
3 Symbolic Knowledge Representation in Recurrent Neural ...
51
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of 3 Symbolic Knowledge Representation in Recurrent Neural ...

3 Symbolic Knowledge Representation inRecurrent Neural Networks: Insights fromTheoretical Models of ComputationChristian W. Omlin a, C. Lee Giles b;ca Department of Computer Science, University of Stellenbosch7600 Stellenbosch, SOUTH AFRICAb NEC Research Institute, Princeton, NJ 08540, USAc UMIACS, University of Maryland, College Park, MD 20742, USAE-mail: [email protected] [email protected] give an overview of some of the fundamental issues found in the realm ofrecurrent neural networks. We use theoretical models of computation to characterizethe representational, computational, and learning capabilitities of recurrent networkmodels. We discuss how results derived for deterministic models can be generalizedto fuzzy models. We then address how these theoretical models can be utilized withinthe knowledge-based neurocomputing paradigm for training recurrent networks, forextracting symbolic knowledge from trained networks, and for improving networktraining and generalization performance by making e�ective use of prior knowledgeabout a problem domain.3.1 IntroductionThis chapter addresses some fundamental issues in regard to recurrent neuralnetwork architectures and learning algorithms, their computational power, theirsuitability for di�erent classes of applications, and their ability to acquire symbolicknowledge through learning. We have found it convenient to investigate some ofthose issues in the paradigm of theoretical models of computation, formal languages,and dynamical systems theory. We will brie y outline some of the issues we discussin this chapter.3.1.1 Why Neural Networks?Neural networks were for a long time considered to belong outside the realm ofmainstream arti�cial intelligence. The development of powerful new architectures

2 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computationand learning algorithms and the success of neural networks at solving real-worldproblems in a wide variety of �elds has established a presence for neural networksas part of the toolbox for building intelligent systems. The reasons why neuralnetworks enjoy tremendous popularity include their ability to learn from examplesand to generalize to new data, and their superior performance compared to moretraditional approaches for solving some real-world problems. Furthermore, theyare universal computational devices; virtually identical network architectures andtraining algorithms can be applied to very di�erent types of applications. Successfulapplications of neural networks include optical character recognition, robotics,speaker recognition and identi�cation, credit rating and credit card fraud detection,and timeseries prediction.3.1.2 Theoretical Aspects of Neural NetworksDespite that neural networks have had a signi�cant impact, their theoretical foun-dations generally lag behind their tremendous popularity. For instance, feedforwardneural networks with hidden layers were in use long before it was shown that a sin-gle hidden layer of sigmoidal neurons was su�cient for approximating continuousfunctions with arbitrary precision [18]. Furthermore, determining the size of the hid-den layer for a particular application remains an open question; in the absence ofde�nitive theoretical results, heuristics for on-line growing and pruning of networkarchitectures have been proposed [24, 25, 17, 76, 42]. Similarly, recent theoreticalresults relate network size and size of training sets to a network's generalizationperformance [9], but there exist no results which guarantee that a network can betrained to reach that generalization performance or more importantly, that train-ing even converges to a solution. Developers side-step that problem by measuringgeneralization performance using test sets or crossvalidation.Even though negative theoretical results demonstrate that training neural net-works is a computationally di�cult problem [56], neural networks have and willcontinue to enjoy tremendous popularity. In addition, methods and heuristics havebeen developed which ease, but do not eliminate the computational challenges; theyinclude use of parallel learning algorithms [20], use of partial prior system infor-mation [82, 104], and training data selection and presentation heuristics. Thus, itappears that theoretical results generally have little bearing on how neural networksare used, particularly when the results do not give hands-on recipes. This is alsothe case for some of the theoretical results regarding the computational power ofrecurrent neural networks which we will discuss here while others have the potentialto have a direct impact on applications.3.1.3 What Kind of Architecture is Appropriate?Selecting the size of the hidden layer of a feedforward neural network is only oneexample of how to choose a network architecture for a particular application. A morefundamental choice is dictated by the nature of the application: Is the application

3.1 Introduction 3limited to dealing with spatial patterns (in the general sense) which are invariantover time or are they time-varying or so-called spatio-temporal patterns? Speechand stock markets are good examples of time-varying patterns.The computational capabilities of feedforward networks are su�cient for learninginput-output mapping between �xed, spatial patterns. If an application deals withtime-varying patterns, we may still be able to use feedforward neural networks.Tapped delay neural networks (TDNNs) are a class of feedforward neural networksproposed for speech recognition, more precisely phoneme recognition [64]. Thesuccess of TDNNs is based on the very limited context of the sampled speech signalsthat is required for phoneme identi�cation. Similarly, feedforward networks may besu�cient for control applications where all system states are observable, i.e. thereare no hidden states, even though we are dealing with time-varying patterns whichrequire long-term context. What do we gain by using recurrent neural networkswith hidden states, and how does it a�ect training? We maintain the position thatrecurrent network architectures signi�cantly expand the range of problems thatneural networks can be applied to.3.1.4 Recurrent Networks and Models of ComputationRecurrent neural networks are appropriate tools for modeling time-varying systems(e.g. �nancial markets, physical dynamical systems, speech recognition, etc.). Net-works can be used to recognize pattern sequences (e.g. speech recognition) or theycan be used for forecasting future patterns (e.g. �nancial markets). These applica-tions are generally not well-suited for addressing fundamental issues of recurrentneural networks such as training algorithms and knowledge representation becausethey come with a host of application-speci�c characteristics (e.g. �nancial data isgenerally non-stationary, feature extraction may be necessary for speaker identi�-cation) which muddle the fundamental issues.We will discuss the capabilities of recurrent neural networks and related issues inthe framework of theoretical models of computation [52]. Models such as �nite-state automata and their corresponding languages can be viewed as a generalparadigm of temporal, symbolic knowledge. No feature extraction is necessary tolearn these languages from examples, and there exist correspondences betweenlevels of complexity of formal languages, their accepting automata, and neuralnetwork models. Furthermore, the dynamics induced into recurrent neural networksthrough learning has a nice correspondence with the dynamics of �nite-stateautomata. Similar approaches have been used for characterizing physical systems[16]. Even though formal languages and automata models may lack the semanticsand complexities of natural languages and some dynamical processes, they havegreat expressive power, and results from these investigations are likely to have animpact on natural language learning [65] and non-linear system identi�cation andcontrol.

4 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computation3.1.5 Knowledge Representation and AcquisitionWe can view representation of automata as a prerequisite for learning their corre-sponding languages, i.e. if an architecture cannot represent an automaton, then itcannot learn it either. These questions have been answered for some automata andsome network models [36, 62]. In some cases, results not only show that networkmodels can represent certain automata, but also how the actual mapping automata! recurrent network can be accomplished [6, 27, 79].3.1.6 Are Neural Networks Blackboxes?One of the reason why expert sytems have found acceptance more easily thanneural networks is their capability to explain how they arrive at a solution fora given problem. The explanation component is a by-product of the automatedreasoning process using the knowledge base and a set of rules describing a domain.Neural networks, on the other hand, do not provide an explanation as part of theirinformation processing. The knowledge that neural networks have gained throughtraining is stored in their weights. Yet until recently, it was a widely acceptedmyth that neural networks were blackboxes, i.e. the knowledge stored in theirweights training was not accessible to inspection, analysis, and veri�cation. Sincethen, research on that topic has resulted in a number of algorithms for extractingknowledge in symbolic form from trained neural networks.For feedforward networks, that knowledge has typically been in the form ofBoolean and fuzzy if-then clauses [34, 49, 102]; excellent overviews of the currentstate-of-the-art can be found in [1, 7]. For recurrent networks, �nite-state automatahave been the main paradigm of temporal symbolic knowledge extraction [14, 28, 38,80, 108, 113]. Clearly, neural networks are no longer blackboxes. Some applications(e.g. application of neural networks to credit rating and lending policy and criticalapplications such as aircraft control) may require that neural networks undergovalidation prior to being deployed. Knowledge extraction could be an importantstage in that process.3.1.7 Overcoming the Bias/Variance DilemmaIt has been accepted for a long time that neural networks cannot be expectedto learn anything useful without some signi�cant prior structure [74]. Recenttheoretical results support that point of view [35]. Therefore, learning with priorknowledge (also known as learning with hints) has attracted increasing attention.The philosophy of learning with hints is that since training neural networks is aninherently di�cult problem, any and all prior knowledge that is available shouldbe taken advantage of. One approach is to prestructure or initialize a networkwith knowledge prior to training [82, 104]. The goal is to reduce training timeand possibly improve network generalization performance. Thus, the role of neuralnetworks then becomes that of knowledge re�nement or even knowledge revision in

3.2 Representation of Symbolic Knowledge in Neural Networks 5the case where the prior knowledge is incorrect [81].3.2 Representation of Symbolic Knowledge in Neural NetworksWe give a brief general discussion of the signi�cance of knowledge extraction andinitialization of neural networks with prior knowledge. We then discuss how thesetwo processes can be combined for knowledge re�nement and even revision.3.2.1 Importance of Knowledge ExtractionThe goal of knowledge extraction is to generate a concise symbolic descriptionof the knowledge stored in a network's weights. Excellent summaries of someexisting knowledge extraction methods can be found in [1, 7]. Of particular concern- and an open issue - is �delity of the extraction process, i.e. how accuratelythe extracted knowledge corresponds to the knowledge stored in the network.Fidelity can be measured by comparing - for a given test set - the performanceof a trained network with the performance of extracted rules. Unfortunately, ruleextraction is a computationally very hard problem. For feedforward networks, ithas been shown that there do not exist polynomial-time algorithms for conciseknowledge extraction [46]. Although no corresponding results exist in the literaturefor recurrent networks, it is likely that a similar result applies. Thus, heuristics havebeen developed for overcoming the combinatorial complexity of the problem.The merits of rule extraction include discovery of unknown salient features andnon-linear relationships in data sets, explanation capability leading to increaseduser acceptance, improved generalization performance, and possibly transfer ofknowledge to new, yet similar learning problems. As we will see later, improvedgeneralization performance applies particularly to recurrent networks whose non-linear dynamical characteristics can easily lead to deteriorating generalizationperformance.Extraction algorithms can broadly be divided into three classes [7]: Decompo-sitional methods infer rules from the internal network structure (individual nodesand weights). Pedagogical methods view neural networks as blackboxes, and usesome machine learning algorithm for deriving rules which explain the network in-put/output behavior. Algorithms which do not clearly �t into either class are re-ferred to as `eclectic', i.e. they may have aspects of decompositional and pedagogicalmethods.3.2.2 Signi�cance of Prior KnowledgePartial prior knowledge has shown to be useful for network training and generaliza-tion. The prior knowledge may be in the form of explicit rules which can be encodedinto networks by programming some of the weights [103], or an initial analysis of thedata may provide hints about a suitable architecture [106]. Fidelity of the mapping

6 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computationof the prior knowledge into a network is also important since a network may not beable to take full advantage of poorly encoded prior knowledge or, if the encodingalters the essence of the prior knowledge, the prior knowledge may actually hinderthe learning process.3.2.3 Neural Networks for Knowledge Re�nementRule insertion and extraction can be combined to perform knowledge re�nement orrevision with neural networks [94]. The goal is to use neural network learning andrule extraction techniques to produce a better or re�ned set of symbolic rules thatapply to a problem domain. Initial domain knowledge - which may also containinformation that is inconsistent with the available training data - is encoded in aneural network; this encoding typically consists of programming some of a network'sweights. Rather than starting with a network whose weights are initialized to smallrandom values, these programmed weights presumably provide a better startingpoint for �nding a solution in weight space. A network is then trained on theavailable data set; training typically requires several passes through the training set,depending on how close the initial symbolic knowledge is to the �nal solution andhow the weights. Re�ned - or revised rules in the case of wrong prior knowledge - canthen be extracted from the trained network. The impact of using prior knowledgein training feedforward neural networks on the generalization capability and therequired sample size for valid generalization has been theoretically investigated in[2, 33].3.3 Computational Models as Symbolic Knowledge3.3.1 A Hierarchy of Automata and LanguagesThis section introduces theoretical models of computation and formal languagesas a convenient framework in which to study the computational capabilities ofvarious network models. Even though these synthetic languages may lack some ofthe characteristics of natural languages, they capture some of those characteristicsand, more importantly, they allow a classi�cation of various levels of languagecomplexities.We will discuss various network architectures and relate them to formal automatain terms of their capability to represent spatio-temporal patterns. This discussionwill build a hierarchy from simple to more powerful network architectures and mod-els of computations. We will not discuss here the details of training algorithms orproofs of equivalence. Instead, we will summarize results reported in the literature.This will also provide a context for the more detailed discussions to follow later on.

3.3 Computational Models as Symbolic Knowledge 71
2
3
4
5
6
7
8
9
10
1 2
3 4
5 6
7 8
(a) (b)Figure 3.1 Examples of DFAs: Shown are two unique, minimal DFAs. (a)Randomly generated DFA with 10 states and two input symbols. State 1 is theDFA's start state. Accepting states are shown with double circles. (b) DFA fortriple parity which accepts all strings over the alphabet � = f0; 1; 2g which containsa multiple of 3 zeroes.3.3.2 Finite-State AutomataA large class of discrete processes can be modeled by deterministic �nite-stateautomata (DFAs). They also form the basic building blocks of theoretical modelsof computation. More powerful models of computation can be obtained by addingnew elements to DFAs; restrictions on the topology of DFAs yield special subclassesof DFA with characteristic properties.We will use the following de�nition of DFAs in the remainder of this chapter:De�nition 3.1A DFAM is a 5-tupleM =< �; Q;R; F; � > where � = fa1; : : : ; akg is the alphabetof the languageL,Q = fs1; : : : ; sNsg is a set of states, R�Q is the start state, F � Qis a set of accepting states, and � : Q��! Q de�ne state transitions in M .Two examples of DFAs are shown in Figure 3.1. A string x is accepted by theDFA M and hence is a member of the regular language L(M) if an accepting stateis reached after the entire string s has been read by M . Alternatively, a DFA Mcan be interpreted as a grammar which generates the regular language L(M). Asequential �nite-state machine [58] is the actual implementation in some logicalform consisting of logic (or neurons) and delay elements that will recognize L whenthe strings are encoded as temporal sequences. It is this type of representation thatthe recurrent neural network will learn.

8 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computation
(a) (b)Figure 3.2 Network Architectures for De�nite Memory Machines: (a) NeuralNetwork Finite Impulse Response (NNFIR) (b) Input Delayed Neural Networks(IDNNs)Since we will focus our discussion on learning regular languages, we give abrief description of regular grammars; see [52] for more details. Regular languagesrepresent the smallest and simplest class of formal languages in the Chomskyhierarchy and are generated by regular grammars. A regular grammar G is aquadruple G =< S; V; T; P > where S is the start symbol, V and T are respectivelynon-terminal and terminal symbols and P are productions of the form A ! a orA! aB where A;B � V and a � T . The regular language generated by G is denotedL(G). A deterministic �nite-state automaton (DFA) M is the recognizer of eachregular language L: L(G) = L(M)The process of learning grammars from example strings is also known as gram-matical inference [32, 8, 72]. The inference of regular grammars from positive andnegative example strings has been shown to be in the worst case a NP-completeproblem [45]. However, good heuristic methods have recently been developed forrandomly generated DFA's [63].We will show in later sections how DFAs can be mapped into fully recurrentnetwork architectures such that the DFA and the recurrent network are equivalent,i.e. accept the same language.3.3.3 Subclasses of Finite-State AutomataWe can identify to network architecture which are capable of representing twosubclasses of DFAs.The �rst architecture - called Neural Network Finite Impulse Response (NNFIR)- is a feedforward network implemented with tapped delay lines (see Figure 3.2). Ingeneral, each neuron has a tapped delay line which stores the outputs of previousd time steps. The output of that node and the stored values are inputs to nodes inthe next layer. The length of the tapped delay line determines the range of input

3.3 Computational Models as Symbolic Knowledge 9
Figure 3.3 De�nite Memory Machine: A NNFIR learned this DMM with 2048stateshistory to which the network is sensitive. It has been shown that NNFIR networksare equivalent with IDNNs (Input Delayed Neural Networks) which only have delaylines for the network input layer [15]. It is obvious that NNFIR can only representDFAs whose state depends on a limited input history.In order to understand the representational capabilities of NNFIRs, an intuitiveargument based on network topology has been made that DFAs can be mappedinto sequential machines [58] using combinational logic and memory elements. Theclass of machines whose current state can always be determined uniquely from theknowledge of the last d inputs is called de�nite memory machines (DMMs). It isobvious that the combinational logic can be implemented by a feedforward neuralnetwork with tapped input delay lines.The transition diagrams of DFAs that can be mapped into DMMs are essentiallyshift registers i.e. only a small amount of `logic' is necessary to compute the nextstate from the current state and previous inputs. Contrary to what one's intuitionabout feedforward network architectures may suggest, these DFAs can have loopsand thus can accept strings of arbitrary length. IDNN architectures can learn DMMswith a large number states (on the order of 1000 states) if the `logic' is su�cientlysimple. Such a large DMM is shown in Figure 3.3.

10 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of ComputationThe representational capability of NNFIR can be increased by augmenting thenetwork architecture with output tapped delay lines that are fed back into thenetwork as inputs; this network architecture is also referred to as Neural NetworkIn�nite Impulse Response (NNIIR) because of itsimilarity to in�nite response �lters.This topology of NNIIR is the same as that of Finite Memory Machines (FMMs)which can be implemented as sequential machines using combinatorial logic (e.g.,memory and combinational logic).FMMs are a subclass of DFAs for which the present state can always be deter-mined uniquely from the knowledge of the last n inputs and last m outputs for allpossible sequences of length max(n;m) (also referred to as FMMs of input-order nand output-order m). Given an arbitrary �nite-state machine, there exist e�cientalgorithms for determining if the machine has �nite memory and its correspondingorder [58]. As in the case of DMMs , large FMMs (i.e., machines with on the orderof 100 states) can be learned if the corresponding logic is relatively simple. It isfairly obvious that the class of �nite memory machines includes the class of de�nitememory machines: DMMs are FFMs with output order 0.3.3.4 Push-Down AutomataThe computational power of DFAs can be increased by adding an in�nite stack. Inaddition to reading input symbols and performing state transitions, input symbolsmay also be pushed and popped onto and from the stack, respectively. This enrichedmodel is called pushdown automaton (PDA).The language L(P ) is called context-free; a string s is a member of the languageL(P ) if the pushdown automaton arrives at an accepting state after s has beenread Similarly to the regular languages, there exists a context-free grammar Gwhich generates exactly the strings accepted by P : L(G) = L(P ).In order to gain an intuitive understanding why PDAs are computationally morepowerful than DFAs, consider the language L = fanbnjn � 0g. Examples areab; aabb; aaabbb, ... . In order for a machine to determine whether or not a string s isa member of the language, it needs to count the number of a's it has seen and checkthe number of b's that follow the a's. This can be achieved by pushing the a's ontothe stack and popping the a's from the stack as soon as the �rst b is encountered.This task cannot be performed by a DFA if the length of the strings is arbitraryFrom this discussion, it is obvious that PDAs can also recognize regular languages(we simply ignore the stack), but DFAs cannot recognize context-free languages.PDAs can be learned by recurrent networks with an external stack [19]. Morerecently, methods for training recurrent networks without the use of an externalstack have been investigated [110]. While recurrent networks have in principlethe computational power of PDAs they cannot simulate arbitrary context-freelanguages. PDAs require in�nite stack depth; this demands in�nite precision in thecomputation of the recurrent network which is not possible. Nevertheless, researchinto the representation of `context-free' languages in recurrent networks seemspromising since some interesting questions regarding the dynamics of networks

3.4 Mapping Automata into Recurrent Neural Networks 11trained to recognize context-free languages can be addressed.3.3.5 Turing MachinesThe stack of PDAs determines the order in which symbols can be read from orwritten to a memory. We can relax that requirement by replacing the stack with anin�nite input tape (or two stacks). This model is referred to as a Turing machine. Inaddition to performing state transitions, a Turing machine may read and write infor-mation from and to the tape, respectively. This model is the most powerful model ofcomputation: It is capable of computing essentially all computable functions (com-putability of a function is often expressed in terms of Turing computability). Giventhe restrictions on how stored data can accessed in PDAs. It is intuitively obviousthat Turing machines are computationally more powerful than PDAs. It has beenshown that recurrent neural networks are computationally as powerful as Turingmachines [95]. However, this equivalence requires in�nite precision in the networkcomputation. For all practical purposes, Turing machines cannot be simulated byrecurrent neural networks.3.3.6 SummaryWe have developed a hierarchy of the computational power of recurrent networkarchitectures by identifying the class of computation each of the neural networkarchitectures discussed here can perform. Even though recurrent networks havein principle the power of Turing machines, they can in practice only performDFA computation due to the �nite precision with which neural networks can besimulated. Thus, we will limit our discussion to DFA computation in the remainderof this paper.3.4 Mapping Automata into Recurrent Neural Networks3.4.1 PreliminariesRecently, much work has focused on the representational capabilities of recurrentnetworks as opposed to their ability to learn certain tasks. The underlying premiseis that if a network model cannot represent a certain structure, then it certainlycannot learn it either. A positive answer to the question of whether or not a givenrecurrent network architecture can represent a certain structure can be of threetypes: (1) The network architecture is in principle computationally rich enoughfor representating a certain structure, but an equivalence with a theoretical modelof computation would require in�nite resources such as in�nite precision [95] orin�nitely many neurons [98]. These answers establish the computational powerof recurrent networks. (2) Networks can represent a certain structure with thegiven resources [62, 61, 96]. These results can guide the selection of a recurrent

12 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computationnetwork architecture for a given application. However, no constructive algorithmis given which guarantees the existence of a solution for a chosen architecture(e.g. network size). (3) We can give an algorithm which maps the structure intoa recurrent network architecture such that the structure and network perform thesame computation on identical inputs for an arbitrary number of computation steps[5, 27, 74, 79]. These results guarantee the existence of a solution, but do notguarantee that it can be learned. In the remainder of this section, we will primarilyanswer questions of the third type for DFAs.3.4.2 DFA Encoding AlgorithmIn showing how DFAs can be mapped into recurrent networks, we must addressthree issues: First, we must establish a mapping from DFA states an internalrepresentation in the network. Then, we must program the network weights suchthat the network dynamics mimic the DFA dynamics. Finally, we must prove thatthe DFA and the derived network perform the same computation for an arbitarynumber of time steps. This is not obvious: DFAs have a discrete state space whereasrecurrent networks with sigmoidal discriminants can exhibit complicated nonlineardynamics [101].We choose for ease of representation networks with second-order weights Wijkshown in Figure 3.4. The continuous network dynamics are described by the fol-lowing equations:St+1i = g(ai(t)) = 11 + e�ai(t) ; ai(t) = bi +Xj;k WijkStjItk;where bi is the bias associated with hidden recurrent state neurons Si; Ik denotesinput neurons; g is the nonlinearity; and ai is the activation of the ith neuron.An aspect of the second order recurrent neural network is that the product StjItkin the recurrent network directly corresponds to the state transition �(qj ; ak) = qiin the DFA. After a string has been processed, the output of a designated neuronS0 decides whether the network accepts or rejects a string. The network accepts agiven string if the value of the output neuron St0 at the end of the string is greaterthan some preset value such as 0.5; otherwise, the network rejects the string. Forthe remainder of this paper, we assume a one-hot encoding for input symbols ak,i.e. Itk 2 f0; 1g.Our DFA encoding algorithm follows directly from the similarity of state transi-tions in a DFA and the dynamics of a recurrent neural network: Consider a statetransition �(sj ; ak) = si. We arbitrarily identify DFA states sj and si with stateneurons Sj and Si, respectively. One method of representing this transition is tohave state neuron Si have a high output � 1 and state neuron Sj have a low output� 0 after the input symbol ak has entered the network via input neuron Ik. Oneimplementation is to adjust the weights Wjjk and Wijk accordingly: setting Wijkto a large positive value will ensure that St+1i will be high and setting Wjjk to

3.4 Mapping Automata into Recurrent Neural Networks 13
Itk
Wijk
Sit+1
S0t+1
unit delay
Figure 3.4 Second-Order Recurrent Neural Network.a large negative value will guarantee that the output St+1j will be low. All otherweights are set to small random values. In addition to the encoding of the knownDFA states, we also need to program theresponse neuron, indicating whether ornot a DFA state is an accepting state. We program the weight W0jk as follows:If state si is an accepting state, then we set the weight W0jk to a large positivevalue; otherwise, we will initialize the weight W0jk to a large negative value. Wede�ne the values for the programmed weights as a rational number H , and let largeprogrammed weight values be +H and small values �H . We will refer to H as thestrength of a rule. We set the value of the biases bi of state neurons than have beenassigned to known DFA states to �H=2. This ensures that all state neurons whichdo not correspond to the the previous or the current DFA state have a low output.Thus, the rule insertion algorithm de�nes a nearly orthonormal internal represen-tation of all known DFA states. We assume that the DFA generated the examplestrings starting in its initial state. Therefore, we can arbitrarily select the outputof one of the state neurons to be 1 and set the output of all other state neuronsinitially to zero.3.4.3 Stability of the DFA RepresentationThe encoding algorithm leads to the following special form of the equation governingthe network dynamics: S(t+1)i = h(x;H) = 11 + eH(1�2x)=2

14 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computation
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
y
x
r=1
r=2
r=4
r=10
u=0.0
u=0.1
u=0.4
u=0.9
Figure 3.5 Fixed Points of the Sigmoidal Discriminant Function: Shown arethe graphs of the function f(x; r) = 11+eH(1�2rx)=2 (dashed graphs) for H = 8 andr = f1; 2; 4; 10g and the function p(x; u) = 11+eH(1�2(x�u))=2 (dotted graphs) for H = 8and u = f0:0; 0:1; 0:4; 0:9g. Their intersection with the function y = x shows theexistence and location of �xed points. In this example, f(x; r) has three �xed pointsfor r = f1; 2g, but only one �xed point for r = f4; 10g and p(x; u) has three �xedpoints for u = f0:0; 0:1g, but only one �xed point for u = f0:6; 0:9g.where x is the input to neuron Si, and H is the weight strength. The proof ofstability of the internal DFA representation makes use of (1) the existence of three�xed points ��; �0 and �+ of the sigmoidal discriminant, (2) 0 < �� < �0 <�+ < 1, (3) the stability of �� and �+ (notice that the �xed point �0 is unstable,and (4) two auxiliary sigmoidal functions f and g whose �xed points ��f and �+gprovide upper and lower bounds on the low and high signals, respectively, in aconstructed network. The graphs in Figure 3.5 illustrate the �xed points of thesigmoidal discriminant function.As can be seen, the discriminant function may not have two stable �xed pointsfor some choices of the parameters. However, the existence of two stable �xedpoints can be guaranteed by establishing a lower bound on the weight strength Hfor given values of n. This is illustrated in Figure 3.5 (see �gure caption for anexplanation). Convergence to the �xed points �� and �+ can be shown using aLyapunov argument: An appropriate energy function can be de�ned and it can beshown that that function only reaches a minimum for either one of the two �xedpoints. The following result can be derived from the above analysis:Theorem 3.1

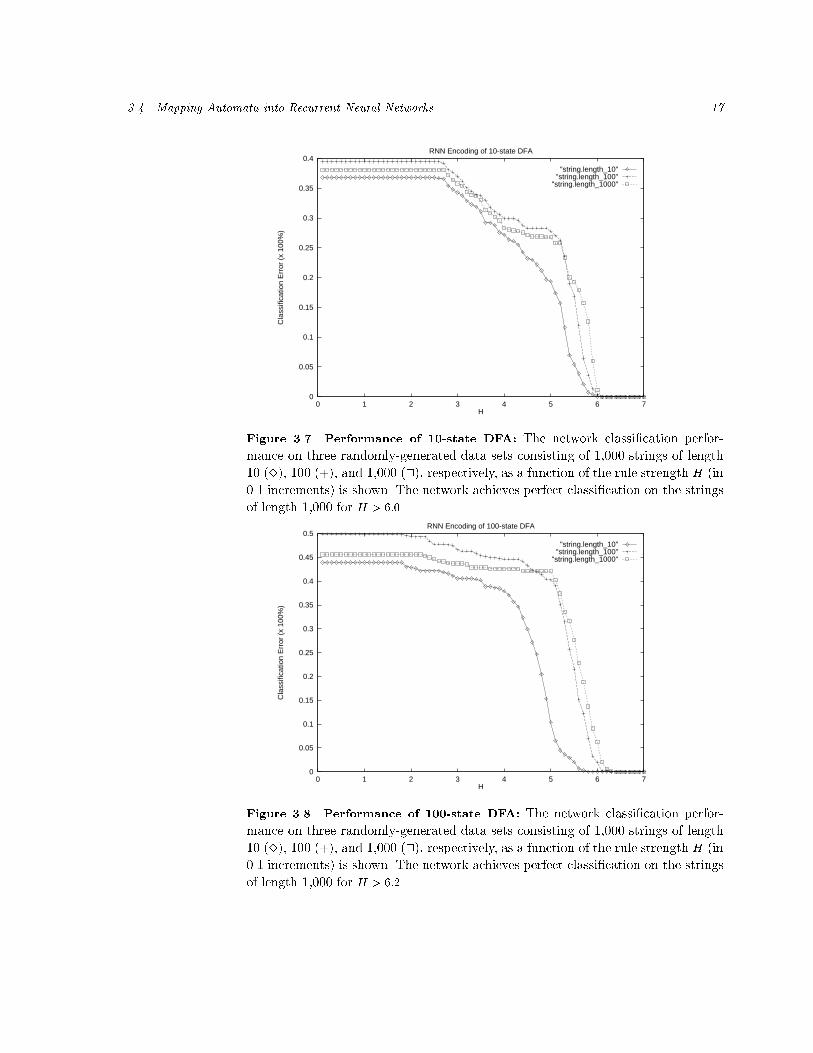
3.4 Mapping Automata into Recurrent Neural Networks 15For any given DFAM with n states and m input symbols, a sparse recurrent neuralnetwork with n+1 sigmoidal state neurons andm input neurons can be constructedfrom M such that the internal state representation remains stable if the followingthree conditions are satis�ed:(1) ��f (n;H) < 1n ( 12 + �0f (n;H)H )(2) �+g (n;H) > 12 + ��f (n;H) + �0g(n;H)H(3) H > max(H�0 (n); H+0 (n))Furthermore, the constructed network has at most 3mn second-order weights withalphabet �w = f�H; 0;+Hg, n + 1 biases with alphabet �b = f�H=2g, andmaximum fan-out 3m.The functionH0(n) is shown in Figure 3.6 (see caption for an explanation). Forany choice H > H�0 (n) and H > H+0 (n) for low and high signals, respectively, thesigmoidal discriminant function is guaranteed to have two stable �xed points.Stable encoding of DFA state is a necessary condition for a neural network toimplement a given DFA. The network must also correctly classify all strings. Theconditions for correct string classi�cation are expressed in the following corollary:Corollary 3.1Let L(MDFA) denote the regular language accepted by a DFA M with n statesand let L(MRNN) be the language accepted by the recurrent network constructedfrom M . Then, we have L(MRNN) = L(MDFA) if(1) �+g (r;H) > 12(1 + 1n + 2�0g(r;H)H )(2) H > max(H�0 (r); H+0 (r))3.4.4 SimulationsIn order to empirically validate our analysis, we constructed networks from ran-domly generated DFAs with 10, 100 and 1,000 states. For each of the three DFAs,we randomly generated di�erent test sets each consisting of 1,000 strings of length10, 100, and 1,000, respectively. The networks' generalization performance on thesetest sets for rule strength H = f0:0; 0:1; 0:2; : : : ; 7:0g are shown in Figures 7-9. Amisclassi�cation of these long strings for arbitrary large values of H would indicatea network's failure to maintain the stable �nite-state dynamics that was encoded.However, we observe that the networks can implement stable DFAs as indicated bythe perfect generalization performance for some choice of the rule strength H andchosen test set. Thus, we have empirical evidence which supports our analysis.All three networks achieve perfect generalization for all three test sets for approxi-

16 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computation
0
2
4
6
8
10
12
14
16
18
20
0 0.2 0.4 0.6 0.8 1
H
x
r=1
r=1
r=1.05
r=1.05
r=1.5
r=1.5
r=0.95
r=0.95
r=0.9
r=0.9
r=0.8
r=0.8
r=0.7
r=0.7
r=2
r=2
r=3
r=3
r=5
r=5
r=10
r=10
H (r)0
Figure 3.6 Existence of Fixed Points: The contour plots of the function h(x; r) =x (dotted graphs) show the relationship between H and x for various values of r.If H is chosen such that H > H0(r) (solid graph), then a line parallel to the x-axisintersects the surface satisfying h(x; r) = x in three points which are the �xed pointsof h(x; r).mately the same value of H . Apparently, the network size plays an insigni�cant rolein determining for which value of H stability of the internal DFA representation isreached, at least across the considered 3 orders of magnitude of network sizes.In our simulations, only few neurons ever exceeded or fell below the �xedpoints ��f and �+g , respectively. Furthermore, the network has a built-in resetmechanism which allows low and high signals to be strengthened. Low signals Stjare strengthened to h(0; H) when there exists no state transition �(:; ak) = qj .In that case, the neuron Stj receives no inputs from any of the other neurons;its output becomes less than ��f since h(0; H) < ��f . Similarly, high signals Sti getstrengthened if either low signals feeding into neuron Si on a current state transition�(fqjg; ak) = qi have been strengthened during the previous time step or when thenumber of positive residual inputs to neuron Si compensates for a weak high signalfrom neurons fqjg. Since constructed networks are able to regenerate their internalsignals and since typical DFAs do not have the worst case properties assumed inthis analysis, the conditions guaranteeing stable low and high signals are generally
3.4 Mapping Automata into Recurrent Neural Networks 17
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0 1 2 3 4 5 6 7
Cla
ssifi
catio
n E
rror
(x
100%
)
H
RNN Encoding of 10-state DFA
"string.length_10""string.length_100"
"string.length_1000"
Figure 3.7 Performance of 10-state DFA: The network classi�cation perfor-mance on three randomly-generated data sets consisting of 1,000 strings of length10 (3), 100 (+), and 1,000 (2), respectively, as a function of the rule strength H (in0.1 increments) is shown. The network achieves perfect classi�cation on the stringsof length 1,000 for H > 6:0.
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
0 1 2 3 4 5 6 7
Cla
ssifi
catio
n E
rror
(x
100%
)
H
RNN Encoding of 100-state DFA
"string.length_10""string.length_100"
"string.length_1000"
Figure 3.8 Performance of 100-state DFA: The network classi�cation perfor-mance on three randomly-generated data sets consisting of 1,000 strings of length10 (3), 100 (+), and 1,000 (2), respectively, as a function of the rule strength H (in0.1 increments) is shown. The network achieves perfect classi�cation on the stringsof length 1,000 for H > 6:2.

18 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computation
0
0.1
0.2
0.3
0.4
0.5
0.6
0 1 2 3 4 5 6 7
Cla
ssifi
catio
n E
rror
(x
100%
)
H
RNN Encoding of 1000-state DFA
"string.length_10""string.length_100"
"string.length_1000"
Figure 3.9 Performance of 1000-state DFA: The network classi�cation perfor-mances on three randomly-generated data sets consisting of 1,000 strings of length10 (3), 100 (+), and 1,000 (2), respectively, as a function of the rule strength H (in0.1 increments). The network achieves perfect classi�cation on the strings of length1,000 for H > 6:1.much too strong for some given DFA.3.4.5 Scaling IssuesThe worst case analysis supports the following predictions about the implementa-tion of arbitrary DFAs:(1) neural DFAs can be constructed that are stable for arbitrary string length for �nitevalue of the weight strength H ,(2) for most neural DFA implementations, network stability is achieved for values of Hthat are smaller than the values required by the conditions in Theorem 3.1,(3) the value of H scales with the DFA size, i.e. the larger the DFA and thus thenetwork, the larger H will be for guaranteed stability.Predictions (1) and (2) are supported by our experiments. However, when wecompare the values H in the above experiments for DFAs of di�erent sizes, we�nd that H � 6 for all three DFAs. This observation seems inconsistent withthe theory. The reason for this inconsistency lies in the assumption of a worstcase for the analysis, whereas the DFAs we implemented represent average cases.For the construction of the randomly generated 100-state DFA we found correctclassi�cation of strings of length 1,000 for H = 6:3. This value corresponds to a

3.4 Mapping Automata into Recurrent Neural Networks 19
3
4
5
6
7
8
9
10
11
0 20 40 60 80 100
wei
ght s
tren
gth
H
maximum indegreeFigure 3.10 Scaling Weight Strength: An accepting state q� in 10 randomlygenerated 100-state DFAs was selected. The number of states qj for which �(qj ; 0) =q� was gradually increased in increments of 5% of all DFA states. The graph showsthe minimum value of H for correct classi�cation of 100 strings of length 100. Hincreases up to � = 75%; for � > 75%, the DFA becomes degenerated causing H todecrease again.DFA whose states have `average' indegree n = 1:5. [The magic value 6 also seemsto occur for networks which are trained. Consider a neuron Si; then, the weightwhich causes transitions between dynamical attractors often has a value � 6 [100].]However, there exist DFAs which exhibit the scaling behavior that is predicted bythe theory. We will brie y discuss such DFAs. That discussion will be followed by ananalysis of the condition for stable DFA encodings for asymptotically large DFAs.3.4.6 DFA States with Large IndegreeWe can approximate the worst case analysis by considering an extreme case of aDFA:(1) Select an arbitrary DFA state q�;(2) select a fraction � of states qj and set �(qj ; ak) = q�.(3) For low values of �, a constructed network behaves similar to a randomly generatedDFA.(4) As the number of states qj for which �(qj ; ak) = q� increases, the behavior graduallymoves toward the worst case analysis where one neuron. receives a large number ofresidual inputs with for a designated input symbol ak.

20 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of ComputationWe constructed a network from a randomly generated DFA M0 with 100 statesand two input symbols. We derived DFAs M�1 ;M�2 ; : : : ;M�R where the fractionof DFA states qj from M�i to M�i+1 with �(qj ; ak) = q� increased by ��; forour experiments, we chose �� = 0:05. Obviously, the languages L(M�i) changefor di�erent values of �i. The graph in Figure 3.8 shows for 10 randomly generatedDFAs with 100 state the minimum weight strength H necessary to correctly classify100 strings of length 100 - a new data set was randomly generated for each DFA- as a function of � in 5% increments. We observe that H generally increases withincreasing values of �; in all cases, the hint strength H sharply decline for somepercentage value �. As the number of connections +H to a single state neuron Siincreases, the number of residual inputs which can cause unstable internal DFArepresentation and incorrect classi�cation decreases.We observed that there are two runs where outliers occur, i.e. H�i > H�i+1 eventhough we have �i < �i+1. Since the value H� depends on the randomly generatedDFA, the choice for q� and the test set, we can expect such an uncharacteristicbehavior to occur in some cases.3.4.7 Comparison with other MethodsDi�erent methods [5, 30, 29, 54, 73] for encoding DFAs with n states and m inputsymbols in recurrent networks are summarized in Table 3.1. The methods di�erin the choice of the discriminant function (hard-limiting, sigmoidal, radial basisfunction), the size of the constructed network and the restrictions that are imposedon the weight alphabet, the neuron fan-in and fan-out. The results in [54] improvethe upper and lower bounds reported in [5] for DFAs with only two input symbols.Those bounds can be generalized to DFAs with m input symbols [53]. Among themethods which use continuous discriminant functions, our algorithm uses no moreneurons than the best of all methods, and consistently uses fewer weights andsmaller fan-out size than all methods.3.5 Extension to Fuzzy Domains3.5.1 PreliminariesThere has been an increased interest in hybrid systems as more applicationsusing hybrid models emerge. One example of hybrid systems is in combiningarti�cial neural networks and fuzzy systems (see [12]). Fuzzy logic [112] provides amathematical foundation for approximate reasoning and has proven very successfulin a variety of applications. Fuzzy �nite-state automata (FFAs) have a long history[21] and can be used as design tools for modeling a variety of systems [13, 60]. Suchsystems have two major characteristics: (1) the current state of the system dependson past states and current inputs, and (2) the knowledge about the system's currentstate is vague or uncertain.

3.5ExtensiontoFuzzyDomains21
author(s) nonlinearity order # neurons # weights weight alphabet fan-in limit fan-out limitMinsky (1967) hard �rst O(mn) O(mn) �W = f1; 2g none noneAlon et al. (1991)1 hard �rst O(n3=4) - no restriction none noneAlon et al. (1991)1 hard �rst O(n) - any restriction none yesFrasconi et al. (1993) sigmoid �rst O(mn) O(n2) no restriction none noneHorne (1994)2 hard �rst O(q mn log nlogm+logn ) - no restriction none noneHorne (1994)2 hard �rst O(pmn logn) O(mn logn) �W = f�1; 1g none noneHorne (1994)2 hard �rst O( mn lognlogm+logn ) O(n) �W = f�1; 1; 2g 2 noneGori et al. (1996)3 sigmoid/radial �rst O(n) O(n2) no restriction none noneGiles & Omlin (1996)4 sigmoid second O(n) O(mn) �W = f�H;�H=2;+Hg none 3mTable 4.1: Comparison of di�erent DFA Encoding Methods: The di�erent methods use di�erentamounts and types of resources to implement a given DFA with n states and m input symbols. 1;2 There alsoexist lower bounds for the number of neurons necessary to implement any DFA. 2 The bounds for � = f0; 1ghave been generalized to arbitrary alphabet size m. 3 The authors use their network with sigmoidal andradial basis functions in multiple layers to train recurrent networks; however, their architecture could beused to directly encode a DFA in a network. 4 The rule strength H can be chosen according to the resultsof Theorem 4.1.
1

22 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of ComputationA variety of implementations of FFAs have been proposed [48, 57, 107], somein digital systems. However, this is the �rst proof that such implementations insigmoid activation RNNs are stable, ie. guaranteed convergence to the correctprespeci�ed membership [84]. Furthermore, these proofs can be for di�erent FFArepresentations, with and without fuzzy state representation. This proof is basedon stably mapping deterministic �nite-state automata (DFAs) in recurrent neuralnetworks discussed above.In contrast to DFAs, a set of FFA states can be occupied to varying degrees atany point in time; this fuzzi�cation of states generally reduces the size of the model,and the dynamics of the system being modeled is often more accessible to a directinterpretation.The proofs of representational properties of AI and machine learning structuresare important for a number of reasons. Many users of a model want guaranteesabout what it can theoretically do, ie. its performance and capabilities; others needthis for use justi�cation and acceptance. The capability of representing FFAs can beviewed as a foundation for the problem of learning FFAs from examples (if a networkcannot represent FFAs, then it certainly will have di�culty in learning them). Astable encoding of knowledge means that the model will give the correct answer(membership in this case) independent of when the system is used or how long itis used. This can lead to robustness that is noise independent. Finally, with theextraction of knowledge from trained neural networks, the methods presented herecould potentially be applied to incorporating and re�ning a priori fuzzy knowledgein recurrent neural networks [71].3.5.2 Crisp Representation of Fuzzy AutomataThe following result allows us to immediately apply the DFA encoding algorithmand stability analysis discussed above in order to map FFA states and statetransitions into recurrent networks [99]:Theorem 3.2Given a regular fuzzy automaton M , there exists a deterministic �nite-state au-tomaton M 0 with output alphabet Z � f� : � is a production weightg [ f0g whichcomputes the membership function � : �� ! [0; 1] of the language L(M 0).An example of such a transformation is shown in Figure 3.11. In order to completethe mapping, we just need to compute the fuzzy membership function of strings.The following lemma is useful:Lemma 3.1For the �xed points �� and �+ of the sigmoidal discriminant, we havelimH!1 �� = 0 and limH!1 �+ = 1Since exactly one neuron corresponding to the current automaton state has a highoutput any given time and all other neuron have an output close to 0, we can

3.5 Extension to Fuzzy Domains 231
2
3
41
2
3
4
5
6 7
a,b/0.3
a/0.5
b/0.2
a/0.7b/0.4
b/0.5
a
b
a
b 0.5
b
b 0.2
0.3
baa
a ab
a
b
(a) (b)Figure 3.11 Transformation of a FFA into its corresponding DFA: (a) A fuzzy�nite-state automaton with weighted state transitions. State 1 is the automaton'sstart state; accepting states are drawn with double circles. Only paths that canlead to an accepting state are shown (transitions to garbage states are not shownexplicitly). A transition from state qj to qi on input symbol ak with weight �is represented as a directed arc from qj to qi labeled ak=�. (b) correspondingdeterministic �nite-state automaton which computes the membership functionstrings. The accepting states are labeled with the degree of membership. Noticethat all transitions in the DFA have weight 1.simply multiply the outputs of all neurons by the fuzzy acceptance label of thecorresponding automaton state and add up all values. Thus, we have the followingresult:Theorem 3.3Any fuzzy �nite-state automatonM can be represented in a second-order recurrentneural network with linear output layer which computes the fuzzy membershipfunction of input strings with arbitrary accuracy.An architecture for this mapping is shown in Figure 3.12. In order to empiricallytest our encoding methodology, we examined how well strings from a randomlygenerated FFAs are classi�ed by a recurrent neural network in which the FFAis encoded. We randomly generated deterministic acceptors for fuzzy regular lan-guages over the alphabet fa; bg with 100 states as follows: For each DFA state,we randomly generated a transition for each of the two input symbols to anotherstate. Each accepting DFA state qi was assigned a membership 0 < �i � 1; for allnon-accepting states qj , we set �j = 0. We encoded these acceptors into recurrentnetworks with 100 recurrent state neurons, two input neurons (one for each of thetwo input symbols 0 and 1), and one linear output neuron.We measured their performance on 100 randomly generated strings of �xed length100 whose membership was determined from their deterministic acceptors. Thegraphs in Figure 3.13 show the average absolute error of the network output asa function of the weight strength H used to encode the �nite-state dynamics for

24 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computation
z−1
input neurons
recurrent state neurons
network output neuron
Wijk
second−order weights
Finite State Dynamics
fuzzy membership weights
String Membership
Figure 3.12 Recurrent Network Architecture for Crisp Representation ofFuzzy Finite-State Automata: The architecture consists of two parts: Recurrentstate neurons encode the state transitions of the deterministic acceptor. Theserecurrent state neurons are connected to a linear output neuron which computesstring membership.DFAs where 1%, 5%, 20%, 30%, 50% and 100% of all states had labels 0 < �i � 1.We observe that the error exponentially decreases with increasing hint strength H(i.e., the average output error can be made arbitrarily small). The DFA size has nosigni�cant impact on the network performance. The network performance dependson the stability of the internal representation of the �nite-state dynamics (the valueof H for which the dynamics of all DFAs used in these experiments remains stablefor strings of arbitrary length is approximately H ' 9:8). When the representationbecomes unstable because the weight strength H has been chosen too small, thenthat instability occurs for very short strings (typically less than �ve iterations).We have also shown that network architectures such as shown in Figure 3.12 learnan internal representation of a deterministic acceptor when trained on fuzzy strings.A deterministic acceptor can then be extracted from a trained network using anyof the known DFA extraction heuristics. Whether or not a fuzzy representation ofa FFA can be extracted remains an open question.

3.5 Extension to Fuzzy Domains 25
0
1
2
3
4
5
6
7
4 6 8 10 12 14 16 18 20
Ave
rage
Abs
olut
e N
etw
ork
Out
put E
rror
Weight Strength H
1%5%
20%
30%
50%
100%
Figure 3.13 Network Performance: The graphs show average absolute error ofthe network output when tested on (a) 100 randomly generated strings of �xedlength 100 and (b) on 100 randomly generated strings of length up to 100 asa function of the weight strength H used to encode the �nite-state dynamics ofrandomly generated DFAs with 100 states. The percentages of DFA states with�i > 0 were 1%, 5%, 20%, 30%, 50% and 100% respectively, of all DFA states.3.5.3 Fuzzy FFA RepresentationIn this section, we present a method for encoding FFAs using a fuzzy representationof states. The method generalizes the algorithm for encoding �nite-state transitionsof DFAs. The objectives of the FFA encoding algorithm are (1) ease of encodingFFAs into recurrent networks, and (2) the direct representation of \fuzziness", i.e.the uncertainties � of individual transitions in FFAs are also parameters in therecurrent networks. The stability analysis of recurrent networks representing DFAsgeneralizes to the stability of the fuzzy network representation of FFAs.We extend the functionality of recurrent state neurons in order to represent fuzzystates as illustrated in Figure 3.14.The main di�erence between the neuron discriminant function for DFAs andFFAs is that the neuron now receives as inputs the weight strength H , the signalx which represents the collective input from all other neurons, and the transitionweight �ijk , where �(ak; qj ; �ijk) = qi; we will denote this triple with (x;H; �ijk).The value of �ijk is di�erent for each of the states that collectively make up thecurrent fuzzy network state. This is consistent with the de�nition of FFAs.The following generalized form of the sigmoidal discriminant function g(:) willbe useful for representing FFA states:

26 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computation~g(x)
y=x
θ
θ x
1
H
x
/ 2θ
θ / 2
Figure 3.14 Fuzzy Discriminant Function for State Representation: A neuronreceives as input the collective signal x from all other neurons, the weight strengthH, and the transition certainty � to compute the function ~g(x;H; �) = �1+eH(��2x)=2� :Thus, the sigmoidal discriminant function used to represent FFA states has variableoutput range. S(t+1)i = ~g(x;H; �ijk) = �ijk1 + eH(�ijk�2x)=2�ijkCompared to the discriminant function g(:) for the encoding of DFAs, the weightH which programs the network state transitions is strengthened by a factor 1/�ijk(0 < �ijk � 1); the range of the function ~g(:) is squashed to the interval [0; �ijk],and it has been shifted towards the origin. Setting �ijk = 1 reduces the function (4)to the sigmoidal discriminant function (2) used for DFA encoding. More formally,the function ~g(x;H; �) has the following important invariant property which willlater simplify the analysis:Lemma 3.2~g(�x;H; �) = � ~g(x;H; 1).Thus, ~g(�x;H; �) can be obtained by scaling ~g(x;H; 1) uniformly in the x� andy�directions by a factor �.The above property of ~g allows a stability analysis of the internal FFA staterepresentation similar to the analysis of the stability of the internal DFA staterepresentation to be carried out.We map FFAs into recurrent networks as follows: Consider state qj of FFA Mand the fuzzy state transition �(ak; qj ; f�ijkg = fqi1 : : : qirg). We assign recurrentstate neuron Sj to FFA state qj and neurons Si1 : : : Sir to FFA states qi1 : : : qir .The basic idea is as follows: The activation of recurrent state neuron Si representsthe certainty �ijk with which some state transition �(ak; qj ; �ijk) = qi is carried out,

3.5 Extension to Fuzzy Domains 27i.e. St+1i ' �ijk . If qi is not reached at time t+ 1, then we have St+1i ' 0.We program the second-order weightsWijk as we did for DFAs with the exceptionthat any neuron with a high output can drive the output of several other neuronto a high value. This encoding algorithm leaves open the possibility for ambiguitieswhen a FFA is encoded in a recurrent network as follows: Consider two FFA statesqj and ql with transitions �(qj ; ak; �ijk) = �(ql; ak; �ilk) = qi where qi is one of allsuccessor states reached from qj and ql, respectively, on input symbol ak. Furtherassume that qj and ql are members of the set of current FFA states (i.e., these statesare occupied with some certainty). Then, the state transition �(qj ; ak; �ijk) = qirequires that recurrent state neuron Si have dynamic range [0; �ijk] while statetransition �(ql; ak; �ilk) = qi requires that state neuron Si asymptotically approach�ilk. For �ijk 6= �ilk , we have ambiguity for the output range of neuron Si:De�nition 3.2We say an ambiguity occurs at state qi if there exist two states qj and ql with�(qj ; ak; �ijk) = �(ql; ak; �ilk) = qi and �ijk 6= �ilk. A FFA M is called ambiguous ifan ambiguity occurs for any state qi 2M .However, there exists a simple algorithm which resolves these ambiguities bysplitting each state for which an ambiguity exists into two or more new unambiguousstates:Theorem 3.4Any FFA M can be transformed into an equivalent, unambiguous FFA M 0.In order to prove stability of a proposed fuzzy FFA encoding, we need to investigateunder what conditions the existence of three �xed points of the fuzzy sigmoidaldiscriminant g() is guaranteed (see equation (3) in Theorem 3.1). Fortunately,the following corollaries establish some useful invariant properties of the functionH0(n; �):Corollary 3.2The value of the minima H(x; n; �) only depends on the value of n and is indepen-dent of the particular values of �.Corollary 3.3For any value � with 0 < � � 1, the �xed points [�]� of the fuzzy discriminantfunction g(x;H; �) have the following invariant relationship:[�]� = � [�]1Their signi�cance is that (1) the �xed points of ~g() can directly be derived fromthe �xed points of a standard sigmoidal discriminant, and (2) we can use the samecondition of Theorem 3.1 to guarantee the existence of three stable �xed points ofthe fuzzy sigmoidal discriminant function.Applying the analysis technique from [79] to prove stability of the fuzzy internalrepresentation of FFAs in recurrent neural networks yields the following result:

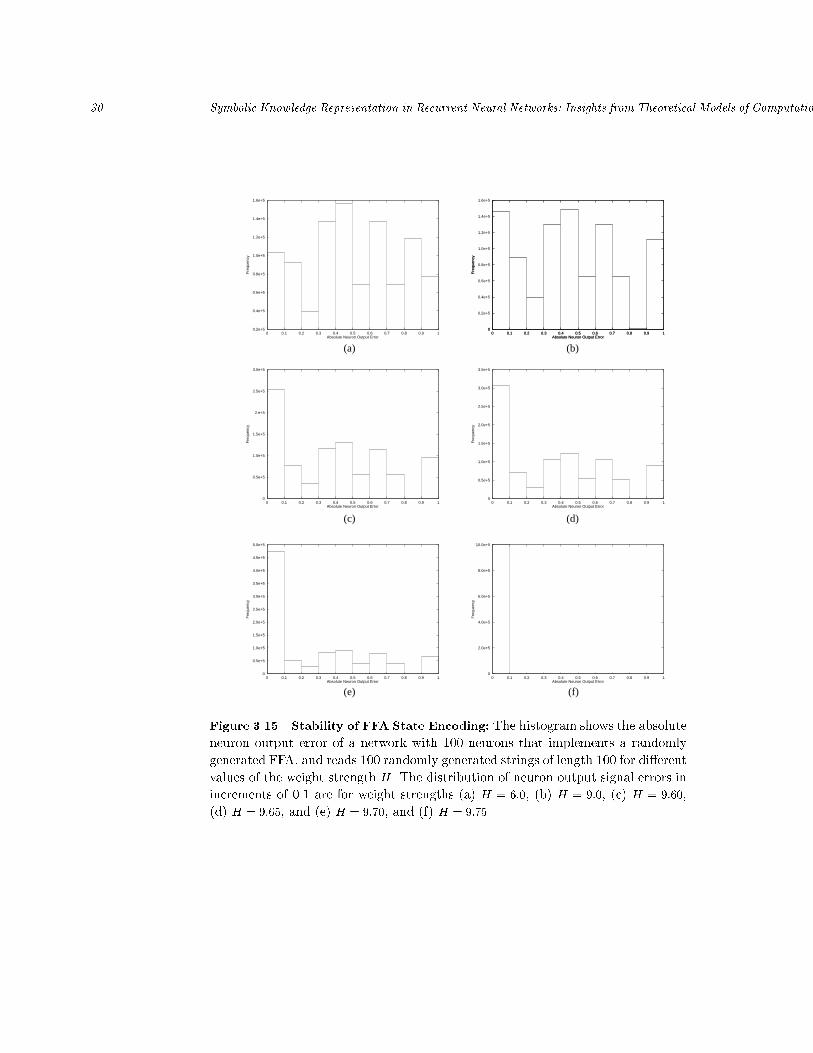
28 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of ComputationTheorem 3.5For some given unambiguous FFA M with n states and m input symbols, let�min and �max denote the minimum and maximum, respectively, of all transitionsweights �ijk in M . Then, a sparse recurrent neural network with n state and m in-put neurons can be constructed fromM such that the internal state representationremains stable if (1) [��f ]1 < 1n �max ( 12 + �min [�0f ]1H )(2) [�+h ]1 > 1�min (12 + �max[��f ]1 + [�0f ]1H )(3) H > max(H�0 (n); H+0 (n)) .Furthermore, the constructed network has at most 3mn second-order weightswith alphabet �w = f�H; 0;+Hg, n+ 1 biases with alphabet �b = f�H=2g, andmaximum fan-out 3m.For �min = �max = 1, conditions (1)-(3) of the above theorem reduce to thosefound for stable DFA encodings. This is consistent with a crisp representation ofDFA states.In order to validate our theory, we constructed a fuzzy encoding of a randomlygenerated FFA with 100 states (after the execution of the FFA transformationalgorithm) over the input alphabet fa; bg. We randomly assigned weights in therange [0; 1] to all transitions in increments of 0.1. We then tested the stability of thefuzzy internal state representation on 100 randomly generated strings of length 100by comparing, at each time step, the output signal of each recurrent state neuronwith its ideal output signal (since each recurrent state neuron Si corresponds toa FFA state qi, we know the degree to which qi is occupied after input symbolak has been read: either 0 or �ijk). A histogram of the di�erences between theideal and the observed signal of state neurons for selected values of the weightstrength H over all state neurons and all tested strings is shown in Figure 3.15.As expected, the error decreases for increasing values of H . We observe that thenumber of discrepancies between the desired and the actual neuron output decreases`smoothly' for the shown values of H (almost no change can be observed for valuesup to H = 6). The most signi�cant change can be observed by comparing thehistograms for H = 9:7 and H = 9:75: The existence of signi�cant neuron outputerrors for H = 9:7 suggests that the internal FFA representation is unstable. ForH � 9:75, the internal FFA state representation becomes stable. This discontinuouschange can be explained by observing that there exists a critical value H0(n) suchthat the number of stable �xed points also changes discontinuously from one to twofor H < H0(n) and H > H0(n), respectively.The `smooth' transition from large output errors to very small errors for mostrecurrent state neurons (Figures 15a-e) can be explained by observing that not allrecurrent state neurons receive the same number of inputs; some neurons may not

3.6 Learning Temporal Patterns with Recurrent Neural Networks 29receive any input for some given input symbol ak at time step t; in that case, thelow signals of those neurons are strengthened to ~g(0; H; �i:k) ' 0.3.6 Learning Temporal Patterns with Recurrent Neural Networks3.6.1 MotivationIt has become popular to use formal languages as testbeds for investigating funda-mental issues, in particular computational capabilities and e�cient learning algo-rithms. The advantage of using formal languages are (1) they represent temporaldependencies, (2) no feature extraction is necessary for learning, (3) they have asolid theoretical foundation and representation in the form of models of computa-tion, and (4) they can serve as benchmark tests for new learning algorithms.3.6.2 Learning AlgorithmsThe two most popular learning algorithms for recurrent networks are real-timerecurrent learning (RTRL) [111] and backpropagation-through-time (BPTT) [91].They are both gradient-descent learning algorithms and di�er only in the mannerin which the gradients are computed. The former computes the gradients in real-time as inputs are fed into a recurrent network whereas the latter unfolds therecurrent network in time and applies the backpropagation algorithm to thisunfolded feedforward network. More recently, a new recurrent learning algorithmhas been proposed which was designed to overcome some of the shortcomings ofboth RTRL and BPTT. Although early results are very encouraging, it is too soonto say whether or not this new algorithm will ful�ll its promise.We will discuss the training algorithm for second-order recurrent networks in-troduced aboved. For a discussion of the training algorithms of other recur-rent neural network models to recognize �nite state languages, see for example[14, 22, 38, 55, 75, 77, 87, 109, 111]. (For a discussion of the training of neu-ral networks to recognize context-free grammars and beyond, see for example[4, 19, 43, 69, 88, 111].)3.6.3 Input DynamicsWe will discuss learning for second-order networks. Algorithms for �rst-ordernetworks are analogous. Each input string is encoded into the input neurons onecharacter per discrete time step t. Each hidden neuron Si in the above equationis updated to compute the next state vector S of the same hidden neurons at thenext time step t + 1. This is why we call the recurrent network \dynamically-driven." Using a unary or one-hot encoding [58], there is one input neuron for eachcharacter in the string alphabet. After this recurrent network is trained on stringsgenerated by a regular grammar, it can be considered as a neural network �nite
30 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computation
(a) (b)
(c) (d)
(e) (f)
0.2e+5
0.4e+5
0.6e+5
0.8e+5
1.0e+5
1.2e+5
1.4e+5
1.6e+5
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Fre
quen
cy
Absolute Neuron Output Error
0
0.2e+5
0.4e+5
0.6e+5
0.8e+5
1.0e+5
1.2e+5
1.4e+5
1.6e+5
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Fre
quen
cy
Absolute Neuron Output Error
00 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Fre
quen
cy
Absolute Neuron Output Error
0
0.5e+5
1.0e+5
1.5e+5
2.e+5
2.5e+5
3.0e+5
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Fre
quen
cy
Absolute Neuron Output Error
0
0.5e+5
1.0e+5
1.5e+5
2.0e+5
2.5e+5
3.0e+5
3.5e+5
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Fre
quen
cy
Absolute Neuron Output Error
0
0.5e+5
1.0e+5
1.5e+5
2.0e+5
2.5e+5
3.0e+5
3.5e+5
4.0e+5
4.5e+5
5.0e+5
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Fre
quen
cy
Absolute Neuron Output Error
0
2.0e+5
4.0e+5
6.0e+5
8.0e+5
10.0e+5
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Fre
quen
cy
Absolute Neuron Output ErrorFigure 3.15 Stability of FFA State Encoding: The histogram shows the absoluteneuron output error of a network with 100 neurons that implements a randomlygenerated FFA, and reads 100 randomly generated strings of length 100 for di�erentvalues of the weight strength H. The distribution of neuron output signal errors inincrements of 0.1 are for weight strengths (a) H = 6:0, (b) H = 9:0, (c) H = 9:60,(d) H = 9:65, and (e) H = 9:70, and (f) H = 9:75.

3.6 Learning Temporal Patterns with Recurrent Neural Networks 31state recognizer or DFA.3.6.4 Real-time On-Line Training AlgorithmFor training, the error function and error update must be de�ned. In addition, thepresentation of the training samples must be considered. The error function E0 isde�ned by selecting a special \output" neuron S0 of the hidden state neurons whichis either on (S0 > 1 � �) if an input string is accepted, or o� (S0 < �) if rejected,where � is the tolerance of the response neuron. Two error cases result from thisde�nition: (1) the network fails to reject a negative string (i.e. S0 > �); (2) thenetwork fails to accept a positive string (i.e. S0 < 1� �).The error function is de�ned as:E0 = 12 (�0 � S(f)0 )2where �0 is the desired or target response value for the response neuron S0. Thetarget response is de�ned as �0 = 0:8 for positive examples and �0 = 0:2 for negativeexamples. The notation S(f)0 indicates the �nal value of S0 after the �nal inputsymbol.A popular training method is an on-line real-time algorithm that updates theweights at the end of each sample string presentation with a gradient-descent weightupdate rule: �Wlmn = �� @E0@Wlmn = �(�0 � S(f)0 ) � @S(f)0@Wlmnwhere � is the learning rate. We also add a momentum term � as an additiveupdate to �Wlmn. To determine �Wlmn, the @S(f)i =@Wlmn must be evaluated.This training algorithm updates the weights at the end of the input string andshould be contrasted to methods that train by predicting the next string [14]. Fromthe recursive network state equation, we see that@S(f)i@Wlmn = g0(�i) � ��ilS(f�1)m I(f�1)n +Pj;kWijkI(f�1)k @S(f�1)j@Wlmn �where g0 is the derivative of the discriminant function. For the last time step f ,replace t and t�1 by f and f�1. (Note that this is a second-order form of the RTRLtraining method of Williams and Zipser [111].) Since these partial derivative termsare calculated one iteration per input symbol, the training rule can be implementedon-line and in real-time. The initial values are @S(0)i =@Wlmn set to zero. Thus theerror term is forward-propagated and accumulated at each time step t. Note that forthis training algorithm each update of @S(t)i =@Wlmn is computationally expensiveand requires O(N4 � K2) terms. For N >> K, this update is O(N4) which isthe same as a forward-propagated linear network. For scaling, it would be mostuseful to use a training algorithm that was not so computationally expensive suchas gradient-descent back-propagation through time.It is common to reinitialize the network state to a con�guration at the beginning

32 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computationof each string which remains �xed throughout training. However, it is also possibleto learn a network's initial state [26].3.6.5 Training ProcedureAll strings used in training were accepted by the DFA in Figure 3.19a (and Figure3.1). This randomly generated automaton is minimal in size and has 4 acceptingstates with the initial state also a rejecting state. The training set consisted of the�rst 500 positive and 500 negative example strings. The strings presentation was inalphabetical order, alternating between positive and negative examples [23, 43, 89].The weights, unless initially programmed, were initialized to small random valuesin the interval [�0:1; 0:1].3.6.6 Deterioration of Generalization PerformanceWe observed that the generalization performance of recurrent networks tends todeteriorate for unseen strings of increasing lengths. This is due to the nonlineardynamics of recurrent networks: Training a network on strings induces dynamicalattractors such as �xed points and periodic orbits and trajectories between thoseattractors (these attractors and orbits correspond to DFA states and loops, respec-tively). These trajectories may deteriorate for strings that were not part of thetraining set. The deterioration becomes worse with increasing string length. Thus,the network dynamics may follow trajectories other than those induced throughtraining. This can cause a network to output a wrong classi�cation for some strings.The problem of deterioration of generalization performance can be somewhat al-leviated by continuously pruning and retraining a network that has found an initialsolution [42]. We have found that pruning outperforms weight decay heuristics.3.6.7 Learning Long-Term DependenciesEven though recurrent neural networks have the computational capability to repre-sent arbitrary nonlinear dynamical systems, gradient descent algorithms can havedi�culties learning even simple dynamical behavior. This di�culty can be at-tributed to the problem of long-term dependencies [10]. This problem arises whenthe desired network output of a system at time T depends on inputs presented attime t << T . In particular, it has been argued that if a system is to store informa-tion robustly, then the error information that the gradient contributes for inputs ntime steps in the past approaches zero as n becomes large. Thus, the network willnot remember inputs it has seen in the distant past that are crucial to computingthe weight update.Even though there exist no methods for completely eliminating the problemof vanishing gradient information, heuristics have been proposed which aim atalleviating the problem. These heuristics either address training data presentationand/or selection,or suggest ways in which to alter the basic network architecture.

3.7 Extraction of Rules from Recurrent Neural Networks 33For applications where input sequences of varying length are available in the train-ing set (as was the case for learning regular languages), a data selection strategywhich favors short strings in the early stages of training induces a good approxima-tion of the desired long-term dynamical behavior of the recurrent network. Longerstrings can then be used to re�ne that dynamical behavior. Similarly, partial priorknowledge about the desired dynamics (see Section 3.8) can facilitate the forma-tion of the network behavior for longer strings [40]. In the absence of short trainingdata or prior knowledge, other heuristics can be employed. Compression of the in-put history that makes global features more prominent is one way to lessen theproblem of vanishing gradient information [93]. The heuristic works well if inputsequences contain local regularities that make them partially predictable. It fails,however,when such regularitiies are absent and when short-term dependencies arealso important.The above heuristics have all involved changing the presentation of the train-ing data. One promising method which alters the network architecture in order toimprove learning of long-term dependencies is the use of embedded memory; pre-vious network states are stored and participate in the network's computation atpre-de�ned time-delay intervals. A comparison study has shown that the use of em-bedded memory (1) is universal in the sense that embedded memory can be addedto any recurrent network architecture, and (2) the heuristic signi�cantly enhances anetwork's ability to learn long-term dependencies [67]. An intuitive explanation canbe given by observing that embedded memories provide a shorter path for propaga-tion gradient information since the stored states do not need to propagate throughnonlinearities; thus, we eliminate the degradation of the error information. A spe-cial case of a network with embedded memory is the so called NARX architecture[68]. It uses a tapped delay line of previous network inputs and outputs. A di�erentarchitectural modi�cation proposes the use of high-order gates [51]. In benchmarktests, the method has been shown to be capable of bridging time intervals in excessof 1000 even in noisy learning environments. This is achieved by modifying the net-work architecture which enforces constant error ow of error information throughspecial units. The heuristic however seems to have problems learning XOR typesequences, i.e. sequences where the presence (or absence) of a single input symbolchanges the desired network output [50].3.7 Extraction of Rules from Recurrent Neural Networks3.7.1 Cluster HypothesisOnce the network is trained (or even during training), we want to extract mean-ingful internal representations of the network, such as rules. For related work onrule extraction from recurrent neural networks see [14, 28, 38, 108, 113]. The con-clusion of [14] was that the hidden unit activations represented past histories andthat clusters of these activations can represent the states of the generating au-

34 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computationtomaton. [38] showed that a complete deterministic �nite-state automata and theirequivalence classes can be extracted from recurrent networks both during and aftertraining. This was extended in [39] to include a method for extracting bounded\unknown" grammars from a trained recurrent network. An alternative approachto state machine extraction was implemented by [109].Since our interest is in \simple" production rules, we describe a heuristic forextracting rules from recurrent networks in the form of DFA's. Di�erent extractionmethods are described in [14, 109, 113]. The algorithm we use is based on theobservation that the outputs of the recurrent state neurons of a trained networktend to cluster in the neuron activation space (see Figure 3.16). The �gure showsthe outputs of two-dimensional projections of hidden neuron activations in the(Si; Sj)-plane for all possible pairs (Si; Sj) (6 projections) for a well-trained 4-neuron recurrent network. This network was trained on strings from a 4-stateDFA and tested on a small test set. If the recurrent network has learned a goodrepresentation of the DFA of the training set, then the same colors should cluster(for a hard-threshold logic neuron or gate, the clusters would represent pointsin the N dimensional neuron space [113].) DFA extraction becomes identifyingclusters in the output space [0; 1]N of all state neurons. We use a dynamical statespace exploration which identi�es the DFA states and at the same time avoids thecomputationally infeasible exploration of the entire space.3.7.2 Extraction AlgorithmThe extraction algorithm divides the output of each of the N state neurons into qintervals or quantization levels of equal size, producing qN partitions in the spaceof the hidden state neurons. Starting in a de�ned initial network state, a stringof inputs will cause the trained weights of the network to follow a discrete statetrajectory connecting continuous state neuron values. The algorithm presents allstrings up to a certain length in alphabetical order starting with length 1. Thisprocedure generates a search tree with the initial state as its root and the numberof successors of each node equal to the number of symbols in the input alphabet.Links between nodes correspond to transitions between DFA states. The searchis performed in breadth-�rst order. Paths are made from one partition to anotherdepending on the following: (1) When a previously visited partition is reached, thenonly the new transition is de�ned between the previous and the current partition,i.e. no new DFA state is created and the search tree is pruned at that node. (2)When an input causes a transition immediately to the same partition, then a loopis created and the search tree is pruned at that node. The algorithm terminateswhen no new DFA states are created from the string set initially chosen and allpossible transitions from all DFA states have been extracted.Obviously, the extracted DFA depends on the quantization level q chosen, i.e.,in general, di�erent DFA will be extracted for di�erent values of q. Furthermore,di�erent DFA may be extracted depending on the order of strings presented whichleads to di�erent successors of a node visited by the search tree. Usually these

3.7 Extraction of Rules from Recurrent Neural Networks 35
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Neuron 0
Neuron 1
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Neuron 0
Neuron 2
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Neuron 0
Neuron 3
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Neuron 1
Neuron 2
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Neuron 1
Neuron 3
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Neuron 2
Neuron 3
Figure 3.16 Clustering of the States of a Known DFA in Hidden NeuronState Space. The network builds an internal representation of the learned DFA inthe space of its hidden neurons. Two-dimensional projections of the hidden neuronstate space [0; 1]4 into the (Si; Sj)-plane for all possible pairs (Si; Sj) are shown asthe �rst 1024 strings are fed into the trained network. These clusters are the trainednetwork's internal representation of the DFA's states. Transitions between clusterscorrespond to state transitions in the DFA.

36 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computationdistinctions are not signi�cant because the minimization algorithm [52] guaranteesa unique, minimal representation for any extracted DFA. Thus, many di�erentDFA's extracted for di�erent initial conditions, di�erent numbers of neurons, etc.collapse into equivalence classes [38]. Finally we must distinguish between acceptingand nonaccepting states. If at the end of a string the output of the response neuronS0 is larger than 0.5, the DFA state is accepting; otherwise, rejecting.We believe that the extraction of DFAs from recurrent networks does not �tthe decompositional class of extraction algorithms because the extraction relieson clustering of the state space of an ensemble of recurrent state neurons. Theknowledge of the weights or activations of individual neurons is insu�cient forextracting DFA states. The global (or input/output) behavior of the network isonly used to label DFA states accept/reject but no learning is involved. Thus, ouralgorithm falls into the class of eclectic extraction methods within the taxonomyproposed in [7].3.7.3 Example of DFA ExtractionAn example of the extraction algorithm is illustrated in Figure 3.17. Assume arecurrent network with 2 state and 2 input neurons is trained on a data set. Therange of possible values of S0 and S1 can be represented as a unit square in the(S0; S1)-plane. For illustration, choose a quantization level q = 3, i.e. the activationof each of the two state neurons is divided into 3 equal length intervals, de�ning32 = 9 discrete partitions. Each of these partitions corresponds to a hypotheticalstate in an unknown DFA. Assign labels 1, 2, 3, ... to the partitions in the orderin which they are visited for the �rst time.The start state of the to-be-extracted DFA is the initial network state vectorused in training - partition 1 in Figure 3.17a which is also an accepting state(denoted by a shaded circle) since the output of the response neuron (S0) is largerthan 0:5. On input '0' and '1', the network makes a transition into partitions 1and 2, respectively. This causes the creation of a transition to a new acceptingDFA state 2 and a transition from state 1 to itself. In the next step, transitionsoccur from partition 2 into partitions 3 and 4 on input '0' and '1', respectively.The resulting partial DFA is shown in Figure 3.17b. The DFA in Figure 3.17cshows the current knowledge about the DFA after all state transitions from states3 and 4 have been extracted from the network. In the last step, only one more newstate is created (Figure 3.17d). When the �nal string of this string set is seen, theextraction algorithm terminates. Notice that not all partitions have been assignedto DFA states. The algorithm usually only visits a subset of all available partitionsfor the DFA extraction. Many more partitions are reached when large test sets(especially when they contain many long strings) are used (e.g. when measuringthe generalization performance on a large test set). The extracted DFA can betransformed into a unique, minimized representation.

3.7 Extraction of Rules from Recurrent Neural Networks 37S
S0
S1
1
10
0
S0
1
10
0
S0
1
10
0
S0
1
1
10
0
12
0
1
12
43
3 4
12
5
12
3 4
5
6
0.5
0.5
0.5
1
0
0
10
1
0
1
0 1
0.5
(a)
(b)
(c)
(d)
S1
S1
1
2
1
2
3
4
1
2
3
4
5
1
2
3
4
56
Figure 3.17 Example of DFA Extraction Algorithm. Example of extraction of aDFA from a recurrent network with 2 state neurons. The state space is representedas a unit square in the (S0; S1)-plane. The output range of each state neuron hasbeen divided into 3 intervals of equal length resulting in 9 partitions in the networksstate space. Shaded states are accepting states.The �gures show the transitionsperformed between partitions and the (partial) extracted DFA at di�erent stagesof the extraction algorithm: (a) the initial state 1 and all possible transitions, (b) alltransitions from state 2, (c) all transitions from states 3 and 4, and (d) all possibletransitions from states 5 and 6.

38 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computation3.7.4 Selection of DFA ModelsIf several DFA's are extracted with di�erent quantization levels qi, then one ormore of the extracted DFA Mqi may be consistent with the given training set, i.ecorrectly classify the training set. To make a choice between di�erent consistentDFA, we devise a heuristic algorithm [83].Let M denote the unknown DFA and L(M) the language accepted by M .By choosing a particular quantization level qi, we extract a minimized �nite-state automaton, the hypothesis Mqi for the grammar to be inferred. A DFAM is de�ned as consistent if it correctly classi�es all strings of the training set;otherwise, it is an inconsistent model of the unknown source grammar. Given aset of consistent hypotheses Mq1 , Mq2 , . . . , MqQ we need a criterion for modelselection that permits the choice of a hypothesis that best represents the unknownlanguage L(M). A possible heuristic for model selection would be to split a givendata set into two disjoint sets (training and testing set), to train the network on thetraining set and to test the network's generalization performance on the test set.However, by disregarding a subset of the original data set for training, we may beeliminating valuable data from the training set which would improve the network'sgeneralization performance if the entire data set were used for training. However,we wish to make a model selection based solely on simple properties of the extractedDFA's and not resort to a test set. [Keep in mind that all DFA's discussed here willaccept strings of arbitrary length.] The model selection algorithm will be motivatedby the simulation results and discussed next.An example of model selection and performance is shown in Figure 3.18. Mini-mized DFA's are extracted from a trained network for quantization levels q = 3,q = 6 and q = 8. All three DFA's are consistent with the training set, i.e. theycorrectly classi�ed all strings in the training set. But which DFA best models theunknown source M?Simulations demonstrated that a policy for selecting a \good" model of theunknown source grammar can be formulated. We choose the DFA Ms which is thesmallest consistent DFA. Ms can be found by extracting DFA's M2; : : : ;Ms�1;Msin that order and the best model is the �rst consistent DFA Ms. We rely on thehypothesize that there always exists an s such that Ms is the smallest consistentDFA. This is an example ofOccam's Razor - complex models should not be preferredover simple models that explain the phenomena equally well.The quality of the extracted rules can be improved through continous networkpruning and retraining [42].3.7.5 Controversy and Theoretical FoundationsAs seen above, our DFA extraction algorithm depends on the discretization ofthe continuous state space into a �nite number of regions. It has been argued[59], that this approach to understanding the computation performed by recurrentneural networks is problematic for the following reasons: (1) Recurrent neural

3.7 Extraction of Rules from Recurrent Neural Networks 391
2
3
4
5
6
78
9
10
1
23
4
5
67
8
910
11
12 1314
15
1617
1819
1
2
3
4
5
67
8
9
10
11
12
13
14
15
16
17
18 19
20
21
22
23
2425
26
27
28
29
3031
32
33
34
35
36
37
38
39
40
41
4243
44
45
46
47
48
49
50
51
52
5354
5556
57
58
59
60
61
62
63
64
65
6667
68
69
70
71
72
73
74
75
76
77
78
79
80
81
8283
84
85
86
87
88
89
90
91
92
93
94
9596
97
98
99
100
101
102
103
104
105
106
107
108
109110
111
112
113
114
115
116
Figure 3.18 Examples of Extracted DFA's. Minimized DFA's extracted from atrained network with quantization levels (a) q=3 (b) q=6 and (c) q=8. All threeDFA's are consistent with the training set, i.e. they correctly classify each stringin the set. Which DFA best models the unknown regular grammar? We contendDFA(a) because it has the least number of states.networks are nonlinear dynamical systems which are sensitivity to initial conditionscapable of producing nondeterministic machines: Their trajectories are determinedby both the initial state of the network and the dynamics of the state transitions.Extraction methods which use single transitions between regions are insu�cientbecause initially nearby states will become separated across several state regionsover time. Thus, no matter how �ne a discrete quantization of the continuousstate space we use, we eventually encounter the situation where an extracted statesplits into multiple trajectories independent of the future input sequence; this ischaracteristic of a nondeterministic state transition. It is, at the very least, verydi�cult to distinguish between a nondeterministic automaton with few states and adeterministic automaton with a large number of states. (2) It is the observer's biaswhich determines that a dynamical system is equivalent to a �nite-state automata,i.e., trivial changes in observation strategies may result in a behavioral descriptionfrom a range of complexity classes for a single system.It has subsequently been shown analytically that objection (1) can be resolved bynoting that sensitivity to initial conditions itself does not pose any problem for DFAextraction: If the reachable points in a partition state are mapped to more than oneother partition state and the recurrent network robustly models some DFA, then

40 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computationthe target partition states must be equivalent. Thus, the following result establishesthe theoretical foundation for DFA extraction from recurrent networks:Theorem 3.6For recurrent neural networks that robustly model a given DFA, for su�ciently largequantization level q, it is su�cient to consider only partitions created by dividingeach neuron's range into q equal partitions to always succeed in extracting the DFAthat is being modeled.This follows from the observation that a recurrent neural network that robustlymodels some DFA must have mutually disjoint, closed sets that correspond to DFAstates. An immediate consequence of the above result is the following corollary:Corollary 3.4A �nite dimensional recurrent neural network can robustly only perform �nite-statemachine computations.The above result follows from the observation that a network's phase space canonly contain a �nite number of disjoint sets due to its compactness. It is relevant inthe context of on-going research on learning and extracting context-free languagesfrom trained recurrent neural networks [110].Objection (2) can be resolved by noting that we use models of su�cient com-plexity that adequately explain the given data. Even in cases where the dynamicsunderlying an unknown system are more complex than that of �nite-state automata,this simple model may in some sense approximate the real dynamics and extractionof this model may o�er important insights not available otherwise.3.8 Recurrent Neural Networks for Knowledge Re�nement3.8.1 IntroductionThe importance of using prior knowledge in a learning problem has been notedby many. [74] state that \... signi�cant learning at signi�cant success rate presup-poses some signi�cant prior structure. Simple learning schemes based on adjustingcoe�cients can indeed be practical and valuable when the partial functions are rea-sonably matched on the task ...". More recently, [35] have investigated the strengthsand weaknesses of neural learning from a statistical viewpoint. In formulating thebias/variance dilemma, they conclude that \... important properties must be built-in or hard-wired, perhaps to be tuned later by experience, but not learned in anystatistical meaningful way". Recently, the use of prior knowledge about a learningtask to be solved with a neural network has been studied by several authors.Inserting a priori knowledge has been shown useful in training feed-forwardneural networks (e.g. see [2, 11, 37, 90, 97, 105]). The resulting networks usuallyperformed better than networks that were trained without a priori knowledge. In

3.8 Recurrent Neural Networks for Knowledge Re�nement 41the context of training feed-forward networks, it has been pointed out by [2] thatusing partial information about the implementation of a function f which usesinput-output examples may be valuable to the learning process in two ways: (1)It may reduce the number of functions that are candidates for f and (2) it mayreduce the number of steps needed to �nd the implementation. In related work,[3] has trained feed-forward networks using hints, thus improving the learning timeand the generalization performance; and [103] has shown how approximate rulesabout a domain are translated into a feed-forward network.Our focus has been on methods for inserting prior knowledge into dynamically-driven recurrent neural networks [19, 28, 31, 41, 70, 82, 92].The work by [28] insertsrules into �rst-order recurrent networks by solving a linear programming problemfor the weights. The theoretical foundation for this approach is discussed in [31].However, [47] has shown that there exist simple deterministic �nite-state automatawhich cannot be represented with a �rst-order, single-layer fully recurrent networkarchitecture unless additional layers of weights (or an end symbol) are added. Givingthe recurrent network helpful hints about the strings, such as too long, etc., hasalso been shown to help learning [19]. It is also useful to put rules directly into thesample strings themselves [70].We encode prior knowledge about the DFA using the algorithm presented insection 3.4.2. The only di�erence is that we may not map entire DFAs into recurrentnetworks, but only known states and state transitions. These hints are encodedas rules which are then inserted directly before training into the recurrence of theneural network. We demonstrate the approach by training recurrent neural networkswith inserted rules to learn to recognize regular languages from grammatical stringexamples. Our simulations show that training recurrent networks with di�erentamounts of partial knowledge to recognize simple grammars usually improves thetraining time up to orders of magnitude, even when only a small fraction ofall transitions are inserted as rules. In addition there appears to be no loss ingeneralization performance.When all known rule transitions have been inserted into the network by encodingthe weights according to the above scheme, the network is trained. Notice that allweights including the ones that have been programmed are still adaptable - theyare not �xed.3.8.2 Variety of Inserted RulesRules (or DFA's) to be inserted prior to training are shown in Figures 19 and 20.They represent various amounts of prior information and also some incorrect priorknowledge.For a baseline comparison, Figure 3.19a represents the entire rule set. Rulesshown in Figures 19b and 19c-f represent respectively no knowledge of self-loopsand partial knowledge of complete segments of the DFA. Figures 19g-h representstrings that the DFA accepts but without knowledge of start or accepting states. Inthis sense these rules can be considered \incorrect." Figures 20i-m are very incorrect

42 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computation1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
101
3
4
5
6 9
1
3
4
5
6
7
8
10
1
3
4
5
6
7
8
10
1
3
4
5
7
8
10
1
2
3
4
5
6
7
8
910
2
3 4 5 6
7 89 10
(a) (b) (c)
(d) (e) (f)
(g) (h)Figure 3.19 Partial Rules Inserted into Networks. Shown are the rules insertedinto the recurrent neural network before training. State 1 is the start state. Accept-ing states are drawn with double circles. State transitions on input symbols '0' and'1' are shown respectively as solid and dashed arcs. The �gures show: (a) all rules(entire DFA), (b) all rules except self-loops, (c) partial DFA, (d) rules for string'(10010)�001', (e) rules for disjointed transitions, (f) rules that do not start with astart state, (g) rules for string '001011011' without programming loop, (h) rules forseparate strings '000' and '0011'

3.8 Recurrent Neural Networks for Knowledge Re�nement 431
2
3 4
5
6
7
89
10
12
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
89
10
1
2
3
4
5
6
78
9
10
(i) (j) (k)
(l) (m)Figure 3.20 Malicious Hints: Rule (i): DFA accepting all strings where thenumber of 1's is a multiple of 10.Rules (j-m): Randomly generated DFA's with10 states.rules which we term \malicious."We made the following signi�cant observations: (1) The improvement in trainintimes was roughly `proportional' to the amount of correct, prior knowledge fora suitable choice of the weight strength H . (2) The generalization performancesof networks trained with and without prior knowledge were comparable. (3) Theinserted knowledge could also be extracted after network training. (4) The choice ofthe weight strength value H had a signi�cant impact on the training times. Whensmall values were chosen for H , then the learning bias was not su�ciently strongfor a signi�cant speed-up. When H was chosen too large, then the network haddi�culties converging to a solution because the bias sti ed the networks' variancenecessary to converge to a solution. We investigated di�erent methods for choosinga `good' value for H . (1) Choosing the minimum value H such that the encodedknowledge could also be extracted from the network prior to training, and (2)choosing H such that the function @E@H had a maximum seemed to work well, i.e.the methods determined initial values for H which compared favorably with theoptimal value found through exhaustive search [78].The problem of changing incorrect rules has been addressed for rule-based sys-tems [44, 86, 85]. We demonstrated that recurrent networks can be used successfullyfor rule veri�cation and revision, i.e. inserted rules can be veri�ed and also corrected.Rule veri�cation consists of four stages: (1) Encode knowledge into the weights ofa network. (2) Train the network on the data set. (3) Check the inserted rules by

44 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computationextracting rules in the form of DFA's from the trained network. (4) Compare therules in the extracted DFA with the initial prior knowledge.3.9 Summary and Future Research DirectionsIt has been argued that learning formal languages is not a well-suited applicationfor neural networks, particularly since the languages learnt to date are generallysimple (e.g. in terms of the complexity of the corresponding grammar). We agreethat, with current learning algorithms, neural networks cannot compete withalgorithms that are tailored to the problem of grammatical inference. However,using theoretical models of computation as a testbed has led to the successfulinvestigation of many fundamental issues. They include computational capabilitiesof di�erent recurrent network architectures, knowledge representation, extractionof symbolic knowledge from trained networks, and use of prior knowledge forimproved learning and generalization performance. Even though not all real-worldapplications can be cast into a symbolic domain, the lessons learned may be usefulfor nonsymbolic applications. Furthermore, some applications which at �rst glanceseem incompatible with a symbolic interpretation (e.g. �nancial forecasting) mayturn out to be amendable to a symbolic analysis after all (e.g., [66]).There are few real-world applications small enough such that neural networksalone could solve the problem. It is much more likely that neural networks will besuccessful as components of larger intelligent systems. The challenge for the nearfuture lies in the design of such hybrid systems which requires that componentssuch as neural networks interface with other technologies.References1. Snowmass, Colorado, December 6, 1996.2. Y. Abu-Mostafa, \Learning from hints in neural networks," Journal of Complexity,vol. 6, p. 192, 1990.3. K. Al-Mashouq and I. Reed, \Including hints in training neural nets," NeuralComputation, vol. 3, no. 4, p. 418, 1991.4. R. Allen, \Connectionist language users," Connection Science, vol. 2, no. 4, p. 279,1990.5. N. Alon, A. Dewdney, and T. Ott, \E�cient simulation of �nite automata byneural nets," Journal of the Association for Computing Machinery, vol. 38, no. 2,pp. 495{514, April 1991.6. R. Alquezar and A. Sanfeliu, \An algebraic framework to represent �nite statemachines in single-layer recurrent neural networks," Neural Computation, vol. 7,no. 5, p. 931, 1995.7. R. Andrews, J. Diederich, and A. Tickle, \A survey and critique of techniques forextracting rules from trained arti�cial neural networks," Knowledge-Based Systems,1995.

REFERENCES 458. D. Angluin and C. Smith, \Inductive inference: Theory and methods," ACMComputing Surveys, vol. 15, no. 3, pp. 237{269, 1983.9. E. Baum and D. Haussler, \What size net gives valid generalization?," NeuralComputation, vol. 1, no. 1, p. 151, 1989.10. Y. Bengio, P. Simard, and P. Frasconi, \Learning long-term dependencies withgradient descent is di�cult," IEEE Transactions on Neural Networks, vol. 5,pp. 157{166, 1994. Special Issue on Recurrent Neural Networks.11. H. Berenji, \Re�nement of approximate reasoning-based controllers byreinforcement learning," in Machine Learning, Proceedings of the EighthInternational International Workshop (L. Birnbaum and G. Collins, eds.), (SanMateo, CA), pp. 475{479, Morgan Kaufmann Publishers, 1991.12. J. Bezdek, ed., IEEE Transactions on Neural Networks { Special Issue on FuzzyLogic and Neural Networks, vol. 3. IEEE Neural Networks Council, 1992.13. F. Cellier and Y. Pan, \Fuzzy adaptive recurrent counterpropagation neuralnetworks: A tool for e�cient implementation of qualitative models of dynamicprocesses," J. Systems Engineering, vol. 5, no. 4, pp. 207{222, 1995.14. A. Cleeremans, D. Servan-Schreiber, and J. McClelland, \Finite state automataand simple recurrent recurrent networks," Neural Computation, vol. 1, no. 3,pp. 372{381, 1989.15. D. Clouse, C. Giles, B. Horne, and G. Cottrell, \Time-delay neural networks:Representation and induction of �nite state machines," IEEE Transactions onNeural Networks, vol. 8, no. 5, pp. 1065{1070, 1997.16. J. Crutch�eld and K. Young, \Computation at the onset of chaos," in Proceedingsof the 1988 Workshop on Complexity, Entropy and the Physics of Information(W. Zurek, ed.), (Redwood City, CA), pp. 223{269, Addison-Wesley, 1991.17. Y. L. Cun, J. Denker, and S. Solla, \Optimal brain damage," in Advances in NeuralInformation Processing Systems 2 (D. Touretzky, ed.), (San Mateo, CA), MorganKaufmann Publishers, 1990.18. G. Cybenko, \Approximation by superpositions of a sigmoidal function,"Mathematics of Control, Signals, and Systems, vol. 2, pp. 303{314, 1989.19. S. Das, C. Giles, and G. Sun, \Learning context-free grammars: Limitations of arecurrent neural network with an external stack memory," in Proceedings of TheFourteenth Annual Conference of the Cognitive Science Society, (San Mateo, CA),pp. 791{795, Morgan Kaufmann Publishers, 1992.20. E. Deprit, \Implementing recurrent back-propagation on the connection machine,"Neural Networks, vol. 2, no. 4, pp. 295{314, 1989.21. D. Dubois and H. Prade, Fuzzy sets and systems: theory and applications, vol. 144of Mathematics in Science and Engineering, pp. 220{226. Academic Press, 1980.22. J. Elman, \Finding structure in time," Cognitive Science, vol. 14, pp. 179{211, 1990.23. J. Elman, \Incremental learning, or the importance of starting small," Tech. Rep.CRL Tech Report 9101, Center for Research in Language, University of Californiaat San Diego, La Jolla, CA, 1991.24. S. Fahlman, \The cascade-correlation learning architecture," in Advances in NeuralInformation Processing Systems 2 (D. Touretzky, ed.), (San Mateo, CA),pp. 524{532, Morgan Kaufmann Publishers, 1990.25. S. Fahlman, \The recurrent cascade-correlation architecture," in Advances in Neural

46 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of ComputationInformation Processing Systems 3 (R. Lippmann, J. Moody, and D. Touretzky,eds.), (San Mateo, CA), pp. 190{196, Morgan Kaufmann Publishers, 1991.26. M. Forcada and R. Carrasco, \Learning the initial state of a second-order recurrentneural network during regular-language inference," Neural Computation, vol. 7,no. 5, pp. 923{930, 1995.27. P. Frasconi, M. Gori, M. Maggini, and G. Soda, \Representation of �nite stateautomata in recurrent radial basis function networks," Machine Learning, vol. 23,no. 1, pp. 5{32, 1996.28. P. Frasconi, M. Gori, M. Maggini, and G. Soda, \A uni�ed approach for integratingexplicit knowledge and learning by example in recurrent networks," in Proceedingsof the International Joint Conference on Neural Networks, vol. 1, p. 811, IEEE91CH3049-4, 1991.29. P. Frasconi, M. Gori, M. Maggini, and G. Soda, \Uni�ed integration of explicitrules and learning by example in recurrent networks," IEEE Transactions onKnowledge and Data Engineering, vol. 7, no. 2, pp. 340{346, 1995.30. P. Frasconi, M. Gori, and G. Soda, \Injecting nondeterministic �nite stateautomata into recurrent networks," tech. rep., Dipartimento di Sistemi eInformatica, Universit�a di Firenze, Italy, Florence, Italy, 1993.31. P. Frasconi, M. Gori, and G. Soda, \Recurrent neural networks and priorknowledge for sequence processing: A constrained nondeterministic approach,"Knowledge-Based Systems, vol. 8, no. 6, pp. 313{332, 1994.32. K. Fu, Syntactic Pattern Recognition and Applications. Englewood Cli�s, N.J:Prentice-Hall, 1982.33. L. Fu, \Learning capacity and sample complexity on expert networks," IEEETransactions on Neural Networks, vol. 7, no. 6, pp. 1517{1520, 1996.34. L. Fu, \Rule generation from neural networks," IEEE Transactions on Systems,Man, and Cybernetics, vol. 24, no. 8, pp. 1114{1124, 1994.35. S. Geman, E. Bienenstock, and R. Dourstat, \Neural networks and thebias/variance dilemma," Neural Computation, vol. 4, no. 1, pp. 1{58, 1992.36. C. Giles, D. Chen, G. Sun, H. Chen, Y. Lee, and M. Goudreau, \Constructivelearning of recurrent neural networks: limitations of recurrent cascade correlationand a simple solution," IEEE Transactions on Neural Networks, vol. 6, no. 4,pp. 829{836, 1995.37. C. Giles and T. Maxwell, \Learning, invariance, and generalization in high-orderneural networks," Applied Optics, vol. 26, no. 23, p. 4972, 1987.38. C. Giles, C. Miller, D. Chen, H. Chen, G. Sun, and Y. Lee, \Learning andextracting �nite state automata with second-order recurrent neural networks,"Neural Computation, vol. 4, no. 3, p. 380, 1992.39. C. Giles, C. Miller, D. Chen, G. Sun, H. Chen, and Y. Lee, \Extracting andlearning an unknown grammar with recurrent neural networks," in Advances inNeural Information Processing Systems 4 (J. Moody, S. Hanson, and R. Lippmann,eds.), (San Mateo, CA), pp. 317{324, Morgan Kaufmann Publishers, 1992.40. C. Giles and C. Omlin, \Extraction, insertion and re�nement of symbolic rules indynamically driven recurrent neural networks," Connection Science, vol. 5, no. 3 &4, pp. 307{337, 1993.41. C. Giles and C. Omlin, \Inserting rules into recurrent neural networks," in Neural

REFERENCES 47Networks for Signal Processing II, Proceedings of The 1992 IEEE Workshop(S. Kung, F. Fallside, J. A. Sorenson, and C. Kamm, eds.), pp. 13{22, IEEE Press,1992.42. C. Giles and C. Omlin, \Pruning recurrent neural networks for improvedgeneralization performance," IEEE Transactions on Neural Networks, vol. 5, no. 5,pp. 848{851, 1994.43. C. Giles, G. Sun, H. Chen, Y. Lee, and D. Chen, \Higher order recurrent networks& grammatical inference," in Advances in Neural Information Processing Systems 2(D. Touretzky, ed.), (San Mateo, CA), pp. 380{387, Morgan Kaufmann Publishers,1990.44. A. Ginsberg, \Theory revision via prior operationalization," in Proceedings of theSixth National Conference on Arti�cial Intelligence, p. 590, 1988.45. E. Gold, \Complexity of automaton identi�cation from given data," Informationand Control, vol. 37, pp. 302{320, 1978.46. M. Golea, \On the complexity of rule-extraction from neural networks andnetwork-querying," tech. rep., Department of Systems Engineering, AustralianNational University, Canberra, Australia, 1996.47. M. Goudreau, C. L. Giles, S.Chakradhar, and D. Chen, \First-order vs.second-order single-layer recurrent neural networks," IEEE Transactions on NeuralNetworks, vol. 5, no. 3, pp. 511{513, 1994.48. J. Grantner and M. Patyra, \Synthesis and analysis of fuzzy logic �nite statemachine models," in Proceedings of the Third IEEE Conference on Fuzzy Systems,vol. I, pp. 205{210, 1994.49. Y. Hayashi and A. Imura, \Fuzzy neural expert system with automated extractionof fuzzy if-then rules from a trained neural network," in Proceedings of the FirstIEEE Conference on Fuzzy Systems, pp. 489{494, 1990.50. S. Hochreiter. Private communication.51. S. Hochreiter and J. Schmidhuber, \Long short term memory," Tech. Rep.FKI-207-95, Fakultaet fuer Informatik, Technische Universitaet Muenchen, 1995.52. J. Hopcroft and J. Ullman, Introduction to Automata Theory, Languages, andComputation. Reading, MA: Addison-Wesley Publishing Company, Inc., 1979.53. B. Horne. Personal Communication.54. B. Horne and D. Hush, \Bounds on the complexity of recurrent neural networkimplementations of �nite state machines," in Advances in Neural InformationProcessing Systems 6, pp. 359{366, Morgan Kaufmann, 1994.55. B. Horne, D. Hush, and C. Abdallah, \The state space recurrent neural networkwith application to regular grammatical inference," Tech. Rep. UNM TechnicalReport No. EECE 92-002, Department of Electrical and Computer Engineering,University of New Mexico, Albuquerque, NM, 87131, 1992.56. S. Judd, \Learning in networks is hard," in Proceedings of the First IEEE AnnualConference on Neural Networks, 1987.57. E. Khan and F. Unal, \Recurrent fuzzy logic using neural networks," in Advancesin fuzzy logic, neural networks, and genetic algorithms (T. Furuhashi, ed.), LectureNotes in Arti�cial Intelligence, Berlin: Springer Verlag, 1995.58. Z. Kohavi, Switching and Finite Automata Theory. New York, NY: McGraw-Hill,Inc., second ed., 1978.

48 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computation59. J. Kolen, \Fool's gold: Extracting �nite state automata from recurrent networkdynamics," in Advanves in Neural Information Processing Systems 6 (J. Cowan,G. Tesauro, and J. Alspector, eds.), (San Francisco, CA), pp. 501{508, MorganKaufmann, 1994.60. E. Kosmatopoulos and M. Christodoulou, \Neural networks for identi�cation offuzzy dynamical systems: Approximation, convergence, and stability and anapplication to identi�cation of vehicle highway systems," tech. rep., Department ofElectronic and Computer Engineering, Technical University of Crete, 1995.61. S. Kremer, \Comments on \constructive learning of recurrent neural networks":Cascading the proof describing limitations of recurrent cascade correlation," IEEETransactions on Neural Networks, 1996. In press.62. S. Kremer, \On the computational power of elman-style recurrent networks," IEEETransactions on Neural Networks, vol. 6, no. 4, pp. 1000{1004, 1995.63. K. Lang, \Random dfa's can be approximately learned from sparse uniformexamples," in Proceedings of the Fifth ACM Workshop on Computational LearningTheory, (Pittsburgh, PA), July 1992.64. K. Lang, A. Waibel, and G. Hinton, \A time-delay neural network architecture forisolated word recognition," Neural Networks, vol. 3, no. 1, pp. 23{43, 1990.65. S. Lawrence, S. Fong, and C. L. Giles, \Natural language grammatical inference: Acomparison of recurrent neural networks and machine learning methods," inSymbolic, Connectionist, and Statistical Approaches to Learning for NaturalLanguage Processing (S. Wermter, E. Rilo�, and G. Scheler, eds.), Lecture notes inAI, pp. 33{47, Berlin: Springer-Verlag, 1996.66. S. Lawrence, C. L. Giles, and A. Tsoi, \Symbolic conversion, grammatical inferenceand rule extraction for foreign exchange rate prediction," in Proceedings of theFourth International Conference on Neural Networks in the Capital Markets(A. W. Y. Abu-Mostafa and A.-P. Refenes, eds.), Singapore: World Scienti�c, 1997.67. T. Lin, B. Horne, and C. Giles, \How embedded memory in recurrent neuralnetwork architectures helps learning long-term temporal dependencies," Tech. Rep.UMIACS-TR-96-28 and CS-TR-3626, Institute for Advanced Computer Studies,University of Maryland, College Park, MD, 1996.68. T. Lin, B. Horne, P. Tino, and C. Giles, \Learning long-term dependencies in narxrecurrent neural networks," IEEE Transactions on Neural Networks, vol. 7, no. 6,pp. 1329{1338, 1996.69. S. Lucas and R. Damper, \Syntactic neural networks," Connection Science, vol. 2,pp. 199{225, 1990.70. R. Maclin and J. Shavlik, \Re�ning algorithms with knowledge-based neuralnetworks: Improving the Chou-Fasman algorithm for protein folding," inComputational Learning Theory and Natural Learning Systems (S. Hanson,G. Drastal, and R. Rivest, eds.), MIT Press, 1992.71. R. Maclin and J. Shavlik, \Using knowledge-based neural networks to improvealgorithms: Re�ning the Chou-Fasman algorithm for protein folding," MachineLearning, vol. 11, pp. 195{215, 1993.72. L. Miclet, \Grammatical inference," in Syntactic and Structural PatternRecognition; Theory and Applications (H. Bunke and A. Sanfeliu, eds.), ch. 9,Singapore: World Scienti�c, 1990.73. M. Minsky, Computation: Finite and In�nite Machines, ch. 3, pp. 32{66.

REFERENCES 49Englewood Cli�s, NJ: Prentice-Hall, Inc., 1967.74. M. Minsky and S. Papert, Perceptrons. Cambridge, MA: MIT Press, 1969.75. M. Mozer and J. Bachrach, \Discovering the structure of a reactive environment byexploration," Neural Computation, vol. 2, no. 4, p. 447, 1990.76. M. Mozer and P. Smolensky, \Skeletonization: A technique for trimming the fatfrom a network via relevance assessment," in Advances in Neural InformationProcessing Systems 1 (D. Touretzky, ed.), (San Mateo, CA), pp. 107{115, MorganKaufmann Publishers, 1989.77. I. Noda and M. Nagao, \A learning method for recurrent networks based onminimization of �nite automata," in Proceedings International Joint Conference onNeural Networks 1992, vol. I, pp. 27{32, June 1992.78. C. Omlin, Symbolic Information in Recurrent Neural Networks: Issues of Learningand Representation. PhD thesis, Rensselaer Polytechnic Institute, Troy, NY, 1994.Ph.D. Dissertation.79. C. Omlin and C. Giles, \Constructing deterministic �nite-state automata inrecurrent neural networks," Journal of the ACM, vol. 43, no. 6, pp. 937{972, 1996.80. C. Omlin and C. Giles, \Extraction of rules from discrete-time recurrent neuralnetworks," Neural Networks, vol. 9, no. 1, pp. 41{52, 1996.81. C. Omlin and C. Giles, \Rule revision with recurrent neural networks," IEEETransactions on Knowledge and Data Engineering, vol. 8, no. 1, pp. 183{188, 1996.82. C. Omlin and C. Giles, \Training second-order recurrent neural networks usinghints," in Proceedings of the Ninth International Conference on Machine Learning(D. Sleeman and P. Edwards, eds.), (San Mateo, CA), pp. 363{368, MorganKaufmann Publishers, 1992.83. C. Omlin, C. Giles, and C. Miller, \Heuristics for the extraction of rules fromdiscrete-time recurrent neural networks," in Proceedings International JointConference on Neural Networks 1992, vol. I, pp. 33{38, June 1992.84. C. Omlin, K. Thornber, and C. Giles, \Fuzzy �nite-state automata can bedeterministically encoded into recurrent neural networks," IEEE Transactions onFuzzy Systems, vol. 6, no. 1, pp. 76{89, 1998.85. D. Oursten and R. Mooney, \Changing rules: A comprehensive approach to theoryre�nement," in Proceedings of the Eighth National Conference on Arti�cialIntelligence, p. 815, 1990.86. M. Pazzani, \Detecting and correcting errors of omission after explanation-basedlearning," in Proceedings of the Eleventh International Joint Conference onArti�cial Intelligence, p. 713, 1989.87. J. Pollack, \The induction of dynamical recognizers," Machine Learning, vol. 7,pp. 227{252, 1991.88. J. Pollack, \Recursive distributed representations," Journal of Arti�cialIntelligence, vol. 46, p. 77, 1990.89. S. Porat and J. Feldman, \Learning automata from ordered examples," MachineLearning, vol. 7, no. 2-3, p. 109, 1991.90. L. Pratt, \Non-literal transfer of information among inductive learners," in NeuralNetworks: Theory and Applications II (R. Mammone and Y. Zeevi, eds.), AcademicPress, 1992.

50 Symbolic Knowledge Representation in Recurrent Neural Networks: Insights from Theoretical Models of Computation91. D. Rumelhart, G. Hinton, and R. Williams, \Learning internal representations byerror propagation," in Parallel Distributed Processing, ch. 8, Cambridge, MA: MITPress, 1986.92. A. Sanfeliu and R. Alquezar, \Understanding neural networks for grammaticalinference and recognition," in Advances in Structural and Syntactic PatternRecognition (H. Bunke, ed.), World Scienti�c, 1992. To appear.93. J. Schmidhuber, \Learning complex, extended sequences using the principle ofhistory compression," Neural Computation, vol. 4, no. 2, pp. 234{242, 1992.94. J. Shavlik, \Combining symbolic and neural learning," Machine Learning, vol. 14,pp. 321{331, 1994. Extended abstract of an invited talk given at the EighthInternational Machine Learning Conference (ML'92).95. H. Siegelmann and E. Sontag, \On the computational power of neural nets,"Journal of Computer and System Sciences, vol. 50, no. 1, pp. 132{150, 1995.96. A. Sperduti, \On the computational power of recurrent neural networks forstructures," Neural Networks, vol. to be published, 1997.97. S. Suddarth and A. Holden, \Symbolic neural systems and the use of hints fordeveloping complex systems," International Journal of Man-Machine Studies,vol. 34, p. 291, 1991.98. G. Sun, H. Chen, Y. Lee, and C. Giles, \Turing equivalence of neural networks withsecond order connection weights," in 1991 IEEE INNS International JointConference on Neural Networks - Seattle, vol. II, (Piscataway, NJ), pp. 357{362,IEEE Press, 1991.99. M. Thomason and P. Marinos, \Deterministic acceptors of regular fuzzy languages,"IEEE Transactions on Systems, Man, and Cybernetics, no. 3, pp. 228{230, 1974.100. P. Tino, 1994. Personal communication.101. P. Tino, B. Horne, and C.L.Giles, \Finite state machines and recurrent neuralnetworks { automata and dynamical systems approaches," Tech. Rep.UMIACS-TR-95-1, Institute for Advance Computer Studies, University ofMaryland, College Park, MD 20742, 1995.102. G. G. Towell and J. W. Shavlik, \The extraction of re�ned rules fromknowledge-based neural networks," Machine Learning, vol. 13, no. 1, pp. 71{101,1993.103. G. Towell, M. Craven, and J. Shavlik, \Constructive induction usingknowledge-based neural networks," in Eighth International Machine LearningWorkshop (L. Birnbaum and G. Collins, eds.), (San Mateo, CA), p. 213, MorganKaufmann Publishers, 1990.104. G. Towell and J. Shavlik, \Knowledge-based arti�cial neural networks," Arti�cialIntelligence, vol. 70, no. 1-2, pp. 119{165, 1994.105. G. Towell, J. Shavlik, and M. Noordewier, \Re�nement of approximately correctdomain theories by knowledge-based neural networks," in Proceedings of the EighthNational Conference on Arti�cial Intelligence, (San Mateo, CA), p. 861, MorganKaufmann Publishers, 1990.106. V. Tresp, J. Hollatz, and S. Ahmad, \Network structuring and training usingrule-based knowledge," in Advances in Neural Information Processing Systems 4(C. Giles, S. Hanson, and J. Cowan, eds.), (San Mateo, CA), Morgan KaufmannPublishers, 1993.

REFERENCES 51107. F. Unal and E. Khan, \A fuzzy �nite state machine implementation based on aneural fuzzy system," in Proceedings of the Third International Conference onFuzzy Systems, vol. 3, pp. 1749{1754, 1994.108. R. Watrous and G. Kuhn, \Induction of �nite-state languages using second-orderrecurrent networks," Neural Computation, vol. 4, no. 3, p. 406, 1992.109. R. Watrous and G. Kuhn, \Induction of �nite state languages using second-orderrecurrent networks," in Advances in Neural Information Processing Systems 4(J. Moody, S. Hanson, and R. Lippmann, eds.), (San Mateo, CA), pp. 309{316,Morgan Kaufmann Publishers, 1992.110. J. Wiles and S. Bollard, \Beyond �nite state machines: Steps towards representingand extracting context-free languages from recurrent neural networks," in NIPS'96Rule Extraction from Trained Arti�cial Neural Networks Workshop (R. Andrewsand J. Diederich, eds.), p. 70, 1996.111. R. Williams and D. Zipser, \A learning algorithm for continually running fullyrecurrent neural networks," Neural Computation, vol. 1, pp. 270{280, 1989.112. L. Zadeh, \Fuzzy sets," Information and Control, vol. 8, pp. 338{353, 1965.113. Z. Zeng, R. Goodman, and P. Smyth, \Learning �nite state machines withself-clustering recurrent networks," Neural Computation, vol. 5, no. 6, pp. 976{990,1993.




















