
WP 20 - Implementing Income Verification in Australia
26
i NATSEM Working Paper 2013/20 Implementing Income Verification in Australia Yogi Vidyattama Robert Tanton Ross Gayler Alan Duncan May 2013
Transcript of WP 20 - Implementing Income Verification in Australia

i
NATSEM Working Paper 2013/20
Implementing Income Verification in Australia
Yogi Vidyattama Robert Tanton
Ross Gayler Alan Duncan
May 2013

i
ABOUT NATSEM
The National Centre for Social and Economic Modelling was established on 1 January 1993,
and supports its activities through research grants, commissioned research and longer term
contracts for model maintenance and development.
NATSEM aims to be a key contributor to social and economic policy debate and analysis by
developing models of the highest quality, undertaking independent and impartial research,
and supplying valued consultancy services.
Policy changes often have to be made without sufficient information about either the
current environment or the consequences of change. NATSEM specialises in analysing data
and producing models so that decision makers have the best possible quantitative
information on which to base their decisions.
NATSEM has an international reputation as a centre of excellence for analysing microdata
and constructing microsimulation models. Such data and models commence with the records
of real (but unidentifiable) Australians. Analysis typically begins by looking at either the
characteristics or the impact of a policy change on an individual household, building up to
the bigger picture by looking at many individual cases through the use of large datasets.
It must be emphasised that NATSEM does not have views on policy. All opinions are the
authors’ own and are not necessarily shared by NATSEM.
© NATSEM, University of Canberra 2013
All rights reserved. Apart from fair dealing for the purposes of research or private study, or
criticism or review, as permitted under the Copyright Act 1968, no part of this publication
may be reproduced, stored or transmitted in any form or by any means without the prior
permission in writing of the publisher.
National Centre for Social and Economic Modelling
University of Canberra ACT 2601 Australia
Phone + 61 2 6201 2780
Fax + 61 2 6201 2751
Email [email protected]
Website www.natsem.canberra.edu.au

ii
CONTENTS
About NATSEM i
Author note iii
General caveat iii
Abstract iv
1 Introduction 1
2 Methodology for income verification 4
2.1 Payslip Method 6
2.2 Matching Method 6
2.3 Modelling Method 7
2.3.1 Regression Approach 8
2.3.2 Data Matching using a modelling technique 10
2.3.3 Imputation Method 11
3 Assessment of the different methods and applying them in Australia 11
4 Conclusions 17
References 19

iii
AUTHOR NOTE
GENERAL CAVEAT
NATSEM research findings are generally based on estimated characteristics of the
population. Such estimates are usually derived from the application of microsimulation
modelling techniques to microdata based on sample surveys.
These estimates may be different from the actual characteristics of the population because
of sampling and nonsampling errors in the microdata and because of the assumptions
underlying the modelling techniques.
The microdata do not contain any information that enables identification of the individuals
or families to which they refer.
The citation for this paper is: Vidyattama Y, Tanton R, Gayler R and Duncan A (2013)
Implementing Income Verification in Australia, NATSEM Working Paper 2013/20,
NATSEM: Canberra

iv
ABSTRACT The recent credit crunch and global recession has forced Governments to consider implementing compulsory income verification for loan applicants. This paper analyses the different methods used in UK and US for income verification and highlights the issues in implementing each method. Finally, each of the methods is assessed with regard to applying a method in Australia. The paper concludes that a modelling approach to income verification will work for the most people.

1
1 INTRODUCTION
In many ways, the cause of the credit crunch that has hit global economies in the past
few years has been identified as bad loan management. The failure of credit providers in
the US has been linked to high risk credit, not only in terms of the credit providers
paying insufficient attention to a borrower’s capacity to pay (which can be tested by
verifying incomes), but also their willingness to pay. Governments in the UK, US and
Australia are now working to minimise the risk that this crisis will happen again by
implementing financial reforms that tighten up the assessment of applications for credit.
The financial crisis that started in 2007 was triggered by an internal shock - namely the
inability of customers to pay their mortgages (Evans and Wright 2010). This was largely
due to the increase in sub-prime mortgages prior to the crises and the realisation of the
hidden risk attached to these loans in the complex securitisation arrangements when the
house price bubble burst.The response to the 2007 financial crisis is reform directed at
ensuring that borrowers have the capacity to pay for any loan taken out, and an
important part of measuring this capacity to pay is getting a reasonable estimate of their
income and verifying that the claimed income is accurate.
This response to the global financial crisis has meant that many countries have reviewed
their credit lending regulations. In the US in mid 2009, President Obama proposed the
establishment of a Consumer Financial Protection Agency (CFPA). In Europe, a new
Consumer Credit Directive (CCD) was adopted in mid 2008 and subsequent regulation
was established in the UK in 2010.
In Australia, the National Consumer Credit Protection Act 2009 was introduced to let
the Commonwealth Government take control of consumer credit regulation. This Act

2
covers the area of both credit licensing and responsible lending conduct, on which the
Australian Securities and Investment Commission (ASIC) issued a regulatory guide in
March 2011 (ASIC 2011). There are three key obligations regarding responsible lending
conduct stated in the regulatory guide. These obligations are:
inquiring about and verifying the consumer’s financial condition and objectives
in taking the credit;
making an assessment of the suitability of the proposed credit contract; and
providing a written copy of the assessment if asked to do so by the consumer.
The first obligation stated above specifically obliges the lenders to take reasonable
steps to verify the consumer’s financial situation, especially income. This regulation
commenced in mid-2010.
One of the underlying issues that all these reforms are designed to address is that there
is an incentive for low income people to overstate their income when applying for credit
to give them a better chance of receiving the credit, or receiving a higher level of credit.
This can range from minor exaggeration to outright fraud. Figure 1 shows two
distributions, one of which (the solid line curve) characterises the ‘self-reported’ income
of applicants, and the other (the dash line curve) shows the actual income distribution. If
fewer individuals report incomes below some lending threshold yL than is actually the
case (a proportion represented by the light shaded region in Figure 1), then some
applicants will be granted the loan despite their incomes falling below the threshold (a
proportion represented by the darker shaded region above). 1
1 A single “lending threshold” is presented here for the purpose of illustration only. In reality, the
threshold income necessary to service a loan varies according to loan value and applicants’

3
Figure 1. Stylised distributions of true and reported incomes
Empirical evidence in the US demonstrates a differential probability of misreporting
amongst loan applicants at different income levels (Greenberg and Halsey 1983; Pedace
and Bates 2000). Given that to be granted a loan by the credit provider for a certain
amount of money requires the applicant’s income to be above a certain threshold, it is
more likely that people over-estimating their incomes will be below this threshold to
give them a greater chance of receiving the loan. Therefore, people on low incomes will
be more likely to overstate their income.
The main aim of this paper is to identify how income has been verified overseas, and
identify how some of these overseas methods could be applied to income verification in
Australia. This paper will look at a number of different ways of verifying incomes,
including manual checks of payslips; automatic verification through a link to an external
characteristics. To aid interpretation, the reader should consider yL in Figure 3 to represent the income
threshold amongst a specific class of loan applicants necessary to service a given value of loan.

4
source of income data like the Australian Tax Office (ATO); and modelling income to
attempt to validate the income stated on a credit application.
The structure of this paper is to start with some background information and context in
Section 1. Section 2 then looks at methods for income verification, section 3 assesses
these different methods, and section 4 provides some conclusions.
2 METHODOLOGY FOR INCOME VERIFICATION
In Section 1, we have established that many countries are now looking at compulsory
income verification to protect against future credit collapse. This section outlines
different methods for income verification. It starts with a literature review on the
different methods, which identifies three broad methods: Payslip, Matching and
Modelling methods.
1. Payslip. This method requires the applicant to provide documentary evidence of
their income through a payslip, Government benefit record, etc. This will only
provide an indication of their salary last pay – so it won’t include any bonuses,
overtime, etc.
2. Matching. This method verifies the applicant’s income by matching against
other datasets. This would verify against an annual income, and could include
bonuses, Government benefits, etc. This matching could be to either
Government datasets or non-Government data providers who first collect
income data, and then supply this information to credit providers.
3. Modelling. This method models the applicant’s income using other data. This
will provide some estimate of what a reasonable income should be for this
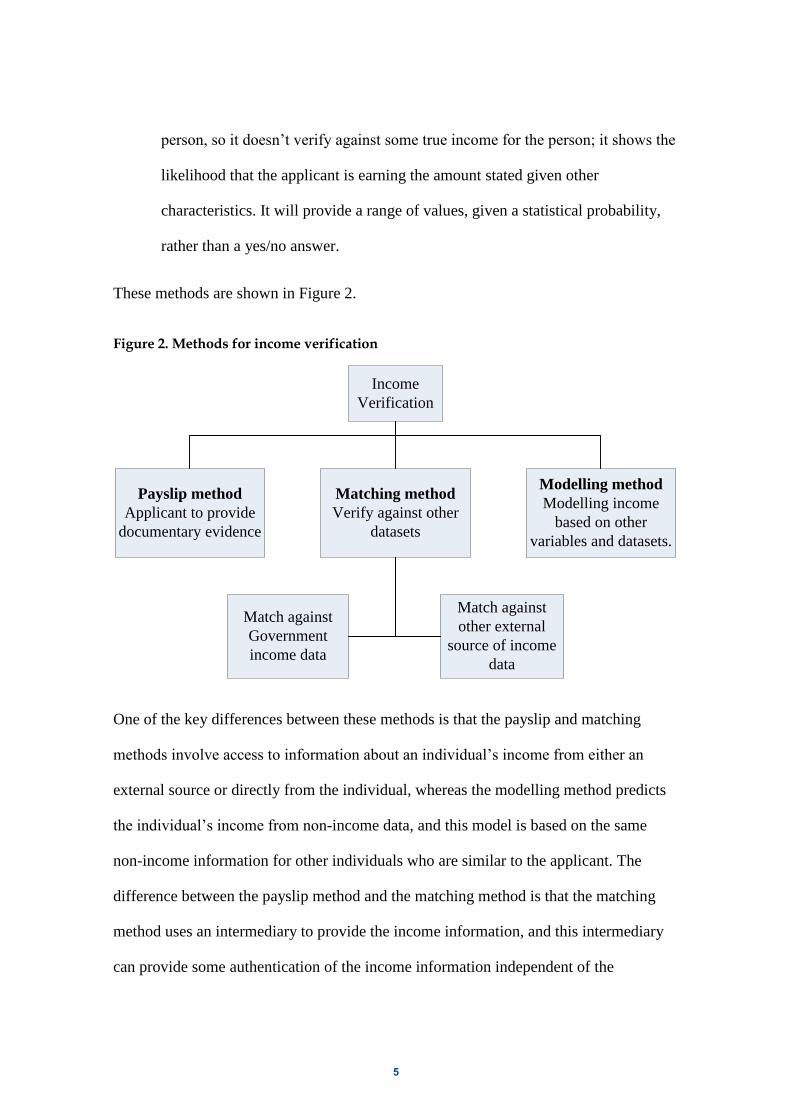
5
person, so it doesn’t verify against some true income for the person; it shows the
likelihood that the applicant is earning the amount stated given other
characteristics. It will provide a range of values, given a statistical probability,
rather than a yes/no answer.
These methods are shown in Figure 2.
Figure 2. Methods for income verification
Income
Verification
Payslip method
Applicant to provide
documentary evidence
Matching method
Verify against other
datasets
Modelling method
Modelling income
based on other
variables and datasets.
Match against
Government
income data
Match against
other external
source of income
data
One of the key differences between these methods is that the payslip and matching
methods involve access to information about an individual’s income from either an
external source or directly from the individual, whereas the modelling method predicts
the individual’s income from non-income data, and this model is based on the same
non-income information for other individuals who are similar to the applicant. The
difference between the payslip method and the matching method is that the matching
method uses an intermediary to provide the income information, and this intermediary
can provide some authentication of the income information independent of the

6
applicant. The payslip method relies on the applicant providing copies of tax returns or
social security benefit documents.
2.1 PAYSLIP METHOD
While the payslip method is conceptually straight forward, it would be very unattractive
to credit providers because it decreases the efficiency of the loan process, imposes
delays and increases the probability that the applicant will not take up the loan because
of the administrative burden. This method is also open to fraud by the applicant, for
instance, providing an old payslip, adjusting the payslip or falsifying a payslip. Other
evidence also suggests that it means that less credit may be available to the client
(Tatom 2009), although this is more likely for automated unsecured loans rather than
secured loans like mortgages. The clear example of this is the ability to offer credit at
point of sale. It is unlikely that a consumer will bring their payslip when they go
shopping for a large item, especially when the payslip then needs to be certified. This
certification needs to ensure that the payslip is a valid payslip, and that it comes from a
current employer of the applicant.
2.2 MATCHING METHOD
The matching method, which has been implemented by the US and UK governments,
can assist the financial sector by making income verification easier through matching
client details with other (in the US and UK case, Government) data on incomes. The US
government, through the Internal Revenue Service (IRS), the US government agency
responsible for tax collection and tax law enforcement, has provided income checking
facilities since the end of 2006. The income checking comes directly from the income
tax information for the borrower, making it difficult for the borrower to provide false

7
information about their income. The detail of these services can be accessed through the
IRS website (IRS 2012)
In September 2009 in the UK, the Financial Service Authority implemented a
requirement that all mortgage applications use income verification. Because of this
change, the UK HM Revenue and Customs (HMRC) prepared an income verification
scheme which has been described in the 2010 UK budget report (HM Treasury 2010).
Although they planned to start releasing their tax data to lenders, in particular mortgage
lenders, for the purposes of income verification in Autumn 2010, the scheme was not
launched until 1 September 2011. Unfortunately, there is not much information on the
scheme on the UK HMRC website. More information on the launch can be collected
from the two partner organisations – the Council of Mortgage Lenders (CML) and the
Building Societies Association (BSA) (CML 2011a; BSA 2011), more specific
information and the referral guide is only available for members of the organisation
(CML 2011b).
2.3 MODELLING METHOD
This method seeks to predict an individual’s income (or the likely range of income)
using explanatory non-income data from a number of sources, and then apply this model
to information on the applicant. This modelling method has been welcomed by the
lenders because of the opportunity for automation and broad coverage. The accuracy of
such a tool requires attention, of course, since its effectiveness as an income verification
device depends on the predictive power of the model. Inevitably, any empirical model
will be subject to error, but will still represent a reasonable approach to income
verification provided that misclassification bounds are ‘small’ in a statistical sense.

8
One of the main challenges with model-based verification is to produce a statistical
device that estimates individual or household incomes with a degree of accuracy that
makes the tool a viable one for credit providers to use as part of the process of granting
loans to applicants. Achieving this aim is likely to require additional risk and locational
factors that are specific to the individual loan applicant, beyond the broad demographic,
human and physical characteristics used as standard in economy level statistical models
for estimating incomes.
2.3.1 Regression Approach
The regression modelling approach comprises two stages, the first of which looks to
predict an expected income (or a quantile of income, or a full distribution of income)
conditional on observed factors. This provides the core input into the second stage,
where the expected income model is applied in the operational environment in order to
verify the applicant’s income. Not all predictors available in the exploratory
environment of stage 1 will be available in the operational environment of stage 2.
Therefore, the model used in Stage 2 is a subset model based only on those predictors
from Stage 1 that will be available during Stage 2.
In summary, the model in Stage 1 could best be described as the “estimation model’, in
that it uses external data to derive the regression coefficients that predict income; and
the model in Stage 2 could be described as the “prediction model”, as it uses the results
from the model in Stage 1 to predict income for a particular individual, where that
income is unknown in Stage 1.

9
In stage 1, a number of estimation techniques for income distributions are proposed in
the literature, including mixture or copula methods (McWilliam et al 2008) in which a
weighted average of parametrically distinct density functions are fitted to a sample of
income data using maximum likelihood, or non-parametric or semi-parametric methods
in which empirical distributions are determined directly by a sample of data, without
any strong parametric form (some discussion on these estimation methods can be found
in Blundell and Duncan, 1998; Cowell and Victoria-Feser, 2007). The parametric
mixture method is more practical in the context of an income verification tool.
However, ultimately the relative performance of these methods in fitting lower tails of
income distributions is an empirical question.
Other statistical methods can add power to the process of verifying incomes. For
example, quantile regression methods (Koenker and Bassett 1978; Fitzenberger et al.
2001) that allow the impact of observed demographic, human capital, location and risk
factors to vary across different parts of the income distribution or multivariate adaptive
regression splines (MARS) that allows the explanatory variables in an income
regression model to have different predictive power for different levels of income
(Friedman 1991).
At stage 2, the process of income verification effectively compares a prediction of ‘true’
income (either an average, or a range of likely incomes) given a set of observed
characteristics with that which is reported on the loan application, for example, using
coefficients provided by an estimated model of the form in Stage 1 above. In addition, it
is entirely feasible to simulate either a range within which the loan applicant’s ‘true’
income is likely to fall (again, conditional on characteristics), or alternatively the
probability that true income falls short of the level of income reported by the loan
applicant by more than some margin of error.

10
These measures take account of individual income uncertainty, and provide an
indication of the likelihood, or probability, that a loan applicant’s income falls short of
some threshold value. A number of methods are available to calculate or simulate
individual uncertainty, depending on how the underlying income modelling tool has
been estimated. Confidence bands or conditional threshold probabilities may be
recovered theoretically for a parametrically estimated income distribution model.
2.3.2 Data Matching using a modelling technique
A second income verification option using a modelling approach uses data matching
methods to compare the income of a loan applicant with the verified incomes of a
matched sample of people with similar characteristics (Chakraborty et al. 2005; Altman
1992). The basic intuition behind this approach is founded on the notion that one can
judge incomes of loan applicants by drawing from a comparator pool of incomes in a
matched sample. This is unlikely to be a feasible approach, due to limitations in
identifying a matched sample, but would be a valid benchmark when calibrating a
parametric income scoring tool.
In applying this method, the databases for the verified incomes could come from several
sources and would need to be statistically matched to loan application data and other
relevant information. The matched database would then need to be validated and
cleaned. Once the database was created, the individual incomes would be modelled
using a data-mining process. This will give some ideas as to which variables are the best
predictors of individual incomes. When a multivariate regression model has shown
which variables have reasonable predictive power for the verified income, and after a
further process of data cleansing, then a more complicated model can be built using the

11
MARS local regression method described above. The actual verified income and the
estimated income would then be matched to get the level of confidence for each income
level.
2.3.3 Imputation Method
The imputation techniques have been developed to impute incomes to individual
respondents to a survey. These methods are similar to the methods used to verify
incomes outlined above. The techniques for imputing incomes broadly fall into two
areas, regression techniques and hot decking techniques. In some cases, hybrid methods
are used – so hot decking is used where possible, and then regression techniques are
used if hot decking is not possible.
One example of a regression technique to imputing income is seen in David et al (1986).
This method used a log earning model based on specifications by Lillard and Willis
(1978), Greenlees et al. (1982), and Betson and Van der Gaag (1983) to estimate
incomes using data from the 1981 Current Population Survey. They also imputed the
error distribution from the income estimation so that they could impute income for
people that had not responded to the income question on the survey. They also find that
it was sometime necessary to make the model non linear by adding the square value of
or the logarithm of variables.
3 ASSESSMENT OF THE DIFFERENT METHODS AND APPLYING THEM IN
AUSTRALIA
This section shows how each of the methods identified could, in theory, be applied in
Australia. Two of the methods (matching and modelling), and the source of data, are all

12
shown in Figure 3. This diagram shows the three levels at which these two types of
income verification could be applied; and the data available at each of these levels.
Figure 3. Models for income verification
Note that a system implemented could use a number of the methods described in
Section 2 – so it could use a hybrid approach, where incomes are verified against other
data as a first instance; and if this is not possible, then credit history data could be used.
Given the legislative framework and the infrastructure requirements, we would expect
that any method that links into ATO or Centrelink data would be a long term rather than
a short or medium term solution. A faster solution may be linking into an external
source of validated incomes, for instance an external agency which has got permission
from loan applicants to share their incomes.
For example in matching data method, Australia has yet to follow the international lead
of making government-held data available to credit providers, but if it does there are
Government/External source
Credit Provider
Credit Bureau
ATO Centrelink
Loan Application Loan Application
Income verification using databases of verified individual incomes (matching method)
Loan Application
Credit History
External data
Limited information
Income verification using credit provider data (modelling method)
Income verification using credit bureau data (modelling method)
Other
Method

13
two government databases that could be used to verify incomes. The first is individual
income from tax returns held by the Australian Tax Office (ATO), and the second is
social security benefits payment data from Centrelink.
If it were available, Australian Tax Office data would show individual income for the
latest financial year and possibly some previous periods. Taxation statistics are currently
published at an aggregate level by the Australian Tax Office (ATO 2011), but to be used
for income verification the individual would need to be matched to the corresponding
tax return records on the ATO dataset. This means that the latest income information
available would be the latest year that the individual has lodged a tax return. The
income data will have been verified through the standard process that the ATO uses to
obtain income information directly from employers. The ATO data will only show
income for, as a minimum, the last financial year (depending on when the individual last
submitted a tax return), so an individual’s income may have changed significantly from
the income information that the ATO can provide, particularly for young people just
joining the work force; or for people who are moving out of a period of part time work
or unemployment.
Data from Centrelink, the Government agency responsible for pensions and social
security benefits in Australia, may not have this issue. The rate of payment of many
benefits depends on the beneficiary´s other non-benefit income. Therefore, Centrelink
asks the beneficiaries to regularly update their non-benefit income data so they receive
the correct amount of government benefits. The non-benefit income data in the
Centrelink database is verified at the end of each financial year, but the self reported
income in the Centrelink database is likely to be underestimated rather than
overestimated because the client may lose their benefit or at least receive a lower benefit
if they report a higher income. The Centrelink information, covering benefit and non-

14
benefit income, should in theory be available historically for a number of years, but at
the moment it is difficult to tell what historical data would be available in practice as
Centrelink do not publish this data.
One of the issues with the matching method is that the person applying for credit needs
to be on the Government dataset. Only those who pay tax will be on a Taxation Office
dataset (for example, retirees, some students and stay at home parents will not be on the
dataset), and only those receiving Government benefits will be on Government benefit
recipient datasets. This may not be a major problem as a credit provider is less likely to
make a loan to those on a low income like students and stay at home parents with no
income. However, an alternative income verification method must be available for
those cases that do arise.
Another issue with the matching method is that it may be difficult to implement in
countries, such as Australia, with strong privacy laws. These pieces of legislation
restrict what personal data the Government of a country can release.
Another workable option for the matching method may be to verify against some other
source of income data, for instance a private company that collects income data. There
are at least two such private income services in the USA called Equifax and talx. The
income information might be obtained directly from employers or from prior credit
applications. Obviously, there are issues to be resolved in ensuring that the income data
is accurate, current, available in a timely fashion, and at a reasonable cost. In Australia,
privacy legislation would need to be considered (privacy law is more restrictive in
Australia than the US), and while these organisations exist in the US, there are none at
the moment in Australia.

15
The modelling methods are certainly feasible using any dataset with both income and an
adequate set of independent variables correlated with income. Examples in Australia
include the Australian Bureau of Statistics (ABS) Surveys of Income and Housing
(SIH) (ABS 2011); and the Household Income and Labour Dynamics in Australia
survey (HILDA) from the Melbourne Institute (Summerfield et al. 2011).
There are several examples on how income has been estimated in Australia. The ABS
uses a hot decking technique for income imputation on their income surveys. This hot
decking technique uses the response of similar people in a survey to estimate the income
of the non-responding individual. This similar person is randomly chosen but has
matching characteristics such as state, sex, age, labour force status, and expenditure.
This method can also provide some information on the distribution of the sample that
we have taken the expenditure from, which could in theory provide some idea of the
accuracy of the estimate.
The Melbourne Institute has used an improved method for imputing incomes in their
HILDA survey (see Starick and Watson 2007). The methods available for HILDA are
slightly different to those used for the ABS surveys, as HILDA is a longitudinal survey
(the same people are surveyed over a number of years), so there may be information on
the respondent from a previous year. Hayes and Watson (2009) explain that there are
three imputation methods used for HILDA. First, if the person who is not responding to
the income question this year is known to have zero income in the previous year, then
the zero income is reinstated. Second, the imputation method based on Little and Su
(1989) that uses the distribution of income among persons (row effect) combined with
changes in income over time (column effect) is used to find a similar individual, and use
this as the income for the person with income missing. The final method is a regression

16
method, which is used if the person does not have any longitudinal information (which
may occur if they have been added to the sample recently to replace a sample loss).
Despite the application on income estimation, additional (potentially matched)
information sources may be required in income verification process to further estimate
the biases between reported and ‘true’ income in sample surveys generally, or for
systematic differences that may exist between ‘true’ incomes and those reported
specifically on loan applications. Therefore, data from the loan application form is
needed to derive an estimate of the applicant’s income to compare to the stated income.
The best estimate would need data from the application form, which means the system
could be with the credit provider, or with some centralised service such as a credit
bureau (although such a system would have to be made compliant with Part IIIA of the
Privacy Act).
Sourcing credit bureau data in Australia is difficult, as they are heavily regulated by the
privacy act. To implement an income verification process in Australia, using credit
bureau data, while complying with the privacy act, would require some legal
negotiation; but is not outside the realms of possibility.
The other thing required to determine how well the modelling will work is some
measure of accuracy, like a confidence interval, from the model. It should be noted that
we are not trying to get an exact estimate on individual incomes from the modelling,
more a range that we are confident that the applicant’s actual income is within.
For example, a confidence interval can be built around the estimates through a monte
carlo method. This method would estimate a number of incomes from a survey, using
the data identified in the model and income from the survey. Statistical analysis would
then be conducted to determine how far off on average the estimate of income is, and

17
this would provide some indicator of the reliability of the model given the different data
from the credit provider and credit bureau.
There is little empirical evidence on the accuracy of each of the income verification
methods discussed above, and different methods will be more accurate for different
types of applicants. So for instance, if ATO or Centrelink could provide the reported last
financial year’s income then the matching method could be applied but it may not be
very accurate for applicants whose income varies year by year (for example, farmers,
consultants, business owner/operators). The payslip method may be considered accurate
if the most recent payslip is used, however it may be an abnormal payslip or the
applicant may have only just lost their job. It is important to note that the proliferation
of smartphones could overcome the issues of having details at hand whilst at the shop.
4 CONCLUSIONS
One part of the reform process after the Global Financial Crisis that has hit global
economies in the past few years involves a change to credit legislation that requires
credit providers to verify the financial circumstances of the applicant. A major
component of this requirement has been interpreted as verifying that the incomes being
provided on loan application forms are correct. This process is called income
verification.
The underlying premise that gives rise to the current legislation requiring lenders to take
“reasonable steps to verify the incomes of loan applicants” is that there exists some
systematic misreporting of income that can give rise to acceptance of loans applications
from those not sufficiently well-positioned to accommodate repayments.

18
The three methods reviewed in this article are:
1) Sighting a payslip or other official document;
2) Matching to an external dataset; and
3) Modelling income.
Checking a payslip is the most conceptually straightforward, but may not have good
coverage; and may take some time if the applicant has not brought a payslip with them.
They are also easy for an applicant to create, so they are open to fraud. Many companies
now have online payslips, so the payslip is simply a printout from an online system,
which is easy to adjust or mock up on a computer.
Matching incomes to some external database is an accurate method for income
verification if an exact match can be found. However, there are security, coverage and
timing issues around matching to some unique identifier. The security issues are around
releasing individual data on personal incomes. The coverage issues are because not
everyone can be covered on an external database of incomes. And the timing issue is
that overseas where a matching method has been implemented, the time taken to verify
the incomes is about 2 days.
The most generalised approach is a modelling approach. Although there will be some
estimation errors and accuracy issues attached, this approach would work for most
people, and would use whatever data were available on the applicant.
To sum up, the choice of best methods for income verification will depend on the
criteria used in the judgement. If the main criterion is accuracy, then one feasible
solution is a hybrid approach comprising the use of payslips where available. If cost
features as a principal concern, or in the absence of available external databases on

19
which to match individual incomes, an alternative is to use a modelling approach using
statistical models to predict individual incomes. Moreover, coupled with a matching
approach using external data drawn either from government or non-government sources,
and then a modelling approach may provide reasonable accuracy.
REFERENCES
ABS (2011). ‘Household Expenditure Survey and Survey of Income and Housing User Guide, Australia, 2009-10’, Cat No. 6503.0, ABS, Canberra
Altman, N. (1992). ‘An introduction to kernel and nearest-neighbour nonparametric regression’, The American Statistician, 46(3), 175 – 185.
ASIC (2011). ‘Credit licensing: Responsible lending conduct, Regulatory Guide 209’, Melbourne: ASIC.
ATO (2011). ‘Taxation statistics 2008-09’, Canberra: Australian Taxation Office.
Betson, D., and Van der Gaag, J. (1983). ‘Working Married Women and Their Impact on the Distribution of Welfare in the United States’, working paper, University of Wisconsin: Institute for Research on Poverty.
BSA (2011) ‘1 September sees launch of Mortgage Verification Scheme to combat fraud’, http://www.bsa.org.uk/mediacentre/press/mortgage_verification_scheme.htm , last accessed 14 February 2012.
Blundell, R. W. and Duncan, A.S. (1998). ‘Kernel Methods in Empirical Microeconomics’, Journal of Human Resources, 33, 62-87.
Chakraborty, A., Hui, K. H., and Bader, F. R. (2005). ‘Method and system for income estimation’, US Patent No. 11/288,073
CML (2011a) ‘HMRC / Lender Mortgage Verification Scheme’ .http://www.cml.org.uk/cml/policy/issues/6365, last accessed 14 February 2012

20
CML (2011b) ‘Mortgage Verification Referral Guidance.’ http://www.cml.org.uk/cml/filegrab/mortgage-verification-referral-guidance-2-.pdf?ref=8015, last accessed 14 February 2012
Commonwealth of Australia (2009). ‘National Consumer Credit Protection Act 2009’, Canberra: Commonwealth of Australia.
Cowell, F. A. and Victoria-Feser, M-P. (2007). ‘Robust stochastic dominance: A semi-parametric approach’, Journal of Economic Inequality, 5(1), 21-37.
David M., Little R. J. A., Samuhel M. E., and Triest R. K. (1986). ‘Alternative Methods for CPS Income Imputation’, Journal of the American Statistical Association, 81(393), 29-41
Evans, D. and Wright, J. (2010). ‘The Effect of the Consumer Financial Protection Agency Act of 2009 on Consumer Credi’t, Loyola Consumer Law Review, 22(3), 277-335
Fitzenberger, B., Koenker, R., and Machado, J. A. F. (2001). ‘Introduction’, Empirical Economics, 26(1), 1-5
Friedman, J. H. (1991). ‘Multivariate Adaptive Regression Splines’. Annals of Statistics, 19 (1), 1–67
Greenberg, D. and Halsey, H. (1983). ‘Systematic Misreporting and Effects of Income Maintenance Experiments on Work Effort: Evidence from the Seattle-Denver Experiment’, Journal of Labor Economics, 1, 380-407.
Greenlees, W. S., Reece, J. S., and Zieschang, K. D. (1982). ‘Imputation of Missing Values When the Probability of Response Depends on the Variable Being Imputed’, Journal of the American Statistical Association, 77, 251- 261.
Hayes, C. and Watson, N. (2009). ‘HILDA Imputation Methods’, HILDA Project Technical Paper Series No. 2/09
HM Treasury (2010), ‘Budget 2010: Securing the recovery’, HM Treasury, London
IRS (2012), ‘Income verification express service’, http://www.irs.gov/individuals/article/0,,id=161649,00.html, last accessed 2 February 2012
Koenker, R. and Bassett, G. (1978). ‘Regression Quantiles’, Econometrica, 46(1), pp. 33–50.

21
Lillard, L. A., and Willis, R. J. (1978). ‘Dynamic Aspects of Earnings Mobility’, Econometrica, 46, 985-1011.
Little, R. J. A., and Su, H. L. (1989). ‘Item Non-response in Panel Surveys’. In Panel Surveys, ed. D. Kasprzyk, G.J. Duncan, G. Kalton, and M.P. Singh. New York: Wiley.
McWilliam, N. , Loh, K-W. and Huang, H. (2008). ‘Incorporating Multidimensional Tail-Dependencies in the Valuation of Credit Derivatives’, Quantitative Finance, 11(12), 1803-1814
Pedace, R. and Bates, N. (2000). ‘Using administrative records to assess earnings reporting error in the survey of income and program participation’, Journal of Economic and Social Measurement, 26, 173-192.
Starick, R. and Watson N. (2007). ‘Evaluation of Alternative Income Imputation Methods for the HILDA Survey’, HILDA Project Technical Paper Series No. 1/07
Summerfield, M., Dunn, R., Freidin, S., Hahn, M., Ittak, P., Kecmanovic, M., Li, N., Macalalad, N., Watson, N., Wilkins, R., and Wooden, M. (2011), ‘HILDA User Manual Release 10’, Melbourne Institute of Applied Economic and Social Research, University of Melbourne
Tatom, J. (2009). ‘Responding to the 2007- 09 financial crisis: A new Consumer Financial Protection Agency?’, MPRA Paper 16174, Germany: University Library of Munich.




















