
安否確認システムの広域冗長化とアクセス予測に関 する研究
132
安否確認システムの広域冗長化とアクセス予測に関 する研究 著者 永田 正樹 発行年 2016-12 出版者 静岡大学 URL http://doi.org/10.14945/00010198
-
Upload
khangminh22 -
Category
Documents
-
view
2 -
download
0
Transcript of 安否確認システムの広域冗長化とアクセス予測に関 する研究

安否確認システムの広域冗長化とアクセス予測に関する研究
著者 永田 正樹発行年 2016-12出版者 静岡大学URL http://doi.org/10.14945/00010198

静岡大学 博士論文
安否確認システムの 広域冗長化とアクセス予測
に関する研究
2016 年 12 月
大学院 自然科学系教育部
情報科学専攻
永田 正樹


i
要旨
本国は、地震や津波、火山噴火などさまざまな自然災害の脅威にさらされてい
る。記憶に新しい大災害として、1995 年 1 月 17 日に発生した阪神・淡路大震災
では約 6,000 名、2011 年 3 月 11 日に発生した東日本大震災では約 20,000 名、
2016 年 4 月 14 日に発生した熊本地震では約 130 名の死者・行方不明者を数え、
現在でも救援および復興活動が続けられている。このような大規模な被害に対す
る耐災害施策について、本国の取り組みでは 2013 年から内閣官房が進める「国
土強靭化計画」がある。これは、災害に対する強くてしなやかな対応策を講じる
ための各種計画であり、人命救助や緊急時の医療活動、企業などの経済活動、電
気・ガス・水道などの生活インフラ、情報通信機能などさまざまな分野に対する
耐性評価を実施し、脆弱箇所や不足箇所の補強および効率的な防災活動を推進す
るためのものである。対象分野には情報伝達に関するものもあり、救助状況の共
有や避難指示などを効率よく伝達できる情報インフラの担保を重要視している。
災害時の情報インフラとして、情報伝達および共有手段に Web システムを用い
た安否確認システムがある。安否確認システムとは、災害時における被災者の安
否情報を収集し、被災者を含む関係者に公開するシステムである。災害時に効率
よく被災者安否を情報発信することで、その後の救助や復興活動の迅速化に寄与
する。昨今では多くの IT ベンダや通信キャリアなどからさまざまな安否確認シ
ステムがサービス提供されその重要性がうかがえる。本研究は、安否確認システ
ムにおける災害時の稼働継続および効果的なサービス運用を提言し、有効な手法
を確立するものである。具体的な手法は、世界規模の複数拠点でシステムを構成
する広域冗長化機構と、アクセス状況に適したサーバ数で運用するアクセス予測
モデル機構である。上記 2 つの手法を安否確認システムに実装し、評価結果から
本研究の有効性を示す。
第 1 章では、災害時の安否情報の収集および共有を実現する安否確認システム
の必要性や本研究にいたった背景を説明する。
第 2 章では、本研究の対象となる Web を用いた安否確認システムの概要およ
び課題や要件を示す。安否確認システムが求められる背景として、災害多発国で

ii
ある本国の災害状況を紹介し、災害時における被災者の安否確認の必要性を「事
業継続計画(Business Continuity Planning:BCP)」の観点を交えて説明する。
安否確認システムに求められる要件として、ユーザ側の立場からは災害時の確実
な稼働が挙げられる。また、平常時と災害時でアクセス流量に差がある安否確認
システムは、システム提供側の立場からはアクセス状況に応じた適切なサーバ数
での運用が挙げられる。本章では、これら要件から課題を整理して、次章以降で
具体的な課題解決技術を説明する。
第 3 章では、災害時の確実な稼働の課題解決技術として、安否確認システムに
おける可用性を向上する広域冗長化技術の概要および実装と評価結果を説明する。
広域冗長化とは、システムを構成するサーバなどのリソースを単拠点でなく複数
拠点に分散配置することで、ある拠点の障害によりシステムの全体停止を回避す
る可用性向上のアプローチである。本研究では、単純に広域拠点にシステムを冗
長化するのではなく、システムを稼働させるクラウドベンダを複数社用いたイン
タークラウド構成を採用し、単一クラウドベンダの障害を避け、かつ地理的に離
れた複数拠点でシステムを分散配置するシステム基盤を構築する。構築したシス
テム基盤に対して、障害発生時のディザスタリカバリ評価をおこない、広域冗長
化基盤による可用性向上を示す。
第 4 章では、アクセス状況に応じたサーバ数での運用の課題解決技術として、
アクセス予測モデルを用いて適切なサーバ数を算出し、負荷分散をおこなう手法
および評価結果を説明する。アクセス予測は、過去の災害や訓練時における安否
確認システムへのアクセスログ分布を分析し、アクセス分布傾向をモデル化する
ことでおこなう。従来研究には、Web システムへのアクセストラヒック分布に各
種の確率分布関数をあてはめてモデル化し、システムへのアクセス分析や負荷テ
ストに効果を示しているものがある。本研究でのアクセス分布のモデル化は、過
去の災害時や訓練時のアクセス分布特性を把握し、その特性に適した確率分布関
数にあてはめておこなう。アクセス分布の特性から、本研究では対数正規分布を
用いてモデル化しアクセス予測モデルを構築する。構築したアクセス予測モデル
に対して、災害シミュレーション評価をし、実アクセス分布に対するアクセス予
測モデルの適合度や、適切なサーバ数算出による運用費用削減を示す。
第 5 章では、本論文のまとめを行う。

iii
目 次
第 1 章 序論 ................................................................................................. 1
1.1. 本研究の背景 ....................................................................................... 1
1.2. 本研究の目的 ....................................................................................... 3
1.3. 本論の構成 .......................................................................................... 4
第 2 章 安否確認システム ............................................................................. 5
2.1. はじめに ............................................................................................. 5
2.2. 背景 .................................................................................................... 6
2.2.1. 本国の災害状況 ............................................................................. 6
2.2.2. 安否確認の必要性 ........................................................................ 10
2.3. 安否確認システムとは ....................................................................... 16
2.4. 従来研究 ........................................................................................... 18
2.5. 静岡大学の安否確認システム ............................................................. 22
2.6. 要件と課題 ........................................................................................ 28
2.6.1. 安否確認システムに求められる要件 ............................................. 28
2.6.2. 課題:広域冗長化 .......................................................................... 29
2.6.3. 課題:アクセス予測(状況に応じたサーバ数) .............................. 30
2.7. おわりに ........................................................................................... 31
第 3 章 広域冗長化技術 .............................................................................. 32
3.1. はじめに ........................................................................................... 32
3.2. 従来研究 ........................................................................................... 33
3.2.1. 広域冗長化 .................................................................................. 33
3.2.2. インタークラウド ........................................................................ 38
3.3. システム概要 ..................................................................................... 43
3.4. インタークラウドでのベンダ間連携 ................................................... 47
3.5. ディザスタリカバリ .......................................................................... 49
3.5.1. フェイルオーバ ........................................................................... 49
3.5.2. ベンダ間フェイルオーバの処理フロー ......................................... 50
3.5.3. ベンダ内フェイルオーバの処理フロー ......................................... 52

iv
3.6. 分散データシステム .......................................................................... 55
3.6.1. Cassandra のデータ構造 ............................................................. 55
3.6.2. Cassandra のデータ管理 ............................................................. 57
3.7. 評価 .................................................................................................. 60
3.7.1. フェイルオーバ ........................................................................... 60
3.7.2. 分散データシステム .................................................................... 62
3.8. おわりに ........................................................................................... 65
第 4 章 アクセス予測技術 ........................................................................... 66
4.1. はじめに ........................................................................................... 66
4.2. 従来研究 ........................................................................................... 67
4.3. アクセス予測モデル .......................................................................... 69
4.3.1. アクセス分布特性 ........................................................................ 69
4.3.2. 対数正規分布を用いたアクセス予測モデルの構築 ........................ 71
4.3.3. 対数正規分布の仮定 .................................................................... 76
4.4. 複数のピークを持つ分布でのアクセス予測 ......................................... 78
4.4.1. 混合対数正規分布を用いたアクセス予測モデルの構築 .................. 78
4.4.2. 実アクセス分布への適合 .............................................................. 82
4.5. スケールアウト ................................................................................. 86
4.5.1. 処理フローとタイミング .............................................................. 86
4.5.2. サーバのアクセス許容量 .............................................................. 89
4.6. 評価 .................................................................................................. 92
4.6.1. サンプルデータ数でのモデル精度 ................................................ 92
4.6.2. サーバ数算出 ............................................................................... 97
4.6.3. シミュレーション評価 ................................................................. 99
4.6.4. 運用費用 ................................................................................... 102
4.7. おわりに ......................................................................................... 105
第 5 章 結論 ............................................................................................. 106
謝辞 ............................................................................................................ 109
参考文献 ...................................................................................................... 110
論文業績 ..................................................................................................... 121

v
図と表の目次
図 1-1 本論文の構成イメージ ......................................................................... 4
図 2-1 全世界における地震回数と活火山数の割合 ........................................... 6
図 2-2 月別地震発生回数(2015 年).............................................................. 7
図 2-3 主な自然災害(2014~2015 年) ......................................................... 8
図 2-4 東日本大震災の被災状況 ...................................................................... 9
図 2-5 災害時の死者・行方不明者数 ............................................................. 10
図 2-6 緊急時における BCP 発動フロー ........................................................ 11
図 2-7 災害発生日の時間および状況 ............................................................. 12
図 2-8 1 週間の生活時間内訳 ......................................................................... 13
図 2-9 安否報告および確認手段 .................................................................... 14
図 2-10 東日本大震災での通信手段 ............................................................... 15
図 2-11 安否確認システムの動作フロー ........................................................ 17
図 2-12 安否確認システム関連研究 ............................................................... 18
図 2-13 静岡大学安否確認システム構成 ........................................................ 22
図 2-14 ユーザ組織機能 ................................................................................ 25
図 2-15 マスタデータベース自動連携 ........................................................... 27
図 3-1 各レイヤの冗長化 .............................................................................. 33
図 3-2 広域冗長化 ........................................................................................ 35
図 3-3 サービス利用形態 .............................................................................. 38
図 3-4 プライベート・クラウドとパブリック・クラウド ............................... 39
図 3-5 インタークラウド概要 ....................................................................... 40
図 3-6 広域冗長型安否確認システムの概要 ................................................... 43
図 3-7 安否確認システムの運用形態 ............................................................. 46
図 3-8 各ベンダの API で相互操作 ................................................................ 47
図 3-9 ベンダ間フェイルオーバ .................................................................... 49
図 3-10 ベンダ内フェイルオーバ .................................................................. 50
図 3-11 ベンダ間フェイルオーバ処理フロー .................................................. 51

vi
図 3-12 ベンダ間フェイルオーバ後のシーケンス .......................................... 52
図 3-13 ベンダ内フェイルオーバ処理フロー ................................................. 53
図 3-14 ベンダ内フェイルオーバ後のシーケンス .......................................... 54
図 3-15 Cassandra のデータ構造 .................................................................. 56
図 3-16 Cassandra と RDB のデータ比較 ...................................................... 57
図 3-17 ノードと replication factor .............................................................. 58
図 3-18 ベンダ間フェイルオーバ .................................................................. 60
図 3-19 ベンダ内フェイルオーバ .................................................................. 61
図 3-20 Cassandra のデータコピーフロー ..................................................... 62
図 3-21 RDB と NOSQL の性能比較 .............................................................. 64
図 4-1 安否確認システムにおけるアクセス予測 ............................................ 68
図 4-2 災害時のアクセス分布 ........................................................................ 69
図 4-3 Q-Q プロット ..................................................................................... 70
図 4-4 TU と D(E-M)の関係 ...................................................................... 74
図 4-5 TU と PR(ANmax/TU)の関係 ......................................................... 75
図 4-6 ユーザ数 20,000 名でのアクセス分布予測 .......................................... 76
図 4-7 2 つのピークを持つアクセス分布 ........................................................ 78
図 4-8 防災訓練 ............................................................................................ 83
図 4-9 大分地震の分布とアクセス予測モデル................................................ 84
図 4-10 訓練時の分布とアクセス予測モデル ................................................. 85
図 4-11 アクセス予測に基づくオートスケーリング機構 ................................ 86
図 4-12 負荷分散 .......................................................................................... 87
図 4-13 安否報告アクセス数と CPU 使用率 .................................................. 91
図 4-14 災害データでの旧モデルと新モデルの比較 ....................................... 96
図 4-15 訓練データでの旧モデルと新モデルの比較 ....................................... 96
図 4-16 アクセスに対するサーバ数算出 ........................................................ 98
図 4-17 複数ピーク分布へのサーバ数算出 .................................................... 99
図 4-18 負荷分散評価構成 .......................................................................... 100
図 4-19 20,000 名ユーザでのオートスケーリング ........................................ 101
図 5-1 本研究の成果 ................................................................................... 106

vii
表 4-1 過去災害・訓練データ(2015 年) ....................................................... 73
表 4-2 スケールアウトのタイミング ............................................................. 88
表 4-3 インスタンスタイプ別 UnixBench 計測結果 ....................................... 89
表 4-4 過去災害・訓練データ(2015~2016 年) ............................................ 93
表 4-5 平常時のサーバ構成及び年間費用 .................................................... 104
表 4-6 各インスタンスタイプの稼働費用 .................................................... 104
表 4-7 (2),(3)の災害対処費用 .............................................................. 104

1
第1章 序論
1.1. 本研究の背景
地震や津波、台風、火山噴火など本国は多種多様な災害問題に直面している。
これら災害対策の施策において、2013 年から内閣官房が進める「国土強靭化計画
[1]」では、避難所や防波堤などの設備設置や、避難経路誘導および救援物資配分
など情報管理の対策などさまざまな耐災害のアプローチがある。情報管理での対
策のうち、被災者の安否情報を収集および共有する安否確認システムがある。災
害時の迅速な被災者安否情報の収集および共有は、その後の救助や復興速度向上
に寄与するため、効率的に安否情報を収集する仕組みが重要である。本研究で対
象とする安否確認システムはあらかじめシステムへ利用登録をしているユーザ間
の安否情報を扱うものである。ユーザは PC やスマートフォンなどから自身の安
否情報の報告や他社の安否情報の閲覧をおこなう。ユーザはこれら端末からアク
セスするため安否確認システムは Web システムを用いた実装が一般的であり、教
育機関や企業体、自治体などさまざまな組織での利用例がある。
安否確認システムは災害時に被災者の安否情報を扱うため、災害時に確実に稼
働することが求められる。旧来の安否確認システムには大学や企業構内のサーバ
にグローバル IP アドレスを付与し、インターネットに公開するオンプレミス型
があった。しかし、災害にてシステムを稼働するサーバが被害を受けるとシステ
ムが停止する恐れがあり、災害時に稼働を求められる安否確認システムの稼働環
境としては可用性の問題があった。そこで昨今の安否確認システムはシステムを
構成するサーバやストレージなどをクラウド・コンピューティング上で稼働する

2
手法が主流となった。クラウド上でこれら稼働環境をサービスとして提供するク
ラウドベンダは、災害対策や情報セキュリティ対策が一般の大学や企業と比較し
て強固であるため、安否確認システムの稼働基盤に適している。また、クラウド・
コンピューティングを用いる経営的なメリットとして、システムリソースを資産
として保持することなくクラウドベンダへアウトソースすることで、ハードウェ
ア費用、システム管理の人件費などの費用作成を可能とし収益性向上に寄与する。
しかし、安易なクラウドベンダへのシステム移管には課題がある。

3
1.2. 本研究の目的
安否確認システムにおける課題から本研究の目的を整理する。
1 つ目の課題は、状況如何に因らない稼働継続である。安否確認システムは災
害時においてユーザの安否情報の収集および共有を目的とするため、災害時は確
実に稼働しなければならない。システム稼働環境をオンプレミス型から強固な耐
災害施策がなされているクラウドへ移管することで災害時および平常時のシステ
ム可用性は向上する。しかし、東日本大震災クラスの災害では災害地域周辺のク
ラウドベンダのデータセンタ施設群が倒壊する恐れがあり、当該データセンタで
安否確認システムを稼働している場合、システム停止が懸念される。また、災害
や事故だけでなくクラウドベンダの経営観点の事業撤退や仕様変更などのシステ
ム停止はユーザの立場からは防ぐ手段がない。
2 つ目の課題は、アクセス状況に応じた適切なサーバ数での運用である。安否
確認システムの特性として平常時と災害時でのアクセス流量差がある。安否確認
システムは災害時にユーザから安否情報報告アクセスが集中するためである。つ
まり災害時は平常時と比較して多数のアクセス処理サーバが必要になる。仮に災
害発生に備え災害時のアクセスに対処可能なサーバ数で常時運用する場合、アク
セスが少ない平常時では過剰なサーバ数となり安否確認システムのような常時稼
働を求められるシステムでは費用面から困難な運用を強いられる。したがって余
分なサーバおよび費用を削減し、平常時と災害時のそれぞれの状況に応じたサー
バ数での運用が望ましい。
本研究の目的は、安否確認システムにおけるこれら 2 つの課題を解決するため
の機構の実現である。状況に因らない稼働継続については、安否確認システムを
構成する各サーバの世界規模での冗長化および複数の異なるクラウドベンダを用
い、単一クラウドベンダの障害に影響されないシステム構成を実装する。アクセ
ス状況に応じたサーバ数については、過去の災害および安否報告訓練でのアクセ
スログを基にアクセス分布傾向を解析し、災害発生後の経過時間によるアクセス
数を予測し、状況に応じた適切なサーバ数を算出する機構を実装する。
4
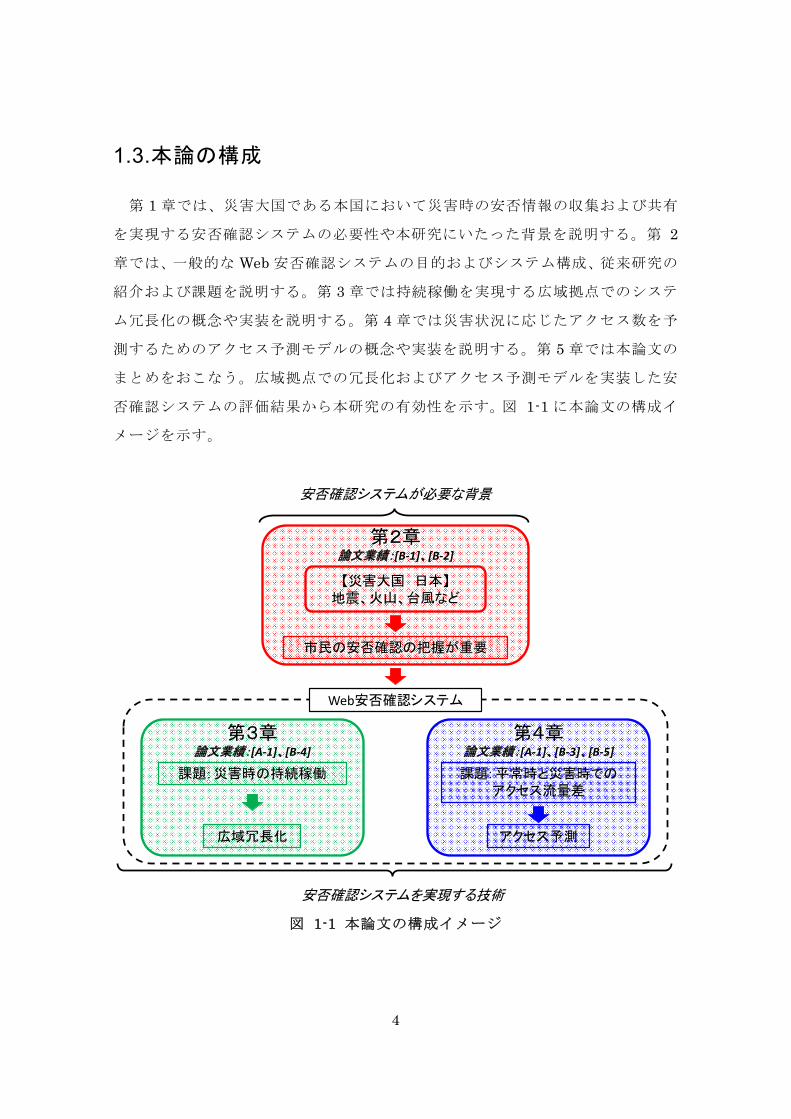
1.3. 本論の構成
第 1 章では、災害大国である本国において災害時の安否情報の収集および共有
を実現する安否確認システムの必要性や本研究にいたった背景を説明する。第 2
章では、一般的な Web 安否確認システムの目的およびシステム構成、従来研究の
紹介および課題を説明する。第 3 章では持続稼働を実現する広域拠点でのシステ
ム冗長化の概念や実装を説明する。第 4 章では災害状況に応じたアクセス数を予
測するためのアクセス予測モデルの概念や実装を説明する。第 5 章では本論文の
まとめをおこなう。広域拠点での冗長化およびアクセス予測モデルを実装した安
否確認システムの評価結果から本研究の有効性を示す。図 1-1 に本論文の構成イ
メージを示す。
図 1-1 本論文の構成イメージ
市民の安否確認の把握が重要
【災害大国 日本】地震、火山、台風など
課題:災害時の持続稼働
広域冗長化
課題:平常時と災害時でのアクセス流量差
アクセス予測
Web安否確認システム
第2章論文業績:[B-1]、[B-2]
安否確認システムが必要な背景
安否確認システムを実現する技術
第3章論文業績:[A-1]、[B-4]
第4章論文業績:[A-1]、[B-3]、[B-5]

5
第2章 安否確認システム
2.1. はじめに
本章では、本研究の対象となる Web を用いた安否確認システムの概要および、
課題や要件を示す。
安否確認システムが求められる背景として、災害多発国である本国の災害状況
を説明する。本国の災害状況を俯瞰すると世界の諸外国と比較して災害回数が多
い。なかでも被害状況が甚大であったいくつかの大災害の詳細状況において、災
害時における被災者の安否確認の必要性を BCP の観点から説明する。また、昨今
ではさまざまな安否確認システム関連の研究が発表されその必要性を説いている。
安否確認システムの関連研究では、情報収集関連や通信関連および Web システム
基盤関連などがあり、本研究では冗長化や負荷分散技術などの Web システム基盤
関連を対象とする。また、本研究では静岡大学安否確認システムを基としている。
静岡大学の安否確認システムは 2009 年 5 月から全学に導入し、約 7 年の運用を
経ている。災害発生時の自動メール送信や、学務/教務マスタデータベースとの
ユーザデータ自動連携など代表的な仕様を概説する。
安否確認システムに求められる要件として、災害時の確実な稼働が挙げられる。
安否確認システムは災害時に被災者の安否情報を共有するため、災害時にこそ確
実に稼働しなければならない。また、安否確認システムの特性である平常時と災
害時でのアクセス流量差に対するリソース管理問題がある。これら 2 つの課題に
対して、地理的に離れた複数地点でシステムを冗長化する広域冗長化技術と、災
害時のユーザアクセスを予測し適切なサーバリソースで運用するアクセス予測技
術を安否確認システムに実装する上での課題と要件をまとめる。
6
2.2. 背景
2.2.1. 本国の災害状況
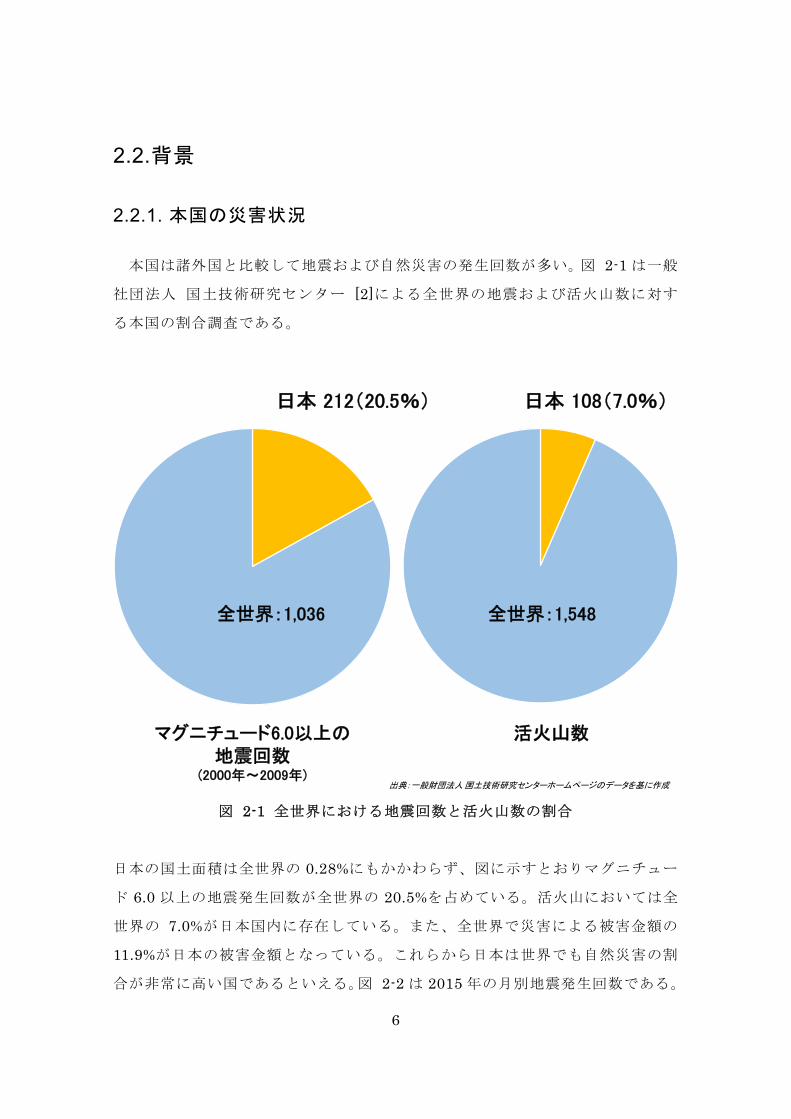
本国は諸外国と比較して地震および自然災害の発生回数が多い。図 2-1 は一般
社団法人 国土技術研究センター [2]による全世界の地震および活火山数に対す
る本国の割合調査である。
図 2-1 全世界における地震回数と活火山数の割合
日本の国土面積は全世界の 0.28%にもかかわらず、図に示すとおりマグニチュー
ド 6.0 以上の地震発生回数が全世界の 20.5%を占めている。活火山においては全
世界の 7.0%が日本国内に存在している。また、全世界で災害による被害金額の
11.9%が日本の被害金額となっている。これらから日本は世界でも自然災害の割
合が非常に高い国であるといえる。図 2-2 は 2015 年の月別地震発生回数である。
マグニチュード6.0以上の地震回数
(2000年~2009年)
全世界:1,036
日本 212(20.5%)
活火山数
日本 108(7.0%)
全世界:1,548
出典:一般財団法人 国土技術研究センターホームページのデータを基に作成

7
図 2-2 月別地震発生回数(2015 年)
震度 5 強以上の地震は 5 回であったが、震度 1 以上はひと月に 低でも 130 回以
上観測されており、ほぼ毎日国内のどこかで地震が発生している状況である。図
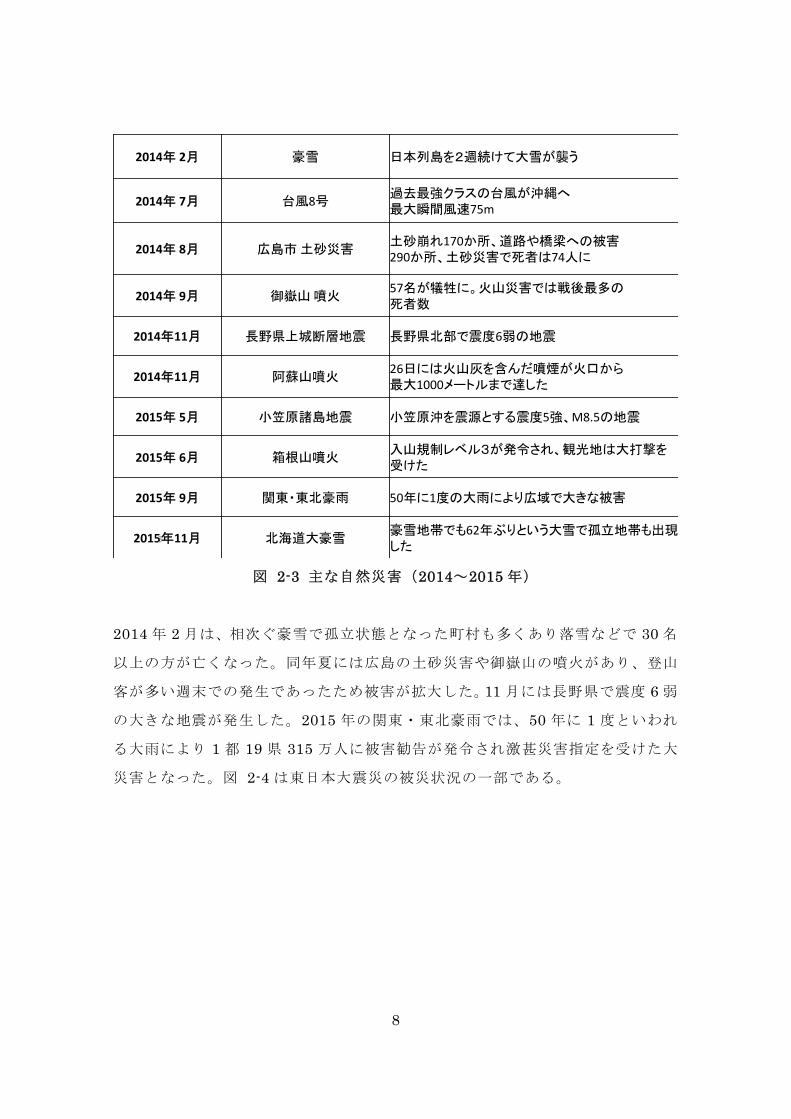
2-3 は 2014~2015 年の主要な自然災害である。
1月 2月 3月 4月 5月 6月 7月 8月 9月 10月 11月 12 月震度6強 0 0 0 0 0 0 0 0 0 0 0 0震度6弱 0 0 0 0 0 0 0 0 0 0 0 0震度5強 0 2 0 0 2 0 1 0 0 0 0 0震度5弱 0 0 0 0 2 1 1 0 1 0 0 0震度4 3 3 2 2 2 4 2 4 1 5 5 1震度3 13 8 17 8 10 10 11 23 11 12 13 13震度2 39 42 33 38 37 38 36 41 37 46 33 54震度1 94 100 90 85 107 107 84 97 80 106 113 111
0
20
40
60
80
100
120
140
160
180
200
2
8
図 2-3 主な自然災害(2014~2015 年)
2014 年 2 月は、相次ぐ豪雪で孤立状態となった町村も多くあり落雪などで 30 名
以上の方が亡くなった。同年夏には広島の土砂災害や御嶽山の噴火があり、登山
客が多い週末での発生であったため被害が拡大した。11 月には長野県で震度 6 弱
の大きな地震が発生した。2015 年の関東・東北豪雨では、50 年に 1 度といわれ
る大雨により 1 都 19 県 315 万人に被害勧告が発令され激甚災害指定を受けた大
災害となった。図 2-4 は東日本大震災の被災状況の一部である。
2014年 2月 豪雪 日本列島を2週続けて大雪が襲う
2014年 7月 台風8号過去最強クラスの台風が沖縄へ最大瞬間風速75m
2014年 8月 広島市 土砂災害土砂崩れ170か所、道路や橋梁への被害290か所、土砂災害で死者は74人に
2014年 9月 御嶽山 噴火57名が犠牲に。火山災害では戦後最多の死者数
2014年11月 長野県上城断層地震 長野県北部で震度6弱の地震
2014年11月 阿蘇山噴火26日には火山灰を含んだ噴煙が火口から最大1000メートルまで達した
2015年 5月 小笠原諸島地震 小笠原沖を震源とする震度5強、M8.5の地震
2015年 6月 箱根山噴火入山規制レベル3が発令され、観光地は大打撃を受けた
2015年 9月 関東・東北豪雨 50年に1度の大雨により広域で大きな被害
2015年11月 北海道大豪雪豪雪地帯でも62年ぶりという大雪で孤立地帯も出現した
3

9
図 2-4 東日本大震災の被災状況
日本国内観測史上 大(世界 4 位)のマグニチュード 9.0(震源深さ約 24km)、
震度 7 を記録し、死者・行方不明者の合計は 2 万名を超えた。発生後、マグニチ
ュード 7 級の余震が連続して生じ、岩手、宮城、福島県の各地区で壊滅的な被害
を被った。東京都内においても震度 5 強を観測した地点もあり災害範囲は非常に
広域であった。地震に伴い波高 10m 以上 大遡上高 43.3m にもおよぶ巨大な津
波が発生し、北海道から関東の太平洋沿岸へ押し寄せ、漁船、港湾施設、さらに
住宅地や農地をのみ込み壊滅的な被害をもたらした。図 2-5 は内閣府 平成 23 年
度版防災白書 [3]での平成元年移行の自然災害での死者・行方不明者数の調査で
ある。

10
図 2-5 災害時の死者・行方不明者数
平成 7 年の阪神・淡路大震災では 6,437 名、平成 23 年の東日本大震災では 23,000
名を超える多くの死者・行方不明者となった。東日本大震災では 2016 年 11 月 10
現在で 2,557 名の方が行方不明であり、捜索活動が引き続きおこなわれている。
このように多くの自然災害が発生しており、大災害に対する防災対策や避難対
応など対災害対策が急務である。特に災害直後の被災者安否情報の取集は、被災
者の救助活動を迅速化し行方不明者低減が期待できるため重要である。
2.2.2. 安否確認の必要性
災害時の迅速な救助および普及活動を援護する安否確認が重要である。また、
企業組織の事業継続においても安否確認は重要な意味をはたす。災害発生後の企
業活動を継続するための計画 BCP において、企業体を構成する組織人員の安否
確認は BCP の初動活動における重要項目である。BCP は、企業が災害などの緊
急事態に陥った際にそこで被る被害を 小限におさえつつ、中核のビジネスの継
時期 災害名 被災地 死者・行方不明者
H2,11/17 雲仙岳噴火 長崎県 44名
H5,7/12 北海道南西沖地震(M7.8) 北海道 230名
H5,7.31-8/7 豪雨 全国 79名
H7,1/17 阪神・淡路大震災(M7.3) 兵庫県 6,437名
H12,3/31-H13,6/28
有珠山噴火 北海道 -
H12,6/25-H17,3/31
三宅島噴火及び新島・神津島近海地震 東京都 1名
H16,10/20-21 台風23号 全国 98名
H16,10/23 H16年新潟県中越地震(M6.8) 新潟県 68名
H17,12-H18,3 豪雪 北陸地方を中心とする日本海側
152名
H19,7/16 H19年新潟県中越沖地震(M6.8) 新潟県 15名
H20,6/14 H20年岩手・宮城内陸地震(M7.2) 東北(特に宮城、岩手)
23名
H22,12-H23,3 雪害 北日本~西日本にかけての日本海側
128名
H23,3/11 東日本大震災 東日本(特に宮城、岩手、福島)
死者15,270名行方不明者8,499名
出典:一般財団法人 国土技術研究センターホームページのデータを基に作成

11
続および早急に業務活動を復旧するために日頃おこなう活動や緊急時の行動をま
とめた計画を指す。東京都では「東京都帰宅困難者対策条例(平成 25 年 4 月 1 日
施行 [4]」において、企業間および家族間での連絡手段確保の事前準備を求めて
いる。また経済産業省での「事業継続計画策定ガイドライン [5]」では、安否確認
実施手順の制定化を求めており、これら施策から BCP における初動対策として
の安否確認の重要性がうかがえる。図 2-6 は中小企業庁 BCP 策定運用方針 [6]
が定める救急時における BCP の発動フローである。
図 2-6 緊急時における BCP 発動フロー
はじめに、緊急事態が発生した際、初動対応をおこなう。そして速やかに顧客や
協力会社へ被災状況を連絡するとともに中核ビジネスの継続方針を立案し、その
実施体制を確立する。その体制に基づき、顧客や協力会社向け対策、従業員や事
業資源対策および財務対策を並行して実施し、復興作業を進める。このフローの
とおり従業員の安否確認は BCP の初動対応として重要であり、安否確認なくし
緊
急
事
態
当 日
顧客・協力会社への連絡
中核事業継続方針立案・体制確立
顧客・協力会社向け対策
従業員・事業
資源対策
財務対策
災害復興
数 日 ~ 数 か 月
地 域 貢 献 活 動
二次災害の防止措置
従業員の参集
安否・被害状況の把握
初動対応
出典:中小企業庁 中小企業BCP策定運用指針ホームページのデータを基に作成

12
て事業継続活動は困難であるといえる。
また、安否確認は災害時の状況によりさまざまなケースが考えられる。図 2-7
はここ直近の災害時の発生日、時間、状況推測である。
図 2-7 災害発生日の時間および状況
阪神淡路大震災の発生時刻は早朝であることから被災者は自宅で就寝中の可能性
が高い時間帯である。まだ多くの被災者は登校や出社しておらず口頭点呼での安
否確認はできないため、何かしらのツールを使用して安否確認をしなければいけ
ない災害である。新潟県中越地震の発生時刻は土曜日の夕方であることから学校
や会社は休日が多くプライベートの時間を過ごしている可能性が高い時間帯であ
る。駿河湾地震の発生時刻はお盆休み期間であったため帰省や旅行中の被災者が
多いと考えられる。さいごに東日本大震災は平日の日中のため勤務中や授業中で
ある可能性が高い。このようにさまざまな時刻や状況で災害が発生するため、ど
のようなケースにおいてもスムーズな安否確認が可能であることがのぞましい。
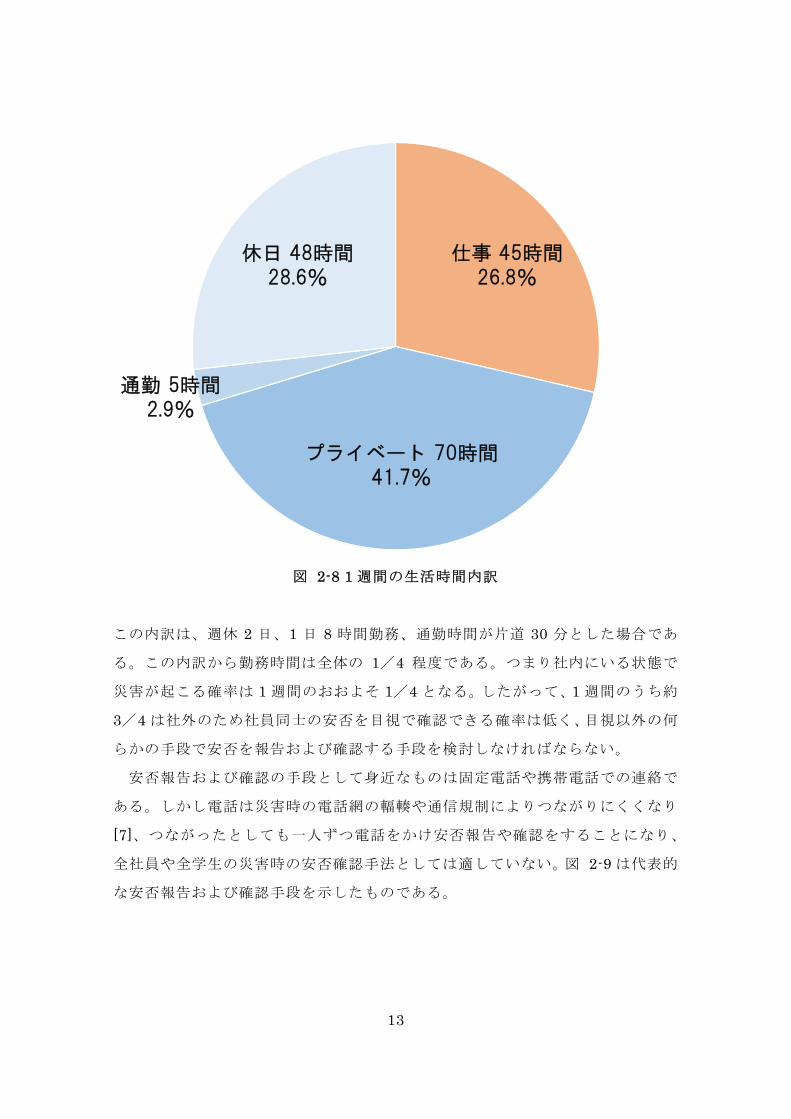
つぎに一般的な社会人の 1 週間の生活時間内訳を図 2-8 のように想定する。
地震 震度 発生日 時間 状況推測
阪神淡路大震災 7 1995年1月17日(火) 05:46 早朝、自宅で就寝中
新潟県中越地震 7 2004年10月23日(土) 17:56 休日の夕方、自宅で過ごしていたりプライベートでの外出
駿河湾地震 6弱 2009年8月11日(火) 05:07 お盆時期の帰省中や旅行中
東日本大震災 7 2011年3月11日(金) 14:45 勤務中、社内または仕事での外出中や出張中
13
図 2-8 1 週間の生活時間内訳
この内訳は、週休 2 日、1 日 8 時間勤務、通勤時間が片道 30 分とした場合であ
る。この内訳から勤務時間は全体の 1/4 程度である。つまり社内にいる状態で
災害が起こる確率は 1 週間のおおよそ 1/4 となる。したがって、1 週間のうち約
3/4 は社外のため社員同士の安否を目視で確認できる確率は低く、目視以外の何
らかの手段で安否を報告および確認する手段を検討しなければならない。
安否報告および確認の手段として身近なものは固定電話や携帯電話での連絡で
ある。しかし電話は災害時の電話網の輻輳や通信規制によりつながりにくくなり
[7]、つながったとしても一人ずつ電話をかけ安否報告や確認をすることになり、
全社員や全学生の災害時の安否確認手法としては適していない。図 2-9 は代表的
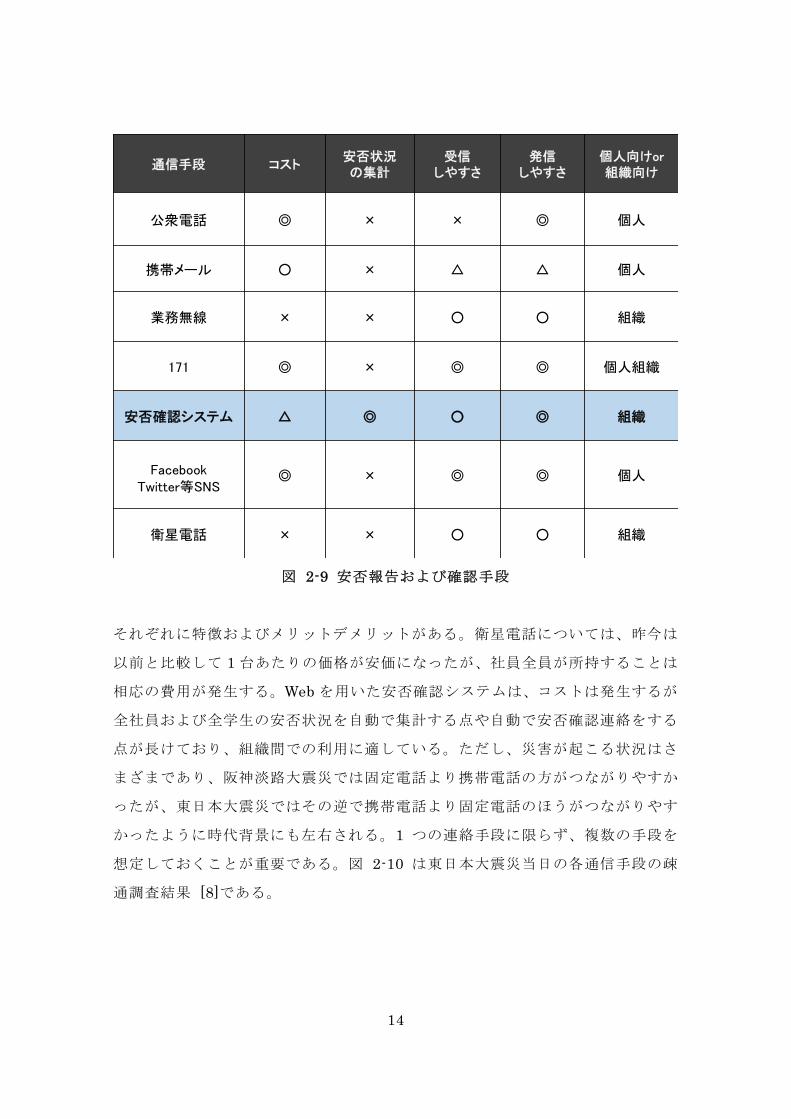
な安否報告および確認手段を示したものである。
仕事 45時間26.8%
通勤 5時間2.9%
プライベート 70時間41.7%
休日 48時間28.6%
14
図 2-9 安否報告および確認手段
それぞれに特徴およびメリットデメリットがある。衛星電話については、昨今は
以前と比較して 1 台あたりの価格が安価になったが、社員全員が所持することは
相応の費用が発生する。Web を用いた安否確認システムは、コストは発生するが
全社員および全学生の安否状況を自動で集計する点や自動で安否確認連絡をする
点が長けており、組織間での利用に適している。ただし、災害が起こる状況はさ
まざまであり、阪神淡路大震災では固定電話より携帯電話の方がつながりやすか
ったが、東日本大震災ではその逆で携帯電話より固定電話のほうがつながりやす
かったように時代背景にも左右される。1 つの連絡手段に限らず、複数の手段を
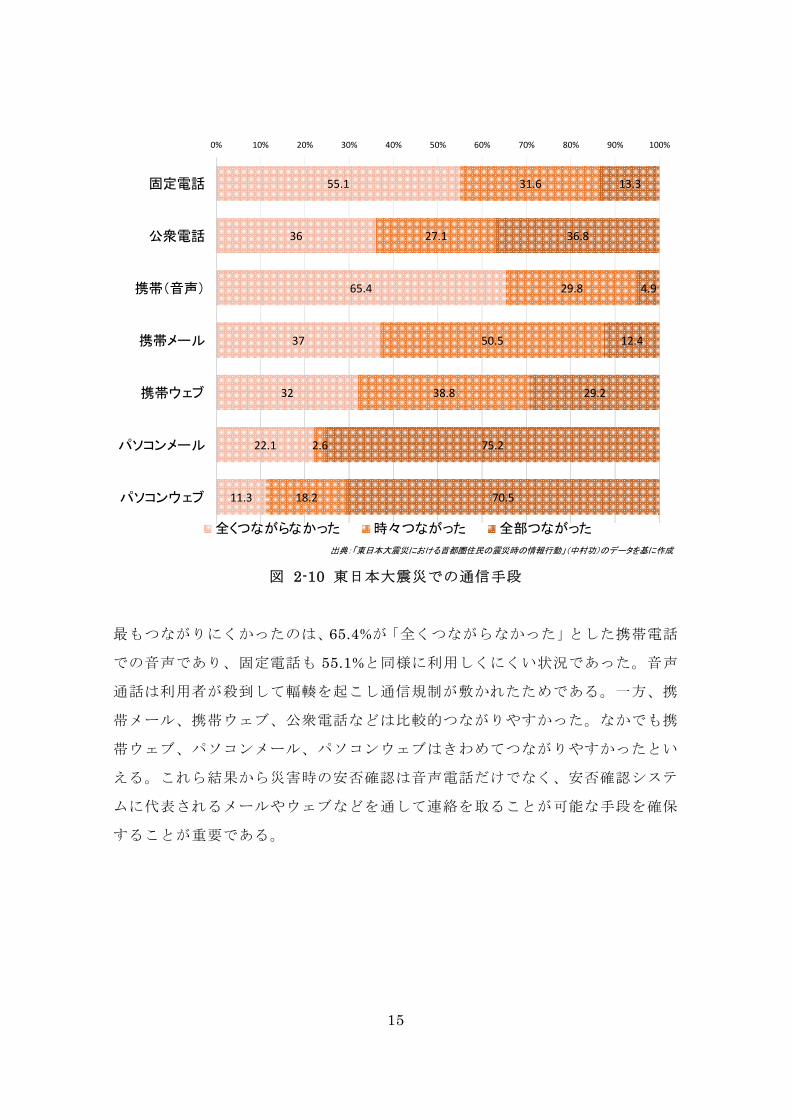
想定しておくことが重要である。図 2-10 は東日本大震災当日の各通信手段の疎
通調査結果 [8]である。
通信手段 コスト安否状況の集計
受信しやすさ
発信しやすさ
個人向けor組織向け
公衆電話 ◎ × × ◎ 個人
携帯メール ○ × △ △ 個人
業務無線 × × ○ ○ 組織
171 ◎ × ◎ ◎ 個人組織
安否確認システム △ ◎ ○ ◎ 組織
FacebookTwitter等SNS
◎ × ◎ ◎ 個人
衛星電話 × × ○ ○ 組織
15
図 2-10 東日本大震災での通信手段
もつながりにくかったのは、65.4%が「全くつながらなかった」とした携帯電話
での音声であり、固定電話も 55.1%と同様に利用しくにくい状況であった。音声
通話は利用者が殺到して輻輳を起こし通信規制が敷かれたためである。一方、携
帯メール、携帯ウェブ、公衆電話などは比較的つながりやすかった。なかでも携
帯ウェブ、パソコンメール、パソコンウェブはきわめてつながりやすかったとい
える。これら結果から災害時の安否確認は音声電話だけでなく、安否確認システ
ムに代表されるメールやウェブなどを通して連絡を取ることが可能な手段を確保
することが重要である。
55.1
36
65.4
37
32
22.1
11.3
31.6
27.1
29.8
50.5
38.8
2.6
18.2
13.3
36.8
4.9
12.4
29.2
75.2
70.5
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
固定電話
公衆電話
携帯(音声)
携帯メール
携帯ウェブ
パソコンメール
パソコンウェブ
全くつながらなかった 時々つながった 全部つながった
出典:「東日本大震災における首都圏住民の震災時の情報行動」(中村功)のデータを基に作成

16
2.3. 安否確認システムとは
安否確認システムとは災害(本研究では地震とする)時に、あらかじめシステ
ムに登録済みの対象ユーザの安否情報を収集および公開する Web システムであ
る。緊急連絡網などを用いた安否確認手法に対して、Web を用いた安否確認シス
テムは迅速かつ効率的に安否情報を収集可能であり、安否情報未確認ユーザを絞
り込み、未確認ユーザに対して再確認や救助活動などいち早く次策を講じるため
の早期の安否情報収集を目的としている。災害時の被災状況や被災者の安否情報
を公開する安否確認システムは、家族および組織間での安否確認や災害後の復旧
活動の迅速化など、災害情報を多数の関係者に公開する仕組みとして Web システ
ムでの実装が適している [9] [10]。一般的な安否確認システムの動作仕様は、災
害発生時にシステムがユーザへ安否報告を促がすメールを送信し、ユーザは受信
したメールに返信やメールに記載された安否確認システムへの URL などから自
身の安否情報を登録・公開しユーザ間で安否情報を共有するものである。
動作フローは図 2-11 となる。まず気象情報を電文形式で公開するサービス(た
とえば [11]。以下、気象情報提供サービス)から災害発生を安否確認システムが
取得する。つぎに安否確認からユーザへ安否報告を促がすメールを送信する。つ
ぎにユーザは安否確認システムに対して安否報告をする。さいごにユーザ間で安
否情報を共有する。

17
図 2-11 安否確認システムの動作フロー

18
2.4. 従来研究
安否確認システムの関連研究には、図 2-12 に示すように、情報収集、通信、
Web システムなどさまざまな分野の研究が関係する。本研究では稼働継続のため
の冗長化、アクセス予測を基にした負荷分散など Web システム基盤を対象とす
る。また、市場でサービスされている安否確認システムには、避難場所や救援物
資、災害場所の画像などさまざまな情報を扱うものもあるが、本研究の安否確認
システムは安否情報のみを扱うものとする。
図 2-12 安否確認システム関連研究
災害時には、地震や火災などによる物理的な通信施設や電源施設の倒壊および
被災者間での連絡や安否情報共有のために固定電話や携帯電話の利用が集中する
ことによる輻輳状態などの諸問題 [12] [13] [14]がある。このような問題に対し
て通信手段を確保する仕組みとして情報通信関連の研究では、ワンセグ放送 [15]
を用いた災害時の安否情報配信がある。ワンセグ放送はカルーセル伝送方式のデ
安否確認システム
Web DB
情報収集
・DTN
・QRコード
情報収集 情報収集
・無線
・ワンセグ
通信
情報収集
・冗長化
・負荷分散
WEBシステム基盤
本研究対象

19
ータ放送に対応しているため、ネットワーク輻輳を発生せずにデータ伝送を可能
とする。ワンセグのデータ放送帯域を用いることでネットワーク輻輳の回避を実
現している。自律的無線ネットワーク [16]を用いた通信システムの提案では、災
害時の確実な通信手段を実現するため、無線ネットワークを構成する無線基地局
の配置に対して被災状況や立地条件などの判断を加味したアルゴリズムを提案し
ている。提案アルゴリズムにより災害発生時の影響を極力受けない十分な耐震強
度を有する建物を無線基地局とすることで災害時の確実な通信手段を実現し有効
性を示している。AODV プロトコルを用いたスマートフォン間通信の提案 [17]
では、ネットワークインフラ施設の倒壊や通信量制限が敷かれている場合の通信
不能の際に、ノード間通信を用いてワイヤレスセンサネットワーク網へ接続し、
確実な安否情報伝達を可能としている。P2P 通信を用いた提案 [18] [19]では、対
等関係のノードをリングトポロジのネットワークとして構築し、ネットワークの
切断や電源障害などによりリングから離脱した場合においても別ノードによりネ
ットワークの存続を維持し、安否情報の流通を可能としている。
情報収集関連の研究では、遅延耐性ネットワーク(Delay Tolerant Networking:
DTN)を用いたすれ違い通信にて安否情報をユーザ間で中継し 終的にソーシャ
ル・ネットワーキング・サービス(SNS)へ登録する提案 [20]や、QR コードを
用いた安否情報の収集 [21]では、収集後の情報管理までを含んだ情報マネージメ
ントシステムの構築を行い利便性の高い安否情報管理を実現している。被災者避
難施設での被災者情報収集システムの提案 [22]では、地方自治体などの各行政機
関が設立する被災者施設間で相互に被災者情報を収集および共有するものである。
被災者情報の登録には社会保障番号を付与した IC カードを用いて個人を特定し、
また情報入力はキーボードを用いず IC カードをカードリーダへかざすだけでお
こない、ICT 機器の扱いに不慣れな子供や高齢者への配慮がなされている。 [23]
では、災害時の情報伝達の機能的障害発見手法を構築し、その手法を用いて情報
伝達の機能的障害を検知し対策することで、災害対応業務をおこなう防災担当者
が被災者に対して必要な情報収集や伝達が確実におこなわれる仕組みを提案して
いる。災害時の安否確認に対して被災者のライフログ情報を活用したシステム
[24]では、あらかじめライフログを収集するスマートフォンアプリケーションを
端末にインストールしておき、平常時から位置情報や行動情報、SNS 投稿、他操

20
作ログなどのライフログをサーバへ蓄積し、災害時に安否確認が困難な状況にお
いてもサーバに蓄積したライフログから直前の行動を取得し、安否情報の手がか
りとなる情報を迅速に収集することが可能となる。 [25]では、被災地の動画や静
止画を、Web システムを介して共有するシステムである。災害時において大規模
な被害を被った箇所以外では TV 報道が継続されることは少ないが、報道されて
いない箇所においても救助活動を迅速におこなうために被害状況を視覚的に把握
する必要がある。本提案では動画および静止画を Web システムにアップロードす
る小型 PC 端末に太陽光での電力を用い、わずかな電力で長期間にわたって被災
地の状況を視覚的に収集可能としている。 [26]では、電力や通信インフラ断絶時
に強い被災者や避難所の詳細な状況を管理する被災者管理システムの提案である。
既存の被災者管理システムには被災者情報入力が細部までできないことや、IC 機
器を用いるための電力や通信インフラに依存した稼働の課題があった。本提案で
は詳細な被災者管理情報を保持可能とし、太陽光発電した電気の充電および家庭
用コンセントから直接充電可能なバッテリユニットを用いて長期間運用を可能と
している。また避難所における被災者の入退場管理に被災者個人の Suica カード
や T カードなどの一般的な NFC(Near Filed Communication)カードを用いて、
入力作業を簡略化している。これら通信および情報収集関連の研究においても情
報管理には一般的に Web システムが用いられているため、災害時の総合的な安否
情報管理には Web システムの持続稼働が重要となる。
Web システム基盤関連の研究では [27] [28]、災害時にシステムのロバストネ
ス向上を目的とし、複数サーバを用いたミラーリングでの冗長化や、DNS ラウン
ドロビンやリダイレクトでのアクセス先振り分けを用いた複数サーバでの負荷分
散の提案がある。しかし冗長化は国内での実装および評価に留まっており東日本
大震災規模の災害ではシステム持続稼働が課題となる。負荷分散は複数サーバを
用いている点は本研究においても同じ立場を取るが、平常時および災害時を問わ
ず常時複数サーバでの構成のため、平常時でのサーバ費用や余剰リソースが課題
となる。 [29]は、従来ではオンプレミス環境で運用していた安否確認システムを
クラウドへリプレースする提案である。クラウドへのリプレースは、オンプレミ
ス環境での災害時の持続稼働の懸念に対して、システム稼働基盤をクラウド環境
とすることで可用性の向上を実現している。このように災害時の持続稼働を要求

21
される安否確認システムは、可用性向上を目的として Web システムをオンプレミ
スでなくクラウド環境下で運用することが必須といえる。
安否情報およびユーザ情報などのデータ管理では、昨今の一般的な安否確認シ
ステムはリレーショナルデータベース(Relational Database:RDB)を用いたデ
ータ管理が多い [30] [31]。理由は、ユーザの安否情報や所属部署・学部などの管
理に対して、ユーザ ID などをキーとした各属性情報の Create、Read、Update、
Delete(CRUD)操作が容易なためである。しかしシステムのアクセスログをみ
ると、氏名や所属部署・学部などのユーザ個人の属性情報への変更や更新アクセ
スは通常ほぼない。多頻度でアクセスされる情報は災害時の安否報告である。つ
まり災害時にはユーザの安否情報を更新するため Update 操作にて相当数の安否
報告アクセスが、マスター/スレーブ構成のうちマスター側 DB に集中する。RDB
には Update アクセスを分散するハッシュ関数を用いたシャーディング技術があ
るが、データ規模拡大にともない ID 採番に変更を加える場合やデータ検索の複
雑化など、必ずしも利点ばかりではない。また、一般的に RDB は CAP 定理のう
ち分断耐性(Partition-tolerance)に弱く、分散システムに向かない特性がある。
これら安否確認システムのデータ管理特性に対して、書き込みに優れかつ分散デ
ータ管理が可能な構成が望ましい。

22
2.5. 静岡大学の安否確認システム
本研究の基となった静岡大学の安否確認システムを概説する。静岡大学では
2009 年 5 月から全学に導入し、約 7 年の運用を経ている。システム構成は図 2-13
となる。Web、DB サーバを用いた一般的な Web 安否確認システムが有する仕様
と同等な機能仕様を実装している。
図 2-13 静岡大学安否確認システム構成
静岡大学の安否確認システムも多くの安否確認システムと同様、システムは PC
やスマートフォンなどのクライアント端末から安否情報登録および閲覧のリクエ
ストを受け、Web サーバが DB サーバに登録されているユーザ情報を、PHP や
CGI などを経由して取得し、安否情報を html としてクライアント端末へ返すも
のである。
代表的な機能仕様は以下となる。
Form CGI
Write CGI
DBサーバ
Read CGI
データベース
WebサーバClient
書き込み
読み込み
insert
select

23
1) Web サーバと DB サーバを Amazon Web Service(AWS) [32]EC2 [33]上に
実装
2) 別システム(たとえば認証システム)と連携しない単独稼働
3) 気象情報提供サービスの災害情報を 5 分毎に監視し災害発生時に自動でシス
テムからユーザへ安否報告促進メール配信
4) 災害発生時に安否確認システムから送付される安否報告促進メールにログイ
ン情報を含んだユーザアカウントデータを基にしたランダムキー付きの
URL を添付し認証処理を省略(通常のユーザ ID と PW でログインも可能)
5) 教育機関に散見される複雑な組織構成を吸収した無制限組織階層機能
6) ユーザのメールアドレス登録有無のみを表示し、メールアドレス自体は非表
示
7) メールアドレスを持たないユーザへの代理安否情報入力
8) メール送信ユーザの属性別あて先絞り込み送信
9) Web 掲示板、アンケート収集機能
10) 学生および教職員の属性データを管理する学務/教務マスタデータベースと
の自動連携機能
1)は、安否確認システムを稼働するサーバを日本国内に設置するのではなく、海
外クラウドサーバを利用することで国内災害による情報インフラの被災状況に依
存することなく安定稼働を実現する。また強固な耐災害対策がなされたクラウド
ベンダを理由することオンプレミスでの構築と比較して可用性も向上する。2)は、
学内の認証システムと安否確認システムの認証を統合せず、安否確認システム単
独でユーザ認証をおこなうものである。静岡大学は国立情報学研究所 [34]が推進
する「学術認証フェデレーション(学認) [35]」に参加している。静岡大学の主
要システム(たとえば学務システム)間は学認に参加している静岡大学の認証サ
ーバに登録された静大 ID で相互にシングルサインオン(SSO)が可能である。安
否確認システムのユーザ ID を静大 ID と統合することで安否確認システムや他
主要システムとの SSO が可能となるが、SSO は静岡大学が保持する国内の認証
基盤を介しておこなうため認証基盤が災害で被災した場合は、安否確認システム
へログインができない懸念がある。このため災害時での稼働を求められる安否確

24
認システムは他システムの影響での停止を回避する設計にしなければならない。
3)は、気象情報提供サービスの RSS などから災害情報を構文解析し、ユーザがシ
ステムに登録した災害情報と発生災害がマッチした場合、自動で安否確認システ
ムがユーザへ安否報告促進メールを送信するものである。災害時にシステムの管
理ユーザが手動でメール送信をすることも可能だが、災害の混乱時ではさまざま
な理由で手動対応が困難である場合が多い。本機能はそれら対応をシステムが自
動でおこなうことでユーザ負担の軽減や作業失念を回避する。4)は、安否報告促
進メールの本文中にユーザ ID や他ユーザ属性情報を基にしたランダムキーを生
成しその値をユーザ毎に独立した安否確認システムへのアクセス URL に埋め込
むことで、アクセス URL 自体にログイン認証を含み、ユーザ ID およびパスワー
ド入力を省略し迅速な安否報告を実現する。安否確認システムは平常時の利用が
少なくシステムへのアクセスも少ないため、ユーザは ID やパスワードを失念し
ている恐れがある。この問題を回避するためにログイン認証付き URL を用いて、
ワンクリックでシステムのアクセスを実現する。5)は、複雑な組織構造を吸収す
る柔軟かつ無制限組織階層機能を用いた組織およびグループ管理である。大学お
よび教育機関ではある部局の担当者が別部局の担当を兼任するなど部署および部
局間をまたぐ複雑な組織構造となる場合がある。このような構造の場合、A 部局
と B 部署に兼務するユーザをそれぞれの部局で安否情報の収集をおこなう際、収
集結果が重複または欠落する恐れがある。このような課題を図 2-14 に示すよう
「兼務機能」や「グループ機能」を用いて収集結果に誤りがないよう組織構成を
可能とする。
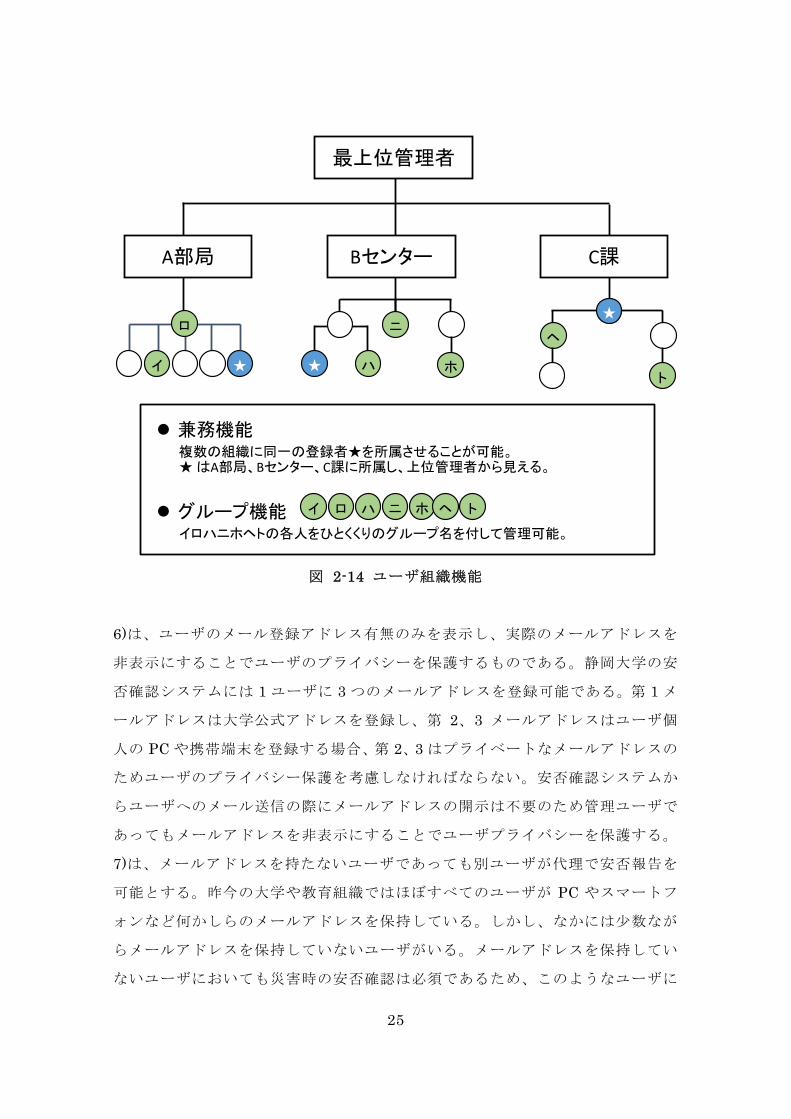
25
図 2-14 ユーザ組織機能
6)は、ユーザのメール登録アドレス有無のみを表示し、実際のメールアドレスを
非表示にすることでユーザのプライバシーを保護するものである。静岡大学の安
否確認システムには 1 ユーザに 3 つのメールアドレスを登録可能である。第 1 メ
ールアドレスは大学公式アドレスを登録し、第 2、3 メールアドレスはユーザ個
人の PC や携帯端末を登録する場合、第 2、3 はプライベートなメールアドレスの
ためユーザのプライバシー保護を考慮しなければならない。安否確認システムか
らユーザへのメール送信の際にメールアドレスの開示は不要のため管理ユーザで
あってもメールアドレスを非表示にすることでユーザプライバシーを保護する。
7)は、メールアドレスを持たないユーザであっても別ユーザが代理で安否報告を
可能とする。昨今の大学や教育組織ではほぼすべてのユーザが PC やスマートフ
ォンなど何かしらのメールアドレスを保持している。しかし、なかには少数なが
らメールアドレスを保持していないユーザがいる。メールアドレスを保持してい
ないユーザにおいても災害時の安否確認は必須であるため、このようなユーザに
兼務機能複数の組織に同一の登録者★を所属させることが可能。★ はA部局、Bセンター、C課に所属し、上位管理者から見える。
グループ機能イロハニホヘトの各人をひとくくりのグループ名を付して管理可能。
ニイ ハ ホロ ヘ ト
最上位管理者
A部局 Bセンター C課
★ ★
ニ
イ ハ ホ
ロ★
ヘ
ト

26
対しては別ユーザが代理で安否報告をする。別ユーザの代理報告の場合は、代理
報告を示すステータスが付与されるため管理ユーザは自発的な安否報告か代理報
告かを判別可能である。8)は、管理ユーザがシステムから手動で再度メール送信
をおこなう際、ユーザの安否確認状況に応じて宛先を自動で絞り込むものである。
災害発生後、気象情報提供サービスの情報を基にして安否確認システムは自動で
安否報告促進メールを送付し、受信したユーザは自身の安否情報を報告する。そ
の際ユーザは安否情報に「無事」や「軽症」などステータスを付与する。絞り込
みメール送信は、たとえばまだ安否報告がなされていないユーザを絞り込み再度
安否報告を催促したり、「軽症」ユーザを全ユーザから抽出しその症状をヒアリ
ングするなどの用途に用いる。9)は、通常の Web 掲示板と同様の機能である。用
途としては管理ユーザが避難場所を指示する際、Web 掲示板に避難経路や避難場
所の情報を投稿しユーザが閲覧する。アンケート収集機能は、安否報告促進メー
ルと同様にユーザへ何かしらの回答を求めるアンケートメールを送信し、受信し
たユーザは安否報告と同様の手順でそのアンケートに回答し、管理ユーザが集計
するものである。たとえば災害の用途とは異なるが学内会議の出欠連絡などに用
いることができる。10)は、学生および教職員の属性データを保持するマスタデー
タベースと安否確認システムのユーザ属性データのデータベースを自動で同期す
る仕組みである。大学および教育機関では毎年 3 月、4 月に大規模な人員移動が
ある。静岡大学では 1 学年が約 2,000 名であり、毎年 2,000 名の卒業生および新
入生の更新がある。このような大規模な人員移動時にマスタデータベースと安否
確認システムのデータベースを手動でメンテナンスすることは相応の手間が発生
し、また更新ミスが懸念される。この問題を解決するために、図 2-15 に示すよ
うに大学のマスタデータベースのデータを定期的に抽出し安否確認システムのデ
ータベースに自動的に同期する仕組みを実装した。静岡大学では毎朝 4:00 に同期
を実行する。

27
図 2-15 マスタデータベース自動連携
マスタデータベースから安否確認システムへのマスタデータ同期の際に、データ
変換サーバを介することでマスタデータベースへは一切アクセスせず、マスタデ
ータの機密性を担保している。

28
2.6. 要件と課題
2.6.1. 安否確認システムに求められる要件
安否確認システムには災害時に確実な稼働が要求される。東日本大震災のよう
な深刻な被害を出した災害では早期の被災者安否の収集および公開が多数の人命
救助につながるため [36]、安否情報を収集および公開する安否確認システムの停
止は避けなければならず災害時に途絶することなくシステムを稼働し続けること
が重要である [37]。昨今の安否確認システムはクラウド・コンピューティングを
利用した実装が主流であり、スケーラブルな基盤上での冗長化や負荷分散技術を
用いて持続可能なサービスを実現している。運用面ではサーバ、スイッチなどの
ハードウェアを資産として保持せずクラウド上へアウトソースすることで、経営
資源、人件費などの費用削減を可能とし収益性向上に寄与する。しかし安否確認
システムを既存のクラウド環境上で運用する場合、2 つの課題がある。
1 つ目の課題は状況如何に因らない稼働継続を実現するための冗長化運用であ
る。安否確認システムは災害時においてユーザの安否情報の収集および公開を目
的とするため、災害時は確実に稼働し続けなければならない。東日本大震災のよ
うな大規模災害では災害地域周辺のデータセンタ施設群が倒壊する恐れがあり、
災害地域のデータセンタで安否確認システムを稼働している場合、システム停止
が懸念される。つまり一地域・一大陸内での冗長化対策では大規模災害時のシス
テム停止リスクを回避できない。また、地域や大陸間をまたぐシステム構成とし
た場合、物理的な冗長性は向上するがこの構成を単一クラウドベンダでのみの実
装とした場合は懸念がある。昨今のクラウドベンダは強固な耐災害施策により自
然災害には強い耐性を持つ。しかし事業撤退など経営面でのシステム停止はユー
ザの立場からは防ぐ手段はない。つまり物理的にシステムを分散配置するだけで
なく、システムを構成するリソースを単一のベンダでなく複数の異なるベンダ間
で構成し、経営面やベンダ固有の障害を回避する構成が重要である。また、多地
点での冗長化であるためシステムデータの分散管理も必要になる。安否確認シス
テムは無停止稼働を求められるため、災害やその他の影響でシステムを構成する
サーバが停止した際、別サーバでの代替運用を可能とする分断耐性に強いデータ

29
管理機構が必要である。2 つ目の課題はアクセス状況に応じた適切なサーバ数で
の運用である。安否確認システムは平常時と災害時でシステムへのアクセス流量
差がある。これは、安否確認システムは災害時にユーザからの安否報告や安否情
報公開リクエストが集中するためであり、また、災害時は平常時と比較すると多
数のアクセス処理サーバが必要になる。仮に災害発生に備え災害時のアクセスに
対処可能なサーバ数で常時運用する場合、アクセスが少ない平常時では過剰リソ
ースとなり安否確認システムのように常時稼働を求められるサービスでは費用面
から困難な運用を強いられる。
2.6.2. 課題:広域冗長化
安否確認システムを停止せずに持続稼働を実現するための課題として、複数の
広域拠点に単一クラウドベンダでなく複数クラウドベンダを用いたインタークラ
ウド構成と、複数サーバにデータを分散配置するデータ管理があげられる。
安否確認システムに限らず Web システムは複数のサーバで構成することが多
い。それぞれのサーバを冗長化し可用性を向上する手法は従来からおこなわれて
きた。しかし多くは単一ベンダ内での冗長化および可用性向上対策であり、通常
災害では効果を発揮しても大規模災害や災害以外での対策としては万全とは言い
難い。その理由は、単一ベンダのみの実装では当該ベンダの経営面や他都合での
サービス停止の可能性を無視できないことに起因する。つまりいかなる状況にお
いても確実な稼働を要求される安否確認システムは一地域でなく多地域および複
数ベンダを連携したインタークラウド構成での広域冗長化が必要となる。
インタークラウド構成を用いることは必然的に分散システムでの実装となる。
RDB は分断耐性に弱く分散システムには不向きであるため、複数サーバが連携す
る分散データ管理に適しているデータベースシステムが望まれる。分散データ管
理では、システムを構成する各ノード間でのデータ同期および障害などであるノ
ードが停止した際でも持続稼働が可能なことが必須である。また災害時は多数の
安否報告アクセスがなされるため、分散データ管理だけでなく Update(書き込
み)特性に優れた機構が理想的である。
AWS や Microsoft Azure [38]に代表されるクラウドベンダは、世界各地にデー
タセンタを有しており広域冗長化を実現するシステム基盤として適している。し

30
かし現状の各サービスは主に同一の地域(以下、リージョン)内での提供が主流
であり、システムを複数地域に跨ぐ構成にする場合は課題がある。負荷分散をお
こなうロードバランシングサービスではロードバランサが稼働している当該リー
ジョン内のサーバに対してのみ通信可能で他リージョンサーバは通信できない。
冗長化では、リージョン内の同ネットワークセグメントのサーバに対してルーテ
ィングテーブルを変更し参照先サーバを切り替えることでフェイルオーバが可能
だが、ルーティングテーブルへは他リージョンのネットワークセグメントを指定
できないため、やはりリージョン内での冗長化になる。つまり 1 リージョン全域
が大災害などで被災しリージョン内のすべてのサービスのサービスが停止した場
合、複数リージョン間での広域冗長化が必要になるため、クラウドベンダの標準
サービスに対して追加の機能実装が必要となる。
2.6.3. 課題:アクセス予測(状況に応じたサーバ数)
平常時と災害時でシステムへのアクセス数に差がある安否確認システムは、ア
クセス状況に応じたサーバ数で運用することで費用削減が可能である。アクセス
集中に対するシステムのリソース管理として も安直な施策は、災害時や平常時
の状況に因らずあらかじめ多数のサーバで常時稼働しておくことである。しかし
常時多数サーバでの運用は、アクセスが少ない平常時のサーバリソースは余剰リ
ソースとなり、そのまま余分費用に直結する。広域冗長化は災害の発生予測が困
難なため常時敷設でなければ意味をなさないが、アクセス状況に応じたサーバ数
をその都度確保する仕組みがあればアクセスの少ない平常時の余剰リソースを削
減でき、安否確認システムのリソース管理としては理想的である。またアクセス
集中後のサーバ追加では、システムが高負荷となった状態での事後対応となりレ
スポンス低下などユーザの利便性を損ねるため、アクセス集中前に適切なサーバ
数算出および追加が望まれる。アクセス状況に応じた適切なサーバ数を算出する
ためには、災害発生からその後のアクセス分布の予測が必要である。

31
2.7. おわりに
本章では、本研究の対象となる Web システムを用いた安否確認システムの概要
を説明した。安否確認システムが必要となる背景では、本国における地震などの
自然災害が諸外国と比較して多く、災害時において被災者の迅速な安否確認がそ
の後の救助活動や復旧活動につながることから、効果的な被災者安否の確認手段
が重要であることを説明した。安否確認システムの関連研究では、情報収集関連
や通信関連および Web システム基盤関連などさまざまなアプローチがあり、本研
究では、システムを稼働する Web システムに注目して先行研究を紹介した。一般
的な Web 安否確認システムが有する機能仕様の紹介として、本研究の基となって
いる静岡大学の安否確認システムの代表的な機能仕様を紹介した。本研究の目的
となる、いかなる状況においても稼働を継続する安否確認システム実現のために
求められる要件をまとめ、可用性を向上する広域冗長化技術と、状況によるアク
セス流量に対して適切なサーバ数で運用するアクセス予測について課題をまとめ
た。
本研究では上記 2 つの課題を解決するため,Web システムを構成するサーバ群
を世界規模で冗長化し,災害時のアクセス数を事前予測し適切なサーバ数にて負
荷分散をおこなう Web 安否確認システムを試作開発し評価結果から有効性を示
す。3 章、4 章では、広域冗長化技術とアクセス予測技術を実現するための研究詳
説を述べる。

32
第3章 広域冗長化技術
3.1. はじめに
本章では、安否確認システムにおける可用性を向上する広域冗長化技術の概要
を述べ、安否確認システムに実装することで可用性を向上する手法および評価を
おこなう。
広域冗長化とは、システムを構成するサーバなどのリソースを単拠点でなく複
数拠点に分散配置することで、ある拠点の障害によりシステムの全体停止を回避
する可用性向上のアプローチである。東日本大震災を代表する大災害時では、自
然災害による設備や機器の損壊およびネットワーク回線の切断などによりサービ
ス提供が停止する課題が表面化した。これら課題対策としてシステム稼働を継続
する可用性向上に関する施策や研究が多数発表された。これら先行研究では効果
的なシステム冗長化手法が提案され、本研究の基礎概念としている。本研究では、
これら先行研究を参考にして、地理的に離れた複数拠点での広域冗長化と、用い
るクラウドベンダを 1 社でなく複数社用いるインタークラウド構成での冗長化施
策を提案する。インタークラウドとは複数のクラウドを用いる概念のことで、さ
まざまな提案や実装手法があるが、本研究では複数社のクラウドベンダを用いそ
れぞれのベンダを透過的にコントロール可能な仕組みを指す。システム基盤をイ
ンタークラウド構成で構築し、安否情報を含むシステム登録ユーザの諸情報を保
持する分散データシステムを用い、単一地点やサーバの障害に依存することなく
システム稼働を継続する広域冗長化基盤を実現する。構築した基盤に対して、障
害発生時のディザスタリカバリ(DR)評価をおこない、広域冗長化基盤による可
用性向上を示す。

33
3.2. 従来研究
3.2.1. 広域冗長化
一般的な冗長化とは、システムを構成するサーバやストレージなどの複数の代
替え機を冗長配置し、障害発生の際に代替え機によりサービス提供を継続し、シ
ステム全体の停止を回避し可用性を向上させる施策である。身近な例でいえば、
工場などが主電源とは別に予備電源を保持し、障害や停電の際に予備電源に切り
替えて稼働継続を可能とするものである。Web システムにおいても同様で、シス
テムを構成する各機器に対して複数の代替機を用いることで冗長化を実現する。
図 3-1 は OSI 参照モデルにおける主要なレイヤの冗長化施策である。
図 3-1 各レイヤの冗長化
レイヤ 3(ネットワーク層)では、ルータなどのゲートウェイの冗長化である。
レイヤ6:プレゼンテーション層 FTP、TELNET、SMTPなど
レイヤ7:アプリケーション層 SMTP、DHCP、HTTPなど
レイヤ5:セッション層 TLS、NetBIOSなど
レイヤ4:トランスポート層 TCP、UDP、など
レイヤ3:ネットワーク層 IP、ARP、ICMPなど
レイヤ2:データリンク層 PPP、Ethernetなど
レイヤ1:物理層 無線、光ケーブルなど
H/W層
S/W層

34
ルータやスイッチを複数設置し、VRRP [39]を用いて仮想ルータを構築すること
である機器が故障した際に代替え機に通信経路を変更し、稼働継続する。機器の
監視には ICMP [40]の echo リクエストを用いてレスポンス状況により稼働有無
を判断する。レイヤ 4(トランスポート層)では、ロードバランサなどを用いた
冗長化である。Web サーバやアプリケーションサーバをロードバランサ配下に複
数配置することで冗長構成を敷く。監視には TCP [41]や UDP [42]で接続を試み
接続有無を確認する。レイヤ 4 では接続有無のみを確認するため、監視対象が Web
サーバであった場合は、Web サービスの稼働有無までは確認できない。レイヤ 7
(アプリケーション層)では、アプリケーションプログラムやサーバを冗長化す
る。たとえば Web サーバであればレイヤ 4 と同様にロードバランサ配下に複数
配置することで冗長化する。レイヤ 4 との違いは監視手法にあり、レイヤ 7 では
アプリケーションの正常稼働を確認し、Web サーバであれば実際に HTTP [43]リ
クエストを発行し正常応答を以てして稼働確認をする。以上が一般的な冗長化の
仕組みであり、施設内のような小規模な範囲で構築することが一般的である。
本研究での広域冗長化とは図 3-2 に示すとおりシステムを構成する各サーバ
や他システムリソースを近接地域で冗長化するのではなく、距離的に離れた遠方
の各所で冗長化し、局所災害に影響を受けない広域分散システム構成を指す。

35
図 3-2 広域冗長化
広域冗長化にはさまざまな設計が考えられ、たとえば主たるユーザの地域をメイ
ンサイトとし別地域や別大陸をバックアップサイトとする運用や、各地のサイト
を同レベルとして扱いユーザがある地点からアクセスした場合、 寄りのサイト
へアクセスしレスポンス向上を目的とする運用などがある。本研究で対象とする
安否確認システムは現在のところ日本国内からのアクセスが主要となるため、前
者のアプローチが適している。
広域拠点にシステムを分散する研究はさまざまあり、 [44] [45]では広域な地理
に分散配備した広域分散ストレージの提案がある。地理的に離れた地域に複数の
サーバを多数配置し地域間を高速なネットワークで接続する。拠点間の高速なデ
ータ通信を実現しつつ、地理的に離れた地域でデータの冗長化をとることにより、
障害および災害などに強いストレージ基盤を実現している。 [46]では、データセ
ンタやクラウドベンダなどのストレージに加えて、個人や企業が所有するスマー
トフォンや NAS などの遊休ストレージを含めた広域分散ストレージを提案して

36
いる。クラウドベンダや個人のスマートフォンなど無尽蔵に近いストレージリソ
ースを有効活用し、各端末との通信は暗号化されセキュアな通信を実現している。
さまざまなストレージリソースを活用することで高い安全性と可用性の向上を可
能としている。 [47]では、分散システムに用いるクラウドデータセンタ間の通信
速度向上を実現している。クラウドを用いることでオンプレミスと比較して低コ
ストに分散システムを構築できるが、クラウドデータセンタ間は通常 Wide Area
Network(WAN)間で接続されているため、WAN の長距離通信による応答性の
劣化が問題となる。この問題に対して分散システムを構成するノード中にインテ
リジェントノードと呼ぶ分散システム調整用のノードを配置し、システム間の通
信時間を短縮し応答性を改善している。クラウド間での応答性が改善されたこと
で利便性の高い広域分散システムを実現している。 [48]では、広域分散システム
の動作検証について重要検証ポイントを言及している。大規模分散システムの特
徴である「スケールアウト性」および「耐障害性」を検証ポイントとして定め、
「スケールアウト性」はサーバやリソースを効率よく使用できているかを資源効
率性の観点から検証し、「耐障害性」ではシステムに障害発生した際に代替機構な
どによりシステムを正常に機能し続けるかを検証している。これら検証ポイント
に対する効率的な検証手法を確立し、さまざまな分散システムの動作検証に流用
可能な仕組みを実現している。 [49] [50]では、広域分散システムの災害などによ
る障害影響を評価する検証プラットフォームを構築している。広域分散システム
上ですでにサービス提供されているシステムに対して、実際の災害に類似した被
害を模倣発生させ被害状況を評価することは困難であることから、障害や故障を
模倣可能な故障発生プラットフォームを構築し、評価対象である広域分散システ
ムに適用し、広域分散システムの耐障害性を評価可能としている。このプラット
フォームにより災害をエミュレートして発生させることで広域分散システムの耐
障害機能が正常に機能することを事前に検証可能としている。 [51] [52]では、広
域分散システムを構成するサーバのライブマイグレーション手法を提案している。
広域分散システムは、地理的に離れた各所にシステムを構成するサーバマシンを
配置しており、障害やバージョンアップ、その他運用問題などにより、ある地点
のサーバ構成を別地点へ移動しなければならないケースがある。本手法は移動透
過通信機能を OpenFlow [53]により実装し、サーバ側の OS 機能を改変すること

37
なく広域ライブマイグレーションを可能としている。広域ライブマイグレーショ
ンを可能とすることで広域分散システムの可用性をさらに向上させることを実現
している。 [54]では、広域分散システム上で稼働する各サービスの障害復旧やデ
ータ同期に対して仮想機械を用いたサービス協調複製基盤を提案している。広域
分散システムは地理的に離れた拠点でサーバを分散稼働するため、各サーバへの
データ同期や障害処理など相応の管理コストが発生する。提案手法は広域分散シ
ステム上の各サービスが互いの状態を複製するサービス協調の仕組みを用いて、
単一サーバ上の小規模なサービスを他サーバ上に複製し可用性向上を実現してい
る。 [55]では、広域分散システム上で単一のファイルシステムを実現するストレ
ージアーキテクチャを提案している。広域分散システムにおける複数個所で単一
ストレージ空間を実現する技術は従来から存在するが、多くはクラウドベンダの
専用 API を用いる場合が多い。本提案ではファイル操作に専用 API を用いず標
準的な POSIX 準拠のファイルアクセスが可能なことを特徴としている。提案ア
ーキテクチャでは、メタデータとユーザデータの両者を広域分散システム上で冗
長保存し、災害発生時のデータセンタ障害においても正常稼働している地域のリ
ソースを用いてサービス継続を可能とする。 [56]では、広域分散システムにおけ
るデータ通信セキュリティ向上の提案である。提案手法は、複数拠点でのグリッ
ドシステム上のファイル共有および高性能並列処理を実現する広域分散ファイル
システムである Gfarm [57]に対して機能拡張をおこなうものである。Gfram は
広域分散システムのファイルシステムとして、高信頼および高可用性を発揮する
がデータセキュリティにおける真正性や完全性の保証には及んでいない。提案手
法は Gfram に対して Public Key Infrastructure(PKI)認証方式をベースにした
時刻認証を用いてファイルの真正性を保証する手法を構築した。以上のように広
域分散システムを実現する広域冗長化にはさまざまな先行研究があり、その重要
性がうかがえる。しかしながら、これらの先行研究では広域拠点の冗長化アーキ
テクチャの提案や実装手法が多くをしめ、実際の稼働評価に乏しい。また、多く
は国内拠点での冗長化実装であり、海外を含む地理的に離れた箇所での検証も乏
しく、広域災害に対する可用性の効果が分かりにくい課題がある。本研究では、
実際の稼働評価および海外を含む広域拠点での実装をおこない効果を検証する。

38
3.2.2. インタークラウド
インタークラウドの基礎となる既存のクラウド・コンピューティングについて
説明する。クラウド・コンピューティングとは、従来はユーザ自身で保持してい
たサーバやスイッチ、ソフトウェアなどをインターネットなどのネットワークを,
通じてサービスとして利用する形式であり、図 3-3 のサービス利用形態がある
[58]。
図 3-3 サービス利用形態
「Software as a Service:SaaS」は、ユーザが、ネットワーク経由でサービスを
利用するスタイルである。サービスは主に Web アプリケーションとして提供され
る。「Platform as a Service:PaaS」は、SaaS アプリケーションの実行基盤や開
発環境を提供するサービスである。「Infrastructure as a Service:IaaS」は、CPU
やストレージなどのハードウェアや OS など、システムを構成するインフラ基盤
アプリケーション
ミドルウェア
OS
ハードウェア
アプリケーション
ミドルウェア
OS
ハードウェア
アプリケーション
ミドルウェア
OS
ハードウェア
IaaSInfrastructureas a Service
PaaSPlatform
as a Service
SaaSSoftware
as a Service
39
を提供するサービスであり、本研究の冗長化やインタークラウド技術の対象とな
るサービスレイヤとなる。
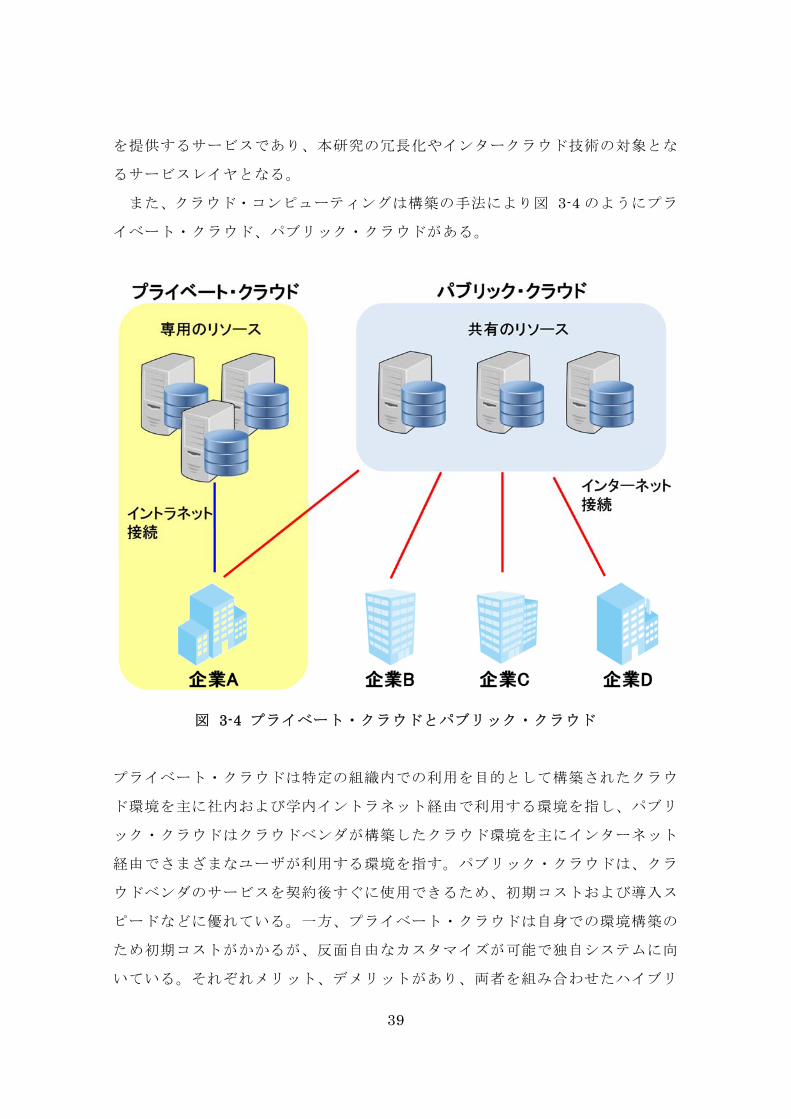
また、クラウド・コンピューティングは構築の手法により図 3-4 のようにプラ
イベート・クラウド、パブリック・クラウドがある。
図 3-4 プライベート・クラウドとパブリック・クラウド
プライベート・クラウドは特定の組織内での利用を目的として構築されたクラウ
ド環境を主に社内および学内イントラネット経由で利用する環境を指し、パブリ
ック・クラウドはクラウドベンダが構築したクラウド環境を主にインターネット
経由でさまざまなユーザが利用する環境を指す。パブリック・クラウドは、クラ
ウドベンダのサービスを契約後すぐに使用できるため、初期コストおよび導入ス
ピードなどに優れている。一方、プライベート・クラウドは自身での環境構築の
ため初期コストがかかるが、反面自由なカスタマイズが可能で独自システムに向
いている。それぞれメリット、デメリットがあり、両者を組み合わせたハイブリ

40
ッド・クラウドの概念もありインタークラウドの基礎概念となっている。
インタークラウドとは、図 3-5 のように複数のクラウドを統合してサービス提
供する形態を指し、単体のクラウドベンダでなく複数のクラウドベンダを用いて
システム環境を構築し可用性を向上する手法である。
図 3-5 インタークラウド概要
単一のクラウドベンダのリソースでなく、複数のクラウドベンダ間でクラウドリ
ソースを共有しシステム連携をおこなうものである [59]。ハイブリッド・クラウ
ドとの違いは、統合するクラウドの多様性にある。ハイブリッド・クラウドは、
たとえば AWS をパブリック・クラウドに用いた場合、AWS にアクセスする API
などの影響で、プライベート・クラウドは AWS と互換性のあるプラットフォー
ムで構築しなければならない。一方、インタークラウドはハイブリッド・クラウ
ドを含む、多種のベンダを相互に接続する概念のため単純なハイブリッド・クラ
ウド構成と比較して提供するサービスに応じて多様な構成が可能となる。サーバ

41
やストレージなどの資源は、クラウドベンダであっても 1 クラウドベンダの資源
は有限であるため、システムの拡張性は当該クラウドベンダの有限リソースの範
囲内となる。インタークラウドでは他ベンダを接続可能とするため 1 ベンダと比
較しより多くの拡張性を持たせることが可能となる。また、災害に対しても他ベ
ンダを用いることで、ある地域のベンダが被災した場合、他ベンダにてサービス
継続が可能となる。このような特徴を持つインタークラウドはさまざまな先行研
究がある。
[60] [61]では、複数のベンダ間を連携するサブシステムを構築し、そのサブシ
ステム上にユーザシステムを稼働させるものである。インタークラウド間の各ク
ラウドベンダはベンダ特有の API や仮想マシンフォーマットを用いている場合
が多く、各ベンダを透過的に扱える API による共通操作が課題となる。本提案で
は、共通操作が可能な機構を構築しユーザにベンダ間の差を意識させることなく
サービス提供を可能としている。 [62]では、商用のクラウドベンダと研究室内に
構築したプライベート・クラウド環境との連携を試みている。状況に応じたクラ
ウド選択ポリシーを用いてサーバの広域分散配置を実現しシームレスなクラウド
環境構築を可能としている。 [63]では、インタークラウドを構成する複数のクラ
ウド間の相互認証を連携する提案である。各クラウドを利用するための認証がそ
れぞれのクラウドベンダや機能に限定されている場合、別クラウドを利用する際
に再度認証を求められ、インタークラウドのスケールメリットが発揮されない課
題がある。本提案では、認証基盤に Shibboleth [64]を用いてインタークラウド間
で SSO を実現し、インタークラウド間の各クラウド利用に対して利便性の高い
認証基盤を実現している。 [65]は、主に教育機関向けに設計されたアカデミック
クラウドアーキテクチャ [66]に対して、各教育機関のクラウドを連携するアカデ
ミックインタークラウドの提案である。大学内の設備には法定点検による全学停
電があり、その際大学内のプライベート・クラウドは停止もしくは稼働制限しな
ければならない。また複数教育機関が共同で推進する研究やプロジェクトでは研
究基盤やデータ共有が求められる。これら課題に対して各教育機関のクラウドと
安全なネットワークで接続することで、高度な研究基盤の提供を可能としている。
[67]は、インタークラウドを構成する Virtual Cloud Provider(VPC)アーキテ
クチャに対して Web サービスバックアップの検証である。VPC は特定のクラウ

42
ドに依存せず、複数のクラウドリソースを統合し、共通のホスト環境イメージを
提供する仕組みである。ホスト環境の構築やアプリケーション移植に課題は残る
が、将来的に Web サービスバックアップの VPC 適用実現の可能性を示唆し、今
後の進展に期待できる。 [68]では、インタークラウドを構成するストレージサー
ビスに着目し、AWS S3 [69]と Azure Blob [70]のデータ転送高速化手法を提案し
ている。インタークラウドの利用が増加するにつれて、クラウド間でのデータ通
信量も増大し転送速度が課題となる。本提案では、クラウドストレージ間で転送
をおこなうアプリケーションノードを実装し、ノード数を増加するほど転送速度
も向上することを示している。 [71]では、インタークラウドを構成する計算サー
バや網リソースの適切な割り当てアルゴリズムを提案している。インタークラウ
ドを設計する際、性能を十分に発揮するためには計算サーバやネットワークなど
の網リソースの適切な割り当てが重要となる。提案アルゴリズムはインタークラ
ウド設計時において、計算サーバを適切に割り当てた場合の網リソースの枯渇や、
両者を適切に割り当てた場合のコスト問題などを解決し、ユーザの要求を満足す
るリソース割り当てを実現している。
このような先行研究では、いずれも単一のクラウドではなくプライベート・ク
ラウドや教育機関間との連携を用いて可用性向上や利便性向上を実現しており、
クラウド間連携の重要性を説いている。しかしながら、プライベート・クラウド
や教育機関のクラウドは商用のクラウドベンダと比較し耐災害性対策に乏しいこ
とから可用性に懸念が残る。したがって、可用性向上を考慮した場合、商用クラ
ウドベンダを用いることが望ましいが、多くの先行研究では商用のクラウドベン
ダを複数連携した実装および評価に乏しい。本研究ではクラウドベンダを複数連
携することで先行研究では得ることが困難な更なる可用性向上を実現する。

43
3.3. システム概要
本研究で目的とする、地理的に離れた複数拠点でのインタークラウドアーキテ
クチャを用いた広域冗長化機構と、災害規模に応じたシステムへのアクセスを予
測するアクセス予測モデルを実装した安否確認システム(以下、本システム)の
概要を図 3-6 に示す。
図 3-6 広域冗長型安否確認システムの概要
本システムは、メインリージョンとサブリージョンに配置し各リージョン内に
異なるクラウドベンダを用いてシステムを構成する。各リージョンは、主たるユ
ーザのアクセス地域(本研究では東京)から、Web アクセスの応答速度を計測す
る httping [72]コマンドでの応答速度が速い順に、メインリージョン、サブリー
ジョン 1、2 とする。メインリージョンを中心として位置的に離れているリージ
ョンをサブリージョンに選択することで、近接地域にかたよることなく広域な冗
安否確認システム
DC_1プライマリ
監視
コントロールサーバ
平常時サイト
気 象 情 報 サ ー ビ ス
DNS
DDS
DDSDDS
Web Web
LB
アクセス予測モデル機構
広域冗長化機構・Zabbix・Cloud API
メインリージョンベンダA
DDS
Web
DC_2セカンダリ
オートスケーリング
コントロールサーバ
LB
安否確認システム
※ベンダAと同様
サブリージョンベンダB
DC_1
DDS
Web
DC_2
DDS
Web
コントロールサーバ
LB
安否確認システム
※ベンダAと同様
サブリージョンベンダC
DC_1
Web
DDS
DC_2
DDS
Web
監視 監視
相互監視
データ同期
Web : Webサーバ,DDS : DDSサーバ,LB : ロードバランサ

44
長化が可能となる。サブリージョンは数が多いほどシステムの可用性が向上する
が、本研究では広域冗長化の基本的動作の実装および評価までを対象とするため
2 つのサブリージョンを用いた。システム正常稼働中のアクセスは、常にメイン
リージョンに向けられ、サブリージョンはメインリージョンのバックアップサイ
トとしてホットスタンバイする。各リージョンには異なる地点に配置されている
データセンタ(DC)がある。
システム基盤には 3 社のクラウドベンダを用い、図 3-6 に示すように各ベンダ
間で連携し運用する。複数ベンダを用いることでベンダ間をまたぐインタークラ
ウド構成となり広域冗長化構成を実現する。各ベンダの役割としてプライマリベ
ンダとセカンダリベンダがある。プライマリベンダとはシステム正常稼働中のア
クセスをすべて引き受けるベンダのことで、ベンダ A となる。セカンダリベンダ
とはプライマリベンダが何らかの事情で停止した際のバックアップベンダとなり、
ベンダ B、C となる。プライマリベンダの障害発生時は、セカンダリベンダにア
クセス先を変更しシステム持続稼働を実現する。各ベンダ内にはそれぞれ安否確
認システムとコントロールサーバを配置する。安否確認システムはユーザの安否
情報の収集および公開をおこない、コントロールサーバはベンダ内およびベンダ
間でのシステム持続稼働のための諸作業をおこなう。
安否確認システムは、Web サーバと分散データベースシステム(Distributed
Database System:DDS)で構成する。本研究での DDS とは複数サーバを連携
してデータの分散管理を実現する仕組みである。ベンダ内の 2 つのデータセンタ
にそれぞれ、Web サーバ、DDS サーバを置き、単一ベンダにおいても閉域冗長構
成を敷く。ベンダ A の場合、DC_1 は Web サーバ 2 台、DDS サーバ 3 台、DC_2
は Web サーバ 1 台、DDS サーバ 1 台となり、DC_1 がプライマリデータセンタ
となる。システム正常稼働中にはすべてのアクセスはプライマリデータセンタに
向き、セカンダリデータセンタはプライマリデータセンタ停止時のバックアップ
サイトである。つまりシステムの正常稼働中は図 3-6 のベンダ A の DC_1 がサ
ービス提供サイトとなる。データセンタ間およびベンダ間でのデータ同期は DDS
のレプリケーション機能を用いておこなう。
コントロールサーバは、安否確認システムやロードバランサなどのクラウドリ
ソースの障害検知および障害時のリカバリを担当する。障害検知は統合監視ソフ

45
トウェアの Zabbix [73]を用いておこなう。各ベンダのコントロールサーバは自ベ
ンダだけでなく他ベンダのシステム監視を相互におこない、障害発生時のリカバ
リを確実に実行することで単一障害点をなくし可用性向上に寄与する。また、安
否確認システムが安否報告促進メールを送信する契機となる災害情報を気象情報
提供サービスなどから検知し、安否確認システムに通知する。また、アクセス予
測モデルに基づいたオートスケーリング機構を有し、災害時のアクセス集中に対
して Web サーバをスケールアウト・インし負荷分散をおこなう。サーバ数の増加
をスケールアウト、削減をスケールインと呼ぶ。Web サーバは同内容のソースコ
ードおよび OS を予めマシンイメージ化しておき、障害発生時やスケールアウト
時には OS イメージから起動した Web サーバをロードバランサ配下に起動する。
マシンイメージとは、ミドルウェア(データベース管理システムなど)、アプリケ
ーションソフトウェア、アプリケーションソースコード、デバイスドライバなど、
OS を含めたサーバの起動情報をイメージ化したものである。マシンイメージを
基に同じ構成のサーバを複製できる。
災害時のアクセス集中のもととなる対象ユーザ数は災害の対象となる顧客から
決定する。本研究の安否確認システムは図 3-7 に示すとおり複数顧客がサーバリ
ソースを共有する運用形態であり、あらかじめシステム登録済みユーザが利用可
能となる。

46
図 3-7 安否確認システムの運用形態
動作概要は、顧客単位で設定した地域および震度閾値に該当する災害が発生した
際に、対象顧客へ安否報告を促がすメールを送信し、受信したユーザが安否報告
をおこなう流れとなる。災害時の対象ユーザ数は、たとえば東京都、神奈川県に
震度 5 強の災害が発生した場合は、図 3-7 から顧客 A、C、E となり対象ユーザ
数は 15,700 名となる。つまり本システムは、災害規模に応じてシステムに登録済
みユーザ数の範囲で対象ユーザ数が変化し、対象ユーザ数に応じてアクセス予測
および負荷分散をおこなう。
安否確認システム
顧客A
・震度:5強・地域:東京都,
神奈川県・ユーザ:3,000名
顧客C
・震度:4・地域:神奈川県,
千葉県・ユーザ:200名
顧客B
・震度:7・地域:東京都,
埼玉県・ユーザ:4,000名
顧客D
・震度:6弱・地域:静岡県,
愛知県・ユーザ:300名
顧客E
・震度:5弱・地域:東京都・ユーザ:12,500名
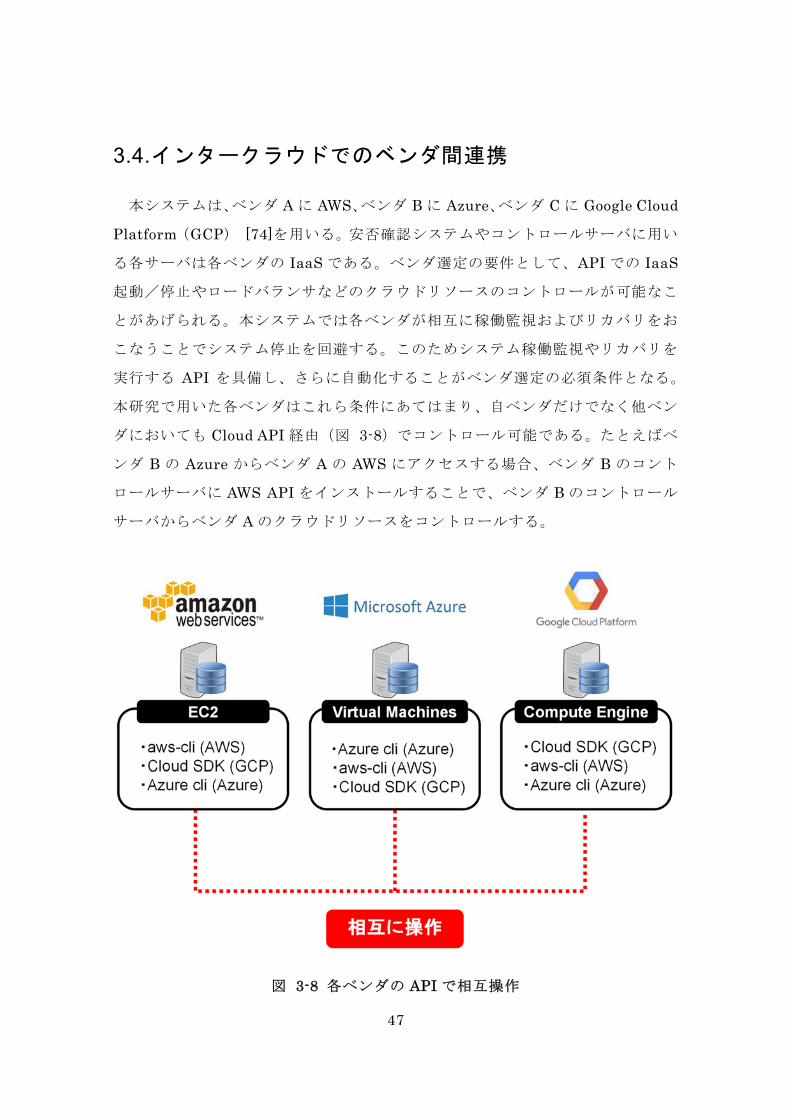
47
3.4. インタークラウドでのベンダ間連携
本システムは、ベンダ A に AWS、ベンダ B に Azure、ベンダ C に Google Cloud
Platform(GCP) [74]を用いる。安否確認システムやコントロールサーバに用い
る各サーバは各ベンダの IaaS である。ベンダ選定の要件として、API での IaaS
起動/停止やロードバランサなどのクラウドリソースのコントロールが可能なこ
とがあげられる。本システムでは各ベンダが相互に稼働監視およびリカバリをお
こなうことでシステム停止を回避する。このためシステム稼働監視やリカバリを
実行する API を具備し、さらに自動化することがベンダ選定の必須条件となる。
本研究で用いた各ベンダはこれら条件にあてはまり、自ベンダだけでなく他ベン
ダにおいても Cloud API 経由(図 3-8)でコントロール可能である。たとえばベ
ンダ B の Azure からベンダ A の AWS にアクセスする場合、ベンダ B のコント
ロールサーバに AWS API をインストールすることで、ベンダ B のコントロール
サーバからベンダ A のクラウドリソースをコントロールする。
図 3-8 各ベンダの API で相互操作

48
システム停止の回避は、複数ベンダを連携するだけは実現できず、システム中
の単一障害点を排除する実装が必要である。たとえば 3 社のベンダを用いてシス
テムを構築したとき、3 社の Web サーバのフロントに 1 社のロードバランサを配
置したのでは、このロードバランサが停止した場合はシステム全体が停止する。
つまりひとつのベンダに依存する実装を避け、あるベンダが停止した際にはシス
テム稼働を継続するためのディザスタリカバリが機能しなければならない。ディ
ザスタリカバリは一般的に二つのアプローチがあり、ひとつは障害発生時におい
てもシステムを停止せずに稼働し続けることを可能とするものと、システムを一
旦停止し再稼働をおこなうものがある。安否確認システムは災害時にこそ稼働を
求められ、また本研究ではインタークラウドを用いた無停止システムを目的とす
るため、前者のアプローチでの実装が必要である。

49
3.5. ディザスタリカバリ
3.5.1. フェイルオーバ
広域冗長化機構はベンダ間やベンダ内のデータ同期や障害発生時のディザスタ
リカバリとしてフェイルオーバを行う。本システムには 2 種類のディザスタリカ
バリがある。ひとつはベンダ間でのディザスタリカバリであり、プライマリベン
ダが停止した場合、DNS の設定を変更しセカンダリデータセンタにアクセス先を
変更するベンダ間でのフェイルオーバである(図 3-9)。
図 3-9 ベンダ間フェイルオーバ
もうひとつはベンダ内のディザスタリカバリであり、ベンダ内のプライマリデー
タセンタが停止した場合、ロードバランサの設定を変更しセカンダリデータセン
タにアクセス先を変更するベンダ内でのフェイルオーバである(図 3-10)。
ベンダA
コントロールサーバ
安否確認システム
LB
DNS
ベンダB
コントロールサーバ
安否確認システム
LB
ベンダC
コントロールサーバ
安否確認システム
LB

50
図 3-10 ベンダ内フェイルオーバ
両者いずれにおいても無停止でのディザスタリカバリを実現するため、各ベンダ
およびベンダ内のサーバ群はホットスタンバイで運用し常にデータ同期をおこな
う。この 2 つのディザスタリカバリ機構でベンダ内およびベンダ間それぞれの障
害対応を可能とし、システム停止を回避する。
3.5.2. ベンダ間フェイルオーバの処理フロー
ベンダ間フェイルオーバは図 3-11 の処理フローとなる。障害発生は各ベンダ
の Zabbix から検知する。
コントロールサーバ
安否確認システム
LB
DNS
DC_1プライマリ
DDS
DDSDDS
Web Web
DDS
Web
DC_2セカンダリ
ベンダA
ベンダB
コントロールサーバ
安否確認システム
ベンダC
コントロールサーバ
安否確認システム

51
図 3-11 ベンダ間フェイルオーバ処理フロー
ベンダ間フェイルオーバは図 3-11 に示すように障害発生を起点に実行し、ア
クセス先をメインリージョンからサブリージョンに変更することで実現する(図
3-9)。アクセス先リージョンの変更は AWS の DNS サービスである Route53 [75]
でおこなう。メインリージョンに障害が発生した場合、サブリージョンのコント
ロールサーバは Route53 を用いてアクセス先の重み付けを変更しサブリージョ
ンにアクセスを向ける。新たにアクセスを受けるサブリージョンはメインリージ
ョンに昇格し元のリージョンが復旧するまでその役目を果たす。新たなメインリ
ージョンの選択基準は、アクセス地域から httping コマンドでの応答速度が旧メ
インリージョンの次に速いサブリージョン 1 であるため、メインリージョンはユ
ーザアクセス地域から常に も応答速度の速いリージョンとなる。また、フェイ
ルオーバ後、元のメインリージョンに復旧するまでの処理シーケンスは図 3-12
となる。
メインリージョンから各サブリージョンへデータ同期
サブリージョンXがRoute53にてアクセス先をメインリージョンからサブリージョンXに変更
サブリージョンXが新たなメインリージョンとなる
広域冗長化機構ベンダ間フェイルオーバ
監視
各ベンダのZabbixが相互監視
NO
メインリージョンに障害発生
YES

52
図 3-12 ベンダ間フェイルオーバ後のシーケンス
3.5.3. ベンダ内フェイルオーバの処理フロー
ベンダ内フェイルオーバの処理フローは図 3-13 となる。ここではメインリー
ジョン(AWS)でのベンダ内フェイルオーバの例とする。
Route53災害情報サービス
サブリージョンX
コントロールサーバ
安否確認システム
メインリージョン
コントロールサーバ
安否確認システム
データ同期障害検知
アクセス先をサブリージョンXに変更
サブリージョンXがメインリージョンとなる
復旧措置
復旧措置
復旧後、アクセス先を旧メインリージョンに変更
本来のメインリージョンで運用
53
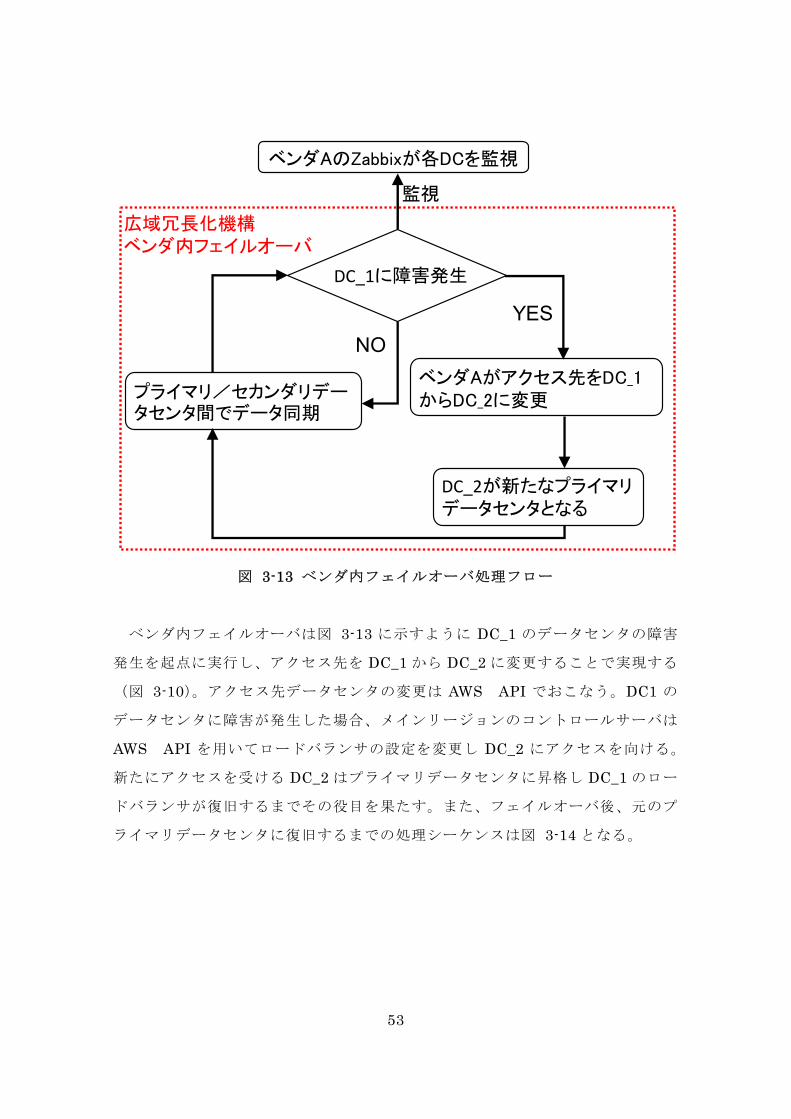
図 3-13 ベンダ内フェイルオーバ処理フロー
ベンダ内フェイルオーバは図 3-13 に示すように DC_1 のデータセンタの障害
発生を起点に実行し、アクセス先を DC_1 から DC_2 に変更することで実現する
(図 3-10)。アクセス先データセンタの変更は AWS API でおこなう。DC1 の
データセンタに障害が発生した場合、メインリージョンのコントロールサーバは
AWS API を用いてロードバランサの設定を変更し DC_2 にアクセスを向ける。
新たにアクセスを受ける DC_2 はプライマリデータセンタに昇格し DC_1 のロー
ドバランサが復旧するまでその役目を果たす。また、フェイルオーバ後、元のプ
ライマリデータセンタに復旧するまでの処理シーケンスは図 3-14 となる。
プライマリ/セカンダリデータセンタ間でデータ同期
ベンダAがアクセス先をDC_1からDC_2に変更
DC_2が新たなプライマリデータセンタとなる
広域冗長化機構ベンダ内フェイルオーバ
監視
ベンダAのZabbixが各DCを監視
NO
DC_1に障害発生
YES
54
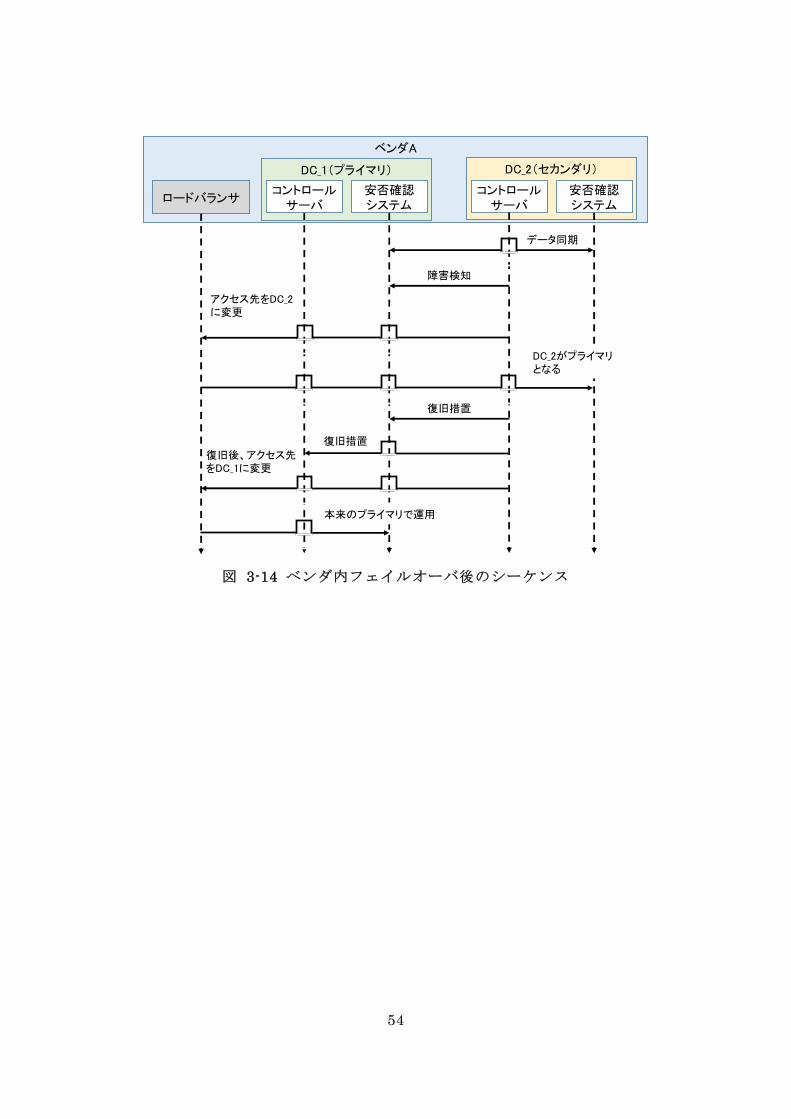
図 3-14 ベンダ内フェイルオーバ後のシーケンス
ベンダA
DC_2(セカンダリ)DC_1(プライマリ)
コントロールサーバ
安否確認システム
コントロールサーバ
安否確認システム
データ同期
障害検知
復旧措置
本来のプライマリで運用
ロードバランサ
アクセス先をDC_2に変更
DC_2がプライマリとなる
復旧措置
復旧後、アクセス先をDC_1に変更

55
3.6. 分散データシステム
3.6.1. Cassandra のデータ構造
インタークラウド構成を用いることは必然的に分散システムの実装となる。デ
ータ管理においても複数個所で共通データを扱う分散データ管理システムが可用
性を向上するための仕組みとして適している。昨今、分散データ管理システムは
多数のユーザを持つ SNS やモノのインターネット(Internet of Things:IOT)
のデータストアに用いられるなど多数の製品が展開されている。Google 社の
Bigtable [76]は、Google の大規模かつ大多数サーバで運用するシステムのデータ
管理を目的に開発されたデータベースであり、列指向データベースである。列指
向データベースとは列のデータをまとまりとして捉え効率的にデータを処理可能
とする設計である。また、Bigtalbe を基にオープンソースの Apacpe HBase [77]
が開発されている。オープンソースの MongoDB [78]はドキュメント DB に分類
され、データモデルに JSON を用いる。独自のクエリを用いて JSON の書き換え
や配列処理など豊富な機能を持つ。シャーディングではキーをハッシュだけでな
く、キー範囲やキーの組み合わせなどさまざまな手法で操作可能であり、詳細な
分散構成を可能としている。Neo4j [79]はグラフデータベースに分類される。グ
ラフデータベースとは複雑につながっているデータ間の処理に向いており、SNS
上のユーザ間処理や電力やネットワークのグリッド網の処理などに適用例がある。
このようにさまざまな分散データ管理システムがあるが、複数のデータセンタ間
への書き込みや従来の安否確認システムのデータ構造の移植などの課題がある。
従来の安否確認システムはデータ管理に RDB を用いているため、極力そのデ
ータ構造を流用可能なデータ管理が望ましい。そこで本システムでは分散データ
管理システムのうち、スキーマ定義を必要とする Cassandra [80] [81]を用いる。
Cassandra はデータアクセスに SQL 文を用いない NOSQL(Not Only SQL)
[82]と呼ばれる分散データ管理システムであり、書き込み特性に優れている [83]。
また、クラスタを構成するノードの複数データセンタへの配置が可能である。
Cassandra のデータ構造は図 3-15 となる。

56
図 3-15 Cassandra のデータ構造
データ管理構造はデータ(Value)に対して一意の標識(Key)にて管理をおこな
う Key-Value-Store(KVS) [84]方式であり、Cassandra は複数ある KVS 方式
の NOSQL のうち、カラム指向型に属する。カラム指向型とは単純な KVS が Key
と Value を 1 対 1 の関係で管理するのに対し、Column と呼ぶ Key と Value の
組み合わせを Row にて複数管理を可能とし、単純な KVS 方式を高度化したもの
である。図 3-16 は Cassandra と RDB の各データ単位の比較である。
Keyspace
・・・
ColumnFamily
ColumnFamilyRow
Columnname value timestamp
Columnname value timestamp
ColumnFamily
ColumnFamily

57
図 3-16 Cassandra と RDB のデータ比較
各データ単位を RDB と対比すると、Keyspace はデータベース、ColumnFamily
はテーブル、Row はレコードに相当する。この構造は安否確認システムにおける
RDB でのユーザ管理属性スキーマとの親和性が高く、他の NOSQL と比較して
データ管理の移行がしやすい。
3.6.2. Cassandra のデータ管理
本システムは、災害時の持続稼働や単一ベンダ障害に依存しない稼働を実現す
るため、Cassandra での分散データ管理が必須となる。Cassandra は単体稼働も
可能だが、通常は複数サーバ(ノード)を用いたクラスタ構成での運用が一般的
である。クラスタを構成する各ノードが連携し、あるノードが停止した際でも別
ノードがその役割を果たし持続稼働を可能とする。Cassandra のデータ管理は
RDB のようなマスター/スレーブの概念を持たず、各ノードが等価である。この
ため単一ノードに依存しないデータ管理を可能とし単一障害点がない。このよう
KeyspaceColumnFamily
Row
Columnname value timestamp
データベース
テーブル テーブル
Cassandra
RDB(PostgreSQL)
レコード
フィールド
58
なアーキテクチャは、RDB においても複数サーバを用いた読み取り専用のリード
レプリカや書き込み分散のシャーディングで可能であるが、これら機能は多くの
RDB ソリューションでは標準機能でなく、ユーザ自身の実装や外部ソフトウェア
依存となり管理および運用が複雑となる。一方、Cassandra はクラスタ構成での
稼働を前提として設計されているため、外部ソフトウェアなどを用いずに RDB
におけるリードレプリカやシャーディング相当の機能を実現可能であり、管理お
よび運用面の簡略化に寄与する。
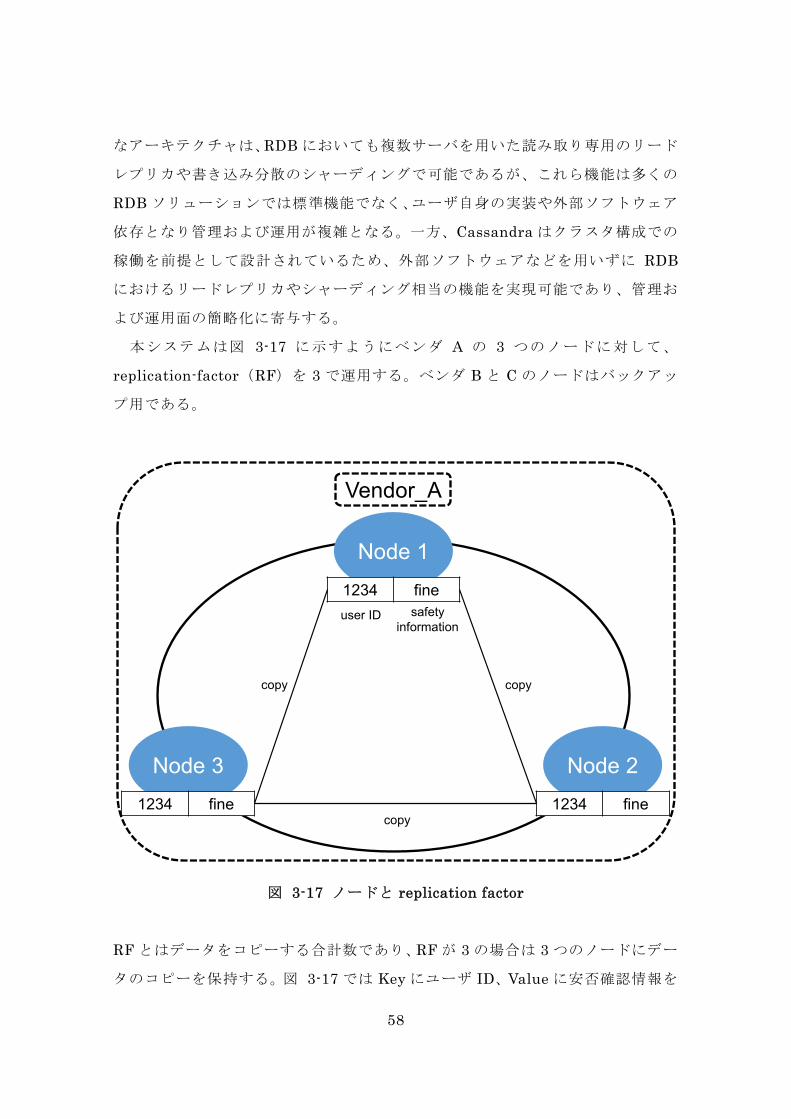
本システムは図 3-17 に示すようにベンダ A の 3 つのノードに対して、
replication-factor(RF)を 3 で運用する。ベンダ B と C のノードはバックアッ
プ用である。
図 3-17 ノードと replication factor
RF とはデータをコピーする合計数であり、RF が 3 の場合は 3 つのノードにデー
タのコピーを保持する。図 3-17 では Key にユーザ ID、Value に安否確認情報を
Node 11234 fine
Node 31234 fine
Node 21234 fine
Vendor_A
user ID safety information
copy
copy
copy

59
設定したデータが 3 つのノードすべてにコピーされる。本システムの場合は、ノ
ードが 3 台で RF も 3 であるため、すべてのノードにデータをコピーすることで
可用性を向上する。また、Cassandra のマルチデータセンタ機能でベンダ A のノ
ードとベンダ B、C のノードが自動でレプリケーションしディザスタリカバリに
備える。このように Cassandra はノード台数、RF などをシステムに適した設定
で運用することで可用性を向上することができ、安否確認システムのような持続
稼働を求められるシステムのデータ管理および保持に適している。
60
3.7. 評価
3.7.1. フェイルオーバ
広域冗長化機構の評価として、インタークラウド下でのベンダ間フェイルオー
バとベンダ内フェイルオーバを実施した。
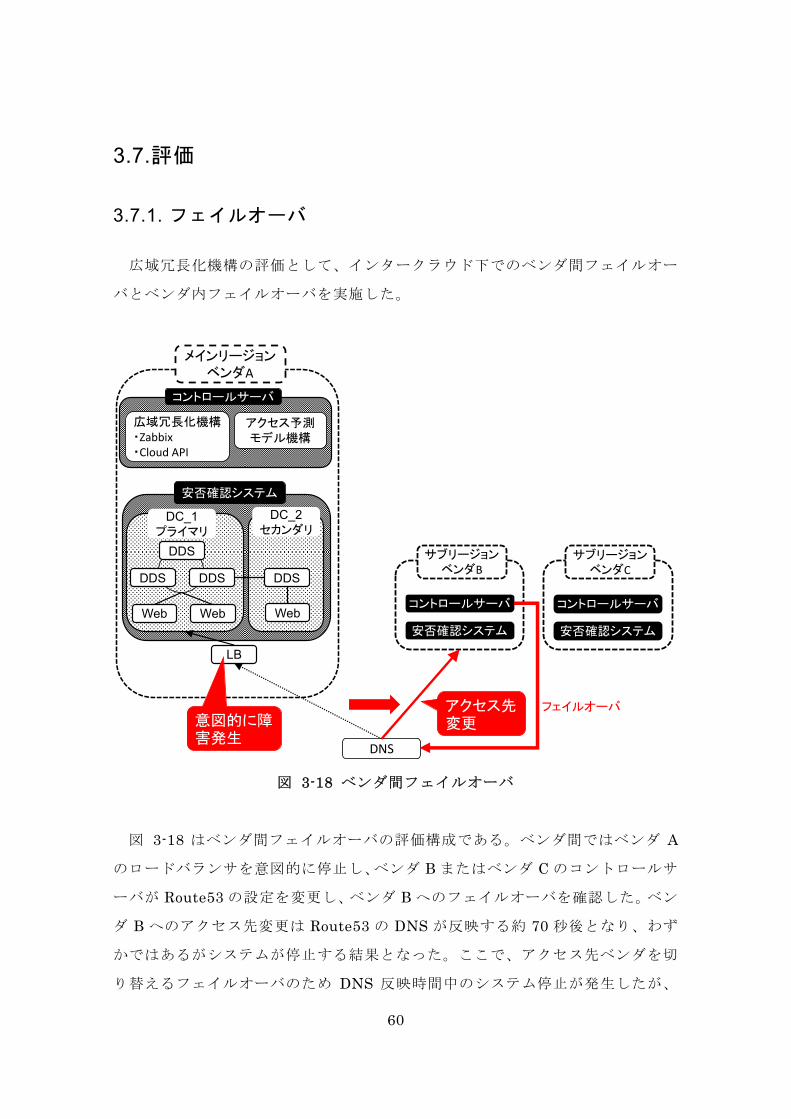
図 3-18 ベンダ間フェイルオーバ
図 3-18 はベンダ間フェイルオーバの評価構成である。ベンダ間ではベンダ A
のロードバランサを意図的に停止し、ベンダ B またはベンダ C のコントロールサ
ーバが Route53 の設定を変更し、ベンダ B へのフェイルオーバを確認した。ベン
ダ B へのアクセス先変更は Route53 の DNS が反映する約 70 秒後となり、わず
かではあるがシステムが停止する結果となった。ここで、アクセス先ベンダを切
り替えるフェイルオーバのため DNS 反映時間中のシステム停止が発生したが、
安否確認システム
DC_1プライマリ
コントロールサーバ
DNS
DDS
DDSDDS
Web Web
LB
アクセス予測モデル機構
広域冗長化機構・Zabbix・Cloud API
メインリージョンベンダA
DDS
Web
DC_2セカンダリ
サブリージョンベンダB
コントロールサーバ
安否確認システム
サブリージョンベンダC
コントロールサーバ
安否確認システム
意図的に障害発生
フェイルオーバアクセス先変更

61
TTL(Time To Live)の調整や Route53 のフロントに別 DNS を用い、各ベンダ
の URL を CNAME 設定するなどして、システム停止を回避する仕組みを今後の
課題としたい。
図 3-19 ベンダ内フェイルオーバ
図 3-19 はベンダ内フェイルオーバの評価構成である。ベンダ内では、ベンダ
A の DC_1 の Web サーバを意図的に停止し、ベンダ B またはベンダ C のコント
ロールサーバがベンダ A のロードバランサの設定を変更し、ベンダ A の DC_2 の
フェイルオーバを確認した。この変更はシステム停止時間がなく瞬時に反映可能
であった。
インタークラウドアーキテクチャは先行研究において、プライベート・クラウ
ドおよびパブリック・クラウドとの連携や複数のクラウドベンダを用いた実装が
提案され、本研究の基礎概念となっている。しかし多くの従来研究ではアーキテ
クチャの提案および実装までであり、またシステムが稼働する地域が国内や近接
安否確認システム
DC_1プライマリ
コントロールサーバ
DNS
DDS
DDSDDS
Web Web
LB
アクセス予測モデル機構
広域冗長化機構・Zabbix・Cloud API
メインリージョンベンダA
DDS
Web
DC_2セカンダリ
サブリージョンベンダB
安否確認システム
サブリージョンベンダC
コントロールサーバ
安否確認システム
意図的に障害発生
フェイルオーバ
アクセス先変更
コントロールサーバ
62
地域のため、実際の稼働評価に乏しい内容となっている。本研究では複数ベンダ
を用いたインタークラウドアーキテクチャの実装から広域拠点での稼働評価を実
施し、広域災害に対するシステム可用性向上が可能であることを示したことに他
研究と比較し優位性を得た。
3.7.2. 分散データシステム
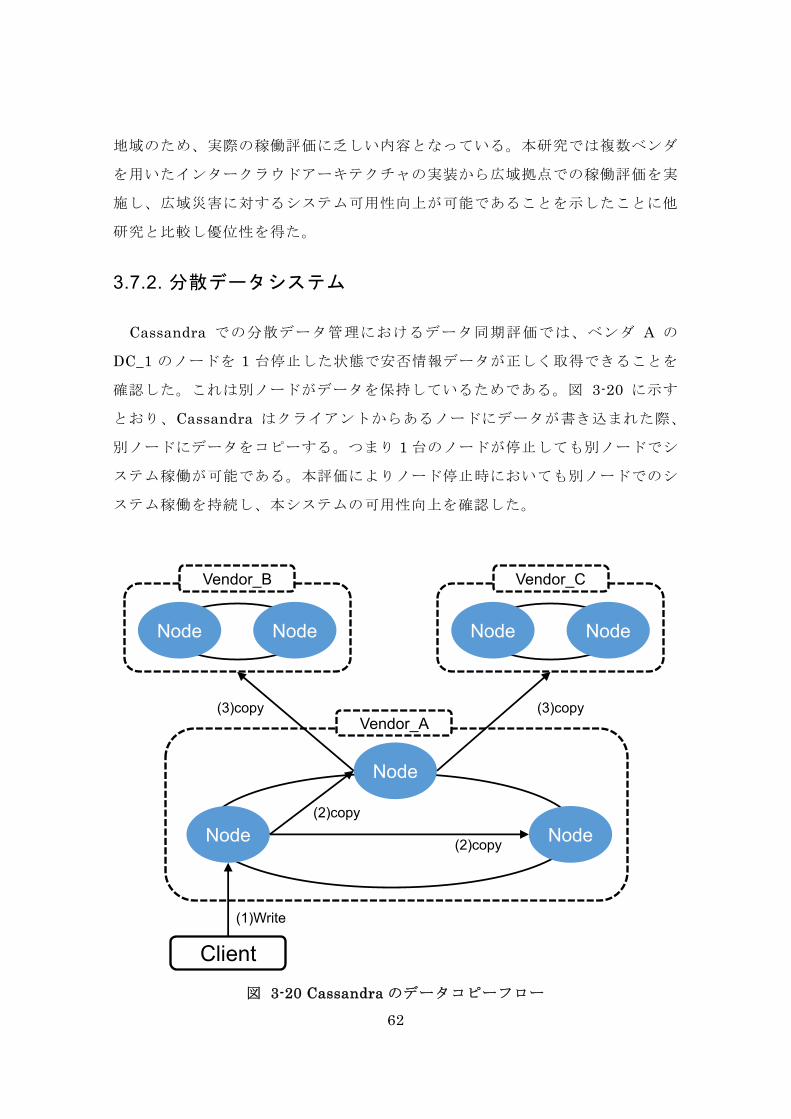
Cassandra での分散データ管理におけるデータ同期評価では、ベンダ A の
DC_1 のノードを 1 台停止した状態で安否情報データが正しく取得できることを
確認した。これは別ノードがデータを保持しているためである。図 3-20 に示す
とおり、Cassandra はクライアントからあるノードにデータが書き込まれた際、
別ノードにデータをコピーする。つまり 1 台のノードが停止しても別ノードでシ
ステム稼働が可能である。本評価によりノード停止時においても別ノードでのシ
ステム稼働を持続し、本システムの可用性向上を確認した。
図 3-20 Cassandra のデータコピーフロー
Vendor_A
(2)copy
(2)copyNode
Node
Node
Client
(1)Write
Node Node
Vendor_B
(3)copy
Node Node
Vendor_C
(3)copy

63
また、ノード停止後、新規ノードを追加し安否情報データが正しく取得できるこ
とを確認した。本システムではノード追加および準備が完了するまでは約 90 秒
程度の時間を要した。ノードの追加は Web サーバと同要領で Cassandra のイン
ストールおよび初期設定済みの OS を各ベンダにてマシンイメージ化しておく。
このとき安否関連のデータはマシンイメージに含まない。Cassandra は起動時に
自身が参加するクラスタに接続し、データ同期をおこなうためマシンイメージの
時点では安否関連情報は不要となる。Cassandra 起動後、データ同期を経て準備
が整うとステータスが「UN(Up Normal)」となり運用可能となる。
RDB を用いた従来システムと DDS を用いた本研究システムでの可用性比較で
は、従来システムのシャーディングやリードレプリカを用いた可用性向上実装は、
実装が複雑化することでシステム不具合発生の頻度が高まり可用性の脅威になる
ことに対して、本研究システムでは Cassandra の標準機能での複数ノードを用い
たクラスタリング機構により比較的容易な実装で可用性向上が可能なため、本シ
ステムは従来システムと比較して可用性向上実装に優れている。
RDB との性能比較は図 3-21 となる。

64
図 3-21 RDB と NOSQL の性能比較
評価環境はベンダ A の DC_1 にてロードバランサ配下に 12 台の Web サーバを配
置し、RDB と Cassandra はともに 1 台ずつとし、JMeter [85]を用いて複数の安
否報告アクセスを提案システムに対して実施した。JMeter とは Web システムに
対して複数のリクエストを送信し負荷を掛けることができるツールである。RDB
は PostgreSQL [86] 8.4.12 を用いた。安否報告アクセスは 10 分間で 0 から 5,000
まで増加し、Web サーバ、DB サーバの CPU 使用率とスループットを計測した。
CPU 使用率は各サーバ上の sar [87]コマンド、スループットは JMeter での計測
である。アクセス数を増加していくと同程度のスループット値でわずかに
Cassandra の CPU 使用率が低いが、ほぼ性能面では両者とも差がない。しかし、
Cassandra は通常、単体では運用しないため、処理性能面では RDB と同程度の
性能であっても、複数ノードを用いた可用性面に RDB と比較し優位性がある。
0
5
10
15
20
25
30
0
5
10
15
20
25
30
35
40
45
50
0 1000 2000 3000 4000 5000
RDB:throughput
NoSQL:throughput
RDB:Web
RDB:DB
NoSQL:Web
NoSQL:DB
平均
CP
U使
用率
(%)
アクセス数
Thro
ughp
ut(P
V/se
c)

65
3.8. おわりに
本章では、大規模災害や事故などで閉域地域内の情報インフラが遮断される状
況下を想定し、安否確認システムの稼働基盤を構成するサーバ群を世界規模で冗
長化し、複数社のクラウドベンダを連携したインタークラウドアーキテクチャを
用いて基礎評価から可用性が向上をすることを示した。マルチリージョンによる
広域かつ複数拠点での冗長化では、ある地域の災害で当該地域のクラウドインフ
ラが停止した際においても、別地域のクラウドインフラを代替稼働することで、
サービス継続を実現した。複数ベンダを用いたインタークラウドでは、災害だけ
でなく、当該ベンダ事情による障害発生や経営面からの事業撤退などのサービス
停止に対して、別ベンダを用いることでサービス停止を回避可能とした。また、
各リージョンに各ベンダのクラウド API をインストールしたコントロールサー
バを配置することで、各クラウドベンダを透過的にコントロール可能としスムー
ズなベンダ間連携を実現した。Cassandra を用いた分散データ管理では、
Cassandra クラスタを構成する各ノードにそれぞれデータコピーを保持するこ
とで単一ノード停止でのシステム全体停止を回避し可用性向上を実現した。
安否確認システムは、災害時にこそサービス継続しなければならない。国内の
複数拠点での冗長化や単一クラウドベンダだけでの構成では、東日本大震災クラ
スの災害においては、万全なシステム構成とはいい難い。本章での複数広域拠点
および複数ベンダを用いることにより上述の課題は回避可能と考える。合わせて、
複数拠点におけるデータ管理に適した分散データ管理システムが重要である。安
否確認システムのデータ管理に、Cassandra を用いた分散データ管理では可用性
向上に対して一定の成果を得た。昨今、分散データシステムはさまざまなソリュ
ーションが発表されており、Cassandra に限定することなく安否確認システムに
より適した他システムの検証および評価を今後の課題としたい。

66
第4章 アクセス予測技術
4.1. はじめに
本章では、災害発生時の安否確認システムに対するユーザのアクセス数を予測
するアクセス予測技術の概要を述べ、安否確認システムに実装することで災害時
に予測したアクセス予測を基に適切なサーバ数で負荷分散をおこなう手法および
評価をおこなう。
アクセス予測は、過去の災害や訓練時における安否確認システムへのアクセス
ログ分布を分析し、アクセス分布傾向をモデル化することでおこなう。従来研究
には、Web システムへのアクセストラヒック分析に各種の確率分布関数をあては
めてモデル化するものや、ある動作を起点としたシステムへのアクセス分布に正
規分布を用いてモデル化するものなどあり、本章のアクセス予測技術の基礎概念
として用いている。アクセス分布のモデル化は、過去の災害時や訓練時のアクセ
ス分布特性を把握し、その特性に適した確率分布関数に当てはめておこなう。本
研究で対象とする安否確認システムへのアクセス分布特性は対数正規分布に類似
した分布特性を持つことが調査の結果わかったため、アクセス予測モデルには対
数正規分布を用いてモデル化する。本研究での安否確認システムへの災害時のシ
ステムへのアクセス分布には、アクセスピークが 1 つのパターンと 2 つのパター
ンがあった。そこで、アクセスピークが 1 つのパターンは単一の対数正規分布を
2 つのパターンは混合対数正規分布を用いてモデル化する。アクセス予測モデル
での評価では、アクセス予測モデルの過去災害の実アクセス分布への適切な適合
性と、災害シミュレーション評価では災害時のアクセス分布に対してサーバ数を
増減し負荷分散することでシステム運用費用の削減効果を示す。

67
4.2. 従来研究
インターネット上のシステムに対してアクセストラヒックや傾向を分析する研
究は従来からおこなわれている。 [88]では、Web システムに用いているサーバの
利用記録やログなどを Web トラヒックとして分析し、トラヒックの分布を確率分
布関数として表現することでアクセス分析をおこなっている。分析に基づきアク
セスネットワークをモデル化することで高効率なネットワーク設計を可能として
いる。 [89]では、Web トラヒック特性の自己相似性に着目し、Web アクセスの
混雑状況に対して転送ファイルサイズやユーザの思考時間がトラヒックに及ぼす
影響を示している。 [90]は、インターネットニュースを提供するニュースサーバ
の記事配送トラヒックの分析とモデル化を試みている。ニュース配信中のトラヒ
ックを観測し確率分布関数を用いてトラヒックをモデル化し、ニュース配信に必
要となるネットワークリソースの見積もりなどに利用可能としている。 [91]では、
Web サービスにおいてさまざまなキャッシュ方式でのトラヒックの分析および
モデル化を検討している。キャッシュを有するネットワークトラヒックに対して、
正規分布や指数分布および対数正規分布など複数の確率分布関数を用い実データ
に も近い分布を求めることで分析をおこなっている。提案手法を用いたモデル
はキャッシュを有するネットワークトラヒックに対しうまく適合することを示し
ている。これらの先行研究ではあるシステムに対するアクセス分布に対してさま
ざまな確率分布関数を用いてのモデル化という点が共通しているが、アクセス分
布のモデル化までの検証や議論が多数を占め、モデルを用いての未経験アクセス
への予測の言及や評価が乏しい。本研究では過去のアクセス分布に対してのモデ
ル化だけでなく構築したモデルを用いて、未経験アクセスの予測をおこなう。
アクセス予測は、これらの先行研究を基にシステムに対してユーザアクセスを
分析しその傾向を把握することでおこなう。安否確認システムにおけるアクセス
予測を図 4-1 に示す。
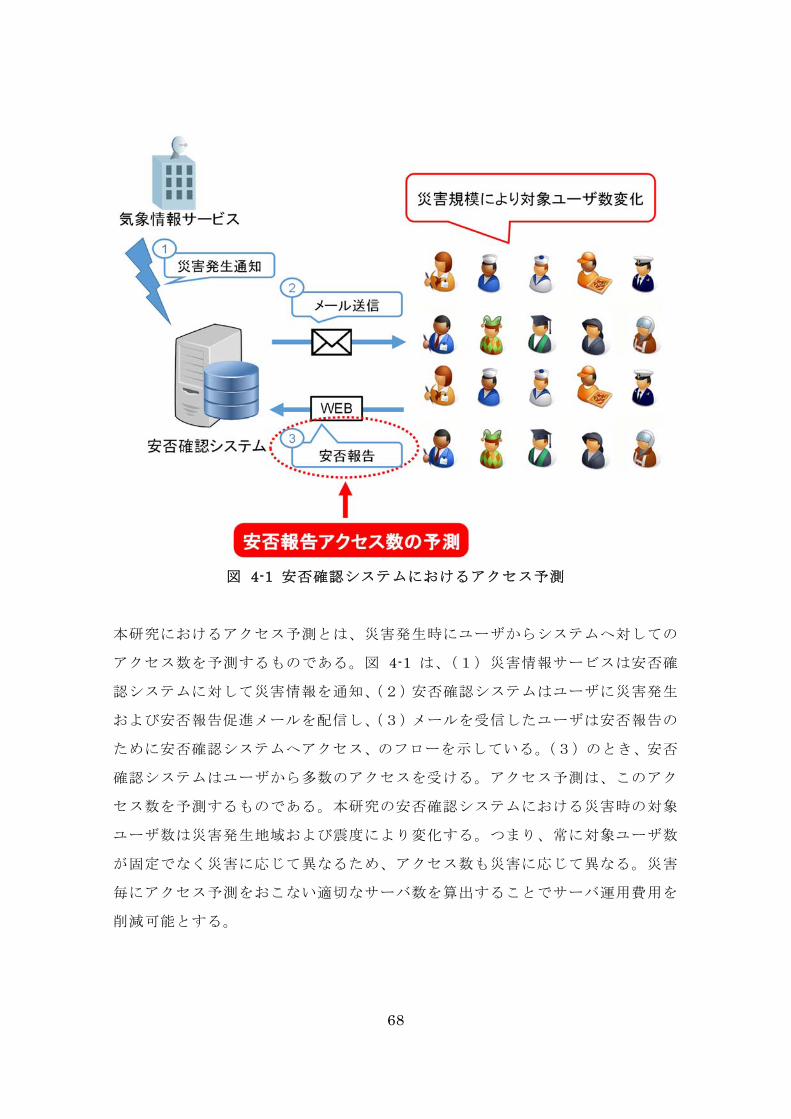
68
図 4-1 安否確認システムにおけるアクセス予測
本研究におけるアクセス予測とは、災害発生時にユーザからシステムへ対しての
アクセス数を予測するものである。図 4-1 は、(1)災害情報サービスは安否確
認システムに対して災害情報を通知、(2)安否確認システムはユーザに災害発生
および安否報告促進メールを配信し、(3)メールを受信したユーザは安否報告の
ために安否確認システムへアクセス、のフローを示している。(3)のとき、安否
確認システムはユーザから多数のアクセスを受ける。アクセス予測は、このアク
セス数を予測するものである。本研究の安否確認システムにおける災害時の対象
ユーザ数は災害発生地域および震度により変化する。つまり、常に対象ユーザ数
が固定でなく災害に応じて異なるため、アクセス数も災害に応じて異なる。災害
毎にアクセス予測をおこない適切なサーバ数を算出することでサーバ運用費用を
削減可能とする。

69
4.3. アクセス予測モデル
4.3.1. アクセス分布特性
アクセス予測モデルは、過去災害データの分析からアクセス傾向をモデル化し、
災害発生後システムに対してのアクセス分布を予測する。アクセス分布の予測に
は過去災害時のアクセス分布特性の把握が必要である。図 4-2 は災害発生時の安
否報告アクセス分布である。
図 4-2 災害時のアクセス分布
アクセス分布は Web サーバに用いている Apache [92]のログファイルから抽出し
た。図 4-2 からアクセス分布は安否確認システムからの安否報告促進メール送信
を起点(0 分時)とし、しばらくしてピークを迎え時間経過とともに減衰する。
ある動作を起点としたシステムへのアクセス分布に対して先行研究 [93]では正
実ア
クセ
ス
0
100
200
300
400
500
600
700
800
900
1,000
0 60 120 180 240 300 360
安否報告数
経過時間(分)
2015年5月30日 小笠原沖地震 震度5強・発生時刻:5/30 20:23・対象ユーザ : 5,955名(サーバ2)・メール送信開始時刻 : 5/30 20:45:15・メール送信終了時刻 : 5/30 20:48:45
実アクセス
70
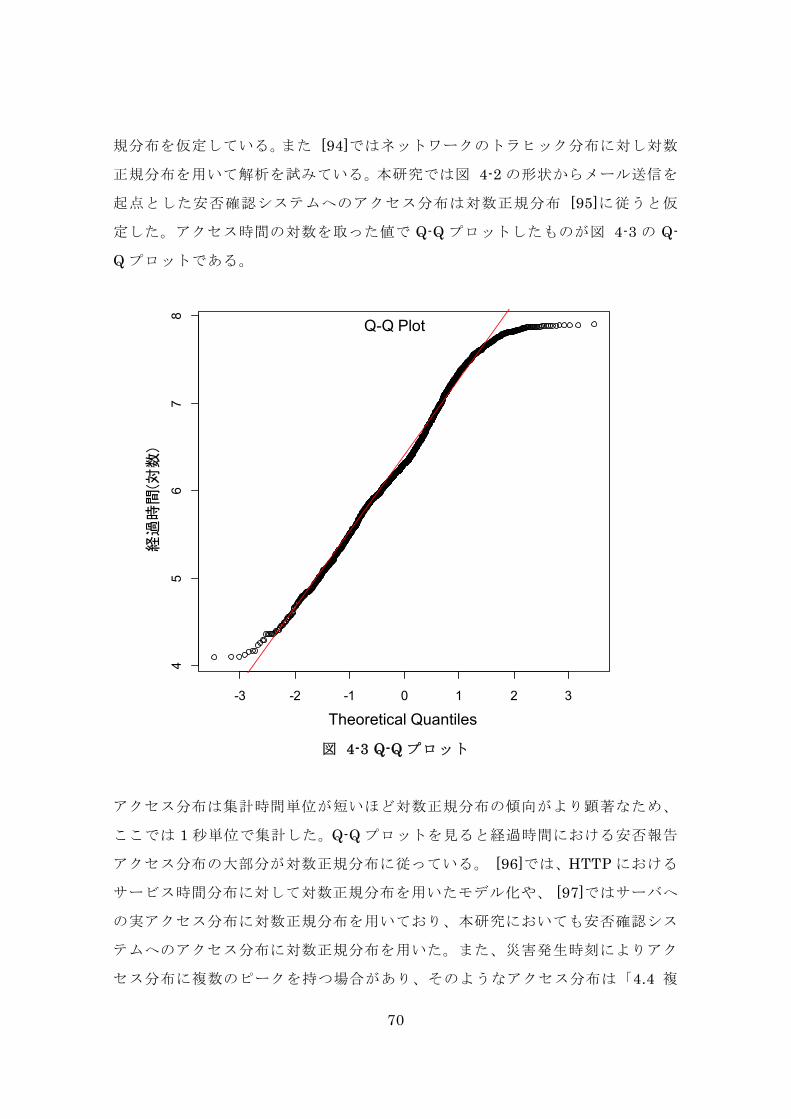
規分布を仮定している。また [94]ではネットワークのトラヒック分布に対し対数
正規分布を用いて解析を試みている。本研究では図 4-2 の形状からメール送信を
起点とした安否確認システムへのアクセス分布は対数正規分布 [95]に従うと仮
定した。アクセス時間の対数を取った値で Q-Q プロットしたものが図 4-3 の Q-
Q プロットである。
図 4-3 Q-Q プロット
アクセス分布は集計時間単位が短いほど対数正規分布の傾向がより顕著なため、
ここでは 1 秒単位で集計した。Q-Q プロットを見ると経過時間における安否報告
アクセス分布の大部分が対数正規分布に従っている。 [96]では、HTTP における
サービス時間分布に対して対数正規分布を用いたモデル化や、 [97]ではサーバへ
の実アクセス分布に対数正規分布を用いており、本研究においても安否確認シス
テムへのアクセス分布に対数正規分布を用いた。また、災害発生時刻によりアク
セス分布に複数のピークを持つ場合があり、そのようなアクセス分布は「4.4 複
-3 -2 -1 0 1 2 3
45
67
8
Theoretical Quantiles
経過
時間
(対数
)
Q-Q Plot

71
数のピークを持つ分布でのアクセス予測」で言及する。
4.3.2. 対数正規分布を用いたアクセス予測モデルの構築
安否報告アクセスの分布を予測するため、対数正規分布の確率密度関数に必要
なパラメータ決定について明らかにする。対数正規分布の定義式は、確率密度関
数 f(x)は式(1)、 頻値 M は式(2)、平均値 E は式(3)となる。
−−= 2
2
2)(lnexp
21)(
σμ
σπx
xxf (1)
)exp( 2σμ −=M (2)
)2
exp(2σμ +=E (3)
μは正規分布の平均値、σは正規分布の標準偏差である。式(1)の確率密度関数に対
してパラメータμ、σを与え確率変数 x(分)の関数としてアクセス分布の確率を
求める。μ、σは、式(2)、式(3)を連立して解くと式(4)、式(5)となる。
3))ln(*2)(ln( EM +=μ (4)
3))ln()(ln(*22 ME −=σ (5)
式(4)、式(5)へ 頻値 M と平均値 E を与えることでμ、σが決定できる。次に災害
発生時、その災害に対しての 頻値 M と平均値 E の算出方法を示す。
頻値 M はアクセスが も多い時間であり、平均値 E は平均アクセス数の時
間となる。 頻値 M と平均値 E は過去災害の対象ユーザ数(TU)と災害発生後

72
のアクセス分布を分析し算出する。表 4-1 は 2015 年の災害および訓練時のアク
セスデータを 10 分間隔で集計したものであり、各パラメータを求めるための分
析対象データである。 頻値 M は表 4-1 から災害および訓練の対象ユーザ数 TU
に因らず 20 分以下でピークを迎えている。したがって今回構築するアクセス予
測モデルでは 頻値 M を固定値 20 とする。平均値 E は、アクセスが開始された
時間からアクセス数が 1 桁台になる時間までのアクセス数の平均値を取り、その
平均値のアクセスがあった時間とする。表 4-1 から平均値 E は、対象ユーザ数
TU に影響を受けない 頻値 M と異なり、対象ユーザ数 TU に応じて値に開きが
ある。

73
表 4-1 過去災害・訓練データ(2015 年)
区分 対象組織,災害 震度 日時 TU M E ANmax D(E-M) PR(ANmax/TU)
訓練 教育機関 A - 2015/4/3 14:01 1,311 20 45 503 25 0.3836 訓練 教育機関 B - 2015/4/10 8:06 371 10 45 78 35 0.2102 訓練 教育機関 C - 2015/7/17 12:30 15,308 20 115 1,425 95 0.0930 訓練 企業 A - 2015/4/15 12:00 229 10 25 98 15 0.4279 訓練 企業 B - 2015/4/19 20:01 794 10 60 199 50 0.2506 訓練 企業 C - 2015/4/22 11:51 229 10 35 83 25 0.3624 訓練 企業 D - 2015/4/30 13:49 129 20 40 26 20 0.2015 災害 宮城県沖(サーバ 1) 5 強 2015/5/13 6:12 717 10 50 160 40 0.2231 災害 奄美大島近海(サーバ 1) 5 弱 2015/5/22 22:28 565 10 30 149 20 0.2637 災害 奄美大島近海(サーバ 2) 5 弱 2015/5/22 22:28 584 10 40 121 30 0.2071 災害 埼玉県北部(サーバ 1) 5 弱 2015/5/25 14:28 510 20 40 70 20 0.1372 災害 埼玉県北部(サーバ 2) 5 弱 2015/5/25 14:28 752 10 35 176 25 0.2340 災害 小笠原諸島(サーバ 1) 5 強 2015/5/30 20:23 1,740 20 50 303 30 0.1741 災害 小笠原諸島(サーバ 2) 5 強 2015/5/30 20:23 5,955 20 60 951 40 0.1596

74
図 4-4 は対象ユーザ数 TU と、平均値 E から 頻値 M を引いた差(D)の関係
である。
図 4-4 TU と D(E-M)の関係
図 4-4 の近似式が式(6)となり対象ユーザ数 TU から D を求めることで平均値 E
が決まる。
0.2802*6039.4 TUME += (6)
これまでで、災害発生時その災害の対象ユーザ数 TU を基に 頻値 M と平均値
E を推定できる。また求めた 頻値 M と平均値 E を式(4)、式(5)に代入するとμ
とσが決定し、同時に式(1)の確率密度関数のパラメータが決まる。
D = 4.6039 * TU0.2802
0
10
20
30
40
50
60
70
80
90
100
0 2,000 4,000 6,000 8,000 10,000 12,000 14,000 16,000
D(E
-M)
対象ユーザ(人)TU

75
次に災害時のアクセス分布曲線を決定するために式(1)に付与する係数 A を算
出する。A は式(1)を対象ユーザ数 TU に応じたピークアクセス数に合わせるた
めの係数であり、式(7)が x 分時のアクセス数 AN を予測するアクセス予測モデ
ルとなる。
)(* xfAAN = (7)
係数 A は式(7)の x に 頻値 M を代入し、AN がピークアクセス数(ANmax)と
なるよう求める。表 4-1 からピークアクセス数 ANmax は対象ユーザ数 TU が
増加するほど対象ユーザ数 TU に対する割合(PR)が減少していく傾向にあ
り、図 4-5 の関係となる。
図 4-5 TU と PR(ANmax/TU)の関係
PR = 0.8305 * TU-0.199
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0 2,000 4,000 6,000 8,000 10,000 12,000 14,000 16,000
PR (A
Nmax
/ TU
)
対象ユーザ(人)TU

76
図 4-5 の近似式にて対象ユーザ数 TU からピークアクセス数 ANmax を求め
る。例として、アクセス予測モデル 式(7)を用いて対象ユーザ数 20,000 人での
アクセス分布を予測すると図 4-6 の各パラメータおよびアクセス分布曲線とな
る。
図 4-6 ユーザ数 20,000 名でのアクセス分布予測
各時間の予測アクセス分布に対して許容可能なサーバ数を割当てることでアクセ
ス数に応じた負荷分散をおこなう。
4.3.3. 対数正規分布の仮定
災害発生後の安否確認システムへのアクセス分布は図 4-2 から対数正規分布
に従うと仮定した。対数正規分布への仮定の背景は、図 4-2 のアクセス分布が図
4-3 の Q-Q プロットにおいてほぼ直線に乗るためであるが、シャピロ‐ウィルク
での正規性検定では p 値は 0.05 以下となり正規性があるとはいえない。ここで
0
500
1,000
1,500
2,000
2,500
0 60 120 180 240 300 360 420 480 540 600
予測アクセス
予測
アク
セス
AN
経過時間(分)x
TU 20,000M 20E 93.83ANmax 2,314.53 μ 4.02σ 1.01A 197,197.31
パラメータ

77
図 4-3 の Q-Q プロットが直線から外れるのは 7.6 付近からとなる。7.6 はアクセ
ス時間の対数を取った値なので Exp(7.6)≒2,000(秒)となり、災害発生後約 30
分後となる。図 4-2 の災害では発生から 30 分後ではアクセスが少なくなってお
り、アクセス予測モデルでのオートスケーリングをおこなうことなく標準構成の
サーバ数でアクセスを許容可能である。つまり災害発生後、システムへのアクセ
ス分布は 繁忙期間において対数正規分布に従っており、この期間において適切
にアクセス予測ができれば安否確認システムにおける災害時の負荷分散は問題な
いと考える。以上が厳密な正規性ではないものの対数正規分布を基にアクセス予
測モデルを構築した理由である。また現状の調査では対象ユーザ数が多いほどア
クセス分布が Q-Q プロットにおいて直線になる傾向があり、たとえば数万名規模
であれば正規性が認められる可能性がある。対象ユーザ数が多いほど対数正規分
布に近づけばアクセス予測モデルの精度を向上でき、さらに適切なサーバ数算出
が期待できる。

78
4.4. 複数のピークを持つ分布でのアクセス予測
4.4.1. 混合対数正規分布を用いたアクセス予測モデルの構築
災害の発生状況によっては安否確認システムへのアクセスピークが 1 つでなく
複数ピークの場合がある。図 4-7 は深夜 3 時 00 分に発生した災害のアクセス分
布である。
図 4-7 2 つのピークを持つアクセス分布
図 4-7 は、災害発生直後に第 1 のアクセスピークがあり、数時間後に第 2 のアク
セスピークがあることを示している。第 2 ピークは深夜 3 時 00 分の災害発生か
ら約 230 分後であり、朝 7 時前後である。これは、災害時に就寝していたユーザ
が朝起床した後にシステムへアクセスし第 2 ピークが生じていることを意味して
いる。このような複数のアクセスピークを持つ災害に対して複数の対数正規分布
0
50
100
150
200
250
300
350
0 100 200 300 400 500 600 700 800
実ア
クセ
ス
経過時間(分)
実アクセス
第1ピーク
第2ピーク
2015年7月13日 大分県南部地震 震度5強・発生時刻:7/13 2:52・対象ユーザ : 5,432名・メール送信開始時刻 : 7/13 03:00:08・メール送信終了時刻 : 7/13 03:05:27

79
を用いたアクセス予測モデルを構築する。
アクセス分布から対数正規分布モデルを構築する仮定および手法は、単一のア
クセスピークを予測する前章「4.3.2 対数正規分布を用いたアクセス予測モデル
の構築」と同様である。複数のアクセスピークを予測するアクセス予測モデルは、
単一のアクセス予測モデルを複数組み合わせることで構築する。先行研究 [98]
[99]では災害時の Twitter [100]の複数ツイートの集中に対して、混合対数正規分
布モデルでの分析を試みている。本研究では、先行研究を参考にして、2 つのピ
ークを持つ災害時のアクセス分布に対して混合対数正規分布を用いて 2 つのピー
クを持つアクセス予測モデルを構築する。
式(1)を基本として混合対数正規分布を式(8)で表す。ここで 2 ピークへの適応
を考慮して 2 つの対数正規分布からなるものとした。
)()()( xgxfxF βα −= (8)
f(x)は第 1 ピークを含む対数正規分布で、g(x)は第 2 ピークを含む対数正規分布モ
デルである。α、βは F(x)の累積確率密度を 1 にするための重み付け係数である。
αとβはα+β=1 という条件を持つものとする。αとβは、2 つのピークを有する F(x)
の微分を取ることにより決定する。F'(x_1)=dF(x_1)/dx であるから、第 1 ピーク
の x 座標を x_1、第 2 ピークの x 座標を x_2 とすると、式(9)、(10)となる。
0)1_()1_()1( =′−′=′ xgxfx_F βα (9)
0)2_()2_()2_( =′−′=′ xgxfxF βα (10)
式(9)、(10)が等しいことと、β=1−αの関係を代入すると式(11)、(12)のように表す
ことができる。

80
( ) ( ){ }( ) ( ) ( ) ( ){ }2_1_2_1_
2_1_xgxgxfxf
xgxg′−′+′−′
′−′=α (11)
( ) ( ){ }( ) ( ) ( ) ( ){ }2_1_2_1_
2_1_xgxgxfxf
xfxf′−′+′−′
′−′=β (12)
したがって F(x)は式(13)のように表せる。
( ) ( ){ }( ) ( ) ( ) ( ){ } ( )
( ) ( ){ }( ) ( ) ( ) ( ){ } ( )
∗
′−′+′−′′−′
−
∗
′−′+′−′′−′
=
xgxgxgxfxf
xfxf
xfxgxgxfxf
xgxgxF
2_1_2_1_2_1_
2_1_2_1_2_1_)(
(13)
ここで、2 つの対数正規分布を混合するため、式(8)は直感的には”+”符号と考えら
れる。しかしながら、以下の理由で本研究のアクセス予測モデルは”−”符号として、
混合対数正規分布モデルを構築した。まず、αとβは f(x)と g(x)がどのくらいの割
合で存在しているかを表すため、α+β=1 で、α、βともに正でなくてはならない。
式(8)の演算子を”+”とするとα、βは式(11a)、(12a)となる。
( ) ( ){ }( ) ( ) ( ) ( ){ }1_2_2_1_
1_2_xgxgxfxf
xgxg′−′+′−′
′−′=α (11a)
( ) ( ){ }( ) ( ) ( ) ( ){ }2_1_1_2_
2_1_xfxfxgxg
xfxf′−′+′−′
′−′=β (12b)
つぎに、α>0 の条件は、式(11a)の「分母・分子ともに正(条件 A)」、あるいは「と
もに負(条件 B)」となる。ここで g’(x_1)は第 1 ピークにおける g(x)の x_1 にお
ける接線の傾きなので正、f’(x_2)は第 2 ピークにおける f(x)の x_2 における接線

81
の傾きなので負となる。つぎに、f’(x_1)は、第 1 ピークにおける f(x)の接線の傾
きを表す。仮に f(x)と g(x)が離れている場合、つまり第 1 ピークと第 2 ピークの
相互影響がない場合、この値は 0 に近づくと考えられる。一方、相互影響がある
場合、g(x_1)の影響を受けて 0 からずれていくと考えられる。しかしながら、そ
の影響度はそれほど大きくなく、f’(x_1)の値を劇的に変えてしまうほどではない
と考える。これは、これまでの過去の多くの災害データの分布がその傾向を示し
ているためである。また、g’(x_2)は、第 2 ピークにおける g(x)の接線の傾きを表
す。仮に f(x)と g(x)が離れている場合(相互影響がほぼない場合)、この値は 0 に
近づくと考えられる。一方、相互影響がある場合、f(x_2)の影響を受けて 0 からず
れていくと考えられる。しかしながら、その影響度はそれほど大きくなく、g’(x_2)
の値を劇的に変えてしまうほどではないと考える。これは、これまでの過去の多
くの災害データの分布がその傾向を示しているためである。このことから、f’(x_1)
と f’(x_2)の大小関係としては、はるかに f’(x_2)が大きく、同様に、g’(x_1)と g’(x_2)
では、g’(x_1)が大きくなる。したがって、f’(x_1)と g’(x_2)は微小と捉え式(11a)を
近似した。この場合、条件 A は成立しない。つまり、条件 B は、g'(x_1) > 0 か
つ g'(x_1)+f'(x_2) > 0、故に g'(x_1) > 0 かつ |g'(x_1)| > |f'(x_2)| (条件 X)とな
る。β>0 の条件は、αと同様に考えると式(12a)は条件 A となる。つまり、条件 A
は、f'(x_2) < 0 かつ g'(x_1)+f'(x_2) < 0、故に f'(x_2) < 0 かつ |g'(x_1)| < |f'(x_2)|
(条件 Y)となる。したがって、条件 X と Y は矛盾があり、α>0、β>0 を同時に満
たすことができないため、”+”符号は問題がある。一方、式(8)の演算子が”−”符号
の場合、α、βは式(11)、(12)となる。g'(x_1) > 0、f'(x_2) < 0 のため、式(11)、(12)
とも条件 A となりα>0、β>0 となるため、"−"符号であれば問題がない。以上が 2
つの対数正規分布に対して、”−”符号で混合した理由である。
式(13)はあくまで確率分布を表すに過ぎず、アクセス分布を表すためにはさら
に重み付け係数が必要となる。そこで、安否報告遷移は式(14)のように表す。
)()()( xFBAxH ∗+= (14)
A は主に第 1 ピーク調整のための係数であり、B は主に第 2 ピーク調整のための

82
係数である。式(14)を展開すると式(15)となる。
)()()()()( xgBxfBxgAxfAxH βαβα −+−= (15)
ここで、式(15)の A と B に対しても、式(11)、(12)の x_1、x_2 における微分係数
の大小関係の考え方を適用し、x_1 地点における大小関係は Aαf(x) >> Aβg(x)、
x_2 地点における大小関係は Bβg(x) >> Bαf(x)、と考える。したがって、仮に相
互影響があったとしても上記のような大小関係のため、式(16)のように近似でき
ると考える。したがって式(16)が 2 つのピークを持つアクセス予測モデルとなる。
)()()( xgBxfAxH βα ∗−∗= (16)
式(16)へ第 1 ピーク時の x_1、第 2 ピーク時の x_2 を代入し連立して解くと,
A および B が決定する。
4.4.2. 実アクセス分布への適合
2 つのピークを持つ実災害のアクセス分布に対して、混合対数正規分布を用い
たモデルの適合性を確認した。適合の対象となるアクセス分布は大分県地震(図
4-7)とある企業の防災訓練のデータ(図 4-8)を用いた。
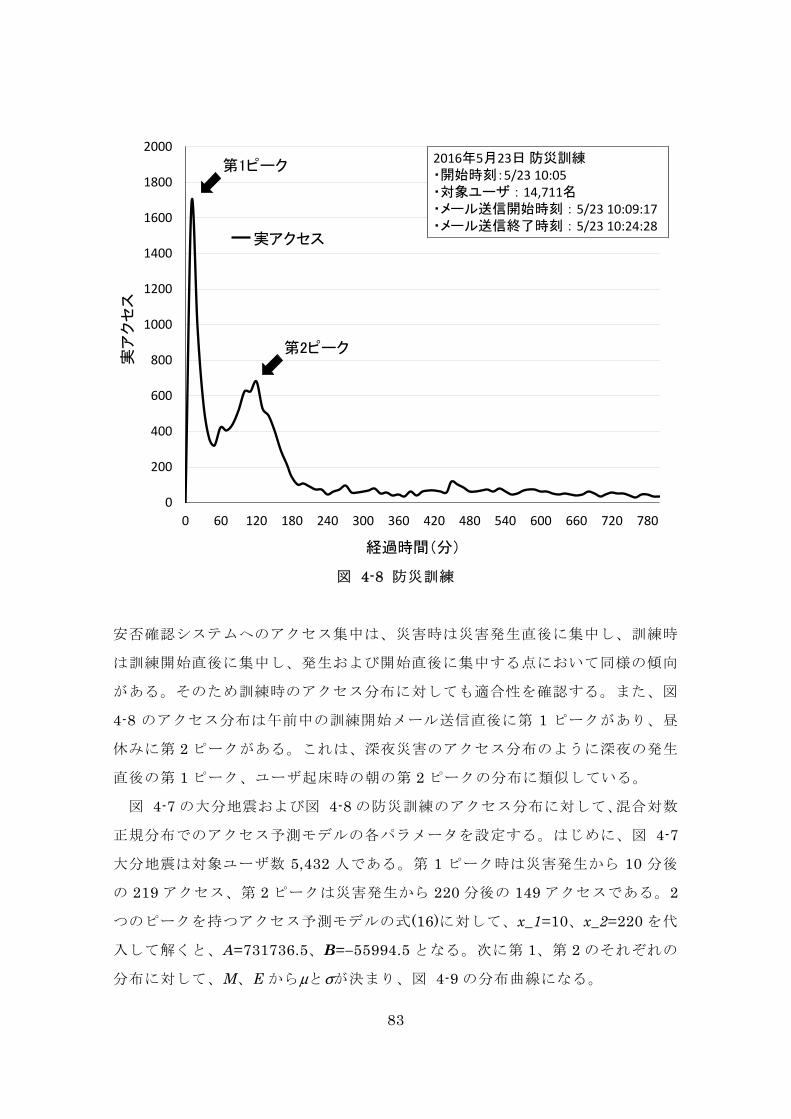
83
図 4-8 防災訓練
安否確認システムへのアクセス集中は、災害時は災害発生直後に集中し、訓練時
は訓練開始直後に集中し、発生および開始直後に集中する点において同様の傾向
がある。そのため訓練時のアクセス分布に対しても適合性を確認する。また、図
4-8 のアクセス分布は午前中の訓練開始メール送信直後に第 1 ピークがあり、昼
休みに第 2 ピークがある。これは、深夜災害のアクセス分布のように深夜の発生
直後の第 1 ピーク、ユーザ起床時の朝の第 2 ピークの分布に類似している。
図 4-7 の大分地震および図 4-8 の防災訓練のアクセス分布に対して、混合対数
正規分布でのアクセス予測モデルの各パラメータを設定する。はじめに、図 4-7
大分地震は対象ユーザ数 5,432 人である。第 1 ピーク時は災害発生から 10 分後
の 219 アクセス、第 2 ピークは災害発生から 220 分後の 149 アクセスである。2
つのピークを持つアクセス予測モデルの式(16)に対して、x_1=10、x_2=220 を代
入して解くと、A=731736.5、B=−55994.5 となる。次に第 1、第 2 のそれぞれの
分布に対して、M、E からμとσが決まり、図 4-9 の分布曲線になる。
0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 60 120 180 240 300 360 420 480 540 600 660 720 780
実ア
クセ
ス
経過時間(分)
実アクセス
2016年5月23日 防災訓練・開始時刻:5/23 10:05・対象ユーザ : 14,711名・メール送信開始時刻 : 5/23 10:09:17・メール送信終了時刻 : 5/23 10:24:28
第1ピーク
第2ピーク

84
図 4-9 大分地震の分布とアクセス予測モデル
アクセス予測モデルは実分布に対して許容する曲線になっており、実分布への適
合性が高いといえる。
次に図 4-8 の防災訓練では対象ユーザ数は 14,711 人である。第 1 ピーク時は
訓練開始から 10 分後の 1,680 アクセス、第 2 ピーク時は訓練発生から 120 分後
の 681 アクセスである。大分地震と同様に式(16)に対して、x_1=10、x_2=120 を
代入して解くと、A= 3,535,204.1、B=−126719 となる。実分布とアクセス予測モ
デルの曲線は図 4-10 となる。
0
50
100
150
200
250
300
350
0 100 200 300 400 500 600 700 800
混合対数正規分布
2015年7月13日 大分県南部地震 震度5強・発生時刻:7/13 2:52・対象ユーザ : 5,432名・メール送信開始時刻 : 7/13 03:00:08・メール送信終了時刻 : 7/13 03:05:27
実ア
クセ
ス
経過時間(分)
第1ピーク
第2ピーク
実アクセス

85
図 4-10 訓練時の分布とアクセス予測モデル
訓練時の分布においても実災害時の分布と同様にアクセス予測モデルの適合性が
高いといえる。
これまで第 2 ピークをもつアクセス分布に対してアクセス予測モデルの適合性
を検証してきた。現状の調査では第 2 ピークが発生する要因として災害発生時刻
や組織特性が影響していると推測している段階であり、本章の適合性評価におい
てもデータ数が乏しいためモデルの信頼度も発展途上である。しかしながら、第
2 ピークをもつ災害は少数データながら発生している事実もあり、たとえば多数
ユーザが対象となった災害の場合、第 1 ピークのみのアクセス予測モデルではア
クセス予測が困難となる可能性も秘めている。第 2 ピークの予測については今後
も検討すべき課題であり、第 1 ピークのみの場合と第 2 ピークをもつ災害の場合
とで、たとえば災害発生時刻に応じて使用するモデルを切り替えるなど、複数モ
デルを用いて状況によりアクセス予測ロジックを選択する仕様を検討していきた
い。
0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 60 120 180 240 300 360 420 480 540 600 660 720 780
実ア
クセ
ス
経過時間(分)
2016年5月23日 防災訓練・開始時刻:5/23 10:05・対象ユーザ : 14,711名・メール送信開始時刻 : 5/23 10:09:17・メール送信終了時刻 : 5/23 10:24:28
第1ピーク
第2ピーク
混合対数正規分布
実アクセス
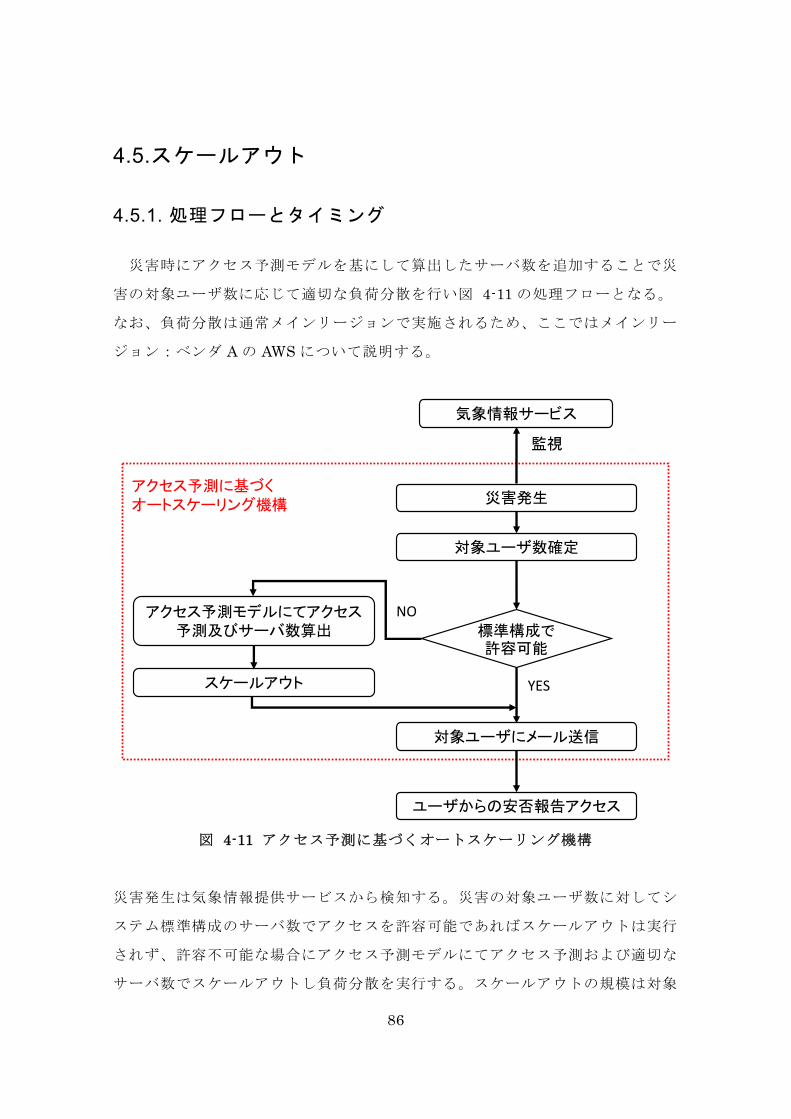
86
4.5. スケールアウト
4.5.1. 処理フローとタイミング
災害時にアクセス予測モデルを基にして算出したサーバ数を追加することで災
害の対象ユーザ数に応じて適切な負荷分散を行い図 4-11 の処理フローとなる。
なお、負荷分散は通常メインリージョンで実施されるため、ここではメインリー
ジョン:ベンダ A の AWS について説明する。
図 4-11 アクセス予測に基づくオートスケーリング機構
災害発生は気象情報提供サービスから検知する。災害の対象ユーザ数に対してシ
ステム標準構成のサーバ数でアクセスを許容可能であればスケールアウトは実行
されず、許容不可能な場合にアクセス予測モデルにてアクセス予測および適切な
サーバ数でスケールアウトし負荷分散を実行する。スケールアウトの規模は対象
災害発生
対象ユーザ数確定
アクセス予測モデルにてアクセス予測及びサーバ数算出
スケールアウト
対象ユーザにメール送信
ユーザからの安否報告アクセス
アクセス予測に基づくオートスケーリング機構
監視
気象情報サービス
標準構成で許容可能
NO
YES

87
ユーザ数に応じて変化する。負荷分散は、AWS のロードバランシングサービス
である Elastic Load Balancing(ELB [101])配下の各 DC に Web サーバを同
数配置することで均等に実行される(図 4-12)。
図 4-12 負荷分散
アクセス予測モデルは、過去災害および訓練時のアクセス分布を分析し構築した
確率分布モデルでありあらかじめシステムへ組み込まれている。このため対象ユ
ーザ数をモデルに与えるだけでサーバ数算出が可能であり、災害状況下での迅速
なスケールアウトを実現する。また、スケールアウト完了後に対象ユーザへメー
ル送信することで、負荷分散環境構築前のアクセス集中を回避する。ここで、ア
クセス集中の回避策の 1 つとして、各ユーザへのメール送信に時間差を設ける
ことで、各ユーザのシステムへのアクセス間隔を分散する方法がある。この方法
は、システムへのアクセス集中を回避し同時にシステム負荷向上も回避すること
が可能であるが、時間差でのメール送信は一斉メール送信の場合と比較して全ユ
コントロールサーバ
安否確認システム
LB
DNS
DC_1プライマリ
DDS
DDSDDS DDS
Web
DC_2セカンダリ
ベンダA
ベンダB
コントロールサーバ
安否確認システム
ベンダC
コントロールサーバ
安否確認システム
Web WebWeb
WebWeb
Web
負荷分散

88
ーザへの送信完了に時間がかかる。安否確認システムの使用ユーザは災害発生
後、迅速なメール通知の要望が多い。極力速くユーザへ通知することで避難指示
や次策検討の速度向上を期待するためである。このため、メール送信は極力迅速
に完了させることが望ましい。一斉メール配信ではユーザへほぼ同時刻にメール
通知されるため、システムへのアクセスが集中し高負荷となるが、アクセス予測
モデルを用いて予想されるアクセスに対してサーバ数を増減することで、アクセ
ス集中に対する負荷分散が可能である。つまり、災害時にはやい時間でのユーザ
へのメール通知を実現し、さらにアクセス集中に対する負荷分散を可能とするア
クセス予測モデルは、時間差メールでの負荷分散と比較し、災害時のシステム対
策として利点が多い。
Web サーバをスケールアウトするタイミングは表 4-2 に示すように、サーバ
を平常時から常に複数台配置する常時配置、アクセス集中後に追加する事後追
加、アクセス集中前に追加する事前追加がある。
表 4-2 スケールアウトのタイミング
常時配置 事後追加 事前追加 (予測なし)
事前追加 (予測あり)
利便性 〇 × △ 〇 費用 × 〇 〇 〇
常時配置はアクセスが少ない平常時は余剰リソースとなり高費用となる。アクセ
ス集中後の事後追加は、システムが高負荷となった状態での事後対応のためレス
ポンスが低下しユーザ利便性を損ねる。アクセス予測なしの事前追加では、サー
バ数算出に明確な根拠が無いためリソース余剰もしくは不足の懸念がある。本シ
ステムで用いるアクセス予測ありの事前追加では、アクセス予測モデルを用いて
状況に応じた必要サーバ数を算出するため、適切なリソース管理が可能である。
また、AWS EC2 は、起動時間にて費用が積算されるため使用時のみのサーバ起
動で費用削減が可能となる。つまりアクセス集中前にアクセス予測をすることで
適切なサーバ数でのスケールアウトを実現し、利便性だけでなく適切な費用での
運用が可能となる。

89
4.5.2. サーバのアクセス許容量
Web システムへのリソース管理において、先行研究 [102]ではサーバ単体の
ベンチマーク結果からシステム全体のリソース管理のモデル化を試みている。本
研究では先行研究を参考に、予測で得られたアクセス数に対しサーバ 1 台のア
クセス許容量から必要台数を算出する。本研究でのアクセス許容量とは、単位時
間あたりに処理可能な安否報告アクセス数とする。ここで、メインリージョン:
ベンダ A で採用するサーバは AWS EC2 タイプ t2.シリーズの t2.small とする。
t2.small を選定した理由は、EC2 の汎用用途向けのインスタンスタイプに対し
て UnixBench [103]の計測結果を基にして決定した。表 4-3 は UnixBench での
測定結果である。
表 4-3 インスタンスタイプ別 UnixBench 計測結果
インスタンスタイプ vCPU メモリ
(GiB)
System Benchmarks Index Score 費用
($/時間)
t2.small 1 2 1702.30 0.034
t2.medium 2 4 2536.00 0.068
t2.large 2 8 2537.20 0.136
m3.medium 1 3.75 848.90 0.077
m3.large 2 7.5 1858.60 0.154
m3.xlarge 4 15 2945.00 0.308
m4.large 2 8 2025.00 0.14
m4.xlarge 4 16 3132.80 0.279
UnixBench は「System Benchmarks Index Score」が総合的なサーバ性能指標
となる。表 4-3 から「vCPU」の増加にともない「System Benchmarks Index
Score」も増加する。しかし、「vCPU」が倍になっても「System Benchmarks
Index Score」単純な倍にならない。つまり 2 つの「vCPU」タイプよりを 1 台
起動するよりも、1 つの「vCPU」タイプを 2 台起動するほうが、低コストで高
い性能を得ることができる。このため「vCPU」が 1 のタイプのうち、「System
Benchmarks Index Score」と 1 時間あたりのコストを考慮して、本システムで

90
は t2.small を採用した。なお、t2 シリーズは、CPU 使用率のベースラインが定
められており CPU 使用率がベースラインを超えた場合、バースト状態となる。
t2 シリーズにおけるバースト状態とは一時的に CPU 性能が向上する状態であ
り、AWS の CPU クレジットを消費して継続可能となる。バースト状態ではベ
ースラインを超えた CPU 使用が可能だが徐々に CPU クレジットを消費してい
きクレジットが尽きた場合、ベースライン以上の CPU 性能が発揮されない仕様
となる。本研究ではバースト状態でのアクセス許容量は考慮せず、t2.small のベ
ースラインとして定められている CPU 使用率 20%までの安否報告アクセス数を
1 台のアクセス許容量とする。なお、本研究では使用料金などから t2.small モ
デルを採用したが、今後クラウドベンダの仕様変更により新たな仕様のサーバが
登場することも予想され、その際使用勝手のよいサーバであれば採用サーバの変
更は十分にあり得る。今回は 1 例として t2.small での例とした。
本研究で対象とする安否システムへの災害時の安否報告アクセスは、主に
Web サーバの CPU リソースを消費する。したがってサーバ 1 台のアクセス許容
量は安否報告アクセス数に対して CPU 使用率の関係から算出する。図 4-13 は
10 分間の安否報告アクセス数と t2.small の CPU 使用率の関係である。

91
図 4-13 安否報告アクセス数と CPU 使用率
図 4-13 から CPU 利用率 20%時点でのアクセス許容量は約 200 安否報告アクセ
ス/10 分間となり、この値を基に必要台数を算出する。CPU 利用率 20%を超え
たバースト状態ではアクセス許容量は増加するが、上述のとおり CPU クレジッ
ト消費での性能低下があり制御が複雑化するためここではバースト状態にならな
い CPU 利用率 20%を基準とする。なお、負荷分散をおこなうメインリージョ
ン:ベンダ A の標準構成では Web サーバに 2 台の t2.small を用いるため、約
400 安否報告アクセス/10 分間が標準構成時のアクセス許容量となる。また、
安否確認システムへの災害発生後のアクセス数は分単位で増減が見られるため、
予測単位時間を細かくするほど詳細な予測が可能となるが、現状の EC2 課金単
位が 1 時間であることと、アクセス予測から Web サーバのスケールアウト完了
までに数分程度要することを考慮して、本研究ではアクセス予測を 10 分単位で
おこなうことを想定し、アクセス許容量を 10 分単位で算出した。
y = 0.0923x
0
5
10
15
20
25
0 50 100 150 200
CP
U使
用率
(%)
: y
10分間の安否報告アクセス(数) : x

92
4.6. 評価
4.6.1. サンプルデータ数でのモデル精度
アクセス予測モデルに用いている対数正規分布の確率密度関数の各パラメータ
は過去の災害データや訓練データから統計分析により決定している。たとえば平
均値 E は、対象ユーザ数 TU と D(平均値 E と 頻値 M の差)に相関があるこ
とから近似式で決定している。つまり、統計分析に用いるサンプルデータが多い
ほどアクセス予測モデルの精度向上が期待できる。そこで、「4.3.2 対数正規分布
を用いたアクセス予測モデルの構築」の単一の正規分布を用いたアクセス予測モ
デルに対して、データ数が少ない旧モデルとデータ数が多い新モデルの比較評価
をおこなった。なお、比較評価はサンプルデータ数の多少による精度比較であり、
用いたモデル式は旧モデルおよび新モデルとも「4.3.2 対数正規分布を用いたア
クセス予測モデルの構築」で構築した共通のモデル式である。サンプルデータ数
は、旧モデルは表 4-1 の 14 個、新モデルは旧モデルのデータに加えて表 4-4 の
合計 59 個である。旧モデルと新モデルの実災害データの適合比較として、図 4-14
の災害データ、図 4-15 の訓練データに各モデルを当てはめた。

93
表 4-4 過去災害・訓練データ(2015~2016 年)
区分 対象組織,災害 震度 日時 TU M E ANmax D(E-M) PR(ANmax/TU)
訓練 教育機関 D - 2015/9/1 13:10 1,682 10 65 502 55 0.2984 訓練 教育機関 E - 2016/7/8 12:30 15,557 20 130 852 110 0.0547 訓練 教育機関 F - 2016/11/4 13:37 19,770 20 125 1,462 105 0.0739 訓練 企業 E - 2015/9/1 11:02 542 10 40 82 30 0.1512 訓練 企業 F - 2015/9/11 9:01 481 10 30 132 20 0.2744 訓練 企業 G - 2015/9/15 16:00 885 10 60 111 50 0.1254 訓練 企業 H - 2015/9/17 12:04 1,547 20 85 126 65 0.0814 訓練 企業 I - 2015/10/15 13:00 584 10 45 112 35 0.1917 訓練 企業 J - 2015/11/4 10:30 4,264 10 80 507 70 0.1189 訓練 企業 K - 2016/1/15 20:00 776 10 50 231 40 0.2976 訓練 企業 L - 2016/5/31 7:00 413 10 20 223 10 0.5399 訓練 企業 M - 2016/6/1 10:00 4,152 10 65 472 55 0.1136 訓練 企業 N - 2016/6/20 10:00 4,213 10 95 432 85 0.1025 訓練 企業 O - 2016/9/6 14:37 15,118 20 105 2,089 85 0.1381 災害 東京湾地震(サーバ 1) 5 弱 2015/9/12 5:55 1,093 10 80 149 70 0.1363 災害 東京湾地震(サーバ 2) 5 弱 2015/9/12 5:55 575 10 25 115 15 0.2000 災害 青森県三八上北(サーバ 1) 5 弱 2016/1/11 15:26 551 10 60 107 50 0.1941 災害 青森県三八上北(サーバ 2) 5 弱 2016/1/11 15:26 480 10 30 110 20 0.2291 災害 浦河沖(サーバ 1) 5 弱 2016/1/14 12:25 550 10 25 167 15 0.3036 災害 浦河沖(サーバ 2) 5 弱 2016/1/14 12:25 480 10 30 220 20 0.4583
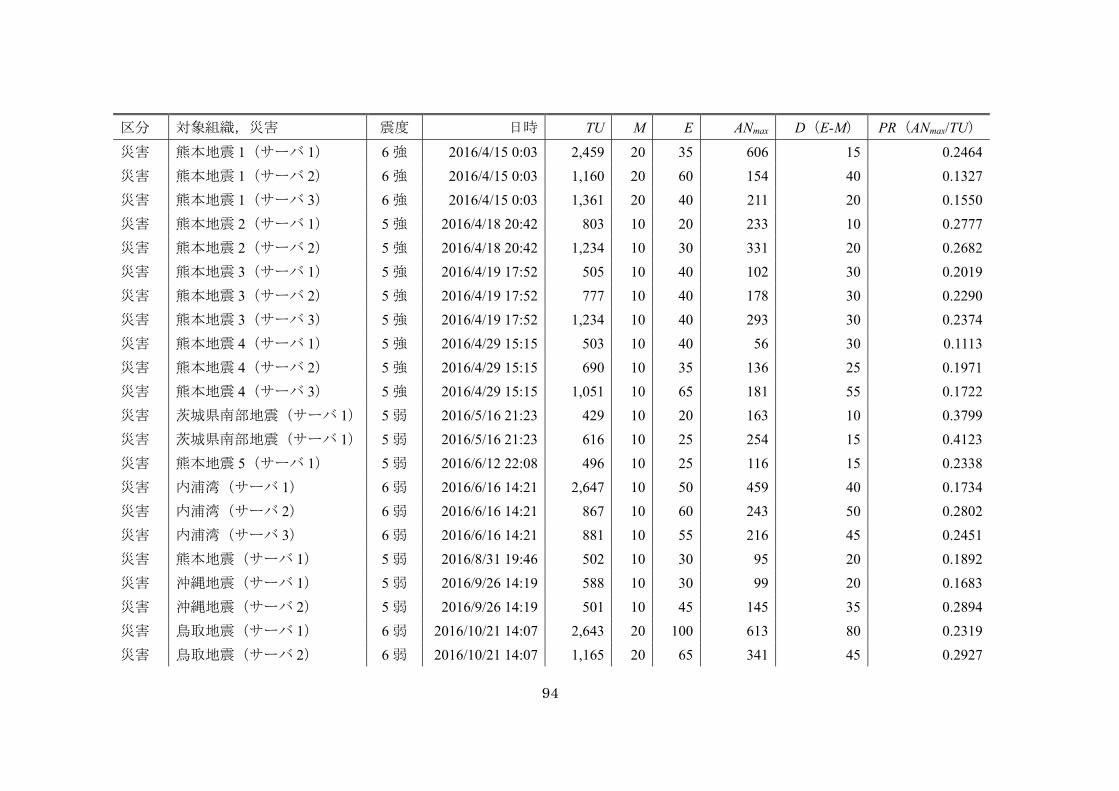
94
区分 対象組織,災害 震度 日時 TU M E ANmax D(E-M) PR(ANmax/TU) 災害 熊本地震 1(サーバ 1) 6 強 2016/4/15 0:03 2,459 20 35 606 15 0.2464 災害 熊本地震 1(サーバ 2) 6 強 2016/4/15 0:03 1,160 20 60 154 40 0.1327 災害 熊本地震 1(サーバ 3) 6 強 2016/4/15 0:03 1,361 20 40 211 20 0.1550 災害 熊本地震 2(サーバ 1) 5 強 2016/4/18 20:42 803 10 20 233 10 0.2777 災害 熊本地震 2(サーバ 2) 5 強 2016/4/18 20:42 1,234 10 30 331 20 0.2682 災害 熊本地震 3(サーバ 1) 5 強 2016/4/19 17:52 505 10 40 102 30 0.2019 災害 熊本地震 3(サーバ 2) 5 強 2016/4/19 17:52 777 10 40 178 30 0.2290 災害 熊本地震 3(サーバ 3) 5 強 2016/4/19 17:52 1,234 10 40 293 30 0.2374 災害 熊本地震 4(サーバ 1) 5 強 2016/4/29 15:15 503 10 40 56 30 0.1113 災害 熊本地震 4(サーバ 2) 5 強 2016/4/29 15:15 690 10 35 136 25 0.1971 災害 熊本地震 4(サーバ 3) 5 強 2016/4/29 15:15 1,051 10 65 181 55 0.1722 災害 茨城県南部地震(サーバ 1) 5 弱 2016/5/16 21:23 429 10 20 163 10 0.3799 災害 茨城県南部地震(サーバ 1) 5 弱 2016/5/16 21:23 616 10 25 254 15 0.4123 災害 熊本地震 5(サーバ 1) 5 弱 2016/6/12 22:08 496 10 25 116 15 0.2338 災害 内浦湾(サーバ 1) 6 弱 2016/6/16 14:21 2,647 10 50 459 40 0.1734 災害 内浦湾(サーバ 2) 6 弱 2016/6/16 14:21 867 10 60 243 50 0.2802 災害 内浦湾(サーバ 3) 6 弱 2016/6/16 14:21 881 10 55 216 45 0.2451 災害 熊本地震(サーバ 1) 5 弱 2016/8/31 19:46 502 10 30 95 20 0.1892 災害 沖縄地震(サーバ 1) 5 弱 2016/9/26 14:19 588 10 30 99 20 0.1683 災害 沖縄地震(サーバ 2) 5 弱 2016/9/26 14:19 501 10 45 145 35 0.2894 災害 鳥取地震(サーバ 1) 6 弱 2016/10/21 14:07 2,643 20 100 613 80 0.2319 災害 鳥取地震(サーバ 2) 6 弱 2016/10/21 14:07 1,165 20 65 341 45 0.2927
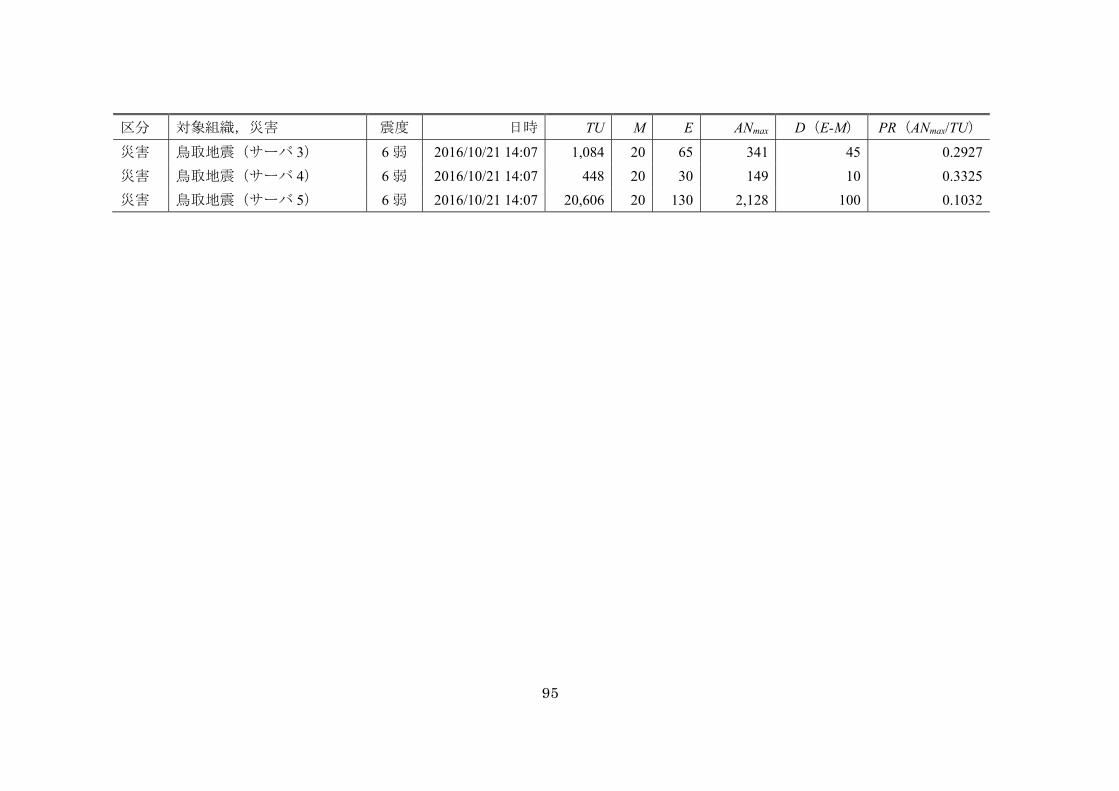
95
区分 対象組織,災害 震度 日時 TU M E ANmax D(E-M) PR(ANmax/TU) 災害 鳥取地震(サーバ 3) 6 弱 2016/10/21 14:07 1,084 20 65 341 45 0.2927 災害 鳥取地震(サーバ 4) 6 弱 2016/10/21 14:07 448 20 30 149 10 0.3325 災害 鳥取地震(サーバ 5) 6 弱 2016/10/21 14:07 20,606 20 130 2,128 100 0.1032
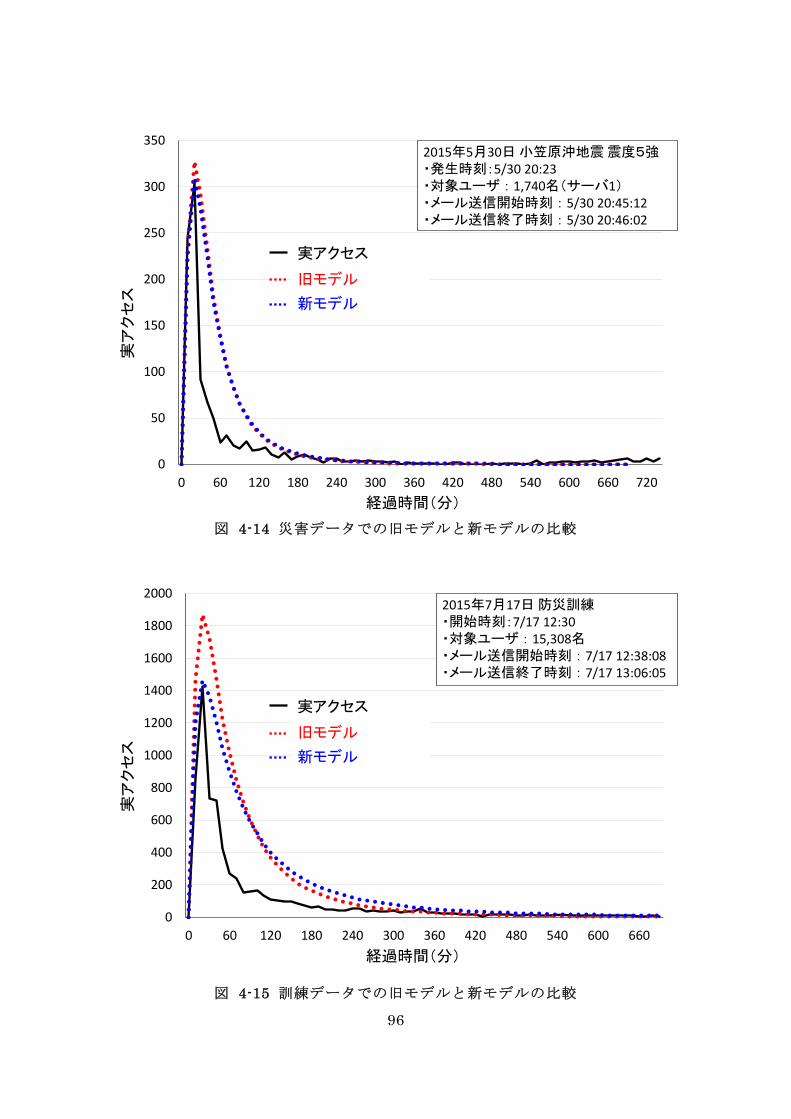
96
図 4-14 災害データでの旧モデルと新モデルの比較
図 4-15 訓練データでの旧モデルと新モデルの比較
0
50
100
150
200
250
300
350
0 60 120 180 240 300 360 420 480 540 600 660 720
実ア
クセ
ス
経過時間(分)
2015年5月30日 小笠原沖地震 震度5強・発生時刻:5/30 20:23・対象ユーザ : 1,740名(サーバ1)・メール送信開始時刻 : 5/30 20:45:12・メール送信終了時刻 : 5/30 20:46:02
旧モデル
実アクセス
新モデル
0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 60 120 180 240 300 360 420 480 540 600 660
実ア
クセ
ス
経過時間(分)
2015年7月17日 防災訓練・開始時刻:7/17 12:30・対象ユーザ : 15,308名・メール送信開始時刻 : 7/17 12:38:08・メール送信終了時刻 : 7/17 13:06:05
旧モデル
実アクセス
新モデル

97
旧モデルと比較すると、災害データおよび訓練データの両者とも新モデルが実ア
クセス分布に対して当てはまりがよく、新モデルの精度が向上していることが分
かる。また、1 万名を超える多ユーザデータでは旧モデル時はデータ数が少なか
ったため傾向把握が困難であったが、新モデル時にはデータ数が増えデータ傾向
も似通っていたため、多ユーザのアクセス予測においてもモデル精度向上が確認
できた。このことから、今後災害データや訓練データが集まるほどモデルへ与え
る各パラメータの傾向がより詳細に把握でき、モデル精度の向上が期待できる。
本研究のモデルは、過去の災害データや訓練データから統計分析により構築し、
実分布への適合においては一定の成果を得られた。しかし、パラメータの決定に
は単純な近似式を用いるなど精度およびロジックには課題がある。今後は、災害
や訓練のアクセス分布だけでなく、災害発生時刻や気候、対象ユーザの組織特性
などを考慮し、機械学習や AI などを用いてモデル精度向上を検討していきたい。
また、複数ピークを持つ災害においては、災害発生から各時点でその後のアクセ
ス分布の再予測も考えられ、その場合は再予測毎にパラメータを調整するなど、
今後も検討を重ねる予定である。
4.6.2. サーバ数算出
「4.6 評価」では、通常時に負荷分散を実施するメインリージョン:ベンダ A の
AWS についての各種評価結果を示す。また、各評価に用いたモデルは「4.6.1 サ
ンプルデータ数でのモデル精度」の新モデルである。サーバは 1 時間単位で使用
料金が加算される AWS の t2.small モデルを用いた。
実災害時のアクセス分布に対してアクセス予測モデルを用いてサーバ数を算出
する。図 4-16 は図 4-15 で用いた防災訓練での実際のアクセス分布と、対象ユ
ーザ数 15,308 名に対してアクセス予測モデルを用いて算出した 10 分単位の予
測アクセス分布である。

98
図 4-16 アクセスに対するサーバ数算出
EC2 は 1 時間単位で課金されるため、1 時間単位の予測アクセス分布に対して 1
台のサーバ許容量を基にサーバ数を算出する。図 4-16 の 0~60 分間の間では
高 1,459 アクセス/10 分間が予測される。t2.small は「4.5.2 サーバのアクセス
許容量」の評価結果のとおり 200 アクセス/10 分間の許容能力があるため、
t2.small を各 DC に 4 台ずつ合計 8 台で負荷分散をおこなう。ここで 0~60 分
の間で実アクセスと予測分布にわずかに差があるが、t2.small の単体の許容能力
内もしくは負荷分散に用いる合計台数の許容能力内でこの差を吸収可能なため、
モデルの精度としては妥当だと考える。次の 60~120 分間では 高 776 アクセ
スが予測されるため、各 DC に 2 台ずつ合計 4 台で負荷分散をおこなう。ま
た、アクセス予測モデルは災害対象ユーザに対するシステムへのアクセス分布を
予測するが、システムへのアクセスが災害以外の事態でおこなわれた場合は予測
の対象外となる。例として、インフルエンザによるパンデミック時の情報共有な
0
200
400
600
800
1000
1200
1400
1600
0 60 120 180 240 300 360 420 480 540 600 660
実ア
クセ
ス
経過時間(分)
実アクセス
予測アクセス
TU 15,308M 20E 129.09ANmax 1459.68 μ 4.23σ 1.11A 151,916.05
2015年7月17日 防災訓練対象ユーザ : 15,308名EC2課金単位
(1時間毎)
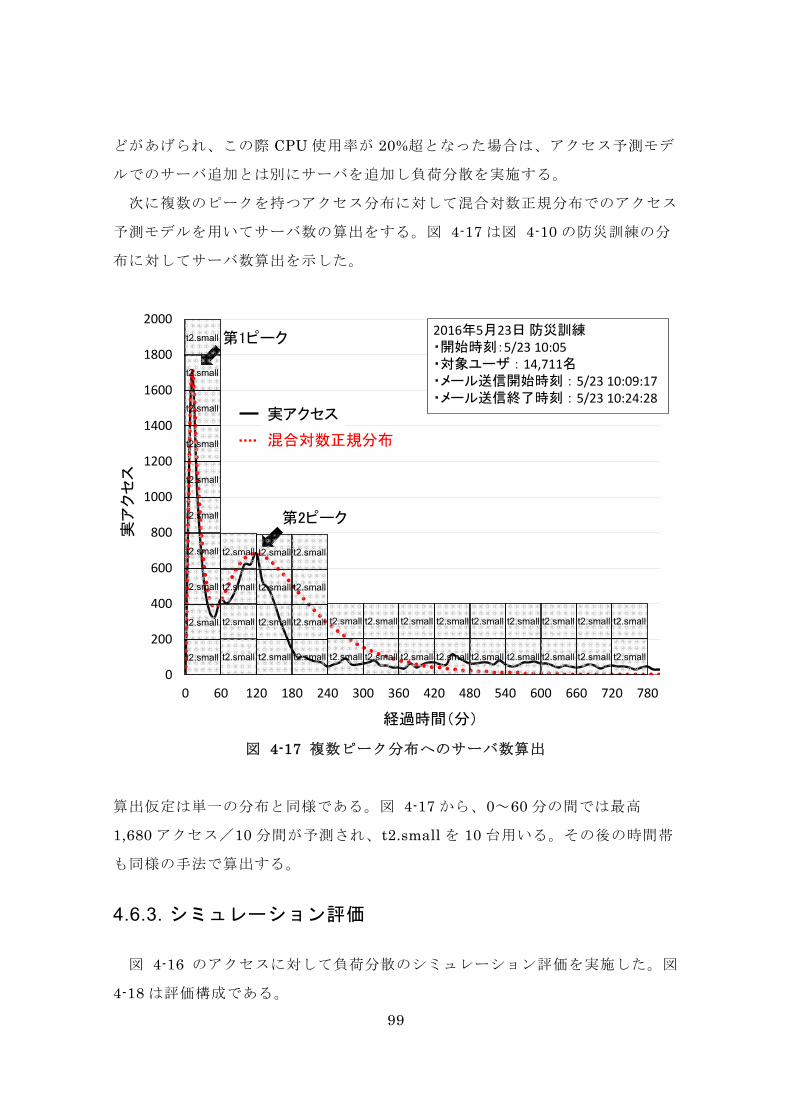
99
どがあげられ、この際 CPU 使用率が 20%超となった場合は、アクセス予測モデ
ルでのサーバ追加とは別にサーバを追加し負荷分散を実施する。
次に複数のピークを持つアクセス分布に対して混合対数正規分布でのアクセス
予測モデルを用いてサーバ数の算出をする。図 4-17 は図 4-10 の防災訓練の分
布に対してサーバ数算出を示した。
図 4-17 複数ピーク分布へのサーバ数算出
算出仮定は単一の分布と同様である。図 4-17 から、0~60 分の間では 高
1,680 アクセス/10 分間が予測され、t2.small を 10 台用いる。その後の時間帯
も同様の手法で算出する。
4.6.3. シミュレーション評価
図 4-16 のアクセスに対して負荷分散のシミュレーション評価を実施した。図
4-18 は評価構成である。
0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 60 120 180 240 300 360 420 480 540 600 660 720 780
スズキ訓練t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
2016年5月23日 防災訓練・開始時刻:5/23 10:05・対象ユーザ : 14,711名・メール送信開始時刻 : 5/23 10:09:17・メール送信終了時刻 : 5/23 10:24:28
第1ピーク
第2ピーク
混合対数正規分布
実アクセス
実ア
クセ
ス
経過時間(分)
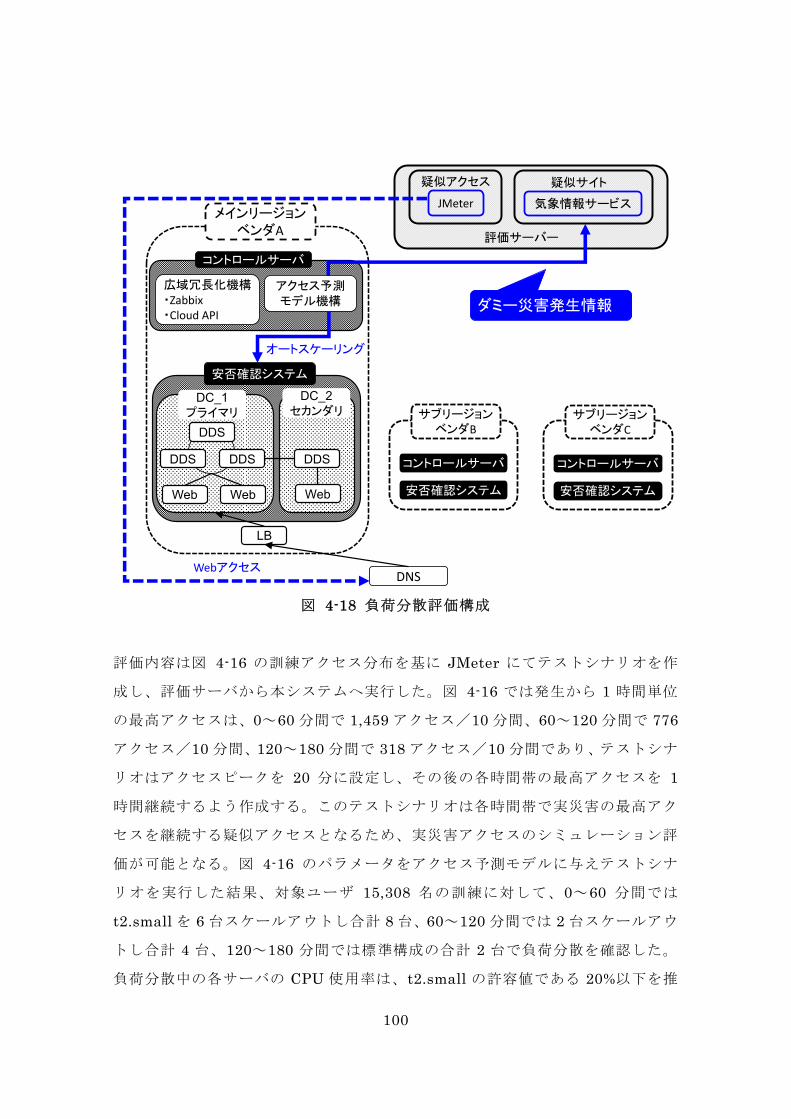
100
図 4-18 負荷分散評価構成
評価内容は図 4-16 の訓練アクセス分布を基に JMeter にてテストシナリオを作
成し、評価サーバから本システムへ実行した。図 4-16 では発生から 1 時間単位
の 高アクセスは、0~60 分間で 1,459 アクセス/10 分間、60~120 分間で 776
アクセス/10 分間、120~180 分間で 318 アクセス/10 分間であり、テストシナ
リオはアクセスピークを 20 分に設定し、その後の各時間帯の 高アクセスを 1
時間継続するよう作成する。このテストシナリオは各時間帯で実災害の 高アク
セスを継続する疑似アクセスとなるため、実災害アクセスのシミュレーション評
価が可能となる。図 4-16 のパラメータをアクセス予測モデルに与えテストシナ
リオを実行した結果、対象ユーザ 15,308 名の訓練に対して、0~60 分間では
t2.small を 6 台スケールアウトし合計 8 台、60~120 分間では 2 台スケールアウ
トし合計 4 台、120~180 分間では標準構成の合計 2 台で負荷分散を確認した。
負荷分散中の各サーバの CPU 使用率は、t2.small の許容値である 20%以下を推
安否確認システム
DC_1プライマリ
コントロールサーバ
DNS
DDS
DDSDDS
Web Web
LB
アクセス予測モデル機構
広域冗長化機構・Zabbix・Cloud API
メインリージョンベンダA
DDS
Web
DC_2セカンダリ サブリージョン
ベンダB
コントロールサーバ
安否確認システム
サブリージョンベンダC
コントロールサーバ
安否確認システム
気象情報サービス
疑似サイト
JMeter
疑似アクセス
評価サーバー
オートスケーリング
ダミー災害発生情報
Webアクセス

101
移し、想定内の CPU 使用率で負荷分散実行を確認した。また、アクセス予測から
負荷分散環境構築完了までの各処理時間は、気象情報提供サービスでの災害検知
からアクセス予測モデルにてアクセス予測およびサーバ数算出に約 10 秒程度、
サーバ起動からスケールアウト完了に約 5 分程度、対象ユーザ 15,308 名へのメ
ール送信に約 10 分となり、メール送信 20 分後のアクセスピーク前にスケールア
ウトが完了し負荷分散が問題なくおこなえることを確認した。
次に、筆者が所属する企業でサービス提供している安否確認システムの顧客
20,000 名に対して、シミュレーション評価をした(図 4-19)。
図 4-19 20,000 名ユーザでのオートスケーリング
図 4-19 から対象ユーザ 20,000 名では、0~60 分間では t2.small を 10 台、60~
120 分間では 6 台、120~180 分間では 4 台と、図 4-16 の対象ユーザ 15,308 名
と比較すると、わずかであるがより大規模なスケールアウト・インとなる。つま
り対象ユーザ数が増加するほどオートスケーリングの規模が大きくなるため、顧
0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 60 120 180 240 300 360 420 480 540 600経過時間(分)x
アクセス(疑似) 期間 アクセス数
0 ~ 60 1,76660 ~ 120 971120 ~ 180 465180 ~ 240 256 240 ~ 300 155300 ~ 360 101360 ~ 420 69420 ~ 480 49480 ~ 540 35540 ~ 600 26
各期間での最高アクセス
アク
セス
数
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small
t2.small

102
客数増加にともない費用対効果の向上が期待できる。
4.6.4. 運用費用
20,000 名ユーザを想定して、平常時費用と災害時費用について各システムの費
用比較をおこなった。比較対象は、(1)筆者所属企業でサービス展開している現
行システム、(2)平常時は 小構成、災害時は対処可能サーバに変更、(3)本シ
ステムの 3 システムである。(2)の平常時は(3)と同構成とし、災害時は過去災
害・訓練データから求めた 大アクセス数を許容するサーバを用いる形態である。
使用するインスタンスタイプ、費用は表 4-6 に示し、各システムの平常時のサー
バ構成および年間費用は表 4-5 である。表 4-5 から(1)は過去災害のアクセス
結果から余裕のある c3.2xlarge を常時用いているため Web、DB 合計費用は
$17,954 となるが、(2)や(3)は、平常時は 小構成のため$4,633 となり年間費
用を約 74%削減できる。ただし、(1)現行システムはすでに製品展開中のため、
余裕を持たせたサーバスペックおよび構成としているため、(3)本システムの構
成として比較して大幅なコスト差が生じることは自明である。本章のアクセス予
測モデルを用いた場合のコスト優位性比較は(2)と(3)となる。ここで(2)と
(3)は、平常時は 小構成で災害時に負荷分散環境を増強する点において同じ立
場を取るが、両者には災害時のサーバ数算出手法に違いがある。表 4-7 は対象ユ
ーザ数 20,000 名でのメインリージョン:ベンダ A の災害対処費用であり、(2)
は現行システムと同様の c3.2xlarge 2 台を 12 時間起動、(3)は図 4-19 のアク
セス予測モデルでの算出である。表 4-7 では(2)の対処用サーバを c3.2xlarge
としたため、(3)の t2.small と比較し差が生じているが、コスト差はたかだか 12
時間で$12 程度である。さらに、スケールアウト/インを伴う災害は年間を通し
ても多頻度では発生しないため、災害対処費用は(2)と(3)で大きな差は生じ
ず、(2)と(3)の効能差も見えづらい。しかし、両者の本質的な違いはアクセス
予測の有無である。(2)は、実際に経験した過去災害および訓練のユーザ数に対
してはアクセス結果から必要サーバ数の事前算出が可能だが、未経験のユーザ数
に対しては過去の経験ユーザ数を基にしたおおよその予想によるサーバ数算出と
なる。一方、(3)本システムは、過去災害および訓練のアクセス分布を統計的に
分析し構築したアクセス予測モデルにて、経験・未経験に因らず対象ユーザ数に

103
応じたアクセス予測が可能である。したがって、両者とも過去の災害データを基
にした予測においては同様であるが、(2)の経験済み対象ユーザ数から予想した
おおよその予測では根拠に乏しく、統計的見地から構築した(3)の本システムに
予測根拠の点に優位性がある。また安否確認システムは新規顧客参入にともない
ユーザ数が増加していくため、ユーザ数変化の都度あらかじめ訓練などで必要サ
ーバ数を求めておくことは相応の手間が発生するが、アクセス予測モデルではそ
の手間は不要となる。また、今回の費用評価は、20,000 名ユーザを対象とし、災
害 1 回の対処費用差は$12 程度であるが、ユーザ数が 10 万名や 100 万名となる
と対処費用も増加する。さらに、「2.2.1 本国の災害状況」のとおり本国は災害の
発生が多いため、多くの災害を本システムで扱うほどモデル有無によるコスト差
が際立つ。したがって、本国のような災害多発国では安否確認システムにおける
アクセス予測モデルでのサーバリソース調整は有効であると考える。採用 EC2 タ
イプは、今回は t2.small としたが、各タイプの性能特性や費用を考慮すれば、さ
らに精度の高い負荷分散や費用効果が期待できる。

104
表 4-5 平常時のサーバ構成及び年間費用
(1)現行システム (2)平常時は 小構成,災害時
は対処可能サーバに変更 (3)本システム
メインリージョン (AWS)
WEB:c3.2xlarge:2 台 DB:c3.2xlarge:2 台
WEB:t2.small:3 台 DB:t2.small:4 台
WEB:t2.small:3 台 DB:t2.small:4 台
サブリージョン 1 (Azure)
- WEB:A1:2 台 DB:A1:2 台
WEB:A1:2 台 DB:A1:2 台
サブリージョン 2 (GCP)
- WEB:n1-standard-1:2 台 DB:n1-standard-1:2 台
WEB:n1-standard-1:2 台 DB:n1-standard-1:2 台
WEB 費用 $8,977 $2,141 $2,141
DB 費用 $8,977 $2,492 $2,492
WEB・DB 合計費用 $17,954 $4,633 $4,633
(1)からの費用削減率 -
WEB:76.1%,DB:72.2% WEB・DB:74.1%
WEB:76.1%,DB:72.2% WEB・DB:74.1%
表 4-6 各インスタンスタイプの稼働費用
1 時間 月間 年間
c3.2xlarge $0.511 $374.0 $4,488.5
t2.small $0.040 $29.2 $351.3
A1 $0.024 $13.8 $166.3 n1-standard-1 $0.055 $28.1 $337.3
表 4-7 (2),(3)の災害対処費用
(2) (3) サーバ数 c3.2xlarge:2 台 t2.small:合計 20 台
(各期間でスケールアウト) 費用 $12.2 $0.8

105
4.7. おわりに
本章では、災害発生時に災害規模に応じて安否確認システムへのアクセス数を
予測するアクセス予測モデルを構築し、災害時のアクセス数を事前予測すること
で適切なサーバ数にて負荷分散をおこないサーバ運用費用を削減できることを示
した。過去災害のアクセスデータに対して対数正規分布の仮定では、現時点で収
集した過去災害データに厳密な正規性は見られないものの、アクセス減衰期まで
は対数正規分布に従っており、実運用時のサーバ数算出において期待した効果を
得られた。複数のピークを持つアクセス分布に対しては、混合対数正規分布を用
いてモデル化することでアクセス分布に対して高い適合性を示した。Web システ
ムへのアクセス分布をモデル化したさまざまな先行研究を基にし、安否確認シス
テムへのアクセス分布に対して対数正規分布モデルを用いた本研究のアクセス予
測モデルは、アクセス分布のモデル化にとどまらず、その後のアクセス予測を可
能とした点に新規性を示した。アクセス予測モデルを用いたサーバ数の算出では、
1 時間単位のアクセス予測分布に対して、1 時間単位の料金形態である AWS EC2
を適切な数だけ起動することで、余分なサーバ費用を削減できることを示した。
20,000 名ユーザでのシミュレーション評価では、1 回の災害対処費用は$12 程度
のコスト削減を示し、今後ユーザ数が増加するにしたがってコストメリット拡大
も期待でき、アクセス予測モデルを用いることでアクセス集中に対する負荷分散
およびコスト削減を可能とした。
本章では安否確認システムにおけるアクセス予測モデル構築の基礎概念を示し
た。今後の課題として、アクセス予測モデルの精度向上が挙げられる。本研究で
のアクセス予測モデルは実災害や訓練時のアクセス分布を基に、統計的に分析し
て構築したモデルである。そのため、サンプルとなるアクセス分布データが多い
ほどより適合度が高い予測ができると推測される。今後もサンプルデータを収集
しモデル精度向上および修正をおこなう予定である。また、第 2 ピークをもつ分
布は災害発生時刻に影響される調査結果から、分布へ影響を与える要因はユーザ
数や発生時刻、気象条件、組織特性など考えられる。今後はこれら要因とアクセ
ス分布への相関調査を課題としたい。
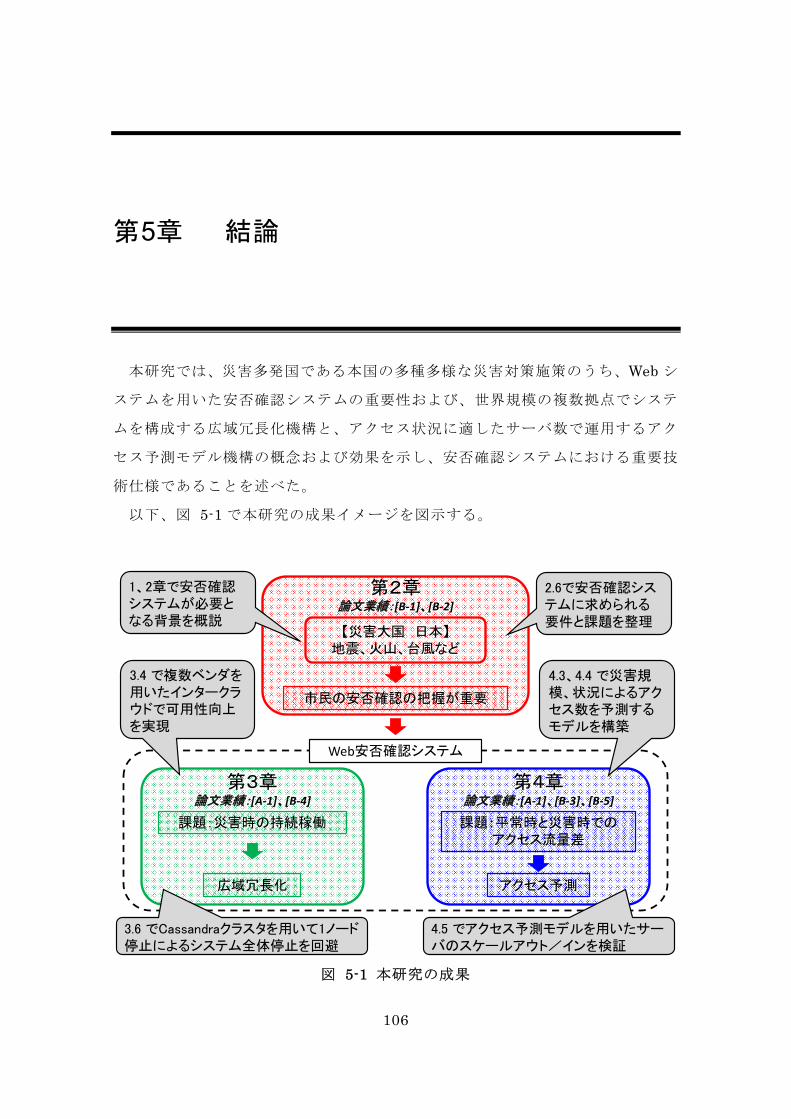
106
第5章 結論
本研究では、災害多発国である本国の多種多様な災害対策施策のうち、Web シ
ステムを用いた安否確認システムの重要性および、世界規模の複数拠点でシステ
ムを構成する広域冗長化機構と、アクセス状況に適したサーバ数で運用するアク
セス予測モデル機構の概念および効果を示し、安否確認システムにおける重要技
術仕様であることを述べた。
以下、図 5-1 で本研究の成果イメージを図示する。
図 5-1 本研究の成果
市民の安否確認の把握が重要
【災害大国 日本】地震、火山、台風など
課題:災害時の持続稼働
広域冗長化
課題:平常時と災害時でのアクセス流量差
アクセス予測
Web安否確認システム
第2章論文業績:[B-1]、[B-2]
第3章論文業績:[A-1]、[B-4]
第4章論文業績:[A-1]、[B-3]、[B-5]
1、2章で安否確認システムが必要となる背景を概説
2.6で安否確認システムに求められる要件と課題を整理
3.4 で複数ベンダを用いたインタークラウドで可用性向上を実現
3.6 でCassandraクラスタを用いて1ノード停止によるシステム全体停止を回避
4.3、4.4 で災害規模、状況によるアクセス数を予測するモデルを構築
4.5 でアクセス予測モデルを用いたサーバのスケールアウト/インを検証

107
第 1 章では、災害時の安否情報の収集および共有の手段に対して、効果的な Web
安否確認システムの実装および運用が重要であるとの着眼から本研究に至った背
景を述べた。研究焦点として、地理的に離れた複数拠点でシステムを冗長化する
広域冗長化と、災害時のアクセス数を事前予測し適切なサーバ数で負荷分散をお
こなうアクセス予測モデルの 2 つの課題を提起した。
第 2 章では、本国の災害が諸外国と比較して多く、災害時の安否確認がその後
の救助活動や復興活動の迅速化に寄与することから安否確認システムの重要性を
説明した。一般的な安否確認システムの概要として静岡大学の安否確認システム
を紹介した。安否システムに求められる要件を背景とし、第 1 章で提起した 2 点
の課題に対して旧来システムの弱点から本研究で解決すべき技術仕様を整理した。
第 3 章では、課題のひとつである災害時の持続稼働を実現する仕組みとして、
システムを構成するサーバ群を地理的には離れた複数拠点に配置する広域冗長化
機構の概念と技術仕様を説明した。広域冗長化を実現する仕組みとして、複数拠
点だけでなく用いるクラウドベンダも複数社用いるインタークラウド構成とし、
1 社の障害や経営状況によるサービス停止を回避した。また、複数サーバを用い
ることで分散システムになることから、複数ノードでデータ共有する Cassandra
を分散データシステムに採用した。インタークラウドおよび分散データシステム
に対するディザスタリカバリ評価では、テストシステムによる意図的な障害に対
して別サーバや別ノードによるフェイルオーバを確認し、災害時のディザスタリ
カバリに対しても有効な実装であることを示した。
第 4 章では、2 つ目の課題であるアクセス状況に応じたサーバ数でシステム運
用をおこなうためのアクセス予測モデルの概念と技術仕様を説明した。安否確認
システムへのアクセスは、平常時には少なく災害時に増加する特性がある。この
特性のため状況によりシステムが必要とするサーバ数が異なる。つまり災害時に
必要なサーバ数で常時運用する場合、平常時は過剰なサーバ数となることから状
況に応じたサーバ数を算出しシステムへ反映する仕組みが重要である。本研究で
は、過去の災害時や訓練時のシステムへのアクセス分布を分析し、災害規模に応
じて必要サーバ数を算出する対数正規分布を用いたサクセス予測モデルを構築し
た。災害の発生時刻によりシステムへのアクセスピークが 1 つでなく複数予測さ
れる場合は、複数の対数正規分布モデルを混合し予測アクセス分布を導きだした。

108
また、災害時にアクセス予測モデルを用いてサーバ数を増減する評価において、
本研究での安否確認システムでは年間約 74%の費用削減の見込みを得ることが
でき、本研究の有効性を示した。

109
謝辞
本学位論文は、筆者が静岡大学創造科学技術大学院自然科学系教育部情報科学
専攻博士課程に在籍中の研究成果をまとめたものです。静岡大学学術院情報学領
域情報科学系列准教授 峰野博史 先生におかれましては指導教官として本研究
の実施と機会を与えて戴き、その遂行にあたって適確なご指導およびご鞭撻を賜
りまして、ここに深く感謝の意を申し上げます。また、静岡大学学術院情報学領
域情報科学系列教授 酒井三四郎 先生、静岡大学学術院情報学領域情報科学系列
教授 杉浦彰彦 先生、静岡大学学術院情報学領域情報科学系列教授 西垣正勝 先
生、静岡大学学術院工学領域電子物質科学系列准教授 荻野明久 先生におかれま
しては副査としてご助言を戴くともに本学位論文の細部にわたりご指導を戴き、
心より感謝申し上げます。また、日常の議論を通じて多くの知識や示唆を頂いた
峰野研究室の皆様および岩田あずさ秘書に感謝申し上げます。
本研究の基となる安否確認システムを設計開発されました静岡大学情報基盤セ
ンター准教授 長谷川孝博 先生、並びに、同センター教授 井上春樹 先生には筆
者の本学修士課程時代からシステムにおける改良点や種々のアドバイスを戴きま
した。心より感謝申し上げます。
筆者所属企業である株式会社アバンセシステムの村山邦彦社長、向井敬二取締
役、山崎國弘執行役員には研究を進めるにあたりさまざまな後方支援を頂き、円
滑に研究を進めることができました。本研究で取り上げた安否確認システムは当
社にて筆者が在学中から開発および販売しております。当システムプロジェクト
チームの、阿部祐輔氏、松村禎久氏、高梨伸行氏、福井美彩都氏、磯部千裕氏、
野中綾乃氏、平田遥氏、向川笑美氏、松浦美穂子氏、下町綾氏、堀田公子氏、
木村佳南子氏、のみなさまには有益な助言や暖かい励ましを頂きまして感謝申し
上げます。
あらためて本学位論文をまとめるにあたり、ご指導およびご助言戴きましたす
べての関係者皆様に厚くお礼申し上げます。

110
参考文献
[1] 内閣官房, “国土強靱化基本計画,” [オンライン]. Available: http://www.
cas.go.jp/jp/seisaku/kokudo_kyoujinka/kihon.html. [アクセス日 : 2017
年 1 月 31 日].
[2] 一般社団法人, 国土技術研究センター, “自然災害の多い国 日本,” [オン
ライン]. Available: http://www.jice.or.jp/knowledge/japan/commentary0
9. [アクセス日: 2016 年 12 月 4 日].
[3] 内閣府, “平成 23 年度版防災白書,” [オンライン]. Available: ttp://www.
bousai.go.jp/kaigirep/hakusho/h23/bousai2011/html/honbun/index.htm.
[アクセス日: 2016 年 12 月 4 日].
[4] 東京都, “東京都防災ホームページ,” [オンライン]. Available: http://ww
w.bousai.metro.tokyo.jp/kitaku_portal/1000050/1000536.html. [アクセ
ス日: 2016 年 12 月 4 日].
[5] 経済産業省, “事業継続計画策定ガイドライン,” [オンライン]. Available:
http://www.meti.go.jp/report/downloadfiles/g50331d06j.pdf. [アクセス
日: 2016 年 12 月 4 日].
[6] 中小企業庁, “中小企業 BCP 策定運用指針,” [オンライン]. Available: h
ttp://www.chusho.meti.go.jp/bcp/. [アクセス日: 2016 年 12 月 4 日].
[7] 樋地正浩, “東日本大震災における情報通信技術の利用と課題,” 電子情報
通信学会論文誌 D, Vol.J95-D, No.5, pp.1070-1080, 2012 年.
[8] 関谷直也 , 橋元良明 , 中村功 , 小笠原盛浩 , 山本太郎 , 千葉直子 , 関良明 ,
高橋克巳, “東日本大震災における首都圏住民の震災時の情報行動,” 東京
大学大学院情報学環紀要, 情報学研究・調査研究編, (28), 2012 年.
[9] 長谷川孝博, 井上春樹, 八卷直一, “低コスト運用でユーザフレンドリな安
否情報システムの開発,” 学術情報処理研究誌, No.13, pp.91-98, 2009 年.
[10] 梶田将司, 太田芳博, 若松進, 林能成 , 間瀬健二 , “高等教育機関のための

111
安否確認システムの段階的構築と運用,” 情報処理学会論文誌, Vol.49, N
o.3, pp.1131-1143, 2008 年.
[11] 一般財団法人, 気象業務支援センター, “オンライン気象情報,” [オンライ
ン]. Available: http://www.jmbsc.or.jp/. [アクセス日: 2016 年 12 月 4 日].
[12] 渡辺尚, 石原進, “災害時における情報通信の課題について,” 電子情報通
信学会総合大会講演論文集, Vol.2004, No.2, pp.286, 2004 年.
[13] 山路栄作, “東日本大震災における通信インフラの災害復旧とその課題,”
電子情報通信学会誌, Vol.95, No.3, pp.195-200, 2012 年.
[14] 総務省, “平成 23 年版 情報通信白書,” [オンライン]. Available: http://
www.soumu.go.jp/johotsusintokei/whitepaper/ja/h23/pdf/n0010000.pdf.
[アクセス日: 2016 年 12 月 4 日].
[15] 西谷薫, 杉浦彰彦, “ワンセグ用データ放送を用いた災害時安否情報配信,”
情報処理学会論文誌, Vol.50, No.2, pp.839-845, 2009 年.
[16] 大瀧龍, 重安哲也, 浦上美佐子, 松野浩嗣, “自律的無線ネットワークを用
いた被災情報提供システム―被災地域の地形を考慮した無線ノード置局ア
ルゴリズムの提案,” 情報処理学会論文誌, Vol.52, No.1, pp.308-318, 20
11 年.
[17] J.Wang, Z.Cheng, I.Nishiyama, Y.Zhou, “Design of a Safety Confir
mation System Integrating Wireless Sensor Network and Smart Ph
ones for Disaster,” In Embedded Multicore Socs, IEEE 6th Interna
tional Symposium, pp.139-143, 2012.
[18] T.Oide, A.Takeda, A.Takahashi,T.Suganuma, “SS5 design of a P2P
information sharing system and its application to communication s
upport in natural disaster,” Cognitive Informatics & Cognitive Co
mputing, 12th IEEE International Conference, pp.118-125, 2013.
[19] 生出拓馬 , 武田敦志 , 高橋晶子 , 菅沼拓夫 , “ネットワークアウェアな P2
P 型安否情報共有システムの提案,” 情報処理学会論文誌, Vol.55, No.2,
pp.607-618, 2014 年.

112
[20] 小山由, 水本旭洋, 今津眞也, 安本慶一, “大規模災害時の安否確認システ
ムと広域無線網利用可能エリアへの DTN に基づいたメッセージ中継法,”
情報処理学会研究報告, Vol.2012-MBL-62, No.29, pp.1-7, 2012 年.
[21] 東田光裕, 林春男, 松下靖, 三宅康一, “社会サービスとしての被災者対応
の質を向上させる情報マネージメントシステムの構築--QR コードを利用
した安否情報収集システムの開発,” 地域安全学会論文集 , No.9, pp.147-
156 , 2007 年.
[22] T.Ishida, A.Sakuraba, K.Sugita, N.Uchida, Y.Shibata, “Construction
of Safety Confirmation System in the Disaster Countermeasures
Headquarters,” P2P, Parallel, Grid, Cloud and Internet Computing,
8th IEEE International Conference, pp.574-577, 2013.
[23] 畑山満則, 安藤恵, “地域防災計画における情報伝達の機能的障害の発見手
法の開発,” 情報処理学会論文誌, Vol.54, No.1, pp.202-212, 2013 年.
[24] 池端優二, 塚田晃司, “安否報告が困難な状況を支援するライフログ活用安
否確認システム,” 情報処理学会研究報告, Vol.2014-GN-90, No.24, pp.1
-7, 2014 年.
[25] 石井創一朗, 齊藤義仰, 西岡大, 村山優子, “被災地におけるグリーンエネ
ルギーによる復興ウォッチャーシステムの提案,” 情報処理学会研究報告,
Vol.2014-IOT-27, No.10, pp.1-6, 2014 年.
[26] 安部惠一, 天城康晴, 山口高男, “インフラ断絶時に強い災害時避難所管理
システムの提案 ,” 情報処理学会研究報告 , Vol.2016-UBI-52, No.11, pp.
1-8, 2016 年.
[27] 越後博之 , 湯瀬裕昭 , 干川剛史 , 沢野伸浩 , 高畑一夫 , 柴田義孝 , “大規模
分散環境におけるロバストネスを考慮した広域災害情報共有システム,” 情
報処理学会論文誌, Vol.48, No.7, pp.2340-2350, 2007 年.
[28] H.Echigo, H.Yuze, T.Hoshikawa, K.Takahata, N.Sawano, Y.Shibata,
“Robust and Large Scale Distributed Disaster Information System
over Internet and Japan Gigabit Network,” 21st International Con
ference on Advanced Information Networking and Applications, IEE

113
E, pp.762-768, 2007.
[29] Y.Hiroaki, N.Suzuki, “Development of Cloud Based Safety Confirm
ation System for Great Disaster,” Advanced Information Networkin
g and Applications Workshops, 26th International Conference on I
EEE, pp.1069-1074, 2012.
[30] 林能成,梶田将司,太田芳博,若松進,木村玲欧,飛田潤,鈴木康弘, 間瀬
健二, “組織特性を考慮した大学向け災害時安否確認システムの開発,” 土
木学会安全問題研究論文集, Vol.3, pp.203-208, 2008 年.
[31] 太田芳博, 梶田将司, 林能成, 若松進, “名古屋大学安否確認システムの構
築と運用,” 電子情報通信学会技術研究報告, IEICE-IA2008-61, Vol.IEIC
E-108, No.409, pp.77-82, 2009 年.
[32] Amazon Web Services, “Amazon Web Services,” [オンライン]. Avai
lable: http://aws.amazon.com/. [アクセス日: 2016 年 12 月 5 日].
[33] Amazon Web Services, “EC2(Elastic Compute Cloud),” [オンライン].
Available: http://aws.amazon.com/ec2/. [アクセス日: 2016 年 12 月 5
日].
[34] 国立情報学研究所 , [オンライン]. Available: http://www.nii.ac.jp/. [アク
セス日: 2016 年 12 月 5 日].
[35] 国立情報学研究所, “学術認証フェデレーション,” [オンライン]. Availab
le: https://www.gakunin.jp/. [アクセス日: 2016 年 12 月 5 日].
[36] 臼井真人, 畑山満則, 福山薫, “地域コミュニティでの情報システムを用い
た安否確認に関する研究,” 地域安全学会論文集, No.16, pp.11-20 , 201
2 年.
[37] 白鳥則郎, 稲葉勉, 中村直毅, 菅沼拓夫, “災害に強いグリーン指向ネバー
ダイ・ネットワーク,” 情報処理学会論文誌, Vol.53, No.7, pp.1821-1831,
2012 年.
[38] Microsoft , “Azure,” [オンライン]. Available: http://azure.microsoft.
com/. [アクセス日: 2016 年 12 月 5 日].

114
[39] The Internet Engineering Task Force, “RFC5798 Virtual Router R
edundancy Protocol(VRRP),” [オンライン]. Available: https://tools.iet
f.org/html/rfc5798. [アクセス日: 2016 年 12 月 5 日].
[40] The Internet Engineering Task Force, “RFC792 Internet Control M
essage Protocol(ICMP),” [オンライン]. Available: https://tools.ietf.org
/html/rfc792. [アクセス日: 2016 年 12 月 5 日].
[41] The Internet Engineering Task Force, “RFC 793 Transmission Con
trol Protocol(TCP),” [オンライン]. Available: https://tools.ietf.org/htm
l/rfc793. [アクセス日: 2016 年 12 月 5 日].
[42] The Internet Engineering Task Force, “RFC 768 User Datagram P
rotocol(UDP),” [オンライン]. Available: https://www.ietf.org/rfc/rfc76
8.txt. [アクセス日: 2016 年 12 月 5 日].
[43] The Internet Engineering Task Force, “RFC7230 Hypertext Transf
er Protocol (HTTP),” [オンライン]. Available: https://tools.ietf.org/ht
ml/rfc7230. [アクセス日: 2016 年 12 月 5 日].
[44] 柏崎礼央,北口善明,近藤徹,楠田友彦,大沼義明,中川郁夫,阿部俊二,
横山重敏,下條真司, “広域分散仮想化環境のための分散ストレージシステ
ムの提案と評価,” 情報処理学会論文誌, Vol.55, No.3, pp.1140-1150, 20
14 年.
[45] 柏崎礼生 , 近堂徹 , 北口善明 , 楠田友彦 , 大沼善朗 , 中川郁夫 , 市川昊平 ,
棟朝雅晴, 高井昌彰, 阿部俊二, 横山重俊, 下條真司, “広域分散ストレー
ジ検証環境における I/O 性能評価,” 情報処理学会研究報告, Vol.2013-IO
T-20, No.19, pp.1-6, 2013 年.
[46] 宮保憲治, 鈴木秀一, 上野洋一郎, 市原和雄, “広域分散ネットワークを活
用したディザスタリカバリ技術の実用化,” 電子情報通信学会論文誌 B, V
ol.J79-B, No.8, pp.583-598, 2014 年.
[47] 奥野通貴, 飯島智之, 石井大輔, “リアルタイム分散クラウド技術の開発-応
答性の高いクラウドを実現するために,” 情報処理学会デジタルプラクティ
ス, Vol.4, No.4, pp.333-341, 2013 年.

115
[48] 坂井俊之, 梅田昌義, 中村英児, 本庄利守, “大規模分散処理システムのソ
フトウェア試験とその実践,” 情報処理学会デジタルプラクティス, Vol.4,
No.1, pp.51-59, 2013 年.
[49] 北口善明, 柏崎礼生, 近堂徹, 市川昊平, 西内一馬, 中川郁夫, 菊池豊, “広
域分散システムの耐障害性を評価する検証プラットフォームの実装と評
価,” 情報処理学会論文誌, Vol.57, No.3, pp.958-966, 2016 年.
[50] 柏崎礼生, 北口善明, 市川昊平, 近堂徹, 西内一馬, 中川郁夫, 菊地豊, “耐
障害性・耐災害性の検証・評価・反映プラットフォームを用いた広域分散ス
トレージの評価,” 情報処理学会研究報告, Vol.2016-IOT-32, No.14, pp.1
-6, 2016 年.
[51] 藤本大地, 近堂徹, 前田香織, 大石恭弘, 相原玲二, “OpenFlow による移
動透過な広域ライブマイグレーションシステムの提案と実装,” 情報処理学
会, インターネットと運用技術シンポジウム, IOTS2015, pp.36-43, 2015
年.
[52] A.Fischer, A.Fessi, G.Carle, H.de Meer, “Wide-area virtual machin
e migration as resilience mechanism,” Reliable Distributed System
s Workshops, 30th IEEE Symposium, pp.72-77, 2011.
[53] N.McKeown, T.Anderson, H.Balakrishnan, G.Parulkar, L.Peterson,
J.Rexford, S.Shenker, J.Turner, “OpenFlow: enabling innovation in
campus networks,” ACM SIGCOMM Computer Communication Rev
iew, Vol.38, No.2, pp.69-74, 2008.
[54] 杉木章義, 大和﨑啓, 加藤和彦, “広域分散環境のための仮想機械を利用し
たサービス協調複製基盤,” 情報処理学会論文誌コンピューティングシステ
ム, Vol.2, No.1, pp.1-11 , 2009 年.
[55] 中川郁夫, “DR を実現する広域分散型クラウドストレージアーキテクチャ
の検討,” 電子情報通信学会技術研究報告, IEICE-IA2011-64, Vol.IEICE
-111, No.356, pp.55-60 , 2012 年.
[56] 渡邉英伸, 大垣哲也, 岩間司, 田光江 , 村田健史 , “広域分散ファイルシス
テムにおける時刻認証を用いたファイル改竄検証システム,” 電子情報通信

116
学会論文誌 B, Vo.J96-B, No.10, pp.1131-1141, 2013 年.
[57] 建部修見, 森田洋平, 松岡聡, 関口智嗣, & 曽田哲之, “ペタバイトスケー
ルデータインテンシブコンピューティングのための Grid Datafarm アー
キテクチャ,” 情報処理学会論文誌ハイパフォーマンスコンピューティング
システム, Vo.43, No.SIG6, pp.184-195, 2002 年.
[58] S.Patidar, R.Dheeraj, J.Pritesh, “A Survey Paper on Cloud Comput
ing,” Advanced Computing & Communication Technologies, Second
International Conference on. IEEE, pp.394-398, 2012.
[59] R.Buyya, R.Ranjan, R.N.Calheiros, “InterCloud: Utility-Oriented Fe
deration of Cloud Computing Environments for Scaling of Applicati
on Services,” International Conference on Algorithms and Architec
tures for Parallel Processing, Springer Berlin Heidelberg, pp.13-31,
2010.
[60] 波戸邦夫, 上水流由香, 岡本隆史, 横山大作, “複数の異種クラウド間にお
けるスケールアウトおよびディザスタリカバリ機構の実装とその評価,” 情
報処理学会デジタルプラクティス, Vol.4, No.4, pp.314-322, 2013 年.
[61] 波戸邦夫, 胡博, 村田祐一, 村山純一, “インタークラウドに向けたシステ
ムアーキテクチャの提案,” 電子情報通信学会技術研究報告, IEICE-IN20
10-169, Vol.IEICE-110, No.449, pp.151-156, 2011 年.
[62] 神屋郁子, 川津祐基, 下川俊彦, 吉田紀彦, “複数のクラウドを利用したサ
ーバ広域分散配置システムの構築,” 電子情報通信学会論文誌 B, Vol.J96-
B, No.10, pp.1164-1175, 2013 年.
[63] 相澤孝至 , 棟朝雅晴 , C.Powell, “Shibboleth を用いたインタークラウド
システムのための認証基盤の設計,” 情報処理学会, インターネットと運用
技術シンポジウム, IOTS2013, pp.58-64, 2013 年.
[64] The Internet2 community, “shibboleth,” [オンライン]. Available: ht
tp://www.internet2.edu/products-services/trust-identity/shibboleth/. [ア
クセス日: 2016 年 12 月 5 日].
[65] 合田憲人, 横山重俊, 吉岡信和, 山中顕次郎, 長久勝, 青木道宏 , 阿部俊二,

117
漆谷重雄, “アカデミックインタークラウドの構想,” 電子情報通信学会
技術研究報告 , IEICE-SC2013-13, Vol.IEICE-113, No.376, pp.1-6, 201
4 年.
[66] 横山重俊, 桑田喜隆, 吉岡信和, “アカデミッククラウドアーキテクチャの
提案と評価,” 情報処理学会論文誌, Vo.54, No.2, pp.688-698, 2013 年.
[67] 横山重俊, 政谷好伸, 吉岡信和, 合田憲人, “Overlay Cloud で構成する
Web サービスバックアップサイト構築例,” 情報処理学会研究報告, Vol.2
015-IOT-30, No.12, pp.1-8, 2015 年.
[68] 千葉立寛, 松岡聡, “インタークラウド間での大規模データ転送の高速化,”
情報処理学会研究報告, Vol.2011-HPC-129, No.25, pp.1-7, 2011 年.
[69] Amazon Web Services, “S3,” [オンライン]. Available: https://aws.a
mazon.com/s3/. [アクセス日: 2017 年 1 月 31 日].
[70] Microsoft, “Azure Blob,” [オンライン]. Available: https://docs.micro
soft.com/en-us/azure/storage/storage-introduction. [アクセス日: 2017 年
1 月 31 日].
[71] 胡博, 波戸邦夫, 村田祐一, 村山純一, “インタークラウド環境におけるリ
ソース割当アルゴリズムの提案,” 電子情報通信学会技術研究報告, IEICE
-IN2010-170, Vol.IEICE-110, No.449, pp157-162 , 2011 年.
[72] GitHub, Inc., “httping,” [オンライン]. Available: https://github.com
/flok99/httping. [アクセス日: 2016 年 12 月 5 日].
[73] Zabbix LLC, “Zabbix,” [オンライン]. Available: http://www.zabbix.c
om/. [アクセス日: 2016 年 12 月 5 日].
[74] Google, “Google Cloud Platform,” [オンライン]. Available: https://cl
oud.google.com/. [アクセス日: 2016 年 12 月 5 日].
[75] Amazon Web Services, “Route53,” [オンライン]. Available: http://a
ws.amazon.com/route53/. [アクセス日: 2016 年 12 月 5 日].
[76] F.Chang, J.Dean, S.Ghemawat, W.C.Hsieh, D.A.Wallach, M.Burrows,
T.Chandra, A.Fikes, R.E.Gruber, “Bigtable: A Distributed Storage

118
System for Structured Data,” ACM Transactions on Computer Sys
tems, Vol.26(2), No.4, 2008.
[77] C.Dorin, E.Lepadatu, M.Gaspar, “Hbase-non sql database, performa
nces evaluation,” International Journal of Advancements in Compu
ting Technology, Vol.2, No.5, pp.42-52, 2010.
[78] L.Yimeng, Y.Wang, Yi.Jin, “Research on the improvement of Mong
oDB Auto-Sharding in cloud environment,” Computer Science & E
ducation, 7th International Conference on. IEEE, pp.851-854, 2012.
[79] J.J.Miller, “Graph database applications and concepts with Neo4j,”
Proceedings of the Southern Association for Information Systems
Conference, pp.141-147, 2013.
[80] The Apache Software Foundation,, “Cassandra,” [オンライン]. Ava
ilable: http://cassandra.apache.org/. [アクセス日: 2016 年 12 月 5 日].
[81] A.Lakshman, P.Malik, “Cassandra: a decentralized structured stora
ge system,” ACM SIGOPS Operating Systems Review, Vol.44, No.2,
pp.35-40, 2010.
[82] J.Han, E.Haihong, G.Le, J.Du, “Survey on NoSQL database,” In
Pervasive computing and applications (ICPCA), IEEE 6th internati
onal conference, pp.363-366, 2011.
[83] 松浦伸彦 , 大畑真生 , 太田賢 , 稲村浩 , 水野忠則 , 峰野博史 , “大規模セン
サデータを処理可能な分散型データ管理システムの提案,” 情報処理学会論
文誌, Vol.54, No.2, pp.721-729, 2013 年.
[84] G.DeCandia, D.Hastorun, M.Jampani, G.Kakulapati, A.Lakshman,
A.Pilchin, S.Sivasubramanian, P.Vosshall, W.Vogels, “Dynamo: ama
zon's highly available key-value store,” ACM SIGOPS Operating S
ystems Review, Vol.41, No.6, pp.205-220, 2007.
[85] Apache Software Foundation, “JMeter,” [オンライン]. Available: ht
tp://jmeter.apache.org/. [アクセス日: 2016 年 12 月 5 日].

119
[86] The PostgreSQL Global Development Group, “PostgreSQL,” [オン
ライン]. Available: https://www.postgresql.org/. [アクセス日: 2016 年 1
2 月 5 日].
[87] GitHub, Inc., “sar(sysstat),” [オンライン]. Available: https://github.
com/sysstat/sysstat. [アクセス日: 2016 年 12 月 5 日].
[88] 名部正彦, 馬場健一, 村田正幸, 宮原秀夫, “インターネット・アクセスネ
ットワーク設計のための WWW トラヒックの分析とモデル化,” 電子情報
通信学会論文誌 B, Vol.J80-B-I, No.6, pp.428-437, 1997 年.
[89] M.E.Crovella, A.Bestavros, “Self-similarity in World Wide Web traf
fic: Evidence and Possible Causes,” IEEE/ACM Transactions on ne
tworking, Vol.5, No.6, pp.835-846, 1997 年.
[90] 菅野浩徳, 曽根秀昭, & 根元義章, “デマンド型ネットニュース配送方式に
おけるトラヒックのモデル化とレスポンスタイム評価,” 情報処理学会論文
誌, Vol.44, No.3, pp.535-543, 2003 年.
[91] 名部正彦, 村田正幸, & 宮原秀夫, “キャッシングを考慮した WWW トラ
ヒック特性の分析とモデル化,” 電子情報通信学会論文誌 B, Vol.J81-B-I,
No.5, pp.325-334, 1998 年.
[92] The Apache Software Foundation, “Apache HTTP SERVER PROJE
CT,” [オンライン]. Available: http://httpd.apache.org/. [アクセス日: 2
016 年 12 月 5 日].
[93] 石原進, 岡田稔, 岩田晃, 櫻井佳一, “イベント駆動方式による LAN 通信
量解析モデル,” 電子情報通信学会論文誌 A, Vol.J78-A, No.8, pp.961-96
4, 1995 年.
[94] I.Antoniou, V.V.Ivanov, Valery.V.Ivanov, P.V.Zrelov, “On the log-nor
mal distribution of network traffic,” Physica D: Nonlinear Phenom
ena, Vol.167, No.1, pp.72-85 , 2002.
[95] 稲田充男, “対数正規分布とその応用(第 5 報混合対数正規分布の択伐林
樹高分布への応用) ,” 島根大学農学部研究報告 , Vol.21, pp34-38, 1987
年.

120
[96] Murta,C.D., Dutra,G.N, “Modeling HTTP service times,” Global T
elecommunications Conference, IEEE, Vol.2, pp.972-976 , 2004.
[97] 稗圃泰彦, 上村郷志, 小頭秀行, 中村元, “一斉報知を用いた遅延発呼制御
方式におけるサーバ同時接続数の安定化に関する一考察,” 電子情報通信学
会論文誌 B, Vol.J95-B, No.3, pp.414-424, 2012 年.
[98] 鳥海不二夫 , 篠田孝祐 , 榊剛史 , 風間一洋 , 栗原聡 , 野田五十樹 , “東日本
大震災時におけるリツイートの分析,” 情報処理学会研究報告, Vol.2012-I
CS-168, No.3, pp.1-6, 2012 年.
[99] 松澤有, セーヨーサンティ, 鳥海不二夫, 陳昱, 大橋 弘忠, “リツイート時
系列の 3 パラメータ混合対数正規分布モデルによる分析,” 第 27 回人工
知能学会全国大会論文集, pp.1-4, 2013 年.
[100] Twitter, Inc., “Twitter,” [オンライン]. Available: https://twitter.com
/. [アクセス日: 2016 年 12 月 5 日].
[101] Amazon Web Services, “Elastic Load Balancing,” [オンライン]. Av
ailable: http://aws.amazon.com/elasticloadbalancing/. [アクセス日: 201
6 年 12 月 5 日].
[102] 藤田靖征, 村田正幸, 宮原秀夫:, “Web サーバシステムのモデル化と性能
評価,” 電子情報通信学会論文誌 B, Vol.J82-B, No.3, pp.347-357, 1999
年.
[103] GitHub, Inc., “byte-unixbench,” [オンライン]. Available: https://gith
ub.com/kdlucas/byte-unixbench. [アクセス日: 2017 年 2 月 13 日].

121
論文業績
A 学位論文申請資格に関わる論文
1) 永田正樹,阿部祐輔,金原一聖,福井美彩都,峰野博史: アクセス予測に基づ
いた広域冗長型安否システムの提案と基礎評価,情報処理学会論文誌 コンシ
ューマ・デバイス&システム,Vol.6,No.1,pp.94-105(2016)
B 学位論文内容に関わる論文
1) 永田正樹,金原一聖,竹村美彩都,峰野博史: AWS を用いたスケーラブルな大
規模安否情報システムの提案,情報処理学会研究報告,Vol.2013-CDS-7,
No.3(2013)
2) 永田正樹,金原一聖,竹村美彩都,峰野博史: AWS を用いたスケーラブルな大
規模安否情報システムの開発,情報処理学会研究報告,Vol.2013-CDS-8,
No.10(2013)
3) Nagata M, Abe Y, Fukui M, Mineno H: An Access Prediction Method for a
Safety Confirmation System Using a Lognormal Distribution Model,
Proceedings of International Workshop on Informatics(IWIN2016), pp.21-
27(2016)
4) 永田正樹,阿部祐輔,福井美彩都,磯部千裕,長谷川孝博,峰野博史: インタ
ークラウドを用いた高可用性安否確認システムの基礎評価,情報処理学会研究
報告,Vol.2016-IOT-35,No.11(2016)
5) Nagata M, Abe Y, Fukui M, Isobe C, Mineno H: Evaluation of Highly
Available Safety Confirmation System Using an Access Prediction Model,
International Journal of Informatics Society(IJIS2016)(条件付き採択の
2017 年 1 月 7 日再投稿結果待ち)
C その他
1) 著書:クラウド VPS 入門,水野信也,永田正樹,坂田智之,長谷川孝博,井
上春樹:静岡学術出版( 2010), ISBN-10: 4903859444, ISBN-13: 978-

122
4903859446
2) 著書:JAVA GUI 編 Swing から Android 開発まで,水野信也, 中田誠, 上杉
徳彦, 永田正樹:静岡学術出版(2011),ISBN-10: 4903859657,ISBN-13: 978-
4903859651














