
An exact bit-parallel algorithm for the maximum clique problem
32
An exact bit-parallel algorithm for the maximum clique problem Pablo San Segundo, Diego Rodríguez-Losada, Agustín Jiménez 5 Intelligent Control Group Universidad Politécnica de Madrid, UPM. C/ Jose Gutiérrez Abascal, 2. 28006, Madrid, Spain 10 Corresponding author: Pablo San Segundo Carrillo Universidad Politécnica de Madrid (UPM-DISAM) C/ Jose Gutiérrez Abascal, 2. 15 28006, Madrid Spain Email: [email protected] 20 Tlf. +34 91 7454660 +34 91 3363061 Fax. +34 91 3363010 25 30
Transcript of An exact bit-parallel algorithm for the maximum clique problem

An exact bit-parallel algorithm for the maximum
clique problem Pablo San Segundo, Diego Rodríguez-Losada, Agustín Jiménez
5
Intelligent Control Group
Universidad Politécnica de Madrid, UPM.
C/ Jose Gutiérrez Abascal, 2. 28006, Madrid, Spain
10
Corresponding author: Pablo San Segundo Carrillo Universidad Politécnica de Madrid (UPM-DISAM) C/ Jose Gutiérrez Abascal, 2. 15 28006, Madrid Spain Email: [email protected] 20 Tlf. +34 91 7454660 +34 91 3363061 Fax. +34 91 3363010
25
30

An exact bit-parallel algorithm for the maximum
clique problem Pablo San Segundo, Diego Rodríguez-Losada, Agustín Jiménez
Universidad Politécnica de Madrid, UPM.
Madrid, Spain 5
Abstract
This paper presents a new exact maximum clique algorithm which improves the
bounds obtained in state of the art approximate coloring by reordering the vertices at
each step. Moreover the algorithm can make full use of bit strings to sort vertices in
constant time as well as to compute graph transitions and bounds efficiently, exploiting 10
the ability of CPUs to process bitwise operations in blocks of size the ALU register
word. As a result it significantly outperforms a current leading algorithm.
Keywords: maximum clique, bit string, branch and bound, coloring, bit-
parallelism. 15
1 Introduction
A complete graph, or clique, is a graph such that all its vertices are pairwise
adjacent. The k-clique problem determines the existence of a clique of size k for a given
graph G and is well known to be NP-complete [1]. The corresponding optimization
problem is the maximum clique problem (MCP) which consists in finding the largest 20
possible clique in G. Finding a maximum clique in a graph has been deeply studied in
graph theory and is a very important NP-hard problem with applications in many fields:
bioinformatics and computational biology [2][3], computer vision [4], robotics [5] etc.
A slightly outdated but nevertheless good survey on maximum clique applications can
be found in Chapter 7 of [6]. 25
Bit parallelism is an optimization technique which exploits the ability of CPUs to
compute bit operations in parallel the size of the ALU register word R (typically 32 or
64 in commercial computers). Bit models are employed frequently to encode board
games. In many chess programs (e.g. [7][8]), the bits in a 64-bit bitboard represent the
Boolean value of a particular property concerning the 64 squares of the chessboard. A 30
typical bit model for the position on the board consists of 12 bitboards (6 for each piece,

each piece having two possible colors), with the interpretation ‘placement of all <type-
of-piece><color> on the board’. Other examples of bit-parallel search outside game
theory are regular expression and string matching where it has become one of the most
popular techniques. In string matching the aim is to find a pattern of length m in a text
of length n; when at most k mismatches are allowed it is referred to as approximate 5
string matching with innumerable applications: text searching, computational biology,
pattern recognition, etc. An important algorithm for approximate string matching is bit-
parallel Shift-Add [9], where the use of bit-parallelism reduces worst case linear
complexity by a factor R.
10
Since the maximum clique problem is NP-hard no efficient exact polynomial time
algorithms are expected to be found. However many efforts have been made at
implementing fast algorithms in practice. An important paradigm for exact maximum
clique is branch and bound as in [10][11][12][13][14]. These algorithms perform a
systematic search pruning false solutions by computing bounds dynamically. The 15
tradeoff between computational cost and tight bounds is maximized using a technique
called vertex-coloring. In vertex-coloring, vertices in a graph are assigned a color such
that pairwise adjacent vertices are all colored differently. The number of colors
employed in the process is an upper bound to the size of the maximum clique in the
graph. Vertex-coloring is also NP-hard [1] so this procedure can only be applied 20
suboptimally to obtain bounds for maximum clique.
In this paper we present improvements to reference maximum clique algorithms
found in [10][14]. Improving the speed of a maximum clique algorithm by selective
reordering of vertices to vary tightness of bounds is experimentally analysed in [14]. 25
We further improve approximate coloring by using an implicit global degree branching
rule which fixes the relative order of vertices throughout the search. Moreover, the new
branching rule maps seamlessly with a bit string encoding so that, at each step, the
implicit ordering is computed in constant time. In addition, graph transitions and
approximate coloring can be implemented through efficient bitwise operations thereby 30
improving overall performance by an additional constant factor.
The proposed bit-parallel algorithm has been tested on random graphs and the
well known DIMACS benchmark developed as part of the Second DIMACS Challenge
[15]. Results show that it outperforms, on average, the current reference algorithms in

some cases by an order of magnitude (exceptionally even more) on the more difficult
dense graphs, while preserving superior performance in the easier sparse instances.
This paper is structured from here in four parts. Section 2 covers a preliminary
review of the basic ideas and notation used throughout the text. Section 3 starts with 5
coverage of previous existing algorithms and strategies for successful MCP exact
solvers, including the basic reference algorithm and approximate coloring procedures.
Subsections 3.2 and 3.3 explain the new bit-parallel maximum clique algorithm. To
preserve clarity, a final subsection has been added to include an explanatory example.
Results of experiments are shown in Section 4. Finally, conclusions as well as current 10
and future lines of research are discussed in Section 5.
2 Preliminaries
2.1 Notation
A simple undirected graph ( , )G V E= consists of a finite set of vertices
{ }1 2 nV v ,v , ,v= and a finite set of edges E made up of pairs of distinct vertices ( E VxV⊂15
).Two vertices are said to be adjacent if they are connected by an edge. The complement
of G is a graph G on the same vertices as G such that two vertices in G are adjacent iff
they are not adjacent in G. For any vertex v V∈ , ( )N v (or ( )GN v when the graph needs
to be made explicit) denotes the neighbor set of v in G, i.e. the set of all vertices w V∈
which are adjacent to v. Additionally, ( )GN v refers to the set of all vertices in V which 20
are adjacent in the complement graph (i.e. those which are non-adjacent to v). For any
U V⊆ , ( ) ( , ( ))G U U E U= is the subgraph induced over G by vertices in U. Standard
notation used for vertex degree is deg(v); ( )GΔ refers to the degree of the graph, the
maximum degree in G of any of its vertices. The density p of a graph is the probability
of having an edge between any two pair of vertices. For simple undirected graphs 25
2( 1)
Ep
V V=
−. ( )Gω refers to the number of vertices in a maximum clique in G and
u(G) denotes any upper bound (i.e. ( ) ( )u G Gω≥ ). Unless otherwise specified, it will be
assumed that vertices in a graph are ordered; iv or V [ i ] refer to the i-th vertex in the
set.

2.2 Bit-parallel computation
A generic bit vector BB (alias bit field, bitmap, bitboard, bit string etc. depending
on the particular field of application) is a one dimensional data structure which stores
individual bits in a compact form and is effective at exploiting bit-level parallelism in
hardware to perform operations quickly (as well as reducing storage space). We are 5
interested in bit models for search domains which allow to implement transition
operators (and perhaps additional semantics) using bitwise operations, thereby reducing
time complexity w.r.t. a standard encoding by a factor the size of the CPU word R
(typically 32 or 64 in commercial computers). Given a population set of cardinality n , a
simple way to obtain a bit model for a subset of related elements is a bit vector BB of n 10
bits which maps each element of the population with a corresponding bit such that its
relative position inside BB univocally determines the element in the original population
set. In this encoding, a 1-bit indicates membership to the referred subset. Notation for
bit vectors used throughout the paper includes a subscript b for the lowest (right-most)
bit in the bit vector, which will always be the first element of the encoded subset (e.g. in 15
a population set {1, 2, 3, 4, 5}, bit vector 00110bBB = encodes the subset {2, 3}). We
note that many high level programming languages (e.g. C, Java) already include specific
data types for managing bits inside data structures. However the extension to bit
collections larger than R is less common.
A negative aspect of encoding sets as bit models is that finding the position of 20
each individual bit in a bit vector is more time consuming w.r.t. a standard encoding.
Obtaining the position of the least significant bit in a bit vector is usually referred to as
forward bit scanning. In many processors bit scanning routines are not included in the
assembler set of instructions, so they have to be programmed. There exist a wide variety
of bit scanning implementations available in literature [16]. In our bit-parallel maximum 25
clique algorithm, forward bit scanning (given R = 64) is implemented in the following
way:
64( ) [( &( )) ] 58BitScan BB BB BB MN= − ⋅ >> (1)
BitScan64 returns the position of the least significant 1-bit for any given bit vector
BB of size up to 64 bits. MN is one magic number from a de Bruijn sequence such as 30
0x07EDD5E59A4E28C2. Bitwise operation BB&(-BB) isolates the least significant bit
in BB and the combined multiplication and right shift operations constitute a perfect

hash function for the isolani to a 6 bit index. A more detailed explanation can be found
in [17].
This paper presents a new branching rule for the maximum clique problem which
can be implemented efficiently using bit strings. As a result a new bit-parallel algorithm
for the maximum clique problem is described which at each step computes new graphs 5
and bounds by efficient bitwise operations outperforming the reference algorithms by a
factor R .
2.3 Theoretical background
The paper proposes a new implicit branching rule for exact maximum clique
(MC). Theoretical foundations for branching rule design related to a local solution rely 10
on the continuous formulation of the problem. In [18] the authors showed that MC is
equivalent to solving the following non convex quadratic program P:
maximize ( )
subject to (e x=1, x 0)
T
T
x Ax⎧⎨
≥⎩
where A is the adjacency matrix of the input graph and e is the all 1s vector, so that for
any global solution z to P , 1( ) (1 )TG z Azω −= − . Global solutions to P are known to be 15
blurred by spurious local optima. Later in [19] the author introduced the following
regularization 1 ( )2
Tx Ix to the objective function:
1maximize ( ( ) )2
subject to (e x=1, x 0)
T
T
x A I x⎧ +⎪⎨⎪ ≥⎩
(2)
whose global solution relates to clique 11( ) (2(1 ( ) ))2
TG z A I zω −= − + . The main
advantage is that now z solves (2) iff z is a characteristic vector of a maximum clique. 20
This formulation of MC was further refined in [20] to a diagonal matrix (instead of
identity I) to take care of best local cliques around every vertex; see also [21] for an
alternate regularized formulation and [22] for related trust region formulation in order to
improve weighing function for branching.
Local non increasing degree branching rule comes from noticing that the gradient 25
of the above formulation is Ax (and degrees Ae ); it was already applied in early [23]. In
the paper a new globally driven by degrees branching rule is proposed, which is
therefore related to the gradient.

On the other hand, at a local optimum the gradient is 0 (by definition of a first
order solution) so that in the complement graph 1A I A= − − , 0Ax S= − where S is
the solution to one such local optimum. As a consequence, the gradient for the stable set
is different from zero, suggesting that it could locally be improved; this fact justifies the
use of approximate coloring as branching rule, by now a typical decision heuristic for 5
the domain.
3 Thesis
3.1 Basic maximum clique procedure
Our reference basic branch and bound procedure for finding a maximum clique is
described in Figure 1. In MaxClique search takes place in a graph space. It uses two 10
global sets S and maxS , where S is the set of vertices of the currently growing clique
and Smax is the set of vertices which belong to the largest clique found so far. The
algorithm starts with an empty set S and recursively adds (and removes) vertices from S
until it verifies that it is no longer possible to unseat the current champion in Smax.
Candidate set U is initially set to G, the input graph. At each level of recursion a 15
new vertex v is added to S from the set of vertices in U. At the beginning of a new step a
maximum color vertex v U∈ is selected and deleted from U (line 2). The result of
vertex coloring ( )C v is an upper bound to the maximum clique in U. The search space
is pruned in line 4, when the sum ( )S C v+ is lower than the size of the largest clique
found so far. If this is not the case v is added to S and a new induced graph 20
( ( ))UG U N v∩ (together with a new coloring C ) is computed to become the new graph
in the next level of recursion (line 8). If a leaf node is reached ( ( )UU N v∩ is the empty
set) and maxS S> (i.e. the current clique is larger than the best clique found so far) the
current champion is unseated and vertices of S are copied to maxS . On backtracking,
the algorithm deletes v from S and picks a new vertex from U until there are no more 25
candidates to examine.
An interesting alternative can be found in [11]. ÖOstergård proposed an iterative
deepening strategy, in some way similar to dynamic programming. Given an input
graph ( , )G V E= where { 1 2, ,..., }nV v v v= the algorithm starts from the last vertex in V
and finds the maximum clique iteratively for subgraphs { {1 1}, , },n n n n nV v V v v− −= = 30

{ { }2 2 1 1, , },...,n n n nV v v v V V− − −= = , the last subgraph 1V being the original graph to be
solved. The intuition behind this apparently redundant search procedure is that better
bounds can be achieved for the larger graphs by the information obtained in the
previously computed smaller graphs. This approach, however, has not proved for the
moment as successful as the reference algorithm described in figure 1. 5
Procedure MaxClique (U, C, Smax) 1. while U φ≠ 2. select a vertex v from U with maximum color C( v ) ; 3. U:=U \ {v}; 4. if maxS C( v ) S+ > then 5. { }S : S v= ∪ 6. if UU N ( v ) φ∩ ≠ then
7. generate a vertex coloring C of UG(U N ( v ))∩
8. MaxClique ( UU N ( v ), C∩ )
9. elseif maxS S> then maxS : S= 10. { }S : S \ v ;= 11. endif return 12. endwhile
Figure 1. The reference basic maximum clique algorithm
3.2 Approximate coloring algorithms 10
MaxClique performance increases with decreasing number of color assignments
in the vertex coloring procedure. Finding the minimum coloring of a graph is NP-hard
[1] so, in practice, some form of approximate coloring has to be used. An elaborate
approximate coloring procedure can significantly reduce the search space but it is also
time-consuming. It becomes important to select an adequate trade-off between the 15
reduction in the search space and the overhead required for coloring. Examples of
coloring heuristics can be found in [24].
Tomita and Seki describe in [10] an important approximate coloring algorithm
(the original approximate coloring procedure employed in MaxClique). They used a
standard greedy coloring algorithm to compute color assignments but combined it with 20
a reordering of vertices so that maximum color vertex selection (Figure 1, line 2) is
achieved in constant time. Let { }1 2 1, , , , ,k m mC C C C C C−= be an admissible m-

coloring for the induced graph ( )G U at the current node. Vertices in the input candidate
set U are selected in the same order and added to the first possible color class kC
available so that every vertex belonging to kC has at least one adjacent vertex in color
classes 1 2 1, , , kC C C − . Once all vertices are colored they are assigned the corresponding
color index ( )kC v C k∈ = and copied back to U in the same order they appear in the 5
color classes (i.e. in ascending order with respect to index k) and in the same relative
order of the input vertex set inside each color class. The approximate coloring procedure
also returns the vertex coloring C. In the next level of recursion MaxClique selects
vertices from U in reverse order (the last vertex in the reordered candidate set
conveniently belongs to the highest color class) and the color index given to each vertex 10
becomes an upper bound for the maximum clique in the remaining subgraph to be
searched.
The number of color classes (an upper bound to the size of the maximum clique in
the input candidate set U) depends greatly on the way vertices are selected. It is well
known that the upper bound is tighter if the vertices presented to the approximate 15
coloring procedure are ordered by non-increasing degree [13]. In [14], Konc and Janezic
improved the Tomita and Seki coloring procedure. They realized that it was necessary
to reorder only those vertices in the input set U with color numbers high enough to be
added to the current clique set S by the MaxClique procedure in a direct descendant.
Any vertex v U∈ with color number ( )C v below a threshold min : 1maxK S S= − + 20
cannot possibly unseat the current champion ( maxS ) in the next level of recursion and is
kept in the same order it was presented to the color algorithm. The key idea is that color
based vertex ordering does not preserve non-increasing degree ordering and therefore
should only be used when strictly necessary. Their experiments show that this strategy
prunes the search space better than the Tomita and Seki coloring algorithm, especially 25
in the case of graphs with high density.
3.3 A bit-parallel maximum clique algorithm
We present in this subsection our efficient bit-parallel implementation BB-
MaxClique of the reference maximum clique procedure described in figure 1. BB-
MaxClique employs two types of bit models for sets in the graph domain. The initial 30
input graph G of size n is encoded such that bits are mapped to edges and the adjacency

matrix is stored in full. Alternatively, for any induced graph G(U), an n-bit bit vector
UBB maps bits to vertices in U. We note that for induced graphs only the vertex set is
stored since the corresponding edge set can always be obtained directly from the bit
model of G when needed. One of the benefits of the proposed bit data structures is that
it is possible to compute at each step the new candidate set input of the approximate 5
coloring algorithm preserving the relative order of vertices of the operand sets (i.e. the
position of 1-bits in the corresponding bit vectors).
More formally, given an initial input graph ( , )G V E= where V n= , bit vector
( )iBB A encodes the i-th row of the adjacency matrix A(G). The full encoding ( )BB A
(alias BBG) uses n such bit vectors, one for every row in A. Encoding the full adjacency 10
matrix requires more space than other graph representations (e.g. adjacency lists), but
this is palliated in part by the R register size compression factor inherent in the compact
bit data structures (e.g. for an input graph of 10.000 vertices, BB(A) occupies
approximately 12Mb of storage space). Once BB(A) has been computed prior to the call
of BB-MaxClique, any induced subgraph G(U) can be encoded as a single bit vector UBB 15
so that the relative position of bits inside UBB corresponds to the initial vertex
enumeration in G (i.e. the i-th bit with a value of 1 in UBB refers to the i-th vertex in V ).
We note that every bit vector which encodes a vertex set of an induced graph over G
requires a storage space of n bits, independent of its real size.
The proposed data structures can be used to efficiently compute the new candidate 20
set UU' U N ( v )= ∩ in the next level of recursion using bitwise operations. Let the
selected vertex v be the i-th vertex in the initial enumeration of input graph G and let
UBB be the bit vector for candidate set U. The previously defined bit models make it
possible to compute U' by AND masking BBU with the bit vector which encodes the i-
th row of the adjacency matrix of the input graph: 25
' ( )BB iU U AND BB A= (3)
The above computation requires just one bitwise operation to be performed over the size
of the initial input graph G (which the encoding conveniently divides in blocks of size
R). The improvement in time complexity w.r.t. a standard encoding (assuming that the
ratio /U G is, on average, half the density of G) is therefore: 30
/( ') 2
( ') 2BB G R UO U p
O U U R p G= = ≅
⋅ (4)

In equation (3) the second operand is always part of the bit model of the initial input
graph G and remains fixed during search. Since bitwise operations preserve order,
vertices in the resulting candidate vertex set 'U are always in the same relative order
as they were initially presented to BB-MaxClique, (conveniently sorted by non
increasing degree). Our experiments show that this produces tighter bounds and 5
therefore prunes the search space more than the Tomita and Seki approximate coloring
algorithm and the improvement proposed by Konc and Janečič (excluding selective
reordering), specially for dense graphs.
We note that the strategy of fixing the relative order of vertices for candidate sets
based on a non increasing degree ordering computed a priori is impractical outside the 10
bit parallel framework. The conditions for efficient selective reordering were
established in [14], showing that it is only adequate to reorder candidate sets in the
shallower levels of the search tree. It is only because the a priori relative order is hard
encoded in the bit data structures that it prevails in the new candidate sets at every step
with zero computational cost and that overall efficiency is improved. All our attempts at 15
dynamically changing the interpretation of bits inside bit vectors did not improve the
speed of BB-MaxClique.
Since efficient vertex selection requires a color ordering different from the a
priori initial sorting, the output of the approximate coloring algorithm cannot be stored 20
in the bit encoded input set. BB-MaxClique manages two different data structures for the
current candidate set U : a bit model BBU input of the approximate coloring procedure
and a standard list of vertices LU on output. At each step vertices are selected from LU
(line 2 of the basic maximum clique procedure) and automatically reordered during the
computation of the new candidate set BBU (equation (3)), so that vertices are always 25
presented to the approximate coloring procedure as they were sorted initially. A side
effect of the UBB/UL decoupling is that LU no longer needs to store the full set of
vertices of the input candidate set BBU but just those vertices with color index C(v)
which may possibly be selected in the next step of the maximum clique procedure.
It is important for overall efficiency to optimize bit scanning operations during 30
search. BB-MaxClique employs bit scanning during approximate coloring, but does not
require bit scanning neither to select the vertex with maximum color nor to compute

new candidate sets. Additional implementation details include bit vectors to encode the
current clique S and the current best clique found so far during search maxS . For these
two sets there is no special advantage in using bit vectors w.r.t. a standard
implementation.
3.4 Bit-parallel approximate coloring 5
We have improved the original approximate coloring algorithm of Tomita and
Seki and the improved variant of Konc and Janečič so as to exploit bit-parallelism over
the proposed bit data structures for sets of vertices and edges. We will refer to the new
bit-parallel coloring algorithm as BB-Color.
BB-Color obtains tighter bounds because it reorders the vertices in the input set U 10
as they were presented initially to the BB-MaxClique procedure (conveniently sorted by
non increasing degree). In practice, the input candidate set is bit encoded (UBB) and
automatically ordered on generation at each level of recursion by BB-MaxClique, prior
to the call to BB-Color. On output, vertices need to be ordered by color so a new
(conventional) data structure UL is used to decouple the input and output sets. UL is not 15
bit encoded to avoid the overhead of bit scanning when selecting vertices from this set
in BB-MaxClique. The decoupling has an additional benefit in that only vertices which
may possibly be selected from BBU by BB-MaxClique in the next level of recursion
need to be explicitly stored. To select these vertices we use the low computational cost
bound based on color assignments proposed by Konc and Janečič in [14]. We note that 20
in [14] (as in the original coloring algorithm) the full candidate input set was reordered.
In the bit-parallel coloring procedure only the filtered vertices are stored.
Another important difference in BB-Color is that color sets are now obtained
sequentially instead of assigning a color to each vertex of the candidate set in turn. The
key idea is that after every vertex assignment to the current color class, the subset of 25
remaining vertices which can still be assigned to that particular color can be computed
by efficient bitwise operations between appropriate bit sets (which share the same
relative order). Let { }1 2, , , kC C C C= be the k-coloring output of BB-Color. At the start
of the procedure the first color class 1C (initially the empty set) is selected and the first
vertex v1 of the input candidate set UBB is added to 1C . The set 'BBU of remaining 30
candidate vertices v U∈ which can still be assigned color 1C must be non adjacent

vertices to 1v , i.e. '1( )
BBBB BB UU U N v= ∩ . Once 'BBU has been obtained, the first vertex
' '1 BBv U∈ is now added to 1C and a new set '
'' ' '1( )
BBBB BB U
U U N v= ∩ is computed. The
process continues until the resulting induced graph is empty, in which case the assigned
vertices are removed from candidate set UBB and the process is repeated for the next
empty color class 2C . BB-Color ends when all vertices in UBB have been assigned a 5
particular color.
Similarly to BB-MaxClique, the proposed data structures for sets of vertices and
edges can be used to compute efficiently, at each step of the coloring procedure, the
remaining vertices which can be assigned to a particular color. In particular, the
expression ' ( )BBBB BB iUU U N v= ∩ where i BBv U∈ can be obtained by the following two 10
bitwise operations:
' ( )BB BB iU U AND NOT BB A= (5)
In the above equation, bitwise operation NOT BBi(A) is the set of non adjacent vertices
to vi in the input graph G; the AND mask selects filters those vertices which belong to
BBU . Two masking operations are now applied over the size of the input set G, so the 15
expected improvement in time complexity w.r.t. a standard encoding for the above
expression (assuming as in (3) that the ration /U G is, on average, half the density of
G) is:
/( ') 4
( ') 2BB G R UO U p
O U U R p G= = ≅
⋅ (6)
Since ( )BB A is fixed at the beginning of the maximum clique procedure and 20
remains constant throughout the search, vertices in BBU in equation (5) must always be
in that same relative order. Because vertices are selected sequentially during coloring
subsets of vertices inside each color class in the output candidate set LU also preserve
the a priori non increasing degree initial sorting of vertices in G.
As explained in section 3.2, the quality of approximate coloring improves on 25
average if vertices are ordered by non increasing degree, so BB-Color is expected to
obtain tighter bounds w.r.t. the reference coloring algorithms as long as the initial vertex
reordering does not degrade quickly with depth. In [14], Konc and Janečič discuss the
effect of selective reordering of the input candidate set by non increasing degree prior to
each call to the approximate coloring procedure. They conclude that the overhead 30

introduced by reordering is only justified for large sets (and therefore shallower depths)
because in this case the additional overhead of reordering (i.e. 2( )O U for a standard
sorting algorithm) is lower than the cost of searching for false solutions which cannot be
pruned with less tighter bounds. But it is precisely at shallower depths in the search tree
that a sorting of vertices based on the relative order of the initial input graph is expected 5
to be closer to optimal. Furthermore, BB-MaxClique can achieve this reordering in
constant time because of the proposed data structures.
We note that the reference coloring algorithm does not preserve any form of
degree ordering at all while the Konc and Janečič variant preserves relative degree
ordering only for vertices with a color index such that they cannot be selected by 10
MaxClique in the next level of recursion. We also note that the coloring C obtained in
the original approximate algorithm (where vertices are assigned a color in turn) is
exactly the same as the one obtained by computing full color sets sequentially iff the
vertices in the input candidate set are in the same order. In the latter case the advantage
is a computational one, only related to the bit data structures. 15
BB-Color is shown in Figure 2. Subscripts BB have been added when necessary to
make bit vectors explicit. Assignments in frame boxes indicate computations where the
bit model is faster than the corresponding computations in a standard encoding (lines 8
and 10). The input of the algorithm is candidate set U and is referred to by the
corresponding bit model UBB. The algorithm has two outputs: the new coloring C and 20
the candidate set LU which contains the subset of vertices in U which may possibly be
selected by MaxClique in the next level of recursion (according to parameter kmin as
proposed by Konc and Janečič in [14]). A subscript L (List) has been added to stress
the fact that it is unnecessary (and inefficient) to use a bit model to encode this set. BB-
MaxClique is described in Figure 3. Notation is the same as in BB-Color. 25

Procedure BB-Color (UBB, UL, C, kmin)
:BB BBQ U ;= 0;k = /* usually : 1min maxk S S= − + */
/* Vertices in the input candidate set UBB must be in the same relative order as in the initial input graph presented to BB-MaxClique */
1. while BBU φ≠ 3. :kC φ= ; 4. while BBQ φ≠ 5. select the first vertex BBv Q∈ 6. { }k kC : C v= ∪ ; 7. { }BB BBQ : Q \ v ;=
8. BBBB BB QQ : Q N ( v )= ∩ ;
9. endwhile
10. :BB BB kU U C= − ;
11. :BB BBQ U= ; 12. if mink k≥ then 13. LU := kC /* in the same order*/ 14. C[ v k∈ ] := k ; 15. endif 16. : 1k k= + ; 17. endwhile
Figure 2. The bit-parallel approximate coloring algorithm. Assignments in frame boxes refer to computations which benefit from bit-parallelism.

Procedure BB-MaxClique (UBB, UL, C, Smax)
/*Initially UBB is a bit model for the set of vertices in the input graph
G (V ,E )= and UL is a standard encoding of V */
1. while U φ≠ 2. select a vertex v from UL in order 3. UBB:=UBB\{v}; 4. if maxS C( v ) S+ > then 5. { }S : S v= ∪
6. if BBBB UU N ( v )∩ φ≠ then /*Computes the new candidate set in the same relative order as G */
7. BB-Color 1BBBB U L max(U N ( v ),U ,C', S S )∩ − +
/*Output set UL is ordered by color */
8. BB-MaxClique ( BB U L maxU N ( v ),U ,C',S∩ )
9. elseif maxS S> then :maxS S= 10. { }:S S \ v ;= 12. endif return 13. endwhile
Figure 3. The bit-parallel maximum clique algorithm
3.5 Initialization
Initially sets S and Smax are the empty sets. Vertices V of input graph G are sorted 5
by non increasing degrees (ties broken randomly). The initial coloring C( v V )∈ sets
numbers ranging from 1 to GΔ to the first GΔ vertices and GΔ to the remaining ones,
a standard procedure described in [10]. After computing BBG, BBU V= , LU V= and
coloring C become the initial inputs of BB-MaxClique. We note that the bit-parallel
algorithm is especially sensible to initial sorting so that improvements here (e.g. in the 10
breaking of ties) may have greater impact on overall efficiency w.r.t. the proposed
reference algorithms.
3.6 A case study
An example of an undirected graph G (V ,E )= is depicted in Figure 4 (A). Graph
G is the input to our bit-parallel maximum clique procedure BB-MaxClique. Vertices in 15
G are conveniently ordered by non-increasing degree, the standard ordering prior to the

execution of the reference maximum clique algorithm. The set of vertices in G, with the
degree of each vertex in parentheses, is { }(6) (5) (5) (4) (4) (4) (4) (4) (4)1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9V = . Our
proposed bit model for G maps bits to edges so that for every row of the adjacency
matrix A( G ) there is a corresponding bit vector (e.g. 1 1 011101110bA BB≡ = encodes
all edges incident to vertex {1}). The bit encoding for the initial candidate set UBB is 5
111111111BB bU V= = (a bit to 1 indicates membership).
For the sake of simplicity, it will be assumed that in the first step UBB is also the
input to the approximate coloring algorithm. Table 1 shows the result of the color
assignments obtained with the standard coloring procedure used in all three algorithms.
10 Table 1. Color assignments obtained by the standard approximate coloring algorithm.
k Ck 1 (6)1 (4)5 2 (5)2 (4)6 3 (5)3 (4)7 4 (4)4 (4)8 5 49( )
After all vertices have been assigned a particular color, the original approximate
algorithm copies them back to the input candidate set as they appear in the color classes 15
and in increasing order with respect to index k. The new ordering for the candidate set
in the next level of recursion becomes { }(6) (4) (5) (4) (5) (4) (4) (4) (4)1 ,5 ,2 ,6 ,3 ,7 ,4 ,8 ,9U = with
coloring { }1 1 2 2 3 3 4 4 5C , , , , , , , ,= , which does not preserve non increasing degree. The
improved Konc and Janečič approximate coloring variant sorts by color index just those
vertices which can possibly be selected by MaxClique in the descendant node; the 20
remaining vertices stay in the same order they were presented to the coloring procedure.
Assuming that at the current node 0S = and 2maxS = , then
1 2 0 1 3min maxk S S= − + = − + = so that only vertices v U∈ with color index equal or
higher than 3C( v ) = are ordered by color. Their improved new candidate set becomes
{ }(6) (5) (4) (4) (5) (4) (4) (4) 4)1 ,2 ,5 ,6 ,3 ,7 ,4 ,8 ,9U = and the coloring { }3 3 4 4 5C , , , , , , , ,= − − − − (a 25
‘− ’ indicates that no color needs to be assigned).
Our improved BB-Color computes color assignments by determining color sets
sequentially, a strategy which can be carried out by efficient bitwise operations over the

proposed data structures. As an example, we will focus on the first color class 1C ,
initially the empty set. Vertices are selected in order from the input candidate set UBB so
initially vertex {1} is selected as member. The vertex set U’ of non adjacent vertices to
vertex {1} (i.e. 1BBBB UU N ( )∩ ={5,9}) can be computed, as explained in (4), by the
following pair of bitwise operations: 5
1 1BB ( A) A (G )≡ 011101110b {2,3,4,6,7,8}
BBU 111111110b {2,3,4,5,6,7,8,9}
11BBBB BBUU N ( ) U AND NOT BB (G )∩ ≡ 100010000b {5,9}
The resulting set preserves the initial sorting of nodes in G since it is implicitly encoded
by the relative position of bits in UBB. Selecting the first vertex from U’ (i.e. {5} in the
example) ends the color assignment to 1C . 10
BB-Color outputs a new candidate set LU containing only the vertices which can
possibly be selected in the next level of recursion (i.e. { }5 4 4 4 43 7 4 8 9( ) ( ) ( ) ( ) )LU , , , ,= with
coloring { }3 3 4 4 5C , , , ,= ). At this step the differences between the output candidate sets
U are irrelevant (the subset of possible candidates which may be selected in the next
step is {3, 7, 4, 8, 9} in all three cases). This is not the case when computing the new 15
candidate set (input of the approximate coloring procedure) in the next step. In the
example, MaxClique now selects the last vertex in the set (vertex {9}), a maximum
color vertex. The new induced graph ' (9)U U N= ∩ is depicted in Figure 4(C) and is
the same for all three algorithms (vertex ordering differs). The new candidate set U’ for
MaxClique is now { }1 2 3 25 2 3 4( ) ( ) ( ) ( )U ' , , ,= . In the case of the Konc and Janečič 20
improvement { }2 1 3 22 5 3 4( ) ( ) ( ) ( )U ' , , ,= , a better ordering w.r.t. non increasing degree.
However BB-Color will receive the best input { }2 3 2 12 3 4 5( ) ( ) ( ) ( )U ' , , ,= because it
preserves the relative initial sorting in G.

4
5
6
7
8
1
2
3
9
0 1 1 1 0 1 1 1 00 1 1 0 0 1 0 1
0 1 1 0 0 0 10 0 0 0 0 1
0 1 0 1 10 1 1 0
0 1 00 0
0
G
⎛ ⎞⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟=⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠
A) An example undirected graph G B) The adjacency matrix of G
{ }(1) (2) (3) (2)' 5 ,2 ,3 ,4TSU =
{ }(2) (1) (3) (2)' 2 ,5 ,3 ,4KJU =
4
5
2
3
{ }(2) (3) (2) (1)' 2 ,3 ,4 ,5BBU =
C) Induced graph 9GG' G( N ( ))= resulting from the selection of candidate vertex 9 in the first step of the maximum clique procedure
D) Different new candidate sets input to the coloring procedure for the induced graph G’ depicted in C). Subscript TS stands for the Tomita and Seki algorithm, subscript KJ for the improved version of Konc and Janecic and subscript BB corresponds to BB-MaxClique.
Figure 4. A maximum clique example

The bitwise operations to compute ' (9)U U N= ∩ are the following:
Experiments confirm that the improved order obtained by BB-MaxClique prunes the
search space better than the two reference algorithms, notably so in the more dense
graphs. This was something expected, since for dense instances orderings obtained at 5
shallower levels in the search tree by BB-MaxClique are closer to optimal on average
(w.r.t degree). We note that in all three cases the ordering is suboptimal, since
maximum degree vertex 3 should ideally be placed first.
The three different orderings for 'U appear in Figure 4(D). Subscript TS stands
for Tomita and Seki (the original coloring procedure), KJ refers to the improved variant 10
of Konc and Janečič and BB refers to BB-MaxClique.
4 Experiments
We have implemented in C language a number of algorithms for the experiments:
MC (the reference MaxClique algorithm proposed by Tomita and Seki which includes
the original approximate coloring procedure), MC-KJ (the Konc and Janečič 15
approximate coloring variant), and our new bit-parallel BB-MaxClique. Computational
experiments were performed on a 2.4 GHz Intel Quad processor with a 64 bit Windows
operating system (R=64). The time limit for all the experiments was set at 5h (18000
seconds) and instances not solved in the time slot were classified as Fail. We note that
neither the compiler nor the hardware supported parallel computation enhancements so 20
our CPU times are directly comparable to those found elsewhere with the corresponding
machine benchmark correction. Our user times for the DIMACS machine benchmark
graphs r100.5-r500.5 are 0.000, 0.031, 0.234, 1.531 and 5.766 seconds respectively. An
important effort has been made in optimizing all three algorithms. This might explain
discrepancies between user times for MC and MC-KJ w.r.t. other results found 25
elsewhere.
A fourth algorithm MCdyn-KJ, also described by Konc and Janečič in [14], was
used for comparison. MCdyn-KJ incorporates selective reordering of vertices prior to
calling the approximate coloring procedure. In this case we found problems in
9 9BB ( A) A (G )≡ 000011110b {2,3,4,5}
BBU 011111111b {1,2,3,4,5,6,7,8}
99BBBB U BBU N ( ) U AND BB ( G )∩ ≡ 000011110b {2,3,4,5}

implementing an efficient version comparable to the other algorithms so it was decided
to use the DIMACS machine benchmark to derive a time comparison rate based on
results in [14]. MCdyn-KJ CPU user times for DIMACS machine benchmark graphs
(r100.5-r500.5) are 0.000, 0.040, 0.400, 2.480 and 9.450 respectively. To compute the
correction time rate the first two graphs from the benchmark were removed (user time 5
was considered too small) and the rest of times averaged to obtain a constant factor of
1.656 in favour of BB-MaxClique. We compared BB-MaxClique with the other three
algorithms using DIMACS graphs (tables 1-2) and random graphs (tables 3-4) recording
in both cases the number of steps taken and the user times (with precision up to
milliseconds). 10
Care has been taken in the implementation to make the comparison between the
reference algorithms and BB-MaxClique as fair as possible. We note that it has not been
possible to efficiently bit encode the Color procedure for both reference algorithms
because it requires local degree ordering at each step. This is incompatible with the 15
fixed ordering that a bit encoding of induced graphs (and the adjacency matrix of the
initial input graph) requires to be effective; an inherent advantage of the implicit global
degree branching rule in practice. We also note that times obtained for the reference
algorithms are comparable to those that can be found in the reference papers for both
algorithms (taking into account the time correction factor). 20
We expected the new branching rule to outperform reference MC and MC-KJ
since it improves over MC-KJ by considering global degree inside color stable sets Ck
with mink k≥ . On the other hand, MCdyn-KJ should be better, on average in the number
of steps since it makes use of local degree information as branching rule. These trends 25
are confirmed by results on the number of steps as shown both for DIMACS and
random graphs with exceptions, the most notable being that, as density increases, the
difference in the number of steps is gradually reduced between BB-MaxClique and
MCdyn-KJ for random graphs.
With respect to overall performance we expected the new branching rule to 30
outperform the rest of algorithms on average because it can be bit encoded seamlessly
as previously explained. This is also confirmed by results. We note that even for very
large sparse graphs, where the explicit bit encoding of the adjacency matrix is a

negative factor, results for BB-MaxClique do not degrade. Detailed comments for
concrete instances now follow.
The bit-parallel coloring algorithm BB-Color reduces, in the general case, the
number of steps to find the maximum clique compared with coloring in MC and the 5
improved MC-KJ. This effect gradually degrades for the less difficult graphs (i.e.
0.4p ≤ ) but turns more acute as density increases (i.e. p in the interval 0.7-0.95). For
example, in random graphs of size 200 the reduction rate w.r.t. MC-KJ in the number of
steps ranges from 1.1 aprox. for 0 5p .= to 3 for 0 95p .= (7.4 for the original MC) as
recorded in table 4. As expected, local reordering in MCdyn-KJ prunes the search space 10
on average better than BB-Color (at the cost of a quadratic overhead on the size of the
graph at the current node). In spite of this, the number of steps for random graphs taken
by BB-MaxClique remain reasonably close to MCdyn-KJ except for very dense graphs
(e.g. for n=200, 0 9p .≤ the maximum rate of improvement in the number of steps is
1.2 approx., but for 0 95p .= the rate rises to almost an order of magnitude). We note, 15
however, that as size and density grows the new branching rule improves over local
degree reordering (e.g. for n=500, p=0.6 or n=1000, p=0.5). This can be explained by
the fact that the homogeneous distribution of edges in large random graphs does not
allow global degree to degrade in the shallower levels of the search tree, which is where
the local degree branching rule is expected to work better. 20
Tables 3 and 5 show CPU user times for tests . BB-MaxClique turns out to be
faster than MCdyn-KJ for values of p in the range 0.5-0.9 (in the case of 0 9p .= more
than 3 times) and only for 0 95p .= does MCdyn-KJ outperform BB-MaxClique by a
factor of just 1.6 approx. For easy random graphs ( 0.3p ≤ ) the number of steps taken
by the original reference algorithm MC is close to best. In the case of BB-MaxClique 25
this can be explained by two facts: 1) The size of the search trees for these graphs is
smaller 2) The difference between candidate sets in a parent node and a direct
descendant is greater w.r.t. the more difficult graphs, so that the relative initial order by
degree degrades more quickly with depth. BB-MaxClique is faster in all cases than MC
and MC-KJ for graphs with 0.6p ≥ by a factor which ranges from 2 to 20. In the case 30
of MCdyn-KJ the difference is less acute, ranging from 1.1 to 4.
For larger graphs with small densities (i.e. 0.2p ≤ ) the difference in time is
relatively small between all four algorithms (we note that this is consistent for n=1000

for MCdyn-KJ , and that no data was available in [14] for higher values of n). In the
case of BB-MaxClique, as explained previously, BB-Color does not produce a
substantial benefit in the pruning of the search space in this scenario. Moreover, the
expected improvement in time for bitwise computation of candidates sets and color
assignments diminishes with p (e.g. the ratio of improvement for color assignments 5
according to equation (4) for 0.1, 64p R= = is( ') 4 4 0.625
( ') 64 0.1BBO U
O U R p x= =
⋅) and
there are a number of operations in BB-Maxclique that do not adapt well, including our
decoupling of UBB and UL . In spite of this, BB-MaxClique remains faster for the vast
majority of less dense graphs and there is no evidence that suggests a strong degradation
of performance for graphs with increasing sizes and decreasing densities. 10
Consistent with results obtained for random graphs, BB-Color prunes the search
space better than MC and MC-KJ in the majority of DIMACS instances by a factor
ranging from 1.1 to an order of magnitude (e.g. the phat family) with exceptions, the
most notable being san200_0.7_1, san400_0.5_1 and san400_0.7_2 (table 2). It appears 15
that BB-Color does not adapt well to the local structure for these instances. We expected
dynamic reordering in MCdyn-KJ to prune the search space consistently better than BB-
MaxClique. This is indeed the case in the brock family (by a factor not more than 1.2)
and the sanr family (by a similar factor) but in the remaining cases BB-MaxClique is at
least equal and even outperforms on average MCdyn-KJ in the phat and san families. 20
For example, MCdyn-KJ is around 4 times better for san200_0.9_1 and san400_0.7_2
but is almost 30 times worse for san200_0.9_3 and san400_0.9_1). This validates BB-
Color pruning for the more structured instances.
User times for DIMACS graphs are recorded in table 3. BB-MaxClique
outperforms on average the other three algorithms by a factor ranging from 1.1 up to 25
200 (e.g. for san400_0.9_1, BB-MaxClique runs faster by a factor of 200, 15 and 25
w.r.t. MCdyn-KJ, MC-KJ and MC respectively). Exceptions where BB-MaxClique does
not perform better are the easier, less dense, graphs where many bit-masking operations
are done over almost empty sets and BB-Color does not prune the search space
significantly better (i.e. phat500-1 and cfat-500-5). Additionally, in two denser graphs 30
(i.e. hamming8-2 and san200_0.7_2) the dynamic reordering in MCdyn-KJ outperforms
BB-MaxClique.

Table 2. Number of steps for DIMACS benchmark graphs. ω is the size of themaximum clique found by at least one of the algorithms
Graph (size, density) ω MC MC-KJ BB-MaxClique MCdyn_KJ
brock200_1 (200, 0.745) 21 485009 402235 295754 229597
brock200_2 (200, 0.496) 12 4440 4283 4004 3566
brock200_3 (200, 0.605) 15 15703 15027 13534 13057
brock200_4 (200, 0.658) 17 87789 78807 64676 48329
brock400_1 (400, 0.748) 27 302907107 269565323 168767856 125736892
brock400_2 (400, 0.749) 29 114949717 103388883 66381296 44010239
brock400_3 (400, 0.748) 31 224563898 194575266 118561387 109522985
brock400_4 (400, 0.749) 33 123832833 107457418 66669902 53669377
brock800_1 (800, 0.649) 23 Fail Fail 1926926638 1445025793
brock800_2 (800, 0.651) 24 Fail Fail 1746564619 1304457116
brock800_3 (800, 0.649) 25 156060599 1474725301 1100063466 835391899
brock800_4 (800, 0.650) 26 1017992114 964365961 730565420 564323367
c-fat200-1 (200, 0.077) 12 216 216 216 214
c-fat200-2 (200, 0.163) 24 241 241 241 239
c-fat200-5 (200, 0.426) 58 308 308 308 307
c-fat500-1 (500, 0.036) 14 520 520 520 743
c-fat500-2 (500, 0.073) 26 544 544 544 517
c-fat500-5 (500, 0.186) 64 620 620 620 542
c-fat500-10 (500, 0.374) 126 744 744 744 618
hamming6-2 (64, 0.905) 32 63 63 63 62
hamming6-4 (64, 0.349) 4 164 164 164 105
hamming8-2 (256, 0.969) 128 255 255 255 254
hamming8-4 (256, 0.639) 16 22035 19641 20313 19107
hamming10-2 (1024, 0.990) 512 1023 1023 1023 2048
hamming10-4 (1024, 0.829) >=40 Fail Fail Fail Fail
johnson8-2-4 (28, 0.556) 4 51 51 51 46
johnson8-4-4 (70, 0.768) 14 295 286 289 221
johnson16-2-4 (120, 0.765) 8 270705 343284 332478 643573
johnson32-2-4 (496, 0.879) >=16 Fail Fail Fail Fail
keller4 (171, 0.649) 11 11948 11879 12105 8991
keller5 (776, 0.752) >=27 Fail Fail Fail Fail
Mann_a9 (45, 0.927) 16 95 95 95 94
Mann_a27 (378, 0.99) 126 38253 38253 38253 38252
Mann_a45 (1035, 0.996) 345 2953135 2953135 2953135 2852231

Table 2 (cont). Number of steps for DIMACS benchmark graphs Graph (size, density) ω MC MC-KJ BB-MaxClique MCdyn_KJ
phat300-1(300, 0.244) 8 2043 2001 1982 2084
phat300-2 (300, 0.489) 25 10734 6866 6226 7611
phat300-3 (300, 0.744) 36 2720585 1074609 590226 629972
phat500-1 (500, 0.253) 9 10857 10361 10179 10933
phat500-2 (500, 0.505) 36 353348 178304 126265 189060
phat500-3 (500, 0.752) 50 179120200 54530478 18570532 25599649
phat700-1 (700, 0.249) 11 33832 31540 30253 27931
phat700-2 (700, 0.498) 44 3668046 1321665 714868 1071470
phat700-3 (700, 0.748) 62 1194633937 1407384483 247991612 292408292
phat1000-1 (1000, 0.245) 10 200875 187331 173892 170203
phat1000-2 (1000, 0.49) 46 210476154 65992319 25693768 30842192
phat1000-3 (1000, 0.744) >=68 Fail Fail Fail Fail
phat1500-1 (1500, 0.253) 12 1249496 1175919 1086747 1138496
phat1500-2 (1500, 0.505) >=65 Fail Fail Fail Fail
san200_0.7_1 (200, 0.7) 30 3817 5455 3512 983
san200_0.7_2 (200, 0.7) 18 1695 1560 1346 1750
san200_0.9_1 (200, 0.9) 70 567117 599368 110813 28678
san200_0.9_2 (200, 0.9) 60 494810 381637 62766 72041
san200_0.9_3 (200, 0.9) 44 76366 56573 13206 327704
san400_0.5_1 (400, 0.5) 13 2821 4673 3927 3026
san400_0.7_1 (400, 0.7) 40 95847 138755 78936 47332
san400_0.7_2 (400, 0.7) 30 22262 33601 39050 9805
san400_0.7_3 (400, 0.7) 22 428974 447719 241902 366505
san400_0.9_1 (400, 0.9) 100 161913 101911 20627 697695
san1000 (1000, 0.502) 15 113724 144305 88286 114537
sanr200_0.7 (200, 0.702) 18 184725 166061 130864 104996
sanr200_0.9 (200, 0.898) 42 46161985 23269028 9585825 6394315
sanr400_0.5 (400, 0.501) 13 301265 287173 257244 248369
sanr400_0.7 (400, 0.7) 21 89734818 80375777 54279188 37806745

Table 3. CPU times (sec.) for DIMACS benchmark graphs. Time is limited to 5hGraph (size, density) ω MC MC-KJ MCdyn_KJ BB-MaxClique
brock200_1 (200, 0.745) 21 1.563 1.359 0.942 0.500
brock200_2 (200, 0.496) 12 0.031 0.015 0.011 <0.001
brock200_3 (200, 0.605) 15 0.062 0.047 0.044 0.015
brock200_4 (200, 0.658) 17 0.219 0.218 0.146 0.078
brock400_1 (400, 0.75) 27 1486.125 1355.953 709.927 502.796
brock400_2 (400, 0.75) 29 647.875 610.797 314.608 211.218
brock400_3 (400, 0.75) 31 1017.680 922.109 564.732 336.188
brock400_4 (400, 0.75) 33 616.015 562.110 321.643 200.187
brock800_1 (800, 0.65) 23 Fail Fail 8661.529 8600.125
brock800_2 (800, 0.65) 24 Fail Fail 8156.112 7851.875
brock800_3 (800, 0.65) 25 9551.438 9196.672 5593.401 5063.203
brock800_4 (800, 0.65) 26 7048.328 6806.484 4335.595 3573.328
c-fat200-1 (200, 0.077) 12 <0.001 <0.001 <0.001 <0.001
c-fat200-2 (200, 0.163) 24 <0.001 0.015 <0.001 <0.001
c-fat200-5 (200, 0.426) 58 0.016 0.016 0.002 <0.001
c-fat500-1 (500, 0.036) 14 <0.001 <0.001 0.021 <0.001
c-fat500-2 (500, 0.073) 26 0.016 0.015 0.001 <0.001
c-fat500-5 (500, 0.186) 64 0.016 0.016 0.002 0.016
c-fat500-10 (500, 0.374) 126 0.047 0.047 0.006 0.031
hamming6-2 (64, 0.905) 32 <0.001 <0.001 <0.001 <0.001
hamming6-4 (64, 0.349) 4 <0.001 <0.001 <0.001 <0.001
hamming8-2 (256, 0.969) 128 0.016 0.031 0.011 0.031
hamming8-4 (256, 0.639) 16 0.078 0.094 0.091 0.031
hamming10-2 (1024, 0.99) 512 0.609 0.609 4.003 0.187
hamming10-4 (1024, 0.829) >=40 Fail Fail Fail Fail
johnson8-2-4 (28, 0.556) 4 <0.001 <0.001 <0.001 <0.001
johnson8-4-4 (70, 0.768) 14 0.016 0.015 <0.001 <0.001
johnson16-2-4 (120, 0.765) 8 0.109 0.187 0.411 0.110
johnson32-2-4 (496, 0.879) >=16 Fail Fail Fail Fail
keller4 (171, 0.649) 11 0.016 0.030 0.024 0.016
keller5 (776, 0.752) >=27 Fail Fail Fail Fail
Mann_a9 (45, 0.927) 16 <0.001 <0.001 <0.001 <0.001
Mann_a27 (378, 0.99) 126 2.218 2.187 4.565 0.547
Mann_a45 (1035, 0.996) 345 1789.640 1792.235 5456.932 242.594
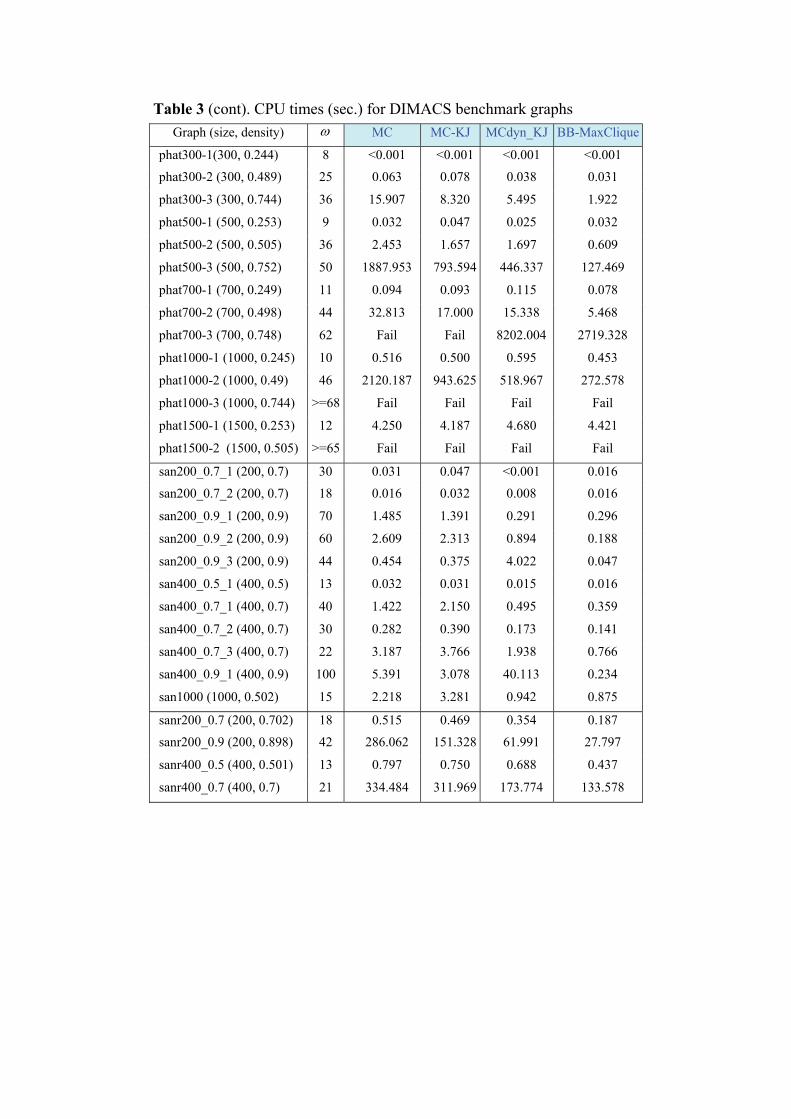
Table 3 (cont). CPU times (sec.) for DIMACS benchmark graphs Graph (size, density) ω MC MC-KJ MCdyn_KJ BB-MaxClique
phat300-1(300, 0.244) 8 <0.001 <0.001 <0.001 <0.001
phat300-2 (300, 0.489) 25 0.063 0.078 0.038 0.031
phat300-3 (300, 0.744) 36 15.907 8.320 5.495 1.922
phat500-1 (500, 0.253) 9 0.032 0.047 0.025 0.032
phat500-2 (500, 0.505) 36 2.453 1.657 1.697 0.609
phat500-3 (500, 0.752) 50 1887.953 793.594 446.337 127.469
phat700-1 (700, 0.249) 11 0.094 0.093 0.115 0.078
phat700-2 (700, 0.498) 44 32.813 17.000 15.338 5.468
phat700-3 (700, 0.748) 62 Fail Fail 8202.004 2719.328
phat1000-1 (1000, 0.245) 10 0.516 0.500 0.595 0.453
phat1000-2 (1000, 0.49) 46 2120.187 943.625 518.967 272.578
phat1000-3 (1000, 0.744) >=68 Fail Fail Fail Fail
phat1500-1 (1500, 0.253) 12 4.250 4.187 4.680 4.421
phat1500-2 (1500, 0.505) >=65 Fail Fail Fail Fail
san200_0.7_1 (200, 0.7) 30 0.031 0.047 <0.001 0.016
san200_0.7_2 (200, 0.7) 18 0.016 0.032 0.008 0.016
san200_0.9_1 (200, 0.9) 70 1.485 1.391 0.291 0.296
san200_0.9_2 (200, 0.9) 60 2.609 2.313 0.894 0.188
san200_0.9_3 (200, 0.9) 44 0.454 0.375 4.022 0.047
san400_0.5_1 (400, 0.5) 13 0.032 0.031 0.015 0.016
san400_0.7_1 (400, 0.7) 40 1.422 2.150 0.495 0.359
san400_0.7_2 (400, 0.7) 30 0.282 0.390 0.173 0.141
san400_0.7_3 (400, 0.7) 22 3.187 3.766 1.938 0.766
san400_0.9_1 (400, 0.9) 100 5.391 3.078 40.113 0.234
san1000 (1000, 0.502) 15 2.218 3.281 0.942 0.875
sanr200_0.7 (200, 0.702) 18 0.515 0.469 0.354 0.187
sanr200_0.9 (200, 0.898) 42 286.062 151.328 61.991 27.797
sanr400_0.5 (400, 0.501) 13 0.797 0.750 0.688 0.437
sanr400_0.7 (400, 0.7) 21 334.484 311.969 173.774 133.578

Table 4. Number of steps for random graphs. n is the number of vertices and p the probability that there is an edge between two vertices in the graph. Results are averaged for 10 runs.
n p ω MC MC-KJ BB-MaxClique MCdyn_KJ 100 0.60 11-12 982 936 876 943 100 0.70 14-15 2347 2043 1806 1940 100 0.80 19-21 7750 5847 4595 4101 100 0.90 29-32 14701 10767 7378 4314 100 0.95 42-45 4032 2195 1339 477 150 0.50 10-11 2093 2018 1929 2217 150 0.60 12-13 6208 5788 5255 5932 150 0.70 16-17 30950 27401 21969 20475 150 0.80 23 207998 162510 110378 88649 150 0.90 35-38 1680197 902625 409727 258853 150 0.95 50-54 417541 148942 61390 14825 200 0.40 9 2117 2086 2053 2409 200 0.50 11-12 8035 7657 7159 7695 200 0.60 13-14 44230 41362 35550 31114 200 0.70 17-18 245636 216647 169819 148726 200 0.80 25-26 3801344 3082280 2003197 1424940 200 0.90 40-42 97465819 49673617 19534465 16404111 200 0.95 61-64 143220609 58337810 14505493 1508657 300 0.40 9-10 10778 10389 9992 12368 300 0.50 12 53869 51603 47126 61960 300 0.60 15-16 417846 391396 328398 387959 300 0.70 20-21 6446501 5679283 4170171 4548515 300 0.80 28-29 223199099 179079625 102087337 159498760 500 0.30 8-10 19831 20365 19831 19665 500 0.40 10-11 120074 128238 120074 123175 500 0.50 13 975599 1104113 975599 9633385 500 0.60 17 14990486 14185138 11423696 15075757
1000 0.10 5-6 3999 3995 3995 1000 0.20 7-8 39287 39037 38641 41531 1000 0.30 9-10 418675 411601 393404 413895 1000 0.40 12 4186301 4079344 3731481 4332149 1000 0.50 14-15 88684726 85902955 74347239 100756405 3000 0.10 6-7 152118 151987 151874 3000 0.20 9 2863781 2839315 2744195 3000 0.30 11 77043380 75925753 71098053 5000 0.10 7 535370 535032 533968 5000 0.20 9-10 31813985 31651639 30887512
10000 0.10 7-8 5688845 5668866 5541681 15000 0.10 8 22038573 21979315 21419998

Table 5. CPU user times (sec.) for random graphs. n is the numberof vertices and p the probability that there is an edge between twovertices in the graph. Results are averaged for 10 runs.
n p ω MC MC-KJ MCdyn_KJ BB-MaxClique 100 0.60 11-12 0.009 0.006 <0.001 0.006 100 0.70 14-15 0.009 0.009 0.004 0.003 100 0.80 19-21 0.028 0.022 0.012 0.010 100 0.90 29-32 0.056 0.053 0.023 0.016 100 0.95 42-45 0.035 0.034 0.004 0.016 150 0.50 10-11 0.006 0.003 0.004 0.006 150 0.60 12-13 0.022 0.022 0.014 0.006 150 0.70 16-17 0.078 0.075 0.057 0.028 150 0.80 23 0.581 0.497 0.366 0.178 150 0.90 35-38 7.381 4.200 2.092 0.984 150 0.95 50-54 2.928 1.175 0.246 0.212 200 0.40 9 <0.001 0.006 0.005 0.003 200 0.50 11-12 0.019 0.025 0.019 0.009 200 0.60 13-14 0.094 0.094 0.078 0.047 200 0.70 17-18 0.662 0.625 0.519 0.250 200 0.80 25-26 12.600 10.994 6.679 3.594 200 0.90 40-42 561.609 302.103 168.898 56.597 200 0.95 61-64 1339.037 562.269 36.547 59.619 300 0.40 9-10 0.028 0.031 0.032 0.016 300 0.50 12 0.134 0.128 0.159 0.066 300 0.60 15-16 1.150 1.088 1.288 0.491 300 0.70 20-21 21.156 18.756 17.249 7.647 300 0.80 28-29 1020.331 821.769 870.748 254.706 500 0.30 8-10 0.047 0.050 0.066 0.031 500 0.40 10-11 0.319 0.312 0.351 0.206 500 0.50 13 3.153 3.087 3.519 1.906 500 0.60 17 51.816 50.078 55.220 27.669
1000 0.10 5-6 0.006 0.006 0.008 1000 0.20 7-8 0.106 0.103 0.233 0.091 1000 0.30 9-10 1.038 1.075 1.408 0.931 1000 0.40 12 13.484 13.656 20.386 11.325 1000 0.50 14-15 336.063 341.722 395.880 267.344 3000 0.10 6-7 0.844 0.753 0.644 3000 0.20 9 12.563 11.200 10.985 3000 0.30 11 339.356 317.375 312.744 5000 0.10 7 5.910 5.259 4.409 5000 0.20 9-10 205.175 187.419 165.091
10000 0.10 7-8 99.037 91.741 93.053 15000 0.10 8 478.528 441.159 410.697

5 Conclusions and Future Work
In this paper we describe an exact bit-parallel algorithm for the maximum-clique
problem. The algorithm employs a new implicit global degree branching rule to obtain
tighter bounds so that the search space is reduced on average w.r.t. leading reference
algorithms. An important advantage is that the new branching rule maps seamlessly to a 5
bit encoding: at every step transitions and bounds are computed efficiently through bit
masking achieving global reordering of vertices as a side effect. This makes the new
heuristic an important contribution to practical exact algorithms for maximum clique.
Effort has also been put in describing implementation details.
Future work can be divided in two areas: algorithmic and computer science. From 10
the algorithmic perspective it would be interesting to analyze the effect of the initial
sorting of vertices in overall performance, since we expect it to have more impact w.r.t.
the leading reference algorithms studied. Our second line of research is implementing a
more efficient bit-parallel software kernel so as to reduce space requirements for sparse
graphs which occur in real geometric correspondence problems. We note that BB-15
MaxClique is also a very interesting starting point to bit encode other NP-complete
problems.
Acknowledgments This work is funded by the Spanish Ministry of Science and Technology (Robonauta: 20
DPI2007-66846-C02-01) and supervised by CACSA whose kindness we gratefully
acknowledge. We also thank Dr. Stefan Nickel for his valuable suggestions.
References 25
[1] Karp R.M.; Reducibility among Combinatorial Problems. Miller, R.E., Thatcher,
J. W. (eds.), New York: Plenum, (1972) 85-103
[2] Bahadur, D.K.C., Akutsu, T., Tomita, E., Seki, T., Fujijama, A.; Point matching
under non-uniform distortions and protein side chain packing based on efficient
maximum clique algorithms. Genome Inform. 13 (2002)143-152 30
[3] Butenko, S., Wilhelm, W.E.; Clique-detection models in computational
biochemistry and genomics, European Journal of Operational Research 173
(2006) 1-17

[4] Hotta, K., Tomita, E., Takahashi, H.: A view invariant human FACE detection
method based on maximum cliques. Trans. IPSJ, 44, SIG14(TOM9) (2003) 57-
70
[5] San Segundo, P., Rodríguez-Losada, D., Matía, F., Galán, R.; Fast exact feature
based data correspondence search with an efficient bit-parallel MCP solver. 5
Applied Intelligence. (2008) (Published Online).
[6] Bomze, I.M., Budinich, M., Pardalos, P.M., Pelillo, M.; HandBook of
Combinatorial Optimization, Supplement A. Kluwer Academic Publishers,
Dordrecht (1999) 1-74.
[7] Heinz, E.A.; How Dark Thought plays chess. ICCA J. 20(3) (1997) 166-176. 10
[8] Heinz, E.A.; Scalable Search in Computer Chess. Vieweg,. (2000)
[9] Baeza-Yates, R. A, Gonnet G. H; A new approach to text searching. Commun.
ACM, 35(10) (1992) 74–82.
[10] Tomita E., Seki, T.; An efficient branch and bound algorithm for finding a
maximum clique. Proc. Discrete Mathematics and Theoretical Computer 15
Science. LNCS 2731, (2003) 278-289
[11] ÖOstergård, P.R.J.; A fast algorithm for the maximum clique problem. Discrete
Applied Mathematics, 120 (1) (2002) 97-207
[12] Wood, D.R.; An algorithm for finding a maximum clique in a graph. Operations
Research Letters 21 (1977) 211-217 20
[13] Carraghan, R, Pardalos, P.M.; An exact algorithm for the maximum clique
problem. Operations Research Letters 9 (1990) 375-382
[14] Konc, J., Janečič, D.; An improved branch and bound algorithm for the
maximum clique problem. MATCH Commun. Math. Comput. Chem. 58 (2007)
569-590. 25
[15] Johnson, D.S. Trick,M.A (eds.); Cliques, coloring and Satisfiability. DIMACS
Series in Discrete Mathematics and Theoretical Computer Science 26. American
Mathematical Society , Providence (1996)
[16] Warren H.S. Jr ; Hacker´s Delight. Addison-Welsey 2002.
[17] Leiserson, C., Prokop, H., and Randall, K.; Using de Bruijn sequences to index a 30
1 in a computer word. http://supertech.csail.mit.edu/papers/debruijn.pdf. (1998)
[18] Motzkin, T.S., Strauss, E.G. Maxima for graphs and a new proof of a theorem of
Turan, 1965.

[19] Bomze, I. M. Evolution towards the maximum clique. J. Global Optimization.,
10(2) (1997) 143-164.
[20] Fortin, D., Tseveendorj, I. Maximum clique regularizations (book chapter),
Series of Computers and Operations Research, Vol.1 Optimization and optimal
control. (ISSN: 1793-7973) World Scientific (2003). 5
[21] Gibbons, L.E., Hearn, D.W., Pardalos, P.M., Ramana, M.V. Continuous
characterizations of the maximum clique problem. Math. Oper. Res., 22(3)
(1997))754-768.
[22] Busygin, S. A new trust region technique for maximum weight clique. Discrete
Applied Mathematics 154(15). Elsevier (2006) 2080-2096. 10
[23] Bron, C., Kerbosch, J.. Finding all cliques of an undirected graph.
Communications of the ACM 16(9) , ACM (1971) 575-577.
[24] Biggs, N.; Some Heuristics for Graph Coloring, R. Nelson, R.J. Wilson, (Eds.),
Graph Colorings, Longman, New York (1990) 87-96.




















