
First Language Phonetic Drift During Second ... - UC Berkeley
Upload
khangminh22Category
view
0download
0
Treball de fi de màster
Màster:
Edició:
Directors:
Any de defensa:
Col⋅lecció: Treballs de fi de màster
Programa oficial de postgrau "Comunicació lingüística i mediació multilingüe"
Departament de Traducció i Ciències del Llenguatge

2
Abstract
This project, which blended two fields of linguistics, language technology and dialectology,
accomplished three main goals. Firstly, it improved TexAFon, a rule and knowledge based
speech processing tool and upgraded it to handle eight northwestern Catalan varieties.
Secondly, it enabled the tool for ASR use. Thirdly, it prepared TexAFon for use as an
automatic pronunciation training system. The dialects were chosen as a result of a thorough
research both in dialectology and language technology so as to define phenomena for Text-
To-Speech (TTS) and Automatic Speech Recognition (ASR) modeling. The result of this
project is an updated version of TexAFon, which can now be used for TTS and ASR in several
Catalan dialects, and provide the basis for its use as an automatic pronunciation training
system. Furthermore, this work also shows the upcoming need for updated dialectological
studies in order to get present information about phenomena in different Catalan dialects.
Keywords: ASR, TTS, Pronunciation Dictionaries, Automatic Phonetic Transcription, TexAFon,
dialects, Catalan.

3
Acknowledgements
I would like to specially thank Juan María Garrido and Esteve Clua for guiding me along this
project. Juanma made me discover the fascinating field of language technology and Esteve
helped me in dialectology. I would also like to thank my family for being always there and
encouraging me to become the person I am today. Finally, I cannot forget to mention Becca
for her final project’s correction.

4
Table of Contents
1. Introduction .................................................................................................... 6 1.1. ASR .................................................................................................................... 6 1.2. Pronunciation dictionaries .................................................................................. 8
1.2.1. Pronunciation dictionaries by corpus and rules .................................................. 9 1.3. Automatic phonetic transcription ..................................................................... 10
1.3.1. Automatic phonetic transcription in Catalan and Spanish ................................ 11 1.3.2. TexAFon ................................................................................................................ 12
1.4. Goals and methodology .................................................................................... 14
2. Definition of variants and selection of phenomena ....................................... 15 2.1. Selected inter-dialectal phenomena.................................................................. 18 2.2. Ribagorçà ......................................................................................................... 19
2.2.1. Primary phenomena .......................................................................................... 19 2.2.2. Secondary phenomena...................................................................................... 20
2.3. Pallarès ............................................................................................................ 21 2.3.1. Primary phenomena .......................................................................................... 21 2.3.2. Secondary phenomena...................................................................................... 22
2.4. Tortosí ............................................................................................................. 22 2.4.1. Primary phenomena .......................................................................................... 22 2.4.2. Secondary phenomena...................................................................................... 23
2.5. Central Area ..................................................................................................... 23 2.5.1. Primary phenomena .......................................................................................... 23
2.6. Northern Valencian .......................................................................................... 24 2.6.1. Primary phenomena .......................................................................................... 24 2.6.2. Secondary phenomena...................................................................................... 24
2.7. Central Valencian ............................................................................................. 25 2.7.1. Primary phenomena .......................................................................................... 25 2.7.2. Secondary phenomena...................................................................................... 25
2.8. Southern Valencian .......................................................................................... 26 2.8.1. Primary phenomena .......................................................................................... 26 2.8.2. Secondary phenomena...................................................................................... 26
2.9. Alacantí ........................................................................................................... 26 2.9.1. Primary phenomena .......................................................................................... 27 2.9.2. Secondary phenomena...................................................................................... 27
2.10. Pseudo-code .................................................................................................. 28
3. Implementation ............................................................................................ 28 3.1. Overview ......................................................................................................... 28 3.2. Limitations on every dialect .............................................................................. 29
3.2.1. Limitations shared in all dialects ....................................................................... 29 3.2.2. Limitations in Pallarès ....................................................................................... 30 3.2.3. Limitations in Ribagorçà .................................................................................... 31 3.2.4. Limitations in Tortosí ......................................................................................... 31 3.2.5. Limitations in Central Area ................................................................................ 32 3.2.6. Limitations in Northern Valencian ..................................................................... 32 3.2.7. Limitations in Central Valencian ........................................................................ 32 3.2.8. Limitations in Southern Valencian ..................................................................... 33 3.2.9. Limitations in Alacantí ....................................................................................... 33
3.3. Exception dictionaries ...................................................................................... 33
4. Evaluation ..................................................................................................... 34

5
4.1. Evaluation of Ribagorçà .................................................................................... 35 4.2. Evaluation of Pallarès ....................................................................................... 36 4.3. Evaluation of Tortosí ........................................................................................ 36 4.4. Evaluation of Central Area ................................................................................ 36 4.5. Evaluation of Northern Valencian ..................................................................... 37 4.6. Evaluation of Central Valencian ........................................................................ 37 4.7. Evaluation of Southern Valencian ..................................................................... 37 4.8. Evaluation of Alacantí ...................................................................................... 38 4.9. Overview of the results .................................................................................... 38
5. Conclusion ..................................................................................................... 39
References ........................................................................................................... 40
Annex 1 ................................................................................................................ 44
Annex 2 ................................................................................................................ 53
Annex 3 ................................................................................................................ 82
Annex 4 ................................................................................................................ 83
Annex 5 ................................................................................................................ 86
Annex 6 ................................................................................................................ 87

6
1. Introduction
Speech technologies are used more and more worldwide, which makes the adaptation of
these tools in different languages an important research path. For an adaptation of this kind,
research in dialects and phonetics is very important. TexAFon (Garrido et al., 2012) is a
multi-functional linguistic processing module primary used for Text-To-Speech (TTS) and the
creation of phonetic dictionaries for Central Catalan and Standard Peninsular Spanish. Fodge
(2014) improved the tool, adding with new capabilities in order for it to be used for
automatic speech recognition (ASR) in several dialects of Spanish.
1.1. ASR
ASR first appeared in the 1930s when Homer Dudley of Bell Laboratories presented a model
for the synthesis and analysis of speech. ASR is technology that allows a computer to identify
words spoken into a microphone or telephone and convert them to written text. In short, a
processing of an ASR begins with a person speaking through a microphone and consequently
producing a waveform, captured by the software. This waveform not only has information
about the words and sentences pronounced by the speaker, but also extraneous sounds and
pauses. The software then has to attempt to decode the speech signal into the best
estimation of a given sentence. For doing so, it first converts the speech signal into a
sequence of vectors, which are measured throughout the duration of the speech signal.
Then, using a syntactic decoder it generates a valid sequence of representations (Rabiner et
al., 2004).
The structure of an ASR includes different modules that will be explained in detail below.
1. A parameter extractor, which extracts the acoustic parameters from the speech
signal.
2. An acoustic recognizer, which identifies the sounds and words extracted from the
module 1.
3. A contextual analyzer, which improves the output of the recognizer with the help of
linguistic information.

7
Figure 1 Speech recognition performance.
The parameter extractor usually extracts the relevant acoustic information for recognition
using Mel Frequency Cepstral Coefficients (Mermelstein, 1976). After obtaining these
parameters, the next module uses acoustic models, which are language-specific, to associate
the input signal with a sound chain (either allophones or phonemes). This part is done by
statistical and probabilistic techniques: Hidden Markov Models (Lamel & Gauvain, 2003) are
the ones used nowadays.
The acoustic models are automatically created by the use of huge amounts of speech
corpus, from the biggest number of speakers possible. The corpus needs to cover as much
variation as possible, so as to get a representative model. The output of the recognizer
usually has errors due to the fact that recognition has been conducted only with acoustic
information.
For the reason above, the recognizer needs extra linguistic information so as to minimize
errors. This extra information can be added by means of a pronunciation dictionary,
grammars or a mix of both (language models). Both tools need manual elaboration and
linguistic knowledge. However, language models, which have probabilistic measures of word
appearance in a given context, are created automatically by the use of statistical techniques.
Grammars and language models are nowadays very used for the post-processing of the
output of the recognition module. The former is a set of sentences that are correct and can
be part of a given discourse. The latter uses the context in order to predict the appearance

8
frequency of a given set of words (expressed in n-grams) so as to choose the most
appropriate or frequent word to correct the output in the recognition module.
Pronunciation dictionaries will be explained in detail later in this paper.
Since it first appeared, this technology has evolved from a simple machine that only
understands a small set of sounds to a sophisticated system that can respond to natural
language spoken in a fluent way. In the 1980s there were some major advances in statistical
modeling of speech, which helped this technology to have numerous applications in tasks
that require a human-machine interface such as automatic call processing (Juang et al.,
2005) or medical transcriptions. These numerous applications require ASR systems to be
trained to operate in complex environments, both acoustically and linguistically (Hain,
2005).
For this reason, researchers realized that “the enormous variation in pronunciation among
speakers of the same language or even the same language variety constitutes a serious
challenge to automatic speech recognition” (Kessens et al., 2003). Consequently, “in order
to obtain reasonable performance, statistical pattern recognition approaches have
dominated research in this field of speech recognition over recent decades” (Hain, 2005).
As seen in the diagram above, one of the important modules for the correct operation of an
ASR is the post-processing module, where linguistic knowledge is needed so as to create
both pronunciation dictionaries and grammars. In section 1.2., the creation of pronunciation
dictionaries is analyzed in detail.
1.2. Pronunciation dictionaries
There are two types of pronunciation dictionaries: the ones for text-to-speech (TTS) and the
ones for ASR. The first only has the prototypical or standard occurrence of a word, whereas
the second needs all the possible pronunciations in a language, since its mission is to
correctly identify all possible realizations of a word. This variation can be caused by general
context dependency or the speed of uttered speech and speaking style in general (Hanžl &
Pollák, 2009). These authors add that emotions, geographical differences –dialect– or
different meanings of a word are also part of the variation in a language.
Torres (2006) go on the idea that ASR applications are for a general public that are not
professionals in the field of speech technologies and consequently the speech they conduct
has some important characteristics. This fact creates a continuous speech with speakers’

9
independence, spontaneous and sometimes in an adverse environment; thus, with a lot of
variation.
When dealing with variation in the field of speech technology, one of the domains that
needs to be improved is related to the phonetics, and especially differences in dialects. As
Strik & Cucchiarini (1999) argues, there are four main decisions when choosing a method for
modeling pronunciation: the type of pronunciation variation, the source of the variation
information, the information representation and the level of modeling, as will be explained
in subsequent sections.
The idea of introducing all possible pronunciations of a word is not feasible from a practical
point of view since adding pronunciation variants can introduce new errors (Wester, 2003).
Thus, variants introduced in the pronunciation dictionary have to be chosen carefully. A
study carried out by Kessens et al. (2003) showed that when “the average number of
variants per word in the lexicon exceeds roughly 2.5, the system with variants starts
performing worse than the baseline system without multiple variants”. For this reason, it is
necessary to find a balance between introducing new variants and not increasing the errors
because “simply adding several alternate pronunciations to the dictionary increases the
confusability of words to the extent that the gains from having them are often more than
nullified” (Byrne et al., 1998).
There are different criteria in order to get this balance and smooth the phonemic
transcription: decision trees (Riley et al., 1999), frequency of occurrence of the variants
(Kessens & Wester, 1997), maximum likelihood criterion (Holter, 1997), confidence
measures (Sloboda & Waibel, 1996) and the degree of confusability between the variants
(Sloboda & Waibel, 1996).
1.2.1. Pronunciation dictionaries by corpus and rules
When creating pronunciation dictionaries, the information source can be data-driven (or
data-derived) or knowledge-based. The first is obtained directly from data, whereas the
knowledge-based information is derived from linguistic studies in which rules have been
formulated (Wester, 2003). Both sources have pros and cons. On the one hand, knowledge-
based information can sometimes be insufficient to cover every variation, since “not all of
the variation that occurs in spontaneous speech has been described” (Wester, 2003), which
is known as undercoverage. Nevertheless, overcoverage can also occur adding variants that
do not figure in a given corpus.

10
On the other hand, in data-driven information, as only a corpus is given, there can be more
cases of undercoverage, since it does not generalize to situations other than the one in
question (Strik & Cucchiarini, 1999). However, having a good corpus can also help to
improve those exceptions not collected by a knowledge-based method. A good option
proposed by Strik & Cucchiarini (1999) is to use a method with two stages: a first stage
consisting of a knowledge-based model, because it can easily be exported to new tasks; and
then a data-driven model to get the remaining pronunciation variation.
In short, there are two types of pronunciation dictionaries: by means of a corpus (Byrne et
al., 1998; Al-Haj et al., 2009; Hain, 2005) or by the creation of rules (Hanžl & Pollák, 2009).
The use of one way or another not only depends on the language being modeled, but also
on the availability of sources: large corpora or literature about variation in a given language.
Moreover, the task we want to carry out is important since if the domain is specific, the
vocabulary can be smaller (Torres, 2006). If the chosen method is using rule-based
automatic phonetic transcription, a lot of linguistic knowledge is needed and it gets better
results when rules are as exhaustive as possible.
1.3. Automatic phonetic transcription
We have seen two different methods of creating a pronunciation dictionary: by rules or by
corpus. What makes rule-based methods suitable when creating a pronunciation dictionary
is the fact that rules can generalize to new words not seen in a corpus. Thus, when little data
is available, rule-based methods get better results.
When creating a pronunciation dictionary by rules, it is common to do so by automatic
phonetic transcription. However, some languages do not have a clear correspondence
between graphemes and phonemes, making it more difficult to create rules. Such is the case
of English, a very opaque language in terms of the grapheme-phoneme relationship. In fact,
“un mismo segmento fonológico se puede representar mediante varias formas grafémicas
distintas” (Cuetos, 1989). Moreover, English has a lot of irregularities, which makes it harder
for a rule-based method to function well and it needs a large lexicon of irregularities and few
rules.
On the other hand, Spanish is very transparent with relatively few irregular words and with
an almost absolute correspondence between graphemes and phonemes (Cuetos, 1989). Ríos
(1993) in his work on automatic phonetic transcription also argues that “el carácter
“fonémico” de la ortografía española hace relativamente fácil esa operación frente a lo que

11
sucede en otras lenguas, como el francés” and word stress is also predictable. The Spanish
characteristics that make it ideal for automatic phonetic transcription by rules in general
also apply to Catalan.
1.3.1. Automatic phonetic transcription in Catalan and Spanish
Some examples of automatic phonetic transcription in Spanish are Diccionario Electrónico
Fonético del Español (Ríos, 1993) using three main dictionaries; a G2P tool by rules for seven
Spanish dialects (Moreno & Mariño, 1998); the improvement of an existing letter-to-phone
system by adding more phonemes and modifying the rules that were not working
(Bonaventura et al., 1998); or SAGA (Nogueiras & Mariño, 2009).
This last project is a tool for Spanish automatic phonetic transcription using SAMPA
alphabet. It has variants of peninsular Spanish and also Latin American dialects defined in
SALA project (Moreno et al., 1998). SAGA project works by arguments and each module has
to be called independently, which requires some computational knowledge to use it.
Some research done in Catalan is Segre (Pachès et al., 2000), Tecnoparla (Shulz et al., 2008;
Shulz et al., 2009) or the TransLectures-UPV toolkit (del Agua et al., 2012). There is an
existing tool that gives the standard pronunciation of words in five dialects (ReSolc, 2010).
However, this tool does not allow for the creation of a whole text and only gives the
standard pronunciation.
All the aforementioned tools take variation into account in one way or another. However,
they do not enter into details of dialect variation and how to analyze it. The one that
explains the most about dialects is Segre, but this tool does not allow the possibility of
having more than one possible pronunciation per dialect, having to choose one dialect with
one only possible pronunciation at a time, making the creation of a pronunciation dictionary
hard.
In this section we have analyzed how automatic phonetic transcription is implemented in
Spanish and Catalan and we have seen that little is done for variation within the second.
Hence in order to create a good pronunciation dictionary for Catalan it is necessary to have a
tool that allows for the creation of more than one variation of a word at a time.
The main purpose of this project is to get a pronunciation dictionary for Catalan
northwestern dialects. In order to fulfill this goal a tool named TexAFon is used. This tool for
now is only TTS but its structure, which will be explained below, allows the creation of more

12
than one pronunciation per word by rules with the idea to create a pronunciation dictionary
suitable for ASR.
1.3.2. TexAFon
TexAFon (Garrido et al., 2012) is a multi-functional linguistic processing module. It is
language dependent, and it has primarily been used for linguistic processing in TTS
applications. Fodge (2014) in her master thesis improved it with new capabilities that allow
the creation of more than one variation per word. She adapted the tool to several dialects of
Spanish. The aim of this work is to introduce different dialects of northwestern Catalan to
TexAFon with the same idea, not only to improve it, but also to enable it to form part of the
post-processing module of an ASR.
TexAFon was fully developed by linguists from Universitat Pompeu Fabra and Barcelona
Media Centre d’Innovació and it is “a set of Catalan/Spanish text processing tools for
automatic normalization, phonetic transcription, syllabication, prosodic segmentation and
stress prediction from text” (Garrido et al., 2012). This is a rule and context based tool and
was used for the creation of this project because of its adaptability and multi-functionality.
This tool was developed using Python and it has a modular architecture, which makes it very
adaptable. According to Garrido et al. (2012) there are three sections (Figure 2):
Figure 2 TexAFon modules (Garrido et al., 2012)

13
These sections are a general processing core, which includes the language-independent
procedures; the language packages (for now in Catalan and Spanish), including modules
and dictionaries specific of the language; and the applications, which call the processing
core depending on their needs.
The language packages are the language-dependent resources that TexAFon uses to process
input according to language-specific rules. Garrido et al. (2012) included Standard Castilian
and Central Catalan and Fodge (2014) augmented with six new Spanish dialects: Castilla la
Nueva, Northern Extremeño and Andalucía, Southern Extremeño and Andalucía, Canario and
Spanish spoken by L1 American English speakers.
As we already said, the language packages are the language-dependent resources that
TexAFon uses to process input according to language-specific rules. There are two language-
dependent modules: an lts module for letter-to-sound translation, stress predictions and
syllabification and a textnorm module for text expansion. There are also three different
dictionaries: one for exceptions of the established rules, one for the most common
abbreviations and one for initials that do not follow the standard spelling rules.
The nature of TexAFon forces not only every language but also every dialect to be an
independent module. Thus, common changes in all dialects being adapted need to be done
separately in every module. However, after the adaptation of TexAFon for ASR purposes a
new program was created in order to get a pronunciation dictionary:
‘crea_dicc_fonetico_con_variantes_de_lista_palabras’ (Fodge, 2014). It is used to test the
behavior of the rules in a hypothetical ASR application, since the input of this program is a
list of words and the output is the phonetic transcription of these words into a given dialect.
In the case when there is more than one variety, the output gives all of them.
The existing program ‘proc_ling’ is a TTS-oriented tool that allows you to obtain the phonetic
transcription of a whole text. In this case, the program uses sentences or paragraphs and
returns the phonetic chain. Despite being part of the first version of TexAFon, it was also
adapted so as to transform a text into different Spanish dialects. Unlike the first program,
that gives all possible pronunciations of a word, this program only gives the most frequent
one. In both cases, the output is written phonetically and two different transcriptions can be
chosen: SAMPA or Cereproc. Finally, this program allows for the creation of neutral vs. not
neutral speech. This feature is not currently used, since there is not a lot of information on
this topic in Catalan.

14
As Fodge (2014) explains “because of its nature as a rule and knowledge-based tool, the
programming of TexAFon requires previous linguistic knowledge; however, the use of it does
not. Users provide their input, input their desired application, and select the language
package they want to work with”.
1.4. Goals and methodology
Although Catalan is not as widely spoken as Spanish throughout the world, there are some
significant differences among dialects. These differences may have some implications when
creating speech technologies, since Central Catalan is the most spoken but not the only one;
thus, leaving some speakers apart of these kinds of technologies. For this main reason, it is a
good idea to implement language variation in speech technologies such as TexAFon in order
to be able to develop pronunciation dictionaries including variants for ASR purposes.
As Kodge (2014) notes in her thesis that those working with TexAFon wanted to prepare this
tool to generate variants simultaneously and for it to be used for ASR. For this reason, this
project has the same three main goals as Kodge’s , not for Spanish dialects but for Catalan.
1. To create an automatic phonetic transcription system oriented to TTS of dialectal
varieties;
2. To improve TexAFon with new capabilities by equipping it to generate several possible
transcriptions for single words, so that multiple possible pronunciations can be modeled for
ASR use;
3. To develop and prepare TexAFon for use as an automatic pronunciation training system.
To do so, analysis of Catalan dialects bibliography was conducted. After getting this
information, rules were created and implemented in TexAFon. Unlike SAGA (Nogueiras &
Mariño, 2009), which works using arguments, each dialect in TexAFon is an independent
module and needs to be created independently: the exception dictionary of each dialect is
also adapted to differences. In section 2 variants are defined and phenomena is chosen so as
to create rules; in section 3 rules are implemented and limitations are explained; in section 4
results are evaluated; and in section 5 progress is being analyzed.

15
2. Definition of variants and selection of phenomena
Depending on the author Catalan is divided into five (Badia, 1981) or six1 (Veny, 1993)
different dialects with some important differences not only among them but also within. As
Colomina (1999) explains “en els darrers anys, l’accés al català a les escoles i als mitjans
audiovisuals de totes les regions […] ha suposat el sorgiment d’alguns problemes de model
de llengua”. In fact, when Fabra created in 1933 a model of Catalan, he did not mention the
oral part. It wasn’t until 1990 that the Institut d’Estudis Catalans (IEC) published a suggestion
of how to pronounce Catalan properly according to different dialects. This publication had
the intention of displaying a standard for each dialect (Institut d’Estudis Catalans, 1990).
However, especially due to reasons of power and politics, Central Catalan has always been
seen as the best dialect. For this reason, a lot of speech technologies tools only take into
account this variety; such is the case of TexAFon.
Dialects are different ways of speaking a language. In fact, first a group of dialects that share
some similar characteristics appears and they are then grouped into a common language.
This variation in a language can be among users or among uses. As the table below shows,
the one we will take into account in this project is the variation among users.
Linguistic variation among users (depending on who the speaker is)
Idiolect variation (depending on idiosyncratic characteristics of each speaker): idiolects
Dialectal variation (depending on
the origin of each speaker): dialects
Historical variation (depending on the historical origin): historical dialects, chronolects or diachronic varieties. Geographic variation (depending on the geographic origin): geographic
dialects, geolects or diatopic varieties. Social variation (depending on the
social origin): social dialects, sociolects or diastratic variety.
Linguistic variation among uses (depending on what the speaker does)
Stylistic variation: registers, diaphasic variety
Table 1 Source: adapted from two tables of Veny & Massanell (2015).
Before discussing which dialects and the particular variations within these dialects to be
included, it is important to note the obstacles to variant selection. Although the main
1 Not a lot of information about Catalan dialects is available; we focus our work in Veny (1993 Veny&Massanell (2015), a recent compilation of all the information accessible and described with) and didactic purposes.

16
differences among dialects is clear, there are many barriers to finding precise and concrete
information about phonetic characteristics, especially regarding context and frequency.
As Fodge (2014) posits in her thesis and to some extent can also be seen in Table 1, “barriers
include clashing sources, lack of numerical support data, deciphering dialectal versus social
and situational variants and assuring variants are modelable”. For these reasons, there are
difficulties in deciding which phenomena can or should be chosen for inclusion in this
project. Although this project focuses on variations of the segmental level and especially
geographic, there are also important changes in the morphological, syntactical and lexical
level (Veny, 1993); however, they will not be considered in this work.
The best solution when deciding which phenomena to include is finding numerical data, the
more recent the better, supporting the prevalence of said phenomena. However, such
information is not available in Catalan and the only information we can find is something like
“que es dóna en parlants de més edat”, “al nord” or “al sud” Veny & Massanell (2015). Work
done in Catalan dialectology is only descriptive, but does not give evidence of the real use of
every characteristic.
In this work two main dialects with their subdialects are being considered: Northwestern
and Valencian. The first one is spoken in Andorra, Franja de Ponent, Lleida province, and
southern Tarragona. It has four subdialects: the one spoken in Ribagorça (Ribagorçà), the
one spoken in both Pallars Jussà and Pallars Sobirà (Pallarès), the one spoken in the former
diocese of Tortosa (Tortosí) and the one spoken in the central area (Central Area)2.
The second one is spoken in the autonomous region of Valencia and a small region called
Carxe, which is in the autonomous region of Murcia. It also has four subdialects. In fact,
Veny & Massanell (2015) only describe three, but differences in a region of the third
subdialect have brought us to posit a new one. These dialects are Northern Valencian,
Central Valencian, Southern Valencian and the one spoken in Alicante (Alacantí). As Veny &
Massanell (2015) argue, “la divisió respecte del català nord-occidental se sol fer tenint en
compte la isoglossa de l’imperfet de subjuntiu: que ell cantés (nord-occidental), que ell
cantara (valencià)”3.
2 Since there is no literature in English talking about these differences, a translation is created by the author of this project. 3 Badia (1981) proposes another division caused by the distinction between o and e in the singular first person: jo canto vs. jo cante.

17
Hence, in this paper, eight Catalan subdialects are being considered: Ribagorçà, Pallarès,
Tortosí, Central Area, Northern Valencian, Central Valencian, Southern Valencian and
Alacantí. The eight Catalan dialects were chosen for three main reasons: because of the
literature available on these dialects, the lack of TTS and ASR tools that model them, and the
fact they differ a lot from Central Catalan, the only dialect available on TexAFon. Eventually,
these dialects could aid the creation of a pronunciation dictionary for dialects of Catalan
other than Central Catalan.
Although we are considering geographic variation, stylistic variation may appear. The reason
is that sometimes researchers in dialectology record data speaking in a formal manner,
which makes the participants also speak in a formal register, making some features
disappear. However, since our data is recovered from a compilation of analyses, this
problem is not considerable.
Once the variants and their phenomena are determined, we must analyze whether or not
they can be coded in TexAFon. As Fodge (2014) explains “phenomena that exist in syllable-
final position carry with them additional difficulty in modeling due to the ordering of
sections and rules in the current version of TexAFon. Currently, information for syllables is
located after rules for grapheme-to-phoneme modeling. However, there are possibilities for
deducing other means of modeling such phenomena, such as looking at the context in which
syllables are formed and generating additional rules”.
Lastly, since ASR rules must be more versatile than those of TTS in order to understand
different idiolects within a dialect, variants are required for ensuring that the system can
recognize the speech of speakers from these new dialects. However, a frequency threshold
must be set in order to make sure the rules are not overly generic. Fodge (2014) divided her
phenomena into primary and secondary in terms of the frequency of appearance. Since
Veny (1993) do not give information about frequency, but do have some information about
population using it (e.g. elderly) or parts of the territory (e.g. only north) this frequency has
been reduced when some extra information is provided.
The main aim is to include as much variation as possible in order to avoid situations in which
speech cannot be recognized. We will divide our primary and secondary phenomena with
this extra information explained above, giving priority to the ones with no information and
secondary those which are reduced either because the population or the territory who
speak in this way it is smaller.

18
2.1. Selected inter-dialectal phenomena
When selecting phenomena from every dialect we must take into account that there are
some characteristics that are shared by the eight varieties. In fact, these shared features
make them part of a bigger group called Western Catalan. These shared characteristics that
do differ from Central Catalan and other dialects from the other group called Eastern
Catalan are all related to vowels.
We will now explain those differences shared with all dialects. First, closed /e/ from Vulgar
Latin is maintained closed [e] as a difference of other dialects where it is opened [ɛ] ([peɾa]).
Moreover, unlike other dialects, there are only five unstressed vowels: [a], [e], [i], [o] and [u]
(p[ɔ]nt but p[o]ntet or v[ɛ]rd but v[e]rdet). Finally, initial unstressed /e/ is pronounced as [a]
when it is part of a locked syllable. These features are summarized in Table 2.
Western dialects Primary phenomena Closed /e/ from Vulgar Latin is maintained closed pera (‘pɛɾəÆpeɾa) Unstressed /ɛ/ and /ɔ/ are pronounced [e] and [o] pontet (pun’tɛtÆpon’tet) verdet (bəɾ’dɛtÆbeɾ’det) Initial unstressed /e/ is pronounced as [a] when part of a locked syllable escola (əskɔləÆaskola) Table 2 Western dialects phenomena
Since there is a bigger division among these eight dialects: Northwestern and Valencian,
individually they also share some characteristics within them. In the case of Northwestern
(Table 3) the initial unstressed /o/ is converted into a diphthong [aw] ([aw]liva) and both
unstressed /ɔ/ and /o/ followed by a stressed /i/ are pronounced as [u] (c[u]nill)4. As Veny &
Massanell (2015) add in their explanation “es dóna l’alternança [o]/[u] segons els pobles i
segons els mots”.
Northwestern dialects Primary phenomena Initial unstressed /o/ is pronounced as [aw] oliva (u’liβəÆaw’liβa) Table 3 Northwestern dialects phenomena
Valencian (Table 4) has some shared characteristics in consonants: /ts/ is palatalized into [tʃ]
(to[tʃ]); there is a falling silent of the intervocalic /ð/ when it comes from the Latin –ATA–
(a[jʃa] for aixada) and both pronunciations are possible when it comes from –ATORE–
(moca[ðo] or moca[o]). As it happens in Tortosí, Romanic TL, DL and [j]L are geminated into 4 This feature is not consistent and it is not widespread along the territory or the users. For this reason, we will not take it into account when creating rules.

19
[ll] or also [l] (bat[ll]e or bat[l]e). Finally, Valencian does not have the phoneme [ʒ] but rather
[dʒ] or [jʒ] in the case of Northern Valencian; this feature has some implications, as some
changes within Valencian subdialects are the devoicing of sibilants.
Valencian dialects Primary phenomena /ts/ is palatalized into [tʃ] tots (totsÆtotʃ) Falling silent of the intervocalic /ð/ when it comes from the Latin –ATA– aixada (ə’ʃaðəÆaj’ʃa ) Possible falling silent of the intervocalic /ð/ when it comes from the Latin –ATORE– mocador (mukə’ðoÆmoka’o or moka’ðo) Romanic groups TL, DL and [j]L do not palatalize, but geminate or are pronounced as [l] batlle (‘baʎ:əÆ’bal:e or bale), motlle (‘mɔʎ:əÆ mɔl:e or mole) Table 4 Valencian dialects phenomena
Despite having these shared features, the structure of TexAFon implies the creation of a
whole new module for every dialect. Thus although we have them in one code, they must be
copied and repeated from one to another. Apart from these characteristics and despite the
aforementioned barriers to phenomena selection, a concrete set of phenomena has been
designated for inclusion in TexAFon for each variant dialect of Catalan. Each of these
phenomena has been translated into pseudo-code rules as a primary step before the Python
code is written. The pseudo-code will be discussed later in section 2.10 and can be consulted
in Annex 1.
2.2. Ribagorçà
It is spoken in Alta and Baixa Ribagorça and in Llitera. Thus, the major part of this dialect is
not spoken in Catalonia, but Aragon. This dialect does share some characteristics with
Pallarès and Tortosí, but not with the Central Area. We will now describe these features
saying which of them are shared by other dialects. In fact, despite not being in a transition
zone between dialects, Ribagorçà does share the characteristics of devoicing all sibilant
sounds with Central Valencian. We will start with the features common in all parts of this
territory and we will later explain secondary features(Veny, 1993). The features of this
dialect are summarized in Table 5.
2.2.1. Primary phenomena
As we will see in Pallarès, there are more [ɛ] than in the rest of Catalan. However, Pallarès
still has more occurrences of this phoneme. Ribagorçà also shares with Pallarès the
characteristic of pronouncing [j] the Latin groups –I–, –D[j]–, –B[j]–, –G[j]–. In the case of this
dialect, when an e or i precede it, it disappears; which does not happen in Pallarès. This

20
dialect is the only one from the Northwestern dialects that does not have voiced sibilants; a
feature shared with Central Valencian. An individual feature of Ribagorçà is the
palatalization of pl, bl, cl, gl qnd fl (Veny&Massanell, 2015).
1. Latin sufix –ARIU is pronounced with a [ɛ]; Example: carrer (kə’reÆka’rɛ)
2. Latin root –ACT– is pronounced either with [ɛ] or [ɛj]; Example: llet (‘ʎetÆ’ʎɛt or ‘ʎɛjt)
3. From the Latin –I–, –D[j]–, –B[j]–, –G[j]–, are all pronounced [j] and not [dʒ] or [ʒ],
except when it is preceded by an e or i, which then it disappears; Examples: pujar
(pu’ʒaÆpu’ja), major (mə’ʒoÆma’jo), passejar (pəsə’ʒaÆpase’a), pitjor (pi’dʒoÆpi’o)
4. Devoicing of sibilants /z/ > /s/, /dz/ > /ts/ and /dʒ/ > /tʃ/; Example: casa (‘kazəÆ’kasa),
tretze (‘tɾedzəÆ’tɾetse), viatge (bi’adʒəÆbi’atʃe)
5. Palatalization of /pl/, /bl/, /cl/, /gl/, /fl/: Example: ploure (‘plɔwɾəÆ‘pʎɔwɾə), blau
(blawÆbʎaw), flor (flɔ 5Æfʎɔ)
6. Final consonant group –rn can be pronounced rn, without n or with a final t; For
example: hivern (iβɛɾnÆ iβɛɾn or iβɛɾ or iβɛɾt)
2.2.2. Secondary phenomena
As Veny & Massanell (2015) explain “a la Ribagorça més occidental, a àtona final llatina s’ha
mantingut com a a tant en posició lliure com travada”. Moreover, in the same territory some
Latin groups explained below are pronounced as [θ]. This characteristic is also part of
Matarranya, a little territory of the Tortosí dialect where some features differ (Veny, 1993).
However, this phenomenon is not consistent, for this reason, we will not take it into account
when creating rules.
1. Unstressed final a in syllable endings do not change into e, they are maintained; For
example: canten (‘kantənÆ’kantan), cares (‘kaɾəsÆ’kaɾas)
Ribagorçà Primary Phenomena Secondary variants Latin suffix –ARIU is pronounced with a [ɛ] carrer (kə’reÆka’rɛ)
Unstressed final a in syllable ending do not change into e, it is maintained canten (‘kantənÆ’kantan), cares (‘kaɾəsÆ’kaɾas)
Latin root –ACT– is pronounced either with [ɛ] or [ɛj] llet (‘ʎetÆ’ʎɛt or ‘ʎɛjt)
From the Latin –I–, –D[j]–, –B[j]–, –G[j]–, all is pronounced [j] and not [dʒ], except when it is preceded by an e or i, which then it disappears pujar (pu’ʒaÆpu’ja), major (mə’ʒoÆma’jo), passejar
5 This is one of many examples where o can both be pronounced as [o] or [ɔ]. See Nadeu&Renwik (in press) for more information about changes in vowels.

21
(pəsə’ʒaÆpase’a), pitjor (pi’dʒoÆpi’o) Devoicing of sibilants /z/ > /s/, /dz/ > /ts/ and /dʒ/ > /tʃ/ casa (‘kazəÆ’kasa), tretze (‘tɾedzəÆ’tɾetse), viatge (bi’adʒəÆbi’atʃe)
Palatalization of /pl/, /bl/, /cl/, /gl/, /fl/ ploure (‘plɔwɾəÆ‘pʎɔwɾə), blau (blawÆbʎaw), flor (flɔ
Æfʎɔ)
Final consonant group –rn can be pronounced rn, without n or with a final t
hivern (iβɛɾnÆ iβɛɾn or iβɛɾ or iβɛɾt)
Table 5 Ribagorçà phenomena
2.3. Pallarès
It is spoken in both Pallars Subirà and Pallars Jussà. However, some features of this variety
can also be seen in Andorra and Alt Urgell. Since this territory was difficult to access, this
dialect is very conservative. The main features can be seen in Table 6.
2.3.1. Primary phenomena
The evolution of this dialect implies that the phoneme [ɛ] is more used than in any other
dialects of Catalan. Although some of these [ɛ] are shared with Ribagorçà, some are unique.
The characteristic of pronouncing [j] the Latin groups of –I–, –D[j]–, –B[j]–, –G[j]–is also
shared with Ribagorçà. It also has a shared feature with dialects from the other group
(Rossellonès and Northern Catalan transition): the disappearance of d in the groups ndr and
ldr.
1. Latin suffix –ARIU is pronounced with a [ɛ]; Example: carrer (kə’reÆka’rɛ)
2. Latin root –ACT– is pronounced with [ɛ]; Example: llet (ʎetÆʎɛt)
3. Latin root –AI– is pronounced with [ɛ]; Example: més (mesÆmɛs)
4. Latin suffix –ORIU is pronounced either with [ɛ] or [e], but not with [o]; Example: voltor
(bul’toÆbol’te or bol’tɛ)
5. From the Latin –I–, –D[j]–, –B[j]–, –G[j]–, all is pronounced [j] and not [dʒ] or [ʒ];
Examples: pujar (pu’ʒaÆpu’ja), major (mə’ʒoÆma’jo), passejar (pəsə’ʒaÆpase’ja),
pitjor (pi’dʒoÆpi’jo)
6. In ndr and ldr groups, d is not pronounced; Example: cendre (‘sɛndɾəÆ’sɛnra), moldre
(‘mɔldɾəÆ’mɔlre)
7. Latin group –NN– is not palatalized; Example: banya (‘baŋəÆ’bana), seny (sɛŋÆsen),
escanyar (əskə’ŋaÆaska’na)

22
2.3.2. Secondary phenomena
There are no secondary phenomena within this dialect. Since until the 10th century a
language similar to Basque was spoken, it has a lot of special characteristics that do not
appear in any other dialects, as seen in the primary phenomena (Veny, 1993).
Pallarès Primary phenomena Latin suffix –ARIU is pronounced with a [ɛ] carrer (kə’reÆka’rɛ) Latin root –ACT– is pronounced with [ɛ] llet (ʎetÆʎɛt) Latin root –AI– is pronounced with [ɛ] més (mesÆmɛs) Latin suffix –ORIU is pronounced either with [ɛ] or [e], but not with [o] voltor (bul’toÆbol’te or bol’tɛ) From the Latin –I–, –D[j]–, –B[j]–, –G[j]–, all is pronounced [j] and not [dʒ] or [ʒ] pujar (pu’ʒaÆpu’ja), major (mə’ʒoÆma’jo), passejar (pəsə’ʒaÆpase’ja), pitjor (pi’dʒoÆpi’jo) In ndr and ldr groups, d is not pronounced cendre (‘sɛndɾəÆ’sɛnra), moldre (‘mɔldɾəÆ’mɔlre) Latin group –NN– is not palatalized banya (‘baŋəÆ’bana), seny (sɛŋÆsen), escanyar (əskə’ŋaÆaska’na) Table 6 Pallarès phenomena
2.4. Tortosí
This variety is considered a transition between Northwestern and Valencian dialects and it is
spoken in Baix Ebre and Montsià, but it also includes features that can be seen in Ribera
d’Ebre, Terra Alta and Matarranya. The characteristics of this dialect are summarized in
Table 7.
2.4.1. Primary phenomena
The phenomena in this dialect are shared with some Valencian dialects, since as explained
above; it is in a transition zone between Nortwestern and Valencian dialects.
1. Approximant articulation of bl and gl; Example: poble (‘pɔbblə 6Æ‘pɔβle), regle
(‘reggləÆ’reɣle)
2. Romanic groups TL, DL and [j]L do not palatalize, but geminate; Example: batlle
(‘ba:ʎəÆ’ba:le), motlle (‘mɔ:ʎəÆ mɔ:le)
6 The one above is the Central Catalan standard pronunciation. However, within this dialect, this word can also be pronounced as [pɔpplə] and [pɔplə]; as is the case with the group gl.

23
2.4.2. Secondary phenomena
These phenomena are located in a small territory called Matarranya, situated between
Aragon and Valencian Country. Since it is isolated, a particular Catalan has been developed
(Veny & Massanell, 2015).
1. Opened preliterate e is pronounced either with [jɛ] or [ja]; Example: mel (mɛlÆmjɛl or
mjal)
Tortosí Primary Phenomena Secondary Variants
Approximant articulation of intervocalic bl and gl
poble (‘pɔbbləÆ‘pɔβle), regle (‘reggləÆ’reɣle) Opened preliterate e is pronounced either with [jɛ] or [ja] mel (mɛlÆmjɛl or mjal)
Romanic groups TL, DL and [j]L do not palatalize, but geminate
batlle (‘ba:ʎəÆ’ba:le), motlle (‘mɔ:ʎəÆ ‘mɔ:le)
Table 7 Tortosí phenomena
2.5. Central Area
It is spoken in Segrià, Pla d’Urgell, les Garrigues and Noguera7. This dialect is the most similar
to the central one, since it is in a transition territory. For this reason, except from the
features shared by all dialects, it only has one primary feature that has to be taken into
account. The features of Central Area dialect are summarized in Table 8.
2.5.1. Primary phenomena
Since this dialect is the most similar to Central Catalan it only has one primary phenomenon.
The unvoiced final /a/ is pronounced [ɛ]. This difference is in fact semantic, since it serves to
differentiate between a feminine and masculine noun as can be seen in the following
example: mestre [mɛstɾe], mestra [mɛstɾɛ]. Moreover, it also helps to distinguish between
the first and third person in verbs when they share the same form: jo cantava [kantaβɛ], ell
cantava [kantaβe]. The characteristic of pronouncing the singular third person with a final
[e] is common in all Northwestern dialects, not the feature of pronouncing the singular first
person as [ɛ], which is only part of the Central Area.
1. Unstressed final /a/ is pronounced [ɛ]; Example: casa (‘kazəÆ’kazɛ), cantava
(kən’taβəÆkan’taβɛ), mestra (mɛstrəÆmɛstɾɛ)
7 Some authors consider Segarra, Urgell, Ribera and Terra Alta to be part of this subdialect.

24
Central Area Primary Phenomena Unstressed final /a/ is pronounced [ɛ] casa (‘kazəÆ’kazɛ), cantava (kən’taβəÆkan’taβɛ), mestra (mɛstrəÆmɛstɾɛ) Table 8 Central Area phenomena
2.6. Northern Valencian
It covers the north of Valencian Country: Ports de Morella, Alt and Baix Maestrat, Alcalatén
and Plana Alta and Baixa. As in the case of Tortosí, this dialect can be seen as a transition
between Valencian and Northwestern dialects. The features of Northern Valencian are
summarized in Table 9.
2.6.1. Primary phenomena
Although there is a segregation of ix group in all Valencian dialects except Alacantí, Northern
Valencian also despalatalize this group, becoming [js]. Moreover, it has another individual
feature as /dz/ is palatalized into [dʒ].
1. Segregation and despalatalization of ix group into [js]; Example: coix (koʃÆkojs), caixa
(kaʃəÆkajsa)
2. /dz/ sound is palatalized into [dʒ]; Example: tretze (tɾedzəÆ tɾedʒe)
2.6.2. Secondary phenomena
There are some secondary phenomena because some features are only encountered in the
north (/dʒ/>[jʒ]) or in the south (distinction between [v] and [b] and maintenance of final r).
1. Distinction between [v] and [b]; Example: vaca (‘bakəÆ’vaka)
2. Maintenance of final r; Example: fuster (fus’teÆfuster), dir (diÆdir)
3. Intervocalic /dʒ/ is converted into [jʒ]; Example: fetge (‘fedʒəÆfejʒe), pluja
(‘pluʒaÆ’plujʒa)
Northern Valencian Primary Phenomena Secondary Variants Segregation and despalatalization of ix group into [is] coix (koʃÆkois), caixa (kaʃəÆkajsa)
Distinction between [v] and [b] vaca (‘bakəÆ’vaka)
/dz/ sound is palatalized into [dʒ] tretze (tɾedzəÆ tɾedʒe)
Maintenance of final r fuster (fus’teÆfuster), dir (diÆdir)
Intervocalic /dʒ/ is converted into [jʒ] fetge (‘fedʒəÆfejʒe), pluja (‘pluʒaÆ’plujʒa)
Table 9 Northern Valencian phenomena

25
2.7. Central Valencian
It is spoken at the central area of Valencian Country. It covers the territory between Palància
and Xúquer rivers. The phenomena of Central Valencian are reviewed in Table 10.
2.7.1. Primary phenomena
This dialect is the only Valencian one that does not have the difference between [b] and [v],
although in Northern Valencian is only found in the south. As explained above, Central
Valencian does have a shared feature with Ribagorçà, as it does not have any voiced sibilant.
In this case, the final t is maintained, which also happens in Southern Valencian; and final r is
also maintained, which is a shared characteristic of Valencian, although in the Northern
Valencian only happens in the south.
1. Decreasing diphthong [wi] instead of a rising diphthong [uj]; Example: buit (bujtÆbwit)
2. Devoicing of sibilants /z/ > /s/, /dz/ > /ts/ and /dʒ/ > /tʃ/; Example: casa (‘kazəÆ’kasa),
tretze (‘tɾedzəÆ’tɾetse), viatge (bi’adʒəÆbi’atʃe)
3. Maintenance of final t in nt and lt groups; Example: molt (molÆmolt), pont (pɔnÆpɔnt)
4. Maintenance of final r; Example: fuster (fus’teÆfuster), dir (diÆdir)
5. Segregation of ix group into [jʃ] in final and intervocalic position; Example: coix
(koʃÆkojʃ)
2.7.2. Secondary phenomena
In this dialect there are no secondary phenomena, since all the differences encountered are
part of all the territory and there is no extra information about their use.
Central Valencian Primary Phenomena Decreasing diphthong [wi] instead of a rising diphthong [uj] buit (bujtÆbwit) Devoicing of sibilants /z/ > /s/, /dz/ > /ts/ and /dʒ/ > /tʃ/ casa (‘kazəÆ’kasa), tretze (‘tɾedzəÆ’tɾetse), viatge (bi’adʒəÆbi’atʃe) Maintenance of final t in nt and lt groups molt (molÆmolt), pont (pɔnÆpɔnt) Maintenance of final r fuster (fus’teÆfuster), dir (diÆdir) Segregation of ix group into [jʃ] in final and intervocalic position coix (koʃÆkojʃ) Table 10 Central Valencian phenomena

26
2.8. Southern Valencian
It goes from central Valencia to the south. The main characteristic of this dialect, which is
only part of Alacantí, is the vowel harmony. The rest of the features are shared with some
other dialects as we have already seen and are summarized in Table 11.
2.8.1. Primary phenomena
1. Decreasing diphthong [wi] instead of a rising diphthong [uj]; Example: buit (bujtÆbwit)
2. Vowel harmony when there is a stressed [ɛ] or [ɔ] ending with a; Example: terra
(tɛrəÆtɛrɛ), olla (oʎəÆɔʎɔ)
3. Distinction between [v] and [b]; Example: vaca (‘bakəÆ’vaka)
4. Maintenance of final t in nt and lt groups; Example: molt (molÆmolt), pont (pɔnÆpɔnt)
5. Maintenance of final r; Example: fuster (fus’teÆfuster), dir (diÆdir)
6. Segregation of ix group into [jʃ] in final and intervocalic position; Example: coix
(koʃÆkojʃ)
2.8.2. Secondary phenomena
In this dialect there are no secondary phenomena, since the ones that should be in this
section are a whole new dialect called Alacantí, and are explained below. We considered the
differences to be important; thus, we created a new dialect with some features that are
individual and some others that are shared with other dialects.
Southern Valencian Primary phenomena Decreasing diphthong [wi] instead of a rising diphthong [uj] buit (bujtÆbwit) Vowel harmony when there is a stressed [ɛ] or [ɔ] ending with a terra (tɛrəÆtɛrɛ), olla (oʎəÆɔʎɔ) Distinction between [v] and [b] vaca (‘bakəÆ’vaka) Maintenance of final t in nt and lt groups molt (molÆmolt), pont (pɔnÆpɔnt) Maintenance of final r fuster (fus’teÆfuster), dir (diÆdir) Segregation of ix group into [jʃ] in final and intervocalic position coix (koʃÆkojʃ) Table 11 Southern Valencian phenomena
2.9. Alacantí
Veny & Massanell (2015) include this dialect in Southern Valencian. However, as we said
earlier, it has some characteristics itself that justify the creation of this dialect alone in order

27
to create rules that only occur within this dialect. As the name indicates, it is spoken in
Alicante and its features are summarized in Table 12.
In most cases Alacantí is very similar to Southern Valencian. However, in some cases it has
individual features and in some others, it resembles other Valencian dialects more than the
Southern one. First, it does have vowel harmony or the distinction between [v] and [b].
However, some other features only appear in this dialect: both [ɔw] and [ow] diphthongs are
pronounced [aw] and there is a falling silent of intervocalic d in all contexts. Finally, there is
an important difference with any other Valencian dialect, since the group ix is pronounced
as [ʃ] and not [jʃ]8.
2.9.1. Primary phenomena
1. Decreasing diphthong [wi] instead of a rising diphthong [uj]; Example: buit (bujtÆbwit)
2. Vowel harmony when there is a stressed [ɛ] or [ɔ] ending with a; Example: terra
(‘tɛrəÆ’tɛrɛ), olla (‘oʎəÆ’ɔʎɔ)
3. Both [ɔw] and [ow] diphthongs are pronounced [aw]; Example: pou (powÆpaw), bou
(bɔwÆbaw)
4. Falling silent of intervocalic d; Example: cadira (kə’ðiɾəÆka’iɾa)
5. Distinction between [v] and [b]; Example: vaca (‘bakəÆ’vaka)
6. Maintenance of final r; Example: fuster (fus’teÆfuster), dir (diÆdir)
2.9.2. Secondary phenomena
Since it is actually a part of another dialect, it only has primary phenomena.
Alacantí Primary phenomena Decreasing diphthong [wi] instead of a rising diphthong [uj] buit (bujtÆbwit) Vowel harmony when there is a stressed [ɛ] or [ɔ] ending with a terra (tɛrəÆtɛrɛ), olla (oʎəÆɔʎɔ) Both [ɔw] and [ow] diphthongs are pronounced [aw] pou (powÆpaw), bou (bɔwÆbaw) Falling silent of intervocalic d cadira (kə’ðiɾəÆka’iɾa) Distinction between [v] and [b] vaca (‘bakəÆ’vaka) Maintenance of final r fuster (fus’teÆfuster), dir (diÆdir)
Table 12 Alacantí phenomena
8 This feature was not added in the list, as changes have to be done in the central Catalan rules. Since this feature is shared with the dialect already present in TexAFon, we decided not to list it.

28
2.10. Pseudo-code
After developing all rules in every dialect, the next step was the creation of pseudo-code in
order to start generating the rules implemented afterwards in TexAFon. This pseudo-code is
created using SAMPA symbols and creating more than one output when phenomena are
secondary. A rule of pseudo-code is included in this section and the rest is part of Annex 1.
Unstressed final /a/ is pronounced as [E]: This first example has been written with no
abbreviations for clarity.
# Transforms all final unstressed /a/ into [E]
if character == “a” and next character == “NIL”:
transcribe “E”
3. Implementation
3.1. Overview
After finishing the pseudo-code, it needed to be included in TexAFon as a Python code.
Concretely, the main structure was created in a function called transducer for Central
Catalan and adaptations needed to be done in order to improve the tool for all eight dialects
described above. Not only were some rules changed, but also some others were included as
new rules in some dialects. Moreover, since secondary variants were defined, they were also
a whole new part of this module, which only had one possibility in the first dialect created.
The rules described in transducer only affect those phonemes within a word and how they
interact with one another. When one rule has more than one variant, the first will be the
one used in TTS and the others for ASR use only, although ASR will also use the first variant.
The fonetica_sintactica9 function is for rules that affect how phonemes between words
relate to and affect each other. Although the structure helps to distinguish those
phenomena, it also complicates the creation of rules, as some rules must be split between
the two sections in order to be complete. However, there are the so-called archiphonemes,
a kind of intermediary symbol that helps both functions to be unified.
The transducer is the function that takes orthographic input and transcribes it phonetically.
After that, fonetica_sintactica processes this output (already phonetically transcribed). Thus,
the tool needs both modules to work: one after the other. As explained in section 1.3.2.
9 In the rules of this project there are not such phenomena.

29
there are two different programs: ‘crea_dicc_fonetico_con_variantes_de_lista_palabras’
and ‘proc_ling’. The first one is used to create pronunciation dictionaries and allows more
than one possible pronunciation per word; whereas the other work in paragraphs and gives
the most frequent option of every dialect. In the next section, limitations when creating
rules are recorded.
3.2. Limitations on every dialect
3.2.1. Limitations shared in all dialects
The rule “Closed /e/ from Vulgar Latin is maintained closed” is not regular enough to make
it; thus, exceptions are created in the exceptions dictionary. Taking advantage of the
methodology used when deciding if a stressed e was open or closed, stressed o was also
analyzed and changed when necessary. The pronunciation of these two stressed phonemes
was checked in ReSolc, an online tool developed by Universitat Pompeu Fabra. This tool is
“una plataforma de consulta en línia per a professionals de la llengua oral […] sobre la
pronúncia correcta i adequada del lèxic en sentit ampli” (ReSolc, 2010). It gives information
about the pronunciation of Catalan terms in different dialects: Balear, Central,
Northwestern, Rossellonès and Valencian. Although it does not have a specific division
within Northwestern and Valencian dialects it does give information in general about these
two dialects. Although this methodology has some limitations that need to be taken into
account when analyzing the output, due to the variety of contexts where these sounds can
appear open or closed, for now it is the best option. However, we need to take into account
that when a word is not included in the exception dictionary the output may be erroneous.
There are some allophones that are not recorded by this model of rules. It is the case, for
example of [ɱ] (àmfora), [β] (acaba) or [ɣ] (rega). However, these allophones are
dissimulated due to its context. A good idea would be to improve this project by means of
these allophones in order for it to sound more natural. For now, the noise caused by the use
of these allophones is higher than the benefits of introducing them.
Another limitation that appears in every dialect is the fact that currently TexAFon exceptions
dictionary can only have one variant per word. Thus, those rules that only affect part of one

30
dialect cannot appear as part of the exception dictionary. This is another area where some
improvements could be make10.
3.2.2. Limitations in Pallarès
In the rule that records “Latin group –NN– is not palatalized” it was decided to convert all [ŋ]
into [n], as the most common words with this phoneme come from the Latin group –NN–. As
Rasico (1982) explains “hi ha forms dialectes antigues amb /n/: an, afanar, bana, cana,
cànem, escanar, enganar, sen”.
Another limitation present in this dialect is the rule “From the Latin –I–, –D[j]–, –B[j]–, –G[j]–
all is pronounced [j] and not [dʒ] or [ʒ]”. Not only the occurrences form the Latin forms
above, but all occurrences concerning these two phonemes where changed into [j]. For this
reason, more cases of this phenomenon appear than should. In the case of Ribagorçà,
however, it is not the case, since there are less cases and another rule alters words with
such characteristics: “Devoicing of sibilants /z/ > /s/, /dz/ > /ts/ and /dʒ/ > /tʃ/”.
Pallarès has another limitation when describing the use of opened stressed [ɛ]. The logical
evolution of this phoneme from Latin is a word containing a followed by a semivowel that
evolved into an open e followed by the same semivowel. These two sounds, in most dialects
were later converted into [e]. In Pallarès, however, this evolution stopped in an intermediate
step, conserving an open [ɛ] without the semivowel. In some cases, Ribagorçà did also
preserve this semivowel (e.g. llet). This evolution makes the development of rules for these
phenomena almost impossible; thus, exceptions have to be included in the exception
dictionary.
These exceptions are not easy to obtain, since some Latin suffixes and roots are responsible
for this evolution. The best way to get them, apart from analyzing a big corpus, is first
getting the words from a reverse dictionary, after that, looking up the list of words in Atles
Lingüístic del Domini Català11 maps in the territories covered by Pallarès dialect in order to
see which words do have an [ɛ]. When getting the list of these words, they have to be
included. However, there is not a single root or suffix that evolved as such. For this reason, a
10 Due to limitations in time, in the case that a rule had more than one possible realization, those varieties that were similar to the original exception dictionary were preserved. 11 Atles Lingüístic del Domini Català is a dialectology project developed by Institut d’Estudis Catalans. The aim is to put in this atlas linguistic information recorded from 1964 to 1978 in order for it to be available for researchers. The atlas includes the whole Catalan geographical area (Badia, Veny & Pons, 1993; Veny&Pons, 2001).

31
lot of research needs to be done and due to the lack of time, these exceptions will not be
included in this project, but can be part of an improvement of TexAFon in the future.
This last limitation includes up to four different rules: “Latin suffix –ARIU is pronounced with
a [ɛ]”, “Latin root –ACT– is pronounced with [ɛ]”, “Latin root –AI– is pronounced with [ɛ]”,
“Latin suffix –ORIU is pronounced either with [ɛ] or [e], but not with [o]”. The first two rules
are also part of Ribagorçà. In the latter dialect, as explained above, the evolution can give
[ɛj] instead of only [ɛ].
3.2.3. Limitations in Ribagorçà
As explained above, although both Pallarès and Ribagorçà have a feature in common, we
treated them differently because another rule alter words with [ʒ] only in Ribagorçà and not
in Pallarès. Thus, words that fit in the rule “From the Latin –I–, –D[j]–, –B[j]–, –G[j]– all is
pronounced [j] and not [dʒ] or [ʒ]” are put in the exception dictionary and then a rule in
order to devoice the rest of these sibilants is created. This method has the limitation of
perhaps forgetting some words that fit in the first rule and as a result, having some words
mispronounced.
Another limitation in this dialect is in the rule “unstressed final a in syllable endings do not
change into e, they is maintained”. Since it is a morphological rule and only applies in plural
([kaɾas]) or some verb endings ([kantan]) for the current architecture of TexAFon it cannot
be adapted. A morphological tagger and a part-of-speech tagger would play a crucial role
when recognizing and creating rules for this phenomena.
3.2.4. Limitations in Tortosí
Tortosí has the feature of pronouncing /g/ and /b/ as approximants when followed by an /l/.
Since TexAFon does not include these approximants, both rules are cancelled. The intention
was to include these phonemes, but for now, noise will be worse than the benefits. Another
limitation is the rule “open preliterary e is pronounced either with [jɛ] or [ja]”, since it
cannot be expressed as a rule, but put in the exception dictionary. However, this
phenomenon is a secondary phenomenon and for now only one variant per word can be
added in the dictionary; thus, this rule cannot be included neither as a rule, nor in the
dictionary. Another improvement of TexAFon would be to allow the exception dictionary to
have more than one variant per word.

32
3.2.5. Limitations in Central Area
There are two main rules regarding the transformation of a final /a/ sound into [ɛ]. One is
related to all types of nouns, which is a rule that only happens in this dialect and it is easy to
model. However, there is a second apparition of this rule that has to do with morphosyntax,
as for the distinction between the first ([ɛ]) and third ([e]) singular person. In this case, since
Catalan is a language without subject, it is difficult to model it only by rules. For this reason,
in this project, only the first case will be taken into account, hoping for future projects to
solve this problem.
3.2.6. Limitations in Northern Valencian
As seen in Pallarès (section 3.2.2.), the evolution of Latin suffixes and roots give different
pronunciations in different Catalan dialects. In the case of –ATORE suffix, it is not clear
whether the Latin evolution or the substrate language spoken in this zone before Catalan
caused it. Irrespective of the cause, there is not an easy way to create a rule for these words.
Moreover, since in this case both pronunciations are possible, we have decided that the one
preserving the intervocalic d will be the only one taken into account. This characteristic is
common in all Valencian languages excepts for Alacantí where all intervocalic d disappear.
On the other hand, a completely different action is done in the case of –ATA suffix. Since
most of the endings in –ada do silence the intervocalic d, a rule was created to make this
phone disappear. Again, this rule is created for all Valencian dialects excepts for Alacantí.
This dialect has more than one secondary variant. In some words, two different secondary
variants appear, producing up to four variants for the same word (major as [maj’ʒo],
[maj’ʒor], [ma’dʒo] or [ma’dʒor]). despite being an applied work, this project is based on
theoretical information; thus, we are not able to know if anyone produces some of the
variants.
3.2.7. Limitations in Central Valencian
The rule “decreasing diphthong [wi] instead of a rising diphthong [uj]” that also affects
Southern Valencian and Alacantí cannot be recorded by TexAFon module lts. There is a
module in charge of syllable segmentation that creates diphthongs and hiatus. In this
project, this module will not be changed. For this reason, this rule will not be regarded in any
of the three subdialects where it appears.

33
3.2.8. Limitations in Southern Valencian
Although vowel harmony in [ɛ] and [ɔ] does follow a clear patter, we have already seen that
there is a problem when deciding if /e/ and /o/ are open or closed by rules, since it is not a
regular phenomenon and it can change from one person to another (Nadeu & Renwik, in
press). As this feature is only present when an open [ɛ] or [ɔ] are followed by an unstressed
final a, and not if the sound is either [e] or [o] (Jiménez, 2001), if a word is pronounced with
a closed /e/ in this dialect (e.g. pera) and the rule for e does not pronounce this word
properly, the vowel harmony rule will not work correctly. For this reason, a list of words that
do have vowel harmony was recorded from Jiménez (2001) in order to be included in the
exceptions dictionary. Moreover, those exceptions already present in the dictionary were
also changed.
3.2.9. Limitations in Alacantí
As in the case of Southern Valencian, rules regarding vowel harmony have been
incorporated in the exception dictionary. For this reason, some words may be left out and
mispronounced in these two subdialects. Again, as in the case of Southern Valencian, rules
for vowel harmony were not created but put in the exceptions dictionary instead.
3.3. Exception dictionaries
The former version of TexAFon Catalan dialect included an exception dictionary in order to
introduce as much vocabulary as possible that did not follow the expressed rules in lts.
However, the words included have the pronunciation of Central Catalan, which includes a
phone that is not present either in Northwestern dialects nor in Valencian dialects: schwa.
For this reason these terms were adapted to the dialects within this project.
The main terms included in the dictionary are those with a final r that is pronounced,
adverbs ending in –ment and some words that have opened or closed stressed e and o
without any regular rule. The first case does not have any implication in most Valencian
dialects, as final r is pronounced. However, adverbs and stressed e and o do have
implications in all dialects. The first because a stressed syllable is not regularly positioned.
The second because the change from Vulgar Latin /e/ to Central Catalan /ɛ/ is not without
exceptions, but seem to lack a systematic character (Rasico, 1982) .
Another difference between the dialects in this project and Central Catalan is the
pronunciation of most Spanish names. As Northwestern and Valencian dialects do not have

34
schwa, there is not a problem in pronouncing the majority of Spanish names that do not
include phonemes such as [θ] or [x]. The methodology in order to create a pronunciation
dictionary for each dialect in the project was the following:
1. To get all terms in Central Catalan exceptions dictionary.
2. To create rules common in all eight dialects in the project12.
3. To run the list in (1) with the rules in (2).
4. To analyze the output in (3) to see which terms were not necessary and which terms had
to be modified.
5. To remove those terms that did not have any problem.
6. To change the pronunciation of those terms that were not correct13.
As a first attempt, the exception dictionary was common for all dialects in our project (the
one of Central Catalan). However, the main intention is to introduce variation within each
dialect. For this reason, all those features easy to implement using regular expressions were
then changed in each exception dictionary in particular. One example is the pronunciation of
the final unstressed a as [ɛ] in the Central Area or the pronunciation of all final r in some
Valencian dialects.
The rule common in all northwestern dialects: “Initial unstressed /o/ is pronounced as [aw]”
was not changed in any of the dialect exception dictionary. Another rule that was not
changed in the exception dictionary and is part of all eight dialects is “Initial unstressed /e/ is
pronounced as [a] when part of a locked syllable” as it was not present in ReSolc.
Since the main purpose of this project is to be open access, a good idea would be to get
feedback from users and introduce to the exception dictionary those words mispronounced.
In this way, the project would take advantage from users all over the Catalan territory to
improve the tool.
4. Evaluation
In order to evaluate changes in TexAFon two different data sets were analyzed. One
regarding changes intra-word and the other cross-word. The first is the one got from the
12 Although the rule that preserves the final r is only part of Valencian dialects, it was included as the majority of the exceptions ending in r where there because it was not silent and it was easier to remove those that did not need to be pronounced. 13 As seen in section 3.2.1 the methodology to change pronunciations is looking up words in ReSolc to see how words are pronounced both in Northwestern and Valencian dialects.

35
program ‘crea_dicc_fonetico_con_variantes_de_lista_palabras’ and is a list of words with its
phonetic transcription correspondence. The second data is from the other program
‘proc_ling’ and the output analyzed is a whole paragraph. Concretely, two lists of words with
two or more occurrences of every phenomenon were analyzed, making up to 99 different
words (Annex 3); and two different paragraphs created specifically for this project, with up
to 511 words (Annex 5), some of them repeated but in different contexts –with a voiced or
unvoiced phoneme afterwards, etc. Words in lists are chosen in order to test all rules
created, some extra words were also included in order to test the whole tool and not only
new rules. The paragraphs include words in the list so as to see them in different contexts.
To get data for analysis, both the lists and the paragraphs were run. The former in the
program ‘crea_dicc_fonetico_con_variantes_de_lista_palabras’ and the latter in ‘proc_ling’.
These materials were analyzed in every dialect in order to see the errors. The metric used is
the one presented in Van Bael et al. (2007) “the sum of all phone substitutions (Sub),
deletions (Del) and insertions (Ins) divided by the total number of phones in the reference
transcription (N)”. The number is the percentage of incorrectness of each dialect. Four
different percentages are obtained from each dialect: two lists of words and two
paragraphs. However, the final result is the mean of all four measures.
Although some phenomena were deleted from the beginning due to different problems (see
3.2), on the evolution, all the errors are analyzed. In the next section every dialect is
analyzed and the errors are explained so as to be improved in future projects. All the errors
are substitutions and there is not any deletion or insertion.
4.1. Evaluation of Ribagorçà
The list in table 13 is a summary of the results in Ribagorçà dialect. This dialect is the one
with worse results, since the morphological rule that alters the endings in some verbs and
plurals is not included; thus, a lot of words are mispronounced14 (e.g. vivien, gallines, olives,
posaven tenien, etc.).
List 1 List 2 Paragraph 1 Paragraph 2 Total 5/60 = 8.3 3/39 = 7.7 25/273 = 9.16 14/238 = 5.9
42/610 = 6.9 8/99 = 8 39/511 = 7.6
Table 13 Results for Ribagorçà in % of incorrectness
14 This rule is part of a secondary phenomenon and should not be analysed as part of the paragraph. However, we considered it to be very important and have many implications so as not to collect it.

36
Most of the errors are expected, since they were not recorded during the creation of the
rules: the phenomena explained above and opened or closed stressed e (e.g. fetge Æ
*‘fɛdʒe). However, there is a phenomenon that was not expected: stress not being well
located, because it is a verb plus an enclitic (treure’s Æ *tɾew’ɾes).
4.2. Evaluation of Pallarès
In the case of Pallarès, what specially makes the errors appear is the fact that the four rules
regarding open e are not included, thus, making some errors appear (e.g. carrer Æ *ka’re,
llet Æ *’ʎet, etc.). Moreover, since we did not go into detail on other occurrences of these
phenomena (see 3.2.2.), maybe some examples are considered as correct in the evaluation
but they are not. Again in this dialect, there is the problem with open and closed stressed e
and the problem with a stress not put in the right position.
List 1 List 2 Paragraph 1 Paragraph 2 Total 8/60 = 13.3 3/39 = 7.7 6/273 =2.2 6/238 = 2.5
23/610 = 3.8 11/99 = 11 12/511 = 2.3
Table 14 Results for Pallarès in % of incorrectness
4.3. Evaluation of Tortosí
In Tortosí there are fewer errors than in Ribagorçà and Pallarès. However, there is an error
that can only be analyzed in the list and not in the paragraphs, since it is part of a secondary
phenomena, thus, it does not appear in the paragraphs: some words such as mel
pronounced as [mjɛl] or [mjal]. Apart from this error, the same errors that appear in Pallarès
are also part of Tortosí: the stress not well located and problems with open and closed e.
List 1 List 2 Paragraph 1 Paragraph 2 Total 6/60 = 10 3/39 = 7.7 3/273 = 1.1 6/238 = 2.5
18/610 = 2.9 9/99 = 9 9/511 = 1.8
Table 15 Results for Tortosí in % of incorrectness
4.4. Evaluation of Central Area
This dialect is the one with the least errors. The ones that are more significant are the ones
related to changes between open and closed stressed e, common to all dialects. The other
error is the stress of a word not located where it should, which is also common to all
dialects.

37
List 1 List 2 Paragraph 1 Paragraph 2 Total 5/60 = 8.3 3/39 = 7.7 3/273 = 1.1 6/238 = 2.5
17/610 = 2.8 8/99 = 8 9/511 = 1.8
Table 16 Results for Central Area in % of incorrectness
4.5. Evaluation of Northern Valencian
The problems this dialect presents are the same that appear in Central Catalan. Moreover,
there is the mispronunciation of mocador, which can be either with or without the
pronunciation of the intervocalic d. This rule was not created (see 3.2.6.) and, thus, this error
is expected but is only part of the errors in the list where more than one variant per word is
recorded. In the paragraph only the first variant is selected; thus, it is not incorrect.
List 1 List 2 Paragraph 1 Paragraph 2 Total 6/60 = 10 3/39 = 7.7 3/273 = 1.1 6/238 = 2.5
18/610 = 2.9 9/99 = 9 9/511 = 1.8
Table 17 Results for Northern Valencian in % of incorrectness
4.6. Evaluation of Central Valencian
This dialect has also the common errors that appears in all dialects and the one presented in
Northern Valencian: the mispronunciation of open or closed stressed e, the stress not well
placed on a word and the pronunciation of intervocalic d in –ATORE suffixes, again only to
be taken into account as an error in the list and not in the paragraph. Moreover, Central
Valencian presents a new error: the diphthong [uj] does not change into [wi].
List 1 List 2 Paragraph 1 Paragraph 2 Total 7/60 = 11.7 3/39 = 7.7 4/273 = 1.5 6/238 = 2.5
20/610 = 3.3 10/99 = 10 10/511 = 2
Table 18 Results for Central Valencian in % of incorrectness
4.7. Evaluation of Southern Valencian
This dialect together with Alacantí are the only ones that have as a primary phenomena the
pronunciation of v as [v] and not [b]. This characteristic poses a problem when the previous
character is an n, since this phoneme should be [ɱ] but it is not part of the inventory of
phonemes of TexAFon (e.g. converteix Æ *[komvertɛjʃ]). Moreover, this dialect as the above
Valencian dialects also pronounced wrong in the list words like mocador, since it pronounces
the intervocalic d and does not give a second option without d.
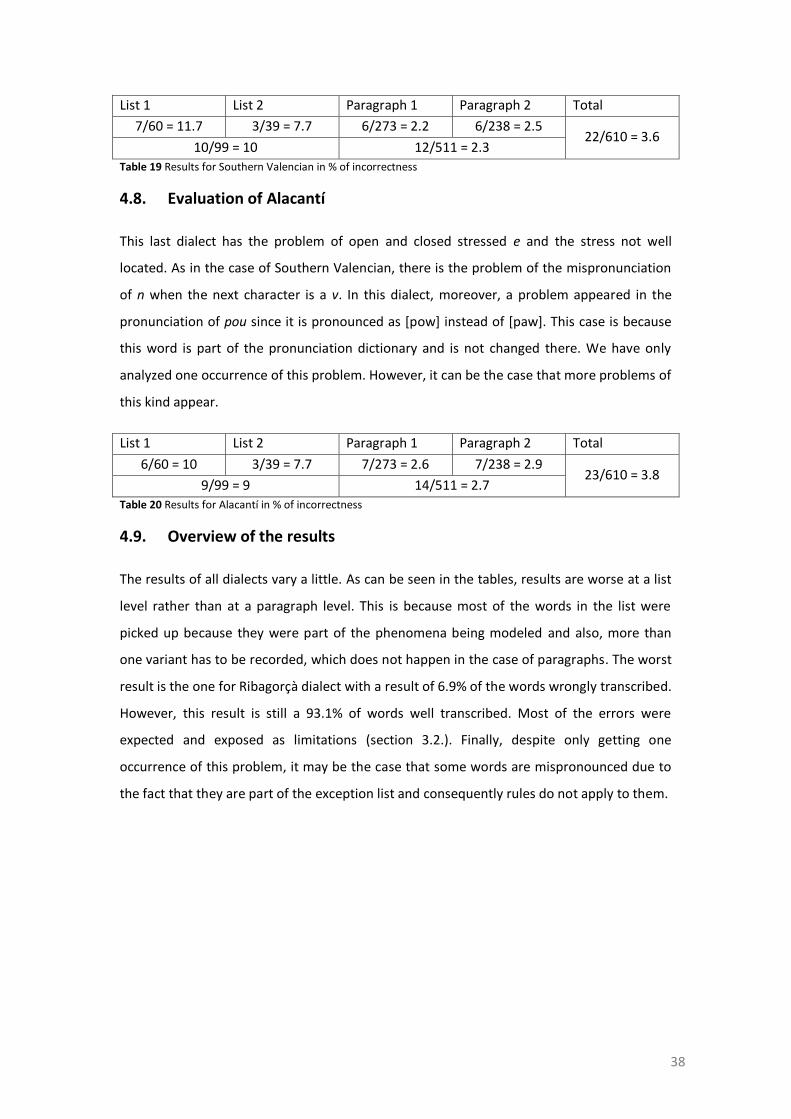
38
List 1 List 2 Paragraph 1 Paragraph 2 Total 7/60 = 11.7 3/39 = 7.7 6/273 = 2.2 6/238 = 2.5
22/610 = 3.6 10/99 = 10 12/511 = 2.3
Table 19 Results for Southern Valencian in % of incorrectness
4.8. Evaluation of Alacantí
This last dialect has the problem of open and closed stressed e and the stress not well
located. As in the case of Southern Valencian, there is the problem of the mispronunciation
of n when the next character is a v. In this dialect, moreover, a problem appeared in the
pronunciation of pou since it is pronounced as [pow] instead of [paw]. This case is because
this word is part of the pronunciation dictionary and is not changed there. We have only
analyzed one occurrence of this problem. However, it can be the case that more problems of
this kind appear.
List 1 List 2 Paragraph 1 Paragraph 2 Total 6/60 = 10 3/39 = 7.7 7/273 = 2.6 7/238 = 2.9
23/610 = 3.8 9/99 = 9 14/511 = 2.7
Table 20 Results for Alacantí in % of incorrectness
4.9. Overview of the results
The results of all dialects vary a little. As can be seen in the tables, results are worse at a list
level rather than at a paragraph level. This is because most of the words in the list were
picked up because they were part of the phenomena being modeled and also, more than
one variant has to be recorded, which does not happen in the case of paragraphs. The worst
result is the one for Ribagorçà dialect with a result of 6.9% of the words wrongly transcribed.
However, this result is still a 93.1% of words well transcribed. Most of the errors were
expected and exposed as limitations (section 3.2.). Finally, despite only getting one
occurrence of this problem, it may be the case that some words are mispronounced due to
the fact that they are part of the exception list and consequently rules do not apply to them.

39
5. Conclusion
All main goals presented in 1.4. were achieved and TexAFon can now be used to transcribe
in eight new dialects of Catalan. Not only can texts be obtained for all dialects but also
pronunciation dictionaries for each dialect can be collected. There is not still a proper
synthetic Catalan voice in order to read the output, but the first step is fulfilled.
The main improvement by our project in comparison with other existing tools is that it can
give more than one variant per word at a time, making it easy to create a pronunciation
dictionary. The functions of this tool cannot be compared with any existing one, since the
most similar project is Segre and it does not give information on evaluation.
As seen above, for now the architecture of TexAFon only allows to run one dialect at a time.
One possible improvement of this tool would be the creation of a program in order to unify
all possible variants of all dialects to get a complete pronunciation dictionary with
information of every dialect. To do so, we need to take into account the idea of improving
the system by giving some variation but not so much as to cause problems (section 1.2.).
There are several problems that have arisen when creating rules. The first one is that
information is not very recent and most of the studies are compilations of materials whose
information was recorded decades ago. Second, most of the bibliography does not have
information about the speakers (age, studies, context, etc.), which has some implications on
the way people speak. TexAFon ‘proc_ling’ program allows for the running of a module of
neutral or not neutral accent (stylistic variation, for example –Section 1.3.2.–), which could
be improved in future projects. Finally, most of the materials do not give information about
frequency, which makes it difficult to decide for primary and secondary phenomena.
After the creation of this project it is clear that languages are always changing and
information is hard to collect without leaving anything out. Speech technologies need to be
updated so as to be as close as possible to real language. For this reason, linguistic
knowledge will be of the utmost importance in the years to come.

40
References
Al-Haj, A., Hsiao, R., Lane, I., Black, A.W., Waibel, A. (2009). Pronunciation modeling for
dialectal arabic speech recognition. ASRU, 2009, pp. 525–528.
Badia, A. (1981) Gramàtica històrica catalana. València: Tres i Quatre.
Badia, A., Veny, J., Pons, L. (1993). Atles Lingüístic del Domini Català. Qüestionari. Barcelona,
Institut d'Estudis Catalans.
Black, A., Lenzo, K., & Pagel, V. (1998). “Issues in building general letter to sound rules.” In
Third ESCA/COCOSDA Workshop on Speech Synthesis, Jenolan Caves House (pp. 77–
80). Blue Mountains, Australia. Retrieved from
http://www.era.lib.ed.ac.uk/handle/1842/1046
Bonaventura, P., Giuliani, F., Garrido, J. M., Ortín, I. (1998). Grapheme-to-Phoneme
Transcription Rules for Spanish, with Application to Automatic Speech Recognition
and Synthesis. Proceedings of the Workshop 'Partially Automated Techniques
Transcribing Naturally Occurring Continuous Speech', 16th August 1998, Université
de Montréal, Montreal, Quebec, Canada, Coling-ACL'98, pp. 33-39.
Braga, D., Coelho, L., & Gil Vianna Resende Jr, F. (2006). A rule-based grapheme-to-phone
converter for tts systems in european portuguese. In VI International
Telecommunications Symposium (ITS2006) (pp. 328–333). Fortaleza: Ieee.
doi:10.1109/ITS.2006.4433293
Byrne et al. (1998). Pronunciation Modelling using a hand-labelled corpus for conversational
speech recognition, Proceedings of the 1998 IEEE International Conference on
Acoustics, Speech and Signal Processing (ICASSP), Volume: 1.
Colomina, J. (1999). Dialectologia catalana. Introducció i guia bibliogràfica. Departament de
Filologia Catalana de la Universitat d’Alacant, Alacant.
Cuetos, F. (1989). Lectura y escritura de palabras a través de la ruta fonológica. Infancia y
Aprendizaje, 89, 71-84.
Del-Agua, M.A., Giménez, A., Serrano, N., Andrés-Ferrer, J., Civera, J., Sanchis, A., Juan, A.
(2014). The transLectures-UPV toolkit. In: Advances in Speech and Language
Technologies for Iberian Languages, (2014) M. A. del-Agua, A. Giménez, N. Serrano,
J. Andr és-Ferrer, J. Civera, A. Sanchis, and A. Juan MLLP, DSIC, Universitat
Politècnica de València (UPV)
Fodge, K. (2014). Introducing Spanish dialects in a linguistic processing module for improved
ASR and novel speech synthesis possibilities. Unpublished master’s thesis, Barcelona:
Departament de Traducció i Ciències del Llenguatge, Universitat Pompeu Fabra.

41
Garrido, J.M., Laplaza, Y., Marquina, Mo., Schoenfelder, C., Rustullet, S. (2012). “TexAFon: a
multilingual text processing tool for text-to-speech applications”. In Torre Toledano,
Doroteo (et al.) (coord.) Proceedings of IberSPEECH 2012: VII Jornadas en Tecnología
del Habla and III Iberian SLTech Workshop: 21-23 November 2012, Madrid. [Madrid]:
[Universidad Autónoma de Madrid]. p. 281-289. ISBN 84-616-1535-2
Hain (2005). Implicit modelling of pronunciation variation in automatic speech recognition,
Speech Communication 46 (2005), pp. 171–188.
Hanžl, V., & Pollák, P. (2009). Accuracy analysis of generalized pronunciation variant
selection in ASR systems doi:10.1007/978-3-642-03320-9_37
Holter, T. (1997). Maximum likelihood modelling of pronunciation in automatic speech
recognition. Ph.D. Thesis, Norwegian University of Science and Technology,
December 1997.
Institut d’Estudis Catalans (1990). roposta per a un est ndard oral de la llengua catalana
on ca (1990, revisió 1999).
iménez, . 2001. L’harmonia vocàlica en valencià . In: August Bover i Font, Maria-Rosa
Lloret & Mercè Vidal-Tibitts, eds., ctes del ov ol lo ui d’ studis atalans a ord-
rica. (Selected Proceedings.) Barcelona, 1998. Barcelona, Publicacions de
l’Abadia de Montserrat: 217-244.
Juang, B. H., Rabiner, L.R. (2005). Automatic speech recognition–a brief history of the
technology development, K. Brown (Ed.) Encyclopedia of Language and Linguistics,
Elsevier.
Kessens, J. M., Cucchiarini, C., & Strik, H. (2003). A data-driven method for modeling
pronunciation variation. Speech Communication, 40(4), 517-534. doi:10.1016/S0167-
6393(02)00150-4
Kessens, J., Wester, M. (1997). Improving recognition performance by modelling
pronunciation variation. In: Proceedings of the CLS opening Academic Year ’97-‘98,
pp. 1-20.
Lamel, L., Gauvain, .L. (2003). “Speech recognition”, in MITKOV, R. (Ed.) The Oxford
Handbook of Computational Linguistics. Oxford: Oxford University Press.
Mermelstein, P. (1976). Distance measures for speech recognition, psychological and
instrumental. En Chen, C. H. (Ed.). Pattern Recognition and Artificial Intelligence (pp.
374–388), New York: Academic.
Moreno, A., Mariño, J.B. (1998). Spanish dialects: phonetic transcription, roc SL ’98,
Sydney, Australia, pp. 189-192.

42
Moreno, A., Hoege, H., Koehler , J., Mariño, J. B. (1998) SpeechDat Across Latin America
Project SALA. Proc. First Int. Conf. On Language Resources & Evaluation. ICLR'98
Nadeu, M. & Renwick, M. E. (Accepted). Variation in the lexical distribution and
implementation of phonetically similar phonemes. To appear in Journal of Phonetics.
Nogueira, A., Mariño, J. B. (2009). SAGA Transcriptor fonético de las variedades dialectales
del español. Recovered on June 14, 16 from TALP group, Universitat Politèncica de
Catalunya: http://www.talp.upc.edu/index.php/technology/tools/signal-processing-
tools/81-saga
Pachès, S. P., de la Mota, C., Riera, M., Perea, P., Febrer, A., Estruch, M., Garrido, J. M.,
Machuca, M. J., Ríos, A., LListerri, J., Esquerra, I., Hernando, J., Padrell, J., Nadeu, C.
(2000). SEGRE: An Automa c Tool for Grapheme-to-Allophone Transcrip on in
Catalan, in CR IN N. D. (Ed.) Proceedings of the Workshop on Developing
Language Resources for Minority Languages: Reusability and Strategic Priorities
(LREC-2000 Second International Conference on Language Resources and
Evaluation). Athens, Greece, 30 May 2000. pp. 52-61.
Rabiner, Lawrence R. and Juang, B.H. (2004). Statistical Methods for the Recognition and
Understanding of Speech. Rutgers University and the University of California, Santa
Barbara; Georgia Institute of Technology, Atlanta.
Rasico, P.D. (1982). Estudis sobre la fonologia del català preliterari. Barcelona, Curial -
Publicacions de l'Abadia de Montserrat. "Textos i Estudis de Cultura Catalana,"
1982).
Recasens, D. (1996). Fonètica descriptiva del català: assaig de caracterització de la pronúncia
del vocalisme i consonantisme del català al segle XX. –2a edició– Barcelona: Institut
d’Estudis Catalans.
ReSolc (2010). Universitat Pompeu Fabra. Recovered from: http://resolc.iula.upf.edu
Riley, M., Byrne, W., Finke, M., Khudanpur, S., Ljolje, A., McDonough, J., Nock, H., Saraßclar,
M., Wooters, C., Zavaliagkos, G. (1999). Stochastic pronunciation modelling from
hand-labelled phonetic corpora. Speech Commun. 29, 209–224.
Ríos, A. (1993). La información lingüística en la transcripción fonética automática del
español, Boletín de la Sociedad Española para el Procesamiento del Lenguaje Natural
13: pp. 381-387.
Schulz, H., Ruiz Costa-Jussà, M., Rodríguez, J. A. (2008). TECNOPARLA - Speech technologies
for Catalan and its application to speech-to-speech translation. Procesamiento del
lenguaje natural. 41 , pp. 319-320.

43
Schulz, H., Fonollosa, J., Rybach, D. (2009). A baseline system for the transcription of Catalan
broadcast conversation, In SLTECH-2009, 49-52.
Sloboda, T., Waibel, A. (1996). Dictionary learning for spontaneous speech recognition. In:
Proceedings of ICSLP-96, Philadelphia, pp. 2328-2331.
Strik, H., & Cucchiarini, C. (1999). Modeling pronunciation variation for ASR: A survey of the
literature. Speech Communication, 29(2), 225-246. doi:10.1016/S0167-
6393(99)00038-2
Torres, M. I. (2006). “El reconocimiento del habla”, in Llisterri, J.- Machuca, M. J. (Eds.) Los
sistemas de diálogo. Bellaterra - Soria: Universitat Autònoma de Barcelona, Servei
de Publicacions - Fundación Duques de Soria (Manuals de la Universitat Autònoma
de Barcelona, Lingüística, 45). pp. 81-98.
Van Bael, C., Boves, L., Van den Heuvel, H., Strik, H. (2007). Automatic Phonetic Transcription
of Large Speech Corpora. Computer Speech & Languag. 21. pp. 652-668.
Veny, J. (1993). Introducció a la dialectologia catalane. –1a reimpressió– Barcelona:
Enciclopedia Catalana
Veny, J., Pons, L. (2001). Atles Lingüístic del Domini Català. Introducció. 1. El cos humà.
Malalties. vol. I. Barcelona, Institut d'Estudis Catalans.
Veny, J., Massanell, M. (2015) Dialectologia catalana. Aproximació pràctica als parlars
catalans. Barcelona, Universitat de Barcelona.
Wester, M. (2003). Pronunciation modeling for ASR – knowledge-based and data-derived
methods, Computer Speech and Language 17 (2003), pp. 69–85.

44
Annex 1
Initial Pseudo-code: Central Area
The following phenomena will be modeled for TTS. They are put in order of appearance in TexAFon.
1. Unstressed final /a/ is pronounced as [E]: This first example has been written with no abbreviations for clarity. # Transforms all final unstressed /a/ into [E] if character == “a” and next character == “NIL”: transcribe “E”
2. Initial unstressed /e/ is pronounced as [a] # Transforms all unstressed initial /e/ into [a] when part of a locked syllable if ch == “e” and pch == “NIL” and nch not in “vowels” and nnch not in “vowels”: transcribe “a”
3. Unstressed /E/ is pronounced as [e]: # Transforms all unstressed /E/ into [e] if character == “e”: transcribe “e”
4. Initial unstressed /o/ is pronounced as [aw] # Transforms all unstressed initial /o/ into [aw] when they are not followed by a vowel: if ch == “o” and pch == “NIL” and nch not in “vowels”: transcribe “aw”
5. Unstressed /O/ is pronounced as [o] # Transforms all unstressed /O/ into [o] if ch == “o”: transcribe “o”
Initial Pseudo-code: Pallarès
1. “ndr” and “ldr” groups, “d” is not pronounced: This first example has been written with no abbreviations for clarity. # Deletes /d/ when preceding letters are /n/ or /l/ and the following letter is /r/ if character == “d” and previous character == “n” or previous character == “l” and next character == “r”: transcribe “_”
2. Initial unstressed /e/ is pronounced as [a] # Transforms all unstressed initial /e/ into [a] when part of a locked syllable if ch == “e” and pch == “NIL” and nch not in “vowels” and nnch not in “vowels”: transcribe “a”
3. Unstressed /E/ is pronounced as [e]: # Transforms all unstressed /E/ into [e] if character == “e”: transcribe “e”

45
4. /Z/ and /dZ/ are pronounced as [j] # Transforms /Z/ and /dZ/ into [j] if ch == “j” and pch == “vowels” and nch == “vowels”:
transcribe “j”15 5. Latin group –NN– is not palatalized
# Transforms /N/ into /n/ if ch == “n” and nch == “y”: transcribe “n”
6. Initial unstressed /o/ is pronounced as [aw] # Transforms all unstressed initial /o/ into [aw] when they are not followed by a vowel: if ch == “o” and pch == “NIL” and nch not in “vowels”: transcribe “aw”
7. Unstressed /O/ is pronounced as [o] # Transforms all unstressed /O/ into [o] if ch == “o”: transcribe “o”
Initial Pseudo-code: Tortosí
1. Initial unstressed /e/ is pronounced as [a]: This first example has been written with no abbreviations for clarity. # Transforms all unstressed initial /e/ into [a] when part of a locked syllable if character == “e” and previous character == “NIL” and next next character not “NIL”: transcribe “a”
2. Unstressed /E/ is pronounced as [e]: # Transforms all unstressed /E/ into [e] if character == “e”: transcribe “e”
3. Conversion of /tL into [ll] # Transforms /L/ into [ll] when preceded by a /t/ if ch == “l” and nch == “l” and pch == “t” or ppch == “vowels” and nnch == “vowels”: transcribe “l l”
4. Initial unstressed /o/ is pronounced as [aw] # Transforms all unstressed initial /o/ into [aw] when they are not followed by a vowel: if ch == “o” and pch == “NIL” and nch not in “vowels”: transcribe “aw”
5. Unstressed /O/ is pronounced as [o] # Transforms all unstressed /O/ into [o] if ch == “o”: transcribe “o”
Initial Pseudo-code: Ribagorçà
15 This was the initial pseudocode. However, in order to get all possibilities, we included up to three different rules: one in j (when surrounded by vowels), one in g (when the previous character is an i) and another in t (when the next character is a j followed by a vowel).

46
1. Initial unstressed /e/ is pronounced as [a]: This first example has been written with no abbreviations for clarity. # Transforms all unstressed initial /e/ into [a] when part of a locked syllable if character == “e” and previous character == “NIL” and next next character not “NIL”: transcribe “a”
2. Unstressed /E/ is pronounced as [e]: # Transforms all unstressed /E/ into [e] if character == “e”: transcribe “e”
3. Devoicing of sibilant /dZ/ > [tS] # Transforms /dZ/ sound into [tS]16 if ch == “j” and pch == “vowels” and nch == “vowels”: transcribe “tS”17
4. /Z/ and /dZ/ are pronounced as [j]18 # Transforms /Z/ and /dZ/ into [j] if ch == “j” and pch == “vowels” and nch == “vowels”:
transcribe “j” 5. Palatalization of /pl/, /bl/, /cl/, /gl/, /fl/
# Transforms /l/ followed by /p, b, c, g, f/ into [L] if ch == “l” and pch == “p” or pch == “b” or pch == “c” or pch == “g” or pch == “f”: transcribe “L”
6. Initial unstressed /o/ is pronounced as [aw] # Transforms all unstressed initial /o/ into [aw] when they are not followed by a vowel: if ch == “o” and pch == “NIL” and nch not in “vowels”: transcribe “aw”
7. Unstressed /O/ is pronounced as [o] # Transforms all unstressed /O/ into [o] if ch == “o”: transcribe “o”
8. Final consonant group “rn” can be pronounced “rn”, “r” or “rt” # Leaves final “rn” as such or transforms it into “r” or “rt” if ch == “r” and nch == “n” and nnch == “NIL”: transcribe “rn”19
transcribe “r” transcribe “rt”
9. Devoicing of sibilant /z/ > [s] # Transforms /z/ into [s] if ch == “s” and pch == “vowels” and nch == “vowels”:
16 In Ribagorçà as in Valencian dialects there is no [Z] sound, but [dZ]. However, this phoneme was once devoiced and was converted into [tS], which is now preserved. 17 This was the initial pseudocode. However, in order to get all possibilities, we changed all occurrences of “jh” (in Cereproc) into “sh” inside the rules. 18 This rule interferes with (3). Thus, it was not treated as a rule itself but put in the exception dictionary of this dialect (see 3.2.) 19 TexAFon rules allow skipping a sound: r is used in the place of rn and so on.

47
transcribe “s”20 10. Devoicing of sibilant /dz/ > [ts]
# Transforms /dz/ into [ts] if ch == “t” and nch == “z”: transcribe “t”21
Initial Pseudo-code: Northern Valencian22
The following phenomena will be modeled for TTS:
1. Falling silent of the intervocalic /D/ when it comes from the Latin –ATA–: This first example has been written with no abbreviations for clarity. # Silence all /d/ between /a/ excepts the ones than only have one phoneme before. if character == "d" and whole previous in (u"bà", u"cà", u"dà", u"fà", u"gà", u"hà", u"jà", u"kà", u"là", u"mà", u"nà", u"pà", u"rà", u"sà", u"tà", u"và", u"xà", u"zà") and next character == "a" and next next character in "NIL":
transcribe “d” if character == "d" and previous character == u"à" and next character == "a" and next next character == "NIL": transcribe “_”
2. Initial unstressed /e/ is pronounced as [a] # Transforms all unstressed initial /e/ into [a] when part of a locked syllable if ch == “e” and pch == “NIL” and nch not in “vowels” and nnch not in “vowels”: transcribe “a”
3. Unstressed /E/ is pronounced as [e]: # Transforms all unstressed /E/ into [e] if character == “e”: transcribe “e”
4. Intervocalic /dZ/ is converted into [jZ]23 # Transforms intervocalic /dZ/ and /Z/ into [jZ] also when a t precedes it if ch == “j” and pch == “vowels” and nch == “vowels”: if ch == “j” and pch == “t” and ppch == “vowels” and nch == “vowels”: if ch == “g” and pch == “t” and ppch == “vowels” and nch == “vowels”: transcribe “jZ” transcribe “dZ”
5. Conversion of /tL into [ll] 20 This is the initial pseudo-code. However, rules in TexAFon do have more occurrences of this phoneme, for this reason all rules regarding s converted into [z] where changed not only in Ribagorçà but also in Central Valencian. 21 Since the general rule in Catalan is voicing a /t/ when the next sound is voiced, this rule is removed instead of creating a new one. Moreover, a rule in order to unvoice z when preceded by a t is created both in Ribagorçà and Central Valencian. 22 There is a rule that covers all Valencian dialects that is not recorded in the rules, since it affects more than one rule: every [ʒ] phoneme is changed into [dʒ]. However, since in Central Valencian this phoneme is devoiced, we did not include this rule in every dialect in the pseudocode but we adapted it in TexAFon code itself. 23 Three different rules were necessary to model this rule.

48
# Transforms /L/ into [ll] when preceded by a /t/ if ch == “l” and nch == “l” and pch == “t” or ppch == “vowels” and nnch == “vowels”: transcribe “l l” transcribe “l”
6. Unstressed /O/ is pronounced as [o] # Transforms all unstressed /O/ into [o] if ch == “o”: transcribe “o”
7. Maintenance of final “r” # Preserves the final r if ch == “r” and nch == “NIL”: transcribe “r”
8. /ts/ is palatalized into [tS] # Transforms /ts/ into [tS] if ch == “t” and nch == “s” and nnch == “NIL”: transcribe “tS”
9. “v” is pronounced as [v] # Makes the distinction between [b] and [v] if ch == “v”: transcribe “v”
10. Segregation and despalatalization of “ix” group into [js] # Transforms /S/ into [js] if ch == “x” and pch == “i”: transcribe “js”
11. /dz/ sound is palatalized into [dZ] # Transforms /dz/ into [dZ] if ch == “z” and pch == “t” and nch == “vowel”: transcribe “Z”
Initial Pseudo-code: Central Valencian
The following phenomena will be modeled for TTS:
1. Falling silent of the intervocalic /D/ when it comes from the Latin –ATA–: This first example has been written with no abbreviations for clarity. # Silence all /d/ between /a/ excepts the ones than only have one phoneme before. if character == "d" and whole previous in (u"bà", u"cà", u"dà", u"fà", u"gà", u"hà", u"jà", u"kà", u"là", u"mà", u"nà", u"pà", u"rà", u"sà", u"tà", u"và", u"xà", u"zà") and next character == "a" and next next character in "NIL":
transcribe “d” if character == "d" and previous character == u"à" and next character == "a" and next next character == "NIL": transcribe “_”
2. Initial unstressed /e/ is pronounced as [a]

49
# Transforms all unstressed initial /e/ into [a] when part of a locked syllable if ch == “e” and pch == “NIL” and nch not in “vowels” and nnch not in “vowels”: transcribe “a”
3. Unstressed /E/ is pronounced as [e]: # Transforms all unstressed /E/ into [e] if character == “e”: transcribe “e”
4. Devoicing of sibilant /dZ/ > [tS] # Transforms /dZ/ sound into [tS]24 if ch == “j” and pch == “vowels” and nch == “vowels”: transcribe “tS”25 if ch == “t” and nch == “j”: transcribe “t”
5. Conversion of /tL into [ll] # Transforms /L/ into [ll] when preceded by a /t/ if ch == “l” and nch == “l” and pch == “t” or ppch == “vowels” and nnch == “vowels”: transcribe “l l” transcribe “l”
6. Unstressed /O/ is pronounced as [o] # Transforms all unstressed /O/ into [o] if ch == “o”: transcribe “o”
7. Maintenance of final “r” # Preserves the final r if ch == “r” and nch == “NIL”: transcribe “r”
8. Devoicing of sibilant /z/ > [s] # Transforms /z/ into [s] if ch == “s” and pch == “vowel and nch == “vowel”: transcribe “s”
9. /ts/ is palatalized into [tS] # Transforms /ts/ into [tS] if ch == “t” and nch == “s” and nnch == “NIL”: transcribe “tS”
10. Maintenance of final “t” in “nt” and “lt” # Preserves de final “t” if ch == “t” and pch == “n” or pch == “l” and nch == “NIL”: transcribe “t”
11. Devoicing of sibilant /dz/ > [ts]
24 First we need to take into account that in Valencian dialects there is no [Z] sound, so in any context where other dialects have this phoneme, Valencian has [dZ]. Having this in mind, whenever there is this phoneme in Central Valencian, it changes into [tS]. This means that there is not a single rule to create this sound, but a concatenation of rules in order to devoice the /t/ sound previous to [Z]. 25 This was the initial pseudocode. However, in order to get all possibilities, we changed all occurrences of “jh” (in Cereproc) into “sh”.

50
# Transforms /dz/ into [ts] if ch == “t” and nch == “z”: transcribe “t”
12. Segregation of “ix” group into [jS] # Transforms /S/ into [jS] if ch == “x” and pch == “i”: transcribe “jS”
Initial Pseudo-code: Southern Valencian
The following phenomena will be modeled for TTS:
1. Falling silent of the intervocalic /D/ when it comes from the Latin –ATA–: This first example has been written with no abbreviations for clarity. # Silence all /d/ between /a/ excepts the ones than only have one phoneme before. if character == "d" and whole previous in (u"bà", u"cà", u"dà", u"fà", u"gà", u"hà", u"jà", u"kà", u"là", u"mà", u"nà", u"pà", u"rà", u"sà", u"tà", u"và", u"xà", u"zà") and next character == "a" and next next character in "NIL":
transcribe “d” if character == "d" and previous character == u"à" and next character == "a" and next next character == "NIL": transcribe “_”
2. Initial unstressed /e/ is pronounced as [a] # Transforms all unstressed initial /e/ into [a] when part of a locked syllable if ch == “e” and pch == “NIL” and nch not in “vowels” and nnch not in “vowels”: transcribe “a”
3. Unstressed /E/ is pronounced as [e]: # Transforms all unstressed /E/ into [e] if character == “e”: transcribe “e”
4. Conversion of /tL into [ll] # Transforms /L/ into [ll] when preceded by a /t/ if ch == “l” and nch == “l” and pch == “t” or ppch == “vowels” and nnch == “vowels”: transcribe “l l” transcribe “l”
5. Unstressed /O/ is pronounced as [o] # Transforms all unstressed /O/ into [o] if ch == “o”: transcribe “o”
6. Maintenance of final “r” # Preserves the final r if ch == “r” and nch == “NIL”: transcribe “r”
7. /ts/ is palatalized into [tS] # Transforms /ts/ into [tS]

51
if ch == “t” and nch == “s” and nnch == “NIL”: transcribe “tS”
8. Maintenance of final “t” in “nt” and “lt” # Preserves de final “t” if ch == “t” and pch == “n” or pch == “l” and nch == “NIL”: transcribe “t”
9. “v” is pronounced as [v] # Makes the distinction between [b] and [v] if ch == “v”: transcribe “v”
10. Segregation of “ix” group into [jS] # Transforms /S/ into [jS] if ch == “x” and pch == “i”: transcribe “jS”
Initial Pseudo-code: Alacantí26
The following phenomena will be modeled for TTS:
1. Falling silent of intervocalic “d”: This first example has been written with no abbreviations for clarity. # Deletes “d” when it is intervocalic if character == “d” and previous character == “vowel” and next character == “vowel” and previous previous character not in “NIL”: transcribe “_”
2. Initial unstressed /e/ is pronounced as [a] # Transforms all unstressed initial /e/ into [a] when part of a locked syllable if ch == “e” and pch == “NIL” and nch not in “vowels” and nnch not in “vowels”: transcribe “a”
3. Unstressed /E/ is pronounced as [e]: # Transforms all unstressed /E/ into [e] if character == “e”: transcribe “e”
4. Conversion of /tL into [ll] # Transforms /L/ into [ll] when preceded by a /t/ if ch == “l” and nch == “l” and pch == “t” or ppch == “vowels” and nnch == “vowels”: transcribe “l l” transcribe “l”
5. Both [Ow] and [ow] are pronounced [aw] # Transforms [Ow] and [ow] into [aw] if ch == “o” and nch == “u”: transcribe “a”
6. Unstressed /O/ is pronounced as [o] 26 As Alacantí has falling silent of all intervocalic /d/, rules containing Latin –ATA– and –ATORE– are not needed.

52
# Transforms all unstressed /O/ into [o] if ch == “o”: transcribe “o”
7. Maintenance of final “r” # Preserves the final r if ch == “r” and nch == “NIL”:
transcribe “r” 8. /ts/ is palatalized into [tS]
# Transforms /ts/ into [tS] if ch == “t” and nch == “s” and nnch == “NIL”: transcribe “tS”
9. “v” is pronounced as [v] # Makes the distinction between [b] and [v] if ch == “v”: transcribe “v”

53
Annex 2
transducer & fonetica_sintactica Final Python Code: Northern Valencian
#!/usr/bin/python # -*- coding: UTF-8 -*- ##-*- coding: ISO-8859-1-*- import sys, string, re, codecs sys.path.append('/home/eva/tts/bin') from lexicon import llexicon import definiciones def es_vocal(paraula, posicio_caracter): vocals= [u'a',u'á',u'à',u'â',u'ä',u'ã',u'å',u'æ',u'e',u'é',u'è',u'ë',u'ê',u'i',u'í',u'ï',u'ĩ',u'o',u'ò',u'ó',u'õ',u'ð',u'ô',u'ö',u'ø',u'u',u'ú',u'ü',u'ů',u'ũ',u'E',u'Ë',u'O',u'Ö'] vocals_fortes = [u'a',u'á',u'à',u'â',u'ä',u'ã',u'å',u'æ',u'e',u'é',u'è',u'ë',u'ê',u'o',u'ò',u'ó',u'ö',u'ô',u'õ',u'ð',u'ô',u'ö',u'ø',u'E',u'Ë',u'O',u'Ö'] consonants = ['b', 'c', u'ç', 'd', 'f', 'g', 'h', 'j', 'k', 'l', 'm', 'n', u'ñ', 'p', 'q', 'r', 's', 't', 'v', 'w', 'x', 'z'] #print "Entro en es_vocal" #print "Paraula:", paraula #print "Caracter:", paraula[posicio_caracter] #print "Posicio caracter:", posicio_caracter sortida = False llargada_paraula = len(paraula) cadena_paraula = "".join(paraula) if paraula[posicio_caracter] in (vocals_fortes): #print "El caracter es vocal" sortida = True if paraula[posicio_caracter] in (u'í',u'ì',u'ï',u'î',u'ĩ',u'ú',u'ù',u'û',u'ů',u'ũ'): #print "El caracter es vocal" sortida = True if paraula[posicio_caracter] == u'ü': sortida = True if posicio_caracter > 0:

54
if paraula[posicio_caracter-1] in (u'q', u'g'): #print "El caracter no es vocal" sortida= False if posicio_caracter < (llargada_paraula-1): if paraula[posicio_caracter+1] in (u'e',u'é',u'è',u'i',u'ì',u'í'): #print "El caracter no es vocal" sortida= False if (paraula[posicio_caracter] in ("u", "i")): sortida = True if posicio_caracter < (llargada_paraula-1): if (posicio_caracter == 0) and (paraula[posicio_caracter+1] in (u'a',u'à',u'á',u'e',u'é',u'è',u'o',u'ò',u'ó')): #print "El caracter no es vocal" sortida = False if posicio_caracter < (llargada_paraula-1) and posicio_caracter > 0: if paraula[posicio_caracter] == u'u' and ((paraula[posicio_caracter-1] in (u'q', u'g')) or (paraula[posicio_caracter-1] in (vocals))) and (paraula[posicio_caracter+1] in (u'a',u'à',u'á',u'e',u'é',u'è',u'o',u'ò',u'ó',u'i',u'í')): #print "El caracter no es vocal" sortida = False if paraula[posicio_caracter] == u'i' and (paraula[posicio_caracter-1] in (vocals)) and (paraula[posicio_caracter+1] in (u'a',u'à',u'á',u'e',u'é',u'è',u'o',u'ò',u'ó')) and (posicio_caracter == 0): #print "El caracter no es vocal" sortida = False if (paraula[posicio_caracter-1] in (vocals_fortes)) and (paraula[posicio_caracter+1] not in (vocals)): #print "El caracter no es vocal: abans hi ha una vocal forta" sortida = False if (paraula[posicio_caracter] == u'u') and (paraula[posicio_caracter-1] in (u'i', u'ï', u'u', u'ü')) and (paraula[posicio_caracter+1] not in (vocals)): #print "El caracter no es vocal: es una combinacio iu, uu" sortida = False if (paraula[posicio_caracter] == u'i') and (paraula[posicio_caracter-1] in (u'i', u'ï')) and (paraula[posicio_caracter+1] not in (vocals)): #print "El caracter no es vocal: es una combinacio ii" sortida = False if posicio_caracter < (llargada_paraula-1) and posicio_caracter > 1:

55
if not ((paraula[posicio_caracter-2] in (u'g', u'q')) and (paraula[posicio_caracter-1] in [u'u',u'ü'])): if paraula[posicio_caracter] == u'i' and (((paraula[posicio_caracter+1] == u'x') and (paraula[posicio_caracter-1] in (vocals))) or ((paraula[posicio_caracter+1] == u'g') and (posicio_caracter+1==len(paraula)))): #print "El caracter no es vocal: es una i seguida de x o g" sortida = False if (paraula[posicio_caracter] == u'i') and (paraula[posicio_caracter-1] in [u'u',u'ü']) and (paraula[posicio_caracter+1] not in (vocals)): #print "El caracter no es vocal: es una combinacio ui, üi" sortida = False if paraula[posicio_caracter] == u'i' and (paraula[posicio_caracter-1] in (vocals)) and (paraula[posicio_caracter+1] in (u'a',u'à',u'á',u'e',u'é',u'è',u'o',u'ò',u'ó')): #print "El caracter no es vocal" sortida = False if posicio_caracter > 0: if (paraula[posicio_caracter-1] in (vocals_fortes)) and ((posicio_caracter-1) == 0): #print "El caracter no es vocal: abans hi ha una vocal forta en posicio inicial" sortida = False if (paraula[posicio_caracter-1] in (vocals_fortes)) and (posicio_caracter == (llargada_paraula-1)): #print "El caracter no es vocal: abans hi ha una vocal forta i esta en posicio final" sortida = False if (paraula[posicio_caracter-1] in (u'i', u'ï', u'u', u'ü')) and ((posicio_caracter-1) == 0): #print "El caracter no es vocal: es una combinacio iu, uu, ii, ui" sortida = False if (paraula[posicio_caracter] == u'u') and (paraula[posicio_caracter-1] in (u'i', u'ï', u'u', u'ü')) and (posicio_caracter == (llargada_paraula-1)): #print "El caracter no es vocal: es una combinacio iu, uu" sortida = False if (paraula[posicio_caracter] == u'i') and (paraula[posicio_caracter-1] in (u'i', u'ï')) and (posicio_caracter == (llargada_paraula-1)): #print "El caracter no es vocal: es una combinacio ii"

56
sortida = False if posicio_caracter > 1: if not ((paraula[posicio_caracter-2] in (u'g', u'q')) and (paraula[posicio_caracter-1] in [u'u',u'ü'])): if (paraula[posicio_caracter] == u'i') and (paraula[posicio_caracter-1] in (u'u', u'ü')) and (posicio_caracter == (llargada_paraula-1)): #print "El caracter no es vocal: es una combinacio iu, uu" sortida = False # Excepcio: casos de 'i' dels sufixos 'isme', 'ista' i plurals if paraula[posicio_caracter] == u'i': if posicio_caracter == (llargada_paraula-2) and posicio_caracter > 0 and cadena_paraula.endswith("ir") and (paraula[posicio_caracter-1] in (vocals)): sortida = True if posicio_caracter == (llargada_paraula-3) and posicio_caracter > 0 and cadena_paraula.endswith("int") and (paraula[posicio_caracter-1] in (vocals)): sortida = True if posicio_caracter == (llargada_paraula-4) and (cadena_paraula.endswith("isme") or cadena_paraula.endswith("ista")): sortida = True if posicio_caracter == (llargada_paraula-5) and (cadena_paraula.endswith("ismes") or cadena_paraula.endswith("istes")): sortida = True if (paraula[posicio_caracter] == u'y'): sortida = False if paraula[posicio_caracter-1] == u'u' and (posicio_caracter == llargada_paraula-1): #print "El caracter y es vocal: esta en un diptongo uy" sortida = True if paraula[posicio_caracter-1] in(consonants) and paraula[posicio_caracter-1] <> "n" and (posicio_caracter == llargada_paraula-1): #print "El caracter y es vocal: esta al final antes de una consonante" sortida = True

57
if posicio_caracter < (llargada_paraula-1): if paraula[posicio_caracter-1] in(consonants) and paraula[posicio_caracter-1] <> "n" and paraula[posicio_caracter+1] in(consonants): #print "El caracter y es vocal: esta entre consonantes" sortida = True return sortida def transducer(ch,nch,nnch,pch,ppch,wholep,wholen,style): # it returns a list of lists salida = [] lista_vocales=set([u'a',u'á',u'à',u'e',u'é',u'è',u'E',u'i',u'í',u'ï',u'o',u'ò',u'ó',u'O',u'u',u'ú',u'ü',u'Ë',u'Ö']) lista_consonantes=set([u'b',u'c'u'ç',u'd',u'f',u'g',u'j',u'k',u'l',u'm',u'n',u'p',u'q',u'r',u's',u't',u'v',u'x',u'y',u'z']) pronoms_febles = ["me", "te", "se", "lo", "la", "los", "les", "ne", "ho", "li","hi", "nos", "vos"] combinacions_pronoms = [u"m¬hi", u"t¬hi", u"li¬ho", u"li¬hi", u"li¬n", u"l¬hi", u"la¬hi", u"los¬hi", u"les¬hi", u"se¬m", u"se¬t", u"-se¬l", u"se¬la", u"s¬ho", u"se¬li", u"s¬hi", u"se¬n", u"se¬ns", u"se¬us", u"se¬ls", u"se¬les", u"n¬hi", u"nos¬el", u"nos¬ho", u"nos¬li", u"nos¬hi", u"nos¬en", u"nos¬els", u"nos¬les", u"vos¬em", u"vos¬el", u"vos¬la", u"vos¬ho", u"vos¬li", u"vos¬hi", u"¬vos¬en", u"vos¬ens", u"vos¬els", u"vos¬les", u"me¬ls", u"te¬ls", u"los¬el", u"los¬la", u"los¬ho", u"los¬hi", u"los¬en", u"nos¬els", u"vos¬els", u"los¬els", u"los¬les", u"les¬hi", u"les¬en"] palabra=wholep+ch+wholen #print "palabra: ", palabra llargada_paraula=len(palabra) #print "llargada paraula: ", llargada_paraula llargada_wholep=len(wholep) #print "llargada wholep: ", llargada_wholep posicio_caracter= llargada_wholep #print "posicio caracter: ", posicio_caracter #print "Empiezo a aplicar las reglas" #print "wholep: ", wholep[-1:] if ch == "a": salida.append(["a0",0,True]) return salida # mb -> m; (b en posicion final precedida por m ) if ch=="b" and pch=="m" and nch=="NIL": salida.append(["",0,True]) return salida if ch=="b" and nch=="NIL": salida.append(["B",0,False])

58
return salida if ch=="b" and nch==u"¬": salida.append(["b",0,False]) return salida #bm ->p submis, subfamilia #if ch=="b" and (nch=="m" or nch=="f"): # return ["p",0,True] # (b en posición final) if ch=="b" and nch=="NIL": salida.append(["p",0,False]) return salida # b -> b if ch == "b": salida.append(["b",0,True]) return salida if ch=="c" and nch=="NIL": salida.append(["G",0,False]) return salida if ch=="c" and nch==u"¬": salida.append(["k",0,False]) return salida # c [EI] -> s ; cicle if ch =="c" and (nch=="E" or nch==u"Ë" or nch=="e" or nch==u"é" or nch==u"è" or nch=="i" or nch==u"Í" or nch==u"í"): salida.append(["s",0,True]) return salida #christosi, technicolor ... if ch=="c" and nch=="h" and (nnch=="r" or nnch=="n" or nnch=="t" or nnch=="g"): salida.append(["k",1,False]) return salida # c h -> ch ; chocolate no al final de paraula if ch =="c" and nch=="h" and not nnch=="NIL": salida.append(["sh",1,True]) return salida if ch=="c" and nch=="c" and not (nnch=="E" or nnch==u"Ë" or nnch=="e" or nnch==u"é" or nnch==u"è" or nnch=="i" or nnch==u"Í" or nnch==u"í"): salida.append(["k",1,False]) return salida if ch=="c" and (nch=="k" or nch=="q"): salida.append(["",0,False]) return salida

59
if ch=="c" and (nch=="m" or nch=="d"): salida.append(["g",0,False]) return salida # c -> k ; casa if ch =="c": salida.append(["k",0,True]) return salida # terminacions ment if ch==u"ç" and nch=="m": salida.append(["z",0,True]) return salida # ç -> s if ch==u"ç" and nch in "NIL": salida.append(["Z",0,True]) return salida if ch==u"ç" and nch in u"¬": salida.append(["s",0,True]) return salida if ch ==u"ç": salida.append(["s",0,True]) return salida #print "Llego a las reglas de la d" # caiguda d en -ada. if ch=="d" and wholep in (u"bà", u"cà", u"dà", u"fà", u"gà", u"hà", u"jà", u"kà", u"là", u"mà", u"nà", u"pà", u"rà", u"sà", u"tà", u"và", u"xà", u"zà") and nch=="a" and nnch in "NIL":
salida.append(["d",0,True]) return salida
if ch=="d" and pch==u"à" and nch=="a" and nnch=="NIL":
salida.append(["",0,False]) return salida
#eudald, dividend if ch=="d" and pch in (u'l', u'n', u'r') and nch== u's' and nnch=="NIL": salida.append(["", 0, False]) return salida if ch=="d" and nch=="NIL": salida.append(["D",0,False]) return salida

60
if ch=="d" and nch==u"¬": salida.append(["d",0,False]) return salida if ch=="d" and ((nch==u's' or nch==u'z') and nnch in "NIL"): salida.append(["t Z", 1, False]) return salida if ch=="d" and nch=="s": salida.append(["t s",0,True]) return salida # d madrid final de paraula if ch=="d" and (nch=="NIL" or nch=="-"): salida.append(["t",0,True]) return salida if ch=="d" and nch=="d": salida.append(["d",1,False]) return salida # d -> d if ch =="d": salida.append(["d",0,True]) return salida # regles E #adreça, neci if ch=="E" or ch==u"Ë": #print "he entrat a les regles de la E. Carcter: ", ch ch_prov = u"" if nch in (u't', u'm', u'j', u'g', u'q', u'b'): ch_prov="ee" elif (nch == u'l' and nnch <> u'l') or (wholen in (u'ssa', u'sses')) or (nch ==u's' and nnch not in (u's', u't')) or (nch ==u'n' and nnch <> u't'): ch_prov="ee" elif nch == u'x' and nnch <> u't' and pch <>u't': ch_prov="ee" elif wholen in (u'u', u'us', u'c', u'cs', u'u¬', u'us¬', u'c¬', u'cs¬'): ch_prov= "ee" elif nch== u'r' and nnch in (u'n', u'r', u't', u'd'): ch_prov="ee" elif nch== u'i': ch_prov= "ee" elif nch== u'c' and nnch== u'a': ch_prov= "ee" else:

61
ch_prov="e" if ch=="E": ch_prov = ch_prov + "1" if ch==u"Ë": ch_prov = ch_prov + "2" salida.append([ch_prov, 0, False]) return salida # e -> e if ch=="e" and pch=="NIL" and nch not in lista_vocales and nnch not in lista_vocales:
salida.append(["a0",0,True]) return salida
if ch=="e":
salida.append(["e0",0,False]) return salida if ch=="f" and nch=="f": salida.append(["f",1,False]) return salida # f -> f if ch =="f": salida.append(["f",0,True]) return salida if ch=="g" and pch=="t" and ppch in lista_vocales and nch in lista_vocales:
salida.append(["DJH",0,True]) salida.append(["j JH",0,True]) return salida
if ch=="g" and pch==u'í' and nch in "NIL": salida.append(["DJH", 0, False]) return salida # g [EI] -> jh ; girona if ch=="g" and pch==u'i' and ppch in (lista_vocales) and nch in "NIL": salida.append(["DJH", 0, False]) return salida if ch=="g" and wholep in (u'mi', u'pui') and nch in "NIL": salida.append(["DJH", 0, False]) return salida if ch=="g" and nch=="NIL": salida.append(["G",0,False]) return salida

62
if ch=="g" and nch==u"¬": salida.append(["g",0,False]) return salida if ch =="g" and (nch=="e" or nch==u"E" or nch==u"é" or nch==u"è" or nch=="i" or nch ==u"í"): salida.append(["d jh",0,True]) return salida # g u [EI] -> g ; guerra if ch =="g" and nch=="u" and (nnch=="e" or nnch==u"è" or nnch=="E" or nnch==u"é" or nnch=="i" or nnch ==u"í"): salida.append(["g",1,True]) return salida # ^ g n -> n ; gnomo if ch =="g" and nch=="n" and pch=="NIL": salida.append(["n",1,False]) return salida if ch=="g" and nch=="g": salida.append(["jh jh",1,False]) return salida if ch=="g" and wholep in ([u'mi', u'pui']): salida.append(["t sh",0,False]) return salida if ch=="g" and pch==u'í' and (nch=="NIL" or nch==u'¬'): salida.append(["t sh",0,False]) return salida if ch=="g" and pch==u'i' and ppch in (lista_vocales)and (nch=="NIL" or (nch==u's'and (nnch=="NIL" or nnch==u'¬')) or nch==u'¬'): salida.append(["t sh",0,False]) return salida if ch=="g" and (nch=="f" or nch=="s" or nch=="NIL"): salida.append(["k",0,False]) return salida # g -> g if ch=="g": salida.append(["g",0,True]) return salida # h -> ; if ch=="h": salida.append(["",0,False]) return salida

63
#print "Llego a las reglas de la i" # regles per la i if ch=="i" and (re.match(r"^semi$",wholep) or re.match(r"^anti$",wholep)): salida.append(["i0",0,True]) return salida if ch=="i" and wholen in (u'sme', u'smes', u'sta', u'stes'): salida.append(["i1",0,True]) return salida if ch=="i" and nch=="x"and ppch in (u'q', u'g')and pch ==u'u': salida.append(["i0", 0, False]) return salida if ch=="i" and nch=="g"and nnch=='NIL' and ppch in (u'q', u'g')and pch==u'u' : salida.append(["i0", 0, False]) return salida if ch=="i" and nch=="g" and wholep == u'pu': salida.append(["", 0, False]) return salida if ch=="i" and nch=="g" and nnch=='NIL' and pch in (u'a', u'à', u'e', u'è', u'é', u'o', u'ò', u'ó', u'E', u'O', u'i', u'ï', u'í', u'ú', u'ü'): salida.append(["", 0, False]) return salida if ch=="i" and pch =="u" and ppch not in (u'q', u'g'): salida.append(["j", 0, False]) return salida if ch=="i" and pch in (u'a', u'à', u'e', u'è', u'é', u'o', u'ò', u'ó', u'E', u'O', u'ú', u'i', u'ï', u'í'): salida.append(["j", 0, False]) return salida if ch=="i" and nch in (u'a', u'à', u'e', u'è', u'é', u'o', u'ò', u'ó', u'E', u'O')and pch=='NIL': salida.append(["j", 0, False]) return salida if ch=="i": salida.append(["i0", 0, False]) return salida # j -> jh
if ch=="j" and pch in lista_vocales and nch in lista_vocales: salida.append(["d jh",0,True]) salida.append(["j jh",0,True]) return salida

64
if ch=="j" and pch=="t" and ppch in lista_vocales and nch in lista_vocales:
salida.append(["d jh",0,True]) salida.append(["j jh",0,True]) return salida
if ch=="j": salida.append(["d jh",0,True]) return salida # ^ k n -> n ; anglicanismes if ch=="k" and ppch=="NIL" and nch=="n": salida.append(["n",1,False]) return salida if ch=="k" and nch=="NIL": salida.append(["G",0,False]) return salida if ch=="k" and nch==u"¬": salida.append(["k",0,False]) return salida # [c] k -> ; anglicanismes #if ch=="k" and pch=="c": # return["",0,False] # k -> k if ch=="k": salida.append(["k",0,False]) return salida # l l $ -> l ; castell??? # l l [C] -> l ; castelldefels # lls, ll$: de vegades català de vegades anglés # l l -> J ; llorar
if ch=="l" and nch=="l" and pch=="t" and ppch in lista_vocales and nnch in lista_vocales:
salida.append(["l l",1,True]) salida.append(["l",1,True]) return salida
if ch=="l" and nch=="l": salida.append(["ll",1,True]) return salida if ch=="l" and nch==u"·" and nnch=="l": salida.append(["l",2,True]) return salida # l -> l if ch=="l":

65
salida.append(["l",0,True]) return salida # mn -> n if ch=="m" and nch==u'n' and pch=="NIL": salida.append(["n",1,True]) return salida # m -> m if ch=="m": salida.append(["m",0,True]) return salida # n y -> ny no quan final de paraula !!inyecto conyugal CATALUNYA if ch=="n" and nch=="y": salida.append(["ny",1,False]) return salida # n n -> n ; NO innovación, innecesario # n -> n # anfora, triunfo enmascarar conmovido convengo if ch=="n" and (nch=="f" or nch=="m" or nch=="v" or nch=="b") : salida.append(["m",0,True]) return salida #excepcions per ng if ch=="n" and nch=="g" and (nnch=="m" or nnch=="n" or nnch==u"ñ" or nnch=="b" or nnch=="d" or nnch=="f" or nnch=="z"): salida.append(["n",0,False]) return salida # ng angola ???, camping ching-chang, washington if ch=="n" and nch=="g" and nnch=="NIL": salida.append(["ng",1,False]) return salida if ch=="n" and nch=="n": salida.append(["n",1,False]) return salida if ch=="n": salida.append(["n",0,True]) return salida # ñ -> ny if ch==u"ñ": salida.append(["ny",0,True]) return salida #print "Llego a las reglas de la O"

66
# Regles O if ch=="O" or ch==u"Ö": ch_prov = u"" if pch==u'h': ch_prov="oo" elif nch==u'p': if pch=='r' and ((nnch==u"NIL") or (nnch==u's' and len(wholen) > 2 and wholen[2] =="NIL")): ch_prov="oo" elif nnch==u's' and len(wholep) > 4 and wholep[2]==u'i' and ((wholep[3]=="NIL") or(wholep[3]==u's' and wholep[4]=="NIL")): ch_prov="oo" elif ((nnch==u'i') or (nnch==u'i' and len(wholep) > 2 and wholep[2]==u's')): ch_prov="oo" else: ch_prov = "o" elif nch == u"t" and nnch == u"a" and wholep == "s": #print "wholep: ", wholep ch_prov="o" elif pch == u"s" and nch == u"b" and nnch == u"r" and len(wholen) > 2 and wholen[2] == "e": #print "wholen: ", wholen ch_prov="o" elif pch==u'l' and ppch==u'p': ch_prov="oo" elif nch==u'b' and nnch==u'r': ch_prov="oo" elif nch==u'l' and nnch==u'l': ch_prov="oo" elif nch==u's': if nnch==u'i': ch_prov="oo" elif nnch==u't' and pch <> u'g': ch_prov = "oo" elif nnch==u'c' and pch <> u'f': ch_prov = "oo" elif nnch==u's' and len(wholen) > 2 and wholen[2] == u'i': ch_prov = "oo" elif nnch==u's' and len(wholen) > 2 and wholen[2] == u'o': ch_prov = "oo" elif nnch==u's' and len(wholen) > 2 and wholen[2] == u'a': ch_prov = "oo" elif pch ==u'r': ch_prov = "oo" elif pch ==u'p': ch_prov = "oo" elif pch ==u'l'and ppch==u'c': ch_prov = "oo"

67
else: ch_prov = "o" elif nch==u'n' and (nnch==u'j' or nnch==u'g'): ch_prov="oo" elif ((nch==u'x') or (nch==u'i' and nnch <> u'x')): ch_prov="oo" elif nch==u'r' and nnch in ([u'd',u'l',u'g',u'b',u'c',u't',u'ç',u'i',u'x',u'f']): ch_prov="oo" elif (nch==u'v' or nch==u'b')and (nnch==u'a' or nnch==u'e'): ch_prov="oo" elif nch==u's' and nnch in ([u'e',u'i',u'o']): ch_prov="oo" elif nch==u't' and (nnch==u'g' or nnch==u'j'): ch_prov="oo" elif nch in ([u'f',u'l',u'g',u'c',u'q',u'ç',u'd',u'u',u't',u'j']): ch_prov="oo" else: ch_prov="o" #print "entro en esta regla" if ch=="O": ch_prov = ch_prov + "1" if ch==u"Ö": ch_prov = ch_prov + "2" salida.append([ch_prov, 0, False]) return salida # o -> o if ch=="o" and (nch==u'u' or nch==u'ú'): salida.append(["oo0", 0, False]) return salida if ch=="o": salida.append(["o0",0,True]) return salida if ch=="p" and pch=="m" and nch=="NIL": salida.append(["",0,False]) return salida if ch=="p" and nch=="NIL": salida.append(["B",0,False]) return salida if ch=="p" and nch==u"¬": salida.append(["p",0,False]) return salida

68
# ^ p s -> psicologo ;?? if ch=="p" and nch=="s" and pch=="NIL": salida.append(["s",1,True]) return salida # p h -> f if ch=="p" and nch=="h": salida.append(["f",1,False]) return salida # campsa, preclampsia if ch=="p" and nch=="s" and pch=="m": salida.append(["",0,False]) return salida # p -> p if ch=="p": salida.append(["p",0,True]) return salida # q u [EI] -> k: if ch=="q" and nch=="u" and (nnch=="e" or nnch==u"é" or nnch=="i" or nnch ==u"í"): salida.append(["k",1,True]) return salida # q -> k if ch=="q": salida.append(["k",0,False]) return salida # r r -> rr if ch=="r" and nch==u'¬': salida.append(["r",0,False]) return salida if ch=="r" and nch=="r": salida.append(["rr",1,True]) return salida #rbol,rganos... -> error?? r principi de mot seguida de consonant. if ch=="r" and pch=="NIL" and re.match(u"[bcdfgjhklmnñpqstvxyz]",nch): salida.append(["r",0,False]) return salida # ^ r -> rr # [LNS] r -> rr # coma-ruga if ch=="r" and (pch=="NIL" or pch=="l" or pch=="n" or pch=="s" or pch=="-"):
salida.append(["rr",0,True]) return salida

69
#r->0 a final de paraula if ch=="r" and ((nch =="NIL") or (nch=="s" and nnch=="NIL")): salida.append(["",0, False]) salida.append(["r",0,False]) return salida # r -> r # r end of word: r or rr; if ch=="r": salida.append(["r",0,True]) return salida # Regles per <s>
# nys -> x/j if ch=="s" and pch=="y" and ppch=="n":
salida.append(["JH",0,True]) return salida
if ch=="s" and nch in "NIL": salida.append(["Z",0,True]) return salida # s s -> s if ch=="s" and nch=="s":
salida.append(["s",1,False]) return salida #print "nch :", nch, " pch$ :", pch if ch=="s" and pch not in (u'¬', u'NIL') and nch == u"¬" and (nnch in (lista_vocales) or(nnch==u"h" and len(wholen) > 2 and wholen[2] in (lista_vocales))):
salida.append(["z",0,True]) return salida if ch=="s" and (nch in (lista_vocales) or (nch==u"h" and nnch in (lista_vocales))) and pch in (lista_vocales):
salida.append(["z",0,True]) return salida if ch=="s" and pch in (lista_vocales) and nch == u'¬' and ((nnch in (lista_vocales)) or (nnch=="h" and len(wholen) > 2 and wholen[2] in (lista_vocales))) :
salida.append(["z",0,True]) return salida # [ ^ d e ] s h -> s ; show if ch=="s" and nch=="h":
salida.append(["sh",1,True]) return salida if ch=="s" and nch in (lista_vocales) and wholep in ("meny", "tran", "enfon"):

70
salida.append(["z",0,True]) return salida # s -> s if ch=="s": salida.append(["s",0,True]) return salida #print "Llego a las reglas de la t" # [ ^ p o s ] t -> ; postguerra but postal, postura, postiza ; postre ; postsandinista?? #if ch=="t" and re.match(r"^pos",wholep) and re.match(u"[bcdfgjklmnñpqsvxyz]",nch): #print "Elimino la t" #return ["",0,True] # t t -> t
if ch=="t" and nch=="g": salida.append(["d jh",1,True])
return salida
if ch=="t" and nch=="j": salida.append(["d jh",1,True]) return salida
if ch=="t" and pch in (u'l', u'n', u'r') and nch== u's' and nnch=="NIL": salida.append(["", 0, False]) return salida if ch=="t" and nch == u"¬" and not (nnch in (lista_vocales) or (nnch==u"h" and len(wholen) > 2 and wholen[2] in (lista_vocales)))and pch==u"n": salida.append(["", 0, False]) return salida if ch=="t" and nch=="NIL": salida.append(["D",0,False]) return salida if ch=="t" and nch==u"¬": salida.append(["t",0,False]) return salida if ch=="t" and (nch==u's' or nch==u'z') and nnch in "NIL": salida.append(["t sh", 1, False]) return salida if ch=="t" and nch=="t": salida.append(["t",1,False]) return salida #noms bascos if ch=="t" and nch=="x":

71
salida.append(["",0,False]) return salida #noms catalans: montserrat, sants, montjuic if ch=="t" and (nch=="s" or nch=="j") and pch=="n": salida.append(["",0,False]) return salida if ch=="t" and nch=="l" and nnch=="l" and pch in lista_vocales:
salida.append(["",0,False]) return salida
#etnologo, rítmico, futbol, atlético if ch=="t" and (nch=="n" or nch=="m" or nch=="b" or nch=="d"): salida.append(["d",0,True]) return salida #casos tz: nacionalitzar if ch=="t" and nch==u'z': salida.append(["d",0,True]) return salida #casos tg: fetge if ch=="t" and nch=="g" and nnch in ("e" or u"è" or u"é" or "i" or u"í"): salida.append(["d",0,True])
return salida # t -> t if ch=="t": salida.append(["t",0,True]) return salida # Regles de la u if ch=="u" and pch in (u'a', u'à', u'Á', u'e', u'è', u'é', u'o', u'ò', u'ó', u'E', u'O', u'u', u'ü', u'ú', u'i',u'ï', u'í', u'Ö', u'Ë'): salida.append(["w", 0, False]) return salida if ch== "u" and nch in (u'a', u'à', u'Á', u'o', u'ò', u'ó', u'O', u'Ö') and pch in (u'q', u'g'): salida.append(["w", 0, False]) return salida if ch== "u" and nch in (u'e', u'è', u'é',u'E', u'Ë', u'i', u'í', u'ï') and pch in (u'q', u'g'): salida.append(["", 0, False]) return salida if ch=="u" and nch in (u'a', u'à', u'Á', u'o', u'ò', u'ó', u'O', u'Ö', u'e', u'è', u'é',u'E', u'Ë') and pch=='NIL': salida.append(["w", 0, False])

72
return salida if ch=="u": salida.append(["u0", 0, False]) return salida # noms russos if ch=="v" and (pch=="o" or pch=="e") and nch=="NIL": salida.append(["f",0,False]) return salida if ch=="v": salida.append(["b",0,True]) salida.append(["v",0,True]) return salida # w -> w ; excepcio: water if ch=="w": salida.append(["w",0,False]) return salida # V x -> k s ; vocal examen if ch=="x" and pch in (u'i', u'ï', u'í') and nch in "NIL": salida.append(["Z", 0, False]) return salida if ch=="x" and wholep in (u'e', u'Ë', u'E', u'ine') and nch in (lista_vocales): salida.append(["g z", 0, False]) return salida #if ch=="x" and posicio_caracter > 0: #if es_vocal(palabra, posicio_caracter-1) and nch in (lista_vocales): #return ["k s", 0, False] if ch=="x" and posicio_caracter > 0: if es_vocal(palabra, posicio_caracter-1) and not (pch in (u'i',u'í') and ppch == u'u') and (nch in (lista_vocales) or (nch == u'h' and nnch in (lista_vocales))): #print "caracter siguiente: ", nch #print "caracter anterior: ", pch #print "caracter doble anterior: ", ppch salida.append(["k s", 0, False]) return salida if ch=="x" and nch in (u'p', u't', u'k', u'c', u'q', u'f', u's'): salida.append(["k s", 0, False]) return salida if ch=="x" and nch in (u'b', u'd', u'g', u'v', u'z', u'l', u'm', u'n', u'r'): salida.append(["g z", 0, False]) return salida

73
if ch=="x" and pch==u't': salida.append(["t sh", 0, False]) return salida
if ch=="x" and pch=="i": salida.append(["s",0,False]) return salida
if ch=="x" and (((nch=="NIL" or nch==u'¬') and pch not in (u'i', u'ï', u'í') and pch not in (lista_consonantes)) or ((nch=="NIL" or nch==u'¬') and pch in (u'i', u'ï', u'í') and ppch not in (lista_vocales))): salida.append(["k Z", 0, False]) return salida if ch=="x": salida.append(["sh", 0, False]) return salida # y $ -> j hoy ;excepcions: muy # y [V] -> j if ch=="y" and (nch=="NIL" or re.match(u"[aàáeéiíoóuúù]$",nch) or re.match(u"[aàáéeéiíoouúù]",nch)): salida.append(["j",0,True]) return salida # y -> i if ch=="y": salida.append(["i0",0,True]) return salida # z z -> d s ; mezzosoprano ; excepcions: puzzle if ch=="z" and nch=="z": salida.append(["d s",1,False]) return salida # z -> th
if ch=="z" and pch=="t" and nch in lista_vocales: salida.append(["jh",0,True])
return salida if ch=="z" and nch in "NIL": salida.append(["Z",0,True]) return salida if ch=="z" and nch in u"¬": salida.append(["s",0,True]) return salida if ch=="z": salida.append(["z",0,True])

74
return salida if ch=="-": salida.append(["",0,True]) return salida if ch=="'": salida.append(["",0,False]) return salida ## Transcripcion de los caracteres con acento if ch==u"á": salida.append(["a1",0,True,1]) return salida if ch==u"à": salida.append(["a1",0,True,1]) return salida if ch==u"é": salida.append(["e1",0,True,1]) return salida if ch==u"è": salida.append(["ee1",0,True,1]) return salida if ch==u"í": salida.append(["i1",0,True,1]) return salida if ch==u"ó": salida.append(["o1",0,True,1]) return salida if ch==u"ò": salida.append(["oo1",0,True,1]) return salida if ch==u"ú": salida.append(["u1",0,True,1]) return salida ## Transcripcion de los caracteres con acento secundario if ch==u"Á": salida.append(["a2",0,True,1]) return salida if ch==u"É":

75
salida.append(["e2",0,True,1]) return salida if ch==u"È": salida.append(["ee2",0,True,1]) return salida if ch==u"Í": salida.append(["i2",0,True,1]) return salida if ch==u"Ó": salida.append(["o2",0,True,1]) return salida if ch==u"Ò": salida.append(["oo2",0,True,1]) return salida if ch==u"Ú": salida.append(["u2",0,True,1]) return salida ##Transcripcion caracteres con dieresis. if ch==u"ï": salida.append(["i1",0,True,1]) return salida if ch==u"ü" and pch in (u'q', u'g'): salida.append(["w", 0, False]) return salida if ch==u"ü": salida.append(["u1",0,True,1]) return salida ##Transcripcion de los caracteres no catalanes if ch in (u'ã', u'ä', u'â', u'æ',u'å'): salida.append(["a0",0,True,1]) return salida if ch in (u'ë', u'ê'): salida.append(["e0",0,True,1]) return salida if ch in (u'ö', u'õ',u'ð',u'ô', u'ø'): salida.append(["o0",0,True,1]) return salida if ch in (u'ĩ'):

76
salida.append(["i0",0,True,1]) return salida if ch in (u"û", u'ů'): salida.append(["u0",0,True,1]) return salida ##Transcripcion de caracteres especiales if ch==u"¬": salida.append(["",0, False]) return salida #return ["ERROR",0,False] salida.append(["",0,False]) return salida def fonetica_sintactica(cadena_trans): lista_vocales = ["a1", "e1", "ee1", "i1", "o1", "oo1", "u1", "@1", "a2", "e2", "ee2", "i2", "o2", "oo2", "u2", "@2", "a0", "e0", "ee0", "i0", "o0", "oo0", "u0", "@0", "a", "e", "E", "i", "o", "O", "u", "@"] lista_consonantes = ["b", "d", "f", "g", "x", "jh", "k", "l", "ll", "m", "n", "ng", "ny", "p", "r", "rr", "s", "sh", "t", "z", "th", "y"] lista_consonantes_sordas = ["f", "x", "k", "p", "s", "sh", "t", "th"] lista_consonantes_sonoras = ["b", "d", "g", "jh", "l", "ll", "m", "n", "ng", "ny", "r", "rr", "z", "y"] lista_semivocales = ["w", "j"] lista_salida = [] lista_entrada = cadena_trans.split() transcripcion_simbolo = u"" num_simbolos_transcripcion = len(lista_entrada) for contador_simbolos in range(num_simbolos_transcripcion): transcripcion_simbolo_siguiente = u"" transcripcion_simbolo_anterior = u"" transcripcion_palabra_siguiente = u"" transcripcion_palabra_actual = u"" #print "contador simbolo: ", contador_simbolos transcripcion_simbolo = lista_entrada[contador_simbolos] if contador_simbolos < num_simbolos_transcripcion-2: if lista_entrada[contador_simbolos+1]=="#": transcripcion_simbolo_siguiente = lista_entrada[contador_simbolos+2] #print "Transcripcion_simbolo_siguiente: ", transcripcion_simbolo_siguiente else: transcripcion_simbolo_siguiente = lista_entrada[contador_simbolos+1]

77
if contador_simbolos > 0: transcripcion_simbolo_anterior = lista_entrada[contador_simbolos-1] lista_prov = [] contador_inicio_palabra = contador_simbolos hay_inicio_palabra = False while contador_inicio_palabra < num_simbolos_transcripcion and not (hay_inicio_palabra): if lista_entrada[contador_inicio_palabra] == u'#': hay_inicio_palabra = True contador_inicio_palabra = contador_inicio_palabra+1 #print "Inicio de palabra siguiente: ", contador_inicio_palabra contador_final_palabra = contador_inicio_palabra hay_final_palabra = False while contador_final_palabra < num_simbolos_transcripcion and not (hay_final_palabra): if lista_entrada[contador_final_palabra] == u'#': hay_final_palabra = True else: contador_final_palabra = contador_final_palabra+1 #print "Final de palabra siguiente: ", contador_final_palabra for contador_prov in range (contador_inicio_palabra, contador_final_palabra): lista_prov.append(lista_entrada[contador_prov]) transcripcion_palabra_siguiente = "".join(lista_prov) #print "transcripcion palabra siguiente: ", transcripcion_palabra_siguiente lista_prov = [] contador_final_palabra = contador_simbolos hay_final_palabra = False while contador_final_palabra < num_simbolos_transcripcion and not (hay_final_palabra): if lista_entrada[contador_final_palabra] == u'#': hay_final_palabra = True else: contador_final_palabra = contador_final_palabra+1 #print "Final de palabra actual: ", contador_final_palabra contador_inicio_palabra = contador_simbolos hay_inicio_palabra = False

78
while contador_inicio_palabra > 0 and not (hay_inicio_palabra): if lista_entrada[contador_inicio_palabra] == u'#': hay_inicio_palabra = True else: contador_inicio_palabra = contador_inicio_palabra-1 #print "Inicio de palabra actual: ", contador_inicio_palabra for contador_prov in range (contador_inicio_palabra, contador_final_palabra): lista_prov.append(lista_entrada[contador_prov]) transcripcion_palabra_actual = "".join(lista_prov) #print "transcripcion palabra actual: ", transcripcion_palabra_actual #Aqui es donde deben venir las reglas para cambiar los archifonemas en simbolos de alofonos # mas antic, assebentar-vos-en, pocs bars if transcripcion_simbolo=="Z": #print "Transcripcion simbolo es un archifonema" #print "cadena de entrada: ", lista_entrada #print "contador simbolo: ", contador_simbolos #print "Transcripcion simbolo: ", transcripcion_simbolo if transcripcion_simbolo_siguiente in (lista_vocales): transcripcion_simbolo = "z" #print "Transcripcion simbolo final: ", transcripcion_simbolo elif transcripcion_simbolo_siguiente in (lista_consonantes_sonoras): transcripcion_simbolo = "z" #print "Transcripcion simbolo final: ", transcripcion_simbolo else: transcripcion_simbolo = "s" #print "Transcripcion simbolo final: ", transcripcion_simbolo #neix avui, neix dema, neix cansat if transcripcion_simbolo=="JH": #print "Transcripcion simbolo es un archifonema" #print "cadena de entrada: ", lista_entrada #print "contador simbolo: ", contador_simbolos #print "Transcripcion simbolo: ", transcripcion_simbolo if transcripcion_simbolo_siguiente in (lista_vocales): transcripcion_simbolo = "jh" #print "Transcripcion simbolo final: ", transcripcion_simbolo elif transcripcion_simbolo_siguiente in (lista_consonantes_sonoras): transcripcion_simbolo = "jh" #print "Transcripcion simbolo final: ", transcripcion_simbolo else: transcripcion_simbolo = "sh" #print "Transcripcion simbolo final: ", transcripcion_simbolo

79
#ets amic, néts-avis, ets valent if transcripcion_simbolo=="DZ": #print "Transcripcion simbolo es un archifonema" #print "cadena de entrada: ", lista_entrada #print "contador simbolo: ", contador_simbolos #print "Transcripcion simbolo: ", transcripcion_simbolo if transcripcion_simbolo_siguiente in (lista_vocales): transcripcion_simbolo = "dz" #print "Transcripcion simbolo final: ", transcripcion_simbolo elif transcripcion_simbolo_siguiente in (lista_consonantes_sonoras): transcripcion_simbolo = "dz" #print "Transcripcion simbolo final: ", transcripcion_simbolo else: transcripcion_simbolo = "ts" #print "Transcripcion simbolo final: ", transcripcion_simbolo #crucifix amic, crucifix valent if transcripcion_simbolo=="GZ": #print "Transcripcion simbolo es un archifonema" #print "cadena de entrada: ", lista_entrada #print "contador simbolo: ", contador_simbolos #print "Transcripcion simbolo: ", transcripcion_simbolo if transcripcion_simbolo_siguiente in (lista_vocales): transcripcion_simbolo = "g z" #print "Transcripcion simbolo final: ", transcripcion_simbolo elif transcripcion_simbolo_siguiente in (lista_consonantes_sonoras): transcripcion_simbolo = "g z" #print "Transcripcion simbolo final: ", transcripcion_simbolo else: transcripcion_simbolo = "k s" #print "Transcripcion simbolo final: ", transcripcion_simbolo #mig obert, maig-abril, mig joguener if transcripcion_simbolo=="DJH": #print "Transcripcion simbolo es un archifonema" #print "cadena de entrada: ", lista_entrada #print "contador simbolo: ", contador_simbolos #print "Transcripcion simbolo: ", transcripcion_simbolo if transcripcion_simbolo_siguiente in (lista_vocales): transcripcion_simbolo = "d jh" #print "Transcripcion simbolo final: ", transcripcion_simbolo elif transcripcion_simbolo_siguiente in (lista_consonantes_sonoras): transcripcion_simbolo = "d jh" #print "Transcripcion simbolo final: ", transcripcion_simbolo else: transcripcion_simbolo = "t sh" #print "Transcripcion simbolo final: ", transcripcion_simbolo #cap buit

80
if transcripcion_simbolo=="B": #print "Transcripcion simbolo es un archifonema" #print "cadena de entrada: ", lista_entrada #print "contador simbolo: ", contador_simbolos #print "Transcripcion simbolo: ", transcripcion_simbolo if transcripcion_simbolo_siguiente in (lista_consonantes_sonoras): transcripcion_simbolo = "b" #print "Transcripcion simbolo final: ", transcripcion_simbolo else: transcripcion_simbolo = "p" #print "Transcripcion simbolo final: ", transcripcion_simbolo #nit brillant if transcripcion_simbolo=="D": #print "Transcripcion simbolo es un archifonema" #print "cadena de entrada: ", lista_entrada #print "contador simbolo: ", contador_simbolos #print "Transcripcion simbolo: ", transcripcion_simbolo if transcripcion_palabra_actual == "sa1nD" and (transcripcion_palabra_siguiente == "@0n.dre1w" or transcripcion_palabra_siguiente == "@0n.too1.ni0"): transcripcion_simbolo = "t" elif transcripcion_palabra_actual == "bi1nD" and transcripcion_simbolo_siguiente in (lista_vocales): transcripcion_simbolo = "t" elif transcripcion_palabra_actual == "se1nD" and transcripcion_simbolo_siguiente in (lista_vocales): transcripcion_simbolo = "t" elif transcripcion_simbolo_anterior in (u'n', u'l'): transcripcion_simbolo = u"" elif transcripcion_simbolo_siguiente in (lista_consonantes_sonoras): transcripcion_simbolo = "d" #print "Transcripcion simbolo final: ", transcripcion_simbolo else: transcripcion_simbolo = "t" #print "Transcripcion simbolo final: ", transcripcion_simbolo #amic valent if transcripcion_simbolo=="G": #print "Transcripcion simbolo es un archifonema" #print "cadena de entrada: ", lista_entrada #print "contador simbolo: ", contador_simbolos #print "Transcripcion simbolo: ", transcripcion_simbolo if transcripcion_simbolo_siguiente in (lista_consonantes_sonoras): transcripcion_simbolo = "g" #print "Transcripcion simbolo final: ", transcripcion_simbolo else: transcripcion_simbolo = "k" #print "Transcripcion simbolo final: ", transcripcion_simbolo

81
lista_salida.append(transcripcion_simbolo) cadena_salida = " ".join(lista_salida) #print "Cadena_salida: ", cadena_salida return cadena_salida

82
Annex 3
Word Checker (Dialect Independent)
List 1
abominable actualitzar acabada adult adorn aixada amistats any banya batlle blau bou buit cada cadena
caixa cares carrer casa civada coix cuidar dits dona es escola eliminar extern fada fetge
fuster germà hivern llet major meda mel mocador moldre motlle oliva olla opi ou passada
passejar pera pitjor ploure pont pontet pou puig pujar regle roig terra tretze viatge voltor
List 2
adober adorn agullots ametlla anyada assetjar bada baixar bateig bitlla
blanc brasa brou calçotets campanya dissoldre enrajolador escacs font fonteta
gerro líder moix nuada ocult oleat pagable pany plaer salvatge
seda sonoritzar sou torneig trastorn triatge truja volatilitzar ximplejar
83
Annex 4
Sample from Word Checker Results: Northern Valencian
Words (List 1)
Variant 1 Variant 2 Variant 3 Variant 4
abominable a . b o . m i . n a_" . b l e
actualitzar a k . t u . a . l i d . Z a_"
a k . t u . a . l i d . Z a_" r
acabada a . k a . b a_" a
adult a . d u_" l D adorn a . d o_" r n aixada a j . s a_" a amistats a . m i s . t
a_" t S
any a_" J banya b a_" . J a batlle b a_" l . l e b a_" l e blau b l a_" w bou b O_" w buit b u_" j D cada k a_" . d a cadena k a . d E_" . n
a
caixa k a_" j . s a cares k a_" . r e Z carrer k a . rr e_" k a . rr e_" r casa k a_" . z a civada s i . b a_" a s i v a_" a coix k o_" j Z cuidar k u j . d a_" k u j . d a_" r dits d i_" t S dona d O_" . n a es e Z escola a s . k O_" . l a eliminar e . l i . m i . n
a_" e . l i . m i . n a_" r
extern e k s . t E_" r n
fada f a_" . d a fetge f E_" d . Z e

84
fuster f u s . t e_" f u s . t e_" r germà d Z e r . m a_" hivern i . b E_" r n i v E_" r n llet L e_" D major m a d . Z o_" m a j . Z o_" m a d . Z
o_" r m a j . Z o_" r
meda m e_" . d a mel m E_" l mocador m o . k a . d
o_" m o . k a . d o_" r
moldre m O_" l . d r e motlle m O_" l . l e m O_" l e oliva o . l i_" . b a o . l i_" v a olla O_" . L a opi O_" . p i ou O_" w passada p a . s a_" a passejar p a . s e d . Z
a_" p a . s e j . Z a_"
p a . s e d . Z a_" r
p a . s e j . Z a_" r
pera p e_" . r a pitjor p i d . Z o_" p i d . Z o_" r ploure p l O_" w . r e pont p O_" n D pontet p o n . t E_" D pou p o_" w puig p u_" DJH pujar p u d . Z a_" p u j . Z a_" p u d . Z
a_" r p u j . Z a_" r
regle rr E_" . g l e roig rr O_" DJH terra t E_" . rr a tretze t r e_" d . Z e viatge b i . a_" d . Z
e v i . a_" d . Z e
voltor b o l . t o_" v o l . t o_" b o l . t o_" r
v o l . t o_" r
Words (List 2)
Variant 1 Variant 2 Variant 3 Variant 4
baixar b a j . s a_" b a j . s a_" r
adober a . d o . b e_" a . d o . b e_" r
adorn a . d o_" r n

85
agullots a . g u . L O_" t S ametlla a . m E_" l . l a a . m E_" l
a
anyada a . J a_" a assetjar a . s e d . Z a_" a . s e d . Z
a_" r
bada b a_" . d a bateig b a . t E_" DJH bitlla b i_" l . l a b i_" l a blanc b l a_" n G brasa b r a_" . z a brou b r O_" w calçotets k a l . s o . t E_" t
S
campanya k a m . p a_" . J a dissoldre d i . s O_" l . d r e enrajolador a n . rr a d . Z o . l a . d
o_" a n . rr a j . Z o . l a . d o_"
a n . rr a d . Z o . l a . d o_" r
a n . rr a j . Z o . l a . d o_" r
escacs a s . k a_" k Z font f O_" n D fonteta f o n . t E_" . t a gerro d Z E_" . rr o líder l i_" . d e r moix m o_" j Z nuada n u . a_" a ocult o . k u_" l D oleat o . l e . a_" D pagable p a . g a_" . b l e pany p a_" J plaer p l a . e_" p l a . e_" r salvatge s a l . b a_" d . Z
e s a l v a_" d . Z e
seda s e_" . d a sonoritzar s o . n o . r i d . Z
a_" s o . n o . r i d . Z a_" r
sou s O_" w torneig t o r . n E_" DJH trastorn t r a s . t o_" r n triatge t r i . a_" d . Z e truja t r u_" d . Z a t r u_" j . Z
a
volatilitzar b o . l a . t i . l i d . Z a_"
v o . l a . t i . l i d . Z a_"
b o . l a . t i . l i d . Z a_" r
v o . l a . t i . l i d . Z a_" r
ximplejar S i m . p l e d . Z a_"
S i m . p l e j . Z a_"
S i m . p l e d . Z a_" r
S i m . p l e j . Z a_" r

86
Annex 5
Paragraph Checker (Dialect Independent)
Paragraph 1
Hi havia una vegada uns germans que vivien en una casa d’un puig roig a un poble petit amb diverses cares. Tenien un perer que feia moltes peres, queien a terra, les posaven en una caixa i les bullien en una olla: cada any en tenien tretze. De les peres en feien un pastís amb un motlle. També tenien vaques per fer llet, gallines per tenir ous i un hort que conreaven amb una aixada i en cultivaven civada i olives per moldre. En aquell poble només hi havia un adult i era el professor de l’escola, pintada de blau. Un amic tenia un bou coix i amb la banya torta lligat amb una cadena al mig del carrer. Com que no hi havia adults, no hi havia batlle i, en canvi, moltes amistats. A l’hivern feia molt fred i es posaven un mocador al cap i als dits com adorn, travessaven el pontet i el pou per passejar, pujar i marxar de viatge. El poble es quedava buit. Un dia, en el viatge va ploure i el pitjor és que un voltor abominable no els parava de seguir. Van intentar eliminar-lo amb un regle que havia fet un fuster, però no ho van aconseguir. Finalment el germà major va dir de tornar perquè li feia mal el fetge, es trobava malament i només tenien opi. Aquest conte és mentida i és només per actualitzar i provar TexAFon, una eina que converteix el text a parla i que ha estat adaptada a diversos dialectes del català: el pallarès, el ribagorçà, el de l’àrea central, el tortosí, el valencià septentrional, central, meridional i l’alacantí.
Paragraph 2
Aquest és el segon text per provar el funcionament de TexAFon. El conte comença amb un torneig d'escacs on la gent anava per treure's un sou. Com a adorn sempre hi posaven agullots per baixar des del sostre i alguna bitlla. El terra era completament blanc com uns calçotets de seda acabats d'estrenar, ja que cada any un enrajolador s'encarregava de deixar-ho com nou. El líder del torneig, que sempre bada i té dotze anys, mai estava content amb el resultat i li agradava ximplejar i quan perdia estava moix i es tornava salvatge. Un any també era el bateig d'un nen de tres anys i per dinar hi havia brou, carn a la brasa i de postres ametlles. No hi havia aigua, però la gent bevia d'una fonteta amb un gerro i vi d'una bona anyada. Perquè la gent reciclés posaven papereres de triatge i taules plegables. De fet, molts feien campanya a favor del medi ambient. L'any passat hi havia una truja voltant per allà, tot i que estava nuada, i també un porc ocult. Quan un adober els va intentar tancar amb pany i clau van agafar un trastorn i van començar a assetjar la gent. Al final, sense saber com, es van volatilitzar, això va causar un gran plaer entre el públic, que va dissoldre una poció que tenien i van insonoritzar les parets per no molestar els veïns que no estaven de festa.

87
Annex 6
Sample from Paragraph Checker Output: Northern Valencian
Paragraph 1
i # a . b i_" . a # u_" . n a # b e . g a_" a # u_" n z # d Z e r . m a_" n s # k e # b i . b i_" . e n # e n # u_" . n a # k a_" . z a # d u_" n # p u_" d Z # rr O_" d Z # a # u_" n # p O_" . b l e # p e . t i_" t # a_" m # d i . b E_" r . s e s # k a_" . r e s [signo_punto]
t e . n i_" . e n # u_" n # p e . r e_" # k e # f E_" . j a # m o_" l . t e s # p e_" . r e s [signo_coma] k E_" . j e n # a # t E_" . rr a [signo_coma] l e s # p o . z a_" . b e n # e n # u_" . n a # k a_" j . s a # i_" # l e z # b u . L i_" . e n # e n # u_" . n a # O_" . L a [signo_dos_puntos]
k a_" . d a # a_" J # e n # t e . n i_" . e n # t r e_" d . Z e [signo_punto]
d e # l e s # p e_" . r e z # e n # f E_" . j e n # u_" n # p a s . t i_" z # a_" m # u_" n # m O_" l . l e [signo_punto]
t a m . b e_" # t e . n i_" . e n # b a_" . k e s # p e r # f e_" # L e_" t [signo_coma] g a . L i_" . n e s # p e r # t e . n i_" # O_" w z # i_" # u_" n # O_" r t # k e # k o n . rr e . a_" . b e n # a_" m # u_" . n a # a j . s a_" a # i_" # e n # k u l . t i . b a_" . b e n # s i . b a_" a # i_" # o . l i_" . b e s # p e r # m O_" l . d r e [signo_punto]
e n # a . k E_" L # p O_" . b l e # n o . m e_" z # i # a . b i_" . a # u_" n # a . d u_" l # i_" # e_" . r a # e l # p r o . f e . s o_" # d e # l e s . k O_" . l a [signo_coma] p i n . t a_" a # d e # b l a_" w [signo_punto]
u_" n # a . m i_" k # t e . n i_" . a # u_" n # b O_" w # k o_" j z # i_" # a_" m # l a # b a_" . J a # t O_" r . t a # L i . g a_" t # a_" m # u_" . n a # k a . d E_" . n a # a l # m i_" d Z # d e l # k a . rr e_" [signo_punto]
k O_" m # k e # n o_" # i # a . b i_" . a # a . d u_" l s [signo_coma] n o_" # i # a . b i_" . a # b a_" l . l e # i_" [signo_coma] e n # k a_" m . b i [signo_coma] m o_" l . t e z # a . m i s . t a_" t S [signo_punto]
a # l i . b E_" r n # f E_" . j a # m o_" l # f r e_" t # i_" # e s # p o . z a_" . b e n # u_" n # m o . k a . d o_" # a l # k a_" p # i_" # a l z # d i_" t S # k O_" m # a . d o_" r n [signo_coma] t r a . b e . s a_" . b e n # e l # p o n . t E_" t # i_" # e l # p o_" w # p e r # p a . s e d . Z a_" [signo_coma] p u d . Z a_" # i_" # m a r . S a_" # d e # b i . a_" d . Z e [signo_punto]

88
e l # p O_" . b l e # e s # k e . d a_" . b a # b u_" j t [signo_punto]
u_" n # d i_" . a [signo_coma] e n # e l # b i . a_" d . Z e # b a_" # p l O_" w . r e # i_" # e l # p i d . Z o_" # e_" s # k e # u_" n # b o l . t o_" # a . b o . m i . n a_" . b l e # n o_" # e l s # p a . r a_" . b a # d e # s e . g i_" [signo_punto]
b a_" n # i n . t e n . t a_" # e . l i . m i . n a_" r l o # a_" m # u_" n # rr E_" . g l e # k e # a . b i_" . a # f e_" t # u_" n # f u s . t e_" [signo_coma] p e . r O_" # n o_" # o # b a_" n # a . k o n . s e . g i_" [signo_punto]
f i . n a_" l . m e_" n # e l # d Z e r . m a_" # m a d . Z o_" # b a_" # d i_" # d e # t o r . n a_" # p e r k E_" # l i_" # f E_" . j a # m a_" l # e l # f E_" d . Z e [signo_coma] e s # t r o . b a_" . b a # m a_" . l a . m e_" n # i_" # n o . m e_" s # t e . n i_" . e n # O_" . p i [signo_punto]
a . k E_" t # k o_" n . t e # e_" z # m e n . t i_" . d a # i_" # e_" z # n o . m e_" s # p e r # a k . t u . a . l i d . Z a_" # i_" # p r o . b a_" # t e k . s a . f o_" n [signo_coma] u_" . n a # E_" j . n a # k e # k o m . b e r . t E_" j z # e l # t e_" k s t # a # p a_" r . l a # i_" # k e # a_" # a s . t a_" t # a . d a p . t a_" a # a # d i . b E_" r . s o z # d i . a . l E_" k . t e z # d e l # k a . t a . l a_" [signo_dos_puntos]
e l # p a . L a . r E_" s [signo_coma] e l # rr i . b a . g o r . s a_" [signo_coma] e l # d e # l a_" . r e . a # s e n . t r a_" l [signo_coma] e l # t o r . t o . z i_" [signo_coma] e l # b a . l e n . s i . a_" # s e p . t e n . t r i . o . n a_" l [signo_coma] s e n . t r a_" l [signo_coma] m e . r i . d i . o . n a_" l # i_" # l a . l a . k a n . t i_" [signo_punto]
Paragraph 2
a . k E_" t # e_" z # e l # s e . g o_" n # t e_" k s t # p e r # p r o . b a_" # e l # f u n . s i . o . n a . m e_" n # d e # t e k . s a . f o_" n [signo_punto]
e l # k o_" n . t e # k o . m E_" n . s a # a_" m # u_" n # t o r . n E_" d Z # d e s . k a_" k z # o n # l a # d Z e_" n # a . n a_" . b a # p e r # t r e w . r e_" z # u_" n # s O_" w [signo_punto]
k O_" m # a # a . d o_" r n # s e m . p r e # i # p o . z a_" . b e n # a . g u . L O_" t S # p e r # b a j . s a_" # d e_" z # d e l # s O_" s . t r e # i_" # a l . g u_" . n a # b i_" l . l a [signo_punto]

89
e l # t E_" . rr a # e_" . r a # k o m . p l E_" . t a . m e_" n # b l a_" n k # k O_" m # u_" n s # k a l . s o . t E_" t S # d e # s e_" . d a # a . k a . b a_" t S # d e s . t r e . n a_" [signo_coma] d Z a_" # k e # k a_" . d a # a_" J # u_" n # a n . rr a d . Z o . l a . d o_" # s e n . k a . rr e . g a_" . b a # d e # d e j . s a_" r o # k O_" m # n O_" w [signo_punto]
e l # l i_" . d e r # d e l # t o r . n E_" t S [signo_coma] k e # s e m . p r e # b a_" . d a # i_" # t e_" # d o_" d . Z e # a_" J S [signo_coma] m a_" j # a s . t a_" . b a # k o n . t e_" n # a_" m # e l # rr e . z u l . t a_" t # i_" # l i_" # a . g r a . d a_" . b a # S i m . p l e d . Z a_" # i_" # k w a_" n # p e r . d i_" . a # a s . t a_" . b a # m o_" j z # i_" # e s # t o r . n a_" . b a # s a l . b a_" d . Z e [signo_punto]
u_" n # a_" J # t a m . b e_" # e_" . r a # e l # b a . t E_" d Z # d u_" n # n E_" n # d e # t r E_" z # a_" J Z # i_" # p e r # d i . n a_" # i # a . b i_" . a # b r O_" w [signo_coma] k a_" r n # a # l a # b r a_" . z a # i_" # d e # p O_% s . t r E_" z # a . m E_" l . l e s [signo_punto]
n o_" # i # a . b i_" . a # a_" j . g w a [signo_coma] p e . r O_" # l a # d Z e_" n # b e . b i_" . a # d u_" . n a # f o n . t E_" . t a # a_" m # u_" n # d Z E_" . rr o # i_" # b i_" # d u_" . n a # b O_" . n a # a . J a_" a [signo_punto]
p e r k E_" # l a # d Z e_" n # rr e . s i . k l e_" s # p o . z a_" . b e n # p a . p e . r e_" . r e z # d e # t r i . a_" d . Z e # i_" # t a_" w . l e s # p l e . g a_" . b l e s [signo_punto]
d e # f e_" t [signo_coma] m o_" l t S # f E_" . j e n # k a m . p a_" . J a # a # f a . b o_" r # d e l # m e_" . d i # a m . b i . e_" n [signo_punto]
l a_" J # p a . s a_" t # i # a . b i_" . a # u_" . n a # t r u_" d . Z a # b o l . t a_" n # p e r # a . L a_" [signo_coma] t o_" t # i_" # k e # a s . t a_" . b a # n u . a_" a [signo_coma] i_" # t a m . b e_" # u_" n # p O_" r k # o . k u_" l [signo_punto]
k w a_" n # u_" n # a . d o . b e_" # e l z # b a_" # i n . t e n . t a_" # t a n . k a_" # a_" m # p a_" J # i_" # k l a_" w # b a_" n # a . g a . f a_" # u_" n # t r a s . t o_" r n # i_" # b a_" n # k o . m e n . s a_" # a # a . s e d . Z a_" # l a # d Z e_" n [signo_punto]
a l # f i . n a_" l [signo_coma] s e_" n . s e # s a . b e_" # k O_" m [signo_coma] e z # b a_" n # b o . l a . t i . l i d . Z a_" [signo_coma] a j . s O_" # b a_" # k a w . z a_" # u_" n # g r a_" n # p l a . e_" # e_" n . t r e # e l # p u_" . b l i k [signo_coma] k e # b a_" # d i . s O_" l . d r e # u_" . n a # p o . s i . o_" # k e # t e . n i_" . e n # i_" # b a_" n # i n .

90
s o . n o . r i d . Z a_" # l e s # p a . r E_" t S # p e r # n o_" # m o . l e s . t a_" # e l z # b e . i_" n s # k e # n o_" # a s . t a_" . b e n # d e # f e_" s . t a [signo_punto]
Copyright © 2022 FDOKUMEN




















