whenincreasingthedecodingresolutionoftheoutputvariables,wedidnotseeameaningfulchangeindecodingaccuracy.OurtuningcurveshadtheformatofaPoissongeneralizedquadraticmodel(Parketal.,2013), which improved the performance over generalized linearmodels on validationdatasets.On the hippocampus dataset, we used the total number of spikes over the same timeintervalasweusedfortheotherdecoders(4binsbefore,theconcurrentbin,and5binsafter).Note thatusinga single timebinof spikes led toverypoorperformance.On themotorcortexandsomatosensorycortexdatasets,thenaïveBayesdecodergaveverypoorperformance regardless of the bins used. We ultimately used bins that gave the bestperformance on a validation set: 2 bins before and the concurrent bin for the motorcortexdataset; 1 binbefore, the concurrentbin, and1bin after for the somatosensorycortexdataset.Hyperparameters:None
Figure4-3:Additionaldecoderdetails,includingequationsandhyperparametersThesedetailsareforthedecoderimplementationsthatweuseinourdemonstrationsandhaveinourcodepackage.