
Ambiguity in medical concept normalization - Oxford Academic
17
Research and Applications Ambiguity in medical concept normalization: An analysis of types and coverage in electronic health record datasets Denis Newman-Griffis , 1,2 Guy Divita, 1 Bart Desmet, 1 Ayah Zirikly, 1 Carolyn P. Ros e, 1,3 and Eric Fosler-Lussier 2 1 Rehabilitation Medicine Department, National Institutes of Health Clinical Center, Bethesda, Maryland, USA, 2 Department of Computer Science and Engineering, The Ohio State University, Columbus, Ohio, USA and 3 Language Technologies Institute, Car- negie Mellon University, Pittsburgh, Pennsylvania, USA Corresponding Author: Denis Newman-Griffis, 6707 Democracy Blvd, Suite 856, Bethesda, MD 20892, USA; denis.griffis@- nih.gov Received 11 February 2020; Revised 13 September 2020; Editorial Decision 11 October 2020; Accepted 17 November 2020 ABSTRACT Objectives: Normalizing mentions of medical concepts to standardized vocabularies is a fundamental compo- nent of clinical text analysis. Ambiguity—words or phrases that may refer to different concepts—has been ex- tensively researched as part of information extraction from biomedical literature, but less is known about the types and frequency of ambiguity in clinical text. This study characterizes the distribution and distinct types of ambiguity exhibited by benchmark clinical concept normalization datasets, in order to identify directions for ad- vancing medical concept normalization research. Materials and Methods: We identified ambiguous strings in datasets derived from the 2 available clinical corpora for concept normalization and categorized the distinct types of ambiguity they exhibited. We then compared observed string ambiguity in the datasets with potential ambiguity in the Unified Medical Language System (UMLS) to assess how representative available datasets are of ambiguity in clinical language. Results: We found that <15% of strings were ambiguous within the datasets, while over 50% were ambiguous in the UMLS, indicating only partial coverage of clinical ambiguity. The percentage of strings in common be- tween any pair of datasets ranged from 2% to only 36%; of these, 40% were annotated with different sets of con- cepts, severely limiting generalization. Finally, we observed 12 distinct types of ambiguity, distributed unequally across the available datasets, reflecting diverse linguistic and medical phenomena. Discussion: Existing datasets are not sufficient to cover the diversity of clinical concept ambiguity, limiting both training and evaluation of normalization methods for clinical text. Additionally, the UMLS offers important se- mantic information for building and evaluating normalization methods. Conclusions: Our findings identify 3 opportunities for concept normalization research, including a need for ambiguity-specific clinical datasets and leveraging the rich semantics of the UMLS in new methods and evalua- tion measures for normalization. Key words: natural language processing, machine learning, Unified Medical Language System, semantics, vocabulary, controlled Published by Oxford University Press on behalf of the American Medical Informatics Association 2020. This work is written by a US Government employee and is in the public domain in the US. 516 Journal of the American Medical Informatics Association, 28(3), 2021, 516–532 doi: 10.1093/jamia/ocaa269 Advance Access Publication Date: 15 December 2020 Research and Applications Downloaded from https://academic.oup.com/jamia/article/28/3/516/6034899 by guest on 10 July 2022
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of Ambiguity in medical concept normalization - Oxford Academic

Research and Applications
Ambiguity in medical concept normalization: An analysis
of types and coverage in electronic health record datasets
Denis Newman-Griffis ,1,2 Guy Divita,1 Bart Desmet,1 Ayah Zirikly,1
Carolyn P. Ros�e,1,3 and Eric Fosler-Lussier2
1Rehabilitation Medicine Department, National Institutes of Health Clinical Center, Bethesda, Maryland, USA, 2Department of
Computer Science and Engineering, The Ohio State University, Columbus, Ohio, USA and 3Language Technologies Institute, Car-
negie Mellon University, Pittsburgh, Pennsylvania, USA
Corresponding Author: Denis Newman-Griffis, 6707 Democracy Blvd, Suite 856, Bethesda, MD 20892, USA; denis.griffis@-
nih.gov
Received 11 February 2020; Revised 13 September 2020; Editorial Decision 11 October 2020; Accepted 17 November 2020
ABSTRACT
Objectives: Normalizing mentions of medical concepts to standardized vocabularies is a fundamental compo-
nent of clinical text analysis. Ambiguity—words or phrases that may refer to different concepts—has been ex-
tensively researched as part of information extraction from biomedical literature, but less is known about the
types and frequency of ambiguity in clinical text. This study characterizes the distribution and distinct types of
ambiguity exhibited by benchmark clinical concept normalization datasets, in order to identify directions for ad-
vancing medical concept normalization research.
Materials and Methods: We identified ambiguous strings in datasets derived from the 2 available clinical
corpora for concept normalization and categorized the distinct types of ambiguity they exhibited. We then
compared observed string ambiguity in the datasets with potential ambiguity in the Unified Medical Language
System (UMLS) to assess how representative available datasets are of ambiguity in clinical language.
Results: We found that <15% of strings were ambiguous within the datasets, while over 50% were ambiguous
in the UMLS, indicating only partial coverage of clinical ambiguity. The percentage of strings in common be-
tween any pair of datasets ranged from 2% to only 36%; of these, 40% were annotated with different sets of con-
cepts, severely limiting generalization. Finally, we observed 12 distinct types of ambiguity, distributed unequally
across the available datasets, reflecting diverse linguistic and medical phenomena.
Discussion: Existing datasets are not sufficient to cover the diversity of clinical concept ambiguity, limiting both
training and evaluation of normalization methods for clinical text. Additionally, the UMLS offers important se-
mantic information for building and evaluating normalization methods.
Conclusions: Our findings identify 3 opportunities for concept normalization research, including a need for
ambiguity-specific clinical datasets and leveraging the rich semantics of the UMLS in new methods and evalua-
tion measures for normalization.
Key words: natural language processing, machine learning, Unified Medical Language System, semantics, vocabulary,
controlled
Published by Oxford University Press on behalf of the American Medical Informatics Association 2020.
This work is written by a US Government employee and is in the public domain in the US. 516
Journal of the American Medical Informatics Association, 28(3), 2021, 516–532
doi: 10.1093/jamia/ocaa269
Advance Access Publication Date: 15 December 2020
Research and Applications
Dow
nloaded from https://academ
ic.oup.com/jam
ia/article/28/3/516/6034899 by guest on 10 July 2022

INTRODUCTION
Identifying the medical concepts within a document is a key step in
the analysis of medical records and literature. Mapping natural lan-
guage to standardized concepts improves interoperability in docu-
ment analysis1,2 and provides the ability to leverage rich, concept-
based knowledge resources such as the Unified Medical Language
System (UMLS).3 This process is a fundamental component of di-
verse biomedical applications, including clinical trial recruitment,4,5
disease research and precision medicine,6–8 pharmacovigilance and
drug repurposing,9,10 and clinical decision support.11 In this work,
we identify distinct phenomena leading to ambiguity in medical con-
cept normalization (MCN) and describe key gaps in current
approaches and data for normalizing ambiguous clinical language.
Medical concept extraction has 2 components: (1) named entity
recognition (NER), the task of recognizing where concepts are men-
tioned in the text, and (2) MCN, the task of assigning canonical
identifiers to concept mentions, in order to unify different ways of
referring to the same concept. While MCN has frequently been stud-
ied jointly with NER,12–14 recent research has begun to investigate
challenges specific to the normalization phase of concept extraction.
Three broad challenges emerge in concept normalization. First,
language is productive: practitioners and patients can refer to stan-
dardized concepts in diverse ways, requiring recognition of novel
phrases beyond those in controlled vocabularies.15–18 Second, a sin-
gle phrase can describe multiple concepts in a way that is more (or
different) than the sum of its parts.19,20 Third, a single natural lan-
guage form can be used to refer to multiple distinct concepts, thus
yielding ambiguity.
Word sense disambiguation (WSD) (which often includes phrase
disambiguation in the biomedical setting) is thus an integral part of
MCN. WSD has been extensively studied in natural language proc-
essing methodology,21–23 and ambiguous words and phrases in bio-
medical literature have been the focus of significant research.24–30
WSD research in electronic health record (EHR) text, however, has
focused almost exclusively on abbreviations and acronyms.31–35 A
single dataset of 50 ambiguous strings in EHR data has been devel-
oped and studied25,36 but is not freely available for current research.
Two large-scale EHR datasets, the ShARe corpus14 and a dataset by
Luo et al,37 have been developed for medical concept extraction re-
search and have been significant drivers in MCN research through
multiple shared tasks.14,38–41 However, their role in addressing am-
biguity in clinical language has not yet been explored.
ObjectiveTo understand the role of benchmark MCN datasets in designing
and evaluating methods to resolve ambiguity in clinical language,
we identified ambiguous strings in 3 benchmark EHR datasets for
MCN and analyzed the causes of ambiguity they capture. Using lexi-
cal semantic theory and the taxonomic and semantic relationships
between concepts captured in the UMLS as a guide, we developed a
typology of ambiguity in clinical language and categorized each
string in terms of what type of ambiguity it captures. We found that
multiple distinct phenomena cause ambiguity in clinical language
and that the existing datasets are not sufficient to systematically cap-
ture these phenomena. Based on our findings, we identified 3 key
gaps in current research on MCN in clinical text: (1) a lack of repre-
sentative data for ambiguity in clinical language, (2) a need for new
evaluation strategies for MCN that account for different kinds of
relationships between concepts, and (3) underutilization of the rich
semantic resources of the UMLS in MCN methodologies. We hope
that our findings will spur additional development of tools and
resources for resolving medical concept ambiguity.
Contributions of this work
• We demonstrate that existing MCN datasets in EHR data are
not sufficient to capture ambiguity in MCN, either for evaluating
MCN systems or developing new MCN models. We analyze the
3 available MCN EHR datasets and show that only a small por-
tion of mention strings have any ambiguity within each dataset,
and that these observed ambiguities only capture a small subset
of potential ambiguity, in terms of the concept unique identifiers
(CUIs) that match to the strings in the UMLS. Thus, new datasets
focused on ambiguity in clinical language are needed to ensure
the effectiveness of MCN methodologies.• We show that current MCN EHR datasets do not provide suffi-
ciently representative normalization data for effective generaliza-
tion, in that they have very few mention strings in common with
one another and little overlap in annotated CUIs. Thus, MCN re-
search should include evaluation on multiple datasets, to mea-
sure generalization power.• We present a linguistically motivated and empirically validated
typology of distinct phenomena leading to ambiguity in medical
concept normalization, and analyze all ambiguous strings within
the 3 current MCN EHR datasets in terms of these ambiguity
phenomena. We demonstrate that multiple distinct phenomena
affect MCN ambiguity, reflecting a variety of semantic and lin-
guistic relationships between terms and concepts that inform
both prediction and evaluation methodologies for medical con-
cept normalization. Thus, MCN evaluation strategies should be
tailored to account for different relationships between predicted
labels and annotated labels. Further, MCN methodologies could
be significantly enhanced by greater integration of the rich se-
mantic resources of the UMLS.
BACKGROUND AND SIGNIFICANCE
Linguistic phenomena underpinning clinical ambiguityLexical semantics distinguishes between 2 types of lexical ambiguity:
homonymy and polysemy.42,43 Homonymy occurs when 2 lexical
items with separate meanings have the same form (eg, “cold” as ref-
erence to a cold temperature or the common cold). Polysemy occurs
when one lexical item diverges into distinct but related meanings
(eg, “coat” for garment or coat of paint). Polysemy can in turn be
the result of different phenomena, including default interpretations
(“drink” liquid or alcohol), metaphors, and metonymy (usage of a
literal association between 2 concepts in a specified domain [eg,
“Foley catheter on 4/12”] to indicate a past catheterization proce-
dure).42,43 While metaphors are dispreferred in the formal setting of
clinical documentation, the telegraphic nature of medical text44
lends itself to metonymy by using shorter phrases to refer to more
specific concepts, such as procedures.45
Mapping between biomedical concepts and terms: The
UMLSThe UMLS is a large-scale biomedical knowledge resource that com-
bines information from over 140 expert-curated biomedical vocabu-
laries and standards into a single machine-readable resource. One
central component of the UMLS that directly informs our analysis
of ambiguity is the Metathesaurus, which groups together synonyms
Journal of the American Medical Informatics Association, 2021, Vol. 28, No. 3 517
Dow
nloaded from https://academ
ic.oup.com/jam
ia/article/28/3/516/6034899 by guest on 10 July 2022

(distinct phrases with the same meaning, [eg, “common cold” and
“acute rhinitis”]) and lexical variants (modifications of the same
phrase [eg, “acute rhinitis” and “rhinitis, acute”]) of biomedical
terms and assigns them a single CUI. The diversity of vocabularies
included in the UMLS (each designed for a unique purpose), com-
bined with the expressiveness of human language, means that many
different terms can be associated with any one concept (eg, the con-
cept C0009443 is associated with the terms cold, common cold, and
acute rhinitis, among others), and any term may be used to refer to
different concepts in different situations (eg, cold may also refer to
C0009264 Cold Temperature in addition to C0009443, as well as to
a variety of other Metathesaurus concepts), leading to ambiguity.
These mappings between terms and concepts are stored in the
MRCONSO UMLS table. In addition to the canonical terms stored
in MRCONSO, the UMLS also provides lexical variants of terms,
including morphological stemming, inflectional variants, and agnos-
tic word order, provided through the SPECIALIST Lexicon and suite
of tools.46,47 Lexical variants of English-language terms from
MRCONSO are provided in the MRXNS_ENG UMLS table. The
MCN datasets used in this study were annotated for mentions of
concepts in 2 widely used vocabularies integrated into the UMLS:
(1) the U.S. edition of the Systematized Nomenclature of Medicine
Clinical Terms (SNOMED CT) vocabulary, a comprehensive clini-
cal healthcare terminology, and (2) RxNorm, a standardized no-
menclature for clinical drugs; we thus restricted our analysis to data
from these 2 vocabularies.
Sense relations and ontological distinctions in the
UMLSIn addition to mappings from terms to concepts, the UMLS Meta-
thesaurus includes information on semantic relationships between
concepts, such as hierarchical relationships that often correspond to
lexical phenomena such as hypernymy and hyponymy, as well as
meronymy and holonymy in biological and chemical structures.42
The UMLS has previously been observed to include not only fine-
grained ontological distinctions, but also purely epistemological dis-
tinctions such as associated findings (eg, C0748833 Open fracture
of skull vs C0272487 Open skull fracture without intracranial in-
jury).48 This yields high productivity for assignment of different
CUIs in cases of ontological distinction, such as reference to
“cancer” to mean either general cancer disorders or a specific type
of cancer in a context such as a prostate exam, as well what Cruse42
termed propositional synonymy (ie, different senses that yield the
same propositional logic interpretation). Additionally, the difficulty
of interterminology mapping at scale means that synonymous terms
are occasionally mapped to different CUIs.49
The role of representative data for clinical ambiguityDevelopment and evaluation of models for any problem are predi-
cated on the availability of representative data.50 Prior research has
highlighted the frequency of ambiguity in biomedical literature24,51
and broken biomedical ambiguity into 3 broad categories of ambig-
uous terms, abbreviations, and gene names,52 but an in-depth char-
acterization of the types of ambiguity relevant to clinical data has
not yet been performed. In order to understand what can be learned
from the available data for ambiguity and identify areas for future
research, it is critical to analyze both the frequency and the types of
ambiguity that are captured in clinical datasets.
MATERIALS AND METHODS
We performed both quantitative and qualitative evaluations of am-
biguity in 3 benchmark MCN datasets of EHR data. In this section,
we first introduce the datasets analyzed in this work and define our
methods for measuring ambiguity in the datasets and in the UMLS.
We then describe 2 quantitative analyses of ambiguity measure-
ments within individual datasets and a generalization analysis across
datasets. Finally, we present our qualitative analysis of ambiguity
types in MCN datasets.
MCN datasetsThe effect of ambiguity in normalizing medical concepts has been
researched significantly more in biomedical literature than in clinical
data. In order to identify knowledge gaps and key directions for
MCN in the clinical setting, where ambiguity may have direct im-
pact on automated tools for clinical decision support, we studied the
3 available English-language EHR corpora with concept normaliza-
tion annotations: SemEval-2015 Task 14,14 CUILESS2016,19 and
n2c2 2019 Track 3.37,41 MCN annotations in these datasets are rep-
resented as UMLS CUIs for the concepts being referred to in the
text; as MCN evaluation is performed based on selection of the
specific CUI a given mention is annotated with, we describe dataset
annotation and our analyses in terms of the CUIs used rather than
the concepts they refer to. Details of these datasets are presented
in Table 1.
SemEval-2015
Task 14 of the SemEval-2015 competition investigated clinical text
analysis using the ShARe corpus, which consists of 531 clinical
documents from the MIMIC (Medical Information Mart for Inten-
sive Care) dataset54 including discharge summaries, echocardio-
gram, electrocardiogram and radiology reports. Each document was
annotated for mentions of disorders and normalized using CUIs
from SNOMED CT.53 The documents were annotated by 2 profes-
sional medical coders, with high interannotator agreement of 84.6%
CUI matches for mentions with identical spans, and all disagree-
ments were adjudicated to produce the final dataset.38,39 Datasets
derived from subsets of the ShARe corpus have been used as the
source for several shared tasks.14,39,40,55 The full corpus was used
for a SemEval-2015 shared task on clinical text analysis,14 split into
298 documents for training, 133 for development, and 100 for test.
In order to preserve the utility of the test set as an unseen data sam-
ple for continuing research, we exclude its 100 documents from our
analysis, and only analyze the training and development documents.
CUILESS2016
A significant number of mentions in the ShARe corpus were not
mapped to a CUI in the original annotations, either because these
mentions did not correspond to Disorder concepts in the UMLS or
because they would have required multiple disorder concepts to an-
notate.14 These mentions were later reannotated in the CUI-
LESS2016 dataset, with updated guidelines allowing annotation
using any CUI in SNOMED CT (regardless of semantic type) and
specified rules for composition.19,56 These data were split into train-
ing and development sets, corresponding to the training and devel-
opment splits in the SemEval-2015 shared task; the SemEval-2015
test set was not annotated as part of CUILESS2016.
518 Journal of the American Medical Informatics Association, 2021, Vol. 28, No. 3
Dow
nloaded from https://academ
ic.oup.com/jam
ia/article/28/3/516/6034899 by guest on 10 July 2022
n2c2 2019
As the SemEval-2015 and CUILESS2016 datasets only included
annotations for mentions of disorder-related concepts, Luo et al37
annotated a new corpus to provide mention and normalization data
for a wider variety of concepts; these data were then used for a 2019
n2c2 shared task on concept normalization.41 The corpus includes
100 discharge summaries drawn from the 2010 i2b2/VA shared task
on clinical concept extraction, for which documents from multiple
healthcare institutions were annotated for all mentions of problems,
treatments, and tests.57 All annotated mentions in the 100 docu-
ments chosen were normalized using CUIs from SNOMED CT and
RxNorm; 2.7% were annotated as “CUI-less.” All mentions were
dually annotated with an adjudication phase; preadjudication inter-
annotator agreement was a 67.69% CUI match (note this figure in-
cluded comparison of mention bounds in addition to CUI matches,
lowering measured agreement; CUI-level agreement alone was not
evaluated). Luo et al37 split the corpus into training and test sets. As
with the SemEval-2015 data, we only analyzed the training set in or-
der to preserve the utility of the n2c2 2019 test set as an unseen data
sample for evaluating generalization in continuing MCN research.
Measuring ambiguityWe utilize 2 different ways of measuring the ambiguity of a string:
dataset ambiguity, which measures the amount of observed ambigu-
ity for a given medical term as labeled in an MCN dataset, and
UMLS ambiguity, which measures the amount of potential ambigu-
ity for the same term by using the UMLS as a reference for normali-
zation. A key desideratum for developing and evaluating statistical
models of MCN, which we demonstrate is not achieved by bench-
mark datasets in practice, is that the ambiguity observed in research
datasets is as representative as possible of the potential ambiguity
that may be encountered in medical language “in the wild.” For ex-
ample, the term cold can be used as an acronym for Chronic Ob-
structive Lung Disease (C0024117), but if no datasets include
examples of cold being used in this way, we are unable to train or
evaluate the effectiveness of an MCN model for normalizing “cold”
to this meaning. The problem becomes more severe if other senses of
cold, such as C0009264 Cold Temperature, C0234192 Cold Sensa-
tion, or C0010412 Cold Therapy are also not included in annotated
datasets. While exhaustively capturing instances of every sense of a
given term in natural utterances is impractical at best, significant
gaps between observed and potential ambiguity impose a fundamen-
tal limiting factor on progress in MCN research.
We defined dataset ambiguity, our measure of observed ambigu-
ity, as the number of unique CUIs associated with a given string
when aggregated over all samples in a dataset. In order to account
for minor variations in EHR orthography and annotations, we used
2 steps of preprocessing on the text of all medical concept mentions
in each dataset: lowercasing and dropping determiners (a, an, and
the).
To measure potential ambiguity, we defined UMLS ambiguity as
the number of CUIs a string is associated with in the UMLS Meta-
thesaurus. While the Metathesaurus is necessarily incomplete,15,58,59 and the breadth and specificity of concepts covered means
that useful term-CUI links are often missing,60 it nonetheless func-
tions as a high-coverage heuristic to measure the number of senses a
term may be used to refer to. However, the expressiveness of natural
language means that direct dictionary lookup of any given string in
the Metathesaurus is likely to miss valid associated CUIs: linguistic
phenomena such as coreference allow seemingly general strings to
take very specific meanings (eg, “the failure” referring to a specific
instance of heart failure); other syntactic phenomena such as predi-
cation, splitting known strings with a copula (see Figure 1 for exam-
ples), and inflection (eg, “defibrillate” vs “defibrillation” vs
“defibrillated”) lead to further variants. We therefore use 3 strate-
gies to match observed strings with terms in the UMLS and the con-
cepts that they are linked to (referred to as candidate matching
strategies), with increasing degrees of inclusivity across term varia-
tions, to measure the number of CUIs a medical concept string may
be matched to in the UMLS:
• Minimal preprocessing—each string was preprocessed using the
2 steps described previously (lowercasing and dropping deter-
miners; eg, “the EKG” becomes “ekg”), and compared with
rows of the MRCONSO table of the UMLS to identify the num-
ber of unique CUIs canonically associated with the string. The
same minimal preprocessing steps were applied to the String field
of MRCONSO rows for matching.• Lexical variant normalization—each string was first processed
with minimal preprocessing, and then further processed with the
luiNorm tool, 61 a software package developed to map lexical
variants (eg, defibrillate, defibrillated, defibrillation) to the same
string. (Mapping lexical variants to the same underlying string is
typically referred to as “normalization” in the natural language
processing literature; for clarity between concept normalization
and string normalization in this article, we refer to “lexical vari-
ant normalization” for this aspect of string processing through-
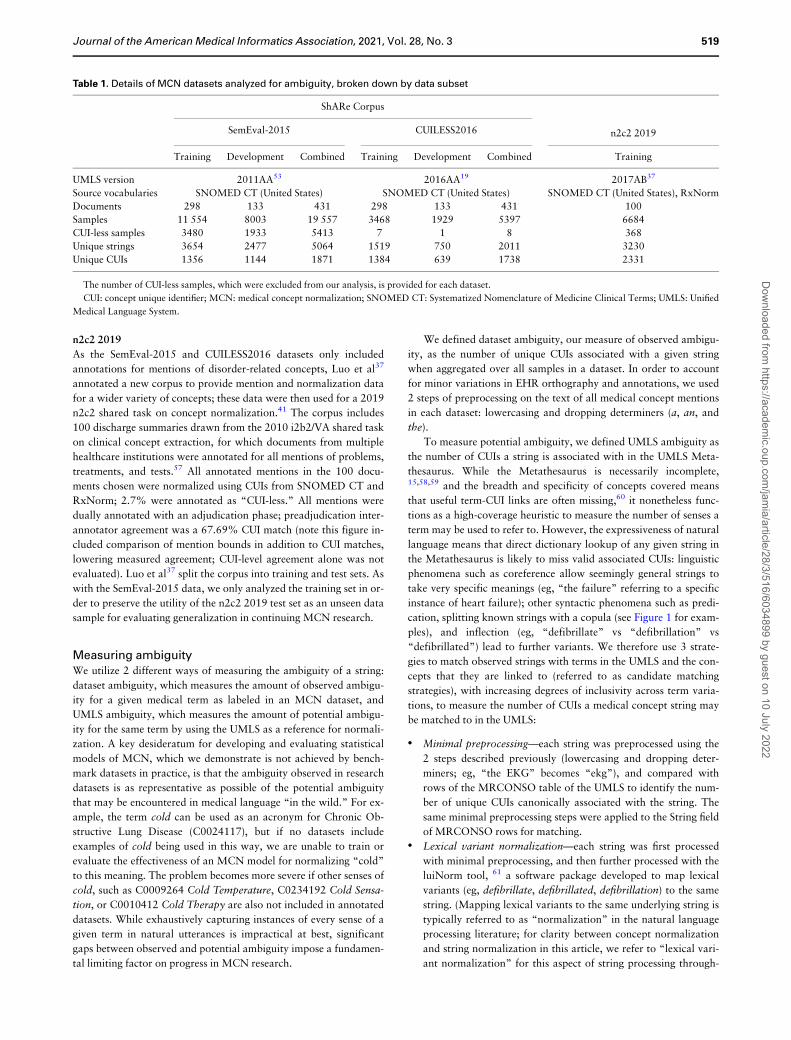
Table 1. Details of MCN datasets analyzed for ambiguity, broken down by data subset
ShARe Corpus
n2c2 2019SemEval-2015 CUILESS2016
Training Development Combined Training Development Combined Training
UMLS version 2011AA53 2016AA19 2017AB37
Source vocabularies SNOMED CT (United States) SNOMED CT (United States) SNOMED CT (United States), RxNorm
Documents 298 133 431 298 133 431 100
Samples 11 554 8003 19 557 3468 1929 5397 6684
CUI-less samples 3480 1933 5413 7 1 8 368
Unique strings 3654 2477 5064 1519 750 2011 3230
Unique CUIs 1356 1144 1871 1384 639 1738 2331
The number of CUI-less samples, which were excluded from our analysis, is provided for each dataset.
CUI: concept unique identifier; MCN: medical concept normalization; SNOMED CT: Systematized Nomenclature of Medicine Clinical Terms; UMLS: Unified
Medical Language System.
Journal of the American Medical Informatics Association, 2021, Vol. 28, No. 3 519
Dow
nloaded from https://academ
ic.oup.com/jam
ia/article/28/3/516/6034899 by guest on 10 July 2022

out.) luiNorm-processed strings were then compared with prepo-
pulated lexical variants in the MRXNS_ENG table of the UMLS
to identify the set of associated CUIs. We used the release of lui-
Norm that corresponded to the UMLS version each dataset was
annotated with (2011 for SemEval-2015, 2016 for CUI-
LESS2016, and 2017 for n2c2 2019), and compared with the
MRXNS_ENG table of the corresponding UMLS release.• Word match—each string was first processed with minimal pre-
processing; we then queried the UMLS search application pro-
gramming interface for the preprocessed string, using the word-
level search option,62 which searches for matches in the Metathe-
saurus with each of the words in the query string (ie, “Heart dis-
ease, acute” will match with strings including any of the words
heart, disease, or acute). We counted the number of unique CUIs
returned as our measure of ambiguity.
In all cases, since each dataset was only annotated using CUIs
linked to specific vocabularies in the UMLS (SNOMED CT for all 3
datasets, plus RxNorm for n2c2 2019), we restricted our ambiguity
analysis to the set of unique UMLS CUIs linked to the source vocab-
ularies used for annotation. Thus, if a string in SemEval-2015 was
associated with 2 CUIs linked to SNOMED CT and an additional
CUI linked only to International Classification of Diseases–Ninth
Revision (and therefore not eligible for use in SemEval-2015 annota-
tion), we only counted the 2 CUIs linked to SNOMED CT in mea-
suring its ambiguity.
Quantitative analyses: Ambiguity measurements and
generalizationAmbiguity measurements within datasets
Given the set of unique mention strings in each MCN dataset, we
measured each string’s ambiguity in terms of dataset ambiguity,
UMLS ambiguity with minimal preprocessing, UMLS ambiguity
with lexical variant normalization, and UMLS ambiguity with word
match, using the version of the UMLS each dataset was originally
annotated with. We also evaluated the coverage of the UMLS
matching results, in terms of whether they included the CUIs associ-
ated with each string in the dataset. For compositional annotations
in CUILESS2016, we treated a label as covered if any of its compo-
nent CUIs were included in the UMLS results. Finally, to establish
concordance with prior findings of greater ambiguity from shorter
terms,63 we evaluated the correlation between string length and am-
biguity measurements, using linear regression with fit measured by
the r2 statistic. We used 2 different measures of string length: (1)
number of tokens in the string (calculated using SpaCy64 tokeniza-
tion) and (2) number of characters in the string.
Cross-dataset generalization analysis
In order to assess how representative the annotated MCN datasets
are for generalizing to unseen data, we evaluated ambiguity in 3
kinds of cross-dataset generalization: (1) from training to develop-
ment splits in a single dataset (using SemEval-2015 and CUI-
LESS2016), (2) between different datasets drawn from the same
corpus (comparing SemEval-2015 to CUILESS2016), and (3) be-
tween datasets from different corpora (comparing SemEval-2015
and CUILESS2016 to n2c2 2019). In each of these settings, we first
identified the portion of strings shared between the datasets being
compared, a key component of generalization, and then analyzed
the CUIs associated with these shared strings in each dataset. Shared
strings were analyzed along 3 axes to measure the generalization of
MCN annotations between datasets: (1) differences in ambiguity
type (for strings which were ambiguous in both datasets), (2) over-
lap in the annotated CUI sets, and (3) the coverage of word-level
UMLS match for retrieving the combination of CUIs present be-
tween the 2 datasets. Finally, we broke down our analysis of CUI set
overlap to identify strings whose dataset ambiguity increases when
combining datasets and strings with fully disjoint annotated CUI
sets.
Qualitative analysis of ambiguous stringsInspired by methodological research demonstrating that different
modeling strategies are appropriate for phenomena such as meton-
ymy65,66 and hyponymy,67–71 we analyzed the ambiguous strings in
each dataset in terms of the following lexical phenomena: homon-
ymy, polysemy, hyponymy, meronymy, co-taxonomy (sibling rela-
tionships), and metonymy (definitions provided in discussion of our
ambiguity typology in the Results).42,43 To measure the ambiguity
captured by the available annotations, we performed our analysis
only at the level of dataset ambiguity (ie, only using the CUIs associ-
ated with the string in a single dataset). For each ambiguous string
Figure 1. Examples of mismatch between medical concept mention string (bold underlined text) and assigned concept unique identifier (shown under the men-
tion), due to (A) coreference and (B) predication. The right side of each subfigure shows the results of querying the Unified Medical Language System (UMLS) for
the mention string with exact match (top) and the preferred string for the annotated concept unique identifier (bottom).
520 Journal of the American Medical Informatics Association, 2021, Vol. 28, No. 3
Dow
nloaded from https://academ
ic.oup.com/jam
ia/article/28/3/516/6034899 by guest on 10 July 2022

in a dataset, we manually reviewed the string, its associated CUIs in
the dataset in question, and the medical concept mention samples
where the string occurs in the dataset, and answered the following 2
questions:
Question 1: How are the different CUIs associated with this
string related to one another?
This question regarded only the set of annotated CUIs and was
agnostic to specific samples in the dataset. We evaluated 2 aspects of
the relationship or relationships between these CUIs: (1) which (if
any) of the previous lexical phenomena was most representative of
the relationship between the CUIs and (2) if any phenomenon partic-
ular to medical language was a contributing factor. We conducted
this analysis only in terms of the high-level phenomena outlined pre-
viously, rather than leveraging the formal semantic relationships be-
tween CUIs in the UMLS; while these relationships are powerful for
downstream applications, they include a variety of nonlinguistic
relationships and were too fine-grained to group a small set of am-
biguous strings informatively.
Question 2: Are the CUI-level differences reflected in the annotations?
Given the breadth of concepts in the UMLS, and the subjective
nature of annotation, we analyzed whether the CUI assignments in
the dataset samples were meaningfully different, and if they reflected
the sample-agnostic relationship between the CUIs.
Ambiguity annotations
Based on our answers to these questions, we determined 3 variables
for each string:
• Category—the primary linguistic or conceptual phenomenon un-
derlying the observed ambiguity;• Subcategory—the biomedicine-specific phenomenon contribut-
ing to a pattern of ambiguity; and• Arbitrary—the determination of whether the CUIs’ use reflected
their conceptual difference.
Annotation was conducted by 4 authors (D.N.-G., G.D., B.D.,
A.Z.) in 3 phases: (1) initial categorization of the ambiguous strings
in n2c2 2019 and SemEval-2015, (2) validation of the resulting ty-
pology through joint annotation and adjudication of 30 random am-
biguous strings from n2c2 2019, and (3) reannotation of all datasets
with the finalized typology. For further details, please see the Sup-
plementary Appendix.
Handling compositional CUIs in CUILESS2016
Compositional annotations in CUILESS2016 presented 2 variables
for ambiguity analysis: single- or multiple-CUI annotations, and am-
biguity of annotations across samples. We categorized each string in
CUILESS as having (1) unambiguous single-CUI annotation, (2) un-
ambiguous multi-CUI annotation, (3) ambiguous single-CUI annota-
tion, or (4) ambiguous annotations with both single- and multi-CUI
labels. The latter 2 categories were considered ambiguous for our
analysis.
RESULTS
Quantitative measurements of string ambiguityAmbiguity within individual datasets
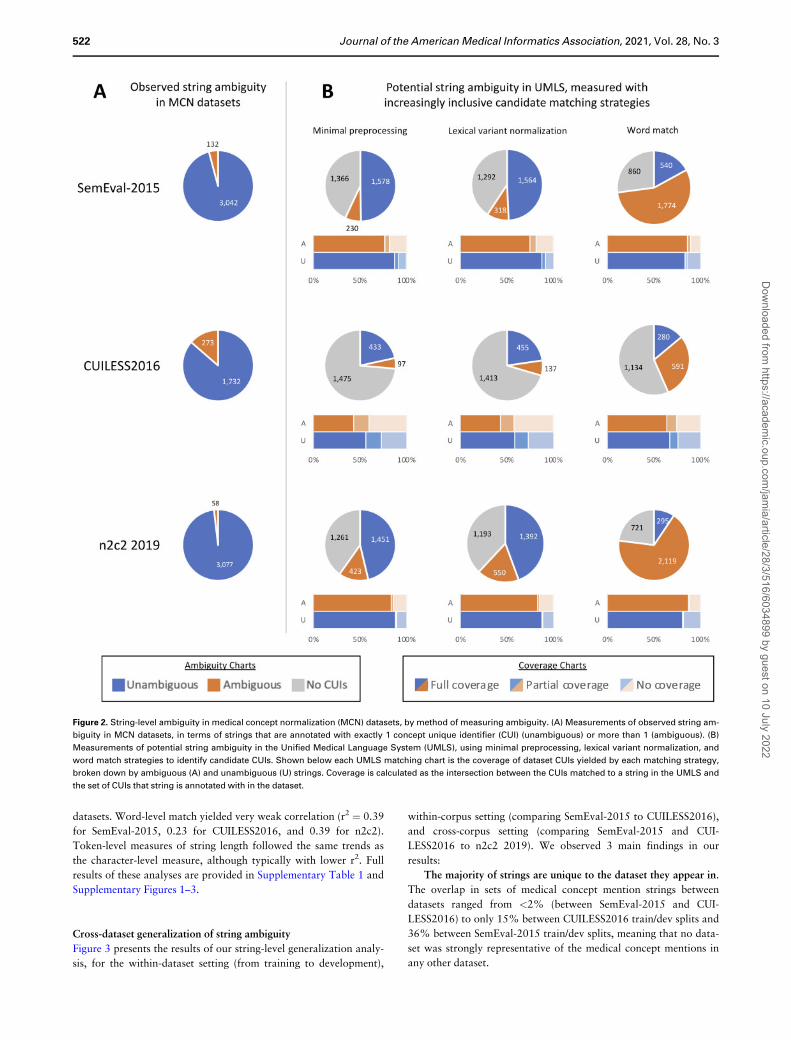
Figure 2 presents the results of our string-level ambiguity analysis
across the 3 datasets. For a fair comparison with the UMLS, we
omitted dataset annotations that were not found in the correspond-
ing version of the UMLS (including “CUI-less,” annotation errors,
and CUIs remapped within the UMLS); Table 2 provides the number
of these annotations and the number of strings analyzed. We ob-
served 5 main findings from our results:
Observed dataset ambiguity is not representative of potential
UMLS ambiguity. Only 2%-14% of strings were ambiguous at the
dataset level (across SemEval-2015, CUILESS2016, and n2c2 2019)
(ie, these strings were associated with more than 1 CUI within a sin-
gle dataset). However, many more strings exhibited potential ambi-
guity, as measured in the UMLS with our 3 candidate matching
strategies. Using minimal preprocessing, in the cases in which at
least 1 CUI was identified for a query string, 13%-23% of strings
were ambiguous; lexical variant normalization increased this to
17%-28%, and word matching yielded 68%-88% ambiguous
strings. The difference was most striking in n2c2 2019: only 58
strings were ambiguous in the dataset (after removing “CUI-less”
samples), but 2,119 strings had potential ambiguity as measured
with word matching, a 37-fold increase.
Many dataset strings do not match any CUIs. A total of 40%-
43% of strings in SemEval-2015 and n2c2 did not yield any CUIs
when using minimal preprocessing to match to the UMLS (74% in
CUILESS2016). Lexical variant normalization increased coverage
somewhat, with 38%-41% of strings failing to match to the UMLS
in SemEval-2015 and n2c2 (70% in CUILESS2016); word-level
search had much better coverage, only yielding empty results for
23%-27% of CUIs in SemEval-2015 and n2c2 and 57% in CUI-
LESS2016. As CUILESS2016 strings often combine multiple con-
cepts, matching statistics are necessarily pessimistic for this dataset.
UMLS matching misses a significant portion of annotated CUIs.
As shown in Figure 2, for the subset of SemEval-2015 and n2c2
2019 strings in which any of the UMLS matching strategies yielded
at least 1 candidate CUI, 8%-23% of the time the identified candi-
date sets did not include any of the CUIs with which those strings
were actually annotated in the datasets. This was consistent for both
strings returning only 1 CUI and strings returning multiple CUIs.
The complex mentions in CUILESS2016 again yielded lower cover-
age: 24%-30% of strings returning only 1 CUI did not return a cor-
rect one and 25%-42% of strings returning multiple CUIs missed all
of the annotated CUIs. This indicates that coverage of both syno-
nyms and lexical variants in the UMLS remains an active challenge
for clinical language.
High coverage yields high ambiguity. Table 2 provides statistics
on the number of CUIs returned for strings from the 3 datasets in
which any of the UMLS candidate matching strategies yielded more
than 1 CUI. Both minimal preprocessing and lexical variant normal-
ization yield a median CUI count per ambiguous string of 2, al-
though higher maxima (maximum 11 CUIs with minimal
preprocessing, maximum 20 CUIs with lexical variant normaliza-
tion) skew the mean number of CUIs per string higher. By contrast,
word matching, which achieves the best coverage of dataset strings
by far, ranges in median ambiguity from 8 in CUILESS2016 to 20 in
n2c2 2019, with maxima over 100 CUIs in all 3 datasets. Thus, ef-
fectively choosing between a large number of candidates is a key
challenge for high-coverage MCN.
Character-level string length is weakly negatively correlated with
ambiguity measures. Following prior findings that shorter terms
tend to be more ambiguous in biomedical literature,63 we observed
r2 values above 0.5 between character-based string length and data-
set ambiguity, UMLS ambiguity with minimal preprocessing, and
UMLS ambiguity with lexical variant normalization in all 3 EHR
Journal of the American Medical Informatics Association, 2021, Vol. 28, No. 3 521
Dow
nloaded from https://academ
ic.oup.com/jam
ia/article/28/3/516/6034899 by guest on 10 July 2022
datasets. Word-level match yielded very weak correlation (r2 ¼ 0.39
for SemEval-2015, 0.23 for CUILESS2016, and 0.39 for n2c2).
Token-level measures of string length followed the same trends as
the character-level measure, although typically with lower r2. Full
results of these analyses are provided in Supplementary Table 1 and
Supplementary Figures 1–3.
Cross-dataset generalization of string ambiguity
Figure 3 presents the results of our string-level generalization analy-
sis, for the within-dataset setting (from training to development),
within-corpus setting (comparing SemEval-2015 to CUILESS2016),
and cross-corpus setting (comparing SemEval-2015 and CUI-
LESS2016 to n2c2 2019). We observed 3 main findings in our
results:
The majority of strings are unique to the dataset they appear in.
The overlap in sets of medical concept mention strings between
datasets ranged from <2% (between SemEval-2015 and CUI-
LESS2016) to only 15% between CUILESS2016 train/dev splits and
36% between SemEval-2015 train/dev splits, meaning that no data-
set was strongly representative of the medical concept mentions in
any other dataset.
Figure 2. String-level ambiguity in medical concept normalization (MCN) datasets, by method of measuring ambiguity. (A) Measurements of observed string am-
biguity in MCN datasets, in terms of strings that are annotated with exactly 1 concept unique identifier (CUI) (unambiguous) or more than 1 (ambiguous). (B)
Measurements of potential string ambiguity in the Unified Medical Language System (UMLS), using minimal preprocessing, lexical variant normalization, and
word match strategies to identify candidate CUIs. Shown below each UMLS matching chart is the coverage of dataset CUIs yielded by each matching strategy,
broken down by ambiguous (A) and unambiguous (U) strings. Coverage is calculated as the intersection between the CUIs matched to a string in the UMLS and
the set of CUIs that string is annotated with in the dataset.
522 Journal of the American Medical Informatics Association, 2021, Vol. 28, No. 3
Dow
nloaded from https://academ
ic.oup.com/jam
ia/article/28/3/516/6034899 by guest on 10 July 2022
Most shared strings have differences in their annotated CUIs. In
all comparisons other than the SemEval-2015 training and develop-
ment datasets, over 45% of the strings shared between a pair of data-
sets were annotated with at least 1 CUI that was only present in 1 of
the 2 datasets (18% of strings even in the case of SemEval-2015 train-
ing and development datasets). Of these, between 33%-74% had
completely disjoint sets of annotated CUIs between the 2 datasets com-
pared. While many of these cases reflected hierarchical differences, a
significant number involved truly distinct senses between datasets.
UMLS match consistently fails to yield all annotated CUIs across
combined datasets. Reflecting our earlier observations within indi-
vidual datasets, word-level UMLS matching was able to fully re-
trieve all CUIs in the combined annotation set for a fair portion of
shared strings (42%-55% in within-dataset comparisons; 54%-85%
in cross-corpus comparisons). However, it failed to retrieve any of
the combined CUIs for 26%-54% of the shared strings.
Figure 4 illustrates changes in ambiguity for shared strings be-
tween the dataset pairs, in terms of how many strings had nonidenti-
cal annotated CUI sets, how many strings in each dataset would
increase in ambiguity if the CUI sets were combined, and how many
of these would switch from being unambiguous to ambiguous when
combining cross-dataset CUI sets. We found that of the sets of
strings shared between any pair of datasets with nonidentical CUI
annotations, between 50% and 100% of the strings in each of these
sets were annotated with at least 1 CUI in one of the datasets that
was not present in the other. Further, up to 66% of the strings with
any annotation differences went from being unambiguous to ambig-
uous when CUI sets were combined across the dataset pairs. Finally,
we found that up to 89% of the strings that had fully disjoint CUI
sets between the 2 datasets were originally unambiguous in each
dataset, indicating that memorizing term-CUI normalization would
work perfectly in each dataset but fail entirely on the other.
Ambiguity typologyWe identified 12 distinct causes of the ambiguity observed in the
datasets, organized into 5 broad categories. Table 3 presents our ty-
pology, with examples of each ambiguity type; brief descriptions of
each overall category are provided subsequently. We refer the inter-
ested reader to the Supplementary Appendix for a more in-depth dis-
cussion.
Polysemy
We combined homonymy (completely disjoint senses) and polysemy
(distinct but related senses)42,43 under the category of Polysemy for
our analysis. While we observed instances of both homonymy and
polysemy, we found no actionable reason to differentiate between
them, particularly as other phenomena causing polysemy (eg, me-
tonymy, hyponymy) were covered by other categories. Thus, the Po-
lysemy category captured cases in which more specific phenomena
were not observed and the annotated CUIs were clearly distinct
from one another. As there is extensive literature on resolving abbre-
viations and acronyms,31–35 we treated cases involving abbrevia-
tions as a dedicated subcategory (Abbreviation; our other
subcategory was Nonabbreviation).
Metonymy
Clinical language is telegraphic, meaning that complex concepts are
often referred to by simpler associated forms. Normalizing these
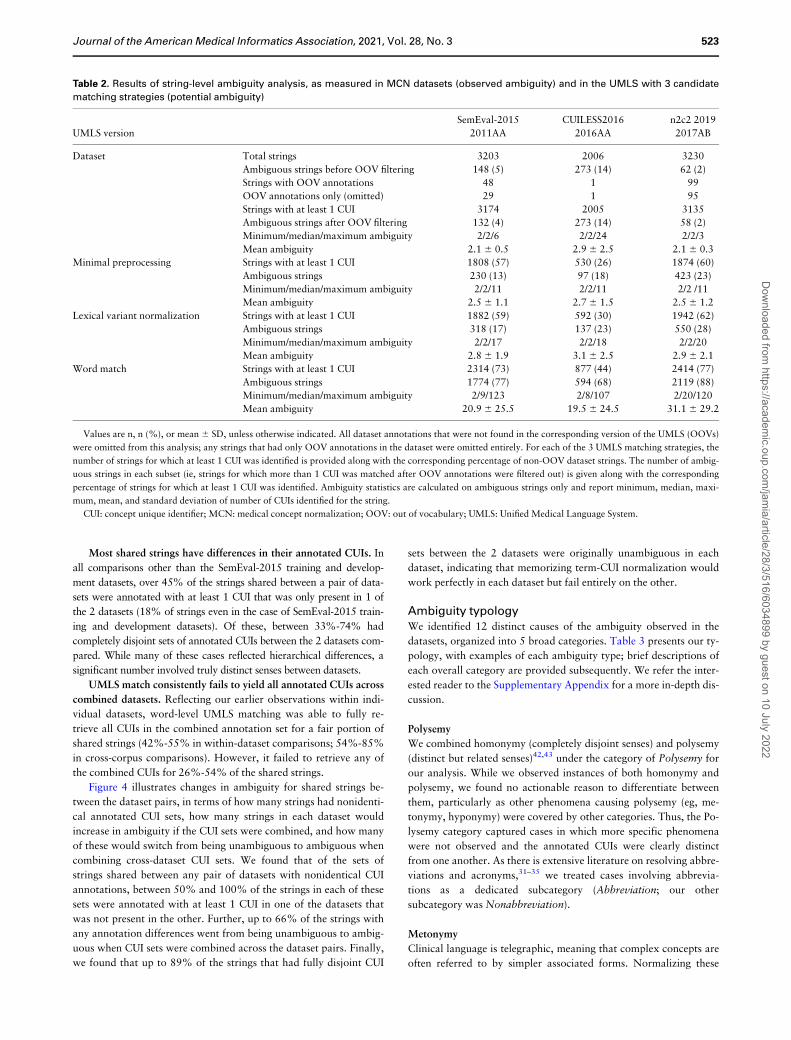
Table 2. Results of string-level ambiguity analysis, as measured in MCN datasets (observed ambiguity) and in the UMLS with 3 candidate
matching strategies (potential ambiguity)
SemEval-2015 CUILESS2016 n2c2 2019
UMLS version 2011AA 2016AA 2017AB
Dataset Total strings 3203 2006 3230
Ambiguous strings before OOV filtering 148 (5) 273 (14) 62 (2)
Strings with OOV annotations 48 1 99
OOV annotations only (omitted) 29 1 95
Strings with at least 1 CUI 3174 2005 3135
Ambiguous strings after OOV filtering 132 (4) 273 (14) 58 (2)
Minimum/median/maximum ambiguity 2/2/6 2/2/24 2/2/3
Mean ambiguity 2.1 6 0.5 2.9 6 2.5 2.1 6 0.3
Minimal preprocessing Strings with at least 1 CUI 1808 (57) 530 (26) 1874 (60)
Ambiguous strings 230 (13) 97 (18) 423 (23)
Minimum/median/maximum ambiguity 2/2/11 2/2/11 2/2 /11
Mean ambiguity 2.5 6 1.1 2.7 6 1.5 2.5 6 1.2
Lexical variant normalization Strings with at least 1 CUI 1882 (59) 592 (30) 1942 (62)
Ambiguous strings 318 (17) 137 (23) 550 (28)
Minimum/median/maximum ambiguity 2/2/17 2/2/18 2/2/20
Mean ambiguity 2.8 6 1.9 3.1 6 2.5 2.9 6 2.1
Word match Strings with at least 1 CUI 2314 (73) 877 (44) 2414 (77)
Ambiguous strings 1774 (77) 594 (68) 2119 (88)
Minimum/median/maximum ambiguity 2/9/123 2/8/107 2/20/120
Mean ambiguity 20.9 6 25.5 19.5 6 24.5 31.1 6 29.2
Values are n, n (%), or mean 6 SD, unless otherwise indicated. All dataset annotations that were not found in the corresponding version of the UMLS (OOVs)
were omitted from this analysis; any strings that had only OOV annotations in the dataset were omitted entirely. For each of the 3 UMLS matching strategies, the
number of strings for which at least 1 CUI was identified is provided along with the corresponding percentage of non-OOV dataset strings. The number of ambig-
uous strings in each subset (ie, strings for which more than 1 CUI was matched after OOV annotations were filtered out) is given along with the corresponding
percentage of strings for which at least 1 CUI was identified. Ambiguity statistics are calculated on ambiguous strings only and report minimum, median, maxi-
mum, mean, and standard deviation of number of CUIs identified for the string.
CUI: concept unique identifier; MCN: medical concept normalization; OOV: out of vocabulary; UMLS: Unified Medical Language System.
Journal of the American Medical Informatics Association, 2021, Vol. 28, No. 3 523
Dow
nloaded from https://academ
ic.oup.com/jam
ia/article/28/3/516/6034899 by guest on 10 July 2022
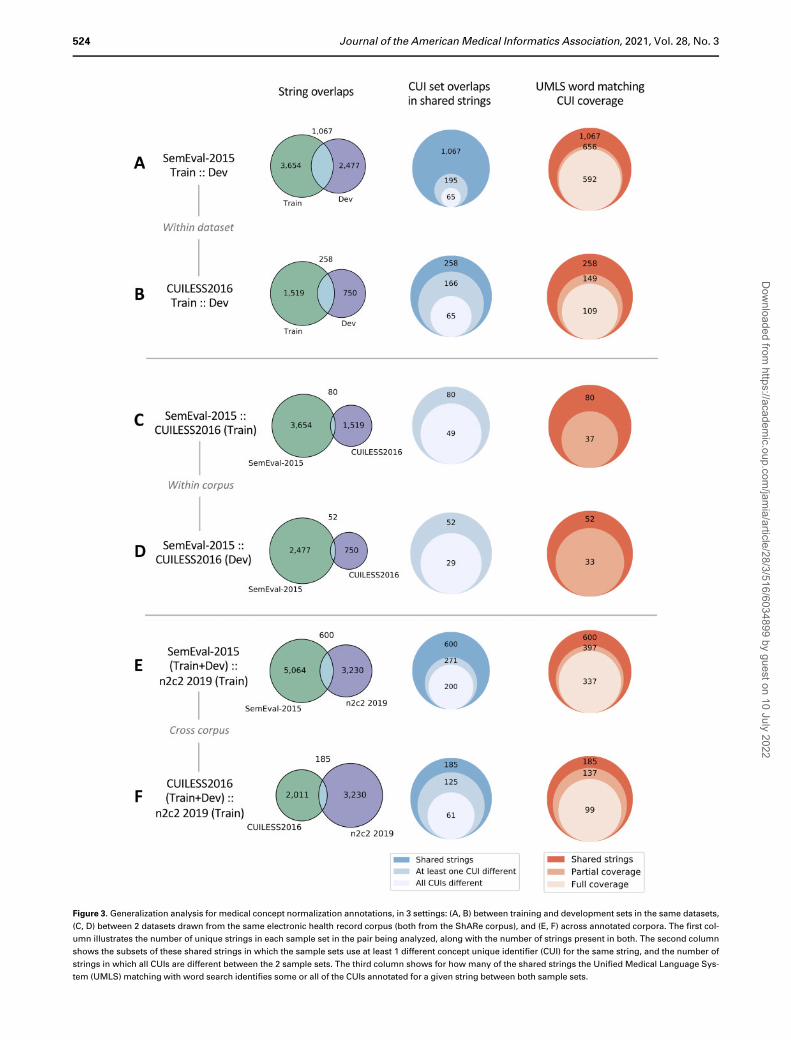
Figure 3. Generalization analysis for medical concept normalization annotations, in 3 settings: (A, B) between training and development sets in the same datasets,
(C, D) between 2 datasets drawn from the same electronic health record corpus (both from the ShARe corpus), and (E, F) across annotated corpora. The first col-
umn illustrates the number of unique strings in each sample set in the pair being analyzed, along with the number of strings present in both. The second column
shows the subsets of these shared strings in which the sample sets use at least 1 different concept unique identifier (CUI) for the same string, and the number of
strings in which all CUIs are different between the 2 sample sets. The third column shows for how many of the shared strings the Unified Medical Language Sys-
tem (UMLS) matching with word search identifies some or all of the CUIs annotated for a given string between both sample sets.
524 Journal of the American Medical Informatics Association, 2021, Vol. 28, No. 3
Dow
nloaded from https://academ
ic.oup.com/jam
ia/article/28/3/516/6034899 by guest on 10 July 2022
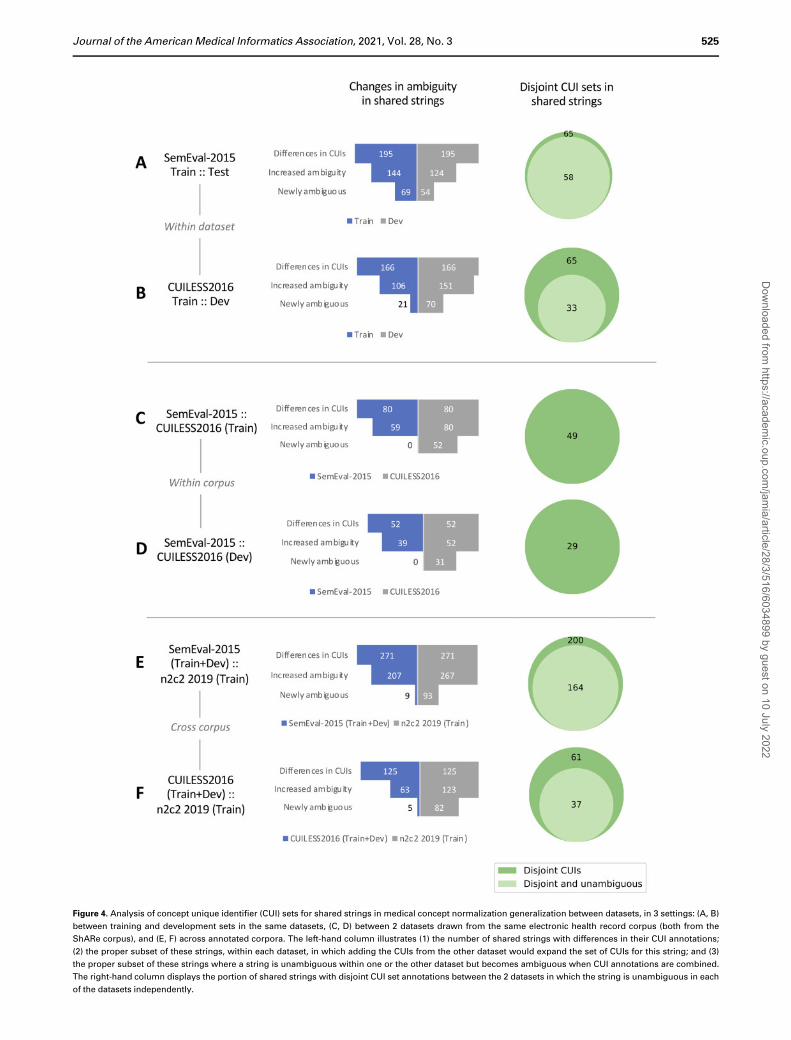
Figure 4. Analysis of concept unique identifier (CUI) sets for shared strings in medical concept normalization generalization between datasets, in 3 settings: (A, B)
between training and development sets in the same datasets, (C, D) between 2 datasets drawn from the same electronic health record corpus (both from the
ShARe corpus), and (E, F) across annotated corpora. The left-hand column illustrates (1) the number of shared strings with differences in their CUI annotations;
(2) the proper subset of these strings, within each dataset, in which adding the CUIs from the other dataset would expand the set of CUIs for this string; and (3)
the proper subset of these strings where a string is unambiguous within one or the other dataset but becomes ambiguous when CUI annotations are combined.
The right-hand column displays the portion of shared strings with disjoint CUI set annotations between the 2 datasets in which the string is unambiguous in each
of the datasets independently.
Journal of the American Medical Informatics Association, 2021, Vol. 28, No. 3 525
Dow
nloaded from https://academ
ic.oup.com/jam
ia/article/28/3/516/6034899 by guest on 10 July 2022
references requires inference from their context: for example, a ref-
erence to “sodium” within lab readings implies a measurement of
sodium levels, a distinct concept in the UMLS. It is noteworthy that
in some cases, examples of the Metonymy category may be consid-
ered as annotation errors, illustrating the complexity of metonymy
in practice; for example, the case of “Sodium 139, [potassium] 4.7”
included in Table 3, annotated as C0032821 Potassium (substance),
would be better annotated as C0428289 Finding of potassium level.
As these concepts are semantically related (while ontologically dis-
tinct), we included such cases in the category of Metonymy. We ob-
served 3 primary trends in metonymic annotations: reference to a
procedure by an associated biological property (Procedure vs Con-
cept), mention of a biological substance to refer to its measurement
(Measurement vs Substance), and the fact that many symptomatic
findings can also be formal diagnoses (Symptom vs Diagnosis; eg,
“emphysema,” “depression”). Other examples of Metonymy falling
outside these trends were placed in the Other subcategory.
Specificity
The rich semantic distinctions in the UMLS (eg, phenotypic variants
of a disease) lead to frequent ambiguity of Specificity. The ambiguity
was often taxonomic, captured as Hierarchical; the other pattern
observed was ambiguity in grammatical number of a finding, typi-
cally due to inflection (eg, “no injuries” meaning not a single injury)
or recurrence (denoted Recurrence/Number).
Synonymy
Many strings were annotated with CUIs that were effectively synon-
ymous; we therefore followed Cruse’s42 definition of Propositional
Synonymy, in which ontologically distinct senses nonetheless yield
the same propositional interpretation of a statement. We also in-
cluded Co-taxonymy in this category, typically involving annotation
with either overspecified CUIs or CUIs separated only by negation.
Error
A small number of ambiguity cases were due to erroneous annota-
tions stemming from 2 causes: (1) typological errors in data entry
(Typos) and (2) selection of an inappropriate CUI (Semantic).
Ambiguity types in each datasetAs with our measurements of string ambiguity, we excluded all data-
set samples annotated as “CUI-less” for analysis of ambiguity type,
as these reflect annotation challenges beyond the ambiguity level.
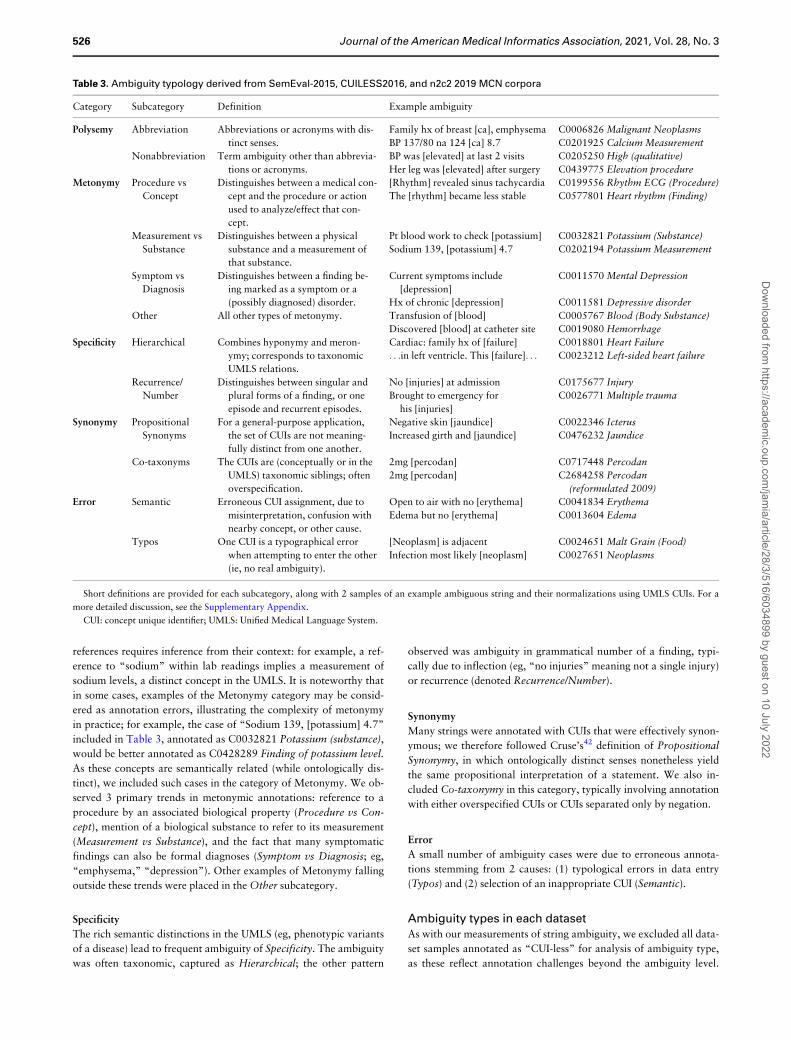
Table 3. Ambiguity typology derived from SemEval-2015, CUILESS2016, and n2c2 2019 MCN corpora
Category Subcategory Definition Example ambiguity
Polysemy Abbreviation Abbreviations or acronyms with dis-
tinct senses.
Family hx of breast [ca], emphysema C0006826 Malignant Neoplasms
BP 137/80 na 124 [ca] 8.7 C0201925 Calcium Measurement
Nonabbreviation Term ambiguity other than abbrevia-
tions or acronyms.
BP was [elevated] at last 2 visits C0205250 High (qualitative)
Her leg was [elevated] after surgery C0439775 Elevation procedure
Metonymy Procedure vs
Concept
Distinguishes between a medical con-
cept and the procedure or action
used to analyze/effect that con-
cept.
[Rhythm] revealed sinus tachycardia C0199556 Rhythm ECG (Procedure)
The [rhythm] became less stable C0577801 Heart rhythm (Finding)
Measurement vs
Substance
Distinguishes between a physical
substance and a measurement of
that substance.
Pt blood work to check [potassium] C0032821 Potassium (Substance)
Sodium 139, [potassium] 4.7 C0202194 Potassium Measurement
Symptom vs
Diagnosis
Distinguishes between a finding be-
ing marked as a symptom or a
(possibly diagnosed) disorder.
Current symptoms include
[depression]
C0011570 Mental Depression
Hx of chronic [depression] C0011581 Depressive disorder
Other All other types of metonymy. Transfusion of [blood] C0005767 Blood (Body Substance)
Discovered [blood] at catheter site C0019080 Hemorrhage
Specificity Hierarchical Combines hyponymy and meron-
ymy; corresponds to taxonomic
UMLS relations.
Cardiac: family hx of [failure] C0018801 Heart Failure
. . .in left ventricle. This [failure]. . . C0023212 Left-sided heart failure
Recurrence/
Number
Distinguishes between singular and
plural forms of a finding, or one
episode and recurrent episodes.
No [injuries] at admission C0175677 Injury
Brought to emergency for
his [injuries]
C0026771 Multiple trauma
Synonymy Propositional
Synonyms
For a general-purpose application,
the set of CUIs are not meaning-
fully distinct from one another.
Negative skin [jaundice] C0022346 Icterus
Increased girth and [jaundice] C0476232 Jaundice
Co-taxonyms The CUIs are (conceptually or in the
UMLS) taxonomic siblings; often
overspecification.
2mg [percodan] C0717448 Percodan
2mg [percodan] C2684258 Percodan
(reformulated 2009)
Error Semantic Erroneous CUI assignment, due to
misinterpretation, confusion with
nearby concept, or other cause.
Open to air with no [erythema] C0041834 Erythema
Edema but no [erythema] C0013604 Edema
Typos One CUI is a typographical error
when attempting to enter the other
(ie, no real ambiguity).
[Neoplasm] is adjacent C0024651 Malt Grain (Food)
Infection most likely [neoplasm] C0027651 Neoplasms
Short definitions are provided for each subcategory, along with 2 samples of an example ambiguous string and their normalizations using UMLS CUIs. For a
more detailed discussion, see the Supplementary Appendix.
CUI: concept unique identifier; UMLS: Unified Medical Language System.
526 Journal of the American Medical Informatics Association, 2021, Vol. 28, No. 3
Dow
nloaded from https://academ
ic.oup.com/jam
ia/article/28/3/516/6034899 by guest on 10 July 2022
However, we retained samples with annotation errors and CUIs
remapped within the UMLS, as these samples inform MCN evalua-
tion in these datasets, and ambiguity type analysis did not require di-
rect comparison to string-CUI associations in the UMLS. This
increased the number of ambiguous strings in SemEval-2015 from
132 to 148; ambiguous string counts in CUILESS2016 and n2c2
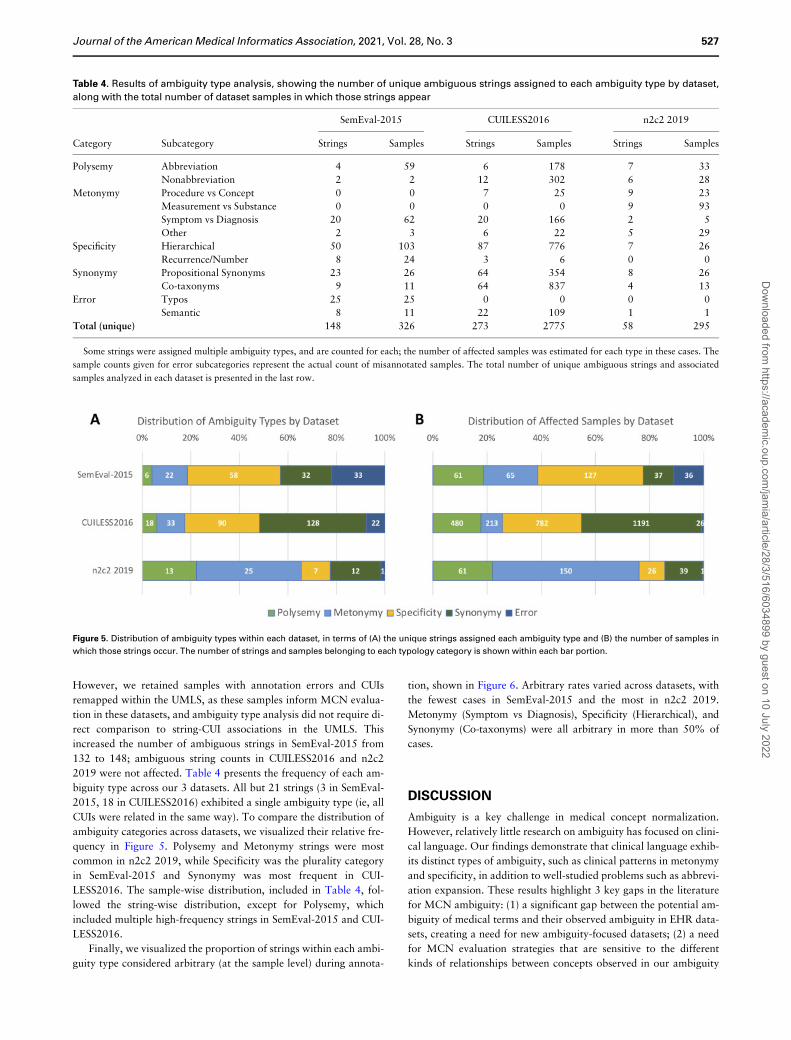
2019 were not affected. Table 4 presents the frequency of each am-
biguity type across our 3 datasets. All but 21 strings (3 in SemEval-
2015, 18 in CUILESS2016) exhibited a single ambiguity type (ie, all
CUIs were related in the same way). To compare the distribution of
ambiguity categories across datasets, we visualized their relative fre-
quency in Figure 5. Polysemy and Metonymy strings were most
common in n2c2 2019, while Specificity was the plurality category
in SemEval-2015 and Synonymy was most frequent in CUI-
LESS2016. The sample-wise distribution, included in Table 4, fol-
lowed the string-wise distribution, except for Polysemy, which
included multiple high-frequency strings in SemEval-2015 and CUI-
LESS2016.
Finally, we visualized the proportion of strings within each ambi-
guity type considered arbitrary (at the sample level) during annota-
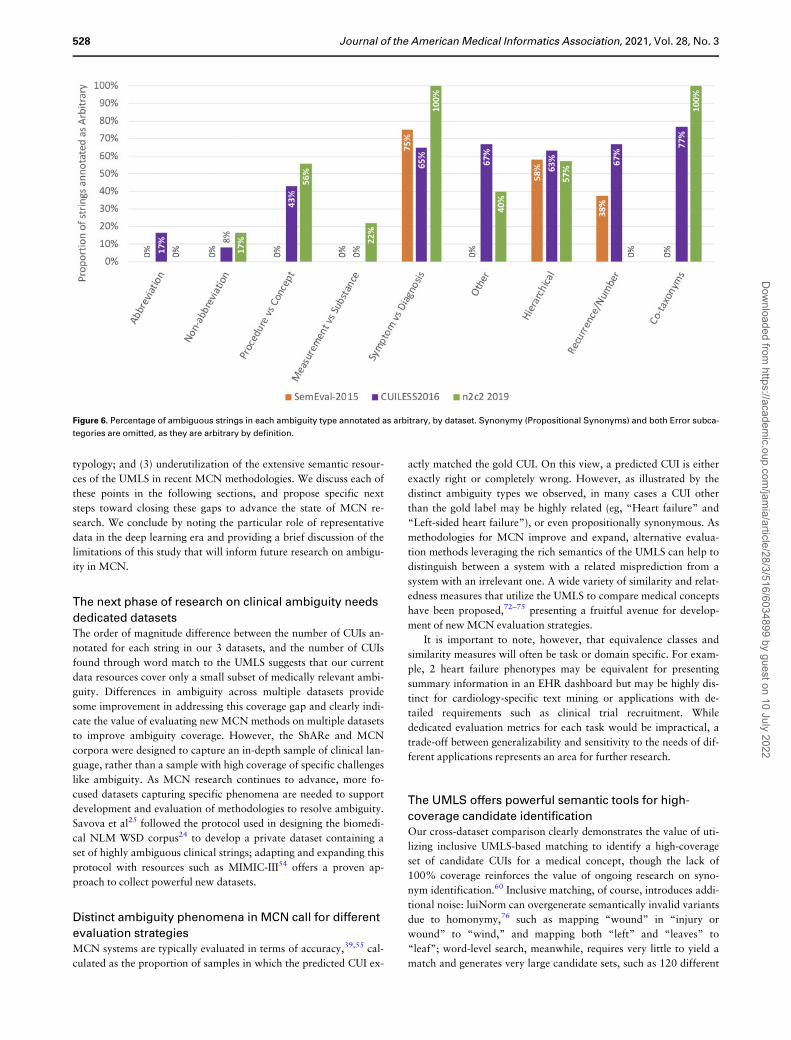
tion, shown in Figure 6. Arbitrary rates varied across datasets, with
the fewest cases in SemEval-2015 and the most in n2c2 2019.
Metonymy (Symptom vs Diagnosis), Specificity (Hierarchical), and
Synonymy (Co-taxonyms) were all arbitrary in more than 50% of
cases.
DISCUSSION
Ambiguity is a key challenge in medical concept normalization.
However, relatively little research on ambiguity has focused on clini-
cal language. Our findings demonstrate that clinical language exhib-
its distinct types of ambiguity, such as clinical patterns in metonymy
and specificity, in addition to well-studied problems such as abbrevi-
ation expansion. These results highlight 3 key gaps in the literature
for MCN ambiguity: (1) a significant gap between the potential am-
biguity of medical terms and their observed ambiguity in EHR data-
sets, creating a need for new ambiguity-focused datasets; (2) a need
for MCN evaluation strategies that are sensitive to the different
kinds of relationships between concepts observed in our ambiguity
Table 4. Results of ambiguity type analysis, showing the number of unique ambiguous strings assigned to each ambiguity type by dataset,
along with the total number of dataset samples in which those strings appear
SemEval-2015 CUILESS2016 n2c2 2019
Category Subcategory Strings Samples Strings Samples Strings Samples
Polysemy Abbreviation 4 59 6 178 7 33
Nonabbreviation 2 2 12 302 6 28
Metonymy Procedure vs Concept 0 0 7 25 9 23
Measurement vs Substance 0 0 0 0 9 93
Symptom vs Diagnosis 20 62 20 166 2 5
Other 2 3 6 22 5 29
Specificity Hierarchical 50 103 87 776 7 26
Recurrence/Number 8 24 3 6 0 0
Synonymy Propositional Synonyms 23 26 64 354 8 26
Co-taxonyms 9 11 64 837 4 13
Error Typos 25 25 0 0 0 0
Semantic 8 11 22 109 1 1
Total (unique) 148 326 273 2775 58 295
Some strings were assigned multiple ambiguity types, and are counted for each; the number of affected samples was estimated for each type in these cases. The
sample counts given for error subcategories represent the actual count of misannotated samples. The total number of unique ambiguous strings and associated
samples analyzed in each dataset is presented in the last row.
Figure 5. Distribution of ambiguity types within each dataset, in terms of (A) the unique strings assigned each ambiguity type and (B) the number of samples in
which those strings occur. The number of strings and samples belonging to each typology category is shown within each bar portion.
Journal of the American Medical Informatics Association, 2021, Vol. 28, No. 3 527
Dow
nloaded from https://academ
ic.oup.com/jam
ia/article/28/3/516/6034899 by guest on 10 July 2022
typology; and (3) underutilization of the extensive semantic resour-
ces of the UMLS in recent MCN methodologies. We discuss each of
these points in the following sections, and propose specific next
steps toward closing these gaps to advance the state of MCN re-
search. We conclude by noting the particular role of representative
data in the deep learning era and providing a brief discussion of the
limitations of this study that will inform future research on ambigu-
ity in MCN.
The next phase of research on clinical ambiguity needs
dedicated datasetsThe order of magnitude difference between the number of CUIs an-
notated for each string in our 3 datasets, and the number of CUIs
found through word match to the UMLS suggests that our current
data resources cover only a small subset of medically relevant ambi-
guity. Differences in ambiguity across multiple datasets provide
some improvement in addressing this coverage gap and clearly indi-
cate the value of evaluating new MCN methods on multiple datasets
to improve ambiguity coverage. However, the ShARe and MCN
corpora were designed to capture an in-depth sample of clinical lan-
guage, rather than a sample with high coverage of specific challenges
like ambiguity. As MCN research continues to advance, more fo-
cused datasets capturing specific phenomena are needed to support
development and evaluation of methodologies to resolve ambiguity.
Savova et al25 followed the protocol used in designing the biomedi-
cal NLM WSD corpus24 to develop a private dataset containing a
set of highly ambiguous clinical strings; adapting and expanding this
protocol with resources such as MIMIC-III54 offers a proven ap-
proach to collect powerful new datasets.
Distinct ambiguity phenomena in MCN call for different
evaluation strategiesMCN systems are typically evaluated in terms of accuracy,39,55 cal-
culated as the proportion of samples in which the predicted CUI ex-
actly matched the gold CUI. On this view, a predicted CUI is either
exactly right or completely wrong. However, as illustrated by the
distinct ambiguity types we observed, in many cases a CUI other
than the gold label may be highly related (eg, “Heart failure” and
“Left-sided heart failure”), or even propositionally synonymous. As
methodologies for MCN improve and expand, alternative evalua-
tion methods leveraging the rich semantics of the UMLS can help to
distinguish between a system with a related misprediction from a
system with an irrelevant one. A wide variety of similarity and relat-
edness measures that utilize the UMLS to compare medical concepts
have been proposed,72–75 presenting a fruitful avenue for develop-
ment of new MCN evaluation strategies.
It is important to note, however, that equivalence classes and
similarity measures will often be task or domain specific. For exam-
ple, 2 heart failure phenotypes may be equivalent for presenting
summary information in an EHR dashboard but may be highly dis-
tinct for cardiology-specific text mining or applications with de-
tailed requirements such as clinical trial recruitment. While
dedicated evaluation metrics for each task would be impractical, a
trade-off between generalizability and sensitivity to the needs of dif-
ferent applications represents an area for further research.
The UMLS offers powerful semantic tools for high-
coverage candidate identificationOur cross-dataset comparison clearly demonstrates the value of uti-
lizing inclusive UMLS-based matching to identify a high-coverage
set of candidate CUIs for a medical concept, though the lack of
100% coverage reinforces the value of ongoing research on syno-
nym identification.60 Inclusive matching, of course, introduces addi-
tional noise: luiNorm can overgenerate semantically invalid variants
due to homonymy,76 such as mapping “wound” in “injury or
wound” to “wind,” and mapping both “left” and “leaves” to
“leaf”; word-level search, meanwhile, requires very little to yield a
match and generates very large candidate sets, such as 120 different
Figure 6. Percentage of ambiguous strings in each ambiguity type annotated as arbitrary, by dataset. Synonymy (Propositional Synonyms) and both Error subca-
tegories are omitted, as they are arbitrary by definition.
528 Journal of the American Medical Informatics Association, 2021, Vol. 28, No. 3
Dow
nloaded from https://academ
ic.oup.com/jam
ia/article/28/3/516/6034899 by guest on 10 July 2022

candidate CUIs for “incision.” However, a variety of syntactically
and semantically informed heuristics can help to filter out uninfor-
mative candidates, including a variety of semantic tools in the
UMLS.76 Contextual features such as identifying document sections
can significantly reduce false positive rates for information extraction;77
for example, a simple regular expression to detect phrase and number
alternations would help identify lab readings sections and resolve ambi-
guity in over 70% of our observed Metonymy (Measurement vs Sub-
stance) samples. In our analysis, filtering the candidate list from UMLS
word-level search to the correct semantic type reduced ambiguity by
37% on average in SemEval-2015 data and by 56% in n2c2 2019 data
(compositional annotations in CUILESS2016 make analysis of ambigu-
ity reduction impractical), demonstrating significant value from seman-
tic type prediction as a component of MCN. Figueroa et al78 and
Patterson and Hurdle79 described sublanguage-based approaches to
prune out unrelated segments of the UMLS in text analysis; similar
methods leveraging UMLS semantics present a clear opportunity for re-
search on MCN methods.
Deep learning for MCN needs data that capture
ambiguityMachine learning techniques, particularly deep neural network–based
models, are increasingly being studied to replace or augment string-
based systems for MCN.80–83 The rush to develop deep learning systems
for MCN only increases the need for data that are more representative
of ambiguity, in 2 distinct ways: modeling a selection process from
many candidate CUIs, and getting an accurate picture of system utility
in evaluation. Deep learning systems for MCN largely model the task as
choosing the right CUI from an entire vocabulary; while this helps to
mitigate the issues we observed of incomplete coverage of annotated
CUIs with even the word-level UMLS matching strategy, it also presents
a much harder problem to solve than choosing between a set of high-
confidence CUIs matched to a string with a rule-based method. More
samples of clinical ambiguity will be highly informative for training
these models, by requiring training to focus on distinguishing between
easily confusable candidates.
More critically, evaluating deep learning systems for MCN with-
out data that are sufficiently representative of ambiguity makes it
very likely that trained models will make serious errors in concept
normalization that will propagate into any downstream clinical tool
building on the deep learning system. For example, the n2c2 2019
training set has only 62 ambiguous strings (the 58 analyzed in this
work plus 4 that are only ambiguous due to “CUI-less” annotations)
out of over 3,200 total strings; it would therefore be quite possible
to achieve high performance on this dataset with a system that
ignores the context of any concept mention it sees and normalizes it
based on a preferred CUI for that term alone. Thus, the same CUI
would be predicted for “depression” in “tender abdominal
depression” and “history of chronic depression,” an error that
would not be reflected in evaluation without annotated examples of
each sense. More practical systems will suffer equally without ap-
propriate evaluation data, as the performance metrics reported for a
system on a nonambiguous dataset will not be an accurate reflection
of its utility with ambiguous language in practice.
LimitationsThe primary limitation of our study was the lack of a broader collec-
tion of clinical datasets for MCN. Because our typology was con-
structed based on the data observed, it is likely that medical
language exhibits ambiguity types that were either not present in
our data or too infrequent to merit a separate subcategory. This is
exacerbated by the limited scope of the datasets analyzed, including
only 4 document types (primarily discharge summaries), with anno-
tations for only a subset of medical concepts in each case (disorders
for ShARe; problems, tests, and treatments for MCN). Thus, our ty-
pology should not be taken as capturing all sources of ambiguity in
clinical language, nor should our observed distributions of category
frequencies be considered universal.
In addition, some ambiguity types were clearer to determine in
practice than others. In particular, Specificity (Hierarchical), Synon-
ymy (Co-taxonyms), and Error (Semantic) accounted for 39 of the
51 strings noted by the annotators as very difficult to classify in CUI-
LESS2016. The typological structure we proposed is one of multiple
that could fit the observed data: for example, “Recurrence/Number”
could be recategorized as Polysemy, and Polysemy could itself be
split between homonymy and polysemy.43 Similarly, several cases of
Metonymy, particularly Measurement vs Substance, fall under the
category of systematic polysemy defined by Pustejovsky and Bogur-
aev, 84 in which polysemy results from a systematic association be-
tween a lexical item and application or measurement of that item,
offering potential recategorization of these cases. Some strings were
also so ambiguous as to defy easy categorization: for example,
“lesion” appears with 24 different labels in CUILESS2016 and
“masses” appears with 20 labels across 50 samples.
Finally, preprocessing decisions affect ambiguity significantly.
Dropping determiners often assisted our analysis, but also errone-
ously collapsed distinct strings like “Hepatitis” and “Hepatitis A.”
We experimented with lemmatization as part of our minimal pre-
processing method but deemed it to combine strings and contexts
too disjoint for a baseline analysis. At the same time, there is signifi-
cant scope for other candidate matching strategies; luiNorm
includes some degree of lemmatization as part of lexical variant
analysis; other tools like BioLemmatizer85 offer alternative
approaches. Word-based search can also be combined with lemmati-
zation approaches to yield even more permissive matching strate-
gies. As observed with lexical variant normalization, the choice of
candidate matching strategy not only can increase the representa-
tiveness of ambiguity, but may also introduce additional noise.
CONCLUSION
Disambiguating words and phrases is a key part of MCN but has been
a subject of limited study in clinical language. We analyzed benchmark
MCN datasets of EHR data and found that only a small portion of
these datasets capture ambiguity, and with much lower concept cover-
age than is available in the UMLS. The ambiguous strings observed
exhibited distinct phenomena from lexical semantics and ontology the-
ory, and these ambiguity types were captured in different proportions
across datasets. Most significantly, we demonstrated that existing data-
sets are not sufficient to cover either all of these phenomena or the di-
versity of ambiguity in the UMLS, impacting both training and
evaluation of MCN methods. Our findings identify 3 opportunities for
future research on improving automated methods for MCN, including
the development of ambiguity-specific clinical datasets, adapting MCN
evaluation measures to reflect the complex relationships between medi-
cal concepts, and leveraging the rich semantics of the UMLS to enhance
new MCN methodologies. Our annotations of ambiguous strings are
available from https://doi.org/10.5061/dryad.r4xgxd29w. The source
code for our analyses is available from https://github.com/CC-RMD-
EpiBio/mcn-ambiguity-analysis.
Journal of the American Medical Informatics Association, 2021, Vol. 28, No. 3 529
Dow
nloaded from https://academ
ic.oup.com/jam
ia/article/28/3/516/6034899 by guest on 10 July 2022

FUNDING
This research was supported by the Intramural Research Program of the Na-
tional Institutes of Health and the U.S. Social Security Administration.
AUTHOR CONTRIBUTIONS
DN-G conceptualized the article, designed methodology, conducted all analy-
ses, and wrote the manuscript. DN-G, GD, BD, and AZ collaboratively vali-
dated and refined the typology and annotated ambiguous strings; GD, BD,
and AZ assisted in editing the manuscript. CPR provided guidance on linguis-
tic conceptualizations, and critically reviewed the manuscript. EF-L assisted
in study conceptualization, and critically reviewed the manuscript.
SUPPLEMENTARY MATERIAL
Supplementary material is available at Journal of the American Medical Infor-
matics Association online.
CONFLICT OF INTEREST STATEMENT
The authors have no conflicts of interest.
REFERENCES
1. Jovanovi�c J, Bagheri E. Semantic annotation in biomedicine: the current
landscape. J Biomed Semantics 2017; 8 (1): 44.
2. Rosenbloom ST, Denny JC, Xu H, Lorenzi N, Stead WW, Johnson KB.
Data from clinical notes: a perspective on the tension between structure
and flexible documentation. J Am Med Inform Assoc 2011; 18 (2): 181–6.
3. Bodenreider O. The Unified Medical Language System (UMLS): integrat-
ing biomedical terminology. Nucleic Acids Res 2004; 32 (Database issue):
D267–70.
4. Weng C, Embi PJ. Informatics approaches to participant recruitment In:
Richesson RL, Andrews JE, eds. Clinical Research Informatics. Cham,
Switzerland: Springer International Publishing; 2019: 109–22.
5. Wu H, Toti G, Morley KI, et al. SemEHR: A general-purpose semantic
search system to surface semantic data from clinical notes for tailored
care, trial recruitment, and clinical research. J Am Med Inform Assoc
2018; 25 (5): 530–7.
6. Lever J, Zhao EY, Grewal J, Jones MR, Jones SJM. CancerMine: a
literature-mined resource for drivers, oncogenes and tumor suppressors in
cancer. Nat Methods 2019; 16 (6): 505–7.
7. Kohler S, Vasilevsky NA, Engelstad M, et al. The Human Phenotype On-
tology in 2017. Nucleic Acids Res 2017; 45 (D1): D865–76.
8. Gonzalez GH, Tahsin T, Goodale BC, Greene AC, Greene CS. Recent
advances and emerging applications in text and data mining for biomedi-
cal discovery. Brief Bioinform 2016; 17 (1): 33–42.
9. Ben Abacha A, Chowdhury MFM, Karanasiou A, Mrabet Y, Lavelli A,
Zweigenbaum P. Text mining for pharmacovigilance: Using machine
learning for drug name recognition and drug–drug interaction extraction
and classification. J Biomed Inform 2015; 58: 122–32.
10. Himmelstein DS, Lizee A, Hessler C, et al. Systematic integration of bio-
medical knowledge prioritizes drugs for repurposing. Elife 2017; 6:
e26726.
11. Al-Hablani B. The use of automated SNOMED CT clinical coding in clini-
cal decision support systems for preventive care. Perspect Heal Inf Manag
2017; 14 (Winter):1f.
12. Savova GK, Masanz JJ, Ogren PV, et al. Mayo clinical Text Analysis and
Knowledge Extraction System (cTAKES): architecture, component evalu-
ation and applications. J Am Med Inform Assoc 2010; 17 (5): 507–13.
13. Soysal E, Wang J, Jiang M, et al. CLAMP – a toolkit for efficiently build-
ing customized clinical natural language processing pipelines. J Am Med
Inform Assoc 2018; 25 (3): 331–6.
14. Elhadad N, Pradhan S, Gorman S, Manandhar S, Chapman W, Savova G.
fSgemfEgval-2015 task 14: analysis of clinical text. In: Proceedings of the
9th International Workshop on Semantic Evaluation (fSgemfEgval
2015). Denver, CO: Association for Computational Linguistics;
2015:303–10.
15. Elkin PL, Brown SH, Husser CS, et al. Evaluation of the content coverage
of SNOMED CT: ability of SNOMED Clinical Terms to represent clinical
problem lists. Mayo Clin Proc 2006; 81 (6): 741–8.
16. He Z, Chen Z, Oh S, Hou J, Bian J. Enriching consumer health vocabulary
through mining a social Q&A site: a similarity-based approach. J Biomed
Inform 2017; 69: 75–85.
17. Kuang J, Mohanty AF, Rashmi VH, Weir CR, Bray BE, Zeng-Treitler Q.
Representation of functional status concepts from clinical documents and
social media sources by standard terminologies. AMIA Annu Symp Proc
2015; 2015: 795–803.
18. Zeng J, Wu Y, Bailey A, et al. Adapting a natural language processing tool
to facilitate clinical trial curation for personalized cancer therapy. AMIA
Jt Summits Transl Sci Proc 2014; 2014: 126–31.
19. Osborne JD, Neu MB, Danila MI, Solorio T, Bethard SJ. CUILESS2016: a
clinical corpus applying compositional normalization of text mentions. J
Biomed Semantics 2018; 9 (1): 2.
20. Do�gan RI, Leaman R, Lu Z. NCBI disease corpus: a resource for disease
name recognition and concept normalization. J Biomed Inform 2014; 47:
1–10.
21. Navigli R. Word sense disambiguation: a survey. ACM Comput Surv
2009; 41 (2): 10.
22. Raganato A, Camacho-Collados J, Navigli R. Word sense disambigua-
tion: a unified evaluation framework and empirical comparison. In: Pro-
ceedings of the 15th Conference of the European Chapter of the
Association for Computational Linguistics: Volume 1, Long Papers;
2017: 99–110. http://aclweb.org/anthology/E17-1010.
23. Ide N, Veronis J. Introduction to the special issue on word sense disambig-
uation: the state of the art. Comput Linguist 1998; 24 (1): 1–40.
24. Weeber M, Mork JG, Aronson AR. Developing a test collection for bio-
medical word sense disambiguation. Proc AMIA Symp 2001; 746–50.
25. Savova GK, Coden AR, Sominsky IL, et al. Word sense disambiguation
across two domains: Biomedical literature and clinical notes. J Biomed In-
form 2008; 41 (6): 1088–100.
26. Stevenson M, Agirre E, Soroa A. Exploiting domain information for word
sense disambiguation of medical documents. J Am Med Inform Assoc
2012; 19 (2): 235–40.
27. Jimeno-Yepes AJ, McInnes BT, Aronson AR. Exploiting MeSH indexing
in MEDLINE to generate a data set for word sense disambiguation. BMC
Bioinformatics 2011; 12 (1): 223.
28. Jimeno-Yepes A. Word embeddings and recurrent neural networks based
on long-short term memory nodes in supervised biomedical word sense
disambiguation. J Biomed Inform 2017; 73: 137–47.
29. Charbonnier J, Wartena C. Using word embeddings for unsupervised ac-
ronym disambiguation. In: Proceedings of the 27th International Confer-
ence on Computational Linguistics; 2018: 2610–9.
30. Pesaranghader A, Matwin S, Sokolova M, Pesaranghader A. deep-
BioWSD: effective deep neural word sense disambiguation of biomedical
text data. J Am Med Inform Assoc 2019; 26 (5): 438–46.
31. Moon S, Pakhomov S, Liu N, Ryan JO, Melton GB. A sense inventory for
clinical abbreviations and acronyms created using clinical notes and medi-
cal dictionary resources. J Am Med Inform Assoc 2014; 21 (2): 299–307.
32. Mowery DL, South BR, Christensen L, et al. Normalizing acronyms and
abbreviations to aid patient understanding of clinical texts: ShARe/CLEF
eHealth Challenge 2013, Task 2. J Biomed Semantics 2016; 7 (1): 43.
33. Wu Y, Denny JC, Trent Rosenbloom S, et al. A long journey to short
abbreviations: developing an open-source framework for clinical abbrevi-
ation recognition and disambiguation (CARD). J Am Med Inform Assoc
2017; 24 (e1): e79–86.
34. Oleynik M, Kreuzthaler M, Schulz S. Unsupervised abbreviation expan-
sion in clinical narratives. Stud Health Technol Inform 2017; 245:
539–43.
530 Journal of the American Medical Informatics Association, 2021, Vol. 28, No. 3
Dow
nloaded from https://academ
ic.oup.com/jam
ia/article/28/3/516/6034899 by guest on 10 July 2022

35. Joopudi V, Dandala B, Devarakonda M. A convolutional route to abbrevi-
ation disambiguation in clinical text. J Biomed Inform 2018; 86: 71–8.
36. Chasin R, Rumshisky A, Uzuner O, Szolovits P. Word sense disambigua-
tion in the clinical domain: a comparison of knowledge-rich and
knowledge-poor unsupervised methods. J Am Med Inform Assoc 2014;
21 (5): 842–9.
37. Luo Y-F, Sun W, Rumshisky A. MCN: A comprehensive corpus for medi-
cal concept normalization. J Biomed Inform 2019; 92: 103132.
38. Pradhan S, Elhadad N, South BR, et al. Evaluating the state of the art in
disorder recognition and normalization of the clinical narrative. J Am
Med Inform Assoc 2015; 22 (1): 143–54.
39. Pradhan S, Elhadad N, Chapman W, Manandhar S, Savova G.
fSgemfEgval-2014 task 7: analysis of clinical text. In: Proceedings of the
8th International Workshop on Semantic Evaluation (fSgemfEgval
2014). Dublin, Ireland: Association for Computational Linguistics; 2014:
54–62.
40. Mowery DL, Velupillai S, South BR, et al. Task 2: ShARe/CLEF eHealth
evaluation lab 2014. In: Online Working Notes of the CLEF 2014 Evalua-
tion Labs and Workshop; 2014. https://hal.archives-ouvertes.fr/hal-
01086544 Accessed February 9, 2020.
41. Uzuner €O, Henry S, Luo Y-F. 2019 n2c2 Shared-Task and Workshop
Track 3: n2c2/UMass Track on Clinical Concept and Normalization.
https://n2c2.dbmi.hms.harvard.edu/track3 Accessed February 6, 2020.
42. Cruse A. Meaning in Language: An Introduction to Semantics and Prag-
matics. New York, NY: Oxford University Press; 2004.
43. Murphy ML. Lexical Meaning. Cambridge, United Kingdom: Cambridge
University Press; 2010.
44. Friedman C, Kra P, Rzhetsky A. Two biomedical sublanguages: a descrip-
tion based on the theories of Zellig Harris. J Biomed Inform 2002; 35 (4):
222–35.
45. Rindflesch TC, Aronson AR. Ambiguity resolution while mapping free
text to the UMLS Metathesaurus. Proc Annu Symp Comput Appl Med
Care 1994; 240–4.
46. McCray AT, Srinivasan S, Browne AC. Lexical methods for managing
variation in biomedical terminologies. Proc Annu Symp Comput Appl
Med Care 1994; 235–9.
47. Aronson AR. Effective mapping of biomedical text to the UMLS
Metathesaurus: the MetaMap program. Proc AMIA Annu Symp
2001; 17–21.
48. Bodenreider O, Smith B, Burgun A. The ontology-epistemology di-
vide: a case study in medical terminology. Form Ontol Inf Syst;
2004: 185–95.
49. Fung KW, Bodenreider O, Aronson AR, Hole WT, Srinivasan S. Combin-
ing lexical and semantic methods of inter-terminology mapping using the
UMLS. Stud Health Technol Inform 2007; 129 (Pt 1): 605–9.
50. Borovicka T, Jirina M Jr, Kordik P, Jirina M. Selecting representative data
sets. Adv Data Min Knowl Discov Appl 2012; 43–70.
51. Schuemie MJ, Kors JA, Mons B. Word sense disambiguation in the bio-
medical domain: an overview. J Comput Biol 2005; 12 (5): 554–65.
52. Stevenson M, Guo Y. Disambiguation in the biomedical domain: the role
of ambiguity type. J Biomed Inform 2010; 43 (6): 972–81.
53. Elhadad N, Savova G, Chapman W, Zaramba G, Harris D, Vogel A.
ShARe Guidelines for the Annotation of Modifiers for Disorders in Clini-
cal Notes. 2012. http://alt.qcri.org/semeval2015/task14/data/uploads/
share_annotation_guidelines.pdf. Accessed January 29, 2020.
54. Johnson AEW, Pollard TJ, Shen L, et al. MIMIC-III, a freely accessible
critical care database. Sci Data 2016; 3 (1): 160035.
55. Pradhan S, Elhadad N, South BR, et al. Task 1: ShARe/CLEF eHealth
Evaluation Lab. In: Online Working Notes of the CLEF 2013 Evaluation
Labs and Workshop; 2013.
56. Osborne JD. Annotation guidelines for annotating CUI-less concepts
in BRAT. https://static-content.springer.com/esm/art%3A10.1186
%2Fs13326-017-0173-6/MediaObjects/13326_2017_173_MOESM1_ESM.pdf
Accessed February 9, 2020.
57. Uzuner €O, South BR, Shen S, DuVall SL. 2010 i2b2/VA challenge on con-
cepts, assertions, and relations in clinical text. J Am Med Inform Assoc
2011; 18 (5): 552–6.
58. Travers DA, Haas SW. Unified Medical Language System coverage of
emergency-medicine chief complaints. Acad Emerg Med 2006; 13 (12):
1319–23.
59. ShafieiBavani E, Ebrahimi M, Wong R, Chen F. Appraising UMLS cover-
age for summarizing medical evidence. In: Proceedings of COLING
2016, the 26th International Conference on Computational Linguistics:
Technical Papers; 2016: 513–24.
60. Lang F-M, Mork JG, Demner-Fushman D, Aronson AR. Increasing
UMLS coverage and reducing ambiguity via automated creation of synon-
ymous terms: first steps toward filling UMLS synonymy gaps. 2017.
https://ii.nlm.nih.gov/Publications/Papers/subsyn.pdf Accessed February
9, 2020.
61. National Library of Medicine. Lexical Tools (11-25-19 version). https://
lexsrv3.nlm.nih.gov/LexSysGroup/Projects/lvg/current/web/download.
html. Accessed April 27, 2020.
62. National Library of Medicine. UMLS REST API. https://documentation.
uts.nlm.nih.gov/rest/home.html Accessed April 28, 2020.
63. Krauthammer M, Nenadic G. Term identification in the biomedical litera-
ture. J Biomed Inform 2004; 37 (6): 512–26.
64. Honnibal M, Montani I. spaCy 2: Natural language understanding with
Bloom embeddings, convolutional neural networks and incremental pars-
ing [Computer software]. 2017. https://spacy.io Accessed January 8,
2020.
65. Markert K, Nissim M. Data and models for metonymy resolution. Lang
Resour Eval 2009; 43 (2): 123–38.
66. Gritta M, Pilehvar MT, Limsopatham N, Collier N. Vancouver welcomes
you! Minimalist location metonymy resolution. In: Proceedings of the
55th Annual Meeting of the Association for Computational Linguistics
(Volume 1: Long Papers). Vancouver, Canada: Association for Computa-
tional Linguistics; 2017: 1248–59.
67. Banerjee S, Pedersen T. An adapted Lesk algorithm for word sense disam-
biguation using WordNet. In: Gelbukh A, ed. LNCS Volume 2276: Com-
putational Linguistics and Intelligent Text Processing: Third International
Conference, CICLing 2002 Mexico City, Mexico, February 17–23, 2002,
Proceedings. New York, NY: Springer; 2002; 136–45.
68. Patwardhan S, Banerjee S, Pedersen T. Using measures of semantic
relatedness for word sense disambiguation. In: Gelbukh A, ed. LNCS
Volume 2276: Computational Linguistics and Intelligent Text Proc-
essing: 4th International Conference, CICLing 2003 Mexico City,
Mexico, February 16–22, 2002, Proceedings. New York, NY:
Springer; 2003: 241–57.
69. Navigli R, Velardi P. Structural semantic interconnections: a knowledge-
based approach to word sense disambiguation. IEEE Trans Pattern Anal
Mach Intell 2005; 27 (7): 1075–86.
70. Navigli R, Lapata M. An experimental study of graph connectivity for
unsupervised word sense disambiguation. IEEE Trans Pattern Anal Mach
Intell 2010; 32 (4): 678–92.
71. Mavroeidis D, Tsatsaronis G, Vazirgiannis M, Theobald M, Weikum G.
Word sense disambiguation for exploiting hierarchical thesauri in text
classification. In: Jorge AM, Torgo L, Brazdil P, Camacho R, Gama J, eds.
Knowledge Discovery in Databases: PKDD 2005. Berlin, Germany:
Springer; 2005: 181–92.
72. McInnes BT, Pedersen T. Evaluating semantic similarity and relatedness
over the semantic grouping of clinical term pairs. J Biomed Inform 2015;
54: 329–36.
73. McInnes BT, Pedersen T, Pakhomov SVS. UMLS-Interface and UMLS-
Similarity: open source software for measuring paths and semantic simi-
larity. AMIA Annu Symp Proc 2009; 2009: 431–5.
74. Andrews JE, Richesson RL, Krischer J. Variation of SNOMED CT coding
of clinical research concepts among coding experts. J Am Med Inform
Assoc 2007; 14 (4): 497–506.
75. Verspoor K, Cohn J, Mniszewski S, Joslyn C. A categorization approach
to automated ontological function annotation. Protein Sci 2006; 15 (6):
1544–9.
76. Aronson AR, Rindflesch TC, Browne AC. Exploiting a large thesaurus for
information retrieval. In: Funck Brentano J-L, Seitz F, eds. Intelligent Mul-
timedia Information Retrieval Systems and Management - Volume 1.
Journal of the American Medical Informatics Association, 2021, Vol. 28, No. 3 531
Dow
nloaded from https://academ
ic.oup.com/jam
ia/article/28/3/516/6034899 by guest on 10 July 2022

RIAO ’94. Paris, France: Le Centre de Hautes Etudes Internationales
D’Informatique Documentaire; 1994: 197–216.
77. Gundlapalli A, Divita G, Carter M, et al. Extracting surveillance data
from templated sections of an electronic medical note: challenges and op-
portunities. Online J Public Health Inform 2013; 5 (1): e75.
78. Figueroa RL, Zeng-Treitler Q, Goryachev S, Wiechmann EP. Tailoring
vocabularies for NLP in sub-domains: a method to detect unused word
sense. AMIA Annu Symp Proc 2009; 2009: 188–92.
79. Patterson O, Hurdle JF. Document clustering of clinical narratives: a sys-
tematic study of clinical sublanguages. AMIA Annu Symp Proc 2011;
2011: 1099–107.
80. Zhao S, Liu T, Zhao S, Wang F. A neural multi-task learning framework
to jointly model medical named entity recognition and normalization. In:
Proceedings of the Thirty-Third AAAI Conference on Artificial Intelli-
gence. Cambridge, MA: AAAI Press; 2019; 817–24.
81. Tutubalina E, Miftahutdinov Z, Nikolenko S, Malykh V. Medical concept
normalization in social media posts with recurrent neural networks. J
Biomed Inform 2018; 84: 93–102.
82. Li H, Chen Q, Tang B, et al. CNN-based ranking for biomedical entity
normalization. BMC Bioinformatics 2017; 18 (S11): 385.
83. Miftahutdinov Z, Tutubalina E. Deep neural models for medical concept
normalization in user-generated texts. In: Proceedings of the 57th Annual
Meeting of the Association for Computational Linguistics: Student Re-
search Workshop; 2019: 393–9.
84. Pustejovsky J, Boguraev B. Lexical Semantics: The Problem of Polysemy.
London, United Kingdom: Oxford University Press; 1997.
85. Liu H, Christiansen T, Baumgartner W. A, Verspoor K. BioLemmatizer: a
lemmatization tool for morphological processing of biomedical text. J
Biomed Semantics 2012; 3 (1): 3.
532 Journal of the American Medical Informatics Association, 2021, Vol. 28, No. 3
Dow
nloaded from https://academ
ic.oup.com/jam
ia/article/28/3/516/6034899 by guest on 10 July 2022




















