Heuristic Search for Non-Bottom-Up Tree Structure Prediction
10
Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, pages 899–908, Edinburgh, Scotland, UK, July 27–31, 2011. c 2011 Association for Computational Linguistics Heuristic Search for Non-Bottom-Up Tree Structure Prediction Andrea Gesmundo Department of Computer Science University of Geneva [email protected] James Henderson Department of Computer Science University of Geneva [email protected] Abstract State of the art Tree Structures Prediction techniques rely on bottom-up decoding. These approaches allow the use of context-free fea- tures and bottom-up features. We discuss the limitations of mainstream techniques in solving common Natural Language Process- ing tasks. Then we devise a new framework that goes beyond Bottom-up Decoding, and that allows a better integration of contextual features. Furthermore we design a system that addresses these issues and we test it on Hierar- chical Machine Translation, a well known tree structure prediction problem. The structure of the proposed system allows the incorpora- tion of non-bottom-up features and relies on a more sophisticated decoding approach. We show that the proposed approach can find bet- ter translations using a smaller portion of the search space. 1 Introduction Tree Structure Prediction (TSP) techniques have become relevant in many Natural Language Pro- cessing (NLP) applications, such as Syntactic Pars- ing, Semantic Role Labeling and Hierarchical Ma- chine Translation (HMT) (Chiang, 2007). HMT approaches have a higher complexity than Phrase- Based Machine Translation techniques, but exploit a more sophisticated reordering model, and can produce translations with higher Syntactic-Semantic quality. TSP requires as inputs: a weighted grammar, G, and a sequence of symbols or a set of sequences en- coded as a Lattice (Chappelier et al., 1999). The input sequence is often a sentence for NLP applica- tions. Tree structures generating the input sequence can be composed using rules, r, from the weighted grammar, G. TSP techniques return as output a tree structure or a set of trees (forest) that generate the input string or lattice. The output forest can be rep- resented compactly as a weighted hypergraph (Klein and Manning, 2001). TSP tasks require finding the tree, t, with the highest score, or the best-k such trees. Mainstream TSP relies on Bottom-up Decod- ing (BD) techniques. With this paper we propose a new framework as a generalization of the CKY-like Bottom-up ap- proach. We also design and test an instantiation of this framework, empirically showing that wider con- textual information leads to higher accuracy for TSP tasks that rely on non-local features, like HMT. 2 Beyond Bottom-up Decoding TSP decoding requires scoring candidate trees, cost(t). Some TSP tasks require only local features. For these cases cost(t) depends only on the local score of the rules that compose t : cost(t)= r i ∈t cost(r i ) (1) This is the case for Context Free Grammars. More complex tasks need non-local features. Those fea- tures can be represented by a non-local factor, nonLocal(t), into the overall t score: cost(t)= r i ∈t cost(r i )+ nonLocal(t) (2) 899
-
Upload
independent -
Category
Documents
-
view
2 -
download
0
Transcript of Heuristic Search for Non-Bottom-Up Tree Structure Prediction

Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, pages 899–908,Edinburgh, Scotland, UK, July 27–31, 2011. c©2011 Association for Computational Linguistics
Heuristic Search for Non-Bottom-Up Tree Structure Prediction
Andrea GesmundoDepartment of Computer Science
University of [email protected]
James HendersonDepartment of Computer Science
University of [email protected]
Abstract
State of the art Tree Structures Predictiontechniques rely on bottom-up decoding. Theseapproaches allow the use of context-free fea-tures and bottom-up features. We discussthe limitations of mainstream techniques insolving common Natural Language Process-ing tasks. Then we devise a new frameworkthat goes beyond Bottom-up Decoding, andthat allows a better integration of contextualfeatures. Furthermore we design a system thataddresses these issues and we test it on Hierar-chical Machine Translation, a well known treestructure prediction problem. The structureof the proposed system allows the incorpora-tion of non-bottom-up features and relies ona more sophisticated decoding approach. Weshow that the proposed approach can find bet-ter translations using a smaller portion of thesearch space.
1 Introduction
Tree Structure Prediction (TSP) techniques havebecome relevant in many Natural Language Pro-cessing (NLP) applications, such as Syntactic Pars-ing, Semantic Role Labeling and Hierarchical Ma-chine Translation (HMT) (Chiang, 2007). HMTapproaches have a higher complexity than Phrase-Based Machine Translation techniques, but exploita more sophisticated reordering model, and canproduce translations with higher Syntactic-Semanticquality.
TSP requires as inputs: a weighted grammar,G,and a sequence of symbols or a set of sequences en-coded as a Lattice (Chappelier et al., 1999). The
input sequence is often a sentence for NLP applica-tions. Tree structures generating the input sequencecan be composed using rules,r, from the weightedgrammar,G. TSP techniques return as output a treestructure or a set of trees (forest) that generate theinput string or lattice. The output forest can be rep-resented compactly as a weighted hypergraph (Kleinand Manning, 2001). TSP tasks require finding thetree, t, with the highest score, or the best-k suchtrees. Mainstream TSP relies on Bottom-up Decod-ing (BD) techniques.
With this paper we propose a new frameworkas a generalization of the CKY-like Bottom-up ap-proach. We also design and test an instantiation ofthis framework, empirically showing that wider con-textual information leads to higher accuracy for TSPtasks that rely on non-local features, like HMT.
2 Beyond Bottom-up Decoding
TSP decoding requires scoring candidate trees,cost(t). Some TSP tasks require only local features.For these casescost(t) depends only on the localscore of the rules that composet :
cost(t) =∑
ri∈tcost(ri ) (1)
This is the case for Context Free Grammars. Morecomplex tasks need non-local features. Those fea-tures can be represented by a non-local factor,nonLocal(t), into the overallt score:
cost(t) =∑
ri∈tcost(ri ) + nonLocal(t) (2)
899

For example, in HMT the Language Model (LM) isa non-local fundamental feature that approximatesthe adequacy of the translation with the sum of log-probabilities of composingn-grams.
CKY-like BD approaches build candidate trees ina bottom-up fashion, allowing the use of DynamicProgramming techniques to simplify the searchspace by mering sub-trees with the same state, andalso easing application of pruning techniques (suchas Cube Pruning, e.g. Chiang (2007), Gesmundo(2010)). For clarity of presentation and follow-ing HMT practice, we will henceforth restrict ourfocus to binary grammars. Standard CKY worksby building objects known asitems (Hopkins andLangmead, 2009). Each item,ι, corresponds to acandidate sub-tree. Items are built linking a ruleinstantiation, r, to two sub-items that representsleft context, ι1, and right context,ι2; formally:ι ≡ 〈 ι1 ⋗ r ⋖ ι2 〉. An item is a triple thatcontains aspan, apostcondition and acarry. Thespan contains the indexes of the starting and end-ing input words delimiting the continuous sequencecovered by the sub-tree represented by the item. Thepostcondition is a string that representsr’s head non-terminal label, telling us which rules may be applied.The carry,κ, stores extra information required tocorrectly score the non-local interactions of the itemwhen it will be linked in a broader context (for HMTwith LM the carry consists of boundary words thatwill form new n-grams).
Items,ι ≡ 〈ι1 ⋗ r ⋖ ι2〉, are scored according tothe following formula:
cost(ι) = cost(r) + cost(ι1) + cost(ι2) (3)
+ interaction(r, κ1, κ2)
Where:cost(r) is the cost associated to the weightedrule r; cost(ι1) andcost(ι2) are the costs of the twosub-items computed recursively using formula (3);interaction(r, κ1, κ2) is the interaction cost betweenthe rule instantiation and the two sub-items. In HMTthe interaction cost includes the LM score of newn-grams generated by connecting the childrens’ sub-spans with terminals ofr. Notice that formula (3) isequal to formula (2) for items that cover the wholeinput sequence.
In many TSP applications, the search space istoo large to allow an exhaustive search and there-
fore pruning techniques must be used. Pruning deci-sions are based on the score of partial derivations.It is not always possible to compute exactly non-local features while computing the score of partialderivations, since partial derivations miss part of thecontext. Formula (3) accounts for the interaction be-tweenr and sub-itemsι1 andι2, but it does not in-tegrate the cost relative to the interaction betweenthe item and the surrounding context. Therefore theitem score computed in a bottom-up fashion is anapproximation of the score the item has in a broadercontext. For example, in HMT the LM score forn-grams that partially overlap the item’s span cannotbe computed exactly since the surrounding wordsare not known.
Basing pruning decisions on approximated scorescan introduce search errors. It is possible to reducesearch errors using heuristics based on future costestimation. In general the estimation of the interac-tion betweenι and the surrounding context is func-tion of the carry,κ. In HMT it is possible to estimatethe cost ofn-grams that partially overlapι’s spanconsidering the boundary words. We can obtain theheuristic cost for an item,ι, adding to formula (3)the factor,est(κ), for the estimation of interactionwith missing context:
heuristicCost(ι) = cost(ι) + est(κ) (4)
And useheuristicCost(ι) to guide BD pruning de-cisions. Anyway, even if a good interaction estima-tion is available, in practice it is not possible to avoidsearch errors while pruning.
More sophisticated parsing models allow the useof non-bottom-up features within a BD framework.Caraballo and Charniak (1998) present best-firstparsing with Figures of Merit that allows condition-ing of the heuristic function on statistics of the inputstring. Corazza et al. (1994), and Klein and Man-ning (2003) propose an A* parsing algorithm thatestimates the upper bound of the parse completionscores using contextual summary features. Thesemodels achieve time efficiency and state-of-the-artaccuracy for PCFG parsing, but still use a BD frame-work that doesn’t allow the application of a broaderclass of non-bottom-up contextual features.
In HMT, knowing the sentence-wide context inwhich a sub-phrase is translated is extremely impor-tant. It is obviously important for word choice: as
900

a simple example consider the translation of the fre-quent English word “get” into Chinese. The choiceof the correct set of ideograms to translate “get” of-ten requires being aware of the presence of particlesthat can be at any distance within the sentence. In acommon English to Chinese dictionary we found 93different sets of ideograms that could be translationsof “get”. Sentence-wide context is also importantin the choice of word re-ordering: as an exampleconsider the following translations from English toGerman:
1. EN : I go home.DE : Ich gehe nach Hause.
2. EN : I say, that I go home.DE : Ich sage, dass ich nach Hause gehe.
3. EN :On Sunday I go home.DE : Am Sonntag gehe ich nach Hause.
The English phrase “I go home” is translated in Ger-man using the same set of words but with differentorderings. It is not possible to choose the correctordering of the phrase without being aware of thecontext. Thus a bottom-up decoder without contextneeds to build all translations for “I go home”, intro-ducing the possibility of pruning errors.
Having shown the importance of contextual fea-tures, we define a framework that overcomes thelimitations of bottom-up feature approximation.
3 Undirected-CKY Framework
Our aim is to propose a new Framework that over-comes BD limitations allowing a better integrationof contextual features. The presented framework canbe regarded as a generalization of CKY.
To introduce the new framework let us focus on adetail of CKY BD. The items are created and scoredin topological order. The ordering constraint can beformally stated as:an item covering the span [i, j]must be processed after items covering sub spans[h, k]|h ≥ i, k ≤ j. This ordering constraint im-plies that full yield information is available whenan item is processed, but information about ances-tors and siblings is missing. Therefore non-bottom-up context cannot be used because of the orderingconstraint. Now let us investigate how the decoding
algorithm could change if we remove the orderingconstraint.
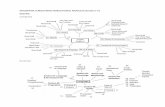
Removing the ordering constraint would lead tothe occurrence of cases in which an item is pro-cessed before all child items have been processed.For example, we could imagine to create and scorean item,ι, with postconditionX and span[i, j], link-ing the rule instantiationr : X→AB with onlythe left sub-item,ιA, while information for the rightsub-item,ιB is still missing. In this case, we canrely on local and partial contextual features to scoreι. Afterwards, it is possible to processιB using theparent item,ι, as a source of additional informa-tion about the parent context and siblingιA yield.This approach can avoid search errors in cases wherepruning at the parent level can be correctly done us-ing only local and partial yield context, while prun-ing at the child level needs extra non-bottom-up con-text to make a better pruning decision. For exam-ple, consider the translation of the English sentence“ I run” into French using the following synchronousgrammar:
r1 : S → X 1 X 2 | X 1 X 2
r2 : X → I | Jer3 : X → run | courser4 : X → run | courirr5 : X → run | coursr6 : X → run | courons...
Where: r1 is aGlue rule and boxed indexes de-scribe the alignment;r2 translates “I” in the cor-responding French pronoun;r3 translates “run” asa noun; remaining rules translate “run” as one ofthe possible conjugations of the verb “courir”. Us-ing only bottom-up features it is not possible to re-solve the ambiguity of the word “run”. If the beamis not big enough the correct translation could bepruned. Anyway a CKY decoder would give thehighest score to the most frequent translation. In-stead, if we follow a non bottom-up approach, asdescribed in Figure 1, we can: 1) first translate “I”;2) Then create an item usingr1 with missing rightchild; 3) finally choose the correct translation for“run” using r1 to access a wider context. Noticethat with this undirected approach it is possible toreach the correct translation using only beam size of
901

Figure 1: Example of undirected decoding for HMT. The arrowspoint to the direction in which information is propa-gated. Notice that the parent link at step 3 is fundamental tocorrectly disambiguate the translation for “run”.
1 and the LM feature.To formalize Undirected-CKY, we define a gen-
eralized item calledundirected-item. Undirected-items, ι, are built linking rule instantiations withelements inL ≡ {left child, right child, parent};for example: ι ≡ 〈ι1 ⋗ r ∨ ιp〉, is built linkingr with left child, ι1, and parent,ιp. We denotewith L+ι the set of links for which the undirected-item, ι, has a connection, and withL−ι the setof missing links. An undirected-item is a triplethat contains a span, a carry and anundirected-postcondition. The undirected-postcondition is aset of strings, one string for each ofι’s missing links,l ∈ L−ι . Each string represents the non-terminal re-lated to one of the missing links available for expan-sion. Bottom-up items can be considered specificcases of undirected-items havingL+ = { left child,right child} andL− = {parent}. We can formallydescribe the steps of the example depicted in Figure1 with:
1)r2 : X → I|Je , terminal : [0, 1]
ι1 : [0, 1, {X p}, κ1]
2)r1 : S → X 1X 2 |X 1X 2 , ι1 : [0, 1, {X p}, κ1]
ι2 : [0, 1, {X 2}, κ2)]
3)r5 :X → run|cours, ι2 : [· · · ] , terminal : [1, 2]
ι3 : [0, 2, {}, κ3 ]
The scoring function for undirected-items can be ob-tained generalizing formula (3):
cost(ι) = cost(r)
+∑
l∈L+
cost(ιl ) (5)
+ interaction(r ,L+)
In CKY, each span is processed separately intopological order, and the best-k items for each spanare selected in sequence according to scoring func-tion (4). In the proposed framework, the selec-tion of undirected-items can be done in any order,for example: in a first step selecting an undirected-item for spans1, then selecting an undirected-itemfor spans2, and in a third step selecting a secondundirected-item fors1, and so on. As in agendabased parsing (Klein and Manning, 2001), all candi-date undirected-items can be handled with an uniquequeue. Allowing the system to decide decoding or-der based on the candidates’ scores, so that candi-dates with higher confidence can be selected earlierand used as context for candidates with lower confi-dence.
Having all candidates in the same queue intro-duces comparability issues. In CKY, candidates arecomparable since each span is processed separatelyand each candidate is scored with the estimation ofthe yield score. Instead, in the proposed framework,
902

the unique queue contains candidates relative to dif-ferent nodes and with different context scope. Toensure comparability, we can associate to candidateundirected-items a heuristic score of the full deriva-tion:
heuristicCost(ι) = cost(ι) + est(ι) (6)
Where est(ι) estimates the cost of the missingbranches of the derivation as a function ofι′s par-tial structure and carry.
In this framework, the queue can be initializedwith a candidate for each rule instantiation. Theseinitializing candidates have no context informationand can be scored using only local features. Ageneric decoding algorithm can loop selecting thecandidate undirected-item with the highest score,ι,and then propagating its information to neighboringcandidates, which can update usingι as context. Inthis general framework the link to the parent node isnot treated differently from links to children. Whilein CKY the information is always passed from chil-dren to parent, in Undirected-CKY the informationcan be propagated in any direction, and any decod-ing order is allowed.
We can summarize the steps done to generalizeCKY into the proposed framework: 1) remove thenode ordering constraint; 2) define the scoring ofcandidates with missing children or parent; 3) usea single candidate queue; 4) handle comparability ofcandidates from different nodes and/or with differ-ent context scope; 5) allow information propagationin any direction.
4 Undirected Decoding
In this section we propose Undirected Decod-ing (UD), an instantiation of the Undirected-CKYframework presented above. The generic frameworkintroduces many new degrees of freedom that couldlead to a higher complexity of the decoder. In ouractual instantiation we apply constraints on the ini-tialization step, on the propagation policy, and fix asearch beam ofk. These constraints allow the sys-tem to converge to a solution in practical time, al-low the use of dynamic programming techniques tomerge items with equivalent states, and gives us thepossibility of using non-bottom-up features and test-ing their relevance.
Algorithm 1 Undirected Decoding1: function decoder (k) : out-forest2: Q← LeafRules();3: while |Q| > 0 do4: ι← PopBest (Q);5: if CanPop(ι) then6: out-forest.Add(ι);7: if ι.HasChildrenLinks()then8: for all r ∈ HeadRules(ι) do9: C← NewUndirectedItems(r , ι);
10: for all c ∈ C do11: if CanPop(c) then12: Q.Insert(c);13: end if14: end for15: end for16: end if17: end if18: end while
Algorithm 1 summarizes the UD approach. Thebeam size,k, is given as input. Atline 2 the queueof undirected-item candidates,Q, is initialized withonly leafs rules. Atline 3 the loop starts, it willterminate whenQ is empty. At line 4 the candi-date with highest score,ι, is popped fromQ. line 5checks ifι is within the beam width: ifι has a spanfor which k candidates were already popped, thenιis dropped and a new iteration is begun. Otherwiseι is added to the out-forest atline 6. From line 7to line 10 the algorithm deals with the generation ofnew candidate undirected-items.line 7 checks ifιhas both children links, if not a new decoding iter-ation is begun.line 8 loops over the rule instantia-tions,r, that can useι as child. Atline 9, the set ofnew candidates,C, is built linking r with ι and anycontext already available in the out-forest. Finally,betweenline 10 and line 12, each elementc in Cis inserted inQ after checking thatc is within thebeam width: ifc has a span for whichk candidateswere already popped it doesn’t make sense to insertit in Q since it will be surely discarded atline 5.
In more detail, the functionNewUndirectedItems(r, ι) at line 9 creates newundirected-items linkingr using: 1)ι as child; 2)(optionally) as other child any other undirected-itemthat has already been inserted in the out-forest and
903

doesn’t have a missing child and matches missingspan coverage; 3) and using as parent context thebest undirected-item with missing child link thathas been incorporated in the out-forest and canexpand the missing child link usingr. In our currentmethod, only the best possible parent context isused because it only provides context for rankingcandidates, as discussed at the end of this section.In contrast, a different candidate is generated foreach possible other child in 2), as well as forthe case where no other child is included in theundirected-item.
We can make some general observations on theUndirected Decoding Algorithm. Notice that, theif statement atline 7 and the way new undirected-items are created atline 9, enforce that eachundirected-item covers a contiguous span. Anundirected-item that is missing a child link cannotbe used as child context but can be used as parentcontext since it is added to the out-forest atline 6before theif statement atline 7. Furthermore, theif statements atline 5 and line 11 check that nomore thank candidates are selected for each span,but the algorithm does not require the the selectionof exactlyk candidates per span as in CKY.
The queue of candidates,Q, is ordered accordingto the heuristic cost of formula (6). The score of thecandidate partial structure is accounted for with fac-tor cost(ι) computed according to formula (5). Thefactorest(ι) accounts for the estimation of the miss-ing part of the derivation. We compute this factorwith the following formula:
est(ι) =∑
l∈L−ι
(localCost(ι, l) + contextEst(ι, l)
)
(7)For each missing link,l ∈ L−ι , we estimate the costof the corresponding derivation branch with two fac-tors: localCost(ι, l) that computes the context-freescore of the branch with highest score that couldbe attached tol; andcontextEst(ι, l) that estimatesthe contextual score of the branch and its interac-tion with ι. Because our model is implemented inthe Forest Rescoring framework (e.g. Huang andChiang (2007), Dyer et al. (2010), Li et al. (2009)),localCost(ι, l) can be efficiently computed exactly.In HMT it is possible to exhaustively represent andsearch the context-free-forest (ignoring the LM),
which is done in the Forest Rescoring framework be-fore our task of decoding with the LM. We exploitthis context-free-forest to computelocalCost(ι, l):for missing child links thelocalCost(·) is the In-side score computed using the (max, +) semiring(also known as the Viterbi score), and for missingparent links thelocalCost(·) is the correspondingOutside score. The factorcontextEst(·) estimatesthe LM score of the words generated by the missingbranch and their interaction with the span coveredby ι. To compute the expected interaction cost weuse the boundary words information contained inι’scarry as done in BD. To estimate the LM cost of themissing branch we use an estimation function, con-ditioned on the missing span length, whose parame-ters are tuned on held-out data with gradient descent,using the search score as objective function.
To show that UD leads to better results than BD,the two algorithms are compared in the same searchspace. Therefore we ensure that candidates em-bedded in the UD out-forest would have the samescore if they were scored from BD. We don’t needto worry about differences derived from the missingcontext estimation factor,est(·), since this factor isonly considered while sorting the queue,Q, accord-ing to theheuristicCost(·). Also, we don’t have toworry about candidates that are scored with no miss-ing child and no parent link, because in that casescoring function (3) for BD is equivalent to scoringfunction (5) for UD. Instead, for candidates that arescored with parent link, we remove the parent linkfactor from thecost(·) function when inserting thecandidate into the out forest. And for the candi-dates that are scored with a missing child, we ad-just the score once the link to the missing child iscreated in the out-forest. In this way UD and BDscore the same derivation with the same score andcan be regarded as two ways to explore the samesearch space.
5 Experiments
In this section we test the algorithm presented, andempirically show that it produces better translationssearching a smaller portion of the search space.
We implemented UD on top of a widely-usedHMT open-source system, cdec (Dyer et al., 2010).We compare with cdec Cube Pruning BD. The ex-
904

0
100
200
300
400
500
600
700
800
900
2 4 6 8 10 12 14 16
Tes
t Set
Beam Size
UD best scoreBD best score
Figure 2: Comparison of the quality of the translations.
periments are executed on the NIST MT03 Chinese-English parallel corpus. The training corpus con-tains 239k sentence pairs with 6.9M Chinese wordsand 8.9M English words. We use a hierarchicalphrase-based translation grammar extracted using asuffix array rule extractor (Lopez, 2007). The NIST-03 test set is used for decoding, it has 919 sentencepairs. The experiments can be reproduced on anaverage desktop computer. Since we compare twodifferent decoding strategies that rely on the sametraining technique, the evaluation is primarily basedon search errors rather than on BLEU. We comparethe two systems on a variety of beam sizes between1 and 16.
Figure 2 reports a comparison of the translationquality for the two systems in relation to the beamsize. The blue area represents the portion of sen-tences for which UD found a better translation. Thewhite area represents the portion of sentences forwhich the two systems found a translation with thesame search score. With beam 1 the two systems ob-viously have a similar behavior, since both the sys-tems stop investigating the candidates for a node af-ter having selected the best candidate immediatelyavailable. For beams 2-4, UD has a clear advan-tage. In this range UD finds a better translation fortwo thirds of the sentences. With beam 4, we ob-serve that UD is able to find a better translation for63.76% of the sentences, instead BD is able to find abetter translation for only 21.54% of the sentences.For searches that employ a beam bigger than 8, wenotice that the UD advantage slightly decreases, and
-126.5
-126
-125.5
-125
-124.5
-124
-123.5
-123
2 4 6 8 10 12 14 16
Sea
rch
Sco
re
Beam Size
Bottom-up DecodingGuided Decoding
Figure 3: Search score evolution for BD and UD.
the number of sentences with equivalent translationslowly increases. We can understand this behaviorconsidering that as the beam increases the two sys-tems get closer to exhaustive search. Anyway withthis experiment UD shows a consistent accuracy ad-vantage over BD.
Figure 3 plots the search score variation for dif-ferent beam sizes. We can see that UD search leadsto an average search score that is consistently bet-ter than the one computed for BD. Undirected De-coding improves the average search score by0.411for beam 16. The search score is the logarithm ofa probability. This variation corresponds to a rel-ative gain of50.83% in terms of probability. Forbeams greater than 8 we see that the two curves keepa monotonic ascendant behavior while converging toexhaustive search.
Figure 4 shows the BLEU score variation. Againwe can see the consistent improvement of UD overBD. In the graph we report also the performance ob-tained using BD with beam 32. BD reaches BLEUscore of 32.07 with beam 32 while UD reaches32.38 with beam 16: UD reaches a clearly higherBLEU score using half the beam size. The differ-ence is even more impressive if we consider that UDreaches a BLEU of32.19 with beam 4.
In Figure 5 we plot the percentage reduction of thesize of the hypergraphs generated by UD comparedto those generated by BD. The size reduction growsquickly for both nodes and edges. This is due to thefact that BD, using Cube Pruning, must selectk can-didates for each node. Instead, UD is not obliged to
905

31.2
31.4
31.6
31.8
32
32.2
32.4
2 4 6 8 10 12 14 16
BLE
U S
core
Beam Size
Bottom-up DecodingUndirected Decoding
BD beam 30
Figure 4: BLEU score evolution for BD and UD.
5
10
15
20
25
30
35
40
2 4 6 8 10 12 14 16
Red
uctio
n (%
)
Beam Size
Nodes ReductionEdges Reduction
Figure 5: Percentage of reduction of the size of the hy-pergraph produced by UD.
selectk candidates perf -node. As we can see fromAlgorithm 1, the decoding loop terminates when thequeue of candidates is empty, and the statements atline 5 andline 11 ensure that no more thank can-didates are selected perf -node, but nothing requiresthe selection ofk elements, and some bad candidatesmay not be generated due to the sophisticated prop-agation strategy. The number of derivations that ahypergraph represents is exponential in the numberof nodes and edges composing the structure. Withbeam 16, the hypergraphs produced by UD containon average4.6k fewer translations. Therefore UDis able to find better translations even if exploring asmaller portion of the search space.
Figure 6 reports the time comparison betweenBD and UD with respect to sentence length. The
0
200
400
600
800
1000
1200
10 15 20 25 30 35 40 45 50
Tim
e (m
s)
Input Sentence Size
Bottom-up Decoding, beam = 16Undirected Decoding, beam = 8
Figure 6: Time comparison between BD and UD.
sentence length is measured with the number ofideogram groups appearing in the source Chinesesentences. We compare BD with beam of 16 andUD with beam of 8, so that we compare two sys-tems with comparable search score. We can noticethat for short sentences UD is faster, while for longersentences UD becomes slower. To understand thisresult consider that for simple sentences UD canrely on the advantage of exploring a smaller searchspace. While, for longer sentences, the amount ofcandidates considered during decoding grows ex-ponentially with the size of the sentence, and UDneeds to maintain an unique queue whose size is notbounded by the beam sizek, as for the queues usedin BD’s Cube Pruning. It may be possible to addressthis issue with more efficient handling of the queue.
In conclusion we can assert that, even if explor-ing a smaller portion of the search space, UD findsoften a translation that is better than the one foundwith standard BD. UD’s higher accuracy is due toits sophisticated search strategy that allows a moreefficient integration of contextual features. This setof experiments show the validity of the UD approachand empirically confirm our intuition about the BD’sinadequacy in solving tasks that rely on fundamentalcontextual features.
6 Future Work
In the proposed framework the link to the parentnode is not treated differently from links to childnodes, the information in the hypergraph can bepropagated in any direction. Then the Derivation
906

Hypergraph can be regarded as a non-directed graph.In this setting we could imagine applying mes-sage passing algorithms from graphical model the-ory (Koller and Friedman, 2010).
Furthermore, considering that the proposedframework lets the system decide the decoding or-der, we could design a system that explicitly learnsto infer the decoding order at training time. Sim-ilar ideas have been successfully tried: Shen et al.(2010) and Gesmundo (2011) investigate the GuidedLearning framework, that dynamically incorporatesthe tasks of learning the order of inference and train-ing the local classifier.
7 Conclusion
With this paper we investigate the limitations ofBottom-up parsing techniques, widely used in TreeStructures Prediction, focusing on Hierarchical Ma-chine Translation. We devise a framework that al-lows a better integration of non-bottom-up features.Compared to a state of the art HMT decoder the pre-sented system produces higher quality translationssearching a smaller portion of the search space, em-pirically showing that the bottom-up approximationof contextual features is a limitation for NLP taskslike HMT.
Acknowledgments
This work was partly funded by Swiss NSF grantCRSI22127510 and European Community FP7grant 216594 (CLASSiC, www.classic-project.org).
References
Sharon A. Caraballo and Eugene Charniak. 1998. Newfigures of merit for best-first probabilistic chart pars-ing, Computational Linguistics, 24:275-298.
J. C. Chappelier and M. Rajman and R. Arages and A.Rozenknop. 1999. Lattice Parsing for Speech Recog-nition. In Proceedings of TALN 1999, Cargse, France.
David Chiang. 2007. Hierarchical phrase-based trans-lation. Computational Linguistics, 33(2):201-228,2007.
Anna Corazza, Renato De Mori, Roberto Gretter andGiorgio Satta. 1994. Optimal Probabilistic Evalu-ation Functions for Search Controlled by StochasticContext-Free Grammars. IEEE Transactions on Pat-tern Analysis and Machine Intelligence, 16(10):1018-1027.
Chris Dyer, Adam Lopez, Juri Ganitkevitch, JohnathanWeese, Ferhan Ture, Phil Blunsom, Hendra Setiawan,Vladimir Eidelman, and Philip Resnik. 2010. cdec:A Decoder, Alignment, and Learning framework forfinite-state and context-free translation models. InProceedings of the Conference of the Association ofComputational Linguistics 2010, Uppsala, Sweden.
Andrea Gesmundo and James Henderson 2010. FasterCube Pruning. Proceedings of the seventh Inter-national Workshop on Spoken Language Translation(IWSLT), Paris, France.
Andrea Gesmundo 2011. Bidirectional Sequence Classi-fication for Tagging Tasks with Guided Learning. Pro-ceedings of TALN 2011, Montpellier, France.
Mark Hopkins and Greg Langmead 2009. Cube prun-ing as heuristic search. Proceedings of the Conferenceon Empirical Methods in Natural Language Processing2009, Singapore.
Liang Huang and David Chiang. 2007. Forest rescoring:Faster decoding with integrated language models. InProceedings of the Conference of the Association ofComputational Linguistics 2007, Prague, Czech Re-public.
Dan Klein and Christopher D. Manning. 2001 Pars-ing and Hypergraphs, In Proceedings of the Interna-tional Workshop on Parsing Technologies 2001, Bei-jing, China.
Dan Klein and Christopher D. Manning. 2003 A* Pars-ing: Fast Exact Viterbi Parse Selection, In Proceed-ings of the Conference of the North American Associ-ation for Computational Linguistics 2003, Edmonton,Canada.
Daphne Koller and Nir Friedman. 2010. ProbabilisticGraphical Models: Principles and Techniques. TheMIT Press, Cambridge, Massachusetts.
Shankar Kumar, Wolfgang Macherey, Chris Dyer, andFranz Och. 2009. Efficient Minimum Error RateTraining and Minimum Bayes-Risk decoding fortranslation hypergraphs and lattices, In Proceedingsof the Joint Conference of the 47th Annual Meeting ofthe ACL and the 4th International Joint Conference onNatural Language Processing of the AFNLP, Suntec,Singapore.
Zhifei Li, Chris Callison-Burch, Chris Dyer, JuriGanitkevitch, Sanjeev Khudanpur, Lane Schwartz,Wren N. G. Thornton, Jonathan Weese, and Omar F.Zaidan. 2009. Joshua: An Open Source Toolkit forParsing-based Machine Translation. In Proceedings ofthe Workshop on Statistical Machine Translation 2009,Athens, Greece.
Adam Lopez. 2007. Hierarchical Phrase-Based Transla-tion with Suffix Arrays. In Proceedings of the Confer-ence on Empirical Methods in Natural Language Pro-cessing 2007, Prague, Czech Republic.
907

Haitao Mi, Liang Huang and Qun Liu. 2008. Forest-Based Translation. In Proceedings of the Conferenceof the Association of Computational Linguistics 2008,Columbus, OH.
Libin Shen, Giorgio Satta and Aravind Joshi. 2007.Guided Learning for Bidirectional Sequence Classifi-cation. In Proceedings of the Conference of the As-sociation of Computational Linguistics 2007, Prague,Czech Republic.
Andreas Stolcke. 2002. SRILM - An extensible lan-guage modeling toolkit. In Proceedings of the Inter-national Conference on Spoken Language Processing2002, Denver, CO.
Andreas Zollmann and Ashish Venugopal. 2006. Syn-tax augmented machine translation via chart parsing,Proceedings of the Workshop on Statistical MachineTranslation, New York City, New York.
908