
Juhel, J., Autier, L., Kermarrec, C., Audusseau, J., & Deline, S. (2015, juin). Réduire...
61
Réduire l'hétérogénéité interindividuelle par dégroupement statistique ou regroupement « informé » des individus : une rencontre incertaine ? J. Juhel, L. Autier, C. Kermarrec, J. Audusseau & S. Deline Université Rennes 2 CRPCC (E.A. 1285) 5 ème Atelier MODEVAIIA - Camaret-sur-Mer 22-24 juin 2015
-
Upload
xn--universit-rennes2-jtb -
Category
Documents
-
view
2 -
download
0
Transcript of Juhel, J., Autier, L., Kermarrec, C., Audusseau, J., & Deline, S. (2015, juin). Réduire...

Réduire l'hétérogénéité interindividuelle par
dégroupement statistique ou
regroupement « informé » des individus :
une rencontre incertaine ?
J. Juhel, L. Autier, C. Kermarrec,
J. Audusseau & S. Deline
Université Rennes 2
CRPCC (E.A. 1285)
5ème Atelier MODEVAIIA - Camaret-sur-Mer 22-24 juin 2015

Niveau singulier : individuelCe qui est observé « en moyenne »
chez un individu donné
entre situations, entre moments
Regroupement
« informé » de certains individus
Modélisation de dynamiques individuelles Identification de patterns de variabilité intra-individuelle
Descriptions comportementales
Niveau général: sous-populationnelCe qui est observé « en moyenne »
sur une catégorie donnée d’individus
entre les individus, entre situations, entre moments
Niveau général : populationnelCe qui est observé « en moyenne »
chez tous les individus,
entre les individus, entre situations, entre moments
Données groupées (en laboratoire:
aléatorisation ; sur le terrain: contrôle
statistique)
Données groupées :
- a priori (par ex., sur la base de
caractérisations, d’attributions
individuelles);
- a posteriori (par ex.,
classification).
Cadre méthodologique

Une réorientation nécessaire ?
• “A manifesto on psychology as idiographic science: Bringing the person back into
scientific psychology, this time forever” (Molenaar, 2004).
• “Psychological methodology will change profoundly due to the necessity to focus on
intra-individual variation” (Molenaar, 2007).
• “Idiographic filters for psychological constructs” (Nesselroade, 2007).
• “The new Person-specific paradigm in psychology” (Molenaar & Campbell, 2009).
Une tâche insurmontable ?
• Au plan pratique : problèmes posés par la répétition des mesures chez une même
personne.
• Au plan méthodologique : explosion du nombre de modèles, modélisation des
idiosyncrasies, impossibilité de généraliser au-delà de ce qui est spécifique à
l’individu (Curran, 2004).
• Peut-on espérer expliquer ainsi les DI (Tuerlinckx, 2004) ?
Cadre méthodologique

Vieillissement et coûts de commutation attentionnelle
Paradigme de switching
Deux conditions expérimentales:
• homogène : une seule consigne (par ex., visage: homme ou femme?), essais répétés;
• mixte : deux consignes (par ex., visage: homme ou femme? Gai ou triste?), essais
répétés et alternés ;
Deux type de coûts de commutation :
• coût global (mixing cost): essais répétés en condition mixte – essais répétés en
condition homogène ;
• coût local (switching cost): essais alternés – essais répétés en condition mixte.
Cadre théorique de la recherche : mécanismes de contrôle
cognitif chez la personne vieillissante

Vieillissement et coûts de commutation attentionnelle
Que sait-on ? (Méta-analyse de Wasylyshyn, Verhaeghen & Sliwinski, 2011; Verhaegen, 2014)
Coût global (TR) : mixte - homogène
• pattern additif : environ 140 msec chez le sujet jeune ;
• augmentation avec l’âge après contrôle du ralentissement lié à l’âge.
Coût local (TR) : alterné - répété
• pattern multiplicatif : environ 40% chez le sujet jeune ;
• pas d’augmentation avec l’âge après contrôle du ralentissement lié à l’âge.
“Older adults can efficiently activate and deactivate the cognitive system to perform task
switches but they are impaired when maintaining and coordinating two task sets in
working memory.” (Wasylyshyn et al., 2011, p. 19)
Cadre théorique de la recherche : mécanismes de contrôle
cognitif chez la personne vieillissante

Participants
• Données en cours de collecte ;
• A ce jour : N=69, 26 hommes, 43 femmes ;
Age moyen : 70,17 ans (étendue de 60 à 84 ans) ;
MMSE : score moyen = 28,83 (étendue de 26 à 30).
La recherche : étude chez la personne vieillissante des coûts
locaux à une tâche de commutation

Procédure expérimentale
Tâche Indice + (C : condition congruence) : appuyer sur le bouton de la même couleur
que celle du stimulus-cible présenté à l’écran : « blanc si blanc » ou « noir si noir ».
Tâche Indice - (I : condition incongruence) : appuyer sur le bouton de la couleur opposée
à celle du stimulus-cible présenté à l’écran : « blanc si noir » ou « noir si blanc ».
La recherche : étude chez la personne vieillissante des coûts
locaux à une tâche de commutation
Indice : 1000 msec.
750 msec.
NOIR : Précision +Temps de Réponse
1000 msec.
Indice: 1000 msec.
750 msec.
NOIR : Précision +Temps de RéponseEssai congruent
Essai incongruent

Procédure expérimentale
• Phase 1 : 17 essais en condition « congruence ».
• Phase 2 : 17 essais en condition « incongruence »;
• Phase 3 : condition mixte - 33 essais d’entrainement (C C C I I I C C C…)
• Phase expérimentale : condition mixte - 208 essais (C C C I I I C C C…)
C C C I I I C C C I I I C C C . . .
. R R A R R A R R A R R A R R ...
Répété Alterné
La recherche : étude chez la personne vieillissante des coûts
locaux à une tâche de commutation

La recherche : étude chez la personne vieillissante des coûts
locaux à une tâche de commutation
Questions posées
1) Quels sont les effets de l’âge sur :
• l’effet d’interférence (essais Incongruents – essais Congruents),
• l’effet d’alternance (essais Alternés – essais Répétés) ?
2) Sujet expérimental en un certain sens comme tous les autres, comme certains autres :
quel est le niveau de généralité de ces effets ?

Données individuelles groupées (1 jeu de données empilées: N × 208 lignes)
• Analyse des effets des manipulations expérimentales sur les TR et la précision :
LM et GLM à effets aléatoires.
• Dégroupement des individus par identification de sous-groupes sur la base des
résultats des analyses de l’étape précédente : classification par les classes latentes.
Données individuelles (N jeux de données de 208 lignes)
• Analyse des effets des manipulations expérimentales sur la précision et les TR:
- TR : moindres carrés généralisés (GLS).
- Précision : GLM autorégressif et à moyenne mobile.
• Regroupement des individus sur la base de critères identifiés après modélisation
des N vecteurs de réponses.
Quelle convergence entre dégroupement et regroupement ?
Démarche d’analyse

Analyse des données individuelles groupées

Le modèle mixte linéaire (L2M)
Yij , j-ième observation continue de l’individu i (i = 1,…, N ; j =1 ,…, n) et
le vecteur des réponses :
Vecteur β des p effets fixes et matrice de plan Xi (dim = n × p).
Vecteur bi des q effets aléatoires et matrice de plan Zi (dim = n × q).
Matrice de variance covariance D des effets aléatoires (dim = q × q).
Matrice de variance covariance Σi des résidus (dim = n × n).
Paramètres du modèle : effets fixes et écarts-types des effets aléatoires et des résidus.
Analyse des Temps de Réponse
1( ,..., ) 'i i inY Y=Y
1 1
(0, ),
(0, ),
les ,..., , ,..., sont indépendants.
i
i i
N N
N D
N Σ
∼
∼
b
ε
b b ε ε
,i i i i iX Z= + +Y β b ε

Le modèle mixte linéaire (L2M)
Conditionnellement aux effets aléatoires bi :
- les Yij sont indépendantes,
- le vecteur des réponses Yi suit une loi normale multivariée de moyennes
et de matrice de variance covariance des résidus
Estimation - ML ou ML restreint (REML: estimateur sans biais des composantes de la
variance).
Analyse des Temps de Réponse
i i iX Z+β b
| ( , ).i i i i i iN X Z+ Σ∼Y b β b
2 .i nσ=Σ I

Analyse des Temps de Réponse
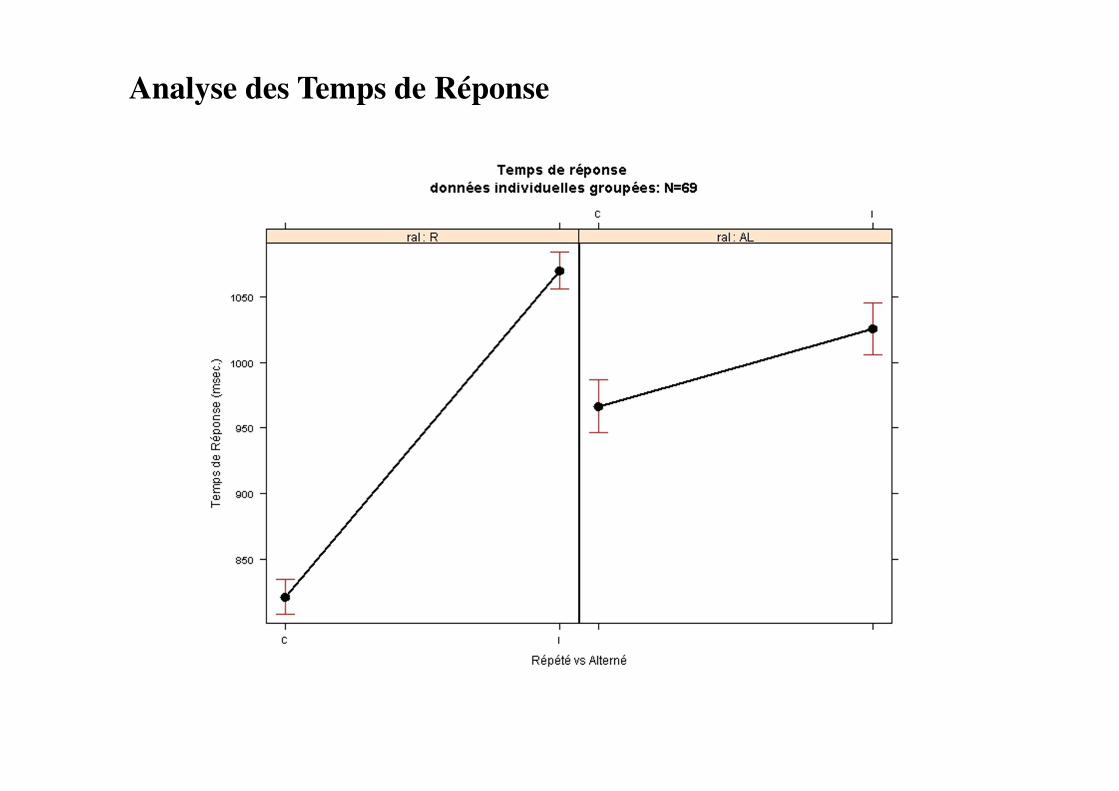
Analyse des Temps de Réponse

L2M : lmer
Comparaison des modèles suivants :
log(tr_br) ~ 1 + (1 | id)
log(tr_br) ~ 1 + ci + (1 | id)
log(tr_br) ~ 1 + ral + (1 | id)
log(tr_br) ~ 1 + ci + ral + (1 | id)
log(tr_br) ~ 1 + ci + (1 + ci | id)
log(tr_br) ~ 1 + ral + (1 + ral | id)
log(tr_br) ~ 1 + ci + ral + ci:ral + (1 | id)
log(tr_br) ~ 1 + ci + ral + (1 + ci | id)
log(tr_br) ~ 1 + ci + ral + (1 + ral | id)
log(tr_br) ~ 1 + ci * ral + (1 + ci | id)
log(tr_br) ~ 1 + ci * ral + (1 + ral | id)
log(tr_br) ~ 1 + ci + ral + (1 + ci + ral | id)
log(tr_br) ~ 1 + ci * ral + (1 + ci + ral | id)
log(tr_br) ~ 1 + ci * ral + (1+ ci * ral | id)
Analyse des Temps de Réponse
BIC12006
10664
11911
10579
10520
11883
10346
10433
10546
10194
10310
10409
10165
10146

Modèle retenu : log(tr_br) ~ 1+ci+ral+ci:ral+(1+ci+ral+ci:ral | id)
AIC BIC logLik deviance df.resid (maximum de vraisemblance)
10033.453 10145.827 -5001.726 10003.453 13233
Scaled residuals:
Min 1Q Median 3Q Max
-6.4878 -0.6739 -0.1310 0.6028 4.4646
Random effects:
Groups Name Variance Std.Dev. Bootstrap : IC 95% corr
id (Intercept) 0.07783 0.2790 [0.2303,0.2830,0.3404]
ciI 0.01759 0.1326 [0.1036,0.1360,0.1681] -0.19
ralAL 0.01181 0.1087 [0.0659,0.0964,0.1273] -0.10 0.39
ciI:ralAL 0.02045 0.1430 [0.0434,0.0756,0.1041] 0.06 -0.65 -0.73
Residual 0.11920 0.3453 [0.3556,0.3607,0.3658]
Number of obs: 13248, (92.31% de bonnes réponses), groups: id, 69
Fixed effects:
Estimate Std. Error t value
(Intercept) 6.60171 0.03400 194.17
ciI 0.30125 0.01765 17.07
ralAL 0.16760 0.01589 10.55
ciI:ralAL -0.20679 0.02139 -9.67
Correlation of Fixed Effects:
(Intr) ciI ralAL
ciI -0.220
ralAL -0.129 0.380
ciI:ralAL 0.083 -0.613 -0.725
Introduction de l’âge dans le modèle
- Pas d’effet d’interaction age × ci, age × ral, age
× ral × ci.
- Amélioration de l’ajustement (BIC: 10134 vs
10145) : effet positif de l’âge mais corrélation
de -.995 entre l’âge et l’intercept.
Analyse des Temps de Réponse
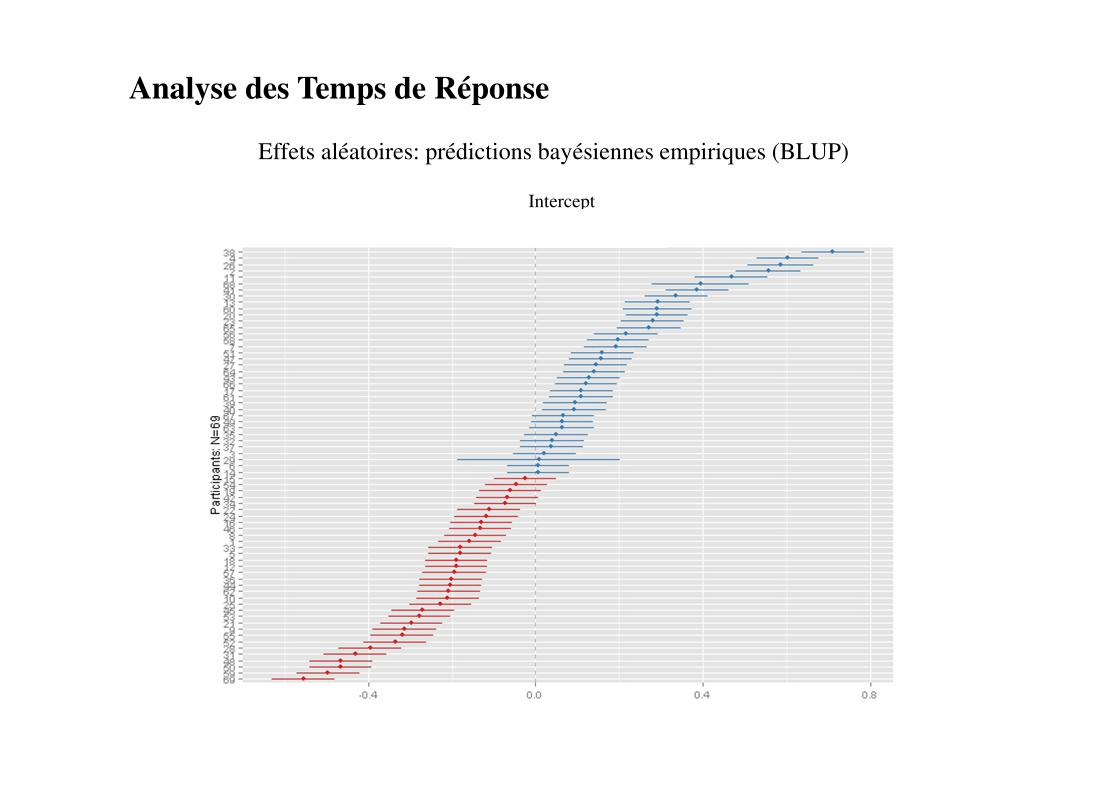
Effets aléatoires: prédictions bayésiennes empiriques (BLUP)
Analyse des Temps de Réponse
Intercept
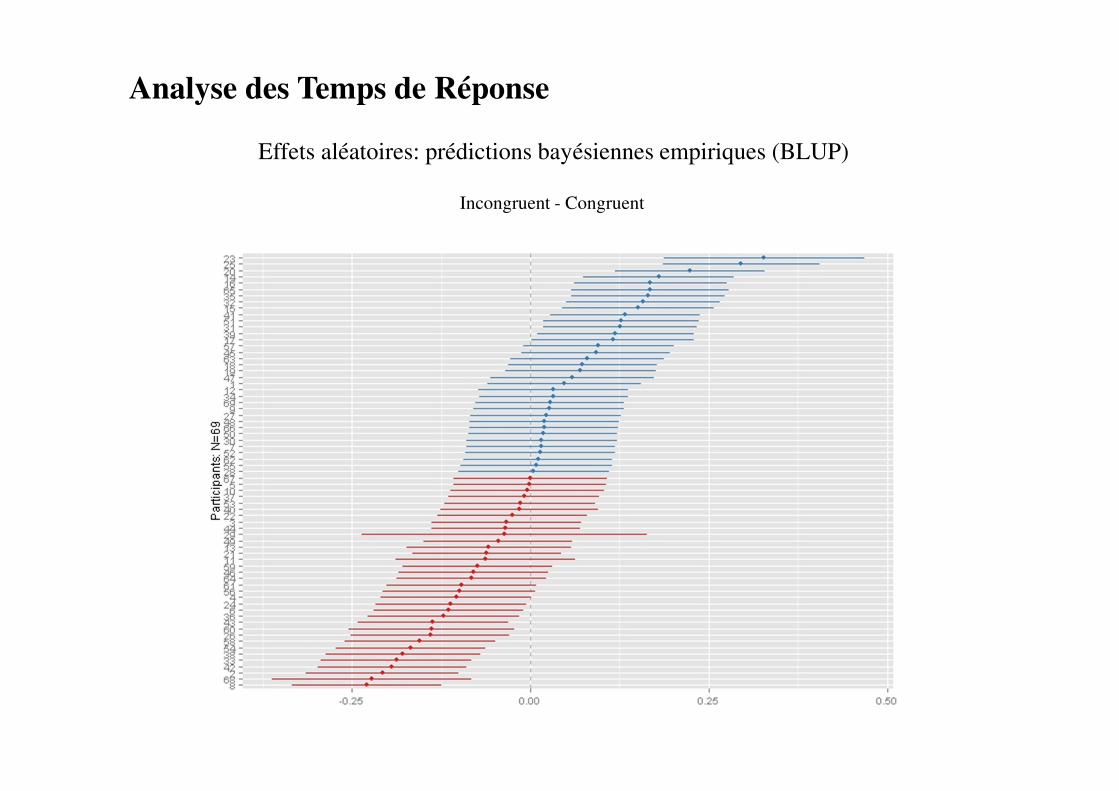
Effets aléatoires: prédictions bayésiennes empiriques (BLUP)
Analyse des Temps de Réponse
Incongruent - Congruent
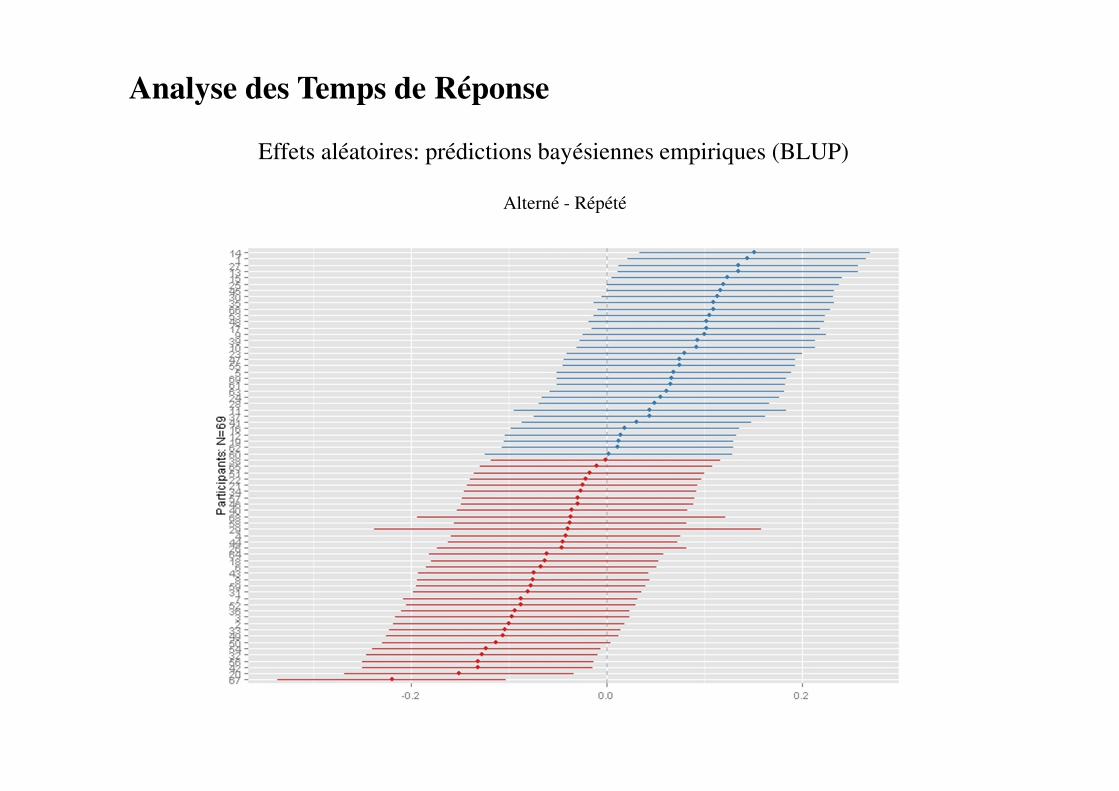
Effets aléatoires: prédictions bayésiennes empiriques (BLUP)
Analyse des Temps de Réponse
Alterné - Répété

Effets aléatoires: prédictions bayésiennes empiriques (BLUP)
Analyse des Temps de Réponse
Interaction C/I × R/AL

Modèle de régression logistique à effets aléatoires (GL2M)
yij, j-ième observation de l’individu i, suit une loi de Bernouilli avec une probabilité de
succès πij :
Moyenne conditionnée par les effets aléatoires :
On suppose que les effets aléatoires bi sont gaussiens, centrés et ont une structure D de
variance covariance :
Vecteur β des p effets fixes et matrice de plan Xi (dim = n × p)
Vecteur bi des q effets aléatoires et matrice de plan Zi (dim = n × q).
Matrice de variance covariance D des effets aléatoires (dim = q × q).
→ L’estimation des β dépend des effets aléatoires bi.
Analyse de la Précision
1| (logit ( )).i i i i iN X Z− +∼y b β b
(0, ).i N D∼b
exp( )( | ) ( | , , , ) .
1 exp( )
i i iij i ij i i i
i i i
X ZE y P y X Z
X Z
+= =
+ +
β bb β b
β b
(1, ).i iB π=y
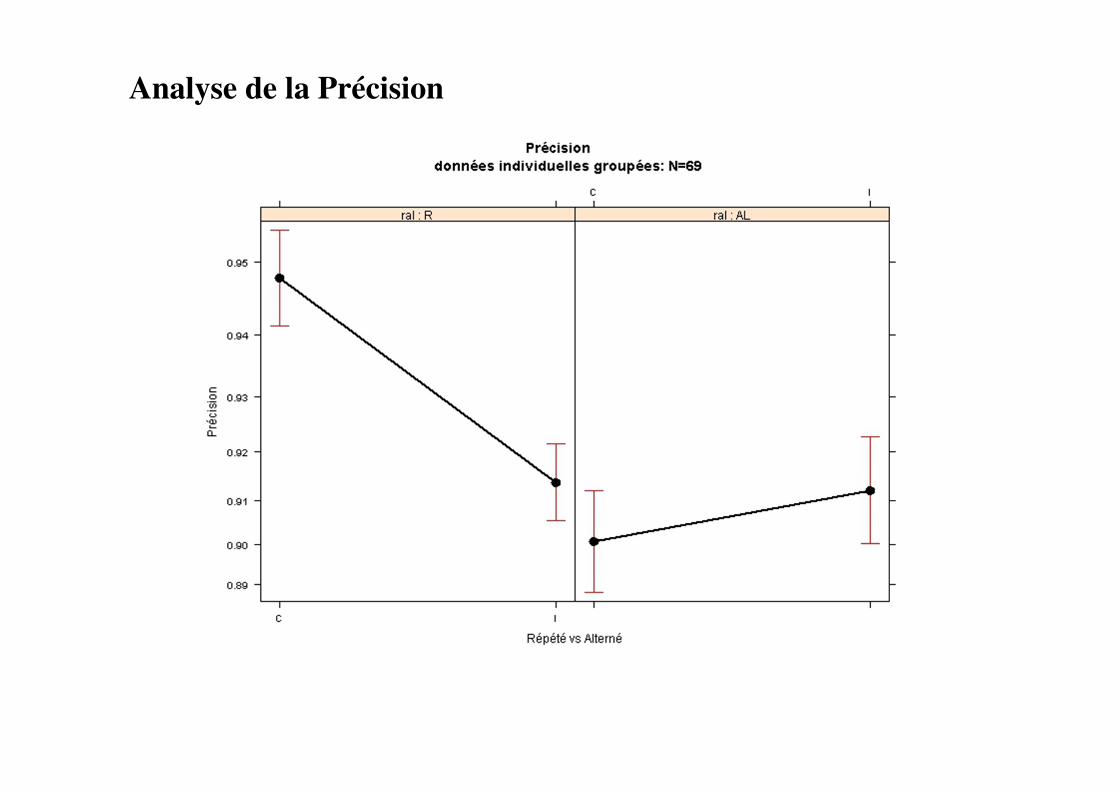
Analyse de la Précision

GL2M : glmer (lien logit)
Comparaison des modèles suivants :
pr ~ 1 + (1 | id)
pr ~ 1 + ci + (1 | id)
pr ~ 1 + ral + (1 | id)
pr ~ 1 + ci + ral + (1 | id)
pr ~ 1 + ci + (ci | id)
pr ~ 1 + ral + (ral | id)
pr ~ 1 + ci + ral + ci:ral + (1 | id)
pr ~ 1 + ci + ral + (ci | id)
pr ~ 1 + ci + ral + (ral | id)
pr ~ 1 + ci + ral + ci:ral + (ci | id)
pr ~ 1 + ci + ral + ci:ral + (ral | id)
pr ~ 1 + ci + ral + (ci + ral | id)
pr ~ 1 + ci + ral + ci:ral + (ci + ral | id)
pr ~ 1 + ci + ral + ci:ral + (ci + ral + ci:ral | id)
Analyse de la Précision
BIC6600
6588
6579
6567
6207
6560
6545
6182
6548
6149
6525
6169
6148
6165

Modèle retenu : pr ~ 1+ci+ral+ci:ral+(1+ci| id)
Generalized linear mixed model fit by maximum likelihood (Laplace Approximation) ['glmerMod']
Family: binomial ( logit )
AIC BIC logLik deviance df.resid
6096.4 6149.4 -3041.2 6082.4 14345
Scaled residuals:
Min 1Q Median 3Q Max
-9.6523 0.1199 0.1779 0.2600 4.8250
Random effects:
Groups Name Variance Std.Dev. Corr
id (Intercept) 1.915 1.384
ciI 1.889 1.375 -0.56
Number of obs: 14352, groups: id, 69
Fixed effects:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.8013 0.1930 19.698 < 2e-16 ***
ciI -0.8130 0.2069 -3.930 8.49e-05 ***
ralAL -1.0054 0.1121 -8.969 < 2e-16 ***
ciI:ralAL 0.9804 0.1468 6.679 2.40e-11 ***
---
Correlation of Fixed Effects:
(Intr) ciI ralAL
ciI -0.620
ralAL -0.313 0.292
ciI:ralAL 0.239 -0.325 -0.764
Introduction de l’âge dans le modèle
- Pas d’effet d’interaction age × ci, age
× ral, age × ral × ci.
- Amélioration de l’ajustement (BIC:
6142 vs 6149) : effet positif de l’âge
mais corrélation de -.991 entre l’âge
et l’intercept.
Analyse de la Précision

Analyse de la Précision
Effets aléatoires: prédictions bayésiennes empiriques (BLUP)
Intercept
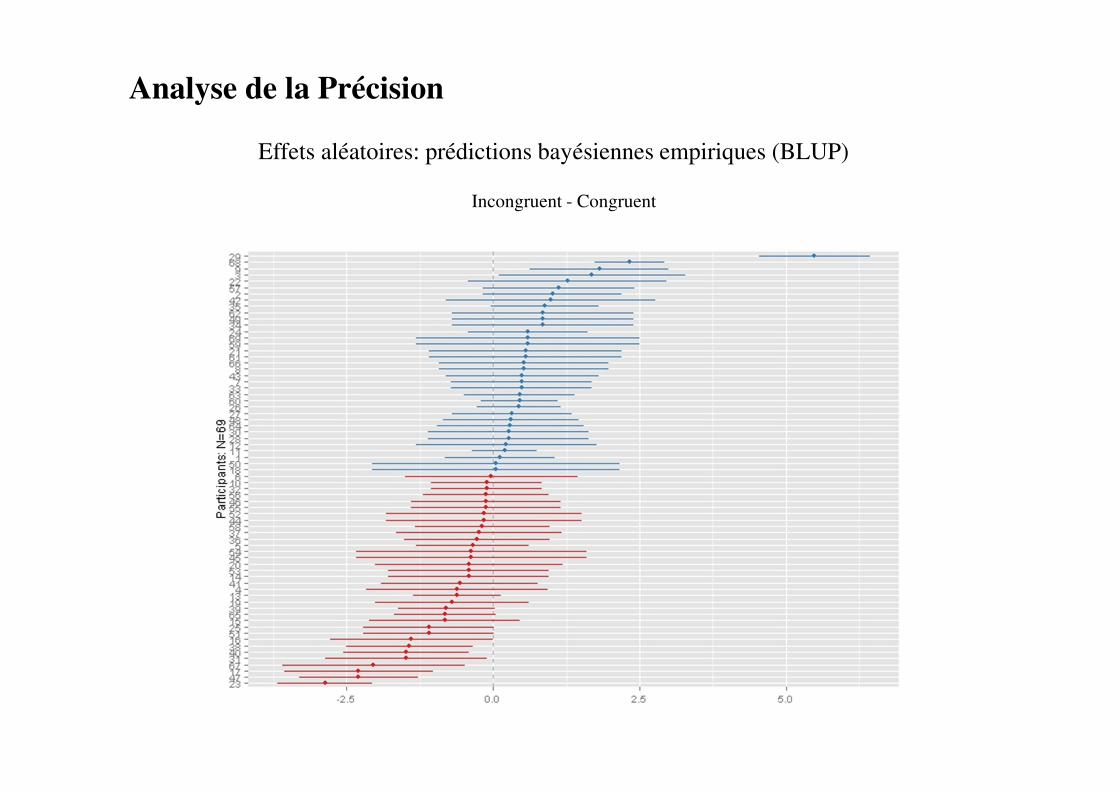
Analyse de la Précision
Effets aléatoires: prédictions bayésiennes empiriques (BLUP)
Incongruent - Congruent

Modèle de classification par les classes latentes
Variables observées continues: données y1, …, yn dans . La densité du mélange
gaussien multidimensionnel s’écrit :
vecteur des paramètres des densités,
K : nombre de clusters,
πk : proportions du mélange,
densité de la loi normale multivariée,
→ Restrictions sur les Σk (par ex., hypothèse d’indépendance locale = matrices Σk diagonales).
dℝ
1
( | ) ( | , ),K
k k k
k
f π ϕ=
= Σ∑y θ y µ
1 1 1( ,..., , ,..., , ,..., )K K Kπ π µ µ Σ Σ :θ
:ϕ
Classification des individus sur la base des effets aléatoires

Modèle de classification par les classes latentes
Estimation : ML avec l’algorithme itératif EM
- Espérance : calcul des probabilités a posteriori d’appartenance des yi aux
classes conditionnellement au paramètre courant.
- Maximisation de la vraisemblance conditionnellement aux : calcul des
proportions , des moyennes et des matrices .
- A la convergence, affectation de chaque individu par la méthode du maximum a
posteriori : chaque individu est rangé dans la classe qui maximise la probabilité a
posteriori d’appartenance à la classe k calculée à partir des estimations de θ.
( ) cikp
( ) cikp
( 1) ckπ + ( 1) c
kµ + ( 1) ck
+Σ
ikp
Classification des individus sur la base des effets aléatoires
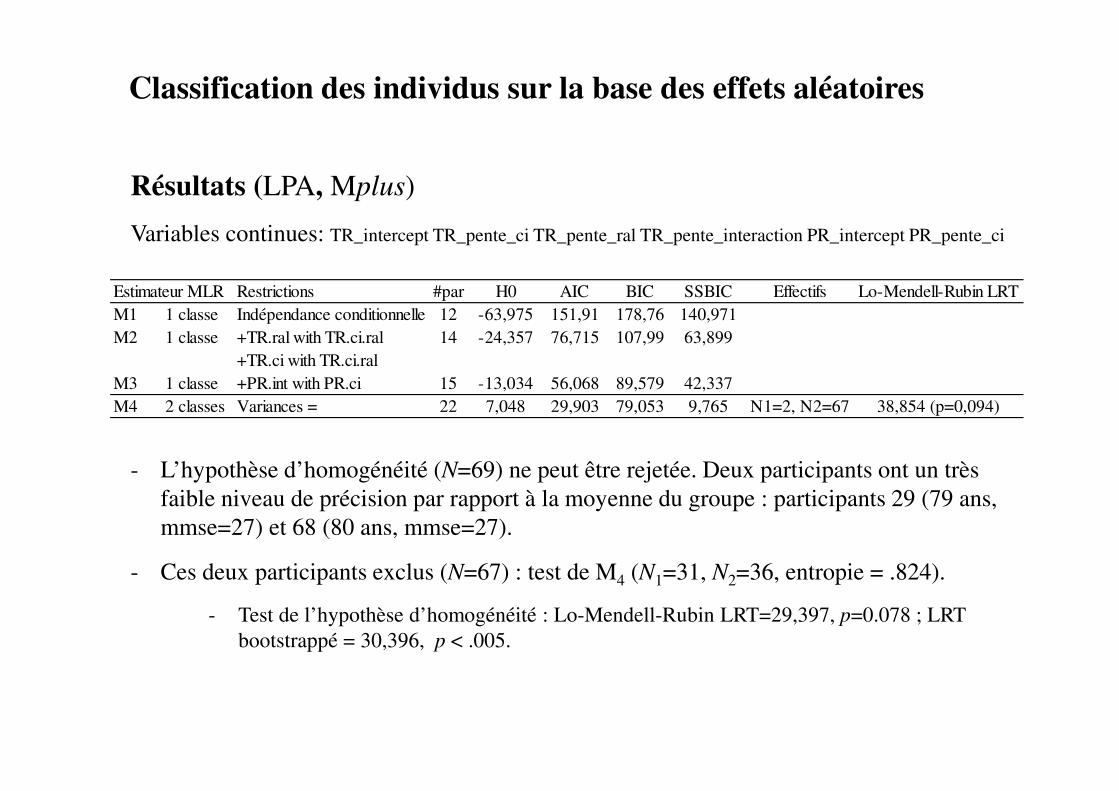
Résultats (LPA, Mplus)
Variables continues: TR_intercept TR_pente_ci TR_pente_ral TR_pente_interaction PR_intercept PR_pente_ci
- L’hypothèse d’homogénéité (N=69) ne peut être rejetée. Deux participants ont un très
faible niveau de précision par rapport à la moyenne du groupe : participants 29 (79 ans,
mmse=27) et 68 (80 ans, mmse=27).
- Ces deux participants exclus (N=67) : test de M4 (N1=31, N2=36, entropie = .824).
- Test de l’hypothèse d’homogénéité : Lo-Mendell-Rubin LRT=29,397, p=0.078 ; LRT
bootstrappé = 30,396, p < .005.
Estimateur MLR Restrictions #par H0 AIC BIC SSBIC Effectifs Lo-Mendell-Rubin LRT
M1 1 classe Indépendance conditionnelle 12 -63,975 151,91 178,76 140,971
M2 1 classe +TR.ral with TR.ci.ral 14 -24,357 76,715 107,99 63,899
+TR.ci with TR.ci.ral
M3 1 classe +PR.int with PR.ci 15 -13,034 56,068 89,579 42,337
M4 2 classes Variances = 22 7,048 29,903 79,053 9,765 N1=2, N2=67 38,854 (p=0,094)
Classification des individus sur la base des effets aléatoires

Résultats (LPA avec Mplus)
Sur N = 67 participants, modèles à 2 classes :
M5: restrictions de M4 +
- invariance de TR_intercept (contrôle du ralentissement lié à l’âge),
- invariance de PR_intercept (comparaison à niveau de précision égal),
- moyenne de l’âge libérée dans chaque groupe.
M6: restrictions de M4 +
- invariance de TR_intercept (contrôle du ralentissement lié à l’âge),
- invariance de PR_intercept (comparaison à niveau de précision égal),
- moyennes de l’âge contrainte à l’égalité dans les deux groupes.
Meilleur modèle: M5 (M5: #par=23, BIC=464.39 ; M6: #par=22, BIC=476.16; ∆χ2=24,56, ddl=1, p<.000).
Classification des individus sur la base des effets aléatoires

Estimation S.E. Est./S.E. p Estimation S.E. Est./S.E. p
Corrélations Corrélations
TR_RAL WITH TR_RAL WITH
TR_CXR -0.650 0.066 -9.917 0.000 TR_CXR -0.650 0.066 -9.917 0.000
TR_CI WITH TR_CI WITH
TR_CXR -0.397 0.100 -3.994 0.000 TR_CXR -0.397 0.100 -3.994 0.000
PR_MU WITH PR_MU WITH
PR_CI -0.255 0.101 -2.529 0.011 PR_CI -0.255 0.101 -2.529 0.011
Moyennes Moyennes
TR_MU -0.006 0.035 -0.184 0.854 TR_MU -0.006 0.035 -0.184 0.854
TR_CI -0.047 0.018 -2.560 0.010 TR_CI 0.044 0.023 1.893 0.058
TR_RAL -0.025 0.016 -1.511 0.131 TR_RAL 0.020 0.016 1.313 0.189
TR_CI X RAL 0.053 0.018 2.964 0.003 TR_CI X RAL -0.046 0.020 -2.352 0.019
PR_MU 0.038 0.107 0.355 0.723 PR_MU 0.038 0.107 0.355 0.723
PR_CI 0.446 0.112 3.997 0.000 PR_CI -0.522 0.152 -3.444 0.001
AGE 63.780 0.701 91.008 0.000 AGE 74.723 0.760 98.262 0.000
Variances Variances
TR_MU 0.080 0.014 5.670 0.000 TR_MU 0.080 0.014 5.670 0.000
TR_CI 0.014 0.003 4.697 0.000 TR_CI 0.014 0.003 4.697 0.000
TR_RAL 0.007 0.001 6.703 0.000 TR_RAL 0.007 0.001 6.703 0.000
TR_CXR 0.009 0.001 6.355 0.000 TR_CXR 0.009 0.001 6.355 0.000
PR_MU 0.772 0.163 4.725 0.000 PR_MU 0.772 0.163 4.725 0.000
PR_CI 0.620 0.119 5.205 0.000 PR_CI 0.620 0.119 5.205 0.000
AGE 12.835 2.644 4.853 0.000 AGE 12.835 2.644 4.853 0.000
Classe 1 (N=30) Classe 2 (N=37)
Comparaison des deux classes
M5_blup67_2cl

Comparaison des deux classes
Conclusion
A tempo de réponse et niveau de précision contraints à l’égalité dans les deux
classes :
1) Individus du SG_1 en moyenne plus jeunes que ceux du SG_2.
2) Chez les individus du SG_1 en comparaison à ceux du SG_2 :
- l’écart des TR entre conditions I et C est plus faible,
- les erreurs sont plus fréquentes aux essais C qu’aux essais I.
Interprétation : biais d’attente (des stimuli I) pouvant s’expliquer par l’engagement
préférentiel d’un mode de contrôle proactif chez les individus du SG_1 en comparaison
à ceux du SG_2.
3) L’effet d’alternance (coût local) varie selon les individus mais n’augmente pas avec
l’âge.

Analyses de niveau individuel
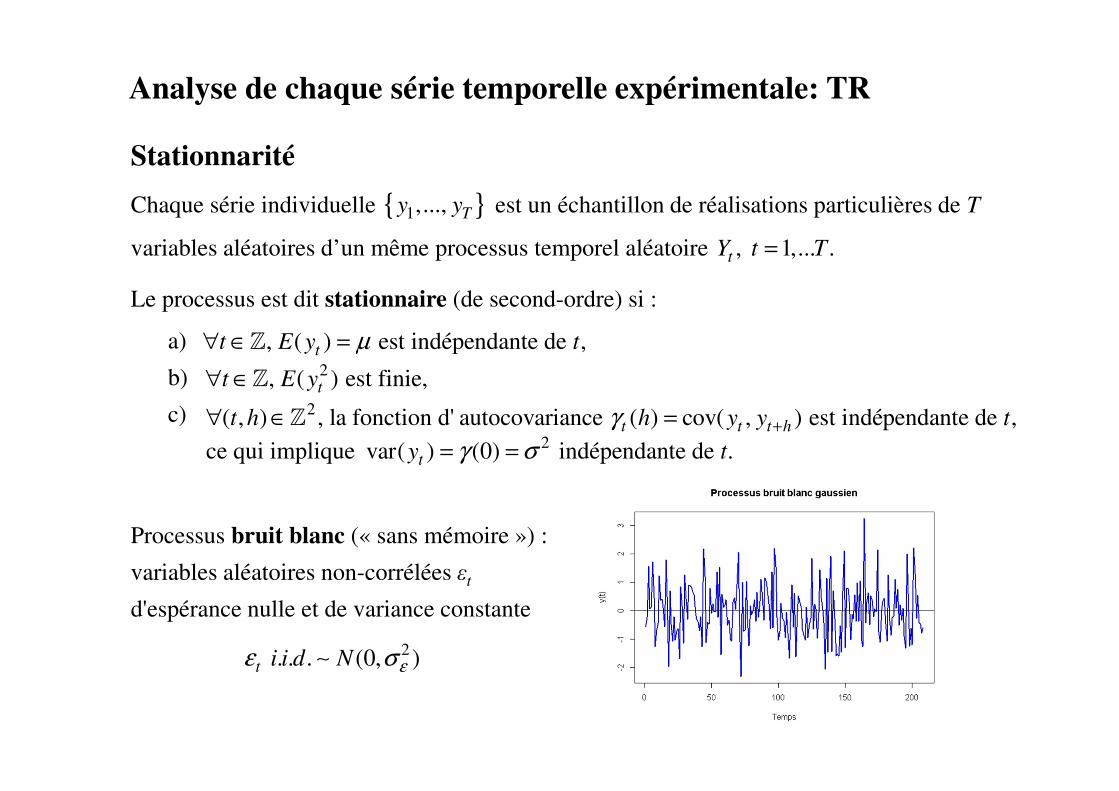
Stationnarité
Chaque série individuelle est un échantillon de réalisations particulières de T
variables aléatoires d’un même processus temporel aléatoire
Le processus est dit stationnaire (de second-ordre) si :
a)
b)
c)
ce qui implique
Processus bruit blanc (« sans mémoire ») :
variables aléatoires non-corrélées εt
d'espérance nulle et de variance constante
Analyse de chaque série temporelle expérimentale: TR
2( , ) , la fonction d' autocovariance ( ) cov( , ) est indépendante de ,t t t ht h h y y tγ +∀ ∈ =ℤ
, 1,... .tY t T=
2, ( ) est finie, tt E y∀ ∈ℤ
, ( ) est indépendante de , tt E y tµ∀ ∈ =ℤ
{ }1,..., Ty y
2var( ) (0) indépendante de .ty tγ σ= =
2 . . . (0, )t i i d N εε σ∼

Stationnarité
→ Test de Dickey-Fuller (H0 : non-stationnarité)
Soit le processus satisfaisant la représentation AR(1) :
avec
Résultats
Les variables Y1, Y2, ..., Yt peuvent être représentées par au moins un processus stochastique
indépendant du temps pour 67 participants.
H0 ne peut être rejetée pour S11 (p=0.075) et S28 (p=0.066).
Analyse de chaque série temporelle expérimentale: TR
, ,ty t ∈ℤ
1 ,t t ty yρ ε−= +
2 . . . (0, ) et .t i i d N εε σ ρ ∈∼ ℝ
( )0 : 1 non stationnarité i.e., marche aléatoire .
: 1.a
H
H
ρ
ρ
=
<

Dépendance sérielle
(Conséquence du) théorème de Wold : n’importe quelle série stationnaire peut être
représentée par une somme pondérée finie de chocs passés.
Processus AR : composante autorégressive d’ordre fini
AR(1) :
Exemple: processus AR(2)
Analyse des Temps de Réponse
1 20.7 0.6 0.15t t t ty y y υ− −= − − +
21
1
, (0, )
,
t t t t
ss
N υε φε υ υ σ
ρ φ ρ φ
−= +
= =
∼
Dépendance sérielle
(Conséquence du) théorème de Wold : n’importe quelle série stationnaire peut être
représentée par une somme pondérée finie de chocs passés.
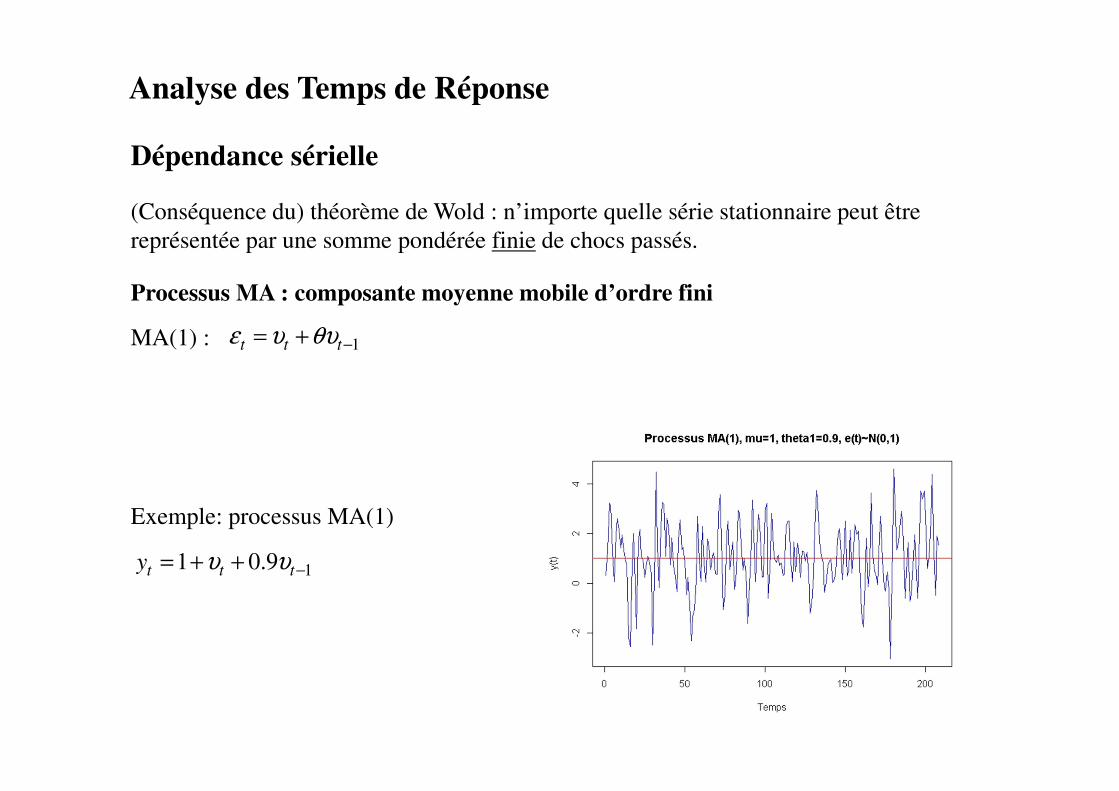
Processus MA : composante moyenne mobile d’ordre fini
MA(1) :
Exemple: processus MA(1)
Analyse des Temps de Réponse
11 0.9t t ty υ υ −= + +
1 t t tε υ θυ −= +

Dépendance sérielle
(Conséquence du) théorème de Wold : n’importe quelle série stationnaire peut être
représentée par une somme pondérée finie de chocs passés.
Processus ARMA : autorégression + moyenne mobile
ARMA(1,1) :
Exemple: processus ARMA(3,1)
Analyse des Temps de Réponse
1 3 12 0.5 0.25 0.5 :t t t t ty y y υ υ− − −= − + + −
1 1t t t tε φε υ θυ− −= + +

Dépendance sérielle
→ Test de Durbin-Watson
Si les résidus {εt, t ∈ Z} obéissent à un bruit blanc, il ne doit pas exister d’autocorrélation
dans la série.
Régression OLS et test de l’autocorrélation d’ordre 1 (test de Durbin Watson).
Sous H0 (autocorrélation nulle), d est proche de 2.
Analyse des Temps de Réponse
2
1
2
1
( )n
t t s
t ss n
i
t s
e e
d
e
−= +
= +
−
=
∑
∑

Moindres carrés généralisés (GLS)
En présence d’erreurs autocorrélées et/ou hétéroscédastiques, les MCO ne peuvent être
employés.
Estimation par les moindres carrés généralisés
Par exemple, avec une autocorrélation des erreurs d’ordre 1 (AR(1)), le modèle linéaire
s’écrit :
Analyse des Temps de Réponse
2
2
2
0
... ... ...
0 0 ...
V
ε
εε
ε
σ
σ
σ
=
21
221 2
21 2
... ... ...
...T T T
Vε
σ
ε σ
ε ε σ
=
1
2
,
avec ,
1, (0, ) et cov( , ) 0.
t t t
t t t
t t t h
y X
N υ
β ε
ε ρε υ
ρ υ σ υ υ
−
+
= +
= +
< =∼
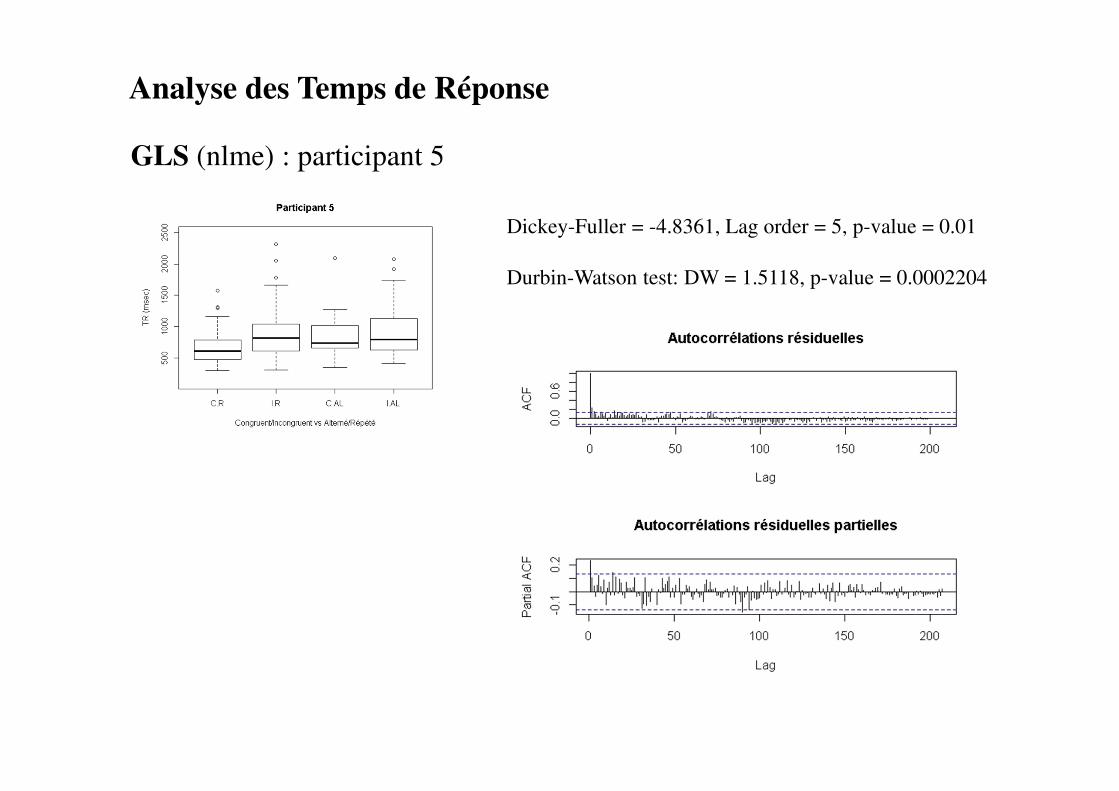
Analyse des Temps de Réponse
GLS (nlme) : participant 5
Dickey-Fuller = -4.8361, Lag order = 5, p-value = 0.01
Durbin-Watson test: DW = 1.5118, p-value = 0.0002204

Analyse des Temps de Réponse
GLS (nlme) : participant 5
1) Structure de corrélation des erreurs - Comparaison des modèles ARMA suivants :
2) Estimation des coefficients structurels avec la structure ARMA identifiée en 1).
p q sbc
ltr~1 1 0 -362.3093
ltr~1 0 0 -357.0667
ltr~1 2 0 -356.4565
ltr~1 3 0 -350.3522
ltr~1 4 0 -344.7611
ltr~1 BIC = 236.8575
ltr~1+ci BIC = 232.8744
ltr~1+ral BIC = 234.5934
ltr~1+ci+ral BIC = 230.6602
ltr~1+ci+ral+ci:ral BIC = 232.562
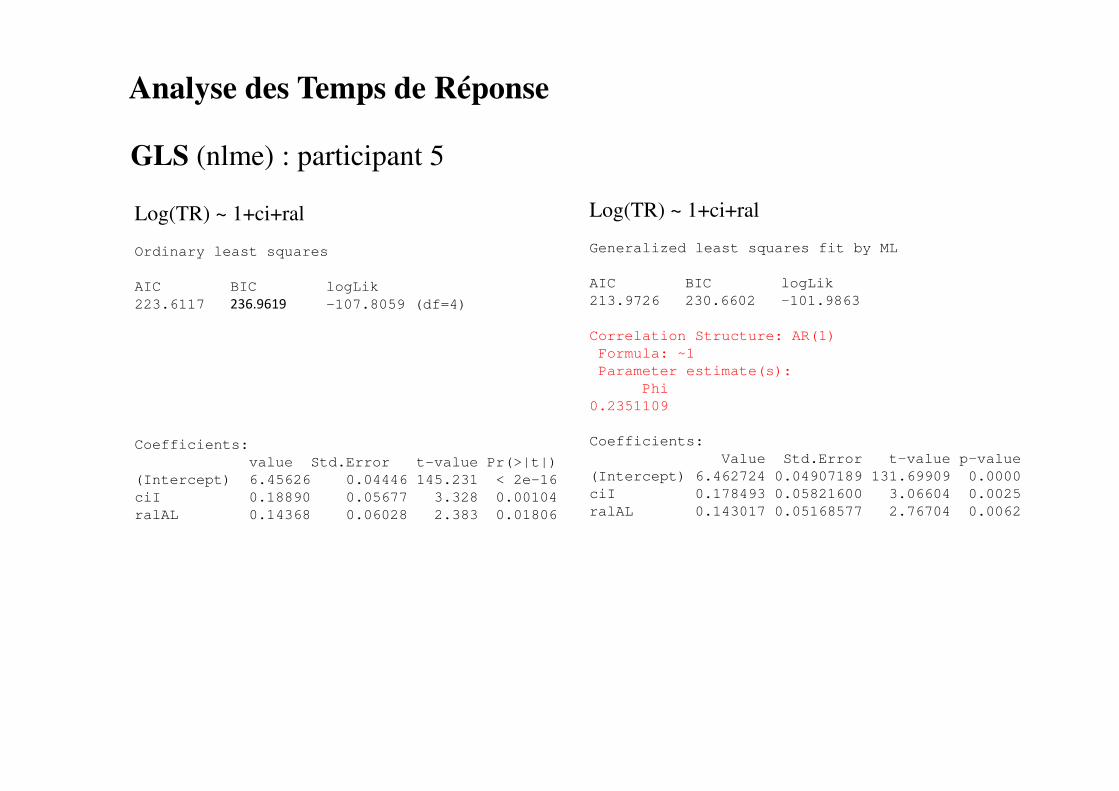
Log(TR) ~ 1+ci+ral
Generalized least squares fit by ML
AIC BIC logLik
213.9726 230.6602 -101.9863
Correlation Structure: AR(1)
Formula: ~1
Parameter estimate(s):
Phi
0.2351109
Coefficients:
Value Std.Error t-value p-value
(Intercept) 6.462724 0.04907189 131.69909 0.0000
ciI 0.178493 0.05821600 3.06604 0.0025
ralAL 0.143017 0.05168577 2.76704 0.0062
Log(TR) ~ 1+ci+ral
Ordinary least squares
AIC BIC logLik
223.6117 236.9619 -107.8059 (df=4)
Coefficients:
value Std.Error t-value Pr(>|t|)
(Intercept) 6.45626 0.04446 145.231 < 2e-16
ciI 0.18890 0.05677 3.328 0.00104
ralAL 0.14368 0.06028 2.383 0.01806
Analyse des Temps de Réponse
GLS (nlme) : participant 5
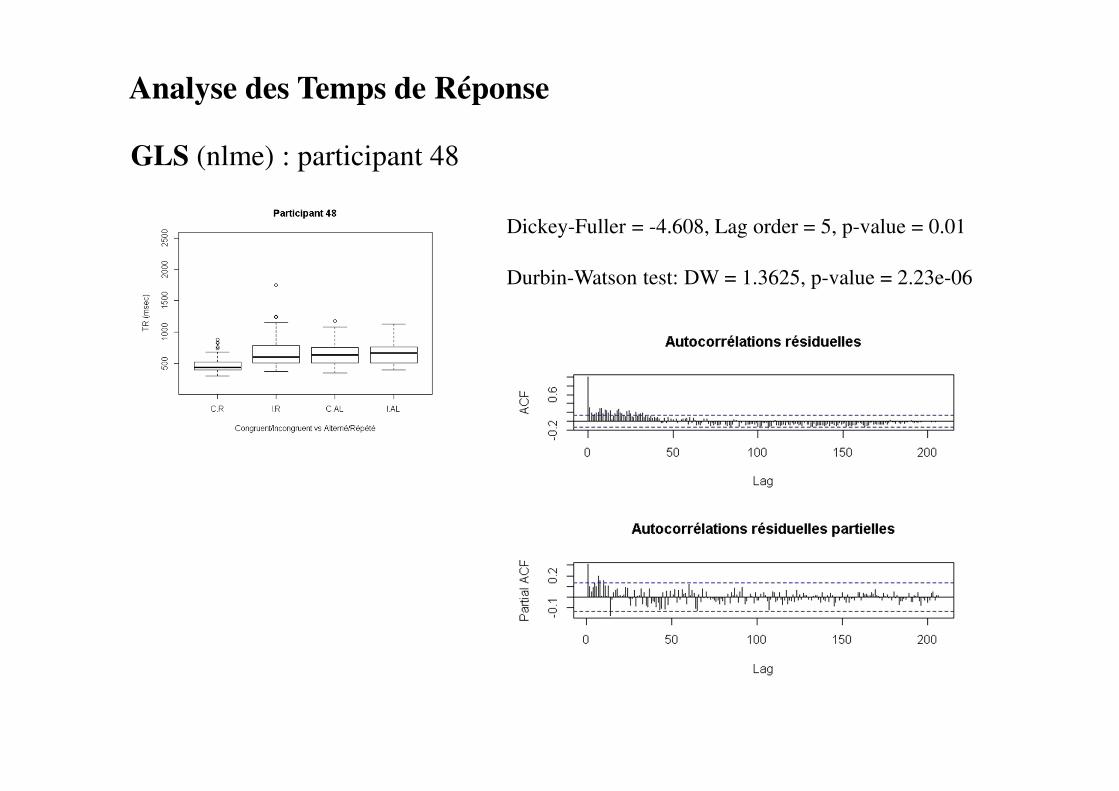
Analyse des Temps de Réponse
GLS (nlme) : participant 48
Dickey-Fuller = -4.608, Lag order = 5, p-value = 0.01
Durbin-Watson test: DW = 1.3625, p-value = 2.23e-06

Log(TR) ~ 1+ci+ral+ci:ral
Generalized least squares fit by ML
AIC BIC logLik
57.90436 84.60466 -20.95218
Correlation Structure: ARMA(2,1)
Formula: ~1
Parameter estimate(s):
Phi1 Phi2 Theta1
1.1068275 -0.1147435 -0.9311400
Coefficients:
Value Std.Error t-value p-value
(Intercept) 6.158753 0.11952561 51.52664 0e+00
ciI 0.333931 0.04698766 7.10678 0e+00
ralAL 0.325652 0.05349052 6.08804 0e+00
ciI:ralAL -0.315635 0.07837832 -4.02707 1e-04
Log(TR) ~ 1+ci+ral+ci:ral
Ordinary least squares
AIC BIC logLik
94.39982 111.0875 -42.19991 (df=5)
Coefficients:
value Std.Error t-value Pr(>|t|)
(Intercept) 6.12308 0.03552 172.388 < 2e-16
ciI 0.32848 0.05078 6.468 7.20e-10
ralAL 0.32424 0.06242 5.195 4.96e-07
ciI:ralAL -0.32073 0.08816 -3.638 0.000348
Analyse des Temps de Réponse
GLS (nlme) : participant 48

Log(TR) ~ 1+ci
Generalized least squares fit by ML
AIC BIC logLik
-20.02201 -6.671861 14.01101
Correlation Structure: ARMA(5,0)
Formula: ~1
Parameter estimate(s):
Phi1 Phi2 Phi3 Phi4 Phi5
0.5019 0.0345 -0.0712 -0.0449 0.1885
Coefficients:
Value Std.Error t-value p-value
(Intercept) 6.445134 0.04299403 149.90767 0
ciI 0.321832 0.03691752 8.71759 0
Log(TR) ~ 1+ci
Ordinary least squares
AIC BIC logLik
40.09535 50.10796 -17.04767 (df=3)
Coefficients:
value Std.Error t-value Pr(>|t|)
(Intercept) 6.43484 0.02575 249.849 <2e-16
ciI 0.34354 0.03660 9.386 <2e-16
Analyse des Temps de Réponse
GLM (nlme) : participant 18

Log(TR) ~ 1
Generalized least squares fit by ML
AIC BIC logLik
170.5718 180.5845 -82.28592
Correlation Structure: AR(1)
Formula: ~1
Parameter estimate(s):
Phi
0.1633852
Coefficients:
Value Std.Error t-value p-value
(Intercept) 6.905264 0.02982811 231.5019 0
Log(TR) ~ 1
Ordinary least squares
AIC BIC logLik
174.1901 180.8651 -85.09503 (df=2)
Coefficients:
value Std.Error t-value Pr(>|t|)
(Intercept) 6.90582 0.02532 272.7 <2e-16
Analyse des Temps de Réponse
GLM (nlme) : participant 58

Modèle GLARMA (Generalized Linear Autoregressive Moving Average)
Yt , réponse binaire au temps t, Xt , vecteur de covariables dont l’effet est
décrit par le vecteur de paramètres β.
Soit Ft-1 l’information contenue dans les réponses binaires passées et πt la probabilité de
Yt conditionnellement à Ft-1 :
On suppose que le processus d’état πt est linéaire dans ses prédicteurs et que les résidus
ont une structure de corrélation ARMA.
Note – Les et ( « résidus prédictifs ») et les Zt sont des fonctions des paramètres
et sont donc calculés à chaque itération au cours de l’optimisation du log-vraisemblance.
Analyse de la précision des réponses
1, 2,..., ;t T=
1 1
logit( )
( )
avec (résidus dePearson).(1 )
Tt t t t
p p
t i t i t i i t i
i i
t tt
t t
W X Z
Z Z e e
Ye
π β
φ θ
π
π π
− − −= =
= = +
= + +
−=
−
∑ ∑
, et β φ θ
1( 1| ).t t tP Y Fπ −= =

Analyse de la précision des réponses
GLARMA : participant 5
1) Structure de corrélation des erreurs - Comparaison des modèles suivants :
2) Estimation des coefficients structurels avec la structure AR ou MA identifiée en 1).
pr~1, AR(1) AIC = 119.6465
pr~1, AR(2) AIC = 120.7464
pr~1, AR(3) AIC = 121.944
pr~1, MA(1) AIC = 117.5413
pr~1, MA(2) AIC = 118.0221
pr~1, MA(3) AIC = 118.3721
pr~1 AIC = 117.5413
pr~1+ci AIC = 118.9646
pr~1+ral AIC = 114.2532
pr~1+ci+ral AIC = 115.5313
pr~1+ci+ral+ci:ral AIC = 112.3576

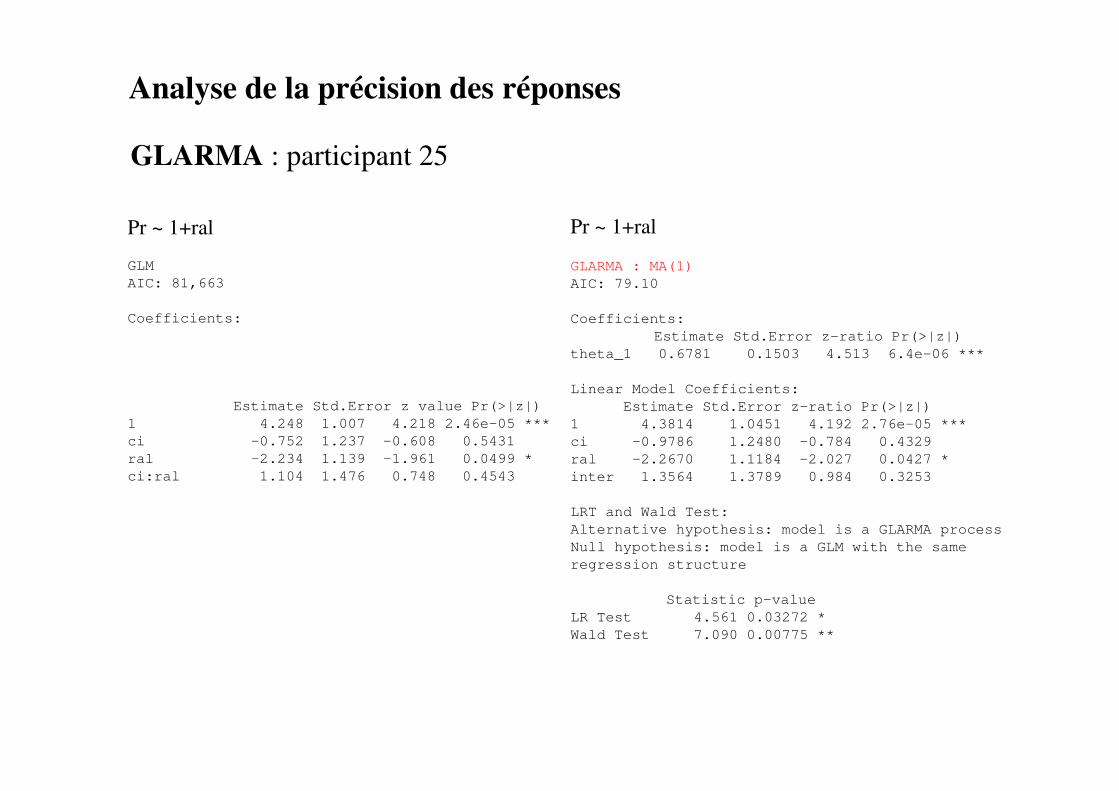
Analyse de la précision des réponses
GLARMA : participant 25
Pr ~ 1+ci
GLARMA : AR(3)
AIC: 104.533
Coefficients:
Estimate Std.Error z-ratio Pr(>|z|)
phi_3 -0.75064 0.07895 -9.508 <2e-16 ***
Linear Model Coefficients:
Estimate Std.Error z-ratio Pr(>|z|)
1 4.5140 0.8464 5.333 9.66e-08 ***
ci -2.4744 1.0778 -2.296 0.0217 *
LRT and Wald Test:
Alternative hypothesis: model is a GLARMA process
Null hypothesis: model is a GLM with the same
regression structure
Statistic p-value
LR Test 10.6 0.00113 **
Wald Test 90.4 < 2e-16 ***
Pr ~ 1+ci
GLM
AIC: 113.13
Coefficients:
Estimate Std.Error z value Pr(>|z|)
1 3.5264 0.5858 6.02 1.74e-09 ***
ci -1.6768 0.6525 -2.57 0.0102 *

Analyse de la précision des réponses
GLARMA : participant 5
Pr ~ 1+ci+ral+ci:ral
GLARMA : MA(1)
AIC: 112.3576
Coefficients:
Estimate Std.Error z-ratio Pr(>|z|)
theta_1 0.7003 0.1833 3.82 0.000133 ***
Linear Model Coefficients:
Estimate Std.Error z-ratio Pr(>|z|)
1 4.5279 0.9557 4.738 2.16e-06 ***
ci -2.1378 1.0760 -1.987 0.0469 *
ral -2.7580 1.0057 -2.742 0.0061 **
Ci:ral 2.4804 1.2058 2.057 0.0397 *
LRT and Wald Test:
Alternative hypothesis: model is a GLARMA process
Null hypothesis: model is a GLM with the same
regression structure
Statistic p-value
LR Test 14.29 0.000157 ***
Wald Test 14.59 0.000133 ***
Pr ~ 1+ci+ral+ci:ral
GLM
AIC: 124.64
Coefficients
Estimate Std.Error z value Pr(>|z|)
1 3.5410 0.7173 4.937 7.95e-07***
ci -1.3760 0.8208 -1.676 0.0937 .
ral -1.5261 0.8932 -1.709 0.0875 .
ci:ral 1.1529 1.0911 1.057 0.2907
Analyse de la précision des réponses
GLARMA : participant 25
Pr ~ 1+ral
GLARMA : MA(1)
AIC: 79.10
Coefficients:
Estimate Std.Error z-ratio Pr(>|z|)
theta_1 0.6781 0.1503 4.513 6.4e-06 ***
Linear Model Coefficients:
Estimate Std.Error z-ratio Pr(>|z|)
1 4.3814 1.0451 4.192 2.76e-05 ***
ci -0.9786 1.2480 -0.784 0.4329
ral -2.2670 1.1184 -2.027 0.0427 *
inter 1.3564 1.3789 0.984 0.3253
LRT and Wald Test:
Alternative hypothesis: model is a GLARMA process
Null hypothesis: model is a GLM with the same
regression structure
Statistic p-value
LR Test 4.561 0.03272 *
Wald Test 7.090 0.00775 **
Pr ~ 1+ral
GLM
AIC: 81,663
Coefficients:
Estimate Std.Error z value Pr(>|z|)
1 4.248 1.007 4.218 2.46e-05 ***
ci -0.752 1.237 -0.608 0.5431
ral -2.234 1.139 -1.961 0.0499 *
ci:ral 1.104 1.476 0.748 0.4543
Résultats d’ensemble
→ N = 67 : exclusion de 2 participants (S29 : 49% de réussite et S68 : 54,8% de
réussite).
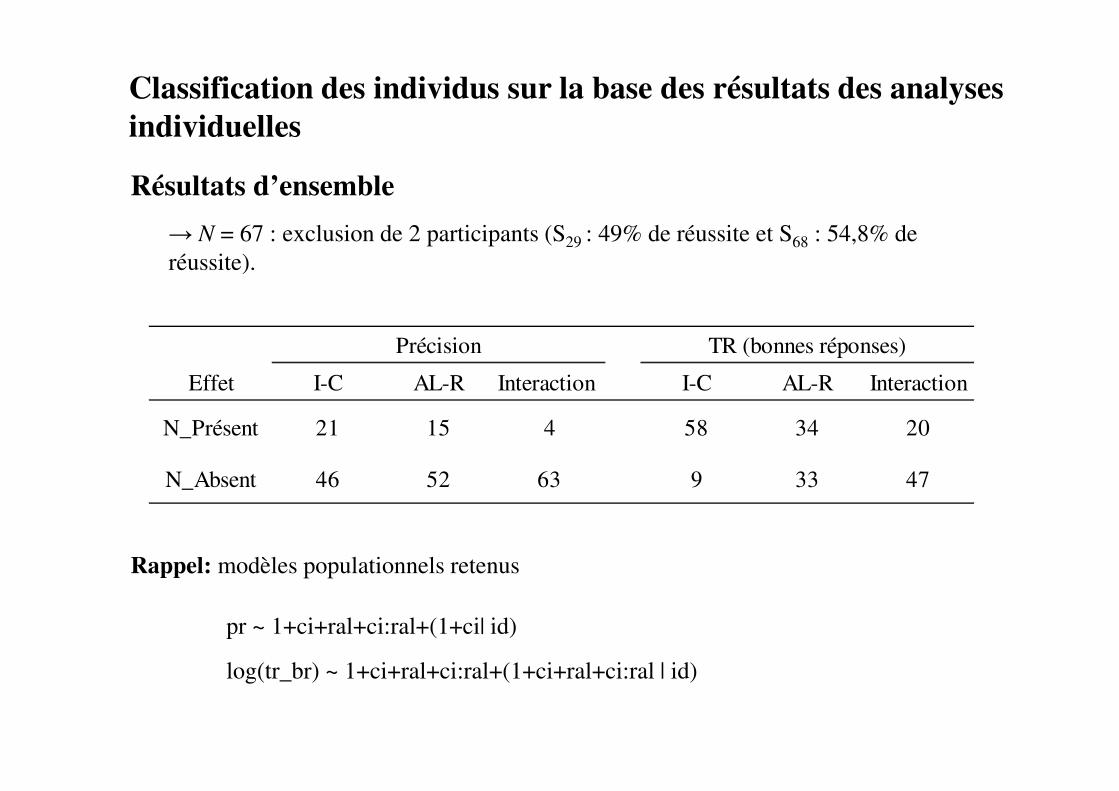
Rappel: modèles populationnels retenus
pr ~ 1+ci+ral+ci:ral+(1+ci| id)
log(tr_br) ~ 1+ci+ral+ci:ral+(1+ci+ral+ci:ral | id)
Classification des individus sur la base des résultats des analyses
individuelles
Effet I-C AL-R Interaction I-C AL-R Interaction
N_Présent 21 15 4 58 34 20
N_Absent 46 52 63 9 33 47
Précision TR (bonnes réponses)

Résultats
→ N = 67 : exclusion de 2 participants (S29 : 49% de réussite et S68 : 54,8% de
réussite).
1er niveau de classification : présence (vs absence) d’un effet d’interférence significatif sur
la précision (Pr.C > Pr.I).
• 21 participants (1 participant pour lequel Pr.I > Pr.C).
• Présence chez 9 de ces participants d’un effet d’alternance sur la précision (Pr.R >
Pr.AL) et chez 4 d’un effet d’interaction.
• Présence chez 20 participants d’un effet d’interférence, chez 14 d’un effet
d’alternance et chez 9 d’un effet d’interaction sur les TR (bonnes réponses).
Groupe 1 : N1=21, âge moyen : 73,52; TR moyen : 1090 msec. ; précision moyenne : 88%.
Classification des individus sur la base des résultats des analyses
individuelles

Résultats
→ N = 46 (N – N0 – N1) : pas d’effet d’interférence ni d’alternance sur la précision.
2nd niveau de classification : présence (vs absence) d’effets d’interférence et d’alternance
sur les TR.
• 20 participants chez qui sont observés des effets d’interférence et d’alternance sur
les TR (bonnes réponses).
• 11 participants chez qui sont observés un effet d’interaction sur les TR.
Groupe 2 : N2=20, âge moyen : 69,30; TR moyen : 924 msec. ; précision moyenne : 96%.
Classification des individus sur la base des résultats des analyses
individuelles

Résultats
→ N = 26 (N – N0 – N1 – N2) : pas d’effet d’interférence ni d’effet d’alternance sur la
précision, pas d’effet d’alternance sur les TR.
3ème niveau de classification : présence (vs absence) d’effet d’interférence sur les TR.
• 19 participants chez qui est observé un effet d’interférence sur les TR (bonnes
réponses).
Groupe 3 : N3=19, âge moyen : 67,32 ; mmse = 29,47; TR moyen : 890 msec. ; précision
moyenne : 97%.
Classification des individus sur la base des résultats des analyses
individuelles

Résultats
→ N = 7 (N – N0 – N1 – N2 – N3) : pas d’effet d’interférence ni d’effet d’alternance
sur la précision, pas d’effet d’alternance ni d’interférence sur les TR.
Groupe 4 : N4=7, âge moyen : 67,71 ; mmse moyen : 28,28 ; TR moyen : 1039 msec. ;
précision moyenne : 93%.
Classification des individus sur la base des résultats des analyses
individuelles

En résumé
Classification des individus sur la base des résultats des analyses
individuelles
Groupe prCI / prRAL / ltrCI / ltrRAL N âge mmse TR PR
1 1111 et 1011 21 73,52 28,71 1090 0,88
2 0011 20 69,30 28,70 924 0,96
3 0010 19 67,32 29,47 890 0,97
4 0000 7 67,71 28,29 1039 0,93
1: présence de l'effet, 0 absence de l'effet
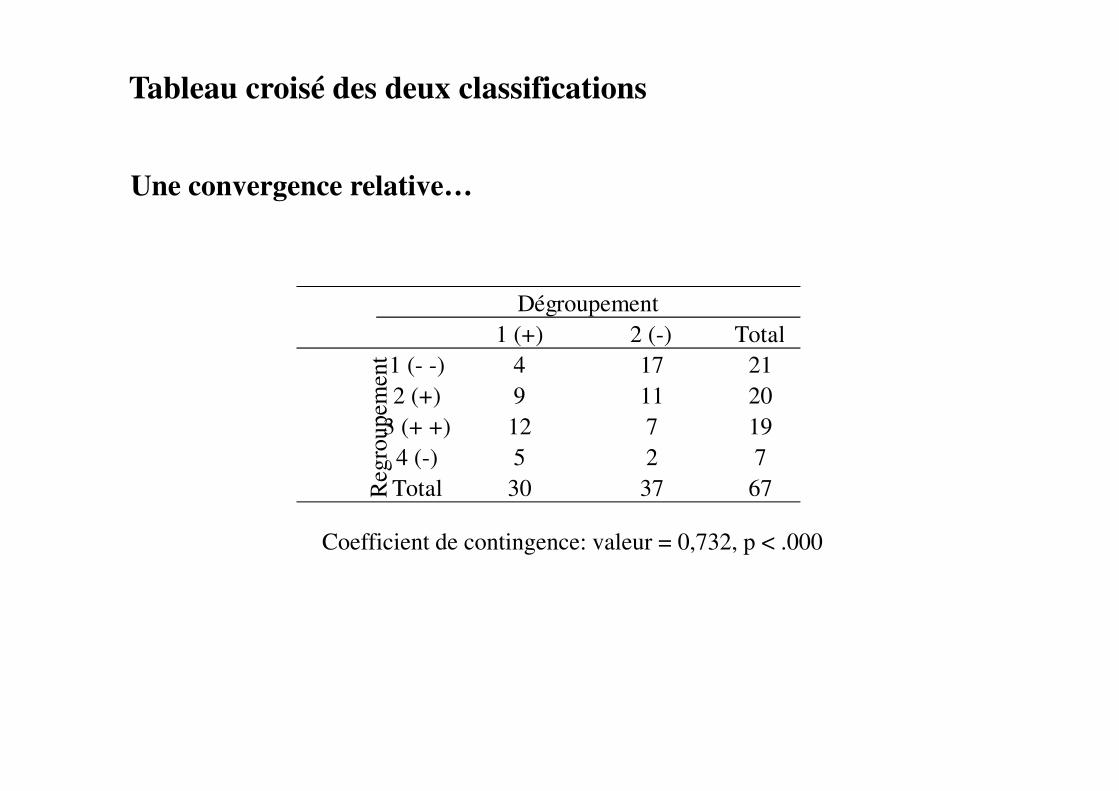
Une convergence relative…
Coefficient de contingence: valeur = 0,732, p < .000
Tableau croisé des deux classifications
1 (+) 2 (-) Total
1 (- -) 4 17 21
2 (+) 9 11 20
3 (+ +) 12 7 19
4 (-) 5 2 7
Total 30 37 67
Dégroupement
Reg
roupem
ent
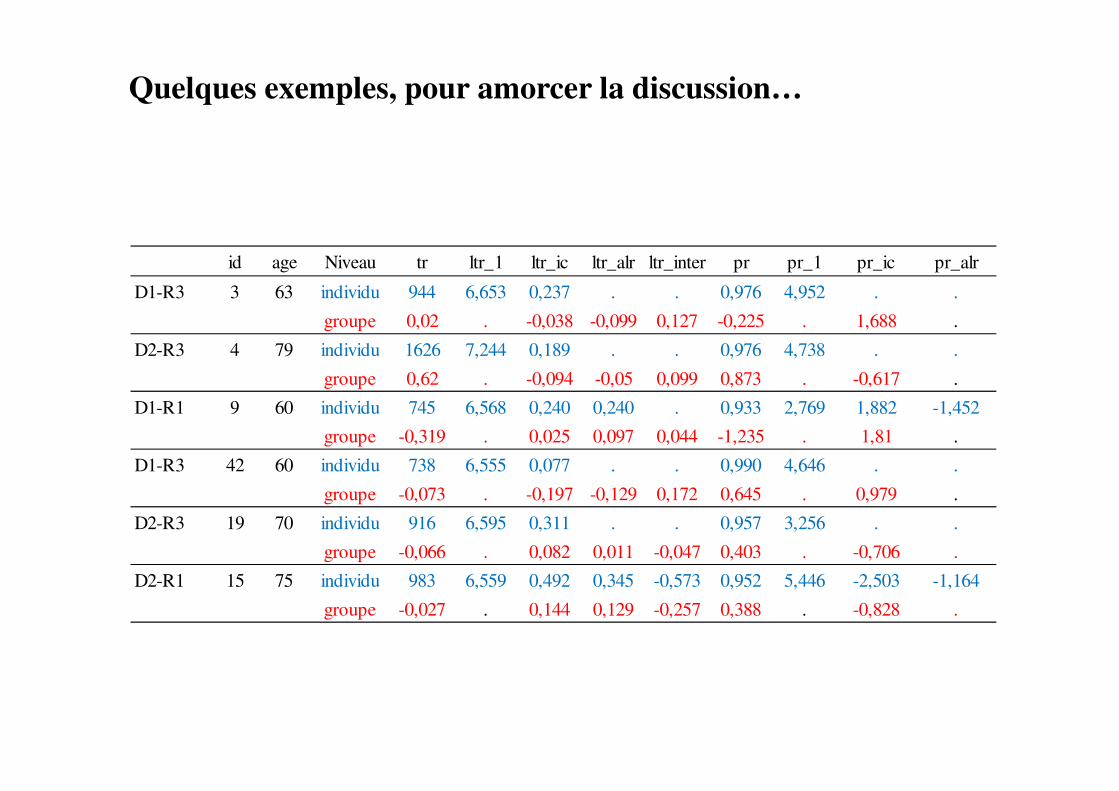
Quelques exemples, pour amorcer la discussion…
id age Niveau tr ltr_1 ltr_ic ltr_alr ltr_inter pr pr_1 pr_ic pr_alr
D1-R3 3 63 individu 944 6,653 0,237 . . 0,976 4,952 . .
groupe 0,02 . -0,038 -0,099 0,127 -0,225 . 1,688 .
D2-R3 4 79 individu 1626 7,244 0,189 . . 0,976 4,738 . .
groupe 0,62 . -0,094 -0,05 0,099 0,873 . -0,617 .
D1-R1 9 60 individu 745 6,568 0,240 0,240 . 0,933 2,769 1,882 -1,452
groupe -0,319 . 0,025 0,097 0,044 -1,235 . 1,81 .
D1-R3 42 60 individu 738 6,555 0,077 . . 0,990 4,646 . .
groupe -0,073 . -0,197 -0,129 0,172 0,645 . 0,979 .
D2-R3 19 70 individu 916 6,595 0,311 . . 0,957 3,256 . .
groupe -0,066 . 0,082 0,011 -0,047 0,403 . -0,706 .
D2-R1 15 75 individu 983 6,559 0,492 0,345 -0,573 0,952 5,446 -2,503 -1,164
groupe -0,027 . 0,144 0,129 -0,257 0,388 . -0,828 .


![E=F9;mklge]j ZYjge]l]j L`ak lae] alÌk h]jkgfYd2 ^jge [gfkme]j lg [g%[j]Ylgj](https://static.fdokumen.com/doc/165x107/631789cb7451843eec0ab6f2/ef9mklgej-zyjgelj-lak-lae-alik-hjkgfyd2-jge-gfkmej-lg-gjylgj.jpg)

















