
A systematic approach to a self-generating fuzzy rule-table for function approximation
17
IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 30, NO. 3, JUNE 2000 431 A Systematic Approach to a Self-Generating Fuzzy Rule-Table for Function Approximation Hector Pomares, Ignacio Rojas, Julio Ortega, Jesus Gonzalez, and Alberto Prieto Abstract—In this paper, a systematic design is proposed to de- termine fuzzy system structure and learning its parameters, from a set of given training examples. In particular, two fundamental problems concerning fuzzy system modeling are addressed: 1) fuzzy rule parameter optimization and 2) the identification of system structure (i.e., the number of membership functions and fuzzy rules). A four-step approach to build a fuzzy system automatically is presented: Step 1 directly obtains the optimum fuzzy rules for a given membership function configuration. Step 2 optimizes the allocation of the membership functions and the conclusion of the rules, in order to achieve a better approximation. Step 3 determines a new and more suitable topology with the information derived from the approximation error distribution; it decides which variables should increase the number of mem- bership functions. Finally, Step 4 determines which structure should be selected to approximate the function, from the possible configurations provided by the algorithm in the three previous steps. The results of applying this method to the problem of function approximation are presented and then compared with other methodologies proposed in the bibliography. Index Terms—Function approximation, fuzzy system construc- tion, fuzzy system design, knowledge acquisition. I. INTRODUCTION T HE PROBLEM of estimating an unknown function f from samples of the form ( ); , ; with , and (i.e., function approxima- tion from a finite number of data points), has been and is still a fundamental issue in a variety of scientific and engineering fields [1]–[7]. The principal goal is to learn an unknown func- tional mapping between input and output vectors, using a set of known training samples [4]. Once this mapping is generated, it can be used for predicting the output values given new input vectors. Inputs and outputs can be continuous and/or categor- ical variables. This paper is concerned with continuous output variables, thus considering regression or function approxima- tion problems, as opposed to classification problems in which the output variable is categorical [2]. Recently, model-free systems, such as artificial neural net- works or fuzzy systems, have been proposed to avoid the knowl- edge-acquisition bottleneck [5], [8]–[11]. Fuzzy systems pro- vide an attractive alternative to the “black boxes” characteristic of neural network models, because their behavior can be easily Manuscript received February 20, 1998; revised August 4, 1998, April 2, 1999, August 18, 1999, and January 16, 2000. This work was supported in part by the CICYT Spanish Project TAP97-1166. This paper was recommended by Associate Editor L. O. Hall. The authors are with the Departamento de Arquitectura y Tecnología de Com- putadores, University of Granada, Granada 18071, Spain. Publisher Item Identifier S 1083-4419(00)04122-4. explained by a human being. In fact, the popularity and prac- ticality of fuzzy systems derives from their ability to express relations that are either complex or not sufficiently understood, in terms of linguistic rules. Historically, fuzzy rule bases have been constructed by knowledge acquisition from experts while the weights within neural nets have been learned from data [12], [13]. The most straightforward approach is to define rules and membership functions subjectively by studying a human operator. However, consulting an expert may be difficult and/or expensive; further- more, translating the human operator’s experience directly into the fuzzy linguistic values can be influenced by the intuition of the operators and designers, so that the fuzzy control rules may be incomplete or even contradict each other [14]. Many fuzzy systems that automatically derive fuzzy IF–THEN rules from numerical data have been proposed in the bibliog- raphy to overcome the problem of knowledge acquisition [3], [5], [15]–[22]. An important study in this context was carried out by Wang et al. [7] presenting a general method for combining numerical and linguistic information into a fuzzy rule-table. The designer must divide each input domain into a fixed configuration of membership functions. A procedure was proposed in which each datum generates a rule. Naturally, this algorithm produces an enormous number of rules when the total input data is con- siderable. There also arises the problem of contradictory rules, that is, rules with the same antecedent but a different consequent. Furthermore, the determination of the consequent of a rule using a single training example can be adversely affected by noisy data in the training examples [13], [17]. Methods similar to Wang’s, in which each datum generates a rule, have also been proposed in [13], [15], and [23]. The approaches presented in [13], [22], and [24] need the mem- bership functions in the antecedent part of the fuzzy rules to be predefined. Furthermore, Rovati et al. [22] fixed the membership functions in the antecedents and even in the consequence of the rules. This fixed structure helps the application of the symbolic minimization step proposed in previous works [25]. However, the distribution of the membership functions (shape and location) has a strong influence on the performance of the systems. Although fuzzy logic can encode expert knowledge directly using linguistic rules, it is usually difficult to define and tune the membership functions and rules. These limitations have justified and encour- aged the creation of intelligent hybrid systems where two or more techniques are combined in a manner that overcomes the limi- tations of individual techniques. Since the tuning and learning of the parameters of a fuzzy system can be analyzed as an opti- mization problem, genetic algorithms (GA’s) and artificial neural networks (ANN’s) offer a possibility to solve this problem [5], 1083–4419/00$10.00 © 2000 IEEE
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of A systematic approach to a self-generating fuzzy rule-table for function approximation

IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 30, NO. 3, JUNE 2000 431
A Systematic Approach to a Self-Generating FuzzyRule-Table for Function Approximation
Hector Pomares, Ignacio Rojas, Julio Ortega, Jesus Gonzalez, and Alberto Prieto
Abstract—In this paper, a systematic design is proposed to de-termine fuzzy system structure and learning its parameters, froma set of given training examples. In particular, two fundamentalproblems concerning fuzzy system modeling are addressed: 1)fuzzy rule parameter optimization and 2) the identification ofsystem structure (i.e., the number of membership functionsand fuzzy rules). A four-step approach to build a fuzzy systemautomatically is presented: Step 1 directly obtains the optimumfuzzy rules for a given membership function configuration. Step2 optimizes the allocation of the membership functions and theconclusion of the rules, in order to achieve a better approximation.Step 3 determines a new and more suitable topology with theinformation derived from the approximation error distribution;it decides which variables should increase the number of mem-bership functions. Finally, Step 4 determines which structureshould be selected to approximate the function, from the possibleconfigurations provided by the algorithm in the three previoussteps. The results of applying this method to the problem offunction approximation are presented and then compared withother methodologies proposed in the bibliography.
Index Terms—Function approximation, fuzzy system construc-tion, fuzzy system design, knowledge acquisition.
I. INTRODUCTION
T HE PROBLEM of estimating an unknown function f fromsamples of the form ( ); , ; with
, and (i.e., function approxima-tion from a finite number of data points), has been and is stilla fundamental issue in a variety of scientific and engineeringfields [1]–[7]. The principal goal is to learn an unknown func-tional mapping between input and output vectors, using a setof known training samples [4]. Once this mapping is generated,it can be used for predicting the output values given new inputvectors. Inputs and outputs can be continuous and/or categor-ical variables. This paper is concerned with continuous outputvariables, thus considering regression or function approxima-tion problems, as opposed to classification problems in whichthe output variable is categorical [2].
Recently, model-free systems, such as artificial neural net-works or fuzzy systems, have been proposed to avoid the knowl-edge-acquisition bottleneck [5], [8]–[11]. Fuzzy systems pro-vide an attractive alternative to the “black boxes” characteristicof neural network models, because their behavior can be easily
Manuscript received February 20, 1998; revised August 4, 1998, April 2,1999, August 18, 1999, and January 16, 2000. This work was supported in partby the CICYT Spanish Project TAP97-1166. This paper was recommended byAssociate Editor L. O. Hall.
The authors are with the Departamento de Arquitectura y Tecnología de Com-putadores, University of Granada, Granada 18071, Spain.
Publisher Item Identifier S 1083-4419(00)04122-4.
explained by a human being. In fact, the popularity and prac-ticality of fuzzy systems derives from their ability to expressrelations that are either complex or not sufficiently understood,in terms of linguistic rules.
Historically, fuzzy rule bases have been constructed byknowledge acquisition from experts while the weights withinneural nets have been learned from data [12], [13]. The moststraightforward approach is to define rules and membershipfunctions subjectively by studying a human operator. However,consulting an expert may be difficult and/or expensive; further-more, translating the human operator’s experience directly intothe fuzzy linguistic values can be influenced by the intuition ofthe operators and designers, so that the fuzzy control rules maybe incomplete or even contradict each other [14].
ManyfuzzysystemsthatautomaticallyderivefuzzyIF–THENrules from numerical data have been proposed in the bibliog-raphy to overcome the problem of knowledge acquisition [3],[5], [15]–[22]. An important study in this context was carried outby Wanget al. [7] presenting a general method for combiningnumerical and linguistic information into a fuzzy rule-table. Thedesignermustdivideeach inputdomain intoa fixedconfigurationof membership functions. A procedure was proposed in whicheach datum generates a rule. Naturally, this algorithm producesan enormous number of rules when the total input data is con-siderable. There also arises the problem of contradictory rules,that is, rules with the same antecedent but a different consequent.Furthermore, the determination of the consequent of a rule usinga single training example can be adversely affected by noisy datain the training examples [13], [17]. Methods similar to Wang’s,in which each datum generates a rule, have also been proposedin [13], [15], and [23].
Theapproachespresented in [13], [22],and[24]needthemem-bership functions in the antecedent part of the fuzzy rules to bepredefined. Furthermore, Rovatiet al.[22] fixed the membershipfunctions in the antecedents and even in the consequence of therules. This fixed structure helps the application of the symbolicminimizationstepproposed inpreviousworks [25].However, thedistributionof themembership functions(shapeandlocation)hasa strong influence on the performance of the systems. Althoughfuzzy logiccanencodeexpertknowledgedirectlyusing linguisticrules, it is usually difficult to define and tune the membershipfunctions and rules. These limitations have justified and encour-aged the creation of intelligent hybrid systems where twoormoretechniques are combined in a manner that overcomes the limi-tations of individual techniques. Since the tuning and learningof the parameters of a fuzzy system can be analyzed as an opti-mizationproblem,geneticalgorithms(GA’s)andartificial neuralnetworks (ANN’s) offer a possibility to solve this problem [5],
1083–4419/00$10.00 © 2000 IEEE

432 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 30, NO. 3, JUNE 2000
[8], [9], [11], [16], [26]–[29]. The analysis of the internal states inthe design of the fuzzy system (mainly the position of the mem-bership functions), with no restriction on the behavior of the GAor ANN, shows [28], [30], that for each input vector many rulesare activated and the overlap is greater than two; moreover, theposition and domain of the membership functions do not usu-ally match the characteristics of the problem being solved. Mosthybrid techniques presented in the bibliography concerning theproblem of modeling an unknown system by a fuzzy rule-basedmodel pay less attention to the linguistic or fuzzy interpretationof the obtained system.
In the above described approaches, prototypes of fuzzyrule bases can be built quickly without the help of humanexperts, thus avoiding a development bottleneck. Nevertheless,most methods assume the structure of the fuzzy system to bepreviously defined, and thus neither optimized nor altered.
In order to improve the accuracy of the function approx-imation, the procedures proposed in [17] and [31] use theinformation provided by the approximation error, and increasethe number of rules by adding a membership function for eachvariable at the point of maximum error. In [17], a three-step ap-proach was proposed to obtain fuzzy systems, first by learningthe membership functions and rules, secondly by simplifyingthe cell-based rules and finally by defining a neural networktopology. However, assigning membership functions at thepoints of greatest error does not produce an efficient solution.There are two main reasons for this: the first one relates to theneed to carry out an overall analysis in the domain of the wholefunction in order to attempt the subsequent optimization of theoverall error and not to concentrate on the subspace where theapproximation function presents the biggest error. The secondconcerns the need for a deeper analysis of the variables thatrequire the greatest increase in the number of membershipfunctions. It is necessary to increase only the most significantvariable, due to the exponential increase in the complexity of afuzzy system when the number of linguistic values grows.
Analyzing the bibliography, we see that methods for automat-ically creating fuzzy systems from data, in which the structureof the fuzzy system and the parameters that define it are simulta-neously optimized, have not been discussed in depth. This paperpresents a general and complete method to obtain the structureof a singleton fuzzy system automatically and simultaneouslyoptimize the configuration of the membership functions (loca-tion and number) and the consequence of the rules of a fuzzysystem. Therefore, the identification of the fuzzy system struc-ture and the tuning of the parameters defining it are performedin conjunction. From an initially simple system, and by meansof an overall analysis of the approximation error, the structureof such a system is modified in an autonomous way. The al-gorithm presented here obtains, automatically, various fuzzysystem structures, each of which is optimized with respect tothe parameters that define it (membership functions in the an-tecedent parts and consequence of the rules). The conclusions ofthe fuzzy rules are obtained optimally, i.e., for a particular con-figuration of membership functions, the consequents minimizethe error between the desired output and that obtained by thefuzzy system. Simultaneously, the fuzzy sets defining the an-tecedent part of the rules are also tuned. As different structures
of fuzzy systems with different degrees of complexity are ableto approximate a given unknown function with different levelsof accuracy, we have constructed an auxiliary fuzzy system toproduce an index reflecting the compromise between the accu-racy and the complexity of the rule set.
The organization of the rest of this paper is as follows. Thestatement of the problem and the notation used is briefly de-scribed in Section II, followed by the key issue of finding theoptimum rules for a fixed configuration of membership func-tions in Section III. The simultaneous optimization of the distri-bution of the membership functions and the consequence of thefuzzy rules is described in Section IV. Section V is concernedwith how the structure of the fuzzy system is modified in an au-tonomous way (by recognizing where it is necessary to assigna larger number or density of rules). Because it is necessary tomake a compromise between the accuracy and the complexityof the obtained system, Section VI proposes an auxiliary fuzzysystem to be responsible for selecting the most suitable struc-ture. Numerical examples and comparative results are presentedin Section VII and some conclusions are drawn in Section VIII.
II. STATEMENT OF THE PROBLEM
We consider the problem of approximating a continuousmulti-input single-output function to clarify the basic ideasof our approach, since the extension of the method to amultiple-output is straightforward. Let us consider a setof desired input–output data pairs, derived from an unknownfunction or system . Each vector datum ( ) can beexpressed as , with ,and . A fuzzy system comprises a set ofIF–THEN fuzzy rules having the following form:
IF is AND is AND AND is
THEN (1)
where , with being the numberof membership functions of the input variable. For the outputvariable, is the numeric consequent of the rule (there-fore singleton fuzzy rules are used in this work). In the litera-ture there are many possibilities for the selection of the fuzzyoperators that determine how to evaluate each individual ruleand how to obtain a final conclusion from all the rules. Thereare also conflicting opinions about the best selection of thesefuzzy primitives [32]–[34]. In this paper, the fuzzy inferencemethod uses the product as T-norm and the centroid methodwith sum-product operator as the defuzzification strategy. Thestrength or -level of rule is calculated by
(2)
where the product operator is used to perform the conjunction ofeach of the individual membership functions within the premiseand is the membership degree of thecomponentof the vector with respect to the linguistic function . Using

POMARESet al.: A SYSTEMATIC APPROACH TO A SELF-GENERATING FUZZY RULE-TABLE 433
the above notation, the fuzzy function can be expressed as fol-lows:
(3)
where an explicit statement is made of the dependency of thefuzzy output, not only on the input vector, but also on the ma-trix of rules and on all the parameters that describe the mem-bership functions . Expression (3) is applicable for a completerule base. If a rule is marked as not used, its degree of activationis considered to be zero.
The problem considered in this paper may be stated in a pre-cise way as that of finding a configurationand generating a setof fuzzy rules from a data set ofinput–output pairs , such that the fuzzysystem correctly approximates the unknown func-tion F using a trade-off between complexity and accuracy. Thefunction to be minimized is the sum of squared errors
(4)
The index selected to determine the degree of accuracy of theobtained fuzzy approximation is the Normalized Root-Mean-Square Error (NRMSE) defined as
NRMSE (5)
where is the variance of the output data, andis the mean-square error between the obtained and the desired output. In thisway, the NRMSE index describes the performance of the ap-proximation, making it independent of scale factors or numberof data.
Together with the information from the parameters com-prising the system’s rule set, it is first necessary to knowhow many membership functions each input variable has(the numbers with ) and thus the totalnumber of rules in the set. In the procedure reported in thefollowing sections, from an initially simple system, the numberof membership functions for each input variable, together withthe number of rules comprising the system, is automaticallydetermined without prior assignment by a human operator,thereby enabling the construction of a self-organized rule base.
III. FINDING THE OPTIMUM RULES FOR AFIXED MEMBERSHIP
FUNCTION CONFIGURATION
The first case to examine is that in which the distributionand number of membership functions are fixed and, therefore,
. Observing (3), is not only a continuous anddifferentiable expression as a function of the consequent of therules , but this dependency is linear. This property al-lows us to find the optimum consequents of the rule-table as in
[35] and subsequently in [36] and [37]. The optimum fuzzy ruleconclusion should cancel the first derivative from, (4) with re-spect to the consequent of the rules
(6)
Substituting in the above expression and introducing the fol-lowing notation:
(7)
we obtain the following system of linear equations:
(8)
where ranges from 1 to from 1 to , etc. This expres-sion represents a system of linear equations thatcoincides with the number of unknowns (the number of conse-quents of the rules). Therefore, if the determinant of the resultingmatrix is not null, the solution is unique. The matrix is alwaystwo-dimensional (2-D) and symmetrical (7). Moreover, it is a co-variance-type matrix and the system can be very quickly solvedusing the Cholesky algorithm [38]. The obtained procedure is in-dependentoftheformanddistributionoftheselectedmembershipfunctions (usually, triangular, Gaussian, trapezoidal, etc.). Then,for a predefined membership function distribution, the optimumrule conclusion can be directly obtained.
IV. SIMULTANEOUS OPTIMIZATION OF FUZZY RULES AND
MEMBERSHIPFUNCTIONS
In Section III, the optimum consequents for a defined config-uration of membership functions were obtained. However, thedistribution of the membership functions (shape and location)

434 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 30, NO. 3, JUNE 2000
has a strong influence on the performance of the systems, thusmaking it necessary to optimize them [5], [39]–[45]. To approachthis issue, it is necessary to define a certain type of membershipfunction. Although the methodology is valid for any type of lin-guisticvalue, inorder tosimplify thealgorithmand thenumberofparameters necessary for the description of the fuzzy system, themembership functionswill be triangular functionswithpair-wiseoverlap, i.e., each variable has a non zero membership value inat most two fuzzy sets. We will use a triangular partition (TP)[13], [37], [46], [47] where only the centers of the membershipfunctions are stored, since the slopes of the triangles are calcu-lated according to the centers of the surrounding membershipfunctions. Because the first and last center of the membershipfunctionshavebeenmadetocoincidewith thedomainof thefunc-tion ineach inputvariable, it isonlynecessary tostore thevalueofthe intermediatemembership functions.This reduces the numberof parameters that must be determined for the construction andsubsequent optimization of a fuzzy system.
Thanks to the membership function configurations selected(TP), it is straightforward for a human operator to understand thefinal fuzzy system obtained. When the overlap is too high thereare two main problems that arise for the implementation andunderstanding of fuzzy systems: first, the number of activatedrules increases exponentially, which becomes important whena hardware implementation is sought. Second, the membershipfunctions lose their linguistic meaning when one input valueactivates more than two of them.
For each variable , the membership degree of the-com-ponent of the vector with respect to the linguistic functionhas the form in (9), shown at the bottom of the page, whererepresents the center of the membership function of the inputvariable . The function is defined as
ifotherwise.
(10)
This decomposition of the domain of the input variables satisfiesthe following property [13]:
(11)
Using this property, it is apparent that the denominator of (3) isalways equal to unity and thus, the fuzzy system considered can
be expressed as
(12)
Not only are few parameters required to define this type ofdistribution of membership functions, but also the interpretationof the system is straightforward for a human operator. In fact,the analysis of the internal states in the design of a fuzzy system(mainly the position of the linguistic values), with no restrictionon the behavior of hybrid-fuzzy optimization techniques suchas neuro-fuzzy networks and fuzzy-genetic algorithms [16],[28]–[30] shows that for each input vector many rules areactivated and that the overlap is greater than two. Moreover,the position and domain of the membership functions do notusually match the characteristics of the problem being solved(the membership functions are sometimes located outside thedomains of the input variables).
With the distribution of the membership functions selectedand with the help of the direct method to determine the conse-quence of the rules (Section III), the number of parameters to beoptimized for the fuzzy system has been sub-stantially reduced. For example, let us consider a fuzzy systemwith three input variables using five membership functions foreach variable. If the rule-base is complete [12] a total of 134 pa-rameters have to be optimized (5consequence and centersof membership functions). However, only the nine centers of thelinguistic values have to be optimized, because for a fixed con-figuration of the membership functions, the remaining parame-ters (the conclusion of the rules) are directly obtained. This im-proves the speed of convergence since it depends strongly withthe number of parameters. Therefore, this section only refers tothe optimization of the centers of the membership functions, itbeing implicit that each time there is a new configuration of themembership functions the optimum rules will be found usingthe method described in Section III.
A. A Prior Stage to Approach a Near Optimum Solution
We wish to minimize function (the error approximation)obtaining rules and membership functions . The depen-dency of is not linear with respect to pa-rameter . Thus, using the gradient descent algorithm directly
if
and
if
(9)

POMARESet al.: A SYSTEMATIC APPROACH TO A SELF-GENERATING FUZZY RULE-TABLE 435
would lead the system to the first nearby local minimum rela-tive to the initial conditions without taking into account whetherthis is the absolute minimum or not. How well it learns de-pends on how well we choose the initial set of parameters in
. It is therefore necessary to include a prior stage in our algo-rithm that allows us to approach a near optimum minimum inan efficient way, and without losing the linguistic interpretationinherent in the parameters defining the membership functions.The simplicity of the proposed system enables this task to beperformed without difficulty. If the centers were to be locatedmanually, without using an algorithm, they would be placed sothat the errors were homogeneously distributed over the wholeoutput range. An approximation that was very close to the orig-inal in one zone of the output range while greatly differing inanother would not be considered a good approximation. There-fore, let us suppose that we can achieve near-optimum solutionsby seeking the distribution of centers that produces equally dis-tributed errors throughout all the areas defined. An overall anal-ysis in the domain of the whole function is carried out to achievethe subsequent optimization of the overall function error. Thegoal is for all the rules derived from the fuzzy system to be asprecise as possible, such that the magnitude of the approxima-tion error within each of the input spaces is similar. In order toobtain an accurate approximation of the unknown function witha homogeneous error distribution, the center of themember-ship function of input variable m is associated with a “slope”
of the form
(13)where and are as defined in Section II, and is usedto normalize the values of the slopes in order to make thewhole process independent of scale factors. Therefore, eachcenter has an associated parameter that represents thedifference between the contribution of the preceding sectorand the succeeding one to the value of the squared error. Apositive value for such a slope means that the contribution tothe left-hand sector is greater than that to the right and so thecenter must be moved to the left to counteract this effect. Asthe order of the centers cannot be allowed to vary, we performthe following movement:
if
if
(14)
in which two new parameters are introduced: the first one is theactive radius “,” which is the maximum variation distance andis used to guarantee that the order of the membership functionlocations remains unchanged (a typical value is , meaningthat, at most, a center can be moved as far as the midpoint be-tween it and its neighbor). The second parameter is the temper-
ature of the center , which indicates how far the centerwill be moved within the limits of possible movement. Thus, forvery high temperatures the centers will move large distances,while at low temperatures these movements will be very small.
At first, temperatures are very high for all centers (typically100–1000), though this is not a critical factor because, as thealgorithm evolves, it adapts itself and adjusts the temperatures.The temperature of a center increases if the modification of thecenter in a certain number of iterations is in the same direction,while the temperature decreases when a change in direction oc-curs. The process finalizes when we obtain the configuration ofcenters that achieves an equidistant distribution of errors overthe output surface (although in itself does not represent a goodapproximation). This procedure requires very few iterations toobtain a fuzzy system which, although in itself does not rep-resent a good approximation, is assumed to be a good startingpoint to search for an approximation close to the optimum of thetarget function, using local-minimum search techniques.
B. Optimizing the Position of the Membership Functions
Once we have a configuration assumed to be a near optimumone (as obtained above), then a method to find a local minimumis employed, thus reaching the desired minimum. One of themost commonly used methods to find local minima is the gra-dient descent. This method usually works well but in the presentproblem does not guarantee that the order of the membershipfunction locations remains unchanged. Therefore, an alternativemethod also based on the gradient is proposed, which limits themovement of the membership function centers and prevents theorder from being changed. The centers are optimized as follows:
(15)
The partial derivative is calculated in the Ap-pendix, is a learning parameter, and is given by
if
if
(16)
In graphic form, the movements of the centers are controlled bya saturation function, as illustrated in Fig. 1. In the linear zone,the usual descent gradient (with no limitation) is employed,while for large movements of the centers, there are saturationregions to ensure the center does not move beyond a fractionbof the distance separating it from its neighbor. The learning pa-rameters are progressively adapted to accelerate the search ina similar way to the parameter 1/ in (14). By this procedure,the center of each input membership function moves indepen-dently in the direction that reduces the squared error, withoutrisking any alteration in the order of the centers and thus main-taining the linguistic interpretation of the fuzzy system obtained.
At this point, we have finally obtained a near optimum con-figuration (location of the membership functions and rules) to
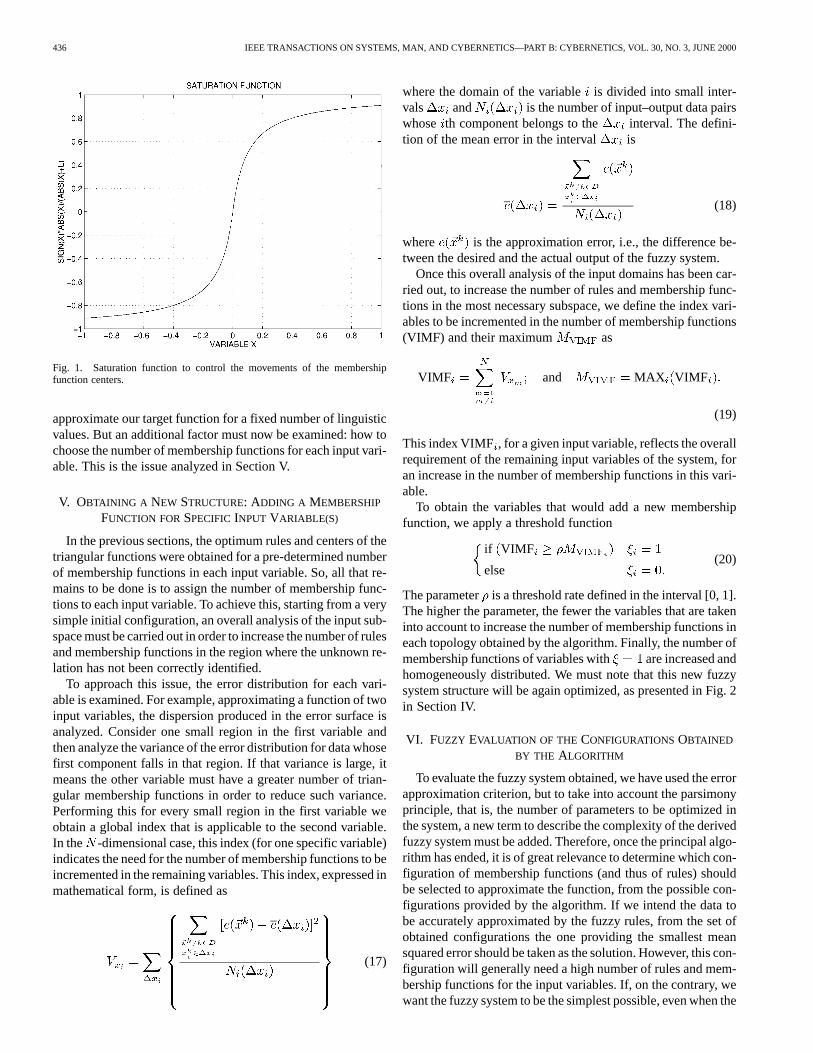
436 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 30, NO. 3, JUNE 2000
Fig. 1. Saturation function to control the movements of the membershipfunction centers.
approximate our target function for a fixed number of linguisticvalues. But an additional factor must now be examined: how tochoose the number of membership functions for each input vari-able. This is the issue analyzed in Section V.
V. OBTAINING A NEW STRUCTURE: ADDING A MEMBERSHIP
FUNCTION FORSPECIFICINPUT VARIABLE(S)
In the previous sections, the optimum rules and centers of thetriangular functions were obtained for a pre-determined numberof membership functions in each input variable. So, all that re-mains to be done is to assign the number of membership func-tions to each input variable. To achieve this, starting from a verysimple initial configuration, an overall analysis of the input sub-space must be carried out in order to increase the number of rulesand membership functions in the region where the unknown re-lation has not been correctly identified.
To approach this issue, the error distribution for each vari-able is examined. For example, approximating a function of twoinput variables, the dispersion produced in the error surface isanalyzed. Consider one small region in the first variable andthen analyze the variance of the error distribution for data whosefirst component falls in that region. If that variance is large, itmeans the other variable must have a greater number of trian-gular membership functions in order to reduce such variance.Performing this for every small region in the first variable weobtain a global index that is applicable to the second variable.In the -dimensional case, this index (for one specific variable)indicates the need for the number of membership functions to beincremented in the remaining variables. This index, expressed inmathematical form, is defined as
(17)
where the domain of the variableis divided into small inter-vals and is the number of input–output data pairswhose th component belongs to the interval. The defini-tion of the mean error in the interval is
(18)
where is the approximation error, i.e., the difference be-tween the desired and the actual output of the fuzzy system.
Once this overall analysis of the input domains has been car-ried out, to increase the number of rules and membership func-tions in the most necessary subspace, we define the index vari-ables to be incremented in the number of membership functions(VIMF) and their maximum as
VIMF and MAX VIMF
(19)
This index VIMF , for a given input variable, reflects the overallrequirement of the remaining input variables of the system, foran increase in the number of membership functions in this vari-able.
To obtain the variables that would add a new membershipfunction, we apply a threshold function
if VIMF
else(20)
The parameter is a threshold rate defined in the interval [0, 1].The higher the parameter, the fewer the variables that are takeninto account to increase the number of membership functions ineach topology obtained by the algorithm. Finally, the number ofmembership functions of variables with are increased andhomogeneously distributed. We must note that this new fuzzysystem structure will be again optimized, as presented in Fig. 2in Section IV.
VI. FUZZY EVALUATION OF THE CONFIGURATIONSOBTAINED
BY THE ALGORITHM
To evaluate the fuzzy system obtained, we have used the errorapproximation criterion, but to take into account the parsimonyprinciple, that is, the number of parameters to be optimized inthe system, a new term to describe the complexity of the derivedfuzzy system must be added. Therefore, once the principal algo-rithm has ended, it is of great relevance to determine which con-figuration of membership functions (and thus of rules) shouldbe selected to approximate the function, from the possible con-figurations provided by the algorithm. If we intend the data tobe accurately approximated by the fuzzy rules, from the set ofobtained configurations the one providing the smallest meansquared error should be taken as the solution. However, this con-figuration will generally need a high number of rules and mem-bership functions for the input variables. If, on the contrary, wewant the fuzzy system to be the simplest possible, even when the

POMARESet al.: A SYSTEMATIC APPROACH TO A SELF-GENERATING FUZZY RULE-TABLE 437
Fig. 2. General flowchart of the proposed algorithm.
approximation error is moderately high, we will choose a solu-tion where the total number of rules is small. In general, the bestmodel will be the one giving the smallest error with the lowestnumber of parameters (i.e., the one presenting least structuralcomplexity). There must exist a compromise between the accu-racy we are looking for and the consequent complexity of thesystem.
One solution to this problem can be found by using theMinimum Description Length [48]. The description length ofa model is defined as the sum of the quantity of data neededto describe it and the quantity needed to describe the errorbetween this model and reality. The problem of selecting fromdifferent fuzzy systems the one presenting the best results,while simultaneously taking into account the goals of accuracyand simplicity, also arises in optimization problems wheremore than one solution can be obtained, i.e., multi-objectiveoptimization or Pareto optimization [49].
Since determining which configuration has optimum char-acteristics is a clear example of fuzzy decision-taking, in thispaper the preferences of the human operator (end user) con-cerning the two objectives considered in evaluating the fuzzysystem are translated into fuzzy rules. Thus, to approach thisproblem, instead of using classical indices such as the Akaikeinformation criterion [50] and the minimum description length[48], we propose a fuzzy system responsible for selecting themost adequate structure from the different solutions providedby the algorithm, taking into account the compromise betweenthe accuracy of the approximation of the fuzzy system and itscomplexity (measured as the number of rules). The output of thisfuzzy system, defined in the interval [0, 10] in this work, is theso-called index of accuracy of the approximation versus systemcomplexity (IAC). In this way, the human operator expresses thedegree of compromise between the accuracy of the system andits complexity by means of fuzzy rules of the following type:IF
438 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 30, NO. 3, JUNE 2000
TABLE IPOSSIBLE RULES TO OBTAIN THE IAC
INDEX
Root Mean Squared Error is Small AND Number of Parametersis Big THEN IAC is Medium. These depend on the particularspecifications of the problem to be resolved. It must be pointedout that one given configuration may seem suitable for certainapplications and not for others. Therefore, it is the final userthat must provide the fuzzy rules to construct the IAC index.A simple example of rules to define this index is presented inTable I. Since this rules are merely an example, the output ofthe IAC system will be considered here as an impartial infor-mation of which configurations seem to have a better trade-offbetween accuracy and complexity. Therefore the best configu-ration will be the one that maximizes the IAC index. Fig. 2 givesa flowchart of the proposed method, showing each of the stepsanalyzed above.
VII. N UMERICAL RESULTS
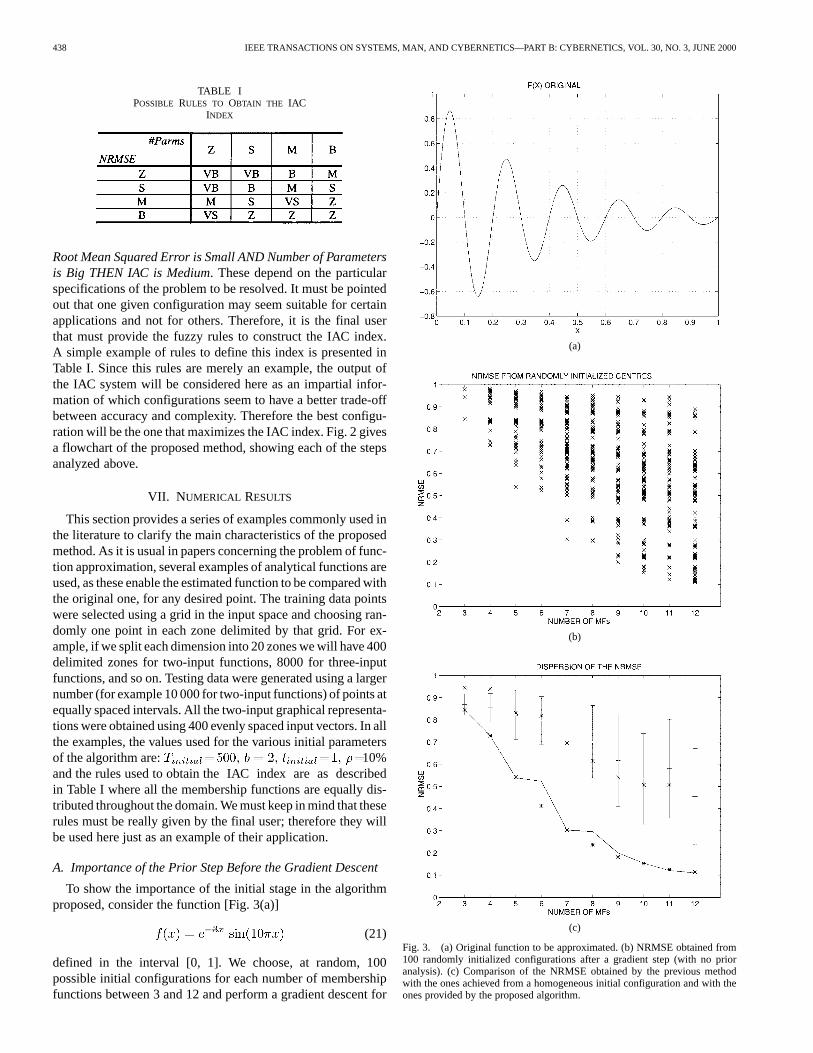
This section provides a series of examples commonly used inthe literature to clarify the main characteristics of the proposedmethod. As it is usual in papers concerning the problem of func-tion approximation, several examples of analytical functions areused, as these enable the estimated function to be compared withthe original one, for any desired point. The training data pointswere selected using a grid in the input space and choosing ran-domly one point in each zone delimited by that grid. For ex-ample, if we split each dimension into 20 zones we will have 400delimited zones for two-input functions, 8000 for three-inputfunctions, and so on. Testing data were generated using a largernumber (for example 10 000 for two-input functions) of points atequally spaced intervals. All the two-input graphical representa-tions were obtained using 400 evenly spaced input vectors. In allthe examples, the values used for the various initial parametersof the algorithm are: 10%and the rules used to obtain the IAC index are as describedin Table I where all the membership functions are equally dis-tributed throughout the domain. We must keep in mind that theserules must be really given by the final user; therefore they willbe used here just as an example of their application.
A. Importance of the Prior Step Before the Gradient Descent
To show the importance of the initial stage in the algorithmproposed, consider the function [Fig. 3(a)]
(21)
defined in the interval [0, 1]. We choose, at random, 100possible initial configurations for each number of membershipfunctions between 3 and 12 and perform a gradient descent for
(a)
(b)
(c)
Fig. 3. (a) Original function to be approximated. (b) NRMSE obtained from100 randomly initialized configurations after a gradient step (with no prioranalysis). (c) Comparison of the NRMSE obtained by the previous methodwith the ones achieved from a homogeneous initial configuration and with theones provided by the proposed algorithm.

POMARESet al.: A SYSTEMATIC APPROACH TO A SELF-GENERATING FUZZY RULE-TABLE 439
TABLE IIANALYSIS OF THE EVOLUTION OF NRMSE DEPENDING ON THESTARTING
POINT WHERE THEGRADIENT DESCENT ISINITIATED
Fig. 4. Six optimized triangular membership functions.
each of these to find the first relative minimum obtained fromeach of these initial configurations. Graphic results are given inFig. 3(b). It is apparent that even for unidimensional functionsthere exist a large number of local minima and that theseare more and more numerous as the number of membershipfunctions to be optimized grows. Table II presents the meanvalues obtained and the standard deviation for each distribu-tion, together with the minimum values. In this table, it is alsoshown the NRMSE obtained both by the complete algorithmand those derived from an equally-distributed configurationof membership functions. These data are presented in graphicform in Fig. 3(c), where “*” represents the minima obtainedby the complete algorithm, “” signifies those derived fromthe equally-distributed initial configuration and a solid lineshows the best values of each of the 100 samples for eachconfiguration.
Several conclusions can be drawn from the above results:
• The use of membership functions that are equally-dis-tributed throughout the input range is not a good solution.Except in the case of the 12 membership functions that, bychance, form a good starting point, the solution is practi-cally equivalent to a random initialization.
• Neither by the use of a reasonably large number of randominitial configurations is it possible to assert that one of
Fig. 5. Original function (solid line), function approximation with anequi-distribution of nine triangular functions (dash-dotted line) and with sixoptimized triangular functions (dashed-line).
Fig. 6. Original output surface.
them is a valid starting point to find an absolute min-imum. In various cases, the approximation determined bythe complete algorithm (using the prior stage) was foundto be superior to the best of the random searches.
• By using the proposed initial stage we obtained an ap-proximation that was always similar to the best of therandom approximations, and on occasions, better. Never-theless, there are configurations for which the best randomapproximation is slightly better than that obtained by theproposed algorithm. As stated in the previous section, thealgorithm cannot guarantee to find the absolute minimum,although it always reaches a “good” one.
B. Example 1
A one-variable target function was selected to demonstratethe ability of the proposed algorithms to construct approxima-tions to highly nonlinear target functions and to gain an insight
440 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 30, NO. 3, JUNE 2000
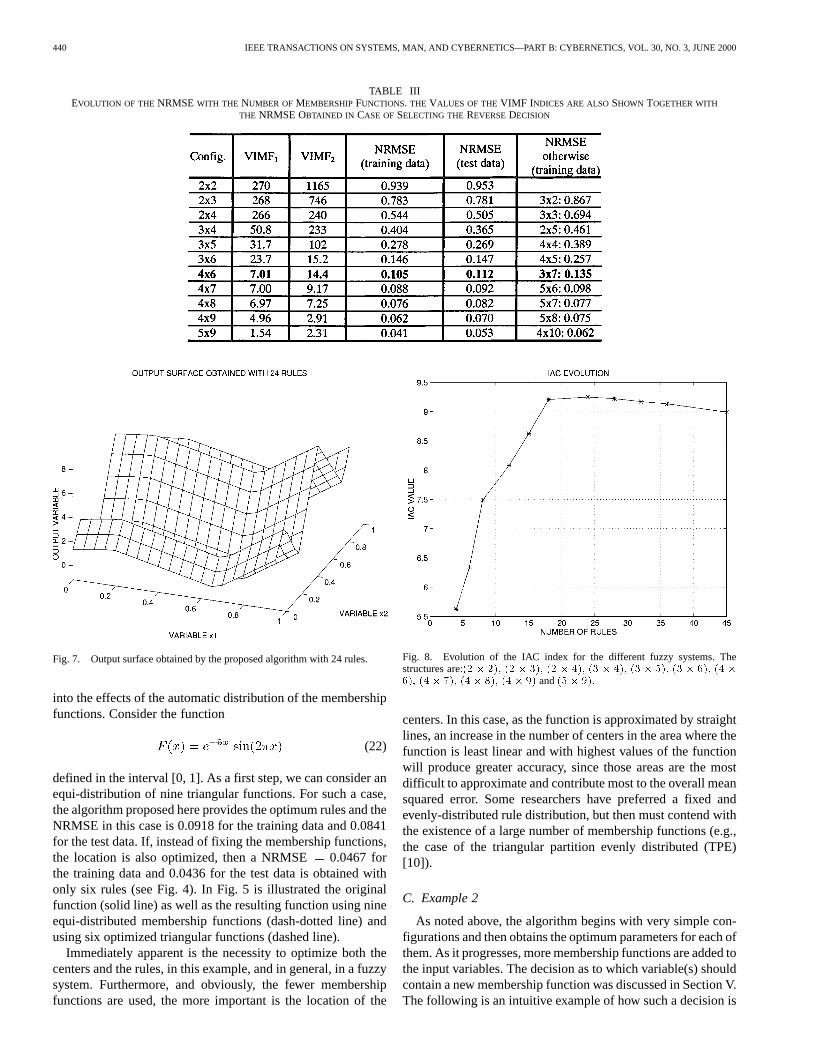
TABLE IIIEVOLUTION OF THE NRMSEWITH THE NUMBER OF MEMBERSHIPFUNCTIONS. THE VALUES OF THEVIMF I NDICES ARE ALSOSHOWN TOGETHER WITH
THE NRMSE OBTAINED IN CASE OFSELECTING THE REVERSEDECISION
Fig. 7. Output surface obtained by the proposed algorithm with 24 rules.
into the effects of the automatic distribution of the membershipfunctions. Consider the function
(22)
defined in the interval [0, 1]. As a first step, we can consider anequi-distribution of nine triangular functions. For such a case,the algorithm proposed here provides the optimum rules and theNRMSE in this case is 0.0918 for the training data and 0.0841for the test data. If, instead of fixing the membership functions,the location is also optimized, then a NRMSE 0.0467 forthe training data and 0.0436 for the test data is obtained withonly six rules (see Fig. 4). In Fig. 5 is illustrated the originalfunction (solid line) as well as the resulting function using nineequi-distributed membership functions (dash-dotted line) andusing six optimized triangular functions (dashed line).
Immediately apparent is the necessity to optimize both thecenters and the rules, in this example, and in general, in a fuzzysystem. Furthermore, and obviously, the fewer membershipfunctions are used, the more important is the location of the
Fig. 8. Evolution of the IAC index for the different fuzzy systems. Thestructures are:(2 � 2); (2 � 3); (2 � 4); (3 � 4); (3 � 5); (3 � 6); (4 �6); (4 � 7); (4� 8); (4� 9) and(5� 9).
centers. In this case, as the function is approximated by straightlines, an increase in the number of centers in the area where thefunction is least linear and with highest values of the functionwill produce greater accuracy, since those areas are the mostdifficult to approximate and contribute most to the overall meansquared error. Some researchers have preferred a fixed andevenly-distributed rule distribution, but then must contend withthe existence of a large number of membership functions (e.g.,the case of the triangular partition evenly distributed (TPE)[10]).
C. Example 2
As noted above, the algorithm begins with very simple con-figurations and then obtains the optimum parameters for each ofthem. As it progresses, more membership functions are added tothe input variables. The decision as to which variable(s) shouldcontain a new membership function was discussed in Section V.The following is an intuitive example of how such a decision is

POMARESet al.: A SYSTEMATIC APPROACH TO A SELF-GENERATING FUZZY RULE-TABLE 441
(a)
(b)
Fig. 9. Membership functions for: (a) variablex and (b) variablex .
reached. Consider the function defined by the following equa-tion, reported in [2]:
(23)
with . It is apparent that the variable is themost influential factor determining the value of the function as,for a fixed value of , the variable only slightly modifiesthe output (see Fig. 6). The algorithm presented here must takethis into account and concentrate a greater number of member-ship functions in the second variable, thus improving the de-gree of approximation whilst maintaining the lowest possiblelevel of system complexity. The evolution of the normalizedroot-mean-square error with the number of fuzzy rules is pre-sented in Table III. The values of the VIMF indices are alsoshown in this table together with the NRMSE obtained in case ofselecting the reverse decision. From the table it can be seen that
(a)
(b)
Fig. 10. (a) Original output surface and (b) output surface obtained by theproposed algorithm with 64 rules. NRMSE= 0:0305.
TABLE IVEVOLUTION OF THE NRMSE FOR THE DIFFERENT STRUCTURES
OBTAINED BY THE ALGORITHM
the algorithm always select the best choice in each case. For thearchitecture with 24 rules (four membership functions for thevariable and six for ), the normalized root-mean-squareerror is 0.112 and we could assume that with this number ofrules the unknown function is adequately approximated (Fig.
442 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 30, NO. 3, JUNE 2000
(a)
(b)
(c)
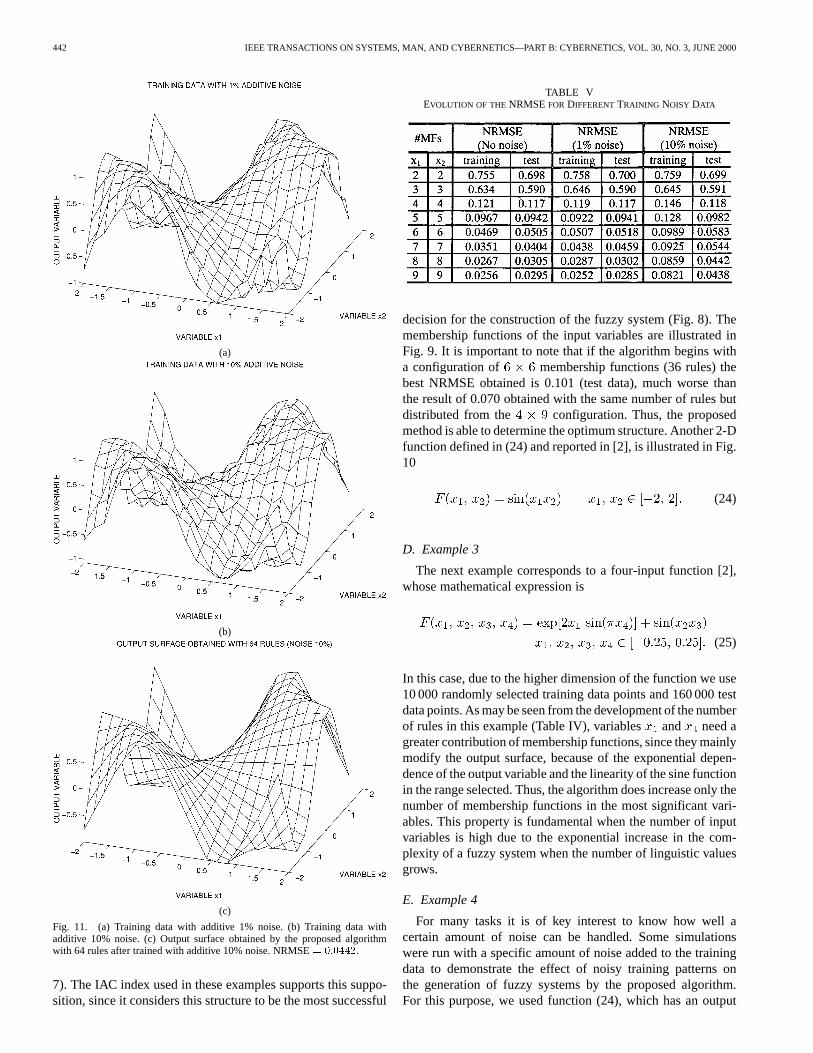
Fig. 11. (a) Training data with additive 1% noise. (b) Training data withadditive 10% noise. (c) Output surface obtained by the proposed algorithmwith 64 rules after trained with additive 10% noise. NRMSE= 0:0442.
7). The IAC index used in these examples supports this suppo-sition, since it considers this structure to be the most successful
TABLE VEVOLUTION OF THE NRMSEFOR DIFFERENTTRAINING NOISY DATA
decision for the construction of the fuzzy system (Fig. 8). Themembership functions of the input variables are illustrated inFig. 9. It is important to note that if the algorithm begins witha configuration of membership functions (36 rules) thebest NRMSE obtained is 0.101 (test data), much worse thanthe result of 0.070 obtained with the same number of rules butdistributed from the configuration. Thus, the proposedmethod is able to determine the optimum structure. Another 2-Dfunction defined in (24) and reported in [2], is illustrated in Fig.10
(24)
D. Example 3
The next example corresponds to a four-input function [2],whose mathematical expression is
(25)
In this case, due to the higher dimension of the function we use10 000 randomly selected training data points and 160 000 testdata points. As may be seen from the development of the numberof rules in this example (Table IV), variables and need agreater contribution of membership functions, since they mainlymodify the output surface, because of the exponential depen-dence of the output variable and the linearity of the sine functionin the range selected. Thus, the algorithm does increase only thenumber of membership functions in the most significant vari-ables. This property is fundamental when the number of inputvariables is high due to the exponential increase in the com-plexity of a fuzzy system when the number of linguistic valuesgrows.
E. Example 4
For many tasks it is of key interest to know how well acertain amount of noise can be handled. Some simulationswere run with a specific amount of noise added to the trainingdata to demonstrate the effect of noisy training patterns onthe generation of fuzzy systems by the proposed algorithm.For this purpose, we used function (24), which has an output
POMARESet al.: A SYSTEMATIC APPROACH TO A SELF-GENERATING FUZZY RULE-TABLE 443
TABLE VIEVOLUTION OF THE NRMSEFOR DIFFERENTNUMBER OF TRAINING DATA
range of . We added to the training data equally dis-tributed additive noise ( i.e., %) in the first case andnoise ten times greater ( i.e., %) in the second one[see Fig. 11(a) and (b)]. The results obtained are presentedin Table V, from which it may be concluded that the noise ispractically eliminated even for the second case and that a smallquantity of noise (1%) has no effect at all. Fig. 11(c) representsthe output obtained for a configuration with 64 rules, usingdata with 10% noise as a training pattern. On comparing thiswith the output obtained in Example 2 [Fig. 10(b)], we see that,although the NRMSE is greater than in the noise-free case,the original pattern of the target function has been recoveredcompletely. As expected, the more complex the system, thegreater is the difference between the systems with and withoutnoise; this is because noise, for these configurations, startsto become a significant factor and affects the values of theparameters to be optimized. Again, the IAC index will be theresponsible for selecting a proper configuration.
F. Effect of the Number of Training Data
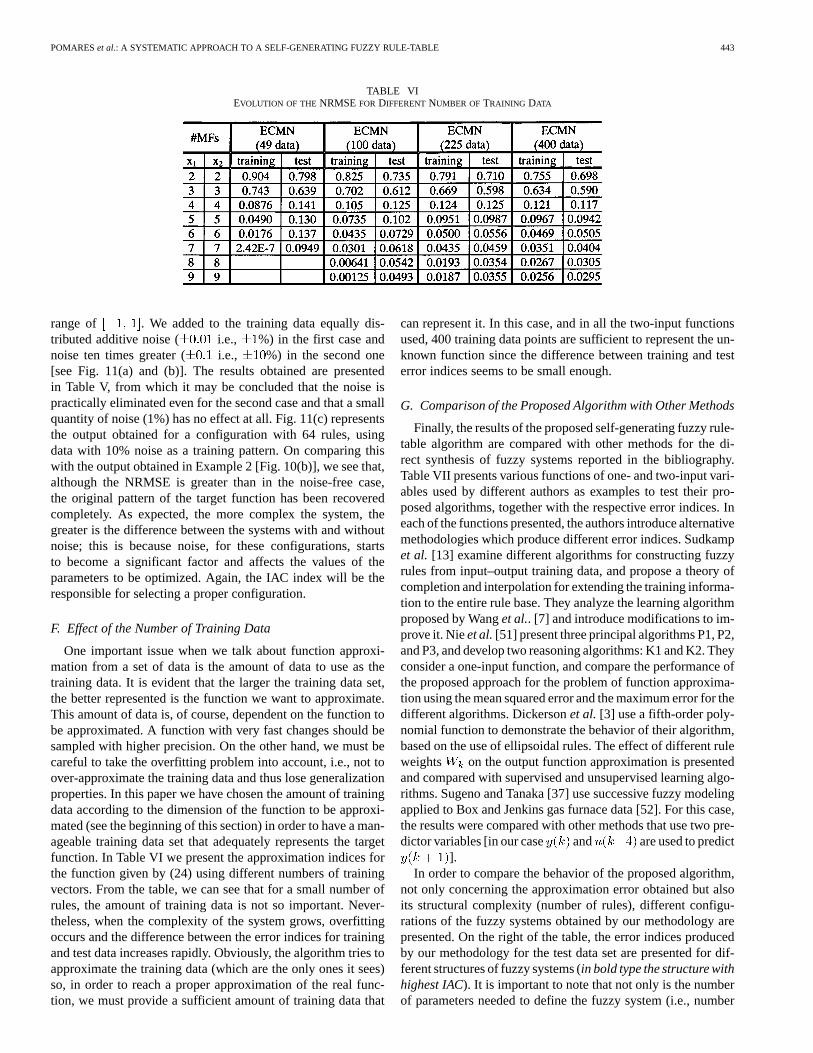
One important issue when we talk about function approxi-mation from a set of data is the amount of data to use as thetraining data. It is evident that the larger the training data set,the better represented is the function we want to approximate.This amount of data is, of course, dependent on the function tobe approximated. A function with very fast changes should besampled with higher precision. On the other hand, we must becareful to take the overfitting problem into account, i.e., not toover-approximate the training data and thus lose generalizationproperties. In this paper we have chosen the amount of trainingdata according to the dimension of the function to be approxi-mated (see the beginning of this section) in order to have a man-ageable training data set that adequately represents the targetfunction. In Table VI we present the approximation indices forthe function given by (24) using different numbers of trainingvectors. From the table, we can see that for a small number ofrules, the amount of training data is not so important. Never-theless, when the complexity of the system grows, overfittingoccurs and the difference between the error indices for trainingand test data increases rapidly. Obviously, the algorithm tries toapproximate the training data (which are the only ones it sees)so, in order to reach a proper approximation of the real func-tion, we must provide a sufficient amount of training data that
can represent it. In this case, and in all the two-input functionsused, 400 training data points are sufficient to represent the un-known function since the difference between training and testerror indices seems to be small enough.
G. Comparison of the Proposed Algorithm with Other Methods
Finally, the results of the proposed self-generating fuzzy rule-table algorithm are compared with other methods for the di-rect synthesis of fuzzy systems reported in the bibliography.Table VII presents various functions of one- and two-input vari-ables used by different authors as examples to test their pro-posed algorithms, together with the respective error indices. Ineach of the functions presented, the authors introduce alternativemethodologies which produce different error indices. Sudkampet al. [13] examine different algorithms for constructing fuzzyrules from input–output training data, and propose a theory ofcompletion and interpolation for extending the training informa-tion to the entire rule base. They analyze the learning algorithmproposed by Wanget al.. [7] and introduce modifications to im-prove it. Nieet al.[51] present three principal algorithms P1, P2,and P3, and develop two reasoning algorithms: K1 and K2. Theyconsider a one-input function, and compare the performance ofthe proposed approach for the problem of function approxima-tion using the mean squared error and the maximum error for thedifferent algorithms. Dickersonet al. [3] use a fifth-order poly-nomial function to demonstrate the behavior of their algorithm,based on the use of ellipsoidal rules. The effect of different ruleweights on the output function approximation is presentedand compared with supervised and unsupervised learning algo-rithms. Sugeno and Tanaka [37] use successive fuzzy modelingapplied to Box and Jenkins gas furnace data [52]. For this case,the results were compared with other methods that use two pre-dictor variables [in our case and are used to predict
].In order to compare the behavior of the proposed algorithm,
not only concerning the approximation error obtained but alsoits structural complexity (number of rules), different configu-rations of the fuzzy systems obtained by our methodology arepresented. On the right of the table, the error indices producedby our methodology for the test data set are presented for dif-ferent structures of fuzzy systems (in bold type the structure withhighest IAC). It is important to note that not only is the numberof parameters needed to define the fuzzy system (i.e., number

444 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 30, NO. 3, JUNE 2000
TABLE VIICOMPARISON OF THEPROPOSEDALGORITHM WITH OTHER METHODS FORDIRECT SYNTHESIS OFFUZZY SYSTEMS
of rules and membership functions) considerably reduced com-pared with other approaches, but also that the performance ofthe fuzzy system obtained is greatly improved.
In the case of the Box and Jenkins gas furnace data (296 data),J is defined as follows:
(26)
where is the output of the furnace at theth pair and isthe output of the model. It should be noted that although Sugenoand Tanaka [37] obtained a fairly good value forusing justtwo fuzzy inferences, each one of these may, in fact, need upto seven parameters (two for each linear membership functionand three for the consequent): in total, thus, up to 14 parame-ters may be used. In our case, for the configuration theparameters to be optimized are nine consequence of the rules

POMARESet al.: A SYSTEMATIC APPROACH TO A SELF-GENERATING FUZZY RULE-TABLE 445
plus two centers of the membership functions (as the extremesare fixed), that is, a total of 11 parameters. Another factor to betaken into account when constructing fuzzy systems, as com-mented in Section IV, is the interpretability of the rules obtained.Systems with TSK-type consequence are hard to understand, al-though they may enable a very good model to be obtained whilstusing a greatly reduced number of fuzzy inferences.
VIII. C ONCLUSIONS
This paper proposes a new learning method to automaticallyobtain the structure of a fuzzy system and derive fuzzy rules andmembership functions from a given set of training data. Due tothe fact that the shape and distribution of the membership func-tions are highly influential in fuzzy system design, an approachto the joint optimization of the membership functions, the rulesand the structure of the fuzzy system has been proposed.
The algorithm presented here is able to recognize where it isnecessary to assign a larger number of rules and to increase thedensity of membership functions in a specific input variable foran accurate approximation of the target function. The proposedapproach to function approximation automatically determinesthe structure and parameters of the fuzzy system, while knowl-edge acquisition or training is very fast. The interpretation of theresulting system, due to the type of membership function distri-bution selected is straightforward for a human operator.
The approximation accuracy of the fuzzy system derived bythe presented method has been empirically compared with theresults of other fuzzy-rule generating methodologies. Thesecomparisons with previous studies reveal that the proposedmethodology not only obtains better approximation results, butalso provides fuzzy systems that, in terms of the number ofrules and membership functions, are less structurally complex;therefore fuzzy systems can be generated even when there is alarge number of input variables.
As a future research, we will try to extent the proposed ap-proach to other kind of membership functions. In the case oftriangular membership functions we can use a triangular parti-tion in the step previous to the gradient descent and then opti-mize all the parameters involved. For Gaussian functions, theproblem is more difficult and the method proposed in Section Vshould also be revised.
APPENDIX
We report the expressions to employ the gradient descent pre-sented in Section IV. To optimize the location of the linguisticvalues it is necessary to calculate the variation of J(R,C) withrespect to the position of each of the centers of the membershipfunctions. For this purpose, we must find
(27)
The denominator of (3) does not normally have to be constant
and thus, in general, we have
From (8), which is only valid for the configuration of trian-gular functions defined previously, the above expression can begreatly simplified
(28)
and, as only the membership functions of variablecan dependon center , we have
(29)
Finally, from (9) it may be seen that
if
if
if
(30)

446 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 30, NO. 3, JUNE 2000
There exists the problem that the derivative is not defined at thepoints where the data coincide with the positions of the centers.At such points, the value of the derivative would have to berepresented by the value of one of the two lateral derivativesor by the semi-sum of these two. In any case, due to the discretenature of our data, this poses no great problem; the centers canmove within a continuum (the accuracy of the floating point ofthe computer) and it is very unusual for one datum to coincideexactly with a center. Moreover, the total derivative is a sum forall the data and the possible effect of any discontinuity in thederivative would be minimized.
Finally, it must be noted that the centers found at the extremesof each variable are considered to be fixed, as their positionsdepend exclusively on the minimum and maximum values ofthe range of each variable.
REFERENCES
[1] D. S. Chen and R. C. Jain, “A robust back propagation learning algo-rithm for function approximation,”IEEE Trans. Neural Networks, vol.5, pp. 467–479, May 1994.
[2] V. Cherkassky, D. Gehring, and F. Mulier, “Comparison of adaptivemethods for function estimation from samples,”IEEE Trans. NeuralNetworks, vol. 7, pp. 969–984, July 1996.
[3] J. A. Dickerson and B. Kosko, “Fuzzy function approximation with ellip-soidal rules,”IEEE Trans. Syst., Man, Cybern. B, vol. 26, pp. 542–560,1996.
[4] J. H. Friedman, “An overview of predictive learning and function ap-proximation,” inFrom Statistics to Neural Networks: Theory and Pat-tern Recognition Applications. ser. NATO ASI Series F, V. Cherkassky,J. H. Friedman, and H. Wechsler, Eds. Berlin: Springer-Verlang, 1994.
[5] J. S. R. Jang, C. T. Sun, and E. Mizutani,Neuro-Fuzzy and Soft Com-puting. Englewood Cliffs, NJ: Prentice-Hall, 1997.
[6] T.-Y. Kwok and D.-Y. Yeung, “Objective functions for training newhidden units in constructive neural networks,”IEEE Trans. NeuralNetworks, vol. 8, pp. 1131–1148, September 1997.
[7] L. X. Wang and J. M. Mendel, “Generating fuzzy rules by learning fromexamples,”IEEE Trans. Syst., Man, Cybern., vol. 22, pp. 1414–1427,Dec. 1992.
[8] M. Funabashi and A. Maeda, “Fuzzy and neural hybrid expert systems:Synergetic AI,”IEEE Expert, pp. 32–40, 1995.
[9] H. Ishibuchi, R. Fujioka, and H. Tanaka, “Neural networks that learnfrom fuzzy if–then rules,”IEEE Trans. Fuzzy Syst., vol. 1, pp. 85–96,May 1993.
[10] J. S. R. Jang and C. T. Sun, “Neuro-fuzzy modeling and control,”Proc.IEEE, vol. 83, no. 3, pp. 378–405, March 1995.
[11] W. Li, “A method for design of a hybrid neuro-fuzzy control systembased on behavior modeling,”IEEE Trans. Fuzzy Syst., vol. 5, pp.128–134, Feb. 1997.
[12] D. Driankov, H. Hellendoorn, and M. Reinfrank,An Introduction toFuzzy Control. Berlin: Springer-Verlag, 1993.
[13] T. Sudkamp and R. J. Hammell, “Interpolation, completion and learningfuzzy rules,” IEEE Trans. Syst., Man, Cybern., vol. 24, pp. 332–342,Feb. 1994.
[14] Z. Zhang and M. Mizumoto, “On rule self-generating for fuzzy control,”Int. J. Int. Syst., vol. 9, pp. 1047–1057, 1994.
[15] S. Abe and M. S. Lan, “Fuzzy rules extraction directly from numericaldata for function approximation,”IEEE Trans. Syst., Man, Cybern., vol.25, pp. 119–129, Jan. 1995.
[16] C. K. Chiang, H. Y. Chung, H. Y. J-J, and H. Y. Lin, “A self-learningfuzzy logic controller using genetic algorithms with reinforcements,”IEEE Trans. Fuzzy Syst., vol. 5, pp. 460–467, Sept. 1997.
[17] C. M. Higgins and R. M. Goodman, “Fuzzy rule-based networks forcontrol,” IEEE Trans. Fuzzy Syst., vol. 2, pp. 82–88, Feb. 1994.
[18] A. Homaifar and E. McCormick, “Simultaneous design of membershipfunctions and rule sets for fuzzy controllers using genetic algorithms,”IEEE Trans. Fuzzy Syst., vol. 3, no. 2, pp. 129–139, May 1995.
[19] T. Hong and C. Lee, “Induction of fuzzy rules and membership functionsfrom training examples,”Fuzzy Sets Syst., vol. 84, pp. 33–37, 1996.
[20] S. Liu and S. Hu, “A method of generating control rule model and itsapplication,”Fuzzy Sets Syst., vol. 52, pp. 33–37, 1992.
[21] V. S. Manorajan, A. S. Lazaro, D. Edwards, and A. Athalye, “A system-atic approach to obtaining fuzzy sets for control systems,”IEEE Trans.Syst., Man, Cybern., vol. 25, pp. 206–213, Jan. 1995.
[22] R. Rovatti and R. Guerrieri, “Fuzzy sets of rules for system identifica-tion,” IEEE Trans. Fuzzy Syst., vol. 4, pp. 89–102, 1996.
[23] H. Tanaka, K. Yokode, and H. Ishibuchi, “GMDH by fuzzy if-then ruleswith certainty factors,” inProc. 5th IFSA World Congress, 1993, pp.802–805.
[24] B. Kosko,Neural Networks and Fuzzy Systems. Englewood Cliffs, NJ:Prentice-Hall, 1992.
[25] R. Rovatti, R. Guerrieri, and G. Baccarani, “An enhanced two-levelboolean synthesis methodology for fuzzy rules minimization,”IEEETrans. Fuzzy Syst., vol. 3, pp. 288–298, Aug. 1995.
[26] C. L. Karr and E. J. Gentry, “Fuzzy control of pH using genetic algo-rithms,” IEEE Trans. Fuzzy Syst., vol. 1, no. 1, pp. 46–53, 1993.
[27] J. Kim and B. P. Zeigler, “Designing fuzzy logic controllers using mul-tiresolutional search paradigm,”IEEE Trans. Fuzzy Syst., vol. 4, pp.213–226, Aug. 1996.
[28] D. Park, A. Kandel, and G. Langholz, “Genetic-based new fuzzy rea-soning models with application to fuzzy control,”IEEE Trans. Syst.,Man, Cybern., vol. 24, no. 1, pp. 39–47, 1994.
[29] I. Rojas, J. J. Merelo, J. L. Bernier, and A. Prieto, “A new approach tofuzzy controller designing and coding via genetic algorithms,” inIEEEInt. Conf. Fuzzy Systems, Barcelona, Spain, July 1997, pp. 1505–1510.
[30] H. Surmann, A. Kanstein, and K. Goser, “Self-organizing and geneticalgorithms for an automatic design of fuzzy control and decision sys-tems,” inProc. EUFIT’93, Sept. 1993, pp. 1097–1104.
[31] K. Mitsubuchi, S. Isaka, and Z. Y. Zhao, “A fuzzy rule generationsystem,” inProc. IFSA World Congress, Seoul, Korea, 1993, pp. 11–14.
[32] M. M. Gupta and J. Qi, “Design of fuzzy logic controllers based ongeneralized T-operators,”Fuzzy Sets Syst., vol. 40, pp. 473–489, 1991.
[33] I. Rojas, J. Ortega, F. J. Pelayo, and A. Prieto, “Statistical analysis of themain parameters in the fuzzy inference process,”Fuzzy Sets Syst., vol.102, pp. 157–173, 1999.
[34] R. R. Yager, “Quantifier guided aggregation using OWA operators,”Int.J. Int. Syst., vol. 11, pp. 49–73, 1996.
[35] T. Takagi and M. Sugeno, “Fuzzy identification of systems and its ap-plications to modeling and control,”IEEE Trans. Syst., Man, Cybern.,vol. SMC-15, pp. 116–132, 1985.
[36] M. Sugeno and G. Kang, “Structure identification of fuzzy model,”Fuzzy Sets Syst., vol. 28, pp. 15–33, 1988.
[37] M. Sugeno and K. Tanaka, “Successive identification of a fuzzy modeland its application to prediction of complex systems,”Fuzzy Sets Syst.,vol. 41, pp. 315–334, 1991.
[38] W. H. Press, B. P. Flannery, S. A. Teukolsky, and W. T. Vetterling,Nu-merical Recipes in C. Cambridge, U.K.: Cambridge Univ. Press, 1993.
[39] J. R. Boston, “Effects of membership function parameters on the perfor-mance of a fuzzy signal detector,”IEEE Trans. Fuzzy Syst., vol. 5, pp.249–255, May 1997.
[40] M. R. Cinvalar and H. J. Trussell, “Constructing membership functionsusing statistical data,”Fuzzy Sets Syst., vol. 18, pp. 1–14, 1986.
[41] J. S. R. Jang, “Anfis: Adaptive-network-based fuzzy inference systems,”IEEE Trans. Syst., Man, Cybern., vol. 23, pp. 665–685, 1993.
[42] H. Nomura, I. Hayashi, and N. Wakami, “A learning method of fuzzyinference rules by descent method,” inProc. IEEE Int. Conf. Fuzzy Syst.,1992, pp. 203–210.
[43] A. Lotfi, H. C. Andersen, and A. C. Tsoi, “Matrix formulation of fuzzyrule-based systems,”IEEE Trans., Syst., Man, Cybern. B, vol. 26, pp.332–339, April 1996.
[44] A. Lotfi and A. C. Tsoi, “Importance of membership functions: A com-parative study on different learning methods for fuzzy inference sys-tems,” inProc. 3rd IEEE Int. Conf. Fuzzy Syst., Orlando, FL, June 1994,pp. 1791–1796.
[45] L.-X. Wang and J. M. Mendel, “Fuzzy basis functions, universal ap-proximation, and orthogonal least square learning,”IEEE Trans. NeuralNetworks, vol. 3, pp. 807–814, Sept. 1992.
[46] E. H. Ruspini, “A new approach to clustering,”Inf. Control, pp. 22–32,1969.
[47] C. C. Lee, “Fuzzy logic in control systems: Fuzzy logic controller—PartI, II,” IEEE Trans. Syst., Man, Cybern., vol. 20, pp. 404–435, 1990.
[48] J. Rissanen, “Modeling by shortest data description,”Automatica, vol.14, pp. 464–471, 1978.
[49] C. M. Fonseca and P. J. Fleming, “Multiobjective optimization and mul-tiple constraint handling with evolutionary algorithms—Part I: A unifiedformulation,” IEEE Trans. Syst., Man, Cybern. A, vol. 28, pp. 26–37,1998.

POMARESet al.: A SYSTEMATIC APPROACH TO A SELF-GENERATING FUZZY RULE-TABLE 447
[50] H. Akaike, “Information theory and extension of the maximum likeli-hood principle,”Akademia, pp. 267–810, 1973.
[51] J. H. Nie and T. H. Lee, “Rule-based modeling: Fast construction andoptimal manipulation,”IEEE Trans. Syst., Man, Cybern. A, vol. 26, pp.728–738, 1996.
[52] G. E. P. Box and G. M. Jenkins,Time Series Analysis, Forecasting andControl, 2nd ed. San Francisco, CA: Holden-Day, 1976.
[53] R. M. Tong, “Synthesis of fuzzy models for industrial processes,”Int. J.General Syst., vol. 4, pp. 143–162, 1978.
[54] W. Pedrycz, “An identification algorithm in fuzzy relational systems,”Fuzzy Sets Syst., vol. 13, pp. 153–167, 1984.
[55] C. Xu and Y. Lu, “Fuzzy model identification and self learning for dy-namic systems,”IEEE Trans. Syst., Man, Cybern., vol. SMC-17, pp.683–689, 1987.
Hector Pomareswas born in 1972. He received theM.A.Sc. degree in electronic engineering in 1995, theM.Sc. degree in physics in 1997, and the Ph.D. degreein 2000, all from the University of Granada, Granada,Spain.
He is currently a Fellowship Holder in the Depart-ment of Computer Architecture and Technology atthe University of Granada. His current areas of re-search interest are in the fields of function approxi-mation and on-line control using adaptive and self-or-ganizing fuzzy systems.
Ignacio Rojas received the M.S. degree in physicsand electronics in 1992 and the Ph.D. degree in 1996,both from the University of Granada, Granada, Spain.
He was at the University of Dortmund, Germany,as Invited Researcher from 1993 to 1995. In 1998,he was a Visiting Researcher at the BISC Group,University of California, Berkeley. He is currently anAssociate Professor in the Department of ComputerArchitecture and Technology, the University ofGranada. His research interests are in the fieldsof hybrid system and combination of fuzzy logic,
genetic algorithms, and neural networks and financial forecasting.
Julio Ortega received the B.Sc. degree in electronicphysics in 1985, the M.Sc. degree in electronics in1986, and the Ph.D. degree in 1990, all from the Uni-versity of Granada, Granda, Spain. His Ph.D. disser-tation has received the Award of Ph.D. dissertation ofthe University of Granada.
He was at the Open University, U.K., and at theDepartment of Electronics, University of Dortmund,Germany, as Invited Researcher. Currently, he is anAssociate Professor in the Department of ComputerArchitecture and Technology, the University of
Granada. His research interests are in the fields of parallel processing andparallel computer architectures, artificial neural networks, and evolutionarycomputation. He has led research projects supported by the Spanish Commis-sion of Science and Technology (CICYT) in the area of parallel algorithms andarchitectures for combinatorial optimization problems.
Jesus Gonzalezwas born in 1974. He received theM.A.Sc. degree in computer science in 1997 fromthe University of Granada, Granada, Spain. He iscurrently a Fellowship holder and Doctorate studentwithin the Department of Computer Architectureand Technology at the same university. His currentareas of research interest are in the fields of functionapproximation using radial basis functions, fuzzysystems, and genetic algorithms.
Alberto Prieto received the B.Sc. degree inelectronic physics in 1968 from the ComplutenseUniversity, Madrid, Spain, and the Ph.D. degreefrom the University of Granada, Granada, Spain,in 1976, obtaining the Award of Ph.D. dissertationsand the Citema Foundation National Award.
From 1969 to 1970, he was at the “Centro deInvestigaciones Técnicas de Guipuzcoa” and at the“E.T.S.I Industriales” of San Sebastián. From 1971to 1984, he was Director of the Computer Center andfrom 1985 to 1990 Dean of the Computer Science
and Technology studies at the University of Granada, where he is currentlyFull Professor and Director of the Department of Computer Architecture andTechnology. He has stayed as Visitor Researcher in different foreign centers asthe University of Rennes, France (1975, Prof. Boulaye), the Open Universit,U.K., (1987, Prof. S. L. Hurst), the Institute National Polythechnique ofGrenoble, France, (1991, Profs. J. Herault and C. Jutten), and the UniversityCollege of London, London, U.K. (1991–1992, Prof. P. Treleaven). Hisresearch interests are in the area of intelligent systems.
Prof. Prieto was the Organization Chairman of theInternational Workshopon Artificial Neural Networks (IWANN’91)(Granada, September 17–19, 1991)and of the7th International Conference on Microelectronics for Neural, Fuzzyand Bio-inspired Systems (MicroNeuro’99)(Granada, Spain, April 7–9, 1999).He is a nominated member of the IFIP WG 10.6 (Neural Computer Systems)and Chairman of the Spanish RIG of the IEEE Neural Networks Council.




















