
A comprehensive approach to operation sequence similarity based part family formation in the...
16
This article was downloaded by: [Indian Institute of Technology Roorkee] On: 23 June 2013, At: 02:12 Publisher: Taylor & Francis Informa Ltd Registered in England and Wales Registered Number: 1072954 Registered office: Mortimer House, 37-41 Mortimer Street, London W1T 3JH, UK International Journal of Production Research Publication details, including instructions for authors and subscription information: http://www.tandfonline.com/loi/tprs20 A comprehensive approach to operation sequence similarity based part family formation in the reconfigurable manufacturing system Kapil Kumar Goyal a , P.K. Jain a & Madhu Jain b a Mechanical and Industrial Engineering Department, Indian Institute of Technology Roorkee, Roorkee, India b Department of Mathematics, Indian Institute of Technology Roorkee, Roorkee, India Published online: 16 Jul 2012. To cite this article: Kapil Kumar Goyal , P.K. Jain & Madhu Jain (2013): A comprehensive approach to operation sequence similarity based part family formation in the reconfigurable manufacturing system, International Journal of Production Research, 51:6, 1762-1776 To link to this article: http://dx.doi.org/10.1080/00207543.2012.701771 PLEASE SCROLL DOWN FOR ARTICLE Full terms and conditions of use: http://www.tandfonline.com/page/terms-and-conditions This article may be used for research, teaching, and private study purposes. Any substantial or systematic reproduction, redistribution, reselling, loan, sub-licensing, systematic supply, or distribution in any form to anyone is expressly forbidden. The publisher does not give any warranty express or implied or make any representation that the contents will be complete or accurate or up to date. The accuracy of any instructions, formulae, and drug doses should be independently verified with primary sources. The publisher shall not be liable for any loss, actions, claims, proceedings, demand, or costs or damages whatsoever or howsoever caused arising directly or indirectly in connection with or arising out of the use of this material.
-
Upload
mmumullana -
Category
Documents
-
view
3 -
download
0
Transcript of A comprehensive approach to operation sequence similarity based part family formation in the...

This article was downloaded by: [Indian Institute of Technology Roorkee]On: 23 June 2013, At: 02:12Publisher: Taylor & FrancisInforma Ltd Registered in England and Wales Registered Number: 1072954 Registered office: Mortimer House,37-41 Mortimer Street, London W1T 3JH, UK
International Journal of Production ResearchPublication details, including instructions for authors and subscription information:http://www.tandfonline.com/loi/tprs20
A comprehensive approach to operation sequencesimilarity based part family formation in thereconfigurable manufacturing systemKapil Kumar Goyal a , P.K. Jain a & Madhu Jain ba Mechanical and Industrial Engineering Department, Indian Institute of Technology Roorkee,Roorkee, Indiab Department of Mathematics, Indian Institute of Technology Roorkee, Roorkee, IndiaPublished online: 16 Jul 2012.
To cite this article: Kapil Kumar Goyal , P.K. Jain & Madhu Jain (2013): A comprehensive approach to operation sequencesimilarity based part family formation in the reconfigurable manufacturing system, International Journal of ProductionResearch, 51:6, 1762-1776
To link to this article: http://dx.doi.org/10.1080/00207543.2012.701771
PLEASE SCROLL DOWN FOR ARTICLE
Full terms and conditions of use: http://www.tandfonline.com/page/terms-and-conditions
This article may be used for research, teaching, and private study purposes. Any substantial or systematicreproduction, redistribution, reselling, loan, sub-licensing, systematic supply, or distribution in any form toanyone is expressly forbidden.
The publisher does not give any warranty express or implied or make any representation that the contentswill be complete or accurate or up to date. The accuracy of any instructions, formulae, and drug doses shouldbe independently verified with primary sources. The publisher shall not be liable for any loss, actions, claims,proceedings, demand, or costs or damages whatsoever or howsoever caused arising directly or indirectly inconnection with or arising out of the use of this material.

International Journal of Production ResearchVol. 51, No. 6, 15 March 2013, 1762–1776
A comprehensive approach to operation sequence similarity based part family formation in the
reconfigurable manufacturing system
Kapil Kumar Goyala*, P.K. Jaina and Madhu Jainb
aMechanical and Industrial Engineering Department, Indian Institute of Technology Roorkee, Roorkee, India; bDepartmentof Mathematics, Indian Institute of Technology Roorkee, Roorkee, India
(Received 6 October 2011; final version received 15 May 2012)
The industrial sector of the twenty-first century faces a highly volatile market in which manufacturing systemsmust be capable of responding rapidly to the market changes, while fully exploiting resources. Thereconfigurable manufacturing system (RMS) is a state of the art technology offering the exact functionalityand capacity needed, which is built around a part family. The configuration of an RMS evolves over a periodto justify the needs of upcoming part families. The foundation for the success of an RMS, therefore, lies in therecognition of appropriate sets of part families. In the present work the authors have developed a noveloperation sequence based BMIM (bypassing moves and idle machines) similarity coefficient using longestcommon subsequence (LCS) and the minimum number of bypassing moves and the quantity of idle machines.The effectiveness of the developed similarity coefficient has been compared with the existing best similarity/dissimilarity coefficients available in the existing literature. An example set of parts has been classified usingthe developed similarity coefficient and average linkage hierarchical clustering algorithm. The developedapproach can also be used very effectively for part family formation in the cellular manufacturing system.
Keywords: reconfigurable manufacturing system; part family; operation sequence; similarity coefficient;hierarchical clustering; cellular manufacturing system
1. Introduction
With expanding global competition and products of ever-increasing variety, coupled with fluctuating demands,short product life-cycles and rapid changes in the process technology, the conventional manufacturing systems havebeen rendered unfit in fulfilling the manufacturing objectives such as flexibility, responsiveness and economy. Thetime reduction for introducing new products to the market with high quality and low cost is a key factor for thesurvival and growth of an enterprise in this new scenario. The reconfigurable manufacturing system is a new class ofmanufacturing system, which justifies need of the hour by combining the high throughput of dedicatedmanufacturing system with the customised flexibility (Mehrabi et al. 2000). The most significant feature of thereconfigurable manufacturing system (RMS) is that the configuration of these systems evolves over time in order toprovide the exact functionality and capacity needed, and when it is needed. According to Koren et al. (1999) theRMS is defined as a system designed to cater for the needs of a part family by adjusting its hardware and softwarecomponents quickly in response to the sudden changes in the market. Thereby the RMS is built around a part familyinitially and later the configuration of RMS evolves in response to changes in the product functionality andcapacity. In contrast, Xiaobo et al. (2000a, 2000b) have considered the RMS to cater for the needs of a set of partfamilies. Initially the RMS is built around a part family and later the configuration of RMS changes in accordancewith the upcoming new part families. Pattanaik et al. (2007) optimised the cell formation in the presence ofreconfigurable machines. Abdi and Labib (2004) concluded that grouping products into part families in RMS has apositive impact on the introduction of new product. Galan et al. (2007b) have developed an approach for productfamily (each product composed of many parts) formation and considered modularity, commonality, compatibility,reusability and product demand as the decision criteria. The decision criteria considered does not represent themanufacturing requirements of parts at the shop floor level, which is the key factor in part family formation. Anyproduct may contain many parts in which each part certainly requires a diverse set of manufacturing operationsalong with the precedence constraints. Therefore merely grouping the products based on the criteria like modularity,
*Corresponding author. Email: [email protected]
ISSN 0020–7543 print/ISSN 1366–588X online
� 2013 Taylor & Francis
http://dx.doi.org/10.1080/00207543.2012.701771
http://www.tandfonline.com
Dow
nloa
ded
by [
Indi
an I
nstit
ute
of T
echn
olog
y R
oork
ee]
at 0
2:12
23
June
201
3

commonality, compatibility, reusability and product demand and ignoring the processing requirements would nothelp in efficient and cost effective manufacturing of parts on the shop floor level.
Thus an effective approach of part family formation, which takes care of all the modalities of RMS, is verycrucial in the efficient execution of reconfigurable manufacturing system. Firstly, in the conventional manufacturingsystems (DMS, FMS, CMS) the operation sequence required for manufacturing a part is generated after knowingthe operational capabilities of the available machine tools; but in RMS the process is reversed. First of all theoperation sequence of parts is generated based on which the RMS configuration is designed. Secondly, in thecellular manufacturing system the machines considered are general purpose, thus machines are grouped based onthe operational requirements of the parts, whereas in RMS the RMTs are used, which are capable of performing avariety of operations in their existing configurations and are also readily reconfigurable. Therefore the grouping ofparts in the first phase has to be carried out and only then can the machines be assigned. Thirdly, approaches such asartificial intelligence, non hierarchical clustering and mathematical programming, in which the number of groups tobe formed need to be decided beforehand, are also not appropriate in RMS as the number of groups depends uponthe similarity levels to be achieved. In case the groups are fixed a priori the efficiency of the system can be badlyaffected. Moreover, the RMSs are suitable for mass manufacturing, thus flow line layout is the most suitable plantlayout for designing the RMS. The consideration of operation sequence in grouping the parts thus becomes mostimportant to accommodate many parts on the same flow line to reduce the reconfigurations required. In a nutshell,the part family formation in the reconfigurable manufacturing systems should be based upon the operation sequencesimilarity and an appropriate clustering algorithm should be adopted. The consideration of operation sequence inthe computation of the similarity/dissimilarity coefficient is crucial for the efficient running of the system.
The RMS is envisaged to fulfil the requirements of a part family, i.e. offering the exact capacity and functionalityneeded to process a part family, and therefore the RMS behaves as DMS during the production phase and canreadily be reconfigured according to the new manufacturing requirements. Therefore like DMS the mostappropriate layout for the RMS is also the flow line layout to support mass manufacturing at the competitive cost.In most of the RMS modelling approaches flow line layout has been adopted (Son 2000, Tang et al. 2004, Youssefet al. 2006, Dou et al. 2009, 2011, Goyal et al. 2011, Saxena and Jain 2012). Further, in designing the flow linelayout, operation sequence similarity plays a pivotal role in reducing the overall cost and reconfigurations required,while producing a set of part families, which in turn can be only achieved through reducing machine idleness alongwith the material handling effort. In previous works on part family formation in RMS, operation sequencesimilarity has not been considered to the best knowledge of the authors (Abdi and Labib 2004, Galan et al. 2007a,2007b, Rakesh et al. 2010). The RMS approaches considering the manufacturing requirements on shop floor levelalso neglect the precedence constraints and apply the basic similarity coefficient like Jaccard’s similarity coefficient(Galan et al. 2007a, Rakesh et al. 2010). Therefore to improve the efficiency and cost effectiveness more practicalapproaches need to be developed.
Even the operation sequence similarity based coefficients developed by the researchers in the field of cellularmanufacturing also lack in the comprehensive approach to consider the material flow and machine idlenessaccurately which influences the similarity index to a great extent.
Therefore, there is an acute need for the development of a novel operation sequence based similarity coefficientwhich should give due consideration to the smoothness of material flow and the idleness of machines jointly. Inorder to develop a novel operation sequence-based BMIM (bypassing moves and idle machines) similaritycoefficient the existing operation sequence-based similarity coefficients, along with their limitations, are discussed inthe following section followed by the development of BMIM similarity coefficient. The developed similaritycoefficient is compared with the existing similarity/distance coefficients. A case study is also presented todemonstrate the developed part family formation approach.
2. Literature on the operation sequence-based similarity/distance coefficients
An important step in any hierarchical clustering procedure is to select a similarity coefficient which will determinethe level of similarity between two objects. This will influence the shape of the clusters, as some objects may be closerto one another according to one coefficient and relatively farther according to the others.
The operation sequence, a sequence of machines on which the part is processed sequentially (Vakharia andWemmerlov 1990), is ignored by most of the researchers while forming the part families. Many researchers havedeveloped the similarity/dissimilarity coefficients based on longest common subsequence (LCS) and the Edit
International Journal of Production Research 1763
Dow
nloa
ded
by [
Indi
an I
nstit
ute
of T
echn
olog
y R
oork
ee]
at 0
2:12
23
June
201
3

distance between two operation sequences (Tam 1990, Ho et al. 1993, Akturk 1996, Akturk and Balkose 1996,Askin and Zhou 1998, Irani and Huang 2000). Tam (1990) indicated that the objective of forming part familieswithout considering operation sequences is to increase production effectiveness by grouping parts that requiresimilar machinery resources and manufacturing them in self sufficient cells, and the routing time inside themanufacturing cells cannot be reduced. The achievement of the objectives by applying group technology in aproduction system is dependent on the choice of machines and impact of the materials flow (Choobineh 1988).Therefore considering the machine requirements can only just reflect the choice of the machines but not the impactof material flow or layout. In recent years, the operation sequence has been emphasised by many researchers, as itcan reveal not only the machine requirements of the parts but also the flow pattern of the parts. Some of the existingbest performing approaches widely accepted by the researchers are discussed below along with their limitations/drawbacks.
2.1 Choobineh’s similarity coefficient
In order to overcome the drawbacks of the Jaccard similarity coefficient which is just based on the operations of theparts, Choobineh (1988) developed a new similarity coefficient which used operation sequences of length 1 to L as asimilarity coefficient of the order L. Each operation in a sequence is counted as 1 toward the total counts of order L.This similarity coefficient is defined as:
Sxy Lð Þ ¼1
LSxy 1ð Þ þ
XLl¼2
Cxy lð Þ
N� lþ 1
" #, L � N ð1Þ
where Cxy is the number of sequences of length l between parts x and y, Ni is the number of operations required inpart i, and N ¼ minðNx,NyÞ. This similarity coefficient reflects the similarity between the operation sequences of twoparts based on the common sequences of length 1 to L, and its value lies between 0 and 1.
2.2 Tam’s dissimilarity coefficient
Tam (1990) presented a dissimilarity coefficient method, to measure the level of dissimilarity between operationsequences based on Levenshtein distance (Levenshtein 1966), for part grouping in cellular manufacturing systems.Levenshtein distance is defined as the minimum number of substitutions, deletions and insertions required to changesource sequence into target sequence. The Levenshtein distance has been the most commonly used measure foraccessing the distance between two operation sequences. In this method, the dissimilarity coefficient Dxy is definedas follows
Dxy ¼ wndn x, y½ � þ wc 1� c x, y½ �� �
ð2Þ
where wn þ wc ¼ 1;wn,wc � 0 and dn½x, y� is the normalised weighted Levenshtein distance between operationsequences x and y.
dn x, y½ � ¼dw x, y½ �
maxfdw p, q½ �j1 � p, q � number of partsg
dw p, q½ � ¼ minfwsns þ wdnd þ winig
ð3Þ
where ws wd and wi are the non-negative weights assigned to the substitutions, deletions and insertions, and ns, nd,and ni are the number of substitution, deletion and insertion transformations required. c x, y½ � is a coefficientdepicting the commonality of operations between operation sequences x and y, which is defined as the number ofcommon operations between operation sequences x and y divided by the total number of the distinct operations inboth the sequences.
2.3 Compliant index based similarity coefficient
Ho et al. (1993) proposed an operation sequence similarity coefficient based on the number of operations in thesequence of a product that are either in-sequence or by-passing with the sequence of flow in both the forward and
1764 K.K. Goyal et al.
Dow
nloa
ded
by [
Indi
an I
nstit
ute
of T
echn
olog
y R
oork
ee]
at 0
2:12
23
June
201
3

backward directions. The operation sequence similarity coefficient is defined as the sums of both compliant indicesdivided by twice the number of operations in the product. This operation sequence similarity coefficient for productx can be determined by the following formula:
COxy ¼ðCFx þ CBxÞ
2�Nxð4Þ
where COxy is the operation sequence similarity coefficient of part x to be merged with part y, CFx is the forwardcompliant index, CBx is the backward compliant index, andNx is the number of operations in the operation sequenceof part x. While finding the similarity coefficient, the part x is assumed with the minimum number of operations in itsoperation sequence out of both the parts; the value of COx lies between 0 and 1. Basically this operation sequencesimilarity coefficient is for designing the multiple product flow line, but this coefficient may also be used for partfamily formation as the intra cell layout design problem is similar to the multiple product layout problems.
2.4 An LCS based similarity coefficient
Askin and Zhou (1998) presented a similarity coefficient based on the LCS between parts for designing flow-linemanufacturing cells. They constructed a tree of all the possible subsequence of operations common in operationsequences of both the parts. Further the concept of non-dominated matches has been applied to reduce the size ofthe tree. The similarity coefficient Sxy between two operation sequences x and y is defined as:
Sxy ¼ maxjLCSxyj
jxj,jLCSxyj
j yj
� �ð5Þ
where LCSij is the longest common subsequence between x and y, and | x | is the number of operations in sequence x.
2.5 Merger similarity coefficient
Irani and Huang (2000) developed merger similarity coefficient based on longest common subsequence to find theminimum number of substitutions, insertions and deletions required to transform one sequence into another. Themerger distance md(x, y) is the minimum number of substitutions and insertions required to derive operationsequence x from y while the interruption distance id(x, y) is the minimum number of non ending deletions requiredfor the transformation. The merger coefficient of similarity mc(x, y) is calculated as follows:
mc x, yð Þ ¼
max 1�md y, xð Þ þ
id ð y, xÞxj j
y�� ��þ 1
" #if xj j4 y
�� ��
max 1�md x, yð Þ þ
id ðx, yÞ
yj j
xj j þ 1
24
35 if xj j5 y
�� ��
max 1�md x, yð Þ þ
id ðx, yÞ
yj j
xj j þ 1, 1�
md y, xð Þ þid ð y,xÞ
xj j
y�� ��þ 1
24
35 if xj j ¼ y
�� ��
8>>>>>>>>>>>><>>>>>>>>>>>>:
ð6Þ
where for any set X, | X | denotes the cardinality of X. The mc(x, y)¼mc(y, x) and ranges from 0 to 1.Huang (2003) further modified the similarity coefficient to consider the difference in length of the pair of
operation sequences for which the similarity is to be accessed as follows:
mc x, yð Þ ¼
max 1�md y,xð Þ þ
id ð y, xÞOmaxþ
xj j� yj jO2
max
y�� �� , 0
24
35 if xj j4 y
�� ��
max 1�md x, yð Þ þ
id ðx, yÞOmaxþ
yj j� xj j
O2max
xj j, 0
24
35 if xj j5 y
�� ��
max 1�md x, yð Þ þ
id ðx, yÞOmax
xj j, 1�
md y, xð Þ þid ð y,xÞOmax
y�� �� , 0
" #if xj j ¼ y
�� ��
8>>>>>>>>>>>>><>>>>>>>>>>>>>:
ð7Þ
International Journal of Production Research 1765
Dow
nloa
ded
by [
Indi
an I
nstit
ute
of T
echn
olog
y R
oork
ee]
at 0
2:12
23
June
201
3
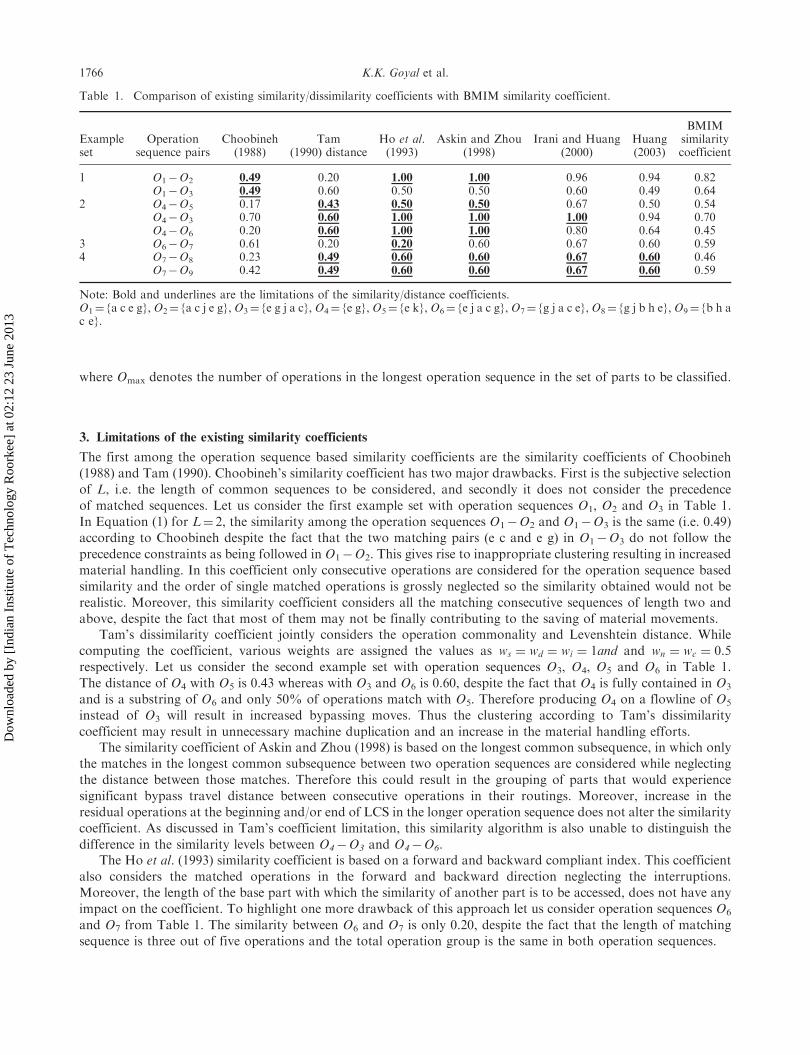
where Omax denotes the number of operations in the longest operation sequence in the set of parts to be classified.
3. Limitations of the existing similarity coefficients
The first among the operation sequence based similarity coefficients are the similarity coefficients of Choobineh(1988) and Tam (1990). Choobineh’s similarity coefficient has two major drawbacks. First is the subjective selectionof L, i.e. the length of common sequences to be considered, and secondly it does not consider the precedence
of matched sequences. Let us consider the first example set with operation sequences O1, O2 and O3 in Table 1.In Equation (1) for L¼ 2, the similarity among the operation sequences O1�O2 and O1�O3 is the same (i.e. 0.49)according to Choobineh despite the fact that the two matching pairs (e c and e g) in O1�O3 do not follow the
precedence constraints as being followed in O1�O2. This gives rise to inappropriate clustering resulting in increasedmaterial handling. In this coefficient only consecutive operations are considered for the operation sequence basedsimilarity and the order of single matched operations is grossly neglected so the similarity obtained would not be
realistic. Moreover, this similarity coefficient considers all the matching consecutive sequences of length two andabove, despite the fact that most of them may not be finally contributing to the saving of material movements.
Tam’s dissimilarity coefficient jointly considers the operation commonality and Levenshtein distance. Whilecomputing the coefficient, various weights are assigned the values as ws ¼ wd ¼ wi ¼ 1and and wn ¼ wc ¼ 0:5respectively. Let us consider the second example set with operation sequences O3, O4, O5 and O6 in Table 1.
The distance of O4 with O5 is 0.43 whereas with O3 and O6 is 0.60, despite the fact that O4 is fully contained in O3
and is a substring of O6 and only 50% of operations match with O5. Therefore producing O4 on a flowline of O5
instead of O3 will result in increased bypassing moves. Thus the clustering according to Tam’s dissimilarity
coefficient may result in unnecessary machine duplication and an increase in the material handling efforts.The similarity coefficient of Askin and Zhou (1998) is based on the longest common subsequence, in which only
the matches in the longest common subsequence between two operation sequences are considered while neglectingthe distance between those matches. Therefore this could result in the grouping of parts that would experience
significant bypass travel distance between consecutive operations in their routings. Moreover, increase in theresidual operations at the beginning and/or end of LCS in the longer operation sequence does not alter the similaritycoefficient. As discussed in Tam’s coefficient limitation, this similarity algorithm is also unable to distinguish the
difference in the similarity levels between O4�O3 and O4�O6.The Ho et al. (1993) similarity coefficient is based on a forward and backward compliant index. This coefficient
also considers the matched operations in the forward and backward direction neglecting the interruptions.Moreover, the length of the base part with which the similarity of another part is to be accessed, does not have anyimpact on the coefficient. To highlight one more drawback of this approach let us consider operation sequences O6
and O7 from Table 1. The similarity between O6 and O7 is only 0.20, despite the fact that the length of matchingsequence is three out of five operations and the total operation group is the same in both operation sequences.
Table 1. Comparison of existing similarity/dissimilarity coefficients with BMIM similarity coefficient.
Exampleset
Operationsequence pairs
Choobineh(1988)
Tam(1990) distance
Ho et al.(1993)
Askin and Zhou(1998)
Irani and Huang(2000)
Huang(2003)
BMIMsimilaritycoefficient
1 O1�O2 0.49 0.20 1.00 1.00 0.96 0.94 0.82O1�O3 0.49 0.60 0.50 0.50 0.60 0.49 0.64
2 O4�O5 0.17 0.43 0.50 0.50 0.67 0.50 0.54O4�O3 0.70 0.60 1.00 1.00 1.00 0.94 0.70O4�O6 0.20 0.60 1.00 1.00 0.80 0.64 0.45
3 O6�O7 0.61 0.20 0.20 0.60 0.67 0.60 0.594 O7�O8 0.23 0.49 0.60 0.60 0.67 0.60 0.46
O7�O9 0.42 0.49 0.60 0.60 0.67 0.60 0.59
Note: Bold and underlines are the limitations of the similarity/distance coefficients.O1¼ {a c e g}, O2¼ {a c j e g}, O3¼ {e g j a c}, O4¼ {e g}, O5¼ {e k}, O6¼ {e j a c g}, O7¼ {g j a c e}, O8¼ {g j b h e}, O9¼ {b h ac e}.
1766 K.K. Goyal et al.
Dow
nloa
ded
by [
Indi
an I
nstit
ute
of T
echn
olog
y R
oork
ee]
at 0
2:12
23
June
201
3

Irani and Huang (2000) have developed the LCS-based merger similarity coefficient by applying trace analysis.Let us consider the operation sequences O4 and O3 from Table 1. The value of merger coefficient between O4 and O3
is 1 irrespective of the fact that in O3 only two out of five machines are common and the rest of the machines willremain idle while producing parts with operation sequence O4. As depicted in the fourth example set with operationsequences O7�O8 and O7�O9 in Table 2 both the Irani and Huang (2000) and Huang (2003) similarity coefficientsare unable to distinguish the difference in the similarities due to the unmatched operations falling in between theLCS or falling before the start and at the end of LCS. The unmatched operations in between the LCS will result inthe bypassing moves and idle machines both but the operations at the beginning or end of LCS will not result in anequal number of bypassing moves.
In a nutshell, various highly referred best similarity/dissimilarity coefficients suffer from the limitations in oneaspect or the other. Therefore authors have developed a novel LCS and shortest composite supersequence (SCS)based BMIM (bypassing moves and idle machines) similarity coefficient which considers the bypassing moves andidleness of machines accurately.
4. Development of BMIM similarity coefficient
From reviewing the past research works it is realised that merely measuring the length of the longest commonsubsequence does not serve the purpose of measuring the interruption in the material flow and the idleness ofmachines. Therefore the elements of the LCS are also necessary for measuring the accurate material flowinterruption and the number of idle machines.
4.1 Finding LCS and SCS
In the first phase of computing the similarity coefficient between two parts, the maximum number of identicaloperations from both the operation sequences which can be performed in order of precedence relationship are to belisted. This list of common operations of both the operation sequences following precedence constraints is formallyknown as longest common subsequence. A subsequence is derived from the original sequence by deleting zeroor more elements and maintaining the order of remaining elements. Longest common subsequence betweentwo sequences is the longest common ordered subsequence of both the sequences with the same operationsand precedence relationship as in both the original sequences. For example, consider two operation sequencesA¼ {a d c b} and B¼ {f d e c h b}. The {d b} is a subsequence of both the sequences A and B but it is not the longestcommon subsequence. The LCS of A and B is {d c b}.
Table 2. Pseudo code to compute LCS between two sequences.
Pseudo code for finding length of LCS byapplying dynamic programming Pseudo code for extracting the LCS
function LCS_length(A, B) function LCS_print(A, B, C)1 m jAj; n jBj; 1 i jAj; j jBj;2 for i 1 to m 2 while (i 6¼ 0 & j 6¼ 0) do4 C[i, 0] 0; end 3 if A[i]¼B[j]5 for j 0 to n 4 print A[i];6 C[0, j] 0; end 5 i i� 1; j j� 1;7 for i 1 to m 6 else if C[i, j� 1]4C[i� 1, j]8 for j 1 to n 7 j j� 1;9 if A[i]¼B[j] 8 else10 C[i, j] C[i� 1, j� 1]þ 1; 9 i i� 1;11 else if C[i� 1, j]�C[i, j� 1] 10 end12 C[i, j] C[i� 1, j]; 11 end13 else14 C[i, j] C[i, j� 1];15 end16 end17 end18 return C[m, n];
International Journal of Production Research 1767
Dow
nloa
ded
by [
Indi
an I
nstit
ute
of T
echn
olog
y R
oork
ee]
at 0
2:12
23
June
201
3

The LCS problem is a special case of edit distance problem. Edit distance is defined by the minimum number ofelementary transformation operations (insertions, deletions and substitutions) required to transform the sourcestring into the target string (Levenshtein 1966). Normalising the weights of insertions and deletions to one andexcluding the substitutions will give the longest common subsequence. Wagner and Fischer (1974) invented theclassic dynamic programming solution to LCS problem which has O (n2) worst case running time. Since then thelongest common subsequence of two strings has been studied extensively by various researchers and manyalgorithms have been proposed to reduce the space complexity and/or the time complexity (Hirschberg 1977, Huntand Szymanski 1977, Masek and Paterson 1980, Nakatsu et al. 1982). For a comprehensive comparison of the well-known algorithms for LCS problem and study of their behaviour in various application environments thecontributions of Bergroth et al. (2000), Crochemore and Rytter (1994) and Stephen (1994) may be referred. Askinand Zhou (1998) presented an algorithm based on non-dominated matches for developing a common sequence treeto list all the common subsequences to find the LCS.
The pseudo code based on Wagner and Fisher (1974), which applies the classical dynamic programming to findthe LCS between two operation sequences, is presented in Table 2. The authors have deliberately used thetraditional approach to record LCS to avoid unnecessary complexity, as the emphasis of the present investigation isto analyse the data further to develop a realistic BMIM (bypass moves and idleness of machines) similaritycoefficient which is based on the accurate computation of the bypassing moves and the idle machines.
The pseudo code of the function LCS_length given in Table 2 computes the length of LCS between twooperation sequences A[1, . . . ,m] and B[1, . . . , n] by computing the lengths of LCS between A[1, . . . , i] and B[1, . . . , j]8 1� i�m and 1� j� n, and stores it in C[i j]. C[m n] will contain the length of the LCS of operation sequences Aand B. Further in the function LCS_print, the LCS is extracted from the matrix C.
The shortest composite supersequence (SCS) is an arrangement obtained from the LCS of both sequences, whichis the shortest possible length of a sequence which accommodates all the operations of both the sequences followingtheir precedence constraints. Several SCSs of the same length may be obtained by using the same LCS by justaltering the position of inserted operations (following precedence constraints) from both the operation sequences. Inthe present work the SCS which gives minimum bypassing moves and the minimum number of idle machines is to bedetermined. The number of idle machines depends only on the length of SCS, which remains unaltered for all thepossible alternative arrangements of the SCS. The length of SCS between two operation sequences x and y may beobtained after finding the LCS using:
SCSxy
�� �� ¼ xj j þ y�� ��� LCSxy
�� �� ð8Þ
4.2 Mathematical model for determining BMIM similarity
The order of appending the left out operations from both the operation sequences into the LCS for obtaining the SCSmay affect the material flow. Therefore the left out operations of an operation sequence to be appended in the LCS toobtain SCS are divided into two categories. The first category is the set of operations which are to be appended inbetween the LCS. In the second category, the operations are the set of operations from each operation sequence to beappended before or after the LCS. The first category does not affect the number of bypassing moves, but the positionof appending second category operations from both the operation sequences to form SCS may affect the number ofbypassing moves. Here an SCS offering a minimum number of bypassing moves is to be determined through theproposed algorithm. In the second category, there are two sets of operations from each operation sequence, one set tobe appended before the LCS and another set to be appended after the LCS. The followingmathematical formulation isadopted to find the minimum number of bypassing moves and idle machines to compute the BMIM similaritycoefficient. The notations for mathematical modelling of the present work are as follows:
Notations
x, y Operation sequence x and y.LCSxy Longest common subsequence between operation sequences x and y.SCSxy Shortest common supersequence between operation sequences x and y.
1768 K.K. Goyal et al.
Dow
nloa
ded
by [
Indi
an I
nstit
ute
of T
echn
olog
y R
oork
ee]
at 0
2:12
23
June
201
3

NOBLx Number of operations of operation sequence x to be appended before the LCSxy to form SCSxy.NOALx Number of operations of operation sequence x to be appended after the LCSxy to form SCSxy.NOILx Number of operations of operation sequence x to be appended in between the LCSxy to form
SCSxy.�x Number of bypassing moves required before the start of LCSxy while producing part with the
operation sequence x on the SCSxy.’x Number of bypassing moves required after the end of LCSxy while producing part with the
operation sequence x on the SCSxy.
The following Equations (9) and (10) find the minimum number of bypassing moves required before and after
the LCSxy while producing the part with the operation sequence x on the SCSxy. Similarly �y and ’y can be
computed for operation sequence y.
�x ¼NOBLy, if ðNOBLy � NOBLxÞ
0, otherwise
�ð9Þ
’x ¼NOALy, if NOALy � NOALx
� �0, otherwise
�ð10Þ
Now the exact number of bypassing moves while producing the part with the operation sequence x on a shortest
composite supersequence of operation sequences x and y can be calculated using:
BPMx ¼ NOILy þ �x þ ’x ð11Þ
Similarly the bypassing moves for producing the part with operation sequence y on the same shortest composite
supersequence is determined using:
BPMy ¼ NOILx þ �y þ ’y ð12Þ
The total number of material handling movements being carried out while producing the part with operation
sequence x can simply be calculated using the bypassing moves. Thus the total number of moves while processing
part x (TMx) can be obtained as:
TMx ¼ BPMx þ xj j þ 1 ð13Þ
Similarly the total number of material handling movements while producing the part with operation sequence y
is computed as:
TMy ¼ BPMy þ y�� ��þ 1 ð14Þ
The number of idle machines in any layout while producing the part is an effective measure of utilisation of
resources; to the best knowledge of the authors, it has not been given due consideration by the operation sequence
based similarity coefficients developed so far. The number of idle machines while producing the part with operation
sequence x on the shortest composite supersequence of operation sequences x and y is computed using:
IMx ¼ SCSxy
�� ��� xj j ð15Þ
Similarly the idle machines during processing of the part with operation sequence y on the same shortest
composite supersequence of operation sequences x and y can be obtained as:
IMy ¼ SCSxy
�� ��� y�� �� ð16Þ
Finally, after computing the exact number of minimum bypassing moves and the number of idle machines
during processing each of the parts on the shortest composite supersequence of both the operation sequences, the
BMIM similarity coefficient is computed as follows:
Sxy ¼ 1�BPMx
2� TMxj jþ
BPMy
2� TMy
�� ��" #
þIMx
2� SCSxy
�� ��þ IMy
2� SCSxy
�� ��" #( )
ð17Þ
International Journal of Production Research 1769
Dow
nloa
ded
by [
Indi
an I
nstit
ute
of T
echn
olog
y R
oork
ee]
at 0
2:12
23
June
201
3

The developed BMIM similarity coefficient ranges from zero to one, i.e. 0 � Sxy � 1 and Sxy ¼ Syx. In thissimilarity coefficient the percentage of bypassing moves of both the operation sequences x and y are divided by twoto consider the 50% contribution of each operation sequence in deriving the exact similarity. Similar is the case withthe percentage idle machines also.
4.3 Illustration for computing the BMIM similarity
For illustrating the computation of BMIM similarity coefficient consider two parts x and y with operationsequences {a w d e r t g b} and {n d t w g f h} respectively. Here the LCSxy is {d t g} of length three. The length ofSCSxy is computed according to Equation (8), which is 12 in this case.
Now to find the exact number of bypassing moves first of all let us consider the operations of operation sequencex which are to be inserted in the LCSxy to form SCSxy. The operations to be appended before the LCSxy (NOBLx)is two, i.e. {a w}, operations to be appended after the end of LCSxy (NOALx) is one, i.e. {b}, and the operations tobe appended in between the LCSxy (NOILx) is two, i.e. {e r}. Similarly the NOBLy is one, i.e. {n}, NOALy is two, i.e.{f h}, and NOILy is one, i.e. {w}. Now according to Equation (9) �x ¼ 1 as the NOBLy � NOBLx and according toEquation (10) ’x ¼ 0, as the NOALy 4NOALx. Similarly �y ¼ 0 and ’y ¼ 1. Now according to Equation (11) andEquation (12) the BPMx ¼ 1þ 1þ 0, i.e. two and BPMy ¼ 2þ 0þ 1, i.e. three. According to Equation (13) whileprocessing the part according to operation sequence x, the total number of moves required TMx¼ 2þ 8þ 1, i.e. 11and similarly according to Equation (14), TMy¼ 3þ 7þ 1, i.e. 11. The number of idle machines while producing thepart with operation sequence x can be computed using Equation (15). Thus IMx ¼ 12� 8, i.e. 4, and similarlyaccording to Equation (16) IMy ¼ 12� 7, i.e. 5. Having all the values computed the BMIM similarity coefficientbetween operation sequences x and y can be calculated using Equation (17) which in this case Sxy is 0.398.
Figure 1 presents the BMIM similarity coefficient computations graphically, in which for the LCS of twooperation sequences, minimum possible bypassing moves and idle machines are depicted in the SCS. There areseveral possible arrangements of SCS with the same LCS, which will depict different values of bypassing moves andidle machines but the mathematical model developed in the present research work computes the minimum numberof bypassing moves and idle machines for the LCS between the operation sequences.
Part x {a w d e r t g b}
Part y{n d t w g f h}
LCSxy {d t g}
*SCSxy {a w n d e r t w g b f h}
Processing of part x { a w n d e r t w g b f h }
Processing of part y { a w n d e r t w g b f h }
Idle machine
By passing move
Total moves (TMx)
Total moves (TMy)
BPMx= 2 IMx = 2 TMx = 11(including entry and exit)
BPMy = 3 IMy = 3 TMx = 11(including entry and exit) Sxy=0.398
*SCSxy is the optimal arrangement of machines as per the mathematical model discussed. A sample suboptimal SCSxy may be {n a w d e r t w g f h b} with BPMx = 3 and BPMy = 4.
|SCSxy| = 12
Figure 1. Graphical representation of BMIM similarity computations.
1770 K.K. Goyal et al.
Dow
nloa
ded
by [
Indi
an I
nstit
ute
of T
echn
olog
y R
oork
ee]
at 0
2:12
23
June
201
3

5. Existing approaches versus BMIM similarity coefficient
The main purpose of measuring the operation sequence similarity/distance between parts is to classify them so as tominimise the material handling effort required and the idleness of machines, while producing the grouped parts on acommon plant layout. The existing best performing and widely accepted operation sequence based similarity/distance coefficients have some limitations/drawbacks, which are already discussed in Section 3. In Table 1 fourexample sets of operation sequences are considered to compare the BMIM similarity coefficient with the existingcoefficients. The limitations/drawbacks of various similarity/distance coefficients are highlighted in bold andunderlined in Table 1.
The first set is to depict the effect of precedence constraints, which are very important. According to theChoobineh (1988) similarity coefficient O1�O2 and O1�O3 are the same despite the fact that in O3 the matchedpairs are not in the sequence. The second set is taken to consider the effect of one string fully contained in anotherstring versus a string contained in the other as a substring. As in the former case only machine idleness is there andno additional material handling is required, whereas in a later case both the bypassing moves and machine idlenessexist. Tam (1990), Ho et al. (1993), Askin and Zhou (1998) similarity/distance coefficients are unable to distinguishthis fact and give equal similarity/distance to O4�O3 and O4�O6. According to Tam (1990) O4 is more close to O5
rather than O3 despite the fact that O4 is fully contained in O3 whereas O4 matches partially with O5. Irani andHuang (2000) grade the similarity of O4�O3 as 1 neglecting the effect of idle machines. The third example setdepicts the drawback of Ho et al. (1993), in which first and last operations are swapped keeping the rest of theoperations the same and the similarity coefficient seems unable to recognise the similarity of matching operations.Therefore according to Ho et al. (1993) the similarity of O6�O7 is only 0.2 despite the three matching operations(j a c). The last example set is considered to emphasise the fact that the unmatched operations falling in between theLCS (e.g. O7�O8) turn into both the bypassing moves and idleness of machines whereas the unmatched operationsfalling before the start of LCS and after the end of LCS (e.g. O7�O9) may not depict the bypassing moves. This factis ignored by all the existing similarity/distance coefficients including the Huang (2003) similarity coefficient.Choobineh (1988) shows the difference but this coefficient does not consider the precedence of matched sequences.
As discussed above, all the existing best performing and widely used operation sequence based similarity/distance coefficients have their own limitations/drawbacks due to which the similarity between parts cannot bemeasured correctly. The newly developed BMIM similarity coefficient works well and gives accurate results invarious situations by considering the bypassing moves and machine idleness accurately.
6. Computation experiments
The BMIM similarity coefficient is based on the LCS and extracting LCS for long operation sequences is consideredto be a complex problem. The authors have developed MATLAB code for the mathematical model presented andused the pseudo code presented in Table 2 for extracting the LCS. The experiments were conducted to measure theexecution time for large problems. Operation sequence for the parts were generated randomly using the randperm()function of the MATLAB. The BMIM similarity coefficient matrix for a three set of part quantities, i.e. 100, 250and 500 with the operation sequence length ranging from 100 to 500 (in the step size of 100 each) for each set ofparts were computed. For each experiment 10 replications were performed on the machine with processor I-5,2.6GHz and the average execution time for the considered experiments are presented in Figure 2.
From Figure 2 it can be observed that the longest experiment containing 500 parts with each part havingoperation sequence length of 500 has been executed in 3493.36 seconds, which can be regarded as a reasonable timefor the design problem. As the problem of part family formation lies in the design domain, thus the quality of theresult would carry more weight in comparison to the computation cost. Now a day computation time can further bereduced by applying parallel computing and high performance work stations.
7. Clustering
The hierarchical clustering procedure groups together similar objects on the basis of the similarities in theirattributes. Hierarchical algorithms, which can be agglomerative (bottom up) or divisive (top down), find successiveclusters using previously established clusters. Agglomerative algorithms begin with each object as a separate clusterand merge them into successively larger clusters based on commonality in attributes measured by a similaritycoefficient. On the other hand the divisive algorithms begin with the whole set as one cluster and proceed to divide it
International Journal of Production Research 1771
Dow
nloa
ded
by [
Indi
an I
nstit
ute
of T
echn
olog
y R
oork
ee]
at 0
2:12
23
June
201
3

into successively smaller clusters. It has been observed that in the context of part family formation or machine grouprecognition, the agglomerative procedure has been widely implemented (Selim et al. 1998, Galan et al. 2007a, 2007b,Rakesh et al. 2010).
The hierarchy of clusters is traditionally represented by a tree-like structure called a dendrogram. Cutting thedendrogram at a defined precision level (similarity level expressed in percentage) provides a set of part families at theselected precision. As the precision level decreases, a coarser clustering occurs which is characterised by a smallernumber of large size clusters. The hierarchical clustering is a well proven and most broadly implemented method inalmost all the fields of engineering and technology, as this approach can easily be adapted as per the variedrequirements of the problems by suitably defining logically and/or probabilistically justifiable similarity coefficients.The selection of a set of families can be interactively made from the dendrogram by restricting either precision levelor the number of groups. Moreover in the non-hierarchical clustering, the erroneous allocation of an object to acluster at the beginning of the procedure cannot be corrected afterwards (Gower 1967) unless a special procedure isembedded in the algorithm.
The three most widely used hierarchical clustering methods are single linkage clustering (SLC) (McAuley 1972),average linkage clustering (ALC) (Seifoddini and Wolf 1986) and complete linkage clustering (CLC) (Mosier 1989and Gupta and Seifoddini 1990). In SLC, two groups are merged together merely because two parts, one from eachgroup have high similarity to each other. If this process continues, it results in a string effect known as chaining.Since CLC is the antithesis of SLC, it is least likely to cause chaining. ALC produces reasonable results betweenthese two extremes (Singh and Rajamani 1996) and therefore it is considered as most appropriate for the study. Thesimilarity between two clusters is defined as the average of the similarity coefficients of all the members of the twoclusters. In ALC algorithm the distance between two clusters P and Q is based upon the average distance betweenelements of each cluster:
1
jPj � jQj
Xx2P
Xy2Q
d ðx, yÞ ð18Þ
From the literature it can be concluded that the average linkage clustering may be applied for the part familyformation in RMS as it neither suffered from the chaining effect nor lost the benefits of similarity among parts.
8. A case study
For illustration of the developed approach, an environment consisting of 19 parts discussed in Huang (2003) hasbeen considered. Table 3 presents the 19 parts along with their operation sequences. The length of operation
0
500
1000
1500
2000
2500
3000
3500
4000
100 200 300 400 500
Run
Tim
e in
Sec
onds
Operation Sequence Length of Parts
100 PARTS
250 PARTS
500 PARTS
Figure 2. Computation experiments of BMIM similarity coefficient.
Table 3. Operation sequences forsample parts.
Part number Operation sequence
1 1, 4, 8, 92 1, 4, 7, 4, 8, 73 1, 2, 4, 7, 8, 94 1, 4, 7, 95 1, 6, 10, 7, 96 6, 10, 7, 8, 97 6, 4, 8, 98 3, 5, 2, 6, 4, 8, 99 3, 5, 6, 4, 8, 910 4, 7, 4, 811 612 11, 7, 1213 11, 1214 11, 7, 1015 1, 7, 11, 10, 11, 1216 1, 7, 11, 10, 11, 1217 11, 7, 1218 6, 7, 1019 12
1772 K.K. Goyal et al.
Dow
nloa
ded
by [
Indi
an I
nstit
ute
of T
echn
olog
y R
oork
ee]
at 0
2:12
23
June
201
3
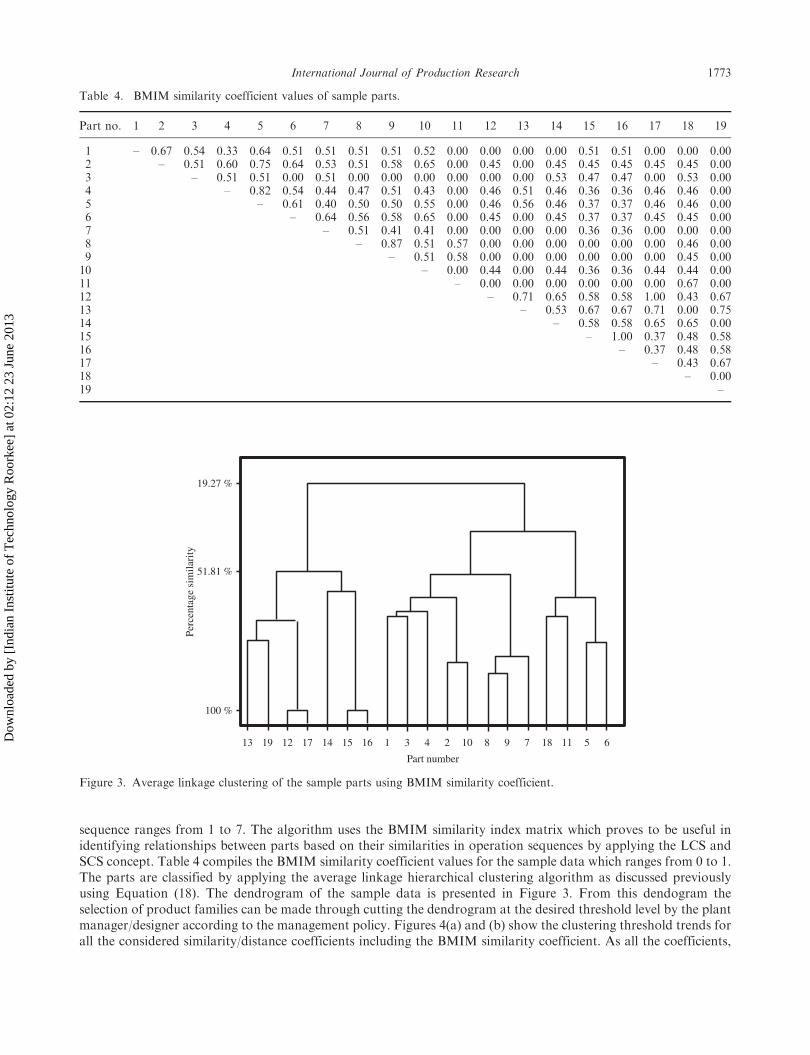
sequence ranges from 1 to 7. The algorithm uses the BMIM similarity index matrix which proves to be useful inidentifying relationships between parts based on their similarities in operation sequences by applying the LCS andSCS concept. Table 4 compiles the BMIM similarity coefficient values for the sample data which ranges from 0 to 1.The parts are classified by applying the average linkage hierarchical clustering algorithm as discussed previouslyusing Equation (18). The dendrogram of the sample data is presented in Figure 3. From this dendogram theselection of product families can be made through cutting the dendrogram at the desired threshold level by the plantmanager/designer according to the management policy. Figures 4(a) and (b) show the clustering threshold trends forall the considered similarity/distance coefficients including the BMIM similarity coefficient. As all the coefficients,
13 19 12 17 14 15 16 1 3 4 2 10 8 9 7 18 11 5 6
100 %
51.81 %
19.27 %
Part number
Perc
enta
ge s
imila
rity
Figure 3. Average linkage clustering of the sample parts using BMIM similarity coefficient.
Table 4. BMIM similarity coefficient values of sample parts.
Part no. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
1 – 0.67 0.54 0.33 0.64 0.51 0.51 0.51 0.51 0.52 0.00 0.00 0.00 0.00 0.51 0.51 0.00 0.00 0.002 – 0.51 0.60 0.75 0.64 0.53 0.51 0.58 0.65 0.00 0.45 0.00 0.45 0.45 0.45 0.45 0.45 0.003 – 0.51 0.51 0.00 0.51 0.00 0.00 0.00 0.00 0.00 0.00 0.53 0.47 0.47 0.00 0.53 0.004 – 0.82 0.54 0.44 0.47 0.51 0.43 0.00 0.46 0.51 0.46 0.36 0.36 0.46 0.46 0.005 – 0.61 0.40 0.50 0.50 0.55 0.00 0.46 0.56 0.46 0.37 0.37 0.46 0.46 0.006 – 0.64 0.56 0.58 0.65 0.00 0.45 0.00 0.45 0.37 0.37 0.45 0.45 0.007 – 0.51 0.41 0.41 0.00 0.00 0.00 0.00 0.36 0.36 0.00 0.00 0.008 – 0.87 0.51 0.57 0.00 0.00 0.00 0.00 0.00 0.00 0.46 0.009 – 0.51 0.58 0.00 0.00 0.00 0.00 0.00 0.00 0.45 0.0010 – 0.00 0.44 0.00 0.44 0.36 0.36 0.44 0.44 0.0011 – 0.00 0.00 0.00 0.00 0.00 0.00 0.67 0.0012 – 0.71 0.65 0.58 0.58 1.00 0.43 0.6713 – 0.53 0.67 0.67 0.71 0.00 0.7514 – 0.58 0.58 0.65 0.65 0.0015 – 1.00 0.37 0.48 0.5816 – 0.37 0.48 0.5817 – 0.43 0.6718 – 0.0019 –
International Journal of Production Research 1773
Dow
nloa
ded
by [
Indi
an I
nstit
ute
of T
echn
olog
y R
oork
ee]
at 0
2:12
23
June
201
3
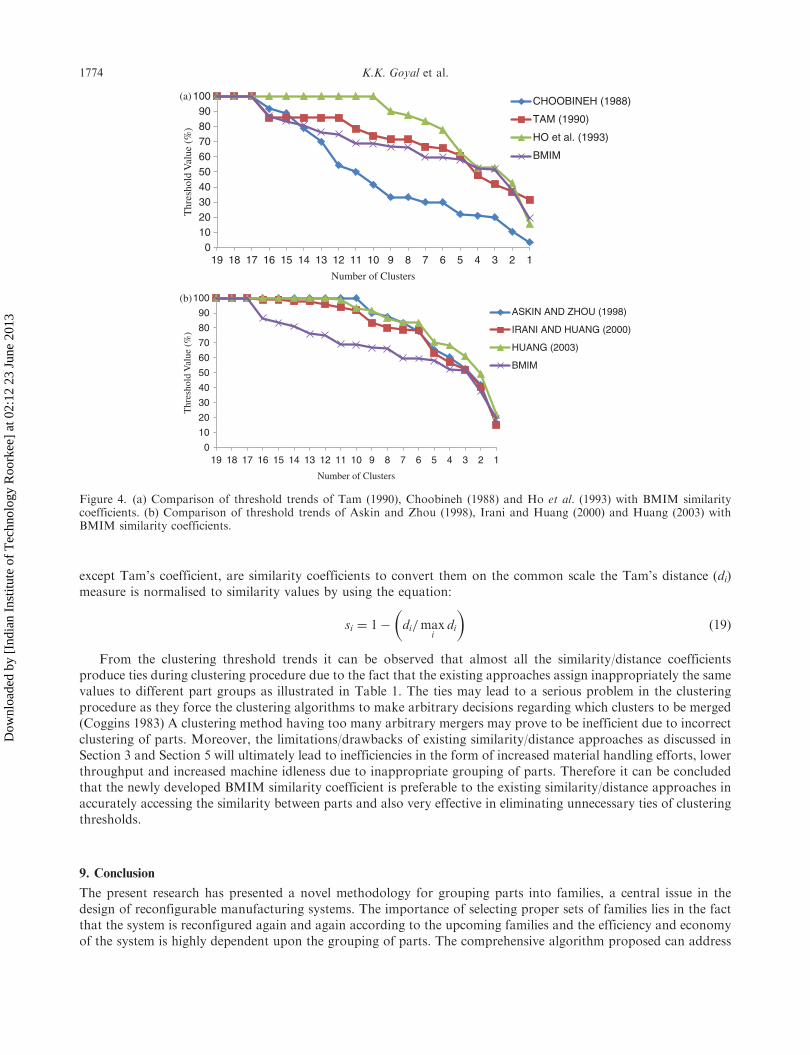
except Tam’s coefficient, are similarity coefficients to convert them on the common scale the Tam’s distance (di)measure is normalised to similarity values by using the equation:
si ¼ 1� di=maxi
di
ð19Þ
From the clustering threshold trends it can be observed that almost all the similarity/distance coefficientsproduce ties during clustering procedure due to the fact that the existing approaches assign inappropriately the samevalues to different part groups as illustrated in Table 1. The ties may lead to a serious problem in the clusteringprocedure as they force the clustering algorithms to make arbitrary decisions regarding which clusters to be merged(Coggins 1983) A clustering method having too many arbitrary mergers may prove to be inefficient due to incorrectclustering of parts. Moreover, the limitations/drawbacks of existing similarity/distance approaches as discussed inSection 3 and Section 5 will ultimately lead to inefficiencies in the form of increased material handling efforts, lowerthroughput and increased machine idleness due to inappropriate grouping of parts. Therefore it can be concludedthat the newly developed BMIM similarity coefficient is preferable to the existing similarity/distance approaches inaccurately accessing the similarity between parts and also very effective in eliminating unnecessary ties of clusteringthresholds.
9. Conclusion
The present research has presented a novel methodology for grouping parts into families, a central issue in thedesign of reconfigurable manufacturing systems. The importance of selecting proper sets of families lies in the factthat the system is reconfigured again and again according to the upcoming families and the efficiency and economyof the system is highly dependent upon the grouping of parts. The comprehensive algorithm proposed can address
0102030405060708090
100
19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1
Thr
esho
ld V
alue
(%
)
Number of Clusters
CHOOBINEH (1988)
TAM (1990)
HO et al. (1993)
BMIM
0
10
20
30
40
50
60
70
80
90
100
19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1
Thr
esho
ld V
alue
(%
)
Number of Clusters
ASKIN AND ZHOU (1998)
IRANI AND HUANG (2000)
HUANG (2003)
BMIM
(a)
(b)
Figure 4. (a) Comparison of threshold trends of Tam (1990), Choobineh (1988) and Ho et al. (1993) with BMIM similaritycoefficients. (b) Comparison of threshold trends of Askin and Zhou (1998), Irani and Huang (2000) and Huang (2003) withBMIM similarity coefficients.
1774 K.K. Goyal et al.
Dow
nloa
ded
by [
Indi
an I
nstit
ute
of T
echn
olog
y R
oork
ee]
at 0
2:12
23
June
201
3

most practical aspects of the part grouping problem. A novel approach to cluster the parts applying the operationsequence similarity based BMIM similarity coefficient and average linkage hierarchical clustering approach ispresented. A more realistic approach based on longest common subsequence and shortest composite supersequenceis developed to jointly consider the material flow smoothness and idleness of machines in accessing the similaritybetween parts. The illustration considered in Table 1 indicates the limitation/drawbacks of existing best performingand widely accepted similarity/distance measures and validates the superiority of the newly developed BMIMsimilarity coefficient. The developed approach is free from inappropriate ties in the clustering threshold values dueto inaccurately assigning the same similarity values to different part groups as observed in the existing approaches.The present research leads to efficient grouping of parts in a reconfigurable manufacturing system which eventuallyresults in an improvement in the system performance measures, such as machine utilisation, transporter utilisation,throughput rate and makespan of jobs. Although the primary application of the present work would be to group theparts in a reconfigurable manufacturing system, it is equally applicable to the cellular manufacturing system toefficiently cluster the parts based on operation sequence similarity. The major recommendations for future workinclude the development of a new approach that can handle the alternative operation sequences. In the presentresearch only operation sequences, irrespective of the operation times, are considered as a basis for part familyformation. Thus problems associated with operation times and sequences may be considered in further research.The multiple objective optimisation for the part family formation considering other objectives like productionvolume can also be attempted in the future.
References
Abdi, M.R. and Labib, A.W., 2004. Grouping and selecting products: the design key of reconfigurable manufacturing systems
(RMSs). International Journal of Production Research, 42 (3), 521–546.
Akturk, M.S., 1996. A note on the within-cell layout problem based on operation sequences. Production Planning and Control,
7 (1), 99–103.
Akturk, M.S. and Balkose, H.O., 1996. Part-machine grouping using a multi-objective cluster analysis. International Journal of
Production Research, 34 (8), 2299–2315.Askin, R.G. and Zhou, M., 1998. Formation of independent flowline cells based on operation requirements and machine
capabilities. IIE Transactions, 30 (4), 319–329.Bergroth, L., Hakonen, H. and Raita, T., 2000. A survey of longest common subsequence algorithms. In:Proceedings of
7th international symposium on string processing information retrieval (SPIRE’00), 27–29 September, A Coruna, Spain.
New York: IEEE Computer Society, 39–48.Choobineh, F., 1988. A framework for the design of cellular manufacturing systems. International Journal of Production
Research, 26 (7), 1161–1172.Coggins, J.M., 1983. Dissimilarity measures for clustering strings. In: D. Sankoff and J.B. Kruskal, eds. Time warps, string edits
and macromolecules: The theory and practice of sequence comparison. Reading, MA: Addison-Wesley, 253–310.Crochemore, C. and Rytter, W., 1994. Text algorithms. New York, NY: Oxford University Press.
Dou, J., Dai, X., and Meng, Z., 2009. Graph theory-based approach to optimise single product flow-line configuration of RMS.
International Journal of Advanced Manufacturing Techniques, 41 (9–10), 916–931.
Dou, J., Dai, X., and Meng, Z., 2011. A GA based approach for optimizing single-part flow-line configurations of RMS. Journal
of Intelligent Manufacturing, 22 (2), 301–317.Galan, R., et al., 2007a. A methodology for facilitating reconfiguration in manufacturing: the move towards reconfigurable
manufacturing systems. International Journal of Advanced Manufacturing Technology, 33 (3–4), 345–353.Galan, R., et al., 2007b. A systematic approach for product families formation in reconfigurable manufacturing systems.
Robotics and Computer-Integrated Manufacturing, 23 (5), 489–502.Gower, J.C., 1967. A comparison of some methods of cluster analysis. Biometrics, 23 (4), 623–637.Goyal, K.K., Jain, P.K., and Jain, M., 2011. Optimal configuration selection for reconfigurable manufacturing system using
NSGA II and TOPSIS. International Journal of Production Research, DOI:10.1080/00207543.2011.599345.
Gupta, T. and Seifoddini, H., 1990. Production data based similarity coefficient for machine-component grouping decisions in
the design of a cellular manufacturing system. International Journal of Production Research, 28 (7), 1247–1269.
Hirschberg, D.S., 1977. Algorithms for the longest common subsequence problem. Journal of the Association of Computing
Machinery, 24 (4), 664–675.Ho, Y.C., Lee, C.C., and Moodie, C.L., 1993. Two sequence-pattern, matching-based, flow analysis methods for multi-flowlines
layout design. International Journal of Production Research, 31 (7), 1557–1578.Huang, H., 2003. Facility layout using layout modules. Dissertation (PhD). Graduate School of the Ohio State University.
International Journal of Production Research 1775
Dow
nloa
ded
by [
Indi
an I
nstit
ute
of T
echn
olog
y R
oork
ee]
at 0
2:12
23
June
201
3

Hunt, J.W. and Szymanski, T.G., 1977. A fast algorithm for computing longest subsequences. Communications of the ACM,20 (5), 350–353.
Irani, S.A. and Huang, H., 2000. Custom design of facility layouts for multiproduct facilities using layout modules. IEEETransactions on Robotics and Automation, 16 (3), 259–267.
Koren, Y., et al., 1999. Reconfigurable manufacturing systems. Annals of the CIRP, 48 (2), 527–540.Levenshtein, V.I., 1966. Binary codes capable of correcting deletions, insertions and reversals. Soviet Physics Doklady, 10 (8),
707–710.Masek, W.J. and Paterson, M., 1980. A faster algorithm computing string edit distances. Journal of Computer and System
Sciences, 20 (1), 18–31.
McAuley, J., 1972. Machine grouping for efficient production. The Production Engineer, 51 (2), 53–57.Mehrabi, M.G., Ulsoy, A.G., and Koren, Y., 2000. Reconfigurable manufacturing systems: key to future manufacturing. Journal
of Intelligent Manufacturing, 11 (4), 403–419.
Mosier, C.T., 1989. An experiment investigating the application of clustering procedures and similarity coefficients to the GTmachine cell formation problem. International Journal of Production Research, 27 (10), 1811–1835.
Nakatsu, N., Kambayashi, Y., and Yajima, S., 1982. A longest common subsequence algorithm suitable for similar text strings.Acta Informatica, 18 (2), 171–179.
Pattanaik, L.N., Jain, P.K., and Mehta, N.K., 2007. Cell formation in the presence of reconfigurable machines. InternationalJournal of Advanced Manufacturing Technology, 34 (2), 335–345.
Rakesh, K., Jain, P.K., and Mehta, N.K., 2010. A framework for simultaneous recognition of part families and operation groups
for driving a reconfigurable manufacturing system. Advances in Production Engineering & Management Journal, 5 (1),45–58.
Saxena, L.K. and Jain, P.K., 2012. A model and optimisation approach for reconfigurable manufacturing system configuration
design. International Journal of Production Research, 50 (12), 3359–3381.Seifoddini, H. and Wolfe, P.M., 1986. Application of the similarity coefficient method in group technology. IIE Transaction,
18 (3), 271–277.
Selim, H.M., Askin, R.G., and Vakharia, A.J., 1998. Cell formation in group technology: review, evaluations and directions forfuture research. Computers and Industrial Engineering, 34 (1), 3–20.
Singh, N. and Rajamani, D., 1996. Cellular manufacturing systems: Design, planning and control. London: Chapman and Hall.Son, S.Y., 2000. Design principles and methodologies for reconfigurable machining systems. Thesis (PhD). University of Michigan.
Stephen, G.A., 1994. String searching algorithms. Singapore: World Scientific.Tam, K.Y., 1990. An operation sequence based similarity coefficient for part families formation. Journal of Manufacturing
Systems, 9 (1), 55–67.
Tang, L., et al., 2004. Concurrent line-balancing, equipment selection and throughput analysis for multi-part optimal line design.International Journal for Manufacturing Science and Production, 6 (1–2), 71–82.
Vakharia, A.J. and Wemmerlov, U., 1990. Designing a cellular manufacturing system: a materials flow approach based on
operation sequences. IIE Transactions, 22 (1), 84–97.Wagner, R.A. and Fischer, M.J., 1974. The string-to-string correction problem. Journal of the Association for Computing
Machinery, 21 (1), 168–173.
Xiaobo, Z., Jiancai, W., and Zhenbi, L., 2000a. A stochastic model of a reconfigurable manufacturing system, Part 1: aframework. International Journal of Production Research, 38 (10), 2273–2285.
Xiaobo, Z., Wang, J., and Luo, Z., 2000b. A stochastic model of a reconfigurable manufacturing system. Part 2: optimalconfigurations. International Journal of Production Research, 38 (1), 2829–2842.
Youssef, A.M.A. and El Maraghy, H.A., 2006. Modelling and optimisation of multiple-aspect RMS configuration. InternationalJournal of Production Research, 44 (22), 4929–4958.
1776 K.K. Goyal et al.
Dow
nloa
ded
by [
Indi
an I
nstit
ute
of T
echn
olog
y R
oork
ee]
at 0
2:12
23
June
201
3




















