







Bahasa
Halaman
Hukum


This article was published in an Elsevier journal. The attached copyis furnished to the author for non-commercial research and
education use, including for instruction at the author’s institution,sharing with colleagues and providing to institution administration.
Other uses, including reproduction and distribution, or selling orlicensing copies, or posting to personal, institutional or third party
websites are prohibited.
In most cases authors are permitted to post their version of thearticle (e.g. in Word or Tex form) to their personal website orinstitutional repository. Authors requiring further information
regarding Elsevier’s archiving and manuscript policies areencouraged to visit:
http://www.elsevier.com/copyright

Author's personal copy
Computational modeling of individual differences in shortterm memory search
Action editor: Fabio Del Missier
Adam Chuderski a,*, Zbigniew Stettner a, Jaroslaw Orzechowski b
a Institute of Psychology, Jagiellonian University, Cracow, Polandb Warsaw School of Social Psychology, Warsaw, Poland
Received 20 February 2007; accepted 3 June 2007Available online 1 July 2007
Abstract
Modeling of individual or group differences, believed to be a powerful test for computational models, is still rare in current cognitivescience. In this paper, we discuss alternative approaches to the computational modeling of both qualitative and quantitative differencesamong individuals as well as groups of individuals. Then, an example is presented of how accounting for individual differences in shortterm memory (STM) search can bring us insight into cognitive processes underlying this phenomenon, insight that otherways would beimpossible. The two-phase computational model of memory search implements the idea of working memory (WM) focus of attention(FA): due to updating process a few items may be actively kept and easily accessed in ACT-R goal buffer. FA is being scanned seriallyfirst, and if the scan result is negative, a parallel chunk retrieval from active part of declarative memory outside the FA may run withcertain probability. The model aptly simulates steep decrease in accuracy as well as steep increase in latency for responses to five mostrecent stimuli. The model also predicts the observed effect of faster negative responses than positive responses to less recent stimuli. Mostimportant, with manipulation to only one of its parameters (i.e., the capacity of FA) our model is able to predict 94% of variance for twogroups of participants that differed in latency patterns (i.e., ‘serial-like’ vs. ‘parallel-like’ groups) of the search process.� 2007 Elsevier B.V. All rights reserved.
Keywords: Focus of attention; Short term memory; Computational modeling; Individual differences
1. Introduction
In the present paper we discuss the need for cognitivemodeling to account for individual differences in humancognitive processing, as an important method that can helpus identify proper models for many cognitive mechanisms.First, we analyze two general approaches to modeling indi-vidual and group data, namely qualitative (structural orstrategic) and quantitative (parametric). Next, we discusssome previous data and then present our original data onshort term memory scanning, that show significant differ-ences in latency patterns of memory scanning (i.e., serial-
like vs. parallel-like). Finally, we replicate these differenceswith a new model that accounts for them in terms of thedifferences in individual capacity of the focus of attention.
Almost all cognitive scientists agree that computationalmodeling is the most promising method for describing,understanding, and predicting how the mechanisms ofmind work. It is believed (Pylyshyn, 1989) that cognitivemodels which show behavioral similarity with human sub-jects in comparable experimental or natural situations,embody also internal processes (weakly or strongly) equiv-alent to those occurring in these subjects. Thus, cognitivemodels give us insight into mechanisms of human informa-tion processing that are otherways unobservable. Even ifthe future development of neuroimaging techniques bringsmore precise data about physiological basis of informationprocessing, we will probably still need computational
1389-0417/$ - see front matter � 2007 Elsevier B.V. All rights reserved.doi:10.1016/j.cogsys.2007.06.001
* Corresponding author. Address: Kazimierza Wielkiego 118/26, 30-082Cracow, Poland. Tel.: +48 605 343 484; fax: +48 12 634 13 05.
E-mail address: [email protected] (A. Chuderski).
www.elsevier.com/locate/cogsys
Cognitive Systems Research 8 (2007) 161–173

Author's personal copy
methods to reduce the complexity of brain-imaging datainto understandable theory of processing.
However, there are some weaknesses of cognitive mod-eling as a scientific method. As all other theories, modelsare inferenced from observations and thus they are morea product of scientists’ imagination than the necessary con-clusion derived from facts. Due to the huge power of gen-eral computational formalisms underlying the models, wecan always transform one good fitting model, constructedwithin any such formal system, into another, built withina different system. This is a so-called identifiability prob-lem: one is often unable to identify right model and rejectothers, which, implementing different computational mech-anisms, give comparable pattern of responses.
One way of approaching the identifiability problem maybe to focus on chronometric data analyses, as the problemof computational equivalence of general formal systemsconcerns the power of models, not the time characteristicsindicating efficiency of models’ processing. However,although modeling more dimensions of subjects’ behaviorincreases the explanatory power of the model, models thattake into account both accuracy and latency patterns at thesame time are still believed to be prone to the identifiabilityproblem. Another way to escape this problem may be toembed particular models in broader computational archi-tectures of cognition (e.g., ACT-R; Anderson et al., 2004;3CAPS; Just & Carpenter, 1992; EPIC; Meyer & Kieras,1997; Soar; Newell, 1990; CAP2; Schneider & Chein,2003), constrained theoretically and/or neurobiologically.The model constructed within a cognitive architectureshould use only computational mechanisms that are pro-posed by an underlying theory. Moreover, models ofhigher level phenomena should inherit as much as possiblefrom parameters estimated for lower level tasks. This waywe reduce the number of free parameters of higher levelmodels. This also helps to propagate theoretical constrainsamong subtheories and constitutes additional test for mod-els (Gobet & Ritter, 2000).
Some authors (Daily, Lovett, & Reder, 2001; Gobet &Ritter, 2000; Lewandowsky & Heit, 2006) pointed out thatmodels should also be able to account for individual data.As most of the models are fitted to aggregate data, they donot reflect individual differences in cognition that can beidentified in any cognitive domain. Accounting for differentcognitive strategies (e.g., analytic or global) or for variancein cognitive latent variables (e.g., working memory capac-ity) prevents losing important data and may provide moreinformation and insight into cognitive mechanisms. It isargued that an ability of a model to include individual dif-ferences constitutes a valuable test of fit.
2. Theoretical background
2.1. Modeling of individual differences
Two classes of computational models accounting forindividual differences can be distinguished, namely: quali-
tative (or structural) and quantitative (or parametric), bothnot to be mistaken with Newell (1990) types of agreementbetween model and data. First group includes models thatassume qualitative differences in cognitive mechanismsmodeled, resulting in differences in processing among indi-viduals. The well-known, early example is Hunt (1980)model of sentence-picture verification task. The modeloriginally assumed first transformation of pictures into ver-bal representations, and then comparison of these repre-sentations. As it appeared, only data from 80% ofsubjects fitted this model, while remaining 20% of subjectsfitted qualitatively different model that assumed transfor-mation of sentences into pictorial representation. Withouttaking into account two completely different cognitivestrategies, Hunt’s model would reach only limited level ofvalidity.
Another example of qualitative modeling of differencesin cognition is 3CAPS computational model solvingRaven’s Progressive Matrices test, developed by Carpenter,Just, and Shell (1990). It is an example of a model that seesthe source of differences in the existence of an additionalcognitive structure in some subjects and lack of it in others.The authors constructed a so-called FAIRRAVEN versionof the model, that was able to reach performance of aver-age intelligent people. The model consisted of productionsthat simulated three groups of processes (perceptual analy-sis of a matrix, rule induction and generalization, and ruleapplication to possible solutions of this matrix) identifiedas necessary for solving easy and medium Raven’s prob-lems. The model fired all applicable productions in parallel.It failed to solve correctly 11 out of 34 problems it wasgiven. A BETTERRAVEN version of the model differedfrom the previous one in two crucial characteristics. First,it included additional rules that allowed the model for thegreater level of abstraction. However, as a result of addi-tion of these rules, in case of the most complex problems,parallel operation of the model evoked too many alterna-tive rules that its control structure could efficiently handle.The main qualitative difference between the two modelswas additional, fourth class of productions that simulatedgoal management with setting strategic and tactical goals,monitoring progress towards them, and changing the goalsaccording to the results of processing. Due to goal manage-ment, the BETTERRAVEN model applied rules serially,and it was able to backtrack from unpromising moves.The model solved all 34 problems, thus simulating theresults of highly intelligent subjects.
Quantitative models mimic individual differences in per-formance only with parameter manipulation, while themodel’s structure remains unchanged. An example of sucha model is Just and Carpenter (1992) 3CAPS theory of sen-tence comprehension (CC READER model). Within thistheory, the efficiency of both storage and processing of textdepends on the same resource: the level of activation. Thereis a model’s parameter that sets the maximum limit forsummary activation in the model. If too many elementshave to be maintained in WM and too much activation is
162 A. Chuderski et al. / Cognitive Systems Research 8 (2007) 161–173

Author's personal copy
needed to boost the activation of elements to be added toWM, summary activation consumed by model productionsmay exceed the limit. Then, the model cuts some propor-tion of activation supplied for each production. It resultsin slowing down the processing and rising the probabilitythat a relevant element in WM falls down below activationthreshold and cannot be any longer accessed. Just and Car-penter (1992) simulated different language performance oflow and high WM span subjects by setting low and highlimits on total amount of activation that is available forproductions within the model. For example, low capacityversion of the model, due to inadequate level of activation,was not able to maintain in WM two interpretations of anambiguous fragment of a sentence for one or two wordsbeyond the ambiguity. As high capacity version couldmaintain two interpretations, it had to fire more produc-tion cycles to process both of them. This explained whyhigh span subjects need more time than low span subjectsto read ambiguous sentences. In the case of unambiguoussentences, both the high capacity version of the modeland high span subjects were faster in sentence processingthan low capacity and low span ones.
The work of Daily et al. (2001) is an excellent example ofparametric modeling that goes beyond group differencesand aims at modeling individual performance. On the basisof underlying ACT-R theory of cognition (Anderson &Lebiere, 1998) the authors constructed the model of work-ing memory functioning in a digit span (MODS) task. Themain purpose of research was to model working memoryperformance on individual subject level with manipulationin only one parameter influencing activation supply. Theauthors assumed that it is not the total amount of activa-tion present in the system (as in 3CAPS), but just theamount of activation spread from the current goal (or, inother words, propagated from the focus of attention con-tents) to memory elements associated with this goal, thatis responsible for working memory performance. With 29values of W parameter controlling amount of activationspread from a goal to memory, where each value repre-sented working memory capacity for each individual, andthree additional global parameters held constant acrosssubjects, model aptly (R2 = 0.92) predicted each subject’saccuracy in four task conditions (i.e., it predicted29 · 4 = 116 data points). Individuals who recalled digitsmore correctly had higher W values estimated. When W
parameter was not adjusted individually R2 dropped to0.66.
Successful prediction of individual performance in WMtask constitutes important test for any working memorytheory (in this case ACT-R). In another study the sameauthors (Lovett, Daily, & Reder, 2000) tested the theoryfurther: they wanted to check whether W parameter valuesestimated for individuals in MODS task can be generalizedand used to predict performance in another task (n-back),even though both tasks (MODS and n-back) differ to greatextend. Such cross-task prediction done for nine partici-pants appeared moderately successful (R2 = 0.79). The
authors tried also to generalize two parameters (W valueand an additional parameter reflecting both perceptualand motor speed), estimated for individuals in two elemen-tary tasks, to individual’s performance in more complextask, namely the simplified air traffic control task (AMBRtask) that required observing simulated aircrafts positionson a simulated radar screen and sending commands tothese aircrafts (Rehling, Lovett, Lebiere, Reder, &Demiral, 2004). The model explained modest proportionof individual variance (R2 ranged from 0.16 to 0.21,depending on measure predicted). However, this researchseems to be an interesting first step in computationalapproach to the prediction of individual performance incomplex tasks.
Both qualitative and quantitative approaches to model-ing individual differences seem to be, at least theoretically,orthogonal to the issue whether we should model differ-ences among individuals, or among groups of individualswhose processing is similar enough to be grouped together.The qualitative approach is best suited for modeling groupdifferences (as in example of 3CAPS model of Raven test),but it is possible (however, probably very complicated andtime consuming) that a modeler constructs qualitativelydifferent models for each individual. Modeling individual’sstrategies of solving a divergent problems with different setsof productions (i.e., modeling subjects’ task-relevantknowledge) is an imaginable example. The quantitativeapproach can easily handle modeling of both individualdifferences (as in MODS task example) as well as group dif-ferences (3CAPS example). Which approach (to modelindividuals or to model groups) is more suitable for under-standing differences in cognition?
Modeling individual data has an advantage of precisionof fine-grained predictions. The ability to simulate behaviorof each subject is a powerful test of the model. Especially,in domains where there is convergent evidence that onegeneral capacity or resource determines large part of vari-ance in related performance, individual data modelingapproach seems to be warranted. An example may be gen-eral working memory capacity variable that explains largevariance in working memory tests and intellectual abilitytests (Oberauer, Schulze, Wilhelm, & Suß, 2005). It is prob-ably due to powerful effect of working memory capacity onWM task performance that successful parametric modelslike the one of Daily et al. (2001) are able to predict huge(0.92) proportion of variance.
However, if there is much proportion of noise in indi-vidual data (what is often the case), modeling individual’sperformance includes also modeling the noise. Thus, indi-vidually fitted model may provide weaker explanation ofa phenomenon modeled. Moreover, modeling individualdata requires additional parameters. For example, theparametric model of color classification task by Nosofskyand Palmeri (1997) required setting values of six parame-ters for each of three participants, whose pattern of per-formance was modeled. It was pointed out that‘‘overparametrized’’ models are less capable of being
A. Chuderski et al. / Cognitive Systems Research 8 (2007) 161–173 163

Author's personal copy
generalizable to new situations (Pitt, Myung, & Zhang,2002).
Lee and Webb (2005) proposed that the optimal strategyfor parametric modeling is to build families of models thatdiffer in parameterization, but each model from the familyrepresents aggregated performance of several subjectswhose behavior looks similar. Formal methods aredescribed that optimize the appropriate number of groups(i.e., a number of models in the family). This methodreduces noise associated with individual data but still pro-vides a way of explaining differences in cognition amonghumans.
Such approach is often undertaken in computationalmodeling of neuropsychological deficits, where models rep-resenting both healthy subjects and clinical subjects havedifferent sets of parameters. They capture key differencesbetween groups but do not account for less interesting dif-ferences between individuals from the same group. Forexample, Kimberg and Farah (1993) in an ACT-R modelof cognitive impairments following frontal lobe damagesimulated impaired subjects with weaker associationsamong elements in working memory, in comparison tohealthy subjects. In Goel, Pullara, and Grafman (2001)model of the Tower of Hanoi task, behavior of patientswith lesions to the prefrontal cortex was modeled withincreasing decay rate of elements in working memory.Thus, differences usually seen as qualitative from outsidemay be caused by quantitative differences inside behavingsystems.
In this paper we take the analogous stance, but we applyit to an elementary cognitive process: short term memory(STM) search. We present a model that accounts for twomodes of processing in STM search task that are oftenregarded as qualitatively different, namely ‘parallel’ asopposite to ‘serial’ memory scanning processes (Towsend,1974). We will try to show that these group differencesmay be in fact the result of a quantitative difference in cru-cial cognitive parameter: the focus of attention capacity.We restrict our quantitative approach only to short termmemory scanning (but we discuss alternative qualitativeexplanations as well). We do not mean that qualitativemodeling has a general advantage over quantitativeapproach. In fact, hybrid approaches, dealing at the sametime both with parameter variations as well as with knowl-edge and strategy differences, may be an especially promis-ing way of research in modeling individual and groupbehavior.
2.2. Individual differences in short term memory search
In his seminal paper, Sternberg (1966) examinedwhether people search STM in a serial or parallel way.He used a new design of memory search task (MST). Sub-jects were shown from 1 up to 6 digits (memory set, MS),and then another digit, that could belong (positive condi-tion) or not (negative condition) to MS. Sternberg foundsteep linear RT curve rising with increased MS size. He
concluded that STM had been searched serially andapproximately 38 ms was needed to scan one MS element.Sternberg result, steep linear MS size curve, was replicatedin countless studies. His study began long-lasting discus-sion, whether STM search nature is serial or parallel.
Some studies show that when MS size exceeds six ele-ments, RT curve slope becomes moderate and it looksrather curvilinear (Theios, 1975) or log-like (Jou, 2000).It may indicate that items which cannot be held in STMare retrieved from long term memory in parallel-like searchprocess (Theios, 1975). Moreover, formal study by Tow-send (1974) showed that even in case of MSs not exceedingsix elements, Sternberg’s results can also be predicted byparallel models that are capacity-limited. One such modelproposed by Murdock (1971) assumed that comparisonspeed of memory elements with targets decreases as MSsize increases. Thus, one cannot discriminate between par-allel and serial models of STM search on the basis of line-arity of MS size curve.
In most of the experiments within Sternberg paradigm,verbal stimuli and relatively long presentation times (about1 s per element) were used. Using non-verbal stimuli and/or shorter presentation times brings even more confusionto the issue of modeling STM search. In such experimentalconditions MS size curves become almost perfectly flat. Forexample Necka, Orzechowski, and Florek (2001) in the ser-ies of experiments used systematic manipulation of the pre-sentation time in the Sternberg’s task (1000 ms, 700 ms,and 300 ms). The number of digits and in MS (4, 6, or 8)was manipulated randomly.
The data obtained in Experiment 1 (1000 ms) and 2(700 ms) replicated the original findings by Sternberg(1966): both RT and the number of errors rised linearlywith growing MS size. The Experiment 3 (300 ms) didbring a dramatic change in the pattern of the obtainedresults. In the positive condition, response latencies forall MS size values did not differ significantly (i.e., RT curvewas flat), what suggests that the STM search seems to beparallel. In other words, in the positive condition peoplerespond with the same speed, regardless of how many digitsthey have to inspect in order to find a target. In the nega-tive condition RT rised linearly with growing MS size. So,what seems to be inconsistent with the results from thepositive condition, the search in negative condition seemsto be serial because the more digits have to be inspected,the more time is needed for that operation.
Another problem in evaluating the proper model ofSTM search appears when individual differences in MSTare examined. In the above mentioned experiments ofNecka et al. some inter-individual differences in STMsearch were revealed. The authors divided each sample inall three studies into two groups, depending on the generalspeed index computed as the grand mean RT (with use ofthe median point). Participants characterized by high speedof information processing responded with the same latencyregardless of MS size. These patterns of results disclosedboth in slow and long conditions of stimuli presentation.
164 A. Chuderski et al. / Cognitive Systems Research 8 (2007) 161–173

Author's personal copy
Participants characterized by slow pace of informationprocessing responded with quite another pattern: theirRT rised linearly with growing MS size. The former prob-ably applied the strategy of parallel search whereas the lat-ter preferred the strategy of serial search. These differencesapplied to both the positive and negative conditions. Accu-racy of both groups did not differ significantly, so the dif-ferences in MS curve slopes cannot be explained in termsof speed-accuracy trade-offs.
It seems that people are capable of both serial-like andparallel-like memory search, and there exist significantintra- and inter-individual differences in this process. Inorder to evaluate the proper model of STM search account-ing for presented differences, in a following research wedecided to examine hypotheses concerning position curves(i.e., a relationship between a position of an item in MSand latency or accuracy of response for that item) ratherthan on MS size curves. The rationale for analyzing posi-tion curves is that they give us more precise insight intothe nature of memory search process. Moreover, MS sizeeffects may be derived directly from position effects, assum-ing that latency (or accuracy, respectively) of a response forthe same target position in both large and small MS sizeconditions are similar (and this was a case in our previousexperiments; Balas, Stettner, & Piotrowski, 2005). Forexample, if RT’s for all target positions do not differ signif-icantly, mean RT (aggregated over all target positions) inlarge MS size condition will be the same as in small MS sizecondition. Alternatively, in case of higher RT’s (or errorrates) for the less recent target positions, we observe risingmean RT (or error rate) with growing MS size. In theexperiment presented in this paper we used only one MSsize condition (8 items) for one more reason. We wantedto exclude any effects of switching between MS conditions,as switching between memorizing small and large MSs mayrequire different strategies and random changes in MS maysurprise participants.
The main aim of the experiment is to examine a positioncurve for both latency and accuracy dependent variables,what should evoke ideas for further computational model-ing of the search process (e.g., whether its two-phase natureis probable). Moreover, on the basis of our above cited pre-vious results, we expect that individual differences in posi-tion curves will appear. Some subjects should obtain steeplatency–position curves. In such case, the less recent an itemis the slower is the response to that item. This may indicate,assuming that memory elements are usually scanned frommost recent to least recent ones, that the nature of the pro-cess of memory scanning is serial. Other subjects shouldobtain flat, at least in part, latency–position curves, andlack of statistically significant differences in time ofresponding to items on different positions within MS mayindicate parallel nature of the search process. We also claimthat the proper model of STM search should predict thesegroup differences in a quantitative manner, optimally withchange in only one of its parameters. Such a model will beproposed and tested against the data from the experiment.
3. Experiment
3.1. Subjects
Forty one students from colleges around Cracow wereexamined. Due to an error in experimental procedure, dataconcerning their age and gender are not available.
3.2. Materials
The computerized MST was used in the experiment,with a pool of 16 consonants as stimuli, each one2 · 1.5 cm in size. Eight-items MS size was used. Fifteentrials for each target position were presented in positivecondition (120 trials total) and another 78 trials in negativecondition, on random. The position of target in MS wasthe only independent variable (0–8, were 0 stands for neg-ative condition). There was eight positive and eight nega-tive training trials preceding experimental trials.
3.3. Procedure
Subjects were first presented with computerized taskinstructions that emphasized accuracy of responding. Thenthey were informed that only responses shorter than 2 swould be regarded as correct ones. Time limit for respond-ing was introduced to reduce hesitation and guessing. Theexperimental session began after successful completion ofthe training session. An asterisk presented before first stim-ulus on each trial served as a fixation point. Stimuli werepresented at a rate of one digit every 800 ms, at the centerof the computer screen. After the presentation of the whole8 digit memory set a mask was shown for 500 ms and thena probe letter appeared inside a rectangle. If subjectsdecided that a probe was presented in MS in a current trial,they had to press key ‘Z’, in opposite case they were topress ‘M’. Cues on computer screen helped subjects toremember proper response keys.
3.4. Results and discussion
Two dependent variables: the proportion of correctresponses and the latency of correct responses, were col-lected and analyzed. We assume that our homogenoussample (young, intelligent people) should not have signifi-cant influence on representativeness of results, as (1) largeinter-individual variance was observed in the data anywayand (2) Sternberg task in a one-MS-size-condition versionis known for not correlating significantly with general fluidintelligence test scores (Chuderski; unpublished results). Alltrials that ended with no response, error, or correctresponse longer than 2 s, were not included in proportionof trials responded correctly. A main effect of the positionindependent variable in the case of accuracy dependentvariable was highly significant, F(8,33) = 45.14, p < 0.001,MSE = 0.018. The accuracy for all pairs of items on neigh-boring target positions differed at least at p < 0.01 level,
A. Chuderski et al. / Cognitive Systems Research 8 (2007) 161–173 165
Author's personal copy
except for difference for positions three and four, whichwas not statistically significant. Strong primacy andrecency effects were observed: average accuracy of responsefor position one was significantly higher than for positiontwo, as well as the accuracy of response for position eight(last item in MS) was significantly higher than for positionseven. The accuracy for negative trials was significantlyhigher than for positions one to five, but significantly lowerfor positions seven and eight. Accuracy proportion curveas a function of position of a target in MS is presented insolid line in Fig. 1.
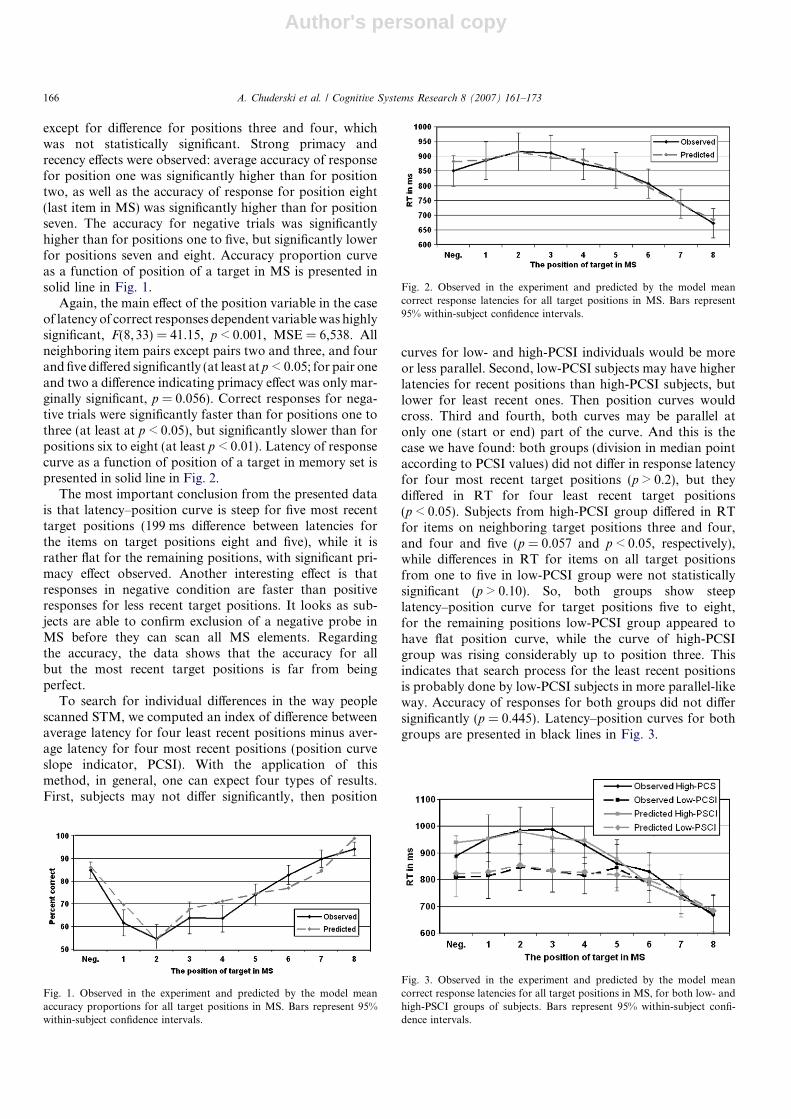
Again, the main effect of the position variable in the caseof latency of correct responses dependent variable was highlysignificant, F(8, 33) = 41.15, p < 0.001, MSE = 6,538. Allneighboring item pairs except pairs two and three, and fourand five differed significantly (at least at p < 0.05; for pair oneand two a difference indicating primacy effect was only mar-ginally significant, p = 0.056). Correct responses for nega-tive trials were significantly faster than for positions one tothree (at least at p < 0.05), but significantly slower than forpositions six to eight (at least p < 0.01). Latency of responsecurve as a function of position of a target in memory set ispresented in solid line in Fig. 2.
The most important conclusion from the presented datais that latency–position curve is steep for five most recenttarget positions (199 ms difference between latencies forthe items on target positions eight and five), while it israther flat for the remaining positions, with significant pri-macy effect observed. Another interesting effect is thatresponses in negative condition are faster than positiveresponses for less recent target positions. It looks as sub-jects are able to confirm exclusion of a negative probe inMS before they can scan all MS elements. Regardingthe accuracy, the data shows that the accuracy for allbut the most recent target positions is far from beingperfect.
To search for individual differences in the way peoplescanned STM, we computed an index of difference betweenaverage latency for four least recent positions minus aver-age latency for four most recent positions (position curveslope indicator, PCSI). With the application of thismethod, in general, one can expect four types of results.First, subjects may not differ significantly, then position
curves for low- and high-PCSI individuals would be moreor less parallel. Second, low-PCSI subjects may have higherlatencies for recent positions than high-PCSI subjects, butlower for least recent ones. Then position curves wouldcross. Third and fourth, both curves may be parallel atonly one (start or end) part of the curve. And this is thecase we have found: both groups (division in median pointaccording to PCSI values) did not differ in response latencyfor four most recent target positions (p > 0.2), but theydiffered in RT for four least recent target positions(p < 0.05). Subjects from high-PCSI group differed in RTfor items on neighboring target positions three and four,and four and five (p = 0.057 and p < 0.05, respectively),while differences in RT for items on all target positionsfrom one to five in low-PCSI group were not statisticallysignificant (p > 0.10). So, both groups show steeplatency–position curve for target positions five to eight,for the remaining positions low-PCSI group appeared tohave flat position curve, while the curve of high-PCSIgroup was rising considerably up to position three. Thisindicates that search process for the least recent positionsis probably done by low-PCSI subjects in more parallel-likeway. Accuracy of responses for both groups did not differsignificantly (p = 0.445). Latency–position curves for bothgroups are presented in black lines in Fig. 3.
Fig. 1. Observed in the experiment and predicted by the model meanaccuracy proportions for all target positions in MS. Bars represent 95%within-subject confidence intervals.
Fig. 2. Observed in the experiment and predicted by the model meancorrect response latencies for all target positions in MS. Bars represent95% within-subject confidence intervals.
Fig. 3. Observed in the experiment and predicted by the model meancorrect response latencies for all target positions in MS, for both low- andhigh-PSCI groups of subjects. Bars represent 95% within-subject confi-dence intervals.
166 A. Chuderski et al. / Cognitive Systems Research 8 (2007) 161–173

Author's personal copy
4. Modeling STM search in ACT-R
4.1. ACT-R model of STM search
ACT-R cognitive architecture (Anderson et al., 2004) isa theory of mind expressed as a central control structureoperating with procedural knowledge (i.e., productions)on chunks of information available in buffers of severalspecialized modules (e.g., visual, auditory, goal, and declar-ative memory modules). Working memory in ACT-R maybe defined in two ways: as a subset of highly active ele-ments of declarative memory or as a process of spreadingsource activation from a current goal to declarative ele-ments strongly linked with that goal. These two conditionsare often strongly correlated: memory traces are highlyactive due to additional activation being spread from thegoal. Two other factors affecting trace accessibility are:learning process strengthening trace’s link to the goal orrising trace base activation, and decay of activation in time.
Within ACT-R there are two methods of trace retrievalfrom working memory (Anderson, Bothell, Lebiere, &Matessa, 1998). In some specific conditions (like time–pres-sure), the most active memory element is retrieved andtested against a probe. The target element may not be themost active one, so a negative response in positive condi-tion (error of omission) is possible. Alternatively, a produc-tion may try to retrieve an element identical to the probe.The higher activation of successfully retrieved element,the lower latency of retrieval. Due to the partial matchingmechanism, an element similar but not identical to theprobe may be retrieved and, by an error of commission,may be accepted as a target. If there is no target or tar-get-like element above certain threshold at all, retrieval fail-ure with long latency occurs.
A simple ACT-R model of word recognition memorywas proposed by Anderson et al. (1998, pp. 222–225). Itretrieves the most active word trace as a candidate andchecks whether it is identical to a probe. Source activationis being spread from the probe to a corresponding trace inmemory. The model predicts almost linear relationshipbetween the number of elements in a list and their recogni-tion latency (Anderson et al., 1998, Figure 7.7). Thus, themodel does not fit some recent data described previouslyin this paper: flat MS size curves of fast responding subjects(Necka et al., 2001) or log-like MS curves (Jou, 2000). It isneither coherent with the data presented in last section: theslope of position curve for five most recent items in Ander-son et al., 1998, Figure 7.8 is approximately 80 ms only,while the same slope observed in our data is 199 ms.Shorter latencies of accurate negative responses than ofpositive responses to less recent stimuli, observed in ourdata, cannot be easily predicted with existing ACT-Rmodel, either. In negative condition (a foil) the modelalways retrieves less active chunk or reaches retrievalthreshold, what causes long retrieval, and thus longresponse latency. Any parameter manipulation (for exam-ple in latency factor), undertaken in order to rise steepness
of a position curve, would probably increase the differencebetween foil and target latency, making the model even lessfitting our data. Finally, existing MST model predicts nearperfect accuracy of response, while our data shows thatalso low (60–75%; for target positions one, three, four,and five) or near random (54%; in case of target positiontwo) accuracy levels were observed.
Relying on retrieval from the active part of declarativememory, as modeled by Anderson et al. (1998), is probablya reasonable strategy in case of semantic material (words),that is presented for long time (1.5 s) and can be intensivelyrehearsed. However, with the use of a small set of letters,the huge level of interference within declarative memoryappears quickly and a task becomes very difficult. Relyingon automatic access to declarative memory may lead tovery low accuracy. Engle (2002) proposes, that in such cir-cumstances, controlled attention, that preserves importantinformation in active and interference-secure state, has tobe involved in the storage of memorized material. It seemsthat existing ACT-R model cannot be generalized to suchconditions. More attentional processes should be imple-mented in the proper model of STM search task withnon-semantic stimuli.
4.2. Two-phase model of STM search
The idea of the WM focus of attention was introducedinto the model of STM search. First of all, we use the term‘short term memory’ instead of ‘working memory’, becauseSternberg task is rather classified as a STM span task. Onthe other hand the mechanism of short term storage is acrucial part of every WM theory and – in consequence –we decided to include a mechanism of WM, i.e., focus ofattention, into our model. Focus of attention is a capac-ity-limited storage mechanism which contains the mostactive information available for direct and reliable access.Functionally, the role of FA is to activate and maintainthe information needed for current processing. There isan agreement that capacity of the focus is very limitedand only the information in the focus is available to con-scious awareness and report (Cowan, 1995; Engle, 2002;McErlee, 2001; Oberauer, 2002). Other characteristics ofthe focus are more controversial. Cowan (2001) argues thataverage FA limit of about four items (chunks) is observedacross various tests, but its mechanism is flexible. It canshift from one type of material or one level of organizationto another (for instance from level of items, like apple,banana, orange, to the fruit category level). Other research-ers (Engle, 2002; McErlee, 2001; Oberauer, 2002) leantowards capacity of FA restricted to one highly activateditem, with separate direct access region which holds 3–4elements. Contents of direct access region are a little bit lessactivated than the item in FA, but they are ready to beimmediately included into the focus. In relation to otheraspects of WM structure, our model was not designed inintentional compliance with (much more general in scope)any particular theory of WM.
A. Chuderski et al. / Cognitive Systems Research 8 (2007) 161–173 167

Author's personal copy
We assume that only elements in WM focus of attentionmay be volitionally updated, and that individual differencesin current FA capacity, resulting in differences in stimuliencoding, affect memory search process and explain results(two different chronometric patterns of search for low- andhigh-PCSI groups) presented earlier in this paper. Themodel presented below is a modified version of the modelpresented in Chuderski, Stettner, and Orzechowski(2006), and is being fitted to new experimental data.
Like most ACT-R models of WM, our model alsoencodes simulated stimuli ‘presented’ on a computer screenduring MST into episodic memory traces. In case of thisstudy, these traces are chunks encoding information thatparticular letter appeared in the current list. However,according to ACT-R theory, making a new trace, withoutadditional effort to hold it active in memory, results inalmost immediate decay of chunk’s activation belowthreshold. To achieve satisfactory level of accuracy, a cog-nitive system runs processes (productions in our model)aimed at activating the traces until the probe arrival. Thismay be done with the focus of attention, which can covera few traces.
In our model, the process of activation occurs afterdecoding one stimulus and before the presentation of anew one, and consist of retrieval of the most active tracefrom declarative memory (maximally twice in a row) andplacing it in one of the slots of the goal buffer, which worksas an attentional focus. Its capacity (i.e., the number ofgoal buffer slots available; a crucial model’s parameter) islimited, so if memory is overloaded, the chunk which wasthe least recently placed in the focus is overwritten by themost recently retrieved chunk. No spreading of activationoccurs from the goal buffer to declarative memory, FA istreated as structurally distinct part of WM. In each cycle,activating production competes with ‘do nothing’ produc-tion, both with the same probability to be run. The latterrepresents lapses of attention that can happen during thememorization of presented stimuli.
When the capacity parameter is set to one element, justone (most probably: currently presented) chunk is acti-vated as much as presentation time allows, and loaded intothe goal buffer. So, the more recent stimulus is, the greaterchance for it to be the only element held in the focus. Whencapacity parameter is set to a greater value, the model canupdate more than one element in its focus of attention. Asletters used in our experiment can probably be perfectlydistinguished one from another, and they are almost voidsemantically (in comparison with words, syllables, andimages), we assume that, along with spreading of activa-tion, also partial matching mechanism may be switchedoff. However, in case of more meaningful material, ourmodel is able to easily implement ACT-R activationspreading process (from a probe to items in memory thatare similar physically or semantically to this probe) andpartial matching mechanism (of these similar items).
When the probe is presented, the model starts searchingmemory traces for a one identical with the probe. Instead
of just retrieving the most active memory trace, as inAnderson et al. (1998), our model runs two phases of mem-ory search. In the first phase, traces in the focus of atten-tion are checked serially, one by one, starting from themost recently updated trace. The model’s focus representsstable, probably self-activating, representations. So, in themodel, these representations (like goal chunks in ACT-R)can be directly reached by search-process productions, atno additional retrieval time. At each test of focus’ contents,traces already checked are marked. The second crucialmodel parameter – the probability of stopping the searchafter the test of each item in the focus of attention – con-trols whether the first phase can be completed and the sec-ond phase can be run at all. If the stop occurs, it results innegative response.
What is the rationale for including the stopping process?As we believe, the higher number of elements is checked inthe first phase, the less probable is memory scanning out-side the FA. Especially, after searching the whole focus,especially if its capacity is large, an additional, probablyerrorful, search outside the focus would yield little proba-bility of success, but would take huge amount of time. Insuch case, in time-pressured conditions, it is much morereasonable to generate the negative answer during orimmediately after the first phase. This phenomenon mayresult in correct negative responses that are faster thanpositive responses generated after the second phase. Webelieve that the parameter regulating the chance of stop-ping the memory search may be strategically altered byparticipants on the basis of their current attentional capac-ity, of the size of MS, and of experimental conditions inwhich the search task is applied. However, this hypothesismust be experimentally verified in future research.
If the capacity parameter is set to one or two elements,only the most recent element(s) are checked in the firstphase, in quite short time in total. If more items are beingheld in FA, due to the longer process of serial testing of lar-ger number of focus contents, the first phase will lastlonger, depending on the exact value of parameter repre-senting time to access each element in the focus. As webelieve, this value should be set to a little lower value thandefault 50 ms for regular ACT-R productions (see also:Wang, Fan, & Johnson, 2004).
If the result of focus check is negative and the modeldoes not stop the search process, it may run the second,parallel phase of STM scanning. When the second phaseruns successfully, the model tries to directly retrieve, froma declarative memory, the trace with a letter slot equal tothe probe letter. The standard mechanism of ACT-R isexploited: the more often and more recent the trace wasbeing activated (i.e., retrieved) during encoding phase, thebetter and faster it is available for retrieval. If the activa-tion of the searched trace is not above the threshold(because it was decayed or a target was not presented atall), long latency retrieval failure occurs. However, such acase does not determine negative response of the model.Sometimes, especially when MS size is large, the model
168 A. Chuderski et al. / Cognitive Systems Research 8 (2007) 161–173

Author's personal copy
tries to guess an answer, with some chance for a positiveresponse. This is based on an assumption, that when manyletters are presented, subjects are probably aware that anunsuccessful retrieval may indicate the fact they did forgetthe element as well as the fact there was no such elementpresented at all. In consequence, the third model’s param-eter controls the probability of guessing ‘yes’ when the sec-ond phase fails to retrieve any memory chunk. The controlflow in the model and the illustration of the focus of atten-tion and the working memory area outside the focus arepresented in Fig. 4.
When the attentional capacity is set to some highervalue, after the presentation of a probe the model has theopportunity to rely its search process on fast but serialaccess to chunks actively maintained in the FA. When cur-rent attentional capacity is low, instead of the serial scan ofthe focus (which in this case is almost empty), relativelyslow but parallel retrieval from declarative memory isexecuted.
Eleven productions, representing assumed task-relevantprocedural knowledge of subjects, control the informa-tion flow in the model. The productions are describedin Table 1.
4.3. Model parameters
The model includes six parameters that were set todefault ACT-R values or to values estimated empirically,and five parameters that should be considered as freeparameters. Three default ACT-R values: 50 ms for timeto fire a production, 0.5 for decay parameter, and 0.0for base level constant, were used. The time to fire a ruleaccessing FA was set to 40 ms, an estimate of attention-operating rules latency taken from an ACT-R model ofattentional networks by Wang et al. (2004). The mostimportant model specific parameter: FA capacity, wasrandomly varied from one to five elements, the valuesclose to those observed by Cowan (2001). Time to activatea trace (what probably most often consists on rehearsingan item) was set to 400 ms, based on an empirical test
of how many digits (i.e., five, on average) participants(N = 3) were able to rehearse silently within two secondsperiod.
Five parameters were optimized to produce the best fitto empirical data, including three ACT-R parameters:retrieval threshold (0.50), latency factor (0.30), and activa-tion noise (0.06). Retrieval threshold depends on the valueof a base level constant parameter and is usually optimizedin most of ACT-R models. Latency factor is used for scal-ing a chunk activation value to latency of that chunk retrie-val. The most interesting optimized parameter is the noisevalue added to activations of memory traces. When it wasset to low values (<0.02), the model behaved in a determin-istic way and could only recognize the most recently pre-sented items. When it was set to relatively high values(>0.20), the probability of correct recognition of a targetfor all its positions in MS oscillated around a similar value(that depended mostly on a value of threshold parameter),and the primacy effect disappeared. The second specificmodel parameter, the probability of stopping the searchduring the first phase was optimized to 0.25. It means thatthe probability of stopping after each focus slot scandepended on the capacity of attention parameter, for exam-ple it could have equaled to 0.125 if the capacity parameterhad been set to two items (0.250/2) or to 0.050 if the capac-ity parameter had been set to five items (0.250/5). The lastmodel specific parameter, the marginal probability ofguessing ‘yes’ in the case of retrieval failure, was set arbi-trary to 0.035 for each additional item outside the FA. Itmeans that in case of memory sets equal or less than thecurrent capacity of FA, the model always guesses answer‘no’ (i.e., it ‘thinks’: if I am not able to recall this item ithas surely not been presented at all), but when memory setsare large (>30 items) and thus impossible to be maintainedin human memory, the model would always guess answer‘yes’ (i.e., it would ‘think’: I have surely seen this itembut I am not able to recall this fact). A value of W param-eter is not relevant to the present simulation, as spreadingof activation from a goal to the declarative memory was setoff.
Fig. 4. The control flow in the model and the example of focus of attention (FA) within declarative memory (DM), which includes three most recentlypresented stimuli.
A. Chuderski et al. / Cognitive Systems Research 8 (2007) 161–173 169

Author's personal copy
The additional intercept parameter (the summary timeneeded to decode a stimulus and to generate a response),which does not affect R2 value, was set to 485 ms.
4.4. Simulation results and discussion
Simulated data were generated in 5000 model’s runs.The model predicted nine accuracy data points with goodfit: R2 equaled to 0.874 (RMSD = 5.0). The model repli-cated all three crucial effects: steep position curve rangingform near perfect to random accuracy, primacy effect,and higher accuracy of response in negative condition thanpositive response for less recent target positions. The mod-el’s fit to nine latency data points was very good: R2equaledto 0.970 (RMSD = 14.1). Again, the model replicatedsteepness of latency–position curve, primacy effect, as wellas shorter latencies of correct responses in negative condi-tion than of responses for items on the four least recent tar-get positions. The simulated accuracy is presented indashed lines in Fig. 1, simulated latency – in Fig. 2.
Crucial for testing the model should be a simulation ofgroup differences in the chronometric pattern of STMsearch. When two separate simulations were run: one withthe capacity parameter value varied between one and two,and the other with its value varied between four and five,all other parameters unchanged, the model predicted differ-ences in position curves for low- and high-PCSI subjects(Fig. 3, gray lines) with R2 = 0.943 (RMSD = 21.8). Thesimulated mean accuracies for both low- and high-PCSIgroups (which were not significantly different in the empir-ical data) were very close one to each other (75.6% and73.1%, respectively) and fell into 95% confidence intervalsof observed means. As there were no significant between-
group differences in accuracy (observed nor simulated)concerning target positions either, we do not report thesedata.
One crucial feature of the model is the stopping rule,which allows for replication of the effect of faster negativeresponses than positive responses for the least recent targetpositions. There are at least two possible alternative expla-nations of this effect (suggested by an anonymousreviewer). Firstly, fast negative responses may possiblyoccur when an STM model (which would be similar tothe model by Anderson et al., 1998) just retrieves the mostactive chunk from memory and gives a negative answerwhen this chunk differs from a target (given that high acti-vation noise and low mismatch penalty are set). However, amodel with high noise value would probably not be able toreplicate steep accuracy–position curve (as discussed in aprevious subsection). In our opinion, it either does notseem plausible to assume low value of mismatch penaltyparameter in case of relatively simple task with easily dis-tinguishable stimuli (letters). Moreover, if such simplermodel would most often give a negative answer on thebasis of a comparison of a target to a result of mismatchedretrieval (what would be necessary for its fast negativeresponses), it would probably not be able to commit asmany errors as was observed in negative condition. Themore complex possible explanation is based on Reder’sSAC model (e.g., Reder et al., 2000). People may calculatea feeling-of-knowing value for the target, and start theretrieval process only when the target looks familiar. Infact, both explanations (i.e., our and SAC model) assumethat retrieval from memory may be ceased in some cases.However, our approach quite roughly approximates theproportion of trials with responses not preceded by any
Table 1Description of all productions controlling information flow in the model
Production Conditions and actions
Decode-Stimulus IF the goal is to decode stimuli and new stimulus is presented and it was not decodedTHEN add new chunk representing stimulus to memory
Activate-Chunks IF the goal is to decode stimuli and new stimulus is not presented and previous stimulus was decodedTHEN retrieve most active chunk not retrieved twice in a row and add it to the focus of attention
Do-Nothing IF the goal is to decode stimuli and new stimulus is not presented and previous stimulus was decodedTHEN do nothing
Activation-Failure IF the goal is to decode stimuli and new stimulus is not presented and no chunk was retrievedTHEN do nothing
Decode-Target IF the goal is to decode stimuli and target is presentedTHEN switch the goal to search memory
Search-Focus IF the goal is to search memory and not all focus’ items are testedTHEN access next focus item and push the goal to compare items
Search-DM IF the goal is to search memory and all focus’ items are testedTHEN retrieve chunk with slot equal to target from declarative memory and switch to the goal to compare items
Searched-All IF the goal is to search memory and all focus’ items are tested and target chunk was not retrieved from declarative memoryTHEN guess yes or no and respond that guess
Stop-Search IF the goal is to compare items and should stop searchTHEN respond no
Compare-Same IF the goal is to compare items and should not stop search and compared items are the sameTHEN respond yes
Compare-Different IF the goal is to compare items and should not stop search and compared items are differentTHEN pop current goal
170 A. Chuderski et al. / Cognitive Systems Research 8 (2007) 161–173

Author's personal copy
retrieval. It is an interesting issue to include more sophisti-cated mechanism of retrieval stopping (e.g., the one pro-posed in the SAC model) into our model.
The second crucial feature of the model is its focus ofattention that can vary in capacity. This feature allowedto replicate steep position curves for both accuracy andlatency variables, and manipulation in the capacity param-eter produced replication of between-group differences inchronometric patterns of memory search. As there aresome other parametric manipulations possible in ACT-R,other sources of chronometric differences should be dis-cussed. First, one could postulate a version of the modelwith the spreading activation mechanism switched on(i.e., propagating activation from a probe to a target trace)and could vary its W parameter. As W parameter nicelyrepresents ACT-R WM capacity (Daily et al., 2001), itmay be possible that with higher W values memory retrie-val becomes faster and position–latency curve in Sternbergtask becomes flatter (i.e., similar to low-PCSI group’scurve). However, rising the value of W would surely resultalso in lower error rates, due to higher summary activationof a target trace. No such effect was found for low-PCSIgroup. Similar argument concerns manipulation in baselevel constant parameter, influencing chunk’s total activa-tion. Moreover, with higher W value RTs would probablyget shorter for all positions, but in experimental data bothgroups differ only in RTs for the least recent target posi-tions (this argument concerns also manipulation in latencyfactor or exponent).
Besides explanation of differential results in terms ofdifferences in parameter values, one could explain themalso in terms of differences in strategy use. For example,in n-back task experiment done by Lovett et al. (2000),in a postexperimental questionnaire subjects admitted theuse of one of two strategies. Some participants used an‘activation’ strategy for encoding stimuli in WM: theywere just activating current stimulus during its presenta-tion. In the decision phase, their responses were basedon subjective familiarity of a new element. Other subjectsused ‘update’ strategy – they actively maintained andupdated recent stimuli in WM. Lovett et al. observedtwo-way (n · group) interaction in accuracy. In our previ-ous experiment, reported in Chuderski et al. (2006), we didnot find any significant inter-group differences in strategyuse as reported by participants in a postexperimental ques-tionnaire. Although this introspective method cannot betaken as a proof for insignificancy of strategic factors, inthe present paper we aimed to replicate different modesof short term memory search only with parameter manip-ulation and not with different strategies (i.e., different pro-ductions) implemented in a model. We think thatexplanation of observed group differences in terms offocus of attention exploitation is simpler than that interms of differences in (more complex in nature) strategies.However, in general, an explanation in terms of strategicfactors cannot be ruled out on the basis of presented dataand simulations.
5. Summary and conclusions
The two-phase model of STM search has a very good fitto the empirical data. Two new crucial features of themodel: the stopping rule and the focus of attention,allowed for replication of several observed effects. In thecontext of modeling of STM search, the model capturessome effects (steep latency and accuracy position curvesand faster negative responses than some positive responses)that seem to lay outside the scope of existing ACT-R modelby Anderson et al. (1998).
The idea of multi-item FA (reflected with ACT-R goalbuffer) may be regarded as potentially inconsistent withone of ACT-R assumptions: that only one chunk can beloaded into the goal buffer. In our model, one and onlygoal chunk includes memory chunks as its slots (maxi-mally five). The ability of the focus of attention to beas flexible as to cover from one to a few items is postu-lated in a recent version of the Cowan’s theory of atten-tion (so-called adjustable-attention hypothesis; Cowan,2005). Although the theoretical issue of how the focusof attention operates needs more clarification in futureresearch, we believe that the concept of multi-item FAis, in general, quite consistent with existing ACT-R the-ory. We suggest that the idea of WM focus of attention,implemented as highly active, easily accessible structuredistinct from declarative memory, which stores informa-tion currently operated on (i.e., that has just been pro-cessed or is just being prepared for processing), shouldbe exploited in ACT-R models to a greater extend asWM attentional focus may be involved in numerousmemory, attention, cognitive control, and decision mak-ing tasks (Cowan, 2001; Engle, 2002).
The most interesting result concerns model’s ability forzero-parameter prediction of different, parallel-like versusserial-like chronometric patterns. As an individual’s datagenerated in MST are noisy to a great extend (e.g., reflect-ing a bias towards positive or negative responding), wewere not interested in modeling individuals’ data. On thecontrary, we were rather interested in modeling two differ-ent groups of individuals showing similar STM scanningbehavior. Modeling at group level eliminated the influenceof unwanted factors as response biases or perceptual-motorspeed, and allowed us to isolate values of the cognitiveparameter crucial for processing in STM – the focus ofattention capacity. Accounting for group differences wasachieved at low cost of additional parameters (i.e., onlythe decision which subsets of the original parameter valuesshould be taken to simulate both groups), but with highbenefit of additional (twice as many) simulated latency datapoints. Easily obtained prediction of group differences is avery strong argument in favor of the model. Thus, the pro-posed model seems to be an apt theoretical proposal thatexplains the mechanism of short term memory search, aphenomenon disputed for over forty years. In this respect,our work contributes to the serial versus parallel memorysearch debate by suggesting the central role of individual
A. Chuderski et al. / Cognitive Systems Research 8 (2007) 161–173 171

Author's personal copy
differences in chronometric characteristics of searchprocess. We believe, that although there really exist pureserial and pure parallel phases of STM search, the processas a whole is the mixture of both types of processing – amixture that is different for different people.
By now, the model presented in this paper is particularlysuitable for predicting data obtained in experiments wherelonger stimuli lists, that include items with low semanticassociations (i.e., letters, digits, geometric figures, etc.),are used. The work aimed at generalization of the modelto search among semantically related items, probablyinvolving the process of spreading activation, will be aninteresting area of future research. As in real life peopleprobably more often search for meaningful material intheir WM, such a future model seems to be more ecologi-cally plausible. Future work should also deal with moresophisticated mechanism responsible for a decision whento stop the search process, mechanisms that may probablybe based on the feeling-of-knowing calculation. Closerexamination of strategic factors determining between-group differences in search process should also beundertaken.
Concluding the role of individual differences in the com-putational modeling of cognitive phenomena, the presentedwork shows that accounting for individual differences evenin such elementary processes as STM search makes it easierto understand the mechanism that underlies this cognitivephenomenon. The flexibility of a model to generate individ-ual or group differences in the observed patterns of resultsconstitutes a powerful test of any model. For example, aresearch project that will deal with modeling of individualdifferences in working memory and their influence on per-formance in reasoning, problem solving, and decision mak-ing tasks, although it will probably take researchersdecades (Lewandowsky & Heit, 2006), is surely worthbeing undertaken.
Acknowledgements
This work was supported by grant N106 043 32/2857(‘‘Computational model of working memory search’’)sponsored by Polish Ministry of Science and Higher Edu-cation. We thank Jaroslaw Kwiatkowski for programmingexperimental task.
References
Anderson, J. R., Bothell, D., Byrne, M. D., Douglass, S., Lebiere, C., &Qin, Y. (2004). An integrated theory of the mind. Psychological
Review, 111, 1036–1060.Anderson, J. R., Bothell, D., Lebiere, C., & Matessa, M. (1998). List
memory. In J. R. Anderson & C. Lebiere (Eds.), Atomic components of
thought (pp. 201–253). Mahwah, NJ: Erlbaum.Anderson, J. R., & Lebiere, C. (1998). Atomic components of thought.
Mahwah, NJ: Erlbaum.Balas, R., Stettner, Z., & Piotrowski, K. T. (2005). Ognisko uwagi w
pamieci roboczej a efekt pozycji [The focus of attention in workingmemory and a position effect]. Studia Psychologiczne, 43, 85–89.
Carpenter, P. A., Just, M. A., & Shell, P. (1990). What one intelligence testmeasures: A theoretical account of the processing in the RavenProgressive Matrices test. Psychological Review, 97, 404–431.
Chuderski, A., Stettner, Z., & Orzechowski, J. (2006). Individualdifferences in working memory search. In Proceedings of the interna-
tional conference on cognitive modeling (6th ed.). Trieste: EdizioniGoliardiche.
Cowan, N. (1995). Attention and memory: An integrated framework. NewYork: Oxford University Press.
Cowan, N. (2001). The magical number 4 in short-term memory: Areconsideration of mental storage capacity. Behavioral and Brain
Sciences, 24, 87–114.Cowan, N. (2005). Understanding intelligence: A summary and an
adjustable-attention hypothesis. In O. Wilhelm & R. W. Engle(Eds.), Handbook of understanding and measuring intelligence
(pp. 469–488). Thousand Oaks, CA: Sage Publications.Daily, L. Z., Lovett, M. C., & Reder, L. M. (2001). Modeling individual
differences in working memory performance: a source activationaccount. Cognitive Science, 25, 315–353.
Engle, R. W. (2002). Working memory capacity as executive attention.Current Directions in Psychological Science, 11, 19–23.
Gobet, F., & Ritter, F. E. (2000). Individual data analysis and unifiedtheories of cognition: A methodological proposal. In N. Taatgen & J.Aasman (Eds.), Proceedings of the third international conference on
cognitive modeling (pp. 150–157). Veenendaal: Universal Press.Goel, V., Pullara, D. S., & Grafman, J. (2001). A computational model of
frontal lobe dysfunction: working memory and the Tower of Hanoitask. Cognitive Science, 25, 287–313.
Hunt, E. B. (1980). Intelligence as an information processing concept. The
British Journal of Psychology, 71, 449–474.Jou, J. (2000). The magic number four: Can it explain Sternberg’s serial
memory scan data? Behavioral and Brain Sciences, 24, 126–127.Just, M. A., & Carpenter, P. A. (1992). A capacity of comprehension:
Individual differences in working memory. Psychological Review, 99,122–149.
Kimberg, D. Y., & Farah, M. J. (1993). A unified account of cognitiveimpairments following frontal lobe damage: The role of workingmemory in complex, organized behavior. Journal of Experimental
Psychology: General, 122, 411–428.Lee, M. D., & Webb, M. R. (2005). Modeling individual differences in
cognition. Psychonomic Bulletin and Review, 12, 605–621.Lewandowsky, S., & Heit, E. (2006). Some targets for memory models.
Journal of Memory and Language, 55, 441–446.Lovett, M. C., Daily, L. Z., & Reder, L. M. (2000). A source activation
theory of working memory: Cross-task prediction of performance inACT-R. Cognitive Systems Research, 1, 99–118.
McErlee, B. (2001). Working memory and focal attention. Journal of
Experimental Psychology: Learning, Memory, and Cognition, 27,817–835.
Meyer, D., & Kieras, D. (1997). A computational theory of executivecognitive processes and multiple-task performance. Part 1: Basicmechanisms. Psychological Review, 104, 3–65.
Murdock, B. B. (1971). A parallel-processing model for scanning.Perception and Psychophysics, 10, 289–291.
Newell, A. (1990). Unified theories of cognition. Cambridge MA: HarvardUniversity Press.
Necka, E., Orzechowski, J., & Florek, S. (2001). Individual differences instrategies to deal with working memory tasks. In XII conference of
European society for cognitive psychology (ESCoP), Edinburgh,September 5–8.
Nosofsky, R. M., & Palmeri, T. J. (1997). An exemplar-based randomwalk model of speeded classification. Psychological Review, 104,266–300.
Oberauer, K. (2002). Access to information in working memory: Explor-ing the focus of attention. Journal of Experimental Psychology:
Learning, Memory, and Cognition, 28(3), 411–421.Oberauer, K., Schulze, R., Wilhelm, O., & Suß, H-M. (2005). Working
memory and intelligence – their correlation and their relation:
172 A. Chuderski et al. / Cognitive Systems Research 8 (2007) 161–173

Author's personal copy
Comment on Ackerman, Beier, and Boyle (2005). Psychological
Bulletin, 131, 61–65.Pitt, M., Myung, I., & Zhang, S. (2002). Toward a method of selecting
among computational models of cognition. Psychological Review, 109,472–491.
Pylyshyn, Z. (1989). Computing in cognitive science. In M. Posner (Ed.),Foundations of cognitive science (pp. 49–92). Cambridge, MA: MITPress.
Reder, L. M., Nhouyvansivong, A., Schunn, C. D., Ayers, M. S.,Angstadt, P., & Hiraki, K. (2000). A mechanistic account of themirror effect for word frequency: A computational model of remem-ber/know judgments in a continuous recognition paradigm. Journal of
Experimental Psychology: Learning, Memory, and Cognition, 26,294–320.
Rehling, J., Lovett, M., Lebiere, C., Reder, L. M., & Demiral, B. (2004).Modeling complex tasks: An individual difference approach. In
Proceedings of the 26th annual conference of the cognitive science
society (pp. 1137–1142). Mahwah, NJ: Erlbaum.Schneider, W., & Chein, J. M. (2003). Controlled and automatic
processing: Behavior, theory, and biological mechanisms. Cognitive
Science, 27, 525–559.Sternberg, S. (1966). High-speed scanning in human memory. Science,
153, 652–654.Theios, J. (1975). The components of response latency in simple human
information processing tasks. In P. M. A. Rabbitt & S. Dornic (Eds.),Attention and performance V (pp. 418–444). London: Academic Press.
Towsend, J. T. (1974). Issues and models concerning the processing of afinite number of inputs. In B. H. Kanowitz (Ed.), Human information
processing: Tutorials in performance and cognition (pp. 133–168).Hillsdale, NJ: Erlbaum.
Wang, H., Fan, J., & Johnson, T. R. (2004). A symbolic model of humanattentional networks. Cognitive Systems Research, 5, 119–134.
A. Chuderski et al. / Cognitive Systems Research 8 (2007) 161–173 173
Top Related
Copyright © 2022 FDOKUMEN

