
SENINAR TESIS ANDHITA DESSY W.
37
KLASIFIKASI POHON SEBAGAI METODE ALTERNATIF BAGI REGRESI LOGISTIK DALAM PENGKLASIFIKASIAN OBYEK (Studi Kasus : Program Wajib Belajar Pendidikan Dasar 9 Tahun) ANDHITA DESSY WULANSARI 1307 201 705
-
Upload
dhita-djilan -
Category
Education
-
view
930 -
download
1
Transcript of SENINAR TESIS ANDHITA DESSY W.

KLASIFIKASI POHON SEBAGAI METODE ALTERNATIF BAGI REGRESI LOGISTIK DALAM PENGKLASIFIKASIAN OBYEK (Studi Kasus : Program Wajib Belajar
Pendidikan Dasar 9 Tahun)
ANDHITA DESSY WULANSARI1307 201 705

PENDAHULUAN

• Program Wajardikdas 9 tahun mewajibkan penduduk Indonesia mempunyai ijasah minimal SMP/sederajat
• Program ini dikatakan berhasil apabila tiap daerahnya mencapai kategori tuntas paripurna
• Untuk mendukung program pemerataan pendidikan di Kabupaten Gresik, diperlukan informasi tentang klasifikasi desa/kelurahan.
• Salah satu metode yang sering digunakan untuk pengklasifikasian obyek adalah regresi logistik.
• Klasifikasi pohon adalah metode alternatif untuk pengklasifikasian obyek.
• Pada penelitian ini, dibandingkan ketepatan klasifikasi antara kedua metode.
LATAR BELAKANG
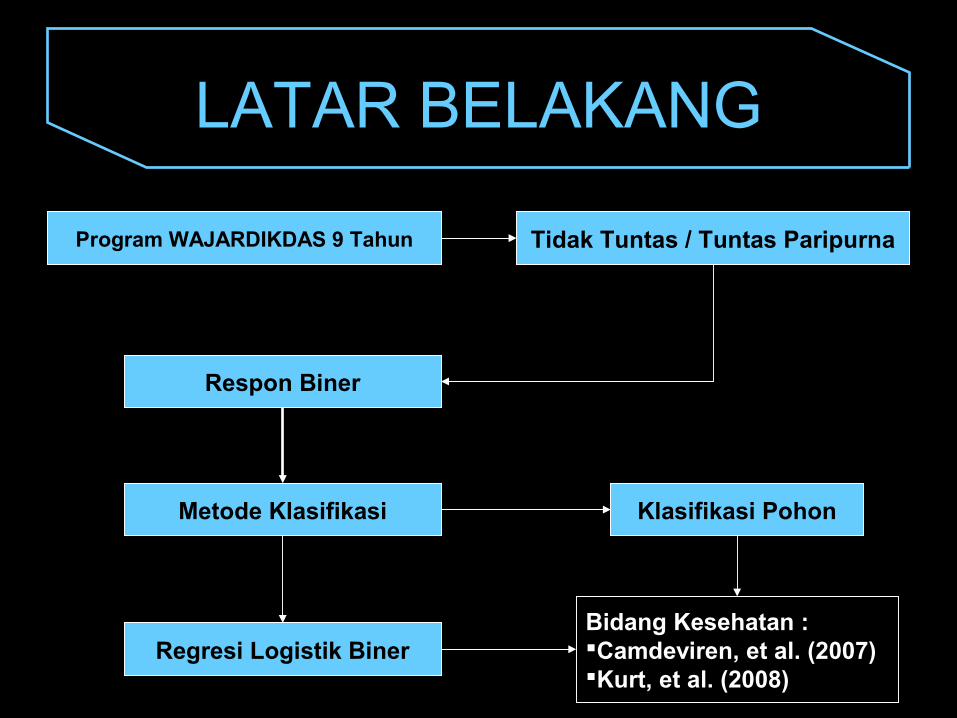
LATAR BELAKANG
Program WAJARDIKDAS 9 Tahun Tidak Tuntas / Tuntas Paripurna
Respon Biner
Metode Klasifikasi Klasifikasi Pohon
Regresi Logistik BinerBidang Kesehatan : Camdeviren, et al. (2007)Kurt, et al. (2008)

• Mendapatkan hasil perbandingan ketepatan klasifikasi yang dihasilkan oleh kedua metode.
• Mendapatkan hasil analisa data dengan metode yang
lebih tepat digunakan untuk mengklasifikasikan desa/kelurahan yang ada di Kabupaten Gresik pada kasus program Wajardikdas 9 tahun.
TUJUAN PENELITIAN

• Dapat meningkatkan wawasan keilmuan yang berkaitan dengan penerapan metode regresi logistik dan klasifikasi pohon pada bidang pendidikan.
• Dapat digunakan sebagai bahan masukan bagi pemerintah Kabupaten Gresik dalam menentukan kebijakan yang berkaitan dengan program gerakan nasional percepatan penuntasan Wajardikdas 9 Tahun.
MANFAAT PENELITIAN

TINJAUAN PUSTAKA

• Digunakan jika variabel responnya berskala nominal dan terdiri 2 kategori (respon biner)
• Model regresi logistik dengan p variabel prediktor :
• Model logitnya :
dimana,
REGRESI LOGISTIK BINER

PENGUJIAN PARAMETER
• UJI OVERALLstatistik uji :
statistik uji G mengikuti distribusi dengan derajat bebas p, tolak H0 jika
• UJI INDIVIDUstatistik uji :
statistik uji W mengikuti distribusi normal, tolak H0 jika
REGRESI LOGISTIK BINER

Klasifikasi pohon juga dikenal sebagai sebagai metode pemilahan rekusif secara biner (binary recursive partitioning), artinya sekelompok data yang terkumpul dalam satu ruang yang disebut sebagai simpul (node) dapat dipilah menjadi 2 simpul anak dan setiap simpul anak dapat dipilah lagi menjadi 2 simpul anak, begitu seterusnya dan akan berhenti jika sudah memenuhi kriteria tertentu (Lewis, 2000).
KLASIFIKASI POHON

Adapun beberapa kelebihan metode klasifikasi pohon adalah :• Metode ini bersifat nonparametrik sehingga tidak memerlukan asumsi-
asumsi yang mengikat bagi variabel prediktor.• Struktur datanya dapat dilihat secara visual sehingga dapat memudahkan
pengambilan keputusan berdasarkan model pohon yang diperoleh.• Variabel yang paling berpengaruh terhadap variabel respon (variabel
dominan) dapat diketahui dari sejumlah variabel prediktor yang dilibatkan.• Tidak hanya memberikan informasi tentang klasifikasi, tetapi juga
probabilitas kesalahan pengklasifikasian. • Hasil klasifikasi akhir berbentuk sederhana dan dapat mengklasikan data
baru secara efesien• Memudahkan interpretasi hasil.
KLASIFIKASI POHON

Kelemahan dari metode klasifikasi pohon adalah,
• Proses penghitungan secara manual sangat sulit dilakukan sehingga memerlukan bantuan software khusus seperti CART (Classification and Regression Trees).
• Tidak ada penetapan fungsi keheterogenan (metode pemilahan simpul), jumlah simpul anak minimal dan penduga yang digunakan.
KLASIFIKASI POHON
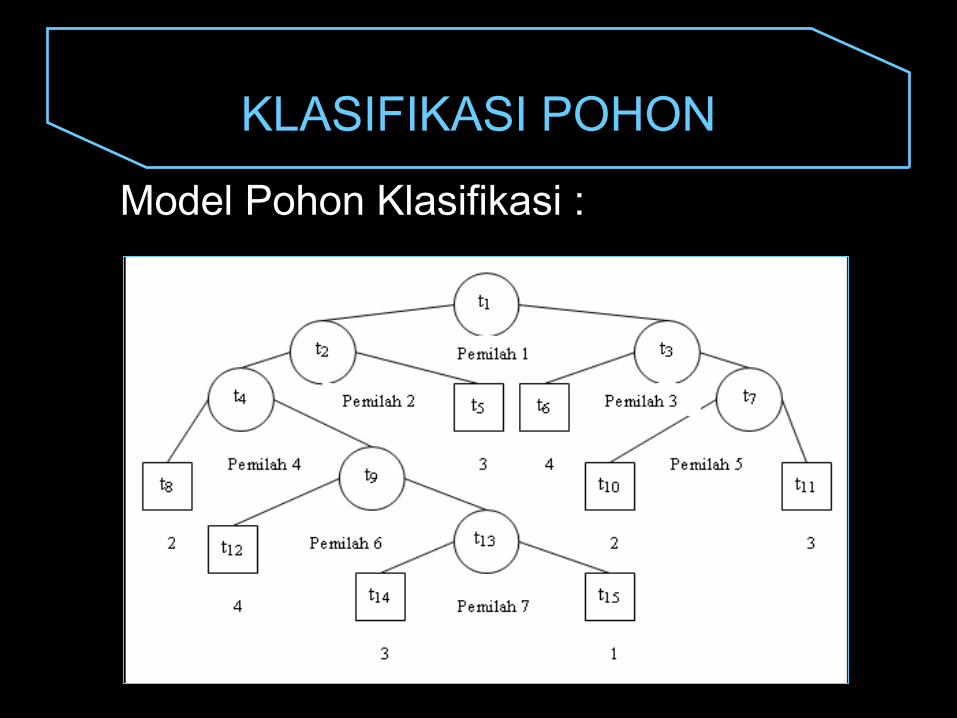
KLASIFIKASI POHON
Model Pohon Klasifikasi :

Pemilah-Pemilah• Fungsi Keheterogenan simpul
• Proses pemilahan simpul– Mencari semua kemungkinan pemilah pada variabel prediktor.– Memilih pemilah terbaik dari masing-masing variabel prediktor.
Pemilah terbaik adalah pemilah yang memaksimumkan ukuran kehomogenan masing-masing simpul anak relatif terhadap simpul induknya dan memaksimumkan ukuran pemisahan antara 2 simpul anak tersebut.
• Kriteria Goodness of split
KLASIFIKASI POHON

Penentuan simpul terminal– Tidak terdapat penurunan keheterogenan yang
berarti– Hanya terdapat satu satu pengamatan pada tiap
simpul anak atau adanya batasan minimum n. Menurut Breiman, et. al., (1984), pengembangan pohon akan berhenti apabila pada simpul terdapat ni<5, ada juga yang membatasi pengembangan pohon dengan banyak obyek dalam simpul terminal ni<10.
– Adanya batasan jumlah level atau tingkat kedalaman pohon, kemudian pohon berhenti.
KLASIFIKASI POHON

Penandaan label kelas
• Jika maka label kelas untuk simpul terminal t adalah, jo yang memberikan nilai kesalahan pengklasifikasian pada simpul t paling kecil sebesar
KLASIFIKASI POHON

proses pembentukan pohon akan berhenti pada saat :
• Terdapat hanya satu pengamatan dalam tiap simpul anak atau adanya batasan minimum n
• Semua pengamatan dalam tiap simpul anak mempunyai variabel prediktor dengan distribusi yang sama atau identik sehingga tidak mungkin lagi terjadi pemilahan.
• Adanya batasan jumlah level atau tingkat kedalaman dalam pohon.
KLASIFIKASI POHON

• Untuk mendapatkan ukuran pohon yang layak ini, dapat dilakukan pemangkasan pohon dengan ukuran cost complexity minimum (Breiman, et. al., 1984).
• dengan dimana :• = Resubtitution estimate (penduga pengganti)• = Complexity parameter (biaya penambahan satu simpul pada pohon T)• = Complexity (banyaknya simpul terminal pada pohon T)
KLASIFIKASI POHON

Macam-macam penduga
• Resubtitution estimate
• Test sample estimate• Cross validation v fold estimate
KLASIFIKASI POHON

• Resubtitution Estimate (penduga pengganti) adalah proporsi amatan yang mengalami kesalahan pengklasifikasian yaitu :
dimana X(.) adalah fungsi indikator berbentuk,
Jika R(T) dipilih sebagai penduga terbaik, maka akan cenderung dipilih pohon ukuran terbesar, sebab semakin besar pohon akan semakin kecil R(T)
KLASIFIKASI POHON

Dua macam penduga yang dapat digunakan untuk mendapatkan pohon klasifikasi optimal (terbaik) adalah :
• Penduga Sampel Uji (Test Sample Estimate)Sampel L dibagi menjadi dua yaitu L1 (Learning set) dan L2 (Testing set). Amatan dalam L1 digunakan untuk membentuk pohon T, sedangkan amatan-amatan dalam L2 digunakan untuk menduga . Jika N2 adalah jumlah amatan dalam L2, maka penduga sampel uji adalah :
Pohon klasifikasi optimum dipilih T* dengan
KLASIFIKASI POHON

• penduga validasi silang lipat V (cross validation V fold estimate)Amatan dalam sampel L dibagi secara acak menjadi V bagian yang saling lepas dengan ukuran kurang lebih sama besar untuk setiap kelasnya. Pohon T(v) dibentuk dari L-Lv dengan v=1,2,…V. Misalkan d(x)(v) adalah hasil pengklasifikasian, penduga sampel uji untuk R(Tt(v)) adalah :
dimana Nv adalah jumlah amatan dalam LvKemudian dilakukan prosedur yang sama menggunakan seluruh L, maka penduga validasi silang lipat V untuk Tt adalah,
Pohon klasifikasi optimal dipilih T* dengan
KLASIFIKASI POHON

• APK adalah perbandingan antara jumlah siswa pada jenjang pendidikan tertentu dengan jumlah penduduk usia yang sesuai dan dinyatakan dalam prosentase.
ANGKA PARTISIPASI KASAR (APK)

Dalam perhitungan angka partisipasi terdapat empat kategori ketuntasan yaitu :
Tuntas Paripurna :
nilai APK sekurang-kurangnya 95% Tuntas Utama :
nilai APK antara 90% sampai dengan <94% Tuntas Madya :
nilai APK antara 84% sampai dengan <90% Tuntas Pratama :
nilai APK antara 80% sampai dengan <84%
ANGKA PARTISIPASI KASAR (APK)

METODOLOGI PENELITIAN

• Data yang digunakan dalam penelitian ini adalah data sekunder, yaitu data statistik SMP/Sederajat untuk desa/kelurahan tahun 2006/2007 yang berasal dari Cabang Dinas P&K dan kecamatan yang ada di Kabupaten Gresik.
SUMBER DATA

– Rasio Murid / Sekolah (MS)– Rasio Murid / Guru (MG)– Rasio Murid / Kelas (MK)– Rasio Kelas / Ruang Belajar (KB) – Angka lulusan (AL)– Angka Murid Mengulang (AM)– Angka Putus Sekolah (APS)– Kategori APK yang dicapai oleh desa/kelurahan di
Kabupaten Gresik
VARIABEL PENELITIAN

Adapun langkah-langkah pada analisa data adalah sebagai berikut :• Mendapatkan hasil ketepatan klasifikasi dari masing-masing metode baik itu regresi logistik maupun
klasifikasi pohon. – Membagi data menjadi 2 bagian secara random yaitu data learning (data yang digunakan dalam dalam
pembentukan model) dan data testing (data yang digunakan dalam validasi model).– Menghitung ketepatan klasifikasi dengan menggunakan data learning dan data testing– Melakukan evaluasi klasifikasi data learning dan data testing
• Mendapatkan metode yang lebih tepat digunakan untuk mengklasifikasikan kelurahan yang ada di Kabupaten Gresik.
– Membandingkan ketepatan klasifikasi antara kedua metode berdasarkan data testing– Menggunakan metode yang mempunyai ketepatan klasifikasi lebih tinggi untuk mengklasifikasikan
desa/kelurahan di Kabupaten Gresik. Apabila metode yang mempunyai ketepatan klasifikasi lebih tinggi adalah metode regresi logistik, maka analisa
data akan dilanjutkan dengan langkah-langkah sebagai berikut : – Membuat model regresi logistik multivariabel antara variabel respon dengan variabel prediktor
kemudian dilakukan pengujian secara overall dan individu terhadap model yang diperoleh.– Menginterpretasi model regresi logistik yang diperoleh.– Mendapatkan faktor yang menyebabkan adanya perbedaan jenis ketuntasan Wajardikdas 9 tahun di
Kabupaten Gresik.Apabila metode yang mempunyai ketepatan klasifikasi lebih tinggi adalah metode klasifikasi pohon, maka
langkah-langkahnya adalah : – Melakukan pembentukan pohon klasifikasi maksimal dengan menggunakan data learning. – Menentukan model pohon klasifikasi terbaik (optimal) dengan cara memangkas (prunning) pohon klasifikasi maksimal
berdasarkan ukuran cost complexity minimum.– Menginterpretasi model pohon klasifikasi optimal yang diperoleh.– Mendapatkan faktor yang menyebabkan adanya perbedaan jenis ketuntasan Wajardikdas 9 tahun di Kabupaten Gresik.
METODE PENELITIAN

• Pie chart untuk kategori APK
HASIL DAN PEMBAHASAN

• Perbandingan ketepatan klasifikasi
HASIL DAN PEMBAHASAN
• Topology pohon klasifikasi maksimal
HASIL DAN PEMBAHASAN

• Misklasifikasi data learning pada pohon klasifikasi maksimal
• Misklasifikasi data testing pada pohon klasifikasi maksimal
HASIL DAN PEMBAHASAN
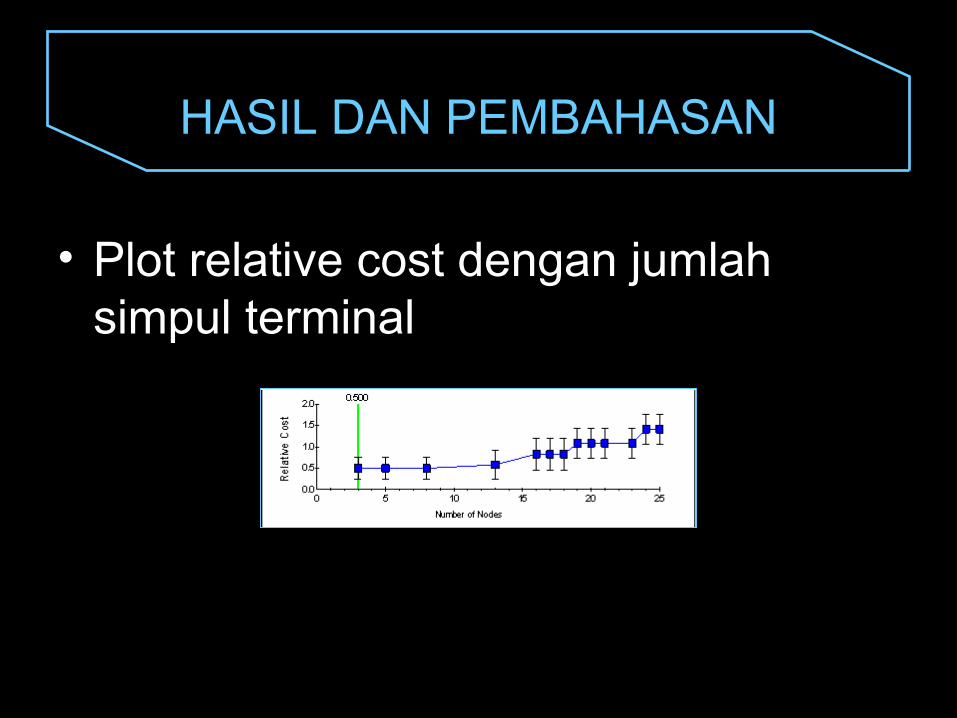
• Plot relative cost dengan jumlah simpul terminal
HASIL DAN PEMBAHASAN
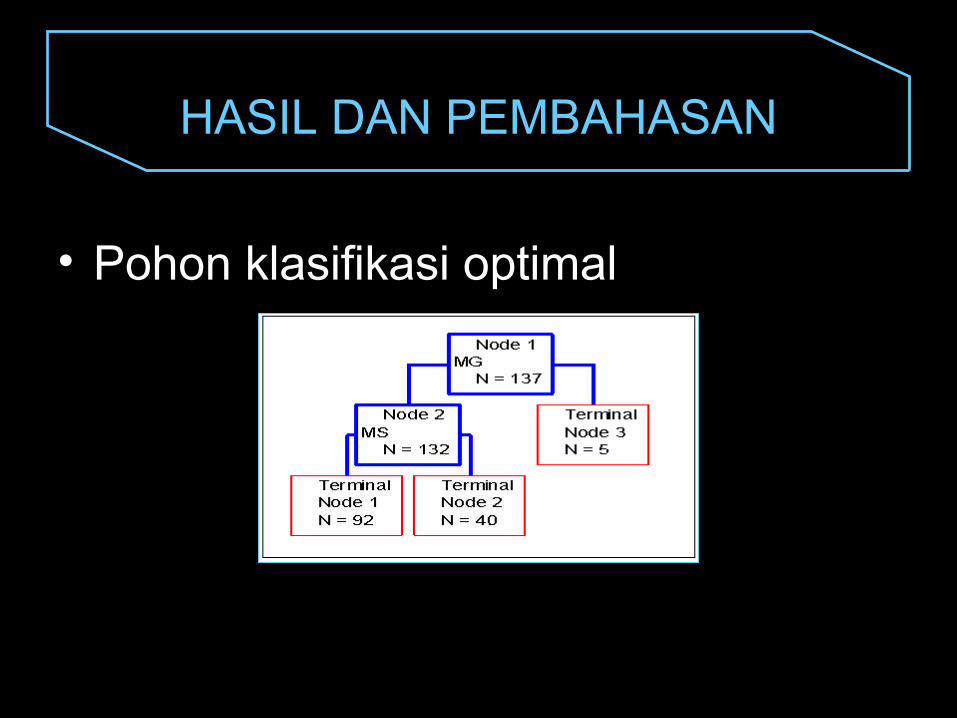
• Pohon klasifikasi optimal
HASIL DAN PEMBAHASAN

• Prediksi Sukses untuk data learning pada pohon optimal
• Prediksi Sukses untuk data testing pada pohon optimal
HASIL DAN PEMBAHASAN

Berdasarkan hasil penelitian dan pembahasan pada Bab 4 maka didapatkan kesimpulan sebagai berikut :
• Ketepatan klasifikasi yang dihasilkan melalui analisa data dengan metode regresi logistik dan klasifikasi pohon untuk pengklasifikasian desa/kelurahan di kabupaten Gresik pada program Wajardikdas 9 tahun mempunyai nilai yang cukup berbeda, terutama untuk data testing. Pada kondisi pembagian data learning 95% dan data testing 5%, untuk metode regresi logistik ketepatan klasifikasi dari data learning-nya adalah 60.58% dan testing-nya adalah 42.86% sedangkan untuk metode klasifikasi pohon ketepatan klasifikasi data learning-nya adalah 62.04% dan testing-nya adalah 71.43%.
• Metode yang lebih tepat dipergunakan untuk pengklasifikasian desa/kelurahan di kabupaten Gresik pada program Wajardikdas 9 tahun adalah klasifikasi pohon dengan data learning 95% dan testing 5%, karena nilai ketepatan klasifikasi yang dihasilkan lebih besar khususnya untuk data testing. Dari metode ini didapatkan variabel yang berpengaruh terhadap kondisi kentuntasan Wajardikdas 9 tahun adalah variabel rasio murid/guru dan rasio murid/sekolah.
KESIMPULAN

TERIMA KASIHMOHON KRITIK
DAN SARAN




















