
IMPLEMENTASI HYBRID SAMPLING TECHNIQUE UNTUK …
33
IMPLEMENTASI HYBRID SAMPLING TECHNIQUE UNTUK PREDIKSI INTERAKSI SENYAWA AKTIF DAN PROTEIN PADA DATA YANG TIDAK SEIMBANG ANGGUN SULIA RAHMI DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2018
Transcript of IMPLEMENTASI HYBRID SAMPLING TECHNIQUE UNTUK …

IMPLEMENTASI HYBRID SAMPLING TECHNIQUE UNTUK
PREDIKSI INTERAKSI SENYAWA AKTIF DAN PROTEIN
PADA DATA YANG TIDAK SEIMBANG
ANGGUN SULIA RAHMI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2018


PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Implementasi Hybrid
Sampling Technique untuk Prediksi Interaksi Senyawa Aktif dan Protein pada Data
yang Tidak Seimbang adalah benar karya saya dengan arahan dari komisi
pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi
mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan
maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan
dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut
Pertanian Bogor.
Bogor, Juli 2018
Anggun Sulia Rahmi
NIM G64140018

ABSTRAK
ANGGUN SULIA RAHMI. Implementasi Hybrid Sampling Technique untuk
Prediksi Interaksi Senyawa Aktif dan Protein pada Data yang Tidak Seimbang.
Dibimbing oleh WISNU ANANTA KUSUMA dan RUDI HERYANTO.
Sistem prediksi formula jamu (Indonesia Jamu Herbs-Ijah) dikembangkan
untuk memprediksi khasiat jamu berdasarkan hubungan interaksi senyawa aktif dan
protein penyakit. Data hubungan interaksi senyawa aktif dan protein merupakan
jenis data tidak seimbang karena banyak data senyawa aktif yang belum diketahui
interaksinya dengan protein target, sehingga menyebabkan hasil prediksi yang
kurang optimal. Pada penelitian ini, hybrid sampling technique dengan
mengombinasikan complementary fuzzy support vector machine (CMTFSVM) dan
sytnthetic minority oversampling technique (SMOTE) digunakan untuk menangani
data interaksi senyawa aktif dan protein yang tidak seimbang pada data Ijah.
Pengujian dilakukan menggunakan geometric mean (Gmean), area under curve
(AUC), dan akurasi. Hasil penelitian menunjukkan bahwa hybrid sampling
technique pada senyawa aktif dan protein pada Ijah berhasil meningkatkan kelas
data minoritas mecapai tiga kali lipat dari data sampel yang digunakan. Model
prediksi yang dihasilkan memiliki akurasi, Gmean, dan AUC secara berurutan
sebesar 0.8346, 0.6812, dan 0.5319.
Kata kunci: CMTFSVM, data tidak seimbang, hybrid sampling technique
ABSTRACT
ANGGUN SULIA RAHMI. Implementation of Hybrid Sampling Technique for
Predicting Active Compound and Protein Interaction in Unbalanced Data.
Supervised by WISNU ANANTA KUSUMA dan RUDI HERYANTO.
Indonesia Jamu Herbs (Ijah) web server aims to predict Jamu efficacy based
on its active compound and disease’s protein interaction. However, the interaction
between compound and protein data is unbalanced since there are many unknown
interactions between active compounds and protein target. Thus, the prediction
result is still not optimal. In this research, the hybrid sampling technique,
combining complementary fuzzy support vector machine (CMTFSVM) and
synthetic minority oversampling technique (SMOTE) was used to handle
imbalanced data interaction between active compound and protein for Ijah.
Performance was measured using geometric mean (Gmean), area under curve
(AUC), and accuracy. The evaluation result show that the hybrid sampling
technique could increase the instance of minority class three times. Moreover, the
prediction model could obtain the value of 0.8346, 0.6812, and 0.5319 for accuracy,
Gmean, and AUC, respectively.
Keywords: CMTFSVM, hybrid sampling technique, unbalanced data

Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer
pada
Departemen Komputer
IMPLEMENTASI HYBRID SAMPLING TECHNIQUE UNTUK
PREDIKSI INTERAKSI SENYAWA AKTIF DAN PROTEIN
PADA DATA YANG TIDAK SEIMBANG
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2018
ANGGUN SULIA RAHMI

Penguji:
1 Husnul Khotimah, SKomp MKom


PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas
segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Penelitian ini
berjudul Implementasi Hybrid Sampling Technique untuk Prediksi Interaksi
Senyawa Aktif dan Protein pada Data yang Tidak Seimbang telah dilaksanakan
sejak bulan Februari 2018.
Terima kasih penulis ucapkan kepada Bapak DrEng. Wisnu Ananta Kusuma,
ST MT dan Bapak Rudi Heryanto, SSi MSi selaku pembimbing. Terima kasih
kepada Ibu Husnul Khotimah, SKomp Mkom sebagai penguji yang telah
memberikan masukan dan saran yang sangat berharga. Terima kasih kepada pihak
Biofarmaka yang telah memberikan dukungan sarana dan dana. Terima kasih
kepada semua pihak yang tidak dapat disebutkan satu persatu namanya karena telah
menyumbangkan pendapat serta memberi dukungan moril maupun materil dalam
penyelesaian penelitian ini. Terima kasih khusus penulis ungkapkan kepada ayah,
ibu, serta keluarga atas dukungan doa, kasih sayang dan kesabaran yang luar biasa.
Semoga karya ilmiah ini bermanfaat.
Bogor, Juli 2018
Anggun Sulia Rahmi

DAFTAR ISI
DAFTAR TABEL viii
DAFTAR GAMBAR viii
DAFTAR LAMPIRAN viii
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
TINJAUAN PUSTAKA 3
Data Tidak Seimbang 3
Complementary Fuzzy Support Vector Machine (CMTFSVM) 3
Synthetic Minority Oversampling Technique (SMOTE) 4
METODE 5
Data Penelitian 5
Tahapan Penelitian 5
Implementasi Hybrid Sampling Technique 6
Pengujian 8
Lingkungan Pengembangan 8
HASIL DAN PEMBAHASAN 9
Pengumpulan Data 9
Praproses Data 9
Pengujian 10
SIMPULAN DAN SARAN 13
Simpulan 13
Saran 14
DAFTAR PUSTAKA 14
LAMPIRAN 13
RIWAYAT HIDUP 15

DAFTAR TABEL
1 Statistik dataset Preuengkarn et al. (2017) 5
2 Deskripsi data penelitian 9
3 Pengujian dataset tidak seimbang menggunakan SVM dan FSVM 10
4 Hasil uji hasil implementasi hybrid sampling technique 11
5 Perbandingan Gmean hasil implementasi dan Pruengkarn et al. (2017) 12
6 Perbandingan AUC hasil implementasi dan Pruengkarn et al. (2017) 12
7 Hasil pengujian menggunakan SVM 13
8 Hasil pengujian hybrid sampling technique pada CPI 13
DAFTAR GAMBAR
1 Ilustrasi CMTFSVM (Pruengkarn et al. 2017) 4 2 Tahapan Penelitian 6 3 Implementasi hybrid sampling technique 7
DAFTAR LAMPIRAN
1 Data compound descriptor dan protein descriptor 16 2 Data Compound Protein Interaction Ijah (Kurnia 2017) 17 3 Dataset Pruengkarn et al. (2017) 18
4 Compound Protein Interaction dataset Ijah 21

1
PENDAHULUAN
Latar Belakang
Jamu merupakan obat herbal tradisional Indonesia yang dipercaya dapat
menjaga kesehatan dan mengatasi penyakit (Torri 2013). Beberapa tanaman
dicampur dan diracik untuk mengatasi masalah kesehatan tertentu. Menurut WHO
(2008) racikan jamu diwariskan secara turun-temurun berlandaskan pengalaman
dan budaya masyarakat.
Penelitian mengenai hubungan antara isi racikan jamu dan khasiat jamu
dalam penyembuhan penyakit dilakukan oleh Afendi et al. (2010) dengan
menganalisis interaksi antara efikasi, jamu, dan komposisi jamu. Khasiat jamu
dimodelkan berdasarkan komposisi dan racikan tanaman dengan menggunakan
partial least square discriminant analysis (PLS-DA). Pemodelan dilakukan
menggunakan data tanaman komposisi jamu dan hubungannya dalam
menyembuhkan penyakit (Afendi et al. 2012). Selain penelitian yang dilakukan
untuk melihat asosiasi tanaman dan penyakit, pencarian formula jamu atau obat
dapat lebih presisi dilakukan dengan melihat hubungan antara senyawa aktif
tanaman dan protein yang terkait dengan penyakit tertentu (Amir 2016).
Terkait dengan penelitian mengenai interaksi antara senyawa dan protein ini,
Kurnia (2017) mengimplementasikan metode bipartite local model network–based
interaction–profile inferring (BLMNII) untuk memprediksi hubungan senyawa aktif
dan protein untuk menyusun formula jamu yang diimpelementasikan ke dalam
aplikasi berbasis web Indonesia Jamu Herbs (Ijah). BLMNII diimplementasikan
dengan menggunakan model kemiripan senyawa dan model kemiripan protein
dengan klasifikasi support vector machine (SVM) untuk memprediksi interaksi
antara senyawa dan protein. Jika protein dan senyawa tidak memiliki informasi
interaksi, maka label kelas dihitung berdasarkan nilai kemiripan dan interaksi dari
data lain. Proses prediksi tanpa data interaksi senyawa dan protein merupakan kasus
terburuk pada perhitungan label kelas interaksi algoritme BLMNII yaitu dengan
kompleksitas O(n2). Penelitian Kurnia (2017) menggunakan data yang tidak
seimbang yaitu hubungan antar senyawa dan protein dengan rasio data positif (data
yang memiliki interaksi) berjumlah 0.0001%. Sifat data yang tidak seimbang
menunjukkan bahwa sebagian besar klasifikasi dilakukan berdasarkan nilai
kemiripan dan interaksi data lain. Sifat data tidak seimbang tidak dapat diatasi pada
implementasi BLMNII sehingga dibutuhkan metode untuk meningkatkan rasio data
minoritas untuk mengatasi data tidak seimbang pada data interaksi senyawa aktif
dan protein dalam Ijah.
Resampling menjadi pendekatan yang dapat digunakan untuk mengatasi data
tidak seimbang, terknik resampling meliputi undersampling dan oversampling.
Teknik oversampling digunakan untuk mengurangi kelas mayoritas sedangkan
teknik undersampling digunakan untuk membuat sampel positif yang baru. Hybrid
sampling merupakan kombinasi antara teknik undersampling dan oversampling.
complementary fuzzy support vector machine (CMTFSVM) dan synthetic minority
oversampling technique (SMOTE) efektif digunakan sebagai teknik hybrid
sampling untuk mengatasi data tidak seimbang pada berbagai dataset (Pruengkarn
et al. 2017). CMTFSVM memanfaatkan konsep komplementer (CMT)

2
menggunakan truth model dan falsity model. Proses identifikasi data yang tidak
pasti dari hasil keluaran model diatasi menggunakan fuzzy support vector machine
(FSVM) berdasarkan pada nilai keanggotaan fuzzy. Teknik oversampling SMOTE
selanjutnya digunakan, sebagai kombinasi hybrid sampling technique, untuk
meningkatkan data minoritas atau data positif sehingga didapatkan data yang
seimbang.
Penelitian ini bertujuan untuk mengimplementasi ulang metode hybrid
sampling CMTFSVM dan SMOTE untuk mengatasi data interaksi protein dan
senyawa aktif yang tidak seimbang pada Ijah. Implementasi metode hybrid
sampling merujuk pada penelitian dilakukan Pruengkarn et al. (2017).
Perumusan Masalah
Berdasarkan latar belakang yang didefinisikan, didapatkan rumusan masalah
yaitu bagaimana mengurangi bias dalam memprediksi interaksi senyawa aktif dan
protein pada data yang tidak seimbang dengan menggunakan hybrid sampling
technique. Selain itu, penelitian ini bertujuan untuk memvalidasi hasil implementasi
hybrid sampling technique yang telah dibuat.
Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1 Mengombinasikan complementary fuzzy support vector machine (CMTFSVM)
dan sytnthetic minority oversampling technique (SMOTE) untuk menangani
masalah data tidak seimbang pada kasus prediksi interaksi senyawa aktif dan
protein
2 Memvalidasi hasil implementasi hybrid sampling technique.
Manfaat Penelitian
Hasil penelitian ini diharapkan dapat meningkatkan akurasi dari prediksi
khasiat jamu pada server web Ijah dan mempercepat waktu eksekusi prediksi.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini, yaitu:
1 Data yang digunakan adalah dataset Pruengkarn et al. (2017) yang bersumber
dari KEEL dan UCI, data penelitian Kurnia (2017) yang bersumber dari data
web server Ijah, PubChem dan UniProt, serta data protein descriptor dan
compound descriptor dari PubChem dan protein feature server (Profeat).
2 Implementasi data Pruengkarn et al. (2017) digunakan untuk validasi hasil
implementasi hybrid sampling technique.
3 Data protein descriptor yang digunakan adalah fitur amino acid composition
(AAC) dan data compound desciptor adalah semua fitur deskriptor senyawa
dari pangkalan data PubChem.

3
TINJAUAN PUSTAKA
Data Tidak Seimbang
Distribusi data tidak seimbang terjadi jika suatu kelas memiliki anggota yang
jauh lebih banyak dibandingkan anggota kelas lainnya (minoritas). Data minoritas
cenderung diklasifikasikan sebagai noise ataupun outlier yang dapat merusak data
sehingga cenderung dihilangkan. Kebanyakan data yang menjadi fokus penelitian
biasanya merupakan data minoritas. Kesalahan pengelompokkan yang disebabkan
sedikitnya data latih pada kelas minoritas dapat meningkatkan kesalahan dalam
penarikan informasi (Ali et al. 2015).
Data tidak seimbang dapat diatasi melalui dua pendekatan. Pendekatan
pertama yaitu teknik sampling pada level data dengan melakukan resampling
sehingga terbentuk kelas data seimbang. Pendekatan kedua adalah memodifikasi
pada algoritme klasifikasi. Teknik sampling pada level data dapat digunakan pada
banyak kasus data tidak seimbang (Ali et al. 2015). Teknik sampling dikategorisasi
sebagai undersampling, oversampling dan hybrid sampling (Pruengkarn et al.
2017).
Undersampling merupakan upaya untuk menurunkan jumlah data pada kelas
mayoritas sedangkan oversampling bertujuan untuk meningkatkan jumlah data
pada kelas minoritas. Contoh teknik undersampling yaitu inverse random under
sampling (IRUS) di mana algoritme menurunkan jumlah sampel mayor dengan
membuat sejumlah batasan data latih yang selanjutnya dapat digunakan untuk
menentukan wilayah keputusan (Tahir et al. 2012). Teknik oversampling dapat
diimplementasikan menggunakan algoritme synthetic minority oversampling
technique (SMOTE) yaitu dengan membuat “data sintetis” untuk memperluas
jangkauan wilayah kelas minoritas. Teknik hybrid sampling merupakan kombinasi
undersampling dan oversampling dengan berbagai classifier. Pruengkarn et al.
(2017) menguji teknik undersampling, oversampling dan hybrid sampling
menggunakan berbagai classifier. Hasil penelitian Pruengkarn et al. (2017)
menunjukkan kombinasi undersampling menggunakan complementary fuzzy
support vector machine (CMTFSVM) dan oversampling menggunakan SMOTE
memiliki performa Gmean yang baik yaitu 95.9% dalam mengatasi masalah data
tidak seimbang.
Complementary Fuzzy Support Vector Machine (CMTFSVM)
CMTFSVM menerapkan konsep komplementer (CMT) dari keluaran truth
target dengan memanfaatkan fuzzy support vector machine (FSVM) sebagai
classifier dalam mengidentifikasi ketidakpastian data. FSVM digunakan untuk
menghilangkan noise dan nilai yang tidak normal (Fan dan He 2010). CTMFSVM
memiliki dua model data, yaitu truth model dan falsity model (komplemen truth
model). Kedua model dilatih sesuai dengan keanggotaan fuzzy masing-masing
model. Hasil data latih yang dibandingkan sebagai indikasi ketidakpastian data
yang kemudian dapat diadaptasi untuk menghilangkan klasifikasi yang tidak benar
(Pruengkarn et al. 2017). Gambar 1 merupakan ilustrasi teknik CMTFSVM.

4
Gambar 1 Ilustrasi CMTFSVM (Pruengkarn et al. 2017).
Pruengkarn et al. (2017) memaparkan bahwa terdapat dua tipe undersampling
technique yaitu CMTFSVM1 dan CMTFSVM2. CMTFSVM1 membuat data latih
dengan membuang data yang tidak terklasifikasi dengan benar berdasarkan falsity
model dan truth model. Hasil data uji CMTFVSM1 merupakan hasil data latih yang
dikurangi data latih yang tidak terklasifikasi dengan benar (CMTFSVM1 = T – (FP
∪ FN)). Hasil data uji CMTFSVM2 merupakan hasil data latih dikurangi data yang
muncul pada truth model dan falsity model (CMTFSVM2 = T – (FP ∩ FN)).
Synthetic Minority Oversampling Technique (SMOTE)
SMOTE dikenalkan oleh Chawla et al. (2002) yang merupakan pendekatan
oversampling dengan membuat data “sintetis” sebagai data latih ekstra dengan
operasi tertentu. Data sintetis merupakan data minoritas “baru” yang dibuat dengan
mengoperasikan ruang fitur. Peningkatan jumlah data minoritas karena data sintetis
membuat wilayah keputusan menjadi besar namun bersifat kurang spesifik. Hal ini
menyebabkan wilayah keputusan yang umum sehingga classifier memiliki
jangkauan wilayah minoritas yang lebih baik (Chawla et al. 2002).
Pseudocode SMOTE
1 If data minoritas SMOTEd<100:
2 Random (T)
3 Hitung k tetangga terdekat untuk data minoritas terpilih
4 If data yang ingin di SMOTE >0:
5 Bangkitkan data sintetis
5
METODE
Data Penelitian
Data pada penelitian ini merujuk pada data penelitian Pruengkarn et al.
(2017), data penelitian Kurnia (2017), dan webcrawling dari situs PubChem. Data
penelitian Pruengkarn terdiri atas tiga dataset yaitu dataset German, Yeast3, dan
Glass5. Semua dataset memiliki kelas biner yaitu positif atau negatif. Dataset
German merupakan dataset untuk mengidentifikasi fraud pada kartu kredit. Kelas
positif menunjukkan terjadinya fraud. Dataset Yeast3 merupakan pengelompokan
ragi menjadi dua kelompok yaitu kelompok ME3 (kelas positif) atau kelompok lain
(kelas negatif). Dataset Glass5 merupakan identifikasi forensik sumber kaca
berdasarkan informasi kimia. Kelas terbagi menjadi kaca yang berasal dari pecahan
selain kontainer (kelas negatif) dan pecahan kaca kontainer (kelas positif). Tabel 1
merupakan ringkasan karakteristik dari dataset yang digunakan. Stastistik dataset
meliputi jumlah data (#instance), persentase kelas mayoritas (%mayor), dan
persentase kelas minoritas (%minor).
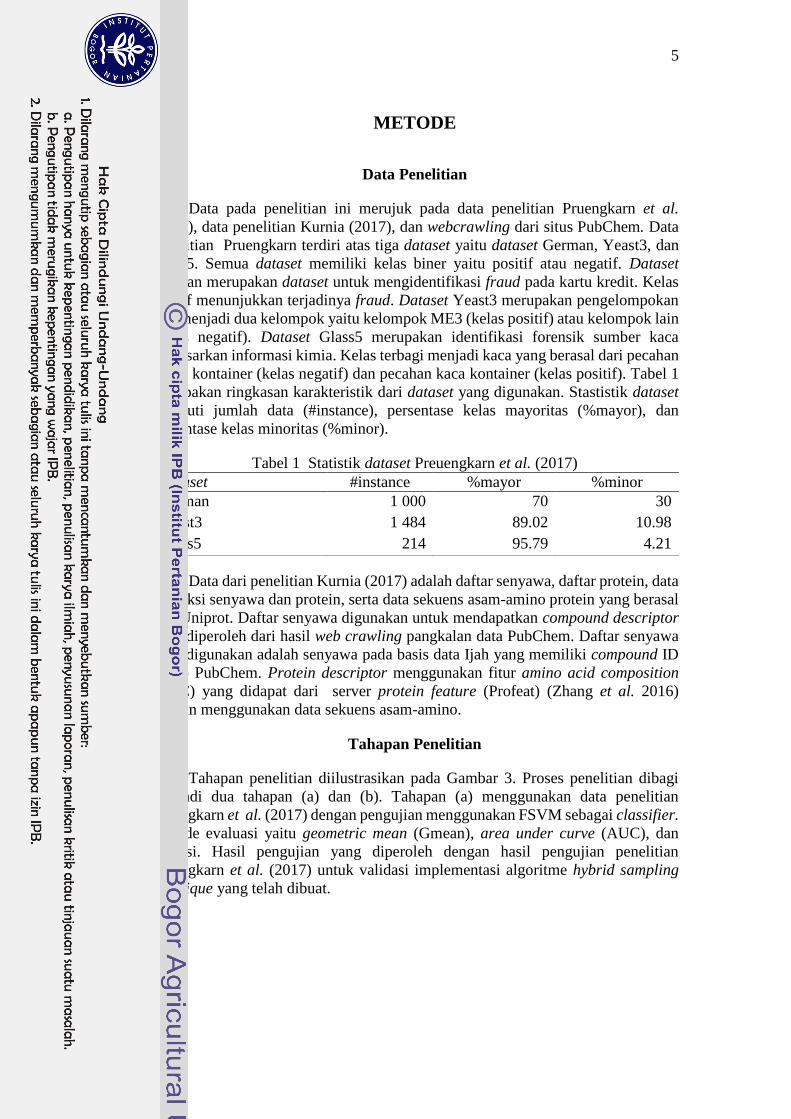
Tabel 1 Statistik dataset Preuengkarn et al. (2017)
Dataset #instance %mayor %minor
German 1 000 70 30
Yeast3 1 484 89.02 10.98
Glass5 214 95.79 4.21
Data dari penelitian Kurnia (2017) adalah daftar senyawa, daftar protein, data
interaksi senyawa dan protein, serta data sekuens asam-amino protein yang berasal
dari Uniprot. Daftar senyawa digunakan untuk mendapatkan compound descriptor
yang diperoleh dari hasil web crawling pangkalan data PubChem. Daftar senyawa
yang digunakan adalah senyawa pada basis data Ijah yang memiliki compound ID
(CID) PubChem. Protein descriptor menggunakan fitur amino acid composition
(AAC) yang didapat dari server protein feature (Profeat) (Zhang et al. 2016)
dengan menggunakan data sekuens asam-amino.
Tahapan Penelitian
Tahapan penelitian diilustrasikan pada Gambar 3. Proses penelitian dibagi
menjadi dua tahapan (a) dan (b). Tahapan (a) menggunakan data penelitian
Pruengkarn et al. (2017) dengan pengujian menggunakan FSVM sebagai classifier.
Metode evaluasi yaitu geometric mean (Gmean), area under curve (AUC), dan
akurasi. Hasil pengujian yang diperoleh dengan hasil pengujian penelitian
Pruengkarn et al. (2017) untuk validasi implementasi algoritme hybrid sampling
technique yang telah dibuat.

6
Gambar 2 Tahapan Penelitian
Tahapan penelitian (b) adalah implementasi pada Ijah di mana penelitian
menggunakan data compound descriptor dan data protein descriptor. Selanjutnya
dibuat persilangan matriks tiap data compound descriptor terhadap data protein
descriptor dengan kelas didasarkan pada compound protein interaction (CPI) yang
mengacu pada penelitian Kurnia (2017). Matriks ini yang digunakan sebagai
dataset Ijah. Pengujian dilakukan dengan mengklasifikasi data tes menggunakan
SVM yang merupakan classifier pada BLMNII. Data kelas yang seimbang setelah
implementasi hybrid sampling technique akan disaring sesuai dengan kemiripan
CPI yang tersedia yang selanjutnya digunakan sebagai data CPI baru yang dapat
diterapkan pada BLMNII.
Implementasi Hybrid Sampling Technique
Implementasi hybrid sampling technique yang dilakukan sesuai ilustrasi pada
Gambar 4. Secara garis besar, terdapat 2 tahapan pada implementasi hybrid
sampling technique, yaitu CMTFSVM dan SMOTE. Urutan implementasi mengacu
pada penelitian Pruengkarn et al. (2017). Penelitian tersebut, Pruengkarn
membandingkan nilai Gmean dan AUC menggunakan pendekatan CMT, SMOTE,
CMT kombinasi SMOTE, dan SMOTE kombinasi CMT dengan berbagai classifier
untuk mengatasi data tidak seimbang. Hasil penelitian menunjukkan CMT yang
dilanjutkan dengan SMOTE (CMTSMT) mengunakan classifier FSVM
menghasilkan nilai terbaik.

7
Gambar 3 Implementasi hybrid sampling technique
Tahap pertama adalah undersampling menggunakan CMTFSVM pada kelas
mayoritas menggunakan dua model yaitu truth model dan falsity model
(komplemen truth model). Training pada truth model menggunakan truth
membership, sedangkan training falsity model menggunakan falsity membership.
Nilai keanggotaan merepresentasikan kepentingan data bagi kelasnya. Fungsi
membership didefinisikan pada Persamaan (1a) dan (1b). Nilai keanggotaan pada
kelas positif direpresentasikan sebagai mi+ dengan contoh data berupa xi
+,
sedangkan mi− merupakan nilai keanggotaan pada kelas negatif dengan contoh
berupa xi−. Kepentingan data bagi kelas masing-masing direpresentasikan oleh f(xi)
yang berkisar [0,1]. Refleksi ketidakseimbangan data direpresentasikan oleh r- dan
r+ di mana r+ > r-. Membership value merupakan interval dari [0, ri] di mana r < 1
menunjukkan kelas negatif. Karena kelas data yang tidak seimbang, pada training
example fuzzy membership digunakan nilai r- = r dan r+= 1.
mi+ = f(xi
+) × r+ (1a)
mi- = f(xi
-) × r- (1b)
Kepentingan data didefinisikan pada persamaan (1c). Variabel β merupakan
kemiringan penurunan dengan kenaikan 0.1 pada interval [0,1]. Adapun variabel
dihyp
merupakan margin fungsional tiap contoh xi yang sebanding dengan nilai
absolut dari nilai keputusan SVM yang didefinisikan melalui persamaan (1d).
Variasi β menyebabkan terdapat sepuluh kemungkinan fuzzy membership value
yang nilai optimumnya dipilih berdasarkan Gmean tertinggi.
fexphyp
(xi) = 2
1 + exp(βdihyp
) (1c)
dihyp
= yi(ω × Φ(xi) + b) (1d)
Tahap kedua pada implementsai hybrid sampling technique adalah
menyeimbangkan data hasil undersampling pada kelas minoritas dengan

8
implementasi oversampling menggunakan SMOTE. Data minoritas akan dipilih
untuk acuan pembuatan data sintetis. Pada data minoritas yang terpilih disimpan
sejumlah dua tetangga terdekatnya. Selanjutnya dilakukan pembuatan sampel
sintetis dengan mengikuti tahapan berikut, yaitu pertama menghitung perbedaan
fitur sampel dan tetangga dari sampel terpilih (dif), kedua mengambil nilai acak
[0,1] (gap), ketiga mengalikan dif dan gap, dan terakhir menambahkan hasil tahap
perkalian dif dan gap dengan nilai fitur sampel yang dipilih. Sampel sintetis
membentuk area menjadi lebih umum sehingga daerah klasifikai menjadi lebih luas.
Pengujian
Pengujian pada penelitian ini dibagi menjadi dua bagian. Kedua pengujian
dilakukan dengan metode10-folds stratified cross validation dengan 20% data uji.
Pengujian pertama dilakukan untuk memvalidasi hasil implementasi CMTFSVM-
SMOTE pada data Pruengkarn et al. (2017) dan pengujian kedua dilakukan dengan
menggunakan data Ijah.
Rincian pengujian tersebut dideskripsikan sebagai berikut. Dataset yang
digunakan merupakan dataset yang berasal dari penelitian Pruengkarn et al. (2017),
yaitu German, Yeast3, dan Glass5. Pengujian kedua dilakukan pada dataset Ijah
yang berupa compound protein interaction (CPI). Metode evaluasi yang digunakan
pada kedua pengujian adalah pengukuran Gmean, AUC, dan akurasi. Pengukuran
Gmean dan AUC dipilih karena pengukuran dapat mengatasi permasalahan kelas
data tidak seimbang (Pruengkarn et al. 2017).
Gmean digunakan untuk mengukur akurasi klasifikasi penggolongan data
tidak seimbang dan didefinisikan sebagai akar dari pengalian true positive rate dan
true negative rate yang diilustrasikan pada Persamaan (2). Adapun AUC adalah
evaluasi menggunakan trade off benefit (TPrate = TP / (TP + FN)) dan cost (FPrate =
FP / (FP + TN)) sebagai pendekatan evaluasi performa. True Positive (TP) dan True
Negative (TN) merupakan jumlah hasil klasifikasi yang tepat pada kelas positif dan
kelas negatif, sedangkan False Positive (FP) dan False Negative (FN) adalah
jumlah hasil klasifikasi yang tidak sesuai dengan kelas seharusnya.
Gmean = √TP
TP+FN×
TN
TN+FP (2)
Lingkungan Pengembangan
Penelitian ini dilakukan menggunakan perangkat keras dan perangkat lunak
dengan spesifikasi sebagai beriku:
1 Perangkat keras berupa personal computer dengan spesifikasi:
Laptop Asus A456U
Processor Inter Core i5-7200U 2.5 GHz
RAM 4 GB
2 Perangkat lunak yang digunakan yaitu:
Windows 10 sebagai sistem operasi
Anaconda Navigator sebagar IDE Python
Sublime Text 3 sebagai text editor
Python 2.7 sebagai bahasa pemrograman

9
Package ‘mlfromscratch’ (Noren 2017) untuk implementasi SVM
Package ‘imblearn’ (Nogueira dan Aridas 2017) untuk implementasi
SMOTE
HASIL DAN PEMBAHASAN
Pengumpulan Data
Pengumpulan data penelitian Pruengkarn et al. (2017) dilakukan dengan
mengunduh dataset German melalui situs UCI serta dataset Glass5 dan dataset
Yeast3 melalui situs KEEL. Pengumpulan data compound descriptor dilakukan
dengan crawling deskriptor senyawa menggunakan compound ID (CID) PubChem
dari daftar senyawa pada penelitian Kurnia (2017) menggunakan API yang tersedia.
Data protein descriptor didapatkan dengan mengunduh fitur amino acid
composition (AAC) melalui protein feature (Profeat) server berdasarkan sekuens
amino protein dalam bentuk fasta yang didapat dari penelitian Kurnia (2017).
Compound descriptor memiliki empat belas variabel yang mendeskripsikan
seyawa secara numerik dari pangkalan data PubChem. Protein descriptor memiliki
dua puluh variabel yang merupakan deskripsi numerik protein didasarkan pada
komposisi asam aminonya. Contoh data compound descriptor dan protein
descriptor hasil pengumpulan data dapat dilihat pada Lampiran 1.
Pengumpulan data compound protein interaction (CPI) adalah data CPI yang
tersedia pada Ijah dan bersumber dari penelitian Kurnia (2017). CPI merupakan
informasi senyawa aktif dan protein yang memiliki interaksi (kelas positif).
Lampiran 2 memuat contoh data CPI penelitian Kurnia (2017) yang digunakan pada
penelitian ini. Tabel 2 menunjukkan daftar deskripsi data penelitian.
Tabel 2 Deskripsi data penelitian
Data Sumber Data Deskripsi
Protein Profeat 3 335 data protein descriptor
Senyawa PubChem 7 119 data compound descriptor
CPI Ijah 3 693 interaksi senyawa-protein
Sekuens asam
amino protein
Uniprot 3 335 sekuens asam amino dalam format
*.fasta
Praproses Data
Praproses data dilakukan pada tiap dataset pada penelitian Pruengkarn.
Praproses pada dataset Glass5 dan Yeast3 dilakukan normalisasi data karena data
yang bersifat numerik. Tidak ada data yang dikategorikan sebagai noise dan outlier
pada semua dataset. Praproses yang dilakukan pada dataset German adalah
transformasi data nominal menggunakan label encoding, transformasi skala pada
data ordinal, dan melakukan normalisasi data numerik.
Pada dataset German, beberapa nilai yang merepresentasikan maksud yang
sama dalam atribut pada data dijadikan satu nilai yang sama. Hal ini dapat dilihat
pada atribut purpose yang merupakan tujuan dari kredit di mana terdapat nilai car
(used) dan car (new) yang kemudian dijadikan atribut car. Atribut car dianggap
10
merepresentasikan tujuan kredit untuk membeli mobil. Hasil label encoding pada
dataset german berupa data biner 0,1 kemudian diubah menjadi -1,1 karena sifat
library classifier SVM yang digunakan mengklasifikasikan data menjadi data
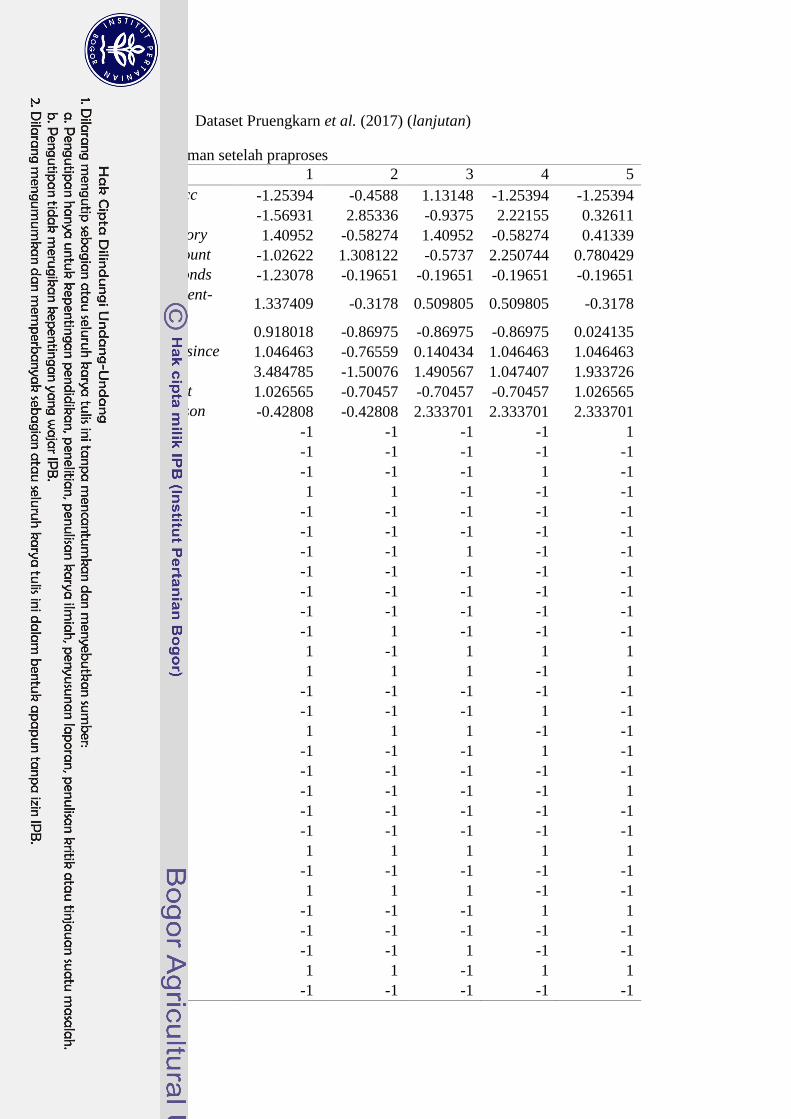
positif (kelas data minoritas) dan negatif (kelas data mayoritas). Lampiran 3
memuat contoh dataset Pruengkarn et al. (2017) sebelum dan sesudah praproses
data.
Dataset Ijah pada penelitian ini memuat informasi protein descriptor,
compound descriptor, dan informasi CPI. Data protein descriptor dan compound
descriptor dijadikan sebuah matriks CPI. Matriks CPI merupakan hasil persilangan
antara tiap protein descriptor dengan compound descriptor yang kemudian diberi
label kelas berdasarkan informasi CPI dari penelitian Kurnia (2017). Matriks CPI
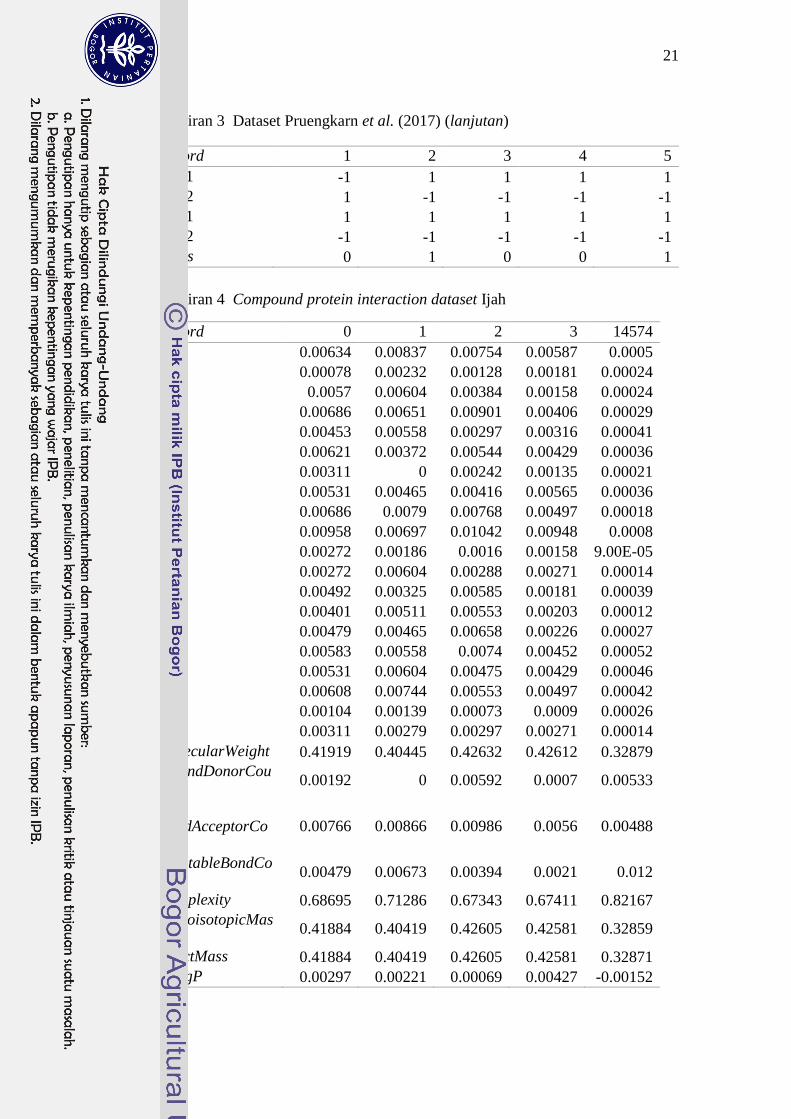
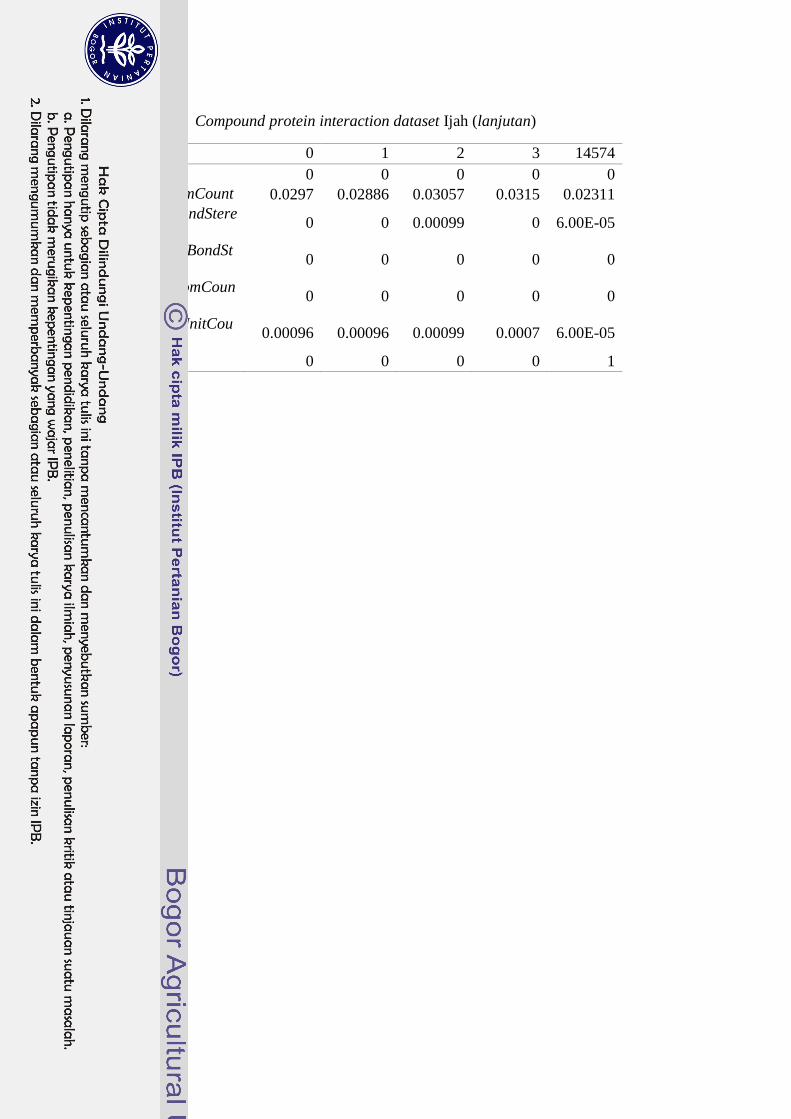
dapat dilihat pada Lampiran 4.
Senyawa pada daftar CPI dalam penelitian Kurnia (2017) tidak semuanya
memiliki CID PubChem, sehingga tidak memiliki data compound descriptor.
Penghapusan data CPI tanpa compound descriptor dilakukan sehingga didapat 2
908 CPI yang selanjutnya digunakan sebagai senyawa aktif dan protein yang
memiliki interaksi (data kelas positif).
Matriks CPI dari hasil persilangan data protein dan compound menghasilkan
23 741 865 record. Dari seluruh data diambil sejumlah 14 575 data senyawa aktif
dan protein yang tidak memiliki interaksi (kelas negatif) dan 2 908 data senyawa
aktif dan protein yang memiliki interaksi (kelas positif) sehingga data inputan
berjumlah 17 483 record dengan perbandingan 0.2:0.8 antara kelas negatif : kelas
positif. Selanjutnya dilakukan normalisasi bagi semua fitur data dengan
menggunakan fungsi normalisasidengan library sklearn.
Pengujian
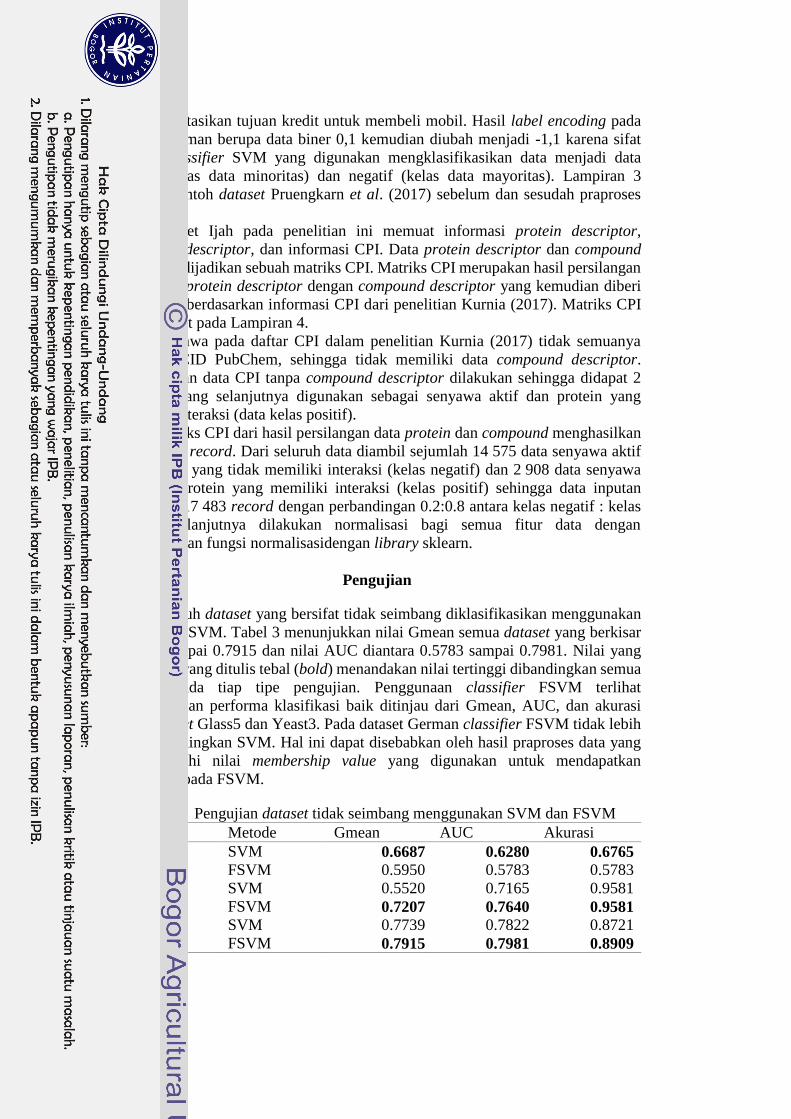
Seluruh dataset yang bersifat tidak seimbang diklasifikasikan menggunakan
SVM dan FSVM. Tabel 3 menunjukkan nilai Gmean semua dataset yang berkisar
0.5520 sampai 0.7915 dan nilai AUC diantara 0.5783 sampai 0.7981. Nilai yang
pada tabel yang ditulis tebal (bold) menandakan nilai tertinggi dibandingkan semua
metode pada tiap tipe pengujian. Penggunaan classifier FSVM terlihat
meningkatkan performa klasifikasi baik ditinjau dari Gmean, AUC, dan akurasi
pada dataset Glass5 dan Yeast3. Pada dataset German classifier FSVM tidak lebih
baik dibandingkan SVM. Hal ini dapat disebabkan oleh hasil praproses data yang
memengaruhi nilai membership value yang digunakan untuk mendapatkan
klasifikasi pada FSVM.
Tabel 3 Pengujian dataset tidak seimbang menggunakan SVM dan FSVM
Dataset Metode Gmean AUC Akurasi
German SVM 0.6687 0.6280 0.6765 FSVM 0.5950 0.5783 0.5783
Glass5 SVM 0.5520 0.7165 0.9581
FSVM 0.7207 0.7640 0.9581
Yeast3 SVM 0.7739 0.7822 0.8721
FSVM 0.7915 0.7981 0.8909
11
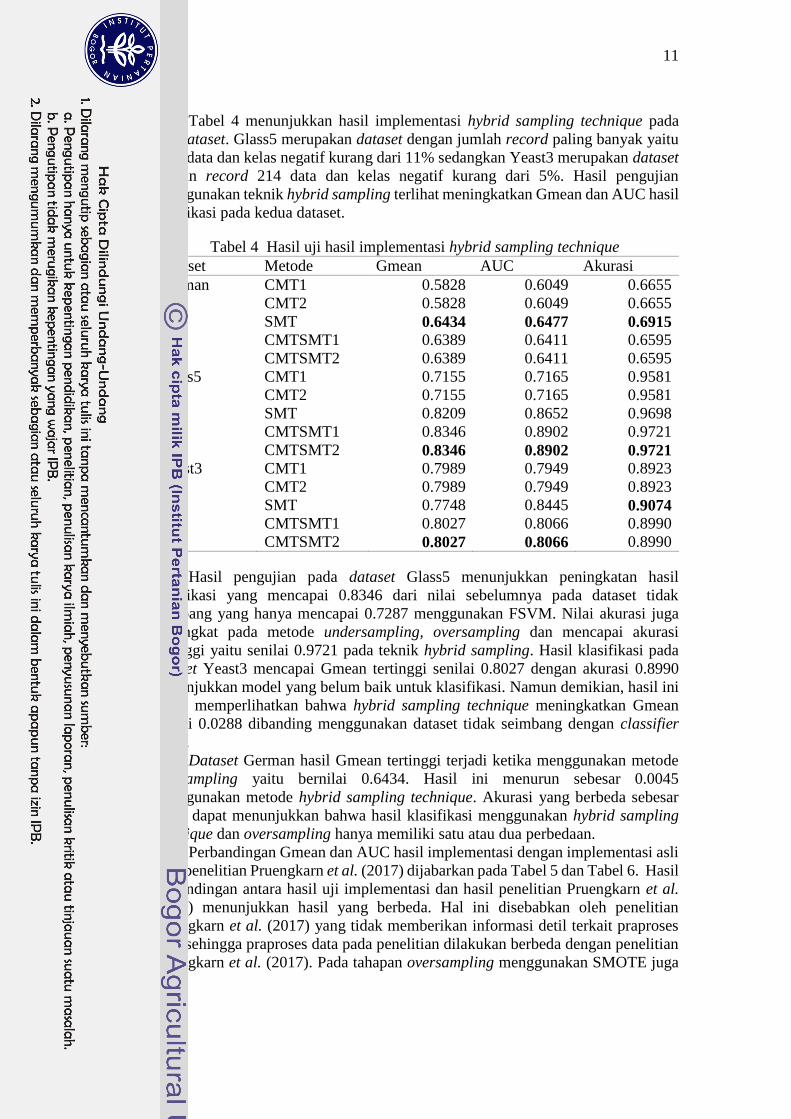
Tabel 4 menunjukkan hasil implementasi hybrid sampling technique pada
tiap dataset. Glass5 merupakan dataset dengan jumlah record paling banyak yaitu
1484 data dan kelas negatif kurang dari 11% sedangkan Yeast3 merupakan dataset
dengan record 214 data dan kelas negatif kurang dari 5%. Hasil pengujian
menggunakan teknik hybrid sampling terlihat meningkatkan Gmean dan AUC hasil
klasifikasi pada kedua dataset.
Tabel 4 Hasil uji hasil implementasi hybrid sampling technique
Dataset Metode Gmean AUC Akurasi
German CMT1 0.5828 0.6049 0.6655
CMT2 0.5828 0.6049 0.6655
SMT 0.6434 0.6477 0.6915
CMTSMT1 0.6389 0.6411 0.6595
CMTSMT2 0.6389 0.6411 0.6595
Glass5 CMT1 0.7155 0.7165 0.9581
CMT2 0.7155 0.7165 0.9581
SMT 0.8209 0.8652 0.9698
CMTSMT1 0.8346 0.8902 0.9721
CMTSMT2 0.8346 0.8902 0.9721 Yeast3 CMT1 0.7989 0.7949 0.8923
CMT2 0.7989 0.7949 0.8923
SMT 0.7748 0.8445 0.9074
CMTSMT1 0.8027 0.8066 0.8990
CMTSMT2 0.8027 0.8066 0.8990
Hasil pengujian pada dataset Glass5 menunjukkan peningkatan hasil
klasifikasi yang mencapai 0.8346 dari nilai sebelumnya pada dataset tidak
seimbang yang hanya mencapai 0.7287 menggunakan FSVM. Nilai akurasi juga
meningkat pada metode undersampling, oversampling dan mencapai akurasi
tertinggi yaitu senilai 0.9721 pada teknik hybrid sampling. Hasil klasifikasi pada
dataset Yeast3 mencapai Gmean tertinggi senilai 0.8027 dengan akurasi 0.8990
menunjukkan model yang belum baik untuk klasifikasi. Namun demikian, hasil ini
sudah memperlihatkan bahwa hybrid sampling technique meningkatkan Gmean
senilai 0.0288 dibanding menggunakan dataset tidak seimbang dengan classifier
SVM.
Dataset German hasil Gmean tertinggi terjadi ketika menggunakan metode
oversampling yaitu bernilai 0.6434. Hasil ini menurun sebesar 0.0045
menggunakan metode hybrid sampling technique. Akurasi yang berbeda sebesar
0.032 dapat menunjukkan bahwa hasil klasifikasi menggunakan hybrid sampling
technique dan oversampling hanya memiliki satu atau dua perbedaan.
Perbandingan Gmean dan AUC hasil implementasi dengan implementasi asli
pada penelitian Pruengkarn et al. (2017) dijabarkan pada Tabel 5 dan Tabel 6. Hasil
perbandingan antara hasil uji implementasi dan hasil penelitian Pruengkarn et al.
(2017) menunjukkan hasil yang berbeda. Hal ini disebabkan oleh penelitian
Pruengkarn et al. (2017) yang tidak memberikan informasi detil terkait praproses
data, sehingga praproses data pada penelitian dilakukan berbeda dengan penelitian
Pruengkarn et al. (2017). Pada tahapan oversampling menggunakan SMOTE juga
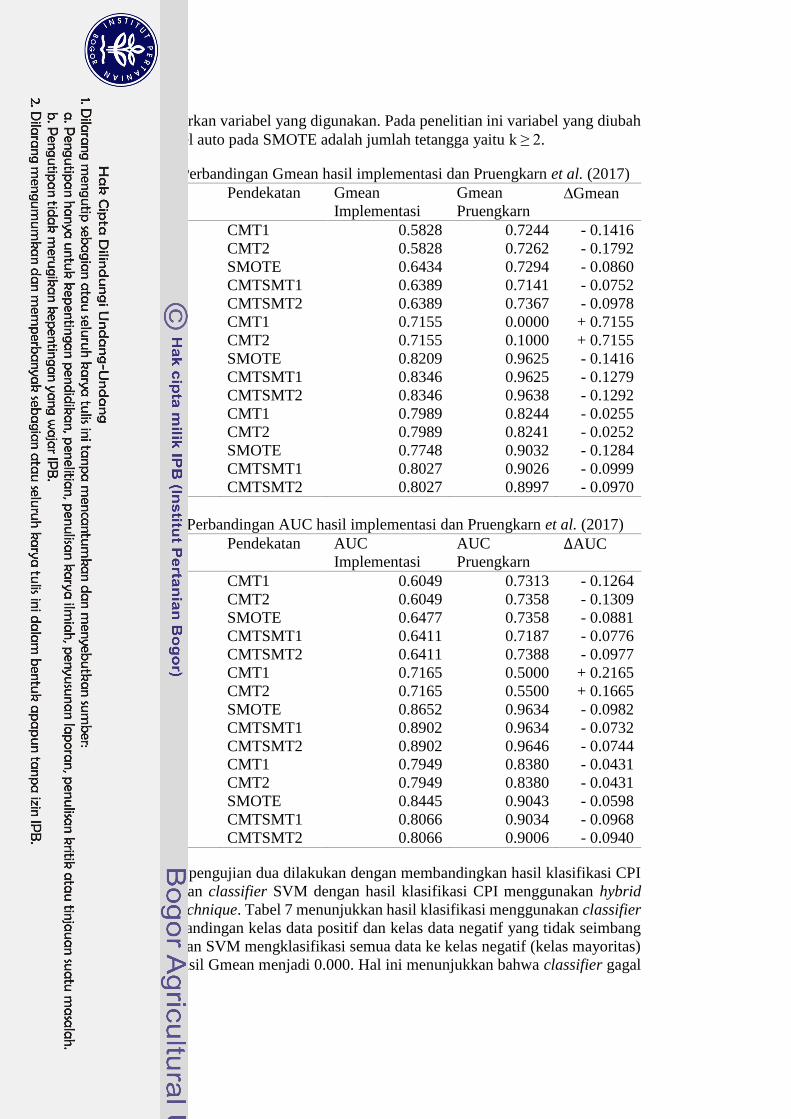
12
tidak dijabarkan variabel yang digunakan. Pada penelitian ini variabel yang diubah
dari variabel auto pada SMOTE adalah jumlah tetangga yaitu k ≥ 2.
Tabel 5 Perbandingan Gmean hasil implementasi dan Pruengkarn et al. (2017)
Dataset Pendekatan Gmean
Implementasi
Gmean
Pruengkarn ∆Gmean
German CMT1 0.5828 0.7244 - 0.1416
CMT2 0.5828 0.7262 - 0.1792
SMOTE 0.6434 0.7294 - 0.0860
CMTSMT1 0.6389 0.7141 - 0.0752
CMTSMT2 0.6389 0.7367 - 0.0978
Glass5 CMT1 0.7155 0.0000 + 0.7155
CMT2 0.7155 0.1000 + 0.7155
SMOTE 0.8209 0.9625 - 0.1416
CMTSMT1 0.8346 0.9625 - 0.1279
CMTSMT2 0.8346 0.9638 - 0.1292
Yeast3 CMT1 0.7989 0.8244 - 0.0255
CMT2 0.7989 0.8241 - 0.0252
SMOTE 0.7748 0.9032 - 0.1284
CMTSMT1 0.8027 0.9026 - 0.0999
CMTSMT2 0.8027 0.8997 - 0.0970
Tabel 6 Perbandingan AUC hasil implementasi dan Pruengkarn et al. (2017)
Dataset Pendekatan AUC
Implementasi
AUC
Pruengkarn ∆AUC
German CMT1 0.6049 0.7313 - 0.1264
CMT2 0.6049 0.7358 - 0.1309
SMOTE 0.6477 0.7358 - 0.0881
CMTSMT1 0.6411 0.7187 - 0.0776
CMTSMT2 0.6411 0.7388 - 0.0977
Glass5 CMT1 0.7165 0.5000 + 0.2165
CMT2 0.7165 0.5500 + 0.1665
SMOTE 0.8652 0.9634 - 0.0982
CMTSMT1 0.8902 0.9634 - 0.0732
CMTSMT2 0.8902 0.9646 - 0.0744
Yeast3 CMT1 0.7949 0.8380 - 0.0431
CMT2 0.7949 0.8380 - 0.0431
SMOTE 0.8445 0.9043 - 0.0598
CMTSMT1 0.8066 0.9034 - 0.0968
CMTSMT2 0.8066 0.9006 - 0.0940
Hasil pengujian dua dilakukan dengan membandingkan hasil klasifikasi CPI
menggunakan classifier SVM dengan hasil klasifikasi CPI menggunakan hybrid
sampling technique. Tabel 7 menunjukkan hasil klasifikasi menggunakan classifier
SVM. Perbandingan kelas data positif dan kelas data negatif yang tidak seimbang
menyebabkan SVM mengklasifikasi semua data ke kelas negatif (kelas mayoritas)
sehingga hasil Gmean menjadi 0.000. Hal ini menunjukkan bahwa classifier gagal

13
dalam melakukan klasifikasi pada data senyawa aktif dan protein yang memiliki
interaksi (kelas positif atau kelas minoritas).
Tabel 7 Hasil pengujian menggunakan SVM pada CPI Ijah
Nilai Uji Gmean 0.0000
AUC 0.5000
Akurasi 0.7677
Data Minoritas Jumlah data minoritas 2 908
Perbandingan data
minoritas : mayoritas
0.2 : 0.8
Hasil pengujian implementasi hybrid sampling technique tedapat pada pada
Tabel 8. Akurasi dari klasifikasi data menggunakan hybrid sampling technique
tergolong baik bagi data tidak seimbang walaupun masih cukup rendah. Akurasi ini
meningkat dibanding dengan melakukan klasifikasi pada data tidak tanpa proses
hybrid sampling technique. Nilai akurasi setelah meningkat sebesar 0.0669. Nilai
Gmean pada Tabel 8 menunjukkan nilai 0.6812 yang sebelumnya pada Tabel 7
bernilai 0.000. Peningkatan nilai Gmean menunjukkan bahwa model telah dapat
mengklasifikasikan kelas positif (kelas minoritas). Hasil evaluasi menggunakan
AUC mengalami peningkatan sebesar 0.0319 dibandingkan hasil pada Tabel 7.
Hasil pada Tabel 8 memperlihatkan peningkatan dari semua metode evaluasi
dibanding Tabel 7 yang tidak menerapkan hybrid sampling technique.
Tabel 8 Hasil pengujian hybrid sampling technique pada CPI Ijah
Nilai Uji Gmean 0.6812
AUC 0.5319
Akurasi 0.8346
Data Minoritas Jumlah data minoritas 9 851
Perbandingan data
minoritas : mayoritas
0.4 : 0.6
Setelah menerapkan hybrid sampling technique jumlah kelas minoritas hasil
berjumlah 13 116 data. Hasil ini kemudian dibandingkan dengan matriks CPI yang
tersedia. Hasil kemudian disaring berdasarkan kemiripan nilai variabel dengan data
pada deskriptor asli, sehingga didapatkan sejumlah 9 851 data dengan pasangan
senyawa aktif dan protein sesuai dengan deskriptor yang ada.
SIMPULAN DAN SARAN
Simpulan
Penelitian telah berhasil melakukan implementasi hybrid sampling technique
menggunakan Complementary Fuzzy Support Vector Machine dan SMOTE. Hasil
implementasi pada hybrid sampling technique menunjukkan selisih Gmean -0.0752
sampai -0.1792 dan selisih AUC sebesar -0.0732 sampai 0.0977 dibanding
implementasi asli. Implementasi pada data Ijah telah berhasil mengatasi data tidak
seimbang pada senyawa aktif dan protein. Hasil implementasi menunjukkan

14
metode berhasil mengklasifikasikan kelas minoritas pada data dan meningkatkan
jumlah kelas data minoritas meningkat tiga kali lipat menjadi 9851 dari data sampel
yang digunakan sebelumnya yang berjumlah. Implementasi memiliki akurasi
sebesar 0.8346 dengan Gmean sebesar 0.6812 dan AUC sebesar 0.5319.
Saran
Penelitian ini menggunakan hybrid sampling technique dengan satu fungsi
keanggotaan fuzzy untuk semua jenis data. Pemilihan fungsi keanggotaan fuzzy
sangat memengaruhi performa klasifikasi. Pendefinisian fungsi keanggotaan fuzzy
yang tepat diperngaruhi oleh sifat data. Perbandingan fungsi kearnggotaan fuzzy
yang tepat untuk CPI pada Ijah dapat menjadi topik yang menarik untuk dibahas.
DAFTAR PUSTAKA
Afendi FM, Darusman LK, Hirai A, Altaf-Ul-Amin M, Takahashi H, Nakamura K,
Kanaya S. 2010. System biology approach for elucidating the relationship
between indonesian herbal plants and the efficacy of jamu. Di dalam: IEEE
International Conference on Data Mining Workshops. 2010 Des 13; Sydney,
Australia. Sydney (AU): IEEE. hlm 661–668. doi:
10.1109/ICDMW.2010.105.
Afendi FM, Darusman LK, Morita AH, Altaf-Ul-Amin M, Takahashi H, Nakamura
K, Tanaka K, Kanaya S. 2012. Efficacy prediction of jamu formulations by
PLS modeling. Current Computer Aided Drug Design. 9(1):46–59.
doi:10.2174/157340913804998775.
Ali A, Shamsuddin SM, Ralescu AL. 2015. Classification with class imbalance
problem: a review. International Journal Advance Soft Computing
Application. 7(3):176-204.
Amir F. 2016. Prediksi formula jamu untuk penyembuhan penyakit diabetes dengan
teknik graph mining[skripsi]. Bogor (ID): Institut Pertanian Bogor.
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP. 2002. SMOTE: Synthetic
minority over-sampling technique. Journal of Artificial Intelligence
Research.16(2002):321-357. doi: 10.1613/jair.953.
Fan X dan He Z. 2010. A fuzzy support vector machine for imbalanced data
classification. Di dalam: International Conference on Optoelectronics and
Image Processing (ICONIP); 2010 Nov 11-12; Haikou, China. Haikou (CN):
IEEE. hlm 11-14. doi: 10.1109/ICOIP.2010.61.
Kurnia A.2017.Prediksi formula jamu berkhasiat menggunakan teknik link
prediction dari jejaring bipartite senyawa aktif dan protein [skripsi]. Bogor
(ID): Institut Pertanian Bogor.
Nogueira F dan Aridas CK. 2017. Imbalanced-learn: a python toolbox to tackle the
curse of imbalanced datasets in machine learning. Journal of Machnine
Learning Research. 18(17):1-5.
Noren EL. 2017. ML-From-Scratch. Github Repository. Tersedia pada:
https://github.com/eriklindernoren/ML-From-Scratch.

15
Pruengkarn R, Wong KW, Fung CC. 2017. Imbalanced data classification using
complementary fuzzy support vector machine technique and SMOTE. IEEE
International Conference on Systems, Man, and Cybernetics (SMC); 2017
Okt 5-8; Banff, Canada. Banff (CA): IEEE. hlm 978-983. doi:
10.1109/SMC.2017.8122737.
Tahir MA, Kittler J, Yan F. 2012. Inverse random undersampling for class
imbalance problem and its application to multi-label classification. Pattern
Recognition. 45(10): 3738-3740. doi: 10.1016/j.patcog.2012.03.014.
Torri MC. 2013. Knowledge and risk perceptions of traditional jamu medicine
among urban consumers. Europeanon Journal of Medicinal Plants. 3(1):25-
39. doi:10.9734/EJMP/2013/1813.
[WHO] World Health Organization. 2008. Traditonal medicine, fact sheet 134.
Geneva (CH): World Health Organization
Zhang P, Tao L, Zeng X, Qin C, Chen SY, Zhu F, Yang SY, Li ZR, Chen WO,
Chen YZ. 2016. Profeat update: a protein features web-server with added
facility to compute network descriptors for studying omics-derived networks.
Journal of Molecular Biology. 429(3):416-425. doi: 10.1016/j.jmb.2016.013.
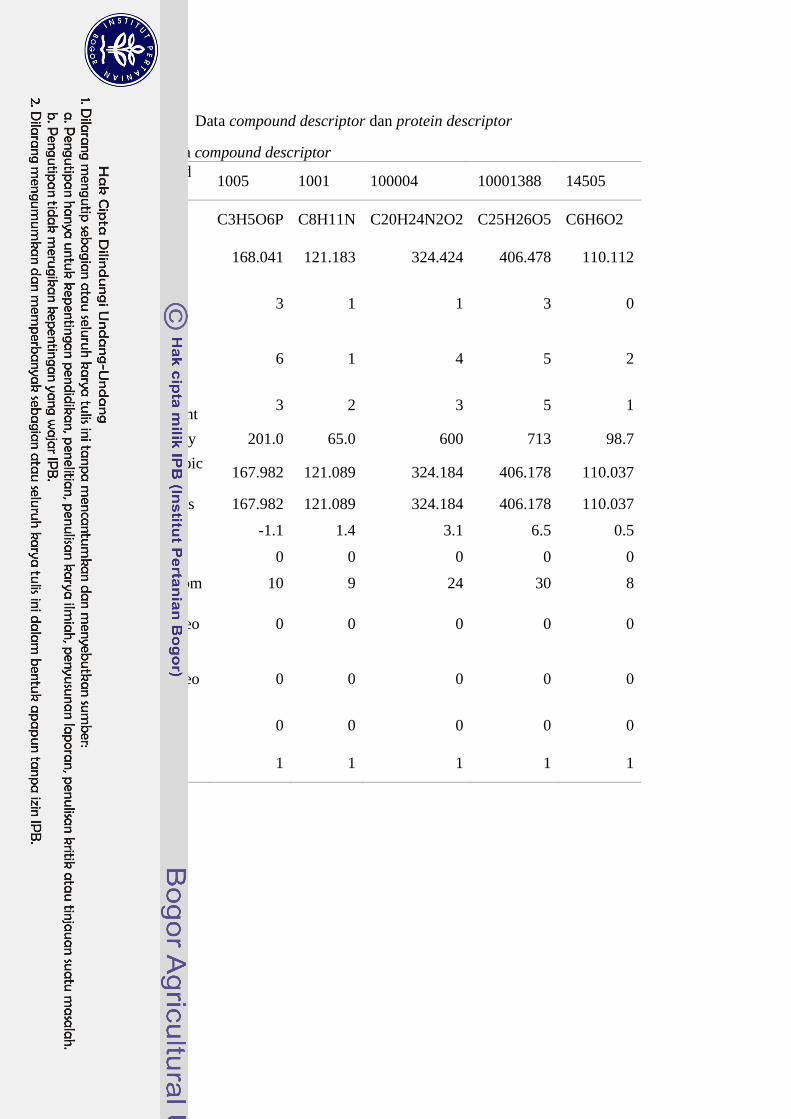
16
Lampiran 1 Data compound descriptor dan protein descriptor
Contoh data compound descriptor
Compound
ID 1005 1001 100004 10001388 14505
Molecular
Formula C3H5O6P C8H11N C20H24N2O2 C25H26O5 C6H6O2
Molecular
Weight 168.041 121.183 324.424 406.478 110.112
H Bond
Donor
Count
3 1 1 3 0
H Bond
Acceptor
Count
6 1 4 5 2
Rotatable
Bond Count 3 2 3 5 1
Complexity 201.0 65.0 600 713 98.7
Monoiotopic
Mass 167.982 121.089 324.184 406.178 110.037
Exact Mass 167.982 121.089 324.184 406.178 110.037
XLogP -1.1 1.4 3.1 6.5 0.5
Charge 0 0 0 0 0
Heavy Atom 10 9 24 30 8
Defined
Bond Stereo
Count
0 0 0 0 0
Undefined
Bond Stereo
Count
0 0 0 0 0
Isotope
Atom 0 0 0 0 0
Covalent
Unit 1 1 1 1 1
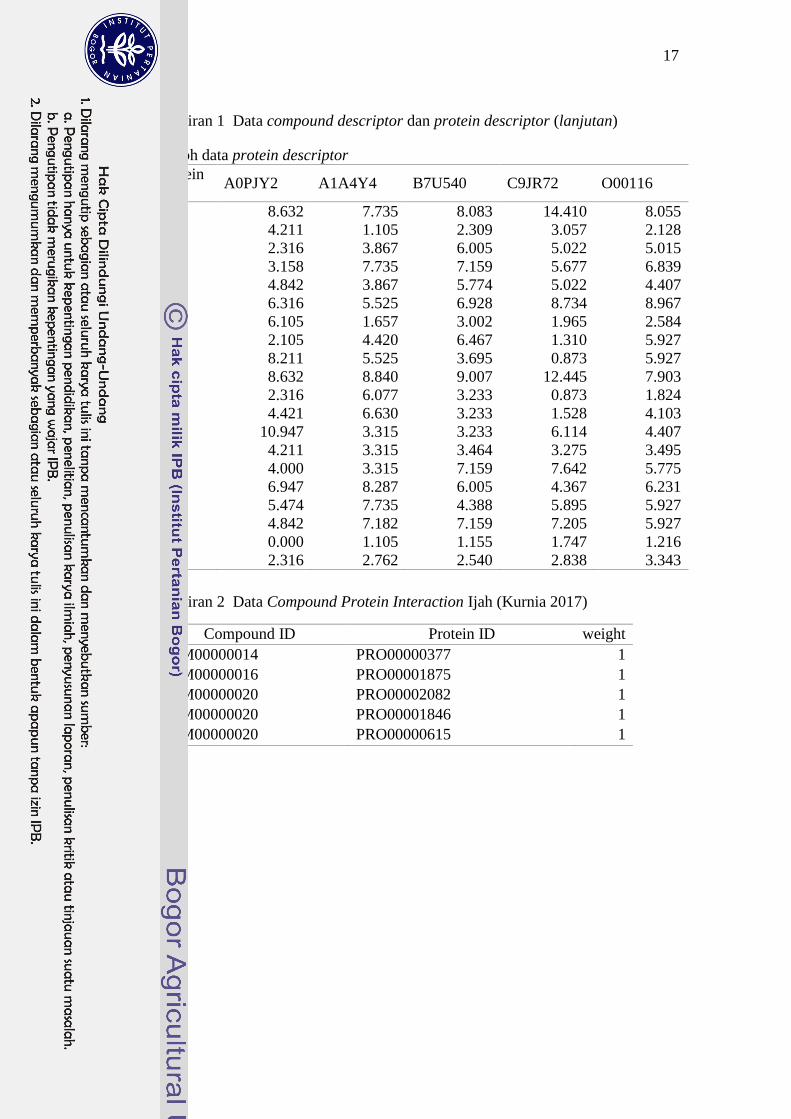
17
Lampiran 1 Data compound descriptor dan protein descriptor (lanjutan)
Contoh data protein descriptor
Protein
ID A0PJY2 A1A4Y4 B7U540 C9JR72 O00116
A 8.632 7.735 8.083 14.410 8.055
C 4.211 1.105 2.309 3.057 2.128
D 2.316 3.867 6.005 5.022 5.015
E 3.158 7.735 7.159 5.677 6.839
F 4.842 3.867 5.774 5.022 4.407
G 6.316 5.525 6.928 8.734 8.967
H 6.105 1.657 3.002 1.965 2.584
I 2.105 4.420 6.467 1.310 5.927
K 8.211 5.525 3.695 0.873 5.927
L 8.632 8.840 9.007 12.445 7.903
M 2.316 6.077 3.233 0.873 1.824
N 4.421 6.630 3.233 1.528 4.103
P 10.947 3.315 3.233 6.114 4.407
Q 4.211 3.315 3.464 3.275 3.495
R 4.000 3.315 7.159 7.642 5.775
S 6.947 8.287 6.005 4.367 6.231
T 5.474 7.735 4.388 5.895 5.927
V 4.842 7.182 7.159 7.205 5.927
W 0.000 1.105 1.155 1.747 1.216
Y 2.316 2.762 2.540 2.838 3.343
Lampiran 2 Data Compound Protein Interaction Ijah (Kurnia 2017)
Compound ID Protein ID weight
COM00000014 PRO00000377 1
COM00000016 PRO00001875 1
COM00000020 PRO00002082 1
COM00000020 PRO00001846 1
COM00000020 PRO00000615 1
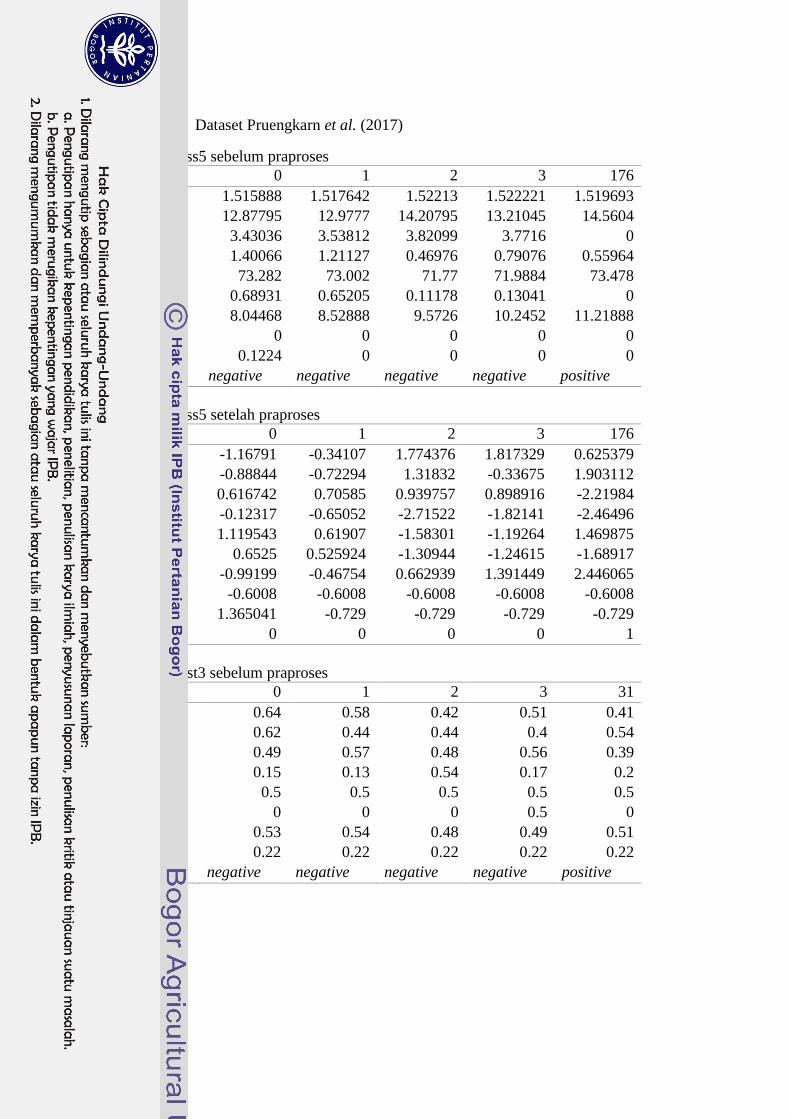
18
Lampiran 3 Dataset Pruengkarn et al. (2017)
Dataset glass5 sebelum praproses
Record 0 1 2 3 176
RI 1.515888 1.517642 1.52213 1.522221 1.519693
Na 12.87795 12.9777 14.20795 13.21045 14.5604
Mg 3.43036 3.53812 3.82099 3.7716 0
Al 1.40066 1.21127 0.46976 0.79076 0.55964
Si 73.282 73.002 71.77 71.9884 73.478
K 0.68931 0.65205 0.11178 0.13041 0
Ca 8.04468 8.52888 9.5726 10.2452 11.21888
Ba 0 0 0 0 0
Fe 0.1224 0 0 0 0
Class negative negative negative negative positive
Dataset glass5 setelah praproses
Record 0 1 2 3 176
RI -1.16791 -0.34107 1.774376 1.817329 0.625379
Na -0.88844 -0.72294 1.31832 -0.33675 1.903112
Mg 0.616742 0.70585 0.939757 0.898916 -2.21984
Al -0.12317 -0.65052 -2.71522 -1.82141 -2.46496
Si 1.119543 0.61907 -1.58301 -1.19264 1.469875
K 0.6525 0.525924 -1.30944 -1.24615 -1.68917
Ca -0.99199 -0.46754 0.662939 1.391449 2.446065
Ba -0.6008 -0.6008 -0.6008 -0.6008 -0.6008
Fe 1.365041 -0.729 -0.729 -0.729 -0.729
Class 0 0 0 0 1
Dataset yeast3 sebelum praproses
Record 0 1 2 3 31
Mcg 0.64 0.58 0.42 0.51 0.41
Gvh 0.62 0.44 0.44 0.4 0.54
Alm 0.49 0.57 0.48 0.56 0.39
Mit 0.15 0.13 0.54 0.17 0.2
Erl 0.5 0.5 0.5 0.5 0.5
Pox 0 0 0 0.5 0
Vac 0.53 0.54 0.48 0.49 0.51
Nuc 0.22 0.22 0.22 0.22 0.22
Class negative negative negative negative positive
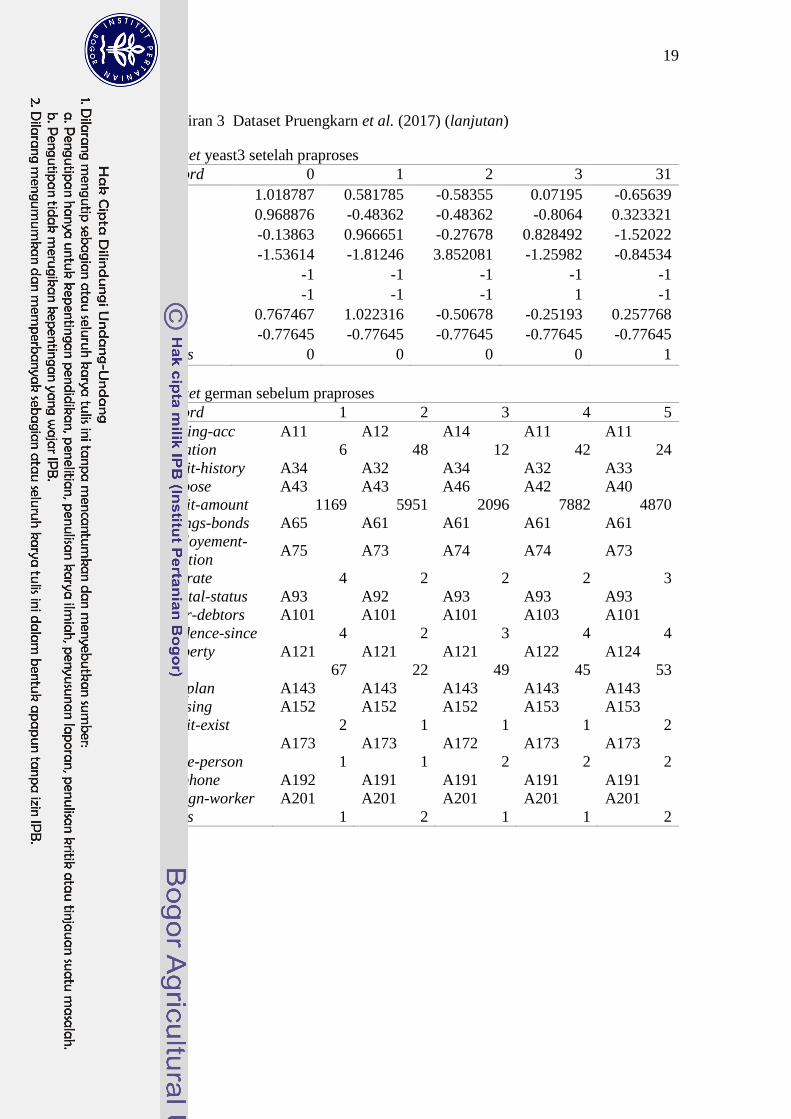
19
Lampiran 3 Dataset Pruengkarn et al. (2017) (lanjutan)
Dataset yeast3 setelah praproses
Record 0 1 2 3 31
Mcg 1.018787 0.581785 -0.58355 0.07195 -0.65639
Gvh 0.968876 -0.48362 -0.48362 -0.8064 0.323321
Alm -0.13863 0.966651 -0.27678 0.828492 -1.52022
Mit -1.53614 -1.81246 3.852081 -1.25982 -0.84534
Erl -1 -1 -1 -1 -1
Pox -1 -1 -1 1 -1
Vac 0.767467 1.022316 -0.50678 -0.25193 0.257768
Nuc -0.77645 -0.77645 -0.77645 -0.77645 -0.77645
Class 0 0 0 0 1
Dataset german sebelum praproses
Record 1 2 3 4 5
existing-acc A11 A12 A14 A11 A11
Duration 6 48 12 42 24
credit-history A34 A32 A34 A32 A33
Purpose A43 A43 A46 A42 A40
credit-amount 1169 5951 2096 7882 4870
savings-bonds A65 A61 A61 A61 A61
employement-
duration A75 A73 A74 A74 A73
inst-rate 4 2 2 2 3
marital-status A93 A92 A93 A93 A93
other-debtors A101 A101 A101 A103 A101
residence-since 4 2 3 4 4
Property A121 A121 A121 A122 A124
Age 67 22 49 45 53
inst-plan A143 A143 A143 A143 A143
Housing A152 A152 A152 A153 A153
credit-exist 2 1 1 1 2
Job A173 A173 A172 A173 A173
liable-person 1 1 2 2 2
telephone A192 A191 A191 A191 A191
foreign-worker A201 A201 A201 A201 A201
Class 1 2 1 1 2
20
Lampiran 3 Dataset Pruengkarn et al. (2017) (lanjutan)
Dataset german setelah praproses
Record 1 2 3 4 5
existing-acc -1.25394 -0.4588 1.13148 -1.25394 -1.25394
Duration -1.56931 2.85336 -0.9375 2.22155 0.32611
credit-history 1.40952 -0.58274 1.40952 -0.58274 0.41339
credit-amount -1.02622 1.308122 -0.5737 2.250744 0.780429
savings-bonds -1.23078 -0.19651 -0.19651 -0.19651 -0.19651
Employement-
duration 1.337409 -0.3178 0.509805 0.509805 -0.3178
inst-rate 0.918018 -0.86975 -0.86975 -0.86975 0.024135
residence-since 1.046463 -0.76559 0.140434 1.046463 1.046463
Age 3.484785 -1.50076 1.490567 1.047407 1.933726
credit-exist 1.026565 -0.70457 -0.70457 -0.70457 1.026565
liable-person -0.42808 -0.42808 2.333701 2.333701 2.333701
A40 -1 -1 -1 -1 1
A410 -1 -1 -1 -1 -1
A42 -1 -1 -1 1 -1
A43 1 1 -1 -1 -1
A44 -1 -1 -1 -1 -1
A45 -1 -1 -1 -1 -1
A46 -1 -1 1 -1 -1
A48 -1 -1 -1 -1 -1
A49 -1 -1 -1 -1 -1
A91 -1 -1 -1 -1 -1
A92 -1 1 -1 -1 -1
A93 1 -1 1 1 1
A101 1 1 1 -1 1
A102 -1 -1 -1 -1 -1
A103 -1 -1 -1 1 -1
A121 1 1 1 -1 -1
A122 -1 -1 -1 1 -1
A123 -1 -1 -1 -1 -1
A124 -1 -1 -1 -1 1
A141 -1 -1 -1 -1 -1
A142 -1 -1 -1 -1 -1
A143 1 1 1 1 1
A151 -1 -1 -1 -1 -1
A152 1 1 1 -1 -1
A153 -1 -1 -1 1 1
A171 -1 -1 -1 -1 -1
A172 -1 -1 1 -1 -1
A173 1 1 -1 1 1
A174 -1 -1 -1 -1 -1
21
Lampiran 3 Dataset Pruengkarn et al. (2017) (lanjutan)
Record 1 2 3 4 5
A191 -1 1 1 1 1
A192 1 -1 -1 -1 -1
A201 1 1 1 1 1
A202 -1 -1 -1 -1 -1
Class 0 1 0 0 1
Lampiran 4 Compound protein interaction dataset Ijah
Record 0 1 2 3 14574
A 0.00634 0.00837 0.00754 0.00587 0.0005
C 0.00078 0.00232 0.00128 0.00181 0.00024
D 0.0057 0.00604 0.00384 0.00158 0.00024
E 0.00686 0.00651 0.00901 0.00406 0.00029
F 0.00453 0.00558 0.00297 0.00316 0.00041
G 0.00621 0.00372 0.00544 0.00429 0.00036
H 0.00311 0 0.00242 0.00135 0.00021
I 0.00531 0.00465 0.00416 0.00565 0.00036
K 0.00686 0.0079 0.00768 0.00497 0.00018
L 0.00958 0.00697 0.01042 0.00948 0.0008
M 0.00272 0.00186 0.0016 0.00158 9.00E-05
N 0.00272 0.00604 0.00288 0.00271 0.00014
P 0.00492 0.00325 0.00585 0.00181 0.00039
Q 0.00401 0.00511 0.00553 0.00203 0.00012
R 0.00479 0.00465 0.00658 0.00226 0.00027
S 0.00583 0.00558 0.0074 0.00452 0.00052
T 0.00531 0.00604 0.00475 0.00429 0.00046
V 0.00608 0.00744 0.00553 0.00497 0.00042
W 0.00104 0.00139 0.00073 0.0009 0.00026
Y 0.00311 0.00279 0.00297 0.00271 0.00014
MolecularWeight 0.41919 0.40445 0.42632 0.42612 0.32879
HBondDonorCou
nt 0.00192 0 0.00592 0.0007 0.00533
H
BondAcceptorCo
unt
0.00766 0.00866 0.00986 0.0056 0.00488
RotatableBondCo
unt 0.00479 0.00673 0.00394 0.0021 0.012
Complexity 0.68695 0.71286 0.67343 0.67411 0.82167
MonoisotopicMas
s 0.41884 0.40419 0.42605 0.42581 0.32859
ExactMass 0.41884 0.40419 0.42605 0.42581 0.32871
XLogP 0.00297 0.00221 0.00069 0.00427 -0.00152
22
Lampiran 4 Compound protein interaction dataset Ijah (lanjutan)
Record 0 1 2 3 14574
Charge 0 0 0 0 0
HeavyAtomCount 0.0297 0.02886 0.03057 0.0315 0.02311
DefinedBondStere
oCount 0 0 0.00099 0 6.00E-05
UndefinedBondSt
ereoCount 0 0 0 0 0
IsotopeAtomCoun
t 0 0 0 0 0
CovalentUnitCou
nt 0.00096 0.00096 0.00099 0.0007 6.00E-05
Class 0 0 0 0 1

23
RIWAYAT HIDUP
Penulis merupakan anak kedua dari tiga bersaudara dari pasangan Suyanto
dan Linsi Apriani yang dilahirkan pada 28 Mei 1996 di Kota Pagaralam, Sumatera
Selatan. Penulis menempuh pendidikan di SMAN 4 Lahat pada tahun 2011 sampai
2014. Pendidikan S1 penulis tempuh di Departemen Ilmu Komputer, Fakultas
Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Selama menempuh pendidikan penulis beberapa kali menjadi asisten
praktikum Departemen Ilmu Komputer. Dimulai dari asisten praktikum pada mata
kuliah Penerapan Komputer pada tahun 2015-2016, asisten praktikum mata kuliah
Artificial Intelligence pada tahun 2017, dan asisten praktikum mata kuliah Sistem
Cerdas pada tahun 2018.
Selain menjadi asisten praktikum, penulis juga aktif di Badan Eksekutif
Mahasiswa pada tahun 2016/2017 sebagai anggota Pengembangan Sumberdaya
Mahasiswa. Penulis juga aktif sebagai anggota Sahabat Beasiswa Chapter Bogor
sejak tahun 2015. Penulis juga mengikuti kegiatan Rumah Belajar Leadership
(RumbeL) dibawah naungan Forum Indonesia Muda Bogor (FIM Hore Bogor) pada
tahun 2014 sampai 2016.




















