
Robust Smartphone App Identification Via Encrypted Network ...
Upload
independentCategory
view
0download
0
P. Perner (Ed.): MLDM 2012, LNAI 7376, pp. 578–592, 2012. © Springer-Verlag Berlin Heidelberg 2012
Machine Learning-Based Classification of Encrypted Internet Traffic
Talieh Seyed Tabatabaei, Mostafa Adel, Fakhri Karray, and Mohamed Kamel
Centre for Pattern Analysis and Machine Intelligence (CPAMI) University of Waterloo, Waterloo, Ontario, Canada
{tseyedta,m22hassa,fakhri,mkamel}@uwaterloo.ca
Abstract. Peer-to-peer (P2P) networking has introduced a major shift in the application and traffic mix of the Internet and established itself as the main driver of increasing traffic volume. The high requirements of some P2P applica-tions result in network operational issues: these applications consume vast amounts of network resources and can prevent mission critical applications from accessing the network. Therefore the ability to correctly identify them can be crucial for many network management and measurement tasks. In this paper some flow-based statistical features of Internet traffic are investigated in order to detect P2P traffic. We propose a system to identify the BT traffic, which is one of the most popular and problematic P2P applications using support vector machines. The accuracy of 94.5% was achieved for recognizing encrypted traf-fic which is a very promising result.
Keywords: Internet traffic classification, support vector machines, feature se-lection, mutual information.
1 Introduction
The concept of identifying protocols and applications through analysis of network traf-fic is known as “traffic classification”. Techniques for traffic classification are used in many different applications, such as Quality of Service (QoS) assignments, traffic shap-ing, Intrusion Detection Systems (IDS) [2] and in network forensics solutions.
In recent years, Peer-to-Peer (P2P) file-exchange applications have overtaken Web applications as the major contributor of traffic on the Internet [1]. Recent estimates put the volume of P2P traffic at 70% of the total broadband traffic. P2P is often used for illegally sharing copyrighted music, video, games, and software. The legal rami-fication of this traffic combined with its aggressive use of network resources has ne-cessitated a strong need for identification of network traffic by application type.
The P2P paradigm has proven to be much more efficient than client-server com-munication especially for fast distribution of large amounts of data, since bottlenecks at servers are avoided by distributing requested data and the available access capacity over a global community of recipients.
The high requirements of some P2P applications result in network operational issues: these applications consume vast amounts of network resources and can prevent mission

Machine Learning-Based Classification of Encrypted Internet Traffic 579
critical applications from accessing the network. On the other hand, P2P applications can cause security and legal troubles for network administrators. Therefor having the ability to correctly identify them can be essential for several network management and measurement tasks, including traffic engineering, service differentiation, perfor-mance/failure monitoring, and security. P2P not only results in increased network com-plexity due to the enormous volume of traffic, but also requires huge extra costs such as the cost of upgrading the infrastructure and network repartitioning [3][4].
In this work we are trying to identify encrypted BitTorrent traffic by using some flow-based statistical features. Support vector machines (SVMs) are used to classify BitTorrent traffic from the aggregate Internet traffic.
The rest of this paper is organized as follows: Section 2 is about related works. Section 3 is a brief review of P2P and BitTorrent architecture. Section 4 demonstrates the structure of the P2P traffic identification system proposed in this work and the corresponding steps. In Section 5 the theory of SVM is concisely discussed. In Sec-tion 6 the experimental results are presented and Section 7 is the conclusion.
2 Related Work
There are two conventional approaches for Internet traffic classification: 1) port-based method and 2) deep packet inspection (DPI). The first method classifies the applica-tion type using the official Internet Assigned Numbers Authority (IANA) list. Initially it was considered to be simple and easy to implement port-based in real time. Howev-er, mapping traffic to applications based on port numbers is now ineffective since many P2P applications now use dynamically assigned ports and other known port numbers (e.g. http and ftp) for their sub transactions to disguise their traffic [5][6].
In the DPI approach packet payloads are examined to search for exact signatures of known applications [6][7]. In this method the protocol specific string in the payload can be used for identification, so the P2P traffic can be identified through analyzing the characteristic bit strings in packet payload [7][8]. Sen et. al [8] suggest an efficient method for detecting the P2P application traffic through application level signatures. They identify the application-level signatures by examining some available documen-tations and packet-level traces, and then use the identified signatures to develop on-line filters that can efficiently and accurately track the P2P traffic even on high-speed network links. M. Roughan et. al [9] provide a solution framework for measurement-based identification of traffic for QoS based on statistical application signatures.
DPI technique is broadly used in commercial tools such as Ipoque, CISCO NBAR, Sandvine, and SonicWall. However, there are a couple of limitations associated with this method: this technique only identifies traffic for which signatures are available and therefor is not adaptive to the new emerging protocols. Second, it can cause pri-vacy concerns. And finally this technique will fail if payload is encrypted. The last problem is the most important reason that makes DPI techniques impractical for de-tecting P2P traffic since most of the popular P2P protocols, such as BitTorrent (BT) are using payload encryption to avoid detection.
Considering the limitations and drawbacks of the aforementioned approaches, ma-chine learning (ML) techniques have become a popular alternative in classifying

580 T.S. Tabatabaei et al.
flows based on application protocol payload-independent statistical features such as packet length and inter-arrival times, flow lengths, etc.
Each traffic flow is characterized by the same set of payload-independent statistical features. A ML classifier is built by training on a representative set of flow instances where the network applications are known. The trained classifier can be applied to determine the class of unknown flows. Statistical analysis based approach treats the problem of application classification as a statistical problem.
ML-based approach is independent of packet payload inspection so it is robust to encryption. Also it is scalable and adaptive when new protocols join. Different classes of traffic based on different applications, different features, and various supervised and unsupervised, deterministic and probabilistic ML methods have been utilized during the recent years in order to classify network traffic flows [5][10][11]. Each flow is described by a set of statistical features and associated feature values and ac-cordingly classify by a machine learned classifier. The idea of using ML techniques for flow classification was first introduced in the context of intrusion detection [13]. Moore et al. [12] used a Naive Bayes classifier which was a supervised machine learning approach to classifying internet traffic. Williams et al. [10] compared five machine learning algorithms, among these algorithms, C4.5 achieved the highest ac-curacy in their results. McGregor et al. [14] used Expectation Maximization (EM) algorithm to cluster flows, but the reported results are not very promising. Zander et al. [15] extended this work by using an EM algorithm called Auto Class, and found the optimal feature subset for classifying traffic.
In this work our focus is on identification of BitTorrent (BT) traffic only as cur-rently it is the most popular p2p file-sharing protocol in North America and pretty much all around the world. Based on the latest Internet traffic report by Sandvine, BitTorrent, and P2P traffic in general, is still dominant in all geographical regions. In North America, Latin America and Asia-Pacific, P2P traffic is responsible for the vast majority of all upstream traffic. BitTorrent remains the most used file-sharing proto-col in North America, and the total amount of P2P traffic is still very significant. Sandvine’s research reveals that on an average day, 53.3% of all upstream traffic can be attributed to P2P applications. The bandwidth usage patterns during peak hours are slightly different, but still a massive 34.31% of all upstream traffic can be attributed to BT at these times.
According to Sandvine’s traffic analysis, the normalized aggregate of all traffic (up/down) during peak hours puts P2P traffic at 19.2% during the first months of 2010. Interestingly, this is up from 15.1% in 2009, which shows that P2P traffic is growing strongly, not only in absolute numbers but also as a share of total Internet traffic in North America.
Different flow-based statistical features are going to be investigated in order to find the most effective and discriminative variables for identifying BT traffic. SVMs which is a powerful supervised classifier is going to be used for classifying the traffic.
3 BitTorrent Architecture Overview
The P2P data dissemination model has become widely popular for a variety of appli-cations including streaming multimedia, voice-over-IP (VoIP) and file sharing. This is

Machine Learning-Based Classification of Encrypted Internet Traffic 581
largely a consequence of the many benefits that P2P architectures offer in comparison to the traditional client/server communication model. The P2P data broadcasting model has become extensively popular for a variety of applications including stream-ing multimedia, voice-over-IP (VoIP) and file sharing. This is mainly a result of the many advantages that P2P architectures offer in comparison to the traditional client/server communication model.
BT is the most popular P2P protocol for file sharing applications. Sharing a file with BT is very simple and proceeds as follows:
1. The file is broken into several fixed-sized pieces. A cryptographic hash is com-puted for each piece to ensure integrity as pieces are shared. This aims to prevent data corruption by malicious peers who distribute invalid pieces. Pieces are further sub-divided into fixed-sized blocks which are typically 16KB in size.
2. To advertise a file’s availability for download with BT, a metadata file is created and published on the web. This metadata file contains a unique identifier called an info hash that is derived from the semantic description of the file, the cryptographic hashes of each piece, a link to a tracker server that helps to organize the peers, the number of pieces, and the piece size. Optionally, other information may be in-cluded.
3. Once the metadata file has been obtained, a new peer wishing to start sharing the file queries the tracker server to obtain a list of other peers who are currently shar-ing the file. Since the peer list may be arbitrarily large, the tracker typically replies with a fixed number of randomly selected peers. This also helps to balance the traf-fic load over the participating peers.
4. The peer requests specific parts of the file, in a non-sequential manner, addressed by piece number and offset.
The tracker functionality may be implemented as a centralized server, a distributed hash table, or a gossip-based peer discovery mechanism and uses a standard HTTP interface. By querying the tracker, a peer implicitly registers itself with the tracker’s peer list and may subsequently receive requests from other peers for particular parts of the file that the peer has obtained. In BitTorrent’s vernacular, peers who possess a full copy of the file being shared are called seeders and peer who are still download-ing are called leechers. The general protocol behavior is shown in Fig 1.
Once a peer has completed a download, they may continue to participate in the protocol to help other peers download, or they may leave. BitTorrent does attempt to mitigate selfish peer behavior by incorporating a “tit-for-tat” mechanism into the piece request process. In essence, it attempts to promote fairness and reciprocity in the piece sharing.
BT has achieved excessive popularity for its ability to efficiently share files. How-ever, it creates several important issues for network operators and copyright enforce-ment agencies:
Peers sharing files use a substantial amount of bandwidth in both down and up-load directions due to the aggressive behavior of BT. On the other hand, broadband Internet service providers (ISPs) have an obligation to their customers for providing a reasonable QoS, even during the peak hours. Excessive BT usage on these networks

582 T.S. Tabatabaei et al.
complicates effective network management. Consequently, ISPs from around the world have adopted various policies for throttling or explicitly blocking BT traffic.
The second issue with BT is the copyright enforcement concerns. Experience has shown that BT’s decentralized nature has made it an attractive tool for users wishing to share copyright protected media content such as popular music, movies, and televi-sion programs. In the client/server model, copyright holders or law enforcement agen-cies may easily identify infringing content and request the hosting server to remove the content, or face a penalty defined by the local legal system. However, with a de-centralized P2P protocol like BT, it is challenging for copyright holders or law en-forcement agencies to contact each individual peer, since there could be millions of peers distributed. Definitively identifying peers who participate in illegal file sharing is a significant challenge.
Fig. 1. File transfer with BT
4 Proposed P2P Identification System
Figure 2 shows the basic structure of the proposed P2P identification system. Details about each step are explained in the following sections.
4.1 Database
The database used in this research is captured from a local computer using WireShark tool. Wireshark is a free and open-source packet analyzer. It is used for network trouble-shooting, analysis, software and communications protocol development, and education.
A total of 5 hours of traffic was collected while running a couple of BitTorrent and µTorrent clients for downloading video and music files. All other applications were closed during P2P application running. Another 2 hours of traffic was collected while running other non-P2P applications including file downloading, live streaming, web

Machine Lea
browsing, email, and SkypTorrent P2P traces and non-
4.2 Pre-filtering
In the pre-filtering stage, thconfidently say are not usesetting proper filters in Wirimproving the performanceand accuracy. List of filterethe field. Here is the list of
─ Address resolution proto─ Internet group managem─ Internet control massage─ NetBIOS name service (─ Common Unix printing s─ Dynamic host configurat─ Dropbox LAN sync prot─ Broadcast packets (i.e. p
4.3 Flow Conversion an
Network monitoring solutiofined as a series of packet (i.e. source address, sourcprotocol). For applications connection tear-down or bterminated by a flow timeou
Fig. 2. The pro
arning-Based Classification of Encrypted Internet Traffic
pe. So the database is divided into two separate files: B-P2P traces.
hose packets corresponding to some protocols that we ed by P2P applications are removed from the datasetreShark tool. By eliminating these packets we are aimine of the system both in terms of computational complexed protocols were decided after consulting with expertprotocols which were removed at this stage:
ocol (ARP) ment protocol (IGMP) e protocol (ICMP) NBNS) protocol system (cups) tion protocol (DHCP) tocol ackets with destination address 255.255.255.255)
nd Features Computation
ons operate on the notion of network flows. A flow is exchanges between two hosts, identifiable by the 5-tu
ce port, destination address, destination port, transprunning over TCP flow termination happens upon proy a flow timeout, whichever occurs first. UDP flows ut. A 600 second flow timeout is considered in this work
oposed ML-based P2P traffic identification system
583
Bit-
can t by g at xity s in
de-uple port oper
are k.

584 T.S. Tabatabaei et al.
Each flow is represented by a set of statistical features and associated feature val-ues. A feature is a descriptive statistic that can be calculated from one or more pack-ets. Thus, a flow can be thought of as a dimensional vector, where is the total number of calculated features and where each feature value in the vector represents a different statistic about the packets collected by that flow. NetMate (Network Mea-surement and Accounting System) was used to generate flows, and to compute feature values. NetMate is a flexible and extensible network measurement tool that can be used for accounting, delay/loss measurement, packet capturing and much more. The main advantage over other existing tools is that it can be easily extended due to its modular (class-based) structure and dynamic loadable packet processing and informa-tion export modules.
Table I shows the 30 features calculated by NetMate. Flows are bidirectional with the first packet determining the forward direction. Our system is completely independent of the payload data and features like IP addresses and source/destination port numbers to avoid problems concerned with this type of information described in section 2.
4.4 Feature Selection and Classification
The task of selecting the most relevant features in a classification task can be viewed as one of the fundamental problems in the field of machine learning. The perfor-mance, robustness, and usefulness of a classification algorithm are improved when relatively few features are involved in the classification. By selecting the most rele-vant subset from the original feature set, we can increase the performance of the clas-sifier and at the same time decrease the computation cost.
In essence, the reduction of the original feature set to a smaller one preserving the relevant information while discarding the redundant ones is referred to as feature selection (FS). The aim is to achieve the minimum classification error rate. Many methods have been proposed in the literature for feature selection. In this work for FS we are using minimum redundancy-maximum relevance criteria which is based on maximum statistical dependency. This method is briefly explained in the following section.
Feature Selection Using Maximum Statistical Dependency Criterion
In feature selection using maximum statistical dependency criteria, minimal error is achieved by maximizing the statistical dependency of the target class c on the data distribution in the subspace (and vice versa). This scheme is called maximal depen-dency (Max Dependency) [16].
The success of a feature selection algorithm depends critically on how much in-formation about the output class is contained in the selected features. Using Fano’s
inequality, the minimal probability of incorrect estimation eP of class c using in-
puts x
is lower bounded by
( | ) 1 ( ) ( ; ) 1
log loge
H c x H c I x cP
N N
− − −≥ =
(1)

Machine Learning-Based Classification of Encrypted Internet Traffic 585
Where H and I are entropy and mutual information respectively. Because the entropy of class, ( )H c , and the number of classes N is fixed, the lower bound of
eP is minimized when ( ; )I x c becomes the maximum. Thus, it is necessary for
good feature selection methods to maximize the mutual information ( ; )I x c .
In other words, the purpose of feature selection is to find a feature set S with m
features { }ix , which jointly have the largest dependency on the target class c :
max ( , ), ({ , 1,..., }; )iD S c D I x i m c= = (2)
But since finding the joint probability in equation (2) is not easy, an alternative crite-rion could be maximal relevance which is defined as:
1max ( , ), ( ; )
| |i
ix S
D S c D I x cS ∈
= (3)
which approximates equation 2 with mean value of all mutual information values
between individual feature ix and class c .
However, there might still exit redundant features in the selected feature subset. When two features are redundant, they highly depend on each other and as a result the respective class-discriminative power would not change if one of them were removed [17]. The minimum redundancy is defined as:
2
,
1min ( ), ( ; )
| |i j
i jx x S
R s R I x xS ∈
= (4)
The two criteria defined in equation 3 and equation 4 can be combined as a maxi-mum-relevant minimum-redundancy (MRMR) criterion. The combined criterion is defined as:
max ( , ),D R D Rφ φ = − (5)
Classification
Machine learning methodology is an artificial intelligence approach to establish and train a model to recognize the pattern or underlying mapping of a system based on a set of training examples consisting of input and output patterns. There are two phases in ML algorithms: learning or training the system with known data and testing where the system performance is tested with new data.
In this work Least Squares SVMs (LS-SVMs) is used as a classifier. A brief over-view of SVMs is presented in the next section.

586 T.S. Tabatabaei et al.
5 Support Vector Machines
SVM was introduced first by Vapnik and co-workers [19], and it is such a powerful classification method that in the few years since its introduction has outperformed most other classifiers in a wide variety of applications. SVM is used in applications of regression and classification; however, it is mostly used as a binary classifier. SVM is based on the principle of structural risk minimization. The optimal boundary is found in such a way that maximizes the margin between two classes of data points.
SVM is based on kernel functions, which are used to map data points to a higher dimensional feature space in order to be linearly separable. The optimization problem here is the dual optimization problem which is solved by Lagrangian method and making use of very important Karush-Kuhn-Tucker (KKT) conditions. Equation 6 shows the dual optimization problem for SVM classifiers:
= =
−=n
i
n
jijijijii xxKyyW
1 1,
).(2
1)(
αααα (6)
subject to constraints
1
0 0, 1,...,n
i i ii
y i nα α=
= ≥ =
where 0≥iα are the Lagrange multipliers and ).( ji xxK
is the kernel function.
Among the different kernel functions, the most common kernels are polynomial, Gaussian Radial Basis function (RBF) and multi-layer perception (MLP).
The final decision rule can be expressed as:
* *
1
( , , ) ( . )svN
o i i i oi
f x b y K x x bα α=
= + (7)
where and denote the number of support vectors and the non-zero Lagrange
multipliers corresponding to the support vectors respectively. In this work Least Squares Support Vector Machines (LS-SVMs) are used. LS-
SVMs are reformulations to the original SVMs which lead to solving linear KKT systems. In LS-SVMs the inequality constraints in SVM are replaced with equality constraints. As a result the solution follows from solving a set of linear equations instead of a quadratic programming problem which we have in original SVM formu-lation of Vapkin, and obviously we can have a faster algorithm.
The primal problem of the LS-SVMs is defined as:
(8)
Subject to
svN *iα
,minw b
=+=
d
iipebw ewebwJ
1
22,, 2121),,( γ
[ ( ) ] 1 , 1,...,Ti i iy w x b e i dφ + = − =

Machine Learning-Based Classification of Encrypted Internet Traffic 587
Table 1. List of calculated features by NetMate
List of Calculated Features
1. protocol (TCP, UDP) 16. max forward inter arrival time
2. total forward packets 17. std dev forward inter arrival time
3. total forward volume 18. min backward inter arrival time
4. total backward packets 19. mean backward inter arrival time
5. total backward volume 20. max backward inter arrival time
6. min forward packet length 21. std dev backward inter arrival time
7. mean forward packet length 22. duration of the flow
8. max forward packet length 23. min active time
9. std dev forward packet length 24. mean active time
10. min backward packet length 25. max active time
11. mean backward packet length 26. std dev active time
12. max backward packet length 27. min idle time
13. std dev backward packet length 28. mean idle time
14. min forward inter arrival time 29. max idle time
15. mean forward inter arrival time 30. std dev idle time
where γ is a parameter analogous to SVM’s regularization parameter (C ). The main characteristic of LS-SVMs is the low computational complexity compar-
ing to SVMs without quality loss in the solution.
6 Experimental Results
MRMR feature selection algorithm sorts out the features based on the criteria given in Equation 5. Order of features is given in Table 2. LS-SVM is used in order to find the first m features in the set which gives the best result in terms of classification accura-cy. As Fig 3 illustrates, the first 19 features presented in Table 2 give us the best iden-tification rate. After that the accuracy starts to drop again.
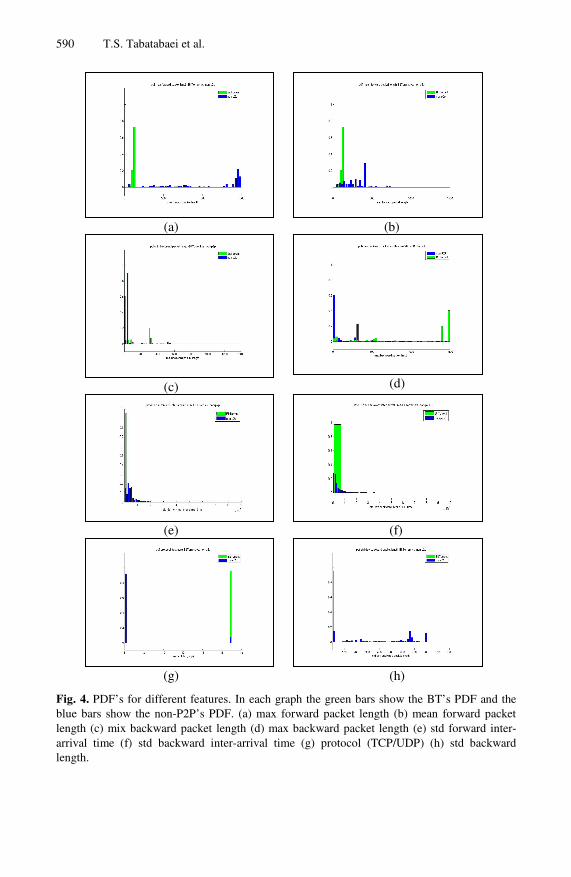
Figure 4 shows the histograms for some of the features, where the blue line corres-ponds to BT traffic and the green line to non-P2P traffic. As it can be seen for forward packet length non-P2P traffic flows expand over higher values compared to BT flows. For backward packet length, on the other hand, BT traffic has higher values. This could be justified since in BT architecture the actual data is going in both direction among peers whereas in the client/server scheme the actual data is going from server to client mostly. Also as part (e) demonstrates, BT traffic is mostly running over UDP while TCP is used for the mail part of non-P2P applications.

588 T.S. Tabatabaei et al.
The selected features by the feature selection unit are fed to a LS-SVM with RBF and linear kernel functions. For the purpose of comparison study linear discriminant classifier with perceptron criterion function, k-nearest neighbors (k-NNs) classifier and K-means clustering algorithm were also applied to the data set.
Fig. 3. Feature selection procedure using MRMR criteria
Table 2. Order of features selected based on MRMR criteria
Order of features by MRMR criteria
1. total forward volume 16. mean idle time
2. total backward packets 17. protocol (TCP, UDP)
3. total backward volume 18. total forward packets
4. mean forward packet length 19. min forward packet length
5. max forward packet length 20. min backward packet length
6. std dev forward packet length 21. mean backward packet length
7. std dev active time 22. std dev backward packet length
8. min active time 23. max forward inter arrival time
9. mean active time 24. max backward packet length
10. max active time 25. min idle time
11. duration of the flow 26. mean backward inter arrival time
12. mean forward inter arrival time 27. min backward inter arrival time
13. std dev forward inter arrival time 28. min forward inter arrival time
14. max idle time 29. max backward inter arrival time
15. std dev idle time 30. std dev backward inter arrival time

Machine Learning-Based Classification of Encrypted Internet Traffic 589
Table 3. Error rate and training time achieved by different classifiers for overall BT classification
Classification Method
SVM linear kernel
SVM RBF kernel
LDA k-NNs K-means
Error rate 20.9% 3.7% 36.1% 10.2% 45.4%
Training time (sec) 25.6 31.8 4.5 No training! No training!
Table 4. Comparision of ML approach and DPI for encrypted and non-encrypted P2P traffic
Application BT-movie downloading
not encrypted µT-movie downloading
encrypted
Recognition rate by ML 91.6% 94.5%
Recognition rate by DPI 92.3% 2.4% Table 3 reports the error rates and training times achieved by different classifiers.
As it shows, the minimum error rate of 3.7% is obtained by SVM with RBF kernel function. Using a linear kernel degrades the performance to 20.9% error rate but it is slightly faster than SVM with RBF kernel. Linear discrimant classifier does not per-form very well in terms of accuracy but compared to SVM the training time is shorter. Another drawback with this method is that it is dependent on the initial values and there is always the problem of local minimas. k-NN algorithm does not involve any training phase and it is a very simple algorithm. The error rate obtained by this me-thod is 10.2%. An obvious disadvantage of the k-NN method is the time complexity of making predictions when number of training samples is very large. Suppose that
there are training examples in . Then applying the k-NN method to one test example requires time, compared to just time to apply a linear clas-
sifier such as a perceptron. K-means algorithm is a very fast and easy to implement clustering algorithm because of simplicity of the algorithm. However, for rather high-dimensional problems such as this one, it does not yield a satisfying result. Also with different initial values different results are obtained.All the parameters, such as kernel function parameters, learning rate, and number of nearest neighbors, were adjusted empirically. The best overall accuracy of 93.6% was achieved by SVM with RBF kernel which is a very promising result. Table 4 compares the recognition results for BT traffic achieved by our ML-based system proposed in this paper using SVM with RBF kernel and DPI method. For the traffic which is not encrypted the performance of DPI method is accurate. However, for encrypted traffic DPI completely fails since it is not possible to examine the payload for finding the string patterns. Our method on the other hand performs very well because it is totally independent of payload. The encrypted traffic was collected using µTorrent (µT) which is a client of BT. µT pro-gram is designed to use minimal computer resources while offering functionality comparable to larger BT clients and is mostly encrypted.
n mR)(nmO )(mO
590 T.S. Tabatabaei et al.
(a)
(b)
(c)
(d)
(e)
(f)
(g)
(h)
Fig. 4. PDF’s for different features. In each graph the green bars show the BT’s PDF and the blue bars show the non-P2P’s PDF. (a) max forward packet length (b) mean forward packet length (c) mix backward packet length (d) max backward packet length (e) std forward inter-arrival time (f) std backward inter-arrival time (g) protocol (TCP/UDP) (h) std backward length.

Machine Learning-Based Classification of Encrypted Internet Traffic 591
7 Conclusion
In this work first we proposed a system to identify the BT traffic, which is one of the most popular and problematic P2P applications, based on ML methodology. The pro-posed system is independent of both IP addresses and payload information in order to evade the issues concerned with these two methods explained in Section 2. Our sys-tem is merely based on some statistical values calculated from traffic flows and LS-SVMs. Thirty flow-based statistical features are calculated from the flows and the most effective subset of feature is identified using feature selection algorithm. The overall accuracy of 93.6% was achieved through this approach. Our experimental results show that the most effective features for identifying BT traffic are forward packet lengths, backward volume, backward packet lengths, forward inter-arrival time, idle and active time and their variations. Our system shows a superior perfor-mance where DPI method fails for recognition of encrypted traffic.
References
1. http://www.ipoque.com/en/resources/internet-studies 2. Dreger, H., Feldmann, A., Mai, M., Paxson, V., Sommer, R.: Dynamic Application-Layer
Protocol Analysis for Network Intrusion Detection. In: USENIX Security Symposium, pp. 257–272 (2006)
3. Szabo, G., Szabo, I., Orincsay, D.: Accurate Traffic Classification. In: IEEE International Symposium on World of Wireless Mobile and Multimedia Networks, pp. 1–8 (2007)
4. Zhou, L., Wang, X., Tu, W., Mutean, G., Geller, B.: Distributed scheduling scheme for video streaming over multi-channel multi-radio multi-hop wireless networks. IEEE Journal on Selected Areas in Communications 28, 409–419 (2010)
5. Constantinou, F., Mavrommatis, P.: Identifying Known and Unknown Peer-to-Peer Traf-fic. In: Fifth IEEE International Symposium on Network Computing and Applications, pp. 93–102 (2006)
6. Moore, A.W., Papagiannaki, K.: Toward the Accurate Identification of Network Applica-tions. In: Dovrolis, C. (ed.) PAM 2005. LNCS, vol. 3431, pp. 41–54. Springer, Heidelberg (2005)
7. Patrick, H., et al.: ACAS: Automated Construction of Application Signatures. In: ACM SIGCOMM Workshop on Mining Network Data, Philadelphia, Pennsylvania, pp. 197–202 (2005)
8. Sen, S., Spatscheck, O., Wang, D.: Accurate, Scalable In-Network Identification of p2p Traffic Using Application Signatures. In: 13th International Conference on World Wide Web, New York, USA, pp. 512–521 (2004)
9. Roughan, M., Sen, S., Spatscheck, O.: Class ofService Mapping for QoS: A Statistical Signature-Sased Approach to IP Traffic Classification. In: 4th ACM SIGCOMM Confe-rence on Internet Measurement, Sicily, Italy, pp. 135–148 (2004)
10. Williams, N., Zander, S., Armitage, G.: A Preliminary Performance Comparison of Five Machine Learning Algorithms for IP Flow Classification. ACM SIGCOMM Computer Communication Review 36, 5–16 (2006)
11. Dusi, M., Gringoli, F., Salgarelli, L.: IP traffic classification for QoS Guarantees: the Inde-pendece of Packets. In: 17th International Conference on Computer Communications and Networks, pp. 1–8 (2008)

592 T.S. Tabatabaei et al.
12. Mellia, M., Pescapè, A., Salgarelli, L.: Traffic Classification and Its Applications to Mod-ern Networks. Computer Networks, 759–760 (2009)
13. Frank, J.: Machine Learning and Intrusion Detection: Current and Future Directions. In: 17th Computer Security Conference (1994)
14. McGregor, A., Hall, M., Lorier, P., Brunskill, J.: Flow Clustering Using Machine Learning Techniques. In: Barakat, C., Pratt, I. (eds.) PAM 2004. LNCS, vol. 3015, pp. 205–214. Springer, Heidelberg (2004)
15. Zander, S., Nguyen, T., Armitage, G.: Automated Traffic Classification and Application Identification Using Machine Learning. In: IEEE Conference on Local Computer Net-works, pp. 250–257 (2005)
16. Arulampalam, G., Ramakonar, V., Bouzerdoum, A., Habibi, D.: Classification of Digital Modulation Schemes Using Neural Networks. In: Fifth International Symposium on Signal Processing and Its Applications, vol. 2, pp. 649–652 (1999)
17. Cristianini, N., Taylor, J.S.H.: An Introduction to Support Vector Machines and Other Kernel-based Methods. Cambridge University Press, United Kingdom (2000)
18. Nguyen, T., Armitage, G.: A survey of techniques for internet traffic classification using machine learning. In: IEEE Comm. Surv. & Tutor, pp. 56–76 (2008)
19. Vapnik, V.: The Nature of Statistical Learning Theory. Springer, Berlin (1995)
Copyright © 2022 FDOKUMEN




















