
Götz, Sandra (2015): Tense and aspect errors in spoken learner language: Implications for language...
24
1 Götz, Sandra (2015): "Tense and aspect errors in spoken learner language: Implications for language testing and assessment". In: Marcus Callies & Sandra Götz (eds), Learner Corpora in Language Testing and Assessment. Amsterdam: John Benjamins, 191- 215. Tense and aspect errors in spoken learner English: Implications for Language Testing and Assessment Sandra Götz Justus Liebig University, Giessen Language testing guidelines like the Common European Framework of Reference for Languages (CEFR) have been very influential for language testing and assessment, yet the way they define proficiency levels using ‘can-do-statements’ has often been criticized as being too vague. In the present paper, I will take a corpus-based approach towards spoken accuracy in advanced German learner English and report on the findings of an error analysis of the most error-prone category in the German component of the Louvain International Database of Spoken English Interlanguage (LINDSEI). Focusing on verb-tense related errors, the present study not only reveals what is especially error-prone in the case of advanced German learners of English in this category (e.g. reported speech, conditionals), but it also shows that even at an advanced level, learners appear to form a fairly heterogeneous group with regard to the number of errors. However, the types of errors committed at this proficiency level are quite systematic, and this allows for a thorough description of advanced learners’ error profiles. In the final section of this paper, I will take these findings to suggest a text- centred description of different proficiency levels in advanced German learners’ speech at the university level and sketch out some avenues for future research. Keywords: computer-aided error analysis, error-tagging, tense and aspect errors, spoken learner English, corpus-based assessment scale 1. Introduction For over two decades now, the systematic analysis of learner corpus data has combined theoretical approaches from second language acquisition (SLA) research (e.g. contrastive analysis or error analysis) and corpus linguistics (see e.g. Díaz-Negrillo & Fernández-Domínguez 2006). Recently, insights gained from learner corpora have also been of great use in the field of language testing and assessment (LTA), especially in order to provide quantitative descriptions of the way proficiency can be operationalized at different levels. In this context, a large number of
-
Upload
uni-marburg -
Category
Documents
-
view
0 -
download
0
Transcript of Götz, Sandra (2015): Tense and aspect errors in spoken learner language: Implications for language...

1
Götz, Sandra (2015): "Tense and aspect errors in spoken learner language: Implications for language testing and assessment". In: Marcus Callies & Sandra Götz (eds), Learner Corpora in Language Testing and Assessment. Amsterdam: John Benjamins, 191-215.
Tense and aspect errors in spoken learner English: Implications for Language Testing and Assessment Sandra Götz Justus Liebig University, Giessen
Language testing guidelines like the Common European Framework of Reference for Languages (CEFR) have been very influential for language testing and assessment, yet the way they define proficiency levels using ‘can-do-statements’ has often been criticized as being too vague. In the present paper, I will take a corpus-based approach towards spoken accuracy in advanced German learner English and report on the findings of an error analysis of the most error-prone category in the German component of the Louvain International Database of Spoken English Interlanguage (LINDSEI). Focusing on verb-tense related errors, the present study not only reveals what is especially error-prone in the case of advanced German learners of English in this category (e.g. reported speech, conditionals), but it also shows that even at an advanced level, learners appear to form a fairly heterogeneous group with regard to the number of errors. However, the types of errors committed at this proficiency level are quite systematic, and this allows for a thorough description of advanced learners’ error profiles. In the final section of this paper, I will take these findings to suggest a text-centred description of different proficiency levels in advanced German learners’ speech at the university level and sketch out some avenues for future research. Keywords: computer-aided error analysis, error-tagging, tense and aspect
errors, spoken learner English, corpus-based assessment scale 1. Introduction For over two decades now, the systematic analysis of learner corpus data has combined theoretical approaches from second language acquisition (SLA) research (e.g. contrastive analysis or error analysis) and corpus linguistics (see e.g. Díaz-Negrillo & Fernández-Domínguez 2006). Recently, insights gained from learner corpora have also been of great use in the field of language testing and assessment (LTA), especially in order to provide quantitative descriptions of the way proficiency can be operationalized at different levels. In this context, a large number of

2
quantitative and qualitative analyses of raw and untagged learner corpora have had important implications and have shed light on learners’ overuse and/or underuse of linguistic features at various proficiency levels and different L1s, for instance in the category of high frequency vocabulary (e.g. Ringbom 1999), modal verbs (e.g. Aijmer 2002), connectors (e.g. Granger & Tyson 1996), collocations and prefabs (e.g. De Cock 1998), discourse markers (e.g. Müller 2005), or the progressive aspect (e.g. Römer 2005), to name but a few. However, learner corpora are “especially useful when they are error-tagged” (Granger 2003: 465), because quantitative and qualitative error analysis opens up even wider options for exhaustive investigations in the area of learners’ misuses of all kinds, i.e. errors on the orthographic, lexical or grammatical level. Computer-aided error analysis (CEA; Dagneaux et al. 1998) of learner corpora thus makes it possible to not only reveal features that are particularly error-prone for a whole learner population, but it also becomes possible to test if there are systematicities regarding the error types across learners in a corpus. Also, learner corpora can “provide information not only on which errors persist, but also about the contexts in which they appear” (Osborne 2007: 344). CEA thus enables researchers and language testers to describe language proficiency on a quantitative level by way of characterizing the frequencies, types and contexts of errors that learners commit at a certain proficiency level.
I will start this chapter by giving a brief overview of theoretical aspects and previous research in the field of how learner corpus research (LCR) can complement the development of descriptor scales and how accuracy and error analysis have been dealt with in English as a foreign language (EFL), applied linguistics (AL) and LCR. I will then briefly introduce the process of error-tagging the 86,000-word German component of the Louvain International Database of Spoken English Interlanguage (LINDSEI; Gilquin et al. 2010) and the methodology used in the present study in more detail. Section 4 will present the major findings and discuss some implications for language testing and assessment of learners at the university level derived from these findings by suggesting a text-centred description of different levels of spoken accuracy in advanced German learners’ speech (see Callies & Götz this volume). Finally, I will conclude this paper by pointing to some caveats and sketching out some avenues for future research. 2. Developing data-based descriptor scales to assess accuracy in
spoken language 2.1 From ‘can-do- statements’ towards learner-corpus-informed
descriptions of proficiency levels The description and assessment of accuracy has been approached in English language teaching (ELT) from two opposing angles. One is to measure the level of proficiency in the learners’ output, where different proficiency

3
levels are measured through a variety of ‘can-do statements’, one very influential framework being the Common European Framework of Reference (CEFR; Council of Europe 2009). For spoken language, the framework suggests descriptor scales for five basic language competences, i.e. range, accuracy, fluency, interaction and coherence, and distinguishes between six basic competence levels ascending from descriptions of basic users (A1, A2) to independent users (B1, B2) and finally to proficient users (C1, C2). Learners are classified according to different descriptions of proficiency at each level. The descriptor scales for grammatical accuracy in conversation are summarized in Table 1. Table 1. Descriptor scale for grammatical accuracy in conversation in
the CEFR (Council of Europe 2009: 114, shortened, emphasis added).
Proficiency Level
CEFR descriptor
C2 Maintains consistent grammatical control of complex language even while attention is otherwise engaged (e.g. in forward planning, in monitoring others’ reactions).
C1 Consistently maintains a high degree of grammatical accuracy; errors are rare and difficult to spot.
B2 Shows a relatively high degree of grammatical control. Does not make mistakes which lead to misunderstanding.
B1 Communicates with reasonable accuracy in familiar contexts; generally good control though with noticeable mother tongue influence. Errors occur, but it is clear what he/she is trying to express.
A2 Uses some simple structures correctly, but still systematically makes basic mistakes – for example tends to mix up tenses and forgets to mark agreement; nevertheless, it is usually clear what he/she is trying to say.
A1 Shows only limited control of a few simple grammatical structures and sentence patterns in a learnt repertoire.
While these descriptors might provide a first impression of the (very) broad proficiency level of a learner, they seem somewhat too global and vague to have an explicitly practical value for language testers to really distinguish between proficiency levels. Neither do they give in-depth linguistic details regarding individual languages or learners’ skills in specific domains of language usage. As a result, there has been an increasing awareness among researchers and CEFR-developers of the benefits of including more specific linguistic descriptors (e.g. North 2014) or “criterial features” (Hawkins & Buttery 2010, Hawkins & Filipović 2012) which may emerge from the analysis of (learner) corpora (e.g. McCarthy 2013, Park 2014). The aim of

4
such corpus-based approaches is to add “grammatical and lexical details of English to CEFR’s functional characterization of the different levels” (Hawkins & Filipović 2012: 5). One large-scale project that has been taking this approach is The English Profile project,1 in which researchers are working towards an “empirical underpinning for any language of the detailed descriptions that accompany each level and sub-level in the framework’s documentation” (McCarthy 2013: 3). For example, the area of lexis has been thoroughly described in the English Vocabulary Profile (EVP), which “offers reliable information about which words (and importantly, which meanings of those words) and phrases are known and used by learners at each level of the Common European Framework” from A1-C2.2 The area of accuracy and grammar development over CEFR levels is dealt with in the large-scale project called the English Grammar Profile (EGP).3 The EGP’s goal is a detailed investigation of certain grammatical features in the Cambridge Learner Corpus, a growing learner corpus of spoken and written learner English from all over the world, taken from all CEFR levels and across developmental stages. As described on the project website, each of the analyses (or so-called “grammar gems”) looks at one grammatical feature in order to describe in laudable detail the developmental sequences and criterial features learners with different L1-backgrounds go through from A1 to C2. This information will be extremely relevant for more detailed descriptions of what learners really ‘can do’ at different CEFR levels.
When looking at the variety and the detail of the major on-going projects in the field, it becomes very apparent that defining criterial features and adding findings from LCR can be very promising and fruitful for LTA. Yet, it also seems to be a highly complex challenge and will require many detailed and thorough studies in order to holistically describe the relevant criterial features across proficiency levels. Hence, the present study will only be able to offer some preliminary and tentative findings from ongoing research that might help to assess more specifically the spoken English of advanced learners and university majors in their third or fourth year of studies at a German university with regard to their verb-tense-related errors. 2.2 Errors and error analysis in LCR The suggestions to extend the CEFR descriptors with information gained from learner corpora is very much in line with recent approaches that LCR has been taking towards accuracy in ELT, namely by analyzing the frequencies, types and contexts of errors in learners’ output. Corder (1984: 25), among others, has described error analysis to be beneficial for language learning on many levels; however, it seems very difficult to define what an error actually is, so that researchers have differing definitions and include different error categories. Gilquin and De Cock (2011), for example, point out some of these difficulties, which become particularly apparent in the 1 http://www.englishprofile.org (19 June 2014) 2 http://www.englishprofile.org/index.php/wordlists (19 June 2014) 3 http://www.englishprofile.org/index.php/grammar-gems ( 19 June 2014)

5
assessment of spoken learner language: spoken English is much more variable than written English in its forms and also in its acceptable standards. Therefore, some linguistic features that would be considered non-standard in writing might be perfectly tolerable in speech (cf. Carter & McCarthy 2006: 168). Another difficulty in the assessment of spoken learner language is the question of how to distinguish a genuine error, i.e. an error of competence, from a mistake, i.e. a performance error or an uncorrected slip of the tongue (Corder 1967).4 Mistakes occur with great frequency not only in the speech of learners but also in that of native speakers, which adds another conceptual difficulty to error analysis of learner speech: in native language, errors in speaking are often considered slips or even innovations, whereas in an assessment of learner speech they are considered to be deviances from a given norm and therefore to be errors. Also, assessing learner speech raises the question of whether or not pronunciation errors should be counted as errors and if so, researchers do not agree whether all kinds of non-standard pronunciations of a word should be included (which seems almost impossible anyway, given the many variants in pronunciation that are available even in native language), or if they should only be included if an inaccurate pronunciation leads to a semantic shift of the mispronounced word (see Osborne 2008). A stereotypical example for a case in point in German learner English would be the difficulty in pronouncing the /θ/-sounds, e.g. think vs. sink are often pronounced as homophones [sɪŋk]. Another problem is whether errors of different sorts should be treated equally, or if there should be a distinction between errors that are perceived only as slight errors and those which are perceived as grave errors (see Gilquin & De Cock 2011). A study by Hughes and Lascratou (1982), for example, showed that there are clear differences in the perception of error gravity. For example, they showed that English teachers rank errors in the use of pronouns or verb forms more gravely than errors in the use of prepositions, word order or spelling. It seems therefore advisable to investigate different error categories in isolation in order not to run the risk of oversimplifying an analysis by relying on the number of errors alone. Further distinctions in error categorization have been made between interlingual and intralingual (Lennon 2000), covert and overt (Corder 1971), local and global (Burt & Kiparsky 1974), as well as knowledge-based and processing-based errors (Lennon 2000).
Another unresolved issue in the description of accuracy in learner language so far is whether the prime concern should be the total number of errors a learner makes or the proportion of accurate vs. inaccurate occurrences of a specific construction. Both approaches have been successful in previous research. For example, some studies that have measured the proportion between accurate and inaccurate uses of a grammatical feature (e.g. Díez-Bedmar & Papp 2008, Murcia-Bielsa & MacDonald 2013, Thewissen 2013) have led to sound results on the competence levels of learners and present valuable insights into SLA and 4 Some studies (e.g. Kämmerer 2012) even suggest that up to one third of all learner errors in speech might not be genuine errors but rather mistakes.

6
interlanguage research. This approach also enables researchers to take into consideration the (proportion of the) accurate uses of potentially more complex constructions that less proficient learners might avoid and who thus, ironically, score a lower number of errors (see also Schachter 1974, Dagut & Laufer 1985). Likewise, it enables researchers to account for learners who experiment with complex constructions and thus risk scoring a higher number of errors (Murcia-Bielsa & MacDonald 2013: 336), and who, at the same time, increase the degree of complexity of their output. However, other studies (e.g. Lennon 1991, Rogatcheva 2012, Twardo 2012) have focused on the numbers and/or types of errors alone and aim to describe, systematize and interpret in detail error patterns only rather than take other features into consideration that might be linked to a learner’s number of errors (e.g. utterance complexity, sentence structure, fluency, task-type, genre, communicative situation, learning context variables, etc.). In the present study, I will apply the latter approach and focus on providing an isolated picture of error-centred and text-based error profiles of advanced learners that can be useful for language testing and assessment purposes, rather than providing a holistic picture of the learners’ proficiency combining different competences. This approach also seems to be more suitable for the error-centred tradition of language testing and assessment in Germany. However, approaches vary and Lennon even suggests focusing neither on erroneous nor on non-erroneous uses when looking at advanced learners, but rather on those instances “which may be ‘infelicitous’ rather than fully erroneous. Any attempt to describe advanced learner performance must take account of this middle ground” (Lennon 1991: 194).
Notwithstanding these difficulties and unresolved issues in the field of error analysis, it seems to be a particularly fruitful method for developing descriptor scales for the assessment of spoken learner language, because it enables researchers to paint an authentic and detailed picture of learners’ developmental stages in a given communicative situation and can describe how the number and types of errors change along with these stages.
While empirical research on learners of English in their early stages has resulted in quite a good understanding of how the early SLA processes function (e.g. Dulay & Burt 1974), the same does not hold for (highly) advanced learners, or, as McCarthy (2013: 4) puts it, “the advanced level is largely unexplored territory”. In a similar vein, Cobb makes the following suggestion:
If instead, advanced learners are seen as learners nonetheless, moving systematically through acquisition sequences and overcoming shared misconceptions about the L2, then instruction can be focused more effectively throughout the learning process. (Cobb 2003: 3)
This suggestion can also be applied to the development of descriptor scales for different proficiency levels, because they can account for and describe

7
any of these systematicities in advanced learners’ errors. Hence, if it is possible to identify common and frequent error types that a large advanced learner population has in common, we might be able to develop descriptor scales that are much more concrete and purely performance-based. With large databases on advanced learner language being compiled and error-tagged, it is becoming possible to describe these categories in more detail. 2.3 Computer-aided error analysis (CEA) In the past decades, there has been a decrease in error analyses in SLA research due to the fact that it is considered to take too simplistic a view on the complex concept of interlanguage, and that analyses of the error patterns of a small number of learners alone can only be of limited benefit for language learners, so that “error taxonomies often confuse description with explanation” (Johnson & Johnson 1998: 112). Thus, in SLA research, error analysis is often considered as a too “fuzzy, unscientific, and unreliable way of approaching learner language” (Granger 2003: 466). However, this view on error analysis has changed since error-tagged versions of learner corpora have become available. Instead of drawing conclusions from the analysis of just a few individual learners, CEA has opened up the possibility to move away from such a fuzzy and unreliable way of analysis towards finding regularities and systematicities across learners. Previous CEAs have proven to be beneficial on various levels for LTA (see e.g. Granger 2003, Thewissen 2013). Some of the benefits of using CEA will be pointed out in the following.
Firstly, the systematic analysis of a large number of learners allows for a more straightforward distinction between errors and mistakes in a learner population because genuine errors are very likely to occur with greater frequency and across many learners in the corpus, whereas slips or mistakes are likely to occur much more randomly, less frequently in total and with regard to the number of learners who make them (see Gilquin & De Cock 2011). Thus, when observing the error types that only occur across a whole learner population, developing descriptor scales might become more concrete and focused on genuine errors, while, at the same time it will become easier to identify and discard individual and random mistakes.
Also, CEA prepares the ground for very thorough and performance-based descriptions of different proficiency levels, for example by identifying and systematizing the linguistic context in which an error occurs (see e.g. Osborne 2007). For instance, in his comparative error analysis of a learner corpus composed of English learners at high school and learners at university, Osborne (2007) shows that the context in which an error is committed changes according to the proficiency level of the learners. Thus, he gives a corpus-based description of the ways in which learners progress in proficiency from school to university. The analysis of the context also allows us to identify where advanced learners seem to have fossilized and how these fossilizations tend to appear in “specifiable frames” (Osborne 2007: 354). Also, for Spanish EFL learners’ written production, Murcia-Bielsa and MacDonald’s (2013) study shows how the number of errors per

8
thousand words decreases from 250 at A1 to 50 at C2. There are a number of further studies that have provided sound evidence for the development of proficiency levels ascertained from learners from various institutional statuses and with different L1s (e.g. Granger 2003, Osborne 2007, 2008, Díez-Bedmar & Papp 2008, Thewissen 2008, 2013, Castello 2013, Murcia-Bielsa & MacDonald 2013). All these studies show impressively that using CEA for developing descriptor scales also allows for a much more detailed description of the linguistic context in which an error occurs at different proficiency levels.
Currently, reflecting a noticeable shift in LCR towards a quantitative approach to the analysis of learner data, a large body of statistical tools and methods is being developed (e.g. Gries & Deshors 2014, Gries forthcoming). With LCR implementing multifactorial methods more frequently and applying them meaningfully to more learner data, it will become possible to describe proficiency levels in even greater detail and with more predictive power in the future. To date, however, most studies on L2 English have dealt with written data and have mainly focused on the International Corpus of Learner English (ICLE; Granger et al. 2009) or on other tailor-made written learner corpora, whereas descriptive studies on spoken error-tagged learner corpora have been rather rare so far, mainly due to the fact that large systematic databases of spoken interlanguage have only recently been compiled. Error-tagged versions of spoken learner corpora are still scarce. The German component of the LINDSEI (LINDSEI-GE) is one of the first spoken learner corpora to be error-tagged and provides great possibilities for error analyses of spoken learner language. I would thus like to briefly introduce the error-tagging system for this corpus. 3. LINDSEI-GE, an error-tagged spoken learner corpus The LINDSEI project was initiated at the Université catholique de Louvain in Belgium and the German subcorpus was compiled at Justus Liebig University Giessen, Germany (see Brand & Kämmerer 2006). To date, LINDSEI consists of 12 subcorpora from different L1-backgrounds, but the corpus is still growing and new subcorpora are currently being compiled. The design of each subcorpus follows the same principles, i.e. it contains fifty learner interviews that consist of three parts, viz. a monologic part, followed by a dialogic part and finally a picture description. Each interview is comprised of c. 2,000 words. Like the other subcorpora, the LINDSEI-GE was orthographically transcribed according to specific guidelines and includes learner profiles with meta-information about the learners (for more detailed information, see Gilquin et al. 2010).
The German learners are university students and English majors in their 3rd or 4th year of study and can thus be considered as advanced learners. This global proficiency measure is based on the learners’ institutional status alone. However, they have to provide their English proficiency by a Test of English as a Foreign Language (TOEFL) score of a minimum of 500 (out of 677) or an International English Language Testing

9
System (IELTS) score with a minimum of 6 before they are admitted to studying English at the University of Giessen. For orientation, according to the TOEFL test developers,5 the TOEFL scores correspond to the CEFR levels according to the following thresholds, illustrated in Table 2. Table 2. TOEFL test scores mapped onto CEFR proficiency levels
(adapted from http://www.ets.org). Total minimum TOEFL ITP scores (Level 1– 310 to 677 pts.)
CEFR Levels
627+ C1 (Proficient User — Effective Operational Proficiency)
543-626 B2 (Independent User — Vantage) 460-542 B1 (Independent User — Threshold) 337-359 A2 (Basic User — Waystage) According to these orientation points, the German learners’ proficiency in English in the LINDSEI-GE can be expected to range from at least an advanced B1 or B2 level to C1/C2. After three or four years of studying at university as English majors and after a stay abroad at an English-speaking university (which 75% of all learners in the corpus had spent), proficiency is likely to have increased, so that the advanced learners under scrutiny can be expected to range anywhere between B2 and C2. Previous research on the LINDSEI-GE has confirmed this variation between the learners regarding a variety of linguistic features (e.g. Götz 2013), so that there are noticeable differences in proficiency in the German subcorpus. This assumption is backed up by Gilquin et al. (2010: 10f.), who submitted random samples of five learners from each subcorpus to professional raters to classify them according to their CEFR level. Here, the ratings for the five German learners also ranged between B2 and C2. Of course, this can only serve as an estimate of the proficiency levels of the whole learner population, because, unfortunately, the learners’ entrance proficiency scores were not recorded at the beginning of their studies in Giessen, and neither were their proficiency levels at the time of corpus compilation. For the time being, the institutional status alone combined with the entrance requirements give reason to “suggest that the proficiency level in LINDSEI is best described as ranging from higher intermediate to advanced” (Gilquin et al. 2010: 10). A more thorough classification of the LINDSEI-GE learners according to their CEFR-level might thus serve to be beneficial for future studies. However, it can be expected that proficiency levels in the LINDSEI-GE may vary between B2 and C2.
In a second phase, the LINDSEI-GE was error-tagged (see Kämmerer 2012). While automatic error annotation procedures are being developed for written learner data and are getting more and more accurate (e.g. Gamallo et 5 https://www.ets.org/toefl_itp/research (26 July 2014)

10
al. this volume), automatic procedures are still rather problematic with regard to error ratios, particularly in spoken learner data. Granger (2003), for example, reports on success rates of only 25%-35% for automatic error annotation of learner data, or Izumi et al. (2004) report that even after training their error tagger, the recall rate could ‘only’ be increased to 43% and the precision rate to 68%, which is already quite promising, but definitely leaves room for further improvement in the future. Thus, the error tagging of the LINDSEI-GE had to be carried out manually. Each error in the corpus was thus manually identified by a team of three researchers, including one native speaker and university lecturer, one teacher-training graduate student and one university professor of English linguistics. The tagging team categorized each error and coded it for a correct target hypothesis according to a revised version of the Error Tagging Manual, developed by the Centre for English Corpus Linguistics of the University of Louvain-la-Neuve for a written learner corpus (Dagneaux et al. 2005). The error-tagging of the LINDSEI-GE was absolutely conservative, meaning that each form that deviated from the British or American English target norm was coded as an error. This line of argumentation follows the same standards that exist in German schools and universities, so that the errors were tagged the same way a high school teacher or university lecturer would mark them as wrong. For instance, an occurrence of a form of would in an if-clause was tagged as an error, although this form sometimes does occur in native English. The error tagging was carried out using a flat level annotation system that allowed for a maximum of four levels for annotation as illustrated in Table 3 for the category “Grammar” (G). Level 1 names the category classification (in this case G for Grammar), followed by up to three modifications that can be used to refine the error, e.g. the tag (GADVO) in (1) stands for an error in the category Grammar (G), Adverb (ADV), Order (O). (_IF) is added if the error is likely to be caused by interference from the learner’s L1. The corrected target hypothesis is put directly after each error between $-signs:
(1) suddenly they have to speak (GADVO_IF) properly German $German properly$ (LINDSEI-GE, GE009)
This error-tagging system “follows the principles for creation of an error-annotation system that is consistent, informative, flexible and reusable” (Granger 2003: 467). Altogether, 56 error tags within six main error categories were used: Form (F), Lexicogrammar (X), Lexis (L), Style (S), Grammar (G), and Words (redundant/missing) / Word order (W). At this point, pronunciation errors (P) and Infelicities (Z) (distinguished from errors) have not yet been included in the annotation, but these are planned to be added at a later stage.

11
Table 3. Flat level error annotation system used for error-tagging the LINDSEI-GE for the category Grammar (adapted from Dagneaux et al. 2005).
Level 1 Level 2 Level 3 [Level 4] Grammar (G)
Determiners (GD) Demonstrative determiners (GDD) Possessive Determiners (GDO) Indefinite Determiners (GDI) Determiner other (GDT)
Articles (GA) Nouns (GN) Noun case (GNC)
Noun number (GNN)
Pronouns (GP) Demonstrative pronouns (GPD) Personal Pronouns (GPP) Possessive pronouns (GPO) Indefinite pronouns (GPI) Reflexive and reciprocal Pronouns (GPF) Relative and interrogative pronouns (GPR) Unclear pronominal reference (GPU)
Adjectives (GADJ) Adjective order (GADJO) Adjective number (GADJN) Comparative / Superlative (GADJCS)
Adverbs (GADV) Adverb order (GADVO) Verbs (GV) Verb number (GVN)
Verb morphology (GVM) Non-finite / Finite verb forms (GVNF) Verb voice (GVV) Verb tense (GVT) Auxiliaries (GVAUX)
Word Class (GVC) The error-analysis was carried out in the following way. To test if there is any systematicity in the error patterns of advanced learners’ output, I first extracted all the errors from the LINDSEI-GE and categorized them for each individual learner in order to see if they share similar error types and if similar error patterns become visible. In a second step I looked more closely into the most error-prone error category in order to see if patterns become visible across proficiency levels and to see if it is possible to formulate descriptor scales of different accuracy levels of the intermediate to advanced learners in the LINDSEI-GE that might be helpful for assessing proficiency levels of university students. 4. Findings 4.1 Total number of errors Altogether, there are 1,326 errors made by the fifty learners in the LINDSEI-GE with a mean frequency of 26 errors per learner and a
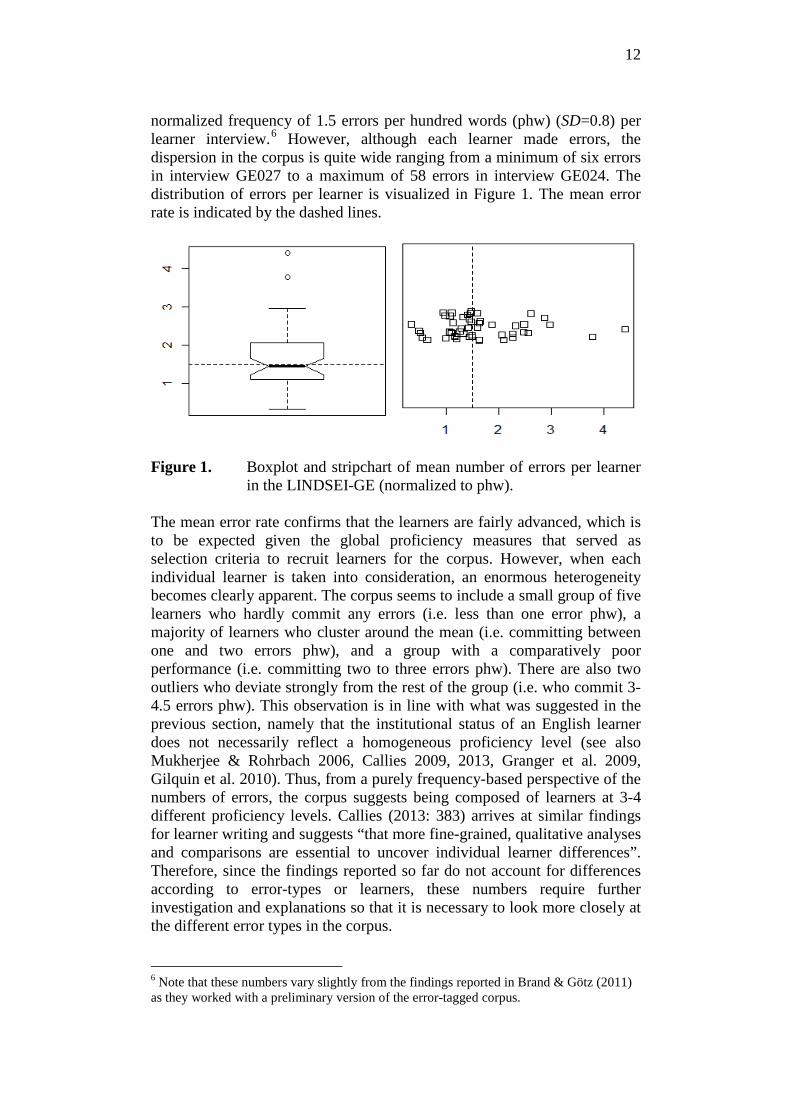
12
normalized frequency of 1.5 errors per hundred words (phw) (SD=0.8) per learner interview.6 However, although each learner made errors, the dispersion in the corpus is quite wide ranging from a minimum of six errors in interview GE027 to a maximum of 58 errors in interview GE024. The distribution of errors per learner is visualized in Figure 1. The mean error rate is indicated by the dashed lines.
Figure 1. Boxplot and stripchart of mean number of errors per learner
in the LINDSEI-GE (normalized to phw). The mean error rate confirms that the learners are fairly advanced, which is to be expected given the global proficiency measures that served as selection criteria to recruit learners for the corpus. However, when each individual learner is taken into consideration, an enormous heterogeneity becomes clearly apparent. The corpus seems to include a small group of five learners who hardly commit any errors (i.e. less than one error phw), a majority of learners who cluster around the mean (i.e. committing between one and two errors phw), and a group with a comparatively poor performance (i.e. committing two to three errors phw). There are also two outliers who deviate strongly from the rest of the group (i.e. who commit 3-4.5 errors phw). This observation is in line with what was suggested in the previous section, namely that the institutional status of an English learner does not necessarily reflect a homogeneous proficiency level (see also Mukherjee & Rohrbach 2006, Callies 2009, 2013, Granger et al. 2009, Gilquin et al. 2010). Thus, from a purely frequency-based perspective of the numbers of errors, the corpus suggests being composed of learners at 3-4 different proficiency levels. Callies (2013: 383) arrives at similar findings for learner writing and suggests “that more fine-grained, qualitative analyses and comparisons are essential to uncover individual learner differences”. Therefore, since the findings reported so far do not account for differences according to error-types or learners, these numbers require further investigation and explanations so that it is necessary to look more closely at the different error types in the corpus. 6 Note that these numbers vary slightly from the findings reported in Brand & Götz (2011) as they worked with a preliminary version of the error-tagged corpus.
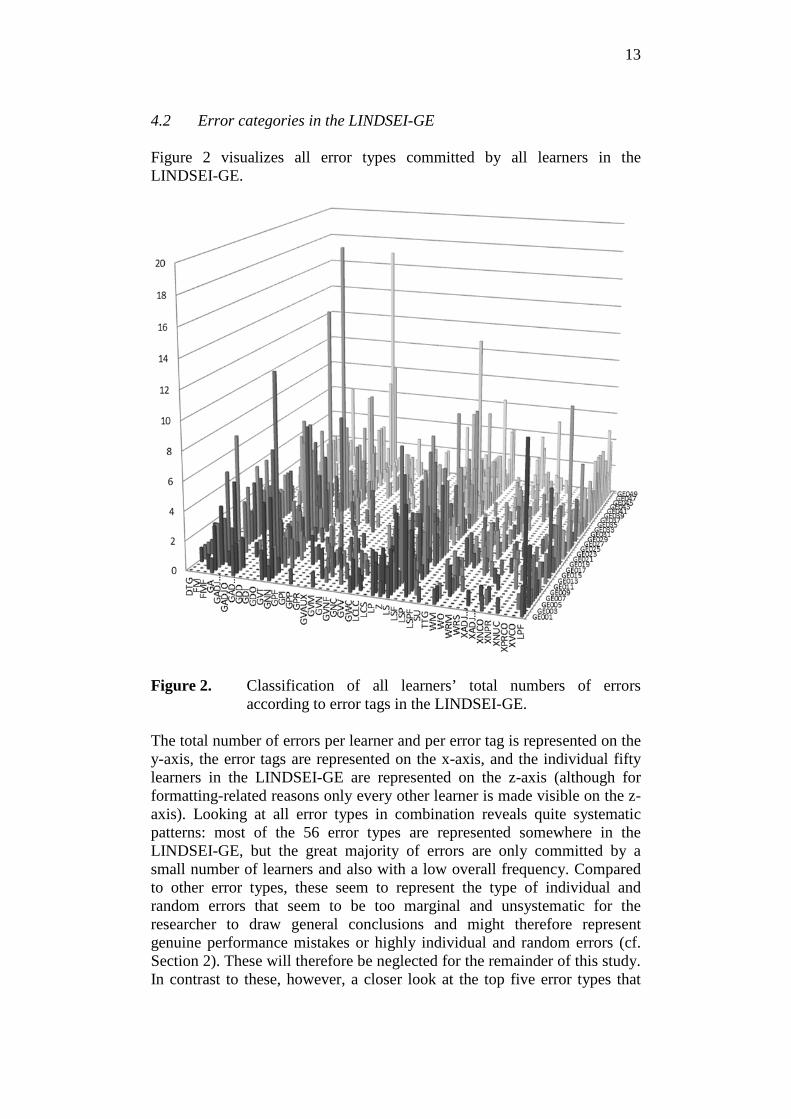
13
4.2 Error categories in the LINDSEI-GE Figure 2 visualizes all error types committed by all learners in the LINDSEI-GE.
Figure 2. Classification of all learners’ total numbers of errors
according to error tags in the LINDSEI-GE. The total number of errors per learner and per error tag is represented on the y-axis, the error tags are represented on the x-axis, and the individual fifty learners in the LINDSEI-GE are represented on the z-axis (although for formatting-related reasons only every other learner is made visible on the z-axis). Looking at all error types in combination reveals quite systematic patterns: most of the 56 error types are represented somewhere in the LINDSEI-GE, but the great majority of errors are only committed by a small number of learners and also with a low overall frequency. Compared to other error types, these seem to represent the type of individual and random errors that seem to be too marginal and unsystematic for the researcher to draw general conclusions and might therefore represent genuine performance mistakes or highly individual and random errors (cf. Section 2). These will therefore be neglected for the remainder of this study. In contrast to these, however, a closer look at the top five error types that

14
appear in the LINDSEI-GE reveals them to be absolutely systematic across the whole corpus, because in all these five types (1) almost all of the fifty learners commit errors in these categories and (2) they do so with very high frequencies. These errors in these five categories do not seem to appear randomly at all, but rather point at systematic misconceptions across all German advanced learners (cf. Section 2.3). Similar trends have already been suggested in a pilot study on five randomly selected learners by Brand and Götz (2011), which can now be confirmed for the complete learner group. These error categories seem particularly interesting to look at in more detail. They are two grammar-related categories and three lexically-related errors. The proportion of the numbers of errors committed in these five categories compared to the total number of errors is summarized in Table 4. Table 4. Top five error categories committed by learners in the
LINDSEI-GE.
error category proportion of errors in LINDSEI-GE
1. GVT (Grammar/Verb/Tense) (n=235, mean no of errors per learner=4.7, SD=4.2)
17.6 %
2. LS (Lexical/Single) (n=141, mean no of errors per learner=2.8, SD=2.6)
10.6%
3. GA (Grammar/Article) (n=135, mean no of errors per learner=2.7, SD=1.9)
10.2%
4. LPF (Lexical/Phrase/False Friend) (n=120, mean no of errors per learner=2.4, SD=2.3)
9%
5. LSP (Lexical/Single/Preposition) (n=108, mean no of errors per learner=2.2, SD=2.0)
8.1%
total 55.2% Altogether, these five most frequent error categories already make up for more than half of all errors in the LINDSEI-GE. Note the high values for standard deviation for all error types which, again, reflect the heterogeneity in the corpus. I will therefore zoom in more closely on the most frequent and particularly error-prone type in the corpus, GVT, in order to see if any systematicities can be found in advanced learners’ performances in this category. 4.3 GVT-related errors as criterial features The categories for the GVT consist of all misuses of either tense or aspect. Some examples for related errors that were coded include the following (adapted from Dagneaux et al. 2005: 24): Simple Present for Past Progressive e.g. during the semester you could . see: how your grade (GVT_IF) goes $was going$ (GE028) Present Progressive for Simple Present

15
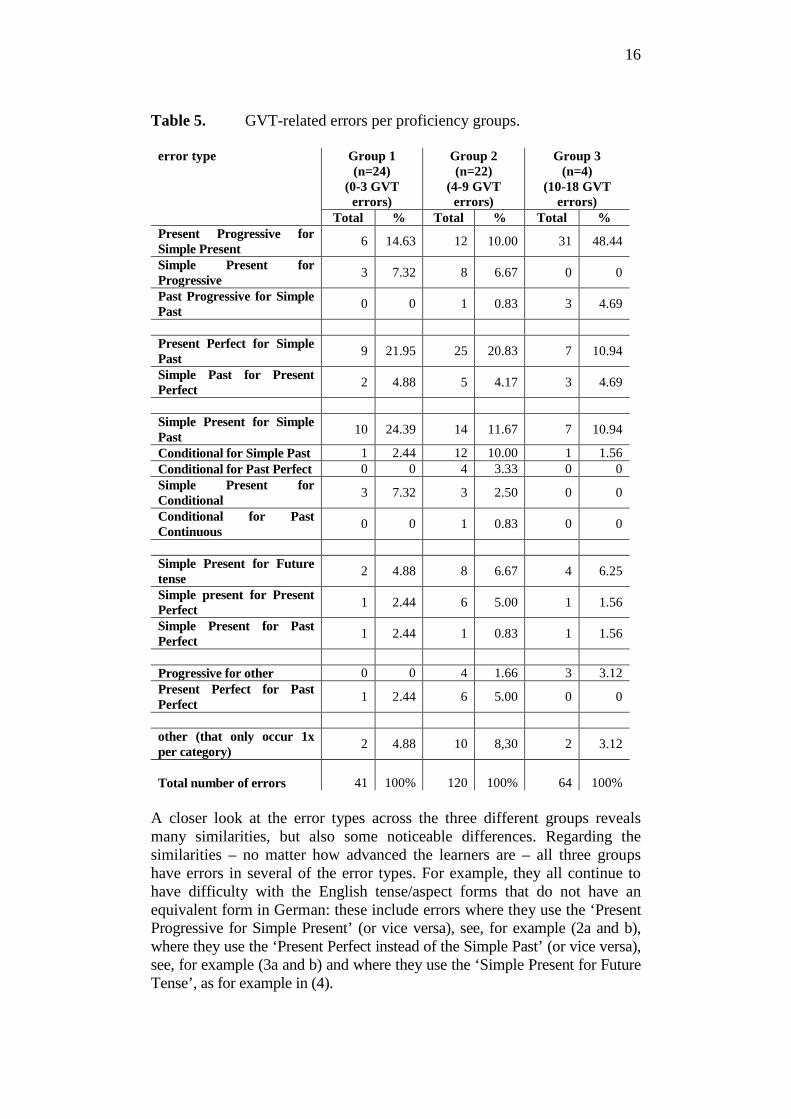
e.g. and: er . in the first . weeks it was very difficult for me to understand . the French because they (GVT) are speaking $speak$ so fast . (GE006) Present Perfect for Simple Past e.g. (GVT_IF) I’ve been $went$ there . two years ago (GE020) Altogether, the GVT category consists of 235 errors, which were committed by the overwhelming majority of 94% of all learners in the corpus ranging from a minimum of zero up to a maximum of 19 GVT-errors in the whole interview (mean=4.7, SD=4.2). Again, there is great heterogeneity in the corpus which calls for more detailed analysis. I will take a closer look at the different types of learners’ errors in this category. The absolute numbers of GVT-errors committed by the fifty individual learners in the LINDSEI-GE are visualized in Figure 3.
Figure 3. Grammar, Verb, Tense (GVT)-errors across learners in the
LINDSEI-GE. In order to test if the types of errors change according to the learners’ increasing proficiency and to systematize the heterogeneity in the corpus meaningfully, a distinction was made between three learner groups in the corpus: Group 1 (n=24) with the highest proficiency level, i.e. they only committed 0-3 GVT-errors (mean=1.7, SD=0.95), Group 2 (n=22), a medium-proficient group which did not significantly deviate from the mean error rate, i.e. they committed between 4-9 GVT-errors (mean=5.9, SD=1.54) and Group 3 (n=4) with the poorest performance, which significantly deviated from the mean error rate in this category, i.e. 10-18 GVT-errors (mean=16, SD=2.58). The learner groups are separated by the vertical lines inserted in Figure 3.
Altogether, the learners in the LINDSEI-GE committed 33 different types of GVT-related errors. When an error-type only occurred once in a learner group, they were conflated with other groups. The GVT-error-distribution per proficiency group is summarized in Table 5.
02468
101214161820
GE0
08G
E025
GE0
38G
E003
GE0
27G
E031
GE0
32G
E042
GE0
46G
E001
GE0
09G
E010
GE0
11G
E012
GE0
14G
E019
GE0
33G
E036
GE0
47G
E007
GE0
13G
E023
GE0
26G
E041
GE0
20G
E034
GE0
35G
E043
GE0
44G
E045
GE0
02G
E004
GE0
22G
E037
GE0
18G
E030
GE0
15G
E021
GE0
28G
E039
GE0
40G
E048
GE0
05G
E016
GE0
17G
E050
GE0
06G
E024
GE0
49G
E029
16
Table 5. GVT-related errors per proficiency groups.
error type Group 1 (n=24)
(0-3 GVT errors)
Group 2 (n=22)
(4-9 GVT errors)
Group 3 (n=4)
(10-18 GVT errors)
Total % Total % Total % Present Progressive for Simple Present 6 14.63 12 10.00 31 48.44
Simple Present for Progressive 3 7.32 8 6.67 0 0
Past Progressive for Simple Past 0 0 1 0.83 3 4.69
Present Perfect for Simple Past 9 21.95 25 20.83 7 10.94
Simple Past for Present Perfect 2 4.88 5 4.17 3 4.69
Simple Present for Simple Past 10 24.39 14 11.67 7 10.94
Conditional for Simple Past 1 2.44 12 10.00 1 1.56 Conditional for Past Perfect 0 0 4 3.33 0 0 Simple Present for Conditional 3 7.32 3 2.50 0 0
Conditional for Past Continuous 0 0 1 0.83 0 0
Simple Present for Future tense 2 4.88 8 6.67 4 6.25
Simple present for Present Perfect 1 2.44 6 5.00 1 1.56
Simple Present for Past Perfect 1 2.44 1 0.83 1 1.56
Progressive for other 0 0 4 1.66 3 3.12 Present Perfect for Past Perfect 1 2.44 6 5.00 0 0
other (that only occur 1x per category) 2 4.88 10 8,30 2 3.12
Total number of errors
41
100%
120
100%
64
100%
A closer look at the error types across the three different groups reveals many similarities, but also some noticeable differences. Regarding the similarities – no matter how advanced the learners are – all three groups have errors in several of the error types. For example, they all continue to have difficulty with the English tense/aspect forms that do not have an equivalent form in German: these include errors where they use the ‘Present Progressive for Simple Present’ (or vice versa), see, for example (2a and b), where they use the ‘Present Perfect instead of the Simple Past’ (or vice versa), see, for example (3a and b) and where they use the ‘Simple Present for Future Tense’, as for example in (4).

17
(2) a. I don't understand the French because they (GVT) are
speaking $speak$ so fast (GE006) b. (GVT_IF) I’m er playing $I play$ in a band (GE039)
(3) a. they (GVT_IF) have been $were$ there forty years ago
(GE009) b. (GVT_IF) I’ve been $went$ there . two years ago (GE020)
(4) well I (GVT_IF) start $will start$ with my teacher training
(GE022) All three of these error types are most likely due to negative transfer from the L1, because standard German does not mark aspect grammatically. Instead, the Present Perfect is the norm in spoken German where Simple Past sounds formal. Forms which do not have an equivalent form in the L1 have been shown to be particularly troublesome (e.g. Zydatiß 1976, Kämmerer 2012, Rogatcheva 2012), so these findings are very much in line with previous research. With regard to quantity for these three error categories observed in the LINDSEI-GE, the higher the proficiency level of the learner, the lower the number of errors produced by that learner.
Another category in which all three proficiency groups show high error frequencies is the use of the Simple Present where the Simple Past should have been used. The contexts in which we find these individual errors reveal that this error type mainly occurred with the use of reported speech, where the learners did not apply the change in the tense of the verb in the reported clause correctly, as exemplified in (5a and b).
(5) a. I thought she (GVT_IF) likes $liked$ me (GE026)
b. maybe she thought . this . this (GVT_IF) is $was$ really her (GE037)
This seems to be caused by negative transfer from the L1 again, as spoken German does not have an obligatory change in the tense of the verb in the reported clause. Altogether, it seems that even advanced learners and English university majors at all proficiency levels still have problems with tense and aspect marking, so these seem to remain particularly error-prone. For the description and assessment of advanced spoken learner language, these four categories need to be included as descriptors. What needs to be taken into consideration, however, is that they occur with descending frequencies with ascending proficiency in the three groups under scrutiny.
There are also differences between the three groups, where one distinctive feature is noticeable: the learners in the most proficient group (Group 1) do not commit errors of all possible types, but mainly have problems with the four categories mentioned above. The other two groups, however, Group 2 and Group 3, also commit errors in other categories, for example, the use of the conditional. This happens very frequently when the learners make use of if-clauses, but use would in the conditional clause

18
instead of the required subjunctive mood, etc. (cf. 6a and b). When the learners used if-clauses they wrongly inserted a conditional would instead of the tense shift in the verb as for example shown in (6a and b). Again, this is likely to be caused by L1 interference from the equivalent form in spoken German. This error also occurs when the learners attempted to express conditionals in general, for example in (7). This error type can be found most frequently in the intermediate group.
(6) a. if you (GVT) would have asked $had asked$ me (GE030)
b. If we w= (GVT_IF) would face $faced$ . (GA_IF) the .. the $0$ bold reality day by day (GE017)
(7) even if i= if this (GVT_IF) is $was$ not a bus stop (GE024)
This is another general problem area even with the intermediate proficiency groups. The most proficient group, however, seems to not have issues with the use of the conditional, as only very few errors with the conditional can be attested in the most advanced group.7 It thus seems that the accurate or inaccurate use of if-clauses and conditionals in general might be a good indicator of assessing a learners’ proficiency level between independent and proficient users.
The last thing that seems to be particularly noteworthy is the high proportion of one error type in the lowest proficiency group. Almost half of the errors committed is the use of the Present Progressive instead of the Simple Present (or vice versa), cf. (4) (see also Dose & Götz 2012). It is error-prone in all three groups, but particularly so in the group with the most frequent errors. Thus, this seems to be an even bigger stumbling block at a lower proficiency level and becomes less of a problem the more advanced a learner becomes. This also shows that describing and assessing proficiency at advanced levels seems to be rather a matter of frequency of certain errors and less of a categorical description. 4.4 Implications for language testing and assessment Looking at the most error-prone category qualitatively helps to identify the major stumbling blocks even advanced (German) learners still encounter and also helps to distinguish even between advanced proficiency levels of English majors at university. However, these error types are counter-intuitive, as one would not have expected university students to have problems with the prototypical error categories of Progressive/Simple Present confusion, if-clauses or reported speech after they had spent some time abroad. It becomes clear that there is a strong need for putting more emphasis even on these basic features again in language practice courses at 7 One might think that an explanation for this could be that the conditional is simply not used by any of the learners in the most proficient group. However, a corpus search for if-clauses showed that the learners in Group 1 used it correctly, i.e. without using would in the conditional clause.

19
university level. Also, since the most error-prone category in the LINDSEI-GE is GVT, the learners’ performance according to the frequency and types of errors in this category seem to be a reliable descriptor of a learner’s proficiency level.
With regard to language testing and assessment at university level, the findings of this pilot study on GVT-errors in the LINDSEI-GE lead to some preliminary ideas how descriptor scales, or “grammar gems” (see Section 2.1) for advanced university learners could be developed. A close look at the individual error types in one of the major criterial features, namely the use of tense and aspect, can add more concrete information as to how learners can be described and assessed at different advanced proficiency levels, even at the university level. Following the analysis of GVT-errors described in 4.3, the descriptor scales for intermediate – advanced university learners could be described in the following way, by taking the CEFR-descriptor scales as a starting point for the wording and adding more linguistic substance to them, cf. Table 6. Table 6. Descriptor scales for grammatical verb accuracy in intermediate-
proficient learner speech for German university students (inspired by the CEFR-descriptor scales; original CEFR-wording in boldprint).
Proficiency level Suggestions for descriptor scales for GVT-related errors for
advanced learners in the LINDSEI-GE
Most proficient university students
Maintains consistent grammatical control of complex language; grammatical tense/aspect-related errors occur hardly ever (c. 0-3 errors per 10 minutes of speaking), errors occur mainly in categories caused by interference, such as Simple Present/Present Progressive confusion, Present Perfect/Simple Past confusion, or reported speech.
Proficient university students
Consistently maintains a high degree of grammatical accuracy; errors are rare and difficult to spot and occur with very low frequency (c. 4-8 errors per 10 minutes of speaking); errors occur mainly in categories that are caused by interference, such Simple Present/Present Progressive confusion, Present Perfect/Simple Past confusion. If-clauses and reported speech can also cause some difficulties.
Intermediate university students
Shows a relatively high degree of grammatical control. Does not make mistakes which lead to misunderstanding, but grammatical tense/aspect-related errors occur occasionally (c. 10-20 errors per 10 minutes of speaking). Errors occur with highest frequency in categories such as Simple Present/Present Progressive confusion, but also a considerable proportion of errors are related to Present Perfect/Simple Past confusion, reported speech, and the use of the Conditional, especially in if-clauses; other tense/aspect related errors also occur.
These descriptions can only serve as preliminary suggestions and ideas of how descriptor scales could be expanded by more detailed linguistic descriptions of error types, patterns and frequencies. Of course, these need to be complemented by more thorough descriptions of other grammatical error categories as well as more learner data (note that the least proficient

20
group only consists of four learners and cannot claim to be representative), but they might still offer some ideas how descriptor scales could be developed if we make use of the valuable suggestions offered in the CEFR and if they are complemented with more concrete linguistic information from CEAs in order to confirm/neglect hypotheses as to L1 interference. Future descriptor scales combining these two aspects might be helpful to raters and assessors, offering them something more reliable and readily available than an overall impression, even at the university level. 5. Conclusion and outlook Overall, the present study has not only revealed structures that are especially error-prone in the case of German learners of English (e.g. reported speech, if-clauses), but it also shows that even at a — globally defined — advanced level, learners appear to form a fairly heterogeneous group with regard to their numbers of errors. A look at the numbers and types of errors committed by the advanced learners in the LINDSEI-GE confirms previous research in that the institutional status alone is no reliable criterion to assess the actual proficiency level of a learner (see also Osborne 2008, Callies 2009, 2013, Granger et al. 2009). It is thus useful and advisable to complement this by CEAs in order to arrive at neutrally assessed proficiency levels in the learner corpus under scrutiny (e.g. Thewissen 2013).
Yet, despite these limitations, the error types found in the LINDSEI-GE are quite systematic despite the heterogeneity in proficiency, allowing for corpus-based descriptions of learners’ error profiles at different levels. Examining the individual error types within a certain category can help describe and assess the exact proficiency levels even of advanced learners.
I would like to conclude this paper by mentioning some points that could be taken up in future research. According to the error-tagging system used for the LINDSEI-GE, there is some room for expansion, in order to account for errors that are exclusive to the spoken medium. For example, the tagging system for spoken learner corpora could be extended by tags for pronunciation errors that lead to misunderstandings. Some suggestions how theses tags could be implemented in the error tagging system used in the LINDSEI-GE have been outlined, for example, by Kämmerer (2009).
Most importantly, however, for developing descriptor scales that are learner-centred, text-based and can be universally used in ELT, it is absolutely crucial to compare and analyse error types across learner populations with different L1s. This is already being tackled in learner writing and has led to sound results, as recent studies by, for example, Díez-Bedmar and Papp (2008) on article use in Spanish and Chinese learners of English, Osborne (2008) on adverb placement across ICLE subcorpora, or by Rogatcheva (2012) on tense/aspect use by German and Bulgarian learners of English have shown. However, it would be very beneficial for more comparative CEA studies on spoken learner corpora across different L1s to follow and compare their results. For the development of global

21
assessment scales like the CEFR, one needs to take into consideration L1-specific as well as potentially “universal” learner error types. References Aijmer, K. 2002. English Discourse Particles: Evidence from a Corpus
[Studies in Corpus Linguistics 10]. Amsterdam and Philadelphia, PA: John Benjamins.
Brand, C. & Götz, S. 2011. Fluency versus accuracy in advanced spoken learner language: A multi-method approach. International Journal of Corpus Linguistics 16(2): 255–275.
Brand, C. & Kämmerer, S. 2006. The Louvain International Database of Spoken English Interlanguage (LINDSEI): Compiling the German component. In Corpus Technology and Language Pedagogy: New Resources, New Tools, New Methods, S. Braun, K. Kohn & J. Mukherjee (eds), 127–140. Frankfurt/Main: Peter Lang.
Burt, M. K. & Kiparsky, C. 1974. Global and local mistakes. In New Frontiers in Second Language Learning, J. H. Schumann & N. Stenson (eds), 71–80. Rowley MA: Newbury House.
Callies, M. 2009. Information Highlighting in Advanced Learner English. The Syntax-Pragmatics Interface in Second Language Acquisition [Pragmatics & Beyond New Series 186]. Amsterdam and Philadelphia, PA: John Benjamins.
Callies, M. 2013. Agentivity as a determinant of lexico-grammatical variation in L2 academic writing. International Journal of Corpus Linguistics 18(3): 357–390.
Castello, E. 2013. Integrating learner corpus data into the assessment of spoken interaction in English in an Italian university context. In Twenty Years of Learner Corpus Research: Looking back, Moving ahead, S. Granger, G. Gilquin & F. Meunier (eds), 61–74. Louvain-la-Neuve: Presses Universitaires de Louvain.
Carter, R. & McCarthy, M. 2006. Cambridge Grammar of English. Cambridge: CUP.
Cobb, T. 2003. Analyzing late interlanguage with learner corpora: Quebec replications of three European studies. Canadian Modern Language Review 59(3): 393–423.
Corder, S. P. 1967. The significance of learners’ errors. International Review of Applied Linguistics 5(4): 161–170.
Corder, S. P. 1971. Idiosyncratic dialects and error analysis. International Review of Applied Linguistics 9(2): 147–159.
Corder, S. P. 1984. The significance of learners’ errors. In Error Analysis: Perspectives on Second Language Acquisition, J. C. Richards (ed.), 19–27. Essex: Longman.
Council of Europe (2009): Common European Framework of Reference for Languages: Learning, Teaching, Assessment. Cambridge: CUP.
Dagneaux, E., Denness, S. & Granger, S. 1998. Computer-aided error analysis. System 26(2): 163–174.

22
Dagneaux, E., Denness, S., Granger, S., Meunier, F., Neff, J. & Thewissen, J. 2005. UCL Error-Tagging Manual. Version 1.2. Centre for English Corpus Linguistics, Université catholique de Louvain: Louvain-la-Neuve.
Dagut, M. B. & Laufer, B. 1985. Avoidance of phrasal verbs: A case for contrastive analysis. Studies in Second Language Acquisition 7(1): 73–79.
De Cock, S. 1998. A recurrent word combination approach to the study of formulae in the speech of native and non-native speakers of English. International Journal of Corpus Linguistics 3(1): 59–80.
Díaz-Negrillo A. & Fernández-Domínguez, J. 2006. Error tagging systems for learner corpora. RESLA 19: 83–102.
Díez-Bedmar, M. B. & Papp, S. 2008. The use of the English article system by Chinese and Spanish learners. In Linking up Contrastive and Learner Corpus Research, G. Gilquin, S. Papp & M. B. Díez-Bedmar (eds), 147–175. Amsterdam: Rodopi.
Dose, S. & Götz, S. 2012. The progressive in advanced spoken learner English: Frequency and accuracy. Paper presented at the 34th annual conference of the International Computer Archive of Modern and Medieval English (ICAME 34), 22-26 May 2013, University of Santiago de Compostela.
Dulay, H. C. & Burt, M. K. 1974. Natural sequences in child second language acquisition. Language Learning 24(1): 37–53.
English Profile. 2011. English Profile. Introducing the CEF for English. Version 1.1, <http://www.englishprofile.org/images/pdf/theenglish profilebooklet.pdf> (19 June 2014).
Gilquin, G., De Cock, S. & Granger, S. 2010. The Louvain International Database of Spoken English Interlanguage. Handbook and CD-ROM. Louvain-la-Neuve: Presses Universitaires de Louvain.
Gilquin, G. & De Cock, S. 2011. Errors and dysfluencies in spoken corpora: Setting the scene. International Journal of Corpus Linguistics 16(2): 141–172.
Götz, S. 2013. Fluency in Native and Nonnative English Speech [Studies in Corpus Linguistics 53]. Amsterdam and Philadelphia, PA: John Benjamins.
Granger, S. 2003. Error-tagged learner corpora and CALL: A promising synergy. CALICO Journal 20(3): 465–480.
Granger, S. & Tyson, S. (eds). 1996. Extending the Scope of Corpus-Based Research: New Applications, New Challenges. Amsterdam: Rodopi.
Granger, S., Dagneaux, E., Meunier, F., Paquot, M. 2009. The International Corpus of Learner English. Version 2. Handbook and CD-Rom. Louvain-la-Neuve: Presses Universitaires de Louvain.
Gries, S. Th. forthcoming. Statistical methods in learner corpus research. In The Cambridge Handbook of Learner Corpus Research, G. Gilquin, S. Granger & F. Meunier (eds). Cambridge: CUP.
Gries, S. Th. & Deshors, S. C. 2014. Using regressions to explore deviations between corpus data and a standard/target: Two suggestions. Corpora 9(1): 109–136.

23
Hawkins, J. A. & Buttery, P. 2010. Criterial features in learner corpora: Theory and illustrations. English Profile Journal 1(1): 1–23.
Hawkins, J. & Filipović, L. 2012. Criterial Features in L2 English. Cambridge: CUP.
Hughes, A. & Lascaratou, C. 1982. Competing criteria for error gravity. ELT Journal 36(3): 175–182.
Izumi, E., Uchimoto, K. & Isahara, H. 2004. SST speech corpus of Japanese learners’ English and automatic detection of learners’ errors. ICAME Journal 28: 31–48.
Johnson, K. & Johnson, H. (eds). 1999. Encyclopedic Dictionary of Applied Linguistics: A Handbook for Language Teaching. Oxford: Blackwell.
Kämmerer, S. 2009. Error-tagging spoken features of (learner) language: The UCL error editor ‘revised’. Paper presented at the 30th annual conference of the International Computer Archive of Modern and Medieval English (ICAME 30), 27–31 May 2009, Lancaster University.
Kämmerer, S. 2012. Interference in advanced English interlanguage: Scope, detectability and dependency. In Input, Process and Product: Developments in Teaching and Language Corpora, J. Thomas & A. Boulton (eds), 284–297. Brno: Masaryk University Press.
Lennon, P. 1991. Error: Some problems of definition, identification and distinction. Applied Linguistics 12(2): 180–196.
Lennon, P. 2000. The lexical element in spoken second language fluency. In Perspectives on Fluency, H. Riggenbach (ed.), 25–42. Ann Arbor MI: The University of Michigan Press.
McCarthy, M. 2013. Putting the CEFR to good use: Designing grammars based on learner-corpus evidence. Language Teaching, FirstView Article, <http://dx.doi.org/10.1017/S0261444813000189> (26 July 2014).
Mukherjee, J. & Rohrbach, J.-M. 2006. Rethinking applied corpus linguistics from a language-pedagogical perspective: New departures in learner corpus research. In Planning, Gluing and Painting Corpora: Inside the Applied Corpus Linguist's Workshop, B. Kettemann & G. Marko (eds), 205–232. Frankfurt/Main: Peter Lang.
Müller, S. 2005. Discourse Markers in Native and Non-Native English Discourse [Pragmatics & Beyond New Series 138]. Amsterdam and Philadelphia, PA: John Benjamins.
Murcia-Bielsa, S. & MacDonald, P. 2013. The TREACLE project: Profiling learner proficiency using error and syntactic analysis. In Twenty Years of Learner Corpus Research: Looking Back, Moving Ahead, S. Granger, G. Gilquin & F. Meunier (eds), 335–344. Louvain-la-Neuve: Presses universitaires de Louvain.
North, B. 2014. Putting the Common European Framework of Reference to good use. Language Teaching 47(2): 228–249.
Osborne, J. 2007. Why do they keep making the same mistakes? Evidence for error motivation in a learner corpus. In Corpora and ICT in

24
Language Studies. PALC 5, J. Waliński, K. Kredens & S. Goźdź-Roszkowski (eds), 343–355. Frankfurt/Main: Peter Lang.
Osborne, J. 2008. Adverb placement in post-intermediate learner English: A contrastive study of learner corpora. In Linking up Contrastive and Learner Corpus Research, G. Gilquin, S. Papp & M. B. Díez-Bedmar (eds), 127–146. Amsterdam: Rodopi.
Park, K. 2014. Corpora and language assessment: The state of the art. Language Assessment Quarterly 11(1): 27–42.
Ringbom, H. 1999. High frequency verbs in the ICLE corpus. Explorations in Corpus Linguistics, A. Renouf (ed.), 191–200. Amsterdam: Rodopi.
Rogatcheva, S. I. 2012. Measuring learner (mis)use: Tense and aspect errors in the Bulgarian and German components of ICLE. In Input, Process and Product. Developments in Teaching and Language Corpora, J. Thomas & A. Boulton (eds), 258–272. Brno: Masaryk University Press.
Römer, U. 2005. Progressives, Patterns, Pedagogy. A Corpus-driven Approach to English Progressive Forms, Functions, Contexts and Didactics [Studies in Corpus Linguistics 18]. Amsterdam and Philadelphia, PA: John Benjamins.
Schachter, J. 1974. An error in error analysis. Language Learning 24(2): 205–214.
Thewissen J. 2008. The phraseological errors of French-, German-, and Spanish speaking EFL learners: Evidence from an error-tagged learner corpus. In Proceedings from the 8th Teaching and Language Corpora Conference (TaLC8), Lisbon, 3-6 July 2008, Associação de Estudos e de Investigação Científica do ISLA-Lisboa (eds), 300–306.
Thewissen, J. 2013. Capturing L2 accuracy developmental patterns: Insights from an error-tagged EFL learner corpus. The Modern Language Journal 97(S1): 77–101.
Twardo, S. 2012. Selected errors in the use of verbs by adult learners of English at B1, B2 and C1 levels. In Input, Process and Product. Developments in Teaching and Language Corpora, J. Thomas & A. Boulton (eds), 273–282. Brno: Masaryk University Press.
Zydatiß, W. 1976. Learning problem expanded form: A performance analysis. IRAL 14(4): 351–71.




















