
Elementos de Econometría Aplicada (3a ed.)
109
Julio H. Cole ELEMENTOS DE ECONOMETRÍA APLICADA Tercera Edición J & G Ediciones ————————————————————————————————– Guatemala
Transcript of Elementos de Econometría Aplicada (3a ed.)

Julio H. Cole
ELEMENTOS DE ECONOMETRÍA APLICADA
Tercera Edición
J & G Ediciones ————————————————————————————————–
Guatemala

Para Gina,
con todo mi amor
Copyright © 1996, 2006, 2014 por Julio H. Cole. Derechos reservados.
J & G Ediciones (Guatemala).
Impreso en Guatemala — Printed in Guatemala
Cole, Julio Harold (1955 – )
Elementos de Econometría Aplicada.
Tercera edición [2014]. Bibliografía.
103 p., ilustrado, tablas.
1. Econometría. I. Título.
330.015195 C689

CONTENIDO
Prefacio a la Segunda Edición …………………………………………………. v . Prefacio a la Tercera Edición ………….………………………………………. v .
Capítulo
1. INTRODUCCIÓN …........................................................................................ 1
2. REGRESIÓN LINEAL SIMPLE …...….............................................................. 5
2.1. Introducción
2.2. Método de Mínimos Cuadrados
2.3. Coeficiente de Determinación (R2)
Preguntas de Repaso
Casos Aplicados
3. REPASO DE ALGEBRA MATRICIAL ……....................................................... 20
3.1. Matrices
3.2. Operaciones con Matrices
3.3. Teoremas sobre Matrices
3.4. Clases Especiales de Matrices
3.5. Traza de una Matriz Cuadrada
3.6. Transposición de Matrices
3.7. Matriz Inversa
Preguntas de Repaso
4. REGRESIÓN LINEAL MÚLTIPLE ……............................................................ 27
4.1. Vector Mínimo-Cuadrático
4.2. Inferencia Estadística en la Regresión Lineal
4.3. Coeficiente de Determinación (R2)
4.4. Aplicación — Costos Administrativos en la Banca Comercial
Casos Aplicados

5. AMPLIACIONES DEL MODELO LINEAL ………............................................. 44
5.1. Estimación de Formas No-Lineales
5.2. Variables Binarias o Cualitativas
5.3. Problemas Especiales en la Regresión Lineal
5.3.1. Variables Omitidas y Variables Irrelevantes
5.3.2. Multicolinealidad
5.3.3. Heteroscedasticidad
Preguntas de Repaso
Casos Aplicados
6. AUTOCORRELACIÓN …................................................................................ 67
6.1. Naturaleza del Problema
6.2. Efectos de la Autocorrelación
6.3. Cómo Detectar la Autocorrelación
6.4. Estimación en Presencia de Autocorrelación
Preguntas de Repaso
Caso Aplicado
7. RETARDOS DISTRIBUIDOS ……................................................................... 82
7.1. Variables Retardadas en Econometría
7.2. Autocorrelación en Regresiones con Retardos
7.3. Aplicación — Inflación en Guatemala
Casos Aplicados
ANEXOS .............................................................................................................. 95 . A-1. Areas de la Distribución Normal Estándar
A-2. Percentiles de la Distribución t (Student)
A-3. Valores Críticos de la Distribución Chi-cuadrado
A-4. Estadístico Durbin-Watson: Valores Críticos (5 %) para dL y dU
REFERENCIAS …............................................................................................... 100

PREFACIO A LA SEGUNDA EDICIÓN
La primera edición de este libro se publicó en 1996. Para esta reedición he man-
tenido la estructura del texto original, pero he aprovechado la oportunidad para
realizar algunas ligeras correcciones y cambios de presentación, y también para
incorporar varios casos aplicados que he desarrollado en estos últimos 10 años.
Estos casos han resultado de gran utilidad en el curso introductorio de econome-
tría que imparto desde hace muchos años en la Universidad Francisco Marroquín,
y me alegro de poder ahora compartirlos con un público más amplio.
J. H. C.
Guatemala, 2006
PREFACIO A LA TERCERA EDICIÓN
Para esta tercera edición he mantenido la estructura del texto original, pero he in-
cluido algunos temas adicionales, y he efectuado algunos ligeros cambios de pre-
sentación. He incluido también algunos casos prácticos que he usado con éxito en
mi curso de econometría en la Universidad Francisco Marroquín, pero que no ha-
bía previamente incorporado al texto. Reitero el gusto que me da ahora poder
compartirlos con un público más amplio.
J. H. C.
Guatemala, 2014


[1]
Capítulo 1
INTRODUCCIÓN
―All models are wrong, but some models
are useful …. ‖
— G. E. P. Box1
― … if you torture the data enough, nature
will always confess .… ‖
— R. H. Coase2
La Econometría es aquella rama de la ciencia económica que aplica los
instrumentos de la economía teórica, del análisis matemático y de la estadística
inferencial al análisis cuantitativo de los fenómenos económicos. Las teorías
económicas típicamente expresan relaciones funcionales entre diferentes
variables. La curva de demanda, por ejemplo, representa la cantidad demandada
de una mercancía como función de su precio. En la teoría de la empresa, por otro
lado, el costo de producción se considera como función de la escala de
producción, mientras que en el análisis macroeconómico la ―función consumo‖
relaciona los gastos de consumo con el nivel de ingreso nacional. Todos estos son
ejemplos de relaciones entre dos variables, aunque por supuesto que una
formulación más completa debe incluir varias variables diferentes en cada
relación.
El propósito de la Econometría consiste en desarrollar métodos para la esti-
mación numérica de los parámetros que definen las relaciones funcionales entre
las diversas variables económicas que nos pueden interesar, y para testar y com-
probar las diversas hipótesis que se pueden postular acerca de dichos parámetros.
El primer paso en cualquier investigación econométrica debe ser la especificación
1Empirical Model-Building and Response Surfaces (New York: Wiley, 1987), p. 424.
2―How Should Economists Choose?‖ [1981], en Ideas, Their Origins, and Their Conse-
quences: Lectures to Commemorate the Life and Work of G. Warren Nutter (Washing-
ton: American Enterprise Institute, 1988), p. 74.

[2]
de un modelo matemático para representar la relación que se desea investigar. En
la práctica, lo común es partir de una ―ecuación de regresión‖ que postula una re-
lación causal entre una variable ―dependiente‖ y una o más variables ―indepen-
dientes.‖ (En econometría, una variable es denominada ―dependiente‖ si podemos
suponer que es función de otras variables, y el análisis de regresión consiste en
―explicar‖ los cambios observados en la variable dependiente por medio de los
cambios observados en estas otras variables independientes.) Luego debemos re-
coger datos relevantes de la economía o sector que deseamos describir por medio
del modelo. Como tercer paso, se utilizan estos datos para estimar los parámetros
del modelo. Por último, se realizan pruebas sobre el modelo estimado, a fin de
determinar si constituye una representación adecuada del fenómeno estudiado, o
si debemos realizar modificaciones en la especificación original.
En la econometría aplicada, la forma funcional que más se utiliza en la
práctica para representar la relación causal entre variables dependientes e
independientes es la función ―lineal,‖ que en su forma más general puede
expresarse de la siguiente manera:
Y = 0 + 1X1 + 2X2 + ... + kXk + u
donde Y representa el valor de la variable dependiente, X1, X2, ... , Xk representan
los valores de las variables independientes, 0 representa la ―ordenada en el
origen,‖ 1, 2 , ... , k representan los coeficientes de las respectivas variables
independientes, y u representa un término de error.
En un problema de econometría aplicada, deseamos obtener estimaciones de
los k + 1 parámetros (0, 1, 2, ... , k) que contiene esta ecuación. Consideremos
la interpretación de estos parámetros, obviando por el momento los problemas de
estimación. El parámetro 0 es relativamente fácil de interpretar, ya que como se
mencionó en el párrafo anterior, es simplemente la ―ordenada en el origen,‖ o sea,
el valor de Y cuando todas las variables independientes son exactamente cero. Por
otra parte, los coeficientes 1, 2, etc., pueden interpretarse como las derivadas
parciales de Y respecto de las respectivas variables independientes: así, 1 nos
dice cuánto cambia Y en respuesta a un cambio de una unidad en X1, suponiendo
que las demás variables independientes no cambian, y los demás coeficientes se
pueden interpretar de la misma manera. Obviamente, es muy importante contar
con estimaciones confiables de la magnitud de estos coeficientes, y el trabajo del
econometrista consiste en proporcionar estas estimaciones.
La presencia del término de error (u) en esta ecuación refleja el hecho de que
los datos económicos nunca se ajustan a funciones matemáticamente exactas, de
modo que funciones simples como la anterior sólo pueden considerarse como
aproximaciones a las verdaderas relaciones que se están investigando. Aún si la

[3]
verdadera relación no es lineal, sin embargo, si el rango relevante de variación de
las variables no es muy grande, entonces la forma lineal podría constituir de todas
maneras una buena aproximación a la verdadera forma funcional.
El Prof. Johnston ha propuesto tres diferentes razones para justificar el tér-
mino de error en un análisis econométrico.3 Por un lado, los datos económicos
siempre contienen errores de medición, ya que las variables económicas no pue-
den ser medidas con exactitud. En este sentido, u puede ser interpretado literal-
mente como un ―error‖ genuino. Por otro lado, en un análisis aplicado sólo pue-
den tomarse en cuenta las variables más importantes para la explicación de un fe-
nómeno, y por tanto las ecuaciones en la práctica no pueden incluir todas las va-
riables que pueden afectar una determinada variable dependiente. El efecto neto
de las variables omitidas se refleja en el término de error, que en este sentido es
interpretado como un ―residuo.‖ Por último, y como ya se mencionó en el párrafo
anterior, las relaciones económicas probablemente no serían exactas aún si no
existiera ningún error de medición, y aún si todas las variables relevantes son in-
cluidas en el análisis. En última instancia, las variables económicas dependen de
la acción humana, y existe una cierta indeterminación en el comportamiento hu-
mano que sólo puede ser representada mediante un término de perturbación alea-
torio, cuya varianza es incrementada por los errores de medición y el efecto resi-
dual de variables omitidas. Se reconoce de entrada, por tanto, que las estimacio-
nes econométricas siempre contienen cierto elemento de incertidumbre. Con téc-
nicas adecuadas, se puede tratar de reducir esta incertidumbre, aunque nunca se
podrá eliminar del todo. El estudiante de econometría debe estar siempre cons-
ciente de las limitaciones de sus métodos de análisis.
El propósito de este texto es familiarizar al estudiante de economía y/o
administración con las técnicas más comunes que se emplean en el análisis
econométrico aplicado. Esencialmente, se trata de estimar los coeficientes de
ecuaciones lineales, tales como la ecuación (1). En el siguiente capítulo se discute
el caso más sencillo, el de una sola variable independiente, que puede ser tratado
con técnicas algebraicas relativamente simples. El caso más general de k variables
independientes requiere de técnicas más sofisticadas, y por esto es que el Capítulo
3 se dedica a un repaso de álgebra matricial, previo a la discusión del modelo de
―Regresión Lineal Múltiple,‖ que es el tema del Capítulo 4. En el Capítulo 5 se
consideran ampliaciones del modelo lineal, como ser la estimación de formas no-
lineales y el uso de variable binarias, y se discuten algunos problemas especiales
que frecuentemente surgen en el análisis de regresión, tales como multi-
colinealidad, heteroscedasticidad y el efecto de variables omitidas, mientras que
el importante problema de la autocorrelación es tratado a fondo en el Capítulo 6.
3J. Johnston, Econometric Methods, 2a ed. (Nueva York: McGraw-Hill, 1972), pp. 10-
11.

[4]
Finalmente, el Capítulo 7 trata de los problemas especiales que puede plantear la
presencia de retardos en las ecuaciones de regresión.
La lectura de este texto presupone que el estudiante conoce los rudimentos del
cálculo, y ciertos elementos de estadística matemática. También es conveniente
cierta familiaridad con las computadoras, y particularmente con el manejo de ho-
jas electrónicas tipo Excel. Como lo indica el título, este es un texto para un curso
introductorio de econometría aplicada. Un texto introductorio debe ser selectivo,
y si bien se ha hecho un esfuerzo por incluir la mayoría de las herramientas que
en la práctica debe emplear el investigador típico en la situación típica, sin duda
existen algunas lagunas más o menos importantes. En aras de la brevedad, por
ejemplo, se ha omitido por completo el tema de la estimación de modelos de
ecuaciones simultáneas, de modo que el texto se limita únicamente al caso de
modelos de ecuación única, e incluso en este caso sólo se discuten los problemas
que más comúnmente se plantean en la práctica. El estudiante que desea especia-
lizarse en este campo podrá subsanar estas deficiencias consultando algunos de
los textos citados en la bibliografía.

[5]
Capítulo 2
REGRESIÓN LINEAL SIMPLE
2.1. Introducción.
En este capítulo consideramos el caso más simple de una regresión lineal, que
es el de una ecuación lineal con una variable dependiente (Y), y una sola variable
independiente (X). Este modelo básico puede ser representado como:
Y = 0 + 1X + u
donde 0 y 1 son los parámetros respectivos, y u es el término de error. (Siempre
conviene recordar que en econometría las relaciones entre variables no son fun-
ciones exactas, sino que son únicamente relaciones estadísticas. Por esto siempre
es necesario incluir una variable de error en la relación.)
El parámetro 0, conocido como la ―ordenada en el origen,‖ nos dice cuánto
es Y cuando X = 0. El parámetro 1, conocido como la ―pendiente,‖ nos dice
cuánto aumenta Y por cada aumento de una unidad en X. Estos parámetros son
desconocidos, y nuestro problema consiste en obtener estimaciones numéricas de
los mismos a partir de una muestra de observaciones sobre las variables estudia-
das. El método de estimación más comúnmente empleado en el análisis de regre-
sión es el método de ―mínimos cuadrados.‖ La mejor forma de ilustrar la aplica-
ción de este método es por medio de un ejemplo práctico.
Consideremos el Cuadro 2.1, que muestra datos mensuales de producción y
costos de operación para una empresa británica de transporte de pasajeros por ca-
rretera durante los años 1949-52. (La producción se mide en términos de miles de
millas-vehículo recorridas por mes, y los costos se miden en términos de miles de
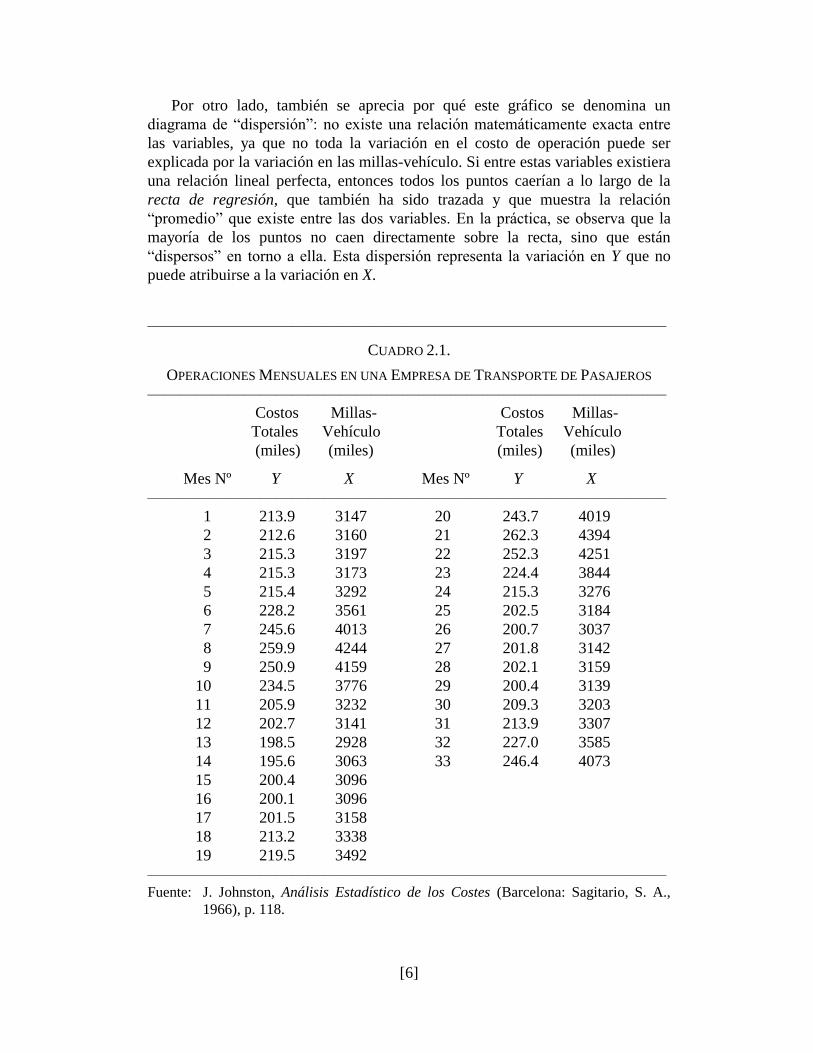
libras por mes). Para poder visualizar el grado de relación que existe entre las va-
riables, como primer paso en el análisis es conveniente elaborar un diagrama de
dispersión, que es una representación en un sistema de coordenadas cartesianas
de los datos numéricos observados. En el diagrama resultante, en el eje X se mi-
den las millas-vehículo recorridas, y en el eje Y se mide el costo de operación
mensual. Cada punto en el diagrama muestra la pareja de datos (millas-vehículo y
costos de operación) que corresponde a un mes determinado. Como era de espe-
rarse, existe una relación positiva entre estas variables: una mayor cantidad de
millas-vehículo recorridas corresponde un mayor nivel de costos de operación.
[6]
Por otro lado, también se aprecia por qué este gráfico se denomina un
diagrama de ―dispersión‖: no existe una relación matemáticamente exacta entre
las variables, ya que no toda la variación en el costo de operación puede ser
explicada por la variación en las millas-vehículo. Si entre estas variables existiera
una relación lineal perfecta, entonces todos los puntos caerían a lo largo de la
recta de regresión, que también ha sido trazada y que muestra la relación
―promedio‖ que existe entre las dos variables. En la práctica, se observa que la
mayoría de los puntos no caen directamente sobre la recta, sino que están
―dispersos‖ en torno a ella. Esta dispersión representa la variación en Y que no
puede atribuirse a la variación en X.
————————————————————————————————–
CUADRO 2.1.
OPERACIONES MENSUALES EN UNA EMPRESA DE TRANSPORTE DE PASAJEROS
————————————————————————————————–
Costos Millas- Costos Millas-
Totales Vehículo Totales Vehículo
(miles) (miles) (miles) (miles)
Mes Nº Y X Mes Nº Y X
————————————————————————————————–
1 213.9 3147 20 243.7 4019
2 212.6 3160 21 262.3 4394
3 215.3 3197 22 252.3 4251
4 215.3 3173 23 224.4 3844
5 215.4 3292 24 215.3 3276
6 228.2 3561 25 202.5 3184
7 245.6 4013 26 200.7 3037
8 259.9 4244 27 201.8 3142
9 250.9 4159 28 202.1 3159
10 234.5 3776 29 200.4 3139
11 205.9 3232 30 209.3 3203
12 202.7 3141 31 213.9 3307
13 198.5 2928 32 227.0 3585
14 195.6 3063 33 246.4 4073
15 200.4 3096
16 200.1 3096
17 201.5 3158
18 213.2 3338
19 219.5 3492
————————————————————————————————– Fuente: J. Johnston, Análisis Estadístico de los Costes (Barcelona: Sagitario, S. A.,
…… 1966), p. 118.
[7]
DIAGRAMA DE DISPERSIÓN
180
200
220
240
260
280
2500 3000 3500 4000 4500
MILLAS
CO
ST
OS

[8]
2.2. Método de Mínimos Cuadrados.
En un análisis de regresión, tratamos de contestar dos preguntas básicas:
1. ¿Cuál es la relación estadística que existe entre la variable dependiente (Y) y la
variable independiente (X)? Para contestar esta pregunta, debemos obtener esti-
maciones de los parámetros de la recta de regresión, es decir, los coeficientes 0 y
1 de la ecuación (1). En el ejemplo concreto que nos concierne aquí, el estima-
dor de 1 nos ayuda a responder una pregunta muy importante: ¿cuánto aumenta,
en promedio, el costo de operación por cada milla-vehículo adicional?
2. ¿Qué porcentaje de la variación total en la variable dependiente se puede atri-
buir a la variación en la variable independiente? Para contestar esta pregunta, de-
bemos comparar la dispersión de los datos en torno a la recta de regresión con la
variación total en la variable dependiente.
La primera de estas dos preguntas supone encontrar la recta que ―mejor‖ se
ajusta a los datos observados, lo que obviamente requiere algún criterio de
selección. Supongamos que tenemos dos estimadores de los coeficientes 0 y 1,
que denotaremos por b0 y b1, respectivamente, y consideremos el i-ésimo punto
del diagrama de dispersión, que representa un valor para la variable
independiente (Xi) y un valor para la variable dependiente (Yi). Dado el valor de
Xi, el valor de Y calculado por la recta de regresión será b0 + b1Xi y la diferencia
entre este valor calculado y el valor realmente observado (Yi) será el error
correspondiente a la i-ésima observación:
ei = Yi – b0 – b1Xi
Sea n el número total de observaciones en la muestra (en este ejemplo n = 33).
Para cada observación individual habrá un error correspondiente, y el método de
―minimos cuadrados‖ consiste en encontrar los valores de b0 y b1 que minimizan
la suma de los errores cuadrados para la muestra en conjunto. Es decir, se trata
de minimizar la variable:
2
1
1
0
1
2 )( i
n
i
i
n
i
i XbbYeQ
Nótese que esta expresión es función de b0 y b1, ya que diferentes valores para
estos parámetros producirán diferentes conjuntos de errores. En otras palabras, la
suma de los errores cuadrados es función de la recta de regresión. Según el
criterio de mínimos cuadrados, la ―mejor‖ recta de regresión es la que minimiza
Q. Aplicando un conocido principio del cálculo, para minimizar Q calculamos las
derivadas parciales respecto de b0 y de b1, y las igualamos a 0:

[9]
0)(2 1
1
0
0
i
n
i
i XbbYb
Q
0)(2 1
1
0
1
ii
n
i
i XXbbYb
Q
Esto nos proporciona un sistema de dos ecuaciones con dos incógnitas. Resol-
viendo el sistema podemos obtener los valores de b0 y b1. En la terminología del
análisis de regresión estas ecuaciones son a veces denominadas las ―ecuaciones
normales.‖ Nótese que la primera de estas ecuaciones equivale a la restricción
0 ie , mientras que la segunda equivale a la restricción 0 iieX . Este es
un resultado importante que será utilizado más adelante en este capítulo. (En lo
sucesivo suprimiremos el uso del subíndice en las sumatorias, para facilitar la no-
tación. Se entiende que todas las sumas se efectúan sobre i = 1, 2, ... , n.) Simpli-
ficando estas ecuaciones, podemos obtener las siguientes expresiones equivalen-
tes:
(1) XbnbY 10
(2) 2
10 XbXbXY
La ecuación (1) también puede expresarse como
(3) xbyb 10
donden
Yy
es el promedio aritmético de los valores para Y, y n
Xx
es el
promedio aritmético de los valores para X. Sustituyendo (3) en (2), y reordenando
términos, obtenemos la siguiente expresión para b1:
(4)
XxX
XyXYb
21
Las fórmulas (3) y (4) nos permiten calcular b0 y b1 a partir de los datos observa-
dos. Para el ejemplo de los costos de transporte, tenemos:
1.231,7Y (por tanto 12424.219331.231,7 y )
879,113X (por tanto 8788.450,333879,113 x )
3.020,216,25XY 769,855,3982X

[10]
Sustituyendo estos valores en la fórmula (4) obtenemos:
044673.0)879,113)(8788.450,3(769,855,398
)879,113)(12424.219(3.020,216,251
b
Por último, sustituyendo este valor en la fórmula (3), juntamente con los valores
para x y y , obtenemos:
963.64)8788.450,3)(044673.0(12424.2190 b
Estos dos parámetros definen la recta de regresión, que podemos expresar como
sigue:
XY 044673.0963.64ˆ
(Usamos el símbolo Y para representar el valor calculado de Y según la recta de
regresión. Es muy importante distinguir claramente entre Y y Y, que es el valor
observado de la variable dependiente.) Según esta estimación, y en números
redondos, podemos esperar que en promedio el costo de operación se incremente
alrededor de 0.045 libras por cada milla-vehículo adicional, mientras que el
―costo fijo‖ mensual (i.e., la parte del costo de operación que no varía con las
millas recorridas) es de aproximadamente 65,000 libras al mes, en promedio.
2.3. Coeficiente de Determinación (R2).
Habiendo calculado la recta de regresión, podemos ahora tratar de responder a
la segunda pregunta planteada en la sección anterior: ¿qué porcentaje de la varia-
ción total en el costo de operación (Y) se debe a la variación en las millas-
vehículo recorridas (X)? En otras palabras, y en términos más generales, ¿cuál es
la proporción de la variación total en Y que puede ser ―explicada‖ por la variación
en X? Para poder contestar esta pregunta, debemos antes descomponer la varia-
ción total en Y en sus dos componentes: la variación ―explicada,‖ que se puede
atribuir a la variación en X, y la variación ―no-explicada,‖ que se debe a factores
desconocidos y que representamos por los errores de la regresión.
Por definición de la recta de regresión, tenemos que para cualquier observa-
ción individual el valor observado de Y será igual a la Y ―calculada‖ más el error:
iii eYY ˆ
Nótese que esto implica que ii YY , ya que se recordará que 0ie por
la primera ecuación normal. Esto implica a su vez que el promedio de las Y es

[11]
exactamente igual a y . Si restamos y de ambos lados de esta ecuación y eleva-
mos al cuadrado tendremos:
iiiiiii eyYeyYeyYyY )ˆ(2)ˆ(])ˆ[()( 2222
Por último, si sumamos sobre todas las observaciones tendremos:
(5) eyYeyYyY )ˆ(2)ˆ()( 222
donde nuevamente hemos suprimido los subíndices para simplificar la notación.
Consideremos ahora la expresión:
eYeyeYeyY ˆˆ)ˆ(
ya que 0e , por la primera ecuación normal. A su vez, por la definición de
Y tenemos que:
0)(ˆ1010 XebebeXbbeY
ya que 0e por la primera ecuación normal, y 0Xe por la segunda
ecuación normal. Por tanto, la ecuación (5) se reduce a la siguiente expresión:
222 )ˆ()( eyYyY
En palabras, esto nos indica que la variación total de la variable dependiente (en
torno a su promedio) se puede descomponer en dos partes: (1) la variación total
de la Y ―calculada‖, y (2) la suma de los errores cuadrados. Puesto que la
variación de la Y ―calculada‖ se debe totalmente a la variación en X, a este primer
componente de la variación total en Y se le conoce como la variación ―explicada,‖
ya que es la parte de la variación en Y que puede ser atribuida a la variación en la
variable independiente. El segundo componente de la variación en Y, la suma de
los errores cuadrados, representa la variación ―no-explicada,‖ ya que es la parte
residual de la variación en Y que no puede ser atribuida a la variación en X. Si
expresamos la variación explicada como porcentaje de la variación total,
obtenemos el siguiente estadístico importante que se conoce como el ―coeficiente
de determinación‖:
2
2
2
2
2
)(1
)(
)ˆ(
yY
e
yY
yYR
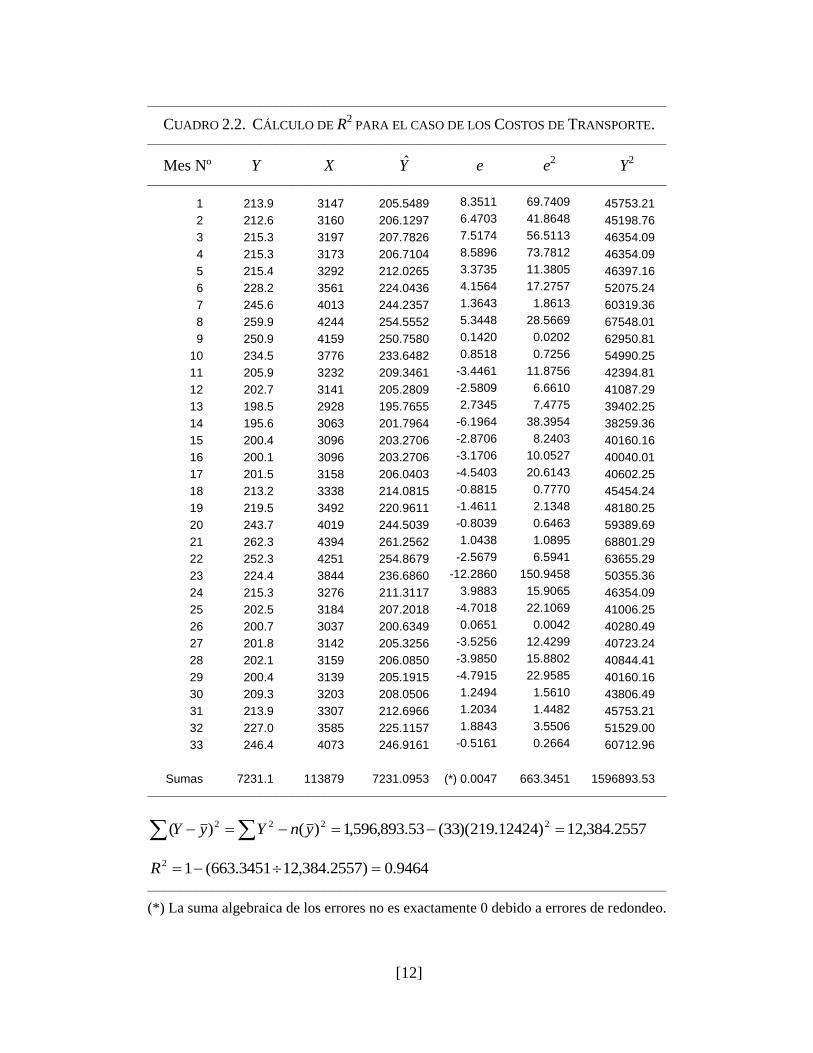
Los cálculos relevantes para el caso de los costos de transporte se muestran en el
Cuadro 2.2. El valor de 0.9464 para R2 nos indica que la variación en las millas-
vehículo recorridas explica el 94.64 % de la variación en el gasto de operación
mensual. El resto de la variación observada (5.36 %) se debe a otros factores.
[12]
————————————————————————————————–
CUADRO 2.2. CÁLCULO DE R2 PARA EL CASO DE LOS COSTOS DE TRANSPORTE.
————————————————————————————————–
Mes Nº Y X Y e e2 Y
2
————————————————————————————————–
1 213.9 3147 205.5489 8.3511 69.7409 45753.21
2 212.6 3160 206.1297 6.4703 41.8648 45198.76
3 215.3 3197 207.7826 7.5174 56.5113 46354.09
4 215.3 3173 206.7104 8.5896 73.7812 46354.09
5 215.4 3292 212.0265 3.3735 11.3805 46397.16
6 228.2 3561 224.0436 4.1564 17.2757 52075.24
7 245.6 4013 244.2357 1.3643 1.8613 60319.36
8 259.9 4244 254.5552 5.3448 28.5669 67548.01
9 250.9 4159 250.7580 0.1420 0.0202 62950.81
10 234.5 3776 233.6482 0.8518 0.7256 54990.25
11 205.9 3232 209.3461 -3.4461 11.8756 42394.81
12 202.7 3141 205.2809 -2.5809 6.6610 41087.29
13 198.5 2928 195.7655 2.7345 7.4775 39402.25
14 195.6 3063 201.7964 -6.1964 38.3954 38259.36
15 200.4 3096 203.2706 -2.8706 8.2403 40160.16
16 200.1 3096 203.2706 -3.1706 10.0527 40040.01
17 201.5 3158 206.0403 -4.5403 20.6143 40602.25
18 213.2 3338 214.0815 -0.8815 0.7770 45454.24
19 219.5 3492 220.9611 -1.4611 2.1348 48180.25
20 243.7 4019 244.5039 -0.8039 0.6463 59389.69
21 262.3 4394 261.2562 1.0438 1.0895 68801.29
22 252.3 4251 254.8679 -2.5679 6.5941 63655.29
23 224.4 3844 236.6860 -12.2860 150.9458 50355.36
24 215.3 3276 211.3117 3.9883 15.9065 46354.09
25 202.5 3184 207.2018 -4.7018 22.1069 41006.25
26 200.7 3037 200.6349 0.0651 0.0042 40280.49
27 201.8 3142 205.3256 -3.5256 12.4299 40723.24
28 202.1 3159 206.0850 -3.9850 15.8802 40844.41
29 200.4 3139 205.1915 -4.7915 22.9585 40160.16
30 209.3 3203 208.0506 1.2494 1.5610 43806.49
31 213.9 3307 212.6966 1.2034 1.4482 45753.21
32 227.0 3585 225.1157 1.8843 3.5506 51529.00
33 246.4 4073 246.9161 -0.5161 0.2664 60712.96
Sumas 7231.1 113879 7231.0953 (*) 0.0047 663.3451 1596893.53
————————————————————————————————–
2557.384,12)12424.219)(33(53.893,596,1)()( 2222 ynYyY
9464.0)2557.384,123451.663(12 R
————————————————————————————————– (*) La suma algebraica de los errores no es exactamente 0 debido a errores de redondeo.

[13]
PREGUNTAS DE REPASO
1. Defina los siguientes conceptos:
a) diagrama de dispersión
b) recta de regresión
c) criterio de mínimos cuadrados
d) coeficiente de determinación.
2. (Regresión por el Origen) En algunas situaciones, se sabe que la relación en-
tre Y y X ―pasa por el origen‖ en el sentido de que 0 = 0. Este sería el caso
cuando Y = 0 por definición cuando X = 0. En este caso la recta de regresión
sería simplemente Y = 1X + u.
a) Derive la fórmula para b1, el estimador de 1, usando el criterio de míni-
mos cuadrados.
b) Nótese que en este caso la suma algebraica de los errores, ie , ya no es
igual a 0. ¿Por qué? ¿Qué implicaciones tiene esto para la interpretación de
R2?
c) En el caso de una regresión lineal convencional, 0 < R2 < 1 por definición.
Sin embargo, en el caso de una regresión por el origen, se puede dar el caso
de una R2 negativa. Muestre gráficamente de qué forma podría darse esta
situación.

[14]
CASOS APLICADOS
Caso A — Elecciones en Florida
En las elecciones presidenciales norteamericanas de Noviembre 2000 los conten-
dientes principales, George Bush y Al Gore, resultaron casi empatados en térmi-
nos de votos electorales, por lo que el resultado dependía crucialmente de los co-
micios en el estado de Florida, donde el escrutinio inicial no dio un resultado de-
finitivo a favor de ninguno de los candidatos. A medida que proseguía el conteo,
surgieron varias anomalías, una de las cuales tuvo que ver con el condado de
Palm Beach. Entre otras cosas, se alegó que en este condado muchos votantes que
deseaban votar por Gore se confundieron, debido al diseño de la papeleta electo-
ral, y votaron por error por un candidato marginal, Pat Buchanan, del Reform
Party. (El condado de Palm Beach tenía una papeleta electoral un tanto confusa y
con un formato diferente a la de los demás condados en el estado.)
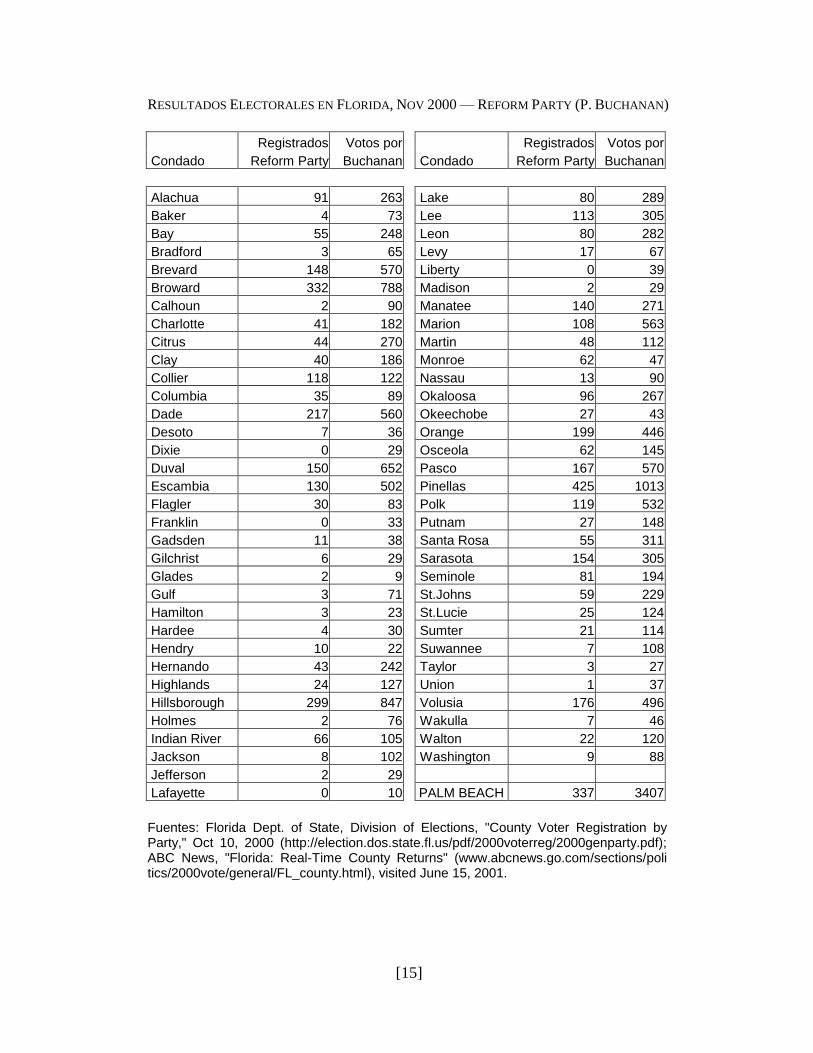
El cuadro adjunto muestra la votación obtenida por Buchanan en todos los con-
dados del estado de Florida, y se aprecia claramente que la cantidad de votos ob-
tenidos por ese candidato en Palm Beach fue exageradamente grande en compa-
ración al resto del estado. Presumiblemente, muchos de estos fueron efectivamen-
te votos erróneos (y probablemente con la intención de votar por Gore, debido al
diseño de la papeleta). La pregunta es si se puede obtener una estimación aproxi-
mada de la cantidad de estos votos erróneos.
Como una primera aproximación, se esperaría que la votación obtenida por Bu-
chanan en un condado determinado estaría positivamente relacionada con la can-
tidad de personas afiliadas al Reform Party residentes en ese condado. Este dato
también se muestra en el cuadro adjunto.
Con esta información:
(a) Construya un diagrama de dispersión, relacionando las dos variables.
(b) Calcule la línea de regresión (excluyendo la observación para Palm
Beach), y con los resultados obtenidos, haga una estimación de la ―vota-
ción excedente‖ obtenida por Buchanan en Palm Beach.
(c) Tomando en cuenta que según los resultados oficiales, Bush ganó a Gore
en Florida por una diferencia de 537 votos (sobre un total de más de
6,100,000 votos emitidos), comente sobre las implicaciones de este análi-
sis para el resultado final de las elecciones presidenciales de ese año.
[15]
RESULTADOS ELECTORALES EN FLORIDA, NOV 2000 — REFORM PARTY (P. BUCHANAN)
Registrados Votos por Registrados Votos por
Condado Reform Party Buchanan Condado Reform Party Buchanan
Alachua 91 263 Lake 80 289
Baker 4 73 Lee 113 305
Bay 55 248 Leon 80 282
Bradford 3 65 Levy 17 67
Brevard 148 570 Liberty 0 39
Broward 332 788 Madison 2 29
Calhoun 2 90 Manatee 140 271
Charlotte 41 182 Marion 108 563
Citrus 44 270 Martin 48 112
Clay 40 186 Monroe 62 47
Collier 118 122 Nassau 13 90
Columbia 35 89 Okaloosa 96 267
Dade 217 560 Okeechobe 27 43
Desoto 7 36 Orange 199 446
Dixie 0 29 Osceola 62 145
Duval 150 652 Pasco 167 570
Escambia 130 502 Pinellas 425 1013
Flagler 30 83 Polk 119 532
Franklin 0 33 Putnam 27 148
Gadsden 11 38 Santa Rosa 55 311
Gilchrist 6 29 Sarasota 154 305
Glades 2 9 Seminole 81 194
Gulf 3 71 St.Johns 59 229
Hamilton 3 23 St.Lucie 25 124
Hardee 4 30 Sumter 21 114
Hendry 10 22 Suwannee 7 108
Hernando 43 242 Taylor 3 27
Highlands 24 127 Union 1 37
Hillsborough 299 847 Volusia 176 496
Holmes 2 76 Wakulla 7 46
Indian River 66 105 Walton 22 120
Jackson 8 102 Washington 9 88
Jefferson 2 29
Lafayette 0 10 PALM BEACH 337 3407
Fuentes: Florida Dept. of State, Division of Elections, "County Voter Registration by Party," Oct 10, 2000 (http://election.dos.state.fl.us/pdf/2000voterreg/2000genparty.pdf); ABC News, "Florida: Real-Time County Returns" (www.abcnews.go.com/sections/poli tics/2000vote/general/FL_county.html), visited June 15, 2001.
[16]
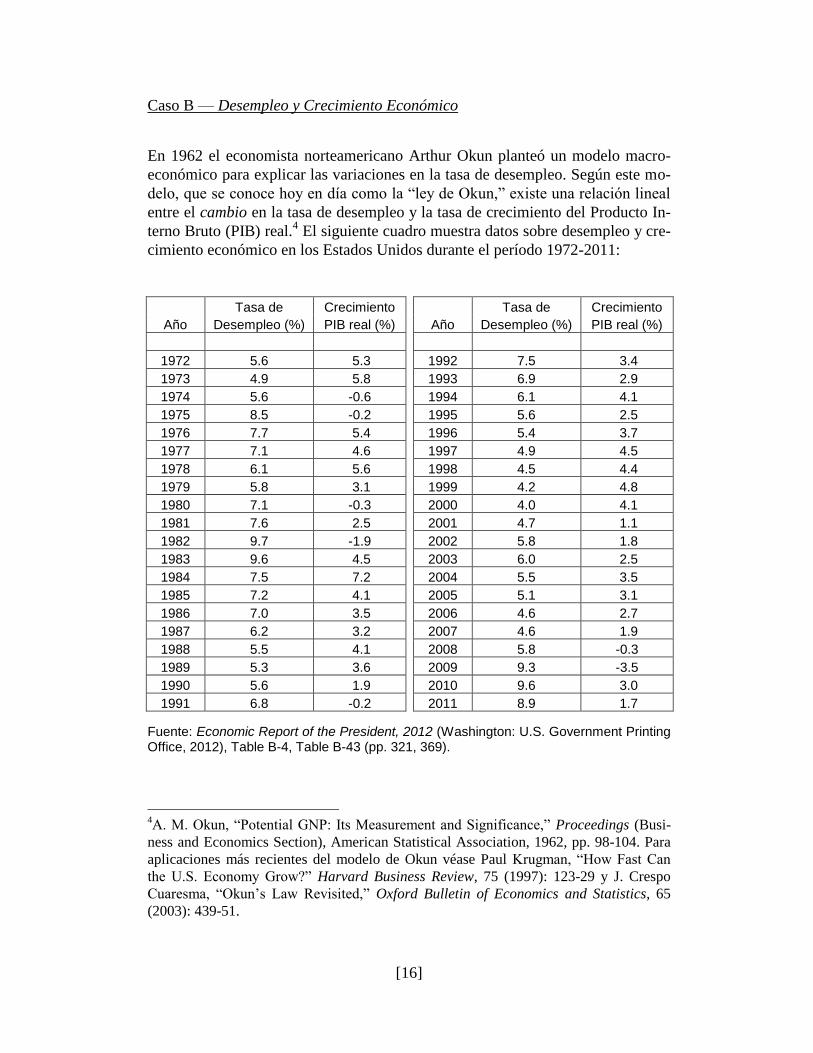
Caso B — Desempleo y Crecimiento Económico
En 1962 el economista norteamericano Arthur Okun planteó un modelo macro-
económico para explicar las variaciones en la tasa de desempleo. Según este mo-
delo, que se conoce hoy en día como la ―ley de Okun,‖ existe una relación lineal
entre el cambio en la tasa de desempleo y la tasa de crecimiento del Producto In-
terno Bruto (PIB) real.4 El siguiente cuadro muestra datos sobre desempleo y cre-
cimiento económico en los Estados Unidos durante el período 1972-2011:
Tasa de Crecimiento Tasa de Crecimiento
Año Desempleo (%) PIB real (%) Año Desempleo (%) PIB real (%)
1972 5.6 5.3 1992 7.5 3.4
1973 4.9 5.8 1993 6.9 2.9
1974 5.6 -0.6 1994 6.1 4.1
1975 8.5 -0.2 1995 5.6 2.5
1976 7.7 5.4 1996 5.4 3.7
1977 7.1 4.6 1997 4.9 4.5
1978 6.1 5.6 1998 4.5 4.4
1979 5.8 3.1 1999 4.2 4.8
1980 7.1 -0.3 2000 4.0 4.1
1981 7.6 2.5 2001 4.7 1.1
1982 9.7 -1.9 2002 5.8 1.8
1983 9.6 4.5 2003 6.0 2.5
1984 7.5 7.2 2004 5.5 3.5
1985 7.2 4.1 2005 5.1 3.1
1986 7.0 3.5 2006 4.6 2.7
1987 6.2 3.2 2007 4.6 1.9
1988 5.5 4.1 2008 5.8 -0.3
1989 5.3 3.6 2009 9.3 -3.5
1990 5.6 1.9 2010 9.6 3.0
1991 6.8 -0.2 2011 8.9 1.7
Fuente: Economic Report of the President, 2012 (Washington: U.S. Government Printing Office, 2012), Table B-4, Table B-43 (pp. 321, 369).
4A. M. Okun, ―Potential GNP: Its Measurement and Significance,‖ Proceedings (Busi-
ness and Economics Section), American Statistical Association, 1962, pp. 98-104. Para
aplicaciones más recientes del modelo de Okun véase Paul Krugman, ―How Fast Can
the U.S. Economy Grow?‖ Harvard Business Review, 75 (1997): 123-29 y J. Crespo
Cuaresma, ―Okun’s Law Revisited,‖ Oxford Bulletin of Economics and Statistics, 65
(2003): 439-51.
[17]
a) Use estos datos para estimar el modelo de Okun, y explique el significado
de los coeficientes obtenidos.
b) En este problema, el punto donde la recta intersecta al eje X tiene un sig-
nificado económico interesante. Determine este punto para este caso, y
explique su significado en términos del modelo de Okun.
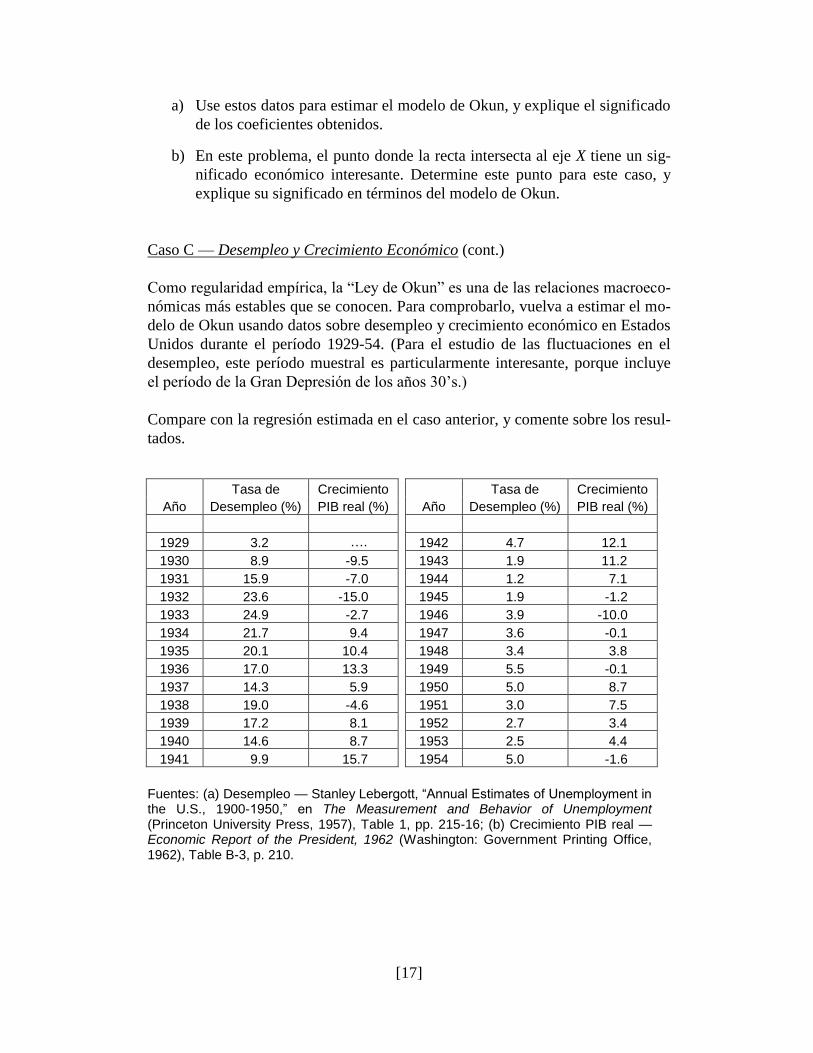
Caso C — Desempleo y Crecimiento Económico (cont.)
Como regularidad empírica, la ―Ley de Okun‖ es una de las relaciones macroeco-
nómicas más estables que se conocen. Para comprobarlo, vuelva a estimar el mo-
delo de Okun usando datos sobre desempleo y crecimiento económico en Estados
Unidos durante el período 1929-54. (Para el estudio de las fluctuaciones en el
desempleo, este período muestral es particularmente interesante, porque incluye
el período de la Gran Depresión de los años 30’s.)
Compare con la regresión estimada en el caso anterior, y comente sobre los resul-
tados.
Tasa de Crecimiento Tasa de Crecimiento
Año Desempleo (%) PIB real (%) Año Desempleo (%) PIB real (%)
1929 3.2 …. 1942 4.7 12.1
1930 8.9 -9.5 1943 1.9 11.2
1931 15.9 -7.0 1944 1.2 7.1
1932 23.6 -15.0 1945 1.9 -1.2
1933 24.9 -2.7 1946 3.9 -10.0
1934 21.7 9.4 1947 3.6 -0.1
1935 20.1 10.4 1948 3.4 3.8
1936 17.0 13.3 1949 5.5 -0.1
1937 14.3 5.9 1950 5.0 8.7
1938 19.0 -4.6 1951 3.0 7.5
1939 17.2 8.1 1952 2.7 3.4
1940 14.6 8.7 1953 2.5 4.4
1941 9.9 15.7 1954 5.0 -1.6
Fuentes: (a) Desempleo — Stanley Lebergott, “Annual Estimates of Unemployment in the U.S., 1900-1950,” en The Measurement and Behavior of Unemployment (Princeton University Press, 1957), Table 1, pp. 215-16; (b) Crecimiento PIB real — Economic Report of the President, 1962 (Washington: Government Printing Office, 1962), Table B-3, p. 210.

[18]
Caso D — Costos de Impresión
Se espera que mientras mayor sea el número de páginas en un libro, mayor sea su
costo de impresión, ceteris paribus. Usted desea estimar la relación entre el costo
promedio por ejemplar y el número de páginas, tomando una muestra de los últi-
mos 10 anuarios publicados por una asociación académica5:
Libro No. Número de
Páginas Cantidad de Ejemplares
Costo Total
1 754 12,400 $ 16,253.00
2 677 12,700 $ 15,471.00
3 689 14,000 $ 16,780.00
4 745 14,800 $ 18,914.00
5 675 15,800 $ 19,759.00
6 615 16,000 $ 18,277.00
7 753 17,700 $ 23,440.00
8 698 18,500 $ 23,362.00
9 652 20,000 $ 23,264.00
10 670 22,500 $ 28,405.00
(a) ¿Qué porcentaje de la variación en el costo promedio se explica por la varia-
ción en el número de páginas?
(b) ¿Cuál sería su estimación del costo marginal por ejemplar para un libro de
500 páginas?
5Los datos sobre costos de publicación fueron tomados de H. F. Williamson, ―Report of
the Secretary for the Year 1966,‖ American Economic Review, 57 (May 1967), p. 690
(Exhibit II).

[19]
Caso E — Costos de Operación en Escuelas Públicas
En un estudio de los costos de operación en escuelas públicas del estado de Wis-
consin,6 el economista John Riew clasificó a 109 escuelas secundarias en grupos
según su tamaño (número de estudiantes inscritos), y encontró que el costo anual
promedio por alumno se comportaba de la siguiente manera:
Tamaño de la Escuela
Número de Escuelas
Costo Promedio por Alumno
143-200 6 $ 531.90
201-300 12 $ 480.80
301-400 19 $ 446.30
401-500 17 $ 426.90
501-600 14 $ 442.60
601-700 13 $ 413.10
701-900 9 $ 374.30
901-1100 6 $ 433.20
1101-1600 6 $ 407.30
1601-2400 7 $ 405.60
Total 109
Use estos datos para obtener una estimación aproximada del costo marginal por
alumno en escuelas de este tipo.
6John Riew, ―Economies of Scale in High School Operation,‖ Review of Economics and
Statistics, 48 (1966), p. 282 (Table 2).

[20]
Capítulo 3
REPASO DE ALGEBRA MATRICIAL
En el capítulo anterior se discutió el caso más simple de una regresión lineal con
una sola variable independiente. Por cierto que la aplicabilidad práctica de este
modelo simple es relativamente limitada, ya que generalmente las variaciones en
la variable dependiente no obedecen a un solo factor, sino que más bien existen
varios factores diferentes que pueden estarla influenciando.
En el caso más general de k diferentes variables independientes, nuestro pro-
blema consiste en estimar los coeficientes de la siguiente ecuación:
Y = 0 + 1X1 + 2X2 + ... + kXk + u
Se puede apreciar que en este caso la aplicación del criterio de ―mínimos cuadra-
dos‖ por medio de métodos algebraicos sería sumamente tedioso y complicado.
Afortunadamente, por medio de álgebra matricial se puede obtener una solución
bastante compacta por medio de unas pocas fórmulas muy simples. Por tanto, en
este capítulo repasaremos los elementos del álgebra de matrices que serán reque-
ridos en el resto del texto.
3.1. Matrices.
Una ―matriz‖ es una colección rectangular de elementos, ordenados en filas y
columnas. En su forma más general, una matriz tiene la siguiente forma:
A =
mnmm
n
n
aaa
aaa
aaa
...
......
......
...
...
21
22221
11211
donde aij (el ―elemento característico‖ de la matriz) es el elemento ubicado en la
fila i y la columna j. Si una matriz tiene m filas y n columnas, se dice que es de

[21]
orden ―m por n‖ ( nm ). La expresión [aij] también se usa para denotar a la ma-
triz que tiene aij como elemento característico. En este caso, A = [aij].
Un ―vector‖ es un caso especial de una matriz que tiene una sola fila (―vector
fila‖) o una sola columna (―vector columna‖). En lo que sigue, usaremos letras
mayúsculas para denotar matrices, y letras minúsculas para denotar vectores.
3.2. Operaciones con Matrices.
a) Igualdad de dos matrices — Se dice que dos matrices A y B son iguales cuan-
do son del mismo orden y aij = bij para todo i, j. Esto es, las matrices deben ser
iguales, elemento por elemento.
b) Suma y resta de matrices — Si A y B son del mismo orden, entonces A + B
será una nueva matriz C tal que cij = aij + bij. Esto es, se suman los elementos co-
rrespondientes de las dos matrices. En forma similar, A – B será una nueva matriz
D tal que dij = aij – bij, esto es, se restan los elementos correspondientes de las dos
matrices.
Ejemplo.
A
3 4 1
0 1 2
1 2 0
B
0 0 1
5 6 4
4 1 6
A B
3 4 2
5 7 6
5 3 6
A B
3 4 0
5 5 2
3 1 6
c) Multiplicación escalar — Si es una constante, entonces el ―producto escalar‖
de por una matriz A será tal que A = [aij]. Esto es, se multiplica cada ele-
mento de A por .
d) Multiplicación de matrices — Si A es una matriz de orden nm , y B es una
matriz de orden pn , entonces el producto AB será una matriz C de orden
pm con elemento característico:
n
k
kjikij bac1

[22]
Es decir, el elemento en la i-ésima fila y j-ésima columna de AB se encuentra
multiplicando los elementos de la i-ésima fila de A por los elementos correspon-
dientes de la j-ésima columna de B, y sumando los productos.
Ejemplo.
A
3 4
0 1
1 2
B 5 6
4 1AB
31 22
4 1
13 8
Nótese que para poder multiplicar dos matrices, el número de columnas de la
primera matriz debe ser igual al número de filas de la segunda matriz (caso con-
trario, el producto no está definido). Cuando se multiplican dos matrices, la ma-
triz resultante tendrá el mismo número de filas que la primera matriz, y el mismo
número de columnas que la segunda matriz. Es muy importante el orden en que
se multiplican las matrices, ya que en el caso de álgebra matricial ―el orden de los
factores sí altera el producto‖: BA generalmente no será igual a AB, y podría no
existir.
3.3. Teoremas sobre Matrices.
(i) Ley Conmutativa de la Suma.
A + B = B + A
Este resultado se desprende directamente de la definición de la suma de ma-
trices.
(ii) La Multiplicación de Matrices no es Conmutativa.
Como ya se mencionó en la sección anterior, en general AB ≠ BA (excepto en
el caso algunas matrices especiales). De hecho, a veces alguno de estos productos
ni siquiera estará definido. Los dos productos AB y BA existirán si las matrices
son de orden nm y mn , respectivamente. En ese caso, el primer producto se-
rá de orden mm , y el segundo de orden nn . (Aún en el caso de que los dos
productos sean del mismo orden, en general no serán iguales.)
(iii) Ley Asociativa de la Suma.
(A + B) + C = A + (B + C)
(iv) Ley Asociativa del Producto.
(AB)C = A(BC)

[23]
(v) Ley Distributiva.
A(B + C) = AB + AC
(A + B)C = AC + BC
3.4. Clases Especiales de Matrices.
Matriz Cuadrada: Se dice que una matriz es ―cuadrada‖ si el número de filas
es igual al número de columnas (m = n).
Matriz Diagonal: Es una matriz cuadrada que tiene elementos, no necesaria-
mente iguales, a lo largo de su ―diagonal principal‖ (los elementos aii), y ceros en
el resto. Obviamente, sólo las matrices cuadradas tienen una diagonal principal.
Matriz Identidad: Es una clase especial de matriz diagonal, que sólo tiene
unos en la diagonal principal. Esta es una matriz muy importante, y se representa
por el símbolo especial I. Se comprueba fácilmente que si se multiplica cualquier
matriz A por una matriz identidad del orden apropiado, entonces AI = A y IA =
A.
Matriz Escalar: Es una matriz diagonal que tiene la misma constante en la
diagonal principal. Si la constante es , entonces la matriz escalar se puede repre-
sentar por I.
Matriz Idempotente: Es una matriz cuadrada tal que AA = A.
3.5. Traza de una Matriz Cuadrada.
La ―traza‖ de una matriz cuadrada de orden n, tr(A), se define como la suma
de los elementos de su diagonal principal:
tr(A) =
n
i
iia1
Es obvio que tr(A + B) = tr(A) + tr(B), y tr(A – B) = tr(A) – tr(B).
La traza también tiene la siguiente propiedad importante: Si el producto de dos
matrices A y B es una matriz cuadrada, entonces tr(AB) = tr(BA).

[24]
Demostración. Sea C = AB, donde A es de orden nm , y B es de orden mn .
Entonces el elemento característico de C será:
n
k
kjikij bac1
tr(AB) =
m
i
n
k
n
k
m
i
ikkikiik
m
i
ii abbac1 1 1 11
= tr(BA)
ya que
m
i
ikki ab1
es el elemento dkk de D = BA.
Corolario: tr(ABC) = tr(BCA) = tr(CAB).
3.6. Transposición de Matrices.
A' (―A transpuesta‖) es la matriz que resulta de A tras intercambiar filas por
columnas. El elemento característico de A' es a'ij = aji. Por ejemplo,
A =
3813
214
12231
A' =
321
8122
13431
Si A' = A, se dice que A es una matriz ―simétrica‖. (Obviamente, para que una
matriz sea simétrica, tiene que ser cuadrada.)
Teoremas sobre Transpuestas.
3.6.1. (A')' = A
3.6.2. (A + B)' = A' + B'
3.6.3. (AB)' = B'A'
Demostración. Si C = AB, entonces
n
k
kjikij bac1
. Por tanto, el elemento carac-
terístico de C' será
n
k
kjik
n
k
jkki
n
k
kijkjiij ababbacc111
'''
que es precisamente el elemento característico del producto B'A'.

[25]
Corolario. (ABC)' = C'B'A'
Otro Corolario. AA' y A'A son simétricas. (Nota: En general AA' ≠ A'A, pero
sus trazas son siempre iguales. ¿Por qué?)
3.7. Matriz Inversa.
Se dice que A–1
es la ―inversa‖ de una matriz cuadrada A, si A–1
A = AA–1
= I.
Propiedades de la Inversa.
3.7.1. (A–1
)–1
= A
3.7.2. (AB)–1
= B–1
A–1
Demostración. AB(B–1
A–1
) = A(BB–1
)A–1
= AA–1
= I
3.7.3. (A')–1
= (A–1
)'
Demostración. Se sabe que
(1) A'(A')–1
= I
Transponiendo (1) tenemos ((A')–1
)'A = I. Por tanto,
(2) ((A')–1
)' = A–1
Transponiendo (2) obtenemos el teorema.
Corolario. Si A es simétrica, entonces A = A', y por tanto (A–1
)' = A–1
(la inversa
de una matriz simétrica es simétrica).

[26]
PREGUNTAS DE REPASO
1. Defina los siguientes términos:
a) Matriz cuadrada
b) Matriz identidad
c) Diagonal principal
d) Matriz simétrica
e) Matriz idempotente
f) Traza de una matriz
2. Construya algunos ejemplos numéricos para verificar los teoremas sobre
matrices enunciados en las secciones 3.3, 3.6 y 3.7.
3. Expanda (A + B)(A – B) y (A – B)(A + B). ¿Son iguales? ¿Por qué no?
4. Compruebe que para una matriz X de orden kn , las siguientes matrices son
idempotentes:
a) X(X'X)–1
X'
b) I – X(X'X)–1
X'
5. Compruebe que para una matriz X de orden kn , tr[I – X(X'X)–1
X'] = n – k.
6. Si y es un vector 1n , y X es una matriz kn , ¿cuál es el orden de la si-
guiente expresión?
(X'X)–1
X'y

[27]
Capítulo 4
REGRESIÓN LINEAL MÚLTIPLE
En este capítulo discutiremos el modelo general de regresión múltiple. En la
primera sección derivamos el estimador mínimo-cuadrático para el caso general
de k variables independientes, siguiendo un razonamiento análogo al del Capítulo
2. En la segunda sección introducimos el tema de la inferencia estadística en la
regresión lineal. Este es un tema nuevo, que no ha sido discutido en capítulos
anteriores. En la tercera sección comentamos sobre la interpretación del
coeficiente de determinación (R2) en el contexto de regresiones múltiples.
Finalmente, en la cuarta sección ilustramos la aplicación de los resultados
analíticos obtenidos por medio de un ejemplo numérico.
4.1. Vector Mínimo-Cuadrático.
4.1.1. Planteo del Problema.
Expresamos una variable ―dependiente‖ Y como función lineal de k variables
―independientes‖ X1, X2, ... , Xk:
Y = 0 + 1X1 + 2X2 + ... + kXk + u
donde 0, 1, 2, ... , k son constantes desconocidas, y u es una variable aleatoria
que refleja la variación en Y que no puede atribuirse a las variables independien-
tes (o ―explicativas‖). El problema consiste en obtener estimaciones de los k + 1
coeficientes en este modelo mediante análisis de n observaciones conjuntas sobre
la variable dependiente y las k variables independientes.
Nótese que podemos representar las observaciones sobre Y como un vector y
de orden 1n , mientras que las observaciones sobre las X podemos representar-
las como una matriz X de orden kn :

[28]
—————————————————————————
Observación
Nº Y X1 X2 .... Xk
—————————————————————————
1 Y1 X11 X12 .... X1k
2 Y2 X21 X22 .... X2k
3 Y3 X31 X32 .... X3k
. . . . .... .
. . . . .... . i Yi Xi1 Xi2 .... Xik
. . . . .... .
. . . . .... .
n Yn Xn1 Xn2 .... Xnk
y X
—————————————————————————
Se comprueba además que si la matriz X se aumenta con una columna de 1’s
(para poder tomar en cuenta 0, la ordenada en el origen), entonces el modelo
lineal para las n observaciones se puede expresar como:
y = X + u
donde es un vector de orden 1)1( k cuyos elementos son los coeficientes del
modelo lineal (0, 1, 2, ... , k), X es una matriz de orden )1( kn de obser-
vaciones sobre la variables independientes (incluyendo la columna de 1’s) y u es
un vector-columna de orden 1n cuyos elementos (u1, u2, ... , un) consisten de n
variables aleatorias idénticamente distribuidas.
Dado un vector b de estimadores de los coeficientes, el vector y también pue-
de expresarse como:
y = Xb + e
donde e es un vector de orden 1n cuyos elementos (e1, e2, ... , en) son los resi-
duos obtenidos de la ecuación estimada. (Esto es, e = y – Xb, donde Xb es la Y
―calculada.‖ No debe confundirse b con , ni e con u.)

[29]
4.1.2. Estimación de b.
El vector b que minimiza la suma de los errores cuadrados (e'e) se llama el
―vector mínimo-cuadrático.‖ Por definición,
e'e = 2
22110
2 )...( kkXbXbXbbYe
(Nuevamente, suprimimos los sub-índices i para facilitar la notación.) Para
minimizar e'e, derivamos respecto de cada uno de los k + 1 coeficientes, e
igualamos a cero. Así, obtenemos las ―ecuaciones normales‖:
(1) 0)...(2'
22110
0
kk XbXbXbbY
b
ee
(2) 0)...(2'
122110
1
XXbXbXbbY
b
eekk
(3) 0)...(2'
222110
2
XXbXbXbbY
b
eekk
. . . . . .
(k + 1) 0)...(2'
22110
kkk
k
XXbXbXbbYb
ee
Estas k + 1 ecuaciones también pueden expresarse como
(1) 0e
(2) 01 eX
(3) 02 eX
. . . . . .
(k + 1) 0 eX k
Se puede comprobar fácilmente que en términos de nuestra notación matricial
este sistema de k + 1 ecuaciones puede expresarse como
X'e = 0

[30]
donde 0 es un vector de ceros de orden 1)1( k . Puesto que e = y – Xb, esto
también lo podemos expresar como
X'(y – Xb) = 0
Por tanto,
X'Xb = X'y
Multiplicando ambos lados por (X'X)–1
obtenemos el vector mínimo-cuadrático:
b = (X'X)–1
X'y
Los k + 1 elementos de este vector-columna (b0, b1, b2, ... , bk) son los respectivos
estimadores de 0, 1, 2, ... , k.
En la práctica el investigador no calculará el vector b directamente usando es-
ta fórmula, ya que existen programas de computadora que hacen todos los cálcu-
los requeridos con mayor rapidez y precisión que lo que podría hacerlo una per-
sona armada únicamente de una calculadora manual. Es importante, sin embargo,
tener una idea clara de qué es lo que hace la computadora cuando se corre un pro-
grama de regresión, y además esta expresión nos será muy útil más adelante para
propósitos analíticos.
4.2. Inferencia Estadística en la Regresión Lineal.
4.2.1. Supuestos Básicos.
El objetivo de esta sección es desarrollar procedimientos para testar hipótesis
sobre los coeficientes del modelo lineal. Para esto, debemos hacer ciertas suposi-
ciones sobre el comportamiento estadístico de los errores. Los dos supuestos más
importantes en el modelo clásico de regresión lineal son los siguientes:
Supuesto No. 1: ui tiene una distribución N(0, 2) para toda i.
En palabras, suponemos que todas las ui tienen una misma distribución normal,
con la misma media (0) y la misma varianza (2). Una implicación de este su-
puesto es que E(u) = 0, es decir, que el valor esperado del vector u es un vector
de ceros.
Supuesto No. 2: E(uu') = 2I.
Nótese que el elemento característico de la matriz uu' es uiuj. Por tanto, suponer
que el valor esperado de uu' es una matriz escalar equivale a suponer lo siguiente:

[31]
(1) E(uiuj) = 0 para i ≠ j, o sea, todos los elementos no-diagonales de E(uu') son
cero. Esto implica que las ui son independientes unas de otras.
(2) E(ui2) =
2, o sea, todos los elementos de la diagonal de E(uu') son iguales a
2. Esto implica que cada ui tiene la misma varianza
2. (Si suponemos que la
media de ui es 0, entonces E(ui2) será la varianza de ui.)
4.2.2. Valor Esperado y Matriz de Varianza-Covarianza de b.
Puesto que según el modelo lineal y = X + u, entonces
b = (X'X)–1
X'y = (X'X)–1
X'(X + u) = + (X'X)–1
X'u
Por tanto, el valor esperado del vector b será
E(b) = + E[(X'X)–1
X'u] = + (X'X)–1
X'E(u) =
dado que E(u) = 0. Este es un resultado muy importante, ya que significa que b es
un estimador insesgado de . Además, puesto que b – = (X'X)–1
X'u, entonces
(b – )( b – )' = (X'X)–1
X'uu'X(X'X)–1
(Recuérdese que X'X es una matriz simétrica.) Si obtenemos el valor esperado de
esta expresión y aplicamos el supuesto No. 2, tendremos:
E[(b – )( b – )'] = (X'X)–1
X'E(uu')X(X'X)–1
= (X'X)–1
X'2IX(X'X)
–1
= 2(X'X)
–1
Nótese que el elemento característico de E[(b – )(b – )'] es E[(bi – i)(bj – j)],
que es la covarianza entre bi y bj. Para i = j (los elementos de la diagonal de esta
matriz) esto se reduce a E[(bi – i)2], que es la varianza de bi. Por tanto, a esta
matriz se le llama la ―matriz de varianza-covarianza del vector b‖.
4.2.3. Estimación de 2 y
2(X'X)
–1.
En general, no conocemos 2, pero podemos obtener un estimador insesgado
de la siguiente manera. Por definición, el vector de residuos de la regresión esti-
mada será
e = y – Xb = y – X(X'X)–1
X'y = [I – X(X'X)–1
X']y
= [I – X(X'X)–1
X'](X + u) = [I – X(X'X)–1
X']u
Nótese que la expresión entre corchetes es una matriz simétrica idempotente, y
que la traza de esta matriz es la diferencia entre las trazas de dos matrices identi-
dad:

[32]
tr[I – X(X'X)–1
X'] = tr(I) – tr[X(X'X)–1
X'] = tr(I) – tr[(X'X)–1
X'X] = n – (k + 1)
ya que la primera matriz identidad es de orden n, y la segunda es de orden (k + 1).
Además, la suma de los errores cuadrados (e'e) es de orden 11 , y por tanto será
igual a su traza:
e'e = tr(e'e) = tr(u'[I – X(X'X)–1
X']u) = tr([I – X(X'X)–1
X']uu')
= tr(uu'[I – X(X'X)–1
X'])
Por último, puesto que la traza es una sumatoria,
E(e'e) = E[tr(uu'[I – X(X'X)–1
X'])] = tr[E(uu')(I – X(X'X)–1
X')]
= tr(2I[I – X(X'X)
–1X'] ) =
2tr[I – X(X'X)
–1X'] =
2(n – k – 1)
Por tanto, puede obtenerse un estimador insesgado de 2 calculando:
11
'2
2
kn
e
kn
eeS
i
y el estimador insesgado de 2(X'X)
–1 será S
2(X'X)
–1. Los elementos de la diago-
nal de esta matriz cuadrada de orden (k + 1) son los estimadores de las varianzas
de los coeficientes del vector b: el primer elemento de la diagonal de S2(X'X)
–1 es
la varianza muestral de b0, el segundo elemento es la varianza muestral de b1,
etc.7
4.2.4. Testado de Hipótesis.
Supongamos que se desea testar la siguiente hipótesis nula sobre uno de los
coeficientes de regresión:
H0: i = * (donde * es algún valor numérico). Para testar esta hipótesis, se cal-
cula el siguiente estadístico:
)(
*
i
i
bs
b
7Esto es para el caso general de un modelo que incluye una ordenada en el origen (0).
Si la regresión es ―por el origen‖ (ver Pregunta de Repaso No. 2 del Capítulo 2), enton-
ces tr[I – X(X'X)–1
X'] = n – k, ya que la matriz X sólo tiene k columnas, y el denomina-
dor en la fórmula para S2 es n – k. El primer elemento de la diagonal de S
2(X'X)
–1 es la
varianza muestral de b1, el segundo elemento es la varianza muestral de b2, etc.

[33]
donde s(bi) es la desviación estándar de bi, o sea, la raíz cuadrada del elemento
correspondiente de la diagonal de S2(X'X)
–1. Este estadístico tiene una distribu-
ción t con n – k – 1 grados de libertad.8 Por tanto, si la prueba es ―a dos colas‖
con un nivel de significancia de 5 %, rechazamos H0 si el valor absoluto de este
estadístico es mayor que el valor crítico de t para 2.5 % y n – k – 1 grados de li-
bertad. (Si la prueba es ―a una cola,‖ usamos el valor crítico para 5 %.)
Muchas veces, la hipótesis nula que queremos testar en un análisis de
regresión es H0: i = 0, o sea, la hipótesis de que la variable independiente Xi no
tiene realmente ningún efecto sobre Y. En este caso, para testar esta hipótesis
simplemente se calcula )( i
i
bs
b y se compara con el valor crítico relevante para la
distribución t. En la terminología del análisis de regresión, esta razón se conoce
como la ―razón t,‖ y si rechazamos la hipótesis nula podemos concluir que Xi sí
tiene un efecto sobre Y. A menudo esto se expresa diciendo que Xi es una variable
―significativa,‖ o que su coeficiente (i) es ―significativamente mayor (o menor)
que 0.‖9
4.3. Coeficiente de Determinación (R2).
En un análisis de regresión múltiple, el coeficiente de determinación (R2) se
define igual que en el caso de la regresión simple, y tiene la misma interpretación,
aunque debe tomarse en cuenta que en este caso lo que estamos midiendo es el
porcentaje de la variación en Y que se explica por la variación conjunta de las
variables independientes. (El estudiante podrá comprobar también que la R2
en
una regresión múltiple es igual a la R2
de la regresión simple de Y contra .Y Esta
segunda interpretación es quizá más fácil de visualizar.)
En general, no podemos descomponer la variación explicada en términos de
cuánto aporta cada variable independiente individual, pero existe un caso especial
donde esto sí es posible. Si la correlación entre las diferentes variables explicati-
vas es exactamente cero, entonces la R2 de la regresión múltiple será igual a la
8Para una demostración rigurosa, véase Johnston, Econometric Methods, pp. 135-38.
(Por lo expuesto en la Nota 7, una regresión ―por el origen‖ cuenta con n – k grados de
libertad.)
9A menudo los econometristas usan la siguiente regla empírica para decidir si una varia-
ble es ―significativa‖ en una regresión lineal: Concluir que la variable es significativa si
su coeficiente estimado es por lo menos dos veces mayor, en valor absoluto, que su des-
viación estándar (o sea, si el valor absoluto de la ―razón t‖ es mayor que 2). ¿Cómo jus-
tificaría usted el empleo de este criterio?

[34]
suma de las R2 de las regresiones simples de cada variable explicativa contra Y.
Es muy raro que suceda esto en la práctica, pero si los datos provienen de un ex-
perimento controlado entonces es posible diseñar el experimento en forma tal que
los datos muestrales tengan esta propiedad.
4.3.1. Comparando dos o más regresiones en términos de R
2.
Un problema que surge cuando se calculan diferentes regresiones para una
misma variable dependiente es que los valores de R2 no son estrictamente compa-
rables. Cuando se agregan variables independientes a una regresión, el resultado
es que la R2 necesariamente aumenta, ya sea que las variables adicionales sean
significativas o no. Recordemos que R2 se calcula por medio de la fórmula:
2
2
2
)(1
yY
eR
Supongamos que tenemos dos regresiones: una primera regresión con k varia-
bles independientes (Regresión 1), y una segunda regresión que contiene, además
de estas variables, una variable adicional Xk+1 (Regresión 2). Puesto que 2)( yY será igual para las dos regresiones, el efecto sobre R
2 dependerá de
los que sucede con .2e Para la Regresión 2 la suma de los errores cuadrados
necesariamente será menor o igual que para la Regresión 1, no importando si Xk+1
es significativa o no. Para entender por qué, notemos que si aumenta 2e cuan-
do se agrega Xk+1, entonces significa que los coeficientes estimados para la Re-
gresión 2 no minimizan ,2e ya que existe otro vector de coeficientes que pro-
ducirá una menor suma de errores cuadrados: este sería un vector que mantiene
los coeficientes de la Regresión 1, y asignando 0 para el coeficiente de Xk+1. Por
tanto 2e no puede ser mayor para la Regresión 2, y sólo será igual en las dos
regresiones si el coeficiente estimado de Xk+1 es exactamente 0, lo cual es muy
poco probable que suceda en la práctica ya que incluso si la variable adicional no
tiene realmente ningún efecto sobre Y, su coeficiente estimado será pequeño pero
no 0, debido a la variación muestral. En la práctica, entonces, 2e siempre será
menor para la Regresión 2, y por tanto R2 siempre aumentará.
4.3.2. R2 ajustada (
2
R ).
Esto significa que R2 no es, por sí sola, una buena guía para comparar diferen-
tes regresiones, ya que este coeficiente siempre aumentará si se agregan más va-
riables independientes, aun cuando éstas no son significativas. Debido a esto,
Henri Theil propuso una modificación a la fórmula convencional, para compensar

[35]
por este efecto cuando se comparan regresiones diferentes.10
En el ajuste propues-
to por Theil se toma en cuenta el hecho de que, para un tamaño de muestra de-
terminado, más variables explicativas en una regresión implican menos grados de
libertad para la estimación. A diferencia de la R2 convencional, que compara la
variación no-explicada (suma de los errores cuadrados) con la variación total en
Y, la R2 ―ajustada‖ (que se representa por medio del símbolo
2
R ) compara la va-
rianza de los errores con la varianza de Y:
2
2
2
2
2
)(1
11
1
)
11)(
)(1
yY
e
kn
n
n
yY
kn
e
YVar
eVarR
Esto también puede expresarse como:
)1(1
11 22
Rkn
nR
2
R puede ser negativa, y su valor siempre será menor o igual que la R2 conven-
cional.11
Además, a diferencia de la R2 convencional,
2
R puede aumentar o dis-
minuir cuando se agregan más variables independientes. La dirección del efecto
dependerá de si la reducción en 2e compensa o no la reducción en los grados
de libertad debido a la inclusión de la variable adicional.
4.4. Aplicación — Costos Administrativos en la Banca Comercial.
Ahora podemos finalmente realizar un ejemplo numérico para ilustrar la apli-
cación de estos conceptos. Como ya se mencionó antes, en la práctica la mayor
parte de los cálculos en un análisis de regresión se realizan por medio de un pro-
grama de computación, por lo que no viene al caso ilustrar numéricamente los
cálculos matriciales. El ejemplo concreto que se desarrolla a continuación está
basado en un estudio estadístico de los costos de administración en los bancos
comerciales guatemaltecos durante el año 1991. Los resultados de este análisis
pueden proporcionar una buena indicación sobre el comportamiento de los costos
para el banco ―típico‖ en Guatemala, aunque la naturaleza misma de un estudio
10
Henri Theil, Principles of Econometrics (New York: John Wiley & Sons, 1971),
pp. 178-79.
11
Por lo expuesto en las Notas 7 y 8, cuando la regresión es ―por el origen‖ el denomina-
dor correcto para el factor de ajuste es n – k.

[36]
de este tipo no puede arrojar resultados estrictamente aplicables a cada uno de los
bancos considerados individualmente. No obstante, a pesar de esto, un estudio de
este tipo de todos modos puede ser muy útil, porque los resultados pueden pro-
porcionar una ―norma‖ o ―estándar‖ contra el cual se pueden comparar los costos
administrativos en un banco particular. En ausencia de un estudio de este tipo, un
banco no tiene realmente un criterio para determinar si sus costos son ―acepta-
bles‖ o ―normales,‖ ya que los bancos difieren enormemente en cuanto a cantidad
de activos, número de sucursales, etc., por lo que el único criterio objetivo sería el
de compararse con un banco de similar tamaño y características. Sin embargo, si
se pudiera obtener una fórmula empírica que permita calcular un valor ―normal‖
o ―promedio‖ para los costos administrativos en función de unas pocas variables
que permitan una medición numérica, entonces se podría fácilmente determinar si
el banco en cuestión está ―mejor‖ o ―peor‖ que el banco ―típico‖ a ese respecto.
(Estos resultados también podrían servir para comparar el comportamiento de los
costos administrativos en los bancos comerciales con los de otros tipos de institu-
ciones financieras.) La variable dependiente para el análisis será el nivel anual de
los ―Gastos Generales y de Administración‖ en los diferentes bancos del sistema.
Si se observa el Cuadro 4.1, se podrá apreciar que estos costos (que en lo sucesi-
vo llamaremos simplemente ―costos administrativos‖) varían enormemente de un
banco a otro. Nuestro problema consistirá, por tanto, en encontrar una lista de va-
riables que nos permitan ―explicar,‖ estadísticamente, esta variación observada.
4.3.1. Primera Aproximación.
A un nivel muy elemental, por supuesto, dicha variación no tiene realmente
ningún misterio, ya que los bancos varían mucho en cuanto a su tamaño, y es más
bien de esperarse que los bancos más ―grandes‖ tengan también costos adminis-
trativos más altos por el sólo hecho de ser más grandes. Nuestra tarea será tradu-
cir esta noción intuitiva en un concepto operativo, y para esto debemos tratar de
expresar el ―tamaño‖ de un banco en términos de alguna variable numérica. En
este estudio, la variable escogida para este propósito fue el Total de Activos del
banco. Con esto, y como una primera aproximación para el análisis, la recta de
regresión será la siguiente:
(1) Yi = 0 + 1Xi + ui
donde Yi = Costos Administrativos del banco i, Xi = Activos Totales del banco i.
Los Activos Totales de un banco son una buena medida de su ―tamaño,‖ aun-
que no es la única medida posible, por lo que la decisión de adoptar esta medida
específica es en cierto modo arbitraria. Por otro lado, el empleo de los Activos
Totales como variable independiente en la regresión facilita en cierto modo la in-
terpretación económica de los coeficientes:
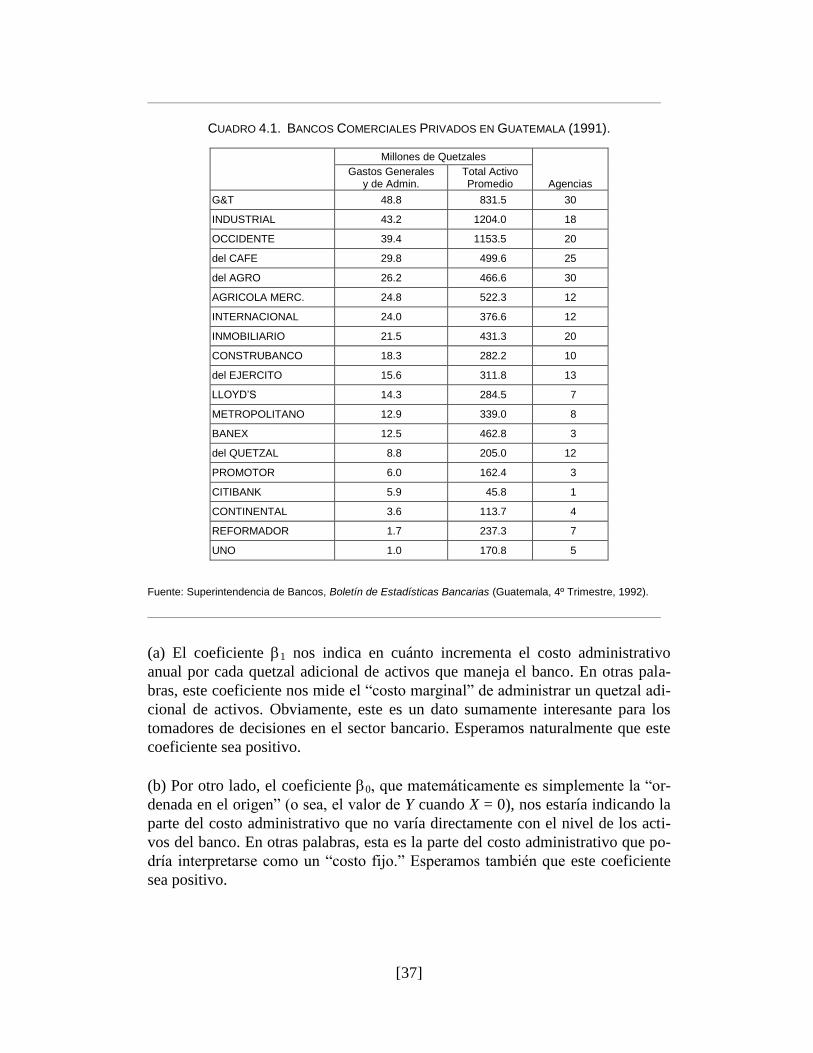
[37]
————————————————————————————————————————————————
CUADRO 4.1. BANCOS COMERCIALES PRIVADOS EN GUATEMALA (1991).
Millones de Quetzales
Gastos Generales y de Admin.
Total Activo Promedio
Agencias
G&T 48.8 831.5 30
INDUSTRIAL 43.2 1204.0 18
OCCIDENTE 39.4 1153.5 20
del CAFE 29.8 499.6 25
del AGRO 26.2 466.6 30
AGRICOLA MERC. 24.8 522.3 12
INTERNACIONAL 24.0 376.6 12
INMOBILIARIO 21.5 431.3 20
CONSTRUBANCO 18.3 282.2 10
del EJERCITO 15.6 311.8 13
LLOYD’S 14.3 284.5 7
METROPOLITANO 12.9 339.0 8
BANEX 12.5 462.8 3
del QUETZAL 8.8 205.0 12
PROMOTOR 6.0 162.4 3
CITIBANK 5.9 45.8 1
CONTINENTAL 3.6 113.7 4
REFORMADOR 1.7 237.3 7
UNO 1.0 170.8 5
Fuente: Superintendencia de Bancos, Boletín de Estadísticas Bancarias (Guatemala, 4º Trimestre, 1992).
————————————————————————————————————————————————
(a) El coeficiente 1 nos indica en cuánto incrementa el costo administrativo
anual por cada quetzal adicional de activos que maneja el banco. En otras pala-
bras, este coeficiente nos mide el ―costo marginal‖ de administrar un quetzal adi-
cional de activos. Obviamente, este es un dato sumamente interesante para los
tomadores de decisiones en el sector bancario. Esperamos naturalmente que este
coeficiente sea positivo.
(b) Por otro lado, el coeficiente 0, que matemáticamente es simplemente la ―or-
denada en el origen‖ (o sea, el valor de Y cuando X = 0), nos estaría indicando la
parte del costo administrativo que no varía directamente con el nivel de los acti-
vos del banco. En otras palabras, esta es la parte del costo administrativo que po-
dría interpretarse como un ―costo fijo.‖ Esperamos también que este coeficiente
sea positivo.

[38]
4.3.2. Segunda Aproximación.
Un posible defecto de la ecuación (1) es la suposición de que todos los bancos
tienen los mismos costos fijos. Por otro lado, se puede apreciar en el Cuadro 4.1
que los bancos comerciales varían mucho en cuanto al número de sucursales o
agencias que operan, y este es un factor que seguramente debe afectar el nivel de
los costos administrativos. Por esto, como una segunda aproximación, se estimará
la siguiente regresión adicional:
(2) Y = 0 + 1X1 + 2X2 + u
donde X1 = Activos Totales del banco i, X2 = Número de Agencias del banco i.
(De aquí en adelante suprimiremos el uso del sub-índice i, para facilitar la nota-
ción. Se entiende que cada observación corresponde a un banco diferente.) En es-
ta segunda regresión, el coeficiente 2 nos está midiendo el incremento en el cos-
to administrativo anual que resulta de manejar una agencia adicional. Esperamos,
por tanto, que este coeficiente sea positivo. (Naturalmente que este coeficiente
tendría que interpretarse como un costo ―promedio‖ por agencia, ya que ninguna
agencia es exactamente igual que otra, por lo que difícilmente pueden tener todas
el mismo costo.) Los demás coeficientes tienen la misma interpretación que en la
ecuación (1).
4.3.3. Datos.
Antes de reportar los resultados de las regresiones, es necesario y conveniente
hacer las siguientes aclaraciones sobre los datos:
(a) Se tomó la decisión de incluir en la muestra únicamente a los bancos comer-
ciales privados, ya que los bancos estatales tienen peculiaridades especiales que
posiblemente resulten en un comportamiento diferente en cuanto a sus costos
administrativos. (Puesto que lo que nos interesa es investigar el comportamiento
de los costos administrativos en el banco comercial ―típico,‖ incluir a los bancos
estatales podría resultar en una distorsión de los resultados, ya que dichos bancos
no son ―típicos‖ a ese respecto.)
(b) Podría existir un problema de comparabilidad de los datos sobre Costos
Administrativos y Activos Totales, dada la manera como se reportan los datos en
la fuente original, ya que las cifras sobre Costos Administrativos corresponden a
los gastos anuales efectuados durante un año determinado, mientras que las cifras
sobre Activos Totales corresponden a los valores al 31 de Diciembre de cada año.
No está del todo claro que la cifra correspondiente al final del año sea la más
adecuada para propósitos del análisis, y probablemente sería mejor contar con una

[39]
cifra para los Activos Totales que represente algún valor promedio durante el año.
Para evitar estos problemas, se optó por calcular un promedio aritmético de los
Activos Totales al 31 de Diciembre de 1991, y al 31 de Diciembre del año
anterior. Esta cifra promedio, si bien no es la solución perfecta para este
problema, probablemente se acerca más al nivel promedio de los Activos Totales
en cada año, y en todo caso será mejor que simplemente usar la cifra de fines de
año.
4.3.4. Resultados.
Los resultados para la ecuación (1) fueron los siguientes (los números entre
paréntesis son las desviaciones estándar de los coeficientes estimados):
103906.0203.2ˆ XY R2 = 0.7935
(2.551) (0.00483) n = 19
Se puede apreciar en primer lugar que esta regresión, a pesar de ser muy sencilla,
tiene un alto grado de poder explicativo: el coeficiente de determinación (R2) in-
dica que la variación en los Activos Totales explica casi 80 % de la variación en
los Costos Administrativos. Como era de esperarse, el valor estimado para b1, la
pendiente de la regresión, es positivo y altamente significativo. Para testar for-
malmente la hipótesis nula 1 = 0, calculamos el estadístico b1/s(b1), que en este
caso tiene un valor de 8.087 (= 0.03906 ÷ 0.00483). Consultando la tabla de valo-
res críticos para la distribución t (ver las tablas al final del texto), se puede ver
que para 17 grados de libertad el valor crítico para 5 % a dos colas es de 2.11.
Puesto que 8.087 > 2.11, en este caso se rechaza la hipótesis de que el verdadero
coeficiente 1 es cero, y por tanto concluimos que X1 es una variable significativa.
Por otro lado, el valor estimado para b0 , la ordenada en el origen, aunque positi-
vo, no es significativo, ya que 2.203 ÷ 2.551 = 0.864 < 2.11.
Los resultados para la ecuación (2) fueron los siguientes:
21 661.00275.022.1ˆ XXY
(1.99) (0.0044) (0.157) R2 = 0.9018
La R
2 para esta segunda regresión es poco más de 90 %, aunque, por lo explicado
en la sección anterior, las dos regresiones no son estrictamente comparables en
términos de la R2 convencional, por lo que debemos aplicar el concepto de R
2
ajustada. Para el primer modelo, con n = 19 y k = 1,
7814.0)7935.01(17
181
2
R

[40]
Para el segundo modelo, con k = 2, .8895.0)9018.01(16
181
2
R Se puede
apreciar claramente que la adición de X2, el número de agencias, incrementa bas-
tante el poder explicativo de la regresión.
Al igual que en el caso anterior, el valor estimado para b1 es positivo y signi-
ficativo, y es interesante notar que es menor al estimado en la primera regresión.
Esto implica que la primera regresión probablemente tiende a sobre-estimar este
coeficiente, debido a que omite el efecto de la variable X2. Como era de esperarse,
el valor estimado para b2 es también positivo y altamente significativo. Por otro
lado, se aprecia que el valor estimado para b0 es negativo y no-significativo. Esto
nos apunta a una conclusión interesante: Al parecer, el componente ―fijo‖ de los
costos administrativos depende básicamente del número de agencias que adminis-
tra el banco.
Puesto que el coeficiente b0 no es significativamente diferente de cero en esta
segunda regresión, corresponde ahora volver a estimar esta regresión ―por el ori-
gen,‖ es decir, sin esta constante. Los resultados son los siguientes:
21 621.00266.0ˆ XXY
(0.0041) (0.141) R2 = 0.8995
Aquí se aprecia que el poder explicativo es básicamente igual que en la regresión
anterior, aunque al haber eliminado un coeficiente posiblemente ―redundante,‖
esta tercera regresión nos proporciona en principio estimaciones más eficientes de
los otros coeficientes:
(a) El coeficiente b1, se recordará, nos mide el costo ―marginal‖ de administrar un
quetzal adicional de activos. Según estas estimaciones, por tanto, se podría con-
cluir que en números redondos el costo administrativo de un banco ―típico‖ au-
mentará entre 2 y 3 centavos por año por cada quetzal adicional de activos que
administre.
(b) El coeficiente b2, se recordará, nos mide el incremento en el costo administra-
tivo anual que resulta de manejar una agencia adicional. Según estas estimacio-
nes, por tanto, se podría concluir en números redondos, y tomando en cuenta que
los datos se expresan en términos de millones de quetzales, que el costo adminis-
trativo de un banco ―típico‖ aumentará alrededor de 620,000 quetzales por año
por cada agencia adicional. (Debe recordarse que estas cifras están expresadas en
términos de quetzales de 1991.)
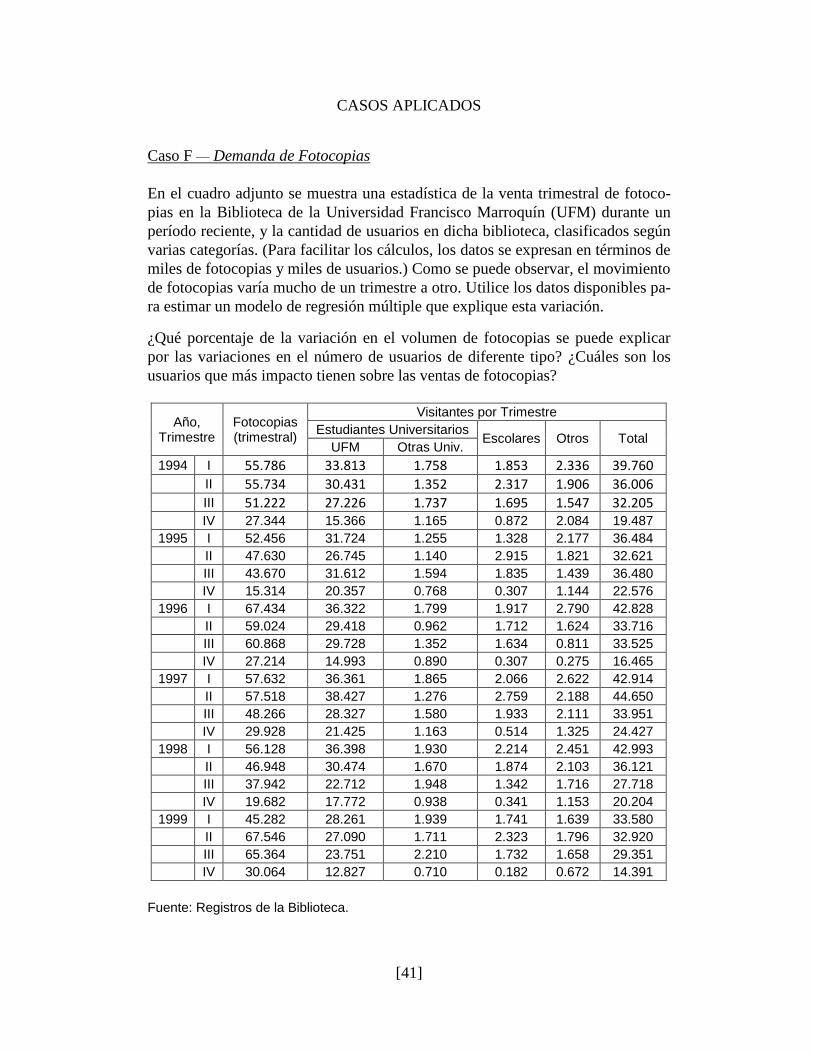
[41]
CASOS APLICADOS
Caso F — Demanda de Fotocopias
En el cuadro adjunto se muestra una estadística de la venta trimestral de fotoco-
pias en la Biblioteca de la Universidad Francisco Marroquín (UFM) durante un
período reciente, y la cantidad de usuarios en dicha biblioteca, clasificados según
varias categorías. (Para facilitar los cálculos, los datos se expresan en términos de
miles de fotocopias y miles de usuarios.) Como se puede observar, el movimiento
de fotocopias varía mucho de un trimestre a otro. Utilice los datos disponibles pa-
ra estimar un modelo de regresión múltiple que explique esta variación.
¿Qué porcentaje de la variación en el volumen de fotocopias se puede explicar
por las variaciones en el número de usuarios de diferente tipo? ¿Cuáles son los
usuarios que más impacto tienen sobre las ventas de fotocopias?
Año, Trimestre
Fotocopias (trimestral)
Visitantes por Trimestre
Estudiantes Universitarios Escolares Otros Total
UFM Otras Univ.
1994 I 55.786 33.813 1.758 1.853 2.336 39.760 II 55.734 30.431 1.352 2.317 1.906 36.006 III 51.222 27.226 1.737 1.695 1.547 32.205
IV 27.344 15.366 1.165 0.872 2.084 19.487
1995 I 52.456 31.724 1.255 1.328 2.177 36.484
II 47.630 26.745 1.140 2.915 1.821 32.621
III 43.670 31.612 1.594 1.835 1.439 36.480
IV 15.314 20.357 0.768 0.307 1.144 22.576
1996 I 67.434 36.322 1.799 1.917 2.790 42.828
II 59.024 29.418 0.962 1.712 1.624 33.716
III 60.868 29.728 1.352 1.634 0.811 33.525
IV 27.214 14.993 0.890 0.307 0.275 16.465
1997 I 57.632 36.361 1.865 2.066 2.622 42.914
II 57.518 38.427 1.276 2.759 2.188 44.650
III 48.266 28.327 1.580 1.933 2.111 33.951
IV 29.928 21.425 1.163 0.514 1.325 24.427
1998 I 56.128 36.398 1.930 2.214 2.451 42.993
II 46.948 30.474 1.670 1.874 2.103 36.121
III 37.942 22.712 1.948 1.342 1.716 27.718
IV 19.682 17.772 0.938 0.341 1.153 20.204
1999 I 45.282 28.261 1.939 1.741 1.639 33.580
II 67.546 27.090 1.711 2.323 1.796 32.920
III 65.364 23.751 2.210 1.732 1.658 29.351
IV 30.064 12.827 0.710 0.182 0.672 14.391
Fuente: Registros de la Biblioteca.

[42]
Caso G — Inflación en América Latina
La llamada Teoría Cuantitativa del Dinero (también conocida como ―monetaris-
mo‖) postula a largo plazo una relación estable entre tres variables macroeconó-
micas muy importantes: el cambio porcentual en el índice general de precios (i.e.,
la tasa de ―inflación‖), el cambio porcentual en la masa monetaria (la tasa de
―crecimiento monetario‖), y el cambio porcentual en el PIB a precios constantes
(la tasa de ―crecimiento real‖).12
Según esta teoría, la inflación estará positiva-
mente relacionada con la tasa de crecimiento monetario, e inversamente relacio-
nada con la tasa de crecimiento económico real.
El cuadro adjunto muestra las tasas anuales promedio de inflación, crecimiento
monetario, y crecimiento real en 16 países latinoamericanos durante el período
1950-69. La inflación fue medida por medio del IPC, y el crecimiento monetario
se basa en el agregado monetario conocido como M1 (efectivo fuera de bancos +
depósitos a la vista en bancos comerciales).
Use estos datos para estimar la siguiente regresión:
Y = 0 + 1X1 + 2X2 + u
donde Y = tasa anual promedio de inflación, X1 = tasa anual promedio de creci-
miento monetario, y X2 = tasa anual promedio de crecimiento en PIB real.
Comente sobre los resultados, e interprete el significado de los coeficientes en
términos de la Teoría Cuantitativa.
12
Para un desarrollo moderno de esta teoría, véase Milton Friedman, ―Money: Quantity
Theory,‖ International Encyclopedia of the Social Sciences (1968), vol. 10, pp. 432-47.
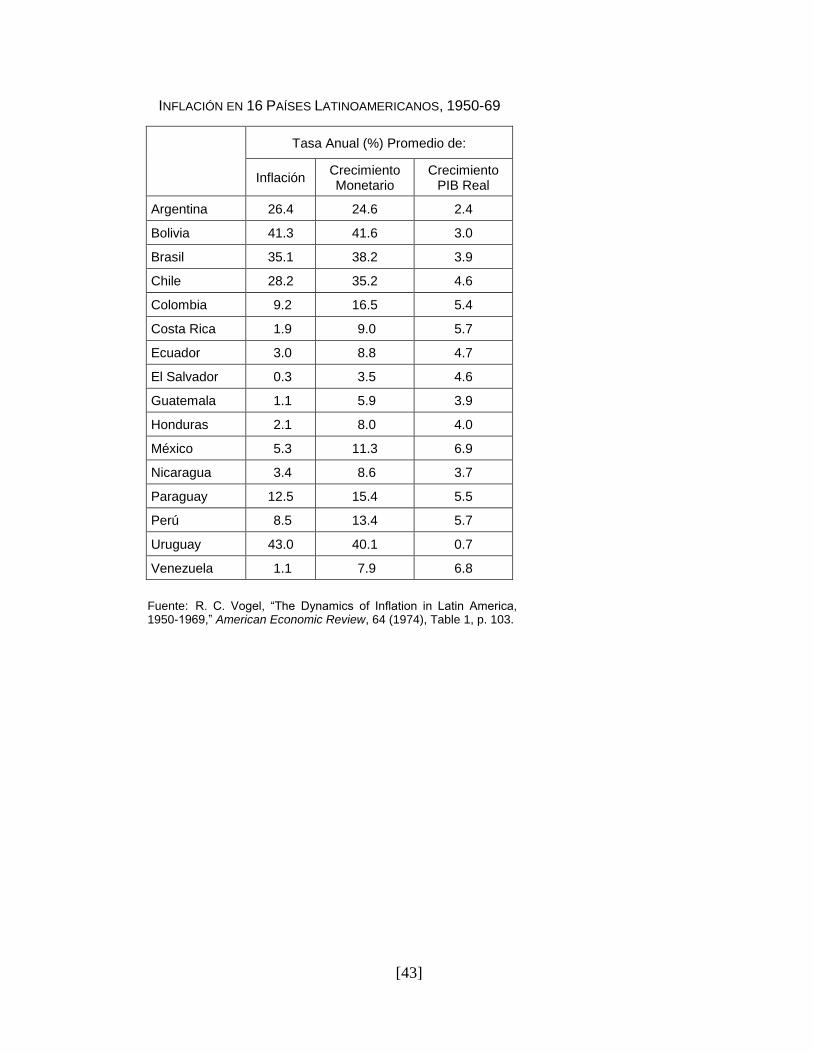
[43]
INFLACIÓN EN 16 PAÍSES LATINOAMERICANOS, 1950-69
Tasa Anual (%) Promedio de:
Inflación
Crecimiento Monetario
Crecimiento PIB Real
Argentina 26.4 24.6 2.4
Bolivia 41.3 41.6 3.0
Brasil 35.1 38.2 3.9
Chile 28.2 35.2 4.6
Colombia 9.2 16.5 5.4
Costa Rica 1.9 9.0 5.7
Ecuador 3.0 8.8 4.7
El Salvador 0.3 3.5 4.6
Guatemala 1.1 5.9 3.9
Honduras 2.1 8.0 4.0
México 5.3 11.3 6.9
Nicaragua 3.4 8.6 3.7
Paraguay 12.5 15.4 5.5
Perú 8.5 13.4 5.7
Uruguay 43.0 40.1 0.7
Venezuela 1.1 7.9 6.8
Fuente: R. C. Vogel, “The Dynamics of Inflation in Latin America, 1950-1969,” American Economic Review, 64 (1974), Table 1, p. 103.

[44]
Capítulo 5
AMPLIACIONES DEL MODELO LINEAL
En este capítulo ampliaremos nuestra discusión del modelo lineal, considerando
primeramente la estimación de formas funcionales no-lineales. La discusión se
concentrará principalmente en la aplicación e interpretación del llamado ―modelo
doble-log,‖ que es el que más se aplica en la práctica. Luego se amplía el modelo
lineal en otra dirección, mediante el uso de variables ―binarias.‖ Por último, se
discuten algunos problemas especiales que pueden surgir en aplicaciones prácti-
cas, como ser el problema de variables omitidas, el problema de ―multicolineali-
dad‖, y el problema de ―heteroscedasticidad.‖
5.1. Estimación de Formas Funcionales No-lineales.
El modelo clásico de regresión lineal se basa en el supuesto de que la varia-
ble dependiente Y es una función lineal de las variables independientes X1, X2,
... , Xk. Ahora bien, esto es mucho menos restrictivo de lo que podría parecer a
primera vista, ya que de hecho es posible estimar los parámetros de algunas fun-
ciones no-lineales por medio del modelo de regresión lineal, si se hacen algunas
transformaciones de las variables.
En esta etapa de nuestro análisis es conveniente hacer una distinción entre (1)
las variables ―explicativas,‖ y (2) los ―regresores‖ que las representan en la ecua-
ción de regresión. Consideremos, por ejemplo, la siguiente relación funcional:
Y = + ln(X)
Obviamente, la relación funcional entre Y y X no es lineal, aunque existe una re-
lación lineal entre Y y el logaritmo de X, y por tanto los parámetros de esta rela-
ción podrían ser estimados por regresión lineal si se toma ln(X) como la variable
independiente. En este caso, si bien la variable ―explicativa‖ es X, el ―regresor‖ es
ln(X). Lo que requiere el modelo clásico de regresión lineal es que la variable de-
pendiente (en la regresión) sea una función lineal de los regresores.13
13
Como un ejemplo, considérese la siguiente función de producción, ―estimada en base a
pruebas de campo realizadas en El Llano, en el Valle Central de Chile en 1962-63:
Y = 18.846512 + 7.586167 N + 2.469969 P – 0.655713 N2 – 0.397513 P
2 + 0.211423 NP

[45]
5.1.1. Modelo Doble-logarítmico.
Tal vez la transformación que más se emplea en la práctica en la econometría
aplicada sea el llamado modelo doble-log, donde todas las variables se expresan
en términos de logaritmos:
ln(Y) = 0 + 1ln(X1) + 2ln(X2) + ... + k ln(Xk) + u
En muchos problemas, el interés del investigador no se centra tanto en la ―pen-
diente,‖ o sea, el cambio en Y que se produce como resultado de un cambio de
una unidad en X, sino en la ―elasticidad,‖ que es el cambio porcentual en Y que se
produce como resultado de un cambio de 1 % en X. En esta situación, el modelo
doble-log es interesante porque los coeficientes del modelo son estimaciones di-
rectas de la elasticidad de Y respecto de las respectivas variables explicativas. Pa-
ra comprobar esto, nótese que
)ln(
)ln(.
i
i
i X
Y
Y
X
X
Y
que es la elasticidad de Y respecto de la i-ésima variable explicativa,14
es preci-
samente el coeficiente i en el modelo doble-log. Debido a esta propiedad, el mo-
delo doble-log se usa con mucha frecuencia en la estimación de funciones de de-
manda.
En el Cuadro 5.1 se detallan las propiedades de otras formas funcionales que
también se emplean a menudo en estudios econométricos. A continuación, ilus-
traremos la aplicación del modelo doble-log por medio de la estimación de una
función de demanda.
donde Y = quintales de trigo por hectárea, N = nitrato de sodio en unidades de 150 kg
por hectárea, y P = triple superfosfato en unidades de 100 kg por hectárea‖ (J. J. Dillon,
The Analysis of Response in Crop and Livestock Production, 2ª ed. [Oxford: Pergamon
Press, 1977], p. 18). El uso de este tipo de función es muy común en el análisis de expe-
rimentos agrícolas. Nótese que en esta ecuación sólo existen dos variables explicativas,
N y P, y su relación con la variable dependiente no es lineal, pero existen cinco regreso-
res, y la relación entre la variable dependiente y los regresores es lineal.
14
R. G. D. Allen, Análisis Matemático para Economistas (Madrid: Aguilar, 1978),
p. 247.

[46]
_________________________________________________________________
Cuadro 5.1.
FORMAS FUNCIONALES ALTERNATIVAS
En la siguiente tabla se hace una comparación de varias formas funcionales dife-
rentes que a menudo se emplean en estudios aplicados. (Para mayor simplicidad,
se presentan las formas funcionales en términos de una sola variable explicativa,
pero los resultados se pueden generalizar para el caso de k variables explicativas).
_________________________________________________________________
Nombre Forma Pendiente Elasticidad
_________________________________________________________________
Lineal Y = 0 + 1X 1 1X/Y
Semi-log Y = 0 + 1ln(X) 1/X 1/Y
Hiperbólica Y = 0 – 1/X 1/X2 1/XY
Doble-log ln(Y) = 0 + 1ln(X) 1Y/X 1
Log-hipérbola ln(Y) = 0 – 1/X 1Y/X2 1/X
_________________________________________________________________
Fuente: A. S. Goldberger, Teoría Econométrica (Madrid: Tecnos, 1970), pp. 227-28.
_________________________________________________________________
5.1.2. Aplicación — Consumo de Textiles en Holanda.
En el Cuadro 5.2 se muestran los datos básicos de un estudio del consumo de
textiles en Holanda durante los años 1923 a 1939 (los datos se expresan como
índices con base 1925 = 100). Podemos utilizar estos datos para calcular la
siguiente regresión doble-log:
ln(Y) = 0 + 1 ln(X1) + 2 ln(X2) + u
donde Y = Indice del consumo per cápita de textiles, X1 = Indice del ingreso real
per cápita, y X2 = Indice del precio relativo de textiles. Estimando esta regresión
por mínimos cuadrados obtenemos los siguientes resultados:
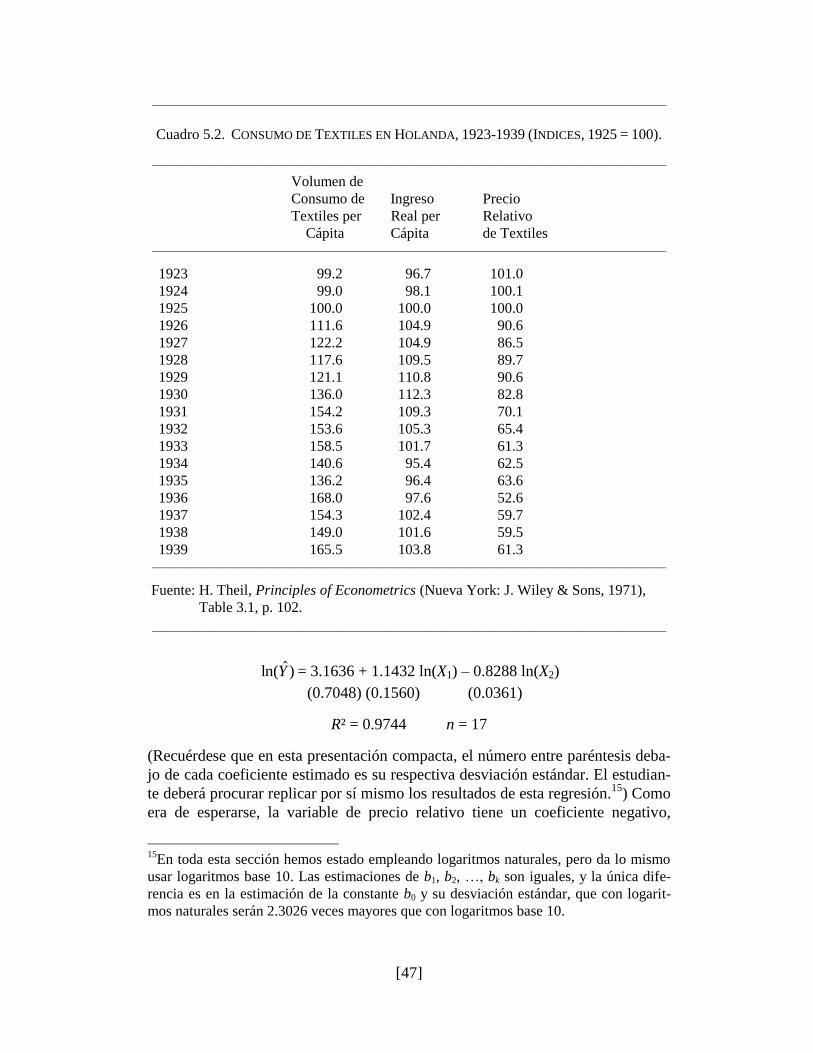
[47]
———————————————————————————————————
Cuadro 5.2. CONSUMO DE TEXTILES EN HOLANDA, 1923-1939 (INDICES, 1925 = 100).
———————————————————————————————————
Volumen de
Consumo de Ingreso Precio
Textiles per Real per Relativo
Cápita Cápita de Textiles
———————————————————————————————————
1923 99.2 96.7 101.0
1924 99.0 98.1 100.1
1925 100.0 100.0 100.0
1926 111.6 104.9 90.6
1927 122.2 104.9 86.5
1928 117.6 109.5 89.7
1929 121.1 110.8 90.6
1930 136.0 112.3 82.8
1931 154.2 109.3 70.1
1932 153.6 105.3 65.4
1933 158.5 101.7 61.3
1934 140.6 95.4 62.5
1935 136.2 96.4 63.6
1936 168.0 97.6 52.6
1937 154.3 102.4 59.7
1938 149.0 101.6 59.5
1939 165.5 103.8 61.3
———————————————————————————————————
Fuente: H. Theil, Principles of Econometrics (Nueva York: J. Wiley & Sons, 1971),
Table 3.1, p. 102.
———————————————————————————————————
)ˆln(Y = 3.1636 + 1.1432 ln(X1) – 0.8288 ln(X2)
(0.7048) (0.1560) (0.0361)
R² = 0.9744 n = 17
(Recuérdese que en esta presentación compacta, el número entre paréntesis deba-
jo de cada coeficiente estimado es su respectiva desviación estándar. El estudian-
te deberá procurar replicar por sí mismo los resultados de esta regresión.15
) Como
era de esperarse, la variable de precio relativo tiene un coeficiente negativo,
15
En toda esta sección hemos estado empleando logaritmos naturales, pero da lo mismo
usar logaritmos base 10. Las estimaciones de b1, b2, …, bk son iguales, y la única dife-
rencia es en la estimación de la constante b0 y su desviación estándar, que con logarit-
mos naturales serán 2.3026 veces mayores que con logaritmos base 10.

[48]
mientras que la variable de ingreso tiene un coeficiente positivo, resultados que
son consistentes con la teoría elemental de la demanda. La razón t para el caso de
X1 es de 7.33 (= 1.1432 ÷ 0.156) y para X2 esta razón es de – 22.96 (= – 0.8288 ÷
0.0.0361). El valor crítico de la distribución t para 5 % y 14 grados de libertad es
2.145 (en pruebas a dos colas), que en ambos casos es excedido por amplio mar-
gen, por lo que podemos concluir que ambas variables son altamente significati-
vas. Por último, las estimaciones indican que la elasticidad-precio de la demanda
de textiles es alrededor de – 0.83, mientras que la elasticidad-ingreso es alrededor
de 1.14. Estos resultados implican, por tanto, que ceteris paribus un aumento de
10 % en el precio relativo de los textiles producirá, en promedio, una reducción
de 8.3 % en el consumo, mientras que un aumento de 10 % en el ingreso per cápi-
ta producirá, en promedio, un aumento de 11.4 % en el consumo de textiles.
5.2. Variables Binarias o Cualitativas.
Otra útil extensión del modelo lineal es el empleo de variables binarias o
cualitativas. Hasta ahora hemos supuesto que todas las variables en el modelo de
regresión pueden medirse cuantitativamente. A veces, sin embargo, la variable
dependiente se verá afectada por factores cualitativos que no pueden medirse
numéricamente, pero no por eso dejan de ser importantes. Estos factores se
pueden tomar en cuenta por medio del empleo de variables binarias.16
Estas son
variables artificiales que sólo pueden tomar dos posibles valores, 1 o 0,
dependiendo de la presencia o ausencia del factor cualitativo que deseamos
incorporar en la regresión. Estas variables también son conocidas como variables
―categóricas‖ o ―dicotómicas‖, ya que el objeto es clasificar las observaciones en
categorías mutuamente excluyentes: por ejemplo, hombre/mujer, fumador/no-
fumador, nacional/extranjero, etc. Muchas veces estas variables también se usan
en el contexto de series cronológicas (por ejemplo, para medir efectos
estacionales).
Como un ejemplo, consideremos el Cuadro 5.3, que muestra datos sobre
eficiencia en el consumo de combustible y otras características de 32 modelos de
automóviles de la temporada 1973-74. De estos 32 vehículos, 19 son de
transmisión automática, y 13 son de transmisión manual. Se puede notar que, en
promedio, el millaje para los vehículos con caja manual tiende a ser bastante
mayor que para los vehículos con caja automática, y al parecer la diferencia es
estadísticamente significativa. Por otro lado, los vehículos con caja automática
tienden a ser más pesados, y también tienden a tener motores más potentes, y se
sabe que estos factores tienden a incrementar el consumo de combustible. Por
tanto, si queremos saber si el tipo de transmisión per se tiene algún efecto sobre tiendenes
16
En inglés la expresión que se usa es ―dummy variables.‖
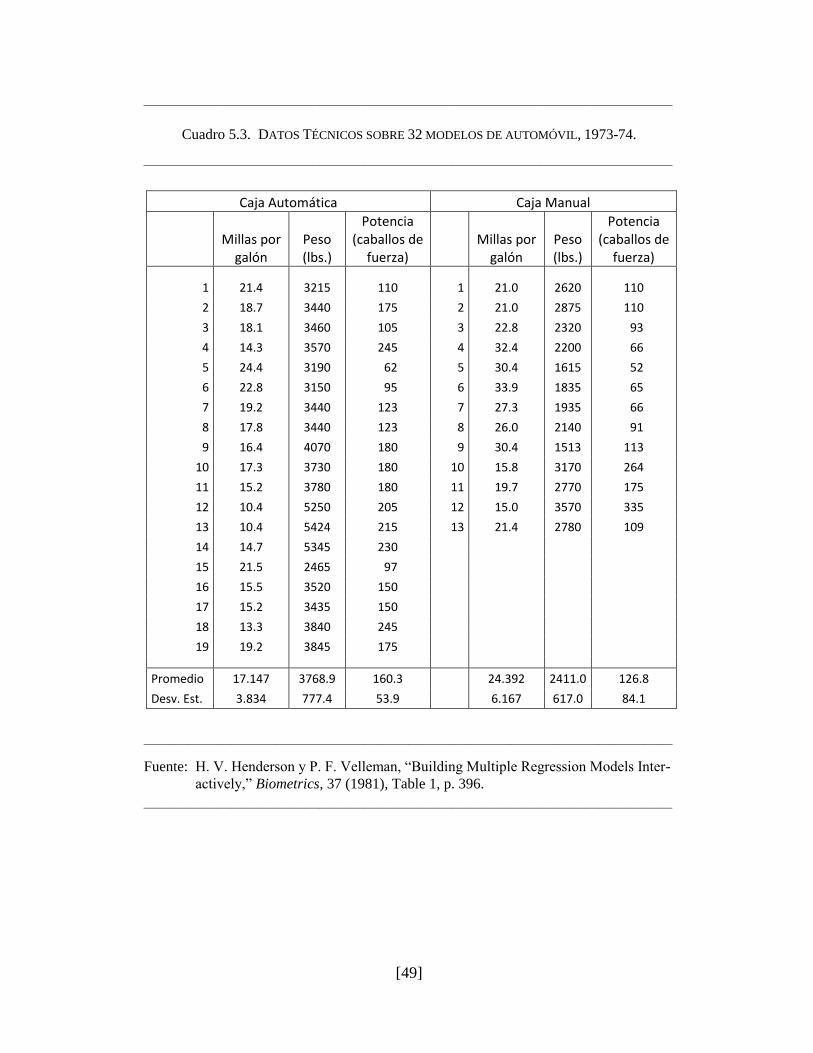
[49]
————————————————————————————————————
Cuadro 5.3. DATOS TÉCNICOS SOBRE 32 MODELOS DE AUTOMÓVIL, 1973-74.
————————————————————————————————————
Caja Automática Caja Manual
Millas por
galón Peso (lbs.)
Potencia (caballos de
fuerza)
Millas por
galón Peso (lbs.)
Potencia (caballos de
fuerza)
1 21.4 3215 110 1 21.0 2620 110
2 18.7 3440 175 2 21.0 2875 110
3 18.1 3460 105 3 22.8 2320 93
4 14.3 3570 245 4 32.4 2200 66
5 24.4 3190 62 5 30.4 1615 52
6 22.8 3150 95 6 33.9 1835 65
7 19.2 3440 123 7 27.3 1935 66
8 17.8 3440 123 8 26.0 2140 91
9 16.4 4070 180 9 30.4 1513 113
10 17.3 3730 180 10 15.8 3170 264
11 15.2 3780 180 11 19.7 2770 175
12 10.4 5250 205 12 15.0 3570 335
13 10.4 5424 215 13 21.4 2780 109
14 14.7 5345 230
15 21.5 2465 97
16 15.5 3520 150
17 15.2 3435 150
18 13.3 3840 245
19 19.2 3845 175
Promedio 17.147 3768.9 160.3
24.392 2411.0 126.8
Desv. Est. 3.834 777.4 53.9
6.167 617.0 84.1
————————————————————————————————————
Fuente: H. V. Henderson y P. F. Velleman, ―Building Multiple Regression Models Inter-
actively,‖ Biometrics, 37 (1981), Table 1, p. 396.
————————————————————————————————————

[50]
el consumo de combustible, tenemos que controlar por estos otros factores. Para
esto, podemos calcular la siguiente regresión múltiple:
Y = 0 + 1X1 + 2X2 + 3X3 + u
donde Y es el millaje (en millas por galón de gasolina), X1 es una variable binaria
(= 0 si el vehículo tiene caja automática, = 1 si es de caja manual), X2 es el peso
del vehículo (en libras), y X3 es la potencia del motor (en caballos de fuerza).
Estimando esta regresión con los datos del Cuadro 5.3 obtenemos:
Y = 34.003 + 2.0837 X1 – 0.0029 X2 – 0.0375X3
(2.643) (1.3764) (0.0009) (0.0096)
R2 = 0.8399 n = 32
Se aprecia aquí que el peso del vehículo y la potencia del motor tienen ambos un
efecto negativo sobre la eficiencia en el consumo de combustible, tal como se es-
peraba, y estos efectos son estadísticamente significativos. Por otro lado, también
se aprecia que, una vez controlamos por los efectos del peso y la potencia, el tipo
de transmisión (automática o manual) no tiene realmente un efecto muy grande
sobre el millaje y el efecto estimado no es estadísticamente significativo: si bien
el coeficiente para esta variable es positivo, su razón t (1.514) está muy por deba-
jo del valor crítico de la distribución t para niveles convencionales de significan-
cia. Por tanto, aunque a primera vista los resultados parecen indicar lo contrario,
no podemos concluir en base a estos datos que el tipo de transmisión tenga por sí
mismo un efecto significativo sobre la eficiencia en el consumo de combustible.
5.2.1. Caso Especial.
El caso de los automóviles es un buen ejemplo para ilustrar cómo se pueden
utilizar variables binarias para estimar los efectos de factores cualitativos en el
contexto de una regresión múltiple.17
Con relación a este tema, hay un aspecto
adicional que vale la pena resaltar. Si se calcula una regresión de Y únicamente
contra una variable binaria, entonces el resultado es equivalente a una prueba de
diferencia de medias convencional. En este caso, la regresión de Y contra X1 da el
siguiente resultado:
Y = 17.147 + 7.245 X1
(1.125) (1.7644)
17
La variable dependiente también podría ser binaria, pero esto plantea problemas
especiales de estimación, que sobrepasan los alcances de este libro. El método de
mínimos cuadrados ordinarios ya no es aplicable en este contexto, y para esto existen
otros métodos no-lineales (por ejemplo, los modelos probit y logit) que son más
apropiados para este caso. Estos modelos son tratados en detalle en textos avanzados de
econometría.

[51]
En este modelo b0 es una estimación del millaje promedio para vehículos con caja
automática (X1 = 0), y es exactamente igual al promedio muestral para esta clase
de vehículos en el Cuadro 5.3. Por otro lado, b1 es una estimación del millaje
adicional para vehículos con caja manual (X1 = 1), y el coeficiente estimado es
igual a la diferencia entre los dos promedios muestrales (24.392 – 17.147 =
7.245). Por tanto, testar la hipótesis de que b1 no es significativamente diferente
de 0 es equivalente a testar la hipótesis de que la diferencia entre las dos medias
muestrales no es estadísticamente significativa.18
5.2.2. Variables Binarias en Regresiones Semi-logarítmicas.19
A veces hay que tener ciertas precauciones al interpretar el coeficiente de una
variable binaria. Un error muy común se da cuando se incluyen variables binarias
en regresiones semi-logarítmicas de la forma:
ln(Y) = 0 + 1X1 + 2X2 + ... + k Xk + u
Si Xi es una variable continua, entonces su coeficiente estimado (bi) es un estima-
dor de la derivada parcial de ln(Y) respecto de Xi :
iii
iX
Y
YX
Y
Y
Y
X
Yb
.
1.
)ln()ln(
Esto, multiplicado por 100, es igual al cambio porcentual en Y debido a un cam-
bio marginal en Xi. Por tanto, en una regresión semi-logarítmica cada coeficiente
puede interpretarse como el cambio porcentual en Y debido a un cambio en la
respectiva variable independiente. Sin embargo, esta interpretación sería incorrec-
ta si Xi es una variable binaria, ya que una variable binaria no es continua, y por
tanto el concepto de una derivada parcial es inaplicable.
Para poder medir el cambio porcentual en Y causado por la presencia del
factor cualitativo representado por una variable binaria, supongamos que la
variable binaria es X1 y que el cambio en Y debido a la presencia del factor
cualitativo es de g por ciento. Nótese que el modelo semi-logarítmico puede
expresarse de la siguiente forma:
18
El estudiante podrá comprobar que la razón t para b1 en esta regresión es exactamente
igual al estadístico de prueba para una prueba de diferencia de medias convencional, y
tiene el mismo número de grados de libertad. 19
La discussion en esta sección se basa en R. Halvorsen y R. Palmquist, ―The Interpreta-
tion of Dummy Variables in Semilogarithmic Equations,‖ American Economic Review,
70 (1980): 474-75.

[52]
))...(()1)(( 2210 kk XXXeegeY
Si X1 = 0, el segundo factor (asociado con la variable binaria) será igual a 1, y si
X1 = 1 este factor será igual a 1 + g, y por tanto g es el cambio porcentual en Y
debido al efecto de la variable binaria. Al expresar esta ecuación en términos de
ln(Y), se puede apreciar que 1= ln(1 + g), y puesto que el estimador de 1 es b1,
el estimador de g será
1ˆ 1 b
eg
y el estimador del cambio porcentual en Y será igual a .ˆ100 g
Para ilustrar podemos usar nuevamente el problema de los automóviles. Si
con esos datos calculamos una regresión semi-logarítmica obtenemos el siguiente
resultado (donde las variables tienen las mismas definiciones que en el caso ante-
rior):
)ˆln(Y = 3.7491 + 0.0517 X1 – 0.000176 X2 – 0.00168 X3
(0.1166) (0.0607) (0.00004) (0.00042)
R2 = 0.8723 n = 32
En términos de R2
este modelo funciona ligeramente mejor que el modelo lineal
estándar.20
Nuevamente, el peso (X2) y la potencia (X3) del automóvil tienen un
efecto negativo sobre el millaje, y estos efectos son estadísticamente
significativos. El coeficiente de la variable binaria implica que tener caja manual
(X1 = 1) incrementa el millaje en 5.3 % (e0.0517
– 1 = 0.053), aunque este efecto no
es significativo.
La magnitud del ajuste en este caso no es muy grande, precisamente porque el
efecto de la variable cualitativa es pequeño. Si el coeficiente de la variable binaria
fuera de 0.517, por ejemplo, entonces el cambio porcentual en Y para X1 = 1 sería
de 67.7 % (e0.517
– 1 = 0.677), una diferencia de 16 % comparado con el
estimador no ajustado. Interpretar el coeficiente de una variable binaria en una
regresión semi-logarítmica como el cambio porcentual en Y debido al efecto de
una variable cualitativa podría causar serios errores si este efecto es relativamente
grande.
20
Véase, sin embargo, la Pregunta de Repaso No. 2, al final de este capítulo.

[53]
5.3. Problemas Especiales en la Regresión Lineal.
5.3.1. Variables Omitidas y Variables Irrelevantes.
En el capítulo anterior se demostró que el vector mínimo-cuadrático b es un
estimador insesgado del vector de coeficientes del modelo ―verdadero‖:
y = X + u
En este punto conviene anotar la siguiente salvedad: el vector b será un estimador
insesgado de , siempre que el modelo de regresión esté bien especificado, o sea,
siempre que se incluyan todas las variables explicativas relevantes. Como se verá
a continuación, si existen algunas variables relevantes que no fueron incluidas en
la regresión, entonces el vector b ya no será generalmente insesgado. Para apre-
ciar esto, recordemos que en nuestra notación matricial, X es una matriz de orden
)1( kn que representa las k variables independientes que afectan a Y (inclu-
yendo una columna de 1’s para representar a la ordenada en el origen). Ahora
bien, puede suceder muchas veces que por una u otra razón no se incluyen todas
las k variables en la regresión estimada: podría ser que no se dispongan de los da-
tos necesarios, o podría ser que se omita alguna variable relevante por simple ig-
norancia. En este caso, la matriz de observaciones usada en la regresión será ―in-
completa‖ en el sentido de que no incluye todas las columnas de X. Para facilitar
el análisis, representemos por X1 la matriz de observaciones sobre las variables
―incluidas,‖ y por X2 la matriz de las variables ―omitidas.‖ Por tanto, el modelo
lineal completo puede ser expresado como:
y = X11 + X22 + u
donde 1 es el vector de los coeficientes de las variables incluidas, y 2 es el vec-
tor de coeficientes de las variables omitidas. Puesto que las variables omitidas no
son incluidas en el análisis, el modelo estimado será
y = X1b1 + e
Obviamente, si las variables omitidas son realmente relevantes, entonces se co-
meterá un error de entrada al suponer que todos sus coeficientes son cero. La pre-
gunta interesante, sin embargo, es si esta omisión tendrá algún efecto sobre la es-
timación del vector b1. Concretamente, podemos plantearnos la pregunta: ¿Será
ahora b1 un estimador insesgado de 1? En otras palabras, ¿si se omiten una o
más variables relevantes de una regresión, introduce esta omisión un sesgo en la
estimación de los otros coeficientes? Para contestar esta pregunta, debemos cal-
cular el valor esperado del vector b1. Notemos en primer lugar que el estimador
mínimo-cuadrático de b1 será:

[54]
b1 = (X1'X1)–1
X1'y
Ahora bien, puesto que y = X11 + X22 + u, entonces
b1 = (X1'X1)–1
X1'(X11 + X22 + u) = 1 + (X1'X1)–1
X1'X22 + (X1'X1)–1
X1'u
El valor esperado de b1 será:
E(b1) = 1 + (X1'X1)–1
X1'X22 + (X1'X1)–1
X1'E(u) = 1 + (X1'X1)–1
X1'X22
Por tanto, b1 generalmente no será un estimador insesgado de 1, ya que general-
mente (X1'X1)–1
X1'X22 ≠ 0. De hecho, esta expresión sólo será igual a 0 bajo dos
condiciones muy especiales:
(1) Si 2 = 0, o sea, si las variables omitidas son realmente ―irrelevantes.‖ En
ese caso, el modelo estimado es realmente el modelo ―completo,‖ y por tanto no
existe ningún problema. Obviamente, este caso no es muy interesante.
(2) Si (X1'X1)–1
X1'X2 = 0. Para entender mejor el significado de esta condición,
nótese que cada columna de esta matriz representa los coeficientes de la regresión
de una de las variables omitidas sobre las variables incluidas. (Para visualizarlo
mejor, consideremos el caso de una sola variable omitida: en ese caso,
(X1'X1)–1
X1'X2 se reduce a un vector, y ese vector no es más que el vector de los
coeficientes de la regresión de la variable omitida sobre las variables incluidas.)
En palabras, lo que esto significa es que no habrá sesgo en la estimación de b1 si
las variables omitidas y las variables incluidas son completamente independientes
unas de otras.
Esta segunda condición es muy difícil que se cumpla en la práctica, al menos
literalmente, y por tanto se puede concluir en términos generales que la omisión
de variables relevantes en una regresión lineal introducirá algún grado de sesgo
en los coeficientes estimados. Esto no significa, por otro lado, que este sesgo será
necesariamente muy grande. Si las variables omitidas no son muy importantes
(esto es, si los coeficientes del vector 2 son ―pequeños‖) y/o si no existe mucha
correlación entre las variables omitidas y las variables incluidas (esto es, si los
elementos de la matriz (X1'X1)–1
X1'X2 son ―pequeños‖), entonces el sesgo será
también pequeño. Por otro lado, si este no es el caso entonces las estimaciones re-
sultantes podrían estar seriamente erradas. Siempre es bueno tener en mente esta
posibilidad, ya que el método de mínimos cuadrados sólo garantiza buenos resul-
tados si el modelo está bien especificado.
Consideremos ahora el problema contrario: ¿Cuál es el efecto de incluir una
variable irrelevante en una regresión lineal? En este caso, las consecuencias son

[55]
menos graves, ya que el verdadero coeficiente de la variable irrelevante es cero, y
lo que tenderá a suceder es que se obtendrá un coeficiente ―no-significativo‖ para
esta variable. Supongamos, por ejemplo, que se estima el siguiente modelo:
Y = b0 + b1X1 + b2X2 + b3X3 + e
Si X3 es realmente irrelevante, entonces 3 = 0. El método de mínimos cuadrados
producirá estimadores insesgados de todos los coeficientes en el modelo estima-
do, incluyendo el coeficiente de la variable irrelevante. En este caso, el valor es-
perado de b3 (el estimador de 3) será precisamente 0. Por cierto que en la prácti-
ca el valor estimado de b3 nunca será exactamente 0, debido a las variaciones de
muestreo, pero puede esperarse que por lo general resulte poco significativo. Lo
más importante, sin embargo, es que la presencia de la variable irrelevante no in-
troduce ningún sesgo en las estimaciones de los demás coeficientes.
Esto no significa, por otro lado, que la presencia de la variable irrelevante no
implica costo alguno. De hecho, existen consecuencias importantes, pero en este
caso el costo no se hace sentir en términos de sesgo sino en términos de la preci-
sión de los estimadores. Lo que tenderá a suceder es que la presencia de variables
irrelevantes incrementará las desviaciones estándar de los coeficientes de las de-
más variables. Esto se debe a una razón muy simple: estadísticamente, lo que su-
cede es que parte de la información contenida en la muestra se está desperdician-
do en la estimación de un parámetro que no existe. Puesto que la información no
está siendo utilizada eficientemente, entonces la precisión de las estimaciones
tenderá a reducirse. En este caso, al incrementarse las desviaciones estándar de
los coeficientes de regresión, se reducirá la ―razón t‖ de todos los coeficientes, y
éstos aparecerán como menos significativos de lo que realmente son. Incluso po-
dría darse el caso de que se concluya erróneamente de que alguna de las variables
no es significativa cuando en realidad sí lo es.
¿Qué conclusiones prácticas se desprenden de este análisis? En la práctica,
por supuesto, el investigador no puede saber de antemano si una determinada va-
riable es relevante o no, ya que generalmente esta es precisamente una de las pre-
guntas que se desean resolver por medio de la investigación. Por otro lado, se
aprecia por el análisis anterior que las consecuencias de omitir variables relevan-
tes son generalmente más graves que las consecuencias de incluir variables irre-
levantes. Por tanto, es mejor errar en la dirección de incluir variables irrelevantes,
que correr el riesgo de omitir alguna variable relevante. Estas consideraciones su-
gieren la conveniencia de aplicar la siguiente estrategia: en la primera etapa de la
investigación, es mejor incluir todas las variables que puedan considerarse como
relevantes. En pocas palabras, ―si está en la duda de si incluir una variable o no,
inclúyala.‖ Si como resultado de la primera regresión algunas de las variables re-
sultan no-significativas, entonces se podrá proceder a descartarlas, y re-estimar la
regresión únicamente con las variables significativas.

[56]
5.3.2. Multicolinealidad.
(a) Naturaleza del Problema.
Imaginemos la siguiente paradoja: se estima una regresión múltiple, se obtie-
ne una alta R2 (digamos, mayor que 0.8), pero ninguno de los coeficientes esti-
mados es significativo, es decir, en ningún caso podemos rechazar la hipótesis de
que el verdadero coeficiente es 0. A primera vista, esto podría parecer contradic-
torio, ya que si la regresión tiene bastante poder explicativo (R2 es alta), entonces
quiere decir que por lo menos una de las variables independientes debe ser signi-
ficativa. Sin embargo, esta situación es de hecho muy común en la econometría
aplicada, y se debe a un problema estadístico conocido como multicolinealidad.
En una regresión lineal múltiple, la multicolinealidad se presenta cuando las
variables explicativas están fuertemente correlacionadas entre sí, ya que si las va-
riables explicativas varían juntas, entonces no se podrá separar el efecto indivi-
dual de cada una. Esto da lugar al síntoma clásico de una alta R2, pero coeficien-
tes individuales poco significativos, porque si bien la alta R2 efectivamente impli-
ca que por lo menos una de las variables independientes es significativa, el pro-
blema es que no podemos determinar cuáles son significativas y cuáles no.
Estadísticamente, la multicolinealidad produce estimadores insesgados de los
coeficientes de regresión, pero con varianzas muy grandes. Esto es de esperarse,
ya que al no poder distinguir el efecto separado de cada variable, las estimaciones
de los coeficientes serán necesariamente muy imprecisas. Para apreciar mejor las
implicaciones de la multicolinealidad, hay que recordar el significado del coefi-
ciente j en el modelo lineal: en última instancia, lo que se trata de medir con este
coeficiente es la derivada parcial de Y respecto de Xj, o sea, el efecto de un cam-
bio en Xj, manteniendo constantes las demás variables independientes. El pro-
blema, sin embargo, es que en la muestra las otras X’s no sólo no se mantienen
constantes, sino que de hecho varían junto con Xj. En este caso es muy difícil se-
parar el efecto individual de cada variable.
Se aprecia entonces que la multicolinealidad es básicamente un problema de
información. Lo que sucede es que estamos pidiendo a los datos más de lo que
nos pueden decir. La muestra de observaciones no contiene suficiente informa-
ción como para estimar el efecto separado de cada variable explicativa. Puesto
que se trata de un problema muestral, es muy poco lo que puede hacerse para re-
solver el problema si no es posible obtener información adicional. Por ejemplo,
se podría pensar en descartar alguna de las variables explicativas, para romper así
la multicolinealidad. Sin embargo, si la variable descartada es una variable rele-
vante, entonces esto podría agravar los problemas, ya que se producirá un sesgo
en los coeficientes de las otras X’s (ver sección anterior). En este caso, los coefi-

[57]
cientes de las variables no-descartadas recogerán su propio efecto, más parte del
efecto de la variable descartada.
Puesto que el problema de multicolinealidad es en última instancia un pro-
blema de información insuficiente, se desprende que la única solución real con-
sistirá en obtener más información. Nótese, sin embargo, que una ampliación de
la muestra (más observaciones) no servirá de mucho si las observaciones adicio-
nales están también correlacionadas entre sí. En otras palabras, seguiremos en la
misma situación si las nuevas observaciones son simplemente ―más de lo mis-
mo.‖ Desafortunadamente, muchas veces esta es precisamente la situación que se
presenta en la investigación económica.
(b) Medidas del Grado de Multicolinealidad.
Regla de Klein — Por la discusión anterior, se aprecia que la multicolineali-
dad no es una cuestión de ―todo o nada,‖ sino más bien una cuestión de grado. En
la mayoría de los casos prácticos es inevitable que exista algún grado de correla-
ción entre los regresores, ya que en la econometría empírica es muy raro que los
datos provengan de un experimento controlado. Lo que necesitamos, entonces, es
algún criterio para determinar si la multicolinealidad existente es ―aceptable,‖ o si
es suficientemente severa como para invalidar los resultados de un análisis. Para
esto existen algunas reglas empíricas. Una de ellas se basa en la siguiente obser-
vación del Profesor Lawrence Klein:
La multicolinealidad o inter-correlación entre las variables no es siempre un
problema, a menos que sea alta en relación con el grado general de correlación
múltiple entre todas las variables [de la regresión].21
Maddala22
se basó en esta observación para formular el siguiente criterio, que se
conoce como la regla de Klein: La multicolinealidad debe considerarse un pro-
blema si para alguno de los regresores 2
jR > R2, donde 2
jR es el coeficiente de de-
terminación de la regresión de Xj contra todas las demás variables explicativas, y
R2 es el coeficiente de determinación de la regresión completa.
Como ejemplo, tomemos nuevamente el caso de los automóviles. En este
caso 2
1R = 0.5597, 2
2R = 0.7351 y 2
3R = 0.5211. Por tanto, puesto que la R2 para
la regresión completa es 0.8399, según el criterio de Klein la multicolinealidad no
es un problema serio en esta regresión.
21
L. R. Klein, An Introduction to Econometrics (London: Prentice-Hall International,
1962), p. 101. 22G. S. Maddala, Econometría (Madrid: McGraw-Hill, 1985), p. 195.

[58]
Factor de Inflación de Varianza — Este criterio se basa en el hecho de que la
varianza muestral del coeficiente de la variable Xj depende en parte de la correla-
ción entre Xj y las demás variables explicativas:
2
2
1
1
)()1()(
jj
jRXVarn
SbVar
donde Var(bj) es la varianza muestral de bj, Var(Xj) es la varianza muestral de Xj,
y S2 es la varianza estimada de los errores de la regresión.
23 Se puede apreciar
aquí que Var(bj) se minimiza cuando 2
jR = 0. Dados los valores muestrales de Xj,
la varianza muestral de bj se va incrementando a medida que aumenta 2
jR (i.e., el
grado de multicolinealidad). Por esto, a la expresión entre paréntesis se le conoce
como el ―factor de inflación de varianza‖ (FIV), ya que mide el aumento en la
varianza de bj que se puede atribuir al hecho de que los regresores no son
completamente independientes entre sí.24
(En la terminología del álgebra lineal,
esto se expresa diciendo que las columnas de la matriz X no son vectores
―ortogonales‖.) Idealmente quisiéramos que FIV = 1, aunque esto es muy difícil
que suceda en la práctica. Como regla empírica, se considera que la
multicolinealidad es ―demasiado‖ alta si para alguno de los coeficientes FIV > 10,
es decir, si la varianza muestral del coeficiente estimado es más de 10 veces
mayor que lo que sería si los regresores fueran ortogonales.25
Aplicando este criterio para el caso de los automóviles tenemos:
271.25597.01
1
1
12
1
1
RFIV
775.37351.01
1
1
12
2
2
RFIV
23
Ver, por ejemplo, W. H. Greene, Econometric Analysis, 5ª ed. (Upper Saddle River,
NJ: Prentice Hall, 2003), p. 57. El estudiante podrá verificar numéricamente que el re-
sultado obtenido al calcular Var(bj) por medio de esta fórmula es idéntico al elemento
correspondiente de la diagonal de la matriz S2(X'X)
–1.
24
Numéricamente, el factor de inflación de varianza para Xj es igual al j-ésimo elemento
diagonal de la inversa de la matriz de correlaciones de los regresores. 25
La expresión ―factor de inflación de varianza‖ fue acuñada por D. W. Marquardt
(―Generalized Inverses, Ridge Regression, Biased Linear Estimation, and Nonlinear
Estimation,‖ Technometrics, 12 [1970], p. 606). Marquardt también fue el primero en
proponer la ―regla del 10‖ (ibid., p. 610).

[59]
088.25211.01
1
1
12
3
3
RFIV
Para los tres regresores FIV < 10, lo cual confirma la conclusión obtenida por
medio de la regla de Klein. Aunque hay cierto grado de correlación entre los
regresores, la multicolinealidad no es un problema serio en esta regresión.26
5.3.3. Heteroscedasticidad.
La heteroscedasticidad es un problema que surge cuando los errores en una
regresión lineal no tienen varianza constante. Esto en sí no plantea un problema
para el cálculo de los coeficientes mínimo-cuadráticos, ya que éstos siguen siendo
estimadores insesgados, pero sí afecta la varianza de los coeficientes estimados.
Se recordará del Capítulo 4 que la inferencia estadística en el modelo clásico
de regresión lineal se basa en los siguientes dos supuestos:
(1) E(u) = 0, lo que equivale a suponer que E(ui) = 0 para todo i. Con base en es-
te supuesto concluimos que b es un estimador insesgado de .
(2) E(uu') = 2I, lo que equivale a suponer que todos los errores tienen la misma
varianza, y que los errores para las diferentes observaciones son independientes.
Con base en este supuesto, concluimos que la matriz de varianza-covarianza del
vector b es 2(X'X)
–1, que estimamos por medio de S
2(X'X)
–1.
Cuando existe heteroscedasticidad falla el segundo de estos supuestos básicos,
y entonces la matriz de varianza-covarianza ya no es igual a 2(X'X)
–1. Siempre
podemos calcular S2(X'X)
–1, pero los elementos diagonales de esta matriz ya no
serán estimadores insesgados de las varianzas de los coeficientes de regresión. De
hecho, las ―varianzas‖ calculadas de este modo tenderán a subestimar las verda-
deras varianzas muestrales.
En una regresión simple es relativamente fácil detectar si existe heteroscedas-
ticidad, ya que se puede visualizar por medio del diagrama de dispersión. En la
Figura 6.1 se muestra el perfil típico de una regresión con heteroscedasticidad.
Cuando hay dos o más variables explicativas el problema ya no se puede visuali-
zar de este modo, pero es posible detectar la heteroscedasticidad por medios nu-
méricos.o
26
Aunque en este caso los dos criterios apuntan a la misma conclusión, esto no siempre
será el caso. La ―regla del 10‖ implica un valor máximo aceptable de 2
jR = 0.9. La regla
de Klein, por otro lado, podría violarse con valores mucho menores de 2
jR , ya que la
conclusión también depende del valor de R2.
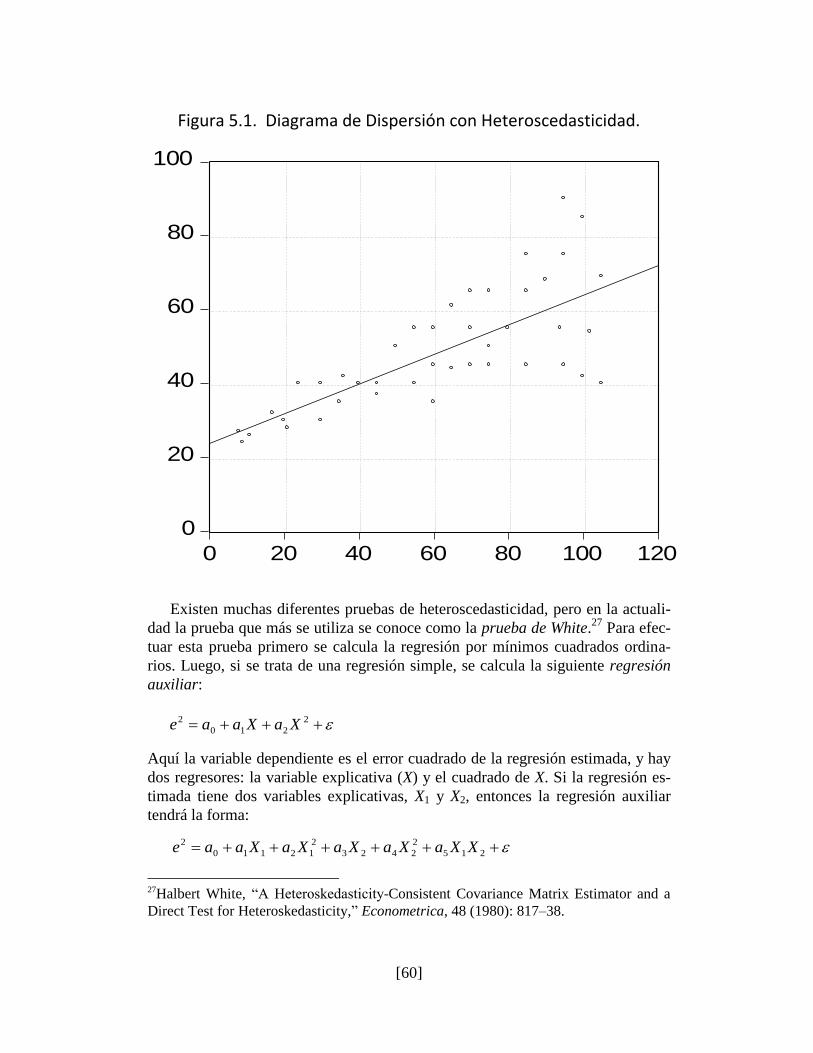
[60]
Figura 5.1. Diagrama de Dispersión con Heteroscedasticidad.
0
20
40
60
80
100
0 20 40 60 80 100 120
Existen muchas diferentes pruebas de heteroscedasticidad, pero en la actuali-
dad la prueba que más se utiliza se conoce como la prueba de White.27
Para efec-
tuar esta prueba primero se calcula la regresión por mínimos cuadrados ordina-
rios. Luego, si se trata de una regresión simple, se calcula la siguiente regresión
auxiliar:
2
210
2 XaXaae
Aquí la variable dependiente es el error cuadrado de la regresión estimada, y hay
dos regresores: la variable explicativa (X) y el cuadrado de X. Si la regresión es-
timada tiene dos variables explicativas, X1 y X2, entonces la regresión auxiliar
tendrá la forma:
215
2
2423
2
12110
2 XXaXaXaXaXaae
27Halbert White, ―A Heteroskedasticity-Consistent Covariance Matrix Estimator and a
Direct Test for Heteroskedasticity,‖ Econometrica, 48 (1980): 817–38.

[61]
En este caso la regresión auxiliar tendrá cinco regresores. En general, la regresión
auxiliar para e2 incluye como regresores todas las variables explicativas, sus cua-
drados, y todos sus productos cruzados.
Luego se toma la R2 de la regresión auxiliar, que denotaremos como 2
aR , y se
multiplica por el número de observaciones. White demostró que si la varianza de
los errores es constante (no existe heteroscedasticidad) entonces 2
aRn tendrá
una distribución chi-cuadrado ( 2 ) con grados de libertad igual al número de re-
gresores en la regresión auxiliar. Tendemos a rechazar la hipótesis de varianza
constante si este producto es ―grande,‖ y por tanto la prueba es ―a una cola‖: con-
cluimos que existe heteroscedasticidad en una regresión si 2
aRn es mayor que el
valor crítico de la distribución chi-cuadrado para los grados de libertad relevan-
tes. (Si se trata de una regresión simple la prueba de White tendrá 2 grados de li-
bertad, y si es una regresión con dos variables explicativas la prueba tendrá 5 gra-
dos de libertad, si son tres variables la prueba tendrá 9 grados de libertad, etc.)
Como ejemplo, podemos utilizar el caso de los costos bancarios, del capítulo
anterior (Sección 4.4). En este problema, X1 = Activos y X2 = Agencias. Calcu-
lando la regresión auxiliar con los errores de la regresión estimada obtenemos:
ê2 21
2
22
2
11 0078.00664.00935.1000085.00254.0752.26 XXXXXX
2
aR = 0.21102 n = 19
Por tanto, 2
aRn = 0094.421102.019 , y puesto que el valor crítico de una
variable chi-cuadrado con 5 grados de libertad y 5 % en la cola derecha es 11.07,
se concluye que no existe heteroscedasticidad en esta regresión.28
28
En caso de que exista heteroscedasticidad, no es necesario ajustar los coeficientes
mínimo-cuadráticos, ya que estos siguen siendo insesgados, pero se debe hacer un ajuste
a la matriz de varianza-covarianza, a fin de obtener estimadores correctos de las
varianzas de los coeficientes estimados. White también desarrolló un método para
efectuar dicho ajuste, pero la explicación de este procedimiento sobrepasa los alcances
de este texto introductorio. La mayoría de los paquetes de software econométrico
(E-Views, GRETL, etc.) incorporan el ―ajuste de White‖ como una opción estándar.

[62]
PREGUNTAS DE REPASO
1. Explique, en palabras, de qué forma podría darse la siguiente situación: Se estima
una regresión lineal, se obtiene una alta R2, pero ninguna de las variables independientes
es ―significativa.‖
2. Si se estima una regresión doble-log o semi-logarítmica, debe tenerse en mente que la
R2 de la regresión estimada mide la proporción de la variación del logaritmo de Y que ha
sido explicada, que no es lo mismo que la proporción de la variación de Y. Para poder
estimar esto último (que es lo que realmente nos interesa en fin de cuentas), debemos
tomar antilogaritmos de los valores calculados de ln(Y), y compararlos con los valores
observados de Y por medio de la fórmula convencional para R2. Haga este ejercicio para
el caso de la demanda de textiles (Secc. 5.1.2) y para el caso de los automóviles (Secc.
5.2.2).
3. En un estudio sobre determinantes del ahorro en países subdesarrollados29
, se repor-
taron las siguientes regresiones para una muestra de 47 países:
)ln(5416.0)ln(8402.1)ln(0258.0ln1624.03209.9ln 21 DDgN
Y
Y
S
)ln(5014.0)ln(8012.1)ln(0271.0ln1501.16341.4ln 21 DDgN
Y
N
S
donde Y = Producto Interno Bruto (PIB), N = población total, S/Y = ahorro nacional (ex-
presado como % del PIB), S/N = ahorro nacional per cápita, g = tasa de crecimiento del
PIB per cápita, D1 = porcentaje de la población menor de 15 años de edad, y D2 = por-
centaje de la población mayor a 65 años de edad.
a) Explique por qué estos resultados estimados no pueden ser correctos.
b) ¿Cree usted que este es un buen modelo teórico para este problema?
4. Para el caso de los costos bancarios (Secc. 4.4), aplique el criterio del ―factor de in-
flación de varianza‖ para medir el grado de multicolinealidad en la regresión estimada.
5. Para el problema de los automóviles (Secc. 5.2), determine si existe
heteroscedasticidad en estas regresiones (tanto en el modelo lineal como en el modelo
semi-logarítmico). Normalmente, en una regresión con tres variables explicativas la
prueba de White tendría 9 grados de libertad. Sin embargo, en este caso sólo tenemos 8
grados de libertad. ¿Por qué?
29
K. L. Gupta, ―Dependency Rates and Savings Rates: Comment,‖ American Economic
Review, 61 (1971): 469-71. La motivación para este problema se basa en un comentario
por A. S. Goldberger, ―Dependency Rates and Savings Rates: Further Comment,‖ Amer-
ican Economic Review, 63 (1973): 232-33.
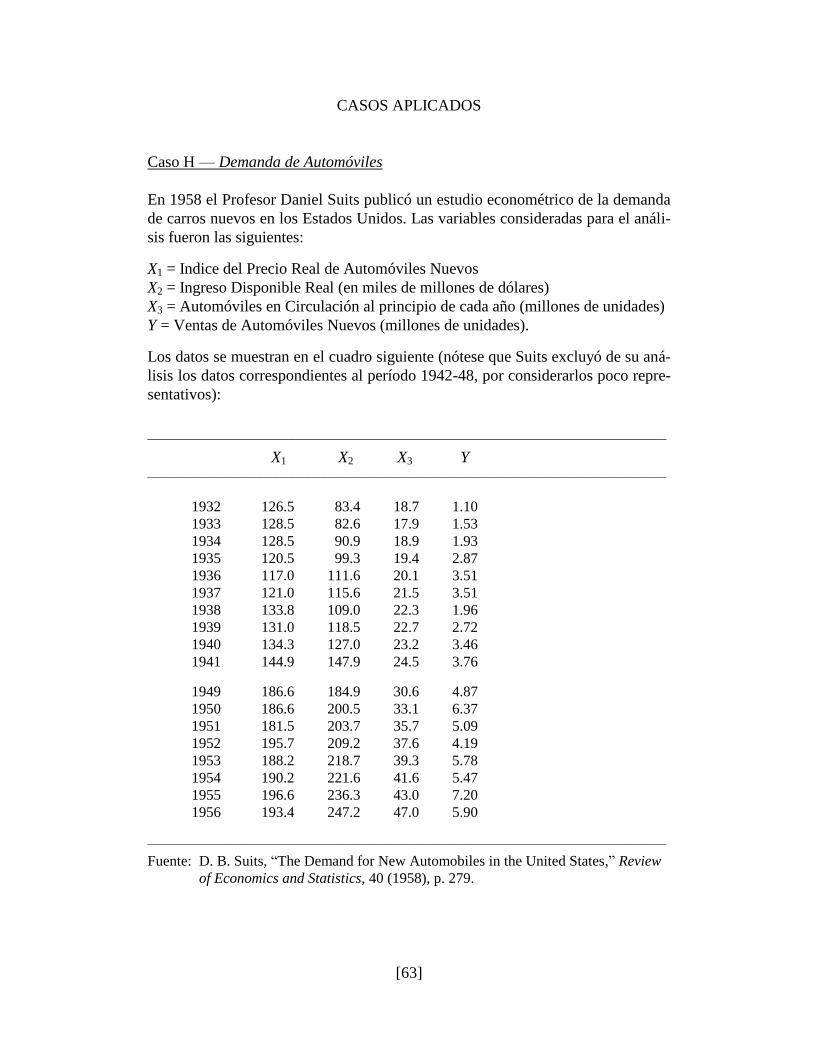
[63]
CASOS APLICADOS
Caso H — Demanda de Automóviles
En 1958 el Profesor Daniel Suits publicó un estudio econométrico de la demanda
de carros nuevos en los Estados Unidos. Las variables consideradas para el análi-
sis fueron las siguientes:
X1 = Indice del Precio Real de Automóviles Nuevos
X2 = Ingreso Disponible Real (en miles de millones de dólares)
X3 = Automóviles en Circulación al principio de cada año (millones de unidades)
Y = Ventas de Automóviles Nuevos (millones de unidades).
Los datos se muestran en el cuadro siguiente (nótese que Suits excluyó de su aná-
lisis los datos correspondientes al período 1942-48, por considerarlos poco repre-
sentativos):
————————————————————————————————–
X1 X2 X3 Y
————————————————————————————————–
1932 126.5 83.4 18.7 1.10
1933 128.5 82.6 17.9 1.53
1934 128.5 90.9 18.9 1.93
1935 120.5 99.3 19.4 2.87
1936 117.0 111.6 20.1 3.51
1937 121.0 115.6 21.5 3.51
1938 133.8 109.0 22.3 1.96
1939 131.0 118.5 22.7 2.72
1940 134.3 127.0 23.2 3.46
1941 144.9 147.9 24.5 3.76
1949 186.6 184.9 30.6 4.87
1950 186.6 200.5 33.1 6.37
1951 181.5 203.7 35.7 5.09
1952 195.7 209.2 37.6 4.19
1953 188.2 218.7 39.3 5.78
1954 190.2 221.6 41.6 5.47
1955 196.6 236.3 43.0 7.20
1956 193.4 247.2 47.0 5.90
————————————————————————————————– Fuente: D. B. Suits, ―The Demand for New Automobiles in the United States,‖ Review
of Economics and Statistics, 40 (1958), p. 279.

[64]
Con estos datos, calcule las siguientes regresiones:
ln(Y) = b0 + b1 ln(X1) + b2 ln(X2) + e
ln(Y) = b0 + b1 ln(X1) + b2 ln(X2) + b3 ln(X3) + e
(a) ¿Cuál de estas dos regresiones funciona mejor? Razone su respuesta.
(b) ¿Cómo se interpreta el significado del coeficiente de la variable X3 en la se-
gunda regresión? ¿Tiene sentido este resultado? ¿Por qué?
Caso I — Convergencia Regional en México
Según el modelo neo-clásico de crecimiento económico, propuesto por Robert
Solow en los años 50’s,30
a largo plazo la tasa de crecimiento en el ingreso per
cápita tiende a disminuir, a medida que aumenta el nivel de ingreso per cápita,
debido al efecto de rendimientos decrecientes en el empleo de capital físico. Esto
implica que si se comparan diferentes países durante un determinado período, se
esperaría encontrar una relación inversa entre la tasa de crecimiento económico
en un país y su nivel de ingreso inicial. Este efecto se conoce como ―convergen-
cia,‖ ya que implica que a largo plazo los niveles de ingreso per cápita tienden a
igualarse entre diferentes regiones. En la práctica sólo se observa este efecto a ni-
vel internacional cuando se comparan países más o menos similares (ya que es
una predicción ceteris paribus, y cuando los países son muy disimilares tiende a
predominar el efecto de otros factores). Por otro lado, sí se observa comúnmente
este efecto cuando se comparan diferentes regiones de un mismo país.31
En el cuadro adjunto, se muestra una estadística de la evolución del ingreso real
per cápita en los diferentes estados de México, entre 1940 y 1995. Use estos datos
para estimar la siguiente regresión:
Y = b + bln(X) + e
donde Y = tasa anual promedio de crecimiento del ingreso real per cápita, 1940-
95, X = ingreso real per cápita en 1940. ¿Son compatibles estos resultados con la
hipótesis de convergencia?
30
R. M. Solow, ―A Contribution to the Theory of Economic Growth,‖ Quarterly Journal
of Economics, 70 (1956): 65-94. 31
Véase, por ejemplo, R. J. Barro, Economic Growth and Convergence, Occasional
Papers No. 46 (San Francisco: International Center for Economic Growth, 1994), y
Xavier Sala-i-Martin, ―The Classical Approach to Convergence Analysis,‖ Economic
Journal, 106 (1996): 1019-36.
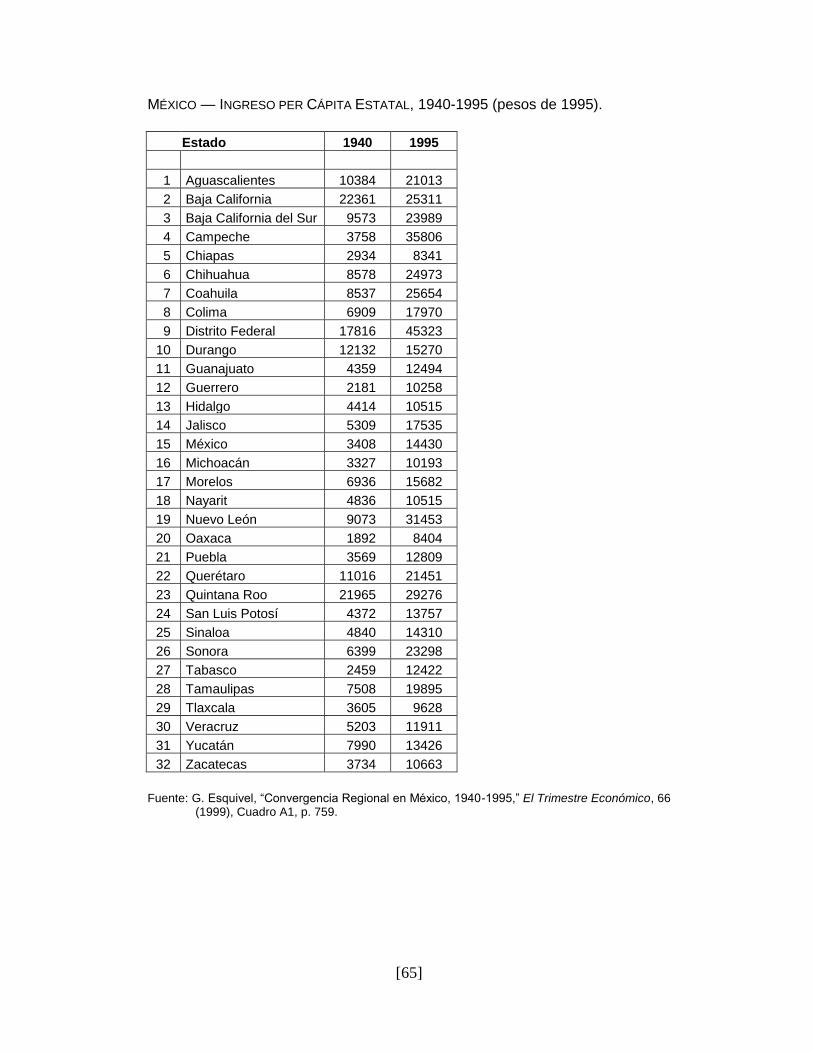
[65]
MÉXICO — INGRESO PER CÁPITA ESTATAL, 1940-1995 (pesos de 1995).
Estado 1940 1995
1 Aguascalientes 10384 21013
2 Baja California 22361 25311
3 Baja California del Sur 9573 23989
4 Campeche 3758 35806
5 Chiapas 2934 8341
6 Chihuahua 8578 24973
7 Coahuila 8537 25654
8 Colima 6909 17970
9 Distrito Federal 17816 45323
10 Durango 12132 15270
11 Guanajuato 4359 12494
12 Guerrero 2181 10258
13 Hidalgo 4414 10515
14 Jalisco 5309 17535
15 México 3408 14430
16 Michoacán 3327 10193
17 Morelos 6936 15682
18 Nayarit 4836 10515
19 Nuevo León 9073 31453
20 Oaxaca 1892 8404
21 Puebla 3569 12809
22 Querétaro 11016 21451
23 Quintana Roo 21965 29276
24 San Luis Potosí 4372 13757
25 Sinaloa 4840 14310
26 Sonora 6399 23298
27 Tabasco 2459 12422
28 Tamaulipas 7508 19895
29 Tlaxcala 3605 9628
30 Veracruz 5203 11911
31 Yucatán 7990 13426
32 Zacatecas 3734 10663
Fuente: G. Esquivel, “Convergencia Regional en México, 1940-1995,” El Trimestre Económico, 66
(1999), Cuadro A1, p. 759.

[66]
Caso J — Producción de Algodón
Los siguientes datos muestran los resultados de un experimento agrícola realizado en
1957 por la Universidad Estatal de Mississippi para investigar los efectos de varia-
ciones en el uso de dos fertilizantes, nitrógeno y ácido fosfórico, sobre el rendimien-
to en el cultivo del algodón:
Rendimiento en el Cultivo de Algodón (kg/Ha) para Diferentes
Combinaciones de Nitrógeno y Acido Fosfórico
–––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
Acido Fosfórico (kg/Ha)
Nitrógeno ——————————————————————————
(kg/Ha) 0 8 16 24 32 40 48 56
–––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
0 710 800 873 932 975 1003 1014 1012
8 985 1078 1155 1217 1264 1295 1311 1312
16 1205 1301 1382 1448 1498 1534 1553 1558
24 1370 1470 1555 1625 1679 1718 1742 1749
32 1481 1584 1673 1747 1804 1847 1875 1886
40 1538 1645 1737 1814 1876 1922 1954 1969
48 1539 1651 1747 1828 1893 1943 1978 1997
–––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
Fuente: C. E. Bishop y W. D. Toussaint, Introducción al Análisis de Economía Agrí-
cola (México: Limusa-Wiley, 1966), p. 119. El experimento original también inclu-
ye resultados para aplicaciones de 56 kg de nitrógeno, y para aplicaciones de 64 kg
de ácido fosfórico, pero se han omitido estos valores del análisis, ya que con estas
cantidades de fertilizante los rendimientos empiezan a disminuir.
(a) Sea Y = rendimiento de la cosecha, X1 = cantidad empleada de nitrógeno, y X2 =
cantidad empleada de ácido fosfórico. Use estos datos para estimar la siguiente fun-
ción por regresión lineal:
Y = A(1+X1)b(1+X2)
c
donde A, b y c son constantes desconocidas. ¿Cómo interpreta usted el significado de
la constante A en esta función?
(b) Determine si existe ―heteroscedasticidad‖ en esta regresión.
(c) Suponiendo que el fertilizante es el único costo variable, y que los otros costos
de cultivo suman $500.00 por hectárea (costo fijo), determine la cantidad óptima que
debería emplearse de cada fertilizante, si el precio del algodón es de $0.80 por kg, y
los costos de aplicación de nitrógeno y de ácido fosfórico son de $5.60 y $2.80 por
kg, respectivamente.
(d) ¿Cuánto deberíamos emplear de cada fertilizante si quisiéramos minimizar el
costo promedio por kg de algodón?

[67]
Capítulo 6
AUTOCORRELACIÓN
En el capítulo anterior se mencionaron algunos problemas prácticos que a menu-
do surgen en las aplicaciones del análisis de regresión. Nos corresponde ahora en
este capítulo tratar el tema de la ―autocorrelación,‖ que es otro problema muy
común en la investigación econométrica aplicada.
6.1. Naturaleza del Problema.
Hasta este punto hemos desarrollado nuestro análisis sin prestar mayor aten-
ción al orden en que se presentan las diferentes observaciones. De hecho, existen
situaciones donde este orden no tiene en sí mayor significado. Por ejemplo, en el
caso de los costos bancarios (Cuadro 4.1), los datos para cada banco fueron orde-
nados de acuerdo al nivel de sus costos administrativos, pero podrían haberse
presentado en cualquier otro orden (por ejemplo, alfabéticamente según el nom-
bre del banco) sin alterar en nada el análisis o las conclusiones.
Esta no es, sin embargo, una situación muy común en econometría, ya que en
la investigación económica los datos por lo general consisten de ―series cronoló-
gicas.‖ En una serie cronológica, cada observación sobre cada variable corres-
ponde a un período de tiempo determinado, y el orden de presentación de los da-
tos es muy importante, ya que corresponde a la secuencia temporal en que fueron
generadas las diferentes observaciones. En este caso, es común agregar un subín-
dice en la notación para indicar el período al cual corresponde cada observación.
De esta forma, expresamos nuestro modelo lineal de la siguiente manera:
Yt = 0 + 1X1t + 2X2t + … + kXkt + ut
donde el subíndice t indica que los valores de las diferentes variables correspon-
den al período t. Cuando los datos son series cronológicas, es muy importante
distinguir a qué período corresponden las observaciones, ya que podría ser que el
valor de la variable dependiente en un período determinado dependa de valores
de las variables explicativas que corresponden a períodos anteriores (o sea, de
valores ―retardados‖ de las variables explicativas). Por ejemplo, en un estudio

[68]
sobre la demanda de alimentos en los Estados Unidos,32
Tobin estimó la siguiente
regresión:
log(Ct) = 1.57 + 0.45 log(Yt ) + 0.11 log(Yt–1) – 0.53 log(Pt)
donde Ct es un índice del consumo per cápita de alimentos en el año t, Yt repre-
senta el ingreso real per cápita en el año t, y Pt es un índice de precios de alimen-
tos en el año t. Se aprecia que en este modelo el consumo de alimentos en un año
determinado no sólo depende del ingreso en ese año, sino también del ingreso del
año anterior. En este caso, si bien Yt y su valor retardado Yt–1 representan una
misma variable independiente, deben ser tratados como regresores diferentes en
la ecuación de regresión. (Los problemas especiales planteados por la presencia
de variables retardadas serán discutidos más a fondo en el siguiente capítulo.)
El problema de autocorrelación surge cuando los errores correspondientes a
diferentes períodos no son independientes. Concretamente, decimos que los erro-
res en una regresión están ―auto-correlacionados‖ si el valor del error en cualquier
período t (ut) depende de los errores correspondientes a períodos anteriores. Co-
mo veremos a continuación, esto viola uno de los supuestos básicos del método
de mínimos cuadrados, y puede conducir a errores en la interpretación de los coe-
ficientes de regresión.
Para visualizar mejor el significado de la autocorrelación en los errores, con-
sideremos la Figura 6.1, que muestra los errores correspondientes a una regresión
basada en los datos del Caso F (Capítulo 4):
Y = 5.869 + 0.923 X1 + 4.446 X2
(8.258) (0.511) (2.997)
R2 = 0.6391 n = 24
donde Y = Fotocopias, X1 = Total de estudiantes universitarios, y X2 = Escolares
más otros usuarios.33
Se puede apreciar claramente que en este caso los errores no son
independientes entre sí, ya que no fluctúan en forma completamente aleatoria,
sino que tienden a estar agrupados en secuencias de acuerdo a su signo: tienden a
haber secuencias de valores positivos alternadas por secuencias de valores
negativos, etc. Este es el típico patrón de una serie que muestra ―autocorrelación
positiva.‖
32
James Tobin, ―A Statistical Demand Function for Food in the U.S.A.,‖ Journal of the
Royal Statistical Society, Series A, 113 (1950): 132. 33
Esta no es necesariamente la mejor especificación para este problema.
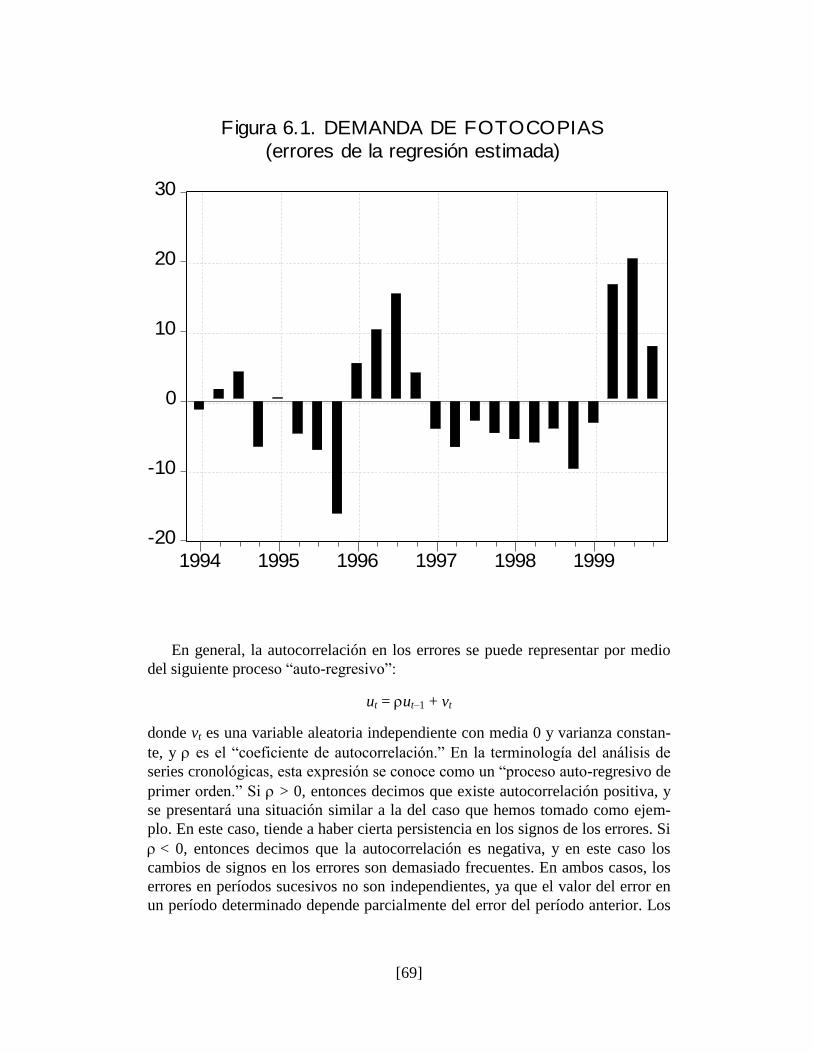
[69]
-20
-10
0
10
20
30
1994 1995 1996 1997 1998 1999
Figura 6.1. DEMANDA DE FOTOCOPIAS
(errores de la regresión estimada)
En general, la autocorrelación en los errores se puede representar por medio
del siguiente proceso ―auto-regresivo‖:
ut = ut–1 + vt
donde vt es una variable aleatoria independiente con media 0 y varianza constan-
te, y es el ―coeficiente de autocorrelación.‖ En la terminología del análisis de
series cronológicas, esta expresión se conoce como un ―proceso auto-regresivo de
primer orden.‖ Si > 0, entonces decimos que existe autocorrelación positiva, y
se presentará una situación similar a la del caso que hemos tomado como ejem-
plo. En este caso, tiende a haber cierta persistencia en los signos de los errores. Si
< 0, entonces decimos que la autocorrelación es negativa, y en este caso los
cambios de signos en los errores son demasiado frecuentes. En ambos casos, los
errores en períodos sucesivos no son independientes, ya que el valor del error en
un período determinado depende parcialmente del error del período anterior. Los

[70]
errores sólo serán completamente independientes si = 0, o sea, si existe ―auto-
correlación cero.‖
En este punto, surgen naturalmente tres preguntas básicas: (1) ¿Qué efectos
tiene la autocorrelación sobre las estimaciones de los coeficientes de regresión?
(2) ¿Cómo se detecta la presencia de autocorrelación en una regresión lineal? (3)
¿Qué se puede hacer para contrarrestar los efectos de la autocorrelación? A fin de
organizar mejor la discusión, trataremos cada uno de estos temas en secciones se-
paradas.
6.2. Efectos de la Autocorrelación.
Supongamos que deseamos estimar la siguiente ecuación lineal:
Yt = 0 + 1X1t + 2X2t + … + kXkt + ut
que en forma matricial expresamos como:
y = X + u
En el modelo clásico de regresión lineal, estimamos el vector de coeficientes
por medio del vector mínimo-cuadrático b = (X'X)–1
X'y. Recordemos nuevamen-
te el segundo supuesto básico del modelo clásico de regresión lineal (Secc. 4.2):
E(uu') = 2I, lo que en términos de nuestra nueva notación equivale a suponer
que E(ut2) =
2 para todo t, y E(utut–s) = 0 para todo s ≠ 0. Es decir, suponemos
que todos los errores tienen la misma varianza, y que los errores para períodos di-
ferentes son independientes. (Se podrá apreciar intuitivamente que la segunda
parte de este supuesto es lo que falla cuando existe autocorrelación.) Con base en
este supuesto, concluimos que la matriz de varianza-covarianza del vector b es
2(X'X)
–1, que estimamos por medio de S
2(X'X)
–1.
Supongamos ahora que los errores en el modelo lineal siguen el siguiente
proceso auto-regresivo:
ut = ut–1 + vt
donde vt es una variable aleatoria independiente con media 0 y varianza constan-
te, y || < 1. (Se podrá apreciar intuitivamente que esta condición es necesaria pa-
ra que el proceso sea ―estable.‖) Esto implica que
utut–1 = (ut–1 + vt)ut–1
Si calculamos el valor esperado de esta expresión obtenemos:

[71]
E(utut–1) = E(2
1tu )
ya que vt es una variable completamente aleatoria, y por tanto será independiente
de ut–1 (es decir, E(vtut–1) = 0). La expresión anterior sólo será igual a 0 si = 0,
es decir, si no existe autocorrelación. Si no es cero, entonces E(utut–1) tampoco
será cero, ya que E(2
1tu ) es necesariamente positiva. Por tanto, esto significa que
si existe autocorrelación (ya sea positiva o negativa), entonces los errores en pe-
ríodos sucesivos no serán independientes. Esto implica que el supuesto de que
E(uu') = 2I ya no es válido, lo que implica a su vez que la matriz de varianza-
covarianza del vector b ya no será de la forma 2(X'X)
–1. Por tanto, no tiene ya
sentido estimar esta matriz por medio de S2(X'X)
–1. Por supuesto que siempre es
posible calcular esta matriz, pero ya no se puede interpretar de la manera conven-
cional. Se recordará que en el caso clásico los elementos de la diagonal de esta
matriz son los estimadores de las varianzas de los coeficientes de regresión. Sin
embargo, si existe autocorrelación en los errores este ya no es el caso. De hecho,
si los errores están auto-correlacionados y tratamos de estimar las varianzas de
los coeficientes por medio del método convencional (que dicho sea de paso, es el
método que viene automáticamente incorporado en los programas de regresión
por computadoras), entonces se tenderá a subestimar estas varianzas. Por otro la-
do, nótese que
ut–1 = ut–2 + vt–1
Por tanto,
ut = ut–2 + vt–1) + vt = vt + vt–1 + 2ut–2 = vt + vt–1 +
2vt–2 +
3vt–3 + ….
El valor esperado de ut será entonces:
E(ut) = E(vt)+ Evt–1) + 2Evt–2) +
3E(vt–3) + …. = 0
Esto será cierto para toda t, y por tanto se sigue manteniendo válido el supuesto
de que E(u) = 0. Esto implica que el vector b sigue siendo insesgado, ya que esta
conclusión depende únicamente de este supuesto.
Para resumir, la autocorrelación no introduce sesgo en los coeficientes de re-
gresión, pero sí hace que se tiendan a subestimar las varianzas de estos coeficien-
tes, si estas varianzas se estiman por medio de la fórmula convencional. En tér-
minos prácticos, esto implica que se tenderá sobre-estimar la ―significancia‖ de
los coeficientes (porque se tenderá a sobre-estimar la ―razón t‖ de cada coeficien-
te), e incluso podría darse el caso de que se tienda a concluir que una variable es
significativa aún cuando realmente no lo sea.

[72]
6.3. Cómo Detectar la Autocorrelación.
La discusión anterior implica que la autocorrelación es un problema serio, y
por tanto es muy importante contar con alguna técnica para detectarla si es que
existe. Lo que necesitamos es alguna prueba confiable para testar la hipótesis
nula:
H0: = 0
Si no podemos rechazar esta hipótesis entonces concluimos que no existe auto-
correlación, lo que significa que los supuestos del modelo clásico de regresión se
aplican, lo mismo que las inferencias basadas en esos supuestos. Por otro lado, si
en un caso determinado encontramos que debemos rechazar esta hipótesis nula,
entonces concluimos que existe autocorrelación, y en ese caso debemos tratar de
remediar la situación, empleando algún método de estimación alternativo.
6.3.1. Prueba de Durbin-Watson.
En la práctica, la prueba que más comúnmente se emplea se basa en el si-
guiente estadístico propuesto por Durbin y Watson34
:
n
t
t
n
t
tt
e
ee
d
1
2
2
2
1 )(
Nótese que este estadístico se basa en los errores de la regresión estimada (que
son los únicos que podemos observar en la práctica). Si desarrollamos el numera-
dor de esta expresión, encontramos que
n
t
t
n
t
t
n
t
tt
n
t
t
e
eeee
d
1
2
1
1
2
2
1
2
2 2
Además, si apreciamos que en forma aproximada
n
t
n
t
t
n
t
tt eee2 1
21
1
22, entonces
el estadístico Durbin-Watson será aproximadamente igual a
2
122
t
tt
e
ee,
34
J. Durbin y G. S. Watson, ―Testing for Serial Correlation in Least Squares Regres-
sion,‖ Biometrika, 37 (1950): 409-28, 38 (1951): 159-78.

[73]
donde hemos suprimido los subíndices de las sumatorias para simplificar la
notación. La expresión entre corchetes es el estimador mínimo-cuadrático del
coeficiente de la regresión (por el origen) de et contra et–1, y el valor esperado de
este coeficiente es precisamente , el coeficiente de autocorrelación. Por tanto,
puesto que varía entre –1 y 1, el valor esperado de d varía entre 0 y 4. Si la
hipótesis nula de cero autocorrelación es cierta ( = 0), entonces el estadístico
Durbin-Watson (que a menudo se representa por las siglas DW) tendrá un valor
esperado de 2. Si d es menor que 2, entonces existirá evidencia de
autocorrelación positiva, y si es mayor que 2 existirá evidencia de autocorrelación
negativa. La relación entre d y se puede visualizar mejor en el siguiente gráfico:
Autocorrelación
———————————————————
Positiva Cero Negativa
1 0 –1
: |—————————|—————————|
0 2 4
d: |—————————|—————————|
Naturalmente que d nunca será exactamente igual a 2 aún cuando sea realmente
cero, debido a variaciones muestrales, por lo que en la práctica sólo rechazamos
la hipótesis de que = 0 cuando d se aleje ―demasiado‖ de 2 (en cualquiera de las
dos direcciones). Durbin y Watson tabularon los valores críticos de d para testar
H0: = 0 contra la alternativa de autocorrelación positiva para varios niveles de
significancia. En la Tabla A-4 del Apéndice presentamos los valores críticos ta-
bulados para 5 % de significancia (que es el nivel que más comúnmente se em-
plea en la práctica).35
Se aprecia que los valores críticos dependen tanto del nú-
mero de observaciones (n) como del número de variables independientes (k), y
que para cada combinación de n y k de hecho existen dos valores críticos: un va-
lor inferior (dL) y un valor superior (dU). En la práctica, la prueba Durbin-Watson
se reduce a la siguiente regla de decisión:
(a) Si d > dU, aceptar H0 (concluir que no existe autocorrelación)
(b) Si d < dL, rechazar H0 (concluir que existe autocorrelación positiva)
(c) Si dL < d < dU, la prueba no es concluyente.
35
La Tabla A-4 del Apéndice se basa en las tablas ampliadas reportadas por N. E. Savin
y K. J. White, ―The Durbin-Watson Test for Serial Correlation with Extreme Sample
Sizes or Many Regressors,‖ Econometrica, 45 (1977): 1989-96.

[74]
Si d > 2, entonces la alternativa relevante es < 0 (autocorrelación negativa). En
este caso, se puede calcular 4 – d, y aplicar la regla anterior como si se estuviera
considerando la alternativa de autocorrelación positiva:
(a) Si 4 – d > dU, aceptar H0 (concluir que no existe autocorrelación)
(b) Si 4 – d < dL, rechazar H0 (concluir que existe autocorrelación negativa)
(c) Si dL < 4 – d < dU, la prueba no es concluyente.
6.3.2. Limitaciones de la Prueba Durbin-Watson.
Uno de los problemas con la prueba Durbin-Watson es la ―región de incerti-
dumbre‖ entre dL y dU, que puede ser muy amplia cuando existen relativamente
pocas observaciones, o cuando el número de regresores es muy grande. En este
caso, en principio no se justifica ninguna conclusión, de modo que ―no sabemos
si existe autocorrelación, pero tampoco estamos seguros de que no existe.‖ Por
cierto que en la práctica tenemos que tomar alguna decisión: o aceptamos las es-
timaciones mínimo-cuadráticas tal cual, o empleamos otro método de estimación.
Si adoptamos la primera alternativa, entonces implícitamente estamos suponiendo
que no existe autocorrelación en los errores de la regresión. La cuestión es si se
justifica tomar esta actitud cuando d cae en la región de incertidumbre. En vista
de que en este caso las consecuencias de aceptar erróneamente la hipótesis nula
(Error Tipo II) son más graves que las de rechazarla incorrectamente (Error Tipo
I), parecería más conveniente concluir que existe autocorrelación a no ser que es-
temos seguros de lo contrario. Por esto, muchos autores recomiendan la siguiente
estrategia conservadora: si d < dU (o si 4 – d < dU), entonces rechazar H0 y con-
cluir que existe autocorrelación.
Otra de las limitaciones de la prueba Durbin-Watson es que los valores críti-
cos tabulados están definidos únicamente para regresiones ―con constante.‖ En el
caso de regresiones por el origen, el valor crítico superior (dU) es igual que en el
caso convencional de regresión con constante, pero el valor crítico inferior (dL) es
menor, lo que implica una mayor ―región de incertidumbre.‖36
Por último, es muy
importante anotar que la prueba Durbin-Watson tampoco es aplicable cuando los
regresores incluyen valores retardados de la variable dependiente. Este caso será
discutido con mayor detalle en el capítulo siguiente.
36
R. W. Farebrother, ―The Durbin-Watson Test for Serial Correlation When There is No
Intercept in the Regression,‖ Econometrica, 48 (1980): 1553-63.

[75]
6.3.3. Ejemplo Práctico.
Para ilustrar la aplicación de la prueba Durbin-Watson consideremos nueva-
mente el ejemplo de la demanda de fotocopias. Los cálculos necesarios se deta-
llan en el Cuadro 6.1. En este caso, para 24 observaciones y 2 variables indepen-
dientes tenemos que los valores críticos para la prueba Durbin-Watson son dL =
1.188 y dU = 1.546. Puesto que 0.921 < 1.188, concluimos que existe evidencia de
autocorrelación positiva en esta regresión.
6.4. Estimación en Presencia de Autocorrelación.
Vimos en la sección 6.2 que cuando los errores en una regresión están auto-
correlacionados, entonces se viola uno de los supuestos del modelo clásico de
regresión lineal, y por tanto las inferencias estadísticas basadas en esos supuestos
ya no son válidas. En este caso, se deberá adoptar algún método de estimación
alternativo. El método más comúnmente empleado es el llamado ―método
iterativo de Cochrane-Orcutt.‖37
Para simplificar la presentación, supongamos que deseamos estimar el si-
guiente modelo lineal simple (las conclusiones se pueden generalizar fácilmente
para el caso de k variables independientes):
(1) Yt = 0 + 1Xt + ut
y que los errores siguen el siguiente proceso auto-regresivo:
(2) ut = ut–1 + vt
Si retardamos la ecuación (1) en un período y pre-multiplicamos por , tendre-
mos:
(3) Yt–1 = 0 + 1Xt–1 + ut–1
Si restamos (1) menos (3), y reordenamos términos, tendremos finalmente:
(4) Yt – Yt–1 = 0(1 – ) + 1(Xt – Xt–1) + vt
Nótese que el error vt en la ecuación (4) ya no está auto-correlacionado, por lo
que en principio podría ser estimada por mínimos cuadrados ordinarios. Por tan-
to, si conociéramos el valor del coeficiente de autocorrelación (), entonces po-
dríamos obtener estimaciones de los coeficientes de la ecuación (1) por medio de
37
P. Cochrane y G. H. Orcutt, ―Application of Least Squares Regression to Relationships
Containing Autocorrelated Error Terms,‖ Journal of the American Statistical Associa-
tion, 44 (1949): 32-61.
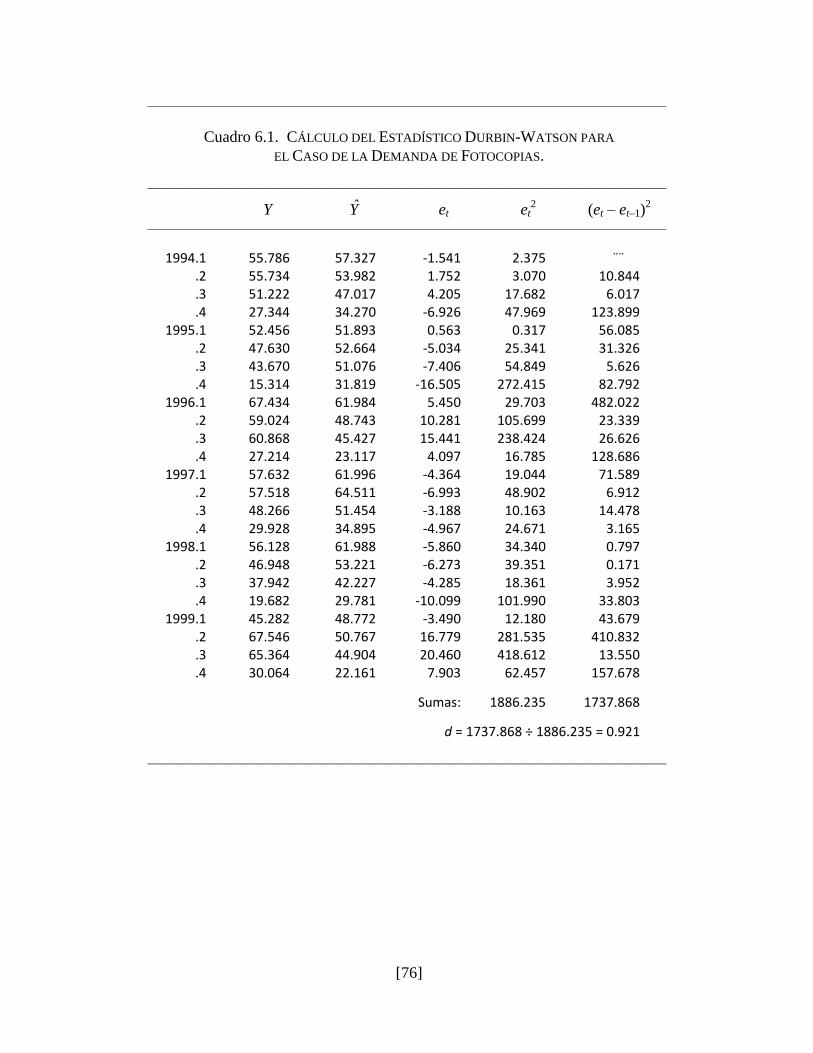
[76]
————————————————————————————————–
Cuadro 6.1. CÁLCULO DEL ESTADÍSTICO DURBIN-WATSON PARA
EL CASO DE LA DEMANDA DE FOTOCOPIAS.
————————————————————————————————–
Y Y et et2 (et – et–1)
2
————————————————————————————————–
1994.1 55.786 57.327 -1.541 2.375 ¨¨ .2 55.734 53.982 1.752 3.070 10.844 .3 51.222 47.017 4.205 17.682 6.017 .4 27.344 34.270 -6.926 47.969 123.899
1995.1 52.456 51.893 0.563 0.317 56.085 .2 47.630 52.664 -5.034 25.341 31.326 .3 43.670 51.076 -7.406 54.849 5.626 .4 15.314 31.819 -16.505 272.415 82.792
1996.1 67.434 61.984 5.450 29.703 482.022 .2 59.024 48.743 10.281 105.699 23.339 .3 60.868 45.427 15.441 238.424 26.626 .4 27.214 23.117 4.097 16.785 128.686
1997.1 57.632 61.996 -4.364 19.044 71.589 .2 57.518 64.511 -6.993 48.902 6.912 .3 48.266 51.454 -3.188 10.163 14.478 .4 29.928 34.895 -4.967 24.671 3.165
1998.1 56.128 61.988 -5.860 34.340 0.797 .2 46.948 53.221 -6.273 39.351 0.171 .3 37.942 42.227 -4.285 18.361 3.952 .4 19.682 29.781 -10.099 101.990 33.803
1999.1 45.282 48.772 -3.490 12.180 43.679 .2 67.546 50.767 16.779 281.535 410.832 .3 65.364 44.904 20.460 418.612 13.550 .4 30.064 22.161 7.903 62.457 157.678
Sumas: 1886.235 1737.868 d = 1737.868 ÷ 1886.235 = 0.921
————————————————————————————————–

[77]
una estimación de la ecuación (4), que viene expresada en términos de las varia-
bles transformadas (Yt – Yt–1) y (Xt – Xt–1).
El problema, naturalmente, es que no conocemos , y por tanto debemos es-
timarlo. Denotemos el valor estimado de por . En el método Cochrane-Orcutt
se procede por pasos de acuerdo a la siguiente secuencia:
Paso Nº 1. Estimar la ecuación (1) por mínimos cuadrados ordinarios.
Paso Nº 2. Estimar a partir de los errores de la ecuación (1) por medio de:
2
1ˆ
t
tt
e
ee
que también podría estimarse como (1 – 0.5d), donde d es el estadístico Dur-
bin-Watson.38
Paso Nº 3. Sustituir el valor estimado de en la ecuación (4), y estimar los coefi-
cientes de esta regresión por mínimos cuadrados ordinarios. [Nótese que la
ordenada en el origen de la ecuación (4) no es un estimador de 0 sino de
0(1–). Para obtener el estimador de 0 deberá dividirse entre (1 – ).]
Paso Nº 4. Sustituir los coeficientes estimados en la ecuación (1), recalcular los
errores, y repetir los pasos 2, 3, y 4.
El proceso se repite iterativamente hasta que converge a un valor fijo. En la
práctica se decide de antemano detener el proceso cuando el cambio en el valor
estimado de de una iteración a otra es menor que algún valor pequeño (diga-
mos, 0.001). Generalmente se produce la convergencia al cabo de unas pocas ite-
raciones.
El método Cochrane-Orcutt es bastante conocido, y muchos paquetes de re-
gresión traen incorporados alguna variante del mismo. Obviamente se trata de un
método mucho más sofisticado que el método de mínimos cuadrados ordinarios.
La pregunta interesante, sin embargo, es si realmente produce mejores resultados.
38
Otra alternativa sería estimar por medio del método propuesto por J. Durbin (―The
Fitting of Time-Series Models,‖ Review of the International Statistical Institute, 28
[1960], p. 237). Si expresamos la ecuación (4) como:
Yt = 0(1 – ) + 1Xt – 1Xt–1 + Yt–1 + vt
y estimamos esta regresión por mínimos cuadrados ordinarios, podríamos tomar el
coeficiente de Yt–1 como un estimador de

[78]
El problema, por supuesto, es que el proceso de estimación no está basado en el
verdadero valor de , sino en su estimador . Debido a esto, es muy común
observar en la práctica que las estimaciones obtenidas por el método Cochrane-
Orcutt difieren mucho de las estimaciones obtenidas por mínimos cuadrados
ordinarios (a tal grado que los coeficientes muchas veces terminan incluso con los
signos cambiados). En este punto es bueno recordar que aún con errores auto-
correlacionados, el vector mínimo-cuadrático sigue siendo al fin y al cabo inses-
gado.
Por último, conviene siempre tener en mente que los métodos tipo Cochrane-
Orcutt no son un remedio para la autocorrelación, sino una forma de estimar los
coeficientes de regresión, dado que los errores están auto-correlacionados. Por
otro lado, la autocorrelación muchas veces es un síntoma de algún problema más
básico: por ejemplo, podría reflejar el efecto de alguna variable omitida, o de al-
gún error en la forma funcional de la ecuación de regresión. En este sentido, antes
de recurrir a técnicas sofisticadas (que en última instancia sólo atacan el ―sínto-
ma‖), es preferible tratar de eliminar la autocorrelación, investigando más a fondo
los factores que podrían estarla causando.

[79]
PREGUNTAS DE REPASO
1. Defina los siguientes conceptos:
a) serie cronológica
b) autocorrelación
c) estadístico Durbin-Watson.
2. ¿Qué efectos tiene la autocorrelación sobre los estimadores mínimo-
cuadráticos en el modelo clásico de regresión?
3. Para los Casos B y C del Capítulo 2 (―ley de Okun‖), determine si existe
heteroscedasticidad y/o autocorrelación en estas regresiones.
4. ¿Cuáles son las principales limitaciones de la prueba Durbin-Watson?
5. Explique los pasos que deben seguirse para estimar una regresión por medio
del método Cochrane-Orcutt.

[80]
CASO APLICADO
Caso K — Función Consumo
Los datos en el cuadro adjunto fueron tomados de un antiguo estudio sobre la
―función consumo‖ en los Estados Unidos. Se desea estimar la siguiente
regresión lineal:
Ct = b0 + b1Yt + et
donde Ct = Gasto de consumo personal en el trimestre t, Yt = Ingreso personal
disponible en el trimestre t (ambos expresados en billones de dólares de 1954), y
et es el error o residuo de la regresión estimada.
a) Determine si hay autocorrelación en esta regresión.
b) Use estos datos para estimar el coeficiente de autocorrelación () por medio
del método de Durbin.
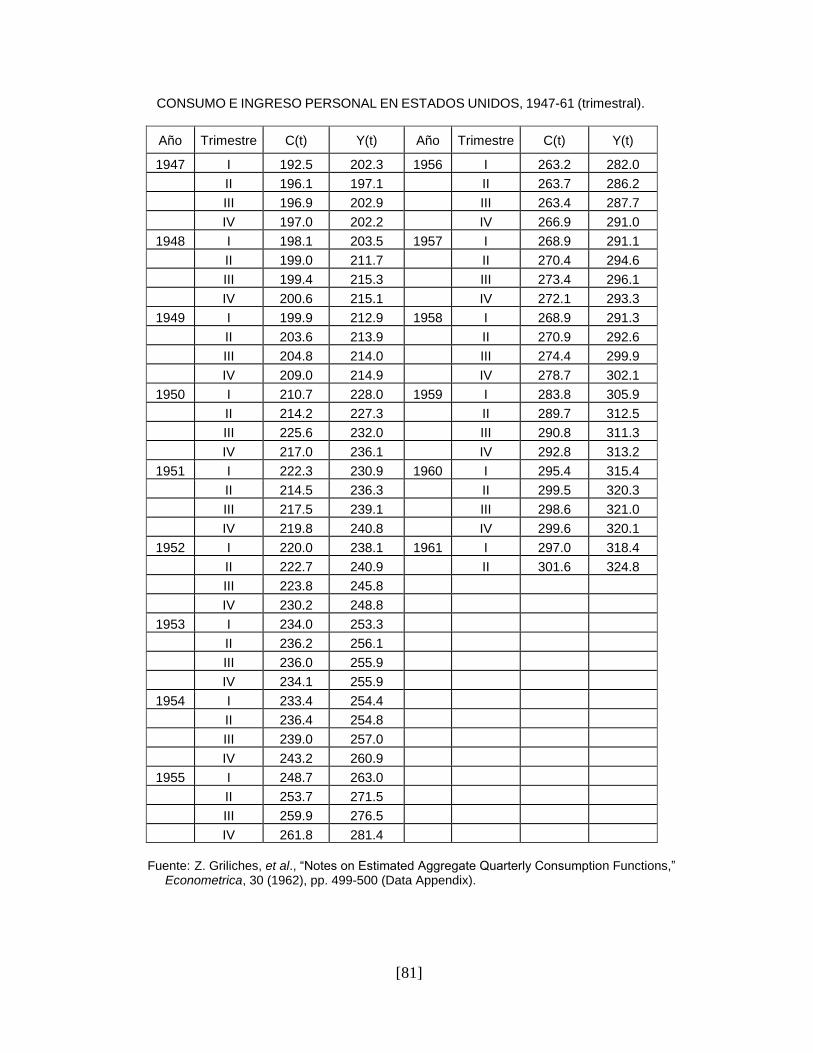
[81]
CONSUMO E INGRESO PERSONAL EN ESTADOS UNIDOS, 1947-61 (trimestral).
Año Trimestre C(t) Y(t) Año Trimestre C(t) Y(t)
1947 I 192.5 202.3 1956 I 263.2 282.0
II 196.1 197.1 II 263.7 286.2
III 196.9 202.9 III 263.4 287.7
IV 197.0 202.2 IV 266.9 291.0
1948 I 198.1 203.5 1957 I 268.9 291.1
II 199.0 211.7 II 270.4 294.6
III 199.4 215.3 III 273.4 296.1
IV 200.6 215.1 IV 272.1 293.3
1949 I 199.9 212.9 1958 I 268.9 291.3
II 203.6 213.9 II 270.9 292.6
III 204.8 214.0 III 274.4 299.9
IV 209.0 214.9 IV 278.7 302.1
1950 I 210.7 228.0 1959 I 283.8 305.9
II 214.2 227.3 II 289.7 312.5
III 225.6 232.0 III 290.8 311.3
IV 217.0 236.1 IV 292.8 313.2
1951 I 222.3 230.9 1960 I 295.4 315.4
II 214.5 236.3 II 299.5 320.3
III 217.5 239.1 III 298.6 321.0
IV 219.8 240.8 IV 299.6 320.1
1952 I 220.0 238.1 1961 I 297.0 318.4
II 222.7 240.9 II 301.6 324.8
III 223.8 245.8
IV 230.2 248.8
1953 I 234.0 253.3
II 236.2 256.1
III 236.0 255.9
IV 234.1 255.9
1954 I 233.4 254.4
II 236.4 254.8
III 239.0 257.0
IV 243.2 260.9
1955 I 248.7 263.0
II 253.7 271.5
III 259.9 276.5
IV 261.8 281.4
Fuente: Z. Griliches, et al., “Notes on Estimated Aggregate Quarterly Consumption Functions,” Econometrica, 30 (1962), pp. 499-500 (Data Appendix).

[82]
Capítulo 7
RETARDOS DISTRIBUIDOS
En este capítulo final, discutiremos la estimación de regresiones que incluyen va-
riables retardadas en la lista de regresores. Como veremos, cuando los datos bási-
cos consisten de series cronológicas, la inclusión de variables retardadas permite
ampliar la flexibilidad del modelo de regresión, pero también plantea problemas
especiales de estimación, que justifican una discusión por separado.
7.1. Variables Retardadas en Econometría.
Cuando se especifica una relación entre variables económicas que son repre-
sentadas por medio de series cronológicas, generalmente es poco realista suponer
que el efecto total de un cambio en las variables explicativas se produce en un
mismo período. Más bien, en muchas situaciones es de esperarse que este efecto
quedará distribuido entre varios períodos futuros. Esto implica a su vez que el va-
lor de Y correspondiente a un período determinado dependerá en parte de los va-
lores de las X’s en ese mismo período, pero también dependerá de los valores de
las X’s correspondientes a períodos anteriores.
Para tomar un ejemplo concreto, recordemos el Caso G del Capítulo 4, donde
se aplicó un modelo basado en la ―Teoría Cuantitativa del Dinero‖ para explicar
la variación en las tasas de inflación en un grupo de países latinoamericanos. Un
problema que se presenta al aplicar este modelo a los datos anuales de un país es-
pecífico es que, en el corto plazo, generalmente existe un retardo en el efecto de
variaciones en la masa monetaria. Por tanto, si aumenta la tasa de crecimiento
monetario en un período determinado, la inflación en ese período también aumen-
tará, aunque probablemente no en la misma proporción, ya que el efecto inflacio-
nario de un cambio monetario toma cierto tiempo. Por esto, parte del efecto del
cambio monetario no se reflejará de inmediato, sino que se reflejará posterior-
mente en la inflación de períodos futuros. Por otro lado, y viéndolo desde otro
ángulo, esto implica que la tasa de inflación en el período actual no depende úni-
camente de la tasa contemporánea de crecimiento monetario, sino que también
dependerá del crecimiento monetario de períodos anteriores. Por tanto, si expre-
samos la tasa de inflación como función únicamente del crecimiento monetario
contemporáneo se obtendrán resultados sesgados, ya que la regresión tenderá a

[83]
subestimar el efecto total de un cambio monetario, debido a la omisión del efecto
retardado. (Debemos recordar en este punto la discusión del Capítulo 5 sobre los
efectos de ―variables omitidas.‖)
Por otro lado, si bien es fácil justificar la presencia de variables retardadas en
una regresión, la teoría relevante rara vez proporciona guías claras sobre la dura-
ción exacta del retardo en un caso concreto, ya que generalmente esta es precisa-
mente una de las cuestiones que deseamos determinar por medio de la investiga-
ción. Si suponemos, para simplificar la presentación, de que Y depende de una so-
la variable explicativa X, entonces podríamos especificar un modelo lineal de la
forma:
(1) Yt = 0 + 1Xt + 2Xt–1 + ... + k+1Xt–k + ut
donde Yt depende del valor contemporáneo de X, y de los valores de X correspon-
dientes a los k períodos anteriores. Una ecuación de este tipo se conoce como un
―retardo distribuido.‖ En principio, se podría determinar el número de valores
retardados (k) por ―prueba y error,‖ empezando con un número relativamente
grande y examinando la significancia de los coeficientes estimados. En la práctica
este procedimiento no es siempre factible, por varias razones. En primer lugar, el
número de observaciones en la muestra impone una limitación al número de re-
tardos que pueden considerarse, ya que si incluimos demasiados valores retarda-
dos en la ecuación, nos quedarán pocos grados de libertad para la estimación. Por
otro lado, típicamente los diferentes valores retardados de X estarán correlaciona-
dos entre sí, lo que puede crear problemas de multicolinealidad.
7.1.1. Transformación de Koyck.39
Una forma de evitar estos problemas es suponer que el retardo es en principio
―infinito,‖ pero imponer algún tipo de restricción sobre la forma de los coeficien-
tes. Supongamos que la relación entre Y y X tiene el siguiente retardo distribuido:
(2) Yt = 0 + 1Xt + 2Xt–1 + 3Xt–2 + … + ut
Por supuesto que sería imposible estimar este modelo directamente. No obstante,
se puede reducir el problema a proporciones manejables si imponemos ciertas
restricciones sobre los coeficientes 1, 2, .... En muchas situaciones, por ejem-
plo, parece razonable suponer que la magnitud del efecto de un cambio en X dis-
39
La discusión en esta sección y la siguiente se basa en Goldberger, Teoría Econométri-
ca, Cap. 6 (pp. 289-90), y Marc Nerlove, ―Distributed Lags,‖ International Encyclope-
dia of the Social Sciences (1968), vol. 4, pp. 214-17. Véase también A. S. Goldberger,
―Review of Distributed Lags and Demand Analysis for Agricultural and Other Com-
modities by Marc Nerlove,‖ American Economic Review, 48 (1958): 1011-13.

[84]
minuye con el tiempo, por lo que esperamos un impacto inicial relativamente
fuerte, un efecto menos fuerte en el período siguiente, etc. Si este es el caso, en-
tonces los coeficientes de la ecuación (2) tenderían a disminuir sistemáticamente
a medida que retrocedemos más y más en el pasado. La llamada ―transformación
de Koyck‖ se basa en el supuesto de que estos coeficientes disminuyen en forma
geométrica:
i = i–1
para i = 1, 2, .... )10(
Con este supuesto, podemos expresar la ecuación (2) como:
(3) Yt = 0 + Xt + Xt–1 + 2Xt–2 + ... + ut
Si retardamos la ecuación (3) en un período y pre-multiplicamos por tendre-
mos:
(4) Yt–1 = 0 + Xt–1 + 2Xt–2 +
3Xt–3 + ... + ut–1
Por último, restando (3) menos (4) y reordenando, obtenemos:
(5) Yt = (1 – )0 + Xt + Yt–1 + (ut – ut–1)
De esta forma, el problema se reduce a la estimación de únicamente tres paráme-
tros. Se notará, sin embargo, que esta ecuación implica un término de error un
tanto complicado. Por otra parte, Nerlove ha propuesto un mecanismo de retardo
que produce una regresión muy similar a la de Koyck, pero con un error más sim-
ple.
7.1.2. Modelo de Ajuste Parcial (Nerlove).
El modelo de Nerlove se basa en el supuesto de que existe una relación lineal
de ―largo plazo‖ entre Y y X, que se expresa de la forma:
(6) Y* = 0 + 1Xt
Aquí, Y* representa el valor de Y que se observaría si el valor de X se mantuviera
igual a Xt por un tiempo ―muy largo.‖ Si cambia X, entonces Y* también cambia,
pero el valor observado de la variable dependiente (Yt) no se ajusta de inmediato
al valor de largo plazo, de modo que en cualquier período determinado habrá dis-
crepancias entre Y* y Yt. En el modelo de Nerlove, se supone que estas discrepan-
cias se corrigen de acuerdo al siguiente mecanismo de ―ajuste parcial‖:
(7) Yt – Yt–1 = (Y* – Yt–1) + ut )10(

[85]
En este modelo, el ―coeficiente de ajuste‖ () mide la rapidez con que Yt se ajusta
a un cambio en Xt. Si es muy grande, entonces el ajuste es rápido, mientras que
si es pequeño, entonces el ajuste es lento. (En el caso límite, si = 1 entonces Yt
= Y*
+ ut, todo el ajuste se produce en el mismo período, y las únicas discrepan-
cias se deben a las fluctuaciones del error aleatorio.) Si sustituimos (6) en (7) y
reordenamos términos, obtenemos:
(8) Yt = 0 + 1Xt + (1 – )Yt–1 + ut
Nótese que este modelo es formalmente idéntico al modelo de Koyck, pero con la
diferencia de que el término de error es más sencillo. Para estimar los parámetros
del modelo, calculamos la siguiente regresión:
(9) Yt = b0 + b1Xt + b2Yt–1 + et
En esta regresión, b0 es el estimador de 0, b1 es el estimador de 1, y b2 es el
estimador de (1 – ). A partir de estos estimadores, podemos estimar 0 por me-
dio de b0/(1 – b2), y 1 por medio de b1/(1 – b2). [Para facilitar la presentación,
hemos desarrollado el modelo de ajuste parcial en términos de una sola variable
explicativa, pero los resultados se pueden fácilmente generalizar para el caso de k
variables independientes. Sin embargo, para evitar confusiones, debe tenerse en
mente que para estimar los parámetros del modelo de largo plazo (0, 1, 2, etc.)
lo que nos interesa es dividir los coeficientes de la regresión (9) entre el estima-
dor de , que será igual a 1 menos el coeficiente de Yt–1 en esa regresión.]
7.2. Autocorrelación en Regresiones con Retardos.
En el capítulo anterior, se mencionó que la prueba Durbin-Watson no es apli-
cable cuando la lista de regresores incluye variables dependientes retardadas. De
hecho, Nerlove y Wallis han demostraron que en este caso el valor del estadístico
Durbin-Watson estará sesgado hacia 2, por lo que se tenderá a aceptar la hipótesis
de cero autocorrelación, aun cuando los errores realmente estén autocorrelacio-
nados.40
En vista de esto, Durbin41
ha propuesto el siguiente estadístico alternativo:
)(1)5.01(
bVarn
ndh
40
Marc Nerlove y K. F. Wallis, ―Use of the Durbin-Watson Statistic in Inappropriate
Situations,‖ Econometrica, 34 (1966): 235-38.
41J. Durbin, ―Testing for Serial Correlation in Least Squares Regression When Some of
the Regressors are Lagged Dependent Variables,‖ Econometrica, 38 (1970): 410-21.

[86]
donde d es el convencional estadístico Durbin-Watson, y Var(b) es la varianza
muestral del coeficiente de Yt–1. (Nótese que el estadístico h no estará definido si
nVar(b) > 1.) Durbin demostró que en grandes muestras h tiene una distribución
que se aproxima a la de una variable normal estándar (es decir, una variable nor-
mal con media 0 y varianza 1). Por tanto, para testar la hipótesis de cero auto-
correlación ( = 0) contra la alternativa de autocorrelación positiva ( > 0) con un
nivel de significancia de 5 %, rechazamos la hipótesis nula y concluimos que
existe autocorrelación si h > 1.645. (Si la alternativa es autocorrelación negativa,
concluimos que existe autocorrelación si h < –1.645.) La prueba h de Durbin es
―asintótica‖ en el sentido de que, en principio, sólo se aplica para el caso de
muestras muy grandes (digamos, n > 30). Sin embargo, Park ha encontrado que la
prueba también funciona razonablemente bien incluso cuando las muestras no son
muy grandes.42
7.3. Aplicación — Inflación en Guatemala.
En un clásico estudio sobre la inflación chilena,43
Harberger propuso el si-
guiente modelo:
Pt = b0 + b1Mt + b2Mt–1 + b3Qt + et
donde Pt representa la tasa de inflación en el año t, Mt es la tasa de crecimiento en
la masa monetaria en el año t, Qt es el cambio porcentual en el PIB real en el año
t, y et es el error o residuo de la regresión estimada. Se puede apreciar que la re-
gresión incluye también como variable independiente el crecimiento monetario
del año anterior, Mt–1, para poder tomar en cuenta posibles ―retardos‖ en el efecto
del crecimiento monetario.44
Este modelo ha sido usado para estudiar la inflación
42
S.-B. Park, ―On the Small-Sample Power of Durbin’s h Test,‖ Journal of the American
Statistical Association, 70 (1975): 60-63.
43A. C. Harberger, ―The Dynamics of Inflation in Chile,‖ en C. F. Christ, et al.,
Measurement in Economics: Studies in Mathematical Economics and Econometrics in
Memory of Yehuda Grunfeld (Stanford University Press, 1963), pp. 219-50. 44
Otra forma de expresar esta misma ecuación es:
Pt = b0 + (b1 + b2)Mt – b2(Mt – Mt–1) + b3Qt + et
donde la tasa de inflación en un período determinado depende de la tasa de crecimiento
monetario en ese período, y del cambio en la tasa de crecimiento monetario. Esto intro-
duce un elemento dinámico en la relación a corto plazo entre inflación y crecimiento
monetario. La relación de largo plazo se da cuando Mt = Mt–1 (i.e., el crecimiento mone-
tario se mantiene constante de un período a otro), y la ecuación entonces se reduce a
Pt = b0 + (b1 + b2)Mt + b3Qt + et
por lo que en el largo plazo el efecto de una determinada tasa de crecimiento monetario
está dado por (b1 + b2).

[87]
en muchos países, con buenos resultados. Algunos economistas, sin embargo,
consideran que el modelo de Harberger no siempre capta bien el retardo en el
efecto monetario, y proponen más bien que se incluya, en lugar del crecimiento
monetario retardado, un valor retardado de la variable dependiente, o sea, la tasa
de inflación del año anterior. En otras palabras, proponen que un modelo más
adecuado sería de la forma:
Pt = b0 + b1Mt + b2Qt + b3Pt–1 + et
que podría interpretarse en términos de un modelo de ajuste parcial tipo Nerlove.
Este segundo modelo fue estimado con datos para Guatemala para el período
1962-95 (Cuadro 7.1). Los resultados obtenidos fueron los siguientes:
Pt = 2.0899 + 0.5922 Mt – 0.8506 Qt + 0.3067 Pt–1
(2.243) (0.1008) (0.3668) (0.1080)
R2 = 0.701 n = 34
Se puede apreciar que, en términos generales, esta regresión funciona relativa-
mente bien. En primer lugar, los regresores explican poco más de 70 % de la va-
riación anual en la tasa de inflación, y en segundo lugar, los coeficientes estima-
dos son todos significativos (con excepción de la constante).
Para determinar si existe autocorrelación en este modelo, calculamos el
estadístico h. Los cálculos básicos se detallan en el Cuadro 7.2. Con estos datos
calculamos el valor del estadístico h de la siguiente manera:
d = 2028.9718 1080.991 = 1.87696 Var(b) = (0.108)2 = 0.01166
4617.001166.0341
34)87696.15.01(
h
En este caso, puesto que h < 1.645, no rechazamos la hipótesis de cero auto-
correlación.
Dado que la constante b0 no es significativa en esta regresión, podemos
obtener estimaciones más eficientes de los otros coeficientes por medio de una
―regresión por el origen.‖ Los resultados son los siguientes:
Pt = 0.6235 Mt – 0.6324 Qt + 0.3403 Pt–1
(0.0948) (0.2817) (0.1016)
R2 = 0.6925 n = 34
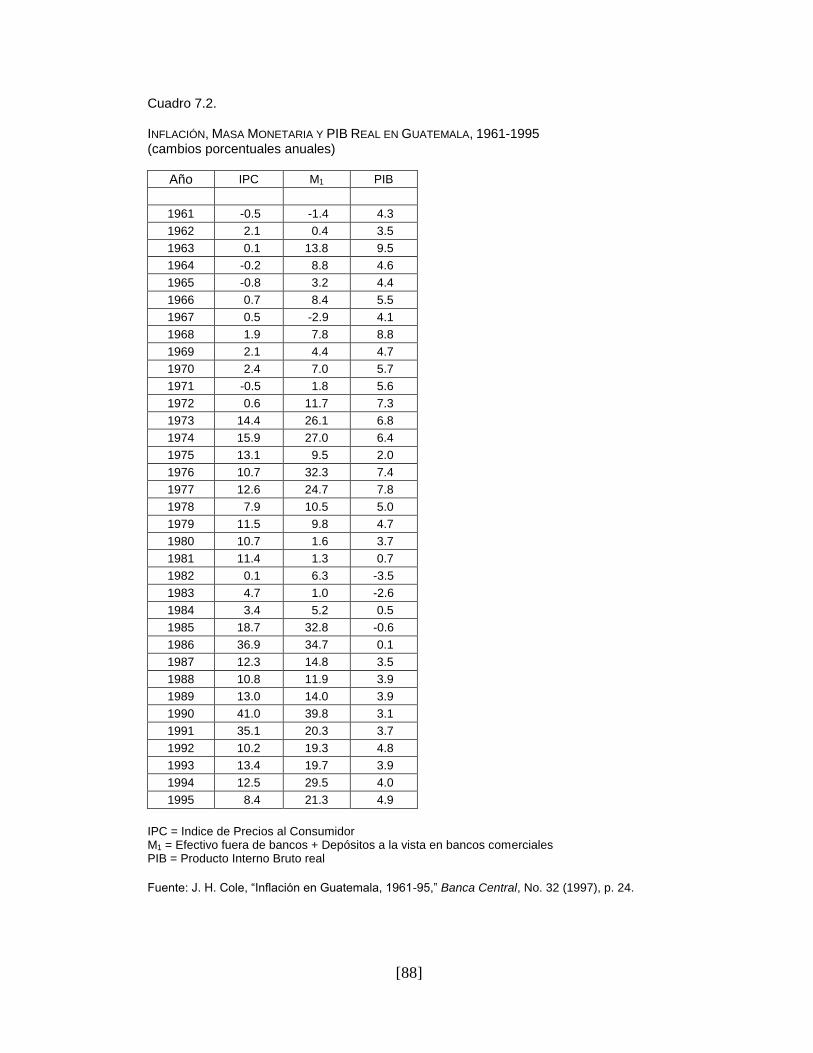
[88]
Cuadro 7.2. INFLACIÓN, MASA MONETARIA Y PIB REAL EN GUATEMALA, 1961-1995 (cambios porcentuales anuales)
Año IPC M1 PIB
1961 -0.5 -1.4 4.3
1962 2.1 0.4 3.5
1963 0.1 13.8 9.5
1964 -0.2 8.8 4.6
1965 -0.8 3.2 4.4
1966 0.7 8.4 5.5
1967 0.5 -2.9 4.1
1968 1.9 7.8 8.8
1969 2.1 4.4 4.7
1970 2.4 7.0 5.7
1971 -0.5 1.8 5.6
1972 0.6 11.7 7.3
1973 14.4 26.1 6.8
1974 15.9 27.0 6.4
1975 13.1 9.5 2.0
1976 10.7 32.3 7.4
1977 12.6 24.7 7.8
1978 7.9 10.5 5.0
1979 11.5 9.8 4.7
1980 10.7 1.6 3.7
1981 11.4 1.3 0.7
1982 0.1 6.3 -3.5
1983 4.7 1.0 -2.6
1984 3.4 5.2 0.5
1985 18.7 32.8 -0.6
1986 36.9 34.7 0.1
1987 12.3 14.8 3.5
1988 10.8 11.9 3.9
1989 13.0 14.0 3.9
1990 41.0 39.8 3.1
1991 35.1 20.3 3.7
1992 10.2 19.3 4.8
1993 13.4 19.7 3.9
1994 12.5 29.5 4.0
1995 8.4 21.3 4.9
IPC = Indice de Precios al Consumidor M1 = Efectivo fuera de bancos + Depósitos a la vista en bancos comerciales PIB = Producto Interno Bruto real
Fuente: J. H. Cole, “Inflación en Guatemala, 1961-95,” Banca Central, No. 32 (1997), p. 24.
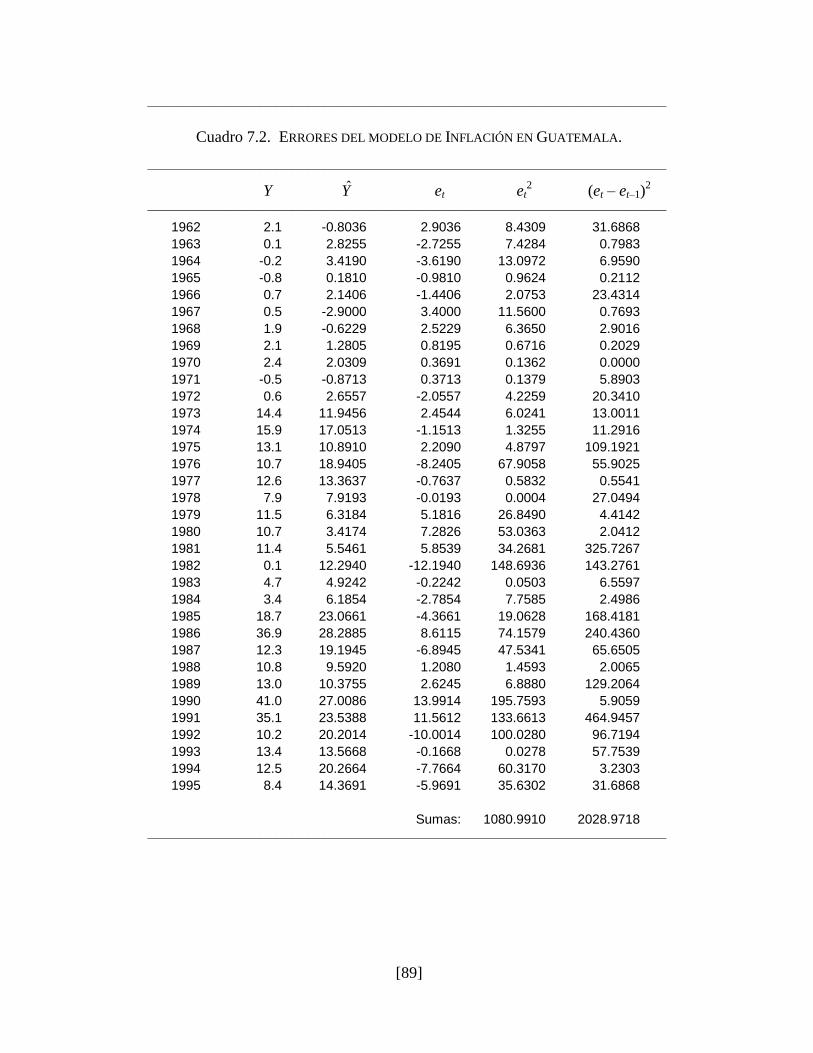
[89]
————————————————————————————————–
Cuadro 7.2. ERRORES DEL MODELO DE INFLACIÓN EN GUATEMALA.
————————————————————————————————–
Y Y et et2 (et – et–1)
2
————————————————————————————————– 1962 2.1 -0.8036 2.9036 8.4309 31.6868
1963 0.1 2.8255 -2.7255 7.4284 0.7983
1964 -0.2 3.4190 -3.6190 13.0972 6.9590
1965 -0.8 0.1810 -0.9810 0.9624 0.2112
1966 0.7 2.1406 -1.4406 2.0753 23.4314
1967 0.5 -2.9000 3.4000 11.5600 0.7693
1968 1.9 -0.6229 2.5229 6.3650 2.9016
1969 2.1 1.2805 0.8195 0.6716 0.2029
1970 2.4 2.0309 0.3691 0.1362 0.0000
1971 -0.5 -0.8713 0.3713 0.1379 5.8903
1972 0.6 2.6557 -2.0557 4.2259 20.3410
1973 14.4 11.9456 2.4544 6.0241 13.0011
1974 15.9 17.0513 -1.1513 1.3255 11.2916
1975 13.1 10.8910 2.2090 4.8797 109.1921
1976 10.7 18.9405 -8.2405 67.9058 55.9025
1977 12.6 13.3637 -0.7637 0.5832 0.5541
1978 7.9 7.9193 -0.0193 0.0004 27.0494
1979 11.5 6.3184 5.1816 26.8490 4.4142
1980 10.7 3.4174 7.2826 53.0363 2.0412
1981 11.4 5.5461 5.8539 34.2681 325.7267
1982 0.1 12.2940 -12.1940 148.6936 143.2761
1983 4.7 4.9242 -0.2242 0.0503 6.5597
1984 3.4 6.1854 -2.7854 7.7585 2.4986
1985 18.7 23.0661 -4.3661 19.0628 168.4181
1986 36.9 28.2885 8.6115 74.1579 240.4360
1987 12.3 19.1945 -6.8945 47.5341 65.6505
1988 10.8 9.5920 1.2080 1.4593 2.0065
1989 13.0 10.3755 2.6245 6.8880 129.2064
1990 41.0 27.0086 13.9914 195.7593 5.9059
1991 35.1 23.5388 11.5612 133.6613 464.9457
1992 10.2 20.2014 -10.0014 100.0280 96.7194
1993 13.4 13.5668 -0.1668 0.0278 57.7539
1994 12.5 20.2664 -7.7664 60.3170 3.2303
1995 8.4 14.3691 -5.9691 35.6302 31.6868
Sumas: 1080.9910 2028.9718
————————————————————————————————–

[90]
Si interpretamos esta regresión en términos de un modelo de ajuste parcial, en-
tonces las estimaciones de los coeficientes de largo plazo para las variables expli-
cativas serían:
Crecimiento Monetario 0.6235 (1 – 0.3403) = 0.945
Crecimiento PIB Real – 0.6324 (1 – 0.3403) = – 0.959
Por tanto, de acuerdo a estas estimaciones, el efecto final de un aumento en la
masa monetaria será un aumento de aproximadamente la misma proporción en el
nivel general de precios, mientras que el efecto final de un aumento en el PIB real
será una reducción de aproximadamente la misma proporción en el nivel de pre-
cios. Estos resultados son compatibles con la teoría económica relevante.
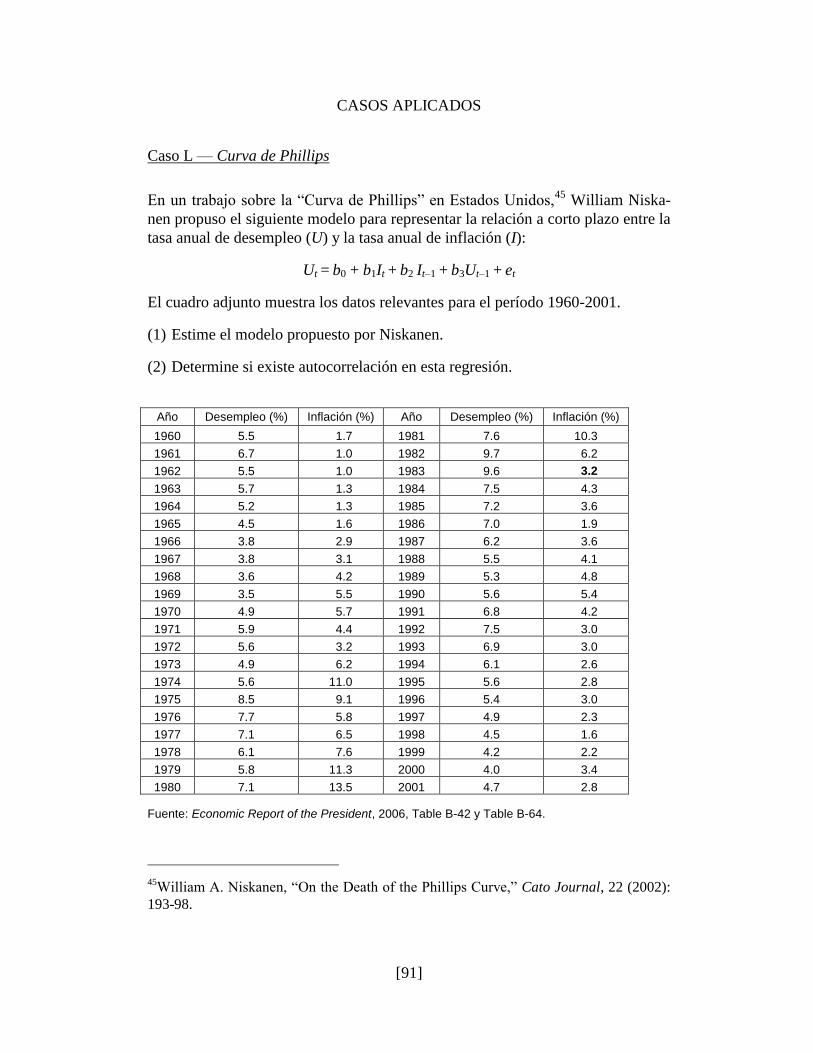
[91]
CASOS APLICADOS
Caso L — Curva de Phillips
En un trabajo sobre la ―Curva de Phillips‖ en Estados Unidos,45
William Niska-
nen propuso el siguiente modelo para representar la relación a corto plazo entre la
tasa anual de desempleo (U) y la tasa anual de inflación (I):
Ut = b0 + b1It + b2 It–1 + b3Ut–1 + et
El cuadro adjunto muestra los datos relevantes para el período 1960-2001.
(1) Estime el modelo propuesto por Niskanen.
(2) Determine si existe autocorrelación en esta regresión.
Año Desempleo (%) Inflación (%) Año Desempleo (%) Inflación (%)
1960 5.5 1.7 1981 7.6 10.3
1961 6.7 1.0 1982 9.7 6.2
1962 5.5 1.0 1983 9.6 3.2
1963 5.7 1.3 1984 7.5 4.3
1964 5.2 1.3 1985 7.2 3.6
1965 4.5 1.6 1986 7.0 1.9
1966 3.8 2.9 1987 6.2 3.6
1967 3.8 3.1 1988 5.5 4.1
1968 3.6 4.2 1989 5.3 4.8
1969 3.5 5.5 1990 5.6 5.4
1970 4.9 5.7 1991 6.8 4.2
1971 5.9 4.4 1992 7.5 3.0
1972 5.6 3.2 1993 6.9 3.0
1973 4.9 6.2 1994 6.1 2.6
1974 5.6 11.0 1995 5.6 2.8
1975 8.5 9.1 1996 5.4 3.0
1976 7.7 5.8 1997 4.9 2.3
1977 7.1 6.5 1998 4.5 1.6
1978 6.1 7.6 1999 4.2 2.2
1979 5.8 11.3 2000 4.0 3.4
1980 7.1 13.5 2001 4.7 2.8
Fuente: Economic Report of the President, 2006, Table B-42 y Table B-64.
45William A. Niskanen, ―On the Death of the Phillips Curve,‖ Cato Journal, 22 (2002):
193-98.
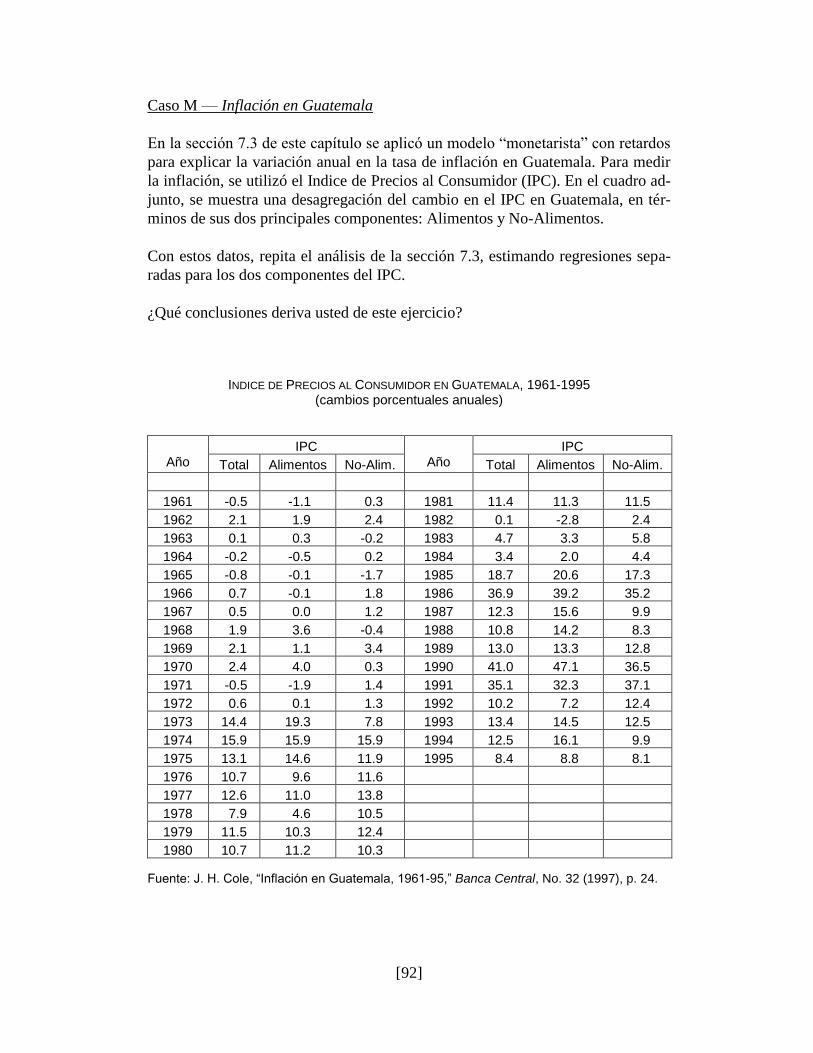
[92]
Caso M — Inflación en Guatemala
En la sección 7.3 de este capítulo se aplicó un modelo ―monetarista‖ con retardos
para explicar la variación anual en la tasa de inflación en Guatemala. Para medir
la inflación, se utilizó el Indice de Precios al Consumidor (IPC). En el cuadro ad-
junto, se muestra una desagregación del cambio en el IPC en Guatemala, en tér-
minos de sus dos principales componentes: Alimentos y No-Alimentos.
Con estos datos, repita el análisis de la sección 7.3, estimando regresiones sepa-
radas para los dos componentes del IPC.
¿Qué conclusiones deriva usted de este ejercicio?
INDICE DE PRECIOS AL CONSUMIDOR EN GUATEMALA, 1961-1995 (cambios porcentuales anuales)
Año
IPC Año
IPC
Total Alimentos No-Alim. Total Alimentos No-Alim.
1961 -0.5 -1.1 0.3 1981 11.4 11.3 11.5
1962 2.1 1.9 2.4 1982 0.1 -2.8 2.4
1963 0.1 0.3 -0.2 1983 4.7 3.3 5.8
1964 -0.2 -0.5 0.2 1984 3.4 2.0 4.4
1965 -0.8 -0.1 -1.7 1985 18.7 20.6 17.3
1966 0.7 -0.1 1.8 1986 36.9 39.2 35.2
1967 0.5 0.0 1.2 1987 12.3 15.6 9.9
1968 1.9 3.6 -0.4 1988 10.8 14.2 8.3
1969 2.1 1.1 3.4 1989 13.0 13.3 12.8
1970 2.4 4.0 0.3 1990 41.0 47.1 36.5
1971 -0.5 -1.9 1.4 1991 35.1 32.3 37.1
1972 0.6 0.1 1.3 1992 10.2 7.2 12.4
1973 14.4 19.3 7.8 1993 13.4 14.5 12.5
1974 15.9 15.9 15.9 1994 12.5 16.1 9.9
1975 13.1 14.6 11.9 1995 8.4 8.8 8.1
1976 10.7 9.6 11.6
1977 12.6 11.0 13.8
1978 7.9 4.6 10.5
1979 11.5 10.3 12.4
1980 10.7 11.2 10.3
Fuente: J. H. Cole, “Inflación en Guatemala, 1961-95,” Banca Central, No. 32 (1997), p. 24.

[93]
Caso N — Demanda de Importaciones en Guatemala
En el cuadro adjunto se muestran datos relacionados con las importaciones en
Guatemala durante el perìodo de 1965 a 2000. Para eliminar el efecto de la infla-
ción, los datos han sido expresados en términos de quetzales de 1958, de modo
que estas cifras ―deflatadas‖ se pueden interpretar como las importaciones
―reales‖ en el sentido de que reflejan cambios en la demanda física de bienes im-
portados. Como una primera aproximación, podemos expresar la ―demanda de
importaciones‖ como función del costo relativo de los productos importados
(comparado con el costo de bienes producidos domésticamente) y del nivel de in-
greso real.
Para medir la primera de estas variables explicativas, tomamos la razón entre el
Deflactor de Importaciones y el Deflactor del Producto Interno Bruto (PIB) total,
y para medir la segunda variable explicativa tomamos el PIB real (a precios de
1958). Puesto que lo que nos interesa saber es la elasticidad de la demanda de
importaciones respecto de cada una de estas variables, estimamos el siguiente
modelo doble-log:
ln(Imp)t = b0 + b1ln(Pm)t + b2ln(PIB)t + b3ln(Imp)t–1 + et
donde ―Imp‖ son las importaciones reales, ―Pm‖ es el precio relativo de las im-
portaciones, y ―PIB‖ es el Producto Interno Bruto real. Para tomar en cuenta po-
sibles retardos en el efecto de estas variables, se agrega también el valor retardado
de la variable dependiente como una tercera variable explicativa.46
(a) Con estos datos estime el modelo propuesto, y utilice los resultados para cal-
cular la elasticidad-precio y la elasticidad-ingreso de la demanda de importacio-
nes, tanto en el corto plazo como en el largo plazo.
(b) Determine si en este modelo existen problemas de autocorrelación.
46
Para una justificación de esta forma funcional y su interpretación en términos de un
modelo de ajuste parcial, véase M. S. Khan, ―Import and Export Demand in Developing
Countries,‖ IMF Staff Papers, 21 (1974): 678-93.
[94]
IMPORTACIONES EN GUATEMALA, 1965-2000.
Año Importaciones
Reales 1/
Precio Relativo 2/
PIB Real 1/
1965 247.0 1.076 1355.2
1966 251.0 1.090 1429.9
1967 267.0 1.088 1488.6
1968 277.7 1.074 1619.2
1969 271.8 1.087 1695.9
1970 293.2 1.087 1792.8
1971 312.0 1.134 1892.8
1972 294.7 1.277 2031.6
1973 324.2 1.352 2169.4
1974 416.4 1.598 2307.7
1975 352.1 1.573 2352.7
1976 457.1 1.524 2526.5
1977 498.1 1.431 2723.8
1978 521.6 1.495 2859.9
1979 482.8 1.603 2994.6
1980 441.2 1.755 3106.9
1981 424.6 1.738 3127.6
1982 334.3 1.687 3016.6
1983 269.2 1.589 2939.6
1984 287.2 1.589 2953.5
1985 250.3 2.358 2936.1
1986 213.6 2.009 2940.2
1987 315.9 2.149 3044.4
1988 327.7 2.117 3162.9
1989 346.9 2.130 3287.6
1990 344.3 2.336 3389.6
1991 369.2 2.055 3513.6
1992 506.0 1.992 3683.6
1993 527.3 1.894 3828.3
1994 553.5 1.790 3982.7
1995 595.5 1.785 4179.8
1996 554.7 1.752 4303.4
1997 662.8 1.599 4491.2
1998 825.2 1.500 4715.5
1999 831.1 1.612 4896.9
2000 882.2 1.679 5072.5
Deflactor de Importación 1/ Millones de quetzales de 1958 2/ Precio Relativo = ———————————— Deflactor del PIB Fuente: Banco de Guatemala, Sección Cuentas Nacionales.

[95]
ANEXOS
A-1. Areas de la Distribución Normal Estándar …………………………….... 96
p.
A-2. Percentiles de la Distribución t (Student) ……………………………….. 97
p.
A-3. Valores Críticos de la Distribución Chi-cuadrado ……………………… 98
p.
A-4. Estadístico Durbin-Watson: Valores Críticos (5 %) para dL y dU ……….. 99
p

[96]
A-1. Areas de la Distribución Normal Estándar.
z .00 .01 .02 .03 .04 .05 .06 .07 .08 .09
0.0 0.0000 0.0040 0.0080 0.0120 0.0160 0.0199 0.0239 0.0279 0.0319 0.0359
0.1 0.0398 0.0438 0.0478 0.0517 0.0557 0.0596 0.0636 0.0675 0.0714 0.0753
0.2 0.0793 0.0832 0.0871 0.0910 0.0948 0.0987 0.1026 0.1064 0.1103 0.1141
0.3 0.1179 0.1217 0.1255 0.1293 0.1331 0.1368 0.1406 0.1443 0.1480 0.1517
0.4 0.1554 0.1591 0.1628 0.1664 0.1700 0.1736 0.1772 0.1808 0.1844 0.1879
0.5 0.1915 0.1950 0.1985 0.2019 0.2054 0.2088 0.2123 0.2157 0.2190 0.2224
0.6 0.2257 0.2291 0.2324 0.2357 0.2389 0.2422 0.2454 0.2486 0.2517 0.2549
0.7 0.2580 0.2611 0.2642 0.2673 0.2704 0.2734 0.2764 0.2794 0.2823 0.2852
0.8 0.2881 0.2910 0.2939 0.2967 0.2995 0.3023 0.3051 0.3078 0.3106 0.3133
0.9 0.3159 0.3186 0.3212 0.3238 0.3264 0.3289 0.3315 0.3340 0.3365 0.3389
1.0 0.3413 0.3438 0.3461 0.3485 0.3508 0.3531 0.3554 0.3577 0.3599 0.3621
1.1 0.3643 0.3665 0.3686 0.3708 0.3729 0.3749 0.3770 0.3790 0.3810 0.3830
1.2 0.3849 0.3869 0.3888 0.3907 0.3925 0.3944 0.3962 0.3980 0.3997 0.4015
1.3 0.4032 0.4049 0.4066 0.4082 0.4099 0.4115 0.4131 0.4147 0.4162 0.4177
1.4 0.4192 0.4207 0.4222 0.4236 0.4251 0.4265 0.4279 0.4292 0.4306 0.4319
1.5 0.4332 0.4345 0.4357 0.4370 0.4382 0.4394 0.4406 0.4418 0.4429 0.4441
1.6 0.4452 0.4463 0.4474 0.4484 0.4495 0.4505 0.4515 0.4525 0.4535 0.4545
1.7 0.4554 0.4564 0.4573 0.4582 0.4591 0.4599 0.4608 0.4616 0.4625 0.4633
1.8 0.4641 0.4649 0.4656 0.4664 0.4671 0.4678 0.4686 0.4693 0.4699 0.4706
1.9 0.4713 0.4719 0.4726 0.4732 0.4738 0.4744 0.4750 0.4756 0.4761 0.4767
2.0 0.4772 0.4778 0.4783 0.4788 0.4793 0.4798 0.4803 0.4808 0.4812 0.4817
2.1 0.4821 0.4826 0.4830 0.4834 0.4838 0.4842 0.4846 0.4850 0.4854 0.4857
2.2 0.4861 0.4864 0.4868 0.4871 0.4875 0.4878 0.4881 0.4884 0.4887 0.4890
2.3 0.4893 0.4896 0.4898 0.4901 0.4904 0.4906 0.4909 0.4911 0.4913 0.4916
2.4 0.4918 0.4920 0.4922 0.4925 0.4927 0.4929 0.4931 0.4932 0.4934 0.4936
2.5 0.4938 0.4940 0.4941 0.4943 0.4945 0.4946 0.4948 0.4949 0.4951 0.4952
2.6 0.4953 0.4955 0.4956 0.4957 0.4959 0.4960 0.4961 0.4962 0.4963 0.4964
2.7 0.4965 0.4966 0.4967 0.4968 0.4969 0.4970 0.4971 0.4972 0.4973 0.4974
2.8 0.4974 0.4975 0.4976 0.4977 0.4977 0.4978 0.4979 0.4979 0.4980 0.4981
2.9 0.4981 0.4982 0.4982 0.4983 0.4984 0.4984 0.4985 0.4985 0.4986 0.4986
3.0 0.4987 0.4987 0.4987 0.4988 0.4988 0.4989 0.4989 0.4989 0.4990 0.4990
Fuente: Hoel (1971)
0 z
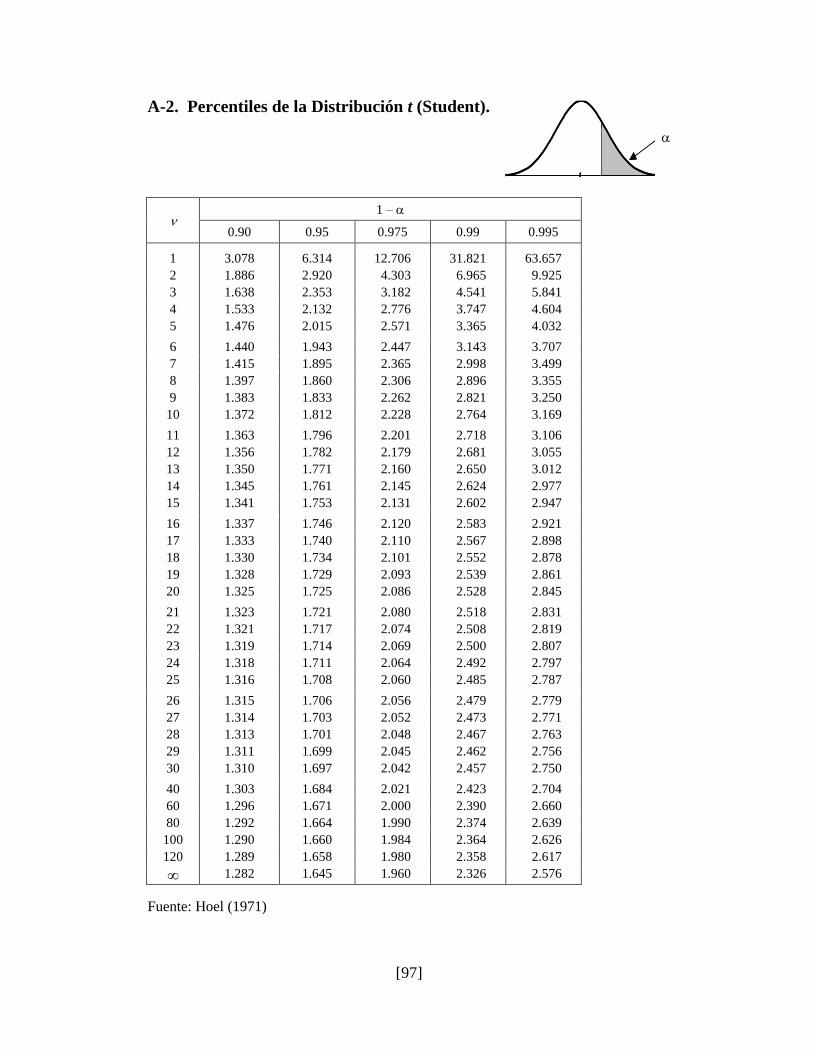
[97]
A-2. Percentiles de la Distribución t (Student).
1 –
0.90 0.95 0.975 0.99 0.995
1 3.078 6.314 12.706 31.821 63.657
2 1.886 2.920 4.303 6.965 9.925
3 1.638 2.353 3.182 4.541 5.841
4 1.533 2.132 2.776 3.747 4.604
5 1.476 2.015 2.571 3.365 4.032
6 1.440 1.943 2.447 3.143 3.707
7 1.415 1.895 2.365 2.998 3.499
8 1.397 1.860 2.306 2.896 3.355
9 1.383 1.833 2.262 2.821 3.250
10 1.372 1.812 2.228 2.764 3.169
11 1.363 1.796 2.201 2.718 3.106
12 1.356 1.782 2.179 2.681 3.055
13 1.350 1.771 2.160 2.650 3.012
14 1.345 1.761 2.145 2.624 2.977
15 1.341 1.753 2.131 2.602 2.947
16 1.337 1.746 2.120 2.583 2.921
17 1.333 1.740 2.110 2.567 2.898
18 1.330 1.734 2.101 2.552 2.878
19 1.328 1.729 2.093 2.539 2.861
20 1.325 1.725 2.086 2.528 2.845
21 1.323 1.721 2.080 2.518 2.831
22 1.321 1.717 2.074 2.508 2.819
23 1.319 1.714 2.069 2.500 2.807
24 1.318 1.711 2.064 2.492 2.797
25 1.316 1.708 2.060 2.485 2.787
26 1.315 1.706 2.056 2.479 2.779
27 1.314 1.703 2.052 2.473 2.771
28 1.313 1.701 2.048 2.467 2.763
29 1.311 1.699 2.045 2.462 2.756
30 1.310 1.697 2.042 2.457 2.750
40 1.303 1.684 2.021 2.423 2.704
60 1.296 1.671 2.000 2.390 2.660
80 1.292 1.664 1.990 2.374 2.639
100 1.290 1.660 1.984 2.364 2.626
120 1.289 1.658 1.980 2.358 2.617
∞ 1.282 1.645 1.960 2.326 2.576
Fuente: Hoel (1971)
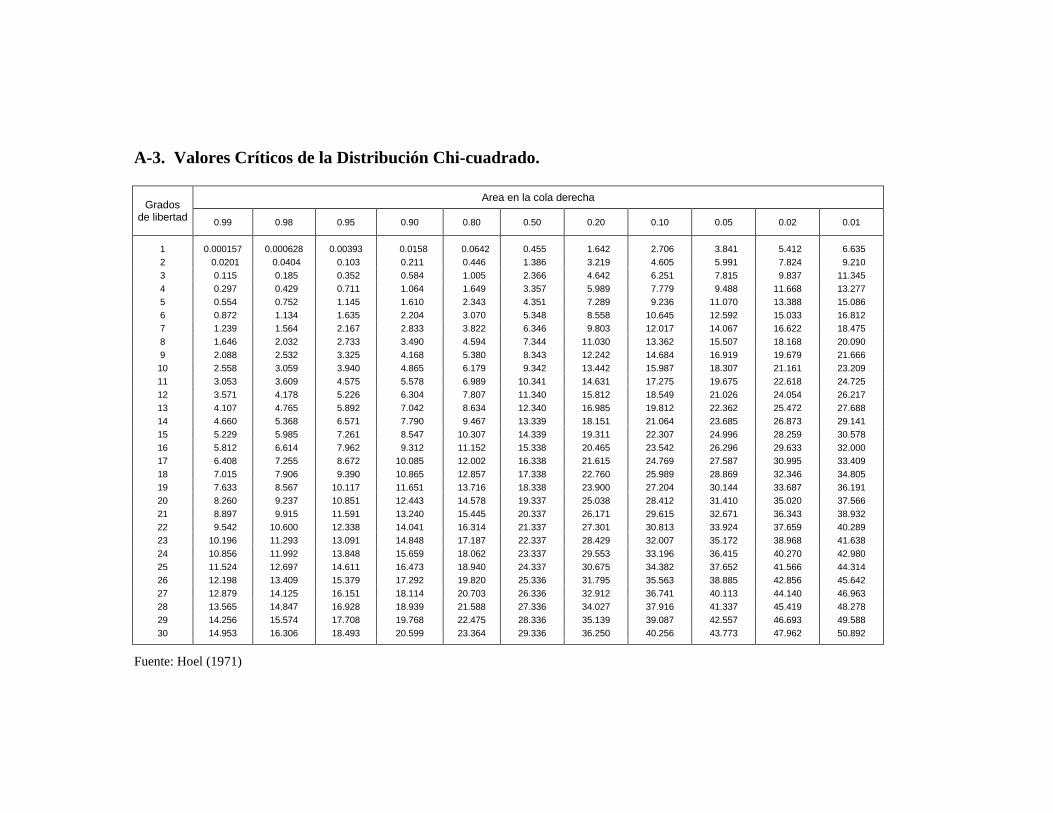
A-3. Valores Críticos de la Distribución Chi-cuadrado.
Grados de libertad
Area en la cola derecha
0.99 0.98 0.95 0.90 0.80 0.50 0.20 0.10 0.05 0.02 0.01
1 0.000157 0.000628 0.00393 0.0158 0.0642 0.455 1.642 2.706 3.841 5.412 6.635
2 0.0201 0.0404 0.103 0.211 0.446 1.386 3.219 4.605 5.991 7.824 9.210
3 0.115 0.185 0.352 0.584 1.005 2.366 4.642 6.251 7.815 9.837 11.345
4 0.297 0.429 0.711 1.064 1.649 3.357 5.989 7.779 9.488 11.668 13.277
5 0.554 0.752 1.145 1.610 2.343 4.351 7.289 9.236 11.070 13.388 15.086
6 0.872 1.134 1.635 2.204 3.070 5.348 8.558 10.645 12.592 15.033 16.812
7 1.239 1.564 2.167 2.833 3.822 6.346 9.803 12.017 14.067 16.622 18.475
8 1.646 2.032 2.733 3.490 4.594 7.344 11.030 13.362 15.507 18.168 20.090
9 2.088 2.532 3.325 4.168 5.380 8.343 12.242 14.684 16.919 19.679 21.666
10 2.558 3.059 3.940 4.865 6.179 9.342 13.442 15.987 18.307 21.161 23.209
11 3.053 3.609 4.575 5.578 6.989 10.341 14.631 17.275 19.675 22.618 24.725
12 3.571 4.178 5.226 6.304 7.807 11.340 15.812 18.549 21.026 24.054 26.217
13 4.107 4.765 5.892 7.042 8.634 12.340 16.985 19.812 22.362 25.472 27.688
14 4.660 5.368 6.571 7.790 9.467 13.339 18.151 21.064 23.685 26.873 29.141
15 5.229 5.985 7.261 8.547 10.307 14.339 19.311 22.307 24.996 28.259 30.578
16 5.812 6.614 7.962 9.312 11.152 15.338 20.465 23.542 26.296 29.633 32.000
17 6.408 7.255 8.672 10.085 12.002 16.338 21.615 24.769 27.587 30.995 33.409
18 7.015 7.906 9.390 10.865 12.857 17.338 22.760 25.989 28.869 32.346 34.805
19 7.633 8.567 10.117 11.651 13.716 18.338 23.900 27.204 30.144 33.687 36.191
20 8.260 9.237 10.851 12.443 14.578 19.337 25.038 28.412 31.410 35.020 37.566
21 8.897 9.915 11.591 13.240 15.445 20.337 26.171 29.615 32.671 36.343 38.932
22 9.542 10.600 12.338 14.041 16.314 21.337 27.301 30.813 33.924 37.659 40.289
23 10.196 11.293 13.091 14.848 17.187 22.337 28.429 32.007 35.172 38.968 41.638
24 10.856 11.992 13.848 15.659 18.062 23.337 29.553 33.196 36.415 40.270 42.980
25 11.524 12.697 14.611 16.473 18.940 24.337 30.675 34.382 37.652 41.566 44.314
26 12.198 13.409 15.379 17.292 19.820 25.336 31.795 35.563 38.885 42.856 45.642
27 12.879 14.125 16.151 18.114 20.703 26.336 32.912 36.741 40.113 44.140 46.963
28 13.565 14.847 16.928 18.939 21.588 27.336 34.027 37.916 41.337 45.419 48.278
29 14.256 15.574 17.708 19.768 22.475 28.336 35.139 39.087 42.557 46.693 49.588
30 14.953 16.306 18.493 20.599 23.364 29.336 36.250 40.256 43.773 47.962 50.892
Fuente: Hoel (1971)
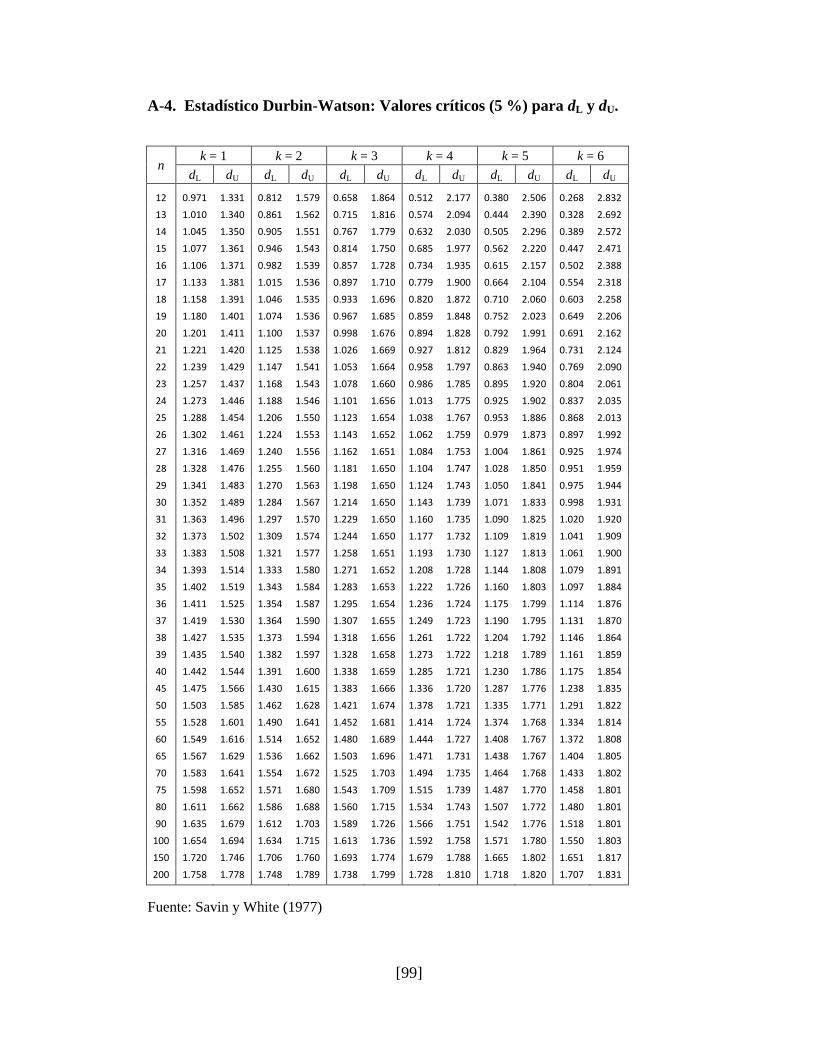
[99]
A-4. Estadístico Durbin-Watson: Valores críticos (5 %) para dL y dU.
n k = 1 k = 2 k = 3 k = 4 k = 5 k = 6
dL dU dL dU dL dU dL dU dL dU dL dU
12 0.971 1.331 0.812 1.579 0.658 1.864 0.512 2.177 0.380 2.506 0.268 2.832
13 1.010 1.340 0.861 1.562 0.715 1.816 0.574 2.094 0.444 2.390 0.328 2.692
14 1.045 1.350 0.905 1.551 0.767 1.779 0.632 2.030 0.505 2.296 0.389 2.572
15 1.077 1.361 0.946 1.543 0.814 1.750 0.685 1.977 0.562 2.220 0.447 2.471
16 1.106 1.371 0.982 1.539 0.857 1.728 0.734 1.935 0.615 2.157 0.502 2.388
17 1.133 1.381 1.015 1.536 0.897 1.710 0.779 1.900 0.664 2.104 0.554 2.318
18 1.158 1.391 1.046 1.535 0.933 1.696 0.820 1.872 0.710 2.060 0.603 2.258
19 1.180 1.401 1.074 1.536 0.967 1.685 0.859 1.848 0.752 2.023 0.649 2.206
20 1.201 1.411 1.100 1.537 0.998 1.676 0.894 1.828 0.792 1.991 0.691 2.162
21 1.221 1.420 1.125 1.538 1.026 1.669 0.927 1.812 0.829 1.964 0.731 2.124
22 1.239 1.429 1.147 1.541 1.053 1.664 0.958 1.797 0.863 1.940 0.769 2.090
23 1.257 1.437 1.168 1.543 1.078 1.660 0.986 1.785 0.895 1.920 0.804 2.061
24 1.273 1.446 1.188 1.546 1.101 1.656 1.013 1.775 0.925 1.902 0.837 2.035
25 1.288 1.454 1.206 1.550 1.123 1.654 1.038 1.767 0.953 1.886 0.868 2.013
26 1.302 1.461 1.224 1.553 1.143 1.652 1.062 1.759 0.979 1.873 0.897 1.992
27 1.316 1.469 1.240 1.556 1.162 1.651 1.084 1.753 1.004 1.861 0.925 1.974
28 1.328 1.476 1.255 1.560 1.181 1.650 1.104 1.747 1.028 1.850 0.951 1.959
29 1.341 1.483 1.270 1.563 1.198 1.650 1.124 1.743 1.050 1.841 0.975 1.944
30 1.352 1.489 1.284 1.567 1.214 1.650 1.143 1.739 1.071 1.833 0.998 1.931
31 1.363 1.496 1.297 1.570 1.229 1.650 1.160 1.735 1.090 1.825 1.020 1.920
32 1.373 1.502 1.309 1.574 1.244 1.650 1.177 1.732 1.109 1.819 1.041 1.909
33 1.383 1.508 1.321 1.577 1.258 1.651 1.193 1.730 1.127 1.813 1.061 1.900
34 1.393 1.514 1.333 1.580 1.271 1.652 1.208 1.728 1.144 1.808 1.079 1.891
35 1.402 1.519 1.343 1.584 1.283 1.653 1.222 1.726 1.160 1.803 1.097 1.884
36 1.411 1.525 1.354 1.587 1.295 1.654 1.236 1.724 1.175 1.799 1.114 1.876
37 1.419 1.530 1.364 1.590 1.307 1.655 1.249 1.723 1.190 1.795 1.131 1.870
38 1.427 1.535 1.373 1.594 1.318 1.656 1.261 1.722 1.204 1.792 1.146 1.864
39 1.435 1.540 1.382 1.597 1.328 1.658 1.273 1.722 1.218 1.789 1.161 1.859
40 1.442 1.544 1.391 1.600 1.338 1.659 1.285 1.721 1.230 1.786 1.175 1.854
45 1.475 1.566 1.430 1.615 1.383 1.666 1.336 1.720 1.287 1.776 1.238 1.835
50 1.503 1.585 1.462 1.628 1.421 1.674 1.378 1.721 1.335 1.771 1.291 1.822
55 1.528 1.601 1.490 1.641 1.452 1.681 1.414 1.724 1.374 1.768 1.334 1.814
60 1.549 1.616 1.514 1.652 1.480 1.689 1.444 1.727 1.408 1.767 1.372 1.808
65 1.567 1.629 1.536 1.662 1.503 1.696 1.471 1.731 1.438 1.767 1.404 1.805
70 1.583 1.641 1.554 1.672 1.525 1.703 1.494 1.735 1.464 1.768 1.433 1.802
75 1.598 1.652 1.571 1.680 1.543 1.709 1.515 1.739 1.487 1.770 1.458 1.801
80 1.611 1.662 1.586 1.688 1.560 1.715 1.534 1.743 1.507 1.772 1.480 1.801
90 1.635 1.679 1.612 1.703 1.589 1.726 1.566 1.751 1.542 1.776 1.518 1.801
100 1.654 1.694 1.634 1.715 1.613 1.736 1.592 1.758 1.571 1.780 1.550 1.803
150 1.720 1.746 1.706 1.760 1.693 1.774 1.679 1.788 1.665 1.802 1.651 1.817
200 1.758 1.778 1.748 1.789 1.738 1.799 1.728 1.810 1.718 1.820 1.707 1.831
Fuente: Savin y White (1977)

[100]
REFERENCIAS
A. Textos de Econometría.
Doti, James L. y Esmael Adibi. The Practice of Econometrics with EViews. Irvine, CA:
Quantitative Micro Software, 1998.
Edwards, A. L. Multiple Regression and the Analysis of Variance and Covariance. San
Francisco: W. H. Freeman & Co., 1979.
Goldberger, Arthur S. Teoría Econométrica. Madrid: Editorial Tecnos, 1970. Versión
original: Econometric Theory [1964].
Goldberger, Arthur S. Topics in Regression Analysis. New York: Macmillan, 1968.
Greene, William H. Econometric Analysis, 5ª ed. Upper Saddle River, NJ: Prentice Hall,
2003.
Gujarati, Damodar N. Econometría, 2ª ed. México: McGraw-Hill, 1992. Versión origi-
nal: Basic Econometrics [1988].
Hernández Alonso, José. Ejercicios de Econometría, 2ª ed. Madrid: ESIC Editorial,
1992.
Hill, R. Carter, William E. Griffiths y George G. Judge. Undergraduate Econometrics,
2ª ed. New York: John Wiley & Sons, 2001.
Johnston, J. Econometric Methods, 2a ed. Nueva York: McGraw-Hill, 1972.
Klein, Lawrence R. An Introduction to Econometrics. London: Prentice-Hall Internatio-
nal, 1962.
Maddala, G. S. Econometría. Madrid: McGraw-Hill, 1985. Versión original: Econome-
trics [1977].
Martín, Guillermina, José M. Labeaga y Francisco Mochón M. Introducción a la Eco-
nometría. Madrid: Prentice-Hall, 1997.
Neter, John y William Wasserman. Applied Linear Statistical Models. Homewood, Ill.:
R. D. Irwin, 1974.
Novales, Alfonso. Econometría, 2ª ed. Madrid: McGraw-Hill, 1993.
Rao, Potluri y R. L. Miller. Applied Econometrics. Belmont, CA: Wadsworth Pub. Co.,
1971.
Studenmund, A. H. y Henry J. Cassidy. Using Econometrics: A Practical Guide. Bos-
ton: Little, Brown and Co., 1987.
Theil, Henri. Principles of Econometrics. New York: John Wiley & Sons, 1971.

[101]
Tirado de Alonso, Irma y M. Dutta. Métodos Econométricos. Cincinnati, OH: South-
Western Publishing Co., 1982.
Walters, A. A. Introducción a la Econometría. Barcelona: Oikos-Tau, 1977. Versión
original: An Introduction to Econometrics [1968].
Wonnacott, Ronald J. y Thomas H. Wonnacott. Econometrics. New York: John Wiley &
Sons, 1970.
Wooldridge, Jeffrey M. Introducción a la Econometría: Un Enfoque Moderno, 4ª ed.
México: Cengage Learning, 2009. Versión original: Introductory Econometrics: A
Modern Approach [2006].
B. Otras Referencias.
Alcaide, Ángel (ed). Lecturas de Econometría. Madrid: Gredos, 1972.
Allen, R. G. D. Análisis Matemático para Economistas. Madrid: Aguilar, 1946. Versión
original: Mathematical Analysis for Economists [1938].
Barro, Robert J. Economic Growth and Convergence. Occasional Papers No. 46. San
Francisco: International Center for Economic Growth, 1994.
Benston, George J. “Multiple Regression Analysis of Cost Behavior,” Accounting Re-
view, 41 (1966): 657-72. (University of Rochester, Graduate School of Manage-
ment, Systems Analysis Reprint Series No. S-6.)
Bishop, C. E. y W. D. Toussaint. Introducción al Análisis de Economía Agrícola. Méxi-
co: Limusa-Wiley, 1966. Versión original: Introduction to Agricultural Economic
Analysis [1958].
Cochrane, D. y G. H. Orcutt. “Application of Least Squares Regression to Relationships
Containing Autocorrelated Errors,” Journal of the American Statistical Association,
44 (1949): 32-61.
Cole, Julio H. “Inflación en Guatemala, 1961-95,” Banca Central, No. 32 (1997): 21-25.
Crespo Cuaresma, Jesús. “Okun’s Law Revisited,” Oxford Bulletin of Economics and
Statistics, 65 (2003): 439-51.
Dillon, John J. The Analysis of Response in Crop and Livestock Production, 2ª ed. Ox-
ford: Pergamon Press, 1977.
Durbin, J. y G. S. Watson. “Testing for Serial Correlation in Least Squares Regression,”
Biometrika, 37 (1950): 409-28, 38 (1951): 159-78.
Durbin, J. “The Fitting of Time-Series Models,” Review of the International Statistical
Institute, 28 (1960): 233-43.
Durbin, J. “Testing for Serial Correlation in Least-Squares Regression When Some of
the Regressors are Lagged Dependent Variables,” Econometrica, 38 (1970): 410-21.

[102]
Esquivel, Gerardo. “Convergencia Regional en México, 1940-1995,” El Trimestre Eco-
nómico, 66 (1999): 725-61.
Farebrother, R. W. “The Durbin-Watson Test for Serial Correlation When There is No
Intercept in the Regression,” Econometrica, 48 (1980): 1553-63.
Friedman, Milton. “Money: Quantity Theory,” International Encyclopedia of the Social
Sciences (1968), vol. 10, pp. 432-47.
Goldberger, Arthur S. “Review of Distributed Lags and Demand Analysis for Agricul-
tural and Other Commodities by Marc Nerlove,” American Economic Review, 48
(1958): 1011-13.
Goldberger, Arthur S. “Dependency Rates and Savings Rates: Further Comment,” Amer-
ican Economic Review, 63 (1973): 232-33.
Griliches, Z., et al., “Notes on Estimated Aggregate Quarterly Consumption Functions,”
Econometrica, 30 (1962): 491-500.
Gupta, Kanhaya L. “Dependency Rates and Savings Rates: Comment,” American Eco-
nomic Review, 61 (1971): 469-71.
Halvorsen, Robert y Raymond Palmquist. “The Interpretation of Dummy Variables in
Semilogarithmic Equations,” American Economic Review, 70 (1980): 474-75.
Harberger, Arnold C. “The Dynamics of Inflation in Chile,” en C. F. Christ, et al.,
Measurement in Economics: Studies in Mathematical Economics and Econometrics
in Memory of Yehuda Grunfeld, pp. 219-50. Stanford, CA: Stanford University
Press, 1963.
Henderson, Harold V. y Paul F. Velleman. “Building Multiple Regression Models Inter-
actively,” Biometrics, 37 (1981): 391-411.
Hoel, Paul G. Introduction to Mathematical Statistics, 4ª ed. Nueva York: John Wiley &
Sons, 1971.
Johnston, J. Análisis Estadístico de los Costes. Barcelona: Sagitario, S. A., 1966. Ver-
sión original: Statistical Cost Analysis [1960].
Khan, M. S. “Import and Export Demand in Developing Countries,” IMF Staff Papers,
21 (1974): 678-93.
Krugman, Paul. “How Fast Can the U.S. Economy Grow?” Harvard Business Review,
75 (July-Aug 1997): 123-29.
Lebergott, Stanley. “Annual Estimates of Unemployment in the United States, 1900-
1950,” en The Measurement and Behavior of Unemployment, pp. 213-41. Princeton:
Princeton University Press, 1957.
Marquardt, Donald W. “Generalized Inverses, Ridge Regression, Biased Linear Estima-
tion, and Nonlinear Estimation,” Technometrics, 12 (1970): 591-612.

[103]
Merrington, Maxine. “Percentage Points of the t-Distribution,” Biometrika, 32 (1941):
300.
Nerlove, Marc. “Distributed Lags,” International Encyclopedia of the Social Sciences
(1968), vol. 4, pp. 214-17.
Nerlove, Marc y K. F. Wallis. “Use of the Durbin-Watson Statistic in Inappropriate
Situations,” Econometrica, 34 (1966): 235-38.
Niskanen, William A. “On the Death of the Phillips Curve,” Cato Journal, 22 (2002):
193-98.
Okun, Arthur M. “Potential GNP: Its Measurement and Significance.” Proceedings
(Business and Economics Section), American Statistical Association, 1962, pp. 98-
104.
Park, Soo-Bin. “On the Small-Sample Power of Durbin’s h Test,” Journal of the Ameri-
can Statistical Association, 70 (1975): 60-63.
Riew, John. “Economies of Scale in High School Operation,” Review of Economics and
Statistics, 48 (1966): 280-87.
Sala-i-Martin, Xavier. “The Classical Approach to Convergence Analysis,” Economic
Journal, 106 (1996): 1019-36.
Savin, N. E. y K. J. White. “The Durbin-Watson Test for Serial Correlation with Ex-
treme Sample Sizes or Many Regressors,” Econometrica, 45 (1977): 1989-96.
Solow, Robert M. “A Contribution to the Theory of Economic Growth,” Quarterly
Journal of Economics, 70 (1956): 65-94.
Suits, Daniel B. “The Demand for New Automobiles in the United States,” Review of
Economics and Statistics, 40 (1958): 273-80.
Tobin, James. “A Statistical Demand Function for Food in the U.S.A.,” Journal of the
Royal Statistical Society, Series A, 113 (1950): 113-41.
Vogel, Robert C. “The Dynamics of Inflation in Latin America, 1950-1969,” American
Economic Review, 64 (1974): 102-14.
White, Halbert. “A Heteroskedasticity-Consistent Covariance Matrix Estimator and a
Direct Test for Heteroskedasticity,” Econometrica, 48 (1980): 817–38.




















