BAB II TINJAUAN PUSTAKA - sinta.unud.ac.id II.pdf · ... peneliti menggunakan beberapa jurnal ......
16
BAB II TINJAUAN PUSTAKA 2.1 Tinjauan Studi Pada penelitian ini, peneliti menggunakan beberapa jurnal sebagai tinjauan studi, yaitu sebagai berikut : a. Pengenalan Huruf Bali Menggunakan Metode Modified Direction Feature (MDF) dan Learning Vector Quantization(MDF) (Agung BW dkk, 2009) Dalam penelitian ini dilakukan pengenalan tulisan daerah Bali , mekanisme pengenalannya menggunakan teknik Modified Direction Feature (MDF) dan menggunakan Jaringan Saraf Tiruan (Learning Vector Quantization) dalam hal klasifikasinya . Penelitian ini menghasilkan tingkat akurasi di atas 70% pada data uji dengan penulis yang berbeda dan di atas 80% dengan penulis yang tulisannya pernah menjadi data training. Dari penelitian ini , untuk penelitian lebih lanjut dalam rangka optimalisasi akurasi sitem dapat dilakukan dengan mencoba menggunakan metode klasifikasi yang lain. b. Arabic numeral Recognition Using SVM Classifier (Sinha et al, 2013) Penelitian ini melakukan pengenalan terhadap Angka Arab . Mekanisme pengenalannya sebagai berikut, untuk tahap ekstraksi fitur menggunakan teknik Image Centroid Zone (ICZ), Zone Centroid Zone (ZCZ), dan penggabungan kedua teknik tersebut. Untuk Klasifikasinya menggunakan Support Vector machine (SVM) yang berdasarkan teori pembelajaran statistik. Penelitian ini menghasilkan tingkat akurasi pengenalan berkisar dari 96.25% - 97.1%. c. Offline Handwriting Recognition using Genetic Algorithm (Kala et al, 2010)
-
Upload
duongquynh -
Category
Documents
-
view
225 -
download
1
Transcript of BAB II TINJAUAN PUSTAKA - sinta.unud.ac.id II.pdf · ... peneliti menggunakan beberapa jurnal ......

BAB II
TINJAUAN PUSTAKA
2.1 Tinjauan Studi
Pada penelitian ini, peneliti menggunakan beberapa jurnal sebagai tinjauan
studi, yaitu sebagai berikut :
a. Pengenalan Huruf Bali Menggunakan Metode Modified Direction
Feature (MDF) dan Learning Vector Quantization(MDF) (Agung BW
dkk, 2009)
Dalam penelitian ini dilakukan pengenalan tulisan daerah Bali ,
mekanisme pengenalannya menggunakan teknik Modified Direction
Feature (MDF) dan menggunakan Jaringan Saraf Tiruan (Learning Vector
Quantization) dalam hal klasifikasinya . Penelitian ini menghasilkan
tingkat akurasi di atas 70% pada data uji dengan penulis yang berbeda dan
di atas 80% dengan penulis yang tulisannya pernah menjadi data training.
Dari penelitian ini , untuk penelitian lebih lanjut dalam rangka optimalisasi
akurasi sitem dapat dilakukan dengan mencoba menggunakan metode
klasifikasi yang lain.
b. Arabic numeral Recognition Using SVM Classifier (Sinha et al, 2013)
Penelitian ini melakukan pengenalan terhadap Angka Arab .
Mekanisme pengenalannya sebagai berikut, untuk tahap ekstraksi fitur
menggunakan teknik Image Centroid Zone (ICZ), Zone Centroid Zone
(ZCZ), dan penggabungan kedua teknik tersebut. Untuk Klasifikasinya
menggunakan Support Vector machine (SVM) yang berdasarkan teori
pembelajaran statistik. Penelitian ini menghasilkan tingkat akurasi
pengenalan berkisar dari 96.25% - 97.1%.
c. Offline Handwriting Recognition using Genetic Algorithm (Kala et al,
2010)

Penelitian ini membahas tentang pengenalan tulisan tangan secara online.
Teknik yang digunakan dalam penelitian ini yaitu algoritma genetika dan
teori tentang graph . Teori graph dan koordinat geometri digunakan untuk
mengkonversi citra menjadi graph. Penggabungan kedua teknik tersebut
menghasilkan tingkat akurasi 98.44% .
2.2 Aksara Bali
Aksara Bali berasal dari aksara Brahmi purba dari India. Selain itu, buku
tersebut juga menyebutkan bahwa aksara Bali memiliki banyak kemiripan dengan
aksara-aksara modern di Asia Selatan dan Asia Tenggara yang berasal dari
rumpun aksara yang sama. Aksara Bali pada abad ke-11 banyak memperoleh
pengaruh dari bahasa Kawi atau Jawa kuno. Versi modifikasi aksara Bali ini
digunakan juga untuk menuliskan bahasa Sasak yang digunakan di Pulau
Lombok. Beberapa kata-kata dalam bahasa Bali meminjam dari
bahasa Sansekerta yang kemudian juga mempengaruhi aksara Bali. Tulisan Bali
tradisional ditulis pada daun pohon siwalan (sejenis palma), tumpukannya
kemudian diikat dan disebut lontar.
Menurut keputusan Pasamuhan Agung tersebut Ejaan Bahasa Bali dengan
Huruf Latin itu disesuaikan dengan ejaan Bahasa Indonesia. maksudnya ialah :
1. Ejaan itu dibuat sesederhana mungkin
2. Ejaan itu harus fonetik, artinya tepat atau mendekati ucapan yang
sebenarnya
Berdasarkan hal- hal tersebut di atas, maka ditetapkan huruf- huruf yang
dipakai untuk menuliskan Bahasa Bali dengan huruf Latin sebagai tersebut di
bawah ini:
a) Aksara suara (vokal) : a, e, i, u, e, o (enam buah, telah diubah pepet dan
taling sama)
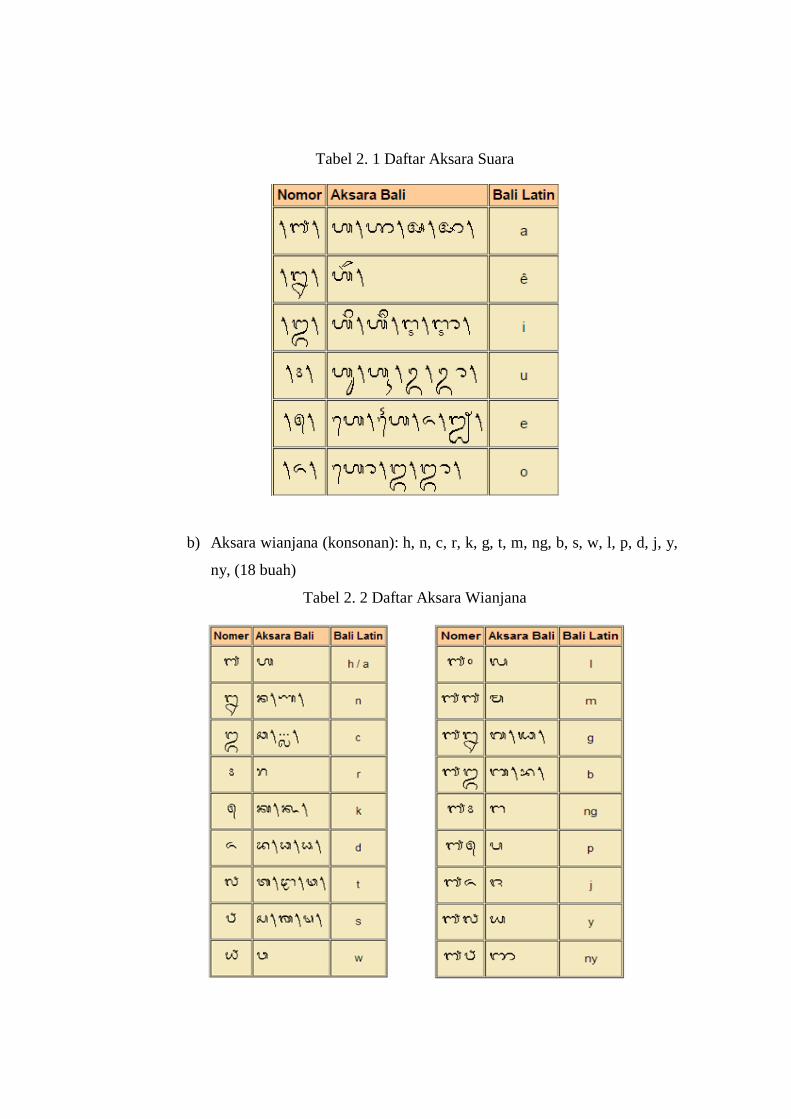
Tabel 2. 1 Daftar Aksara Suara
b) Aksara wianjana (konsonan): h, n, c, r, k, g, t, m, ng, b, s, w, l, p, d, j, y,
ny, (18 buah)
Tabel 2. 2 Daftar Aksara Wianjana
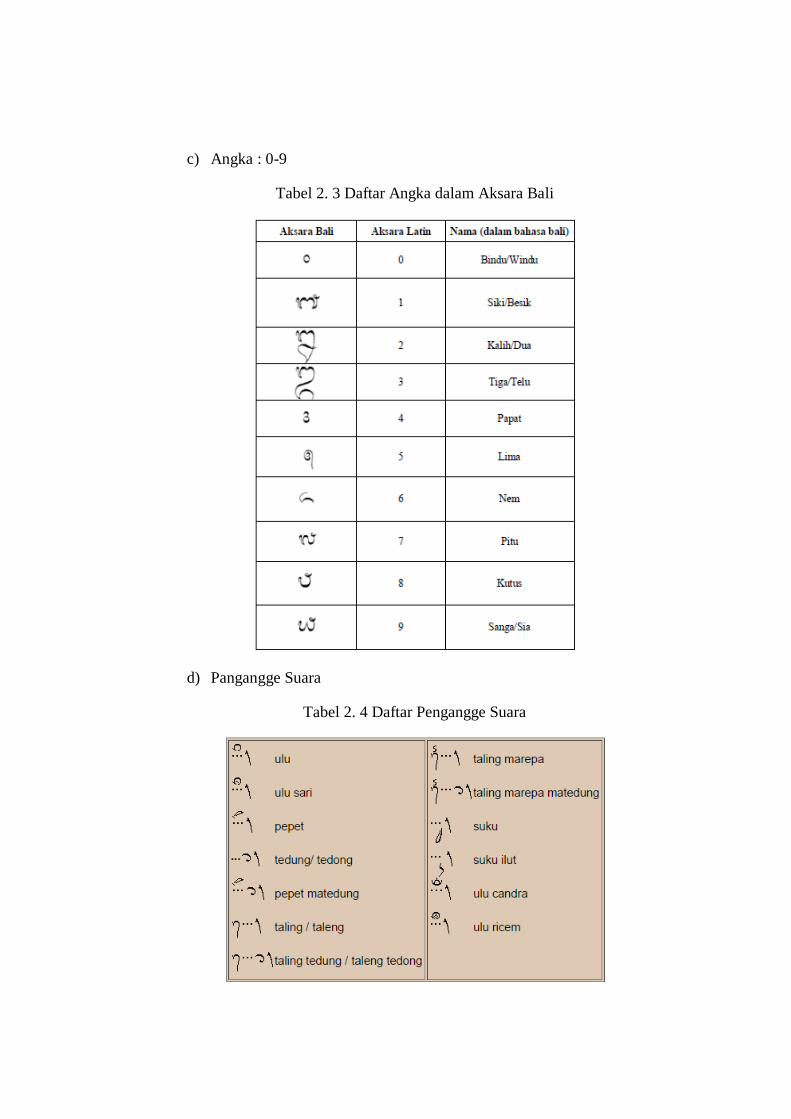
c) Angka : 0-9
Tabel 2. 3 Daftar Angka dalam Aksara Bali
d) Pangangge Suara
Tabel 2. 4 Daftar Pengangge Suara

2.3 Pengolahan Citra Digital
Citra merupakan fungsi dua dimensi dari intensitas kecerahan f(x,y) . Citra
digital merupakan sebuah citra dengan fungsi f(x,y) yang nilai kecerahan maupun
posisi koordinatnya telah didiskritkan , sehingga nilainya berada dalam rentang
jangkauan tertentu . Citra digital direpresentasikan dalam bentuk matriks . Matriks
dimana baris dan kolomnya merepresentasikan sebuah posisi dari citra tersebut ,
nilai dari posisi yang bersangkutan merupakan tingkat kecerahan dari posisi
tersebut pada citra yang sebenarnya . Berdasarkan pada penelitian bahwa sebuah
warna merupakan kombinasi dari tiga warna dasar, yaitu merah, hijau, dan biru
(Red, Green, Blue - RGB). Kualitas suatu citra dapat diperbaiki dengan
melakukan pengolahan citra , pengolahan citra berguna juga untuk mengolah
informasi yang terdapat pada suatu citra untuk pengenalan suatu objek secara
otomatis dan dapat diinterpretsikan oleh mata manusia . Pada dasarnya
pengolahan citra terbagi menjadi :
a) Peningkatan kualitas citra (image enhancement)
b) Pemulihan citra (image restoration)
c) Pemampatan citra
d) Analisis citra
e) Segmentasi citra
f) Rekonstruksi citra, dan lain-lain
Pada penelitian, dilakukan beberapa pengolahan citra terhadap citra
inputan, tahap pengolahan citra ini merupakan tahap pengolahan data awal .
Pengolahan citra yang dilakukan pada penelitian ini yaitu pengolahan warna pada
citra sampai mendapatkan citra biner, pemampatan citra agar bisa diekstraksi fitur
dari citra , kemudian segmentasi, untuk mengambil koordinat dari citra yang
mengandung informasi mengenai karakter aksara Bali.
2.4 Pengolahan Warna dalam Citra
Dalam suatu citra , setiap piksel menyimpan informasi, yaitu informasi
warna yang terdiri dari tiga elemen Red, Green, Blue (RGB). Setiap elemen
tersebut bias memiliki nilai yang beragam, dan hasil kombinasi dari ketiga elemen
warna tersebut akan menghasilkan kombinasi warna yang berbeda – beda pula.

Ada beberapa citra menurut nilai yang terkandung pada ketiga elemen warna
yang dimiliki oleh setiap pikselnya, berikut beberapa jenis citra berdasarkan nilai
RGB yang dimiliki :
2.4.1 Citra RGB
Pada citra RGB, setiap piksel atau elemen citra mempunyai informasi nilai
warna mulai dari 0 sampai dengan 255, nilai 0 menyatakan tidak ada elemen
warna pada piksel dan 255 menyatakan nilai maksimum elemen tersebut pada
pixel. RGB terdiri dari elemen Red (R), Green (G), dan Blue(B) , kombinasi dari
ketiga warna tersebutlah yang akan menghasilkan susunan warna yang luas.
Sebuah jenis warna dapat digambarkan sebagai sebuah vektor di ruang 3 dimensi
(x,y,z). Maka sebuah vektor dituliskan sebagai r = (x,y,z). Untuk warna
komponen- komponen tersebut digantikan oleh red, green, dan blue . Sehingga ,
untuk warna putih = RGB(255,255,255) , warna hitam = RGB(0,0,0), begitu pun
untuk kombinasi warna lainnya.
2.4.2 Grayscale
Citra grayscale merupakan citra yang setiap pikselnya berada dalam
rentang gradasi warna hitam dan putih. Pengolahan citra menjadi citra grayscale
biasanya dilakukan dengan memberikan bobot untuk masing – masing elemen
red, green, dan blue. Tetapi cara yang cukup mudah adalah dengan membuat nilai
rata- rata dari ketiga elemen dasar warna tersebut dan kemudian mengisi setiap
piksel dari citra dengan warna dasar tersebut dengan rata – rata nilai warna yang
dihasilkan .
Komponen R memberikan kontribusi 30 % , komponen G 60 % , dan
komponen B 10 % terhadap pencahayaan dari warna. Untuk menentukan nilai
grayscale sesuai dengan menghitung pencahayaan standar yang digunakan oleh
industri televisi (Gomes & Velho, 1997 ) yaitu dengan rumus 2.1 berikut :
Grayscale = R*0.299 + G*0.587 + B*0.114 ........................... (2.1)
dimana :
R : intensitas warna Red (merah)
B : intensitas warna Blue (biru)
G : intensitas warna Green (hijau)

2.4.3 Biner
Citra biner merupakan citra yang setiap pikselnya hanya mungkin
memiliki warna hitam atau putih saja. Hitam atau putihnya warna dari piksel
tersebut diperoleh melalui proses pemisahan piksel- piksel berdasarkan derajat
keabuannya. Diperlukan batas atau threshold atau nilai ambang untuk melakukan
pemisahan tersebut , jadi piksel yang memiliki nilai derajat keabuan di atas
threshold akan diubah menjadi warna putih , sedangkan piksel yang memiliki nilai
derajat keabuan dibawah threshold akan diubah menjadi warna hitam .
2.5 Thinning
Definisi image thinning adalah proses morfologi citra yang merubah bentuk
asli citra biner menjadi citra yang menampilkan batas-batas obyek/ foreground
hanya setebal satu piksel. Algoritma thinning secara iteratif menghapus piksel-
piksel pada binary image, dimana transisi dari 0 ke 1 (atau dari 1 ke 0 pada
konvensi lain) terjadi sampai dengan terpenuhi suatu keadaan dimana satu
himpunan dari lebar per unit (satu piksel) terhubung menjadi suatu garis.
Algoritma zhang suen merupakan salah satu contoh untuk algoritma
thinning. Algoritma ini sederhana dan pemrosesan yang cepat. Setiap iterasi dari
metode ini terdiri dari dua sub iterasi yang berurutan yang dilakukan terhadap
contour points dari wilayah citra. Contour point adalah setiap pixel dengan nilai 1
dan memiliki setidaknya satu 8-neighbor yang memiliki nilai 0.
Tabel 2. 5 Ketetanggaan Piksel
Kondisi:
1) 2 ≤ N(p1) ≤ 6
2) S(p1) = 1

3) p2 • p4 • p6 = 0
4) p4 • p6 • p8 = 0
5) 2 ≤ N(p1) ≤ 6
6) S(p1) = 1
7) p2 • p4 • p8 = 0
8) p2 • p6 • p8 = 0
Dimana:
N(p1) = jumlah dari tetangga p1 yang tidak nol
S(p1) = jumlah transisi 0 – 1 dalam urutan p2, p3, ...
Langkah-langkahnya:
a) Beri tanda semua piksel 8-tetangga yang memenuhi kondisi (1) sampai
dengan (4).
b) Hapus piksel tengahnya.
c) Beri tanda semua piksel 4-tetangga yang memenuhi kondisi (5) sampai
dengan (8).
d) Hapus piksel tengahnya.
e) Lakukan langkah a sampai d berulang kali, sampai tidak ada perubahan.
2.6 Segmentasi
Segmentasi adalah membagi suatu citra ke dalam beberapa daerah
berdasarkan kesesuaian bentuk/objek. Proses segmentasi akan selesai apabila
objek yang diperhatikan dalam aplikasi sudah terisolasi.
Algoritma segmentasi secara umum berbasiskan pada salah satu dari dua
sifat dasar nilai intensitas:
1) diskontinu: membagi suatu citra berdasarkan perubahan besar nilai intensitas
(seperti sisi)

2) similaritas: membagi suatu citra berdasarkan similaritas sesuai kriteria
tertentu yang sudah didefinisikan.
Segmentasi sering digunakan sebagai fase pertama dalam analisis citra.
Tujuan utamanya adalah membagi citra ke dalam basis elemen sesuai dengan
kriteria yang ditentukan. Bentuk elemen bergantung pada aplikasi. Misalkan citra
yang terdiri dari udara hingga daratan, cukup memishkan antara jalan dari
lingkungan dan kendaraan yang bergerak di atas jalan. Segmentasi citra otomatis
merupakan model yang sangat sulit dalam pengolahan citra. Berikut langkah-
langkah metode Profile Projection (Hendry, 2011) :
1) Input citra
2) Ubah citra menjadi citra biner
3) Bentuk proyeksi horisontal dengan menjumlahkan pixel black tiap baris dari
citra, proyeksi dilakukan terhadap X
4) Bentuk proyeksi vertikal dengan menjumlahkan pixel black tiap kolom dari
citra, proyeksi dilakukan terhadap Y
5) Jika proyeksi horizontal dan vertikal sudah terbentuk, selanjutnya adalah
proses pemotongan untuk mendapatkan citra yang penting.
6) Tentukan proyeksi vertikal untuk memisalkan baris-baris yang mengandung
karakter dalam citra
7) Potong tiap baris berdasarkan titik terendah dan tertinggi dari tiap proyeksi
vertikal
8) Untuk tiap baris hasil pemotongan proyeksi vertikal, potonglah tiap karakter
dengan menggunakan koordinat dari proyeksi horizontal.
Pemotongan dilakukan dengan mencari jumlah proyeksi vertikal dan
horizontal yang tidak nol tetapi koordinatnnya tepat berada sebelum atau sesudah
nol. Karena nol dianggap adalah spasi atau pemisah karakter maupun baris.
2.7 Pengenalan Pola
Sebuah pola merupakan tiruan dari suatu model, namun ketika
menjelaskan berbagai tipe objek dalam dunia fisik dan abstrak dapat dikatakan
bahwa pola itu sendiri adalah setiap antarhubungan data baik analog maupun
digital, kejadian dan atau konsep yang dapat dibeda- bedakan. Secara garis besar ,

pengenalan pola dibedakan menjadi dua yaitu pengenalan pola langsung (konkret)
dan tidak langsung (konseptual). Pengenalan pola konkret mencakup pengenalan
visual dan aural spasial (contohnya gambar, tulisan, sidik jari, wajah) dan
temporal (contohnya gelombang, suara) dimana dibutuhkan bantuan alat
penginderaan ( sensor). Pengenalan pola abstrak seperti gagasan di satu pihak
dapat dilakukan tanpa bantuan sensor.
Berdasarkan pada subjek pelakunya, pengenalan pola dibedakan menjadi
dua. Pertama pengenalan pola oleh manusia atau jasad hidup lainnya, contohnya
disiplin ilmu fisiologi, biologi,psikologi,dan lain sebagainya. Kedua mengenai
pengembangan teori dan teknik unuk merancang sebuah alat yang dapat
melakukan tugas pengenalan sevara otomatis, berhubungan dengan komputerisasi
serta ilmu teknik dan informatika.
Pengenalan pola yang berhubungan dengan komputerisasi memiliki dua
fase dalam system pengenalan polanya, yaitu fase pelatihan (training) dan fase
pengenalan. Untuk pengenalan pola melalui suatu citra, pada fase pelatihannya
beberapa sampel citra dipelajari untuk menentukan fitur/ciri yang akan digunakan
untuk pengenalan dan prosedur klasifikasinya. Kemudian pada fase
pengenalannya , diambil fitur atau ciri dari citra tersebut kemudian ditentukan
kelas/kelompoknya.
Pada penelitian kali ini, metode yang digunakan untuk melakukan
ekstraksi fitur yaitu :
2.7.1 Direction Feature (DF)
Direction Feature (DF) adalah pencarian nilai fitur berdasarkan label arah
dari sebuah piksel. Pada metode ini setiap piksel foreground pada gambar
memiliki arah tersendiri dimana arah yang digunakan terdiri dari 4 arah dan
masing-masing arah diberikan nilai atau label yang berbeda. Arah yang digunakan
pada pelabelan arah dapat dilihat seperti berikut :

Gambar 2. 1 Pelabelan Arah Piksel
Matriks ketetanggaannya seperti berikut :
Tabel 2. 6 Matriks Ketetanggaan
X1 X2 X3
X8 O X4
X7 X6 X5
Untuk melakukan pelabelan arah pada masing masing piksel dapat
dilakukan dengan cara sebagai berikut:
1. Lakukan pengecekan secara raster dari kiri ke kanan.
2. Apabila menemukan sebuah piksel foreground maka lakukan pengecekan
dengan melihat tetangga dari piksel tersebut.
3. O adalah piksel yang akan dicek, kemudian pengecekan dilakukan dari X1 –
X8. Apabila pada posisi tetangga dari X1 sampai X8 ditemukan pixel
foreground, maka ubahlah nilai O menjadi nilai arah berdasarkan aturan
dibawah ini:
a) Jika pada posisi X1 atau X5 maka nilai arah adalah 5
b) Jika pada posisi X2 atau X6 maka nilai arah adalah 2
c) Jika pada posisi X3 atau X7 maka nilai arah adalah 3
d) Jika pada posisi X4 atau X8 maka nilai arah adalah 4
2.7.2 Transition Feature (TF)
Sesuai namanya , transition feature yaitu menghitung posisi transisi dan
jumlah transisi pada bidang vertikal maupun horizontal dari citra. Transisi

merupakan posisi dimana terjadi perubahan piksel dari background menjadi
foreground tetapi tidak sebaliknya. Nilai TF ini didapatkan dari hasil pembagian
antara posisi transisi dengan panjang maupun lebar citra tersebut. Nilai TF
diambil dari 4 arah transisi yaitu kiri ke kanan, kanan ke kiri, atas ke bawah, dan
bawah ke atas. Kisaran nilai TF selalu antara 0-1, dan hasilnya selalu menurun .
Jumlah transisi yang dilakukan tergantung dari jumlah transisi maksimal yang
ditentukan , apabila lebih makanya nilainya tidak dihitung, apabila kurang maka
nilai TF yang diberikan adalah 0.
2.7.3 Modified Direction Feature (MDF)
Metode ekstraksi ciri Modified Direction Feature (MDF)
mengkombinasikan ciri/ fitur arah dan informasi struktur global yang ada pada
karakter. Ciri/fitur yang dihasilkan berupa vektor dengan nilai berkisaran 0-1
dengan panjang 120-161. Pendekatan yang dilakukan MDF yaitu dengan deteksi
nilai arah (DF) , mencari nilai transisi (TF), dan menentukan banyaknya transisi
yang dipakai.
1. Pencarian Titik Awal
Titik awal pertama adalah piksel pertama yang ditemukan pada citra
karakter yang paling bawah dan paling kiri. Titik awal yang baru adalah setiap
piksel yang mempunyai arah yang berbeda dari segmen baris sebelumnya. Iterasi
pencarian titik awal dan nilai arah dimulai dari titik awal pertama sampai tidak
ada lagi piksel-piksel pembentuk karakter yang belum mempunyai nilai arah.
Semua titik awal yang ditemukan akan digantikan dengan nilai 8 untuk sementara.
Nilai 8 ini selanjutnya akan dinormalisasi pada proses selanjutnya setelah semua
titik awal ditemukan dan piksel-piksel lain selain titik-titik awal mempunyai nilai
arah.
2. Menentukan Nilai Transisi
Dalam menentukan nilai transisi hal pertama yang dilakukan yaitu
melakukan pemindaian pada masing masing piksel dari masing masing arah. Nilai
transisi (TF) adalah nilai dari pembagian antara posisi dari transisi dengan
panjang atau lebar dari citra. Apabila pemindaian dilakukan dari kiri ke kanan

atau dari kanan ke kiri maka nilai transisi diambil dari pembagian posisi transisi
dengan lebar gambar. Apabila proses pemindaian dari atas ke bawah atau dari
bawah ke atas maka nilai transisi diambil dari pembagian posisi transisi dengan
panjang gambar. TF selalu berkisar antara 0 – 1. Transisi pertama yang ditemukan
selalu mempunyai TF yang terbesar.
3. Menentukan Nilai Arah
Ketika sebuah transisi ditemukan, selain menyimpan TF, DF juga
disimpan. DF ini diambil dari pembagian label arah pada posisi ditemukan transisi
dengan nilai pembagi. Pada penelitian ini nilai pembagi yang digunakan adalah 10
Apabila jumlah transisi yang ditemukan kurang dari jumlah transisi yang
digunakan maka DF sisanya diberikan nilai 0.
4. Normalisasi Nilai Arah
Proses ini dilakukan untuk mengubah nilai 8 yang merupakan nilai
sementara untuk titik awal. Terdapat dua langkah yang dilakukan pada proses ini.
Langkah pertama adalah mencari frekuensi kemunculan nilai arah yang paling
besar pada suatu segmen garis yang bermula pada suatu titik awal. Langkah kedua
yaitu menggunakan nilai arah dengan frekuensi kemunculan paling besar tersebut
untuk menggantikan nilai 8 pada titik awal tersebut.
Dengan MDF, ciri suatu karakter didapatkan dari nilai-nilai arah dan
lokasi dari nilai arah tersebut. Pada setiap arah pencarian tersebut akan dihasilkan
dua buah matriks, matriks pertama berisi letak piksel arah yang membentuk
karakter (Location Transition (LT)), sedangkan matriks ke dua berisi nilai arah
pada piksel tersebut (Direction Transition (DT)). Setiap matriks akan berukuran 5
x 3 pada MDF3 dan 5 x 4 pada MDF4. Sehingga hasil akhir vektor yang
didapatkan akan berjumlah 4 x 2 x 5 x 3=120 pada MDF3 dan 4 x 2 x 5 x 4=160
pada MDF4 (4 = banyak arah pencarian, 2 = jumlah matriks pada setiap arah
pencarian (DT<), 5*3 = ukuran matriks MDF3, 5*4 = ukuran matriks MDF4).
2.8 Artificial Neural Network
Artificial Neural Network (ANN) atau Jaringan saraf tiruan (JST) adalah
sebuah sistem pengolahan informasi yang karakteristik kinerjanya menyerupai
jaringan saraf biologis. Jaringan saraf tiruan telah banyak dikembangkan sebagai

generalisasi model matematika dari pengertian manusia atau saraf biologi . Seperti
halnya manusia yang otaknya selalu belajar dari lingkungan sehingga dapat
mengelola lingkungan dengan baik berdasarkan pengalaman yang sudah
didapatkan, ANN, yang dalam pengenalan pola sebagai model yang digunakan
untuk proses pengenalan, membutuhkan proses pelatihan agar dapat melakukan
pengenalan kelas suatu data uji baru yang ditemukan. Proses pelatihan dalam
ANN dapat menggunakan algoritma-algoritma seperti Perceptron,
Backpropagation, Self - Organizing Map (SOM), Delta, Associative Memory,
Learning Vector Quantization dan sebagainya.
Secara umum, ada 4 macam fungsi aktivasi yang dipakai di berbagai jenis
ANN, yaitu
a) Fungsi aktivasi linear
Fungsi aktivasi ini biasanya digunakan untuk keluaran ANN
yang nilai keluarannya diskret. Jika v adalah nilai gabungan dari semua
oleh penambah, sinyal keluaran y didapatkan dengan memberikan nilai
v apa adanya untuk menjadi nilai keluaran. Nilai y diformulasikan
dengan :
𝑦 = 𝑠𝑖𝑔𝑛 𝑣 = 𝑣 ............................................ (2.1)
b) Fungsi aktivasi undak (step)
Jika v adalah nilai gabungan dari semua vektor oleh penambah,
keluaran y didapatkan dengan melakukan pengambangan
(thresholding) pada nilai v berdasarkan nilai T yang diberikan. Nilai y
diformulasikan dengan :
𝑦 = 𝑠𝑖𝑔𝑛 𝑣 = 1 𝑗𝑖𝑘𝑎 𝑣 ≥ 𝑇−1 𝑗𝑖𝑘𝑎 𝑣 < 𝑇
.............................. (2.2)
Bentuk di atas disebut juga step/threshold bipolar, ada juga
yang berbentuk biner. Berikut contohnya :
𝑦 = 𝑠𝑖𝑔𝑛 𝑣 = 1 𝑗𝑖𝑘𝑎 𝑣 ≥ 𝑇0 𝑗𝑖𝑘𝑎 𝑣 < 𝑇
............................. (2.3)

2.9 Generalized Learning Vector Quantization
Generalized Learning Vector Quantization (GLVQ) dikembangkan oleh Atsushi
Sato dan Keiji Yamada pada tahun 1996 untuk menangani masalah perbedaan
serius dengan. Sato dan Yamada memecahkan masalah ini dengan metode
pembelajaran baru untuk meminimalkan fungsi biaya (cost function). Perumusan
GLVQ dimulai dengan mendefinisikan perbedaan jarak relatif x sebagai
berikut :
21
21
dd
ddx
................................................ (2.4)
dimana d1 adalah jarak antara x dengan w1, dan d2 adalah jarak antara x dengan w2.
x bernilai antara -1 sampai 1. Jika x bernilai negatif maka x
diklasifikasikan benar, jika x bernilai positif maka x diklasifikasikan salah.
Dengan demikian ukuran pembelajaran diformulasikan dengan meminimalkan
cost function S sebagai berikut :
N
i
ixfS1
.......................................... (2.5)
dimana N adalah vektor input pada pembelajaran. Untuk meminimalkan S, w1,
dan w2 yaitu dengan cara diperbarui dengan menggunakan persamaan berikut :
12
21
211 wx
dd
dfww
.................................... (2.6)
dan
22
21
122 wx
dd
dfww
................................... (2.7)
Dimana
fadalah turunan dari fungsi sigmoid
tetf
1
1,
Generalized Learning Vektor Quantization (GLVQ) merupakan bagian
dari metode Jaringan Syaraf Tiruan (JST), yang di mana metode tersebut
melakukan pembelajaran pada lapisan kompetetif yang terawasi. Suatu lapisan

kompetetif akan secara otomatis belajar untuk mengklasifikasikan vektor-vektor
input. Adapun algoritma dari GLVQ adalah (Atsushi Sato, 1996):
1) Tetapkan bobot (w), maksimum epoh (MaxEpoh), error minimum yang
diharapkan (Eps), Learning rate (α), Pengurang rasio (dec).
2) Tentukan
i. Input : x (m,n)
ii. Target : T (1,n)
3) Tetapkan kondisi awal epoh = 0
4) Kerjakan jika : (epoh < MaxEpoh) atau (α > eps)
i. Epoh = epoh + 1
ii. Kerjakan untuk i = 1 sampai n
1. Tentukan j sedemikian hingga ||x-Wj|| minimum (sebut sebagai Cj )
2. Perbaiki Wj dengan ketentuan
a. Jika T = Cj maka , hitung Wj(baru) dengan rumus W 1 berikut:
𝑊𝑗 (baru) = 𝑊𝑗 (lama) + α 𝑓 ′|𝑢(𝑣𝑖) 4 𝑑2
𝑑1+𝑑2 2 (x - 𝑤𝑙𝑎𝑚𝑎 )……….(2.8)
b. Jika T ≠ Cj maka hitung Wj(baru) dengan rumus W 2 berikut:
𝑊𝑗 (baru) = 𝑊𝑗 (lama) - α 𝑓 ′|𝑢(𝑣𝑖) 4 𝑑2
𝑑1+𝑑2 2 (x - 𝑤𝑙𝑎𝑚𝑎 )………..(2.9)
dimana :
m, n = Matriks gambar
α = Learning rate
Wj = Bobot terdekat pada kelas yang sama dan salah
d1 = Jarak antara x dengan Wlama
5) Kurangi learning rate α = α * pengurang rasio
Tes kondisi berhenti, yaitu kondisi yang mungkin menetapkan sebuah jumlah
tetap dari iterasi atau rating pembelajaran mencapai nilai kecil yang cukup.