
Evaluation of the C2IEDM as an Interoperability-Enabling Ontology
13
European Simulation Interoperability Workshop Toulouse, France, June 2005 05E-SIW-045 - 1 - Evaluation of the C2IEDM as an Interoperability-Enabling Ontology Charles Turnitsa Dr. Andreas Tolk Virginia Modeling Analysis & Simulation Center (VMASC) Old Dominion University Norfolk, VA 23529 [email protected] [email protected] Keywords: Ontology, Data Modeling, Simulation Interoperability, C2IEDM ABSTRACT: The science of linguistics tells us that Ontology is the specification of meaning for the elements of a language, and the relationships between those elements. Within the world of data modeling, as different models must interact with each other, the ability to describe the ontology of a data model becomes increasingly more important. This is especially true in the realm of simulation interoperability, where each different simulation system has it’s own data model, and therefore, it’s own ontology. One of the most crucial paths of research currently being explored by a number of different parties is the use of the Command and Control Information Exchange Data Model (C2IEDM) as a referential tool enabling the interchange of data between two (or more) distinct systems. The C2IEDM necessarily has it’s own ontology, but is it sufficiently complete to serve as a referential ontology for simulation interoperability? This paper will first describe what defines an ontology, and what is a sufficiently complete ontology to serve as a reference for simulation interoperability. A review of the functional areas of the C2IEDM will follow, and finally based on this review, an evaluation will be made as to whether the C2IEDM is a sufficiently complete ontology. 1 Introduction A Model is defined to be “a meaningful abstraction of reality.” As such, it comes with a lot of constraints and assumptions that have to be communicated in order to achieve interoperability between different models and their implementing systems. Currently, the application of ontologies delivers promising results in the domains of semantic web applications. Our working thesis for the research is that ontologies can support interoperability of distributed M&S applications as well, as ontologies are able to capture the different meaningful abstractions and make them comparable. Ontology is very loosely defined as a specification of a conceptualization [1]. Through that view it should be readily apparent that every set of ideas that conceptualizes of something else – whether it is a language, a data model, or an interpretation of a view – would have it’s own ontology. From this is should be readily apparent that everything – every system we use in particular – has an ontology. What is difficult, and what requires study, is that there is not a standardized method for discussing and describing ontology, or for studying and evaluating the ontology of a particular data model so it can be compared to others. This is true in any field, but it is of particular interest to the Simulation Interoperability Standards Organization (SISO) in the domain of command and control (C2), and modeling and simulation (M&S) interoperability. 1.1 Why Ontology? Why should the fields of C2 and M&S stand out in this regard? Why should the study of ontology be important here, within a body concerned with simulation interoperability standards? The reason for that is apparent once we recognize a number of different things: this environment has many, many different systems – each employing their own inherent data models. In many cases, those systems interoperate (either simulation system to simulation system, or simulation system to C2 system). It should be pointed out that when we say that they “interoperate,” we are talking generally of technical interoperability. A further level is needed, and this has been referred to and described in [2] as operational interoperability. This issue is addressed every day, by doing extensive work just getting two systems to understand each other, and it is hoped that a method based approach to achieve higher levels of interoperability would significantly reduce the amount of work required to bring together a federation of systems. 1.2 Beyond Technical Interoperability When systems are required to interoperate, they are sharing effects and reporting on entities and phenomena that exist within a single synthetic environment (the simulated world). The total of those
Transcript of Evaluation of the C2IEDM as an Interoperability-Enabling Ontology

European Simulation Interoperability Workshop Toulouse, France, June 2005
05E-SIW-045 - 1 -
Evaluation of the C2IEDM as an Interoperability-Enabling Ontology
Charles Turnitsa Dr. Andreas Tolk
Virginia Modeling Analysis & Simulation Center (VMASC) Old Dominion University
Norfolk, VA 23529 [email protected] [email protected]
Keywords: Ontology, Data Modeling, Simulation Interoperability, C2IEDM
ABSTRACT: The science of linguistics tells us that Ontology is the specification of meaning for the elements of a language, and the relationships between those elements. Within the world of data modeling, as different models must interact with each other, the ability to describe the ontology of a data model becomes increasingly more important. This is especially true in the realm of simulation interoperability, where each different simulation system has it’s own data model, and therefore, it’s own ontology. One of the most crucial paths of research currently being explored by a number of different parties is the use of the Command and Control Information Exchange Data Model (C2IEDM) as a referential tool enabling the interchange of data between two (or more) distinct systems. The C2IEDM necessarily has it’s own ontology, but is it sufficiently complete to serve as a referential ontology for simulation interoperability? This paper will first describe what defines an ontology, and what is a sufficiently complete ontology to serve as a reference for simulation interoperability. A review of the functional areas of the C2IEDM will follow, and finally based on this review, an evaluation will be made as to whether the C2IEDM is a sufficiently complete ontology.
1 Introduction A Model is defined to be “a meaningful abstraction of reality.” As such, it comes with a lot of constraints and assumptions that have to be communicated in order to achieve interoperability between different models and their implementing systems. Currently, the application of ontologies delivers promising results in the domains of semantic web applications. Our working thesis for the research is that ontologies can support interoperability of distributed M&S applications as well, as ontologies are able to capture the different meaningful abstractions and make them comparable. Ontology is very loosely defined as a specification of a conceptualization [1]. Through that view it should be readily apparent that every set of ideas that conceptualizes of something else – whether it is a language, a data model, or an interpretation of a view – would have it’s own ontology. From this is should be readily apparent that everything – every system we use in particular – has an ontology. What is difficult, and what requires study, is that there is not a standardized method for discussing and describing ontology, or for studying and evaluating the ontology of a particular data model so it can be compared to others. This is true in any field, but it is of particular interest to the Simulation Interoperability Standards Organization (SISO) in the domain of command and control (C2), and modeling and simulation (M&S) interoperability.
1.1 Why Ontology? Why should the fields of C2 and M&S stand out in this regard? Why should the study of ontology be important here, within a body concerned with simulation interoperability standards? The reason for that is apparent once we recognize a number of different things: this environment has many, many different systems – each employing their own inherent data models. In many cases, those systems interoperate (either simulation system to simulation system, or simulation system to C2 system). It should be pointed out that when we say that they “interoperate,” we are talking generally of technical interoperability. A further level is needed, and this has been referred to and described in [2] as operational interoperability. This issue is addressed every day, by doing extensive work just getting two systems to understand each other, and it is hoped that a method based approach to achieve higher levels of interoperability would significantly reduce the amount of work required to bring together a federation of systems.
1.2 Beyond Technical Interoperability When systems are required to interoperate, they are sharing effects and reporting on entities and phenomena that exist within a single synthetic environment (the simulated world). The total of those

European Simulation Interoperability Workshop Toulouse, France, June 2005
05E-SIW-045 - 2 -
entities and phenomena within that synthetic environment is treated as “ground truth” by the systems. If each system (or, rather, each system’s data model) has it’s own conceptualization of that ground truth, how does each system reliably communicate with another system? The fact that there is communication between systems, and in fact federations of systems are routinely set up, attests to the fact that there is some communication going on – but it has been at a steep price of special purpose and non-reusable work being done over and over again. When one thinks of assembling a federation of perhaps a dozen different systems, and having them all intercommunicate with each other, the task seems daunting. When it is accomplished, there is a great deal of room for misinterpretation and miscommunication. That situation can be made easier, to a certain extent, if we can come up with a way to draw similarities between the many different types of data, and classes of data, that need to be intercommunicated. When datum can be narrowed down by it’s properties into a tight group, or class, then it can be much more easily be identified to another system. Those similarities, which are derived from an orderly categorization of the properties that comprise a concept, are part of a system’s ontology. The fact that an international standards organization [3] exists to assist in helping simulations to interoperate attests to the fact that there are a vital and commercial interests, and that it is a non-trivial task. Technical interoperability exists today, and has for several decades – through first DIS and then through HLA, and now through web services, and some of the proposed ideas of the XMSF. Even today, although this area has been “solved,” it is still a very important contribution to our domain. However, it is important to realize that it is just technical interoperability – the potential to exchange data in the correct protocol, or syntax. The difficulty remains as to what the target system will do with data (even data employing the correct syntax) it receives. This difficulty is especially true if the target system has no understanding of what the assumptions and conceptualizations behind that data are made by the source system. That understanding (of both assumptions and conceptualizations) amounts to the semantics behind the data. Therefore, what is really needed for meaningful, semantic understanding between systems is not just technical interoperability exchanging data, but information interoperability1. The systems must be able to translate semantic languages one to another or have it done through a reference system. Having a
1 This is based on the Network Centric Value Chain,
which goes from data quality over information and knowledge quality to awareness quality. Examples for this are given in [2].
central reference model – one espousing a core ontology – that understands and encompasses the semantic understanding (with any attendant assumptions) is one method to allow for interoperability beyond the technical level. As each source system communicates with another through the central reference system, the aggregation or decomposition of data elements is made to ensure semantic understanding by the target system. The need for this core ontology, and its value, is clearly laid out in [4],
A complete and extensible ontology that expresses the basic concepts that are common across a variety of domains and can provide the basis for specialization into domain-specific concepts and vocabularies, is essential for well-defined mappings between domain-specific knowledge representations (i.e., metadata vocabularies) and the subsequent building of a variety of services such as cross-domain searching, browsing, data mining and knowledge extraction.
To finish the introduction and illustrate how ontology is important, please consider that, as any linguist will attest, to translate any but the most simplistic of phrases from another language, you must understand the concepts of that language. You must understand its ontology.
2 WHAT IS AN ONTOLOGY? The first step in any exploration is to define your goals and determine the boundaries of your search. Similarly, if we are going to explore the ontology of a C4ISR data model, it is first important to define what that means. What is an ontology?
2.1 Definition It all started out when Aristotle, in his Metaphysics, declared being qua being. Things belong in groups with each other, in short. Based on this idea, Aristotle explored the idea of classifying things in his universe based on their properties and similarities to each other. The idea of classifying things really came into it’s own in the 18th and 19th centuries as natural philosophers (scientists) began formulating the complex system of biological ontology, where different animal species (as well as plants and other living beings – fungi, protista, and monera) are classed into kingdom, phylum, class, order, family, and genus. Each one of these layers exhibits a different layer of shared properties between its members. The study of linguistics realized that within a language there exists the capability of dividing words, which represent concepts, into classes. Within and between these classes, there are also relationships. The rules for combining these different concepts, or ontological entities (which, in natural language ontology, are

European Simulation Interoperability Workshop Toulouse, France, June 2005
05E-SIW-045 - 3 -
represented by words), are found within the rules of grammar for the language in question. Moving out of linguistics and into information science, we enter the realm of executable ontologies, ontologies of conceptual data models, and non-linguistic ontologies. Some examples of these can be found at [9], [10] and [11], respectively. In the world of information science, there is a very important, but very subtle, difference from linguistics. In linguistics, an ontological concept represents a thing, event, or phenomenon in a universe of discourse (the domain addressed by the language the ontology is specifying). With information science, the ontology of a data model contains concepts describing some sort of data token that represents a thing, event, or phenomena. It is not the thing itself. This sometimes brings into play some differences in requirement of ontology specification (for instance, the protocol or data type of the token representing a concept can be considered to be among the properties of that concept definition – depending on the intended use of the ontology schema, this may or may not be important). Much work in this area continues today, as upper ontology work such as the IEEE SUMO project [5]. There are also a number of ongoing efforts [6] [7] to provide rigorous linguistic analysis. The field of linguistics is also very much interested in supporting work and design ideas behind the semantic web [8], where data available on internet web pages will have ontological metadata available that will help to make searches much more accurate and efficient. Mentioned earlier, in the introduction to this paper, the definition of Tom Gruber was used. Specifically this is “an explicit specification of a conceptualization” [1]. To break that down, we begin with a conceptualization. This is referring to the complete conceptual view of a universe of discourse. As mentioned above, a universe of discourse is the domain addressed by the ontology we are considering. If this were a natural language, its universe of discourse would be anything addressable by a speaker of the language. Within information science, specifically with the data model of a system, when we consider the universe of discourse we are talking about the sum of all concepts that are addressable by that models tokens of representation. In many cases, those concepts can be iteratively redefined at a higher resolution by sub-concepts, and so on, until we arrive at base properties. In many cases, those properties are not specifically part of the data model, but are implicitly included due to the assumptions made by the engineers of the model (and by the system that relies on that model). We understand, therefore, what the conceptualization is. To arrive at an explicit specification, we must have a rigorous enumeration of all the concepts of the data model, with their sub-concepts defined. This enumeration, with definition, allows for a complete view into all concepts that are addressable by the
ontology, and allows for an unambiguous understanding of what those concepts represent. Since we are not just interested in the wider domain of computer science, but more specifically in the realm of C4ISR systems, we will now turn to a definition from that field of study. Tolk and Blais have defined ontology as “… an attempt to formulate an exhaustive and rigorous conceptual schema within a given domain“ [24]. The fact that we are talking about a schema here implies even stronger the need for relationships. Other than that, the definitions are very similar in concept.
2.2 Concepts Diane Ehrlich, in her Instructional Design glossary of terms, defines a concept as “a mental picture of a group of things that have common characteristics” [12]. A more generalized definition is “a general idea derived or inferred from specific instances or occurrences” [13]. Dr. Ehrlich’s definition is appropriate and useful for us, especially when we consider the science of Formal Concept Analysis (FCA). Within FCA, each concept is thought of as something that is comprised of lesser properties. Within [14] it is shown that a concept is a “formal object” and that it is comprised of “formal properties.” The idea of FCA, and the reason for defining “formal object” and “formal property” the way that Priss does in [14] is clear once we understand the underlying premise. FCA is based on a duality concept known as the “Galois Connection” [23]. Simply put, this connection is the link between two different things (for instance, concepts and properties). The principle states that due to the necessary defining nature of one to the other, as you increase the number of one, you necessarily decrease the number of the other. For instance, if you have a large number of defining properties, then the number of concepts that satisfy the classing together of those properties becomes smaller and smaller, yet if we only have a few defining properties, then the number of concepts that satisfy the classing together of those properties will become larger and larger. With this in mind, we will state that a concept is anything that is a set of one or more addressable properties. A concept that is comprised of only one property is an atomic concept. Anything within our conceptualization (our ontology) that has addressable properties is a concept. This includes, looking back to the seminal work of Gottlob Frege [15] the three ideas of concept, object, and copula. Concept, from Frege, is a primary entity, event, or phenomena within a statement, or in the terms of our definition, a conceptualization. Object is a similar idea, but is related more to the thought of a defining type. For instance, in the conceptualization of “that animal is a dog,” animal is the concept and dog is the object. Copula is the relating predicate, or the idea that relates the concept to the object. All three of these

European Simulation Interoperability Workshop Toulouse, France, June 2005
05E-SIW-045 - 4 -
ideas (concept, object and copula) are concepts within our definition. To avoid confusion of terms, we will refer to concept and object both as entities. The first is a subject entity, and the second is an object entity, but for our purposes, both can be considered part of the same defining idea of entity. For our purposes, copula can be thought of as a relationship. It is an important part of our conceptualization, and as with entities, relations can be broken down into sub concepts, or properties. How these ideas can be applied to data models have been shown in [22], where properties, propertied concepts, and associated concepts are defined to cope with these ideas.
2.3 Entities Entities are the things of our ontology. They are physical objects, types of objects, events (which are objects with a time component), and phenomena (examples – emotion, action). Within our universe of discourse, the world of military data models, there is really one domain: the battle space and all it’s entities. Many systems address that domain, each with their own data model comprising a unique conceptualization – meaning different definitions of entities, different rules for relations, and different assumptions behind all these concepts. To define the concepts that comprise a data model addressing this domain unambiguously, it is required that all of the attendant entities be definable with sub-entities, and those should be definable with sub-entities, and so on to base properties or atomic concepts. One of the benefits of having an unambiguous definition of all the assumptions and properties for each of your concepts is that it becomes easier to interact with target systems that may have similar assumptions to a source system, but at a higher or lower level of resolution. So far we have spoken about how to iteratively redefine a concept at a higher level of resolution, given clear understand of its properties and assumptions. It is also possible to bring concepts together, based on the similarity of defining properties (more on similarities later), and define these into lower resolution concepts. If the properties and assumptions of the initial concepts are understood, and there is order to the grouping together of these concepts, then the resultant lower resolution concept should necessarily be well defined. This is also iterative redefinition – but we can now see that it is possible to go in both directions. That is, towards higher resolution, or towards lower resolution. An ontology that can support this iterative redefinition of understanding of its component concepts at different levels of resolution is a fractal ontology.
2.4 Relationships For concepts, especially subject and object entities, to be brought together and assembled into semantic statements, there is a need for a special type of concept known as a relationship. In Frege’s work, this relates to the idea of the copula. It is the relating together, in a sense of being of two or more concepts, or entities. In linguistics, there are a number of different types of relationships, unary, binary and trinary. This refers to the number of concepts involved in what the relationship is trying to convey. If it is a simple declarative about the existence of a concept, then it is a unary relationship. For instance, the two sample semantic ideas of
tank is
tank moves
tell us that a tank exists, and in the second example, what state it is in. The second type of relationship is much more common, and it brings together the idea of relating two distinct concepts. Some examples of this are
tank is Italian
tank moves fast
In both of those cases, the initial concept, which is a subject entity, is related to a separate concept, or an object entity, to bring out a much more complex and meaningful semantic idea. Finally, the third type of relationship is one where the object entity also serves as its own subject entity (with an attendant object entity). A pair of examples of that type of relation would be
tank is Italian in manufacture
tank moves fast by Route 66
Further relationships with more concepts are possible, but these are the basic forms. Those additional types of relationships are formed by, again, iteratively redefining the semantic idea that the relationship forms. For instance if
X => Y
(where X is a subject concept, Y is a target concept, and the symbol => is the relationship) you could redefine the subject concept X by replacing it with it’s own semantic idea, or relationship. Therefore, by replacing X with (X1 relates to Y1) we end up with
(X1 => Y2) => Y
The semantic idea formed by a trinary relationship may appear to be of this form, whereby the subject/object structure that are at the end of the semantic statement are just the substructure of a binary relationship. This is not so, and it differs from
X => (X1 => Y2)
in that with a trinary relationship, the semantic idea related by
European Simulation Interoperability Workshop Toulouse, France, June 2005
05E-SIW-045 - 5 -
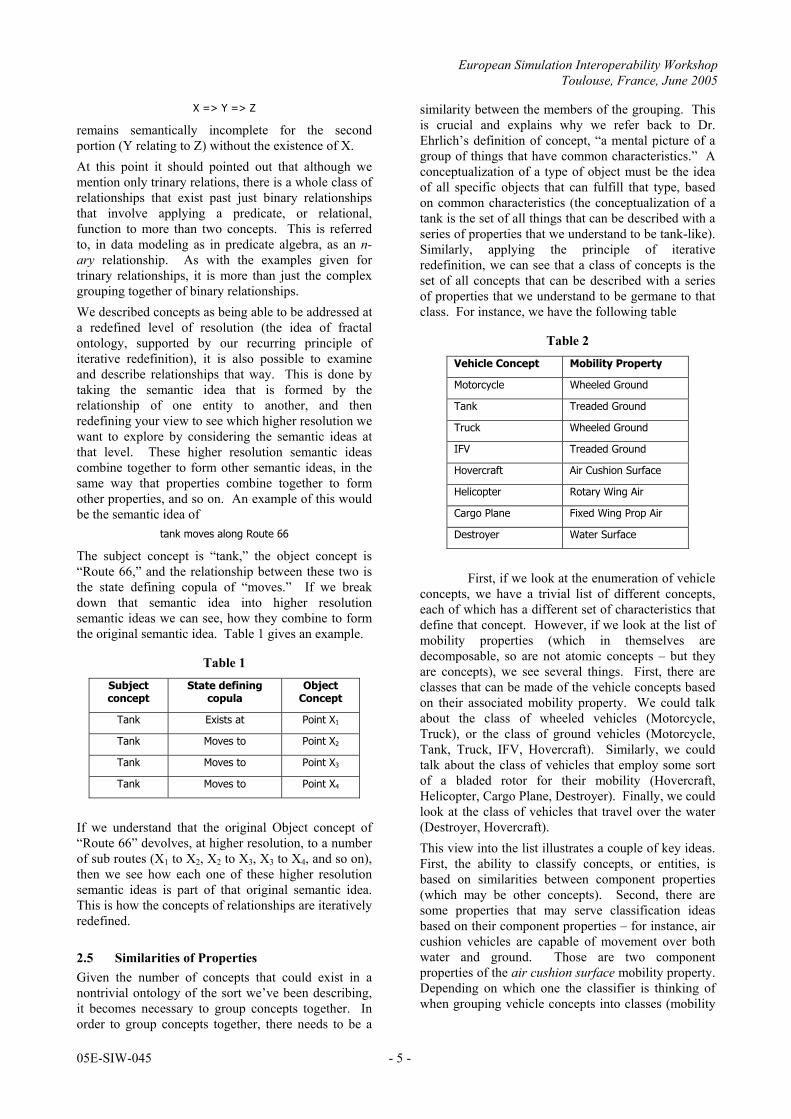
X => Y => Z
remains semantically incomplete for the second portion (Y relating to Z) without the existence of X. At this point it should pointed out that although we mention only trinary relations, there is a whole class of relationships that exist past just binary relationships that involve applying a predicate, or relational, function to more than two concepts. This is referred to, in data modeling as in predicate algebra, as an n-ary relationship. As with the examples given for trinary relationships, it is more than just the complex grouping together of binary relationships. We described concepts as being able to be addressed at a redefined level of resolution (the idea of fractal ontology, supported by our recurring principle of iterative redefinition), it is also possible to examine and describe relationships that way. This is done by taking the semantic idea that is formed by the relationship of one entity to another, and then redefining your view to see which higher resolution we want to explore by considering the semantic ideas at that level. These higher resolution semantic ideas combine together to form other semantic ideas, in the same way that properties combine together to form other properties, and so on. An example of this would be the semantic idea of
tank moves along Route 66
The subject concept is “tank,” the object concept is “Route 66,” and the relationship between these two is the state defining copula of “moves.” If we break down that semantic idea into higher resolution semantic ideas we can see, how they combine to form the original semantic idea. Table 1 gives an example.
Table 1
Subject concept
State defining copula
Object Concept
Tank Exists at Point X1
Tank Moves to Point X2
Tank Moves to Point X3
Tank Moves to Point X4
If we understand that the original Object concept of “Route 66” devolves, at higher resolution, to a number of sub routes (X1 to X2, X2 to X3, X3 to X4, and so on), then we see how each one of these higher resolution semantic ideas is part of that original semantic idea. This is how the concepts of relationships are iteratively redefined.
2.5 Similarities of Properties Given the number of concepts that could exist in a nontrivial ontology of the sort we’ve been describing, it becomes necessary to group concepts together. In order to group concepts together, there needs to be a
similarity between the members of the grouping. This is crucial and explains why we refer back to Dr. Ehrlich’s definition of concept, “a mental picture of a group of things that have common characteristics.” A conceptualization of a type of object must be the idea of all specific objects that can fulfill that type, based on common characteristics (the conceptualization of a tank is the set of all things that can be described with a series of properties that we understand to be tank-like). Similarly, applying the principle of iterative redefinition, we can see that a class of concepts is the set of all concepts that can be described with a series of properties that we understand to be germane to that class. For instance, we have the following table
Table 2
Vehicle Concept Mobility Property
Motorcycle Wheeled Ground
Tank Treaded Ground
Truck Wheeled Ground
IFV Treaded Ground
Hovercraft Air Cushion Surface
Helicopter Rotary Wing Air
Cargo Plane Fixed Wing Prop Air
Destroyer Water Surface
First, if we look at the enumeration of vehicle concepts, we have a trivial list of different concepts, each of which has a different set of characteristics that define that concept. However, if we look at the list of mobility properties (which in themselves are decomposable, so are not atomic concepts – but they are concepts), we see several things. First, there are classes that can be made of the vehicle concepts based on their associated mobility property. We could talk about the class of wheeled vehicles (Motorcycle, Truck), or the class of ground vehicles (Motorcycle, Tank, Truck, IFV, Hovercraft). Similarly, we could talk about the class of vehicles that employ some sort of a bladed rotor for their mobility (Hovercraft, Helicopter, Cargo Plane, Destroyer). Finally, we could look at the class of vehicles that travel over the water (Destroyer, Hovercraft). This view into the list illustrates a couple of key ideas. First, the ability to classify concepts, or entities, is based on similarities between component properties (which may be other concepts). Second, there are some properties that may serve classification ideas based on their component properties – for instance, air cushion vehicles are capable of movement over both water and ground. Those are two component properties of the air cushion surface mobility property. Depending on which one the classifier is thinking of when grouping vehicle concepts into classes (mobility

European Simulation Interoperability Workshop Toulouse, France, June 2005
05E-SIW-045 - 6 -
property, ground sub-property), it can serve as a further definition of a class similarity. Specific entities can be described using the concepts, and this is especially easy once we realize that the placement of an entity in space and time is simple, when we associate the properties of x, y, z coordinates, and time t with the concept of the entity we are thinking of. Other specifying concept-properties that can be applied are specifically intended for building similarities. For instance, the specific entities X, Y, and Z, which are all tank concepts, all have associated properties describing which unit they are part of. If that property has a similarity for entities X, Y, and Z, then it is easily to understand how they class together into the same unit by the similarity of their unit affiliation property. We have spoken of iterative redefinition as being able to decompose concepts into higher resolution ideas by examining some of the component concepts that group together. As mentioned earlier, it is also possible to conceive of and describe iteratively redefined concepts into lower resolution ideas by grouping together existing concepts by one or more similarities. An evaluating technique whereby we can test the similarity of concepts classes (subject concepts, object concepts, and relationships) is found in [16]. In short, the technique is to form a semantic idea containing your original concept. Then substitute other concepts from the same defined class, where your class definition fits the relational concept, and if the other substituted in concepts satisfy the epistemology of the semantic idea, then you have a valid classification of concepts. A useful part of understanding similarity is based on the idea of dividing similarities up into two basic classes. The first class is internal similarities. These are the different class similarities of a concept that are definitional to that concepts existence. It is most likely (but not necessary) that these similarities are going to be useful when considering the concept as a subject concept. For instance, if we look at the following generic semantic idea (Vehicle Concept) moves by (water route X)
We can replace the generic Vehicle Concept by any in the same class of concepts that have internal similarities of (1) being a vehicle, and (2) capable of water movement. This makes the two property concept similarities of vehicle type and water mobility to be internal similarities. The second type of similarity is external similarities. This type of similarity defines how a property of a concept allows it to be a subject object of a semantic idea. For instance, if we consider the following generic semantic idea
(Small arms fire) eliminates (Target Concept)
We can replace the generic Target Concept by any in the same class of concepts that share an external similarity of “being able to be eliminated by small
arms fire.” The property enabling the similarity to be drawn is a property that is defined for those concepts in terms of an external concept introducing some sort of phenomena or affect – in short, of the concept being a subject concept. Finally, it should be mentioned that fractal ontologies must be able to cope with composites of concepts as well as with aggregates of concepts2, and must be able to combine these different concepts. This idea is not yet well established in the community.
2.6 Rules Based Relationships We have seen that an effective ontology definition consists of a schema defining all of the concepts of a universe of discourse, including entities (subject and object concepts) and relationships. We have demonstrated that those concepts are comprised of properties, and that in fact an effective ontology will support iterative redefinition of concepts in terms of higher or lower resolution, based on a similarity of concept-properties. We have also shown how relationships can serve to connect concepts into semantic ideas. What has not yet established is the fact that an ontology, if it is going to be true to its epistemology, must have its allowable relationships (the building blocks for semantic ideas) based on rules. We have already seen how the addressing and organizing of subject and object concepts is made feasible, at least on the scale of a non-trivially sized ontology, by the employment of similarity based classification. We need to also be able to classify which relationships can link together which concepts into semantic ideas. In [17] Guarino refers to this idea as the “set of logical axioms designed to account for the intended meaning of a vocabulary.” The defining principles for that classification (of which relationships may go with which concepts) are what we refer to as rules based relationships. The admittance of relationships into the ontology necessarily must be based on similarity of properties between allowable classes of concepts (for the same reason that the classification of concepts must exist and be based on similarities – the scope of how many relationships could possibly exist). The nature of the relationship determines which classes of subject and object concepts are allowable. The simplest of copula are those that merely suggest a state of being. The following statement is an example.
Tank is
This statement merely establishes the fact that the tank exists. However, if we rely on other copula, especially
2 Composites comprise all properties of the composing
concepts; aggregates define higher properties which values are derived by functions applied to the property values of the underlying concepts (such as sums, average, standard deviation, etc.)

European Simulation Interoperability Workshop Toulouse, France, June 2005
05E-SIW-045 - 7 -
those which infer the current state of the subject concept, then it becomes necessary that we only allow for those subject concepts which have an internal similarity to the necessary properties required to attain the state hinted at by the copula. For instance, if we have the following unary relationship statement
(Subject Concept) Moves
Then we must limit all possible subject concepts to only those which can exhibit a mobility property. If we have a potential subject concept, such as “Coastline,” it does not have an inherited property implying mobility; therefore, it cannot serve as the subject concept for the above unary relationship. This set of rules gets both more complex, and at the same time, more apparent when we consider binary and trinary relationships. For instance, if we consider the following binary relationship
(Vehicle Concept) Moves along (Route 66)
We have to satisfy the selection of subject and object concepts based on a couple of things. First, the vehicle concept must be something of which is capable of moving along Route 66. Second, if we apply a specific instance of the concept class, we must choose one which is either somewhere on Route 66, or capable of getting there.
3 A Method for Evaluating Ontology In section 2, we laid out several different functional areas that define what should comprise an Ontology. Based on the definition, we will now address each of those functional areas, and describe what is required of an evaluated ontology to satisfy the completeness of those functional areas. Given this segmented evaluation, once the understanding of how well each separate area is satisfied, this method can support the evaluation of the entire ontology for completeness.
3.1 Concepts Ontology is the specification of a conceptualization. It is the specified understanding of the epistemology of the universe of discourse that the ontology in question (and it’s attendant data model) addresses. As we have mentioned in section 2.2, a concept is anything within our ontology that has addressable properties. The first test would be to see if the ontology allows for the individual identification of the concepts that make up it’s overall conceptualization, and then to assess whether the ontology supports the addressing of the component properties of those concepts. Furthermore, we have discussed the principle of iterative redefinition. This requires that concepts have properties that can be grouped together (composed or aggregated) based on similarities. As we have seen above, especially when we consider concepts in light of Frege’s work [15], the conceptualization should be broken up into entities
(both subject and object entities) and relations (copula). We will address those two functional areas, entities and relationships, separately below.
3.2 Entities Entities are defined above as the objects, events, and phenomena that comprise the universe of the ontology. As a sub-category of concepts, entities must have, as a minimum, addressable properties. As a test for completeness, those properties must be evaluated as to their supporting the redefinition of entities to provide for completely unambiguous understanding. In many cases, this means redefinition through component properties and concepts down to atomic properties and properties (or property values). At each level, these component properties must also satisfy the basic definition of a concept – meaning that the propertied concept itself has addressable properties. To satisfy the principle of iterative redefinition, the properties that comprise entities must have attribution that lends itself to similarity classification. This attribution exists in such a manner as to support redefinition at both higher and lower levels of resolution.
3.3 Relationships The class of concepts that support and allow for relationships between other concepts should be flexible enough to support unary, binary, and n-ary relationships. Again, as with entities, relationships must have (as a minimum) addressable properties. The specific relationships themselves are semantic ideas, and they should be decomposable into properties. The completeness of an ontology’s support of relationships is based on whether these properties can be identified, and if they are comprised of sufficient attribution to again allow for the building of similarities. Complete support of relationships will allow for the iterative redefinition of the semantic ideas presented by formed relationships into higher or lower resolution ideas.
3.4 Rules In section 2.5 above, we described the similarities that exist between the properties of different concepts. Those similarities can be drawn based on internal similarities and external similarities. Once those similarities are defined, or definable, it is then possible for an ontology to establish rules about how concepts can be assembled into semantic statements. In section 2.6, it was shown how there are too many enumerable relationships in all but the most trivial of ontologies. To assess how well a data model can ontologically represent semantic statements based on relationships, there must therefore be an assessment of

European Simulation Interoperability Workshop Toulouse, France, June 2005
05E-SIW-045 - 8 -
the rules that ontology employs in limiting those relationships. To assess the completeness of how well an ontology supports the building of relationships and semantic statements based on rules, an assessment must be made as to the completeness of the similarities that can be drawn between different classes of concepts, and how well rules based on those similarities can define the relationships to be built.
3.5 Overall Assessment Once there is an assessment of each of these functional areas, Concepts, Entities, Relationships, and Rules, then an overall assessment can be made as to the completeness of the ontology. The method presented here envisions that an investigation is done into these four functional areas, and findings on each are presented. Finally, the overall assessment is presented, showing how the completeness or lack of completeness of the different functional areas affects each other, and how well the ontology of the data model in question serves to exhibit that data model’s epistemology.
4 C2IEDM – a Survey The Command and Control Information Exchange Data Model is a data model that was designed to serve for information exchange and for data management. In both cases, the data concerned is data related to the battle space, and therefore the model deals naturally with orders, missions, tasks, situational awareness data, etc. C2IEDM explicitly copes with four different aspects of the battle space, and these are — Objects of interest and their inherent properties — Past, present, or future situations as represented
by facts about the objects — Past, present, or future activities that involve the
objects (planned, executed, observed) — Containers for grouping data into information
packages These four aspects of the battle space are described with associations of propertied concepts. This is done in a very orderly and specific method, which will be described below.
4.1 Overview3 The C2IEDM is a robust data model. Part of its strength lies in the fact that inherent to its design is the trait of extensibility. The C2IEDM is designed to be extensible in any direction that is necessary, and the employment of such an extension is fairly well documented. The C2IEDM is a data model with two decades of development history, and is maintained by
3 Much of this section is based on content from [20]
the Multilateral Interoperability Program (MIP). This voluntary and independent organization represents more than two-dozen countries and headquarters organizations. MIP is concerned with deriving a common data architecture and data model for multi-national interoperability.
Figure 1: 15 independent entities of the C2IEDM and top-level associations
What is even more important than its technical maturity is the fact that C2IEDM is derived through consensus and has active configuration management. It is a coherent data model, which leverages object type and subtype hierarchy structures to simplify the complexity. Its applicability to Command and Control (C2) as well as to Modeling and Simulation (M&S) issues has been documented. The C2IEDM is much more than just “another data model” for tactical data exchange and storage. The C2IEDM is comprised of common vocabulary consisting of 176 information categories that include over 1500 content elements related to all domains of military operations, such as maneuver, fire support, air defense, engineering, civil military operations, and anti terror special operations. All data and relationships are well documented and publicly available. However, the most important point is that all participating MIP nations agreed that the information exchange captured in C2IEDM is operationally relevant and sufficient for allied operations. In other words, military and technical experts from ten full member nations (Canada, Denmark, France, Germany, Italy, The Netherlands, Norway, Spain, The United Kingdom, and The United States) as well as 14 associate member nations agreed that C2IEDM is an adequate and operationally

European Simulation Interoperability Workshop Toulouse, France, June 2005
05E-SIW-045 - 9 -
meaningful way to exchange information about military operations. Of the 176 different information categories, fifteen key areas have the potential to exist as independent entities. All of the other information categories support these fifteen independent entities to allow them to show ideas with sufficient defining attribution, or properties.
4.2 Objects and Object Tree Every object within the C2IEDM is in terms of type and instance. The two structures of the C2IEDM that make this happen are the core of the Object tree. They are the two ideas of OBJECT_ITEM and OBJECT_TYPE, and every OBJECT_ITEM is a specific instance of an OBJECT_TYPE. This idea is key to understanding how the C2IEDM handles objects, and their specification. Every object that can exist in the battle space has its persistent properties (those that are key to the definition of the object, as well as those that are not dynamic in nature) defined in relationship to the OBJECT_TYPE. A specific object, that has persistent properties identified by its class definition, and which may have additional non-persistent properties (which are separate from those key to the class definition portrayed in OBJECT_TYPE) is seen through the C2IEDM entity OBJECT_ITEM. It is a specific instance of an OBJECT_TYPE.
Figure 2: Object Tree and Categories
An example of this is the thought of an M1A1 tank. There is a class of specific types of M1A1 tanks that are defined through a number of related entities, each linked to the OBJECT_TYPE of “M1A1 tank”, and each of which define some of the class properties of that type. These class properties are the persistent properties (physical parameters, capabilities, operational capabilities, etc). Then there may be a specific instance of an M1A1 tank that belongs to part of a notional (in the case of a simulated entity) or actual (in the case of a reported-on real entity) unit. It will then have a number of additional properties. Such
as location, current state, associated supplies (fuel, ammo, food), and other parameters. It will also have links to an organizational hierarchy showing where in the military structure it belongs (unit, subunit, etc). While some of these are definitely non-persistent data items, such as location and associated supplies, some are thought of as persistent (such as parent unit). These things are persistent when we consider the OBJECT_ITEM, but not when we consider the OBJECT_TYPE. These two different ideas of persistency in data about an object (those that are persistent to the object’s class, and those that are persistent to the particular object in question) are important to distinguish – especially when the C2IEDM is used for information exchange. This idea is seen when we consider three different sources of data about an object that might have to be sent from a source system to a target system: — The source would have to end the persistent
item for the class to a target system only once for the entire class (OBJECT_TYPE), for it’s instantiation.
— The source would have to send the persistent data only once for a specific object (OBJECT_ITEM) to a target system for that object’s instantiation.
— The source would have to continually send the non-persistent data as frequently as it changes (or is potentially changed).
Not all systems observe the need to only send persistent data once, but for those that do, it is important to realize what satisfies this category (of persistency), and this is especially important where the attribute properties of an item are defined in such an object oriented, removed layer method such as the C2IEDM employs. Nonetheless, just the fact that otherwise implicit assumptions are made explicit, as every source has to lay his assumptions open, is a good thing. In support of the OBJECT_TYPE and OBJECT_ITEM structure are many other entities within the C2IEDM that serve to identify and unambiguously define the associated properties for an object within the system. Before briefly introducing those, it should be pointed out that OBJECT_ITEM and OBJECT_TYPE devolve into five basic subdivisions, to make the identifying of entities easier. These subdivisions are FACILITY, PERSON, ORGANIZATION, MATERIAL, and FEATURE. These five exist as types and specifics, and can serve to define most items (notional and actual, physical and conceptual) within a battle space. Other areas of the C2IEDM that provide further property identification for objects are designed to allow the employing system to give as much detail as desired. In fact, there is no real “requirement” to even devolve the addressing of an object into the ideas of OBJECT_TYPE and OBJECT_ITEM, as you can

European Simulation Interoperability Workshop Toulouse, France, June 2005
05E-SIW-045 - 10 -
satisfy the requirements of the C2IEDM with either one (since they are both “independent” entities and don’t require one another to describe or transport data). The other areas give further definition into both the persistent and non-persistent properties of an object. Capabilities, group-characteristics, and location - all of these things are provided for among the 176 different information categories.
4.3 Actions and Action Tree Within the C2IEDM, all activity is denoted by representation from the ACTION entity, and its related sub-entities. Through a structure of definition, and property, adding substructures the ACTION tree is able to show all types of actions. These are divided up into ACTION_TASK, which is a deliberately planned activity for an object to undertake, and ACTION_ EFFECT, which is the external affectation of one or more entities by external actions. These external actions can be the results of an ACTION_TASK undertaken by another entity, or the results of some external activity – such as weather or other outside influences or phenomena. The basic definition of an ACTION comes from the five sub-entities that are immediately linked to it. These are listed below: — ACTION_RESOURCE exists to allow entities
(OBJECT_ITEMS or OBJECT_TYPES) to exist as the resource performing the activity
— ACTION_OBJECTIVE exists to allow entities (OBJECT_ITEMS or OBJECT_TYPES) to be the objective of an activity
— ACTION_EFFECT exists to describe either the planned or actual effects (outcome results) of an ACTION – this may include intended outcomes or accidental outcomes
— ACTION_TEMPORAL_ASSOCIATION exists to allow an ACTION to be associated with a particular time, or a dependency of one ACTION on the state of another ACTION
— ACTION_FUNCTIONAL_ASSOCIATION exists to allow different ACTIONS to be functionally associated with each other, in order to build more complex actions, and also to signify when the completion of one ACTION is required for the initialization of another
Notice that the two of these sub-entities that deal with objects, namely ACTION_RESOURCE and ACTION_ OBJECTIVE are capable of devolving into addressing either an OBJECT_ITEM or an OBJECT_TYPE.
4.4 Associations and Relationships So far, we have seen how the various entities of the C2IEDM structure combine and are subdivided to describe not only objects (both class and instance) but
also activity. We have also seen how other independent ideas separate from objects and actions serve to further define the properties of those two concepts. In the next section, the method the C2IEDM uses to associate these various data entities with each other will be described. The C2IEDM provides for relationships between data entities (and their supporting structures) through the concept of association. For instance, to link an ACTION_TASK to an OBJECT_ITEM there will be an entity enumerating a particular OBJECT_ITEM_ ASSOCIATION containing a property that allows an OBJECT_ITEM to relate to an ACTION_TASK. There are many such association entities within the C2IEDM, and they provide for all the many types of relationships that can exist. One of the entity areas that link to ACTION, and also to OBJECT is the entity of CAPABILITY. This is another type of association, and is provided for through the existence of the entity ACTION_REQUIRED_ CAPABILITY. This entity links a capability to an action. The capability is further linked to an object through the entity, OBJECT_ITEM_CAPABILITY. A capability can also be linked to a class of object, or an OBJECT_TYPE, through the entity OBJECT_ITEM_ CAPABILITY_NORM. The association of CAPABILITY (and it’s attendant properties) is the method through which several different ideas about what an OBJECT_ITEM or OBJECT_TYPE is capable of performing. CAPABILITY itself is subdivided into the areas of — ENGINEERING_CAPABILITY defining
which engineering tasks the object is capable of and defining the maximum parameters of either construction or destruction
— STORAGE_CAPABILITY defining which types of storage and which quantities an object is capable of
— MISSION_CAPABILITY defining which objects are capable of being assigned which ACTION_TASK items
— MOBILITY_CAPABILITY defining which objects are capable of which mobility types
— SURVEILLANCE_CAPABILITY defining an objects capability for performing image, electronic, or communication surveillance
— FIRE_CAPABILITY defining which types of ammunition the object is capable of firing.
This short description of C2IEDM was done in the light of our ontology definition and cannot replace the extensive study of its original documentation [19].
5 Evaluating the Ontology of C2IEDM In the next paragraphs, we will examine the ontology of the C2IEDM and evaluate it for completeness. As

European Simulation Interoperability Workshop Toulouse, France, June 2005
05E-SIW-045 - 11 -
described above, we will first do an evaluation of each of the different functional areas of the ontological definition given in section 2, and then we will give an overall assessment of the complete ontology of the C2IEDM. The purpose of this investigation and evaluation is two-fold. The first is to make use of the method proposed and to present a set of findings enumerated as forecast in the method definition. The second purpose for this investigation is using the method for what it is designed for – an evaluation of the ontology inherent in the C2IEDM, to assess it’s completeness and suitability for use as a reference data model.
5.1 C2IEDM Concepts The C2IEDM supports its concepts with a well-formed structure of defining attributes, or properties. These are capable of being iteratively redefined to a higher resolution down to atomic properties. The properties themselves are concepts with their own properties, and there is enough definition of properties within each of these defining concepts to allow grouping together of appropriate classes of concepts into lower level resolution groupings.
5.2 C2IEDM Entities The C2IEDM supports the representation of objects, events, and phenomena with a great deal of defining detail. As subsets of concepts, the same principles of support for iterative redefinition exist here, as well. For the most part, objects in particular, but also events and phenomena (to a lesser extent) are provided for in the OBJECT_TYPE and OBJECT_ITEM structure, and the method the C2IEDM has for separating the necessary definitional properties that make up for class persistent data, as well as instance persistent data is very well formed. Containers within the model also exist to show the sorts of dynamic data required for situational awareness data exchange. Events and phenomena also exist through the ACTION tables, meaning both sub-divisions of ACTION_TASK and ACTION_EVENT. Again, as with the OBJECT tree, there is sufficient coverage of the defining properties to address all of the iterative redefinition qualities found in all the other concepts. However, C2IEDM is limited to handle composites. Aggregates cannot be modeled explicitly. Furthermore, it is not possible to model similarities explicitly in the current version.
5.3 C2IEDM Relationships The capability of forming both complex and simple relationships within the C2IEDM is quite well supported, especially through the association entities within the model. The semantic ideas formed by the construction of these relationships are easy to convey within the model, but there does not appear to be much
structure supporting the defining of the properties of such a semantic idea. To be sure, as mentioned above in 5.1 and 5.2 the definition of the concepts in general and entities in particular are well supported, but once these are gathered together into the more complex structure of a semantic idea, there does not seem to be formal structure for defining the properties of such an idea. Presumably, the understanding of such definition is left to the systems making use of the model.
5.4 C2IEDM Rules The rules on relationships and relationship forming are present within the C2IEDM, but they are not sufficient. The nature and extent of relationship determining rules is limited by the association functionality. There also exists, through the CAPABILITY entity a manner for defining several capabilities of entities, especially in terms of tasks to be performed. These are based, however, on the idea of internal similarities of properties (see section 2.5). As mentioned earlier, internal similarities tend to be related to concepts used in a subject role, and not when a concept is used in an object role. The rules that support the formation of relationships within the C2IEDM seem to be limited to rules about what an entity can perform, as a relationship to a dynamic event (such as activity) that it is capable of initiating itself. What seems to be lacking, is the support for rules governing relationships formed on similarities based on properties of how a concept is affect by outside effects – that is events, actions or phenomena initiated outside of the affected concept.
5.5 C2IEDM Ontology – an Overall Assessment4 In summary, enumerating and reducing the functional area assessments, we see that the ontology of the C2IEDM supports concepts and entities very well. This is to be expected, as in structure the C2IEDM is an entity oriented data model. It has slightly weaker, but perhaps still sufficient support for the formation of relationships. However, in the area of support for rules directing the formation of relationships, the model and its ontology are lacking. To serve as a referential data model, we have seen how the principle of iterative redefinition of concepts is important. Again, here the C2IEDM supports this with entities quite well, but it is weak when it comes to definition of properties (and, therefore, redefinition of properties) concerning semantic ideas – the result of relationship formation. The ontology resulting from these requirements must be fractal and must be able to cope with the challenge of aggregations and composites. Paper [22] showed
4 The results of this section are first tentative results and
the research work is ongoing. We are planning to give an update on the results during the Fall SIW 2005.

European Simulation Interoperability Workshop Toulouse, France, June 2005
05E-SIW-045 - 12 -
how the C2IEDM could serve as a common reference information exchange data model, but only if we can assume that both system share a similar resolution necessary to make obvious that two concepts share properties and can be considered similar. This area requires much more research. As we consider the areas where the ontology is strong, it seems that the original intent of the C2IEDM – the exchange of Command and Control Information – is indeed very well supported, if the participating system are of similar resolution and share concepts. However, if it is to serve a larger role, especially in supporting an executable, dynamic view of the battle space (as we get with a simulation), there is room for improvement. The distinction between aggregates and composites is not made and similarity of concepts is not supported.
6 Implications for Simulation Interoperability
In this paper, we gave alternative definitions for ontology, recommended one of them, devised a method for evaluating the ontology of a data, applied that method to an existing data model (C2IEDM), and reported the tentative findings of that assessment. How does this help the general community of Modeling and Simulation, and more specific, the community of Simulation Interoperability? The research done so far – the refinement of ontology defining concepts into a working description, the formulation of a method for evaluation, and the evaluating of a state of the art data model – has led to an understanding of three key points of how this work can benefit the simulation interoperability community, and updates will be given in upcoming SIW: • First, it is possible, based on current trends not
only in the modeling and simulation community, but in the wider computer science community, to define methods for researching and supporting data interoperability at much higher levels than currently exist.
• Second, for the most part these methods are not yet applied within the modeling and simulation community.
• Third, applying such a method to a current state of the art data model (including not only referential data models, but system data models, and also object models such as a FOM) will serve to proof those models and identify any shortcomings they may have.
Based on these three points of how it can value the community, we believe that SISO should strongly support study groups in this area, and support the spread of additional research and development. The concepts described in this paper are going further than the current simulation standards DIS and HLA, which are limited to the syntactic level of
interoperability. System interoperability based on ontologies at least reaches the level of semantic interoperability and touches pragmatic interoperability. The question if higher concepts of interoperability can be supported as well by ontologies has not been part of the evaluation of this study so far.
7 Acknowledgements The research work underlying this paper was performed as an independent study in Modeling and Simulation curriculum of Old Dominion University. The work was partly funded by US Joint Forces Command and the Defense Modeling & Simulation Office.
8 References
[1] Gruber, Tom; “Toward Principles for the design of ontologies used for knowledge sharing,” Technical Report KSL 93-04, International Workshop on Formal Ontology, Padova, Italy, 1993
[2] Tolk, Andreas; “Beyond Technical Interoperability – Introducing a Reference Model for Measures of Merit for Coalition Interoperability,” 2003 Command and Control Research and Technology Symposium, Washington, D.C., June 2003
[3] Simulation Interoperability Standards Organization, http://www.siso.org/
[4] Doerr M, Hunter J, Lagoze C; “Towards a Core Ontology for Information Integration,“ Article 169, 2003-04-09, Journal of Digital Information, Volume 4 Issue 1
[5] Niles I, Pease A; “Towards a Standard Upper Ontology,” 2001 Proceedings of the International Conference on Formal Ontology in Information Systems, Ogunquit, Maine 2001
[6] Farrar S, Lewis WD, Langendoen DT; “A Common Ontology for Linguistic Concepts,” 2002 Proceedings of the Knowledge Technologies Conference, Seattle, Washington 2002
[7] Bender EM, Flickinger D, Good J, Sag IA; “Montage: Leveraging Advances in Grammar Engineering, Linguistic Ontologies, and Mark-Up for the Documentation of Underdescribed Languages,” 2004 Proceedings of the Workshop on First Steps for the Documentation of Minority Languages: Computational Linguistic Tools for Morphology, Lexicon and Corpus Compilation, Lisbon, Portugal, 2004
[8] Berners-Lee T, Hendler J, Lassila O; “The Semantic Web,” May 2001 Scientific American
[9] Raubal M, Kuhn W; “Ontology-based Task Simulation,” 2004 Spatial Cognition and Computation 4(1)
[10] Murphy, Richard, “FEA Reference Model Ontology (FEA-RMO) and Model Driven Service Patterns,” 2005 Armed Forces Communications and Electronics Association ArchitecturePlus Seminar, Bethesda, Maryland, January 2005

European Simulation Interoperability Workshop Toulouse, France, June 2005
05E-SIW-045 - 13 -
[11] Bateman, John; “Linguistic and non-linguistic ontologies: can we find the line between them?” 2003 Computational Linguistics Colloquium, University of the Saarland, Saarbrucken, Germany, May 2003
[12] Ehrlich, Diane; “Glossary of Terms for HRD408”, From the teaching materials for HRD408: Instructional Design II, Northeastern Illinois University, Educational Leadership and Development Department, http://www.neiu.edu/~dbehrlic/hrd408/glossary.htm
[13] American Heritage Dictionary of the English Language, Fourth Edition
[14] Priss, Uta; “Formal Concept Analysis in Information Science,” Annual Review of Information Science and Technology number 40, 2006
[15] Frege, Gotlob; “Über Begriff und Gegenstand (On Concept and Object),” Vierteljahresschrift für wissenschaftliche Philosophie, XVI, 1892
[16] Hallock, Patrick; “Natural Language Modeling”, Journal of Conceptual Modeling Issue 18, February 2001
[17] Guarino, Nicola; “Formal Ontology and Information Systems”, 1998 Proceedings of Formal Ontology and Information Systems, Trento, Italy, June 1998
[18] NATO ADatP-32, Edition 2.0: “The Land C2 Information Exchange Data Model,“ NATO HQ, Brussels, March 2000
[19] The Multilateral Interoperability Program (MIP) website: http://www.mip-site.org
[20] Turnitsa, Kovurri, Tolk, DeMasi, Dobbs, Sudnikovich; “Lessons Learned from C2IEDM Mappings within XBML,” Paper 04F-SIW-111, 2004 Fall Simulation Interoperability Workshop, Orlando, Florida, September 2004
[21] Multilateral Interoperability Program, “Overview of the C2 Information Exchange Data Model (C2IEDM),” November 2003
[22] Tolk, Andreas; “Moving towards a Lingua Franca for M&S and C3I – Developments concerning the
C2IEDM,” Paper 04E-SIW-016, 2004 European Simulation Interoperability Workshop, Edinburgh, Scotland, June 2004
[23] Ganter B, Wille R; “Formal Concept Analysis,” Mathematical Foundations, Berlin: Springer 1999
[24] Andreas Tolk, Curt L. Blais: “Taxonomies, Ontologies, and Battle Management Languages – Recommendations for the Coalition BML Study Group,” Spring Simulation Interoperability Workshop 2005, Paper 05S-SIW-007, San Diego, California, April 2005
9 Authors' Biography CHARLES TURNITSA is the Lab Manager for the Battle Lab at Virginia Modeling Analysis and Simulation Center (VMASC) of Old Dominion University (ODU) of Norfolk, Virginia. In addition to his work as Lab Manager, he also performs as a system engineer and researcher on several VMASC research projects. He has served in many roles as an IT professional for over a decade, performing analysis, design, and development tasks on many research projects for NASA and the US Military. ANDREAS TOLK is Senior Research Scientist at the Virginia Modeling Analysis and Simulation Center (VMASC) of the Old Dominion University (ODU) of Norfolk, Virginia. He has over 14 years of international experience in the field of Applied Military Operations Research and Modeling and Simulation of and for Command and Control Systems. In addition to his research work, he gives lectures in the Modeling and Simulation program of ODU. His domain of expertise is the integration of M&S functionality into real world applications based on open standards.




















