
La medicina personalizada del futuro: plataformas de microtest en oncología clínica La medicina...
68
1 Laredo, 23 de junio de 2007 1 La medicina personalizada del futuro: plataformas de microtest en oncología clínica La medicina personalizada del futuro: plataformas de microtest en oncología clínica Pedro Gómez Vilda, Emil Raul Maluţan, Fran Díaz Pérez, Rafael Martínez Olalla Grupo de Informática Aplicada al Procesado de Señal e Imagen (GIAPSI) Universidad Politécnica de Madrid, Campus de Montegancedo, s/n 28660 Boadilla del Monte, Madrid, Spain E-mail: [email protected] Laredo, 23 de junio de 2007 2 Resumen Resumen • Pequeña introducción a la genómica • ¿Qué es el Procesado de Señal Genómica (PSG)? • Principales conceptos en PSG • Procesado de Señal para Genómica • Microarrays Genómicos • ¿Es suficientemente robusto el PSMG? • Procesado robusto de imágenes de Microarrays • Estimación robusta de la expresión en Microarrays • Análisis de componentes independientes • Modelado de hibridación de Microarrays • Campos emergentes: IT’s going Bio: Labs On-Chip • ¿Conclusiones?
-
Upload
independent -
Category
Documents
-
view
1 -
download
0
Transcript of La medicina personalizada del futuro: plataformas de microtest en oncología clínica La medicina...

1
Laredo, 23 de junio de 2007 1
La medicina personalizada del futuro:plataformas de microtest en oncología
clínica
La medicina personalizada del futuro:plataformas de microtest en oncología
clínica
Pedro Gómez Vilda, Emil Raul Maluţan, Fran Díaz Pérez, Rafael Martínez Olalla
Grupo de Informática Aplicada al Procesado de Señal e Imagen (GIAPSI)
Universidad Politécnica de Madrid, Campus de Montegancedo, s/n
28660 Boadilla del Monte, Madrid, Spain
E-mail: [email protected]
Laredo, 23 de junio de 2007 2
ResumenResumen
• Pequeña introducción a la genómica• ¿Qué es el Procesado de Señal Genómica (PSG)?• Principales conceptos en PSG• Procesado de Señal para Genómica• Microarrays Genómicos• ¿Es suficientemente robusto el PSMG?• Procesado robusto de imágenes de Microarrays• Estimación robusta de la expresión en Microarrays• Análisis de componentes independientes• Modelado de hibridación de Microarrays• Campos emergentes: IT’s going Bio: Labs On-Chip• ¿Conclusiones?

2
Laredo, 23 de junio de 2007 3
Pequeña introducción a la genómicaPequeña introducción a la genómica
• El procesado de señal genómica es un campo recientemente desarrollado
• Hay muchos aspectos abiertos a la investigación• La metodología de estudio es muy adecuada para
principios y procedimientos traslacionales: adaptación de teorías y metodologías de otros campos científicos a este específico
• Esto implica muchas oportunidades para que los jóvenes científicos puedan hibridar sus currícula
• Esto también implica riesgos que han de ser tenidos en cuenta
Laredo, 23 de junio de 2007 4
Pequeña introducción a la genómicaPequeña introducción a la genómica
• 1953 Watson y Crick predicen la estructura química del ADN (Nobelen 1962 junto con Wilkins)
• 1959 Nobel de Ochoa (RNA Polimerasa) y Kornberg (DNA polimerasa) -> Encima empleada en PCR
• 1970 Baltimore Temin, RT (transcriptasa inversa) (permite obtener cDNA a partir de mRNA) (Nobel 1972)
• 1977 secuenciamiento de ADN Gilbert y Sanger (Nobel en 1980)• 1980 Nobel en química para Berg por estudios en rDNA
(recombinante) (empleado hoy entre otras cosas para generar bibliotecas de clones para análisis de microarrays)
• Principios de los 80: PCR (Mullis et al)• Años 70 Waggoner y Stryer, marcadores fluorescentes para
examinar membranas biológicas.• Finales de los 80, Mirzabekov experimentos de hibridación

3
Laredo, 23 de junio de 2007 5
Algunos datosAlgunos datos
TIPO
cDNA; 65%
Otros; 1%Tejidos; 6,6%
Proteinas; 1,4%
Oligonucleótidos; 26%
ORGANISMO
Arabidopsis; 3,7%
Drosófila; 2,1%
C. elegans; 1,3%
Hombre; 58%
E. coli; 4%
Levadura; 12%
Rata; 7,4%
Ratón; 13%
(De Schena)
Laredo, 23 de junio de 2007 6
Algunos datosAlgunos datos
APLICACIÓN
Exp. Genética; 81,5%
Otros; 0,9%Tejidos; 4,6%Proteinas; 1%
Genotipado; 12%
PAÍS
China; 1,3%Finlandia; 1%Francia; 2,2%
Australia; 1,6%
Suecia; 1,5%
EEUU; 71%
Canadá; 2,8%
UK; 6,5%
Alemania; 4,1%
Japón; 8%
(De Schena)

4
Laredo, 23 de junio de 2007 7
Algunos datosAlgunos datos
TEJIDO (HUMANOS)
Corazón; 5,5%
Vejiga; 2,9%
Piel; 2,8%
Riñón; 7,2%
Colon; 7,7%
Cerebro; 19%
Pulmón; 8,9%
Pecho; 16%Próstata; 11%
Hígado; 19%
ENFERMEDAD (HUMANOS)
Autismo; 0,4%Anemia; 0,4%
Sida; 1,8%
Fibrosis quística; 1,3% Parquinson; 0,6%
Cancer; 84%
Apoplejía; 2,2%
Cardiovascular; 2,8%
Alzeimer; 2,4%
Diabetes; 4,6%
(De Schena)
Laredo, 23 de junio de 2007 8
Principios de la codificación nucleótidaPrincipios de la codificación nucleótida
(De Vaidyanathan)

5
Laredo, 23 de junio de 2007 9
Puentes de hidrógenoPuentes de hidrógeno
(De Vaidyanathan)
Laredo, 23 de junio de 2007 10
Codificación de aminoácidosCodificación de aminoácidos
(De Vaidyanathan)

6
Laredo, 23 de junio de 2007 11
Síntesis de proteinasSíntesis de proteinas
Las proteínas tienen propiedades estructurales, funcionales y de comportamiento:
Pueden ser elásticas, rígidas, duras, blandas, extendidas linealmente o en volumen, resistir la extensión, compresión, doblado, reaccionar a los campos eléctricos, al calor, desplegarse o plegarse, capturar y soltar elementos atómicos individuales, actuar como agentes catalizadores o líticos, etc.
(De Vaidyanathan)
Laredo, 23 de junio de 2007 12
Es un término recientemente acuñado que se refiere de forma más o menos vaga a alguno de los siguientes conceptos:
– “El procesado de DNA, RNA y secuencias de aminoácidos”(Vaidyanathan, 2004)
– El uso de herramientas clásicas de procesado de señal adaptadas y de otras nuevas para estimar y procesar información genómica y proteómica
– La genómica se refiere preferentemente a las secuencias de ADN y ARN: secuenciamiento, clasificación, minería, cuantificación
– La proteómica es un término empleado cuando nos referimos a secuencias compuestas por proteínas: lo mismo que antes + descripción de su estructura, plegados, desplegado, construcción y descomposición.
¿Qué es el procesado de señal genómica?¿Qué es el procesado de señal genómica?

7
Laredo, 23 de junio de 2007 13
El Procesado de Señal Genómica es un campo interdisciplinar que involucra conocimientos de:El Procesado de Señal Genómica es un campo interdisciplinar que involucra conocimientos de:
• Biología• Bioquímica• Farmacología• Medicina clínica• Biotecnología• Matemáticas y estadística aplicadas• Teoría de control• Ingeniería eléctrica• Micromecánica• Informática• Otros
Laredo, 23 de junio de 2007 14
Algunos tópicos importantes en PSGAlgunos tópicos importantes en PSG
• Análisis de secuencias• Metodologías de procesado de señal y estadística en selección genética
Selección de características genéticas
Clasificación
Clustering
De biochips a sistemas laboratory-on-a-chip
• Modelado e inferencia estadística de Redes Reguladoras Genéticas• Arrays de imágenes, Procesado de Señal de Sistemas Biológicos y Aplicaciones en Diagnóstico y Tratamiento de Enfermedades
Compresión de arrays de imágenes genómicas y proteómicas paraanálisis estadísticos
Genómica y proteómica del cáncer y aplicaciones clínicas
Aproximación integral a sistemas biológicos computacionales

8
Laredo, 23 de junio de 2007 15
Más tópicos en PSGMás tópicos en PSG
Fundamentos de codificación de nucleótidosPuentes de hidrógenoCodificación de aminoácidosSíntesis de proteínasIndicador de secuencias y sus FFT´sPotenciales de interacción electrón-iónHMM Parsing de secuencias de ADNGenómica comparativaGramáticasMicroarrays de cDNA y mRNADinámica de hibridación
Laredo, 23 de junio de 2007 16
Métodos de Procesado de Señal en GenómicaMétodos de Procesado de Señal en Genómica
• Redes bayesianas• Redes probabilísticas booleanas• Clustering de genes: k-means, hierarchical, GMM’s• Técnicas de Dynamic Time Warping• Principal Component Analysis• Independent Component Analysis• Higher Order Statistics• Spatial FFT Filtering• Adaptive Estimation and Modeling (Direct and Inverse)• Multiple Regression Methods• Optimal Estimation• Sequence Detection: HMM’s• Mutual Information Methods

9
Laredo, 23 de junio de 2007 17
Expresión genéticaExpresión genética
(De Vaidyanathan)
Laredo, 23 de junio de 2007 18
Indicador de secuencias y sus FFT’sIndicador de secuencias y sus FFT’sSea por ejemplo xA(n) = 000110111000101010. . . , donde 1 indica la
presencia de una A y 0 indica su ausencia. Los indicadores de secuencias para las otras bases se definen de forma similar.
Sea XA[k] la transformada de Fourier discreta o DFT de longitud N de xA(n):
Las DFTs de XT [k], XC [k] y XG[k] se definen de forma similar
1Nk0;e)n(x)n(X1N
0n
N/kn2jAA −≤≤= ∑
−
=
− π
(De Vaidyanathan)
Identificación de exones en virtud del pico a 2π/3 producido por el sesgo en la traducción de codonesen aminoácidos

10
Laredo, 23 de junio de 2007 19
HMM parsing de sequencias genéticasHMM parsing de sequencias genéticas
(De Vaidyanathan)
Aplicación de los HMM en genómica:Identificación de genes, identificación de secuencias específicas en el ADN, alineamiento de secuencias de ADN.
Laredo, 23 de junio de 2007 20
HMM Parsing de secuencias de ADNHMM Parsing de secuencias de ADN
1. Dado un HMM (i.e., dadas las matrices Σ -transiciones entre estados- y Π -probabilidad de salida-) y una secuencia de salidas y(1), y(2), . . . , calcular la secuancia de estados x(k) que con mayor probabilidad la generaron. Esto se resuelve mediante el algoritmo de Viterbi.
2. Dado el HMM y la secuencia de salidas y(1), y(2), . . . Calcular la probabilidad de que un HMM dado la genere. El algoritmo forward-backward lo resuelve.
3. El tercer problema es el del entrenamiento: ¿cómo se deben diseñar los parámetros del modelo de modo que sean óptimos para una aplicación dada, p. ej., para representar exones?.El algoritmo más popular para esto es el de “expectationmaximization” conocido como algoritmo EM o algoritmo de Baum-Welch.

11
Laredo, 23 de junio de 2007 21
Termodinámica de genómica y proteómica: Potenciales de Interacción Electrón-ión
Termodinámica de genómica y proteómica: Potenciales de Interacción Electrón-ión
(De Vaidyanathan)
Si un grupo de proteínas tiene una función en común, el producto de los espectros de potencia de las secuencias de EIIP (espectro de consenso) presenta un pico significativo en una frecuencia característica (0,0234 para hemoglobinas, 0,3203 para glucagón).
Aplicación potencial: síntesis artificial de péptidos con una propiedad determinada.
Laredo, 23 de junio de 2007 22
Genómica ComparativaGramáticas
Genómica ComparativaGramáticas
(De Vaidyanathan)

12
Laredo, 23 de junio de 2007 23
From S. K. Moore, “Making Chips”, IEEE Spectrum, March 2001, pp. 54-60
Microarrays GenómicosMicroarrays Genómicos
Laredo, 23 de junio de 2007 24
Microarrays GenómicosMicroarrays Genómicos

13
Laredo, 23 de junio de 2007 25
D.J. Duggon, M. Bittner, Y. Chen, P. Meltzer, and J.M. Trent, “Expression profilingusing cDNA microarrays,” Nature Genetics, vol. 21, pp. 10-14, 1999.
Tecnología de Microarrays de ADN
Laredo, 23 de junio de 2007 26
Microarrays de Oligonucleótidos
S. K. Moore, “Making Chips”, IEEE Spectrum, March 2001, pp. 54-60

14
Laredo, 23 de junio de 2007 27
Tecnología de microarrays de OligonucleótidosTecnologTecnologííaa de de microarraysmicroarrays de de OligonucleOligonucleóótidostidos
Mismatch probe cells
mRNA reference sequence
Perfect Match probe cells
5' 3'
x x x x x x xx x x x
Reference sequence
…TGTGATGGTGGGAATGGGTCAGAAGGACTCCTATGATACACCCACGCA ...ACCCAGTCTTCCTGAGGATACTAT Perfect Match OligoACCCAGTCTTCCAGAGGATACTAT Mismatch Oligo
Fluorescence Intensity Image
Space DNA probe pairs
Probe Pairs
Laredo, 23 de junio de 2007 28
Arrays de oligonucleótidosArrays de oligonucleótidos
Se producen empleando tecnologías de microchips derivadas de VLSI
Affymetrix produce arrays de oligonucleótidos en los que lassecuencias de test de se sintetizanmediante máscaras fotolitográficas.
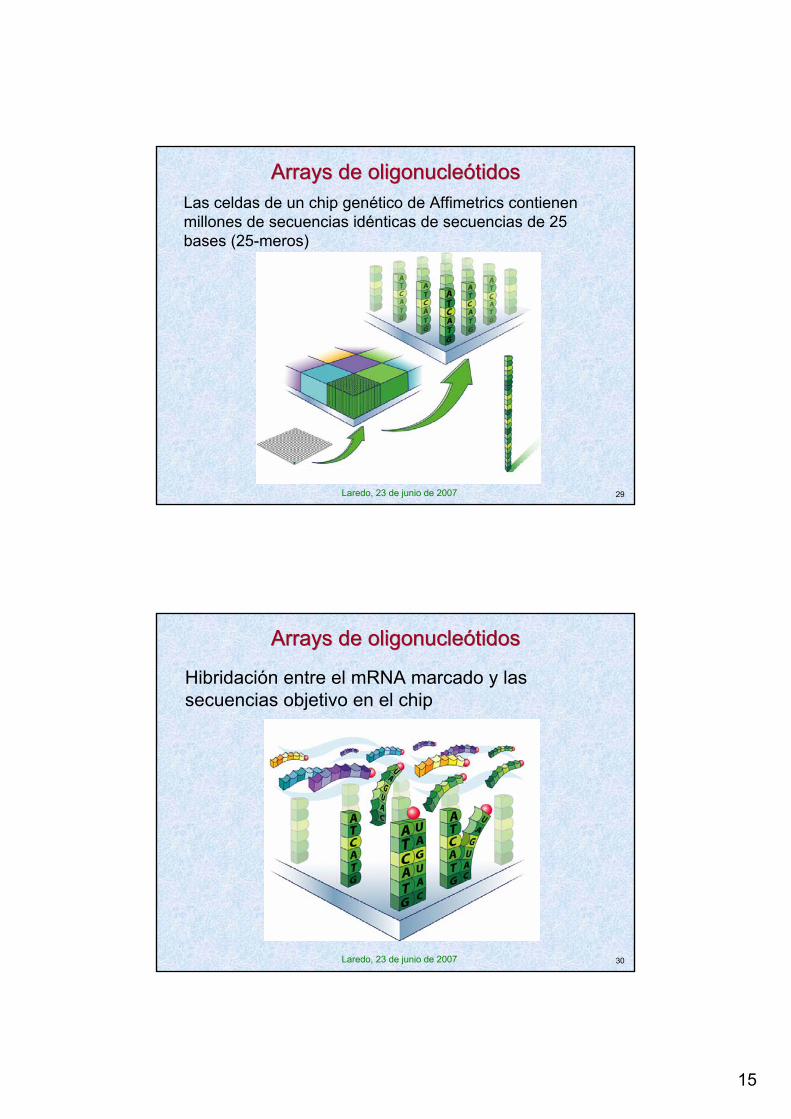
15
Laredo, 23 de junio de 2007 29
Arrays de oligonucleótidosArrays de oligonucleótidosLas celdas de un chip genético de Affimetrics contienenmillones de secuencias idénticas de secuencias de 25 bases (25-meros)
Laredo, 23 de junio de 2007 30
Arrays de oligonucleótidosArrays de oligonucleótidos
Hibridación entre el mRNA marcado y lassecuencias objetivo en el chip

16
Laredo, 23 de junio de 2007 31
Arrays de oligonucleótidosArrays de oligonucleótidos
Un láser induce fluorescencia en las sondas marcadas. Éstoes detectado mediante un scáner.
Laredo, 23 de junio de 2007 32
Affymetrix GeneChipTM
18 µm
Millions of copies of a specificoligonucleotide sequence element
Image of Hybridised Array
>400,000 differentcomplementary oligonucleotides
Single stranded, labeled RNA sampleOligonucleotide element
* **
**
1.28cm
GeneChip® ArrayHybridised Spot
_________________________________________________________________
Arrays de oligonucleótidosArrays de oligonucleótidos

17
Laredo, 23 de junio de 2007 33
Microarrays de oligonucleótidosMicroarrays de oligonucleótidos
Probe set
Probe pair
Each Gene Chip contains tens of thousands of probe sets
Data for the same gene
Mismatch (MM)
Perfect Match (PM)
Probe cell
Laredo, 23 de junio de 2007 34
Metodología de Detección Diferencial PM-MM para la estimación de la
Expresión
Metodología de Detección Diferencial PM-MM para la estimación de la
Expresión
Kevin R. Coombes and Keith A. Baggerly:http://bioinformatics.mdanderson.org/MicroarrayCourse/Lectures/index.html

18
Laredo, 23 de junio de 2007 35
Detección PM-MMDetección PM-MM
Kevin R. Coombes and Keith A. Baggerly:http://bioinformatics.mdanderson.org/MicroarrayCourse/Lectures/index.html
Laredo, 23 de junio de 2007 36
• Ruido de fondo: uniformemente distribuido
• Distorsiones en la densidad: localmente distribuidas
• Contaminación: localmente distribuida
• Dinámicas de hibridación diferencial: aleatoriamentedistribuidas
Objetivo: Estimación robusta de la expresión del PM-MM
Problemas en la detección de la expresión PM-MM

19
Laredo, 23 de junio de 2007 37
Estimación de la Expresión a partir de los patrones PM-MM
Estimación de la Expresión a partir de los patrones PM-MM
Takenfrom:
Coombes& Baggerly
Laredo, 23 de junio de 2007 38
Estabilidad de la estimación PM-MM
Estabilidad de la estimación PM-MM
After:
Coombes& Baggerly

20
Laredo, 23 de junio de 2007 39
Algoritmos para la Estimación de la ExpresiónAlgoritmos para la Estimación de la Expresión
Laredo, 23 de junio de 2007 40
¿Es suficientemente robusto el PSMG?¿Es suficientemente robusto el PSMG?
La mayor parte de los defectos proceden del manejo inadecuado que los operadores humanos realizan de los microarrays

21
Laredo, 23 de junio de 2007 41
ProcesamientoProcesamiento de de imimáágenesgenes de de datosdatos de de MicroarraysMicroarrays
Laredo, 23 de junio de 2007 42
Procesamiento de imágenes de datos de Microarrays

22
Laredo, 23 de junio de 2007 43
Procesamiento de imágenes de datos de Microarrays
Laredo, 23 de junio de 2007 44
Otros defectos habitualesOtros defectos habitualesOriginal log image selected by Row+Column Reticled De-mean
50 100 150 200 250
50
100
150
200
250

23
Laredo, 23 de junio de 2007 45
Procesamiento Robusto de Imágenes de Microarrays
Procesamiento Robusto de Imágenes de Microarrays
Excerpts from: Benjamin Stetter, “Gene expression estimation by automatic detection ofhybridization spots in cDNA microarray images”, Diplomarbeit in Informatik, TechnischeUniversität München, 9 August 2006. Work done under Erasmus Mobility Agreement betweenTUM and UPM
Laredo, 23 de junio de 2007 46
La Transformada de Fourier discreta de 2D es:
( ) ( )∑ ∑−
=
−
=
⎟⎠⎞
⎜⎝⎛ +−
=1M
0x
1N
0y
Nvy
Mux2j
ey,xfv,uFπ u = 0, ..., M-1,
v = 0, …, N-1
La Transformada inversa de Fourier discreta de 2D es:
( ) ( )∑ ∑−
=
−
=
⎟⎠⎞
⎜⎝⎛ +
=1M
0u
1N
0v
Nvy
Mux2j
ev,uFMN1y,xf
π x = 0, …, M-1,y = 0, ..., N-1
Sea una imagen MxN f(x,y), x=0,…,M-1, y=0,…,N-1
Algunos problemas pueden resolverse mediante post-procesado: filtrado espacial
Algunos problemas pueden resolverse mediante post-procesado: filtrado espacial

24
Laredo, 23 de junio de 2007 47
Filtrado espacialFiltrado espacial
Si f(x,y) es real, su transformada F(u,v) es en general compleja.
Espectro of F(u,v); magnitud:
fase:
( ) ( ) ( )[ ] 2/122 v,uIv,uRv,uF +=
( ) ( )( )⎥⎦
⎤⎢⎣
⎡= −
v,uRv,uItanv,u 1Φ
R(u,v) y I(u,v) son los componentes real e imaginario de F(u,v)
Laredo, 23 de junio de 2007 48
El filtrado en el dominio espacial consiste en la convolución de unaimagen f(x,y) con la máscara de un filtro h(x,y).
( ) ( ) ( ) ( )v,uFv,uHy,xhy,xf ⋅⇔∗
La convolución lineal espacial se puede implementar en el dominio frecuencial mediante el producto de la transformada de Fourier de la la imagen F(u,v) con la transformada de Fourier de la máscara del filtro H(u,v).
Para obtener la imagen filtrada en el dominio espacial, basta con calcular la transformada inversa de Fourier del producto H(u,v).F(u,v).
Filtrado espacialFiltrado espacial

25
Laredo, 23 de junio de 2007 49
Para filtrar una imagen de un chip genético, se emplea un filtro en el dominio espacial
El filtro empleado es un filtro gausiano paso bajo (GLF):
( ) ( )( )∑∑
=
1 2n n21g
21g21 n,nh
n,nhn,nh ( ) ( ) ( )22
221 2/nn
21g en,nh σ+−=
donde n1, n2 especifican el número de filas y columnas y σ es la desviación estándar.
Filtrado espacialFiltrado espacial
Laredo, 23 de junio de 2007 50
El objetivo del filtrado es la detección de patrones de corrupción(fibras o motas de polvo) en la imagen escaneada
Filtrado espacialFiltrado espacial

26
Laredo, 23 de junio de 2007 51
Modelo de composición para preprocesado FFTModelo de composición para preprocesado FFT
Pd * Xh * Pn = Yo
lnn
lhh
ldd
lo www PXPY ++=
( ) ( ) ( ) ( )nlnh
lhd
ldo
lo log;log;log;log PPXXPPYY ====
donde Y0, Pd, Xh and Pn son las matrices de observaciones (datos del microarray), la matriz de disposición de targets (patrón de distribuciones), la matriz de hibridación cuya detección es el objetivo y la matriz del proceso quecorrompe (matriz de ruido)
Laredo, 23 de junio de 2007 52
m, n son los índices espaciales del array, j, k los índices de los armónicos, NxN el tamaño de la matriz de observaciones Yo e i la unidad imaginaria. Se aplica un filtro paso alto bidimensional Hu a la matriz resultante Ψo paraproducir la matriz de observaciones relacionada con contenidos en altafrecuencia (perturbaciones de pequeña longitud de onda)
Modelo de preprocesadoModelo de preprocesado
∑∑−−
=j
N2ijn
N2ikm
k
loo ee)n,m()k,j(
ππ
YΨ
ouu ΨHΨ =
∑∑=j
N2ijn
N2ikm
ku2u ee)k,j(
N1)n,m(
ππ
ΨY

27
Laredo, 23 de junio de 2007 53
Empleo de 2D-FFT para eliminar ruido localmente distribuido
Empleo de 2D-FFT para eliminar ruido localmente distribuido
Kevin R. Coombes and Keith A. Baggerly:http://bioinformatics.mdanderson.org/MicroarrayCourse/Lectures/index.html
Laredo, 23 de junio de 2007 54
Imagen contaminada Imagen filtrada
HT: High, Thin
HB: High, Bold
Filtrado espacialFiltrado espacial

28
Laredo, 23 de junio de 2007 55
LT: Low, Thin
LB: Low, Bold
Imagen contaminada Imagen filtrada
Filtrado espacialFiltrado espacial
Laredo, 23 de junio de 2007 56
MT: Medium, Thin
MB: Medium, Bold
Imagen contaminada Imagen filtrada
Filtrado espacialFiltrado espacial

29
Laredo, 23 de junio de 2007 57
Análisis de Componentes IndependientesAnálisis de Componentes Independientes
• Es una herramienta propuesta para diferentes fines en el Procesado Robusto de Micoarrays: eliminación de ruido, extracción de relaciones independientes entre genes, estimación robusta de la expresión, etc.
• Se basa en invertir modelos de mezclas empleando momentos de orden superior (kurtosis, cumulantes de orden k, etc)
Laredo, 23 de junio de 2007 58
Análisis de Componentes Independientes para Procesado Robusto de Microarrays
Análisis de Componentes Independientes para Procesado Robusto de Microarrays
After: A. Cichocki & S. I. Amari
Adaptive Blind Signal and Image Processing
John Wiley, 2003
ICA puede ser usado en microarrays para detectar procesos ocultos que se expresan

30
Laredo, 23 de junio de 2007 59
Modelo ICA - PM vs MMModelo ICA - PM vs MM
[ ] ⎥⎦
⎤⎢⎣
⎡=
ch
phmp ,
XX
AYY
[ ] ⎥⎦
⎤⎢⎣
⎡= +
m
pchph
ˆ,ˆYY
WXX
Modelo de composición
Modelo de detección
21;ˆˆ
ˆˆijij
jcip
jcipij cc −==
+
+
γxx
xxModelo de selección
Xph: Señal de expresión genética que muestra un patrón de hibridación proporcional
Xch: Señal de expresión genética con hibridación corrupta
Yp: Patrón de Perfect Match (observaciones)
Ym: Patrón de Mismatch (observaciones)
|xc |cosβ
xp
xc
β
Laredo, 23 de junio de 2007 60
Ortogonalización y alineamiento de datosOrtogonalización y alineamiento de datos
El proceso de alineación de datos se puedederivar facilmente del modelo geométrico de proyecciónLa componente colineal del vector MM
La componente ortogonal:
2
,
pi
pi
mip
iici
x
xxxx == λ
2
,
pi
pi
mim
ipii
mi
oi
x
xxxxxx −=−= λ

31
Laredo, 23 de junio de 2007 61
Análisis de Componentes IndependientesAnálisis de Componentes Independientes
• Dado un conjunto de observaciones de variables independientes {x1,x2,…,xn}
• Se asume que están generadas poruna mezcla lineal de componentes independientes {s1,s2,…,sm}
• ICA consiste en estimar tanto la matriz desconocida Acomo las fuentes si tan sólo con la observación de xi
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
mn s
ss
A
x
xx
......2
1
2
1
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
nmnn
m
m
aaa
aaaaaa
A
..........................
21
22221
11211
Laredo, 23 de junio de 2007 62
Modelo ICAModelo ICA
• Se emplea un sistema con „variables latentes“• sk se considera una variable aleatoria en vez de una
señal temporal• xj = aj1s1 + aj2s2 + .. + ajmsm, para todo j de 1 a n• Modelo ICA:
ai - functiones basesi - componentes independentes (IC‘s)
∑=
=
=m
1iii sax
Asx

32
Laredo, 23 de junio de 2007 63
Resolución del modelo ICAResolución del modelo ICA
• Suposiciones adicionales:– Las IC‘s son estadísticamente independentes
y con distribución no gausiana– A cuadradae invertible
• Se estima A• Se calcula W = A-1
• Se obtienen las IC‘s de:– s = Wx
Laredo, 23 de junio de 2007 64
Preprocesado para ICAPreprocesado para ICA
Antes de aplicar un algoritmo ICA es necesario un preprocesado de los datos
1. Centrado – el proceso de centrado de la variable x consiste en sustraer la media del vector paraconvertirlo en una variable de media cero
2. Blanqueado – el blanqueado de las variables consisteen transformar el vector x de modo que el nuevovector sea blanco: sus componentes incorreladas y con varianza la unidad

33
Laredo, 23 de junio de 2007 65
Algoritmo FastICAAlgoritmo FastICA
• based on a fixed-point iteration scheme for finding a maximum of the nongaussianity of wTx
• tanh
• pow3
• skew
( ) ( ){ } ( ){ }[ ]2GEyGEyJ ν−∝
( ) ( )uatanhguacoshloga1G 1111
1 =→=
( ) ( ) 32
42 uugu
41uG =→=
( ) ( ) 23
33 uugu
31uG =→=
Laredo, 23 de junio de 2007 66
Algoritmo FastICA (cont)Algoritmo FastICA (cont)
The basic steps for one unit algorithm:1. Choose an initial (e.g. random) weight vector w2. Let
3. Let
4. If not converging, go back to 2.
( ){ } ( ){ }wxwgExwxgEw T'T −=+
++= w/ww

34
Laredo, 23 de junio de 2007 67
ICA for oligo-microarray dataICA for oligo-microarray data
• data from HG133A chip array was analyzed using a gene expression method based on correlation coefficient algorithm
• initial Dataset contained 22283 genes in 4 tissue experiments
• after thresholding for γ>0.3, 2160 genes left
• the chip was first analyzed with MAS 5.0
Laredo, 23 de junio de 2007 68
ICA MethodologyICA Methodology
• The well known MATLAB toolbox from A. Cichocki & S. I. Amari was used
• Nat. Grad. -FICA yielded quite good results• Expression matrices were converted to gray
images and processed• PM and MM matrices were used as inputs to the
algorithm

35
Laredo, 23 de junio de 2007 69
DatasetDataset
Laredo, 23 de junio de 2007 70
Preprocessing of datasetPreprocessing of dataset

36
Laredo, 23 de junio de 2007 71
FastICA results – ICs using “tanh”FastICA results – ICs using “tanh”
Laredo, 23 de junio de 2007 72
Results: reliable probeResults: reliable probe
37
Laredo, 23 de junio de 2007 73
Results: unreliable probeResults: unreliable probe
Laredo, 23 de junio de 2007 74
eColi matrixeColi matrix

38
Laredo, 23 de junio de 2007 75
Rel. Exp. Gene position: 190, 401Rel. Exp. Gene position: 190, 401
Laredo, 23 de junio de 2007 76
Unrel. Expl. Gene position: 219, 1Unrel. Expl. Gene position: 219, 1

39
Laredo, 23 de junio de 2007 77
Resumen de resultadosResumen de resultados
73,11
15,59
11,30
100,00
Rel. (%)
5346Unrel. expressed p. s.
1140Relat. rel. probe sets
826Highly reliable probe s.
7312Genes analizados
AbsoluteConcepto
Laredo, 23 de junio de 2007 78
Procesado de Microarrays de cDNAProcesado de Microarrays de cDNA

40
Laredo, 23 de junio de 2007 79
Procesado de MicroarraysProcesado de Microarrays
Laredo, 23 de junio de 2007 80
Segmentación de ImágenesSegmentación de Imágenes

41
Laredo, 23 de junio de 2007 81
Segmentación de ImágenesSegmentación de Imágenes
Laredo, 23 de junio de 2007 82
Estimación de la intensidad del SpotEstimación de la intensidad del Spot

42
Laredo, 23 de junio de 2007 83
Estimación de la intensidad del SpotEstimación de la intensidad del Spot
Laredo, 23 de junio de 2007 84
Procesado de MicroarraysProcesado de Microarrays

43
Laredo, 23 de junio de 2007 85
SegmentaciónSegmentación
Laredo, 23 de junio de 2007 86
AddressingAddressing

44
Laredo, 23 de junio de 2007 87
Sobre-excitaciónSobre-excitación
Laredo, 23 de junio de 2007 88
DesalineamientoDesalineamiento

45
Laredo, 23 de junio de 2007 89
Gridding Global Gridding Global
Laredo, 23 de junio de 2007 90
GriddingGridding
WTH: White Top Hat transformation based on background removal
46
Laredo, 23 de junio de 2007 91
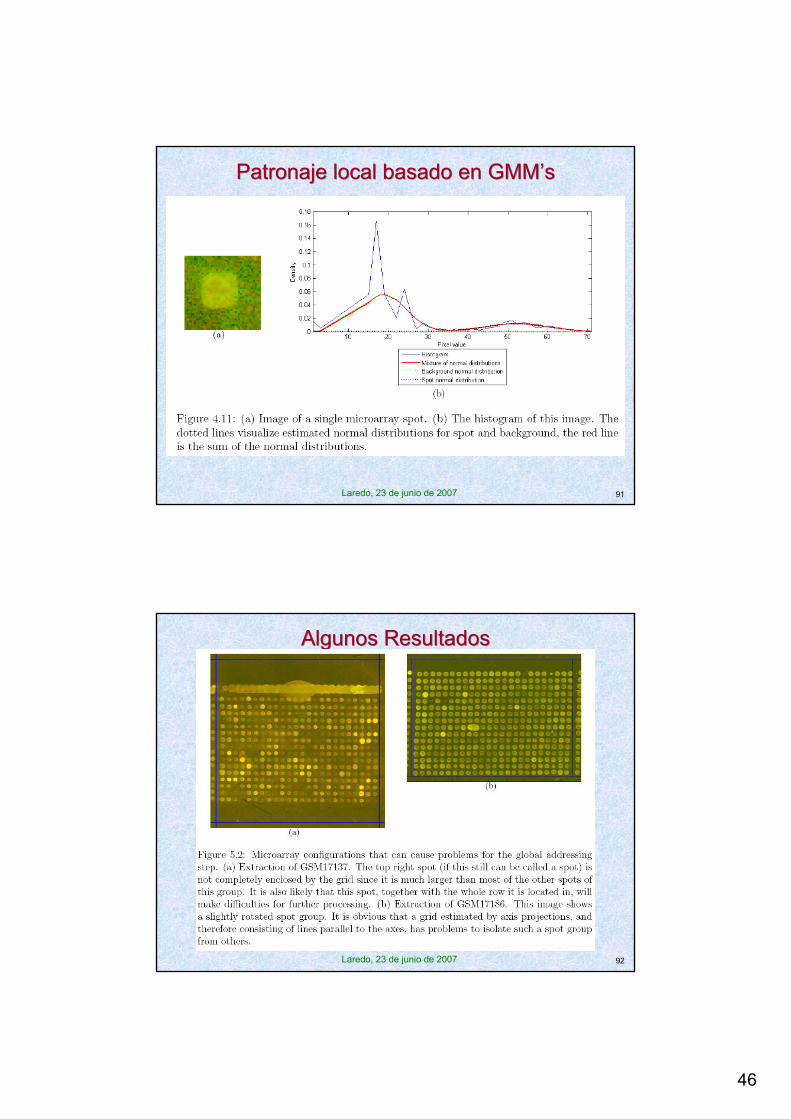
Patronaje local basado en GMM’sPatronaje local basado en GMM’s
Laredo, 23 de junio de 2007 92
Algunos ResultadosAlgunos Resultados

47
Laredo, 23 de junio de 2007 93
Algunos resultadosAlgunos resultados
Laredo, 23 de junio de 2007 94
Algunos resultadosAlgunos resultados

48
Laredo, 23 de junio de 2007 95
Algunos resultadosAlgunos resultados
Laredo, 23 de junio de 2007 96
Otras estrategias: detección sin malladoOtras estrategias: detección sin malladoOriginal selected image
50 100 150 200 250
50
100
150
200
250
Original log image selected by Row+Column Reticled De-mean
50 100 150 200 250
50
100
150
200
250
Original log image selected by Row+Column Reticled De-mean Thresholded
50 100 150 200 250
50
100
150
200
250
Main Technology: Image Processing
Spatial Filtering
Spot Detection, Clustering, Estimation

49
Laredo, 23 de junio de 2007 97
Projectos: ACIMEG, ICAGEM Projectos: ACIMEG, ICAGEM
Reticle borders and centers of gravity
50 100 150 200 250
50
100
150
200
250
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
Second Placement
50 100 150 200 250
50
100
150
200
250
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Row+Column Reticle De-meaned
50 100 150 200 250
50
100
150
200
250
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Image ProcessingTools: Wavelet
BasedSelesnik et al., IEEE SP Magazine, November 2005
Laredo, 23 de junio de 2007 98
Acción encimática o del
calor
Modelado de Hibridación de MicroarraysModelado de Hibridación de Microarrays

50
Laredo, 23 de junio de 2007 99
)|(),,(
)|(),,(
,,,,
,,,,m
kikitkim
ki
pkikitki
pki
zspyxsx
zspyxsx
ρ
ρ
=
=
0;,;1)|(0 /,, ≥∀≤≤ tkizsp mpkikit
12/
,,/
,, );|()|(12
ttzspzsp mpkikit
mpkikit >∀≥
1)|( /,,lim =
∞→
mpkikit
tzsp
12,,,, );|()|(12
ttzspzsp mkikit
pkikit =∀≥
Modelo de probabilidad:
Consistencia:
Monotonicidad:
Saturación:
Dominancia:
Modelado de Hibridación de MicroarraysModelado de Hibridación de Microarrays
Densidad superficial del segmento i en el gen k para el punto x,y
Probabilidad de hibridación en el tiempo t
Cantidad de material hibridado
Laredo, 23 de junio de 2007 100
0t);e1)(0(p)z|s(pm/p
k,itm/pk,i
m/pk,ik,it ≥−= − τ∆
12mk,ik,itk,i
pk,ik,it tt);z|s(p)z|s(p
12==η
j,i;k,jk,i ∀=ηη
m/pk,i
m/pk,i
m/pk,i
m/pk,ik,it t);0(pt)z|s(p ττ <<≅
τnN
dtdn −
=Modelo generador:
Soluciones Naturales:
Linearización:
Linearidad:
Homogeneidad:
Modelado de Hibridación de MicroarraysModelado de Hibridación de Microarrays

51
Laredo, 23 de junio de 2007 101
TT
satm/p
k,iRT
E
satm/p
k,im/p
k,i
m/pk,i
m/pk,i
epep)T(p−−
==
Donde es la Temperatura de Hibridación del segmento i del gen k respecto a sus pares perfect match mismatch, lo que en general dependerá de la estructura de los segmentos a hibridar
m/pk,iT
Modelado de Hibridación de MicroarraysModelado de Hibridación de MicroarraysBajo estas condiciones las probabilidades de hibridación dependerán de la temperatura de acuerdo con la siguiente expresión dinámica:
Obviamente, para un microarray estándar donde diferentes segmentos de genes se hibridan de forma simultánea bajo las mismas condiciones termodinámicas esto va a producir una corrupción dinámica diferencial. Esto necesitará ser eliminado mediante métodos de regresión múltiple.
Laredo, 23 de junio de 2007 102
Ejemplos de condiciones de hibridación diferencialEjemplos de condiciones de hibridación diferencial

52
Laredo, 23 de junio de 2007 103
Modelado de la dinámica de HibridaciónModelado de la dinámica de Hibridación
El modelo de hibridación empleado se basa en la suposición de quelas cantidades de material hibridado para los pares de sondas iperfect match ( ) y mismatch ( ) relacionadas con el gen kresponden a probabilidades de hibridación proporcionales:
Que deben ser proporcionales bajo condiciones temporales y termodinámicas invariantes:
pk,i
mk,i
mk,ik,it
pk,ik,it
k,i)z|s(p
)z|s(p
τ
τη ==
donde 0m/pk,i >τ
Son las constantes de tiempo para los PM ó MM de lospares de segmentos i, k
pk,ix
)z|s(p pk,ik,it )z|s(p m
k,ik,it
mk,ix
Laredo, 23 de junio de 2007 104
Modelado de la HibridaciónModelado de la Hibridación
La hipótesis de proporcionalidad: j,i;k,jk,i ∀=ηη
1. Reliably expressed probe sets – la hipótesis se cumple en ciertamedida.
2. Unreliably expressed probe sets – casos en los que la proporcionalidaf estricta no se cumple
Objectivo: Como detectar si un conjunto de test se expresa de forma fiable o no

53
Laredo, 23 de junio de 2007 105
¿Cómo detectar conjuntos de sondas que se expresan de forma no fiable?
¿Cómo detectar conjuntos de sondas que se expresan de forma no fiable?
El parámetro de proporcionalidad para el gen i, λi se emplea para medir si un conjunto de sondas se expresa de forma fiable. El diagrama vectorial muestra el caso en el que la hipótesis muestra un alto grado de colinearidad entre losvectores PM y MM.
mix
pix
imi cos βx
cix
oix
iβ
∑
∑
=
==== K
1k
pk,ik,i
2t
K
1k
mk,ik,it
pk,ik,it
2pi
pi
mi
pi
imi
i
)z|s(p
)z|s(p)z|s(p,cos
x
xx
x
x βλ
mix
pix
iβ
- vector de test PM
- vector de test MM
- ángulo entre los vectores PM y MM
Laredo, 23 de junio de 2007 106
Modelado de hibridación de MicroarraysModelado de hibridación de Microarrays
Ejemplos de dos conjuntos de expresiones diferentes: expresado de forma fiable (izquierda) y de forma no fiable (derecha)

54
Laredo, 23 de junio de 2007 107
Fundamentos Termodinámicos de la HibridaciónFundamentos Termodinámicos de la Hibridación
CTPbK
fK
⎯⎯ ⎯←⎯⎯→⎯
+
( ) ( )[ ]τtexp1KT
TtC −−+
=
fb kkK =
( )KTk1
f +=τ
El proceso de hibridación debe ser considerado desde el punto de vista de lascondiciones termodinámicas generales de las interacciones químicas reversibles. Un concepto básico en este sentido es el de la probabilidad de hibridación de un segmento de sonda P con un segmento de test TLa probabilidad de hibridación de un segmento de test dado se definirá mediantesus condiciones termodinámicas, es decir, mediante su temperatura de hibridación.El proceso de hibridación responderá a la ecuación dinámica:
• P - concentración de oligos disponible para hibridación• T - concentración de test de RNA objetivo• C - número de complejos enlazados• kf , kb – tasas de hibridación y desnaturalización dinámica
- Constante de disociación de equilibrio
La solución en el dominio del tiempo viene dada por la expresión:
Constante de tiempo dependientede la dinámica de
equilibrio
Laredo, 23 de junio de 2007 108
Soluciones iterativas de regresiónSoluciones iterativas de regresión
( )( )bxexp1ay −−=
( )( )
( )∑
∑
=+
=+
−+=
−−+=
n
1iikikk,ibkk1k
n
1iikk,iakk1k
xbexpxa2bb
xbexp12aa
εβ
εβ
( )( )[ ]ikkik,i xbexp1ay −−−=ε bk,aβ
El problema a resolver es la forma de estimar los parámetros dinámicos del modelo (constantes de tiempo) a partir de experimentos de hibridacióndiacrónicos (llevados a cabo sobre las mismas configuraciones de microarrayspermitiendo diferentes tiempos de hibridación bajo las mismas condicionestermodinámicas. Para ello se considerará que las estimaciones discretas se deben ajustar según una forma funcional:
Lo que se puede resolver de forma iterativa mediante el par de recursiones:
Con la función de error y pasos de iteración:

55
Laredo, 23 de junio de 2007 109
Modelado de Hibridación de MicroarraysModelado de Hibridación de Microarrays
Laredo, 23 de junio de 2007 110
IteracionesIteraciones

56
Laredo, 23 de junio de 2007 111
Diagramas de convergenciaDiagramas de convergencia
Laredo, 23 de junio de 2007 112
Evolución de las Iteraciones: AmplitudesEvolución de las Iteraciones: Amplitudes

57
Laredo, 23 de junio de 2007 113
Evolución de las Iteraciones: constantes de tiempoEvolución de las Iteraciones: constantes de tiempo
Laredo, 23 de junio de 2007 114
Resultados finalesResultados finales

58
Laredo, 23 de junio de 2007 115
Un caso de aplicación: Herrameintas de Ayuda Clínica en Tratamientos Coadyuvantes
Un caso de aplicación: Herrameintas de Ayuda Clínica en Tratamientos Coadyuvantes
• Los tratamientos coadyuvantes son una herramienta importante para parar o ralentizar el progreso de las metástasis en el tratamiento del cáncer
• Se basan en la aplicación de ciertas drogas cuya toxicidad es selectivamente mayor en las células malignas que en las normales
• El umbral entre las dosis terapéuticas y las potencialmente peligrosas es muy tenue
• Es de crucial interés en estos casos establecer un límite claro en:– Resistencia de un paciente dado a una dosis específica de una droga– Grado de eficiencia de la droga medida según el decrecimiento del tamaño
del tumor, supervivencia, efectos secundarios, alteración en el balance bioquímico, etc.
– Establecer la mejor temporización para sucesivas aplicaciones de una dosis de una droga
• Para ello, se debe diseñar un modelo holístico y sistemático de las condiciones del paciente y de los protocolos de administración de drogas y de resultados
Laredo, 23 de junio de 2007 116
PROMISSEPROMISSE
• Objetivos:– Establecer un protocolo para la prognosis y diagnosis
de tratamientos coadyuvantes en cánceres de pecho y colon empleando microarrays como principales herramientas de test
– Establecer una metodología sincrónica y diacrónica para el procesado de microarrays
– Determinar las drogas y dosis más apropadas para un paciente específico dependiendo del balance bioquímico y hemodinámico y de las condiciones clínicas generales

59
Laredo, 23 de junio de 2007 117
Realimentación de ControlRealimentación de Control• Los tratamientos coadyuvantes pueden verse como procesos
exógenos que influyen en la expresión genética bloqueando o alterando el funcionamiento general del sistema realimentado:– Alteración de segmentos de secuencias de ADN– Modificaciones en la expresión de ADN– Interferencia en la amplificación de mRNA– Interferencia en la síntesis de aminoácidos– Alteraciones en la operación de encimas y ribosomas– Etc.
• Estos procesos pueden afectar los niveles de expresión general de oncogenes y de otros genes que marcan el metabolismo y la dinámica del tumor
• El trazado de los niveles de expresión de los oncogenes y de los genes metabólicos es una de las fuentes de información para inferir el estado de la célula bajo tratamiento (control plant approach)
• Experimento de Lee y Batzoglou• Independent Component Analysis
Laredo, 23 de junio de 2007 118
El problema del sistema de control bioquímicoEl problema del sistema de control bioquímico
Metabolismo celular
Motor asociativo
Tipo de droga dosificación
temporización
Procesos Exógenos:
Nutricionales, medioambientales,
condiciones de salud,
Estado observado: marcadores, bioquímicos,
proteínas, encimas, hemodinámica, etc.
Datos clínicos: condiciones
generales de salud, sueño, apetito,
nauseas, efectos secundarios, etc.
Base de datos
Historia clínica

60
Laredo, 23 de junio de 2007 119
Datos clínicos
Clustering Prognosis
Clustering de Microarrays GenómicosClustering de Microarrays Genómicos
Laredo, 23 de junio de 2007 120
Metodologías de ClusteringMetodologías de Clustering• Artificial Neural Networks• Independen Component Analysis• Principal Component Analysis• Hierarchical and k-means clustering• Fuzzy Systems
HierarchicalClustering
Raul E. Malutan, Pedro Gómez Vilda, Monica E. Borda, “Microarray imageclassification and recognition for cancer treatment. K-Means clustering of publicdata base from breast cancer treatment”, Proceedings of the Symposium of Electronics and Telecommunications ETc2004 - Volume: 49 pp. 337-342, Timisoara, Rumanía

61
Laredo, 23 de junio de 2007 121
• Las tecnologías de la Información han desarrollado poderosos métodos y herramientas durante los últimos años en principio destinadas a otros campos
• Ahora es el momento de traducir esas herramientas, métodos y soluciones al mundo de las Biociencias(también ciencias de la vida)
• La teccnología de lo ultra-pequeño (microtecnología) se ha aplicado de forma satisfactoria en la producción y proceado de microarrays
• Es posible traducir más herrameintas, métodos y soluciones
• Éste es un campo abierto con multitud de oportunidades para la investigación y el desarrollo
• El campo de los sistemas y ciencias de la vida es un área emergente
IT’s going BioIT’s going Bio
Laredo, 23 de junio de 2007 122
IT’s going Bio: Labs On-ChipIT’s going Bio: Labs On-Chip

62
Laredo, 23 de junio de 2007 123
Labs On-ChipLabs On-Chip
Laredo, 23 de junio de 2007 124
Labs On-ChipLabs On-Chip

63
Laredo, 23 de junio de 2007 125
Labs On-ChipLabs On-Chip
Laredo, 23 de junio de 2007 126
Labs On-ChipLabs On-Chip
MEMS: Micro Electro-Mechanical Systems

64
Laredo, 23 de junio de 2007 127
Labs On-ChipLabs On-Chip
Laredo, 23 de junio de 2007 128
Micro Electro-Mechanical SystemsMicro Electro-Mechanical Systems

65
Laredo, 23 de junio de 2007 129
MEMS for Genomic Signal ProcessingMEMS for Genomic Signal Processing
Mass can be estimated from resonant frequency
Laredo, 23 de junio de 2007 130
More on MEMS for GSPMore on MEMS for GSP
• Resonant cantilever sensing is a method to detect the presence of various analytes in anenvironment.
• Cantilevers are coated with a receptor material that selectively binds to specific chemical orbiological species.
• The attachment changes the mass of the cantilever, thereby changing its resonantfrequency.
• Mass resolution on the order of attograms(10-18 grams) has been reported using cantileverdetectors.
• For comparison, the mass of single virus particles can be on the order of 10’s of attograms.

66
Laredo, 23 de junio de 2007 131
Hand-held microarray processingHand-held microarray processing
Charge-CoupledDevice
A/D Converter
CCD Control+Spot Processing+
USB Port Interfacing (VHDL)
USB 2
Memory
FPGA-Based Control Unit
CCD-A/D Controls
Expression Evaluated Microarray Files
Hand-held fixed mount CCD bar code-like double light laser
scanner
Scanned Microarray Raw Images in a 2-light laser
system
Scanner Controls
Laredo, 23 de junio de 2007 132
Future of microarraysFuture of microarrays
• The cost of a single microarray test is now around 1000$• Will microarrays become a routine test within five years?• Could we expect a Moore’s Law for microarrays?

67
Laredo, 23 de junio de 2007 133
ConclusionesConclusiones
• El Procesado de Señal Genómica es un campo de estudio y desarrollo muy prometedor
• Hay que resolver muchos problemas específicos• Uno de los puntos esenciales es el de la
interdisciplinariedad• Se requieren grupos de investigación con suficiente
experiencia en la mayoría de los campos• En los próximos años se espera que este campo
acapare una financiación importante• Las acciones supra-nacionales son esenciales• Es importante estar posicionado de cara a los próximos
años creando grupos de investigación y definiendo objetivos
Laredo, 23 de junio de 2007 134
Reflections from the moveReflections from the move• Conclusions in this field are efimerous: the train is moving
so fast… (this is a big move!)• Information Technologies are moving to Life Sciences:
strong thurst.• Two samples:
– IEEE/NML on Life Sciences, Systems and Applications(NIH, Bethesda, Maryland, July 2006) 90% Eng. 10% MD or Biologists
– Advances on Voice Quality (School of MD, Groningen, The Netherlands, October 2006) 80% Eng. 20% MD
• Engineers are very active in translational knowledge, MD and Bio should move fast as well, for the better of all
• SP as part of IT is a powerful tool when combined withMEMS
• Labs On-Chip are a reality• Labs On-Body are waiting at the other side of the corner…

68
Laredo, 23 de junio de 2007 135
ReferencesReferences
1. Moore, S. K., “Making Chips”, IEEE Spectrum, March 2001, pp. 54-602. Vaidyanathan, P., “Genomics and Proteomics: A Signal Processor’s Tour”,
IEEE Circuits and Systems Magazine, October 2004, pp. 6-293. Amaratunga, D. and Cabrera, J., Exploration and analysis of DNA
microarray and protein array data, Ed. Wiley Interscience, Hobooken, N.J., 2004
4. Doughtery, E. R., Shmulevich, I., Chen, J., and Wang, Z. J. (editors), Genomic Signal Processing and Statistics, Eurasip Book Series on Signal Processing and Communications, 2005
5. Schena, M., Microarray Analysis, 1st Edition, J. Wiley & Sons, Hoboken, NJ, 2003
6. Proceedings of the IEEE/NML Life Sciences, Systems and Applications Workshop, National Institute of Health, Bethesda, Maryland, July 13-14, 2006
7. Special Issue on Genomic Signal Processing, IEEE Trans. On SignalProcessing, Vol. 54, No. 6, June 2006




















