
Discovery of high-level tasks in the operating room
8
Discovery of high-level tasks in the operating room q L. Bouarfa * , P.P. Jonker, J. Dankelman Department of Biomechanical Engineering, Delft University of Technology, Mekelweg 2, 2628CD Delft, The Netherlands article info Article history: Received 11 February 2009 Available online 7 January 2010 Keywords: Ubiquitous computing Activity recognition High-level activity Cognitive environment Hidden Markov Model Surgical workflow Noisy sensors Uncertainty Bayesian networks abstract Recognizing and understanding surgical high-level tasks from sensor readings is important for surgical workflow analysis. Surgical high-level task recognition is also a challenging task in ubiquitous computing because of the inherent uncertainty of sensor data and the complexity of the operating room environ- ment. In this paper, we present a framework for recognizing high-level tasks from low-level noisy sensor data. Specifically, we present a Markov-based approach for inferring high-level tasks from a set of low- level sensor data. We also propose to clean the noisy sensor data using a Bayesian approach. Preliminary results on a noise-free dataset of ten surgical procedures show that it is possible to recognize surgical high-level tasks with detection accuracies up to 90%. Introducing missed and ghost errors to the sensor data results in a significant decrease of the recognition accuracy. This supports our claim to use a cleaning algorithm before the training step. Finally, we highlight exciting research directions in this area. Ó 2010 Elsevier Inc. All rights reserved. 1. Introduction An emerging field of surgical workflow analysis fosters formal- ization and acquisition of surgical task descriptions from real-time surgical interventions in the operating room (OR) [9]. This ap- proach is widely used in the domain of business process modeling (BPM) to improve organizational performance [19]. Usually, the workflow follows a formal description of processes in the form of flow-diagrams, showing directed flows between processes. Recent years have seen a growing scientific and industrial inter- est in workflow analysis for cognitive environments, such as the OR and the cockpit. Human abstraction in cognitive environments is, however, impossible because of the more complex tasks that human beings display, including aspects like cognition, uncertainty and self-consciousness [15]. In this case, the formal approach needs to be adapted to deal with the complexity and uncertainty of tasks displayed by humans in cognitive environments. The emerging field of activity recognition aims to recognize hu- man tasks from a series of observations. The research in ubiquitous computing strives to discover human high-level tasks from low-le- vel sensor data. Successful and accurate activity recognition sys- tems will provide cognitive support to humans in cognitive environments. A classic scenario of activity recognition is creating smart houses to enable the elderly to live a more independent life at home [2]. Furthermore, different fields may refer to activity rec- ognition; one can find applications ranging from surveillance to entertainment [17]. The main challenge of ubiquitous computing is its real-world application in different environments. This article aims to build upon already available ubiquitous techniques to recognize high-level surgical tasks in the OR using low-level instrument signals. We first propose a conceptual frame- work to infer high-level tasks from low-level sensor data. We then attempt to answer the following questions: (1) how accurate can we predict high-level tasks using noise-free instrument sensor data? and (2) how does the accuracy of the system respond to com- mon sensor noise? The rest of this paper is organized as follows: in the background section we briefly describe the concept of high-level task recogni- tion and the related parameters. Section 3 discusses the related work. In Section 4, we introduce our conceptual framework for inferring high-level tasks from low-level sensor data. To evaluate the clarity and the reliability of the conceptual framework, ten sur- gical procedures are considered for the pilot study represented in Section 5. The experimental evaluation of our framework is dis- cussed in Section 6. Finally, Section 7 concludes this paper and highlights our future work directions and challenges for this re- search area. 2. Background The prime objective of a context learning system is to infer a specific high-level task (HLT ) from a set of observable low-level tasks 1532-0464/$ - see front matter Ó 2010 Elsevier Inc. All rights reserved. doi:10.1016/j.jbi.2010.01.004 q This research is financed by STW. * Corresponding author. E-mail address: [email protected] (L. Bouarfa). URL: http://www.bmeche.tudelft.nl (L. Bouarfa). Journal of Biomedical Informatics 44 (2011) 455–462 Contents lists available at ScienceDirect Journal of Biomedical Informatics journal homepage: www.elsevier.com/locate/yjbin
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Discovery of high-level tasks in the operating room

Journal of Biomedical Informatics 44 (2011) 455–462
Contents lists available at ScienceDirect
Journal of Biomedical Informatics
journal homepage: www.elsevier .com/locate /y jb in
Discovery of high-level tasks in the operating room q
L. Bouarfa *, P.P. Jonker, J. DankelmanDepartment of Biomechanical Engineering, Delft University of Technology, Mekelweg 2, 2628CD Delft, The Netherlands
a r t i c l e i n f o
Article history:Received 11 February 2009Available online 7 January 2010
Keywords:Ubiquitous computingActivity recognitionHigh-level activityCognitive environmentHidden Markov ModelSurgical workflowNoisy sensorsUncertaintyBayesian networks
1532-0464/$ - see front matter � 2010 Elsevier Inc. Adoi:10.1016/j.jbi.2010.01.004
q This research is financed by STW.* Corresponding author.
E-mail address: [email protected] (L. Bouarfa).URL: http://www.bmeche.tudelft.nl (L. Bouarfa).
a b s t r a c t
Recognizing and understanding surgical high-level tasks from sensor readings is important for surgicalworkflow analysis. Surgical high-level task recognition is also a challenging task in ubiquitous computingbecause of the inherent uncertainty of sensor data and the complexity of the operating room environ-ment. In this paper, we present a framework for recognizing high-level tasks from low-level noisy sensordata. Specifically, we present a Markov-based approach for inferring high-level tasks from a set of low-level sensor data. We also propose to clean the noisy sensor data using a Bayesian approach. Preliminaryresults on a noise-free dataset of ten surgical procedures show that it is possible to recognize surgicalhigh-level tasks with detection accuracies up to 90%. Introducing missed and ghost errors to the sensordata results in a significant decrease of the recognition accuracy. This supports our claim to use a cleaningalgorithm before the training step. Finally, we highlight exciting research directions in this area.
� 2010 Elsevier Inc. All rights reserved.
1. Introduction
An emerging field of surgical workflow analysis fosters formal-ization and acquisition of surgical task descriptions from real-timesurgical interventions in the operating room (OR) [9]. This ap-proach is widely used in the domain of business process modeling(BPM) to improve organizational performance [19]. Usually, theworkflow follows a formal description of processes in the form offlow-diagrams, showing directed flows between processes.
Recent years have seen a growing scientific and industrial inter-est in workflow analysis for cognitive environments, such as theOR and the cockpit. Human abstraction in cognitive environmentsis, however, impossible because of the more complex tasks thathuman beings display, including aspects like cognition, uncertaintyand self-consciousness [15]. In this case, the formal approachneeds to be adapted to deal with the complexity and uncertaintyof tasks displayed by humans in cognitive environments.
The emerging field of activity recognition aims to recognize hu-man tasks from a series of observations. The research in ubiquitouscomputing strives to discover human high-level tasks from low-le-vel sensor data. Successful and accurate activity recognition sys-tems will provide cognitive support to humans in cognitiveenvironments. A classic scenario of activity recognition is creatingsmart houses to enable the elderly to live a more independent life
ll rights reserved.
at home [2]. Furthermore, different fields may refer to activity rec-ognition; one can find applications ranging from surveillance toentertainment [17]. The main challenge of ubiquitous computingis its real-world application in different environments.
This article aims to build upon already available ubiquitoustechniques to recognize high-level surgical tasks in the OR usinglow-level instrument signals. We first propose a conceptual frame-work to infer high-level tasks from low-level sensor data. We thenattempt to answer the following questions: (1) how accurate canwe predict high-level tasks using noise-free instrument sensordata? and (2) how does the accuracy of the system respond to com-mon sensor noise?
The rest of this paper is organized as follows: in the backgroundsection we briefly describe the concept of high-level task recogni-tion and the related parameters. Section 3 discusses the relatedwork. In Section 4, we introduce our conceptual framework forinferring high-level tasks from low-level sensor data. To evaluatethe clarity and the reliability of the conceptual framework, ten sur-gical procedures are considered for the pilot study represented inSection 5. The experimental evaluation of our framework is dis-cussed in Section 6. Finally, Section 7 concludes this paper andhighlights our future work directions and challenges for this re-search area.
2. Background
The prime objective of a context learning system is to infer aspecific high-level task (HLT) from a set of observable low-level tasks

456 L. Bouarfa et al. / Journal of Biomedical Informatics 44 (2011) 455–462
(LLT). The majority of tasks displayed by humans in the OR are con-sidered high-level tasks HLTs. Although two HLTs might be seman-tically identical, they can consist of different LLT sequences. Weconsider tasks performed by surgeons in the OR as HLTs havingthe following characteristics:
� goal-oriented;� characterized by planning and maneuvering protocols;� not described by a single LLT sequence, and thus may be per-
formed in various ways.
The problem of mapping LLTs to a specific HLT is known as thesemantic gap. The semantics of a specific task depend on the con-text in which it is regarded. This requires transferring high-leveltacit knowledge of human agents to explicit knowledge, a processknown as articulation [12]. The LLTs that are most interesting fordeducing the underlying HLTs are those that:
� allow the discrimination over a large number of other LLT setsthat correspond to other HLTs;
� are invariant to task distortion, i.e. when a specific HLT is per-formed in different ways;
� are compact in size. A small-set of LLTs is beneficial for complex-ity constraints, since otherwise a large number of LLT-sets needto be stored and monitored in the environment. An excessivelyshort representation, might not be sufficient to discriminateamong similar HLTs;
� are easy to monitor. The monitoring of LLTs should not be com-plex. For real-time performance, the system requires high com-putational efficiency for both the monitoring of the LLT-sequence and the inference of the corresponding HLT.
2.1. System parameters
The parameters of a HLT recognition system should be chosenbased on the application and the cognitive environment or the con-text in which it is used. They are useful to evaluate and comparedifferent HLT recognition systems. A number of these parametersinclude the following:
� Robustness/invariance: the ability to accurately infer a specificHLT regardless of the level of variance in task execution andthe level of distortion in the environment (e.g. unexpectedsituations).
� Discriminative power: the ability to discriminate between simi-lar, but different HLTs (i.e. not the same). This may be conflictingwith other requirements, such as robustness and complexity.
� Accuracy: the number of correct HLT inferences, missed infer-ences and wrong inferences.
� Granularity: the ability to infer a specific HLT from a small(incomplete) set of observed LLT’s.
3. Related work
Human activity recognition is a crucial topic in the field of ubiq-uitous computing. Although the research in ubiquitous computingusually strives to discover user activity through low level sensordata, the real-world applications of ubiquitous systems pose greatchallenges in the discovery of specific domain knowledge. To con-vert human activity into a signal representation, different types ofsensors can be deployed. For every application it is a challenge toselect the appropriate sensors and the inference algorithm to use.
In ubiquitous computing, small and simple state-change sen-sors are used for data collection. Vankipuram et al. [18] used active
RFID tags in a dynamic medical environment for human and equip-ment tracking. Tapia et al. [16] used ‘‘tape on and forget” sensors torecognize activities in home setting, and Pham et al. [13] usedultrasonic sensors to classify trajectories of movement of patientsand elderly in indoor environments. Besides ubiquitous computing,human activity recognition is studied in vision and media research.In the past two decades, significant progress has been made in spe-cific areas such as speech recognition, face recognition and videosurveillance [14,11].
Sensors allow continuous data collection on a large scale. How-ever, there are various problems which hinder the adoption of sen-sors in reliability critical environments, such as noisy sensoroutputs, missed readings and inferences. Accordingly, differentdata cleaning approaches are proposed in literature to allow cor-rect interpretation and analysis of sensor data. Darcy et al. [3] im-proved the missed data restoration process of RFID tags usingBayesian Networks. Vankipuram et al. [18] found that the tag datais extremely noisy and used Hidden Markov Models to improve themotion recognition accuracy. Gonzalez et al. [5] proposed a Dy-namic Bayesian Networks (DBN) based cleaning method of RFIDdata sets that takes tag readings as noisy observations of hiddenstates and performs effective data cleaning.
To infer HLTs from sensor data, graphical probabilistic modelsare used with the underlying assumption that there exist hiddenstates that represent the HLTs, and that the hidden states are evolv-ing. Graphical probabilistic models enable the inference of hiddenstates from the observable LLTs up to temporal or causal relation-ships, for example Bayesian Networks (BN) [16,5], Hidden MarkovModels (HMM) [10] and Conditional Random Field models (CRF)[6]. For pre-selection of the observation set, Tapia et al. [16] useda feature window per HLT by assuming that different HLTs have adifferent mean of their length in time (duration). The features usedfor inference are then calculated within the window size. Thisassumption is however not applicable to cognitive environmentswith high time-variability of HLTs. Hu et al. [6] used an adaptedversion of the Conditional Random Field model to identify multi-ple-goal behaviors, such as concurrent and interleaving activities.
Application of these techniques in recognizing human activitiesin the OR represents a small minority in prior work. Padoy et al.[10] used instruments signals to infer surgical HLTs. The signalswere directly processed by the inference engine in the form of aHidden Markov Model (HMM). The fact that no pre-processingwas used to filter robust LLTs, required extra filtering in the infer-ence phase by merging states of the HMM. Instruments are valu-able signals in the OR environment for surgical activityrecognition, as it is easy to monitor whether or not an instrumentis in use, by using RFID tags or applying image processing algo-rithms on endoscopic video. For an accurate recognition of HLTs,this paper proposes an integrated framework for inferring LLTsand HLTs from sensor data. The proposed framework is used toshow how accurately instrument signals can predict surgicalHLTs, how these signals can be pre-processed to obtain a more ro-bust and discriminative observation sequence for training, andhow to use RFID tags and image processing algorithms for an accu-rate and robust HLT recognition.
4. Conceptual framework
To infer HLTs from sensor data, we present an embedded frame-work in Fig. 1. This framework allows for the cleaning of noisy sen-sor data by taking advantage of Bayesian Networks to infer thecorrect LLT from faulty sensor readings and fill gaps in the dataset.The inferred LLTs are further used to infer the corresponding HLTsusing HMMs. This system allows the inference of a specific HLT

t
T
t+1
1
1δ
tδ
1tδ +
Tδ
1:tt:t+1
t+1:T
Fig. 1. Conceptual framework: embedded Bayesian Hidden Markov Model.
L. Bouarfa et al. / Journal of Biomedical Informatics 44 (2011) 455–462 457
based not only on the available sensor data related to their LLTs,but also on their previously inferred HLTs.
4.1. LLT-inference
To infer LLTs from sensor data we need a classifier that takes asinput, the sensor data ðS; tÞjðf1; f2; . . . ; f nÞ. Each fi is a featuredescribing one characteristic of the object identified by the sensorS at time t, and makes a prediction of the form ðS; tÞ : O; conf , whereO is binary value, if O ¼ true the tracked object is detected, and confis the prediction confidence of the classifier.
The process of inferring LLTs is known as the cleaning process ofsensor data [3,5]. Since sensor data is known to be noisy, a cleaningprocess assumes there is a hidden process that determines the truesignal of the sensor, such as presence of a tag in case of RFID, from anoisy and uncompleted set of features. To cope with the incom-plete set of sensor signals, we propose to use Bayesian Networksto define the structure of the sensor signals that occur for a specificLLT . In case of RFID, features may describe one or more character-istics of the tag detected: the item to which the tag is attached, thelocation where the reading took place or the reader of the tag.
1 LC protocol of Reinier de Graaf Hospital (RdGG), Delft, The Netherlands.2 Dr. L.P.S. Stassen, a head surgeon at RdGG hospital and author of the LC protocol.
4.2. HLT-inference
To infer HLTs from the observed LLTs we need a classifier thattakes as input, the observed LLTs, ðC; tÞ; ðO1;O2; . . . ; OkÞ. Each Oi isthe observation at time t, and makes a prediction of the formðC; tÞ : H; conf , where H is the value corresponding to the inferredHLT , and conf is the prediction confidence of the classifier.
When the cognitive environment deals with a maneuveringprotocol, it is necessary to include knowledge from previous HLTinferences. DBN allows the representation of time constrained cau-sality, i.e. when and if events occur and the periodic nature of pro-cesses. It is normally assumed that the model parameters
(transition probabilities and model structure) of the temporal net-work do not change, (i.e. the model is invariant) [7]. A special cat-egory of DBN is HMM. They are strictly repetitive models with anextra assumption that the past has no impact on the future giventhe present [7]. This means that the next HLT depends only onthe current HLT. The HLTs represent the hidden states of theHMM. The observable parameters of the HMM are the LLT nodes.
5. Pilot study
This pilot study was conducted to evaluate the clarity and reli-ability of the conceptual framework in recognizing surgical HLTsusing noise-free low level instrument signals. As such this studyassumes perfect classification of sensor data conf ¼ 1.
5.1. Dataset
Laparoscopic cholecystectomy (LC) is one of the most frequentand standardized procedures in minimally invasive surgery. In thispilot study 10 LC procedures were recorded using three cameras. Intotal three videos were recoded; one overview video of the OR andone pointing at the surgical toolbox and the endoscopic video (seeFig. 2). These video were synchronized and annotated using Elansoftware [8].
5.1.1. HLT-setThe HLTs are the laparoscopic surgical steps as described in the
hospital’s LC protocol.1 In total the five laparoscopic surgical stepsare considered as HLTs, as illustrated in Table 1. Note that only lap-aroscopic HLTs are considered, open surgical steps like incision andsuturing are excluded. The definition of the surgical steps was veri-fied with the co-operating surgeon.2
The HLTs are represented as discrete signals, each discrete levelcorresponding to the surgical steps of table 1. This results in theHLT-signals illustrated in Fig. 3(a).
5.1.2. LLT-setThe LLTs are represented as binary signals corresponding to
instrument utilization; 1 if an instrument is in used, 0 if not inuse; resulting LLT-signals are displayed in Fig. 3(b).
5.2. LLT pre-processing
The pre-processing step should retain the maximum contextualrelevant information from the monitored LLTs. At this stage aninvariant observation set O ¼ O1;O2; . . . ; On should be calculatedfrom the observed LLTs. This observation set should allow the infer-ence of similar HLTs regardless of the level of variance in their exe-cution. This is a consequence of the robustness requirement. Itshould also allow the discrimination over a large number of otherobservation sets that correspond to other HLTs. Note that thisrequirement is conflicting with the robustness requirement. Boththe robustness and the discriminating power are important forthe evaluation of the system performance.
At this stage it is necessary to take the characteristics of thedataset in consideration. In the LC procedure four trocars are in-serted to introduce the laparoscopic instruments in the patient’sbody. Fig. 4 illustrates the use of the trocars.
� one main trocar (master), is maintained by the dominating handof the surgeon. It is mainly used to insert instruments like dis-sectors, scissors, to remove the gallbladder;

Fig. 2. Three video streams (overview, surgical table, endoscopic view).
Fig. 3. Example of how training samples are created for (a) HLT- and thecorresponding (b) LLT-signals.
Table 1Surgical steps of laparoscopic cholecystectomy.
(1) Skeletonization of calot’s triangle(2) Clipping and dissection(3) Gallbladder removal(4) Gallbladder packaging(5) Cleaning
3 For interpretation of the references to color in this figure legend, the reader isreferred to the web version of this paper.
458 L. Bouarfa et al. / Journal of Biomedical Informatics 44 (2011) 455–462
� two other trocars (slaves), are maintained by the non-dominanthand of the surgeon. They are mainly used to insert gaspers tohold the gallbladder for removal;
� one view trocar is used to insert the endoscopic camera.
In total, 10 instruments are used during the LC procedure, from
which 3 can be used simultaneously, leading to 103
� �possible
sets. Considering all these sets for training is trivial. To reducethe observation set for training we consider two datasets:
� the first dataset is pre-processed for the LLT ‘‘taking instrumentX from the surgical toolbox”. The LLT-observation matrix is con-verted to the observation-set Otoolbox ¼ O1;O2; . . . ; Ok with Obeing the label of the last changed instrument value (both 0and 1 are considered);
� the second dataset is pre-processed for the LLT ‘‘inserting instru-ment X into the master trocar”. The LLT-observation matrix isconverted to the observation-set Otrocar ¼ O1;O2; . . . ; On, with Obeing the label of the instrument inserted into the master trocar.This LLT exploits the high correlation between the slave and themaster trocars.
In a prior work, Padoy et al. [10] used a dataset similar to Otoolbox,the major difference is that we adopt an asynchronous processingby excluding the time component in both datasets, by using the la-bel of the last used instrument. Instead, in [10] they include allsample points in the training Ok;t ¼ 1 if instrument k is active attime t. In a previous work [1] we demonstrated that the asynchro-nous approach of training outperforms the synchronous approach.
5.3. HMM training
A HMM can be denoted as follows, k ¼ ðp;A;BÞ where p de-scribed the initial distribution, A is the transition matrix of theMarkov process and B ¼ biðxÞ is the emission matrix, indictingthe probability of emission of symbol x from a hidden state i.
Training a HMM consists of estimating the transition matrix Aand the emission matrix B according the observed sequences. Here,the Baum–Welch EM algorithm is used on both observation-setsOtoolbox and Otrocar . The Baum–Welch algorithm estimates modelparameters (A and B) from the observed sequence while maximiz-ing the log-likelihood of the model. For inference of the surgicalsteps, the Viterbi algorithm is used to calculate the most likely pathof states (the sequence of visited states), also called the Viterbipath. The Viterbi path relies on global criteria, meaning that thelow-level variation in the data is smoothed. The use of Viterbi pathreduces false rejections in the system.
5.3.1. HMM-outputsGiven an observation-set O ¼ O1;O2; . . . ; On and a HMM, the
most probable state sequence is found using the Viterbi algorithm.This sequence was found for all the ten cases using the trainedHMM. Fig. 5 shows an example of an HMM output using the LLT-dataset Otrocar of a specific LC-procedure. The inferred states HLTsby the HMM (red line)3 matches the true states of the system(black-line) for the majority of the data-points. Moreover, the in-ferred states are more sensitive to instrument transitions than thesubjective ground truth states as defined by the surgeon. In the nextsection, the performance of the system is evaluated on both datasetsin more detail.
6. Experimental results
In this section, we aim to answer several open questions thathave not been addressed in previous research: (1) how accuratecan we predict HLTs using noise-free instrument sensor data?and (2) how does the accuracy of the system respond to commonsensor noise?
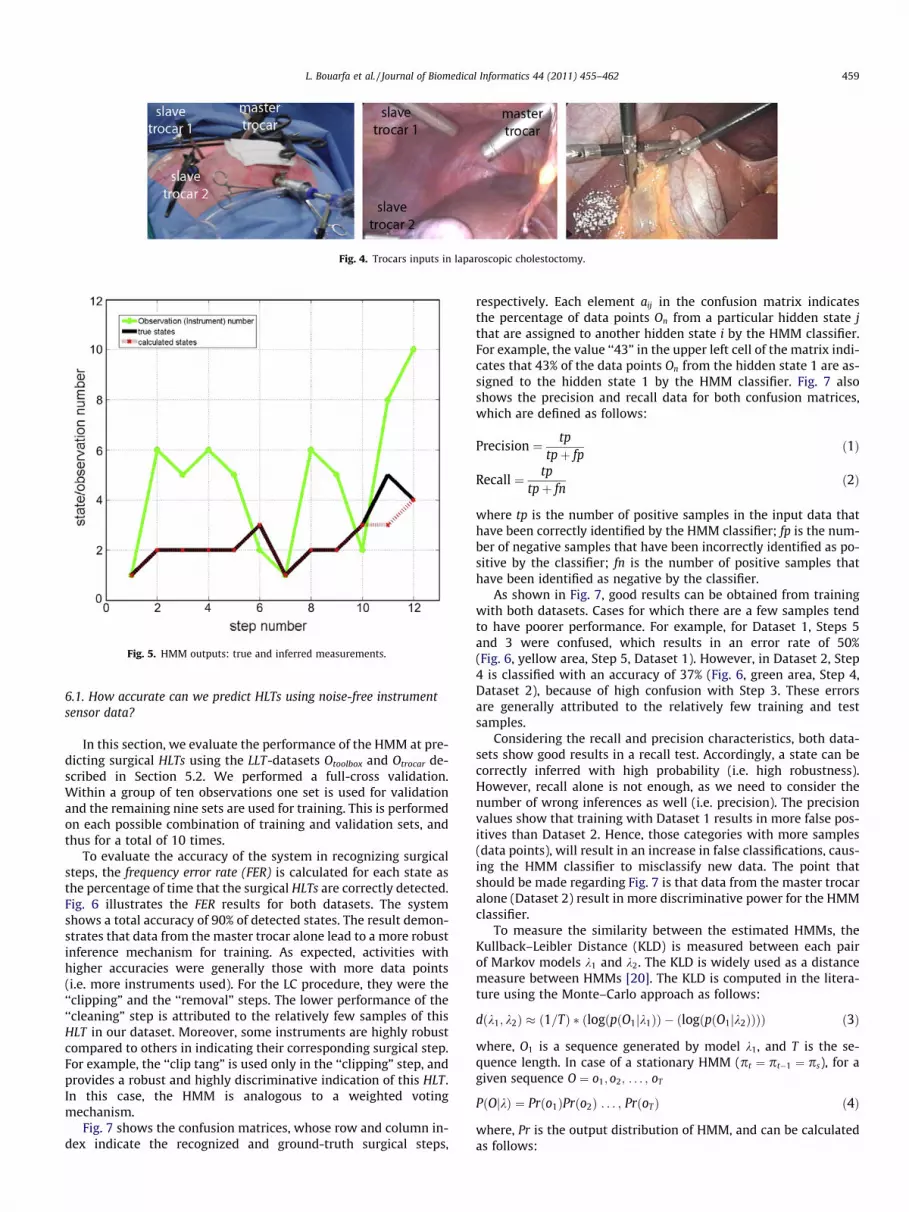
Fig. 5. HMM outputs: true and inferred measurements.
Fig. 4. Trocars inputs in laparoscopic cholestoctomy.
L. Bouarfa et al. / Journal of Biomedical Informatics 44 (2011) 455–462 459
6.1. How accurate can we predict HLTs using noise-free instrumentsensor data?
In this section, we evaluate the performance of the HMM at pre-dicting surgical HLTs using the LLT-datasets Otoolbox and Otrocar de-scribed in Section 5.2. We performed a full-cross validation.Within a group of ten observations one set is used for validationand the remaining nine sets are used for training. This is performedon each possible combination of training and validation sets, andthus for a total of 10 times.
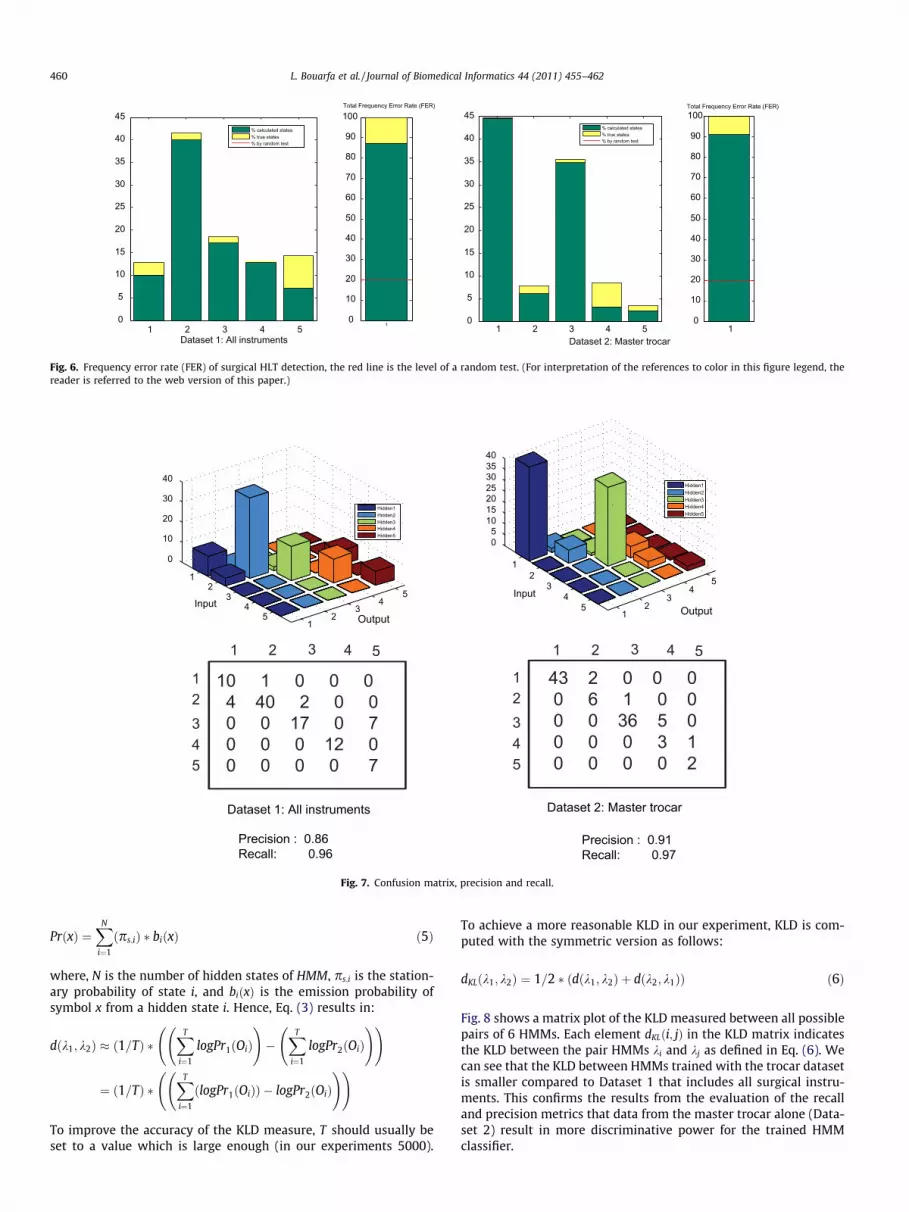
To evaluate the accuracy of the system in recognizing surgicalsteps, the frequency error rate (FER) is calculated for each state asthe percentage of time that the surgical HLTs are correctly detected.Fig. 6 illustrates the FER results for both datasets. The systemshows a total accuracy of 90% of detected states. The result demon-strates that data from the master trocar alone lead to a more robustinference mechanism for training. As expected, activities withhigher accuracies were generally those with more data points(i.e. more instruments used). For the LC procedure, they were the‘‘clipping” and the ‘‘removal” steps. The lower performance of the‘‘cleaning” step is attributed to the relatively few samples of thisHLT in our dataset. Moreover, some instruments are highly robustcompared to others in indicating their corresponding surgical step.For example, the ‘‘clip tang” is used only in the ‘‘clipping” step, andprovides a robust and highly discriminative indication of this HLT.In this case, the HMM is analogous to a weighted votingmechanism.
Fig. 7 shows the confusion matrices, whose row and column in-dex indicate the recognized and ground-truth surgical steps,
respectively. Each element aij in the confusion matrix indicatesthe percentage of data points On from a particular hidden state jthat are assigned to another hidden state i by the HMM classifier.For example, the value ‘‘43” in the upper left cell of the matrix indi-cates that 43% of the data points On from the hidden state 1 are as-signed to the hidden state 1 by the HMM classifier. Fig. 7 alsoshows the precision and recall data for both confusion matrices,which are defined as follows:
Precision ¼ tptpþ fp
ð1Þ
Recall ¼ tptpþ fn
ð2Þ
where tp is the number of positive samples in the input data thathave been correctly identified by the HMM classifier; fp is the num-ber of negative samples that have been incorrectly identified as po-sitive by the classifier; fn is the number of positive samples thathave been identified as negative by the classifier.
As shown in Fig. 7, good results can be obtained from trainingwith both datasets. Cases for which there are a few samples tendto have poorer performance. For example, for Dataset 1, Steps 5and 3 were confused, which results in an error rate of 50%(Fig. 6, yellow area, Step 5, Dataset 1). However, in Dataset 2, Step4 is classified with an accuracy of 37% (Fig. 6, green area, Step 4,Dataset 2), because of high confusion with Step 3. These errorsare generally attributed to the relatively few training and testsamples.
Considering the recall and precision characteristics, both data-sets show good results in a recall test. Accordingly, a state can becorrectly inferred with high probability (i.e. high robustness).However, recall alone is not enough, as we need to consider thenumber of wrong inferences as well (i.e. precision). The precisionvalues show that training with Dataset 1 results in more false pos-itives than Dataset 2. Hence, those categories with more samples(data points), will result in an increase in false classifications, caus-ing the HMM classifier to misclassify new data. The point thatshould be made regarding Fig. 7 is that data from the master trocaralone (Dataset 2) result in more discriminative power for the HMMclassifier.
To measure the similarity between the estimated HMMs, theKullback–Leibler Distance (KLD) is measured between each pairof Markov models k1 and k2. The KLD is widely used as a distancemeasure between HMMs [20]. The KLD is computed in the litera-ture using the Monte–Carlo approach as follows:
dðk1; k2Þ � ð1=TÞ � ðlogðpðO1jk1ÞÞ � ðlogðpðO1jk2ÞÞÞÞ ð3Þ
where, O1 is a sequence generated by model k1, and T is the se-quence length. In case of a stationary HMM (pt ¼ pt�1 ¼ ps), for agiven sequence O ¼ o1; o2; . . . ; oT
PðOjkÞ ¼ Prðo1ÞPrðo2Þ . . . ; PrðoTÞ ð4Þ
where, Pr is the output distribution of HMM, and can be calculatedas follows:
Dataset 1: All instruments Dataset 2: Master trocar1 2 3 4 5
0
5
10
15
20
25
30
35
40
45
10
10
20
30
40
50
60
70
80
90
100Total Frequency Error Rate (FER)
% calculated states% true states% by random test
1 2 3 4 50
5
10
15
20
25
30
35
40
45
10
10
20
30
40
50
60
70
80
90
100Total Frequency Error Rate (FER)
% calculated states% true states% by random test
Fig. 6. Frequency error rate (FER) of surgical HLT detection, the red line is the level of a random test. (For interpretation of the references to color in this figure legend, thereader is referred to the web version of this paper.)
1 2
3 4
5
12
34
5
05
10152025303540
OutputInput
Hidden1Hidden2Hidden3Hidden4Hidden5
12345
1 2 3 4 5
Dataset 2: Master trocar
1 2
3 4
5
12
34
5
0
10
20
30
40
OutputInput
Hidden1Hidden2Hidden3Hidden4Hidden5
1 2 3 4 5
12345
43 2 0 0 0 0 6 1 0 0 0 0 36 5 0 0 0 0 3 1 0 0 0 0 2
10 1 0 0 0 4 40 2 0 0 0 0 17 0 7 0 0 0 12 0 0 0 0 0 7
Dataset 1: All instruments
Precision : 0.86Recall: 0.96
Precision : 0.91Recall: 0.97
Fig. 7. Confusion matrix, precision and recall.
460 L. Bouarfa et al. / Journal of Biomedical Informatics 44 (2011) 455–462
PrðxÞ ¼XN
i¼1
ðps;iÞ � biðxÞ ð5Þ
where, N is the number of hidden states of HMM, ps;i is the station-ary probability of state i, and biðxÞ is the emission probability ofsymbol x from a hidden state i. Hence, Eq. (3) results in:
dðk1; k2Þ � ð1=TÞ �XT
i¼1
logPr1ðOiÞ !
�XT
i¼1
logPr2ðOiÞ ! !
¼ ð1=TÞ �XT
i¼1
ðlogPr1ðOiÞÞ � logPr2ðOiÞ ! !
To improve the accuracy of the KLD measure, T should usually beset to a value which is large enough (in our experiments 5000).
To achieve a more reasonable KLD in our experiment, KLD is com-puted with the symmetric version as follows:
dKLðk1; k2Þ ¼ 1=2 � ðdðk1; k2Þ þ dðk2; k1ÞÞ ð6Þ
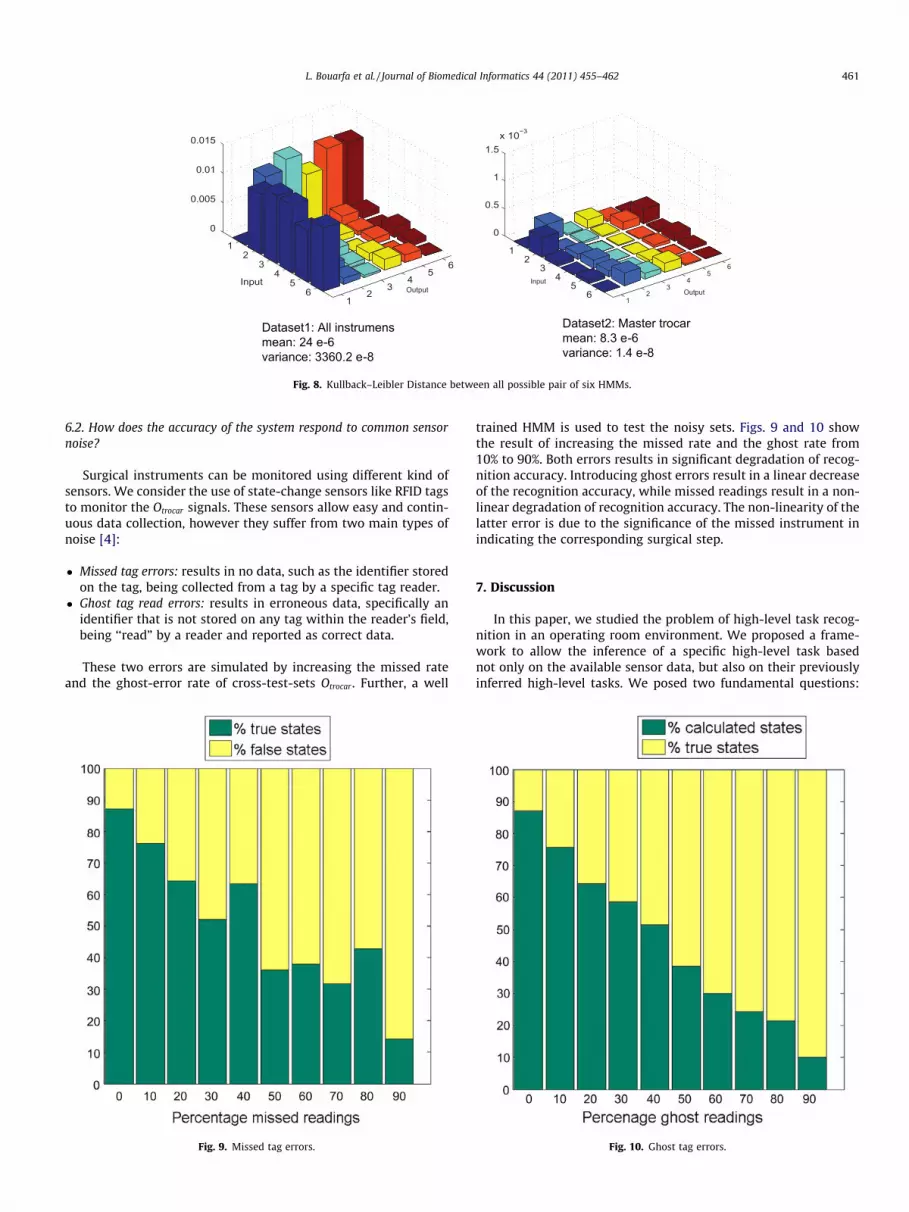
Fig. 8 shows a matrix plot of the KLD measured between all possiblepairs of 6 HMMs. Each element dKLði; jÞ in the KLD matrix indicatesthe KLD between the pair HMMs ki and kj as defined in Eq. (6). Wecan see that the KLD between HMMs trained with the trocar datasetis smaller compared to Dataset 1 that includes all surgical instru-ments. This confirms the results from the evaluation of the recalland precision metrics that data from the master trocar alone (Data-set 2) result in more discriminative power for the trained HMMclassifier.
Dataset1: All instrumensmean: 24 e-6variance: 3360.2 e-8
Dataset2: Master trocarmean: 8.3 e-6variance: 1.4 e-8
1 2
3 4
5 6
12
34
56
0
0.5
1
1.5x 10−3
OutputInput
1 2
3 4
5 6
12
34
56
0
0.005
0.01
0.015
OutputInput
Fig. 8. Kullback–Leibler Distance between all possible pair of six HMMs.
L. Bouarfa et al. / Journal of Biomedical Informatics 44 (2011) 455–462 461
6.2. How does the accuracy of the system respond to common sensornoise?
Surgical instruments can be monitored using different kind ofsensors. We consider the use of state-change sensors like RFID tagsto monitor the Otrocar signals. These sensors allow easy and contin-uous data collection, however they suffer from two main types ofnoise [4]:
� Missed tag errors: results in no data, such as the identifier storedon the tag, being collected from a tag by a specific tag reader.
� Ghost tag read errors: results in erroneous data, specifically anidentifier that is not stored on any tag within the reader’s field,being ‘‘read” by a reader and reported as correct data.
These two errors are simulated by increasing the missed rateand the ghost-error rate of cross-test-sets Otrocar . Further, a well
Fig. 9. Missed tag errors.
trained HMM is used to test the noisy sets. Figs. 9 and 10 showthe result of increasing the missed rate and the ghost rate from10% to 90%. Both errors results in significant degradation of recog-nition accuracy. Introducing ghost errors result in a linear decreaseof the recognition accuracy, while missed readings result in a non-linear degradation of recognition accuracy. The non-linearity of thelatter error is due to the significance of the missed instrument inindicating the corresponding surgical step.
7. Discussion
In this paper, we studied the problem of high-level task recog-nition in an operating room environment. We proposed a frame-work to allow the inference of a specific high-level task basednot only on the available sensor data, but also on their previouslyinferred high-level tasks. We posed two fundamental questions:
Fig. 10. Ghost tag errors.

462 L. Bouarfa et al. / Journal of Biomedical Informatics 44 (2011) 455–462
(1) how accurate can we predict high-level tasks using noise-freeinstrument sensor data? and (2) how does the accuracy of the sys-tem respond to common sensor noise? By analyzing ten laparo-scopic cholecystectomy, we showed that the system can predict90% of the surgical high-level tasks using noise-free instrumentsensor data.
The second fundamental question in high-level task recognitionis the noisy sensor outputs, like missed and ghost readings. In ourframework, we proposed to take advantage of Bayesian Networksto clean noisy values of sensor readings and infer correct low-leveltask from faulty sensor readings. As we did not have real-sensordata available for testing, we empirically simulated the recognitionaccuracy by introducing missed readings and ghost readings ratingfrom 10% to 90% in our training-set. Both errors results in signifi-cant degradation of recognition accuracy. This supports our claimto use a cleaning algorithm before the training step.
In addition to the cleaning and the inference algorithm, the pre-processing of sensor data is a crucial step. The preprocessing stepshould retain the maximum relevant domain information fromsensor data and reduce the number of possible observations fortraining. Hence, we have demonstrated for the laparoscopic choles-toctomy procedure that sensor data from the master trocar leads toa more robust accurate and discriminative recognition comparedto sensor data from the surgical toolbox.
In our pilot, we used instrument signals in the operating roomas data for automatic task recognition. This begs the question;can other sensor-friendly data be extracted from the OR for high-level task recognition? In a real operating room, a number of activ-ities are performed by nurses, surgeons and surgeon-assistants. Ifwe could automatically recognize high-level tasks of every staff-member and derive the hierarchical relationships between thesetasks, the resulting output will provide crucial information aboutthe overall surgical workflow.
In our experiment, we have shown that different recognitionaccuracies can be achieved under different level of sensor noise.In a future work we need to automatically infer the high-level taskfrom a real incomplete and/or noisy set of sensor data using theproposed Bayesian cleaning algorithm. This issue is also relatedto the granularity requirement discussed in Section 2.1. Hu et al.[6] showed that different recognition accuracies can be achievedunder different levels of granularities. For our application, it is veryinteresting to automatically set the task granularity level fromavailable (incomplete or noisy) sensor data. This is important for
applications in reliability environments, such as the OR, where acertain accuracy of recognition need to be achieved before systemintrusion. The future challenge is to automatically set the level ofgranularity the system can support with the available (noisy) sen-sor data, given the hard constraint of high accuracy.
References
[1] Bouarfa L, Jonker PP, Dankelman J. Surgical context discovery by monitoringlow-level activities in the OR. In: MICCAI workshop on modeling andmonitoring of computer assisted interventions (M2CAI). London, UK; 2009.
[2] Chan M, Hariton C, Ringeard P, Campo E. Smart house automation system forthe elderly and the disabled. In: IEEE international conference on systems, manand cybernetics, 1995. Intelligent systems for the 21st century, vol. 2; 1995.
[3] Darcy PJ, Stantic B, Derakhshan R, Parsons D. Correcting stored RFID data withnon-monotonic reasoning. Int J Principles Appl Inform Sci Technol 2007;1(1).
[4] Engels DW. On ghost reads in RFID systems; 2005.[5] Gonzalez H, Han J, Shen X. Cost-conscious cleaning of massive RFID data sets.
In: IEEE 23rd international conference on data engineering, 2007. ICDE 2007;2007. p. 1268–72.
[6] Hu DH, Pan SJ, Zheng VW, Liu NN, Yang Q. Real world activity recognition withmultiple goals. In: Proceedings of the 10th international conference onUbiquitous computing. NY, USA: ACM New York; 2008. p. 30–9.
[7] Jensen FV. Bayesian networks and decision graphs. Springer; 2001.[8] Johnston T, Schembri A. The use of ELAN annotation software in the Auslan
Archive/Corpus Project. In: Presentation at the ethnographic eresearchannotation conference. University of Melbourne; 2005.
[9] Neumuth T, Strauss G, Meixensberger J, Lemke HU, Burgert O. Acquisition ofprocess descriptions from surgical interventions. Lect Notes Comput Sci2006;4080:602.
[10] Padoy N, Blum T, Feußner H, Berger M, Navab N. On-line recognition of surgicalactivity for monitoring in the operating room. In: Proceedings of the 20thconference on innovative applications of artificial intelligence (IAAI-08); 2008.
[11] Pantic M, Pentland A, Nijholt A, Huang TS. Human computing and machineunderstanding of human behavior: a survey. Lect Notes Comput Sci 2007;4451:47.
[12] Patel VL, Arocha JF, Kaufman DR. Expertise and tacit knowledge in medicine.Tacit knowledge in professional practice: researcher and practitionerperspectives; 1999. p. 75–99.
[13] Pham VT, Qiu Q, Wai AAP, Biswas J. Application of ultrasonic sensors in a smartenvironment. Pervasive Mobile Comput 2007;3(2):180–207.
[14] Rabiner LR et al. Proc IEEE 1989;77(2):257–86.[15] Shortliffe EH, Cimino JJ, NetLibrary I. Biomedical informatics: computer
applications in health care and biomedicine. Springer; 2006.[16] Tapia EM, Intille SS, Larson K. Activity recognition in the home using simple
and ubiquitous sensors. Lect Notes Comput Sci 2004:158–75.[17] Turaga P, Chellappa R, Subrahmanian VS, Udrea O. Machine recognition of
human activities: a survey. IEEE Trans Circuits Syst Video Technol2008;18(11):1473–88.
[18] Vaknkipuram MS, Kahol K, Islam G, Cohen T, Patel VL. Visualization andanalysis of medical errors in immersive virtual environments. ISO Press; 2009.
[19] van der Aalst W, van Hee KM. Workflow management: models, methods, andsystems. MIT Press; 2002.
[20] Zeng J, Duan J, Wu C. A new distance measure for Hidden Markov Models. ExpSyst Appl 2009;0.




















