
Early Prediction of Student Success: Mining Students Enrolment Data by Zlatko J. Kovačić
82
İST502 VERİ MADENCİLİĞİ MAKALE SUNUMU Early Prediction of Student Success: Mining Students Enrolment Data by Zlatko J.Kovačić Proceedings of Informing Science & IT Education Conference (InSITE) 2010 148307119 Simge DENİZ 158303223 Şima KÜÇÜKDİLEK
Transcript of Early Prediction of Student Success: Mining Students Enrolment Data by Zlatko J. Kovačić

İST502 VERİ MADENCİLİĞİ MAKALE SUNUMU
Early Prediction of Student Success:
Mining Students Enrolment Databy Zlatko J.Kovačić
Proceedings of Informing Science & IT Education Conference (InSITE) 2010
148307119 Simge DENİZ
158303223 Şima KÜÇÜKDİLEK
İÇERİK
Makale
CRISP-DMDescriptives & Feature
SelectionKarar Ağaçları
Sonuç

MAKALE
Sosyo-demografik değişkenler ve eğitim ortamının derse devam/terk üzerine etkisi araştırılmaktadır. Bu faktörlerden
etkilenen veriler incelenmektedir.

MAKALE
• Open Polytechnic uzaktan eğitim veren bir kuruluştur. • Öğrenci bilgi sisteminden 2006-2009 yılları arasında kaydolan öğrencilerin verileri kullanılmaktadır.
• Analiz için, 71150 Bilgi Sistemleri adlı online derse kaydolan 450 öğrencinin bilgileri dikkate alınmaktadır.
• Veri madenciliği teknikleri ile• Öğrenci başarısına etki eden en önemli faktörler• Başarılı ve başarısız öğrencilerin genel profili belirlenmektedir.
• Çapraz doğrulama ve kazanım diyagramı kullanılarak risk tahmini yapılmaktadır.
• Sonuçların akademik ve idari personele etkileri tartışılmaktadır.

MAKALE
• Bilgi sistemleri dersi, IT alanında uzmanlaşacak öğrenciler için temel derstir. Aynı zamanda, birçok öğrencinin Open Polytechnic’te aldığı ilk ders olduğu için geçiş sayılmaktadır.
• Temel amaç: Open Polytechnic’teki Bilgi Sistemleri dersi çıktılarını etkileyen faktörleri bulmak
• Alt amaçlar:• Ders çıktılarının erken tahmini için model geliştirmek• Sınıflandırma doğruluğu açısından bu modelleri değerlendirmek
• Sonuçları kullanıcıların kolayca anlayabileceği şekilde açıklamak

İÇERİK
Makale
CRISP-DMDescriptives & Feature
SelectionKarar Ağaçları
Sonuç

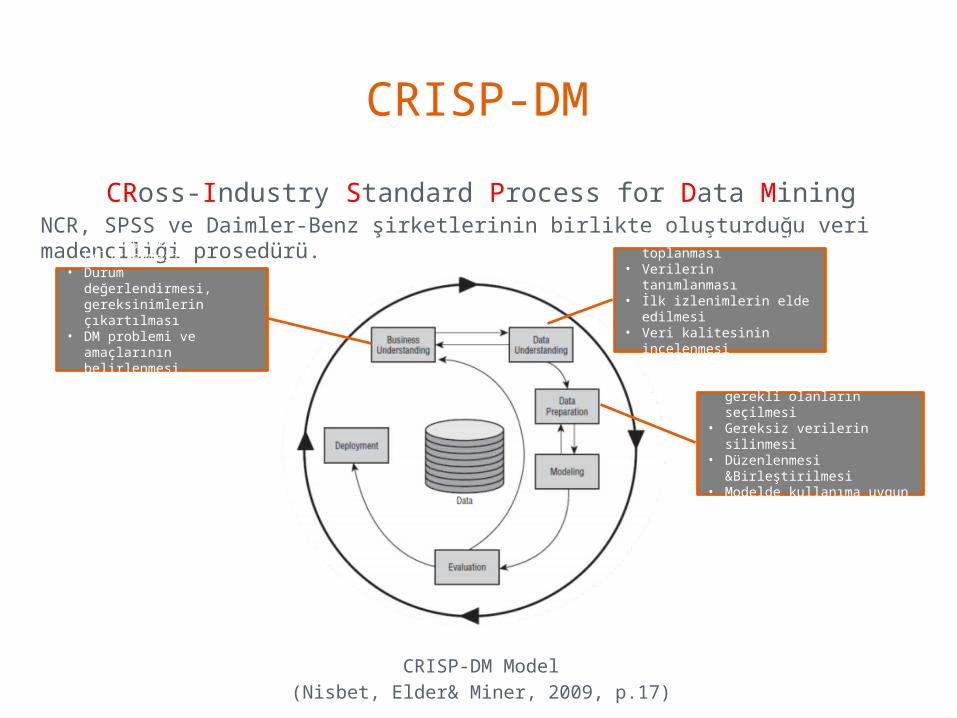
CRISP-DMCRoss-Industry Standard Process for Data Mining
NCR, SPSS ve Daimler-Benz şirketlerinin birlikte oluşturduğu veri madenciliği prosedürü.
CRISP-DM Model(Nisbet, Elder& Miner, 2009, p.17)

CRISP-DMCRoss-Industry Standard Process for Data Mining
NCR, SPSS ve Daimler-Benz şirketlerinin birlikte oluşturduğu veri madenciliği prosedürü.
CRISP-DM Model(Nisbet, Elder& Miner, 2009, p.17)
• Çok sayıda veri• Eksik/aykırı veri• Modelde kullanım• Verilerden çıkan sonuçların kaydı ve yeniden kullanılması

CRISP-DMCRoss-Industry Standard Process for Data Mining
NCR, SPSS ve Daimler-Benz şirketlerinin birlikte oluşturduğu veri madenciliği prosedürü.
CRISP-DM Model(Nisbet, Elder& Miner, 2009, p.17)
• İş amaçlarının belirlenmesi
• Durum değerlendirmesi, gereksinimlerin çıkartılması
• DM problemi ve amaçlarının belirlenmesi
• Proje planının çıkartılması

CRISP-DMCRoss-Industry Standard Process for Data Mining
NCR, SPSS ve Daimler-Benz şirketlerinin birlikte oluşturduğu veri madenciliği prosedürü.
CRISP-DM Model(Nisbet, Elder& Miner, 2009, p.17)
• Başlangıç verilerinin toplanması
• Verilerin tanımlanması
• İlk izlenimlerin elde edilmesi
• Veri kalitesinin incelenmesi
• İş amaçlarının belirlenmesi
• Durum değerlendirmesi, gereksinimlerin çıkartılması
• DM problemi ve amaçlarının belirlenmesi
• Proje planının çıkartılması
CRISP-DMCRoss-Industry Standard Process for Data Mining
NCR, SPSS ve Daimler-Benz şirketlerinin birlikte oluşturduğu veri madenciliği prosedürü.
CRISP-DM Model(Nisbet, Elder& Miner, 2009, p.17)
• Başlangıç verilerinin toplanması
• Verilerin tanımlanması
• İlk izlenimlerin elde edilmesi
• Veri kalitesinin incelenmesi
• İş amaçlarının belirlenmesi
• Durum değerlendirmesi, gereksinimlerin çıkartılması
• DM problemi ve amaçlarının belirlenmesi
• Proje planının çıkartılması
• Başlangıç verilerinden gerekli olanların seçilmesi
• Gereksiz verilerin silinmesi
• Düzenlenmesi &Birleştirilmesi
• Modelde kullanıma uygun formata getirilmesi

CRISP-DMCRoss-Industry Standard Process for Data Mining
NCR, SPSS ve Daimler-Benz şirketlerinin birlikte oluşturduğu veri madenciliği prosedürü.
CRISP-DM Model(Nisbet, Elder& Miner, 2009, p.17)
• Başlangıç verilerinin toplanması
• Verilerin tanımlanması
• İlk izlenimlerin elde edilmesi
• Veri kalitesinin incelenmesi
• İş amaçlarının belirlenmesi
• Durum değerlendirmesi, gereksinimlerin çıkartılması
• DM problemi ve amaçlarının belirlenmesi
• Proje planının çıkartılması
• Başlangıç verilerinden gerekli olanların seçilmesi
• Gereksiz verilerin silinmesi
• Düzenlenmesi &Birleştirilmesi
• Modelde kullanıma uygun formata getirilmesi
• Modelleme teknğinin seçilmesi
• Optimal test değerlerinin belirlenmesi
• Model kurulması• Modelin test edilmesi
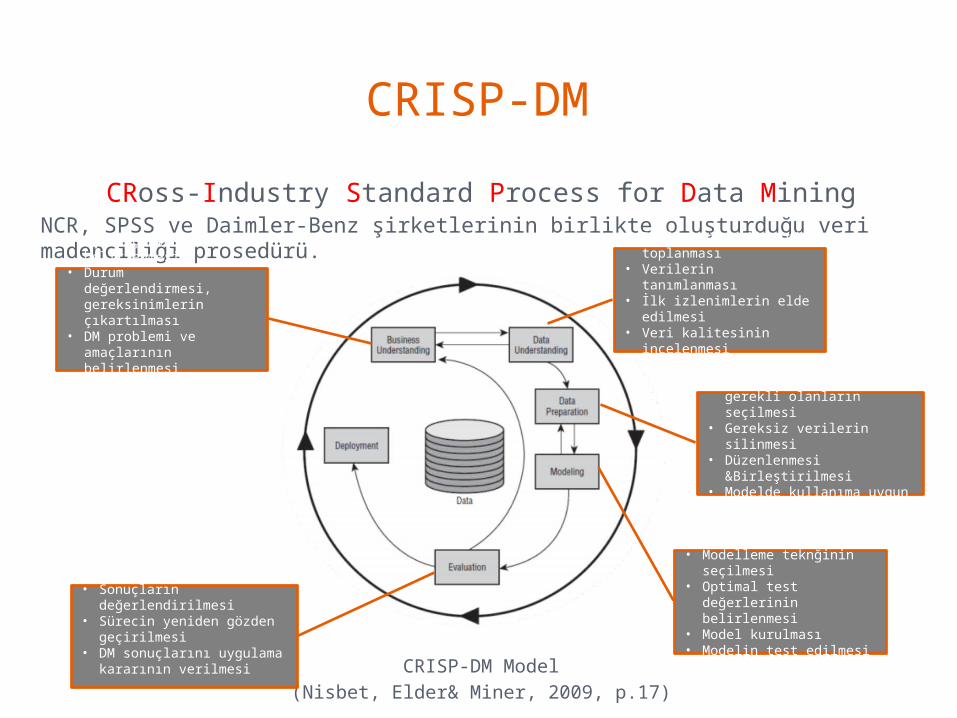
CRISP-DMCRoss-Industry Standard Process for Data Mining
NCR, SPSS ve Daimler-Benz şirketlerinin birlikte oluşturduğu veri madenciliği prosedürü.
CRISP-DM Model(Nisbet, Elder& Miner, 2009, p.17)
• Başlangıç verilerinin toplanması
• Verilerin tanımlanması
• İlk izlenimlerin elde edilmesi
• Veri kalitesinin incelenmesi
• Başlangıç verilerinden gerekli olanların seçilmesi
• Gereksiz verilerin silinmesi
• Düzenlenmesi &Birleştirilmesi
• Modelde kullanıma uygun formata getirilmesi
• İş amaçlarının belirlenmesi
• Durum değerlendirmesi, gereksinimlerin çıkartılması
• DM problemi ve amaçlarının belirlenmesi
• Proje planının çıkartılması
• Sonuçların değerlendirilmesi
• Sürecin yeniden gözden geçirilmesi
• DM sonuçlarını uygulama kararının verilmesi
• Modelleme teknğinin seçilmesi
• Optimal test değerlerinin belirlenmesi
• Model kurulması• Modelin test edilmesi

CRISP-DMCRoss-Industry Standard Process for Data Mining
NCR, SPSS ve Daimler-Benz şirketlerinin birlikte oluşturduğu veri madenciliği prosedürü.
CRISP-DM Model(Nisbet, Elder& Miner, 2009, p.17)
• Başlangıç verilerinin toplanması
• Verilerin tanımlanması
• İlk izlenimlerin elde edilmesi
• Veri kalitesinin incelenmesi
• İş amaçlarının belirlenmesi
• Durum değerlendirmesi, gereksinimlerin çıkartılması
• DM problemi ve amaçlarının belirlenmesi
• Proje planının çıkartılması
• Uygulamanın planlanması• Modelin kontrol ve
bakımının planlanması• Sonuç raporlarının
oluşturulması• Projenin gözden
geçirilmesi
• Sonuçların değerlendirilmesi
• Sürecin yeniden gözden geçirilmesi
• DM sonuçlarını uygulama kararının verilmesi
• Başlangıç verilerinden gerekli olanların seçilmesi
• Gereksiz verilerin silinmesi
• Düzenlenmesi &Birleştirilmesi
• Modelde kullanıma uygun formata getirilmesi
• Modelleme teknğinin seçilmesi
• Optimal test değerlerinin belirlenmesi
• Model kurulması• Modelin test edilmesi
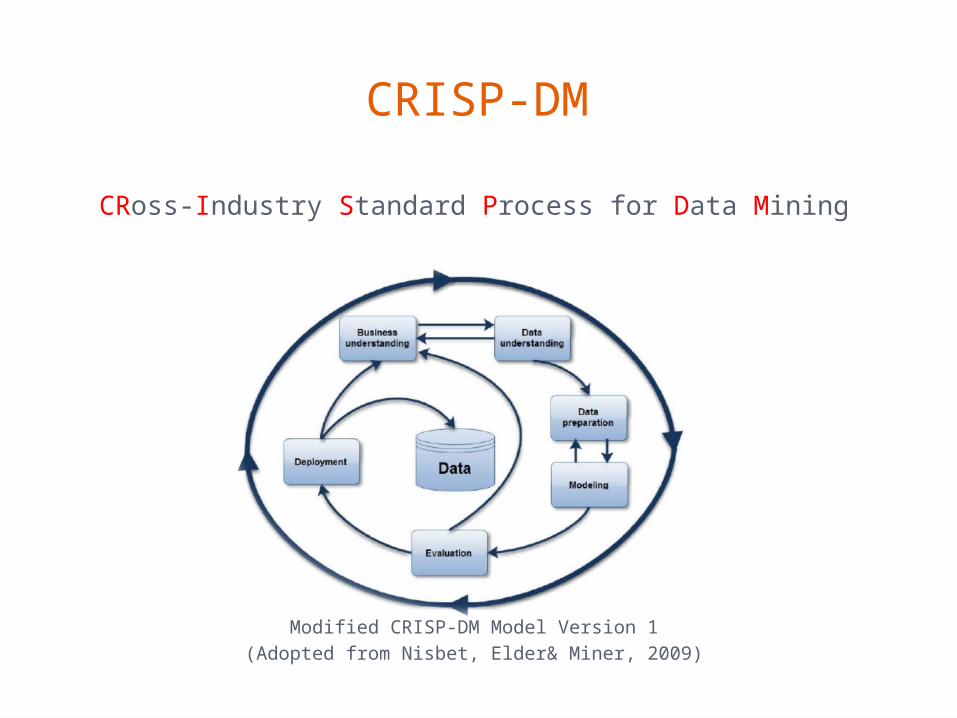
CRISP-DM
CRoss-Industry Standard Process for Data Mining
Modified CRISP-DM Model Version 1(Adopted from Nisbet, Elder& Miner, 2009)

CRISP-DM
CRoss-Industry Standard Process for Data Mining
Modified CRISP-DM Model Version 1(Adopted from Nisbet, Elder& Miner, 2009)
• Bilgi sistemleri dersini tamamlanma oranının arttırılması
• Bazı faktörler dersi başarıyla tamamlamayı engelleyebilir.
• Başarılı öğrenci profilinin çıkartılması
• Demografik özellikler ve çalışma ortamına göre ayırt edilmesi

CRISP-DM
CRoss-Industry Standard Process for Data Mining
Modified CRISP-DM Model Version 1(Adopted from Nisbet, Elder& Miner, 2009)
• Bilgi sistemleri dersini tamamlanma oranının arttırılması
• Bazı faktörler dersi başarıyla tamamlamayı engelleyebilir.
• Başarılı öğrenci profilinin çıkartılması
• Demografik özellikler ve çalışma ortamına göre ayırt edilmesi
• ÖBS’de, derse yeni kaydolan öğrencilere dair verilerin kullanılması
• Demografik, akademik ve iletişim bilgileri ile başlangıç veri tablosunun oluşturulması

CRISP-DM
CRoss-Industry Standard Process for Data Mining
• Demografik: cinsiyet, yaş, etnik köken, engelli olma durumu, eğitim düzeyi, çalışma durumu, erken kayıt• Çalışma ortamı: ders programı, dersin açıldığı dönem • Bağımlı değişken: öğrencinin dersi geçmesi/başarısız olması
• ÖBS’de, derse yeni kaydolan öğrencilere dair verilerin kullanılması
• Demografik, akademik ve iletişim bilgileri ile başlangıç veri tablosunun oluşturulması
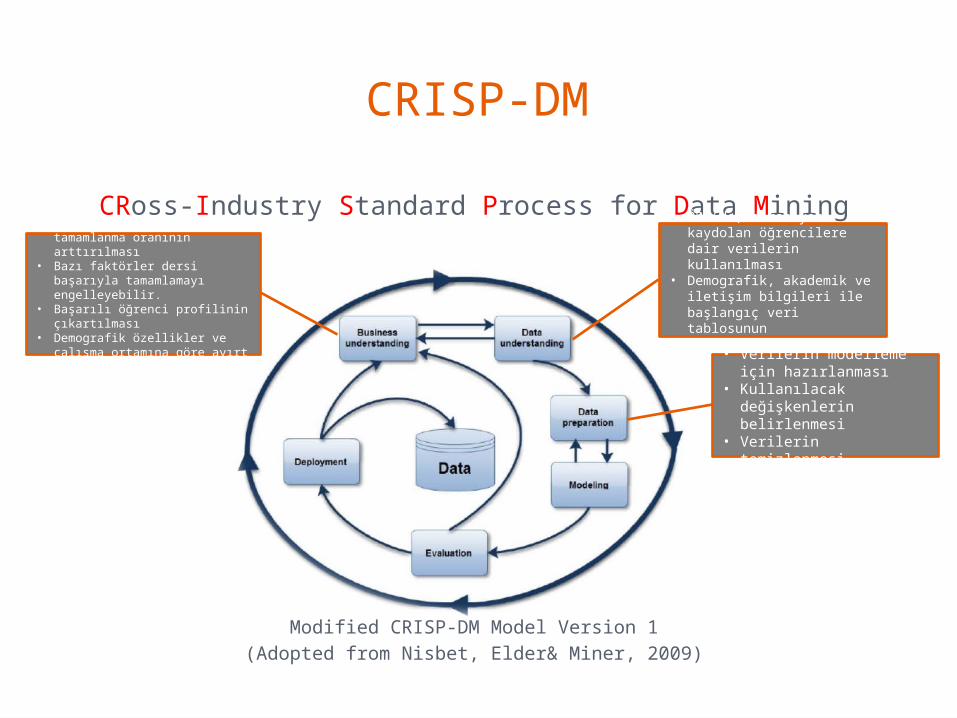
CRISP-DM
CRoss-Industry Standard Process for Data Mining
Modified CRISP-DM Model Version 1(Adopted from Nisbet, Elder& Miner, 2009)
• Bilgi sistemleri dersini tamamlanma oranının arttırılması
• Bazı faktörler dersi başarıyla tamamlamayı engelleyebilir.
• Başarılı öğrenci profilinin çıkartılması
• Demografik özellikler ve çalışma ortamına göre ayırt edilmesi
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi
• ÖBS’de, derse yeni kaydolan öğrencilere dair verilerin kullanılması
• Demografik, akademik ve iletişim bilgileri ile başlangıç veri tablosunun oluşturulması

CRISP-DM
CRoss-Industry Standard Process for Data Mining
•Cinsiyet 0-1 değişkenolarak tanımlanıyor.
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi

CRISP-DM
CRoss-Industry Standard Process for Data Mining
• Veri kümesinin büyüklüğünden dolayı sürekli değişkenler kategorik değişkenlere dönüştürülüyor.
• Yaş kategorileri:• <30 1• 30-40 2• <40 3
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi

CRISP-DM
CRoss-Industry Standard Process for Data Mining
• Etnik kökeni Maori ve Pasifik olanöğrenciler modelde fazla dağılma olmaması için birleştiriliyor.• Çünkü; Maori ve Pasifik öğrencileri
• İki değişkenli ön analizde farklılık göstermiyorlar.(*)• Verinin küçük bir kısmını (<%10) oluşturuyorlar.
(*)Modelleme&hazırlama etkileşimli olarak yapılmaktadır.
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi

CRISP-DM
CRoss-Industry Standard Process for Data Mining
•Engelli olma durumu binary değişken olarak tanımlanıyor.
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi

CRISP-DM
CRoss-Industry Standard Process for Data Mining
• NCA 2 seviyesine kadar olan tüm öğrenciler bir grupta birleştiriliyor.• Kategorik değişkenler:
• No sec./NCA1/NCA2• Üniversite giriş/NCA3• Denizaşırı/diğerleri
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi

CRISP-DM
CRoss-Industry Standard Process for Data Mining
• Çalışma durumu 0-1 değişken olarak tanımlanıyor.
• Çalışıyor yes• Çalışmıyor no
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi

CRISP-DM
CRoss-Industry Standard Process for Data Mining
• Dönem başlangıç tarihi ve kursa katılım tarihine göre öğrencinin erken kayıt olma durumu binary değişken olarak tanımlanıyor:
• Erken kayıtyes• Değil no
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi

CRISP-DM
CRoss-Industry Standard Process for Data Mining
• Bilgi Sistemleri dersini alan öğrenciler normalde üç programa kayıtlı:
• BA (6 öğrenci - genellenemez)• B.A.Sc.• B.Bus
• Dikkate alınan kurs programları:• B.A.Sc.• B.Bus.
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi

CRISP-DM
CRoss-Industry Standard Process for Data Mining
•Dersin açıldığı dönemler:• Semester 1• Semester 2• Semester 3 (yaz)
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi

CRISP-DM
CRoss-Industry Standard Process for Data Mining
• Dersin çıktıları geçme/kalma olarak ölçülüyor ve binary değişken olarak tanımlanıyor.
• Başarılı tamamlama pass• Başarısız tamamlama fail
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi

Makale
CRISP-DM Descriptives & Feature
SelectionKarar Ağaçları
Sonuç

DESCRIPTIVES
CRoss-Industry Standard Process for Data Mining• Verilerin modelleme
için hazırlanması• Kullanılacak
değişkenlerin belirlenmesi
• Verilerin temizlenmesi

DESCRIPTIVES
CRoss-Industry Standard Process for Data Mining
• Bilgi Sistemleri dersini alanöğrencilerin çoğunluğunu
bayan öğrenciler oluşturmaktadır.• Tüm öğrenciler arasında
başarılı olanların %65’i bayandır.
%63.1/%65?Bayan öğrencilerin dersi
geçmesi daha olasıdır.
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi

DESCRIPTIVES
CRoss-Industry Standard Process for Data Mining
• Öğrencilerin çoğunluğunu 30-40 yaş aralığındaki öğrenciler
oluşturmaktadır.• Dersten kalan 30-40 yaş
• aralığındaki öğrencilerin oranı Katılan 30-40 yaş aralığındaki
öğrencilerin oranından fazladır. • Bu nedenle; 30-40 yaş
aralığındaki öğrencilerin dersten kalması daha olasıdır.
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi

DESCRIPTIVES
CRoss-Industry Standard Process for Data Mining
• Engelli olmak Bilgi Sistemleri dersini alan öğrenciler için
dezavantajdır.
• Engelli öğrencilerin bu dersten kalması diğerlerine
göre daha olasıdır.
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi

DESCRIPTIVES
CRoss-Industry Standard Process for Data Mining
• Etnik kökeni farklı olan öğrencilerin başarı oranları arasında çok büyük
farklar vardır.
• Maori & Pasifik öğrencilerinin dersten kalması diğerlerine göre
daha olasıdır.
• Hatta, katılım oranına göre geçme oranı çok düşük ve kalma
oranı çok büyük olduğu için «risk grubu» olarak tanımlanmıştır.
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi

DESCRIPTIVES
CRoss-Industry Standard Process for Data Mining
• Derse katılan öğrencilerin %40’ından çoğu en fazla
NCA2’ye kadar okul derecesine sahiptir.
• Bu öğrenciler de diğer derecelerdeki öğrencilere göre
dersten kalmaya en müsait gruptur.
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi

DESCRIPTIVES
CRoss-Industry Standard Process for Data Mining
• Bilgi Sistemleri dersini alanöğrencilerin %75’inden fazlası
okula devam ederken aynı zamanda çalışmaktadır.
• Çalışan öğrencilerin dersi geçmesi çalışmayanlara göre
daha olasıdır.
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi

DESCRIPTIVES
CRoss-Industry Standard Process for Data Mining
• Erken kayıt motivasyon ve zaman yönetimi açısından
dikkate alınmıştır.
• Erken kaydolan öğrencilerin başarı göstermesi diğerlerine
göre daha olasıdır.
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi

DESCRIPTIVES
CRoss-Industry Standard Process for Data Mining
• Bilgi Sistemleri dersini alan • öğrencilerin çoğunluğu işletme
programına kayıtlıdır.
• Ancak, uygulamalı bilimler programındaki öğrencilerin
dersten kalması daha olasıdır.
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi

DESCRIPTIVES
CRoss-Industry Standard Process for Data Mining
•Bilgi Sistemleri dersini yaz döneminde alan
öğrencilerin bu dersten kalması daha olasıdır.
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi

FEATURE SELECTION
•Veri madenciliğinde kullanılan değişkenler predictor, attribute ya da feature olarak bilinmektedir.
•Makalede kullanılan özellikler sayıca fazla değildir (9), bu yüzden alt küme seçilmesine gerek yoktur ve bunların tamamı kullanılmaktadır.
•Ancak sonraki çalışmalarda, regresyonda veya sınıflandırmada kullanılması amacıyla bu özellikler önem derecelerine göre sıralanabilir.

FEATURE SELECTION
CRoss-Industry Standard Process for Data Mining• ÖBS’de, derse yeni
kaydolan öğrencilere dair verilerin kullanılması
• Demografik, akademik ve iletişim bilgileri ile başlangıç veri tablosunun oluşturulması
Predictors

FEATURE SELECTION
CRoss-Industry Standard Process for Data Mining
• İlk üç özelliğin ki-kare değeri için p değerleri %10 düzeyinde
anlamlı bulunmuştur.
• Analiz sonucunda sadece bu üç özelliğin alt küme olarak seçilmesi gerekir.
• Ancak karar ağaçlarında (CART hariç) bunların tümü dikkate alınmıştır.
• ÖBS’de, derse yeni kaydolan öğrencilere dair verilerin kullanılması
• Demografik, akademik ve iletişim bilgileri ile başlangıç veri tablosunun oluşturulması
Predictors
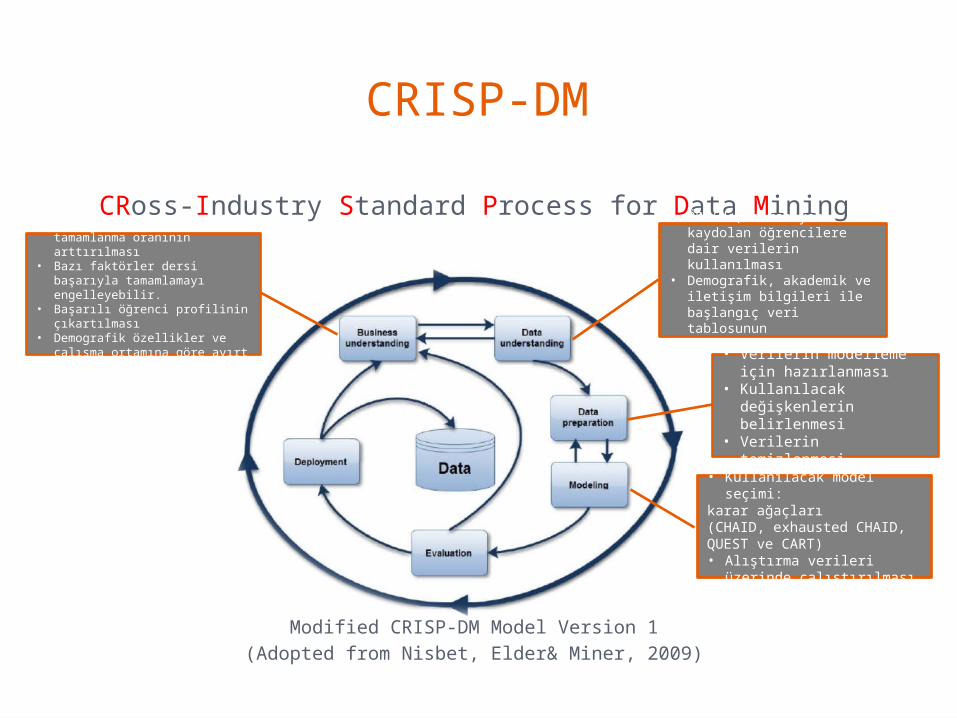
CRISP-DM
CRoss-Industry Standard Process for Data Mining
Modified CRISP-DM Model Version 1(Adopted from Nisbet, Elder& Miner, 2009)
• Bilgi sistemleri dersini tamamlanma oranının arttırılması
• Bazı faktörler dersi başarıyla tamamlamayı engelleyebilir.
• Başarılı öğrenci profilinin çıkartılması
• Demografik özellikler ve çalışma ortamına göre ayırt edilmesi
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi
• ÖBS’de, derse yeni kaydolan öğrencilere dair verilerin kullanılması
• Demografik, akademik ve iletişim bilgileri ile başlangıç veri tablosunun oluşturulması
• Kullanılacak model seçimi:
karar ağaçları(CHAID, exhausted CHAID, QUEST ve CART)• Alıştırma verileri
üzerinde çalıştırılması
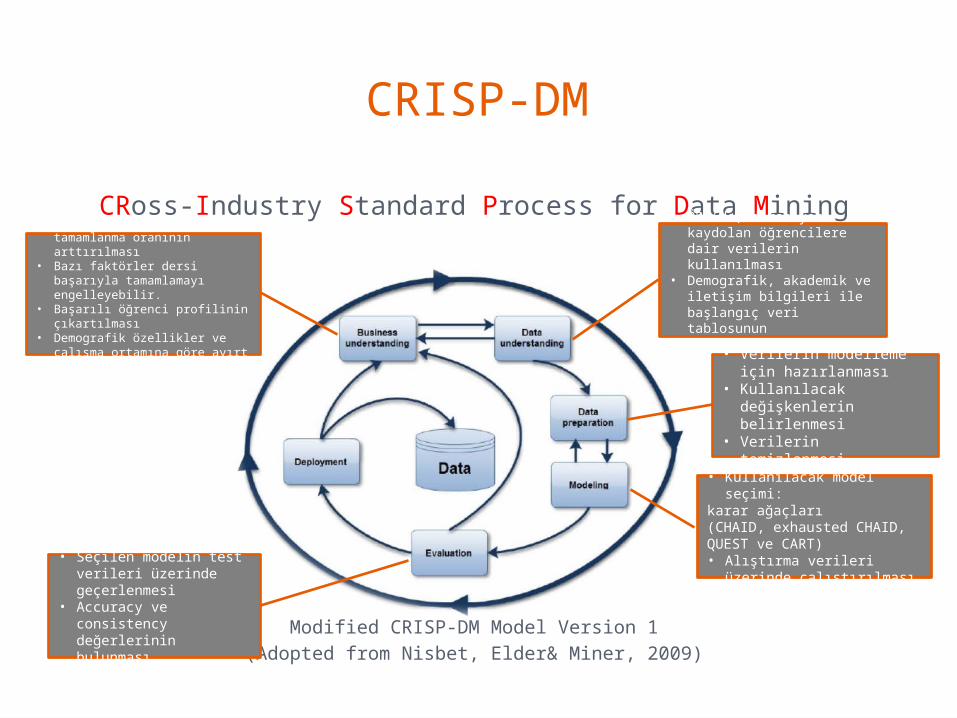
CRISP-DM
CRoss-Industry Standard Process for Data Mining
Modified CRISP-DM Model Version 1(Adopted from Nisbet, Elder& Miner, 2009)
• Bilgi sistemleri dersini tamamlanma oranının arttırılması
• Bazı faktörler dersi başarıyla tamamlamayı engelleyebilir.
• Başarılı öğrenci profilinin çıkartılması
• Demografik özellikler ve çalışma ortamına göre ayırt edilmesi
• Seçilen modelin test verileri üzerinde geçerlenmesi
• Accuracy ve consistency değerlerinin bulunması
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi
• ÖBS’de, derse yeni kaydolan öğrencilere dair verilerin kullanılması
• Demografik, akademik ve iletişim bilgileri ile başlangıç veri tablosunun oluşturulması
• Kullanılacak model seçimi:
karar ağaçları(CHAID, exhausted CHAID, QUEST ve CART)• Alıştırma verileri
üzerinde çalıştırılması

CRISP-DM
CRoss-Industry Standard Process for Data Mining
Modified CRISP-DM Model Version 1(Adopted from Nisbet, Elder& Miner, 2009)
• Bilgi sistemleri dersini tamamlanma oranının arttırılması
• Bazı faktörler dersi başarıyla tamamlamayı engelleyebilir.
• Başarılı öğrenci profilinin çıkartılması
• Demografik özellikler ve çalışma ortamına göre ayırt edilmesi
• En uygun modelin mevcut veriye uygulanması
• Scoring• Sonuçların kullanıcı
için yorumlanması• Kontrol & Bakım
• Verilerin modelleme için hazırlanması
• Kullanılacak değişkenlerin belirlenmesi
• Verilerin temizlenmesi
• ÖBS’de, derse yeni kaydolan öğrencilere dair verilerin kullanılması
• Demografik, akademik ve iletişim bilgileri ile başlangıç veri tablosunun oluşturulması
• Kullanılacak model seçimi:
karar ağaçları(CHAID, exhausted CHAID, QUEST ve CART)• Alıştırma verileri
üzerinde çalıştırılması• Seçilen modelin test
verileri üzerinde geçerlenmesi
• Accuracy ve consistency değerlerinin bulunması
Makale
CRISP-DMDescriptives & Feature
SelectionKarar Ağaçları
Sonuç

KARAR AĞAÇLARI
• Sınıflandırma ağacına dayanan analizin amacı başarısız öğrencilerden başarılı öğrencileri ayırmada en çok katkıda bulunan faktörleri belirlemektir.
• Sınıflandırma ağacı biçimlendirildiği zaman, her bir öğrencinin başarılı olma olasılığı hesaplanabilir.
• Sınıflandırma ağacı bir kere biçimlendirildiğinde, daha sonra yeni kayıt yaptıran öğrencilerin kursta başarılı olup olamayacağını belirlemede yeni veri kümesinde kullanılabilir.
• Makalede CHAID, exhaustive CHAID, QUEST ve CART sınıflandırma ağaçları kullanılmıştır.

CHAID
• Her bir düğümde başarılı ve başarısız öğrencilerin sayısı, her kategorinin yüzdesi, düğümlerin göreli ve mutlak boyutları verilmiştir.
• Bu yöntem her bir düğümdeki her kestirim değişkeni için tüm olası bölünmeleri gösterir.

CHAID
• Ağacı oluşturmak için iki değişken kullanılmıştır.
• Bunlar değişkenler arasında ki kare değeri en yüksek olan iki değerdir.
• En uç durum olarak, her öğrenci için uç düğümü oluşturana kadar ağacı bölme işlemine devam edİlebilir.
• Ancak bu bölünmeye izin vermek veriyi ezberleyen çok büyük bir karar ağacı oluşmasına neden olabilir. Bu duruma «overfitting» denir.

CHAID
• En geniş başarı gurubu 274 öğrenci(%60,5) içermektedir.

CHAID
• En geniş başarı gurubu 274 öğrenci(%60,5) içermektedir.
• En geniş başarısız grup(düğüm 4)138 öğrenci içerir.

CHAID
• En geniş başarı gurubu 274 öğrenci(%60,5) içermektedir.
• En geniş başarısız grup(düğüm 4)138 öğrenci içerir.
• Başarısız öğrencilerden oluşan bir sonraki en büyük grup ise (node1) bütün öğrencilerin %9,1 ini oluşturmaktadır.

CHAID• Sınıflandırma modelininin doğruluğunu değerlendirmek için CHAID sınıflandırma matrisi kullanılmıştır.

CHAID• Sınıflandırma modelininin doğruluğunu değerlendirmek için CHAID sınıflandırma matrisi kullanılmıştır.
• Açıklama!!!

CHAID• Sınıflandırma modelininin doğruluğunu değerlendirmek için CHAID sınıflandırma matrisi kullanılmıştır.
• Kalanlar ve geçenler için tahmin edilen değerler %59,4 oranında doğru bulunmuştur.

CHAID• Sınıflandırma modelininin doğruluğunu değerlendirmek için CHAID sınıflandırma matrisi kullanılmıştır.
• Kalanlar ve geçenler için tahmin edilen değerler %59,4 oranında doğru bulunmuştur.
• Çapraz doğrulama risk tahmini %40.6 bulunmuştur.

CHAID• Sınıflandırma modelininin doğruluğunu değerlendirmek için CHAID sınıflandırma matrisi kullanılmıştır.
• Kalanlar ve geçenler için tahmin edilen değerler %59,4 oranında doğru bulunmuştur.
• Çapraz doğrulama risk tahmini %40.6 bulunmuştur.
• Yani bir öğrenciyi hatalı sınıflandırma riski yaklaşık olarak %41 dir.

CHAID• Modelin kalitesini değerlendirmek için kullanılan bir diğer araç kazanç tablosudur.
• İyi bir model için kazanç tablosunun %100 e doğru dik bir şekilde yükselmesi ve sonra frenlenmesi gerekmektedir.
• Çapraz referans çizgisine yakın olan kazanç tablosu modelin iyi çalışmadığını gösterir.
• Yani başarısız öğrencilerden başarılı öğrenciler iyi bir şekilde ayrılamamaktadır.

CHAID
IF-THEN Kuralları
•Karar ağacına göre sınıflandırma kurallarının oluşturulması için; bilgiler if-then kuralları ile ifade edilir.
•Kökten yaprağa doğru her yol için kural oluşturulur. Bu karar ağacı kuralları yeni kayıt yapan öğrencileri kullanmada ve açıklamada kolaylık sağlayabilir.

CHAID
IF-THEN KurallarıCHAİD sınıflandırma ağacının kuralları 3 düğüm için verilmiştir:
• Node 1:IF Ethnicity = “Maori” OR “Pacific Islanders” THEN Study outcome = “Fail” with probability 0.854• Node 3IF Ethnicity = "Pakeha” OR “Others” AND Course programme = “Bachelor of Business” THEN Study outcome = “Pass” with probability 0.555• Node 4:IF Ethnicity = “Pakeha” OR “Pacific Islanders” AND Course programme = “Bachelor of Applied Sciences” THEN Study outcome = “Fail” with probability 0.594

CHAID
IF-THEN Kuralları
Sadece düğüm 1 deki CHAİD sınıflandırma ağacı bu düğümdeki başarısız olan öğrencilerin yüksek olasılığından dolayı başarılı ve başarısız öğrenciler arasında net bir ayrım yapar.
• Node 1:IF Ethnicity = “Maori” OR “Pacific Islanders” THEN Study outcome = “Fail” with probability 0.854

CHAID
IF-THEN KurallarıDiğer iki sonuç düğümleri için durumlar neredeyse eşit bölünmüş yani bu düğümlerde dersi geçmek yada kalmak için öğrenciler için neredeyse eşit şans var. Diğer bir değişle bu düğümlerde model tam bir kestirim yapamaz.
• Node 3IF Ethnicity = "Pakeha” OR “Others” AND Course programme = “Bachelor of Business” THEN Study outcome = “Pass” with probability 0.555• Node 4:IF Ethnicity = “Pakeha” OR “Pacific Islanders” AND Course programme = “Bachelor of Applied Sciences” THEN Study outcome = “Fail” with probability 0.594
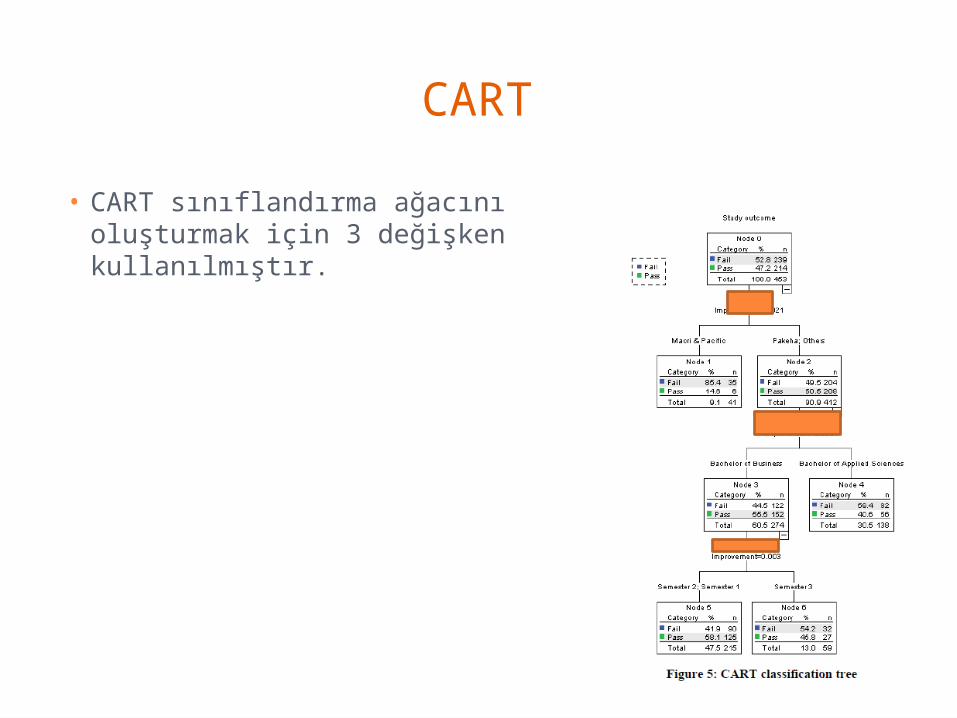
CART
• CART sınıflandırma ağacını oluşturmak için 3 değişken kullanılmıştır.

CART
• CART sınıflandırma ağacını oluşturmak için 3 değişken kullanılmıştır.
• En geniş başarı gurubu, 215 öğrenci içeriyor ve öğrencilerin %47,5’ini oluşturmaktadır.
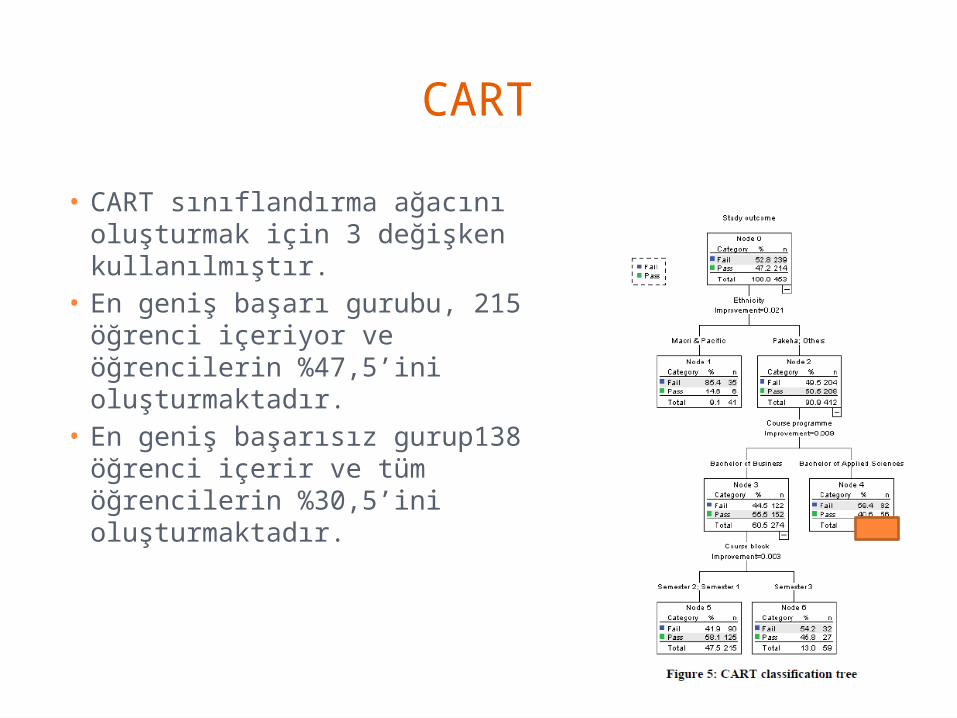
CART
• CART sınıflandırma ağacını oluşturmak için 3 değişken kullanılmıştır.
• En geniş başarı gurubu, 215 öğrenci içeriyor ve öğrencilerin %47,5’ini oluşturmaktadır.
• En geniş başarısız gurup138 öğrenci içerir ve tüm öğrencilerin %30,5’ini oluşturmaktadır.

CART
• CART sınıflandırma ağacını oluşturmak için 3 değişken kullanılmıştır.
• En geniş başarı gurubu, 215 öğrenci içeriyor ve öğrencilerin %47,5’ini oluşturmaktadır.
• En geniş başarısız gurup138 öğrenci içerir ve tüm öğrencilerin %30,5’ini oluşturmaktadır.
• Bir sonraki en geniş grup 41 kişi içeriyor ve tüm öğrencilerin %9,1’i. Bu grup, başarısız öğrenciler olarak nitelendiriliyor.

CART• CART sınıflandırma ağacını oluşturmak için 3 değişken kullanılmıştır.
• En geniş başarı gurubu, 215 öğrenci içeriyor ve öğrencilerin %47,5’ini oluşturmaktadır.
• En geniş başarısız gurup138 öğrenci içerir ve tüm öğrencilerin %30,5’ini oluşturmaktadır.
• Bir sonraki en geniş grup 41 kişi içeriyor ve tüm öğrencilerin %9,1’i. Bu grup, başarısız öğrenciler olarak nitelendiriliyor.
• Maori ve Pasifik öğrencilerinin %85,4’ü başarısızdır.
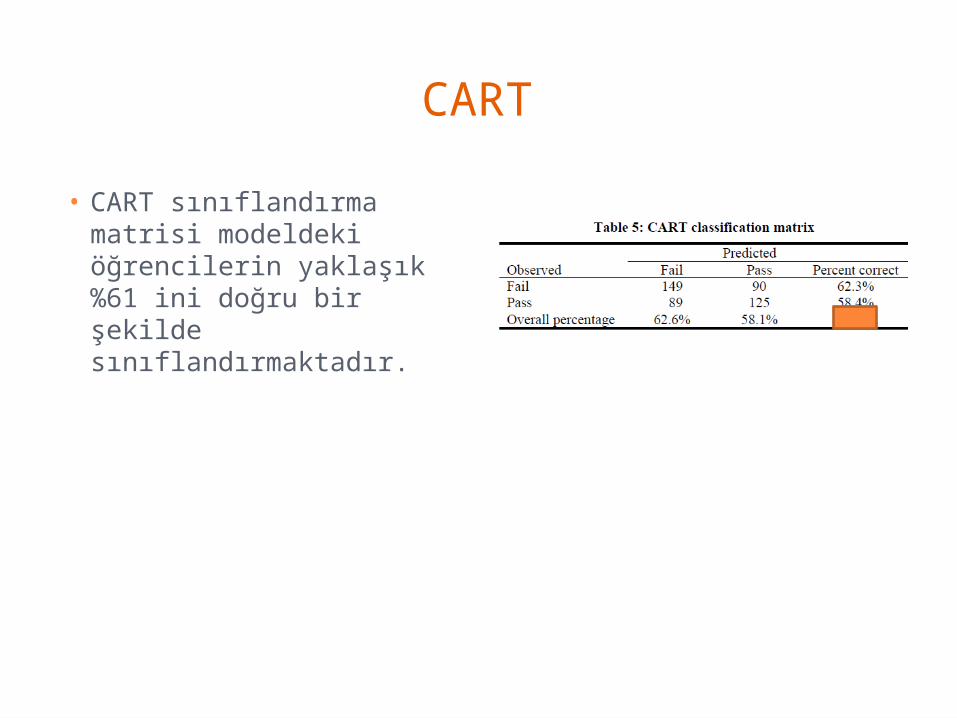
CART
• CART sınıflandırma matrisi modeldeki öğrencilerin yaklaşık %61 ini doğru bir şekilde sınıflandırmaktadır.

CART
• CART sınıflandırma matrisi modeldeki öğrencilerin yaklaşık %61 ini doğru bir şekilde sınıflandırmaktadır.
• Bu değer, CHAID modeline kıyasla biraz daha artmıştır.

CART
• CART sınıflandırma matrisi modeldeki öğrencilerin yaklaşık %61 ini doğru bir şekilde sınıflandırmaktadır.
• Bu değer, CHAID modeline kıyasla biraz daha artmıştır.
• CART modeli için false positivelerin sayısı azalmış ve pozitif kestirim değeri %62,3’e kadar artmıştır.

CART• CART sınıflandırma matrisi modeldeki öğrencilerin yaklaşık %61 ini doğru bir şekilde sınıflandırmaktadır.
• Bu değer, CHAID modeline kıyasla biraz daha artmıştır.
• CART modeli için false positivelerin sayısı azalmış ve pozitif kestirim değeri %62,3 e kadar artmıştır.
• CART modeli başarısız öğrencileri belirlemede CHAİD modeline göre daha iyi çalışacaktır.

CART
•CART sınıflandırma ağacı için kazanç tablosu şekildeki gibi çizilmiştir.

CART
•CART sınıflandırma ağacı için kazanç tablosu şekildeki gibi çizilmiştir.
•CART modeli için elde edilen kazanç tablosu ile CHAID modeli için elde edilen kazanç tablosu neredeyse aynıdır.

CART
IF-THEN KurallarıCART karar ağacı için kurallar dört düğümde açıklanmıştır:
• Node 1:IF Ethnicity = “Maori” OR “Pacific Islanders” THEN Study outcome = “Fail” with probability0.854• Node 4IF Ethnicity = “Maori” OR “Pacific Islanders” AND Course programme = “Bachelor of AppliedSciences” THEN Study outcome = “Fail” with probability 0.594

CART
IF-THEN KurallarıCART karar ağacı için kurallar dört düğümde açıklanmıştır:
• Node 5:IF Ethnicity = “Pakeha” OR “Other” AND Course programme = “Bachelor of Business” ANDCourse block = “Semester 1” OR “Semester 2” THEN Study outcome = “Pass” with probability0.581• Node 6:IF Ethnicity = “Pakeha” OR “Other” AND Course programme = “Bachelor of Business” ANDCourse block = “Semester 3” THEN Study outcome = “Fail” with probability 0.542
Bu kurallar yeni kayıt öğrenciler için olası çalışma sonucunda karar vermede yeni veri setinde kullanılabilir.

CART
Algoritmadan çıkan sonuçlar:• Bilgi Sistemleri kursu çalışma sonuçları için sınıflandırma ağaçlarına göre, cinsiyet, yaş, engellilik, çalışma durumu gibi arka plandaki bilgiler başarılı öğrencileri başarısız öğrencilerden ayıran faktörlerin değerleri olarak sınıflandırma ağacı algoritması tarafından belirlenememiştir. Önemli olan demografik faktörler sadece etnik köken, kurs programı ve kurs dönemi gibi dersle ilgili özelliklerdir.
• Fakat bu faktörler risk altında olan öğrencileri belirlemede yeterince başarılı değildir. Bu sonuçlar diğer yayınlanan araştırma sonuçları ile oldukça uyumludur. Örneğin Kotsiantis, Pierrakeas ve Pintelas sadece demografik değişkenler kullanıldığında benzer tahmin doğruluğunu elde etmişlerdir.

Makale
CRISP-DMDescriptives & Feature
SelectionKarar Ağaçları
Sonuç

SONUÇ
• CHAID ve CART karar ağaçlarının sonuçlarına dayalı olarak başarılı öğrencileri başarısız öğrencilerden ayırmada yardımcı en önemli faktörler etnik köken, kurs programı ve kurs dönemi olarak bulunmuştur.
• Cinsiyet ve yaş gibi demografik veriler önemli ölçüde ders çıktılarıyla(geçmek/kalmak) ilgili olmasına rağmen feature selection sonucuna göre, sınıflandırma ağaçlarında kullanılmamıştır.
• Maalesef sınıflandırma doğruluğu çok yüksek bulunmamıştır.
• CHAID uygulamasında sınıflama doğruluğu %59.4 , CART ağacında ise %60,5 gibi biraz daha yüksek bir değer bulunmuştur. Bu durum kayıt sürecinde toplanan bilgilerin başarılı ve başarısız öğrencilerin doğru ayrılmasında yeterli bilgiyi içermediğini göstermektedir.

SONUÇ
• Bağımlı değişkenin (study outcome), kursta başarısız olanlar, kurs değiştirenler ve kurstan çekilenler olmak üzere üç kategoriye ayrılması muhtemelen daha iyi bir profil sağlayacaktır.
• Öğrenciler, her düğüm için mevcut olan kurallara ve ön kayıt bilgilerine dayanarak sınıflandırılacağı için, idari ve akademik personeller öğrenciler daha derslerine başlamadan önce bile kursu bırakma riski olan öğrencileri belirleyebilecektir. ☺
• Ayrıca oryantasyon , tavsiye ve danışmanlık programları gibi öğrenci destek sistemleri öğrencilerin akademik başarılarını olumlu yönde etkilemek için kullanılabilir.

ÖNERİLERSORULAR

TEŞEKKÜRLERMAYIS 2015




















