
Benchmarking Snowflake vs Spark for Optimized DataOps
28
© 2022 Larsen & Toubro Infotech Limited Benchmarking Snowflake vs Spark for Optimized DataOps Whitepaper by Fosfor
-
Upload
khangminh22 -
Category
Documents
-
view
4 -
download
0
Transcript of Benchmarking Snowflake vs Spark for Optimized DataOps

© 2022 Larsen & Toubro Infotech Limited
BenchmarkingSnowflakevs Spark forOptimized DataOps
Whitepaper
by Fosfor

© 2022 Larsen & Toubro Infotech Limited
Overview• The DataOps Paradigm Shift• About Snowflake• About Spectra
Snowflake vs Apache Spark: A general comparison• Architecture• Data Access• Simplicity• Versatility• Data Structure
Snowflake vs. Spark: Performance Comparison• Experiment Context• Test Setup• Data Processing Semantics
Experiments, Execution and Results• Data Extraction• Row level transformation• Aggregate• Join• Merge• Concurrency
Overall Observation
Spectra with Snowflake
Conclusion
Table of Contents 4556
777788
991011
13131417192122
25
26
28
© 2022 Larsen & Toubro Infotech Limited
List of TablesTable 1:Data Extraction Execution Time Comparison – Snowflake vs. Spark
Table 2:Row level Transformation Execution Time Comparison – Snowflake vs. Spark
Table 3:Aggregate Execution Time Comparison – Snowflake vs. Spark
Table 4:Join Execution Time Comparison – Snowflake vs. Spark
Table 5:Merge Execution Time Comparison – Snowflake vs. Spark
Table 6:BI Execution Time Comparison – Snowflake vs. Spark
14
16
18
20
22
23

Data processing at speed and at scale is the core of any DataOps platform. Now more than ever, organizations need the ability to accelerate DataOps with purpose-built, cloud native ETLs, while ensuring minimal technical debt. This technical whitepaper explores various comparative scenarios to select the best data processing engine for Spectra. It helps data and analytics professionals to understand core differences between Apache Spark and Snowflake, in terms of their respective processing power.
This Document Will Take You Through How
• Volume and scale affect a solution’s time-to-market
• Architectural differences affect the processing of high-volume data
• Scalability and workload management differ between the platforms
OverviewThis whitepaper provides detailed analyses, with supporting evidence, on features and capabilities of the Snowflake and the open-source Apache Spark data processing engines. Some thought-provoking findings of the research include:
• Performance: The data processing capability of Snowflake is twice that of the Apache Spark analytics engine. In terms of performance and Total Cost of Ownership (TCO), Snowflake not only runs faster, but in many cases outperforms Spark by a large margin over the entire ETL cycle. Assuming its other features align well with your business needs, Snowflake becomes a better choice to be integrated and used with Spectra.
• Agility: Data pipelines executed on a Spark cluster took ~5 minutes to start running, thus delaying the overall processing, whereas on Snowflake, all data executions start instantaneously.
• Stability: Some job failures due to memory or other issues—which were harder to debug and conduct Root Cause Analysis (RCA) on—were observed when running on Spark. Not a single job failure was observed during Snowflake execution.
• Ease-of-use: There are an array of parameters to be configured to extract performance out of Spark, whereas for Snowflake everything just works out of the box.
• Concurrency: Snowflake performed 3X better even with 25% of the resources. The Spark cluster struggled to manage 100+ concurrent users.
© 2022 Larsen & Toubro Infotech Limited 4

About Snowflake
Snowflake Data Cloud is one of the key platforms that is architected from scratch for the cloud, enabling secure and governed access to all data with a multi-cluster compute layer for running isolated workloads without any resource contention. Snowflake is a unified data platform with near-zero administration running on all 3 major cloud platforms (AWS, Google Cloud Platform, and Azure), supporting many workloads, including Data Engineering, Data Lake, Data Warehouse, Data Applications, Data Science, and Data Exchange. Snowflake Data Cloud and its innovative data sharing features allow organizations to share data without any moving or copying, as well as to access hundreds of third-party datasets like those offered by S&P Global, Factset and many others, using the Snowflake Data Marketplace.
The DataOps Paradigm ShiftOver the past 10 years, digital transformation has brought about a massive increase in the volume and variety of data and in the velocity of its lifecycle. This has changed everything related to how data is managed. Organizations have adapted and recognized the need to become data-driven for a competitive advantage. At the core, the process is simple and has been the foundation of enterprise information systems for decades. What changed is the way the new information started coming in.
With “Big Data” came a flood of raw, unstructured data. Technology, standards, and systems evolved accordingly to handle data beyond that which had been aggregated in traditional data warehouses. Enterprises then started looking at cloud-based data lakes. Many moved to the cloud, others remained with on-premises data warehouses, while some have chosen a hybrid approach to leverage the best of both worlds. Embracing cloud technology had lots of benefits but came with its own challenges such as finding the right infrastructure, managing cost, or drawing the right insights. Eventually, many organizations realized that even after massive investments in cloud-based analytics solutions, they failed to achieve their desired ROI and lacked the right insights at the right time and at scale. The solution required an approach that would allow strategic investment in data solutions that are scalable, cost-effective, and easy-to-manage.
• The platforms compare on TCO for computation, cluster management cost, etc.
• The abstracted layer approach of Spectra allows easy runtime engine selection
Above all, we will explain how Spectra gives the user an ability to focus on important tasks and reduces complexity while offloading computation to their choice of runtime engine.
© 2022 Larsen & Toubro Infotech Limited 5

About Spectra
Spectra is a modern DataOps platform. It enables businesses to efficiently use collected data by turning it into insights that are easy to understand and act upon. This improves not only decision quality, but also decision speed and confidence. This increased confidence then further translates into faster execution and better implementation.
Snowflake Key Features Include
Key Features of Spectra Include
Data connectivity& ingestion
DataOps on Cloud
Managing any type of workload
High performance and scalability
Organized collaboration & operationalization
Integrated enterprise governance & security
© 2022 Larsen & Toubro Infotech Limited 6
High performance, scalable architecture
Security, governance, and data protection
Standard & extended SQL support
Data sharing
Integration with key technology partners
Data import and export
Database replication and failover

Snowflake vs. Apache Spark: A General Comparison Spectra works well with both Snowflake and Spark. To help you make an informed choice, however, we present here a comparison between the two platforms.
Architecture
Snowflake Snowflake’s architecture is a smart mix of shared-disk and shared-nothing approaches. All of the data is kept in a central storage disk, which is accessible from all the compute nodes (and therefore shared). However, the processing power relies on the shared-nothing approach. All the virtual warehouses work in parallel with each other, and there is no sharing of computing resources between the two.
Spark On the other hand, Spark takes the data engineering approach. Processing takes place at the ETL stage and once that data has been processed to be ready for analytics, it is saved in the warehouse. It provides faster query execution, and thus better performance and a near-real-time experience.
Data Access
Snowflake Snowflake has decoupled the storage and compute layers, allowing both storage and processing to be scaled up or down independently of the other. To facilitate this, data is transferred to Snowflake’s servers for processing; while the customer maintains ownership of the data, Snowflake manages the governance and security of data storage and accessibility.
Spark Spark has also decoupled storage and processing in order to provide flexibility to choose the volume of dedicated resources; it accomplishes this by first loading the data into a Delta Lake in Parquet format. Unlike Snowflake, Spark leaves management of the governance and security of the data up to the user.
Simplicity
Snowflake Being a true SaaS, Snowflake is simple to get started with. There is no hardware or software to install, configure, and manage. Snowflake manages the maintenance operations on its part.
Spark Spark delivers a technology built by experts for experts. It might be challenging for less tech-savvy teams to switch to this paradigm to work with their data.
© 2022 Larsen & Toubro Infotech Limited 7

Versatility
Snowflake Snowflake has been designed to handle the best Business Intelligence scenarios. It uses SQL as the query language to retrieve and process data. It focuses specifically on BI and for any use cases involving advanced analytics, data science and machine learning, and it provides easy integration with third-party vendors. Thus, Snowflake users are open to use specialized services for all their use cases.
Spark Spark is designed to handle all the processes throughout the data pipeline. Thus, it is as suitable for data operations as it is for implementing Machine Learning solutions. It supports multiple programming languages giving an option to the user to choose the one they are most comfortable with.
Data Structure
Snowflake Snowflake enables organizations to store any format of data in one place (Structured, Semi-Structured and Unstructured), and provides seamless access to any format of data, which eliminates the need for organizations to invest in multiple data platforms or in creating data marts.
Spark Spark comes closer to data lakes in its behavior viz-a-viz the data structure. You can work with structured, semi-structured, or unstructured data in Spark.
Simplicity
Snowflake Being a true SaaS, Snowflake is simple to get started with. There is no hardware or software to install, configure, and manage. Snowflake manages the maintenance operations on its part.
Spark Spark delivers a technology built by experts for experts. It might be challenging for less tech-savvy teams to switch to this paradigm to work with their data.
© 2022 Larsen & Toubro Infotech Limited 8

Snowflake vs. Spark: Performance ComparisonPerformance comparisons in the Data Extraction, Transformation, Loading (ETL) process can provide a more tangible metric to make the final call. The ETL cycle is generally implemented in either of two methods:
• Method 1: In the first case, data is extracted from the source cloud storage and copied into a natively supported format of the underlying execution engines. Extraction happens as a separate job from Transformation and Load operations. Thus, Extract is one job with its own costs and results and Transform and Load are other jobs.
• Method 2: ETL can be done as one complete cycle as well. In this scenario, there is no staging of data. Data is extracted from the source, transformations are done to it, and then it is subsequently sent for loading. Hence, the complete ETL process takes place as a single job.
Snowflake uses its external tables to extract data from external data sources. These tables contain the address of the original data, and thus, act as a reference to that. After transformations have been applied to it, the final dataset is loaded into the destination table.
Spark reads data directly from cloud storage. It extracts the data, applies transformations to it, and loads it into cloud storage in Delta/Parquet format.
Experiment Context
To understand the performance of Snowflake vs. Spark under various scenarios, we performed a series of experiments. All the environments (Snowflake and Spark) were in the AWS Sydney region. The cloud storage used was S3 object storage from the same region. For ELT jobs (ingestion and transformation) we used the Jobs Compute Premium SKU (0.10 / DBU).
For concurrency tests, we used the All-Purpose Compute Premium SKU (0.55 / DBU).
© 2022 Larsen & Toubro Infotech Limited 9

Product Versions Used
Product
Spectra
Snowflake
Spark
Versions Details
9.0.2
Enterprise EditionAWS, Asia Pacific (Sydney)
Spark 3.1.1AWS, Sydney Region
Test Setup
Using the Spectra cluster configuration feature, multiple different types of clusters for data processing were added. For this study, Snowflake and Spark were configured with similar cluster configurations as below:
Data Preparation
The TPC-DS benchmark was used to generate data volumes of various sizes.The TPC-DS utility supports data generation only in a delimited format. However, for this study, JSON was selected as the source data format.
Data Generation
The TPC-DS utility can generate the data on a local disk, which needs to be copied into distributed storage. For simplicity, a utility https://github.com/Spark/spark-sql-perf wasused to generate the TPC-DS dataset on S3 cloud storage in JSON format.
Snowflake Warehouse Configuration Equivalent Spark Executor Configuration
Small
Medium
Large
X-Large
2X-Large
(8 cores 32GB memory)*2
(8 cores 32GB memory)*4
(8 cores 32GB memory)*8
(8 cores 32GB memory)*16
(8 cores 32GB memory)*32
© 2022 Larsen & Toubro Infotech Limited 10

The data extraction from source to staging is done by running a Spark job which reads the data from the source storage i.e., S3 object storage and then writes to Parquet format using Snappy compression on target S3 object storage. Once the data lands in the staging area, a new Spark job is triggered for Transformation and Load.
JSON/CSV Delta/Parquet Delta/Parquet
Source(Cloud Storage)
Staging(Cloud Storage)
Load(Cloud Storage)
Spark Job(Extract)
Spark Job(Transformation)
Spark E+TL Semantics
E+TL.
JSON/CSV SnowflakesInternal Table
SnowflakesInternal Table
Source(Cloud Storage)
StagingSnowflake COPY(Extract)
SnowflakeProcedure
(Transform)
Snowflake E+TL Semantics
E+TL.
Data Volumes
The TPC-DS data generation utility allows us to generate data of different volumes e.g., 10GB, 100GB, 1TB and 10TB in a delimited format. However, when the same data is generated in JSON format the data volume changes to 30GB, 300GB, 3TB and 30TB. Hence, throughout this study only JSON data volume is considered.
Data Processing SemanticsIn this study, a complete end-to-end ETL lifecycle is considered.
Data Extraction From Source to Staging Before Transformationand Load (E+TL)
In this type of use case, data is extracted from the source cloud storage S3 object storage and then converted into native formats for the underlying execution engine platforms. All the benchmarks involve loading data to staging, time and resources are added up to the actual transformation and load stage. i.e., E+TL.
© 2022 Larsen & Toubro Infotech Limited 11
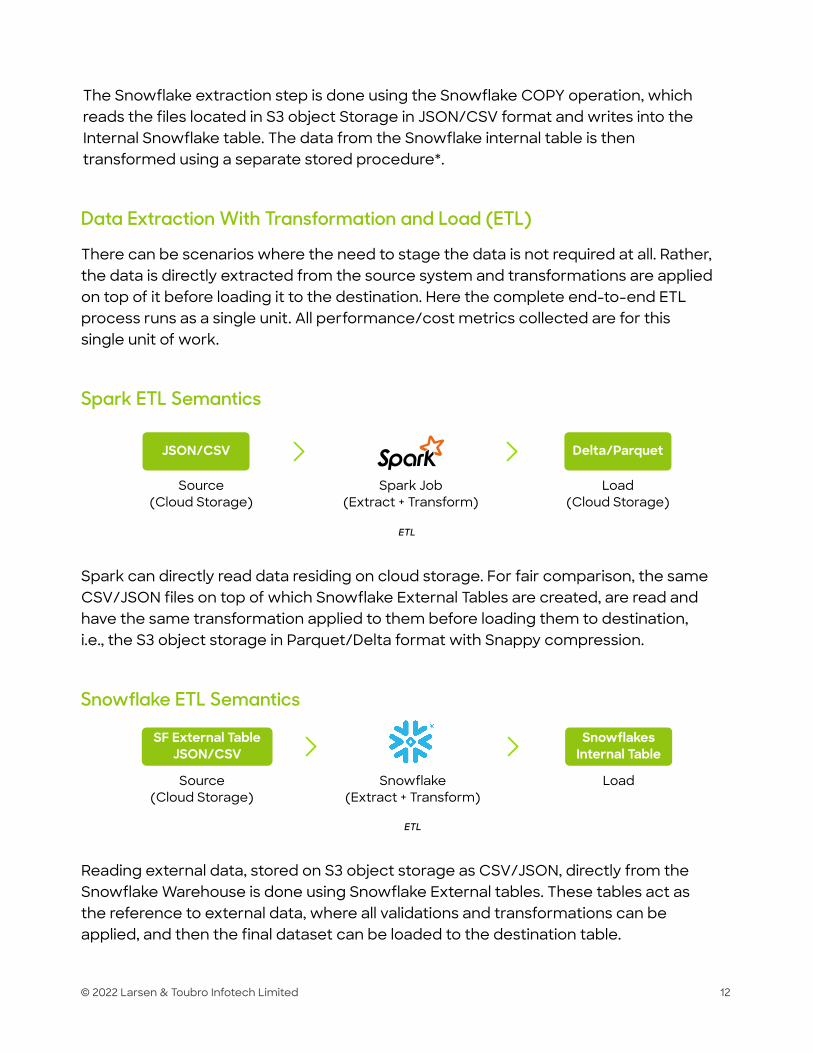
The Snowflake extraction step is done using the Snowflake COPY operation, which reads the files located in S3 object Storage in JSON/CSV format and writes into the Internal Snowflake table. The data from the Snowflake internal table is then transformed using a separate stored procedure*.
Spark can directly read data residing on cloud storage. For fair comparison, the same CSV/JSON files on top of which Snowflake External Tables are created, are read and have the same transformation applied to them before loading them to destination, i.e., the S3 object storage in Parquet/Delta format with Snappy compression.
Reading external data, stored on S3 object storage as CSV/JSON, directly from the Snowflake Warehouse is done using Snowflake External tables. These tables act as the reference to external data, where all validations and transformations can be applied, and then the final dataset can be loaded to the destination table.
Spark ETL Semantics
JSON/CSV
Source(Cloud Storage)
Spark Job(Extract + Transform)
Delta/Parquet
Load(Cloud Storage)
ETL
Snowflake ETL Semantics
SF External TableJSON/CSV
Source(Cloud Storage)
Snowflake(Extract + Transform)
SnowflakesInternal Table
Load
ETL
Data Extraction With Transformation and Load (ETL)
There can be scenarios where the need to stage the data is not required at all. Rather, the data is directly extracted from the source system and transformations are applied on top of it before loading it to the destination. Here the complete end-to-end ETL process runs as a single unit. All performance/cost metrics collected are for this single unit of work.
© 2022 Larsen & Toubro Infotech Limited 12

Data Extraction
All data extraction for (E+TL) flows are done collectively irrespective of the job. Datasets considered for data extraction include the following datasets from TPC-DS:
• Union operation catalog_sales, store_sales and web_sales to create a cumulative sales dataset by selecting common columns between all of them
• Other datasets considered include item, customer, customer_address, household_demographics and income_band
The data extraction job for sales_union is done in a single job and data extraction of all other datasets is done in a separate job.
SnowflakeFor Snowflake data extraction, external tables are created in Snowflake that refer to the JSON dataset present on S3 object storage. In Spectra flows, data is read from these Snowflake External tables and the UNION ALL operation is performed to create a sales table, which is a Snowflake internal table. Similarly, for other datasets as well the process is the same: reading the external tables and then creating internal staging tables.
SparkSimilarly, for Spark, flows are created that read the data from S3 object storage in JSON format and write in Parquet format using Snappy compression. For Spark as well, the Sales dataset is created by performing a UNION ALL operation on all three sales datasets. Similarly, other datasets are extracted and are written to S3 OBJECT STORAGE in Parquet format using Snappy compression.
Experiment Execution and ResultsThe execution details and related results of our performance benchmarking research follow.
© 2022 Larsen & Toubro Infotech Limited 13
Observations
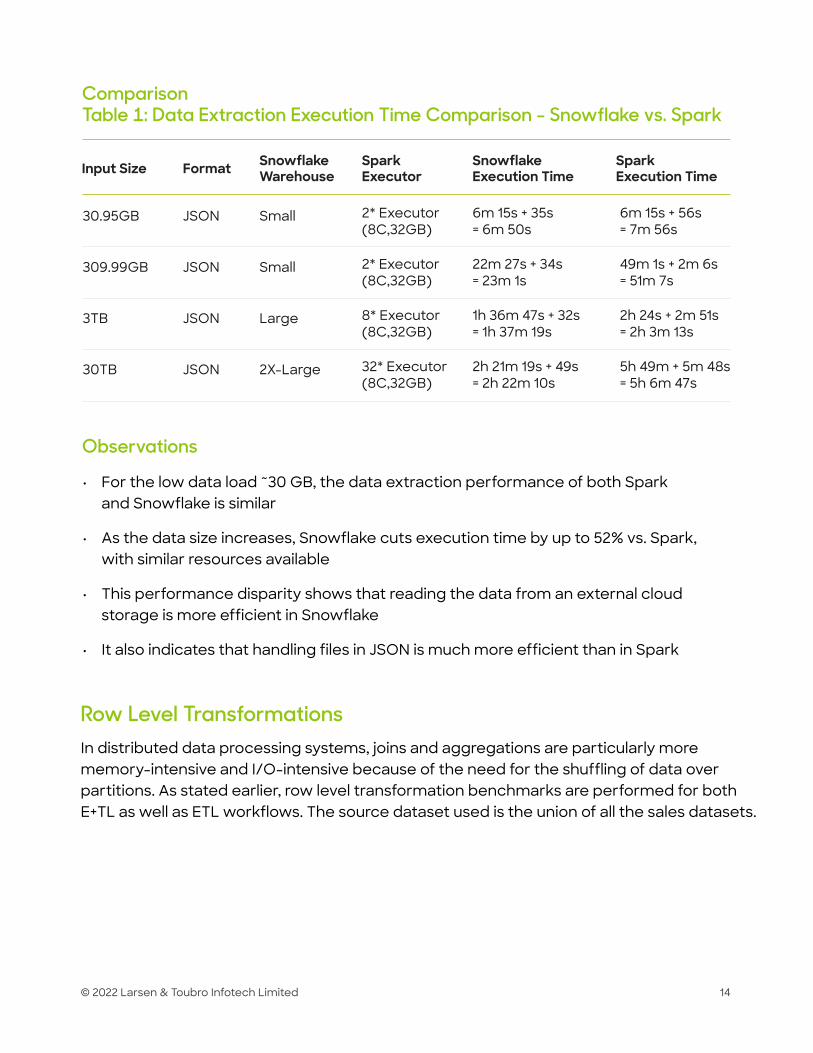
• For the low data load ~30 GB, the data extraction performance of both Spark and Snowflake is similar
• As the data size increases, Snowflake cuts execution time by up to 52% vs. Spark, with similar resources available
• This performance disparity shows that reading the data from an external cloud storage is more efficient in Snowflake
• It also indicates that handling files in JSON is much more efficient than in Spark
ComparisonTable 1: Data Extraction Execution Time Comparison - Snowflake vs. Spark
Input Size Format SnowflakeWarehouse
SnowflakeExecution Time
SparkExecution Time
SparkExecutor
30.95GB
309.99GB
3TB
30TB
JSON
JSON
JSON
JSON
Small
Small
Large
2X-Large
2* Executor(8C,32GB)
2* Executor(8C,32GB)
8* Executor(8C,32GB)
32* Executor(8C,32GB)
6m 15s + 35s= 6m 50s
22m 27s + 34s= 23m 1s
1h 36m 47s + 32s= 1h 37m 19s
2h 21m 19s + 49s= 2h 22m 10s
6m 15s + 56s= 7m 56s
49m 1s + 2m 6s= 51m 7s
2h 24s + 2m 51s= 2h 3m 13s
5h 49m + 5m 48s= 5h 6m 47s
Row Level TransformationsIn distributed data processing systems, joins and aggregations are particularly more memory-intensive and I/O-intensive because of the need for the shuffling of data over partitions. As stated earlier, row level transformation benchmarks are performed for both E+TL as well as ETL workflows. The source dataset used is the union of all the sales datasets.
Snowflake • For E+TL flows, the sales union data extracted in the Test Setup section was used from the staging internal Snowflake table as a source. All transformations were performed on that dataset
• For ETL flows, all three sales datasets were directly read from the S3 object storage using the Snowflake external tables feature and then a UNION ALL operation was performed on top of it before performing the transformations
Spark• For E+TL flows, the sales union data which was stored in Parquet format in the Test Setup section was taken as the input and row level transformations were applied on top of it
• Similarly, ETL flows, directly read sales datasets in JSON format and perform UNION ALL operation before executing the Row level transformations
© 2022 Larsen & Toubro Infotech Limited 14

Comparison
The following transformations were executed as part of this flow for each dataset
• Concat (SS_ITEM_SK, SS_PROMO_SK)
• UPPER (SS_CUSTOMER_SK)
• LOWER (SS_CUSTOMER_SK)
• ABS (SS_EXT_DISCOUNT_AMT)
• ROUND (SS_COUPON_AMT)
• LTRIM (SS_PROMO_SK)
• RTRIM (SS_PROMO_SK)
• LENGTH (SS_PROMO_SK)
• TOSTRING (SS_ITEM_SK)
Row Level TransformationsIn distributed data processing systems, joins and aggregations are particularly more memory-intensive and I/O-intensive because of the need for the shuffling of data over partitions. As stated earlier, row level transformation benchmarks are performed for both E+TL as well as ETL workflows. The source dataset used is the union of all the sales datasets.
Snowflake • For E+TL flows, the sales union data extracted in the Test Setup section was used from the staging internal Snowflake table as a source. All transformations were performed on that dataset
• For ETL flows, all three sales datasets were directly read from the S3 object storage using the Snowflake external tables feature and then a UNION ALL operation was performed on top of it before performing the transformations
Spark• For E+TL flows, the sales union data which was stored in Parquet format in the Test Setup section was taken as the input and row level transformations were applied on top of it
• Similarly, ETL flows, directly read sales datasets in JSON format and perform UNION ALL operation before executing the Row level transformations
© 2022 Larsen & Toubro Infotech Limited 15

Operation InputSize
InputFormat
SnowflakeWarehouse
SparkExecutor
SnowflakeExecution Time
SparkExecution Time
E+TL (Row LevelTransformation)
E+TL (Row Level Transformation)
ETL (Row LevelTransformation)
ETL (Row LevelTransformation)
E+TL (Row LevelTransformation)
ETL (Row LevelTransformation)
E+TL (Row LevelTransformation)
ETL (Row LevelTransformation)
E+TL (Row LevelTransformation)
ETL (Row LevelTransformation)
30.6GB
308.7GB
30.6GB
308.7GB
3TB
3TB
30TB
30TB
30TB
30TB
JSON
JSON
JSON
JSON
JSON
JSON
JSON
JSON
JSON
JSON
Small
Small
Small
Small
Large
Large
2X-Large
2X-Large
X-Large
X-Large
2* Executor(8C, 32GB)
2* Executor(8C, 32GB)
2* Executor(8C, 32GB)
2* Executor(8C, 32GB)
8* Executor(8C, 32GB)
8* Executor(8C, 32GB)
32* Executor(8C, 32GB)
32* Executor(8C, 32GB)
32* Executor(8C, 32GB)
32* Executor(8C, 32GB)
6m 15s + 39s= 6m 54s
22m 27s +4m 2s26m 29s
7m
21m 20s
1h 36m 47s +9m 53s =1h 46m 40s
51m 32s
2h 21m 19s +29m 7s =2h 40m 26s
2h 24m 7s
4h 54m 18s +51m 46s =5h 46m 4s
4h 44m 27s
6m + 2m 40s = 8m 40s
49m 1s +9m 20s =58m 21s
6m 29s
48m 30s
2h 24s +11m 32s =2h 11m 56s
2h 1m 14s
5h 49s +27m 46s =5h 28m 35s
4h 58m 11s
5h 49s +27m 46s =5h 28m 35s
4h 58m 11s
Table 2: Row level Transformation ExecutionTime Comparison - Snowflake vs. Spark
Observations
• Row level transformations are highly parallelized workloads. No data shuffling or broadcasting is needed
• As shown in Table 2, if we consider the complete ETL cycle, Snowflake can reduce the execution time by more than 50%
• For E+TL flows where extraction is done in a separate flow, the transformation operations take similar time for both Snowflake and Spark. However, for extraction alone, Snowflake consistently takes less time—up to 53% less. This indicates that Snowflake handles JSON files much more efficiently than Spark
• Across data volumes we see a clear trend that Snowflake delivers better execution times in nearly all cases, and for some data sets reduces execution times by more than 50%
© 2022 Larsen & Toubro Infotech Limited 16

Observations
• Row level transformations are highly parallelized workloads. No data shuffling or broadcasting is needed
• As shown in Table 2, if we consider the complete ETL cycle, Snowflake can reduce the execution time by more than 50%
Snowflake vs Spark
• For E+TL flows where extraction is done in a separate flow, the transformation operations take similar time for both Snowflake and Spark. However, for extraction alone, Snowflake consistently takes less time—up to 53% less. This indicates that Snowflake handles JSON files much more efficiently than Spark
• Across data volumes we see a clear trend that Snowflake delivers better execution times in nearly all cases, and for some data sets reduces execution times by more than 50%
Aggregate
The Aggregate operation involves grouping rows together and then extracting meaningful and manageable information. This transformation reduces the output by combining multiple rows together, since one output row is dependent on multiple input rows. Hence, this operation involves a lot of I/O operations and involves shuffling for distributed systems.
SnowflakeSimilar to row level transformation, the benchmarking scenarios covered are for E+TL and ETL aggregate workloads. For the E+TL workload, input is the sales data generated as mentioned in the Test Setup section. For ETL again all three sales datasets are read using Snowflake External Tables and a UNION ALL operation is performed before running aggregate transformation.
SparkSimilarly, for Spark, the sales union dataset extracted in the Test Setup section is taken as input to the aggregate operation for E+TL workflow. The ETL flow reads the sales data from the raw JSON dataset, does a UNION ALL, and then does the aggregation.
© 2022 Larsen & Toubro Infotech Limited 17
• MAX (LIST_PRICE)
• MIN (LIST_PRICE)
• AVG (LIST_PRICE)
• MAX(WHOLESALE_COST)
• MIN (WHOLESALE_COST)
• AVG (WHOLESALE_COST)
• MAX (SALES_PRICE)
• MIN (SALES_PRICE)
• AVG (SALES_PRICE)
• MAX (EXT_DISCOUNT_AMT)
• MIN (EXT_DISCOUNT_AMT)
• AVG (EXT_DISCOUNT_AMT)
• MAX (EXT_SALES_PRICE)
• MIN (EXT_SALES_PRICE)
• AVG (EXT_SALES_PRICE)
• MAX (EXT_WHOLESALE_COST)
• MIN (EXT _LIST_PRICE)
• AVG (EXT_WHOLESALE_COST)
• MAX (EXT_LIST_PRICE)
• MIN (EXT_LIST_PRICE)
• AVG (EXT_LIST_PRICE)
• MIN (NET_PROFIT)
• MAX (NET_PROFIT)
• AVG (NET_PROFIT)
• MIN (NET_PAID)
• MAX (NET_PAID)
• AVG (NET_PAID)
Grouping Keys: item_id & customer idAggregate functions

OperationInputSize
InputFormat
SnowflakeWarehouse
SparkExecutor
SnowflakeExecution Time
SparkExecution Time
E+TL(Aggregate)
E+TL(Aggregate)
ETL(Aggregate)
ETL(Aggregate)
E+TL (Aggregate)
ETL (Aggregate)
E+TL (Aggregate)
ETL (Aggregate)
E + TL(Aggregate)
ETL (Aggregate)
30.6GB
308.7GB
30.6GB
308.7GB
3TB
3TB
30TB
30TB
3TB
3TB
JSON
JSON
JSON
JSON
JSON
JSON
JSON
JSON
JSON
JSON
Small
Small
Small
Small
Large
Large
2X-Large
2X-Large
Medium
Medium
2* Executor(8C, 32GB)
2* Executor(8C, 32GB)
2* Executor(8C, 32GB)
2* Executor(8C, 32GB)
8* Executor(8C, 32GB)
8* Executor(8C, 32GB)
32* Executor(8C, 32GB)
32* Executor(8C, 32GB)
8* Executor(8C, 32GB)
8* Executor(8C, 32GB)
6m 15s + 57s= 7m 12s
22m 27s +8m 9s =30m 36s
5m 35s
27m 57s
1h 36m 47s +24m =2h 47s
1h 2m 35s
2h 21m 19s +1h 13m 49s =3h 35m 8s
2h 58m 29s
2h 2m 7s +47m 10s =2h 49m 17s
2h 15m 43s
6m + 3m 43s = 9m 43s
49m 1s +27m 8s =1h 16m 9s
7m 41s
1h 10m 17s
2h 24s +1h 2m 8s =3h 2m 32s
3h 3m 51s
5h 49s +1h 38m 38s =6h 39m 27s
6h 52m 4s
2h 24s +1h 2m 8s =3h 2m 32s
3h 3m 51s
Table 3: Aggregate Execution Time Comparison - Snowflake vs. Spark
© 2022 Larsen & Toubro Infotech Limited 18

Observations
• For a small data load, where cluster resources are ample, Spark and Snowflake perform aggregation in similar time frames, although Snowflake is generally faster
• However, as data volume increases the performance gap widens, with Snowflake’s execution times often coming in below 50% of Spark’s
• Even after doubling the resources for Spark the performance is still similar
• For the 3TB and 30TB workloads, Spark was taking unrealistically long for execution. As the default shuffle partition and default parallelism value of 200 is too small for large data loads and doesn’t scale well with increased resources, it was changed to 2000 for the 3TB workload and to 10,000 for the 30TB workload
Join
Needs all the data to be scanned/loaded as applicable. In this type of transformation, there is a possibility of data shuffling across nodes in case of distributed processing.
In this experiment, the Join operations are performed between the sales_union dataset with item, customer, customer_address, household_demographics and income_band.
Join is performed on both E+TL and ETL operations to gauge the performance.
SnowflakeFor E+TL operations, all the tables extracted in the Test Setup section are taken as input and the join operation is performed on top of them. And for ETL, the data is read directly from the source using Snowflake external tables.
SparkSimilarly, for Spark the E+TL flow reads input datasets in Parquet format as generated in the Test Setup section and the ETL flow reads directly from raw JSON data.
Comparison
Join Expression
• NODE_SALES_UNIONALL_STG AS SALES_UNION
• LEFT OUTER JOIN ITEM_STG I ON SALES_UNION.ss_item_sk = I._item_sk
• LEFT OUTER JOIN CUSTOMER_STG C ON SALES_UNION.ss_customer_sk = C.c._customer_sk
• LEFT OUTER JOIN CUSTOMER_ADDRESS_STG CA ON SALES_UNION.s_addr_sk= CA.ca_address_sk
• LEFT OUTER JOIN HOUSEHOLD_DEMOGRAPHICS_STG HD ON SALES_UNION.ss_hdemo_sk = HD.hd_demo_sk
• LEFT OUTER JOIN INCOME_BAND_STG IB ON HD.hd_income_band_sk = IB.ib_income_band_sk
© 2022 Larsen & Toubro Infotech Limited 19

Comparison
Join Expression
• NODE_SALES_UNIONALL_STG AS SALES_UNION
• LEFT OUTER JOIN ITEM_STG I ON SALES_UNION.ss_item_sk = I._item_sk
• LEFT OUTER JOIN CUSTOMER_STG C ON SALES_UNION.ss_customer_sk = C.c._customer_sk
OperationInputSize
InputFormat
SnowflakeWarehouse
SparkExecutor
SnowflakeExecution Time
SparkExecution Time
E+TL(Join)
E+TL(Join)
ETL(Join)
ETL(Join)
E+TL (Join)
ETL (Join)
E+TL (Join)
ETL (Join)
30.95GB
309.99GB
30.95GB
309.99GB
30TB
30TB
3TB
3TB
JSON
JSON
JSON
JSON
JSON
JSON
JSON
JSON
Small
Small
Small
Small
2X-Large
2X-Large
Medium
Medium
2* Executor(8C, 32GB)
2* Executor(8C, 32GB)
2* Executor(8C, 32GB)
2* Executor(8C, 32GB)
32* Executor(8C, 32GB)
32* Executor(8C, 32GB)
8* Executor(8C, 32GB)
8* Executor(8C, 32GB)
6m 15s + 35s + 4m 4s = 10m 54s
22m 27s +34s + 34m 37s =57m 38s
4m 37s
38m 27s
2h 21m 19s + 49s +4h 38m 42s =7h 50s
5h 39m 50s
2h 2m 7s + 45s +2h 3m 17s =4h 5m 24s
2h 20m 21s
6m + 1m 56s +10m 10s = 18m 6s
49m 1s + 2m 6s +1h 33m 28s =2h 24m 35s
14m 54s
2h 26m 08s
5h 49s + 5m 48s + 5h 58m 5s =11h 4m 43s
8h 35m 30s
2h 24s + 2m 51s +7h 13m 40s =9h 16m 55s
1h 1m 13s
Table 4: Join Execution Time Comparison - Snowflake vs. Spark
• LEFT OUTER JOIN CUSTOMER_ADDRESS_STG CA ON SALES_UNION.s_addr_sk= CA.ca_address_sk
• LEFT OUTER JOIN HOUSEHOLD_DEMOGRAPHICS_STG HD ON SALES_UNION.ss_hdemo_sk = HD.hd_demo_sk
• LEFT OUTER JOIN INCOME_BAND_STG IB ON HD.hd_income_band_sk = IB.ib_income_band_sk
© 2022 Larsen & Toubro Infotech Limited 20

Observations
• Given equal resources, Snowflake’s performance significantly exceeds Spark’s in 7 of the 8 scenarios tested
• Since, in many cases, we were seeing huge differences between the timings of two platforms, we increased the Spark resources. Even after doubling the resources for Spark, it still lags by around 30% in these cases
• It seems the data shuffling in Spark is the main performance bottleneck here, so we changed the value of “spark.sql.shuffle.partitions” (which has a default value of 200). This value is quite small for a heavier workload. At the same time, it is quite large for smaller workload. Due to scheduling delays if the value is increased too much then it reduces performance. However, if the value is small then larger partitions are shuffled across different executors during join and aggregate operations, which increases the network overhead to move large data across the network. This took some playing around with to get it right
• For executing 30TB data volume initially an executor size of (8 cores and 32GB memory) * 16 was selected. But it resulted in getting out of memory errors on the executors after running the job for some time
• To overcome that, the number of executors were increased from 16 to 32 to keep it comparable with Snowflake 2X-Large warehouse. So, the configuration that is considered for 30TB data load is (8 cores and 32GB memory) * 32
Merge
In a merge type of operation existing rows in a dataset are updated with new data based on unique keys. If there is no match for a given set of keys, then the row is inserted. This type of operation is generally used in incremental load types of scenarios. This type of operation involves searching for keys in the dataset for each incoming row. This consumes a lot of compute and IO resources and could be a bottleneck if not handled efficiently.
For this benchmark we took the sales datasets in a staging area generated in Test Setup section as a base dataset of volume 300GB & 3TB. The incremental load volume is roughly 10% of the base dataset, i.e., 30GB and 300GB. We took ‘order id’ and ‘item id’ keys for merge operation.
SnowflakeThe staging internal Snowflake table generated in the Test Setup section is taken as a base table and JSON files stored on S3 object store were taken as a source dataset for the merge operation.
SparkThe staging data was stored in delta format. The Incremental load was performed on top of it by reading data from JSON format.
© 2022 Larsen & Toubro Infotech Limited 21

Merge
In a merge type of operation existing rows in a dataset are updated with new data based on unique keys. If there is no match for a given set of keys, then the row is inserted. This type of operation is generally used in incremental load types of scenarios. This type of operation involves searching for keys in the dataset for each incoming row. This consumes a lot of compute and IO resources and could be a bottleneck if not handled efficiently.
For this benchmark we took the sales datasets in a staging area generated in Test Setup section as a base dataset of volume 300GB & 3TB. The incremental load volume is roughly 10% of the base dataset, i.e., 30GB and 300GB. We took ‘order id’ and ‘item id’ keys for merge operation.
ComparisonTable 5: Merge Execution Time Comparison - Snowflake vs. Spark
Input Size InputFormat
SnowflakeWarehouse
SnowflakeExecution Time
SparkExecution Time
SparkExecutor
30GB on300GB
300GB on3TB
JSON
JSON
Small
Small
4* Executor(8C,32GB)
4* Executor(8C,32GB)
1m 15s
16m 6s
6m 41s
59m 41s
Observations
In the merge type of use case, Snowflake’s execution time is 63% to 81% better than Spark’s, while using 50% of the resources.
Concurrency
Various BI tools can connect to both Spark Interactive cluster, as well as Snowflake over JDBC interface. And in general, many users of the BI tools fire up similar queries most of the time. When there are too many concurrent users, it becomes necessary for the system to scale up to cater to the needs of the users. Here both Spark Interactive clusters as well as Snowflake virtual warehouses offer an auto-scaling capability.
A peak load type of a scenario was stimulated where there are more than 100 concurrent users (120 to be more precise) trying to access the data. There were 40 unique queries fired up 3 times resulting in 120 parallel requests hitting the system at the same time. The queries were a combination of Join, Aggregate and various filters. The data taken is 3TB data extracted in the Test Setup section.
SnowflakeThe Snowflake data was read from the Snowflake internal table. The client connected using JDBC and fired 120 queries in parallel. Cluster auto-scaling was disabled here.
SparkSimilarly, for Spark as well a cluster was fired up and the tables being read were stored in Delta format. The VMs used were Delta Cache optimized. A JDBC client was used to fire 120 queries in parallel.
SnowflakeThe staging internal Snowflake table generated in the Test Setup section is taken as a base table and JSON files stored on S3 object store were taken as a source dataset for the merge operation.
SparkThe staging data was stored in delta format. The Incremental load was performed on top of it by reading data from JSON format.
© 2022 Larsen & Toubro Infotech Limited 22

Concurrency
Various BI tools can connect to both Spark Interactive cluster, as well as Snowflake over JDBC interface. And in general, many users of the BI tools fire up similar queries most of the time. When there are too many concurrent users, it becomes necessary for the system to scale up to cater to the needs of the users. Here both Spark Interactive clusters as well as Snowflake virtual warehouses offer an auto-scaling capability.
A peak load type of a scenario was stimulated where there are more than 100 concurrent users (120 to be more precise) trying to access the data. There were 40 unique queries fired up 3 times resulting in 120 parallel requests hitting the system at the same time. The queries were a combination of Join, Aggregate and various filters. The data taken is 3TB data extracted in the Test Setup section.
SrNo. Operation
SnowflakeW/H
SparkExecutor
SnowflakeExecution Time
SparkExecution Time
1
2
3
4
5
6
7
8
9
4 MediumWarehouse withNo Cache
4 Medium Warehouse without Result Cache
4 Medium Warehouse with Cache
2 Medium Warehouse with Cache
1 Medium Warehouse with Cache
1 Medium Warehouse with all Cache
Spark Delta
Spark Delta
Spark Delta
4 * Medium
4 *Medium
4 *Medium
2*Medium
1*Medium
NA (SeeObservations)
NA (SeeObservations)
NA (SeeObservations)
NA (SeeObservations)
NA (SeeObservations)
NA (SeeObservations)
NA (SeeObservations)
NA (SeeObservations)
NA (SeeObservations)
NA (SeeObservations)
32* Executor(8C,61GB)
32* Executor(16C,122GB)
32* Executor(16C,122GB)
NA (SeeObservations)
NA (SeeObservations)
NA (SeeObservations)
NA (SeeObservations)
NA (SeeObservations)
NA (SeeObservations)
43.51m
24.8m
18.4m
8m
6m 55s
5m 10s
6m 2s
8m 49s
30s
NA (SeeObservations)
NA (SeeObservations)
NA (SeeObservations)
Table 6: BI Execution Time Comparison - Snowflake vs. Spark
SnowflakeThe Snowflake data was read from the Snowflake internal table. The client connected using JDBC and fired 120 queries in parallel. Cluster auto-scaling was disabled here.
SparkSimilarly, for Spark as well a cluster was fired up and the tables being read were stored in Delta format. The VMs used were Delta Cache optimized. A JDBC client was used to fire 120 queries in parallel.
© 2022 Larsen & Toubro Infotech Limited 23

Observations
SnowflakeSnowflake uses smart caching to cache the query result and preserves it for 24 hours.Hence, during the test run the result of the queries were cached resulting in instantaneous query output. To include the actual execution time of the query, caching was disabled for the first run and re-enabled in subsequent runs for each warehouse combination.
1. For this Medium Warehouse we disabled the cached results for all 120 queries. Since caching was disabled, all queries went to the warehouse for execution
2. For this Medium Warehouse we disabled the cached results for all 120 queries, but the warehouse was kept running. Since caching was disabled but the warehouse was running, warehouse cache was utilized, resulting in performance improvement over non-cached execution
3. For this Medium Warehouse, 40 queries were executed by disabling the cache. Later the same set of queries were executed twice, making it 120 queries in all. Interestingly, even though it was defined to use a maximum of 4 cluster warehouses, here Snowflake chose to use only 3 warehouses. The subsequent 80 queries picked up the result from the cache and returned instantaneous response
4. This scenario is the same as #3 but with 2 cluster warehouses. Here it took marginally more time compared to previous execution with 3 warehouses
5. This scenario is the same as #3 but with 1 cluster warehouse. Here it took 4 more minutes to complete the execution. It shows that it’s always better to configure auto scaling with enough head room, if the number of concurrent users is high
6. In this scenario all 120 queries were executed simultaneously with the result cache enabled. The warehouse was in a suspended state and it didn’t bother to start and all query results were picked up from the result cache that was formed from previous executions. This means the computation cost is essentially zero for subsequent query executions if caching is enabled
Spark Spark provides interactive clusters which are meant to handle concurrent user sessions. When we tried to keep the resources the same as Snowflake in terms of processing cores and number of executors, the queries were taking too long for execution and were eventually failing to generate any results.
7. To successfully support 120 concurrent users, we started with double the resources than we used for Snowflake, e.g., min. 16 and max. 32 with 8 cores and 61GB memory. Here, it took 43 minutes to execute the same queries that with Snowflake took 5 minutes. This processing time is not acceptable for BI use cases
8. To further bring down the time, we bumped up the executor configuration from 8 cores/61GB to 16 cores/122GB with a minimum of 32 executors. Here we observed some improvement in performance. In this case Spark took 24 minutes which is still 5X more time than Snowflake, even though it was using 4X more resources
9. To bring down the time further, we adjusted the ‘spark.default.parallelism’ and ‘spark.sql.shuffle.partitions’ and set it to 1000 to improve Join and Aggregate operations. Everything else was kept the same. This further reduced 6 minutes from the execution time and completed all the queries in 18 minutes. However, this duration is still 3X more than Snowflake and is still too high for BI use cases. Additionally, with this configuration if the queries are executed on a smaller dataset, it will aggravate scheduling delays and cause a performance hit
This test tells us that Spark Interactive clusters are not suitable for handling a large number of concurrent users. And if the cluster is tuned for one type of workload, then there is a high probability that it will adversely impact the other types of workloads.
© 2022 Larsen & Toubro Infotech Limited 24

Overall Observations• In terms of price and performance, given that it not only runs faster than Spark, but in several cases does so using half of the compute resources, Snowflake emerges as a winner
• It outperforms Spark by a large margin in the whole ETL cycle. If its other features align well with your business needs, Snowflake becomes a better choice to be integrated and used with Spectra
• All the above flows were executed using the Spark Jobs cluster which takes around 5 minutes to start running. This introduces delay in the overall processing. The Snowflake warehouse starts running immediately
• With Spark, some jobs observed failures due to memory or other issues which are harder to debug to identify the root cause. Not a single job failure was observed during Snowflake execution
• For long-running jobs, Spark executors went down multiple times, resulting in delays
• There are several parameters to be configured to extract performance out of Spark, whereas for Snowflake everything just works out-of-the-box
• Many Spark parameters are to be tuned based on the workload to extract the best performance out of it. If the parameters are tuned for a specific type of workload, it adversely impacts other scenarios
Observations
SnowflakeSnowflake uses smart caching to cache the query result and preserves it for 24 hours.Hence, during the test run the result of the queries were cached resulting in instantaneous query output. To include the actual execution time of the query, caching was disabled for the first run and re-enabled in subsequent runs for each warehouse combination.
1. For this Medium Warehouse we disabled the cached results for all 120 queries. Since caching was disabled, all queries went to the warehouse for execution
2. For this Medium Warehouse we disabled the cached results for all 120 queries, but the warehouse was kept running. Since caching was disabled but the warehouse was running, warehouse cache was utilized, resulting in performance improvement over non-cached execution
3. For this Medium Warehouse, 40 queries were executed by disabling the cache. Later the same set of queries were executed twice, making it 120 queries in all. Interestingly, even though it was defined to use a maximum of 4 cluster warehouses, here Snowflake chose to use only 3 warehouses. The subsequent 80 queries picked up the result from the cache and returned instantaneous response
4. This scenario is the same as #3 but with 2 cluster warehouses. Here it took marginally more time compared to previous execution with 3 warehouses
5. This scenario is the same as #3 but with 1 cluster warehouse. Here it took 4 more minutes to complete the execution. It shows that it’s always better to configure auto scaling with enough head room, if the number of concurrent users is high
6. In this scenario all 120 queries were executed simultaneously with the result cache enabled. The warehouse was in a suspended state and it didn’t bother to start and all query results were picked up from the result cache that was formed from previous executions. This means the computation cost is essentially zero for subsequent query executions if caching is enabled
Spark Spark provides interactive clusters which are meant to handle concurrent user sessions. When we tried to keep the resources the same as Snowflake in terms of processing cores and number of executors, the queries were taking too long for execution and were eventually failing to generate any results.
7. To successfully support 120 concurrent users, we started with double the resources than we used for Snowflake, e.g., min. 16 and max. 32 with 8 cores and 61GB memory. Here, it took 43 minutes to execute the same queries that with Snowflake took 5 minutes. This processing time is not acceptable for BI use cases
• The data extraction capability of Snowflake is more efficient than that of Spark. We consistently observed Snowflake’s processing time to be half for the same data volume and resources
• Spark interactive cluster struggles to handle 100+ concurrent users even after throwing resources at it. Queries get queued up and response time suffers. This makes it hard to use it for interactive sessions. Snowflake performs 3X better even with 25% resources. The query response time is quite good and because queries line up, the warehouse scales instantaneously
8. To further bring down the time, we bumped up the executor configuration from 8 cores/61GB to 16 cores/122GB with a minimum of 32 executors. Here we observed some improvement in performance. In this case Spark took 24 minutes which is still 5X more time than Snowflake, even though it was using 4X more resources
9. To bring down the time further, we adjusted the ‘spark.default.parallelism’ and ‘spark.sql.shuffle.partitions’ and set it to 1000 to improve Join and Aggregate operations. Everything else was kept the same. This further reduced 6 minutes from the execution time and completed all the queries in 18 minutes. However, this duration is still 3X more than Snowflake and is still too high for BI use cases. Additionally, with this configuration if the queries are executed on a smaller dataset, it will aggravate scheduling delays and cause a performance hit
This test tells us that Spark Interactive clusters are not suitable for handling a large number of concurrent users. And if the cluster is tuned for one type of workload, then there is a high probability that it will adversely impact the other types of workloads.
© 2022 Larsen & Toubro Infotech Limited 25

Overall Observations• In terms of price and performance, given that it not only runs faster than Spark, but in several cases does so using half of the compute resources, Snowflake emerges as a winner
• It outperforms Spark by a large margin in the whole ETL cycle. If its other features align well with your business needs, Snowflake becomes a better choice to be integrated and used with Spectra
• All the above flows were executed using the Spark Jobs cluster which takes around 5 minutes to start running. This introduces delay in the overall processing. The Snowflake warehouse starts running immediately
• With Spark, some jobs observed failures due to memory or other issues which are harder to debug to identify the root cause. Not a single job failure was observed during Snowflake execution
• For long-running jobs, Spark executors went down multiple times, resulting in delays
• There are several parameters to be configured to extract performance out of Spark, whereas for Snowflake everything just works out-of-the-box
• Many Spark parameters are to be tuned based on the workload to extract the best performance out of it. If the parameters are tuned for a specific type of workload, it adversely impacts other scenarios
Spectra With SnowflakeSpectra comes with out-of-the-box support for Snowflake cloud-native transformation. It harnesses Snowflake’s capabilities enabling businesses to benefit most out of this combination.
Spectra with Snowflake offers following features
• Spectra comes with an intuitive point-and-click Graphical user interface. It integrates easily and efficiently with data present in Snowflake, bringing data closer to the compute layer from siloes
• Spectra’s architecture puts Snowflake’s cloud-native architecture to its best use by taking advantage of its high scalability and performance. So, Snowflake’s highly performance-oriented architecture is fully leveraged
• Spectra supports cloud-native pushdown data transformations for Snowflake. This enables it to take advantage of procedures already stored in Snowflake, with a future scope of integrating well with new products and services such as Snowpark that Snowflake is rolling out
• Spectra has features natively built for easy configuration of Snowflake. Thus, any application built specifically for any Snowflake warehouse execution can be managed easily with Spectra. It also provides drag-and-drop features for the easy creation of Snowflake workloads
• Spectra comes with multi-engine support capability and provides easier resource configuration for Spark workloads as well. Spark configuration benefits from being fine-tuned for every performance run
• Spectra supports easy migration of Spark customers to Snowflake. This is also facilitated by Spectra’s support for multiple execution engines
• The data extraction capability of Snowflake is more efficient than that of Spark. We consistently observed Snowflake’s processing time to be half for the same data volume and resources
• Spark interactive cluster struggles to handle 100+ concurrent users even after throwing resources at it. Queries get queued up and response time suffers. This makes it hard to use it for interactive sessions. Snowflake performs 3X better even with 25% resources. The query response time is quite good and because queries line up, the warehouse scales instantaneously
© 2022 Larsen & Toubro Infotech Limited 26

• Spectra platform has better non-functional features than other data integrators. These enable better footprints for Snowflake credit consumption and overall Snowflake usage experience. These features include User Management, Audit Management, Scheduling & Monitoring, Version Control, and User Code management and migration
Key Benefits of Using Spectra With Snowflake
27
Faster time- to-market
Maximizing returns on investments
Reduction in total cost of ownership
Competitive edge with better performance

© 2022 Larsen & Toubro Infotech Limited
The Fosfor Product Suite is the only end-to-end suite for optimizing all aspects of the data-to-decisions lifecycle.Fosfor helps you make better decisions, ensuring you have the right data in more hands in the fastest time possible.The Fosfor Product Suite is made up of Spectra, a comprehensive DataOps platform; Optic, a data fabric to facilitate data discovery-to-consumption journeys; Refract, a Data Science and MLOps platform; Aspect, a no-code unstructured data processing platform; and Lumin, an augmented analytics platform. Taken together, the Fosfor suite helps businesses discover the hidden value in their data. The Fosfor Data Products Unit is part of LTI, a global technology consulting and digital solutions company with hundreds of clients and operations in 31 countries. For more information, visit Fosfor.com.
ConclusionSpectra supports both Spark and Snowflake. When we test Spectra’s performance on each of the platforms, Snowflake outperforms Spark at all the stages in the ETL lifecycle. Overall, fine tuning the processes to execute requires less effort on Snowflake compared to Spark. We therefore conclude that the combination of Snowflake + Spectra yields a DataOps platform optimized for both time-to-solution and ROI.




















