
A kernel regression framework for SMT
16
Mach Translat (2010) 24:87–102 DOI 10.1007/s10590-010-9079-0 A kernel regression framework for SMT Zhuoran Wang · John Shawe-Taylor Received: 26 October 2009 / Accepted: 25 May 2010 / Published online: 12 June 2010 © Springer Science+Business Media B.V. 2010 Abstract This paper presents a novel regression framework to model both the translational equivalence problem and the parameter estimation problem in statistical machine translation (SMT). The proposed method kernelizes the training process by formulating the translation problem as a linear mapping among source and tar- get word chunks (word n-grams of various length), which yields a regression prob- lem with vector outputs. A kernel ridge regression model and a one-class classifier called maximum margin regression are explored for comparison, between which the former is proved to perform better in this task. The experimental results conceptually demonstrate its advantages of handling very high-dimensional features implicitly and flexibly. However, it shares the common drawback of kernel methods, i.e. the lack of scalability. For real-world application, a more practical solution based on locally linear regression hyperplane approximation is proposed by using online relevant train- ing examples subsetting. In addition, we also introduce a novel way to integrate lan- guage models into this particular machine translation framework, which utilizes the language model as a penalty item in the objective function of the regression model, since its n-gram representation exactly matches the definition of our feature space. Keywords Statistical machine translation · Kernel methods · Discriminative learning · Regression · Language modeling Z. Wang (B ) · J. Shawe-Taylor Department of Computer Science, Centre for Computational Statistics and Machine Learning, University College London, Gower Street, London WC1E 6BT, UK e-mail: [email protected] 123
-
Upload
independent -
Category
Documents
-
view
3 -
download
0
Transcript of A kernel regression framework for SMT

Mach Translat (2010) 24:87–102DOI 10.1007/s10590-010-9079-0
A kernel regression framework for SMT
Zhuoran Wang · John Shawe-Taylor
Received: 26 October 2009 / Accepted: 25 May 2010 / Published online: 12 June 2010© Springer Science+Business Media B.V. 2010
Abstract This paper presents a novel regression framework to model both thetranslational equivalence problem and the parameter estimation problem in statisticalmachine translation (SMT). The proposed method kernelizes the training processby formulating the translation problem as a linear mapping among source and tar-get word chunks (word n-grams of various length), which yields a regression prob-lem with vector outputs. A kernel ridge regression model and a one-class classifiercalled maximum margin regression are explored for comparison, between which theformer is proved to perform better in this task. The experimental results conceptuallydemonstrate its advantages of handling very high-dimensional features implicitly andflexibly. However, it shares the common drawback of kernel methods, i.e. the lackof scalability. For real-world application, a more practical solution based on locallylinear regression hyperplane approximation is proposed by using online relevant train-ing examples subsetting. In addition, we also introduce a novel way to integrate lan-guage models into this particular machine translation framework, which utilizes thelanguage model as a penalty item in the objective function of the regression model,since its n-gram representation exactly matches the definition of our feature space.
Keywords Statistical machine translation · Kernel methods · Discriminativelearning · Regression · Language modeling
Z. Wang (B) · J. Shawe-TaylorDepartment of Computer Science, Centre for Computational Statistics and Machine Learning,University College London, Gower Street, London WC1E 6BT, UKe-mail: [email protected]
123

88 Z. Wang, J. Shawe-Taylor
1 Introduction
One of the fundamental assumptions in training a word- or phrase-based SMT modelis that bilingual sentence pairs can be word-aligned. Based on the word alignments,one extracts word or phrase translation tables and computes translation model proba-bilities. Such alignments can be viewed as a sort of linear correspondences betweensource and target sentences. However, in classical SMT models the usage of thoselinear correspondences is naive. One only generates the conditional translation prob-abilities between pairs of words or word groups (i.e. phrases), while assuming thetranslation of a word or phrase to be independent of the words that are not aligned toit. By doing this, one significantly reduces the complexities of computing a probabi-listic model, but it also looses a lot of meaningful contextual information that a humantranslator could use to understand a source sentence.
Weston et al. (2002) and Cortes et al. (2005) suggested that high-dimensional linearcorrespondences among the features of inputs and outputs can be captured via regres-sion approaches. It poses the question that: Can we capture the correspondences ofphenomena in two languages by a linear mapping between high-dimensional spaces,with the expectation that when we translate a word or phrase, besides itself its con-textual words will also be able to contribute to the chance of the occurrence of atranslation?
Motivated by Cortes et al. (2005) work and the kernel methods (Shawe-Taylor andCristianini 2004), in this paper, we proposed a novel SMT framework based on kernelregression techniques. In our method, the translation task is viewed as a string-to-string mapping, for which a regression model is employed with both source and targetsentences embedded into their respective kernel induced feature spaces. We investi-gate two regression models that can predict vector outputs for comparison, which arethe maximum margin regression (MMR) introduced by Szedmák et al. (2006) and thekernel ridge regression (KRR) due to Cortes et al. (2005). Preliminary experimentsshow that the latter performs better in this task. Thus, based on the KRR, we fur-ther explore the scalable training problems and the language model (LM) integrationissues. Although due to the complexities of the proposed method, its capability ofbeing applied to a real-world SMT problem will still be regarded as restricted, wedemonstrate its advantages on a small-scale toy corpus. Moreover, we show that itsperformance approaches existing techniques in an SMT shared task.
The reminder of this article is organized as follows. Section 2 explains the regres-sion view of the machine translation problem, and gives both the explicit and implicitdefinitions of the feature spaces. Section 3 introduces two kernel regression techniquesthat can predict vectored outputs. In Sect. 4, we discuss the pre-image solutions for theproposed approach, i.e. how to decode the final translation from a real-valued outputfeature vector estimated by the regression models. We report some preliminary exper-imental results based on a small-scale low-perplexity toy data in Sect. 5 and addressthe scalable training issues in Sect. 6. Different ways for LM integration are proposedin Sect. 7. Thereafter experimental results on real-world data are reported in Sect. 8,where our model is compared to a number of state-of-the-art existing systems. Finally,we conclude and give further discussions in Sect. 9.
123

A kernel regression framework for SMT 89
aux questions marquées
marquées questions
questions
marquées
nous revenons aux
revenonsaux
aux
nous revenons
revenons
nous
1
1
1
1
1
1
1
1
1
1
1000000000
1.9.00000000
1.1.8.0000000
1.1.08.000000
0000100000
00002.7.001.0
1.0001.1.4.1.1.1.
00003.007.00
00001.2.01..60
00001.001.0.8
1
1
1
1
1
1
1
1
1
1
to marked questions
marked questions
questions
marked
return to we
return to
to
return we
return
we
⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
Fig. 1 From alignment to linear mapping: a generalization
2 Translating by mapping
Many text processing related problems, e.g. part-of-speech tagging, named entityrecognition, natural language parsing, etc., can be viewed as string-to-string map-pings. Cortes et al. (2005) proposed a kernel-based regression framework to addressthis kind of transduction problem. In their approach, both input and output stringsare embedded into their respective reproducing kernel Hilbert spaces (RKHS), alsoknown as feature spaces, and then, ridge regression is applied to learn a linear mappingfrom the input feature space to the output feature space. In this paper we follow theirmethod and apply the kernel regression technique to the particular task of SMT.
Concretely, if we define the feature space Hx of our source language X as all itspossible informative word chunks (i.e. a group of contiguous words), and define themapping φ : X → Hx , then a sentence x ∈ X can be expressed by its feature vectorφ(x) ∈ Hx . Each element of φ(x) is indexed by a word chunk with the value being thefrequency of its occurrence in x. Similarly, we define the feature space Hy of our targetlanguage Y , with corresponding mapping ψ : Y → Hy . Now in order to translate asource sentence x to a target sentence y, we will need to seek a matrix representedlinear operator W, such that:
ψ(y) = Wφ(x) (1)
This linear operator can be viewed as a natural generalization of the word or phrasealignment diagrams that are widely used in traditional training procedures of SMTmodels. An alignment diagram itself yields an explicit (unweighted) mapping matrix,where, however, only those words or phrases within a pair of aligned entities may havecorrespondences. Figure 1 illustrates this point of view.
The key ingredient here is to investigate an algorithm to learn the W that capturespotentially very high-dimensional correspondences among the source and target fea-tures on a given training set, and generalizes well for unseen examples. We start byintroducing our feature selection and kernel function to implicitly induce the featurespaces.
2.1 Feature space selection
As mentioned above, a possible way to select features for this regression-style SMTproblem is to use all informative word chunks. However, to define an informative word
123

90 Z. Wang, J. Shawe-Taylor
chunk is a difficult task itself. In principle, if we take all possible word strings up to acertain length as features on both source and target sides, a well-designed regressionmodel will assign higher weights to the entities containing more information aboutsome language phenomena than those having less information in them. Hence, wesimply use all source and target word n-grams with n increasing from 1 up to k as ourfeatures.
2.2 N -gram string kernel
Although the feature spaces under the above definition will be of very high dimen-sion, we can avoid explicitly dealing with them by using the ‘kernel trick’, since ourregression models can be formulated in such way that only inner products of featurevectors will occur in practical calculations, as to be shown in the next section. Then-gram string kernel (Shawe-Taylor and Cristianini 2004) that compares two stringsby counting how many contiguous substrings of length n they have in common givesan ideal solution for this task.
We denote by xi : j a substring of sentence x starting with the i th word and endingwith the j th. Then for two sentences x and z, the n-gram string kernel is computed as:
κn(x, z) :=|x|−n+1∑
i=1
|z|−n+1∑
j=1
I
(xi :i+n−1 = z j : j+n−1
)(2)
where | · | denotes the length of the sentence, and I(·) is the indicator function for thepredicate. Then, by counting the substrings of length from 1 to n simultaneously, weobtain a blended n-gram string kernel κ(x, z) := ∑n
p=1 κp(x, z) which induces theproposed feature spaces.
3 Regression models with vector outputs
Now we explore two regression approaches that can predict vector outputs for com-parison. The first one is the kernel ridge regression (KRR) introduced by Cortes et al.(2005). The other one is called maximum margin regression (MMR) introduced bySzedmák et al. (2006). The expectation is that KRR, as a well-formulated regressionmodel, can be expected to give more accurate predictions, whilst MMR, as a sort ofone-class approximation of multi-class classification, offers much more efficiency insolving its optimization problem. In addition, a benefit of these two models is thatthey both work as kernel methods.
3.1 Kernel ridge regression
Given a set of training examples, i.e. bilingual sentence pairs S := {(xi , yi )|i =1, . . . ,m}, we modify the original ridge regression to learn the linear operator W inEq. 1 by seeking the one minimizing the regularized squared loss in Hy , which yieldsthe following quadratic program (QP):
123

A kernel regression framework for SMT 91
minW
‖WMφ − Mψ‖2F + ν‖W‖2
F (3)
where Mφ := (φ(x1), φ(x2), . . . , φ(xm)) ,Mψ := (ψ(y1), ψ(y2), . . . , ψ(ym)) ,
‖ · ‖F denotes the Frobenius norm, and ν is a coefficient adjusting the effect of theregularization. The function of regularization is to improve the conditioning of theproblem, thus enabling a numerical solution.
Differentiating the expression and setting it to zero gives the explicit solution forQP (3). The detailed derivations can be found in Cortes et al. (2005). Here we onlygive the result:
W = Mψ(Kφ + νI)−1M�φ (4)
where I is the identity matrix, and Kφ := M�φ Mφ = (
κφ(xi , x j )1≤i, j≤m)
is the Grammatrix. Here, we use the kernel function κφ(·, ·) to denote the inner product betweentwo feature vectors of the source language. Similarly, in future discussions we willdenote by κψ(·, ·) the kernel of two sentences in the target language.
Inserting Eq. 4 into Eq. 1, we obtain our prediction:
ψ(y) = Wφ(x) = Mψ(Kφ + νI)−1kφ(x) (5)
where kφ(x) := (κφ(x, xi )1≤i≤m
)is an m × 1 column matrix.
3.2 Maximum margin regression
Suppose we have two vectors v1 and v2 of fixed norms. The inner product of them〈v1, v2〉 will reach the maximum if and only if the two vectors are in the same direc-tion. Following this principle, MMR gives an SVM-like formulation of the regressionproblem as:
minW,ξ
1
2‖W‖2
F + Cm∑
i=1
ξi (6)
s.t. 〈ψ(yi ),Wφ(xi )〉Hy ≥ 1 − ξi , ∀i; ξi ≥ 0, ∀i.
where C > 0 is the regularization coefficient and ξi are the slack variables. Its Lagrangedual problem with dual variables αi gives:
minα
m∑
i=1
m∑
j=1
αiα jκφ(xi , x j )κψ(yi , y j )−m∑
i=1
αi (7)
s.t. 0 ≤ αi ≤ C, ∀i.
This dual problem has the same computational complexity as a standard SVM.Szedmák et al. (2006) also developed a perceptron-type incremental subgradient algo-rithm to solve it efficiently.
123

92 Z. Wang, J. Shawe-Taylor
The explicit solution of MMR can be expressed as:
W =m∑
i=1
αiψ(yi )φ(xi )� (8)
Thus, our prediction is obtained as:
ψ(y) = Wφ(x) =m∑
i=1
αiψ(yi )κφ(xi , x) (9)
In the MMR case, the position of the origin with respect to the data in feature spacesinfluences the performance, as a poorly positioned origin will cause an ill-conditionedGram matrix. We can improve this by data centering (Meila 2003). In addition, wealso normalize the data to cancel the bias of the kernel function on longer sentences.Accordingly, we use κφ(·, ·) and κψ(·, ·) to denote the kernels defined for the cen-tered and normalized vectors (denoted as φ(·) andψ(·)) in replacement of the originalκφ(·, ·) and κψ(·, ·), respectively.
4 Decoding algorithm
To find the target sentence y from the feature vector ψ(y) predicted in Eq. 1, we seekthe y whose feature vector ψ(y) is closest to our prediction ψ(y). That is, for KRR:
y = arg miny∈Y(x)
‖Wφ(x)− ψ(y)‖2
= arg miny∈Y(x)
κψ(y, y)− 2kψ(y)(Kφ + νI)−1kφ(x) (10)
where Y(x) ⊂ Y denotes a finite set consisting of all potential translations for a givensource sentence x, and kψ(y) := (
κψ(y, yi )1≤i≤m), and for MMR:
y = arg maxy∈Y(x)
〈ψ(y),Wφ(x)〉Hy
= arg maxy∈Y(x)
m∑
i=1
αiκψ(yi , y)κφ(xi , x) (11)
A proper Y(x) can be generated according to a lexicon that contains possible trans-lations for every component (word or phrase) in x. This lexicon can be either extractedfrom the training corpus, as is used in traditional SMT systems, or created manuallyby linguists as in RBMT systems. But the size of it will grow exponentially with thelength of x, which poses implementation issues for a search algorithm.
123

A kernel regression framework for SMT 93
(a) (b)
Fig. 2 Search states with restricted distortion. a Appending a phrase directly. b Adjacent phrasesexchanging positions
4.1 Beam search
A most widely used SMT decoding method is the beam search algorithm for phrase-based models (Koehn 2004). The beam search decoder generates target sentences fromleft to right in the form of hypotheses (search states). The search process starts froman initial (empty) hypothesis. At each time, it expands a hypothesis by extending theoutput with a translation of a phrase not yet translated in the source sentence to createa new hypothesis. It estimates a current score and a future score for the new hypoth-esis, inserts it into a stack indexed by the number of the source words translated, andreranks and prunes the hypotheses in the stack at the same time according to theirscores. When all the words in the source sentence are covered, the search reachesfinal states, among which the highest scored one is selected as the best translation. Inprevious models, the scores for a hypothesis are usually computed incrementally bythe sum of a serial of log-probabilities, each of which depends on the features in alocal area only, e.g. a phrase pair for translation model, a word n-gram for languagemodel, etc. This is very convenient as the scores can be accumulated phrase by phraseduring the expansion of hypotheses.
However, in our case, because of the κψ(y, y) item in Eq. 10 and the normaliza-tion operation in MMR, neither the expression in Eq. 10 nor the one in Eq. 11 canbe decomposed into a sum of subfunctions each involving feature components in alocal area only. It means we will not be able to estimate exactly how well a part ofa source sentence is translated, until we obtain a translation for the entire sentence,which prevents us doing a straightforward beam search. Note here, on the other handκψ(y, y) in Eq. 10 and the normalization in MMR have the effect to penalize the biasof the respective scores on longer sentences, and therefore they control the length ofpredictions.
To simplify the situation, we restrict the reordering (distortion) of phrases that yieldoutput sentences by only allowing adjacent phrases to exchange their positions. Now,if we go back to the implementation of a beam search decoder, the distortion restrictionguarantees that in each expansion of the search states (hypotheses) we always have apartial source sentence x1:lx translated to a y1:ly , either like state (a) or like state (b)in Fig. 2, where lx is the number of words translated in the source sentence, and ly
is the number of words obtained in the translation. In other words, we always have acontiguous partial source sentence translated to a contiguous partial translation.
We assume that if y is a good translation of x, then y1:ly is a good translation ofx1:lx as well. So we can expect that for hypotheses yielding good translations, thesquared loss in KRR ‖Wφ(x1:lx )−ψ(y1:ly )‖2
2 is small, or the inner product in MMR〈ψ(y1:ly ),Wφ(x1:lx )〉Hy is large. Accordingly, the hypotheses in search stacks canthus be ranked with the following score functions, for KRR:
123

94 Z. Wang, J. Shawe-Taylor
S(x1:lx , y1:ly ) := 2kψ(y1:ly )(Kφ + νI)−1kφ(x1:lx )− κψ(y1:ly , y1:ly ) (12)
and for MMR:
S(x1:lx , y1:ly ) :=m∑
i=1
αiκψ(yi , y1:ly )κφ(xi , x1:lx ) (13)
Therefore, to decode we just employ a beam search algorithm similar to Koehn(2004), except we limit the derivation of new hypotheses with the distortion restric-tion mentioned above and score them according to Eqs. 12 and 13 for KRR and MMR,respectively.
5 Preliminary experiments on toy data
Training such regression models on a large-scale data set will be very expensive,however, the word n-gram distributions in a small corpus will be too sparse to yieldreliable statistics for training an SMT system. In order to give a preliminary view ofthe performance of the proposed methods, we construct a small-scale toy data set witha restricted vocabulary. We take 12,600 sentence pairs from the 1996–2003 French–English Europarl corpus (Koehn 2005), from which 12k are selected for training (fromwhich random subsets of size 4k, 6k, 8k and 10k are selected for scaling-up training),300 are selected as the test set , and another 300 are used for the validation of parametersettings in our regression models as well as for the development of a baseline phrase-based log-linear SMT model. The entire training corpus consists of about 130k Frenchwords and 120k English words, of which the vocabulary sizes are around 9k and 7k,respectively. The LM perplexities of the validation and test sets are 27.19 and 26.41,respectively.
To compare with existing techniques, we take Pharaoh (Koehn 2004) as a baselinesystem. We train a Kneser–Ney smoothed tri-gram language model for it. Its log-linearparameters are developed based on the minimum error rate training (MERT) method(Och 2003). In the following experiments, to facilitate comparison, each time we trainour regression models and Pharaoh’s language model and translation model on a com-mon corpus, and use the same phrase translation table as Pharaoh’s to decode oursystems.
5.1 Results
Based on the 4k training corpus and the validation set, we test the effects of regulariza-tion coefficient values. Firstly, for KRR we analyze the distribution of the eigenvaluesof our Gram matrix, and plot the histogram of them in Fig. 3a. It can be found thataround 94% of the eigenvalues are above 1 and over 78% of them are above 10. Inaddition, the eigenvalues below 1 drop sharply, which can be regarded as noise. Thuswe select our ν from {0.001, 0.01, 0.1, 1} to test and draw Fig. 3b. In addition, wealso give the result of a least squares regression without the ridge that is based on the
123

A kernel regression framework for SMT 95
−14 −12 −10 −8 −6 −4 −2 0 2 40
500
1000
1500
2000
2500
3000
3500
log(λ)0 0.001 0.01 0.1 1
30
31
32
33
34
35
36
37
38
39
40
ν / C−1
BLE
U [%
]
KRRMMR
(a) (b)
2 3 4 5 6 730
31
32
33
34
35
36
37
38
39
40
N
BLE
U [%
]
KRRMMR
4000 6000 8000 10000 1200030
32
34
36
38
40
42
44
TRAINING SET SIZE
BLE
U [%
]
MMRKRRPharaoh
(c) (d)
Fig. 3 Experimental results on the toy data. a Distribution of eigenvalues. b BLEU versus regularizationcoefficient. c BLEU versus n-gram length. d BLEU versus training set size
pseudo-inversion of the Gram matrix (computed in MATLAB), which is shown by thepoint with ν = 0 in the figure. Accordingly, for MMR we use C = 1
νto compare the
results. It can be seen that both KRR and MRR are insensitive to the regularizationcoefficient, and ν = 0.01 can be a good value for them. Then we validate the BLEUscore performance of KRR and MMR with n in the blended n-gram string kernelsincreasing from 2 to 7. Figure 3c shows the results. It can be seen that the performancebecomes stable when n reaches a certain value. In further experiments we will fixn = 3 for KRR and n = 5 for MMR, since a larger n results in a higher computationalcost. Finally, we scale up the training set, and compare the BLEU score performanceof our models with Pharaoh on the test set in Fig. 3d. We can see that the KRR modelperforms almost as well as Pharaoh, whose differences in BLEU score are within 0.5%when the training set is larger than 6k. But MMR model performs significantly worsethan the baseline.
To summarize, we conclude that in the above preliminary experiments KRR showsacceptable performance in this SMT task. However, the performance of MMR in thistask is not promising. Therefore, in further investigations, we will discard MMR andfocus on improving KRR-based approaches.
123

96 Z. Wang, J. Shawe-Taylor
6 Retrieval-based locally linear approximation
As a kernel method, our model suffers from the major drawback of high computationalcomplexities. The matrix inversion operation in Eq. 4 requires O(m3) time and O(m2)
space. Moreover, our preliminary experiments suggest that the eigenvalue distributionof the KRR Gram matrix is dense. Therefore, sparse greedy matrix approximationapproaches will not help in this case. Hence, we propose a more practical solution forhandling real-world SMT problems via dynamically subsetting the training data.
In the feature spaces defined above, we will be able to obtain a good translation aslong as we find a hyperplane passing though or close enough to the test data point.So we do not necessarily need all the training examples, but only those covering thefeatures of the test point well, in other words, relevant to the test point. Hence, we canretrieve a set of training sentence pairs whose source is close to it, and train a regres-sion model only on this small relevant set to predict the translation. Similar strategieshave been used in the earlier research in domain adaptation for SMT systems, whichare usually found to be significantly helpful (see Hildebrand et al. 2005 for example.)
Our previous research (Wang and Shawe-Taylor 2009) shows that to measure how‘close’ two sentences are, the tf-idf (term frequency—inverse document frequency)metric which is widely used in information retrieval fields works properly. Here, thetf-score of a word in a sentence is its frequency in that sentence normalized by thesentence length, while the idf-score of it is computed as the logarithm of the quotientof the training set size and the number of sentences containing it.
7 Language model integration
The effect of contextual information in the translation process can be understood asfollows. A source phrase may have multiple possible target translations that might notbe confidently decided on according to the source itself only, but if one of its contextualphrase has a more confident translation, the system would give preference to thosepotential targets that have contextual correspondences with the confident one. Thisprocess is normally modelled into two separate components in traditional SMT sys-tems: a translation model scoring how confident a phrase translation is and a languagemodel scoring the contextual correspondences among the translations. The proposedregression model gives a novel attempt to model this process. The high-dimensionalcorrespondences between the source and target phrases in principle allow all the con-textual source phrases to contribute to the confidence of a target translation, whilstit utilizes the nature of the overlapped word n-grams to reconstruct the target sen-tences. The preliminary experiments in Sect. 5 conceptually indicate that this ideaworks properly, when the distribution of word n-grams is relatively dense, as theKRR method without any LM components achieves almost identical performance toa “mainstream” model. However, the word n-gram distribution will be very sparsein real-world open-domain data. The word reordering relying only on the regressionmodel will be inadequate, due to the lack of sufficient evidence of words contextualcorrespondences. Therefore, an additional language model will be crucially helpful tothe practical application of the proposal approach.
123

A kernel regression framework for SMT 97
7.1 λ-integration
The most straightforward solution is to add a weight λ to adjust the strength of theregression based translation score and the LM score during the decoding procedure. Tochoose an optimal value for λ, we can employ an algorithm that is based on the sameprinciple as MERT but is much simpler, as we only have one parameter to tune. Infuture discussions, we call this method λ-integration and the corresponding languagemodel obtained λ-LM, for short.
7.2 ν-integration
Alternatively, as language models are typically n-gram-based which exactly matchthe definition of our feature space, we can add an LM loss to the objective function ofour regression model as follows.
If we take a tri-gram model as an example, which is expressed as:
P(y) = p(y1)p(y2|y1)
n∏
i=3
p(yi |yi−2 yi−1)
where y = y1 y2 . . . yn is a sentence of length n(≥ 3), and yi denotes the i th word init, then we can rewrite the logarithm of the LM probability of y to:
log P(y) = v�ψ(y)
where v is a weight vector with its elements vy′′ y′ y := log p(y|y′′y′), for all word tri-grams y′′y′y. Note here, in order to match our blended tri-gram indexed feature vectorψ(y), we must make v of the same dimension as it, with the components correspondingto uni-grams and bi-grams set to 0 or possibly encoding lower order language models.Note that for a language model of higher-order than the output n-gram feature space,we have to use λ-integration, as the dimension of the language model vector v doesnot agree with the weight matrix W.
After this, we reformulate the regression problem as:
minW
1
2‖WMφ − Mψ‖2
F + ν1
2‖W‖2
F − ν2v�WMφ1 (14)
where ν2 is a coefficient adjusting the effect of the LM loss, and 1 denotes a vectorwith components 1. The point is that now we are seeking the matrix W which balancesbetween the prediction being close to the target feature vector and being a fluent targetsentence.
Differentiating the objective function of QP (14) with respect to W and setting theresult to zero, yields:
(WMφ − Mψ)M�φ + ν1W − ν2v1�M�
φ = 0
⇔ W = AM�φ
123

98 Z. Wang, J. Shawe-Taylor
where:
A = − 1
ν1(WMφ − Mψ)+ ν2
ν1v1�
Substituting the expression for W in the equation for A gives:
A(Kφ + ν1I) = Mψ + ν2v1�
which implies the explicit solution for W. That is:
W = (Mψ + ν2v1�)(Kφ + ν1I)−1M�φ (15)
We will refer to this method as ν-integration and name the corresponding languagemodel ν-LM in future discussions.
8 Evaluations on large-scale real-world data
We evaluate the complete system based on the French–English, German–English andSpanish–English portions of the data sets from the WMT 2008 Shared TranslationTask (Callison-Burch et al. 2008), which are certain splits of the respective portionsof the 1996–2006 Europarl corpus. Translations are carried out bidirectionally on thecorpus in each language pair. These parallel corpora each contains approximately1.3M sentence pairs and 36–41M words in each language.
In the following experiments, we retrieve 1500 relevant sentence pairs for each testexample from its respective training set based on the tf-idf measure to train a KRRmodel with blended tri-gram kernels applied to both source and target sides. Thisrelevant subset size is selected according to some initial experiments on these corpora.Our previous research (Wang and Shawe-Taylor 2009) shows that in the retrieval-basedapproximation process, the translation quality grows with the subset size up to a certainnumber, and after that a too large relevant set could be harmful. This is because in aclosed training set, to retrieve a too large relevant set means that a number of examplesof little relevance to the test point may be forced to enter the it, which therefore wouldcorrespond to adding noise.
8.1 Experiments with language models
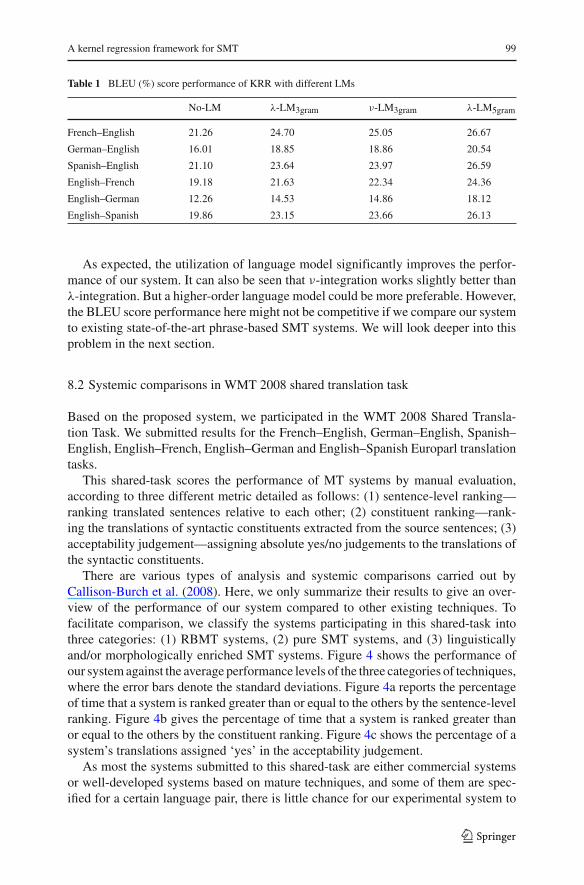
Firstly, we investigate the effect of different types of language models. Here, weexperiment with four versions of the proposed system. In the first version, there is nolanguage model used. Then, we train a tri-gram language model for each language,and insert them into our systems using λ-integration and ν-integration, respectively.In addition, we also train 5-gram language models and integrate them to our systemsusing λ-integration, yielding the fourth version. Table 1 shows the BLEU score resultsfor each language pair.
123
A kernel regression framework for SMT 99
Table 1 BLEU (%) score performance of KRR with different LMs
No-LM λ-LM3gram ν-LM3gram λ-LM5gram
French–English 21.26 24.70 25.05 26.67
German–English 16.01 18.85 18.86 20.54
Spanish–English 21.10 23.64 23.97 26.59
English–French 19.18 21.63 22.34 24.36
English–German 12.26 14.53 14.86 18.12
English–Spanish 19.86 23.15 23.66 26.13
As expected, the utilization of language model significantly improves the perfor-mance of our system. It can also be seen that ν-integration works slightly better thanλ-integration. But a higher-order language model could be more preferable. However,the BLEU score performance here might not be competitive if we compare our systemto existing state-of-the-art phrase-based SMT systems. We will look deeper into thisproblem in the next section.
8.2 Systemic comparisons in WMT 2008 shared translation task
Based on the proposed system, we participated in the WMT 2008 Shared Transla-tion Task. We submitted results for the French–English, German–English, Spanish–English, English–French, English–German and English–Spanish Europarl translationtasks.
This shared-task scores the performance of MT systems by manual evaluation,according to three different metric detailed as follows: (1) sentence-level ranking—ranking translated sentences relative to each other; (2) constituent ranking—rank-ing the translations of syntactic constituents extracted from the source sentences; (3)acceptability judgement—assigning absolute yes/no judgements to the translations ofthe syntactic constituents.
There are various types of analysis and systemic comparisons carried out byCallison-Burch et al. (2008). Here, we only summarize their results to give an over-view of the performance of our system compared to other existing techniques. Tofacilitate comparison, we classify the systems participating in this shared-task intothree categories: (1) RBMT systems, (2) pure SMT systems, and (3) linguisticallyand/or morphologically enriched SMT systems. Figure 4 shows the performance ofour system against the average performance levels of the three categories of techniques,where the error bars denote the standard deviations. Figure 4a reports the percentageof time that a system is ranked greater than or equal to the others by the sentence-levelranking. Figure 4b gives the percentage of time that a system is ranked greater thanor equal to the others by the constituent ranking. Figure 4c shows the percentage of asystem’s translations assigned ‘yes’ in the acceptability judgement.
As most the systems submitted to this shared-task are either commercial systemsor well-developed systems based on mature techniques, and some of them are spec-ified for a certain language pair, there is little chance for our experimental system to
123

100 Z. Wang, J. Shawe-Taylor
En−Fr En−Ge En−Es Fr−En Ge−En Es−En0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9RBMT Pure SMT Enriched SMT UCL−KRR
(a)
En−Fr En−Ge En−Es Fr−En Ge−En Es−En0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
RBMT Pure SMT Enriched SMT UCL−KRR
(b)
En−Fr En−Ge En−Es Fr−En Ge−En Es−En0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
RBMT Pure SMT Enriched SMT UCL−KRR
(c)
Fig. 4 Systemic comparisons in the WMT 2008 Shared Translation Task. a Sentence-level ranking.b Syntactic constituent ranking. c Constituent acceptability judgement
significantly outperform them. But the results show that our system can beat the RBMTsystems in most of the constituent ranking judgements and acceptability judgements.It also approaches the average level of the existing SMT techniques in some translationtasks. In addition, the sentence-level and the syntactic constituent ranking judgements
123

A kernel regression framework for SMT 101
show that a considerable portion of our translation outputs are at least as good as othersystems.
9 Conclusion and further discussions
In this article, we present a novel framework for machine translation based on kernelregression techniques with high-dimensional vector outputs. Although at this stage themain contribution is still more conceptual than practical, its feasibility in an applicationto the SMT field is preliminarily demonstrated. As a kernel method, this framework hasthe advantage of capturing global correspondences among the phenomena of sourceand target languages in very high-dimensional feature spaces. But the drawback is itshigh computational complexities.
A solution to the scalable training problem is the locally linear approximation strat-egy. Experimental results in Wang and Shawe-Taylor (2009) show that if the retrievedrelevant examples cover the source sentence well, a satisfactory translation can beachieved. However, in a real-world corpus, because of the data spareness problemas mentioned above, one may not always obtain adequate examples of high rele-vance. Great interest is shown recently on data source acquisition for natural languageprocessing tasks by mining the world wide web. Representative works related to thecontext here include web-based parallel corpora construction (Resnik and Smith 2003;Munteanu and Marcu 2005) and web-based machine translation post-selection (Caoand Li 2002) and post-editing (Way and Gough 2003). The above works suggest apossible direction for our future exploration on practicalizing the kernel regressionapproach for SMT. If one could retrieve sufficient parallel bilingual relevant trainingexamples for given source sentences from the web or a resource much larger than justa closed training set, the advantages of the regression model as a kernel method wouldbe significantly improved.
Besides plain text, the kernel regression method offers a flexible framework forthe incorporation of various types of features. Higher-level linguistic knowledge canbe utilized easily by selecting corresponding kernels, e.g. string kernels for part-of-speech tag sequences or convolution kernels for parse trees (Collins and Duffy2001). The insight here is that not only does the linguistic knowledge provides moreinformation for the translation, also in comparison with the words themselves, thedistribution of language phenomena represented by such high-level linguistic sym-bols will be mush less sparse. In addition, soft matching string kernels (Shawe-Taylor and Cristianini 2004) can be applied to morphologically rich languages torelieve the data sparseness problem. A recent state-of-the-art approach to SMT, thefactored translation model (Koehn and Hoang 2007), also enables the integrationof linguistic annotations into phrase-based translation models. Compared to theirmethod where the factors can only be self-influential, our regression frameworkallows interactions among different linguistic features, which could be a potentialadvantage.
These issues are left open here, but will be investigated in our future work.
Acknowledgements This work is supported by the EU project SMART (FP6-033917). We thank SándorSzedmák for numerous useful discussions and providing the code for MMR. We also thank the anonymousreviewers for their helpful commands.
123

102 Z. Wang, J. Shawe-Taylor
References
Callison-Burch C, Fordyce C, Koehn P, Monz C, Schroeder J (2008) Further meta-evaluation of machinetranslation. In: Proceedings of the third ACL workshop on statistical machine translation, pp 70–106
Cao Y, Li H (2002) Base noun phrase translation using web data and the EM algorithm. In: Proceedings ofthe 19th international conference on computational linguistics (COLING), pp 1–7
Collins M, Duffy N (2001) Convolution kernels for natural language. In: Dietterich TG, Becker S, Ghahra-mani Z (eds) Advances in Neural information processing systems, vol 14. MIT Press, Cambridge
Cortes C, Mohri M, Weston J (2005) A general regression technique for learning transductions. In: Pro-ceedings of the 22nd international conference on machine learning (ICML)
Hildebrand AS, Eck M, Vogel S, Waibel A (2005) Adaptation of the Translation model for statistical machinetranslation. In: Proceedings of European association for machine translation 10th annual conference(EAMT)
Koehn P (2004) Pharaoh: a beam search decoder for phrase-based statistical machine translation models. In:Proceedings of the 6th conference of the association for machine translation in the Americas (AMTA)
Koehn P (2005) Europarl: a parallel corpus for statistical machine translation. In: Proceedings of machinetranslation summit X
Koehn P, Hoang H (2007) Factored translation models. In: Proceedings of the 2007 joint conferenceon empirical methods in natural language processing and computational natural language learning(EMNLP-CoNLL), pp 868–876
Meila M (2003) Data centering in feature space. In: Proceedings of the 9th international workshop onartificial intelligence and statistics (AISTATS)
Munteanu DS, Marcu D (2005) Improving machine translation performance by exploiting non-parallelcorpora. Comput Linguist 31(4):477–504
Och FJ (2003) Minimum error rate training in statistical machine translation. In: Proceedings of the 41stannual meeting on association for computational linguistics (ACL), pp 160–167
Resnik P, Smith NA (2003) The web as a parallel corpus. Comput Linguist 29(3):349–380Shawe-Taylor J, Cristianini N (2004) Kernel Methods for pattern analysis. Cambridge University Press,
CambridgeSzedmák S, Shawe-Taylor J, Parado-Hernandez E (2006) Learning via linear operators: maximum margin
regression; multiclass and multiview learning at one-class complexity. Technical Report, Universityof Southampton
Wang Z, Shawe-Taylor J (2009) Kernel based machine translation. In: Goutte C, Cancedda N, DymetmanM, Foster G (eds) Learning machine translation, NIPS workshop series. MIT Press, Cambridge, pp169–184
Way A, Gough N (2003) wEBMT: developing and validating an example-based machine translation systemusing the world wide web. Comput Linguist 29(3):421–457
Weston J, Chapelle O, Elisseeff A, Schölkopf B, Vapnik V (2002) Kernel dependency estimation. In: BeckerS, Thrun S, Obermayer K (eds) Advances in neural information processing systems, vol 15. MIT Press,Cambridge
123




















