
Functional characterization of the cell polarity proteins ...
Upload
khangminh22Category
view
0download
0
Computing Sentiment Polarity of Texts at Document and Aspect Levels 67
Computing Sentiment Polarity of Texts atDocument and Aspect Levels
Vivek Kumar Singh1 , Rajesh Piryani2 ,
Pranav Waila3 , and Madhavi Devaraj4 , Non-members
ABSTRACT
This paper presents our experimental work on twoaspects of sentiment analysis. First, we evaluate theperformance of different machine learning as well aslexicon based methods for sentiment analysis of textsobtained from variety of sources. Our performanceevaluation results are on six different datasets of dif-ferent kinds, including movie reviews, blog posts andtwitter feeds. To the best of our knowledge no suchwork on comprehensive evaluative account involvingdifferent techniques on variety of datasets have beenreported earlier. The second major work that we re-port here is about the heuristic based scheme thatwe devised for aspect-level sentiment profile genera-tion of movies. Our algorithmic formulation parsesthe user reviews for a movie and generates a sen-timent polarity profile of the movie based on opin-ion expressed on various aspects in the user reviews.The results obtained for the aspect-level computa-tion are also compared with the corresponding re-sults obtained from the document-level approach. Insummary, the paper makes two important contribu-tions: (a) it presents a detailed evaluative account ofboth supervised and unsupervised algorithmic formu-lations on six datasets of different varieties, and (b)it proposes a new heuristic based aspect-level senti-ment computation approach for movie reviews, whichresults in a more focused and useful sentiment profilefor the movies.
Keywords: Aspect-oriented Sentiment, Document-level Sentiment, Opinion Mining, Sentiment Analysis,SentiWordNet.
1. INTRODUCTION
Sentiment analysis is language processing task thatuses an algorithmic formulation to identify opinion-ated content and categorize it as having ‘positive’,‘negative’ or ‘neutral’ polarity. It has been formally
Manuscript received on August 31, 2013.Final manuscript received March 31, 2013.1,2 The authors are with Department of Computer Sci-
ence, South Asian University, New Delhi, India, E-mail:[email protected] and [email protected] The author is with DST-CIMS, Banaras Hindu University,
Varanasi, India, E-mail: [email protected] The author is with Department of Computer Science &
Engineering, Gautam Buddha Technical University, Lucknow,India, E-mail: [email protected]
defined as an approach that works on a quintuple<Oi, Fij, Skijl, Hk, Tl>; where, Oi is the target ob-ject, Fij is a feature of the object Oi, Skijl is thesentiment polarity (+ve, -ve or neutral) of opinionof holder k on jth feature of object i at time l, andTl is the time when the opinion is expressed [1]. Itcan be clearly inferred from this definition that senti-ment analysis involves a number of tasks ranging fromidentifying whether the target carries an opinion ornot and if it carries an opinion then to classify theopinion as having ‘positive’ or ‘negative’ polarity. Inthis paper, we have restricted our discussion to com-puting sentiment polarity only and have purposefullyexcluded the subjectivity analysis.
The sentiment analysis task may be done at differ-ent levels, document-level, sentence-level or aspect-level. The document-level sentiment analysis prob-lem is essentially as follows: given a set of documentsD, a sentiment analysis algorithm classifies each doc-ument d ϵ D into one of the two classes ‘positive’or ‘negative’. Positive label denotes that the docu-ment d expresses an overall positive opinion and neg-ative label means that d expresses an overall negativeopinion of the user. Sometimes degree of positivityor negativity is also computed. The document-levelsentiment analysis assumes that each document con-tains opinion of user about a single object. If thedocument contains opinions about multiple objectswithin the same document, the sentiment analysis re-sults may be inaccurate. The aspect-level sentimentanalysis on the other hand assumes that a documentcontains opinion about multiple aspects/ entities ofone or more objects in a document. It is thereforenecessary to identify about which entity an opinionis directed at. The phrases and sentence structuresare usually parsed by using knowledge of linguisticsfor this purpose.
There are broadly two kinds of approaches for sen-timent analysis: those based on machine learningclassifiers and those based on lexicon. The machinelearning classifiers for sentiment analysis are usuallya kind of supervised machine learning paradigm thatuses training on labelled data before they can be ap-plied to the actual sentiment classification task. Inthe past, varieties of machine learning classifiers havebeen used for sentiment analysis, such as nave bayes,support vector machine and maximum entropy clas-sifiers. The lexicon-based methods usually employ a

68 ECTI TRANSACTIONS ON COMPUTER AND INFORMATION TECHNOLOGY VOL.8, NO.1 May 2014
sentiment dictionary for computing sentiment polar-ity of a text. Another kind of effort for sentimentanalysis includes the SO-PMI-IR algorithm, which isa purely unsupervised approach, which uses the mu-tual occurrence frequency of selected words on theWorld Wide Web (hereafter referred to as Web) inorder to compute the sentiment polarity.
Sentiment analysis is now a very useful task acrossa wide variety of domains. Whether it is commercialexploitation by organizations for identifying customerattitudes/ opinions about products/ services, or iden-tifying the election prospect of political candidates;sentiment analysis finds its applications. The usercreated information is of immense potential to com-panies which try to know the feedback about theirproducts or services. This feedback helps them intaking informed decisions. In addition to being use-ful for companies, the reviews are helpful for generalusers as well. For example, reviews about hotels in acity may help a user visiting that city in locating agood hotel. Similarly, movie reviews help other usersin deciding whether the movie is worth watch or not.However, the large number of reviews becomes in-formation overload in absence of automated methodsfor computing their sentiment polarities. Sentimentanalysis fills this gap by producing a sentiment profilefrom large number of user reviews about a product orservice. The new transformed user-centric, participa-tive Web allows extremely large number of users toexpress themselves on the Web about virtually end-less topics. People now write reviews about movies,products, services; write blogs to express their opin-ion about different socio-political events; and expresstheir immediate emotions in short texts on Twitter.The social media is now a major phenomenon on theWeb and a large volume of the content so created isunstructured textual data. It is this reason why sen-timent analysis has become an important task in textanalytics with lots of applications.
The rest of the paper is organized as follows.Section 2 describes the popularly used document-level sentiment analysis approaches based on ma-chine learning classifiers (such as naive bayes andsupport vector machine) and algorithmic formulationbased on the SentiWordNet library. The section 3describes the dataset used, performance metrics com-puted and experimental setup for document-level sen-timent analysis task. Section 4 presents the experi-mental results of document-level sentiment analysison different datasets. The section 5 describes our al-gorithmic design for aspect-level sentiment profilingand the corresponding experimental results. The pa-per concludes with a summary of the contribution ofthis work stated in Section 6.
2. DOCUMENT-LEVEL SENTIMENT ANAL-YSIS
Sentiment analysis at document-level has been ex-plored in many past works. Pang Lee et al. in theirwork reported in 2002 [2] and 2004 [3] applied navebayes, support vector machine and maximum entropyclassifiers for document-level sentiment analysis ofmovie reviews. In a later work reported in 2005 [4],they have applied support vector machine, regressionand metric labeling for assigning sentiment of a docu-ment using a 3 or 4-point scale. Gamon in a publishedwork in 2004 [5] used support vector machine to as-sign sentiment of a document using a 4-point scale.Dave et al. in their work reported in 2003 [6] usedscoring, smoothing, nave bayes, maximum entropyand support vector machine for assigning sentimentto documents. Kim and Hovy in a work reported in2004 [7] used a probabilistic method for assigning sen-timent to expressions. Turney in the work reportedin 2002 [8], [9] used the unsupervised SO-PMI-IR al-gorithm for sentiment analysis of movie and travelreviews. Bikel et al. in their work in 2007[10] imple-mented subsequence kernel based voted perceptronand compared its performance with standard supportvector machine. Durant and Smith [11] tried senti-ment analysis of political weblogs; Sebastiani [12] andEsuli & Sebastiani[13] worked towards gloss analysisand proposed the SentiWordNet approach for sen-timent analysis. Many other important works havebeen reported on sentiment analysis at document-level. However, we did not aim to present a detailedsurvey on sentiment analysis, which can be foundin some recent works [14] and [15]. Here, our aimis largely to compares the performance of machinelearning classifier based approaches vis-a-vis unsuper-vised SentiWordNet based approaches for sentimentanalysis of diverse textual data. We briefly describethe three important approaches we compared in thefollowing paragraphs.
2.1 Nave Bayes Algorithm
It is supervised probabilistic machine learning clas-sifier that can be used to classify textual documents.The sentiment analysis problem using nave bayes(NB) classifier can be visualized as text classificationproblem of two classes, those with ‘positive’ polar-ity and those with ‘negative’ polarity. Every doc-ument is thus assigned to one of these two classes.The main concern that needs to be addressed whileusing naıve bayes classifier for sentiment analysis iswhether all terms occurring in documents should beused as features as it done in normal text classifica-tion or to select specific terms which may be in moreconcrete forms of expression of opinions. We haveused full term profile based on result reported in [2]and [3] that accuracy of classification improves if allfrequently occurring words are considered rather thanonly adjectives. Once the feature selection is done,

Computing Sentiment Polarity of Texts at Document and Aspect Levels 69
the actual classification task is a simple probabilisticestimate based on term occurrence profiles. In navebayes classifier, the probability of document d beingin class c is computed as:
P (c|d) ∝ P (c)∏
1≤k≤nd
P (tk|c) (1)
where, the term P(c) refer to prior probability of adocument occurring in class c and corresponds to themajority class. The expression P (tk/c) is the condi-tional probability of a term tk occurring in a docu-ment of class c. The term P(tk/c) is interpreted to bethe measure of how much evidence the term tk con-tributes that c is correct class. The main idea in thisclassification is to classify the document based on sta-tistical pattern of occurrence of terms. The objectivein text classification using nave bayes is to determinethe best class for a document. The best class in navebayes classification is the maximum posteriori (MAP)class which can be computed as:
cmap = argmaxcϵC
P (c|d) = argmaxcϵC
P (c)∏
1≤k≤nd
P (tk|c)
(2)where, P indicates estimated value found from thetraining set. The multiplication of many conditionalprobability terms can be reduced by adding loga-rithms of probabilities. Therefore, equation (2) canbe written as:
cmap = argmaxcϵC
logP (c) +∑
1≤k≤nd
logP (tk|c)
(3)
In equation (3) each P(tk/c) term refer to the weightwhich specify how good an indicator the term tk is forclass c, and in similar way the prior log P(c) indicatesthe relative frequency of class c. The nave bayes ap-proach has two variants: the multinomial nave bayesand the Bernuoulli’s nave bayes [16]. We have imple-mented the multinomial nave bayes which takes intoaccount the term occurrence frequencies as opposedto only measuring term presence in the Bernoulli’snave bayes scheme. We have used only Unigram re-sults for comparison of different methods across thedatasets.
2.2 Support Vector Machine Algorithm
Support Vector Machine (SVM) is another well-known and wide margin machine learning based clas-sifier. It is vector space model based classifier thatneeds feature vectors transformed into numerical val-ues before it can be used for classification. Usuallythe text documents are converted to a multidimen-sional tf.idf vector. Now, the whole problem is toclassify each text document represented by the fea-ture vectors in specific classes. Here, the main idea
is to find a decision vector/surface that is maximallyaway from any data point (document vectors in ourcase). The margin of the classifier can be found outthrough distance from the decision surface to the clos-est data point. The target is to maximize this margin.Suppose D = xi,yi) represents the training set datapoints, where each element refers to pair of point xiand a class label yi corresponding to it. The two dataclasses are always named as +1 and -1 and supportvector machine as such is a linear classifier two-classclassifier [16]. Then linear classifier is:
f(x) = sign(wTx+ b) (4)
The value of -1 represent one class and value of+1 represents the other class. The reduction prob-lem that attempts to determine w and b such that(a) 1/2w
Tw is minimized, and (b) for all {(xi, yi)},yi(w
Txi + b) >= 1. This represents the quadraticoptimization problem that can be solved by meansof standard quadratic programming libraries. In thesolution, a lagrange multiplier αi is related with eachconstant yi(w
Txi + b) >= 1. The goal is then to findα1, α2, . . . αN such that:∑
αi
−1
2
∑i
∑jαiαjyiyjx
Ti xj (5)
is maximized subject to constraints Σiαiyi = 0 andαi >= 0 for all 1 <= i <= N . The solution is of theform:
w =∑
αiyixi
b = yk − wTxkfor any such xk s.t. αk = 0 (6)
The classification function thus becomes:
f(x) = sign(∑
αiyixTi x+ b
)(7)
In the solution, most of the αi are zero. Each non-zero αi indicates that the corresponding xi is a sup-port vector. In our experimental implementation,for solving the quadratic optimization problem, weused Sequential Minimal Optimizer (SMO) availablein weka[17]. Through SMO the quadratic program-ming problem splits into numerous small problems,solving these problems sequentially gives the sameanswer as solving the big quadratic convex problem.The support vector machine is used for sentimentanalysis at document-level as it is essentially a two-class linear classifier. For feature vectors, we haveused the entire vocabulary of the documents withoutany bias for selected words such as those having POStag as adjectives.
2.3 SentiWordNet based Approach
The third algorithmic approach we implemented isan unsupervised lexicon based method based on theSentiWordNet library [12], [13]. A sentiment analysis

70 ECTI TRANSACTIONS ON COMPUTER AND INFORMATION TECHNOLOGY VOL.8, NO.1 May 2014
approach using this library parses the term profile ofa textual review document, extracts terms having de-sired POS tags, compute their sentiment orientationvalues from the library and then aggregates all suchvalues to assign either ‘positive’ or ‘negative’ label tothe whole document. These approaches usually tar-get terms with a specific POS tag, which are believedto be opinion carriers (such as adjectives, adverbs orverbs). Thus subjecting the review text to a POStagger becomes a prerequisite step for applying theSentiWordNet based approaches. After doing POStagging, words with appropriate POS tag labels areselected and the SentiWordNet library is looked intofor their sentiment polarity scores. Usually the termshaving ‘positive’ sentiment orientation, have polar-ity values greater than zero. Terms having ‘negative’sentiment orientation, have polarity value less thanzero. In the past, researchers have explored usingwords with POS tags adjectives, adjectives precededby adverbs and verbs etc. The polarity scores forall extracted terms in a review document are thenaggregated using some aggregation formula and theresultant score is used to decide whether the docu-ment should be labeled as having ‘positive’ or ‘nega-tive’ sentiment. Thus, two key issues in SentiWord-Net based approaches are to decide: (a) which POStag patterns from the document should be extractedfor lookup in the library, and (b) how to decide theweightage of scores of different POS tags extractedwhile computing the aggregate score.
We have implemented several versions of Senti-WordNet based approach by exploring with differ-ent linguistic features and weightage & aggregationschemes. Studies in computational linguists suggestthat adjectives are good markers of opinions. For ex-ample, if a review sentence says “The movie was ex-cellent”, then use of adjective ’excellent’ tells us thatthe movie was liked by the review writer and possiblys/he had a wonderful experience watching it. Some-times, adverbs further modify the opinion expressedin review sentences. For example, the sentence “Themovie was extremely good” expresses a more positiveopinion about the movie than the sentence “the moviewas good”. A related previous work [18] has alsoconcluded that ‘adverb+adjective’ combine producesbetter results than using adjectives alone. Hencewe preferred the ‘adverb+adjective’ combine over ex-tracting ‘adjective’ alone. The adverbs are usuallyused as complements or modifiers. Few more exam-ples of adverb usage are: he ran quickly, only adults,very dangerous trip, very nicely, rarely bad, rarelygood etc. In all these examples adverbs modify theadjectives. Though adverbs are of various kinds, butfor sentiment classification only adjectives of degreeseem useful. Some other previous works on lexicon-based sentiment analysis reported in [19] and [20]state that including words with ‘verb’ POS tag playsa role in improving the sentiment classification accu-
racy. We have therefore implemented another versionthat incorporates verb scores as well. In total we im-plemented three variants of the SentiWordNet basedsentiment analysis approach. The detailed implemen-tation these schemes is explained in section 3.4.
3. DATASET AND EXPERIMENTAL SETUP
We evaluated performance of naıve bayes, supportvector machine and SentiWordNet based sentimentanalysis approaches on six different data sets.
3.1 Datasets
We used a total of six datasets for evaluating dif-ferent sentiment analysis schemes. This includes twoexisting movie review data sets, one movie reviewdataset collected by us, two existing blog datasetsand one twitter datasets. The existing movie reviewdatasets are from Cornell sentiment polarity dataset[21]. We downloaded polarity Dataset v1.0 (referredas Dataset 1) and v2.0 (referred as Datasets 2). Thedatasets 1 comprises of 700 positive and 700 negativeprocessed reviews, whereas the Dataset2 comprisesof 1000 positive and 1000 negative processed reviews.The third datasets (referred as Dataset 3) is our owncollection comprising of 1000 reviews of Hindi movies,with 10 reviews each of 100 Hindi movies from themovie database site IMDB [22].The blog datasets aredrawn from an earlier collection [23] and then pro-cessed and labeled using Alchemy API [24]. The blogdata used is about the ‘Arab Spring’ is opinionatedin nature. We refer these datasets as Dataset 4 andDataset 5. The Twitter dataset is obtained from [25]and is comprised of twitter feeds used earlier for sen-timent analysis. We refer to this dataset as Dataset6. Thus in total we work on three different kindsof data items, reviews, blog posts and twitter feeds.Some statistics about the datasets used is describedin table 1.
Table 1: Datasets.
Dataset DescriptionSize/ Avg.
Number length(in words)
700+700 Movie Reviews 1400 6551000+1000 Movie Reviews 2000 6561000 Reviews of Hindi
1000 323MoviesBlog posts on Libyan
1486 1130RevolutionBlog posts on Tunisian
807 1171RevolutionTwitter Dataset 20000 13

Computing Sentiment Polarity of Texts at Document and Aspect Levels 71
3.2 Implementing Nave Bayes Algorithm
We have implemented the multinomial version ofnaıve bayes algorithm using JAVA with Eclipse IDE.All the labeled datasets have been fed to the Navebayes algorithm as k-folds; in our case k is 10. A 10-fold application of test data means that the datasetis divided into 10 equal parts and then 9 of the 10parts becomes the training data and remaining 1 partconstitute test data. This is done by choosing each ofthe possible permutations as training and test data indifferent runs. We have taken the entire set of termsas features, both due to motivation from the pastresults and in order to compare the results with the‘adverb+adjective’ and ‘adverb+verb’ combinationsof SentiWordNet approach implementation. Averageof the 10-fold runs is reported as the performancelevel.
3.3 Implementing Support Vector MachineAlgorithm
The support vector machine (SVM) algorithm isimplemented in the Weka environment. Being a vec-tor space model based classifier; it first required us totransform the textual movie reviews to vector spacerepresentation. We used tf.idf representation fortransforming the textual reviews to numerical vec-tors for all the six datasets. No stop word removal orstemming was performed. This was done purposefullyso that no feature having sentimental value gets ex-cluded in the representation. We have thereafter usedthe same fold scheme as stated earlier and run our im-plementation of SVM and observed the results. Thereported results are averaged over 10-folds of runs.
3.4 Implementing SentiWordNet based Ap-proaches
We here implemented three different versions ofSentiWordNet based approach, all in Java using Net-Beans 7 IDE. In the first implementation we used only‘adjectives’ as features. However, we have used it onlyas a baseline for internal evaluation of the other twoimplementations and did not show its results in resulttables. Since it has been reported in the past works[19], [20], that adverbs and verbs play an importantrole in accurate sentiment analysis, we implementedtwo more versions, for which we have shown the per-formance evaluation results. In the second version,we used both ‘adverbs’ and ‘adjectives’ as features.And in the third version, we used ‘adverb+adjective’and ‘adverb+verb’ as features for sentiment polaritycomputation. Thus, in the second version implemen-tation, we only extract ’adjectives’ and any ‘adverbs’preceding the adjectives. In the third version, weextract both ’adjectives’ and ’verbs’, along with any’adverbs’ preceding them.
Since ‘adverbs’ are modifying the scores of suc-ceeding terms (in both the implemented versions), it
needs to be decided as to what proportion the senti-ment score of an ‘adjective’ or a ‘verb’ should be mod-ified by the preceding ‘adverb’. We have taken themodifying weightage (scaling factor) of adverb scoreas 0.35, based on the conclusions reported in [19].The other main issue that remains to be addressedis how should the sentiment scores of extracted ’ad-verb+adjective’ and ’adverb+verb’ combines in a sen-tence of the review document should be aggregated.For this we have tried different weight factors rang-ing from 10% to 100%, i.e. the ’adverb+verb’ scoresare added to ‘adverb+adjective’ scores in a weightedmanner, giving weightage of 10-100% in the aggre-gated score. Thus if sentiment polarity score to-tal of an ‘adverb+adjective’ combine is ‘x’ and ‘ad-verb+verb’ combine is ‘y’; then the net sentimentscore of these two taken together will be x + 0.3y,if the weightage factor for ‘adverb+verb’ combine is30%.
The implementation version involving ‘adverb+adjective’ combination only is referred hereafter asSWN(AAC). The ‘AAC’ in it is used as short formof ‘adverb+adjective combine’. As stated earlier, wehave chosen a scaling factor sf = 0.35, equivalent togiving only 35% weight to ’adverb’ scores, when ‘ad-verb’ and ‘adjective’ scores are added up.. The mod-ifications in adjective scores are thus in a fixed pro-portion to adverb scores. Since we chose a value ofscaling factor sf = 0.35, the adjective scores will get ahigher priority in the combined score. The indicativepseudo-code for this scheme is illustrated below:
Here, adj refers to ‘adjectives’ and adv refers to ‘ad-verbs’. The final sentiment values (fsAAC) are scaledform of adverb and adjective SentiWordNet scores,where the adverb score is given 35% weightage. Thepresence of ‘not’ is handled by negating the obtainedpolarity score for a word from the SentiWordNet li-brary. First of all we extract sentence boundaries of areview and then we process all the sentences. For eachsentence we extract the adv+adj combines and thencompute their sentiment scores as per the scheme de-

72 ECTI TRANSACTIONS ON COMPUTER AND INFORMATION TECHNOLOGY VOL.8, NO.1 May 2014
scribed in the pseudo-code. The final document senti-ment score is then an aggregation of sentiment scoresfor all sentences occurring in it. The aggregate scorevalue determines the polarity of the review. If the ag-gregate score is above a threshold value (usually 0),the document is labeled as ’positive’ and ‘negative’otherwise.
The implementation version involving both ‘ad-verb+adjective’ and ‘adverb+verb’ sentiment scoresis referred hereafter as SWN (AAAVC). The‘AAAVC’ in this is used as short form of ‘ad-verb+adjective, adverb+verb combine’. It is similarto the previous scheme in its way of combining ad-verbs with adjectives or verbs, but differs in the sensethat it counts both adjectives and verbs for decidingthe overall sentiment score. The indicative pseudo-code of key steps for this scheme is illustrated below:
Since we need to combine ‘adverb+adjective’ and ‘ad-verb+verb’ scores together, we have tried with dif-ferent aggregation weights for ‘adverb+verb’ scoreswith respect to ‘adverb+adjective’ patterns. No sin-gle weight assignment appears to work well for allthe six datasets. The figures 4 and 5 show the vari-ation performance with change in the weightage fac-
tor. The occurrence of ‘not’ has been handled ina similar manner as in previous scheme. The ‘ad-verb+adjective’ and ‘adverb+verb’ polarity in eachsentence are then aggregated and the overall aggre-gated value for the document then decides its polar-ity. If it is greater than a threshold (usually0), thedocument is labeled as ‘positive’ and ’negative’ other-wise. A more detailed discussion on our SentiWord-Net based implementations are reported in [26] and[27].
3.5 Performance Measures
We have evaluated performance of four differentimplementations for sentiment analysis on six differ-ent datasets. Our performance evaluation involvedcomputation of standard metrics of Accuracy, Preci-sion, Recall, F-measure and Entropy. The expressionfor computing Accuracy is:
Accuracy =NOCC
n(8)
where, NOCC is Number of Correctly Classified Doc-ument and n is the total number of documents. Theexpressions for Precision, recall and F-Measure are asshown in the equations below:
Pr(l, c) = nlc
/nc (9)
Re(l, c) = nlc
/nc (10)
Fmeasure(l, c) =2∗Re(l, c)∗Pr(l, c)
Re(l, c) + Pr(l, c)(11)
Fmeasure =∑
i
ni
nmax(Fmeasure(i, c)) (12)
where, nlc is number of documents with original la-bel l and classified label c; Pr(l,c) and Re(l,c) arethe Precision and Recall respectively; nc is numberof documents classified as c, and n is number of doc-uments in original class with label l. The expressionfor Entropy E is as per the equation below:
Ec = −∑
lP (l, c)∗ log(P (l, c)) (13)
E =∑
c
n∗cEc
n(14)
where, P (l, c) is the probability of documents of clas-sified class with label c belonging to original class withlabel l, and n is total number of documents. The de-sired values for Accuracy and F-measure are close to 1and for Entropy in close to 0. As far as time complex-ity of the algorithms we implemented is concerned, wedid not consider it primarily because of two reasons.One that all approaches are linear in time complexityand second that machine learning classifiers involve

Computing Sentiment Polarity of Texts at Document and Aspect Levels 73
training and test phases whereas SentiWordNet basedapproaches do not require a training phase. In thissituation, it may not be appropriate or useful to com-pare them in terms of time complexity.
4. RESULTS
We have evaluated performance of four differentsentiment analysis schemes on six different datasets.Out of the four implementations, two (NB andSVM) are machine learning classifiers, whereas theremaining two (SWN(AAC) and SWN(AAAVC)) arelexicon-based methods. The table 2 below presentsthe Accuracy, F-measure and Entropy values for theseimplementations on all six datasets.
Table 2: Performance results of four methods on allthe six datasets.
The results for accuracy, F-measure and Entropy
indicate that no method is the best across all thedatasets. For some datasets NB performs betterand for other SVM performs better than NB. Theperformance level of NB and SVM are close. TheSWN(AAC) and SWN(AAAVC) implementations lagbehind NB and SVM implementations. The accu-racy level for SWN(AAC) varies from 56.56% to78.10%, whereas for SWN (AAAVC), it varies from58.71% to 79.60%, across all the six datasets. TheSWN(AAAVC) scheme however is relatively supe-rior in performance to SWN(AAC) scheme. TheSVM method seems to work best for narrow domainshort texts from twitter with accuracy level of morethan 98%, whereas SWN approaches perform worstwith the twitter dataset. Though machine learningbased classifiers perform better than SentiWordNetbased approaches, they require prior training withlabelled data. In case of SentiWordNet based ap-proaches the performance level is a bit poor than themachine learning classifiers, but they can be imple-mented without any prior requirement of training.Thus if obtaining an indicative sentiment profile isthe goal, SentiWordNet based scheme may be useddue to its ease of implementation. However, if accu-racy is an important issue, a machine learning clas-sifier would be a better method to use for sentimentanalysis.
The table 3 presents total percentage of ‘positive’and ‘negative’ classifications for all the six datasets,whereas the table 4 specifies the exact number ofcorrectly assigned documents across all the differentdatasets.
Fig.1: Plot of accuracy values on the six datasetsfor the four versions implemented.
The figures 1, 2 and 3 present the results for accu-racy, F-measure and Entropy, respectively, for thefour different methods implemented across six differ-ent datasets, in order to have a comprehensive andeasy to understand graphical account of the perfor-mance of different methods.
We have also tried to find out the best weigh-
74 ECTI TRANSACTIONS ON COMPUTER AND INFORMATION TECHNOLOGY VOL.8, NO.1 May 2014
Table 3: Total percentage of ‘positive’ and ‘negative’labels assigned by all four methods.
Table 4: Total number of correctly assigned ‘posi-tive’ and ‘negative’ labels by all four methods.
Fig.2: Plot of F-measure values on the six datasetsfor the four versions implemented.
Fig.3: Plot of Entropy values on the six datasets forthe four versions implemented.
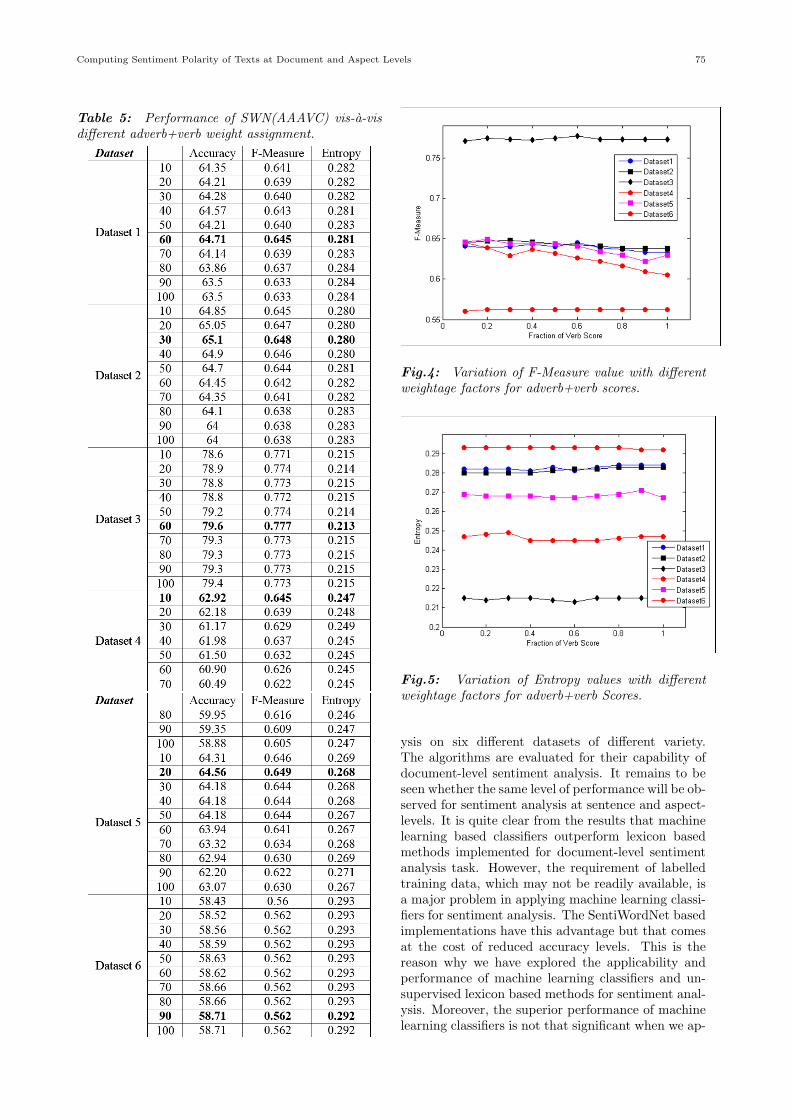
tage assignment for ‘adverb+verb’ patterns with ‘ad-verb+adjective’ patterns used in the SWN(AAAVC)scheme. However, there appear to be variation inthe best weightage factor across the six datasets. Forsome dataset, 60% weightage factor gives the best re-sult and for some other 30%. What is however clearlyseen is that the net effect of different weightage factorassignment on the performance of SWN(AAAVC) isnot very significant. Interestingly, the performancelevel does not vary a lot on a particular dataset withdifferent weightage factor selection. The figures 4and 5 present the effect of varying weightage assign-ment of ‘adverb+verb’ scores with ‘adverb+adjective’scores, on the F-measure and Entropy levels, respec-tively. The table 5 presents a detailed account ofnumerical performance values obtained on these vari-ations.
In summary, we have obtained performance eval-uation results for machine learning based classifiersand lexicon based implementation for sentiment anal-
Computing Sentiment Polarity of Texts at Document and Aspect Levels 75
Table 5: Performance of SWN(AAAVC) vis-a-visdifferent adverb+verb weight assignment.
Fig.4: Variation of F-Measure value with differentweightage factors for adverb+verb scores.
Fig.5: Variation of Entropy values with differentweightage factors for adverb+verb Scores.
ysis on six different datasets of different variety.The algorithms are evaluated for their capability ofdocument-level sentiment analysis. It remains to beseen whether the same level of performance will be ob-served for sentiment analysis at sentence and aspect-levels. It is quite clear from the results that machinelearning based classifiers outperform lexicon basedmethods implemented for document-level sentimentanalysis task. However, the requirement of labelledtraining data, which may not be readily available, isa major problem in applying machine learning classi-fiers for sentiment analysis. The SentiWordNet basedimplementations have this advantage but that comesat the cost of reduced accuracy levels. This is thereason why we have explored the applicability andperformance of machine learning classifiers and un-supervised lexicon based methods for sentiment anal-ysis. Moreover, the superior performance of machinelearning classifiers is not that significant when we ap-

76 ECTI TRANSACTIONS ON COMPUTER AND INFORMATION TECHNOLOGY VOL.8, NO.1 May 2014
proach to do sentiment analysis at an aspect-level.
5. ASPECT-LEVEL SENTIMENT ANALY-SIS
The document-level sentiment analysis is a reason-able measure of positivity or negativity expressed ina review. However, in selected domains it may be agood idea to explore the sentiment of the reviewerabout various aspects of the item in that domain,expressed in that review. Moreover, the assumptionthat a review is only about a single object may notalways hold as practically most of the reviews haveopinion about different aspects of an item, some ofwhich may be positive while some other negative.For example, a review about a mobile phone maystate both positive and negative aspects about cer-tain features of the mobile phone. It may, therefore,be inappropriate to insist on a document-level sen-timent polarity expressed in a review for the item.The document-level sentiment analysis is not a com-plete, suitable and comprehensive measure for de-tailed analysis of positive and negative aspects of theitem under review. The aspect-level sentiment analy-sis on the other hand allows us to analyze the positiveand negative aspects of an item. The aspect-orientedanalysis however is often domain specific. It must beknown in advance as to which aspects of an item arebeing opined by the review writers. Once the aspectsare identified, opinion targeted about that aspect maybe identified and its polarity computed. The aspect-level sentiment analysis thus involves the following:(a) identifying which aspects are to be analyzed, (b)locating the opinionated content about that aspect inthe review, and (c) determining the sentiment polar-ity of views expressed about the aspect.
Due to the domain specific nature of aspect-oriented sentiment analysis, we have chosen to workonly on movie reviews. First of all we identified theaspects about movies that are evaluated by the re-viewers. For this task, we manually pursued a largenumber of movie reviews from IMDB and those inour datasets. We also made an elaborate search foridentifying the aspects as categorized in different filmawards, movie review sites and film magazines. Basedon inputs from all these sources, we worked out thelist of aspects for which we will compute the sen-timent of movie reviews. Since a particular aspectis expressed by different words in different reviews(such as screenplay, screen presence, acting all to re-fer acting performance), we created an aspect-vectorfor all aspects under consideration. More precisely,we make a matrix of aspect features, where each rowis an aspect and every column in that row contains asynonymous word used by the review and sentimentvalue on that aspect in each review. The table 6below presents the indicative structure of the aspectmatrix. The synonymous words are stored as commaseparated values and Rev. 1 to Rev. N refer to the
N reviews that a movie may have.
Table 6: Aspect Matrix Structure.
After creating aspect vector, we had to locate theopinion about the aspects. In order to this, we parseeach review text sentence-by-sentence. First of all welocate any term belonging to aspect vector in the re-view text. If a sentence contains a mention about anaspect, we select the sentence for sentiment polaritycomputation about that aspect. It should be men-tioned here that sometimes we encounter sentenceslike “the screenplay is good but the storyline is poor”.For these sentences, it would be difficult to use a sim-ple sentence based sentiment classifier. Therefore, webreak these sentences into two, one sentence for eachaspect described. Once we get individual sentences,we simply apply the SWN(AAAVC) approach for sen-timent polarity computation of that aspect. Thus weprocess all the aspects in one review. This is done forall the reviews of a movie and scores for a particularaspect from all the reviews are combined to have anet sentiment score for that aspect for that movie.Thus, at the end we obtain a sentiment profile of amovie on certain selected aspects.
A summary of steps followed in the aspect-levelsentiment profile generation for a movie is given be-low. The steps are indicative steps for parsing all thereviews of a particular movie. The final sentimentprofile of the movie on different aspects is generatedbased on the aggregation of the aspect-level sentimentresult obtained for each movie review. The analysis isnow aspect-wise, where we look for opinion about anaspect in all the reviews and this process is repeatedfor all the aspects under consideration. Different re-views may have different sentiment polarities associ-ated with an aspect. Therefore, all the polarity scoresobtained using the SentiWordNet library are aggre-gated together to have an overall sentiment score forthat aspect.

Computing Sentiment Polarity of Texts at Document and Aspect Levels 77
5.1 Result of Aspect-Level Sentiment Classi-fication
We have implemented the aspect-level sentimentanalysis work on the movie review dataset 3. Foreach movie, we scan all its 10 reviews for selected as-pects. Thus for n reviews and m aspects, the totalscans would be nXm. The sentiment polarities of thedesired aspects are computed using SWN(AAAVC)scheme. We present here example results for two se-lected movies from the dataset 3 on 11 different as-pects, including one on the movie in general. The gen-eral comment about the movie is usually found in theinitial or last sentences of a review. The figures 6 and7 present sentiment profiles of two different movies,an aspect-level sentiment analysis result. We also dis-play the document-level result for the correspondingmovie in the figures to correlate the aspect-level sen-timent analysis result with the document-level result.
As seen in figure 6, the sentiment profile is morepositively oriented with many aspects rated morepositive. This is also congruent to the actual andSWN(AAAVC) obtained document-level result. Sim-ilarly, the figure 7 presents the sentiment profile fora movie which appears more negatively oriented interms of review polarity. The document-level re-sults here (both actual and those obtained usingSWN(AAAVC)), have a majority of the reviews neg-ative. This aspect-level result is also congruent tothe document-level sentiment analysis result. Thismethod of aspect-level sentiment analysis is thus atleast as accurate as the document-level sentimentanalysis results. In fact the accuracy levels here maybe better than the document-level sentiment analy-sis result, which however need to be confirmed withmore experimental work. The aspect-level sentimentanalysis scheme we devised is a very simple lexicon-based method with accuracy levels equivalent to thedocument-level results. Further, the pictorial rep-resentation of sentiment about different aspects ofthe movie is more expressive and useful than a sim-ple document-level sentiment analysis result. The
method is an unsupervised one and does not re-quire any training data. In fact it can be appliedin any domain with the only change required beingthe aspect matrix. Another, important point to ob-serve is that SWN(AAAVC) seems to work betterat aspect-level sentiment analysis task as comparedto the document-level sentiment analysis. We needto evaluate this aspect-level sentiment analysis workwith some related past work reported in [28]. Thiswould further strengthen our belief in performancelevel of our aspect-level sentiment analysis implemen-tation.
Fig.6: Sentiment profile of a positively rated moviewith actual and observed document-level Sentimentscores.
Fig.7: Sentiment Profile of a negatively rated moviewith actual and observed document-level Sentimentscores.
6. CONCLUSIONS
We have done experimental work on performanceevaluation of some popular sentiment analysis tech-niques (both supervised machine learning classifiersand unsupervised lexicon-based. The performancecomparison is done at document-level sentiment anal-ysis task. The results demonstrate that machine

78 ECTI TRANSACTIONS ON COMPUTER AND INFORMATION TECHNOLOGY VOL.8, NO.1 May 2014
learning classifiers obtain better accuracy levels (andbetter values for other performance evaluation met-rics). This is congruent to the earlier findings re-ported in earlier papers in isolated works. Here, wehave made a comprehensive performance evaluationon six datasets, of three different kinds. The tech-niques are evaluated on movie reviews, blog postsand twitter datasets. The machine learning classi-fiers however do not seem to be a suitable method forapplying on an aspect-based sentiment analysis task.One of the prominent reasons for this is lack of avail-ability of labeled training data. Moreover, the differ-ent in accuracy levels of machine learning classifica-tion and unsupervised lexicon-based approaches seemto diminish in aspect-level sentiment analysis work.This is clearly evident from the close congruence ofthe generated sentiment profile for movies and theiractual document-level sentiment labels. This showsthat lexicon-based methods are not inherently inferiorin performance. What actually goes against achievingbetter accuracy levels in document-level sentimentanalysis task with lexicon-based methods is that theassumption of review being only about a particularaspect does not hold in practical situations. We havepresented a detailed account of both document-leveland aspect-levels sentiment analysis task and tech-niques.
Our experimental work makes three importantcontributions to the work on sentiment analysis.First, it presents a detailed evaluative account of ma-chine learning and lexicon-based (unsupervised Sen-tiWordNet) sentiment analysis approaches on differ-ent kinds of textual data. Second, it explores indepth the use of ‘adverb+verb’ combine with ‘ad-verb+adjective’ combine for document-level senti-ment analysis, including the effect of different weigh-tage factor assignments for these scores. Third,it proposes a new and simple aspect-based heuris-tic scheme for aspect-level sentiment analysis in themovie review domain. The proposed approach resultsin a more useful sentiment profile for movies and haveaccuracy levels equivalent to the document-level ap-proach. Moreover, the algorithmic formulation usedfor aspect-level sentiment profile generation is verysimple, quick to implement, fast in producing resultsand does not require any previous training. It can beused on the run and produces very useful and detailedsentiment profile of a movie on different aspects of in-terest. This part of the implementation can also beused as an add-on step in movie recommendation sys-tems that use content-filtering, collaborative-filteringor hybrid approaches. The sentiment profile can beused as an additional filtering step for designing ap-propriate movie recommender systems as suggestedearlier in [29] and [30].
References
[1] B. Liu, “Sentiment analysis and opinion min-ing,” Proceedings of 5th Text Analytics Summit,Boston, June 2009.
[2] B. Pang, L. Lee & S. Vaithyanathan, “Thumbsup? Sentiment classification using machinelearning techniques”, Proceedings of the Confer-ence on Empirical Methods in Natural LanguageProcessing, pp. 79-86, Philadelphia, US, 2002.
[3] B. Pang & L. Lee, “A Sentimental education:sentiment analysis using subjectivity summa-rization based on minimum cuts, Proceedings ofthe ACL, 2004.
[4] B. Pang & L. Lee, “Seeing stars: Exploiting classrelationship for sentiment categorization with re-spect to rating scales,” Proceedings of 43rd An-nual Meeting of the Association for Computa-tional Linguistics, USA, pp. 115-124, 2005.
[5] M. Gamon, “Sentiment classification on cus-tomer feedback data: Noisy data, large featurevectors and the role of linguistic analysis,” Pro-ceedings of the 20th International Conference onComputational Linguistics (COLING), Geneva,Switzerland, pp. 841-847, 2004.
[6] K. Dave, S. Lawerence & D. Pennock, “Miningthe peanut gallery- Opinion extraction and se-mantic classification of product reviews,” Pro-ceedings of the 12th International World WideWeb Conference, pp. 519-528, 2003.
[7] S.M. Kim & E. Hovy, “Determining sentiment ofopinions,” Proceedings of the COLING Confer-ence, Geneva, 2004.
[8] P. Turney, “Thumbs up or thumbs down? Se-mantic orientation applied to unsupervised clas-sification of reviews,” Proceedings of 40th AnnualMeeting of the Association for ComputationalLinguistics, pp. 417-424, Philadelphia, US, 2002.
[9] P. Turney & M.L. Littman, “UnsupervisedLearning of Semantic Orientation from aHundred-Billion-Word corpus,” NRC Publica-tions Archive, 2002.
[10] D.M. Bikel & J. Sorensen, “If we want youropinion,” International Conference on SemanticComputing, 2007.
[11] K.T. Durant & M.D. Smith, “Mining sentimentclassification from political web logs,” Proceed-ings of WEBKDD’06, ACM, 2006.
[12] F. Sebastiani, “Machine learning in automatedtext categorization,” ACM Computing Surveys,34(1): 1-47, 2002.
[13] A. Esuli & F. Sebastiani, “Determining the se-mantic orientation of terms through gloss analy-sis,” Proceedings of CIKM-05, 14th ACM Inter-national Conference on Information and Knowl-edge Management, pp. 617-624, Bremen, DE,2005.
[14] R. Prabowo & M. Thelwall, “Sentiment analysis:

Computing Sentiment Polarity of Texts at Document and Aspect Levels 79
A combined approach,” Journal of Informetrics,3, pp. 143-157, 2009.
[15] B. Pang & L. Lee, “Opinion mining and senti-ment analysis,” Foundations and Trends in In-formation Retrieval 2(1-2), pp. 1-135, 2008.
[16] C.D. Manning, P. Raghavan & H. Schutze, “In-troduction to Information Retrieval,” CambridgeUniversity Press, New York, USA, 2008.
[17] Weka Data Mining Software in JAVA,http://www.cs.waikato.ac.nz/ml/weka/
[18] F. Benamara, C. Cesarano & D. Reforigiato,“Sentiment Analysis: Adjectives and Adverbsare better than Adjectives Alone,” Proceedingsof ICWSM 2006, CO USA, 2006.
[19] M. Karamibeker & A.A. Ghorbani, “Verb ori-ented sentiment classification,” Proceedings ofInternational Conference on web Intelligence andIntelligent Agent Technology, 2012.
[20] P. Chesley, B. Vincent, L. Xu & R.K. Srihari,“Using verbs and adjectives to automaticallyclassify blog sentiment,” American Associationfor Artificial Intelligence, 2006.
[21] http://www.cs.cornell.edu/people/pabo/movie-review-data/
[22] Internet Movie Database,http://www.imdb.com
[23] D. Mahata & N. Agarwal, “What does every-body know? Identifying event-specific sourcesfrom social media,” Proceedings of the fourthInternational Conference on Computational As-pects of Social Networks (CASoN 2012), SaoCarlos, Brazil, 2012.
[24] Alchemy API, retrieved fromwww.alchemyapi.org on Dec. 15, 2012.
[25] Twitter Sentiment Analysis dataset, available athttp://www.textanalytics.in/datasets/twittersentiment01
[26] V. K. Singh, R. Piryani, A. Uddin & P. Waila,“Sentiment analysis of movie reviews and blogposts: Evaluating SentiWordNet with differ-ent linguistic Features and scoring schemes,”in Proceedings of 2013 IEEE International Ad-vanced Computing Conference, Ghaziabad, In-dia, IEEE, Feb. 2013.
[27] V.K. Singh, R. Piryani, A. Uddin & P. Waila,“Sentiment analysis of movie reviews: A newfeature-based heuristic for aspect-level senti-ment classification,” Proceedings of the 2013International Multi-Conference on Automation,Communication, Computing, Control and Com-pressed Sensing, Kerala, India, IEEE, pp. 712-717, 2013.
[28] T.T. Thet, J.C. Na & C.S.G. Khoo, “Aspect-based sentiment analysis of movie reviews on dis-cussion boards,” Journal of Information Science,36(6), pp. 823-848, 2010.
[29] V. K. Singh, M. Mukherjee & G. K. Mehta,“Combining collaborative filtering and senti-ment analysis for improved movie recommenda-
tions,” in C. Sombattheera et al. (Eds.): Multi-disciplinary Trends in Artificial Intelligence,LNAI 7080, Springer-Verlag, Berlin-Heidelberg,pp. 38-50, 2011.
[30] V. K. Singh, M. Mukherjee & G. K. Mehta,“Combining a content filtering heuristic and sen-timent analysis for movie recommendations,” inK.R. Venugopal & L.M. Patnaik (Eds.): ICIP2011, CCIS 157, pp. 659-664, Springer, Heidel-berg, 2011.
Vivek Kumar Singh received Mas-ters’s and Doctoral degree in ComputerScience from the University of Alla-habad, Allahabad, India during 2001and 2010, respectively. From 2004 to2011, he has been Assistant Professorin Computer Science at Banaras HinduUniversity, Varanasi, India. Currentlyhe is working as Assistant Professor inComputer Science at South Asian Uni-versity, New Delhi, India. He is a senior
member of IEEE, and member of ACM and IEEE-CS. His re-search interests include Collective Intelligence and Text Ana-lytics. His research on text Analytics is funded by DST, Govt.of India and UGC, Govt. of India.
Rajesh Piryani obtained Bachelors’degree in Computer Engineering fromTribhuvan University, Kathmandu, Nepalin 2010 and Masters’ degree in Com-puter Application from South AsianUniversity, New Delhi, India in 2013.His research interests include SentimentAnalysis, Information Extraction andSemantic Annotation. Rajesh is a mem-ber of IEEE.
Pranav Waila has obtained MastersDegree in Computer Application fromPondicherry Central University, Indiaduring 2005-2008. Currently he is Doc-toral program student at Banaras HinduUniversity, Varanasi, India. Earlierhe worked in industry sector assign-ments in SCM Microsystems Chennai,Huawei Technology and MakeMyTrip.His broad research interest lies in com-putational matchmaking, recommender
systems and social media analytics. Pranav is a student mem-ber of ACM and IEEE.
Madhavi Devaraj received Master ofComputer Applications and M.Phil. De-grees in Computer Science from Madu-rai Kamaraj University, Madurai, In-dia in 2000 and 2004, respectively. Sheis currently a Ph.D. student at Gau-tam Buddha Technical University, Luc-know, India. Earlier she was an As-sistant Professor in Invertis Institute ofManagement and Technology, Bareilly,India from July 2006 to Feb. 2007 and
in Babu Banarasi Das University, Lucknow, India from April2012 to April 2013. Her research interests include Algorithmicapplications on Information Extraction and Sentiment Analy-sis.
Copyright © 2022 FDOKUMEN



















