
Web News Extraction via Path Ratios
10
Web News Extraction via Path Ratios Gongqing Wu 1 , Li Li 1 , Xuegang Hu 1 , Xindong Wu 1, 2 1 School of Computer Science and Information Engineering, Hefei University of Technology, Hefei 230009, China 2 Department of Computer Science, University of Vermont, Burlington, VT 05405, U.S.A. [email protected], [email protected], [email protected], [email protected] ABSTRACT In addition to the news content, most web news pages also contain navigation panels, advertisements, related news links etc. These non-news items not only exist outside the news region, but are also present in the news content region. Effectively extracting the news content and filtering the noise have important effects on the follow-up activities of content management and analysis. Our extensive case studies have indicated that there exists potential relevance between web content layouts and their tag paths. Based on this observation, we design two tag path features to measure the importance of nodes: Text to tag Path Ratio (TPR) and Extended Text to tag Path Ratio (ETPR), and describe the calculation process of TPR by traversing the parsing tree of a web news page. In this paper, we present Content Extraction via Path Ratios (CEPR) - a fast, accurate and general on-line method for distinguishing news content from non-news content by the TPR/ETPR histogram effectively. In order to improve the ability of CEPR in extracting short texts, we propose a Gaussian smoothing method weighted by a tag path edit distance. This approach can enhance the importance of internal-link nodes but ignore noise nodes existing in news content. Experimental results on the CleanEval datasets and web news pages randomly selected from well-known websites show that CEPR can extract across multi-resources, multi-styles, and multi-languages. The average F and average score with CEPR is 8.69% and 14.25% higher than CETR, which demonstrates better web news extraction performance than most existing methods. Categories and Subject Descriptors H.3.3 [Information Search and Retrieval]: Information filtering; H.3.1 [Content Analysis and Indexing]: Abstracting methods General Terms Algorithms, Experimentation Keywords Content extraction, web news, text to tag path ratio, weighted Gaussian smoothing 1. INTRODUCTION The Web has become a platform for content producing and consuming. According to Pew Internet & American Life tracking surveys, reading news is one of the most popular behaviors of Internet users. An investigation in November 2005 showed that over 46% Internet users read web news on a typical day 1 . Besides, the traditional newspapers have also developed their corresponding web news sites to follow this trend. As reading web news is the fastest way to acquire rich information, web news owns a huge user community. Table 1 shows the top 5 popular news websites and their estimated numbers of unique monthly visitors as of May 1, 2013 2 . Table 1. The top 5 most popular news websites and their estimated unique monthly visitors Popular News Website Unique Monthly Visitors Yahoo! News 110 million CNN 74 million MSNBC 73 million Google News 65 million New York Times 59.5 million Besides news content, a typical web news page contains title banners, advertisements, related links, copyrights and disclaimer notices. These additional non-news items, which are also known as noise, are responsible for roughly 40-50% of content on news websites [1]. Therefore, many web applications need to clean up news web pages. For instance, with highly-cleaned news inputted, the quality of web news summaries will be improved [2]; pocket- sized devices with small screens like mobile phones or PADs will achieve a better effect of user experience. In addition, the noise costs more data storage space and more computing time in web information retrieval, web content management and analysis, and reduces the quality of service at the same time. Our goal is to extract news content and filter non-news noise from web pages. This goal does not seem very complicated, but extracting news content from millions of websites without consistent news publication standards is really a non-trivial problem. Massive and heterogeneous web news brings a data management challenge to handcrafted or rule-based learning techniques. These techniques are suitable for building wrappers for specific websites, but they usually become invalid in extracting news from massive and heterogeneous web pages in an open environment. In addition, most vision-based or template- based wrappers have failed to keep up with the changes of 1 http://www.pewinternet.org/~/media/Files/Reports/2005/PIP_Sea rchData_1105.pdf.pdf 2 http://www.ebizmba.com/articles/news-websites, May 1, 2013. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from [email protected]. CIKM'13, October 27 - November 01, 2013, San Francisco, CA, USA. Copyright 2013 ACM 978-1-4503-2263-8/13/10…$15.00. http://dx.doi.org/10.1145/2505515.2505558
Transcript of Web News Extraction via Path Ratios

Web News Extraction via Path Ratios Gongqing Wu 1, Li Li 1, Xuegang Hu 1, Xindong Wu 1, 2
1 School of Computer Science and Information Engineering, Hefei University of Technology, Hefei 230009, China 2 Department of Computer Science, University of Vermont, Burlington, VT 05405, U.S.A.
[email protected], [email protected], [email protected], [email protected]
ABSTRACT In addition to the news content, most web news pages also contain navigation panels, advertisements, related news links etc. These non-news items not only exist outside the news region, but are also present in the news content region. Effectively extracting the news content and filtering the noise have important effects on the follow-up activities of content management and analysis. Our extensive case studies have indicated that there exists potential relevance between web content layouts and their tag paths. Based on this observation, we design two tag path features to measure the importance of nodes: Text to tag Path Ratio (TPR) and Extended Text to tag Path Ratio (ETPR), and describe the calculation process of TPR by traversing the parsing tree of a web news page. In this paper, we present Content Extraction via Path Ratios (CEPR) - a fast, accurate and general on-line method for distinguishing news content from non-news content by the TPR/ETPR histogram effectively. In order to improve the ability of CEPR in extracting short texts, we propose a Gaussian smoothing method weighted by a tag path edit distance. This approach can enhance the importance of internal-link nodes but ignore noise nodes existing in news content. Experimental results on the CleanEval datasets and web news pages randomly selected from well-known websites show that CEPR can extract across multi-resources, multi-styles, and multi-languages. The average F
and average score with CEPR is 8.69% and 14.25% higher than CETR, which demonstrates better web news extraction performance than most existing methods.
Categories and Subject Descriptors H.3.3 [Information Search and Retrieval]: Information filtering; H.3.1 [Content Analysis and Indexing]: Abstracting methods
General Terms Algorithms, Experimentation
Keywords Content extraction, web news, text to tag path ratio, weighted Gaussian smoothing
1. INTRODUCTION The Web has become a platform for content producing and consuming. According to Pew Internet & American Life tracking surveys, reading news is one of the most popular behaviors of Internet users. An investigation in November 2005 showed that over 46% Internet users read web news on a typical day1. Besides, the traditional newspapers have also developed their corresponding web news sites to follow this trend. As reading web news is the fastest way to acquire rich information, web news owns a huge user community. Table 1 shows the top 5 popular news websites and their estimated numbers of unique monthly visitors as of May 1, 20132.
Table 1. The top 5 most popular news websites and their
estimated unique monthly visitors
Popular News Website Unique Monthly Visitors Yahoo! News 110 million CNN 74 million MSNBC 73 million Google News 65 million New York Times 59.5 million
Besides news content, a typical web news page contains title banners, advertisements, related links, copyrights and disclaimer notices. These additional non-news items, which are also known as noise, are responsible for roughly 40-50% of content on news websites [1]. Therefore, many web applications need to clean up news web pages. For instance, with highly-cleaned news inputted, the quality of web news summaries will be improved [2]; pocket-sized devices with small screens like mobile phones or PADs will achieve a better effect of user experience. In addition, the noise costs more data storage space and more computing time in web information retrieval, web content management and analysis, and reduces the quality of service at the same time.
Our goal is to extract news content and filter non-news noise from web pages. This goal does not seem very complicated, but extracting news content from millions of websites without consistent news publication standards is really a non-trivial problem. Massive and heterogeneous web news brings a data management challenge to handcrafted or rule-based learning techniques. These techniques are suitable for building wrappers for specific websites, but they usually become invalid in extracting news from massive and heterogeneous web pages in an open environment. In addition, most vision-based or template-based wrappers have failed to keep up with the changes of 1 http://www.pewinternet.org/~/media/Files/Reports/2005/PIP_Sea
rchData_1105.pdf.pdf 2http://www.ebizmba.com/articles/news-websites, May 1, 2013.
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from [email protected]. CIKM'13, October 27 - November 01, 2013, San Francisco, CA, USA. Copyright 2013 ACM 978-1-4503-2263-8/13/10…$15.00. http://dx.doi.org/10.1145/2505515.2505558

websites’ layouts or structures. It is difficult for traditional models and techniques to distinguish non-news items from content segments. Let’s take a news article from the New York Times as an example, which appeared on October 23, 2012, as shown in Figure 1. This is a typical web news page. The content in the solid frame is web news, and the content in the dotted boxes is noise. Obviously, the banners, related links and advertisements occupy over one half of the page. Besides, we notice that the news in the solid frame also contains two non-news areas.
Figure 1. A news page from New York Times
In this paper, we propose a highly effective content extraction algorithm for distinguishing news content from non-news content effectively. Our news extraction technique is based on the potential relevance between web content layouts and their tag paths on the parsing trees, which is summarized as follows: on a typical web news page, news segments commonly have similar tag paths and contain long text and more punctuations, whereas the noise items usually have similar tag paths and contain brief text and less punctuations.
By this intuition, we design two features based on the tag paths for measuring the importance of text nodes: a Text to tag Path Ratio (TPR) and an Extended Text to tag Path Ratio (ETPR). Once an HTML document is parsed into a DOM tree, we calculate the text to tag path ratio for every text node. A higher text to tag path ratio implies the node is more likely to represent a news segment. In case of a high value of link text, we extend the Text to tag Path Ratio to the Extended Text to tag Path Ratio by adding the punctuation information and some statistical information. In order to improve the ability in extracting short text, a Gaussian smoothing method weighted by a tag path edit distance is designed. Empirical results will show that this is a fast, accurate and general content extraction approach that outperforms existing content extraction methods on large data sets.
The difference between our approach and existing methods is that we do not assume there are any particular HTML tags, any specific structures, or any common structures between web news pages. We seek to make a full use of tag paths on the parsing trees of web pages to explore an accurate online web news extraction method.
This paper makes the following main contributions:
(1) the notion introduction of the text to tag path ratio (TPR), an extraction feature based on tag paths;
(2) methods for extracting news content from web pages: CEPR-TPR, CEPR-ETPR and CEPR-SETPR;
(3) a Gaussian smoothing technique weighted by a tag path edit distance, which resolves short text extraction and non-news filtering problems effectively; and
(4) a verification that the TPR feature applies to massive, heterogeneous and dynamic web news extraction.
The paper is organized as follows. After briefly reviewing related work in Section 2, we propose two different definitions for text to tag path ratios in Section 3. Next, we introduce the content extraction threshold method CEPR based on the TPR feature and a Gaussian smoothing method weighted by a tag path edit distance in Section 4. Then, in Section 5, we describe our evaluation criteria and parameter settings, compare the performance of our method with CETR, a state-of-the-art method, and discuss the empirical results. Finally, conclusions and future work can be found in Section 6.
2. RELATED WORK The research on web content extraction could be traced back to the integration investigation of heterogeneous structured data and semi-structured data, and was also promoted by the Automatic Content Extraction (ACE) evaluation conference, which was organized by the National Institute of Standards and Technology (NIST). The evaluation conference was held several times from 2000 to 2007 [3]. During the past years, with the development of search engines, news aggregation, web mining and web intelligence, many research efforts have been made on extracting titles, content or other attributes from web pages.
Perhaps the most simplistic and straightforward approaches are seen in handcrafted Web Information Extraction (WIE) systems which were built by traditional programming languages like Java, Perl or specialized languages designed by users. Handcrafted WIE systems include Minerva [4], Web-OQL [5], W4F [6], XWRAP [7] etc. All of them require users to have sophisticated programming skills, be familiar with data sources and results’ output formats, and understand the meanings of data items and extraction rules. The biggest advantage of these methods is they can solve extraction problems in particular fields. Obviously, the disadvantages lie in the low automation, high construction cost, and poor extensibility. Furthermore, the changes in data sources, output formats or semantics of data items makes such systems in need of continuous manual maintenance.
In view of the above problems of manual extraction systems, a growing trend is to promote the automation and accuracy of a WIE system. With the help of supervised, semi-supervised and unsupervised learning techniques, the extraction rules can be configured automatically. In addition, the extraction accuracy could be improved and the labeling costs or scales could be reduced at the same time.
Supervised WIE systems like WHISK [8], DEByE [9], SoftMealy [10], SRV [11] and PPWIE [12, 2, 13], get extraction rules by labeling training documents manually or with tools. Such systems do not require users to have programming skills or well understand the extraction tasks. These systems can achieve high

extraction accuracy, and have a good extensibility. While the disadvantage of these systems lies in the fact that the professional annotation requirement and intensive workload make general users disqualified for the extraction tasks.
Semi-supervised WIE systems like IEPAD [14], OLERA [15] and Thresher [16], learn extraction rules by roughly annotating a training corpus or selecting target patterns. Compared to supervised WIE systems, these techniques somewhat reduce the annotating work. However, due to the embedded domain knowledge, these systems are mainly used for extracting data records, and the shortcomings lie in lacks of extensibility.
Unsupervised WIE systems such as RoadRunner [17], EXALG [18], DeLa [19], DEPTA [20] and NET [21], do not ask for a training corpus. These systems assume that web pages are generated by templates firstly. Then, how to detect the original templates from those pages and how to get the embedded content are discussed further. The advantage of these systems is the light workload. But these systems turn out to be limited in practical applications because of the above assumption or the missing data. Besides, lots of wrappers need to be built for thousands of websites. Any update of the pages’ templates may result in the wrappers’ failure, which leads to high production and maintenance consumption.
A different approach is vision based algorithms [22, 23, 24] in which documents are segmented into visual block trees. In the Vision Page Segmentation technique introduced by Cai et al. [22] , DOM trees also need to be built for computing visual features. Generally speaking, compared to other methods, vision-based methods occupy more computing resources. In 2007, Zheng et al. presented a similar method which treats each node in the DOM tree as a rectangular visual block [23]. Each block has a composite feature derived from a series of visual features to evaluate its importance. With machine learning methods, wrappers could be built for every news site. The problem is that the training sets used in these methods were generated by manual annotationa, which is a time-consuming process. Wang et al. introduced some novel visual features and combined them with machine learning methods to set up a training model only based on one website’s training sets [24]. The experimental results tested on 12 websites have demonstrated that these visual features have good generalization performance.
Current web information extraction techniques meet great challenges in an open environment. For example, in the CleanEval task [25], only a few pages are available from the same site. Assumptions about specific structures (such as, contains <table>), the adjacency of main content, prescient formats or sharing common templates, make current methods fail to extract in an open field. Thus, a more general approach is required urgently.
There are some approaches that can extract news content real-time and online. Real-time means neither pretreatment nor precognition for page structures, and online means adapting any web pages perfectly. One of such methods is CCB [26], which describes the documents’ characters by CCV (Content Code Vector). Each character corresponds to a symbol relying on its original attribute. Then content code ratios (CCR) were calculated from the CCV basis, and then were judged to be content meaningful or not. Another online method is CETR [27], which uses an HTML document’s tag ratios for extracting news content from diverse web pages. This approach computes tag ratios on a
line-by-line basis and clusters the resulting values into content and noise areas. As 1-dimensional histograms do not contain ordered sequence information, 2-dimensional tag ratios were constructed subsequently. Experiments have shown that CETR is laconic and efficient, and can extract across multi-languages.
However, the online methods mentioned above do not pay much attention to structures, but only rely on the characters or lines of each web page. Many efforts have demonstrated that there are potential relationships between the tag path structure and the content of a web page. XWrap [7] introduced by Liu et al. in 2000 locates the extracted objects mainly relying on the tag paths. Without a specific learning algorithm or extraction rules, but requiring the user’s understanding of the HTML parsing trees, XWrap could extract meaningful content accurately. To solve the auto-acquisition problem of path patterns in the Content Extraction Model [2, 13], Wu et al. proposed an extraction algorithm - MPM based on the path patterns mining [12]. A visual labeling tool was designed to annotate the training sets by adding (attribute, value) pairs in the nodes of the parsing trees, and a distinguishing path pattern mining method was proposed according to the path of positive nodes or negative nodes annotated before. The experimental results showed that if appropriate parameters are selected then MPM can achieve good performance. Vertex [28], a web information extraction system developed by Yahoo!, uses learned extraction rules based on XPath for extracting structured data records from template pages. This technique has already been used in practical applications and extracted above 250 million records from more than 200 websites.
3. TEXT TO TAG PATH RATIOS From Figure 1, it was found that the news segments on the web page are usually included in one part and have the same layout, while the noise often has many parts and each part is highly formatted. Analyzing that structure further, we find that news segments often have similar tag paths. Based on this observation, we describe DOM trees and tag paths first and then define a text to tag path ratio to distinguish news nodes from noise nodes.
3.1 DOM Tree and Tag Path The Document Object Model (DOM) is a standardized interface designed by W3C for accessing HTML and XML documents. Each HTML page corresponds to a DOM tree where tags are internal nodes and the detailed text is on leaf nodes. Thus we can use DOM trees to process HTML documents.
EXAMPLE 1. A brief segment of HTML codes from Figure 1.
1. <div id="main"> 2. <div id="article"> 3. <div class="columnGroup first"> 4. <h1 class="articleHeadline"> 5. BBC Episode Examines…</div> 6. <div class="articleBody"> 7. <p itemprop="articleBody"> 8. The unusual spectacle… 9. <a> Britain </a> 10. <p itemprop="articleBody"> 11. Previous BBC associates… 12. </div></div></div>
Example 1 shows a segment of HTML codes from Figure1, and Figure 2 shows the DOM tree of Example 1.

For convenience of description, this paper adopts the labeled ordered tree model to formalize an HTML page. According to the extraction demands, we extend the labeled ordered tree model, and meanwhile, ensure all operations could be operated on the DOM tree conveniently. If no confusion in the context, we treat the extended labeled ordered tree and the DOM tree as the same concept.
Figure 2. The DOM tree of Example 1
Definition 1 (Extended Labeled Ordered Tree): L = {l0, l1, l2, …} is a set of finite alphabetic elements, and each li is a tag of the HTML language. The extended labeled ordered tree on L is defined as a 7-tuple expression T = (V, E, v0, , L, l(•), c(•)). In this expression, V is a set of nodes, E is a set of edges, v0 V, is the sibling relationship set of nodes, and G = (V, E, v0, ) is an ordered tree with v0 as the root. Mapping l: V → L is a label function, v V, l(v) is the label of node v. Mapping c: V → String is a content function, v V, c(v) represents the content of node v.
The mapping c(•) in an extended labeled ordered tree could be defined in different ways based on the actual applications. In this paper, we define it as the text node.
Definition 2 (Tag Path): Given an extended labeled ordered tree T, whose root node is v0. v V, v0v1…vk is the node sequence of tree T from v0 to vk, parent(vi) = vi-1 (1 ≤ i ≤ k), vk = v, and l(v0) l(v1)…l(vk) is called the tag path of node v, denoted as path(v).
To extract content from a web page, we take advantage of typical text features related to the DOM tree to distinguish content segments from noise parts. Plenty of case studies have indicated that on a typical web news page:
(1) Content nodes commonly have similar tag paths;
(2) Noise nodes also have similar tag paths;
(3) Content nodes often contain more text;
(4) Noise nodes often contain less text; and
(5) All the text nodes are leaf nodes.
3.2 Text to Tag Path Ratio Once an HTML document has been parsed to a tree T, the tag path of each text node (leaf node) can be figured out and the text feature, e.g. number of text characters, of each node also can be calculated. Then such statistical information can be integrated into the tag path feature.
pathNum: the occurring times of a tag path in the tree T.
txtNum: number of all characters in the node.
Furthermore, we can compute the ratio of the number of characters to the occurring times per tag path. Now, the Text to tag Path Ratio (TPR) can be defined, as the basis of our method.
Given a node v of a tree T, c(v) is the text of v, and length(c(v)) is the text length of v.
Suppose p is a tag path of a tree T, and accNodes(p)={ 1pv , 2
pv ,…,
mpv } is the set of accessible nodes collocated for p. The occurring
times of p is the size of its accessible node set, which is )( paccNodes .
Definition 3 (Text to Tag Path Ratio): Suppose p is a tag path. Then the Text to tag Path Ratio (TPR) of p is the ratio of its txtNum to its pathNum.
TPR(p)= ( )( ( ))
| ( ) |v accNodes p
length c v
accNodes p
(1)
TPR(p) is a measure of each tag path in the parsing tree of a web page, and it is also a measure of each node in the parsing tree, because each node corresponds to a unique tag path. It assigns high values for paths that contain long text and low values for other paths. It is useful to determine whether a node of a parsing tree is meaningful or not. Clearly, content nodes in a parsing tree will be assigned relatively high TPR values.
Algorithm CalculateTPRs INPUT: a tree T. OUTPUT: a tag path set P.
1: P ← ; 2: CountTxtPathNums(root(T), P); 3: for each pObj in P do 4: pObj.TPR ← pObj.txtNum / pObj.pathNum; 5: return P.
Figure 3. CalculateTPRs
Procedure CountTxtPathNums(v, P) Parameters: a node v in the tree T, a tag path set P. Function: Computing the characters of each text node and the number of paths in tree T rooted on v. 1: if (v is a text node) { 2: Get a pObj from P with the key path(v); 3: if (pObj == null) { 4: Create a tag path object pObj; 5: pObj.path ← path(v); 6: pObj.txtNum ← length(c(v)); 7: pObj.pathNum ← 1; 8: P ← P {pObj};
9: } else { 10: pObj.txtNum ←pObj.txtNum + length(c(v)); 11: p.pathNum ← p.pathNum + 1; 12: } 13: } else { 14: for each v' in v.children do 15: CountTxtPathNums(v', P); 16: }
Figure 4. CountTxtPathNums
Computing text to tag path ratios is a recursive task, as shown by Aalgorithm CalculateTPRs in Figure 3.
BBC Episode
Examines Its…
div
div
div div
h1 p p
a The unusualspectacle…
Britain
Previous BBCassociates…
#1 #3
#4#2
The main activity of Algorithm CaluateTPRs is the traversal of a tree, so its running time is linear in the number of nodes in the tree T, that is O(n), where n is the scale of nodes in T. As the number of characters for each text node is stored, along with the number of tag paths and TPR values, it needs an auxiliary space of O(m), where m is the number of unique tag paths in T.
Before performing the computation, script, comment and style tags are removed from the parsing tree because such information is not visible hence should not be included in the calculation. In addition, the entire non-text nodes are also ignored because they are not among our extraction objects.
Based on the definition of TPR, Example 2 below shows the text to tag path ratio for each tag path of Example 1.
EXAMPLE 2. The text to tag path ratios for four text nodes in Example 1 are computed as follows.
1. #1 text node: tag path=<div.div.div.h1>, txtNum=40, pathNum =1, TPR=40
2. #2 text node: tag path=<div.div.div.p>, txtNum=645, pathNum =2, TPR=322.5
3. #3 text node: tag path=<div.div.div.p.a>, txtNum=7, pathNum =1, TPR=1
4. #4 text node: tag path=<div.div.div.p>, txtNum=645, pathNum =2, TPR=322.5
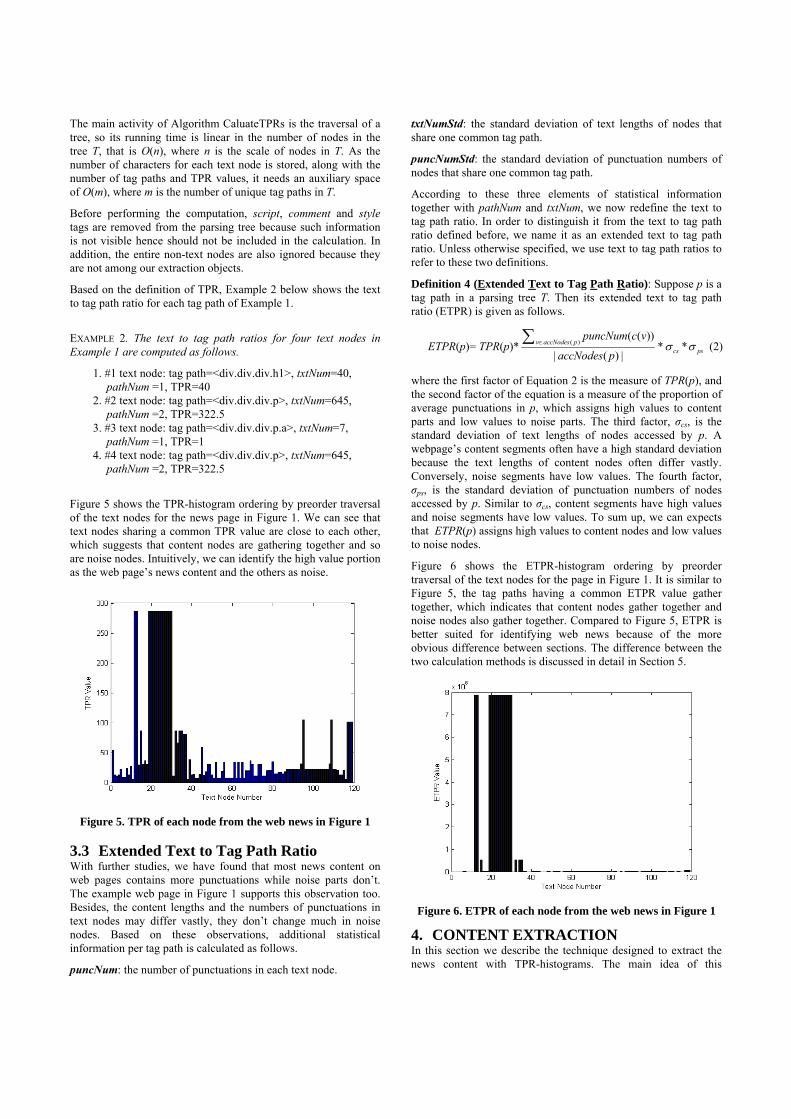
Figure 5 shows the TPR-histogram ordering by preorder traversal of the text nodes for the news page in Figure 1. We can see that text nodes sharing a common TPR value are close to each other, which suggests that content nodes are gathering together and so are noise nodes. Intuitively, we can identify the high value portion as the web page’s news content and the others as noise.
Figure 5. TPR of each node from the web news in Figure 1
3.3 Extended Text to Tag Path Ratio With further studies, we have found that most news content on web pages contains more punctuations while noise parts don’t. The example web page in Figure 1 supports this observation too. Besides, the content lengths and the numbers of punctuations in text nodes may differ vastly, they don’t change much in noise nodes. Based on these observations, additional statistical information per tag path is calculated as follows.
puncNum: the number of punctuations in each text node.
txtNumStd: the standard deviation of text lengths of nodes that share one common tag path.
puncNumStd: the standard deviation of punctuation numbers of nodes that share one common tag path.
According to these three elements of statistical information together with pathNum and txtNum, we now redefine the text to tag path ratio. In order to distinguish it from the text to tag path ratio defined before, we name it as an extended text to tag path ratio. Unless otherwise specified, we use text to tag path ratios to refer to these two definitions.
Definition 4 (Extended Text to Tag Path Ratio): Suppose p is a tag path in a parsing tree T. Then its extended text to tag path ratio (ETPR) is given as follows.
ETPR(p)= TPR(p)* ( )( ( ))
| ( ) |v accNodes p
puncNum c v
accNodes p
* *cs ps (2)
where the first factor of Equation 2 is the measure of TPR(p), and the second factor of the equation is a measure of the proportion of average punctuations in p, which assigns high values to content parts and low values to noise parts. The third factor, σcs, is the standard deviation of text lengths of nodes accessed by p. A webpage’s content segments often have a high standard deviation because the text lengths of content nodes often differ vastly. Conversely, noise segments have low values. The fourth factor, σps, is the standard deviation of punctuation numbers of nodes accessed by p. Similar to σcs, content segments have high values and noise segments have low values. To sum up, we can expects that ETPR(p) assigns high values to content nodes and low values to noise nodes.
Figure 6 shows the ETPR-histogram ordering by preorder traversal of the text nodes for the page in Figure 1. It is similar to Figure 5, the tag paths having a common ETPR value gather together, which indicates that content nodes gather together and noise nodes also gather together. Compared to Figure 5, ETPR is better suited for identifying web news because of the more obvious difference between sections. The difference between the two calculation methods is discussed in detail in Section 5.
Figure 6. ETPR of each node from the web news in Figure 1
4. CONTENT EXTRACTION In this section we describe the technique designed to extract the news content with TPR-histograms. The main idea of this
approach is to determine a threshold τ that divides nodes into content and noise sections.
4.1 Threshold The idea of content extraction based on the text to tag path ratio is straightforward. Suppose v is a text node in a DOM tree T. With a threshold τ, if TPR(path(v)) ≥ τ, then identify v as a content node; otherwise, v is a noise node. The problem then becomes a matter of finding the best value of τ and a way to extract the content nodes completely. Section 5.2 shows the method to set τ.
4.2 Smoothing After the ETPR-histogram is calculated, a smoothing pass is made on the histogram. Many important content nodes might be lost without smoothing. Different from other methods, short text nodes often have high values in our method because the nodes accessed by one tag path have a common value. Therefore, our method aims to smooth the text to tag path histogram. According to the analysis of example pages, it was found that specially formatted short texts which are meaningful like internal-links often come with lower values. Without smoothing, such important information might be lost.
To solve the above problem, we propose a weighted Gaussian smoothing technique by making use the similarity of tag paths. Standard Gaussian smoothing algorithms are generally applied to processing images or handling smoothing problems with continuous attributes, which do not suit for our purpose. Therefore the algorithm used in this approach was re-implemented as a discrete function operating in a single dimension. Equation 3 shows the construction of a Gaussian kernel k with a radius of r, giving a total window size of 2r+1.
2
22 ,i
rik e r i r
(3)
Next, Equation 4 shows that k is normalized to form k’.
' ,ii r
jj r
kk r i r
k
(4)
Finally, the Gaussian kernel k’ is convolved with H in order to form a smoothed histogram H′ as shown in Equation 5.
' ' , ( )r
i ij j i jj r
H w k H r i len H r
(5)
Thereinto,
1,
1,
( ( , ))
i j
iji j
i j
p p
wp p
dist p p
(6)
In Equation 6, dist(pi, pj) is an edit distance of strings pi and pj [29]. α is a smoothing parameter and wij is a value to measure the contribution of smoothing data. In Equation 6, along with the increase of α, the smoothing contribution of nodes with long edit distances will decrease. Because the edit distance of content nodes’ tag paths is commonly lower than that of noise nodes, wij could improve the values of internal links and short text nodes, and meanwhile reduce the values of noise nodes that are mixed with content nodes such as noise link nodes.
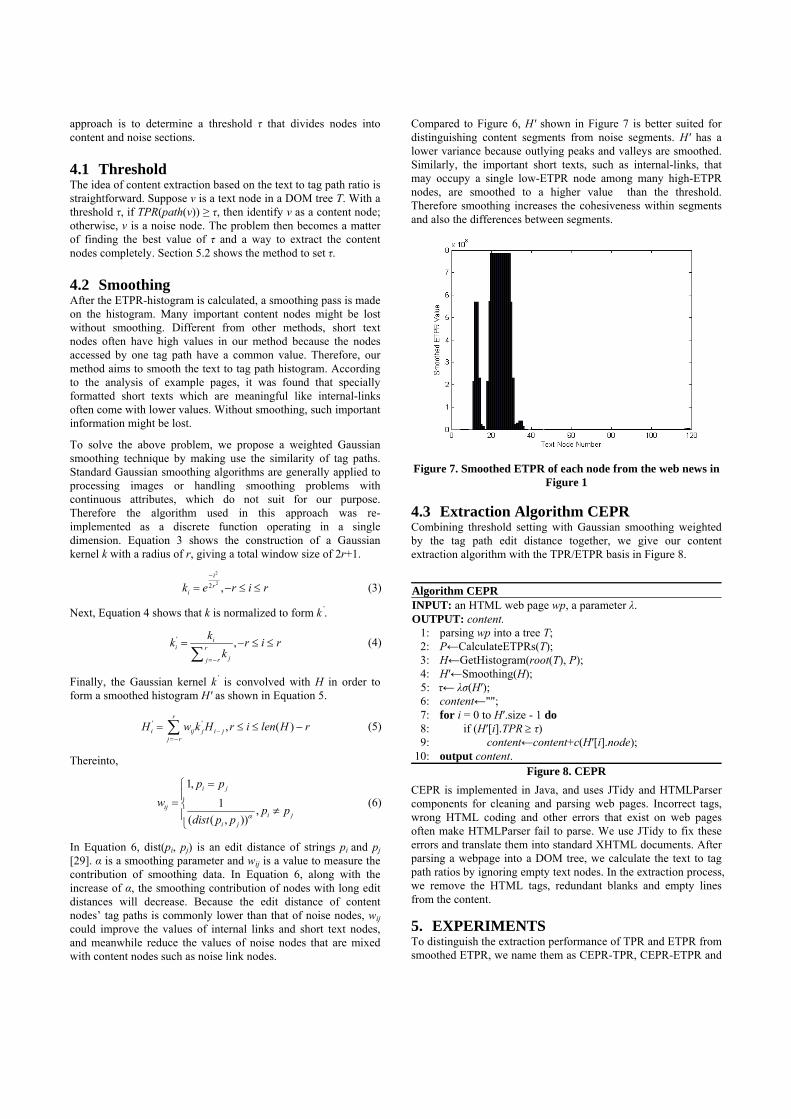
Compared to Figure 6, H′ shown in Figure 7 is better suited for distinguishing content segments from noise segments. H′ has a lower variance because outlying peaks and valleys are smoothed. Similarly, the important short texts, such as internal-links, that may occupy a single low-ETPR node among many high-ETPR nodes, are smoothed to a higher value than the threshold. Therefore smoothing increases the cohesiveness within segments and also the differences between segments.
Figure 7. Smoothed ETPR of each node from the web news in Figure 1
4.3 Extraction Algorithm CEPR Combining threshold setting with Gaussian smoothing weighted by the tag path edit distance together, we give our content extraction algorithm with the TPR/ETPR basis in Figure 8.
Algorithm CEPR INPUT: an HTML web page wp, a parameter λ. OUTPUT: content. 1: parsing wp into a tree T; 2: P←CalculateETPRs(T); 3: H←GetHistogram(root(T), P); 4: H′←Smoothing(H); 5: τ← λσ(H′); 6: content←""; 7: for i = 0 to H′.size - 1 do 8: if (H′[i].TPR τ) 9: content←content+c(H′[i].node); 10: output content.
Figure 8. CEPR
CEPR is implemented in Java, and uses JTidy and HTMLParser components for cleaning and parsing web pages. Incorrect tags, wrong HTML coding and other errors that exist on web pages often make HTMLParser fail to parse. We use JTidy to fix these errors and translate them into standard XHTML documents. After parsing a webpage into a DOM tree, we calculate the text to tag path ratios by ignoring empty text nodes. In the extraction process, we remove the HTML tags, redundant blanks and empty lines from the content.
5. EXPERIMENTS To distinguish the extraction performance of TPR and ETPR from smoothed ETPR, we name them as CEPR-TPR, CEPR-ETPR and

CEPR-SETPR respectively, and three methods are collectively referred to as the CEPR method.
In this section we describe experiments on real world data from various web sites to demonstrate the effectiveness of our methods. Data sets used in our experiments and evaluation measures are described first. We then compare with the CETR method and discuss the experimental results. The configuration of our experiments is as follows: Intel(R) Core(TM) 2 Duo CPU E7500 @ 2.93GHZ, 2.93GHZ, 2GB RAM, Windows XP, and JDK 1.6 are chosen as the development platform.
5.1 Data Sets and Performance Metrics
5.1.1 Data Sets The data used in our experiments was taken from one source: the web news from CETR [27], which consists of two kinds of data sets.
CleanEval: The CleanEval project was started by the ACL’s SIGWAC and initially took place as a competition during the summer of 2007. Besides extracting content, it also asked for participants to mark the structure of the web pages, such as identifying lists, paragraphs and headers. In this paper, we only consider content extraction. The corpus includes four divisions: a development set and an evaluation set in both English and Chinese languages which are all annotated manually. Many of these pages use various styles and structures. There are 723 English news items and 714 Chinese news items in this data set.
News: This data set includes news from 7 different English news websites: Tribune, Freep, NY Post, Suntimes, Techweb, BBC and NYTimes. Each website contains 50 pages chosen randomly.
5.1.2 Performance Metrics Standard metrics are used to evaluate and compare the performance of different approaches. In this paper the extraction results and the evaluation sets are regarded as word sequences in English, and as character sequences in Chinese. Let e be the text in the extraction result, Se be the set of words/characters from e, l be the text in the gold standard, and Sl be the set of words/characters from l in the extraction result. This paper uses two kinds of standard metrics to evaluate the quality of web news extraction as follows.
(1) Precision, Recall and F-score
The precision (P), recall (R), and F-score are defined as follows.
2
, ,e l e l
e l
S S S S R PP R F
S S P R
(7)
F is a composite indicator to evaluate the extraction performance.
(2) Score based on the common subsequence
The score of the extraction result is defined as follows.
lengthleLCSlengthllengthe
lengthleLCSleScore
).,(..
).,(),(
(8)
This scoring method is transformed from the metric used by the CleanEval competition, where LCS(e, l) is the longest common subsequence between text e and text l.
In the CleanEval competition, the scoring method was based on the Levenshtein Distance from the output of an extraction algorithm to the gold standard text, while the Levenshtein distance is relatively expensive to compute, taking O(|e|×|l|) time. When the text size is large, the scoring method of CleanEval takes a long time to return results, or even an “out of memory” error. Therefore, we implement the evaluation function using Equation 8 instead.
Equation 7 gives the evaluation criteria used in CETR, which is our comparison algorithm. The basis of Equation 7 is “common words matching”. So Equation 7 is a metric at the word level and the evaluation results mainly depend on the length of text. Compared with the criteria in Equation 7, the score in Equation 8 at the subsequence level is an “extraction matching”. We use all criteria in both Equations 7 and 8 as standard metrics to evaluate and compare the performance of our approach and CETR.
5.2 Parameter Setting
5.2.1 Threshold Parameter λ After one webpage is parsed into a tree, we can calculate a TPR or ETPR histogram easily. Content nodes are often with high values and noise nodes have low values. But how to make a good use of high values from low values? In other words, how to distinguish content nodes from noise nodes? In this paper, we use a threshold technique. According to the above definitions of precision, recall and F-score, we find that with the increase of threshold τ, there might be a corresponding increase of precision and a sharp decrease of recall. Then how to select an available τ to balance the recall and precision to get the highest F-score is considered to be a key issue.
Figure 9. Precision, Recall and F-score tradeoff for NY Post as the threshold coefficient (λ) increases from 0 to 2
Common threshold selection methods include the middle value, the average value and the standard deviation. However, from ETPR histograms, we can figure out that the number of lower values in ETPR is far more than the higher ones. The middle value might be affected by low values, and the average value might be affected by high values, so we choose the standard deviation σ to set the threshold. We set τ=λσ, where λ is a threshold parameter. Figure 9 shows the tradeoff of precision, recall and F-score along with λ when extracting the source of the NY Post corpora. We can see that with the λ increasing, the recall reduces and the precision increases. When λ=0 all text nodes are
included, while the recall is not 100%. This is because that there exists noise in the gold sets provided by CETR. For the NY Post corpora, a good tradeoff might be λ=0.8. It is hard to find a good threshold value appropriate for all web news fields. In our experiments, the empirical values of λ we set for CEPR-TPR, CEPR-ETPR and CEPR-SETPR are 1.7, 0.7 and 0.8 respectively.
5.2.2 Smoothing Parameter α The smoothing parameter α is used for adjusting the contribution of the smoothing data in nodes that are closed to the current node. From Equation 6, the larger α is, the lager negative smoothing effect in nodes that have large tag path edit distances. If α is set too low, the smoothing effect of nodes with large tag path edit distances will differ slightly to that of nodes with small tag path edit distances. When α is set as 0, 1, 2 and 3, the extracting performances of CEPR-SETPR in the Techweb corpora are shown in Figure 10, while the window size (2r+1) is 3 and the threshold parameter λ is 0.8.
The results shown in Figure 10 demonstrate that the smoothed extractions outperform unsmoothed extraction. During the smoothing process, with the increase of α, the average P increases but average R decreases, and the highest average F (92.60%) is obtained when α is set as 1.
0.80.820.840.860.880.9
0.920.940.960.98
1
Valu
e
P R F
No Smoothing α=0 α=1 α=2 α=3
Figure 10. The extraction performance of CEPR-SETPR for the Techweb corpora with different smoothing settings
In our experiments, the empirical value of α for CEPR-SETPR is set as 1.
5.3 Evaluations
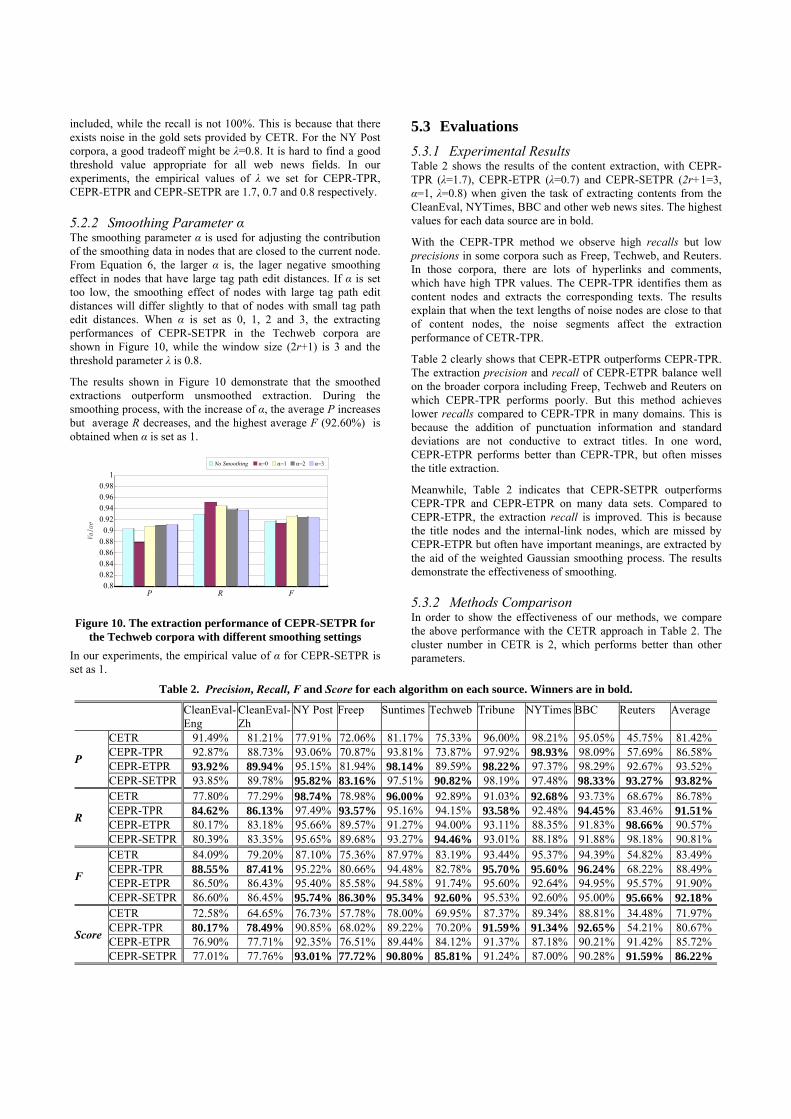
5.3.1 Experimental Results Table 2 shows the results of the content extraction, with CEPR-TPR (λ=1.7), CEPR-ETPR (λ=0.7) and CEPR-SETPR (2r+1=3, α=1, λ=0.8) when given the task of extracting contents from the CleanEval, NYTimes, BBC and other web news sites. The highest values for each data source are in bold.
With the CEPR-TPR method we observe high recalls but low precisions in some corpora such as Freep, Techweb, and Reuters. In those corpora, there are lots of hyperlinks and comments, which have high TPR values. The CEPR-TPR identifies them as content nodes and extracts the corresponding texts. The results explain that when the text lengths of noise nodes are close to that of content nodes, the noise segments affect the extraction performance of CETR-TPR.
Table 2 clearly shows that CEPR-ETPR outperforms CEPR-TPR. The extraction precision and recall of CEPR-ETPR balance well on the broader corpora including Freep, Techweb and Reuters on which CEPR-TPR performs poorly. But this method achieves lower recalls compared to CEPR-TPR in many domains. This is because the addition of punctuation information and standard deviations are not conductive to extract titles. In one word, CEPR-ETPR performs better than CEPR-TPR, but often misses the title extraction.
Meanwhile, Table 2 indicates that CEPR-SETPR outperforms CEPR-TPR and CEPR-ETPR on many data sets. Compared to CEPR-ETPR, the extraction recall is improved. This is because the title nodes and the internal-link nodes, which are missed by CEPR-ETPR but often have important meanings, are extracted by the aid of the weighted Gaussian smoothing process. The results demonstrate the effectiveness of smoothing.
5.3.2 Methods Comparison In order to show the effectiveness of our methods, we compare the above performance with the CETR approach in Table 2. The cluster number in CETR is 2, which performs better than other parameters.
Table 2. Precision, Recall, F and Score for each algorithm on each source. Winners are in bold.
CleanEval-Eng
CleanEval-Zh
NY Post Freep Suntimes Techweb Tribune NYTimes BBC Reuters Average
P
CETR 91.49% 81.21% 77.91% 72.06% 81.17% 75.33% 96.00% 98.21% 95.05% 45.75% 81.42%CEPR-TPR 92.87% 88.73% 93.06% 70.87% 93.81% 73.87% 97.92% 98.93% 98.09% 57.69% 86.58%CEPR-ETPR 93.92% 89.94% 95.15% 81.94% 98.14% 89.59% 98.22% 97.37% 98.29% 92.67% 93.52%CEPR-SETPR 93.85% 89.78% 95.82% 83.16% 97.51% 90.82% 98.19% 97.48% 98.33% 93.27% 93.82%
R
CETR 77.80% 77.29% 98.74% 78.98% 96.00% 92.89% 91.03% 92.68% 93.73% 68.67% 86.78%CEPR-TPR 84.62% 86.13% 97.49% 93.57% 95.16% 94.15% 93.58% 92.48% 94.45% 83.46% 91.51%CEPR-ETPR 80.17% 83.18% 95.66% 89.57% 91.27% 94.00% 93.11% 88.35% 91.83% 98.66% 90.57%CEPR-SETPR 80.39% 83.35% 95.65% 89.68% 93.27% 94.46% 93.01% 88.18% 91.88% 98.18% 90.81%
F
CETR 84.09% 79.20% 87.10% 75.36% 87.97% 83.19% 93.44% 95.37% 94.39% 54.82% 83.49%CEPR-TPR 88.55% 87.41% 95.22% 80.66% 94.48% 82.78% 95.70% 95.60% 96.24% 68.22% 88.49%CEPR-ETPR 86.50% 86.43% 95.40% 85.58% 94.58% 91.74% 95.60% 92.64% 94.95% 95.57% 91.90%CEPR-SETPR 86.60% 86.45% 95.74% 86.30% 95.34% 92.60% 95.53% 92.60% 95.00% 95.66% 92.18%
Score
CETR 72.58% 64.65% 76.73% 57.78% 78.00% 69.95% 87.37% 89.34% 88.81% 34.48% 71.97%CEPR-TPR 80.17% 78.49% 90.85% 68.02% 89.22% 70.20% 91.59% 91.34% 92.65% 54.21% 80.67%CEPR-ETPR 76.90% 77.71% 92.35% 76.51% 89.44% 84.12% 91.37% 87.18% 90.21% 91.42% 85.72%CEPR-SETPR 77.01% 77.76% 93.01% 77.72% 90.80% 85.81% 91.24% 87.00% 90.28% 91.59% 86.22%

CETR is a web extraction algorithm by computing tag ratios. It calculates the tag ratios line-by-line, clusters the tag ratio histogram and extracts the news content based on the clustering results. Due to the ordered sequence information not being considered in 1-dimensional tag ratio histograms, it applies a smoothing pass to the histograms and then constructs a 2D model to improve the performance. It is noteworthy that CETR is similar to our approach but ignores the structural information of web pages. As the parsing tree could reflect structural features, CEPR is more interpretative than CETR too.
Table 2 presents the comparison results between CEPR-TPR, CEPR-ETPR, CEPR-SETPR and CETR on each source. Clearly, no matter in precision, recall, F or score, CEPR-TPR, CEPR-ETPR and CEPR-SETPR all perform better than CEPR. CEPR-SETPR outperforms CETR by an average 8.69% of F and an average 14.25% of score, especially on Freep, Techweb and Reuters, on which the average F CEPR-SETPR achieved is higher than CETR by 10.94%, 9.41% and 40.84% respectively. But on NYTimes, CEPR-SETPR performs poorly. This is because the gold standard of NYTimes treats recommended links embedded in news content as content, but CEPR-SETPR counts them as noise, which results in a decreased recall.
5.4 Discussion The empirical results above demonstrate that CEPR is an effective and robust content extraction algorithm, which performs better than CETR.
The experimental results in Table 2 show the significant difference between the precision and the recall that CEPR-TPR has achieved. For example, for Freep, Techweb and Reuters, the precision is nearly 20% lower than the recall. It is likely due to the fact that these pages contain many hyperlinks with long texts and the TPR values are higher than the threshold. Then they are be extracted by mistake.
Analyzing the results in Table 2, we find that the precision CEPR-ETPR has achieved is higher than CEPR-TPR, but the recall is lower. The added statistical information like the number of punctuations enhances the differentiation between content segments and noise segments, and decreases the values of hyperlink nodes which CEPR-TPR could not handle. But the title information is missed at the same time. In a typical web page, there often exists only one title which contains few punctuations. For example, the title path shown in Figure 2 is <div.div.div.h1>. This path only collects one node, whose standard deviation of text lengths and punctuation numbers are both 0, thus σcs=σps=0. So the ETPR value is 0, which means CEPR-ETPR does not extract the information, and then the recall is decreased.
EXAMPLE 3. The ETPR values for the four nodes in Figure 2 are computed as follows.
1. #1 text node: tag path=<div.div.div.h1>, txtNum=40, puncNum=0, pathNum=1, σcs=0, σps=0, ETPR=0
2. #2 text node: tag path=<div.div.div.p>, txtNum=645, puncNum=15, pathNum=2, σcs=104.5, σps=1.5, ETPR=379139.0625
3. #3 text node: tag path=<div.div.div.p.a>, txtNum=7, puncNum=0, pathNum=1, σcs=0, σps=0, ETPR=0
4. #4 text node: tag path=<div.div.div.p>, txtNum=645, puncNum=15, pathNum=2, σcs=104.5, σps=1.5, ETPR=379139.0625
Comparing CEPR-ETPR with CEPR-SETPR, we find that CEPR-SETPR achieves both higher recall and precision. Based on the path similarity, the smoothing method extracts the content nodes with low ETPR values. For instance, Example 3 shows the ETPR value of each node presented in Figure 2.
The ETPR values of node #2 and node #4 are both 0, which must be lower than the threshold, while these nodes are content nodes. Let’s set the window size as 3, the smoothing parameter α as 1, and take node #3 as the node being smoothed. After smoothing, the ETPR value of node #3 is 207768.206, which has been improved significantly. In the same way, we can improve the ETPR value of title paths to enhance the recall score.
Most web page extraction methods obtain a webpage’s title through extracting the <title> tag. However the content in the <title> tag might not really be the title displayed on the web page, which can contain several noise words. By contrast, the CEPR method has a significant advantage compared to other methods in title extraction.
In addition, CEPR is a real-time and online method, which requires no training to be done, no models to be learned, and no assumptions on the structure of a webpage; all it requires is a web news page as input, and then cleaned content is returned. Furthermore, CEPR can also extract across web languages due to TPR, the basis of the method, concerning no characteristics of webpage languages.
6. CONCLUSIONS This paper presented a novel online approach for extracting news content from web pages in an open environment using TPR features, based on the observation that news nodes belonged to the same segment have similar paths. As noise segments have less punctuations and smaller text lengths than news content, we extended the TPR feature to the ETPR feature, which is more effective than the former for extracting web news. In order to extract news content completely, we designed a Gaussian smoothing method weighted by a tag path edit distance, which has been verified for extracting short texts and ignoring noise. Experimental results have shown that when compared to CETR, which is one of leading online content extraction methods, our CEPR method performs better on average.
In addition to its effectiveness, the greatest strength of our CEPR method over other methods is the simplicity of its concept and implementation. CEPR depends only on the parsing tree without any assumption about web page layouts or structures, which makes it an effective domain-independent and site-independent method. This approach is suitable for handling web-scale news extraction because it is fully automatic and does not need any additional domain information other than the web news pages.
Lastly, CEPR provides an accurate method that can extract across multi-resources, multi-styles, and multi-languages pages.
Future Work The explosive growth of the Internet has produced a huge number of web new pages, and the web news influence continues to grow. Thus, automatic news content extraction remains a popular technique for discovering useful information. With this in mind, there are several research issues to be further explored.
In this paper we have only focused on the text to tag path ratio feature, which is short of diversity. There might exist other tag path

feathers that are more interpretative, or we can find more tag path features to be integrated for a better diversity of web news pages.
Another area for further investigation is the threshold technique used in CEPR for determining whether the content is meaningful or not. Selecting a best threshold appropriate for all web news fields is really a tedious and unreasonable task. We do not claim that the threshold technique is optimal, and there may be other methods such as clustering that could bring better results.
ACKNOWLEDGMENTS This work is supported by the National High Technology Research and Development Program of China (863 Program) under award 2012AA011005, the National 973 Program of China under award 2013CB329604, and the National Natural Science Foundation of China (NSFC) under awards 61273297, 61229301, 61273292 and 61202227.
REFERENCES [1] Gibson, D., Punera, K. and Tomkins, A. 2005. The volume and
evolution of web page templates. In Proceedings of WWW ′05. New York, NY, USA, ACM Press, 830-839.
[2] Wu, X., Wu, G.-Q., Xie, F., Zhu, Z., Hu, X.-G., Lu, H., and Li, H. 2010. News filtering and summarization on the web. IEEE Intelligent Systems. 25(5): 68-76.
[3] Doddington, G., Mitchell, A., Przybocki, M., Ramshaw, L., Strassel, S., and Weischedel, R. 2004. The Automatic Content Extraction (ACE) program--tasks, data, and evaluation. In Proceedings of LREC '04. 837-840.
[4] Crescenzi, V. and Mecca, G. 1998. Grammars have exceptions. Information Systems. December 1998, 23(8): 539-565.
[5] Arocena, G.O. and Mendelzon, A.O. 1998. WebOQL: Restructuring documents, databases, and webs, In Proceedings of ICDE '98. Orlando, Florida, USA, Feb 23-27, 1998, 24-33.
[6] Sahuguet, A. and Azavant, F. 2001. Building intelligent web applications using lightweight wrappers. Data and Knowledge Engineering. March 2001, 36(3): 283-316.
[7] Liu, L., Pu, C., and Han, W. 2000. XWRAP: An XML-enabled wrapper construction system for web information sources, In Proceedings of ICDE '00. San Diego, California, USA, February 28-March 03, 2000, 611-621.
[8] Soderland, S. 1999. Learning information extraction rules for semi-structured and free text. Journal of Machine Learning. February 1999, 34(1-3): 233-272.
[9] Laender, A.H.F., Ribeiro-Neto, B., and Silva, A.S. 2002. DEByE - Data extraction by example. Data and Knowledge Engineering. February 2002, 40(2): 121-154.
[10] Hsu, C.N. and Dung, M.T. 1998. Generating finite-state transducers for semi-structured data extraction from the web. Journal of Information Systems. 1998, 23(8): 521-538.
[11] Freitag, D. 1998. Information extraction from HTML: Application of a general learning approach, In Proceedings of AAAI '98. Madison, Wisconsin, USA, July 26-30, 1998, 517-523.
[12] Wu, G. and Wu, X. 2012. Extracting Web News Using Tag Path Patterns. In Proceedings of WI-IAT '12, Macau, China, December 4-7, 2012, 588-595.
[13] Wu, X., Xie, F., Wu, G.-Q., and Ding, W. 2011. Personalized news filtering and summarization on the web, In Proceedings of ICTAI '11. Boca Raton, Florida, USA, November 07-09, 2011.
[14] Chang, C.H. and Lui, S.C. 2001. IEPAD: Information extraction based on pattern discovery. In Proceedings of WWW '01. Hong-Kong, China, May 01-05, 2001, 223-231.
[15] Chang, C.H. and Kuo, S.C. 2004. OLERA: A semi-supervised approach for web data extraction with visual support. IEEE Intelligent Systems. November 2004, 19(6): 56-64.
[16] Hogue, A. and Karger, D. 2005. Thresher: automating the unwrapping of semantic content from the World Wide Web. In Proceedings of WWW '05. ACM, New York, NY, USA, 86-95.
[17] Crescenzi, V., Mecca, G., and Merialdo, P. 2001. RoadRunner: Towards automatic data extraction from large web sites. In Proceedings of VLDB '01. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 109-118.
[18] Arasu, A. and Garcia-Molina, H. 2003. Extracting structured data from web pages. In Proceedings of SIGMOD '05. ACM, New York, NY, USA, 337-348.
[19] Wang, J. and Lochovsky, F.H. 2003. Data extraction and label assignment for web databases. In Proceedings of WWW '03. Budapest, Hungary, May 20-24, 2003, 187-196.
[20] Zhai, Y. and Liu, B. 2005. Web data extraction based on partial tree alignment. In Proceedings of WWW '05. Japan, 2005, 76-85.
[21] Liu, B. and Zhai, Y. 2005. NET - A system for extracting web data from flat and nested data records, In Proceedings of WISE '05. 487-495.
[22] Cai, D., He, X., Wen, J.R., and Ma, W.Y. 2004. Block-level link analysis. In Proceedings of SIGIR '04. Sheffield, UK, July 25-29, 2004, 440-447.
[23] Zheng, S., Song, R., and Wen, J.R. 2007. Template-independent news extraction based on visual consistency. In Proceedings of AAAI '07. Vancouver, British Columbia, Anthony Cohn (Ed.), Vol. 2. AAAI Press, 1507-1512.
[24] Wang, J., Chen, C., Wang, C., Pei, J., Bu, J., Guan, Z., and Zhang, W.V. 2009. Can we learn a template-independent wrapper for news article extraction from a single training site? In Proceedings of KDD '09. Paris, France, 1345-1354.
[25] Baroni, M., Chantree, F., Kilgarriff, A., and Sharoff, S. 2008. Cleaneval: a competition for cleaning web pages. In Proceedings of LREC '08. Marrakech, Morocco, May 28-30, 2008, 638-643.
[26] Gottron, T. 2008. Content code blurring: a new approach to content extraction. In Proceedings of DEXA '08. IEEE Computer Society, Washington, DC, USA, 29-33.
[27] Weninger, T., Hsu, W.H., and Han, J. 2010. CETR: content extraction via tag ratios. In Proceedings of WWW '10. A Raleigh, North Carolina, USA, April 26-30, 2010, 971-980.
[28] Gulhane, P., Madaan, A., Mehta, R., Ramamirtham, J., Rastogi, R., Satpal, S., Sengamedu, S. H., Tengli, A., and Tiwari, C. 2011. Web-scale information extraction with vertex. In Proceedings of ICDE '11. Hannover, Apr 11-16, 2011, 1209-1220.
[29] Levenshtein V.I. 1966. Binary codes capable of correcting deletions, insertions, and reversals. Soviet Physics Doklady 10(8): 707-710.




















