
ANÁLISIS ACÚSTICO DE LA SECUENCIA: ES EL SUJETO QUE ELIGE
14
ANÁLISIS ACÚSTICO DE LA SECUENCIA: ES EL SUJETO QUE ELIGE Juan Byron RESUMEN El primer paso es la presentación del oscilograma de la secuencia objeto de análisis para la identificación de los segmentos. Además, se presenta la duración en milisegundos y las intensidades en decibeles de los segmentos. Luego se exponen los espectros LPC y FFT de cada una de las realizaciones, los valores formánticos y la intensidad de estos. Finalmente se presenta un espectrograma de banda ancha de la secuencia para la obser- vación del comportamiento de las transiciones. Palabras clave: oscilograma, espectro, espectrograma, transición. El objetivo de este trabajo es el análisis acústico de la secuencia es el sujeto que elige [eh el suhéto ke: líhe], realizada por un profesor universitario dominicano. La muestra se obtuvo de una grabación televisiva mediante una tarjeta de televisión TV@Anywhere Plus, montada en una ranura PCI de una computadora clon con un procesador AMD Athlon IIx2 240 de 2.79 GHz y 4 GB de memoria RAM de 1333 MHz. El programa utilizado para la obtención de la muestra fue el Speech Analyzer, de SIL Internacional, de Estados Unidos. Los oscilogramas se obtuvieron mediante el programa Praat, de la Universidad de Amsterdan. Los espectros LPC y FFT se logra- ron mediante el programa Speech Filing System, del Colegio Universitario de Londres, y el espectrograma de banda ancha se logró por medio del pro- grama WaveSurfer, de la Universidad de Estocolmo. La secuencia consta de 16 segmentos: ocho vocálicos y ocho consonánti- cos. En relación con las vocales cabe decir que la única que no se realiza es la central baja o densa neutra [a] y que la vocal más frecuente es la anterior media o densa aguda [e], que se realiza cinco veces. En la secuencia apare- ce una posterior alta o difusa grave [u] y una posterior media o densa grave [o]. Con relación a las consonantes se presentan dos interruptas: una dental sorda o áfona [t] y una velar áfona [k]. Las restantes son las fricativas pre- dorsoalveolar áfona [s] y la faríngea [h], que aparece tres veces.
-
Upload
independent -
Category
Documents
-
view
9 -
download
0
Transcript of ANÁLISIS ACÚSTICO DE LA SECUENCIA: ES EL SUJETO QUE ELIGE

ANÁLISIS ACÚSTICO DE LA SECUENCIA:
ES EL SUJETO QUE ELIGE
Juan Byron
RESUMEN
El primer paso es la presentación del oscilograma de la secuencia objeto de análisis para
la identificación de los segmentos. Además, se presenta la duración en milisegundos y
las intensidades en decibeles de los segmentos. Luego se exponen los espectros LPC y
FFT de cada una de las realizaciones, los valores formánticos y la intensidad de estos.
Finalmente se presenta un espectrograma de banda ancha de la secuencia para la obser-
vación del comportamiento de las transiciones.
Palabras clave: oscilograma, espectro, espectrograma, transición.
El objetivo de este trabajo es el análisis acústico de la secuencia es el sujeto
que elige [eh el suhéto ke: líhe], realizada por un profesor universitario
dominicano. La muestra se obtuvo de una grabación televisiva mediante
una tarjeta de televisión TV@Anywhere Plus, montada en una ranura PCI
de una computadora clon con un procesador AMD Athlon IIx2 240 de 2.79
GHz y 4 GB de memoria RAM de 1333 MHz. El programa utilizado para
la obtención de la muestra fue el Speech Analyzer, de SIL Internacional, de
Estados Unidos. Los oscilogramas se obtuvieron mediante el programa
Praat, de la Universidad de Amsterdan. Los espectros LPC y FFT se logra-
ron mediante el programa Speech Filing System, del Colegio Universitario
de Londres, y el espectrograma de banda ancha se logró por medio del pro-
grama WaveSurfer, de la Universidad de Estocolmo.
La secuencia consta de 16 segmentos: ocho vocálicos y ocho consonánti-
cos. En relación con las vocales cabe decir que la única que no se realiza es
la central baja o densa neutra [a] y que la vocal más frecuente es la anterior
media o densa aguda [e], que se realiza cinco veces. En la secuencia apare-
ce una posterior alta o difusa grave [u] y una posterior media o densa grave
[o]. Con relación a las consonantes se presentan dos interruptas: una dental
sorda o áfona [t] y una velar áfona [k]. Las restantes son las fricativas pre-
dorsoalveolar áfona [s] y la faríngea [h], que aparece tres veces.

2
Fig. 1
En la figura 1 se presenta un oscilograma de la secuencia. En el gráfico es
posible observar los segmentos periódicos, que constituyen la mayoría. El
primer segmento corresponde a la densa grave [e]. El segundo segmento
corresponde a la primera fricativa faríngea [ĥ]. Cabe señalar que esta con-
sonante presenta cierta periodicidad, lo que se refleja, como veremos, en su
espectro. La segunda [e] es el sonido siguiente, que precede a la primera
lateral alveolar [l]. A continuación aparece la fricativa predorso alveolar
[s], seguida por la difusa grave [u] y la segunda [h]. Los siguientes seg-
mentos son la densa aguda [e], la interrupta dental [t], la densa grave[o], la
interrupta velar [k], la cuarta densa aguda[e] y la segunda lateral [l]. Los
tres segmentos finales son los siguientes: la difusa aguda o anterior alta [i],
la tercera fricativa faríngea y la quinta densa aguda [e].

3
Fig. 2
La figura 2 presenta un oscilograma en el que se puede observar prima
facie la duración de los segmentos. A continuación se presenta una tabla
con la duración en milisegundos (ms) de los segmentos:
[e]1 = 64 ms [h]1 = 50 ms
[e]2 = 50 ms [l]1 = 58 ms
[s]1 = 87 ms [u]1 = 84 ms
[h]2 = 51 ms [e]3 = 91 ms
[t]1 = 83 ms 1 [o]1 = 74 ms
[k]1 = 52 ms2 [e]4 = 110 ms
3
[l]2 = 61 ms [i]1 = 78 ms
[h]3 = 57 ms [e]5 = 81 ms
Como se puede deducir, las vocales generalmente poseen una duración
mayor que las consonantes. De estas, la fricativa predorsoalveolar áfona es
la que presenta mayor duración (87 ms). La duración media de las vocales
es 78 milisegundos, en tanto que la duración media de las consonantes es
62.3 milisegundos.

4
Fig. 3
Una curva de intensidad y un espectrograma de banda ancha se presentan
en la figura 3. En el gráfico, el segmento que presenta mayor debilidad es
la segunda fricativa faríngea [h], cuya intensidad es 33.5 decibeles; la in-
tensidad de las otras dos fricativas faríngeas es, en ambos casos, 46 decibe-
les. En la curva de intensidad todas las fricativas faríngeas se señalan con
flechas. Las oclusivas áfonas dental [t] y velar [k] también presentan una
baja intensidad (41.7 dB), mientras que los segmentos que muestran mayor
intensidad son las vocales difusa aguda [i] –60 decibeles– compacta grave
[o] –59 decibeles– y la tercera compacta aguda [e] –60.8 decibeles–.
La figura 4 presenta los espectros LPC y FFT de la primera [e] de la se-
cuencia. La frecuencia del primer formante (F1) es 492 hercios y su inten-
sidad 18 decibeles; el segundo formante (F2) muestra una frecuencia de
2296 hercios, con una intensidad de 8 decibeles, en tanto que la frecuencia
del tercer formante (F3) es 2848 hercios y intensidad es 11 decibeles.

5
Fig. 4. Espectros de la primera [e].
Los espectros LPC y FFT de la primera fricativa faríngea (en posición pos-
nuclear) se muestran en la figura 5. Es posible observar un pico de energía
de 21 decibeles a 451 hercios, que corresponde a la sonorización de esta
consonante, en tanto que el inicio de la turbulencia empieza a 3448 hercios
con una intensidad de 7 decibeles.
Fig. 5. Espectros de la primera [h].
6
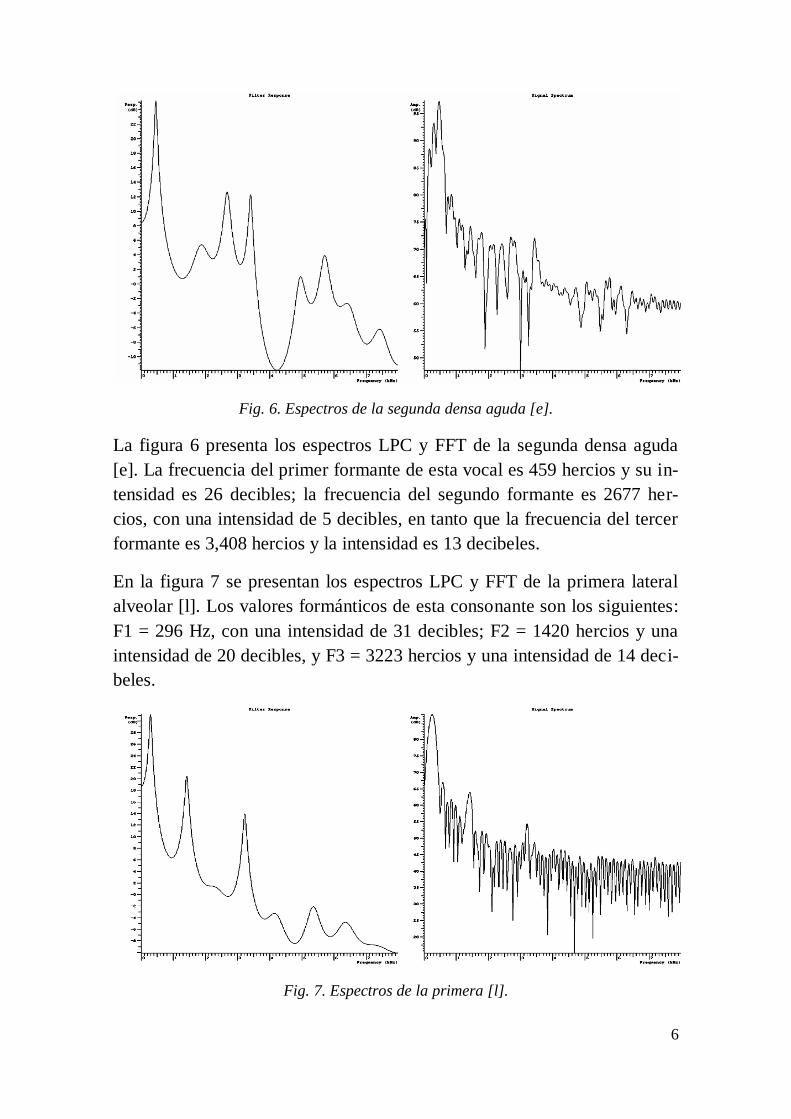
Fig. 6. Espectros de la segunda densa aguda [e].
La figura 6 presenta los espectros LPC y FFT de la segunda densa aguda
[e]. La frecuencia del primer formante de esta vocal es 459 hercios y su in-
tensidad es 26 decibles; la frecuencia del segundo formante es 2677 her-
cios, con una intensidad de 5 decibles, en tanto que la frecuencia del tercer
formante es 3,408 hercios y la intensidad es 13 decibeles.
En la figura 7 se presentan los espectros LPC y FFT de la primera lateral
alveolar [l]. Los valores formánticos de esta consonante son los siguientes:
F1 = 296 Hz, con una intensidad de 31 decibles; F2 = 1420 hercios y una
intensidad de 20 decibles, y F3 = 3223 hercios y una intensidad de 14 deci-
beles.
Fig. 7. Espectros de la primera [l].
7
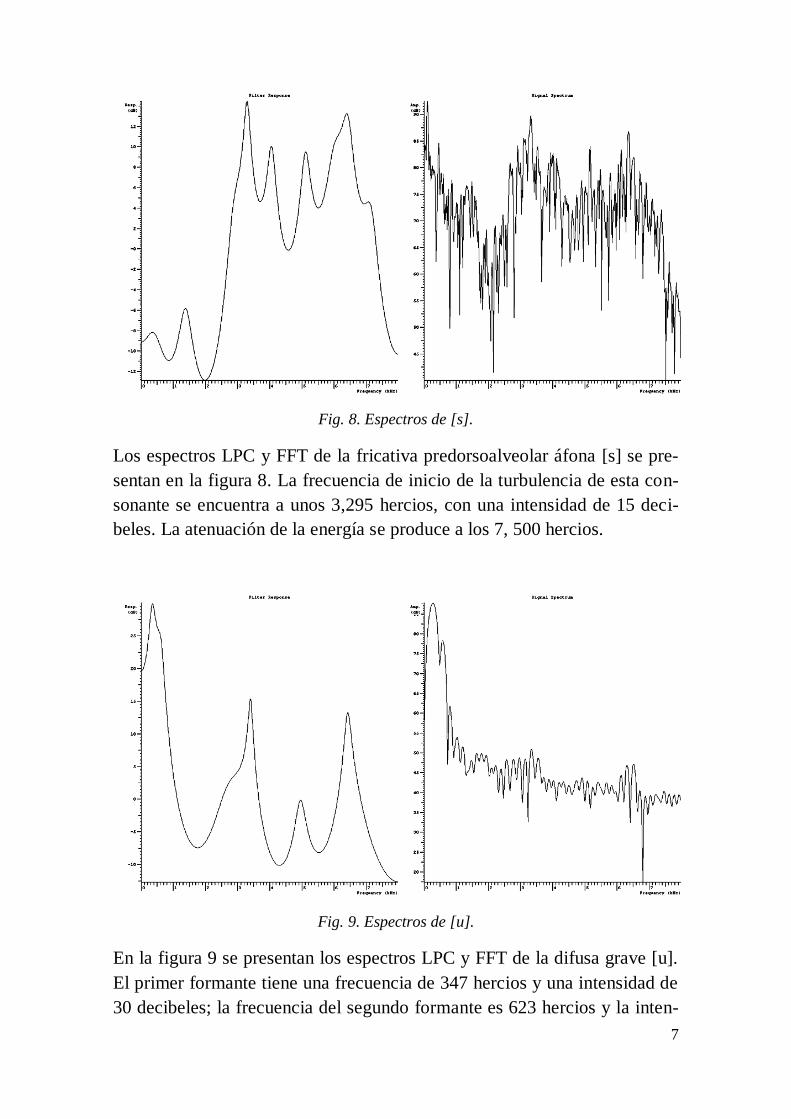
Fig. 8. Espectros de [s].
Los espectros LPC y FFT de la fricativa predorsoalveolar áfona [s] se pre-
sentan en la figura 8. La frecuencia de inicio de la turbulencia de esta con-
sonante se encuentra a unos 3,295 hercios, con una intensidad de 15 deci-
beles. La atenuación de la energía se produce a los 7, 500 hercios.
Fig. 9. Espectros de [u].
En la figura 9 se presentan los espectros LPC y FFT de la difusa grave [u].
El primer formante tiene una frecuencia de 347 hercios y una intensidad de
30 decibeles; la frecuencia del segundo formante es 623 hercios y la inten-

8
sidad es 26 decibeles, en tanto que el tercer formante tiene una frecuencia
de 3,405 hercios y la intensidad es 4 decibeles.
Los espectros de la segunda fricativa faríngea [ĥ] se presentan en la figura
10. Un pico de energía de unos 31 decibeles se puede observar a la fre-
cuencia de 451 hercios, que corresponde a cierta sonorización, en tanto que
el inicio de la turbulencia de esta consonante ocurre a 3,436 hercios, con
una intensidad de 10 decibeles.
Fig. 10. Espectros de [ĥ].
Fig. 11. Espectros de la tercera [e].
9
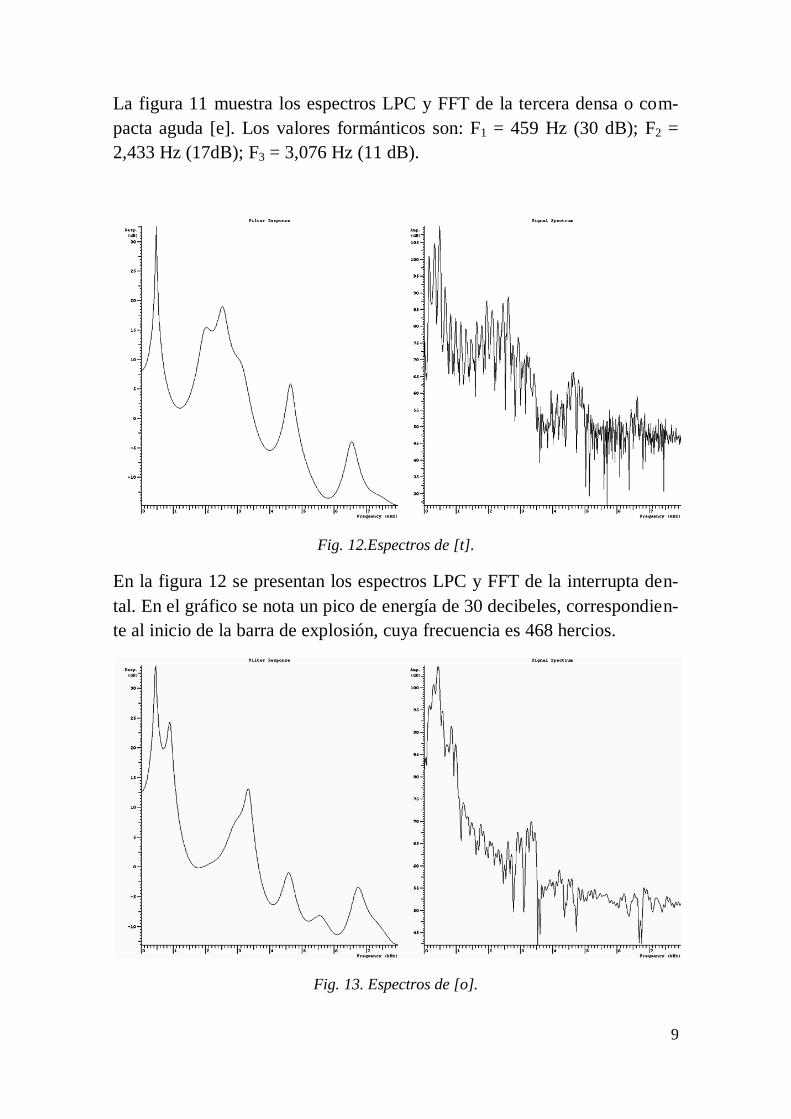
La figura 11 muestra los espectros LPC y FFT de la tercera densa o com-
pacta aguda [e]. Los valores formánticos son: F1 = 459 Hz (30 dB); F2 =
2,433 Hz (17dB); F3 = 3,076 Hz (11 dB).
Fig. 12.Espectros de [t].
En la figura 12 se presentan los espectros LPC y FFT de la interrupta den-
tal. En el gráfico se nota un pico de energía de 30 decibeles, correspondien-
te al inicio de la barra de explosión, cuya frecuencia es 468 hercios.
Fig. 13. Espectros de [o].

10
Los espectros LPC y FFT de la compacta grave [o] se muestran en la figura
13. La frecuencia del primer formante de esta consonante es 446 hercios y
la intensidad de esta es 36 decibeles; el segundo formante tiene una fre-
cuencia de 899 hercios, con una intensidad de 24 decibeles, en tanto que la
frecuencia del tercer formante es 3,347 hercios y su intensidad es 12 deci-
beles.
Fig. 14. Espectros de [k].
Los espectros LPC y FFT se presentan en la figura 14. La frecuencia de
inicio de la barra de explosión es 439 hercios y la intensidad 30 decibeles.
Fig. 15. Espectros de [e].

11
En la figura 15 se presentan los espectros de la cuarta compacta aguda [e].
Los valores formánticos son los siguientes: F1 = 447 hercios, con una
intensidad de 37 decibeles; F2= 2,260 Hz, con una intensidad 17 decibeles;
F3 = 2,988 hercios y una intensidad de 16 decibeles.
Fig. 16. Espectros de [l].
Un espectro LPC y uno FFT de la segunda lateral alveolar [l] se presenta en
la figura 16. El primer formante de esta líquida es 329 hercios y su intensi-
dad es 25 decibeles. El segundo formante es 2,459 hercios, con una intensi-
dad de 21 decibeles. El tercer formante es 3,345 hercios y la intensidad es 7
decibeles.
Fig.17. Espectros de [i].

12
Los espectros LPC y FFT de la difusa aguda [i] se presentan en la figura
17. Los valores formánticos de esta vocal son los siguientes: F1 = 381 Hz
(16 dB); F2 = 2,488 Hz (11 dB); F3 = 3,497 Hz (20 dB).
Fig. 18. Espectro de [h].
Los espectros LPC y FFT de la tercera fricativa faríngea [h] se muestran en
la figura 18. Un pico de energía de apenas 3 decibeles ocurre a 324 hercios,
en tanto que el inicio de la turbulencia se produce a 2,485 decibeles, con
una intensidad de 7 decibeles.
Fig. 19. Espectros de [e].

13
En la figura 19 se presentan los espectros LPC y FFT de la quinta compacta
aguda [e]. El primer formante tiene una frecuencia de 413 hercios y una
intensidad de 33 decibeles. La frecuencia del segundo formante es 2,112
hercios y su intensidad es 16 decibeles. El tercer formante tiene una fre-
cuencia de 2,918 hercios y una intensidad de 13 decibeles.
Fig. 20
La figura 20 presenta un espectrograma de banda ancha de la secuencia [eh
el suhéto ke: líhe]. El gráfico permite observar el comportamiento de las
transiciones de las interruptas dental y velar. La segunda transición de la
interrupta dental es positiva, en tanto que la tercera es negativa. En relación
con la interrupta velar, la segunda transición y la tercera son positivas. El
comportamiento del segundo y tercer formantes de [t] y [k] coinciden con
el planteamiento de Quilis (1981: 205).

14
Conclusión
En sentido general, las vocales poseen una duración mayor que las conso-
nantes. El valor medio de la duración de las vocales fue 78 milisegundos,
en tanto que la duración media de las consonantes fue 62.3 milisegundos.
Asimismo, la intensidad de las vocales –60.8 decibeles en el caso de la ter-
cera [e]– es mayor que la de las consonantes. De estas la que presenta ma-
yor intensidad es la fricativa predorsoalveolar [s] (52.6 dB), en tanto que
las fricativas faríngeas son las más débiles, debido al carácter estridente de
la primera y mate de la segunda. Según Quilis (1981:255), las consonantes
estridentes tienen una intensidad mayor que las consonantes mates.
Es conveniente señalar que las intensidades de los segmentos, analizadas
con el programa WaveSurfer, muestran ciertas diferencias con respecto a
las intensidades de las frecuencias formánticas consideradas individual-
mente, y analizadas con el programa Speech Filing System.
Es necesario indicar que en la secuencia es el sujeto que elige, la primera
fricativa predorsoalveolar [s] es realizada como una aspiración –fricativa
faríngea [h]–.
1. Las interruptas poseen dos fases: una oclusiva y otra explosiva. La fase oclusiva de la
interrupta dental es 72 milisegundos.
2. La interrupta velar posee una fase oclusiva que dura 40 milisegundos.
3. Existe un solapamiento entre las dos compactas agudas contiguas en la secuencia [ke
elíhe]
Referencias
Denes, P. y Pinson, E. 1973. The Speech Chain: The Physics and Biology
of Spoken Language. Anchor Books, New York.
Malmberg, Bertil.1964. La fonética. EUDEBA, Buenos Aires.
Quilis, A. 1981. Fonética acústica de la lengua española. Editorial Gredos,
Madrid.




















