
Diseño e implementación sobre FPGA de sistemas digitales ...
305
ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA INFORMÁTICA Departamento de Tecnología Electrónica Tesis doctoral Diseño e implementación sobre FPGA de sistemas digitales de bajo coste para la sincronización de equipos sobre redes de comunicación usando el protocolo SNTP Realizada por Julián Viejo Cortés Ingeniero en Informática Dirigida por Dr. Jorge Juan Chico Prof. Titular de Universidad Dr. Alejandro Millán Calderón Prof. Contratado Doctor Sevilla, marzo de 2011
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of Diseño e implementación sobre FPGA de sistemas digitales ...

ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA INFORMÁTICA
Departamento de Tecnología Electrónica
Tesis doctoral
Diseño e implementación sobre FPGA de sistemas
digitales de bajo coste para la sincronización
de equipos sobre redes de comunicación usando
el protocolo SNTP
Realizada por
Julián Viejo Cortés
Ingeniero en Informática
Dirigida por
Dr. Jorge Juan Chico
Prof. Titular de Universidad
Dr. Alejandro Millán Calderón
Prof. Contratado Doctor
Sevilla, marzo de 2011

2

3
Escuela Técnica Superior de Ingeniería Informática
Departamento de Tecnología Electrónica
Tesis doctoral
Diseño e implementación sobre FPGA de sistemas digitales de
bajo coste para la sincronización de equipos sobre redes de
comunicación usando el protocolo SNTP
Realizada por
Julián Viejo Cortés
Ingeniero en Informática
Dirigida por
Dr. Jorge Juan Chico
Prof. Titular de Universidad
Dr. Alejandro Millán Calderón
Prof. Contratado Doctor
Sevilla, marzo de 2011

4

Resumen
En este documento se presenta el trabajo de tesis doctoral realizado den-
tro del Programa de Doctorado “Informática Industrial” del Departamento
de Tecnología Electrónica de la Universidad de Sevilla. Dicho trabajo con-
siste en el diseño e implementación sobre dispositivos programables FPGA
de sistemas digitales dedicados a la sincronización de equipos sobre redes de
comunicación empleando el protocolo estándar SNTP. Estos sistemas pre-
sentan una serie de características innovadoras respecto de las alternativas
de sincronización existentes en la actualidad, ya que se trata de dispositivos
autónomos, compactos, precisos y de bajo coste y consumo de potencia. Esto
posibilita la integración de servicios de sincronización en sistemas empotra-
dos, de forma que no sea necesario emplear ningún dispositivo externo que
elimine las ventajas de este tipo de sistemas. Sin embargo, la implementación
de estos servicios en hardware supone un reto ya que resulta necesario, por
un lado, el desarrollo teórico de algoritmos de sincronización y de sistemas
de control del reloj adecuados y, por otro, el desarrollo de aspectos prácticos,
como por ejemplo, la implementación hardware de la pila de protocolos de
comunicación o la recepción y transmisión de la información temporal.
5

6

Agradecimientos
Quiero dar las gracias a mi familia por su apoyo y aliento durante estos
años de trabajo, a mis compañeros del Departamento de Tecnología Elec-
trónica y, en especial, a mis directores de tesis y compañeros del grupo de
Investigación y Desarrollo Digital (ID2) por su ayuda e implicación.
Este trabajo ha sido parcialmente financiado por el Ministerio de Indus-
tria, Turismo y Comercio a través de los proyectos de investigación MITYC
PTC FIT-330100-2006-60 (Fases I y II), MEC HIPER TEC-2007-61802 y
MITYC SEPIC TSI-020100-2008-258 del Gobierno Español.
7

8

Índice general
Resumen 5
Agradecimientos 7
Abreviaturas 31
1. Introducción 37
1.1. Sincronización en redes de comunicación . . . . . . . . . . . . 38
1.2. Protocolos de sincronización . . . . . . . . . . . . . . . . . . . 41
1.3. Sincronización de sistemas empotrados . . . . . . . . . . . . . 44
1.4. Objetivos y estructura de la tesis . . . . . . . . . . . . . . . . 48
I Análisis del estado del arte 51
2. Sincronización temporal sobre redes de comunicación 53
2.1. Protocolos de sincronización . . . . . . . . . . . . . . . . . . . 54
2.1.1. Network Time Protocol . . . . . . . . . . . . . . . . . . 54
2.1.2. Simple Network Time Protocol . . . . . . . . . . . . . 67
2.1.3. Precision Time Protocol . . . . . . . . . . . . . . . . . 69
2.1.4. Otros protocolos de sincronización . . . . . . . . . . . . 72
2.2. Equipos y dispositivos de sincronización . . . . . . . . . . . . 74
2.2.1. Equipos comerciales discretos de sincronización . . . . 74
2.2.2. Alternativas de sincronización para sistemas empotrados 78
2.3. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
9

10 Índice general
II Desarrollo de hardware para sincronización de sis-
temas empotrados 83
3. Arquitectura del sistema 85
3.1. Arquitectura del cliente y del servidor . . . . . . . . . . . . . . 87
3.2. Módulos estándares . . . . . . . . . . . . . . . . . . . . . . . . 93
3.2.1. Controlador Ethernet MAC . . . . . . . . . . . . . . . 93
3.2.2. Controlador del puerto serie . . . . . . . . . . . . . . . 97
3.3. Módulos de baja complejidad . . . . . . . . . . . . . . . . . . 100
3.3.1. Módulo de recepción de información temporal . . . . . 100
3.3.2. Módulo de transmisión de información temporal . . . . 103
3.4. Interfaz de protocolos y configuración . . . . . . . . . . . . . . 105
3.4.1. Gestión de la configuración . . . . . . . . . . . . . . . . 108
3.4.2. Gestión de direcciones físicas . . . . . . . . . . . . . . . 112
3.4.3. Control de comunicaciones y marcado temporal . . . . 115
3.5. Módulo de sincronización . . . . . . . . . . . . . . . . . . . . . 122
3.5.1. Cálculo del desplazamiento . . . . . . . . . . . . . . . . 125
3.5.2. Modelo de reloj local . . . . . . . . . . . . . . . . . . . 126
3.5.3. Control del reloj local . . . . . . . . . . . . . . . . . . 130
3.6. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
4. Metodologías de diseño para la implementación hardware 139
4.1. Metodologías de diseño . . . . . . . . . . . . . . . . . . . . . . 140
4.2. Análisis de las metodologías planteadas . . . . . . . . . . . . . 141
4.3. Metodología de diseño con PicoBlaze . . . . . . . . . . . . . 145
4.4. Metodología de diseño con System Generator for DSP . 146
4.5. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
5. Implementación de la plataforma de sincronización 153
5.1. Implementación hardware de los módulos del sistema . . . . . 154
5.1.1. Controlador Ethernet MAC . . . . . . . . . . . . . . . 154
5.1.2. Controlador del puerto serie . . . . . . . . . . . . . . . 156
5.1.3. Módulo de recepción de información temporal . . . . . 157
5.1.4. Módulo de transmisión de información temporal . . . . 160

Índice general 11
5.1.5. Interfaz de protocolos y de configuración . . . . . . . . 164
5.1.6. Módulo de sincronización . . . . . . . . . . . . . . . . . 168
5.2. Simulación funcional . . . . . . . . . . . . . . . . . . . . . . . 173
5.3. Resultados de implementación hardware . . . . . . . . . . . . 180
5.4. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183
III Metodologías de verificación, pruebas del sistema
y resultados 185
6. Metodologías de verificación y pruebas del sistema 187
6.1. Verificación de sistemas en dispositivos programables . . . . . 188
6.2. Soluciones para la verificación de sistemas en dispositivos pro-
gramables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
6.3. Plataforma de verificación para sistemas de sincronización . . 192
6.3.1. Arquitectura de la plataforma de verificación propuesta 194
6.3.2. Software de procesamiento y análisis . . . . . . . . . . 197
6.3.3. Comparativa de la plataforma frente a Chipscope Pro198
6.4. Definición de parámetros de calidad . . . . . . . . . . . . . . . 205
6.4.1. Parámetros cualitativos . . . . . . . . . . . . . . . . . . 205
6.4.2. Parámetros cuantitativos . . . . . . . . . . . . . . . . . 206
6.5. Escenarios de pruebas . . . . . . . . . . . . . . . . . . . . . . 208
6.5.1. Pruebas de operación básicas . . . . . . . . . . . . . . 209
6.5.2. Pruebas completas en configuración típica . . . . . . . 210
6.5.3. Pruebas para diferentes cargas y topologías de red . . . 210
6.5.4. Pruebas de robustez . . . . . . . . . . . . . . . . . . . 211
6.6. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212
7. Resultados 213
7.1. Pruebas de operación básicas . . . . . . . . . . . . . . . . . . 213
7.2. Pruebas completas en configuración típica . . . . . . . . . . . 217
7.2.1. Pruebas completas para el servidor SNTP . . . . . . . 218
7.2.2. Pruebas completas para el cliente SNTP . . . . . . . . 222
7.3. Pruebas para diferentes cargas y topologías de red . . . . . . . 235

12 Índice general
7.3.1. Pruebas para diferentes cargas de red . . . . . . . . . . 235
7.3.2. Pruebas para diferentes topologías de red . . . . . . . . 241
7.4. Pruebas de robustez . . . . . . . . . . . . . . . . . . . . . . . 246
7.5. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . 248
Conclusiones finales 251
Publicaciones 253
Bibliografía 257
A. Configuración del sistema: valores de los parámetros y he-
rramienta de configuración 271
A.1. Rango de valores admitidos para los parámetros de configura-
ción. Valores por defecto . . . . . . . . . . . . . . . . . . . . . 271
A.2. Herramienta para la configuración de los parámetros estáticos 275
B. Gráficas de las pruebas realizadas para el cliente SNTP 277
B.1. Gráficas de las pruebas completas . . . . . . . . . . . . . . . . 277
B.2. Gráficas de las pruebas para diferentes cargas de red . . . . . 292
B.2.1. Carga del conmutador con tráfico de red general no
dirigido al servidor SNTP . . . . . . . . . . . . . . . . 292
B.2.2. Carga del conmutador con tráfico NTP dirigido al ser-
vidor SNTP . . . . . . . . . . . . . . . . . . . . . . . . 294
B.3. Gráficas de las pruebas para diferentes topologías de red . . . 301
B.3.1. Varios niveles de conmutadores y carga moderada . . . 301
B.3.2. Tres niveles de conmutadores y diferentes cargas de red 303

Índice de tablas
1.1. Clases de sincronización definidas por el estándar IEC 61850. . 43
2.1. Modos de operación definidos por el protocolo NTP. . . . . . . 59
2.2. Valores de stratum definidos por el protocolo NTP. . . . . . . 59
3.1. Señales que forman la interfaz independiente del medio. . . . . 96
3.2. Datos generados por el módulo de recepción de información
temporal. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
3.3. Señales de entrada y salida del módulo de interfaz de proto-
colos y configuración. . . . . . . . . . . . . . . . . . . . . . . . 108
3.4. Parámetros de configuración. . . . . . . . . . . . . . . . . . . . 110
5.1. Clasificación de los parámetros de configuración. . . . . . . . . 165
5.2. Acciones realizadas por los scripts Matlab desarrollados. . . 177
5.3. Resultados de implementación hardware del cliente SNTP. . . 180
5.4. Resultados de implementación hardware del servidor SNTP. . 181
5.5. Porcentajes de recursos hardware empleados por los módulos
que forman el cliente SNTP. . . . . . . . . . . . . . . . . . . . 181
5.6. Porcentajes de recursos hardware empleados por los módulos
que forman el servidor SNTP. . . . . . . . . . . . . . . . . . . 181
6.1. Bit rates calculados para algunas velocidades típicas. . . . . . 195
6.2. Configuración de señales específicas para la verificación de los
diseños del cliente y del servidor SNTP. . . . . . . . . . . . . . 202
6.3. Frecuencia máxima de operación para cada alternativa. . . . . 205
6.4. Parámetros cualitativos a analizar. . . . . . . . . . . . . . . . 206
13

14 Índice de tablas
6.5. Parámetros cuantitativos a medir. . . . . . . . . . . . . . . . . 207
7.1. Número de peticiones por segundo inyectadas en cada prueba. 238
7.2. Medidas de la deriva ante desconexión. . . . . . . . . . . . . . 249
7.3. Estadísticos matemáticos de las medidas de la deriva ante des-
conexión en valor absoluto. . . . . . . . . . . . . . . . . . . . . 249
A.1. Rango de valores admitidos para los parámetros del sistema y
valores por defecto. . . . . . . . . . . . . . . . . . . . . . . . . 272
A.2. Velocidades del puerto serie admitidas. . . . . . . . . . . . . . 273
A.3. Valores del flanco activo del PPS permitidos. . . . . . . . . . . 274

Índice de figuras
1.1. Conexión de equipos mediante redes de comunicación. . . . . . 38
1.2. Alternativa de sincronización basada en referencias absolutas. 40
1.3. Alternativa de sincronización basada en protocolos de sincro-
nización. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
1.4. Estructura por bloques de las FPGA de Xilinx. . . . . . . . . 46
2.1. Organización en niveles de los servidores y clientes NTP. . . . 57
2.2. Formato del mensaje NTP. . . . . . . . . . . . . . . . . . . . . 58
2.3. Protocolo de comunicación NTP. . . . . . . . . . . . . . . . . 62
2.4. Procesos que componen el demonio del protocolo NTP. . . . . 65
3.1. Esquema general de la solución planteada basada en el uso de
clientes y servidores SNTP sobre redes de área local. . . . . . 86
3.2. Diagrama de bloques del servidor SNTP. . . . . . . . . . . . . 88
3.3. Diagrama de bloques del cliente SNTP. . . . . . . . . . . . . . 89
3.4. Módulos estándares: controlador Ethernet MAC y del puerto
serie. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
3.5. Capas del modelo OSI en las que opera Ethernet. . . . . . . . 94
3.6. Conexión del controlador Ethernet MAC con la capa física y
con las capas superiores. . . . . . . . . . . . . . . . . . . . . . 95
3.7. Controlador del puerto serie. . . . . . . . . . . . . . . . . . . . 98
3.8. Módulos de baja complejidad: recepción y transmisión de la
información temporal. . . . . . . . . . . . . . . . . . . . . . . 100
3.9. Formato de la trama RMC. Ejemplo. . . . . . . . . . . . . . . 101
3.10. Módulo de recepción de información temporal. . . . . . . . . . 102
15

16 Índice de figuras
3.11. Módulo de transmisión de información temporal. . . . . . . . . 104
3.12. Módulo de alta complejidad: interfaz de protocolos y configu-
ración. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
3.13. Capas del modelo OSI donde se sitúan los protocolos de Inter-
net implementados en la interfaz de protocolos y configuración. 106
3.14. Interfaz de protocolos y configuración. . . . . . . . . . . . . . 107
3.15. Diagrama básico de control de servicios. . . . . . . . . . . . . 116
3.16. Diagrama avanzado de control de servicios. . . . . . . . . . . . 118
3.17. Módulo de alta complejidad: módulo de sincronización. . . . . 123
3.18. Módulo de sincronización. . . . . . . . . . . . . . . . . . . . . 124
3.19. Diagrama de bloques que forman el módulo de sincronización. 124
3.20. Modelo de reloj hardware basado en un oscilador controlado
por tensión. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
3.21. Modelo de reloj hardware completamente digital propuesto. . . 127
3.22. Arquitectura del módulo de control de frecuencia. . . . . . . . 128
3.23. Cálculo de la corrección. . . . . . . . . . . . . . . . . . . . . . 131
3.24. Estados que forman el algoritmo de sincronización del cliente
SNTP. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
3.25. Estados que forman el algoritmo de sincronización del servidor
SNTP. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
4.1. Metodología de diseño basada en el microprocesador Pico-
Blaze. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
4.2. Metodología de diseño basada en System Generator for
DSP. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
5.1. Bloques que forman el controlador Ethernet MAC. . . . . . . 155
5.2. Bloques que forman el controlador del puerto serie. . . . . . . 156
5.3. Bloques que forman el módulo de recepción de información
temporal. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
5.4. Bloques que forman el módulo de transmisión de información
temporal. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
5.5. Bloques que forman la interfaz de protocolos y configuración. . 164
5.6. Ejemplo de codificación de los parámetros dinámicos. . . . . . 166

Índice de figuras 17
5.7. Organización y posiciones que ocupan los paquetes dentro de
la memoria RAM. . . . . . . . . . . . . . . . . . . . . . . . . . 168
5.8. Bloques que forman el módulo de sincronización. . . . . . . . . 169
5.9. Bloques que forman el módulo de cálculo del desplazamiento
usando System Generator for DSP. . . . . . . . . . . . . 174
5.10. Bloques que forman el módulo de cálculo de correcciones usan-
do System Generator for DSP. . . . . . . . . . . . . . . 175
5.11. Simulación funcional de la recepción de un paquete de confi-
guración usando HDL co-simulation. . . . . . . . . . . . . . . 176
5.12. Simulación funcional del módulo de ajuste del reloj. . . . . . . 178
5.13. Simulación funcional del programa de PicoBlaze usando
KPicoSim. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 178
5.14. Resultados de la simulación funcional del programa usando
KPicoSim. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
5.15. Simulación funcional del bloque de conversión de hora. . . . . 179
6.1. Campo de aplicación de las herramientas de verificación ana-
lizadas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193
6.2. Arquitectura del analizador de eventos lógicos. . . . . . . . . . 194
6.3. Arquitectura de ChipScope Pro. . . . . . . . . . . . . . . . 198
6.4. Número de LUT empleadas en función del número de señales
y de muestras usando ChipScope Pro. . . . . . . . . . . . . 200
6.5. Número de FF empleados en función del número de señales y
de muestras usando ChipScope Pro. . . . . . . . . . . . . . 200
6.6. Número de BRAM empleadas en función del número de señales
y de muestras usando ChipScope Pro. . . . . . . . . . . . . 201
6.7. Recursos empleados para verificar el cliente SNTP en función
del número de muestras para 256 señales de datos usando
ChipScope Pro. . . . . . . . . . . . . . . . . . . . . . . . . . 203
6.8. Recursos empleados para verificar el cliente SNTP en función
del número de señales usando el LEA. . . . . . . . . . . . . . . 204
6.9. Composición del escenario 2 planteado en la segunda fase de
pruebas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 211

18 Índice de figuras
7.1. Comprobación de la carga de configuración. . . . . . . . . . . 214
7.2. Comprobación de la operación de los protocolos de comunica-
ción. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 215
7.3. Comparación de las señales de PPS generadas por el GPS
(canal 1) y el servidor SNTP (canal 2). . . . . . . . . . . . . . 216
7.4. Comparación de las señales de PPS generadas por el GPS
(canal 1) y el cliente SNTP (canal 2). . . . . . . . . . . . . . . 216
7.5. Comprobación de la transmisión de las tramas RMC. . . . . . 217
7.6. Representaciones del desplazamiento frente al tiempo obteni-
das para el servidor SNTP empleando diferentes valores del
factor de convergencia. . . . . . . . . . . . . . . . . . . . . . . 219
7.7. Representaciones de la función de distribución de frecuencias
del desplazamiento obtenidas para el servidor SNTP emplean-
do diferentes valores del factor de convergencia. . . . . . . . . 220
7.8. Representaciones de los estadísticos matemáticos calculados
para el servidor SNTP empleando diferentes valores del factor
de convergencia. . . . . . . . . . . . . . . . . . . . . . . . . . . 220
7.9. Representaciones del tiempo hasta la sincronización (despla-
zamiento menor que 1 ms, 100 µs y 25 µs) para el servidor
SNTP empleando diferentes valores del factor de convergencia. 221
7.10. Representaciones de los desplazamientos máximos obtenidos
para el cliente SNTP empleando diferentes valores del periodo
entre peticiones y del factor de convergencia. . . . . . . . . . . 223
7.11. Representaciones de los desplazamientos medios obtenidos pa-
ra el cliente SNTP empleando diferentes valores del periodo
entre peticiones y del factor de convergencia. . . . . . . . . . . 223
7.12. Representaciones de las desviaciones típicas del desplazamien-
to obtenidas para el cliente SNTP empleando diferentes valores
del periodo entre peticiones y del factor de convergencia. . . . 224
7.13. Representaciones de las precisiones (desplazamiento medio ±
error) calculadas para el cliente SNTP empleando diferentes
valores del factor de convergencia para los valores del intervalo
entre peticiones de 1, 2, 4 y 8 s. . . . . . . . . . . . . . . . . . 224

Índice de figuras 19
7.14. Representaciones de las precisiones (desplazamiento medio ±
error) calculadas para el cliente SNTP empleando diferentes
valores del factor de convergencia para los valores del intervalo
entre peticiones de 16, 32 y 64 s. . . . . . . . . . . . . . . . . . 225
7.15. Representaciones del tiempo hasta la sincronización (despla-
zamiento menor que 1 ms) para el cliente SNTP empleando
diferentes valores del periodo entre peticiones y del factor de
convergencia. . . . . . . . . . . . . . . . . . . . . . . . . . . . 226
7.16. Representaciones del tiempo hasta la sincronización (despla-
zamiento menor que 100 µs) para el cliente SNTP empleando
diferentes valores del periodo entre peticiones y del factor de
convergencia. . . . . . . . . . . . . . . . . . . . . . . . . . . . 227
7.17. Representaciones del tiempo hasta la sincronización (despla-
zamiento menor que 25 µs) para el cliente SNTP empleando
diferentes valores del periodo entre peticiones y del factor de
convergencia. . . . . . . . . . . . . . . . . . . . . . . . . . . . 227
7.18. Representaciones de los retrasos de propagación máximos ob-
tenidos para el cliente SNTP empleando diferentes valores del
periodo entre peticiones y del factor de convergencia. . . . . . 228
7.19. Representaciones de los retrasos de propagación medios obte-
nidos para el cliente SNTP empleando diferentes valores del
periodo entre peticiones y del factor de convergencia. . . . . . 229
7.20. Representaciones de las desviaciones típicas del retrasos de
propagación obtenidas para el cliente SNTP empleando di-
ferentes valores del periodo entre peticiones y del factor de
convergencia. . . . . . . . . . . . . . . . . . . . . . . . . . . . 229
7.21. Representaciones de las precisiones (retraso medio ± error)
calculadas para el cliente SNTP empleando diferentes valores
del factor de convergencia para los valores del intervalo entre
peticiones de 1, 2, 4 y 8 s. . . . . . . . . . . . . . . . . . . . . 230

20 Índice de figuras
7.22. Representaciones de las precisiones (retraso medio ± error)
calculadas para el cliente SNTP empleando diferentes valores
del factor de convergencia para los valores del intervalo entre
peticiones de 16, 32 y 64 s. . . . . . . . . . . . . . . . . . . . . 230
7.23. Representaciones del desplazamiento frente al retraso de pro-
pagación obtenidas para el cliente SNTP empleando diferentes
valores del factor de convergencia y un periodo entre peticiones
de 1 s. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231
7.24. Representaciones del desplazamiento frente al retraso de pro-
pagación obtenidas para el cliente SNTP empleando diferentes
valores del factor de convergencia y un periodo entre peticiones
de 2 s. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231
7.25. Representaciones del desplazamiento frente al retraso de pro-
pagación obtenidas para el cliente SNTP empleando diferentes
valores del factor de convergencia y un periodo entre peticiones
de 4 s. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232
7.26. Representaciones del desplazamiento frente al retraso de pro-
pagación obtenidas para el cliente SNTP empleando diferentes
valores del factor de convergencia y un periodo entre peticiones
de 8 s. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232
7.27. Representaciones del desplazamiento frente al retraso de pro-
pagación obtenidas para el cliente SNTP empleando diferentes
valores del factor de convergencia y un periodo entre peticiones
de 16 s. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233
7.28. Representaciones del desplazamiento frente al retraso de pro-
pagación obtenidas para el cliente SNTP empleando diferentes
valores del factor de convergencia y un periodo entre peticiones
de 32 s. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233
7.29. Representaciones del desplazamiento frente al retraso de pro-
pagación obtenidas para el cliente SNTP empleando diferentes
valores del factor de convergencia y un periodo entre peticiones
de 64 s. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 234

Índice de figuras 21
7.30. Representaciones de los estadísticos matemáticos del despla-
zamiento calculados para el cliente SNTP cargando el conmu-
tador con tráfico no dirigido al servidor SNTP. . . . . . . . . . 236
7.31. Representaciones de los estadísticos matemáticos del retraso
de propagación calculados para el cliente SNTP cargando el
conmutador con tráfico no dirigido al servidor SNTP. . . . . . 236
7.32. Representaciones del desplazamiento frente al retraso de pro-
pagación obtenidas para el cliente SNTP cargando el conmu-
tador con tráfico no dirigido al servidor SNTP. . . . . . . . . . 237
7.33. Representaciones de los estadísticos matemáticos del despla-
zamiento calculados para el cliente SNTP cargando el conmu-
tador con tráfico NTP dirigido al servidor SNTP (para todos
los casos). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 239
7.34. Representaciones de los estadísticos matemáticos del retraso
de propagación calculados para el cliente SNTP cargando el
conmutador con tráfico NTP dirigido al servidor SNTP (para
todos los casos). . . . . . . . . . . . . . . . . . . . . . . . . . . 239
7.35. Representaciones del desplazamiento frente al retraso de pro-
pagación obtenidas para el cliente SNTP cargando el conmu-
tador con tráfico NTP dirigido al servidor SNTP (entre 10 y
100 peticiones por segundo). . . . . . . . . . . . . . . . . . . . 240
7.36. Representaciones del desplazamiento frente al retraso de pro-
pagación obtenidas para el cliente SNTP cargando el conmu-
tador con tráfico NTP dirigido al servidor SNTP (entre 500 y
10000 peticiones por segundo). . . . . . . . . . . . . . . . . . . 240
7.37. Representaciones del desplazamiento frente al retraso de pro-
pagación obtenidas para el cliente SNTP cargando el conmu-
tador con tráfico NTP dirigido al servidor SNTP (entre 17000
y 20000 peticiones por segundo). . . . . . . . . . . . . . . . . . 241

22 Índice de figuras
7.38. Representaciones de los estadísticos matemáticos del despla-
zamiento calculados para el cliente SNTP para una condición
de carga moderada dirigida al servidor SNTP abarcando des-
de la conexión directa (prueba 1) hasta la conexión mediante
tres niveles de conmutadores (prueba 4). . . . . . . . . . . . . 242
7.39. Representaciones de los estadísticos matemáticos del retraso
de propagación calculados para el cliente SNTP para una con-
dición de carga moderada dirigida al servidor SNTP abarcando
desde la conexión directa (prueba 1) hasta la conexión median-
te tres niveles de conmutadores (prueba 4). . . . . . . . . . . . 243
7.40. Representaciones del desplazamiento frente al retraso de pro-
pagación obtenidas para una condición de carga moderada di-
rigida al servidor SNTP abarcando desde la conexión directa
(prueba 1) hasta la conexión mediante tres niveles de conmu-
tadores (prueba 4). . . . . . . . . . . . . . . . . . . . . . . . . 243
7.41. Representaciones de los estadísticos matemáticos del desplaza-
miento calculados para el cliente SNTP para diferentes cargas
de red donde el cliente y el servidor se han conectado mediante
tres niveles de conmutadores. . . . . . . . . . . . . . . . . . . 244
7.42. Representaciones de los estadísticos matemáticos del retraso
de propagación calculados para el cliente SNTP para diferentes
cargas de red donde el cliente y el servidor se han conectado
mediante tres niveles de conmutadores. . . . . . . . . . . . . . 245
7.43. Representaciones del desplazamiento frente al retraso de pro-
pagación obtenidas para el cliente SNTP para diferentes cargas
de red donde el cliente y el servidor se han conectado mediante
tres niveles de conmutadores. . . . . . . . . . . . . . . . . . . 245
7.44. Representaciones del desplazamiento frente al tiempo obteni-
das para el servidor y el cliente SNTP. Comportamiento frente
a operación continuada. . . . . . . . . . . . . . . . . . . . . . 247
7.45. Representaciones del desplazamiento frente al tiempo obteni-
das para el servidor y el cliente SNTP. Comportamiento frente
a pérdidas de sincronización en las fuentes de referencia. . . . 247

Índice de figuras 23
A.1. Formato del comando data2mem. . . . . . . . . . . . . . . . . 276
B.1. Representaciones del desplazamiento frente al tiempo obte-
nidas para el cliente SNTP empleando diferentes valores del
factor de convergencia y un periodo entre peticiones de 1 s. . . 278
B.2. Representaciones del desplazamiento frente al tiempo obte-
nidas para el cliente SNTP empleando diferentes valores del
factor de convergencia y un periodo entre peticiones de 2 s. . . 278
B.3. Representaciones del desplazamiento frente al tiempo obte-
nidas para el cliente SNTP empleando diferentes valores del
factor de convergencia y un periodo entre peticiones de 4 s. . . 279
B.4. Representaciones del desplazamiento frente al tiempo obte-
nidas para el cliente SNTP empleando diferentes valores del
factor de convergencia y un periodo entre peticiones de 8 s. . . 279
B.5. Representaciones del desplazamiento frente al tiempo obte-
nidas para el cliente SNTP empleando diferentes valores del
factor de convergencia y un periodo entre peticiones de 16 s. . 280
B.6. Representaciones del desplazamiento frente al tiempo obte-
nidas para el cliente SNTP empleando diferentes valores del
factor de convergencia y un periodo entre peticiones de 32 s. . 280
B.7. Representaciones del desplazamiento frente al tiempo obte-
nidas para el cliente SNTP empleando diferentes valores del
factor de convergencia y un periodo entre peticiones de 64 s. . 281
B.8. Representaciones de la función de distribución de frecuencias
del desplazamiento obtenidas para el cliente SNTP empleando
diferentes valores del factor de convergencia y un periodo entre
peticiones de 1 s. . . . . . . . . . . . . . . . . . . . . . . . . . 281
B.9. Representaciones de la función de distribución de frecuencias
del desplazamiento obtenidas para el cliente SNTP empleando
diferentes valores del factor de convergencia y un periodo entre
peticiones de 2 s. . . . . . . . . . . . . . . . . . . . . . . . . . 282

24 Índice de figuras
B.10.Representaciones de la función de distribución de frecuencias
del desplazamiento obtenidas para el cliente SNTP empleando
diferentes valores del factor de convergencia y un periodo entre
peticiones de 4 s. . . . . . . . . . . . . . . . . . . . . . . . . . 282
B.11.Representaciones de la función de distribución de frecuencias
del desplazamiento obtenidas para el cliente SNTP empleando
diferentes valores del factor de convergencia y un periodo entre
peticiones de 8 s. . . . . . . . . . . . . . . . . . . . . . . . . . 283
B.12.Representaciones de la función de distribución de frecuencias
del desplazamiento obtenidas para el cliente SNTP empleando
diferentes valores del factor de convergencia y un periodo entre
peticiones de 16 s. . . . . . . . . . . . . . . . . . . . . . . . . . 283
B.13.Representaciones de la función de distribución de frecuencias
del desplazamiento obtenidas para el cliente SNTP empleando
diferentes valores del factor de convergencia y un periodo entre
peticiones de 32 s. . . . . . . . . . . . . . . . . . . . . . . . . . 284
B.14.Representaciones de la función de distribución de frecuencias
del desplazamiento obtenidas para el cliente SNTP empleando
diferentes valores del factor de convergencia y un periodo entre
peticiones de 64 s. . . . . . . . . . . . . . . . . . . . . . . . . . 284
B.15.Representaciones del retraso de propagación frente al tiempo
obtenidas para el cliente SNTP empleando diferentes valores
del factor de convergencia y un periodo entre peticiones de 1 s. 285
B.16.Representaciones del retraso de propagación frente al tiempo
obtenidas para el cliente SNTP empleando diferentes valores
del factor de convergencia y un periodo entre peticiones de 2 s. 285
B.17.Representaciones del retraso de propagación frente al tiempo
obtenidas para el cliente SNTP empleando diferentes valores
del factor de convergencia y un periodo entre peticiones de 4 s. 286
B.18.Representaciones del retraso de propagación frente al tiempo
obtenidas para el cliente SNTP empleando diferentes valores
del factor de convergencia y un periodo entre peticiones de 8 s. 286

Índice de figuras 25
B.19.Representaciones del retraso de propagación frente al tiempo
obtenidas para el cliente SNTP empleando diferentes valores
del factor de convergencia y un periodo entre peticiones de 16 s.287
B.20.Representaciones del retraso de propagación frente al tiempo
obtenidas para el cliente SNTP empleando diferentes valores
del factor de convergencia y un periodo entre peticiones de 32 s.287
B.21.Representaciones del retraso de propagación frente al tiempo
obtenidas para el cliente SNTP empleando diferentes valores
del factor de convergencia y un periodo entre peticiones de 64 s.288
B.22.Representaciones de la función de distribución de frecuencias
del retraso de propagación obtenidas para el cliente SNTP
empleando diferentes valores del factor de convergencia y un
periodo entre peticiones de 1 s. . . . . . . . . . . . . . . . . . 288
B.23.Representaciones de la función de distribución de frecuencias
del retraso de propagación obtenidas para el cliente SNTP
empleando diferentes valores del factor de convergencia y un
periodo entre peticiones de 2 s. . . . . . . . . . . . . . . . . . 289
B.24.Representaciones de la función de distribución de frecuencias
del retraso de propagación obtenidas para el cliente SNTP
empleando diferentes valores del factor de convergencia y un
periodo entre peticiones de 4 s. . . . . . . . . . . . . . . . . . 289
B.25.Representaciones de la función de distribución de frecuencias
del retraso de propagación obtenidas para el cliente SNTP
empleando diferentes valores del factor de convergencia y un
periodo entre peticiones de 8 s. . . . . . . . . . . . . . . . . . 290
B.26.Representaciones de la función de distribución de frecuencias
del retraso de propagación obtenidas para el cliente SNTP
empleando diferentes valores del factor de convergencia y un
periodo entre peticiones de 16 s. . . . . . . . . . . . . . . . . . 290
B.27.Representaciones de la función de distribución de frecuencias
del retraso de propagación obtenidas para el cliente SNTP
empleando diferentes valores del factor de convergencia y un
periodo entre peticiones de 32 s. . . . . . . . . . . . . . . . . . 291

26 Índice de figuras
B.28.Representaciones de la función de distribución de frecuencias
del retraso de propagación obtenidas para el cliente SNTP
empleando diferentes valores del factor de convergencia y un
periodo entre peticiones de 64 s. . . . . . . . . . . . . . . . . . 291
B.29.Representaciones del desplazamiento frente al tiempo obteni-
das para el cliente SNTP cargando el conmutador con tráfico
no dirigido al servidor SNTP. . . . . . . . . . . . . . . . . . . 292
B.30.Representaciones de la función de distribución de frecuencias
del desplazamiento obtenidas para el cliente SNTP cargando
el conmutador con tráfico no dirigido al servidor SNTP. . . . . 293
B.31.Representaciones del retraso de propagación frente al tiempo
obtenidas para el cliente SNTP cargando el conmutador con
tráfico no dirigido al servidor SNTP. . . . . . . . . . . . . . . 293
B.32.Representaciones de la función de distribución de frecuencias
del retraso de propagación obtenidas para el cliente SNTP
cargando el conmutador con tráfico no dirigido al servidor SNTP.294
B.33.Representaciones del desplazamiento frente al tiempo obteni-
das para el cliente SNTP cargando el conmutador con tráfico
NTP dirigido al servidor SNTP (entre 10 y 100 peticiones por
segundo). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 295
B.34.Representaciones del desplazamiento frente al tiempo obteni-
das para el cliente SNTP cargando el conmutador con tráfico
NTP dirigido al servidor SNTP (entre 500 y 10000 peticiones
por segundo). . . . . . . . . . . . . . . . . . . . . . . . . . . . 295
B.35.Representaciones del desplazamiento frente al tiempo obteni-
das para el cliente SNTP cargando el conmutador con tráfico
NTP dirigido al servidor SNTP (entre 17000 y 20000 peticio-
nes por segundo). . . . . . . . . . . . . . . . . . . . . . . . . . 296
B.36.Representaciones de la función de distribución de frecuencias
del desplazamiento obtenidas para el cliente SNTP con tráfico
NTP dirigido al servidor SNTP (entre 10 y 100 peticiones por
segundo). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 296

Índice de figuras 27
B.37.Representaciones de la función de distribución de frecuencias
del desplazamiento obtenidas para el cliente SNTP con tráfico
NTP dirigido al servidor SNTP (entre 500 y 10000 peticiones
por segundo). . . . . . . . . . . . . . . . . . . . . . . . . . . . 297
B.38.Representaciones de la función de distribución de frecuencias
del desplazamiento obtenidas para el cliente SNTP con tráfico
NTP dirigido al servidor SNTP (entre 17000 y 20000 peticio-
nes por segundo). . . . . . . . . . . . . . . . . . . . . . . . . . 297
B.39.Representaciones del retraso de propagación frente al tiempo
obtenidas para el cliente SNTP cargando el conmutador con
tráfico NTP dirigido al servidor SNTP (entre 10 y 100 peti-
ciones por segundo). . . . . . . . . . . . . . . . . . . . . . . . 298
B.40.Representaciones del retraso de propagación frente al tiempo
obtenidas para el cliente SNTP cargando el conmutador con
tráfico NTP dirigido al servidor SNTP (entre 500 y 10000 pe-
ticiones por segundo). . . . . . . . . . . . . . . . . . . . . . . . 298
B.41.Representaciones del retraso de propagación frente al tiempo
obtenidas para el cliente SNTP cargando el conmutador con
tráfico NTP dirigido al servidor SNTP (entre 17000 y 20000
peticiones por segundo). . . . . . . . . . . . . . . . . . . . . . 299
B.42.Representaciones de la función de distribución de frecuencias
del retraso de propagación obtenidas para el cliente SNTP
cargando el conmutador con tráfico NTP dirigido al servidor
SNTP (entre 10 y 100 peticiones por segundo). . . . . . . . . . 299
B.43.Representaciones de la función de distribución de frecuencias
del retraso de propagación obtenidas para el cliente SNTP
cargando el conmutador con tráfico NTP dirigido al servidor
SNTP (entre 500 y 10000 peticiones por segundo). . . . . . . . 300
B.44.Representaciones de la función de distribución de frecuencias
del retraso de propagación obtenidas para el cliente SNTP
cargando el conmutador con tráfico NTP dirigido al servidor
SNTP (entre 17000 y 20000 peticiones por segundo). . . . . . 300

28 Índice de figuras
B.45.Representaciones del desplazamiento frente al tiempo obteni-
das para el cliente SNTP para una condición de carga mode-
rada dirigida al servidor SNTP abarcando desde la conexión
directa (prueba 1) hasta la conexión mediante tres niveles de
conmutadores (prueba 4). . . . . . . . . . . . . . . . . . . . . 301
B.46.Representaciones de las funciones de distribución de frecuen-
cias del desplazamiento obtenidas para el cliente SNTP para
una condición de carga moderada dirigida al servidor SNTP
abarcando desde la conexión directa (prueba 1) hasta la cone-
xión mediante tres niveles de conmutadores (prueba 4). . . . . 302
B.47.Representaciones del retraso de propagación frente al tiempo
obtenidas para el cliente SNTP para una condición de carga
moderada dirigida al servidor SNTP abarcando desde la cone-
xión directa (prueba 1) hasta la conexión mediante tres niveles
de conmutadores (prueba 4). . . . . . . . . . . . . . . . . . . . 302
B.48.Representaciones de las funciones de distribución de frecuen-
cias del retraso de propagación obtenidas para el cliente SNTP
para una condición de carga moderada dirigida al servidor
SNTP abarcando desde la conexión directa (prueba 1) hasta
la conexión mediante tres niveles de conmutadores (prueba 4). 303
B.49.Representaciones del desplazamiento frente al tiempo obteni-
das para el cliente SNTP para diferentes cargas de red donde
el cliente y el servidor se han conectado mediante tres niveles
de conmutadores. . . . . . . . . . . . . . . . . . . . . . . . . . 304
B.50.Representaciones de la función de distribución de frecuencias
del desplazamiento obtenidas para el cliente SNTP para di-
ferentes cargas de red donde el cliente y el servidor se han
conectado mediante tres niveles de conmutadores. . . . . . . . 304
B.51.Representaciones del retraso de propagación frente al tiempo
obtenidas para el cliente SNTP para diferentes cargas de red
donde el cliente y el servidor se han conectado mediante tres
niveles de conmutadores. . . . . . . . . . . . . . . . . . . . . . 305

Índice de figuras 29
B.52.Representaciones de la función de distribución de frecuencias
del retraso de propagación obtenidas para el cliente SNTP
para diferentes cargas de red donde el cliente y el servidor se
han conectado mediante tres niveles de conmutadores. . . . . . 305

30 Índice de figuras

Abreviaturas
ARM Advanced RISC Machines.
ARP Address Resolution Protocol.
ASCII American Standard Code for Information Interchange.
ASIC Application-Specific Integrated Circuit.
BCD Binary-Coded Decimal.
BOOTP Bootstrap Protocol.
BRAM Block RAM.
CDMA Code Division Multiple Access.
CLB Configurable Logic Block.
COL Collision Detected.
CPLD Complex Programmable Logic Device.
CRC Cyclic Redundancy Check.
CRS Carrier Sense.
CSMA/CD Carrier Sense Multiple Access with Collision Detection.
CTS Clear To Send.
DAC Digital-to-Analog Converter.
31

32 Abreviaturas
DCD Data Carrier Detect.
DCM Digital Clock Manager.
DDR Double Data Rate.
DHCP Dynamic Host Configuration Protocol.
DSP Digital Signal Processing.
DSR Data Set Ready.
DTR Data Terminal Ready.
DTSS Digital Time Synchronization Service.
EIA Electronic Industries Alliance.
ESA European Space Agency.
FF Flip Flop.
FFT Fast Fourier Transform.
FIFO First In First Out.
FIR Finite Impulse Response.
FPGA Field Programmable Gate Array.
FSM Finite State Machine.
GPS Global Positioning System.
HDL Hardware Description Language.
HTP HTTP Time Protocol.
HTTP HyperText Transfer Protocol.
HTTPS HyperText Transfer Protocol Secure.
IC Integrated Circuit.

Abreviaturas 33
ICMP Internet Control Message Protocol.
ICON Integrated CONtroller.
ICS Internet Clock Service.
ID2 Investigación y Desarrollo Digital.
IEC International Electrotechnical Commission.
IEEE Institute of Electrical and Electronics Engineers.
ILA Integrated Logic Analyzer.
IOB Input/Output Block.
IP Internet Protocol o Intellectual Property.
IRIG Inter-Range Instrumentation Group.
IS Integrated System.
ISO International Organization for Standardization.
JTAG Joint Test Action Group Boundary-scan.
LAN Local Area Network.
LEA Logical Event Analyzer.
LLC Logical Link Control.
LUT Look-Up Table.
MAC Media Access Control.
MDC Management Data Clock.
MDIO Management Data Input/Output.
MII Media Independent Interface.
NCD Native Circuit Description.

34 Abreviaturas
NIC Network Interface Card.
NMEA National Marine Electronics Association.
NTP Network Time Protocol.
OCXO Oven Controlled Crystal Oscillator.
OLA On-chip Logic Analyzers.
OSI Open System Interconnect.
P2P Peer-to-Peer
PCI Peripheral Component Interconnect.
PDU Protocol Data Unit.
PHY Physical layer.
PPM Parts-Per-Million.
PPS Pulse Per Second.
PTC Plataforma Tecnológica Común.
PTP Precision Time Protocol.
RAM Random Access Memory.
RFC Request for Comments.
RI Ring Indicator.
RMC Recommended Minimum sentence C.
RS Recommended Standard.
RTS Request To Send.
RTU Remote Terminal Unit.
RX_CLK Receive Clock.

Abreviaturas 35
RX_ER Receive Error.
RX_DV Receive Data Valid.
RXD Receive Data.
SDRAM Synchronous Dynamic Random Access Memory.
SEPIC Sistemas Empotrados para Infraestructuras Críticas.
SFD Start Frame Delimiter.
SLA Standalone Logic Analyzers.
SNMP Simple Network Management Protocol.
SNTP Simple Network Time Protocol.
SoC System on Chip.
SoPC System on a Programmable Chip.
SSH Secure SHell.
SSL Secure Socket Layer.
TAI International Atomic Time.
TCXO Temperature Compensated Crystal Oscillator.
TTL Transistor-Transistor Logic.
TX_CLK Transmit Clock.
TX_EN Transmit Enable.
TX_ER Transmit Coding Error.
TXD Transmit Data.
UART Universal Asynchronous Receiver-Transmitter.
UDP User Datagram Protocol.

36 Abreviaturas
UTC Coordinated Universal Time.
VCO Voltage-Controlled Oscillator.
VFO Variable Frequency Oscillator.
VHDL VHSIC Hardware Description Language.
VHSIC Very High Speed Integrated Circuits.
WWW World Wide Web.
XDL Xilinx Design Language.
XOR Exclusive Disjunction.

Capítulo 1
Introducción
En este primer capítulo se realiza una introducción general a los temas
que se abordan en este trabajo de tesis doctoral. Las tareas desarrolladas
se encuadran dentro del área de diseño e implementación de sistemas de
sincronización sobre redes de comunicación para sistemas empotrados, en
la que viene trabajando desde hace algunos años el grupo de investigación
al que pertenece el autor, y que han estado soportadas principalmente por
los proyectos de investigación PTC: Plataforma Tecnológica Común para
Unidades Terminales Remotas (Remote Terminal Unit, RTU) (PTC FIT-
330100-2006-60, FASE I y II), HIPER: Técnicas de altas prestaciones para
la verificación y diseño de circuitos digitales CMOS VLSI (TEC-2007-61802)
y SEPIC: Sistemas Empotrados Para Infraestructuras Críticas (SEPIC TSI-
020100-2008-258). Dichos proyectos han estado financiados por el Ministerio
de Industria, Turismo y Comercio del Gobierno Español.
Dentro de esta área genérica, esta tesis aborda el problema concreto del
estudio de metodologías de diseño, técnicas y algoritmos que permitan la im-
plementación completamente hardware de soluciones empotradas compactas,
de bajo coste y consumo de potencia dedicadas a la sincronización de equipos
sobre redes de comunicación y basadas en protocolos estándares.
Este capítulo está formado por un primer apartado dedicado a presentar
cómo se realiza y por qué es importante la sincronización temporal de los
equipos que forman parte de una red de comunicación, un segundo apartado
37

38 Capítulo 1. Introducción
en el que se introducen los protocolos de sincronización estándares utilizados
en la actualidad y un tercer apartado en el que se aborda la problemática de
la sincronización en sistemas empotrados. Además, al final del capítulo, se
concretan los objetivos fundamentales de la tesis y se detalla la estructura
del resto del documento.
1.1. Sincronización en redes de comunicación
En la actualidad, la expansión de las redes de comunicación ha permitido
que diferentes equipos separados físicamente puedan comunicarse entre sí, ya
sea a nivel local o global (Fig. 1.1). Asimismo, este hecho ha abierto nuevos
campos de estudio como por ejemplo el de la computación distribuida que se
encarga de estudiar los sistemas distribuidos.
Un sistema distribuido está formado por múltiples equipos autónomos
conectados a través de una red de comunicación que interaccionan entre sí
para conseguir un objetivo común. En relación con la utilización de este tipo
de sistemas se puede decir que han sido ampliamente aplicados a multitud
de escenarios, destacando los siguientes:
Redes de telecomunicaciones. Algunos ejemplos de aplicación en este
ámbito son las redes de computadores como Internet, redes de sensores
inalámbricos y algoritmos de rutado.
Aplicaciones de red. Aquí destacan las redes World Wide Web (WWW)
y Peer-to-Peer (P2P), sistemas de administración de bases de datos
Figura 1.1: Conexión de equipos mediante redes de comunicación.

1.1. Sincronización en redes de comunicación 39
distribuidas, sistemas de ficheros en red y sistemas de procesamiento
de información distribuidos.
Control de procesos en tiempo real. Ampliamente utilizados en sistemas
industriales de control y medida distribuidos, siendo ejemplos típicos
la adquisición de datos por unidades terminales remotas empleadas
en redes de distribución de gas y electricidad y la medida de fasores
sincronizados (sincrofasores) aplicados a redes de potencia [Carta et al.,
2008, 2009; Han and Jeong, 2010; Carta et al., 2011].
Computación paralela. En este ámbito destacan dos tipos de compu-
tación distribuida: en cluster y en grid o malla. La principal diferencia
entre estos dos tipos de computación radica en que en el primer caso
todos los equipos se encuentran en el mismo lugar conectados entre sí
mediante una red de área local, mientras que en el segundo los equipos
no tienen por qué situarse en el mismo espacio geográfico.
Sin embargo, como se presenta en los trabajos [Mills, 1990; Johannessen,
2004], en multitud de aplicaciones y especialmente en aquellas diseñadas
para operar de forma distribuida se requiere que los equipos que forman
el sistema estén sincronizados, lo que significa que todos deben mostrar la
misma hora en un mismo instante de tiempo. En este sentido, la importancia
de la sincronización tiene especial relevancia en los sistemas industriales de
control y medida, donde resulta imprescindible mantener el sincronismo entre
los diferentes equipos con objeto de secuenciar de forma correcta y dentro de
los márgenes temporales establecidos las diferentes acciones de control, y de
poder establecer con precisión las marcas temporales (timestamps) asignadas
a las muestras tomadas por los sistemas de adquisición.
A partir del esquema planteado en la Fig. 1.1, se distinguen principalmen-
te dos grupos de alternativas de sincronización que consisten en: (1) conectar
directamente a cada equipo una referencia de tiempo absoluta y (2) utilizar
la propia infraestructura de comunicación como medio para sincronizar los
equipos, empleando protocolos estándares de comunicación.
En relación con el primer grupo, en la Fig. 1.2 se observa cómo se orga-
nizaría la red de comunicación, destacando el hecho de que resulta necesario

40 Capítulo 1. Introducción
Figura 1.2: Alternativa de sincronización basada en referencias absolutas.
conectar a cada equipo una referencia absoluta como un reloj atómico, un
receptor del Sistema de Posicionamiento Global (Global Positioning System,
GPS), un dispositivo que emplee señales de telefonía móvil CDMA (Code
Division Multiple Access) como referencia precisa de tiempo o un reloj con-
trolado por radio. A continuación, se van a exponer las principales ventajas
e inconvenientes de las alternativas presentadas.
En general todas las referencias de tiempo absolutas comentadas presen-
tan la ventaja de que proporcionan información de tiempo altamente precisa
a los equipos; asimismo, en el proceso de sincronización en ningún caso se
emplea la red de comunicación para dicha finalidad. Los principales incon-
venientes se enumeran a continuación. En primer lugar, el coste de un reloj
atómico o de un receptor GPS puede ser elevado, no pudiéndose justificar
en la mayoría de aplicaciones. En segundo lugar, la instalación de un recep-
tor GPS conectado a cada equipo no es siempre posible dado que este tipo
de dispositivos necesitan situar sus antenas en el exterior y con línea visual
directa a un número suficiente de satélites; en este caso, para sistemas ubi-
cados dentro de edificios, la infraestructura de GPS necesaria puede resultar
demasiado costosa. Una solución a este problema consiste en la utilización de
dispositivos que se sincronizan a las estaciones base del sistema CDMA (a su
vez sincronizadas por receptores GPS) y proporcionan la información de ho-

1.2. Protocolos de sincronización 41
ra a los equipos que la requieran. La principal ventaja de esta alternativa es
que funciona correctamente dentro de un edificio, empleando únicamente una
pequeña antena, mientras se garantiza una precisión dentro de los 10 µs. El
principal inconveniente es que este servicio es ofrecido por las compañías de
telefonía móvil en numerosas partes del mundo, pero en Europa es práctica-
mente inexistente. En tercer y último lugar, los relojes de radio se sincronizan
mediante códigos de tiempo transmitidos por estaciones de radio situadas en
diferentes países, pudiendo conseguir una precisión entorno a un milisegundo
relativa a la hora estándar; dicha precisión generalmente se encuentra limita-
da por variabilidades en la propagación de la señal de radio derivadas de la
hora del día, condiciones atmosféricas o interferencias causadas por edificios,
pudiendo resultar insuficiente en determinadas aplicaciones.
En cuanto al segundo grupo, en la Fig. 1.3 se presenta el esquema de esta
alternativa. De acuerdo a este esquema, por un lado, el servidor de hora ad-
quiere información de hora precisa mediante una referencia absoluta como un
reloj atómico o un receptor GPS estándar. Por otro lado, los clientes de hora,
localizados en el mismo espacio físico que los equipos, se sincronizan con el
servidor a través de la red de comunicación y proporcionan a cada máquina
la información temporal y de sincronización que necesitan, emulando un re-
ceptor GPS. La ventaja de esta alternativa es que se evita tener que instalar
referencias absolutas en los equipos, de forma que resulta una opción de muy
bajo coste. Sin embargo, presenta el inconveniente de que se emplea la propia
red de comunicación como medio para sincronizar los equipos, afectando este
hecho a la precisión de sincronización que se puede alcanzar.
1.2. Protocolos de sincronización
En relación con los protocolos de sincronización, actualmente existen va-
rios protocolos estándares de comunicación dedicados a la distribución de
hora a través de redes de comunicación, siendo los más extendidos el Net-
work Time Protocol (NTP) [Mills et al., 2010], empleado para sincronizar
equipos en redes globales como Internet, y su versión simplificada, el Simple
Network Time Protocol (SNTP) [Mills, 2006b], utilizado principalmente en

42 Capítulo 1. Introducción
Figura 1.3: Alternativa de sincronización basada en protocolos de sincroni-zación.
redes de área local (Local Area Network, LAN), aunque no limitado a este ti-
po de redes. Además, otro protocolo que está cobrando especial relevancia en
los últimos años es el estándar IEEE-1588 sobre el Precision Time Protocol
(PTP) [IEEE, 2008] publicado por el Institute of Electrical and Electronics
Engineers (IEEE) en 2002 y que aparece como una alternativa al protocolo
SNTP restringida al ámbito de redes locales y que pretende solucionar las
limitaciones de precisión del protocolo NTP.
Ambos protocolos, NTP y PTP, basan su operación en un intercambio de
mensajes entre un cliente y un servidor que almacenan los instantes (marcas
de tiempo) en los que cada mensaje abandona y alcanza el cliente y el servi-
dor. A partir de estos datos el cliente es capaz de calcular el desplazamiento
de su reloj local respecto al del servidor y el retraso de propagación de la
red. Sin embargo, la precisión alcanzable por una implementación de estos
protocolos depende considerablemente de la precisión en la colocación de las
marcas de tiempo en el mensaje y de otros factores relacionados con la trans-
misión de los paquetes a través de la red de comunicación, en especial de la
latencia variable introducida por los equipos de red al procesar los paquetes.
En relación con la precisión alcanzable por los diferentes protocolos de
sincronización comentados, el estándar de control International Electrotech-

1.2. Protocolos de sincronización 43
nical Commission (IEC) 61850 [Technical Committee 57, 2008] define cinco
clases de sincronización, desde T1 a T5, dependiendo de la precisión de sin-
cronización que se pueda conseguir (Tabla 1.1). Atendiendo a estas clases, a
continuación se analizan las acciones necesarias para conseguir una sincroni-
zación precisa empleando cada uno de los protocolos presentados.
Las implementaciones software de NTP típicamente consiguen tiempos de
sincronización en el orden de un milisegundo con respecto al servidor (clase
IEC T1). Dicha precisión se encuentra limitada debido a que las marcas de
tiempo son registradas por clientes/servidores corriendo como una aplicación
a nivel de usuario, de forma que el error en la marca de tiempo dependerá
del tiempo empleado en procesar el datagrama y en subir la pila de protoco-
los y capas software, siendo a su vez estos aspectos dependientes de la carga
del sistema, correcta implementación software, etc. Por otro lado, sincronizar
equipos en redes con latencias muy variables requiere la implementación de
algoritmos avanzados que permitan mitigar los efectos derivados de dicha va-
riabilidad en el retraso, resultando este problema complejo de resolver debido
a la heterogeneidad de las redes actuales.
La precisión de sincronización del protocolo NTP puede ser ampliamente
mejorada si se implementan las siguientes consideraciones: (1) se incluye so-
porte del protocolo NTP en el kernel del sistema operativo para realizar el
control del reloj y (2) la operación de registrar las marcas de tiempo se realiza
en las capas más bajas [Skeie et al., 2001], obteniendo la mejor precisión si
el marcado temporal se realiza en el hardware del dispositivo Ethernet tan
pronto como los paquetes lleguen o abandonen la interfaz de red. Esto último
sólo es posible si se realiza una modificación del controlador Ethernet a nivel
Nombre de la clase Precisión conseguida
Clase IEC T1 1 msClase IEC T2 0,1 msClase IEC T3 25 µsClase IEC T4 4 µsClase IEC T5 1 µs
Tabla 1.1: Clases de sincronización definidas por el estándar IEC 61850.

44 Capítulo 1. Introducción
hardware y se desarrolla un driver específico. En este caso, se puede alcanzar
una precisión en torno a los 100 µs (clase IEC T2).
En lo que se refiere al protocolo SNTP, éste es una versión simplificada del
protocolo NTP que cubre la sincronización con un único servidor y no imple-
menta el conjunto de algoritmos avanzados de NTP. En estas condiciones, en
redes con latencias muy variables como por ejemplo la red mundial Internet,
la precisión alcanzable se encuentra en el orden de fracciones significativas
de un segundo. Sin embargo, de acuerdo al documento de especificaciones
del protocolo SNTP [Mills, 2006b] y otros autores [Skeie et al., 2001, 2003;
Johannessen, 2004; Holmeide and Skeie, 2006] la precisión de sincronización
empleando SNTP puede ser ampliamente mejorada trabajando sobre redes de
área local Ethernet conmutadas, pudiéndose alcanzar en este caso las clases
IEC T3, T4 y T5 en función de aspectos como la arquitectura de conmuta-
ción de la red y el tipo de elementos de conmutación empleados o del lugar
donde se realice el marcado temporal de los mensajes de hora.
Finalmente, en el caso del protocolo PTP, la mayoría de los principios
expuestos anteriormente fueron considerados en la especificación de la pri-
mera versión del estándar PTP (IEEE 1588-2002), en especial la necesidad
de aplicar las marcas de tiempo desde implementaciones hardware. En esta
primera versión, el objetivo marcado fue conseguir una precisión de sincro-
nización por debajo del microsegundo. En la segunda versión del estándar
(IEEE 1588-2008) se añadieron mejoras como la tecnología de reloj trans-
parente, que consiste en incluir el soporte de sincronización necesario a los
equipos de red que unen el servidor de hora con los clientes finales. En es-
te caso, se pretendió alcanzar una precisión del orden del nanosegundo; sin
embargo, en la actualidad la mayoría de equipos implementando PTPv2 sólo
consiguen una precisión en el orden de 100 ns, la cual por otro lado es la
precisión típica proporcionada por los receptores GPS.
1.3. Sincronización de sistemas empotrados
La evolución tecnológica ha dado lugar a un aumento tan significativo
de la densidad de integración que está propiciando que cada vez más par-

1.3. Sincronización de sistemas empotrados 45
tes de un sistema completo estén incluidas dentro del núcleo principal del
mismo constituido por un único chip. Si bien, tradicionalmente se ha venido
llamando a este chip circuito integrado (Integrated Circuit, IC), debido a las
múltiples partes del sistema que incluye, es más adecuado el término sistema
integrado (Integrated System, IS) o bien el de System on Chip (SoC).
Desde su aparición, los SoC han experimentado un gran desarrollo, muy
ligado a la creciente evolución y penetración en la sociedad de los sistemas
empotrados: electrónica de consumo, automóviles, telefonía móvil, etc. La
principal ventaja de los SoC consiste en que al integrar toda la funcionalidad
del sistema en un único chip se consigue reducir el tamaño, el coste y el con-
sumo energético del mismo, permitiendo incluso su uso en sistemas móviles
alimentados por baterías. La principal limitación encontrada es un menor
rendimiento en comparación con sistemas electrónicos tradicionales, como
por ejemplo, los ordenadores personales. No obstante, el rendimiento ofre-
cido es suficiente para la gran mayoría de aplicaciones existentes, actuando
como núcleo del producto desarrollado o como parte de un sistema electró-
nico completo resolviendo una necesidad específica. En consecuencia, su uso
está muy extendido tanto en el ámbito académico como en el industrial.
En lo que se refiere a las tecnologías de implementación de sistemas em-
potrados, en la actualidad existe la tendencia cada vez mayor de utilizar
dispositivos programables tipo Field Programmable Gate Array (FPGA). La
tecnología FPGA fue inventada a mediados de los años ochenta por la compa-
ñía Xilinx [Xilinx] y se considera la evolución de los Complex Programmable
Logic Device (CPLD). Las FPGA son dispositivos semiconductores progra-
mables basados en bloques lógicos configurables (Configurable Logic Blocks,
CLB) conectados entre sí empleando una red de interconexión configurable y
con el exterior a través de bloques de entrada/salida (Input/Output Blocks,
IOB) (Fig. 1.4). Los CLB constituyen la unidad reprogramable básica y están
formados por varias celdas lógicas denominadas Slices. Los Slices se compo-
nen a su vez por varias tablas de búsqueda (Look-Up Table, LUT) de un
determinado número de entradas que permiten definir cualquier función lógi-
ca de aridad igual al número de éstas, un sumador completo que incluye lógica
de acarreo, multiplexores y biestables (Flip Flops, FF). Además, disponen de

46 Capítulo 1. Introducción
Figura 1.4: Estructura por bloques de las FPGA de Xilinx.
bloques de memoria volátil denominados Block RAM (BRAM) y bloques de
gestión digital del reloj (Digital Clock Manager, DCM), ambos distribuidos
por su área. Con este tipo de dispositivos es posible implementar cualquier
circuito digital, siendo las únicas restricciones los recursos hardware disponi-
bles en el chip y la frecuencia máxima de operación que se pueda alcanzar.
En este sentido, también es posible implementar un SoC sobre un dispositi-
vo programable recibiendo este tipo de sistemas el nombre de System on a
Programmable Chip (SoPC).
Las principales ventajas de las FPGA derivan de su característica funda-
mental: la reconfigurabilidad1. Esta característica reduce considerablemente
los tiempos de desarrollo de un circuito digital, ya que simplifica y determina
el ciclo de diseño y posibilita la reconfiguración del dispositivo (incluso de
forma remota y parcial en tiempo de ejecución) un número prácticamente
1Existen FPGA que incorporan una tecnología de memoria de programación basada enfusibles permitiendo configurar el dispositivo una única vez.

1.3. Sincronización de sistemas empotrados 47
ilimitado de veces. Estas características les otorgan una gran flexibilidad,
convirtiéndolas en una destacada herramienta para labores de investigación
y/o de prototipado. Como aspectos negativos, en comparación con los circui-
tos integrados para aplicaciones específicas (Application-Specific Integrated
Circuit, ASIC), cabe citar que esta última permite una mayor especificidad
del hardware a cambio de perder parte de la flexibilidad proporcionada por
las FPGA, consiguiendo una reducción de coste (para grandes tiradas) y de
consumo y aumentando la frecuencia máxima de operación.
Actualmente existen varios fabricantes de FPGA, entre ellos destacan
Xilinx, Altera [Altera], Lattice Semiconductor [Lattice] y Actel
[Actel], siendo los dos primeros los líderes del sector.
En relación con la sincronización de sistemas empotrados, un SoPC que
requiera funcionalidades de sincronización de hora tendrá que usar equipos de
sincronización externos o implementar algoritmos y componentes de sincro-
nización como parte del sistema. Por un lado, depender de un equipo externo
elimina las ventajas del SoPC de ser un dispositivo compacto y de bajo coste
y consumo de potencia. Por otro lado, implementar completamente en hard-
ware los algoritmos avanzados de los protocolos NTP o PTP dentro del SoPC
tiene la ventaja principal de proporcionar alta precisión a la vez que un bajo
coste y consumo de energía; no obstante, realizar dichas implementaciones
puede resultar una tarea compleja que puede tener un impacto considerable
en los recursos hardware del sistema. En este sentido, la alternativa de sin-
cronización más adecuada para SoPC puede consistir en la implementación
de un protocolo simplificado pero de precisión suficiente sobre redes de área
local como SNTP.
Aunque se han usado SoPC para implementar soluciones de sincronización
precisas, siendo los trabajos [Höller, 2003; Meier et al., 2008] algunos ejem-
plos, en la mayoría de las ocasiones estos sistemas sólo se dedican a realizar
algunas tareas críticas por hardware como por ejemplo el marcado temporal,
necesitando un sistema basado en microprocesador y software adicional para
implementar el resto de funciones de sincronización. Este hecho puede reper-
cutir en el coste final de SoPC ya que esto supone la necesidad de incluir
hardware adicional externo al chip, generalmente dispositivos de memoria

48 Capítulo 1. Introducción
volátil como Synchronous Dynamic Random Access Memory (SDRAM) o
Double Data Rate (DDR) y no volátil (FLASH), para poder ejecutar los
programas desarrollados. En este sentido, la integración de servicios de sin-
cronización en un SoPC es un tema aún sin resolver, siendo ésta la temática
principal que se va a abordar en este trabajo de tesis doctoral.
1.4. Objetivos y estructura de la tesis
El objetivo general de este trabajo de tesis consiste en investigar los
métodos, arquitecturas, algoritmos y soluciones técnicas que permitan im-
plementar en hardware un conjunto de módulos de sincronización que sean
fácilmente integrables en un SoPC, de forma que cualquier sistema empotra-
do pueda incorporar funciones de sincronización de hora precisa de manera
compacta, flexible y con un coste reducido.
Estos módulos implementarán en hardware la funcionalidad requerida
por el sistema de sincronización: control de acceso al medio, pila básica de
protocolos, interfaz con el GPS, marcado temporal, disciplina de reloj, salida
de referencia de tiempo, etc. Así, estos módulos podrían ser combinados para
proporcionar sólo funcionalidad básica (como por ejemplo, sólo el marcado
temporal de los paquetes) o una solución completa (un cliente o un servidor
de hora autónomo implementado completamente en hardware).
A continuación, se presentan de forma más detallada los objetivos con-
cretos que se han planteado para alcanzar el objetivo general comentado en
el párrafo anterior:
1. Análisis de métodos y teorías empleadas que soporten tecnologías de
sincronización de hora basadas en redes de comunicación.
2. Análisis de implementaciones actuales de los protocolos de sincroniza-
ción presentados tanto software como asistidas por hardware.
3. Investigación de arquitecturas, metodologías de diseño y algoritmos de
sincronización que permitan la implementación de soluciones de sincro-
nización en hardware, teniendo en cuenta diferentes aspectos como los

1.4. Objetivos y estructura de la tesis 49
protocolos de comunicación y los algoritmos de disciplina y ajuste del
reloj.
4. Aplicación al diseño de un servidor y un cliente SNTP realizados com-
pletamente en hardware.
5. Validación de los resultados mediante la definición de un extenso con-
junto de pruebas y el desarrollo de las herramientas necesarias para su
aplicación.
Finalmente, se indica cómo se organiza el resto del documento:
Parte I: en el capítulo 2 se presentan las características de los protocolos
de sincronización presentados y el estado del arte de las soluciones
actuales, en concreto los equipos comerciales ofertados por las diferentes
compañías líderes en el sector y las soluciones de sincronización basadas
en SoC y/o FPGA encontradas en la bibliografía.
Parte II: en el capítulo 3 se definen la arquitectura del sistema de
sincronización, los bloques de funcionalidad básica y los algoritmos de
sincronización, prestando especial atención a que su implementación sea
abordable completamente en hardware. En el capítulo 4 se presentan las
metodologías de diseño que se van a emplear para diseñar e implementar
cada una de las partes de las que se compone el sistema de referencia. En
el capítulo 5 se va a comentar cómo se han implementado los diferentes
bloques y algoritmos que componen el sistema, destacando los aspectos
más significativos.
Parte III: en el capítulo 6 se presentan diferentes metodologías de verifi-
cación de sistemas empotrados, poniendo de manifiesto la necesidad de
diseñar herramientas de verificación específicas que permitan validar
las soluciones de sincronización planteadas. Además, se indicarán los
parámetros que van a analizarse y los diferentes escenarios de pruebas
a los que va a someterse al sistema. En el capítulo 7 se presentan los re-
sultados de las diferentes pruebas realizadas, de los cuales se extraerán
las conclusiones más relevantes de este trabajo.

50 Capítulo 1. Introducción

Parte I
Análisis del estado del arte
51


Capítulo 2
Sincronización temporal sobre
redes de comunicación
Como se ha comentado en el capítulo de introducción, la sincronización
temporal sobre redes de comunicación es requerida en multitud de aplicacio-
nes, siendo un aspecto de vital importancia en aquellos sistemas diseñados
para operar de forma distribuida.
Para realizar la sincronización temporal de los equipos que forman la red
de comunicación existen diferentes protocolos de sincronización de red, des-
tacando principalmente los protocolos NTP, su versión simplificada SNTP
y PTP. De esta forma, la primera parte de este capítulo se va a dedicar a
presentar las principales características de estos protocolos: formato de men-
saje, formato de las marcas de tiempo, protocolo de comunicación, fuentes
de error y algoritmos de sincronización implementados.
Una vez presentadas las principales características de los protocolos de
sincronización comentados, en la segunda parte se va a proceder a estudiar
los equipos comerciales y las alternativas de sincronización basadas en SoC
y FPGA encontradas en la bibliografía. En este sentido, por un lado, en el
campo de la sincronización hay un amplio rango de productos comerciales
soportando los protocolos NTP y PTP. Estos productos son principalmente
servidores de tiempo dedicados (computadores de propósito general con hard-
ware específico para marcado temporal y control del reloj), clientes discretos
53

54 Capítulo 2. Sincronización temporal sobre redes de comunicación
dedicados que proporcionan diferentes salidas de sincronización, y tarjetas
para bus PCI (Peripheral Component Interconnect) empleadas por servido-
res de información estándares u ordenadores personales como referencias de
tiempo para sincronizarse de forma precisa. Algunos buenos ejemplos de estos
productos son los ofertados por Symmetricom [Symmetricom] y Meinberg
[Meinberg]. Por otro lado, en el campo de los sistemas empotrados, como
se comentó en el Capítulo 1, se han aportado soluciones de sincronización
aunque en la mayoría de los casos estos sistemas sólo realizan en hardwa-
re algunas tareas críticas como el marcado temporal o el control del reloj,
implementando el conjunto de algoritmos del protocolo de sincronización a
nivel software.
Finalmente, tras finalizar el análisis de los equipos y alternativas de sin-
cronización, se comentarán las conclusiones más importantes de este capítulo.
2.1. Protocolos de sincronización
En esta sección se van a describir los diferentes protocolos de sincroni-
zación empleados en la actualidad, centrándonos en el protocolo NTP al ser
el más extendido. En primer lugar, se presentarán las características de este
protocolo así como los algoritmos de corrección y ajuste del reloj empleados.
Para comprender mejor el funcionamiento de estos algoritmos se incluye un
análisis de las principales fuentes de error extensible a otros protocolos de
sincronización. Finalmente, el resto de protocolos se describirán a partir del
protocolo NTP ya que comparten muchas características de forma que sólo
se comentarán las principales diferencias.
2.1.1. Network Time Protocol
El Network Time Protocol es un protocolo de Internet ampliamente uti-
lizado para sincronizar la hora de equipos informáticos y routers en redes
locales o a través de Internet. Es uno de los protocolos de Internet más
antiguos que siguen empleándose en la actualidad. En concreto, la primera
versión de este protocolo (versión 0) se propuso en septiembre de 1985 co-

2.1. Protocolos de sincronización 55
mo un Request for Comments (RFC). La versión 2 estuvo considerada como
un estándar y la versión 3 como un borrador de estándar. La versión actual
del protocolo (versión 4), publicada en junio de 2010, está propuesta para
estándar. Todas las versiones se encuentran formalizadas en RFC: versión 0
- RFC 958 [Mills, 1985], versión 1 - RFC 1059 [Mills, 1988], versión 2 - RFC
1119 [Mills, 1989], versión 3 - RFC 1305 [Mills, 1992b] y versión 4 - RFC
5905 [Mills et al., 2010].
Para llevar a cabo la sincronización, el protocolo NTP se encarga de
transmitir información temporal desde servidores primarios sincronizados con
referencias de tiempo precisas a servidores secundarios y clientes a través de
redes privadas o la red pública Internet. Para realizar esta comunicación,
NTP define su propio formato de mensaje, modos de operación y protocolo
de comunicación. Además, otro aspecto importante consiste en el formato en
el que se transmite la información temporal; en este sentido, NTP también
define su propio formato para representar las marcas de tiempo.
En los siguientes apartados, se va a describir el protocolo de sincroni-
zación NTP introduciendo los aspectos antes comentados: formato de las
marcas de tiempo usadas para la sincronización, modos de operación, forma-
to del mensaje NTP y protocolo de comunicación. Una vez expuestos todos
estos aspectos se analizarán la principales fuentes de error que afectan a la
sincronización. Finalmente, se presentarán de forma resumida los algoritmos
implementados por el protocolo NTP para mitigar estos errores y ajustar la
hora del reloj local.
Formato de las marcas de tiempo
La versión 4 del protocolo NTP [Mills et al., 2010] define tres formatos
para representar la hora: un formato corto de 32 bits empleado en algunos
campos de la cabecera del mensaje donde no se necesita mayor precisión,
un formato de 64 bits usado para representar las marcas de tiempo inter-
cambiadas entre clientes y servidores y un formato de 128 bits que extiende
notablemente los rangos de fechas representables y la precisión de la repre-
sentación.

56 Capítulo 2. Sincronización temporal sobre redes de comunicación
En cuanto al formato de 64 bits las marcas de tiempo se especifican
como números en punto fijo sin signo representando el número de segundos
transcurridos desde las 0 horas del 1 de enero de 1900. Estas marcas de
tiempo se dividen en dos partes: una primera formada por 32 bits (los más
significativos) que representa la parte entera o número de segundos y una
segunda parte formada por los 32 bits menos significativos representando las
fracciones de segundo.
Modos de operación
El protocolo NTP establece una estructura jerárquica en forma de ár-
bol compuesta por servidores primarios, servidores secundarios y clientes
(Fig. 2.1). Dentro de esta organización el nivel de cada servidor en la je-
rarquía se define por un número de stratum donde los servidores primarios
se asientan en el nivel más alto de la jerarquía o stratum 1 y los servidores
secundarios ocupan los niveles inferiores. Como se observa en la Fig. 2.1 un
servidor primario es aquel que se sincroniza directamente a una referencia de
tiempo absoluta como un reloj atómico, un receptor GPS o un reloj de radio.
Un servidor secundario es aquel que se sincroniza a uno o más servidores
primarios o secundarios y a su vez proporciona sincronización a otros servi-
dores secundarios o clientes. Los clientes son aquellos equipos que, situados
en las hojas, se sincronizan a uno o más servidores de nivel superior pero no
proporcionan sincronización a ningún otro servidor o cliente.
Teniendo en cuenta que una implementación de NTP puede operar como
cliente y/o servidor se distinguen 3 modos de operación dentro del protocolo
NTP: cliente/servidor, broadcast y simétrico. En el primer modo, un equipo
operando como cliente envía peticiones de hora a un equipo configurado como
servidor y a continuación espera las respuestas de ese servidor. En el segun-
do, el servidor envía mensajes a una dirección de broadcast que son recibidos
por múltiples clientes. Finalmente, el protocolo NTP también dispone de un
modo simétrico donde un conjunto de equipos normalmente situados en el
mismo stratum operan de forma colaborativa intercambiándose información
de sincronización mutuamente aunque ésta no es utilizada necesariamente

2.1. Protocolos de sincronización 57
Figura 2.1: Organización en niveles de los servidores y clientes NTP.
para sincronizarse; la principal ventaja de este modo es que permite una
reconfiguración automática de la red en el caso de que uno de estos equi-
pos pierda todas sus referencias de tiempo. Cuando esto ocurre éste puede
emplear los equipos con los que colabora para mantenerse sincronizado.
Formato del mensaje NTP
El protocolo NTP es un cliente del User Datagram Procotol (UDP) en
el nivel de transporte y del Internet Protocol (IP) en el nivel de red del
modelo Open System Interconnect (OSI) de la International Organization
for Standardization (ISO). Estos protocolos se encuentran especificados en
los RFC 768 [Postel, 1980] y RFC 791 [Postel, 1981] respectivamente. Ambos,
UDP e IP, son protocolos no orientados a la conexión, es decir, no realizan
control de flujo, detección de errores ni retransmisión de paquetes en caso de
pérdida.
En lo que se refiere al formato del mensaje NTP, éste consiste en una
serie de palabras de 32 bits donde algunos campos ocupan varias palabras y
otros son empaquetados para ocupar una única. En la Fig. 2.2 se muestra el
formato del mensaje, cuyos campos pasamos a describir a continuación.

58 Capítulo 2. Sincronización temporal sobre redes de comunicación
Figura 2.2: Formato del mensaje NTP.
Leap Indicator (LI): Código de aviso de 2 bits indicando que un segundo
intercalar (leap second)1 debe ser añadido o borrado del último minuto
1El estándar de tiempo Coordinated Universal Time (UTC) está basado en el Inter-national Atomic Time (TAI). Este tiempo debe ser ajustado ocasionalmente añadiendo oeliminando segundos intercalares (leap seconds) para asegurar que la diferencia entre unaescala de tiempo uniforme definida por un reloj atómico no difiere del tiempo de rotaciónde la Tierra en más de 0,9 segundos.

2.1. Protocolos de sincronización 59
del día actual. Cuando un servidor comienza a operar utiliza este campo
para indicar a los clientes que su reloj no está sincronizado a ninguna
referencia de sincronización. Una vez sincronizado ya no vuelve a utili-
zarlo más para este fin aun cuando todas las fuentes de sincronización
sean inalcanzables o se encuentren desincronizadas.
Version Number (VN): Campo de tres bits que indica el número de ver-
sión (actualmente versión 4).
Mode: Número de 3 bits indicando el modo de operación. En la Tabla 2.1
se muestran los modos de operación definidos por el protocolo NTP.
Stratum: Este campo se interpreta como un número entero sin signo de 8
bits y representa el stratum. En la Tabla 2.2 se muestran los valores de
stratum definidos por el protocolo NTP.
Poll interval : Valor entero sin signo de 8 bits usado como un exponente de
dos donde el valor resultante (medido en segundos) se interpreta como
Modo Significado
Modo 0 ReservadoModo 1 Simétrico activoModo 2 Simétrico pasivoModo 3 ClienteModo 4 ServidorModo 5 BroadcastModo 6 Reservado para mensajes de controlModo 7 Reservado para uso privado
Tabla 2.1: Modos de operación definidos por el protocolo NTP.
Stratum Significado
Stratum 0 No especificado o inválidoStratum 1 Referencia primaria (sincronizada
a una fuente absoluta de tiempo)Stratum 2-255 Referencia secundaria (sincroni-
zada por NTP)
Tabla 2.2: Valores de stratum definidos por el protocolo NTP.

60 Capítulo 2. Sincronización temporal sobre redes de comunicación
el intervalo máximo entre mensajes sucesivos.
Precision: Valor entero con signo de 8 bits usado como un exponente de
dos donde el valor resultante (medido en segundos) se interpreta como
la precisión del reloj del sistema.
Root delay : Este campo indica el retraso de propagación total en segun-
dos relativo a la fuente de referencia primaria. Se representa usando el
formato corto de NTP.
Root dispersion: Este campo indica el error máximo (dispersión) en segun-
dos relativo a la fuente de referencia primaria. Se representa usando el
formato corto de NTP.
Reference identifier : Cadena de 32 bits que identifica una fuente de refe-
rencia particular.
Reference timestamp: Este campo de 64 bits indica la hora local a la cual
el reloj local fue actualizado por última vez. Esta hora se representa
usando el formato de marcas de tiempo de NTP.
Originate timestamp (OT): Este campo de 64 bits indica la hora local
del cliente en el instante en el que la petición de hora salió para el
servidor, representada en el formato de marcas de tiempo de NTP.
Receive timestamp (RT): Este campo de 64 bits indica la hora local del
servidor en el instante en el que la petición llegó al servidor, represen-
tada en el formato de marcas de tiempo de NTP.
Transmit timestamp (TT): Este campo de 64 bits indica la hora local
del servidor a la cual la respuesta salió para el cliente, representada en
el formato de marcas de tiempo de NTP.
Authenticator (opcional): Este campo es opcional empleándose sólo
cuando se desea implementar el esquema de autenticación planteado
en el documento de especificación del protocolo NTP [Mills, 1992b].
Al no emplearse este esquema en el trabajo que se está abordando se
va a obviar la información acerca de este mecanismo de autenticación.

2.1. Protocolos de sincronización 61
Protocolo de comunicación
El protocolo de comunicación (on-wire protocol) define el mecanismo se-
guido por clientes y servidores NTP para intercambiar mensajes de hora.
Entre las principales características de este protocolo destacan que: (1) es re-
sistente ante perdidas o duplicidad de paquetes, (2) la integridad de los datos
se asegura mediante las sumas de verificación (checksums) de las cabeceras
IP y UDP y (3) no necesita implementar ningún mecanismo de control de
flujo o retransmisión de paquetes.
El hecho de no necesitar un mecanismo de control de flujo y retransmisión
se debe a que el protocolo usa marcas de tiempo extraídas desde el reloj local
en los instantes en los que se reciben o se transmiten los paquetes. En caso de
tener que retransmitir un paquete estas marcas de tiempo ya no reflejarían
el instante real en el que se transmite el mismo lo cual provoca un cálcu-
lo incorrecto del desplazamiento y del retraso. Así, resulta más aconsejable
transmitir un nuevo paquete con la hora actualizada.
El protocolo NTP define dos modos de comunicación diferentes: unicast y
broadcast. El modo unicast es el más utilizado ya que permite calcular de for-
ma precisa tanto el retraso de propagación de la red como el desplazamiento
del reloj del cliente relativo al del servidor, lo cual es un aspecto crítico a la
hora de conseguir la mejor precisión de sincronización. A diferencia de uni-
cast, el modo broadcast no permite calcular el retraso de propagación ya que
no se disponen de todas las marcas de tiempo. Este último es especialmente
recomendable en entornos donde se necesite sincronizar un número elevado
de equipos y las exigencias de precisión no sean muy elevadas, ya que de esta
forma se reduce considerablemente el tráfico de red.
A continuación, se va a describir cómo funciona el protocolo de comu-
nicación para el caso más general, es decir, dos equipos intercambiándose
mensajes en modo unicast. En la Fig. 2.3 se observa cómo el cliente envía
una petición al servidor mediante la emisión de un paquete UDP donde se
incluye una marca de tiempo con la hora de su reloj local (T1) correspon-
diente a la salida del mensaje. Cuando el servidor recibe la petición se genera
una nueva marca de tiempo T2 con la hora de recepción (dada por el reloj

62 Capítulo 2. Sincronización temporal sobre redes de comunicación
Figura 2.3: Protocolo de comunicación NTP.
local del servidor). Después de procesar la petición, el servidor emite una
respuesta incluyendo las dos marcas anteriores y la hora a la que la respuesta
abandona el servidor (T3). Finalmente, cuando el cliente recibe el mensaje de
respuesta también se anota la hora de llegada del mismo (T4) denominada
Destination Timestamp (DT).
Con este conjunto de marcas de tiempo, el cliente puede calcular el retraso
de propagación (δ) y el desplazamiento del reloj del sistema (θ) relativo al
servidor. Asumiendo una conexión simétrica, es decir, el tiempo de llegada de
la petición al servidor es igual al tiempo de regreso de la respuesta al cliente,
estos dos tiempos se definen de acuerdo a (2.1) y (2.2).
δ = (T4 − T1)− (T3 − T2) (2.1)
θ =(T2 − T1) + (T3 − T4)
2(2.2)
Fuentes de error
Una vez comentado el protocolo de comunicación es importante expli-
car dónde se originan los errores que afectan al cálculo del desplazamiento
y el retraso de propagación. En principio, existen muchas fuentes de error

2.1. Protocolos de sincronización 63
algunas de las cuales producen errores sistemáticos fijos e invariables en el
tiempo de forma que, una vez medidos, éstos se pueden corregir; sin embargo,
existen otras causas que producen errores que no pueden ser determinados
exactamente suponiendo éstos las principales fuentes de error en el proceso
de sincronización.
Entre estas causas destacan principalmente tres: (1) el nivel o capa donde
se realiza el marcado temporal de los mensajes entrantes y salientes, (2) la
asimetría en la comunicación de red y (3) los errores producidos por acciones
malintencionadas de algunos servidores no fiables. A continuación, se pasa a
describir detalladamente las causas de cada uno de estos errores.
En relación a la primera fuente, este error se debe al intervalo de tiempo
variable desde que: (a) se registra la marca en el datagrama y el instante real
en que éste abandona la interfaz de red y (b) se recibe el mensaje y el instante
real en que se registra la marca de tiempo asociada. En implementaciones
software de NTP, estas marcas de tiempo son registradas por clientes/ser-
vidores software corriendo a nivel de aplicación de forma que el error en la
marca de tiempo dependerá del tiempo empleado en preparar o procesar el
datagrama y en bajar o subir la pila de protocolos y capas software y de la
impredecibilidad de varios factores como la variabilidad en la planificación de
tareas del sistema operativo o el tiempo en acceder a la red. Por tanto, este
error dependerá en gran medida de la carga del sistema operativo, correcta
implementación software, etc.
En cuanto a la segunda fuente de error, el principal problema consiste
en la asimetría en la comunicación de red donde el tiempo de llegada de la
petición al servidor difiere significativamente del tiempo de regreso de la res-
puesta al cliente. Esto se debe a latencias no predecibles en los equipos de
la red, especialmente cuando se incrementa el número de dispositivos involu-
crados. Las variaciones de tiempo en la comunicación por la red dependen de
la carga de la red, de la arquitectura del conmutador (switch) y del número
de conmutadores entre el cliente y el servidor [Skeie et al., 2001; Holmeide
and Skeie, 2001]. La práctica totalidad de los conmutadores actuales están
basados en la tecnología store & forward, esto es, las tramas Ethernet de-
ben ser completamente recibidas en un puerto de entrada y examinadas para

64 Capítulo 2. Sincronización temporal sobre redes de comunicación
detección de errores antes de ser retransmitidas por el puerto de salida co-
rrespondiente. Así, el retardo de retransmisión de cualquier trama depende
directamente de la velocidad del enlace de salida y del tamaño de la trama.
Estos retardos son del orden del milisegundo para enlaces de 10 Mbps y de
unas centenas de microsegundo para enlaces de 100 Mbps. Además, el retar-
do puede incrementarse significativamente si se forman colas de paquetes que
han de ser retransmitidos por el mismo puerto de salida; no obstante, el he-
cho de encolar los paquetes presenta la ventaja de que las colisiones son raras
o inexistentes. En casos típicos, la latencia introducida por los conmutadores
en una red Ethernet puede variar entre unas pocas decenas de microsegundos
hasta varios milisegundos incluso cuando la carga media global de la red es
baja (en torno al 10 ó 20 %) [Holmeide and Skeie, 2001]. Para las tecnologías
empleadas actualmente en redes comerciales de muy altas prestaciones un
conmutador o un elemento de la capa de red similar puede introducir en el
mejor de los casos variabilidades en el retardo de transmisión del orden de
500 ns.
Finalmente, según se expone en [Mills, 2006a] una causa común de error
en la sincronización consiste en el mal funcionamiento de algún elemento de
la red resultante de la recepción de información temporal alterada, fallos en
el servidor o interrupciones en la comunicación provocadas de forma malin-
tencionada. En este caso, si los parámetros calculados para estos servidores
no fiables son empleados para corregir el reloj local esto puede originar un
error de sincronización importante.
Algoritmos del protocolo NTP
Para mitigar los errores presentados en el apartado anterior y mejorar
la precisión de sincronización, el protocolo NTP define un conjunto de al-
goritmos avanzados que permiten la distribución de información temporal
precisa en redes con altas latencias variables como por ejemplo la red pública
Internet. La base de estos algoritmos consiste en emplear en el proceso de
sincronización varios servidores de hora situados en diferentes caminos de red
y además asumir que no todos proporcionan información temporal fraudu-

2.1. Protocolos de sincronización 65
Figura 2.4: Procesos que componen el demonio del protocolo NTP.
lenta al mismo tiempo. Así, operar con varios servidores permite determinar
fallos en los enlaces de red, en las fuentes de sincronización e incluso acciones
hostiles por parte de servidores malintencionados.
Todos estos algoritmos se incluyen en la implementación software de re-
ferencia distribuida por el NTP Public Services Project2. La implementación
software consiste en un demonio del sistema operativo corriendo como un
proceso a nivel de usuario. Para comprender cómo funcionan estos algorit-
mos se van a describir los diferentes procesos que componen este demonio.
En la Fig. 2.4 se observa cómo para cada servidor de sincronización existe
un proceso de transmisión/recepción que implementa el protocolo de comu-
nicación de NTP. El proceso de transmisión se encarga de enviar mensajes
al servidor a intervalos variables y el proceso de recepción de recibir las
respuestas, verificarlas para detectar posibles fallos y calcular el retraso de
propagación y el desplazamiento del reloj local de acuerdo a (2.1) y (2.2).
Dentro del proceso de recepción, los valores de tiempo calculados son proce-
sados por un algoritmo de filtrado que selecciona el mejor desplazamiento de
2La implementación software de referencia está disponible en http://www.ntp.org/

66 Capítulo 2. Sincronización temporal sobre redes de comunicación
ese servidor de entre los ocho desplazamientos previos.
El proceso del sistema se ejecuta cada vez que el algoritmo de filtrado
de un proceso receptor devuelve un nuevo desplazamiento. En este proce-
so los mejores desplazamientos relativos a cada servidor son procesados por
un conjunto de algoritmos: selección, agrupación y combinación. El objetivo
del algoritmo de selección es encontrar y descartar los servidores no fiables
y pasar al algoritmo de agrupación sólo los servidores fiables. El algoritmo
de agrupación se encarga de seleccionar de los servidores no descartados los
valores de tiempo más precisos y fiables basándose en una serie de principios
estadísticos. El algoritmo de combinación promedia los desplazamientos se-
leccionados por el algoritmo de agrupación de forma que el resultado en este
punto consiste en un único valor de tiempo representando el mejor desplaza-
miento relativo a la población de servidores en su conjunto.
El proceso de disciplina implementa una serie de algoritmos que calculan
los ajustes necesarios que permiten controlar la fase y la frecuencia del reloj
del sistema implementado como un oscilador de frecuencia variable (Variable
Frequency Oscillator, VFO). El proceso de ajuste se ejecuta una vez por
segundo y se encarga de incorporar al reloj local las correcciones de tiempo y
frecuencia calculadas por el proceso de disciplina y mantener una frecuencia
constante. A partir del reloj del sistema se determinan las marcas de tiempo
cerrándose el lazo.
Adicionalmente, NTP proporciona un mecanismo de autenticación crip-
tográfica que proporciona una protección extra ante acciones hostiles de ser-
vidores de hora fraudulentos. Sin embargo, también es importante comentar
que estos algoritmos de encriptación pueden hacer un uso intensivo de re-
cursos (microprocesador, memoria,etc.) pudiéndose degradar seriamente la
precisión del sistema al utilizarlos.
En términos de precisión alcanzable, mediante el uso de estos algoritmos
se pueden conseguir precisiones de 1 a 50 ms dependiendo de las característi-
cas de la fuente de sincronización y del tipo de red [Mills, 1992b, 1991, 1995,
2003]. Para mejorar la precisión de sincronización algunos sistemas operati-
vos como Linux [Linux], FreeBSD [FreeBSD], Mac OS X [Apple] o Solaris
[Solaris] incluyen soporte de NTP en el kernel [Mills and Kamp, 2000]. En

2.1. Protocolos de sincronización 67
este caso, los algoritmos de disciplina y ajuste del reloj se integran en el
kernel mejorándose el control que se realiza sobre el reloj del sistema, de for-
ma que la precisión de sincronización puede aumentarse considerablemente
alcanzando valores inferiores a los 100 µs.
2.1.2. Simple Network Time Protocol
El Simple Network Time Protocol consiste en una versión simplificada del
protocolo NTP. Ambos protocolos, NTP y SNTP, comparten el mismo for-
mato de datos, formato del mensaje y protocolo de comunicación, siendo la
principal diferencia que SNTP cubre la sincronización con un único servidor
de hora y no implementa el conjunto de algoritmos avanzados descritos ante-
riormente. En efecto, al sincronizarse un cliente SNTP con un único servidor,
los algoritmos de selección, agrupación y combinación no son necesarios ya
que sólo se calcula el desplazamiento de tiempo relativo a ese servidor. Ade-
más, el protocolo SNTP tampoco especifica ningún mecanismo de disciplina
y ajuste del reloj de forma que las correcciones pueden consistir simplemente
en sumar el desplazamiento calculado al reloj local.
Esta alternativa presenta una serie de inconvenientes: (1) si el proceso de
sincronización se realiza sobre redes como Internet sólo se pueden conseguir
precisiones en el rango de unos pocos segundos a muchos segundos, ya que
no es posible controlar las altas latencias variables de este tipo de redes,
(2) sin mecanismos de autenticación criptográfica los clientes SNTP pueden
ser vulnerables a ataques ya que no implementan el conjunto de algoritmos
avanzados de NTP y (3) empleando el mecanismo de ajuste comentando se
puede violar el principio de monotonía. Según este principio, en un sistema
de sincronización todos los relojes deben crecer monótonamente, es decir, un
reloj nunca puede contar hacia atrás. En este caso, este principio puede no
cumplirse ya que los incrementos pueden ser positivos o negativos.
Sin embargo, de acuerdo al documento de especificaciones del protocolo
SNTP y otros autores [Skeie et al., 2001, 2003; Johannessen, 2004; Holmeide
and Skeie, 2006], si se opera en determinadas condiciones se podría conse-
guir una precisión de tiempo en el orden de un microsegundo, consiguiendo

68 Capítulo 2. Sincronización temporal sobre redes de comunicación
alcanzar la clase IEC T5 (Tabla 1.1, página 43). A continuación, se van a
comentar las acciones que hay que llevar a cabo para conseguir una sincroni-
zación precisa en redes Ethernet conmutadas empleando el protocolo SNTP.
Generalmente se admite que empleando el protocolo SNTP es posible
alcanzar la clase IEC T3 siempre y cuando los clientes estén conectados con el
servidor mediante un único conmutador [Skeie et al., 2001]. Además, debido a
que la precisión en las marcas de tiempo se degrada considerablemente por los
retrasos variables introducidos por el sistema operativo (en la planificación
de tareas, en la pila de protocolos, etc.), para conseguir la clase IEC T3
es necesario hacer el marcado temporal de los mensajes en hardware o en
rutinas de servicio de interrupción con prioridad absoluta. Adicionalmente,
puede resultar necesario implementar alguna técnica de filtrado en el lado del
cliente destinada a eliminar peticiones de hora que incluyen retrasos extras
derivados del procesamiento que el conmutador realiza sobre los paquetes
que recibe.
Debido a las múltiples fuentes de retardo y variabilidad en el retardo,
lograr una sincronización altamente precisa (clase IEC T4 y T5) en redes
Ethernet conmutadas no resulta sencillo. En particular, la variabilidad en
los retardos introducidos por los conmutadores es un factor que limita de
manera directa la precisión que es posible alcanzar, independientemente de
la precisión posible a priori en el servidor y los clientes como evidencian
numerosos estudios [Skeie et al., 2001; MacGregor et al., 2004; Smotlacha,
2005]. Como se ha comentado previamente, estos retrasos introducidos por los
conmutadores vienen condicionados por la carga de la red y la arquitectura de
conmutación de la red. Así, alcanzar las clases IEC T4 y T5 con SNTP sólo es
posible si el servidor emplea una fuente de tiempo adecuada como un receptor
GPS, el marcado temporal de los mensajes se realiza en hardware tanto en
el cliente como en el servidor y los diferentes elementos de red integran un
servidor SNTP [Skeie et al., 2001]. Empleando estos conmutadores los efectos
de la variabilidad en el retraso de red se reducen significativamente y es
posible alcanzar una precisión en el orden de un microsegundo incluso en
redes excesivamente cargadas [Holmeide and Skeie, 2001].
Adicionalmente, en relación con la utilización de un mecanismo de auten-

2.1. Protocolos de sincronización 69
ticación, en este tipo de entornos se puede evitar implementando una serie
de comprobaciones de seguridad:
La marca de tiempo en el campo originate timestamp en la respuesta
del servidor debería coincidir con la marca de tiempo colocada en el
campo transmit timestamp por el cliente al enviar la petición. En caso
de no coincidir se trataría de un mensaje falso.
Si el servidor mantiene información acerca de la última petición, se
detectaría un paquete duplicado si la marca de tiempo en el campo
transmit timestamp de una nueva petición coincide con la marca de
tiempo en ese mismo campo del mensaje anterior.
Como se ha comentado anteriormente, la integridad de los datos se
proporciona por las sumas de verificación de las cabeceras IP y UDP.
Además, sería aconsejable comprobar en la respuesta que la dirección
IP del servidor y el puerto utilizado coinciden con los enviados en la
petición de hora, si se dispone de esa información. Así se asegura que
no ha sido otro servidor diferente al que se le envío la petición el que
ha contestado.
Sería aconsejable realizar comprobaciones de los diferentes campos: LI,
VN, Mode, Stratum, Root Delay, Root Dispersion, etc., descartándose
la respuesta del servidor en caso de detectar alguna inconsistencia.
2.1.3. Precision Time Protocol
El Precision Time Protocol es un estándar del IEEE definido en los están-
dares IEEE 1588-2002 y 1588-2008. Aunque este protocolo fue originalmente
desarrollado por Agilent [Eidson et al., 2002] para realizar tareas de testado
y medida, actualmente consiste en un estándar empleado para sincronizar de
forma muy precisa los relojes de dispositivos finales sobre redes de comunica-
ción. El protocolo PTP ha cobrado especial relevancia en el sector industrial
donde es ampliamente utilizado. Otros sectores como el militar o el de las

70 Capítulo 2. Sincronización temporal sobre redes de comunicación
comunicaciones y la distribución de potencia eléctrica también han mostrado
interés en usar este protocolo.
El protocolo PTP se desarrolló desde un principio para operar en peque-
ñas redes de área local (no aplicándose a nivel de Internet) y se puso especial
énfasis en que fuera una solución de bajo coste que empleara pocos recursos
de forma que se pudiera implementar en cualquier dispositivo final por muy
limitado que éste fuera. Otros objetivos de PTP consistieron en que tanto el
ancho de banda necesario como el esfuerzo de configuración y administración
fueran reducidos. Así, este protocolo permite configurar automáticamente
un dominio de PTP usando el algoritmo denominado the best master clock
algorithm; asimismo, también proporciona un protocolo de gestión.
Al igual que en el protocolo NTP, los dispositivos o relojes se organizan
en clases distinguiéndose entre grand master, master y slave clocks. Los grand
master clocks son dispositivos sincronizados a una fuente de tiempo precisa
(reloj atómico, receptor GPS, etc.) y ocupan la clase más alta. Los master
clocks son aquellos dispositivos que se sincronizan a un grand master clock o
a otros relojes maestros y proporcionan sincronización a otros master o slave
clocks. Finalmente, un slave clock es aquel que se sincroniza a un maestro
pero no proporciona sincronización a ningún otro dispositivo.
En cuanto al protocolo de comunicación, PTP está basado en una co-
municación UDP/IP multicast y, aunque es normalmente empleado sobre
redes Ethernet, no está restringido a este tipo de redes pudiéndose utilizar
en cualquier tecnología que soporte multicasting. El protocolo de comunica-
ción difiere del implementado por NTP/SNTP ya que en el caso de PTP el
proceso de sincronización se divide en dos fases; la primera se destina a cal-
cular el desplazamiento y la segunda a determinar el retraso de propagación.
A continuación, se describirá brevemente el protocolo de comunicación que
especifica el protocolo PTP.
Durante la primera fase, el reloj maestro transmite un mensaje de sin-
cronización (sync) a los relojes esclavos a intervalos definidos (por defecto
cada 2 segundos). Este primer mensaje contiene una marca que representa el
instante de tiempo estimado en el que se transmitió el mensaje. Tras enviar
este primer mensaje, el maestro transmite un nuevo mensaje (follow up) con

2.1. Protocolos de sincronización 71
el tiempo exacto de transmisión del primero. Una vez recibido este segundo
mensaje, el esclavo calcula el desplazamiento de su reloj local relativo al reloj
del maestro en base a la marca de tiempo del mensaje follow up y a la marca
de tiempo registrada por el esclavo en la recepción del mensaje sync. El reloj
del esclavo debe ajustarse en función del desplazamiento calculado.
La segunda fase del proceso de sincronización permite calcular el retraso
entre el esclavo y el maestro. Para ello, el reloj esclavo envía al maestro un
mensaje denominado delay request y durante este proceso se determina el
tiempo exacto de transmisión de este paquete. El maestro genera una marca
de tiempo a la recepción de la petición y envía una respuesta al esclavo delay
response conteniendo esta marca. A la llegada de la respuesta el esclavo
calcula el retraso a partir de estas dos marcas de tiempo. Este proceso se
realiza irregularmente y en intervalos más grandes que el proceso de medida
del desplazamiento (valor aleatorio entre 4 y 60 segundos). De esta forma, la
red y especialmente los dispositivos terminales no son cargados en exceso.
En cuanto a las fuentes de error, al igual que ocurre para el protocolo
NTP, la precisión de sincronización depende en gran medida del nivel donde
se registran las marcas de tiempo y de la asimetría en la comunicación de red.
No obstante, el protocolo PTP proporciona soluciones a cada uno de estos
aspectos críticos; por un lado, PTP propone realizar el marcado temporal
de los tiempos de transmisión y recepción de los mensajes por hardware tan
próximo al nivel físico como sea posible. De esta forma es posible eliminar los
retrasos originados por la pila de protocolos y demás capas software. Por otro
lado, para resolver el problema de la asimetría, en la versión 1 del protocolo
PTP se propuso el uso de conmutadores especiales denominados IEEE 1588
boundary clocks. Estos conmutadores incorporan un reloj y crean dominios
de sincronización separados mediante la segmentación de la ruta de sincro-
nización desde los relojes maestros a los esclavos. Los mensajes Ethernet
estándares se transmiten a través del conmutador mientras que los mensajes
de sincronización se utilizan para sincronizar el boundary clock. Estos con-
mutadores son efectivos en redes en los que los esclavos no están separados
de los maestros a través de muchos boundary clocks conectados en cascada
[Gordon, 2009]. Debido a que frecuentemente se encuentran redes con topo-

72 Capítulo 2. Sincronización temporal sobre redes de comunicación
logías donde los conmutadores se organizan en cascada, en la versión 2 se
introdujeron los transparent clocks [Nylund and Holmeide, 2004]; estos dis-
positivos calculan el retraso y actualizan un campo dentro de los mensajes
de PTP de forma que posteriormente es posible compensarlo.
Finalmente, en términos de precisión una implementación de PTP sin
soporte hardware permite alcanzar una sincronización de tiempo en torno a
los 100 µs. Sin embargo, implementando el soporte hardware de las marcas de
tiempo y usando boundary clocks como elementos de red, la precisión puede
ser mejorada considerablemente estando en el rango de los nanosegundos
[Loschmidt et al., 2008].
2.1.4. Otros protocolos de sincronización
En este apartado se comentarán brevemente otros protocolos de sincro-
nización que se usan o se han usado en redes de comunicación. Entre estos
protocolos se pueden destacar los siguientes:
DCNET Internet Clock Service. El DCNET Internet Clock Service
(ICS) es un servicio definido en 1981 y especificado en el RFC 778 por
D.L. Mills. Este protocolo propone un mecanismo de sincronización de
reloj y medida del retraso basado en el uso de los mensajes Timestamp
y Timestamp Reply del Internet Control Message Protocol (ICMP).
De este protocolo se puede destacar que tanto el formato del mensaje
como el protocolo de comunicación son muy parecidos al del protocolo
NTP: primero un equipo envía un mensaje ICMP Timestamp que
contiene una marca de tiempo indicando el momento en que el mensaje
abandona el equipo; una vez recibida la respuesta el equipo de destino
responde con un mensaje ICMP Timestamp Reply donde incluye la
marca anterior y dos nuevas relativas a su reloj (hora de llegada y de
envío de la respuesta). En este protocolo el formato y el significado
de la marca de tiempo es diferente al del protocolo NTP ya que cada
marca se representa como un dato de 32 bits indicando el número de
milisegundos transcurridos desde la medianoche en hora universal.

2.1. Protocolos de sincronización 73
DAYTIME protocol. El servicio DAYTIME es un protocolo de Internet
definido en 1983 y especificado en el RFC 867. Este protocolo opera
tanto sobre TCP como UDP utilizando el puerto 13. La operación del
protocolo consiste en que un equipo se conecta a un servidor que soporta
este protocolo y a continuación el servidor le devuelve la hora y la fecha
actual representada como una cadena ASCII (American Standard Code
for Information Interchange). Este protocolo se emplea principalmente
en redes de computadores para propósitos de testado y medida.
TIME protocol. El servicio TIME es un protocolo de Internet definido en
1983 y especificado en el RFC 868. Este protocolo opera tanto sobre
TCP como UDP utilizando el puerto 37. La operación del protocolo
consiste en que un equipo se conecta a un servidor que soporta este
protocolo y a continuación el servidor le devuelve un número binario
sin signo de 32 bits que representa el número de segundos transcurridos
desde las 0 horas del 1 de enero de 1900. Este protocolo ofrece a un
equipo un mecanismo rápido para confirmar o corregir su reloj a partir
de la información temporal recibida de varios servidores de tiempo in-
dependientes sobre la red. Este protocolo fue sustituido por el protocolo
NTP.
Digital Time Synchronization Service. El Digital Time Synchroniza-
tion Service (DTSS) es un servicio de sincronización presentado por
Digital Equipment Corporation en 1989. Este servicio perseguía
el mismo objetivo que el protocolo NTP pero empleando una estrategia
diferente. Aunque este protocolo presentó algunas ideas interesantes
que fueron adoptadas por el protocolo NTP el principal problema
que presentaba esta alternativa era que no incluía un algoritmo de
disciplina de la frecuencia del reloj. Este hecho significaba una per-
dida significativa de precisión en comparación con la obtenida por el
protocolo NTP.
HTTP Time Protocol. El HTTP Time Protocol (HTP) se usa para sin-
cronizar la hora de un equipo empleando servidores web como referen-

74 Capítulo 2. Sincronización temporal sobre redes de comunicación
cias de tiempo. HTP no define un protocolo en sí mismo sino que utiliza
una característica del protocolo HyperText Transfer Protocol (HTTP)
que consiste en que un servidor web coloca una marca de tiempo en la
cabecera de la respuesta que envía al navegador web. En este sentido
si se combinan varias marcas de tiempo procedentes de varios servido-
res web podría determinarse la hora y la fecha con una precisión en el
orden de un segundo.
SynUTC. SynUTC es una tecnología de sincronización desarrollada por
Höller [Höller et al., 2002] y basaba en la inserción de información tem-
poral muy precisa en paquetes de datos dedicados. Dicha inserción se
realizaba por hardware en la interfaz independiente del medio (Media
Independent Interface, MII) entre el transceptor (transceiver) de la ca-
pa física y el controlador de red tanto en la transmisión como en la
recepción del paquete.
2.2. Equipos y dispositivos de sincronización
Como se ha comentado anteriormente, en la actualidad existen diferentes
compañías que proporcionan soluciones de sincronización en la forma de equi-
pos discretos. Asimismo, también se encuentran alternativas que resuelven
algunos de los aspectos críticos que se han analizado y que toman la forma
de sistemas empotrados implementados sobre dispositivos programables.
En este sentido, este apartado se va a dedicar a presentar los principales
equipos de sincronización encontrados en el mercado, así como las aporta-
ciones más significativas que se han realizado en lo que se refiere a la imple-
mentación de sistemas empotrados dedicados a la sincronización temporal.
Para cada caso, se destacarán las principales características de cada una de
las soluciones presentadas.
2.2.1. Equipos comerciales discretos de sincronización
En este subapartado se va a analizar la tecnología de sincronización desa-
rrollada por las diferentes empresas que lideran este sector. Como empre-

2.2. Equipos y dispositivos de sincronización 75
sas líderes encontramos a Symmetricom y a Meinberg aunque existe un
gran número de compañías que suministran algún tipo de equipo de sin-
cronización: EndRun Technologies [EndRun], FEI-Zyfer [FEI-Zyfer],
Galleon Systems [Galleon], OnTime Networks [Ontime], Oregano
Systems [Oregano], Oscilloquartz [Oscilloquartz], Spectracom [Spec-
tracom] y Time and Frequency Solutions [TimeFreq].
Tipos de equipos disponibles
En cuanto a los productos que se ofertan, tanto Symmetricom como
Meinberg disponen de una amplia gama cubriendo casi todos los niveles de
la jerarquía de sincronización:
Servidores de sincronización NTP. Symmetricom dispone de la serie
SyncServer modelos S200, S250, S300 y S350 y Meinberg de la se-
rie LANTIME M modelos M900, M600, M400, M300, M200 y M100.
También destacan las series CM300 y CM400 de OnTime Networks.
Servidores de sincronización PTP. Symmetricom proporciona dos
grandmaster clocks: TimeProvider 5000 y XLi IEEE 1588 Grand-
master. Meinberg dispone de los grandmaster clocks LANTIME
M600/GPS/PTPv2 y LANTIME M400/GPS/PTPv2; estos equipos
también incluyen soporte de NTP/SNTP. También destacan las series
CM300 y CM400 para PTP de OnTime Networks ya que incluyen
soporte de NTP y pueden funcionar como clientes PTP.
Clientes PTP. En cuanto a relojes esclavos PTP tanto Symmetri-
com como Meinberg disponen de un único equipo discreto con esta
funcionalidad denominados TimeProvider 500 y PTPv2 SyncBox res-
pectivamente.
Dispositivos de red con soporte PTP. En este caso, Symmetricom
dispone de un conmutador denominado SyncSwitch TC100 que imple-
menta la tecnología de transparencia de reloj. Por otro lado, Meinberg
no dispone de ningún dispositivo de este tipo pero oferta el conmutador

76 Capítulo 2. Sincronización temporal sobre redes de comunicación
Ethernet modelo MICE MS-20 Industrial Ethernet Switch de Hirsch-
man. Este conmutador proporciona soporte PTP y funciona como un
boundary clock. También destaca el conmutador de Cisco modelo IE
3000 que incluye soporte de PTP y puede ser configurado en los modos
transparente y boundary.
Adaptadores de red con soporte PTP. En este caso Meinberg propor-
ciona una tarjeta PCI Express denominada PTP270PEX que incluye
soporte de PTP. Este dispositivo se sincroniza a un IEEE 1588 grand-
master clock y puede ser empleado por el equipo al que se conecta como
una fuente de referencia de tiempo.
Características de los equipos
Una vez presentados los equipos que suministran las diferentes empresas,
se aprecia como en general estas compañías se centran en el desarrollo de
servidores de sincronización. Así, se considera importante remarcar que en
este apartado se van a analizar fundamentalmente las características más
importantes que proporcionan estos equipos servidores.
En general, los equipos servidores analizados presentan unas caracterís-
ticas comunes como son la arquitectura en la que se basan, los servicios que
ofrecen o los tipos de osciladores que utilizan. A continuación, se va a pre-
sentar un breve análisis de estas características.
La arquitectura de estos equipos se basa en un microprocesador ejecu-
tando un sistema operativo GNU/Linux con soporte en el kernel de los di-
ferentes protocolos de sincronización. Entre los servicios de sincronización
que se ofrecen se encuentran NTP, SNTP, PTP, TIME y DAYTIME. Ade-
más, todos estos dispositivos soportan un amplio rango de protocolos de red
comúnmente empleados para configuración, mantenimiento, administración
remota y monitorización de la red, como por ejemplo, Dynamic Host Confi-
guration Protocol (DHCP), Simple Network Management Protocol (SNMP),
Secure SHell (SSH), Secure Socket Layer (SSL), HTTP, HyperText Transfer
Protocol Secure (HTTPS), etc.
Prácticamente todos los equipos analizados aceptan un receptor GPS co-

2.2. Equipos y dispositivos de sincronización 77
mo referencia de tiempo, siendo ésta la opción habitual frente a otros tipos
de fuentes de sincronización. Emplear un GPS como referencia temporal per-
mite sincronizar los relojes con una precisión en el orden de algunas decenas
de nanosegundos. A su vez, este hecho posibilita que las marcas de tiempo
mantengan una precisión en el orden del microsegundo, incluso cuando se
procesan gran cantidad de peticiones de hora por segundo.
Un aspecto importante consiste en definir cómo se debe comportar un
equipo ante la pérdida de la señal de sincronización proporcionada por el
GPS. En este caso se pueden distinguir dos acciones: (1) emplear otras refe-
rencias de tiempo si el equipo dispone de ellas y (2) permitir que el reloj del
servidor derive (opere en holdover) si se pierde la señal del GPS. La deriva
de un reloj operando en holdover es una característica que depende del tipo
de oscilador que se utilice. En este aspecto, los fabricantes incorporan un
Temperature Compensated Crystal Oscillator (TCXO) en sus equipos con la
opción de poder ser sustituido por otros osciladores que proporcionan mejo-
res características como, por ejemplo, un Oven Controlled Crystal Oscillator
(OCXO) o un oscilador de rubidio. En términos cuantitativos, la deriva por
holdover de un oscilador TCXO se encuentra en torno a unas decenas de
milisegundos por día, la de un OCXO en un milisegundo por día y la de un
oscilador de rubidio en el rango de unas decenas de microsegundos por día.
También es destacable que ciertos equipos presentan características espe-
cíficas que les aportan mejores prestaciones. Por un lado, los dispositivos de
gama alta incluyen soporte para múltiples referencias de tiempo adicionales
al GPS como por ejemplo una señal de pulso por segundo (Pulse Per Second,
PPS), señal de 10 MHz, señal de radio de baja frecuencia (DCF77 [Zimber,
2007], JJY [Kurihara, 2003], MSF [NPL, 2007], WWVB [Lombardi, 2002]),
códigos de tiempo basados en Inter-Range Instrumentation Group (IRIG)
[RCC, 2004] u otros servidores de tiempo. Disponer de varias fuentes permi-
te asegurar un servicio de sincronización preciso de forma continuada ya que
en caso de fallar una siempre se dispone de otra fuente de referencia de respal-
do. De igual forma, estos equipos generan múltiples salidas de sincronización
de similares características: PPS, 10 MHz, IRIG, etc. Por otro lado, algunos
equipos son compactos y se pueden montar sobre un carril DIN. Este hecho,

78 Capítulo 2. Sincronización temporal sobre redes de comunicación
junto con el resto de características presentadas, hacen de estos equipos una
solución óptima para ser implantada en muchas aplicaciones industriales ta-
les como la automatización de subestaciones o en sistemas de automatización
industrial y control de procesos.
Sin embargo, estas alternativas también presentan una serie de inconve-
nientes en algunas aplicaciones: en primer lugar, dependiendo de la arqui-
tectura del sistema podría ser necesario disponer de varios de estos equipos
ocupando un espacio físico en el mismo lugar donde se encuentran ubicados
los equipos que requieren sincronización. Esto puede originar un problema
tanto de espacio, si éste es limitado, como de costes, ya que el precio de estos
equipos oscila entre los 4000 y 12000 e lo cual puede suponer un desembolso
económico importante; en segundo lugar, el consumo de potencia de estos
dispositivos varía entre los 25 y 30 W llegando a un máximo de 45 W cuando
se incorpora el oscilador de rubidio.
2.2.2. Alternativas de sincronización para sistemas em-
potrados
A partir de las características de los equipos comerciales que se han pre-
sentado, se observa cómo los principales inconvenientes vienen motivados
por el gran tamaño, alto coste económico y alto consumo de potencia de
estos dispositivos. En este sentido, como se ha comentado en el Capítulo 1,
cobra especial interés el hecho de disponer de soluciones de sincronización im-
plementadas completamente en hardware que permitan incluir este tipo de
funciones dentro de sistemas empotrados de forma sencilla y flexible. Así, im-
plementar sistemas empotrados sobre dispositivos programables tipo FPGA
que integren servicios de sincronización presenta una serie de ventajas que
resuelven los problemas encontrados en los equipos discretos, ya que se trata
de alternativas compactas, de bajo coste y bajo consumo de potencia.
A continuación, se van a presentar trabajos y productos para sincroniza-
ción que tienen aplicación en sistemas empotrados, al menos parcialmente:
Butner y Vahey [Butner and Vahey, 2002] realizan una modificación a
una tarjeta de red para incluir un módulo hardware específico que se

2.2. Equipos y dispositivos de sincronización 79
encarga de realizar el marcado temporal de los mensajes de tiempo del
protocolo NTP. Este módulo se implementa mediante lógica programa-
ble.
Höller et al. [Höller et al., 2002; Horauer et al., 2002; Höller et al., 2003;
Höller, 2003] desarrollan en hardware una interfaz de red y un módulo
complementario para un conmutador para soportar PTP y su propia
tecnología de sincronización SynUTC.
Yamada et al. [Yamada et al., 2006] usan una FPGA para implementar
soporte hardware para protocolos de sincronización alternativos para
redes Gigabit Ethernet.
Toriyama et al. [Toriyama et al., 2006] usan una FPGA para imple-
mentar un servidor SNTP hardware que funciona como una tarjeta de
expansión en un ordenador personal con el objetivo de soportar tráfico
elevado.
Skeie et al. [Skeie et al., 2001; Holmeide and Skeie, 2001; Skeie et al.,
2002, 2003, 2006; Holmeide and Skeie, 2006] emplean también una
FPGA para realizar el marcado temporal de los mensajes de un cliente
SNTP software corriendo sobre el sistema operativo VxWorks [Win-
driver] en una plataforma hardware basada en el microprocesador Ad-
vanced RISC Machines (ARM). Además, también integran un servidor
SNTP en un conmutador cumpliendo la clase IEC T5 de sincronización
sobre una red Ethernet conmutada.
Meier et al. [Meier et al., 2008] del Institute of Embedded Sys-
tems de la Zurich University of Applied Science proporcionan
unos controladores Ethernet para ordenadores personales que soportan
PTP para propósitos académicos y de test. Estos controladores están
implementados usando dispositivos FPGA. Este instituto también pro-
porciona un ejemplo de diseño en código VHSIC Hardware Description
Language (VHDL) de una unidad de marcado temporal y de control
de reloj para el protocolo PTP.

80 Capítulo 2. Sincronización temporal sobre redes de comunicación
Excel y Loschmidt [Exel and Loschmidt, 2009] usan un dispositivo pro-
gramable para diseñar un sistema que realiza en hardware el marcado
temporal de los mensajes e implementa un conjunto de métodos de
estimación de fase y frecuencia con la finalidad de conseguir una alta
precisión de sincronización del sistema.
La empresa Symmetricom dispone de dos subsistemas empotrados
denominados SCi 1100 and SCi 1200 Embedded Subsystems que im-
plementan clientes PTP. Estos subsistemas se ofertan como un módulo
de pequeño tamaño que se puede integrar fácilmente en otros sistemas
como por ejemplo conmutadores o routers. Además, también posibili-
tan la obtención del módulo a través del pago de una licencia para su
integración directa dentro del sistema que se esté desarrollando.
La empresa OnTime Networks oferta un módulo de propiedad inte-
lectual (Intellectual Property, IP) que realiza el marcado temporal hard-
ware de paquetes PTP e incluye un reloj de alta resolución pudiéndose
implementar con esta tecnología un reloj transparente completamente
en hardware.
La empresa Oregano Systems comercializa chips y módulos IP para
su uso en sistemas empotrados, en concreto, los módulos de la serie
syn1588 R©Clock [Oregano, 2010]. Estos módulos realizan en hardwa-
re el marcado temporal de los paquetes PTP e implementan un reloj
hardware, lo cual permite generar diferentes señales de salida, como por
ejemplo, una señal PPS.
2.3. Conclusiones
Como se ha comentado en el Capítulo 1, el objetivo principal de este tra-
bajo consiste en la implementación completamente hardware de un conjunto
de módulos de sincronización, basados en protocolos estándares de comuni-
cación, que permitan integrar de manera compacta, flexible y con un bajo

2.3. Conclusiones 81
coste y consumo de potencia funciones de sincronización en los sistemas em-
potrados que requieran este tipo de funcionalidad.
Como se ha presentando en este capítulo, en la actualidad no existen
soluciones adecuadas para la sincronización de sistemas empotrados ya que,
por un lado, el uso de equipos externos elimina las ventajas de dichos siste-
mas de ser soluciones compactas y de bajo coste y, por otro, las soluciones
basadas en SoPC existentes limitan el soporte hardware a realizar el marcado
temporal y, en algunos casos, el control del reloj, implementando el resto de
operaciones de sincronización a nivel software.
Sin embargo, una implementación completamente hardware de los algo-
ritmos avanzados de los protocolos NTP y PTP puede suponer un fuerte
impacto en los recursos hardware del sistema. Por esta razón, en este trabajo
se va a abordar la implementación hardware de un protocolo simplificado
como el protocolo SNTP, pero de precisión suficiente cuando se restringe
su uso a redes de área local. En este sentido, tal y como se ha analizado,
empleando el protocolo SNTP es posible alcanzar la clase IEC T3 sin im-
plementar los algoritmos avanzados de NTP, siempre y cuando se realice en
hardware el marcado temporal de los paquetes de hora y se limite el número
de conmutadores entre el cliente y el servidor.

82 Capítulo 2. Sincronización temporal sobre redes de comunicación

Parte II
Desarrollo de hardware para
sincronización de sistemas
empotrados
83


Capítulo 3
Arquitectura del sistema
Como se ha concluido en el Capítulo 2, en este trabajo se va a abor-
dar el diseño e implementación de un sistema de sincronización basado en el
protocolo SNTP y restringido al ámbito de las redes de área local Ethernet
conmutadas. Concretamente, se explora la implementación completamente
hardware de un cliente y un servidor SNTP empleando dispositivos progra-
mables FPGA de baja densidad y bajo coste y sin necesidad de incluir ningún
recurso hardware adicional como memorias SDRAM, discos o memorias de
almacenamiento masivo, etc. De esta forma, estas soluciones presentarán un
tamaño, un coste y un consumo de potencia reducidos en comparación con
las implementaciones software tradicionales corriendo en sistemas basados
en computador. Además, en estas implementaciones, el marcado temporal
de los paquetes se va a hacer en el controlador de red por lo que se evita la
latencia no predecible encontrada en las soluciones software. Esto permiti-
rá alcanzar la máxima precisión para la configuración planteada siendo ésta
comparable a los productos comerciales asistidos por hardware existentes en
la actualidad. Adicionalmente, una vez verificados los diseños, estos podrían
integrarse fácilmente en los equipos que forman la red de comunicación con
un reducido coste en recursos hardware.
El esquema general de la solución planteada se presenta en la Fig. 3.1,
donde se observa cómo el servidor SNTP adquiere información de hora precisa
mediante un receptor GPS y los clientes se sincronizan con el servidor a través
85

86 Capítulo 3. Arquitectura del sistema
Figura 3.1: Esquema general de la solución planteada basada en el uso declientes y servidores SNTP sobre redes de área local.
de la red local y proporcionan a los equipos la información de sincronización
que necesitan.
No obstante, la implementación completamente hardware del sistema de
sincronización conlleva una serie de retos importantes. Por un lado, se ha-
ce imprescindible el desarrollo de arquitecturas y soluciones prácticas que
permitan afrontar en hardware la implementación de funciones estándares
comúnmente implementadas a nivel software: acceso al controlador Ethernet
Media Access Control (MAC), pila de protocolos de comunicación, recep-
ción de información temporal del GPS, etc. Por otro lado, también resulta
necesario realizar desarrollos teóricos de algoritmos de sincronización y de
mecanismos de control y ajuste del reloj que sean abordables para su im-
plementación hardware. Por último, al estar SNTP basado en los protocolos
UDP/IP, otro aspecto importante consiste en la necesidad de proporcionar
una configuración de red a los dispositivos de sincronización para que puedan
trabajar sobre estos protocolos; además, puede resultar necesario suministrar
otro tipo de información de configuración relacionada con el protocolo SNTP

3.1. Arquitectura del cliente y del servidor 87
o propia del diseño.
Como se observa en la Fig. 3.1, para la configuración del todo el sistema
se propone que los dispositivos tomen la configuración desde un servidor
de configuración usando el Bootstrap Protocol (BOOTP), de forma que la
configuración pueda estar centralizada en un único lugar.
Finalmente, en este capítulo se van a presentar las arquitecturas del clien-
te y del servidor SNTP, describiéndose con cierto detalle las características
más importantes de cada uno de los bloques que las componen.
3.1. Arquitectura del cliente y del servidor
La implementación completamente hardware, tanto del cliente como del
servidor SNTP, presenta una serie de problemas que hacen necesario esta-
blecer una arquitectura flexible y modular de forma que se permita, por un
lado, la reutilización de los módulos comunes y, por otro, la escalabilidad del
diseño de forma que sea posible ampliar las funcionalidades del mismo de
manera sencilla y con el menor gasto de recursos posible. En este sentido, en
las Fig. 3.2 y 3.3 se presentan los diagramas de bloques del servidor y del
cliente SNTP respectivamente. Como se observa en estas figuras las arqui-
tecturas de ambos diseños son muy similares lo cual permite compartir gran
parte de la funcionalidad de cada diseño.
A partir de las arquitecturas presentadas, una primera clasificación de
los módulos que las forman se podría hacer en relación con la funcionalidad
que cada uno desempeña; de acuerdo a este criterio se pueden distinguir tres
grupos claramente diferenciados:
1. Módulos dedicados a la comunicación de datos en redes Ethernet con-
mutadas: Controlador Ethernet MAC e interfaz de protocolos y confi-
guración.
2. Módulos dedicados a la comunicación de datos vía serie: Universal
Asynchronous Receiver-Transmitter (UART) y bloques de recepción
(servidor) y transmisión (cliente) de información temporal.

88 Capítulo 3. Arquitectura del sistema
Figura 3.2: Diagrama de bloques del servidor SNTP.
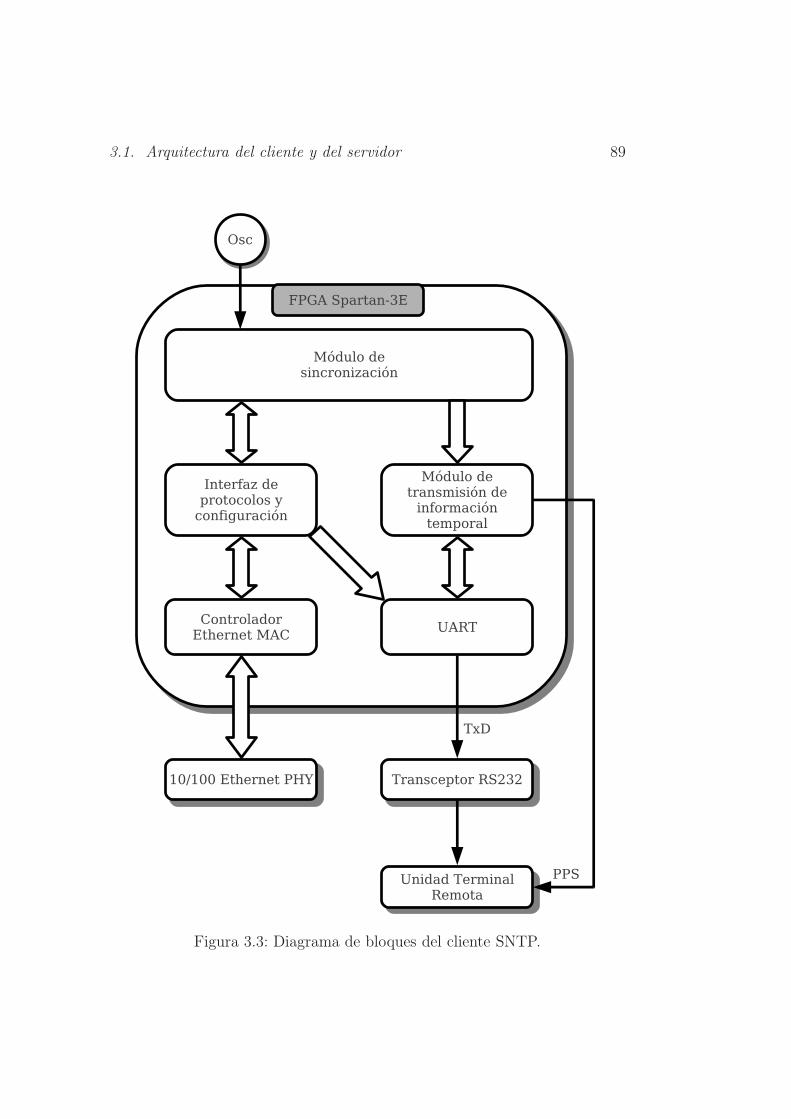
3.1. Arquitectura del cliente y del servidor 89
Figura 3.3: Diagrama de bloques del cliente SNTP.

90 Capítulo 3. Arquitectura del sistema
3. Módulo de sincronización.
En referencia al primer grupo, por un lado, el controlador Ethernet MAC
se encarga de controlar un dispositivo Fast Ethernet PHY (Physical layer),
permitiendo la transmisión y recepción de tramas Ethernet conforme a la
especificación estándar IEEE 802.3 [IEEE, 2005]. Por otro lado, el módulo
de interfaz de protocolos y configuración implementa todos los protocolos de
nivel superior necesarios: Address Resolution Protocol (ARP), IP, UDP, NTP
y BOOTP proporcionando una capa independiente del controlador Ethernet
MAC y mejorando la reusabilidad.
En cuanto al segundo grupo, por un lado, la UART será empleada por el
servidor SNTP para la recepción serie de las tramas National Marine Elec-
tronics Association (NMEA) enviadas por el receptor GPS; posteriormente,
el módulo de recepción de información temporal procesará estas tramas para
generar la información de hora necesaria en el formato NTP. Por otro lado,
el cliente SNTP utilizará la UART para transmitir vía serie la trama que
informa de la fecha y hora y que será generada por el módulo de transmisión
de información temporal a partir de la hora local del sistema.
El módulo de sincronización se encarga de sincronizar el reloj local a
partir de los desplazamientos calculados respecto de la referencia de hora
que se utilice en cada caso (receptor GPS o servidor SNTP).
Una vez presentada la funcionalidad de cada módulo puede resultar in-
teresante hacer una segunda clasificación en función de la complejidad y los
aspectos innovadores que presentan cada uno de los módulos y que resultan
en las principales aportaciones de este trabajo. En este sentido, los módulos
se pueden organizar también en tres grupos:
1. Módulos que implementan funcionalidad estándar: controlador Ether-
net MAC y UART.
2. Módulos específicos de baja complejidad: bloques de recepción y trans-
misión de información temporal.
3. Módulos específicos de alta complejidad: módulo de sincronización e
interfaz de protocolos y configuración.

3.1. Arquitectura del cliente y del servidor 91
En el primero de los grupos, tanto el controlador Ethernet MAC como la
UART, son bloques cuya funcionalidad se encuentra muy bien especificada
en estándares de comunicación, lo cual origina que sean ampliamente utili-
zados y que existan multitud de soluciones implementadas en hardware. Más
relacionado con el trabajo que se está presentando también es importante
destacar que se dispone de alternativas hardware de estos módulos en la for-
ma de módulos IP especialmente adaptados para su implementación sobre
FPGA.
El segundo grupo corresponde a módulos específicos y no existe ningún
estándar que determine las tareas que deben realizar los bloques de recepción
y transmisión de información temporal. Estos módulos son de complejidad
relativamente baja y su diseño no tiene un carácter especialmente innova-
dor. No obstante, es conveniente destacar que para diseñar estos bloques es
importante definir una arquitectura que no emplee excesivos recursos hard-
ware de forma que la mayor parte de los mismos se destinen a los módulos
principales.
Finalmente, el tercer grupo está formado por módulos de alta compleji-
dad: los módulos de sincronización e interfaz de protocolos y configuración.
Éstos son los bloques principales del sistema ya que introducen aspectos nove-
dosos teniéndose que centrar sobre ellos el mayor esfuerzo a la hora de definir
métodos y técnicas que permitan su correcta implementación hardware.
En relación con la interfaz de protocolos y configuración, comúnmente la
pila de protocolos de Internet se implementa a nivel software tanto en equipos
convencionales como en sistemas empotrados. Cuando se diseña un sistema
empotrado que necesita servicios de red la opción más habitual consiste en
implementar un sistema basado en microprocesador que ejecuta un sistema
operativo. Dentro del sistema operativo vienen incluidos generalmente un
conjunto de drivers, bibliotecas de programación y aplicaciones que resuel-
ven la mayoría de problemas de acceso a la red de comunicación. No obstante,
esta alternativa presenta los mismos problemas que las soluciones software
tradicionales ya que las variaciones en los retrasos originados por el planifica-
dor de tareas y la pila de protocolos ocurren en igual medida. Además, para
ejecutar dicho software se necesita incluir un conjunto de componentes hard-

92 Capítulo 3. Arquitectura del sistema
ware adicionales: procesador, controlador de memoria, memorias SDRAM
externas al chip, buses, etc. que podrían comprometer el área disponible e
incrementar el coste final del sistema. Por estas razones, se ha optado por una
implementación completamente hardware de todos los protocolos de Internet
necesarios en el diseño del cliente y servidor SNTP.
Sin embargo, el hecho de tener que implementar en hardware todo el
conjunto de protocolos indicado anteriormente y otros más que se pudieran
necesitar en el futuro hace de este módulo una de las partes más críticas del
sistema. Así, resulta imprescindible desarrollar una arquitectura flexible y
escalable que permita incorporar de una forma rápida y sencilla el conjunto
de servicios de red necesarios para una aplicación concreta y además ofrezca la
posibilidad de añadir nuevos servicios sin tener que rediseñar completamente
dicha arquitectura. Además, no hay que olvidar que otro aspecto clave que
debe realizar este módulo consiste en el marcado temporal de los mensajes de
hora. En este sentido, también se hace necesario investigar algunas técnicas
que reduzcan la variabilidad en el retraso a la hora de colocar las marcas de
tiempo en los mensajes.
En cuanto al módulo de sincronización, como se ha comentado anterior-
mente, los algoritmos avanzados especificados por el protocolo NTP no son
abordables para su implementación hardware por lo que se deben explorar
otras alternativas implementables completamente en hardware que permitan
una correcta sincronización de los equipos. En principio, de acuerdo al es-
cenario presentado en este capítulo, el protocolo SNTP se presenta como la
mejor solución para ser abordada en hardware debido a que simplifica la fun-
cionalidad del protocolo NTP. Sin embargo, no se puede decir que ésta sea
una solución completa ya que el protocolo SNTP no especifica ningún modelo
de reloj ni algoritmos de ajuste y disciplina del reloj. En este sentido, una de
las tareas principales de este trabajo consiste en definir un modelo de reloj y
una serie de algoritmos para el cálculo de correcciones, ajuste y disciplina del
reloj adecuados para su implementación hardware y que proporcionen una
alta precisión en la sincronización.
En los siguientes apartados, se van a presentar detalladamente todos los
aspectos comentados en esta sección, poniendo especial énfasis en los módulos

3.2. Módulos estándares 93
de sincronización e interfaz de protocolos y configuración.
3.2. Módulos estándares
En esta sección, se van a definir la funcionalidad básica, la interfaz de en-
trada/salida y las operaciones generales que realizan los módulos estándares,
es decir, los controladores Ethernet MAC y del puerto serie. Como se observa
en la Fig. 3.4, tanto el cliente como el servidor comparten ambos módulos de
forma que éstos serán comentados de manera general.
3.2.1. Controlador Ethernet MAC
Debido a que tanto el cliente como el servidor SNTP deben operar en una
red Ethernet conmutada el primer requisito que se debe satisfacer consiste
en definir el conjunto de protocolos y dispositivos necesarios que permitan
esta operación. Ethernet opera en las dos capas inferiores del modelo OSI
(Fig. 3.5) definiendo los protocolos de la capa de enlace de datos y las tec-
nologías de la capa física. En concreto, el estándar de Ethernet denominado
IEEE 802.3 define la capa física y la mitad inferior de la capa de enlace de
datos conocida como subcapa de control de acceso al medio mientras que la
Figura 3.4: Módulos estándares: controlador Ethernet MAC y del puertoserie.

94 Capítulo 3. Arquitectura del sistema
Figura 3.5: Capas del modelo OSI en las que opera Ethernet.
subcapa superior o de control de enlace lógico (Logical Link Control, LLC)
se define en el estándar IEEE 802.2 [IEEE, 1998].
Como se observa en la Fig. 3.6, el módulo Fast Ethernet PHY implementa
la capa física según las especificaciones del estándar IEEE 802.3, permitiendo
velocidades de 10/100 Mbps, y el controlador Ethernet MAC toda la funcio-
nalidad definida en el estándar para la subcapa de control de acceso al medio.
La interconexión con la capa física se realiza a través de la interfaz indepen-
diente del medio, también definida en el estándar IEEE 802.3. La principal
ventaja que aporta esta interfaz es que independiza del medio físico al contro-
lador Ethernet MAC, contribuyendo significativamente a la compatibilidad
de tecnologías y a la reutilización de módulos ya que un mismo controlador
Ethernet MAC puede interactuar con diferentes módulos PHY que conec-
tan a medios diferentes sin necesidad de rediseñar o adaptar el controlador
Ethernet MAC existente.
En la Tabla 3.1 se describen las señales que forman la MII. Estas seña-
les se pueden clasificar formando tres grupos: señales de administración, de

3.2. Módulos estándares 95
Figura 3.6: Conexión del controlador Ethernet MAC con la capa física y conlas capas superiores.
estado del medio y de transferencia de datos. Las señales de administración
Management Data Clock (MDC) y Management Data Input/Output (MDIO)
se usan para transferir información de control y estado entre el controlador
Ethernet MAC y el PHY. Las de estado del medio Carrier Sense (CRS) y
Collision Detected (COL) indican la presencia de portadora y la detección de
colisiones respectivamente. En cuanto a las de transferencia de datos se ob-
serva cómo se han separado en dos canales diferentes las señales de recepción
y de transmisión de los datos. Así, cada canal dispone de su señal de reloj:
Receive Clock (RX_CLK) y Transmit Clock (TX_CLK), de datos: Recei-
ve Data (RXD) y Transmit Data (TXD) y de control: Receive Data Valid
(RX_DV), Receive Error (RX_ER) y Transmit Enable (TX_EN), Transmit
Coding Error (TX_ER).
En lo que se refiere a la comunicación con las capas superiores, general-
mente, en una implementación software, ésta se suele hacer a través de la
subcapa de control de enlace lógico. Así, en una máquina corriendo un siste-

96 Capítulo 3. Arquitectura del sistema
Nombre Descripción
MDC Referencia de tiempo para transferir información a tra-vés de la señal MDIO.
MDIO Señal de datos de la unidad de administración.COL Detección de colisiones.CRS Detección de portadora.RX_CLK Reloj de recepción. Proporciona una referencia de tiem-
po para la transferencia de las señales RX_DV, RX_ERy RXD desde el PHY al controlador Ethernet MAC.
RX_DV Dato recibido válido.RX_ER Error en la recepción.RXD(3:0) Dato recibido.TX_CLK Reloj de transmisión. Proporciona una referencia de
tiempo para la transferencia de las señales TX_EN,TX_ER y TXD desde el controlador Ethernet MAC alPHY.
TX_EN Habilitación de la transmisión.TX_ER Error en la transmisión.TXD(3:0) Dato a transmitir.
Tabla 3.1: Señales que forman la interfaz independiente del medio.
ma operativo esta subcapa puede considerarse como el controlador o driver
de la tarjeta de interfaz de red (Network Interface Card, NIC). En el tra-
bajo que se está abordando, al ser un diseño implementando totalmente en
hardware se debe habilitar otro mecanismo que permita la comunicación con
las capas superiores. En este caso, como se observa en la Fig. 3.6 se van a
disponer de dos colas o buffers (First In First Out, FIFO), una dedicada a la
transmisión y otra a la recepción. Cada una de estas FIFO proporciona una
serie de señales de control y estado que permitirán gestionar la transmisión
y recepción de los paquetes Ethernet.
Una vez comentado cómo se realiza la comunicación con las capas supe-
riores e inferiores se van a presentar las operaciones que debe implementar
el controlador Ethernet MAC. Así, de acuerdo al estándar de Ethernet las
tareas que debe realizar la capa de control de acceso al medio consisten en:
construcción y delimitación de tramas, direccionamiento, detección de erro-
res, control de acceso al medio y control de flujo.

3.2. Módulos estándares 97
En cuanto a la primera operación, cuando se forma una trama la subcapa
MAC agrega una cabecera y una cola a la unidad de datos del protocolo
(Protocol Data Unit, PDU) de la capa de red del modelo OSI. Además, al
transmitir, el controlador debe delimitar el inicio de la trama agregando dos
campos más (preámbulo y delimitador de inicio de trama o Start Frame
Delimiter, SFD) que se utilizan para la sincronización entre los dispositivos
de envío y de recepción. De esta forma, el receptor puede determinar el
comienzo y el final de la trama.
Otra operación que realiza el controlador consiste en el direccionamiento.
En el encabezado de cada trama se incorpora la dirección física tanto del nodo
origen como del destino. Esto hace posible que los datos puedan entregarse a
una máquina destino dentro de la red y que ésta conozca el equipo que envío
el mensaje.
Una función importante que realiza esta capa es la detección de errores.
Cada trama Ethernet añade al final un campo que contiene una secuencia
de verificación (Cyclic Redundancy Check, CRC). Así, cada vez que el nodo
receptor recibe una trama calcula esta secuencia y la compara con la que
viene al final de la misma de forma que si éstas coinciden se puede asumir
que los datos se recibieron sin errores.
Debido a que la topología lógica subyacente de Ethernet es un bus al
que pueden acceder múltiples dispositivos esto significa que todos los nodos
comparten el mismo medio físico. En este sentido, Ethernet especifica el
Carrier sense multiple access with collision detection (CSMA/CD) como el
mecanismo que permite controlar el acceso al medio.
Finalmente, el controlador Ethernet MAC debe realizar un control de
flujo que consiste en un mecanismo por el cual un equipo puede solicitar a
otro que deje de transmitir temporalmente mediante el envío de una trama
de PAUSA o PAUSE frame.
3.2.2. Controlador del puerto serie
La mayoría de receptores GPS proporcionan información temporal me-
diante la transmisión de un conjunto de tramas definidas por el estándar

98 Capítulo 3. Arquitectura del sistema
NMEA-0183 [NMEA, 2002]. Debido a que este estándar usa un protocolo
serie sencillo para la comunicación de los datos es necesario disponer de un
controlador de puerto serie o UART. Un aspecto importante es que este con-
trolador no genera o recibe directamente las señales externas sino que usa un
dispositivo transceptor que convierte los niveles lógicos de las señales de la
UART a y desde los niveles de señalización externa (Fig. 3.7).
Algunos estándares de comunicación serie definidos por la Electronic In-
dustries Alliance (EIA) son Recommended Standard 232 (RS-232), RS-422
y RS-485. En relación con los sistemas empotrados es muy habitual la uti-
lización de RS-232 ya que en el mercado existen chips de bajo coste que
permiten convertir señales de un nivel lógico determinado (como por ejemplo
Transistor-Transistor Logic, TTL) a los niveles de señal de RS-232.
El estándar RS-232 define un conjunto de señales de control: Data Termi-
nal Ready (DTR), Data Carrier Detect (DCD), Data Set Ready (DSR), Ring
Indicator (RI), Request To Send (RTS) y Clear To Send (CTS), y de datos:
Transmitted Data (TxD) y Received Data (RxD). Sin embargo, en diseños
Figura 3.7: Controlador del puerto serie.

3.2. Módulos estándares 99
que no requieran control de flujo es muy común emplear sólo las señales de
datos TxD y RxD (Fig. 3.7).
Como se observa en la Fig. 3.7, este módulo permite la comunicación
con otros bloques del sistema a través de dos FIFO separadas, una dedicada
a la transmisión y otra a la recepción. Estas FIFO serán empleadas como
buffers que permiten adaptar la velocidad del puerto serie a la frecuencia de
operación del sistema. El envío y la lectura de la información se realiza a
través de la señales de datos y de control que permiten almacenar y leer los
datos de la FIFO correspondiente. Las señales de estado indican el estado del
buffer y se emplean para controlar la comunicación. Una vez que hay datos
en la FIFO de transmisión este controlador se encarga de transmitir vía serie
la información a través de la señal TxD. Para la recepción de los datos la
UART recibe la información serie por la señal RxD y la va almacenado en la
FIFO de recepción.
Además, este controlador debe realizar una serie de operaciones adiciona-
les necesarias para conseguir una comunicación funcional a través del puerto
serie: (1) transmitir y recibir la información en un formato de dato y a una
velocidad o baud rate establecido y (2) detectar posibles condiciones de error.
En cuanto al formato de los datos se pueden establecer diferentes confi-
guraciones de bits de datos, de stop y de paridad. Una configuración típica
es la denominada “8N1” (8 bits de datos, 1 bit de stop y sin paridad). En
relación con el baud rate, velocidades típicas admitidas se sitúan entre los
4800 y 115200 baudios, aunque también se pueden soportar velocidades su-
periores. La configuración del baud rate se realiza mediante el parámetro de
configuración baud rate1.
Finalmente, el controlador debe detectar errores en la línea de comunica-
ción, en concreto, detectar una condición de ruptura o break condition por la
que un transmisor fuerza un nivel bajo sobre la línea debido posiblemente a
que está apagado en ese instante. En este caso, el receptor interpretará esto
como un bit de start seguido por un dato todo a 0 pero detectará que el bit
de stop no es válido descartando el dato. A continuación, el receptor esperará
1Los parámetros de configuración se detallarán más adelante en este capítulo (aparta-do 3.4.1).

100 Capítulo 3. Arquitectura del sistema
hasta que la línea serie vuelva a estar en alto.
3.3. Módulos de baja complejidad
En esta sección, se van a definir los módulos de baja complejidad, en
concreto, los módulos de recepción y transmisión temporal. Como se observa
en la Fig. 3.8, estos módulos son específicos para cada diseño de forma que
serán comentados de manera independiente.
3.3.1. Módulo de recepción de información temporal
El módulo de recepción de información temporal es un bloque específico
de servidor SNTP cuya función principal consiste en la generación de la in-
formación temporal necesaria para sincronizar el reloj de hora local. Dicha
información se genera a partir de la señal PPS y de las tramas NMEA que
transmite el receptor GPS conectado al puerto serie del servidor SNTP. La
señal PPS emitida por el GPS es una señal cuadrada que indica de forma
muy precisa el inicio del segundo mediante un cambio de nivel lógico de la
señal. Dependiendo del modelo de GPS el inicio del segundo viene determi-
nado por un cambio de nivel bajo a nivel alto o de nivel alto a nivel bajo
Figura 3.8: Módulos de baja complejidad: recepción y transmisión de la in-formación temporal.

3.3. Módulos de baja complejidad 101
pudiendo ser la señal PPS activa en flanco de subida o en flanco de bajada
respectivamente. Debido a que la señal PPS no informa de la fecha y hora
actual es necesario combinarla con otra fuente de hora menos precisa que
proporcione esta información; en este caso, las tramas NMEA enviadas por
el receptor GPS. En efecto, el GPS tras el flanco activo de la señal PPS
comienza a transmitir un conjunto de tramas del protocolo NMEA, cada
una conteniendo un tipo de información diferente. La trama que informa de
la fecha y hora se denomina Recommended Minimum sentence C (RMC) y
presenta el formato mostrado en la Fig. 3.9. Como se observa en la figura
anterior no se proporciona información de fracciones de segundos ya que el
valor del campo de hora es relativo al instante en que se produce el flanco
activo de la señal PPS, es decir, al cambio de segundo por lo que la parte
fraccionaria es cero en ese momento.
Una vez comentadas las señales que transmite el receptor GPS, en la
Fig. 3.10 se presenta un diagrama que resume el conjunto de señales de
entrada y salida que recibe y genera respectivamente este módulo. Por un
lado, en la Fig. 3.10 se observa cómo este bloque se comunica con la UART
a través del conjunto de señales que proporciona la FIFO de recepción para
la lectura de los datos recibidos. Además, se dispone de dos señales: PPS y
configuración; la primera se refiere a la señal PPS y la segunda se corresponde
con el parámetro de configuración flanco activo que indica el flanco activo
Figura 3.9: Formato de la trama RMC. Ejemplo.

102 Capítulo 3. Arquitectura del sistema
Figura 3.10: Módulo de recepción de información temporal.
Nombre Descripción
Número segundos Representa el número de segundos en formatoNTP de la fecha y hora recibida.
Estado GPS Información de estado: flanco activo detectado,GPS sincronizado, detección de error en la recep-ción de la trama RMC.
Estado conversión Indica si la información temporal recibida se haconvertido correctamente al formato NTP.
Tabla 3.2: Datos generados por el módulo de recepción de información tem-poral.
del PPS. Por otro lado, en la Tabla 3.2 se recoge el significado de las señales
de salida que ofrece este módulo y que se corresponden con la información
temporal que necesita el bloque de sincronización para ajustar el reloj de
hora local.
Finalmente, se comentarán las principales operaciones que debe realizar

3.3. Módulos de baja complejidad 103
este módulo. En primer lugar, se debe detectar el flanco activo del PPS ya que
éste será el punto de partida del resto de acciones. En segundo lugar, tras de-
tectar el flanco activo se procederá a leer las tramas NMEA transmitidas por
el GPS. Todas las tramas NMEA recibidas se descartarán excepto la trama
RMC que será procesada para determinar la fecha y la hora. Además, duran-
te este procesado se debe comprobar el campo que informa del estado para
determinar si el GPS está sincronizado y calcular una suma de verificación de
los datos recibidos que consiste en la operación lógica exclusive disjunction
(XOR) de los caracteres entre el $ y el *. La suma de verificación calculada
será comparada con la que viene al final de la trama para comprobar si ha
habido errores en la recepción de los datos. La última operación consiste en
la conversión de la fecha y la hora recibida al formato NTP. Cuando finaliza
cada una de las operaciones se genera una señal que indica el estado de dicha
operación.
3.3.2. Módulo de transmisión de información temporal
El módulo de transmisión de información temporal es un bloque específico
del cliente SNTP cuya función principal consiste en la generación y trans-
misión de una señal PPS y trama RMC que permitirán la sincronización de
los equipos finales a través del puerto serie, de igual forma que si tuvieran
conectado un receptor GPS. Dichas señales se generarán a partir de la hora
local en formato NTP y de una señal que indica el estado de sincronización
del cliente SNTP y que permite actualizar el campo de estado de la trama
RMC (Fig. 3.11). En cuanto a la transmisión de la trama RMC, este bloque
transmite los datos a través del conjunto de señales que proporciona la FI-
FO de transmisión de la UART. En el envío de esta trama se debe tener en
cuenta que no se dispone de ninguna fuente que posibilite la determinación
de campos como la latitud, la longitud o la velocidad sobre la tierra por lo
que este módulo sólo se limitará a rellenar los campos de fecha, hora, estado
y suma de verificación dejando el resto con un valor por defecto como por
ejemplo a cero. En relación con el flanco activo del PPS se va a considerar que
siempre va a estar activo en flanco de subida por lo que no se va a necesitar

104 Capítulo 3. Arquitectura del sistema
Figura 3.11: Módulo de transmisión de información temporal.
ningún parámetro de configuración.
Finalmente, se comentarán las principales operaciones que debe realizar
este módulo. En primer lugar, se procederá a la generación de la señal PPS
que indica el cambio de segundo. En segundo lugar, como la trama RMC
se debe enviar tras el flanco activo del PPS la siguiente tarea consiste en
detectar el cambio del nivel bajo al nivel alto de esta señal. En tercer lugar,
tras detectar el flanco de subida se debe realizar la conversión de la hora local
en formato NTP al formato de fecha DD/MM/AA (día, mes, año) y hora
HH:MM:SS (hora, minuto y segundo); para esta conversión sólo se empleará
la parte entera de la hora local que es la que indica el número de segundos.
Por último, se debe construir la trama RMC incluyendo la fecha, la hora y
el estado y transmitirse a través del puerto serie incluyendo al final la suma

3.4. Interfaz de protocolos y configuración 105
de verificación calculada para los datos transmitidos.
3.4. Interfaz de protocolos y configuración
En esta sección, se comentará uno de los módulos de alta complejidad
presentados, en concreto, la interfaz de protocolos y configuración. En la
Fig. 3.12 se observa cómo este módulo se incluye tanto en el cliente como en
el servidor. A continuación, se van a definir la funcionalidad y las operaciones
que debe realizar este módulo, teniendo en cuenta que se definen algunos
aspectos de su funcionalidad según se trate de la versión para el cliente o el
servidor.
La interfaz de protocolos y configuración debe implementar todos los pro-
tocolos de comunicación de nivel superior necesarios para el diseño del cliente
y del servidor SNTP. En la Fig. 3.13 se representan las capas del modelo OSI
donde se sitúan los protocolos de Internet implementados. Como se obser-
va en esta figura, aparte del protocolo de sincronización de hora SNTP, se
requiere el empleo de otros protocolos como el BOOTP y el ARP. Esto se
debe a que SNTP opera empleando los protocolos UDP/IP en las capas de
transporte y de red por lo que resulta imprescindible resolver dos aspectos
críticos que se basan en la necesidad de: (1) establecer una configuración de
Figura 3.12: Módulo de alta complejidad: interfaz de protocolos y configura-ción.

106 Capítulo 3. Arquitectura del sistema
Figura 3.13: Capas del modelo OSI donde se sitúan los protocolos de Internetimplementados en la interfaz de protocolos y configuración.
red para el servidor y los clientes SNTP y (2) poder determinar la dirección
física de los diferentes dispositivos que forman la red de sincronización de
acuerdo a la configuración de red establecida. Para la primera acción se va a
emplear el protocolo BOOTP que permite a los clientes de BOOTP obtener
su dirección IP automáticamente y para la segunda el protocolo de resolución
de direcciones ARP.
De lo expuesto en el párrafo anterior se desprende que este módulo debe
encargarse de transmitir y recibir información de configuración, resolución
de direcciones físicas y hora, enviando y recibiendo paquetes de petición y
respuesta de BOOTP, ARP y NTP respectivamente. Para ello, este bloque
emplea el conjunto de señales que proporciona el controlador Ethernet MAC
y que permiten la lectura y escritura de las FIFO de recepción y transmi-
sión que dicho controlador pone a disposición del resto para esta finalidad
(Fig. 3.14). Además, en la figura anterior se observa un conjunto de señales
de entrada y salida, algunas de la cuales son comunes tanto para el cliente

3.4. Interfaz de protocolos y configuración 107
Figura 3.14: Interfaz de protocolos y configuración.
como para el servidor y otras dependientes del modo en el que se esté ope-
rando (Tabla 3.3). La señal de entrada hora local representa la hora local en
formato NTP y se utiliza para realizar el marcado temporal de los paquetes
NTP entrantes y salientes. En modo servidor, además de las marcas de tiem-
po se debe proporcionar información acerca del estado de sincronización y del
servidor, necesaria para rellenar ciertos campos de la respuesta: stratum (0 si
no está sincronizado y 1 en caso contrario), precision y reference timestamp.
En modo cliente, las marcas de tiempo, junto con el estado del servidor, se
deben proporcionar al módulo de sincronización para su procesamiento. En
cualquiera de los dos modos, este módulo pondrá a disposición del resto de
bloques un conjunto de parámetros de configuración junto con una señal de
estado que indica cuándo éstos son válidos.
En cuanto a las operaciones que debe realizar este módulo, éstas se pueden
clasificar en tres grupos: (1) gestión de la configuración, (2) gestión de direc-
ciones físicas y (3) control de las comunicaciones y marcado temporal. Como

108 Capítulo 3. Arquitectura del sistema
Nombre Descripción Modo
Hora local Representa la hora local en for-mato NTP.
Ambos
Estado servidor Agrupa un conjunto de señalescomo la precisión alcanzada y lamarca de tiempo que indica a quehora fue actualizado el reloj localpor última vez (reference times-tamp).
Servidor
Estado sincronización Indica si el servidor está sincroni-zado con el GPS. Se emplea paraactualizar el campo de stratum.
Servidor
Marcas de tiempo Marcas de tiempo recibidas en elpaquete de hora.
Cliente
Estado mensaje NTP Indica el estado del servidor: sin-cronizado, no sincronizado o nooperativo.
Cliente
Configuración Parámetros de configuración. AmbosEstado configuración Indica cuándo se dispone de infor-
mación de configuración válida.Ambos
Tabla 3.3: Señales de entrada y salida del módulo de interfaz de protocolosy configuración.
se introdujo anteriormente, la correcta implementación de estas operaciones
en hardware supone una de las tareas críticas del sistema resultando impres-
cindible definir una arquitectura flexible y escalable, que permita manejar los
servicios descritos, y estrategias de diseño que minimicen la variabilidad en
el retraso a la hora de realizar el marcado temporal de los paquetes NTP. A
continuación, en los siguientes subapartados, se describirán detalladamente la
arquitectura y las estrategias planteadas para conseguir el objetivo marcado.
3.4.1. Gestión de la configuración
Para llevar a cabo las operaciones de sincronización los diferentes dispo-
sitivos que forman la plataforma deben estar correctamente configurados. En
este sentido, es necesario desarrollar un sistema que permita gestionar la con-
figuración adecuadamente. En este apartado, en primer lugar se presentan

3.4. Interfaz de protocolos y configuración 109
los parámetros de configuración requeridos tanto por el cliente como por el
servidor SNTP y en segundo lugar el sistema de configuración planteado.
El hecho de que la plataforma de sincronización emplee una red IP per-
mite clasificar el conjunto de parámetros de configuración en dos grupos. Por
un lado, es necesario que cada uno de los equipos disponga de su propia con-
figuración de red de forma que los integrantes de una misma subred puedan
comunicarse entre sí. Por otro lado, cada dispositivo requiere un conjunto
de parámetros de configuración empleados por los diferentes módulos del
sistema.
Con respecto a la configuración de red, el uso del protocolo SNTP im-
plica la utilización de los niveles físico, enlace de datos, red, transporte y
aplicación del modelo OSI. Mientras que para el nivel físico no se requiere
ninguna configuración, para el nivel de enlace de datos es necesario confi-
gurar la dirección MAC, para el nivel de red la dirección IP y para el nivel
de transporte el número de puerto (en este caso se empleará el número de
puerto recomendado por la Assigned Numbers Authority, IANA, que
es el 123). Además, en el caso del cliente SNTP para el nivel de aplicación
se tiene que proporcionar la dirección IP del servidor de sincronización.
Atendiendo a los parámetros de configuración de los módulos, en la Ta-
bla 3.4 se describe la operación asociada a cada parámetro, si éste es específico
del cliente o del servidor o se emplea en ambos y el módulo de destino que lo
necesita. En cada uno de los módulos donde se utilizan estos parámetros se
detallará la funcionalidad de los mismos. En el Apéndice A se comentan los
rangos de valores admitidos que pueden tomar estos parámetros y los valores
por defecto establecidos para cada uno de ellos.
En relación con el sistema de configuración empleado se han analizado
diferentes modos de suministrar la información de configuración a los disposi-
tivos que forman la plataforma. La primera alternativa consiste en establecer
todos los parámetros tanto de red como específicos en la fase de diseño, de
forma que éstos ya se incluyan en el fichero binario (bitstream) que permite
la configuración del dispositivo programable. Esta primera opción presenta
la ventaja de que no es necesario implementar ningún sistema de configura-
ción pero como contrapartida supone un mecanismo rígido que no permite

110 Capítulo 3. Arquitectura del sistema
Nombre Descripción Modo Módulo de destino
Baud rate Velocidad en baudios delpuerto serie.
Ambos UART
ARP timeout Define el timeout entrepeticiones de ARP.
Cliente Interfaz de protoco-los y configuración
BOOTP timeout Define el timeout entrepeticiones de BOOTP.
Ambos Interfaz de protoco-los y configuración
Número ciclos Número de ciclos por se-gundo. Dependiente delreloj del sistema y em-pleado por los timers delos servicios.
Ambos Interfaz de protoco-los y configuración
Flanco activo Flanco activo de la señalPPS.
Servidor Módulo de recep-ción de informacióntemporal
p Intervalo entre peticionesde hora.
Cliente Módulo de sincro-nización
q Factor de convergencia. Ambos Módulo de sincro-nización
Factor prescaler Factor para ajustar elprescaler.
Ambos Módulo de sincro-nización
D nominal Valor nominal del pará-metro de ajuste.
Ambos Módulo de sincro-nización
Tabla 3.4: Parámetros de configuración.
la reconfiguración mientras el sistema está en funcionamiento, de forma que
cualquier cambio en la configuración supone la modificación del bitstream
y reprogramación de la FPGA. En este sentido, para proporcionar mayor
flexibilidad y debido a que puede resultar aconsejable la modificación de de-
terminados parámetros durante la operación del sistema se ha planteado una
segunda alternativa que consiste en la distribución automática de la configu-
ración empleando un protocolo de configuración de red, de forma que toda
la configuración pueda gestionarse de manera centralizada en un único servi-
dor de configuración. De este modo, si un dispositivo necesita conseguir sus
parámetros de configuración, efectúa una petición al servidor que responde
con la información correspondiente. Si se desea modificar la configuración de
un dispositivo, basta con acceder al servidor e indicarle los cambios, que son

3.4. Interfaz de protocolos y configuración 111
comunicados al equipo en su próxima consulta.
En concreto, esta segunda solución planteada se basa en el uso de un
protocolo de gestión de direcciones IP para implementar el sistema de con-
figuración. Entre los protocolos existentes destacan BOOTP y DHCP. El
primero de ellos, definido en el RFC 951 [Croft and Gilmore, 1985] y am-
pliado en el RFC 2132 [Alexander and Droms, 1997], surgió en 1985 con el
objetivo de permitir a una máquina cliente que carece de almacenamiento
no volátil obtener la información de configuración necesaria para descargar-
se de un servidor una imagen del software a ejecutar. Para ello precisa su
propia configuración IP, la dirección del servidor y la ruta donde se aloja la
imagen del software. El protocolo DHCP, definido en el RFC 2131 [Droms,
1997] y ampliado en el RFC 2132 [Alexander and Droms, 1997], está basado
en BOOTP pero mejora su funcionalidad, contemplando la asignación diná-
mica de direcciones. En la actualidad ambos protocolos se encuentran muy
extendidos para la configuración de dispositivos, especialmente DHCP, con
la aparición de las redes inalámbricas y la difusión de dispositivos móviles.
En este sentido, ambos protocolos proporcionan la funcionalidad necesaria
para la configuración de la plataforma; sin embargo, el hecho de que los clien-
tes y servidores que componen la plataforma se desarrollen completamente
en hardware tiene un peso determinante para seleccionar BOOTP como el
protocolo a utilizar, ya que las nuevas funcionalidades introducidas hacen de
DHCP un protocolo más complejo para ser implementado en hardware.
El funcionamiento del protocolo BOOTP está basado en el intercambio
de dos mensajes entre el cliente y el servidor: petición (BOOTPREQUEST )
y respuesta (BOOTPREPLY ). Los paquetes están encapsulados en data-
gramas UDP y las peticiones y respuestas comparten el mismo formato de
paquete. El proceso de configuración del protocolo BOOTP es el siguiente:
1. El cliente inicia el proceso de configuración con una petición (BOOT-
PREQUEST ), rellenando los siguientes campos: identificación de peti-
ción con un número aleatorio, dirección IP del cliente con su dirección
(en caso de conocerla) y dirección de nivel de enlace de datos con su
dirección MAC. El cliente usa la dirección MAC de broadcast como
dirección destino del paquete.

112 Capítulo 3. Arquitectura del sistema
2. El servidor recibe la petición BOOTP y comprueba si puede suminis-
trar una configuración al cliente. Para ello, dispone de una base de datos
con todos los pares (Dirección MAC, Configuración), además del fichero
de configuración que, dependiendo de la implementación del servidor,
puede bloquear asignaciones. Si el servidor no encuentra una configu-
ración a aplicar no responde a la petición y el proceso de comunicación
finaliza, aunque el cliente puede seguir enviando peticiones.
3. En caso de estar configurado para ello, el servidor manda la respuesta
(BOOTPREPLY ) al cliente. Los campos completados por el servidor
son la dirección IP asignada por el servidor, la dirección IP de la puerta
de enlace, la ruta del fichero de arranque y el campo de extensión, que
incluye la máscara de red.
El protocolo BOOTP define claramente la distribución de los parámetros
de configuración propios de una red TCP/IP. Sin embargo, podría resultar
necesario transmitir también configuración propia de la plataforma de sincro-
nización. A tal efecto se ha considerado utilizar el campo de ruta del fichero
de arranque, modificando la semántica definida en el RFC, de modo que éste
contenga una cadena de caracteres hexadecimales que indique la configura-
ción del dispositivo. En cada caso, el formato de dicha cadena dependerá del
número de parámetros del sistema que se quieran configurar empleando esta
última alternativa. Así, se debe establecer el orden que ocupa y el número
de dígitos hexadecimales que componen cada parámetro de forma que este
módulo sea capaz de interpretar correctamente el significado de la cadena re-
cibida. En el Capítulo 5 se indicarán los parámetros que se van a configurar
empleando este campo del mensaje de configuración.
3.4.2. Gestión de direcciones físicas
Como se ha comentado en los apartados anteriores, cada dispositivo re-
quiere configurar su propia dirección física o MAC. Como la dirección MAC
establecida por defecto durante la fase de diseño no variará una vez gene-
rado el fichero binario que permite programar la FPGA, resulta necesario

3.4. Interfaz de protocolos y configuración 113
habilitar algún mecanismo que permita la modificación de este parámetro a
partir del fichero de programación sin tener que realizar de nuevo la síntesis e
implementación del diseño. Además, este mismo procedimiento se podría se-
guir para aquellos parámetros de configuración específicos que permanezcan
invariantes de forma que se simplifique el proceso de configuración. Como se
presenta en el trabajo [Reichardt, 2007] la modificación de la dirección física
y del resto de parámetros es posible si éstos se almacenan en un bloque RAM
interno de la FPGA y posteriormente se modifica su contenido empleando la
herramienta data2mem [Xilinx, 2010] proporcionada por Xilinx. Este pro-
ceso se detalla en el Apéndice A, donde se describe una aplicación software
desarrollada para esta finalidad.
Tras el proceso de configuración, todos los equipos disponen de los pará-
metros necesarios para comenzar el proceso de sincronización. Este proceso lo
debe comenzar el cliente SNTP enviando una petición de hora al servidor; sin
embargo, la comunicación dentro de la red de área local no podrá comenzar
si no se habilita un mecanismo que permita a los dispositivos que forman la
plataforma de sincronización resolver las direcciones físicas del resto. En este
sentido, el protocolo empleado comúnmente para la resolución de direcciones
físicas es el protocolo ARP definido en el RFC 826 [Plummer, 1982]. Así,
resulta necesario que tanto clientes como servidores SNTP implementen, al
menos, una versión simplificada del protocolo ARP.
Al igual que ocurre para BOOTP, el protocolo ARP se basa en el inter-
cambio de dos mensajes: petición (ARPREQUEST ) y repuesta (ARPRE-
PLY ). En este caso, los paquetes no van encapsulados en un datagrama IP
ya que este protocolo define su propio Ethertype y formato de paquete (com-
partido por peticiones y respuestas). El proceso de resolución de direcciones
físicas es el siguiente:
1. El equipo que necesita conocer la dirección física asociada a una direc-
ción IP inicia el proceso enviando una petición (ARPREQUEST ) a la
dirección de broadcast. En el paquete ARP rellena los campos con su
dirección MAC y con las direcciones IP de origen y destino.
2. Aunque todos los dispositivos de la red reciben esta petición, sólo el

114 Capítulo 3. Arquitectura del sistema
equipo al que pertenece la dirección IP por la que se pregunta debe res-
ponder (ARPREPLY ). En este caso, este equipo completa la respuesta
con su dirección MAC y responde únicamente al que hizo la petición.
3. Una vez recibida la respuesta el dispositivo procesa la información y la
registra, manteniendo una tabla de ARP de pares de direcciones MAC
e IP.
Una vez comentado el proceso de resolución, un aspecto importante con-
siste en analizar los posibles inconvenientes derivados de la implementación
hardware de este protocolo. En este sentido, se van a estudiar de forma se-
parada las soluciones planteadas tanto para el cliente como para el servidor
de sincronización.
En principio la implementación hardware de este protocolo en el cliente
SNTP a priori no presenta ningún problema: los clientes realizan peticiones de
ARP al servidor SNTP y reciben las respuestas. Con la información recibida
actualizan la tabla de ARP que dispone de una única entrada correspondiente
a la pareja de dirección IP y MAC del servidor. Además, para mantener total
compatibilidad con otro tipo de soluciones (tanto hardware como software),
resulta necesario que éstos respondan a las peticiones de ARP que pudieran
recibir.
En el lado del servidor, en principio resulta fundamental que éste pueda
responder a las peticiones de ARP que le envían los clientes; sin embargo,
un posible inconveniente puede surgir si se pretende que el servidor SNTP
gestione una tabla de ARP que incluya los pares de direcciones IP y MAC
de todos los clientes que se comunican con el mismo. Por un lado, el hecho
de disponer de una tabla de ARP actualizada aporta fiabilidad al sistema ya
que permite detectar fallos en la configuración o acciones malintencionadas
de algún equipo que está intentando suplantar a otro de la red. Por otro la-
do, mantener dicha tabla presenta una serie de problemas. En primer lugar,
como el número de clientes no es fijo no es posible dimensionar el tamaño de
esta tabla; en este aspecto, si se hace demasiado grande esto puede suponer
un gasto innecesario de recursos y si es demasiado pequeña puede ocurrir que
no se disponga de posiciones para todos los clientes. En segundo lugar, como

3.4. Interfaz de protocolos y configuración 115
se va a estudiar en mayor profundidad en el siguiente apartado, actualizar
esta tabla supone realizar peticiones de ARP a los diferentes clientes; si el
número de clientes es apreciable esto puede suponer tener que encolar mu-
chos paquetes en la FIFO de transmisión del controlador Ethernet MAC lo
cual podría introducir retrasos en los mensajes de respuesta NTP enviados
a dichos clientes. Por todo ello, y al no ser estrictamente necesario disponer
de esta tabla, la solución planteada para este caso consiste en prescindir de
la misma y emplear las direcciones MAC de los clientes que se encuentran en
los mensajes de petición de hora.
3.4.3. Control de comunicaciones y marcado temporal
Como se ha comentado en los apartados anteriores, por un lado, se nece-
sitan al menos tres protocolos de comunicación para realizar todas las tareas
que se requieren: BOOTP (gestión de la configuración), ARP (resolución de
las direcciones físicas) y SNTP (sincronización del sistema con una fuente
de hora precisa), lo cual implica tener que administrar como mínimo estos
tres servicios. Por otro lado, también se ha analizado cómo para conseguir
sincronización de hora altamente precisa uno de los objetivos fundamentales
consiste en reducir las latencias variables en el marcado temporal de los pa-
quetes, principalmente realizando dicho marcado por hardware en las capas
más bajas. A partir de los dos últimos aspectos comentados se observa có-
mo una de las tareas más importantes de este trabajo consiste en especificar
una arquitectura de control y estrategias de diseño que permitan el correcto
control de las comunicaciones y marcado temporal de los mensajes. En este
sentido, en los siguientes subapartados se comentará cómo se va a realizar
el control de las comunicaciones y el marcado temporal para conseguir el
objetivo mencionado.
Control de comunicaciones
Para realizar el control de las comunicaciones, un aspecto importante con-
siste en que los protocolos de comunicación empleados se basan en el modelo
cliente-servidor; básicamente, este modelo consiste en que un cliente del pro-

116 Capítulo 3. Arquitectura del sistema
tocolo envía una petición a un servidor, el cual emite una respuesta una vez
procesada la petición recibida. Así, se observa cómo, independientemente de
hablar de un cliente y servidor SNTP, dichos diseños deberán actuar simultá-
neamente como clientes de unos protocolos y servidores de otros. Este hecho
implica que dentro de cada diseño haya que distinguir entre servicios clien-
tes, definidos como aquellos que envían peticiones a un servidor y esperan
la respuesta del mismo y servicios servidores, es decir, aquellos que esperan
una petición de un cliente para responder con la información solicitada.
En este sentido, como se observa en el Fig. 3.15, un control básico con-
siste en disponer de una serie de temporizadores (timers) asociados a cada
servicio cliente y un conjunto de señales que informan de la recepción de peti-
ciones a los servicios servidores, de forma que éstas indiquen a cada servicio
cuando deben transmitir un paquete asociado al protocolo que gestionan.
Sin embargo, el sistema planteado hasta ahora presenta el inconveniente de
que al tratarse de servicios independientes, cada uno controlado por su pro-
pio temporizador o señal de recepción de petición, existe la posibilidad de
que varios servicios intenten transmitir un paquete en un mismo intervalo de
tiempo, produciéndose en este caso un acceso incontrolado al módulo que se
encargaría de generar, actualizar y transmitir los paquetes de peticiones y
respuestas (módulo de transmisión).
Para solucionar este problema, se ha planteado el diseño de una unidad
para el control de las comunicaciones que controla la activación de los servi-
Figura 3.15: Diagrama básico de control de servicios.

3.4. Interfaz de protocolos y configuración 117
cios y gestiona el acceso a los recursos compartidos del sistema, en especial al
módulo de transmisión (Fig. 3.16). Así, los servicios activos deben establecer
un proceso de negociación con la unidad de control de las comunicaciones
y conseguir la asignación del módulo de transmisión antes de poder actuali-
zar y transmitir un paquete. A continuación, se detalla en qué consiste este
proceso de negociación:
1. Un servicio hace una petición a la unidad de control solicitando el uso
del módulo de transmisión.
2. La unidad de control recibe la solicitud y la registra junto a otras en
una lista de peticiones pendientes.
3. La unidad de control comprueba si otro servicio tiene asignado el módu-
lo de transmisión. En caso de estar asignado, mantiene las peticiones
realizadas y espera a que el servicio que está transmitiendo libere el
recurso.
4. Si el módulo de transmisión está libre, la unidad de control debe revisar
la lista de peticiones y asignar este módulo a uno de los servicios que
lo haya solicitado. Para ello, se pueden establecer diferentes criterios:
por orden de petición, en base a prioridades previamente configuradas,
etc.
5. La unidad de control informa al servicio seleccionado que tiene asignado
el módulo y lo elimina de la lista de peticiones.
6. El servicio se comunica con el módulo de transmisión para actualizar
los campos del paquete y para comenzar la escritura del mismo en la
FIFO de transmisión. Cuando ésta finaliza el servicio informa de este
hecho a la unidad de control liberando el recurso.
7. La unidad de control debe repetir el proceso de asignación mientras
haya peticiones pendientes.

118 Capítulo 3. Arquitectura del sistema
Figura 3.16: Diagrama avanzado de control de servicios.
Marcado temporal
Una vez comentado cómo se realiza el control de los servicios, otro aspecto
crítico consiste en estudiar si la solución planteada presenta algún problema
a la hora de realizar el marcado temporal de los mensajes. En este sentido,
en el sistema que se está presentando el marcado temporal se realiza en la
interfaz de protocolos a diferencia de los trabajos [Skeie et al., 2001; Höller
et al., 2002] donde se realizaba entre el nivel físico y el controlador Ethernet
MAC o directamente en el controlador Ethernet MAC. El hecho de realizar
el marcado en este módulo viene motivado por la siguientes razones:
1. Las soluciones presentadas en [Skeie et al., 2001; Höller et al., 2002] no
estaban implementadas completamente en hardware sino que consistían
en una plataforma software que disponía de soporte hardware para el
marcado temporal de los mensajes. Así, en este tipo de soluciones la
variabilidad en el retraso introducida por la pila de protocolos, plani-
ficador de tareas y demás capas software no hacían posible realizar el
marcado temporal de los mensajes en niveles superiores al controlador
Ethernet MAC sin una pérdida importante de precisión.

3.4. Interfaz de protocolos y configuración 119
2. Según el trabajo [Skeie et al., 2001], los factores determinantes para
colocar una marca de tiempo precisa no dependen del nivel donde ésta
se registra sino que consisten en realizar el marcado en el mismo nivel
tanto en el cliente como en el servidor SNTP y evitar posibles variabili-
dades en el retraso que se pudieran originar tanto en la recepción como
en la transmisión de los mensajes NTP. De esta forma, la comunicación
resulta lo más simétrica posible compensándose los retrasos del cliente
con los del servidor.
3. Realizar el marcado temporal a este nivel permite independizar el con-
trolador Ethernet MAC de la interfaz de protocolos, mejorando la fle-
xibilidad y modularidad de la arquitectura presentada.
De estas tres razones se puede concluir que para asegurar un correcto mar-
cado temporal de los mensajes NTP se deben analizar las principales fuentes
de variabilidad en el retraso de la solución hardware. Una vez localizadas se
deben establecer estrategias de diseño que permitan controlarlas.
Al tratarse tanto el cliente como el servidor SNTP de soluciones hardware
específicas que disponen de una interfaz Ethernet exclusivamente dedicada
a realizar las tareas de sincronización, de forma que ningún otro servicio de
red empleará esta interfaz a excepción de los presentados en este trabajo
(BOOTP para la configuración y ARP para la resolución de direcciones),
se puede decir que la única fuente que podría introducir variabilidad en el
retraso consiste en el hecho de que el controlador Ethernet MAC emplea una
FIFO de recepción y otra de transmisión para almacenar los paquetes; así, en
el caso de que se formen colas de paquetes en las FIFO, esto puede dar lugar
a retrasos que afectarían a la precisión de las marcas de tiempo colocadas en
los mensajes. A continuación, se va a analizar cómo influye este factor en el
marcado temporal de los mensajes NTP.
Para comenzar este análisis se va a estudiar cómo puede afectar al encola-
miento de los paquetes, tanto en recepción como en transmisión, el hecho de
que la velocidad de operación del sistema sea mayor que la velocidad con la
que se reciben o transmiten dichos paquetes. Así, para el caso de la recepción,
este hecho presenta la ventaja de que el sistema es capaz de leer los paquetes

120 Capítulo 3. Arquitectura del sistema
de la FIFO más rápido de lo que puede escribirlos el controlador Ethernet
MAC, no produciéndose colas de paquetes en este caso. Sin embargo, para
la transmisión presenta el inconveniente de que el sistema puede escribir los
paquetes más rápido de lo que puede transmitirlos el controlador Ethernet
MAC, pudiéndose formar colas de paquetes. Por esto último, el estudio y la
solución al problema que se va presentar se centra en las causas que pueden
producir el encolamiento de paquetes en la FIFO de transmisión.
Dentro de este estudio, en primer lugar, cabe recordar los diferentes pa-
quetes que tienen que transmitir el cliente y el servidor SNTP. Por un lado,
el cliente debe encargarse de: (1) enviar peticiones de BOOTP, ARP y SNTP
y (2) tras recibir peticiones de ARP, enviar las respuestas; por otro lado, el
servidor se dedicará a: (1) envío de peticiones de BOOTP y (2) transmisión
de los paquetes de respuestas a peticiones de ARP y SNTP. Como se ha
comentando previamente, el servidor SNTP no realiza peticiones de ARP a
los clientes.
El segundo aspecto que se va a tratar consiste en el establecimiento de
los intervalos de petición de los distintos servicios. Dichos intervalos admiten
configuración a través de los parámetros BOOTP timeout, ARP timeout y
p (Tabla 3.4); estos parámetros representan números enteros sin signo y se
usan como exponentes de dos, de forma que los valores resultantes se inter-
pretan como los periodos de tiempo (medidos en segundos) entre peticiones
de BOOTP, ARP y SNTP, respectivamente. Tal y como se especifica en el
Apéndice A, para los servicios de configuración y de resolución de direcciones
se ha considerado adecuado un intervalo de petición de 26 segundos; para el
caso de las peticiones de hora, no se ha establecido un intervalo fijo de pe-
tición pudiendo oscilar éste entre las potencias de 2 comprendidas entre 1 y
26 segundos.
A partir de los dos puntos anteriores, para el caso del cliente SNTP,
debido a que el intervalo entre peticiones de mensajes NTP es menor o igual
al del resto de servicios, si se hacen coincidir las peticiones de BOOTP y
ARP en el mismo segundo, esto significa que de las 26−p peticiones de NTP
posibles como máximo sólo una podría coincidir con el resto de peticiones
(BOOTP y ARP). Este hecho permite dividir el análisis en el estudio del

3.4. Interfaz de protocolos y configuración 121
caso más favorable, es decir, aquel caso en el que únicamente se tiene que
realizar la petición de NTP y del caso menos favorable que consiste en aquel
en el que se tiene que enviar el mensaje de hora junto con otras peticiones
de BOOTP/ARP o respuestas de ARP.
En relación con el caso más favorable, al ser el intervalo entre peticiones
del orden del segundo en ningún caso se producirán colas en la FIFO de
transmisión y por tanto no habrá variaciones en el retraso. Para el caso
menos favorable, se pueden producir colas si el tiempo entre dos peticiones de
servicios diferentes es menor que el tiempo que se tarda en sacar de la FIFO
la primera petición que se realiza. Sin embargo, el aspecto crítico consiste
en encolar los paquetes de petición de hora. Así, se plantean las siguientes
estrategias para evitar encolar dichos paquetes:
1. Para el caso en que haya que refrescar tanto la configuración como la
dirección MAC del servidor se transmitirán estos dos paquetes de peti-
ción y el servicio de petición de hora quedará bloqueado a la espera de
que se reciban y se procesen los paquetes de respuestas de BOOTP y
ARP. Una vez procesados, se permite el envío de la petición de NTP.
Esta acción presenta varias ventajas ya que ante un cambio de confi-
guración (establecimiento de un nuevo servidor SNTP) o de dirección
física del servidor, el cliente puede actuar en consecuencia y enviar su
petición con los campos actualizados, evitando así introducir tráfico in-
necesario en la red. Además, con esta medida se evita formar una cola
ya que en el instante de envío del mensaje NTP no queda en la FIFO
ningún paquete pendiente de procesar.
2. Para el caso en que coincida enviar una petición de NTP junto con una
respuesta de ARP, se ha establecido un sistema de prioridad de forma
que en primer lugar se envía el mensaje de hora y a continuación la
respuesta de ARP. Con esta acción no se introduce ningún retraso en
el envío del mensaje de hora.
En lo que se refiere al servidor SNTP se van a analizar los problemas que
pueden surgir a la hora de transmitir las respuestas de NTP y ARP, teniendo
en cuenta para ello los dos aspectos que se comentan a continuación: (1) la

122 Capítulo 3. Arquitectura del sistema
velocidad de operación del sistema es mayor que la velocidad con la que el
controlador Ethernet MAC escribe los datos en la FIFO de recepción y (2)
la recepción y transmisión se realizan simultáneamente (comunicación full
duplex ). En este sentido, el tiempo que se tarda en la lectura y procesado de
la petición y en la actualización y escritura de la respuesta en la FIFO de
transmisión es muy reducido (todas estas tareas se realizan a la frecuencia
de operación del sistema), de forma que en el peor caso el envío de dicha
respuesta se puede simultanear con la recepción de una nueva petición. Esto
significa que las peticiones se van a gestionar de una en una evitándose el
encolamiento de paquetes.
Finalmente, el envío de peticiones de BOOTP que podrían coincidir con el
envío de respuestas de NTP se resuelve asignando mayor prioridad a los men-
sajes de hora, de forma similar a cómo se resuelve el envío de las respuestas
de ARP en el lado del cliente SNTP.
3.5. Módulo de sincronización
En esta sección, se comentará el otro módulo de alta complejidad pre-
sentado: el módulo de sincronización. En la Fig. 3.17 se observa cómo este
módulo se incluye tanto en el cliente como en el servidor. A continuación, se
van a definir la funcionalidad y las operaciones que debe realizar este módulo,
teniendo en cuenta los aspectos específicos de la versión para el cliente y el
servidor.
El módulo de sincronización debe implementar todas las acciones nece-
sarias que permitan una correcta sincronización de los equipos que reclamen
este servicio. Para ello, en primer lugar, resulta necesario especificar un mo-
delo de reloj local que permita: (1) mantener la hora local en formato NTP
y (2) suministrarla a otros módulos del sistema en el instante en que éstos la
requieran. En segundo lugar, se debe encargar de calcular el desplazamiento
de la hora local relativo a la hora de la fuente de sincronización (receptor
GPS o servidor SNTP). Así, como se observa en la Fig. 3.18, por un lado, el
servidor SNTP emplea, para calcular dicho desplazamiento, las señales nú-
mero segundos, estado GPS y estado conversión procedentes del módulo de

3.5. Módulo de sincronización 123
Figura 3.17: Módulo de alta complejidad: módulo de sincronización.
recepción de información temporal; por otro lado, el cliente SNTP utiliza las
marcas de tiempo que recibe en respuesta a la petición que él mismo realiza.
Finalmente, debe realizar ajustes del reloj local a partir del desplazamiento
calculado.
Debido a la simplicidad del protocolo SNTP, en el documento de especi-
ficaciones del estándar no se define ningún mecanismo que permita ajustar
y disciplinar el reloj local. En este sentido, como se comentó en el aparta-
do 2.1.2 del Capítulo 2, la solución más básica consiste en sumar al reloj
local el desplazamiento calculado; sin embargo, esta solución presentaba dos
inconvenientes muy importantes: por un lado, al no implementar ningún al-
goritmo de disciplina la precisión alcanzable es baja y, por otro lado, dicha
acción incumple el principio de monotonía también presentado anteriormen-
te.
En definitiva, para conseguir sincronizar el sistema con cierta precisión re-
sulta conveniente especificar algoritmos de sincronización más avanzados que
permitan disciplinar el reloj local de forma más adecuada y cuya implemen-
tación sea totalmente abordable en hardware. En este sentido, se va a definir
una serie de operaciones para el cálculo de las correcciones y de acciones que
se realizarán en función del estado de sincronización y que permitirán ajustar
y controlar la deriva del reloj local. A partir de las operaciones definidas, en
la Fig. 3.19 se presenta el diagrama de bloques que componen el módulo de

124 Capítulo 3. Arquitectura del sistema
Figura 3.18: Módulo de sincronización.
Figura 3.19: Diagrama de bloques que forman el módulo de sincronización.
sincronización.
Finalmente, en los siguientes subapartados se van a explicar detallada-
mente todas las operaciones que realiza este módulo. Así, en primer lugar, se
describirá cómo se realiza el cálculo del desplazamiento, distinguiéndose los
casos del cliente y del servidor SNTP; esta distinción se debe a que cada op-
ción recibe la información temporal de una fuente de referencia distinta. En
segundo lugar, se presentará el modelo de reloj hardware propuesto, mostrán-

3.5. Módulo de sincronización 125
dose los mecanismos de ajuste y control de la deriva. Por último, se detallará
cómo se realiza el control del reloj que engloba el cálculo de las correcciones
y el algoritmo de sincronización empleado para llevar a cabo el proceso de
sincronización.
3.5.1. Cálculo del desplazamiento
Debido a que el cliente y el servidor SNTP emplean fuentes de referencia
diferentes, el procedimiento para calcular el desplazamiento difiere para cada
caso.
En el caso del cliente, en el estándar SNTP se especifica claramente cómo
se calculan tanto el retraso de propagación de la red (δ) como el desplazamien-
to (θ) (ecuaciones 2.1 y 2.2) en función de las marcas de tiempo contenidas
en el mensaje de respuesta del servidor.
Sin embargo, para el caso del servidor SNTP en dicho estándar no se
encuentran especificadas las acciones que se deben realizar para la sincroni-
zación de éste con una fuente de referencia de tiempo, como por ejemplo,
un receptor GPS. Así, resulta necesario definir un mecanismo para calcular
el desplazamiento del reloj local del servidor relativo a la hora del GPS. En
principio, la alternativa más básica consiste en calcular dicho desplazamien-
to en el flanco activo del PPS, ya que éste indica de manera muy precisa el
cambio de segundo. Sin embargo, realizar el cálculo en ese instante presen-
ta el inconveniente de que aún no se ha obtenido la fecha y hora relativa a
ese flanco de PPS, ya que dicha información se transmite en la trama RMC
que se envía tras producirse el flanco. De esta forma, la solución propuesta
consiste en mantener registrado el número de segundos en formato NTP (cal-
culado por el módulo de recepción de información temporal tras procesar la
trama RMC) correspondiente al flanco anterior de manera que el cálculo del
desplazamiento se realiza en cada flanco activo del PPS de acuerdo a (3.1).
θ = (numero segundosflanco anterior + 1)− hora reloj local (3.1)
Finalmente, para asegurar que el cálculo se ha realizado correctamente,
tras completar la conversión de la fecha y hora actual se debe comprobar

126 Capítulo 3. Arquitectura del sistema
que el número de segundos actual coincide con el empleado para calcular el
desplazamiento. En caso de no coincidir, esto puede indicar un fallo en la
comunicación serie o una pérdida de sincronización del receptor GPS.
3.5.2. Modelo de reloj local
El modelo de reloj implementado se basa en un esquema de reloj hardware
presentado en [Mills, 1992a]. En dicho trabajo se introducen varios modelos
de reloj siendo el más simple aquel formado por un oscilador estabilizado por
cristal de cuarzo, un contador de reloj implementado en hardware y, finalmen-
te, un prescaler que reduce la frecuencia del oscilador hasta una frecuencia de
operación conveniente. Sin embargo, este esquema tan básico presenta algu-
nos inconvenientes derivados de que un sistema que intenta sincronizarse con
una fuente externa de hora debe disponer de algún mecanismo para corregir
la hora y la frecuencia de acuerdo a los parámetros de ajuste calculados por
el algoritmo de sincronización.
En este sentido, una solución consiste en ampliar el modelo anterior em-
pleando un oscilador controlado por tensión (Voltage-Controlled Oscillator,
VCO), en el cual la frecuencia se ajusta mediante un conversor digital a
analógico (Digital-to-Analog Converter, DAC) (Fig. 3.20). Para realizar los
ajustes de hora, se incluye un sumador que permita sumar correcciones al
contador cuando sea necesario.
No obstante, el modelo anterior presenta el inconveniente de que resulta
necesario emplear componentes hardware adicionales externos al dispositivo
programable. En este sentido, para conseguir que el diseño sea totalmente
implementable sobre dispositivos programables (FPGA) y portable a otras
tecnologías, se va a definir un modelo de reloj completamente digital que
consiste en sustituir el VCO y el DAC por un oscilador de frecuencia fija y
realizar una modificación del prescaler para incluir un módulo digital capaz
de producir una frecuencia de salida promedio variable basada en la frecuen-
cia del oscilador. En la Fig. 3.21 se presenta el esquema del modelo de reloj
hardware propuesto.
Como se observa en la figura anterior, por un lado, el ajuste de la hora

3.5. Módulo de sincronización 127
Figura 3.20: Modelo de reloj hardware basado en un oscilador controlado portensión.
Figura 3.21: Modelo de reloj hardware completamente digital propuesto.
se realiza al igual que en el caso anterior, es decir, sumando directamente el
desplazamiento a la hora del contador. Sin embargo, este tipo de ajustes sólo
debe hacerse cuando la hora local es sustancialmente diferente de la hora de
referencia ya que mediante esta acción se incumple el principio de monotonía.
Por otro lado, el ajuste de frecuencia se realiza a partir del módulo de
ajuste. Dentro de este módulo, en primer lugar, el prescaler se encarga de

128 Capítulo 3. Arquitectura del sistema
Figura 3.22: Arquitectura del módulo de control de frecuencia.
reducir la frecuencia del oscilador (fosc) a una frecuencia (fpres) un poco
mayor que la frecuencia nominal a la que debería operar el contador de ho-
ra local para mantener una hora exacta (fnom). La frecuencia de operación
del reloj local depende de su resolución de forma que fnom = 2n, donde
n representa el número de bits que forman su parte fraccionaria. El factor
de reducción del prescaler se controla por configuración a través del pará-
metro factor prescaler (fp); esto permite adaptar este módulo a diferentes
resoluciones del contador de hora local y diferentes frecuencias del oscilador
principal. Una vez realizada esta reducción, el módulo de control de frecuen-
cia se encarga de realizar el ajuste de frecuencia a partir del parámetro de
corrección D, calculado por el algoritmo de sincronización que se describe en
el siguiente subapartado.
En la Fig. 3.22 se muestra la arquitectura del módulo de control de fre-
cuencia. Como se observa, el módulo se compone de n− 2 etapas donde n es
el número de bits de la parte fraccionaria del contador de hora local, mencio-
nado anteriormente. La etapa i-ésima recibe una señal de reloj de entrada y
genera una señal de reloj de salida, estando controlada por un bit de control
Di. Si Di = 0, la señal de salida es igual a la de entrada (tiene la misma
frecuencia). Sin embargo, si Di = 1, el módulo i-ésimo genera una señal de
salida similar a la de entrada pero eliminando uno de cada 2n−i ciclos de
la señal de entrada. De esta forma, la frecuencia promedio de la señal de
salida respecto de la de entrada en la etapa i-ésima se ve reducida en un
factor (1− Di
2n−i ), incluyendo el bit de control Di. Aplicando este factor a las
sucesivas etapas del módulo de control de frecuencia se obtiene la siguiente
expresión (3.2):

3.5. Módulo de sincronización 129
fsal = fpresn−3∏
i=0
(
1−Di
2n−i
)
(3.2)
Desarrollando el producto y despreciando los términos cruzados se obtiene
que:
fsal ≈ fpres
(
1−D
2n
)
, (3.3)
donde:
D =n−3∑
i=0
Di2i, (3.4)
esto es, D es el valor numérico cuando los bits Di se interpretan como
cifras de un número representado en base 2.
Si además, se considera que fpres ≈ fnom = 2n, se obtiene que:
fsal ≈ fpres −D (3.5)
En (3.5) puede verse claramente que la arquitectura propuesta permite
modificar de forma controlada la frecuencia de entrada (fpres) mediante el
valor D, de forma que la frecuencia de salida puede modificarse sin más que
modificar D en una magnitud equivalente:
∆fsal ≈ −∆D (3.6)
En relación con la arquitectura propuesta, cabe destacar algunos aspectos
de interés.
1. El hecho de prescindir de las etapas n−1 y n−2 se debe a que éstas sólo
se activarían cuando fuera necesario realizar ajustes superiores a los 250
ms; en este caso, tal y como se ha explicado anteriormente, para aplicar
estas correcciones tan significativas resulta más conveniente realizar un
ajuste de hora sumando directamente el desplazamiento al reloj local.
2. De todos los posibles valores de D, cabe destacar aquel que consigue
que la frecuencia de salida sea igual a la frecuencia nominal del contador
de hora local (fsal = fnom). Este valor denominado D nominal (Dnom),

130 Capítulo 3. Arquitectura del sistema
una vez calculado, se proporciona al sistema como un parámetro de
configuración (Tabla 3.4 y Apéndice A).
3. A partir de Dnom se pueden establecer los siguientes intervalos de fun-
cionamiento:
[0, Dnom). El contador funciona a una frecuencia mayor que su
frecuencia nominal.
Dnom. El contador funciona a su frecuencia nominal.
(Dnom, 2n−2−1]. El contador funciona a una frecuencia menor que
su frecuencia nominal.
4. De la definición de los anteriores intervalos se desprende que la solución
planteada cumple el principio de monotonía ya que el ajuste de la
frecuencia se realiza cambiando el valor de este parámetro, lo cual hará
que el contador avance más rápido o más despacio que con su frecuencia
nominal, pero siempre incrementándose en el tiempo.
Una vez explicado el modelo de reloj hardware, en el siguiente apartado
se describirá cómo se realiza el control del reloj local.
3.5.3. Control del reloj local
Debido a que el cliente y el servidor SNTP emplean fuentes de sincroni-
zación diferentes resulta necesario establecer un algoritmo de sincronización
específico para cada alternativa. No obstante, como los dos implementan el
mismo modelo de reloj, el cálculo de las correcciones (parámetro D) es común
para los dos casos. Así, en primer lugar, se va a presentar cómo se calculan
las correcciones a partir de los desplazamientos y, en segundo lugar, las ope-
raciones que realizan los algoritmos de sincronización propuestos en base a
las correcciones calculadas.
Cálculo de correcciones
A la hora de calcular la corrección, un aspecto importante es que la conver-
gencia del desplazamiento no es un proceso inmediato, de forma que resulta

3.5. Módulo de sincronización 131
necesario aplicar múltiples correcciones antes de que la precisión de sincro-
nización se sitúe dentro de unos límites adecuados. Este hecho implica que
en cada iteración no se debe tener en cuenta únicamente el desplazamiento
calculado para ese instante, sino que en la corrección debe incluirse de alguna
forma el estado previo del proceso de sincronización. En este sentido, en la
Fig. 3.23 se presentan los fundamentos que se van a aplicar para el cálculo
de esta corrección.
En dicha figura se representa el desplazamiento θ en función del tiempo
para varios intervalos de ajuste, que tienen una duración de 2p s. Así, supon-
gamos que tras calcular y aplicar la corrección Di−1 en el instante de tiempo
ti−1 (punto A) el siguiente desplazamiento llega a situarse en el punto B,
instante en que se debe calcular una nueva corrección. En este punto, si no
se modifica la corrección, el desplazamiento seguirá derivando con la misma
pendiente hasta situarse en el punto C una vez transcurrido otro intervalo
de ajuste.
En esta situación, el objetivo es modificar el valor de D para que el sis-
tema deje de derivar y que tienda, en la medida de lo posible, a cancelar el
desplazamiento. En este sentido, el valor de D en el instante ti (Di) se mo-
dificará en una magnitud ∆Di que se divide en dos componentes de acuerdo
con (3.7).
∆Di = ∆D0
i +∆DCi (3.7)
El primer término, ∆D0i , es el valor del incremento de D que corregiría la
Figura 3.23: Cálculo de la corrección.

132 Capítulo 3. Arquitectura del sistema
deriva del sistema, haciendo que el desplazamiento se mantuviera constante
en el próximo intervalo, alcanzando el punto P en la Fig. 3.23. Para ello,
∆D0i debe ser tal que compense la variación del desplazamiento prevista en
la Fig. 3.23 (∆θC = ∆θB).
Teniendo en cuenta que ∆θ es igual al incremento de ciclos del contador
de hora local durante 2p s y que ∆D es igual al incremento de ciclos del
contador de hora local en un segundo (3.6), ∆D0i puede calcularse como:
∆D0
i = −∆θC2p
= −∆θB2p
= −θi − θi−1
2p(3.8)
Por otra parte, ∆DCi es la componente de la corrección de D que hace
que el desplazamiento tienda a reducirse durante el siguiente intervalo de
corrección. Siguiendo un razonamiento análogo al aplicado para el cálculo de
∆D0i , el desplazamiento puede ser anulado durante el siguiente intervalo sin
más que aplicar el ajuste mostrado en (3.9), lo que llevaría al punto P0 en la
Fig. 3.23.
∆DCi = −
θi2p
(3.9)
Sin embargo, realizar una corrección completa del desplazamiento pre-
senta algunos inconvenientes derivados de los errores que se comenten en el
cálculo del mismo, de forma que un error grande podría provocar que el sis-
tema derivara en exceso y no se produjera la convergencia. En este sentido,
resulta más conveniente atenuar la convergencia, es decir, no aplicar correc-
ciones completas del desplazamiento, sino calcular incrementos del paráme-
tro de ajuste que permitan hacer converger al sistema en varios intervalos de
ajuste. Con esta alternativa se consigue mejorar el proceso de sincronización,
ya que al aplicar correcciones menores también se está consiguiendo reducir
la influencia de los errores, lo que se traduce en un mejor control de la deriva
del reloj local, a costa de hacer más lento el proceso de convergencia.
Para atenuar la convergencia se emplea el parámetro de configuración q
de modo que la componente de ∆Di que posibilita la convergencia se calcula
a partir de (3.10).
∆DCi = −
θi2p
×1
2q= −
θi2p+q
(3.10)

3.5. Módulo de sincronización 133
De acuerdo a esta ecuación, para q = 0 se cancela completamente el des-
plazamiento en un único intervalo (caso anterior), para q = 1 se alcanzaría el
punto P1 y para valores mayores de q se alcanzarían otros puntos intermedios
de cancelación: un cuarto para q = 2 (P2), un octavo para q = 3, etc.
Finalmente, a partir de las ecuaciones anteriores se va a indicar cómo se
calcula el valor de la corrección en el instante ti (Di). Debido a que en deter-
minados momentos del proceso de sincronización puede resultar conveniente
aplicar cada una de las correcciones anteriores (cancelación de la deriva y
cancelación del desplazamiento) por separado, el valor de Di que únicamente
permite cancelar la deriva (D0i ) se calcula de acuerdo a (3.11). El valor final
de Di en función de D0i se calcula según (3.12).
∆D0
i = D0
i −Di−1 = −θi − θi−1
2p→ D0
i = Di−1 −θi − θi−1
2p(3.11)
∆Di = Di −Di−1 = −θi − θi−1
2p−
θi2p+q
→
Di = Di−1 −θi − θi−1
2p−
θi2p+q
= D0
i −θi
2p+q(3.12)
Algoritmos de sincronización
Una vez expuesto cómo se calcula la corrección a aplicar por el módulo
de ajuste se van a presentar los algoritmos de sincronización propuestos para
el cliente y el servidor SNTP.
El proceso de sincronización del cliente SNTP abarca el conjunto de es-
tados que se presentan en la Fig. 3.24. Este proceso se activa cada vez que se
recibe una respuesta a la petición de hora emitida por el cliente. En primer
lugar, tras la puesta en marcha o reset del sistema se comienza en el estado
detenido donde tras obtener los parámetros de configuración que necesita el
cliente (p, q, factor prescaler y D nominal) se pasa al estado sincronizando.
En el estado sincronizando, una vez procesada la respuesta recibida del
servidor y determinado el estado del mismo se procede cómo se indica a

134 Capítulo 3. Arquitectura del sistema
Figura 3.24: Estados que forman el algoritmo de sincronización del clienteSNTP.
continuación:
1. Si el servidor no está sincronizado o no responde, no se realizan ni el
cálculo del desplazamiento ni el de la corrección y por tanto no se aplica
ningún ajuste. Además, se permanece en el mismo estado a la espera
de una nueva respuesta del servidor.
2. Si el servidor está sincronizado en primer lugar se calcula el desplaza-
miento θi y, a continuación, se realizan las siguientes comprobaciones:
Si θi > 125 ms se ajusta la hora del reloj local sumando el despla-
zamiento calculado. Como este ajuste no cumple el principio de
monotonía se permanece en el estado sincronizando.
Si θi < 125 ms se calcula la corrección a aplicar, es decir, un
nuevo valor del parámetro D y se pasa al estado sincronizado. La
primera vez que se realiza este cálculo, se considera θi−1 = 0 y
Di−1 = Dnom. En el paso del estado sincronizado a sincronizando
θi−1 se debe iniciar a 0.

3.5. Módulo de sincronización 135
Por último, en el estado sincronizado, tras la llegada de una petición de
hora se realizan las siguientes tareas:
1. Si el servidor no está sincronizado o no responde se pasa al estado
sincronizando y se deja operar al cliente con el último valor de D0i
calculado.
2. Si el servidor está sincronizado se calcula el desplazamiento θi y se
realizan las siguientes comprobaciones:
Si θi > 250 ms se pasa al estado sincronizando y se ajusta la hora
del reloj local sumando el desplazamiento calculado.
Si θi < 250 ms se calcula y se aplica una nueva corrección y se
permanece en el estado sincronizado.
El proceso de sincronización del servidor SNTP abarca el conjunto de
estados que se presentan en la Fig. 3.25. Este proceso se activa cada vez que
se detecta un flanco activo del PPS o se finaliza la conversión de la hora que
llega en la trama RMC. En primer lugar, tras la puesta en marcha o reset del
sistema se comienza en el estado detenido. En este estado, una vez obtenidos
los parámetros de configuración que necesita el servidor (p, q, flanco activo,
factor prescaler y Dnom) se empiezan a procesar las tramas RMC emitidas
por el GPS. Una vez que se detecta que el GPS está sincronizado se pasa al
siguiente estado.
En el estado comprobar GPS sincronizado se vuelve a comprobar si el
GPS está sincronizado (procesando la siguiente trama RMC) y en caso afir-
mativo se realiza la conversión de la hora al formato NTP y se pasa al estado
sincronizando. En caso negativo, se vuelve al estado detenido. Esta compro-
bación resulta necesaria para solucionar ciertos problemas detectados que se
producen cuando el GPS vuelve a sincronizarse tras perder la sincronización.
Al pasar del estado anterior al estado sincronizando se dispone de la
hora en formato NTP relativa al anterior flanco activo del PPS. En este
estado se espera hasta que se detecta un nuevo flanco activo, momento en el
que se actualiza el reloj de hora local y el contador de segundos (utilizado

136 Capítulo 3. Arquitectura del sistema
Figura 3.25: Estados que forman el algoritmo de sincronización del servidorSNTP.
para calcular el desplazamiento); se inicia el valor del desplazamiento previo
θi−1 = 0 y comienza a operar el módulo de ajuste. Por último, se pasa al
estado sincronizado.
Finalmente, en el estado sincronizado se realizan las siguientes tareas:
1. Tras detectar un flanco activo de la señal PPS se incrementa en una
unidad el contador de segundos, se calcula el desplazamiento actual
θi y una nueva corrección Di a aplicar por el módulo de ajuste. Para
realizar estos cálculos, la primera vez que se hace el cambio del estado
sincronizando a sincronizado se considera que Di−1 = Dnom; para el
resto de ocasiones, se utilizará el último valor calculado de D antes de
que el GPS perdiera la sincronización.

3.6. Conclusiones 137
2. Se procesan las tramas RMC recibidas tras el flanco activo del GPS para
extraer el estado del GPS y la información de hora, que será convertida
al formato NTP. Una vez finalizada la conversión se comprobará que la
hora generada coincide con la que mantiene el contador de segundos.
En caso de no coincidir estas horas o detectar que el GPS no está
sincronizado se pasa al estado detenido pero se deja operar al servidor
con el último valor de D0i calculado.
3.6. Conclusiones
En este capítulo se ha presentando la arquitectura del cliente y del ser-
vidor SNTP, donde se han distinguido tres bloques: (1) módulos que imple-
mentan funcionalidad estándar, (2) módulos que implementan funcionalidad
básica para la recepción y transmisión de información temporal y (3) mó-
dulos que implementan funcionalidad avanzada destinada, por un lado, al
control de las comunicaciones, de la configuración y al marcado temporal de
los mensajes y, por otro, al control y ajuste de la hora local.
En relación con el control de las comunicaciones, el aspecto más destacado
es que se ha especificado una unidad de control que permite: (1) integrar y
administrar los diferentes servicios de red que se requieren de forma sencilla,
(2) controlar los retrasos derivados del procesamiento de los paquetes y (3)
realizar el correcto marcado temporal de los paquetes de hora.
Finalmente, se ha definido un modelo de reloj, que incluye un módulo
de ajuste de la frecuencia del oscilador que permite disciplinar el reloj local
para conseguir una sincronización precisa. Además, como complemento a
dicho modelo, se han especificado algoritmos de sincronización y mecanismos
para cálculo de correcciones. La principal aportación realizada consiste en
que todos los elementos descritos son totalmente implementables sobre un
dispositivo programable FPGA.

138 Capítulo 3. Arquitectura del sistema

Capítulo 4
Metodologías de diseño para la
implementación hardware
Para poder afrontar el diseño de un sistema empotrado como SoPC en
un tiempo y con unas garantías de fiabilidad razonables, un aspecto muy
importante consiste en definir metodologías de diseño adecuadas al tipo de
sistema digital que se vaya a implementar. En este sentido, una tarea previa
fundamental consiste en la división del sistema en módulos, de forma que
sea posible separar las partes principales de las secundarias. Esta separación
permite que el mayor esfuerzo de diseño e innovación recaiga sobre las par-
tes más críticas del sistema (mediante el estudio de metodologías novedosas
que faciliten el diseño) mientras que para las partes menos críticas la me-
jor alternativa consiste en emplear metodologías muy bien establecidas que
simplifiquen el diseño en la medida de lo posible.
En relación con el diseño e implementación del cliente y servidor SNTP,
en el capítulo anterior se presentó la arquitectura general del sistema y se
hizo una división en módulos del mismo. A partir de esta división, se reali-
zó una exposición donde se clasificaban los bloques en función de si: (1)
estaban completamente especificados y se disponía de una implementación
hardware (controlador Ethernet MAC y UART), (2) no estaban especificados
pero se trataban de módulos de baja complejidad (módulos de transmisión y
recepción de la información temporal) y (3) presentaban características inno-
139

140 Capítulo 4. Metodologías de diseño para la implementación hardware
vadoras, considerándose las partes críticas del sistema (interfaz de protocolos
y configuración y módulo de sincronización).
A continuación, se va a exponer cómo queda organizado este capítulo. En
el primer apartado, se va a introducir qué metodología se ha considerado más
adecuada para diseñar cada uno de los grupos comentados. En el segundo
apartado, se realizará un análisis más detallado de las metodologías plantea-
das. En el tercer y cuarto apartado, se presentarán los flujos de diseño de
dichas metodologías, explicando las tareas principales que se realizan en cada
una de las fases. Por último, se destacarán las conclusiones más importantes
del capítulo.
4.1. Metodologías de diseño
De acuerdo a la clasificación de bloques presentada, parece razonable que
para aquellas partes que tienen implementaciones hardware disponibles en
la forma de módulos de propiedad intelectual la mejor alternativa de diseño
consista en la reutilización de estos bloques. La principal ventaja de emplear
módulos ya implementados es que se reduce significativamente el tiempo
de desarrollo ya que las labores del diseñador consisten simplemente en la
integración y adaptación del módulo IP a la aplicación específica que se esté
desarrollando. Como inconveniente se puede decir que el uso y/o distribución
de estos módulos de propiedad intelectual están sujetos en muchas ocasiones
al pago de licencias, lo cual puede suponer un desembolso importante que
sería necesario valorar. No obstante, gracias a la comunidad de usuarios del
portal OpenCores [OpenCores] es posible disponer de una gran variedad
de módulos IP totalmente funcionales y que pueden ser empleados en los
diseños sin ningún coste asociado.
Para las partes no críticas del sistema, se debe establecer una metodología
muy bien conocida que facilite el diseño. En este sentido, para el diseño de
los bloques de transmisión y recepción de la información temporal se ha
planteado una metodología basada en microcontrolador. Esto se debe a que
el diseño de sistemas con microcontroladores está muy extendido, sobre todo
en el sector industrial, ya que éstos ofrecen muchas ventajas: son fáciles de

4.2. Análisis de las metodologías planteadas 141
programar, disponen de muchos periféricos de entrada/salida, ofrecen una
solución económica y de bajo consumo de potencia, etc.
Para el diseño de las partes críticas se ha planteado una metodología
basada en la herramienta a nivel de sistemas System Generator for
Digital Signal Processing (DSP) [Xilinx, 2008b] de Xilinx. Esta he-
rramienta, integrada dentro del entorno de desarrollo Matlab y Simulink
[MathWorks, 2009a,b] de The MathWorks [MathWorks], presenta funda-
mentalmente dos ventajas: (1) el conjunto de bloques que se ponen a disposi-
ción de los diseñadores permiten implementar de forma rápida y sencilla un
sistema digital complejo y (2) la facilidad para generar los patrones de test y
realizar la posterior simulación del sistema, usando las funcionalidades avan-
zadas del entorno Matlab/Simulink, hacen que se reduzca notablemente
el tiempo de simulación y por tanto el tiempo de diseño.
Una vez diseñados todos los módulos del sistema, empleando las diferentes
metodologías, resulta necesario realizar una última fase que comprende las
tareas de integración de la partes y verificación del sistema completo. En
este aspecto, los fabricantes de FPGA ponen a disposición de los diseñadores
entornos de desarrollo que posibilitan no sólo dicha integración y verificación
sino que también automatizan todas las labores de síntesis, implementación
y programación del dispositivo programable. Como la herramienta a nivel
de sistemas seleccionada ha sido System Generator for DSP, todas las
tareas de esta última fase se han realizado empleando el entorno de desarrollo
ISE [Xilinx, 2009b] de Xilinx.
4.2. Análisis de las metodologías planteadas
En relación con la metodología basada en microcontrolador se puede de-
cir que este tipo de dispositivos son utilizados frecuentemente, sobre todo en
el sector industrial, para implementar sistemas que resuelvan alguna tarea
específica, ya que gracias a esta alternativa es posible convertir una tarea
de diseño hardware de un módulo del sistema en una tarea de programación
software de dicho microcontrolador. Sin embargo, existen situaciones en que
el uso de microcontroladores no resuelve adecuadamente el problema, como

142 Capítulo 4. Metodologías de diseño para la implementación hardware
ocurre cuando se pretende implementar las partes más críticas del sistema en
un dispositivo programable tipo FPGA. Efectivamente, en este caso puede
surgir el problema de que entre las diferentes partes del sistema (críticas y
no críticas) deba establecerse una comunicación prácticamente instantánea,
lo cual no permite que las tareas se dividan en chips separados (microcon-
trolador y FPGA).
Una alternativa muy adecuada para resolver este problema viene dada por
los microprocesadores tipo softcore. Estos microprocesadores son totalmente
sintetizables sobre dispositivos programables de forma que esto supone dis-
poner de un microcontrolador integrado dentro de una FPGA para realizar
aquellas tareas menos críticas del sistema. En este sentido, los diferentes fa-
bricantes de FPGA han desarrollado microprocesadores para este propósito.
Como ejemplos podemos citar MicroBlaze y PicoBlaze [Xilinx, 2008a;
Chapman, 2005] de Xilinx, NIOS [Altera, 2004] de Altera o MICO32
[Lattice, 2007] de Lattice. En general, todas las alternativas mencionadas
son privativas excepto para el caso de MICO32 cuyo código ha sido libera-
do y puesto a disposición de los diseñadores como un módulo IP de fuentes
abiertas; en este sentido, una limitación encontrada a la hora de emplear es-
tos microprocesadores softcore en el diseño de un sistema es que sólo pueden
ser sintetizados e implementados en dispositivos programables de su mismo
fabricante. Esto se debe a que no se dispone de una codificación en un len-
guaje de descripción de hardware (Hardware Description Language, HDL)
que emplee primitivas estándares sino de una descripción que instancia com-
ponentes propios de la FPGA en la que va a ser implementado, lo cual por
otro lado presenta la ventaja de que están muy optimizados para ese tipo de
FPGA. Frente a estos microprocesadores privativos también existen alterna-
tivas de especificaciones abiertas como son OpenSPARC [SunMicrosystems,
2006] de Oracle [Oracle], OpenRisc [Lampret, 2001] diseñado por la co-
munidad de usuarios de OpenCores y LEON2 [Gaisler, 2004] desarrollado
por Aeroflex Gaisler [Gaisler] y la Agencia Espacial Europea (European
Space Agency, ESA) [ESA]. En los siguientes trabajos [Viejo et al., 2006b;
Ostua et al., 2005, 2006, 2008; Muñoz et al., 2007, 2008a,b; Villar et al.,
2008a,b, 2009] se presentan metodologías de diseño de SoPC basadas en los

4.2. Análisis de las metodologías planteadas 143
microprocesadores MicroBlaze, LEON2 y OpenRisc y su aplicación en
algunos sistemas de control industrial.
Una vez comentados los diferentes microprocesadores disponibles, se pue-
de destacar que todos son fácilmente integrables dentro del diseño de un
sistema digital para su implementación sobre FPGA. Este hecho da lugar a
varias ventajas como: no necesitar chips externos a la propia FPGA para el
diseño del sistema, poder alcanzar velocidades de operación mucho más altas
que la de los microcontroladores comerciales (en definitiva, el microprocesa-
dor operará a la frecuencia de reloj que se alcance para el diseño del sistema
digital sobre la FPGA), reducir aún más el consumo de energía gracias a la
integración del sistema en un único chip, poder adaptarlo con gran facilidad
al resto del sistema digital del que formen parte, etc.
Sin embargo, aun siendo fácilmente integrables, dentro de los micropro-
cesadores softcore existen algunos de mayor complejidad y capacidad como,
por ejemplo, MicroBlaze, NIOS, MICO32, OpenSPARC, OpenRisc y
LEON2, y otros de características mucho más simples como es el caso de
PicoBlaze, que proporcionan una funcionalidad similar a la del microcon-
trolador 8742 [Intel, 1991] de Intel [Intel]. Los microprocesadores de mayor
complejidad se suelen emplear como núcleos principales de un SoPC basado
en microprocesador mientras que los microprocesadores de capacidades más
reducidas son idóneos en partes específicas de sistemas digitales para resolver
problemas más simples, de la misma forma que operan los microcontroladores
en un sistema de control.
Para el caso que nos concierne se ha optado por el uso del microproce-
sador PicoBlaze como núcleo de procesamiento de las tareas no críticas
del sistema diseñado. En este aspecto, se ha propuesto una metodología de
diseño basada en PicoBlaze, aplicándose con éxito al desarrollo de deter-
minados sistemas específicos tal y como se refleja en los siguientes trabajos
publicados por el autor de esta tesis doctoral [Viejo et al., 2005, 2006d, 2008b;
Ostua et al., 2009]. Entre los trabajos publicados se incluyen aquellos donde
se presentan los sistemas diseñados para la recepción y transmisión de la
información temporal a través del puerto serie, y cuya funcionalidad se ha
explicado en el capítulo anterior.

144 Capítulo 4. Metodologías de diseño para la implementación hardware
En cuanto a la metodología basada en herramientas a nivel de sistemas,
en los últimos años los fabricantes de FPGA han puesto a disposición de los
diseñadores un conjunto de herramientas de más alto nivel que los lenguajes
de descripción de hardware tradicionales. Estas herramientas trabajan a nivel
de sistemas integrándose en otros entornos de desarrollo ampliamente conoci-
dos y utilizados por la comunidad científica como son Matlab y Simulink.
La combinación de estos entornos junto con plataformas de diseño de siste-
mas digitales, que se integran en los mismos, presenta las siguientes ventajas:
(1) al tratarse de herramientas de diseño a nivel de sistemas no resulta ne-
cesario aprender ningún lenguaje de descripción de hardware, ya que para la
implementación del sistema se emplean los bloques proporcionados por dicha
herramienta, (2) la simulación del sistema digital viene asistida por el en-
torno Matlab/Simulink y la generación de patrones se realiza fácilmente
mediante la programación de eventos en lenguaje Matlab o con bloques de
Simulink y (3) el código generado por estas herramientas está optimizado,
siendo completamente sintetizable sobre el dispositivo programable donde se
vaya a implementar el diseño.
En relación con el diseño de sistemas empotrados usando esta alterna-
tiva, el Proyecto de Investigación del doctorando titulado “Diseño e imple-
mentación de funciones de DSP sobre FPGA” [Viejo, 2006] presenta una
metodología de diseño basada en la herramienta a nivel de sistemas System
Generator for DSP. Dicha metodología ha sido empleada en trabajos
previos al diseño e implementación del cliente y servidor SNTP demostrán-
dose la validez de la misma [Viejo et al., 2006c,b,a]. Además, en los trabajos
[Viejo et al., 2007b,a, 2008a] se presenta una comparativa de la metodología
propuesta frente a la metodología típica de codificación directa en un len-
guaje de descripción de hardware. De estos trabajos se pueden extraer las
siguientes conclusiones:
1. El uso de herramientas a nivel de sistema facilita en gran medida las
tareas de diseño y de simulación, permitiendo a los diseñadores cen-
trarse en la arquitectura del sistema y reducir el tiempo de diseño de
forma importante. Así, por un lado, en estas herramientas los bloques
disponibles para diseñar el sistema empotrado son completamente con-

4.3. Metodología de diseño con PicoBlaze 145
figurables: se puede decidir qué bloques deben usar recursos on-chip
(como BRAM o multiplicadores empotrados) o elegir diferentes confi-
guraciones de latencia, precisión de los datos, tratamiento del overflow,
entre otras opciones disponibles. Este hecho permite a los diseñadores
controlar en su totalidad la forma en que un diseño es implementado y
obtener una estructura muy eficiente. Por otro lado, la simulación del
sistema se realiza empleando el entorno de desarrollo donde se integra
la misma, lo cual facilita la generación de los estímulos de entrada y
el análisis de las salidas, de forma que el tiempo de pruebas se reduce
significativamente y, en definitiva, el tiempo de diseño.
2. Los resultados obtenidos por estas herramientas a nivel de sistemas
en términos de precisión, recursos hardware empleados y frecuencia de
operación son muy similares frente a los conseguidos mediante la co-
dificación directa en un lenguaje de descripción de hardware. Esto se
debe principalmente a que los componentes proporcionados están opti-
mizados para las FPGA del fabricante de la herramienta, de forma que
a priori no tienen por qué obtenerse mejores resultados para el código
generado por un diseñador empleando primitivas HDL estándares.
A continuación, en los siguientes apartados se van a presentar las dos
metodologías tratadas en este apartado con cierto detalle.
4.3. Metodología de diseño con PicoBlaze
En la Fig. 4.1 se muestra el conjunto de tareas que resulta necesario
realizar para diseñar un sistema digital basado en el microprocesador Pico-
Blaze. El primer paso de esta metodología consiste en describir el sistema
empleando lenguajes de descripción de hardware. Como se observa en la
Fig. 4.1, la estructura mínima de este tipo de sistemas se compone de: (1)
el módulo de PicoBlaze adecuado a la FPGA que se vaya a programar
(kcpsm3.vhd), (2) la memoria que almacena el programa (<ROM>.vhd) y (3)
un conjunto de componentes hardware dependientes del sistema específico
que se vaya a diseñar. En este sentido, como el módulo de PicoBlaze ya es

146 Capítulo 4. Metodologías de diseño para la implementación hardware
proporcionado por el fabricante, las tareas que hay que realizar en este primer
paso consisten en la generación de la memoria de programa y en el diseño
de los componentes específicos. Además, se debe realizar el conexionado de
todos los bloques mediante una descripción HDL estructural.
En relación con la primera tarea, en primer lugar, se debe escribir el pro-
grama en lenguaje ensamblador empleando el conjunto de instrucciones de
PicoBlaze (<ROM>.psm). Una vez escrito el programa, se utiliza el ensam-
blador proporcionado junto con el microprocesador para generar el fichero
HDL que define la memoria que contiene el programa (<ROM>.vhd).
En cuanto a la segunda, la definición de las funciones de procesado espe-
cíficas se deben realizar mediante una descripción estructural o de compor-
tamiento en algún lenguaje de descripción de hardware. Además, dentro de
estos componentes, se deben incluir las interfaces que permiten la comunica-
ción del microprocesador con el resto de módulos del sistema.
Una vez descrito completamente el sistema, se debe verificar su correcto
funcionamiento empleando un simulador lógico. Si tras finalizar la simula-
ción, se detecta que el diseño no se ajusta correctamente a las especificaciones
deberán realizarse las modificaciones oportunas del programa y/o del con-
junto de componentes específicos, repitiendo este paso hasta que se obtenga
el comportamiento deseado.
Finalmente, cuando la fase de simulación funcional del diseño finalice
se dispondrá del código verificado que podrá ser integrado con el resto de
módulos del sistema.
4.4. Metodología de diseño con System Gene-
rator for DSP
Como se ha comentando anteriormente, en el Proyecto de Investigación
del doctorando se presentó una metodología de diseño de funciones de
DSP sobre FPGA. Dicha metodología estaba basada en la herramienta
System Generator for DSP y se centraba en la implementación de
dichas funciones como periféricos del microprocesador MicroBlaze [Viejo

4.4. Metodología de diseño con System Generator for DSP 147
Figura 4.1: Metodología de diseño basada en el microprocesador PicoBlaze.

148 Capítulo 4. Metodologías de diseño para la implementación hardware
et al., 2006c,b,a]. En este apartado, se va a presentar una metodología de
diseño similar a la desarrollada con anterioridad pero adaptada para la
implementación de los módulos principales de la plataforma cliente/servidor
SNTP.
En la Fig. 4.2 se muestra el flujo de diseño seguido para la implemen-
tación de un sistema digital usando las herramientas Matlab/Simulink y
System Generator for DSP. Como se observa en la Fig. 4.2 el primer
paso consiste en el modelado del sistema digital. Para realizar dicho mode-
lado se ha empleado una metodología típica de diseño de un sistema digital
basada en una unidad de control y una ruta de datos.
De forma general, el diseño de la unidad de control se realiza mediante
el diseño de una máquina de estados finitos (Finite State Machine, FSM),
descrita en un lenguaje de descripción de hardware según las directrices de
[Cummings, 2002]. En este sentido, la herramienta utilizada permite importar
módulos escritos en HDL a través de un bloque específico del Xilinx Blockset
denominado Black Box. Este hecho facilita el diseño ya que una máquina de
estados finitos es una estructura fácil de implementar en HDL mientras que
con bloques de System Generator for DSP puede resultar una tarea
laboriosa.
Para el diseño de la ruta de datos se emplean bloques propios del Xilinx
Blockset y del Xilinx Reference Blockset. Entre estos bloques destacan suma-
dores, multiplicadores, divisores, memorias y otros más avanzados, que no
serán empleados en el diseño del cliente y servidor SNTP, como son los que
implementan filtros de respuesta finita al impulso (Finite Impulse Response,
FIR) o la transformada rápida de Fourier (Fast Fourier Transform, FFT).
Una vez modelado el sistema, se procede a la configuración de los blo-
ques que forman el diseño estableciendo el tipo de datos de las señales, el
tratamiento del overflow y la cuantización, la latencia de cada uno, etc. Ade-
más, en caso de que el dispositivo programable que se vaya a emplear para
la implementación del diseño disponga de recursos on-chip (multiplicadores
empotrados, memorias BRAM) también se puede indicar a la herramienta
qué módulos del sistema deben utilizarlos. De esta forma, distribuyendo de
forma adecuada los recursos disponibles se consigue optimizar el diseño ya

4.4. Metodología de diseño con System Generator for DSP 149
Figura 4.2: Metodología de diseño basada en System Generator forDSP.

150 Capítulo 4. Metodologías de diseño para la implementación hardware
que, por un lado, se reduce el área ocupada y, por otro, se incrementa la
velocidad máxima de operación.
Cuando se ha finalizado la fase de configuración, el siguiente paso consiste
en la simulación funcional del sistema. Un aspecto interesante al trabajar
con Matlab/Simulink es precisamente poder emplear la herramienta de
simulación de sistemas Simulink. No obstante, al estar una parte del diseño
codificada en HDL surge la necesidad de emplear un simulador lógico externo
como ISE Simulator [Xilinx, 2009b] de Xilinx o ModelSim [Mentor,
2008] de Mentor Graphics [Mentor]. Este tipo de simulación, denominada
cosimulación HDL (HDL co-simulation), permite que el código HDL pueda
participar directamente en la simulación con Simulink. A continuación, se
explica detalladamente en qué consiste este tipo de simulación:
1. Simulink se encarga de la generación de los estímulos de entrada al di-
seño, importando los datos generados por funciones escritas en lenguaje
Matlab o mediante bloques del Sources Blockset. Al mismo tiempo,
Simulink genera el código HDL adicional propio de la simulación y
establece una comunicación con el simulador lógico.
2. Por su parte, el simulador compila todo el código HDL y espera a que
Simulink comience a programar eventos de simulación. Una vez co-
menzada la simulación, Simulink controla el intercambio de informa-
ción con el simulador lógico, que se encargará de actualizar las salidas
para cada evento generado.
3. Simulink calcula los resultados a partir de los estímulos de entrada y
de las señales de control proporcionadas por el simulador lógico.
4. Los resultados del procesado se visualizan mediante los bloques del
Sinks Blockset. También pueden ser almacenados en una variable de
Matlab para su posterior análisis o comparación con otros resultados
obtenidos mediante otros medios.
Si tras la simulación se detecta que el sistema no se ajusta a las especi-
ficaciones, se deben realizar las modificaciones necesarias bien en la fase de
modelado o en la de configuración.

4.5. Conclusiones 151
Finalmente, una vez verificado el correcto funcionamiento del diseño se
procede a la generación automática del código HDL que describe el sistema
digital.
4.5. Conclusiones
Este capítulo se ha dedicado al análisis de las diferentes metodologías
de diseño que se van a emplear para realizar una correcta implementación
hardware de los bloques que forman la arquitectura del cliente y del servidor
SNTP. A continuación, se presentan las conclusiones más significativas.
La primera consiste en que, antes de abordar el diseño de un sistema,
resulta imprescindible el análisis de los bloques que lo forman, de manera
que se puedan determinar las partes críticas. Sobre estas partes deberá recaer
la mayor parte del esfuerzo, mientras que para el resto deberán emplearse
metodologías bien establecidas que simplifiquen las tareas a realizar. Así, para
las partes de las que se dispone de implementaciones hardware en la forma
de módulos IP (controlador Ethernet MAC y UART), la mejor alternativa
consiste en su reutilización, de manera que las únicas tareas que se requieran
consistan en la adaptación e integración del módulo.
Para abordar el diseño del resto de módulos se han propuesto dos me-
todologías de diseño; la primera está basada en el uso de microprocesadores
softcore y se va a emplear para diseñar los módulos no críticos del siste-
ma, en concreto, para el diseño de los módulos que reciben y transmiten
la información temporal. Este hecho se debe a que, por una lado, este tipo
de microprocesadores facilitan en gran medida el diseño del sistema, ya que
convierten la tarea de diseño hardware en una tarea de programación soft-
ware del microprocesador. Por otro lado, a que las tareas que deben realizar
los módulos anteriores pueden adaptarse fácilmente para su implementación
como una rutina software del microprocesador.
La segunda metodología está basada en la utilización de herramientas
a nivel de sistemas y se va a emplear para diseñar los módulos críticos del
sistema: interfaz de protocolos y configuración y módulo de sincronización.
En este caso, este tipo de herramientas presentan muchas ventajas ya que

152 Capítulo 4. Metodologías de diseño para la implementación hardware
facilitan en gran medida las tareas de diseño y sobre todo las de simulación
a la vez que presentan unos resultados similares, en términos de recursos
hardware empleados y frecuencia máxima de operación alcanzada, a los de las
implementaciones realizadas directamente en HDL. En definitiva, se pretende
proporcionar una metodología de diseño que reduzca el tiempo de diseño y
de simulación y, por tanto, el coste del dispositivo final.

Capítulo 5
Implementación de la plataforma
de sincronización
Una vez comentada la arquitectura de la plataforma y las operaciones
que debe realizar cada uno de los módulos que la componen, en este capítulo
se van a exponer los detalles de implementación más significativos encontra-
dos en el desarrollo del cliente y servidor SNTP. Para ello, a partir de las
metodologías de diseño propuestas, se comentarán aspectos relativos a la in-
tegración de los módulos IP del controlador Ethernet MAC y del puerto serie
utilizados, así como a la implementación hardware del resto de módulos.
Tras exponer los aspectos de implementación más destacados, se mostra-
rán los resultados de simulación de los bloques más relevantes, siendo una de
las principales ventajas de la metodología basada en el uso de herramientas a
nivel de sistemas la simplificación de las tareas de simulación de los diseños.
Finalmente, se mostrarán los resultados de implementación hardware tan-
to del cliente como del servidor SNTP y se discutirán las conclusiones más
importantes.
153

154 Capítulo 5. Implementación de la plataforma de sincronización
5.1. Implementación hardware de los módulos
del sistema
En este primer apartado se comentarán los detalles de implementación
más destacados de cada uno de los módulos del sistema. Así, en lo que se
refiere a los módulos de recepción/transmisión de información temporal se
detallará cómo se han diseñado los módulos hardware de conversión de for-
matos horarios así como las funciones software de PicoBlaze programadas
para el control de estos módulos. En relación con la interfaz de protocolos y
configuración se explicará cómo se gestionan los temporizadores y la confi-
guración; y cómo se realiza la recepción, actualización y transmisión de los
paquetes Ethernet. Para el caso del módulo de sincronización se comentarán
las resoluciones del contador de hora local y del conjunto de operaciones que
permiten el cálculo de correcciones y se expondrá cómo se ha realizado el
diseño hardware del controlador de reloj.
5.1.1. Controlador Ethernet MAC
Para la implementación del controlador Ethernet MAC se ha em-
pleado el módulo IP disponible en el portal OpenCores denominado
10_100_1000 Mbps tri-mode ethernet MAC [Gao, 2006]. Este módulo
implementa completamente el estándar IEEE 802.3 y permite confi-
gurar determinados parámetros relativos a la velocidad de transmisión
(10/100/1000 Mbps) y al modo de comunicación (duplex o half-duplex ).
Además, incluye control de flujo para la generación y aceptación de tramas
de PAUSA.
En este sentido, en la Fig. 5.1 se muestran los bloques que forman este
controlador. Por un lado, el bloque transmisor se encarga de transmitir los
paquetes almacenados en la FIFO de transmisión, delimitando el inicio de la
trama, controlando el acceso al medio y generando la suma de verificación que
se añade al final de la trama. Por otro lado, el bloque de recepción se encarga
de recibir los paquetes y comprobar que se reciben sin errores recalculando
la suma de verificación; una vez que se comprueba que no se han producido

5.1. Implementación hardware de los módulos del sistema 155
Figura 5.1: Bloques que forman el controlador Ethernet MAC.
errores se escriben los paquetes en la FIFO de recepción.
En cuanto a aspectos de implementación cabe destacar que este controla-
dor, para reducir la dependencia tecnológica, infiere las memorias que necesi-
ta empleando componentes lógicos del dispositivo programable. Sin embargo,
como los puntos críticos del diseño del cliente y del servidor SNTP son las
FIFO de transmisión y recepción se ha optado por implementar estas memo-
rias mediante BRAM. De acuerdo a [Xilinx, 2005], estos recursos hardware
de la FPGA son idóneos para la implementación de FIFO ya que ofrecen un
alto rendimiento y disponen de una interfaz síncrona simple de forma que
las operaciones de lectura y escritura son similares a leer o escribir desde un
registro. En definitiva, con esta acción se consigue optimizar este módulo ya
que se mejora el tiempo de acceso a los datos de la FIFO lo que a su vez
se puede traducir en una reducción en el retardo de procesar los paquetes
Ethernet y se reduce la variabilidad en el retraso ya que todas las operacio-
nes tienen la misma duración. Esto no ocurre cuando se implementan estas
FIFO empleando lógica de la FPGA ya que dicha implementación depende
del resto de componentes del sistema y del lugar en el que éstos se sitúan
dentro del dispositivo programable.

156 Capítulo 5. Implementación de la plataforma de sincronización
5.1.2. Controlador del puerto serie
Para la implementación del controlador del puerto serie se ha utilizado un
módulo IP de Xilinx [Chapman, 2002] incluido junto con el microprocesador
PicoBlaze para el desarrollo de aplicaciones. En la Fig. 5.2 se observa cómo
este controlador está compuesto por dos módulos separados, uno de recepción
y otro de transmisión. Cada módulo dispone de una FIFO de 16 bytes que
se emplea como buffer.
A continuación, se van a exponer las principales características de imple-
mentación y adaptaciones realizadas a este módulo:
Figura 5.2: Bloques que forman el controlador del puerto serie.

5.1. Implementación hardware de los módulos del sistema 157
Se ha establecido un formato fijo para los datos, compuesto por 1 bit
de start, 8 bits de datos, 1 bit de stop y sin paridad (“8N1”).
En cuanto a la velocidad del puerto serie se ha realizado una modifica-
ción del módulo para permitir la configuración del baud rate en tiempo
de ejecución. En concreto, se ha añadido un generador de reloj confi-
gurable a partir del parámetro que indica la velocidad en baudios a la
que se deben transmitir y recibir los datos.
Como se observa en la Fig. 5.2, los bloques de transmisión y recepción
son totalmente independientes pudiéndose implementar, en función de
la aplicación, conjuntamente o por separado.
Para implementar las FIFO que almacenan los datos se han empleado
bloques lógicos del dispositivo programable. Esto se debe a que son
buffers muy pequeños (sólo 16 bytes) y a que no se espera de ellos
un alto rendimiento de forma que su implementación mediante BRAM
únicamente supondría desaprovechar este tipo de recursos.
Como los tamaños de las FIFO son reducidos, para controlar el estado
del buffer se dispone de dos señales denominadas buffer_half_full y
buffer_full que se activan cuando el buffer está medio o completamente
lleno respectivamente. Para el caso de la recepción, la FIFO incorpora
una señal de buffer_data_present que indica que el buffer contiene uno
o más bytes de datos recibidos disponibles para su lectura.
Finalmente, un aspecto a destacar es que este controlador está optimi-
zado para su implementación sobre dispositivos programables ya que se ha
diseñado mediante la instanciación de componentes específicos de la FPGA.
Este hecho se traduce en una reducción del número de recursos hardware
utilizados y en un aumento de la frecuencia máxima de operación.
5.1.3. Módulo de recepción de información temporal
En la Fig. 5.3 se muestran los bloques que forman el módulo de recepción
de información temporal. Como se observa en dicha figura este módulo se

158 Capítulo 5. Implementación de la plataforma de sincronización
Figura 5.3: Bloques que forman el módulo de recepción de información tem-poral.
compone de dos bloques, uno dedicado al procesamiento de la señal PPS y
tramas NMEA (unidad de procesado) y otro a la conversión de la hora y la
fecha en el formato HH:MM:SS y DD/MM/AA al formato NTP (conversor
de formato). A continuación, se van a describir detalladamente estos dos
bloques.
La unidad de procesamiento, basada en el microprocesador PicoBlaze,
se encarga de las operaciones de: (1) detección del flanco activo del PPS, (2)
procesado de las tramas RMC para la obtención de la información de estado
del GPS y la fecha y hora en el formato HH:MM:SS y DD/MM/AA, (3)
detección de errores en la comunicación mediante el cálculo y la comprobación

5.1. Implementación hardware de los módulos del sistema 159
de la suma de verificación enviada al final de la trama y (4) generación de las
señales de estado empleadas por el módulo de sincronización. La conexión
de las señales de PPS y de datos/estado de la FIFO de recepción se realiza
mediante los puertos de entrada de PicoBlaze mientras que por los puertos
de salida se controlan las señales de control de la FIFO y las señales de
estado que recibirá el módulo de sincronización. Además, esta unidad incluye
una serie de registros de números en formato decimal codificado en binario
(Binary-Coded Decimal, BCD) (registro de horas, minutos y segundos y de
días, meses y años) que permiten almacenar la fecha y la hora obtenidas de
la trama RMC y simplificar las operaciones de conversión de formato. Estos
registros son también controlados por los puertos de salida de PicoBlaze.
Para la realización de las tareas anteriores se ha implementado un conjun-
to de subrutinas en el lenguaje ensamblador de PicoBlaze que facilitan las
operaciones de lectura de datos de la FIFO y que permiten resolver una serie
de problemas encontrados por el hecho de que los datos recibidos representan
caracteres ASCII. A continuación, se detallan los aspectos más importantes
de las subrutinas implementadas:
Dentro de la subrutina de lectura de datos de la FIFO se va realizando
el cálculo de la suma de verificación conforme se van recibiendo los
datos. De esta forma, una vez procesada la trama completa se dispone
del valor final de esta suma no siendo necesario almacenar los datos
recibidos.
Antes de proceder a la escritura de los registros BCD resulta necesa-
rio convertir los caracteres ASCII recibidos a su correspondiente valor
BCD. Para ello, se ha implementado una subrutina que automatiza este
proceso de escritura.
Al igual que en el caso anterior, para comparar la suma de verificación
calculada con la que viene al final de la trama se necesita convertir los
dos caracteres ASCII que forman ésta última a sus correspondientes dí-
gitos hexadecimales. Este problema se ha resuelto implementando una
subrutina que permite convertir un carácter ASCII a su valor hexade-
cimal equivalente.

160 Capítulo 5. Implementación de la plataforma de sincronización
El módulo de conversión de formato se encarga de adaptar la fecha y hora
en el formato de entrada HH:MM:SS y DD/MM/AA a un único registro de
32 bits que representa la parte entera de la hora en formato NTP, es decir, el
número de segundos transcurridos desde el 1 de enero de 1900. Este módulo
hardware se ha implementado mediante la descripción de una FSM emplean-
do un lenguaje de descripción de hardware. Como este módulo no presenta
ninguna restricción temporal, ya que para el cálculo del desplazamiento se
emplea el contador de segundos que se incrementa con el flanco activo del
PPS, se ha optado por un diseño donde los registros BCD que almacenan
la información de fecha y hora se procesan secuencialmente, consiguiendo
optimizar los recursos hardware. La máquina de estados implementada se
encarga de ir sumando sucesivamente los segundos correspondientes a cada
registro BCD, considerando la duración de los diferentes meses y los años
bisiestos, hasta obtener el valor requerido.
El motivo por el que se emplean registros BCD, en lugar de variables
binarias representando el número de años, meses, días, horas, minutos y se-
gundos, es que se evita la conversión de los caracteres recibidos a binario lo
cual supone una multiplicación por 10 del dígito más significativo. Con la
solución planteada sólo resulta necesario implementar un pequeño módulo
que permita decrementar adecuadamente el valor del registro BCD corres-
pondiente.
5.1.4. Módulo de transmisión de información temporal
En la Fig. 5.4 se muestran los bloques que forman el módulo de transmi-
sión de información temporal. Como se observa en dicha figura este módulo
se compone de dos bloques, uno dedicado a la generación de la señal PPS
y a la conversión de la hora en formato NTP al formato de HH:MM:SS
y DD/MM/AA (generador PPS y conversor de formato) y otro al procesa-
miento de los datos anteriores para la construcción y transmisión de la trama
RMC que se envía tras cada flanco activo del PPS (unidad de procesamiento).
A continuación, se comentan los detalles de implementación más destacados
de estos módulos.

5.1. Implementación hardware de los módulos del sistema 161
Figura 5.4: Bloques que forman el módulo de transmisión de informacióntemporal.
El bloque de generación del PPS y de conversión de formato se encarga en
primer lugar de generar la señal PPS a partir del bit más significativo de la
parte fraccionaria de la hora en formato NTP. Esta señal será conectada a la
salida DSR del puerto serie. Además, monitoriza la señal PPS para detectar
el flanco activo, momento en el que comienza la conversión de la hora al
formato utilizado por el protocolo NMEA para la transmisión de la fecha
y la hora. Para realizar esta conversión sólo se emplea la parte entera de
la hora en formato NTP, que es la que indica el número de segundos. Un
aspecto importante que debe ser tenido en cuenta es que el año se representa

162 Capítulo 5. Implementación de la plataforma de sincronización
empleando únicamente dos dígitos, por lo que resulta necesario establecer
una fecha de referencia diferente a la especificada por el protocolo NTP, en
concreto, el 1 de enero de 2000; para solucionar este problema se ha restado
a la hora local el número de segundo transcurridos desde el 1 de enero de
1900 hasta la fecha de referencia.
En cuanto a la implementación de este bloque, ésta se ha realizado me-
diante la descripción en HDL de una FSM y una serie de sumadores y di-
visores (estos últimos implementados mediante un LogiCORE IP [Xilinx,
2011] de Xilinx). Así, se ha usado un primer divisor que divide el número de
segundos de la nueva hora establecida por el número de segundos en un día,
obteniéndose como cociente el número de días desde el 1 de enero de 2000 y
como resto el número de segundos del día actual. A partir del cociente de la
operación anterior se obtienen los valores de la fecha (día, mes y año) em-
pleando un conjunto de sumadores que tendrán en cuenta la duración de los
diferentes meses y los años bisiestos. Para calcular la hora a partir del número
de segundos del día actual, resulta necesario realizar varias divisiones para
calcular los valores de hora, minuto y segundo. Además, para representar es-
tos valores en formato BCD también se necesita realizar divisiones por 10. En
este sentido, se ha diseñado una ruta de datos que utilizando un único divisor
permite obtener la hora en el formato esperado. Las diferentes operaciones
que realiza la ruta de datos son controladas mediante una unidad de control,
implementada como una FSM en un lenguaje de descripción de hardware.
Una vez finalizada la conversión, los resultados obtenidos se almacenan en
registros BCD que representan la fecha y la hora a transmitir.
La unidad de procesado se encarga de realizar las siguientes operaciones:
(1) determinar el instante en que se debe comenzar a transmitir la trama
RMC (coincide con la detección del flanco activo del PPS), (2) controlar la
adquisición de los datos generados por el bloque de conversión (fecha y hora)
y por el módulo de sincronización (estado de sincronización), (3) procesar
los datos adquiridos, (4) generar y transmitir la trama RMC a partir de la
información procesada y (5) controlar la transmisión de los datos (llenado de
la FIFO de transmisión del puerto serie). Para la adquisición de los datos, las
salidas del módulo de conversión junto con la señal de estado se multiplexan

5.1. Implementación hardware de los módulos del sistema 163
hacia los puertos de entrada de PicoBlaze; además, para el control de la
transmisión, también resulta necesario multiplexar las señales de estado de la
FIFO hacia estos puertos de entrada. Por último, las señales de datos/control
de la FIFO de transmisión se controlan a través de los puertos de salida.
Para la realización de todas estas tareas se ha implementado un conjun-
to de subrutinas, en el lenguaje ensamblador de PicoBlaze, que facilitan
las operaciones de adquisición y procesado, resolviendo de nuevo los pro-
blemas encontrados en relación con el formato de los datos a transmitir.
A continuación, se detallan los aspectos más importantes de las subrutinas
implementadas:
La adquisición de los datos se va realizando conforme van siendo nece-
sario transmitirlos. Una vez adquirido cada dato, esta información debe
ser procesada para convertir el valor del registro BCD o información de
estado en su correspondiente carácter ASCII.
Dentro de la subrutina de escritura se va realizando el cálculo parcial
de la suma de verificación conforme se van transmitiendo los datos. De
esta forma, una vez transmitida toda la trama se dispone de la suma
final sin necesidad de almacenar ningún dato intermedio.
En relación con la transmisión de la suma de verificación, ésta debe
procesarse antes de su envío. Este procesamiento consiste en separar
la suma en dos dígitos hexadecimales y obtener la representación en
código ASCII de cada uno de ellos.
Finalmente, debido a que la escritura de los datos en la FIFO de trans-
misión de la UART presenta ciertos inconvenientes (el tamaño de la FIFO
es de 16 bytes y PicoBlaze escribe los datos más rápido de lo que puede
transmitir el puerto serie) ha sido necesario programar una subrutina de con-
trol de la transmisión que evite el desbordamiento del buffer y por tanto la
pérdida de datos. Para realizar este control, esta subrutina emplea la señal de
estado de la FIFO buffer_half_full. De esta forma, PicoBlaze comprueba
periódicamente el estado de esta señal y en caso de estar activa espera a que
la FIFO deje de estar medio llena para continuar con el envío de los datos.

164 Capítulo 5. Implementación de la plataforma de sincronización
5.1.5. Interfaz de protocolos y de configuración
En la Fig. 5.5 se presenta el diagrama de bloques que forman la interfaz
de protocolos y configuración. A continuación, se van a comentar los aspectos
de implementación más relevantes de cada uno de estos módulos.
El módulo de recepción implementa una máquina de estados finitos que se
encarga de la lectura y procesamiento de los paquetes Ethernet almacenados
en la FIFO de recepción del controlador Ethernet MAC. Dicha máquina de
estados se ha descrito empleando un lenguaje de descripción de hardware y
realiza las siguientes tareas concretas:
Determinar si el paquete recibido viene dirigido a ese dispositivo o a la
dirección de broadcast. En caso afirmativo, se procesa el paquete y en
caso negativo se descarta.
Determinar el tipo de servicio de forma que durante el procesamiento
del paquete se pueda realizar una correcta separación de los campos,
registrando los necesarios y descartando el resto. Así, en el caso de
un paquete NTP será necesario registrar las marcas de tiempo y el
Figura 5.5: Bloques que forman la interfaz de protocolos y configuración.

5.1. Implementación hardware de los módulos del sistema 165
stratum (que permite determinar el estado), en el caso de BOOTP la
dirección IP asignada al dispositivo y los parámetros de configuración
y en relación con ARP las direcciones MAC e IP de origen y destino.
Tras procesar el paquete, generar las señales de validación o de estado
que permitan continuar con el resto de operaciones.
En el caso del cliente, controlar si se ha recibido respuesta a la última
petición de hora realizada y en caso contrario actualizar la señal de
estado para informar al módulo de sincronización de este hecho.
El módulo de configuración se encarga de administrar todos los aspectos
relacionados con la configuración. Como se ha comentado en el Capítulo 3,
los parámetros de configuración se pueden dividir en parámetros de configu-
ración de la red local y parámetros del sistema. Además de esta clasificación,
los parámetros de configuración se pueden organizar atendiendo al carácter
variable de los mismos: parámetros estáticos que permanecen invariantes du-
rante el funcionamiento del dispositivo y parámetros dinámicos cuyos valores
pueden cambiar en tiempo de ejecución. En la Tabla 5.1 se organizan los
parámetros existentes de acuerdo a las clasificaciones anteriores.
En cuanto a la implementación hardware de este módulo, el hecho de
Nombre Tipo Valor
Dirección MAC Configuración de red EstáticoDirección IP Configuración de red DinámicoDirección IP servidor Configuración de red DinámicoBaud rate Configuración del sistema DinámicoARP timeout Configuración del sistema EstáticoBOOTP timeout Configuración del sistema EstáticoNúmero ciclos Configuración del sistema EstáticoFlanco activo Configuración del sistema Dinámicop Configuración del sistema Dinámicoq Configuración del sistema EstáticoFactor prescaler Configuración del sistema EstáticoD nominal Configuración del sistema Estático
Tabla 5.1: Clasificación de los parámetros de configuración.

166 Capítulo 5. Implementación de la plataforma de sincronización
disponer de dos tipos de parámetros (estáticos y dinámicos) ha motivado la
decisión de dividir este bloque en dos partes claramente diferenciadas. Por un
lado, los parámetros estáticos se han almacenando en una memoria BRAM
del dispositivo programable de forma que, tras la puesta en funcionamiento
o tras un reset del sistema, se procede a leer esta memoria y a guardar los
parámetros de configuración en registros accesibles por el resto de módulos
del sistema. Estas dos acciones se realizan mediante la codificación en HDL
de una FSM. Por otro lado, los parámetros dinámicos se consiguen mediante
el protocolo de configuración de red BOOTP. Así, para el caso del cliente se
obtendrá la dirección IP, la velocidad del puerto serie, el intervalo entre peti-
ciones de tiempo y la dirección IP del servidor SNTP. En el caso del servidor
se obtendrá la dirección IP, la velocidad del puerto serie y el flanco activo del
PPS. Como se comentó en el apartado 3.4.1, los parámetros dinámicos (salvo
la dirección IP) se codifican en el campo de ruta del fichero de arranque del
protocolo BOOTP. Para ello se emplean cadenas de caracteres hexadecimales
como las mostradas en el ejemplo de la Fig. 5.6
Para realizar la implementación de este bloque se ha descrito una FSM
que tras la llegada de una respuesta de BOOTP se encarga de procesar los
parámetros de configuración recibidos. En concreto, esta máquina de estados
realiza las siguientes operaciones:
Convertir los datos recibidos (en formato ASCII) a sus correspondientes
Figura 5.6: Ejemplo de codificación de los parámetros dinámicos.

5.1. Implementación hardware de los módulos del sistema 167
valores hexadecimales.
Comprobar los valores de los parámetros recibidos para detectar posi-
bles errores o valores fuera de rango. Tras la detección de un error se
finaliza el procesamiento y se procede a generar una señal de estado
que informa del error detectado.
Al finalizar el procesamiento, si no se han detectado errores, almacenar
los parámetros de configuración en registros y generar una señal de
validación que informe de la nueva configuración.
En relación con el módulo de control de comunicaciones y de servicios se
ha implementado toda la funcionalidad comentada en el Capítulo 3 mediante
la codificación en HDL de varias máquinas de estados finitos. Estas máquinas
de estados se controlan a partir de las señales de validación del módulo de
recepción, que indican la llegada de peticiones o respuestas a los servicios,
y de los temporizadores implementados para cada servicio cliente a partir
de la información de configuración. Para la generación de los temporizadores
se han diseñado varios contadores usando bloques específicos de System
Generator for DSP. Así, en primer lugar, uno de estos contadores se
dedica a contar el número de ciclos en un segundo indicando mediante una
señal el final de la cuenta (este número es conocido a partir del parámetro
de configuración número ciclos de la Tabla 3.4, pág. 110). En segundo lugar,
la señal de fin de cuenta del contador de segundos anterior se utiliza como
señal de incremento de los diferentes temporizadores existentes. Por último,
el final de cuenta de cada uno de estos temporizadores se controla por el
timeout definido para cada servicio mediante configuración.
Además de las operaciones anteriores, el módulo de control de comuni-
caciones y de servicios se encarga de controlar los módulos de transmisión
y actualización de campos de los paquetes. Estos dos módulos manejan una
memoria de acceso aleatorio (Random Access Memory, RAM) donde se en-
cuentran almacenados los paquetes; en la Fig. 5.7 se muestran las posiciones
de memoria que ocupan cada uno de ellos. De esta forma, por un lado, el pro-
ceso de actualización, iniciado por la unidad de control, consiste en escribir

168 Capítulo 5. Implementación de la plataforma de sincronización
Figura 5.7: Organización y posiciones que ocupan los paquetes dentro de lamemoria RAM.
las posiciones de memoria relativas a los campos del paquete que se necesitan
actualizar: direcciones MAC e IP de destino, hora local, precisión, stratum,
hora de la última actualización, etc. Por otro lado, tras la actualización del
paquete, el proceso de transmisión consiste en la lectura de las posiciones de
memoria que ocupan los paquetes y su escritura en la FIFO de transmisión
del controlador Ethernet.
Finalmente, al igual que en el caso de las FIFO de recepción y transmi-
sión, esta memoria RAM se ha implementado usando un bloque RAM de la
FPGA (BRAM) ya que así es posible controlar el tiempo que se tarda en leer
y escribir los datos y reducir la variabilidad de estas operaciones. En relación
con los módulos de actualización y de transmisión, ambos se han implemen-
tado también como máquinas de estados finitos descritas en un lenguaje de
descripción de hardware.
5.1.6. Módulo de sincronización
En la Fig. 5.8 se presentan los bloques que forman el módulo de sincro-
nización. A continuación, se comentan los detalles de implementación más
significativos de cada uno de ellos.
El reloj de hora local se ha implementado mediante un contador de 54 bits
(empleando bloques propios de System Generator for DSP), donde los
32 bits más significativos representan la parte entera o número de segundos y

5.1. Implementación hardware de los módulos del sistema 169
Figura 5.8: Bloques que forman el módulo de sincronización.
los 22 bits menos significativos la parte fraccionaria o fracciones de segundo.
A partir de la información anterior es posible determinar la resolución del
contador de hora local que es de 2−22 s, es decir, 238 ns, en esta configura-
ción. Esto resulta en una frecuencia nominal del contador de hora local de
4,19 MHz.
En lo que se refiere al módulo de ajuste del reloj, incluido dentro del blo-
que del reloj de hora local, una vez establecida la resolución del contador de
hora local, resulta necesario fijar el factor de reducción del prescaler así como
el número de etapas del bloque de control de frecuencia (apartado 3.5.2). Tal
y como se especifica en el Apéndice A, el factor de reducción depende ade-
más de la frecuencia del oscilador habiéndose fijado en un valor de 11 para
la siguiente configuración: oscilador de 50 MHz y resolución del contador de
238 ns. Con este valor se obtiene una frecuencia de salida del prescaler igual
a 4,54 MHz lo que supone un periodo de 220 ns. En relación con el número
de etapas del módulo de control de frecuencia (Fig. 3.22), este parámetro
viene definido por el número de bits de la parte fraccionaria del contador de
hora local de forma que en este caso el módulo de control de frecuencia se

170 Capítulo 5. Implementación de la plataforma de sincronización
compone de 20 etapas.
Para abordar el diseño del módulo de control se ha programado una etapa
genérica en un lenguaje de descripción de hardware (Código 5.1). A partir
de esta etapa, la implementación del bloque de control de frecuencia consiste
en instanciar 20 veces este componente indicando el valor del exponente (que
se traducirá en el tamaño del contador interno que se emplea para contar el
número de ciclos que van llegando) y el bit del parámetro D correspondiente
a esa etapa. En el Código 5.2 se muestra cómo se realiza la interconexión
de las etapas para implementar el bloque de control de frecuencia. Con este
número de etapas la frecuencia mínima de salida del módulo de ajuste es
de 3,50 MHz y la frecuencia máxima de salida es igual a la frecuencia del
prescaler (4,54 MHz).
Código 5.1: Etapa genérica del módulo de control de frecuencia implementada
en VHDL.1 --//////////////////////////////////////////////////////////////////////
2 --//// stage_2_pot_n_minus_i .vhd ////
3 --//////////////////////////////////////////////////////////////////////
4
5 library IEEE;
6 use IEEE. STD_LOGIC_1164.ALL ;
7 use IEEE. STD_LOGIC_ARITH.ALL ;
8 use IEEE. STD_LOGIC_SIGNED.ALL ;
9
10 entity stage_2_pot_n_minus_i is
11 generic (
12 exp : integer -- exp = n_menos_i
13 );
14
15 Port (
16 clk : in std_logic ;
17 rst : in std_logic ;
18 en : in std_logic ;
19 en_in : in std_logic ;
20 di : in std_logic ;
21 en_out : out std_logic
22 );
23 end stage_2_pot_n_minus_i ;
24
25 architecture Behavioral of stage_2_pot_n_minus_i is
26
27 signal Counter : std_logic_vector(exp -1 downto 0);
28

5.1. Implementación hardware de los módulos del sistema 171
29 begin
30 Counter_2_pot_n_minus_i : process (clk , rst , en)
31 begin
32 if(rst = ’1’) then
33 Counter <= (others => ’0’);
34 elsif(clk = ’1’ and clk ’event) then
35 if (en = ’1’ and en_in = ’1’) then
36 Counter <= Counter + 1;
37 end if;
38 end if;
39 end process ;
40 Generate_Outputs: process (Counter , di, en_in )
41 begin
42 if(di = ’1’ and Counter = "0") then
43 en_out <= ’0’;
44 else
45 en_out <= en_in;
46 end if;
47 end process ;
48 end Behavioral ;
Código 5.2: Implementación del bloque de control de frecuencia en VHDL.1 --//////////////////////////////////////////////////////////////////////
2 --//// clock_controller.vhd ////
3 --//////////////////////////////////////////////////////////////////////
4
5 library IEEE;
6 use IEEE.STD_LOGIC_1164.ALL ;
7 use IEEE.STD_LOGIC_ARITH.ALL ;
8 use IEEE.STD_LOGIC_SIGNED.ALL ;
9
10 entity clock_controller is
11 Port ( clk : in std_logic ;
12 rst : in std_logic ;
13 en : in std_logic ;
14 en_in : in std_logic ;
15 di : in std_logic_vector (19 downto 0);
16 en_out : out std_logic
17 );
18 end clock_controller;
19
20 architecture Behavioral of clock_controller is
21 component stage_2_pot_n_minus_i
22 generic (
23 exp : integer := 0
24 );
25 port (
26 clk : in std_logic ;
27 rst : in std_logic ;

172 Capítulo 5. Implementación de la plataforma de sincronización
28 en : in std_logic ;
29 en_in : in std_logic ;
30 di : in std_logic ;
31 en_out : out std_logic
32 );
33 end component ;
34
35 signal en_out_1 , en_out_2 , en_out_19 : std_logic ;
36 -- Declaration of the rest of internal signals
37
38 begin
39 Counter_2_pot_3: stage_2_pot_n_minus_i
40 generic map (
41 exp => 3
42 )
43 port map (
44 clk => clk ,
45 rst => rst ,
46 en => en ,
47 en_in => en_in ,
48 di => di(19),
49 en_out => en_out_1
50 );
51 Counter_2_pot_4: stage_2_pot_n_minus_i
52 generic map (
53 i => 4
54 )
55 port map (
56 clk => clk ,
57 rst => rst ,
58 en => en ,
59 en_in => en_out_1 ,
60 di => di(18),
61 en_out => en_out_2
62 );
63 -- Instantiation and connection of the rest of stages
64 Counter_2_pot_22: stage_2_pot_n_minus_i
65 generic map (
66 exp => 22
67 )
68 port map (
69 clk => clk ,
70 rst => rst ,
71 en => en ,
72 en_in => en_out_19 ,
73 di => di(0),
74 en_out => en_out
75 );
76 end Behavioral ;

5.2. Simulación funcional 173
Un aspecto a destacar de la implementación realizada es que se ha dise-
ñado una estructura escalable. Este hecho permite la adaptación del sistema
a diferentes configuraciones de frecuencias del oscilador y resoluciones del
contador de hora local de forma que se pueda determinar, en función de
las exigencias de precisión de cada aplicación, la implementación óptima a
aplicar.
El bloque de control del reloj (Fig. 5.8) se divide en dos partes; la primera
de ellas se encarga de implementar los algoritmos de sincronización presenta-
dos en el Capítulo 3, apartado 3.5.3 y la segunda de calcular las correcciones
a partir de los desplazamientos calculados por el bloque de cálculo del des-
plazamiento. Para la implementación del algoritmo de sincronización se ha
realizado la descripción en HDL de una FSM que permite controlar el resto
de módulos en función del estado de sincronización en el que se encuentre
el cliente o el servidor SNTP. Para el cálculo del desplazamiento y de las
correcciones se ha implementado una ruta de datos empleando sumadores,
restadores, divisores y registros específicos de System Generator for
DSP. En concreto, se ha puesto especial énfasis en la implementación de es-
tos módulos intentando aprovechar al máximo la potencia de la herramienta
a nivel de sistemas comentada en el Capítulo 4, apartado 4.4. Esta potencia
reside en el hecho de que System Generator for DSP facilita en gran
medida el proceso de implementación permitiendo a los diseñadores centrarse
en la optimización de la arquitectura y obtener una estructura del sistema
muy eficiente [Viejo et al., 2007a]. En las Fig. 5.9 y 5.10 se muestran los
módulos de cálculo del desplazamiento y de correcciones, observándose cómo
las operaciones se realizan empleando números en punto fijo. Otro detalle
importante es que los resultados de las diferentes operaciones realizadas son
siempre proporcionados con precisión completa evitando así la acumulación
de errores de truncado o redondeo en el cálculo de las correcciones.
5.2. Simulación funcional
Dentro de las metodologías de diseño presentadas, una parte importante
de las mismas consiste en la simulación funcional de los diseños. Para reali-
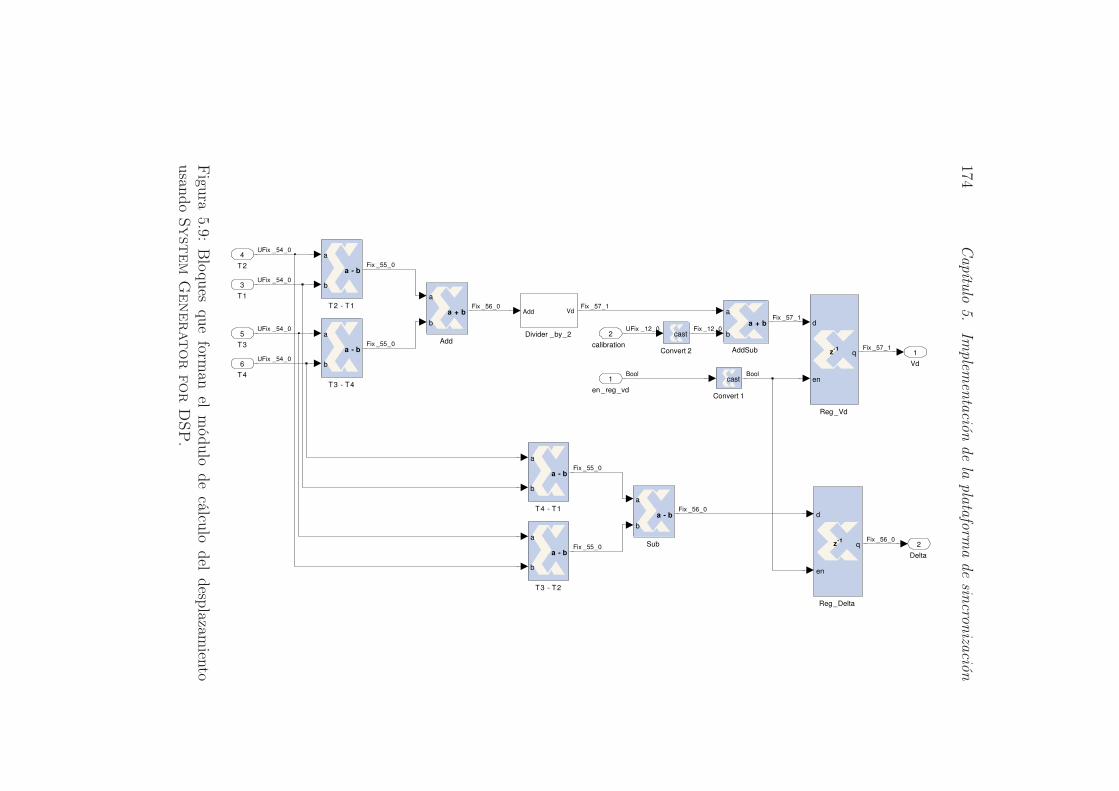
174C
apítulo5.
Implem
entaciónde
laplataform
ade
sincronización
Delta
2
Vd
1
T4 - T1
a
b
a - b
T3 - T4
a
b
a - b
T3 - T2
a
b
a - b
T2 - T1
a
b
a - b
Sub
a
b
a - b
Reg_Vd
d
en
qz-1
Reg_Delta
d
en
qz-1
Divider _by_2
Add Vd
Convert 2
cast
Convert 1
cast
AddSub
a
b
a + b
Add
a
b
a + b
T4
6
T3
5
T2
4
T1
3
calibration
2
en_reg_vd
1
Fix _56_0
Fix _55_0
Fix _55_0
UFix _54_0
UFix _54_0
UFix _54_0
UFix _54_0
Bool Bool
Fix _57_1
Fix _57_1
UFix _12_0 Fix _12_0
Fix _56_0
Fix _55_0
Fix _55_0
Fix _56_0
Fix _57_1
Figura
5.9:B
loquesque
forman
elm
ódulode
cálculodel
desplazamiento
usandoSyst
em
Generator
for
DSP
.

5.2.Sim
ulaciónfuncional
175
d0
2
d
1
Vs - Vsp
a
b
a - b
Register 2
d qz-1
Reg_D0
d
en
qz-1
Reg_D
d
en
qz-1
Mux 2
sel
d0
d1
d2
Mux 1
sel
d0
d1
d2Mux
sel
d0
d1
Logical
or
z-0
Divider _2_exp _q
a
q
Vd _div _2_exp _q
D
a
b
a - bz-1
Convert 3
cast
Convert 2
cast
Check_D0
D0_in
sel _d0
d0
d0_max
d0_min
Check_D
D_in
sel _d
d
d_max
d_min
AddSub
a
b
a - b
(Vs_div _2_exp _q)_div _2_exp _p
p
a
AD 2
(Vs - Vsp)_div _2_exp _p
a
p
AD 1
parameters _ready
7
nominal _d
6
q
5
p
4
en_reg_d
3
Vdp
2
Vd
1
UFix _20 _0
Fix _32 _10
Fix _32 _10
Fix _32 _10
Fix _32 _10
UFix _4_0
UFix _4_0
UFix _20 _0
UFix _20 _0
Bool
UFix _1_0
UFix _1_0
Bool
Bool
Fix _32 _10
Fix _32 _10
Fix _32 _10
UFix _2_0
UFix _20 _0
UFix _20 _0
UFix _20 _0
UFix _20 _0
UFix _2_0
UFix _20 _0
UFix _20 _0
UFix _20 _0
UFix _20 _0
UFix _20 _0
Fix _32 _10
Fix _32 _10
Figura
5.10:Bloques
queform
anelm
ódulode
cálculode
correccionesusando
Syst
em
Generator
for
DSP
.

176 Capítulo 5. Implementación de la plataforma de sincronización
zar dicha simulación se ha desarrollado un conjunto de scripts en lenguaje
Matlab y se ha empleado una serie de herramientas que han permitido
comprobar el correcto funcionamiento de los diferentes bloques que forman
la plataforma de sincronización implementada. A continuación, se van a co-
mentar los aspectos de simulación más importantes.
En relación con la simulación empleando el entorno de desarrollo Mat-
lab/Simulink se ha programado un total de 10 scripts que permiten realizar
las siguientes acciones: (1) programación de la memoria RAM que almacena
los paquetes a transmitir, (2) programación de la memoria RAM que contie-
ne los parámetros de configuración estáticos del diseño y (3) generación de
los estímulos de entrada a los módulos de interfaz de protocolos y configura-
ción y de sincronización. Estos estímulos simulan la recepción de peticiones
o respuestas de los servicios implementados (Fig. 5.11) o la llegada de la
información temporal del GPS. En la Tabla 5.2 se detallan las acciones que
realizan cada uno de los scripts desarrollados.
Figura 5.11: Simulación funcional de la recepción de un paquete de configu-ración usando HDL co-simulation.
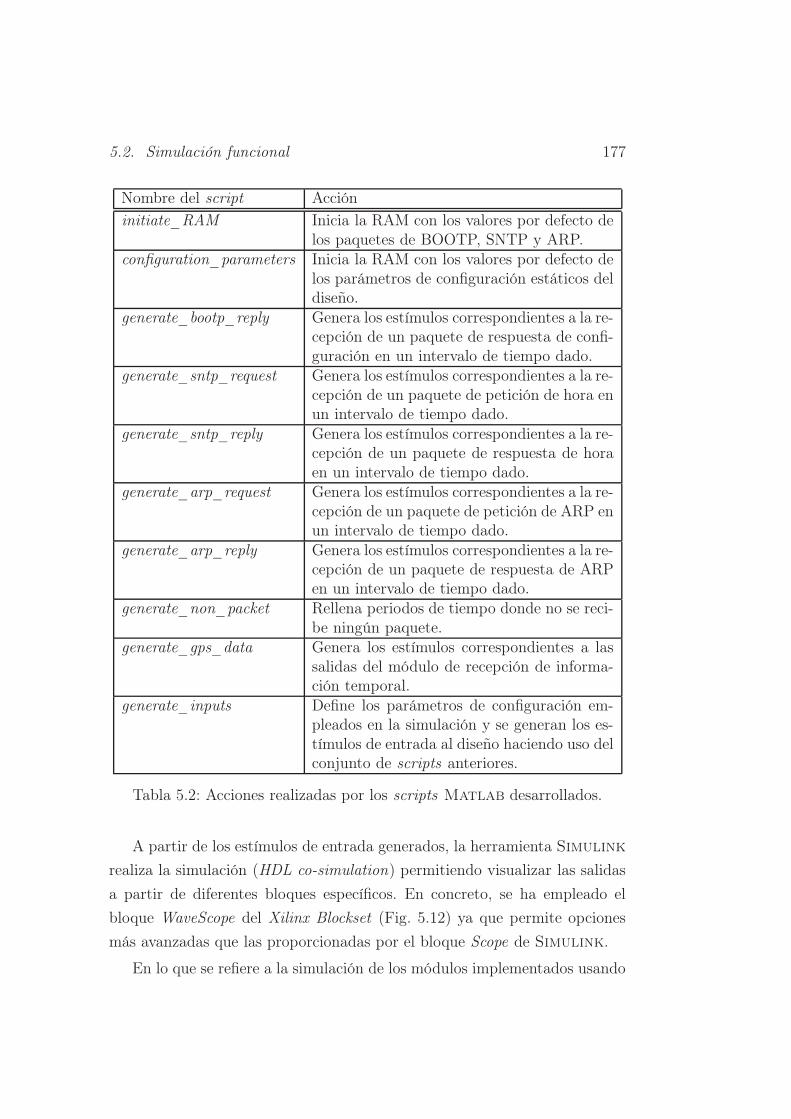
5.2. Simulación funcional 177
Nombre del script Acción
initiate_RAM Inicia la RAM con los valores por defecto delos paquetes de BOOTP, SNTP y ARP.
configuration_parameters Inicia la RAM con los valores por defecto delos parámetros de configuración estáticos deldiseño.
generate_bootp_reply Genera los estímulos correspondientes a la re-cepción de un paquete de respuesta de confi-guración en un intervalo de tiempo dado.
generate_sntp_request Genera los estímulos correspondientes a la re-cepción de un paquete de petición de hora enun intervalo de tiempo dado.
generate_sntp_reply Genera los estímulos correspondientes a la re-cepción de un paquete de respuesta de horaen un intervalo de tiempo dado.
generate_arp_request Genera los estímulos correspondientes a la re-cepción de un paquete de petición de ARP enun intervalo de tiempo dado.
generate_arp_reply Genera los estímulos correspondientes a la re-cepción de un paquete de respuesta de ARPen un intervalo de tiempo dado.
generate_non_packet Rellena periodos de tiempo donde no se reci-be ningún paquete.
generate_gps_data Genera los estímulos correspondientes a lassalidas del módulo de recepción de informa-ción temporal.
generate_inputs Define los parámetros de configuración em-pleados en la simulación y se generan los es-tímulos de entrada al diseño haciendo uso delconjunto de scripts anteriores.
Tabla 5.2: Acciones realizadas por los scripts Matlab desarrollados.
A partir de los estímulos de entrada generados, la herramienta Simulink
realiza la simulación (HDL co-simulation) permitiendo visualizar las salidas
a partir de diferentes bloques específicos. En concreto, se ha empleado el
bloque WaveScope del Xilinx Blockset (Fig. 5.12) ya que permite opciones
más avanzadas que las proporcionadas por el bloque Scope de Simulink.
En lo que se refiere a la simulación de los módulos implementados usando
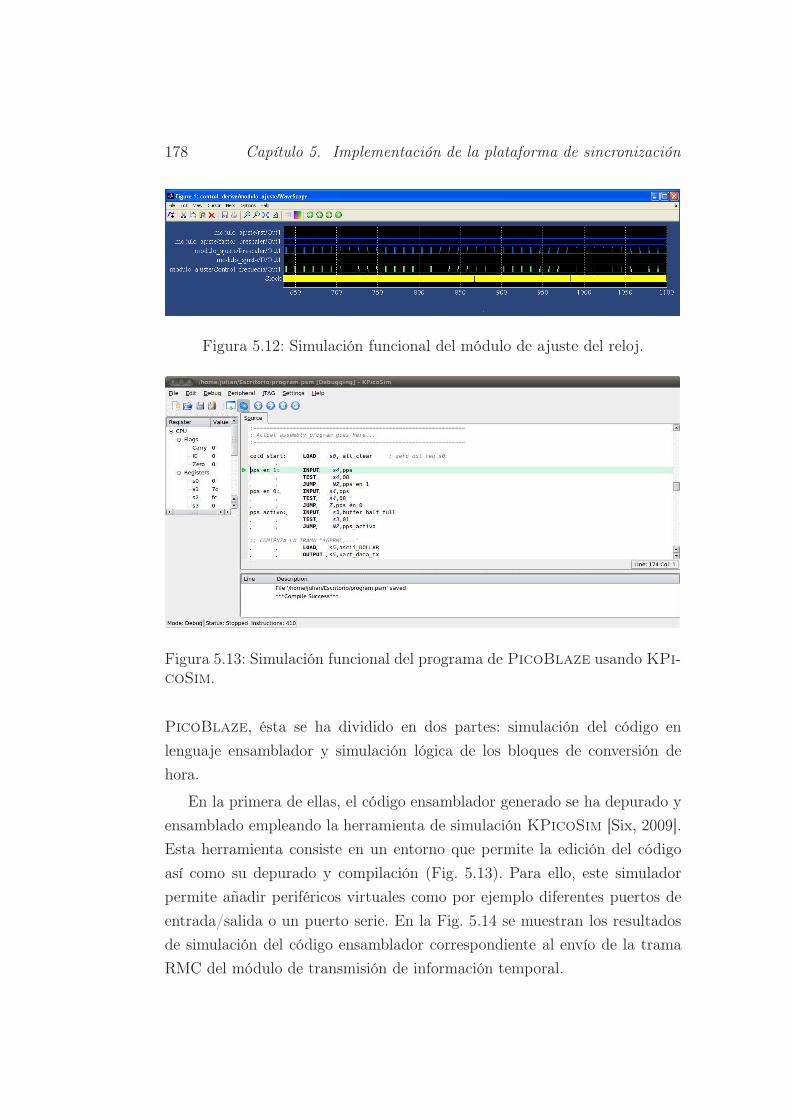
178 Capítulo 5. Implementación de la plataforma de sincronización
Figura 5.12: Simulación funcional del módulo de ajuste del reloj.
Figura 5.13: Simulación funcional del programa de PicoBlaze usando KPi-coSim.
PicoBlaze, ésta se ha dividido en dos partes: simulación del código en
lenguaje ensamblador y simulación lógica de los bloques de conversión de
hora.
En la primera de ellas, el código ensamblador generado se ha depurado y
ensamblado empleando la herramienta de simulación KPicoSim [Six, 2009].
Esta herramienta consiste en un entorno que permite la edición del código
así como su depurado y compilación (Fig. 5.13). Para ello, este simulador
permite añadir periféricos virtuales como por ejemplo diferentes puertos de
entrada/salida o un puerto serie. En la Fig. 5.14 se muestran los resultados
de simulación del código ensamblador correspondiente al envío de la trama
RMC del módulo de transmisión de información temporal.

5.2. Simulación funcional 179
La segunda parte de la simulación se ha realizado empleando un simulador
lógico. Así, en la Fig. 5.15 se muestra la simulación funcional del bloque de
conversión de hora empleando la herramienta ISE Simulator de Xilinx.
Figura 5.14: Resultados de la simulación funcional del programa usando KPi-coSim.
time_valid
0 ns 500 ns 1,000 ns 1,500 ns
Figura 5.15: Simulación funcional del bloque de conversión de hora.

180 Capítulo 5. Implementación de la plataforma de sincronización
5.3. Resultados de implementación hardware
En esta sección se van a comentar los principales resultados de implemen-
tación hardware obtenidos. En este sentido, por un lado, se van a analizar
los recursos de la FPGA ocupados por los diseños del cliente y del servidor
SNTP y, por otro lado, la cantidad de recursos empleados por cada uno de
los módulos implementados respecto del total ocupado por cada diseño.
En relación con los primeros resultados la implementación del cliente y
de servidor SNTP se ha realizado sobre una FPGA de la familia Spartan de
Xilinx. En concreto, se ha utilizado una FPGA Spartan-3E XC3S500E,
con una equivalencia de 500000 puertas lógicas, que se encuentra en la gama
media de su serie y cuyas principales características son su bajo coste y
el hecho de disponer de recursos on-chip como multiplicadores y memorias
RAM empotradas.
En las Tablas 5.3 y 5.4 se muestran los resultados de implementación
del cliente y del servidor SNTP, respectivamente. Como se observa en estas
tablas la ocupación en slices se sitúa en el 77% para el cliente y en el 62%
para el servidor; para el resto de recursos (Slice Flip Flops, 4-input LUT y
BRAM), todos se encuentran por debajo del 50%. Estos resultados indican
que aún es posible incluir nuevas funcionalidades para mejorar la arquitectura
y los algoritmos desarrollados sin tener que emplear un dispositivo de gama
superior y, por tanto, de mayor coste.
En cuanto a los recursos empleados por cada módulo respecto del diseño
completo, en las Tablas 5.5 y 5.6 se proporciona información relativa a los
porcentajes de cada recurso empleados por los módulos que forman el cliente
y el servidor SNTP, respectivamente. A continuación, se va a realizar un
Recurso Usado Disponible Utilización ( %)
Slices 3615 4656 77 %Slice Flip Flops 3753 9312 40 %4-input LUT 4475 9312 48 %RAMB16 5 20 25 %
Tabla 5.3: Resultados de implementación hardware del cliente SNTP.

5.3. Resultados de implementación hardware 181
Recurso Usado Disponible Utilización ( %)
Slices 2927 4656 62 %Slice Flip Flops 2941 9312 31 %4-input LUT 3424 9312 36 %RAMB16s 5 20 25 %
Tabla 5.4: Resultados de implementación hardware del servidor SNTP.
Módulo Slices Slice FFs LUTs RAMB16s
Top level del diseño 16,82 % 0,19 % 15,60 % 0 %Controlador Ethernet MAC 14,91 % 21,50 % 16,14 % 40 %Controlador del puerto serie 0,38 % 0,40 % 0,79 % 0 %Interfaz de protocolos y comu-nicación
31,34 % 38,37 % 26,09 % 40 %
Módulo de sincronización 16,86 % 13,75 % 20,63 % 0 %Módulo de transmisión de in-formación temporal
19,69 % 25,79 % 20,75 % 20 %
Total 100 % 100 % 100 % 100 %
Tabla 5.5: Porcentajes de recursos hardware empleados por los módulos queforman el cliente SNTP.
Módulo Slices Slice FFs LUTs RAMB16s
Top level del diseño 21,22 % 0,24 % 18,78 % 0 %Controlador Ethernet MAC 19,59 % 27,44 % 20,66 % 40 %Controlador del puerto serie 0,98 % 1,36 % 2,29 % 0 %Interfaz de protocolos y comu-nicación
33,78 % 44,17 % 26,48 % 40 %
Módulo de sincronización 17,91 % 20,09 % 19,99 % 0 %Módulo de recepción de infor-mación temporal
6,52 % 6,70 % 11,80 % 20 %
Total 100 % 100 % 100 % 100 %
Tabla 5.6: Porcentajes de recursos hardware empleados por los módulos queforman el servidor SNTP.
análisis de los resultados mostrados en las tablas anteriores:
1. Los recursos empleados por los top levels de los diseños se deben a que
éstos incluyen un módulo de control de la señal de reset y de reloj
necesario para el correcto funcionamiento del circuito tras la puesta en

182 Capítulo 5. Implementación de la plataforma de sincronización
marcha del dispositivo.
2. En relación con las BRAM utilizadas, éstas únicamente se han emplea-
do en los diseños del controlador Ethernet MAC para implementar las
FIFO de recepción y transmisión de paquetes, en la interfaz de pro-
tocolos y configuración para almacenar los paquetes y los parámetros
de configuración estáticos y en los módulos de transmisión y recep-
ción serie para guardar el programa que ejecuta PicoBlaze. En este
sentido, aún queda disponible un 75% de las BRAM que podrían ser
empleadas para mejorar el algoritmo de sincronización. Así, una po-
sible mejora consiste en el almacenamiento en BRAM de más de un
desplazamiento previo, de forma que se pueda plantear un algoritmo
de cálculo de correcciones más avanzado que permita incrementar la
precisión y estabilidad de la solución actual.
3. El módulo que más recursos emplea es la interfaz de protocolos y con-
figuración. Este hecho se debe a que este bloque es el que realiza la
mayor parte de las tareas críticas del sistema, integrando el control de
las comunicaciones, la gestión de la configuración, los temporizadores,
etc. En el lado opuesto, los módulos que menos recursos emplean son
los controladores de puerto serie, destacando en este caso el empleo
de lógica distribuida para la implementación de las FIFO debido a su
pequeño tamaño (sólo 16 bytes).
4. Otro aspecto a destacar es que la implementación del módulo de sincro-
nización no emplea excesivos recursos hardware por lo que se podrían
plantear mejoras relativas a aumentar la resolución del reloj local y
el número de etapas (siempre y cuando se disponga de un oscilador
adecuado para la nueva configuración).
5. La diferencia de recursos entre los módulos de transmisión y recepción
de información temporal se debe a que en el primero se emplean diviso-
res y sumadores hardware para realizar la conversión de hora mientras
que en el segundo se han utilizado únicamente sumadores para realizar
esta tarea.

5.4. Conclusiones 183
Finalmente, en cuanto a la frecuencia máxima de operación se han obte-
nido unos resultados de 50,32 MHz y 50,69 MHz para los diseños del cliente
y del servidor, respectivamente. En este aspecto, al disponer de un oscilador
de 50 MHz las frecuencias obtenidas cumplen las restricciones del sistema no
siendo necesario optimizar los diseños en términos de velocidad de operación.
5.4. Conclusiones
En este capítulo se han abordado diferentes aspectos de la implementación
hardware de los bloques que forman la arquitectura del cliente y del servidor
SNTP. Así, en primer lugar, se han comentado los detalles de implementación
más importantes. En segundo lugar, se han presentado aspectos relacionados
con la simulación de los módulos. Por último, se han analizado los recursos
hardware empleados por cada diseño. A continuación, se van a presentar la
conclusiones más importantes.
En relación con los detalles de implementación, el primer aspecto a des-
tacar consiste en la utilización de BRAM del dispositivo programable para
la implementación de las FIFO de recepción y transmisión del controlador
Ethernet MAC. Mediante esta acción se ha conseguido mejorar el tiempo de
acceso de las operaciones de lectura y escritura de los paquetes Ethernet,
lo que a su vez se traduce en una reducción de la variabilidad en el retraso
de dichas operaciones. En relación con la implementación de los bloques de
recepción y transmisión de información temporal destaca la programación
de una serie de subrutinas en el lenguaje ensamblador de PicoBlaze que
implementan la mayor parte de la funcionalidad de estos módulos, realizando
únicamente en hardware la conversión entre formatos de hora. En cuanto a la
implementación de la interfaz de protocolos y configuración y del módulo de
sincronización, los aspectos más importantes consisten en la descripción de
un conjunto de módulos empleando lenguajes de descripción de hardware y
bloques específicos de la herramienta a nivel de sistemas System Genera-
tor for DSP. Entre estos módulos destacan aquellos que se encargan del
cálculo del desplazamiento y las correcciones y del ajuste del reloj local. De
este último módulo se puede resaltar el hecho de que es totalmente configu-

184 Capítulo 5. Implementación de la plataforma de sincronización
rable y escalable, pudiéndose adaptar fácilmente a diferentes configuraciones
de frecuencias del oscilador y resoluciones del contador de hora local.
En cuanto a la simulación de los bloques cabe destacar el desarrollo de
un conjunto de scripts Matlab que permiten la verificación funcional de los
bloques implementados dentro del entorno de simulación Simulink. Además,
para la verificación del código ensamblador se ha presentando una herramien-
ta que permite depurar de forma sencilla el código desarrollado.
Finalmente, en términos de resultados de implementación hardware es
importante comentar que se ha empleado un dispositivo programable de ba-
jo coste para la programación de los diseños. Una vez implementados, cabe
destacar que tanto el cliente como el servidor SNTP no han ocupado el total
de recursos de la FPGA utilizada, lo cual indica que se trata de soluciones
compactas que se podrían integrar dentro de sistemas más complejos, habi-
tualmente implementados en dispositivos de mayor capacidad y prestaciones.

Parte III
Metodologías de verificación,
pruebas del sistema y resultados
185


Capítulo 6
Metodologías de verificación y
pruebas del sistema
Una vez implementada la plataforma de sincronización, una tarea impor-
tante consiste en la verificación de los sistemas ya implementados (test), esto
es del cliente y del servidor SNTP. Para realizar este proceso de validación
resulta necesario establecer una metodología de verificación adecuada al tipo
de sistema que se quiere validar y donde su implementación sobre un disposi-
tivo programable juega un papel fundamental. En este sentido, en la primera
parte de este capítulo se van a presentar las principales ventajas del uso de
dispositivos programables con respecto a la verificación de sistemas, y ana-
lizar las soluciones de verificación actuales ofertadas fundamentalmente por
los fabricantes de este tipo de dispositivos.
En relación con las herramientas de verificación para FPGA existentes,
éstas presentan una serie de limitaciones derivadas del hecho de que las mues-
tras capturadas se almacenan empleando recursos internos del dispositivo
programable, lo cual supone un gran inconveniente cuando se persigue ve-
rificar el sistema durante un periodo largo de tiempo. Un buen ejemplo de
este hecho consiste en la plataforma de sincronización desarrollada en este
trabajo, donde resulta imprescindible la adquisición de información interna
del diseño cada pocos segundos durante un periodo de días o incluso semanas
para poder determinar el correcto funcionamiento del sistema. Así, en la se-
187

188 Capítulo 6. Metodologías de verificación y pruebas del sistema
gunda parte del capítulo se va a presentar una plataforma de verificación para
sistemas de sincronización que resuelve las limitaciones de las herramientas
comerciales y permite la validación de este tipo de sistemas.
Finalmente, para llevar a cabo la verificación de los sistemas implementa-
dos, resulta necesario definir una serie de escenarios a los que la plataforma
de sincronización debe someterse y un conjunto de parámetros de calidad que
una vez medidos y evaluados determinarán el correcto funcionamiento de la
misma. En este aspecto, en la última parte del capítulo se propondrán tanto
los parámetros de calidad que se van a medir como los escenarios de pruebas
que se van a analizar.
6.1. Verificación de sistemas en dispositivos
programables
En la última década las FPGA se han convertido en la tecnología de im-
plementación de sistemas digitales empotrados más extendida debido prin-
cipalmente a que su capacidad de reconfiguración aporta grandes ventajas
frente a otras tecnologías como los ASIC. A continuación, se van a presentar
las ventajas más importantes.
La primera ventaja consiste en la reducción del tiempo de diseño, ya que al
emplear esta tecnología no resulta necesario imponer una fase de simulación
del diseño tan exhaustiva como ocurre en el caso del ASIC. Esto se debe
a que estos dispositivos permiten un rápido prototipado del circuito y su
depuración sobre hardware real, lo cual facilita la verificación durante la fase
de diseño y reduce significativamente el tiempo de desarrollo.
La segunda es la capacidad de emplear las FPGA más allá de la etapa
de prototipado. En este sentido, el coste cada vez más reducido de estos
dispositivos junto con un creciente aumento de sus prestaciones hacen que
esta tecnología sea adecuada no sólo para fabricar un prototipo sino también
para producir un volumen bajo o medio de unidades.
De la primera ventaja expuesta se deduce que, empleando dispositivos
programables, la verificación del diseño se pueda realizar bien por simulación

6.2. Soluciones para la verificación de sistemas en dispositivosprogramables 189
funcional o bien por ejecución en hardware real [Wheeler et al., 2001; Graham,
2001; Ohba and Takano, 2006]. La simulación funcional es especialmente útil
durante las primeras etapas del flujo de diseño para asegurar la correcta ope-
ración del sistema. Sin embargo, hay escenarios donde la simulación no es una
alternativa factible, como ocurre en la verificación de un sistema empotrado
complejo, debido a que el tiempo de simulación podría ser extremadamente
amplío y por tanto los recursos computaciones disponibles podrían resultar
escasos. En estos casos, la ejecución hardware es una alternativa interesan-
te, derivada de la naturaleza re-programable de las FPGA, que permite la
observación del diseño bajo test en tiempo real durante su operación. Tales
observaciones son realizadas empleando analizadores lógicos externos (Stan-
dalone Logic Analyzers, SLA) o los denominados analizadores lógicos on-chip
(On-chip Logic Analyzers, OLA) como ChipScope Pro [Xilinx, 2009a] de
Xilinx o SignalTap [Altera, 2009] de Altera. Estos analizadores lógicos
on-chip son capaces de adquirir datos a una frecuencia muy elevada y alma-
cenar los resultados en memoria para su posterior procesado. A continuación,
en el siguiente apartado, se van a analizar las características de los diferentes
tipos de analizadores comentados.
6.2. Soluciones para la verificación de sistemas
en dispositivos programables
Actualmente, hay tres tipos de soluciones cuando se pretende realizar la
verificación de un sistema digital implementado en un dispositivo programa-
ble: (1) analizadores lógicos externos, (2) analizadores lógicos on-chip y (3)
soluciones a medida para propósitos específicos.
Tradicionalmente, el testado de un sistema digital se ha realizado em-
pleando analizadores lógicos externos. Estos equipos proporcionan un gran
número de canales (100 o más) y son capaces de adquirir datos de cualquier
señal accesible a través de los pines del chip. Además, al presentar una ve-
locidad de captura muy elevada posibilitan la depuración de sistemas que
trabajan a alta frecuencia. Sin embargo, estos analizadores lógicos presentan

190 Capítulo 6. Metodologías de verificación y pruebas del sistema
principalmente dos inconvenientes a la hora de testar un circuito implemen-
tado en un chip:
1. El acceso a las señales del sistema sólo se puede realizar a través de pines
de la FPGA. Esto hace necesario tener que enrutar las señales internas
que se deseen capturar hacia pines del chip, lo cual presenta a su vez
una serie de limitaciones. Por un lado, la conexión de las sondas del
analizador lógico con los pines de la FPGA resulta una tarea compleja
y en algunas ocasiones imposible debido a que con las tecnologías de
empaquetado actuales no se puede asegurar una completa visibilidad
de todos los pines de la FPGA. Por otro lado, estas conexiones de
señales internas a pines de la FPGA generan nuevos caminos lógicos
con temporizaciones diferentes de las originales.
2. El tamaño de la ventana temporal de captura está limitado por el
número de muestras máximo que permita almacenar en memoria el
analizador lógico que se esté empleando.
Por estas razones se ha hecho imprescindible la adopción de nuevas me-
todologías y herramientas eficientes para la depuración y verificación de los
diseños implementados sobre FPGA [Graham, 2001; Wheeler et al., 2001;
Ohba and Takano, 2006]. Así, desde hace unos años se han puesto a disposi-
ción de los diseñadores un conjunto de herramientas de verificación basadas
en la integración de un analizador lógico dentro del propio dispositivo progra-
mable [Ehrenpreis et al., 2006; Lee et al., 2007; Knittel et al., 2008; Xilinx,
2009a; Altera, 2009]. Este tipo de verificación se ha denominado depuración
on-chip ya que el analizador se añade como un componente más del siste-
ma y se implementa sobre el dispositivo programable junto con el diseño.
Con estas herramientas se consigue resolver el problema de poder acceder
a las señales internas del sistema, aunque siguen presentando los siguientes
inconvenientes:
1. Realizar la conexión de las señales con el analizador requiere un esfuerzo
por parte del diseñador, sobre todo si es necesario capturar señales
pertenecientes a subsistemas muy alejados del top level del sistema.

6.2. Soluciones para la verificación de sistemas en dispositivosprogramables 191
2. Estas alternativas emplean recursos de la FPGA tanto para la im-
plementación del analizador lógico integrado como para almacenar las
muestras capturadas. En este sentido, los recursos utilizados dependen
del número de señales y del número de muestras, estando limitado el
tamaño de la ventana temporal de captura por la cantidad de memoria
RAM que deja libre el diseño bajo test [Arshak et al., 2006; Ehrenpreis
et al., 2006].
3. La introducción de lógica adicional es una técnica invasiva. Esto signi-
fica que el rendimiento total del sistema bajo test será menor e incluso
podría presentar características funcionales y temporales diferentes a
las del circuito original [Ohba and Takano, 2006].
4. No son capaces de capturar muestras de determinados tipos de señales
como por ejemplo de señales triestado.
Como se puede deducir del análisis realizado, el principal problema que
presentan estas dos alternativas consiste en que el número de muestras que se
pueden capturar del sistema está limitado por la cantidad de memoria dispo-
nible. En este aspecto, existen multitud de aplicaciones donde esta limitación
no resulta un serio inconveniente para la verificación del sistema. En efecto,
en la actualidad el aspecto crítico suele ser la velocidad de captura debido
a que en general los circuitos bajo test trabajan a frecuencias de operación
elevadas. Por esta razón, las herramientas presentadas no están optimizadas
para la adquisición de un gran número de muestras sino para capturar datos
a alta frecuencia.
No obstante, existe otro tipo de aplicaciones en las que, para realizar
una correcta verificación del sistema, resulta necesario el análisis de un gran
número de eventos distribuidos sobre un largo periodo de tiempo, lo cual
requiere a su vez una gran cantidad de recursos de almacenamiento. Un caso
concreto de este tipo de diseños son los sistemas de sincronización que se
están abordando en este trabajo, donde los eventos sobre los que se realiza
el test de fiabilidad tienen una separación del orden de los segundos y son
analizados durante días, semanas o incluso meses. Así, al no adaptarse las

192 Capítulo 6. Metodologías de verificación y pruebas del sistema
herramientas existentes a las características de los sistemas que se pretende
verificar, esto obliga a desarrollar nuevas herramientas que permitan abordar
la verificación de este tipo de diseños.
La alternativa de verificación on-chip propuesta es una plataforma de
verificación que denominamos analizador de eventos lógicos o Logical Event
Analyzer (LEA). Este nombre se debe a que esta herramienta no va a realizar
una verificación del diseño ciclo a ciclo de reloj sino que estará controlada
por eventos lógicos espaciados en el tiempo; cada vez que se produzca uno
de estos eventos se procederá a adquirir el estado del sistema en ese instan-
te y a continuación se transmitirá la información adquirida a través de un
puerto estándar RS-232 o Joint Test Action Group Boundary-scan (JTAG),
no siendo necesario el almacenamiento de las muestras dentro del dispositivo
programable.
En definitiva, con el LEA se pretende cubrir uno de los huecos dejados
por los analizadores lógicos existentes tal y como se muestra en la Fig. 6.1.
En concreto, nos referimos a la limitación de los analizadores, tanto externos
como on-chip, de poder capturar únicamente un número finito y no muy
elevado de muestras. Con esta nueva herramienta se consigue que los recursos
de almacenamiento empleados para realizar la depuración del diseño sean
independientes del número de muestras de forma que el sistema pueda ser
testado indefinidamente.
En el siguiente apartado se describe en detalle la plataforma de verifica-
ción propuesta.
6.3. Plataforma de verificación para sistemas
de sincronización
La plataforma de verificación que se presenta en este apartado se ha
desarrollado para verificar el sistema de sincronización implementado, aun-
que debido a su arquitectura flexible podría adaptarse a otros diseños de
características similares. Como se ha comentado anteriormente, esta plata-
forma debe tener la capacidad de adquirir un número elevado de eventos del

6.3. Plataforma de verificación para sistemas de sincronización 193
Figura 6.1: Campo de aplicación de las herramientas de verificación analiza-das.
sistema lo cual implica que las muestras capturadas no pueden ser almacena-
das empleando recursos propios de la FPGA. De esta forma, la solución que
se plantea consiste en transmitir los datos capturados, siendo una aplicación
software externa la que se encargue de procesar y almacenar la información
enviada. Esto resulta factible debido a que los eventos a partir de los que
se van a tomar muestras del sistema están espaciados en el tiempo, pudien-
do oscilar el rango de estos eventos desde unos pocos segundos a muchos
minutos.
A continuación, en los siguientes subapartados se van a presentar la ar-
quitectura desarrollada y el software de recepción y almacenamiento de la
información. Una vez introducidos estos dos elementos, se realizará una com-
parativa de esta herramienta frente a la herramienta comercial ChipScope
Pro donde se analizará el consumo de recursos empleados por cada una de
estas alternativas en función del número de muestras y del número de señales

194 Capítulo 6. Metodologías de verificación y pruebas del sistema
a capturar.
6.3.1. Arquitectura de la plataforma de verificación pro-
puesta
La arquitectura del analizador de eventos lógicos propuesto se basa en
el microprocesador PicoBlaze de Xilinx (Fig. 6.2). En concreto, se ha
empleado la versión de PicoBlaze adaptada para dispositivos Spartan3
la cual permite el direccionamiento de 256 puertos de entrada de 8 bits.
Como se observa en la figura anterior, un conjunto de puertos de entrada
de PicoBlaze se reserva para las señales de disparo, reloj y control de la
comunicación; los restantes puertos se utilizan para capturar las señales de
datos. Así, usando un único módulo de PicoBlaze y dedicando N puertos a
las señales de disparo, reloj y control, este analizador permite capturar (256−
N)× 8 señales de un bit. Sin embargo, como se va a exponer a continuación,
el número de señales de datos que se pueden adquirir está también limitado
por la velocidad a la que se puede transmitir la información capturada fuera
del chip.
En relación con el último punto tratado en el párrafo anterior, PicoBla-
ze emplea uno de sus puertos de salida para comunicarse con una UART que
se encarga de enviar los datos capturados vía serie. Esta UART permite con-
figurar su velocidad (baud rate) mediante la señal conf_baud y proporciona
Figura 6.2: Arquitectura del analizador de eventos lógicos.

6.3. Plataforma de verificación para sistemas de sincronización 195
una señal de estado de su buffer interno, que será usada por PicoBlaze para
controlar la escritura de los datos a la UART. Asumiendo la siguiente confi-
guración para la UART: formato fijo del dato de envío “8N1”, comunicación
a través de los pines RX/TX (sin usar otros adicionales) y control de flujo
desactivado, la velocidad máxima efectiva en bits por segundo (bitratemax)
que se puede obtener en función del baud rate se calcula de acuerdo a (6.1).
En la Tabla 6.1 se muestran los bit rates calculados para algunos baud rates
típicos.
bitratemax =baudrate× 8
10(6.1)
A partir de las características presentadas, si la herramienta desarrollada
se configura para adquirir el mayor número de señales posible, es decir, se
emplea únicamente un puerto para las señales de disparo, reloj y control, el
número máximo de señales que se puede capturar sería 255×8 = 2040 señales
de un bit. De acuerdo a la Tabla 6.1, se observa cómo una velocidad de 4800
baudios resulta suficiente para transmitir este número de bits si el intervalo
entre eventos es como mínimo un segundo.
No obstante, si fuera necesario capturar más señales de datos una solu-
ción sencilla consiste en añadir un registro externo de n bits (controlado por
PicoBlaze) que amplíe la señal de selección de puerto port_id. Con esta
alternativa, el número máximo de señales de un bit (numsignalsmax) que se
puede capturar en este proceso de muestreo se calcula en base a (6.2). Se
debe considerar que N < 256 × 2n para dedicar al menos un puerto para
Baud rate Bit rate
4800 38409600 768019200 1536038400 3072057600 46080115200 92160
Tabla 6.1: Bit rates calculados para algunas velocidades típicas.

196 Capítulo 6. Metodologías de verificación y pruebas del sistema
señales de datos.
numsignalsmax = (256× 2n −N)× 8 (6.2)
De forma general, a partir de (6.1) y (6.2), la velocidad mínima requerida
para transmitir la información de todos los puertos de datos durante un
intervalo de t segundos se calcula de acuerdo a (6.3).
baudratemin =(256× 2n −N)× 10
t(6.3)
Como se desprende del análisis anterior, en sistemas donde el intervalo
entre eventos es del orden del segundo o incluso del minuto no se requieren
altas velocidades de transmisión del puerto serie. En este sentido, esta ca-
racterística se puede aprovechar para transmitir información adicional que
facilite el posterior procesado de los datos por parte de la herramienta soft-
ware. Así, se han tomado las siguientes consideraciones a la hora de diseñar
esta herramienta:
Para cada dato capturado se transmite una cadena ASCII que repre-
senta el dato en formato hexadecimal.
Dentro de la cadena ASCII se ha empleado un carácter delimitador (,)
que permite distinguir cada dato.
Al final de la trama se incluye una suma de verificación para la com-
probación de errores.
Finalmente, el módulo de programa se corresponde con el programa que
ejecuta PicoBlaze. Este programa realiza las siguientes tareas:
Verificación de la condición de disparo. PicoBlaze lee los puertos
asignados a las señales de disparo y aplica la función lógica configurada.
En caso de verificarse comienza la adquisición de los datos. En este
punto es importante comentar que PicoBlaze dispone de un amplio
conjunto de instrucciones que permite configurar muchas opciones de
disparo.

6.3. Plataforma de verificación para sistemas de sincronización 197
Adquisición de los datos de acuerdo a la señal de reloj. La señal de reloj
se corresponde con algún evento del sistema diseñado, de forma que
siempre que este evento ocurre se procede a leer los datos conectados
a los puertos de entrada de PicoBlaze.
Procesamiento y envío de los datos a la UART. Este procesado consiste
en calcular una suma de verificación de los datos transmitidos de forma
que el receptor pueda verificar la correcta recepción de la información.
Una vez procesados, los datos serán enviados a la UART.
Control de la comunicación con la UART. Periódicamente, el micro-
procesador comprobará la señal de estado del buffer de la UART. Si
está activa significa que más del 50% de la capacidad del buffer está
ocupada, de forma que PicoBlaze esperará hasta que se desactive la
señal de estado antes de seguir enviando más datos a la UART.
6.3.2. Software de procesamiento y análisis
La herramienta software desarrollada consiste en una aplicación progra-
mada en el lenguaje de programación Python [Brandl, 2010] y que se eje-
cuta en la línea de comandos. Dicha aplicación emplea la librería pySerial
[Liechti, 2010] para acceder al puerto serie y, además, implementa una se-
rie de funciones auxiliares que permiten la conversión de los datos recibidos,
representados en formato hexadecimal, a números decimales con y sin signo.
El programa realizado se encarga de realizar las siguientes tareas:
Recibir las cadenas transmitidas por el dispositivo cliente o servidor
SNTP.
Separar los datos a partir de los delimitadores.
Procesar los datos con la finalidad de detectar errores en la transmisión
(mediante la comprobación de la suma de verificación).
Almacenar los datos en un fichero para su posterior procesado.

198 Capítulo 6. Metodologías de verificación y pruebas del sistema
Una vez almacenados un conjunto de muestras se puede proceder a su
análisis mediante la utilización de entornos como Matlab o similares, como
por ejemplo, Octave [Eaton et al., 2008].
6.3.3. Comparativa de la plataforma frente a Chipsco-
pe Pro
En este apartado se presenta un estudio comparativo del analizador de
eventos lógicos diseñado frente a una de las herramientas de verificación on-
chip más utilizadas en la actualidad: ChipScope Pro. Antes de comenzar
este análisis, se considera de especial importancia definir adecuadamente los
siguientes aspectos: (1) arquitectura y características de ChipScope Pro y
(2) parámetros sobre los cuales se realizará la comparación.
En relación con el primer punto, en la Fig. 6.3 se muestra la arquitectura
de ChipScope Pro. Como se puede observar en esta figura, ChipScope
Pro incluye dos tipos de componentes dentro de la FPGA:
Analizador Lógico Integrado (Integrated Logic Analyzer, ILA). Un ILA
consiste en un analizador lógico configurable que permite monitorizar
cualquier señal interna del sistema. Cada ILA permite la adquisición
Figura 6.3: Arquitectura de ChipScope Pro.

6.3. Plataforma de verificación para sistemas de sincronización 199
de un máximo de 256 señales y emplea recursos internos, generalmente
BRAM de la FPGA, para almacenar las muestras capturadas.
Controlador Integrado (Integrated CONtroller, ICON). Este componen-
te se encarga de controlar hasta un máximo de 15 ILA y de comunicar
los datos capturados al equipo donde se encuentra instalado el software
de procesado y visualización de los resultados usando el puerto JTAG
de la FPGA.
En relación con el segundo punto, del apartado 6.2 de este capítulo se
desprende que los parámetros más importantes que se deberían analizar son:
(1) los recursos de la FPGA empleados para la verificación en función del
número de muestras y del número de señales y (2) la influencia del analizador
lógico integrado en las características funcionales y temporales del sistema
original.
Con respecto a la utilización de recursos se han realizado un conjunto de
pruebas que han permitido determinar los recursos de la FPGA consumidos
por cada herramienta. Para cada caso, una vez integrado el analizador ló-
gico on-chip se han obtenido resultados para diferentes configuraciones de
número de señales y número de muestras a capturar. Una ventaja que apor-
ta ChipScope Pro durante el proceso de configuración es que es capaz de
proporcionar una estimación de los recursos que consumirá el módulo de ve-
rificación. A diferencia del LEA, esta ventaja permite conocer los recursos
consumidos sin necesidad de realizar la fase de implementación pudiéndose
estimar incluso aquellas configuraciones en las que el diseño resultante no es
implementable sobre el dispositivo programable.
A continuación, en las Fig. 6.4, 6.5 y 6.6 se presentan los resultados ge-
nerales obtenidos empleando la herramienta ChipScope Pro. Estas figuras
muestran, respectivamente, el número de LUT, FF y BRAM empleadas por
ChipScope Pro en función del número de señales y del número de muestras.
Realizando un breve análisis de los resultados, por un lado, en las Fig. 6.4
y 6.5 se observa cómo el uso de LUT y FF depende principalmente del nú-
mero de señales. Por otra parte, de la Fig. 6.6 se desprende que el número de
BRAM es directamente proporcional al producto del número de señales y del

200 Capítulo 6. Metodologías de verificación y pruebas del sistema
5121024
20484096
819216384
3264
128256
512
0
500
1000
1500
2000
Número de señalesNúmero de muestras
Núm
ero
de L
UT
Figura 6.4: Número de LUT empleadas en función del número de señales yde muestras usando ChipScope Pro.
5121024
20484096
819216384
3264
128256
512
0
500
1000
1500
Número de señalesNúmero de muestras
Núm
ero
de F
F
Figura 6.5: Número de FF empleados en función del número de señales y demuestras usando ChipScope Pro.

6.3. Plataforma de verificación para sistemas de sincronización 201
5121024
20484096
819216384
3264
128256
512
0
200
400
600
Número de señalesNúmero de muestras
Núm
ero
de B
RA
M
Figura 6.6: Número de BRAM empleadas en función del número de señalesy de muestras usando ChipScope Pro.
número de muestras, lo cual es previsible ya que éste es el recurso empleado
para almacenar los datos capturados. Además, se ha encontrado otro factor
que influye en el cálculo del número total de BRAM utilizadas y que depende
de las características de la propia herramienta. Así, se ha observado cómo
el hecho de añadir una nueva ILA ya supone de partida el empleo de una
BRAM debido a que al menos se van a adquirir muestras de una señal y que
éstas se van a almacenar empleando este recurso. En este sentido, conside-
rando que estos analizadores lógicos integrados manejan BRAM completas,
es decir, no son capaces de aprovechar los espacios libres de las BRAM em-
pleadas por otras ILA, cabe sugerir que hay que prestar especial cuidado a la
hora de configurar esta herramienta, ya que ciertas configuraciones podrían
desaprovechar en exceso los recursos, no permitiendo la correcta verificación
del sistema. Un claro ejemplo de este hecho se encuentra en una configura-
ción donde se desea muestrear 15 señales y para ello se añaden 15 ILA, cada
una de ellas dedicada al almacenamiento de una señal de datos; esto supone
desaprovechar 14 BRAM ya que sólo una ILA y por tanto una BRAM sería

202 Capítulo 6. Metodologías de verificación y pruebas del sistema
suficiente para muestrear estas 15 señales.
Debido a que el análisis realizado es aplicable de forma general a cualquier
diseño, ya que éste refleja el número de recursos empleados por ChipScope
Pro para cualquier configuración de número de señales y de muestras, a
continuación, se presentan los resultados obtenidos en función del dispositivo
programable utilizado y de la configuración de señales específica empleada
para la verificación del cliente y del servidor SNTP. En este sentido, se ha
configurado como señal de disparo la señal que indica que el dispositivo se ha
configurado correctamente y como reloj la señal de escritura del parámetro
de corrección D, de forma que se pueda obtener el estado del sistema para
cada nueva corrección. En cuanto a las señales de datos, en la Tabla 6.2 se
indican las señales de cada dispositivo que se van a muestrear. Para el caso
de los parámetros de configuración, éstos sólo se van a transmitir cuando la
condición de disparo se verifique por primera vez. En cuanto a las marcas de
tiempo sólo se transmiten los bits menos significativos.
Para el conjunto de señales de la tabla anterior, y para el caso de la
Nombre de la señal Modo
Parámetros de configuración AmbosEstado del servidor AmbosEstado del cliente ClienteHora del GPS en formato NTP ServidorHora del contador de segundos en formato NTP ServidorOriginate timestamp ClienteReceive timestamp ClienteTransmit timestamp ClienteHora local en formato NTP AmbosDesplazamiento del reloj local AmbosRetraso de propagación ClienteValor del incremento de D0 calculado AmbosValor del parámetro D0 calculado AmbosValor del incremento de DC calculado AmbosValor del parámetro D calculado Ambos
Tabla 6.2: Configuración de señales específica para la verificación de los di-seños del cliente y del servidor SNTP.
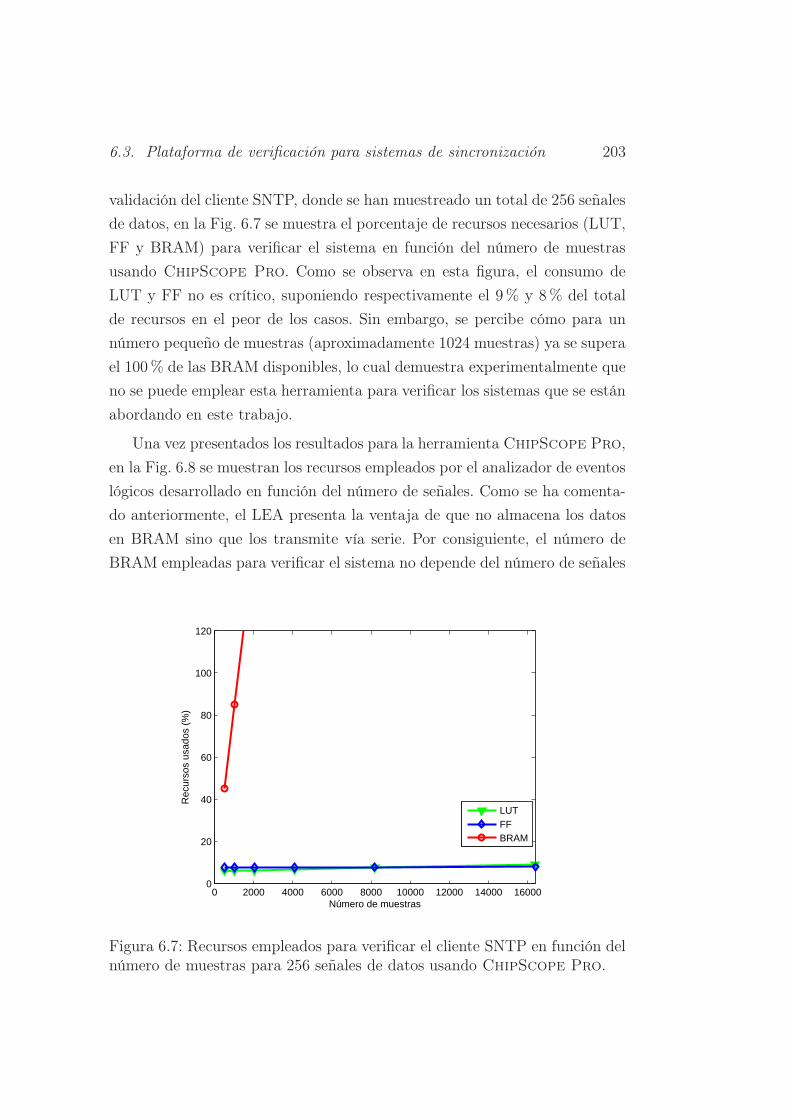
6.3. Plataforma de verificación para sistemas de sincronización 203
validación del cliente SNTP, donde se han muestreado un total de 256 señales
de datos, en la Fig. 6.7 se muestra el porcentaje de recursos necesarios (LUT,
FF y BRAM) para verificar el sistema en función del número de muestras
usando ChipScope Pro. Como se observa en esta figura, el consumo de
LUT y FF no es crítico, suponiendo respectivamente el 9 % y 8 % del total
de recursos en el peor de los casos. Sin embargo, se percibe cómo para un
número pequeño de muestras (aproximadamente 1024 muestras) ya se supera
el 100 % de las BRAM disponibles, lo cual demuestra experimentalmente que
no se puede emplear esta herramienta para verificar los sistemas que se están
abordando en este trabajo.
Una vez presentados los resultados para la herramienta ChipScope Pro,
en la Fig. 6.8 se muestran los recursos empleados por el analizador de eventos
lógicos desarrollado en función del número de señales. Como se ha comenta-
do anteriormente, el LEA presenta la ventaja de que no almacena los datos
en BRAM sino que los transmite vía serie. Por consiguiente, el número de
BRAM empleadas para verificar el sistema no depende del número de señales
0 2000 4000 6000 8000 10000 12000 14000 160000
20
40
60
80
100
120
Número de muestras
Rec
urso
s us
ados
(%
)
LUTFFBRAM
Figura 6.7: Recursos empleados para verificar el cliente SNTP en función delnúmero de muestras para 256 señales de datos usando ChipScope Pro.

204 Capítulo 6. Metodologías de verificación y pruebas del sistema
0 100 200 300 400 5000
5
10
15
Número de señales
Rec
urso
s us
ados
(%
)
LUTFFSlicesBRAM
Figura 6.8: Recursos empleados para verificar el cliente SNTP en función delnúmero de señales usando el LEA.
o del número de muestras. Este hecho permite que el sistema se pueda testar
de forma indefinida, con el único límite de los recursos del equipo externo
que ejecuta el software de procesamiento y almacenamiento de las muestras.
En este sentido, destaca la utilización de una única BRAM, empleada para
almacenar el programa que ejecuta PicoBlaze, lo que supone un porcen-
taje constante del 5 % para cualquier configuración de señales. En cuanto al
resto de recursos de la FPGA, éstos pasan a ser únicamente dependientes del
número de señales.
Para la misma configuración de señales presentada para la herramienta
anterior (verificación del cliente SNTP muestreando 256 señales de datos), el
porcentaje de uso de LUT, FF y Slices ha sido del 3,79%, 1,68% y 5,35%
respectivamente, lo cual mejora significativamente los resultados obtenidos
por ChipScope Pro.
Finalmente, en relación con la influencia de cada herramienta en el com-
portamiento del diseño original, en la Tabla 6.3 se muestra la frecuencia má-
xima de operación estimada por la herramienta ISE para cada alternativa.

6.4. Definición de parámetros de calidad 205
Caso Frecuencia de operaciónDiseño original 50,32 MHzDiseño con ChipScope Pro 50,02 MHzDiseño con LEA 50,26 MHz
Tabla 6.3: Frecuencia máxima de operación conseguida para cada alternativa.
En esta tabla se observa cómo ninguno de los dos módulos afecta signifi-
cativamente a la temporización del diseño original. De este hecho se puede
sacar la conclusión de que la integración de estas herramientas dentro del
mismo dispositivo, para el caso analizado, no afectará a las características
funcionales y temporales del sistema original.
6.4. Definición de parámetros de calidad
En este apartado se van a definir los parámetros de calidad que serán eva-
luados para cada dispositivo y que determinarán el correcto funcionamiento
de la plataforma de sincronización. En este sentido, se van a distinguir dos
clases de parámetros: cualitativos y cuantitativos. Los parámetros cualitati-
vos se refieren a la operación correcta o no de diferentes funciones del sistema,
mientras que los parámetros cuantitativos proporcionan valores mensurables
que deben ser analizados y contrastados con las especificaciones.
6.4.1. Parámetros cualitativos
Los parámetros cualitativos que se van a analizar se recogen en la Ta-
bla 6.4. A continuación, se realiza una descripción de cada uno de ellos:
Carga de la configuración: Realización con éxito de la carga de configu-
ración del cliente y del servidor SNTP desde el servidor de configura-
ción.
Operación de los protocolos de comunicación: Correcta operación del
cliente y del servidor SNTP al procesar los paquetes correspondientes
a los diferentes protocolos de comunicación empleados (NTP, BOOTP,
ARP, etc.) de acuerdo con los estándares en uso.

206 Capítulo 6. Metodologías de verificación y pruebas del sistema
Identificador Nombre del parámetro
PCL1 Carga de la configuración.PCL2 Operación de los protocolos de comunicación.PCL3 Existencia de sincronización.PCL4 Transmisión de la trama RMC.PCL5 Operación continuada.PCL6 Operación ante desconexión.
Tabla 6.4: Parámetros cualitativos a analizar.
Existencia de sincronización: Correcta sincronización de los dispositivos
cliente y servidor SNTP respecto de las fuentes que sirven de referencia
temporal.
Transmisión de la trama RMC: Correcta transmisión de la trama RMC
que proporciona la información de fecha y hora.
Operación continuada: Capacidad del cliente y del servidor SNTP para
operar correctamente de forma continuada en periodos largos de tiempo
donde no se produzcan pérdidas de sincronización del GPS, cortes de
comunicación o sobrecarga de la red.
Operación ante desconexión: Capacidad del cliente y del servidor SNTP
para operar correctamente incluso aunque se produzcan pérdidas de
sincronización del GPS, cortes de comunicación o sobrecarga de la red.
Asimismo, capacidad de los sistemas para recuperar su operación ha-
bitual una vez que se han restablecido las condiciones normales de
operación del sistema.
6.4.2. Parámetros cuantitativos
Los parámetros cuantitativos que se van medir en las pruebas se reco-
gen en la Tabla 6.5. Estos parámetros, como se observa en dicha tabla, se
pueden agrupar en: (1) estadísticos matemáticos, (2) representación gráfica
de funciones de distribución de frecuencias relativas de los parámetros estu-
diados (desplazamiento y retraso de propagación), (3) representación gráfica

6.4. Definición de parámetros de calidad 207
Identificador Nombre del parámetro
PTC1 Representación del desplazamiento frente al tiempo.PTC2 Frecuencia relativa del desplazamiento.PCT3 Desplazamiento o retraso máximo.PCT4 Desplazamiento o retraso medio.PCT5 Desviación típica.PCT6 Precisión.PTC7 Tiempo hasta la sincronización.PTC8 Representación del retraso frente al tiempo.PTC9 Frecuencia relativa del retraso del propagación.PTC10 Representación del desplazamiento frente al retraso.PTC11 Número de peticiones por segundo soportadas.PTC12 Deriva ante desconexión.
Tabla 6.5: Parámetros cuantitativos a medir.
de un parámetro frente al tiempo o a otro parámetro y (4) tiempo hasta
sincronización, número de peticiones por segundo soportadas y deriva ante
desconexión. A continuación, se pasa a describir cada uno de ellos:
Representación del desplazamiento frente al tiempo: Gráfica que re-
presenta el desplazamiento frente al tiempo.
Frecuencia relativa del desplazamiento: Representación gráfica de la
función de distribución de frecuencias del desplazamiento.
Desplazamiento o retraso máximo: Desplazamiento o retraso de propa-
gación máximo, medido en µs, calculado a partir de un número de
muestras de desplazamientos o retrasos consecutivas.
Desplazamiento o retraso medio: Desplazamiento o retraso de propaga-
ción medio, medido en µs, calculado a partir de un número muestras
de desplazamientos o retrasos consecutivas.
Desviación típica: Desviación típica del desplazamiento o del retraso de
propagación, medida en µs, calculada a partir de un número muestras
de desplazamientos o retrasos consecutivas.

208 Capítulo 6. Metodologías de verificación y pruebas del sistema
Precisión: Precisión del desplazamiento o del retraso de propagación, me-
dida en µs, calculada a partir del valor medio y del error máximo esti-
mado. Dicho error se calculará como tres veces la desviación típica de
las medidas.
Tiempo hasta la sincronización: Tiempo medido en segundos que se tar-
da en alcanzar un determinado valor de precisión en la sincronización.
Este tiempo se medirá bien al comienzo de la operación del sistema o
bien al recuperar su operación normal tras desconexión de su fuente de
referencia.
Representación del retraso frente al tiempo: Gráfica que representa
el retraso de propagación frente al tiempo (esta gráfica sólo se obtendrá
para el caso del cliente SNTP).
Frecuencia relativa del retraso de propagación: Representación gráfi-
ca de la función de distribución de frecuencias del retraso de propaga-
ción (esta gráfica sólo se obtendrá para el caso del cliente SNTP).
Representación del desplazamiento frente al retraso: Gráfica que re-
presenta la dispersión del desplazamiento frente al retraso de propaga-
ción (esta gráfica sólo se obtendrá para el caso del cliente SNTP).
Número de peticiones por segundo soportadas: Máximo número de
peticiones por segundo que acepta el servidor SNTP sin que la precisión
en el cliente se vea alterada de forma significativa.
Deriva ante desconexión: Deriva del reloj local ante la pérdida de la fuen-
te de sincronización, medida en partes por millón (Parts-Per-Million,
PPM).
6.5. Escenarios de pruebas
A la hora de realizar la verificación del cliente y del servidor SNTP, se
van a definir cuatro conjuntos de pruebas o fases que permitirán la validación

6.5. Escenarios de pruebas 209
de los desarrollos de forma escalonada y sucesiva, de cara a depurar posibles
anomalías y a obtener medidas válidas respecto de las prestaciones reales de
los dispositivos. Todas las pruebas emplean una metodología similar consis-
tente en la obtención de algunos de los parámetros de calidad definidos en
el apartado anterior para diferentes escenarios y en el posterior análisis y
validación de los resultados frente a las especificaciones. La finalidad de estas
fases se describe a continuación:
Fase 1: Pruebas de operación básicas. Esta fase permitirá realizar la verifi-
cación funcional del sistema en condiciones básicas.
Fase 2: Pruebas completas en configuración típica. Esta fase permitirá ana-
lizar el funcionamiento general del sistema para diferentes valores del
intervalo entre peticiones y del factor de convergencia en una configu-
ración típica de la plataforma.
Fase 3: Pruebas para diferentes cargas y topologías de red. Mediante el
conjunto de pruebas realizadas en esta fase será posible determinar
el comportamiento de la plataforma de sincronización para diferentes
configuraciones de cargas y topologías de red, donde se contempla que
el tráfico generado vaya dirigido al servidor SNTP o no y entre el cliente
y el servidor puedan existir varios niveles de conmutadores.
Fase 4: Pruebas de robustez. Destinadas a comprobar el correcto compor-
tamiento del sistema bajo condiciones de operación continuada y ante
desconexión.
A continuación, en los siguientes apartados se detallan las condiciones de
operación y los escenarios de cada fase.
6.5.1. Pruebas de operación básicas
En la primera fase, se va a establecer un escenario de pruebas que tiene co-
mo finalidad la verificación funcional del sistema en condiciones de operación
simples: intervalo entre peticiones establecido a 1 s, factor de convergencia

210 Capítulo 6. Metodologías de verificación y pruebas del sistema
no variable y sin pérdidas de sincronización en la fuente de referencia o fallos
en la red. Este conjunto de pruebas es similar a las pruebas llevadas a cabo
de forma sistemática durante el desarrollo del cliente y del servidor SNTP,
pero que deben ser repetidas durante la validación final. A continuación, se
describe el escenario de prueba planteado para esta fase:
Escenario 1: Conexión del servidor SNTP con un receptor GPS modelo
Garmin 18 LVC [Garmin, 2005]. Conexión de un cliente SNTP con el
servidor mediante un conmutador Linksys modelo EZXS88W 10/100
[Cisco, 2008]. En este escenario no se introducirá carga adicional en el
conmutador.
6.5.2. Pruebas completas en configuración típica
En la segunda fase, se va a establecer un escenario de pruebas que tie-
ne como finalidad estudiar cómo influye tanto el intervalo entre peticiones
como el factor de convergencia en el proceso de sincronización de acuerdo a
los algoritmos desarrollados. Estas pruebas estarán dirigidas a determinar el
mejor valor del factor de convergencia para cada intervalo entre peticiones.
Para ello, se va a utilizar el siguiente escenario:
Escenario 2: Conexión de un cliente y un servidor SNTP mediante un con-
mutador. En condiciones de carga típica (aproximadamente 20 peti-
ciones de NTP por segundo) dirigida al servidor SNTP, se realizarán
variaciones del intervalo entre peticiones (parámetro p). Para cada con-
figuración del parámetro p se medirá como influye el factor de conver-
gencia (parámetro q). La carga adicional será introducida por dos equi-
pos auxiliares que, conectados al conmutador, se encargarán de generar
el tráfico necesario para realizar las pruebas correspondientes (Fig. 6.9).
6.5.3. Pruebas para diferentes cargas y topologías de
red
En la tercera fase, se van a establecer dos escenarios de pruebas que tienen
como finalidad el análisis de la plataforma de sincronización desarrollada ante

6.5. Escenarios de pruebas 211
Figura 6.9: Composición del escenario 2 planteado en la segunda fase depruebas.
diferentes configuraciones de cargas y topologías de red. Para realizar las
pruebas que se proponen en esta fase se va a utilizar la mejor configuración
del intervalo entre peticiones y del factor de convergencia determinado en la
fase anterior. A continuación, se comentan los escenarios que se proponen en
esta fase:
Escenario 3.1: Conexión de un cliente y un servidor mediante un conmu-
tador. En este escenario se realizarán diferentes pruebas de carga de la
red para distintos tipos de tráfico, distinguiéndose entre tráfico dirigido
y no dirigido al servidor SNTP. Para ello, se emplearán varios equipos
auxiliares que, conectados al conmutador, se encargarán de generar el
tráfico necesario para realizar las pruebas correspondientes.
Escenario 3.2: Conexión de un cliente y un servidor mediante varios ni-
veles de conmutadores. En primer lugar, para una condición de carga
moderada dirigida al servidor se analizará cómo influye en la precisión
del sistema el hecho de introducir varios niveles de conmutadores. En
segundo lugar, para el mismo escenario, se estudiará cómo repercute
el hecho de cargar los conmutadores con tráfico no dirigido al servidor
SNTP.
6.5.4. Pruebas de robustez
La cuarta fase se destina a realizar pruebas de robustez, es decir, a estu-
diar cómo se comporta la plataforma de sincronización ante condiciones de

212 Capítulo 6. Metodologías de verificación y pruebas del sistema
operación continuada y fallos en las fuentes de referencia o en las comunica-
ciones de red. Así, se plantea el siguiente escenario:
Escenario 4: En condiciones de carga típica dirigida al servidor SNTP, se
dejará operar a la plataforma de sincronización durante varios días de
forma que se pueda validar la operación continuada de la plataforma de
sincronización. Una vez validada la operación continuada, se someterá
a dicha plataforma a fallos en las fuentes de sincronización (descone-
xión del receptor GPS o desconexión del cliente de la red local) con la
finalidad de medir la deriva ante desconexión.
6.6. Conclusiones
En este capítulo se ha abordado la problemática existente en lo que se
refiere al testado del sistema de sincronización, derivada del hecho de que para
realizar una correcta validación del mismo resulta necesario la adquisición de
información durante un periodo de tiempo elevado. En este sentido, tal y
como se ha analizado en este capítulo, ninguna solución disponible se adapta
bien para realizar esta clase de verificación a largo plazo, de forma que los
diseñadores tienen que desarrollar soluciones a medida para los diseños que
requieran de este tipo de verificación.
Para solucionar el problema planteado, se ha presentado una herramienta
más general y flexible que se puede adaptar fácilmente a múltiples sistemas,
evitando el coste de diseñar lógica de verificación a medida. La solución
propuesta consiste en un módulo basado en el microprocesador PicoBlaze y
una herramienta software asociada que permite la verificación a largo plazo de
sistemas digitales implementados sobre FPGA. Dicha herramienta tiene unos
bajos requisitos, tanto de recursos hardware internos como de procesamiento
software externo, en comparación con los analizadores lógicos off-chip y on-
chip existentes.
Finalmente, se han presentado los parámetros de calidad y las pruebas
del sistema que se van a realizar para la validación de los desarrollos.

Capítulo 7
Resultados
En este capítulo se van a presentar y analizar los resultados obtenidos
para cada una de las fases comentadas en el capítulo anterior: (1) pruebas de
operación básicas, (2) pruebas completas en configuración típica, (3) pruebas
de operación para diferentes cargas y topologías de red y (4) pruebas de
robustez.
7.1. Pruebas de operación básicas
En este apartado se van a realizar un conjunto de pruebas básicas des-
tinadas a validar el correcto funcionamiento de la plataforma. En concreto,
se van a comprobar los parámetros cualitativos PCL1, PCL2, PCL3 y PCL4
(Tabla 6.4, página 206). Para realizar la verificación de estos parámetros
se ha empleado un conjunto de herramientas que han facilitado el proceso
de validación. A continuación, se indican las herramientas utilizadas para la
comprobación de cada parámetro y los resultados obtenidos:
Carga de configuración (PCL1). La correcta carga de los parámetros
de configuración se ha comprobado empleando el analizador de eventos
lógicos desarrollado (LEA). Así, tanto el cliente como el servidor SNTP,
tras disponer de todos los parámetros de configuración necesarios para
comenzar su operación normal, envía una cadena empleando el LEA
donde informa de su configuración actual: dirección MAC, dirección IP
213

214 Capítulo 7. Resultados
(el cliente también incluye la dirección IP del servidor SNTP con el que
se va a sincronizar), intervalo entre peticiones, factor de convergencia
y factor prescaler (Fig. 7.1).
Operación de los protocolos de comunicación (PCL2). Esta operación
se ha comprobado empleando el analizador de red WireShark [Lam-
ping et al., 2010] (Fig. 7.2) que permite capturar y analizar el tráfico de
la red de comunicación. Para poder visualizar el tráfico de todos los ele-
mentos que forman la plataforma de sincronización (cliente y servidor
SNTP y servidor de configuración) se ha utilizado un equipo auxiliar
donde se han instalado el servidor de configuración y el analizador de
red; además, este equipo dispone de dos interfaces de red configuradas
para funcionar como un bridge o puente de red donde se han conecta-
do el cliente y el servidor SNTP. A partir de esta configuración, con
este analizador se puede: (1) verificar la recepción de los paquetes de
configuración del servidor y del cliente SNTP (BOOTP Request) y las
correspondientes respuestas del servidor de configuración instalado en
el equipo auxiliar (BOOTP Reply), (2) verificar la resolución de la di-
rección MAC del servidor SNTP mediante el análisis de los paquetes
ARP Request (enviado por el cliente SNTP) y ARP Reply (enviado por
el servidor SNTP) y (3) comprobar la correcta operación del protocolo
Figura 7.1: Comprobación de la carga de configuración.

7.1. Pruebas de operación básicas 215
Figura 7.2: Comprobación de la operación de los protocolos de comunicación.
NTP analizando las peticiones del cliente y las respuestas del servidor;
para ello, se puede verificar que los diferentes campos de los paquetes
(direcciones MAC, direcciones IP, stratum, precisión, marcas de tiem-
po, etc.) se actualizan correctamente y que las peticiones se realizan en
los intervalos de tiempo configurados.
Existencia de sincronización (PCL3). La correcta sincronización del
servidor y del cliente SNTP se ha comprobado comparando las señales
de PPS generadas por el receptor GPS y por cada dispositivo mediante
un osciloscopio (Fig. 7.3 y 7.4). Con objeto de realizar esta comparación
se ha incorporado una salida PPS al servidor que no se usa durante su
operación normal. Como se observa en las figuras anteriores, tras un
intervalo de funcionamiento de la plataforma, las diferencias entre la
señal PPS generada por el GPS (canal 1) y la señal generada por cada
dispositivo (canal 2) se encuentran en el rango del microsegundo (para
una configuración básica de la plataforma donde el cliente y el servidor
se conectan mediante un conmutador y el intervalo entre peticiones es
de 1 segundo) de forma que se puede concluir que se ha conseguido el
nivel de precisión de sincronización previsto, es decir, se ha alcanzado
la clase IEC T3.
Transmisión de la trama RMC (PCL4). Para verificar la correcta tras-
misión de la trama RMC generada por el cliente SNTP se ha empleado
un terminal de puerto serie (Fig. 7.5). Como se observa en dicha figura,
al igual que ocurre cuando se emplea un receptor GPS, las tramas RMC

216 Capítulo 7. Resultados
Figura 7.3: Comparación de las señales de PPS generadas por el GPS (canal1) y el servidor SNTP (canal 2).
Figura 7.4: Comparación de las señales de PPS generadas por el GPS (canal1) y el cliente SNTP (canal 2).

7.2. Pruebas completas en configuración típica 217
Figura 7.5: Comprobación de la transmisión de las tramas RMC.
que tienen marcado el campo de estado como no válido no completan
todos los campos aunque sí incluyen la información de fecha y hora. Por
otro lado, las tramas RMC que marcan como válido su campo de estado
completan todos los campos aunque, al no disponer de la información a
la que se refiere cada uno, se transmiten valores por defecto que debe-
rán ser descartados por los dispositivos finales. Así, dichos dispositivos
sólo deberán procesar la información de fecha y hora proporcionada.
7.2. Pruebas completas en configuración típica
En este segundo apartado, una vez realizada la verificación funcional de la
plataforma, se va a analizar exhaustivamente el comportamiento general tan-
to del servidor como del cliente SNTP. Para ello, se va a realizar un conjunto
de pruebas de acuerdo al escenario planteado en el capítulo anterior para esta
fase: conexión del cliente y del servidor SNTP mediante un conmutador en
condiciones de carga típica. Así, en primer lugar, se va a estudiar el proce-
so de sincronización del servidor SNTP con el receptor GPS para diferentes
valores del factor de convergencia; en este caso, el valor del intervalo entre

218 Capítulo 7. Resultados
peticiones permanece fijo a 1 s debido a que se emplea la señal PPS que llega
del GPS para comenzar el proceso de cálculo de la corrección. En segundo
lugar, se va a analizar el comportamiento del cliente SNTP sincronizado al
servidor SNTP para diferentes valores del intervalo entre peticiones (entre 1
y 64 s) y del factor de convergencia (entre 0 y 3).
En este sentido, para cada una de las pruebas que hay que realizar se
va a proceder a capturar un conjunto de muestras de desplazamientos y de
retrasos de propagación. Para la obtención de las muestras se ha empleado el
analizador de eventos lógicos, el cual envía el estado del dispositivo (Tabla 6.2,
página 202, y Fig. 7.1) cada vez que se produce el evento configurado como
reloj, en este caso, la escritura del registro del parámetro de corrección. En
relación con el número de muestras a adquirir, se ha capturado un total de
1100 muestras para cada prueba de forma que, para el mayor intervalo entre
peticiones de hora (fijado a 64 s), el tiempo de obtención de las muestras no
ha superado un día completo.
En los siguientes subapartados, a partir de los datos adquiridos, se van
a calcular y representar los parámetros cuantitativos PCT1 - PCT7 para
el servidor SNTP y los parámetros PCT1 - PCT10 para el cliente SNTP
(Tabla 6.5, página 207).
7.2.1. Pruebas completas para el servidor SNTP
Para comenzar este análisis, en las Fig. 7.6 y 7.7 se representan los despla-
zamientos frente al tiempo (PCT1) y las funciones de distribución de frecuen-
cias del desplazamiento (PCT2), respectivamente, para diferentes valores del
factor de convergencia. Como se observa en estas gráficas, una vez alcanzada
la sincronización, los desplazamientos calculados se mantienen siempre por
debajo de los 1,5 µs en todos los casos y centrados en el valor 0 µs, excepto
para q = 3 donde se observa cómo los desplazamientos están concentrados
en torno al valor 0,5 µs. Los resultados anteriores se ven mejor reflejados en
la Fig. 7.8 donde se presentan los estadísticos matemáticos (PCT3, PCT4,
PCT5 y PCT6) calculados para cada valor del factor de convergencia. Ade-
más, en esta última figura se observa cómo las desviaciones típicas de los
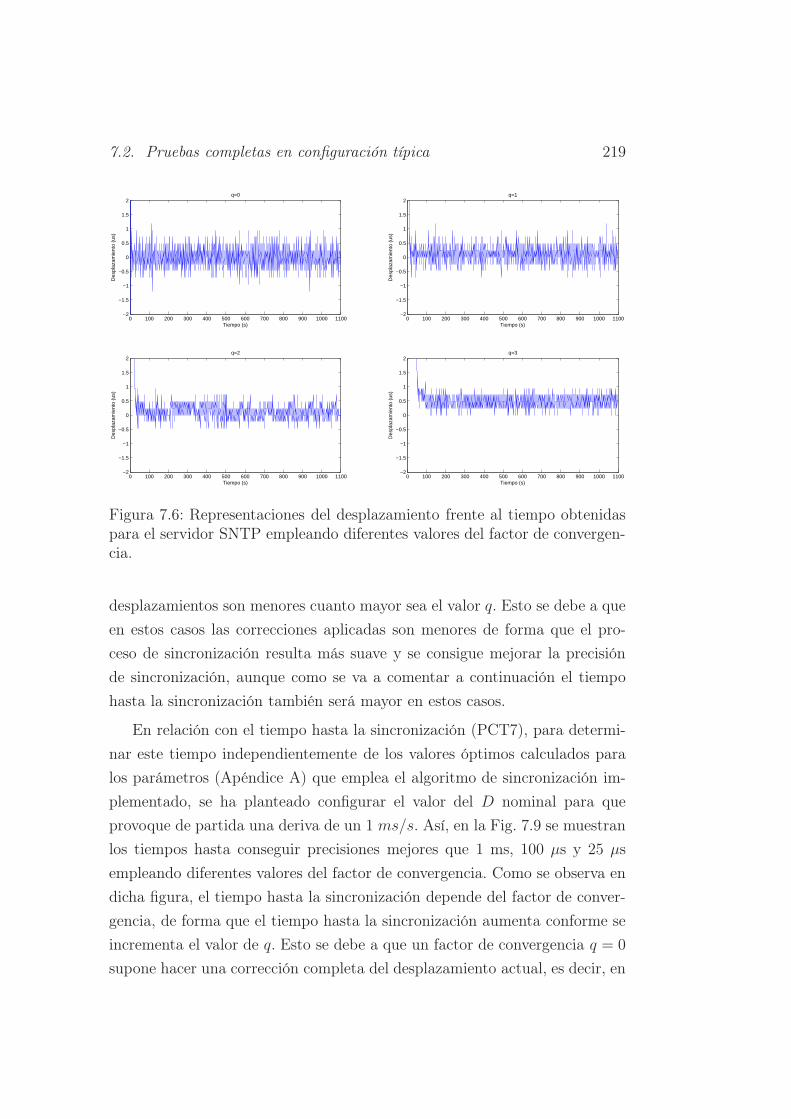
7.2. Pruebas completas en configuración típica 219
0 100 200 300 400 500 600 700 800 900 1000 1100−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
Tiempo (s)
Des
plaz
amie
nto
(us)
q=0
0 100 200 300 400 500 600 700 800 900 1000 1100−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
Tiempo (s)
Des
plaz
amie
nto
(us)
q=1
0 100 200 300 400 500 600 700 800 900 1000 1100−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
Tiempo (s)
Des
plaz
amie
nto
(us)
q=2
0 100 200 300 400 500 600 700 800 900 1000 1100−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
Tiempo (s)
Des
plaz
amie
nto
(us)
q=3
Figura 7.6: Representaciones del desplazamiento frente al tiempo obtenidaspara el servidor SNTP empleando diferentes valores del factor de convergen-cia.
desplazamientos son menores cuanto mayor sea el valor q. Esto se debe a que
en estos casos las correcciones aplicadas son menores de forma que el pro-
ceso de sincronización resulta más suave y se consigue mejorar la precisión
de sincronización, aunque como se va a comentar a continuación el tiempo
hasta la sincronización también será mayor en estos casos.
En relación con el tiempo hasta la sincronización (PCT7), para determi-
nar este tiempo independientemente de los valores óptimos calculados para
los parámetros (Apéndice A) que emplea el algoritmo de sincronización im-
plementado, se ha planteado configurar el valor del D nominal para que
provoque de partida una deriva de un 1 ms/s. Así, en la Fig. 7.9 se muestran
los tiempos hasta conseguir precisiones mejores que 1 ms, 100 µs y 25 µs
empleando diferentes valores del factor de convergencia. Como se observa en
dicha figura, el tiempo hasta la sincronización depende del factor de conver-
gencia, de forma que el tiempo hasta la sincronización aumenta conforme se
incrementa el valor de q. Esto se debe a que un factor de convergencia q = 0
supone hacer una corrección completa del desplazamiento actual, es decir, en

220 Capítulo 7. Resultados
−2 −1.5 −1 −0.5 0 0.5 1 1.5 20
5
10
15
20
25
30
35
40
45
50
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=0
−2 −1.5 −1 −0.5 0 0.5 1 1.5 20
5
10
15
20
25
30
35
40
45
50
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=1
−2 −1.5 −1 −0.5 0 0.5 1 1.5 20
5
10
15
20
25
30
35
40
45
50
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=2
−2 −1.5 −1 −0.5 0 0.5 1 1.5 20
5
10
15
20
25
30
35
40
45
50
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=3
Figura 7.7: Representaciones de la función de distribución de frecuenciasdel desplazamiento obtenidas para el servidor SNTP empleando diferentesvalores del factor de convergencia.
0 1 2 30
0.5
1
1.5
q
Des
plaz
amie
nto
máx
imo
(us)
0 1 2 30
0.5
1
1.5
q
Des
plaz
amie
nto
med
io (
us)
0 1 2 30
0.5
1
1.5
q
Des
viac
ión
típic
a de
l des
plaz
amie
nto
(us)
0 1 2 3−1.5
−1
−0.5
0
0.5
1
1.5
q
Des
plaz
amie
nto
med
io ±
err
or (
us)
Figura 7.8: Representaciones de los estadísticos matemáticos calculados parael servidor SNTP empleando diferentes valores del factor de convergencia.
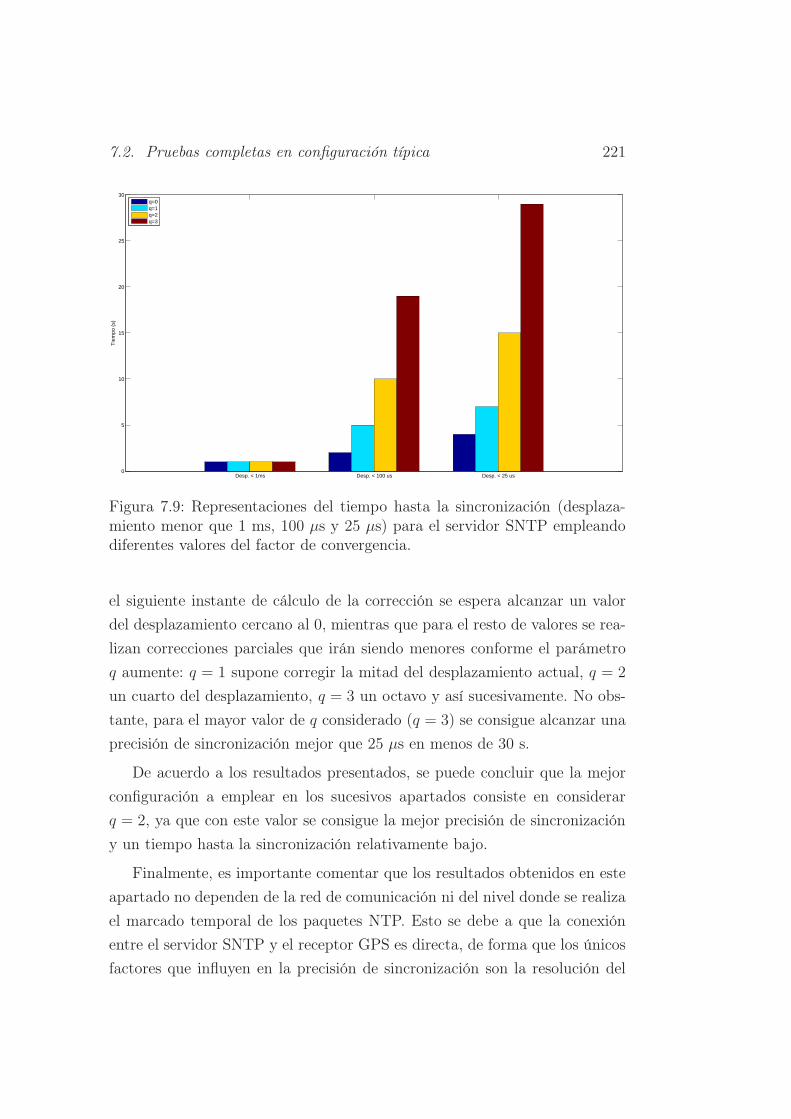
7.2. Pruebas completas en configuración típica 221
Desp. < 1ms Desp. < 100 us Desp. < 25 us0
5
10
15
20
25
30
Tie
mpo
(s)
q=0q=1q=2q=3
Figura 7.9: Representaciones del tiempo hasta la sincronización (desplaza-miento menor que 1 ms, 100 µs y 25 µs) para el servidor SNTP empleandodiferentes valores del factor de convergencia.
el siguiente instante de cálculo de la corrección se espera alcanzar un valor
del desplazamiento cercano al 0, mientras que para el resto de valores se rea-
lizan correcciones parciales que irán siendo menores conforme el parámetro
q aumente: q = 1 supone corregir la mitad del desplazamiento actual, q = 2
un cuarto del desplazamiento, q = 3 un octavo y así sucesivamente. No obs-
tante, para el mayor valor de q considerado (q = 3) se consigue alcanzar una
precisión de sincronización mejor que 25 µs en menos de 30 s.
De acuerdo a los resultados presentados, se puede concluir que la mejor
configuración a emplear en los sucesivos apartados consiste en considerar
q = 2, ya que con este valor se consigue la mejor precisión de sincronización
y un tiempo hasta la sincronización relativamente bajo.
Finalmente, es importante comentar que los resultados obtenidos en este
apartado no dependen de la red de comunicación ni del nivel donde se realiza
el marcado temporal de los paquetes NTP. Esto se debe a que la conexión
entre el servidor SNTP y el receptor GPS es directa, de forma que los únicos
factores que influyen en la precisión de sincronización son la resolución del

222 Capítulo 7. Resultados
contador de hora local y la frecuencia del oscilador empleado.
7.2.2. Pruebas completas para el cliente SNTP
Como se ha comentado anteriormente, en este apartado se va a analizar
el comportamiento del cliente SNTP para diferentes valores del intervalo
entre peticiones y del factor de convergencia. En concreto, se van a analizar
los parámetros cuantitativos PCT1 a PCT10: desplazamiento, tiempo hasta
la sincronización, retraso de propagación y desplazamiento en función del
retraso.
Análisis del desplazamiento en función del intervalo entre peticio-
nes y del factor de convergencia
En el Apéndice B, apartado B.1, se recogen todas las representaciones
de los parámetros cuantitativos PCT1 (desplazamiento frente al tiempo) y
PCT2 (funciones de distribución de frecuencias del desplazamiento) en fun-
ción del intervalo entre peticiones y del factor de convergencia (Fig. B.1 a
B.14). A modo de resumen, en las Fig. 7.10 a 7.14 se muestran los estadísticos
matemáticos del desplazamiento (parámetros cuantitativos PCT3-PCT6).
De las gráficas de los estadísticos matemáticos se extrae, como cabía es-
perar, que la precisión de sincronización mejora conforme más pequeño sea el
intervalo entre peticiones. Esto viene motivado porque un intervalo pequeño
supone realizar correcciones más frecuentemente, de forma que los diferentes
errores existentes al calcular las correcciones no provocarán que el reloj local
derive en exceso y el sistema se pueda recuperar rápidamente de correcciones
no adecuadas. Para intervalos entre peticiones altos, la actualizaciones son
menos frecuentes de forma que los posibles errores en las correcciones pueden
producir que el sistema no consiga ajustar su deriva y alcanzar el nivel de
sincronización deseado. Este último hecho se observa principalmente en las
representaciones de los desplazamiento frente al tiempo para los casos de in-
tervalos entre peticiones de 16 a 64 s y q > 1 (Fig. B.5 a B.7) donde el error
es tan grande respecto del desplazamiento medio obtenido (Fig. 7.14) que las
correcciones calculadas no modifican el sentido de la convergencia provocan-

7.2. Pruebas completas en configuración típica 223
0 1 2 3 4 5 60
10
20
30
40
50
60
p
Des
plaz
amie
nto
máx
imo
(us)
q=0q=1q=2q=3
Figura 7.10: Representaciones de los desplazamientos máximos obtenidos pa-ra el cliente SNTP empleando diferentes valores del periodo entre peticionesy del factor de convergencia.
0 1 2 3 4 5 6−2
0
2
4
6
8
10
p
Des
plaz
amie
nto
med
io (
us)
q=0q=1q=2q=3
Figura 7.11: Representaciones de los desplazamientos medios obtenidos parael cliente SNTP empleando diferentes valores del periodo entre peticiones ydel factor de convergencia.

224 Capítulo 7. Resultados
0 1 2 3 4 5 60
5
10
15
20
25
p
Des
viac
ión
típic
a de
l des
plaz
amie
nto
(us)
q=0q=1q=2q=3
Figura 7.12: Representaciones de las desviaciones típicas del desplazamientoobtenidas para el cliente SNTP empleando diferentes valores del periodo entrepeticiones y del factor de convergencia.
0 1 2 3−5
−4
−3
−2
−1
0
1
2
3
4
5
q
Des
plaz
amie
nto
med
io ±
err
or (
us)
p=0
0 1 2 3−5
−4
−3
−2
−1
0
1
2
3
4
5
q
Des
plaz
amie
nto
med
io ±
err
or (
us)
p=1
0 1 2 3−5
−4
−3
−2
−1
0
1
2
3
4
5
q
Des
plaz
amie
nto
med
io ±
err
or (
us)
p=2
0 1 2 3−5
−4
−3
−2
−1
0
1
2
3
4
5
q
Des
plaz
amie
nto
med
io ±
err
or (
us)
p=3
Figura 7.13: Representaciones de las precisiones (desplazamiento medio ±error) calculadas para el cliente SNTP empleando diferentes valores del factorde convergencia para los valores del intervalo entre peticiones de 1, 2, 4 y 8 s.

7.2. Pruebas completas en configuración típica 225
0 1 2 3−60
−40
−20
0
20
40
60
80
q
Des
plaz
amie
nto
med
io ±
err
or (
us)
p=4
0 1 2 3−60
−40
−20
0
20
40
60
80
q
Des
plaz
amie
nto
med
io ±
err
or (
us)
p=5
0 1 2 3−60
−40
−20
0
20
40
60
80
q
Des
plaz
amie
nto
med
io ±
err
or (
us)
p=6
Figura 7.14: Representaciones de las precisiones (desplazamiento medio ±error) calculadas para el cliente SNTP empleando diferentes valores del factorde convergencia para los valores del intervalo entre peticiones de 16, 32 y 64 s.
do que el sistema diverga; este efecto se ve aumentado para los valores de q
comentados, ya que en estos casos las correcciones son menos agresivas que
para los valores más pequeños de este parámetro.
Además, de acuerdo a los resultados obtenidos, se observa cómo el cliente
SNTP para valores del intervalo entre peticiones pequeños (entre 1 y 8 s)
consigue sincronizarse adecuadamente independientemente del valor del fac-
tor de convergencia utilizado, ya que como se observa en la Fig. 7.13 el
desplazamiento medio y el error van a ser pequeños en cualquier caso. Para
intervalos entre peticiones mayores, el desplazamiento acumulado entre in-
tervalos de ajustes puede ser más alto, y por tanto, realizar correcciones más
rápidas (usando valores pequeños del factor de convergencia) puede resultar
más apropiado.
Análisis del tiempo hasta la sincronización en función del intervalo
entre peticiones y del factor de convergencia
En las Fig. 7.15 a 7.17 se representan los tiempos hasta la sincronización
(parámetro cuantitativo PCT7) calculados para cada una de las pruebas
realizadas.
En relación con los resultados presentados se observa cómo estos tiempos
dependen del intervalo entre peticiones obteniéndose los mejores resultados
para valores pequeños de p. Como se ha comentado anteriormente, este hecho
se debe a que cuanto menor es el intervalo utilizado se realizan correcciones

226 Capítulo 7. Resultados
0 1 2 3 4 5 60
500
1000
1500
2000
2500
3000
3500
p
Tie
mpo
(s)
q=0q=1q=2q=3
Figura 7.15: Representaciones del tiempo hasta la sincronización (desplaza-miento menor que 1 ms) para el cliente SNTP empleando diferentes valoresdel periodo entre peticiones y del factor de convergencia.
más frecuente lo cual supone acelerar el proceso de convergencia. Dentro de
cada intervalo, se puede comprobar cómo el tiempo hasta la sincronización
también depende del valor del factor de convergencia lo cual es lógico ya que
para valores grandes las correcciones son menores y por tanto se tarda más
en alcanzar las sincronización deseada. Además, se observa cómo se alcanza
una sincronización mejor que 25 µs en todas las pruebas, excepto para un
intervalo entre peticiones de 64 s (p = 6) y factores de convergencia mayores
que uno.
Análisis del retraso de propagación en función del intervalo entre
peticiones y del factor de convergencia
En referencia a cómo se comporta la plataforma de sincronización en su
conjunto ante la configuración típica planteada: conexión del cliente y el servi-
dor SNTP mediante un conmutador con una carga adicional de 20 peticiones
de hora por segundo dirigida al servidor, en el Apéndice B, apartado B.1, se
recogen todas las representaciones de los parámetros cuantitativos PCT8 (re-
traso de propagación frente al tiempo) y PCT9 (funciones de distribución de

7.2. Pruebas completas en configuración típica 227
0 1 2 3 4 5 60
500
1000
1500
2000
2500
3000
3500
p
Tie
mpo
(s)
q=0q=1q=2q=3
Figura 7.16: Representaciones del tiempo hasta la sincronización (desplaza-miento menor que 100 µs) para el cliente SNTP empleando diferentes valoresdel periodo entre peticiones y del factor de convergencia.
0 1 2 3 4 5 60
500
1000
1500
2000
2500
3000
3500
p
Tie
mpo
(s)
q=0q=1q=2q=3
Figura 7.17: Representaciones del tiempo hasta la sincronización (desplaza-miento menor que 25 µs) para el cliente SNTP empleando diferentes valoresdel periodo entre peticiones y del factor de convergencia.
frecuencias del retraso de propagación) en función del intervalo entre peticio-
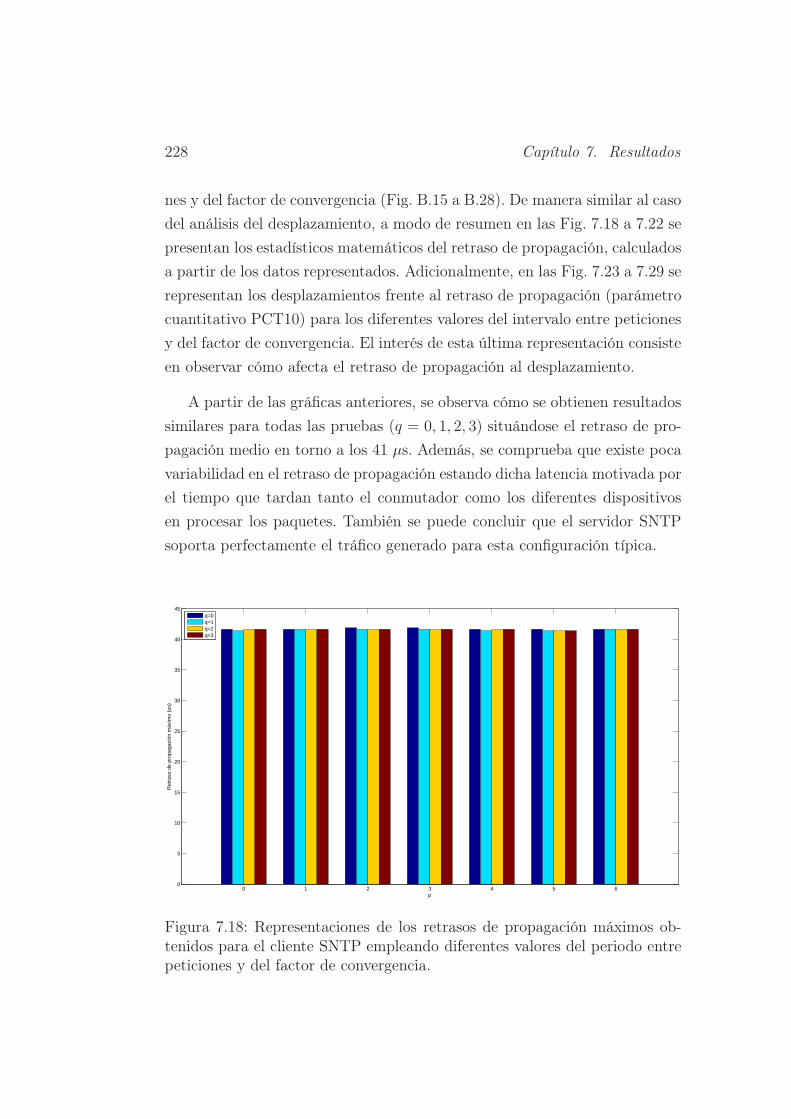
228 Capítulo 7. Resultados
nes y del factor de convergencia (Fig. B.15 a B.28). De manera similar al caso
del análisis del desplazamiento, a modo de resumen en las Fig. 7.18 a 7.22 se
presentan los estadísticos matemáticos del retraso de propagación, calculados
a partir de los datos representados. Adicionalmente, en las Fig. 7.23 a 7.29 se
representan los desplazamientos frente al retraso de propagación (parámetro
cuantitativo PCT10) para los diferentes valores del intervalo entre peticiones
y del factor de convergencia. El interés de esta última representación consiste
en observar cómo afecta el retraso de propagación al desplazamiento.
A partir de las gráficas anteriores, se observa cómo se obtienen resultados
similares para todas las pruebas (q = 0, 1, 2, 3) situándose el retraso de pro-
pagación medio en torno a los 41 µs. Además, se comprueba que existe poca
variabilidad en el retraso de propagación estando dicha latencia motivada por
el tiempo que tardan tanto el conmutador como los diferentes dispositivos
en procesar los paquetes. También se puede concluir que el servidor SNTP
soporta perfectamente el tráfico generado para esta configuración típica.
0 1 2 3 4 5 60
5
10
15
20
25
30
35
40
45
p
Ret
raso
de
prop
agac
ión
máx
imo
(us)
q=0q=1q=2q=3
Figura 7.18: Representaciones de los retrasos de propagación máximos ob-tenidos para el cliente SNTP empleando diferentes valores del periodo entrepeticiones y del factor de convergencia.

7.2. Pruebas completas en configuración típica 229
0 1 2 3 4 5 60
5
10
15
20
25
30
35
40
45
p
Ret
raso
de
prop
agac
ión
med
io (
us)
q=0q=1q=2q=3
Figura 7.19: Representaciones de los retrasos de propagación medios obte-nidos para el cliente SNTP empleando diferentes valores del periodo entrepeticiones y del factor de convergencia.
0 1 2 3 4 5 60
0.05
0.1
0.15
0.2
0.25
0.3
0.35
p
Des
viac
ión
típic
a de
l ret
raso
de
prop
agac
ión
(us)
q=0q=1q=2q=3
Figura 7.20: Representaciones de las desviaciones típicas del retrasos de pro-pagación obtenidas para el cliente SNTP empleando diferentes valores delperiodo entre peticiones y del factor de convergencia.

230 Capítulo 7. Resultados
0 1 2 335
36
37
38
39
40
41
42
43
44
45
q
Ret
raso
med
io ±
err
or (
us)
p=0
0 1 2 335
36
37
38
39
40
41
42
43
44
45
q
Ret
raso
med
io ±
err
or (
us)
p=1
0 1 2 335
36
37
38
39
40
41
42
43
44
45
q
Ret
raso
med
io ±
err
or (
us)
p=2
0 1 2 335
36
37
38
39
40
41
42
43
44
45
q
Ret
raso
med
io ±
err
or (
us)
p=3
Figura 7.21: Representaciones de las precisiones (retraso medio ± error) cal-culadas para el cliente SNTP empleando diferentes valores del factor de con-vergencia para los valores del intervalo entre peticiones de 1, 2, 4 y 8 s.
0 1 2 335
36
37
38
39
40
41
42
43
44
45
q
Ret
raso
med
io ±
err
or (
us)
p=4
0 1 2 335
36
37
38
39
40
41
42
43
44
45
q
Ret
raso
med
io ±
err
or (
us)
p=5
0 1 2 335
36
37
38
39
40
41
42
43
44
45
q
Ret
raso
med
io ±
err
or (
us)
p=6
Figura 7.22: Representaciones de las precisiones (retraso medio ± error) cal-culadas para el cliente SNTP empleando diferentes valores del factor de con-vergencia para los valores del intervalo entre peticiones de 16, 32 y 64 s.
Establecimiento del intervalo entre peticiones y del factor de con-
vergencia para las sucesivas pruebas
A partir de todos los resultados presentados, se va a decidir qué valores
del intervalo entre peticiones y del factor de convergencia se van a emplear
en las siguientes fases de pruebas. En este sentido, para una configuración

7.2. Pruebas completas en configuración típica 231
0 5 10 15 20 25 30 35 40 45 50−4
−3
−2
−1
0
1
2
3
4
Retraso (us)
Des
plaz
amie
nto
(us)
q=0
0 5 10 15 20 25 30 35 40 45 50−4
−3
−2
−1
0
1
2
3
4
Retraso (us)
Des
plaz
amie
nto
(us)
q=1
0 5 10 15 20 25 30 35 40 45 50−4
−3
−2
−1
0
1
2
3
4
Retraso (us)
Des
plaz
amie
nto
(us)
q=2
0 5 10 15 20 25 30 35 40 45 50−4
−3
−2
−1
0
1
2
3
4
Retraso (us)
Des
plaz
amie
nto
(us)
q=3
Figura 7.23: Representaciones del desplazamiento frente al retraso de pro-pagación obtenidas para el cliente SNTP empleando diferentes valores delfactor de convergencia y un periodo entre peticiones de 1 s.
0 5 10 15 20 25 30 35 40 45 50−4
−3
−2
−1
0
1
2
3
4
Retraso (us)
Des
plaz
amie
nto
(us)
q=0
0 5 10 15 20 25 30 35 40 45 50−4
−3
−2
−1
0
1
2
3
4
Retraso (us)
Des
plaz
amie
nto
(us)
q=1
0 5 10 15 20 25 30 35 40 45 50−4
−3
−2
−1
0
1
2
3
4
Retraso (us)
Des
plaz
amie
nto
(us)
q=2
0 5 10 15 20 25 30 35 40 45 50−4
−3
−2
−1
0
1
2
3
4
Retraso (us)
Des
plaz
amie
nto
(us)
q=3
Figura 7.24: Representaciones del desplazamiento frente al retraso de pro-pagación obtenidas para el cliente SNTP empleando diferentes valores delfactor de convergencia y un periodo entre peticiones de 2 s.

232 Capítulo 7. Resultados
0 5 10 15 20 25 30 35 40 45 50−4
−3
−2
−1
0
1
2
3
4
Retraso (us)
Des
plaz
amie
nto
(us)
q=0
0 5 10 15 20 25 30 35 40 45 50−4
−3
−2
−1
0
1
2
3
4
Retraso (us)
Des
plaz
amie
nto
(us)
q=1
0 5 10 15 20 25 30 35 40 45 50−4
−3
−2
−1
0
1
2
3
4
Retraso (us)
Des
plaz
amie
nto
(us)
q=2
0 5 10 15 20 25 30 35 40 45 50−4
−3
−2
−1
0
1
2
3
4
Retraso (us)
Des
plaz
amie
nto
(us)
q=3
Figura 7.25: Representaciones del desplazamiento frente al retraso de pro-pagación obtenidas para el cliente SNTP empleando diferentes valores delfactor de convergencia y un periodo entre peticiones de 4 s.
0 5 10 15 20 25 30 35 40 45 50−8
−6
−4
−2
0
2
4
6
8
Retraso (us)
Des
plaz
amie
nto
(us)
q=0
0 5 10 15 20 25 30 35 40 45 50−8
−6
−4
−2
0
2
4
6
8
Retraso (us)
Des
plaz
amie
nto
(us)
q=1
0 5 10 15 20 25 30 35 40 45 50−8
−6
−4
−2
0
2
4
6
8
Retraso (us)
Des
plaz
amie
nto
(us)
q=2
0 5 10 15 20 25 30 35 40 45 50−8
−6
−4
−2
0
2
4
6
8
Retraso (us)
Des
plaz
amie
nto
(us)
q=3
Figura 7.26: Representaciones del desplazamiento frente al retraso de pro-pagación obtenidas para el cliente SNTP empleando diferentes valores delfactor de convergencia y un periodo entre peticiones de 8 s.

7.2. Pruebas completas en configuración típica 233
0 5 10 15 20 25 30 35 40 45 50−15
−10
−5
0
5
10
15
Retraso (us)
Des
plaz
amie
nto
(us)
q=0
0 5 10 15 20 25 30 35 40 45 50−15
−10
−5
0
5
10
15
Retraso (us)
Des
plaz
amie
nto
(us)
q=1
0 5 10 15 20 25 30 35 40 45 50−15
−10
−5
0
5
10
15
Retraso (us)
Des
plaz
amie
nto
(us)
q=2
0 5 10 15 20 25 30 35 40 45 50−15
−10
−5
0
5
10
15
Retraso (us)
Des
plaz
amie
nto
(us)
q=3
Figura 7.27: Representaciones del desplazamiento frente al retraso de pro-pagación obtenidas para el cliente SNTP empleando diferentes valores delfactor de convergencia y un periodo entre peticiones de 16 s.
0 5 10 15 20 25 30 35 40 45 50−30
−20
−10
0
10
20
30
Retraso (us)
Des
plaz
amie
nto
(us)
q=0
0 5 10 15 20 25 30 35 40 45 50−30
−20
−10
0
10
20
30
Retraso (us)
Des
plaz
amie
nto
(us)
q=1
0 5 10 15 20 25 30 35 40 45 50−30
−20
−10
0
10
20
30
Retraso (us)
Des
plaz
amie
nto
(us)
q=2
0 5 10 15 20 25 30 35 40 45 50−30
−20
−10
0
10
20
30
Retraso (us)
Des
plaz
amie
nto
(us)
q=3
Figura 7.28: Representaciones del desplazamiento frente al retraso de pro-pagación obtenidas para el cliente SNTP empleando diferentes valores delfactor de convergencia y un periodo entre peticiones de 32 s.

234 Capítulo 7. Resultados
0 5 10 15 20 25 30 35 40 45 50
−50
−40
−30
−20
−10
0
10
20
30
40
50
Retraso (us)
Des
plaz
amie
nto
(us)
q=0
0 5 10 15 20 25 30 35 40 45 50
−50
−40
−30
−20
−10
0
10
20
30
40
50
Retraso (us)
Des
plaz
amie
nto
(us)
q=1
0 5 10 15 20 25 30 35 40 45 50
−50
−40
−30
−20
−10
0
10
20
30
40
50
Retraso (us)
Des
plaz
amie
nto
(us)
q=2
0 5 10 15 20 25 30 35 40 45 50
−50
−40
−30
−20
−10
0
10
20
30
40
50
Retraso (us)
Des
plaz
amie
nto
(us)
q=3
Figura 7.29: Representaciones del desplazamiento frente al retraso de pro-pagación obtenidas para el cliente SNTP empleando diferentes valores delfactor de convergencia y un periodo entre peticiones de 64 s.
típica, donde el número de equipos que van a realizar peticiones de hora
se encuentra en el rango de algunas decenas, establecer un intervalo entre
peticiones de 1 s en el ámbito de las redes de área local puede considerarse
como un valor adecuado ya que no sobrecarga la red y mejora la precisión.
En cuanto al factor de convergencia, como se ha comentado anteriormente,
emplear valores de q pequeños acelera la convergencia; no obstante, este hecho
puede presentar un inconveniente cuando se produce una desconexión del
dispositivo de su fuente de referencia, de forma que cuanto mayor haya sido
la última corrección calculada mayor será la deriva del sistema ante holdover.
Por ello, se va a establecer un valor del factor de convergencia de 2 ya que
para p = 0 los resultados obtenidos en términos de precisión son similares
al resto mientras que el tiempo hasta la sincronización no aumenta en gran
medida.

7.3. Pruebas para diferentes cargas y topologías de red 235
7.3. Pruebas para diferentes cargas y topolo-
gías de red
En esta fase, en primer lugar, se va a analizar cómo se comporta la plata-
forma de sincronización ante diferentes cargas de red. En este sentido, para el
escenario 3.1 presentado en el apartado 6.5.3 (página 211), se van a realizar
un conjunto de pruebas que se pueden agrupar en dos bloques: (1) pruebas
cargando el conmutador con tráfico general, es decir, tráfico no dirigido al ser-
vidor SNTP y (2) pruebas de carga del servidor SNTP, donde se determinará
el número de peticiones de hora por segundo que soporta el servidor SNTP.
En segundo lugar, a partir del escenario 3.2, se van a mostrar los resultados
de la plataforma para diferentes topologías de red y tipos de tráfico.
7.3.1. Pruebas para diferentes cargas de red
Carga del conmutador con tráfico de red general no dirigido al
servidor SNTP
Para el primer bloque propuesto, las pruebas se han realizado empleando
equipos auxiliares conectados a los puertos del conmutador, como se describió
en el escenario 3.1. Se han realizado cuatro pruebas inyectando diferente
tráfico de red: (1) 25 Mbps, (2) 50 Mbps, (3) 75 Mbps y (4) carga máxima
que permite generar el equipo utilizado, respectivamente.
En relación con los resultados obtenidos, al igual que para las pruebas
completas, en el Apéndice B, apartado B.2.1, se recogen las representaciones
del desplazamiento y del retraso de propagación frente al tiempo y de la fun-
ción de distribución de frecuencias del desplazamiento y del retraso para cada
prueba realizada (Fig. B.29 a B.32). A modo de resumen, en las Fig. 7.30 y
7.31 se muestran los estadísticos matemáticos calculados para los desplaza-
mientos y retrasos de propagación obtenidos. Finalmente, en la Fig. 7.32 se
muestran los desplazamientos frente al retraso de propagación.
Analizando los resultados presentados, se observa cómo en el escenario
planteado el tráfico de red no destinado al servidor SNTP no interfiere con el
tráfico dirigido al mismo, aún en condiciones de carga elevada como ocurre

236 Capítulo 7. Resultados
1 2 3 40
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
Prueba
Des
plaz
amie
nto
máx
imo
(us)
1 2 3 40
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Prueba
Des
plaz
amie
nto
med
io (
us)
1 2 3 40
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
Prueba
Des
viac
ión
típic
a de
l des
plaz
amie
nto
(us)
1 2 3 4−5
−4
−3
−2
−1
0
1
2
3
4
5
Prueba
Des
plaz
amie
nto
med
io ±
err
or (
us)
Figura 7.30: Representaciones de los estadísticos matemáticos del desplaza-miento calculados para el cliente SNTP cargando el conmutador con tráficono dirigido al servidor SNTP.
1 2 3 40
5
10
15
20
25
30
35
40
45
Prueba
Ret
raso
de
prop
agac
ión
máx
imo
(us)
1 2 3 40
5
10
15
20
25
30
35
40
45
Prueba
Ret
raso
de
prop
agac
ión
med
io (
us)
1 2 3 40
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
Prueba
Des
viac
ión
típic
a de
l Ret
raso
de
prop
agac
ión
(us)
1 2 3 435
36
37
38
39
40
41
42
43
44
45
Prueba
Ret
raso
med
io ±
err
or (
us)
Figura 7.31: Representaciones de los estadísticos matemáticos del retraso depropagación calculados para el cliente SNTP cargando el conmutador contráfico no dirigido al servidor SNTP.

7.3. Pruebas para diferentes cargas y topologías de red 237
0 5 10 15 20 25 30 35 40 45 50−4
−3
−2
−1
0
1
2
3
4
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 1
0 5 10 15 20 25 30 35 40 45 50−4
−3
−2
−1
0
1
2
3
4
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 2
0 5 10 15 20 25 30 35 40 45 50−4
−3
−2
−1
0
1
2
3
4
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 3
0 5 10 15 20 25 30 35 40 45 50−4
−3
−2
−1
0
1
2
3
4
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 4
Figura 7.32: Representaciones del desplazamiento frente al retraso de propa-gación obtenidas para el cliente SNTP cargando el conmutador con tráficono dirigido al servidor SNTP.
en la prueba 4, obteniéndose resultados similares en todos los casos. Este
hecho se puede verificar fácilmente comparando las figuras mostradas con
las obtenidas en la fase anterior (donde no se incluía carga adicional al con-
mutador) para la configuración p = 0 y q = 2. No obstante, es conveniente
aclarar que estos resultados sólo demuestran una correcta implementación de
la arquitectura del conmutador utilizado para realizar las pruebas, pudiendo
variar los resultados obtenidos en función del tipo de conmutador emplea-
do; esto significa que en función del conmutador podría obtenerse una alta
variabilidad en la latencia debido al tráfico no destinado al servidor SNTP.
Carga del conmutador con tráfico NTP dirigido al servidor SNTP
En relación con el segundo bloque, se han planteado diez pruebas donde
los equipos auxiliares han transmitido diferentes números de peticiones de
hora por segundo hacia el servidor SNTP (Tabla 7.1). El objetivo de esta
prueba consiste en comprobar la capacidad del servidor SNTP para admitir
una gran cantidad de peticiones por segundo y medir la degradación de la

238 Capítulo 7. Resultados
Prueba Número de peticiones
1 10 peticiones/s2 20 peticiones/s3 50 peticiones/s4 100 peticiones/s5 500 peticiones/s6 2000 peticiones/s7 5000 peticiones/s8 1000 peticiones/s9 17000 peticiones/s10 20000 peticiones/s
Tabla 7.1: Número de peticiones por segundo inyectadas en cada prueba.
calidad de la sincronización en los clientes como consecuencia de la saturación
del servidor. Para ello, en el Apéndice B, apartado B.2.2, se recogen las
representaciones del desplazamiento y del retraso de propagación frente al
tiempo y de la función de distribución de frecuencias del desplazamiento y del
retraso para cada prueba realizada (Fig. B.33 a B.44). A modo de resumen,
en las Fig. 7.33 y 7.34 se muestran los estadísticos matemáticos calculados
para los desplazamientos y retrasos de propagación obtenidos. Finalmente,
en las Fig. 7.35 a 7.37 se muestran los desplazamientos frente al retraso de
propagación.
Realizando un análisis de los resultados presentados, se observa cómo para
un número de peticiones por segundo comprendido entre 10 y 100 (pruebas
1 a 4), los paquetes de hora no se retrasan en el conmutador obteniéndo-
se resultados similares a los conseguidos anteriormente; para un número de
peticiones entre 500 y 10000 (pruebas 5 a 8) se observa cómo aumenta la
variabilidad en el retraso debido al encolamiento de los paquetes de hora en
el conmutador y por tanto aumenta el error en el cálculo del desplazamiento,
disminuyendo ligeramente la precisión de sincronización. Finalmente, para un
número de peticiones elevado (entre 17000 y 20000) se observa un salto en
relación a la precisión alcanzable que se sitúa por encima de los 5 µs debido
a que en estas pruebas la variabilidad en el retraso es más elevada respecto
a los casos anteriores.

7.3. Pruebas para diferentes cargas y topologías de red 239
1 2 3 4 5 6 7 8 9 100
2
4
6
8
10
12
Prueba
Des
plaz
amie
nto
máx
imo
(us)
1 2 3 4 5 6 7 8 9 100
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Prueba
Des
plaz
amie
nto
med
io (
us)
1 2 3 4 5 6 7 8 9 100
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
Prueba
Des
viac
ión
típic
a de
l des
plaz
amie
nto
(us)
1 2 3 4 5 6 7 8 9 10−10
−8
−6
−4
−2
0
2
4
6
8
10
Prueba
Des
plaz
amie
nto
med
io ±
err
or (
us)
Figura 7.33: Representaciones de los estadísticos matemáticos del desplaza-miento calculados para el cliente SNTP cargando el conmutador con tráficoNTP dirigido al servidor SNTP (para todos los casos).
1 2 3 4 5 6 7 8 9 100
10
20
30
40
50
60
Prueba
Ret
raso
de
prop
agac
ión
máx
imo
(us)
1 2 3 4 5 6 7 8 9 100
10
20
30
40
50
60
Prueba
Ret
raso
de
prop
agac
ión
med
io (
us)
1 2 3 4 5 6 7 8 9 100
0.5
1
1.5
2
2.5
3
Prueba
Des
viac
ión
típic
a de
l ret
raso
de
prop
agac
ión
(us)
1 2 3 4 5 6 7 8 9 1030
35
40
45
50
55
Prueba
Ret
raso
med
io ±
err
or (
us)
Figura 7.34: Representaciones de los estadísticos matemáticos del retraso depropagación calculados para el cliente SNTP cargando el conmutador contráfico NTP dirigido al servidor SNTP (para todos los casos).

240 Capítulo 7. Resultados
40 45 50 55 60
−10
−5
0
5
10
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 1
40 45 50 55 60
−10
−5
0
5
10
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 2
40 45 50 55 60
−10
−5
0
5
10
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 3
40 45 50 55 60
−10
−5
0
5
10
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 4
Figura 7.35: Representaciones del desplazamiento frente al retraso de propa-gación obtenidas para el cliente SNTP cargando el conmutador con tráficoNTP dirigido al servidor SNTP (entre 10 y 100 peticiones por segundo).
40 45 50 55 60
−10
−5
0
5
10
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 5
40 45 50 55 60
−10
−5
0
5
10
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 6
40 45 50 55 60
−10
−5
0
5
10
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 7
40 45 50 55 60
−10
−5
0
5
10
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 8
Figura 7.36: Representaciones del desplazamiento frente al retraso de propa-gación obtenidas para el cliente SNTP cargando el conmutador con tráficoNTP dirigido al servidor SNTP (entre 500 y 10000 peticiones por segundo).

7.3. Pruebas para diferentes cargas y topologías de red 241
40 45 50 55 60
−10
−5
0
5
10
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 9
40 45 50 55 60
−10
−5
0
5
10
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 10
Figura 7.37: Representaciones del desplazamiento frente al retraso de propa-gación obtenidas para el cliente SNTP cargando el conmutador con tráficoNTP dirigido al servidor SNTP (entre 17000 y 20000 peticiones por segundo).
Otro aspecto que se va a medir en este punto consiste en el número
máximo de peticiones de hora por segundo soportado por el servidor SNTP
(parámetro cuantitativo PCT11). En este sentido, a partir de los resultados
mostrados se puede concluir que el servidor SNTP es capaz de soportar un
número elevado de peticiones por segundo sin que la precisión en los clientes
se vea afectada excesivamente ya que para todas las pruebas realizadas se ha
obtenido una precisión mejor que 10 µs.
7.3.2. Pruebas para diferentes topologías de red
Varios niveles de conmutadores y carga moderada
Una vez presentados los resultados para diferentes cargas de red y tipos
de tráfico, se va a estudiar el comportamiento de la plataforma de sincroniza-
ción frente a diferentes niveles de conmutadores para una condición de carga
moderada (aproximadamente 100 peticiones por segundo) dirigida al servi-
dor SNTP, de acuerdo al escenario 3.2 del apartado 6.5.3. En este sentido,
se han realizado cuatro pruebas que abarcan desde la conexión directa de un
cliente con un servidor SNTP (prueba 1, realizada para tomar una referencia
de la latencia introducida por los dispositivos) hasta un máximo de 3 niveles
de conmutadores (prueba 4). De manera similar a los apartados anteriores,
en el Apéndice B, apartado B.3.1, se recogen las representaciones del despla-
zamiento y del retraso de propagación frente al tiempo y de la función de

242 Capítulo 7. Resultados
distribución de frecuencias del desplazamiento y del retraso para cada prueba
realizada (Fig. B.45 a B.48). A modo de resumen, en las Fig. 7.38 y 7.39 se
muestran los estadísticos matemáticos calculados para los desplazamientos y
retrasos de propagación obtenidos. Finalmente, en la Fig. 7.40 se muestran
los desplazamientos frente al retraso de propagación.
Como se observa en estas figuras, para las condiciones planteadas se obtie-
nen resultados similares para todos los casos no viéndose afectada la precisión
de sincronización. Este hecho se debe principalmente a que aunque el retraso
de propagación aumenta conforme se van añadiendo niveles de conmutado-
res (aproximadamente 20 µs por nivel) la carga introducida es relativamente
pequeña en comparación con la carga máxima que puede soportar la red de
forma que la variabilidad en el retraso es reducida y, por consiguiente, el error
en el cálculo del desplazamiento también lo es en todos los casos estudiados.
0 1 2 30
1
2
3
4
5
6
7
8
9
10
Prueba
Des
plaz
amie
nto
máx
imo
(us)
0 1 2 30
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Prueba
Des
plaz
amie
nto
med
io (
us)
0 1 2 30
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Prueba
Des
viac
ión
típic
a de
l des
plaz
amie
nto
(us)
0 1 2 3−5
−4
−3
−2
−1
0
1
2
3
4
5
Prueba
Des
plaz
amie
nto
med
io ±
err
or (
us)
Figura 7.38: Representaciones de los estadísticos matemáticos del desplaza-miento calculados para el cliente SNTP para una condición de carga mode-rada dirigida al servidor SNTP abarcando desde la conexión directa (prueba1) hasta la conexión mediante tres niveles de conmutadores (prueba 4).
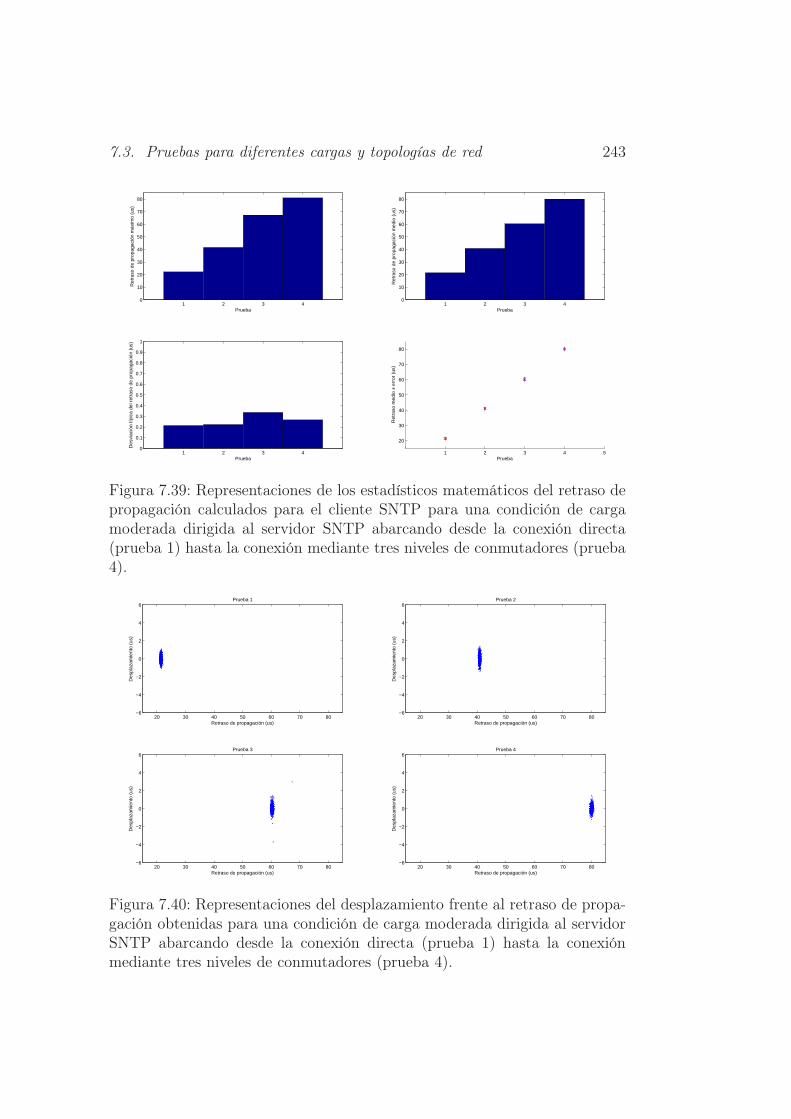
7.3. Pruebas para diferentes cargas y topologías de red 243
1 2 3 40
10
20
30
40
50
60
70
80
Prueba
Ret
raso
de
prop
agac
ión
máx
imo
(us)
1 2 3 40
10
20
30
40
50
60
70
80
Prueba
Ret
raso
de
prop
agac
ión
med
io (
us)
1 2 3 40
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Prueba
Des
viac
ión
típic
a de
l ret
raso
de
prop
agac
ión
(us)
1 2 3 4 5
20
30
40
50
60
70
80
Prueba
Ret
raso
med
io ±
err
or (
us)
Figura 7.39: Representaciones de los estadísticos matemáticos del retraso depropagación calculados para el cliente SNTP para una condición de cargamoderada dirigida al servidor SNTP abarcando desde la conexión directa(prueba 1) hasta la conexión mediante tres niveles de conmutadores (prueba4).
20 30 40 50 60 70 80−6
−4
−2
0
2
4
6
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 1
20 30 40 50 60 70 80−6
−4
−2
0
2
4
6
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 2
20 30 40 50 60 70 80−6
−4
−2
0
2
4
6
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 3
20 30 40 50 60 70 80−6
−4
−2
0
2
4
6
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 4
Figura 7.40: Representaciones del desplazamiento frente al retraso de propa-gación obtenidas para una condición de carga moderada dirigida al servidorSNTP abarcando desde la conexión directa (prueba 1) hasta la conexiónmediante tres niveles de conmutadores (prueba 4).

244 Capítulo 7. Resultados
Tres niveles de conmutadores y diferentes cargas de red
En este caso, se va a analizar el comportamiento de la plataforma de
sincronización cuando se conecta el cliente y servidor SNTP mediante tres
niveles de conmutadores y se inyecta en la red diferente tráfico de red no
dirigido al servidor SNTP. En concreto, se han medido los mismos niveles de
carga presentados anteriormente: (1) 25 Mbps, (2) 50 Mbps, (3) 75 Mbps y
(4) carga máxima. En el Apéndice B, apartado B.3.2, se recogen las repre-
sentaciones del desplazamiento y del retraso de propagación frente al tiempo
y de la función de distribución de frecuencias del desplazamiento y del retra-
so para cada prueba realizada (Fig. B.49 a B.52). A modo de resumen, en
las Fig. 7.41 y 7.42 se muestran los estadísticos matemáticos calculados para
los desplazamientos y retrasos de propagación obtenidos. Finalmente, en la
Fig. 7.43 se muestran los desplazamientos frente al retraso de propagación.
1 2 3 40
500
1000
1500
Prueba
Des
plaz
amie
nto
máx
imo
(us)
1 2 3 4−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
Prueba
Des
plaz
amie
nto
med
io (
us)
1 2 3 40
50
100
150
200
250
300
350
400
450
500
Prueba
Des
viac
ión
típic
a de
l des
plaz
amie
nto
(us)
1 2 3 4−1000
−800
−600
−400
−200
0
200
400
600
800
1000
Prueba
Des
plaz
amie
nto
med
io ±
err
or (
us)
Figura 7.41: Representaciones de los estadísticos matemáticos del desplaza-miento calculados para el cliente SNTP para diferentes cargas de red donde elcliente y el servidor se han conectado mediante tres niveles de conmutadores.
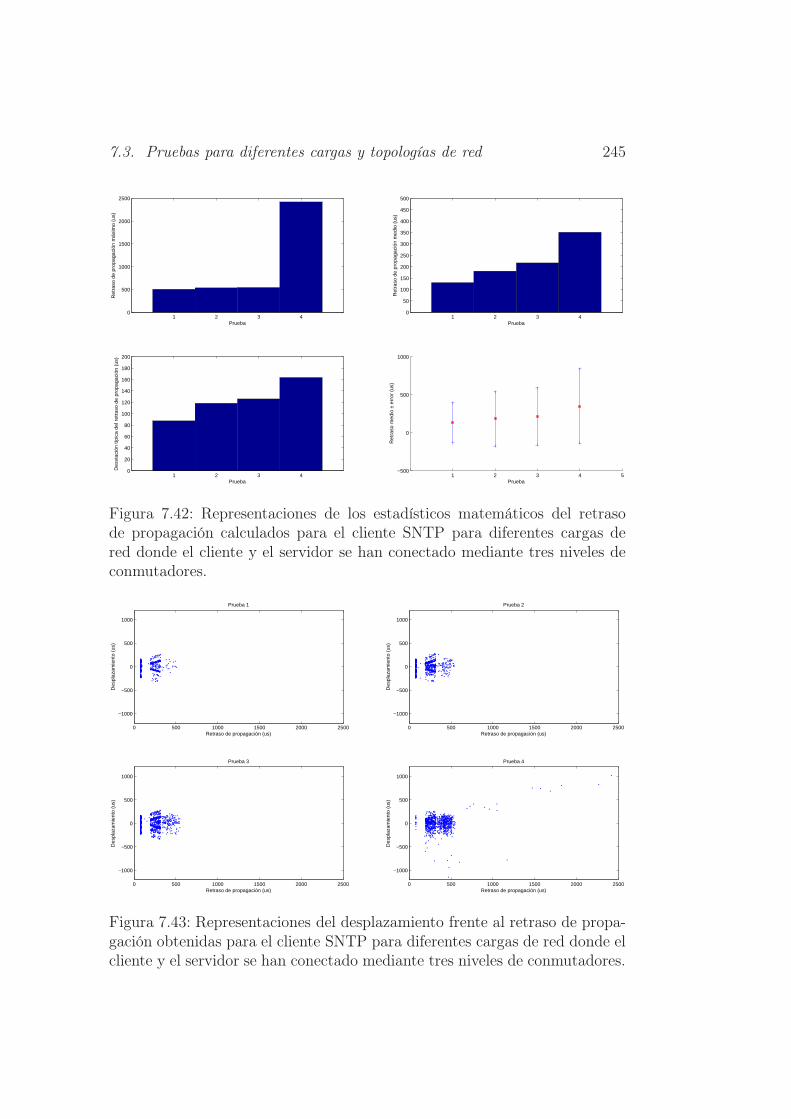
7.3. Pruebas para diferentes cargas y topologías de red 245
1 2 3 40
500
1000
1500
2000
2500
Prueba
Ret
raso
de
prop
agac
ión
máx
imo
(us)
1 2 3 40
50
100
150
200
250
300
350
400
450
500
Prueba
Ret
raso
de
prop
agac
ión
med
io (
us)
1 2 3 40
20
40
60
80
100
120
140
160
180
200
Prueba
Des
viac
ión
típic
a de
l ret
raso
de
prop
agac
ión
(us)
1 2 3 4 5−500
0
500
1000
Prueba
Ret
raso
med
io ±
err
or (
us)
Figura 7.42: Representaciones de los estadísticos matemáticos del retrasode propagación calculados para el cliente SNTP para diferentes cargas dered donde el cliente y el servidor se han conectado mediante tres niveles deconmutadores.
0 500 1000 1500 2000 2500
−1000
−500
0
500
1000
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 1
0 500 1000 1500 2000 2500
−1000
−500
0
500
1000
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 2
0 500 1000 1500 2000 2500
−1000
−500
0
500
1000
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 3
0 500 1000 1500 2000 2500
−1000
−500
0
500
1000
Retraso de propagación (us)
Des
plaz
amie
nto
(us)
Prueba 4
Figura 7.43: Representaciones del desplazamiento frente al retraso de propa-gación obtenidas para el cliente SNTP para diferentes cargas de red donde elcliente y el servidor se han conectado mediante tres niveles de conmutadores.

246 Capítulo 7. Resultados
A partir de los resultados obtenidos, se puede observar cómo para todos
los casos planteados la variabilidad en el retraso de propagación aumenta
significativamente, lo cual provoca que los errores en el cálculo del despla-
zamiento también aumenten y por tanto la precisión de sincronización se
reduzca considerablemente. Esto se observa fundamentalmente comparando
las Fig. 7.30 y 7.41, donde se comprueba cómo el error para un nivel de
conmutación y tráfico elevado se encuentra en el orden del microsegundo
mientras que para tres niveles pasa a situarse en el orden de varias centenas
de microsegundos. Este hecho es debido a que en estos casos tanto los mensa-
jes de hora como el tráfico generado van dirigidos al mismo puerto de salida
lo cual provoca que los mensajes de hora se encolen y aumente significativa-
mente la latencia (Fig. 7.43). No obstante, se observa cómo la precisión de
sincronización se sitúa siempre por debajo de 500 µs.
7.4. Pruebas de robustez
En este último apartado, se van a presentar los resultados relativos a los
parámetros cualitativos PCL5 y PCL6, es decir, cómo se comporta la plata-
forma de sincronización cuando opera de forma continuada y/o se producen
pérdidas de sincronización en las fuentes de referencias o fallos en la comuni-
cación. Además, para este último caso se medirá la deriva ante desconexión
(parámetro cuantitativo PCT12).
En relación con la capacidad del cliente y del servidor SNTP para ope-
rar correctamente de forma continuada, en la Fig. 7.44 se representan los
desplazamientos frente al tiempo tanto del cliente como del servidor para un
periodo de tiempo de 3 días. En esta figura se observa cómo los desplazamien-
tos calculados por los dos dispositivos siempre se mantienen sincronizados en
torno al valor cero, no perdiendo la sincronización en ningún instante ni
apreciándose signos indicativos de mal comportamiento de la plataforma de
sincronización.
En cuanto a la operación ante desconexión, en la Fig 7.45 se muestra
cómo el reloj local del cliente y del servidor SNTP comienzan a derivar una
vez eliminadas las fuentes de sincronización.
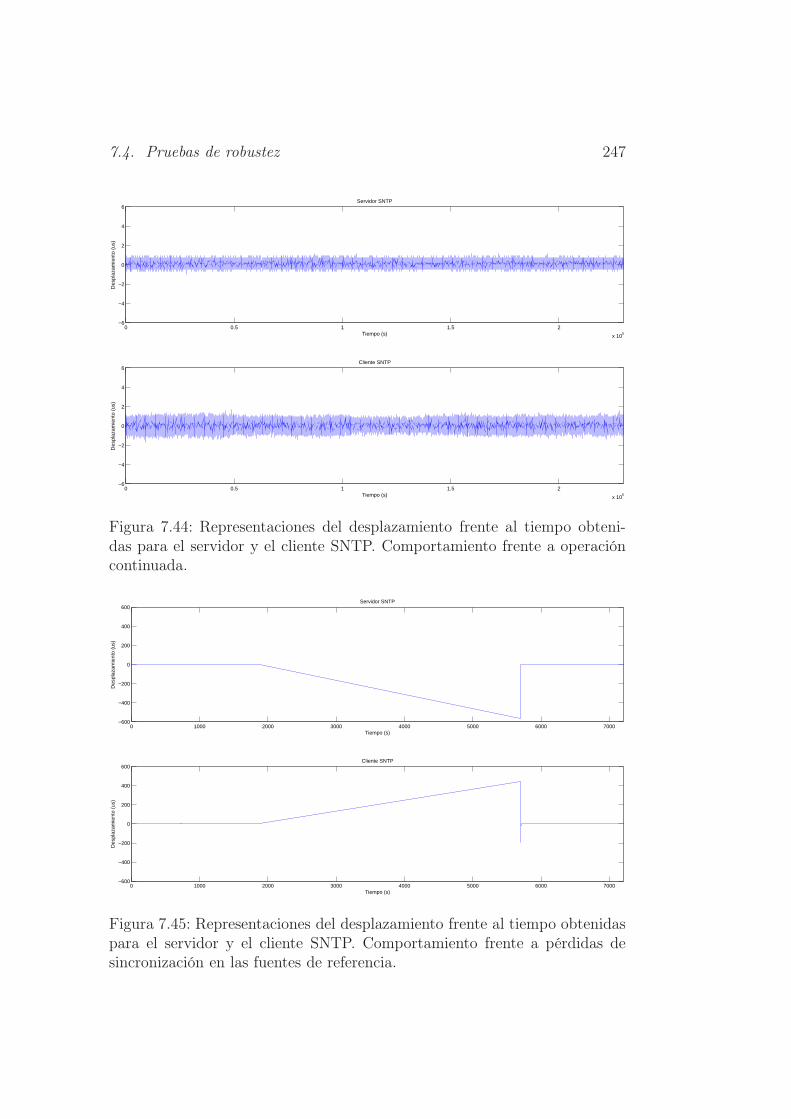
7.4. Pruebas de robustez 247
0 0.5 1 1.5 2
x 105
−6
−4
−2
0
2
4
6
Tiempo (s)
Des
plaz
amie
nto
(us)
Servidor SNTP
0 0.5 1 1.5 2
x 105
−6
−4
−2
0
2
4
6
Tiempo (s)
Des
plaz
amie
nto
(us)
Cliente SNTP
Figura 7.44: Representaciones del desplazamiento frente al tiempo obteni-das para el servidor y el cliente SNTP. Comportamiento frente a operacióncontinuada.
0 1000 2000 3000 4000 5000 6000 7000−600
−400
−200
0
200
400
600
Tiempo (s)
Des
plaz
amie
nto
(us)
Servidor SNTP
0 1000 2000 3000 4000 5000 6000 7000−600
−400
−200
0
200
400
600
Tiempo (s)
Des
plaz
amie
nto
(us)
Cliente SNTP
Figura 7.45: Representaciones del desplazamiento frente al tiempo obtenidaspara el servidor y el cliente SNTP. Comportamiento frente a pérdidas desincronización en las fuentes de referencia.

248 Capítulo 7. Resultados
Esta deriva se debe a que no es posible calcular un nuevo valor de correc-
ción de forma que los dos dispositivos siguen operando con el último valor de
la corrección calculado. En la Fig. 7.45 también se observa cómo la sincroni-
zación se recupera rápidamente una vez que las fuentes de referencia vuelven
a sincronizarse.
Se ha realizado un conjunto de pruebas que han permitido determinar
cuantitativamente la deriva ante desconexión. En la Tabla 7.2 se muestra la
duración de cada prueba y los valores de las derivas obtenidas, medidas en
varias unidades: µs, PPM y ms/día. Asimismo, en la Tabla 7.3 se muestran
los estadísticos matemáticos calculados a partir de los datos presentados. Co-
mo se observa en las tablas anteriores, los valores de deriva pueden tomar
valores negativos y positivos, lo cual dependerá del último valor de corrección
aplicado. Otro aspecto destacable es cómo la deriva media calculada se sitúa
en 17,5 ms/día (6,4 s/año), siendo ésta totalmente comparable con la obteni-
da por los equipos comerciales que emplean un oscilador TCXO. Por último,
se observa cómo para el peor caso, se obtiene una deriva de 41,7 ms/día lo
cual supone únicamente una deriva de 15,2 segundos al año.
7.5. Conclusiones
En este capítulo se han presentado y analizado los resultados obtenidos
para cada una de las fases expuestas en el capítulo anterior. Así, en primer
lugar, se han comentado los resultados de un conjunto de pruebas básicas que
han permitido verificar el correcto funcionamiento de la plataforma de sincro-
nización. En segundo lugar, para una configuración típica de la plataforma,
se ha analizado el comportamiento de los algoritmos desarrollados ante una
variedad de valores del intervalo entre peticiones y del factor de convergencia
alcanzando precisiones en torno al microsegundo. Como resultado de estas
pruebas se han determinado los valores óptimos de dichos parámetros que
serán empleados para realizar las restantes pruebas. En tercer lugar, se ha
comprobado la influencia de determinados aspectos relacionados con la con-
figuración de red. En este sentido, se han planteado pruebas con diferentes
cargas y topologías de red que han demostrado que el sistema implementado
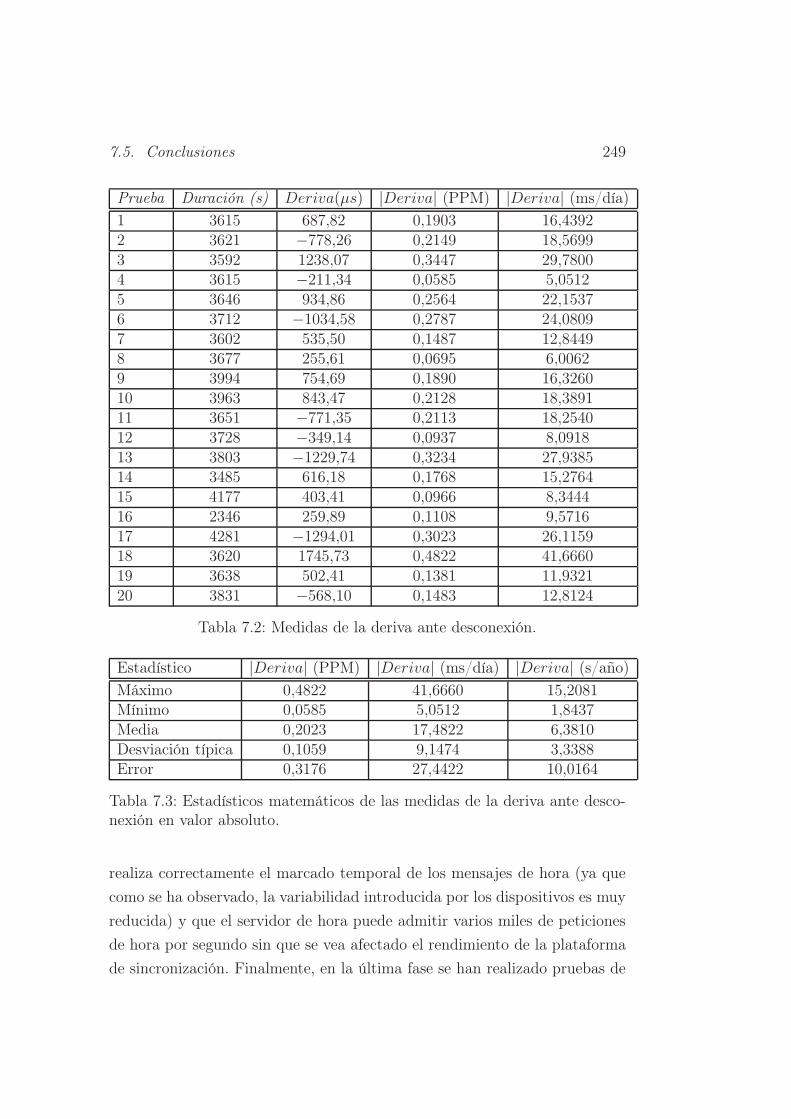
7.5. Conclusiones 249
Prueba Duración (s) Deriva(µs) |Deriva| (PPM) |Deriva| (ms/día)
1 3615 687,82 0,1903 16,43922 3621 −778,26 0,2149 18,56993 3592 1238,07 0,3447 29,78004 3615 −211,34 0,0585 5,05125 3646 934,86 0,2564 22,15376 3712 −1034,58 0,2787 24,08097 3602 535,50 0,1487 12,84498 3677 255,61 0,0695 6,00629 3994 754,69 0,1890 16,326010 3963 843,47 0,2128 18,389111 3651 −771,35 0,2113 18,254012 3728 −349,14 0,0937 8,091813 3803 −1229,74 0,3234 27,938514 3485 616,18 0,1768 15,276415 4177 403,41 0,0966 8,344416 2346 259,89 0,1108 9,571617 4281 −1294,01 0,3023 26,115918 3620 1745,73 0,4822 41,666019 3638 502,41 0,1381 11,932120 3831 −568,10 0,1483 12,8124
Tabla 7.2: Medidas de la deriva ante desconexión.
Estadístico |Deriva| (PPM) |Deriva| (ms/día) |Deriva| (s/año)
Máximo 0,4822 41,6660 15,2081Mínimo 0,0585 5,0512 1,8437Media 0,2023 17,4822 6,3810Desviación típica 0,1059 9,1474 3,3388Error 0,3176 27,4422 10,0164
Tabla 7.3: Estadísticos matemáticos de las medidas de la deriva ante desco-nexión en valor absoluto.
realiza correctamente el marcado temporal de los mensajes de hora (ya que
como se ha observado, la variabilidad introducida por los dispositivos es muy
reducida) y que el servidor de hora puede admitir varios miles de peticiones
de hora por segundo sin que se vea afectado el rendimiento de la plataforma
de sincronización. Finalmente, en la última fase se han realizado pruebas de

250 Capítulo 7. Resultados
robustez donde se han analizado factores como la operación continuada y
la deriva ante desconexión. Así, los resultados muestran cómo se consigue
alcanzar la sincronización en un intervalo pequeño de tiempo y mantenerla
de forma continuada en ausencia de fallos; asimismo, cuando éstos se produ-
cen se comprueba cómo la plataforma es capaz de recuperarse rápidamente
de los mismos, una vez restablecidas las condiciones normales de operación
del sistema. En definitiva, todos estos resultados demuestran y garantizan la
validez de la arquitectura y los algoritmos desarrollados.

Conclusiones finales
A continuación pasamos a resumir las conclusiones más relevantes de este
trabajo:
Se ha analizado el estado del arte de los sistemas y protocolos de sin-
cronización sobre redes de comunicación, constatando las carencias de
las tecnologías existentes para su aplicación en el campo de los sistemas
empotrados.
Se han desarrollado nuevos algoritmos y arquitecturas adecuadas para
la implementación hardware de sistemas de sincronización sobre redes
de comunicación, incluyendo un modelo de reloj local de alta precisión
empleando únicamente componentes digitales estándares, y un algorit-
mo de control del reloj de altas prestaciones y de bajo coste en recursos
hardware.
Se han diseñado módulos hardware para la realización de las tareas
fundamentales requeridas por los sistemas de sincronización, incluyen-
do una pila de protocolos básica, una unidad de marcado temporal y
módulos que implementan los nuevos algoritmos y modelos aportados.
Empleando los módulos mencionados, se ha construido una arquitectu-
ra para el diseño de clientes y servidores SNTP y, tras analizar las meto-
dologías disponibles, se ha realizado la implementación de un cliente y
un servidor SNTP completamente en hardware programable, ofreciendo
una alternativa flexible y de muy bajo coste a los sistemas existentes.
Se ha establecido una exhaustiva metodología de verificación de los
sistemas diseñados y de los nuevos algoritmos que implementan. Con
251

252 Conclusiones finales
objeto de llevar a cabo esta metodología, se ha desarrollado una pla-
taforma genérica de verificación de sistemas empotrados en hardware
programable con la capacidad de testar sistemas de forma indefinida
mediante la captura de eventos lógicos en las señales internas del circui-
to y su inmediata transmisión al exterior del chip mediante una interfaz
serie.
De las pruebas realizadas se extrae que, operando en condiciones típi-
cas, los sistemas desarrollados se sincronizan con una precisión en torno
a 1 µs, y que la sincronización es alcanzada pocos segundos después del
inicio de operación de los mismos, lo que es comparable a las figuras de
mérito de equipos industriales discretos, pero empleando una fracción
de los recursos y del coste.
Asimismo, se ha constatado la robustez de los sistemas implementados
ante fallos en la comunicación y saturación de la red de forma que, a
modo de ejemplo, el servidor SNTP es capaz de proporcionar datos de
sincronización precisos (en el orden de los 10 µs) incluso sometido a
una carga de más de 20000 peticiones por segundo.
En definitiva, se han desarrollado y demostrado experimentalmente tec-
nologías de sincronización sobre redes de comunicación para sistemas em-
potrados que suponen, en nuestra opinión, un claro avance en el estado del
arte y que abren la puerta a que una diversidad de sistemas empotrados
incorporen funciones de sincronización de alta precisión a muy bajo coste.

Publicaciones
Proyectos de investigación
Las tareas llevadas a cabo durante la realización de este trabajo se en-
marcan dentro de los siguientes proyectos de investigación (especialmente ha
supuesto una contribución importante a los proyectos PTC - Fases I y II,
HardNTP y SEPIC):
OpenRTU: plataforma embebida abierta en tiempo real para unidades
terminales remotas en sistemas de control (FIT-330101-2004-5).
META: Modelado, estimación y técnicas de análisis de alta precisión a
nivel lógico del consumo de potencia e intensidad en circuitos y sistemas
digitales CMOS VLSI (TEC-2004-00840/MIC).
PTC: Plataforma Tecnológica Común para UTR - Fases I y II (FIT-
330100-2006-60).
OFU: Sistemas Empotrados Abiertos de Unidades Terminales para Sis-
temas de Control Industrial (CICE OFU TIC-1023).
HIPER: Técnicas de altas prestaciones para la verificación y diseño de
circuitos digitales CMOS VLSI (MEC TEC-2007-61802).
HardNTP: Desarrollo de un servidor hardware NTP (OTRI 08-TIC-
264).
SEPIC: Sistemas Empotrados Para Infraestructuras Críticas (TSI-
020100-2008-258).
253

254 Publicaciones
Resultados directos
La realización de este trabajo ha dado lugar de manera directa a las
siguientes publicaciones:
J. Viejo, J. Juan, M. J. Bellido, E. Ostua, A. Millan, P. Ruiz-de-Clavijo,
A. Muñoz, and D. Guerrero (2008). Design and implementation of a
SNTP client on FPGA. Proc. 2008 IEEE International Symposium
on Industrial Electronics (ISIE), Cambridge (United Kingdom), 1971–
1975.
J. Viejo, E. Ostua, M. J. Bellido, P. Ruiz-de-Clavijo, A. Muñoz, and A.
Millan (2008). Aplicación de Picoblaze al diseño de sistemas de control
industrial. Proc. 5th International Conference on Telecommunications,
Electronics and Control (TELEC), Santiago de Cuba (Cuba).
J. Viejo, J. Juan, E. Ostua, M. J. Bellido, A. Millan, A. Muñoz, and
J. I. Villar (2009). Accurate and compact implementation of a hard-
ware SNTP Client. Proc. 15th Iberchip Workshop (IWS), Buenos Aires
(Argentina), 504–509.
J. Viejo, J. Juan, E. Ostua, A. Millan, P. Ruiz-de-Clavijo, J. I. Villar,
and J. Quiros (2009). Implementación sobre FPGA de un cliente SNTP
de bajo coste y alta precisión. Proc. 9th Jornadas de Computación
Reconfigurable y Aplicaciones (JCRA), Madrid (Spain), 359–366.
E. Ostua, M. J. Bellido, J. Viejo, A. Millan, A. Muñoz, and D. Gue-
rrero (2009). Aplicación de Picoblaze como Emulador/Receptor de un
GPS en el diseño hardware de un cliente/servidor SNTP. Proc. 9th Jor-
nadas de Computación Reconfigurable y Aplicaciones (JCRA), Madrid
(Spain), 193–202.
J. Quiros, J. Viejo, A. Muñoz, A. Millan, E. Ostua, J. I. Villar (2010).
Implementación sobre FPGA de un cliente SNTP usando MicroBlaze.
Proc. 16th Iberchip Workshop (IWS), Iguazu Falls (Brazil).

Publicaciones 255
J. Viejo, J. I. Villar, J. Juan, A. Millan, M. J. Bellido, E. Ostua (2010).
Design and implementation of a suitable core for on-chip long-term ve-
rification. Proc. 5th IEEE International Symposium on Industrial Em-
bedded Systems (SIES), Trento (Italy), 234–237.
J. Viejo, J. I. Villar, J. Juan, A. Millan, M. J. Bellido, J. Quiros (2010).
Verificación on-chip de larga duración de sistemas con eventos lógicos
dispersos en el tiempo. Proc. 10th Jornadas de Computación Reconfi-
gurable y Aplicaciones (JCRA), Valencia (Spain), 269–276.
J. Viejo, J. I. Villar, J. Juan, A. Millan, E. Ostua, J. Quiros (2010).
Long-term on-chip verification of systems with logical events scattered
in time. Proc. 25th Conference on Design of Circuits and Integrated
Systems (DCIS), Lanzarote (Spain), 323–326.
J. Quiros, J. Viejo, A. Millan, A. Muñoz, J. I. Villar, D. Guerrero
(2011). Implementation of a configuration server for a hardware SNTP
synchronization platform based on FPGA. Proc. 7th Southern Confe-
rence on Programmable Logic (SPL), Cordoba (Argentina). Pendiente
de publicación.
Resultados indirectos
Además de las publicaciones citadas, algunas de las tareas llevadas a
cabo durante la realización de este trabajo han supuesto una aportación
importante en los siguientes artículos:
J. Viejo, E. Ostua, M. J. Bellido, J. Juan, A. Millan, P. Ruiz-de-Clavijo,
and D. Guerrero (2005). Diseño, implementación y aplicación a SOC
del microprocesador Picoblaze. Proc. 11th Iberchip Workshop (IWS),
Salvador de Bahia (Brazil), 431–432.
J. Viejo, E. Ostua, M. J. Bellido, J. Juan, A. Millan, P. Ruiz-de-Clavijo,
and D. Guerrero (2006). Diseño e implementación óptima de periféricos

256 Publicaciones
de DSP con System Generator para MicroBlaze. Proc. 12th Iberchip
Workshop (IWS), San Jose (Costa Rica), 49–52.
J. Viejo, E. Ostua, M. J. Bellido, J. Juan, A. Millan, P. Ruiz-de-Clavijo,
and D. Guerrero (2006). Diseño e implementación de SOPC basados
en el microprocesador PicoBlaze. Proc. 7th Congreso de Tecnologías
Aplicadas a la Enseñanza de la Electrónica (TAEE), Madrid (Spain),
319–320.
J. Viejo, M. J. Bellido, A. Millan, E. Ostua, J. Juan, P. Ruiz-de-
Clavijo, and D. Guerrero (2006). Efficient Design and Implementation
on FPGA of a MicroBlaze Peripheral for Processing Direct Electri-
cal Networks Measurements. Proc. 1st IEEE Symposium on Industrial
Embedded Systems (IES), Antibes-Juan les Pins (France).
J. Viejo, M. J. Bellido, A. Millan, E. Ostua, J. Juan, P. Ruiz-de-Clavijo,
and D. Guerrero (2006). DSP peripheral on FPGA for electrical net-
works measurements. Proc. 21th Conference on Design of Circuits and
Integrated Systems (DCIS), Barcelona (Spain).
J. Viejo, A. Millan, M. J. Bellido, J. Juan, P. Ruiz-de-Clavijo, D. Gue-
rrero, E. Ostua, and A. Muñoz (2007). Design of a FFT/IFFT module
as an IP core suitable for embedded systems. Proc. 2nd IEEE Inter-
national Symposium on Industrial Embedded Systems (SIES), Lisbon
(Portugal), 337–340.
J. Viejo, A. Millan, M. J. Bellido, J. Juan, P. Ruiz-de-Clavijo, D. Gue-
rrero, E. Ostua, and A. Muñoz (2007). Evaluación de metodologías pa-
ra la implementación de un módulo FFT/IFFT sobre FPGA mediante
herramientas a nivel de sistema. Proc. 7th Jornadas de Computación
Reconfigurable y Aplicaciones (JCRA), Zaragoza (Spain), 205–211.
J. Viejo, A. Millan, M. J. Bellido, E. Ostua, P. Ruiz-de-Clavijo, A. Mu-
ñoz (2008). Implementation of a FFT/IFFT module on FPGA: Com-
parison of methodologies. Proc. 4th Southern Conference on Program-
mable Logic (SPL), San Carlos de Bariloche (Argentina), 7–11.

Bibliografía
Actel. Actel Home Page. URL http://www.actel.com/.
S. Alexander and R. Droms. DHCP Options and BOOTP Ven-
dor Extensions. RFC 2132 (Draft Standard), March 1997. URL
http://www.ietf.org/rfc/rfc2132.txt. Updated by RFCs 3442, 3942,
4361, 4833.
Altera. Altera Home Page. URL http://www.altera.com/.
Altera. NIOS 3.0 CPU Data Sheet, Rev. 2.2. Altera Corp., October 2004.
Altera. Design Debugging Using the SignalTap II Embedded Logic Analyzer.
Altera Corporation, November 2009.
Apple. Mac OS X Home Page. URL http://www.apple.com/es/macosx/.
K. Arshak, E. Jafer, and C. Ibala. Testing FPGA based digital system using
XILINX ChipScopeTM logic analyzer. In 29th International Spring Se-
minar on Electronics Technology (ISSE), pages 355–360, St. Marienthal
(Germany), May 2006.
G. Brandl. Documenting Python Release 3.1.3, 2010. URL
http://docs.python.org/py3k/.
S. E. Butner and S. Vahey. Nanosecond-scale Event Synchronization over
Local-area Networks. In 27th Annual IEEE Conference on Local Computer
Networks (LNC), pages 261–269, Tampa, Florida (USA), November 2002.
257

258 Bibliografía
A. Carta, N. Locci, C. Muscas, and S. Sulis. A Flexible GPS-Based System
for Synchronized Phasor Measurement in Electric Distribution Networks.
IEEE Transactions on Instrumentation and Measurement, 57(11):2450–
2456, 2008.
A. Carta, N. Locci, and C. Muscas. A PMU for the Measurement of
Synchronized Harmonic Phasors in Three-Phase Distribution Networks.
IEEE Transactions on Instrumentation and Measurement, 58(10):3723–
3730, 2009.
A. Carta, N. Locci, C. Muscas, F. Pinna, and S. Sulis. GPS and IEEE 1588
synchronization for the measurement of synchrophasors in electric power
systems. Computer Standards & Interfaces, 33(2):176–181, 2011.
K. Chapman. UART Transmitter and Receiver Macros. Xilinx, Inc., October
2002.
K. Chapman. PicoBlaze 8-Bit Embedded Microcontroller User Guide for
Spartan-3, Virtex-II and Virtex-II PRO FPGAs. Xilinx, Inc., November
2005.
Cisco. EtherFast 10/100 8-Port Workgroup Switch Model: EZXS88W Datas-
heet. Cisco, 2008.
W. J. Croft and J. Gilmore. Bootstrap Protocol. RFC 951 (Draft Standard),
September 1985. URL http://www.ietf.org/rfc/rfc951.txt. Updated
by RFCs 1395, 1497, 1532, 1542.
C. E. Cummings. The Fundamentals of Efficient Synthesizable Finite State
Machine Design using NC-Verilog and BuildGates. In International Ca-
dence Usergroup conference (ICU), San Jose, California (USA), September
2002.
R. Droms. Dynamic Host Configuration Protocol. RFC 2131 (Draft Stan-
dard), March 1997. URL http://www.ietf.org/rfc/rfc2131.txt. Up-
dated by RFCs 3396, 4361.

Bibliografía 259
J. W. Eaton, D. Bateman, and S. Hauberg. GNU Octave Manual Version 3.
Network Theory Limited, United Kingdom, 2008. ISBN 0-9546120-6-X.
L. Ehrenpreis, P. Ellervee, and K. Tammemae. Open Source On-Chip Logic
Analyzer for FPGAs. In 2006 International Baltic Electronics Conference,
pages 1–4, Tallinn (Estonia), October 2006.
J. Eidson, M. Fischer, and J. White. IEEE 1588 Standard for a Precision
Clock Synchronization Protocol for Networked Measurement and Control
Systems. In Proc. Precise Time and Time Interval (PTTI), Washington
(USA), December 2002.
EndRun. EndRun Technologies Home Page. URL
http://www.endruntechnologies.com/.
ESA. European Space Agency Portal. URL http://www.esa.int/.
R. Exel and P. Loschmidt. High Accurate Timestamping by Phase and Fre-
quency Estimation. In 2009 International IEEE Symposium on Precision
Clock Synchronization for Measurement, Control and Communication, pa-
ges 126–131, Brescia (Italy), October 2009.
FEI-Zyfer. FEI-Zyfer Home Page. URL http://www.zyfer.com/.
FreeBSD. FreeBSB Project Home Page. URL http://www.freebsd.org/.
Gaisler. Aeroflex Gaisler Home Page. URL http://www.gaisler.com/.
J. Gaisler. LEON2 Processor User’s Manual XST Edition. Gaisler Research,
May 2004.
Galleon. Galleon Systems Home Page. URL http://www.galleon.eu.com/.
J. Gao. 10_100_1000 Mbps Tri-mode Ethernet MAC Specification. OPEN-
CORES.ORG, January 2006.
Garmin. GPS 18 Technical Specifications, 190-00307-00, Revision D. Garmin
International, Inc., June 2005.

260 Bibliografía
C. Gordon. White Paper Introduction to IEEE 1588 & Transparent Clocks,
2009.
P. S. Graham. Logical Hardware Debuggers for FPGA-Based Systems. Phd
dissertation, Bringham Young University, Department of Electrical and
Computer Engineering, 2001.
J. Han and D. Jeong. A Practical Implementation of IEEE 1588-2008 Trans-
parent Clock for Distributed Measurement and Control Systems. IEEE
Transactions on Instrumentation and Measurement, 59(2):433–439, 2010.
R. Höller. FPGAs for High Accuracy Clock Synchronization over Ethernet
Networks. Field-Programmable Logic and Applications - Lecture Notes in
Computer Science, Springer Berlin / Heidelberg, 2778:960–963, 2003.
R. Höller, G. Gridling, M. Horauer, N. Kerö, U. Schmid, and K. Schossmaier.
SynUTC - High Precision Time Synchronization over Ethernet Networks.
In 8th Workshop on Electronics for LHC Experiments, pages 428–432, Col-
mar (France), September 2002.
R. Höller, T. Sautert, and N. Kerö. Embedded SynUTC and IEEE 1588
Clock Synchronization for Industrial Ethernet. In IEEE Conference on
Emerging Technologies and Factory Automation (ETFA), pages 422–426,
Lisboa (Portugal), September 2003.
Ø. Holmeide and T. Skeie. Time Synchronization in Swithed Ethernet. In-
dustrial Ethernet Book, 7(26), 2001.
Ø. Holmeide and T. Skeie. Synchronised: Switching. IET Computing and
Control Engineering, 17(2):42–47, 2006.
M. Horauer, K. Schossmaier, U. Schmid, R. Höller, and N. Kerö. PSynUTC
- Evaluation of a high precision time synchronization prototype system for
Ethernet LANs. In 34th Annual Precise Time and Time Interval Meeting
(PTTI), pages 263–279, Reston, Virginia (USA), December 2002.
IEEE. ANSI/IEEE Standard 802.2-1998 Part 2: Logical Link Control, 1998.

Bibliografía 261
IEEE. IEEE Standard 802.3-2005 Part 3: Carrier sense multiple access with
collision detection (CSMA/CD) access method and physical layer specifi-
cations, 2005.
IEEE. IEEE Standard for a Precision Clock Synchronization Protocol for
Networked Measurement and Control Systems. PTP Version 2 (1588-
2008), 2008.
Intel. Intel Corporation Home Page. URL http://www.intel.com/.
Intel. 8742 Universal peripheral interface 8-bit slave microcontroller. Intel,
November 1991.
S. Johannessen. Time Synchronization in a Local Area Network. IEEE
Control Systems Magazine, 24(2):61–69, 2004.
G. Knittel, S. Mayer, and C. Rothlaender. Integrating Logic Analyzer Fun-
ctionality into VHDL Designs. In 2008 International Conference on Re-
configurable Computing and FPGAs, pages 127–132, Cancun (Mexico), De-
cember 2008.
N. Kurihara. JJY, The National Standard on Time and Frequency in Ja-
pan. Journal of the National Institute of Information and Communications
Technology, 50(1/2):179–186, 2003.
U. Lamping, R. Sharpe, and E. Warnicke. Wireshark User’s Guide 35270 for
Wireshark 1.4. 2010.
D. Lampret. OpenRISC 1200 IP Core Specification. OPENCORES.ORG,
September 2001.
Lattice. Lattice Semiconductor Corporation Home Page. URL
http://www.latticesemi.com/.
Lattice. LatticeMico32 Processor Reference Manual. Lattice Corp., August
2007.

262 Bibliografía
T. Lee, Y. Fan, S. Yen, C. Tsai, and R. Hsiao. An Integrated Functional Ve-
rification Tool for FPGA Systems. In International Conference on Innova-
tive Computing, Information and Control, page 203, Kumamoto (Japan),
September 2007.
C. Liechti. pySerial v2.5 documentation, 2010. URL
http://pyserial.sourceforge.net/.
Linux. Linux Home Page at Linux Online. URL http://www.linux.org/.
M. A. Lombardi. NIST Time and Frequency Services. NIST Special Publi-
cation 432, National Institute of Standards and Technology, United States
Department of Commerce, 2002.
P. Loschmidt, R. Exel, A. Nagy, and G. Gaderer. Limits of Synchronization
Accuracy Using Hardware Support in IEEE 1588. In International IEEE
Symposium on Precision Clock Synchronization for Measurement, Control
and Communication (ISPCS), pages 12–16, Ann Arbor, Michigan (USA),
September 2008.
M. H. MacGregor, A. Dittrich, and K. Sullivan. Precise Measurement of One-
Way Delay in an NTPv3 Environment. In 2004 International Symposium
on Performance Evaluation of Computer and Telecommunication Systems
(SPECTS), San Jose, California (USA), July 2004.
MathWorks. MathWorks Home Page. URL http://www.mathworks.com/.
MathWorks. MATLAB 7 Getting Started Guide. MathWorks, September
2009a.
MathWorks. Simulink 7 Getting Started Guide. MathWorks, September
2009b.
S. Meier, H. Weibel, and K. Weber. IEEE 1588 Syntonization and Synchro-
nization Functions Completely Realized in Hardware. In 2008 IEEE Inter-
national Symposium on Precision Clock Synchronization for Measurement,
Control and Communication (ISPCS), Ann Arbor, MI (USA), September
2008.

Bibliografía 263
Meinberg. Meinberg Funkuhren GmbH & Co. KG Home Page. URL
http://www.meinberg.de/english/.
Mentor. Mentor Graphics Home Page. URL http://www.mentor.com/.
Mentor. ModelSim Reference Manual, Software Version 6.3g. Mentor Grap-
hics, May 2008.
D. L. Mills. Network Time Protocol (NTP). RFC 958, September 1985. URL
http://www.ietf.org/rfc/rfc958.txt. Obsoleted by RFCs 1059, 1119,
1305.
D. L. Mills. Network Time Protocol (version 1) specifica-
tion and implementation. RFC 1059, July 1988. URL
http://www.ietf.org/rfc/rfc1059.txt. Obsoleted by RFCs 1119,
1305.
D. L. Mills. Network Time Protocol (version 2) specification and
implementation. RFC 1119 (Standard), September 1989. URL
http://www.ietf.org/rfc/rfc1119.txt. Obsoleted by RFC 1305.
D. L. Mills. On the accuracy and stability of clocks synchronized by the
Network Time Protocol in the Internet system. ACM Computer Commu-
nication Review, 20(1):65–75, 1990.
D. L. Mills. Internet time synchronization: the Network Time Protocol. IEEE
Transactions on Communications, 39(10):1482–1493, 1991.
D. L. Mills. Modelling and analysis of computer network clocks. Report
92-3-1, University of Delaware, Electrical Engineering Department, 1992a.
D. L. Mills. Network Time Protocol (Version 3) Specification, Implemen-
tation and Analysis. RFC 1305 (Draft Standard), March 1992b. URL
http://www.ietf.org/rfc/rfc1305.txt.
D. L. Mills. Improved algorithms for synchronizing computer network clocks.
IEEE/ACM Transactions on Networking, 3(3):245–254, 1995.

264 Bibliografía
D. L. Mills. A brief history of NTP time: confessions of an Internet timekee-
per. ACM Computer Communications Review, 33(2):9–22, 2003.
D. L. Mills. Computer Network Time Synchronization: The Network Time
Protocol. CRC Press, Inc., Boca Raton, FL, USA, 2006a. ISBN 0-8493-
5805-1.
D. L. Mills. Simple Network Time Protocol (SNTP) Version 4 for IPv4,
IPv6 and OSI. RFC 4330 (Informational), January 2006b. URL
http://www.ietf.org/rfc/rfc4330.txt.
D. L. Mills and P. H. Kamp. The nanokernel. In Proc. Precision Time and
Time Interval (PTTI) Applications and Planning Meeting, pages 423–430,
Reston VA (USA), November 2000.
D. L. Mills, J. Martin, J. Burbank, and W. Kasch. Network Time Protocol
Version 4: Protocol and Algorithms Specification. RFC 5905 (Standards
Track), June 2010. URL http://www.ietf.org/rfc/rfc5905.txt.
A. Muñoz, E. Ostua, P. Ruiz-de Clavijo, M. J. Bellido, J. Viejo, A. Millan,
J. Juan, and D. Guerrero. Un ejemplo de implantación de una distribu-
ción Linux en un SoC basado en hardware libre. In Proc. 7th Jornadas
de Computación Reconfigurable y Aplicaciones (JCRA), pages 85–92, Za-
ragoza (Spain), September 2007.
A. Muñoz, E. Ostua, M. J. Bellido, A. Millan, J. Juan, and D. Guerrero.
Building a SoC for industrial applications based on LEON microproces-
sor and a GNU/Linux distribution. In Proc. 2008 IEEE International
Symposium on Industrial Electronics (ISIE), pages 1727–1732, Cambridge
(United Kingdom), June 2008a.
A. Muñoz, E. Ostua, M. J. Bellido, P. Ruiz-de Clavijo, J. I. Villar, and
J. Quiros. Ampliación de periféricos para aplicaciones embebidas basadas
en hardware y software libre. In Proc. 5th International Conference on
Telecommunications, Electronics and Control (TELEC), Santiago de Cuba
(Cuba), July 2008b.

Bibliografía 265
NMEA. NMEA 0183 Standard. NMEA 0183 V 4.00, January 2002.
NPL. MSF The Time from National Physical Laboratory (NPL), April 2007.
URL http://www.clockco.co.uk/documents/msf.pdf.
S. Nylund and Ø. Holmeide. IEEE 1588 Ethernet switch transparency - No
need for Boundary Clocks. In 2004 Conference on IEEE 1588 Standard
for a Precision Clock Synchronization Protocol, 2004.
N. Ohba and K. Takano. Hardware debugging method based on signal tran-
sitions and transactions. In IEEE Proc Asia and South Pacific conf on
Design Automation, pages 454–459, Yokohama (Japan), January 2006.
Ontime. Ontime Networks Home Page. URL http://www.ontimenet.com/.
OpenCores. OpenCores Home Page. URL http://opencores.org/.
Oracle. Oracle Home Page. URL http://www.oracle.com/.
Oregano. Oregano Systems Home Page. URL http://www.oregano.at/.
Oregano. syn1588 VIP Brief Data Sheet, Version 1.4. Oregano Systems,
January 2010.
Oscilloquartz. Oscilloquartz Home Page. URL
http://www.oscilloquartz.com/.
E. Ostua, J. Viejo, M. J. Bellido, J. Juan, A. Millan, P. Ruiz-de Clavijo, and
D. Guerrero. Entorno de desarrollo para SOC basado en el microprocesador
LEON2. In Proc. 11th Iberchip Workshop (IWS), pages 429–430, Salvador
de Bahia (Brazil), March 2005.
E. Ostua, J. Juan, J. Viejo, M. J. Bellido, D. Guerrero, A. Millan, and P. Ruiz-
de Clavijo. A SOC design methodology for LEON2 on FPGA. In Proc. 12th
Iberchip Workshop (IWS), pages 242–245, San Jose (Costa Rica), March
2006.

266 Bibliografía
E. Ostua, J. Viejo, M. J. Bellido, A. Millan, J. Juan, and A. Muñoz. Digital
Data Processing Peripheral Design for an Embedded Application Based on
the Microblaze Soft Core. In Proc. 4th Southern Conference on Program-
mable Logic (SPL), pages 197–200, San Carlos de Bariloche (Argentina),
March 2008.
E. Ostua, M. J. Bellido, J. Viejo, A. Millan, A. Muñoz, and D. Guerrero.
Aplicación de Picoblaze como Emulador/Receptor de un GPS en el di-
seño hardware de un cliente/servidor SNTP. In Proc. 9th Jornadas de
Computación Reconfigurable y Aplicaciones (JCRA), pages 193–202, Ma-
drid (Spain), September 2009.
D. Plummer. Ethernet Address Resolution Protocol: Or Converting Net-
work Protocol Addresses to 48.bit Ethernet Address for Transmission
on Ethernet Hardware. RFC 826 (Standard), November 1982. URL
http://www.ietf.org/rfc/rfc826.txt. Updated by RFC 5227.
J. Postel. User Datagram Protocol. RFC 768 (Standard), August 1980. URL
http://www.ietf.org/rfc/rfc768.txt.
J. Postel. Internet Protocol. RFC 791 (Standard), September 1981. URL
http://www.ietf.org/rfc/rfc791.txt. Updated by RFC 1349.
RCC. IRIG serial time code formats from Range Commanders Council
(RCC). IRIG STANDARD 200-04, September 2004.
J. Reichardt. Reprogramming Block RAM Memory in Virtex FPGAs. Ham-
burg University of Applied Sciences, October 2007.
M. Six. kpicosim. A simulator and assembler for the PicoBlaze, 2009. URL
http://www.xs4all.nl/ marksix/kpicosim.html.
T. Skeie, S. Johannessen, and Ø. Holmeide. Highly accurate time synchroni-
zation over switched Ethernet. In Proc. 8th IEEE International Conference
on Emerging Technologies and Factory Automation (ETFA), pages 195–
204, Antibes-Juan les Pins (France), October 2001.

Bibliografía 267
T. Skeie, S. Johannessen, and C. Brunner. Ethernet in substation automa-
tion. IEEE Control Systems Magazine, 22(3):43–51, 2002.
T. Skeie, S. Johannessen, T. Løkstad, and Ø. Holmeide. Same time - Different
place. ABB Review, (2):9–14, 2003.
T. Skeie, S. Johannessen, and Ø. Holmeide. Timeliness of real-time IP com-
munication in switched industrial Ethernet networks. IEEE Transactions
on Industrial Informatics, 2(1):25–39, 2006.
V. Smotlacha. Clock Synchronization in CESNET Monitoring Infras-
tructure. CESNET Technical Report 1/2006, December 2005. URL
http://www.cesnet.cz/doc/techzpravy/2006/tsync/.
Solaris. Solaris Home Page. URL http://www.oracle.com/solaris/.
Spectracom. Spectracom Home Page. URL
http://www.spectracomcorp.com/.
SunMicrosystems. OpenSPARC T1 Microarchitecture Specification. Sun Mi-
crosystems, Inc., August 2006.
Symmetricom. Symmetricom Home Page. URL
http://www.symmetricom.com/.
I. E. C. Technical Committee 57. IEC 61850 Communication Networks and
Systems In Substations. IEC 61850 Edition 2 and other extensions, June
2008.
TimeFreq. Time and Frequency Solutions Home Page. URL
http://www.timefreq.com/.
H. Toriyama, A. Machizawa, T. Iwama, and A. Kaneko. Development of A
Hardware SNTP Server. IEICE Transactions on Communications (Japa-
nese Edition), J89(B(10)):1867–1873, 2006.
J. Viejo. Diseño e implementación de funciones de DSP sobre FPGA. Proyec-
to de investigación, Universidad de Sevilla, Departamento de Tecnología
Electrónica, 2006.

268 Bibliografía
J. Viejo, E. Ostua, M. J. Bellido, J. Juan, A. Millan, P. Ruiz-de Clavijo, and
D. Guerrero. Diseño, implementación y aplicación a SOC del microproce-
sador Picoblaze. In Proc. 11th Iberchip Workshop (IWS), pages 431–432,
Salvador de Bahia (Brazil), March 2005.
J. Viejo, M. J. Bellido, A. Millan, E. Ostua, J. Juan, P. Ruiz-de Clavijo,
and D. Guerrero. DSP peripheral on FPGA for electrical networks mea-
surements. In Proc. 21th Conference on Design of Circuits and Integrated
Systems (DCIS), Barcelona (Spain), November 2006a.
J. Viejo, M. J. Bellido, A. Millan, E. Ostua, J. Juan, P. Ruiz-de Clavijo,
and D. Guerrero. Efficient Design and Implementation on FPGA of a
MicroBlaze Peripheral for Processing Direct Electrical Networks Measu-
rements. In Proc. 1st IEEE Symposium on Industrial Embedded Systems
(IES), Antibes-Juan les Pins (France), October 2006b.
J. Viejo, E. Ostua, M. J. Bellido, J. Juan, A. Millan, P. Ruiz-de Clavijo,
and D. Guerrero. Diseño e implementación óptima de periféricos de DSP
con System Generator para MicroBlaze. In Proc. 12th Iberchip Workshop
(IWS), pages 49–52, San Jose (Costa Rica), March 2006c.
J. Viejo, E. Ostua, M. J. Bellido, J. Juan, A. Millan, P. Ruiz-de Clavijo,
and D. Guerrero. Diseño e implementación de SOPC basados en el micro-
procesador PicoBlaze. In Proc. 7th Congreso de Tecnologías Aplicadas a
la Ense nanza de la Electrónica (TAEE), pages 319–320, Madrid (Spain),
July 2006d.
J. Viejo, A. Millan, M. J. Bellido, J. Juan, P. Ruiz-de Clavijo, D. Guerrero,
E. Ostua, and A. Muñoz. Evaluación de metodologías para la implemen-
tación de un módulo FFT/IFFT sobre FPGA mediante herramientas a
nivel de sistema. In Proc. 7th Jornadas de Computación Reconfigurable y
Aplicaciones (JCRA), pages 205–211, Zaragoza (Spain), September 2007a.
J. Viejo, A. Millan, M. J. Bellido, J. Juan, P. Ruiz-de Clavijo, D. Guerrero,
E. Ostua, and A. Muñoz. Design of a FFT/IFFT module as an IP core

Bibliografía 269
suitable for embedded systems. In Proc. 2nd IEEE International Sym-
posium on Industrial Embedded Systems (SIES), pages 337–340, Lisbon
(Portugal), July 2007b.
J. Viejo, A. Millan, M. J. Bellido, E. Ostua, P. Ruiz-de Clavijo, and A. Mu-
ñoz. Implementation of a FFT/IFFT module on FPGA: Comparison of
methodologies. In Proc. 4th Southern Conference on Programmable Logic
(SPL), pages 7–11, San Carlos de Bariloche (Argentina), March 2008a.
J. Viejo, E. Ostua, M. J. Bellido, P. Ruiz-de Clavijo, A. Muñoz, and A. Mi-
llan. Aplicación de Picoblaze al diseño de sistemas de control industrial.
In Proc. 5th International Conference on Telecommunications, Electronics
and Control (TELEC), Santiago de Cuba (Cuba), July 2008b.
J. I. Villar, M. J. Bellido, E. Ostua, D. Guerrero, J. Juan, and A. Muñoz. Me-
todología de Diseño de SoC basada en OpenRISC sobre FPGA con Cores
y Herramientas Libres. In Proc. 8th Jornadas de Computación Reconfigu-
rable y Aplicaciones (JCRA), pages 247–256, Madrid (Spain), September
2008a.
J. I. Villar, M. J. Bellido, E. Ostua, D. Guerrero, J. Juan, and A. Muñoz.
Metodología de diseño SoC con OpenRISC sobre FPGA. In Proc. 5th
International Conference on Telecommunications, Electronics and Control
(TELEC), Santiago de Cuba (Cuba), July 2008b.
J. I. Villar, J. Juan, and M. J. Bellido. Efficient techniques and methodologies
for embedded system design using free hardware and open standards. In
Proc. 19th International Conference on Field Programmable Logic and Ap-
plications (FPL), pages 719–720, Prague (Czech Republic), August 2009.
T Wheeler, P. Graham, B. Nelson, and B. Hutchings. Using Design-Level
Scan to Improve Design Observability and Controllability for Functional
Verification of FPGAs. In 2001 Proceedings International Conference on
Field-Programmable Logic and Applications (FPL), pages 483–492, Belfast,
Northern Ireland (UK), August 2001.

270 Bibliografía
Windriver. Wind River Home Page. URL http://www.windriver.com/.
Xilinx. Xilix, Inc. Home Page. URL http://www.xilinx.com/.
Xilinx. Using Block RAM in Spartan-3 Generation FPGAs. Xilinx, Inc.,
March 2005.
Xilinx. Microblaze Processor Reference Guide, Rev. 9.0. Xilinx, Inc., January
2008a.
Xilinx. System Generator for DSP Getting Started Guide Release 10.1. Xi-
linx, Inc., March 2008b.
Xilinx. ChipScope Pro 11.1 Software and Cores User Guide. Xilinx, Inc.,
April 2009a.
Xilinx. ISE 11 In-Depth Tutorial. Xilinx, Inc., June 2009b.
Xilinx. Data2MEM User Guide. Xilinx, Inc., July 2010.
Xilinx. LogiCORE IP Divider Generator v3.0. Xilinx, Inc., March 2011.
Y. Yamada, S. Ohta, and H. Uematsu. Hardware-based precise time syn-
chronization on Gb/s ethernet enhanced with preemptive priority. IEICE
Transactions on Communications, E89-B(3):683–689, 2006.
Y. Zimber. Official DCF77 web page at the Physikalisch-
Technische Bundesanstalt (PTB), May 2007. URL
http://www.ptb.de/en/org/4/44/442/dcf77_1_e.htm.

Apéndice A
Configuración del sistema: valores
de los parámetros y herramienta
de configuración
A.1. Rango de valores admitidos para los pará-
metros de configuración. Valores por de-
fecto
Como se ha comentado en el Capítulo 3 los parámetros de configuración
se pueden clasificar como parámetros de red y del sistema. En este apartado,
se van a comentar los rangos de valores que se admiten para cada parámetro
y los valores por defecto establecidos.
En relación con los parámetros de red se han tomado las siguientes con-
sideraciones:
Los dispositivos implementados se pueden configurar empleando cual-
quier dirección MAC, exceptuando la dirección de broadcast. Por defec-
to, para los dispositivos cliente y servidor se emplean direcciones MAC
localmente administradas. Este tipo de direcciones se distinguen de las
administradas universalmente porque establecen a 1 el segundo bit me-
nos significativo del byte más significativo de la dirección. Un ejemplo
271

272Apéndice A. Configuración del sistema: valores de los parámetros y
herramienta de configuración
sería la dirección 02:00:00:00:00:00 empleada en el cliente SNTP; para
el servidor se ha utilizado la dirección 02:00:00:00:00:01.
Se admite cualquier configuración de red, ya sea dentro de una red
pública o privada, siempre y cuando los dispositivos cliente y servidor
se configuren para formar parte de la misma subred. Por defecto, no se
han establecido valores para las direcciones IP ya que éstas deben ser
proporcionadas por el servidor de configuración.
En lo que se refiere a los parámetros del sistema, en la Tabla A.1 se recoge
el tamaño en bits de cada parámetro, el rango admitido y el valor por defecto
establecido. A continuación, se comenta como se interpreta cada parámetro:
Baud rate: Este dato de 4 bits representa la velocidad del puerto serie en
baudios. La Tabla A.2 recoge las velocidades admitidas. Se ha estable-
cido un valor por defecto de 4800 baudios debido a que el receptor GPS
utilizado para realizar las pruebas transmite las tramas NMEA a esta
velocidad.
ARP timeout : Este dato de 4 bits representa un número entero sin signo
y se usa como exponente de dos, indicando el intervalo de tiempo en
segundos entre dos peticiones de ARP. De esta forma, el valor 0 repre-
senta un intervalo de 20 s, el valor 1 representa 21 s y así sucesivamente
Nombre Tamaño Rango admitido Valor por defecto
Baud rate 4 bits 0 - 5 0ARP timeout 4 bits 0 - 15 6BOOTP timeout 4 bits 0 - 15 6Número ciclos 28 bits 0 - 268435455 50000000Flanco activo 1 bit 0-1 1Intervalo entre peticiones (p) 4 bits 0-15 0Factor de convergencia (q) 4 bits 0-15 2Factor prescaler 8 bits 0-255 11D nominal 20 bits 0 - 1048575 328155
Tabla A.1: Rango de valores admitidos para los parámetros del sistema yvalores por defecto.

A.1. Rango de valores admitidos para los parámetros de configuración.Valores por defecto 273
Valor Velocidad
0 4800 baudios1 9600 baudios2 19200 baudios3 38400 baudios4 57600 baudios5 115200 baudios
6 - 15 4800 baudios
Tabla A.2: Velocidades del puerto serie admitidas.
hasta el valor 15 que representa un intervalo de 215 s. Por defecto, se
ha establecido un intervalo de 26 s ya que éste es un valor típico en
implementaciones software.
BOOTP timeout : Este dato de 4 bits representa un número entero sin
signo y se usa como exponente de dos, indicando el intervalo de tiempo
en segundos entre dos peticiones de configuración. Por defecto, se ha
establecido un intervalo de 26 s de forma que se hagan coincidir las
peticiones de ARP y BOOTP en el mismo segundo.
Número ciclos: Este dato de 28 bits representa el número de ciclos por se-
gundo. Debido a que la frecuencia del oscilador empleado es de 50 MHz,
por defecto, se ha establecido un valor de 50000000 de ciclos por se-
gundo.
Flanco activo: Este bit indica el flanco activo del PPS. Los valores permi-
tidos y su significado se muestran en la Tabla A.3. El valor por defecto
se establece a 1 debido a que el receptor GPS utilizado presenta esta
configuración para el flanco activo del PPS.
Intervalo entre peticiones (p): Este dato de 4 bits representa un número
entero sin signo y se usa como exponente de dos, indicando el intervalo
de tiempo en segundos entre dos peticiones de NTP. Por defecto, se
establece un intervalo de 20 s. Debido a que el efecto de este parámetro
sobre la precisión de sincronización será estudiado se va a permitir la

274Apéndice A. Configuración del sistema: valores de los parámetros y
herramienta de configuración
Valor Significado
0 Flanco activo de bajada1 Flanco activo de subida
Tabla A.3: Valores del flanco activo del PPS permitidos.
variación de este valor pudiendo oscilar entre pocos segundos y algunos
minutos.
Factor de convergencia (q): Este dato de 4 bits representa un número
entero sin signo y se usa como exponente de dos, indicando el factor de
convergencia aplicado. De acuerdo al análisis realizado en el Capítulo 7,
por defecto, se ha establecido un valor de 2, lo que significa que el
desplazamiento calculado se corrige en cuatro intervalos de ajuste.
Factor prescaler (fp): Este dato de 8 bits representa un número entero
sin signo, indicando el factor de reducción del prescaler. De esta forma,
la frecuencia de salida del prescaler (fpres) se calcula en función de la
frecuencia del oscilador (fosc) de acuerdo a (A.1). Debido a que la fre-
cuencia del oscilador empleado para realizar las pruebas es de 50 MHz
y la resolución del contador de hora local es de 238 ns, por defecto,
se ha establecido un valor de 11 de forma que fpres = 4,54 MHz. Esta
frecuencia supone una frecuencia algo mayor que la frecuencia nominal
del contador de hora local (4,19 MHz), siendo esto lo que se pretende.
fpres =foscfp
(A.1)
D nominal: Este dato de 20 bits representa el número de ciclos de reloj que
hay que eliminar de fpres para que la frecuencia de salida del módulo
de control de frecuencia sea igual a la frecuencia nominal del contador
de hora local. El valor por defecto de este parámetro se ha establecido
de forma experimental a 328155.

A.2. Herramienta para la configuración de los parámetros estáticos 275
A.2. Herramienta para la configuración de los
parámetros estáticos
Como se ha comentado en el Capítulo 5, se han implementado dos meca-
nismos de configuración. El primero está basado en la utilización del protocolo
de configuración de red BOOTP. Así, esta alternativa se ha empleado para
la obtención de los parámetros variables del sistema: las direcciones IP del
cliente y del servidor SNTP, la velocidad del puerto serie y el flanco activo del
PPS (dependientes del receptor GPS utilizado) y el intervalo entre peticiones
de NTP.
Aunque el resto de parámetros permanecen estáticos durante la operación
de los dispositivos, ha resultado necesario habilitar un segundo mecanismo
para la modificación de la dirección MAC antes de la programación del dise-
ño en la FPGA; esto es debido a que cada equipo debe tener asignada una
dirección MAC y ésta tiene que ser única para cada uno dentro de una misma
subred. Puesto que el objetivo principal consiste en proporcionar un meca-
nismo flexible que evite tener que realizar la síntesis e implementación de los
diseños para cada posible configuración, la alternativa planteada se basa en
la modificación de los ficheros binarios obtenidos tras la implementación del
diseño.
Como valor añadido este mismo mecanismo permite la modificación del
resto de parámetros estáticos del sistema. Así, esta acción posibilita la adap-
tación de los diseños a otras especificaciones diferentes de las planteadas en
este trabajo, como por ejemplo, la utilización de un oscilador de mayor o me-
nor frecuencia. A continuación, se va a presentar la herramienta que permite
la configuración de los parámetros estáticos de los diseños.
La herramienta software desarrollada se basa en el utilización de la apli-
cación en línea de comandos data2mem de Xilinx. Esta aplicación permite
reprogramar el contenido de una BRAM de la FPGA sin tener que realizar
de nuevo el proceso de síntesis e implementación. En este sentido, el formato
de entrada de este comando se presenta en la Fig. A.1. Como se observa en
la figura anterior, resulta necesario especificar la posición de la BRAM que
se ha utilizado para almacenar los parámetros de configuración (fichero en

276Apéndice A. Configuración del sistema: valores de los parámetros y
herramienta de configuración
Figura A.1: Formato del comando data2mem.
formato BMM), así como el nuevo contenido a programar (fichero en forma-
to MEM). Para ello, la herramienta que se ha desarrollado proporciona una
interfaz gráfica que se encarga de automatizar estas tareas generando estos
archivos y haciendo a continuación una llamada al programa data2mem. Para
la localización de la BRAM se ha empleado otra aplicación de línea de coman-
dos (xdl) que permite la generación de un fichero en formato Xilinx Design
Language (XDL) a partir de un fichero en formato Native Circuit Descrip-
tion (NCD) obtenido tras la fase de implementación. Este último programa
realiza principalmente dos tareas: (1) extraer la información del diseño del
fichero NCD (binario) y (2) generar un fichero XDL con información de im-
plementación del sistema en un formato entendible y que se pueda procesar.

Apéndice B
Gráficas de las pruebas realizadas
para el cliente SNTP
En este apéndice se recogen todas las representaciones del desplazamiento
y del retraso de propagación frente al tiempo y todas las representaciones de
la función de distribución de frecuencias del desplazamiento y del retraso de
propagación obtenidas para las diferentes pruebas realizadas al cliente SNTP.
B.1. Gráficas de las pruebas completas
En las Fig. B.1 a B.7 se representan los desplazamientos frente al tiempo
y en las Fig. B.8 a B.14 las funciones de distribución de frecuencias del
desplazamiento obtenidas para el cliente SNTP empleando diferentes valores
del factor de convergencia y periodos entre peticiones de 1, 2, 4, 8, 16, 32 y
64 s.
De igual forma, en las Fig. B.15 a B.21 se representan los retrasos de
propagación frente al tiempo y en las Fig. B.22 a B.28 las funciones de dis-
tribución de frecuencias del retraso de propagación obtenidas para el cliente
SNTP empleando diferentes valores del factor de convergencia y periodos
entre peticiones de 1, 2, 4, 8, 16, 32 y 64 s.
277

278 Apéndice B. Gráficas de las pruebas realizadas para el cliente SNTP
0 100 200 300 400 500 600 700 800 900 1000 1100−4
−3
−2
−1
0
1
2
3
4
Tiempo (s)
Des
plaz
amie
nto
(us)
q=0
0 100 200 300 400 500 600 700 800 900 1000 1100−4
−3
−2
−1
0
1
2
3
4
Tiempo (s)
Des
plaz
amie
nto
(us)
q=1
0 100 200 300 400 500 600 700 800 900 1000 1100−4
−3
−2
−1
0
1
2
3
4
Tiempo (s)
Des
plaz
amie
nto
(us)
q=2
0 100 200 300 400 500 600 700 800 900 1000 1100−4
−3
−2
−1
0
1
2
3
4
Tiempo (s)
Des
plaz
amie
nto
(us)
q=3
Figura B.1: Representaciones del desplazamiento frente al tiempo obtenidaspara el cliente SNTP empleando diferentes valores del factor de convergenciay un periodo entre peticiones de 1 s.
0 200 400 600 800 1000 1200 1400 1600 1800 2000 2200−4
−3
−2
−1
0
1
2
3
4
Tiempo (s)
Des
plaz
amie
nto
(us)
q=0
0 200 400 600 800 1000 1200 1400 1600 1800 2000 2200−4
−3
−2
−1
0
1
2
3
4
Tiempo (s)
Des
plaz
amie
nto
(us)
q=1
0 200 400 600 800 1000 1200 1400 1600 1800 2000 2200−4
−3
−2
−1
0
1
2
3
4
Tiempo (s)
Des
plaz
amie
nto
(us)
q=2
0 200 400 600 800 1000 1200 1400 1600 1800 2000 2200−4
−3
−2
−1
0
1
2
3
4
Tiempo (s)
Des
plaz
amie
nto
(us)
q=3
Figura B.2: Representaciones del desplazamiento frente al tiempo obtenidaspara el cliente SNTP empleando diferentes valores del factor de convergenciay un periodo entre peticiones de 2 s.

B.1. Gráficas de las pruebas completas 279
0 500 1000 1500 2000 2500 3000 3500 4000−4
−3
−2
−1
0
1
2
3
4
Tiempo (s)
Des
plaz
amie
nto
(us)
q=0
0 500 1000 1500 2000 2500 3000 3500 4000−4
−3
−2
−1
0
1
2
3
4
Tiempo (s)
Des
plaz
amie
nto
(us)
q=1
0 500 1000 1500 2000 2500 3000 3500 4000−4
−3
−2
−1
0
1
2
3
4
Tiempo (s)
Des
plaz
amie
nto
(us)
q=2
0 500 1000 1500 2000 2500 3000 3500 4000−4
−3
−2
−1
0
1
2
3
4
Tiempo (s)
Des
plaz
amie
nto
(us)
q=3
Figura B.3: Representaciones del desplazamiento frente al tiempo obtenidaspara el cliente SNTP empleando diferentes valores del factor de convergenciay un periodo entre peticiones de 4 s.
0 1000 2000 3000 4000 5000 6000 7000 8000−8
−6
−4
−2
0
2
4
6
8
Tiempo (s)
Des
plaz
amie
nto
(us)
q=0
0 1000 2000 3000 4000 5000 6000 7000 8000−8
−6
−4
−2
0
2
4
6
8
Tiempo (s)
Des
plaz
amie
nto
(us)
q=1
0 1000 2000 3000 4000 5000 6000 7000 8000−8
−6
−4
−2
0
2
4
6
8
Tiempo (s)
Des
plaz
amie
nto
(us)
q=2
0 1000 2000 3000 4000 5000 6000 7000 8000−8
−6
−4
−2
0
2
4
6
8
Tiempo (s)
Des
plaz
amie
nto
(us)
q=3
Figura B.4: Representaciones del desplazamiento frente al tiempo obtenidaspara el cliente SNTP empleando diferentes valores del factor de convergenciay un periodo entre peticiones de 8 s.
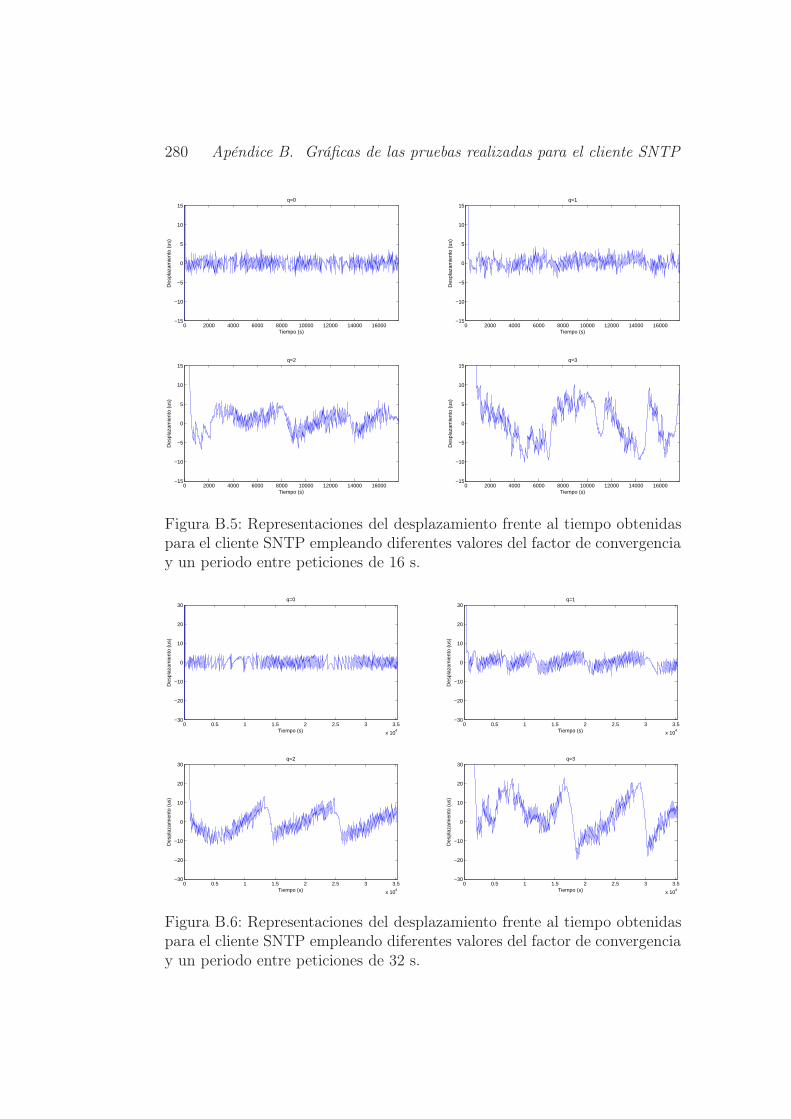
280 Apéndice B. Gráficas de las pruebas realizadas para el cliente SNTP
0 2000 4000 6000 8000 10000 12000 14000 16000−15
−10
−5
0
5
10
15
Tiempo (s)
Des
plaz
amie
nto
(us)
q=0
0 2000 4000 6000 8000 10000 12000 14000 16000−15
−10
−5
0
5
10
15
Tiempo (s)
Des
plaz
amie
nto
(us)
q=1
0 2000 4000 6000 8000 10000 12000 14000 16000−15
−10
−5
0
5
10
15
Tiempo (s)
Des
plaz
amie
nto
(us)
q=2
0 2000 4000 6000 8000 10000 12000 14000 16000−15
−10
−5
0
5
10
15
Tiempo (s)
Des
plaz
amie
nto
(us)
q=3
Figura B.5: Representaciones del desplazamiento frente al tiempo obtenidaspara el cliente SNTP empleando diferentes valores del factor de convergenciay un periodo entre peticiones de 16 s.
0 0.5 1 1.5 2 2.5 3 3.5
x 104
−30
−20
−10
0
10
20
30
Tiempo (s)
Des
plaz
amie
nto
(us)
q=0
0 0.5 1 1.5 2 2.5 3 3.5
x 104
−30
−20
−10
0
10
20
30
Tiempo (s)
Des
plaz
amie
nto
(us)
q=1
0 0.5 1 1.5 2 2.5 3 3.5
x 104
−30
−20
−10
0
10
20
30
Tiempo (s)
Des
plaz
amie
nto
(us)
q=2
0 0.5 1 1.5 2 2.5 3 3.5
x 104
−30
−20
−10
0
10
20
30
Tiempo (s)
Des
plaz
amie
nto
(us)
q=3
Figura B.6: Representaciones del desplazamiento frente al tiempo obtenidaspara el cliente SNTP empleando diferentes valores del factor de convergenciay un periodo entre peticiones de 32 s.
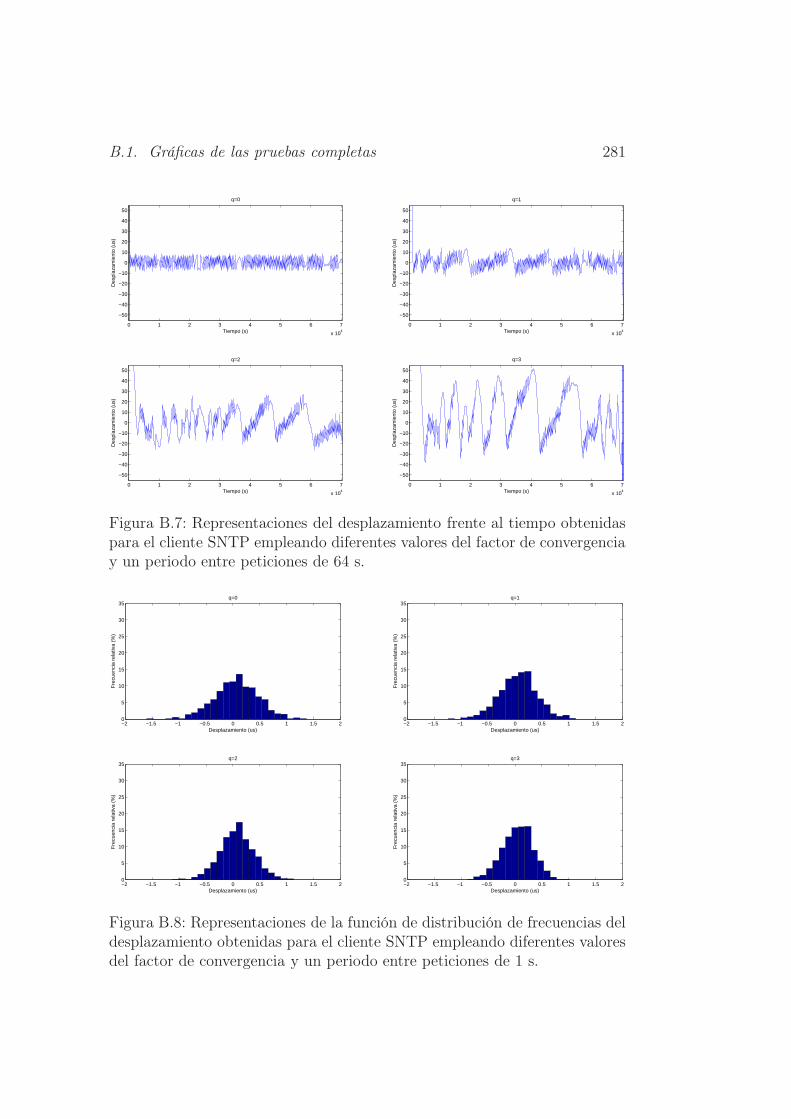
B.1. Gráficas de las pruebas completas 281
0 1 2 3 4 5 6 7
x 104
−50
−40
−30
−20
−10
0
10
20
30
40
50
Tiempo (s)
Des
plaz
amie
nto
(us)
q=0
0 1 2 3 4 5 6 7
x 104
−50
−40
−30
−20
−10
0
10
20
30
40
50
Tiempo (s)
Des
plaz
amie
nto
(us)
q=1
0 1 2 3 4 5 6 7
x 104
−50
−40
−30
−20
−10
0
10
20
30
40
50
Tiempo (s)
Des
plaz
amie
nto
(us)
q=2
0 1 2 3 4 5 6 7
x 104
−50
−40
−30
−20
−10
0
10
20
30
40
50
Tiempo (s)
Des
plaz
amie
nto
(us)
q=3
Figura B.7: Representaciones del desplazamiento frente al tiempo obtenidaspara el cliente SNTP empleando diferentes valores del factor de convergenciay un periodo entre peticiones de 64 s.
−2 −1.5 −1 −0.5 0 0.5 1 1.5 20
5
10
15
20
25
30
35
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=0
−2 −1.5 −1 −0.5 0 0.5 1 1.5 20
5
10
15
20
25
30
35
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=1
−2 −1.5 −1 −0.5 0 0.5 1 1.5 20
5
10
15
20
25
30
35
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=2
−2 −1.5 −1 −0.5 0 0.5 1 1.5 20
5
10
15
20
25
30
35
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=3
Figura B.8: Representaciones de la función de distribución de frecuencias deldesplazamiento obtenidas para el cliente SNTP empleando diferentes valoresdel factor de convergencia y un periodo entre peticiones de 1 s.

282 Apéndice B. Gráficas de las pruebas realizadas para el cliente SNTP
−2 −1.5 −1 −0.5 0 0.5 1 1.5 20
5
10
15
20
25
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=0
−2 −1.5 −1 −0.5 0 0.5 1 1.5 20
5
10
15
20
25
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=1
−2 −1.5 −1 −0.5 0 0.5 1 1.5 20
5
10
15
20
25
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=2
−2 −1.5 −1 −0.5 0 0.5 1 1.5 20
5
10
15
20
25
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=3
Figura B.9: Representaciones de la función de distribución de frecuencias deldesplazamiento obtenidas para el cliente SNTP empleando diferentes valoresdel factor de convergencia y un periodo entre peticiones de 2 s.
−3 −2 −1 0 1 2 30
5
10
15
20
25
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=0
−3 −2 −1 0 1 2 30
5
10
15
20
25
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=1
−3 −2 −1 0 1 2 30
5
10
15
20
25
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=2
−3 −2 −1 0 1 2 30
5
10
15
20
25
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=3
Figura B.10: Representaciones de la función de distribución de frecuencias deldesplazamiento obtenidas para el cliente SNTP empleando diferentes valoresdel factor de convergencia y un periodo entre peticiones de 4 s.
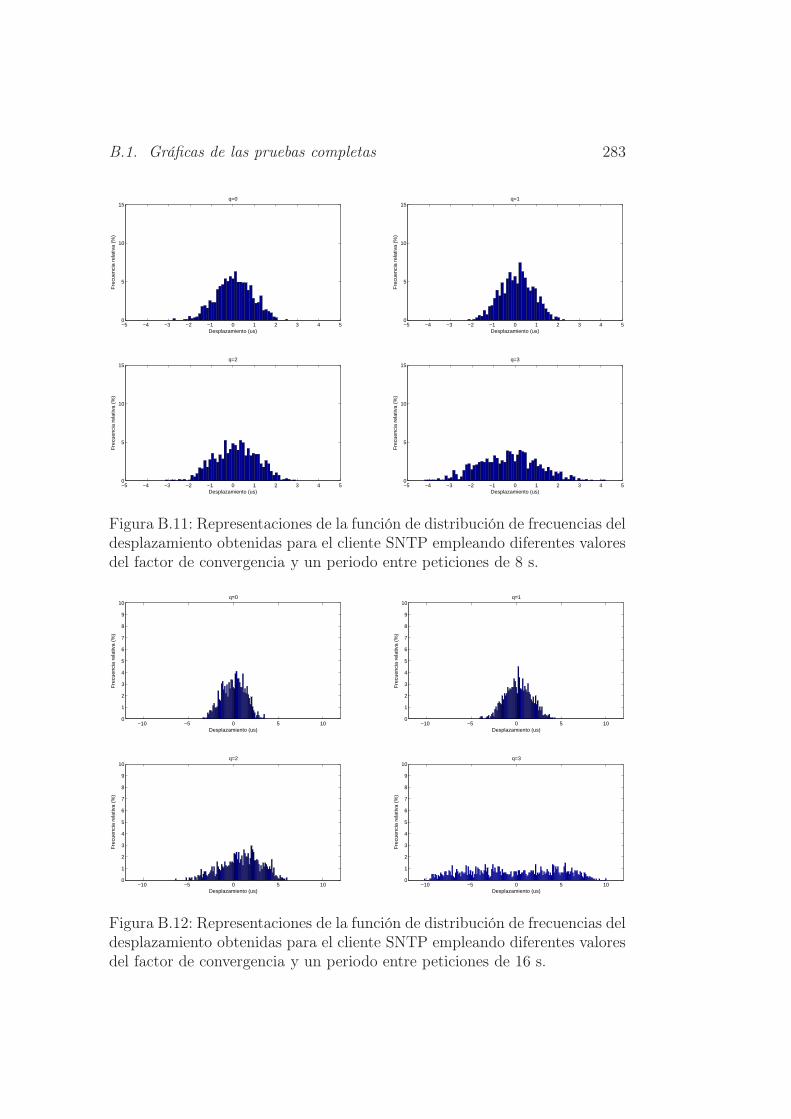
B.1. Gráficas de las pruebas completas 283
−5 −4 −3 −2 −1 0 1 2 3 4 50
5
10
15
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=0
−5 −4 −3 −2 −1 0 1 2 3 4 50
5
10
15
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=1
−5 −4 −3 −2 −1 0 1 2 3 4 50
5
10
15
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=2
−5 −4 −3 −2 −1 0 1 2 3 4 50
5
10
15
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=3
Figura B.11: Representaciones de la función de distribución de frecuencias deldesplazamiento obtenidas para el cliente SNTP empleando diferentes valoresdel factor de convergencia y un periodo entre peticiones de 8 s.
−10 −5 0 5 100
1
2
3
4
5
6
7
8
9
10
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=0
−10 −5 0 5 100
1
2
3
4
5
6
7
8
9
10
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=1
−10 −5 0 5 100
1
2
3
4
5
6
7
8
9
10
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=2
−10 −5 0 5 100
1
2
3
4
5
6
7
8
9
10
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=3
Figura B.12: Representaciones de la función de distribución de frecuencias deldesplazamiento obtenidas para el cliente SNTP empleando diferentes valoresdel factor de convergencia y un periodo entre peticiones de 16 s.
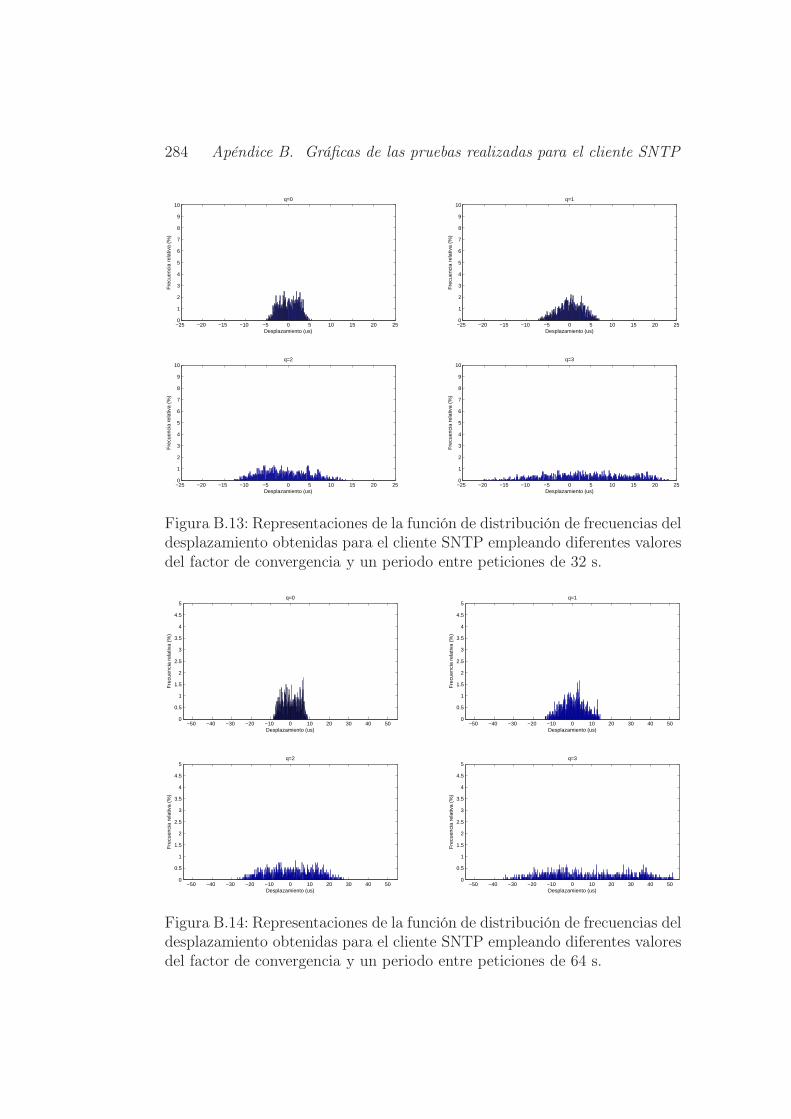
284 Apéndice B. Gráficas de las pruebas realizadas para el cliente SNTP
−25 −20 −15 −10 −5 0 5 10 15 20 250
1
2
3
4
5
6
7
8
9
10
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=0
−25 −20 −15 −10 −5 0 5 10 15 20 250
1
2
3
4
5
6
7
8
9
10
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=1
−25 −20 −15 −10 −5 0 5 10 15 20 250
1
2
3
4
5
6
7
8
9
10
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=2
−25 −20 −15 −10 −5 0 5 10 15 20 250
1
2
3
4
5
6
7
8
9
10
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=3
Figura B.13: Representaciones de la función de distribución de frecuencias deldesplazamiento obtenidas para el cliente SNTP empleando diferentes valoresdel factor de convergencia y un periodo entre peticiones de 32 s.
−50 −40 −30 −20 −10 0 10 20 30 40 500
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=0
−50 −40 −30 −20 −10 0 10 20 30 40 500
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=1
−50 −40 −30 −20 −10 0 10 20 30 40 500
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=2
−50 −40 −30 −20 −10 0 10 20 30 40 500
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
q=3
Figura B.14: Representaciones de la función de distribución de frecuencias deldesplazamiento obtenidas para el cliente SNTP empleando diferentes valoresdel factor de convergencia y un periodo entre peticiones de 64 s.

B.1. Gráficas de las pruebas completas 285
0 100 200 300 400 500 600 700 800 900 1000 110040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=0
0 100 200 300 400 500 600 700 800 900 1000 110040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=1
0 100 200 300 400 500 600 700 800 900 1000 110040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=2
0 100 200 300 400 500 600 700 800 900 1000 110040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=3
Figura B.15: Representaciones del retraso de propagación frente al tiempoobtenidas para el cliente SNTP empleando diferentes valores del factor deconvergencia y un periodo entre peticiones de 1 s.
0 200 400 600 800 1000 1200 1400 1600 1800 2000 220040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=0
0 200 400 600 800 1000 1200 1400 1600 1800 2000 220040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=1
0 200 400 600 800 1000 1200 1400 1600 1800 2000 220040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=2
0 200 400 600 800 1000 1200 1400 1600 1800 2000 220040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=3
Figura B.16: Representaciones del retraso de propagación frente al tiempoobtenidas para el cliente SNTP empleando diferentes valores del factor deconvergencia y un periodo entre peticiones de 2 s.

286 Apéndice B. Gráficas de las pruebas realizadas para el cliente SNTP
0 500 1000 1500 2000 2500 3000 3500 400040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=0
0 500 1000 1500 2000 2500 3000 3500 400040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=1
0 500 1000 1500 2000 2500 3000 3500 400040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=2
0 500 1000 1500 2000 2500 3000 3500 400040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=3
Figura B.17: Representaciones del retraso de propagación frente al tiempoobtenidas para el cliente SNTP empleando diferentes valores del factor deconvergencia y un periodo entre peticiones de 4 s.
0 1000 2000 3000 4000 5000 6000 7000 800040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=0
0 1000 2000 3000 4000 5000 6000 7000 800040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=1
0 1000 2000 3000 4000 5000 6000 7000 800040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=2
0 1000 2000 3000 4000 5000 6000 7000 800040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=3
Figura B.18: Representaciones del retraso de propagación frente al tiempoobtenidas para el cliente SNTP empleando diferentes valores del factor deconvergencia y un periodo entre peticiones de 8 s.

B.1. Gráficas de las pruebas completas 287
0 2000 4000 6000 8000 10000 12000 14000 1600040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=0
0 2000 4000 6000 8000 10000 12000 14000 1600040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=1
0 2000 4000 6000 8000 10000 12000 14000 1600040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=2
0 2000 4000 6000 8000 10000 12000 14000 1600040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=3
Figura B.19: Representaciones del retraso de propagación frente al tiempoobtenidas para el cliente SNTP empleando diferentes valores del factor deconvergencia y un periodo entre peticiones de 16 s.
0 0.5 1 1.5 2 2.5 3 3.5
x 104
40
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=0
0 0.5 1 1.5 2 2.5 3 3.5
x 104
40
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=1
0 0.5 1 1.5 2 2.5 3 3.5
x 104
40
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=2
0 0.5 1 1.5 2 2.5 3 3.5
x 104
40
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=3
Figura B.20: Representaciones del retraso de propagación frente al tiempoobtenidas para el cliente SNTP empleando diferentes valores del factor deconvergencia y un periodo entre peticiones de 32 s.

288 Apéndice B. Gráficas de las pruebas realizadas para el cliente SNTP
0 1 2 3 4 5 6 7
x 104
40
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=0
0 1 2 3 4 5 6 7
x 104
40
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=1
0 1 2 3 4 5 6 7
x 104
40
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=2
0 1 2 3 4 5 6 7
x 104
40
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
(us
)
q=3
Figura B.21: Representaciones del retraso de propagación frente al tiempoobtenidas para el cliente SNTP empleando diferentes valores del factor deconvergencia y un periodo entre peticiones de 64 s.
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=0
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=1
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=2
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=3
Figura B.22: Representaciones de la función de distribución de frecuencias delretraso de propagación obtenidas para el cliente SNTP empleando diferentesvalores del factor de convergencia y un periodo entre peticiones de 1 s.
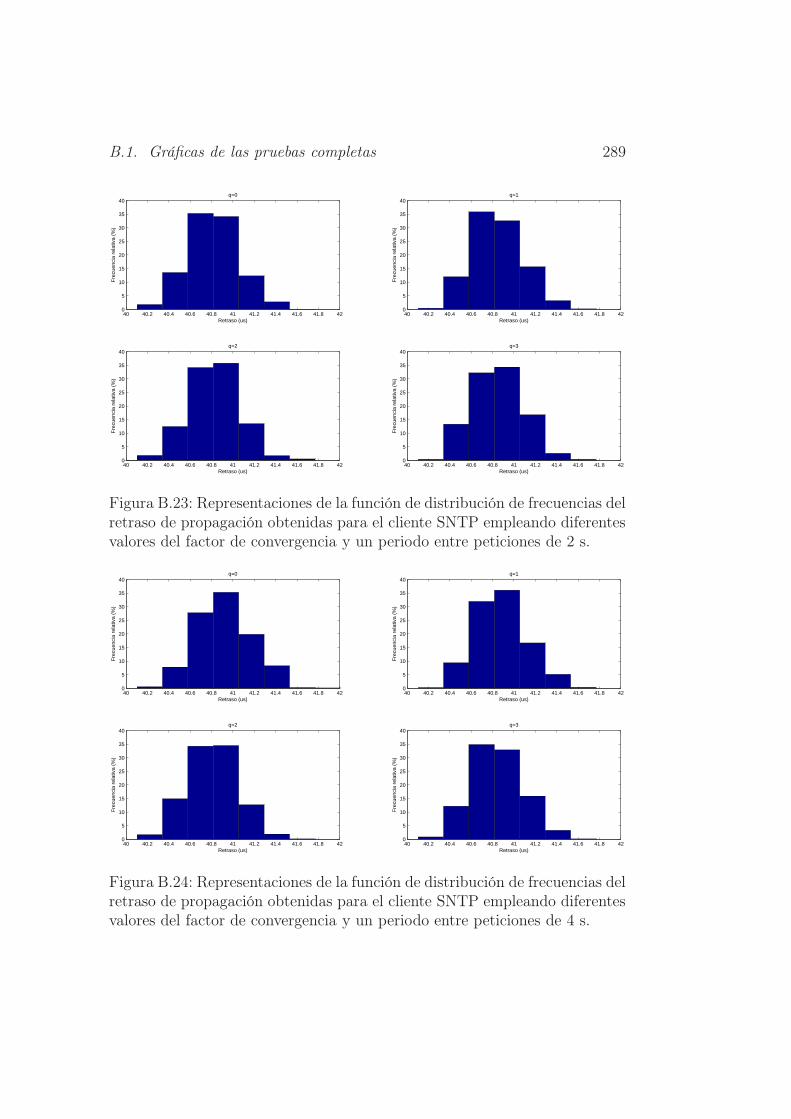
B.1. Gráficas de las pruebas completas 289
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=0
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=1
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=2
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=3
Figura B.23: Representaciones de la función de distribución de frecuencias delretraso de propagación obtenidas para el cliente SNTP empleando diferentesvalores del factor de convergencia y un periodo entre peticiones de 2 s.
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=0
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=1
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=2
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=3
Figura B.24: Representaciones de la función de distribución de frecuencias delretraso de propagación obtenidas para el cliente SNTP empleando diferentesvalores del factor de convergencia y un periodo entre peticiones de 4 s.
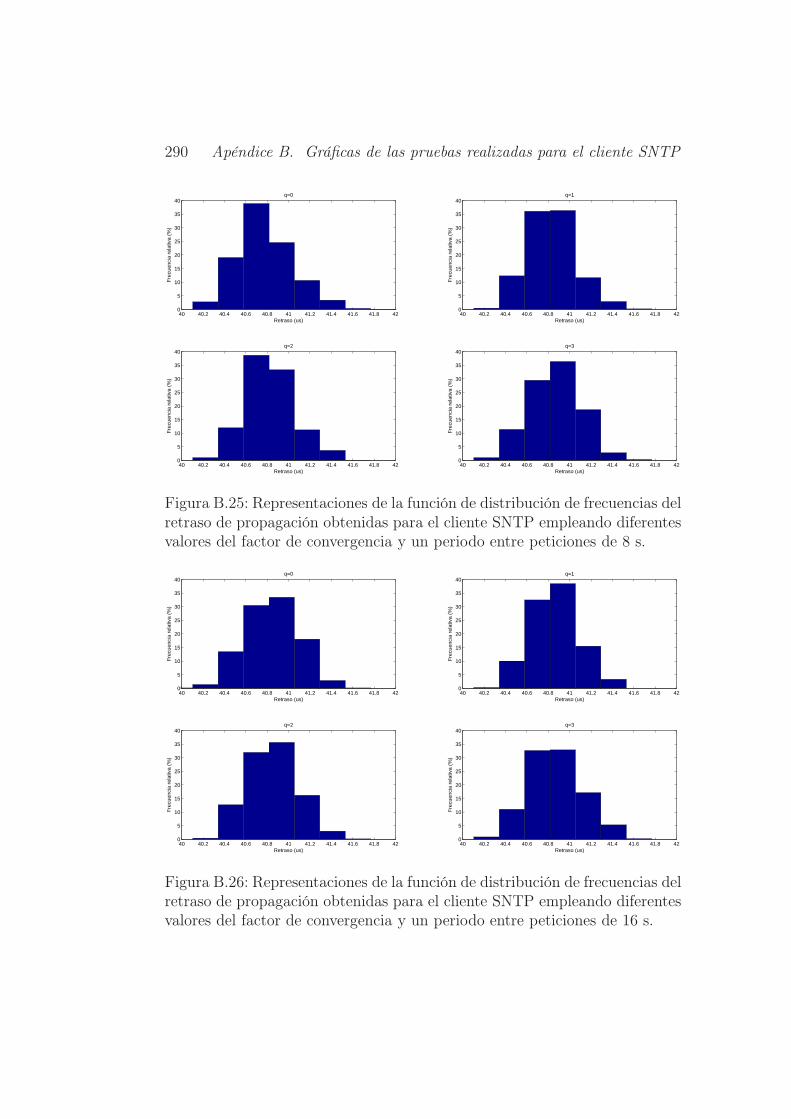
290 Apéndice B. Gráficas de las pruebas realizadas para el cliente SNTP
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=0
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=1
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=2
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=3
Figura B.25: Representaciones de la función de distribución de frecuencias delretraso de propagación obtenidas para el cliente SNTP empleando diferentesvalores del factor de convergencia y un periodo entre peticiones de 8 s.
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=0
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=1
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=2
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=3
Figura B.26: Representaciones de la función de distribución de frecuencias delretraso de propagación obtenidas para el cliente SNTP empleando diferentesvalores del factor de convergencia y un periodo entre peticiones de 16 s.

B.1. Gráficas de las pruebas completas 291
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=0
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=1
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=2
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=3
Figura B.27: Representaciones de la función de distribución de frecuencias delretraso de propagación obtenidas para el cliente SNTP empleando diferentesvalores del factor de convergencia y un periodo entre peticiones de 32 s.
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=0
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=1
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=2
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso (us)
Fre
cuen
cia
rela
tiva
(%)
q=3
Figura B.28: Representaciones de la función de distribución de frecuencias delretraso de propagación obtenidas para el cliente SNTP empleando diferentesvalores del factor de convergencia y un periodo entre peticiones de 64 s.

292 Apéndice B. Gráficas de las pruebas realizadas para el cliente SNTP
B.2. Gráficas de las pruebas para diferentes
cargas de red
B.2.1. Carga del conmutador con tráfico de red general
no dirigido al servidor SNTP
En las Fig. B.29 y B.30 se muestran las representaciones del desplaza-
miento frente al tiempo y de la función de distribución de frecuencias del
desplazamiento para las cuatro pruebas realizadas en este bloque que consis-
ten en cargar el conmutador con tráfico general no dirigido al servidor SNTP.
En concreto, se han probado las siguientes cargas de red: (1) 25 Mbps, (2)
50 Mbps, (3) 75 Mbps y (4) carga máxima.
Asimismo, en las Fig. B.31 y B.32 se representan los retrasos de pro-
pagación frente al tiempo y las funciones de distribución de frecuencias del
retraso.
0 100 200 300 400 500 600 700 800 900 1000 1100−4
−3
−2
−1
0
1
2
3
4
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 1
0 100 200 300 400 500 600 700 800 900 1000 1100−4
−3
−2
−1
0
1
2
3
4
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 2
0 100 200 300 400 500 600 700 800 900 1000 1100−4
−3
−2
−1
0
1
2
3
4
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 3
0 100 200 300 400 500 600 700 800 900 1000 1100−4
−3
−2
−1
0
1
2
3
4
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 4
Figura B.29: Representaciones del desplazamiento frente al tiempo obteni-das para el cliente SNTP cargando el conmutador con tráfico no dirigido alservidor SNTP.

B.2. Gráficas de las pruebas para diferentes cargas de red 293
−2 −1.5 −1 −0.5 0 0.5 1 1.5 20
5
10
15
20
25
30
35
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 1
−2 −1.5 −1 −0.5 0 0.5 1 1.5 20
5
10
15
20
25
30
35
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 2
−2 −1.5 −1 −0.5 0 0.5 1 1.5 20
5
10
15
20
25
30
35
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 3
−2 −1.5 −1 −0.5 0 0.5 1 1.5 20
5
10
15
20
25
30
35
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 4
Figura B.30: Representaciones de la función de distribución de frecuenciasdel desplazamiento obtenidas para el cliente SNTP cargando el conmutadorcon tráfico no dirigido al servidor SNTP.
0 100 200 300 400 500 600 700 800 900 1000 110040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
de
prop
agac
ión
(us)
Prueba 1
0 100 200 300 400 500 600 700 800 900 1000 110040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
de
prop
agac
ión
(us)
Prueba 2
0 100 200 300 400 500 600 700 800 900 1000 110040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
de
prop
agac
ión
(us)
Prueba 3
0 100 200 300 400 500 600 700 800 900 1000 110040
40.2
40.4
40.6
40.8
41
41.2
41.4
41.6
41.8
42
Tiempo (s)
Ret
raso
de
prop
agac
ión
(us)
Prueba 4
Figura B.31: Representaciones del retraso de propagación frente al tiempoobtenidas para el cliente SNTP cargando el conmutador con tráfico no diri-gido al servidor SNTP.

294 Apéndice B. Gráficas de las pruebas realizadas para el cliente SNTP
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 1
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 2
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 3
40 40.2 40.4 40.6 40.8 41 41.2 41.4 41.6 41.8 420
5
10
15
20
25
30
35
40
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 4
Figura B.32: Representaciones de la función de distribución de frecuenciasdel retraso de propagación obtenidas para el cliente SNTP cargando el con-mutador con tráfico no dirigido al servidor SNTP.
B.2.2. Carga del conmutador con tráfico NTP dirigido
al servidor SNTP
En las Fig. B.33 a B.35 se representan los desplazamientos frente al tiempo
y en las Fig. B.36 a B.38 las funciones de distribución de frecuencias de los
desplazamientos para cada una de las pruebas realizadas que consisten en
cargar el conmutador con tráfico NTP dirigido al servidor SNTP. En concreto,
se han probado las siguientes cargas de red (peticiones de hora por segundo):
(1) 10 peticiones, (2) 20 peticiones, (3) 50 peticiones, (4) 100 peticiones, (5)
500 peticiones, (6) 2000 peticiones, (7) 5000 peticiones, (8) 10000 peticiones,
(9) 17000 peticiones y (10) 20000 peticiones.
De manera similar, en las Fig. B.39 a B.41 se muestran las representacio-
nes del retraso de propagación frente al tiempo y en las Fig. B.42 a B.44 las
representaciones de la función de distribución de frecuencias de los retrasos.

B.2. Gráficas de las pruebas para diferentes cargas de red 295
0 100 200 300 400 500 600 700 800 900 1000 1100
−10
−5
0
5
10
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 1
0 100 200 300 400 500 600 700 800 900 1000 1100
−10
−5
0
5
10
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 2
0 100 200 300 400 500 600 700 800 900 1000 1100
−10
−5
0
5
10
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 3
0 100 200 300 400 500 600 700 800 900 1000 1100
−10
−5
0
5
10
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 4
Figura B.33: Representaciones del desplazamiento frente al tiempo obtenidaspara el cliente SNTP cargando el conmutador con tráfico NTP dirigido alservidor SNTP (entre 10 y 100 peticiones por segundo).
0 100 200 300 400 500 600 700 800 900 1000 1100
−10
−5
0
5
10
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 5
0 100 200 300 400 500 600 700 800 900 1000 1100
−10
−5
0
5
10
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 6
0 100 200 300 400 500 600 700 800 900 1000 1100
−10
−5
0
5
10
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 7
0 100 200 300 400 500 600 700 800 900 1000 1100
−10
−5
0
5
10
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 8
Figura B.34: Representaciones del desplazamiento frente al tiempo obtenidaspara el cliente SNTP cargando el conmutador con tráfico NTP dirigido alservidor SNTP (entre 500 y 10000 peticiones por segundo).
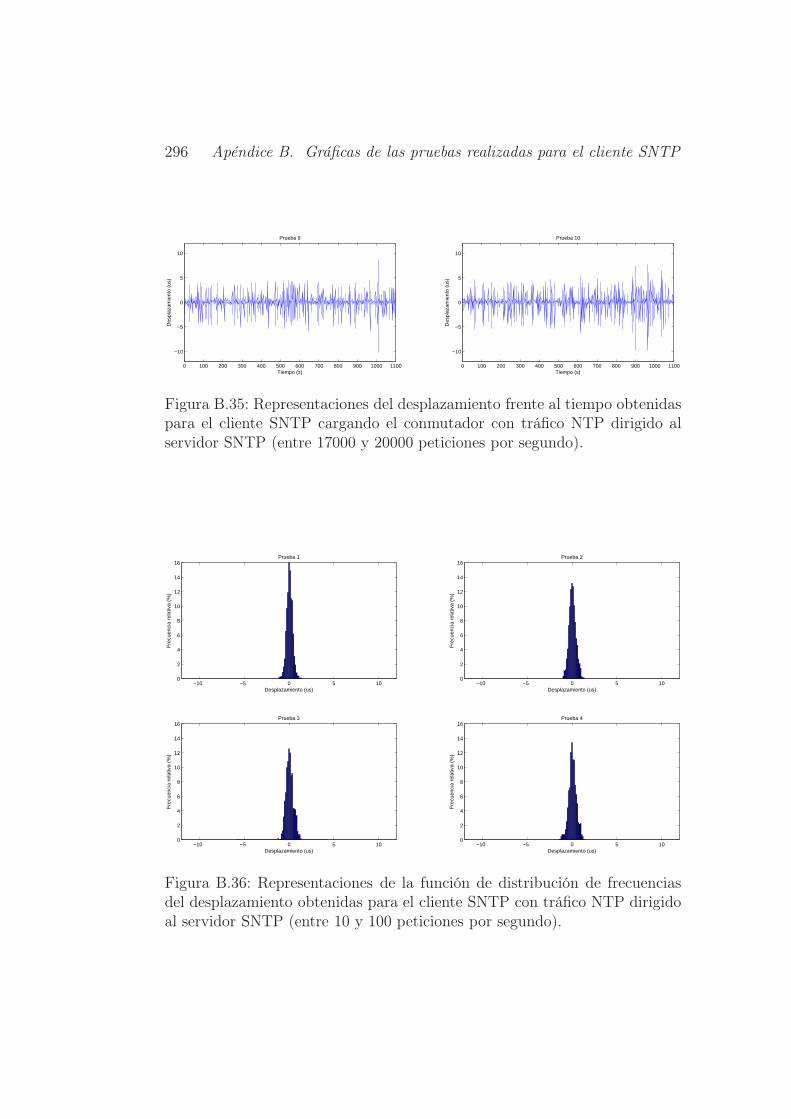
296 Apéndice B. Gráficas de las pruebas realizadas para el cliente SNTP
0 100 200 300 400 500 600 700 800 900 1000 1100
−10
−5
0
5
10
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 9
0 100 200 300 400 500 600 700 800 900 1000 1100
−10
−5
0
5
10
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 10
Figura B.35: Representaciones del desplazamiento frente al tiempo obtenidaspara el cliente SNTP cargando el conmutador con tráfico NTP dirigido alservidor SNTP (entre 17000 y 20000 peticiones por segundo).
−10 −5 0 5 100
2
4
6
8
10
12
14
16
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 1
−10 −5 0 5 100
2
4
6
8
10
12
14
16
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 2
−10 −5 0 5 100
2
4
6
8
10
12
14
16
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 3
−10 −5 0 5 100
2
4
6
8
10
12
14
16
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 4
Figura B.36: Representaciones de la función de distribución de frecuenciasdel desplazamiento obtenidas para el cliente SNTP con tráfico NTP dirigidoal servidor SNTP (entre 10 y 100 peticiones por segundo).

B.2. Gráficas de las pruebas para diferentes cargas de red 297
−10 −5 0 5 100
2
4
6
8
10
12
14
16
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 5
−10 −5 0 5 100
2
4
6
8
10
12
14
16
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 6
−10 −5 0 5 100
2
4
6
8
10
12
14
16
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 7
−10 −5 0 5 100
2
4
6
8
10
12
14
16
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 8
Figura B.37: Representaciones de la función de distribución de frecuenciasdel desplazamiento obtenidas para el cliente SNTP con tráfico NTP dirigidoal servidor SNTP (entre 500 y 10000 peticiones por segundo).
−10 −5 0 5 100
2
4
6
8
10
12
14
16
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 9
−10 −5 0 5 100
2
4
6
8
10
12
14
16
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 10
Figura B.38: Representaciones de la función de distribución de frecuenciasdel desplazamiento obtenidas para el cliente SNTP con tráfico NTP dirigidoal servidor SNTP (entre 17000 y 20000 peticiones por segundo).

298 Apéndice B. Gráficas de las pruebas realizadas para el cliente SNTP
0 100 200 300 400 500 600 700 800 900 1000 1100
40
45
50
55
60
Tiempo (s)
Ret
raso
de
prop
agac
ión
(us)
Prueba 1
0 100 200 300 400 500 600 700 800 900 1000 1100
40
45
50
55
60
Tiempo (s)
Ret
raso
de
prop
agac
ión
(us)
Prueba 2
0 100 200 300 400 500 600 700 800 900 1000 1100
40
45
50
55
60
Tiempo (s)
Ret
raso
de
prop
agac
ión
(us)
Prueba 3
0 100 200 300 400 500 600 700 800 900 1000 1100
40
45
50
55
60
Tiempo (s)
Ret
raso
de
prop
agac
ión
(us)
Prueba 4
Figura B.39: Representaciones del retraso de propagación frente al tiempoobtenidas para el cliente SNTP cargando el conmutador con tráfico NTPdirigido al servidor SNTP (entre 10 y 100 peticiones por segundo).
0 100 200 300 400 500 600 700 800 900 1000 1100
40
45
50
55
60
Tiempo (s)
Ret
raso
de
prop
agac
ión
(us)
Prueba 5
0 100 200 300 400 500 600 700 800 900 1000 1100
40
45
50
55
60
Tiempo (s)
Ret
raso
de
prop
agac
ión
(us)
Prueba 6
0 100 200 300 400 500 600 700 800 900 1000 1100
40
45
50
55
60
Tiempo (s)
Ret
raso
de
prop
agac
ión
(us)
Prueba 7
0 100 200 300 400 500 600 700 800 900 1000 1100
40
45
50
55
60
Tiempo (s)
Ret
raso
de
prop
agac
ión
(us)
Prueba 8
Figura B.40: Representaciones del retraso de propagación frente al tiempoobtenidas para el cliente SNTP cargando el conmutador con tráfico NTPdirigido al servidor SNTP (entre 500 y 10000 peticiones por segundo).

B.2. Gráficas de las pruebas para diferentes cargas de red 299
0 100 200 300 400 500 600 700 800 900 1000 1100
40
45
50
55
60
Tiempo (s)
Ret
raso
de
prop
agac
ión
(us)
Prueba 9
0 100 200 300 400 500 600 700 800 900 1000 1100
40
45
50
55
60
Tiempo (s)
Ret
raso
de
prop
agac
ión
(us)
Prueba 10
Figura B.41: Representaciones del retraso de propagación frente al tiempoobtenidas para el cliente SNTP cargando el conmutador con tráfico NTPdirigido al servidor SNTP (entre 17000 y 20000 peticiones por segundo).
40 45 50 55 600
5
10
15
20
25
30
35
40
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 1
40 45 50 55 600
5
10
15
20
25
30
35
40
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 2
40 45 50 55 600
5
10
15
20
25
30
35
40
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 3
40 45 50 55 600
5
10
15
20
25
30
35
40
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 4
Figura B.42: Representaciones de la función de distribución de frecuencias delretraso de propagación obtenidas para el cliente SNTP cargando el conmu-tador con tráfico NTP dirigido al servidor SNTP (entre 10 y 100 peticionespor segundo).
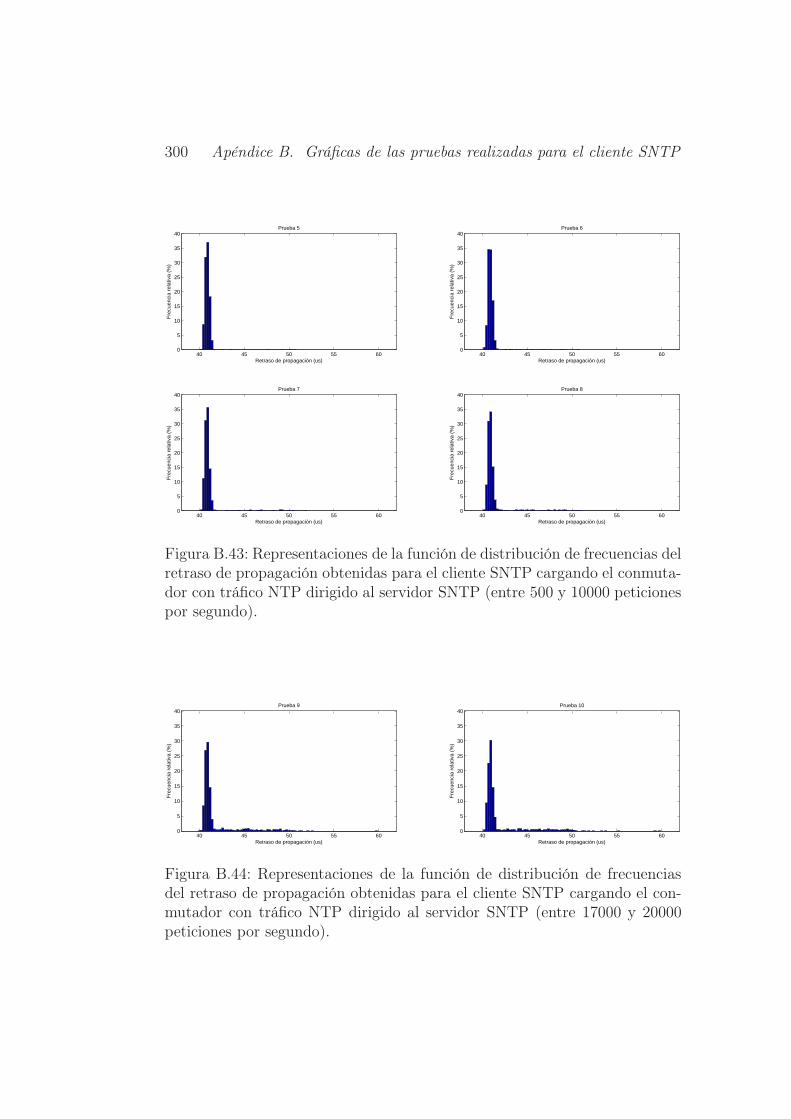
300 Apéndice B. Gráficas de las pruebas realizadas para el cliente SNTP
40 45 50 55 600
5
10
15
20
25
30
35
40
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 5
40 45 50 55 600
5
10
15
20
25
30
35
40
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 6
40 45 50 55 600
5
10
15
20
25
30
35
40
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 7
40 45 50 55 600
5
10
15
20
25
30
35
40
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 8
Figura B.43: Representaciones de la función de distribución de frecuencias delretraso de propagación obtenidas para el cliente SNTP cargando el conmuta-dor con tráfico NTP dirigido al servidor SNTP (entre 500 y 10000 peticionespor segundo).
40 45 50 55 600
5
10
15
20
25
30
35
40
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 9
40 45 50 55 600
5
10
15
20
25
30
35
40
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 10
Figura B.44: Representaciones de la función de distribución de frecuenciasdel retraso de propagación obtenidas para el cliente SNTP cargando el con-mutador con tráfico NTP dirigido al servidor SNTP (entre 17000 y 20000peticiones por segundo).

B.3. Gráficas de las pruebas para diferentes topologías de red 301
B.3. Gráficas de las pruebas para diferentes to-
pologías de red
B.3.1. Varios niveles de conmutadores y carga modera-
da
En las Fig. B.45 y B.46 se muestran las representaciones del desplaza-
miento frente al tiempo y de la función de distribución de frecuencias de los
desplazamientos para cada una de las pruebas realizadas que consisten en
estudiar el comportamiento de sistema frente a diferentes niveles de conmu-
tadores para una condición de carga moderada dirigida al servidor SNTP.
En concreto, se han realizado cuatro pruebas que abarcan desde la conexión
directa hasta tres niveles de conmutadores.
De manera similar, en las Fig. B.47 y B.48 se muestran las representacio-
nes del retraso de propagación frente al tiempo y de la función de distribución
de frecuencias de los retrasos.
0 100 200 300 400 500 600 700 800 900 1000 1100−6
−4
−2
0
2
4
6
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 1
0 100 200 300 400 500 600 700 800 900 1000 1100−6
−4
−2
0
2
4
6
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 2
0 100 200 300 400 500 600 700 800 900 1000 1100−6
−4
−2
0
2
4
6
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 3
0 100 200 300 400 500 600 700 800 900 1000 1100−6
−4
−2
0
2
4
6
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 4
Figura B.45: Representaciones del desplazamiento frente al tiempo obtenidaspara el cliente SNTP para una condición de carga moderada dirigida al servi-dor SNTP abarcando desde la conexión directa (prueba 1) hasta la conexiónmediante tres niveles de conmutadores (prueba 4).

302 Apéndice B. Gráficas de las pruebas realizadas para el cliente SNTP
−6 −4 −2 0 2 4 60
5
10
15
20
25
30
35
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 1
−6 −4 −2 0 2 4 60
5
10
15
20
25
30
35
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 2
−6 −4 −2 0 2 4 60
5
10
15
20
25
30
35
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 3
−6 −4 −2 0 2 4 60
5
10
15
20
25
30
35
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 4
Figura B.46: Representaciones de las funciones de distribución de frecuen-cias del desplazamiento obtenidas para el cliente SNTP para una condiciónde carga moderada dirigida al servidor SNTP abarcando desde la conexióndirecta (prueba 1) hasta la conexión mediante tres niveles de conmutadores(prueba 4).
0 100 200 300 400 500 600 700 800 900 1000 11000
10
20
30
40
50
60
70
80
Tiempo (s)
Ret
raso
de
prop
agac
ión
(us)
Prueba 4
Prueba 1Prueba 2Prueba 3Prueba 4
Figura B.47: Representaciones del retraso de propagación frente al tiempoobtenidas para el cliente SNTP para una condición de carga moderada diri-gida al servidor SNTP abarcando desde la conexión directa (prueba 1) hastala conexión mediante tres niveles de conmutadores (prueba 4).

B.3. Gráficas de las pruebas para diferentes topologías de red 303
15 16 17 18 19 20 21 22 23 24 250
5
10
15
20
25
30
35
40
45
50
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 1
35 36 37 38 39 40 41 42 43 44 450
5
10
15
20
25
30
35
40
45
50
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 2
55 56 57 58 59 60 61 62 63 64 650
5
10
15
20
25
30
35
40
45
50
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 3
75 76 77 78 79 80 81 82 83 84 850
5
10
15
20
25
30
35
40
45
50
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 4
Figura B.48: Representaciones de las funciones de distribución de frecuenciasdel retraso de propagación obtenidas para el cliente SNTP para una condiciónde carga moderada dirigida al servidor SNTP abarcando desde la conexióndirecta (prueba 1) hasta la conexión mediante tres niveles de conmutadores(prueba 4).
B.3.2. Tres niveles de conmutadores y diferentes cargas
de red
En las Fig. B.49 y B.50 se muestran las representaciones del desplaza-
miento frente al tiempo y de la función de distribución de frecuencias del
desplazamiento para las cuatro pruebas realizadas en este bloque que con-
sisten en conectar el cliente y el servidor SNTP mediante tres niveles de
conmutadores y aplicar diferentes cargas de red (tráfico general no dirigido
al servidor SNTP). En concreto, se han probado las siguientes cargas de red:
(1) 25 Mbps, (2) 50 Mbps, (3) 75 Mbps y (4) carga máxima.
Asimismo, en las Fig. B.51 y B.52 se representan los retrasos de pro-
pagación frente al tiempo y las funciones de distribución de frecuencias del
retraso.

304 Apéndice B. Gráficas de las pruebas realizadas para el cliente SNTP
0 100 200 300 400 500 600 700 800 900 1000 1100
−1000
−500
0
500
1000
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 1
0 100 200 300 400 500 600 700 800 900 1000 1100
−1000
−500
0
500
1000
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 2
0 100 200 300 400 500 600 700 800 900 1000 1100
−1000
−500
0
500
1000
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 3
0 100 200 300 400 500 600 700 800 900 1000 1100
−1000
−500
0
500
1000
Tiempo (s)
Des
plaz
amie
nto
(us)
Prueba 4
Figura B.49: Representaciones del desplazamiento frente al tiempo obtenidaspara el cliente SNTP para diferentes cargas de red donde el cliente y elservidor se han conectado mediante tres niveles de conmutadores.
−1000 −500 0 500 10000
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 1
−1000 −500 0 500 10000
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 2
−1000 −500 0 500 10000
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 3
−1000 −500 0 500 10000
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
Desplazamiento (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 4
Figura B.50: Representaciones de la función de distribución de frecuenciasdel desplazamiento obtenidas para el cliente SNTP para diferentes cargas dered donde el cliente y el servidor se han conectado mediante tres niveles deconmutadores.

B.3. Gráficas de las pruebas para diferentes topologías de red 305
0 100 200 300 400 500 600 700 800 900 1000 11000
500
1000
1500
2000
2500
Tiempo (s)
Ret
raso
de
prop
agac
ión
(us)
Prueba 1
0 100 200 300 400 500 600 700 800 900 1000 11000
500
1000
1500
2000
2500
Tiempo (s)
Ret
raso
de
prop
agac
ión
(us)
Prueba 2
0 100 200 300 400 500 600 700 800 900 1000 11000
500
1000
1500
2000
2500
Tiempo (s)
Ret
raso
de
prop
agac
ión
(us)
Prueba 3
0 100 200 300 400 500 600 700 800 900 1000 11000
500
1000
1500
2000
2500
Tiempo (s)
Ret
raso
de
prop
agac
ión
(us)
Prueba 4
Figura B.51: Representaciones del retraso de propagación frente al tiempoobtenidas para el cliente SNTP para diferentes cargas de red donde el clientey el servidor se han conectado mediante tres niveles de conmutadores.
0 100 200 300 400 500 600 7000
5
10
15
20
25
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 1
0 100 200 300 400 500 600 7000
5
10
15
20
25
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 2
0 100 200 300 400 500 600 7000
5
10
15
20
25
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 3
0 100 200 300 400 500 600 7000
5
10
15
20
25
Retraso de propagación (us)
Fre
cuen
cia
rela
tiva
(%)
Prueba 4
Figura B.52: Representaciones de la función de distribución de frecuenciasdel retraso de propagación obtenidas para el cliente SNTP para diferentescargas de red donde el cliente y el servidor se han conectado mediante tresniveles de conmutadores.




















