
BAB III METODOLOGI PENELITIAN A. -...
22
25 BAB III METODOLOGI PENELITIAN A. Lokasi Penelitian Penelitian ini mengambil daerah penelitian di wilayah Tapal Kuda Provinsi Jawa Timur pada tahun 2010-2014. Dimana wilayah Tapal kuda ini meliputi tiga sub-wilayah yaitu : pulau Madura ( Kab. Bangkalan, Kab. Sampang, Kab.Pamekasan, Kab. Sumenep ), Selat Madura ( Kota Surabaya dan Kab. Sidoarjo )dan Teluk Madura ( Kab. Pasuruan, Kab. Probolinggo, Kab. Situbondo ). Penlitian ini merupakan studi mengenai Potensi Pertumbuhan Ekonomi Di Wilayah Tapal Kuda Provinsi Jawa Timur Tahun 2010-2014. B. Jenis Penelitian Jenis penelitian yang digunakan dalam penelitian ini adalah penelitian deskriptif kuantitatif ;meliputi data sekunder yang di peroleh dari BPS ( badan pusat statistik) jurnal-jurnal dan dari hasil penelitian terdahulu. C. Definisi Operasional Dan Pengukuran Variabel Definisi operasional adalah pernyataan tentang definisi, batasan , pengertian dan pengambilan variable dalam penelitian. Variabel adalah subyek penelitian atau apa yang menjadi titik perhatian suatu peneliti. Variabel dalam penelitian ini meliputi : 1. Laju pertumbuhan ekonomi
Transcript of BAB III METODOLOGI PENELITIAN A. -...

25
BAB III
METODOLOGI PENELITIAN
A. Lokasi Penelitian
Penelitian ini mengambil daerah penelitian di wilayah Tapal Kuda
Provinsi Jawa Timur pada tahun 2010-2014. Dimana wilayah Tapal
kuda ini meliputi tiga sub-wilayah yaitu : pulau Madura ( Kab.
Bangkalan, Kab. Sampang, Kab.Pamekasan, Kab. Sumenep ), Selat
Madura ( Kota Surabaya dan Kab. Sidoarjo )dan Teluk Madura ( Kab.
Pasuruan, Kab. Probolinggo, Kab. Situbondo ). Penlitian ini merupakan
studi mengenai Potensi Pertumbuhan Ekonomi Di Wilayah Tapal Kuda
Provinsi Jawa Timur Tahun 2010-2014.
B. Jenis Penelitian
Jenis penelitian yang digunakan dalam penelitian ini adalah
penelitian deskriptif kuantitatif ;meliputi data sekunder yang di peroleh
dari BPS ( badan pusat statistik) jurnal-jurnal dan dari hasil penelitian
terdahulu.
C. Definisi Operasional Dan Pengukuran Variabel
Definisi operasional adalah pernyataan tentang definisi, batasan ,
pengertian dan pengambilan variable dalam penelitian.
Variabel adalah subyek penelitian atau apa yang menjadi titik
perhatian suatu peneliti. Variabel dalam penelitian ini meliputi :
1. Laju pertumbuhan ekonomi

26
Laju pertumbuhan ekonomi adalah kenaikan PDRB tanpa
memandang apakah kenaikan itu lebih besar atau lebih kecil dari
pertumbuhan penduduk atau apakah perubahan struktur ekonomi
berlaku atau tidak. Laju pertumbuhan ekonomi diukur dengan
indikator perkembangan PDRB dari tahun ke tahun yang dinyatakan
dalam persen per tahun.
2. Pertumbuhan sektor ekonomi
Pertumbuhan sektor ekonomi adalah pertumbuhan nilai barang
dan jasa setiap sektor ekonomi yang dihitung dari angka PDRB atas
dasar harga berlaku tahun 2010 dan dinyatakan dalam persen
3. Produk Domestik Regional Bruto (PDRB)
PDRB dalam penelitian ini dilihat menurut pendekatan produksi
yaitu merupakan jumlah nilai produk barang dan jasa akhir yang
dihasilkan oleh berbagai unit produksi (di suatu region) pada suatu
jangka waktu tertentu (setahun). Unit- unit produksi tersebut dalam
penyajian ini dikelompokkan menjadi 17 ( tujuh belas ) sektor.
Dalam penyajian ini PDRB dihitung berdasarkan harga tetap
(harga konstan), yaitu harga yang berlaku pada tahun dasar yang
dipilih yaitu tahun 2010. Perhitungan berdasarkan harga konstan
dilakukan karena sudah dibersihkan dari unsur inflasi.
4. Sektor -sektor Ekonomi
Sektor -sektor ekonomi yaitu sektor pembentuk angka PDRB
yang berperan dalam menentukan laju pertumbuhan ekonomi.

27
5. Sektor Basis dan Non Basis
Sektor basis adalah sektor -sektor yang mengekspor barang-
barang dan jasa ke tempat di luar batas perekonomian masyarakat
yang bersangkutan atas masukan barang dan jasa mereka kepada
masyarakat yang datang dari luar perbatasan perekonomian
masyarakat yang bersangkutan.
Sektor non basis adalah sektor-sektor yang menjadikan barang-
barang yang dibutuhkan oleh orang yang bertempat tinggal di dalam
batas perekonomian masyarakat bersangkutan. Sektor -sektor ini
tidak mengekspor barang.
6. Sektor Potensial
Sektor potensial adalah sektor yang pertumbuhannya lebih lambat
namun sektor tersebut apabila di kembangkan dengan baik akan
mempunyai pengaruh yang signifikan terhadap pertumbuhan
ekonomi daerah yang akhirnya dapat meningkatkan pendapatan
daerah secara optimal.
7. Jumlah penduduk
Data jumlah penduduk wilayah Tapal Kuda pada tahun 2010-2014
yaitu meliputi : kab. Sampang, kab. Pamekasan, kab. Sumenep, kab.
Bangkalan, kab. Sidoarjo, kota Surabaya, kab. Pasuruan , kab.
Situbondo, kab. Probolinggo.

28
8. Ketimpangan Ekonomi
Ketimpangan ekonomi antar wilayah merupakan
ketidakseimbangan pertumbuhan ekonomi di suatu wilayah.
Ketimpangan ekonomi antar wilayah merupakan aspek yang umum
terjadi dalam kegiatan ekonomi suatu daerah. Ketimpangan muncul
karena adanya perbedaan kandungan sumberdaya alam dan
perbedaan kondisi demografi yang terdapat pada masing-masing
wilayah. Sehingga kemampuan suatu daerah dalam proses
pembangunan juga menjadi berbeda. Oleh karena itu, pada setiap
daerah terdapat wilayah maju dan wilayah terbelakang.
Ketimpangan juga memberikan implikasi terhadap tingkat
kesejahteraan masyarakat antar wilayah yang akan mempengaruhi
formulasi kebijakan pembangunan wilayah yang dilakukan oleh
pemerintah.
9. Ketimpangan Pendapatan
Ketimpangan pendapatan adalah suatu proses dimana distribusi
pendapatan yang diterima masyarakat tidak merata. Ketimpangan
ditentukan oleh tingkat pembangunan, heterogenitas etnis,
ketimpangan juga berkaitan dengan kediktatoran dan pemerintah
yang gagal mengahrgai property rights
10. Pertumbuhan Ekonomi
Pertumbuhan ekonomi dapat didefinisikan sebagai penjelasan
mengenai faktor-faktor apa yang menentukan kenaikan output

29
perkapita dalam jangka panjang, dan penjelasan mengenai
bagaimana faktor-faktor tersebut sehingga terjadi proses
pertumbuhan.
D. Jenis dan Sumber Data
Jenis data yang digunakan dalam penelitian ini data panel
dimana data panel ini gabungan dari data time series dan cross section.
Data time series dalam penelitian menggunakan kurun waktu selama 5
tahun yaitu pada tahun 2010- 2014. Sedangkan untuk cross section
menggunakan banyaknya objek penelitian yaitu sebanyak 9 kab/kota
wilayah Tapal Kuda. Jadi apabila di gabungkan antara data time series
dan cross section menjadi 45.
Dalam penelitian akan menggunakan sumber data yang di
publikasikan oleh instansi-instansi terkait yang diperlukan selama proses
penelitian Sumber data penelitian ini adalah BPS ( Badan Pusat
Statistik)
E. Teknik Pengumpulan Data
1. Library Research
Merupakan penelitian dengan mempelajari literatur-literatur di
perpustakaan yang berhubungan dengan permasalahan yang akan
diangkat yang digunakan untuk mencari landasan teori yang
berhubungan dengan perpajakan yang nantinya akan digunakan
sebagai acuan dalam penelitian sehingga dapat melakukan dugaan-
dugaan atau hipotesa.

30
2. Teknik Dokumentasi
Teknik atau proses untuk memperoleh data dengan jalan
mengumpulkan dan mencatat data-data yang telah di publikasikan.
3. Data Sekunder
Penelitian keputusan yaitu dengan cara mengumpulkan data
melalui buku-buku ilmiah, tulisan, karangan ilmiah yang berkaitan
dengan penelitian.
F. Teknik Analisis Data
Teknik analisis data yang digunakan dalam penelitian ini adalah
menggunakan Tipologi klasen, LQ, Analisis shift share, Indeks
Williamson dan Regresi Data Panel. Dimana Tipologi Klasen digunakan
untuk mengetahui gambaran tentang pola dan struktur pertumbuhan
ekonomi daerah. Sedangkan analisis LQ digunakan untuk menentukan
kategori suatu sektor yang berpotensi yaitu sektor basis dan non basis.
Analisis shift share digunakan untuk mengetahui perubahan struktur
ekonomi daerah (kab/kota) dan membandingkan dengan regional (
provinsi). Indeks Williamson digunakan untuk mengukur ketimpangan
pembangunan antar daerah di wilayah Tapal Kuda. Dan Regresi Data
Panel digunakan untuk mengetahui keterkaitan pertumbuhan ekonomi
dengan ketimpangan ekonomi di wilayah Tapal Kuda.
Adapun perhitungan untuk menguji hipotesis yaitu :

31
1. LQ (Location Quotient)
Metode Location Quotient (Robinson Tarigan,2005)
digunakan untuk mengetahui sektor basis atau potensial suatu
daerah tertentu. Metode ini menyajikan perbandingan relatif
antara kemampuan sektor di daerah (kabupaten/kota) dengan
kemampuan sektor yang sama pada daerah yang lebih luas (
wilayah Tapal Kuda). Rumus Location Quotient (LQ) adalah
(Robinson Tarigan,2005)
LQ = 𝑆𝑖 𝑆⁄
𝑁𝑖 𝑁⁄
Dimana :
Si : nilai tambah sektor i daerah studi k (kab/kota)
S : PDRB total semua sektor di daerah studi k
Ni : nilai tambah sektor i daerah referensi p (wilayah Tapal
Kuda )
N : PDRB total semua sektor daerah referensi p (provinsi)
Dari perhitungan Location Quotient (LQ) suatu sektor, kriteria
umum yang dihasilkan adalah :
a. Jika LQ > 1, disebut sektor basis, yaitu sektor yang tingkat
spesialisnya lebih tinggi dari wilayah acuan.
b. Jika LQ < 1, di sebut sektor non basis, yaitu sektor yang
tingkat spesialisnya lebih rendah dari wilayah acuan.

32
c. Jika LQ = 1 , maka tingkat spesialisasi daerah sama dengan
tingkat wilayah acuan.
2. Analisis Shift Share
Analisis Shift share merupakan salah satu model pertumbuhan
ekonomi wilayah yang juga bertujuan untuk mengetahui faktor
penentu pertumbuhan ekonomi pada wilayah tersebut. (Sjafrijal
2012)
Mengikuti Blair (1991), formulasi analisis Shift share ini
dengan menggunakan perhitungan matematika sederhana dapat di
jelaskan sebagai berikut:
∆𝑦𝑖 = [𝑦𝑖 (𝑌𝑡/ 𝑌0- 1)] + [𝑦𝑖 (𝑌𝑖
𝑡 / 𝑌𝑖0) – (𝑌𝑡/ 𝑌0)] + [𝑦𝑖 (𝑦𝑖
𝑡 / 𝑦𝑖0)
- (𝑌𝑖𝑡 / 𝑌𝑖
0) ]
Di mana ∆𝑦𝑖 = peningkatan nilai tambah sektor i:
𝑦𝑖0 = nilai tambahan sektor i di tingkat daerah pada tahun awal
periode
𝑦𝑖𝑡= nilai tambahan sektor i di tingkat daerah pada akhir periode
𝑌𝑖0= nilai tambahan sektor i di tingkat nasional pada awal periode
𝑌𝑖𝑡= nilai tambahan sektor i di tingkat nasional pada akhir periode
Persamaan diatas menunjukkan bahwa peningkatan produksi
atau nilai tambah suatu sektor di tingkat daerah dapat diuraikan atas
tiga bagian. Bagian pertama pada sisi kiri persamaan tersebut adalah:
a. Regional Share: [𝑦𝑖 (𝑌𝑡/ 𝑌0- 1)] adalah merupakan komponen
pertumbuhan ekonomi daerah yang disebabkan oleh faktor luar

33
yaitu: peningkatan kegiatan ekonomi daerah akibat
kebijaksanaan nasional yang berlaku pada seluruh daerah.
b. Proportionality shift ( mix shift): [𝑦𝑖 (𝑌𝑖𝑡 / 𝑌𝑖
0) – (𝑌𝑡/ 𝑌0)] adalah
komponen pertumbuhan ekonomi daerah yang disebabkan oleh
struktur ekonomi daerah yang baik, yaitu berspesialisasi pada
sektor yang pertumbuhannya cepat seperti sektor industri.
c. Differential shift (competitive shift) : [𝑦𝑖 (𝑦𝑖𝑡 / 𝑦𝑖
0)
- (𝑌𝑖𝑡 / 𝑌𝑖
0) ]adalah komponen pertumbuhan ekonomi daerah
karena kondisi spesifik daerah yang bersifat kompetitif. Unsur
pertumbuhan inilah yang merupakan keuntungan kompetitif
daerah yang dapat mendorong pertumbuhan ekspor daerah
bersangkutan.
Model Analisis Shift Share:
a. Analisis Shift -Share Klasik
Secara ringkas , dengan analisis shift-share dapat
dijelaskan bahwa perubahan suatu variabel regional suatu
sektor di suatu wilayah dalam kurun waktu tertentu
dipengaruhi oleh pertumbuhan nasional, bauran industri dan
keunggulan kompetitif.
𝐷𝑖𝑗= 𝑁𝑖𝑗 + 𝑀𝑖𝑗 + 𝐶𝑖𝑗
Keterangan :
𝐷𝑖𝑗= perubahan suatu variabel regional sektor i di wilayah j
dalam kururn waktu tertentu

34
𝑁𝑖𝑗= komponen pertumbuhan nasional sektor i di wilayah j
𝑀𝑖𝑗= bauran industri sektor i di wilayah j
𝐶𝑖𝑗= keunggulan kompetitif sektor i di wilayah j
Bila tiap komponen shift-share dijumlahkan untuk semua
sektor maka tanda hasil penjulahan itu akan menunjukkan arah
peruabhan dalam pangsa wilayah kesempatan kerja nasional.
Pengaruh bauran industri total akan positif/negatif/nol di
semua wilayah bila kesempatan kerja suatu sektor tumbuh
diatas/dibawah/sama dengan kesempatan kerja nasional.
Pengaruh keunggulan kompetitif total akan
positif/negatif/nol di wilayah-wilayah , dimana kesempatan
kerja berkembang lebih cepat/lebih lambat atau sama dengan
pertumbuhan kesempatan kerja sektor yang bersangkutan di
tingkat nasional.
b. Modifikasi Estaban-Marquillas (E-M) terhadap Analisis Shift-
share Klasik
Modifikasi yang dilakukan oleh Estaban-Marquillas
(1972) ini mendefinisikan kembali keunggulan kompetitif
(𝐶𝑖𝑗) dari teknik shift-share klasik sehingga mengandung
unsur baru yaitu homothetic employment di suatu sektor
wilayah.
𝐸′𝑖𝑗= 𝐸𝑗 (𝐸𝑖𝑛/ 𝐸𝑛)
Keterangan :

35
𝐸′𝑖𝑗= homothetic employment sektor i di wilayah j
𝐸𝑗= total employment di wilayah j
Homothetic employment di defenisikan sebagai
employment atau output atau pendapatan atau nilai tambah
yang di capai suatu sektor di suatu wilayah. Bila struktur
kesempatan kerja di wilayah itu sama dengan struktur
nasional, sehingga komponen keunggulan kompetitif menjadi
:
𝐶𝑖𝑗= 𝐸𝑖𝑗 (𝑟𝑖𝑗 − 𝑟𝑖𝑛)
Keterangan :
𝐶𝑖𝑗= keunggulan kompetitif
𝐸𝑖𝑗= total employment di wilayah j
𝑟𝑖𝑗= laju pertumbuhan sektor i di wilayah j
𝑟𝑖𝑛= laju pertumbuhan nasional
𝐶𝑖𝑗 mengukur keunggulan atau ketidakunggulan kompetitif
sektor i di wilayah j bila komponen homothetic employment
tumbuh sesuai laju selisih antara laju pertumbuhan sektor i
wilayah j dengan laju pertumbuhan sektor i perekonomian
nasional.
𝐴𝑖𝑗= ( 𝐸𝑖𝑗-𝐸′𝑖𝑗)(𝑟𝑖𝑗-𝑟𝑖𝑛)
Keterangan :
𝐴𝑖𝑗= pengaruh alokasi untuk sektor i di wilayah j

36
𝐴𝑖𝑗 merupakan bagian dari pengaruh keunggulan
kompetitf tradisional (klasik) yang menunjukkan adanya
tingkat spesialisasi di sektor i di wilayah j.
𝐴𝑖𝑗mempresentasikan perbedaan antara kesempatan kerja
nyata di sektor i di wilayah j dan kesempatan kerja sektor i di
wilayah j bila struktur kesempatan kerja wilayah tersebut
sama dengan rtuktur kesempatan kerja nasional, dimana nilai
perbedaan tersebut dikalikan dengan perbedaan antara laju
pertumbuhan sektor i di wilayah j dengan laju pertumbuhan
sektor i secara nasional.
Persamaan ini menunjukkan bahwa bila suatu wilayah
mempunyai spesialisasi di sektor-sektor tertentu, maka sektor-
sektor itu juga menikmati keunggulan kompetitif yang lebih
baik. Efek alokasi ini dapat positif atau negatif.
c. Modifikasi Arcelus terhadap analisis shift share Klasik
Modifikasi yang dilakukan oleh Arcelus (1984) ini
mengganti keunggulan kompetitif dengan sebuah komponen
yang disebabkan oleh pertumbuhan wilayah dan sebuah
komponen bauran industri regional. Arcelus menekankan
komponen kedua yang mencerminkan adanya aglomeration
economics (penghematan biaya persatuan karena
kebersamaan lokasi satuan-satuan usaha).

37
Komponen regional growth effect (pengaruh
pertumbuhan wilayah) dirumuskan sebagai berikut:
𝑅𝑖𝑗= 𝐸′𝑖𝑗 (𝑟𝑗-𝑟𝑛)+(𝐸𝑖𝑗- 𝐸′𝑖𝑗)(𝑟𝑗-𝑟𝑛)
Keterangan :
𝑅𝑖𝑗= komponen pengaruh pertumbuhan wilayah terhadap
sektor i di wilayah j
𝑟𝑗= laju pertumbuhan wilayah j
Komponen bauran industri regional menurut Arcelus
dirumuskan sebagai berikut:
𝑅𝐼𝑖𝑗= 𝐸′𝑖𝑗 {(𝑟𝑖𝑗-𝑟𝑗) – (𝑟𝑖𝑗-𝑟𝑛)} + (𝐸𝑖𝑗- 𝐸′𝑖𝑗) {( 𝑟𝑖𝑗-𝑟𝑗)- (𝑟𝑖𝑛-𝑟𝑛)}
Keterangan :
𝑅𝐼𝑖𝑗= komponen bauran industri regional sektor i di wilayah j.
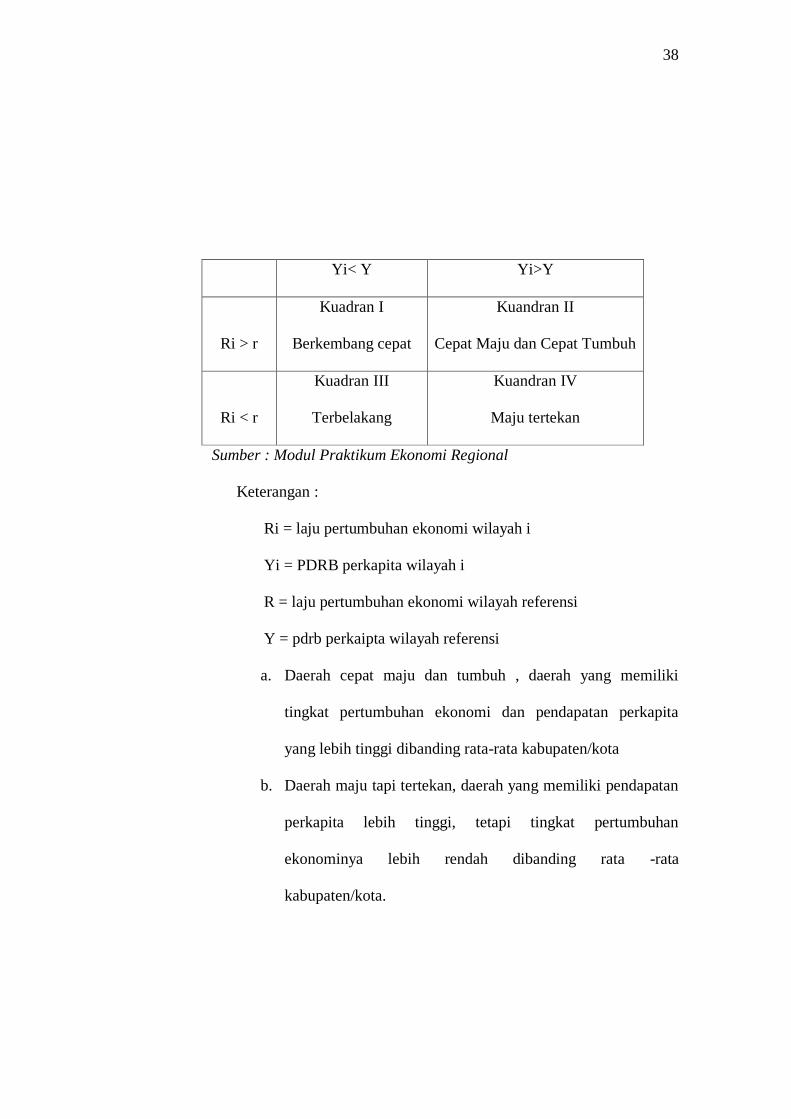
3. Tipologi Klasen
Analisis Tipologi Klassen digunakan untuk mengetahui
gambaran tentang pola dan struktur pertumbuhan ekonomi
masing-masing daerah. Tipologi klasen pada dasarnya membagi
daerah berasarkan dua indikator utama, yaitu pertumbuhan
ekonomi daerah dan pendapatan per kapita daerah.
Melalui analisis ini diperoleh empat karakteristik pola dan
struktur pertumbuhan ekonomi yang berbeda yaitu : daerah cepat
maju dan cepat tumbuh, daerah maju tapi tertekan , daerah
berkembang cepat dan daerah relatif tertinggal ( Kuncoro dan
Aswandi, 2002 ).
38
Yi< Y Yi>Y
Ri > r
Kuadran I
Berkembang cepat
Kuandran II
Cepat Maju dan Cepat Tumbuh
Ri < r
Kuadran III
Terbelakang
Kuandran IV
Maju tertekan
Sumber : Modul Praktikum Ekonomi Regional
Keterangan :
Ri = laju pertumbuhan ekonomi wilayah i
Yi = PDRB perkapita wilayah i
R = laju pertumbuhan ekonomi wilayah referensi
Y = pdrb perkaipta wilayah referensi
a. Daerah cepat maju dan tumbuh , daerah yang memiliki
tingkat pertumbuhan ekonomi dan pendapatan perkapita
yang lebih tinggi dibanding rata-rata kabupaten/kota
b. Daerah maju tapi tertekan, daerah yang memiliki pendapatan
perkapita lebih tinggi, tetapi tingkat pertumbuhan
ekonominya lebih rendah dibanding rata -rata
kabupaten/kota.

39
c. Daerah berkembang cepat, adalah daerah yang memiliki
tingkat pertumbuhan tinggi , tetapi tingkat pendapatan
perkapita lebih rendah dibanding rata-rata kab/kota.
d. Daerah relatif tertinggal adalah daerah yang memiliki tingkat
pertumbuhan ekonomi dan pendapatan perkapita yang lebih
rendah dibanding rata-rata kab/kota.
4. Indeks Williamson
Ketimpangan ekonomi antar kab/kota di wilayah Tapal
kuda Provinsi Jawa Timur diukur menggunakan Indeks
Williamson dengan rumus sebagai berikut :
𝐼𝑊 =√∑𝑖(𝑌𝑖 − 𝑌)2.
𝑓𝑖
𝑛
𝑌
Dimana :
IW : indeks williamson
Fi : jumlah penduduk kabupaten/kota ke-i
N : jumlah penduduk provinsi jawa timur
Yi : PDRB per kapita kabupaten/kota ke-i
Y : PDRB per kapita provinsi jawa timur
Indeks Williamson berkisar antara 0 < IW < 1, dimana
semakin mendekati nol artinya wilayah tersebut semakin tidak
timpang, sedangkan apabila mendekati satu maka semakin timpang
wilayah yang diteliti. (Sjafrizal, 2012).

40
5. Model Regresi Data Panel
Data panel adalah data yang mempunyai dua dimensi yaitu
individu (cross-section) dan waktu (time series), di mana
setiap unit cross-section (individu) diulang dalam beberapa
periode waktu. Bentuk model data panel untuk satu variabel
independen (yang dapat dibuat umum untuk lebih dari satu
variabel independen) yaitu
it i it itY a X
Dimana : ai = variabel tak terobservasi yang spesifik bagi
setiap individu dan diasumsikan bernilai konstan sepanjang
waktu untuk setiap individu.
a. Model common effects
Model common – effect (CE) adalah model paling
sederhana yang mengasumsikan bahwa tidak ada
keheterogenan antar individu yang tidak terobservasi
(intersep sama), karena semua keheterogenan telah
dijelaskan oleh variabel independen. Estimasi parameter
model common – effect menggunakan metode OLS.
Model common – effect (pooling) yang dapat digunakan
untuk memodelkan data panel adalah:
𝑌𝑖𝑡 = 𝛼 + 𝑋𝑖𝑡𝛽 + 𝑒𝑖𝑡
Dimana :

41
𝑌𝑖𝑡 = adalah observasi dari unit ke i dan diamati pada
periodeke t. (dependen)
𝑋𝑖𝑡 = adalah variabel independen yang diamati dari unit i
pada periode t. Dan diasumsikan 𝑋𝑖𝑡 memuat konstanta.
𝑒𝑖𝑡 = adalah komponen error yang diasumsik memilikiharga
mean 0 dan variansi homogen dalam waktu serta independen
dengan 𝑋𝑖𝑡.
b. Model Fixed Effects
Model fixed – effect (FE) pada data panel
diasumsikan bahwa koefisien slope konstan tetapi intersep
bervariasi sepanjang unit individu. Istilah fixed effect
berasal dari kenyataan bahwa meskipun intersep 𝛽𝑜𝑖
berbeda antar individu namun intersep antar waktu sama
(time invariant), sedangkan slope tetap sama antar
individu dan antar waktu. Bentuk umum model fixed effect
adalah sebagai berikut:
Terdapat keheterogenan antar individu yang tidak
terobservasi, maka nilai intersep untuk setiap variabel
independen berbeda tapi memiliki slope yang sama.
Estimasi parameter model fixed – effect menggunakan
metode Least Square Dummy Variable, yaitu dengan
menambahkan variabel dummy yang bersesuaian untuk
masing – masing nilai variabel independen.

42
𝑌𝑖𝑡 = 𝑌𝑖𝑡 + ∑ 𝛽𝑘𝑋𝑘,𝑖𝑡
𝑝
𝑖=1+ 𝑒𝑖𝑡
Dengan di adalah Variabel Dummy ke I, i= 2,3…., N
dan N adalah banyaknya unit cross section. Pendugaan
parameter regresi data panel dilakukan dengan
menggunakan Ordinary Least Square.
c. Model Random Effect
Model random – effect (RE) digunakan untuk
mengatasi permasalahan yang ditimbulkan oleh model
fixed effect dengan perubah semu (dummy) pada data
panel menimbulkan permasalahan hilangnya derajad
bebas dari model. Estimasi parameter model random –
effect menggunakan metode Generalized Least Square.
𝑌𝑖𝑡 = 𝛽𝑜𝑖 + ∑ 𝛽𝑘𝑋𝑘,𝑖𝑡
𝑝
𝑖=1+ 𝜇𝑖𝑡 + 𝑒𝑖𝑡
d. Uji chow
Uji ini digunakan untuk memilih salah satu model
pada regresi data panel, yaitu model efek tetap (Fixed
Effect Model) dengan model koefisien tetap (common
effect model). Hipotetsis dalam uji chow adalah:
H0 : Common Effect Model
H1 : Fixed Effect Model

43
Dasar penolakan terhadap hipotesis diatas adalah
dengan membandingkan perhitungan F−statistik dengan
F−tabel. Perbandingan dipakai apabila hasil F hitung lebih
besar (>) dari F tabel maka H0 ditolak yang berarti model
yang paling tepat adalah Fixed Effect Model. Begitupun
sebaliknya, jika F hitung lebih kecil (<) dari F tabel maka
H0 diterima dan model yang digunakan adalah Common
Effect Model(Widarjono, 2009). Perhitungan F statistic
didapat dari uji Chow dengan rumus:
𝐹 =
(𝑆𝑆𝐸1−𝑆𝑆𝐸2)
(𝑛−1)
𝑆𝑆𝐸2
(𝑛𝑡−𝑛−𝑘)
Dimana:
SSE1 : Sum Square Error dari model Common Effect
SSE2 : Sum Square Error dari model Fixed Effect
n : Jumlah provinsi (cross section)
k : Jumlah variabel independen
Sedangkan F tabel didapat dari:
𝐹 − 𝑡𝑎𝑏𝑒𝑙 = {𝛼 ∶ 𝑑𝑓(𝑛 − 1, 𝑛𝑡 − 𝑛 − 𝑘)}
Dimana:
α : Tingkat signifikasi yang dipakai (alfa)
n : Jumlah provinsi
nt : Jumlah cross section x jumlah time series

44
k : Jumlah variabel independen
e. Uji Langrange Multiplier (LM) Breush-pagan
Uji Lagrange Multiplier (LM) digunakan untuk
mengetahui signifikan teknik Random Effect. Uji
Lagrange Multiplier (LM) digunakan untuk memilih
antara OLS (Common Effect) tanpa variabel dummy atau
Random Effect. Uji signifikan Random Effect ini
dikembangkan oleh Bruesch – pagan. Adapun nilai
statistik LM dihitung berdasarkan formula sebagai berikut
:
LM = nT
2 (T−1)[
∑ [∑ eitTt=1 ]n
i=1
∑ ∑ eit2T
t=1ni=1
-1]2 = nT
2 (T−1)
Keterangan :
N= Jumlah Individu
T = Jumlah Periode Waktu
E = Residual metode OLS
Hipotesis untuk pengujian ini yaitu :
H0= OLS tanpa variabel dummy ( Common Effect)
H1= Random Effect Model
Ketentuan :

45
1. Apabila Probabilitas Breusch-Pagan <alpha (0,05), maka
H0 ditolak dan H1 diterima, berarti bahwa model Random
Effect merupakan model yang tepat.
2. Apabila Probabilitas Breusch-Pagan >alpha (0,05), maka
H0 diterima dan H1 ditolak, berarti bahwa model OLS
tanpa variabel dummy (Common Effect) merupakan
model yang tepat.
f. Uji hausman
Kegunaan uji Hausman adalah untuk memilih antara
Fixed Effect atau Random Effect. Uji Hausman digunakan
apabila metode Fixed Effect dan Random Effect lebih baik
dari metode OLS (Common Effect). Statistik uji Hausman
mengikuti chi square dengan degree of freedom sebanyak
jumlah variabel bebas dari model. Dengan ketentuan:
H0 : Random Effect
H1 : Fixed Effect
Apabila hasil dari Hausman test menunjukkan
bahwa nilai probabilitasnya lebih kecil dari tingkat
signifikasi 0,05, maka dengan demikian hipotesis nol
ditolak dan model yang digunakan Fixed Effect. Uji
Hausman digunakan apabila metode Fixed Effect dan
Random Effect lebih baik dari metode OLS (Common
Effect). Rumus uji Hausman yaitu:

46
𝑚 = �̂�𝑉𝑎𝑟(�̂�)−1�̂�
Keterangan:
�̂� = (�̂� − �̂�𝐺𝐿𝑆)
𝑉𝑎𝑟(�̂�) = 𝑉𝑎𝑟(�̂�) − 𝑉𝑎𝑟(�̂�𝐺𝐿𝑆)
Ketentuan:
1. Apabila Hausman hitung ≥ Tabel Chi Square, maka Ho
ditolak dan Ha diterima, berarti bahwa model Fixed
Effect merupakan model yang tepat.
2. Apabila Hausman hitung ≤ Tabel Chi Square, maka Ho
diterima dan ha ditolak, berarti model Random Effect
merupakan model yang tepat.


















![[Jurnal] Analisis Faktor-faktor Yang Mempengaruhi Audit Delay Pada Perusahaan Lq 45 Yang Terdaftar Di Bursa Efek Indonesia](https://static.fdokumen.com/doc/165x107/55cf9df4550346d033b005ec/jurnal-analisis-faktor-faktor-yang-mempengaruhi-audit-delay-pada-perusahaan-56895c4753354.jpg)

