
John Agard Hans Christian Andersen Awards 2019 UK Writer ...
Upload
independentCategory
view
4download
0
Writer Identification Based on Graphology Techniques
Omar Santana, Carlos M. Travieso, Jesus B. Alonso, Miguel A. Ferrer Dpto. de Senates y COllUlnicaclones, Universldad de Las Palmas de Gran Canaria
ABSTRACT
Herein, an innovative system biometric of specific writers' identification based on technical expert calligraphic and graphology on handwritten script is presented. It has been developed working in the off-line mode on a Spanish words image database, fonned by 29 different individuals. All extractions of characteristics carried out on the images have been used for the identification and were carried out by means of the estimate of several elements objects using studies from The French Graphology School. They are commonly employed by handwriting experts in judicial matters. The success percentage achieved with five of these characteristics from this database of 29 writers is 99 .34%. In new experimentation, with these same parameters and enlarging the database to 70 users, a success rate of9 2% was reached.
INTRODUCTION
The computational and technological development and electronic devices demand the proliferation of new measures and safe-deposit systems [1]. For this reason, the Biometric Recognition Systems have become of great importance in the last decades [2, 3]. Its objective is to substitute any type of conventional key (passwords, cards, PINs, etc.) for the individual's innate keys, because these characteristics are personal and unique [ 2 ], providing simplicity and robustness. In particular, some biometric disciplines have begun its development and growth, as in the case of the handwritten writing [3, 4 ].
The handwritten writing recognition has great importance in the area of calligraphic know-how and in judicial matters [3], contributing a value added in any security and biometric
Authm's Current Address: o. Santana. C.M Tavieso, I.B. Alonso 8IId M.A. Ferrer, ))pto. de Senales y Comunicaciones. Univcniclad de Las Palmas de Gran Canaria, Campus de Taflf8, 35017 Las Palmas de Gran C8IIaria, Spain. Based on a �OI\ at Carnahan 2008. 088518985110/ $26.00 USA C 2010 IEEE
IEEE A&E SYSTEMS MAGAZINE, JUNE 2010
system. The motivation of this work is to develop a software tool in order to help the tasks writers' recognition. Nowadays, this present work is quasi-automated and has a scarce parameterization; therefore, it requires the final participation of a handwriting expert to analyze the obtained results. Its advantages are the automation of expert analysis for manuscripts and the additional infonnation that would be added to the professional's verdict, even being able to - in the future - avoid a contrary verdict or end up in a supervised system.
The cause of these systems being not so vel)' developed at present is due to the great disparity of styles in the writing, not only for different writers, but also for the same writer. The reason for this is because it is vel)' difficult for the parameterization of this action that is carried out by the brain [3].
As a consequence nowadays, it is necessary to create a reliable and automated system that gives an expert report or detennine whether a document is dubitable or indubitable, contributing with information that supports the expert's failure.
Based on this idea, in the present work we describe a writer's recognition system that distinguishes, with a high degree of success, among different writers from our database (DB). The identification has been carried out by the parametrization from several segmented words from a paragraph, that have usually been studied by The French Graphology School [3] . In this way, the principles, which establish the calligraphic know-how, have been integrated in the characteristic extraction module (although not the principles of graphology, but the principles of graphometrics and their observations). Additionally, it has used the laws of writing, which are used by calligraphic experts in legal matters (testaments, falsifications, etc.). Finally, it wants to show the importance in the election of the optimum group of characteristics for the final system.
As in all biometric systems, three basic blocks have been defined: pre-processing, characteristics extraction, and classification and evaluation systems [ 4 , 5]. For the first block, we designed, in order to carry out the minimum possible operations to do minimum distortion to the original images; thus reducing it to the binarization process by the
3S

,Ucop
sample 1
! Subject Xl
!
~ Fig. 1. Example of tbe words extraction for a sample
elimination of the noise sait-pepper, elimination of punctuation signs, and finally, the correction of the skew. After this pre-processing, the new image was stored.
DATABASE
The initial database (DB) which was carried out in this work contains 29 Spanish words images from different and heterogeneous writers, with 10 samples/writer and 34 images/sample, for a total of 9860 images. The design considerations for the building of our database were basically the following three:
36
• It was always the same pen type used, (ballpoint with black ink),
• The same group of images from a restricted lexicon for all users (34 different words) and an image processing off-line (the words were previously digitized), and
• Each user wrote his samples on paper DIN-A4 of 80 grams per sheet, using a rigid support surface, for one week with discontinuous conditions; at different hours of the day, and different days of the week. With those discontinuous conditions, an effect of temporal invariance was obtained for our database.
Semiautomatic extraction, 51ectlon of vowels 'a' and '0' (possibility of other vowels, consonants or syllables In the future).
SUCCESS RATE
X%
Fig. 2. General diagram of the proposed system
Trying to approach a real situation for the writers, we avoided some restrictions on the writing style, such as margins, separations among lines, capitals, lower-case, and the useful space of the sheet. In Figure 1, an example of the words extraction for a sample is shown.
From this same database and for the study of parameters, two auxiliary databases were created; one contains the final vowel "a" of 15 words, and another contains the final "0" of 4 words.
The extraction of these vowels was obtained by a semiautomatic application, supervised by an operator. The decision for the use of this application is because it simplifies the work and facilitates the work on the development of the biometric system, In the future, we plan to carry out this application on an automatic process. The election of these vocals and non-vocals was because people write the vowels in middle of the words differently, but the final vowels generally are similar. Besides they are easier to extract. In Figure 2, the diagram of blocks of the proposed system are shown.
PARAMETERIZATION
The parameterization was carried out on binarized images, with the writer's independence and in a holistic mode, that is to say, considering the full word without processing and segmentation (6). The characteristics, which were extracted in this work, can be divided into two groups: the first
IEEE A&E SYSTEMS MAGAZINE, JUNE 2010

Table 1. Developed Parameters and their Dependencies on the Writer and the Word
Parameter's dependence
Parameters Writer Word
Skew Yes No
Slant Yes No
Pressure Yes No
VowelinfoA Yes No
VowelinfoO Yes No
Correlation Yes Yes
Length Yes Yes
Union of letters Yes Yes
Thinning area Yes Yes
depends only on the writer and his/her writing. The other group depends on the written words and the writer.
In the first group, characteristics are the inclination regarding the horizontal (called skew), the deviation regarding the vertical (called slant), the exercised pressure and finally, characteristics extracted on the ovals of the vowels "a" and "0," called in the rest of the document "infovocalA " and "in/ovocalO " In the second group, we estimated measures as the correlation among the same words, the length of the words, the union of letters (that gives us the idea of writing speed) and the area of the word (it is the number of "ON" pixels).
Table 1 shows the summary of the developed parameters in this work and, in successive lines, some brief descriptions are given.
Skew The skew was obtained making use of horizontal
projections [6, 7], rotating the images (a E [-10:0.1 :10])
regarding the geometrical centre (because it allows better correction for words with oscillating or sine skew) and use as cost function, the maximization of the variance of the
foreground pixels.
Slant The slant was implemented by means of a slight
modification of the algorithms of Bozinovic and Srihari [2, 8, 9], where instead of eliminating the whole line when it is a group of foreground pixels bigger than the threshold Max
IEEE A&E SYSTEMS MAGAZINE, JUNE 2010
Run (MR), only this pixel group is eliminated without losing the rest of information. In Figure 3, some examples of the summarized procedure of these two estimates are shown.
-(1 lnl>MR? --+ °1=0
) lOI<= SH? --+ °1=0
'I 13 ; 12 :/
J 1 1 45 6 7 10 11 ' 14 » r;l'� ( :I
+(1 " ,.
, ]I) 40 50 60
" 70 80 9CI 100 110
aSKEW = 1.7' V {�\o.� (II,YI)} {Cat II} lliER °1-' ' I -. 2OOc .. = .. ,= .. = .. ,:-:-: ... -:,-:. , .= ... = , .. = .. . = , .. = . . . �:�: ---fr.: --, PYA»X1 'YI) Cat 21
J l� ujmm .um Luu .: u.LutiuUU] U ! uuj"u. 1
� .,00 ..... ,....... . . ....... , ...... , .....• , ..... ....... ,..... ..... �cat l� > : : : : : : : : : : 9 = tag --II • : : : : : : : : 11 Cat 2
·11 � " -4 .2 0 4 6 I II ( Angulo, e - (9 ) SLANT-mean I
Fig. 3. Examples of skew estimation (left column) and of the slant procedure (right column)
in the words of our database
Pressure The quantification of the pressure, defined as the
width of the stroke on the force exercised by means of the scriptural useful (pen). We carried out several initial tests that provided scarce percentages in the rate of success during the classification stage. Due to this, and in a completely independent way with the system that here intends, we decided to carry out a previous study performed by 10 samples of 4 different writers. The study consisted of measuring the pressure in function of the resolution adopted during the acquisition of the samples (scanned at 100, 150, 200, 300, 600 and 1200 dpi.), and to compare the estimate of the pressure like the mode at the same time in front of the pressure like the pondered mean of the widths of lines. In this study, we concluded that the pressure, like the pondered mean, is better estimation that the pressure, like the statistical mode, and that the discriminate information is not extracted for high resolution, because in both type of approaches the highest success rate was reached for 150 dpi. This analysis is summarized in Table 2, where the rate average of success, the maximum rate, the minimum rate and variance are shown. Besides, this study was repeated 10 times; for this reason, the results are shown with mean and variance. Finally, that experiment was done
37

Table 2. Results of the Study of the Pressure, in Functi on of the Ad opted Resolution in the Acquisiti on of the Samples and of the Type of Writer
Pressure as the Mode
Pressure as the Pondered Mean
dpi . 156
AVERAGE (0/0) 49
MINIMUM (0/0) 40
MAXIMUM 50
VARIANCE 10
on supervised classification, using a Neural Network as the Classifier [ 13]; and where 50% of our database was used for the training mode, and the rest, for the test mode.
VOWE LIN FOA I VOWE LIN FOO
The parameters infovocalA and infovocalO are characteristics formed by diverse measures, obtained from the ovals of the vowel "a" and of the vowel "0" on our databases, respectively. The estimation consists of a vector with seven elements. In particular, a short description of those elements will be shown.
38
1. Oval processing without distortion (allows us to distinguish among the persons that close the vowel and those that do not).
2. Oval processing with minimum distortion (discriminates among those individuals that write the vowel with a soft opening as opposed to those that perform a severe opening).
3. Oval processing for even and odd symmetry (provides information regarding the two previous estimates and also allows us to discriminate among several classes from people with severe opening). See Figure 4.
4. Diametrical index (provides the relationship between the height and width of the oval).
5. Minimum oval box (facilitates the distinction among vowels having different forms and dimensions present the same diametrical index).
300 1200
45.5 25
45 25
50 25
2.5 0
.)
Ill)
c)
4)
.)
f)
0..
Q../-'
a
156 300 1200
63 51 41
60 35 40
65 65 50
6.66 82.22 10
Fig. 4. Example of some of the different types of v o wels "a" that all o ws us to differentiate the processing
f or even and odd symmetry, calculating the connected c omponents and the areas
in the right c olumn
6. Distances min-max (provides the distance between the minimum and the maximum of the vowel).
IEEE A&E SYSTEMS MAGAZINE, JUNE 2010

7. The longitude of the vowel (that does not provide infonnation on the ovals but on the space that occupies the vowel).
CORRELATION
The correlation parameter between two images (A(x,y) and B(x,y» of the same words was obtained applying the correlation and the convolution [10] in two dimensions (See Equations 1 and 2 , respectively), and obtaining the coordinate of the axis "x" of abscissa where the maximum similarity takes place. This measure allows us to know the grade of resemblance between two samples of the same word, taken at different times and belonging to the same writing body.
1 M-I N4 ..(�y)*��y)=- LL..(mn)-�x-my-n) (1)
MNrwlJrr=()
LENGTH
The characteristic of the length of the vowels was considered as the distance measured in pixels that occupies the word along the axis ''x'' of the Cartesian system.
UNION OF LETTERS
The union of letters allows us to know how each writer makes the writing and was considered as a function of the connected components inside the word. This way allows us to discriminate against other writers, who write the letters of the word completely united, partially united, or completely divided.
THINNING AREA
The last parameter is the area of the words, which are usually measured by the handwriting experts, like the area contained by the minimum box of the word. Nevertheless, in this work, better discriminatory results were obtained with another procedure, which consists of calculating the area occupied by the foreground pixels of the thinning word [11]. But before, the punctuation signs must be eliminated in a word. This process was done by thresholds, obtaining a success rate of 99.6% on all our database. Later, that word suffers three processes of image processing: thinning, dilation, and again, thinning. The process can be observed in Figure 5.
All the parameters described in this section are characteristic of great utility in calligraphic know-how. The skew and the slant have previously been estimated by other
IEEE ME SYSTEMS MAGAZINE. JUNE 2010
Original Image
Image without punctuation
signs
State 1
State 2
State 3
:tt't�r�/j w � � � � � ro � � � m
:tt' tJt&i f� Ij w � � � � � ro � � � m
:tf�t�t�fj w � � � � � ro � � � m
:tf���Jj w � � � � � ro � � � m
:ff/��Jj Fig. S. Example of tbe process for
obtaining tbe tbinning area
authors by means of djverse techniques. But in this present work, they have been carried out with small modifications at two of these techniques (Horizontal Projections Method [ 2 , 6, 7]; and the other, Bozinovic and Srihari Method [ 2 ]). These modifications have improved the estimation of parameters. The rest of the parameters are innovations of present work. The good success obtained with them is shown in the Experiments section and the Results section.
CLASSIFICATION SYSTEM
In all automatic identification systems, it is necessary to employ an element classifier that allows for the distinction among the classes. Although a main point is the discrimination grade of the extracted characteristics, they must have a high level of similarity for the intra-class samples in order to be recognised as belonging to the same pattern [ 2, 7]. Besides, the inter-class relation must be very short in order to be discriminatory. These module classifiers previously need to be trained for a supervised classification (training and test mode), because, for biometric applications, we must know the identity of the person. In particular, we have used a classifier based on Neural Networks (NN) that uses the back-propagation algorithm for training [5, 12, 13], and whose structure is shown in Figure 6. Besides, a Support
39

Input layer
Hidden layer
Fig. 6. Diagram of blocks of a feed-forward neural networks
Neural Network1
Neural Network2
Neural Network N
Algorithm of the Most
Voted
Fig. 7. Structure of The Most Voted Algorithm (MV A)
process) to N (in our case, N = 20) neural networks (see Figure 7). This process individually trains each neural network, but their outputs are combined in order to choose the output most repeated. Then to train we separated each net with these data and, later, applied to each the same test samples from N nets, establishing the convergence of the
Table 3. Classification Results for the Parameter's Components "vowelinflA" Using Neural Networks Like Classifier
i+l
i+2
i+3
i+4
i+5
i+6
VowelinfoA's Components
ovalsinfoAwd
ovalsinfoAmd
ovalsinfoAeos
diametriind
minovalbox
minmaxdist
vowellong
Vector Machine (SVM) with RBF kernel was used in the final system to have invariance of the classifier, and extend the experiments with robust classification systems.
For both classification techniques, the methodology that has been applied consists of supervised training, dedicating 50% of the samples of our database for training mode and the rest of the samples, for the test mode. This means that five samples of each writer have been chosen to train and the other five used for test. For the classification with NN [ 13], has been repeated in each experiment 10 times, and later, we have obtained the average success. The method used that allows us to improve the efficiency of the classifier correcting the errors from the back-propagation algorithm is called The Most Voted Algorithm (MVA). That method consists of applying the same training samples (parallel
40
Success Rate (%)
(individually)
18.34 t 17.50 t
19.86 t 14.55 t 21.24 t 7.52 t
7.63 t
Success Rate (%)
(fusion i with i-previous)
18.34
22.80
32.13
37.37
47.52
56.27
73.38
solution; what is translated in an estimate of the system of more precise identification and, consequently, in an increase of the rate of success.
This is possible because in each neural network, the weight of aU layers are randomly initialized.
EXPERIMENTS
In Table 3, the recognition rate of each isolated graphological parameter of the vowel "a" is shown. Besides, the percentage of the partial increase and its sum is shown, until we get the vector final of the parameter "vowelinfoA." The results of this table were obtained without applying the algorithm of the most voted, simply adjusting the number of neurons in the hidden layer of the classifier.
IEEE A&E SYSTEMS MAGAZINE, JUNE 2010
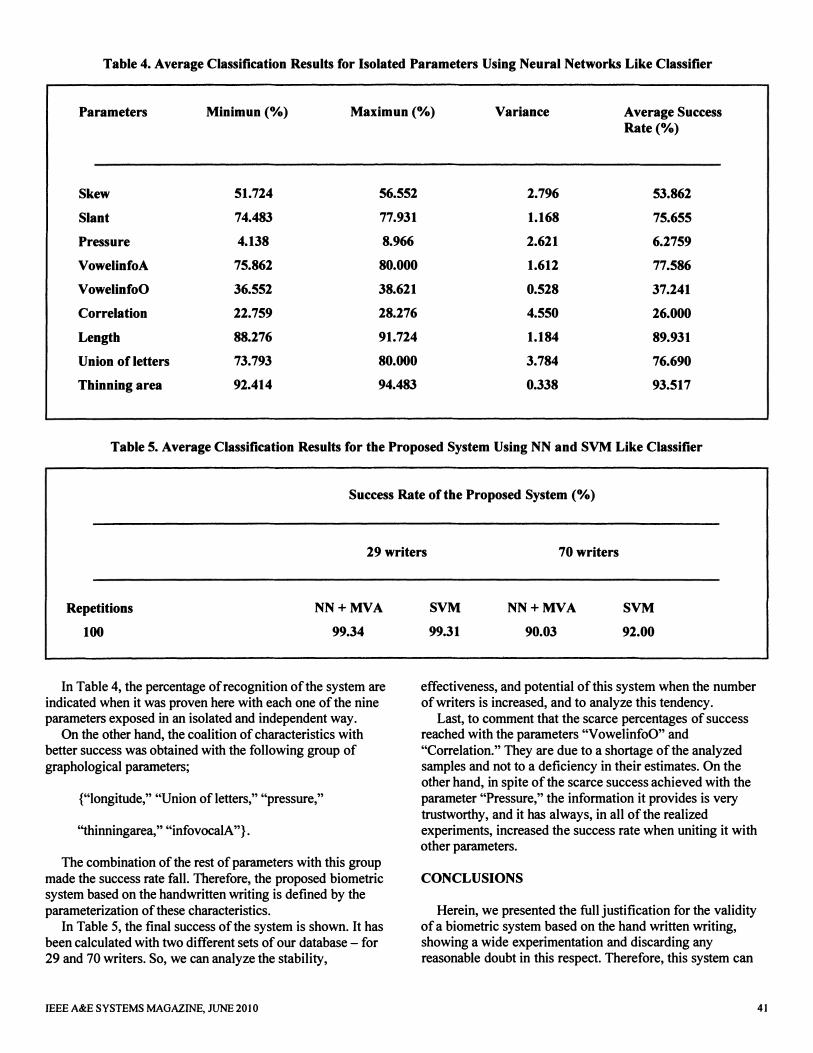
Table 4. Average Classification Results for Isolated Parameters Using Neural Net works Like Classifier
Parameters Minimun (%) Maximun (%) Variance Average Success Rate (%)
Ske w 51.724 56.552 2.796 53.862
Slant 74.483 77.931 1.168 75.655
Pressure 4.138 8.966 2.621 6.2759
Vo welinfoA 75.862 80.000 1.612 77.586
Vo welinfoO 36.552 38.621 0.528 37.241
Correlation 22.759 28.276 4.550 26.000
Length 88.276 91.724 1.184 89.931
Union of letters 73.793 80.000 3.784 76.690
Thinning area 92.414 94.483 0.338 93.517
Table 5. Average Classification Results for the Proposed System Using NN and S VM Like Classifier
Success Rate of the Proposed System (%)
29 writers 70 writers
Repetitions
100
NN+M VA
99.34
In Table 4 , the percentage of recognition of the system are indicated when it was proven here with each one of the nine parameters exposed in an isolated and independent way.
On the other hand, the coalition of characteristics with better success was obtained with the following group of graphological parameters;
{"longitude," "Union of letters," "pressure,"
''thinningarea,'' "infovocalA"}.
The combination of the rest of parameters with this group made the success rate fall. Therefore, the proposed biometric system based on the handwritten writing is defined by the parameterization of these characteristics.
In Table 5, the final success of the system is shown. It has been calculated with two different sets of our database - for 2 9 and 70 writers. So, we can analyze the stability,
IEEE A&E SYSTEMS MAGAZINE, JUNE 2010
S VM
99.31
NN+MVA
90.03
SVM
92.00
effectiveness, and potential of this system when the number of writers is increased, and to analyze this tendency.
Last, to comment that the scarce percentages of success reached with the parameters "VowelinfoO" and "Correlation." They are due to a shortage of the analyzed samples and not to a deficiency in their estimates. On the other hand, in spite of the scarce success achieved with the parameter "Pressure," the information it provides is very trustworthy, and it has always, in all of the realized experiments, increased the success rate when uniting it with other parameters.
CON CL USIONS
Herein, we presented the full justification for the validity of a biometric system based on the hand written writing, showing a wide experimentation and discarding any reasonable doubt in this respect. Therefore, this system can
41

be good as a support tool for the handwriting experts, contributing in the decision of her/his verdict in front of the responsibility of a decision for an illicit or non-document.
The system allows for the distinguishing with a success rate of 99.34% among the different writers from our database, using only 5 graphological parameters and integrating them in the automatic biometric system based on NN+MV A for short database or SYM when the number of writers for our database is increased. These graphological parameters are "longitude," "Union of letters," "pressure," "thinningarea," and "infovocalA."
Therefore, the use of adequate parameters is a main reason for obtaining stability and efficiency on the implemented system. Finally, the independence of the system is also demonstrated regarding the used classifier, because it provides similar success for 29 writers, and a bit better SYM vs. NN, when the database is increased.
A CKNOWLEDGEMENT
This work was supported by an investigation scholarship "Catedra Telef6nica-ULPGC" provided by the Spanish telephony operator "Telef6nica" in the call for 2007 research works.
RE FEREN CES
[I] Jain Anil, Bolle Ruud and Sarta Pankanti, Biometrics, Personal Identification in Networked Society,
Kluwer Academic Publishers, 1999.
(2) Adolfo Gustavo and Sum-ez Lorenzo,
Segmentaci6n de texto manuscrito, PFC, ULPGC, ETSIT, 2001.
(3) Centro de Estudios S6crates, Master en Pericia Caligr6fica y Documentoscopia,
S6crates & Books Studies Center, pp. [1-27, 39-58, 63-76), 2005.
(4) Carlos F. Romero, Carlos M. Travieso, JesUs B. Alonso and Miguel A. Ferrer,
Medici6n de la altura del cuerpo medio en la escritura,
Revista Argentina de Trabajos Estudiantiles,
Vol. I, pp. 47-51, Febrero 2006.
[5] Carlos F. Romero, Carlos M. Travieso, JesUs B. Alonso
and Miguel A. Ferrer,
Using off-line handwritten text for writer identification, WSEAS Transactions on Signal Processing, Issue I, Vol. 3, pp. 56-61, January 2007.
(6] Moises Pastor i Gadea,
Aportaciones aI Reconocimiento Automiltico de Texto Manuscrito, Tesis doctoral, Universidad Politecnica de Valencia, Abril 2007.
(7] Alejandro Hector Toselli,
Reconocimiento de Texto Manuscrito Continuo,
Tesis doctoral, Universidad Politecnica de Valencia, Marzo 2004.
(8) Alessandro Vinciarelli and Samy Bengio,
Writer Adaptation Techniques in Off-Line Cursive Word Recognition,
Proceedings of the Eighth International Workshop on
Frontiers in Handwriting Recognition, IEEE, pp. 1-5, 2002.
[9] Scott D. Connell and Anil K. Jain,
Writer Adaptation for Online Handwriting Recognition,
IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 24, No. 3, pp. 329-342, March 2002.
(10) Rafael C. Gonzalez and Richard E. Woods, Digital Image Processing,
Prentice- Hall, Inc., Second Edition, 2002.
[ I I) Rafael C. Gonzalez, Richard E. Woods and Steven L. Eddins, Digital Image Processing Using Matlab,
Pearson Prentice Hall, 2004.
(12] D. Valkaniotis, J. Sirigos, N. Antoniales and N. Fakotakis, Text-Independent Off-Line Writer Recognition Using
Neural Networks, ICECS '96, p. 692-695.
(13) C. Bishop,
Neural Networks for Pattern Recognition,
Clarendon, UK: Oxford University Press. 1996.
Call for 2010 Pioneer Award Nominees
42
The AESS Pioneer Award is given annual1y to an individual or team for "contributions significant to bringing into being systems that are still in
existence today. " These systems fall within the specific areas of interest to the society, that is, electronic or aerospace systems. The contributions for which the award
is bestowed are to have been made at least twenty (20) years prior to the year of the award, to ensure proper historical perspective. It is not a condition that awardees should have been sole or original inventor or developer; "significant contribution"
of a specific nature is the key criterion. Nominations are being accepted now and should be submitted by 30 August 2010.
Contact Erwin Gangl, AESS Awards Chair, to receive nomination information at [email protected], (937) 431-4030.
IEEE A&E SYSTEMS MAGAZINE, JUNE 2010
Copyright © 2022 FDOKUMEN




















