
Contextual Variation in L2 Spanish: Voicing Assimilation in Advanced Learner Speech
29
Contextual Variation in L2 Spanish: Voicing Assimilation in Advanced Learner Speech 1 Lauren B. Schmidt University of Missouri-St. Louis Abstract The present study examines whether, and to what degree, regressive voicing assimilation of Spanish /s/ (as in rasgo /rasgo/ [ˈraz.ɣ ̞ o]) occurs in the speech of advanced second language (L2) learners of Spanish. Acoustic analyses of L2 productions of /s/ in the voicing context (preceding a voiced consonant) and in the non-voicing context (preceding a voiceless consonant) elicited from a contextualized picture-description task revealed a contextual voicing effect in the speech of only a limited number of the advanced L2 speakers. The low occurrence of the assimilation process even amongst the advanced learners may be attributed in part to the variable nature of voicing in the input and to the complexity of the process (i.e. subject to different stylistic, linguistic, and social factors). The study also provides a phonetic description of the variants of L2 Spanish /s/ and finds that when voicing does occur, it is phonetically similar to native Spanish voicing in terms of the phonetic contexts in which voicing occurs, patterns of durational differences of /s/ according to voicing, and the variable nature of its occurrence. 1. Introduction Assimilation, or “the optional variation in the phonetic description of a speech sound as it becomes more like an adjacent speech unit” (Ellis & Hardcastle 2002, p. 374), is a pervasive characteristic of connected speech found across the world’s languages. Assimilations can be regressive (anticipatory) or progressive (preservative), as well as categorical, possibly resulting in neutralizations, or variable and gradient. While there is some discussion as to whether assimilations are phonological or are simply phonetic coarticulation effects, the degree of different assimilatory processes – such as place assimilation, voicing assimilation, or vowel harmony – seems to be language- and even dialect-specific. Furthermore, assimilations are many times subject to a wide degree of inter-speaker as well as intra-speaker variation (e.g. Ellis & Hardcastle 2002). Assimilatory processes appear to occur below the level of consciousness or awareness of speakers (Mahmood 2007), and may be utilized by listeners perceptually to anticipate forthcoming contexts (Gow 2001). It is still not entirely clear, however, what role assimilatory processes play in L2 systems. Few studies have examined assimilations in a second language, and least so in consideration of target-like assimilations in L2 production. What does seem to be evident, however, is the transfer of some – but not all – L1 assimilatory processes into pronunciation of the L2 (e.g. Altenberg & Vago 2006, Cebrian 2000, Zsiga 2003 and Zsiga & Kim 2005). Some explanations offered for why some L1 assimilations transfer and others do not include recoverability (or the importance of conserving 1 AUTHOR’S MANUSCRIPT To appear in Studies in Hispanic and Lusophone Linguistics, 7(1).
Transcript of Contextual Variation in L2 Spanish: Voicing Assimilation in Advanced Learner Speech

Contextual Variation in L2 Spanish: Voicing Assimilation in Advanced Learner Speech1
Lauren B. Schmidt
University of Missouri-St. Louis
Abstract The present study examines whether, and to what degree, regressive voicing assimilation of Spanish /s/ (as in rasgo /rasgo/ [ˈraz.ɣ̞o]) occurs in the speech of advanced second language (L2) learners of Spanish. Acoustic analyses of L2 productions of /s/ in the voicing context (preceding a voiced consonant) and in the non-voicing context (preceding a voiceless consonant) elicited from a contextualized picture-description task revealed a contextual voicing effect in the speech of only a limited number of the advanced L2 speakers. The low occurrence of the assimilation process even amongst the advanced learners may be attributed in part to the variable nature of voicing in the input and to the complexity of the process (i.e. subject to different stylistic, linguistic, and social factors). The study also provides a phonetic description of the variants of L2 Spanish /s/ and finds that when voicing does occur, it is phonetically similar to native Spanish voicing in terms of the phonetic contexts in which voicing occurs, patterns of durational differences of /s/ according to voicing, and the variable nature of its occurrence. 1. Introduction Assimilation, or “the optional variation in the phonetic description of a speech sound as it becomes more like an adjacent speech unit” (Ellis & Hardcastle 2002, p. 374), is a pervasive characteristic of connected speech found across the world’s languages. Assimilations can be regressive (anticipatory) or progressive (preservative), as well as categorical, possibly resulting in neutralizations, or variable and gradient. While there is some discussion as to whether assimilations are phonological or are simply phonetic coarticulation effects, the degree of different assimilatory processes – such as place assimilation, voicing assimilation, or vowel harmony – seems to be language- and even dialect-specific. Furthermore, assimilations are many times subject to a wide degree of inter-speaker as well as intra-speaker variation (e.g. Ellis & Hardcastle 2002). Assimilatory processes appear to occur below the level of consciousness or awareness of speakers (Mahmood 2007), and may be utilized by listeners perceptually to anticipate forthcoming contexts (Gow 2001).
It is still not entirely clear, however, what role assimilatory processes play in L2 systems. Few studies have examined assimilations in a second language, and least so in consideration of target-like assimilations in L2 production. What does seem to be evident, however, is the transfer of some – but not all – L1 assimilatory processes into pronunciation of the L2 (e.g. Altenberg & Vago 2006, Cebrian 2000, Zsiga 2003 and Zsiga & Kim 2005). Some explanations offered for why some L1 assimilations transfer and others do not include recoverability (or the importance of conserving
1AUTHOR’S MANUSCRIPT To appear in Studies in Hispanic and Lusophone Linguistics, 7(1).

acoustic cues, Zsiga 2003), the nature of the assimilation (articulatory timing effects vs. categorical rules, Zsiga & Kim 2005), and the level at which the assimilation occurs (word-internal vs. word-final assimilations, Cebrian 2000). Secondly, a small number of studies have examined how non-native (or L2) assimilations are perceptually compensated (e.g. Darcy, Peperkamp & Dupoux 2007, Gow & Im 2004, Kochetov & So 2007 and Weber 2001). For example, Darcy and colleagues (2007) found that while beginning L2 learners of French and of English perceptually compensated more for native (L1) than non-native (L2) assimilation processes when hearing the L2, advanced L2 learners performed differently, compensating for the target assimilations in the L2 in a way similar to native speakers of the language (however, see Gow & Im 2004 for different results1). Thus, the results of these few studies suggest that L2 speakers may transfer assimilatory processes from the L1 into the L2 in both production and perception of the L2. Furthermore, there is evidence that highly proficient L2 speakers may discontinue the transfer of L1 assimilations into the L2 and may acquire the non-native L2 assimilatory processes, at least with respect to their use in speech perception and processing (Darcy, Peperkamp & Dupoux 2007). The incorporation of L2 assimilatory processes in pronunciation, however, is less clear, as research on production of non-native assimilations is lacking. The current study, thus, contributes to a further understanding of assimilatory processes by investigating to what degree these language-specific processes surface in production of a non-native (second) language.
Specifically, this research investigates the presence of Spanish regressive voicing assimilation in the speech of advanced English-speaking learners of Spanish. In those dialects of Spanish that retain syllable-final /s/, the sibilant may undergo regressive voicing assimilation (e.g. Quilis & Fernandez 1985), resulting in contextual variation according to the voicing of the following consonant: este /este/ [ˈes.te] vs. desde /desde/ [ˈdez.ðe̞]. If learners of Spanish as a second language are indeed moving towards the target of the native Spanish phonology, then highly proficient learners should come to apply this process of sibilant regressive voicing assimilation in their own production. However, acquisition of Spanish sibilant voicing assimilation by English-speaking learners may be a challenging task, as the native and second languages differ in the phonemic status of [s] and [z] and in the direction and contexts of voicing assimilation processes, among other possible influences (e.g. orthography). Furthermore, voicing assimilation in Spanish is a variable rather than categorical process, which may further complicate its acquisition. The objective of this study, thus, is to determine if L2 learners of Spanish voice the Spanish sibilant in the appropriate voicing context (i.e. preceding a voiced consonant). This study is preliminary in that it examines the production of just one level of learners, those enrolled in an upper-level collegiate Spanish course. However, this study is important in that it tests whether the L2 learners readily realize sibilant voicing once they have achieved greater proficiency and fluency in the language. For this reason, advanced learners were chosen as the focus of the study. Furthermore, the study contributes to a greater understanding of the acquisition of phonological processes in L2 Spanish. Although the acquisition of spirantization of Spanish voiced stops /b, d, g/ (as in bebé /bebe/ [be.ˈβe̞]) by native-English speakers has been examined previously in the literature (e.g. Gonzalez-Bueno 1997, Face & Menke 2009 and Zampini 1994), the acquisition of other processes – or contextual variations – by L2 learners of Spanish has been largely ignored. Indeed, this is the first study that investigates the assimilatory process of /s/ voicing in L2 Spanish speech.

The following section (Section 2) begins with an overview of previous research on L2 acquisition of allophonic variation in Spanish and is followed by a description of sibilant voicing assimilation in Spanish as well as a depiction of the sibilants and assimilation patterns in English, the native language of the learners included in this study. A description of the methodology employed to address the research questions then follows in Section 3. Section 4 presents the results of the study and Section 5 a discussion of the findings. The final section of the paper offers the conclusions of the study. 2. Background 2.1 Acquisition of allophonic variation in L2 Spanish Studies within the field of second language Spanish phonology have explored the pronunciation of several Spanish sounds that cause potential difficulty to English-speaking learners. These include the production of Spanish voiceless stops /p t k/ (Diaz-Campos 2004, Diaz-Campos & Lazar 2003 and Gonzalez-Bueno 1997), the tap and trill /ɾ r/ (Face 2006, Reeder 1998, Rose 2010 and Waltmunson 2005), Spanish vowels (Menke & Face 2010), and the lateral /l/ and palatal nasal /ɲ/ (Diaz-Campos 2004).
While these studies reveal valuable information regarding the acquisition of the production of new (categorical) target language sounds, understanding of the acquisition of forms beyond the level of the segment – such as phonological processes (e.g. Zampini 1994 and Geeslin & Gudmestad 2011), stress (e.g. Carlson 2006), and intonation (e.g. Henriksen, Geeslin & Willis 2010) – is much more limited. Of particular interest has been the study of the acquisition of spirantization of Spanish voiced stops (e.g. Gonzalez-Bueno 1995, Diaz-Campos 2004, Face & Menke 2009, Shea & Curtin 2011 and Zampini 1994, 1997). This process is characterized by the production of a spirantized (or approximant) variant [β ̞ð ̞ɣ̞] rather than a stop [b d g] in certain phonetic contexts (e.g. intervocalically, as in lobo /lobo/ [ˈlo.βo̞]). Overall, these studies find that while the application of spirantization is limited at low levels of L2 Spanish (Gonzalez-Bueno 1995 and Zampini 1994), by advanced levels, graduating Spanish majors and Ph.D. students, L2 Spanish learners do show a tendency to produce the spirantized variant in the intervocalic context (Face & Menke 2009). Furthermore, changes in the phonetic cues used in producing [β ̞ð ̞ɣ̞] are found with increased experience, as well as sensitivity to gradient patterns of approximation (spirantization) (Shea & Curtin 2011).
Geeslin & Gudmestad (2011) have also explored L2 weakening of Spanish syllable- and word-final /s/ to aspiration or deletion (e.g. rostro /rostɾo/ [ˈroh.tɾo], [ˈro.tɾo]), a phonological process that is subject to geographic, social, and linguistic variation. The authors found acquisition of the L2 process with increased experience (i.e. level). In contrast to the spirantization studies described in the preceding paragraph, however, /s/-weakening was limited to the most advanced L2 speakers – primarily graduate students – and was totally absent at the lower levels. Additionally, even amongst those highly advanced L2 speakers (graduate students) who aspirated or deleted /s/ in their speech, the rates of the weakened variants were much lower than those of the spirantized forms produced by the graduate students in Face & Menke’s study (20-25% and 80%, respectively). However, as Geeslin & Gudmestad point out, the variable use of the weakened forms of /s/ by the L2 learners does

reflect native-like /s/-weakening, as this process is variably rather than categorically realized in Spanish. The current study aims to expand the study of phonological processes in L2 Spanish to investigate the acquisition of sibilant voicing assimilation, a process which is also subject to linguistic variation (i.e. is not categorical) but is most likely not as socially and geographically marked as /s/-weakening. The following section continues with a description of sibilant voicing assimilation in Spanish. 2.2 Contextual voicing effects: Spanish sibilant voicing assimilation The Spanish sibilant /s/ – like all Spanish stops and fricatives in syllable-final position – may undergo voicing when it precedes a voiced consonant (Quilis 1993). This regressive voicing assimilation occurs both word-internally (example 1) as well as in word-final position when followed by a word beginning with a voiced consonant (2) (Hualde 2005). Preceding a voiceless consonant (3) or a vowel (4), however, the sibilant is not voiced (with the exception of some limited dialects, e.g. Lipski 1989). Examples of the contextual variation of the voiced and voiceless variants of Spanish /s/ are presented in (1-4): (1) desdeñoso /desdeɲoso/ [dez.ðe.ˈɲo.so] (/s/ is voiced word internally) (2) los dedos /losdedos/ [loz.ˈðe.ðos] (/s/ is voiced word finally) (3) destinario /destinaɾio/ [des.ti.ˈna.ɾio̯] (/s/ is not voiced) (4) deseo /deseo/ [de.ˈse.o] (/s/ is not voiced) Regressive voicing assimilation of /s/ has been reported for many varieties across the Spanish-speaking world (e.g. Dykstra 1955, Obaid 1973 and Torreblanca 1978, 1986). However, voicing does not appear to occur categorically in the voicing context (Romero 1999 and Schmidt & Willis 2011). Romero (1999) finds that while voicing of /s/ before a voiced stop is greater than before a voiceless stop, the magnitude of laryngeal gestures in /s/ + voiced stop sequences (/sb sd sg/) is in fact less than in singleton voiced stops (/b d g/), indicative of non-categorical voicing. Likewise, Schmidt & Willis (2011) found voicing of /s/ in only two-thirds of the contexts where it is predicted to occur (i.e. preceding a voiced consonant) in a contextualized picture description task completed by speakers from Mexico City. Furthermore, they found a good deal of individual speaker variation in frequency of voicing of /s/, with some speakers voicing /s/ in the voicing context as infrequently as 21% of the time, while others realized voicing in all relevant contexts (100%). While voicing of /s/ is not affected by the position of the /sCvoiced/ cluster within the word (word internal vs. across word boundaries) (Romero 1999), position within the phrase may play a role in its variability, at least in Mexico City Spanish. Schmidt & Willis (2011) found a lesser presence of voicing in phrase-final position than phrase-internally for the Mexican female speakers – but not a significant effect for the males – suggesting a role of other linguistic and sociolinguistic factors in voicing assimilation. Further supporting this is the effect of the place of articulation of the following voiced stop that Romero observed in his data, with greater voicing of /s/ before labial stops than before dental or velar stops. 2.3 Voicing assimilation in English

Voicing assimilation of obstruents also occurs in English, the native language of the L2 learners tested in this study. However, English and Spanish differ in the direction of voicing assimilation. While Spanish is characterized by the regressive assimilation process described above, progressive assimilation of voice is the norm in English (Cuartero Torres 2001). In sequences of a voiceless obstruent (C1) followed by a voiced one (C2) in English, there is a tendency for C2 to be partially devoiced (example 5), both within words and across word boundaries. Moreover, in certain contexts (e.g. across morpheme boundaries with the plural –s, possessive –s, and third person singular –s suffixes), progressive voicing assimilation has been described in English as a more complete rather than partial process (example 6). (5) book bag [bʊk.bæ̥g] (/b/ is partially devoiced, progressive assimilation) (6) dogs [daʊgz] (/s/ is voiced, progressive assimilation) (7) cats [kæts] (/s/ remains voiceless)
Regressive assimilation of voice has also been reported for English; traditionally, however, regressive assimilation has been limited to a devoicing effect and not a voicing one. An English voiced obstruent (C1), when followed by a voiceless obstruent (C2), may undergo partial devoicing (example 8). Recent acoustic study of English obstruent clusters, however, also points to a regressive voicing effect in specific contexts (Jansen 2007). Jansen finds that the English velar stops /k, g/ (C1) increase in amount of voicing when they precede /z/ (C2) (9) (but not when they precede /d/ (C2), example 10).2 (8) bad taste [bæd.̥teɪst] (/d/ is partially devoiced, regressive assimilation) (9) patchwork zebra [ˈpætʃ.wɚk.ˈzi.bɹə̩] (greater amount of voicing of /k/,
regressive assimilation) (10)patchwork duvet [ˈpætʃ.wɚk.du.ˈvɛt] (no effect on amount of voicing of /k/)
Finally, in word-internal position preceding a voiced obstruent or sonorant, the English alveolar sibilant tends to be voiced, as in osmosis [ɒz.ˈmoʊ.sis] and wisdom [ˈwiz.dəm] (Jansen 2007, p. 274). This is not the case for non-alveolar fricatives [f θ ʃ] in the same position. All English fricatives, however, tend to be voiceless word internally when preceding a voiceless obstruent. Jansen argues that the voiced alveolar sibilant in the word-internal context should not be considered as an assimilation process, however, but rather as a consequence of a general, non-assimilatory one (see his discussion p. 274). 2.4 Predictions for regressive voicing assimilation in L2 learner speech To summarize, Spanish is characterized by regressive voicing assimilation whereby an obstruent assimilates in voice to a following obstruent, both within a word and across word boundaries, while the English norm is progressive voicing assimilation, with partial or total devoicing of a voiced obstruent that follows a voiceless obstruent. Regressive voicing assimilation is much more limited in English (see discussion above). As the nature and direction of voicing assimilation appears to be language-dependent to some extent and differs across the two languages, English-speaking learners of Spanish must learn to apply this voicing process in new phonetic contexts if they are moving towards a native target. Thus, as with other aspects of a new, L2 phonology, native-like production of /s/ voicing may be subject to

developmental stages and may not emerge until certain levels of proficiency and fluency, if at all. Moreover, several factors may influence the acquisition of Spanish sibilant voicing. First, the phonemic status of the voiced and voiceless sibilants is different in English and Spanish. While the voiceless and voiced variants are not contrastive in Spanish (i.e. they are allophonic variants of a single phonemic category, /s/), they do correspond to two distinct phonemes in English, rendering minimal pairs such as sack and Zack and price and prize. It is highlighted, however, that there are very few contexts in English where voiced and voiceless fricatives create a contrast (minimal or near-minimal pairs) in syllable-final position within the word (Jansen 2007). Second, there are differences between the grapheme-sound correspondences in the two languages. In those dialects of Spanish that do not weaken syllable-final /s/ (see below) both orthographic <s> and orthographic <z> are realized as the voiceless sibilant [s], except in syllable-final position where both may undergo voicing assimilation; this, with the exception of Castilian Spanish, which is characterized by the interdental fricative /θ/, corresponding to the graphemes <z>, <ce>, and <ci>. In English, on the other hand, the grapheme <z> corresponds to the voiced sibilant, while the grapheme <s> does not have a transparent grapheme-sound correspondence, but may be realized with different pronunciations, including [s z ʃ ʒ] (Hammond 2001). Influences of the L1 grapheme-sound correspondences on pronunciation in a L2 have been previously documented, such as the labiodental fricative pronunciation of /b/ for orthographic <v> by English-speaking learners of Spanish (e.g. Zampini 1994). Moreover, L2 learners may be taught that the [z] sound does not exist in Spanish and that it should be not be used in attempts to avoid transfer from the L1 of voiced intervocalic <s> (e.g. presidente) and of <z> (e.g. zebra).3
Finally, the variable nature of voicing in the context preceding a voiced consonant and the variety of other forms of the Spanish /s/ in the same position may delay acquisition of the voicing process by L2 learners. Spanish syllable-final /s/ frequently undergoes aspiration and deletion in many dialects of the Spanish-speaking world, resulting in other (non-sibilant) variants of /s/ in the input that L2 learners receive, with forms such as rasgo /rasgo/ [ˈrah.ɣ̞o] (with possible voicing of [h], e.g. Jiménez-Sabater 1975) or [ˈra.ɣ̞o]. In fact, Hammond (2001) reports that nearly 50% of the world’s Spanish speakers weaken syllable-final /s/; these regions include Andalucía, the Canary Islands, and the coastal and insular regions of Latin America. As such, frequency of voiced-/s/ ([z]) in the input may be quite low for L2 learners exposed primarily to /s/-weakening varieties of Spanish. Additionally, even in those varieties of Spanish that retain syllable-final /s/, voicing of the sibilant is variable rather than categorical. The variable occurrence of [z] in the input (even for those learners exposed to /s/-conserving dialects) may further hinder or delay the incorporation of voicing in the appropriate phonetic contexts by L2 learners. 2.5 Research questions
The review of the literature on the differences in the nature and direction of voicing assimilation in Spanish and English in addition to other phonological and orthographic complexities, together with the limited research on second language acquisition of allophonic variation in Spanish, lead to the following research questions:

1. Do advanced second language learners of Spanish realize regressive voicing assimilation of /s/ in their speech? Is there evidence of allophonic variation according to the phonetic context (i.e. voicing of the following consonant)?
2. How is voicing realized phonetically? What are the characteristics of the voiced and voiceless sibilant forms produced by the advanced L2 learners?
3. Methodology 3.1 Participants University students enrolled in the same fourth-year advanced Spanish linguistics course4 were recruited to complete a series of production tasks. Fifteen second language learners of Spanish, native speakers of English, participated in the study. The data from one of the fifteen learners was not included in the analysis due to poor quality of the recording. Of the final fourteen learners, eleven were female and three male. All learners had begun to take Spanish courses in either middle school or high school. At the university level, the learners had previously taken an average of four introductory literature, linguistics, culture, or language courses at the third-year level (following beginning and intermediate language courses; SD=0.832, range of 3-5) and an average of one advanced topics course at the fourth-year level in addition to the fourth-year course in which they were currently enrolled (SD=0.806, range of 0-2).
Although all the participants from this study were enrolled in the same Spanish course, they had varying amounts of previous courses taken at the university level and different linguistic experiences outside of the language classroom and as such cannot be thought of as a completely homogenous group. On a written language background questionnaire, the learners ranked themselves in proficiency in Spanish in reading, writing, listening, speaking, and pronunciation on an eight-point scale.5 The self-identified proficiency rankings varied from high intermediate to advanced; one outlying learner identified herself as near-native for several skills (1F). Most, however, ranked themselves at an advanced level. As self-rating is not necessarily a reliable measure of L2 proficiency, however, the learners were additionally assigned foreign accent ratings by two native speaker judges (university language instructors, one from Argentina and one from Colombia) on a scale of 1 (strong foreign accent) to 7 (native accent), based on two sentences spoken by each learner taken from the reading task. Four native speaker voices were also heard by the raters to encourage full use of the scale and to provide a comparison. The average rating for the group of learners was 4.67 (of 7) and 6.75 for the native speaker group. Foreign accent ratings ranged from 3.75 (learner 8F) to 6 (learner 1F). Foreign accent ratings are reported in the presentation of individual results in Section 4.3 (see Table 6).
Most of the L2 learners in the group (N=10) had previously participated in a study abroad program in a Spanish-speaking country. Overwhelmingly Spain (Madrid, Salamanca, Leon) was the most frequented region (N=9); few participants had (additional) experience in Argentina (N=1) and/or Mexico (N=2). Of those who had been abroad, approximately half spent 1½ to 2 months abroad and the other half 4 to 9 months abroad. The average duration of time abroad was approximately 3 months (M=2.8 months, SD=2.65). It is important to note that the majority of the L2 learners had spent time in a /s/-conserving dialectal region (i.e. syllable-final /s/ is not weakened to aspiration or deletion, see Section 2.4), and thus should have been exposed to /s/-voicing in that context. Finally, only one of the fourteen participants had previously taken a Spanish phonetics course; this was the same participant who

ranked herself as near-native (participant 1F). In addition, 4 participants reported intermediate or advanced proficiency in one or more of the following languages:6 Portuguese (intermediate: 1F, 2M; high intermediate: 6F), French (high intermediate: 7F), Dutch (intermediate: 1F), Japanese (advanced: 1F). 3.2 Data elicitation The data was recorded by the author in a linguistics laboratory7 at a large public Midwestern university in April 2008 using a Shure WH20 head-mounted microphone and a Sony MZ-RH1 Hi-MD minidisc recorder. The recordings were then digitally transferred as wav files to a laptop computer and were analyzed with Praat software (Boersma & Weenik 2008). The informants completed two production tasks, which were similar to those reported in Schmidt & Willis (2011) in a study of native speaker voicing assimilation. Each participant was recorded individually and completed each of the tasks one time. The first task completed was a contextualized picture-description task presented in a PowerPoint presentation, followed by a 200-word story reading task. These were followed by a written language background questionnaire, which elicited information regarding the language(s) spoken by the informant, self-rated proficiency in different language skills in Spanish, experiences abroad in Spanish-speaking regions, and interactions with other Spanish-speaking contacts in the United States. The participants also ranked three statements regarding attitudes and motivations towards speaking Spanish and interacting with native Spanish speakers on a ten-point scale. The current analysis considers only the data elicited from the contextualized picture-description task and the language background questionnaire. 3.3 Contextualized picture-description task The picture-description task was designed in order to elicit semi-directed continuous speech in the form of phrase-long utterances. Through the use of this task, the same contexts were elicited across participants in a more natural way than a simple reading task. The picture-description task, administered via PowerPoint, used pictures to present scenes on individual slides of a street market vendor in an imaginary market place, the Mercado Santiago, with one of their wares for sale. The task was created for the purpose of the research study. Before beginning the descriptions in the Mercado, participants first completed a training session in which they were familiarized with the pictures and vocabulary items used in the second part of the task. In the training session (vocabulary naming practice), participants saw pictures of the objects on individual PowerPoint slides along with two or three letters of the beginning of the targeted words so as to encourage the participants to produce the desired lexical items.
The second half of the task presented individual slides that contained vendor names and pictures as well as images of the objects that the vendor sold. For each slide, the informants were asked to state the vendor’s name, what he or she sold, and the number of said objects (for example, Ernesto vende tres vestidos). The names of the vendors and the objects were chosen specifically to present both word-internal and word-final contexts of /s/ followed by voiced and voiceless consonants. The vendors’ names (but not the names of the objects being sold) were presented visually on the slides. Each name was presented two times throughout the task while each object was seen only once8. The participants were given five seconds per slide to

report on the vendor’s stall before automatically advancing to encourage a consistent speech rate. There were a total of 54 slides, and thus 54 elicitations of the phrase “Name vende number object”. The informants were offered a short optional break approximately halfway through the task. The picture-description task (including the training session) took on average ten minutes to complete, while the entire experiment (including the short reading task and background questionnaire) was completed in approximately twenty-five to thirty minutes.
There were a total of 95 possible tokens of /s/ preceding a voiced or voiceless consonant per participant, provided the speaker produced all of the elicited names and objects in the production task. Two phonetic contexts where Spanish /s/-voicing occurs were included: (1) word-internal /s/ preceding a voiced consonant and (2) word-final /s/ preceding a voiced consonant. A third context, (3) word-internal /s/ preceding a voiceless consonant, was also targeted in the task as a control context. Although an attempt was made to include all following voiced consonant types both word internally and word finally, word-internal contexts preceding a voiced consonant were limited to nasals, the voiced bilabial stop, and the lateral liquid. There were also far fewer tokens for the word-internal voicing context than the word-final context. This is due to the low occurrence of Spanish lexical items with word-internal /s/ preceding other voiced consonant types and to the restriction of the task to lexical items that could be represented by images and sold in a market. In addition to these targeted contexts, a total of 53 tokens that did not present the phonetic context of /s.C/ were included in the task as distractors (N=18 vendor names, N=35 objects).
Finally, 10 of the original 95 possible tokens were excluded from the analysis after the data recording. These ten tokens represent two productions each of five vendor names (Esmeralda, Israel, Ismael, Osvaldo, Mercedes), cognates in English that may be realized with a voiced sibilant [z] in the native language (English). As such, the motivation for producing a voiced sibilant in these contexts is not clear (i.e. application of the Spanish voicing process or production of a form from the L1?). Table 1 presents the distribution of token types according to the phonetic context for the final 85 tokens (see Appendix A for the complete list of contexts elicited).
Word Position
Phonetic Context
Following Segment Examples N
internal /VsCvoiceless/ /p t k/ discos, postres, Ernesto 17
internal /VsCvoiced/ /b l m n/ isla, cisne 8
final /VsCvoiced/ /b d g ʝ w l m n r/ dos botas, tres lunas, Dolores vende 60
Total 85 Table 1. Contexts elicited in the picture-description task 3.4 Data analysis For each of the fourteen participants, all tokens of word-internal and word-final /s/ preceding a voiced or voiceless consonant were extracted from the larger speech sample elicited, for a total of 985 tokens. Using Praat software (Boersma & Weenik 2008, version 5.0.27) for acoustic analysis, measurements of the duration of voiced sibilance and of voiceless sibilance were made for each token, as well as the duration

of the total /s/ segment. Location of voiced sibilance was also noted for tokens with partial voicing (left-edge, right-edge, both left- and right-edge).
The analysis of the L2 leaner data followed the procedure described in Schmidt & Willis (2011) for native Spanish speaker sibilant voicing (see the original paper for a detailed description). The sibilant segment was defined by the visual presence in the spectrogram of strong high-frequency frication, around 8000 to 9000 Hertz. Voicing was determined by the presence of (1) visible regular glottal pulses in the voice bar and (2) regular periodic patterns in the waveform. A percentage voiced was calculated for each token, by dividing the duration of voiced sibilance by the total duration of the sibilant segment.
Initially, tokens of /s/ with 60-100% of the segment voiced were categorized as voiced [z] and those with less than 60% voicing as voiceless [s]. This was done in order to compare the results of the L2 learner group with those of the native Mexican speakers reported in Schmidt and Willis. An anonymous reviewer points out that comparison of L2 speakers with a monolingual population of the target language (and to a variety to which the L2 group did not necessarily have a good deal of exposure) results in unrealistic expectations for the L2 learner group (see Hopp & Schmid 2011). However, comparison with the monolingual Mexican control group is made in this preliminary study – with this limitation in mind – due to the dearth of empirical data available on voicing of /s/ in monolingual and bilingual Spanish varieties.
The tokens were additionally coded according to a second set of categories that distinguished five types of voicing: no voicing (0%), initial voicing (1-33%), partial voicing (34-66%),9 majority voicing (67-99%), and total voicing (100%). These categories were chosen as they recognize varying degrees of voicing. Each token of /s/ was also coded according to (a) voicing of the following consonant (voiced vs. voiceless), (b) position within the word (internal vs. final), (c) token (lexical item), and (c) participant. In order to test for the presence of contextual variation in voicing of /s/ by the L2 learners, the voiceless consonant context was used as a control with which to compare patterns of voicing in the voicing context (before a voiced consonant). If there is a voicing assimilation effect, the L2 learners should exhibit a greater degree of voicing of /s/ (i.e. greater percentage voiced) before a voiced consonant than before a voiceless one. Statistical analyses were conducted with percentage voicing and duration of voiced sibilance as the dependent variables in order to determine if there were significant group or individual differences in voicing according to the phonetic context. Pearson product-moment correlations and univariate general linear models with Bonferroni adjustments for multiple comparisons were conducted and are further discussed in the following section. It is stressed that the dependent variables included in the analyses were the gradient data (i.e. percentage voiced and duration of voiced sibilance) – not the categorical data (i.e. categories of voicing). This was done in order to capture the truly gradient nature of the voicing and to avoid influences of arbitrary categorization (see Abdelli-Beruh 2011 for a discussion of the problems in arbitrarily partitioning voicing distributions in studies of French voicing assimilation).

4. Results 4.1 Distribution of voiced and voiceless variants of /s/ The results section begins with the distribution of voiced [z] and voiceless [s] variants observed in the speech of the L2 speakers as compared with that distribution reported for a similar task completed by Mexican informants in Schmidt & Willis (2011) (see discussion in Section 3.4 regarding comparison with this monolingual group).10 The 60% voicing percentage cut-off was used to define the voiced variant [z] in order to compare with the results from Schmidt & Willis. While both the L2 learners and native speakers overwhelmingly produced a voiceless variant [s] preceding a voiceless consonant, the two groups pattern differently in the voiced consonant context (see Table 2). The majority (63.3%) of the tokens of /s/ preceding a voiced consonant were voiced [z] by the Mexican group, while only 5.6% of the tokens of /s/ in this same context were voiced variants for the L2 group. A general linear model with percentage of tokens voiced as the dependent variable revealed a significant interaction between speaker group (L2 vs. Mexican) and context (following voiceless consonant vs. voiced consonant), F(1, 24) = 52.990, p < .001. Unsurprisingly, results from Bonferroni post-hoc comparisons revealed a significant difference between the two speaker groups in percentage of tokens voiced for the voiced consonant context only, p < .001.
Context Variant L2 Speakers Mexican Speakers+
/VsCvoiceless/ [s] 99.5% (212) 94.7% (177) [z] 0.5% (1) 5.4% (10)
/VsCvoiced/ [s] 94.4% (729) 36.7% (61) [z] 5.6% (43) 63.3% (105)
Table 2. Frequency percentage of voiced and voiceless variants according to the context (N tokens). +Mexican data from Schmidt & Willis (2011: 7) 4.2 Phonetic description of L2 Spanish /s/ The distribution of voicing percentages for the two phonetic contexts is presented for the L2 group as a histogram in Figure 2. The distribution of voicing percentages is similar for the two phonetic contexts, with the data clustering around the lower end of the range of percentages for both the voiceless and the voiced consonant contexts. The two distributions differ, however, in that – few as they may be – there are cases with voicing up to 100% of the segment in the voiced consonant context but not in the voiceless consonant context.

Figure 1. Distribution of L2 tokens (in frequency percent) according to the percentage voiced for each phonetic context
What is striking in Figure 1 is that most of the productions of /s/, regardless of context, had some degree of voicing (i.e. were not totally voiceless). Only 9.9% and 3.6% of the variants of /s/ preceding a voiceless consonant or a voiced consonant, respectively, were totally voiceless (0% voiced). Overwhelmingly the most frequent realization of /s/ – for either phonetic context – was voicing extending up to one-third of the duration of the segment. This was the case for 89.2% (N=190) of the contexts preceding a voiceless consonant and for 88.1% (N=680) of the contexts preceding a voiced consonant. Figure 2 is an example of this most frequent pattern of a short period of voicing into frication. An initial period of voicing at the left-edge of the sibilant segment (v+) is followed by an extended period of voiceless sibilance (v-) in the coda /s/ of Francisco. This initial period of voicing seems to be a coarticulatory effect of preservative voicing from the preceding vowel, and was also observed in monolingual Spanish as well by Schmidt and Willis (2011; see discussion in Section 5.2).

Figure 2 . Example of initial voicing into frication in /VsCvoiceless/ context, Francisco, learner 5M While the majority of the cases of /s/ are characterized by an initial period of voicing extending up to one-third of the duration of the segment, there are also cases of voicing extending up to two-thirds of the duration of the segment (N=21) and cases of total, or 100%, voicing (N=43). These partially and totally voiced variants make up 2.7% and 5.6% of the data, respectively, in the context preceding a voiced consonant; they are practically nonexistent in the voiceless consonant context. The following (Figure 3) is an example of a case of total voicing by the same L2 speaker in the voicing context dos nubes. The /s/ segment is voiced throughout (v+), as can be observed from the regular periodic patterns in the waveform and glottal pulses in the voice bar.

Figure 3. Example of total voicing in the /VsCvoiced/ context, dos nubes, learner 5M It is recalled that the voicing percentage is calculated by dividing the total duration of voiced sibilance by the duration of the segment, regardless of where voicing occurs in the segment. The question remains, thus, as to where voicing occurs in those tokens that have some degree of (but not total) voicing. As observed in Table 3, voicing of /s/ overwhelmingly occurs at the left-edge of segment. Only 16 cases of right-edge voicing were observed in the L2 data and always preceding a voiced consonant. Moreover, these cases were predominantly characterized by voicing at both edges with a period of voiceless sibilance in the middle of the segment. Appendix B is an example of this latter voicing type. The average duration of voiced sibilance found at the right-edge of the /s/ segment was 9.7 ms (SD=5.544).
Left-edge Voicing Right-edge Voicing Left- and Right-edge Voicing
VsCvoiceless/ 191 (100%) - - /VsCvoiced/ 685 (97.7%) 2 (0.3%) 14 (2.0%)
Total 876 2 14 Table 3. Location of voicing for tokens with some degree of voicing (N=892)
As described in Section 3.4, the data was further categorized into five voicing categories in order to further explore the phonetic characteristics of the variants of /s/ according to degree of voicing. Descriptive statistics for the total duration of the segment, the duration of voicing, and the percentage voiced are reported in Table 4 across the five voicing categories. The /sCvoiceless/ and /sCvoiced/ contexts are reported

together as the patterns were similar across the two contexts. As there were no cases of voicing of 67-99% of the segment, this category is omitted from the table.
Voicing Category N Statistic Total Duration Duration of
Voicing % Voiced
no voicing (0%) 49
M 103.0 ms .0 ms 0.00% SD 61.64 0.00 0.00
Range 40.7-394.7 ms - -
initial voicing (1-33%)
870 M 112.5 ms 10.5 ms 11.10% SD 69.10 4.90 6.12
Range 17.8-886.2 ms 2.1-37.5 ms 1.0-33.2%
partial voicing
(34-66%) 22
M 70.0 ms 31.2 ms 45.7% SD 26.38 10.38 7.41
Range 38.6-134.6 ms 19.0-51.1 ms 34.2-64.4%
total voicing (100%)
44
M 61.3 ms 61.3 ms 100.00% SD 19.91 19.91 0.00
Range 28.6-140.5 ms 28.6-140.5 ms -
Table 4. Descriptive statistics according to voicing category
Several phonetic differences according to degree of voicing are found. First, those variants with less voicing (no voicing, initial voicing) are longer on average in their total duration of the segment than those variants with more voicing (partial voicing, total voicing). The average total duration of the sibilant segment was 103 ms and 113 ms for those cases with no voicing or initial voicing, respectively, and only 70 ms and 61 ms for those variants with partial or total voicing. A Pearson product-moment correlation was used to determine whether there was a significant relationship between voicing of /s/ (voicing percentage, 0-100%) and duration of the segment. Indeed, a significant negative correlation was found, r(985) = -.287, p < .001.
Second, although there is some overlap in the range of duration of voicing between all categories with some degree of voicing, duration of voicing extends farther for the partially voiced cases (range = 19-51 ms) than the initially voiced ones (2-38 ms), and most so for the totally voiced cases (29-141 ms). Not surprisingly, a large positive correlation between duration of voiced sibilance and degree of voicing (voicing percentage, 0-100%) was found, r(985) = .899, p < .001.
Finally, the results for phonetic characteristics of the L2 variants are compared to those reported for the native Mexican speakers in Schmidt & Willis (2011). The average duration of voicing for those [s] variants (as defined by < 60% voicing) in the /sCvoiced/ context was 15 ms, or 22% of the segment, for the Mexican speakers. The Mexican [z] variants had on average 60 ms of voicing, or an average of 99.6% of the segment. Considering the same context (/sCvoiced/)and categorization (60% cut-off) for the L2 group, the average duration of voicing of the L2 [s] variants was 11 ms, or 11% of the segment, and 61 ms, or 100% of the segment, for the [z] variants.

4.3 Contextual variation in individual L2 speech The objective of the study was to determine whether advanced L2 learners of Spanish exhibit contextual variation of /s/ in their speech. The results reported in Section 4.1 reveal that voicing assimilation of the sibilant is certainly not present in the learner group to the degree that it is in a native speaker comparison group. However, select cases of partial and total voicing before a voiced consonant are observed in the learner data (Figure 2). We turn now to determine whether a contextual effect is still present, albeit to a much smaller degree than that observed for the native speaker group. In Table 5 the total duration of the segment, the average duration of voiced sibilance, and the percentage voiced is reported according to the voicing of the following consonant and the position within the word. It is recalled that the voiceless consonant context was limited to word-internal position (e.g. postre), while the voiced consonant context included both word-internal (isla) and word-final positions (dos botas).
Context Position N Total Duration Duration of Voicing % Voiced
/VsCvoiceless/ internal 213 92.8 ms (31.71) 9.2 ms (5.67) 10.8% (9.17)
/VsCvoiced/
internal 55 88.2 ms (31.23)*
11.9 ms (12.08)
15.6% (21.23)
final 717 115.1 ms (76.02)*
13.9 ms (14.25)
16.6% (22.07)
total 772 113.2 ms (74.04)
13.7 ms (14.11)
16.5% (22.00)
Table 5. Descriptive statistics for each phonetic context for L2 group, N=985 tokens (SD) *Significant difference in total duration of /s/ according to word position, /VsCvoiced/ context The percentage voiced and the duration of voicing appears to be greater in the context preceding a voiced consonant – both word-internally and word-finally – than preceding a voiceless consonant. However, as addressed later in this section, this contextual voicing effect is limited to specific individual L2 speakers. Furthermore, while total duration of the /s/ segment before a voiced consonant was significantly longer in word-final than word-internal position (F(1, 770) = 6.786, p = .009), no significant differences were found in the voicing percentage or in raw duration of voiced sibilance according to word position. Thus, the results for the word-internal and word-final /sCvoiced/ context are considered together throughout the paper, all the while recognizing that the longer average total duration of /s/ before a voiced consonant than before a voiceless one is an effect of word position and not of voicing. Different patterns in voicing according to context are observed across the individual L2 speaker data in Table 6. For the /sCvoiceless/ context, individuals range in average duration of voiced sibilance between 7-14 ms and 7%-21% in voicing percentage. Indeed, the majority of the L2 learners also falls within these same

ranges in the /sCvoiced/ context and thus do not display a difference in voicing according to phonetic context. However, some select L2 speakers pattern differently and exhibit a greater duration of voiced sibilance and a greater voicing percentage in the appropriate voicing context.
Speaker /VsCvoiceless/ /VsCvoiced/
Code
Foreign Accent Rating
(max. 7)
Mean Total
Duration (ms)
Mean Duration Voicing
(ms)
Mean %
Voiced
Mean Total
Duration (ms)
Mean Duration Voicing
(ms)
Mean %
Voiced
1F* 6 85 10 13% 100 20 28% 2M* 5.5 78 14 21% 87 21 35% 3F 4 119 7 7% 141 10 10%
4F* 4 82 7 8% 76 13 19% 5M* 5.5 97 12 13% 122 38 45% 6F 5.5 75 6 8% 115 8 7% 7F 4.75 99 8 8% 96 12 15% 8F 3.75 79 11 15% 88 14 19% 9F 4.5 128 10 8% 170 10 8%
10F 3.75 116 7 6% 149 8 8% 11M 3.25 88 9 11% 112 7 7% 12F 5.75 100 9 10% 123 10 10% 13F 4.75 85 9 10% 108 10 10% 14F 4.25 84 10 12% 135 12 11%
Total 4.7 (avg.) 93 9 11% 113 14 17% Table 6. Descriptive statistics according to L2 participant and phonetic context, N=985 tokens *Significant difference in percentage voiced according to phonetic context A univariate general linear model was tested using SPSS software with percentage voiced (0-100%) as the dependent variable and voicing of the following consonant (voiceless, voiced) and participant (N=14) as factors in the model. The model revealed significant effects of the following consonant, F(1, 957) = 17.784, p < .001, and of participant, F(13, 957) = 7.781, p < .001, as well as a significant interaction between the two factors, F(13, 957) = 3.299 p < .001. Results from Bonferroni post-hoc comparisons revealed a significant effect of the following consonant on the percentage voiced only for participants 1F (p = .002), 2M (p = .007), 4F (p = .030), and 5M (p < .001). All other comparisons were not significant. An effect of phonetic context and individual participant was also tested in the same way for the raw duration of voiced sibilance (ms). The univariate general model was the same as that described above but with duration of voiced sibilance as the dependent variable. Significant effects were found for the following consonant, F(1, 957) = 29.003, p < .001, participant, F(13, 957) = 8.681, p < .001, and an interaction

between the two factors, F(13, 957) = 4.047, p < .001. Bonferroni post hoc comparisons revealed significant differences in duration of voiced sibilance according to phonetic context for participants 1F (p = .001), 2M (p = .033), and 5M (p < .001); however, this difference was not significant at the α = .05 level for participant 4F (p = .057). In consideration of the individual differences observed amongst the fourteen L2 speakers included in the study, Pearson product-moment correlations were run between (a) percentage voiced and duration of voiced sibilance (ms) for the /sCvoiced/ context and (b) accent rating to determine if there was a relationship between voicing of /s/ and the foreign accent rating assigned each L2 speaker by the native judges (see Section 3.1). Positive correlations approaching significance were found for both comparisons. In general, the greater the average percentage voiced of /s/ in the /sCvoiced/ context, the higher the accent rating assigned (i.e. more native sounding), r(14) = .482, p =. 08. Likewise, the greater the average duration of voiced sibilance (ms), the higher the accent rating (more native sounding), r(14) = .481, p = .08. Finally, to conclude the results section, the frequency count of voiceless [s] and voiced [z] variants in the context preceding a voiced consonant are presented in Table 7 according to individual L2 learner. The number of tokens varied across individual participants as not all possible lexical items (tokens) were produced by all participants; learner 3F in particular frequently did not complete the entire elicited phrase, perhaps due to unfamiliarity with the vocabulary. Schmidt & Willis (2011) categorization cut-off is again used here in order to allow comparison with the individual Mexican speaker patterns reported in their study (see Section 3.4). Six L2 learners did not produce a single token of [z] and are not included in the table (6F, 9F, 10F, 11M, 12F, 14F). The most prolific voicing effect is found in learner 5M’s speech, who voices /s/ in the /sCvoiced/ context 34% of the time. He is followed in frequency of voicing by learners 1F and 2M, who voice /s/ in 16.7% and 14% of the relevant contexts, respectively. Five additional learners produced at least one token of [z] before a voiced consonant.
Allophonic Variant L2 Participant
5M 1F 2M 4F 8F 13F 3F 7F
[s] (voicing % < 60%)
33 (66%)
50 (83%)
49 (86%)
60 (95%)
54 (96%)
66 (98%)
43 (98%)
62 (98%)
[z] (voicing % ≥ 60%)
17 (34%)
10 (17%)
8 (14%)
3 (5%)
2 (4%)
1 (2%)
1 (2%)
1 (2%)
Total 50 60 57 63 56 67 44 63
Table 7. Frequency count of voiceless and voiced tokens in the /VsCvoiced/ context, according to individual L2 learner (percentage of contexts voiceless or voiced) Additionally, there were cases of partial voicing of /s/ before a voiced consonant, with voicing extending up to two-thirds of the segment (N=22). While in these cases the percentage of /s/ voiced did not form the majority of the segment and did not

make the 60% voicing cut-off, it did exceed the range of percentage voiced in the control context, preceding a voiceless consonant. Interestingly, one individual speaker (2M) seemed to account for many of these cases (11 of the 22 tokens). 5. Discussion 5.1 Regressive voicing assimilation in L2 Spanish 5.1.1 Contextual variation in advanced learner speech In comparing the advanced group of L2 learners with the Mexican speakers reported in Schmidt & Willis (2011), it is found that this group of learners – although already at a level appropriate for a 4th year (undergraduate) advanced Spanish topics course – is far from approximating the native voicing pattern. Both the L2 group and the Mexican group almost categorically realize the voiceless form [s] before a voiceless consonant. However, while the Mexican group displays a tendency for voicing [z] before a voiced consonant (in 63% of the cases), the L2 group shows an opposite pattern with the overwhelming majority of productions in this context being voiceless [s] (94%). Evidence is not found, thus, for productive regressive voicing assimilation of syllable-final /s/ in the speech of this group of advanced learners of Spanish; the L2 group overwhelmingly produces a voiceless sibilant regardless of the voicing of the following consonant. This is somewhat surprising as L2 learners of Spanish at comparable levels have been found to produce the allophonic spirantized variants in appropriate contexts (see Section 2.1). It is recalled that even at much lower levels (2nd and 4th semester), spirantized forms of /b d g/ were observed to some degree in the speech of the L2 learners (Face & Menke 2009, Zampini 1994), and even as much as half of the time (Gonzalez-Bueno 1995). Why would L2 Spanish learners by a 4th year advanced level produce the spirantized variants of /b d g/ but not the voiced variant of /s/? As discussed previously in Section 2.3, there are several factors that may hinder regressive voicing assimilation of /s/ in the speech of the English-speaking learners of Spanish. These include: (a) the opposite direction of voicing assimilation in English and Spanish, (b) differences in grapheme-sound correspondences in the two languages, (c) the phonemic (contrastive) nature of [s] and [z] in English as opposed to their allophonic status in Spanish, and (d) the variable nature of sibilant voicing found in native speaker speech. While any and all of these factors may contribute to hinder or delay acquisition of voicing assimilation, specific attention is brought to the latter two.
The allophonic status of [s] and [z] in Spanish may contribute to the paucity of voicing assimilation in the advanced L2 learner group’s speech. As there is no functional importance of the voiced and voiceless forms of syllable-final /s/ in Spanish, whether the L2 learner voices /s/ before a voiced consonant or not will never lead to miscommunications or misunderstandings. The same, indeed, may be said of the spirants; the spirant [β ̞ð ̞ɣ̞] and occlusive [b d g] forms of the voiced stops are also allophonic and not contrastive. However, while producing an occlusive variant in the spirantization context (e.g. in intervocalic position) does not lead to a difference in meaning, it may sound particularly non-native-like as the spirantization process more consistently (frequently) applies in native speech. Future research might test whether stop production where spirants are expected as opposed to voiceless variants of /s/ in the voicing context have different effects on perception of a foreign or non-native accent (see discussion below on foreign accent ratings).

Moreover, the contrastive (i.e. phonemic) importance of the voiced sibilant /z/ in the L1 may further contribute to its limited presence as an allophonic variant of syllable-final /s/ in the advanced L2 speech. L2 learners may be less willing to produce the voiced form as for them it could potentially create a difference in meaning. Indeed, Zampini (1994) claims such an effect of the contrastive status of sounds in the L1 on production of those sounds as allophones in the L2. The 2nd and 4th semester English-speaking learners of Spanish produced fewer spirantized forms of /d/ than of /b g/, which Zampini suggests is due to the fact that [ð] (but not [β]̞ or [ɣ̞]) is phonemic in the L1 (e.g. then / ðen/ vs. den /den/).11 This pattern, however, appears to change somewhat with increased proficiency level, as Face & Menke (2009) found, for example, that graduating Spanish majors and Ph.D. students (but not 4th semester students) produce [ɣ̞] least frequently (while [β]̞ is still produced most frequently).
The variable nature of sibilant voicing in the input may also play an important role in hindering its acquisition, both because [z] is less frequent in the input and because of its complexity of occurrence. First, depending on the varieties of Spanish to which the L2 learners are exposed (i.e. conservative vs. weakening varieties spoken by language instructors, regions of travel and study abroad), it is unclear how frequently the voiced variants appear in the input. It is interesting to note, however, that the majority of the participants in the current study had been exposed to /s/-voicing to some extent as most had experience studying or traveling in /s/-conserving regions (see Section 3.1). Second, even in those varieties that conserve (and thus voice) syllable-final /s/, voicing is variable and appears to be subject to different linguistic (Campos-Astorkiza 2010), stylistic (Torreblanca 1978, 1986), and social factors (Schmidt & Willis 2011). Spanish voicing of /s/ is gradient, resulting in partial or total voicing of the sibilant, and it is not yet clear whether voicing is coupled with a durational difference of the preceding vowel, which is an acoustic cue in the English /Vs/ - /Vz/ distinction (e.g. Hogan & Rozsypal 1980 and Raphael 1972). Moreover, voicing of the sibilant occurs in syllable-final position while spirantization of the voiced stops frequently occurs in intervocalic position, and previous literature has suggested greater perceptual salience of sounds in intervocalic than in syllable-final position (e.g. Bradley & Delforge 2006). As such, it is possible that the syllable-final voiced-/s/ is not very perceptually salient to English-speaking learners. If the learners do not perceive a difference between (the variably occurring) [ˈtʃis.me] ~ [ˈtʃiz.me] (chisme /tʃisme/), for instance, they may not, in turn, come to produce a voiced form of /s/ in this context.
Further support for this idea of an important effect of the variable voicing in the input is that the results found here for L2 voicing assimilation seem to more similarly pattern with those of L2 /s/ aspiration and deletion (Geeslin & Gudmestad 2011). The /s/-weakening process is likewise variably occurring in the input, as it is limited to certain geographic and social groups, and even within these groups variably occurs with other weakened and conserved forms. Geeslin and Gudmestad found that production of weakened variants of /s/ was infrequent and did not appear until the most advanced levels, graduate students of Spanish and one 4th year undergraduate student. The variability in the input and the complexity of occurrence may possibly make acquisition of these second language processes a more challenging task for the L2 learner.

5.1.2 Individual patterns of voicing While as a group, the L2 learners in this study did not productively voice /s/ in the appropriate voicing context (preceding a voiced consonant), an analysis of the individual L2 learner patterns found that voicing was indeed present in the speech of some individuals. By comparing the percentage of voicing of /s/ according to the voicing of the following consonant for each individual, a contextual voicing effect (i.e. greater percentage of voicing before a voiced consonant) was revealed for 4 of the 14 learners. For the remaining 10 learners in the group, however, there was no significant difference in voicing of the sibilant according to the voicing of the following consonant. The rates of voiced tokens in the voicing context (as defined by Schmidt & Willis’ 60% voicing cut-off based on patterns in their Mexican corpus) varied across the 4 learners who did show a voicing effect. The L2 learner with the most productions of the voiced variant (learner 5M) voiced the sibilant in approximately one-third of the appropriate voicing contexts; he was the only participant to fall within the distribution of rates of voicing reported for the individual Mexican speakers. Participants 1F and 2M produced the voiced variant in 17% and 14% of the relevant voicing contexts, respectively, and participant 4F, who did not show a significant effect of phonetic context on voicing in terms of the raw duration of voiced sibilance but did have a significant effect according to voicing percentage, realized [z] in only 5% of the relevant contexts. Why do individual L2 learners enrolled in the same advanced topics Spanish linguistics course vary in the incorporation of (or lack of) sibilant voicing assimilation in their speech? First, although these participants were enrolled in the same course, they do not necessarily make up a homogenous group. Due to the nature of the language program, some students may have already taken several other advanced Spanish topics courses prior to this one, while others may have entered directly from the basic introductory 3rd year course that serves as the course prerequisite. Thus, students may vary in the number of semesters of university-level study of Spanish, not to mention in types and durations of experiences with Spanish outside of the classroom (see Section 3.1).
From a comparison of the information provided from each of the participants in the written Language Background Questionnaire, it is not overwhelmingly clear what characteristics of the backgrounds of these four individuals might differentiate them from the rest of the group. This is due in part to the relatively small number of participants (N=14) and to incomplete responses provided by some of the participants to some of the questions on the questionnaire. Nonetheless, that some of the L2 learners in this advanced group voiced /s/ in the phonetic context where regressive voicing assimilation is predicted in Spanish suggests that more native-like patterns of voicing may emerge amongst more proficient L2 speakers, or L2 speakers with greater experience with Spanish. Future research is needed to determine if L2 learners of Spanish do voice the sibilant in the voicing context as they have increased experience in the target language. Additionally, by incorporating a larger population of L2 learner participants with different experiences and exposure types to Spanish, studies may shed light on what factors contribute to the acquisition of the contextual variation of the [s] and [z] allophonic variants in L2 speech (e.g. learner or linguistic factors). What is striking, however, is that a positive correlation – although approaching significance – was observed between voicing of /s/ and foreign accent rating. In

general, greater frequency of voicing of /s/ (greater average percentage voiced, greater mean duration of voiced sibilance) correlated with higher foreign accent ratings (i.e. more native-sounding ratings). It is not clear, however, if incorporating the sibilant voicing process in one’s speech is directly responsible for a more native-sounding accent. Sibilant voicing could be a reflection of more fluent, connected speech in general, leading to higher ratings, or it could be the case that if the L2 speaker incorporates this phonological process in his or her speech, he or she has also acquired other features and processes that lead to the perception of more native-like speech. Furthermore, not all individual L2 leaners who received high accent ratings demonstrated voicing of /s/ in the appropriate context (e.g. learners 6F and 12F). While this interesting relationship between /s/ voicing and accent rating emerges in the present study, future research is needed to further explore these individual differences and to determine which features (or combination of features) in L2 speech lead to the perception of a more native-like accent. 5.2 Phonetic characterization of L2 Spanish sibilants Finally, the second research question asks how the voiced and voiceless variants of the Spanish sibilant are phonetically realized by the advanced L2 learner group. From an acoustic analysis of the learner productions of [s], a strong tendency was observed for some degree of initial voicing of the sibilant segment by the advanced English-speaking learners of Spanish, regardless of the voicing of the following consonant. Total voicelessness of the sibilant (i.e. 0% voicing) was limited to only 10% and 4% of the data in the contexts preceding a voiceless consonant and a voiced consonant, respectively. Rather, the most frequent production of /s/ was initial (left-edge) voicing extending up to one-third of the segment, and accounting for 89% of the data preceding a voiceless consonant and 88% preceding a voiced consonant. Schmidt & Willis (2011) also found a period of initial voicing in the Mexican speaker corpus, with an average of 14 ms of voicing (21% of the segment) in voiceless realizations of syllable-final /s/ (including /VsV/, /VsCvoiced/, and /VsCvoiceless/ contexts). They attributed this initial period of voicing to a “co-articulatory effect of vocalic preservative voicing into the sibilance” (p. 16). Continuation of voicing from a preceding vocalic element into the following consonant constriction is reported for other languages, including English (Stevens, Blumstein, Glicksman, Burton & Kurowski 1992), the native language of the L2 learners in the present study. In the context preceding a voiced consonant, there were cases of partial voicing (34-66% of the segment voiced) and total voicing (100% of the segment voiced); these cases were found principally in the speech of the four L2 learners who displayed a contextual effect. Interestingly, there were no cases of voicing extending 67-99% of the segment. If voicing extended past two-thirds of the segment it continued throughout the entire duration of the /s/. However, due to the few cases of voicing observed in the current L2 learner database, future studies should determine if this finding is a systematic pattern or simply characteristic of this small number of participants and the few cases of voicing amongst them.
Those variants of the sibilant with a greater degree of voicing (partially and totally voiced) were shorter in total duration of the segment than those variants that were primarily voiceless. This follows the durational differences for fricatives according to voicing reported for many languages, including English and Spanish (e.g. Klatt 1976 and Schmidt & Willis 2011). As the voiced variants are shorter in

total duration than the voiceless variants, it is possible that what appears to be an increase in voicing (i.e. greater voicing percentage) is actually simply an effect of a smaller denominator (voicing % = duration voiced sibilance / total duration of sibilance). However, an increase in the raw duration of voiced sibilance was also found as percentage voicing increased. For example, those cases with initial voicing (up to one-third of the segment) had on average 11 ms of voicing, while those totally voiced cases were characterized by an average of 61 ms of voiced sibilance. As such, the greater voicing percentage is not due simply to a shorter total duration of the segment, but rather is indeed reflective of an increased duration of voiced frication.
The location of voicing within the segment and the effect of position within the word were also explored for the L2 data. With respect to the location of voicing within the segment, in the majority of cases voicing occurred at the left-edge of the sibilant. There were only two cases of voicing solely at the right-edge and fourteen cases of voicing on both edges with a period of voiceless sibilance in the middle of the segment; all such cases occurred in the /sCvoiced/ context. Right-edge voicing was also very infrequent in the Mexico City corpus (Schmidt & Willis 2011). Thus, what appears to most differentiate voicing in the two phonetic contexts lies in how far vocalic preservative voicing extends into the fricative segment, with greater continuation of left-edge voicing in the /sCvoiced/ context. Finally, no effect of position within the word on voicing of /s/ was observed for the L2 group. The duration of voiced sibilance and the voicing percentage were similar for both the word-internal context (e.g. chisme) and the word-final context (e.g. dos mesas). In this respect the L2 group – or, rather, those few individual speakers in whose speech cases of voicing assimilation were observed – patterns in a native-like manner. Romero (1999) likewise found no difference in native Spanish voicing according to environment (within the word vs. across word boundaries). The limited number of contexts of /s/ followed by a voiced consonant in word-internal position in the current study (see Section 3.3), however, warrants further study to replicate this finding. Future study should also investigate whether specific following voiced consonants elicit L2 voicing of /s/ to a greater degree than others (it is recalled that Romero found more voicing of /s/ before /b/ than /d/ or /g/). In order to explore this effect, a greater number of tokens of word-internal and word-final /s/ preceding all possible Spanish voiced and voiceless consonants is needed. While this was not possible for the current study, the contextualized picture-description task (see discussion on task limitations in Section 3.3), a more balanced token set could be elicited using other task types, such as a reading task (however, with the caveat that such a task could potentially lead to samples of less “natural” speech, and certainly a different speech style). 6. Conclusions This study offers a preliminary investigation of the production of contextual allophonic variation of the voiced and voiceless variants of Spanish /s/ by English-speaking learners of Spanish as a second language. Through the use of a contextualized picture-description task, specific contexts of /s/ followed by a voiceless or a voiced consonant were elicited, but in a more naturalistic speech style than a reading task, for example. While regressive voicing assimilation was not observed in the speech of the majority of L2 learners at this level, four individual speakers did demonstrate differences in voicing according to the phonetic context,

although only one of these four fell within the frequency range of voicing reported previously for native speakers from Mexico. A phonetic analysis of the L2 productions of Spanish /s/ revealed several similarities between native and L2 realizations of the sibilant: voicing of /s/ was found to be gradient with both partial and total voicing, the voiced variants were shorter in total duration than the voiceless forms, and even for those cases of voiceless /s/, there was an initial period of voicing which extended up to one-third of the sibilant segment. Furthermore, voicing of /s/ – when it did occur – was found both word-internally and across word boundaries. The phonetic characterization of the variants of /s/ was included with the intention of providing a descriptive baseline and method for future large-scale study of voicing assimilation in L2 Spanish that includes cross-sectional or longitudinal data in order to identify patterns of acquisition of the allophonic variants. Future work is also required to determine what linguistic (e.g. speech rate, continuity of speech, manner of articulation of following consonant) and learner factors (e.g. type and degree of experience with Spanish, role of phonetics training) are involved in acquisition of this variable assimilation process. Acknowledgments I would like to thank Kimberly Geeslin, Erik Willis, Kara McBride, and two anonymous reviewers for their comments and feedback on earlier versions of this paper. Notes 1 Gow & Im (2004) claim that listeners make use of universal perceptual
processes rather than language-specific mechanisms, based on their results from a series of experiments testing native and non-native monitoring of Hungarian and Korean segments in different assimilation and non-assimilation contexts. See, however, the response from Darcy, Ramus, Christophe, Kinzler & Dupoux (2009, pp. 296-297) which accounts for the seemingly contradictory results in Gow & Im (2004).
2 While the amount of voicing of the preceding velar stop did not increase before /d/, there was an effect on F1, which Jansen also interprets as an assimilatory effect.
3 In fact, in earlier editions of their textbook on Spanish phonetics and phonology, Schwegler and colleagues recommend that beginning English-speaking learners first attempt to pronounce all sibilant sounds as the voiceless [s] and to never produce the voiced [z] form (e.g. Schwegler & Kempff 2007, p. 274).
4 An anonymous reviewer points out that as the participants had a knowledge of linguistics, they may see through the purpose of the study and adjust their speech accordingly. However, this does not seem to be the case here due to the nature of the task, as several participants commented after completing the experiment that they believed the study was measuring vocabulary knowledge.
5 The eight categories were: beginner, low intermediate, intermediate, high intermediate, advanced, high advanced, near-native, native. No specific definition or explanation of each of the proficiency categories was given to the participants.
6 It is noted that regressive voicing assimilation is also characteristic of several of the additional L2s reported: Portuguese (e.g., Mateus & d’Andrade 2000),

French (e.g., Snoeren, Halle & Segui 2006), and Dutch (in specific contexts, see, for example, Grijzenhout & Kramer 2000).
7 The linguistics laboratory was not a sound-proof facility. However, any external noise was minimal and did not affect the quality of the recordings or the data analysis.
8 Vendor names were repeated twice in the task as the number of relevant tokens was more limited due to the more restricted lexical category (proper names), as compared with the market objects, for example.
9 In this L2 data set, there were no tokens with 61-66% voicing; thus the distribution of tokens with the majority or totally voiced happened to be the same for both coding schemes.
10 The Mexican speakers completed a modified version of the same contextualized picture-description task; however, the Mexican data reported in Schmidt & Willis is limited to word-internal contexts only and also included some additional lexical items that were not part of the task completed by the L2 learners in the current study.
11 An anonymous reviewer points out, however, that as the English phoneme /ð/ is a voiced interdental fricative while the most frequent spirantized variant of Spanish /d/ is in fact an approximant realization (not a fricative one), said effect of the contrastive status of [ð] in the L1 may not be relevant in this case.
Appendix A List of tokens elicited in the contextualized picture-description task (five contexts excluded from the analysis) ____________________________________________________________________ Word-internal Word-final / VsCvoiced / / VsCvoiceless / / VsCvoiced / beisbol discos dos barcos dos mascaras seis manzanas tres rocas bisnietos espejo dos bebidas dos mesas seis narices tres vestidos chisme mácaras dos bisnietos dos monos seis nueces cisne moscas dos botas dos nubes seis vasos Andres vende esmalte pescados dos delfines dos ratones tres ballenas Carlos vende fantasma postres dos dulces dos refrescos tres discos Dolores vende isla refrescos dos globos dos rosas tres gorras Ines vende rosbif revistas dos hierbas jugadores de tres libros Luis vende (Esmeralda) vestidos dos huellas las gafas tres limones Marcos vende (Ismael) Cristina tres hielos los labios tres lunas (Mercedes vende) (Israel) Ernesto tres huesos seis dientes tres moscas Milagros vende (Osvaldo) Francisco dos lápices seis gatos tres naranjas Nicolás vende
Oscar dos mangos seis llaves tres ranas Tomas vende ____________________________________________________________________
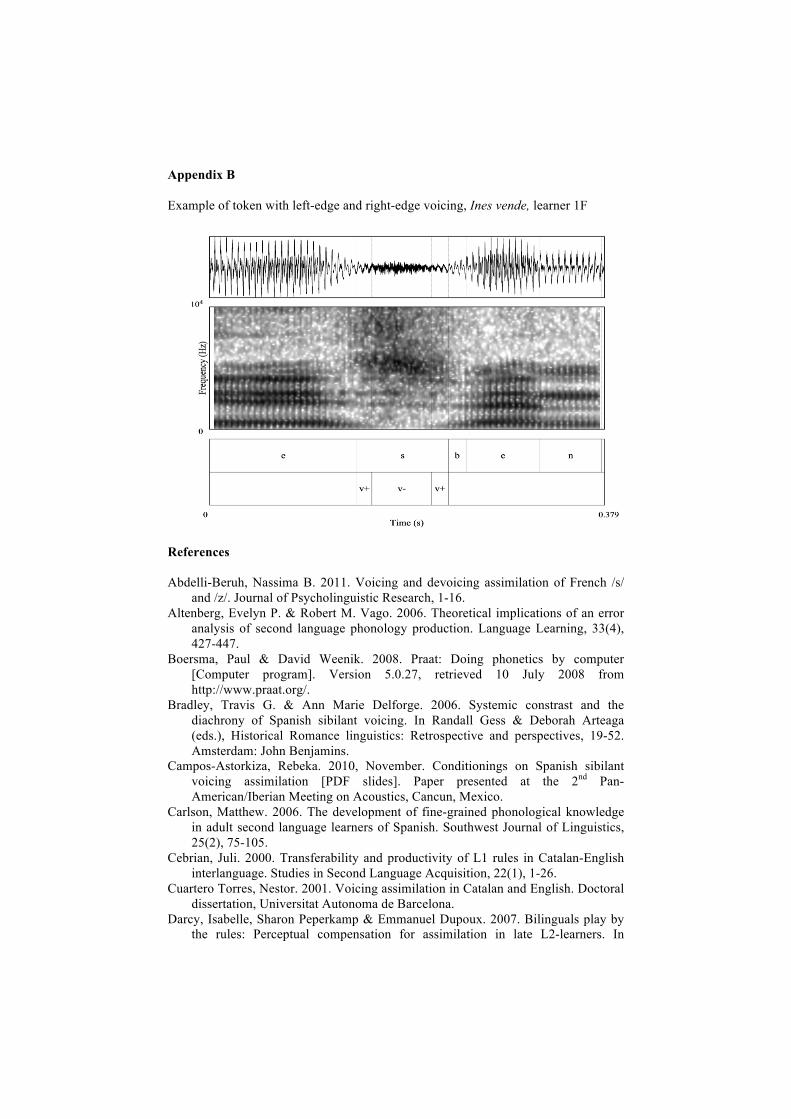
Appendix B Example of token with left-edge and right-edge voicing, Ines vende, learner 1F
References Abdelli-Beruh, Nassima B. 2011. Voicing and devoicing assimilation of French /s/
and /z/. Journal of Psycholinguistic Research, 1-16. Altenberg, Evelyn P. & Robert M. Vago. 2006. Theoretical implications of an error
analysis of second language phonology production. Language Learning, 33(4), 427-447.
Boersma, Paul & David Weenik. 2008. Praat: Doing phonetics by computer [Computer program]. Version 5.0.27, retrieved 10 July 2008 from http://www.praat.org/.
Bradley, Travis G. & Ann Marie Delforge. 2006. Systemic constrast and the diachrony of Spanish sibilant voicing. In Randall Gess & Deborah Arteaga (eds.), Historical Romance linguistics: Retrospective and perspectives, 19-52. Amsterdam: John Benjamins.
Campos-Astorkiza, Rebeka. 2010, November. Conditionings on Spanish sibilant voicing assimilation [PDF slides]. Paper presented at the 2nd Pan-American/Iberian Meeting on Acoustics, Cancun, Mexico.
Carlson, Matthew. 2006. The development of fine-grained phonological knowledge in adult second language learners of Spanish. Southwest Journal of Linguistics, 25(2), 75-105.
Cebrian, Juli. 2000. Transferability and productivity of L1 rules in Catalan-English interlanguage. Studies in Second Language Acquisition, 22(1), 1-26.
Cuartero Torres, Nestor. 2001. Voicing assimilation in Catalan and English. Doctoral dissertation, Universitat Autonoma de Barcelona.
Darcy, Isabelle, Sharon Peperkamp & Emmanuel Dupoux. 2007. Bilinguals play by the rules: Perceptual compensation for assimilation in late L2-learners. In

Jennifer S. Cole & Jose Ignacio Hualde (eds.), Laboratory phonology 9, 411-442. Berlin: Mouton de Gruyter.
Darcy, Isabelle, Franck Ramus, Anne Christophe, Katherin Kinzler & Emmanuel Dupoux. 2009. Phonological knowledge in compensation for native and non-native assimilation. In Frank Kugler, Caroline Fery & Ruben van de Vijver (eds.), Variation and gradience in phonetics and phonology, 265-309. Berlin, New York: Mouton de Gruyter.
Gow, David W. & Aaron M. Im. 2004. A cross-lingusitic examination of assimilation context effects. Journal of Memory and Language, 51, 279-296.
Díaz-Campos, Manuel. 2004. Context of learning in the acquisition of Spanish second language phonology. Studies in Second Language Acquisition, 26(2), 249-273.
Díaz-Campos, Manuel & Nicole Lazar. 2003. Acoustic analysis of voiceless initial stops in the speech of study abroad and regular class students: Context of learning as a variable in Spanish second language acquisition. In Paula Kempchinsky & Carlos-Eduardo Piñeros (eds.), Theory, practice, and acquisition: Papers from the 6th Hispanic Linguistics Symposium and the 5th Conference on the Acquisition of Spanish and Portuguese, 352-370. Somerville, MA: Cascadilla.
Dykstra, Gerald. 1955. Spectrographic analysis of Spanish sibilants and its relation to Navarro’s physiological phonetic descriptions. Doctoral dissertation, University of Michigan.
Ellis, Lucy & William J. Hardcastle. 2002. Categorical and gradient properties of assimilation in alveolar to velar sequences: Evidence from EPG and EMA data. Journal of Phonetics, 30, 373-396.
Face, Timothy. 2006. Intervocalic rhotic pronunciation by adult learners of Spanish as a second language. In Carol Klee & Timothy Face (eds.), Selected proceedings of the 7th Conference on the Acquisition of Spanish and Portuguese as First and Second Languages, 47-58. Somerville, MA: Cascadilla.
Face, Timothy L. & Mandy R. Menke. 2009. Acquisition of the Spanish voiced spirants by second language learners. In Joseph Collentine, Maryellen Garcia, Barbara Lafford & Francisco Marcos Marin (eds.), Selected proceedings of the 11th Hispanic Linguistics Symposium, 39-52. Somerville, MA: Cascadilla Proceedings Project.
Geeslin, Kimberly L. & Aarnes Gudmestad. 2011. The acquisition of variation in second-language Spanish: An agenda for integrating studies of the L2 sound system. Journal of Applied Linguistics, 5(2), 137-157.
González-Bueno, Manuela. 1995. The acquisition of fricative allophones of Spanish voiced stops for learners of Spanish as a second language. Estudios de Linguistica Aplicada, 13(21-22), 64-79.
González-Bueno, Manuela. 1997. The effects of formal instruction on the acquisition of Spanish stop consonants. In W. Glass & A.T. Pérez-Leroux (eds.), Contemporary perspectives on the acquisition of Spanish, vol. 2: Production, processing, and comprehension, 57-75. Somerville, MA: Cascadilla Press.
Gow, David W. 2001. Assimilation and anticipation in continuous spoken word recognition. Journal of Memory and Language, 45, 133-159.
Gow, David W. & Aaron M. Im. 2004. A cross-linguistic examination of assimilation context effects. Journal of Memory and Language, 51, 279-296.
Grijzenhout, Janet & Martin Kramer. 2000. Final devoicing and voicing assimilation in Dutch derivation and cliticization. In Barbara Stiebels & Dieter Wunderlich (eds.), Lexicon in focus, 55-82. Berlin: Akademie Verlag.

Hammond, Robert M. 2001. The sounds of Spanish. Somerville, MA: Cascadilla Press.
Henriksen, Nicholas C., Kimberly L. Geeslin & Erik W. Willis. 2010. The development of L2 Spanish intonation during a study abroad immersion program in Leon, Spain: Global contours and final boundary movements. Studies in Hispanic and Lusophone Linguistics, 3(1), 113-162.
Hogan, John T. & Anton J. Rozsypal. 1980. Evaluation of vowel duration as a cue to the voicing distinction in the following word-final consonant. The Journal of the Acoustical Society of America, 67(5), 1764–1771.
Hopp, Holger & Monika S. Schmid. 2011. Perceived foreign accent in first language attrition and second language acquisition: The impact of age of acquisition and bilingualism. Applied Psycholinguistics, 34(2), 361-394.
Hualde, Jose Ignacio. 2005. The sounds of Spanish. New York: Cambridge University Press.
Jansen, Wouter. 2007. Phonological ‘voicing’, phonetic voicing, and assimilation in English. Language Sciences, 29, 270-293.
Jiménez-Sabater, Maximilano. 1975. Más datos sobre el español de la Republica Dominicana. Santo Domingo: Ediciones Intec.
Klatt, Dennis H. 1976. The linguistic uses of segmental duration in English: Acoustic and perceptual evidence. Journal of the Acoustical Society of America, 59, 1208-1221.
Kochetov, Alexei & Connie K. So. 2007. Place assimilation and phonetic grounding: A cross-linguist perceptual study. Phonology, 24, 397-432.
Lipski, John. 1989. /s/-voicing in Ecuadoran Spanish: Patterns and principles of consonantal modification. Lingua, 79(1), 49-71.
Obaid, Antonio. 1973. The vagaries of the Spanish ‘s’. Hispania, 56(1), 60-67. Mahmood, Arshad. 2007. Assimilation: A fluency tool. NUML Research Magazine,
1, 87-102. Mateus, Maria Helena & Ernesto d’Andrade. 2000. The phonology of Portuguese.
Oxford: Oxford University Press. Menke, Mandy R. & Timothy L. Face. 2010. Second language Spanish vowel
production: An acoustic analysis. Studies in Hispanic and Lusophone Linguistics, 3(1), 181-213.
Quilis, Antonio & Joseph A. Fernández. 1985. Curso de fonética y fonología españolas: para estudiantes angloamericanos. Madrid: Consejo Superior de Investigaciones Científicas.
Raphael, Lawrence J. 1972. Preceding vowel duration as a cue to the perception of the voicing characteristic of word-final consonants in American English. The Journal of the Acoustical Society of America, 51(4), 1296-1303.
Reeder, Jeffrey T. 1998. English speakers’ acquisition of voiceless stops and trills in L2 Spanish. Texas Papers in Foreign Language Education, 3, 101-118.
Romero, Joaquin. 1999. The effect of voicing assimilation on gestural coordination. Proceedings of the 14th International Congress of Phonetic Sciences, 1793-1796. San Francisco, California.
Rose, Marda. 2010. Intervocalic tap and trill production in the acquisition of Spanish as a second language. Studies in Hispanic and Lusophone Linguistics, 3(2), 379-417.
Schmidt, Lauren B. & Erik W. Willis. 2011. Systematic investigation of voicing assimilation of Spanish /s/ in Mexico City. In Scott M. Alvord (ed.), Selected proceedings of the 5th Conference on Laboratory Approaches to Romance Phonology, 1-20. Somerville, MA: Cascadilla Proceedings Project.

Schwegler, Armin & Juergen Kempff. 2007. Fonética y fonología españolas, 3rd edition. Hoboken, NJ: Wiley.
Schwegler, Armin, Juergen Kempff & Ana Amael-Guerra. 2010. Fonética y fonología españolas, 4th edition. Hoboken, NJ: Wiley.
Shea, Christine E. & Suzanne Curtin. 2011. Experience, representations, and the production of second language allophones. Second Language Research, 27(2), 229-250.
Snoeren, Natalie D., Pierre A. Halle & Juan Segui. 2006. A voice for the voiceless: Production and perception of assimilated stops in French. Journal of Phonetics, 34, 2, 241-268.
Stevens, Kenneth N., Sheila E. Blumstein, Laura Glicksman, Martha Burton & Kathleen Kurowski. 1992. Acoustic and perceptual characteristics of voicing in fricatives and fricative clusters. The Journal of the Acoustical Society of America, 91(5), 2979-3000.
Torreblanca, Máximo. 1978. El fonema /s/ en la lengua española. Hispania, 61(3), 498-503.
Torreblanca, Máximo. 1986. Prevocalic voiced s in modern Spanish. Thesaurus, 41(1-3), 59-69.
Waltmunson, Jeremy C. 2005. The relative degree of difficulty of L2 Spanish /d, t/, trill, and tap by L1 English speakers: Auditory and acoustic methods of defining pronunciation accuracy. Doctoral dissertation, University of Washington.
Weber, Andrea. 2001. Help or hindrance: How violation of different assimilation rules affects spoken-language processing. Language and Speech, 44(1), 95-118.
Zampini, Mary. 1994. The role of native language transfer and task formality in the acquisition of Spanish spirantization. Hispania, 77(3), 470-481.
Zampini, Mary. 1997. L2 Spanish spirantization, prosodic domains, and interlanguage rules. In S. J. Hannahs & Martha Young-Scholten (eds.), Focus on phonological acquisition, 209-234. Amsterdam: John Benjamins.
Zsiga, Elizabeth C. 2003. Articulatory timing in a second language. Studies in Second Language Acquisition, 25, 399-432.
Zsiga, Elizabeth C. & Hyouk-Keun Kim. 2005. What transfers? Word integrity and assimilation in Korean-English interlanguage. Proceedings of the annual Boston University conference on language development, 29(2), 674-685.




















