
An Efficient LSM-tree-based SQLite-like Database Engine for ...
13
JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1 An Efficient LSM-tree-based SQLite-like Database Engine for Mobile Devices Zhaoyan Shen, Yuanjing Shi, Zili Shao,Yong Guan Abstract—SQLite has been deployed in millions of mobile devices from web to smartphone applications on various mobile operating systems. However, due to the uncoordinated IO inter- actions with the underlying file system (e.g., ext4), SQLite is not efficient with low transactions per second. In this paper, we for the first time propose a new SQLite-like database engine, called SQLiteKV, which adopts the LSM-tree-based data structure but retains the SQLite operation interfaces. With its SQLite interface, SQLiteKV can be utilized by existing applications without any modification, while providing high performance with its LSM- tree-based data structure. We separate SQLiteKV into the front-end and back-end. In the front-end, we develop a light-weight SQLite-to-KV compiler to solve the semantic mismatch, so SQL statements can be efficiently translated into KV operations. We also design a novel coordination caching mechanism with memory defragmentation so query results can be effectively cached inside SQLiteKV by alleviating the discrepancy of data management between front-end SQLite statements and back-end data organization. In the back-end, we adopt an LSM-tree-based key-value database engine, and propose a lightweight metadata management scheme to mitigate the memory requirement. We have implemented and deployed SQLiteKV on a Google Nexus 6P smartphone. Experiments results with various workloads show that SQLiteKV outperforms SQLite up to 6 times. Index Terms—Mobile device, SQLite, LSM-tree, Key-value, Database engine. I. I NTRODUCTION Smart mobile devices, e.g., smartphones, phablets, tablets, and smartTVs, are becoming prevalent. SQLite [1], which is a server-less, transactional SQL database engine, is of vital importance and has been widely deployed in these mobile devices [2–4]. Popular mobile applications such as messenger, email and social network services, rely on SQLite for data management. However, due to the inefficient date organization and the poor coordination between its database engine and the underlying storage system, SQLite suffers from poor transactional performance [5–10]. Many efforts have been done to optimize the performance of SQLite. These optimization approaches mainly fall into two categories. (1) Investigating I/O characteristics of different Zhaoyan Shen is with the School of Computer Science and Tech- nology, Shandong University, China (e-mail: [email protected] & [email protected]) Yuanjing Shi is with the Department of Computing, Hong Kong Polytechnic University, Hong Kong (e-mail: [email protected]) Zili Shao is with the Department of Computer Science and Engineering, The Chinese University of Hong Kong (e-mail: [email protected]), Yong Guan is with the Beijing Advanced Innovation Center for Imaging Technology, College of Computer and Information Management, Capital Normal University, Beijing 100000, China (e-mail: [email protected]) Manuscript received on December, 2017. workloads of SQLite and mitigating its journaling over journal problem [5–7, 10, 11]. Lee et al. [7] points out that the excessive IO activities caused by uncoordinated interactions between EXT4 journaling and SQLite journaling are one of the main sources that incur inefficiency to mobile devices. Jeong et al. [5] integrate external journaling to eliminate unnecessary file system metadata journaling in the SQLite environment. Shen et al. [6] optimize SQLite transactions by adaptively allowing database files to have their custom file system journaling mode. (2) Utilizing emerging non-volatile memory technology, such as phase change memory (PCM), to eliminate small, random updates to storage devices [12– 15]. Oh et al. [12] optimize SQLite by persisting small insertions or updates in SQLite with the non-volatile, byte- addressable PCM. Kim et al. [13] develop NVWAL (NVRAM Write-Ahead Logging) for SQLite to exploit byte addressable NVRAM to maintain the write-ahead log and to guarantee the failure atomicity and the durability of a database transaction. Though various mechanisms have been proposed, they all cul- minate with limited performance improvement. In this work, we for the first time propose to leverage the LSM-tree-based key-value data structure to improve SQLite performance. Key-value database engine, which offers higher efficiency, scalability, availability, and usually works with simple NoSQL schema, is becoming more and more popular [16–19]. Key- value databases have simple interfaces (such as Put() and Get()) and are more efficient than the traditional relational SQL databases in cloud environments [20–22]. To utilize the advantages of key-value database under SQL environments, Apache Phoenix [23] provides an SQL-like interface which translates SQL statements into a series of key-value operations in a NoSQL database HBase. Phoenix demonstrates outstand- ing performance in data cluster environment. However, the approach cannot be directly adopted by resource limited mo- bile devices as targeting at scalable and distributed computing environments with large datasets [24, 25]. There exist key-value databases on mobile device, such as SnappyDB [26], UnQlite [27], and Leveldown-Mobile [28]. However, they are not widely used in mobile devices for two major reasons. Firstly, nowadays, most mobile applications are built with SQL statements. Lacking of the SQL interface causes semantic mismatch between applications and key- value database engine. Thus, mobile applications need to be redesigned to adopt key-value databases, which incurs too much overhead. Secondly, current key-value databases require large memory footprints to maintain in-memory metadata [29– 31]. Such an in-memory metadata management approach in- troduces the overhead of notable memory occupation. In most
-
Upload
khangminh22 -
Category
Documents
-
view
8 -
download
0
Transcript of An Efficient LSM-tree-based SQLite-like Database Engine for ...

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1
An Efficient LSM-tree-based SQLite-like DatabaseEngine for Mobile Devices
Zhaoyan Shen, Yuanjing Shi, Zili Shao,Yong Guan
Abstract—SQLite has been deployed in millions of mobiledevices from web to smartphone applications on various mobileoperating systems. However, due to the uncoordinated IO inter-actions with the underlying file system (e.g., ext4), SQLite is notefficient with low transactions per second. In this paper, we forthe first time propose a new SQLite-like database engine, calledSQLiteKV, which adopts the LSM-tree-based data structure butretains the SQLite operation interfaces. With its SQLite interface,SQLiteKV can be utilized by existing applications without anymodification, while providing high performance with its LSM-tree-based data structure.
We separate SQLiteKV into the front-end and back-end. Inthe front-end, we develop a light-weight SQLite-to-KV compilerto solve the semantic mismatch, so SQL statements can beefficiently translated into KV operations. We also design a novelcoordination caching mechanism with memory defragmentationso query results can be effectively cached inside SQLiteKVby alleviating the discrepancy of data management betweenfront-end SQLite statements and back-end data organization. Inthe back-end, we adopt an LSM-tree-based key-value databaseengine, and propose a lightweight metadata management schemeto mitigate the memory requirement. We have implementedand deployed SQLiteKV on a Google Nexus 6P smartphone.Experiments results with various workloads show that SQLiteKVoutperforms SQLite up to 6 times.
Index Terms—Mobile device, SQLite, LSM-tree, Key-value,Database engine.
I. INTRODUCTION
Smart mobile devices, e.g., smartphones, phablets, tablets,and smartTVs, are becoming prevalent. SQLite [1], which isa server-less, transactional SQL database engine, is of vitalimportance and has been widely deployed in these mobiledevices [2–4]. Popular mobile applications such as messenger,email and social network services, rely on SQLite for datamanagement. However, due to the inefficient date organizationand the poor coordination between its database engine andthe underlying storage system, SQLite suffers from poortransactional performance [5–10].
Many efforts have been done to optimize the performanceof SQLite. These optimization approaches mainly fall intotwo categories. (1) Investigating I/O characteristics of different
Zhaoyan Shen is with the School of Computer Science and Tech-nology, Shandong University, China (e-mail: [email protected] &[email protected])
Yuanjing Shi is with the Department of Computing, Hong Kong PolytechnicUniversity, Hong Kong (e-mail: [email protected])
Zili Shao is with the Department of Computer Science and Engineering,The Chinese University of Hong Kong (e-mail: [email protected]),
Yong Guan is with the Beijing Advanced Innovation Center for ImagingTechnology, College of Computer and Information Management, CapitalNormal University, Beijing 100000, China (e-mail: [email protected])
Manuscript received on December, 2017.
workloads of SQLite and mitigating its journaling over journalproblem [5–7, 10, 11]. Lee et al. [7] points out that theexcessive IO activities caused by uncoordinated interactionsbetween EXT4 journaling and SQLite journaling are one ofthe main sources that incur inefficiency to mobile devices.Jeong et al. [5] integrate external journaling to eliminateunnecessary file system metadata journaling in the SQLiteenvironment. Shen et al. [6] optimize SQLite transactions byadaptively allowing database files to have their custom filesystem journaling mode. (2) Utilizing emerging non-volatilememory technology, such as phase change memory (PCM),to eliminate small, random updates to storage devices [12–15]. Oh et al. [12] optimize SQLite by persisting smallinsertions or updates in SQLite with the non-volatile, byte-addressable PCM. Kim et al. [13] develop NVWAL (NVRAMWrite-Ahead Logging) for SQLite to exploit byte addressableNVRAM to maintain the write-ahead log and to guarantee thefailure atomicity and the durability of a database transaction.Though various mechanisms have been proposed, they all cul-minate with limited performance improvement. In this work,we for the first time propose to leverage the LSM-tree-basedkey-value data structure to improve SQLite performance.
Key-value database engine, which offers higher efficiency,scalability, availability, and usually works with simple NoSQLschema, is becoming more and more popular [16–19]. Key-value databases have simple interfaces (such as Put() andGet()) and are more efficient than the traditional relationalSQL databases in cloud environments [20–22]. To utilize theadvantages of key-value database under SQL environments,Apache Phoenix [23] provides an SQL-like interface whichtranslates SQL statements into a series of key-value operationsin a NoSQL database HBase. Phoenix demonstrates outstand-ing performance in data cluster environment. However, theapproach cannot be directly adopted by resource limited mo-bile devices as targeting at scalable and distributed computingenvironments with large datasets [24, 25].
There exist key-value databases on mobile device, such asSnappyDB [26], UnQlite [27], and Leveldown-Mobile [28].However, they are not widely used in mobile devices for twomajor reasons. Firstly, nowadays, most mobile applicationsare built with SQL statements. Lacking of the SQL interfacecauses semantic mismatch between applications and key-value database engine. Thus, mobile applications need to beredesigned to adopt key-value databases, which incurs toomuch overhead. Secondly, current key-value databases requirelarge memory footprints to maintain in-memory metadata [29–31]. Such an in-memory metadata management approach in-troduces the overhead of notable memory occupation. In most

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 2
of cloud computing environments, this is not a critical issue.However, for mobile devices with constrained memory space,this is nontrivial [32].
To make mobile applications benefit from the efficient key-value database engine, in this paper, we propose a novelSQLite-like database engine, called SQLiteKV, which adoptsthe LSM-tree-based key-value data structure but retains theSQLite interfaces. SQLiteKV consists of two layers: (1) Afront-end layer that includes an SQLite-to-KV compiler and anovel coordination caching mechanism. (2) A back-end layerthat includes an LSM-tree-based key-value database enginewith an effective metadata management scheme.
In the front-end, the SQLite-to-KV compiler receives SQLstatements and translates them into the corresponding key-value operations. A read cache mechanism is designed to alle-viate the discrepancy of data organization between SQLite andthe key-value database. Considering the memory constraintsissue in mobile devices, we manage the caching with a slab-based approach to eliminate memory fragmentation. Cachespace is firstly segmented into slabs while each slab is furtherstriped into an array of slots with equal size. One query resultis buffered into the slab whose slot size is of the best fit withits own size [33–35].
For the back-end, we deploy an LSM-tree-based key-valuedatabase engine. The LSM-tree-based key-value database en-gine transforms random writes to sequential writes by ag-gregating multiple updates in memory and dumping them tostorage in a “batch” manner, which makes it I/O efficient.Besides, it stores all key-value items in a sorted order, thusimproving its query performance. To deal with the limitedmemory and energy resources for mobile devices [36], wefurther propose to store exclusively the metadata for the toplevels of the LSM tree in memory and leave others on storageto mitigate the memory requirement.
We have implemented and deployed the proposedSQLiteKV on a Google Nexus Android platform based on akey-value database-SnappyDB [26]. The experimental resultswith various workloads show that, our SQLiteKV presents upto 6 times performance improvement compared with SQLite.Our contributions are concluded as follows:
• We for the first time propose to improve the performanceof SQLite by adopting the LSM-tree-based key-valuedatabase engine while remaining the SQLite interfacesfor mobile devices.
• We design a slab-based coordination caching scheme tosolve the semantic mismatch between the SQL interfacesand the key-value database engine, which also effectivelyimproves the system performance.
• To mitigate the memory requirement for mobile devices,we have re-designed the index management policy for theLSM-tree-based key-value database engine.
• We have implemented and deployed a prototype ofSQLiteKV with a real Google Android platform, andthe evaluation results show the effective of our proposeddesign.
The rest of paper is organized as follows. Section II presentssome background information. Section III gives the motivation
Use
r
KV Store Management Module
Ke
rne
l
Block Device Driver
PCIE Device Driver
Read/Write/Erase
Storage Pool
VMM Kernel
Virtual Machine
Kernel
Environment-Adaptive
KV Stores
Storage Manager Network
NVM-Assisted KV Stores
RAM Buffer NVM Buffer
Use
r
Hybrid Memory Controller
(DRAM & NVM)
KV-density-based LSM Trees
Ke
rne
l
GC Consolidation
Software Defined Flash
NANDNANDNANDNANDNANDNANDNANDNAND
NANDNANDNANDNAND……
NANDNANDNANDDRAMNANDNANDNANDNVM
NANDNANDNANDNVM
Storage (HDDs/SSDs)
KV Caching System KV NoSQL DB in Public Cloud KV NoSQL DataBase
KV Stores Spanning Multiple
Scales
Thinking
Big
See
Small
Core
B-Tree
Pager
OS Interface
Backend
SQL Interface
SQL Command Processor
Virtual Machine
Tokenizer
Parser
CodeGenerator
SQL Compiler
Page Page
Root Page
Disk
Fig. 1: Architecture of SQLite.
for this paper. Section IV describes the design and imple-mentation. Experimental results are presented in Section V.Section VI concludes the paper.
II. BACKGROUND
This section introduces some background information aboutSQLite, the LSM-tree-based key-value database, and otherSQL-compatible key-value databases.
A. SQLite
SQLite is an in-process library, as well as an embedded SQLdatabase widely used in mobile devices [1, 37]. Figure 1 givesthe architecture of SQLite. SQLite exposes SQL interfacesto applications, and works by compiling SQL statements tobytecode, which then will be executed by a virtual machine.During the compiling of one SQL statement, the SQL com-mand processor first sends it to the tokenizer. The tokenizerbreaks the SQL statement into tokens and passes those tokensto the parser. The parser assigns meaning to each token basedon its context, and assembles the tokens into a parse tree.Thereafter, the code generator analyzes the parser tree andgenerates virtual machine code that performs the work of theSQL statement. The virtual machine will run the generatedvirtual machine code with different operations files.
The data organization of SQLite is based on B-tree. Oneseparate B-tree is used for each table in the database. The B-tree indexes data from the disk in fix-sized pages. The pagescan be either data page, index page, free page or overflowpage. All pages are of the same size and are comprisedof multi-byte fields. The pager is responsible for reading,writing, and caching these pages. SQLite communicates withthe underlying file system by system calls like open, writeand fsync. Moreover, SQLite uses a journal mechanism forcrush recovery, which makes the database file and journalfile [38, 39] synchronized frequently with the disk and leadsto a performance degradation consequently.
B. LSM-tree-based Key-Value Database
An LSM-tree-based key-value database maps a set of keysto associated values [16, 17, 40]. Applications access their

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 3
Use
r
KV Store Management Module
Ke
rne
l
Block Device Driver
PCIE Device Driver
Read/Write/Erase
Storage Pool
VMM Kernel
Virtual Machine
Kernel
Environment-Adaptive
KV Stores
Storage Manager Network
NVM-Assisted KV Stores
RAM Buffer NVM Buffer
Use
r
Hybrid Memory Controller
(DRAM & NVM)
KV-density-based LSM Trees
Ke
rne
l
GC Consolidation
Software Defined Flash
NANDNANDNANDNANDNANDNANDNANDNAND
NANDNANDNANDNAND……
NANDNANDNANDDRAMNANDNANDNANDNVM
NANDNANDNANDNVM
Storage (HDDs/SSDs)
KV Caching System KV NoSQL DB in Public Cloud KV NoSQL DataBase
KV Stores Spanning Multiple
Scales
Thinking
Big
See
Small
Core
B-Tree
Pager
OS Interface
Backend
Interface
SQL Command Processor
Virtual Machine
Tokenizer
Parser
CodeGenerator
SQL Compiler
Page Page
Root Page
Disk
L2
L1
SST SST SST SST SST SST
SST SST SST SST
L0 SSTSST
MemTableImmutableMemTable Metadata
Compaction (to L2)
put/get
DumpMemory
Disk
Fig. 2: Architecture of the LSM-tree-based database.
data through simple Put() and Get() interfaces, that arethe most generally used in NoSQL database [41–43]. Figure 2presents the architecture of an LSM-tree-based key-valuestorage engine, which consists of two MemTables in mainmemory and a set of sorted SSTables (shown as SST) in thedisk. To assist database query operations, metadata, includingindexes, bloom filters, key-value ranges and sizes of these on-disk SSTables, are maintained in memory [21, 35].
The LSM-tree-based key-value design is based on twooptimizations: (1) New data must be quickly admitted into thestore to support high-throughput writes. The database first usesan in-memory buffer, called MemTable, to receive incomingkey-value items. Once a MemTable is full, it is first transferredinto a sorted immutable MemTable, and dumped to disk as anSSTable. Key-value items in one SSTable are sorted accordingto their keys. Key ranges and a bloom filter of each SSTableare maintained as metadata cached in memory space to assistkey-value query operations. (2) Key-value items in the storeare sorted to support fast data localization. A multilevel tree-like structure is built to progressively sort key-value items inthis architecture as shown in Figure 2.
The youngest level, Level0, is generated by writing theimmutable MemTable from memory to disk. Each level hasa limitation on the maximum number of SSTables. In order tokeep the stored data in an optimized layout, a compactionprocess will be conducted to merge overlapping key-valueitems to the next level when the total size of Levell exceedsits limitation.
C. Other SQL-Compatible Key-Value Databases
Apache Phoenix [23] is an open source relational database,in which an SQL statement is compiled into a series ofkey-value operations for HBase [44], a distributed, key-valuedatabase. Phoenix provides well-defined and industry standardAPIs for OLTP and operational analytics for Hadoop [45, 46].Nevertheless, without a deep integration with the Hadoopframework, it is difficult for mobile devices to adopt eitherHBase as its storage engine or Phoenix for SQL-to-KVtransitions. Besides, Phoenix, along with other Hadoop relatedmodules, is designed for scalable and distributed computingenvironments with large datasets [47], which means they canhardly fit in mobile environments with limited resources [48].
In this paper, we propose an efficient LSM-tree-basedlightweight database engine, SQLiteKV, which retains theSQLite interface for mobile devices, provides better perfor-
mance compared with SQLite and adopts an efficient LSM-tree structure on its storage engine.
III. MOTIVATION
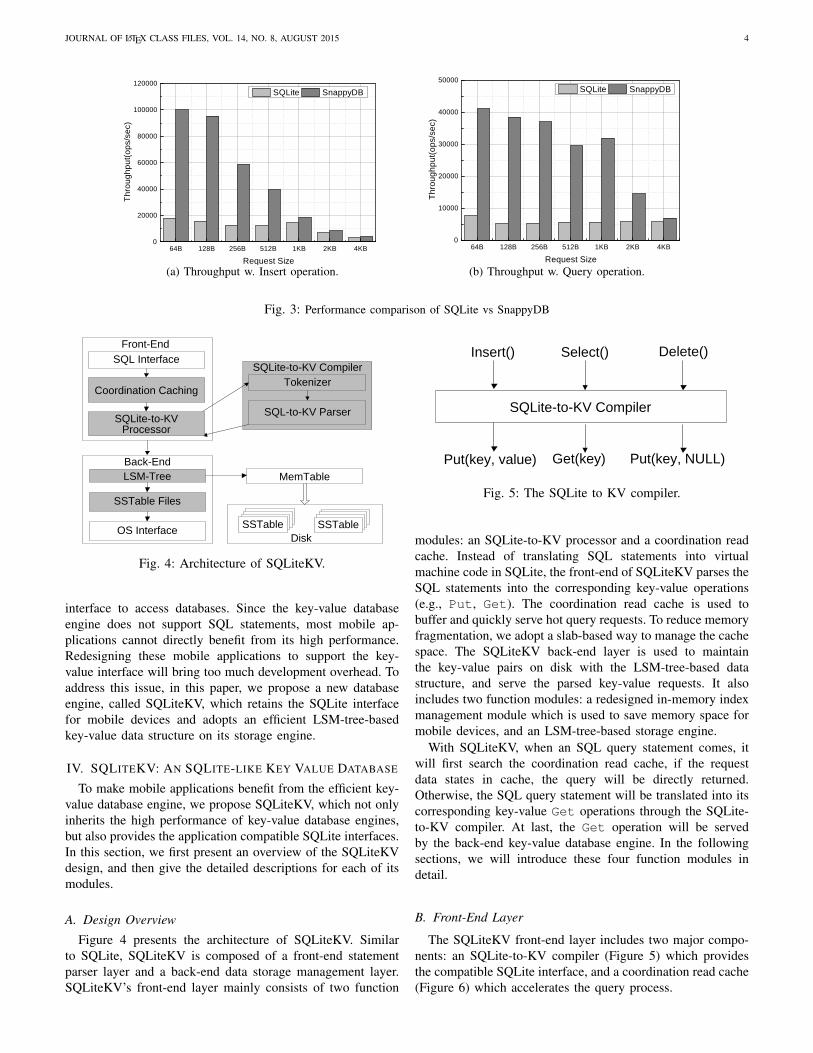
To compare the performance of SQLite and the key-valuebased database engine, we choose one lightweight LSM-tree-based key-value database, called SnappyDB [26], and measurethe throughput (operation per second, ops/sec) by runningthem with a Google Nexus smartphone. We use the Zipfiandistribution [49] to generate the request popularity and requestsizes are varied from 64 bytes to 4096 bytes. Figure 3 presentsthe throughput for both insert and query operations of thesetwo databases, respectively.
Figure 3(a) shows the throughput for insert operations withSQLite and SnappyDB over vary-sized requests. It is obviousthat SnappyDB outperforms SQLite significantly across theboard. For instance, with the request size of 64 bytes, Snap-pyDB outperforms SQLite 7.3 times. The reason is mainly twofolds. First, SQLite is a relational database which has strictdata organization schema. All insert requests have to strictlyfollow the data organization schema and the slow transactionprocess of SQLite. The second reason is the journaling ofjournal problem. In SQLite, an insert transaction firstly logsthe insertion at an individual SQLite journal, and then insertsthe record to the actual database table. At the end of eachphase, SQLite calls fsync() to persist the results. Each fsync()call makes the underlying file system (e.g., ext4) update thedatabase file and write the new metadata to the file systemjournal. Hence, a single insert operation may result in upto 9 I/Os to the storage device, and each I/O is done withthe 4KB unit. This uncoordinated IO interaction brings muchwrite amplification and sacrifices the performance of SQLitea lot. On the other hand, SnappyDB maintains a shared log,and an insert operation is firstly logged in the log file, andthen served by its memory table as shown in Figure 2. Thisprocess is much simple and incurs less IOs to the storagedevice compared with SQLite.
It can also be observed from Figure 3(a) that with therequest size increasing, the performance improvement ofSnappyDB over SQLite decreases. This is because when thefunction fsync() is called, the underlying file system will dowrite operation with the 4KB unit. With the request sizeincreasing close to 4KB, the write amplification overheaddecreases. When the request size is of 4KB, the throughputof SQLite and SnappyDB are almost the same. When therecord size is larger than 4KB, the performances of SQLite andSnappyDB show the same trend and are basically the same.So, we omit the results for records with the sizes larger than4KB in Figure 3. Figure 3(b) gives the throughput for queryoperations of SQLite and SnappyDB, and it shows the sametrend with insert operations.
We can conclude that the efficient LSM-tree-based key-value database engine outperforms the traditional relationaldatabase SQLite significantly, and directly deploying applica-tions based on the LSM-tree-based key-value database def-initely improves applications’ performance. However, mostapplications running on mobile devices depend on the SQL
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 4
6 4 B 1 2 8 B 2 5 6 B 5 1 2 B 1 K B 2 K B 4 K B0
2 0 0 0 0
4 0 0 0 0
6 0 0 0 0
8 0 0 0 0
1 0 0 0 0 0
1 2 0 0 0 0
Throu
ghpu
t(ops
/sec)
R e q u e s t S i z e
S Q L i t e S n a p p y D B
(a) Throughput w. Insert operation.
6 4 B 1 2 8 B 2 5 6 B 5 1 2 B 1 K B 2 K B 4 K B0
1 0 0 0 0
2 0 0 0 0
3 0 0 0 0
4 0 0 0 0
5 0 0 0 0
Throu
ghpu
t(ops
/sec)
R e q u e s t S i z e
S Q L i t e S n a p p y D B
(b) Throughput w. Query operation.
Fig. 3: Performance comparison of SQLite vs SnappyDB
Front-End
LSM-Tree
SSTable Files
OS Interface
Back-End
SQL Interface
Coordination CachingTokenizer
SQL-to-KV Parser
SQLite-to-KV Compiler
SSTable SSTable
MemTable
Disk
SQLite-to-KV Processor
Fig. 4: Architecture of SQLiteKV.
interface to access databases. Since the key-value databaseengine does not support SQL statements, most mobile ap-plications cannot directly benefit from its high performance.Redesigning these mobile applications to support the key-value interface will bring too much development overhead. Toaddress this issue, in this paper, we propose a new databaseengine, called SQLiteKV, which retains the SQLite interfacefor mobile devices and adopts an efficient LSM-tree-basedkey-value data structure on its storage engine.
IV. SQLITEKV: AN SQLITE-LIKE KEY VALUE DATABASE
To make mobile applications benefit from the efficient key-value database engine, we propose SQLiteKV, which not onlyinherits the high performance of key-value database engines,but also provides the application compatible SQLite interfaces.In this section, we first present an overview of the SQLiteKVdesign, and then give the detailed descriptions for each of itsmodules.
A. Design Overview
Figure 4 presents the architecture of SQLiteKV. Similarto SQLite, SQLiteKV is composed of a front-end statementparser layer and a back-end data storage management layer.SQLiteKV’s front-end layer mainly consists of two function
SQLite-to-KV Compiler
Insert() Select()
Put(key, value) Get(key)
Delete()
Put(key, NULL)
Fig. 5: The SQLite to KV compiler.
modules: an SQLite-to-KV processor and a coordination readcache. Instead of translating SQL statements into virtualmachine code in SQLite, the front-end of SQLiteKV parses theSQL statements into the corresponding key-value operations(e.g., Put, Get). The coordination read cache is used tobuffer and quickly serve hot query requests. To reduce memoryfragmentation, we adopt a slab-based way to manage the cachespace. The SQLiteKV back-end layer is used to maintainthe key-value pairs on disk with the LSM-tree-based datastructure, and serve the parsed key-value requests. It alsoincludes two function modules: a redesigned in-memory indexmanagement module which is used to save memory space formobile devices, and an LSM-tree-based storage engine.
With SQLiteKV, when an SQL query statement comes, itwill first search the coordination read cache, if the requestdata states in cache, the query will be directly returned.Otherwise, the SQL query statement will be translated into itscorresponding key-value Get operations through the SQLite-to-KV compiler. At last, the Get operation will be servedby the back-end key-value database engine. In the followingsections, we will introduce these four function modules indetail.
B. Front-End Layer
The SQLiteKV front-end layer includes two major compo-nents: an SQLite-to-KV compiler (Figure 5) which providesthe compatible SQLite interface, and a coordination read cache(Figure 6) which accelerates the query process.

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 5
1) SQLite-to-KV Compiler: As shown in Figure 5, thefunction of the SQLite-to-KV compiler is to translate anSQL statement to the corresponding key-value operations.It provides users SQLite-compatible interface while stor-ing/retrieving key-value pairs with Put and Set operationsin the back-end database. When an SQL statement comes,the SQLite-to-KV compiler firstly breaks down the statementinto several tokens. Then it will assign each token a meaningbased on the context and assemble it into a parser tree.The parsing process of the compiler is similar to SQLite.The noteworthy difference is that the SQLite-to-KV compilergenerates key-value operations based on the result of the parsetree instead of SQL bytecode that must be run with a virtualmachine. The reason why SQLite is utilizing such a virtual-machine layer between SQL statements and execution is that,query processing is becoming increasingly CPU-bound. Witha virtual-machine layer, SQLite can provide portability with arelatively reasonable performance. However, the circumstanceshave changed on mobile devices, since it is obvious that atypical mobile platform, like Android, is still resource-limitedand the utilization of such a VM layer does not prove to be asefficient as it is on mainstream big-data platforms [50]. In ourSQLiteKV, we use the SQLite-to-KV compiler to transformSQL operations to key-value operations, and the back-endLSM-tree-based key-value database provides direct executionof key-value operations, which make it more efficient.
Basically, the SQLite-to-KV compiler translates themost commonly used SQLite interfaces Insert() andSelect() to the corresponding key-value Put() andSet() operations. Since we adopt an LSM-tree-based key-value database engine that does not support in-place updates,the SQLite interface delete() is transferred into one key-value Put() operations with an invalid value (e.g., “NULL”in Figure 5). To perform these interface translation, we builda mapping between records in the relational database and key-value items in the key-value database. In our experiments, wefound that for mobile applications, the data schema of SQLitedatabase is very simple. Many database tables only includetwo columns. Thus, when transforming a relational record toone key-value item, we make the primary key of this record asthe key for the key-value item and make the other columns asthe value of this item. This mapping is done by the SQLite-to-KV compiler, and there is no need for any additional mappingdata structure.
Algorithm IV.1 presents the working process for one insertoperation in SQLiteKV. When SQLiteKV receives one insertSQL statement, it firstly begins a new transaction for thisoperation. Then SQLiteKV analyzes the tokens (Primary key,column1, and column2) contained in this SQL statement andput them into the parse tree (container). SQLiteKV organizesthe key and value pair for this SQL request based on thisparse tree. In this example, SQLiteKV directly makes theprimary key as the key, and the column1 as the value. At last,the corresponding Put() operation with the newly identifiedkey-value pair is issued to the back-end key-value databaseengine. As described above, the LSM-tree-based key-valueengine does not support in-place updates, so the delete()statement is performed by the put() operation with an invalid
Algorithm IV.1 Insert operation in SQLiteKV.
Input:1: insert values(Primary key, column1)
Output: Perform key-value put operation2: SQLiteKV.getWriteableDatabase();3: //open the database for write4: SQLiteKV.beginTransaction();5: Container.put(Primary key);6: //construct the key for KV pair7: container.put(column1);8: //construct the value for KV pair9: SQLiteKV.put(container.key, container.value);
10: //put the KV item in the container to the KV database11: SQLiteKV.endTransaction();12: return;
Algorithm IV.2 Query operation in SQLiteKV.
Input:1: select from testwhere column = values
Output: Perform key-value get operation2: SQLiteKV.getRriteableDatabase();3: select token = column+”=?”;4: arg token = values;5: hash sql = hash(select token, arg token);6: result = SQLiteKV.Cache.get(hash sql)7: // first access cache8: if result == NULL then // not in cache9: result = SQLiteKV.get(arg token);
10: //get KV pairs from KV database11: SQLiteKV.Cache.put(hash sql, result);12: //buffer the result in cache13: end if14: return result;
value part (NULL) in SQLiteKV as shown in Algorithm IV.3.Algorithm IV.2 describes the working process for a query
operation in SQLiteKV. Similar to insert operation, SQLiteKVfirstly parse the SQL statement into tokens (lines 3-4). Thenit calculates a hash value based on these tokens, and searchthe cache with the hashed value. With cache hits, the data isdirectly returned from the cache. Otherwise, a correspondingkey-value Get() operation is issued to the key-value databaseengine to retrieve the value to users and store it in the cache.
The SQLite-to-KV compiler makes it possible that existingapplications run smoothly with original SQL statements andleverage the potentials of key value storage.
2) Coordination Caching: Caching mechanism is of vitalimportance for improving the query efficiency of databases.Through buffering part of hot data in memory, query opera-tions can be served fast without accessing the low-latency disk.In SQLiteKV, there are two cache configuration choices. Asshown in Figure 6, the first choice is to maintain the cache inthe back-end key-value database engine, and the second one isto put the cache in the front-end and before the SQLite-to-KVcompiler module.
In SQLiteKV, we propose to adopt the second configuration

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 6
Algorithm IV.3 Delete operation in SQLiteKV.
Input:1: delete from testwhere column = values
Output: Perform key-value delete operation2: SQLiteKV.getWriteableDatabase();3: delete token = column+”=?”;4: arg token = values;5: hash sql = hash(delete token, arg token);6: result = SQLiteKV.Cache.get(hash sql)7: // first access cache8: if result != NULL then // clean cache9: SQLiteKV.Cache.delete(hash sql);
10: end if11: SQLiteKV.put(arg token, NULL);12: return;
SQLite-to-KV Compiler
An SQL statement
KV operationsBack-End
KV StoreKV Cache
An SQL statement
Back-End KV Store
Front-End
SQLite-to-KV Compiler
Front-EndSQL Cache
Allen, 5Aye, 16Ben, 3
Dan, 20
Data Block 0 Data Block 1
…
Data Block n Index Block
Sorted
Data Block 2
Ray, 8Sonny, 1
(a) SQLiteKV without Cache (b) SQLiteKV with Cache
KV operations
Fig. 6: SQLiteKV Coordination Caching Mechanism.
as shown in Figure 6(b). The reason is that in Figure 6(a), theKV cache module stays in the back-end key-value databaseengine. Hot data buffered by this cache are maintained in theformat of key-value pairs. When an SQL statement comes,if the data hit in cache, this configuration firstly needs to re-organize the data in key-value pairs to the SQL column formatand then return to the users. Besides, in this configuration,whether cache hits or not, an incoming SQL statement alwaysneeds to go through the SQLite-to-KV compiler, which incursreasonable overhead. In the second configuration, the cachestays in the front-end layer, and the hot data are maintained inan SQL statement-oriented approach. When an SQL statementcomes, if cache hits, the results can be directly returnedwithout performing the SQLite-to-KV translation.
To further utilize the memory space efficiently, we adopt aslab-based memory allocation scheme as shown in Figure 7.We first segment the cache memory space into slabs with afixed size (e.g., 1MB). Each slab is further divided into an
…
hash(SQL)Bucket
Index
md(key)
Memory slabs
sid offset
Index
mdSlab Slot
32B 64B 128B
Fig. 7: Slab-based cache management.
DRAMDisk
……
Level 0
Level 110 MB
Level 2100 MB
SSTables
Log
Manifest
Current
Put() Get()
❶
❷
………
Minor Compaction
Major Compaction
KV data
Index
SST11
KV data
Index
SST12
KV data
Index
SST13
KV data
Index
SST01
KV data
Index
SST02
KV data
Index
SST21
KV data
Index
SST22
KV data
Index
SST23
KV data
Index
SST24
MemTableKV ItemKV ItemKV Item
ImmuteTableKV ItemKV ItemKV Item
MetaDataBloom FiltersBloom Filters
Indexes
sort
Fig. 8: Back-End in-memory index management.
array of equal-sized slots. Each slot stores one request data.Slabs are logically organized into different slab classes basedon the slot sizes (e.g., 32B, 64B, 128B, ..., 4KB, ...). The datafor one SQL query is stored into a class whose slot size isthe best fit for its size. For example, if a key-value pair withsize 6KB needs to be buffered in the cache, one slab will beallocated to the class with the slot size that is equal to 8KB(the best fit for the 6KB key-value item), and a slot will beused to buffer this key-value pair. A hash mapping table isused to record the position of each SQL statement. The keyfor the hash table is calculated by hashing tokens of each SQLquery request as shown in Algorithm IV.2. When one querycomes, SQLiteKV firstly analyzes its tokens, gets the hashvalue, and then read the data by combining the slab “sid” withoffset “offset”. Such a design can effectively address the issueof memory fragmentation, and utilizes the limited embeddedmemory resource more properly.
C. Back-End Layer
In SQLiteKV, we adopt an LSM-tree-based key-valuedatabase engine, like Google’s LevelDB [16], and Facebook’sCassandra [17]. In this section, we will introduce our proposednew metadata management scheme, and the data storage in thisdatabase engine.
1) Data Storage Management: Figure 8 shows the datastorage engine for the back-end LSM-tree-based key-valuestore. As described in Section II, LSM-tree-based data storeaggregates key-value items into equal-sized tables. There arethree kinds of tables in the key-value database engine: mem-ory table (MemTable), immutable table (ImmuteTable),and on-disk SSTable (SST). Memtable and ImmuteTableare maintained in memory, and SSTables are stored ondisk. The SSTables are maintained in several levels (e.g.,Level0, Level1, Level2). Each level contains different num-bers of SSTables, and its capacity grows exponentially. Log,Manifest, and Current, are three configuration files usedto assist the working process of the database engine.

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 7
SQLite-to-KV Compiler
A SQL statement
Multi KV operations
Back-End
KV Store
KV Cache
A SQL statement
Multi KV operations
Back-End
KV Store
Front-End
SQLite-to-KV Compiler
Front-EndKV Cache
Allen, 5
Aye, 16
Ben, 3
Dan, 20
Data Block 0 Data Block 1
…
Data Block n Index Block
Sorted
Data Block 2
Ray, 8
Sonny, 1
Fig. 9: Data management in SSTable.
When a key-value write request comes, it will first bewritten to the disk Log file in order to guarantee the overallconsistency, and then buffered into the MemTable in memory.So, all the key-value items stored in MemTable also have apersistent copy in the Log file, and the data durability canbe promised. In this work, we do not optimize the Log filedesign, which can be a good research direction for future work.Once the MemTable becomes full, the key-value items inthis table will be sorted and stored in the ImmuteTable.A minor compaction process will flush the key-value itemsin ImmutaTable to one disk SSTable in Level0. Key-valuepairs stored in SSTables are sorted with their keys as shownin Figure 9. Each SSTable consists of several data blocks andindex blocks. The index blocks maintain the mapping of thekey range to the data blocks. With more SSTables flushed, ifone level runs out of its space, a major compaction will betriggered to select one of its SSTable and do the merge sortoperation with several SSTables in the next level (As shown inFigure 8, one SSTable in Level1 is compacted with 4 SSTablesin Level2).
2) Index Management: As described, each SSTable main-tains some indexes to assist the quick search of key-valueitems. Usually, the indexes are stored at the end of eachSSTable. To accelerate the query process, LSM-tree-basedstorage engines commonly scan over the entire disk andmaintain a copy of all indexes in memory [51]. Hence when aquery operation is to be executed, the in-memory meta data isaccessed quickly with the target key to locate the data blockon disk. Thus, the data block is visited to get the key-valueitem. Generally, one disk seek is required for a single queryon LSM-tree-based key-value database engines.
However, this approach is not practical nor efficient for mo-bile devices. Since most mobile devices are memory constraintand cannot accommodate all the indexes in memory. Consid-ering this limitation, we redesign the indexing managementapproach, which exclusively stores indexes of data blocks fromhigher levels, like Level0 and Level1, of the entire LSM tree.The reason is that as the level goes further down, data at lowerlevels are less likely to be visited. In other words, the data ontop levels are fresher and more likely to be visited, since nearly90 percent request are served by Level0 and Level1 [20].This approach helps reduce the memory requirement in ourkey-value database with minimum overhead.
V. EVALUATION
We have prototyped the proposed efficient LSM-tree-basedSQLite-like database engine - SQLiteKV, on a Google mo-bile platform. Our implementation of the database engineis based on SnappyDB [26], which is a representative key-value database for mobile devices. Our SQLiteKV totally
includes 2,506 lines in Java. In this section, we will firstintroduce the basic experimental setup, and then provide theexperimental results with real-world benchmarks [49] andsynthetic workloads.
A. Experiment Setup
The prototype of our proposed SQLiteKV is implementedon a Google mobile platform - Google Nexus 6p, which isequipped with a 2.0GHz oct-core 64 bit Qualcomm Snap-dragon 810 processor, 3GB LPDDR4 RAM, and 32GB Sam-sung eMMC NAND Flash device. We use the Android 8.0operating system with Linux Kernel 3.10. In the evaluation,SQLite 3.18 is utilized in the experiments as it is the currentversion in Android 8.0 Oreo. The page size of SQLite is set as1024 bytes, which is the default value. SnappyDB 0.5.2, whichis the latest version of a Java implementation of Google’sLevelDB, is adopted. The performance of the LSM-tree-baseddatabase engine is evaluated with the indexes of all the levelsof the entire LSM tree buffered in memory.
Since in most real-world SQLite workloads, one SQLitequery always carry more than one records. So, in our experi-ments, we make each SQL statement in SQLite contains up to999 records, which is the maximum value allowed. With thisperformance tuning method, we can make a fair comparisonbetween SQLiteKV and SQLite. Moreover, trivial calls, likemoving cursors after queries in SQLite, are omitted for thesake of efficiency.
B. Basic Performance
We first evaluate the basic performance of SQLiteKV andSQLite, mainly in terms of throughput (operations per second,ops/sec). In this experiment, we set the data size vary from64 bytes to 4096 bytes, and investigate the throughputs ofboth random and sequential accesses. We test and comparethe throughput of SQLiteKV and SQLite with the commonlyused insert, query, and delete operations.
1) Insertion Performance: Figure 10a and Figure 10b showthe performances of SQLiteKV and SQLite with randomand sequential insertion operations, respectively. The requestsizes vary from 64 bytes to 4096 bytes. For the sequentialaccess workload, the requests are in ascending order, whilethe requests are randomly traversed for the random case.
It can be observed that the performances of SQLiteKVoutperform SQLite significantly for request of all sizes. Forsequential operations, with the request size of 64 bytes,the throughput of SQLiteKV is 1.41 × 105, which is 6.1times higher than that of SQLite. For random operations,the SQLiteKV outperforms SQLite 3.8 times in maximumwith request size of 64 bytes. As the request size increases,the throughputs decrease across the board for both SQLiteand SQLiteKV. The performance improvement of SQLiteKVover SQLite also decreases with the request size increasing.This is because the write amplification effect caused bySQLite’s journal of journal problem declines as the requestsize increases. Besides, it can be observed that for SQLitKV,the insertion performance with sequential access workloadsare better than that with random access ones (the average

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 8
6 4 B 1 2 8 B 2 5 6 B 5 1 2 B 1 K B 2 K B 4 K B0
2 0 0 0 0
4 0 0 0 0
6 0 0 0 0
8 0 0 0 0
Throu
ghpu
t(ops
/sec)
R e q u e s t S i z e
S Q L i t e S Q L i t e K V
(a) Random insertions.
6 4 B 1 2 8 B 2 5 6 B 5 1 2 B 1 K B 2 K B 4 K B0
2 0 0 0 0
4 0 0 0 0
6 0 0 0 0
8 0 0 0 0
1 0 0 0 0 0
1 2 0 0 0 0
1 4 0 0 0 0
1 6 0 0 0 0
Throu
ghpu
t(ops
/sec)
R e q u e s t S i z e
S Q L i t e S Q L i t e K V
(b) Sequential insertions.
Fig. 10: Insertion throughput vs. Request size
6 4 B 1 2 8 B 2 5 6 B 5 1 2 B 1 K B 2 K B 4 K B0
1 0 0 0 0
2 0 0 0 0
3 0 0 0 0
4 0 0 0 0
Throu
ghpu
t(ops
/sec)
R e q u e s t S i z e
S Q L i t e S Q L i t e K V
(a) Random queries.
6 4 B 1 2 8 B 2 5 6 B 5 1 2 B 1 K B 2 K B 4 K B0
2 0 0 0 0
4 0 0 0 0
6 0 0 0 0
8 0 0 0 0
1 0 0 0 0 0
1 2 0 0 0 0
Throu
ghpu
t(ops
/sec)
R e q u e s t S i z e
S Q L i t e S Q L i t e K V
(b) Sequential queries.
Fig. 11: Basic performance of SQLiteKV and SQLite.
6 4 B 1 2 8 B 2 5 6 B 5 1 2 B 1 K B 2 K B 4 K B1
1 0
1 0 0
1 0 0 0
1 0 0 0 0
1 0 0 0 0 0
1 0 0 0 0 0 0
Throu
ghpu
t(ops
/sec)
R e q u e s t S i z e
S Q L i t e S Q L i t e K V
Fig. 12: Delete throughput vs. Delete operations.
W r i t e _ R a n R e a d _ R a n W r i t e _ S e q R e a d _ S e q D e l e t e0
2 0 0 0 0
4 0 0 0 0
6 0 0 0 0
8 0 0 0 0
1 0 0 0 0 0
1 2 0 0 0 0
1 4 0 0 0 0
Throu
ghpu
t(ops
/sec)
D i s t r i b u t i o n
S Q L i t e S Q L i t e K V
Fig. 13: Throughput vs. Request size with Zipfan model.
improvement is 40%). On the contrary, for SQLite, there arebasically no differences between the random and sequentialcases.
2) Query Performance: Figure 11b shows the performanceof SQLiteKV and SQLite with random and sequential queryoperations, respectively. Basically, query operations show thesame trend with insert operations. For sequential queries, withthe request size of 64 bytes, the throughput of SQLiteKV is1.01×105, which is 4.91 times higher than that of SQLite. Forrandom queries, the performance improvement of SQLiteKVover SQLite is up to 5.4 times with the request size of
128 bytes. Furthermore, the sequential query throughput ofSQLiteKV is much higher than the random query one, whichis about 1.3 times.
3) Delete Performance: Figure 12 presents the throughputof delete operations for SQLiteKV and SQLite, respectively.It is obvious that the throughput for delete operations ofSQLiteKV is much higher than that of SQLite. For instance,with the request size of 4KB, it even takes more than severalminutes to delete a record for SQLite. However, in SQLiteKV,the delete operation is implemented by the key-value Putoperation with invalid data area. Thus, the delete operations

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 9
of SQLiteKV perform the same as insert operations.We further test the random insert, random query, sequential
insert, and sequential query performance of SQLiteKV andSQLite with request sizes that follow the Zipfian [33, 49, 52]distribution. The results are given in Figure 13. We canconclude that SQLiteKV outperforms SQLite for all cases.Especially, for sequential write operations, the improvementis up to 5.3 times.
C. Overall Performance
TABLE I: Workload characteristics.
Workload(s) Query InsertUpdate Heavy 0.5 0.5Read Most 0.95 0.05Read Heavy 1 0Read Latest 0.95 0.05
To evaluate the overall performance, we further test the pro-posed SQLiteKV with a set of YCSB [49, 50] core workloadsthat define a basic benchmark as shown in Table I. Here,the update heavy workload has a mix of 50/50 reads andwrites, the read most workload has a 95/5 reads/write mix,the read heavy workload is 100% read, and in the read latestworkload, new records are inserted, and the most recentlyinserted records are the most popular.
To conduct the experiments, we first generate 100 thousandkey value pairs to populate SQLiteKV and SQLite, and thenuse the object popularity model to generate 100 thousandrequests sequence. The object popularity, which determines therequests sequence, follows the Zipfian distribution [33, 49, 52],by which records in the head will be extremely popular whilethose in the tail are not. For the read latest workload, we makemost recently inserted records in the head that will be accessedmore frequently. For the request size, similarly, we use boththe fixed request sizes from 64 bytes to 4KB and the requestsizes which follows the Zipfian distribution.
Figure 14 shows the experimental results by runningSQLiteKV and SQLite with the four workloads in Table I.For each workload, the request sizes vary from 64 bytes to4096 bytes. It can be observed that, compared with SQLite,SQLiteKV significantly increases the throughput across theboard with varied request sizes. For the update heavy work-load, the throughput of SQLiteKV is 3.9 times higher than thatof SQLite on average. With the request size of 256 bytes, theperformance improvement achieves the highest point, whichis about 5.9 times. On average, the performance improvementof SQLiteKV over SQLite for the other three workloads: readmost, read heavy and read latest, are 2 times, 2.4 times and1.9 times, respectively.
We also notice that when the key-value sizes are over 2048bytes, SQLiteKV only outperform SQLite slightly. The reasonis that bigger request size can reduce the write amplificationeffect in SQLite. Besides, for LSM-tree-based databases, keysand values are written at least twice: the first time forthe transactional log and the second time for storing data
to storage devices. Thus, the per-operation performance ofSQLiteKV is degraded by extra write operations. Regardlessof this degradation, as most data sets in mobile applicationsonly contain very few large requests, SQLiteKV can stillsignificantly outperform SQLite in practice.
We also test the database performance with request sizesfollowing the Zipfian distribution [33, 49, 52]. Figure 15presents the results with the four workloads. It can be observedthat with the update heavy workload, SQLiteKV achieves thehighest performance improvement over SQLite, which is 2.7times. On average, the SQLiteKV outperforms SQLite 1.7times for all these four workloads.
We further evaluate the efficiency of our proposed coordina-tion read cache with different workloads . Figure 16 presentsthe performance comparisons of SQLiteKV with and withoutcache. Similarly, the request sizes vary from 64 bytes to4KB, and for all these experiments, we configured the cachesize fixed with 1MB. Through the figures, we can clearlysee that the coordination cache can effectively improve thedatabase performance. The average performance improvementare 12.7% for the update heavy workload, 28.9% for theread most workload, 14.7% for the read heavy workload, and43% for the read latest workload. The highest performanceimprovement with the coordination cache achieves 57.9% forthe read latest workload with the request size of 256 bytes.We also test the cache effect with the request sizes that followthe Zipfian distribution. As shown in Figure 17 , similarly thecoordination cache effectively improves the throughput acrossall the workloads.
D. CPU and Memory Consumption
In this section, we will investigate the efficiency of ourre-designed index management policy, and then compare thememory and CPU consumption of SQLite, SnappyDB, andSQLiteKV. For SQLiteKV, we have enabled the coordinationcache. In this experiment, we also generated 100 thousandrequest data to pollute the database, and then issue insert andquery requests to investigate their effects on the CPU andmemory.
TABLE II: CPU and memory consumption.
Databases CPU/(%) Memory/(MB)Insert Query Insert Query
SQLite 41 38 165.06 148.89SnappyDB 26 50 188.28 192.29SQLiteKV 32 61 82.47 81.9
Memory Footprint. Table II presents the memory utiliza-tion status for SQLite, SnappyDB, and SQLiteKV. SnappyDBconsumes the most memory space for both insert and queryoperations. The reason is that in SnappyDB, the LSM-tree-based data structure needs to maintain the indexes of all theSSTables from all the levels in memory, which is non-trivial.As we have described in Section IV-C, nearly 90 percent queryrequests goes to Level0 and Level1 in real key-value storeapplications [20]. Thus, in SQLiteKV, we only maintain theindexes of Level0 and Level1 in memory, and leaves the

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 10
6 4 B 1 2 8 B 2 5 6 B 5 1 2 B 1 K B 2 K B 4 K B01 0 0 0 02 0 0 0 03 0 0 0 04 0 0 0 05 0 0 0 06 0 0 0 07 0 0 0 08 0 0 0 09 0 0 0 0
1 0 0 0 0 0
Throu
ghpu
t(ops
/sec)
R e q u e s t S i z e
S Q L i t e S Q L i t e K V
(a) Throughput w. Update heavy workload.
6 4 B 1 2 8 B 2 5 6 B 5 1 2 B 1 K B 2 K B 4 K B0
1 0 0 0 0
2 0 0 0 0
3 0 0 0 0
4 0 0 0 0
5 0 0 0 0
6 0 0 0 0
7 0 0 0 0
8 0 0 0 0
Throu
ghpu
t(ops
/sec)
R e q u e s t S i z e
S Q L i t e S Q L i t e K V
(b) Throughput w. Read most workload.
6 4 B 1 2 8 B 2 5 6 B 5 1 2 B 1 K B 2 K B 4 K B01 0 0 0 02 0 0 0 03 0 0 0 04 0 0 0 05 0 0 0 06 0 0 0 07 0 0 0 08 0 0 0 09 0 0 0 0
1 0 0 0 0 0
Throu
ghpu
t(ops
/sec)
R e q u e s t S i z e
S Q L i t e S Q L i t e K V
(c) Throughput w. Read heavy workload.
6 4 B 1 2 8 B 2 5 6 B 5 1 2 B 1 K B 2 K B 4 K B0
1 0 0 0 0
2 0 0 0 0
3 0 0 0 0
4 0 0 0 0
5 0 0 0 0
6 0 0 0 0
7 0 0 0 0
8 0 0 0 0
Throu
ghpu
t(ops
/sec)
R e q u e s t S i z e
S Q L i t e S Q L i t e K V
(d) Throughput w. Read latest workload.
Fig. 14: Overall Performance
U p d a t e _ h e a v y R e a d _ m o s t R e a d _ h e a v y R e a d _ l a t e s t0
1 0 0 0 0
2 0 0 0 0
3 0 0 0 0
4 0 0 0 0
5 0 0 0 0
6 0 0 0 0
Throu
ghpu
t(ops
/sec)
W o r k l o a d
S Q L i t e S Q L i t e K V
Fig. 15: Performance evaluation.
others on disk. The experimental results in Table II showthat our index management policy significantly reduces thememory requirement. Comparing with SnappyDB, SQLiteKVsaves 56.2% and 57.4% memory space for insert and queryoperations, respectively.
We have conducted experiments to compare the perfor-mances of SQLiteKV with the index of all levels (SQLiteKVin Figure 18) are cached and with the index of Level 0 andLevel 1 are cached (SQLiteKV L01 in Figure 18). Figure 18shows the result. We can conclude that our re-designed indexmanagement policy does bring some overhead to SQLiteKV,
but the overhead is acceptable. With workload composed of allread requests (Read heavy), the performance overhead is thehighest, which is 10.8%. On average, our re-designed indexmanagement policy decreased the SQLiteKV throughput by6.5%.
CPU Utilization. We can observe that for insert operations,SQLite requires the most CPU resource. This is becauseSQLite needs to maintain its in-memory B-tree index structure,which may include many split and compaction processes.On the contrary, the indexes management for SnappyDBand SQLiteKV maintain the bloom filters and key rangesinformation, whose operation are relatively simple. However,we also notice that our SQLiteKV consumes nearly 20%more CPU resource compared with SnappyDB. The reasonis that in SQLiteKV, the SQLite-to-KV compiler requires theparticipation of CPU to keep translating the incoming SQLstatements into the corresponding key-value operations. Forquery operations, SnappyDB and SQLiteKV require moreCPU resources compared with SQLite, and SQLiteKV con-sumes the most. Since in SnappyDB and SQLiteKV, to locatea request, they may need to check several bloom filters and theindexes of SSTables in more than one levels, which requiresextra CPU resource. For SQLiteKV, except the SQLite-to-KV compiler consumption, it may need to do more search tolocated one key-value item compared with SnappyDB, sinceit only stores the metadata of Level0 and Level1 in memory.Thus, SQLiteKV requires the most CPU resource.

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 11
6 4 B 1 2 8 B 2 5 6 B 5 1 2 B 1 K B 2 K B 4 K B0
2 0 0 0 0
4 0 0 0 0
6 0 0 0 0
8 0 0 0 0
1 0 0 0 0 0
1 2 0 0 0 0
Throu
ghpu
t(ops
/sec)
R e q u e s t S i z e
S Q L i t e K V S Q L i t e K V - C a c h e
(a) Throughput w. Update heavy workload.
6 4 B 1 2 8 B 2 5 6 B 5 1 2 B 1 K B 2 K B 4 K B0
2 0 0 0 0
4 0 0 0 0
6 0 0 0 0
8 0 0 0 0
1 0 0 0 0 0
1 2 0 0 0 0
Throu
ghpu
t(ops
/sec)
R e q u e s t S i z e
S Q L i t e K V S Q L i t e K V - C a c h e
(b) Throughput w. read most workload.
6 4 B 1 2 8 B 2 5 6 B 5 1 2 B 1 K B 2 K B 4 K B0
2 0 0 0 0
4 0 0 0 0
6 0 0 0 0
8 0 0 0 0
1 0 0 0 0 0
1 2 0 0 0 0
Throu
ghpu
t(ops
/sec)
R e q u e s t S i z e
S Q L i t e K V S Q L i t e K V - C a c h e
(c) Throughput w. Read heavy workload.
6 4 B 1 2 8 B 2 5 6 B 5 1 2 B 1 K B 2 K B 4 K B0
2 0 0 0 0
4 0 0 0 0
6 0 0 0 0
8 0 0 0 0
1 0 0 0 0 0
1 2 0 0 0 0
Throu
ghpu
t(ops
/sec)
R e q u e s t S i z e
S Q L i t e K V S Q L i t e K V - C a c h e
(d) Throughput w. Read latest workload.
Fig. 16: Performance of SQLiteKV with and without cache.
U p d a t e _ h e a v y R e a d _ m o s t R e a d _ h e a v y R e a d _ l a t e s t0
1 0 0 0 0
2 0 0 0 0
3 0 0 0 0
4 0 0 0 0
5 0 0 0 0
6 0 0 0 0
7 0 0 0 0
8 0 0 0 0
Throu
ghpu
t(ops/
sec)
W o r k l o a d
S Q L i t e K V S Q L i t e K V - C a c h e
Fig. 17: Cache effect with Zipfian distributed requestsizes.
U p d a t e _ h e a v y R e a d _ m o s t R e a d _ h e a v y R e a d _ l a t e s t0
1 0 0 0 0
2 0 0 0 0
3 0 0 0 0
4 0 0 0 0
5 0 0 0 0
6 0 0 0 0
Throu
ghpu
t(ops/
sec)
W o r k l o a d
S Q L i t e K V S Q L i t e K V _ L 0 1
Fig. 18: Performance of different index managementpolicies.
VI. CONCLUSION AND FUTURE WORK
In this paper, we propose a new database engine for mo-bile devices, called SQLiteKV, which is an SQLite-like key-value database engine. SQLiteKV adopts the LSM-tree-baseddata structure but retains the SQLite operation interfaces.SQLiteKV consists of two parts: a front end that contains alight-weight SQLite-to-key-value compiler and a coordinationcaching mechanism; a back end that adopts a LSM-tree-based key-value database engine. We have implemented anddeployed our SQLiteKV on a Google Nexus 6P Androidplatform based on a key-value database SnappyDB. Experi-mental results with various workloads show that the proposedSQLiteKV outperforms SQLite significantly.
As the first exploration of SQLite-like key-value databaseengines, the translation of SQL operations to key-value op-erations in SQLiteKV is straightforward. In the future, wewill extend the compiler design to make its translation moreefficient and complete.
ACKNOWLEDGEMENTS
The work described in this paper is partially supported bythe grants from the Research Grants Council of the Hong KongSpecial Administrative Region, China (GRF 152223/15E, GRF152736/16E, and GRF 152066/17E) and Shenzhen Scienceand Technology Foundation (JCYJ20170816093943197).

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 12
REFERENCES
[1] A. SQLite, https://www.sqlite.org/.[2] H. Falaki, R. Mahajan, S. Kandula, D. Lymberopoulos,
R. Govindan, and D. Estrin, “Diversity in smartphoneusage,” in The 8th International Conference on MobileSystems, Applications, and Services (MobiSys’10), 2010,pp. 179–194.
[3] J.-M. Kim and J.-S. Kim, “Androbench: benchmarkingthe storage performance of android-based mobile de-vices,” Springer Frontiers in Computer Education, pp.667–674, 2012.
[4] H. Kim, N. Agrawal, and C. Ungureanu, “Revisitingstorage for smartphones,” ACM Transactions on Storage(TOS), vol. 8, p. 14, 2012.
[5] S. Jeong, K. Lee, S. Lee, S. Son, and Y. Won, “I/O stackoptimization for smartphones.” in USENIX Conferenceon Usenix Annual Technical Conference (ATC 2013),2013, pp. 309–320.
[6] K. Shen, S. Park, and M. Zhu, “Journaling of journalis (almost) free.” in USENIX Conference on File andStorage Technologies (FAST 2014), 2014, pp. 287–293.
[7] K. Lee and Y. Won, “Smart layers and dumb result:IO characterization of an android-based smartphone.” inProceedings of the tenth ACM international conferenceon Embedded software (EMSOFT 2012), 2012, pp. 23–32.
[8] D. Jeong, Y. Lee, and J.-S. Kim, “Boosting quasi-asynchronous IO for better responsiveness in mobiledevices.” in USENIX Conference on File and StorageTechnologies (FAST 2015), 2015, pp. 191–202.
[9] C. Lee, D. Sim, J. Hwang, and S. Cho, “F2FS: a newfile system for flash storage.” in USENIX Conference onFile and Storage Technologies (FAST 2015), 2015, pp.273–286.
[10] W.-H. Kim, B. Nam, D. Park, and Y. Won, “Resolvingjournaling of journal anomaly in android i/o: multi-version b-tree with lazy split.” in USENIX Conferenceon File and Storage Technologies (FAST 2014), 2014,pp. 273–285.
[11] W.-H. Kang, S.-W. Lee, B. Moon, G.-H. Oh, and C. Min,“X-ftl: transactional FTL for SQLite databases,” in ACMSIGMOD International Conference on Management ofData (SIGMOD 2013), 2013, pp. 97–108.
[12] G. Oh, S. Kim, S.-W. Lee, and B. Moon, “SQLiteoptimization with phase change memory for mobileapplications.” International Conference on Very LargeDatabases (VLDB 2015), pp. 1454–1465, 2015.
[13] W.-H. Kim, J. Kim, W. Baek, B. Nam, and Y. Won,“NVWAL: exploiting NVRAM in write-ahead logging.”2016, pp. 385–398.
[14] D. Kim, E. Lee, S. Ahn, and H. Bahn, “Improving thestorage performance of smartphones through journalingin non-volatile memory,” IEEE Transactions on Con-sumer Electronics, vol. 59, pp. 556–561, 2013.
[15] C. Pan, M. Xie, C. Yang, Y. Chen, and J. Hu, “Exploitingmultiple write modes of nonvolatile main memory inembedded systems,” ACM Transactions on Embedded
Computing Systems (TECS), vol. 16, no. 4, 2017.[16] S. Ghemawat and J. Dean, “Leveldb, a fast and
lightweight key/value database library by google,” 2014.[17] A. Cassandra, http://cassandra.apache.org/.[18] Y.-T. Chen, M.-C. Yang, Y.-H. Chang, T.-Y. Chen, H.-
W. Wei, and W.-K. Shih, “Kvftl: optimization of stor-age space utilization for key-value-specific flash storagedevices,” in IEEE 22nd Asia and South Pacific DesignAutomation Conference (ASP-DAC 2017), 2017, pp. 584–590.
[19] B. Debnath, S. Sengupta, and J. Li, “Flashstore: highthroughput persistent key-value store,” Proceedings of theVery Large Data Bases Conference (VLDB 2010), pp.1414–1425, 2010.
[20] W. Deng, R. Svihla, and DataStax, “The missing manualfor leveled compaction strategy.” goo.gl/En73gW, 2016.
[21] F. Chang, J. Dean, S. Ghemawat, W. C. Hsieh, D. A.Wallach, M. Burrows, T. Chandra, A. Fikes, and R. E.Gruber, “Bigtable: a distributed storage system for struc-tured data.” ACM Transactions on Computer Systems(TOCS), vol. 26, p. 4, 2008.
[22] B. Atikoglu, Y. Xu, E. Frachtenberg, S. Jiang, andM. Paleczny, “Workload analysis of a large-scale key-value store.” in ACM SIGMETRICS Performance Evalu-ation Review (SIGMETRICS 2012), 2012.
[23] A. Phoenix, https://phoenix.apache.org/.[24] L. Long, L. Duo, L. Liang, X. Zhu, K. Zhong, Z. Shao,
and E. H.-M. Sha, “Morphable resistive memory opti-mization for mobile virtualization,” IEEE Transactionson Computer-Aided Design of Integrated Circuits andSystems, vol. 35.
[25] R. Chen, Y. Wang, J. Hu, D. Liu, Z. Shao, andY. Guan, “vflash: virtualized flash for optimizing thei/o performance in mobile devices,” IEEE Transactionson Computer-Aided Design of Integrated Circuits andSystems, vol. 36, pp. 1203–1214, 2017.
[26] SnappyDB, “SnappyDB: a key-value database for An-droid.” http://www.snappydb.com/.
[27] UnQlite, “UnQlite: an embeddable NoSQL database en-gine.” https://unqlite.org/.
[28] Leveldown-Mobile, https://github.com/No9/leveldown-mobile.
[29] H. Lim, B. Fan, D. G. Andersen, and M. Kaminsky, “Silt:a memory-efficient, high-performance key-value store,”in ACM Symposium on Operating Systems Principles(SOSP 2011), 2011, pp. 1–13.
[30] B. Debnath, S. Sengupta, and J. Li, “Skimpystash: Ramspace skimpy key-value store on flash-based storage,”in ACM SIGMOD International Conference on Manage-ment of data (SIGMOD 2011), 2011, pp. 25–36.
[31] X. Hu, X. Wang, Y. Li, L. Zhou, Y. Luo, C. Ding,S. Jiang, and Z. Wang, “Lama: optimized locality-awarememory allocation for key-value cache.” in USENIXAnnual Technical Conference (ATC2015), 2015, pp. 57–69.
[32] H. G. Lee and N. Chang, “Energy-aware memory alloca-tion in heterogeneous non-volatile memory systems.” inInternational Symposium on Low Power Electronics and

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 13
Design (ISLPED 2003), 2003, pp. 420–423.[33] Z. Shen, F. Chen, Y. Jia, and Z. Shao, “DIDACache: a
deep integration of device and application for flash basedkey-value caching.” in USENIX Conference on File andStorage Technologies (FAST 2017), 2017, pp. 391–405.
[34] R. Nishtala, H. Fugal, S. Grimm, M. Kwiatkowski,H. Lee, H. C. Li, R. McElroy, M. Paleczny, D. Peek,P. Saab et al., “Scaling memcache at facebook.” inUSENIX Symposium on Networked Systems Design andImplementation (NSDI 2013), 2013, pp. 385–398.
[35] R. Sears and R. Ramakrishnan, “bLSM: a general pur-pose log structured merge tree.” in ACM SIGMOD Inter-national Conference on Management of Data (SIGMOD2012), 2012, pp. 217–228.
[36] Z. Shao, Y. Liu, Y. Chen, and T. Li, “Utilizing PCMfor energy optimization in embedded systems.” in IEEEComputer Society Annual Symposium on VLSI (ISVLSI2012), 2012, pp. 398–403.
[37] L. Junyan, X. Shiguo, and L. Yijie, “Application researchof embedded database sqlite,” in International Forum onInformation Technology and Applications (IFITA 2009),vol. 2, 2009, pp. 539–543.
[38] V. Prabhakaran, A. C. Arpaci-Dusseau, and R. H. Arpaci-Dusseau, “Analysis and evolution of journaling file sys-tems.” in USENIX Annual Technical Conference (ATC2005), pp. 196–215.
[39] S. Best, “Jfs log: how the journaled file system performslogging,” in Proceedings of the 4th annual Linux Show-case, 2000, p. 9.
[40] P. ONeil, E. Cheng, D. Gawlick, and E. ONeil, “Thelog-structured merge-tree (lsm-tree),” Springer Acta In-formatica, vol. 33, pp. 351–385, 1996.
[41] J. Han, H. E, G. Le, and J. Du, “Survey on nosqldatabase,” in IEEE International Conference on Perva-sive computing and applications (ICPCA 2011), 2011,pp. 363–366.
[42] J. Pokorny, “Nosql databases: a step to database scala-bility in web environment,” Emerald Group PublishingLimited International Journal of Web Information Sys-tems, vol. 9.
[43] A. Moniruzzaman and S. A. Hossain, “Nosql database:new era of databases for big data analytics-classification,characteristics and comparison,” arXiv preprintarXiv:1307.0191, 2013.
[44] A. Hbase, https://hbase.apache.org/.[45] S. B. Elagib, a. A. H. H. Atahur Rahman Najeeb, and
R. F. Olanrewaju, “Big data analysis solutions usingmapreduce framework,” in IEEE International Confer-ence on Computer and Communication Engineering (IC-CCE 2014), 2014, pp. 127–130.
[46] J. Zhang, J.-S. Wong, T. Li, and Y. Pan, “A comparisonof parallel large-scale knowledge acquisition using roughset theory on different mapreduce runtime systems,” El-sevier International Journal of Approximate Reasoning,vol. 55, pp. 896–907, 2014.
[47] G. H. Forman and J. Zahorjan, “The challenges of mobilecomputing.” Computer, pp. 38–47, 1994.
[48] S. Sinha and W. Zhang, “Low-power FPGA design us-
ing memorization-based approximate computing.” IEEETransactions on Very Large Scale Integration Systems(VLSI 2016), pp. 2665–2678, 2016.
[49] B. F. Cooper, A. Silberstein, E. Tam, R. Ramakrishnan,and R. Sears, “Benchmarking cloud serving systemswith YCSB.” in ACM Symposium on Cloud Computing(SOCC 2010), 2010, pp. 143–154.
[50] R. Nambiar and M. Poess, Performance evaluation andbenchmarking, traditional to big data to Internet ofthings, 2017.
[51] X. Wu, Y. Xu, Z. Shao, and S. Jiang, “LSM-trie: anLSM-tree-based ultra-large key-value store for smalldata items.” in USENIX Conference on Usenix AnnualTechnical Conference (ATC 2015), 2015, pp. 71–82.
[52] S. Barahmand and S. Ghandeharizadeh, “D-zipfian: adecentralized implementation of zipfian,” in Proceedingsof the 6th International Workshop on Testing DatabaseSystems, 2013.
Zhaoyan Shen received the BE and ME degrees inthe Department of Computer Science and Technol-ogy, Shandong University, China, in 2012 and 2015,respectively, and the Ph.D. degree in Departmentof Computing, Hong Kong Polytechnic University,in 2018. Currently, he is an assistant professor ofShandong University. His research interests includebig data systems, storage systems, embedded sys-tems, system architecture, and hardware/softwarecodesign.
Yuanjing Shi received the BS degree in computingfrom the Hong Kong Polytechnic University, HongKong, China in 2018. He is currently an upcominggraduate student at the University of Illinois atUrbana-Champaign. His research interests includeDatabases, Data-Intensive Systems, Distributed Sys-tems and Cyber-Physical Systems.
Zili Shao is currently an Associate Professor withthe Department of Computer Science and Engi-neering at the Chinese University of Hong Kong(CUHK). Before joining CUHK in 2018, he waswith the Department of Computing, the Hong KongPolytechnic University, where he served since 2005.He received the B.E. degree in electronic mechan-ics from the University of Electronic Science andTechnology of China, Sichuan, China, in 1995, andthe M.S. and the Ph.D. degrees from the Departmentof Computer Science, University of Texas at Dallas,
Dallas, TX, USA, in 2003 and 2005,respectively. His current research in-terests include big data systems, storage systems, embedded software andsystems and related industrial applications. He is an associate Editor forIEEE Transactions on Computers, IEEE Transactions on Computer-AidedDesign of Integrated Circuits and Systems, ACM Transactions on Cyber-Physical Systems, and ACM Transactions on Design Automation of ElectronicSystems.
Yong Guan received the Ph.D. degree in computerscience from China University of Mining and Tech-nology, China, in 2004. Currently, he is a professorof Capital Normal University. His research interestsinclude formal verification, PHM for power andembedded system design. Dr. Guan is a member ofChinese Institute of Electronics Embedded ExpertCommittee. He is also a member of Beijing Instituteof Electronics Professional Education Committee,and Standing Council Member of Beijing Societyfor Information Technology in Agriculture.




















