



Bahasa
Halaman
Hukum


ĐẠI HỌC QUỐC GIA THÀNH PHỐ HỒ CHÍ MINHĐẠI HỌC CÔNG NGHỆ THÔNG TINKHOA HỆ THỐNG THÔNG TIN
------------
LUẬN VĂN TỐT NGHIỆP
Tên đề tài: HỆ THỐNG KHUYẾN NGHỊ DỰA TRÊN BỐI
CẢNH
Cán bộ hướng dẫn: Th.s Huỳnh Hữu ViệtSinh viên thực hiện:
Huỳnh Tùng - 07520505 Nguyễn Thị Kim Quy – 07520493

Tp.HCM, ngày tháng năm 2011
1

LỜI CÁM ƠN
Trước tiên, chúng tôi xin gửi lời cảm ơn và
lòng biết ơn sâu sắc nhất tới Thạc sĩ Huỳnh Hữu Việt
người đã tận tình chỉ bảo và hướng dẫn nhóm trong suốt quá
trình thực hiện khoá luận tốt nghiệp.
Chúng tôi chân thành cảm ơn các thầy, cô đã tạo cho
tôi những điều kiện thuận lợi để nhóm chúng tôi học tập,
nghiên cứu tại trường Đại Học Công Nghệ Thông Tin.
Cuối cùng, chúng tôi muốn gửi lời cảm tới gia đình và
bạn bè đã luôn bên cạnh và động viên chúng tôi trong suốt
quá trình thực hiện khóa luận tốt nghiệp.
Nhóm sinh viên thực hiện
2

NHẬN XÉT CỦA GIÁO VIÊN HƯỜNG DẪN
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
3

NHẬN XÉT CỦA GIÁO VIÊN PHẢN BIỆN
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
........................................................
4

MỤC LỤC
LỜI CÁM ƠN..............................................ii
NHẬN XÉT CỦA GIÁO VIÊN HƯỜNG DẪN.......................iii
NHẬN XÉT CỦA GIÁO VIÊN PHẢN BIỆN........................iv
DANH MỤC HÌNH..........................................vii
DANH MỤC BẢNG.........................................viii
DANH MỤC CÁC THUẬT NGỮ, TỪ VIẾT TẮT.....................ii
CHƯƠNG 1: TỔNG QUAN VỀ ĐỀ TÀI............................1
1.1.Đặt vấn đề.........................................11.2.Mục tiêu...........................................21.3.Phạm vi khóa luận..................................21.4.Phương pháp nghiên cứu và nội dung thực hiện.......31.5.Kết quả dự kiến:...................................31.6.Bố cục báo cáo:....................................4
CHƯƠNG 2: HỆ THỐNG KHUYẾN NGHỊ: KHÁI NIỆM VÀ CÁC PHƯƠNG
PHÁP TIẾP CẬN............................................4
2.1.Hệ thống khuyến nghị...............................42.1.1 Khái niệm.....................................................................................................42.1.2 Các chức năng của hệ thống khuyến nghị..............................................52.1.3 Các phương pháp khai thác dữ liệu được sử dụng................................6
2.2.Khuyến nghị dựa trên lọc cộng tác- đánh giá độ tươngquan9
2.2.1 Các vấn đề phát sinh trong lọc cộng tác.................................................92.2.2 Ưu điểm của lọc cộng tác..........................................................................92.2.3 Các hình thức tiếp cận.............................................................................102.2.4 Các vấn đề phát sinh................................................................................12
2.3.Các giải thuật nâng cao áp dụng trong lọc cộng tác 122.3.1 Tổng quan.................................................................................................122.3.2 Baseline predictors:..................................................................................13
5

2.3.3 SVD.............................................................................................................132.3.4 SVD++.........................................................................................................14
2.4.Hệ thống khuyến nghị dựa trên ngữ cảnh............152.4.1 Ngữ cảnh...................................................................................................152.4.2 Các phương pháp tiếp cận:.....................................................................15
CHƯƠNG 3: TRIỂN KHAI....................................18
3.1.Hệ thống khuyến nghị:.............................183.2.HỆ THỐNG..........................................18
CHƯƠNG 4: ĐÁNH GIÁ KẾT QUẢ..............................19
4.1.Các tiêu chí đánh giá.............................194.2.Kết quả...........................................21
CHƯƠNG 5: TỔNG KẾT......................................21
5.1.ABC...............................................215.2.XYZ...............................................21
KẾT LUẬN VÀ HƯỚNG PHÁT TRIỂN............................22
TÀI LIỆU THAM KHẢO......................................23
6

DANH MỤC HÌNHNo table of figures entries found.
7

DANH MỤC BẢNGNo table of figures entries found.
8

DANH MỤC CÁC THUẬT NGỮ, TỪ VIẾT TẮT
No table of figures entries found.
9

CHƯƠNG 1: TỔNG QUAN VỀ ĐỀ TÀI
1.1. Đặt vấn đề
Cùng với nhu cầu tìm kiếm thông tin trên Internet
ngày càng trở nên phổ biến là một lượng lớn thông tin
được đưa lên Internet hằng ngày. Vì thế một nhu cầu mới
đặt ra là một thông tin nên hay không nên được đọc,
chia sẻ đến cho một đối tượng người sử dụng Internet?
Thông tin nào sẽ có khả năng được đánh giá cao bởi một
đối tượng người sử dụng? Và làm thế nào để xác định
được là thông tin đó có khả năng được người dùng đánh
giá cao hay thấp?
Để giải quyết vấn đề trên đã rất nhiều bài nghiên cứu
đã được thực hiện trên các lĩnh vực khác nhau, đối
tượng thông tin khác nhau. Kết quả của các bài nghiên
cứu đó nhằm hỗ trợ đưa ra một Hệ thống khuyến nghị
(Recommender Systems) phù hợp nhất. Hệ thống khuyến
nghị có thể là một chương trình, một tập hợp các kỹ
thuật nhằm đưa ra các khuyến nghị về các đối tượng cho
người dùng mà có khả năng được người dùng sử dụng nhất.
Quá trình đưa ra các khuyến nghị là một chuỗi các quá
trình đưa ra các quyết định cho nhiều loại đối tượng.
Ví dụ như: Khách hàng A nên mua các sản phẩm nào của
siêu thị, khách hàng B nên ăn món ăn gì ở khu vực Quận
Tân Bình, TP HCM…
10

Hệ thống khuyến nghị đưa ra các khuyến nghị dựa trên
quá trình thu thập, xử lý và phân tích dữ liệu mà người
dùng. Dữ liệu đó được chia làm 2 loại là tường minh và
ngầm định. Dữ liệu tường minh do người dùng cung cấp
thông qua các bài nhận xét, bình luận, đánh giá theo
thang điểm, cảm nhận thích hoặc không thích cho một sản
phẩm, một bài hát, một món ăn. Dữ liệu ngầm định bao
gồm mức độ quan tâm đến sản phẩm, số lần xem, thời gian
xem tin…
Trong quá trình nghiên cứu và thực nghiệm Hệ thống
khuyến nghị thì có các vấn đề xuất hiện như sau:
- Khả năng đáp ứng (Scalability):
- Tính đa dạng của các đối tượng được khuyến nghị
(Diversity):
- Sự thay đổi sở thích của người dùng theo thời gian.
Sự thay đổi sở thích của người dùng theo sự chi phối
của ngữ cảnh, môi trường bên ngoài.
1.2. Mục tiêu
- Nghiên cứu và xây dựng hệ thống khuyến nghị dựa vào
ngữ cảnh của người dùng.
- Đề tài khóa luận sẽ chọn Đối tượng dùng để khuyến
nghị là các Nhà hàng và Món ăn. Thông tin khuyến nghị
sẽ được rút trích từ các bài chia sẽ kinh nghiệm của
người dùng đã từng đến Nhà hàng và thưởng thức Món ăn
tại Nhà hàng đó.
11

- Đánh giá so sánh kết quả của các 2 phương pháp sử
dụng Memory-Based và Model-Based.
1.3. Phạm vi khóa luận
Phạm vi của khóa luận nhằm nghiên cứu, phân tích hành
vi và sở thích của ăn uống của người dùng thông qua các
bài chia sẻ kinh nghiệm.
Đối tượng khuyến nghị:
o Các nhà hàng được lấy dữ liệu từ Internet.
o Các món ăn được lấy từ Internet.
o Các bài chia sẻ kinh nghiệm ăn uống được thực
hiện thông qua Google Form và trực tiếp trên hệ
thống.
Đối tượng được khuyến nghị:
o Người dùng trên hệ thống: Là người dùng có tài
khoản trên hệ thống. Là người dùng xác định đã
thể hiện một vài hành vi trên hệ thống.
o Khách vãng lai: Là người dùng không có tài khoản
trên hệ thống, chỉ ghé thăm hệ thống trong một
thời điểm nhất thời, và hành vi để lại rất ít.
Nội dung khuyến nghị:
o Sản phẩm hoặc danh sách các món ăn/ nhà hàng phù
hợp với một người dùng xác định trong một ngữ
cảnh được xác định.
Đối tượng liên quan:
o Ngữ cảnh: là tập hợp bao gồm các yếu tố.
12

Thời gian: Bao gồm thời gian trong ngày,
ngày trong tuần và mùa trong năm.
Vị trí, khoảng cách: Vị trí của người dùng,
khoảng cách xa, gần.
Người đi cùng: đi một mình, đi với người
yêu, đi với bạn bè, đi với gia đình và đi
với đối tác trong công việc.
Trạng thái của nhà hàng: Thể hiện nhà hàng
đang có các chương trình khuyến mãi hay
không.
1.4. Phương pháp nghiên cứu và nội dung thực hiện
Cách tiếp cận: Sử dụng 2 phương pháp
o Memory-Based:
o Model-Based:
Nội dung thực hiện:
o Khảo sát nghiên cứu các vấn đề liên quan đến Hệ
thống khuyến nghị, tập trung vào phương pháp Lọc
cộng tác (Colaborative Filtering – CF).
o Tìm hiểu so sánh 2 phương pháp Memory-Based và
Model Based.
o Thu thập dữ liệu nhà hàng, món ăn, các Bài chia
sẻ kinh nghiệm ăn uống từ người dùng.
o Tìm hiểu các thuật toán liên quan đến 2 phương
pháp Memory-Based và Model-Based.
o Đề ra phương pháp áp dụng vào Hệ thống khuyến
nghị.
13

o Xây dựng một Hệ thống khuyến nghị mẫu.
o Tiến hành kiểm thử kết quả, đánh giá và báo cáo.
1.5. Kết quả dự kiến:
Xây dựng thành công thuật toán nhằm đưa ra các khuyến
nghị về món ăn/ nhà hàng phù hợp với người dùng trong
một ngữ cảnh nhất định.
Xây dựng một Hệ thống nhỏ để áp dụng thuật toán và
tương tác với người dùng thông qua đó:
o Đầu vào:
Người dùng sẽ đăng nhập hệ thống, chia sẽ
các sở thích của mình thông qua các dữ liệu
của các giao tác bao gồm tường minh (bài
chia sẻ kinh nghiệm, đánh giá nhà hàng, món
ăn) và ngầm định (số lần xem tin về nhà hàng
và món ăn).
o Đầu ra:
Các khuyến nghị:
Khuyến nghị về các món ăn/ nhà hàng nên
ăn vào ngữ cảnh hiện tại (mặc định)
hoặc do người dùng chọn.
Khuyến nghị các món ăn nên ăn nhất ở
một nhà hàng.
Đưa ra bảng kết quả đánh giá phương pháp dựa
trên các thông số đánh giá lý thuyết và thực
nghiệm từ phản hồi của người dùng.
Hoàn thành báo cáo khóa luận tốt nghiệp.
14

1.6. Bố cục báo cáo:
Trong Chương 1, nhóm tác giả đã trình bày khái quát về
mục tiêu, phạm vi, phương pháp và nội dung thược hiện.
Ở các chương sau nhóm sẽ đi sau vào cơ sở lý thuyết và
phương pháp tiếp cận, cài đặt và triển khai hệ thống.
Cụ thể như sau:
Chương 2: Hệ thống khuyến nghị: Trình bày những nội
dung cơ bản về hệ thống khuyến nghị và phương pháp tiếp
cận.
Chương 3: Triển khai hệ thống: Trình bày hệ khuyến nghị
được xây dựng trong khóa luận
Chương 4: Đánh giá kết quả thực nghiệm
Chương 5: Tổng kết khóa luận.
CHƯƠNG 2: HỆ THỐNG KHUYẾN NGHỊ: KHÁI NIỆM VÀ CÁC
PHƯƠNG PHÁP TIẾP CẬN2.1. Hệ thống khuyến nghị
2.1.1 Khái niệm
Hệ thống khuyến nghị là kỹ thuật cung cấp những gợi ýcho nhu cầu về một sản phẩm, dịch vụ nào đó trên Internetcho người sử dụng. Những gợi ý được cung cấp là nhằm mụcđích hỗ trợ người sử dụng trong quá trình ra quyết địnhlựa chọn sản phẩm, dịch vụ, chẳng hạn như những sách nàocó thể người dùng muốn mua, những bài hát nào có thể ngườidùng thích nghe, hoặc tin tức nào người dùng muốn đọc. Mộtvài ứng dụng nổi tiếng về hệ thống khuyến nghị như: khuyến
15

nghị sản phầm của Amazon.com [paper của amazon], hệ tư vấnphim của NetFlix…[paper của về Netflix] Hệ thống khuyếnnghị đã chứng minh được ý nghĩa to lớn: giúp cho người sửdụng trực tuyến đối phó với tình trạng quá tải thông tin.Hệ khuyến nghị trở thành một trong những công cụ mạnh mẽvà phổ biến trong thương mại điện tử.
Trong hầu hết các trường hợp, bài toán khuyến nghịđược coi là bài toán ước lượng trước hạng (rating) của cácsản phẩm (phim, cd, nhà hàng …) chưa được người dùng xemxét. Việc ước lượng này thường dựa trên những đánh giá đãcó của chính người dùng đó hoặc những người dùng khác.Những sản phẩm có hạng cao nhất sẽ được dùng để khuyếnnghị.
Bài toán khuyến nghị được mô tả như sau:
Gọi U là tập tất cả người dùng (users); I là tập tấtcả các sản phẩm (items) có thể tư vấn. Tập I có thể rấtlớn, từ hàng trăm ngàn (sách, cd…) đến hàng triệu (nhưwebsite).
Hàm r (u, i) đo độ phù hợp (hay hạng) của sản phẩm ivới user u:
Trong đó R là tập các đánh giá (rating) được sắp thứtự. Với mỗi người dùng u ∈ U, cần tìm sản phẩm i ∈ I saocho hàm r (u, i) đạt giá trị lớn nhất.
2.1.2 Các chức năng của hệ thống khuyến nghị
Hệ thống khuyến nghị là công cụ phần mềm với các đềxuất cho người dùng những sản phầm, dịch vụ mà họ có thểmuốn sử dụng. Dưới đây là một số chức năng của hệ thống:
16
r: U x I → R

Tăng số lượng các mặt hàng bán ra cho các hệ thốngthương mại điện tử: Đây có lẽ là chức năng quan trọng nhấtcủa hệ thống khuyến nghị. Thay vì người dùng chỉ mua mộtsản phẩm mà họ cần, họ được khuyến nghị mua những sản phẩm‘có thể họ cũng quan tâm’ mà bản thân họ không nhận ra. Hệthống khuyến nghị tìm ra những ‘mối quan tâm ẩn’. Bằngcách đó, hệ thống khuyến nghị làm gia tăng nhu cầu củangười dùng và gia tăng số lượng mặt hàng bán ra.Tương tựđối với các hệ thống phi thương mại (như các trang báo),hệ thống khuyến nghị sẽ giúp người dùng tiếp cận với nhiềuđối tượng hơn.
Bán các mặt hàng đa dạng hơn trên các hệ thống thươngmại điện tử: Đây là chức năng quan trọng thứ hai của hệthống khuyến nghị. Hầu hết các hệ thống thương mại đều cócác mặt hàng hết sức là đa dạng. Khi nắm bắt được nhu cầucủa người dùng, hệ thống khuyến nghị dễ dàng mang đến sựđa dạng trong sự lụa chọn hàng hóa.
Tăng sự hài lòng người dùng: Vai trò chủ đạo của hệthống khuyến nghị là hiểu nhu cầu của người dùng, gợi ýcho họ những thứ họ cần...Chính vì vậy hệ thống khuyếnnghị tăng sự hài lòng của người dùng trên hệ thống.
Tăng độ tin cậy, độ trung thực của người dùng: Mộtkhi hệ thống gợi ý cho người dùng những lựa chọn và họ hàilòng vể những gợi ý đó thì lòng tin của họ đối với hệthống (nơi mà giúp họ tìm ra những thứ họ thực sự quantâm) được nâng lên một cách đáng kể. Đây thật sự là mộtđiều thích thú và thu hút người dùng. Có một điểm quantrọng là hệ thống khuyến nghị hoạt động dựa trên những xếphạng thật từ chính bản thân người dùng trong quá khứ. Dođó, khi người dùng càng tin cậy vào hệ thống, đưa ra nhữngđánh giá trung thực cho các sản phẩm, hệ thống sẽ mang lại
17

cho người dùng nhiều gợi ý chính xác hơn, phù hợp với nhucầu, sở thích của họ.
2.1.3 Các phương pháp khai thác dữ liệu được sử dụng
Có rất nhiều cách để dự đoán, ước lượng hạng/điểm chocác sản phẩm như sử dụng học máy, lí thuyết xấp sỉ, cácthuật toán dựa trên kinh nghiệm… Theo [paper thống kê cácphương pháp], các hệ thống tư vấn thường được phân thànhba loại dựa trên cách nó dùng để ước lượng hạng của sảnphẩm:
Khuyến nghị dựa trên nội dung (Content-BasedRecommendation System):
Khuyến nghị dựa trên nội dung được dựa trên sự sẵn cócủa mô tả về đối tượng. Phương pháp tư vấn dựa trên nộidung, dựa trên độ phù hợp r (u, i) của sản phẩm i vớingười dùng u được đánh giá dựa trên độ phù hợp r (u, ii),trong đó ii ϵ I và tương tự như i. Ví dụ, để gợi ý một bộphim cho người dùng u, hệ thống tư vấn sẽ tìm các đặc điểmcủa những bộ phim từng được u đánh giá cao (như diễn viên,đạo diễn…); sau đó chỉ những bộ phim tương đồng với sởthích của c mới được giới thiệu.
Hướng tiếp cận dựa trên nội dung bắt nguồn từ nhữngnghiên cứu về thu thập thông tin (IR-informationretrieval) và lọc thông tin (IF - information filtering).Do đó, rất nhiều hệ thống dựa trên nội dung hiện nay tậptrung vào tư vấn các đối tượng chứa dữ liệu text như vănbản, tin tức, website… Những tiến bộ so với hướng tiếp cậncũ của IR là do việc sử dụng hồ sơ về người dùng (chứathông tin về sở thích, nhu cầu…). Hồ sơ này được xây dựngdựa trên những thông tin được người dùng cung cấp trựctiếp (khi trả lời khảo sát) hoặc gián tiếp (do khai pháthông tin từ các giao dịch của người dùng).
18

Khuyến nghị dựa trên nội dung có những ưu điểm:
o Đầu tiên, nó không yêu cầu số lượng người sửdụng lớn để đạt được độ chính xác đề nghị hợplý.
o Ngoài ra, các mặt hàng mới có thể được khuyếnnghị ngay dựa trên thuộc tính có sẵn.
Tuy nhiên, nhược điểm của khuyến nghị dựa trên nộidung là khi thông tin mô tả đối tượng có chất lượng kém vàbị lỗi. Trong một số trường hợp, những mô tả về nội dungrất khó để so sánh và rút ra gợi ý, chẳng hạn so sánh nộidung của các file video, audio...Việc phân tích nội dungcủa các đối tượng sản phẩm để đưa ra các sản phẩm tương tựnhau, từ đó đưa ra các khuyến nghị cho người dùng vẫn chưaphản ánh đúng sở thích của người dùng đó với các sản phẩm
Khuyến nghị lọc cộng tác để đánh giá tương quan (Collaborative Filtering Recomnendation System):
Ý tưởng cơ bản của các hệ thống này là dựa vào cácđánh giá của những người dùng quá khứ lên các sản phẩm,dịch vụ để dự đoán sự đánh giá của họ lên các sản phẩm,dịch vụ mà họ chưa đánh.
Bài toán lọc cộng tác (hay đánh giá độ tương quan) dựa trên hành vi quá khứ của người dùng (trong việc đánh giá sản phẩm) để đưa ra dự đoán.
Đầu vào của bài toán là ma trận thể hiện những hành vi quá khứ, gọi là ma trận Người dùng- Sản phẩm (m trận User x Item). Hàng là người dùng, cột là sản phẩm, giá trịmỗi ô là đánh giá của người dùng lên sản phẩm đó.
19
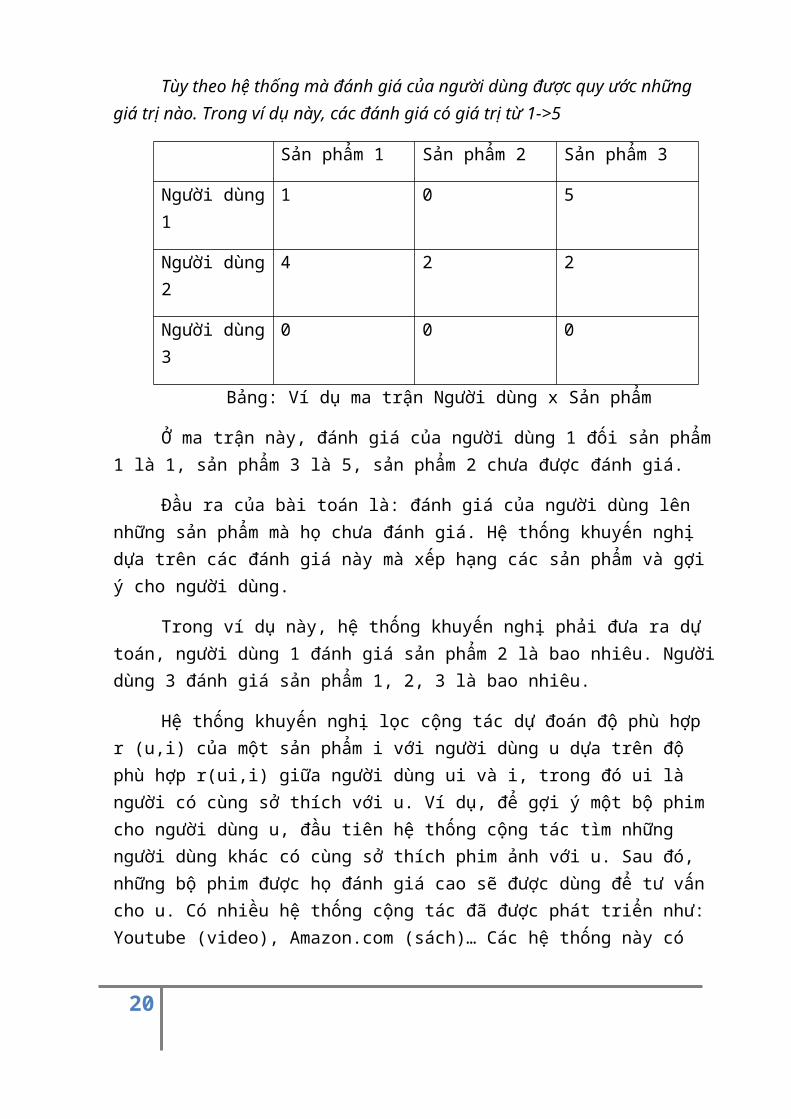
Tùy theo hệ thống mà đánh giá của người dùng được quy ước những giá trị nào. Trong ví dụ này, các đánh giá có giá trị từ 1->5
Sản phẩm 1 Sản phẩm 2 Sản phẩm 3
Người dùng1
1 0 5
Người dùng2
4 2 2
Người dùng3
0 0 0
Bảng: Ví dụ ma trận Người dùng x Sản phẩm
Ở ma trận này, đánh giá của người dùng 1 đối sản phẩm1 là 1, sản phẩm 3 là 5, sản phẩm 2 chưa được đánh giá.
Đầu ra của bài toán là: đánh giá của người dùng lên những sản phẩm mà họ chưa đánh giá. Hệ thống khuyến nghị dựa trên các đánh giá này mà xếp hạng các sản phẩm và gợi ý cho người dùng.
Trong ví dụ này, hệ thống khuyến nghị phải đưa ra dự toán, người dùng 1 đánh giá sản phẩm 2 là bao nhiêu. Ngườidùng 3 đánh giá sản phẩm 1, 2, 3 là bao nhiêu.
Hệ thống khuyến nghị lọc cộng tác dự đoán độ phù hợp r (u,i) của một sản phẩm i với người dùng u dựa trên độ phù hợp r(ui,i) giữa người dùng ui và i, trong đó ui là người có cùng sở thích với u. Ví dụ, để gợi ý một bộ phim cho người dùng u, đầu tiên hệ thống cộng tác tìm những người dùng khác có cùng sở thích phim ảnh với u. Sau đó, những bộ phim được họ đánh giá cao sẽ được dùng để tư vấn cho u. Có nhiều hệ thống cộng tác đã được phát triển như: Youtube (video), Amazon.com (sách)… Các hệ thống này có
20

thể chia thành hai loại: dựa trên kinh nghiệm (heuristic-based hay memory-based) và dựa trên mô hình (model-based).
Kết hợp các phương pháp (Hybrid):
Các cách tiếp cận khác nhau có những ưu điểm và nhượcđiểm riêng. Do đó cần thiết kết hợp các kỹ thuật khác nhauđể tận dụng ưu điểm và nhược điểm của các cách tiếp cận đểcó được hệ thống khuyến nghị chính xác hơn.
Có thể phân thành bốn cách kết hợp như sau:
Cài đặt hai phương pháp riêng rẽ rồi kết hợp dự đoán của chúng: Cóhai kịch bản cho trường hợp này. Cách 1: Kết hợp kết quảcủa cả hai phương pháp thành một kết quả chung duy nhất,sử dụng cách kết hợp tuyến tính (linear combination) hoặcvoting scheme. Cách 2: Tại mỗi thời điểm, chỉ chọn phươngpháp cho kết quả tốt hơn (dựa trên một số độ đo chất lượngtư vấn nào đó). Ví dụ, hệ thống DailyLearner system chọnphương pháp nào đưa ra gợi ý với độ chính xác (confidence)cao hơn.
Tích hợp các đặc trưng của phương pháp dựa trên nội dung vào hệthống cộng tác: Một số hệ thống lai (như Fab) dựa chủ yếutrên các kĩ thuật cộng tác nhưng vẫn duy trì hồ sơ vềngười dùng (theo dạng của mô hình dựa trên nội dung). Hồsơ này được dùng để tính độ tương đồng giữa hai ngườidùng, nhờ đó giải quyết được trường hợp có quá ít sản phẩmchung được đánh giá bởi cả hai người. Một lợi ích khác làcác gợi ý sẽ không chỉ giới hạn trong các sản phẩm đượcđánh giá cao bởi những người cùng sở thích (gián tiếp), màcòn cả với những sản phẩm có độ tương đồng cao với sởthích của chính người dùng đó (trực tiếp).
Tích hợp các đặc trưng của phương pháp cộng tác vào hệ thống dựatrên đặc trưng: Hướng tiếp cận phổ biến nhất là dùng các kĩ
21

thuật giảm số chiều trên tập hồ sơ của phương pháp dựatrên nội dung. Ví dụ, [Paper 29] sử dụng phân tích ngữnghĩa ẩn (latent semantic analysis) để tạo ra cách nhìncộng tác (collaborative view) với tập hồ sơ người dùng(mỗi hồ sơ được biểu diễn bởi một vector từ khóa).
Xây dựng mô hình hợp nhất, bao gồm các đặc trưng của cả hai phươngpháp: [Paper 10] đề xuất kết hợp đặc trưng của cả haiphương pháp vào một bộ phân lớp dựa trên luật (rule-basedclassifier). Popescul và cộng sự trong [Paper 25] đưa raphương pháp xác suất hợp nhất dựa trên phân tích xác suấtngữ nghĩa ẩn (probabilistic latent semantic analysis).[Paper 6] giới thiệu mô hình hồi quy Bayes sử dụng dâyMarkov Monte Carlo để ước lượng tham số.
Một vài bài báo như [Paper 9] đã thực hiện so sánhhiệu năng của hệ thống lai ghép với các hệ thống dựa trênnội dung hoặc cộng tác thuần túy và cho thấy hệ thống laighép có độ chính xác cao hơn.
Phương pháp Ưu điểm Nhược điểm
Dựa trên nội dung
Lọc cộng tác
2.2. Khuyến nghị dựa trên lọc cộng tác- đánh giá độ tương
quan
2.2.1 Các vấn đề phát sinh trong lọc cộng tác
Khi xây dựng Hệ thống khuyến nghị dựa trên phươngpháp tiếp cận nội dung (Content-Based Recommendation), cócác phát sinh như sau:
22

o Đặc tính nội dung của một Đối tượng là không đủđể sử dụng khi khuyến nghị. Ví dụ như chúng takhông thể xác định được một bài hát hay là khônghay nếu chỉ dựa vào tông nhạc và 2 bài hát đó sửdụng cùng một tông.
o Khuyến nghị bị giới hạn: khi có một bài hát mớivào hệ thống thì bài hát đó được xác định là sẽđược người dùng U đánh giá cao nếu như nó cáccác đặc tính tương đồng cao với các bài hát màngười dùng U thích trong quá khứ và ngược lại.Chính điều này làm giới hạn việc khuyến nghị khicó một số sản phẩm có thể người dùng U thíchnhưng lại không có các đặc tính tương đồng vớicác bài hát mà người dùng U đã thích trong quákhứ.
o Tốc độ xử lý: tốc độ xử lý bị ảnh hưởng khi nộidung của Đối tượng dùng để khuyến nghị có tínhchất phức tạp như hình ảnh, âm thanh…
2.2.2 Ưu điểm của lọc cộng tác
Ngược lại với phướng tiếp cận dựa trên nội dung thì
phương pháp tiếp lọc cộng tác lại khắc phục được các
giới hạn trên:
o Không giới hạn về loại Đối tượng dùng để khuyến
nghị: phương pháp Lọc cộng tác dựa hoàn toàn vào
đánh giá của những người dùng để đưa ra các nhận
định về sở thích của người dùng, chính vì thế
các tính chất của Đối tượng được khuyến nghị
không có ảnh hưởng đển quá trình khuyến nghị. Ưu
điểm này giúp cho phương pháp Lọc cộng tác được
23

áp dụng đa dạng trên nhiều hệ thống khác nhau,
từ trang thông tin đến âm nhạc, hình ảnh …
o Khuyến nghị đa dạng: Khắc phục được giới hạn của
phương pháp tiếp cận dựa trên nội dung, phương
pháp Lọc cộng tác có thể đưa ra các Đối tượng
sản phẩm khuyến nghị hoàn toàn khác so với các
sản phẩm mà người dùng U đã thích trong quá khứ.
o Bên cạnh đó phương pháp tiếp cận CF còn có các
ưu điểm cần chú ý như sau:
2.2.3 Các hình thức tiếp cận
Phương pháp tiếp cận dự trên bộ nhớ (Memory base)
Ý tưởng
Tính toán toàn bộ và lưu vào ma trận UxI.
Vấn đề chuẩn hóa (Normalization)
Các phương pháp chuẩn hóa:
Phương pháp Mean-Centering: Ý tưởng
chính của phương pháp này là so sánh
một Đánh giá của người dùng là âm hay
dương (tốt hay xấu) so với Đánh giá
trung bình.
H (rui) = rui - rui
Nhược điểm của phương pháp này là khi
hai người dùng A và B có cùng giá trị
trung bình của các đánh giá, thì sự24

phản ảnh của 2 người dùng này là giống
nhau mặc dù trên thược tế người dùng A
có thể có các đánh giá 2,3,4 trong khi
người dùng B lại có cả 3 đánh giá đều
mang giá trị là 3.
Phương pháp Z-Score:
Phương pháp này khắc phục được nhược
điểm của phương pháp Mean-Centering.
Phương pháp này phân hóa các đánh giá
là tốt hay xấu dựa trên độ lệch chuẩn
của các đánh giá.
H (rui) = (rui – ri) / oi
Phương pháp tính độ tương tự
Các phương pháp tính Độ tương đồng:
Phương pháp dựa trên Cosine Vector:
Phương pháp dựa trên Peason
Correalation:
Phương pháp dựa trên Adjusted Cosine:
Phương pháp dựa trên Mean Squared
Different (MSD).
Phương pháp dựa trên Spearman Rank
Corelation (SRC)
Lựa chọn số lượng lân cận (Neighborhood Selection)
Việc lựu chọn số lượng lân cận trong
phương pháp tiếp cận Memory-Based là rất quan
25

trọng vì nó ảnh hưởng trực tiếp đến chất lượng
của khuyến nghị. Nếu chọn số lượng lân cận lớn
rõ ràng chất lượng của khuyến nghị sẽ được nâng
lên. Tuy nhiên, đi theo đó là các chi phí về bộ
nhớ, thời gian tính toán cũng phải tăng theo.
Ngược lại, nếu lựa chọn số lân cận quá thấp thì
sẽ ảnh hưởng đến chất lượn của khuyến nghị. Có
một vài phương pháp nhằm giải quyết việc lựa
chọn như sau:
Chọn top-N: Chọn ra N lân cận có độ tương
đồng cao nhất và lưu trữ các chỉ số tương
đồng này lại trong cơ sở dữ liệu. Khi tính
toán thì chỉ cần tính toán trên các lân cận
này thôi.
Chọn theo ngưỡng: Định ra một ngưỡng cho độ
tương đồng, các lân cận nào có độ tương đồng
vượt qua ngưỡng thì được lưu trữ lại và tính
toán.
Tính âm:
Ưu điểm và nhược điểm
Ưu điểm:
o Tính đơn giản: triển khai khá đơn giản
o Khả năng diễn giải: giúp người dùng hiểu
vì sao đưa ra các khuyến nghị trên.
26

o Tính hiệu quả: là điểm mạnh nhất của hệ
thống khuyến nghị.
o Tính ổn định: khi một người dùng hoặc
một sản phẩm mới vào hệ thống thì chỉ
cần tính toán lại một vài thông số về độ
tương đồng sau một vài hành vi của người
dùng.
Nhược điểm:
o Giới hạn phủ (Limited Coverage): Phương
pháp này chủ yếu dựa trên độ tương đồng
của các lân cận. Chính vì thế 2 đối
tượng được xem là tương đồng khi và chỉ
khi chúng đều được đánh giá như nhau
hoặc 2 người dùng được xem là tương đồng
nếu họ có cùng các đánh giá trên cùng
các sản phẩm. Giả định này làm cho việc
khuyến nghị bị giới hạn.
o Dữ liệu thưa: Khi trong hệ thống xuất
hiện càng nhiều người dùng, đồng thời số
lượng đối tượng dùng khuyến nghị tăng
lên, trong khi đó số lượng đánh giá của
mỗi người dùng trên mỗi đối tượng chỉ
dừng lại ở mức 5 đến 10 đánh giá. Chính
vì thế làm cho ma trận đánh giá UxI trở
nên thưa, đồng thời làm tập đối tượng
được khuyến nghị chung bởi 2 người dùng
27

càng trở nên nhỏ hơn. Cuối cùng, kết quả
của khuyến nghị trở nên không chính xác
và đáng tin cậy.
Model base
Ý tưởng
Phương pháp giảm số chiều
Phương pháp đồ thị
2.2.4 Các vấn đề phát sinh
2.3. Các giải thuật nâng cao áp dụng trong lọc cộng tác
2.3.1 Tổng quan
Khi dữ liệu thưa, ví dụ như dữ liệu của Netflix cóđến 99% là thiếu các giá trị đánh giá của người dùng. Ýtưởng chung là tạo tạo ra được một mô hình với các tham sốsao cho phù hợp với các giá trị hiện hữu trong dữ liệunhất. Một số vấn đề gặp phải khi thực hiện ý tưởng này làOverfitting. Phương pháp đánh giá cuối cùng dựa trênphương pháp đánh giá chéo (Cross Validation)
2.3.2 Baseline predictors:
bui= u + bu + bi
Trong đó:
o bui: giá trị đánh giá ước lượng
o u: là giá trị đánh giá trung bình của người dùng
trên toàn bộ các sản phẩm.
o bu: là giá trị phương sai của các đánh giá của
người dùng u.
28

o bi: là giá trị phương sai của các đánh giá trên
sản phẩm i.
2.3.3 SVD
Sử dụng mô hình phân rã ma trận, SVD đưa người
dùng u và sản phẩm I vào trong cùng một không gian
ẩn với nhiều chiều. Không gian ẩn này đưa ra một mô
hình nhằm giải thích đánh giá của người dùng u trên
sản phẩm i dựa trên các hành vi của người dùng. Ví
dụ như, khi người dùng xem tin tức thì chúng ta có
thể có các nhân tố sau: số lượng các hành động của
người dùng trên trang tin, chủng loại bài viết, thời
gian xem tin …
Người dùng u được định nghĩa bởi vector pu.
Trong đó mỗi giá trị trong vector đó thể hiện sự ưu
thích của người dùng u trên các sản phẩm thông qua
các nhân tố được xác định. Cùng với đó, mỗi đối
tượng dùng khuyến nghị i được biểu diễn bởi vector
qi, trong đó mỗi giá trị của vector này thể hiện
tính chất của đối tượng này trên các nhân tố được
xác định.
Luật:
Hàm mục tiêu(objective function): tìm ra các
tham số nhằm tối thiểu hóa hàm mục tiêu sau:
Phương pháp tiếp cận xử lý:
Least Square:
29

Stochastic Gradient Descent (Phương pháp
xuống đồi).
Giải thuật:
bu bu + y (Eui – x4.bu)
bi bu + y (Eui – x4.bu)
qi qi + y (Eui.pu – x4.qi)
pu pu + y (Eui.qi – x4.pu)
Tham số x4 là tham số chuẩn hóa nhằm hạn chế
hiện tượng Overfitting.
Tham số y là tham số bước nhảy trong quá trình
học.
Các tham số này được điều chỉnh phù hợp nhất dựa
trên phương pháp Cross Validation.
2.3.4 SVD++
Nhằm tăng độ chính xác của các khuyến nghị,
thuật toán cố gắng áp dụng các phản hồi ngầm định
của người dùng. Việc này thật sự hữu ích với một số
người dùng chỉ cung cấp các hành vi ngầm định và ít
cung cấp các hành vi tường minh, ví dụ như một số
khách vãng lai. SVD++ là thuật toán hướng đến việc
xác định mối quan tâm của người dùng u đến một nhóm
đối tượng I người dùng u đã đánh giá mà không quan
tâm đến các giá trị của các đánh giá đó. Việc xác
30

định này được dùng làm yếu tố ngầm định nhằm bổ sung
cho thuật toán SVD.
Như vậy, khi nhân tố đối tượng (item factor)
được thêm vào mô hình thì tương ứng với một đối
tượng j mà người dùng đã bình chọn ta có một vector
nhân tố yj (j thuộc R(u)). Với R(u) là tập hợp các
đối tượng mà người dùng u đã đánh giá.
Luật:
Ở đây vector pu vẫn được học dựa trên các phản
hồi tường minh như ở phương pháp SVD. Vector này
được hỗ trợ thêm (bù) bởi tổng các vector yi phản
ánh các phản hồi ngầm định của người dùng u trên các
đối tượng dùng khuyến nghị đã được người dùng này
đánh giá. Bởi vì tổng của các yi hướng về giá trị 0.
Nên chính vì thế tổng này được chuẩn hóa bởi tham số
|R (u) |1/2.
Giải thuật:
bu bu + d (Eui – x5.bu)
bi bu + d (Eui – x5.bu)
qi qi + d (Eui. (pu + |R (u) |1/2 – x6.qi)
pu pu + d (Eui.qi – x4.pu)
Với mỗi yj thuộc R (u).
yj yj + d ( Eui. |R (u) |1/2. qi – x6.qi)
Tham số x4, x5, x6 là tham số chuẩn hóa nhằm hạn chế
hiện tượng Overfitting.
Tham số d là tham số bước nhảy trong quá trình học.
31

Các tham số này được điều chỉnh phù hợp nhất dựa
trên phương pháp Cross Validation.
2.4. Hệ thống khuyến nghị dựa trên ngữ cảnh
2.4.1 Ngữ cảnh
Hệ thống khuyến nghị đã đem lại những thay đổi lớn,
chính vì vậy cải thiện hệ thống khuyến nghị chưa bao
giờ là một bài toán cũ. Các hệ thống khuyến nghị
càng ngày càng phải hướng người dùng nhiều hơn.
Chính vì thế yếu tố ngữ cảnh (context) là một trong
những yếu tố mang tình hướng người dùng cao, bởi vì
với các ngữ cảnh khác nhau, rõ ràng con người có
những hành động khác nhau.
Ngữ cảnh đề cập đến bất kì thông tin nào có thể mô
tả được hoàn cảnh của một đối tượng: thời gian, nơi
chốn, thời tiết, là vị trí hiện tại... những yếu tố
mà ảnh hưởng đến hành vi của đối tượng. Ví dụ như,
việc một người dùng quyết định có đến ăn ở một nhà
hàng hay không tùy thuộc vào khoảng cách từ vị trí
hiện tại của cô ấy đến nhà hàng là xa hay gần. Hay
còn tùy thuộc vào vị trí của nhà hàng như là nhà
hàng đó có gần trạm xe buýt không, có gần tram ATM
hay không...
2.4.2 Các phương pháp tiếp cận:
Không giống như một số hệ thống khuyến nghị truyền thống chỉ xét đến hai yếu tố người dùng đánh giá sản phẩm đó bao nhiêu. Một cách tổng quát ta có:
32

Đánh giá <= Người dùng x Sản Phẩm
Hệ thống khuyến nghị dựa trên bối cảnh của người dùngphải xem xét các ngữ cảnh ảnh hưởng đến đánh giá của họ. Ví dụ, cùng một món ăn, khi người dùng ăn với vào lúc trờimưa thì họ đánh giá 2, lúc trời không mưa họ 5. Một cách tổng quát, ta có:
Đánh giá <= Người dùng x Sản phẩm x Bối cảnh
Các phươn pháp tiếp cận sẽ tập trung giải quyết bài toán, có thêm yếu tố ngữ cảnh thì những dự toán về đánh giả của người dùng lên một sản phẩm sẽ được xử lý như thế nào. Theo [hand book] thì có 3 phương pháp như sau:
Xử lý ngữ cảnh đầu vào: Contextual Pre-Filtering:Trong mô hình này, thông tin về bối cảnh được sử dụng để lựa chọn hoặc xây dựng các thiết lậpcó liên quan của bản ghi dữ liệu (tức là, xếp hạng). Sau đó, xếp hạng có thể được dự đoán sử dụng bất kỳ hệ thống khuyến nghị 2D truyền thống trên các dữ liệu đã chọn.
Xử lý ngữ cảnh đầu ra: Contextual Post-Fitering:Trong mô hình này, ngữ cảnh thông tin ban đầu bị bỏ qua, và xếp hạng được dự đoán bằng cách sử dụng bất kỳ phương pháp khuyến nghị 2D truyền thống trên toàn bộ dữ liệu. Sau đó, các khuyến nghị được điều chỉnh (contextualized) cho mỗi người sử dụng bằng cách sử dụng các thông tin theo ngữ cảnh. Theo [handbook] phươngpháp tiếp cận xử lý ngữ cảnh ở đầu ra được phânlàm hai hướng tiếp cận:
33

Heuristic based: Tập trung vào tìm ra các thuộc tính của một user cụ thể trong một ngữcảnh cụ thể. Sau đó dựa những thuộc tính để điều chỉnh và tìm ra những khuyến nghị phù hợp. Việc điều chỉnh khuyến nghị theo ngữ cảnh bao gồm hai bước:
Lọc (Filtering): loại những khuyến nghịít liên quan đến các thuộc tính ở trên.
Xếp hạng (Ranking): xếp hạng giảm dần các khuyến nghị có liên quan đến các thuộc tính ở trên.
Model based (hay còn được gọi là mô hình hóa): Phương pháp này xây dựng một mô hình dự toán. Mô hình này có thể đưa ra xác suất một người dùng cụ thể chọn một sản phẩm cụ thể trong một bối cảnh cụ thể là bao nhiêu. Sau đó xác suất này được dùng để điều chỉnh và tìm ra khuyến nghị phù hợp. Việc điều chỉnh bao gồm hai bước:
Lọc (Filtering): loại những sản phẩm màxác suất người dùng chọn sản phẩm đó trong bối cảnh cụ thể nhỏ hơn một ngưỡng định sẵn trước.
Xếp hạng (Ranking): xếp hạng từ cao đếnthấp cho các sản phẩm có xác suất được chọn cao hơn ngưỡng.
Việc lựa chọn hướng tiếp cận nào cần được dựa trên các tiêu chí mà ứng dụng (mà sử dụng hệ thống khuyến nghị) hướng đến.
Mô hình hóa ngữ cảnh: Contextual Modeling:
34

Cả hai cách tiếp cận ở trên, thì ngữ cảnh đượcxem xét theo hướng đưa bài toán trở về mô hìnhtruyền thống -Người dùng x Sản phẩm (reduced-based). Trong cách tiếp cận này, thông tin theongữ cảnh được sử dụng trực tiếp trong kỹ thuậtmô hình hóa như là một phần của dự toán đánhgiá.
Có 3 cách tiếp cận:
Model based:
Heuristic based:
Hybrid:
35

CHƯƠNG 3: TRIỂN KHAI
3.1. Chức năng
Website timquanh.com bao gồm các chức năng:
o Người dùng vãng lai xem thông tin, đăng ký, đăngnhập
o Hiện thị các địa điểm lên bản đồ
o Chia sẻ địa điểm
o Thêm địa điểm (nhà hàng, quán ăn, quán cafe)
o Người dùng bình luận và chia sẻ kinh nghiệm
o Thu thập dữ liệu ngữ cảnh từ người dùng:
Giả định rằng hệ thống có thể thu thập được các thông tin ngữ cảnh cần thiết.
- Thời tiết, nhiệt độ: thông qua hệ thống dự báothời tiết.
- Thời điểm: người dùng nhập hoặc lấy mặc định từ hệ thống.
- Vị trí: Thông qua chia sẻ của người dùng, dùngcông nghệ HTML 5 GeoLocation
- Giả định rằng người dùng cho phép chia sẽ các thông tin ngữ cảnh của họ.
- Người dùng chia sẻ vị trí hiện tại của mình.
- Người dùng chia sẻ ai đi cùng với mình
Khuyến nghị:
o Đối tượng khuyến nghị: Nhà hàng / Món ăn
36

o Phạm vi: TP.HCM
o Điều kiện: Ngữ cảnh (bao gồm Thời tiết, Nhiệt độ, Người đi cùng, Khoảng cách, Ngày trong tuần,Thời điểm trong ngày.
o Đối tượng được khuyến nghị:
Người dùng đăng nhập: Dùng khuyến nghị nhà hàng và món ăn phù hợp với người dùng hiện tại nhất trong ngữ cảnh hiện tại của người dùng đó.
Đối với khách không đăng nhập: Dùng thống kêdựa trên ngữ cảnh của khách. Nhà hàng được ưa chuộng nhất quanh vị trí người dùng. Món ăn thích hợp nhất trong thời tiết hiện tại.
o Nội dung khuyến nghị:
Nhà hàng / Món ăn phù hợp nhất với một ngườidùng xác định trong một ngữ cảnh xác định.
Món ăn nên ăn ở một nhà hàng xác định.
Mô hình học:
o Thuật toán SVD áp dụng trên ma trận 2 chiều UxI.Thuật toán SVD chạy trên từng ngữ cảnh khác nhauvà lưu các tham số phù hợp với ngữ cảnh đó vào trong CSDL.
o Gọi C là một ngữ cảnh, C bao gồm các yếu tố:
Thời tiết (W) với W= { 1,0} tương ứng Có mưa và Không có mưa.
Nhiệt độ (H) với T={1,0,-1} tương ứng với Nóng, Lạnh.
37
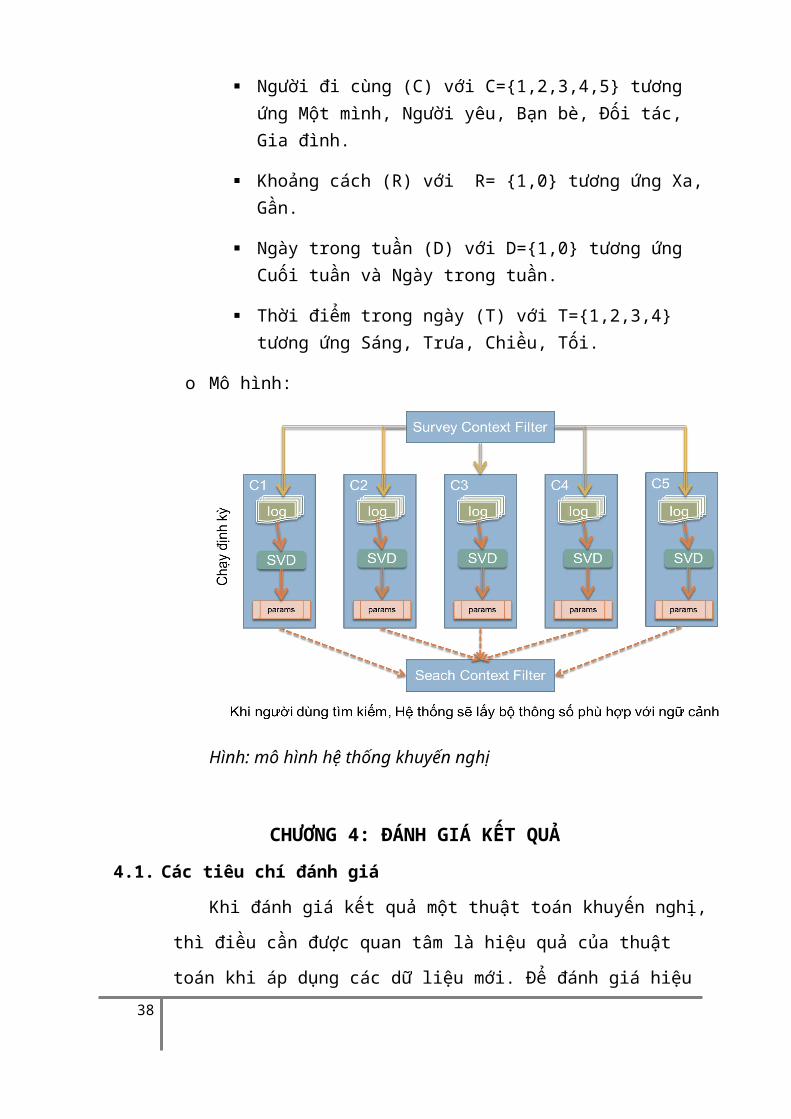
Người đi cùng (C) với C={1,2,3,4,5} tương ứng Một mình, Người yêu, Bạn bè, Đối tác, Gia đình.
Khoảng cách (R) với R= {1,0} tương ứng Xa, Gần.
Ngày trong tuần (D) với D={1,0} tương ứng Cuối tuần và Ngày trong tuần.
Thời điểm trong ngày (T) với T={1,2,3,4} tương ứng Sáng, Trưa, Chiều, Tối.
o Mô hình:
Hình: mô hình hệ thống khuyến nghị
CHƯƠNG 4: ĐÁNH GIÁ KẾT QUẢ4.1. Các tiêu chí đánh giá
Khi đánh giá kết quả một thuật toán khuyến nghị,
thì điều cần được quan tâm là hiệu quả của thuật
toán khi áp dụng các dữ liệu mới. Để đánh giá hiệu 38

quả cũng như đo độ sai sót của thuật toán, nhóm tác
giả chia tập dữ liệu ra làm hai phần: tập huấn
luyện (traning dataset) và tập kiểm tra (test
dataset). Dữ liệu huấn luyện được dùng trong việc
học các thông số cho mô hình. Dữ liệu kiểm tra dùng
để đánh giá mức độ hiệu quả của mô hình. Dữ liệu
test hoàn toàn khác và độc lập với dữ liệu huấn
luyện để có được đánh giá về độ lỗi của mô hình mang
tính tin cậy.
Người ta đưa ra performance metric để đánh giá
tính hiệu quả của từng phương pháp ứng với những
điều kiện khác nhau. Một vài performance metrics:
mean absolute error (MAE), mean squared error (MSE),
so sánh chỉ số rating dự đoán với chỉ số rating thật
sự từ Users, precision, recall, F-measure, and the
ROC characteristics …
Áp dụng trong trường bài toán khuyến nghị của
mình, nhóm tác giả chọn performance metrics MSE.
Cho performance metric µA,X (Y) trong đó:
A: thuật toán dùng để recommend
X: tập training data
Y: tập testing data
X ∩ Y = ∅
Một số ký hiệu được dùng:
39

Với mỗi d thuộcY, có:
d.R: chỉ số rating thật từ users
d.RA,x: chỉ số rating được dự đoán bởi thuật toán A
Ta có MSE= (d.R.A,x- d.R) ∑ 2
4.2. Kết quả
Nhóm tác giả thực hiện tính toán dựa trên bốn bộ
test. Movielen (3 bộ), Yahoo(1 bộ)
CHƯƠNG 5: TỔNG KẾT5.1. ABC
5.2. XYZ
40

KẾT LUẬN VÀ HƯỚNG PHÁT TRIỂN
41

TÀI LIỆU THAM KHẢO
42
Copyright © 2022 FDOKUMEN

