
Critical Book Franciska
64
JUDUL BUKU : STATISTIK TEORI DAN APLIKASI EDISI ENAM PENGARANG BUKU : J.SUPRANTO PENERBIT/TAHUN TERBIT : PENERBIT ERLANGGA, JAKARTA 2000 RINGKASAN BUKU Menurut Websters’s New World Dicitionary, data berarti sesuatu yang diketahui atau dianggap. Dengan demikian data dapat memberikan gambaran tentang suatu keadaan atau persoalan. Data tentang sesuatu pada umumnya dikaitkan dengan tempat dan waktu. Kegunaan data pada dasarnya adalah untuk membuat keputusan oleh para pembuat keputusan (decision makers). Statistik dapat membantu kita dalam (1) menjabarkan dan memahami suatu hubungan, (2) mengambil keputusan lebih baik, (3) menangani perubahan. Dalam Pemecahan Masalah Secara Statistik ada beberapa langkah-langkah dasar yang dapat dilakukan yaitu : (1) Mengidentifikasi masalah atau peluang, (2) Mengumpulkan fakta yang tersedia,
-
Upload
franciska-febriani-siregar -
Category
Documents
-
view
509 -
download
96
Transcript of Critical Book Franciska

JUDUL BUKU : STATISTIK TEORI DAN APLIKASI
EDISI ENAM
PENGARANG BUKU : J.SUPRANTO
PENERBIT/TAHUN TERBIT : PENERBIT ERLANGGA, JAKARTA 2000
RINGKASAN BUKU
Menurut Websters’s New World Dicitionary, data berarti sesuatu yang
diketahui atau dianggap. Dengan demikian data dapat memberikan gambaran
tentang suatu keadaan atau persoalan. Data tentang sesuatu pada umumnya
dikaitkan dengan tempat dan waktu. Kegunaan data pada dasarnya adalah untuk
membuat keputusan oleh para pembuat keputusan (decision makers). Statistik
dapat membantu kita dalam (1) menjabarkan dan memahami suatu hubungan,
(2) mengambil keputusan lebih baik, (3) menangani perubahan.
Dalam Pemecahan Masalah Secara Statistik ada beberapa langkah-langkah
dasar yang dapat dilakukan yaitu :
(1) Mengidentifikasi masalah atau peluang,
(2) Mengumpulkan fakta yang tersedia,
(3) Mengumpulkan data orisinil yang baru,
(4) Mengklasifikasikan dan mengikhtisarkan data,
(5) Menyajikan Data,
(6) Menganalisis Data.
Data juga mempunyai syarat yang harus dipenuhi untuk menghasilkan
keputusan yang baik,yaitu Objektif, Representatif (mewakili), Kesalahan
Sampling (sampling error) kecil, Tepat Waktu, Relevan.

Data-data yang ada dapat dikumpulkan dari sumber-sumber internal dan
eksternal, dan data orisinil baru dapat diperoleh dari wawancara secara pribadi
dan kuesioner. Setelah data diperoleh kita perlu membahas tentang metode
penarikan data secara rinci. Akan tetapi, perlu diperhatikan bahwa semua data
yang akan ditarik akan berupa hasil perhitungan atau hasil pengukuran oleh suatu
instrumen.
Data juga dapat dikelompokkan antara lain, Data Menurut Sifatnya
dibedakan antara Data Kualitatif dan Data Kuantitatif, Data Menurut Sumbernya
dibedakan menjadi Data Internal dan data Eksternal, Data Menurut Cara
Memperolehnya dibedakan menjadi Data Primer dan Data Sekunder, dan Data
Menurut Waktu Pengambilannya dibedakan menjadi Data Cross Section dan Data
Berkala.
Dalam arti sempit, Statistik berarti data ringkasan berbentuk angka
(kuantitatif) sedangkan dalam arti luas berarti suatu ilmu yang mempelajari cara
pengumpulan, pengolahan/pengelompokan, penyajian dan analisis data serta cara
pengambilan kesimpulan dengan memperthitungkan unsur ketidakpastian
berdasarkan konsep probabilitas. Tetap dalam bukunya Statistical Theory In
Research, Anderson and Bancrof mengatakan Statistika adalah ilmu dan seni
pengembangan dan penerapan metode yang paling efektif sehingga kemungkinan
kesalahan dalam kesimpulan dan estimasi yang diperkirakan dengan
menggunakan penalaran induktif berdasarkam matematika probabilitas.
Bab 2 menjelaskan tentang Pengumpulan dan Pengolahan Data. Tujuan
pengumpulan data yaitu untuk mengetahui jenis elemen (unit terkecil dari objek
penelitian), karakteristik (sifat-sifat yang dilakukan oleh elemen), populasi dan
sampel. Dalam statistik ada dua cara untuk memperoleh data yaitu cara Sensus
(pengumpulan data apabila seluruh elemen populasi diselidiki satu persatu), data
yang diperoleh disebut Parameter. Yang kedua adalah cara Sampling (cara
pengumpulan data apabila diselidiki adalah elemen sampel dari suatu populasi),
data yang diperoleh merupakan Data Perkiraan. Dibandingkan dengan sensus.

Pengumpulandata degancara sampling membutuhkan biaya yang jauh lebih
sedikit, memerlukan waktu yang lebih cepat, tenaga yang tidak terlalu banyak dan
dapat menghasilkan cakupan data yang lebih luas serta terperinci. Dalam
pengambilan sampel ada dua cara yang sering dipakai yaitu secara acak dan
bukan acak. Alat yang dipakai untuk memperoleh keterangan dari objek yaitu
daftar pertanyaan (questionnaire), wawancara, observasi, melalui pos/alat
komunikasi lain dan alat ukur lainnya. Akan tetapi hal yang terpenting dalam
pengumpulan data adalah merancang kuesioner (daftar isian yang berupa satu
set pertanyaan yang tersusun secara sistematis dan standar sehingga pertanyaan
yang sama dapat diajukan kepada setiap responden). Sistematis yang dimaksud
adalah bahwa item-item pertanyaan disusun menurut logika (logical sequence)
sesuai dengan maksud dan tujuan pengumpulan data. Sedangkan yang dimaksud
dengan standar adalah setiap item pertanyaan mempunyai pengertian,konsep,dan
definisi yang sama. Ada dua tujuna utama dalam membuat kuesioner suatu survei
yang baik yaitu:
1. memperoleh informasi/data yang berhubungan dengan maksud dan tujuan
survei
2. mengumpulkan informasi dengan kecermatan dan ketelitian yang dapat
dipertanggungjawabkan.
Secara umum metode pengolahan data dibedakan menjadi dua yaitu
pengolahan data decara manual (yang dilakukan untuk jumlah obesrvasi yang
tidak terlalau banyak dan memerlukan waktu yang sangat lama karena harus
menelitisatu persatu dari setiap obesrvasi) dan pengolahan data secara
elektronik (dengan menggunakan komputer).
Bab 3 menjelaskan tentang Penyajian Data. Data dapat disajikan dengan
Tabel dan Grafik. Penyajian data dalam bentuk tabel adalah penyajian dalam
kumpulan angka-angka yang disusun menurut kategori-kategori,sehingga
memudahkan untuk pembuatan analisis data. Ada beberapa bentuk tabel yaitu :

(1) Tabel Satu Arah (one way table),tabel yang memuat keterangan mengenai satu
hal/karakteristik saja,
(2) Tabel Dua Arah (two way table),tabelyang menunjukkan hubungan dua
hal/karakteristik,
(3) Tabel Tiga Arah (three way table),tabel yang menunjukkan tiga
hal/karakteristik.
Penyajian data dalam bentuk grafik adalah penyajian dalam bentuk gambar
yang menunjukkan secara visual data berupa angka yang dapat memudahkan
pengambilan kesimpulan dengan cepat. Ada beberapa bentuk grafik yaitu :
(1) Grafik Garis Tunggal (single line chart),grafik yang terdiri dari satu garis
untuk menggambarkan perkembangan dari suatu karakteristik,
(2) Grafik Garis Berganda (multiple line chart),grafik yang terdiri dari beberapa
garis untuk menggambarkan perkembangan beberapa hal sekaligus,
(3) Grafik Garis Komponen Berganda (multiple component line chart),mirip
dengan grafik berganda tetapi garis yang terakhir menggambarkan jumlah dari
komponen-komponen,
(4) Grafik Garis Persentase Komponen Berganda (multiple percentage component
line chart),mirip dengan grafik garis berganda kecuali masing-masing nilai
komponen dinyatakan dalam persentase sehingga garis terakhir merupakan garis
yang menunjukkan nilai 100%,
(5) Grafik Garis Berimbang Neto (net balanced line),grafik yang nilai-nilai selisih
dengan garis timbangan dapat diberi warna yang berbeda untuk menilai selisih
positif dan negatif,
(6) Grafik Batangan Tunggal (single bar chart)
(7) Grafik Batangan Berganda (multiple bar chart)
(8) Grafik Batangan Komponen Berganda (multi component bar chart)

(9) Grafik Batangan Persentase Komponen Berganda (multiple percentage
component bar chart)
(10) Grafik Batangan Berimbang Neto (net balanced bar chart)
(11) Grafik Lingkaran Tunggal (single pie chart)
(12) Grafik Lingakaran Berganda (multi pie chart)
(13) Grafik Peta (cartogram chart)
(14) Grafik gambar (pictogram chart)
Bab 4 menjelaskan tentang Distribusi Frekuensi. Distribusi frekuensi
menunjukkan banyaknya item dalam setiap kategori atau kelas. Dalam distribusi
frekuensi terdapat frekuensi relatif dari suatu kelas adalah proporsi item dalam
setiap kelas terhadap jumlah kesuluruhan item data tersebut. Jika sekelompok data
memiliki n observasi.maka frekuensi relatif dari kategori atau kelas akan
diberikan sebagai berikut.
Frekuensirelatif dari suatukelas= Frekuensi kelasn
Ada tiga hal yang perlu diperhatikan dalam menentukan kelas bagi distribusi
frekuensi untuk data kuantitatif yaitu :
1. Jumlah Kelas
Pada tahun 1926 H.A. Sturges menulis artikel dengan judul “The Choice
of a Class Interval” yang mengemukakan rumus untuk menentukan
banyaknya kelas yaitu :
k = 1 + 3,322 log n
2. Interval Kelas

Pemilihan interval kelas dan jumlah kelas sebenarnya tidak independen.
Semakin banyak jumlah kelas berarti semakin kecil interval kelas dan
sebaliknya.
c = Xn± X 1
k
3. Batas Kelas
Batas kelas bawah menunjukkan kemungkinan nilai data terkecil pada
suatu kelas sedangkan batas kelas atas mengidentifikasi kemungkinan nilai
data terbesar dalam suatu kelas.
Sering kali data dari tabel disajikan dalam bentuk grafik misalnya dalam
bentuk histogram/grafik batangan,frekuensi poligon dan frekeunsi kurva. Grafik
batangan biasanya digunakan untuk menyajikan datayang bukan merupakan tabel
frekuensi. Dalam analisis ekonomi,khususnya pada masalah pemerataan
pendapatan dikenal suatu kurva yang disebut Kurva Lorenz. Pada dasarnya
kurva ini sama dengan kurva frekuensi kumulatif. Dalam kurva ini ditunjukkan
pembagian pendapatan yang sama sehingga menunjukkan keadilan atau makin
tidak sama, makin tidak adil. Pembagian pendapatan yang tidak sama atau kurang
merata disebut dengan Income Gap yaitu jurang pemisah antara yang
berpendapatan tinggi dengan yang berpendapatan rendah. Apabila income gap
semakin besar sering terjadi kekacauan yang menimbulkan pemberontakan.
Bab 5 menjelaskan tentang Ukuran Pemusatan. Rata-rata (average) adalah
nilai yang mewakii himpunan atau sekelompok data (a set of data). Nilai rata-rata
umumnya cenderung terletak di tengah suatu kelompok data yang disusun
menurut besar kecilnya nilai. Rata-rata yang sering digunakan dalam ukuran
pemusatan adalah Rata-rata Hitung (arithmetic mean), Rata-rata Ukur (geometric
mean) dan Rata-rata Harmonis (harmonic mean).
Rata-rata Hitung

Apabila kita mempunyai nilai variabel X, sebagai hasil pengamatan sebanyak
N kali, yaitu X1, X2,. . ., Xi, . . . , XN maka :
a) Rata-rata sebenarnya (populasi)
µ = 1N∑i=1
N
Xi
b) Rata-rata Perkiraan (sampel)
X= 1n∑i=1
n
Xi
BEBERAPA SIFAT/CIRI RATA-RATA HITUNG
Rata-rata hitung memiliki beberapa sifat yaitu :
I. Jumlah deviasi atau selisih kelompok nilai terhadap nilai terhadap
rata-ratanya sama dengan nol.
II. Jumlah deviasi kuadrat dari suatu kelompok nilai terhadap nilai k
akan minimum jika k = X .
III. Apabila ada kelompok nilai :
Kelompok Pertama sebanyak f1 nilai dengan rata-rata X 1
Kelompok Kedua sebanyak f2 nilai dengan rata-rata X 2
Kelompok ke-i sebanyak fi nilai rata-rata dengan rata-rata X i
IV. Apabila k adalah sembarang nilai yang merupakan nilai rata-rata
asumsi/anggaran dan di merupakan deviasi dari nilai Xi terhadap k
(di = Xi – k,i = 1,2,.......,n)
V. Jika suatu kelompok data sangat heterogen, maka rata-rata hitung
tidak dapat mewakili masing-masing nilai dari kelompok tersebut
dengan baik. Rata-rata hitung hanya dapat mewakili dengan
sempurna atau nilainya tepat bila kelompok datanya homogen.
MEDIAN (DATA TIDAK BERKELOMPOK)

Apabila ada sekelompok nilai sebanyak n diurutkan mulai dari yang
terkecil Xi sampai dengan yang terbesar Xn, maka nilai yang ada ditengah disebut
Median.
Untuk n Ganjil ditulis : n= 2k + 1
Untuk n Genap ditulis : median = 12 (Xk + Xk+1)
MEDIAN (DATA BERKELOMPOK)
Secara Geometrik, median juga merupakan nilai X dari absis (sumbu
horizontal) sesuai dengan jarak tegak lurus yang membagi suatu histogram
menjadi dua daerah sama luasnya. Jadi seluruh observasi seolah-olah dibagi
menjadi dua,setengah di sebelah kiri median (yang terdiri dari observasi yang
nilainya sama atau lebih kecil dari median) dan setengah di sebelah kanan median
(yang terdiri dari observasi yang nilainya sama atau lebih besar dari median)
med = L0 + c { n2−(∑ fi ) 0
fm }MODUS
Modus dari suatu kelompok nilai adalah nilai kelompok tersebut yang
mempunyai frekuensi tertinggi atau nilai yang paling banyak terjadi didalam suatu
kelompok nilai. Apabila data sudah dikelompokkan dan disajikan dalam tabel
frekeunsi maka dalam mencari modusnya digunakan rumus :
Modus = L0 + c { (f 1 ) 0( f 1 )0+ (f 2 ) 0 }

dimana,
L0 = nilai batas bawah, kelas yang memuat modus
fm0 = frekeunsi kelas yang memuat modus
(f1)0 = fm() – f(m0-1) (selisih frekeunsi kelas yang memuat modus dengan
frekeunsi kelas sebelumnya)
(f2)0 = fm() – f(m0+1) (selisih frekeunsi kelas yang memuat modus dengan
frekeunsi kelas sesudahnya)
C = besarnya jarak antara nilai batas atas dan nilai batas bawah dari
kelas yang memuat modus
PERBANDINGAN ANTARA RATA-RATA, MEDIAN, DAN MODUS
Apabila distribusi frekuensi mempunyai kurva yang simetris dengan satu
puncak saja, maka letak rata-rata X , median dan modus adalah sama yaitu X =
mod = med. Bila kurva menceng ke kanan, maka nilai rata-rata adalah yang paling
besar,diikuti dengan median, lalu modus. Bila kurva menceng ke kiri, maka nilai
rata-rata paling kecil, diikuti median lalu modus. Tetapi bila distribusinya tidak
terlalu melenceng maka terdapat hubungan :
rata-rata – modus = 3 (rata-rata – median) atau,
modus = rata-rata – 3 (rata-rata – median)
RATA-RATA UKUR
Untuk mencapai rata-rata ukur dapat digunakan rumus :
G = n√ X ₁× X ₂ .. . Xn

Log G = ∑ log Xi
n
G = antilog (∑ log Xi
n )
RATA-RATA HARMONIS
Rata-rata Harmonis (RH) dari n angka, X1, X2, . . ., Xn adalah nilai yang
diperoleh dengan jalan membagi n dengan jumlah kebalikan dari masing-masing
X tersebut di atas. Rumusnya adalah sebagai berikut :
RH =
n
∑i=1
n1Xi
Bila kita berbicara tentang median, maka nilai ini seolah-olah membagi
kelompok dan menjadi 2 bagian yang sama. Artinya 50% dari kelompok data ini
mempunyai nilai sama atau lebih kecil dari median, sedangkan 50% lainnya
mempunyai nilai yang sama atau lebih besar dari median tersebut. Nilai median
merupakan salah satu dari nilai observasi/ pengamatan. Untuk kelompok data
dimana n ≥ 4, kita tentukan tiga nilai, katakanlah Q1, Q2, Q3, yang membagi
kelompok data tersebut menjadi 4 bagian yang sama yaitu setiap bagian memuat
data yang sama. Nilai-nilai tersebut dinamakan kuartil pertama, kedua dan
ketiga. Pembagian itu adalah sedemikian rupa sehingga nilai 25% data sama atau
lebih kecil dari Q1, 50% data sama atau lebih kecil dari Q2, 75 % data sama atau
lebih kecil dari Q3.
KUARTIL, DESIL, PERSENTIL (DATA BERKELOMPOK)
Kuartil merupakan ukuran yang membagi sekelompok nilai menjadi empat
bagian yang sama. Rumus Kuartil yaitu :

Qi = L0 + c { ¿4−(∑ fi ) 0
fq }, i = 1,2,3
dimana :
L0 = nilai batas bawah, kelas yang memuat kuartil ke-i
n = banyaknya observasi
∑ (f1)0 = jumlah frekeunsi dari semua kelas sebelum kelas yang
mengandung kuartil ke-i
fq = frekeunsi dari kelas yang mengandung kuartil ke-i
c = besarnya kelas interval yang mengandung kuartil ke-i atau jarak
nilai batas bawah (atas) dari suatu kelas terhadap nilai batas bawah (atas)
kelas berikutnya
i = 1,2,3
in = i kali n
Desil merupakan ukuran yang membagi sekelompok nilai menjadi 10
bagian yang sama. Rumus desil yaitu :
Di = L0 + c { ¿10
−(∑ fi ) 0
fd }Persentil adalah ukuran yang membagi sekelompok nilai menjadi 100
bagian yang sama. Rumus persentil yaitu :
Pi = L0 + c { ¿100
−(∑ fi ) 0
fp }dimana :

L0 = nilai batas bawah, kelas yang memuat desil ke-i (persentil ke-i)
n = banyaknya observasi
∑ (f1)0 = jumlah frekeunsi dari semua kelas sebelum kelas yang
mengandung desil ke-i (persentil ke-i)
fd = frekeunsi dari kelas yang memuat desil ke-i
fp = frekeunsi dari kelas yang memuat persentil ke-i
c = besarnya kelas interval yang memuat desil ke-i (persentil ke-i)
Bab 6 menjelaskan tentang Ukuran Variasi atau Dispersi. Ada beberapa
macam ukuran variasi atau dispersi, misalnya nilai jarak (range), rata-rata
simpangan (mean deciation), simpangan baku (standard deviation), dan koefisien
variasi (coefficient of varitation). Diantara ukuran variasi tersebut simpangan
baku yang sering dipergunakan, khususnya untuk keperluan analisis data. Dispersi
dipelajari untuk membandingkan sebaran data dari dua informasi distribusi nilai.
Misalnya untuk membandingkan tingkat produktivitas dari dua perusahaan.
Meskipun kita mengetahui bahwa produksi rata-rata dari dua perusahaan mobil
adalah 20 mobil sehari, namun kita tentu tidak dapat langsung mengatakan bahwa
tingkat produksi mereka identik. Kita perlu melihat bagaimana sebaran nilai
(jumlah produksi harian) dari kedua perusahaan tersebut. Mungkin perusahaan
pertama cenderung lebih homogen, dalam arti bahwa jumlah produksi harian tidak
jauh dari kisaran rata-rata. Mungkin pula pperusahaan kedua ternyata cenderung
memiliki tingkat distribusi produksi yang lebih heterogen, yang berarti bahwa
jumlah produksi harian sangat beragam dan menyebar jauh disekitar rata-rata.

PENGUKURAN DISPERSI DATA TIDAK DIKELOMPOKKAN
Nilai Jarak
Diantara ukuran variansi yang paling sederhana dan paling mudah
dihitung ialah nilai jarak (range). Bila suatu kelompok nilai sudah disusun
menurut urutan yang terkecil (X1) sampai dengan yang tersebar (Xn), maka untuk
menghitung nilai jaraj dapat digunakan rumus :
Nilai Jarak = Nilai Maksimum (Xn) – Nilai Minimum
(X1)
Rata-rata Simpangan
Rata-rata simpangan adalah rata-rata hitung dari nilai absolut simpangan
yang dirumuskan :
RS = in∑ |Xi−X|
sedangkan simpangan terhadap median dapat dirumuskan :
RS = in
∑ |Xi−Med|
Simpangan Baku
Diantara ukuran dispersi atau variasi, simpangan baku adalah yang paling
banyak dipergunakan, karena mempunyai sifat-sifat matematis yang sangat
penting dan berguna sekali untuk pembahasan teori dan analisis. Simpangan baku
adalah salah satu ukuran dispersi yang diperoleh dari akar kuadrat positif varians.
Varians adalah rata-rata hitung dari kuadrat simpangan setiap pengamatan
terhadap rata-rata hitungnya. Simbol dari varians populasi adalah σ 2 dimana
rumusnya adalah :

σ 2 = i
N ∑
i=1
N
( Xi−μ )2
Dimana (X−μ) adalah simpangan deviasi dari observasi terhadap rat-rata
sebenarnya. Dirumuskan sebagai berikut :
S2 = i
n ±1 ∑i=1
N
( Xi−X )2
Dimana ( Xi−X ) adalah simpangan deviasi dari obseravasi terhadap rata-
rata sampel. Rumus dan simbol dari simpangan baku populasi adalah :
σ=¿ √∑i=1
N
( Xi−μ ) 2
N
dimana σ merupakan simpangan baku dari X.
PENGUKURAN DISPERSI DATA DIKELOMPOKKAN
Nilai Jarak
Untuk data yang berkelompok, nilai jarak (NJ) dapat dihitung dengan dua cara
yaitu :
a) NJ = Nilai tengah kelas akhir - Nilai tengah kelas pertama
b) NJ = Batas atas kelas terakhir – Batas bawah kelas pertama
Simpangan Baku
Untuk data yang berkelompok dan sudah disajikan dalam tabel frekeunsi,
rumus simpangan baku populasi adalah :

σ = √∑i=1
k
fi ( Mi−μ )2
N
Mi = nilai tengah dari kelas ke-i, i = 1,2, . . . , k.
atau
σ=c √∑i=1
k
fidi2
N±(∑i=1
k
fidi
N)
2
, untuk kelas interval yang sama
dimana :
c = besarnya kelas interval
fi = frekeunsi kelas ke-i
di = deviasi = simpangan dari kelas ke-i terhadap titik asal asumsi
dan
σ=√ 1N {∑
i=1
k
fiMi2−(∑
i=1
k
fiMi)2
N }untuk kelas interval yang tidak sama, Mi = nilai tengah kelas ke-i.
Untuk data sampel diperoleh simpangan baku sampel dengan rumus :
S = c √∑i=1
k
fidi2
n± 1−[∑i=1
k
fidi
n−1 ]2
untuk kelas yang sama,
dan

S = √ 1n−1 {∑
i=1
k
fiMi2−(∑
i=1
k
fiMi)2
n−1 } untuk kelas tidak sama.
Variabel X yang mempunyai rata-rata µ dengan simpangan baku σ . Jadi,
Xiσ
merupakan nilai baku dari Xi, dan Zi = Xi−μ
σ merupakan nilai simpangan atau
deviasi yang baku. Simpangan baku yang sudah dibahas diatas mempunyai satuan
yang sama dengan satuan data aslinya. Hal ini menjadi suatu kelemahan kalau kita
ingin membandingkan dua kelompok data, misalnya harga 10 mobil dengan harge
10 ekor ayam atau berat 10 ekor gajah dengan berat 10 ekor semut. Walaupun
nilai simpangan baku untuk berat gajah atau harga mobil lebih besar, nilai ini
belum tentu lebih heterogen atau lebih bervariasi daripada harga semut atau harga
ayam. Untuk keperluan perbandingan dua kelompok nilai dipergunakan Koefisien
Variasi (KV) yang bebas dari satuan data asli dimana rumusnya adalah :
KV = σμ × 100%, untuk populasi
kv = SX
×100%, untuk sampel
Jika ada dua kelompok data dengan KV1 dan KV2, dimana KV1 > KV2,
maka kelompok pertama lebih bervariasi atau lebih heterogen daripada kelompok
kedua.
UKURAN KEMENCENGAN DAN KERUNCINGAN KURVA
Apabila kita mempunyai sekelompok data sebanyak n: X1,X2,....,Xn, maka
yang disebut momen dengan momen ke-r (Mr) adalah :
Mr = 1n
∑i=1
n
X ir . . . untuk data tak berkelompok
Untuk data yang sudah dikelompokkan menjadi k kelas, dengan Mi
merupakan nilai tengah kelas ke-i, maka rumus momen ke-r (Mr) yaitu :

x
yQ
QQ 1
Mr = 1n ∑
i=1
k
fiM ir . . . untuk data berkelompok
Untuk r = 1, maka M1 merupakan rata-rata hitung. Momen tersebut
merupakan terhadap titik asal, sedangkan momen terhadap rata-rata hitung
adalah :
Mr = in∑i=1
n
( Xi−X )r. . . untuk data tak berkelompok
Mr = in∑i=1
k
fi ( Mi−X )r . . . untuk data berkelompok
Untuk r = 2, maka M2 merupakan varians(kuadrat dari simpangan baku =
S2). Momen ketiga dan keempat yaitu M3 dan M4 bergunan untuk mengukur
kemencengan (skewness) dan keruncingan (kurtosis) dari suatu distribusi
frekuensi.
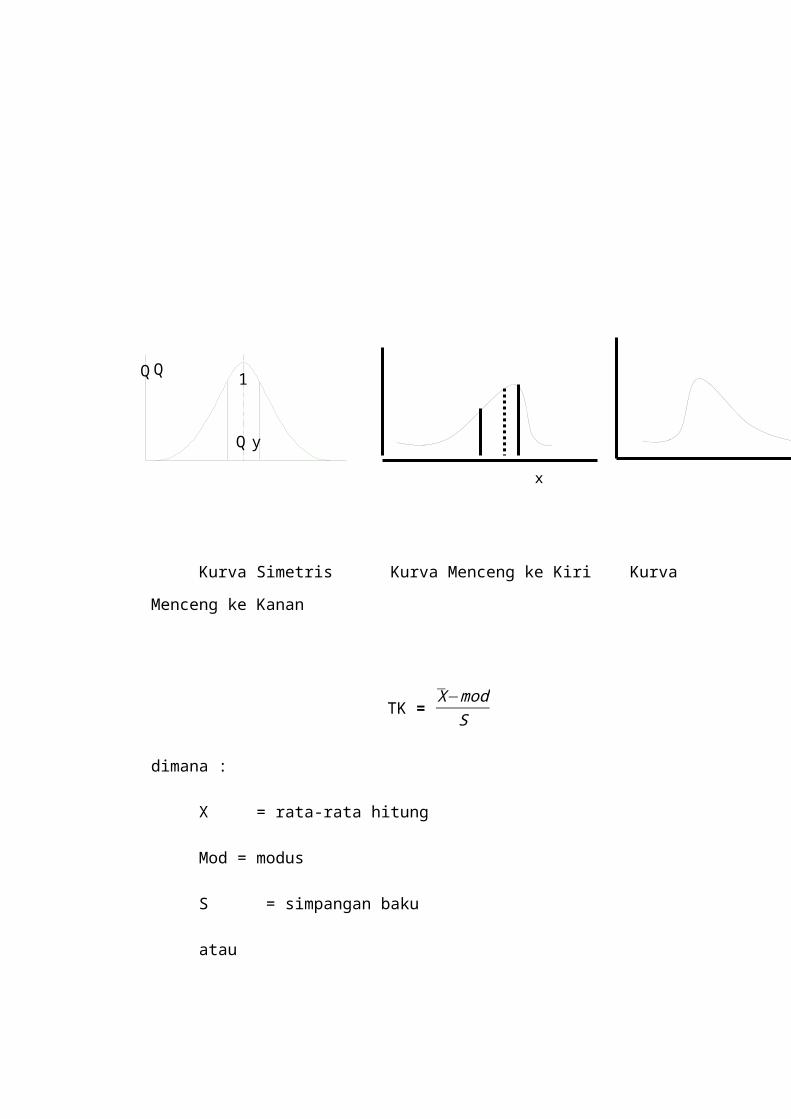
Ukuran Kemencengan Kurva (Skewness)
Kurva yang tidak simetris dapat menceng ke kiri atau ke kanan. Di dalam
kurva yang tidak simetris, letak median, modus dan rata-rata (X ) sama. Ukuran
tingkat kemencengan menurut Pearson yaitu :

Kurva Simetris Kurva Menceng ke Kiri Kurva
Menceng ke Kanan
TK = X−mod
S
dimana :
X = rata-rata hitung
Mod = modus
S = simpangan baku
atau
TK = 3 ( X−med )
S
Ukuran tingkat kemencengan dapat juga dihitung berdasarkan momen
ketiga dengan rumus :
α 3=M 3
S3 = 1nS3 ∑
i=1
n
( X i−X )3 . . . untuk data tak berkelompok
atau
α 3=M 3
S3 = 1nS3 ∑
i=1
k
f i ( M i−X )3. . . untuk data berkelompok
Semakin besar α 3, maka kurva suatu distribusi semakin menceng atau
miring.

Ukuran Keruncingan Kurva (Kurtosis)
Dilihat dari tingkat keruncingannya kurva distribusi frekeunsi dibagi
menjadi 3 yaitu mesokurtis, leptokurtis dan platykurtis yang bentuk kurvanya
adalah :
Untuk menghitung tingkat keruncingan suatu kurva distribusi
dipergunakan α 4,yaitu moment coefficient of kurtosis yang rumusnya sebagai
berikut :
α 4 = M 4
S4 = 1n∑i=1
n
( X i−X )4
S4
. . . (untuk data tidak berkelompok)
α 4 = M 4
S4 = 1n∑i=1
k
f i ( M i−X )4
S4
. . . (untuk data berkelompok)
Bab 7 menjelaskan tentang Analisis Korelasi dan Regresi Liniear
Sederhana. Didalam perencanaan, selain data masa lampau dan masa sekarang,
juga diperlukan data hasil ramalan yang menggambarkan kemampuan di masa
yang akan datang. Apabila dua variabel X dan Y mempunyai hubungan, maka
nilai variabel X yang sudah diketahui dapat dipergunakan untuk memperkirakan /
menaksir Y. Ramalan pada dasarnya merupakan perkiraan mengenai terjadinya

suatu kejadian. Variabel Y yang nilainya akan diramalkan disebut variabel tidak
bebas (dependent variabel), sedangkan variabel X yang nilainya dipergunakan
untuk meramalkan nilai Y disebut variabel bebas (independent variabel). Jadi
analisis korelasi ini memungkinkan kita untuk mengetahui sesuatu di luar hasil
penyelidikan, misalnya dengan ramalan kita dapat mengetahui terjadinya suatu
kejadian baik secara kualitatif maupun kuantitatif.
KOEFISIEN KORELASI DAN KEGUNAANYA
Hubungan dua variabel ada yang positif dan negatif. Hubungan X dan Y
dikatakan positif apabila kenaikan (penurunan) X pada umumnya diikuti oleh
kenaikan (penurunan) Y. Sebaliknya dikatakan negatif apabila kenaikan
(penurunan) X pada umumnya diikuti oleh penurunan (kenaikan) Y. Jadi apabila
antara variabel X dan Y terdapat hubungan, maka bentuk diagram pencarnya
adalah mulus / teratur dimana yang pertama menunjukkan gerakan diagram
pencar dari kiri bawah ke kanan atas (hubungan positif), sedangkan yang kedua
bergerak dari kiri atas ke kanan bawah (hubungan negatif). Apabila bentuk
diagram pencar tidak teratur, artinya kenaikan/penurunan X pada umumnya tidak
diikuti oleh naik turunnya Y, maka dikatakan X dan Y tidak berkorelasi. Kuat dan
tidaknya hubungan antara X dan Y apabila dapat dinyatakan dengan fungsi
liniear, diukur dengan suatu nilai yang disebut Koefisien Korelasi. Nilai koefisien
korelasi ini paling sedikit -1 dan paling besar 1. Jadi, jika r = koefisien korelasi,
maka nilai r dapat dinyatakan sebagi berikut :
-1 ≤ r ≤ 1
Cara menghitung r adalah sebagai berikut :
r =
∑i=1
n
x i y i
√∑i=1
n
x i2 √∑
i=1
n
y i2

Dapat juga disebut dengan koefisien korelasi Pearson.
Untuk menghitung koefisein korelasi data yang sudah berkelompok dapat dicari
dengan rumus :
r = n (∑ uvf )−(∑ uf u ) (∑ vf v)
√n(∑u2 f u )−(∑ uf u )2√n (∑ v2 f v )−(∑ vf v )2
Koefisien korelasi anatar Rank dapat dihitung dengan rumus :
1 - 6∑ d i
2
n (n2−1 )
dimana di = selisih dari pasangan rank ke-i ;
n = banyaknya pasangan rank
rumus ini disebut rumus Spearman.
KOLERASI DATA KUALITATIF
Untuk data yang kualitatif yang dipergunakan dalam mengukur kuatnya
hubungan disebut Contingency Coefficient (Koefisien Bersyarat) yang
mempunyai pengertian sama seperti koefisien korelasi. Untuk menghitung nilai
koefisien bersyarat (Cc) digunakan rumus :
Cc = √ X2
X2+n
TEKNIK RAMALAN DAN ANALISIS REGRESI
Tujuan utama subbab ini adalah bagaimana menghitung suatu perkiraan
atau persamaan regresi yang akan menjelaskan hubungan antara dua

variabel.Pembahasan terbatas pada regresi sederhana, yaitu mengenai hubungan
antara dua variabel yang biasanya cukup tepat dinyatakan dalam suati garis lurus.
Diagram Pencar (Scatter Diagram)
Setelah ditetapkan bahwa terdapat dua hubungan logis diantara variabel,
maka untuk mendukung analisis lebih jauh, barangkali tahap selanjutnya adalah
menggunakan grafik. Grafik ini disebut Diagram Pencar, yang menunjukkan titik-
titik tertentu. Setiap titik memperlihatkan sesuatu hasil yang kita nilai sebagai
variabel tak bebas (dependent) maupun bebas (independent). Diagram Pencar ini
memiliki dua manfaat yaitu :
(1) Membantu menunjukkan apakah terdapat hubungan yang bermanfaat
antara dua variabel,
(2) Membantu menetapkan tipe persamaan yang menunjukkan hubungan
antara kedua variabel tersebut.
Persamaan Regresi Liniear
Persamaan regresi linear dapat dihitung dengan rumus :
Y’ = a + b X
dimana
a = Y pintasan, (nilai Y’ bila X = 0)
b = kemiringan dari regresi atau koefisien regresi, yang mengukur
besarnya pengaruh X terhadap Y kalau X naik satu unit
X = nilai tertentu dari variabel bebas
Y’ = nilai yang diukur atau dihitung pada variabel tidak bebas

Penggunaan Persamaan Regresi dalam Peramalan
Tujuan utama penggunaan persamaan regresi adalah untuk memperkirakan nilai
dari variabel tak bebas pada nilai variabel bebas tertentu. Persamaan regresi dalam
ramalan dapat dihitung dengan rumus:
Y’ = 1,02 + 5,14 (x)
Bab 8 menjelaskan tentang Regresi Liniear Berganda dan Regresi
Nonliniear. Dalam bab 7 telah dibahas tentang korelasi antara dua variabel X dan
Y yang sering diberi simbol rxy atau r saja.
rxy = ∑ Xi .Yi
√∑ x i2 .∑ y i
2
Jikalau kita ingin mengetahui kuatnya hubungan anatara variabel Y
dengan beberapa variabel X lainnya, maka kita menggunakan suatu koefisien
kolerasi yang disebut koefisien korelasi linear berganda (KKLB)Untuk
Koefisien Korelasi Liniear Berganda dapat dihitung dengan rumus :
KKLB = √ r 1 y2 +r 2 y
2 −2 r1 y r2 y r12
1−r122
Apabila KKLB dikuadratkan, maka akan diperoleh koefisien penentuan
(KP) berganda, yaitu suatu nilai untuk mengukur besarnya sumbangan dari
variabel X terhadap variasi Y,dimana rumusnya adalah :
KP = R y .122

Koefisien Korelasi Parsial
Apabila variabel Y berkorelasi dengan X1 dan X2, maka koefisien korelasi
anatara Y dan X1 (X2 konstan), antara Y dan X2 (X1 konstan), dan antara X1 dan X2
(Y konstan) disebut Koefisien Korelasi Parsial (KKP) dengan rumus sebagai
berikut :
r1y.2 = r1 y−r2 y r12
√1−r2 y2 √1−r12
2
(Koefisien korelasi parsial X1 dan Y, kalau X2 konstan)
r2y.1 = r2 y−r1 y r12
√1−r1 y2 √1−r12
2
(Koefisien korelasi parsial X2 dan Y, kalau X1 konstan)
r12.y = r12−r1 y r2 y
√1−r1 y2 √1−r2 y
2
(Koefisien korelasi parsial X1 dan X2, kalau Y konstan)
TREND PARABOLA
Garis trend pada dasarnya adalah garis regresi dimana variabel bebas X
merupakan variabel waktu. Baik garis regresi maupun trend dapat berupa garis
lurus maupun tidak lurus. Persamaan garis trend parabola adalah sebagai berikut :
Y’ = a + bX + cX2 (X = waktu)
TREND EKSPONENSIAL (LOGARITMA)
Trend Eksponensial sering dipergunakan untuk meramalkan junlah
penduduk, pendapatan nasional, produksi, hasil penjualan, dan kejadian-kejadian
lain yang perkembangan/pertumbuhannya meningkat secara geometris. Trend
Eksponensial mempunyai bentuk persamaan seperti Y’ = abx atau Y’ = aXb.
TREND EKSPONENSIAL YANG DIUBAH
Seperti yang telah diuraikan sebelumnya, trend eksponensial mempunyai
persamaan yang masing-masing melalui proses transformasi menjadi bentuk
liniear dalam semi log dan sepenuhnya log yaitu:
(semi log)
Y’0 = a0 + bo X Y’0 = log Y’
a0 = log a
b0 = log b
(log)
Y’0 = a0 + b X Y’0 = log Y’
a0 = log a
X0 = log X
Bentuk Y’ = abX dapat dikonversi dengan jalan menambah bilangan
konstanta k. Dengan demikian, persamaannya menjadi :
Y’ = k + abX

Karena bentuk trend eksponensial yang diubah tidak dapat dijadikan
bentuk linear dengan jalan transformasi, maka untuk memperkirakan atau
menghitung nilai koefisien a dan b tidak dapat digunakan metode kuadrat
terkecil (least square method).
TREND LOGISTIK
Trend Logistik biasanya dipergunakan untuk mewakili data yang
menggambarkan perkembangan / pertumbuhan yang mula-mula cepat sekali,
tetapi kemudian melambat, dimana kecepatan pertumbuhannya makin berkurang
sampai tercapai suatu titik jenuh. Contoh bentuk trend logistik adalah sebagai
berikut :
Y’ = k
1+10a+bX , dimana : k,a dan b konstan, biasanya b < 0.
TREND GOMPERTZ
Trend Gompretz biasanya dipergunakan untuk meramalkan jumlah
penduduk pada usia tertentu. Bentuk daripada Trend ini adalah :
Y’ = kabX , dimana k,a, dan b konstan.
Untuk mengenali jenis trend baik linear, parabola, eksponensial, logistik
maupun Gompertz, kita harus membuat diagram pencar. Dengan melihat diagram
pencar kita bisa menentukan jenis trend apa yang cocok atau tepat untuk
meramalkan.
Bab 9 menjelaskan tentang Analisis Data Berkala. Data berkala (time
series data) adalah data yang dikumpulkan dari waktu ke waktu untuk
menggambarkan perkembangan suatu kegiatan. Analisis data berkala

memungkinkan kita untuk mengetahui perkembangan suatu atau beberapa
kejadian serta hubungan atau pengaruhnya terhadap kejadian lainnya. Gerakan /
variasi data berkala terdiri dari empat komponen yaitu sebagai berikut :
(1) Gerakan Trend Jangka Panjang, yaitu suatu gerakan yang
menunjukkan arah perkembangan secara umum (kecendrungan
menaik/menurun). Garis trend ini berguna untuk membuat ramalan yang
diperlukan bagi perencanaan (T).
(2) Gerakan/Variasi Siklis, yaitu gerakan/variasijangka panjang disekitar
garis trend (berlaku untuk data tahunan) dan disimbolkan dengan C
(cycle).
(3) Gerakan/Variasi Musiman, yaitu gerakan yang mempunyai pola
tetap dari waktu ke waktu yang disimbolkan dengan S (seasonal).
(4) Gerakan/Variasi yang Tidak Teratur, yaitu gerakan/variasi yang
sifatnya sporadis, disimbolkan dengan I (irregular).
Apabila gerakan trend, siklis, musiman, dan acak masing-masing diberi
simbol T, C, S, dan I, maka data berkala Y merupakan hasil kali dari 4 komponen
tersebut yaitu :
Y = T × C × S × I
MENENTUKAN TREND
Ada beberapa metode yang umum digunakan untuk menggambarkan garis
trend, ada beberapa metode yang bisa digunakan yaitu :
Metode Tangan Bebas
Adapun langkah-langkah yang digunakan dalam metode ini adalah :
(1) Buat sumbu tegak Y dan sumbu mendatar X,

(2) Buat Scatter Diagram, yaitu kumpulan titik-titik koordinat (X, Y); X =
variabel waktu,
(3) Dengan jalan observasi langsung terhadap bentuk Scatter Diagram.
Cara menarik Garis Trend dengan tangan bebas meruoakan cara yan
paling mudah, tetapi sifatnya sangat subjektif.
Metode Rata-rata Semi
Cara dengan metode ini memerlukan langkah-langkah sebagai berikut :
(1) Data dikelompok menjadi dua, masing-masing kelompok harus
mempunyai jumlah data yang sama,
(2) Masing-masing kelompok dicari rata-ratanya,
(3)Titik absis harus dipilih dari variabel X yang berada di tengah masing-
masing kelompok,
(4)Titik koordinat terdiri dari b) dan c) dimasukkan kedalam persamaan
Y=a+bX
Metode ini tidak memerlukan grafik, kita dapat mempreloeh nilai ramalan
langsung dari persamaan.
Metode Rata-rata Bergerak
Rata-rata bergerak sering dipergunakan untuk memuluskan fruktuasi yang
terjadi dalam data tersebut. Proses pemulusan ini disebut pemulusan data
berkala. Apabila rata-rata bergerak dibuat dari data tahunan atau bulanan
sebanyak n waktu maka rata-rata bergerak disebut rata-rata bergerak tahunan atau
bulanan dengan orde n.

Metode Kuadrat Terkecil
Garis trend linear dapat ditulis sebagai persamaan garis lurus :
Y’ = a + bX
Di mana Y’ = data berkala (time seri data)
X = waktu
a dan b = bilangan konstan
Untuk mencari persamaan trend garis lurus dengan metode kuadrat terkecil
dapat dilakukan dengan dua cara, yaitu:
Cara 1
Untuk mengadakan perhitungan diperlukan nilai tertentu pada variabel
waktu (X) sedemikian rupa, sehingga jumlah nilai variabel waktu adalah nol.
∑i=1
n
X i=0
a) Untuk n ganjil → n=2k+1
b) Untuk n genap → n=2k
Cara 2
Cara lain untuk menentukan garis trend lurus adalah dengan menentukan
periode awal dari variabel waktu X = 1, jadi tidak perlu lagi membuat ∑ X i=0.
Garis trend lurus dengan cara ini dapat dicari dengan rumus :

a=Y−b X
b=n∑ X iY i−∑ X i Y i
n∑ X i2−¿¿¿
Bab 10 menjelaskan tentang Indeks Musiman dan Gerakan Siklis.
Gerakan musiman (seasonal movement or variation) adalah gerakan yang teratur
sehingga fluktuasinya terjadi pada waktu-waktu yang sama atau sangat
berdekatan. Untuk keperluan analisis, sering kali data berkala dinyatakan dalm
bentuk angka indeks. Apabila kita ingin menunjukkan ada / tidaknya gerakan
musiman, perlu dibuat indeks musiman (seasonal index). Dalam menghitung
angka indeks musiman, ada beberapa metode yang dapat dilakukan yaitu :
1. Metode Rata-rata Sederhana (simple average method)
2. Metode Relatif Bersambung (link relative method)
Untuk menggunakan metode relatif bersambung, data bulanan yang asli
mula-mula dinyatakan sebagai presentase dari data pada bulan yang
mendahuluinya. Persentase-persentase yang didapat dengan cara demikian disebut
relatif bersambung. Jadi, relatif bersambung menghubungkan data pada bulan
yang mendahuluinya. Dalam metode ini dapat dihitung denga dua cara yaitu :
(1) Dengan menggunakan rata-rata,
(2) Dengan menggunakan median berdasarkan rata-rata.
3. Metode Rasio terhadap Trend (ratio to trend method)
Dalam metode ini, data asli untuk setiap bulan dinyatakan sebagai
persentase dari nilai-nilai trend bulanan. Rata-rata (median) dari persentase ini

merupakan indeks musiman. Apabila rata-rata indeks ≠ 100% atau jumlahnya
tidak = 1.200%, perlu diadakan penyesuaian.
4. Metode Rasio terhadap Rata-rata Bergerak (ratio to moving
average method)
Dalam metode ini, harus dihitung terlebih dahulu rata-rata bergerak selama
12 bulan. Karena hasil perhitungan rata-rata bergerak 12 bulan ini terletak antara
dua bulan yang berdekatan, tidak terletak pertengahan bulan, maka harus dibuat
rata-rata bergerak dua bulan yang didasarkan atas data rata-rata bergerak 12 bulan
tersebut. Yang terakhir ini sering disebut rata-rata bergerak 12 bulan terpusat.
MENGHILANGKAN PENGARUH MUSIMAN DAN TREND
Apabila kita ingin menghilangkan pengaruh musiman terhadap data
berkala, maka setiap nilai (data asli) bulanan dari tahun ke tahun harus dibagi
dengan indeks musiman.
GERAKAN SIKLIS DAN CARA MENGUKURNYA
Seperti kita ketahui, data berkala diberi simbol Y = TCSI. Apabila dibagi
dengan S, maka :
YS
=TCSIS
= TCI (bebas pengaruh musiman) yang kemudian kalau dibagi
denagn T:
YST
=TCIT
= CI (bebas pengaruh musiman dan trend).

MENEMUKAN UKURAN MUSIMAN DENGAN PENGGUNAAN
REGRESI BERGANDA
Pada bab terakhir kita akan mengetahui bahwa metode kedua, yaitu yang
lebih kompleks untuk menemukan indeks musiman adalah metode yang cukup
memadai untuk data yang memiliki trend kuat. Akan tetapi, kita dapat
menggabungkan pengetahuan pada data dan membutuhkan pekerjaan yang lebih
sederhana dibandingkan metode kedua.
Dengan data yang disajikan kita dapat membangun persamaan regresi dari rumus:
Y=a+b1t+b2 S2+b3 S3+b4 S4
Dimana :
Y (= Y topi)
t = periode waktu
S j = variabel indikator yang menunjukkan musim semi, panas, dan
gugur.
Bab 11 menjelaskan tentang Angka Indeks. Angka indeks pada dasarnya
merupakan suatu angka yang dibuat sedemikian rupa sehingga dapat
dipergunakan untuk melakukan perbandingan antara kegiatan yang sama dalam
dua waktu yang berbeda. Tujuan pembuatan angka indeks adalah mengukur
secara kuantitatif terjadinya perubahan dalam dua waktu yang berlainan. Di dalam
membuat angka indeks diperlukan dua macam waktu, yaitu :
(1) waktu dasar (base period),yaitu waktu di mana suatu kegiatan
diperlukan sebagai dasar perbandingan,

(2) waktu yang bersangkutan atau sedang berjalan (current period),
yaitu waktu dimana suatu kegiatan (kejadian) dipergunakan sebagai dasar
perbandingan terhadap kegiatan pada waktu dasar.
INDEKS HARGA RELATIF SEDERHANA DAN AGREGATIF
Indeks harga relatif sederhana (simple relative price index) ialah indeks
yang terdiri dari satu macam barang saja, baik untuk indeks produksi maupun
indeks harga. Indeks agregatif merupakan indeks yang terdiri dari beberapa
barang. Indeks agregartif memungkinkan untuk melihat persoalan secara
agregatif, yaitu secara keseluruhan, bukan melihat satu per satu.
Rumus indeks harga sederhana (simple index) adalah:
I t , 0=Pt
P0
×100 %
Dimana: I t , 0=indeks harga pada waktu t denganwaktu dasar 0
Pt=harga pada waktu t
P0 = harga pada waktu 0
Rumus untuk menghitung indeks produksi sama seperti untuk menghitung
indeks harga hanya huruf p-nya saja diganti dengan q.
I t , 0=qt
q0
× 100 %

Dimana: I t , 0=indeks harga pada waktu t denganwaktu dasar 0
q t=harga pada waktu t
q0 = produksi dalam waktu 0
INDEKS AGREGATIF TIDAK TERTIMBANG
Digunakan untuk unit-unit yang mempunyai satuan yang sama. Indeks ini
diperoleh dengan jalan membagi hasil penjumlahan harga pada waktu yang
bersangkutan dengan hasil penjumlahan harga pada waktu dasar. Dapat
dirumuskan sebagai berikut:
I t , 0=∑ Pi
∑ P0
×100 %
INDEKS AGREGATIF TERTIMBANG
Indeks agregatif tertimbang ialah indeks yang dalam pembuatannya telah
dipertimbangkan faktor-faktor yang akan mempengaruhi naik turunnya angka
indeks tersebut.
Timbangan yang akan dipergunakan untuk pembuatan indeks biasanya :
1. Kepentingan Relatif (relative importance)
2. Hal-hal yang ada hubungannya atau ada pengaruhnya terhadap naik-
turunnya indeks tersebut.
Kelemahan dari Indeks ini adalah :
1. Satuan atau unit harga barang sangat mempengaruhi indeks harga.
2. Tidak memperhitungkan kepentingan relatif barang-barang yang
tercakup dalam pembuatan indeks.

INDEKS RATA-RATA HARGA RELATIF
Indeks rata-rata harga relatif dinyatakan oleh persamaan berikut:
I t , 0=1n [∑ p t
p0
× 100 %]
Dimana, n adalah banyaknya jenis barang.
Ada beberapa rumus angka indeks tertimbang, yaitu rumus Laspeyres dan
rumus Passche, yaitu nama dari penemunya.
I t , 0=∑ Piq0
∑ P0 q0
× 100 %
(rumus indeks harga agregatif tertimbang)
Dimana: L = indeks Laspeyres
pt=harga waktu t
p0=harga waktu0
q0=harga waktu0 , sebagaitimbangan
I t , 0=∑ P0q t
∑ P0 q0
× 100 %
(rumus indeks produksi agregatif tertimbang)
Dimana: q t=produksi waktu t
q0=produksi waktu0

p0=harga waktu0 , sebagai timbanga
Pt ,0=∑ Pt q t
∑ P0 qt
×100 %
(rumus indeks harga agregatif tertimbang)
Dimana: P=indeks Paasche
pt=harga waktu t
p0=harga waktu0
q t=produksi waktu t , sebagai timbangan
Pt ,0=∑ Pt q t
∑ Pt q0
×100 %
(rumus indeks produksi agregatif tertimbang)
Dimana: q t=produksi waktu t
q0=produksi waktu0
Pt = harga waktu t, sebagai timbangan
VARIASI DARI INDEKS HARGA TERTIMBANG
Rumus Laspeyres baik dalam praktek, lemah dalam teori, sedangkan
rumus Paasche baik dalam teori sukar penggunaannya dalam praktek. Sampai
akhirnya muncul Irving Fisher dengan rumusnya yang baru:

I=√ L× P
¿√ pt q0
p0q0
×p t q t
p0 qt
×100 %
Rumus lainnya dimunculkan oleh Drobisch yaitu :
I= L+P2
¿(∑ pt q0
∑ p0q0
+∑ pt q t
∑ p0 q t)×100%
ANGKA INDEKS BERANTAI
Dalam membuat indeks berantai,terlebih dahulu harus ditentukan
berapa satuan waktu dasar. Rumus yang digunakan untuk mencapai Indeks
Berantai yaitu :
I t , t−1=q t
qt−1
×100 %
Dimana: q t=ekspor tah un t
q t−1=ekspor tahunt−1
Keuntungan menggunakan angka indeks ini adalah :
1. Memungkinkan kita untuk memasukkan komoditi-komoditi baru
yang diperlukan sebagai timbangan,
2. Apabila sudah dibuat indeks berantai dengan waktu dasar yang
berubah-ubah, kita dapat menurunkan dari indeks berantai tersebut

suatu indeks pada tahun-tahun tertentu dengan waktu dasar yang
tetap.
PENENTUAN DAN PENGGESERAN WAKTU DASAR
Tujuan utama pembuatan angka indeks adalah untuk melakukan
perbandingan mengenai suatu kegiatan pada waktu yang berbeda. Ada beberapa
syarat yang perlu diperhatikan dalam menentukan waktu dasar yaitu :
1. Waktu sebaiknya menunjukakan keadaan perekonomian yang stabil,
dimana harga tidak berubah dengan cepat sekali.
2. Waktu jangan terlalu jauh dibelakang, usahakan paling lama 10
tahun atau lebih baik kurang dari 5 tahun.
3. Waktu dimana terjadi peristiwa penting.
4. Waktu dimana tersedia data untuk keperluan timbangan.
Jika waktu dasar dari angka indeks dianggap sudah out of date karena
sudah terlalu lama atau terlalu jauh ketinggalan, maka perlu diadakan penggeseran
waktu dasar (shifting the base period). Ada dua cara untuk melakukan pergeseran,
yaitu :
1. Apabila data asli masih tersedia, maka angka pada waktu atau tahun
tertentu yang akan dipakai sebagai tahun dasar yang baru itu diberi
nilai 100%, sedangkan angka-angka lainnya dibagi dengan
angkadari waktu tersebut, kemudian dilakukan dengan 100%.
2. Indeks pada tahun yang akan dipilih sebagai waktu dasar diberi nilai
100%, kemudian angka indeks pada tahun-tahun lainnya dibagi
dengan indeks dari tahun dasar baru, dan mengalikannya dengan
100%. Cara ini sering digunakan apabila data aslinya sudah tidak
ada lagi.
PENGUJIAN ANGKA INDEKS DAN PENDEFLASIAN DATA BERKALA

Kesempurnaan angka indeks biasanya dilihat dari kenyataan apakah
indeks yang bersangkutan memenuhi beberapa kriteria pengujian (test criteria).
Indeks ideal dari Fisher secara teoritis lebih baik daripada indeks Laspeyres atau
Paasche karena indeks ideal lebih banyak memenuhi kriteria pengujian daripada
Laspeyres dan Paasche. Beberapa kriteria pengujian adalah time reversal test, dan
factor reversal test.
Suatu indeks dikatakan memenuhi time reversal test, apabila memenuhi
persamaan sebagai berikut :
I t , 0× I 0 , t=1
(indeks belum dinyatakan dalam persentase)
Dimana: I t , 0=indeks waktu t denganwaktudasar 0
I 0 ,t=¿ indeks waktu 0 dengan waktu dasar t
Sedangkan pada factor reversal test, langkah awal pengujiannya adalah
mencari nilai.
v=p ×q
Dimana: v=nilai
p=harga per satuan
q=banyaknya barangdalam satuan
Pendeflasian Data Berkala
Data berkala (time series data), menujukkan perkembangan mengenai
kegiatan dari waktu ke waktu. Untuk mendapatkan data berkala yang riil (real

term), dan pendapatan nyata (real wages,real income), angka-angka tersebut
harus dibagi dengan indeks biaya hidup (cost of living index).
Bab 12 menjelaskan tentang Probabilitas. Secara umum, probabilitas
merupakan peluang bahwa sesuatu akan terjadi. Secara lengkap, probabilitas
didefenisikan sebagai berikut :
“Probability”is a measure of a likelihood of the occurance of a
random event. (Mendenhall dan Reinmuth, 1982)
Terjemahan bebasnya:
“Probabilitas” ialah suatu nilai yang dipergunakan untuk mengukur
tingkat terjadinya suatu kejadian yang acak.
Dalam mempelajari probabilitas, ada 3 yang harus diketahui:
eksperimen, hasil (outcome), dan kejadian atau peristiwa (event).
PENDEKATAN PERHITUNGAN PROBABILITAS
Ada dua pendekatan dalam menghitung probabilitas yaitu pendekatan
yang bersifat objektif dan subjektif. Probabilitas objektif dibagi menjadi dua
yaitu :
1. Pendekatan Klasik
Perhitungan probabilitas secara klasik didasarkan pada asumsi
bahwa seluruh hasil dari suatu eksperimenmempunyai
kemungkinan (peluang) yang sama. Dapat dirumuskan sebagai
berikut:
a) P ( A )= xn
b) P ( A )=1−P( A)
Dimana: x = frekuensi relatif kejadian i

n = ukuran sampel (jumlah observasi)
2. Konsep Frekeunsi Relatif
Pendekatan yang mutakhir adalah perhitungan yang didasarkan
atas limit dari frekuensi relatif. Perhitungan probabilitaas dengan
pendekatan frekuensi relative yaitu:
P ( X i )=limn →∞
f i
n
Dimana: f i = frekuensi relatif kejadian i
X i = kejadian i
n = total jumlah observasi
Probabilitas Subjektif, didasarkan atas penilaian seseorang dalam
menyatakan tingkat kepercayaan. Hal ini biasanya terjadi dalam bentuk opini atau
pendapat yang dinyatakan dalam suatu nilai probabilitas.
KEJADIAN/PERISTIWA DAN NOTASI HIMPUNAN
Hasil yang berbeda-beda dari suatu eksperimen disebut titik sample.
Sedangkan himpunan dari seluruh kemungkinan hasil disebut ruang sample.
Ruang sample merupakan himpunan hasil eksperimen. Suatu himpunan
merupakan kumpulan yang lengkap atas elemen-elemen sejenesi tetapi dapat
dibedakan satu sama lain.
Hasil eksperimen dapat berbeda-beda, sehingga pada umumnya hasil
eksperimen bersifat acak, di mana kita sering menggunakan istilah variabel acak
untuk maksud perhitungan probabilitas terjadinya hasil suatu eksperimen.
1. Notasi Himpunan

Himpunan dari seluruh kejadian yang ada disebut himpunan
semesta (universal set). Himpunan bagian yang paling kecil
dari suatu himpunan disebut himpunan kosong (null set).
2. Komplemen Suatu Kejadian
3. Interseksi Dua Kejadian
4. Union Dua Kejadian
5. Beberapa Aturan/Hukum dalam Himpunan
a. Hukum penutup (Law of Closure)
Untuk setiap pasang himpunan A dan B, terdapat himpunan-
himpunan yang unik yaitu himpunan A∪B=A ∩ B
b. Hukum komutatif (Commutative Law)
A∪B=B∪A dan A ∩ B=B ∩ A
c. Hukum asosiatif (Associative Law)
( A∪B )∪C=A∪(B∪C )
( A ∩ B ) ∩C=A ∩(B ∩C)
d. Hukum distributif (Distributive Law)
A ∩ ( B∪C )= ( A ∩ B )∪ ( A ∩C )
A∪ ( B∩ C )= ( A∪B ) ∩( A∪C )
e. Hukum identitas (Identity Law)
Ada himpunan ∅ dan S yang unik, sedemikian rupa sehinggauntuk setiap
himpunan A selalu berlaku persamaan A ∩ S=A dan A ∩∅=A .∅=¿ himpunan
kosong.
f. Hukum komplementasi (Complementation Law)
g. Bersesuaian dengan setiap himpunan A ada himpunan
A,

yang unik sedemikian rupa sehingga A ∩ A=∅ dan A∪ A=S .
BEBERAPA ATURAN DASAR PROBABILITAS
1. Aturan Penjumlahan
Untuk menerapkan aturan penjumlahan ini, harus dilihat dari jenis
kejadiannya apakah bersifat saling meniadakan (mutually exclusive) atau tidak
saling meniadakan.
a. Kejadian saling meniadakan
Disebut juga dengan penjumlahan khusus yang dapat diartikan bahwa
kejadian dimana jika sebuah kejadian terjadi, maka kejadian yang kedua adalah
kejadian yang saling meniadakan.
P ( A∪B )=P ( A )+P (B )
P ( A∪B∪C )=P ( A )+P (B )+P (C )
P ( A1∪A2∪…∪ Ak )=∑ P (A i)
b. Kejadian tidak saling meniadakan
P ( A∪B )=P ( A )+P (B )−P( A ∩ B)
2. Aturan Perkalian
Aturan perkalian diterapkan secara berbeda menurut jenis kejadiannya.
Ada dua jenis kejadian dalam hal ini, yaitu :
a. Kejadian Tak Bebas / Bersyarat
Adalah probabilitas terjadinya kejadian A dengan syarat bahwa B sudah
terjadi atau akan terjadi. Pada umumnya probabilitas bersyarat dirumuskan
sebagai berikut :
P (B/A) ¿P (A ∩B)
P( A )
P (A/B) ¿P (A ∩B)
P(B)

b. Probabilitas Kejadian Interseksi
Rumus yang digunakan dalam probabilitas ini adalah :
P ( A ∩B )=P ( A ) P(B/A) =P(B)P(A/B)
3. Kejadian Bebas (Independent Event)
Dua kejadian atau lebih dikatakan merupakan kejadian bebas apabila
terjadinya kejadian tersebut tidak saling. Dua kejadian A dan B dikatakan bebas,
apabila kejadian A tidak mempengaruhi atau sebaliknya.
P(A/B) = P(A)
P(B/A) = P(B)
P( A ∩ B) = P(A)P(B) = P(B)P(A)
4. Probabilitas Marjinal
Untuk mencari probabilitas marjinal dapat dirumuskan sebagai berikut :
P(R) =∑ P ( Si ) P ¿¿R/Si)
5. Rumus Bayes
Seorang ahli matematika dari Inggris, Thomas Bayes (1702 – 1761),
mengembangkan teori untuk menghitung probabilitas tentang sebab-sebab
terjadinya suatu kejadian (causes) berdasarkan pengaruh yang dapat diperoleh
sebagai hasil observasi. Teori Bayes ini bertujuan untuk memecahkan masalah
pembuatan keputusan yang mengandung ketidakpastian (decision making under
uncertainty). Rumus Bayes dapat ditulis :

P ¿/A)¿P ( Ai ) P( A
A i
)
∑i=1
k
P ( A i ) P ( AA i
)
PERMUTASI DAN KOMBINASI
Permutasi adalah suatu pengaturan atau urutan beberapa elemen atau
objek dimana urutan itupenting ( AB ≠ BA ), sedangkan Kombinasi adalah
susunan dari beberapa elemen dimana urutan tidak diperhatikan ( AB = BA ).
Permutasi dapat dirumuskan sebagai berikut :
mPm=m! → permutasi m objek diambil m setiap kali
mP x=m!
(m−x ) ! → permutasi m objek diambil x setiap kali
Kombinasi dapat dirumuskan sebagai berikut :
mC x=m!
x! (m− x ) ! , kombinasi m objek diambil x setiap kali
KELEBIHAN BUKU :
Buku ini menjelaskan tentang teori statistika dan penerapan aplikasinya
secara gamblang. Pada buku ini dilengkapi dengan istilah-istilah penting,
ringkasan rumus, dan lampiran dasar-dasar matematika untuk statistik sehingga
lebih membantu mahasiswa untuk memahami konsep-konsep yang ada pada
setiap bab. Selain itu pada buku ini juga dilengkapi dengan penerapan Statistik
pada aplikasi komputer, seperti pada Bab 3, Bab 4, Bab 5, Bab 7, Bab 8 dan Bab
9. Dengan adanya penerapan pada aplikasi komputer tersebut, mahasiswa dapat
mahir dan lebih mengetahui secara mendalam cara menggunakan Statistik dengan
teknologi komputer sehingga dapat mempercepat proses pengolahan atau
pengoperasian data statistik yang ada.

KEKURANGAN BUKU :
Dalam buku ini kesalahan atau kekurangan data hampir jarang ditemui, hal
ini dikarenakan buku ini merupakan buku edisi yang ke tujuh dimana buku ini
telah menerima berbagai macam saran dan kritikan dari berbagai pihak. Akan
tetapi dari segi visual atau penampilan setiap teks, gambar atau grafik pada pada
buku ini hanya sebagian saja yang dilengkapi dengan cetakan yang berwarna.
Akan lebih baik jika buku ini mencetak teks dan gambarnya dalam cetakan penuh
warna sehingga tidak membuat para pembaca atau mahasiswa yang membaca
buku ini sedikit jenuh.




















