
Document Clustering Based on Maximal Frequent Sequences
11
T. Salakoski et al. (Eds.): FinTAL 2006, LNAI 4139, pp. 257 – 267, 2006. © Springer-Verlag Berlin Heidelberg 2006 Document Clustering Based on Maximal Frequent Sequences Edith Hernández-Reyes, Rene A. García-Hernández, J.A. Carrasco-Ochoa, and J.Fco. Martínez-Trinidad National Institute for Astrophysics, Optics and Electronics Luis Enrique Erro No.1 Sta. Ma. Tonantzintla, Puebla, México C.P. 72840 {ereyes, renearnulfo, ariel, fmartine}@inaoep.mx Abstract. Document clustering has the goal of discovering groups with similar documents. The success of the document clustering algorithms depends on the model used for representing these documents. Documents are commonly repre- sented with the vector space model based on words or n-grams. However, these representations have some disadvantages such as high dimensionality and loss of the word sequential order. In this work, we propose a new document repre- sentation in which the maximal frequent sequences of words are used as fea- tures of the vector space model. The proposed model efficiency is evaluated by clustering different document collections and compared against the vector space model based on words and n-grams, through internal and external measures. 1 Introduction Document clustering is an important technique widely used in text mining and infor- mation retrieval systems [1]. Document clustering was proposed to increase the preci- sion and recall of information retrieval systems. Recently, it has been used for brows- ing documents and generating hierarchies [2]. Document clustering consists in dividing a set of documents into groups. In a lan- guage-independent framework, the most common document representation is the vector space model based on words proposed by Salton in 1975 [3]. Here, every document is represented as a vector of features, where the features correspond to the different words of the document collection. Many works use the vector space model based on words as document representation [4] [5] [6]. However, a disadvantage of the vector space model based on words is the high dimensionality because a document collection might contain a huge amount of words. For example, the well-known Reuters-21578[7] document collection is not considered as a big collection but it contains around 38 thousand differ- ent words from 1.4 million words used in the whole collection. In consequence, there are some researches trying to reduce the dimensionality of the vector space model based on words. Another drawback of this representation is that it does not preserve the origi- nal order of the words. For example, documents like “This text is concerned about find gold mining” and “Text mining is concerned about find gold text” are treated as identi- cal in this model, because both are represented with the same words without considering combinations of terms that appear in the document like “text mining” and “gold min- ing” which could help to distinguish them.
-
Upload
independent -
Category
Documents
-
view
2 -
download
0
Transcript of Document Clustering Based on Maximal Frequent Sequences

T. Salakoski et al. (Eds.): FinTAL 2006, LNAI 4139, pp. 257 – 267, 2006. © Springer-Verlag Berlin Heidelberg 2006
Document Clustering Based on Maximal Frequent Sequences
Edith Hernández-Reyes, Rene A. García-Hernández, J.A. Carrasco-Ochoa, and J.Fco. Martínez-Trinidad
National Institute for Astrophysics, Optics and Electronics Luis Enrique Erro No.1 Sta. Ma. Tonantzintla, Puebla, México C.P. 72840 {ereyes, renearnulfo, ariel, fmartine}@inaoep.mx
Abstract. Document clustering has the goal of discovering groups with similar documents. The success of the document clustering algorithms depends on the model used for representing these documents. Documents are commonly repre-sented with the vector space model based on words or n-grams. However, these representations have some disadvantages such as high dimensionality and loss of the word sequential order. In this work, we propose a new document repre-sentation in which the maximal frequent sequences of words are used as fea-tures of the vector space model. The proposed model efficiency is evaluated by clustering different document collections and compared against the vector space model based on words and n-grams, through internal and external measures.
1 Introduction
Document clustering is an important technique widely used in text mining and infor-mation retrieval systems [1]. Document clustering was proposed to increase the preci-sion and recall of information retrieval systems. Recently, it has been used for brows-ing documents and generating hierarchies [2].
Document clustering consists in dividing a set of documents into groups. In a lan-guage-independent framework, the most common document representation is the vector space model based on words proposed by Salton in 1975 [3]. Here, every document is represented as a vector of features, where the features correspond to the different words of the document collection. Many works use the vector space model based on words as document representation [4] [5] [6]. However, a disadvantage of the vector space model based on words is the high dimensionality because a document collection might contain a huge amount of words. For example, the well-known Reuters-21578[7] document collection is not considered as a big collection but it contains around 38 thousand differ-ent words from 1.4 million words used in the whole collection. In consequence, there are some researches trying to reduce the dimensionality of the vector space model based on words. Another drawback of this representation is that it does not preserve the origi-nal order of the words. For example, documents like “This text is concerned about find gold mining” and “Text mining is concerned about find gold text” are treated as identi-cal in this model, because both are represented with the same words without considering combinations of terms that appear in the document like “text mining” and “gold min-ing” which could help to distinguish them.

258 E. Hernández-Reyes et al.
In a vector space framework, other common representation is based on using n consecutive words obtained from the document i.e. the well known n-gram model. In this case, each n-gram appearing in the document collection corresponds to one fea-ture of the vector. However, the high dimensionality also is a disadvantage of the vector space model based on n-grams because the number of word combinations can be enormous. In the n-gram model, the 2-grams are commonly used like in [8] [9], using 1-gram corresponds to the model proposed by Salton.
In a vector space framework, an alternative text representation for document clus-tering is the employment of consecutive word sequences that are repeated frequently in a document. In this sense, a word sequence will be frequent if it appears at least β times. A maximal frequent sequence (MFS) is a sequence such that it is not contained (subsequence) in other frequent sequence. So, the MFS’s are a compact representation of the frequent sequences.
Ahonen[10] developed the first algorithm to find sequential patterns in a docu-ment collection. Recently, the MFS’s have been used by Doucet [11] in the docu-ment retrieval task, his algorithm finds the MFS’s from a document collection too. Unlike Ahonen and Doucet algorithms, in [12] an algorithm to find efficiently the maximal consecutive frequent sequences of words but from a single document was proposed.
In this work we propose a document representation for document clustering using the vector space model based on the MFS’s obtained from each document in the col-lection. In this case, the sequential order of the words is preserved which could help to distinguish among documents with almost the same words but in different order. With this proposed document representation we have a smaller size of the vector based on MFS’s than using words or n-grams. In order to test the proposed document represen-tation, some document clustering experiments were done with two document collec-tions: the English document collection Reuters-21578 and the Spanish document collection Disasters; this last one contains news of natural disasters divided into four categories (forest, hurricane, inundation and drought). The quality obtained in the document clustering experiments, with the proposed representation, was compared against the one obtained with the other two representations, through internal and ex-ternal clustering quality measures.
This paper is organized as follows. Section 2 describes the maximal frequent se-quences. Section 3 presents the new document representation. Section 4 gives the methodology used in this work and the experimental results. Finally, in section 5 we present our conclusions and some directions for future work.
2 Maximal Frequent Sequences
The text of a document is expressed by words in a sequential order. Therefore, it could be useful to determine the consecutive word sequences that appear frequently in a document. Also, it is possible to determine which of the frequent sequences are not contained in any other frequent sequence i.e. which of them are maximal. In this pro-posal, the main focus is the set of MFS’s because they are a compact representation of the frequent sequences.

Document Clustering Based on Maximal Frequent Sequences 259
The maximal frequent sequences are formally defined as follows [12]:
Definition 1. A sequence P=p1p2…pn is a subsequence of a sequence S=s1s2…sm, denoted P⊆S, if there exists an integer l≤i such that p1=si,p2=si+1, p3=si+2,…,pn=si+n-1
Definition 2. Let X⊆S and Y⊆S then X and Y are mutually excluded if X and Y do not share items i.e., if (xn=si and y1=sj) or (yn=si and x1=sj) then i<j.
Definition 3. Given a text T expressed as a sequence and a user-specified threshold β. A sequence S is frequent in T, if it is contained at least β times in T in a mutually excluded way.
Definition 4. A frequent sequence is maximal if it is not a subsequence of any other frequent sequence.
Table 1 presents an example of MFS’s for two documents with β=2
Table 1. MFS’s for two documents
d1= bank said had provided money market further billion assistance bank afternoon session brings billion bank total help compares revised shortage forecast moneymarket.
MFS’s = bank, money market, billion d2= bank billion provided money market late assistance system brings bank total help
compares money market latest forecast shortage system today. MFS’s = bank, money market, system
The MFS’s presents some important characteristics. First, they keep the sequential order of words; it means the MFS’s do not lose the sequential order of the text. Sec-ond, the length of the MFS’s is not previously determined; it is determined by the document content. And third, the MFS’s can be obtained independently of the lan-guage of the documents.
In this work, the algorithm proposed in [12] was used to obtain the MFS’s of a document.
3 Vector Space Model Based on MFS’s
Common document representations such as vector of words or n-grams have some disadvantages like high dimensionality and loss of important information from the sequential order of the original text. In order to reduce these drawbacks we propose a new document representation using MFS’s. This representation, based on the vector space model, consists in obtaining the MFS’s from each document and using them to build the vector (figure 1). Every MFS founded is associated to one element of the vector. Therefore, each document of the collection is represented by an M dimen-sional vector; M is the number of different MFS’s founded in all the documents of the collection. The document collection is represented by an NxM matrix where N is the number of documents.

260 E. Hernández-Reyes et al.
MFS1 MFS2 . . . MFSM
Doc1
Doc2
…DocN
Documents
Extractionof MFS´s
Fig. 1. Proposed representation
Following the idea of the vector space model, the Boolean and TF-IDF weighting are used to assign a weight to each MFS in the vector, both term weightings are widely used for the vector based on words. In Boolean weighting, each MFS receives 1 as weight if it occurs in the document and 0 otherwise. In TF-IDF weighting, the weight of each MFS in the vector for a document T is the product of its frequency in T and the log of its inverse frequency in the collection. Also we propose to use the length of the MFS’s as term weighting in order to allow the comparison taking advan-tage of the size of the MFS’s since if two documents are similar in large sequences they must be more similar than if they are similar in short sequences.
Considering the example presented in table 1, we built the vector based on MFS’s using the three different term weighting (figure 2).
Boolean term weightingbank money market billion system
d1 1 1 1 0d2 1 1 1 1
TF-IDF term weightingbank money market billion system
d1 0 0 0,602 0d2 0 0 0,301 0,602
Length term Weighting bank money market billion system
d1 1 2 1 0d2 1 2 1 1
Fig. 2. Term weighting
Note that in our example both documents talk about the same topic and we need only 4 MFS’s to represent them. In case of the vector based on words, the vector would have 22 elements to represent the documents without considering stop words.
4 Experimentation
In order to test the proposed representation we used the Reuters-21578 and Natural Disasters collection which are written in English and Spanish, respectively. Table 2 and 3 present a description of the data used for the experiments done with Reuters-21578 and Natural Disasters collections. For each experiment, the name of the used classes, number of documents and the number of required clusters are shown. Also, the number of words, n-grams and MFS’s with and without stop words (SW) from each experiment, are provided.

Document Clustering Based on Maximal Frequent Sequences 261
Table 2. Data used for the experiments with the Reuters-21578 collection
Exp. 1 Exp. 2 Exp. 3 Exp. 4
Classes Acq, earn Money, acq, earn Acq, earn, crude Gold,acq,trade,reserve,earn
Documents 100 120 253 Required clusters 2 3 3 5Words with SW 2456 3195 3952 5768 2-grams with SW 7697 9128 9541 17534 MFS’s with SW 1023 1635 1864 2746 Words without SW 1546 2354 2541 4294 2-grams without SW 3357 7652 7768 12927 MFS’s without SW 484 726 821 1693
Table 3. Data used for the experiment with the Natural Disasters collection
Exp. 1 Exp. 2 Exp. 3 Exp. 4 Exp. 5 Exp. 6
Classes
Forest, hurricane
Forest, inundation
Drought, Inundation
Forest, earth-quake,
inundation
Forest, drought, inundation
Forest, drought, hurricane
Documents 80 80 80 120 120 120 Required clusters 2 2 2 3 3 3 Words with SW 4767 4737 4896 6118 6226 5637 2-grams with SW 12685 12613 12726 18462 18742 16686 MFS’s with SW 1513 1391 1745 2014 4593 1797 Words without SW 4611 4583 4825 5963 6059 4593 2-grams without SW 12608 12329 12846 16574 17126 15549 MFS’s without SW 944 914 953 1286 2652 1133
4.1 Methodology
In all the experiments, the methodology showed in the figure 2 was used. We pre-processed the documents removing punctuation, number and special characters. As we can see in table 2 and table 3, some experiments were done removing stop-words too. Then, the vectors based on words, n-grams and MFS’s were obtained. We only use 2-grams since it is the most common n-gram model. For extracting the MFS’s, we have used the algorithm described in [12] taking β equal to 2 since it is the lowest threshold which produced longer MFS’s. Boolean and TF-IDF weighting were used for the three representations. In addition, for the case of MFS’s, the number of words of each MFS was used to weight the features of the vector in order to allow the com-parison taking advantage of the size of the MFS’s because being similar in big se-quences is more important than in small sequences.
Documents were clustered with the k-means algorithm using the cosine similarity measure which is calculated with the next expression:
Finally, the clustering was evaluated with internal and external quality measures. Internal measures evaluate the internal cohesion and external separation of the
2121)2,1cos(
dddd
dd•
=

262 E. Hernández-Reyes et al.
Term weighting
Vector of words
Vector of MFS’s
Vector of 2-grams
Clustering Algorithm
Clustering Evaluation
Pre processing
Documents
Fig. 3. Methodology of the experiments
resulting groups without using previous knowledge about the original classes of the collection. In this work, the global similarity [5] and the global silhouette (GS) were used as internal measures.
It is appropriate underline that in real clustering problems the original classes are unknown. On the other hand, the external measures are employed to evaluate the quality clustering by comparing the obtained groups against the previously defined classes, which have been determined by a human criterion. In this paper, total entropy and general F-measure [5] were used.
For the global silhouette, global similarity and general F-measure higher values represent better quality of the clusters. In the case of the total entropy, smaller values represent better quality.
The internal and external measures used in this work are described in table 4.
4.2 Results
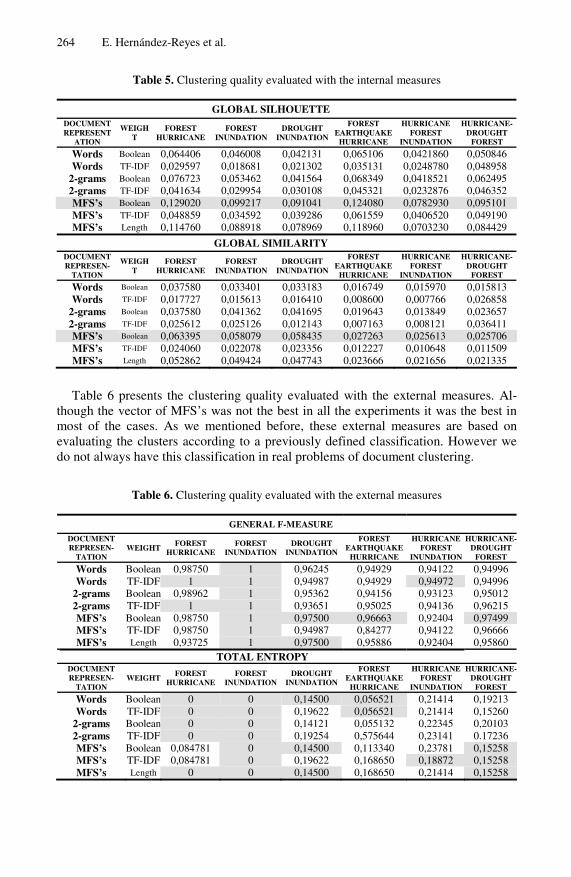
The results of the experiments for Spanish and English are shown on tables 5-7 and 8-10, respectively. In these tables, the first column specifies the used document repre-sentation while the second column shows the term weighting used for each represen-tation; the next columns provide the results of each experiment. For each experiment, the best results are highlighted.
For the experiments whit the Natural Disasters collection, table 5 shows the clus-tering quality, obtained by the three document representation, evaluated with the in-ternal measures. We can observe that the vector of MFS’s obtained clusters with higher internal cohesion and external separation than the groups obtained with the

Document Clustering Based on Maximal Frequent Sequences 263
vector based on words or based on 2-grams. This shows that the vector model based on MFS’s is a good option for representing documents. Also, we can observe that the highest clustering quality was obtained by the vector representation using MFS’s with Boolean weights, and the smallest quality was obtained by the vector representation using words with TF-IDF term weighting.
Table 4. Internal and external measures for clustering quality
INTERNAL MEASURES
Silhouette value of the ith document
AVGD_BETWEEN(i,k):average distance from the i-th document to all documents in other clusters. AVGD_WHITHIN(i): average distance from the i-th0 document to the others documents in its own cluster.
Cluster Silhoutte |Cj| = number of documents in cluster Cj
K = number of clusters
where: K = number of clusters Ci = cluster i Similarity(Ci) =
EXTERNAL MEASURES
where: K = number of classes = number of clusters |classi| = number of documents in the class i N = total number of documents Fmeasure(i,j)= Pij = precision of class i with cluster j Rij = recall of class i with cluster j where: K = number of clusters nj = number of documents in cluster i N = total number of documents Entropyj= pij= probability that a documents from the cluster j belongs to class i.
( ){ }∑=
= ⎥⎦
⎤⎢⎣
⎡=
K
i
kj
i jiFmeasureN
classasureGeneralFme
1
..1,max
K
Csimilarity
ilarityGloabalSim
K
i
i∑== 1
)(
∑∈∈
i
iCdCd
i
ddC '2
)',cos(1
ijij
ijij
RP
RP
+2
∑=
=K
j
jj
N
EntropynpyTotalEntro
1
*
)(log2 ij
i
ijpp∑−
)),(_),(_())(_),(_(
)(kiBETWEENAVGDiWITHINAVGDMAX
iWITHINAVGDkiBETWEENAVGDMINis
−=
∑=
=jC
i
jisS
1
)(
∑=
=K
j
jS
KoutteGlobalSilh
1
1
264 E. Hernández-Reyes et al.
Table 5. Clustering quality evaluated with the internal measures
GLOBAL SILHOUETTE
DOCUMENT REPRESENT
ATION
WEIGHT
FOREST HURRICANE
FOREST INUNDATION
DROUGHT INUNDATION
FOREST EARTHQUAKE
HURRICANE
HURRICANE FOREST
INUNDATION
HURRICANE- DROUGHT
FOREST
Words Boolean 0,064406 0,046008 0,042131 0,065106 0,0421860 0,050846 Words TF-IDF 0,029597 0,018681 0,021302 0,035131 0,0248780 0,048958
2-grams Boolean 0,076723 0,053462 0,041564 0,068349 0,0418521 0,062495 2-grams TF-IDF 0,041634 0,029954 0,030108 0,045321 0,0232876 0,046352 MFS’s Boolean 0,129020 0,099217 0,091041 0,124080 0,0782930 0,095101 MFS’s TF-IDF 0,048859 0,034592 0,039286 0,061559 0,0406520 0,049190 MFS’s Length 0,114760 0,088918 0,078969 0,118960 0,0703230 0,084429
GLOBAL SIMILARITY DOCUMENT REPRESEN-
TATION
WEIGHT
FOREST HURRICANE
FOREST INUNDATION
DROUGHT INUNDATION
FOREST EARTHQUAKE
HURRICANE
HURRICANE FOREST
INUNDATION
HURRICANE- DROUGHT
FOREST
Words Boolean 0,037580 0,033401 0,033183 0,016749 0,015970 0,015813 Words TF-IDF 0,017727 0,015613 0,016410 0,008600 0,007766 0,026858
2-grams Boolean 0,037580 0,041362 0,041695 0,019643 0,013849 0,023657 2-grams TF-IDF 0,025612 0,025126 0,012143 0,007163 0,008121 0,036411 MFS’s Boolean 0,063395 0,058079 0,058435 0,027263 0,025613 0,025706 MFS’s TF-IDF 0,024060 0,022078 0,023356 0,012227 0,010648 0,011509 MFS’s Length 0,052862 0,049424 0,047743 0,023666 0,021656 0,021335
Table 6 presents the clustering quality evaluated with the external measures. Al-though the vector of MFS’s was not the best in all the experiments it was the best in most of the cases. As we mentioned before, these external measures are based on evaluating the clusters according to a previously defined classification. However we do not always have this classification in real problems of document clustering.
Table 6. Clustering quality evaluated with the external measures
GENERAL F-MEASURE
DOCUMENT REPRESEN-
TATION WEIGHT
FOREST HURRICANE
FOREST INUNDATION
DROUGHT INUNDATION
FOREST EARTHQUAKE
HURRICANE
HURRICANE FOREST
INUNDATION
HURRICANE- DROUGHT
FOREST
Words Boolean 0,98750 1 0,96245 0,94929 0,94122 0,94996 Words TF-IDF 1 1 0,94987 0,94929 0,94972 0,94996
2-grams Boolean 0,98962 1 0,95362 0,94156 0,93123 0,95012 2-grams TF-IDF 1 1 0,93651 0,95025 0,94136 0,96215 MFS’s Boolean 0,98750 1 0,97500 0,96663 0,92404 0,97499 MFS’s TF-IDF 0,98750 1 0,94987 0,84277 0,94122 0,96666 MFS’s Length 0,93725 1 0,97500 0,95886 0,92404 0,95860
TOTAL ENTROPY DOCUMENT REPRESEN-
TATION WEIGHT
FOREST HURRICANE
FOREST INUNDATION
DROUGHT INUNDATION
FOREST EARTHQUAKE
HURRICANE
HURRICANE FOREST
INUNDATION
HURRICANE- DROUGHT
FOREST
Words Boolean 0 0 0,14500 0,056521 0,21414 0,19213 Words TF-IDF 0 0 0,19622 0,056521 0,21414 0,15260
2-grams Boolean 0 0 0,14121 0,055132 0,22345 0,20103 2-grams TF-IDF 0 0 0,19254 0,575644 0,23141 0.17236 MFS’s Boolean 0,084781 0 0,14500 0,113340 0,23781 0,15258 MFS’s TF-IDF 0,084781 0 0,19622 0,168650 0,18872 0,15258 MFS’s Length 0 0 0,14500 0,168650 0,21414 0,15258

Document Clustering Based on Maximal Frequent Sequences 265
It is important to mention that in all the experiments carried out the number of terms, obtained with the vector of MFS’s, was smaller than the one obtained with the vector of words or n-grams. In table 7 we present the number of terms for each repre-sentation and the reduction percentage obtained by the vector of MFS’s. The column 5 shows the reduction percentage obtained by using MFS’s instead of words and col-umn 6 presents the reduction percentage obtained by using MFS’s instead of 2-grams. You can see that reduction is in both cases greater than 60% in all the experiments.
Table 7. Reduction percentage of terms
EXPERIMENTS DISASTERS
NUMBER OF WORDS
NUMBER OF 2-GRAMS
NUMBER OF MFS’s
REDUCTION WORDS VS MFS’s
REDUCTION 2-GRAMS VS MFS’s
1 4611 12608 944 79,52% 92,52% 2 4583 12329 914 80,05% 92,58% 3 4825 12846 953 80,24% 92,58% 4 5963 16574 1286 78,43% 92,24% 5 6059 17126 2652 56,23% 84,51% 6 4593 15544 1133 75,33% 92,71%
Tables 8-9 present the results of the clustering quality, obtained with the docu-ments in English. Thus, Table 8 shows the clustering quality evaluated with internal measures. Again, we can observe that using the vector of MFS’s the formed groups have high internal cohesion and external separation. The highest clustering quality was obtained by the vector representation using MFS’s with Boolean weights, and the smallest quality was obtained by the vector representation using words with TF-IDF term weighting.
Table 8. Clustering quality evaluated with the internal measures
GLOBAL SILHOUETTE
DOCUMENT REPRESENTATION WEIGHT ACQ, EARN
MONEY,ACQ, EARN
ACQ,ERAN CRUDE
GOLD, ACQ, TRADE,
RESERVE, EARN
Words Boolean 0,121110 0,103910 0,103140 0,13152 Words TF-IDF 0,072247 0,060720 0,077011 0,09483
2-grams Boolean 0,123654 0,135121 0,101261 0,12756 2-grams TF-IDF 0,081652 0,070266 0,065244 0,08273 MFS’s Boolean 0,181210 0,144870 0,153840 0,18023 MFS’s TF-IDF 0,103850 0,076099 0,102890 0,12938 MFS’s Length 0,146760 0,096807 0,126850 0,15021
GLOBAL SIMILARITY
DOCUMENT REPRESENTATION WEIGHT ACQ, EARN
MONEY,ACQ, EARN
ACQ,ERAN CRUDE
GOLD, ACQ, TRADE,
RESERVE, EARN
Words Boolean 0,048405 0,045655 0,019496 0,02511 Words TF-IDF 0,022866 0,022851 0,010897 0,01360
2-grams Boolean 0,058621 0,042365 0,019562 0,02347 2-grams TF-IDF 0,030200 0,012365 0,011236 0,02046 MFS’s Boolean 0,062359 0,059618 0,025336 0,03372 MFS’s TF-IDF 0,030447 0,027392 0,013815 0,02173 MFS’s Length 0,047538 0,043986 0,019786 0,28910

266 E. Hernández-Reyes et al.
Table 9 presents the result of the clustering quality evaluated with the external measures. The vectors based on words and based on MFS’s, both obtained very simi-lar results, and in some cases they were tied.
Table 9. Clustering quality evaluated with the external measures
GENERAL F-MEASURE
DOCUMENT REPRESENTATION
WEIGHT ACQ, EARN MONEY,ACQ,
EARN ACQ,ERAN,
CRUDE
GOLD, ACQ, TRADE,
RESERVE, EARN
Words Boolean 0,88865 1 0,90756 0,91238 Words TF-IDF 0,88865 1 0,90756 0,91238
2-grams Boolean 0,88865 1 0,90712 0,91221 2-grams TF-IDF 0,87635 1 0,90765 0,91071 MFS’s Boolean 0,88865 1 0,90076 0,91238 MFS’s TF-IDF 0,87825 1 0,90076 0,91031 MFS’s Length 0,87825 0,98735 0,90076 0,91045
TOTAL ENTROPY
DOCUMENT REPRESENTATION
WEIGHT ACQ, EARN MONEY,ACQ,
EARN ACQ,ERAN,
CRUDE
GOLD, ACQ, TRADE,
RESERVE, EARN Words Boolean 0,41528 0 0,39332 0,42294 Words TF-IDF 0,41528 0 0,39332 0,42294
2-grams Boolean 0,41528 0 0,41236 0,43432 2-grams TF-IDF 0,42345 0 0,40564 0,43251 MFS’s Boolean 0,41528 0 0,40991 0,42294 MFS’s TF-IDF 0,43948 0 0,40991 0,42458 MFS’s Length 0,43948 0,084449 0,40991 0,42981
Also, as in the experiment with documents in Spanish, in the experiments with documents in English the number of obtained MFS’s is less than the number of words or n-grams, and it did not affect the clustering quality. The reduction is shown in table 10 where the column 5 shows the reduction percentage obtained by using MFS’s instead of words and column 6 presents the reduction percentage obtained by using MFS’s instead of 2-grams. The reduction is in both cases greater than 60% in all the experiments. Moreover, when the MFS’s are used instead of 2-grams, which preserve part of the word sequential order, the reduction is around 88% in all the experiments. The reduction is possible because the MFS’s are a compact representation of the fre-quent sequences in a document. This reduction of the vector size is an advantage of the representation based on MFS’s over the vector based on words or n-grams.
Table 10. Reduction percentage of terms
EXPERIMENTS REUTERS
NUMBER OF WORDS
NUMBER OF 2-GRAMS
NUMBER OF MFS’s
REDUCTION WORDS VS MFS’s
REDUCTION 2-GRAMS VS MFS’s
1 1546 3357 484 68,69% 85,58% 2 2354 7652 726 69,15% 90,51% 3 2541 7768 821 67,69% 89,43% 4 4294 12927 1693 60.58% 86.90%

Document Clustering Based on Maximal Frequent Sequences 267
5 Conclusions
In this paper, we have introduced the vector space model based on MFS’s as a docu-ment representation. The experiments established that using the maximal frequent sequences as features in the vector space model is a good option for document cluster-ing. In addition, the amount of MFS’s, obtained from documents, is smaller than the amount of words or n-grams, therefore our proposal based on MFS’s allows a com-pact document representation. The experimental results showed that the vector based on MFS’s always obtained clusters with best internal cohesion and external separa-tion. When the proposed representation was evaluated with external measures, it ob-tained better quality in most of the experiments.
It is appropriate to underline that the objective of this work was to analyze the MFS’s performance as document representation for document clustering. However the MFS’s have some useful characteristics that could improve even more the docu-ment clustering, therefore as future work we will propose a new document representa-tion using MFS’s but without following the vector space model. Also we will define a new way to evaluate the similarity among documents when they are represented by MFS’s without the vector space model.
References
1. Zhong Su, Li Zhang, Yue Pan. Document Clustering Based on Vector Quatization and Growing-Cell Structure. Springer-Verlag Berlin Heidelberg, pp 326-336, 2003.
2. Yoelle S., Fagin, Ronald, Ben-Shaul, Israel Z. y Pelleg, Dan. Ephemeral Document Clus-tering for Web Applications. IBM Research. Report RJ 10186, 2000
3. G. Salton, A. Wang, C.S. Yang. A Vector Space Model for Information Retrieval. Journal of the American Society for information Science, pp 613-620, 1975.
4. L. Jing, Michael k.,Jun Ku, Joshua Z. H. Subspace Clustering of Text Documents with Feature Weighting k-means Algorithm, 9th Pacific-Asia Conference on Knowledge Dis-covery and Data Mining (PAKDD-05), Springer-Verlag 2005, pp. 802-812.
5. M. Steinbach, G. Karypis, V. Kumar. A Comparison of Document Clustering Techniques. Proc. Text mining workshop, KDD, 2000.
6. Patrick Pantel, Dekang Lin. Efficiently Clustering Documents with Committees. Pacific Rim International Conferences on Artificial Intelligence (PRICAI 2002), Springer-verlag 2002, pp.424-433.
7. [http://www.ics.uci.edu/~kdd/databases/reuters21578/reuters21578.html] 8. Christopher D. Manning, Hinrich Schütze. Foundations of Statical Natural Language Proc-
essing. Massachussets Institute of Technology. 2001. 9. Xiao Luo, Nur Zincir-Heywood. Analyzing the Temporal Sequences for Text Categori-
zation. Springer-Verlag Berlin Heildeberg, pp 498-505, 2004. 10. Helena Ahonen-Myka. Finding All Maximal Frequent Sequences in Text. Proc. of the
ICML99 Workshop on Machine Learning in Text Data Analysis, pages 11--17, 1999 11. Antoine Doucet. Advanced Document Description, a Sequential Approach. Thesis PhD.
University of Helsinki Finland. 2005 12. René A. García-Hernández, José Fco. Martínez-Trinidad and Jesús Ariel Carrasco-Ochoa,
A Fast Algorithm to Find All the Maximal Frequent Sequences in a Text, 9th Iberoameri-can Congress on Pattern Recognition (CIARP’2004), Lecture Notes in Computer Science vol. 3287 Springer-Verlag 2004.pp. 478-486.




















