Estruturas Avançadas de Dados II (Hash
54
Estruturas Avançadas de Dados II (Hash) Professor Patricia Jaques (Esses slides são versões modificadas dos slides do professor Gilberto Irajá Müller) Última atualização 22/08/2013
-
Upload
independent -
Category
Documents
-
view
1 -
download
0
Transcript of Estruturas Avançadas de Dados II (Hash

Estruturas Avançadas de Dados II (Hash)
Professor Patricia Jaques (Esses slides são versões modificadas
dos slides do professor Gilberto Irajá Müller)
Última atualização 22/08/2013

Tipo Abstrato de Dados (TAD)
• Um Tipo Abstrato De Dados (TAD) é a especificação matemática de um conjunto de dados e das operações que podem ser executadas sobre esses dados.
• TAD define o que cada operação faz, mas não como faz.
• Em Java, um TAD pode ser expresso por uma interface. (Goodrich, 2007)

Estrutura de Dados • Para implementar um TAD, numa linguagem
de programação, é necessário encontrar uma forma de representá-los nessa linguagem utilizando tipos e operações suportadas pelo computador.
• Estrutura de Dados (ED) = materialização do TAD • Em Java, ED é modelado por uma classe.
• Dados em TAD: representado por variáveis na classe • Operações em TAD: representados por método na classe.
(Goodrich, 2007)

Estrutura de Dados
• Um mesmo tipo abstrato de dados pode ser concretizado (ou implementado) de diversas formas.
• TADs são materializados pela estruturas de dados. • TAD Lista Linear Geral:
• Lista Encadeada (implementação com referências)
• Lista com alocação estática (implementação usando array)
(Goodrich, 2007)

Tipo Abstrado de Dados
• Mapas: • Armazena um par chave-valor (k,v), chamado
de entradas, onde k é a chave e v é o valor. • Permite que os elementos possam ser
rapidamente localizados pela sua chave. • Elementos devem ter chaves únicas.
• Dicionários: • Semelhante ao dicionário, mas permite que
múltiplos elementos possam ter a mesma chave.
(Goodrich, 2007)

Introdução
• Hashtable • ED que implementa os TADs mapa e dicionário
• Faz as mesmas operações que listas sequenciais (arrays) • Porém, mais eficientemente
• Array - operações: • tempo constante para:
• setar um elemento em uma determinada posição • acessar um elemento em uma determinada posição

Introdução
• Vetores utilizam índices para armazenar as informações.
• Através do índice as operações sobre vetores são realizadas no tempo O(1).
1 2 3 4 5 6
3024-8111 3211-1000 3324-5667 3211-4565 3211-9000 3211-8976
Telefones (nome de amigos são números)
Telefones[1] = “3024-8111” Telefones[3] ? “3211-1000”
E se o nome do amigo não for um número?

Introdução
• Vetores não fornecem mecanismos para calcular o índice a partir de uma informação armazenada. • A pesquisa não é O(1). • Pesquisa é O(n)
• varredura de toda a array
• Problema do telefone: • quero acessar o telefone de um amigo pelo
seu nome em tempo constante - O(1)

Hashtable
• Hashtable • Indexam valores por chaves • Objetivo: manter um conjunto de dados que
evoluem (se modifiquem constantemente) • Dados: transações, IP addresses, pessoas+dados
• Operações de Hashtable • Inserção de um novo registro • Deleção de um registro • Acesso a um registro
usando uma chave
Tempo O(1)*
Desejável, mas depende da implementação (função de hash)

Aplicações de Hashtable
• (Des)duplicação: • Entrada: uma “stream” de objetos
• Exs: • arquivo de log de um servidor • dados chegando em real-time
• Objetivo: remover dados duplicados • Ex:
• verificar número de visitantes de um site web
• Solução: usar hashtable • Cada vez que um novo dado chega:
• acessa a hashtable H para verificar se a chave já existe em H • se já existe substitui valor, • caso contrário insere registro.

Aplicações de Hashtable
• Soma de 2 números com total T • Entrada: array não-ordenada de inteiros • Objetivo: determinar se existe 2 nos inteiros x e y,
tal que x+y=T. • Solução:
• inocente: O(n2) • busca exaustiva (2 laços for): O(n2)
• melhor: O(nlog(n)) • ordenar array usando heapsort: O(nlog(n)) • buscar com busca binária T-x: n*O(log(n)) = O(nlog(n))
• ainda melhor:O(n) • usando hashtable
• para cada elemento x na lista de n integers: O(n) • busca T-x na hashtable: O(1)
Hashtable é uma boa escolha quando é necessário fazer muitos acessos por chave.

Operação de Busca por chave
• Os métodos de pesquisa vistos até agora buscam informações armazenadas com base na comparação de suas chaves.
• Para obtermos algoritmos eficientes, armazenamos os elementos ordenados e tiramos proveito dessa ordenação.
• Conclusão: os algoritmos mais eficientes de busca mostrados até o momento (busca em árvore) demandam esforço computacional O(log n).
• Veremos agora, o método de pesquisa conhecido como tabelas de hash (tabela de dispersão) ou método de cálculo de endereço. Na média dos casos, é possível encontrar a chave com apenas UMA OPERAÇÃO de LEITURA. • Complexidade de Tempo: O(1)

Função de Hash
• Hash é o termo empregado para designar alguma função que transforma uma chave em endereço “d”, para acesso ao registro que contém a chave; • h(k) = d
• A ideia central do Hashing é utilizar uma função,
aplicada sobre parte da informação (chave), para retornar o índice onde a informação deve ou deveria estar armazenada.
• Esta função que mapeia a chave para um índice de um vetor é chamada de Função de Hash;

Hashtables
• A estrutura de dados Hash é comumente chamada de Tabela Hash ou hashtable; • Usada para implementar as TADs Mapas e Dicionários
• Em Computação a Tabela Hash é uma estrutura de dados especial, que armazena as informações desejadas associando chaves de pesquisa a estas informações;
• Objetivo: a partir de uma chave, fazer uma busca rápida (tempo O(1)) e obter o valor desejado;
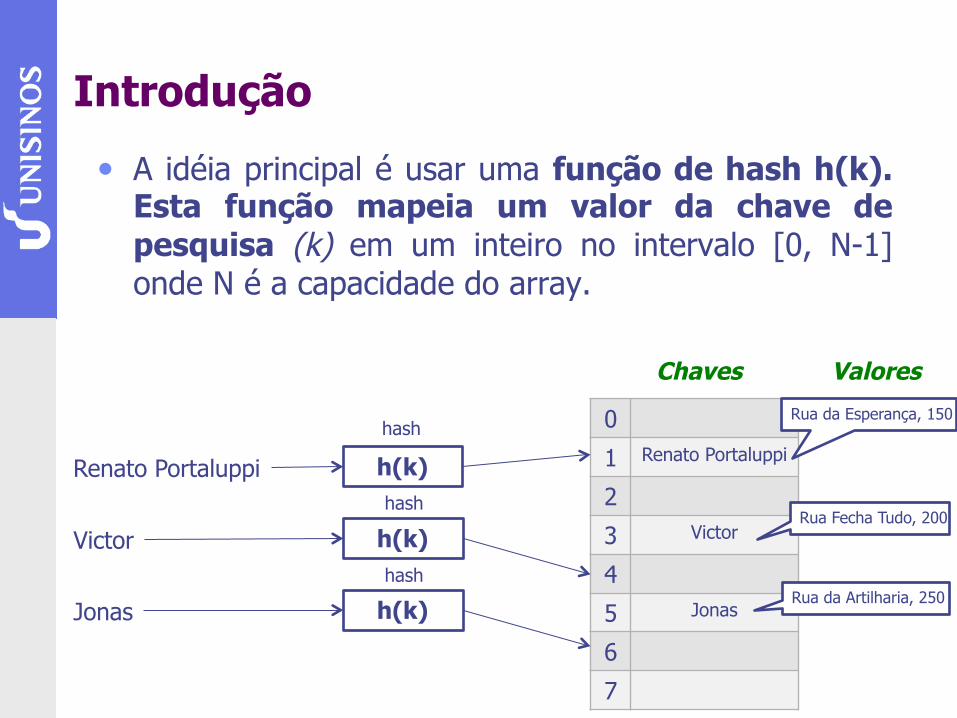
Introdução
• A idéia principal é usar uma função de hash h(k). Esta função mapeia um valor da chave de pesquisa (k) em um inteiro no intervalo [0, N-1] onde N é a capacidade do array.
0
1 Renato Portaluppi
2
3 Victor
4
5 Jonas
6
7
Renato Portaluppi h(k)
Victor h(k)
Jonas h(k)
Rua da Esperança, 150
Rua Fecha Tudo, 200
Rua da Artilharia, 250
Chaves Valores
hash
hash
hash

Comportamento da Função de Hash
• Função de hash: Executa a transformação do valor de uma chave em um endereço, pela aplicação de operações aritméticas e/ou lógicas
n Os valores da chave podem ser numéricos, alfabéticos ou alfa-numéricos.
registro com chave k d = h (k) K
chave
1 2
X
N-2 N-1
registro
dados 0

Classificação de Hashing
• Hashing Perfeito Para quaisquer chaves x e y diferentes e pertencentes a A, a função utilizada fornece saídas diferentes;

Classificação de Hashing Colisão
• Hashing Imperfeito Existem chaves x e y diferentes e pertencentes a A, onde a função Hash utilizada fornece saídas iguais;
• Nesse caso, quando a função de hash pode gerar o mesmo valor (índice no array) para duas chaves diferentes, dizemos que aconteceu uma colisão.
Colisão

Exemplo de Colisão • h(k)=k.charAt(0)-97;
Fonte: Wikipédia (2013)

Funções de Hash • Geralmente, formada por 2 partes:
• (1) Criação do Código (Valor) de Hash: • Transformação da chave K em um número inteiro
• não precisa estar no intervalo [0,N-1], onde N é o tamanho da array
• (2) Função de compressão: • Transforma número inteiro em um valor no intervalo [0,N-1],
onde N é o tamanho da array • IDEAL: N deve ser um número primo para:
• “espalhar” a distribuição de valores • diminui colisão
• Método da divisão: k mod N • k = chave
• Método MAD: (ak+b) mod N • a>0, b>=0, N=número primo

Função de Hash
• Exemplo: • Distribua as seguintes chaves
{200,205,210,220,225, 300, 305, 310, 320, 325} • em um array de tamanho 100 • em um array de tamanho 101 (número primo)
• Quantas colisões acontecem em cada situação?

Função hash h
• Exemplos: • Se a chave é um inteiro:
• h(k)=k mod N, se k é um valor inteiro
• Se a chave é uma String • k =
• onde chave[i] é o valor ASCII do i-ésimo caractere da chave e p[i] é um peso
• A função de hash é usada para localizar registros para as operações de acesso, inserção, bem como eliminação.

Classificação de Hashing
• Na prática funções de hashing perfeitas ou quase perfeitas: • são encontradas apenas onde a colisão não é
tolerável (nas funções de hashing na criptografia);
• Quando conhecemos previamente o conteúdo a ser armazenado na tabela.
• Nas Tabelas Hash comuns a colisão é apenas indesejável, diminuindo o desempenho do sistema.

FORMAS DE IMPLEMENTAR TABELAS HASH

Como representar tabelas Hash?
• O b u c k e t ( b a l d e ) é u m a u n i d a d e d e armazenamento que contém um ou mais registros.
• Array de buckets:
(Goodrich, 2007)

Como representar tabelas Hash?
• Vetor: cada posição do vetor armazena uma informação. Se a função de hashing aplicada a um conjunto de elementos determinar as informações I1, I2, ..., In, então o vetor V[0...N-1] é usado para representar a tabela hash; • Endereçamento Aberto
• Vetor + Lista Encadeada: o vetor contém ponteiros para as listas que representam as informações. • Encadeamento Separado

Como representar tabelas Hash?
• Encadeamento Separado • Usa array + Lista Encadeada
• Cada posição do bucket (array) é uma lista encadeada
• Espera-se que o número de elementos em cada posição da array (em cada bucket) seja igual ao fator de carga
• fator de carga = n/N • n = número de elementos • N = tamanho da array
• Endereçamento aberto • Usa apenas array • N >= n.
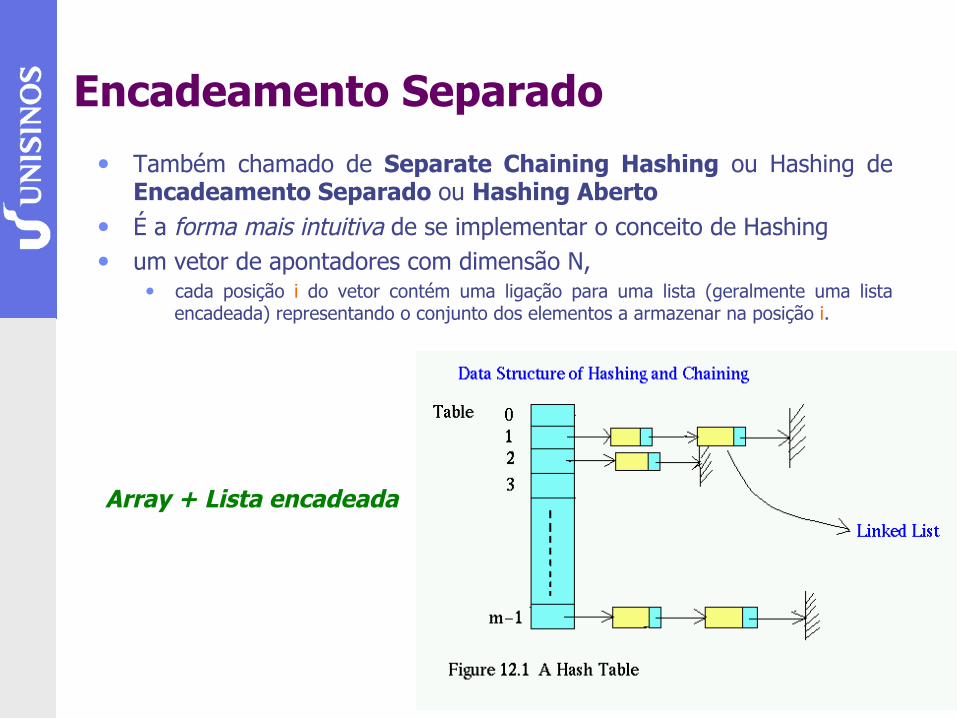
Encadeamento Separado • Também chamado de Separate Chaining Hashing ou Hashing de
Encadeamento Separado ou Hashing Aberto • É a forma mais intuitiva de se implementar o conceito de Hashing • um vetor de apontadores com dimensão N,
• cada posição i do vetor contém uma ligação para uma lista (geralmente uma lista encadeada) representando o conjunto dos elementos a armazenar na posição i.
Array + Lista encadeada

Encadeamento Separado
• Reduz o número de comparações, em média, do tamanho do vetor se comparado com a procura sequencial;
• Necessidade de espaço em memória para armazenar o array de listas ligadas.
• Busca: a procura de um elemento no encadeamento separado efetua-se da seguinte forma: • Calcular a partir de uma chave qual entrada do array é a
cabeça da lista que se pretende; • Utiliza-se uma técnica qualquer para pesquisa dentro da lista
de elementos armazenados, geralmente utiliza-se a técnica de pesquisa sequencial em lista ligada.

Encadeamento Separado
• Ex.: Pretende-se armazenar os números numa tabela de hash de forma a melhorar o processo de procura desses elementos armazenados. Os elementos são os seguintes: 19, 26, 33, 70, 79, 103, 110. Defina a função de hashing.

Encadeamento Separado
• Ex.: Pretende-se armazenar os números numa tabela de hash de forma a melhorar o processo de procura desses elementos armazenados. Os elementos são os seguintes: 19, 26, 33, 70, 79, 103, 110. Defina a função de hashing.
h(k)=|k| mod N

Encadeamento Separado Busca

Encadeamento Separado Inserção

Encadeamento Separado Remoção

Encadeamento Separado Tratamento de Colisão
• A função de hash h(k) define a posição do array de bucket • Sempre-se irá inserir a chave no final da
lista encadeada na posição h(k)

Encadeamento Separado
• Vantagem: • implementação simples
de Hashtable
• Desvantagem: • Precisa de ED adicional
para tratar colisão • Em algumas aplicações
isso é desvantajoso • Dispositivos de pequeno
porte
Fonte: javatroops.blogspot.com

Endereçamento Aberto
• Também chamado de Open Addressing Hashing ou de Endereçamento Aberto ou Hashing Fechado
• Não é a forma mais intuitiva de se implementar o conceito de Hashing;
• Era a forma mais utilizada antigamente, na qual se utiliza somente uma estrutura de dados de tamanho fixo para implementar a hashtable. • Esta estruturação utiliza, na sua implementação, um vetor onde
são armazenados os valores, não se utilizando quaisquer apontadores.
• Como funciona: • Utiliza-se uma função de hash que dada uma chave devolve a
primeira posição onde procurar na tabela de hash; • Colisões tratadas de outras formas;

Endereçamento Aberto

OPERAÇÕES SOBRE HASHTABLE COM ENDEREÇAMENTO ABERTO

Endereçamento Aberto Busca
• Usar função de hash h(k) para calcular a primeira posição do vetor onde o registro com a chave k poderia se encontrar. • A função de hash h(k) define qual a primeira posição no vetor onde
procurar, • Se a posição estiver vazia, pára busca • Se a posição não estiver vazia (ocupada por outro registro – colisão),
então, procura-se no vetor usando um método de tratamento de colisão para endereçamento aberto
• usar outra função de hash h’(k)
• O processo de procura de uma posição vazia no vetor (lista circular) só termina quando o programa chega de novo ao ponto de partida. Só neste momento é que se pode considerar que uma chave não existe ou que não existe uma posição vazia.

Endereçamento Aberto Inserção
• Usar função de hash h(k) para calcular a primeira posição do vetor para inserir o registro R com chave K. • A função de hash h(k) define qual a primeira posição no vetor onde colocar
o registro R, • Caso a posição esteja vazia, coloca-se o registro R nesta posição • Caso a posição esteja ocupada por outro registro (ou ocupada por um
valor deleted), • então, define-se próxima posição no vetor usando um método de tratamento de colisão para
endereçamento aberto
• usar outra função de hash h’(k)
• O Processo de procura de uma posição vazia no vetor (lista circular) só termina quando o programa chega de novo ao ponto de partida. Só neste momento é que se pode considerar que uma chave não existe ou que não existe uma posição vazia.

Endereçamento Aberto Remoção
• Usar função de hash h(k) para calcular a primeira posição do vetor onde o registro com a chave a ser removida poderia se encontrar. • A função de hash h(k) define qual a primeira posição no vetor onde
procurar, • Se a posição estiver vazia (empty), pára busca • Se a posição não estiver vazia (ocupada por outro registro – colisão),
então, procura-se no vetor usando um método de tratamento de colisão para endereçamento aberto
• usar outra função de hash h’(k)
• Se a posição estiver ocupada pelo registro a ser removido • marca posição com palavra deleted
• O processo de procura de uma posição vazia no vetor (lista circular) só termina quando o programa chega de novo ao ponto de partida. Só neste momento é que se pode considerar que uma chave não existe ou que não existe uma posição vazia.

Endereçamento aberto • Como marcar posição da hashtable com deleted
ou empty • 1) criando coluna adicional para guardar esses
valores • 2) criando um objeto Node que contém um campo
para guardar o estado

Encadeamento Separado X Endereçamento Aberto
• As técnicas de endereçamento aberto (EA) economizam algum espaço se comparadas com a técnica de encadeamento separado (ES) • mas EA não é mais rápido que ES
• Análises teóricas e experimentais mostraram que: • ES é competitivo ou mais rápido que os outros fatores,
dependendo do fator de carga
• Se uso da memória não for uma restrição • sugere-se escolher ES
• Se necessário economizar memória: • usar EA com boa função de hash e boa função de
tratamento de colisão.
Fonte: (GOODRICH, 2006)

TRATAMENTO DE COLISÃO

Endereçamento Aberto Tratamento de Colisão
• Teste Linear • Ex.: Pretende-se armazenar os números numa tabela de hash
estática fechada a fim de melhorar o processo de busca desses elementos armazenados. Os elementos são os seguintes: 19, 26, 33, 70, 79, 103, 110, 203, 210.
Uma estratégia simples para o tratamento de colisões com método de endereçamento aberto é o teste linear. Teste linear h (k)=i mod N (1ª tentativa) h’1 (k)=(i+1) mod N (2ª tentativa, se h(k) estava ocupado) h’2 (k)=(i+2) mod N (3ª tentativa, se h’1(k) estava ocupado

Fatores de Carga
• fator de carga (λ) = n/N • n = número de elementos • N = tamanho array
• Experimentos e análises de caso médio sugerem que fatores de carga desejáveis são: • Endereçamento aberto λ<0.5 • Encadeamento separado λ<0.9
• Valor do Fator de carga próximo de 1 • aumenta consideravelmente a probabilidade de
colisão, o que deteriora a performance da busca, inserção e remoção na tabela de hash.

Rehashing
• Se hashtable atinge fator de carga máximo permitido (λm) • necessário fazer rehash
• Rehash – como funciona: • aloca nova array
• nova array geralmente tem o dobro do tamanho da array anterior
• define-se nova função de hash • reinsere-se cada item da tabela anterior na
nova tabela

Endereçamento Aberto– Complexidade
• Estas complexidades são diferentes para as duas filosofias de implementação de hashing: encadeamento separado e endereçamento aberto, na qual: • T(n) vai tender a ser algo em torno de n/N (onde n é o número de
elementos e N é o tamanho da tabela). No caso ideal, n = N e T(n)=O(1).
• Nos casos menos ideais, T(n) varia muito. • Nos T(n) da tabela abaixo estamos considerando que temos uma
boa função de hash que espalha bem os dados.
Melhor Caso
Pior Caso
Busca O(1) O(n)
Inserção O(1) O(1)
Remoção O(1) O(n)
Melhor Caso
Pior Caso
Busca O(1) O(n)
Inserção O(1) O(n)
Remoção O(1) O(n)
Encadeamento Separado Endereçamento aberto

Hashtable na API do Java • classe java.util.HashMap ou java.util.Hashtable
• HashMap: • não é thread-safe • permite uma chave null e vários valores null
• Hashtable: • thread-safe • não permite chaves e valores null
• java.util.HashMap • usa encadeamento separado • usa como valor default fator de carga máximo λm=0,75
• usuário pode redefinir λm • faz rehash quando fator de carga atinge 0,75 • dobra de tamanho quando faz rehash • capacidade inicial (tamanho da array) = 16

Hashtable – Vantagens
• Simplicidade, na medida em que é muito fácil de definir um algoritmo para implementar um hashtable;
• Escalabilidade, dado que podemos adequar o tamanho da tabela (N) da hashtable ao número de elementos;
• Eficiência para grande número de elementos, para trabalharmos com problemas envolvendo N = 100.000 de dados, podemos imaginar uma tabela de hash com n=1.000 entradas, onde temos uma divisão do espaço de procura da ordem de N/1.000 de imediato;

Hashtable – Desvantagens
• Dependência da escolha da função de hash, para que o tempo de acesso médio seja mantido, é necessário que a função de hash divida o universo dos dados de entrada em conjuntos de tamanho aproximadamente igual;
• Ineficiência para os últimos elementos das listas ligadas e pode ser mais demorado do que em implementações em árvore;

Exercício
• Monte uma hashtable com encadeamento separado utilizando a seguinte função hash: • h (k) = (5 • k) mod 8
Utilize os seguinte números como chaves: 1055, 1492, 1776, 1812, 1918, 1945 e 2002

Bibliografia
• GOODRICH, MICHAEL T. ; TAMASSIA, ROBERTO. Estruturas de dados e algoritmos em Java. 4.ed. Bookman. 2007.
• Silberchatz, A; Korth, H. F., Sudarshan, S. Sistema de Banco de Dados. 3ª. Edição, Makron Books, 1999.
• PARDO, T. A. S. Métodos de Busca: Projeto de Algoritmos.