
Deferred locking with shadow transaction for client-server DBMSs
21
Deferred locking with shadow transaction for client–server DBMSs Hyeokmin Kwon a, * , Songchun Moon b a Department of Software, Semyung University, San21-1, Shinwoul-dong, Jecheon-si, Chungbuk 390-711, Republic of Korea b KAIST Graduate School of Management 207-43, Cheongryang, Dongdaemun, Seoul 130-722, Republic of Korea Received 22 February 2004; received in revised form 5 August 2005; accepted 7 September 2005 Available online 9 November 2005 Abstract Data-shipping systems that allow inter-transaction caching raise the need of a transactional cache consistency mainte- nance (CCM) protocol because each client is able to cache a portion of the database dynamically. Deferred locking (DL) is a new CCM scheme that is capable of reducing the communication overhead required for cache consistency checking. Due to its low communication overhead, DL could show a superior performance, but it tends to exhibit a high ratio of trans- action abort. To cope with this drawback, we develop a new notion of shadow transaction, which is a backup-purpose one that is kept ready to replace an aborted transaction. This notion and the locking mechanism of DL have been incorporated into deferred locking with shadow transaction. Using a distributed database simulation model, we evaluate the perfor- mance of the proposed schemes under a wide range of workloads. Ó 2005 Elsevier B.V. All rights reserved. Keywords: Concurrency control; Cache consistency; Transaction processing; Performance evaluation 1. Introduction With the proliferation of inexpensive, high-per- formance workstations and networks, client–server database management systems (DBMSs) have been receiving a lot of interest in distributed environ- ments. Client–server DBMSs can be categorized into two classes [7,12,14]: query-shipping and data- shipping. Most commercial relational DBMSs are based on a query-shipping approach in which most query processing is performed at the server. In con- trast, data-shipping systems transfer data items to clients so that query processing can be performed at clients. Most distributed object-oriented DBMSs [11,16,17] today are based on a data-shipping approach. Since data-shipping systems migrate much of DBMS functions from the server to clients, they can off-load shared server machines. However, they are susceptible to network congestion that can arise if a high volume of data is requested by clients. In data-shipping systems, inter-transaction cach- ing, where cached contents of clients are retained even across transaction boundaries, is an effective technique for improving the performance. Inter- transaction caching enables client resources such 1383-7621/$ - see front matter Ó 2005 Elsevier B.V. All rights reserved. doi:10.1016/j.sysarc.2005.09.002 * Corresponding author. Tel.: +82 43 649 1269; fax: +82 43 649 1278. E-mail addresses: [email protected] (H. Kwon), [email protected] (S. Moon). Journal of Systems Architecture 52 (2006) 373–393 www.elsevier.com/locate/sysarc
Transcript of Deferred locking with shadow transaction for client-server DBMSs

Journal of Systems Architecture 52 (2006) 373–393
www.elsevier.com/locate/sysarc
Deferred locking with shadow transaction forclient–server DBMSs
Hyeokmin Kwon a,*, Songchun Moon b
a Department of Software, Semyung University, San21-1, Shinwoul-dong, Jecheon-si, Chungbuk 390-711, Republic of Koreab KAIST Graduate School of Management 207-43, Cheongryang, Dongdaemun, Seoul 130-722, Republic of Korea
Received 22 February 2004; received in revised form 5 August 2005; accepted 7 September 2005Available online 9 November 2005
Abstract
Data-shipping systems that allow inter-transaction caching raise the need of a transactional cache consistency mainte-nance (CCM) protocol because each client is able to cache a portion of the database dynamically. Deferred locking (DL) isa new CCM scheme that is capable of reducing the communication overhead required for cache consistency checking. Dueto its low communication overhead, DL could show a superior performance, but it tends to exhibit a high ratio of trans-action abort. To cope with this drawback, we develop a new notion of shadow transaction, which is a backup-purpose onethat is kept ready to replace an aborted transaction. This notion and the locking mechanism of DL have been incorporatedinto deferred locking with shadow transaction. Using a distributed database simulation model, we evaluate the perfor-mance of the proposed schemes under a wide range of workloads.� 2005 Elsevier B.V. All rights reserved.
Keywords: Concurrency control; Cache consistency; Transaction processing; Performance evaluation
1. Introduction
With the proliferation of inexpensive, high-per-formance workstations and networks, client–serverdatabase management systems (DBMSs) have beenreceiving a lot of interest in distributed environ-ments. Client–server DBMSs can be categorizedinto two classes [7,12,14]: query-shipping and data-
shipping. Most commercial relational DBMSs arebased on a query-shipping approach in which most
1383-7621/$ - see front matter � 2005 Elsevier B.V. All rights reserved
doi:10.1016/j.sysarc.2005.09.002
* Corresponding author. Tel.: +82 43 649 1269; fax: +82 43 6491278.
E-mail addresses: [email protected] (H. Kwon),[email protected] (S. Moon).
query processing is performed at the server. In con-trast, data-shipping systems transfer data items toclients so that query processing can be performedat clients. Most distributed object-oriented DBMSs[11,16,17] today are based on a data-shippingapproach. Since data-shipping systems migratemuch of DBMS functions from the server to clients,they can off-load shared server machines. However,they are susceptible to network congestion that canarise if a high volume of data is requested by clients.
In data-shipping systems, inter-transaction cach-ing, where cached contents of clients are retainedeven across transaction boundaries, is an effectivetechnique for improving the performance. Inter-transaction caching enables client resources such
.

374 H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393
as memories and CPUs to be effectively used fordatabase-related processing. This also makes it pos-sible to reduce the network traffic and message pro-cessing overhead for both the server and clients.However, multiple copies of a data item inevitablyhappen to exist because each client is able to cachea portion of the database dynamically. Therefore,inter-transaction caching raises the need of a trans-actional cache consistency maintenance (CCM) pro-tocol that basically possesses both aspects of replicamanagement and concurrency control.
Since the CCM scheme employed is consideredto be substantially affecting the performance ofDBMSs, various algorithms [1,7,9,12,13,15,19,21–23] have been proposed in the literature. Tran-sactional CCM schemes must ensure that notransactions that access any stale data copies areallowed to commit. According to their policy forguaranteeing this, CCM schemes can be classifiedinto two classes [14]: avoidance-based and detec-tion-based. Avoidance-based schemes ensure thatall existing copies at clients are always valid. Theyusually employ a read-one and write-all (ROWA)protocol [4] for replica management. The natureof ROWA makes them perform read operationson cached copies efficiently without contacting theserver. However, they require a substantial amountof work for ensuring that cached pages are validwhenever an updating transaction attempts to com-mit or to perform a write operation. In addition,these consistency maintenance actions must be per-formed at one or more remote clients.
In contrast, detection-based schemes allow staledata copies to reside in client caches, and thus eachtransaction is required to check the validity of anycached copy that it accesses sometime prior to itscommit. In detection-based schemes, these consis-tency checking actions for a single transactioninvolve only its origin site and the server. Therefore,they could be more robust against client failure thanavoidance-based ones. The adaptive optimistic con-currency control (AOCC) [1,15] and caching two-phase locking [7,12] can be categorized in this class.AOCC can significantly reduce the number of mes-sages required for consistency checking since eachtransaction is allowed to access cached copies with-out any constraint. However, it could induce a highratio of transaction abort, since transactions mayread stale data copies. The caching two-phase lock-ing (C2PL), which has been designed on the basis ofthe primary-copy locking (PCL) algorithm [4],could cope with the frequent transaction aborts.
C2PL presumes that cached copies at client buffersare not valid, thus each client transaction is requiredto check the validity of cached copies before access-ing them.
A PCL-based scheme usually has the followingdesirable properties: (1) it is simple and easy toimplement, (2) it could be relatively robust againstclient failure, (3) it could show a low abort ratio.Despite these potential advantages, many studies[7,12,14] report that C2PL shows a low perfor-mance mainly due to its overhead associated withmessage requirements for consistency checking.These observations imply that a PCL-based algo-rithm can be widely adopted if it is refined with amechanism to reduce the communication overhead.In this respect, we devise a novel CCM scheme fun-damentally on the basis of the PCL algorithm. Inthe proposed scheme, validity check of cached cop-ies is deferred until a client–server interaction isinevitably required due to a cache miss, hence wecall this approach deferred locking scheme, DL forshort. Although DL is a PCL-based algorithm likeC2PL, it differs from C2PL in that consistencychecking is performed on each cache miss, ratherthan on each access.
DL is capable of reducing client–server interac-tions significantly by combining a number of lockrequests and a data-shipping request into a singlemessage packet. However, it could induce a highratio of transaction abort due to its lazy buffer val-idation. This may not be a problem for some kindsof application domain, where transactions arestrictly under program control, and also user-initi-ated requests can be redone on transaction abortwithout further input. However, the high abort rateof DL could make it unsuitable for interactive appli-cation domains since a user is obliged to perform allhis/her activities again in case of transaction aborts.For this kind of application domain, a mechanismfor minimizing negative impacts of transactionaborts would be very beneficial even if it burdenssome extra overheads on system resources. Fromthis perspective, we develop a new notion of shadowtransaction, which is a backup-purpose one that iskept ready to replace an aborted transaction. Then,we have incorporated this notion and the lockingmechanism of DL into deferred locking with sha-dow transaction, DL–ST for short.
The remainder of this paper is organized as fol-lows. We present various CCM schemes in Section2 and then we describe the details of the proposedschemes in Section 3. We present a simulation model

H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393 375
for evaluating performance tradeoffs in Section 4and we describe performance results in Section 5.Finally, Section 6 has concluding remarks.
2. Related works
In this section, we describe various transactionalcache consistency maintenance protocols that havebeen proposed in the literature, especially focusingon the schemes included in the simulation study.
2.1. Avoidance-based schemes
Avoidance-based CCM schemes ensure that allcached copies at clients are valid by employing aread-one and write-all (ROWA) approach [4]. AROWA protocol guarantees that all existing copiesof an updated item have the same value when anupdating transaction commits. A transaction, inavoidance-based schemes, is usually allowed to readany cached copy that exists in its local cache. How-ever, when a transaction wishes to update a page, itshould acquire a global write permission on thatdata page sometime prior to its commit in orderto reflect its update at all of the copies that existin the system. The optimistic two-phase locking(O2PL) [7,12,14], callback locking (CBL) [7,12,22]and notify locking (NL) [23] can be categorized inthis class. The main difference between them lies inthe time at which global write permissions areacquired. In O2PL and NL, acquisitions of globalwrite permissions on updating pages are deferreduntil the updating transaction enters its commitphase. In contrast, each client transaction, inCBL, synchronously contacts the server to acquirea global write permission whenever it tries to updatea page on which the client does not possess a writepermission.
The O2PL schemes are based on a distributedoptimistic locking scheme studied in [8]. Underthem, each client sets read and write locks locallyduring transaction execution phase. A transactionupdates pages in its local cache, and these changedpages are transferred to the server along with thecommit request. Upon receipt of this request, theserver sends a prepare-to-commit message to allother clients that are caching any of the updatedpages. These clients should acquire exclusive lockson those pages. Once all of the relevant locks havebeen granted, various remote update actions canbe implemented. In [7,12,14], three variants ofO2PL have been proposed: O2PL-I, O2PL-P, and
O2PL-D. In O2PL-I, each client simply purges itscopies of the updated pages, while O2PL-P employsa propagation policy for the changed pages. O2PL-
D dynamically chooses either invalidation or pro-pagation. O2PL schemes defer the detection ofconflicts among locks set at clients until transactioncommit time and thus a transaction�s fate, commit orabort, tends to be determined in last minute of itslifetime. In addition, whenever an updating transac-tion attempts to commit, remote update actionsshould be performed at several clients. To illustratehow this factor can greatly affect the performance,consider the following execution schedule.
Example 1 (Performance limitation in O2PL due tocommit overhead). Suppose that an updating trans-action on x, T1 at client C1, wishes to commit.Assume also that both C2 and C3 have cached copyof x and T3 at C3 has already read x.
If the server receives the commit request of T1, itsends a prepare-to-commit message to C2 and C3.C2 can immediately reply, since no transaction holdsa conflicting lock on x. However, the reply messagefrom C3 should be delayed until T3 releases its readlock on x. If T3 started just a while ago and thusmuch work remains to be done, the delay could bevery long. Unfortunately, the delay incurred isobserved by the committing transaction. Moreover,unnecessary invalidations of local copies can beinduced in O2PL-I. In the above execution sche-dule, C2 invalidates its copy of x prior to sending areply message. Later, if T1 is involved in deadlocksdue to the blocking at C3 and is selected as a victim,the purging of x at C2 will be an unnecessaryinvalidation. Although O2PL-I could prevent thissort of false invalidation by employing a two-phasecommit protocol, it requires an additional commu-nication cost.
The CBL schemes allow locks to be cachedlocally across transaction boundaries. In CBL, thereis no need for a client to contact the server to accessa data page if a proper lock is cached. However, cli-ents must obtain a lock from the server prior toaccessing a data page, if they do not have the properlock cached locally. When a client requests a lockthat conflicts with one or more locks that are cur-rently cached at other clients, the server calls backthe conflicting locks by sending callback request tothose sites. This lock request is granted only whenthe server has determined that all conflicting locksare released, so the CBL schemes ensure that clientscan never concurrently hold conflicting locks. As a

376 H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393
result, transactions can commit after completingtheir executions without any consistency mainte-nance actions. However, whenever a conflicting lockis requested, callback messages should be sent toseveral clients during transaction execution phase.
The notify locking (NL) [23] is similar to O2PL-P
in that it uses propagation for remote updateactions. However, it differs from O2PL-P in that itemploys a preemption policy for resolving conflictsin favor of the committing transaction. When atransaction wishes to commit, the NL scheme pre-empts conflicting locks held by other ongoing trans-actions. Therefore, unlike O2PL, it can avoid a longsuspension delay to wait for releasing conflictinglocks at commit time. However, committing a trans-action requires handshakes between clients and theserver to avoid race conditions among committingtransactions.
2.2. Detection-based schemes
Detection-based schemes allow stale data copiesto reside in client caches for some period of time.Therefore, a transaction should check the validityof any cached copy that it accesses sometime priorto its commit. The caching two-phase locking(C2PL) [7,12] and adaptable optimistic concurrencycontrol (AOCC) [1,15] are categorized in this class.The C2PL scheme is a primary-copy lockingalgorithm in which inter-transaction caching ispermitted. In C2PL, whenever a client transactionattempts to access a data page, it should set a properlock on the central lock table at the server. In C2PL,cache consistency is maintained using a check-on-access policy [10]. When a client requests a read lockto the server for a locally cached page, it sends themessage with the log sequence number (LSN) ofthe page. After the server has granted the read lock,then it checks whether or not the client�s copy isup-to-date by comparing the client�s LSN with itsown. If the client�s copy is obsolete, the server sendsa lock response message with a valid copy of thepage. Although C2PL permits inter-transactioncaching, C2PL burdens each transaction with around trip of messages for consistency checkingon every page access, even though that page hasbeen cached locally.
The AOCC scheme is developed on the basis ofan optimistic concurrency control. In AOCC, check-ing the validities of the cached copies that a transac-tion accesses is deferred until the transaction entersits commit phase. Despite its nature of optimism,
AOCC is capable of reducing wasted work by abort-ing conflicting transactions early at their executionphase by sending out invalidation messages forpurging obsolete cached copies. However, AOCCcould show a high ratio of transaction abort, sinceresolution of data conflicts simply resorts to trans-action aborts. As noted in [1], if some pessimisticapproach could be integrated in AOCC, it wouldhave very desirable performance characteristics ina wide range of workloads.
3. Cache consistency maintenance schemes:DL and DL–ST
In this section, we present some assumptions andthen describe the proposed schemes. In deferredlocking (DL), cached pages at clients should be ver-ified to be the same as the primary copies at the ser-ver. For this purpose, we assume that each page istagged with a version number that uniquely identi-fies its state. Data pages are typically tagged withsuch a number as log sequence number (LSN) forthe purpose of crash recovery. We also assume thateach transaction is tagged with its time-stamp toresolve deadlocks.
3.1. Basic principles of deferred locking
DL is designed on the basis of a primary-copylocking algorithm, and thus the server should setproper locks on its lock table on behalf of clienttransactions. Under DL, a client transaction isallowed to access cached pages without checkingtheir validities. This action is deferred until a cli-ent–server interaction is inevitably required due toa cache miss. When a client experiences a cachemiss, it necessarily sends a data-shipping requestfor the target data to the server. At this point, theclient sends a number of lock requests in a piggy-back way so that locks can be acquired for cachedcopies that were accessed at the client in the intervalfrom the previous cache miss to the current one.
Prior to granting those locks piggybacked on thedata-shipping request, the server should guaranteethat the client has not read obsolete pages. This willbe described in the next section in details. Onceall accessed pages are verified to be valid and allrequested locks have been granted, the serversearches the database for the target data, and thensends it to the client. In DL, no messages arerequired except data-shipping request and its replyduring transaction execution phase. As a result,

H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393 377
DL is capable of reducing the communication over-head required for consistency checking. The DL
scheme can be classified as detection-based schemethat employs an asynchronous policy for checkingthe validities of cached copies.
3.2. Locking mechanism in deferred locking
In DL, the server maintains a central lock tableand a transaction wait-for-graph for detecting dead-locks. A deadlock is resolved by aborting the youn-gest transaction involved. We normally maintainthe lock table chronologically to schedule lockrequests in FIFO discipline for fairness. In DL, wemake use of three kinds of lock type: read lock(R-lock), write lock (W-lock), and commit lock(C-lock). The compatibility matrix between them isgiven in Table 1.
In DL, a transaction asynchronously setsW-locks at the central lock table for updating datapages. These W-locks are converted into C-locks
when the transaction enters into commit phase. Cli-ents can request two different types of R-lock to theserver. A data-shipping request implicitly includesan R-lock for the target data. This R-lock is referredto as Rlock-Implicit (Rlock-I) in this paper. Sinceour Rlock-I is identical to the conventional R-lock,it is scheduled in the same way as the R-lock inthe traditional 2PL. A data-shipping request canalso contain a number of R-locks explicitly for thedata pages that have been already accessed at theclient but not been validated at the server. ThisR-lock is referred to as Rlock-Explicit (Rlock-E).
Our Rlock-E is different from the conventionalR-lock in that its associated read operation has beenalready performed before setting a proper lock. Thisimplies that the transaction should be aborted if anyrequest of its Rlock-Es cannot be granted. Prior togranting an Rlock-E on x, the server should ensurethat the client has accessed an up-to-date version ofx by comparing the client�s LSN and its own. If the
Table 1Lock compatibility matrix
Holder Requester
Rlock-I Rlock-E W-lock
R-lock C C I, NBW-lock I, B Rule 1 I, NBC-lock I, B I, AR I, NB
Notations—C: compatible; I: incompatible; AR: abort requester;B: block requester; NB: do not block requester; Rule 1: seedescription in main text.
cached copy is valid, an Rlock-E is scheduled inaccordance to the lock compatibility matrix; other-wise, the transaction should be aborted. If any con-flicting W-lock exists, an Rlock-E is scheduledaccording to the following rule.
Rule 1 (Rlock-E scheduling against W-locks). AnRlock-E request can be granted if the requester isolder, in terms of its timestamp, than any of thepreviously scheduled conflicting W-lock requesters.Otherwise, the requester is destined to be aborted.
Rule 1 is employed for providing a favor to theoldest transaction rather than simply aborting theRlock-E requester. The violation of FIFO schedul-ing can happen only when an Rlock-E is grantedagainst conflicting W-locks. An Rlock-E requestagainst C-locks is scheduled in favor of the C-locks;if any conflicting C-lock exists, an Rlock-E cannotbe granted and thus the requester should beaborted. This rule stems from the fact that C-lock
implicitly means that the lock holder has progressedclose to commit phase; if an R-lock is grantedagainst conflicting C-locks, committing a transac-tion could take a substantial amount of time sincethe committing transaction should wait until theR-lock is released.
When a transaction wishes to update a data page,the new value is saved at its local buffer. Its associ-ated write lock is requested to the server along withthe next message being sent to the server. It is notdetermined during transaction execution phasewhether the W-lock can be granted or not. Thisdecision is made after the W-lock is converted intothe C-lock. Although the W-lock requester may beaborted due to deadlocks, it is never blocked. Thisblocking is deferred until the commit phase of thetransaction. When a client transaction attempts tocommit, it sends a commit request to the server withnew copies at its local buffer. Upon receipt of thismessage, the server converts the transaction�sW-locks with C-locks. The only purpose of C-locks
is to inform the lock manager that the transac-tion has proceeded to commit phase. Whether eachC-lock is granted or not is determined depending onthe status of the lock table. If no lock exists ahead ofa C-lock, the C-lock can be granted. Remember thatwe usually maintain the lock table chronologically.The committing transaction should be blocked untilall of its C-locks are granted. If all of the C-locks aregranted, the server installs new copies into the data-base and finally sends a commit acknowledgment tothe client.

t2
Ti
t4t0 time
Ti(k-1)
Results
t3t1
opk-1 opm-1opk
Ti(k)
Ti(m-2)
opk opk
Ti(k)
opmopk+1
t2 t4t0
Continuous cache-hit interval
Ti(k-1)Ti(k-1)
Datashipping request
to server
t3
Executed
t1
opk-1opk-1 opm-1opm-1opkopk
Ti(k)Ti(k)
Ti(m-2)Ti(m-2)
Legends: opk Means an operationwith cache miss;
Means an operationwith cache hit;
Means spawning a shadow transaction, Ti(k).
opkopk
Ti(k)Ti(k)
opmopk+1opk+1
Fig. 1. Forgery of shadow transactions.
378 H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393
In DL, it is possible to schedule the executions ofa transaction without setting W-locks during its exe-cution phase, like O2PL. In this case, however, itmay cause to spend a lot of time in granting C-locksat the commit phase, since many R-locks can begranted ahead of C-locks. The purpose of W-locks
is to schedule lock requests roughly in the sameorder as their operations have been processed at cli-ents for fairness. An additional benefit of W-locks isthat they enable deadlocks to be detected early inthe execution phase of transactions.
3.3. Notion of shadow transaction
The main drawback of DL is that it can induce ahigh abort ratio due to its lazy buffer validation.Even this factor could contribute to increase the per-formance, since it enables to establish a balancebetween transaction aborts and blockages to a cer-tain degree. Traditional locking schemes tend to suf-fer a performance degradation due to thrashingbehavior which results from frequent lock-conflictblockage [2,24]. However, the performance is notthe only issue. For an example, in interactive applica-tion domains, the amount of user interaction timeshould be treated as importantly as the systemthroughput. In this sort of application domains, amechanism for minimizing negative impacts of trans-action aborts would be very beneficial even if it bur-dens some extra overheads on system resources.
The basic philosophy behind shadow transactionis minimization of wasted work caused by transac-tion aborts. When a transaction has a possibilityof violating the serializability, it spawns a backuptransaction. This backup transaction is referred toas shadow one. The shadow transaction essentiallyhas the same execution history, results, and statusesas those of its original one at the time when the sha-dow transaction is spawned. Later, this transactioncan be executed in lieu of its original one if thepotential inconsistencies materialize. The notion ofshadow transaction is similar to that in [5,6]. How-ever, the issues regarding how to recognize thethreat of violating the serializability, how to verifyit, and how to guarantee the correctness of shadowtransactions are different from those in [5,6].
3.4. Deferred locking with shadow transaction
In this section, we develop a new CCM scheme,DL–ST, on the basis of the notion of shadow trans-action. In DL–ST, reading a cached page without
checking its validity is regarded as the potentialthreat of violating the serializability. Therefore,prior to reading a cached page, a shadow transac-tion is spawned on behalf of the currently executingone, and it remains in a blocked status until it is ver-ified whether its original one has read obsolete pagesor not. The original transaction optimistically pre-sumes that cached pages are always valid, and pro-ceeds with these pages. In contrast, shadowtransactions initially remain in a blocked status withthe presumption that cached pages are not valid.Later, if the optimistic assumption is verified to befalse, one of shadow transactions can be taken offto be executed, rather than restarting the originalone from its very beginning. To elucidate this appli-cation more clearly, consider the following execu-tion history (Example 2).
Example 2 (Application of the notion of shadow
transaction). Suppose that there is a transaction, Ti,that lives up to a certain time instance, say t2 inFig. 1, and it so far has not read any stale data page.
In this execution schedule, the notation Ti(k) isused to denote a shadow transaction of Ti, whichhas been spawned just after kth operation. Hence,shadow transaction Ti(k) possesses the results andstatuses that Ti has produced until the time whenkth operation is finished. Since operation opk issupposed to be executed with a cached page, Ti
spawns a shadow transaction Ti(k�1). In this way,whenever Ti meets a cache hit, it spawns a shadowtransaction.
Now suppose that Ti experiences a cache miss att4 and thus sends a data-shipping request. Thismessage is accompanied with a number of lockrequests for locally cached pages that have beenaccessed in the interval from t2 to t4. Based on theclient�s LSNs tagged on those lock requests, the

H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393 379
server can determine the destiny of Ti and itsshadows. Depending on the server�s response, theclient can decide whether Ti continues to beexecuted or which shadow is taken off for Ti. Foran example, if the response reports that Ti has readstale data during a certain operation, say operationopk+1 in Fig. 1, Ti is destined to be aborted. Then,the shadow transaction Ti(k) is awakened from theblocked status, and begins to be executed on behalfof Ti. The other shadows of Ti are purged out eitherbecause they are less progressed than Ti(k) orbecause they also exposed themselves by a dirtyread during the operation opk+1. If it is ensured thatTi has not read any stale data, all shadows of Ti arepurged out.
The locking mechanism of DL–ST is nearly thesame as that of DL. The only difference betweentheir locking mechanisms lies in the managementof Rlock-E, since the notion of shadow transactionis closely related to read operations on cached pages;when an Rlock-E request cannot be granted due to adirty read, DL–ST could resume a shadow transac-tion in lieu of the requester, while DL simply abortsthe requester. More importantly, when an Rlock-E
requester is destined to be aborted due to eitherany C-lock or elder W-lock in conflict, one of itsshadows can be taken off to be executed. In this case,the shadow transaction is forced to request an Rlock-
I for the data page that had been associated with theRlock-E, which has caused the original one to beaborted. If the shadow transaction requests anRlock-E for that page again, it is liable to fall intothe same fate as its original one, since either C-lock
or W-lock in conflict could still be existent.In a locking mechanism, the correctness of trans-
action executions is guaranteed by locks. It is note-worthy that the results, which have been existentuntil the time when a shadow transaction is forkedoff, have obviously been guaranteed to be valid bylocks set on behalf of the original one. This retro-spectively implies that the shadow transactionshould have the same lock statuses as its originalone for its results to be guaranteed to be valid.Therefore, when a transaction Ti aborts and canbe replaced with one of its shadows, the lock man-ager at the server does not release Ti�s locks, insteadit regards these locks to have been set on behalf ofthe shadow transaction. Sometimes, some of thoselocks might be required to be released. However,these partial lock releases can be easily determinedand simply implemented.
If a transaction reads a number of, say n, datapages, there could simultaneously exist as many asn shadows. This could lead to a substantial amountof overhead for creating shadows and saving theirresults. Therefore, the number of shadows wouldbe better to be restricted to prevent client buffersbeing exhausted to an extent that the system perfor-mance might be significantly degraded. In thisrespect, we restrict DL–ST to allow no more thank shadows to exist simultaneously on behalf of atransaction. One way for creating shadows wouldbe to let a new shadow transaction be forged when-ever an operation is executed with cache hit as longas the maximum number of shadows, k in our algo-rithm, is not exhausted. This scheme is named DL–ST/k in this paper.
3.5. Discussion of performance optimization issues
DL-based schemes employ a combination ofpropagation and invalidation for remote updateactions. If a transaction is verified to have read staledata pages, up-to-date pages at the server areshipped along with the reply message for updatingcached copies at the client. After an updating trans-action has successfully committed, data pages that ithas changed are not valid any longer at client buf-fers except its origin site. To notify this, the serversends invalidation messages to those clients thatare caching the changed pages. If a client receivesan invalidation message for a data page x, it simplypurges x from its cache, thus avoiding a potentialthreat of reading obsolete pages. These invalidationmessages are piggybacked on other messages beingexchanged between clients and the server.
DL-based schemes employed each cache miss asthe synchronization point in order to piggybacklock requests on a data-shipping request message,and thus they are capable of reducing the communi-cation overhead required for consistency checking.However, we could further enhance DL-based
schemes by varying the synchronization point forsome workloads. In environments where client–ser-ver interactions rarely occur, it would be very bene-ficial for reducing transaction aborts to synchronizeafter a certain time interval. These environmentscould include user interactive workloads where alarge amount of user interaction time is required,and the environments where the client cache hitratio is very high. For DL-ST/k, we employed a sim-ple policy for creating k shadows to make ourscheme concise. However, it could be an interesting

380 H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393
research issue to develop a novel policy for creatingk shadows. In DL-ST/k, the value of k does notneed to be static for all environments. It can beset to a value that reflects the degree of data conten-tion. In an environment where data contention issevere, a higher value of k would be beneficial.However, in an opposite case, the higher value ofk tends to induce merely the overhead for creatingshadows without any great accompanying benefit.The value of k can be dynamically changed to reflectthe degree of data contention in a system. In addi-tion, the value of k does not need to be the samefor all transactions. Each transaction could haveits own value of k to reflect its degree of data con-tention. In this paper, we leave this kind of perfor-mance issues for future studies.
3.6. Comparison between detection-based schemes
DL-based schemes can be classified as detection-based ones. Two other representative detection-based CCM schemes are C2PL, which is based ona pure pessimistic approach, and AOCC, which isdesigned on the basis of a pure optimistic approach.These detection-based schemes can be differentiatedon the basis of the points at which the validity ofaccessed data is checked and guaranteed. C2PL
employed a check-on-access policy while AOCCused a commit-time validation policy. DL-based
schemes employed a check-on-cache-miss policy.According to their policies for consistency checking,they provide a range from pessimistic and optimistictechniques. C2PL lies at one end of pessimistic tech-niques, while AOCC is at the other end. DL-based
schemes are somewhere in the middle of C2PL
and AOCC. Due to these different policies, they rep-resent different tradeoffs between consistency check-ing overhead and possible transaction aborts.Deferring consistency actions makes it possible forthese actions to be bundled together in order toreduce consistency maintenance overhead. How-
Netw orkManager
Other Clien
NetworkManager
Transaction Generator
Resource Manager(CPU)
Client
TransactionManager
BufferManager
Fig. 2. Simulati
ever, it could lead to a high ratio of transactionabort. We will thoroughly analyze these tradeoffsusing a simulation approach in Section 5.
4. Simulation model
In this section, we design a simulation model toevaluate the performance of DL and DL–ST. Forperformance comparison, we have chosen twodetection-based schemes (C2PL and AOCC) andone avoidance-based scheme (O2PL-I). C2PL ischosen because it is a PCL-based algorithm likeDL. AOCC and O2PL-I are chosen, since they areknown to be among the best CCM schemes[7,12,15] in terms of transaction throughput rate.As a representative of DL–ST, DL–ST/1 isemployed in this study, since we expect that allow-ing only one shadow to exist simultaneously isenough to capture the performance tradeoffs causedby shadow transactions. Much of our simulationmodel is borrowed from [7,12], but we haveincreased the number of disks to mitigate the perfor-mance bottleneck due to disk access. The simulationmodel in Fig. 2 was implemented with the CSIM[20] discrete event simulation language.
The simulation model consists of a networkmanager, client and server modules. The networkmanager is modeled as a FIFO server that managescommunication between the server and clients. Thetransaction generator (TG) generates user transac-tions one after another; upon completion of a trans-action, TG submits a new transaction immediately.We assume that all transactions are generated onlyat clients. Transaction manager coordinates the exe-cutions of transactions, and it is also in charge ofsome form of concurrency control actions depend-ing on the CCM scheme in use. Resource managershandle physical resources such as disks and CPUs.We assume that all clients are diskless but the serverhas a number of disks. The server and every clientrespectively have one CPU. Access requests for
ts
Se rver
(CPU, Disks)
Server
Resource Manager
TransactionManager
BufferManager
on model.

H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393 381
CPUs and disks are served in FIFO discipline. Thebuffer manager is responsible for managing the buf-fer pools according to an LRU page replacementpolicy.
The simulation parameters for transaction andsystem resources, and processing overheads areshown in Tables 2 and 3, respectively. The databaseconsists of a collection of DbSize pages. MeanTran-
Size defines the average number of pages accessedby a transaction. Actual number of pages accessedby a transaction is uniformly distributed in theinterval of ±20% deviation of MeanTranSize. Whena transaction is restarted due to its abort, there arebasically two kinds of restart policy: real restart,where the restarted transaction accesses the samedata pages as its original one, and fake restart,where it is regenerated as a new independent trans-action. If a transaction aborts, a user may attemptto run a different one sometimes, instead of running
Table 2Transaction and system resource parameters
Parameters Meaning
DbSize Database sizePageSize Page sizeMeanTranSize Mean transaction sizeUpdateProbability Update ProbabilityFakeRestartPct % of fake-restarted traNumClients Number of clientsNumDisks Number of disksClientCPU Instruction rate of clieServerCPU Instruction rate of servNetBandwidth Network bandwidthClientBufSize Buffer size of clientsServerBufSize Buffer size of server
Table 3System overhead parameters
Parameters Meaning
CtrlMsgSize Size of control messagesPageInst Insts. for reading a pageFixedMsgInst Fixed insts. per messagePageMsgInst Additional insts. per pageLockInst Insts. per lock/unlock pairValidationInst Validation insts. in AOCCRegisterInst Insts. to lookup caching sites
register/unregister a cached coForgeShadowInst Insts. to forge a shadow transSpaceForShadow Space overhead for saving res
statuses of a shadow transactiDiskOhInst CPU overhead per disk I/OMinDiskAcc Minimum disk access timeMaxDiskAcc Maximum disk access time
the original one again. To reflect this, we define thefake restart probability, denoted by FakeRestartPct,which means the probability with which an abort-destined transaction is regenerated as a new inde-pendent one.
When a client transaction reads a data page, itrequires PageInst CPU instructions processing time.In case of a write operation, the time required isdoubled. The CPU cost for message handling ismodeled as a fixed number of instructions, Fixed-
MsgInst, per message plus additional charge,PageMsgInst, per page. This CPU cost shall be con-sidered at both the sending and receiving site. Thesize of a control message, such as a lock requestand a data-shipping request, is defined by CtrlMsg-
Size. This message size is doubled in case of AOCC
and DL-based schemes due to the piggyback mes-sage. AOCC is charged for performing commit-timevalidation: each read-set entry of a committing
Settings
1000 pages4096 bytes20 pages20%
nsactions 20%1–25 ClientsFour disks
nt CPU 15 MIPSer CPU 30 MIPS
10 Mbits/s25% of DbSize
50% of DbSize
Settings
256 bytes30,000 inst.10,000 inst.5000 inst.300 inst.0–300 inst.
orpy
300 inst.
action 100,000 inst.ults andon
10 pages (40,960 byte)
5000 inst.10 ms30 ms

382 H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393
transaction is searched for in the invalid set of itsorigin site. For small invalid sets, the cost is 10instructions per invalid set entry. For large invalidsets, the cost is fixed at 300 instructions.
The disk used to service a particular access ischosen uniformly from among all disks at the ser-ver. If a transaction is finally determined to commit,the server updates the changed data pages in its buf-fer pool, and it marks those pages with a dirty flag.The server writes the dirty pages back to disks onlywhen they are actually selected for buffer replace-ment. The disk access time is uniformly distributedbetween MinDiskAcc and MaxDiskAcc.
In our simulation parameters, it is quite impor-tant to determine the overhead for forging a shadowtransaction, since this overhead is only related to thenegative side of DL–ST. We think that the notion ofshadow transaction can be implemented throughthread fork in the sense that a shadow transactionis basically a replica of its original one. It is reportedin [3] that making a copy of Ultrix null processrequires execution time 11,300 ls on a CVAX uni-processor workstation. However, if operating sys-tem kernel-level thread is employed, executiontime of only 948 ls is required for a null fork onthe same machine. Therefore, most overheads bur-dened on the forgery of a shadow transaction canbe considered to be caused to make a replica of itsoriginal one. Whenever a shadow transaction isforged, the cost of ForgeShadowInst processing timeis burdened on the client CPU. The cost defined forForgeShadowInst, 100,000 instructions, can be con-sidered to be large enough in the sense that even20 data pages could be copied within this amountof instruction cycles. SpaceForShadow defines thespace overhead for saving results and statuses of ashadow transaction.
The main performance metric used in this studyis the transaction throughput rate which is definedas the number of transactions that successfully com-mit per second. Transaction response time is definedto be the difference between when a transaction issubmitted and when it is successfully completed.This includes all the time spent in waiting queuesand spent due to restarts. A number of additionalmetrics are evaluated to interpret performanceresults, including transaction abort ratio, messageexchanges, cache hit ratio, and resource utilization.The blocking ratio of transactions is also investi-gated. It is measured to be the percent ofblocked transactions among all transactions in thesystem.
For this simulation study, we employ the replica-tion approach [18], which requires independent runsof the simulation experiments with different initialrandom seeds. We use the initial-data deletionmethod [18] to account for the initial transientphase. We discarded the results of the initial 800commits for purging the initial biases. In this paper,we pursued a 95% level of confidence with a certainprecision of half-length, which is set to 2% of theaverage response time. To achieve this, we ran eachsimulation for six times with run length of 5000committed transactions using different randomseeds.
5. Experiments and results
We ran the simulations under three forms ofworkloads to reflect different data-sharing patterns:UNIFORM, HIGHCON, and HOTCOLD. In eachexperiment, transactions read 20 distinct pages onaverage and updates them with a certain probabil-ity. The update probability is set to 20%, unlessnoted specially. In O2PL-I, the server sometimessends a prepare-to-commit message to a numberof clients. For sending this message, we employeda multicasting strategy to mitigate the commit over-head in O2PL-I. We assume that this cost is thesame as that of sending a control message to a singlesite.
Prior to main simulation runs, we have cau-tiously observed performance behaviors of bothC2PL and O2PL-I. We have found that the perfor-mance of O2PL-I could be degraded if an imperti-nent interval of global deadlock detection isemployed and that of C2PL tends to be loweredsince a large portion of client buffer could be con-sumed with invalid data pages. We think that the1 s interval in O2PL-I [7,12] is too large for someworkloads. So, we have traced the optimal intervalfor all workloads used in this study. O2PL-Ix
denotes O2PL-I scheme that employs an x-secondinterval for global deadlock detection; x is an opti-mal value for a given workload. In order to purgeinvalid pages out reasonably quickly in C2PL, theserver sends invalidation messages to all relevant cli-ents in the same way as in DL. This scheme isreferred to as C2PL-Invalidation (C2PL-I). Wesometimes omit simulation results of C2PL andO2PL-I in cases that their performances are not sta-tistically significant or they poorly perform com-pared to their variations.

H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393 383
5.1. Experiment 1—UNIFORM workload
In UNIFORM workload, each data page is cho-sen uniformly from all pages in the database, andthus all pages are presumed to be equally accessed.This workload is characterized with a low referencelocality. Its degree of data contention lies in themiddle of HIGHCON and HOTCOLD.
5.1.1. Effect of multiprogramming level
Fig. 3 presents transaction throughput rates andtransaction blocking ratios. Fig. 4 shows messageexchanges per transaction commit and resource uti-lizations. In this experiment, the highest throughput
2
4
6
8
10
12
14
1 5 10 15 20 25Number of Clients
Tra
nsac
tion
Thr
ough
put.
DLDL-ST/1C2PLC2PL-IO2PL-IO2PL-I0.5AOCC
UpdateProbability = 20%
(a)
Fig. 3. (a) Transaction throughput;
10
20
30
40
50
60
1 5 10 15 20 25
Number of Clients
Mes
sage
s Se
nt P
er C
omm
it
DLDL-ST/1C2PL-IO2PL-IO2PL-I0.5AOCC
(a) (
Fig. 4. (a) Message exchanges per co
is exhibited by DL and DL-ST/1, followed byAOCC and O2PL-I0.5. As NumClients increases,the performance of each scheme levels off or beginsto be degraded, but it results from different reasons.C2PL and O2PL-I show transaction blocking ratiosof 29% and 27%, respectively, when 15 clients exist,while they show blocking ratios of 41% and 36%with 20 clients. Although NumClients has beenincreased by 5, the number of active transactionsappears to inflate in small scale, only 1.15 and1.85 in C2PL and O2PL-I, respectively. In C2PL,note that an average of 10.65 (15 · 0.71) activetransactions are executing at 15 clients, while about11.8 (20 · 0.59) active ones exist at 20 clients. This
Number of Clients
0
0.1
0.2
0.3
0.4
0.5
0.6
1 5 10 15 20 25
Tra
nsac
tion
Blo
ckin
g R
atio
.
DLDL-ST/1C2PL-IO2PL-IO2PL-I0.5AOCC
(b)
(b) transaction blocking ratio.
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Res
ourc
e U
tiliz
atio
n
Network Util.
Server CPU Util.
1 5 10 15 20 25
Number of Clientsb)
mmit; (b) resource utilization.
0
0.1
0.2
0.3
0.4
0.5
1 5 10 15 20 25
Number of Clients
Abo
rt A
nd C
ache
Hit
Rat
io
DL DL-ST/1C2PL-I O2PL-I0.5AOCC
Cache Hit Ratio
Abort Ratio
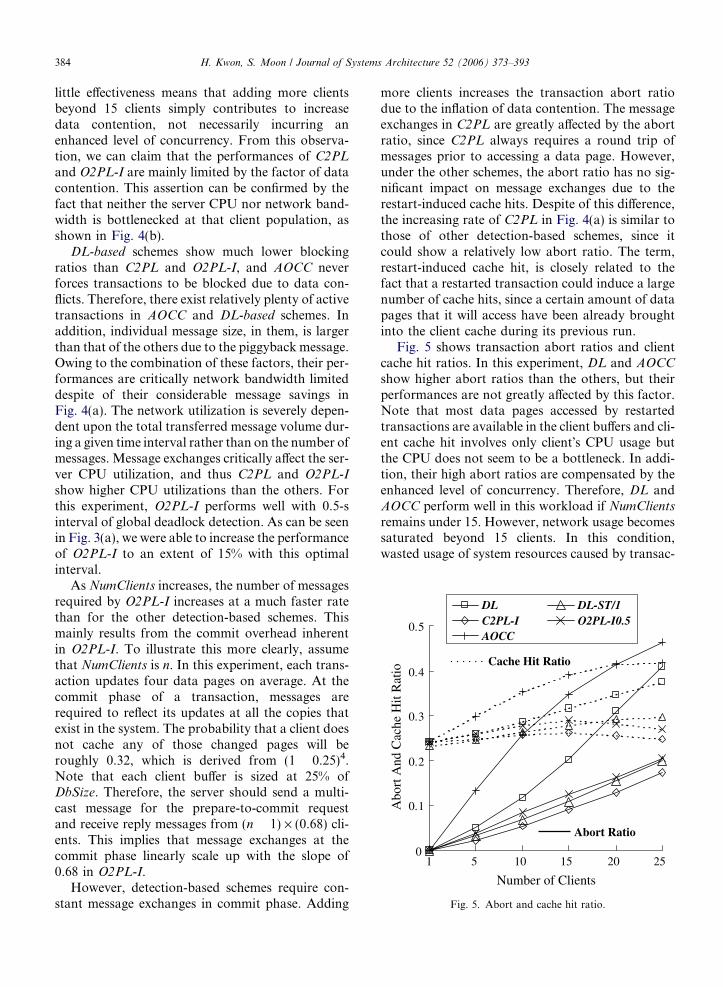
Fig. 5. Abort and cache hit ratio.
384 H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393
little effectiveness means that adding more clientsbeyond 15 clients simply contributes to increasedata contention, not necessarily incurring anenhanced level of concurrency. From this observa-tion, we can claim that the performances of C2PL
and O2PL-I are mainly limited by the factor of datacontention. This assertion can be confirmed by thefact that neither the server CPU nor network band-width is bottlenecked at that client population, asshown in Fig. 4(b).
DL-based schemes show much lower blockingratios than C2PL and O2PL-I, and AOCC neverforces transactions to be blocked due to data con-flicts. Therefore, there exist relatively plenty of activetransactions in AOCC and DL-based schemes. Inaddition, individual message size, in them, is largerthan that of the others due to the piggyback message.Owing to the combination of these factors, their per-formances are critically network bandwidth limiteddespite of their considerable message savings inFig. 4(a). The network utilization is severely depen-dent upon the total transferred message volume dur-ing a given time interval rather than on the number ofmessages. Message exchanges critically affect the ser-ver CPU utilization, and thus C2PL and O2PL-I
show higher CPU utilizations than the others. Forthis experiment, O2PL-I performs well with 0.5-sinterval of global deadlock detection. As can be seenin Fig. 3(a), we were able to increase the performanceof O2PL-I to an extent of 15% with this optimalinterval.
As NumClients increases, the number of messagesrequired by O2PL-I increases at a much faster ratethan for the other detection-based schemes. Thismainly results from the commit overhead inherentin O2PL-I. To illustrate this more clearly, assumethat NumClients is n. In this experiment, each trans-action updates four data pages on average. At thecommit phase of a transaction, messages arerequired to reflect its updates at all the copies thatexist in the system. The probability that a client doesnot cache any of those changed pages will beroughly 0.32, which is derived from (1 � 0.25)4.Note that each client buffer is sized at 25% ofDbSize. Therefore, the server should send a multi-cast message for the prepare-to-commit requestand receive reply messages from (n � 1) · (0.68) cli-ents. This implies that message exchanges at thecommit phase linearly scale up with the slope of0.68 in O2PL-I.
However, detection-based schemes require con-stant message exchanges in commit phase. Adding
more clients increases the transaction abort ratiodue to the inflation of data contention. The messageexchanges in C2PL are greatly affected by the abortratio, since C2PL always requires a round trip ofmessages prior to accessing a data page. However,under the other schemes, the abort ratio has no sig-nificant impact on message exchanges due to therestart-induced cache hits. Despite of this difference,the increasing rate of C2PL in Fig. 4(a) is similar tothose of other detection-based schemes, since itcould show a relatively low abort ratio. The term,restart-induced cache hit, is closely related to thefact that a restarted transaction could induce a largenumber of cache hits, since a certain amount of datapages that it will access have been already broughtinto the client cache during its previous run.
Fig. 5 shows transaction abort ratios and clientcache hit ratios. In this experiment, DL and AOCC
show higher abort ratios than the others, but theirperformances are not greatly affected by this factor.Note that most data pages accessed by restartedtransactions are available in the client buffers and cli-ent cache hit involves only client�s CPU usage butthe CPU does not seem to be a bottleneck. In addi-tion, their high abort ratios are compensated by theenhanced level of concurrency. Therefore, DL andAOCC perform well in this workload if NumClients
remains under 15. However, network usage becomessaturated beyond 15 clients. In this condition,wasted usage of system resources caused by transac-

H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393 385
tion aborts could affect the performance greatly.Therefore, their transaction throughput rates beginto be degraded beyond that point. The performanceof DL-ST/1 is lower than that of DL in the range of1–15 clients due to the overhead associated with sha-dow transactions. The notion of shadow transactionbegins to take an effect as data contention becomessevere, and thus DL-ST/1 begins to outperform DL
beyond 15 clients.Adding more clients gives rise to two competing
effects on the cache hit ratio. First, as NumClients
increases, the abort ratio rapidly increases. Thispositively affects the cache hit ratio due to restart-induced cache hits. Second, the invalidating rate ofclient cache is gradually inflated with the numberof clients. This decreases the number of buffer slotsthat are caching up-to-date data copies, and thusnegatively affects the hit ratio. Although the cachehit ratios of C2PL-I and O2PL-I slightly increasedue to the positive effect until NumClients reachesto 15, this effect commences to be offset by the neg-ative effect beyond that point, and thus their hitratios begin to decrease. However, the positive effectalways surpasses the negative one in DL andAOCC. Therefore, their hit ratios consistentlyincrease at all the client ranges. The hit ratio inDL-ST/1 steadily increases due to cache hits thatoccur when a shadow transaction is taken off andthen executes to the point where its original one isdestined to be aborted. The main reason for thelow hit ratio of DL-ST/1 in the range of 1–10 clientsis that it consumes a certain amount of client bufferslots for saving results of shadow transactions.
8
10
12
14
16
18
20
Tra
nsac
tion
Thr
ough
put.
DLDL-ST/1C2PL-IO2PL-I0.5AOCC
NumClients = 20
0 5 10 15 20 25 30 35UpdateProbability(a) (
Fig. 6. (a) Transaction throughput; (b
5.1.2. Effect of data contention
This experiment was run with 20 clients by vary-ing the update probability to evaluate the perfor-mance under various levels of data contention.Fig. 6 shows transaction throughput rates and mes-sage exchanges. The main drawback of O2PL-I isthat it can incur a significant overhead at commitphase. However, commit overhead is not so high,as long as the update probability remains low. Inan extreme case that there are no updates, O2PL-I
induces exactly the same amount of commit over-head as the others. Hence, O2PL-I0.5 performsthe best when UpdateProbability is in the range of0–10%. In this condition, transaction blocking isunusual, and thus the network utilization isstretched to more than 95% in every scheme. Hence,at a low range of UpdateProbability, the networkbandwidth limit is a more crucial factor on the sys-tem throughput than data contention. DL-based
schemes relatively poorly perform in this conditiondue to their natures of piggyback message.
AOCC performs the worst when UpdateProbabil-
ity is in the range of 5–15%. AOCC also requirespiggyback messages like DL-based schemes. More-over, the abort ratio in AOCC reaches up to 35%in that range, while other schemes could show rela-tively low abort ratios. Due to these reasons, AOCC
performs the worst in this condition. As Update-Probability increases beyond 20%, C2PL-I andO2PL-I0.5 begin to suffer from lack of active trans-actions due to lock conflicts. In addition, the abortratios, in them, begin to increase greatly. Therefore,their decreasing rates in transaction throughput are
10
20
30
40
50
60
70
0 5 10 15 20 25 30 35UpdateProbability
Mes
sage
s Se
nt P
er C
omm
it.
DLDL-ST/1C2PL-IO2PL-I0.5AOCC
b)
) message exchanges per commit.

386 H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393
faster than AOCC. Eventually, AOCC commencesto outperform C2PL-I and O2PL-I0.5 beyond20% of UpdateProbability.
As the update probability increases, messageexchanges in both C2PL-I and O2PL-I0.5 graduallyincrease. In C2PL-I, message exchanges increasedue to transaction aborts, while they increase inO2PL-I0.5 mainly due to the commit overhead.For the case of DL-based schemes, neither theupdate probability nor the abort ratio has a crucialimpact on message exchanges. Therefore, they con-sistently require fewer messages than C2PL-I andO2PL-I0.5. Moreover, as the update probabilityincreases beyond 10%, the network congestion,which is a main cause of their low relative perfor-mances, begins to be mitigated due to the inflationof blocked transactions. Hence, DL-based schemesbegin to outperform C2PL-I and O2PL-I0.5 as theupdate probability increases beyond 10%. DL-based
schemes outperform AOCC except when there areno updates, since they can show lower abort ratiosthan AOCC.
Effective cache sizes and cache hit ratios are pre-sented in Fig. 7. The term, effective cache size, isused for the number of buffer slots that are filledwith up-to-date data pages. As UpdateProbability
increases, the abort ratio rapidly increases. Thispositively affects the cache hit ratio. However, theinvalidating rate of client cache is gradually inflatedwith the increment of UpdateProbability. Thisresults in a smaller effective cache size, and thus neg-atively affects the hit ratio. Although the effectivecache size significantly decreases, the cache hit ratio
100
120
140
160
180
200
220
240
260
Eff
ectiv
e C
lient
Cac
he S
ize
DLDL-ST/1C2PL-IC2PLO2PL-I0.5AOCC
NumClients = 20
0 5 10 15 20 25 30 35
UpdateProbability(a) (b
Fig. 7. (a) Effective client cache si
gradually increases on the contrary in most schemessince the negative effect is always surpassed by thepositive one.
At a low range of UpdateProbability, DL-ST/1shows a smaller effective cache size and a lowercache hit ratio than the others owing to the spaceoverhead for shadow transactions. However, itshit ratio gradually increases and eventually becomeshigher than the others except DL and AOCC. Onemight expect that O2PL-I shall always keep muchlarger effective cache size than the others, since inva-lid data pages never consume client buffer slots.However, as UpdateProbability increases, the effec-tive cache size of O2PL-I becomes smaller thanAOCC and DL-based schemes due to the false inval-idations illustrated in Example 1. From Fig. 7(a), wecan perceive that C2PL consumes a substantialamount of buffer slots with obsolete pages. This wellexplains its low hit ratio in Fig. 7(b). DL, AOCC,and C2PL-I employed exactly the same policy forinvalidating client buffer slots, but they showslightly different effective cache size. DL shows aslightly larger effective cache size than C2PL-I sinceit has the feature of bringing new data pages into cli-ent cache when a transaction is destined to beaborted due to dirty reads. AOCC shows the largesteffective cache size since it can bring up-to-date datapages more frequently to client caches due to plentyof active transactions. Although all schemes exceptC2PL keep a similar amount of effective bufferslots, they show largely different cache hit ratiosmainly due to the differences in restart-inducedcache hits.
0
0.1
0.2
0.3
0.4
0.5
0 5 10 15 20 25 30 35
UpdateProbability
Clie
nt C
ache
Hit
Rat
io
DLDL-ST/1C2PL-IC2PLO2PL-I0.5AOCC
)
ze; (b) client cache hit ratio.

H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393 387
5.1.3. Effect of user interaction time
This experiment was run with user interactivetransactions. We modeled interactive transactionsin a way of performing a number of reads, thinkingfor some period of time, and then performing theirwrites. This kind of model was motivated by a largebody of form-screen applications where data is putup on the screen, a user may change some of thefields after staring at the screen awhile, and thenthe user types ‘‘enter’’, causing the updates to be per-formed. User interaction time is therefore taken tobe required per write operation. Although we haveexperimented with different values of user interac-tion time in the range of 1–10 s, different results werenot found in relative performances of CCM
schemes. This is mainly because this user interactiontime is considerably large compared to the actualexecution time of transactions. Hence, we presentthe results of the simulation performed only with atypical instance of user interaction time, which is 3 s.
Transaction throughput rates and averagewasted user interaction times per transaction com-mit are presented in Fig. 8. User activities arerequired for interactive transactions to proceed.When a transaction is aborted, user activities thathave been done until that time are wasted. Thewasted user interaction time means the time for useractivities caused by aborted transactions. In thisexperiment, AOCC outperforms the others in termsof the transaction throughput. O2PL-I0.5 shows asimilar performance as DL-based schemes. The infe-rior performance of C2PL-I can be explainedmainly by its high blocking ratio. If user activitiesare involved in the execution of transactions, the
1 5 10 15 20 25 30 35
Number of Clients
0
0.2
0.4
0.6
0.8
1
1.2
1.4
Tra
nsac
tion
Thr
ough
put
DLDL-ST/1C2PL-IO2PL-I0.5AOCC
(a) (b
Fig. 8. (a) Transaction throughput; (
resource utilization can be significantly lowered.Therefore, a certain amount of aborts can be with-stood if the performance is only concerned. How-ever, transaction abort makes valuable useractivities useless. In this respect, although AOCC
shows the highest performance, its substantialamount of wasted interaction time would make itunsuitable for this kind of interactive applicationdomains. Although C2PL-I provides the lowestwasted interaction time, its significantly low perfor-mance would be undesirable also.
Both DL-ST/1 and O2PL-I0.5 show lower per-formances than AOCC. However, they are capableof reducing a vast amount of wasted interactiontime inherent in AOCC. Therefore, they would bemore preferable in this sort of user interactive work-load than AOCC. In this experiment, the commitoverhead of O2PL-I seems to have little effect onthe performance. Note that most of the commitoverhead is burdened on the server CPU and net-work, but they are sparsely utilized. Actually, theserver CPU and network are utilized below 10%.In addition, global deadlocks are detected at nearlyreal time since the detection interval in O2PL-I0.5 issmall enough to be considered as real time com-pared to the user interaction time.
5.2. Experiment 2—HIGHCON workload
In this workload, we presume a 250-page HIGH-CON region in the database, and 80% of each trans-action�s accesses are directed to this region. Theremaining accesses go to the rest of the database.This workload is characterized with a high data
0
2
4
6
8
10
12
14
16
18
1 5 10 15 20 25 30 35
Number of Clients
Was
ted
Use
r In
tera
ctio
n T
ime
UpdateProbability = 20%
User InteractionTime = 3 Seconds
)
b) wasted user interaction time.

0
2
4
6
8
10
12
14
16
1 5 10 15 20 25
Number of Clients1 5 10 15 20 25
Number of Clients
Tra
nsac
tion
Thr
ough
put
DL DL-ST/1C2PL C2PL-IO2PL-I O2PL-I0.1AOCC
0
10
20
30
40
50
60
70
80
90
100
Mes
sage
s Se
nt P
er C
omm
it
DLDL-ST/1C2PL-IO2PL-IO2PL-I0.1AOCC
UpdateProbability = 20%
(b)(a)
Fig. 9. (a) Transaction throughput; (b) message exchanges per commit.
388 H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393
contention. Fig. 9 shows transaction throughputrates and message exchanges. In this experiment,AOCC and DL-based schemes outperform the oth-ers by a significant margin. Their superior perfor-mances mainly come from their low-degree natureof transaction blocking as well as their savings inmessage exchanges. In this experiment, DL andDL-ST/1 show blocking ratios of 24% and 28%,respectively, at 15 clients, while O2PL-I0.1 andC2PL show blocking ratios of 35% and 53%. How-ever, the abort ratio in DL reaches to 56% at thatclient population. Although this high abort ratiocould be compensated by an enhanced level of con-currency to a certain degree, it will obviouslyrequire additional consumption of system resources.Compared to DL, the blocking ratio in DL-ST/1
could be considered to be reasonably low from theperspective that it shows abort ratio of 36% at 15clients. This low abort ratio at a reasonable block-ing ratio leads to DL-ST/1�s superior performanceover other schemes beyond 10 clients.
In this sort of high contention environments,pure locking-based schemes (C2PL-I and O2PL-I)incur very frequent transaction blockages due tolock conflicts. For every blocking transaction inthem, the equivalent situation can lead to eitherabort or commit in AOCC. In data-shipping cli-ent–server systems, the abort processing actions ofa transaction do not have a major impact on theperformance of the other transactions, since mostof abort processing cost is burdened on the client.This situation is different from that in centralizeddatabase systems, where a transaction�s abort pro-
cessing has an impact on the performance of othertransactions. In this workload, the blocking over-heads of C2PL-I and O2PL-I dominate the abortoverhead of AOCC, and thus AOCC outperformsC2PL-I and O2PL-I.
In previous works [7,12], C2PL outperformedO2PL-I in this sort of high data contention environ-ment. However, we found that this mainly resultsfrom the fact that O2PL schemes suffer from a longdelay suspension for global deadlocks to bedetected. As shown in Fig. 9(a), we were able toenhance the performance of O2PL-I with a substan-tial performance margin by employing an optimalinterval for deadlock detection.
In this workload, each scheme can show ahigher cache hit ratio than in UNIFORM case,since most data pages are accessed from theHIGHCON region. Hence, as long as NumClients
remains low, most schemes require fewer messageswith this workload than with UNIFORM one. Inthis workload, a large number of transactionaborts are inevitable. Restart-induced cache hitsof HIGHCON workload are not anticipated asmuch as those of UNIFORM case, since pre-fetched pages during previous runs are susceptibleto be invalidated soon. Message exchanges there-fore increase at a faster rate in this workload thanin UNIFORM case. In O2PL-I, its inherent com-mit overhead leads to a marginal increment of mes-sage traffics. The graph of O2PL-I0.1 rises moresteeply than that of O2PL-I, since the differenceof cycle check overhead between them becomesenlarged.

0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
1 5 10 15 20 25Number of Clients
1 5 10 15 20 25Number of Clients
Abo
rt R
atio
And
Cac
he H
it R
atio.
DLDL-ST/1C2PL-IO2PL-I0.1AOCC
0
50
100
150
200
250
Tot
al a
nd H
IGH
CO
N C
ache
Siz
es
C2PL
Total Cache Size
HIGHCON Cache Size
Client Cache Hit Ratio
Abort Ratio
(a) (b)
Fig. 10. (a) Abort and cache hit ratio; (b) effective cache size.
H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393 389
Fig. 10(a) shows transaction abort ratios andcache hit ratios. It is interesting to note that AOCC
shows a similar abort ratio as DL. In AOCC, atransaction can successfully commit if its accessedpages have not been invalidated by other writingtransactions during its execution time. Therefore,if a transaction is executed quickly, its abort proba-bility is significantly lowered. In AOCC, a transac-tion�s fate, commit or abort, tends to bedetermined after it is relatively much progressed.This means that restarted transactions can be exe-cuted quickly since most of data pages that it willaccess have been already brought into client cacheduring its previous run. If a transaction in DL isexecuted quickly, its abort probability decreasesalso, but a restarted transaction in DL cannot beexecuted as fast as in AOCC due to lock conflicts.This results in the abort ratio of restarted transac-tions being lower in AOCC than in DL. However,the probability that a transaction successfully com-mits during its first run is higher in DL than inAOCC. Due to these reasons, the difference betweentheir abort ratios is not large in this workload.AOCC shows a similar abort ratio as DL and itnever incurs transaction blocking. Nevertheless,AOCC does not outperform DL because AOCC
induces more wasted work than DL.Fig. 10(b) presents total effective cache sizes and
effective HIGHCON cache sizes. The HIGHCONcache size denotes the number of buffer slots thatare filled with valid data pages in HIGHCONregion. The abort ratio of each scheme dramaticallyincreases as NumClients goes high, and thus one
might expect that the hit ratio in each scheme alsoincreases. However, the result up to 10 clients isthe very reverse to what one may expect. The reasonfor this can be explained by the fact that the effectiveHIGHCON cache size greatly decreases as NumC-lients increases. Data pages in HIGHCON regionare likely to be cached in each client buffer, but theyare also susceptible to be invalidated. When there isno invalidation, each scheme fills most buffer slots,more than 70%, with data pages in HIGHCONregion. However, when NumClients reaches onlyto 10, the ratio of the effective HIGHCON cachesize to the total effective cache size becomes below40%. This ratio further decreases as NumClients
increases. The total effective cache size does notdecrease so much as the HIGHCON cache size. Thisis mainly because non-HIGHCON data pages couldbe kept in buffer slots for a long time, once theyhave been cached. It should be noted that emptybuffer slots are very liable to exist due to a vastamount of invalidations of HIGHCON data pages.This implies that non-HIGHCON data pages arenot likely to be replaced for the reason of LRUalgorithm. In addition, they are not liable to beinvalidated, since the probability of accesses to themis very low.
5.3. Experiment 3—HOTCOLD workload
In this workload, each client is presumed to haveits own 40-page favorite region, denoted by HOT, inthe database that is disjointed with each other, and80% of each transaction�s accesses are directed to its

390 H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393
own HOT region. The remaining accesses go else-where in the database. This workload is character-ized with a high reference locality and a low datacontention. In this experiment, ClientBufSize is setto 10% of DbSize.
5.3.1. Effect of multiprogramming level
Transaction throughput rates and messageexchanges are presented in Fig. 11. In this work-load, each transaction�s accesses are directed to itsown HOT region. This results in the reduction ofcommit overhead in O2PL-I and the reduction ofstale data reads in AOCC and DL-based schemes.Moreover, this leads to a very high cache hit ratioin every scheme. C2PL-I can not take advantageof this high hit ratio as much as the others becauseit employed a check-on-access policy. This leads toits significantly inferior performance compared tothe others. Due to the reduced commit overhead,O2PL-I could show a reasonable performance atall the client ranges. In an environment where thedegree of data contention is low, forgery of shadowtransactions merely induces a space overhead aswell as a processing overhead without any accompa-nying benefit. Therefore, DL-ST/1 exhibits a lowerperformance in the range of 1–10 clients than otherschemes (except C2PL-I). However, beyond that cli-ent population, this overhead could be compensatedto a certain degree by reduced wasted work, andthus it shows nearly the same level of performanceas them. The performance of AOCC is comparableto those of DL and O2PL-I in the range of 1–10 cli-ents. However, beyond that point, it begins to exhi-
0
5
10
15
20
25
30
35
1 5 10 15 20 25
Number of Clients
Tra
nsac
tion
Thr
ough
put
DLDL-ST/1C2PL-IO2PL-IAOCC
UpdateProbability = 20%
(a) (
Fig. 11. (a) Transaction throughput; (b
bit a slightly inferior performance mainly due to itshigh abort ratio.
Fig. 12 shows transaction abort ratios andresource utilizations. The differences in the serverCPU utilization for each scheme mainly come fromthe fact that they require different numbers of mes-sages per transaction commit. Since C2PL requiresmore messages, the server CPU is heavily utilized.In C2PL, the network utilization can not increaseas quickly as the others due to the message process-ing delay in the server CPU.
The results in Fig. 12(b) indicate that the perfor-mances of all schemes (except C2PL) appear to benetwork bandwidth limited. To understand this,total transferred message volume during a given timeinterval should be examined. For a transaction�s suc-cessful commit, an average of eight data pages aretransferred through the network, including fourdata-shippings for cache misses and four pages forinstalling updated pages. Here, four data-shippingsare derived from the fact that the cache hit ratio shallbe around 0.8 in this workload. When 15 clientsexist, all schemes (except C2PL) show about oneand half times the transaction throughput rate ofC2PL. This means that they require four more pagesto be transferred than C2PL during the time intervalof a transaction�s successful commit in C2PL. Thismessage volume corresponds to the overhead fortransferring 64 control messages in terms of networkbandwidth. This means that total transferredmessage volume in them is larger than that inC2PL during a given time interval. Note that mostof messages required in C2PL are control ones due
1 5 10 15 20 25
Number of Clients
0
10
20
30
40
50
Mes
sage
Exc
hang
es DLDL-ST/1C2PL-IO2PL-IAOCC
b)
) message exchanges per commit.

0
0.05
0.1
0.15
0.2
0.25
0.3
1 5 10 15 20 25
Number of Clients1 5 10 15 20 25
Number of Clients
Tra
nsac
tion
Abo
rt R
atio
DLDL-ST/1C2PL-IO2PL-IAOCC
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Res
ourc
e U
tiliz
atio
n
Server CPU Util.
Network Util.
(a) (b)
Fig. 12. (a) Transaction abort ratio; (b) resource utilization.
H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393 391
to the high cache hit ratio in this workload. Thisanalysis well explains the results in Fig. 12(b). AOCC
and DL-based schemes show slightly higher networkutilizations than O2PL-I due to their piggybackmessages. In this workload, all schemes show nearlythe same level of cache hit ratio, about 80%.Although NumClients increases, there are littlechanges in cache hit ratio because data conflictsare rare and page invalidations are unusual.
5.3.2. Effect of network speed
This experiment was intended to probe how thenetwork speed affects the system throughput. AsNetBandwidth increases, system resources, such as
0
20
40
60
80
100
120
5 10 20 30 40 50Network Bandwidth (Mbps)
Tra
nsac
tion
Thr
ough
put
DLDL-ST/1C2PL-IO2PL-I0.1O2PL-IAOCC
UpdateProbability = 20%NumClients = 25
(a) (
Fig. 13. (a) Transaction throughp
CPUs and disks, could be heavily utilized, and thustheir speeds tend to be performance bottlenecks. Toalleviate this factor, we have tripled our default diskspeed for this experiment. That is, the disk accesstime is uniformly distributed between 5 and 10, inunit of millisecond. We have also increased thespeeds of client- and server-CPUs to 30 and 60,respectively in MIPS. We have set NumClients tobe relatively large, 25 clients, to provide enoughtransactions to utilize the increased capacities ofsystem resources.
Fig. 13 presents transaction throughput rates andresource utilizations. Transaction throughput ratesin all schemes (except C2PL-I and O2PL-I) linearly
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Res
ourc
e U
tiliz
atio
n
Server CPU Util.Network Util.
5 10 20 30 40 50Network Bandwidth (Mbps)b)
ut; (b) resource utilization.

392 H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393
scale up until NetBandwidth reaches to 30 Mbps.Although performance discrepancies betweenO2PL-I0.1 and DL-based schemes cannot be dis-cerned well when NetBandwidth lies in 5–20 Mbps,DL-based schemes always show similar or betterperformances than O2PL-I0.1. Beyond 30 Mbps,where the network congestion begins to be miti-gated, the performance discrepancies become dis-tinct. The performance of AOCC is very similar tothose of DL-based schemes; when NetBandwidth
remains below 30 Mbps, DL-based schemes per-forms slightly better than AOCC, but AOCC showsnearly the same performance as DL-based schemesbeyond 40 Mbps. When NetBandwidth increasesbeyond 40 Mbps, the performances of O2PL-I0.1,AOCC, and DL-based schemes commence to bedisk-bound. In C2PL-I, the server CPU is severelyutilized when NetBandwidth reaches to 30 Mbps,and thus transaction throughput does not increasebeyond that point. The increased capacities of sys-tem resources are not efficiently utilized in O2PL-I
due to its long delay suspension for global dead-locks to be detected.
6. Conclusions
In this paper, we have proposed new CCM
schemes, named DL and DL–ST, on the basis ofthe primary-copy locking algorithm. The primarydesign philosophy of DL in optimizing its per-formance was the minimization of the resultingcommunication cost. We have realized this bycombining a number of lock requests and a data-shipping request into a single message packet. How-ever, DL tends to show a high ratio of transactionaborts due to its lazy buffer validation. The highabort ratio of DL would make it unsuitable forinteractive application domains since it could inducea large amount of wasted work in user activities. Tominimize this negative impact of transaction aborts,we have introduced the notion of shadow transac-tion. This notion and the locking mechanism ofDL have been incorporated into DL–ST.
We have evaluated the performance of the pro-posed schemes using a simulation approach in a cli-ent–server DBMS architecture. The simulationresults indicate that the proposed schemes are capa-ble of providing reasonable or superior perfor-mances across a wide range of workloads. Thefollowing essential properties in them lead to theirsuperior performances: (1) they could significantlyreduce the number of message exchanges, (2) they
could keep relatively large effective cache sizes, (3)they could provide enhanced levels of concurrency.
The most perceptible advantage of DL-based
schemes is that they are capable of outperformingO2PL-I and C2PL by a significant margin in highdata contention environments. This property wouldmake them more attractive, since database enginesof these days are required to support a substantiallyenhanced level of concurrency due to ever-increas-ing CPU and I/O processing speeds, which tendsto cause a high level of data contention. DL-based
schemes can outperform AOCC in most workloadsexcept in environments where system resources aresparsely utilized. Between the proposed schemes,DL–ST is inferior to DL at low data contentionenvironments due to the overhead associated withshadow transactions. However, DL–ST is capableof reducing a substantial amount of the wastedwork in user activities compared to DL. A moreobvious advantage of DL–ST is that it provides abetter performance than DL in an environmentwhere the level of data contention is so severe thateven DL could not withstand. In the future we planto further investigate cache consistency maintenanceschemes for hybrid architecture where data-shippingand query-shipping are combined.
References
[1] A. Adya, R. Gruber, B. Liskov, U. Maheshwari, Efficientoptimistic concurrency control using loosely synchronizedclocks, in: Proc. ACM SIGMOD Conf., San Jose, CA, 1995,pp. 23–34.
[2] D. Agrawal, A. El Abbadi, A.E. Lang, Performance char-acteristics of protocols with ordered shared locks, in: Proc.IEEE Data Engineering Conf., Kobe, Japan, 1991, pp. 592–601.
[3] T.E. Anderson, B.N. Bershad, E.D. Lazowska, H.M. Levy,Scheduler activations: effective kernel support for the user-level management of parallelism, ACM Trans. Comput.Systems 10 (1) (1992) 53–79.
[4] P.A. Bernstein, V. Hadzilacos, N. Goodman, Concurrencycontrol and recovery in database systems, Addison-Wesley,1987.
[5] A. Bestavros, S. Braoudakis, Value-cognizant speculativeconcurrency control, in: Proc. VLDB Conf., Zurich, Swit-zerland, 1995, pp. 122–133.
[6] A. Bestavros, S. Braoudakis, Value-cognizant speculativeconcurrency control for real-time databases, Informat.Systems 21 (1) (1996) 75–101.
[7] M.J. Carey, M.J. Franklin, M. Linvy, E.J. Shekita, Datacaching tradeoffs in client–server DBMS architectures, in:Proc ACM SIGMOD Conf., Denver, CO, 1991, pp. 357–366.
[8] M.J. Carey, M. Livny, Conflict detection tradeoffs forreplicated data, ACM Trans. Database Systems 16 (4)(1991) 703–746.

H. Kwon, S. Moon / Journal of Systems Architecture 52 (2006) 373–393 393
[9] M.J. Carey, M.J. Franklin, M. Zaharioudakis, Fine-grainedsharing in a page-server OODBMS, in: Proc. ACM SIG-MOD Conf., Minneapolis, MN, 1994, pp. 359–370.
[10] A. Dan, P.S. Yu, Performance analysis of coherency controlpolicies through lock retention, in: Proc. ACM SIGMODConf., San Diego, CA, 1992, pp. 114–123.
[11] O. Deux et al., The O2 system, Commun. ACM 34 (10)(1991) 34–48.
[12] M.J. Franklin, M.J. Carey, Client–server caching revisited,Technical Report 1089, Department of Computer Sciences,University of Wisconsin–Madison, 1992.
[13] M.J. Franklin, M.J. Carey, M. Linvy, Global memorymanagement in client–server database systems, in: Proc.VLDB Conf., Vancouver, Canada, 1992, pp. 596–609.
[14] M.J. Franklin, M.J. Carey, M. Livny, Transactional client–server cache consistency: alternatives and performance,ACM Trans. Database Systems 22 (3) (1997) 315–363.
[15] R. Gruber, Optimism vs. locking: a study of concurrencycontrol for client–server object-oriented databases, Ph.D.Thesis, Massachusetts Institute of Technology, 1997.
[16] W. Kim, J.F. Garza, N. Ballou, D. Woelk, The architectureof the ORION next-generation database system, IEEETrans. Knowledge Data Eng. 2 (1) (1990) 109–124.
[17] C. Lamb, G. Landis, J. Orenstein, D. Weinreb, TheObjectStore database system, Commun. ACM 34 (10)(1991) 50–63.
[18] A.M. Law, W.D. Kelton, Simulation Modeling and Anal-ysis, McGraw-Hill, 1991.
[19] M.T. Ozsu, K. Voruganti, R.C. Unrau, An asynchronousavoidance-based cache consistency algorithm for clientcaching DBMSs, in: Proc. VLDB Conf., New York, USA,1998, pp. 440–451.
[20] H. Schwetman, CSIM Users� Guide for Use with CSIMRevision 16, Microelectronics and Computer TechnologyCorporation, Austin, TX, 1992.
[21] K. Voruganti, M.T. Ozsu, R.C. Unrau, An adaptivehybrid server architecture for client caching ODBMSs,in: Proc. VLDB Conf., Edinburgh, Scotland, 1999, pp.150–161.
[22] Y. Wang, L.A. Rowe, Cache consistency and concurrencycontrol in a client/server DBMS architecture, in: Proc. ACMSIGMOD Conf., Denver, CO, 1991, pp. 367–376.
[23] K. Wilkinson, M. Neimat, Maintaining consistency of clientcached data, in: Proc. VLDB Conf., Brisbane, Australia,1990, pp. 122–133.
[24] P.S. Yu, D.M. Dias, Performance analysis of concurrencycontrol using locking with deferred blocking, IEEE Trans.Software Eng. 19 (10) (1993) 982–996.
Hyeokmin Kwon received the M.S. andPh.D. degree in information and com-munication engineering from Koreaadvanced Institute of Science and Tech-nology (KAIST), in 1994 and 1998respectively, and joined the University ofSemyung in 1999. He is currently anassistant professor of Software Depart-ment at the University of Semyung. Hiscurrent research interests include data-base systems, distributed and mobile
computing, and performance modeling.
Songchun Moon received his Ph.D.degree in Computer Science from theUniversity of Illinois at Urbana–Cham-paign in 1985. He has been working forKAIST since then. He has developed amultiuser relational database manage-ment system, IM, which is the first pro-totype ever in Korea in 1990 and also adistributed database management sys-tem, DIME, in 1992, which is anotherfirst prototype ever in Korea. His
research interests include database security, data modeling, anddata warehousing.




















