
ANALISIS PERBANDINGAN COSINE NORMALIZATION DAN MIN...
117
ANALISIS PERBANDINGAN COSINE NORMALIZATION DAN MIN-MAX NORMALIZATION PADA PENGELOMPOKAN TERJEMAHAN AYAT AL QURAN MENGGUNAKAN ALGORITMA K-MEANS CLUSTERING Skripsi Diajukan sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer Oleh : Dewinta Fenny 11150910000048 PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA 2019 M/1441 H
Transcript of ANALISIS PERBANDINGAN COSINE NORMALIZATION DAN MIN...

ANALISIS PERBANDINGAN
COSINE NORMALIZATION DAN
MIN-MAX NORMALIZATION PADA PENGELOMPOKAN
TERJEMAHAN AYAT AL QURAN MENGGUNAKAN
ALGORITMA K-MEANS CLUSTERING
Skripsi
Diajukan sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer
Oleh :
Dewinta Fenny
11150910000048
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH
JAKARTA
2019 M/1441 H

ii
ANALISIS PERBANDINGAN
COSINE NORMALIZATION DAN
MIN-MAX NORMALIZATION PADA PENGELOMPOKAN
TERJEMAHAN AYAT AL QURAN MENGGUNAKAN
ALGORITMA K-MEANS CLUSTERING
Skripsi
Diajukan sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer
Oleh :
Dewinta Fenny
11150910000048
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH
JAKARTA
2019 M/1441 H

iii
LEMBAR PERSETUJUAN

iv
LEMBAR PENGESAHAN

v
HALAMAN PERNYATAAN ORISINALITAS

vi
HALAMAN PERNYATAAN PERSETUJUAN PUBLIKASI
Sebagai civitas akademik UIN Syarif Hidayatullah Jakarta, saya yang bertanda
tangan di bawah ini:
Nama : Dewinta Fenny
NPM : 11150910000048
Program Studi : Teknik Informatika
Departemen : Teknik Informatika
Fakultas : Sains dan Teknologi
Jenis Karya : Skripsi
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada
Universitas Islam Negeri Syarif Hidayatullah Jakarta Hak Bebas Royalti
Nonekslusif (Non-exclusive Royalty Free Right) atas karya ilmiah yang berjudul:
ANALISIS PERBANDINGAN COSINE NORMALIZATION DAN
MIN-MAX NORMALIZATION PADA PENGELOMPOKAN
TERJEMAHAN AYAT AL QURAN MENGGUNAKAN
ALGORITMA K-MEANS CLUSTERING
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti
Noneksklusif ini Univesitas Islam Negeri Syarif Hidayatullah Jakarta berhak
menyimpan, mengalihmedia/formatkan, mengelola dalam bentuk pangkalan data
(database), merawat, dan mempublikasikan tugas akhir saya selama tetap
mencantumkan nama saya sebagai penulis/pencipta dan sebagai pemilih Hak Cipta.
Demikian pernyataan ini saya buat dengan sebenarnya.
Dibuat di: Jakarta
Pada tanggal: November 2019
Yang menyatakan
(Dewinta Fenny)
NYATAAN PERSETUJUAN PUBLIKASI

vii
KATA PENGANTAR
Bismillahirrahmanirrahim...
Puji syukur penulis panjatkan kepada Allah SWT, karena atas nikmat dan
rahmat-Nya sehingga penulis dapat menyelesaikan skripsi ini. Penulisan skripsi ini
dilakukan dalam rangka memenuhi salah satu syarat untuk mencapai gelar Sarjana
Komputer Program Studi Teknik Informatika Fakultas Sains dan Teknologi
Universitas Islam Negeri Syarif Hidayatullah Jakarta. Proses penyelesaian skripsi
ini tidak lepas dari berbagai bantuan, dukungan, saran, dan kritik yang telah
penulis dapatkan, oleh karena itu dalam kesempatan ini penulis ingin
mengucapkan terima kasih kepada:
1. Kedua Orang tua dan keluarga penulis yang selalu mendo’akan, dan
mendukung penulis dalam mengerjakan skripsi.
2. Ibu Prof. Dr. Lily Surayya Eka Putri, M. Env. Stud selaku Dekan Fakultas
Sains dan Teknologi.
3. Bapak Dr. Imam Marzuki Shofi, M. T. selaku ketua Program Studi Teknik
Informatika, serta Bapak Andrew Fiade, M.Kom. selaku sekretaris Program
Studi Teknik Informatika.
4. Bapak Dr. Imam Marzuki Shofi, M. T. selaku Dosen Pembimbing I dan Ibu
Siti Ummi Masruroh, M.Sc., selaku Dosen Pembimbing II yang telah
memberikan bimbingan, motivasi, dan arahan kepada penulis, sehingga
skripsi ini bisa selesai dengan baik.
5. Kepada teman seperjuangan Teknik Informatika angkatan 2015, khususnya
TI-B yang sudah mensupport penulis dalam menyelesaikan skripsi ini, terima
kasih atas semua kenangan dan kebersamaan selama ini. Semoga kita bisa
lebih baik lagi dan sukses di masa yang akan datang.
6. Sahabat sekaligus teman suka duka serta canda tawa bersama semasa kuliah:
Ahmad Maulana Fazri, Fahmi Alfian , Nur Rina Utami, Nadya Maharani ,
Farah Manthovani, Putri Navia Rena, Alifia Ayu Z, Intan Maryam S, Dhimas
Endira, Renaldy Irfan, Kunhadji Rahmata , Nichyta Dian dan Agung Sidang.

viii
7. Seluruh pihak yang secara langsung maupun tidak langsung membantu
penulis dalam menyelesaikan skripsi ini.
Akhir kata, penulis menyadari bahwa dalam penyajian skripsi ini masih
jauh dari sempurna. Apabila ada kebenaran dari penulisan ini maka kebenaran
tersebut datangnya dari Allah, tetapi apabila ada kesalahan dalam penulisan ini
maka kesalahan ini berasal dari penulis. Semoga skripsi ini membawa manfaat
bagi pengembangan ilmu. Penulis berharap Allah SWT berkenan membalas
segala kebaikan semua pihak yang telah membantu dan meridhai segala usaha
kita.
Jakarta, November 2019
Dewinta Fenny
11150910000048

ix
Nama : Dewinta Fenny
Program Studi : Teknik Informatika
Judul : Analisis Perbandingan Cosine Normalization dan Min-
max Normalization pada Pengelompokan Terjemahan
Ayat Al Quran Menggunakan Algoritma K-Means
Clustering
ABSTRAK
Penerapan Text Mining dalam memahami Al Quran sangat mungkin dilakukan,
karena dengan Text Mining dapat mencari kata-kata yang mewakili isi dari
dokumen sehingga dapat dilakukan analisis keterhubungan antar dokumennya.
Salah satu metode yang dapat digunakan dalam Text Mining yaitu clustering.
Algoritma K-Means merupakan salah satu metode clustering yang sering digunakan
dalam pengelompokan data. Metode Text Mining dengan menggunakan kata term
sebagai fitur akan menghasilkan dimensi vektor yang cukup besar. Selain itu pada
beberapa dataset terdapat rentang nilai yang berbeda disetiap atribut sehingga
dibutuhkan metode normalisasi untuk menyamakan rentang nilai. Penelitian ini
dilakukan dengan tahapan proses pre-processing, pembobotan data, normalisasi
data dan pengelompokan data. Pada penelitian ini dilakukan analisis perbandingan
metode normalisasi antara Cosine Normalization dan Min-max Normalization pada
pengelompokan terjemahan ayat Al Quran dengan menggunakan Algoritma K-
Means Clustering. Data sample yang digunakan pada penelitian ini adalah surah Al
Baqarah sebanyak 286 ayat. Hasil yang didapatkan berupa cluster dan analisis nilai
Silhouette Coefficient, runtime dan memory consumption. Hasil dari penelitian ini
clustering dengan metode Min-max Normmalization mendapatkan nilai Silhouette
Coefficient terbesar yaitu 0,611 pada nilai k=2 dan clustering dengan Cosine
Normalization memiliki nilai terbaik untuk runtime dan memory consumption.
Kata Kunci : Clustering, Terjemahan Ayat Al Quran, K-Means, Cosine
Normalization, Min-max Normalization.
Jumlah Pustaka : 16 buku dan 22 jurnal.
Jumlah Halaman : 115 halaman

x
Name : Dewinta Fenny
Program Studi : Teknik Informatika
Title : Comparison Analysis of Cosine Normalization and
Min-max Normalization in Clustering Translation of Al-
Quran Verses Using K-Means Clustering Algorithm
ABSTRACT
The application of mining text in the Qur'an is very possible because by mining the
text can search for words that represent the contents of the document so that it can
be analyzed the relationship between the documents. One method that can be used
in Text Mining is clustering. K-Means algorithm is one of the grouping methods
that are often used in grouping data. The Text Mining method using the term as a
feature will produce a large vector dimension. Also in some datasets, a different
value is needed in each attribute Normalization method is needed to equalize the
range of values. This research was conducted with the stages of the pre-processing
process, weighting data, normalization data and grouping data. In this study, an
analysis of the normalization method between Cosine Normalization and Min-max
Normalization in the grouping of translation of Al-Quran verses using the K-Means
Clustering Algorithm. The sample data used in this study is Surah Al Baqarah as
many as 286 verses. The results obtained consist of cluster and analysis of
Silhouette Coefficient values, runtime, and memory consumption. The results of
this study grouping with the Min-max Normalization method get the largest
silhouette coefficient value of 0.611 at k = 2 and grouping with Cosine
Normalization has the best value for runtime and memory consumption.
Keywords : Clustering, Translation of Quranic Verse, K-Means, Cosine
Normalization, Min-max Normalization.
Bibliography : 16 books and 22 journals.
Number of Pages : 115 pages

xi
DAFTAR ISI
LEMBAR PERSETUJUAN................................................................................... iii
LEMBAR PENGESAHAN ................................................................................... iii
HALAMAN PERNYATAAN ORISINALITAS .................................................... v
HALAMAN PERNYATAAN PERSETUJUAN PUBLIKASI ............................. vi
KATA PENGANTAR .......................................................................................... vii
ABSTRAK ............................................................................................................. ix
ABSTRACT ............................................................................................................ x
DAFTAR ISI .......................................................................................................... xi
DAFTAR GAMBAR ............................................................................................ xv
DAFTAR TABEL ................................................................................................ xvi
BAB 1 PENDAHULUAN ...................................................................................... 1
1.1 Latar Belakang ......................................................................................... 1
1.2 Rumusan Masalah .................................................................................... 4
1.3 Batasan Masalah ....................................................................................... 4
1.4 Tujuan Penelitian ...................................................................................... 5
1.5 Manfaat Penelitian .................................................................................... 5
1.5.1 Bagi Penulis ...................................................................................... 5
1.5.2 Bagi Universitas ................................................................................ 6
1.5.3 Bagi Pembaca .................................................................................... 6
1.6 Metodologi Penelitian .............................................................................. 6
1.6.1 Metode Pengumpulan Data ............................................................... 6
1.6.2 Metode Pengembangan Sistem ......................................................... 7
1.6.3 Metode Pengambilan Keputusan....................................................... 7
1.7 Sistematika Penulisan ............................................................................... 7
BAB 2 LANDASAN TEORI .................................................................................. 9
2.1. Al Quran ................................................................................................... 9
2.2. Text Mining ............................................................................................... 9
2.3. Clustering ............................................................................................... 10
2.4. Algoritma ................................................................................................ 10
2.5. Text Preprocessing ................................................................................. 11
2.5.1. Case Folding ................................................................................... 11

xii
2.5.2. Tokenization .................................................................................... 11
2.5.3. Filtering .......................................................................................... 12
2.5.4. Stemming ......................................................................................... 12
2.6. Algoritma Nazief & Andriani ................................................................ 12
2.6.1. Tahapan Algoritma Nazief & Andriani........................................... 13
2.6.2. Alasan menggunakan Algoritma Nazief & Andriani ...................... 14
2.7. Algoritma TF-IDF .................................................................................. 14
2.8. Normalisasi ............................................................................................. 15
2.8.1. Cosine Normalization ..................................................................... 16
2.8.2. Min-max Normalization .................................................................. 16
2.9. Algoritma K-Means Clustering .............................................................. 17
2.9.1. Pengertian Algoritma K-Means Clustering ..................................... 17
2.9.2. Tahapan Algoritma K-Means Clustering ........................................ 17
2.10. Silhouette Coefficient .......................................................................... 18
2.11. Metode Perbandingan Eksponensial ................................................... 20
2.11.1. Tahapan Metode Perbandingan Eksponensial ............................. 20
2.11.2. Formulasi Perhitungan Metode Perbandingan Eksponensial ...... 20
2.11.3. Keuntungan Metode Perbandingan Eksponensial ....................... 21
2.12. Studi Pustaka....................................................................................... 21
2.13. Metode Simulasi ................................................................................. 22
2.13.1. Problem Formulation .................................................................. 22
2.13.2. Conceptual Model ....................................................................... 22
2.13.3. Input / Output Data ..................................................................... 23
2.13.4. Modelling ..................................................................................... 23
2.13.5. Simulation .................................................................................... 24
2.13.6. Verification and Validation ......................................................... 24
2.13.7. Eksperimentation ......................................................................... 24
2.13.8. Output Analysis ........................................................................... 24
2.14. Studi Literatur Sejenis ........................................................................ 25
BAB 3 METODOLOGI PENELITIAN................................................................ 30
3.1. Metode Pengumpulan Data .................................................................... 30
3.1.1. Sumber Data .................................................................................... 30
3.1.2. Studi Pustaka ................................................................................... 30
3.2. Metode Pengembangan Sistem .............................................................. 31

xiii
3.2.1. Problem Formulation ...................................................................... 31
3.2.2. Conceptual Model ........................................................................... 31
3.2.3. Input Output Data ........................................................................... 31
3.2.4. Modelling ........................................................................................ 32
3.2.5. Simulation ....................................................................................... 32
3.2.6. Verification and Validation ............................................................. 32
3.2.7. Experimentation .............................................................................. 32
3.2.8. Output Analysis ............................................................................... 33
3.3. Kerangka Berpikir .................................................................................. 33
BAB 4 IMPLEMENTASI, SIMULASI, DAN EKSPERIMEN ........................... 35
4.1. Problem Formulation ............................................................................. 35
4.2. Conceptual Model .................................................................................. 35
4.2.1. Conceptual Model Preprocessing ................................................... 36
4.2.2. Conceptual Model Algoritma K-Means Clustering dengan
menggunakan Cosine Normalization ............................................................ 41
4.2.3. Conceptual Model Algoritma K-Means Clustering dengan
menggunakan Min-max Normalization ......................................................... 44
4.3. Input/Output Data .................................................................................. 45
4.3.1. Input ................................................................................................ 45
4.3.2. Output .............................................................................................. 46
4.4. Modelling ................................................................................................ 46
4.4.1. Konstruksi Cosine Normalization pada Clustering Algoritma K-
Means 46
4.4.2. Konstruksi Min-max Normalization pada Clustering Algoritma K-
Means 59
4.5. Simulation ............................................................................................... 68
4.6. Verification and Validation .................................................................... 69
4.7. Experimentation ..................................................................................... 69
4.8. Output Analisys ...................................................................................... 69
BAB 5 HASIL DAN PEMBAHASAN................................................................. 70
5.1 Verifikasi dan Validasi (Verification and Validation) ........................... 70
5.2 Eksperimentasi (Experimentation) ......................................................... 71
5.3 Analisis Keluaran (Output Analysis) ...................................................... 72
5.3.1 Skenario 1 ....................................................................................... 72
5.3.1.1 Nilai k=2 ...................................................................................... 72

xiv
5.3.1.2 Nilai k=3 ...................................................................................... 72
5.3.1.3 Nilai k=4 ...................................................................................... 73
5.3.1.4 Nilai k=5 ...................................................................................... 74
5.3.1.5 Nilai k=6 ...................................................................................... 74
5.3.1.6 Nilai k=7 ...................................................................................... 75
5.3.1.7 Nilai k=8 ...................................................................................... 76
5.3.2 Skenario 2 ....................................................................................... 76
5.3.2.1 Nilai k=2 ...................................................................................... 76
5.3.2.2 Nilai k=3 ...................................................................................... 77
5.3.2.3 Nilai k=4 ...................................................................................... 78
5.3.2.4 Nilai k=5 ...................................................................................... 79
5.3.2.5 Nilai k=6 ...................................................................................... 79
5.3.2.6 Nilai k=7 ...................................................................................... 80
5.3.2.7 Nilai k=8 ...................................................................................... 81
5.4 Analisis Hasil Perbandingan................................................................... 81
5.4.1 Skenario 1 ....................................................................................... 82
5.4.2 Skenario 2 ....................................................................................... 84
5.5 Analisis Output dengan Metode Perbandingan Eksponensial ................ 86
BAB 6 PENUTUP ................................................................................................ 93
6.1 Kesimpulan ............................................................................................. 93
6.2 Saran ....................................................................................................... 93
DAFTAR PUSTAKA ........................................................................................... 95
LAMPIRAN .......................................................................................................... 98

xv
DAFTAR GAMBAR
Gambar 3.1 Kerangka Berfikir .............................................................................. 34 Gambar 4.1 Diagram Alur Preprocessing ............................................................. 36 Gambar 4.2 Flowchart Case Folding .................................................................... 37 Gambar 4.3 Flowchart Tokenization .................................................................... 38 Gambar 4.4 Flowchart Stopwords Removal ......................................................... 39 Gambar 4.5 Flowchart Algoritma Nazief & Andriani .......................................... 40 Gambar 4.6 Proses Skenario 1 Clustering K-Means dengan Cosine Normalization
............................................................................................................................... 41
Gambar 4.7 Proses Algoritma K-Means ............................................................... 43 Gambar 4.8 Proses Skenario 2 Clustering K-Means dengan Min-max
Normalization ........................................................................................................ 44 Gambar 4.9 Contoh Simulasi Skenario 1 .............................................................. 68 Gambar 4.10 Contoh Simulasi Skenario 2 ............................................................ 69 Gambar 5.1 Hasil Runtime Skenario 1 ................................................................. 82 Gambar 5.2 Hasil Memory Consumption Skenario 1 ........................................... 83 Gambar 5.3 Hasil Silhouette Coefficient Skenario 1 ............................................ 83 Gambar 5.4 Hasil Runtime Skenario 2 ................................................................. 85 Gambar 5.5 Hasil Memory Consumption Skenario 2 ........................................... 85 Gambar 5.6 Hasil Silhouette Coefficient Skenario 2 ............................................ 86

xvi
DAFTAR TABEL
Tabel 2.1 Studi Literatur Sejenis ........................................................................... 26 Tabel 4.1 Contoh Hasil Case Folding ................................................................... 37 Tabel 4.2 Contoh Hasil Tokenization ................................................................... 38 Tabel 4.3 Contoh Hasil Stopword Removal ......................................................... 39 Tabel 4.4 Contoh Hasil Stemming ........................................................................ 40 Tabel 4.5 Teks terjemahan ayat Al Quran ............................................................ 47 Tabel 4.6 Hasil Case folding ................................................................................. 47 Tabel 4.7 Hasil Tokenization ................................................................................ 48
Tabel 4.8 Hasil Stopword Removal ...................................................................... 49 Tabel 4.9 Hasil Stemming ..................................................................................... 49 Tabel 4.10 Hasil Perhitungan IDF ........................................................................ 50 Tabel 4.11 Hasil Perhitungan W (term weighting) ............................................... 51 Tabel 4.12 Hasil Normalisasi Cosine Normalization ............................................ 53 Tabel 4.13 Centroid Awal Skenario-1 .................................................................. 54 Tabel 4.14 Jarak dari hasil iterasi ke-1 Skenario-1 ............................................... 55 Tabel 4.15 Hasil Clustering Iterasi ke-1 Skenario-1 ............................................. 55 Tabel 4.16 Centroid Baru ke-1 Skenario-1 ........................................................... 55 Tabel 4.17 Jarak dari hasil iterasi ke-2 Skenario-1 ............................................... 56 Tabel 4.18 Hasil Clustering Iterasi ke-2 Skenario-1 ............................................. 56 Tabel 4.19 Centroid Baru ke-2 Skenario-1 ........................................................... 56 Tabel 4.20 Jarak dari hasil iterasi ke-3 Skenario-1 ............................................... 57 Tabel 4.21 Hasil Clustering Iterasi ke-3 Skenario-1 ............................................. 57
Tabel 4.22 Centroid Baru ke-3 Skenario-1 .......................................................... 57 Tabel 4.23 Hasil Akhir Clustering Skenario 1 ...................................................... 57 Tabel 4.24 Hasil perhitungan nilai a(i) Skenario-1 ............................................... 58 Tabel 4.25 Hasil perhitungan nilai d(i,C) dan b(i) Skenario-1 ............................. 58 Tabel 4.26 Hasil perhitungan nilai s(i) Skenario-1 ............................................... 59
Tabel 4.27 Hasil Perhitungan IDF ........................................................................ 60 Tabel 4.28 Hasil Perhitungan W (term weighting) ............................................... 61 Tabel 4.29 Hasil Normalisasi Min-max Normalization ........................................ 62 Tabel 4.30 Centroid Awal Skenario-2 .................................................................. 64 Tabel 4.31 Jarak dari hasil iterasi ke-1 Skenario-2 ............................................... 64
Tabel 4.32 Hasil Clustering Iterasi ke-1 Skenario-2 ............................................. 65 Tabel 4.33 Centroid Baru ke-1 Skenario-2 ........................................................... 65 Tabel 4.34 Jarak dari hasil iterasi ke-2 Skenario-2 .............................................. 65
Tabel 4.35 Hasil Clustering Iterasi ke—2 Skenario-2 .......................................... 65 Tabel 4.36 Centroid Baru ke-2 Skenario-2 ........................................................... 66 Tabel 4.37 Centroid ke-2 Skenario-2 ................................................................... 66 Tabel 4.38 Hasil Akhir Clustering Skenario-2 ...................................................... 66
Tabel 4.39 Hasil perhitungan nilai a(i) Skenario-2 ............................................... 67 Tabel 4.40 Hasil perhitungan nilai d(i,C) dan b(i) Skenario-2 ............................. 67 Tabel 4.41 Hasil perhitungan nilai s(i) Skenario-2 ............................................... 68

xvii
Tabel 5.1 Pengujian ............................................................................................... 71 Tabel 5.2 Hasil Nilai k=2 Skenario-1 ................................................................... 72 Tabel 5.3 Hasil Nilai k=3 Skenario-1 ................................................................... 72 Tabel 5.4 Hasil Nilai k=4 Skenario-1 ................................................................... 73 Tabel 5.5 Hasil Nilai k=5 Skenario-1 ................................................................... 74 Tabel 5.6 Hasil Nilai k=6 Skenario-1 ................................................................... 74 Tabel 5.7 Hasil Nilai k=7 Skenario-1 ................................................................... 75 Tabel 5.8 Hasil Nilai k=8 Skenario-1 ................................................................... 76 Tabel 5.9 Hasil Nilai k=2 Skenario-2 ................................................................... 76 Tabel 5.10 Hasil Nilai k=3 Skenario-2 ................................................................. 77 Tabel 5.11 Hasil Nilai k=4 Skenario-2 ................................................................. 78 Tabel 5.12 Hasil Nilai k=5 Skenario-2 ................................................................. 79
Tabel 5.13 Hasil Nilai k=6 Skenario-2 ................................................................. 79 Tabel 5.14 Hasil Nilai k=7 Skenario-2 ................................................................. 80 Tabel 5.15 Hasil Nilai k=8 Skenario-2 ................................................................. 81 Tabel 5.16 Hasil Perbandingan Skenario 1 ........................................................... 82 Tabel 5.17 Hasil Perbandingan Skenario 2 ........................................................... 84 Tabel 5.18 Penentuan Kriteria............................................................................... 87 Tabel 5.19 Pembobotan masing-masing kriteria ................................................... 88 Tabel 5.20 Pemberian Nilai Kriteria ..................................................................... 88 Tabel 5.21 Prioritas Keputusan ............................................................................. 91

1
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Pengetahuan menjadi hal yang penting dan utama dalam kehidupan
manusia. Bukan hanya ilmu pengetahuan umum tetapi ilmu agama juga
menjadi suatu kewajiban bagi umat muslim untuk dipelajari. Kitab suci Al
Quran tidak akan lepas dari umat islam, dikarenakan Al Quran merupakan
sumber ilmu pengetahuan yang diberikan oleh Allah SWT kepada
hambanya. Allah SWT telah menjelaskan hikmah dari diturunkannya Al
quran yaitu untuk ditadabburi dan diambil pelajarannya, sebagaimana
disebutkan dalam firman-Nya (Ukkasyah, 2018).
“Ini adalah sebuah Kitab yang Kami turunkan kepadamu penuh
dengan berkah supaya mereka metadabburi ayat-ayatnya dan supaya
orang-orang yang mempunyai pikiran (sehat) mendapat pelajaran.” (QS.
Shaad :29).
Menurut Dr. Subhi as-Salih mendefinisikan “Al Quran sebagai
kalam Allah SWT yang merupakan mukzijat yang diturunkan kepada Nabi
Muhammad SAW dan ditulis pada mushaf serta diriwayatkan dengan
mutawir, membacanya termasuk ibadah”. Sedangkan menurut
Muhammad Ali ash-Shabuni mendefinisikan “Al Quran sebagai firman
Allah SWT yang tiada tandingannya, diturunkan kepada Nabi Muhammad
SAW penutup para nabi dan rasul, dengan perantaraan Malaikat Jibril a.s,,
dan ditulis pada mushaf-mushaf yang kemudian disampaikan kepada kita
secara mutawatir, membaca dan mempelajarinya merupakan ibadah yang
dimulai dari surah al-Fatihah dan ditutup dengan surah an-Naas” (Hamid,
2016).

2
UIN Syarif Hidayatullah Jakarta
Al Quran terdiri atas banyak tema dari setiap surah yang berbeda.
Untuk mendapatkan cerminan utuh, pembaca harus melihat dan merujuk
semua bagian yang saling berhubungan (Abbas, 2009).
Penerapan text mining dalam memahami Al Quran sangat mungkin
dilakukan, karena secara komputasi, Al Quran memiliki informasi semi
terstruktur karena diatur dalam struktur nomor surat dan ayat. Ini
memudahkan pemodelan, berbeda dengan teks tidak terstruktur seperti
novel atau biografi (Ahmad et al., 2013). Pengelompokan ayat yang
memiliki kemiripan tema akan memudahkan pengguna menemukan suatu
tema dalam Al Quran.
Penelitian sebelummnya oleh (Faizin, 2018) telah
mengimplementasikan Text Mining untuk mengelompokkan terjemahan
ayat Al Quran dalam Bahasa Indonesia. Text mining, yang juga disebut
sebagai Teks Data Mining (TDM) atau Knowledge Discovery in Text
(KDT), secara khusus dikembangkan untuk proses ekstraksi informasi dari
dokumen-dokumen teks tak terstruktur (unstructured). Text mining
memiliki definisi menambang data berupa teks di mana sumber data
biasanya didapatkan dari dokumen dan tujuannya adalah untuk mencari
kata-kata yang dapat mewakili isi dari dokumen sehingga dapat dilakukan
analisis keterhubungan antar dokumen (Yulian, 2018). Salah satu metode
yang digunakan dalam Text Mining yaitu clustering. Algoritma K-Means
adalah salah satu metode clustering yang sering digunakan dalam
pengelompokan data. Untuk menguji hasil dari clustering diperlukan juga
suatu metode yang dapat mengukur kekuatan dan kualitas sebuah cluster,
salah satu metode yang dapat digunakan adalah Metode Sillhouette
Coefficient.
Sebelumnya terdapat beberapa penelitian yang menerapkan
algoritma K-Means. Penelitian pertama yaitu yang telah disebutkan
sebelummnya oleh (Faizin, 2018) telah mengimplementasikan Text
Mining untuk mengelompokkan terjemahan ayat Al Quran dalam Bahasa
Indonesia menggunakan Algoritma K-Means Clustering menghasilkan

3
UIN Syarif Hidayatullah Jakarta
akurasi 43%. Penelitian kedua yaitu membandingkan Algoritma K-Means
dan DBSCAN pada pengelompokan data rumah kost mahasiswa
dikelurahan Tembalang Semarang mendapati hasil Algoritma K-Means
lebih unggul dari DBSCAN dengan nilai indeks silhouette 0,463
(Budiman, Safitri, & Ispriyanti, 2016).
Sebelum melakukan proses clustering ada beberapa tahapan dasar
yang harus dilakukan yaitu preprocessing dan pembobotan kata atau term
weighting. Menurut (Hudin, Fauzi, & Adinugroho, 2018) metode Text
Mining dengan menggunakan kata term sebagai fitur akan menghasilkan
dimensi vektor yang cukup besar. Selain itu pada beberapa dataset terdapat
rentang nilai yang berbeda disetiap atribut. Menurut (Domeniconi, Moro,
B, & Sartori, 2016) perhitungan dokumen dengan TF-IDF akan memiliki
nilai bobot yang berbeda tergantung dengan panjang tidaknya suatu
dokumen. Perbedaan rentang nilai pada setiap atribut menyebabkan tidak
berfungsinya atribut yang memiliki nilai jauh lebih kecil dibandingkan
dengan atribut-atribut lainnya (Nasution, Khotimah, & Chamidah, 2019).
Sehingga disarankan untuk menambahkan metode yang dapat
mereduksi ukuran dimensi yang cukup besar tersebut. Secara umum
ada dua tipe metode reduksi yang biasa digunakan antara lain
transformasi fitur dan feature selection (Hudin et al., 2018). Menurut
(Nasution et al., 2019) dan (Domeniconi et al., 2016) transformasi fitur
dengan normalisasi dapat menyamakan rentang nilai pada setiap atribut
dengan skala tertentu.
Pada penelitian sebelumnya yang dilakukan oleh (Faizin, 2018) telah
mengimplementasikan normalisasi sebagai transformasi fitur dengan
menggunakan Cosine Normalization pada pengelompokan teks
terjemahan ayat Al Quran dan menghasilkan akurasi sebesar 43% pada
nilai k=4. Selain Cosine Normalization, transformasi data dengan
normalisasi dapat dilakukan juga dengan beberapa cara, yaitu Min-
max Normalization, Z-score Normalization, Decimal Scaling, Sigmoid,
dan Softmax (Nasution et al., 2019). Penelitian sebelumnya oleh (Nasution

4
UIN Syarif Hidayatullah Jakarta
et al., 2019) telah melakukan perbandingan metode normalisasi yaitu pada
Decimal Scaling, Min-max Normalization dan Z-score Normalization
untuk klasifikasi wine menggunakan Algoritma K-NN, menghasilkan
akurasi terbaik pada metode Min-max Normalization dengan K=1 sebesar
65,92%. Penelitian sebelumnya juga telah dilakukan oleh (Jamdar,
Abraham, Khanna, & Dubey, 2015) yaitu menerapkan Min-max
Normalization sebagai feature scaling atau normalisasinya menghasilkan
rata-rata akurasi sebesar 83,40%. Dalam penelitian (Virmani, Taneja, &
Malhotra, 2015) menyatakan bahwa normalisasi dapat meningkatkan
efektifitas dari hasil yang dikeluarkan oleh sistem, terutama pada
sistem yang menggunakan jarak euclidean seperti Algoritma K-Means.
Berdasarkan uraian latar belakang yang telah dijelaskan, maka
penulis ingin melakukan sebuah penelitian membandingkan kedua metode
normalisasi tersebut dengan melakukan pengujian nilai silhouette
coefficient, runtime dan memory consumption yang berjudul “ Analisis
Perbandingan Cosine Normalization dan Min-max Normalization
pada Pengelompokan Teks Terjemahan Ayat Al Quran
Menggunakan Algoritma K-Means Clustering”.
1.2 Rumusan Masalah
Berdasarkan latar belakang sebelumnya maka dapat disimpulkan
rumusan permasalahan yang akan diangkat pada penelitian ini adalah
Bagaimana perbandingan nilai silhouette coefficient, runtime dan memory
consumption Cosine Normalization dan Min-max Normalization pada
Pengelompokan teks terjemahan ayat Al Quran dengan Algoritma K-
Means Clustering.
1.3 Batasan Masalah
Dalam penelitian ini, peneliti melakukan pembatasan masalah
terhadap masalah penelitian yang akan dilakukan, yakni:
1. Dataset yang digunakan sebagai sample pada penelitian ini adalah
Surah Al Baqarah ayat 2-286.

5
UIN Syarif Hidayatullah Jakarta
2. Nilai k yang digunakan pada Algoritma K-Means Clustering adalah k
= 2, k=3, k=4, k=5, k=6, k=7, k=8 .
3. Menggunakan Algoritma Nazief dan Andriani pada proses stemming.
4. Menggunakan Algoritma TF-IDF pada proses pembobotan kata.
5. Metode Implementasi yang digunakan dalam penelitian ini yaitu
metode simulasi.
6. Skenario yang diambil dalam simulasi berdasarkan metode normalisasi
yang dipakai.
7. Pengujian cluster dilakukan dengan menggunakan metode sillhouette
coefficient.
8. Parameter perbandingan kinerja algoritma yang digunakan, yaitu
waktu pemrosesan (runtime), memori yang digunakan untuk
pemrosesan (memory consumption) dan nilai silhouette coefficient.
9. Perbandingan (runtime) dan (memory consumption) menggunakan
metode pengambilan keputusan yaitu menggunakan Metode
Perbandingan Eksponensial.
1.4 Tujuan Penelitian
Tujuan yang ingin dicapai dalam penelitian ini adalah menganalisa
tingkat nilai silhouette coefficient, (runtime) dan (memory consumption)
dari hasil perbandingan Cosine Normalization dan Min-max
Normalization pada pengelompokan teks terjemahan ayat Al Quran
dengan Algoritma K-Means Clustering.
1.5 Manfaat Penelitian
Adapun manfaat yang didapat dari hasil penelitian ini adalah :
1.5.1 Bagi Penulis
1) Dapat menerapkan ilmu-ilmu yang telah diajarkan selama masa
perkuliahan.
2) Membandingkan teori yang telah didapat saat kuliah dengan
masalah yang sebenarnya.

6
UIN Syarif Hidayatullah Jakarta
3) Memberikan referensi untuk penulisan penelitian dengan
menggunakan algoritma yang sama.
4) Menjadi tolak ukur untuk mahasiswa untuk penelitian
selanjutnya agar lebih baik lagi dari penelitian sebelumnya.
1.5.2 Bagi Universitas
1) Mengetahui kemampun mahasiswa dalam mengusai materi
teori yang telah diperoleh pada masa kuliah ataupun materi yang
sesuai dengan program studinya.
2) Mengukur tingkat kemampuan mahasiswa dalam menerapkan
ilmu akademis maupun non-akademis di lingkungan
masyarakat.
1.5.3 Bagi Pembaca
1) Menambah wawasan pembaca mengenai Min-max
Normalization dan Algoritma K-Means Clustering, dalam
melakukan pengelompokan teks.
2) Membantu pembaca dalam menerapkan Min-max
Normalization dan Algoritma K-Means Clustering.
1.6 Metodologi Penelitian
Metode yang digunakan penulis dalam penulisan dan penelitian
dibagi menjadi tiga, yaitu metode pengumpulan data, metode
pengembangan sistem dan metode pengambilan keputusan. Berikut
penjelasan kedua metode tersebut :
1.6.1 Metode Pengumpulan Data
Metode pengumpulan data dilakukan dengan studi
kepustakaan untuk mengumpulkan data dengan mencari informasi
lewat buku, jurnal, e-book, dan sumber-sumber tertulis lainnya baik
tercetak maupun elektronik yang bertujuan untuk mendukung
sebuah penelitan.

7
UIN Syarif Hidayatullah Jakarta
1.6.2 Metode Pengembangan Sistem
Pada penelitian ini Penulis melakukan simulasi terhadap
sistem yang dibuat. Adapun langkah-langkah yang dilakukan yaitu :
1. Problem Formulation
2. Conceptual Model
3. Input Output Data
4. Modelling
5. Simulation
6. Verification and Validation
7. Experimentation
8. Output Analysis
1.6.3 Metode Pengambilan Keputusan
Penulis menggunakan metode pengambilan keputusan, yaitu
Metode Perbandingan Eksponensial yang digunakan untuk
perankingan hasil dari masing-masing metode normalisasi, sehingga
dapat diketahui metode normalisasi yang terbaik.
1.7 Sistematika Penulisan
Untuk memudahkan dalam penulisan laporan tugas akhir ini, penulis
menyusunnya ke dalam beberapa bagian. Setiap babnya terdiri dari
beberapa sub bab tersendiri. Dimana bab tersebut secara keseluruhan
saling berkaitan satu sama lain. Berikut penjelasan singkat dari masing-
masing bab:
BAB 1 PENDAHULUAN
Pada bab ini peneliti menjelaskan terkait latar belakang dari dari
sebuah permasalahan yang diangkat, tujuan penelitian, manfaat
penelitian, rumusan masalah, batasan masalah, metodologi
penelitian, dan sistematika penulisan pada tugas skripsi ini.
BAB 2 LANDASAN TEORI

8
UIN Syarif Hidayatullah Jakarta
Pada bab ini peneliti menjelaskan tentang materi-materi apa saja
yang dipakai untuk dijadikan dasar penelitian yang sedang
dilakukan.
BAB 3 METODE PENELITIAN
Pada bab ini peneliti menjelaskan tentang metode penelitian apa
yang dipakai untuk mendapatkan data dan metode untuk
pengembangan sistem yang telah dibuat serta kerangka berpikir
pembuatan tugas akhir ini.
BAB 4 IMPLEMENTASI, SIMULASI, DAN EKSPERIMEN
Pada bab ini menjelaskan tentang implementasi dari metode yang
telah digunakan untuk perancangan membangun sebuah sistem dan
tahapan proses menganalisa simulasi.
BAB 5 HASIL DAN PEMBAHASAN
Pada bab ini peneliti membahas tentang hasil yang telah didapat dari
proses simulasi yang telah dilakukan pada bab sebelumnya.
BAB 6 PENUTUP
Pada bab ini peneliti menjelaskan tentang kesimpulan dari hasil yang
telah didapat dan menjawab semua pokok permasalahan yang
dirancang serta saran-saran yang digunakan untuk penelitian lebih
lanjut.

9
BAB 2
LANDASAN TEORI
2.1. Al Quran
Al-Quran bagi kaum muslimin adalah kalam Allah SWT yang
diwahyukan kepada Nabi Muhammad SAW melalui perantaraan Jibril as
selama kurang lebih dua puluh tiga tahun. Kitab suci ini memiliki kekuatan
luar biasa yang berada di luar kemampuan seluruh makhluk Allah swT.
"Sekiranya kami turunkan Al-Qur'an ini kepada sebuah gunung, maka kamu
akan melihatnya tunduk terpecah belah karena takut kepada Allah SWT” (QS,
al-Hasyr [59]: 21).
Kandungan pesan llahi yang disampaikan oleh Nabi SAW dalam
bentuk Al Quran ini telah menjadi landasan kehidupan individual dan sosial
kaum Muslimin dalam segala aspeknya, bahkan masyarakat Muslim
mengawali eksistensinya dan telah memperoleh kekuatan hidup dengan
merespons dakwah Al Quran. Itulah sebabnya Al Quran berada di jantung
kehidupan umat Muslim. Namun tanpa pemahaman yang semestinya
terhadap Al Quran, kehidupan, pemikiran, dan kebudayaan kaum Muslimin
sangat sulit dipahami (Hamid, 2016).
2.2. Text Mining
Text mining (penambangan teks) adalah penambangan yang dilakukan
oleh komputer untuk mendapatkan sesuatu yang baru, sesuatu yang tidak
diketahui sebelumnya atau menemukan kembali informasi yang tersirat
secara implisit, yang berasal dari informasi yang di ekstrak secara otomatis
dari sumber-sumber data teks yang berbeda-beda (Feldman & Sanger, 2007).
Text mining merupakan teknik yang digunakan untuk menangani masalah
klasifikasi, pengklasteran, ekstraksi informasi dan information retrival (Berry
& Kogan, 2010).
Pada dasarnya proses kerja text mining banyak mengadopsi dari
penelitian data mining namun yang menjadi perbedaan adalah pola yang
digunakan oleh text mining diambil dari sekumpulan bahasa alami yang tidak

10
UIN Syarif Hidayatullah Jakarta
terstruktur sedangkan dalam data mining pola yang diambil dari database
yang terstruktur (Han, Kamber, & Pei, 2011). Tahap- tahap text mining secara
umum adalah text preprocessing dan seleksi fitur (Feldman & Sanger, 2007).
2.3. Clustering
Clustering atau klasterisasi adalah suatu teknik atau metode untuk
mengelompokkan data. Menurut Tan, 2006 clustering adalah sebuah proses
untuk mengelompokan data ke dalam beberapa cluster atau kelompok
sehingga data dalam satu cluster memiliki tingkat kemiripan yang maksimum
dan data antar cluster memiliki kemiripan yang minimum. Clustering
merupakan proses partisi satu set objek data ke dalam himpunan bagian yang
disebut dengan cluster, Objek yang di dalam cluster memiliki kemiripan
karakteristik antar satu sama lainnya dan berbeda dengan cluster yang lain.
Partisti tidak dilakukan secara manual melainkan dengan suatu algoritma
clustering, Oleh karena itu, clustering sangat berguna dan bisa menemukan
group atau kelompok yang tidak dikenal dalam data (Irwansyah & Faisal,
2015).
Menurut (Merliana, Ernawati, & Santoso, 2015) clustering juga bisa
dikatakan suatu proses dimana mengelompokan dan membagi pola data
menjadi beberapa jumlah data set sehingga akan membentuk pola yang serupa
dan dikelompokkan pada cluster yang sama dan memisahkan diri dengan
membentuk pola yang berbeda di cluster yang berbeda.
Dapat disimpulkan clustering adalah proses untuk mengelompokan
data menjadi beberapa kelompok, dimana setiap isi kelompok memiliki pola
yang sama.
2.4. Algoritma
Beberapa definisi dari algoritma, yaitu algoritma adalah deretan
langkah-langkah komputasi yang mentransformasikan data masukan menjadi
keluaran. Algoritma adalah deretan instruksi yang jelas untuk
memecahkan persoalan, yaitu untuk memperoleh luaran yang diinginkan dari
suatu masukan dalam jumlah waktu yang terbatas (Munir & Lidya, 2016).

11
UIN Syarif Hidayatullah Jakarta
Sedangkan menurut (Sitorus, 2015) Algoritma adalah susunan langkah
penyelesaian suatu masalah secara sistematika dan logis.
Dapat disimpulkan, algoritma adalah langkah-langkah untuk
menyelesaikan masalah untuk menghasilkan suatu ouput.
2.5. Text Preprocessing
Text Preprocessing merupakan tahapan dari proses awal terhadap teks
untuk mempersiapkan teks menjadi data yang akan diolah lebih lanjut. Suatu
teks tidak dapat diproses langsung oleh algoritma pencarian, oleh karena itu
dibutuhkan preprocessing text untuk mengubah teks menjadi data numeric.
Sebuah teks yang ada harus dipisahkan, hal ini dapat dilakukan dalam
beberapa tingkatan yang berbeda. Suatu dokumen dapat di pecah menjadi
bab, sub-bab, paragraf, kalimat dan pada akhirnya menjadi potongan
kata/token. Selain itu pada tahapan ini keberadaan digit angka, huruf kapital,
atau kerakter-karakter yang lainnya dihilangkan dan dirubah (Feldman &
Sanger, 2007).
Proses preprocessing dilakukan agar data yang digunakan bersih dari
noise, memiliki dimensi yang lebih kecil, serta lebih terstruktur, sehingga
dapat diolah lebih lanjut. Tahap preprocessing memiliki beberapa proses,
yaitu case folding, stopwords removing, tokenizing, dan stemming
(Prasidhatama & Suryaningrum, 2018). Berikut ini tahapan-tahapan dari text
preprocessing :
2.5.1. Case Folding
Case Folding adalah mengubah semua huruf dalam dokumen
menjadi huruf kecil. Hanya huruf a sampai z yang diterima.
Karakter selain huruf dihilangkan dan dianggap delimiter (Salim,
2017).
2.5.2. Tokenization
Tokenization adalah proses dimana sebuah kalimat dipotong
untuk menghasilkan kata-kata yang akan digunakan untuk proses
selanjutnya (Prasidhatama & Suryaningrum, 2018).

12
UIN Syarif Hidayatullah Jakarta
2.5.3. Filtering
Filtering adalah tahap mengambil kata-kata penting dari
hasil token. Terdapat beberapa algoritma dalam filtering yaitu Stop-
list dan word-list. Algoritma stop- word merupakan algoritma yang
digunakan untuk mengeliminasi kata-kata yang tidak deskriptif.
Algoritma word-list adalah algoritma yang digunakan menyimpan
kata-kata memiliki nilai deskriptif (Salim, 2017).
2.5.4. Stemming
Stemming adalah proses untuk menggabungkan atau
memecahkan setiap varian-varian suatu kata menjadi kata dasar.
Proses stemming pada kata Bahasa Indonesia berbeda dengan
stemming bahasa Inggris. Proses stemming pada kata bahasa inggris
adalah proses untuk mengelimininasi sufiks pada kata, sementara
proses stemming bahasa Indonesia adalah proses untuk
mengeliminasi sufiks, prefiks, dan konfiks (Salim, 2017). Proses
stemming membutuhkan algoritma stemming. Algoritma stemming
adalah prosedur komputasi yang mencari asal kata dari suatu kata
dalam kalimat yang dilakukan dengan cara memisahkan masing-
masing kata dari kata dasar dan imbuhannya. Pada saat ini ada
beberapa algoritma stemming untuk Bahasa Indonesia yang telah
dikembangkan diantaranya yaitu: Algoritma Nazief dan Andriani,
Algoritma Porter, serta Algoritma Arifin dan Setiono (Novitasari,
2016).
2.6. Algoritma Nazief & Andriani
Algortima Stemming Nazief dan Andriani, Algoritma ini dibuat oleh
Boby Nazief dan Mirna Andriani dari Fakultas Ilmu Komputer Universitas
Indonesia tahun 1996, algoritma ini mengacu pada aturan morfologi Bahasa
Indonesia yang mengelompokkan imbuhan, yaitu imbuhan yang
diperbolehkan atau imbuhan yang tidak diperbolehkan. Pengelompokan ini
termasuk imbuhan di depan (awalan), imbuhan kata belakang (akhiran),

13
UIN Syarif Hidayatullah Jakarta
imbuhan kata di tengah (sisipan), dan kombinasi imbuhan pada awal dan
akhir kata (konfiks). Algoritma ini menggunakan kamus kata keterangan yang
digunakan untuk mengetahui bahwa proses stemming telah mendapatkan kata
dasar (Novitasari, 2016).
2.6.1. Tahapan Algoritma Nazief & Andriani
Berikut ini tahapan dari Algoritma Nazief & Andriani
(Nugroho, 2017).
1. Cari kata yang akan distem dalam kamus. Jika
ditemukan maka diasumsikan bahwa kata tesebut
adalah root word. Maka algoritma berhenti.
2. Inflection Suffixes(“-lah”, “-kah”, “-ku”, “- mu”, atau
“-nya”) dibuang. Jika berupa particles (“-lah”, “-
kah”, “-tah” atau “-pun”) maka langkah ini diulangi
lagi untuk menghapus Possesive Pronouns(“-ku”, “-
mu”, atau “-nya”), jika ada.
3. Hapus Derivation Suffixes(“-i”, “-an” atau “- kan”).
Jika kata ditemukan di kamus, maka algoritma
berhenti. Jika tidak maka ke langkah 3a.
a. Jika “-an” telah dihapus dan huruf terakhir
dari kata tersebut adalah “- k”, maka “-k” juga
ikut dihapus. Jika kata tersebut ditemukan
dalam kamus maka algoritma berhenti. Jika
tidak ditemukan maka lakukan langkah 3b.
b. Akhiran yang dihapus (“-i”, “-an” atau “-
kan”) dikembalikan, lanjut ke langkah 4.
4. Hapus Derivation Prefix. Jika pada langkah 3 ada
sufiks yang dihapus maka pergi ke langkah 4a, jika
tidak pergi ke langkah 4b.
a. Periksa tabel kombinasi awalan- akhiran yang
tidak diijinkan. Jika ditemukan maka

14
UIN Syarif Hidayatullah Jakarta
algoritma berhenti, jika tidak pergi ke langkah
4b.
b. For i = 1 to 3, tentukan tipe awalan kemudian
hapus awalan. Jika root word belum juga
ditemukan lakukan langkah 5, jika sudah
maka algoritma berhenti. Catatan: jika awalan
kedua sama dengan awalan pertama algoritma
berhenti.
5. Melakukan recoding.
6. Jika semua langkah telah selesai tetapi tidak juga
berhasil maka kata awal diasumsikan sebagai root
word. Proses selesai.
2.6.2. Alasan menggunakan Algoritma Nazief & Andriani
Penulis menggunakan Algoritma Nazief & Andriani karena
menurut (Rezalina, 2016) pada penelitiannya yang membandingkan
tiga algoritma stemming bahwa algoritma Nazief & Adriani lebih
unggul dalam hal kecepatan dan akurasi dibandingkan dengan
algoritma Porter dan Arifin Setiono. Pada penelitian lain yang
dilakukan oleh (Prasidhatama & Suryaningrum, 2018) Algoritma
stemming Nazief & Adriani memiliki akurasi yang lebih tinggi
dibandingkan dengan algoritma stemming Idris.
2.7. Algoritma TF-IDF
Menurut (Melita, Amrizal, Suseno, & Dirjam, 2018), Metode Term
Frequency-Inverse Document Frequency (TF-IDF) adalah cara pemberian
bobot hubungan suatu kata (term) terhadap dokumen. TF-IDF ini adalah
sebuah ukuran statistik yang digunakan untuk mengevaluasi seberapa penting
sebuah kata di dalam sebuah dokumen atau dalam sekelompok kata. Untuk
dokumen tunggal tiap kalimat dianggap sebagai dokumen. Frekuensi
kemunculan kata di dalam dokumen yang diberikan menunjukkan seberapa
penting kata itu di dalam dokumen tersebut. Frekuensi dokumen yang

15
UIN Syarif Hidayatullah Jakarta
mengandung kata tersebut menunjukkan seberapa umum kata tersebut. Bobot
kata semakin besar jika sering muncul dalam suatu dokumen dan semakin
kecil jika muncul dalam banyak dokumen (Melita et al., 2018).
Algoritma TF-IDF menggunakan rumus untuk menghitung bobot (W)
masing-masing dokumen terhadap kata kunci dengan rumus berikut :
Wdt = TFdt * IDFt
Dimana:
d = dokumen ke-d
t = kata ke-t dari kata kunci
W = bobot dokumen ke-d terhadap kata ke-t
TF = banyaknya kata yang dicari pada sebuah dokumen
IDF = Inversed Document Frequency
IDF = log (𝑁
𝐷𝐹)
N = total dokumen
DF = banyak dokumen yang mengandung kata yang dicari.
2.8. Normalisasi
Normalisasi adalah teknik penskalaan atau teknik pemetaan atau tahap
pra-pemrosesan (Patro & Kumar, 2015). Dengan normalisasi data dapat
diubah menjadi rentang baru dari rentang yang ada (Patro, Sahoo, Panda, &
Sahu, 2015). Sedangkan pengertian lain normalisasi merupakan proses
pengubahan data menjadi bentuk normal. Proses ini dilakukan penskalaan
terhadap data menjadi dalam rentang nilai tertentu. Normalisasi sangat
diperlukan ketika data yang ada bernilai tidak seimbang yaitu sangat besar
atau sangat kecil (Haryati, Abdillah, & Hadiana, 2016).
Normalisasi dilakukan terhadap vektor fitur dokumen untuk
menghilangkan pengaruh anggapan bahwa dokumen panjang lebih relevan
dibandingkan dokumen pendek. Dengan normalisasi ini dapat membantu
menormalkan batas nilai dengan melakukan standarisasi nilai ke dalam
interval 0 sampai dengan 1 (Amalia, 2016).

16
UIN Syarif Hidayatullah Jakarta
Dapat disimpulkan bawah normalisasi adalah proses untuk
menyederhanakan nilai data yang besar dan kecil agar seimbang dengan skala
nilai tertentu. Ada beberapa metode untuk menormalisasikan data, berikut
normalisasi yang dipakai dalam penelitian ini.
2.8.1. Cosine Normalization
Cosine Normalization adalah teknik normalisasi yang paling
umum digunakan dalam vector space model (Singhal, Buckley, &
Mitra, 2017). Cosine Normalization dihitung dengan menggunakan
kombinasi komponen tiap bobot atribut pertama, kedua dan
seterusnya. Cosine Normalization akan menjaga nilai tetap pada
rentang 0 sampai dengan 1 (Albate & Minker, 2011). Berikut
persamaan rumus Cosine Normalization :
𝑤(𝑤𝑜𝑟𝑑𝑖) =(𝑤𝑜𝑟𝑑𝑖)
√𝑤2(𝑤𝑜𝑟𝑑1) + 𝑤2(𝑤𝑜𝑟𝑑2) + ⋯ + 𝑤2(𝑤𝑜𝑟𝑑𝑛)
Dimana w adalah bobot setiap kata pada dokumen yang sama.
2.8.2. Min-max Normalization
Min-max Normalization merupakan metode normalisasi
dengan strategi linier yang mentransformasikan data dari satu
rentang nilai ke rentang nilai yang baru, sehingga menghasilkan
keseimbangan nilai perbandingan antar data saat sebelum dan
sesudah proses. Data diubah menjadi seimbang antara 0 sampai
dengan 1. Metode Min-Max Normalization merupakan salah satu
metode mengubah data yang kompleks dengan tidak
menghilangkan isi, sehingga lebih mudah diolah (Wimmer, 2018).
Berikut persamaan Min-max Normalization :
𝑋𝐼 = 𝑋 − 𝑋𝑚𝑖𝑛
𝑋𝑚𝑎𝑥 − 𝑋𝑚𝑖𝑛
Dimana :
XI = Data atribut yang akan dinormalisasi.
Xmin = Nilai terkecil atribut tersebut.

17
UIN Syarif Hidayatullah Jakarta
Xmax = Nilai tertinggi atribut tersebut.
Metode normalisasi dengan Min-max Normalization akan
melakukan transformasi linier terhadap data asli sehingga
menghasilkan keseimbangan nilai perbandingan antar data saat
sebelum dan sesudah proses (Nasution et al., 2019).
2.9. Algoritma K-Means Clustering
2.9.1. Pengertian Algoritma K-Means Clustering
Algoritma K-Means Clustering merupakan salah satu metode
pengelompokan data nonhierarki (sekatan) yang berusaha
mempartisi data yang ada ke dalam bentuk dua atau lebih kelompok.
Metode ini mempartisi data ke dalam kelompok sehingga data
berkarakteristik sama dimasukkan ke dalam satu kelompok yang
sama dan data yang berkarakteristik berbeda dikelompokkan ke
dalam kelompok yang lain. Adapun tujuan pengelompokan data ini
adalah untuk meminimalkan fungsi objektif yang diset dalam proses
pengelompokan, yang pada umumnya berusaha meminimalkan
variasi di dalam suatu kelompok dan memaksimalkan variasi antar
kelompok (Prasetyo, 2012).
2.9.2. Tahapan Algoritma K-Means Clustering
Pada penelitian (Rohmawati, Defiyanti, & Jajuli, 2015),
Sarwono mengemukakan secara lebih detail, algoritma K-Means
adalah sebagai berikut:
1. Menentukan k sebagai jumlah cluster yang ingin di
bentuk.
2. Membangkitkan nilai random untuk pusat cluster
awal (centroid) sebanyak k.
3. Menghitung jarak setiap data input terhadap masing
– masing centroid menggunakan rumus jarak
Euclidean (Euclidean Distance) hingga ditemukan
jarak yang paling dekat dari setiap data dengan

18
UIN Syarif Hidayatullah Jakarta
centroid. Berikut adalah persamaan Euclidian
Distance:
𝑑(𝑥𝑖, µ𝑗) = √∑(𝑥𝑖 − µ𝑗) 2
Dimana :
xi : data kriteria,
µj : centroid pada cluster ke-j
4. Mengklasifikasikan setiap data berdasarkan
kedekatannya dengan centroid (jarak terkecil).
5. Memperbaharui nilai centroid. Nilai centroid baru
di peroleh dari rata-rata cluster yang bersangkutan
dengan menggunakan rumus:
µ𝑗(𝑡 + 1) =1
𝑁𝑠𝑗∑ 𝑥𝑗
𝑗∈𝑆𝑗
Dimana:
µj(t+1) : centroid baru pada iterasi ke (t +1)
Nsj : banyak data pada cluster Sj.
6. Melakukan perulangan dari langkah 2 hingga 5, sampai
anggota tiap cluster tidak ada yang berubah.
Jika langkah 6 telah terpenuhi, maka nilai pusat cluster (µj)
pada iterasi terakhir akan digunakan sebagai parameter untuk
menentukan clustering data .
2.10. Silhouette Coefficient
Silhouette Coefficient merupakan salah satu metode yang digunakan
untuk menguji kualitas dan kekuatan dari sebuah cluster. Metode silhouette
coefficient merupakan gabungan dari metode cohesion dan metode
separation. Metode cohesion sendiri merupakan suatu metode yang
digunakan untuk mengukur seberapa dekat relasi antar objek dalam satu
cluster yang sama. Sedangkan metode separation digunakan untuk mengukur
seberapa jauh sebuah cluster terpisah dengan cluster yang lain (Hudin et al.,
2018). Nilai indeks Silhouette dihitung sebagai derajat kepercayaan dalam
proses clustering pada suatu pengamatan dengan cluster yang dikatakan

19
UIN Syarif Hidayatullah Jakarta
terbentuk baik bila nilai indeks mendekati 1 dan kondisi sebaliknya jika nilai
indeks mendekatai angka -1 (Irwansyah & Faisal, 2015). Silhoutte memiliki
tiga tahap dalam perhitungannya, berikut tahap perhitungan Silhoutte
Coefficient (Hudin et al., 2018):
1. Hitung rata-rata jarak dari suatu dokumen misalkan i dengan
semua dokumen lain yang berada dalam satu cluster, dengan
menggunakan persamaan
𝑎(𝑖) = 1
[𝐴] − 1∑ 𝐽 ∈ 𝐴, 𝑗 ≠ 𝑖 𝑑(𝑖, 𝑗)
2. Kemudian Hitung rata-rata jarak dari dokumen i tersebut
dengan semua dokumen di cluster lain, dan diambil nilai
terkecilnya, dengan menggunakan persamaan
𝑑(𝑖, 𝐶) = 1
[𝐴]∑ 𝐽 ∈ 𝐶 𝑑(𝑖, 𝑗)
Dengan d (i, C) adalah jarak rata-rata dokumen i dengan
semua objek pada cluster lain C dimana A ≠ C.
𝑏(𝑖) = min 𝐶 ≠ 𝐴 𝑑(𝑖, 𝐶)
3. Kemudian menghitung nilai silhouette coefficient dengan
persamaan
𝑠(𝑖) = 𝑏(𝑖) − 𝑎(𝑖)
max (𝑎(𝑖), 𝑏(𝑖)
Berikut ini merupakan ukuran nilai silhouette menurut Kaufman dan
Rousseeuw (Kaufman & Rousseeuw, 1990). Nilai silhouette coefficient (SC):
1. 0,7 < SC <= 1 strong structure
2. 0,5 < SC <= 0,7 medium structure
3. 0,25 <SC <= 0,5 weak structure
4. SC <= 0,25 no structure

20
UIN Syarif Hidayatullah Jakarta
2.11. Metode Perbandingan Eksponensial
Metode perbandingan eksponensial (MPE) merupakan salah satu
metode pengambilan keputusan yang mengkualifikasikan pendapat
seseorang atau lebih dalam skala tertentu. Metode ini mampu menentukan
urutan prioritas alternatif keputusan dengan menggunakan beberapa kriteria
(Kriteria Majemuk) (Sari, 2018).
2.11.1. Tahapan Metode Perbandingan Eksponensial
Menurut (Pratiwi, 2016), tahapan metode perbandingan
eksponensial sebagai berikut:
1. Menyusun alternatif-alternatif keputusan yang akan dipilih
2. Menentukan kriteria atau perbandingan relatif kriteria
keputusan yang penting untuk dievaluasi dengan menggunakan
skala konversi tertentu sesuai dengan keinginan pengambil
keputusan
3. Menentukan tingkat kepentingan relatif dari setiap kriteria
keputusan atau pertimbangan kriteria. Penentuan bobot
ditetapkan pada setiap kriteria untuk menunjukkan tingkat
kepentingan suatu kriteria
4. Melakukan penilaian terhadap semua alternatif pada setiap
kriteria dalam bentuk total skor tiap alternatif.
2.11.2. Formulasi Perhitungan Metode Perbandingan Eksponensial
Formulasi perhitungan total nilai setiap pilihan keputusan
adalah sebagai berikut (Pratiwi, 2016):
Total Nilai (TNi) = ∑ (RKij)𝑇𝐾𝐾𝑗𝑚
𝑗=1
Keterangan :
TNi = Total nilai alternatif ke-i
Rkij = Derajat kepentingan relatif kriteria ke-j pada
pilihan keputusan i

21
UIN Syarif Hidayatullah Jakarta
TKKj = Derajat kepentingan kriteria keputusan ke-j; TKKj
> 0; bulat
n = Jumlah pilihan keputusan
m = Jumlah kriteria keputusan
Penentuan tingkat kepentigan kriteria dilakukan dengan
cara wawancara dengan si pengambil keputusan atau melalui
kesepakatan curah pendapat. Sedangkan penentuan skor alternatif
pada kriteria tertentu dilakukan dengan memberi nilai setiap
alternatif berdasarkan nilai kriterianya. Semakin besar nilai
alternatif semakin besar pula skor alternatif tersebut. Total skor
masing-masing alternatif keputusan akan relatif berbeda secara
nyata karena adanya fungsi eksponensial.
2.11.3. Keuntungan Metode Perbandingan Eksponensial
Metode Perbandingan Eksponensial dapat mengurangi bias
yang mungkin terjadi dalam analisis. Nilai skor yang
menggambarkan urutan prioritas menjadi besar dalam hal fungsi
eksponensial ini menyebabkan urutan prioritas alternatif keputusan
menjadi lebih nyata (Pratiwi, 2016).
2.12. Studi Pustaka
Studi kepustakaan merupakan studi terhadap kajian teoritis dan
referensi lain yang berkaitan dengan nilai, budaya dan norma yang
berkembang pada situasi sosial yang diteliti, selain itu studi kepustakaan
sangat penting dalam melakukan penelitian, hal ini dikarenakan penelitian
tidak akan lepas dari literatur-literatur ilmiah (Sugiyono, 2017). Studi
pustaka memiliki peranan penting dalam suatu penelitian. Dengan melakukan
studi pustaka, para peneliti mempunyai pengetahuan yang luas dan mendalam
tentang permasalahan yang hendak diteliti (Fitrah & Luthfiyah, 2017).
Penulis menggunakan metode studi pustaka dalam pengumpulan data
karena metode ini cocok dilakukan untuk mengumpulkan data dan informasi
sebagai bahan dasar peneliti dan acuan dalam penelitian.

22
UIN Syarif Hidayatullah Jakarta
2.13. Metode Simulasi
Menurut (Siregar, 2016) simulasi merupakan teknik penyusunan model
dari suatu keadaan nyata (sistem), kemudian dilakukan percobaan pada
model tersebut. Pada umumnya simulasi cocok bila diterapkan untuk
menganalisa interaksi masalah yang rumit dari sistem, sedangkan
penggunaan teknik analisa yang ada sangat terbatas. Simulasi juga
berguna untuk mengetahui pengaruh atau akibat suatu keputusan dalam
jangka waktu tertentu.
Menurut (Sajjad, 2010) yang dikutip dari skripsi (Hanum, Shofi, &
Masruroh, 2018) metode simulasi terdiri dari beberapa tahapan yang terdiri
dari:
2.13.1. Problem Formulation
Proses simulasi dimulai dengan masalah praktis yang
memerlukan pemecahan atau pemahaman. Sebagai contoh
sebuah perusahaan kargo ingin mencoba untuk mengembangkan
strategi baru untuk pengiriman truk, contoh lain yaitu astronom
mencoba memahami bagaimana sebuah nebula terbentuk. Pada
tahap ini kita harus memahami perilaku dari sistem, mengatur
operasi sistem sebagai objek untuk percobaan. Maka kita perlu
menganalisa berbagai solusi dengan menyelidik hasil sebelumnya
dengan masalah yang sama. Solusi yang paling diterima yang harus
dipilih.
2.13.2. Conceptual Model
Langkah ini terdiri dari deskripsi tingkat tinggi dari
struktur dan perilaku sebuah sistem dan mengidentifikasi semua
benda dengan atribut dan interface mereka. Kita juga harus
menentukan variabel state-nya, bagaimana cara mereka
berhubungan, dan mana yang penting untuk penelitian. Pada tahap
ini dinyatakan aspek-aspek kunci dari requirement. Selama definisi
model konseptual, kita perlu mengungkapkan fitur yang penting.

23
UIN Syarif Hidayatullah Jakarta
Kita juga harus mendokumentasikan informasi non-fungsional,
misalnya seperti perubahan pada masa yang akan datang,
perilaku nonintuitive atau non-formal, dan hubungan dengan
lingkungan.
2.13.3. Input / Output Data
Pada tahap ini kita mempelajari sistem untuk
mendapatkan data input dan output. Untuk melakukannya kita
harus mengumpulkan dan mengamati atribut yang telah
ditentukan pada tahap sebelumnya. Ketika entitas sistem yang
dipelajari, maka dicoba mengaitkannya dengan waktu. Isu penting
lainnya pada tahap ini adalah pemilihan ukuran sampel yang valid
secara statistik dan format data yang dapat diproses dengan
komputer. Kita harus memutuskan atribut mana yang stokastik
dan deterministik. Dalam beberapa kasus, tidak ada sumber data
yang dapat dikumpulkan (misalnya pada sistem yang belum ada).
Dalam kasus tersebut kita perlu mencoba untuk mendapatkan set
data dari sistem yang ada (jika tersedia). Pilihan lain yaitu dengan
menggunakan pendekatan stokastik untuk menyediakan data yang
diperlukan melalui generasi nomor acak.
2.13.4. Modelling
Pada tahap pemodelan, kita harus membangun
representasi yang rinci dari sistem berdasarkan model konseptual
dan input/output data yang dikumpulkan. Model ini dibangun
dengan mendefinisikan objek, atribut, dan metode menggunakan
paradigma yang dipilih. Pada tahap ini spesifikasi model dibuat,
termasuk set persamaan yang mendefinisikan perilaku dan
struktur. Setelah menyelesaikan definisi ini, kita harus
membangun struktur awal model (mungkin berkaitan sistem dan
metrik kerja).

24
UIN Syarif Hidayatullah Jakarta
2.13.5. Simulation
Pada tahap simulasi, kita harus memilih mekanisme
untuk menerapkan model (dalam banyak kasus menggunakan
komputer dan bahasa pemrograman dan alat-alat yang memadai),
dan model simulasi yang dibangun. Selama langkah ini, mungkin
perlu untuk mendefinisikan algoritma simulasi dan
menerjemahkannya ke dalam program komputer.
2.13.6. Verification and Validation
Pada tahap-tahap sebelumnya, tiga model yang berbeda
dibangun: model konseptual (spesifikasi), model sistem (desain),
dan model simulasi (executable program). Kita perlu untuk
memverifikasi dan memvalidasi model ini. Verifikasi terkait
dengan konsistensi internal antara tiga model. Validasi
difokuskan pada korespondensi antara model dan realitas: adalah
hasil simulasi yang konsisten dengan sistem yang dianalisis.
2.13.7. Eksperimentation
Kita harus menjalankan model simulasi, menyusul tujuan
yang dinyatakan pada model konseptual. Selama fase ini kita harus
mengevaluasi output dari simulator menggunakan korelasi
statistik untuk menentukan tingkat presisi untuk metrik kerja.
Fase ini dimulai dengan desain eksperimen, dengan
menggunakan teknik yang berbeda. Beberapa teknik ini meliputi
analisis sensitivitas, optimasi,dan seleksi (dibandingkan dengan
sistem alternatif).
2.13.8. Output Analysis
Pada tahap analisa keluaran, keluaran simulasi dianalisis
untuk memahami perilaku sistem. Keluaran ini digunakan untuk
mendapatkan tanggapan tentang perilaku sistem yang asli. Pada
tahap ini, alat visualisasi dapat digunakan untuk membantu proses
tersebut.

25
UIN Syarif Hidayatullah Jakarta
2.14. Studi Literatur Sejenis
Pada penelitian ini, penulis menggunakan literatur penelitian sejenis
yang sudah ada sebelumnya. Hal ini dimaksudkan untuk membandingkan
studi literatur tersebut. Berikut ini tabel literatur sejenis.

26
UIN Syarif Hidayatullah Jakarta
Tabel 2.1 Studi Literatur Sejenis
No Peneliti
(Tahun)
Judul Penelitian Algoritma Nilai k Stemming Pembobot
an
Normalisasi
Data
Pengujian Hasil
1 Muhamm
ad Sholeh
Hudin
(2018)
Implementasi
Metode Text
Mining dan K-
Means Clustering
untuk
Pengelompokan
Dokumen Skripsi
K-Means Nilai
k=2,3,4
5,6,8.
Algoritma
Stemming
Porter
TF-IDF - Pengujian
mencari
cluster terbaik
dengan
Silhoutte
Coefficient.
Nilai optimal terdapat
pada nilai k=4 dengan
nilai silhouette 0,483.
2 Ahmad
Salam
Wahid
Faizin
(2018)
Implementasi K-
Means Clustering
Pada Terjemahan
Al Quran
Berdasarkan
Keterkaitan Topik
K-Means Nilai
k=4
Algoritma
Nazief &
Andriani
TF-IDF Cosine
Normalizatio
n
Tidak
disebutkan
Peneliti menyimpulkan
bahwa penelitian
menggunakan algoritma
K-Means untuk
melakukan clustering
terjemahan ayat Al
Quran menghasilkan
akurasi 43% dengan nilai
k=4

27
UIN Syarif Hidayatullah Jakarta
3 Darnisa
Azzahra
Nasution,
Hidayah
Husnul
Khotimah
dan Nurul
Chamidah
(2019)
Perbandingan
Normalisasi Data
Untuk Klasifikasi
Wine
Menggunakan
Algoritma K-NN
K-NN K=3, 5,
7, dan
11
- - Min-max
normalizatio
n, Decimal
scaling dan
Z-score
normalizatio
n
Tidak
disebutkan
Akurasi tertinggi
metode min-max
normalization K = 1
sebesar 65,92%.
4 Adit
Jamdar,
Jessica
Abraham,
Karishma
Khanna
dan Rahul
Dubey
(2015)
Emotion Analysis
of songs based on
lyrical and audio
features
K-NN Tidak
disebutk
an
Tidak
disebutka
n
TF-IDF Min-max
normalizatio
n
Tidak
disebutkan
Menghasilkan akurasi
dengan rata-rata sebesar
83,40%.

28
UIN Syarif Hidayatullah Jakarta
5 Dewinta
Fenny
(2019)
Perbandingan
Cosine
Normalization dan
Min-max
Normalization pada
Pengelompokan
Terjemahan Ayat
Al-Quran
Menggunakan K-
Means Clustering
K-Means Nilai k =
2,3,4,5,6
,8.
Algoritma
Nazief &
Andriani
TF-IDF Cosine
Normalizatio
n dan Min-
max
Normalizatio
n
Pengujian
mencari
cluster terbaik
dengan
Silhoutte
Coefficient
dan
membandingk
an performa
dari metode
normalization.
Menemukan nilai k
terbaik untuk clustering
dan mengetahui metode
normalization yang
terbaik untuk
pengelompokan
terjemahan ayat Al
Quran.

29
UIN Syarif Hidayatullah Jakarta
Adapun perbedaan antara peneliti saat ini dengan peneliti sebelumnya
yaitu :
1. Peneliti membuat dua skenario, pertama menggunakan metode
normalisasi Cosine Normalization dan skenario ke dua
menggunakan metode normalisasi Min-max Normalization.
2. Peneliti melakukan pengujian cluster dengan menggunakan
metode silhouette coefficient.
3. Pada penelitian sebelumnya telah menggunakan nilai k = 4. Oleh
karena itu pada penelitian ini penulis menggunakan nilai k 2-8
yaitu nilai lebih kecil dan lebih besar dari nilai k = 4.
4. Peneliti menambahkan perbandingan performa dan kinerja pada
masing-masing skenario yaitu memory consumption dan runtime
sebagai pembeda dari peneliti sebelumnya.

30
BAB 3
METODOLOGI PENELITIAN
3.1. Metode Pengumpulan Data
Pada metode pengumpulan data peneliti mengumpulkan informasi yang
dibutuhkan dalam rangka mencapai tujuan penelitian. Oleh karena itu peneliti
memerlukan metode pengumpulan data guna mendukung penelitian ini.
Proses pengumpulan data sebagai berikut.
3.1.1. Sumber Data
Pada penelitian ini, penulis menggunakan sumber teks
terjemahan Al Quran dari website Tanzil.net. Penulis menggunakan
teks terjemahan Bahasa Indonesia yang diterjemahkan oleh
Indonesian Ministry of Religious Affairs (Departemen Agama
Indonesia) berasal dari http://tanzil.net/docs/resources yang sudah
didigitalisasi dalam format sql. Jumlah data yang digunakan sebagai
sample yaitu surah Al Baqarah ayat 2 – 286.
3.1.2. Studi Pustaka
Peneliti melakukan studi pustaka dengan pengumpulan
literatur-literatur yang berkaitan dengan penulisan skripsi sebagai
bahan untuk melengkapi penelitian. Pencarian literatur dilakukan di
perpustakaan dan secara online melalui internet. Literatur yang
dipakai berasal dari berbagai buku referensi, e-book, skripsi, jurnal
dan artikel yang terkait dengan penelitian ini. Studi pustaka juga
dimaksudkan untuk mencari literatur yang mempunyai persamaan
atau keterkaitan dengan penelitian yang sedang dilakukan, yaitu
penelitian yang terkait dengan pengelompokan data atau teks dengan
menggunakan Algoritma K-Means Clustering dan normalisasi data.
Hal ini dimaksudkan untuk mengevaluasi dan dijadikan bahan untuk
perbandingan agar bisa dilakukan pengembangan yang lebih baik
dari penelitian sebelumnya. Pustaka yang dijadikan acuan dapat
dilihat pada Daftar Pustaka.

31
UIN Syarif Hidayatullah Jakarta
3.2. Metode Pengembangan Sistem
Dalam penelitian ini, penulis menggunakan metode simulasi untuk
melihat perbandingan dari hasil clustering data teks terjemahan ayat Al Quran
menggunakan normalisasi data Min-max Normalization dan Cosine
Normalization pada Algoritma K-Means Clustering. Metode simulasi terdiri
dari beberapa tahapan, yaitu:
3.2.1. Problem Formulation
Pada tahap problem formulation, penulis memilih suatu
permasalahan untuk dianalisis. Penulis melakukan studi pustaka dan
studi literatur, penulis memutuskan untuk melakukan penelitian
mengenai penerapan algoritma k-means clustering dan
perbandingan penerapan norrmalisasi data dalam proses
pengelompokan terjemahan ayat Al Quran Bahasa Indonesia. Pada
penelitian sebelumnya yaitu penelitian dari (Faizin, 2018)
menggunakan Cosine Nomalization pada pengelompokan
terjemahan ayat Al Quran Bahasa Indonesia.
3.2.2. Conceptual Model
Pada tahapan ini peneliti membuat model konsep yang akan
dilakukan yaitu membahas keseluruhan penelitian ini. Konsep
pertama membuat konsep pada proses preprocessing. Kedua,
membuat konsep untuk skenario 1 yaitu menerapkan Cosine
Nomalization pada clustering Algoritma K-Means. Ketiga, membuat
konsep skenario 2 yaitu menerapkan Min-max Normalization pada
clustering Algoritma K-Means.
3.2.3. Input Output Data
Data masukan seperti kamus kata dasar KBBI, kamus
stopword dan data teks terjemahan ayat Al Quran Bahasa Indonesia
menjadi input pada penelitian ini. Data yang diambil sebagai sample
sebanyak 286 ayat. Data pada aplikasi ini diolah menggunakan
algoritma K-Means Clustering untuk menghasilkan output berupa

32
UIN Syarif Hidayatullah Jakarta
cluster dan nilai sillhoutte, runtime, dan memory consumption dari
skenario 1 dan skenario 2.
3.2.4. Modelling
Pada tahap ini penulis melakukan pemodelan dalam
membuat rancangan sistem yang akan dibuat secara manual.
Pemodelan atau skenario yang dibuat yaitu skenario penerapan
Cosine Nomalization pada algoritma K-Means Clustering dan
skenario penerapan Min-max Normalization pada algoritma K-
Means Clustering.
3.2.5. Simulation
Pada tahapan ini, sistem yang telah dibuat akan dijalankan
untuk mensimulasikan kinerja algoritma sesuai dengan konsep dan
skenario yang telah ditentukan sebelumnya. Hasil simulasi dicatat
dan kemudian akan dilakukan tahap verifikasi.
3.2.6. Verification and Validation
Pada tahapan ini peneliti melakukan verifikasi dan validasi
dari tahapan sebelumnya. Verifikasi dilakukan untuk memastikan
adanya kesalahan atau tidak yang terjadi ketika sistem dijalankan.
Validasi dilakukan untuk memastikan kesesuaian proses simulasi
yang dibuat berdasarkaan model pengkonsepan dengan formulasi
masalah yang dibuat. Jika validasi tidak terpenuhi, maka peneliti
kembali ketahap conceptual model untuk membuat model
pengkonsepan yang baru.
3.2.7. Experimentation
Pada tahapan ini, penulis melakukan eksperimentasi sesuai
dengan model yang dibuat pada saat tahapan modelling. Pada setiap
model skenario dilakukan percobaan sebanyak enam kali dengan
memasukan nilai k yang berbeda yaitu k=2, k=3, k=4, k=5, k=6, k=8
dan setiap percobaan dijalankan sebanyak lima kali.

33
UIN Syarif Hidayatullah Jakarta
3.2.8. Output Analysis
Pada tahap terakhir ini, peneliti menganalisis output simulasi
yang dilakukan pada saat eksperimentasi. Output direpresentasikan
dalam bentuk tabel yang menyatakan nilai sillhoutte, waktu
pemrosesan (runtime) dan memori yang digunakan (memory
consumption) dari masing-masing nilai k yang telah ditentukan.
3.3. Kerangka Berpikir
Dalam penyusunan skripsi ini, peneliti melakukan tahapan-tahapan
dengan mengacu pada kerangka berpikir berikut ini :

34
UIN Syarif Hidayatullah Jakarta
Gambar 3.1 Kerangka Berfikir

35
UIN Syarif Hidayatullah Jakarta
BAB 4
IMPLEMENTASI, SIMULASI, DAN EKSPERIMEN
4.1. Problem Formulation
Pada tahapan formulasi masalah ini, penulis melakukan identifikasi
masalah berdasarkan penelitian sebelumnya. Penelitian sebelumnya oleh
(Faizin, 2018) yaitu mengimplementasikan Algoritma K-Means Clustering
dengan menggunakan Cosine Nomalization pada pengelompokan ayat-ayat
Al Quran menghasilkan akurasi sebesar 43%.
Menurut (Hudin et al., 2018) pengelompokan teks menggunakan
metode text mining menggunakan kata atau term sebagai fitur akan
menghasilkan dimensi vektor yang cukup besar. Sehingga disarankan untuk
menambahkan suatu metode yang dapat mereduksi ukuran dimensi yang
cukup besar. Secara umum ada dua tipe metode reduksi yang biasa
digunakan antara lain transformasi fitur dan feature selection.
Setelah melakukan studi pustaka mengenai Algoritma K-Means
Clustering pada pengelompokan data teks penulis memutuskan untuk
menggunakan transformasi fitur dengan menormalisasi data menggunakan
Min-max Normalization. Peneliti akan membandingkan Cosine
Normalization dengan Min-max Normalization pada pengelompokan teks
terjemahan ayat Al Quran menggunakan Algoritma K-Means Clustering.
Peneliti menggunakan nilak k 2-8 dan membandingkan nilai silhouette
coefficient, waktu pemrosesan (runtime), memori yang digunakan
(memory consumption) dari masing-masing metode normalisasi sebagai
pembeda dengan penelitian sebelumnya. Pengujian dengan membandingkan
metode normalisasi Cosine Normalization dan Min-max Normalization, hal
ini dilakukan untuk mengetahui apakah Min-max Normalization dapat
membantu dalam pengelompokan.
4.2. Conceptual Model
Pada tahap conceptual model ini dilakukan pengkonsepan sistem yang
akan dibangun dan membahas alur keseluruhan dari penelitian ini yang

36
UIN Syarif Hidayatullah Jakarta
berkaitan dengan input, proses dan output. Berikut ini merupakan konsep
alur keseluruhan dari sistem yang dibangun oleh peneliti.
4.2.1. Conceptual Model Preprocessing
Dalam penelitian ini data terlebih dahulu diproses dengan tahapan
preprocessing. Preprocessing data dilakukan dengan menggunakan bahasa
pemrograman php. Tahapan preprocessing yang dilakukan pada penelitian
ini adalah proses case folding, tokenizing, stopwords removal dan stemming.
Algoritma stemming yang digunakan dalam penelitian ini adalah Algoritma
nazief & andriani. Berikut ini diagram alur tahapan preprocessing yang
dilakukan dalam penelitian ini :
Gambar 4.1 Diagram Alur Preprocessing
Berikut ini penjelesan dari tahapan preprocessing :
1. Pada tahap pertama preprocessing yaitu proses case folding, adalah
proses yang digunakan untuk menyamakan bentuk huruf menjadi
huruf kecil dan menghapus karakter selain huruf.

37
UIN Syarif Hidayatullah Jakarta
Gambar 4.2 Flowchart Case Folding
Berikut contoh hasil Case folding :
Tabel 4.1 Contoh Hasil Case Folding
Input output
Kitab (Al Quran) ini tidak
ada keraguan padanya;
petunjuk bagi mereka
yang bertakwa,
kitab al quran ini tidak ada keraguan
padanya petunjuk bagi mereka yang
bertakwa
2. Tahapan kedua yaitu Tokenization, adalah proses pemisahan kata-kata
dari suatu kalimat.

38
UIN Syarif Hidayatullah Jakarta
Gambar 4.3 Flowchart Tokenization
Berikut contoh hasil Tokenization :
Tabel 4.2 Contoh Hasil Tokenization
Input output
kitab al quran ini tidak
ada keraguan padanya
petunjuk bagi mereka
yang bertakwa
'kitab', 'al', 'quran', 'ini', 'tidak', 'ada',
'keraguan', 'padanya', 'petunjuk', 'bagi',
'mereka', 'yang', 'bertakwa'
3. Tahapan ketiga yaitu Stopword Removal, adalah proses penghilangan
token atau menghapus kata-kata yang dianggap tidak relevan.

39
UIN Syarif Hidayatullah Jakarta
Gambar 4.4 Flowchart Stopwords Removal
Berikut contoh hasil Stopword Removal :
Tabel 4.3 Contoh Hasil Stopword Removal
Input output
'kitab', 'al', 'quran', 'ini',
'tidak', 'ada', 'keraguan',
'padanya', 'petunjuk',
'bagi', 'mereka', 'yang',
'bertakwa'
'kitab', 'al', 'quran', 'keraguan',
'petunjuk', 'bertakwa'
4. Tahapan terakhir yaitu Stemming, adalah proses menghilangkan
imbuhan pada sebuah kata menjadi kata dasar sesuai KBBI dengan

40
UIN Syarif Hidayatullah Jakarta
menggunakan Algoritma Nazief & Andriani. Berikut adalah gambar
flowchart Algoritma Nazief & Andriani :
Gambar 4.5 Flowchart Algoritma Nazief & Andriani
Berikut contoh hasil Stemming :
Tabel 4.4 Contoh Hasil Stemming
Input output
'kitab', 'al', 'quran',
'keraguan', 'petunjuk',
'bertakwa'
'kitab', 'al', 'quran', 'ragu', 'tunjuk',
'takwa'

41
UIN Syarif Hidayatullah Jakarta
4.2.2. Conceptual Model Algoritma K-Means Clustering dengan
menggunakan Cosine Normalization
Skenario yang pertama pada penelitian ini secara alur dari analisis
pengelompokan dengan menggunakan Cosine Normalization pada
algoritma K-Means Clustering sebagai metode untuk mentransormasikan
data dapat dijelaskan pada gambar dibawah ini :
Gambar 4.6 Proses Skenario 1 Clustering K-Means dengan Cosine Normalization
Berikut penjelasan dari setiap proses saat melakukan
pengelompokan dengan Algoritma K-Means Clustering menggunakan
Cosine Normalization :

42
UIN Syarif Hidayatullah Jakarta
1. Menyiapkan dataset terjemahan ayat Al Quran dalam format
sql.
2. Melakukan proses preprocessing sesuai dengan tahapan 4.2.1
yaitu conceptual model preprocessing.
3. Melakukan pembobotan kata setelah proses preprocessing
selesai dengan menggunakan Algoritma TF-IDF.
4. Setelah mendapatkan nilai weighting maka selanjutnya data
dinormalisasikan dengan menggunakan Cosine Normalization.
5. Nilai weighting yang sudah di normalisasi dihitung totalnya,
lalu diproses menggunakan Algoritma K-Means Clustering.
Berikut alur dari Algoritma K-Means Clustering :

43
UIN Syarif Hidayatullah Jakarta
Gambar 4.7 Proses Algoritma K-Means
Penjelesan untuk proses Algoritma K-Means Clustering sudah
dijelaskan pada sub-bab 2.9.2
6. Setelah didapatkan cluster sesuai dengan nilai k yang
ditentukan, maka tahap selanjutnya adalah evaluasi cluster.
7. Evaluasi cluster dilakukan dengan menghitung nilai sillhoutte
coefficient, runtime, dan memory consumption.

44
UIN Syarif Hidayatullah Jakarta
4.2.3. Conceptual Model Algoritma K-Means Clustering dengan
menggunakan Min-max Normalization
Skenario yang kedua pada penelitian ini secara alur dari analisis
pengelompokan dengan menggunakan Min-max Normalization pada
algoritma K-Means Clustering sebagai metode untuk mentransormasikan
data dapat dijelaskan pada gambar dibawah ini :
Gambar 4.8 Proses Skenario 2 Clustering K-Means dengan Min-max Normalization

45
UIN Syarif Hidayatullah Jakarta
Berikut penjelasan dari setiap proses saat melakukan
pengelompokan dengan Algoritma K-Means Clustering menggunakan Min-
max Normalization :
1. Menyiapkan dataset terjemahan ayat Al Quran dalam format
sql.
2. Melakukan proses preprocessing sesuai dengan tahapan
4.2.1 yaitu conceptual model preprocessing.
3. Melakukan pembobotan kata setelah proses preprocessing
selesai dengan menggunakan Algoritma TF-IDF.
4. Setelah mendapatkan nilai weighting maka selanjutnya data
dinormalisasikan dengan menggunakan Min-max
Normalization.
5. Nilai weighting yang sudah di normalisasi dihitung totalnya,
lalu diproses menggunakan Algoritma K-Means Clustering.
6. Setelah didapatkan cluster sesuai dengan nilai k yang
ditentukan, maka tahap selanjutnya adalah evaluasi cluster.
7. Evaluasi cluster dilakukan dengan menghitung nilai
sillhoutte coefficient, runtime, dan memory consumption.
4.3. Input/Output Data
4.3.1. Input
Data masukan seperti kamus kata dasar KBBI, kamus stopword dan
data teks terjemahan ayat Al Quran. Data teks terjemahan ayat Al Quran
yang digunakan berbahasa Indonesia yang diterjemahkan oleh Indonesian
Ministry of Religious Affairs (Departemen Agama Indonesia) berasal dari
http://tanzil.net/docs/resources yang sudah didigitalisasi dalam format sql.
Jumlah data teks yang digunakan sebanyak 286 ayat yaitu Surah Al
Baqarah.

46
UIN Syarif Hidayatullah Jakarta
4.3.2. Output
Data keluaran atau ouput dari hasil simulasi ini adalah cluster dari
data yang sudah diproses oleh sistem dan nilai sillhoutte coefficient, waktu
pemrosesan (runtime), memori yang digunakan (memory consumption)
dari masing-masing nilai k yang dimasukan.
4.4. Modelling
Dalam modelling phase atau fase pemodelan pada penelitian ini,
dilakukan pemodelan konstruksi pengelompokan teks terjemahan ayat Al
Quran dengan menggunakan Cosine Normalization dan Min-max
Normalization sebagai metode untuk mentransformasikan data. Berikut ini
dapat dilihat pemodelan-pemodelan tersebut secara lengkap.
4.4.1. Konstruksi Cosine Normalization pada Clustering Algoritma
K-Means
Konstruksi Cosine Normalization pada pengelompokan teks
terjemahan ayat Al Quran menggunakan Algoritma K-Means, ini
merupakan skenario 1 di dalam penelitian ini. Secara keseluruhan
konstruksi pengelompokan teks terjemahan ayat Al Quran menggunakan
Cosine Normalization sebagai metode untuk mentransformasikan data pada
Algoritma K-Means dapat dijelaskan dibawah ini (konsep diambil dari sub-
bab 4.2.2 dan dapat dilihat pada gambar 4.6 ) :
1. Menyiapkan dataset terjemahan ayat Al Quran dalam format
sql.
2. Melakukan proses preprocessing sesuai dengan tahapan 4.2.1
yaitu conceptual model preprocessing. Sebagai contoh
digunakan enam ayat untuk melakukan clustering dengan
algoritma k-means. Enam ayat yang digunakan diambil secara
acak menggunakan microsoft excel.

47
UIN Syarif Hidayatullah Jakarta
Tabel 4.5 Teks terjemahan ayat Al Quran
No No Ayat Data (Terjemahan Ayat)
1 2 Kitab (Al Quran) ini tidak ada keraguan
padanya; petunjuk bagi mereka yang
bertakwa,
2 43 Dan dirikanlah shalat, tunaikanlah zakat
dan ruku?lah beserta orang-orang yang
ruku?.
3 53 Dan (ingatlah), ketika Kami berikan kepada
Musa Al Kitab (Taurat) dan keterangan
yang membedakan antara yang benar dan
yang salah, agar kamu mendapat petunjuk.
4 99 Dan sesungguhnya Kami telah menurunkan
kepadamu ayat-ayat yang jelas; dan tak ada
yang ingkar kepadanya, melainkan orang-
orang yang fasik.
5 122 Hai Bani Israil, ingatlah akan nikmat-Ku
yang telah Ku-anugerahkan kepadamu dan
Aku telah melebihkan kamu atas segala
umat.
6 242 Demikianlah Allah menerangkan
kepadamu ayat-ayat-Nya (hukum-hukum-
Nya) supaya kamu memahaminya.
Tahapan preprocessing
1) Case folding
Tabel 4.6 Hasil Case folding
No Hasil Case folding
1 kitab al quran ini tidak ada keraguan padanya petunjuk
bagi mereka yang bertakwa

48
UIN Syarif Hidayatullah Jakarta
2 dan dirikanlah shalat tunaikanlah zakat dan rukulah
beserta orang-orang yang ruku
3 dan ingatlah ketika kami berikan kepada musa al kitab
taurat dan keterangan yang membedakan antara yang
benar dan yang salah agar kamu mendapat petunjuk
4 dan sesungguhnya kami telah menurunkan kepadamu
ayat ayat yang jelas dan tak ada yang ingkar
kepadanya melainkan orang orang yang fasik
5 hai bani israil ingatlah akan nikmatku yang telah
kuanugerahkan kepadamu dan aku telah melebihkan
kamu atas segala umat
6 demikianlah allah menerangkan kepadamu ayat
ayatnya hukum hukumnya supaya kamu
memahaminya
2) Tokenization
Tabel 4.7 Hasil Tokenization
No Hasil Tokenization
1 'kitab', 'al', 'quran', 'ini', 'tidak', 'ada', 'keraguan',
'padanya', 'petunjuk', 'bagi', 'mereka', 'yang', 'bertakwa'
2 'dan', 'dirikanlah', 'shalat', 'tunaikanlah', 'zakat', 'dan',
'rukulah', 'beserta', 'orang-orang', 'yang', 'ruku'
3 'dan', 'ingatlah', 'ketika', 'kami', 'berikan', 'kepada',
'musa', 'al', 'kitab', 'taurat', 'dan', 'keterangan', 'yang',
'membedakan', 'antara', 'yang', 'benar', 'dan', 'yang',
'salah', 'agar', 'kamu', 'mendapat', 'petunjuk'
4 'dan', 'sesungguhnya', 'kami', 'telah', 'menurunkan',
'kepadamu', 'ayat-ayat', 'yang', 'jelas', 'dan', 'tak', 'ada',
'yang', 'ingkar', 'kepadanya', 'melainkan', 'orang-
orang', 'yang', 'fasik'

49
UIN Syarif Hidayatullah Jakarta
5 'hai', 'bani', 'israil', 'ingatlah', 'akan', 'nikmatku', 'yang',
'telah', 'kuanugerahkan', 'kepadamu', 'dan', 'aku',
'telah', 'melebihkan', 'kamu', 'atas', 'segala', 'umat'
6 'demikianlah', 'allah', 'menerangkan', 'kepadamu',
'ayat', 'ayat, 'nya', 'hukum', 'hukum', 'nya', 'supaya',
'kamu', 'memahaminya'
3) Stopword removal
Tabel 4.8 Hasil Stopword Removal
No Hasil Stopword removal
1 'kitab', 'al', 'quran', 'keraguan', 'petunjuk', 'bertakwa'
2 'dirikanlah', 'shalat', 'tunaikanlah', 'zakat', 'rukulah',
'beserta', 'ruku'
3 'ingatlah', 'musa', 'al', 'kitab', 'taurat', 'keterangan',
'membedakan', 'benar', 'salah', 'petunjuk'
4 'sesungguhnya', 'menurunkan', 'kepadamu', 'ayat',
'ayat', 'jelas', 'ingkar', 'fasik'
5 'hai', 'bani', 'israil', 'ingatlah', 'nikmatku',
'kuanugerahkan', 'kepadamu', 'melebihkan', 'umat'
6 ‘allah', 'menerangkan', 'kepadamu', 'ayat', 'ayat', 'nya',
'hukum', 'hukum', 'nya', 'memahaminya'
4) Stemming
Tabel 4.9 Hasil Stemming
No Hasil Stemming
1 'kitab', 'al', 'quran', 'ragu', 'tunjuk', 'takwa'
2 'diri', 'shalat', 'tunai', 'zakat', 'ruku', 'serta', 'ruku'
3 'ingat', 'musa', 'al', 'kitab', 'taurat', 'terang', 'beda',
'benar', 'salah', 'tunjuk'
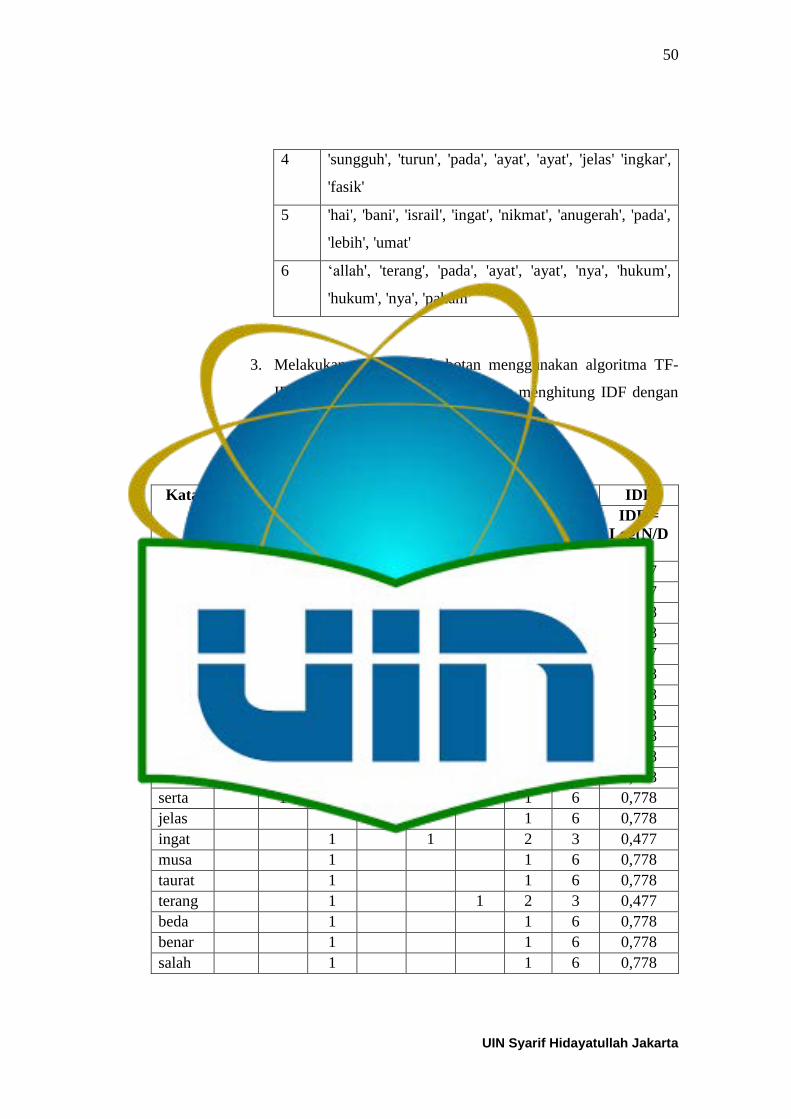
50
UIN Syarif Hidayatullah Jakarta
4 'sungguh', 'turun', 'pada', 'ayat', 'ayat', 'jelas' 'ingkar',
'fasik'
5 'hai', 'bani', 'israil', 'ingat', 'nikmat', 'anugerah', 'pada',
'lebih', 'umat'
6 ‘allah', 'terang', 'pada', 'ayat', 'ayat', 'nya', 'hukum',
'hukum', 'nya', 'paham'
3. Melakukan proses pembobotan menggunakan algoritma TF-
IDF. Proses perhitungan awal yaitu menghitung IDF dengan
rumus yang dapat dilihat pada sub-bab 2.7.
Tabel 4.10 Hasil Perhitungan IDF
Kata TF DF N/D
F
IDF
A1 A2 A3 A4 A5 A6 IDF =
Log(N/D
F)
kitab 1
1
2 3 0,477
al 1
1
2 3 0,477
quran 1
1 6 0,778
ragu 1
1 6 0,778
tunjuk 1
1
2 3 0,477
takwa 1
1 6 0,778
diri
1
1 6 0,778
shalat
1
1 6 0,778
tunai
1
1 6 0,778
zakat
1
1 6 0,778
ruku
2
1 6 0,778
serta
1
1 6 0,778
jelas
1
1 6 0,778
ingat
1
1
2 3 0,477
musa
1
1 6 0,778
taurat
1
1 6 0,778
terang
1
1 2 3 0,477
beda
1
1 6 0,778
benar
1
1 6 0,778
salah
1
1 6 0,778

51
UIN Syarif Hidayatullah Jakarta
sunggu
h
1
1 6 0,778
turun
1
1 6 0,778
pada
1 1 1 3 2 0,301
ayat
2
2 2 3 0,477
ingkar
1
1 6 0,778
fasik
1
1 6 0,778
hai
1
1 6 0,778
bani
1
1 6 0,778
israil
1
1 6 0,778
nikmat
1
1 6 0,778
anuger
ah
1
1 6 0,778
lebih
1
1 6 0,778
umat
1
1 6 0,778
allah
1 1 6 0,778
nya
2 1 6 0,778
hukum
2 1 6 0,778
paham
1 1 6 0,778
Keterangan :
A = dokumen ayat terjemahan.
Seteleh mendapatkan nilai IDF, selanjutnya menghitung nilai
bobotnya (term weighting) dengan rumus yang dapat dilihat
pada sub-bab 2.7
Tabel 4.11 Hasil Perhitungan W (term weighting)
Kata W (W=TF*IDF)
A1 A2 A3 A4 A5 A6
kitab 0,477 0,000 0,477 0,000 0,000 0,000
al 0,477 0,000 0,477 0,000 0,000 0,000
quran 0,778 0,000 0,000 0,000 0,000 0,000
ragu 0,778 0,000 0,000 0,000 0,000 0,000
tunjuk 0,477 0,000 0,477 0,000 0,000 0,000
takwa 0,778 0,000 0,000 0,000 0,000 0,000
diri 0,000 0,778 0,000 0,000 0,000 0,000
shalat 0,000 0,778 0,000 0,000 0,000 0,000
tunai 0,000 0,778 0,000 0,000 0,000 0,000
zakat 0,000 0,778 0,000 0,000 0,000 0,000
ruku 0,000 1,556 0,000 0,000 0,000 0,000

52
UIN Syarif Hidayatullah Jakarta
serta 0,000 0,778 0,000 0,000 0,000 0,000
jelas 0,000 0,000 0,000 0,778 0,000 0,000
ingat 0,000 0,000 0,477 0,000 0,477 0,000
musa 0,000 0,000 0,778 0,000 0,000 0,000
taurat 0,000 0,000 0,778 0,000 0,000 0,000
terang 0,000 0,000 0,477 0,000 0,000 0,477
beda 0,000 0,000 0,778 0,000 0,000 0,000
benar 0,000 0,000 0,778 0,000 0,000 0,000
salah 0,000 0,000 0,778 0,000 0,000 0,000
sungguh 0,000 0,000 0,000 0,778 0,000 0,000
turun 0,000 0,000 0,000 0,778 0,000 0,000
pada 0,000 0,000 0,000 0,301 0,301 0,301
ayat 0,000 0,000 0,000 0,954 0,000 0,954
ingkar 0,000 0,000 0,000 0,778 0,000 0,000
fasik 0,000 0,000 0,000 0,778 0,000 0,000
hai 0,000 0,000 0,000 0,000 0,778 0,000
bani 0,000 0,000 0,000 0,000 0,778 0,000
israil 0,000 0,000 0,000 0,000 0,778 0,000
nikmat 0,000 0,000 0,000 0,000 0,778 0,000
anugerah 0,000 0,000 0,000 0,000 0,778 0,000
lebih 0,000 0,000 0,000 0,000 0,778 0,000
umat 0,000 0,000 0,000 0,000 0,778 0,000
allah 0,000 0,000 0,000 0,000 0,000 0,778
nya 0,000 0,000 0,000 0,000 0,000 1,556
hukum 0,000 0,000 0,000 0,000 0,000 1,556
paham 0,000 0,000 0,000 0,000 0,000 0,778
Nilai bobot setiap
dokumen
3,766 5,447 6,276 5,146 6,225 6,401
4. Setelah mendapatkan nilai weighting /bobot maka selanjutnya
data dinormalisasikan dengan menggunakan Cosine
Normalization. Normalisasi bobot dihitung dengan
menggunakan persamaan Cosine Normalization. Persamaan
Cosine Normalization dapat dilihat dalam sub-bab 2.8.1
Sebagai contoh normalisasi dari A1 dengan kata “kitab” dengan
hasil TF-IDF adalah 0,477.
𝑤(𝑘𝑖𝑡𝑎𝑏) =0,477
√0,4772+0,4772+0.7782+0,7782+0,4772+0,7782= 0,302
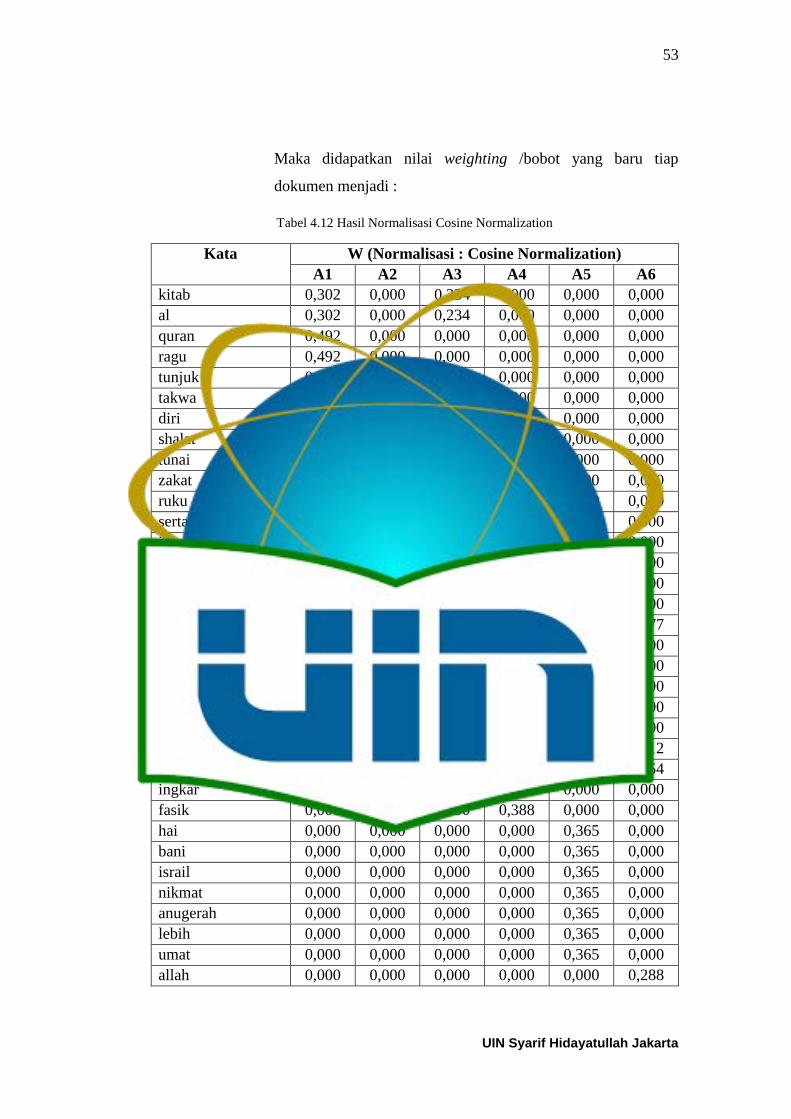
53
UIN Syarif Hidayatullah Jakarta
Maka didapatkan nilai weighting /bobot yang baru tiap
dokumen menjadi :
Tabel 4.12 Hasil Normalisasi Cosine Normalization
Kata W (Normalisasi : Cosine Normalization)
A1 A2 A3 A4 A5 A6
kitab 0,302 0,000 0,234 0,000 0,000 0,000
al 0,302 0,000 0,234 0,000 0,000 0,000
quran 0,492 0,000 0,000 0,000 0,000 0,000
ragu 0,492 0,000 0,000 0,000 0,000 0,000
tunjuk 0,302 0,000 0,234 0,000 0,000 0,000
takwa 0,492 0,000 0,000 0,000 0,000 0,000
diri 0,000 0,333 0,000 0,000 0,000 0,000
shalat 0,000 0,333 0,000 0,000 0,000 0,000
tunai 0,000 0,333 0,000 0,000 0,000 0,000
zakat 0,000 0,333 0,000 0,000 0,000 0,000
ruku 0,000 0,667 0,000 0,000 0,000 0,000
serta 0,000 0,333 0,000 0,000 0,000 0,000
jelas 0,000 0,000 0,000 0,388 0,000 0,000
ingat 0,000 0,000 0,234 0,000 0,224 0,000
musa 0,000 0,000 0,381 0,000 0,000 0,000
taurat 0,000 0,000 0,381 0,000 0,000 0,000
terang 0,000 0,000 0,234 0,000 0,000 0,177
beda 0,000 0,000 0,381 0,000 0,000 0,000
benar 0,000 0,000 0,381 0,000 0,000 0,000
salah 0,000 0,000 0,381 0,000 0,000 0,000
sungguh 0,000 0,000 0,000 0,388 0,000 0,000
turun 0,000 0,000 0,000 0,388 0,000 0,000
pada 0,000 0,000 0,000 0,150 0,141 0,112
ayat 0,000 0,000 0,000 0,475 0,000 0,354
ingkar 0,000 0,000 0,000 0,388 0,000 0,000
fasik 0,000 0,000 0,000 0,388 0,000 0,000
hai 0,000 0,000 0,000 0,000 0,365 0,000
bani 0,000 0,000 0,000 0,000 0,365 0,000
israil 0,000 0,000 0,000 0,000 0,365 0,000
nikmat 0,000 0,000 0,000 0,000 0,365 0,000
anugerah 0,000 0,000 0,000 0,000 0,365 0,000
lebih 0,000 0,000 0,000 0,000 0,365 0,000
umat 0,000 0,000 0,000 0,000 0,365 0,000
allah 0,000 0,000 0,000 0,000 0,000 0,288

54
UIN Syarif Hidayatullah Jakarta
nya 0,000 0,000 0,000 0,000 0,000 0,577
hukum 0,000 0,000 0,000 0,000 0,000 0,577
paham 0,000 0,000 0,000 0,000 0,000 0,288
Nilai bobot setiap
dokumen
2,382 2,333 3,075 2,564 2,916 2,372
5. Nilai weighting / bobot setiap dokumen kemudian diproses
menggunakan Algoritma K-Means Clustering untuk
menghasilkan cluster. Prosesnya dapat dilihat pada gambar 4.7
dan penjelasannya bisa dilihat pada sub-bab 2.9.2.
a. Menentukan nilai k. Pada penulisan penelitian ini
digunakan contoh perhitungan dengan nilai k =3.
b. Menentukan centroid awal sebanyak nilai k, yaitu
centroid awal yang dipilih secara acak atau random.
Tabel 4.13 Centroid Awal Skenario-1
Keterangan :
C = Cluster
c. Menghitung jarak dari setiap ayat ke centroid awal yang
sudah ditentukan dengan menggunakan rumus
euclidean distance. Rumus euclidean distance
sebelumnya sudah dijelaskan dalam sub-bab 2.9.2
Berikut contoh perhitungan jarak menggunakan
euclidean distance
ayat 2 pada centroid ke − 1 =
√(2,382 − 2,382)2 = 0,000
ayat 2 pada centroid ke − 2 =
√(2,382 − 2,333)2 = 0,049
ayat 2 pada centroid ke − 3 =
√(2,382 − 3,075)2 = 0,693
C1 C2 C3
2,382 2,333 3,075

55
UIN Syarif Hidayatullah Jakarta
Tabel 4.14 Jarak dari hasil iterasi ke-1 Skenario-1
d. Mengelempokan ayat yang sesuai dengan kedekatan
centroid (jarak minimum) ke dalam masing-masing
cluster.
Tabel 4.15 Hasil Clustering Iterasi ke-1 Skenario-1
e. Memperbarui nilai centroid dengan menghitung rata-
rata dari setiap cluster.
Centroid baru cluster 1 : (2,382 + 2,564 + 2,372) / 3 =
2,439
Centroid baru cluster 2 : 2,333
Centroid baru cluster 3 : (3,075 + 2,916) / 2 = 2,996
Maka dihasilkan centroid baru, yaitu :
Tabel 4.16 Centroid Baru ke-1 Skenario-1
f. Melanjutkan iterasi sampai tidak ada ayat yang
berpindah cluster dengan menghitung kembali jarak
minimum antara ayat dengan centroid baru
menggunakan euclidean distance.
Ayat ke- C1 C2 C3
2 0,000 0,049 0,693
43 0,049 0,000 0,742
53 0,693 0,742 0,000
99 0,182 0,230 0,511
122 0,534 0,583 0,159
242 0,010 0,038 0,703
C1 C2 C3
2,382 2,333 3,075
2,564 2,916
2,372
C1 C2 C3
2,439 2,333 2,996

56
UIN Syarif Hidayatullah Jakarta
Tabel 4.17 Jarak dari hasil iterasi ke-2 Skenario-1
g. Mengelempokan kembali ayat yang sesuai dengan
kedekatan centroid (jarak minimum) ke dalam masing-
masing cluster.
Tabel 4.18 Hasil Clustering Iterasi ke-2 Skenario-1
h. Memperbarui nilai centroid dengan menghitung rata-
rata dari setiap cluster.
Centroid baru cluster 1 : 2,564
Centroid baru cluster 2 : (2,382 + 2,333 + 2,372) / 3 =
2,362
Centroid baru cluster 3 : (3,075 + 2,916) / 2 = 2,996
Maka dihasilkan centroid baru, yaitu :
Tabel 4.19 Centroid Baru ke-2 Skenario-1
i. lanjutkan iterasi sampai tidak ada ayat yang berpindah
cluster dengan menghitung kembali jarak minimum
antara ayat dengan centroid baru menggunakan
euclidean distance.
Ayat ke- C1 C2 C3
2 0,057 0,049 0,614
43 0,106 0,000 0,662
53 0,636 0,742 0,079
99 0,125 0,230 0,432
122 0,477 0,583 0,079
242 0,067 0,038 0,624
C1 C2 C3
2,564 2,382 3,075
2,333 2,916
2,372
C1 C2 C3
2,564 2,362 2,996

57
UIN Syarif Hidayatullah Jakarta
Tabel 4.20 Jarak dari hasil iterasi ke-3 Skenario-1
j. Mengelempokan kembali ayat yang sesuai dengan
kedekatan centroid (jarak minimum) ke dalam masing-
masing cluster.
Tabel 4.21 Hasil Clustering Iterasi ke-3 Skenario-1
k. Nilai centroid tidak berubah setelah mendapatkan iterasi
ke-3, yaitu :
Tabel 4.22 Centroid Baru ke-3 Skenario-1
l. Karena tidak terjadi perubahan atau perpindahan
cluster lagi dari setiap ayatnya, maka iterasi dari proses
K-Means berhenti. Selesai.
6. Mendapatkan hasil proses dari pengelompokan ayat dengan
menggunakan Algoritma K-Means Clustering.
Tabel 4.23 Hasil Akhir Clustering Skenario 1
7. Setelah didapatkan cluster sesuai dengan nilai k yang
ditentukan, maka tahap selanjutnya adalah evaluasi cluster.
Ayat ke- C1 C2 C3
2 0,182 0,020 0,614
43 0,230 0,029 0,662
53 0,511 0,713 0,079
99 0,000 0,201 0,432
122 0,352 0,554 0,079
242 0,192 0,009 0,624
C1 C2 C3
2,564 2,382 3,075
2,333 2,916
2,372
C1 C2 C3
2,564 2,362 2,996
Ayat W Ayat W Ayat W
99 2,564 2 2,382 53 3,075
43 2,333 122 2,916
242 2,372
C1 C2 C3

58
UIN Syarif Hidayatullah Jakarta
Evaluasi cluster dilakukan dengan menghitung nilai sillhoutte
coefficient, memory consumption dan runtime. Berikut ini
langkah untuk menghitung nilai sillhoutte coefficient :
a. Menghitung rata-rata jarak objek dengan semua
dokumen yang berada dalam satu cluster dengan
menggunakan euclidean distance, sehingga didapatkan
nilai a(i).
Tabel 4.24 Hasil perhitungan nilai a(i) Skenario-1
b. Menghitung rata-rata jarak dari dokumen i dengan
semua dokumen di cluster lain dengan menggunakan
euclidean distance. Setelah itu diambil nilai minimum
dari nilai d (i, C) untuk mendapatkan nilai b(i). Nilai
d(i,C) yang dihasilkan akan memiliki 2 nilai
dikarenakan jumlah cluster pada contoh perhitungan ini
berjumlah 3.
Tabel 4.25 Hasil perhitungan nilai d(i,C) dan b(i) Skenario-1
c. Menghitung nilai silhouette coefficient dengan
menggunakan rumus pada sub-bab 2.10.
Berikut contoh perhitungan nilai s(99) pada ayat ke-99
a(i) Hasil
a(2) 0,020
a(43) 0,029
a(53) 0,079
a(99) 0,000
a(122) 0,079
a(242) 0,016
d(i,C) Hasil d(i,C) Hasil b(i) Hasil
d(2,1) 0,182 d(2,2) 0,614 b(2) 0,182
d(43,1) 0,230 d(43,2) 0,662 b(43) 0,230
d(53,1) 0,511 d(53,2) 0,717 b(53) 0,511
d(99,1) 0,206 d(99,2) 0,432 b(99) 0,206
d(122,1) 0,352 d(122,2) 0,559 b(122) 0,352
d(242,1) 0,192 d(242,2) 0,624 b(242) 0,192

59
UIN Syarif Hidayatullah Jakarta
𝑠(99) =0,206 − 0,000
max (0,000 ; 0,206)= 1,000
Tabel 4.26 Hasil perhitungan nilai s(i) Skenario-1
4.4.2. Konstruksi Min-max Normalization pada Clustering Algoritma
K-Means
Konstruksi Min-max Normalization pada pengelompokan teks
terjemahan ayat Al Quran menggunakan Algoritma K-Means, ini
merupakan skenario 2 di dalam penelitian ini. Secara keseluruhan
konstruksi pengelompokan teks terjemahan ayat Al Quran menggunakan
Min-max Normalization sebagai metode untuk mentransformasikan data
pada Algoritma K-Means dapat dijelaskan dibawah ini (konsep diambil
dari sub-bab 4.2.3 dan dapat dilihat pada gambar 4.7 ) :
1. Menyiapkan dataset terjemahan ayat Al Quran dalam format
sql.
2. Melakukan proses preprocessing sesuai dengan tahapan 4.2.1
yaitu conceptual model preprocessing. Sebagai contoh
digunakan enam ayat untuk melakukan clustering dengan
algoritma k-means. Enam ayat yang digunakan diambil secara
acak menggunakan microsoft excel. Ayat yang digunakan dalam
skenario ini sama dengan ayat yang digunakan pada skenario
pertama.
s(i) Hasil
s(2) 0,875
s(43) 0,865
s(53) 0,893
s(99) 1,000
s(122) 0,863
s(242) 0,905
rata-rata 0,900
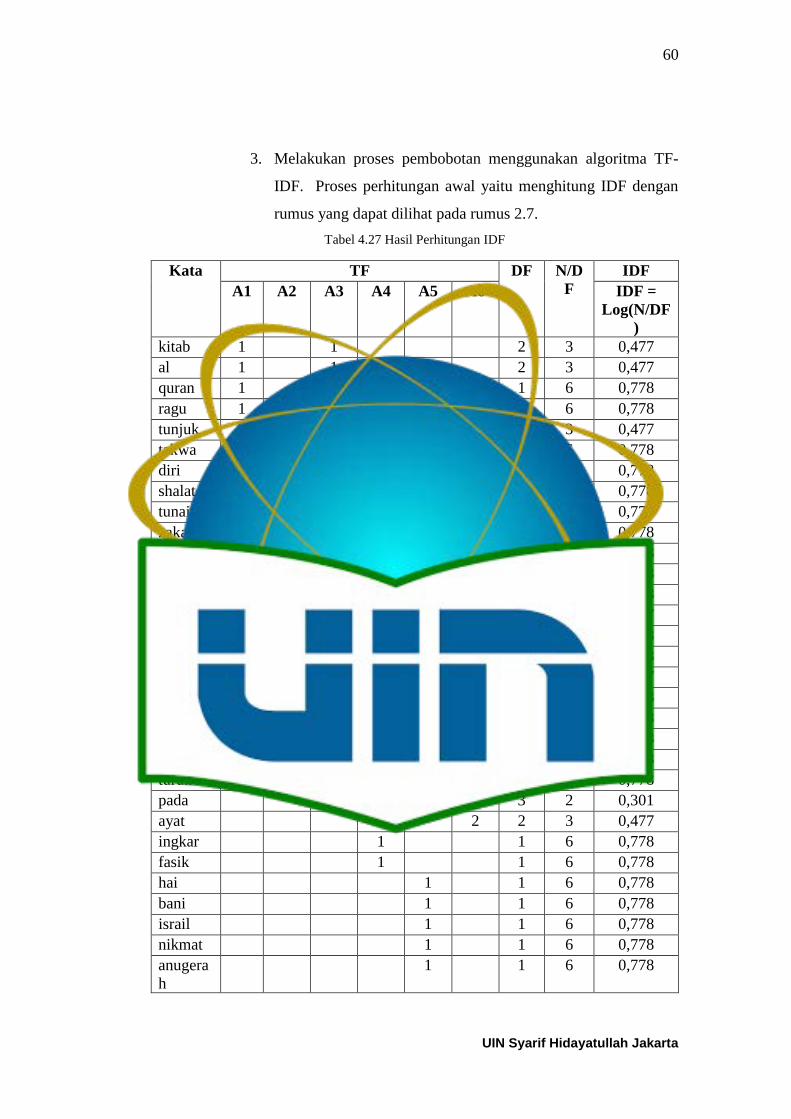
60
UIN Syarif Hidayatullah Jakarta
3. Melakukan proses pembobotan menggunakan algoritma TF-
IDF. Proses perhitungan awal yaitu menghitung IDF dengan
rumus yang dapat dilihat pada rumus 2.7.
Tabel 4.27 Hasil Perhitungan IDF
Kata TF DF N/D
F
IDF
A1 A2 A3 A4 A5 A6 IDF =
Log(N/DF
)
kitab 1
1
2 3 0,477
al 1
1
2 3 0,477
quran 1
1 6 0,778
ragu 1
1 6 0,778
tunjuk 1
1
2 3 0,477
takwa 1
1 6 0,778
diri
1
1 6 0,778
shalat
1
1 6 0,778
tunai
1
1 6 0,778
zakat
1
1 6 0,778
ruku
2
1 6 0,778
serta
1
1 6 0,778
jelas
1
1 6 0,778
ingat
1
1
2 3 0,477
musa
1
1 6 0,778
taurat
1
1 6 0,778
terang
1
1 2 3 0,477
beda
1
1 6 0,778
benar
1
1 6 0,778
salah
1
1 6 0,778
sungguh
1
1 6 0,778
turun
1
1 6 0,778
pada
1 1 1 3 2 0,301
ayat
2
2 2 3 0,477
ingkar
1
1 6 0,778
fasik
1
1 6 0,778
hai
1
1 6 0,778
bani
1
1 6 0,778
israil
1
1 6 0,778
nikmat
1
1 6 0,778
anugera
h
1
1 6 0,778
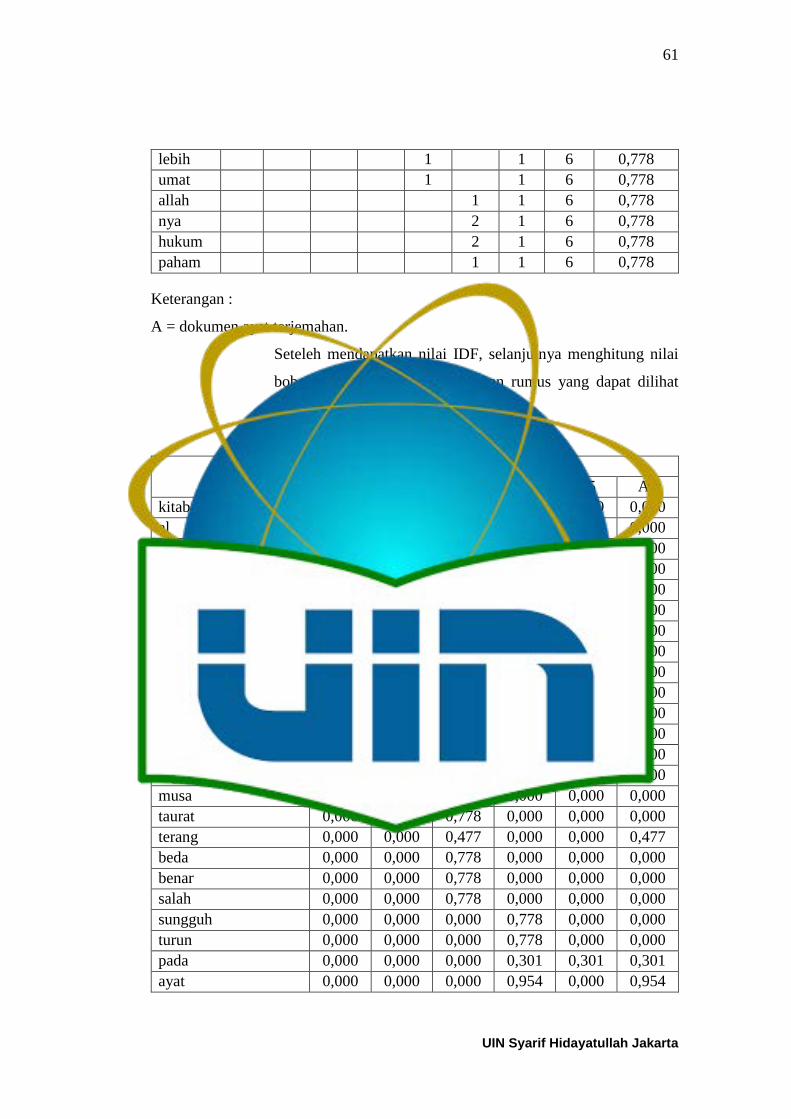
61
UIN Syarif Hidayatullah Jakarta
lebih
1
1 6 0,778
umat
1
1 6 0,778
allah
1 1 6 0,778
nya
2 1 6 0,778
hukum
2 1 6 0,778
paham
1 1 6 0,778
Keterangan :
A = dokumen ayat terjemahan.
Seteleh mendapatkan nilai IDF, selanjutnya menghitung nilai
bobotnya (term weighting) dengan rumus yang dapat dilihat
pada sub-bab 2.7
Tabel 4.28 Hasil Perhitungan W (term weighting)
Kata W (W=TF*IDF)
A1 A2 A3 A4 A5 A6
kitab 0,477 0,000 0,477 0,000 0,000 0,000
al 0,477 0,000 0,477 0,000 0,000 0,000
quran 0,778 0,000 0,000 0,000 0,000 0,000
ragu 0,778 0,000 0,000 0,000 0,000 0,000
tunjuk 0,477 0,000 0,477 0,000 0,000 0,000
takwa 0,778 0,000 0,000 0,000 0,000 0,000
diri 0,000 0,778 0,000 0,000 0,000 0,000
shalat 0,000 0,778 0,000 0,000 0,000 0,000
tunai 0,000 0,778 0,000 0,000 0,000 0,000
zakat 0,000 0,778 0,000 0,000 0,000 0,000
ruku 0,000 1,556 0,000 0,000 0,000 0,000
serta 0,000 0,778 0,000 0,000 0,000 0,000
jelas 0,000 0,000 0,000 0,778 0,000 0,000
ingat 0,000 0,000 0,477 0,000 0,477 0,000
musa 0,000 0,000 0,778 0,000 0,000 0,000
taurat 0,000 0,000 0,778 0,000 0,000 0,000
terang 0,000 0,000 0,477 0,000 0,000 0,477
beda 0,000 0,000 0,778 0,000 0,000 0,000
benar 0,000 0,000 0,778 0,000 0,000 0,000
salah 0,000 0,000 0,778 0,000 0,000 0,000
sungguh 0,000 0,000 0,000 0,778 0,000 0,000
turun 0,000 0,000 0,000 0,778 0,000 0,000
pada 0,000 0,000 0,000 0,301 0,301 0,301
ayat 0,000 0,000 0,000 0,954 0,000 0,954

62
UIN Syarif Hidayatullah Jakarta
ingkar 0,000 0,000 0,000 0,778 0,000 0,000
fasik 0,000 0,000 0,000 0,778 0,000 0,000
hai 0,000 0,000 0,000 0,000 0,778 0,000
bani 0,000 0,000 0,000 0,000 0,778 0,000
israil 0,000 0,000 0,000 0,000 0,778 0,000
nikmat 0,000 0,000 0,000 0,000 0,778 0,000
anugerah 0,000 0,000 0,000 0,000 0,778 0,000
lebih 0,000 0,000 0,000 0,000 0,778 0,000
umat 0,000 0,000 0,000 0,000 0,778 0,000
allah 0,000 0,000 0,000 0,000 0,000 0,778
nya 0,000 0,000 0,000 0,000 0,000 1,556
hukum 0,000 0,000 0,000 0,000 0,000 1,556
paham 0,000 0,000 0,000 0,000 0,000 0,778
Nilai bobot setiap
dokumen
3,766 5,447 6,276 5,146 6,225 6,401
4. Setelah mendapatkan nilai weighting /bobot maka selanjutnya
data dinormalisasikan dengan menggunakan Min-max
Normalization. Normalisasi bobot dihitung dengan
menggunakan persamaan Min-max Normalization. Persamaan
Min-max Normalization dapat dilihat dalam sub-bab 2.8.2.
Sebagai contoh normalisasi dari A1 dengan kata “kitab” dengan
hasil TF-IDF adalah 0,477.
0,477 =0,477 − 0,000
0,778 − 0,000= 0,613
Maka didapatkan nilai weighting / bobot yang baru tiap
dokumen menjadi :
Tabel 4.29 Hasil Normalisasi Min-max Normalization
Kata W (Normalisasi: Min Max Normalization)
A1 A2 A3 A4 A5 A6
kitab 0,613 0,000 0,613 0,000 0,000 0,000
al 0,613 0,000 0,613 0,000 0,000 0,000
quran 1,000 0,000 0,000 0,000 0,000 0,000
ragu 1,000 0,000 0,000 0,000 0,000 0,000
tunjuk 0,613 0,000 0,613 0,000 0,000 0,000
takwa 1,000 0,000 0,000 0,000 0,000 0,000
diri 0,000 0,500 0,000 0,000 0,000 0,000

63
UIN Syarif Hidayatullah Jakarta
shalat 0,000 0,500 0,000 0,000 0,000 0,000
tunai 0,000 0,500 0,000 0,000 0,000 0,000
zakat 0,000 0,500 0,000 0,000 0,000 0,000
ruku 0,000 1,000 0,000 0,000 0,000 0,000
serta 0,000 0,500 0,000 0,000 0,000 0,000
jelas 0,000 0,000 0,000 0,815 0,000 0,000
ingat 0,000 0,000 0,613 0,000 0,613 0,000
musa 0,000 0,000 1,000 0,000 0,000 0,000
taurat 0,000 0,000 1,000 0,000 0,000 0,000
terang 0,000 0,000 0,613 0,000 0,000 0,307
beda 0,000 0,000 1,000 0,000 0,000 0,000
benar 0,000 0,000 1,000 0,000 0,000 0,000
salah 0,000 0,000 1,000 0,000 0,000 0,000
sungguh 0,000 0,000 0,000 0,815 0,000 0,000
turun 0,000 0,000 0,000 0,815 0,000 0,000
pada 0,000 0,000 0,000 0,315 0,387 0,193
ayat 0,000 0,000 0,000 1,000 0,000 0,613
ingkar 0,000 0,000 0,000 0,815 0,000 0,000
fasik 0,000 0,000 0,000 0,815 0,000 0,000
hai 0,000 0,000 0,000 0,000 1,000 0,000
bani 0,000 0,000 0,000 0,000 1,000 0,000
israil 0,000 0,000 0,000 0,000 1,000 0,000
nikmat 0,000 0,000 0,000 0,000 1,000 0,000
anugerah 0,000 0,000 0,000 0,000 1,000 0,000
lebih 0,000 0,000 0,000 0,000 1,000 0,000
umat 0,000 0,000 0,000 0,000 1,000 0,000
allah 0,000 0,000 0,000 0,000 0,000 0,500
nya 0,000 0,000 0,000 0,000 0,000 1,000
hukum 0,000 0,000 0,000 0,000 0,000 1,000
paham 0,000 0,000 0,000 0,000 0,000 0,500
Nilai bobot setiap
dokumen
4,839 3,500 8,066 5,393 8,000 4,113
5. Nilai weighting / bobot setiap dokumen kemudian diproses
menggunakan Algoritma K-Means Clustering untuk
menghasilkan cluster. Prosesnya dapat dilihat pada gambar
4.2.6. dan penjelasannya bisa dilihat pada sub-bab 2.9.2.
a. Menentukan nilai k. Pada penulisan penelitian ini
digunakan contoh perhitungan dengan nilai k =3.

64
UIN Syarif Hidayatullah Jakarta
b. Menentukan centroid awal sebanyak nilai k, yaitu
centroid awal yang dipilih secara acak atau random.
Tabel 4.30 Centroid Awal Skenario-2
Keterangan :
C = Cluster
c. Menghitung jarak dari setiap ayat ke centroid awal yang
sudah ditentukan dengan menggunakan rumus
euclidean distance. Rumus euclidean distance
sebelumnya sudah dijelaskan dalam sub-bab 2.9.2
Berikut contoh perhitungan jarak menggunakan
euclidean distance
ayat 2 pada centroid ke − 1 =
√(4,839 − 4,839)2 = 0,000
ayat 2 pada centroid ke − 2 =
√(4,839 − 3,500)2 = 1,339
ayat 2 pada centroid ke − 3 =
√(4,839 − 8,066)2 = 3,226
Tabel 4.31 Jarak dari hasil iterasi ke-1 Skenario-2
C1 C2 C3
4,839 3,500 8,066
Ayat ke- C1 C2 C3
2 0,000 1,339 3,226
43 1,339 0,000 4,566
53 3,226 4,566 0,000
99 0,553 1,893 2,673
122 3,161 4,500 0,066
242 0,726 0,613 3,953

65
UIN Syarif Hidayatullah Jakarta
d. Mengelempokan ayat yang sesuai dengan kedekatan
centroid (jarak minimum) ke dalam masing-masing
cluster.
Tabel 4.32 Hasil Clustering Iterasi ke-1 Skenario-2
e. Memperbarui nilai centroid dengan menghitung rata-
rata dari setiap cluster.
Centroid baru cluster 1 : (4,839 + 5,393) / 2 = 5,116
Centroid baru cluster 2 : (3,500 + 4,113) / 2 = 3,807
Centroid baru cluster 3 : (8,066 + 8,000) / 2 = 8,033
Maka dihasilkan centroid baru, yaitu :
Tabel 4.33 Centroid Baru ke-1 Skenario-2
f. Melanjutkan iterasi sampai tidak ada ayat yang
berpindah cluster dengan menghitung kembali jarak
minimum antara ayat dengan centroid baru
menggunakan euclidean distance.
Tabel 4.34 Jarak dari hasil iterasi ke-2 Skenario-2
g. Mengelempokan kembali ayat yang sesuai dengan
kedekatan centroid (jarak minimum) ke dalam masing-
masing cluster.
Tabel 4.35 Hasil Clustering Iterasi ke—2 Skenario-2
C1 C2 C3
4,839 3,500 8,066
5,393 4,113 8,000
C1 C2 C3
5,116 3,807 8,033
Ayat ke- C1 C2 C3
2 0,277 1,033 3,193
43 1,616 0,307 4,533
53 2,950 4,259 0,033
99 0,277 1,586 2,640
122 2,884 4,193 0,033
242 1,003 0,307 3,920

66
UIN Syarif Hidayatullah Jakarta
h. Memperbarui nilai centroid dengan menghitung rata-
rata dari setiap cluster.
Centroid baru cluster 1 : (4,839 + 5,393) / 2 = 5,116
Centroid baru cluster 2 : (3,500 + 4,113) / 2 = 3,807
Centroid baru cluster 3 : (8,066 + 8,000) / 2 = 8,033
Maka dihasilkan centroid baru, yaitu :
Tabel 4.36 Centroid Baru ke-2 Skenario-2
Lanjutkan iterasi sampai tidak ada ayat yang berpindah
cluster atau nilai centroid tidak berubah.
i. Nilai centroid tidak berubah setelah mendapatkan iterasi
ke-2, yaitu :
Tabel 4.37 Centroid ke-2 Skenario-2
j. Karena tidak terjadi perubahan atau perpindahan
cluster lagi dari setiap ayatnya, maka iterasi dari proses
K-Means berhenti. Selesai.
6. Mendapatkan hasil proses dari pengelompokan ayat dengan
menggunakan Algoritma K-Means Clustering.
Tabel 4.38 Hasil Akhir Clustering Skenario-2
7. Setelah didapatkan cluster sesuai dengan nilai k yang
ditentukan, maka tahap selanjutnya adalah evaluasi cluster.
Evaluasi cluster dilakukan dengan menghitung nilai sillhoutte
C1 C2 C3
4,839 3,500 8,066
5,393 4,113 8,000
C1 C2 C3
5,116 3,807 8,033
C1 C2 C3
5,116 3,807 8,033
Ayat W Ayat W Ayat W
2 4,839 43 3,500 53 8,066
99 5,393 242 4,113 122 8,000
C1 C2 C3

67
UIN Syarif Hidayatullah Jakarta
coefficient. Berikut ini langkah untuk menghitung nilai
sillhoutte coefficient :
a. Menghitung rata-rata jarak objek dengan semua
dokumen yang berada dalam satu cluster dengan
menggunakan euclidean distance, sehingga didapatkan
nilai a(i).
Tabel 4.39 Hasil perhitungan nilai a(i) Skenario-2
b. Menghitung rata-rata jarak dari dokumen i dengan
semua dokumen di cluster lain dengan menggunakan
euclidean distance. Setelah itu diambil nilai minimum
dari nilai d (i, C) untuk mendapatkan nilai b(i). Nilai
d(i,C) yang dihasilkan akan memiliki 2 nilai
dikarenakan jumlah cluster pada contoh perhitungan ini
berjumlah 3.
Tabel 4.40 Hasil perhitungan nilai d(i,C) dan b(i) Skenario-2
c. Menghitung nilai silhouette coefficient dengan
menggunakan rumus pada sub-bab 2.10.
Berikut contoh perhitungan nilai s(122) pada ayat ke-
122
a(i) Hasil
a(2) 0,277
a(43) 0,307
a(53) 0,033
a(99) 0,277
a(122) 0,033
a(242) 0,307
d(i,C) Hasil d(i,C) Hasil b(i) Hasil
d(2,1) 1,033 d(2,2) 3,193 b(2) 1,033
d(43,1) 1,616 d(43,2) 4,533 b(43) 1,616
d(53,1) 2,950 d(53,2) 4,259 b(53) 2,950
d(99,1) 1,586 d(99,2) 2,640 b(99) 1,586
d(122,1) 2,884 d(122,2) 4,193 b(122) 2,884
d(242,1) 1,003 d(242,2) 3,920 b(242) 1,003

68
UIN Syarif Hidayatullah Jakarta
𝑠(122) =2,884 − 0,033
max (0,033 ; 2,884)= 0,990
Tabel 4.41 Hasil perhitungan nilai s(i) Skenario-2
4.5. Simulation
Penulis memakai windows 8.1 Pro sebagai sistem operasi yang
digunakan untuk seluruh proses simulasi. Dan menggunakan notepad++
dalam proses pengkodingan. Berikut ini tahapan pembangunan server yang
penulis lakukan untuk mempersiapkan proses simulasi :
1. Melakukan instalasi appserver, dalam hal ini penulis
menggunakan XAMPP
2. Melakukan instalasi editor notepad++ yang digunakan untuk
membuat kode script
Berikut contoh simulasi yang dilakukan oleh penulis, skenario pertama
dan skenario kedua dalam sekali percobaan nilai k=3.
Gambar 4.9 Contoh Simulasi Skenario 1
s(i) Hasil
s(2) 0,743
s(43) 0,809
s(53) 0,990
s(99) 0,830
s(122) 0,990
s(242) 0,691
rata-rata 0,842

69
UIN Syarif Hidayatullah Jakarta
Gambar 4.10 Contoh Simulasi Skenario 2
4.6. Verification and Validation
Penjelasan dan pembahasan mengenai verification and validation
dijelaskan pada BAB V skripsi ini tentang hasil dan pembahasan.
4.7. Experimentation
Penjelasan dan pembahasan mengenai experimentation dijelaskan pada
BAB V skripsi ini tentang hasil dan pembahasan.
4.8. Output Analisys
Penjelasan dan pembahasan mengenai output analisys dijelaskan pada
BAB V skripsi ini tentang hasil dan pembahasan.

70
BAB 5
HASIL DAN PEMBAHASAN
5.1 Verifikasi dan Validasi (Verification and Validation)
Tahapan ini merupakan tahapan untuk melakukan verifikasi dan
validasi dari tahapan-tahap sebelumnya yaitu konseptual model, dan
model simulasi. Pada tahap ini dilakukan koreksi atau perbaikan jika
terjadi kesalahan dengan menguji apakah keseluruhan proses simulasi
telah berjalan sesuai dengan flowchart pada tahapan conceptual model.
Sedangkan validasi dilakukan dengan menguji apakah keseluruhan
proses simulasi telah sesuai dengan ketentuan-ketentuan pada tahapan
conceptual model, input output data, dan modelling. Verifikasi dilakukan
untuk memastikan bahwa setiap tahapan pada bab-bab sebelumnya saling
memiliki hubungan, dalam hal ini setiap tahapan pada bab 4 diulas kembali
untuk memastikan tiap tahap tersebut saling terkait. Verifikasi juga
memastikan bahwa input dan output sesuai dengan yang diharapkan
dimulai dari tahap problem formulation (formulasi masalah) hingga
simulation phase (simulasi).
Pengujian program merupakan pengujian yang dilakukan untuk
membandingkan hasil perhitungan dengan cara manual dengan hasil
perhitungan algoritma di sistem. Dalam pengujian nilai silhouette
coefficient hasil algoritma ini hasil yang didapat harus sama untuk
keduanya, karena perhitungan manual merupakan acuan dalam
menentukan algoritma tersebut benar. Skenario yang digunakan dalam
pengujian manual ini sebanyak enam data sample dan nilai k yang
digunakan adalah tiga.
Berdasarkan perhitungan manual pada modelling pada sub-bab 4.4.1
dan 4.4.2 dan pada saat program dijalankan hasil akhir dari clustering
sudah sesuai dengan hasil screenshoots pada sub-bab 4.5 gambar 4.9 dan
gambar 4.10.

71
UIN Syarif Hidayatullah Jakarta
Tabel 5.1 Pengujian
Metode
Normalisasi
Nilai k Nilai
Sillhoutte
(Manual)
Nilai
Sillhoutte
(Program)
Status
Sesuai
Cosine
Normalization
3 0,900 0,900 Sesuai
Min-max
Normalization
3 0,842 0,842 Sesuai
Berdasarkan tabel diatas menunjukan bahwa sistem telah sesuai
dengan perhitungan manual.
Hasil pengelompokan juga sudah divalidasi oleh Dosen TIK Islam,
Dosen Teknik Informatika, Fakultas Sains dan Teknologi, Universitas
Islam Negeri Jakarta yaitu Drs. M. Tabah Rosyadi, M.A. bahwa hasil
pengelompokan sudah baik dan untuk penentuan tema dari setiap
kelompoknya sangat memungkin diambil dari kata yang sering muncul
dari setiap pengelompokannya.
5.2 Eksperimentasi (Experimentation)
Eksperimen yang dilakukan yaitu dengan membandingkan hasil dari
simulator. Fase ini dimulai dengan desain eksperimen sesuai dengan yang
penulis susun pada tahap simulasi, dan dengan teknik tertentu berdasar
pada beberapa faktor yang menguji nilai parameter untuk melakukan
analisa pada output hasil dari proses simulasi. Pada penulisan ini
penulis membandingkan perbedaan yang terjadi jika nilai k yang ada pada
proses simulasi tersebut diubah, Penulis menggunakan parameter-
parameter, yaitu : nilai sillhoutte, runtime dan memory consumption
diujikan pada kedua skenario, yaitu Cosine Normalization dan Min-max
Normalization. Dari eksperimen tersebut dilakukan analisis outputnya
yang akan dibahas pada tahapan Output Analysis.

72
UIN Syarif Hidayatullah Jakarta
5.3 Analisis Keluaran (Output Analysis)
5.3.1 Skenario 1
5.3.1.1 Nilai k=2
Tabel 5.2 Hasil Nilai k=2 Skenario-1
Output Percobaan Ke- Rata-
Rata 1 2 3 4 5
Runtime (s) 0,514 0,492 0,489 0,497 0,516 0,502
Memory
Consumption
(kb)
28804 28804 28804 28804 28804 28804
Accuracy 0,572 0,572 0,572 0,572 0,572 0,572
Tabel diatas menunjukan hasil skenario 1 pada metode
normalisasi Cosine Normalization. Percobaan dilakukan sebanyak
lima kali dan diambil nilai rata-ratanya. Hasil runtime tercepat
terdapat pada percobaan tiga yaitu 0,489 s serta rata-rata
sebesar 0,502 s. Memory consumption pada percobaan ini tidak
berubah, yaitu sebesar 28804 kb dari percobaan satu sampai
percobaan lima. Sedangkan, untuk nilai dari nilai silhouette
coefficient nya sebesar 0,572.
5.3.1.2 Nilai k=3
Tabel 5.3 Hasil Nilai k=3 Skenario-1
Output Percobaan Ke- Rata-
Rata 1 2 3 4 5
Runtime (s) 0,497 0,639 0,496 0,514 0,513 0,532

73
UIN Syarif Hidayatullah Jakarta
Memory
Consumption
(kb)
29334 29334 29334 29334 29334 29334
Accuracy 0,548 0,548 0,548 0,548 0,548 0,548
Tabel diatas menunjukan hasil skenario 1 pada metode
normalisasi Cosine Normalization. Percobaan dilakukan sebanyak
lima kali dan diambil nilai rata-ratanya. Hasil runtime tercepat
terdapat pada percobaan tiga yaitu 0,496 s serta rata-rata sebesar
0,532 s. Memory consumption pada percobaan ini tidak
berubah, yaitu sebesar 29334 kb dari percobaan satu sampai
percobaan lima. Sedangkan, untuk nilai dari nilai silhouette
coefficient nya sebesar 0,548.
5.3.1.3 Nilai k=4
Tabel 5.4 Hasil Nilai k=4 Skenario-1
Output Percobaan Ke- Rata-
Rata 1 2 3 4 5
Runtime (s) 0,516 0,562 0,501 0,670 0,558 0,561
Memory
Consumption
(kb)
31156 31156 31156 31156 31156 31156
Accuracy 0,543 0,543 0,543 0,543 0,543 0,543
Tabel diatas menunjukan hasil skenario 1 pada metode
normalisasi Cosine Normalization. Percobaan dilakukan sebanyak
lima kali dan diambil nilai rata-ratanya. Hasil runtime tercepat
terdapat pada percobaan tiga yaitu 0,501 s serta rata-rata

74
UIN Syarif Hidayatullah Jakarta
sebesar 0,561 s. Memory consumption pada percobaan ini tidak
berubah, yaitu sebesar 31156 kb dari percobaan satu sampai
percobaan lima. Sedangkan, untuk nilai dari nilai silhouette
coefficient nya sebesar 0,543.
5.3.1.4 Nilai k=5
Tabel 5.5 Hasil Nilai k=5 Skenario-1
Output Percobaan Ke- Rata-
Rata 1 2 3 4 5
Runtime (s) 0,511 0,503 0,649 0,516 0,511 0,538
Memory
Consumption
(kb)
30178 30178 30178 30178 30178 30178
Accuracy 0,517 0,517 0,517 0,517 0,517 0,517
Tabel diatas menunjukan hasil skenario 1 pada metode
normalisasi Cosine Normalization. Percobaan dilakukan sebanyak
lima kali dan diambil nilai rata-ratanya. Hasil runtime tercepat
terdapat pada percobaan dua yaitu 0,503 s serta rata-rata
sebesar 0,538 s. Memory consumption pada percobaan ini tidak
berubah, yaitu sebesar 30178 kb dari percobaan satu sampai
percobaan lima. Sedangkan, untuk nilai dari nilai silhouette
coefficient nya sebesar 0,517.
5.3.1.5 Nilai k=6
Tabel 5.6 Hasil Nilai k=6 Skenario-1
Output Percobaan Ke- Rata-
Rata 1 2 3 4 5
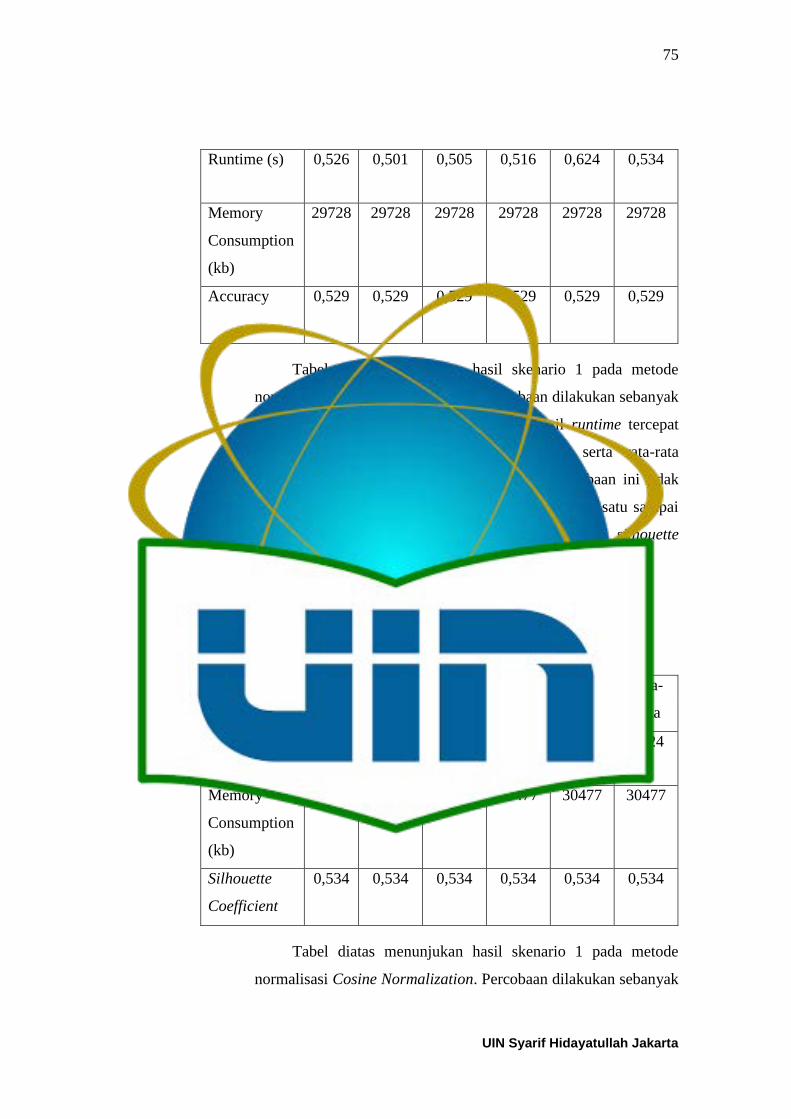
75
UIN Syarif Hidayatullah Jakarta
Runtime (s) 0,526 0,501 0,505 0,516 0,624 0,534
Memory
Consumption
(kb)
29728 29728 29728 29728 29728 29728
Accuracy 0,529 0,529 0,529 0,529 0,529 0,529
Tabel diatas menunjukan hasil skenario 1 pada metode
normalisasi Cosine Normalization. Percobaan dilakukan sebanyak
lima kali dan diambil nilai rata-ratanya. Hasil runtime tercepat
terdapat pada percobaan dua yaitu 0,501 s serta rata-rata
sebesar 0,534 s. Memory consumption pada percobaan ini tidak
berubah, yaitu sebesar 29728 kb dari percobaan satu sampai
percobaan lima. Sedangkan, untuk nilai dari nilai silhouette
coefficient nya sebesar 0,529.
5.3.1.6 Nilai k=7
Tabel 5.7 Hasil Nilai k=7 Skenario-1
Output Percobaan Ke- Rata-
Rata 1 2 3 4 5
Runtime (s) 0,503 0,518 0,506 0,528 0,563 0,524
Memory
Consumption
(kb)
30477 30477 30477 30477 30477 30477
Silhouette
Coefficient
0,534 0,534 0,534 0,534 0,534 0,534
Tabel diatas menunjukan hasil skenario 1 pada metode
normalisasi Cosine Normalization. Percobaan dilakukan sebanyak

76
UIN Syarif Hidayatullah Jakarta
lima kali dan diambil nilai rata-ratanya. Hasil runtime tercepat
terdapat pada percobaan satu yaitu 0,503 s serta rata-rata
sebesar 0,524 s. Memory consumption pada percobaan ini tidak
berubah, yaitu sebesar 30477 kb dari percobaan satu sampai
percobaan lima. Sedangkan, untuk nilai dari nilai silhouette
coefficient nya sebesar 0,534.
5.3.1.7 Nilai k=8
Tabel 5.8 Hasil Nilai k=8 Skenario-1
Output Percobaan Ke- Rata-
Rata 1 2 3 4 5
Runtime (s) 0,564 0,517 0,504 0,513 0,518 0,523
Memory
Consumption
(kb)
30509 30509 30509 30509 30509 30509
Silhouette
Coefficient
0,531 0,531 0,531 0,531 0,531 0,531
Tabel diatas menunjukan hasil skenario 1 pada metode
normalisasi Cosine Normalization. Percobaan dilakukan sebanyak
lima kali dan diambil nilai rata-ratanya. Hasil runtime tercepat
terdapat pada percobaan tiga yaitu 0,504 s serta rata-rata sebesar
0,523 s. Memory consumption pada percobaan ini tidak
berubah, yaitu sebesar 30509 kb dari percobaan satu sampai
percobaan lima. Sedangkan, untuk nilai dari nilai silhouette
coefficient nya sebesar 0,531.
5.3.2 Skenario 2
5.3.2.1 Nilai k=2
Tabel 5.9 Hasil Nilai k=2 Skenario-2

77
UIN Syarif Hidayatullah Jakarta
Output Percobaan Ke- Rata-
Rata 1 2 3 4 5
Runtime (s) 0,585 0,514 0,520 0,593 0,516 0,546
Memory
Consumption
(kb)
28574 28574 28574 28574 28574 28574
Silhouette
Coefficient
0,611 0,611 0,611 0,611 0,611 0,611
Tabel diatas menunjukan hasil skenario 2 pada metode
normalisasi Min-max Normalization. Percobaan dilakukan
sebanyak lima kali dan diambil nilai rata-ratanya. Hasil runtime
tercepat terdapat pada percobaan satu yaitu 0,514 s serta rata-
rata sebesar 0,546 s. Memory consumption pada percobaan ini
tidak berubah, yaitu sebesar 28574 kb dari percobaan satu
sampai percobaan lima. Sedangkan, untuk nilai dari nilai
silhouette coefficient nya sebesar 0,611.
5.3.2.2 Nilai k=3
Tabel 5.10 Hasil Nilai k=3 Skenario-2
Output Percobaan Ke- Rata-
Rata 1 2 3 4 5
Runtime (s) 0,525 0,538 0,544 0,587 0,527 0,544
Memory
Consumption
(kb)
28640 28640 28640 28640 28640 28640
Silhouette
Coefficient
0,570 0,570 0,570 0,570 0,570 0,570

78
UIN Syarif Hidayatullah Jakarta
Tabel diatas menunjukan hasil skenario 2 pada metode
normalisasi Min-max Normalization. Percobaan dilakukan
sebanyak lima kali dan diambil nilai rata-ratanya. Hasil runtime
tercepat terdapat pada percobaan satu yaitu 0,525 s serta rata-
rata sebesar 0,543 s. Memory consumption pada percobaan ini
tidak berubah, yaitu sebesar 28640 kb dari percobaan satu
sampai percobaan lima. Sedangkan, untuk nilai dari nilai
silhouette coefficient nya sebesar 0,570.
5.3.2.3 Nilai k=4
Tabel 5.11 Hasil Nilai k=4 Skenario-2
Output Percobaan Ke- Rata-
Rata 1 2 3 4 5
Runtime (s) 0,529 0,617 0,537 0,596 0,527 0,561
Memory
Consumption
(kb)
30934 30934 30934 30934 30934 30934
Silhouette
Coefficient
0,551 0,551 0,551 0,551 0,551 0,551
Tabel diatas menunjukan hasil skenario 2 pada metode
normalisasi Min-max Normalization. Percobaan dilakukan
sebanyak lima kali dan diambil nilai rata-ratanya. Hasil runtime
tercepat terdapat pada percobaan lima yaitu 0,527 s serta rata-
rata sebesar 0,561 s. Memory consumption pada percobaan ini
tidak berubah, yaitu sebesar 30934 kb dari percobaan satu
sampai percobaan lima. Sedangkan, untuk nilai dari nilai
silhouette coefficient nya sebesar 0,551.
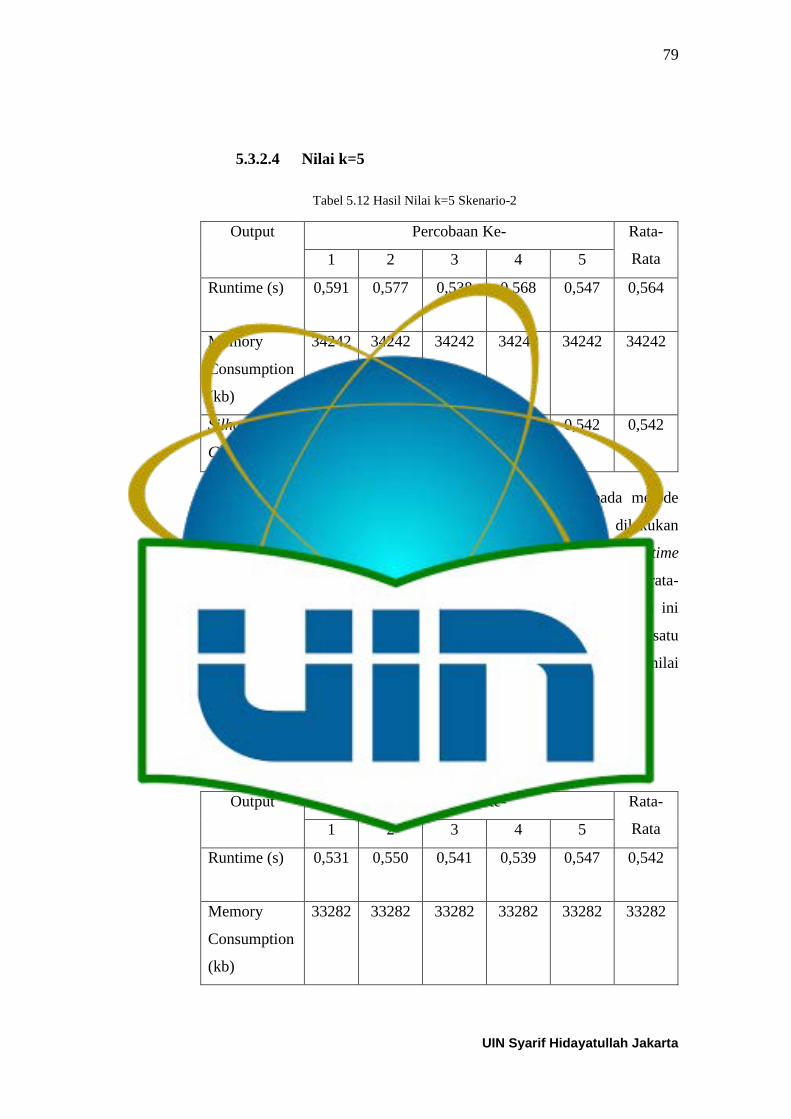
79
UIN Syarif Hidayatullah Jakarta
5.3.2.4 Nilai k=5
Tabel 5.12 Hasil Nilai k=5 Skenario-2
Output Percobaan Ke- Rata-
Rata 1 2 3 4 5
Runtime (s) 0,591 0,577 0,538 0,568 0,547 0,564
Memory
Consumption
(kb)
34242 34242 34242 34242 34242 34242
Silhouette
Coefficient
0,542 0,542 0,542 0,542 0,542 0,542
Tabel diatas menunjukan hasil skenario 2 pada metode
normalisasi Min-max Normalization. Percobaan dilakukan
sebanyak lima kali dan diambil nilai rata-ratanya. Hasil runtime
tercepat terdapat pada percobaan tiga yaitu 0,538 s serta rata-
rata sebesar 0,564 s. Memory consumption pada percobaan ini
tidak berubah, yaitu sebesar 34242 kb dari percobaan satu
sampai percobaan lima. Sedangkan, untuk nilai dari nilai
silhouette coefficient nya sebesar 0,542.
5.3.2.5 Nilai k=6
Tabel 5.13 Hasil Nilai k=6 Skenario-2
Output Percobaan Ke- Rata-
Rata 1 2 3 4 5
Runtime (s) 0,531 0,550 0,541 0,539 0,547 0,542
Memory
Consumption
(kb)
33282 33282 33282 33282 33282 33282

80
UIN Syarif Hidayatullah Jakarta
Silhouette
Coefficient
0,548 0,548 0,548 0,548 0,548 0,548
Tabel diatas menunjukan hasil skenario 2 pada metode
normalisasi Min-max Normalization. Percobaan dilakukan
sebanyak lima kali dan diambil nilai rata-ratanya. Hasil runtime
tercepat terdapat pada percobaan satu yaitu 0,531 s serta rata-
rata sebesar 0,542 s. Memory consumption pada percobaan ini
tidak berubah, yaitu sebesar 33282 kb dari percobaan satu
sampai percobaan lima. Sedangkan, untuk nilai silhouette
coefficient nya sebesar 0,548.
5.3.2.6 Nilai k=7
Tabel 5.14 Hasil Nilai k=7 Skenario-2
Output Percobaan Ke- Rata-
Rata 1 2 3 4 5
Runtime (s) 0,529 0,541 0,547 0,545 0,529 0,538
Memory
Consumption
(kb)
32762 32762 32762 32762 32762 32762
Silhouette
Coefficient
0,531 0,531 0,531 0,531 0,531 0,531
Tabel diatas menunjukan hasil skenario 2 pada metode
normalisasi Min-max Normalization. Percobaan dilakukan
sebanyak lima kali dan diambil nilai rata-ratanya. Hasil runtime
tercepat terdapat pada percobaan satu dan lima, yaitu 0,529 s
serta rata-rata sebesar 0,538 s. Memory consumption pada
percobaan ini tidak berubah, yaitu sebesar 32762 kb dari
percobaan satu sampai percobaan lima. Sedangkan, untuk nilai
silhouette coefficient nya sebesar 0,531.

81
UIN Syarif Hidayatullah Jakarta
5.3.2.7 Nilai k=8
Tabel 5.15 Hasil Nilai k=8 Skenario-2
Output Percobaan Ke- Rata-
Rata 1 2 3 4 5
Runtime (s) 0,587 0,551 0,535 0,539 0,571 0,557
Memory
Consumption
(kb)
32799 32799 32799 32799 32799 32799
Silhouette
Coefficient
0,514 0,514 0,514 0,514 0,514 0,514
Tabel diatas menunjukan hasil skenario 2 pada metode
normalisasi Min-max Normalization. Percobaan dilakukan
sebanyak lima kali dan diambil nilai rata-ratanya. Hasil runtime
tercepat terdapat pada percobaan tiga yaitu 0,535 s serta rata-
rata sebesar 0,557 s. Memory consumption pada percobaan ini
tidak berubah, yaitu sebesar 32799 kb dari percobaan satu
sampai percobaan lima. Sedangkan, untuk nilai silhouette
coefficient nya sebesar 0,514.
5.4 Analisis Hasil Perbandingan
Setelah setiap skenario dijalankan dan data-data output pada
setiap percobaan didapatkan, maka hasil output tersebut digunakan
untuk melakukan analisis kinerja masing-masing skenario berdasarkan
parameter runtime tercepat dengan melihat waktu terkecil serta
memperhatikan memory consumption dengan nilai-nilai terkecil dan
melihat nilai silhouette coefficient terbesar.
Output analisis kinerja dijabarkan dengan menggunakan tabel
dari setiap skenario yang sudah dilakukan sebanyak dua skenario
dengan 14 simulasi yaitu dengan memasukan nilai k = 2-8.

82
UIN Syarif Hidayatullah Jakarta
5.4.1 Skenario 1
Berikut ini rata-rata hasil dari skenario 1 pada simulasi nilai
k=2 sampai k=8. :
Tabel 5.16 Hasil Perbandingan Skenario 1
Output k=2 k=3 k=4 k=5 k=6 k=7 k=8
Runtime (s) 0,502 0,532 0,561 0,538 0,534 0,524 0,523
Memory
Consumption
(kb)
28804 29334 31156 30178 29728 30477 30509
Nilai
Silhouette
Coefficient
0,572 0,548 0,543 0,517 0,529 0,534 0,531
Pada tabel di atas menunjukkan hasil simulasi pada skenario
1 yang dilakukan terhadap nilai k=2 sampai k=8 yang diambil dari
nilai rata-ratanya.
Gambar 5.1 Hasil Runtime Skenario 1
Grafik di atas menunjukkan perbandingan nilai rata-rata
runtime untuk masing-masing nilai k. Semakin kecil nilai runtime
pada proses simulasi maka hasil ini semakin bagus. Pada hasil
skenario 1 , Nilai k=2 memiliki nilai runtime yang terbaik.
0,502
0,532
0,561
0,538 0,5340,524 0,523
0,460
0,480
0,500
0,520
0,540
0,560
0,580
Cosine Normalization
Runtime Skenario 1
k=2 k=3 k=4 k=5 k=6 k=7 k=8

83
UIN Syarif Hidayatullah Jakarta
Gambar 5.2 Hasil Memory Consumption Skenario 1
Grafik di atas menunjukkan perbandingan nilai rata-rata
memory consumption untuk masing-masing nilai k. Semakin kecil
nilai memory consumption pada proses simulasi maka hasil ini
semakin bagus. Sebab akan membutuhkan resource yang lebih
kecil. Pada hasil skenario 1 , Nilai k=2 memiliki nilai memory
consumption yang terbaik.
Gambar 5.3 Hasil Silhouette Coefficient Skenario 1
Grafik di atas menunjukkan perbandingan nilai rata-rata
nilai silhouette coefficient untuk masing-masing nilai k. Nilai nilai
silhouette coefficient merupakan suatu ukuran yang menunjukan
seberapa ketat data dikelompokan dalam cluster. Pada hasil
skenario 1 , Nilai k=2 memiliki nilai nilai silhouette coefficient
2880429334
31156
3017829728
30477 30509
27000
28000
29000
30000
31000
32000
Cosine Normalization
Memory Consumption Skenario 1
k=2 k=3 k=4 k=5 k=6 k=7 k=8
0,572
0,5480,543
0,517
0,5290,534 0,531
0,480
0,500
0,520
0,540
0,560
0,580
Cosine Normalization
Silhouette coefficient Skenario 1
k=2 k=3 k=4 k=5 k=6 k=7 k=8

84
UIN Syarif Hidayatullah Jakarta
yang terbaik. Semakin tinggi nilai k yang digunakan semakin kecil
nilai silhouette coefficient yang didapatkan. Sejalan dengan
penelitian (Hudin et al., 2018) yang melakukan penelitian pada
pengelompokan dokumen skripsi yaitu pada saat nilai k yang
digunakan semakin besar nilai nilai silhouette coefficient yang
didapatkan menurun dikarenakan merusak pengelompokan yang
seharusnya berada pada satu cluster tetapi menjadi terpisah antar
cluster.
5.4.2 Skenario 2
Berikut ini rata-rata hasil dari skenario 2 pada simulasi nilai
k=2 sampai k=8. :
Tabel 5.17 Hasil Perbandingan Skenario 2
Output k=2 k=3 k=4 k=5 k=6 k=7 k=8
Runtime (s) 0,546 0,544 0,561 0,564 0,542 0,538 0,557
Memory
Consumption
(kb)
28574 28640 30934 34242 33282 32762 32799
Nilai
Silhouette
Coefficient
0,611 0,570 0,551 0,542 0,548 0,531 0,514
Pada tabel di atas menunjukkan hasil simulasi pada skenario
2 yang dilakukan terhadap nilai k=2 sampai k=8 yang diambil dari
nilai rata-ratanya.

85
UIN Syarif Hidayatullah Jakarta
Gambar 5.4 Hasil Runtime Skenario 2
Grafik di atas menunjukkan perbandingan nilai rata-rata
runtime untuk masing-masing nilai k. Semakin kecil nilai runtime
pada proses simulasi maka hasil ini semakin bagus. Pada hasil
skenario 2 , Nilai k=7 memiliki nilai runtime yang terbaik.
Gambar 5.5 Hasil Memory Consumption Skenario 2
Grafik di atas menunjukkan perbandingan nilai rata-rata
memory consumption untuk masing-masing nilai k. Semakin kecil
nilai memory consumption pada proses simulasi maka hasil ini
semakin bagus. Sebab akan membutuhkan resource yang lebih
kecil. Pada hasil skenario 2 , Nilai k=2 memiliki nilai memory
consumption yang terbaik.
0,546 0,544
0,5610,564
0,5420,538
0,557
0,520
0,530
0,540
0,550
0,560
0,570
Min-max Normalization
Runtime Skenario 2
k=2 k=3 k=4 k=5 k=6 k=7 k=8
28574 28640
30934
3424233282 32762 32799
24000
26000
28000
30000
32000
34000
36000
Min-max Normalization
Memory Consumption Skenario 2
k=2 k=3 k=4 k=5 k=6 k=7 k=8

86
UIN Syarif Hidayatullah Jakarta
Gambar 5.6 Hasil Silhouette Coefficient Skenario 2
Grafik di atas menunjukkan perbandingan nilai rata-rata
nilai silhouette coefficient untuk masing-masing nilai k. Nilai nilai
silhouette coefficient merupakan suatu ukuran yang menunjukan
seberapa ketat data dikelompokan dalam cluster. Pada hasil
skenario 2 , Nilai k=2 memiliki nilai nilai silhouette coefficient
yang terbaik. Sama halnya seperti pada skenario pertama bahwa
hasil skenario kedua juga sejalan dengan penelitian (Hudin et al.,
2018).
5.5 Analisis Output dengan Metode Perbandingan Eksponensial
Dalam menghitung dan membandingkan proses pengelompokan
dari dua skenario tersebut sebagai berikut:
1. Menentukan alternatif
Dalam penelitian ini, parameter yang digunakan untuk
membandingkan metode normalisasi adalah runtime dan
memory consumption. Dari hasil analisis perbandingan
kecepatan (runtime) dan memori yang digunakan (memory
consumption).
2. Menentukan kriteria
Untuk dapat membandingkan kedua alternatif tersebut,
maka selanjutnya perlu dilakukan penentuan kriteria dalam
0,611
0,5700,551 0,542 0,548
0,5310,514
0,450
0,500
0,550
0,600
0,650
Min-max Normalization
Silhouette coefficient Skenario 2
k=2 k=3 k=4 k=5 k=6 k=7 k=8

87
UIN Syarif Hidayatullah Jakarta
menganalisis proses dan cara kerjanya. Untuk kriterianya
dapat dilihat pada tabel berikut :
Tabel 5.18 Penentuan Kriteria
Kriteria Keterangan
Runtime yaitu jumlah waktu
yang digunakan dalam
melakukan pengelompokan
Perhitungan waktu dihitung
pada saat tombol submit
diklik yaitu dari mulai
semua fungsi sampai selesai
Memory consumption yaitu
besar memori yang
digunakan saat melakukan
pengelompokan
Perhitungan pemakaian
memori dihitung pada saat
tombol submit diklik yaitu
dari mulai semua fungsi
sampai selesai
3. Menentukan bobot kriteria
Penentuan bobot merupakan salah satu komponen yang
sangat berpengaruh terhadap nilai analisis, untuk itu
menentukan bobot kriteria berdasarkan tingkatan pengaruh
dalam menentukan kecepatan dalam melakukan
pengelompokan. Berdasarkan penelitian sebelumnya (Hanum et
al., 2018) telah melakukan wawancara dengan narasumber
pakar dalam penentuan bobot kriteria, kecepatan eksekusi dan
konsumsi memori merupakan suatu hal yang penting dalam
suatu proses pembuatan sistem dan dapat dijadikan sebagai
perbandingan untuk menentukan performa dari setiap algoritma.
Dari hasil wawancara tersebut di dapatkan hasil rata-rata
pembobotan penilaian, runtime dan memory consumption
adalah sebesar 0,5.

88
UIN Syarif Hidayatullah Jakarta
Tabel 5.19 Pembobotan masing-masing kriteria
Kriteria Presentase
Pengaruh Kriteria
Bobot Range
(0-1)
Runtime (s) 50% 0,5
Memory
consumption (kb)
50% 0,5
4. Pemberian nilai pada setiap kriteria
Pada kriteria yang telah dibentuk harus diberikan nilai.
Nilai tersebut dapat dilihat pada contoh di bawah ini yang
dimana nilainya diambil berdasarkan analisa skenario
sebelumnya.
Tabel 5.20 Pemberian Nilai Kriteria
Alternatif Simulasi
ke-
Nilai
k
Kriteria
Runtime Memory
consumption
Cosine
Normalization
1 2 0,502 28804
2 3 0,532 29334
3 4 0,561 31156
4 5 0,538 30178
5 6 0,534 29728
6 7 0,524 30477
7 8 0,523 30509
Min-max
Normalization
1 2 0,546 28574
2 3 0,544 28640
3 4 0,561 30934
4 5 0,564 34242
5 6 0,542 33282
6 7 0,538 32762
7 8 0,557 32799
5. Menghitung nilai
Setelah semua kriteria terisi, maka proses selanjutnya adalah
melakukan perhitungan dengan menggunakan rumus dari

89
UIN Syarif Hidayatullah Jakarta
Metode Perbandingan Eksponensial (MPE). Proses
perhitungannya sebagai berikut:
a. Proses Perhitungan total nilai pada simulasi nilai k=2 :
Nilai Cosine Normalization
= (0,502)0,5 + (28804)0,5
= 0.70851 + 169.71741
= 170.42593
Nilai Min-max Normalization
= (0,546)0,5 + (28574)0,5
= 0.73891 + 169.03845
= 169.77737
b. Proses Perhitungan total nilai pada simulasi nilai k=3 :
Nilai Cosine Normalization
= (0,532)0,5 + 29334)0,5
= 0.72938 + 171.27171
= 172.00109
Nilai Min-max Normalization
= (0,544)0,5 + (28640)0,5
= 0.73756 + 169.23356
= 169.97112
c. Proses Perhitungan total nilai pada simulasi nilai k=4 :
Nilai Cosine Normalization
= (0,561)0,5 + (31156)0,5
= 0.74899 + 176.51062
= 177.25962
Nilai Min-max Normalization
= (0,561)0,5 + (30934)0,5
= 0.74899 + 175.88064
= 176.62964
d. Proses Perhitungan total nilai pada simulasi nilai k=5 :
Nilai Cosine Normalization

90
UIN Syarif Hidayatullah Jakarta
= (0,538)0,5 + (30178)0,5
= 0.73348 + 173.71816
= 174.45164
Nilai Min-max Normalization
= (0,564)0,5 + (34242)0,5
= 0.75099 + 185.04594
= 185.79693
e. Proses Perhitungan total nilai pada simulasi nilai k=6 :
Nilai Cosine Normalization
= (0,534)0,5 + (29728)0,5
= 0.73075 + 172.41809
= 173.14884
Nilai Min-max Normalization
= (0,542)0,5 + (33282)0,5
= 0.73620 + 182.43355
= 183.16975
f. Proses Perhitungan total nilai pada simulasi nilai k=7 :
Nilai Cosine Normalization
= (0,524)0,5 + (30477)0,5
= 0.72387 + 174.57663
= 175.30050
Nilai Min-max Normalization
= (0,538)0,5 + (32762)0,5
= 0.73348 + 181.00276
= 181.73624
g. Proses Perhitungan total nilai pada simulasi nilai k=8 :
Nilai Cosine Normalization
= (0,523)0,5 + (30509)0,5
= 0.72318 + 174.66826
= 175.39144
Nilai Min-max Normalization

91
UIN Syarif Hidayatullah Jakarta
= (0,557)0,5 + (32799)0,5
= 0.74632 + 181.10494
= 181.85126
h. Menghitung nilai prioritas keputusan
Total nilai Cosine Normalization
= 170.42593 + 172.00109 + 177.25962 + 174.45164 +
173.14884 + 175.30050 + 175.39144
= 1.217,97906
Total nilai Min-max Normalization
= 169.77737 + 169.97112 + 176.62964 + 185.79693 +
183.16975 + 181.73624 + 181.85126
= 1.248,93231
6. Menentukan hasil atau prioritas keputusan
Setelah diperoleh nilai akhir atau total nilai dari masing-
masing, alternatif, maka tahapan selanjutnya yang perlu
dilakukan adalah menentukan prioritas keputusan berdasarkan
nilai dari masing-masing alternatif. Hasil prioritas keputusan
dapat dilihat pada tabel dibawah ini :
Tabel 5.21 Prioritas Keputusan
Alternatif Total Nilai Ranking
Cosine
Normalization
1.217,97906 1
Min-max
Normalization
1.248,93231 2
Dari hasil perhitungan dengan menggunakan Metode
Perbandingan Eksponensial, dapat diketahui bahwa metode
normalisasi yang paling efektif dengan parameter runtime dan
memory consumption adalah Cosine Normalization.
Setiap metode normalisasi yang dipakai pada setiap
skenario ini memiliki kelebihan dan kekurangannya masing-

92
UIN Syarif Hidayatullah Jakarta
masing. Dari analisis kinerja yang telah penulis lakukan,
untuk parameter runtime, Cosine Normalization adalah metode
yang paling baik digunakan untuk nilai k yang kecil,
sedangkan Min-max Normalization adalah metode yang paling
baik digunakaan jika nilai k yang digunakan besar.
Untuk paramater memory consumption, semakin besar
nilai k yang digunakan, maka masing-masing metode
normalisasi akan membutuhkan memori yang semakin
banyak. Namun, dari hasil analisis yang telah penulis
lakukan, memory consumption terkecil adalah Min-max
Normalization.
.

93
BAB 6
PENUTUP
6.1 Kesimpulan
Hasil perbandingan metode normalisasi Cosine Normalization dan
Min-max Normalization pada pengelompokan terjemahan ayat Al Quran,
peneliti mendapatkan hasil tingkat nilai silhouette coefficient tertinggi
yaitu pada skenario kedua menggunakan Min-max Normalization pada
saat nilai k=2. Hasil perbandingan nilai silhouette coefficient menunjukan
bahwa antara Cosine Normalization dengan Min-max Normalization tidak
terlalu signifikan, sama-sama pada medium structure. Dapat disimpulkan
pada setiap metode normalisasi yang dipakai pada pengelompokan
terjemahan ayat Al Quran menggunakan Algoritma K-Means Clustering
bahwa semakin besar nilai k yang digunakan maka semakin kecil nilai
silhouette coefficientnya. Sedangkan hasil perbandingan runtime dan
memory consumption dengan menggunakan Metode Perbandingan
Eksponensial (MPE) menunjukan bahwa Cosine Normalization memiliki
nilai terbaik pada runtime dan memory consumption.
6.2 Saran
Pada penelitian saat ini peneliti menyadari bahwa masih banyak
kekurangan dan keterbatasan. Oleh karena itu, ada beberapa hal yang bisa
sarankan untuk penelitian selanjutnya agar hasilnya lebih memuaskan dan
lebih baik, yaitu:
1. Pada penelitian ini masih banyak kata yang sama muncul pada setiap
clusternya seperti kata maha, sungguh. Diharapkan penelitian
selanjutnya bisa menambahkan kata-kata tersebut kedalam kamus
stopword.
2. Penelitian ini hanya berfokus pada perbandingan metode normalisasi
dan pemilihan nilai k yang terbaik, diharapkan pada penelitian
selanjutnya dapat dibuat rancang bangun aplikasi berbasis mobile.

94
UIN Syarif Hidayatullah Jakarta
3. Pada penelitian ini hanya menampilkan kata yang sering muncul dari
setiap clusternya, diharapkan pada penelitian selanjutnya dilakukan
penentuan oleh ahli dari setiap kata yang sering muncul tersebut untuk
dijadikan tema.
4. Penelitian ini hanya menggunakan terjemahan surah Al Baqarah saja.
Diharapkan penelitian selanjutnya bisa menggunakan seluruh
terjemahan ayat Al Quran.
5. Untuk mengetahui hasil perbandingan yang lebih luas dapat
menggunakan bahasa pemrograman yang lain dengan implementasi
ke objek yang berbeda.

95
DAFTAR PUSTAKA
Abbas, N. H. (2009). Quran “Search for a Concept” Tool and Website. The
University of Leeds.
Ahmad, O., Hyder, I., Iqbal, R., Murad, M. A. A., Mustapha, A., Sharef, N. M., &
Mansoor, M. (2013). A Survey of Searching and Infomation Extraction on a
Classical Text Using Ontology-based semantics modelling: A Case of Quran.
Life Science Journal.
Albate, A., & Minker, W. (2011). Semi-Supervised and Unsupervised Machine
Learning. Wiley.
Amalia, N. A. (2016). Implementasi Support Vector Machine (SVM) Pada
Klasifikasi Laporan Skripsi. Universitas Komputer Indonesia.
Berry, M. W., & Kogan, J. (2010). Text Mining Applications and Theory. (J. Wiley,
Ed.). West Sussex.
Budiman, S. A. D., Safitri, D., & Ispriyanti, D. (2016). Perbandingan Metode K-
Keans dan Metode DBSCAN pada Pengelompokan Rumah Kost Mahasiswa
Di Kelurahan Tembalang Semarang. Jurnal Gaussian, 5, 757–762.
Domeniconi, G., Moro, G., B, R. P., & Sartori, C. (2016). A Comparison of Term
Weighting Schemes for Text Classification and Sentiment Analysis with a
Supervised Variant of tf . idf, 39–58. https://doi.org/10.1007/978-3-319-
30162-4
Faizin, A. S. W. (2018). Implementasi K-Means Clustering pada Terjemahan Al-
Qur’an Berdasarkan Keterkaitan Topik. UIN Sunan Kalijaga.
Feldman, R., & Sanger, J. (2007). The Text Mining Handbook : Advanced
Approaches in Analyzing Unstructured Data. New York: Cambridge
University Press.
Fitrah, M., & Luthfiyah. (2017). Metodologi Penelitian; Penelitian Kualitatif,
Tindakan Kelas & Studi Kasus. (Ruslan & M. M. Effendi, Eds.). Sukabumi:
CV Jejak.
Hamid, A. (2016). Pengantar Studi Al-Qur’an (1st ed.). Jakarta: Prenadamedia
Group.
Han, J., Kamber, M., & Pei, J. (2011). Data Mining : Concepts and Techniques
(Third Edition). Waltham: Morgan Kaufmann Publishers.
Hanum, N. R., Shofi, I. M., & Masruroh, S. U. (2018). Analisis Perbandingan
Kinerja Algoritma Boyer Moore, Horspoo,Dan Zhu Takaoka Pada Repositori
Hadist Bukhori Terjemahan Bahasa Indonesia. UIN Syarif Hidayatullah
Jakarta.

96
UIN Syarif Hidayatullah Jakarta
Haryati, D. F., Abdillah, G., & Hadiana, A. I. (2016). Klasifikasi Jenis Batubara
Menggunakan Jaringan Syaraf Tiruan Dengan Algoritma Backpropagatiion.
Seminar Nasional Teknologi Informasi Dan Komunikasi, 2016(Sentika), 18–
19.
Hudin, M. S., Fauzi, M. A., & Adinugroho, S. (2018). Implementasi Metode Text
Mining dan K-Means Clustering untuk Pengelompokan Dokumen Skripsi (
Studi Kasus : Universitas Brawijaya ). Pengembangan Teknologi Informasi
Dan Ilmu Komputer, 2(11), 5518–5524.
Irwansyah, E., & Faisal, M. (2015). Advanced Clustering : Teori dan Aplikasi.
Yogyakarta: Deepublish.
Jamdar, A., Abraham, J., Khanna, K., & Dubey, R. (2015). Emotion Analysis Of
Songs Based On Lyrical And Audio Features. International Journal of
Artificial Intelligence & Applications (IJAIA), 6(3).
Kaufman, L., & Rousseeuw, P. J. (1990). Finding Groups in Data. New York:
Wiley.
Melita, R., Amrizal, V., Suseno, H. B., & Dirjam, T. (2018). Penerapan Metode
Term Frequency Inverse Document Frequency (TF-IDF) Dan Cosine
Similarity Pada Sistem Temu Kembali Informasi Untuk Mengetahui Syarah
Hadist Berbasis Web (Studi Kasus: Hadist Shahih Bukhari-Muslim). UIN
Syarif Hidayatullah Jakarta.
Merliana, N. P. E., Ernawati, & Santoso, J. (2015). Analisa Penentuan Jumlah
Cluster Terbaik Pada Metode K-Means, 978–979.
Munir, R., & Lidya, L. (2016). Algoritma dan Pemrograman Dalam Bahasa
PASCAL, C, dan C++ Edisi Keenam. Informatika.
Nasution, D. A., Khotimah, H. H., & Chamidah, N. (2019). Perbandingan
Normalisasi Data Untuk Klasifikasi Wine Menggunakan Algoritma K-NN.
CESS (Journal of Computer Engineering System and Science), 4(1), 78–82.
Novitasari, D. (2016). Perbandingan Algoritma Stemming Porter Dengan Arifin
Setiono Untuk Menentukan Tingkat Ketepatan Kata Dasar, 1(2), 120–129.
Nugroho, H. T. (2017). Pengaruh Algoritma Stemming Nazief-Adriani Terhadap
Kinerja Algoritma Winnowing Untuk Mendeteksi Plagiarisme Bahasa
Indonesia. Jurnal ULTIMA Computing, 9(1), 36–40.
https://doi.org/10.31937/sk.v9i1.572
Patro, S. G. K., & Kumar, K. (2015). Normalization : A Preprocessing Stage,
(April). https://doi.org/10.17148/IARJSET.2015.2305
Patro, S. G. K., Sahoo, P. P., Panda, I., & Sahu, K. K. (2015). Technical Analysis
on Financial Forecasting. International Journal of Computer Sciences and
Engineering, 3(1), 1–6.
Prasetyo, E. (2012). Data Mining Konsep dan Aplikasi menggunakan MATLAB. (N.

97
UIN Syarif Hidayatullah Jakarta
WK, Ed.). Gresik: CV Andi Offset.
Prasidhatama, A., & Suryaningrum, K. M. (2018). Perbandingan Algoritma Nazief
& Adriani Dengan Algoritma Idris Untuk Pencarian Kata Dasar. Jurnal
Teknologi & Manajemen Informatika, 4(1), 1–4.
Pratiwi, H. (2016). Buku Ajar Sistem Pendukung Keputusan. Bandung: Abdi
Sistematika.
Rezalina, O. (2016). Perbandingan Algoritma Stemming Nazief & Andriani, Porter
dan Arifin Setiono Untuk Dokumen Teks Bahasa Indonesia, 1–5.
Rohmawati, N., Defiyanti, S., & Jajuli, M. (2015). Implementasi Algoritma K-
Means Dalam Pengklasteran Mahasiswa Pelamar Beasiswa. Jurnal Ilmiah
Teknologi Informasi Terapan, I(2), 62–68.
Salim, M. A. (2017). Pengembangan Aplikasi Penilaian Ujian Essay Berbasis
Online Menggunakan Algoritma Nazief Dan Adriani Dengan Metode Cosine.
Jurnal IT-EDU, 2, 126–135.
Sari, F. (2018). Metode Dalam Pengambilan Keputusan. Yogyakarta: Pendidikan
Deepublish.
Singhal, A., Buckley, C., & Mitra, M. (2017). Pivoted Document Length
Normalization, 51(2).
Siregar, K. (2016). Simulasi Dan Pemodelan. Yogyakarta: Deepublish.
Sitorus, L. (2015). Algoritma dan Pemprograman. (A. Pramesta, Ed.). Yogyakarta:
CV Andi Offset.
Sugiyono. (2017). Metode Penelitian Kuantitatif, Kualitatif, dan R&D. Bandung:
Alfabeta.
Ukkasyah, S. A. (2018). Klasifikasi Kitab Tafsir Al Qur’an. Retrieved March 21,
2019, from https://muslim.or.id/36639-klasifikasi-kitab-tafsir-al-quran-
01.html
Virmani, D., Taneja, S., & Malhotra, G. (2015). Normalization based K means
Clustering Algorithm, 1–5.
Wimmer, H. (2018). Effects of Normalization Techniques on Logistic Regression
in Data Science. Proceedings of the Conference on Information Systems
Applied Research, 1–9.
Yulian, E. (2018). Text Mining dengan K-Means Clustering pada Tema LGBT
dalam Arsip Tweet Masyarakat Kota Bandung, 4(1), 53–58.

98
LAMPIRAN
I Kata yang sering muncul pada skenario 1 nilai k=2
Cluster 1 Cluster 2
allah (150)
sungguh (61)
maha (45)
iman (42)
kata (35)
ketahu (33)
kepada (29)
buat (27)
jadi (25)
nya (24)
al (23)
kitab (22)
benar (21)
kafir (21)
bagi (21)
i (20)
ingat (20)
tuhan (20)
baik (20)
tunjuk (17)
nar (16)
hai (16)
dapat (16)
takwa (16)
ku (16)
atas (16)
allah (190)
sungguh (63)
maha (50)
nya (48)
bagi (41)
tuhan (39)
kata (37)
i (35)
iman (33)
jadi (31)
hari (30)
ketahu (29)
anak (26)
buat (26)
datang (24)
dua (24)
kepada (24)
jalan (23)
manusia (22)
ister (21)
baik (21)
dapat (21)
atas (21)
dosa (20)
kafir (20)
ingat (19)

99
UIN Syarif Hidayatullah Jakarta
jalan (15)
manusia (14)
hati (13)
hukum (13)
barangsiapa (19)
hati (19)
kitab (17)
turun (17)
II Kata yang sering muncul pada skenario 2 nilai k=2
Cluster 1 Cluster 2
allah (194)
sungguh (88)
maha (53)
iman (49)
nya (44)
ketahu (43)
kata (41)
tuhan (38)
i (33)
bagi (32)
jadi (30)
kepada (29)
buat (29)
kitab (29)
kafir (28)
ingat (26)
jalan (26)
baik (25)
dapat (25)
benar (25)
al (22)
tunjuk (21)
manusia (21)
takwa (20)
allah (146)
maha (42)
sungguh (36)
kata (31)
bagi (30)
hari (28)
nya (28)
jadi (26)
iman (26)
buat (24)
kepada (24)
i (22)
tuhan (21)
ketahu (19)
atas (18)
anak (18)
dosa (18)
datang (16)
barangsiapa (16)
baik (16)
manusia (15)
dua (15)
ikan (15)
cara (15)

100
UIN Syarif Hidayatullah Jakarta
turun (20)
ister (20)
atas (19)
datang (19)
hukum (18)
terang (18)
hati (15)
bum (14)
al (14)
ingat (13)
kafir (13)
rasul (12)











![Implementasi Algoritme F5 untuk Penyisipan Pesan Rahasia ... · (Discrete Cosine Transform), kuantisasi, dan penyandian entropi (Huffman Coding) [3]. Gambar 1 Proses Standar Kompresi](https://static.fdokumen.com/doc/165x107/5c82c69f09d3f29c618c98b2/implementasi-algoritme-f5-untuk-penyisipan-pesan-rahasia-discrete-cosine.jpg)








