
Vulnerability Exploration and Data Protection in End-User ...
230
VULNERABILITY EXPLORATION AND DATA PROTECTION IN END-USER APPLICATIONS by Rui Zhao
-
Upload
khangminh22 -
Category
Documents
-
view
2 -
download
0
Transcript of Vulnerability Exploration and Data Protection in End-User ...

VULNERABILITY EXPLORATION
AND DATA PROTECTION IN
END-USER APPLICATIONS
by
Rui Zhao

A thesis submitted to the Faculty and the Board of Trustees of the Colorado School of Mines in
partial fulfillment of the requirements for the degree of Doctor of Philosophy (Computer Science).
Golden, Colorado
Date
Signed:
Rui Zhao
Signed:
Dr. Chuan Yue
Thesis Advisor
Golden, Colorado
Date
Signed:
Dr. Tracy Camp
Professor and Director
Division of Computer Science
ii

ABSTRACT
Using different end-user applications on personal computers and mobile devices has become
an integral part of our daily lives. For example, we use Web browsers and mobile applications to
perform many important tasks such as Web browsing, banking, shopping, and bill-paying. How-
ever, due to the security vulnerabilities in many applications and also due to the lack of security
knowledge or awareness of end users, users’ sensitive data may not be properly protected in those
applications and can be leaked to attackers resulting in severe consequences such as identity theft,
financial loss, and privacy leakage. Therefore, exploring potential vulnerabilities and protecting
sensitive data in end-user applications are of great need and importance.
In this dissertation, we explore the vulnerabilities in both end-user applications and end users.
In terms of end-user applications, we focus on Web browsers, browser extensions, stand-alone
applications, and mobile applications by manually or automatically exploring their vulnerabilities
and by proposing new data protection mechanisms. Specifically, we (1) investigate vulnerabilities
of the password managers in the five most popular Web browsers, (2) investigate vulnerabilities
of two commercial browser extension and cloud based password managers, (3) propose a frame-
work for automatic detection of information leakage vulnerabilities in browser extensions, (4)
propose a secure cloud storage middleware for end-user applications, and (5) investigate cross-site
input inference attacks on mobile Web users. In terms of end users, we focus on phishing attacks
by investigating users’ susceptibility to both traditional phishing and Single Sign-On phishing.
Specifically, we (6) explore the feasibility of creating extreme phishing attacks and evaluate the
effectiveness of such phishing attacks.
By conducting these research projects, we expect to advance the scientific and technological
understanding on protecting users’ sensitive data in applications, and make users’ online experi-
ence more secure and enjoyable.
iii

TABLE OF CONTENTS
ABSTRACT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iii
LIST OF FIGURES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xii
LIST OF TABLES. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xv
ACKNOWLEDGMENTS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .xvii
CHAPTER 1 INTRODUCTION . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1
1.1 A Secure and Usable Cloud-based Password Manager . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4
1.2 A Security Analysis of Two Commercial Browser and Cloud Based Password
Managers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .5
1.3 Automatic Detection of Information Leakage Vulnerabilities in Browser Extensions . . .5
1.4 A Secure Cloud Storage Middleware for End-user Applications . . . . . . . . . . . . . . . . . . . . . . . . . .6
1.5 Cross-site Input Inference Attacks on Mobile Web Users . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .7
1.6 The Highly Insidious Extreme Phishing Attacks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .8
CHAPTER 2 A SECURE AND USABLE CLOUD-BASED PASSWORD MANAGER .. . . . . .9
2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .9
2.2 Related Work and Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2.1 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2.2 Password Manager Feature of Browsers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.3 Vulnerability Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3.1 Threat Model and Assumptions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3.2 The Essential Problem and An Analogy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
iv

2.3.3 Without a Master Password Mechanism . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3.4 With a Master Password Mechanism. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.4 CSF-BPM Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.4.1 High-level Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.4.2 Design Details . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.4.3 Design Rationales and Security Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.5 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.6 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.6.1 Correctness . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.6.2 Performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
2.6.2.1 Micro-benchmark Experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
2.6.2.2 Macro-benchmark Experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.6.3 Usability . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.6.3.1 Participants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.6.3.2 Scenario and Procedure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
2.6.3.3 Data Collection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2.6.3.4 Results and Analysis. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
2.7 Discussion .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
2.8 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
CHAPTER 3 A SECURITY ANALYSIS OF TWO COMMERCIAL BROWSER AND
CLOUD BASED PASSWORD MANAGERS .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.2 Related Work and Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
v

3.2.1 Related Work on Text Password and Password Manager . . . . . . . . . . . . . . . . . . . . . . . 44
3.2.2 Background Information of LastPass and RoboForm . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.3 Security Analysis of LastPass and RoboForm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
3.3.1 Threat Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
3.3.1.1 Credentials . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
3.3.1.2 Attackers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.3.1.3 Attacks Under Consideration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.3.1.4 Attacks Outside of Consideration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.3.2 Security Analysis Methodology .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
3.3.3 LastPass Security Design and Vulnerability Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.3.3.1 Outsider Attackers’ Local Decryption Attacks . . . . . . . . . . . . . . . . . . . . . . . 53
3.3.3.2 Outsider Attackers’ Brute Force Attacks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
3.3.3.3 Insider Attackers’ Brute Force Attacks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
3.3.4 RoboForm Security Design and Vulnerability Analysis . . . . . . . . . . . . . . . . . . . . . . . . 57
3.3.4.1 Outsider Attackers’ Local Decoding Attacks . . . . . . . . . . . . . . . . . . . . . . . . 59
3.3.4.2 Outsider Attackers’ Brute Force Attacks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
3.3.4.3 Insider Attackers’ Server-side Request Monitoring Attacks. . . . . . . . . 62
3.4 Discussions and Suggestions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
3.4.1 Risk Levels of the Vulnerabilities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
3.4.2 Suggestions to Secure BCPM Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
3.5 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
CHAPTER 4 AUTOMATIC DETECTION OF INFORMATION LEAKAGE
VULNERABILITIES IN BROWSER EXTENSIONS . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
vi

4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
4.2 Motivating Example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
4.3 Overall Framework . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
4.3.1 Design Overview and Rationale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.3.2 Call Graph and Variable Use Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
4.3.2.1 Instrumentation and Call Graph Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
4.3.2.2 Variable Use Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
4.3.3 Transitive Variable Relation Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
4.3.3.1 Function-level Relation Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
4.3.3.2 Program-level Relation Analysis. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
4.3.4 Vulnerability Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
4.4 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
4.4.1 Case Study of RoboForm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
4.4.2 Overall Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
4.4.3 Responsible Disclosure and Feedback . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
4.4.4 Performance Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
4.4.5 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
4.5 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
4.6 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
CHAPTER 5 A SECURE CLOUD STORAGE MIDDLEWARE FOR END-USER
APPLICATIONS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
5.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
5.2 Background and Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
vii

5.3 Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
5.3.1 Threat Model and Assumptions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
5.3.2 Requirements and Challenges . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
5.3.3 Overview and Rationale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
5.3.4 Interception Component . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
5.3.4.1 Interception Strategy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
5.3.4.2 Memory Structure and Interceptions. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
5.3.5 Data Protection Component . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
5.3.6 Cloud Driver Component . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
5.3.6.1 User Authentication . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
5.3.6.2 Cloud Data Retrieval, Save, and Consistency . . . . . . . . . . . . . . . . . . . . . . . 111
5.4 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
5.5 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
5.5.1 Correctness . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
5.5.2 Performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
5.5.2.1 Memory Structure Maintenance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
5.5.2.2 Cryptographic Operations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
5.5.2.3 Data Save and Retrieval Latencies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
5.5.2.4 Data Block Read and Write Frequency . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
5.6 Security Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
5.7 Discussion .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
5.8 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
CHAPTER 6 CROSS-SITE INPUT INFERENCE ATTACKS ON MOBILE WEB USERS . 123
viii

6.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
6.2 Threat Model and Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
6.2.1 Threat Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
6.2.2 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
6.3 Design of Cross-site Input Inference Attacks. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
6.3.1 Overview of the Framework . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
6.3.2 Motion Sensor Data Segmentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
6.3.3 Training Data Screening . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
6.3.4 Fine-grained Data Filtering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
6.3.5 Feature Extraction and Model Training . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
6.3.5.1 Feature Extraction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
6.3.5.2 Model Training . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
6.4 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
6.4.1 Data Collection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
6.4.1.1 Participants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
6.4.1.2 Websites Setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
6.4.1.3 Procedure and Dataset . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144
6.4.2 Accuracy Metrics and Evaluation Methodology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
6.4.3 Overall Accuracy with Training Data Screening . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 146
6.4.4 Overall Accuracy with Fine-Grained Data Filtering . . . . . . . . . . . . . . . . . . . . . . . . . . . 150
6.4.5 Further Overall Accuracy Comparison and Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . 153
6.4.6 Per Key Inference Accuracy and Confusion Metrics . . . . . . . . . . . . . . . . . . . . . . . . . . . 155
6.4.7 Accuracy of Sensor Data Segmentation without Key Events . . . . . . . . . . . . . . . . . . 157
ix

6.5 Potential Defense Techniques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
6.5.1 Data Perturbation by Reducing the Sampling Frequency . . . . . . . . . . . . . . . . . . . . . . 160
6.5.2 Data Perturbation by Adding Noises . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
6.5.3 Tradeoff between Accuracy and Utility .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
6.6 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164
CHAPTER 7 THE HIGHLY INSIDIOUS EXTREME PHISHING ATTACKS . . . . . . . . . . . . . . 166
7.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 166
7.2 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 168
7.3 Extreme Phishing and Our Goal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
7.3.1 Metrics for Look and Feel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170
7.3.2 Existing Phishing Websites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171
7.3.3 Our Goal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172
7.4 Design and Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173
7.4.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173
7.4.2 Link Substitution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175
7.4.2.1 Static Link Substitution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175
7.4.2.2 Dynamic Link Substitution. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 176
7.4.3 Web SSO Login Window Generation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 176
7.4.4 Implementation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 178
7.5 User Study. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 178
7.5.1 Testbed. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 178
7.5.2 Participants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
7.5.3 Procedure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 180
x

7.5.4 Data Collection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181
7.5.5 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181
7.6 Discussion .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182
7.7 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185
CHAPTER 8 CONCLUSION. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 186
REFERENCES CITED . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
APPENDIX A - KEYBOARDS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 206
APPENDIX B - DETAILS ABOUT THE OVERALL ACCURACY WITH TRAINING
DATA SCREENING. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 207
APPENDIX C - DETAILS ABOUT THE OVERALL ACCURACY WITH
FINE-GRAINED DATA FILTERING . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 210
APPENDIX D - DETAILS ABOUT THE PER KEY INFERENCE ACCURACY AND
CONFUSION METRICS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212
APPENDIX E - DETAILS ABOUT THE ACCURACY OF SENSOR DATA
SEGMENTATION WITHOUT KEY EVENTS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213
xi

LIST OF FIGURES
Figure 1.1 Research roadmap in this dissertation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3
Figure 2.1 The (a) genuine and (b) fake master password entry dialog box in Firefox. . . . . . . . 19
Figure 2.2 High-level architecture of the Cloud-based Storage-Free BPM (CSF-BPM). . . . . . 21
Figure 2.3 The basic format of an ELIR record. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
Figure 2.4 The Per-User Protected ELIRs (PUPE) data object saved for each SRS user. . . . . . 23
Figure 2.5 Detailed implementation of CSF-BPM in Firefox. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
Figure 2.6 PUPE upload and retrieval time vs. the number of ELIR records in the PUPE
object.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
Figure 2.7 Mean ratings to questions Q1 to Q8. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
Figure 3.1 An overview of the threat model for BCPMs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
Figure 3.2 High-level security design of LastPass. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
Figure 3.3 High-level Security Design of RoboForm. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
Figure 4.1 Code excerpt of a real example extension . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
Figure 4.2 The overall workflow of the LvDetector framework (the shaded components
are ours) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
Figure 4.3 The analysis results for the code excerpt. The dashed lines in (b) and (c)
represent the computed transitive relations; to simplify the figure, we only
kept the operators and omitted the variables in the labels of those dashed
lines, and we only drew the two newly computed transitive relations in (c). . . . . . . 78
Figure 4.4 Function-level relation analysis algorithm .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
Figure 4.5 Program-level relation analysis algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
Figure 4.6 Vulnerability analysis algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
xii

Figure 5.1 High-level architecture of SafeSky. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
Figure 5.2 Memory structure and data protection in SafeSky . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
Figure 5.3 Pseudo code for the write() function . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
Figure 5.4 Cryptographic operation performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
Figure 5.5 Measured worst-case file save and retrieval latencies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
Figure 5.6 Single data block save and retrieval latencies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
Figure 5.7 Data block (a) read and (b) write frequency in a browsing session. . . . . . . . . . . . . . . . 119
Figure 6.1 Two types of cross-site input inference attacks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
Figure 6.2 The framework for cross-site input inference attacks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
Figure 6.3 Sensor data segmentation algorithms in the two phases . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
Figure 6.4 Keystroke data quality estimation algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
Figure 6.5 Overall accuracy on letter, digit, and mixed charsets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
Figure 6.6 Distribution of the best percentage values . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
Figure 6.7 The average keystroke quality scores for participants. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
Figure 6.8 Overall accuracy improvement (upon the results in Figure 6.5) achieved by
using fine-grained data filtering. “O” is for Octave sub-bands; “E” is for
equally divided sub-bands. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
Figure 6.9 Hit probability in one to four tries for three charsets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153
Figure 6.10 Inference accuracy on poor-quality keystrokes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154
Figure 6.11 Per key overall inference accuracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
Figure 6.12 Examples of Euclidean distance and direction relation between keys. . . . . . . . . . . . . 156
Figure 6.13 Confusion metrics on three charsets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
Figure 6.14 Overall data segmentation accuracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
Figure 6.15 Per key data segmentation accuracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 160
xiii

Figure 6.16 Inference accuracy reduction on the letter charset by using data perturbation . . . . 162
Figure 6.17 A representative example of perturbing z axis acceleration force data of some
letter inputs in 15 seconds . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164
Figure 7.1 The classification of phishing attacks based on the second-layer context . . . . . . . . . 170
Figure 7.2 High level design of the toolkit. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 174
Figure A.1 Google Keyboard layouts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 206
xiv

LIST OF TABLES
Table 2.1 Basic information of BPMs in five most popular browsers. . . . . . . . . . . . . . . . . . . . . . . . . . . 13
Table 2.2 The 30 websites. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
Table 2.3 Tasks in Procedure-A using Firefox-A. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
Table 2.4 Tasks in Procedure-B using Firefox-B. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
Table 2.5 The eight close-ended questions. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
Table 3.1 The properties related to the master password in LastPass and RoboForm. . . . . . . . . . 45
Table 3.2 The average brute force attack effort on the master password for LastPass. . . . . . . . . . 56
Table 3.3 The average brute force attack effort on the master password for RoboForm.. . . . . . . 61
Table 3.4 Likelihood, impact, and overall risk ratings. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
Table 4.1 Vulnerability classification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
Table 4.2 Analysis results on 28 Firefox * and Google Chrome + extensions . . . . . . . . . . . . . . . . . . 90
Table 5.1 Intercepted file operation functions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
Table 6.1 Nine 1
2Octave and nine equal sub-bands . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
Table 6.2 Extracted statistical features . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
Table 6.3 Pangrams used in the study. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144
Table 6.4 Inference accuracy across participants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155
Table B.1 Overall Accuracy with Training Data Screening on the Letter Charset . . . . . . . . . . . . . 207
Table B.2 Overall Accuracy with Training Data Screening on the Digit Charset . . . . . . . . . . . . . . 208
Table B.3 Overall Accuracy with Training Data Screening on the Mixed Charset . . . . . . . . . . . . 209
Table C.1 Overall Accuracy with Fine-Grained Data Filtering on the Letter Charset . . . . . . . . . 210
xv

Table C.2 Overall Accuracy with Fine-Grained Data Filtering on the Digit Charset . . . . . . . . . . 210
Table C.3 Overall Accuracy with Fine-Grained Data Filtering on the Mixed Charset. . . . . . . . . 211
Table D.1 Confusion Table on the Letter Charset. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212
Table D.2 Confusion Table on the Digit Charset . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212
Table D.3 Confusion Table on the Mixed Charset . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212
Table E.1 Accuracy of Sensor Data Segmentation without Key Events . . . . . . . . . . . . . . . . . . . . . . . . 213
xvi

ACKNOWLEDGMENTS
First and foremost I want to thank my advisor Professor Chuan Yue. It has been an honor to
be his first Ph.D. student. I would like to thank him for encouraging my research and for allowing
me to grow as a research scientist. I appreciate all his contributions of time, ideas, and funding to
make my Ph.D. experience productive and stimulating. His advice on both research as well as on
my career have been priceless. The joy and enthusiasm he has for his research was contagious and
motivational forme, even during tough times in my Ph.D. pursuit.
I would like to thank my committee members, Professor Xiaoli Zhang, Professor Qi Han,
Professor Dinesh Mehta, Professor Hua Wang, and Professor Hao Zhang for serving as my com-
mittee members, for letting my defense be an enjoyable moment, and for brilliant comments and
suggestions. I would also like to thank Professor Tracy Camp for providing a valuable teaching
opportunity. I would especially like to thank all my collaborators in my Ph.D. study (Professor Kun
Sun, Professor Qing Yi, Dr. Byungchul Tak, Dr. Chunqiang Tang, Professor Brandon E. Gavett,
and Professor Qi Han) from both the academia and industry, and I have enjoyed working with all
of you.
Lastly, I would like to thank my family for all their love and encouragement. Words cannot
express how grateful I am to my mother-in law, father-in-law, my mother, and father for all of the
sacrifices that you’ve made on my behalf. Your prayer for me was what sustained me thus far. I
would also like to thank all of my friends who supported me in writing, and incented me to strive
towards my goal. At the end I would like express appreciation to my beloved wife Xijuan who
spent sleepless nights with and was always my support in the moments when there was no one to
answer my queries.
xvii

CHAPTER 1
INTRODUCTION
Using different end-user applications on personal computers and mobile devices has become
an integral part of our daily lives. For example, we use Web browsers and mobile applications to
perform many important tasks such as Web browsing, banking, shopping, and bill-paying. How-
ever, due to the security vulnerabilities in many applications and also due to the lack of security
knowledge or awareness of end users, users’ sensitive data may not be properly protected in those
applications and can be leaked to attackers resulting in severe consequences such as identity theft,
financial loss, and privacy leakage. Therefore, exploring potential vulnerabilities and protecting
sensitive data in end-user applications are of great need and importance.
In security, a big topic is passwords. Regarding the secure practice of online passwords, re-
searchers have provided many valuable suggestions: use strong passwords that are sufficiently long
and contain numbers, punctuation, and upper- and lower-case letters, change passwords frequently,
and do not reuse passwords. However, the security of online passwords also relies on the design of
the systems that process those passwords. Due to the vulnerabilities in Yahoo Web services, 500
million Yahoo accounts (including names, email addresses, phone numbers, dates of birth, hashed
passwords, and security questions and answers) were stolen in 2014 [1]. Two years later, in 2016,
117 million Linkedin accounts (including email and password combinations) were stolen [2]. Re-
cently on October 21, 2016, because the default administrative passwords of millions of Internet
of Things (IoT) devices are not changeable, attackers compromised those devices using the default
passwords and launched a distributed denial-of-service (DDoS) attack which targeted the Domain
Name System (DNS) server in the Dyn network [3].
Not only in Web services, vulnerabilities also exist in many other software systems due to
the software defects introduced by inexperienced developers. In April 2014, the Heartbleed vul-
nerability [4] caused by an implementation bug in the OpenSSL cryptography library was pub-
1

licly disclosed and millions of systems that use the OpenSSL library were affected. In the recent
DDoS attack, computer systems that run on the IoT devices and are vulnerable to the Linux-based
malware were turned into remotely controlled botnets by a malicious software called Mirai [5].
Meanwhile on mobile platforms, researchers found that 88% of 11,748 Android applications that
use cryptographic APIs make at least one mistake due to the lack of security knowledge of de-
velopers [6]; for example, they found that 5,656 applications used the weak ECB mode for AES
encryption and 3,644 applications used constant symmetric encryption keys.
Besides software vulnerabilities, the security awareness of end users is another important fac-
tor in the success of attacks, especially in phishing that uses spoofed websites to steal users on-
line identities and sensitive information. As Anti-Phishing Working Group [7] reported, 289,371
unique phishing websites were found in the first quarter of 2016 and 123,555 were found in March
2016 alone. On March 3, 2016, an attacker pretended to be the Snapchat chief executive and
tricked an employee into emailing over 700 current and former Snapchat employee accounts [8].
In 2016, the income tax fraud that launched by phishing scams cost American taxpayers about $21
billion [9].
In this dissertation, we explore the vulnerabilities in both end-user applications and end users
by conducting six projects as illustrated in Figure 1.1. We expect to advance the scientific and
technological understanding on protecting users’ sensitive data in applications, and make users’
online experience more secure and enjoyable.
In terms of end-user applications, we focus on Web browsers, browser extensions, stand-alone
applications, and mobile applications by manually or automatically exploring their vulnerabilities
and by proposing new data protection mechanisms. We start from the password security in popular
Web browsers, that have password managers to help online users save and auto-fill their website
login credentials. However, whether those browser built-in password managers securely protect
users’ online passwords remains a question. To answer such a question, we investigate the vulner-
abilities of password managers in the five most popular Web browsers in the first project. Besides
browsers, many third-parties also provide various browser and cloud based password managers
2

Figure 1.1 Research roadmap in this dissertation
in browser vendors’ online stores. To study their security protections of users’ online passwords,
we investigate the vulnerabilities of two commercial browser extension and cloud based password
managers, LastPass and RoboForm, in the second project. In browser vendors’ online stores, a
large number of browser extensions exist and serve various functionalities other than password
managers. Meanwhile, many of them process sensitive information either supplied by end users
or captured from the visited webpages. Therefore, it is even more important to investigate whether
those browser extensions will accidentally leak users’ sensitive information out of the browsers
without any protection. Correspondingly, we propose a framework for automatic detection of in-
formation leakage vulnerabilities in browser extensions in the third project. In these three projects,
we mainly focus on the vulnerability exploration in Web browsers.
Not only Web browsers, but many other applications also process users’ sensitive data. As
cloud computing is a significant trend, it is often desirable and even essential for many appli-
cations to have the secure cloud storage capability to enhance their functionality, usability, and
data security and accessibility. However, it is nontrivial for ordinary developers to either enhance
legacy applications or build new applications to properly have the secure cloud storage capability
3

due to the development efforts involved as well as the security knowledge and skills required. In
our fourth project, from the perspective of the data protection, we propose a secure cloud storage
middleware to immediately enable end-user applications to use the cloud storage services securely
and efficiently as shown in Figure 1.1.
Besides programs running on desktops and laptops, rich application functionalities are also
enabled on smartphones with a variety of built-in sensors. However, the side effects of using
smartphones can be collected via sensors and utilized by attackers as side channels to breach user
security and privacy. One typical example of the side channel attacks on smartphones is that the
high-resolution motion sensor data can be correlated to both the tapping behavior of a user and the
positions of the keys on a keyboard, which is known as input inference attacks. In our fifth project,
we aim to explore vulnerabilities on smartphones by investigating cross-site input inference attacks
on mobile Web users.
In terms of end users, we focus on phishing attacks by investigating users’ susceptibility to both
traditional phishing and Single Sign-On phishing. Specifically, in the sixth project, we explore the
feasibility of creating extreme phishing attacks that have the almost identical look and feel as those
of the targeted legitimate websites, and evaluate the effectiveness of such phishing attacks.
In the rest of this chapter, we will briefly introduce these six projects and will provide more
details about them in the following chapters.
1.1 A Secure and Usable Cloud-based Password Manager
Web users are confronted with the daunting challenges of creating, remembering, and using
more and more strong passwords than ever before in order to protect their valuable assets on dif-
ferent websites. Password manager is one of the most popular approaches designed to address these
challenges by saving users’ passwords and later automatically filling the login forms on behalf of
users. Fortunately, all the five most popular Web browsers have provided password managers as a
useful built-in feature.
4

In this project, we uncover the vulnerabilities of existing BPMs and analyze how they can be
exploited by attackers to crack users’ saved passwords. Moreover, we propose a novel Cloud-
based Storage-Free BPM (CSF-BPM) design to achieve a high level of security with the desired
confidentiality, integrity, and availability properties. We have implemented a CSF-BPM system
into Firefox and evaluated its correctness, performance, and usability. Our evaluation results and
analysis demonstrate that CSF-BPM can be efficiently and conveniently used. We believe CSF-
BPM is a rational design that can also be integrated into other popular browsers to make the online
experience of Web users more secure, convenient, and enjoyable. We detail this work in Chapter 2.
1.2 A Security Analysis of Two Commercial Browser and Cloud Based Password Managers
All the major browser vendors have provided password manager as a built-in feature. Third-
party vendors have also provided many password managers.
In this project, we analyze the security of two very popular commercial password managers:
LastPass and RoboForm. Both of them are Browser and Cloud based Password Managers (BCPMs),
and both of them have millions of active users worldwide. We investigate the security design
and implementation of these two BCPMs with the focus on their underlying cryptographic mech-
anisms. We identify several critical, high, and medium risk level vulnerabilities that could be
exploited by different types of attackers to break the security of these two BCPMs. Moreover,
we provide some general suggestions to help improve the security design of these and similar
BCPMs. We hope our analysis and suggestions could also be valuable to other cloud-based data
security products and research. We detail this work in Chapter 3.
1.3 Automatic Detection of Information Leakage Vulnerabilities in Browser Extensions
Popular web browsers all support extension mechanisms to help third-party developers extend
the functionality of browsers and improve user experience. A large number of extensions exist in
browser vendors’ online stores for millions of users to download and use. Many of those extensions
process sensitive information from user inputs and webpages; however, it remains a big question
whether those extensions may accidentally leak such sensitive information out of the browsers
5

without protection.
In this project, we present a framework, LvDetector, that combines static and dynamic program
analysis techniques for automatic detection of information leakage vulnerabilities in legitimate
browser extensions. Extension developers can use LvDetector to locate and fix the vulnerabilities
in their code; browser vendors can use LvDetector to decide whether the corresponding extensions
can be hosted in their online stores; advanced users can also use LvDetector to determine if certain
extensions are safe to use. The design of LvDetector is not bound to specific browsers or JavaScript
engines, and can adopt other program analysis techniques. We implemented LvDetector and eval-
uated it on 28 popular Firefox and Google Chrome extensions. LvDetector identified 18 previously
unknown information leakage vulnerabilities in 13 extensions with a 87% accuracy rate. The eval-
uation results and the feedback to our responsible disclosure demonstrate that LvDetector is useful
and effective. We detail this work in Chapter 4.
1.4 A Secure Cloud Storage Middleware for End-user Applications
As the popularity of cloud storage services grows rapidly, it is desirable and even essential
for both legacy and new end-user applications to have the cloud storage capability to improve
their functionality, usability, and accessibility. However, incorporating the cloud storage capability
into applications must be done in a secure manner to ensure the confidentiality, integrity, and
availability of users’ data in the cloud. Unfortunately, it is non-trivial for ordinary application
developers to either enhance legacy applications or build new applications to properly have the
secure cloud storage capability, due to the development efforts involved as well as the security
knowledge and skills required.
In this project, we propose SafeSky, a middleware that can immediately enable an applica-
tion to use the cloud storage services securely and efficiently, without any code modification or
recompilation. A SafeSky-enabled application does not need to save a user’s data to the local
disk, but instead securely saves them to different cloud storage services to significantly enhance
the data security. We have implemented SafeSky as a shared library on Linux. SafeSky supports
6

applications written in different languages, supports various popular cloud storage services, and
supports common user authentication methods used by those services. Our evaluation and anal-
ysis of SafeSky with real-world applications demonstrate that SafeSky is a feasible and practical
approach for equipping end-user applications with the secure cloud storage capability. We detail
this work in Chapter 5.
1.5 Cross-site Input Inference Attacks on Mobile Web Users
Smartphones with built-in sensors have enriched applications with various functionalities. How-
ever, smartphone sensors have also created many new vulnerabilities for attackers to compromise
users’ security and privacy. One typical vulnerability is that high-resolution motion sensors could
be used as side channels for attackers to infer users’ sensitive keyboard tappings on smartphones.
In this project, we highlight and investigate severe cross-site input inference attacks that may
compromise the security of every mobile Web user, and quantify the extent to which they can be
effective. We formulate our attacks as a typical multi-class classification problem, and build an
inference framework that trains a classifier in the training phase and predicts a user’s new inputs
in the attacking phase. To make our attacks effective and realistic, we design unique techniques,
and address major data quality and data segmentation challenges. We intensively evaluate the
effectiveness of our attacks using 98,691 keystrokes collected from 20 participants, and provide
an in-depth analysis on the evaluation results. Overall, our attacks are effective, for example,
they are about 10.8 times more effective than the random guessing attacks regarding inferring
letters. We also perform experiments to evaluate the effect of using data perturbation defense
techniques on decreasing the accuracy of our input inference attacks. Our results demonstrate that
researchers, smartphone vendors, and app developers should pay serious attention to the severe
cross-site input inference attacks that can be pervasively performed, and start to design and deploy
effective defense techniques. We detail this work in Chapter 6.
7

1.6 The Highly Insidious Extreme Phishing Attacks
One of the most severe and challenging threats to Internet security is phishing, which uses
spoofed websites to steal users’ passwords and online identities. Phishers mainly use spoofed
emails or instant messages to lure users to the phishing websites. A spoofed email or instant
message provides the first-layer context to entice users to click on a phishing URL, and the phish-
ing website further provides the second-layer context with the look and feel similar to a targeted
legitimate website to lure users to submit their login credentials.
In this project, we focus on the second-layer context to explore the extreme of phishing attacks;
we explore the feasibility of creating extreme phishing attacks that have the almost identical look
and feel as those of the targeted legitimate websites, and evaluate the effectiveness of such phishing
attacks. We design and implement a phishing toolkit that can support both the traditional phishing
and the newly emergent Web Single Sign-On (SSO) phishing; our toolkit can automatically con-
struct unlimited levels of phishing webpages in real time based on user interactions. We design
and perform a user study to evaluate the effectiveness of the phishing attacks constructed from this
toolkit. The user study results demonstrate that extreme phishing attacks are indeed highly effec-
tive and insidious. It is reasonable to assume that extreme phishing attacks will be widely adopted
and deployed in the future, and we call for a collective effort to effectively defend against them.
We detail this work in Chapter 7.
8

CHAPTER 2
A SECURE AND USABLE CLOUD-BASED PASSWORD MANAGER
2.1 Introduction
Text-based passwords still occupy the dominant position in online user authentication [10–12].
They protect online accounts with valuable assets, and thus have been continuously targeted by
various cracking and harvesting attacks. Password security heavily depends on creating strong
passwords and protecting them from being stolen. However, researchers have demonstrated that
strong passwords that are sufficiently long, random, and hard to crack by attackers are often diffi-
cult to remember by users [13–17]. Meanwhile, no matter how strong they are, online passwords
are also vulnerable to harvesting attacks such as phishing [7, 18, 19]. These hard problems have
been further aggravated by the fact that Web users have more online accounts than ever before, and
they are forced to create and remember more and more usernames and passwords probably using
insecure practices such as sharing passwords across websites [20, 21].
Password manager, particularly Browser-based Password Manager (BPM) is one of the most
popular approaches that can potentially well address the online user authentication and password
management problems. Browser integration enables BPMs to easily save users’ login information
including usernames and passwords into a database, and later automatically fill the login forms on
behalf of users. Therefore, users do not need to remember a large number of strong passwords;
meanwhile, BPMs will only fill the passwords on the login forms of the corresponding websites and
thus can potentially protect against phishing attacks. Fortunately, mainly to support the password
autofill and management capability, all the five most popular browsers Internet Explorer, Firefox,
Google Chrome, Safari, and Opera have provided password managers as a useful built-in feature.
In this project, we uncover the vulnerabilities of existing BPMs and analyze how they can be
exploited by attackers to crack users’ saved passwords. Moreover, we propose a novel Cloud-
based Storage-Free BPM (CSF-BPM) design to achieve a high level of security with the desired
9

confidentiality, integrity, and availability properties. CSF-BPM is cloud-based storage-free in the
sense that the protected data will be completely stored in the cloud – nothing needs to be stored
on a user’s computer. We want to move the storage into the cloud for two main reasons. One is
that in the long run trustworthy storage services in the cloud [22–27] can better protect a regular
user’s data than local computers (which may not be timely and properly patched) do, especially if
a storage service uses secret sharing schemes such as the (k, n) threshold scheme [28] to only save
pieces of the encrypted data to different cloud vendors [22]. The other reason is that the stored
data can be easily accessible to the user across different OS accounts on the same computer and
across computers at different locations at anytime.
We have implemented a CSF-BPM system and seamlessly integrated it into the Firefox Web
browser. We have evaluated the correctness, performance, and usability of this system. We believe
CSF-BPM is a rational design that can also be integrated into other popular browsers to make the
online experience of Web users more secure, convenient, and enjoyable. We have followed stan-
dard responsible disclosure practices and reported those vulnerabilities to the respective browser
vendors. Our vulnerability verification tools and the CSF-BPM system can be demonstrated and
be shared with responsible researchers.
We provide four main contributions in this project. First, we compare the BPMs of the five
most popular browsers and identify the inconsistencies in their functionality and interface designs
(Section 2.2). Second, we uncover the security vulnerabilities of the five BPMs and analyze how
they can be exploited by attackers to crack users’ saved passwords (Section 2.3). Third, we propose
a novel CSF-BPM design to achieve a high level of security (Section 2.4). Finally, we present an
implementation (Section 2.5) and evaluation (Section 2.6) of the Firefox version CSF-BPM system,
and discuss its limitations (Section 2.7).
2.2 Related Work and Background
In this section, we briefly review the related password and password manager research, and
provide the background information on the BPMs of the five most popular browsers.
10

2.2.1 Related Work
Morris and Thompson pointed out long ago in 1979 that weak passwords suffer from brute-
force and dictionary attacks [16]. Later, Feldmeier and Karn further emphasized that increasing
password entropy is critical to improving password security [14]. However, strong passwords that
are sufficiently long, random, and hard to crack by attackers are often difficult to remember by
users due to human memory limitations. Adams and Sasse discussed password memorability and
other usability issues and emphasized the importance of user-centered design in security mech-
anisms [13]. Yan et al. [17] analyzed that strong password requirements often run contrary to
the properties of human memory, and highlighted the challenges in choosing passwords that are
both strong and mnemonic. Recently, Florencio and Herley performed a large-scale study of Web
password habits and demonstrated the severity of the security problems such as sharing passwords
across websites and using weak passwords [20]. A large-scale user study recently performed by
Komanduri et al. demonstrated that many Web users write down or otherwise store their passwords,
and especially those higher-entropy passwords [15].
To help Web users better manage their online accounts and enhance their password security,
researchers and vendors have provided a number of solutions such as password managers [29–
31], Web Single Sign-On (SSO) systems [32–35], graphical passwords [36–38], and password
hashing systems [39–41]. As analyzed in Section 2.1, password managers especially BPMs have
the great potential to well address the challenges of using many strong passwords and protecting
against phishing attacks. The insecurity of third-party commercial password managers such as
LastPass [42] and RoboForm [31] are analyzed by Zhao et al. in [43]. Web Wallet [29] is an
anti-phishing solution and is also a password manager that can help users fill login forms using
stored information; however, as pointed out by the authors, users have a strong tendency to use
traditional Web forms for typing sensitive information instead of using a special browser sidebar
user interface. In addition, Web Wallet is not cloud-based. In terms of Web SSO systems, their
security vulnerabilities such as insecure HTTP referrals and implementations are analyzed in [32,
44, 45], their business model limitations such as insufficient adoption incentives are analyzed by
11

Sun et al. in [33], and their vulnerabilities to phishing attacks against the identity provider (such as
Google and Facebook) accounts are highlighted by Yue in [46]. Security limitations of graphical
passwords are analyzed in [36–38]. Security and usability limitations of password hashing systems
are analyzed in [39, 47]. We do not advocate against any of these other approaches. We simply
focus on the BPM security in this project.
2.2.2 Password Manager Feature of Browsers
Table 2.1 lists the basic information on the BPM feature of the recent versions of the five most
popular Web browsers. The second column of the table provides the sequence of menu items
that a user must click in order to finally access the BPM feature configuration interface. We can
see that the BPM feature configuration locations are very different among browsers. Indeed, the
feature configuration interfaces shown on those locations are also very different among browsers
in terms of the configuration options and functions. The third column shows that the BPM feature
is enabled by default in four browsers but not in Safari. The fourth column shows that only Firefox
employs a master password mechanism, which is, however, not enabled by default and users may
not be aware of its importance. Note that Opera employed a weak master password mechanism in
its early versions such as version 12.02 [48]. The fifth column shows that Firefox, Google Chrome,
and Opera provide a password synchronization mechanism that can allow users to access the saved
passwords across different computers.
In terms of the dynamic behavior, the interfaces for triggering the remembering and autofill of
passwords are inconsistent among browsers. For one example, all the browsers display a dialog
box to ask a user whether the entered password for the current website should be remembered. The
dialog boxes displayed by Firefox, Google Chrome, and Opera are associated with the address bar,
thus technically hard to be spoofed. For another example, Internet Explorer, Firefox, and Opera
require a user action before auto-filling the password value on a website; however, Google Chrome
and Safari autofill the username and password values once a user visits a login webpage, providing
more opportunities for malicious JavaScript to manipulate the login form and information.
12
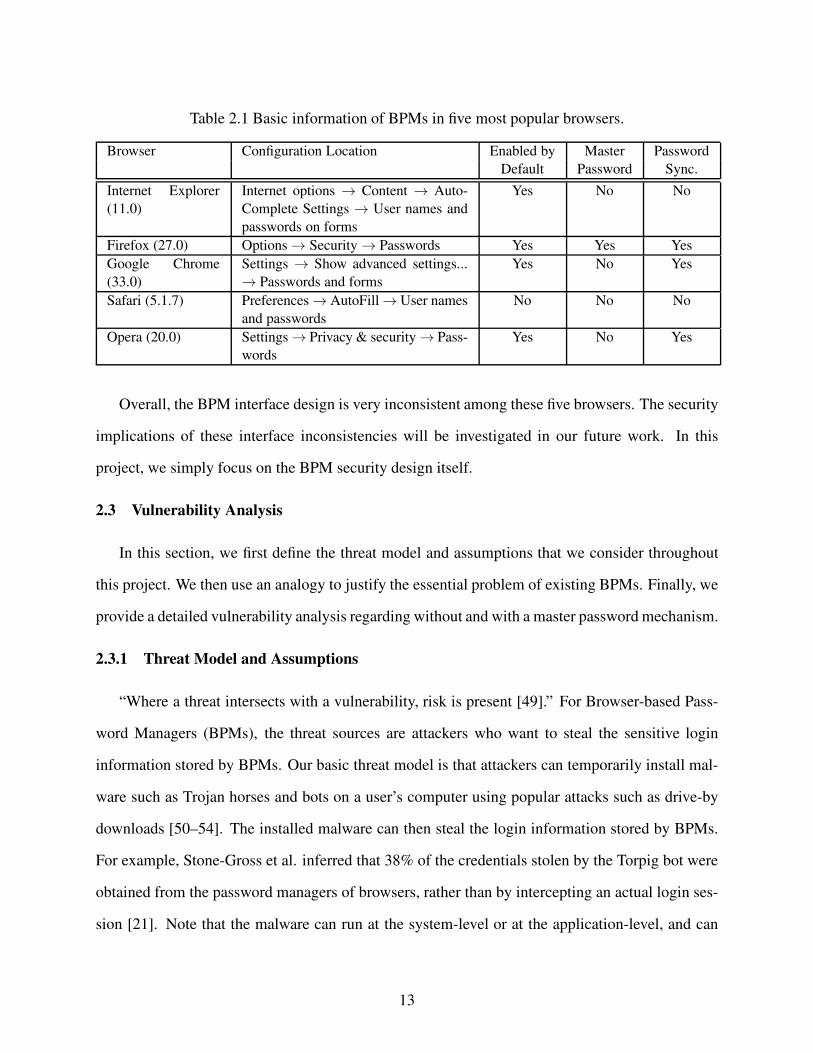
Table 2.1 Basic information of BPMs in five most popular browsers.
Browser Configuration Location Enabled by Master Password
Default Password Sync.
Internet Explorer
(11.0)
Internet options → Content → Auto-
Complete Settings → User names and
passwords on forms
Yes No No
Firefox (27.0) Options → Security → Passwords Yes Yes Yes
Google Chrome
(33.0)
Settings → Show advanced settings...
→ Passwords and forms
Yes No Yes
Safari (5.1.7) Preferences → AutoFill → User names
and passwords
No No No
Opera (20.0) Settings → Privacy & security → Pass-
words
Yes No Yes
Overall, the BPM interface design is very inconsistent among these five browsers. The security
implications of these interface inconsistencies will be investigated in our future work. In this
project, we simply focus on the BPM security design itself.
2.3 Vulnerability Analysis
In this section, we first define the threat model and assumptions that we consider throughout
this project. We then use an analogy to justify the essential problem of existing BPMs. Finally, we
provide a detailed vulnerability analysis regarding without and with a master password mechanism.
2.3.1 Threat Model and Assumptions
“Where a threat intersects with a vulnerability, risk is present [49].” For Browser-based Pass-
word Managers (BPMs), the threat sources are attackers who want to steal the sensitive login
information stored by BPMs. Our basic threat model is that attackers can temporarily install mal-
ware such as Trojan horses and bots on a user’s computer using popular attacks such as drive-by
downloads [50–54]. The installed malware can then steal the login information stored by BPMs.
For example, Stone-Gross et al. inferred that 38% of the credentials stolen by the Torpig bot were
obtained from the password managers of browsers, rather than by intercepting an actual login ses-
sion [21]. Note that the malware can run at the system-level or at the application-level, and can
13

even be malicious browser extensions [55]. Indeed, if the occurrences of such threats are rare or do
not have high impacts, BPMs would not bother to encrypt their stored passwords in the first place.
Therefore, our focus will be on investigating the vulnerabilities of BPMs that could be exploited
by potential threat sources to easily decrypt the passwords stored by BPMs.
We assume that it is very difficult for the installed malware to further compromise the oper-
ating system to directly identify cryptographic keys from a computer’s memory [56] because this
identification often requires elevated privilege and is prone to false positives. We assume that the
installed malware can be removed from the system by security-conscious users in a timely man-
ner, so that even though sensitive login information stored by BPMs can be stolen within a short
period of time, it is very difficult for attackers to use tools such as keyloggers to further intercept
users’ passwords for a long period of time. One typical example is that anti-malware programs
such as Microsoft Forefront Endpoint Protection may detect the infection, report the suspicious
file transmission, and finally remove the malware and infected files. Another typical example is
that solutions such as the Back to the Future framework [57] can restore the system to a prior good
state and preserve system integrity. The users can then have the opportunities to install security
patches and enforce stricter security policies on their systems. A similar assumption is also made
in other systems such as Google’s 2-step verification system [58].
We also assume that domain name systems are secure and reliable and we do not specifically
consider pharming attacks. This assumption is made in all the BPMs and we believe pharming and
other DNS attacks should be addressed by more general solutions. Similarly, we do not consider
other Web attacks such as cross-site scripting that can also steal sensitive login information because
those attacks have their own specific threat models and assumptions.
2.3.2 The Essential Problem and An Analogy
The essential problem is that the encrypted passwords stored by BPMs of the five most popular
browsers are very weakly protected in many situations. In our investigation, we found without
the protection of a master password mechanism, the encrypted passwords stored by the five BPMs
14

(Table 2.1) can be trivially decrypted by attackers for logging into victims’ accounts on the cor-
responding websites. We have developed tools and verified this severe vulnerability of the latest
versions (by March 2014 as shown in Table 2.1) of the five BPMs on Windows 7. This vulnerability
is common to all these browsers because the keys used by these browsers for encrypting/decrypt-
ing a user’s login information can be easily extracted or generated by attackers. The decrypted
login information can be easily sent out to attackers and the entire attack could be finished in one
second. In the cases when a master password is used by a user in Firefox (Table 2.1), the problem
is that even though decrypting a user’s login information becomes harder, brute force attacks and
phishing attacks against the master password are still quite possible. We believe that it is critical
for users to choose strong master passwords, and it is also critical for BPMs to properly use and
protect master passwords.
We term these problems as vulnerabilities because they are security design weaknesses of
existing BPMs that can be exploited by popular attacks such as drive-by downloads [50–54]; we
do not mean these existing BPMs do not work as they were designed.
A BPM is analogous to a safe, and a master password is analogous to the combination to the
safe. The current reality is that the “safe” of Google Chrome, Internet Explorer, and Safari does
not allow a user to set a “combination” at all. Our decryption tools can easily and accurately open
the “safe”. Firefox allows a user to set a “combination”, but does not make it mandatory. Our
decryption tools can also easily and accurately open the “safe” of Firefox if a “combination” was
not set. For example, using drive-by downloads, an attacker can deliver our decryption tools to a
user’s computer and trigger their execution. In one second, all the passwords and usernames saved
by BPMs can be completely decrypted and sent back to the attacker’s website or email account.
The malware detector installed on the user’s computer may report suspicious activities, and the
user may immediately take actions to disable the Internet connection. But it could be too late!
With a successful drive-by download, attackers can perform many types of malicious activities.
However, similar to burglars, if attackers know they can easily open the “safe”, they would like to
first steal the most valuable items from the “safe” within a short period of time.
15

2.3.3 Without a Master Password Mechanism
Through source code analysis, binary file analysis, and experiments, we found that Firefox uses
the three-key Triple-DES algorithm to encrypt a user’s passwords for different websites. Firefox
saves each encrypted username, encrypted password, and plaintext login webpage URL address
into the login table of an SQLite [59] database file named signons.sqlite. The Triple-DES keys are
generated once by Firefox and then saved into a binary file named key3.db starting from the byte
offset location 0x2F90. Although the keys generated on different computers are different, they
are not bound to a particular computer or protected by other mechanisms. Therefore, as verified
by our tools, an attacker can simply steal both the signons.sqlite file and the key3.db file and then
accurately decrypt every username and password pair on any computer.
In their latest Window 7 versions, all the other four browsers Internet Explorer, Google Chrome,
Safari, and Opera use the Windows API functions CryptProtectData [60] and CryptUnprotect-
Data [61] to perform encryption and decryption, respectively. The key benefit of using these two
functions is that “typically, only a user with the same logon credential as the user who encrypted
the data can decrypt the data [60].” To use these two API functions, an application (e.g., a browser)
does not generate or provide encryption/decryption keys because the symmetric keys will be de-
terministically generated in these two functions based (by default) on the profile of the current
Windows user. An application can use the dwFlags input parameter to specify that the keys should
be simply associated with the current computer; it can also use the pOptionalEntropy input param-
eter to provide additional entropy to the two functions.
We found Google Chrome saves each plaintext username, encrypted password, and plaintext
login webpage URL address into the logins table of an SQLite [59] database file named Login
Data. Google Chrome does not provide additional entropy to the two API functions. Opera (ver-
sion 20.0) uses the identical mechanism as that of Google Chrome, although its early versions such
as version 12.02 used a different mechanism [48]. Safari saves each plaintext username, encrypted
password, and plaintext login webpage URL address into a special property list file named key-
chain.plist. Safari provides a static 144-byte salt as the additional entropy to the two API functions.
16

Internet Explorer encrypts each username and password pair and saves the ciphertext as a value
data under the Windows registry entry: “HKEY CURRENT USER\Software\Microsoft\Internet
Explorer\IntelliForms\Storage2\”. Each saved value data can be indexed by a value name, which
is calculated by hashing the login webpage URL address. Internet Explorer also provides the login
webpage URL address as the additional entropy to the two API functions.
We found all these four browsers set the dwFlags input parameter value as the default value
zero, which means that the symmetric keys are associated with each individual Windows 7 user.
Therefore, it is not very easy for attackers to decrypt the stolen ciphertexts on another computer or
using another Windows account. However, attackers who can steal the ciphertexts (for example,
using bots [21] or Trojan horses) can simply decrypt the ciphertexts on the victim’s machine when
the victim is logged into the Windows; then, the decrypted login information can be directly sent
back to attackers. We have developed tools that can decrypt the ciphertexts stored by all these four
browsers. In more details, for Google Chrome, our tool selects each record from the logins table
of the Login Data SQLite database, converts the encrypted password from the SQLite BLOB [59]
type to a string type, and supplies the encrypted password to the CryptUnprotectData [61] func-
tion. The decryption tool for Opera version 20.0 is identical to that for Google Chrome, and
we also have the decryption tool for Opera version 12.02 [48]. For Safari, our tool converts the
keychain.plist property list file to an XML document, parses the XML document to obtain each
encrypted password, and supplies the encrypted password and that static 144-byte salt to the Cryp-
tUnprotectData function. For Internet Explorer, our tool hashes the popular login webpage URL
addresses contained in a dictionary, queries the Windows registry using each hashed URL address
to identify a matched value name, and supplies the associated value data and the corresponding
login webpage URL address (as the additional entropy) to the CryptUnprotectData function.
2.3.4 With a Master Password Mechanism
The BPM of Firefox allows a user to set a master password (Table 2.1) to further protect the
encryption keys or encrypted passwords. In Firefox, the master password and a global 160-bit
17

salt will be hashed using a SHA-1 algorithm to generate a master key. This master key is used to
encrypt those three Triple-DES keys before saving them to the key3.db file. Firefox also uses this
master key to encrypt a hard-coded string “password-check” and saves the ciphertext to the key3.db
file; later, Firefox will decrypt this ciphertext to authenticate a user before further decrypting the
three Triple-DES keys.
Using a master password can better protect the stored passwords in Firefox. However, a master
password mechanism should be carefully designed to maximize security. One main security con-
cern is the brute force attacks against the master password. For one example, if the computation
time for verifying a master password is very small as in Firefox (which rejects an invalid master
password in one millisecond), it is still possible to effectively perform brute force attacks against a
user’s master password. For another example, encrypting the hard-coded “password-check” string
in Firefox for user authentication does not increase security and may actually decrease security
in the case when both the signons.sqlite file and the key3.db file (containing the 160-bit salt) are
stolen. Although decrypting the Triple-DES keys is still very difficult if the master password is
unknown, an attacker can simply bypass this user authentication step using an instrumented Fire-
fox. Moreover, this hard-coded plaintext and its ciphertext encrypted by the master key can also be
used by an attacker to verify the correctness of dictionary or brute-force attacks against the master
password.
Another main security concern is the phishing attacks against the master password. Fig-
ure 2.1(a) illustrates the genuine master password entry dialog box in Firefox, which will be dis-
played to a user for the first autofill operation in a browsing session. Figure 2.1(b) illustrates
one fake master password entry dialog box created by the JavaScript prompt() function. Such a
fake dialog box can be displayed by any regular webpage on all the five browsers without being
blocked by browsers’ “block pop-up windows” options because it is not a separate HTML doc-
ument window. We speculate that even such a simple spoofing technique can effectively obtain
master passwords from vulnerable users. Indeed, a regular webpage can also use JavaScript and
CSS (Cascading Style Sheets) to create sophisticated dialog boxes that are more similar to a gen-
18

(a)
(b)
Figure 2.1 The (a) genuine and (b) fake master password entry dialog box in Firefox.
uine master password entry dialog box. Such attacks are similar to the Web-based spoofing attacks
on OS password-entry dialogs illustrated by Bravo-Lillo et al. [62] and the Web single sign-on
phishing attacks illustrated by Yue [46]. Overall, our position is that a BPM should not use these
types of easy-to-spoof master password entry dialog boxes at all, and should not frequently ask a
user to enter the master password in a single browsing session.
2.4 CSF-BPM Design
We now present the design of the Cloud-based Storage-Free BPM (CSF-BPM). It is cloud-
based storage-free in the sense that the protected data will be completely stored in the cloud –
nothing needs to be stored on a user’s computer. We want to move the storage into the cloud for
two key reasons. One is that in the long run trustworthy storage services in the cloud [22–27] can
better protect a regular user’s data than local computers (which may not be timely and properly
patched) do, especially if a storage service uses secret sharing schemes such as the (k, n) threshold
scheme [28] to only save pieces of the encrypted data to different cloud vendors [22]. The other
reason is that the stored data can be easily accessible to the user across different OS accounts on
the same computer and across computers at different locations at anytime. This design differs from
19

the BPM designs of all the five most popular browsers. Based on the threat model and assumptions
defined in the last section, we design CSF-BPM to synthesize the desired security properties such
as confidentiality, integrity, and availability.
2.4.1 High-level Architecture
Figure 2.2 illustrates the high-level architecture of CSF-BPM. The BPM of the browser simply
consists of a User Interface (UI) component, a Record Management (RM) component, a Record
Generation (RG) component, a Record Decryption (RD) component, and a record synchronization
(Sync) component. The UI component will provide configuration and management interfaces ac-
cessible at a single location. The BPM itself does not include any persistent storage component
such as a file or database; instead, it will generate Encrypted Login Information Records (ELIRs),
save protected ELIRs to a Secure and Reliable Storage (SRS) service in the cloud, and retrieve
protected ELIRs in real-time whenever needed. Such a generic BPM design can be seamlessly
integrated into different browsers.
An SRS service simply needs to support user authentication (e.g., over HTTPS) and per-user
storage so that its deployment in the cloud can be easily achieved. For example, the synchroniza-
tion service associated with Firefox or Google Chrome (Table 2.1) could be directly used as an
SRS service without making any modification. The SRS service will store a Per-User Protected
ELIRs (PUPE) data object (to be illustrated in Figure 2.4) for each SRS user. The communication
protocol between the BPM and SRS is also very simple: after a user is authenticated to SRS, the
Sync component of BPM will transparently send HTTPS requests to SRS to retrieve or save the
protected ELIRs of the user. An SRS service should be highly reliable and available. However,
to further increase reliability and availability, the BPM can store protected ELIRs to multiple in-
dependent SRS services. One of them is used as the primary SRS service; others will be used as
secondary SRS services. The Sync component of BPM will transparently synchronize protected
ELIRs from the primary SRS service to secondary SRS services.
20

Figure 2.2 High-level architecture of the Cloud-based Storage-Free BPM (CSF-BPM).
2.4.2 Design Details
To use CSF-BPM, a user needs to remember a Single Strong Master Password (SSMP) with
the strength [63, 64] assured by the traditional proactive password checking techniques and certain
length requirements [65–67], or by the latest reactive proscriptive intervention techniques [68].
Using a master password is also advocated in other proposed systems such as Nigori [69]. The
user also needs to set up an account (srsUsername, srsPassword) on an SRS service and configure
this service once through the UI component of BPM. At the beginning of each browsing session,
the user needs to authenticate to the SRS service and provide the SSMP to BPM. After that, BPM
will take care of everything else such as triggering the remembering of website passwords, en-
crypting and decrypting ELIRs, and triggering the autofill of passwords. Both the srsUsername
and srsPassword pair and SSMP need be provided only once in a session through the special UI
component of BPM. This requirement adds some burden to users in exchange of the increased se-
curity. This special UI component is integrated into the configuration UI of Firefox, thus cannot be
easily spoofed by JavaScript (e.g., using the prompt() function) on regular webpages. Meanwhile,
CSF-BPM can detect and require that the SSMP to be different from the srsPassword and any web-
site password. These design choices could be helpful in protecting SSMP against phishing attacks.
Note that if multiple SRS services are used, providing the srsUsername and srsPassword for each
SRS service atthe beginning of each session may be unwieldy; we will investigate the potential of
21

Figure 2.3 The basic format of an ELIR record.
using password hashing techniques [39–41] to address this issue in the future.
The basic format of an ELIR record is shown in Figure 2.3. Here, recordSalt is a large and
sufficiently random per-record salt generated by BPM. It is used to calculate the symmetric record
key (denoted recordKey) for encrypting a user’s plaintext password (denoted sitePassword) for an
account (denoted siteUsername) on a website (with siteURL as the login webpage URL address).
The recordKey can be deterministically generated by using a password-based key derivation func-
tion such as PBKDF2 specified in the PKCS5 specification version 2.0 [70]. The basic format of
an ELIR record can also include the IDs (or names) of the username and password fields in the
login webpage, and it can be further extended if necessary.
Using PBKDF2 [70], our SSMP-based key derivation and password encryption process con-
sists of five steps illustrated in Formulas 2.1, 2.2, 2.3, 2.4, and 2.5. The input parameters mainSalt
and aeSalt in Formulas 2.1 and 2.2 are large and sufficiently random per-user salts generated by
BPM at the first time when a user authenticates to the SRS service through the UI component of
BPM. In Formulas 2.1, 2.2, and 2.3, the input parameters c1, c2, and c3 represent iteration counts
for key stretching; the input parameters dkLen1, dkLen2, and dkLen3 represent lengths of the de-
rived keys, and they are related to the underlying pseudorandom function used in the PBKDF2
implementation.
mainKey= PBKDF2(SSMP,mainSalt, c1, dkLen1) (2.1)
aeKey= PBKDF2(mainKey, aeSalt, c2, dkLen2) (2.2)
recordKey = PBKDF2(mainKey, recordSalt, c3, dkLen3) (2.3)
22

Figure 2.4 The Per-User Protected ELIRs (PUPE) data object saved for each SRS user.
encryptedSitePassword=E(recordKey, sitePassword) (2.4)
protectedELIRs=AE(aeKey, concatenatedELIRs) (2.5)
The salts and iteration counts in PBKDF2 are used to secure against dictionary and brute-force
attacks, and they need not be kept secret [70]. The strength of SSMP also helps secure against these
two types of attacks. In Formula 2.1, a mainKey is calculated and will be used in each browsing
session. SSMP is typed only once and will be erased from memory after mainKey is calculated. In
Formula 2.3, a unique recordKey is generated (using the per-record recordSalt) for each website
account of the user. In Formula 2.4, a NIST-approved symmetric encryption algorithm E such as
AES [71] (together with a block cipher mode of operation if the sitePassword is long) can be used
to encrypt the sitePassword. In Formula 2.5, a NIST-approved Authenticated Encryption block
cipher mode AE such as CCM (Counter with CBC-MAC) [72] can be used to simultaneously
protect confidentiality and authenticity (integrity) of the concatenatedELIRs of an SRS user. The
aeKey used here is generated by Formula 2.2.
The iteration count c1 used in Formula 2.1 should be large so that the mainKey calculation will
take a few seconds; therefore, brute force attacks against SSMP become computationally infeasi-
ble. But c1 should not be too large to make a user wait for a long period of time at the beginning
of a session. Iteration counts c2 and c3 should not be too large so that generating aeKey and
recordKey would not cause a user to perceive any delay. The mainKey is kept in memory in the
23

whole browsing session. Identifying a single key in the memory is more difficult than identifying
a block of key materials with structural information [56]. Therefore, the aeKey and recordKey are
scrubbed immediately after use so that less structural information (i.e., the keys and the related
website information) will be left in the memory for attackers to exploit. Although Formula 2.5
will simultaneously protect confidentiality and authenticity (integrity) of the concatenatedELIRs
of an SRS user, encrypting each sitePassword in Formula 2.4 is still important. This is because
the concatenatedELIRs is also kept in memory in the whole browsing session. In comparison with
the mainKey which is basically a random-looking value, the structure of ELIR records and con-
catenatedELIRs can be easily identified from memory. Therefore, assuming an attacker cannot
easily identify the mainKey but can easily identify ELIR records (which contain structural infor-
mation) from memory, it is still computationally infeasible for the attacker to crack each individual
recordKey and decrypt the corresponding sitePassword.
Overall, all the computations including salt generation, key derivation, encryption, and decryp-
tion etc. are performed on BPM. Neither the SSMP nor any derived cryptographic key will be
revealed to an SRS service or a third party. An SRS service does not need to provide any special
computational support to BPM; it simply needs to save a PUPE data object for each SRS user.
As illustrated in Figure 2.4, each PUPE object contains the protectedELIRs (Formula 2.5) of
an SRS user and all the algorithm related information. Here, PBKDF-id specifies the identifier
for the PBKDF2 key derivation function [70]; PBKDF-params specify the PBKDF2 parameters
such as c1, c2, c3, dkLen1, dkLen2, and dkLen3 used in Formulas 2.1, 2.2, and 2.3. E-id and E-
params specify the identifier and parameters, respectively, for the symmetric encryption algorithm
(and the mode of operation) used in Formula 2.4. AE-id and AE-params specify the identifier and
parameters, respectively, for the authenticated encryption block cipher mode used in Formula 2.5.
For example, if AE-id specifies the CCM authenticated encryption block cipher mode [72], then
AE-params will contain the Nonce and the Associated Data input parameters used by CCM. Each
PUPE data object can be simply saved as a binary or encoded string object for an SRS user because
its structure does not need to be known or taken care of by any SRS service. Such a PUPE data
24

object design makes the selection of algorithms and the selection of SRS services very flexible.
The iteration counts c1, c2, and c3 can be flexibility adjusted by BPM with or without user
intervention to maximize security while minimizing inconvenience to users [73]. In our current
design, CSF-BPM adaptively computes the maximum values of iteration counts based on the spec-
ified computation times for Formulas 2.1, 2.2, and 2.3, respectively. For example, if a 10-second
computation time is specified for deriving the mainKey, CSF-BPM will run Formula 2.1 for 10
seconds to derive the mainKey and meanwhile finalize the corresponding c1 value. Such a scheme
allows CSF-BPM to easily maximize the security strength of key derivation within a specified
delay limit on each individual computer.
To decrypt the saved website passwords for autofill, BPM will perform five steps: (1) retrieve
the PUPE data object saved for the SRS user; (2) generate the mainKey and aeKey using Formu-
las 2.1 and 2.2; (3) decrypt and verify the protectedELIRs using the reverse process of Formula 2.5
such as the CCM Decryption-Verification process [72]; (4) obtain the recordSalt of each ELIR and
generate the recordKey using Formula 2.3; (5) finally, decrypt the encryptedSitePassword using
the reverse process of Formula 2.4. Note that at step (3), both the integrity of the protectedELIRs
and the authenticity of the BPM user are verified because the success of this step relies on using
the correct SSMP. Also at this step, siteURL and siteUsername of all the ELIRs can be obtained by
BPM to determine whether this user has previously saved login information for the currently vis-
ited website. Normally, the first three steps will be performed once for the entire browsing session,
and the last two steps will be performed once for each website that is either currently visited by the
user, or its domain name is queried by the user to simply look up the corresponding username and
password. In comparison with the password manager of Firefox, CSF-BPM uses the steps (2) and
(3) to ensure a much stronger confidentiality and integrity guarantee, even if attackers can steal the
retrieved PUPE object.
Because all the salts are randomly generated by BPM, the protectedELIRs saved to different
SRS accounts or different SRS services will be different. BPM can transparently change mainSalt,
aeSalt, and every recordSalt whenever necessary. A user also has the flexibility to change SSMP
25

and any sitePassword whenever necessary. In these cases, all what need to be done by BPM is to
update the new PUPE data object and ELIRs to each corresponding SRS service account. A user
can also flexibly change any srsPassword, which is completely independent of SSMP.
2.4.3 Design Rationales and Security Analysis
We now further justify the important design rationales of CSF-BPM by focusing on analyzing
its confidentiality, integrity, and availability security properties, and by comparing its design with
other design alternatives.
In terms of the confidentiality, first, by having a unique cloud-based storage-free architecture,
CSF-BPM can in the long run effectively reduce the opportunities for attackers to steal and further
crack regular users’ saved website passwords. Second, even if attackers (including insiders of an
SRS service) can steal the saved data, it is computationally infeasible for attackers to decrypt the
stolen data to obtain users’ login information for different websites. CSF-BPM provides this se-
curity guarantee by mandating a strong SSMP that satisfies certain strength requirements [65–67],
by using the PBKDF2 key derivation function [70] with randomly generated salts and adaptively
computed large iteration counts, and by following NIST-approved symmetric encryption [71] and
authenticated encryption [72] algorithms. Basically, even if attackers can steal the saved data, they
have to guess (albeit stealing attacks are still possible as discussed in Section 2.7) a user’s strong
SSMP in a very large space determined mainly by the length and character set requirements of
SSMP with each try taking seconds of computation time.
We can estimate the effort of brute force attacks based on the computational power exemplified
in a very popular cryptography textbook [74] authored by William Stallings. In the Table 2.2
(chapter 2, page 38, and 5th edition) of this textbook, a high performance system takes 10−12
second to perform a basic cryptographic operation such as an encryption, decryption, or SHA-
1/SHA-2 [75] hash operation. If each master password character can be an upper case letter, a
lower case letter, or a decimal digit, then it could be one of the 62 (26+26+10) possibilities. The
search space for an 8-character master password will be 628. Therefore, it will take at most 1.8
26

minutes for that high performance system to successfully perform a brute force attack against a
user’s 8-character master password used in Firefox. However, with the c1 value as 300,000, CSF-
BPM increases the brute force effort to 300,000 times of 1.8 minutes, that is about one year for
the same high performance system. In 10 seconds, a C++ version PBKDF2 implementation can
further increase the c1 value and increase the security.
In terms of the integrity, the NIST-approved CCM authenticated encryption algorithm [72]
enables CSF-BPM to accurately detect both any invalid SSMP try and any modification to a saved
PUPE data object. Moreover, this detection is securely performed in the sense that attackers cannot
take advantage of it to effectively conduct brute force attacks against the SSMP.
In terms of the availability, an SRS simply needs to be a storage service in the cloud and it does
not need to provide any special computational support. Such a design decision makes it very easy
to either use an existing storage service in the cloud as an SRS service or deploy a new SRS service
by an organization. CSF-BPM supports multiple SRS services and it uses a simple HTTPS-based
communication protocol; these design decisions also further enhance the availability.
CSF-BPM offers a better security in comparison with the BPM of Firefox that also provides
a master password mechanism. Firefox saves the encrypted data locally on a user’s computer and
does not use strong key derivation functions (Section 2.3.4); thus, its confidentiality assurance is
weak in consideration of brute force attacks. Firefox can detect an invalid master password try, but
the detection mechanism is not secure (Section 2.3.4). Firefox does not detect any modification to
the saved data; the modified data will still be decrypted into incorrect and often non-displayable
values, but no information is provided to a user. In addition, the synchronization mechanism of
Firefox is tightly bound to Mozilla’s own server [76]; thus, the availability of the saved data is not
well assured by the BPM.
Other cloud-based password system design alternatives also exist, but they often have different
design objectives and limitations. For one example, Passpet [41] can help a user generate pass-
words for different websites based on a master password. Similar to Password Multiplier [39],
Passpet is essentially a password generator instead of a password manager because it uses pass-
27

word hashing techniques to deterministically generate website passwords instead of remembering
users’ original passwords. Requiring users to migrate their original passwords to hashed pass-
words is a biggest limitation of hashing-based password generation solutions as acknowledged in
the Password Multiplier project [39]. In addition, Passpet imposes very special requirements on
its remote storage server: the SRP authentication protocol [77] must be used and some specific
commands must be supported. These requirements limit the deployability of Passpet. For another
example, LastPass [42] and RoboForm [31] are two very popular cloud-based BPMs. However,
both of them have severe security flaws such as very vulnerable to insider attacks, local decryption
attacks, and brute-force attacks; we refer readers to our recent paper [43] for the details.
2.5 Implementation
CSF-BPM is designed to be implementable in different Web browsers and to be able to easily
use different SRS services. In this section, we briefly describe some important details of our
Firefox version CSF-BPM implementation; we hope these details can be helpful for others to
integrate CSF-BPM into more browsers.
We have implemented a CSF-BPM system and seamlessly integrated it into the Firefox Web
browser. This system can directly use the Firefox Sync server operated by Mozilla [76] as an
SRS service without making any modification to this server; thus, a free of charge SRS service
is directly available to users. It is important to note that in our implementation, the interfaces for
triggering the remembering and autofill of passwords in Firefox (Section 2.2.2) are not changed;
only the operations happening behind the scenes are changed.
Figure 2.5 illustrates more details about our Firefox implementation of CSF-BPM. We mainly
implemented two new modules in Firefox: an In-memory Record Management Service (ImRMS)
and a Key Management Service (KMS). Both modules are implemented as JavaScript version XP-
COM (Cross-Platform Component Object Model) [78] components and run as services in Firefox.
ImRMS is responsible for generating the PUPE object, uploading or retrieving the PUPE object,
and maintaining all the ELIR records. In essence, ImRMS replaced the original persistent password
28

storage of Firefox (Section 2.3) with an in-memory ELIR array and its corresponding add/delete/-
modify/search interface. KMS is responsible for generating salts, deriving keys, and preparing for
other parameters used in Formulas 2.1, 2.2, 2.3, 2.4, and 2.5. In our current implementation, all the
salts are 128-bit random numbers, and the default length of all those keys is also 128-bit. However,
we can easily change the default length to 256-bit for all the salts and keys. Currently, we used
the PBKDF2 [70], CCM [72], and AES [71] implementations provided in the Stanford JavaScript
Crypto Library [79].
Figure 2.5 Detailed implementation of CSF-BPM in Firefox.
In addition to implementing ImRMS and KMS, we also made some important modifications
to the Sync module in Firefox. In the original Sync module, a 26-character recovery key will be
generated when a user creates a Sync account. This recovery key is not shared with the Firefox
Sync server, and it is mainly used to protect other cryptographic keys that are stored on the Firefox
Sync server for a user. A user must save this recovery key and provide it to Firefox on different
computers together with the Sync account username and password whenever the Sync mechanism
needs to be used. This requirement limits the usability of the Sync mechanism; meanwhile, the
recovery key is not needed at all in the CSF-BPM design. Therefore, in our implementation, one
main modification to the Sync module is removing the dependence of using Firefox Sync server
on recovery key for the password manager feature. As a result, a user does not need to save and
provide the recovery key at all if he or she uses CSF-BPM and uses the Firefox Sync server as
the SRS service. The other main modification is that we use a Weave Basic Object (WBO) [76]
29

assigned to the default Mozilla passwords collection to store the PUPE object in the Firefox Sync
server. Both modifications are specific to using the Firefox Sync server as the SRS service.
2.6 Evaluation
We built the Firefox version CSF-BPM on a Ubuntu Linux system. We tested the correctness
of our implementation and its integration with the Firefox Web browser, we intensively evaluated
its performance, and we also evaluated its usability through a user study.
2.6.1 Correctness
We selected 30 websites as listed in Table 2.2 to perform the correctness verification. Most of
the websites were selected from the top 50 websites listed by Alexa.com; however, we removed
non-English websites, gray content websites, and the websites that did not allow us to create an
account. We also selected some of our frequently used websites.
Table 2.2 The 30 websites.
mail.google.com facebook.com mail.yahoo.com
wikipedia.com twitter.com amazon.com
linkedin.com wordpress.com ebay.com
fc2.com craigslist.org imdb.org
aol.com digg.com careerbuilder.com
buy.com aaa.com newegg.com
tumblr.com alibaba.com 4shared.com
cnn.com nytimes.com foxnews.com
weather.com groupon.com photobucket.com
myspace.com webmail.uccs.edu portal.prod.uccs.edu
On each website, we went through four main steps. First, we opened Firefox and typed an
SRS account (i.e., a Firefox Sync account) and SSMP. Second, we logged into the website and
confirmed to save the website password. Third, we logged out the website and logged into it
again with the auto-filled password. Finally, we closed Firefox, re-opened Firefox, typed the SRS
account and SSMP, and logged into the website again with the auto-filled password.
Through the execution of those steps, we verified that our implementation works precisely as
designed; meanwhile, it integrates smoothly with Firefox and does not cause any logic or runtime
30

error. In more details, we observed that CSF-BPM can correctly save and auto-fill passwords on all
those websites. It also works correctly in the situation when two or more accounts on a website are
used. In addition, it does not affect the functionality of other features in Firefox such as the form
autocomplete feature and the Sync feature. We also verified that nothing is saved to the original
persistent password storage of Firefox.
We have two other observations in our experiments. One is that some other websites share the
same siteURL (i.e., the login webpage URL) values with the websites listed in Table 2.2. For ex-
ample, youtube.com and mail.google.com share the same siteURL, flickr.com and mail.yahoo.com
share the same siteURL, and msn.com and live.com share the same siteURL. The evaluation re-
sults are correct on those websites for both CSF-BPM and the original Firefox BPM. The other
observation is that some other websites such as paypal.com and wellsfargo.com set the autocom-
plete=“off” property on their password fields or login forms; therefore, passwords will not be
saved at all by BPMs including our CSF-BPM.
2.6.2 Performance
We performed both micro-benchmark experiments and macro-benchmark experiments to eval-
uate the performance of CSF-BPM. In these experiments, we ran CSF-BPM on a desktop computer
with 2.33GHz CPU, 3.2 GB memory, and 100Mbps network card. All the experiments were re-
peated 5 times and we present the average results.
2.6.2.1 Micro-benchmark Experiments
In micro-benchmark experiments, we ran CSF-BPM using scripts to evaluate the following
four aspects of performance.
(a) Key derivation: We mentioned in Section 2.4 that CSF-BPM adaptively computes the max-
imum values of the iteration counts c1, c2, and c3 based on the specified computation times for
Formulas 2.1, 2.2, and 2.3, respectively. Those three formulas have the same performance because
in our implementation they use the same PBKDF2 [70] algorithm, same salt length, and same key
length. The performance impact of different SSMP lengths in Formula 2.1 is negligible because the
31

intermediate values will have the same length as the key length after the first iteration. Therefore,
in our experiments, we simply increased the computation time of the PBKDF2 algorithm from one
second to 20 seconds to calculate the iteration count values.
Overall, the iteration count values increase linearly with the increasing of the computation
time. The larger the iteration counts, the more secure the derived keys [70]. As suggested in RFC
2898 [70] in year 2000, “A modest number of iterations, say 1000, is not likely to be a burden
for legitimate parties when computing a key, but will be a significant burden for opponents.” This
suggested number should definitely be increased with the increasing computing powers of potential
attackers [73, 80]. Currently, CSF-BPM uses 10 seconds, one second, and one second as the default
times for adaptively computing iteration counts c1, c2, and c3, respectively. Correspondingly, the
value of c1 is around 300,000 and the values of c2 and c3 are around 30,000 on our test computer.
We chose 10 seconds as the default computation time of c1 to impose a significant SSMP guessing
burden on attackers. Asking a user to wait for 10 seconds once at the beginning of a browsing
session is still acceptable as shown in our user study in Section 2.6.3, but this waiting time should
not be too long taking the usability in consideration [10, 81].
(b) Password encryption and decryption: This performance refers to Formula 2.4 and its reverse
process. In our experiments, we observed that the JavaScript implementation of AES [71] provided
in the Stanford JavaScript Crypto Library [79] can consistently encrypt and decrypt one 16-byte
block within one millisecond (ms).
(c) concatenatedELIRs encryption and decryption: This performance refers to Formula 2.5 and
its reverse process, more specifically, the CCM Authentication-Encryption process and its reverse
Decryption-Verification process [72]. In our experiments, we varied the total number of randomly
generated ELIR records (Figure 2.3) from one to 400. We observed that both the size of concate-
natedELIRs and the size of PUPE increase linearly with the increasing of the number of ELIRs.
The size of PUPE for 400 records is 107KB, which is much smaller than the size (448KB) of
the physical SQLite database file (signons.sqlite) in Firefox for 400 records. We observed that
the CCM Authentication-Encryption process and the CCM Decryption-Verification process can
32
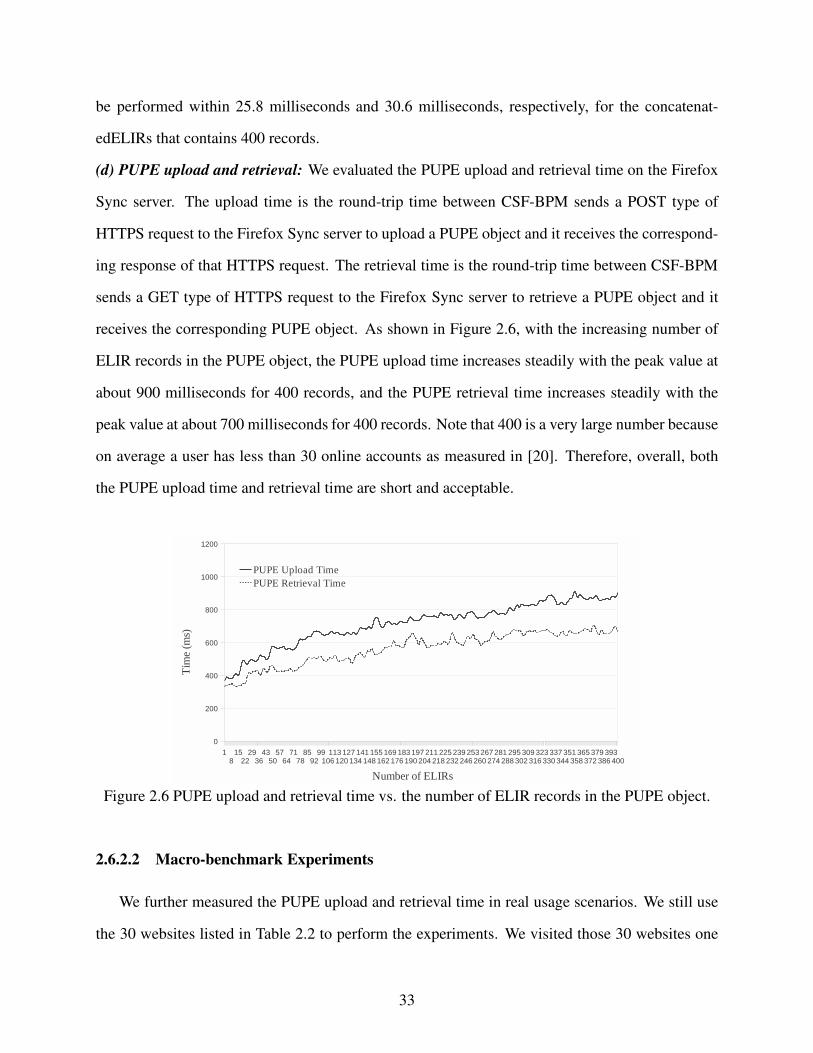
be performed within 25.8 milliseconds and 30.6 milliseconds, respectively, for the concatenat-
edELIRs that contains 400 records.
(d) PUPE upload and retrieval: We evaluated the PUPE upload and retrieval time on the Firefox
Sync server. The upload time is the round-trip time between CSF-BPM sends a POST type of
HTTPS request to the Firefox Sync server to upload a PUPE object and it receives the correspond-
ing response of that HTTPS request. The retrieval time is the round-trip time between CSF-BPM
sends a GET type of HTTPS request to the Firefox Sync server to retrieve a PUPE object and it
receives the corresponding PUPE object. As shown in Figure 2.6, with the increasing number of
ELIR records in the PUPE object, the PUPE upload time increases steadily with the peak value at
about 900 milliseconds for 400 records, and the PUPE retrieval time increases steadily with the
peak value at about 700 milliseconds for 400 records. Note that 400 is a very large number because
on average a user has less than 30 online accounts as measured in [20]. Therefore, overall, both
the PUPE upload time and retrieval time are short and acceptable.
Figure 2.6 PUPE upload and retrieval time vs. the number of ELIR records in the PUPE object.
2.6.2.2 Macro-benchmark Experiments
We further measured the PUPE upload and retrieval time in real usage scenarios. We still use
the 30 websites listed in Table 2.2 to perform the experiments. We visited those 30 websites one
33

by one to let CSF-BPM incrementally record website passwords. The results show that the PUPE
upload time is less than 330 milliseconds in all the cases, and the PUPE retrieval time also stays
around 200 milliseconds. In each Web browsing session, the PUPE retrieval operation is performed
only once, and the PUPE upload operation is performed only when the PUPE object is created or
updated. Therefore, these performance results in the realistic usage scenarios further demonstrate
that CSF-BPM can efficiently use the Firefox Sync server as an SRS service. Indeed, we did not
observe any noticeable delay in this set of macro-benchmark experiments.
2.6.3 Usability
To evaluate the usability of the Firefox version CSF-BPM, we conducted a user study. To be
fair, we compared the usability between our Firefox version CSF-BPM and the original password
manager of Firefox that uses both the master password and the Sync mechanism. We mainly
measured whether there are statistically significant usability differences between using our Firefox
version CSF-BPM and using the original password manager of Firefox. This user study was pre-
approved by the IRB (Institutional Review Board) of our university.
2.6.3.1 Participants
Thirty adults, 15 females and 15 males, participated in our user study. They were voluntary
students (9), faculty members (1), staff members(3), and general public members (17) randomly
recruited on our campus library, bookstore, and cafeteria, etc.; they came from 14 different majors.
Eighteen participants were between ages of 18 and 30, and twelve participants were over 30 years
old; we did not further ask their detailed ages. All the participants claimed that they use computers
and Web browsers daily, and five of them claimed that they use the password manager of Firefox,
Google Chrome, or Opera to manage their online passwords. We did not collect any other demo-
graphic or sensitive information from participants. We did not screen participants based on any of
their Web browsing experience. We did not provide monetary compensation to the participants.
34

2.6.3.2 Scenario and Procedure
On a Ubuntu Linux system, we installed an original Firefox as Firefox-A, and installed another
Firefox with our CSF-BPM as Firefox-B. To have a fair comparison, we only told participants that
there are two different password managers in two Firefox browsers (Firefox-A and Firefox-B), but
we did not tell them which one is the original Firefox and which one is ours.
We asked each participant to perform two procedures: Procedure-A and Procedure-B. In Procedure-
A, a participant uses Firefox-A to first perform an Initial Visit scenario on one computer to let the
password manager of Firefox remember the accounts of three testing websites (mail.yahoo.com,
www.amazon.com, and www.facebook.com), and then perform a Revisit scenario on another com-
puter (i.e., using CSF-BPM on a new computer) to let the password manager automatically fill the
login forms on the three visited testing websites. In Procedure-B, a participant uses Firefox-B to
perform a similar Initial Visit scenario and a Revisit scenario, but the password manager is CSF-
BPM. The detailed tasks in these two procedures are listed in Table 2.3 and Table 2.4, respectively.
Table 2.3 Tasks in Procedure-A using Firefox-A.
The Initial Visit Scenario:
A1: Open Firefox
A2: Go to the “Sync” tab, supply the testing Sync account and the recovery key
A3: Visit and log into mail.yahoo.com, www.amazon.com, and www.facebook.com, respectively
A4: Supply the testing master password once and let the password manager remember the accounts of the
three testing websites
A5: Close Firefox
The Revisit Scenario:
A6: Repeat Tasks A1 to A2
A7: Revisit the three testing websites, supply the testing master password once, and log into the three
websites after the password manager automatically fill the corresponding login forms
A8: Close Firefox
We provided these tasks to the participants for them to perform the two procedures. Before
they perform the procedures, we also explained the main differences between the tasks in these two
procedures. For example, we mentioned that the password manager in Firefox-A uses a recovery
key and a master password to ensure the security; a user needs to supply the recovery key when
the Sync mechanism is used and needs to supply the master password at least once in a browsing
35

Table 2.4 Tasks in Procedure-B using Firefox-B.
The Initial Visit Scenario:
B1: Open Firefox
B2: Go to the “Security” tab, supply the testing Sync account
B3: On the same tab, supply the testing master password and wait for 10 seconds until the dialog box
indicates a completion status
B4: Visit and log into mail.yahoo.com, www.amazon.com, and www.facebook.com, respectively
B5: Let the password manager remember the login accounts of the three testing websites
B6: Close Firefox
The Revisit Scenario:
B7: Repeat Steps B1 to B3
B8: Revisit the three testing websites and log into the three websites after the password manager automati-
cally fill the corresponding login forms
B9: Close Firefox
session. In contrast, the password manager in Firefox-B only uses a master password to ensure the
security; it does not use a recovery key, but requires a user to wait for 10 seconds after supplying
the master password once at the beginning of a browsing session. We also answered participants’
questions on the usage of the two password managers.
We created the accounts of the three testing websites and the Firefox testing Sync account, so
that there is no risk to the personal information or accounts of any participant. We also created the
testing master password that is used in both procedures. To mitigate potential response bias, we
randomly assigned one half of the participants to first perform Procedure-A and then Procedure-B,
and assigned the other half of the participants to first perform Procedure-B and then Procedure-A.
2.6.3.3 Data Collection
We collected data through observation and questionnaire. When a participant was perform-
ing a procedure, we observed the progress of all the tasks. After a participant completed the two
procedures, we asked the participant to answer a five-point Likert-scale (Strongly disagree, Dis-
agree, Neither agree nor disagree, Agree, Strongly Agree) [82] questionnaire. The questionnaire
consists of eight close-ended questions as listed in Table 2.5. We also asked participants to write
down open-ended comments on using the password managers of Firefox-A and Firefox-B. Partic-
ipants were encouraged to ask us for a clarification of each individual question before providing
36

Table 2.5 The eight close-ended questions.
Q1: In Firefox-A, it is a burden to supply the recovery key every time after configure the testing Sync
account
Q2: In Firefox-B, it is a burden to wait for 10 seconds every time before start my browsing
Q3: I cannot perceive any difference between Firefox-A and Firefox-B when they remember an online
password in an initial visit
Q4: I cannot perceive any difference between Firefox-A and Firefox-B when they automatically fill a
remembered online password in a revisit
Q5: Overall, it is easy to use the password manager of Firefox-A
Q6: Overall, it is easy to use the password manager of Firefox-B
Q7: Overall, I would like to use the password manager of Firefox-A in the future
Q8: Overall, I would like to use the password manager of Firefox-B in the future
the answer to it. Some participants indeed asked us for clarifications, so we can assume that those
questions are clear to the participants.
2.6.3.4 Results and Analysis
We observed that all the 30 participants successfully completed the two procedures. We con-
verted the responses to the Likert-scale questionnaire to numeric values (1=Strongly disagree,
2=Disagree, 3=Neither agree nor disagree, 4=Agree, 5=Strongly Agree). Figure 2.7 illustrates the
mean ratings to the eight questions. Strictly speaking, since the responses are ordinal data, they do
not necessarily have interval scales. We performed such a conversion simply to ease the compari-
son of the responses from a relative perspective. In practice, this type of conversion is acceptable
and commonly used such as in [47]. We mainly use t-tests (one-sample and two-sample) with 95%
confidence interval to compare these mean ratings.
The mean rating to Q1 is 4.17. One-sample t-test against the test-value 4 shows this mean rating
is higher than 4 without statistical significance (two-tailed p value is 0.134). This result indicates
that most participants do agree that “In Firefox-A, it is a burden to supply the recovery key every
time after configure the testing Sync account”. In other words, supplying a 26-character recovery
key in the password manager of the original Firefox is indeed a burden to most users. In contrast,
the mean rating to Q2 is 2.17. One-sample t-test against the test-value 2 shows this mean rating
is higher than 2 without statistical significance (two-tailed p value is 0.169). This result indicates
37
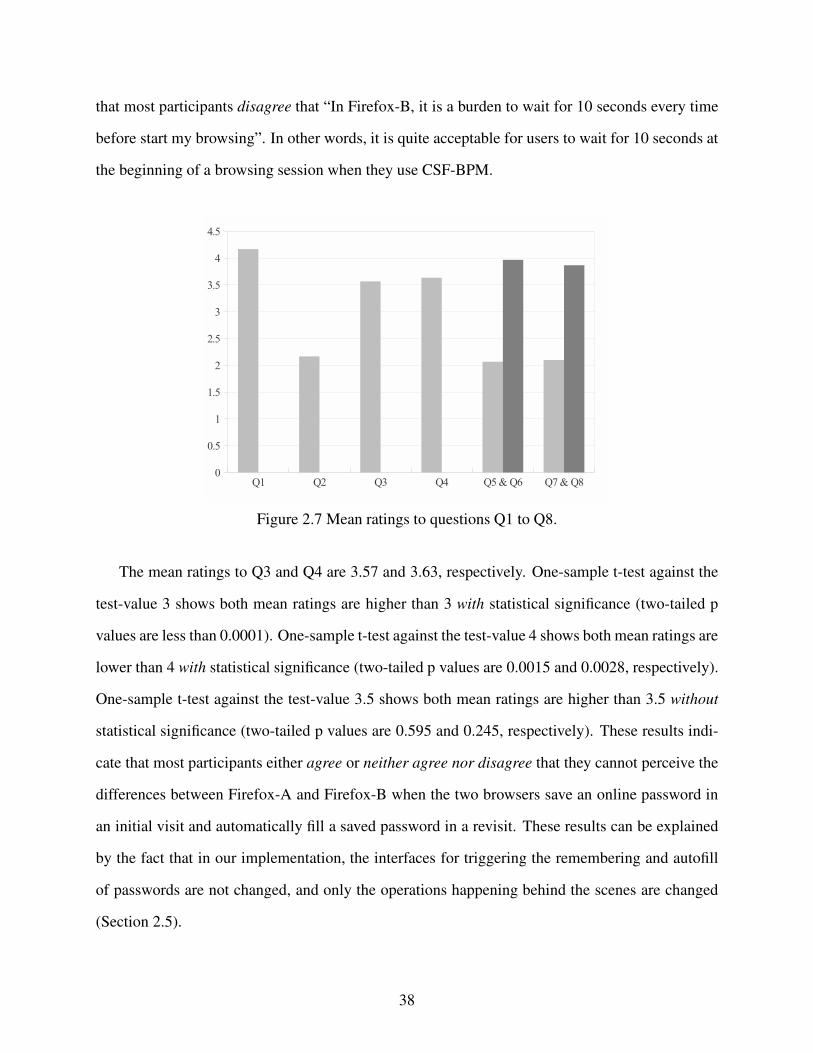
that most participants disagree that “In Firefox-B, it is a burden to wait for 10 seconds every time
before start my browsing”. In other words, it is quite acceptable for users to wait for 10 seconds at
the beginning of a browsing session when they use CSF-BPM.
Figure 2.7 Mean ratings to questions Q1 to Q8.
The mean ratings to Q3 and Q4 are 3.57 and 3.63, respectively. One-sample t-test against the
test-value 3 shows both mean ratings are higher than 3 with statistical significance (two-tailed p
values are less than 0.0001). One-sample t-test against the test-value 4 shows both mean ratings are
lower than 4 with statistical significance (two-tailed p values are 0.0015 and 0.0028, respectively).
One-sample t-test against the test-value 3.5 shows both mean ratings are higher than 3.5 without
statistical significance (two-tailed p values are 0.595 and 0.245, respectively). These results indi-
cate that most participants either agree or neither agree nor disagree that they cannot perceive the
differences between Firefox-A and Firefox-B when the two browsers save an online password in
an initial visit and automatically fill a saved password in a revisit. These results can be explained
by the fact that in our implementation, the interfaces for triggering the remembering and autofill
of passwords are not changed, and only the operations happening behind the scenes are changed
(Section 2.5).
38

The mean rating to Q5 is 2.07. One-sample t-test against the test-value 2 shows this mean
rating is higher than 2 without statistical significance (two-tailed p value is 0.424). The mean
rating to Q6 is 3.97. One-sample t-test against the test-value 4 shows this mean rating is lower than
4 without statistical significance (two-tailed p value is 0.326). Meanwhile, two-sample t-test shows
the mean rating to Q5 is lower than that to Q6 with statistical significance (two-tailed p value is
less than 0.0001). These results clearly indicate that most participants disagree that “it is easy to
use the password manager of Firefox-A”, and agree that “it is easy to use the password manager of
Firefox-B”.
The mean rating to Q7 is 2.1. One-sample t-test against the test-value 2 shows this mean rating
is higher than 2 without statistical significance (two-tailed p value is 0.415). The mean rating to Q8
is 3.87. One-sample t-test against the test-value 4 shows this mean rating is lower than 4 without
statistical significance (two-tailed p value is 0.161). Meanwhile, two-sample t-test shows the mean
rating to Q7 is lower than that to Q8 with statistical significance (two-tailed p value is less than
0.0001). These results clearly indicate that most participants would like to use CSF-BPM rather
than the original password manager of Firefox in the future.
In our open-ended question, we asked participants to write down any other comments (if they
have) regarding using the password managers of Firefox-A and Firefox-B. We found 22 (or 73.3%
of) participants commented that supplying the 26-character recovery key is a burden to them. Their
main opinion is that the recovery key is too long to be remembered or conveniently carried with,
and they may make mistakes when they supply this recovery key. Some of them were even worried
about losing the recovery key thus making the saved passwords irrecoverable. We also found nine
participants commented that waiting for 10 seconds is acceptable especially for the sake of better
security. These results further confirmed the difference in the participants’ responses to Q1 and
Q2, and further explained the difference in the participants’ responses to Q5 and Q6. Our overall
conclusion is that CSF-BPM does have usability advantages over the original password manager
of Firefox.
39

2.7 Discussion
We analyzed in Section 2.4 that CSF-BPM provides a high level of security. We further eval-
uated in Section 2.6 the correctness, performance, and usability of our Firefox version CSF-BPM.
We now briefly discuss a few main limitations of CSF-BPM.
First, if a CSF-BPM user forgets the SSMP, all the passwords saved on SRS services cannot
be correctly decrypted. Therefore, remembering the SSMP becomes very important for CSF-BPM
users. However, remembering an SSMP should be much easier than remembering many strong
passwords for different websites.
Second, at the beginning of a Web browsing session, a user has to wait for 10 seconds so that
CSF-BPM can complete the mainKey derivation. However, once the mainKey is derived, password
remembering and autofill operations can be smoothly performed as usual.
Third, our current CSF-BPM is implemented in JavaScript. The security and performance of
CSF-BPM can be further improved if those cryptographic algorithms are implemented in C++. For
example, those cryptographic algorithms can be implemented into an XPCOM [78] component for
Firefox using C++.
Fourth, we expect that the SSMP is strong with its strength [63, 64] assured by the traditional
proactive password checking techniques and certain length requirements [65–67], or by the latest
reactive proscriptive intervention techniques [68]. However, these techniques are statistical in
nature and do not ensure an absolutely strong password for every single user. Therefore, insincere
cloud storage service providers or attackers who can steal the encrypted data may still be able to
launch brute force attacks on weak SSMPs. In addition, although the special UI component of
CSF-BPM can help protect SSMP against phishing attacks (Section 2.4.2), users should still pay
attention to any suspicious dialog box that asks for the SSMP.
Finally, in our threat model we assumed that it is very difficult for malware to directly identify
cryptographic keys from a computer’s memory and malware can be removed from the system by
security-conscious users in a timely manner. Relatively speaking those assumptions are reason-
able as justified in Section 2.3, but users should still pay attention to the potential risks. With a
40

successful drive-by download attack and with the malware persisting on a user’s computer, attack-
ers may still log keystrokes and steal the data from the memory to obtain the master password,
mainKey, and website passwords. Therefore, we expect users not to type the SSMP or log into
a website if they perceive (e.g., with the help from the anti-malware programs on their comput-
ers) some suspicious activities; instead, they should immediately address the malware problem
by either cleaning up or reinstalling the system. This is a common expectation for using all the
browser-based password managers.
2.8 Summary
In this project, we uncovered the vulnerabilities of existing BPMs and analyzed how they can
be exploited by attackers to crack users’ saved passwords. Moreover, we proposed a novel Cloud-
based Storage-Free BPM (CSF-BPM) design to achieve a high level of security with the desired
confidentiality, integrity, and availability properties. We implemented a CSF-BPM system and
seamlessly integrated it into the Firefox Web browser. We evaluated the correctness, performance,
and usability of this system. Our evaluation results and analysis demonstrate that CSF-BPM can be
efficiently and conveniently used to manage online passwords. We believe CSF-BPM is a rational
design that can also be integrated into other popular Web browsers to make the online experience
of Web users more secure, convenient, and enjoyable.
41

CHAPTER 3
A SECURITY ANALYSIS OF TWO COMMERCIAL BROWSER AND CLOUD BASED
PASSWORD MANAGERS
3.1 Introduction
Text passwords still occupy the dominant position in online user authentication, and they can-
not be replaced in the foreseeable future due to their security and especially their usability and
deployability advantages [10–12]. Password security heavily relies on using strong passwords and
protecting them from being guessed or stolen. However, strong passwords that are sufficiently
long and random are often difficult to remember by users [13–15, 17]. Even if passwords are
strong enough, they are still vulnerable to harvesting attacks such as phishing [18, 19, 83, 84].
These hard problems have been further aggravated by the facts that users have to create and man-
age more online passwords than before and they often have insecure practices such as sharing the
same password across different websites [20] and writing down passwords [15].
Password manager is one of the most popular solutions that can potentially well address the
aforementioned password security problems [11]. In general, password managers work by saving
users’ online passwords and later auto-filling the login forms on behalf of users. Therefore, a
remarkable benefit brought by password managers is that users do not need to remember many
passwords. This benefit is the main reason behind designing various password managers by many
vendors and using them by millions of users.
All the major browser vendors have provided password manager as a built-in feature in their
browsers (e.g., the top five most popular browsers: Internet Explorer, Firefox, Google Chrome,
Safari, and Opera); meanwhile, third-party vendors have also provided many password managers.
Popular commercial password managers often have two attractive properties: they are browser-
based and cloud-based. We refer to such password managers as Browser and Cloud based Pass-
word Managers (BCPMs). They are browser-based in the sense they provide browser extension
42

editions that can be seamlessly integrated into different Web browsers to achieve the same level
of usability as browsers’ built-in password managers. They are cloud-based in the sense they can
store the saved websites passwords in the cloud storage servers and allow users to access the saved
data from any place and at any time. This desired cloud-based usability property is not present
or well supported in popular browsers, providing the opportunity for third-party vendors to gain a
good share in the password manager market.
In this project, we analyze the security of two very popular commercial BCPMs: LastPass [42]
and RoboForm [31]. Both of them have millions of active users worldwide and are often ranked
among the best password managers by media such as InformationWeek and PC Magazine. Our
key motivation is to see whether these two very popular BCPMs are really secure and can properly
protect users’ online passwords. With this motivation, we make the following contributions: (1)
define a threat model for analyzing the security of BCPMs, (2) investigate the design and imple-
mentation of these two BCPMs with the focus on their underlying cryptographic mechanisms, (3)
identify several vulnerabilities of these two BCPMs that could be exploited by outsider and insider
attackers to obtain users’ saved websites passwords, (4) analyze the security risk levels of the iden-
tified vulnerabilities, and (5) provide some general suggestions to help improve the security design
of BCPMs. Beyond these direct contributions to the security design of BCPMs, our analysis and
suggestions could also be valuable to other cloud-based data security products and research.
The rest of this chapter is structured as follows. Section 3.2 reviews related work and provides
the background information of LastPass and RoboForm. Section 3.3 analyzes the security of these
two BCPMs. Section 3.4 provides further discussions and suggestions on secure BCPM design.
Section 3.5 concludes the project.
3.2 Related Work and Background
In this section, we briefly review the related text password security research, and provide back-
ground information of LastPass and RoboForm browser extensions.
43

3.2.1 Related Work on Text Password and Password Manager
It has been known for a long time that weak passwords suffer from brute force attacks and
dictionary attacks [16], and increasing password entropy is critical to improving password secu-
rity [14]. However, the dilemma is that strong passwords that are sufficiently long and random are
often difficult to remember by users due to human memory limitations [13, 17]. Large-scale stud-
ies of Web password habits further demonstrated the severity of the password security problems
such as using weak passwords and sharing passwords across websites [15, 20].
To improve the security of text passwords, researchers and vendors have provided many so-
lutions such as password managers [29, 31, 42], password hashing systems [39–41], and single
sign-on systems [33, 85]. In general, usability is the main concern for password hashing sys-
tems [39, 47], while security and business model are the main concerns for single sign-on sys-
tems [32, 33, 86]. As highlighted in Section 3.1, password manager is one of the most popular
solutions that can potentially well address the password security problems. We analyzed the inse-
cure design (e.g., lack of a master password mechanism) of browsers’ built-in password managers
in [48]. Our focus in this project is on analyzing the security of two very popular commercial
BCPMs: LastPass [42] and RoboForm [31].
3.2.2 Background Information of LastPass and RoboForm
LastPass is mainly designed and implemented as browser extensions for the top five most pop-
ular browsers [42]; we focus on its Firefox and Google Chrome browser extensions that share the
same design. RoboForm has both stand-alone and browser extension editions [31]; we also focus
on its Firefox and Google Chrome browser extensions that share the same design. In this project,
we use LastPass and RoboForm to refer to their Firefox and Google Chrome extensions, which
are representative Browser and Cloud based Password Managers (BCPMs) that provide important
usability benefits to users as highlighted in Section 3.1.
Similar to other password managers, LastPass and RoboForm save users’ websites login in-
formation (i.e., usernames and passwords for different websites), and later automatically fill the
44
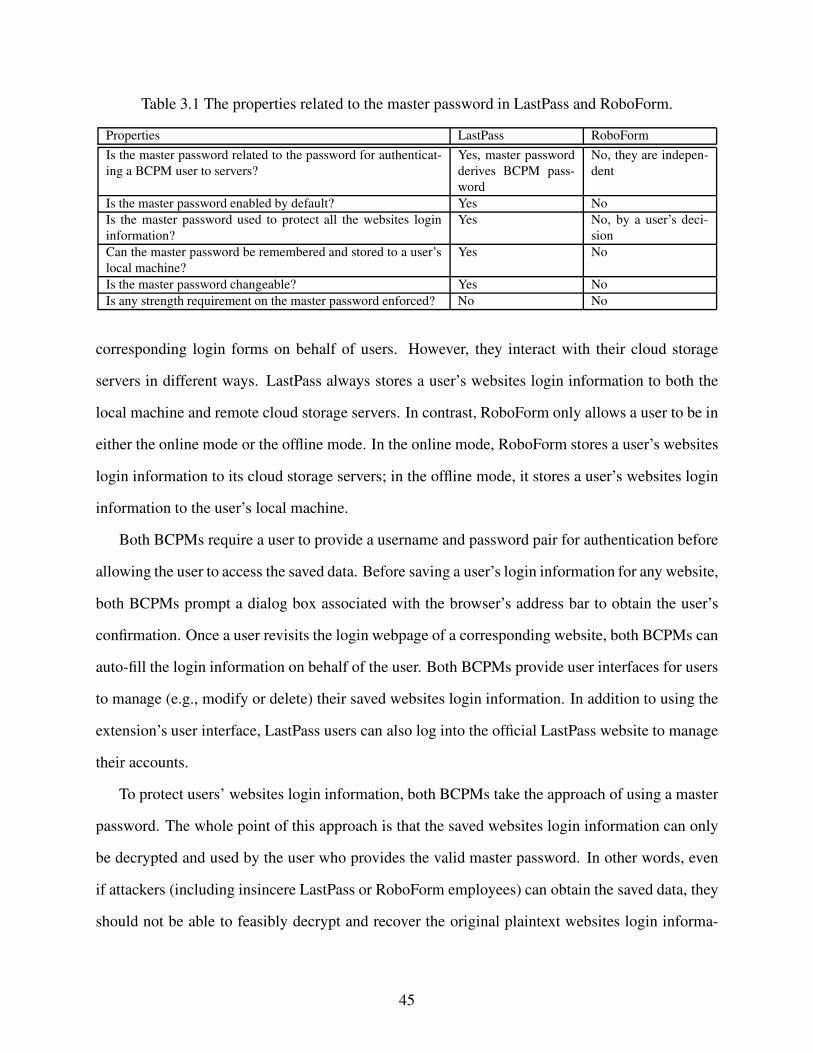
Table 3.1 The properties related to the master password in LastPass and RoboForm.
Properties LastPass RoboForm
Is the master password related to the password for authenticat-
ing a BCPM user to servers?
Yes, master password
derives BCPM pass-
word
No, they are indepen-
dent
Is the master password enabled by default? Yes No
Is the master password used to protect all the websites login
information?
Yes No, by a user’s deci-
sion
Can the master password be remembered and stored to a user’s
local machine?
Yes No
Is the master password changeable? Yes No
Is any strength requirement on the master password enforced? No No
corresponding login forms on behalf of users. However, they interact with their cloud storage
servers in different ways. LastPass always stores a user’s websites login information to both the
local machine and remote cloud storage servers. In contrast, RoboForm only allows a user to be in
either the online mode or the offline mode. In the online mode, RoboForm stores a user’s websites
login information to its cloud storage servers; in the offline mode, it stores a user’s websites login
information to the user’s local machine.
Both BCPMs require a user to provide a username and password pair for authentication before
allowing the user to access the saved data. Before saving a user’s login information for any website,
both BCPMs prompt a dialog box associated with the browser’s address bar to obtain the user’s
confirmation. Once a user revisits the login webpage of a corresponding website, both BCPMs can
auto-fill the login information on behalf of the user. Both BCPMs provide user interfaces for users
to manage (e.g., modify or delete) their saved websites login information. In addition to using the
extension’s user interface, LastPass users can also log into the official LastPass website to manage
their accounts.
To protect users’ websites login information, both BCPMs take the approach of using a master
password. The whole point of this approach is that the saved websites login information can only
be decrypted and used by the user who provides the valid master password. In other words, even
if attackers (including insincere LastPass or RoboForm employees) can obtain the saved data, they
should not be able to feasibly decrypt and recover the original plaintext websites login informa-
45

tion. The vendors of these two BCPMs claimed on their websites [31, 42] that they do not know
users’ master passwords, cannot resend or reset master passwords, and do not know users’ login
information for different websites.
Table 3.1 illustrates that the ways of using master passwords in LastPass and RoboForm are
quite different. The second row shows that LastPass derives a user’s password for authenticating
to LastPass servers from the user’s master password, while no dependency between these two
passwords exists in RoboForm. The third row shows that LastPass uses the master password by
default, but RoboForm allows a user to decide whether a master password will be used. The fourth
row shows that LastPass uses the master password to protect all the websites login information, but
RoboForm depends on a user’s decision. The fifth row shows that LastPass can even remember and
save a user’s master password to the local machine so that the user will be automatically logged
into the extension next time, while RoboForm does not have such a property. The sixth row shows
that LastPass allows a user to change the master password, but RoboForm does not provide such a
flexibility. The last row shows that both BCPMs do not enforce any strength requirement on users’
master passwords.
Overall, these master password related properties have important security implications. Rela-
tively speaking, enabling the master password by default and protecting all the websites login infor-
mation in LastPass will provide better security. Similarly, making the master password changeable
in LastPass will provide flexibility and better security. However, remembering and storing the mas-
ter password to the local machine in LastPass could lead to security risks. Furthermore, it could
also lead to security risks when a strength requirement on master passwords is not enforced in both
BCPMs. In the next two sections, we analyze the security of these two BCPMs and provide more
discussions and suggestions on improving their security design.
3.3 Security Analysis of LastPass and RoboForm
In this section, we first define the threat model that we consider for BCPMs. We then describe
our security analysis methodology. Finally, we analyze in detail the security of LastPass and
46
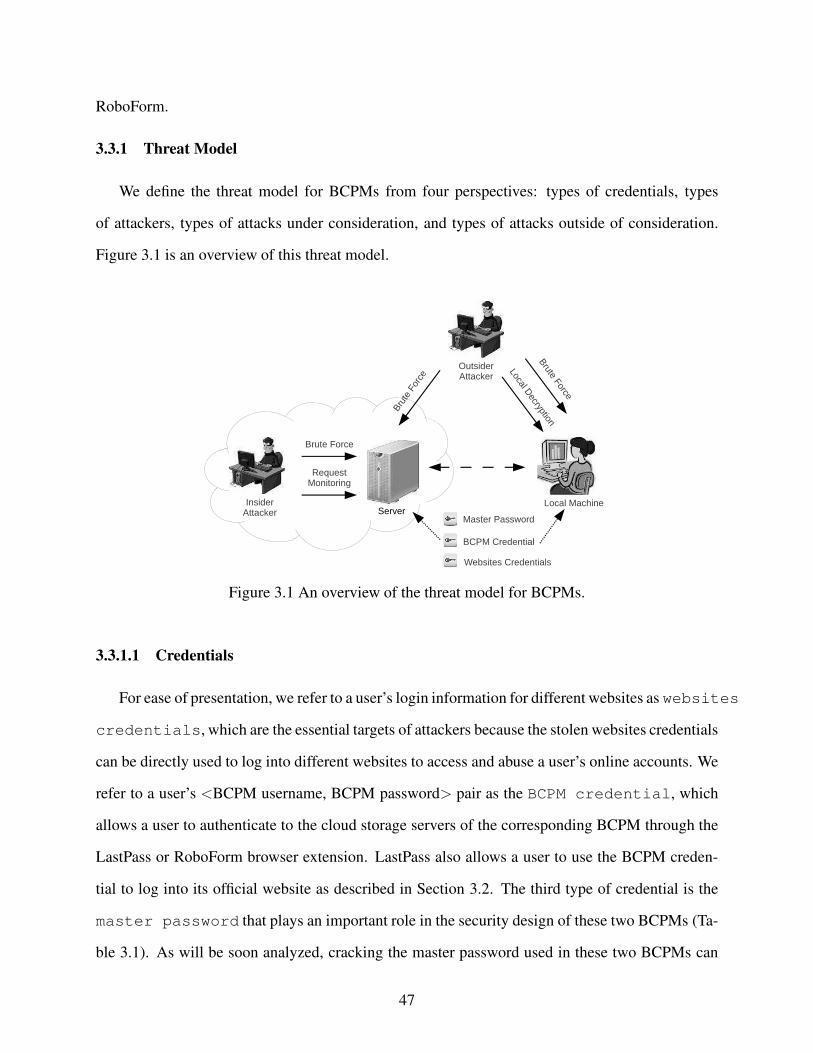
RoboForm.
3.3.1 Threat Model
We define the threat model for BCPMs from four perspectives: types of credentials, types
of attackers, types of attacks under consideration, and types of attacks outside of consideration.
Figure 3.1 is an overview of this threat model.
Figure 3.1 An overview of the threat model for BCPMs.
3.3.1.1 Credentials
For ease of presentation, we refer to a user’s login information for different websites as websites
credentials, which are the essential targets of attackers because the stolen websites credentials
can be directly used to log into different websites to access and abuse a user’s online accounts. We
refer to a user’s <BCPM username, BCPM password> pair as the BCPM credential, which
allows a user to authenticate to the cloud storage servers of the corresponding BCPM through the
LastPass or RoboForm browser extension. LastPass also allows a user to use the BCPM creden-
tial to log into its official website as described in Section 3.2. The third type of credential is the
master password that plays an important role in the security design of these two BCPMs (Ta-
ble 3.1). As will be soon analyzed, cracking the master password used in these two BCPMs can
47

greatly facilitate the cracking of websites credentials.
3.3.1.2 Attackers
Two types of attackers may target those credentials: outsider attackers and insider
attackers. Outsider attackers are unauthorized or illegitimate entities who initiate attacks from
outside of the security perimeter of a BCPM vendor’s system resources. They could be from ama-
teur pranksters to organized criminals and even hostile governments. Outsider attackers may have
the server-side stealing capability, i.e., intruding into the cloud storage servers of
a BCPM vendor to steal the data saved for users. The attack happened on LastPass in 2011 [87]
exemplifies such server-side stealing capability.
Outsider attackers may also have the client-side stealing capability, i.e., at-
tacking users’ machines to steal locally saved data. They may even have the client-side
computation capability, i.e., temporarily running either benign or malicious programs
on users’ machines to perform some computations. For these two client-side capabilities, pop-
ular attacks such as drive-by-downloads [50–54] are representative examples, in which attackers
can install and run malware on a user’s machine in a few seconds. We do not assume malware
can persist on the victim’s machine – anti-malware software such as Microsoft Forefront Endpoint
Protection may eventually detect and remove the malware, or solutions such as the Back to the Fu-
ture framework [57] may restore the system to a prior good state and preserve the system integrity.
However, within that few seconds, the installed malware can either directly send back the stolen
data for decrypting on attackers’ machines, or, if necessary, decrypt the stolen data on the victim’s
machine and then send the results back to attackers.
Insider attackers are entities that are authorized to access a BCPM vendor’s system resources
but use them in a non-approved way. Examples of insider attackers could be insincere employees
or former employees who can still access a BCPM vendor’s system resources. Similar to out-
sider attackers, insider attackers may have the server-side stealing capability to
steal the saved data. In addition, insider attackers may have the server-side monitoring
48

capability, i.e., directly monitoring the communication between BCPMs and their cloud stor-
age servers. Considering insider attackers in analyzing the security of BCPMs is of particular im-
portance because although BCPM vendors store the encrypted data in their cloud storage servers,
they should not be able to feasibly decrypt and recover any user’s websites credentials and master
password.
3.3.1.3 Attacks Under Consideration
We focus on the underlying cryptographic mechanisms of LastPass and RoboForm and mainly
consider three types of attacks that could be performed to obtain credentials either from cloud stor-
age servers or from users’ local machines: brute force attacks, local decryption
attacks, and request monitoring attacks. The solid-line arrows in Figure 3.1 denote
these attacks that could be performed by outsider and insider attackers.
Brute force attacks can be performed by both outsider and insider attackers to mainly crack a
user’s master password, from which other credentials can be further cracked. Note that we consider
the effort of brute force attacks as the upper bound – attackers can definitely use different dictio-
naries to reduce their effort. Local decryption attacks aim to crack a user’s websites credentials
from the user’s local machine without using brute force, and they can be performed by outsider
attackers using drive-by-downloads and running malware on the victim’s local machine. Request
monitoring attacks aim to obtain a user’s websites credentials by intercepting the requests sent
from BCPMs to their cloud storage servers. Because BCPMs normally use the HTTPs protocol to
secure their communication with cloud storage servers and meanwhile we do not assume malware
can persist on a user’s local machine, we mainly consider request monitoring attacks performed by
insider attackers from the server-side.
3.3.1.4 Attacks Outside of Consideration
We do not consider general Web attacks such as cross-site scripting, cross-site request forgery,
and DNS spoofing, as well as their potential interactions with browser extensions [88]. We do not
consider privilege escalation related vulnerabilities of browsers and browser extensions. Specific
49

attacks (e.g., side-channel and hypervisor privilege escalation) against the cloud storage servers of
BCPMs are also out of the scope of our analysis.
3.3.2 Security Analysis Methodology
“Where a threat intersects with a vulnerability, risk is present [49].” We have defined and dis-
cussed threat agents (attackers) and attack vectors (attacks) in the above threat model for BCPMs.
If the occurrences of such threats are rare or do not have high impacts, BCPMs would not bother
to encrypt their stored websites credentials in the first place. Therefore, we do not intend to further
identify threat sources, but focus on investigating the vulnerabilities in the cryptographic mecha-
nisms of the two BCPMs and correlating them to potential security risks and attacks. We mainly
investigated the two BCPMs on the Windows 7 platform.
Both BCPMs are browser extensions written mainly in JavaScript, and their developers used
different obfuscation techniques to make their JavaScript code difficult for other people to read and
understand. Using Eclipse (www.eclipse.org) and JS Beautifier (jsbeautifier.org), we de-obfuscate
the JavaScript code of the two BCPMs for us to analyze. Besides analyzing the source code, we use
Mozilla’s JavaScript Debugger [89] and Google Chrome’s developer tools to help us understand
the dynamic execution of the two BCPMs. To understand the communication between the two
BCPMs and their cloud storage servers, we use the stand-alone edition HTTP Analyzer [90] to
monitor and analyze all the incoming and outgoing traffic. To further confirm our understanding
of the security design of the two BCPMs, we perform experiments and verify the related features
such as storage, user authentication, and key derivation.
We estimate the effort of brute force attacks based on the computational power exemplified in a
very popular cryptography textbook [74] authored by William Stallings. In the Table 2.2 (chapter
2, page 38, and 5th edition) of this textbook, Stallings used two computer systems with
different computational power to estimate the brute force effort for searching cryptographic keys.
The first system is more like a regular desktop computer, and it takes 10−6 second to perform
a basic cryptographic operation. The second system is more like a cluster of high
50

performance servers with multi-core processors and GPUs, and it takes 10−12 second to perform
a basic cryptographic operation.
In our estimation, we consider either a DES (Data Encryption Standard) or an AES (Advanced
Encryption Standard) decryption as a basic cryptographic operation as in [74]. Meanwhile, for
simplicity but without loss of generality, we also consider either a SHA-1 or SHA-2 [75] hash op-
eration as a basic cryptographic operation, although this is a conservative consideration because a
hash operation is normally more efficient than a decryption operation. That means, in our estima-
tion, the running time for each of these four basic cryptographic operations is 10−6 second on the
aforementioned first system and 10−12 second on the aforementioned second system. We use this
running time information in the following analysis and discussion of attackers’ brute force effort.
3.3.3 LastPass Security Design and Vulnerability Analysis
LastPass mainly uses JavaScript to support all of its functionalities including the cryptographic
operations. It can also include an additional binary component to perform some cryptographic op-
erations. If the binary component is not installed or not compatible with the system, cryptographic
operations will be completely performed by JavaScript. LastPass always stores a user’s websites
credentials both locally to the user’s machine and remotely to cloud storage servers.
We draw Figure 3.2 to illustrate the high-level security design of LastPass. Basically, a user
only remembers a master password and a BCPM username. A g local key is derived from the
master password and the BCPM username, and it will be used to encrypt the user’s websites cre-
dentials. A g local hash is further derived from the master password and the g local key, and it
will be used as the BCPM password. The <BCPM username, BCPM password> pair will be
submitted to the cloud storage servers of LastPass for user authentication.
To perform both derivations, LastPass uses a variation of the deterministic password-based
key derivation function PBKDF2 specified in RFC 2898 [70]. The main variation is replacing the
pseudorandom function recommended in the PBKDF2 specification [70] with the SHA-256 secure
hashing function [75] to perform the underlying cryptographic operations. This replacement in
51
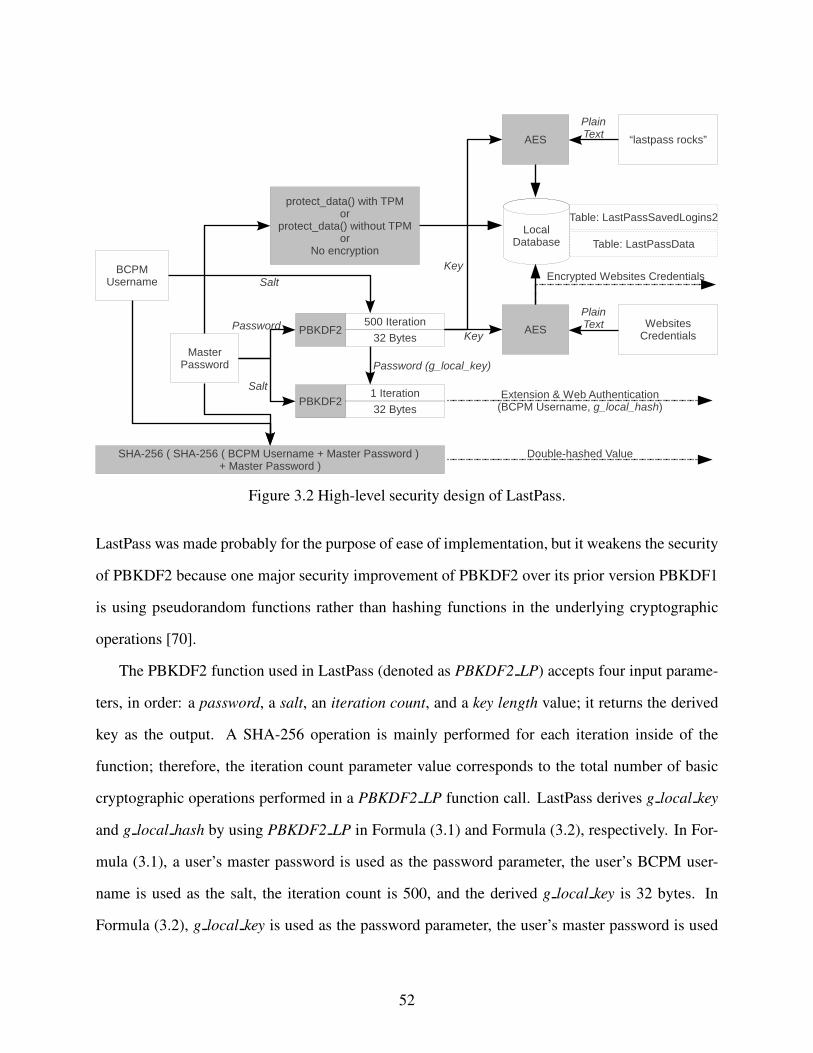
Figure 3.2 High-level security design of LastPass.
LastPass was made probably for the purpose of ease of implementation, but it weakens the security
of PBKDF2 because one major security improvement of PBKDF2 over its prior version PBKDF1
is using pseudorandom functions rather than hashing functions in the underlying cryptographic
operations [70].
The PBKDF2 function used in LastPass (denoted as PBKDF2 LP) accepts four input parame-
ters, in order: a password, a salt, an iteration count, and a key length value; it returns the derived
key as the output. A SHA-256 operation is mainly performed for each iteration inside of the
function; therefore, the iteration count parameter value corresponds to the total number of basic
cryptographic operations performed in a PBKDF2 LP function call. LastPass derives g local key
and g local hash by using PBKDF2 LP in Formula (3.1) and Formula (3.2), respectively. In For-
mula (3.1), a user’s master password is used as the password parameter, the user’s BCPM user-
name is used as the salt, the iteration count is 500, and the derived g local key is 32 bytes. In
Formula (3.2), g local key is used as the password parameter, the user’s master password is used
52

as the salt, the iteration count is one, and the derived g local hash is also 32 bytes.
g local key = PBKDF2 LP (master password,BCPM username, 500, 32) (3.1)
g local hash = PBKDF2 LP (g local key,master password, 1, 32) (3.2)
We now reveal the vulnerabilities in the security design of LastPass and discuss three types
of potential attacks: outsider attackers’ local decryption attacks, outsider attackers’ brute force
attacks, and insider attackers’ brute force attacks. We analyze how a user’s master password
can be cracked. With the cracked master password, attackers can directly derive the g local key
to completely decrypt all the websites credentials of the user, and can further derive the BCPM
password (i.e., g local hash) of the user.
3.3.3.1 Outsider Attackers’ Local Decryption Attacks
The vulnerability (referred to as LastPass-Vul-1) lies in the insecure design of the master pass-
word remembering mechanism in LastPass. As shown in Figure 3.2, LastPass can even remember
a user’s master password (with the BCPM username) into a local SQLite [59] database table Last-
PassSavedLogins2, allowing the user to be automatically authenticated whenever LastPass is used
again. Whether and how LastPass protects the master password before saving it into the database
table depends on the configuration of the user’s machine. There are three possible cases: (1) if
LastPass includes an aforementioned binary component and the TPM (Trusted Platform Module)
of the machine is available, the protect data() function of the binary component will use the Win-
dows API function CryptProtectData() with the TPM support to encrypt the master password; (2)
if the binary component exists but the TPM of the machine is not available, the protect data()
function will use CryptProtectData() without the TPM support to encrypt the master password;
and (3) if the binary component does not exist, LastPass will not encrypt the master password at
all.
53

A locally saved master password, no matter encrypted or not, is vulnerable to local decryption
attacks that can be performed by outsider attackers with the client-side stealing capability and/or
the client-side computation capability (Section 3.3.1.2). In the cases (1) and (2) where the pro-
tect data() function of the binary component is used in the encryption, outsider attackers can call
the corresponding unprotect data() function of the binary component on the victim’s machine to
decrypt the master password. In other words, attackers need to have both the client-side steal-
ing capability and the client-side computation capability. The unprotect data() function will use
the corresponding Windows API function CryptUnprotectData() either with or without the TPM
support (based on the configuration of the user’s machine) to perform the decryption. In the case
(3) where no encryption is applied, outsider attackers with the client-side stealing capability can
directly steal the saved plaintext master password.
In all the three cases, outsider attackers can directly steal the plaintext BCPM username from
the LastPassSavedLogins2 database table. Therefore, using Formula (3.1) and Formula (3.2), out-
sider attackers can derive g local key and g local hash to completely recover all the plaintext web-
sites credentials of a user.
We performed experiments and validated the effectiveness of such local decryption attacks. We
verified that the time effort for performing such attacks is very low – within one second, the entire
decryption process can be completed and all the plaintext websites credentials of a user can be
accurately obtained by outsider attackers.
3.3.3.2 Outsider Attackers’ Brute Force Attacks
Even if a master password is not saved by LastPass into the LastPassSavedLogins2 database
table on a user’s local computer, it is still vulnerable to brute force attacks performed by outsider
attackers. The vulnerability (referred to as LastPass-Vul-2) lies in the insecure design of the local
user authentication mechanism and the insecure application of the PBKDF2 function in LastPass.
As shown in Figure 3.2, to locally authenticate a user and make the user’s websites credentials
accessible when the network connection is not available, LastPass encrypts a hard-coded string
54

“lastpass rocks” using AES and writes the ciphertext into another local SQLite [59] database table
LastPassData, in which the encrypted websites credentials are also saved. The key used in this
AES encryption operation is the same key (i.e., g local key) used for encrypting a user’s websites
credentials. Therefore, in a local user authentication, if the key derived from Formula (3.1) based
on the BCPM username and the master password provided by a user can decrypt the ciphertext for
“lastpass rocks” back to the correct plaintext, the authentication will be successful and LastPass
will further decrypt the websites credentials for the user.
Outsider attackers with the client-side stealing capability (Section 3.3.1.2) can perform brute
force attacks using the following steps after stealing the BCPM username and the ciphertext for
“lastpass rocks”. First, an attacker derives g local key (Formula (3.1)) by trying one possible
master password together with the stolen BCPM username. Second, the attacker tries to decrypt
the ciphertext for “lastpass rocks” using AES with the derived g local key as the decryption key.
Third, if the decrypted result is “lastpass rocks”, the brute force attack is successful and the at-
tacker obtains the user’s real master password; otherwise, the attacker repeats above steps with
another possible master password. Each master password try consists of 501 (500 iterations in
Formula (3.1) plus one AES decryption) basic cryptographic operations, thus taking 501*10−6
seconds and 501*10−12 seconds, respectively, on the two systems referred in Section 3.3.2.
The effectiveness of such brute force attacks also depends on the size of the master password
space, which is determined by the length of the master password and the number of possibilities for
each master password character. If each master password character can be an upper case letter, a
lower case letter, or a decimal digit, then it could be one of the 62 (26+26+10) possibilities. Based
on this number, we list different master password lengths and their corresponding space sizes in
the first column and the second column of Table 3.2, respectively. The third and fourth columns of
Table 3.2 list the outsider attackers’ average brute force attack effort (i.e., overall effort divided by
two) with one try’s running time at 501*10−6 seconds and 501*10−12 seconds, respectively. For
example, on average, outsider attackers can crack an 8-character master password in about 1734.3
years and 15.2 hours, respectively, on the aforementioned two systems.
55
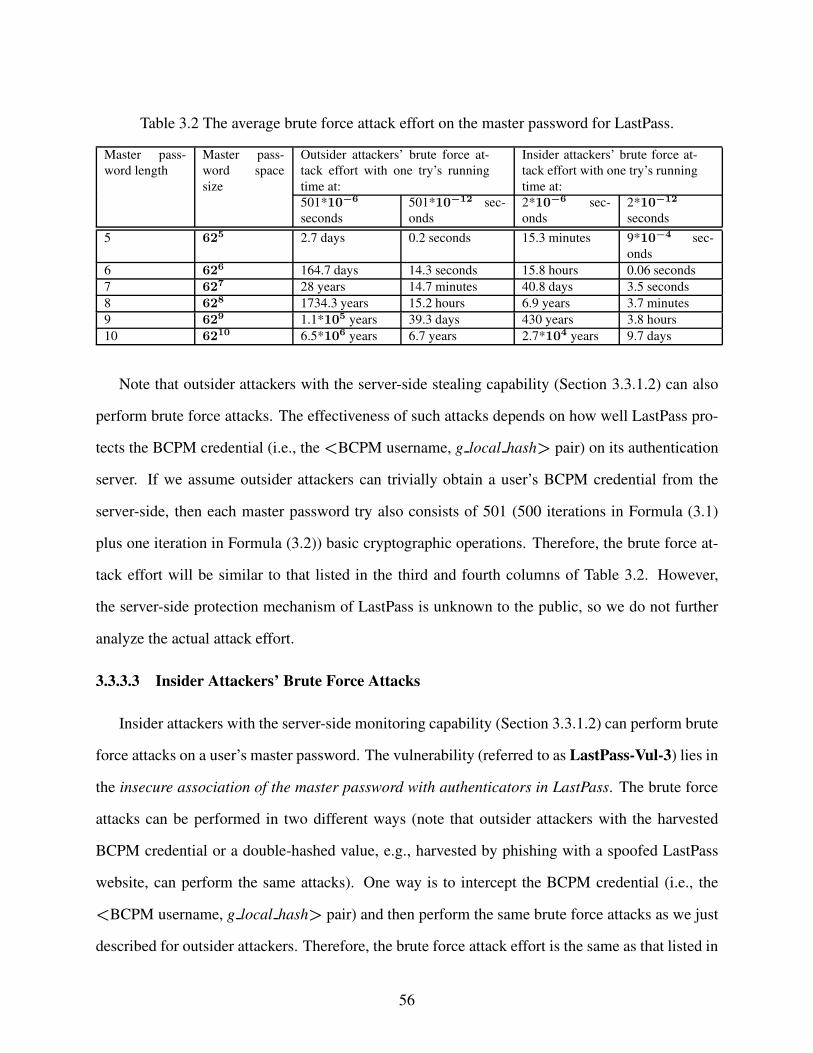
Table 3.2 The average brute force attack effort on the master password for LastPass.
Master pass-
word length
Master pass-
word space
size
Outsider attackers’ brute force at-
tack effort with one try’s running
time at:
Insider attackers’ brute force at-
tack effort with one try’s running
time at:
501*10−6
seconds
501*10−12 sec-
onds
2*10−6 sec-
onds
2*10−12
seconds
5 625 2.7 days 0.2 seconds 15.3 minutes 9*10−4 sec-
onds
6 626 164.7 days 14.3 seconds 15.8 hours 0.06 seconds
7 627 28 years 14.7 minutes 40.8 days 3.5 seconds
8 628 1734.3 years 15.2 hours 6.9 years 3.7 minutes
9 629 1.1*105 years 39.3 days 430 years 3.8 hours
10 6210 6.5*106 years 6.7 years 2.7*104 years 9.7 days
Note that outsider attackers with the server-side stealing capability (Section 3.3.1.2) can also
perform brute force attacks. The effectiveness of such attacks depends on how well LastPass pro-
tects the BCPM credential (i.e., the <BCPM username, g local hash> pair) on its authentication
server. If we assume outsider attackers can trivially obtain a user’s BCPM credential from the
server-side, then each master password try also consists of 501 (500 iterations in Formula (3.1)
plus one iteration in Formula (3.2)) basic cryptographic operations. Therefore, the brute force at-
tack effort will be similar to that listed in the third and fourth columns of Table 3.2. However,
the server-side protection mechanism of LastPass is unknown to the public, so we do not further
analyze the actual attack effort.
3.3.3.3 Insider Attackers’ Brute Force Attacks
Insider attackers with the server-side monitoring capability (Section 3.3.1.2) can perform brute
force attacks on a user’s master password. The vulnerability (referred to as LastPass-Vul-3) lies in
the insecure association of the master password with authenticators in LastPass. The brute force
attacks can be performed in two different ways (note that outsider attackers with the harvested
BCPM credential or a double-hashed value, e.g., harvested by phishing with a spoofed LastPass
website, can perform the same attacks). One way is to intercept the BCPM credential (i.e., the
<BCPM username, g local hash> pair) and then perform the same brute force attacks as we just
described for outsider attackers. Therefore, the brute force attack effort is the same as that listed in
56

the third and fourth columns of Table 3.2.
The second way is to intercept the double-hashed value sent to the official website of LastPass.
As shown in Figure 3.2, when a user logs into the official website of LastPass using a browser, a
SHA-256 double-hashed value generated from the BCPM username and the master password is
also sent to the server. Brute force attacks against the master password can be more efficiently
performed by insider attackers with the intercepted double-hashed value. An insider attacker only
needs to calculate the double-hashed value (i.e., two basic cryptographic operations) from the
BCPM username and a possible master password. If the calculated double-hashed value matches
the intercepted one, the brute force attack is successful and the attacker recovers the user’s master
password; otherwise, the attacker repeats the calculation on another possible master password.
Each master password try takes 2*10−6 seconds and 2*10−12 seconds, respectively, on the two
systems referred in Section 3.3.2; the fifth and sixth columns of Table 3.2 list the corresponding
average brute force attack effort of insider attackers.
3.3.4 RoboForm Security Design and Vulnerability Analysis
Unlike LastPass, RoboForm is implemented in pure JavaScript and it has two modes: online
mode and offline mode. In the offline mode, RoboForm stores a user’s websites credentials to
the user’s local machine. In the online mode, RoboForm uploads a user’s websites credentials
to its remote cloud storage servers through the HTTPS communication. Figure 3.3 illustrates the
high-level security design of RoboForm.
In the offline mode, RoboForm also uses a variation of the deterministic password-based key
derivation function PBKDF2 specified in RFC 2898 [70]. The main variation is replacing the pseu-
dorandom function recommended in the PBKDF2 specification [70] with the SHA-1 secure hash-
ing function [75] to perform the underlying cryptographic operations. Similar to that of LastPass,
such a replacement in RoboForm weakens the security of PBKDF2. Meanwhile, using SHA-1
rather than SHA-2 [75] further weakens the security.
57
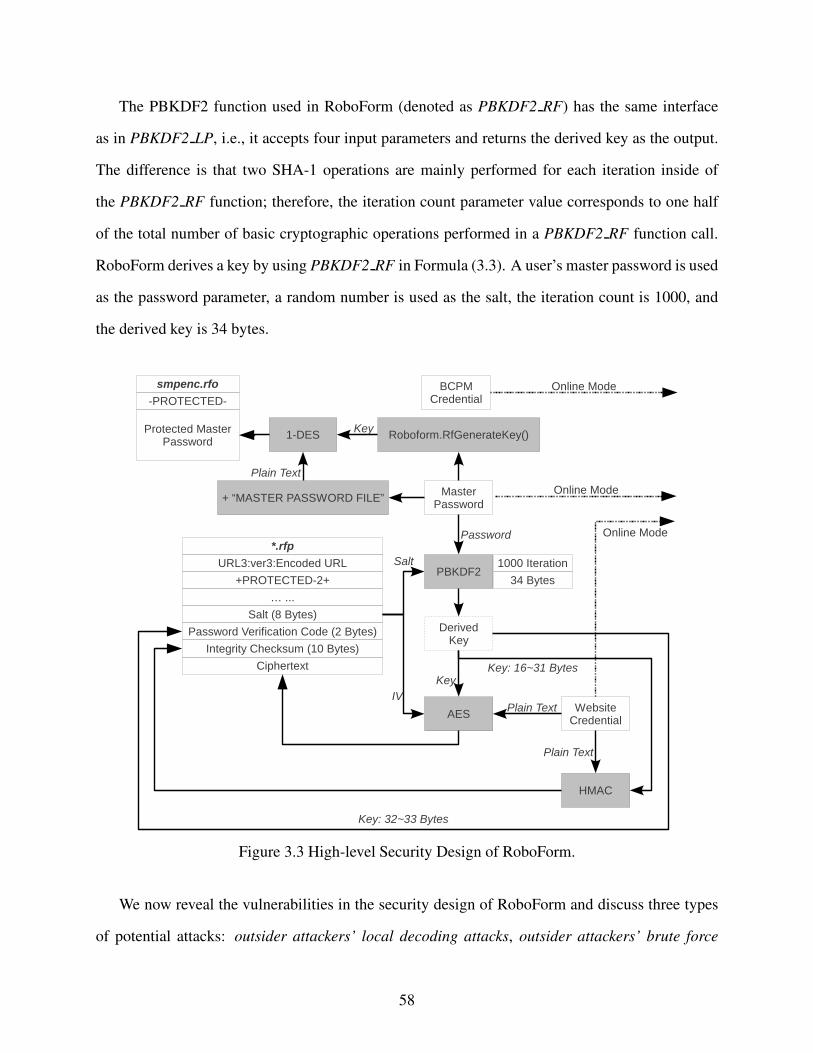
The PBKDF2 function used in RoboForm (denoted as PBKDF2 RF) has the same interface
as in PBKDF2 LP, i.e., it accepts four input parameters and returns the derived key as the output.
The difference is that two SHA-1 operations are mainly performed for each iteration inside of
the PBKDF2 RF function; therefore, the iteration count parameter value corresponds to one half
of the total number of basic cryptographic operations performed in a PBKDF2 RF function call.
RoboForm derives a key by using PBKDF2 RF in Formula (3.3). A user’s master password is used
as the password parameter, a random number is used as the salt, the iteration count is 1000, and
the derived key is 34 bytes.
Figure 3.3 High-level Security Design of RoboForm.
We now reveal the vulnerabilities in the security design of RoboForm and discuss three types
of potential attacks: outsider attackers’ local decoding attacks, outsider attackers’ brute force
58

key = PBKDF2 RF (master password, random number, 1000, 34) (3.3)
attacks, and insider attackers’ request monitoring attacks. The first two types of attacks are related
to the offline mode of RoboForm. The third type of attacks are related to the online mode of
RoboForm.
3.3.4.1 Outsider Attackers’ Local Decoding Attacks
The vulnerability (referred to as RoboForm-Vul-1) lies in the zero protection to local storage
when a master password is not used in RoboForm. In the offline mode, RoboForm saves each
website credential into a separate .rfp file. Each .rfp file is organized into three parts: a header,
a flag, and a data block. The header is always a string concatenated from a hard-coded string
“URL3:ver3” and the encoded website login URL. The formats of the other two parts depend on
whether a master password has been used. In the case when a master password is not used, the flag
will be a hard-coded string “@PROTECTED@” and the data block will be the encoded format of a
user’s website credential (note that we did not draw this case in Figure 3.3). In other words, a user’s
website credential is not encrypted at all, it is simply encoded without using any cryptographic
key. The encoding and decoding schemes are implemented in the RoboForm RfGarbleString() and
RfUngarbleStringW() JavaScript functions, respectively.
Therefore, outsider attackers with the client-side stealing capability (Section 3.3.1.2) can sim-
ply steal the .rfp files of those RoboForm users who do not use a master password. With the stolen
.rfp files, outsider attackers can run the decoding function RfUngarbleStringW() on any computer
to completely recover a user’s websites credentials. Note that local decoding attacks can be re-
garded as the simplest and most special forms of local decryption attacks in which no decryption
keys are needed to recover the plaintexts.
We performed experiments and validated the effectiveness of such local decoding (or decryp-
tion) attacks. Meanwhile, we verified that the time effort for performing such attacks is very low
59

– within one second, the entire decoding process can be completed and all the plaintext websites
credentials of a user can be accurately obtained by outsider attackers.
3.3.4.2 Outsider Attackers’ Brute Force Attacks
In the offline mode and if a master password has been used as shown in Figure 3.3, outsider
attackers with the client-side stealing capability (Section 3.3.1.2) can still perform brute force
attacks against a user’s master password. With the cracked master password, attackers can further
obtain all the websites credentials of the user. The vulnerability (referred to as RoboForm-Vul-2)
lies in the weak protection to the local storage when a master password is used in RoboForm. In
more details, the brute force attacks can be performed in two different ways. One is based on the
.rfp files and the other is based on the smpenc.rfo file.
(a) Based on the .rfp files: In the case when a master password is used, in each .rfp file, the
flag will be a hard-coded string “+PROTECTED-2+”, and the data block will consist of an 8-byte
salt, a 2-byte password verification code, a 10-byte integrity checksum, and a ciphertext. The
salt is a random number used as the second input parameter to the PBKDF2 RF (Formula (3.3))
function. The first 32 bytes of the derived key will be used in the AES encryption to convert a
website credential into the ciphertext. The password verification code comes from the last two
bytes of the derived key, and it is used to verify the correctness of a user’s master password in the
offline mode. The integrity checksum is calculated from the HMAC (Keyed-Hashing for Message
Authentication, RFC 2104) function on the website credential using the second 16 bytes of the
derived key, and it is used to verify the integrity of the data saved in the .rfp file.
Therefore, with the stolen .rfp files, outsider attackers can first derive a key from a possible
master password using the PBKDF2 RF function with 1000 iterations. They can then compare the
calculated password verification code with the one saved in a .rfp file. If a comparison is success-
ful, they can further decrypt the ciphertext and verify the calculated integrity checksum against the
one saved in the .rfp file. If this final verification is successful, the brute force attack is successful;
otherwise, if any mismatch happens, attackers can simply try another possible master password.
60
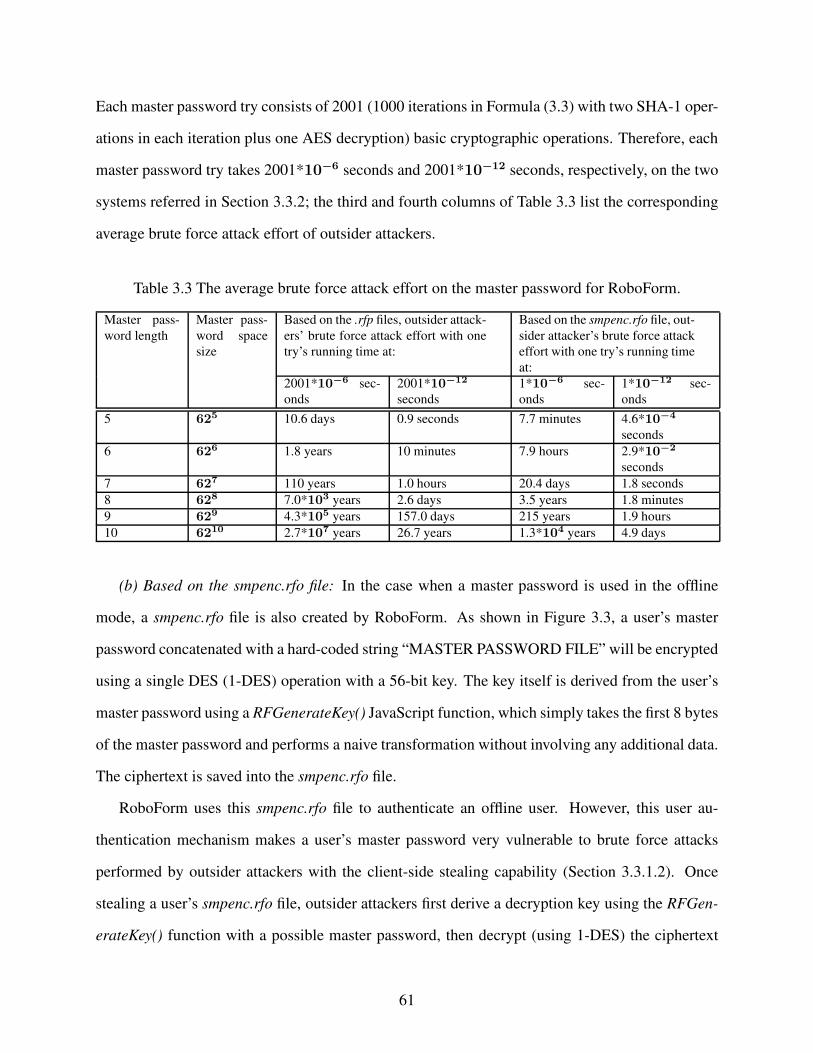
Each master password try consists of 2001 (1000 iterations in Formula (3.3) with two SHA-1 oper-
ations in each iteration plus one AES decryption) basic cryptographic operations. Therefore, each
master password try takes 2001*10−6 seconds and 2001*10−12 seconds, respectively, on the two
systems referred in Section 3.3.2; the third and fourth columns of Table 3.3 list the corresponding
average brute force attack effort of outsider attackers.
Table 3.3 The average brute force attack effort on the master password for RoboForm.
Master pass-
word length
Master pass-
word space
size
Based on the .rfp files, outsider attack-
ers’ brute force attack effort with one
try’s running time at:
Based on the smpenc.rfo file, out-
sider attacker’s brute force attack
effort with one try’s running time
at:
2001*10−6 sec-
onds
2001*10−12
seconds
1*10−6 sec-
onds
1*10−12 sec-
onds
5 625 10.6 days 0.9 seconds 7.7 minutes 4.6*10−4
seconds
6 626 1.8 years 10 minutes 7.9 hours 2.9*10−2
seconds
7 627 110 years 1.0 hours 20.4 days 1.8 seconds
8 628 7.0*103 years 2.6 days 3.5 years 1.8 minutes
9 629 4.3*105 years 157.0 days 215 years 1.9 hours
10 6210 2.7*107 years 26.7 years 1.3*104 years 4.9 days
(b) Based on the smpenc.rfo file: In the case when a master password is used in the offline
mode, a smpenc.rfo file is also created by RoboForm. As shown in Figure 3.3, a user’s master
password concatenated with a hard-coded string “MASTER PASSWORD FILE” will be encrypted
using a single DES (1-DES) operation with a 56-bit key. The key itself is derived from the user’s
master password using a RFGenerateKey() JavaScript function, which simply takes the first 8 bytes
of the master password and performs a naive transformation without involving any additional data.
The ciphertext is saved into the smpenc.rfo file.
RoboForm uses this smpenc.rfo file to authenticate an offline user. However, this user au-
thentication mechanism makes a user’s master password very vulnerable to brute force attacks
performed by outsider attackers with the client-side stealing capability (Section 3.3.1.2). Once
stealing a user’s smpenc.rfo file, outsider attackers first derive a decryption key using the RFGen-
erateKey() function with a possible master password, then decrypt (using 1-DES) the ciphertext
61

stored in the smpenc.rfo file, and finally verify whether the decrypted result is the concatenation
of the tried master password and the hard-coded string “MASTER PASSWORD FILE”. If the
verification is successful, the brute force attack is successful; otherwise, attackers can simply try
another possible master password. Each master password try consists of one basic cryptographic
operation, which is the 1-DES decryption because the overhead of the naive transformation in the
RFGenerateKey() function can be ignored. Therefore, each master password try takes 1*10−6
seconds and 1*10−12 seconds, respectively, on the two systems referred in Section 3.3.2; the fifth
and sixth columns of Table 3.3 list the corresponding average brute force attack effort of outsider
attackers.
Comparing to the brute force attacks based on the .rfp files, brute force attacks based on the
smpenc.rfo file are more efficient. With the same client-side stealing capability (Section 3.3.1.2)
requirement in both types of attacks, it is reasonable to believe that attackers would choose to take
the efficient approach of using the stolen smpenc.rfo file.
3.3.4.3 Insider Attackers’ Server-side Request Monitoring Attacks
When the online mode is used, all the credentials of a user including the master password, the
BCPM credential, and websites credentials will be sent to the cloud storage servers of RoboForm
through the HTTPS communication as shown by the dashed lines in Figure 3.3. The vulnerability
(referred to as RoboForm-Vul-3) lies in the zero protection to the data received by the insiders of
RoboForm.
As we verified through source code inspection and traffic analysis, RoboForm does not encrypt
any of those information – it simply transmits the plaintexts of those information through the
HTTPS communication. Here are some concrete examples: when a user registers a RoboForm
account, the BCPM credential is sent to the cloud storage servers of RoboForm in plaintext; when
a user remembers a website credential using RoboForm, the website credential is sent to the cloud
storage servers in plaintext; when a user sets or types the master password, the master password
is sent to the cloud storage servers in plaintext; when a user asks RoboForm to auto-fill a website
62

login form, the cloud storage servers will send back the website credential in plaintext.
Therefore, although HTTPS encrypts the client-server communication and protects against
the man-in-the-middle attacks, insider attackers with the server-side monitoring capability (Sec-
tion 3.3.1.2) can directly and completely obtain all the credentials of a user – they simply need to
monitor the incoming HTTPS requests and wait for their decryption at the server-side. This is a
severe vulnerability because insiders (BCPM vendors) should not be able to feasibly decrypt and
recover any user’s websites credentials and master password as we highlighted in the definition of
the threat model for BCPMs.
3.4 Discussions and Suggestions
In this section, we first discuss the risk levels of the vulnerabilities identified in LastPass and
RoboForm. We then provide some general suggestions to help improve the security design of
BCPMs. We hope our analysis and suggestions could also be valuable to other cloud-based data
security products and research.
3.4.1 Risk Levels of the Vulnerabilities
We follow the OWASP (Open Web Application Security Project) Risk Rating Methodology [91]
to rate the risks of the six vulnerabilities that we identified in Section 3.3. We use the standard risk
model: Risk = Likelihood * Impact. We directly rate the likelihood and impact levels for the
six vulnerabilities as LOW, MEDIUM, or HIGH values as shown in the second column and the
third column of Table 3.4, respectively. We will soon explain our ratings, but will not provide
the detailed numerical scores for calculating the likelihood and impact levels because numerical
scores could be customizable and subjective [91]. In other words, we provide the ratings based
on our perceptions; a reader may definitely have different opinions. Following the “Determining
Severity” table provided in the OWASP Risk Rating Methodology [91], we combine the likelihood
and impact ratings to derive the corresponding overall risk severity ratings as shown in the fourth
column of Table 3.4.
63
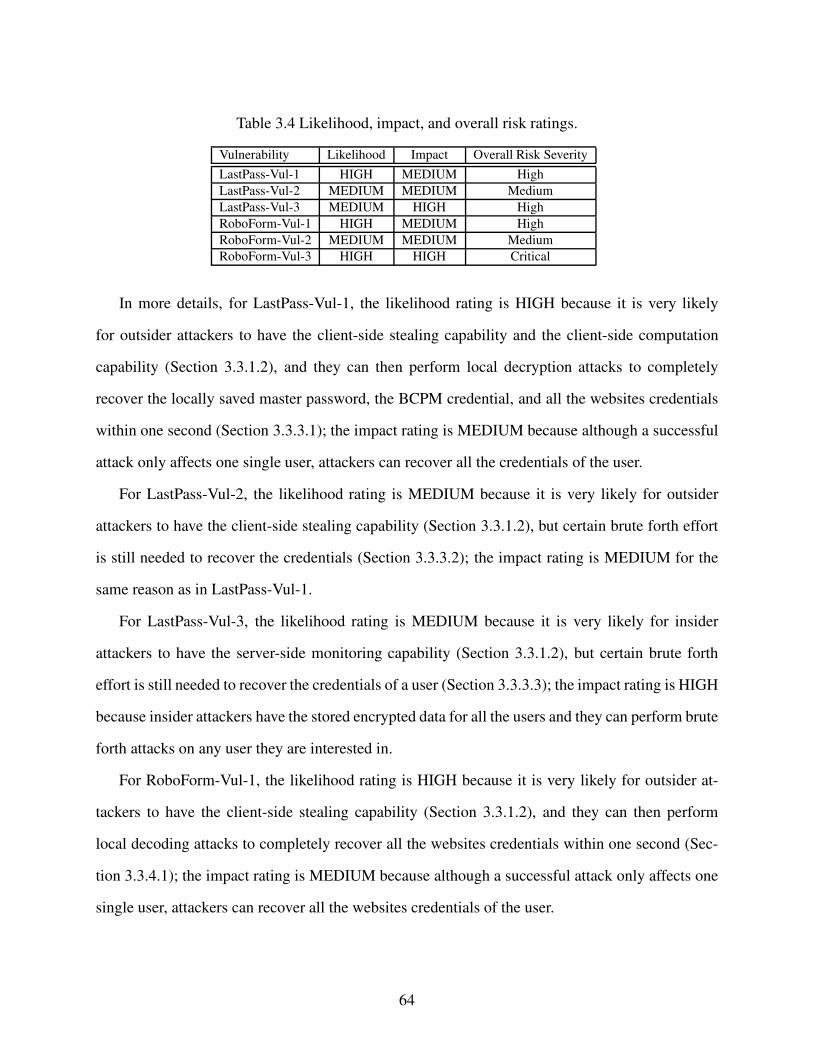
Table 3.4 Likelihood, impact, and overall risk ratings.
Vulnerability Likelihood Impact Overall Risk Severity
LastPass-Vul-1 HIGH MEDIUM High
LastPass-Vul-2 MEDIUM MEDIUM Medium
LastPass-Vul-3 MEDIUM HIGH High
RoboForm-Vul-1 HIGH MEDIUM High
RoboForm-Vul-2 MEDIUM MEDIUM Medium
RoboForm-Vul-3 HIGH HIGH Critical
In more details, for LastPass-Vul-1, the likelihood rating is HIGH because it is very likely
for outsider attackers to have the client-side stealing capability and the client-side computation
capability (Section 3.3.1.2), and they can then perform local decryption attacks to completely
recover the locally saved master password, the BCPM credential, and all the websites credentials
within one second (Section 3.3.3.1); the impact rating is MEDIUM because although a successful
attack only affects one single user, attackers can recover all the credentials of the user.
For LastPass-Vul-2, the likelihood rating is MEDIUM because it is very likely for outsider
attackers to have the client-side stealing capability (Section 3.3.1.2), but certain brute forth effort
is still needed to recover the credentials (Section 3.3.3.2); the impact rating is MEDIUM for the
same reason as in LastPass-Vul-1.
For LastPass-Vul-3, the likelihood rating is MEDIUM because it is very likely for insider
attackers to have the server-side monitoring capability (Section 3.3.1.2), but certain brute forth
effort is still needed to recover the credentials of a user (Section 3.3.3.3); the impact rating is HIGH
because insider attackers have the stored encrypted data for all the users and they can perform brute
forth attacks on any user they are interested in.
For RoboForm-Vul-1, the likelihood rating is HIGH because it is very likely for outsider at-
tackers to have the client-side stealing capability (Section 3.3.1.2), and they can then perform
local decoding attacks to completely recover all the websites credentials within one second (Sec-
tion 3.3.4.1); the impact rating is MEDIUM because although a successful attack only affects one
single user, attackers can recover all the websites credentials of the user.
64

For RoboForm-Vul-2, the likelihood rating is MEDIUM because it is very likely for outsider
attackers to have the client-side stealing capability (Section 3.3.1.2), but certain brute forth effort
is still needed to recover the credentials (Section 3.3.4.2); the impact rating is MEDIUM because
although a successful attack only affects one single user, attackers can recover the master password
and all the websites credentials of the user.
For RoboForm-Vul-3, the likelihood rating is HIGH because it is very likely for insider attack-
ers to have the server-side monitoring capability (Section 3.3.1.2), and they can perform request
monitoring attacks to completely obtain all the credentials of any user (Section 3.3.4.3); the impact
rating is HIGH because a successful attack affects all the users who have the online interactions
with RoboForm.
As noted in Section 3.3.1.3, we consider the effort of brute force attacks as the upper bound,
and attackers can definitely use different dictionaries to reduce their effort. In addition, attackers
can also use multiple computers to reduce their brute force attack effort. Therefore, although
the likelihood rating of LastPass-Vul-2, LastPass-Vul-3, and RoboForm-Vul-2 is MEDIUM, we
should never overlook their potential risks especially because the brute force effort is not daunting
as estimated in Table 3.2 and Table 3.3.
3.4.2 Suggestions to Secure BCPM Design
Based on our detailed vulnerability and risk analysis results, we provide the following general
suggestions to help improve the security design of BCPMs.
Suggestion 1: user data should be protected with strong confidentiality and authenticity mech-
anisms before being sent to cloud storage servers. In other words, strong protection (as will be
further explained in the following suggestions) must be performed at the client-side and a BCPM
should assure users that no insider can obtain users’ websites credentials by any feasible means.
This suggestion corresponds to the critical security risk of RoboForm-Vul-3.
Suggestion 2: outsider attackers’ client-side stealing capability and client-side computation
capability (Section 3.3.1.2) should be seriously considered by BCPM designers given the rampancy
65

of client-side attacks such as drive-by-downloads [50–54]; therefore, locally saved sensitive data
should be strongly protected, and convenient mechanisms such as master password remembering
should not be provided if they will sacrifice the security of the BCPM. This suggestion corresponds
to the high security risk of LastPass-Vul-1 and RoboForm-Vul-1.
Suggestion 3: a master password mechanism must be provided in a BCPM, and users should
be mandated to use a strong master password with the strength assured by a proactive password
checker. A strong master password is the only thing (if a second authentication factor such as a
security token does not exist) that a user can count on to defend against both insider and outsider
attackers. Protecting websites credentials without using a master password is analogous to protect-
ing valuables in a safe without setting a combination [48]. This suggestion corresponds to the high
security risk of RoboForm-Vul-1 because a master password is optional in RoboForm (Table 3.1);
it also corresponds to the high security risk of LastPass-Vul-3 and the medium security risk of
LastPass-Vul-2 and RoboForm-Vul-2 because both BCPMs do not have any strength requirement
on a user’s master password (Table 3.1).
Suggestion 4: large iteration count values should be used in the password based key derivation
functions such as PBKDF2 [70] so that the effort for each master password try will be non-trivial
(e.g., taking a few seconds) and brute force attacks against a strong master password will be com-
putationally infeasible. This suggestion corresponds to the high security risk of LastPass-Vul-3
and the medium security risk of LastPass-Vul-2 and RoboForm-Vul-2 because neither LastPass
nor RoboForm uses large iteration count values as shown in Formulas (3.1), (3.2), and (3.3).
Suggestion 5: a user’s master password should be used to authenticate the user, but it should
not be insecurely associated with any authenticator that will be sent to the cloud storage servers
or saved locally to the user’s machine. This suggestion corresponds to the high security risk of
LastPass-Vul-3 because attackers can try a possible master password and verify against either
the BCPM credential or the double-hashed value sent to the cloud storage servers of LastPass;
it also corresponds to the medium security risk of LastPass-Vul-2 and RoboForm-Vul-2 because
attackers can try a possible master password and verify against the locally saved authenticator. We
66

separate this suggestion from suggestion 4 because an authenticator (e.g., the BCPM password in
RoboForm) is not necessarily derived from password based key derivation functions.
Suggestion 6: data authenticity should be assured and an authenticity verification should not
weaken confidentiality. This suggestion corresponds to the medium security risk of RoboForm-
Vul-2 because the integrity checksum in a .rfp file can be used in the brute force attacks and should
be more securely generated by following the above suggestion 4. LastPass does not verify the
authenticity (integrity and source) of the records saved in its database tables; therefore, this last
suggestion also applies to LastPass.
3.5 Summary
In this project, we analyzed the security design of two very popular commercial BCPMs: Last-
Pass and RoboForm. We identified several critical, high, and medium risk level vulnerabilities
in both BCPMs and analyzed how insider and outsider attackers can exploit those vulnerabilities
to perform different attacks. We provided some general suggestions to help improve the security
design of BCPMs. We hope our analysis and suggestions could also benefit other cloud-based data
security products and research.
67

CHAPTER 4
AUTOMATIC DETECTION OF INFORMATION LEAKAGE VULNERABILITIES IN
BROWSER EXTENSIONS
4.1 Introduction
Popular web browsers all support extension mechanisms to help third-party developers extend
the functionality of browsers and improve user experience. A large number of extensions exist
in browser vendors’ online stores for millions of users to download and use. Quite often, those
extensions are written in JavaScript; they have higher privileges than regular webpages do, thus
have become a popular vector for performing web-based attacks [92, 93].
Because many extensions have security vulnerabilities [92–99] and some extensions are even
malicious, browser vendors have taken stricter measures to control the extensions that can be in-
stalled on browsers. For example, Google bans Windows version chrome extensions found outside
the Chrome Web Store starting from January 2014, and inspects the extensions in the Chrome Web
Store to exclude the malicious ones.
Researchers have extensively studied privilege escalation related vulnerabilities in JavaScript-
based extensions and shown that a lack of sufficient security knowledge in developers is one of
the main reasons for many vulnerabilities [92–94, 97, 99]. However, an often overlooked problem
is that extensions may accidentally leak users’ sensitive information out of the browsers without
protection.
Many browser extensions process sensitive information coming from either user inputs or web-
pages. For example, some extensions save users’ website passwords, some extensions remember
users’ shopping preferences, and some extensions manage users’ bookmarks. If such sensitive in-
formation is leaked out of the browser without protection, it can be used by unauthorized parties
to illegally access users’ online accounts, steal their online identities, or track their online behav-
iors. Therefore, banning extensions that may leak users’ sensitive information is also necessary
68

and important.
Yet detecting information leakage in JavaScript-based web browser extensions is especially
challenging. One source of the challenges is JavaScript itself, an interpreted prototype-based
object-oriented programming language with just-in-time code loading/generation [100–103] and
dynamic uses of functions, fields and prototypes [104–106]. The other source of the challenges is
the highly complex interactions among browser extensions, internal components of browsers, and
webpages [93, 94, 97, 99]. Only a handful of solutions have been proposed to address the problem
of information leakage in JavaScript-based browser extensions [95, 96, 98]; however, they took
either pure dynamic approaches or pure static approaches, thus suffering from many limitations
(Section 4.5).
In this project, we present a framework, LvDetector, that combines static and dynamic pro-
gram analysis techniques for automatic detection of information leakage vulnerabilities in legit-
imate browser extensions. LvDetector focuses on legitimate browser extensions because lots of
them are used by millions of users [107, 108], thus the impact level of their information leakage
vulnerabilities is high. LvDetector does not aim to be sound at the whole program level (Sec-
tion 4.3.1); it aims to be a practical and accurate utility by (1) using a dynamic scenario-driven call
graph construction scheme to reduce the overall false positives in the analysis as much as possi-
ble, and (2) using static analysis based on each dynamically constructed call graph to extensively
analyze the corresponding scenario. Extension developers can use LvDetector to locate and fix
the vulnerabilities in their code; browser vendors can use LvDetector to decide whether the corre-
sponding extensions can be hosted in their online stores; advanced users can also use LvDetector
to determine if certain extensions are safe to use. Note that detecting potentially malicious code or
intentional vulnerabilities is out of the scope of the current LvDetector framework.
The design of LvDetector is not bound to specific web browsers or JavaScript engines, and can
adopt other program analysis techniques. We implemented LvDetector in Java and evaluated it on
28 popular Firefox and Google Chrome extensions. LvDetector identified 18 previously unknown
information leakage vulnerabilities in 13 extensions with a 87% accuracy rate. The evaluation
69

results and the feedback to our responsible disclosure demonstrate that LvDetector is useful and
effective.
The main contributions of this work include: (1) a dynamic scenario-driven call graph con-
struction scheme, (2) a formulation of transitive relations and function/program-level static anal-
ysis algorithms for effective exploration of information flow paths in browser extensions, (3) a
unique framework that combines static and dynamic program analysis techniques for automatic
detection of information leakage vulnerabilities in JavaScript-based browser extensions, and (4) an
effectiveness evaluation of LvDetector.
The rest of this chapter is organized as follows. Section 4.2 uses an example to illustrate
the vulnerability analysis problem targeted by this project. Section 4.3 presents the details of
the LvDetector framework. Section 4.4 evaluates the effectiveness of LvDetector. Section 4.5
discusses the related work. Finally, Section 4.6 makes a conclusion.
4.2 Motivating Example
Many legitimate browser extensions process sensitive information coming from either user
inputs or webpages. If such sensitive information is leaked out of the browser without protection,
it can be used by unauthorized parties to illegally access users’ online accounts, steal their online
identities, or track their online behaviors. Figure 4.1 depicts a code excerpt of a real example
browser extension that manages users’ website passwords. In the code excerpt, this extension
obtains the website password and username of a user in the save() function, encodes the password
and username in the encode() function, and sends the encoded string to the remote server of the
extension through the send() method of an XMLHttpRequest object in the post() function.
When this example extension was submitted to the extension web store of a browser vendor, the
developers claimed that they cannot know users’ website passwords. The browser vendor wants
to verify this claim and identify potential information leakage vulnerabilities in this extension, but
manually inspecting about 26,000 lines of code in this extension is time and effort consuming. The
browser vendor can use LvDetector to easily perform this inspection task in three steps: (1) runs
70

function save() {
var pwd = document.getElementById("pwd").value;
var usr = document.getElementById("usr").value;
var str = encode(pwd, usr);
post(str);
}
...
function encode(pwd, usr) {
return encodeURI(pwd) + encodeURI(usr);
}
...
function post(content) {
var req = new XMLHttpRequest();
var url = "https://www.remoteserver.com/"
req.open("POST", url);
req.send(content);
}
Figure 4.1 Code excerpt of a real example extension
LvDetector to instrument this extension, (2) executes a website password saving scenario using
the instrumented extension, and (3) runs LvDetector to automatically detect potential information
leakage vulnerabilities and generate a report. The browser vendor can also directly perform the
third step by using the execution traces supplied by other LvDetector users (Section 4.3.2.1).
The generated vulnerability report contains a vulnerable information flow record: the website
password assigned to the “pwd” variable in the save() function is propagated through the encode()
function to the “content” variable in the post() function, and is leaked out in a send() method call.
All the detailed operations in this vulnerable information flow are also provided in the report.
A user’s website password should only be known by the user and the corresponding website -
sending the unprotected website password to the remote server of the extension allows server-side
attackers to directly obtain the user’s website login information. LvDetector correctly identifies
this vulnerability, providing evidence for the browser vendor to disprove the extension developers’
claim.
4.3 Overall Framework
Our key objective is to design LvDetector as a framework that can be easily used by analysts
(extension developers, browser vendors, or advanced users) to automatically detect information
71
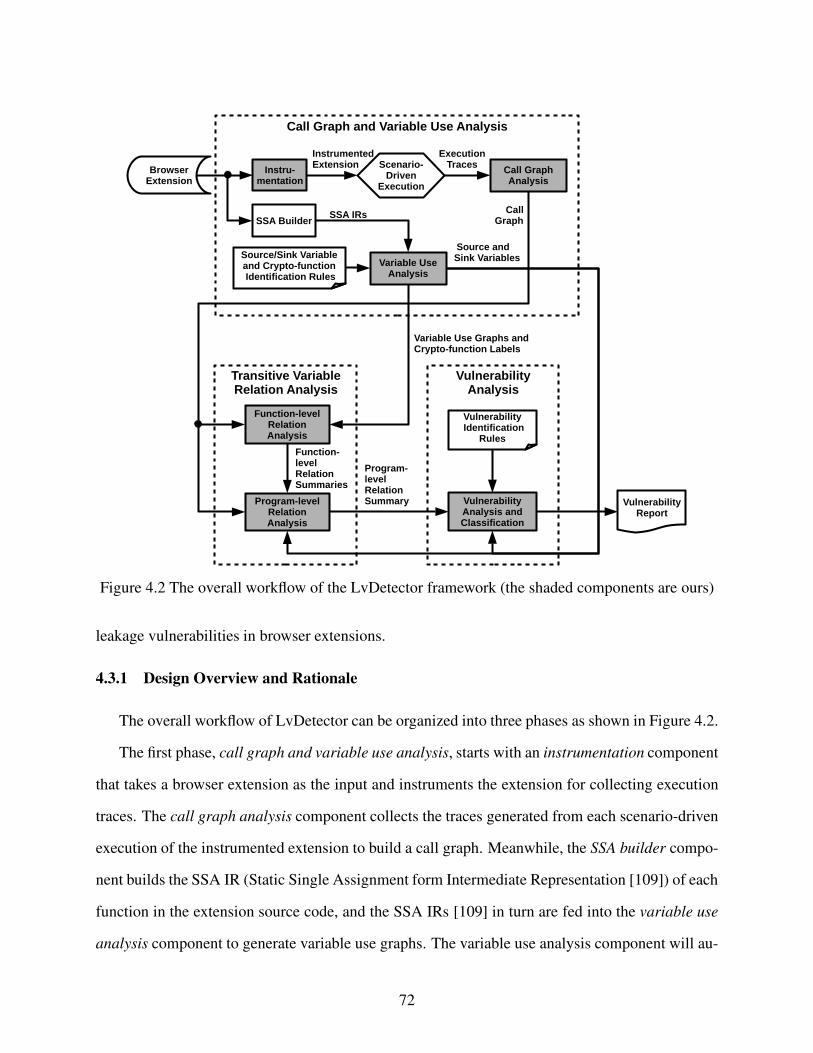
Figure 4.2 The overall workflow of the LvDetector framework (the shaded components are ours)
leakage vulnerabilities in browser extensions.
4.3.1 Design Overview and Rationale
The overall workflow of LvDetector can be organized into three phases as shown in Figure 4.2.
The first phase, call graph and variable use analysis, starts with an instrumentation component
that takes a browser extension as the input and instruments the extension for collecting execution
traces. The call graph analysis component collects the traces generated from each scenario-driven
execution of the instrumented extension to build a call graph. Meanwhile, the SSA builder compo-
nent builds the SSA IR (Static Single Assignment form Intermediate Representation [109]) of each
function in the extension source code, and the SSA IRs [109] in turn are fed into the variable use
analysis component to generate variable use graphs. The variable use analysis component will au-
72

tomatically identify (1) commonly used cryptographic functions (e.g., AES encryption/decryption
and SHA hash functions), (2) source variables that accept values from either user inputs or web-
pages (e.g., through form fields), and (3) sink variables that contain values either saved to the local
disk (e.g., through the setItem() method call of the localStorage object in HTML5) or sent across
the network (e.g., through the send() method call of an XMLHttpRequest object). Sink variables
are extracted from the sink statements, which are either common or specific to different browsers
and are XMLHttpRequest, window object, SQLite database, file, local storage, bookmark, and
password manager related statements. These criteria for identifying standard/nonstandard crypto-
graphic functions, source variables, and sink variables in Google Chrome and Firefox extensions
are included in a rule file.
The second phase, transitive variable relation analysis, computes a transitive summary of the
relations among each pair of the source and sink variables. Specifically, the function-level relation
analysis component iteratively computes a function-level relation summary for each function based
on its variable use graph, the call graph, and the labeled cryptographic functions; the program-level
relation analysis component computes the program-level relation summary based on the call graph
and the function-level relation summaries.
Finally, the third phase, vulnerability analysis, identifies all the potential vulnerable informa-
tion flows that may lead to sensitive information leakage. It analyzes vulnerabilities based on
the program-level relation summary and the source-sink variable pairs, and generates an intuitive
report with a list of classified vulnerability records for each scenario-driven execution.
The overall workflow takes a hybrid approach to analyze JavaScript browser extensions. It
uses scenario-driven execution traces to dynamically and accurately construct a call graph; it then
statically performs variable use analysis and transitive variable relation analysis based on SSA
IR [109] to summarize the overall information flows among variables both within a single func-
tion and across function boundaries. The dynamic aspects of our approach accurately capture
intricate across-function-boundary information flows that often occur in JavaScript extensions due
to reflection, function objects, event handlers, asynchronous calls, DOM interactions, and so on.
73

The static aspects of our approach extensively extract both explicit and implicit information flows
within each function. This hybrid approach is superior to pure static approaches by effectively
reducing false positives in the construction of call graphs [106], which are often the foundation of
the overall program analysis. This approach is not bound to specific web browsers or JavaScript
engines; it is superior to pure dynamic approaches by avoiding users’ or browsers’ responses to
runtime alerts, incomplete information flow exploration, runtime overhead, and browser-specific
instrumentation [92, 96, 110, 111].
Most analysis tools for statically typed programming languages choose to be sound rather
than complete. However, due to the complexity and dynamic features of the JavaScript language
(Section 4.1), achieving soundness in the static analysis of the full JavaScript language is very
difficult or impossible [106, 112, 113]. Meanwhile, LvDetector bases its static analysis on the call
graphs constructed from the scenario-driven execution traces, which may not cover all the possible
execution paths in the program. Due to these reasons, LvDetector does not aim to be sound at
the whole program level; it aims to be a practical and accurate utility. Note that scenario-driven
execution traces can be more extensively collected as discussed in Section 4.3.2.1.
4.3.2 Call Graph and Variable Use Analysis
In this phase, LvDetector performs browser extension instrumentation, and call graph and vari-
able use analysis.
4.3.2.1 Instrumentation and Call Graph Analysis
While call graph construction has been commonly used in whole program analysis of C and
Java code [114, 115], accurately constructing call graphs for JavaScript code is very challenging
due to its extremely dynamic (1) code loading and generation [100–103], (2) uses of functions,
fields, and prototypes [104–106], and (3) interactions with other components of the browsers and
webpages [93, 94, 97, 99].
To accurately construct call graphs that are the foundation of the overall analysis, we take an
instrumentation approach to dynamically extract call relations among different functions within
74

a browser extension. As shown in Figure 4.2, this instrumentation component takes a browser
extension as input, automatically inserts program tracing statements to the extension, and outputs
the instrumented extension.
Specifically, it (1) formats the source code of the extension so that each line contains one
JavaScript statement, (2) adds unique prototype names to the functions (including methods) that do
not have explicit ones so that all the functions can be uniquely identified, (3) inserts print statements
before each function/method call so that the detailed callsite information such as the prototype
name of the caller, the call statement, and the callsite position can be recorded, and (4) inserts a
print statement at the entry point of each function definition so that the detailed information about
the callee can be recorded. Because these transformations are simple and minimal, they do not
interfere with the original program functionality and semantics. In the cases that some extensions
use the dynamic features of JavaScript such as the eval() function to obfuscate their original source
code, this instrumentation component uses the Closure Compiler [116] and the ScriptEngine class
in Java to evaluate the eval() statements and de-obfuscate the source code before performing the
aforementioned transformations. The de-obfuscated extension source code does not further contain
any eval() as observed in our experiments (Section 4.4), indicating that JavaScript in legitimate
browser extensions rarely uses multi-level obfuscation.
An analyst can install and run such an instrumented extension to generate the execution traces
for each particular use scenario. Because the execution traces only contain the call relations and
do not contain any information from users, they can also be shared (e.g., in a repository along
with the extensions) among the analysts to further cover more execution paths of the extension.
For example, extension developers can run LvDetector and contribute execution traces based on
their test cases, browser vendors can run LvDetector and contribute execution traces based on their
inspection tasks, and advanced users can run LvDetector and contribute execution traces based on
their trial runs. All these traces can be leveraged to automatically perform or replicate the actual
vulnerability analysis.
75

The call graph analysis component analyzes the dynamically generated execution traces to
build a call graph that precisely reflects the actual call relations in the real use scenario. The
output call graph is a directed graph. Its nodes and edges are all the functions and call relations
traversed in a scenario-driven execution, respectively. Such a call graph can accurately capture
the complex and dynamic function/method calls that often occur in JavaScript extensions due to
reflection, function objects, event handlers, asynchronous calls, DOM interactions, and so on.
4.3.2.2 Variable Use Analysis
The purpose of this component is to construct a graph that precisely defines the immediate
value flow relations among variables in each function, based on an SSA IR [109] constructed from
the source code of the browser extension.
For each function, its variable use graph is a directed graph with nodes representing all the
variables defined/used in the function, and edges representing the operations used to propagate
values among variables. The direction of an edge represents the value flow direction. Since the
input program is converted to its SSA IR, each variable is statically and precisely defined once and
thus is associated with a single value. Therefore, the static definition and uses of every variable in
the program can be precisely correlated.
Our variable use analysis directly employs the output from an existing SSA builder [117]. The
IR output of the SSA builder contains mappings between SSA variables and the original JavaScript
variables, and mappings between SSA instructions and the original JavaScript statements. This
mapping information will be used in the vulnerability analysis phase to generate intuitive vulnera-
bility reports.
The main step of the variable use analysis is to extract the operands and operators from the
instructions in SSA IR. Each operand represents a unique variable in SSA IR, and each operator
represents an operation that may propagate values among variables. The operations include ob-
ject field reference, getters/setters, string operation, array access, binary/unary operation, global
variable reference, assignment operation, Φ-function [109], and function call. The variable use
76

graph is then constructed in a straightforward fashion to precisely record such immediate explicit
and implicit (via Φ-functions) value flow relations. Meanwhile, a list of global variable references
will also be maintained. This list will be used in the transitive variable relation analysis phase to
compute information flows across functions. Based source/sink variable and crypto-function iden-
tification rules in the rule file (Section 4.3.1), this component also automatically identifies all the
source/sink variables and cryptographic functions, and feeds them to the next two analysis phases.
Figure 4.3(a) illustrates the three variable use graphs for the code excerpt in Figure 4.1. Here the
edge v10+−→ v13 in the variable use graph for the encode() function represents a value flow from
v10 to v13 through a string concatenation operation, and the edge v3encode()−−−−−→ v7 in the variable
use graph for the save() function represents a value flow from v3 to v7 through the encode()
function call.
4.3.3 Transitive Variable Relation Analysis
This phase summarizes the transitive relations between each pair of source and sink variables
at both the function-level and the program-level.
4.3.3.1 Function-level Relation Analysis
This component iteratively computes a function-level relation summary for each function based
on its variable use graph, the call graph, and the labeled cryptographic functions. Such a summary
contains the transitive relations between each pair of variables in that function.
We formulate the dynamically generated call graph as G in Formula 4.1. We categorize the
original operators in a variable use graph into a set of abstract operators, Operator, defined in
Formula 4.2. For example, the string concatenation and substring operators are categorized as
“STRING OP”, the arithmetic operators are categorized as “BINARY OP”, the calls to the labeled
encryption functions are categorized as “ENCRYPT”, the calls to the labeled decryption functions
are categorized as “DECRYPT”, the calls to the JavaScript global functions (e.g., encodeURI())
are categorized as “JS GLOBAL”, and the calls to all other JavaScript functions are initially cate-
gorized as “UNKNOWN”. The Φ-function used in SSA IR [109] is categorized as “Φ”. We define
77
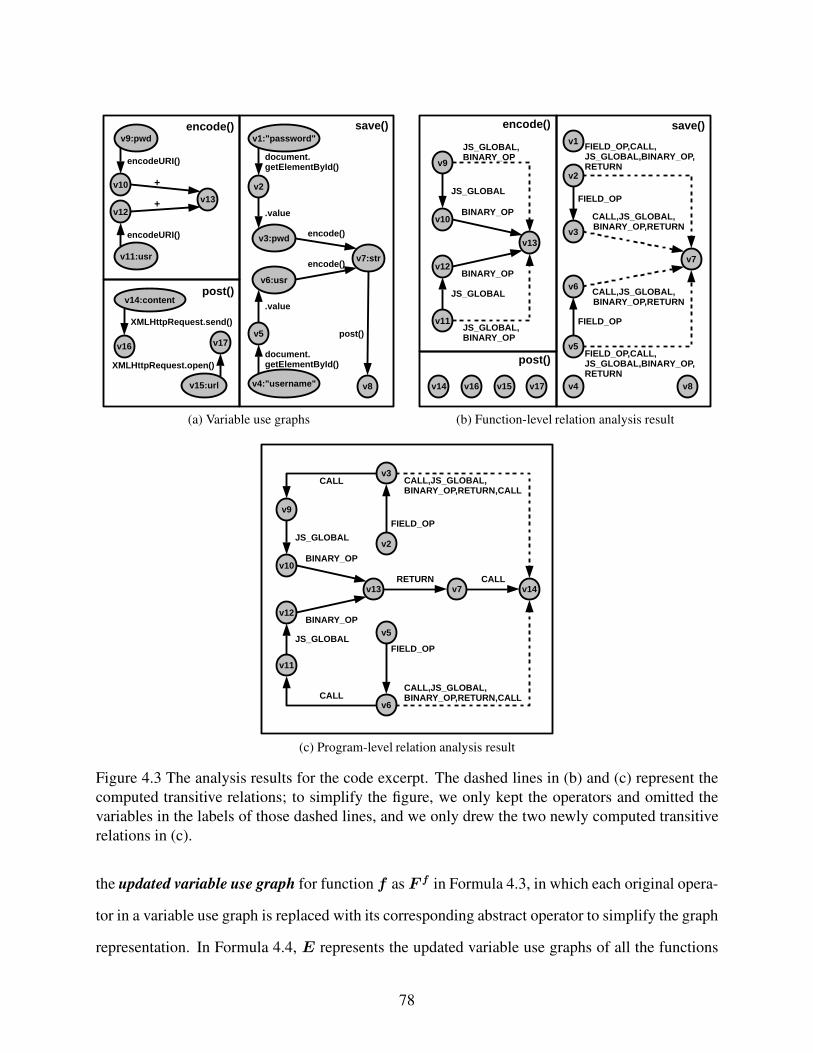
(a) Variable use graphs (b) Function-level relation analysis result
(c) Program-level relation analysis result
Figure 4.3 The analysis results for the code excerpt. The dashed lines in (b) and (c) represent the
computed transitive relations; to simplify the figure, we only kept the operators and omitted the
variables in the labels of those dashed lines, and we only drew the two newly computed transitive
relations in (c).
the updated variable use graph for function f as F f in Formula 4.3, in which each original opera-
tor in a variable use graph is replaced with its corresponding abstract operator to simplify the graph
representation. In Formula 4.4, E represents the updated variable use graphs of all the functions
78

in the call graph G.
G = {fis−→ fj | s is a callsite from function fi to fj} (4.1)
Operator = {ENCRY PT, DECRY PT, JS GLOBAL,
PROTOTY PE, CONSTRUCT, FIELD OP,
ATTRIBUTE OP, ARRAY OP, STRING OP
UNARY OP, BINARY OP, Φ, UNKNOWN} (4.2)
F f = {xf op−→ yf | x, y are variables referenced in f,
f ∈ G, relation y = op(x) is in f, op ∈ Operator} (4.3)
E =⋃
f∈G
F f (4.4)
The value of a variable in a caller function may be passed to a variable in a callee function;
we use an abstract operator CALL to represent this type of value passing operation, and define
Cforward in Formula 4.5 as the set of all such call value flows extracted from the call graph G.
The value of a variable in a caller function may be also updated with the return value from a callee
function; we use an abstract operator RETURN to represent this type of value return operation,
and define Cbackward in Formula 4.6 as the set of all such return value flows extracted from the
call graph G. In Formula 4.7, E+ defines the extended variable use graphs, and it is the union of
E, Cforward, and Cbackward. In Formula 4.8, Operator+ defines the extended set of abstract
operators, and it is the union of Operator and {CALL,RETURN}.
We use Formula 4.9 to define the transitive relation summary Qf for function f , which is the
set of transitive relations between each pair of variables x and y in the same function f . Each
transitive relation is represented by a sequence of abstract operators and variables through which
a value is passed from x to y. In Formula 4.10, Q defines the function-level relation summaries
for all the functions in the call graph G.
79

Cforward = {argfiCALL−−−−→ parafj | fi
s−→ fj ∈ G,
argfi is the argument of the callsite s in fi,
parafj is the corresponding parameter of fj} (4.5)
Cbackward = {retfjRETURN−−−−−−→ recfi | fi
s−→ fj ∈ G,
retfj is the variable returned in fj, recfi accepts
the returned value from callsite s in fi} (4.6)
E+ = E ∪ Cforward ∪ Cbackward (4.7)
Operator+ = Operator ∪ {CALL, RETURN} (4.8)
Qf (x, y) = {(xf , op1, vf1
1 , op2, vf2
2 , · · · , vfk−1
k−1 , opk, yf) |
f, f1, f2, . . . , fk−1 ∈ G, op1, op2, . . . opk ∈ Operator+,
xf op1−−→ vf1
1 , vf1
1
op2−−→ vf2
2 , . . . , vfk−1
k−1
opk−−→ yf ∈ E+} (4.9)
Function level relation summaries Q =⋃
f∈G
Qf (4.10)
Figure 4.4 illustrates the function-level relation analysis algorithm for computing Q. The algo-
rithm consists of two procedures. The Compute-ExtendedVariableUseGraphs procedure constructs
the variable use graphs E (Formula 4.4) from line 2 to line 4, constructs Cforward (Formula 4.5)
from line 5 to line 8, constructs Cbackward (Formula 4.6) from line 9 to line 12, and finally returns
the extended variable use graphs E+ (Formula 4.7) at line 14.
The Compute-FunctionLevelRelations procedure initializes each transitive relation summary
Qf for function f with its updated variable use graph F f at line 2 in the first for loop. In the fol-
lowing do-while loop, for each function f in the post-order traversal of G, this procedure updates
Qf with the newly computed transitive relations for each pair of variables in that function f from
line 6 to line 7. The post-order traversal is used at line 5 so that callee functions are analyzed prior
to their caller functions whenever possible. This update is an iterative process, and the do-while
80

loop terminates when no more update occurs to any Qf . The union of all the Qf s is returned at
line 10.
The compute transitive summary sub-procedure is capable of summarizing paths and cycles to
compute transitive relations on a graph, based on the transitive operations defined for a given prob-
lem. In this sub-procedure, cycles are summarized using their equivalent directed acyclic graphs
(DAGs) [118], and “UNKNOWN” operators are replaced with their corresponding transitive re-
lations in the callee functions; therefore, the do-while loop from line 4 to line 8 must terminate.
Many existing transitive closure computation algorithms such as [118, 119] could be adapted to
implement this sub-procedure. We implement this sub-procedure in our framework by adapting
the algorithm in [118], which is an efficient algorithm with a time complexity linear to the number
of nodes and edges in the input graph.
Figure 4.3(b) illustrates the function-level relation analysis result for the code excerpt in Fig-
ure 4.1. For example, the computed transitive relation from v3 to v7 is labeled with “CALL,JS GLOBAL,
BINARY OP,RETURN”; we only kept these operators and omitted the variables in the label to
simplify the figure.
4.3.3.2 Program-level Relation Analysis
The purpose of the program-level relation analysis is to compute program-level relation sum-
mary based on the call graph and the function-level relation summaries. Specifically, it aims to
further summarize transitive relations between each pair of the specified source and sink variables,
irrespective of whether the pair of variables are defined in the same function or in different func-
tions.
It is important to note that partial cross-function relations (i.e., Cforward and Cbackward) have
been included in the function-level relation analysis algorithm shown in Figure 4.4. Computing
function-level relation summaries based on small-size and localized extended variable use graphs
before computing program-level relation summary is critical for the LvDetector framework to
efficiently analyze large and complex extensions; otherwise, directly analyzing transitive relations
81

Compute-ExtendedVariableUseGraphs (P , G)
// P : program; G: call graph.
1 E = Cforward = Cbackward = ∅;
2 for each function f ∈G do
3 F f = get updated var use graph(P , f );
4 E = E ∪ F f ;
5 for each edge fis−→ fj ∈G do
6 argfi = argument of callsite(s);
7 parafj = parameter of function(fj);
8 Cforward = Cforward ∪ (argfiCALL−−−−→ parafj );
9 for each edge fis−→ fj ∈G do
10 retfj = return var of function(fj);
11 recfi = accept return value var(s);
12 Cbackward = Cbackward ∪ (retfjRETURN−−−−−−→ recfi);
13 E+ = E ∪ Cforward ∪ Cbackward;
14 return E+;
Compute-FunctionLevelRelations (P , G, E+)
// P : program; G: call graph;
// E+: extended variable use graphs.
1 for each function f ∈G do
2 Qf = F f = get updated var use graph(P , f );
3 varsf = get nodes in(F f );
4 do
5 for each function f in the post-order traversal of G do
6 for each pair of variables src, dst ∈ varsf do
7 Qf(src, dst) =
compute transitive summary(E+, src, dst);8 while at least one Qf is updated
9 Q =⋃
f∈G Qf ;
10 return Q;
Figure 4.4 Function-level relation analysis algorithm
on a program-level graph consisting of many extended variable use graphs with complex cycles
and paths will be very inefficient. This is the key reason for us to explicitly divide the transitive
variable relation analysis into two steps at the function-level and program-level.
The value of a variable in a function may be passed to another variable in another function
through global variables or JavaScript events. We use an abstract operator GLOBAL to repre-
sent the type of value passing through global variables, and define Cglobal in Formula 4.11 as the
set of all such global value flows extracted from the whole program P ; we use an abstract oper-
ator MESSAGE to represent the type of value passing through JavaScript events, and define
82

Cmessage in Formula 4.12 as the set of all such message value flows extracted from the whole
program P . In Formula 4.13, E′ defines the further-extended variable use graphs, and it is the
union of E+, Cglobal, and Cmessage; in Formula 4.14, Operator′ defines the further-extended
set of abstract operators, and it is the union of Operator+ and {GLOBAL,MESSAGE}.
Formula 4.15 defines the transitive relation summary, T fi,fj , which is the set of transitive
relations from any variable x in function fi to any variable y in function fj. Formula 4.16 defines
the program-level relation summary, T , which is the output of the program-level relation analysis
component.
Cglobal = {vfiGLOBAL−−−−−−→ vfj |
global variable v is defined in fi and used in fj} (4.11)
Cmessage = {argfiMESSAGE−−−−−−−→ parafj |
an event is dispatched in fi, and processed in fj,
argfi is the argument to this event,
parafj is the corresponding parameter of fj} (4.12)
E′ = E+ ∪ Cglobal ∪ Cmessage (4.13)
Operator′ = Operator+ ∪ {GLOBAL, MESSAGE} (4.14)
T fi,fj(x, y) = {(xfi, op1, vf1
1 , · · · , vfk−1
k−1 , opk, yfj) |
fi, f1, . . . , fk−1, fj ∈ G, op1, . . . opk ∈ Operator′,
xfiop1−−→ vf1
1 , . . . , vfk−1
k−1
opk−−→ yfj ∈ E′} (4.15)
Program level relation summary T =⋃
fi,fj∈G
T fi,fj (4.16)
Figure 4.5 illustrates the overall program-level relation analysis algorithm for computing T .
It constructs Cglobal (Formula 4.11) from line 2 to line 5, constructs Cmessage (Formula 4.12)
from line 6 to line 9, builds the further-extended variable use graphs E′ (Formula 4.13) at line
83

Compute-ProgramLevelRelations (P , Q, E+, sV ars, dV ars)
// P : program; Q: function-level relation summaries;
// E+: extended variable use graph;
// sV ars: a set of source variables;
// dV ars: a set of destination (sink) variables.
1 Cglobal = Cmessage = ∅; T = Q;
2 for each global variable v in P do
3 defs = get definitions(v); uses = get uses(v);
4 for each pair of vfi ∈ defs and vfj ∈ uses do
5 Cglobal = Cglobal ∪ (vfiGLOBAL−−−−−−→ vfj );
6 for each event evt dispatched in fi and processed in fj do
7 argfi = argument of event(evt);8 parafj = parameter of function(fj);
9 Cmessage = Cmessage ∪ (argfiMESSAGE−−−−−−−→ parafj );
10 E′ = E+ ∪ Cglobal ∪ Cmessage;
11 for each pair of src ∈ sV ars and dst ∈ dV ars do
12 T fi,fj(src, dst) = // src is in fi, dst is in fj
compute transitive summary(E′, src, dst);13 return T ;
Figure 4.5 Program-level relation analysis algorithm
10, updates T with the newly computed transitive relations from line 11 to line 12 for each pair
of variables constructed from the input sets sV ars and dV ars, and finally returns T . The
compute transitive summary sub-procedure at line 12 is the same one that is used in the function-
level relation analysis algorithm (Figure 4.4). It is worth mentioning that in the program-level
relation analysis, the number of edges will not increase exponentially because paths and cycles
were summarized in the compute transitive summary sub-procedure, and the transitive relations
computed in the function-level analysis will not be computed again in the program-level analysis.
Figure 4.3(c) illustrates the program-level relation analysis result for the code excerpt in Fig-
ure 4.1. The source variables are v3 and v6, and the sink variable is v14. Two new transitive
relations are computed from v3 to v14 and from v6 to v14, respectively; both of them are labeled
with “CALL,JS GLOBAL,BINARY OP,RETURN,CALL”.
84

4.3.4 Vulnerability Analysis
The purpose of this phase is to analyze vulnerabilities based on the program-level relation sum-
mary and the source-destination (sink) variable pairs as shown in Figure 4.6. For all the relations
from a source variable to a destination (sink) variable, currently LvDetector reports vulnerabili-
ties based on two rules. One is that the ENCRYPT abstract operator does not appear in a relation
(line 3); the other is that both the ENCRYPT and DECRYPT abstract operators appear in a rela-
tion, but no ENCRYPT abstract operator appears after the last DECRYPT abstract operator (line
5). Otherwise, LvDetector simply records a relation as a non-vulnerable information flow (line 8).
Application developers may misuse cryptographic primitives as demonstrated by Egele et al. [120].
The current version of LvDetector does not further examine cryptographic misuses such as using
constant keys or non-random initialization vectors in browser extensions, thus its vulnerability
detection is more like a lower-bound analysis.
Analyze-Vulnerability (T , sV ars, dV ars)
// T : program-level relation summary;
// sV ars: a set of source variables;
// dV ars: a set of destination (sink) variables.
1 for each pair of src ∈ sV ars and dst ∈ dV ars do
2 for each relation r ∈ T (src, dst) do
3 if the ENCRYPT operator does not appear in r then
4 report vulnerability(r);
5 else if the DECRYPT operator appears in r but no
ENCRYPT appears after the last DECRYPT then
6 report vulnerability(r);
7 else
8 record non vulnerable flow(r);
Figure 4.6 Vulnerability analysis algorithm
The report vulnerability sub-procedure automatically classifies the source variables into two
categories. All the source variables that accept sensitive information (e.g., the password type in-
puts, cookies, and bookmarks) either from user inputs or webpages are in the sensitive category,
and the rest are in the other category. This sub-procedure also groups the sink variables into the net-
work category and the local disk category, with their values sent across the network or saved to the
85

local disk, respectively. It further classifies the reported vulnerabilities as high-severity, medium-
severity, and unranked ones as shown in Table 4.1. Those vulnerabilities that leak information
from the sensitive source variables to the network sink variables are classified as high-severity.
Those vulnerabilities that leak information from the sensitive source variables to the local disk
sink variables are classified as medium-severity because unprotected sensitive information on a
user’s local disk can also lead to security breaches due to, for example, bots [21]. The rest are
classified as unranked because their source variables are not automatically classified as sensitive;
an analyst can further classify these unranked ones based on whether the source variables can be
considered as sensitive.
Each vulnerability report contains a list of high-severity, medium-severity, and unranked vul-
nerability records for each scenario-driven execution. Each record includes the complete informa-
tion flow, and highlights the original variables and operations to provide more intuitive information.
For example, for the code excerpt in Figure 4.1, the information flow from the variable “pwd” in the
save() function to the variable “content” in the post() function is identified as a high-severity vulner-
ability, and the corresponding record is: v3(pwd)CALL(encode())−−−−−−−−−→ v9(pwd)
JS GLOBAL(encodeURI())−−−−−−−−−−−−−−−→
v10()BINARY OP (+)−−−−−−−−−−→ v13()
RETURN(encode())−−−−−−−−−−−→ v7(str)CALL(post())−−−−−−−−→ v14(content). Note that the
contents in the parentheses such as “pwd”, “+”, and “encode()” are the original variables, opera-
tions, and function calls in the source code. In addition, the locations (i.e., file names, function
names, and line numbers) of the original variables, operations, and function calls are also provided
in each record. This intuitive information can help analysts easily locate the reported vulnerabili-
ties in the extensions.
Table 4.1 Vulnerability classification
❵❵❵❵❵❵❵❵❵❵❵❵
Source Vars
Sink VarsNetwork Local disk
Sensitive High-severity Medium-severity
Other Unranked Unranked
86

4.4 Evaluation
We implemented LvDetector in Java. We also integrated two popular compilers into the LvDe-
tector framework. In the instrumentation component, we used Closure Compiler [116] to identify
all the functions and callsites. We chose WALA Compiler [117] as the SSA builder to generate
SSA IRs. We evaluated LvDetector on 28 most popular or top rated extensions that belong to six
categories as shown in Table 4.2; 17 of them were selected from the Firefox extension store [107],
and 11 of them were selected from the Google Chrome extension store [108]. The main criteria
for choosing these extensions are: they must use cryptographic functions; they must have sen-
sitive source variables and network sink variables so that high-severity vulnerabilities may exist
(Section 4.3.4). In the following subsections, we detail one case study, the overall analysis results
for 28 extensions, the responsible disclosure and feedback, and the performance results; we also
further discuss the false positives and false negatives.
4.4.1 Case Study of RoboForm
RoboForm (Lite) is a Firefox extension that can help users remember and auto-fill their web-
site passwords [31]. It provides a master password mechanism to further protect users’ website
passwords. We used LvDetector to analyze RoboForm on six use scenarios.
Scenario 1: A user provides the master password in a ‘password’ type input field to RoboForm
to protect the saved website passwords. The master password is automatically classified as sen-
sitive; it should only be known by the user and should not be sent out even to the remote server
of RoboForm. LvDetector identified one high-severity vulnerable information flow, in which the
master password is leaked out through one sink statement, the send() method call of an XML-
HttpRequest object, without the protection of any cryptographic function. We verified that this
information flow is indeed vulnerable.
Scenario 2: A user allows RoboForm to save a website password to its remote server. The
website password is automatically classified as sensitive; it should only be known by the user
and the corresponding website. LvDetector identified two high-severity vulnerable information
87

flows, in which the website password is leaked out through the same sink statement as in scenario
1 without the protection of any cryptographic function. They are two flows because they take
different code branches. We verified that these two information flows are indeed vulnerable.
Scenario 3: A user allows RoboForm to save a website password to the local disk without
using a master password. LvDetector identified one medium-severity vulnerable information flow,
in which the website password is leaked out through one sink statement, the write() method call of
a FileOutputStream object, without the protection of any cryptographic function. We verified that
this information flow is indeed vulnerable.
Scenario 4: A user allows RoboForm to save a website password to the local disk with the
protection of a master password. LvDetector identified two information flows and simply recorded
them as non-vulnerable: one saves the website password to the local disk after performing an
AES encryption, the other saves the master password to the local disk after performing a DES
encryption. We verified that these two information flows are indeed non-vulnerable.
Scenarios 5 and 6: A user creates (scenario 5) and types (scenario 6) a RoboForm login account
in a dialog box. The RoboForm login password is automatically classified as sensitive; it should
only be known by the user and RoboForm. LvDetector identified one high-severity vulnerable
information flow in each of the two scenarios. The RoboForm login password is leaked out through
the same sink statement as in scenario 1 without the protection of any cryptographic function.
However, these two information flows should not be identified as vulnerable because the RoboForm
login password is sent only to the remote server of RoboForm.
4.4.2 Overall Results
Table 4.2 summarizes the overall analysis results on the 28 extensions. The second column lists
the number of the use scenarios chosen in each extension. The third column lists the number of
analyzed statements over the total number of statements in each extension. The fourth column lists
the number of different cryptographic functions identified in each extension. The fifth column lists
the number of the source variables in each extension for all the chosen scenarios. The sixth column
88

lists the number of the sink variables in each extension for all the chosen scenarios. The seventh
column lists the number of true positives (TP) that are vulnerable information flows correctly
identified by LvDetector; correspondingly, the eighth column lists the number of false positives
(FP) that include nonexistent flows and non-vulnerable existent flows. The ninth column lists
the number of true negatives (TN) that are non-vulnerable information flows correctly identified
by LvDetector; correspondingly, the last column lists the number of false negatives (FN) that
are vulnerable information flows incorrectly identified by LvDetector as non-vulnerable. These
TP/FP/TN/FN numbers come from our examination of the information flows reported/recorded by
LvDetector (Figure 4.6).
For example, we chose six scenarios in the RoboForm case study (Section 4.4.1). LvDetec-
tor analyzed 6880 out of the total 26120 lines of code. LvDetector automatically identified six
different cryptographic functions, and automatically identified seven source variables and 19 sink
variables, LvDetector detected six vulnerable information flows with four true positives and two
false positives, and recorded two non-vulnerable information flows with two true negatives and
zero false negative.
The following five formulas present the precision, recall, F-measure, accuracy, and false posi-
tive rate calculations for the results in Table 4.2.
Precision(Pre) =TP (18)
TP (18) + FP (6)= 75% (4.17)
Recall(Rec) =TP (18)
TP (18) + FN(0)= 100% (4.18)
F − measure =2 × Rec(100%)× Pre(75%)
Rec(100%) + Pre(75%)= 86% (4.19)
Accuracy =TP (18) + TN(23)
TP (18) + TN(23) + FP (6) + FN(0)= 87% (4.20)
89
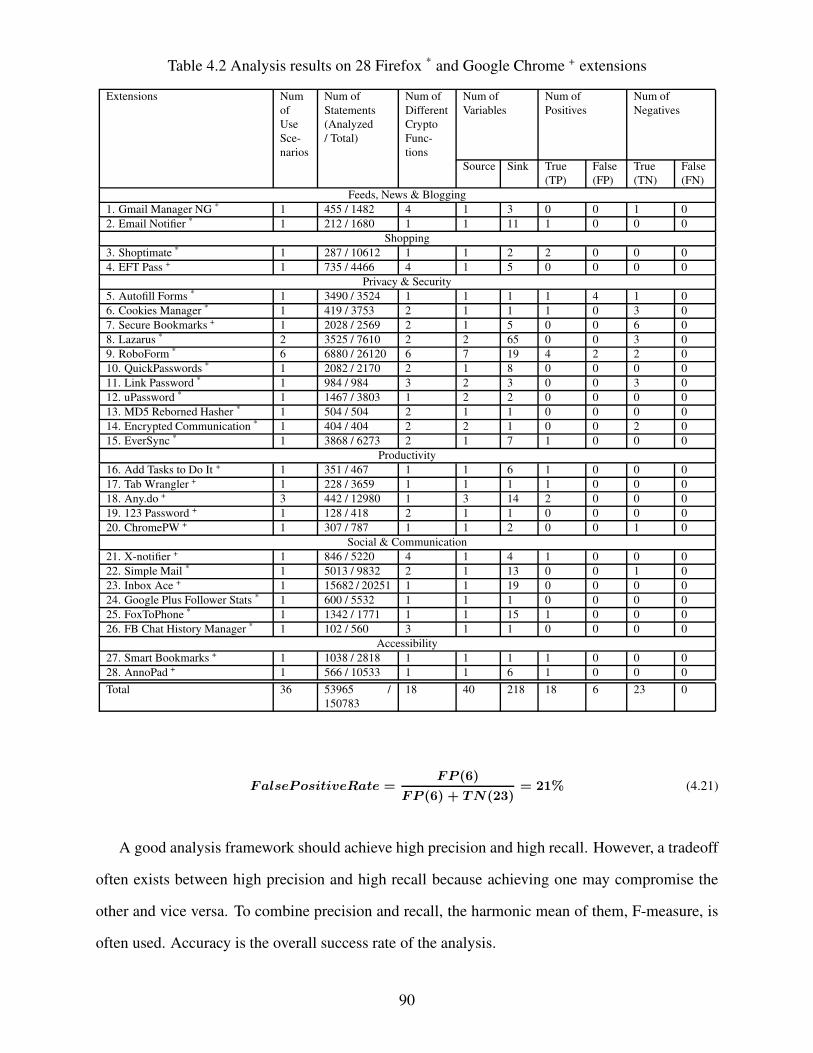
Table 4.2 Analysis results on 28 Firefox * and Google Chrome + extensions
Extensions Num
of
Use
Sce-
narios
Num of
Statements
(Analyzed
/ Total)
Num of
Different
Crypto
Func-
tions
Num of
Variables
Num of
Positives
Num of
Negatives
Source Sink True
(TP)
False
(FP)
True
(TN)
False
(FN)
Feeds, News & Blogging
1. Gmail Manager NG * 1 455 / 1482 4 1 3 0 0 1 0
2. Email Notifier * 1 212 / 1680 1 1 11 1 0 0 0
Shopping
3. Shoptimate * 1 287 / 10612 1 1 2 2 0 0 0
4. EFT Pass + 1 735 / 4466 4 1 5 0 0 0 0
Privacy & Security
5. Autofill Forms * 1 3490 / 3524 1 1 1 1 4 1 0
6. Cookies Manager * 1 419 / 3753 2 1 1 1 0 3 0
7. Secure Bookmarks + 1 2028 / 2569 2 1 5 0 0 6 0
8. Lazarus * 2 3525 / 7610 2 2 65 0 0 3 0
9. RoboForm * 6 6880 / 26120 6 7 19 4 2 2 0
10. QuickPasswords * 1 2082 / 2170 2 1 8 0 0 0 0
11. Link Password * 1 984 / 984 3 2 3 0 0 3 0
12. uPassword * 1 1467 / 3803 1 2 2 0 0 0 0
13. MD5 Reborned Hasher * 1 504 / 504 2 1 1 0 0 0 0
14. Encrypted Communication * 1 404 / 404 2 2 1 0 0 2 0
15. EverSync * 1 3868 / 6273 2 1 7 1 0 0 0
Productivity
16. Add Tasks to Do It + 1 351 / 467 1 1 6 1 0 0 0
17. Tab Wrangler + 1 228 / 3659 1 1 1 1 0 0 0
18. Any.do + 3 442 / 12980 1 3 14 2 0 0 0
19. 123 Password + 1 128 / 418 2 1 1 0 0 0 0
20. ChromePW + 1 307 / 787 1 1 2 0 0 1 0
Social & Communication
21. X-notifier + 1 846 / 5220 4 1 4 1 0 0 0
22. Simple Mail * 1 5013 / 9832 2 1 13 0 0 1 0
23. Inbox Ace + 1 15682 / 20251 1 1 19 0 0 0 0
24. Google Plus Follower Stats * 1 600 / 5532 1 1 1 0 0 0 0
25. FoxToPhone * 1 1342 / 1771 1 1 15 1 0 0 0
26. FB Chat History Manager * 1 102 / 560 3 1 1 0 0 0 0
Accessibility
27. Smart Bookmarks + 1 1038 / 2818 1 1 1 1 0 0 0
28. AnnoPad + 1 566 / 10533 1 1 6 1 0 0 0
Total 36 53965 /
150783
18 40 218 18 6 23 0
FalsePositiveRate =FP (6)
FP (6) + TN(23)= 21% (4.21)
A good analysis framework should achieve high precision and high recall. However, a tradeoff
often exists between high precision and high recall because achieving one may compromise the
other and vice versa. To combine precision and recall, the harmonic mean of them, F-measure, is
often used. Accuracy is the overall success rate of the analysis.
90

From these calculations, we can conclude that LvDetector is an effective framework. It achieves
a high precision rate (75%), indicating that the majority of the identified vulnerable flows are in-
deed vulnerable. It achieves a high recall rate (100%), indicating that LvDetector can identify
the majority of the actually vulnerable flows for the executed scenarios. It also achieves a high
F-measure rate (86%) and a high accuracy rate(87%). The false positive rate is 21%; however, the
detection results of LvDetector will be used by analysts to more easily identify information flow
vulnerabilities. This usage is different from that of other systems such as intrusion detection or
online malware detection systems, in which the detection results will be used to make immediate
decisions such as dropping network packets or removing malicious programs. Therefore, a 21%
false positive rate will not cause too much inconvenience to the analysts.
Overall, LvDetector identified 18 true information leakage vulnerabilities in 13 extensions.
These vulnerabilities are previously unknown, and they exist in 46% of the analyzed extensions.
Nine of them are high-severity vulnerabilities, and seven of them are medium-severity vulnerabil-
ities. The remaining two are unranked because their source variables that accept users’ notes are
not automatically classified as sensitive; they can be further classified as one high-severity and one
medium-severity vulnerabilities, respectively, since users’ notes and tasks may contain sensitive
information. We examined that three main reasons account for those 18 vulnerabilities: developers
did not realize the importance of protecting sensitive data before sending or saving them, protec-
tion was not applied to all the code branches for sensitive information flows, code had bugs such
as sending or saving plaintext rather than ciphertext. These information leakage problems deserve
serious attention from extension developers, browser vendors, researchers, and users.
4.4.3 Responsible Disclosure and Feedback
Among the 13 extensions that have vulnerabilities, 12 of them contain contact information on
their websites or extension store webpages. We emailed those 12 developers asking if they would
like to know the details about the vulnerabilities in their extensions, and received eight replies.
We further provided the detailed vulnerabilities to the eight developers respectively. Two of them
91

patched their extensions in the online stores; one of them removed his extension from the Google
extension store; four of them did not further respond to us; one of them disagreed with our analysis
result, and mentioned that tons of extensions persist much more sensitive data all over the place and
his extension does not encrypt data because the browser’s storage APIs do not provide encryption
options.
4.4.4 Performance Results
We measured the running time of LvDetector in analyzing the vulnerabilities in each exten-
sion on a desktop computer with 2.83GHz CPU, 2.96GB memory, 32-bit Windows 7 operating
system, and Java Runtime Environment 1.7. For the vulnerability analysis of the 36 use scenarios
(Table 4.2), the maximum running time is about 48 minutes (corresponding to the scenario 1 of
the RoboForm case study described in Section 4.4.1), the minimum running time is less than one
minute, the median running time is six minutes, and the average running time is 12 minutes with
a standard deviation of 13. Because LvDetector is an offline analysis framework, such a running
time performance is quite acceptable. Note that the running time is not linear to the Lines of Code,
and it is often related to the code complexity.
4.4.5 Discussion
False positives may come from a few sources. First, in the variable use analysis, the conditions
in the control flow of the SSA IR are not currently considered; therefore, extra (i.e., nonexis-
tent) information flows could be later included in the function-level relation analysis. Second, in
the variable use analysis, the individual elements in a collection type of object such as array or
linkedlist are not further differentiated from each other - the analysis granularity is only at the
object level; therefore, extra information flows could be later included in the function-level rela-
tion analysis. Third, in the program-level relation analysis, all possible edges are created between
global variable definitions and their uses; therefore, extra information flows could be included.
Fourth, if the value of a sensitive variable is leaked to an intended remote server for further pro-
cessing, this type of leakage should not be identified as vulnerable. Among the 6 false positives
92

reported in our evaluation results (Section 4.4.2), four of them come from the first source, and the
remaining two come from the fourth source as explained in the scenarios 5 and 6 of the RoboForm
case study (Section 4.4.1). Although in our evaluation we did not observe any false positive com-
ing from the second and the third sources, analysts should still pay attention to these sources when
they use LvDetector.
False negatives may occur due to reasons such as the misuses of cryptographic primitives [120],
which are not further examined by the current version of LvDetector (Section 4.3.4). In addition,
because LvDetector builds call graphs from the scenario-driven execution traces, vulnerabilities
will not be identified for the scenarios that are not executed by analysts.
In the future, we plan to consider the conditions in the control flow of the SSA IR, differentiate
the elements in an Array from each other, and refine the mappings between global variable defini-
tions and their uses; with these enhancements, we expect that false positives can be reduced. We
also plan to investigate potential cryptographic misuses [120] in browser extensions and other path
exploration techniques such as [121, 122] to see if LvDetector can identify more vulnerabilities.
4.5 Related Work
Existing research on analyzing the security of JavaScript-based extensions mostly focused
on identifying privilege escalation related vulnerabilities that could lead to web-based attacks or
malware installation. Researchers applied static information flow analysis techniques [92] and
dynamic taint analysis techniques [123] to identify privilege escalation related vulnerabilities in
buggy browser extensions. Guha et al. proposed a new model for secure development, verifica-
tion, and deployment of browser extensions to limit potential over-privilege problems [97]. Barth
et al. designed a new extension system for Google Chrome that uses least privilege, privilege
separation, and strong isolation mechanisms [93]. Carlini et al. manually reviewed and evalu-
ated the effectiveness of those three mechanisms in a set of Google Chrome extensions [94]. Liu
et al. revealed that malicious attacks can still violate the least privilege and privilege separation
mechanisms of the Google Chrome extension system, and proposed some countermeasures [99].
93

Only a handful of existing solutions [95, 96, 98] aimed to address the same problem targeted by
our LvDetector, but they took either pure dynamic approaches or pure static approaches. In [95],
Chang and Chen proposed a framework, iObfus, to dynamically protect against the potential sensi-
tive information leakage through browser extensions. iObfus marks sensitive web elements, obfus-
cates the sensitive information before performing any I/O operation, and de-obfuscates the infor-
mation only for trusted domains. In [96], Dhawan and Ganapathy proposed a framework, Sabre,
to dynamically track information flows in JavaScript-based Firefox extensions. Sabre associates
security labels with JavaScript objects, tracks the propagation of those labels at runtime in the Spi-
derMonkey JavaScript engine of Firefox, and raises an alert if an object with a sensitive label is
written to a low-sensitivity sink point. These frameworks are not publicly available for compar-
ison. However, generally speaking, only using online dynamic techniques without performing a
static analysis in advance suffers from three main drawbacks: (1) asking users to respond to run-
time alerts may not be wise, while using default response options may become too restrictive [92];
(2) it is not possible to detect all information flows dynamically [110, 111]; (3) performance and
memory overhead can often be incurred to the system [92]. In addition, dynamic approaches are
often browser-specific and require high instrumentation effort [96]. In [98], Kashyap and Hard-
ekopf proposed an abstract interpretation approach to validate the pre-defined security signatures
for browser extensions; however, pure static analysis of JavaScript-based extensions can often in-
cur high false positives as we discussed in Section 4.3.1. Our LvDetector combines both static
and dynamic program analysis techniques, and aims to automatically identify information leakage
vulnerabilities in browser extensions before they are released to users.
Static and dynamic program analysis techniques have also been used to address other JavaScript
security problems in web applications. On the one hand, static program analysis techniques have
been used to detect JavaScript malware [104, 124], detect web application vulnerabilities such as
injection and cross-site scripting [125], and examine a restricted version of JavaScript that enables
the API confinement verification [126]. Static techniques can provide a comprehensive code cover-
age, but may over-estimate the actual execution paths and incur false positives. On the other hand,
94

dynamic program analysis techniques have been used to enforce information flow security for a
set of core features in JavaScript [127], detect privacy-violating information flows such as cookie
stealing and history sniffing [128], and identify client-side code injection vulnerabilities [122].
Dynamic techniques can capture the precise program execution information, but may overlook
certain potential execution paths and incur false negatives. Static and dynamic program analysis
techniques have also been combined to prevent cross-site scripting attacks [111, 129], track in-
formation flow in JavaScript code injection attacks [105], and extract the dynamically generated
code for analyzing script injection attacks [130]. Our LvDetector uses both static and dynamic
program analysis techniques but focuses on addressing a different problem than those addressed
by this body of work.
4.6 Summary
In this project, we present a framework, LvDetector, that combines static and dynamic program
analysis techniques for automatic detection of information leakage vulnerabilities in legitimate
browser extensions. Extension developers can use LvDetector to locate and fix the vulnerabilities
in their code; browser vendors can use LvDetector to decide whether the corresponding extensions
can be hosted in their online stores; advanced users can also use LvDetector to determine if certain
extensions are safe to use. LvDetector is not bound to specific web browsers or JavaScript engines;
it follows a modular design principle, and can adopt other program analysis techniques. We imple-
mented LvDetector in Java and evaluated it on 28 popular Firefox and Google Chrome extensions.
The evaluation results and the feedback to our responsible disclosure demonstrate that LvDetector
is useful and effective.
95

CHAPTER 5
A SECURE CLOUD STORAGE MIDDLEWARE FOR END-USER APPLICATIONS
5.1 Introduction
Cloud computing is a significant trend and it can offer many benefits such as cost efficiency,
elasticity, scalability, and convenience to millions of organizations and end users. For many ap-
plications, especially end-user applications, it is often desirable and even essential to have the
cloud storage capability to enhance their functionality, usability, and accessibility. For example,
document processing applications may want to save users’ sensitive documents to the cloud, ac-
counting or healthcare applications may want to save users’ financial or health information to the
cloud, and Web browsers may want to save users’ browsing data such as bookmarks and histories
to the cloud [131]; in all these cases, one considerable benefit to users is that their data stored in
the cloud can be available and readily usable anytime, anyplace, and on any computer.
However, one of the major concerns that inhibits the cloud adoption is security [132–134].
Not only many new security problems such as unexpected side channels and covert channels as
well as insider attacks can occur in the cloud, but also organizations and end users do not have
sufficient confidence in hosting sensitive data in the cloud. Therefore, the cloud storage capability
must be securely equipped to end-user applications (referred to as having the secure cloud storage
capability) to ensure the confidentiality, integrity, and availability of the data saved to the cloud.
Unfortunately, it is nontrivial for ordinary application developers to either enhance legacy ap-
plications or build new applications to properly have the secure cloud storage capability. The
complexity of both applications and cloud storage services often requires deep domain expertise
from developers, thus mandating a substantial development effort for the cloud storage capability
integration. Moreover, a lack of sufficient security knowledge and skills in application developers
can often incur design, implementation, and deployment vulnerabilities as shown in many stud-
ies [135–137].
96

Researchers have proposed many systems to continuously improve the security, reliability, and
availability of cloud storage services [23–27, 138, 139]; however, merely focusing on the sever-end
enhancement is insufficient because a particular cloud storage service may still be compromised
by outsider or insider attackers. Therefore, to provide a strong security guarantee, applications
must properly protect users’ data at the user-end in the first place. Like us, some researchers
have realized the importance of facilitating end-user applications to have the secure cloud storage
capability [22, 140]; however, those solutions suffer from the deployment and usage limitations as
discussed in Section 5.2.
In this project, we take a middleware approach and design SafeSky, a secure cloud storage
middleware that can immediately enable either legacy or new end-user applications to have the
secure cloud storage capability without requiring any code modification or recompilation to them.
SafeSky is designed as a middleware library that can be dynamically loaded with different appli-
cations; it sits between the applications and the operating system to intercept the applications’ file
operations and transform them into secure cloud storage operations. To integrate this middleware
into an application, developers or even advanced users can simply copy the SafeSky library and
create a corresponding command for starting the application with the library. A SafeSky-enabled
application does not need to save any data to the local disk, but instead securely saves the data to
multiple free cloud storage services to simultaneously enhance the data confidentiality, integrity,
and availability. To use a SafeSky-enabled application, end users simply need to provide their
cloud storage accounts to SafeSky at the beginning of each application session, while SafeSky will
transparently take care of everything else behind the scenes.
We have implemented SafeSky in C and built it into a shared library on Linux. It supports
applications written in languages such as C, Java, and Python as long as they interact with the
underlying operating system through the dynamically linked GNU libc library. It supports popu-
lar cloud storage services such as Amazon Cloud Drive, Box, Dropbox, Google Drive, Microsoft
OneDrive, and Rackspace; it also supports common user authentication methods used by the pop-
ular cloud storage services. We have evaluated the correctness and performance of SafeSky by
97

using three real-world applications: HomeBank, SciTE Text Editor, and Firefox Web browser; we
have also analyzed the security of SafeSky. Our evaluation and analysis results demonstrate that
SafeSky is a feasible and practical approach for equipping end-user applications with the secure
cloud storage capability.
The main contributions of this work include: (1) a novel middleware approach for immediately
enabling either legacy or new end-user applications to have the secure cloud storage capability
without requiring any code modification or recompilation (Section 5.3); (2) a concrete SafeSky
middleware system for flexibly supporting diverse end-user applications, cloud storage services,
and authentication methods (Sections 5.3 and 5.4); (3) an evaluation of SafeSky using real-world
applications (Section 5.5); (4) a security analysis of SafeSky (Section 5.6).
5.2 Background and Related Work
A large number of cloud storage services have been deployed and widely used [141–147]. Most
cloud storage services offer free accounts and storage spaces to regular users, and many of them fol-
low the predominant REST (Representational State Transfer) Web service design model [148, 149]
and allow different client applications to easily access them through their REST APIs. Organiza-
tions and advanced users can also deploy their own cloud storage services. For example, one
popular cloud storage software is OpenStack Swift [150], which is free and also provides REST
APIs to client applications. Note that we do not intend to build any new cloud storage service,
but focus on enabling SafeSky to directly use these widely deployed and easily accessible cloud
storage services.
As highlighted in Section 5.1, having the cloud storage capability is desirable and even essen-
tial for many end-user applications to provide better functionality, usability, and accessibility to
users. Existing end-user applications (e.g., for document processing, accounting, healthcare, task
scheduling, contact management, and browsing) as well as the potential future applications can all
use the cloud storage capability to benefit users by enabling them to conveniently access their data
anytime, anyplace, and on any computer. However, this considerable benefit does not come with-
98

out the risks of losing data confidentiality, integrity, and availability. The recent leak of celebrity
photos in iCloud [151] is just one of the numerous reported or even unreported data breaches.
Vendors and researchers have proposed a number of systems to continuously improve the relia-
bility, availability, and security of cloud storage services. Popa et al. proposed CloudProof, a secure
storage system that enables customers to detect violations of data integrity, write-serializability,
and freshness in the cloud [25]. Wang et al. proposed a distributed storage verification scheme to
ensure the correctness and availability of cloud data [26]. Kamara and Lauter proposed a virtual
private storage service to combine the security benefits of using private clouds with the availability
and reliability benefits of using public clouds [139]. Mahajan et al. proposed Depot, a cloud stor-
age system that provides safety and liveness guarantees to clients without even requiring them to
trust the correctness of Depot servers [24]. The Windows Azure team developed a highly available
cloud storage architecture as described in [27].
Researchers have also emphasized the importance of incorporating redundancy into the cloud
storage services to further improve their reliability, availability, and security. Bowers et al. pro-
posed HAIL, a distributed cryptographic system that applies RAID (Redundant Arrays of In-
expensive Disks)-like techniques to achieve high-availability and integrity across cloud storage
providers, and allows servers to prove to a client that a stored file is intact and retrievable [23].
Abu-Libdeh et al. proposed RACS, a proxy that also applies RAID-like techniques, but focuses
on transparently using multiple providers to achieve cloud storage diversity, avoid vendor lock-in,
and better tolerate provider outages or failures [138].
However, merely focusing on the sever-end enhancements is insufficient because a particular
cloud storage service may still be compromised by outsider or insider attackers [151]. In addition,
end users should also consider the risks of cloud service vendor lock-in [133, 138]. Therefore, to
provide a strong security guarantee, applications must properly protect users’ data at the user-end
in the first place. Like us, some researchers have realized the importance of facilitating end-
user applications to have the secure cloud storage capability. They have explored the API library
approach [22] and the file system proxy approach [140] reviewed as below.
99

Bessani et al. proposed DepSky, a system that sits on top of multiple cloud storage services
to form a cloud-of-clouds [22] and applies the Shamir’s (k, n) secret sharing scheme [28] to
improve the overall data availability and confidentiality. We also emphasize the importance of
incorporating redundancy, and DepSky is more similar to our SafeSky in terms of applying the
Shamir’s (k, n) secret sharing scheme to achieve a high-level security and availability. However,
DepSky took an API library approach and requires developers to use its APIs to modify their
code; therefore, it still suffers from the problem that developers may misuse APIs and may fail
to follow secure design, implementation, and deployment practices [135–137]. In contrast, our
SafeSky can enable either legacy or new end-user applications to immediately have the secure
cloud storage capability without requiring any code modification or recompilation to them, thus
bringing important deployment and security benefits.
Another work, BlueSky [140], is similar to our SafeSky in terms of not requiring any applica-
tion modification. However, BlueSky is a file system proxy that aims to lower the cost and improve
the performance of using cloud storage services by adopting a log-structured data layout for the
file system stored in the cloud [140]. Thus, its design requirements and decisions are different
from those of SafeSky that put security as the first priority. Furthermore, its file system proxy
approach is heavier than our middleware approach because clients need to mount the BlueSky file
systems, which need to be properly set up and maintained by system administrators; therefore, it is
more appropriate for using BlueSky to provide services to clients in enterprise environments [140].
Our SafeSky is informed by traditional cryptographic file systems such as [152, 153], but it is a
lightweight cloud-oriented middleware that can be simply incorporated by developers and individ-
ual end users into their applications.
5.3 Design
Our objective is to design a secure cloud storage middleware, SafeSky, that can immediately
enable either legacy or new end-user applications to have the secure cloud storage capability with-
out requiring any code modification or recompilation to them. A SafeSky-enabled application does
100

not need to save any data to the local disk, but instead securely saves the data to multiple free cloud
storage services to simultaneously enhance the data confidentiality, integrity, and availability.
5.3.1 Threat Model and Assumptions
The basic threat model that we consider in the design of SafeSky is that attackers can obtain
users’ data saved in a particular cloud storage service and may then further compromise the data
confidentiality, integrity, and availability. Attackers could be outsider unauthorized or illegitimate
entities who initiate attacks from outside of the security perimeter of a cloud storage service;
examples of outsider attackers could be from amateur pranksters to organized criminals and even
hostile governments. Attackers could also be insider entities who are authorized to access certain
resources of a cloud storage service, but use them in a non-approved way; examples of insider
attackers could be insincere or former employees who can still access the resources of a cloud
storage service. We do not aim to prevent the stealing of users’ data saved in a cloud storage
service, a goal that is difficult to achieve given the many data breaches reported everyday. Instead,
we focus on ensuring that it is computationally or even absolutely infeasible for attackers to decrypt
and use the data stolen from a particular cloud storage service.
We assume that on a user’s computer, the operating system is secure and no malware is installed
to steal the user’s data, for example, from memory or input devices; meanwhile, SafeSky itself is
not compromised because it is part of the trusted computing base of the system. We assume that in
the cloud, multiple storage service providers do not collude to compromise the security of a user’s
data; meanwhile, a user’s multiple cloud accounts are not compromised at the same time (e.g., due
to shared or weak passwords) by attackers for them to further steal the user’s data. In addition, if
an application directly transmits a user’s data to a server through network connections, SafeSky
does not protect the security of such data because manipulating network transmissions can easily
break the functionality and semantics of the application.
101

5.3.2 Requirements and Challenges
To achieve our objective, we identify five key design requirements for SafeSky: (1) confiden-
tiality and integrity: Users’ data often contain highly sensitive information, and may determine the
execution logic of applications. Therefore, SafeSky must securely protect the data at the user-end
before saving them to cloud storage services, so that it is computationally or even absolutely infea-
sible for either outsider or insider attackers to compromise the data confidentiality and integrity.
(2) availability: Saving the data to the cloud can benefit users for accessing the data from different
places and computers, but it may suffer from the problem that some cloud storage services could
be unavailable occasionally. Therefore, SafeSky needs to ensure high data availability, so that
applications can access their data anytime even if certain cloud storage services are unavailable.
(3) deployability: Incorporating the secure cloud storage capability into applications could be a
challenging task for many developers and could be error-prone. Therefore, SafeSky must be easily
deployable, so that different applications can immediately have the secure cloud storage capabil-
ity without requiring any code modification or recompilation to them. (4) consistency: SafeSky
should satisfy the single-reader single-writer consistency semantics for supporting single-user ap-
plications that are most widely used. (5) performance: SafeSky should not incur any perceivable
performance overhead to end users.
These requirements bring a few challenges to the design and implementation of SafeSky. Si-
multaneously achieving the three security requirements confidentiality, integrity, and availability
in user data protection is the foremost challenge because we need to properly choose and synthe-
size different cryptographic primitives, and consider both insider and outsider attackers. Making
SafeSky easily deployable and transparent to applications is the second major challenge because
we need to consider a variety of file operations that could be issued by different applications. En-
suring the consistency and efficient access of users’ data in the cloud is the third major challenge
because we need to consider the heterogeneous nature of cloud storage services in terms of their
different user authentication methods and application programming interfaces, and the diverse
workload characteristics of different applications.
102

5.3.3 Overview and Rationale
Figure 5.1 illustrates the high-level architecture of SafeSky. It consists of three components:
interception, data protection, and cloud driver. Originally without SafeSky (as shown in the left
dashed box in Figure 5.1), to perform local disk file operations, applications invoke function or
system calls through C libraries such as the GNU libc library. Note that any Unix-like or Linux-like
operating system needs a C library. With SafeSky, applications perform local disk file operations as
usual, while SafeSky intercepts the original file operations in its interception component, protects
the intercepted data in its data protection component, and saves the protected data to multiple cloud
storage services in its cloud driver component. The applications can be implemented in languages
such as C, Java, and Python as long as they interact with the underlying operating system through
the dynamically linked C libraries.
We design SafeSky as a middleware library that can be dynamically loaded with different ap-
plications. To integrate this middleware into an application, developers or advanced users simply
need to copy the SafeSky library and create a corresponding command for starting the application
with the SafeSky library dynamically loaded before other libraries. To use the SafeSky-enabled
application, end users simply need to provide their cloud storage accounts to SafeSky at the be-
ginning of each application session, while SafeSky will transparently take care of everything else
behind the scenes.
The interception component intercepts applications’ text and binary file operations either at
the standard C function level (e.g. the buffered fread() and fwrite() functions) or at the system
call wrapper function level (e.g. the unbuffered read() and write() functions), and manages the
intercepted data with block-level granularity for each file in a memory structure. Interception at
either of those two levels has its own advantages and disadvantages. Interception at the standard C
function level has the platform independence benefit and can immediately support the applications
to run on different operating systems, but it does not support the applications that do not use
the standard C functions. Interception at the system call wrapper function level can immediately
support different applications (on a given operating system) regardless of whether they use standard
103

Figure 5.1 High-level architecture of SafeSky
C functions or not, but it does not support the applications that run on other operating systems. If
an application calls standard C functions, SafeSky performs the interception at the standard C
function level; otherwise, it performs the interception at the system call wrapper function level.
Therefore, different applications on different platforms can be flexibly supported by SafeSky, no
matter they use one or both types of functions.
The data protection component securely protects each new or updated data block in the mem-
ory structures before letting the cloud driver component send the data block to the cloud. It first
applies the authenticated encryption to a new or updated data block in a memory structure (for a
file) to ensure that it is computationally infeasible for attackers to break the data confidentiality
and integrity. Furthermore, it applies the Shamir’s (k, n) secret sharing scheme [28] to split the
protected data block as well as the corresponding authenticated encryption key and parameters into
n pieces for saving to n different cloud storage services, so that it is absolutely infeasible [28] for
attackers to break the data confidentiality, given that they do not compromise k or more cloud stor-
age services at the same time. Using this secret sharing scheme also ensures high data availability
because the protected data blocks and the keys can be reconstructed from any k available cloud
storage services.
104

The cloud driver component saves/retrieves the split data block pieces to/from different cloud
storage services. At the beginning of each application session, this component authenticates a user
to the cloud storage services using the user’s protected cloud accounts. Within the session, when a
data block is read for the first time by the application, this component retrieves k data block pieces
from any k of the n cloud storage services to reconstruct the protected data block, which will
be authenticated and decrypted by the data protection component to recover that data block; this
retrieval operation will only occur once in a session for each data block of each file. Whenever a
data block of a file is created or updated by the application and its n data block pieces are generated
by the data protection component, the cloud driver component saves those data block pieces to n
different cloud storage services. We refer to this “one retrieval and multiple saves” mechanism as
saves-after-retrieval.
This high-level architecture is a rational design for SafeSky to meet those five key require-
ments and address those major design and implementation challenges (Section 5.3.2). It applies
authenticated encryption and secret sharing schemes to ensure the data security in the cloud. It uses
dynamic loading techniques and supports the file operation interception at two levels, so that the
secure cloud storage capability can be easily deployed to different applications without modifying
or recompiling them. Saving data to the cloud and using the secret sharing scheme collectively
ensure high data availability. SafeSky saves the data with their versions to the cloud and uses a
simple saves-after-retrieval mechanism to correctly satisfy the single-reader single-writer con-
sistency semantics. The interception component updates the memory structures as soon as the
application performs write operations, while multiple dedicated threads and reusable TCP connec-
tions are used by the data protection component and the cloud driver component to perform their
tasks in a parallel and asynchronous manner, thus minimizing the perceivable performance over-
head to end users. A SafeSky-enabled application does not need to save any data to the local disk,
and the latest copy of the data can always be conveniently accessed from the cloud.
105

5.3.4 Interception Component
The interception component intercepts applications’ file operations either at the standard C
function level or at the system call wrapper function level using dynamic loading techniques. One
widely used dynamic loading technique on the Linux platform is based on the LD PRELOAD
environment variable, which specifies other shared libraries that can be preloaded into an applica-
tion’s running process to take precedence over the original dynamically linked libraries used by the
application. The functions implemented in the preloaded libraries will override the corresponding
functions in the original libraries; therefore, the behavior of the application can be changed as
desired without requiring any code modification or recompilation to the application.
5.3.4.1 Interception Strategy
The interception component intercepts both text and binary file operations at both the standard
C function level and the system call wrapper function level. Table 5.1 lists the key intercepted file
operations. If an application calls standard C functions, this component performs the interception
at the standard C function level, and the operation will not be further passed down to the system call
wrapper function level; otherwise, it performs the interception at the system call wrapper function
level. This strategy allows SafeSky to flexibly support different applications on different platforms
as discussed in Section 5.3.3.
Table 5.1 Intercepted file operation functions
File operations
Standard C
function level
fopen(), fclose(), fread(), fwrite(), ...
System call
wrapper function level
open(), open64(), creat(), creat64(), close(),
read(), write(), lseek(), lseek64(), stat(),
stat64(), lstat(), lstat64(), fstat(), fstat64(), ...
SafeSky allows developers or advanced users to specify the files, for which the data will be
securely saved to the cloud, in the Rules for Interception configuration file as shown in Figure 5.1.
One reason for using such a configurable mechanism is that in addition to users’ data files, applica-
tions often write many temporary files which are not necessary to be saved to the cloud; the other
106

reason is that users can have the flexibility to specify the files they want to save to the cloud.
5.3.4.2 Memory Structure and Interceptions
Figure 5.2 Memory structure and data protection in SafeSky
For each specified data file, SafeSky will maintain a block-level granularity memory structure
that includes the folder name, file name, file open mode, read/write offset, file length, block size,
and a table of data blocks as shown in Figure 5.2. The read/write offset is the file offset (very
similar to the current active pointer in the FILE structure in C), and it is the start position for
reading/writing data from/to a data block in the memory structure. Each data block contains the
index, length, memory version, cloud version, and content information; the contents of all the data
blocks in a memory structure constitute the content of the corresponding file accessed so far; the
memory version records the current version number of a data block in the memory structure; the
cloud version records the version number of a data block saved to the cloud.
In the file opening functions (e.g. open() and fopen()) implemented in SafeSky, once a specified
file is opened, a memory structure is created. To present the same semantics to an application
between using the file system and using the cloud storage, SafeSky supports frequently used file
operation flags such as O CREAT and O APPEND as well as rarely used flags such as O SYNC.
In the file closing functions (e.g. close() and fclose()) implemented in SafeSky, once a specified
107

file is closed, the newly created or updated data blocks are protected and uploaded to the cloud by
the data protection component and the cloud driver component, respectively.
ssize t write(int fildes , const void ∗buf , size t nbyte)
1 file name = getNameFromFileDescriptor(fildes);
2 int ret ;
3 if isSpecifiedInTheRuleFile(file name) then
4 ret = writeMemoryStructure(file name , buf , nbyte);
5 if isSynchronizedWrite(file name) then
6 ret = sendDataSaveMessage();
7 else
8 ret = orig write(fildes, buf , nbyte);
9 return ret ;
Figure 5.3 Pseudo code for the write() function
In the file writing functions (e.g. write() and fwrite()) implemented in SafeSky, the written data
will be updated to the corresponding data blocks in the memory structure. Figure 5.3 illustrates
the pseudo code for the write() system call wrapper function implemented in SafeSky. If the
file is specified in the Rules for Interception configuration file, this function updates the memory
structure and its data blocks at line 4, and sends a message to the data protection and cloud driver
components to immediately protect and save the newly written data blocks to the cloud at line 6
if the file is opened with synchronized file operation flags such as O SYNC; otherwise at line 8, it
calls the original write() system call wrapper function, whose pointer orig write was obtained
through the system call dlsym(RTLD NEXT, “write”) when SafeSky was initialized.
The logic of the implemented file reading functions (e.g. read() and fread()) in SafeSky is
similar to that of the file writing functions; however, the corresponding data blocks existing in the
memory structure will be directly returned to the application, while nonexistent data blocks will
be retrieved and recovered from the cloud.
Since SafeSky maintains each memory structure at the block-level, read and write operations
performed on-demand by applications can be efficiently supported. Note that if the size of the
memory structures becomes too large, the least-recently used (LRU) cache replacement algorithm
can be used to evict some data blocks and free certain memory space.
108

5.3.5 Data Protection Component
When a data block needs to be saved to the cloud, its memory version, block index, block
length, and block content together with the metadata such as file length and block size in the mem-
ory structure are extracted to form a plaintext. The small-size metadata is always bound to the data
block in a plaintext so that its transmission and maintenance overhead could be minimized. This
plaintext is first protected using an authenticated encryption algorithm (e.g. the NIST-approved
CCM algorithm [72]) with a randomly generated key; the generated ciphertext along with the ci-
pher type (AE-type), the parameters (AE-params), and the key (AE-key) used in the authenticated
encryption are then supplied to the Shamir’s (k, n) secret sharing scheme [28] with parameters N
and K to produce N secret-shared data block pieces, each of which together with the parameters
N , K, and the version (copied from the memory version) form a cloud data object. Each cloud
data object will be finally saved by the cloud driver component to a storage service, and indexed
by an id generated from the hash of the folder name, file name, block index, and the identifier (e.g.
domain name) of that cloud storage service.
In the decryption and verification process, any K cloud data objects of a data block can be used
by the secret sharing scheme [28] to recover the ciphertext, which will be decrypted and verified
using the authenticated decryption algorithm to reconstruct that data block.
The authenticated encryption algorithm is used to ensure both the confidentiality and integrity
of the data blocks, so that it is computationally infeasible for attackers to decrypt the ciphertext,
and any unauthorized modification to the cloud data objects can be detected. The secret sharing
scheme is used to further strengthen the confidentiality and ensure the availability of the cloud data
objects. In terms of the confidentiality, even if attackers can compromise any K− 1 cloud storage
services and steal any K − 1 cloud data objects of a data block, it is absolutely infeasible [28] to
recover the entire ciphertext of that data block, and further recover the corresponding plaintext due
to the incomplete ciphertext. In terms of the availability, the entire ciphertext of the data block can
be recovered from any K or more cloud data objects [28] retrieved from any K or more available
cloud storage services. This availability guarantee can also help mitigate the cloud service vendor
109

lock-in risks [133, 138].
It is worth mentioning that the cipher type, parameters, and key used in the authenticated
encryption algorithm is also secret shared (Figure 5.2) so that they need not be locally saved or
deterministically derived based on certain secret information provided by a user. Similarly, the
parameters N and K used in the secret sharing scheme [28] are saved to the cloud along with
each secret-shared data block piece so that they need not be locally saved or provided by a user.
5.3.6 Cloud Driver Component
The cloud driver component saves/retrieves the cloud data objects to/from different cloud stor-
age services. As highlighted in Section 5.2, popular cloud storage services offer free accounts and
storage spaces to regular users, and they follow the predominant REST (Representational State
Transfer) Web service design model to allow different client applications to easily access them.
The cloud driver component needs to use the REST APIs of those cloud storage services to per-
form LIST, PUT, GET, and DELETE interactions with them. SafeSky simply uses the storage
capability of cloud storage services, and it does not need any special computational support from
them and does not require any modification to them. This design decision is important for SafeSky
to easily support the use of different cloud storage services.
5.3.6.1 User Authentication
At the beginning of each application session, this component authenticates a user to the cloud
storage services using the protected cloud accounts provided by the user. It supports common
user authentication methods used by popular cloud storage services. One method is the traditional
password based authentication, which is used by services such as Rackspace and Swift. Another
method is the single sign-on authentication that uses access tokens for accessing services, and
it becomes increasingly popular in recent years with the wide adoption of the OpenID [34] and
OAuth [35] standards; for example, Dropbox, Box, Google Drive, Microsoft OneDrive, etc., all
require client applications to use the OAuth 2.0 protocol to obtain access to their services.
110

Correspondingly, a user’s cloud accounts can include both username/password pairs and single
sign-on access or refresh tokens. Based on the user’s preference, the cloud accounts can be pro-
tected either by the operating system (e.g. using the keyring mechanism on the Linux platform) or
by using an additional master password supplied by the user. Based on the number of the provided
cloud accounts, SafeSky can suggest the default values for the parameters N and K used in the
secret sharing scheme [28], and advanced users can also modify the default values if they want.
5.3.6.2 Cloud Data Retrieval, Save, and Consistency
Within an application session, when a data block is read for the first time by the application,
the cloud driver component retrieves K cloud data objects from any K of the N cloud storage
services; this retrieval operation will only occur once in a session for each data block of each file.
SafeSky creates a separate master thread to periodically inspects the memory structures for all the
files. In a memory structure (Figure 5.2), if the memory version of a data block is newer than its
cloud version, this master thread wakes up an idle worker thread in a thread pool to instruct the
data protection component for protecting the corresponding plaintext, and instruct the cloud driver
component with a pool of reusable TCP connections for saving the N cloud data objects to N
different cloud storage services. When the application closes files or its session ends, the master
thread also examines the memory structures to see if some final protection and save operations are
needed.
Such a saves-after-retrieval consistency mechanism is simple and appropriate for single-user
applications, which are most widely used and they only need to satisfy the single-reader single-
writer consistency semantics. Once a memory structure is constructed from the cloud data objects
retrieved from the cloud for a file, no more data will be retrieved from the cloud to replace the data
blocks in the memory structure; it can only be further updated by the interception component of
SafeSky based on the application’s write operations. By using a separate master thread, a pool of
worker threads, and a pool of reusable TCP connections, and by using the saves-after-retrieval con-
sistency mechanism, the data protection component and the cloud driver component perform their
111

tasks in a parallel and asynchronous manner for reducing the perceivable performance overhead
to end users. In addition, the cloud driver component contains a cache, which can hold the data
prefetched from the cloud and potentially further reduce the perceivable performance overhead to
end users.
Such a simple design also allows us to correctly meet the consistency requirement of SafeSky.
SafeSky requires that the value of K must be greater than a half of that of N . A successful
save operation requires that the freshest version of at least K cloud data objects of a data block
are successfully uploaded to K available cloud storage services; the freshest version number is
copied from the memory version as shown in Figure 5.2. SafeSky uses the majority consensus
solution [154, 155] to identify the freshest version number of the retrieved cloud data objects; a
successful retrieval operation requires that the freshest version of at least K cloud data objects
of a data block are successfully retrieved from K available cloud storage services. SafeSky will
perform retries for failed operations with the assumption that at least K cloud storage services are
available at any time in an application session.
5.4 Implementation
We implemented SafeSky as a C shared library on a Ubuntu Linux system. It supports applica-
tions written in languages such as C, Java, and Python as long as they interact with the underlying
operating system through the dynamically linked GNU libc library, which is used as the C library
in the GNU systems and most systems with the Linux kernel [156]. It supports popular cloud
storage services such as Amazon Cloud Drive, Box, Dropbox, Google Drive, Microsoft OneDrive,
Rackspace, and Swift; it supports both password and single sign-on user authentication methods
used by those services.
In the implementation of the data protection component, we used the libcrypto library for
authenticated encryption and decryption, and used the libgfshare library for Shamir’s (k, n) secret
sharing scheme [28]. In the implementation of the cloud driver component, we used the libcurl
library for user authentication and REST API interactions with cloud storage services, and used
112

the libjson library for parsing the received responses from cloud storage services. All these four
libraries are provided by default on Linux systems such as Ubuntu. The total number of lines of
code in SafeSky is about 6,300.
5.5 Evaluation
We used three free and full-blown applications, HomeBank, SciTE Text Editor, and Firefox
Web browser, from the Ubuntu Software Center to evaluate SafeSky. HomeBank [157] can assist
users in managing their personal accounting. It has many analysis and graphical representation
features, and can use different types of files to save users’ personal accounting information. SciTE
Text Editor [158] is similar to most text editors. It has additional features such as automatic syntax
styling and can partially understand the error messages produced by many programing languages.
Firefox is a popular Web browser that saves many types of users’ browsing data such as bookmarks,
history records, cookies, form values, and website passwords. These three applications cover both
text and binary file operations at both the standard C function level and the system call wrapper
function level.
We used four cloud storage services, Dropbox [143], Box [142], and two Swift [150] services
deployed on two Amazon EC2 instances. Dropbox and Box use OAuth based user authentication,
while Swift uses password based user authentication. The two Swift services are located at the
east coast and the west coast, respectively, to purposefully consider geolocation diversity in our
performance evaluation. We used four as the value for both parameters N and K in the Shamir’s
(k, n) secret sharing scheme [28]; the value of K is maximum so that we can measure and report
the worst case performance in our evaluation, while in the real use of SafeSky the value of K can
often be less than that of N as we also tested.
We evaluated the correctness and performance of SafeSky on a computer with 3.4GHz CPU
and 8 GiB memory. We ran the experiments 10 times and present the average results. We have not
done a usability study for SafeSky yet because we focus on its feasibility in this project.
113

5.5.1 Correctness
We intensively and manually experimented with the file operation related features of the three
applications to examine if SafeSky has been seamlessly loaded into them. We verified that the
three applications worked properly as usual, while users’ data are saved to the cloud rather than to
the local disk. In the interception component, SafeSky correctly intercepted all the file operations,
created and maintained memory structures, and returned data to applications. In the data protection
component, SafeSky correctly performed the authenticated encryption, authenticated decryption,
and secret sharing operations. In the cloud driver component, SafeSky correctly performed user
authentication, data save, and data retrieval operations with the four cloud storage services.
5.5.2 Performance
We automatically evaluated the memory structure maintenance and cryptographic operation
performance, evaluated the cloud data save and retrieval latencies, and measured the data block
read and write frequency of the applications.
5.5.2.1 Memory Structure Maintenance
We compared the time for reading/writing data from/to a memory structure (i.e., with the using
of SafeSky by the applications) with the time for reading/writing the same data from/to a local disk
file (i.e., without the using of SafeSky by the applications). Overall, the memory structure mainte-
nance performed by SafeSky in a read or write interception does add small additional performance
overhead due to the memory allocation and memory copy operations. However, the overhead is
negligible and only at the microsecond level.
5.5.2.2 Cryptographic Operations
Figure 5.4 illustrates the performance of the authenticated encryption, authenticated decryp-
tion, secret sharing encryption, and secret sharing decryption operations. As the data size increases
from 2KB to 64KB, both the AES-CCM [72] encryption time and decryption time remain small
within one millisecond. The secret sharing encryption time and decryption time increase linearly
114
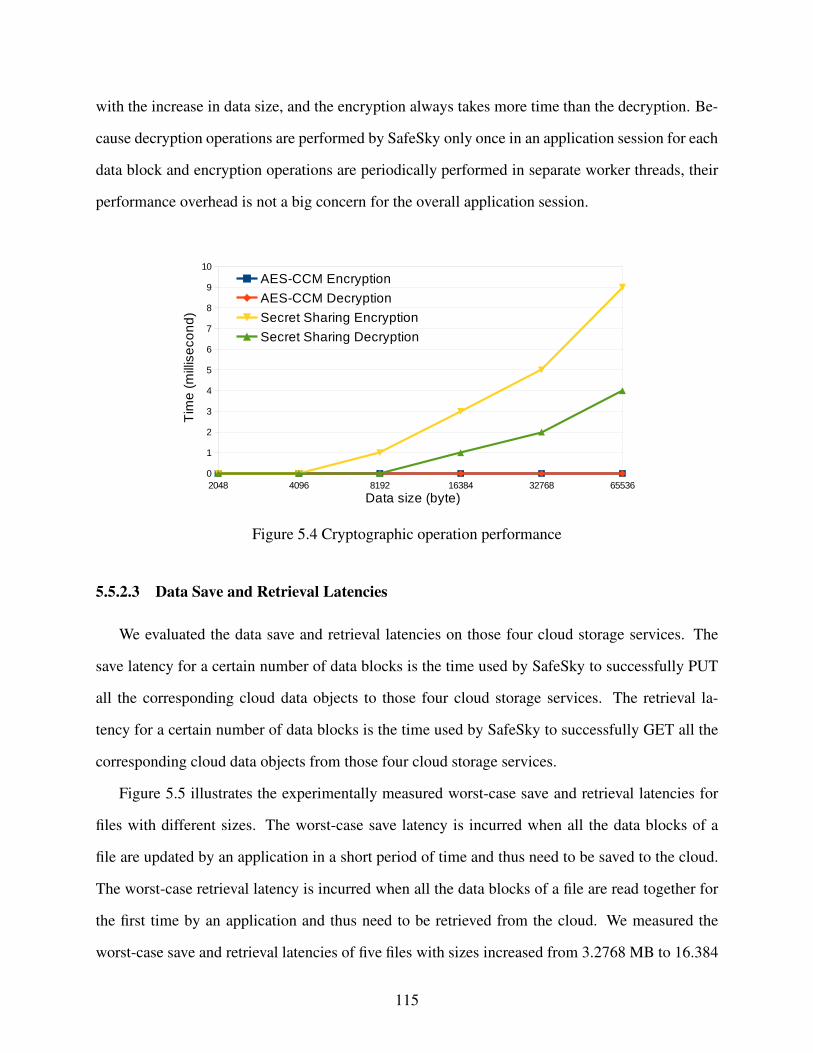
with the increase in data size, and the encryption always takes more time than the decryption. Be-
cause decryption operations are performed by SafeSky only once in an application session for each
data block and encryption operations are periodically performed in separate worker threads, their
performance overhead is not a big concern for the overall application session.
Figure 5.4 Cryptographic operation performance
5.5.2.3 Data Save and Retrieval Latencies
We evaluated the data save and retrieval latencies on those four cloud storage services. The
save latency for a certain number of data blocks is the time used by SafeSky to successfully PUT
all the corresponding cloud data objects to those four cloud storage services. The retrieval la-
tency for a certain number of data blocks is the time used by SafeSky to successfully GET all the
corresponding cloud data objects from those four cloud storage services.
Figure 5.5 illustrates the experimentally measured worst-case save and retrieval latencies for
files with different sizes. The worst-case save latency is incurred when all the data blocks of a
file are updated by an application in a short period of time and thus need to be saved to the cloud.
The worst-case retrieval latency is incurred when all the data blocks of a file are read together for
the first time by an application and thus need to be retrieved from the cloud. We measured the
worst-case save and retrieval latencies of five files with sizes increased from 3.2768 MB to 16.384
115
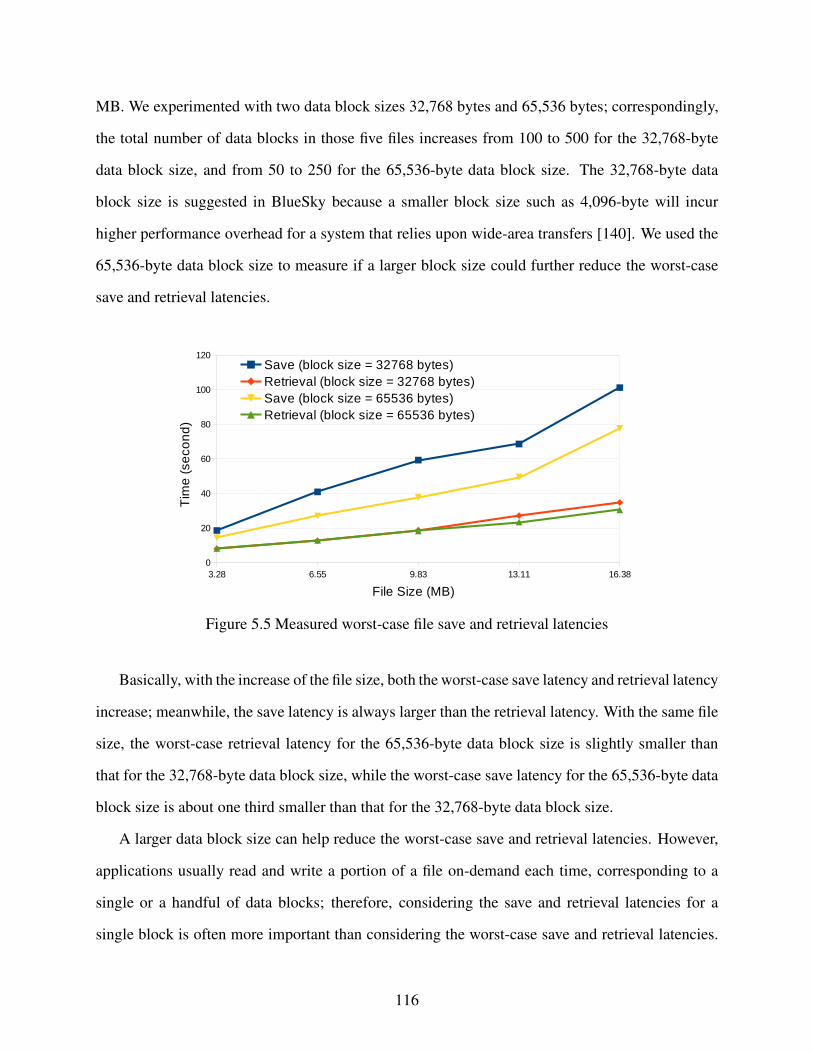
MB. We experimented with two data block sizes 32,768 bytes and 65,536 bytes; correspondingly,
the total number of data blocks in those five files increases from 100 to 500 for the 32,768-byte
data block size, and from 50 to 250 for the 65,536-byte data block size. The 32,768-byte data
block size is suggested in BlueSky because a smaller block size such as 4,096-byte will incur
higher performance overhead for a system that relies upon wide-area transfers [140]. We used the
65,536-byte data block size to measure if a larger block size could further reduce the worst-case
save and retrieval latencies.
Figure 5.5 Measured worst-case file save and retrieval latencies
Basically, with the increase of the file size, both the worst-case save latency and retrieval latency
increase; meanwhile, the save latency is always larger than the retrieval latency. With the same file
size, the worst-case retrieval latency for the 65,536-byte data block size is slightly smaller than
that for the 32,768-byte data block size, while the worst-case save latency for the 65,536-byte data
block size is about one third smaller than that for the 32,768-byte data block size.
A larger data block size can help reduce the worst-case save and retrieval latencies. However,
applications usually read and write a portion of a file on-demand each time, corresponding to a
single or a handful of data blocks; therefore, considering the save and retrieval latencies for a
single block is often more important than considering the worst-case save and retrieval latencies.
116
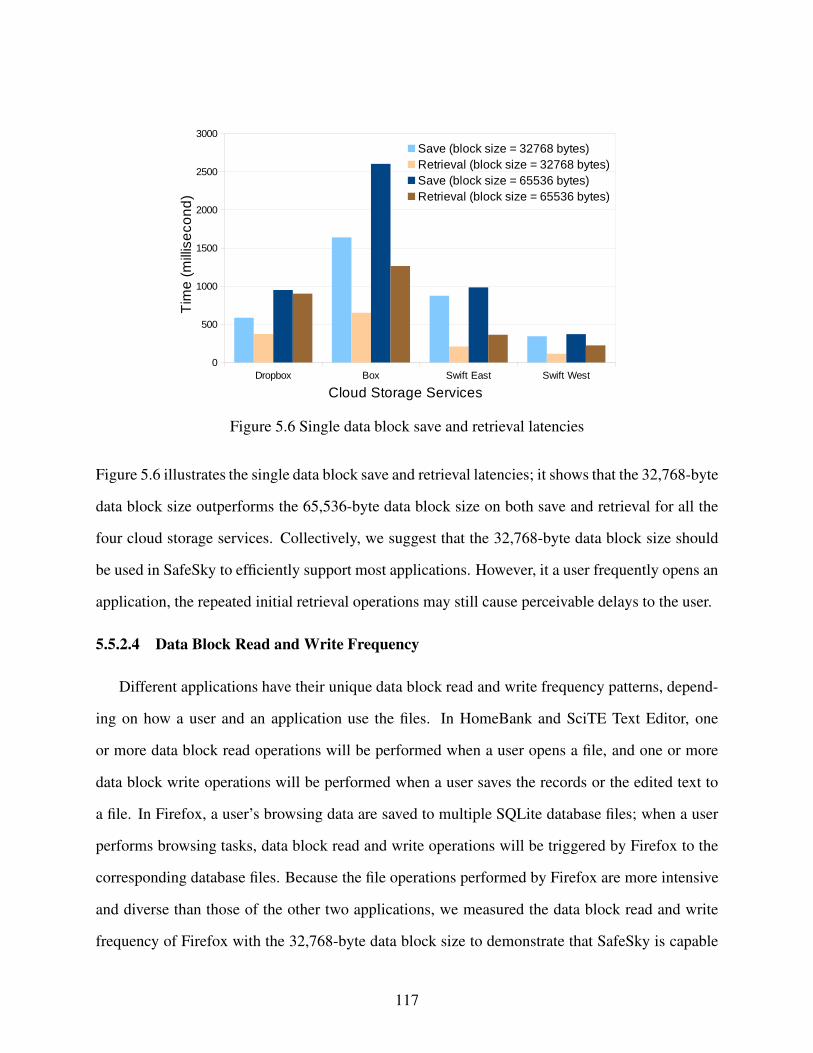
Figure 5.6 Single data block save and retrieval latencies
Figure 5.6 illustrates the single data block save and retrieval latencies; it shows that the 32,768-byte
data block size outperforms the 65,536-byte data block size on both save and retrieval for all the
four cloud storage services. Collectively, we suggest that the 32,768-byte data block size should
be used in SafeSky to efficiently support most applications. However, it a user frequently opens an
application, the repeated initial retrieval operations may still cause perceivable delays to the user.
5.5.2.4 Data Block Read and Write Frequency
Different applications have their unique data block read and write frequency patterns, depend-
ing on how a user and an application use the files. In HomeBank and SciTE Text Editor, one
or more data block read operations will be performed when a user opens a file, and one or more
data block write operations will be performed when a user saves the records or the edited text to
a file. In Firefox, a user’s browsing data are saved to multiple SQLite database files; when a user
performs browsing tasks, data block read and write operations will be triggered by Firefox to the
corresponding database files. Because the file operations performed by Firefox are more intensive
and diverse than those of the other two applications, we measured the data block read and write
frequency of Firefox with the 32,768-byte data block size to demonstrate that SafeSky is capable
117

of handling the intensive file operations performed by complex end-user applications.
We designed a browsing session scenario consisting of seven main steps. Step 1, we visit the
Google homepage, add it to bookmarks, perform a search using the keyword “security”, and click
one link on the response page. Step 2, we visit the CNN homepage and add it to bookmarks. Step
3, we visit the Facebook login page, add it to bookmarks, log into it, allow Firefox to remember
the login password, and log out. Step 4, we visit the Fox News homepage and add it to bookmarks.
Step 5, we visit the Gmail login page, add it to bookmarks, log into it, allow Firefox to remember
the login password, and log out. Step 6, we visit the YouTube homepage, add it to bookmarks, and
click the link to one video. Step 7, we revisit all those six webpages from their bookmarks, and let
Firefox autofill the login forms on the Facebook and Gmail login pages.
We performed this browsing session scenario quickly in approximately two minutes to in-
tensively trigger the file operations of Firefox. During the browsing session, Firefox reads/writes
bookmark records and history records from/to the places.sqlite database file, reads/writes name and
value pairs of form fields from/to the formhistory.sqlite database file, reads/writes website cookies
from/to the cookies.sqlite database file, and reads/writes login passwords from/to the signons.sqlite
database file.
Figures 5.7(a) and 5.7(b) illustrate the data block read frequency and write frequency of those
four database files in our browsing session, respectively. These are the results for just one brows-
ing session; averaging the results from multiple runs does not make sense because file operation
characteristics is unique for every browsing session. Read operations on the places.sqlite and
signons.sqlite database files occurred most frequently because bookmark, history, and form field
records are frequently examined by Firefox on each webpage. Read operations on the formhis-
tory.sqlite database file occurred only for webpages that contain forms. Read operations on the
cookies.sqlite database file occurred only at the beginning of the browsing session; we conjecture
that this phenomenon is due to the possible reason that Firefox caches all the cookies in memory at
the beginning of a browsing session, so that the intensive use of cookies in almost every webpage
will not incur too much performance overhead. Correspondingly, we observed that write opera-
118
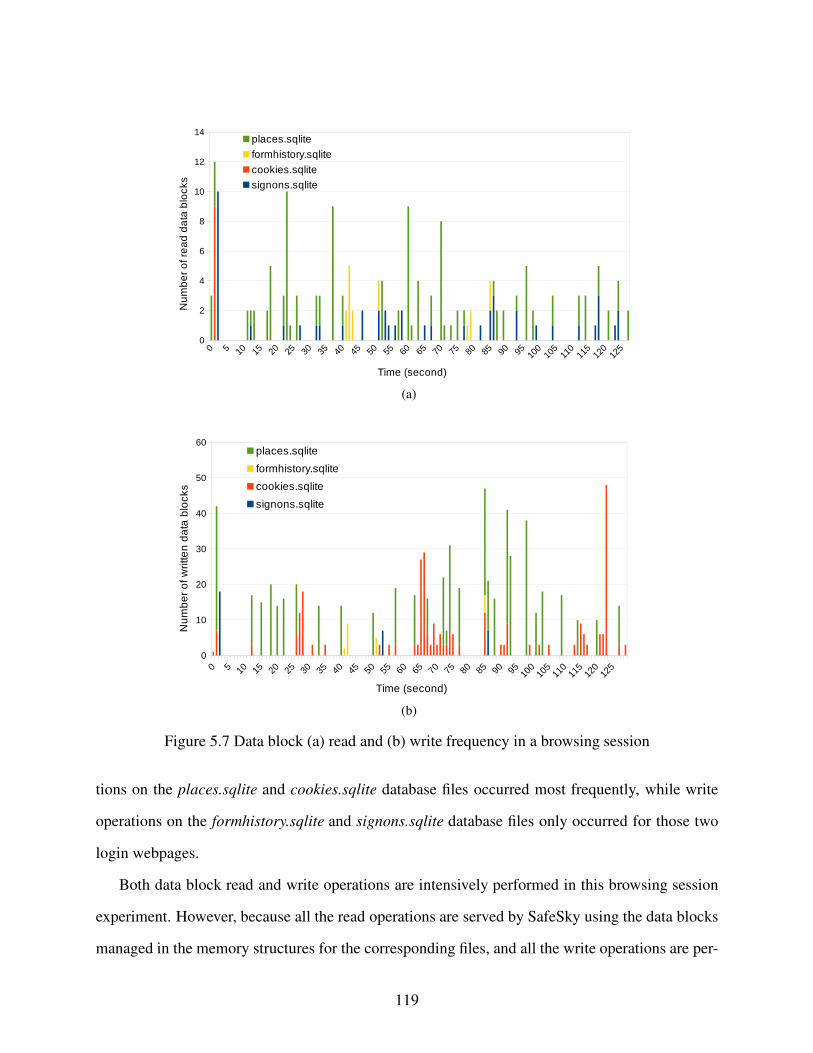
(a)
(b)
Figure 5.7 Data block (a) read and (b) write frequency in a browsing session
tions on the places.sqlite and cookies.sqlite database files occurred most frequently, while write
operations on the formhistory.sqlite and signons.sqlite database files only occurred for those two
login webpages.
Both data block read and write operations are intensively performed in this browsing session
experiment. However, because all the read operations are served by SafeSky using the data blocks
managed in the memory structures for the corresponding files, and all the write operations are per-
119

formed to the memory structures while separate worker threads are used to save data to the cloud,
such intensive and complex read and write file operations from Firefox can still be smoothly pro-
cessed by SafeSky. We did not perceive any performance overhead in this browsing session. These
performance evaluation results demonstrate that SafeSky can efficiently perform its functionality
and can meet its performance requirement.
5.6 Security Analysis
As analyzed in Section 5.3.5, SafeSky first applies the authenticated encryption to ensure that
it is computationally infeasible for attackers to break the data confidentiality and integrity. Fur-
thermore, it applies the Shamir’s (k, n) secret sharing scheme [28] to ensure: (1) it is absolutely
infeasible for attackers to break the data confidentiality, given that they do not compromise k or
more cloud storage services at the same time; (2) a high level of data availability can be achieved,
given that any k cloud storage services are available to a user. A user’s cloud data objects could
still be obtained by unauthorized parties from k or more cloud storage services in highly rare sit-
uations, for example, due to simultaneous data breaches in k cloud storage services, the collusion
of k cloud storage service providers, or the government surveillance; furthermore, by identifying
the k corresponding cloud data objects of a data block, the unauthorized parties can compromise
the confidentiality of that data block. However, SafeSky makes such an identification difficult by
uniquely generating the ids of cloud data objects from a hash function salted with the storage ser-
vice identifiers (Figure 5.2), albeit the timing information of block interactions may still be used
by attackers.
At the user-end, if malware exists on a user’s computer, the plaintext data, the cryptographic
keys, and cloud accounts could be directly stolen from the memory to compromise the data con-
fidentiality. Such potential attacks are out of the scope of this project because they pose common
risks to all the applications and data on a computer. However, users should still pay serious at-
tention to the risks of malware and should immediately address the malware problem by either
cleaning up or reinstalling the system.
120

As described in Section 5.3.6, a user’s cloud accounts can be protected either by the operating
system or by using an additional master password supplied by the user. It is possible that the
protected cloud accounts may be damaged or lost, for example, due to the crashing of the file
system or the careless deletion by the user. However, in such cases, SafeSky ensures that the
user’s data can still be available; the user can simply use password reset mechanisms provided
by the cloud storage services to regain cloud accounts, and then retrieve the cloud data objects to
completely recover their data.
5.7 Discussion
SafeSky supports user authentication and data save/retrieval operations on multiple cloud stor-
age services such as Amazon Cloud Drive [141], Box [142], Dropbox [143], Google Drive [144],
Microsoft OneDrive [147], and Swift [150]. Note that some of these services are not free for using
their REST APIs and storage by client applications. For example, the costs of using Amazon Cloud
Drive [141] and Google APIs Console in Google Drive [144] are both based on the storage size and
network traffic. Users can have their own choices to select cloud storage services based on their
preference and budget. For example, regular users can select free cloud storage services such as
Box [142] and Dropbox [143], enterprise users may select paid cloud storage services with larger
storage capability, and advanced users may set up their own storage services using software such
as Swift [150]. Further reducing the cost of using cloud storage services that are not free is out of
the scope of this project, and we refer readers to the BlueSky paper [140] for more information.
Currently, SafeSky focuses on satisfying a simple single-reader single-writer consistency se-
mantics for single-user applications that are most widely used, thus a saves-after-retrieval mech-
anism is sufficient. Satisfying a more general single-writer multi-readers consistency semantics
is feasible by letting readers periodically check cloud storage services to retrieve fresher cloud
data objects. Some collaborative applications allow multiple users to work on a common task si-
multaneously, and they require a more complex multi-reader multi-writer consistency semantics;
however, supporting this consistency semantics by a solution such as our SafeSky is very difficult
121

if not impossible because SafeSky simply uses the storage capability of cloud storage services
without requiring any special computational support from them or any modification to them. In
addition, currently SafeSky does not support the memory mapping operations such as mmap() and
network operations such as send() because it cannot ascertain and may compromise the semantics
of those operations.
5.8 Summary
In this project, we took a middleware approach and designed SafeSky, a secure cloud storage
middleware that can immediately enable either legacy or new end-user applications to have the se-
cure cloud storage capability without requiring any code modification or recompilation to them. A
SafeSky-enabled application does not need to save any data to the local disk, but instead securely
saves the data to multiple free cloud storage services to simultaneously enhance the data confi-
dentiality, integrity, and availability. We implemented SafeSky as a C shared library on Linux.
SafeSky supports applications written in different languages, various popular cloud storage ser-
vices, and common user authentication methods used by cloud storage services. We evaluated the
correctness and performance of SafeSky by using real-world applications and analyzed its security.
Our evaluation and analysis results demonstrate that SafeSky is a feasible and practical approach
for equipping end-user applications with the secure cloud storage capability.
122

CHAPTER 6
CROSS-SITE INPUT INFERENCE ATTACKS ON MOBILE WEB USERS
6.1 Introduction
Smartphones with a variety of built-in sensors enable rich application functionalities and make
the daily activities of Internet users highly convenient and enjoyable. For example, accelerometer
sensors are used in fitness apps to monitor users’ physical exercises, gyroscope sensors are used
in game apps to facilitate gesture-based interactions, and ambient light sensors are used in e-book
apps to adjust the screen brightness. However, smartphones have been severely targeted by cyber-
crimes, and their sensors have created many new vulnerabilities for attackers to compromise users’
security and privacy. One typical vulnerability is that high-resolution motion sensors, such as ac-
celerometer and gyroscope, could be used as side channels for attackers to infer users’ sensitive
keyboard tappings on smartphones, which is known as input inference attacks. Such attacks are
feasible because motion sensor data are often correlated to both the tapping behavior of a user and
the positions of the keys on a keyboard.
Some researchers have studied the effectiveness of input inference attacks on smartphones, but
their threat models and focuses are completely different from ours, and their attacks are not as chal-
lenging as ours. First, existing efforts mainly focused on investigating the attacks performed by the
native apps [159–163], and they assumed that malicious apps have been installed on users’ smart-
phones to access the motion sensor data. Second, existing efforts mainly focused on investigating
the attacks that target at touchscreen lock PINs [159, 160, 163, 164], which could be valuable only
if they are reused by smartphone owners on online services or if the smartphone itself is stolen.
Third, existing efforts often used apps’ built-in keyboards [159, 160, 163] and/or large digit-only
keyboards [159, 160, 163, 164] to collect motion sensor data and perform experiments, and they
did not study the attack effectiveness using real alphanumeric keyboards. Last but not the least, ex-
isting efforts often collected the key down and up events to accurately segment motion sensor data
123

(i.e., identifying the start and end time) to infer individual keystrokes [159, 163, 164]; however, in
reality smartphone platforms do not allow the cross-app collection of key down or up events for
security reasons.
While input inference attacks can be performed by malicious native apps, they can indeed
be more pervasively performed by malicious webpages to cause even severer consequences to
mobile Web users, who interact with webpages through either mobile browsers or WebView [165,
166] components of native apps. On both iOS and Android platforms, JavaScript code on regular
webpages can register to receive device motion events and access motion sensor data. This motion
sensor data access does not require a user to explicitly grant any permission, install any software,
or perform any configuration. It can even be performed cross-site from one origin to another
origin, creating a powerful side channel to bypass the fundamental Same Origin Policy [167]
that protects the security of the Web.
Especially, we highlight that two types of cross-site input inference attacks can occur. One
is parent-to-child cross-site input inference attacks, in which a parent document collects motion
sensor data to infer users’ sensitive inputs in a child (e.g., iframe) document. The other is child-
to-parent cross-site input inference attacks, in which a child document collects motion sensor data
to infer users’ sensitive inputs in a parent document. Both types of attacks can be pervasively
performed to severely compromise the security of millions of mobile Web users. As representative
scenarios, insecure Web Single Sign-On (SSO) relying party websites [44, 45, 168] or malicious
ones can infer users’ highly valuable SSO identity provider (e.g., Google or Facebook) accounts
by performing the first type of attacks; malicious or compromised third-party advertising web-
sites [169, 170] can infer users’ sensitive inputs on first-party websites through embedded adver-
tisements by performing the second type of attacks. Unfortunately, to date, little attention has been
paid to investigate these two types cross-site input inference attacks.
In this project, we investigate such severe cross-site input inference attacks that may compro-
mise the security of every mobile Web user, and quantify the extent to which they can be effective.
We formulate our attacks as a typical multi-class classification problem, and build an inference
124

framework that takes the supervised machine learning approach to train a classifier in the training
phase for predicting a user’s new inputs in the attacking phase. Collecting training data is feasible
because attackers can trick a user to type some specific (i.e., labeled) non-sensitive inputs on their
webpages, in which JavaScript code collects not only motion sensor data but also key down and
up events from the same origin. Attackers will then segment motion sensor data for individual
keystrokes (i.e., key taps), extract features, and train the classifier. Later, attackers will use the
trained classifier to infer sensitive inputs based on their corresponding motion sensor data. Our
attacks aim to infer any type of sensitive Web inputs composed of letters, digits, and special char-
acters, and aim to infer the inputs performed on real soft keyboards that often have compact sizes
and overlapped keys.
However, two major challenges need to be well addressed to make our attacks effective and
realistic. The first challenge is on data quality, i.e., the quality of the collected motion sensor data
for certain keystrokes could be low due to many reasons. For example, the motion sensor signal
for a keystroke can be weak by itself when a user taps very gently on a screen; meanwhile, various
noises can be introduced by human body movements such as arm raising, and by the hardware of
sensors due to the existence of manufacturing imperfections [171, 172]. The second challenge is
on data segmentation, i.e., the key down and up events cannot be obtained in the attacking phase
to accurately segment motion sensor data for individual keystrokes because the cross-site (or cross-
origin) collection of key events is prohibited by the Same Origin Policy [167]. Unfortunately, these
two challenges were not sufficiently addressed or not even considered in existing research [159–
162, 164, 173].
To address the data quality challenge, we designed two main techniques: training data screen-
ing and fine-grained data filtering. The first technique calculates character-specific quality scores
for individual keystrokes, and only uses the motion sensor data of good-quality keystrokes to train
the classifier. Ensuring the quality of training data is often useful in many machine learning ap-
plications, thus it is important for us to explore ways to integrate this technique into our inference
framework. The second technique selects frequency bands for data filtering at a fine granularity
125

to reduce the noise in the motion sensor data. By fine granularity, we mean the frequency bands
are selected with varying lengths instead of being fixed, for example, to a low-pass or high-pass
band; meanwhile, different frequency bands are selected to effectively attack different users. To
address the data segmentation challenge, we design a key down timestamp detection and adjust-
ment technique, in which motion peak reference points representing key down event timestamps
are identified to segment motion sensor data, and the segmentation windows are further refined.
These techniques have not been explored in existing research efforts yet; however, we found in our
experiments that they are indeed very effective in improving the accuracy of our input inference
attacks.
To evaluate the effectiveness of our cross-site input inference attacks, we collected 98,691
keystrokes on 26 letters, 10 digits, and 3 special characters from 20 participants. On average, our
attacks achieved 38.83%, 50.79%, and 31.36% inference accuracy (based on F-measure scores)
on three charsets lower-case letters, digits together with special characters, and all the 39 charac-
ters, respectively. Intuitively, on the letter charset, our attacks are about 10.8 times more effective
than the random guessing attacks. Our training data screening technique improved the inference
accuracy against all participants by 8.03%, 9.93%, and 7.21% on the three charsets, respectively;
our fine-grained data filtering technique improved the the inference accuracy against the majority
of participants by 1.14%, 1.76%, and 1.27% on the three charsets, respectively. Our key down
timestamp detection and adjustment technique achieved 86.32% accuracy on keystroke data seg-
mentation. In terms of inferring inputs across participants, our attacks can still achieve 28.27%,
35.68%, and 21.02% accuracy on the three charsets, respectively. We also calculated the detailed
confusion matrix regarding which keys are more frequently mis-labeled as which other keys. We
have shared the basic idea of our cross-site input inference attacks with the W3C (World Wide Web
Consortium) community, and we are in the progress of further sharing the technical details of the
attacks and our evaluation results with them.
We make five main contributions in this project: (1) we highlight and investigate two types
of cross-site input inference attacks (parent-to-child and child-to-parent) that can be pervasively
126

performed by malicious webpages to cause severe consequences to mobile Web users; (2) we ad-
dress the data quality and data segmentation challenges in input inference attacks by designing and
experimenting with three unique techniques: training data screening, fine-grained data filtering,
and key down timestamp detection and adjustment; (3) we build a concrete framework for collect-
ing a user’s motion sensor data, training a classifier, and inferring the user’s sensitive inputs; (4)
we evaluate the effectiveness of our attacks using the real data collected from 20 participants and
provide an in-depth analysis on the evaluation results; (5) we also perform experiments to evaluate
the effect of using data perturbation defense techniques on decreasing the accuracy of our input
inference attacks.
The rest of this chapter is organized as follows. Section 6.2 introduces the threat model for
cross-site input inference attacks and reviews the related work. Section 6.3 presents the design
of our input inference framework and its key techniques. Section 6.4 describes our experiments
and discusses the evaluation results. Section 6.5 discusses potential defense techniques. Finally,
Section 6.6 makes a conclusion.
6.2 Threat Model and Related Work
6.2.1 Threat Model
The basic threat model in our cross-site input inference attacks is that malicious JavaScript code
can collect smartphone motion sensor data and train a machine learning classifier to infer a user’s
sensitive inputs cross websites, thus bypassing the security protection of Same-Origin Policy [167].
Especially, we highlight that two types of cross-site input inference attacks, parent-to-child and
child-to-parent, can occur as shown in Figure 6.1. On both iOS and Android platforms, these
attacks do not require a user to explicitly grant any permission, install any software, or perform
any configuration.
In the parent-to-child cross-site input inference attacks, a parent document collects motion
sensor data to infer users’ sensitive inputs in a child (e.g., iframe) document. As shown in Fig-
ure 6.1(a), malicious JavaScript code in a parent document (“Domain P”) can register to receive
the device motion events from the window object for obtaining accelerometer and gyroscope sensor
127

(a) parent-to-child (b) child-to-parent
Figure 6.1 Two types of cross-site input inference attacks
data [174], and send the collected data to the attacker’s remote server. Because keystrokes for input
fields in a child document (“Domain C”) will not trigger temporally correlated DOM (Document
Object Model [175]) events in the parent document, the portion of the motion sensor data for the
child window can be easily extracted by the attacker for further inferring the corresponding letters,
digits, and special characters tapped on the child document.
As a representative example, users’ highly valuable Web Single Sign-On (SSO) identity provider
(IdP) (e.g., Google or Facebook) accounts including usernames and passwords can be the targets
of parent-to-child cross-site input inference attacks. Researchers have shown that security vul-
nerabilities are pervasive in Web SSO relying party websites [44, 45, 168]. An attacker can take
advantage of those vulnerabilities or even set up a malicious Web SSO relying party website to
collect motion sensor data and infer the Web SSO IdP accounts tapped by users in a child iframe
document. The attacker can accurately identify the domain name of the child document for the
inferred inputs because a parent document directly has the URL context information of its child
documents. It is very attractive for attackers to deploy parent-to-child input inference attacks be-
cause the inferred Web SSO IdP accounts can allow them to impersonate the victims not only on
individual IdPs but also on tens of thousands of relying party websites [34].
128

In the child-to-parent cross-site input inference attacks, a child document collects motion sen-
sor data to infer users’ sensitive inputs in a parent document. As shown in Figure 6.1(b), malicious
JavaScript code in a child document (“Domain C”) can register to receive the device motion events
from the window object for obtaining accelerometer and gyroscope sensor data, and send the col-
lected data to the attacker’s remote server. An attacker can then extract the portion of the motion
sensor data for the parent window to further infer the corresponding inputs tapped on the parent
document.
Using child iframe documents to include advertisements is a common practice on millions of
first-party websites. Researchers have shown that attackers often compromise the legitimate online
advertising networks or directly construct malicious advertisements [169, 170]. Leveraging com-
promised or malicious advertisements, an attacker can collect motion sensor data and infer users’
sensitive inputs on a first-party website by performing child-to-parent cross-site input inference
attacks. The attacker can accurately identify the domain name of the first-party website for the
inferred inputs because a child document can use the HTML document.referrer value to obtain the
URL context information of its parent document. It is also very attractive for attackers to deploy
child-to-parent input inference attacks because they can use a small number of compromised or
malicious advertising documents to infer sensitive inputs of users on millions of first-party web-
sites.
Collecting training data is feasible because attackers can trick a user to type some specific (i.e.,
labeled) non-sensitive inputs on their webpages - attackers can collect the motion sensor data, and
can also collect the corresponding key down and up events from the same webpages to accurately
segment these training data. An attacker can construct each individual user-specific classifier,
which is trained from the motion sensor data of a particular user to infer the sensitive inputs of the
same user. An attacker can also construct a general classifier, which is trained from the motion
sensor data of one or many users to infer the sensitive inputs of any user. Intuitively, a user-specific
classifier will be more accurate than a general classifier. While our experiments in Section 6.4
confirmed this intuition, both types of classifiers can be useful to attackers.
129

6.2.2 Related Work
Some researchers have studied the effectiveness of input inference attacks on smartphones. For
example, Aviv et al. investigated the feasibility for background apps to infer users’ touchscreen
lock PINs typed to the foreground apps based on the accelerometer sensor data [159]; they used
a large customized number-only keyboard to collect 4,800 PINs from 12 participants, and showed
that they can identify 43% and 20% PINs in controlled and uncontrolled settings, respectively.
Cai and Chen used smartphone orientation data, and inferred 70% of the 449 touchscreen lock
PINs typed on their large customized number-only keyboard [160]; in a following up work, they
collected 47,814 keystrokes from 21 participants, used both accelerometer and gyroscope sensor
data, and correctly inferred 30-33% letters and 49% digits [161]. Owusu et al. collected 1,300
key presses on small areas of the screen and 2,700 key presses on characters from four partic-
ipants [162]; they used accelerometer sensor data, and achieved an 18% inference accuracy on
areas. Xu et al. inferred PINs on a large customized number-only keyboard using both accelerom-
eter and gyroscope sensor data [163]; they achieved a 36.4% inference accuracy, but did not report
the number of participants and the size of their data samples. Mehrnezhad et al. used a large
numerical keypad to collect 2,400 keystrokes tapped on a webpage by 12 participants [164]; they
used accelerometer and gyroscope sensor data to infer PINs and achieved an inference accuracy
between 56% and 70%.
However, the threat models and focuses of these existing efforts are completely different from
ours, and their attacks are not as challenging as ours. First, they mainly focused on investigating the
attacks performed by the native apps [159–163], and they assumed that malicious apps have been
installed on users’ smartphones to access the motion sensor data. Second, they mainly focused on
investigating the attacks that target at touchscreen lock PINs [159, 160, 163, 164], which could
be valuable only if they are reused by smartphone owners on online services or if the smartphone
itself is stolen. Third, they often used apps’ built-in keyboards [159, 160, 163] and/or large digit-
only keyboards [159, 160, 163, 164] to collect motion sensor data and perform experiments, and
they did not study the attack effectiveness using real alphanumeric keyboards. Fourth, they often
130

collected the key down and up events to accurately segment motion sensor data (i.e., identifying the
start and end time) to infer individual keystrokes [159, 163, 164]; however, in reality smartphone
platforms do not allow the cross-app collection of key down or up events for security reasons.
Furthermore, the data quality and data segmentation challenges that we highlighted in Section 6.1
were not sufficiently addressed or not even considered in these existing efforts; the techniques
that we design (Section 6.3) to address these two challenges have not yet been explored by those
researchers either.
Liu et al. used the accelerometer data collected from a smartwatch to infer banking PINs typed
on a POS (Point of Sale) terminal and recover English text typed on a QWERTY keyboard [176].
For example, they collected accelerometer data for 4,920 movements from 8 participants to in-
fer the PINs from three different participants, and showed that the probability of identifying the
correct PINs from top 3 predicted results can reach 65%. Wang et al. used motion and orienta-
tion sensor data collected from smartwatches to infer personal PINs on ATM keypads and regular
keyboards [177]; they achieved an 80% inference accuracy based on 5,000 key entry traces of 20
participants. However, the threat model and focus of these researchers are also different from ours.
They assumed that malicious apps have been installed on users’ smartwatches to access the motion
sensor data; they still focused on inferring PINs instead of general Web inputs as in our work.
Therefore, their inference attacks are not as severe and pervasive as ours.
6.3 Design of Cross-site Input Inference Attacks
In this section, we first give an overview of our input inference framework, and then present
its technical details on motion sensor data segmentation, training data screening, fine-grained data
filtering, as well as feature and model selection.
6.3.1 Overview of the Framework
We formulate our attacks as a typical multi-class classification problem, and build an infer-
ence framework that takes the supervised machine learning approach to train a classifier in the
training phase for predicting a user’s new inputs in the attacking phase as shown in Figure 6.2.
131

The framework consists of six components. The sensor data segmentation component segments
motion sensor data for individual keystrokes. The training data screening component calculates
the character-specific quality scores for individual keystrokes and selects the motion sensor data of
good-quality keystrokes into the training dataset. The fine-grained data filtering component selects
user-specific frequency bands with varying lengths for reducing the noise in the motion sensor data.
The feature extraction component statistically derives both time-domain and frequency-domain
features from the filtered motion sensor data. The model training component trains a machine
learning classifier from the extracted features. The prediction component uses the trained classifier
to predict new characters tapped by a user.
In the training phase, attackers are capable of using JavaScript code to collect both motion sen-
sor data and key events (i.e., key down and key up) at the client side on a user’s smartphone as we
described in Section 6.2.1; these data are then sent to an attacker’s server, and further segmented,
screened, and filtered for extracting features to train a classifier. By leveraging the correspond-
ing key events for identifying the start and end time, this motion sensor data segmentation for
individual keystrokes in the training phase can be accurately performed. By selecting the motion
sensor data of good-quality keystrokes and by further filtering out the noise at a fine granularity,
the classifier can be more accurately trained for performing the attacks.
In the attacking phase, attackers are only capable of collecting motion sensor data because
cross-site (or cross-origin) collection of key events is prohibited by the Same Origin Policy; the
motion sensor data are then sent to the attacker’s server, and further segmented and filtered for
extracting features to predict the tapped characters using the trained classifier. Due to the lack
of key events in the attacking phase, accurate motion sensor data segmentation becomes very
challenging and an effective technique must be designed. Character-specific quality scores cannot
be calculated in the attacking phase because the tapped characters are unknown and are indeed the
targets of the inference attacks; meanwhile, it is difficult to identify a general metric for estimating
the quality of motion sensor data across characters. Therefore, our framework currently does
not include data screening in the attacking phase. However, the fine-grained data filtering is still
132
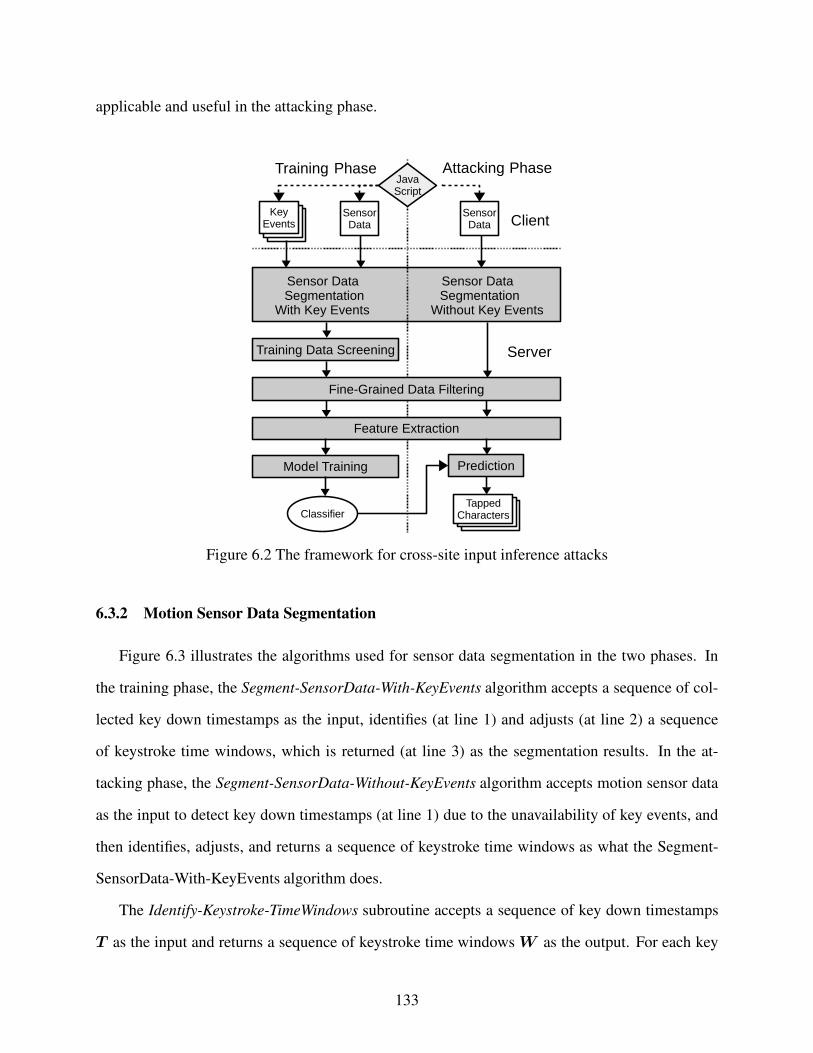
applicable and useful in the attacking phase.
Figure 6.2 The framework for cross-site input inference attacks
6.3.2 Motion Sensor Data Segmentation
Figure 6.3 illustrates the algorithms used for sensor data segmentation in the two phases. In
the training phase, the Segment-SensorData-With-KeyEvents algorithm accepts a sequence of col-
lected key down timestamps as the input, identifies (at line 1) and adjusts (at line 2) a sequence
of keystroke time windows, which is returned (at line 3) as the segmentation results. In the at-
tacking phase, the Segment-SensorData-Without-KeyEvents algorithm accepts motion sensor data
as the input to detect key down timestamps (at line 1) due to the unavailability of key events, and
then identifies, adjusts, and returns a sequence of keystroke time windows as what the Segment-
SensorData-With-KeyEvents algorithm does.
The Identify-Keystroke-TimeWindows subroutine accepts a sequence of key down timestamps
T as the input and returns a sequence of keystroke time windows W as the output. For each key
133

down timestamp Tj , the timestamps Tj − offset start and Tj + offset end are identified
as the start and end of the corresponding keystroke time window, respectively. This simple time
window identification method has been commonly used by many researchers in input inference
attacks [159, 162–164, 173]. They often use 100 milliseconds and 150 milliseconds as the values
of offset start and offset end, respectively, according to their observations on the time
relationship between motion sensor data and key events; we have the similar observation on this
relationship, and thus used the same offset values in this subroutine.
The Detect-KeyDown-Timestamps subroutine accepts the motion sensor data S from timestamp
t1 to timestamp tn as the input, finds their peak values, and returns a sequence of key down
timestamps T as the output. The subroutine first applies a band filter from start frequency
to end frequency on the sensor data S at line 1. Because the peak values of sensor data are
often well captured by their high frequency components, using a filter with a high-pass band (e.g.,
from 10Hz to 30Hz in our case) here can help us accurately detect the key down timestamps.
To comprehensively consider acceleration forces and rotation rates along all the three axes, the
subroutine computes the Euclidean magnitude values MAt
(for acceleration forces) and MRt
(for
rotation rates) at line 4 for each timestamp t. At line 5, the peak values in MA and MR are
identified using a sliding window based on the average keystroke duration observed in the training
data, and their timestamps are saved to the sequences, TA and TR, respectively. Because TA and
TR may not always properly align their timestamps, they are further merged at line 6 by including
their distinct timestamps and combining their common ones. The merged timestamps are returned
for segmenting motion sensor data in the attacking phase.
As we highlighted in the introduction, many researchers assumed the availability of key events
and did not actually address the data segmentation challenge in the attacking phase; in other words,
they only used the Identify-Keystroke-TimeWindows subroutine to perform motion sensor data
segmentation in both the training and attacking phases [159, 162–164, 173]. Only Cai and Chen
considered to segment the sensor data in the attacking phase [160, 161]. In [160], they used the
Peak-to-Average ratios of β and γ angles of device orientation to determine the start time and
134

// S = (St1, St2 , · · · , Stn): motion sensor data from time t1 to tn// Sti = (xti , yti , zti , αti , βti , γti): motion sensor data at time ti,
where xti , yti , zti represent acceleration forces on three axes x, y, z,
and αti , βti , γti represent rotation rates on three axes z, x, y// T = (T1, T2, · · · , Tm): a sequence of m key down timestamps
// W = (W1,W2, · · · ,Wm): a sequence of m identified time windows,
where Wi = (WSi ,WE
i ) represents the start and end time of a window
Segment-SensorData-With-KeyEvents (T ) // Used in the training phase
1 W = Identify-Keystroke-TimeWindows (T )
2 W = Adjust-Keystroke-TimeWindows (W )
3 return W
Segment-SensorData-Without-KeyEvents (S) // Used in the attacking phase
1 T = Detect-KeyDown-Timestamps (S)
2 W = Identify-Keystroke-TimeWindows (T )
3 W = Adjust-Keystroke-TimeWindows (W )
4 return W
Detect-KeyDown-Timestamps (S)
1 S = Filter-Data (S, start frequency, end frequency)
2 MA = MR = () // Magnitude for acceleration forces and rotation rates
3 for t in t1 : tn
4 MAt =
√
xt2 + yt
2 + zt2; MRt =
√
αt2 + βt
2 + γt2
5 TA = Find-Peak-Timestamps (MA); TR = Find-Peak-Timestamps (MR)
6 T = Merge-Peak-Timestamps (TA, TR)
7 return T
Identify-Keystroke-TimeWindows (T )
1 for j in 1 : m2 WS
j = Tj − offset start; WEj = Tj + offset end
3 return W
Adjust-Keystroke-TimeWindows (W )
1 for j in 1 : m − 12 overlap = WE
j − WSj+1
// Overlap between two keystrokes
3 if overlap ≤ 0 // No overlap
4 // Do nothing
5 else if overlap > ((WSj+1
+ offset start)−(WE
j − offset end)) × overlap threshold // Heavy overlap
6 mark Wj and Wj+1 as heavily overlapped time windows
7 else // Slight overlap, split the overlapped region
8 WEj = WE
j − overlap/2; WSj+1
= WSj+1
+ overlap/2
9 remove the marked heavily overlapped time windows from W10 return W
Figure 6.3 Sensor data segmentation algorithms in the two phases
135

end time of a keystroke. However, this method only uses the absolute device orientation angles
from two axes and may not be able to accurately segment the sensor data in different tapping
situations. Our Detect-KeyDown-Timestamps subroutine comprehensively uses both acceleration
forces and rotation rates on all the three axes, thus can be more robust in segmenting motion sensor
data. In [161], they used a library of keystroke motion waveform patterns to perform sensor data
segmentation. However, this method requires a library to be pre-built; its accuracy depends on
the quality of the library and the applicability of those patterns to different users. Unfortunately
in both [160] and [161], the authors did not further provide the details of their methods or make
their implementations available; therefore, we are not able to compare our method with theirs in
our experiments.
The Adjust-Keystroke-TimeWindows subroutine adjusts the identified keystroke time windows
in both training and attacking phases because some adjacent time windows may overlap and affect
the input inference accuracy. For every two adjacent time windows Wj and Wj+1, the subroutine
calculates the overlap between them at line 2. If they heavily overlap (i.e., the overlap region is
greater than a certain percentage threshold, overlap threshold, of the timespan between their
corresponding key down events at line 5), the subroutine marks both of them as heavily overlapped
time windows at line 6. If they slightly overlap, the subroutine adjusts their boundary to be the
middle of the overlapped region at line 8. Finally all the heavily overlapped time windows are
discarded at line 9, and the remaining time windows are returned at line 10. This adjustment step
was not considered in any existing work on input inference attacks; however, we observed in our
experiments that about 5% of the identified time windows (either with or without using key events)
heavily overlap (with overlap threshold = 80%), and this adjustment can indeed improve the
overall inference accuracy (Sections 6.4.4) by approximately 1%.
6.3.3 Training Data Screening
Training data screening is one key technique that we designed to address the data quality chal-
lenge in cross-site input inference attacks. It calculates character-specific quality scores for indi-
136

vidual keystrokes, and only uses the motion sensor data of good-quality keystrokes to train the
classifier.
In signal processing, the signal to noise ratio (SNR) is a commonly used quality estimation
metric. Calculating SNR requires the characterization of the noise based on either the standard
deviation of the random noise or the power spectrum density of the non-random noise. However,
motion sensor data in input inference attacks may contain mixed random and non-random noises
which are introduced from multiple sources such as the hardware of sensors due to the existence
of manufacturing imperfections [171, 172], and human body movements, for example, arm rais-
ing. Therefore, there is no standard way to characterize the noises, and computing SNR in input
inference attacks will not be reliable.
We propose a unique motion sensor data quality estimation algorithm Estimate-Keystroke-
Data-Quality for screening the training data as shown in Figure 6.4. Overall, given m keystrokes
of a specific user for a specific key, the algorithm first calculates their mean values of acceleration
forces and rotation rates to obtain six averaged waveforms c for c ∈ {x, y, z, α, β, γ} at line
1; it then compares the waveforms of each individual keystroke with the averaged waveforms to
calculate a quality score for the keystroke from line 3 to line 7. While it is not reliable to directly
compute SNR, averaging m measurements of a signal can ideally improve the SNR in propor-
tion to the√m [178]. This is the reason why our algorithm uses the averaged waveforms as the
reference to calculate quality scores. In more details, at line 4, the algorithm computes cross cor-
relation values sci
between each individual keystroke Ki and the averaged waveforms c for each c
to represent their level of similarity. Then at line 5, the algorithm computes weights wc for each
c by averaging the cross correlation values of m keystrokes. At line 6 and line 7, the algorithm
computes a quality score Qi for each keystroke Ki by adding its weighted cross correlation values
on x, y, z, α, β, and γ.
This quality estimation algorithm does not rely on any special heuristic or threshold, and it can
be executed online efficiently with polynomial time complexity. Using this algorithm, the training
data screening component computes quality scores of individual keystrokes of a user for a specific
137

Estimate-Keystroke-Data-Quality (K)
// K = (K1,K2, · · · , Km): m keystrokes of a user for a specific key
// Ki = ((xitn, yi
tn, zi
tn, αi
tn, βi
tn, γi
tn),
(xitn+1
, yitn+1
, zitn+1
, αitn+1
, βitn+1
, γitn+1
), · · · ,(xi
tn+j, yi
tn+j, zi
tn+j, αi
tn+j, βi
tn+j, γi
tn+j): acceleration forces x, y, z
and rotation rates α, β, γ of the i-th keystroke from time tn to tn+j
// Q = (Q1, Q2, · · · , Qm): quality scores for m keystrokes in K1 calculate each c = (ctn , ctn+1
, · · · , ctn+j) for c ∈ {x, y, z, α, β, γ}
where ctk =Mean (c1tk , c2tk, · · · , cmtk )
2 s = () // Cross-correlation values of m keystrokes for x, y, z, α, β, γw = () // Weights for x, y, z, α, β, γ
3 for each Ki in (K1, K2, · · · ,Km)4 calculate each sci = Cross-Correlation ((citn, c
itn+1
, · · · , citn+j), c)
for c ∈ {x, y, z, α, β, γ}5 calculate each wc = Mean (sc
1, sc
2, · · · , scm) for c ∈ {x, y, z, α, β, γ}
6 for each Ki in (K1, K2, · · · ,Km)7 Qi = sxi × wx + syi × wy + szi × wz + sαi × wα
i +
sβi × wβ + sγi × wγ
8 return Q
Figure 6.4 Keystroke data quality estimation algorithm
key, and ranks the keystrokes based on their quality scores. Later, only a certain percent of top-
quality keystrokes will be selected to perform fine-grained data filtering and feature extraction for
training a classifier.
6.3.4 Fine-grained Data Filtering
Fine-grained data filtering is the other key technique that we designed to address the data
quality challenge in cross-site input inference attacks. It selects frequency bands for data filtering
at a fine granularity to reduce the noise in the motion sensor data. As shown in Figure 6.2, this
filtering technique is applied to the screened data in the training phase to identify the most effective
filters, which are used to reduce the noise in both the training and attacking phases.
Frequency domain data filtering is a commonly noise reduction technique. In the context of
input inference attacks, some researchers neglected the application of this useful technique [160,
164]. Some other researchers applied filters with fixed bands [161], used interpolation-based data
smoothing methods [162, 173], or used Discrete Fourier Transformation (DFT) and inverse DFT
138

methods [159]. All these methods essentially discard high-frequency components and are equiv-
alent to using certain fixed-band low-pass filters; however, it is not shown in these studies that a
fixed-band low-pass filter is most appropriate and effective. Liu et al. used amplitude filters to keep
dominant-frequency components of the arm movement related sensor data [176]. This method is
applicable to the detection of large arm movements with their signal dominating the power spec-
trum; however, it is not applicable to our input inference attacks in which subtle finger tappings on
specific characters are the target of the detection. Therefore, it is important to thoroughly investi-
gate effective filtering techniques that are applicable to our input inference attacks.
We propose a fine-grained data filtering technique, in which the frequency bands are selected
with varying lengths instead of being fixed, for example, to a low-pass or high-pass band; mean-
while, different frequency bands are selected to effectively attack different users. Specifically, our
technique divides the entire frequency band into multiple finer-granularity sub-bands, iterates all
the consecutive concatenations of one or multiple sub-bands, and selects the concatenated band
that performs the best as the frequency band for a particular user.
One typical band division method is the 1n
Octave method [179], which first divides an entire
frequency band into two halves, then recursively divides the low frequency half multiple times in
the same manner, and finally further equally divides each current sub-band into n new sub-bands.
The 1n
Octave method favors low frequency components by dividing them into finer-granularity
sub-bands, and it is often used in processing audio data that are dominated by low frequency
components [179]. We use the 12
Octave method to divide the entire frequency band (i.e., 0Hz to
30Hz, which is the mirrored first half of 60Hz sampling frequency in Google Chrome used for
collecting our motion sensor data) into ten sub-bands (four recursive divisions and one final 12
division), but merge the first two low-frequency sub-bands into one due to their small sizes; the
second column of Table 6.1 lists the nine final Octave sub-bands. Alternative division methods
exist, for example, a straightforward method is to divide the entire frequency band into sub-bands
with an equal size; we also use this method to derive nine equal sub-bands as shown in the third
column of Table 6.1. We are interested in measuring if one method will be more effective than the
139
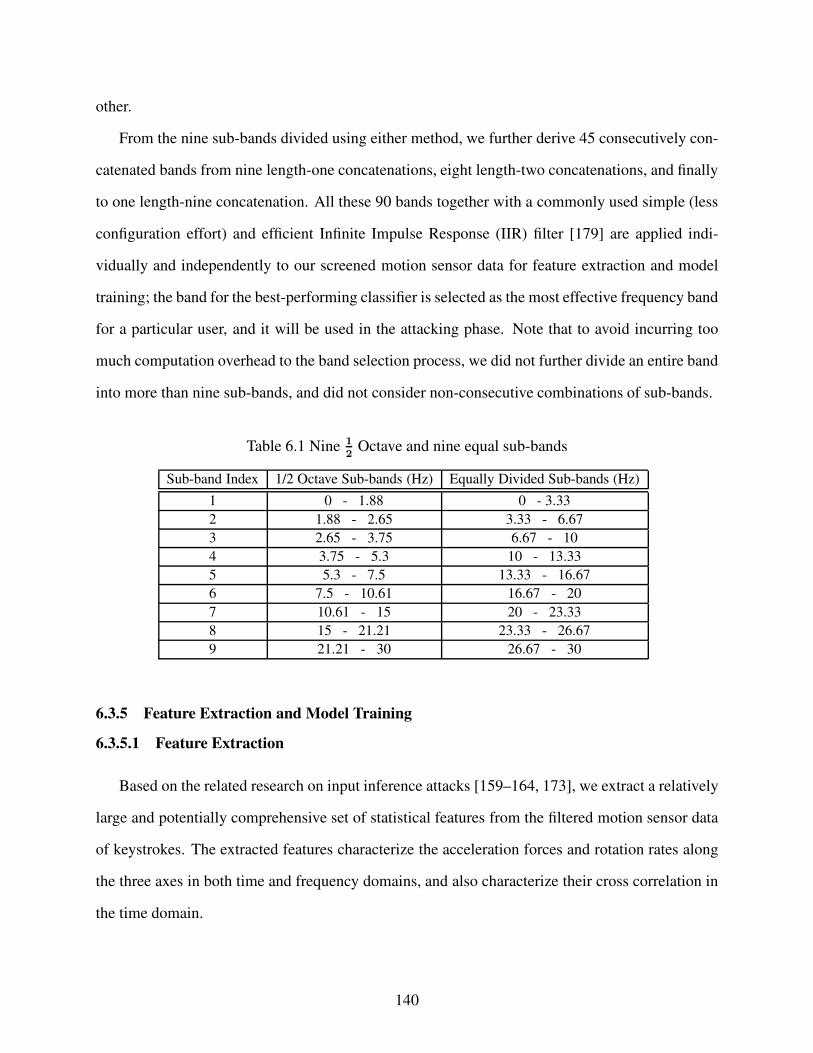
other.
From the nine sub-bands divided using either method, we further derive 45 consecutively con-
catenated bands from nine length-one concatenations, eight length-two concatenations, and finally
to one length-nine concatenation. All these 90 bands together with a commonly used simple (less
configuration effort) and efficient Infinite Impulse Response (IIR) filter [179] are applied indi-
vidually and independently to our screened motion sensor data for feature extraction and model
training; the band for the best-performing classifier is selected as the most effective frequency band
for a particular user, and it will be used in the attacking phase. Note that to avoid incurring too
much computation overhead to the band selection process, we did not further divide an entire band
into more than nine sub-bands, and did not consider non-consecutive combinations of sub-bands.
Table 6.1 Nine 12
Octave and nine equal sub-bands
Sub-band Index 1/2 Octave Sub-bands (Hz) Equally Divided Sub-bands (Hz)
1 0 - 1.88 0 - 3.33
2 1.88 - 2.65 3.33 - 6.67
3 2.65 - 3.75 6.67 - 10
4 3.75 - 5.3 10 - 13.33
5 5.3 - 7.5 13.33 - 16.67
6 7.5 - 10.61 16.67 - 20
7 10.61 - 15 20 - 23.33
8 15 - 21.21 23.33 - 26.67
9 21.21 - 30 26.67 - 30
6.3.5 Feature Extraction and Model Training
6.3.5.1 Feature Extraction
Based on the related research on input inference attacks [159–164, 173], we extract a relatively
large and potentially comprehensive set of statistical features from the filtered motion sensor data
of keystrokes. The extracted features characterize the acceleration forces and rotation rates along
the three axes in both time and frequency domains, and also characterize their cross correlation in
the time domain.
140

As shown in Table 6.2, we use 30 types of raw and derived motion sensor data of a given
keystroke to extract statistical features. Sixteen types of data are singletons, and fourteen types of
data are pairs. The 16 singletons include acceleration forces (x, y, z), rotation rates (α, β, γ), the
magnitude of acceleration forces (MA), the magnitude of rotation rates (MR), and all their first
differences (D(x), D(y), D(z), D(α), D(β), D(γ), D(MA), D(MR)). The 14 pairs include three
pairs of acceleration forces ((x, y), (y, z), (z, x)), three pairs of rotation rates ((α, β), (β, γ), (γ,
α)), one pair of the magnitudes of acceleration forces and rotation rates ((MA, MR)), and seven
pairs of their corresponding first differences.
From the 16 singletons, the feature extraction component extracts (from both time and fre-
quency domains) nine types of statistical features: maximum value, minimum value, mean value,
variance, standard derivation, root mean square (RMS), skewness, kurtosis, and area under curve
(AUC); as a result, 16 × 2 × 9 = 288 features are extracted from the 16 singletons. Given the
motion sensor data of a keystroke in the time domain, the maximum and minimum values are the
peak and valley values; the mean value is the averaged amplitude; the variance, standard deviation,
and RMS measure the deviations on amplitude; the skewness measures the symmetry of the mo-
tion sensor data; the kurtosis measures whether the motion sensor data are heavily or lightly tailed
in comparison to a normal distribution; the AUC measures the power of the motion sensor data.
In the frequency domain, all these nine features statistically measure the distribution of frequency
components of the motion sensor data. From the 14 pairs, the component extracts their 14 cross
correlation values in the time domain. Therefore, in total, 288+14 = 302 statistical features are
extracted from the motion sensor data of a keystroke, and then are used in training and prediction.
6.3.5.2 Model Training
In the model training, we experiment with a variety of machine learning algorithms using
Weka [180], a popular machine learning package. These algorithms include Logistic Regression,
Naive Bayes, Bayes Network, Support Vector Machine (SVM), K-Nearest Neighbors, Decision
Tree, Random Forest Tree, and Multi-layer Perceptron in Artificial Neural Network; some of them
141
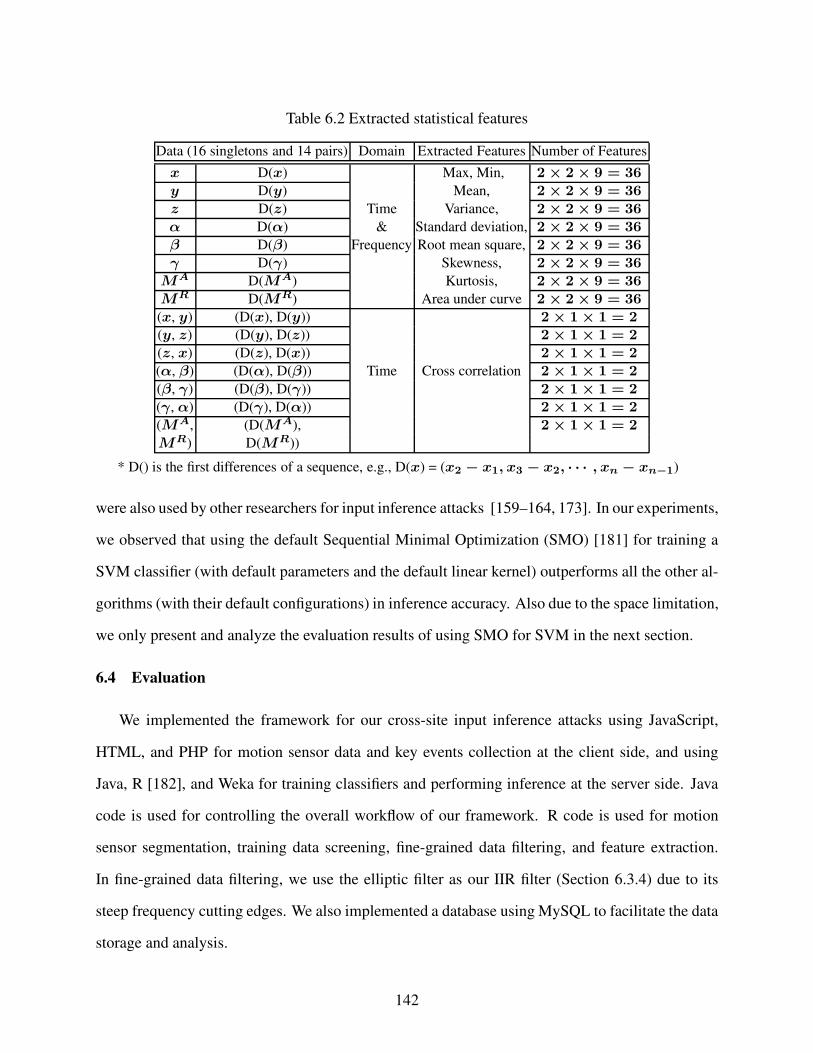
Table 6.2 Extracted statistical features
Data (16 singletons and 14 pairs) Domain Extracted Features Number of Features
x D(x) Max, Min, 2 × 2 × 9 = 36y D(y) Mean, 2 × 2 × 9 = 36z D(z) Time Variance, 2 × 2 × 9 = 36α D(α) & Standard deviation, 2 × 2 × 9 = 36β D(β) Frequency Root mean square, 2 × 2 × 9 = 36γ D(γ) Skewness, 2 × 2 × 9 = 36
MA D(MA) Kurtosis, 2 × 2 × 9 = 36MR D(MR) Area under curve 2 × 2 × 9 = 36(x, y) (D(x), D(y)) 2 × 1× 1 = 2(y, z) (D(y), D(z)) 2 × 1× 1 = 2(z, x) (D(z), D(x)) 2 × 1× 1 = 2(α, β) (D(α), D(β)) Time Cross correlation 2 × 1× 1 = 2(β, γ) (D(β), D(γ)) 2 × 1× 1 = 2(γ, α) (D(γ), D(α)) 2 × 1× 1 = 2(MA, (D(MA), 2 × 1× 1 = 2MR) D(MR))
* D() is the first differences of a sequence, e.g., D(x) = (x2 − x1, x3 − x2, · · · , xn − xn−1)
were also used by other researchers for input inference attacks [159–164, 173]. In our experiments,
we observed that using the default Sequential Minimal Optimization (SMO) [181] for training a
SVM classifier (with default parameters and the default linear kernel) outperforms all the other al-
gorithms (with their default configurations) in inference accuracy. Also due to the space limitation,
we only present and analyze the evaluation results of using SMO for SVM in the next section.
6.4 Evaluation
We implemented the framework for our cross-site input inference attacks using JavaScript,
HTML, and PHP for motion sensor data and key events collection at the client side, and using
Java, R [182], and Weka for training classifiers and performing inference at the server side. Java
code is used for controlling the overall workflow of our framework. R code is used for motion
sensor segmentation, training data screening, fine-grained data filtering, and feature extraction.
In fine-grained data filtering, we use the elliptic filter as our IIR filter (Section 6.3.4) due to its
steep frequency cutting edges. We also implemented a database using MySQL to facilitate the data
storage and analysis.
142

In the following subsections, we will first describe our data collection procedure and introduce
the metrics for evaluating the accuracy of our inference attacks. We will then discuss the evaluation
results regarding (1) the overall accuracy with training data screening, (2) the overall accuracy with
further fine-grained data filtering, (3) further overall accuracy comparison and analysis, (4) detailed
per key inference accuracy and confusion metrics, and (5) motion sensor data segmentation without
key events.
6.4.1 Data Collection
6.4.1.1 Participants
With the IRB (institutional review board) approval from our university in November 2015, we
recruited 14 male and 6 female adults who voluntarily participated in our data collection without
receiving monetary compensation. They are students and faculty members from seven depart-
ments, and they are all daily smartphone users. We asked all the participants to use their own or
our provided Android smartphones, and use the Google Chrome Web browser with the default
Google Keyboard (Appendix A) to perform input tasks. In the recruitment process, potential par-
ticipants were administered the informed consent, in which they were told that the study examines
if smartphone motion sensor data can be used to infer the actual inputs of a user. They were also
told that they do not need to type any sensitive information, but their motion sensor data will still
be kept confidential.
6.4.1.2 Websites Setup
We created two websites: one of them (i.e., the “malicious” website) uses JavaScript code to
perform cross-site motion sensor data collection from the other website (i.e., the “victim” website).
From the “victim” website that we own, we were also able to collect the key events for segment-
ing the motion sensor data, and the tapped characters for labeling the corresponding individual
keystrokes. The “victim” website contains four webpages. Each webpage displays a different let-
ter pangram and a different digit pangram, and asks our participants to type the two pangrams in
two input fields, respectively. As shown in Table 6.3, each letter pangram is a sentence using every
143

letter of the alphabet exactly once so that a participant does not need to type a longer sentence in
each input field. Also note that only lower case letters are used in these pangrams, thus we do not
consider the mix of upper and lower case letters in our data collection and experiments. Each digit
pangram contains ten unique digits, and also contains three special characters that are at the left,
middle, and right parts of the keyboard. On every input field, “autocomplete” and “autocorrect”
properties were turned off so that a participant will type every character of a pangram, and the
input values were verified so that the complete pangram will eventually be typed.
Table 6.3 Pangrams used in the study
Webpage Letter Pangrams Digit Pangrams
1 cwm fjord bank glyphs vext quiz @83294&60571)
2 squdgy fez blank jimp crwth vox &56920)71438@
3 tv quiz drag nymphs blew jfk cox )45372&80916@
4 q kelt vug dwarf combs jynx phiz @28513)97604&
6.4.1.3 Procedure and Dataset
We asked every participant to perform four tasks by visiting the four webpages and typing the
displayed pangrams in each session. We asked each participant to complete a total number of 26
sessions in two weeks, but allowed them to do so at any places; therefore, we were able to collect
a relatively large amount of data from participants in their real daily environments without any
restriction. We asked participants to use one hand to hold the smartphone and use the other hand to
tap the inputs, but we do not know if they strictly followed this rule in all their sessions. Overall,
we collected 4 × 26 = 104 keystroke samples for each of the 39 characters (lower-case letters,
digits, and three special characters) from each individual participant. Due to the error correction in
typing, our participants indeed contributed 17,571 additional keystroke samples in their sessions.
As a result, the total number of keystroke samples in our final dataset is 104×39×20+17, 571 =
98, 691.
144

6.4.2 Accuracy Metrics and Evaluation Methodology
To evaluate the accuracy of a trained multi-class classifier, we first count the true positive
(TP), false positive (FP), true negative (TN), and false negative (FN) numbers. For a given class
(e.g., letter “a”), a true positive is an instance correctly predicted as belonging to that class (e.g.,
letter “a” is correctly predicted as “a”), a false positive is an instance incorrectly predicted as
belonging to that class (e.g., letter “b” is incorrectly predicted as “a”), a true negative is an instance
correctly predicted as not belonging to that class (e.g., letter “b” is correctly predicted not as “a”),
a false negative is an instance incorrectly predicted as not belonging to that class (e.g., letter “a” is
incorrectly predicted not as “a”). We further calculate false positive rate (FPR), precision, recall
(i.e., true positive rate, or TPR), and F-measure accuracy metrics for each class, and average their
corresponding values across classes as the accuracy for the multi-class classifier. The F-measure
metric is the harmonic mean of precision and recall, and is often used to represent the overall
accuracy of a classifier; thus, in the following subsections, we mainly present and analyze the
results based on this metric while leaving the details of other metrics in the appendixes. Note that
we do not specifically calculate the accuracy as the ratio of true instances to all the instances due to
the accuracy paradox [183], in which true negatives dominate this ratio and make it meaningless.
In the evaluation, our classifier is trained and assessed using the 10-fold cross validation, and
we run the cross validation for 5 rounds and present their averaged results. We evaluate the infer-
ence accuracy explicitly on all the three charsets: the letter charset (i.e., 26 lower-case letters), the
digit charset (i.e., 10 digits together with 3 special characters), and the mixed charset (i.e., all the
39 characters). This is because in real scenarios, an attacker may know the type information of an
input regarding if it is a letter or digit, and can directly use a classifier specific to the inference of
either letters or digits. For example, if an attacker aims to infer a credit card number, the classifier
specific to the digit charset will be used; or, if the attacker does not have the type information of
an input, the classifier specific to the mixed charset will be used instead.
145

6.4.3 Overall Accuracy with Training Data Screening
In this subsection, we evaluate the overall accuracy of our inference attacks with the focus on
quantifying the extent to which our training data screening technique can improve the accuracy. We
use the keystroke data quality estimation algorithm (Figure 6.4) to rank the keystrokes of a given
participant for each specific key, and select a certain percent of top-quality keystrokes for training a
classifier and performing the 10-fold cross validation. Specifically, we choose 10 percentage values
from 0.1 (i.e., 10%), 0.2 (i.e., 20%), ..., to 1.0 (i.e., 100%). In particular, the 100% value means that
all the keystrokes will be used in training, and the corresponding inference accuracy serves as the
baseline in our accuracy comparison. Given a specific percentage value and a specific charset, we
ensure that the sample sizes are roughly equal for different characters to avoid training a classifier
using unbalanced data. Eventually, the percentage value that yields the highest inference accuracy
will be selected for each participant as the best percentage value for screening the training data.
Note that in this percentage value selection process, fine-grained data filtering is turned off to avoid
the occurrence of circular dependency.
Figures 6.5(a), 6.5(b), and 6.5(c) illustrate the overall inference accuracy for the 20 participants
on the three charsets, respectively. In each subfigure, we compare the inference accuracy (i.e., F-
measure) for each participant between that from the baseline (i.e., 100%) and that from his or her
best percentage value. Regarding the inference accuracy from the baseline, the F-measure scores
for the 20 participants vary from 12.97% to 58.14% with the average at 30.12% for the letter
charset, from 21.21% to 66.91% with the average at 39.71% for the digit charset, and from 9.17%
to 46.97% with the average at 23.45% for the mixed charset. By using training data screening
with the best percentage values, the F-measure scores for the 20 participants are improved (upon
those of the baseline) from 3.41% to 20.45% with the average at 8.03% for the letter charset, from
1.96% to 18.75% with the average at 9.93% for the digit charset, and from 2.8% to 16.96% with
the average at 7.21% for the mixed charset. The inference accuracy is improved for all the 20
participants, demonstrating that our training data screening technique is indeed effective.
146
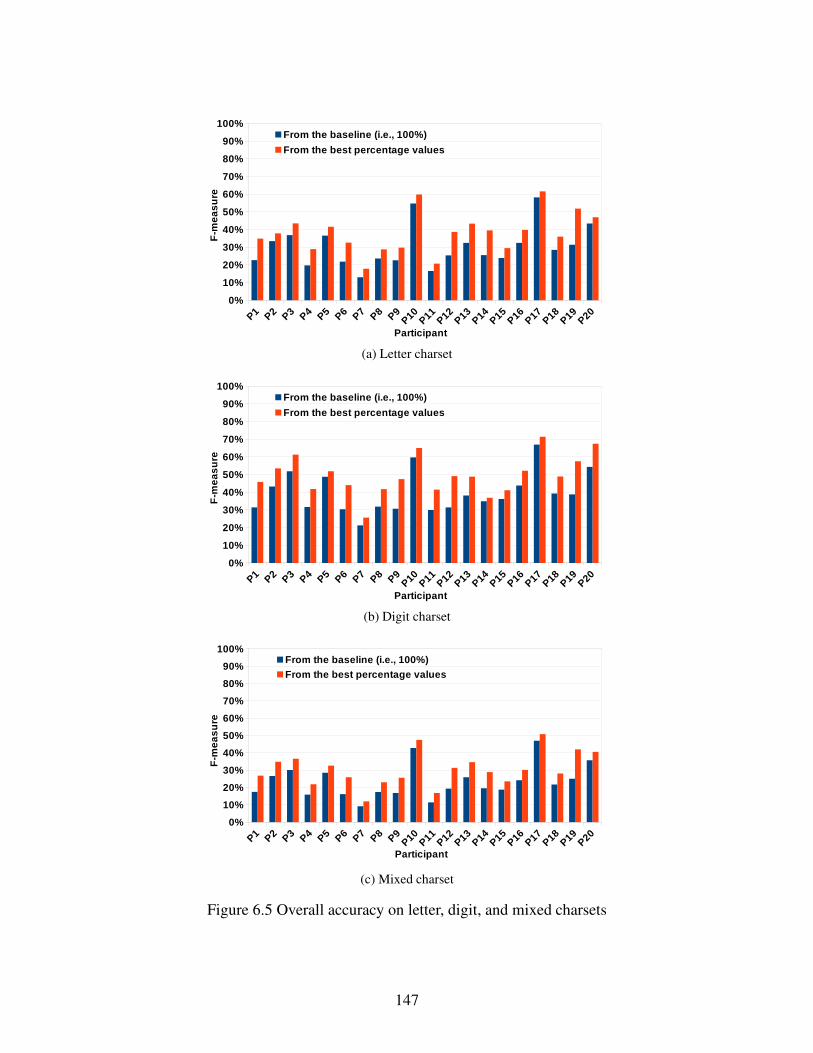
(a) Letter charset
(b) Digit charset
(c) Mixed charset
Figure 6.5 Overall accuracy on letter, digit, and mixed charsets
147

Two additional observations from Figure 6.5 are worth mentioning. One is that for almost all
the participants, the corresponding inference accuracy on the digit charset is higher than that on the
letter charset, which is further higher than that on the mixed charset. For example, for participant
P12, the inference accuracy on the digit, letter, and mixed charsets is 49.13%, 38.63%, and 31.29%,
respectively. The other observation is that the relative inference accuracy differences among the
participants are highly consistent across the three charsets. For example, the inference accuracy
for participant P7 is the lowest among all the participants across the three charsets, while that for
participant P17 is always the highest. More details are provided in Appendix B.
We further characterize the distribution of those best percentage values in Figure 6.6. For
most participants, the best percentage values are 0.2, 0.3, or 0.4 for the letter and mixed charsets,
and are 0.1, 0.2, 0.3, or 0.5 for the digit charset. It is clear that including all the keystrokes
and ignoring their quality cannot achieve the best inference accuracy, which is true for all the 20
participants. In some cases, the best percentage value is 0.1; one reason could be that the motion
sensor data collected in some sessions are very noisy. However, in most cases, with the increase of
the percentage value from 0.1 to 1.0, the inference accuracy first increases and then decreases; this
can be explained by the common sense that a reasonable size should be ensured for the training
dataset but not many noisy samples should be included into it. Note that for the same participant,
the best percentage values can be different for the three charsets (e.g., 10%, 50%, and 20% for
participant P4 as shown in Appendix B).
Figure 6.7 provides the detailed keystroke quality scores calculated using the algorithm in Fig-
ure 6.4. These scores are averaged from all the keystrokes on the 39 characters for each participant.
The range of keystroke quality scores is from 0.0 to 6.0 because the quality calculation formula (at
line 7 in Figure 6.4) contains six terms and each of them is the multiplication of two values with
the range from 0.0 to 1.0. We can observe that the average keystroke quality scores vary among
participants. The highest score (3.51 for participant P17) is almost twice of the lowest score (1.80
for participant P14). The scores of most participants are below 3.0, indicating that, overall, our
collected motion sensor data are noisy. By comparing these quality scores to the overall inference
148
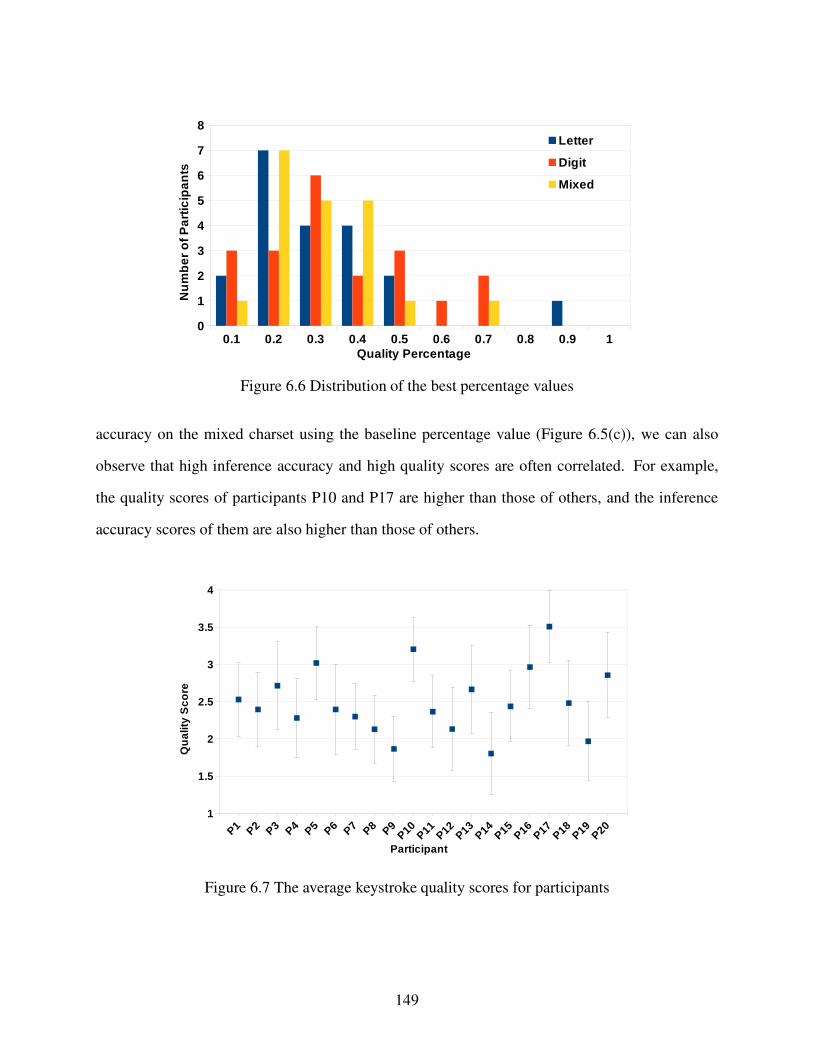
Figure 6.6 Distribution of the best percentage values
accuracy on the mixed charset using the baseline percentage value (Figure 6.5(c)), we can also
observe that high inference accuracy and high quality scores are often correlated. For example,
the quality scores of participants P10 and P17 are higher than those of others, and the inference
accuracy scores of them are also higher than those of others.
Figure 6.7 The average keystroke quality scores for participants
149

6.4.4 Overall Accuracy with Fine-Grained Data Filtering
In this subsection, we evaluate the overall accuracy of our inference attacks with the focus on
quantifying the extent to which our fine-grained data filtering technique can further improve the
accuracy. This improvement is upon the results achieved by using the best percentage values for
screening the training data as presented in the last subsection.
As described in Section 6.3.4, our fine-grained data filtering technique selects the band (among
the 90 consecutively concatenated bands) for the best-performing classifier as the most effective
frequency band for a particular user. Figure 6.8 illustrates the overall inference accuracy improve-
ment (upon the results in Figure 6.5) achieved by using fine-grained data filtering. The horizontal
lines in the three subfigures indicate the most effective frequency bands on the x axis, and the per-
centage values of the inference accuracy improvement on the y axis. Our fine-grained data filtering
technique improves the inference accuracy for the majority of the participants, and only their re-
sults are illustrated in the three subfigures. In more details, by using the most effective frequency
bands, the F-measure scores are improved from 0.1% to 3.39% with the average at 1.14% for 12
participants on the letter charset, from 0.39% to 5.71% with the average at 1.76% for 13 partici-
pants on the digit charset, and from 0.45% to 3.54% with the average at 1.27% for 11 participants
on the mixed charset.
On the three charsets, although the majority of the most effective frequency bands are low-pass
bands, their stop frequencies are often different. For example, on the letter charset (Figure 6.8(a)),
the stop frequencies for participants P1, P9, P13, P16, and P19 are around 15Hz, while those
for participants P3, P4, P7, and P20 are above 20Hz. High-pass and band-pass frequency bands
are indeed more effective than low-pass ones for some participants. For example, on the digit
charset (Figure 6.8(b)), the high-pass frequency band [1.88Hz-30Hz] is most effective for partic-
ipants P6 and P10, and the band-pass frequency bands [7.5Hz-15Hz] and [1.88Hz-21.22Hz] are
most effective for participants P7 and P11, respectively. For some participants, the most effective
frequency bands on the three charsets are the same or similar, e.g., the low-pass frequency band
[0.0Hz-26.67Hz] for participant P3.
150
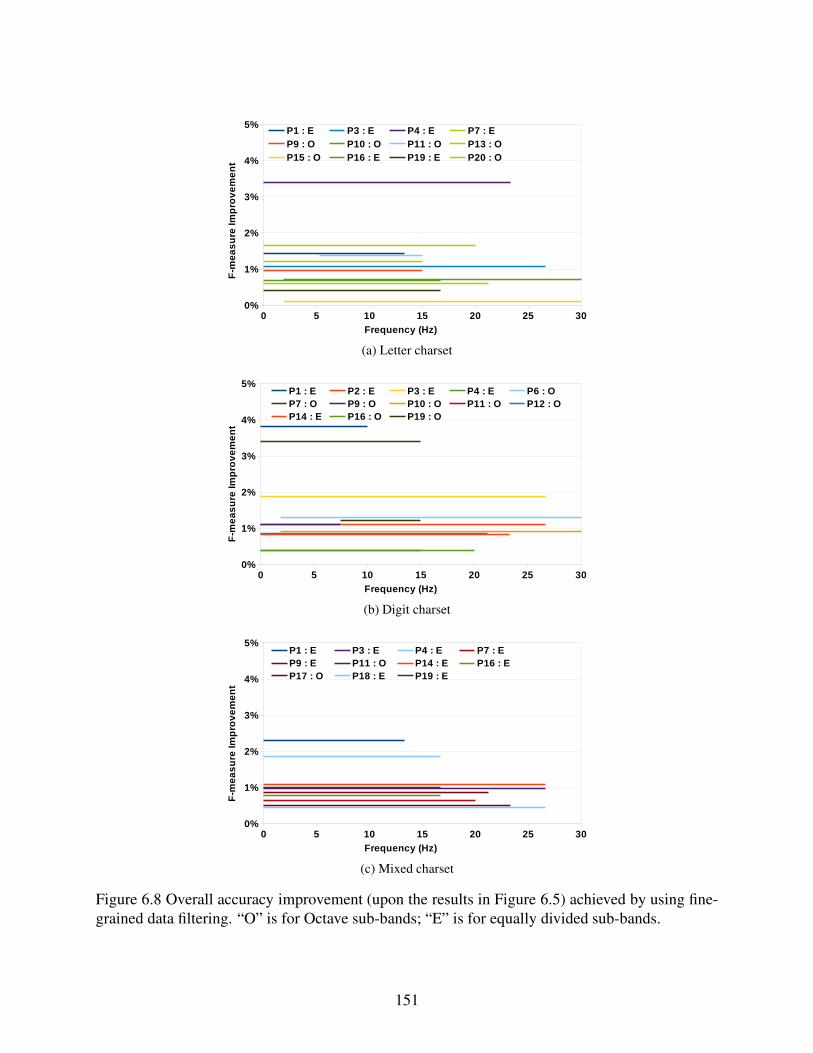
(a) Letter charset
(b) Digit charset
(c) Mixed charset
Figure 6.8 Overall accuracy improvement (upon the results in Figure 6.5) achieved by using fine-
grained data filtering. “O” is for Octave sub-bands; “E” is for equally divided sub-bands.
151

Among the 12 most effective frequency bands on the letter charset (Figure 6.8(a)), half of
them are concatenated from the 12
Octave sub-bands and half of them are concatenated from the
equally divided sub-bands. Among the 13 most effective frequency bands on the digit charset
(Figure 6.8(b)), 8 of them are concatenated from the 12
Octave sub-bands and 5 of them are con-
catenated from the equally divided sub-bands. Among the 11 most effective frequency bands on
the mixed charset (Figure 6.8(c)), 9 of them are concatenated from the 12
Octave sub-bands and
2 of them are concatenated from the equally divided sub-bands. Thus it seems that the 12
Oc-
tave method performs better on the digit charset, while equally dividing the entire frequency band
performs better on the mixed charset. More details are provided in Appendix C.
In summary, by selecting the most effective frequency bands for different users with varying
lengths (instead of being fixed), our fine-grained data filtering technique indeed further improves
the inference accuracy. With this further improvement shown in Figure 6.8, our input inference
attacks overall (1) achieve 2.45%, 39.74%, 38.77%, and 38.83% regarding FPR, precision, recall
(TPR), and F-measure, respectively, on the letter charset, (2) achieve 4.1%, 51.45%, 50.75%,
and 50.79% regarding the four metrics, respectively, on the digit charset, and (3) achieve 1.81%,
32.04%, 31.42%, and 31.36% regarding the four metrics, respectively, on the mixed charset. The
authors of the related work often report their digit or letter input inference accuracy only using
recall values [159–161, 163, 164, 173]. Simply in terms of recall values, our input inference
attacks achieve comparable or better results on inferring letters or digits, and also achieve good
results on inferring inputs with mixed letters and digits, which was not considered in the related
work. However, it is worth emphasizing again that our attacks are much more challenging than
theirs because ours are Web based, targeting at any sensitive Web inputs, and using real Google
Keyboard, but theirs are native app based, targeting at touchscreen lock PINs, and using apps’
built-in keyboards and/or large digit-only keyboards.
152
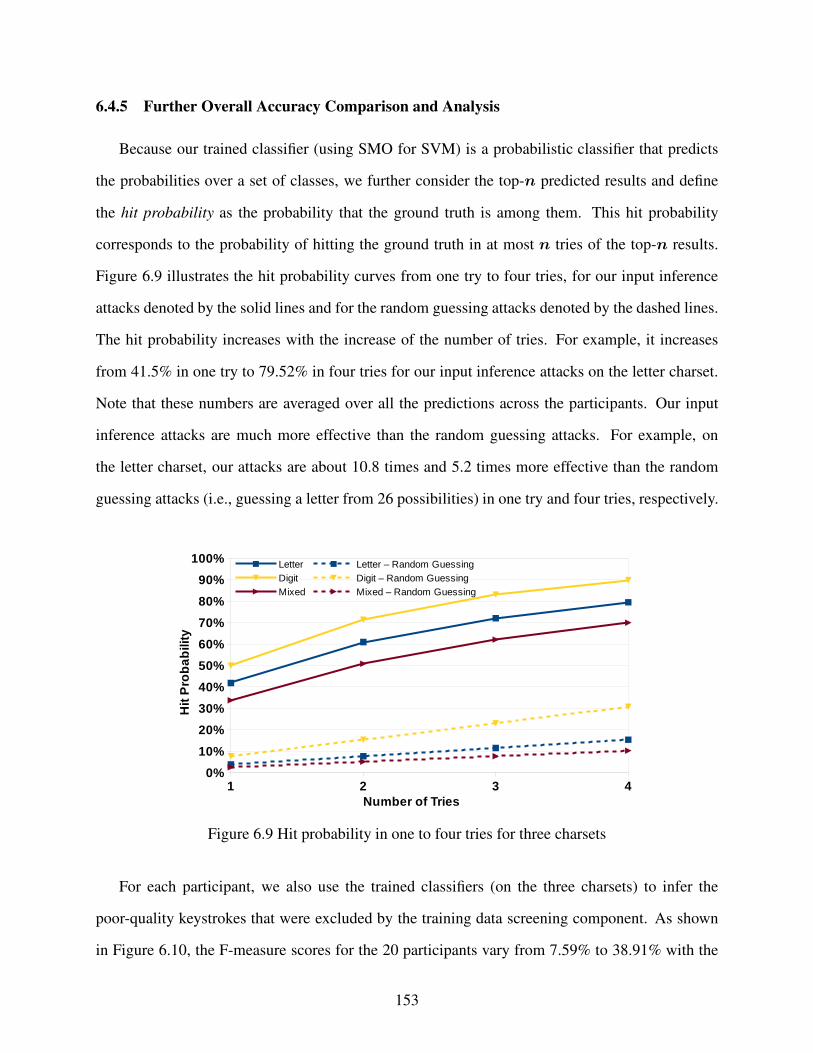
6.4.5 Further Overall Accuracy Comparison and Analysis
Because our trained classifier (using SMO for SVM) is a probabilistic classifier that predicts
the probabilities over a set of classes, we further consider the top-n predicted results and define
the hit probability as the probability that the ground truth is among them. This hit probability
corresponds to the probability of hitting the ground truth in at most n tries of the top-n results.
Figure 6.9 illustrates the hit probability curves from one try to four tries, for our input inference
attacks denoted by the solid lines and for the random guessing attacks denoted by the dashed lines.
The hit probability increases with the increase of the number of tries. For example, it increases
from 41.5% in one try to 79.52% in four tries for our input inference attacks on the letter charset.
Note that these numbers are averaged over all the predictions across the participants. Our input
inference attacks are much more effective than the random guessing attacks. For example, on
the letter charset, our attacks are about 10.8 times and 5.2 times more effective than the random
guessing attacks (i.e., guessing a letter from 26 possibilities) in one try and four tries, respectively.
Figure 6.9 Hit probability in one to four tries for three charsets
For each participant, we also use the trained classifiers (on the three charsets) to infer the
poor-quality keystrokes that were excluded by the training data screening component. As shown
in Figure 6.10, the F-measure scores for the 20 participants vary from 7.59% to 38.91% with the
153
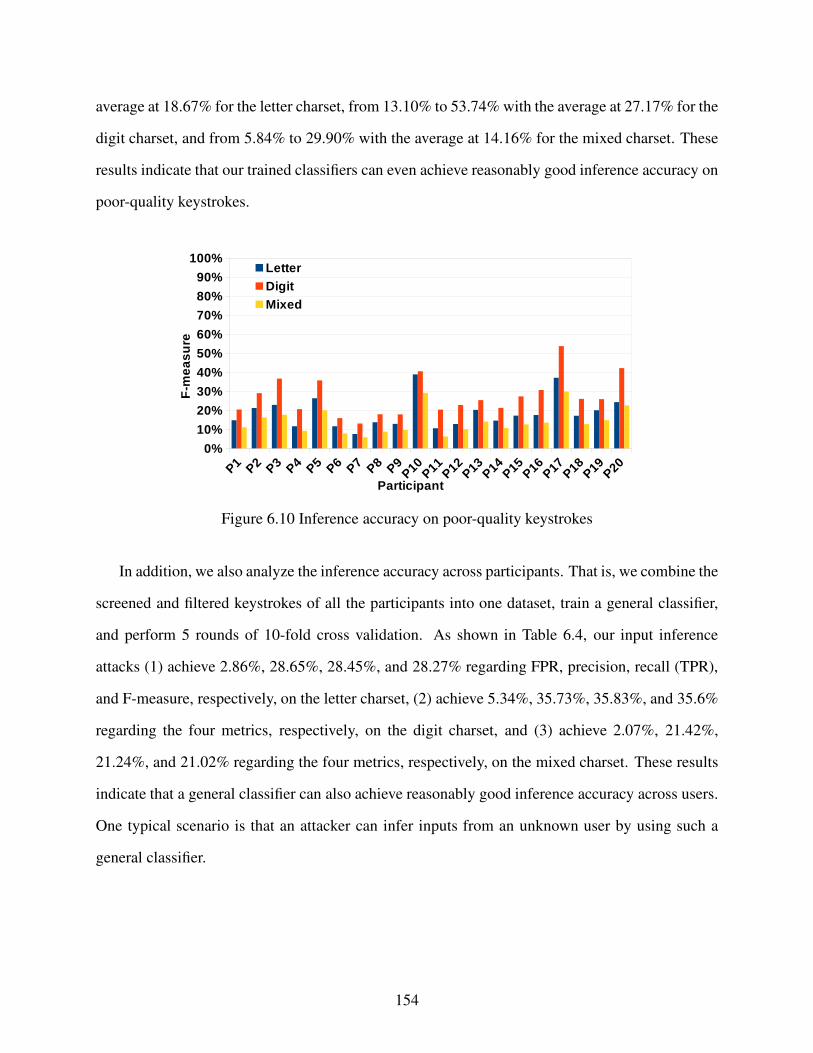
average at 18.67% for the letter charset, from 13.10% to 53.74% with the average at 27.17% for the
digit charset, and from 5.84% to 29.90% with the average at 14.16% for the mixed charset. These
results indicate that our trained classifiers can even achieve reasonably good inference accuracy on
poor-quality keystrokes.
Figure 6.10 Inference accuracy on poor-quality keystrokes
In addition, we also analyze the inference accuracy across participants. That is, we combine the
screened and filtered keystrokes of all the participants into one dataset, train a general classifier,
and perform 5 rounds of 10-fold cross validation. As shown in Table 6.4, our input inference
attacks (1) achieve 2.86%, 28.65%, 28.45%, and 28.27% regarding FPR, precision, recall (TPR),
and F-measure, respectively, on the letter charset, (2) achieve 5.34%, 35.73%, 35.83%, and 35.6%
regarding the four metrics, respectively, on the digit charset, and (3) achieve 2.07%, 21.42%,
21.24%, and 21.02% regarding the four metrics, respectively, on the mixed charset. These results
indicate that a general classifier can also achieve reasonably good inference accuracy across users.
One typical scenario is that an attacker can infer inputs from an unknown user by using such a
general classifier.
154

Table 6.4 Inference accuracy across participants
Charset FPR Precision Recall (TPR) F-measure
Letter 2.86% 28.65% 28.45% 28.27%
Digit 5.34% 35.73% 35.83% 35.68%
Mixed 2.07% 21.42% 21.24% 21.02%
6.4.6 Per Key Inference Accuracy and Confusion Metrics
In this subsection, we analyze the inference accuracy from the perspective of individual char-
acters (i.e., if the inference accuracy is higher on certain characters than on some others) and the
confusions among them (i.e., if certain characters are more likely to be mis-classified as some
others) on Google Keyboard.
Figure 6.11 illustrates the per key inference accuracy (i.e., F-measure scores) on two charsets
averaged across 20 participants. The darker the background of a key, the higher its inference
accuracy. The F-measure scores are greater than 33% for all the letters, and greater than 36% for
all the digits and special characters. In general, keys on the left and right sides of the keyboard often
achieve the highest inference accuracy, followed by the keys on the middle part of the keyboard,
and then the rest. One possible reason for these differences is that tapping keys on different parts of
the keyboard incurs different levels of acceleration forces and rotation rates. However, the accuracy
difference between the keys on different rows is not obvious, and one possible reason is that all the
three rows of the keyboard are located at the bottom part of the smartphone.
Confusion metrics can help us intuitively understand if certain characters are more likely to
be mis-classified as some others. We characterize confusions using both the Euclidean distance
and the direction relation between two keys on the Google Keyboard. For example, the distance
between two vertically or horizontally adjacent keys is one, and the direction relation between them
is from the center of one key to the center of the other key; Figure 6.12 provides more examples.
155

(a) On 26 letters
(b) On 10 digits and 3 special characters
Figure 6.11 Per key overall inference accuracy
Figure 6.12 Examples of Euclidean distance and direction relation between keys
In a classification, the 1st confusion happens when a mis-classification occurs in the predicted
result with the highest probability, the 2nd confusion happens when a mis-classification further
occurs in the predicted result with the second highest probability, and so on. The 1st, 2nd, and
3rd confusions accumulated from all the participants on the three charsets are represented as nine
summaries in Figure 6.13. Each confusion summary includes the probability (Prob) density of the
distance (Dist) values in two columns on the right, and the probability density of the confusion
directions in a figure of arrows (starting characters are confused to ending characters) on the left.
156

All the vertical arrows have the single distance value of one. We found that all the horizontal
arrows have the distance value of one or two. Each diagonal arrow represents a rough confusion
direction ignoring its accurate degree value, and we found that all the diagonal arrows have the
distance value between one and two.
From the two 1st confusion summaries for the letter and digit charsets, respectively, we can
observe that a key is most likely to be mis-classified as the key to its left or right with the distance
value of one. From the 1st confusion summary of the mixed charset, we can observe that a key is
most likely to be mis-classified as the key overlapped at the same location (thus with the distance
value of zero) on the other keyboard (i.e., for letters or digits as shown in Figure 6.11); this result
indicates that attackers may need to obtain the type information (e.g., letter or digit) of an input in
order to address such confusions and increase the inference accuracy. From the 2nd and 3rd con-
fusion summaries, we can observe that mis-classifications are further spread out to other directions
and larger distance values, while many of them still occur between neighbors on the same row.
More details about the confusion metrics are in Appendix D.
6.4.7 Accuracy of Sensor Data Segmentation without Key Events
In this subsection, we evaluate the accuracy of the Detect-KeyDown-Timestamps subroutine
by comparing its detection results with the collected ground-truth key down timestamps. This
accuracy determines the accuracy of the Segment-SensorData-Without-KeyEvents algorithm shown
in Figure 6.3.
For the purpose of this evaluation, we need to define a new set of accuracy metrics. If a
time window (identified by the Identify-Keystroke-TimeWindows subroutine in Figure 6.3) for a
detected key down timestamp contains any ground-truth key down timestamp, a true positive (TP)
is counted; otherwise, a false positive (FP) is counted. If a ground-truth key down timestamp is
not in any of those identified time windows, a false negative (FN) is counted. However, we are not
able to count true negatives because they are simply not definable.
157

(a) Confusions on the letter charset
(b) Confusions on the digit charset
(c) Confusions on the mixed charset
Figure 6.13 Confusion metrics on three charsets
Because Google Chrome on Android does not report the key down and up events of special
keys (e.g., caps lock key, keyboard switching key, and enter key) to the JavaScript code on regular
webpages, we do not have the ground-truth to exclude the keystrokes for special keys, and our
false positive numbers are unavoidably over-counted in this evaluation. Therefore, to represent the
accuracy of the key down timestamp detection, it is more reasonable for us to use the recall (TPR)
scores instead of the precision or F-measure scores (which are affected by the over-counted false
positives, and their details are in Appendix E).
Figure 6.14 illustrates that the recall scores are above 80% for the majority of the participants,
demonstrating that our Segment-SensorData-Without-KeyEvents algorithm is indeed effective in
segmenting sensor data for true keystrokes. Comparing these results with the results presented
in the previous subsections, we can see that high key down timestamp detection accuracy is also
158
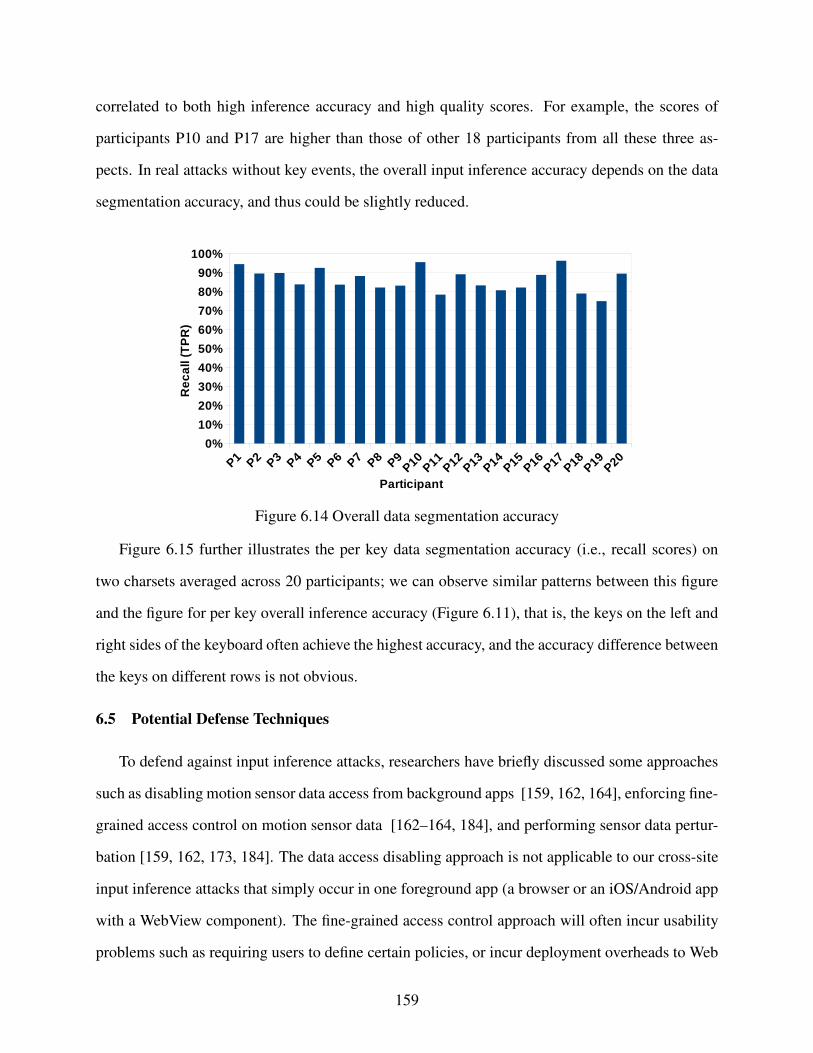
correlated to both high inference accuracy and high quality scores. For example, the scores of
participants P10 and P17 are higher than those of other 18 participants from all these three as-
pects. In real attacks without key events, the overall input inference accuracy depends on the data
segmentation accuracy, and thus could be slightly reduced.
Figure 6.14 Overall data segmentation accuracy
Figure 6.15 further illustrates the per key data segmentation accuracy (i.e., recall scores) on
two charsets averaged across 20 participants; we can observe similar patterns between this figure
and the figure for per key overall inference accuracy (Figure 6.11), that is, the keys on the left and
right sides of the keyboard often achieve the highest accuracy, and the accuracy difference between
the keys on different rows is not obvious.
6.5 Potential Defense Techniques
To defend against input inference attacks, researchers have briefly discussed some approaches
such as disabling motion sensor data access from background apps [159, 162, 164], enforcing fine-
grained access control on motion sensor data [162–164, 184], and performing sensor data pertur-
bation [159, 162, 173, 184]. The data access disabling approach is not applicable to our cross-site
input inference attacks that simply occur in one foreground app (a browser or an iOS/Android app
with a WebView component). The fine-grained access control approach will often incur usability
problems such as requiring users to define certain policies, or incur deployment overheads to Web
159

(a) On 26 letters
(b) On 10 digits and 3 special characters
Figure 6.15 Per key data segmentation accuracy
application developers. In contrast, the data perturbation approach, if properly designed, could be
both effective and usable due to its nature of being transparent to users. Therefore, in this section,
we focus on experimenting with two popular data perturbation techniques: reducing the sampling
frequency and adding noises.
6.5.1 Data Perturbation by Reducing the Sampling Frequency
While it is intuitive to understand that reducing the sampling frequency can reduce the accu-
racy of input inference attacks, researchers have observed different results in their experiments.
Miluzzo et al. observed that the reduction of inference accuracy is linearly proportional to the re-
duction of sampling frequency [173], and Owusu et al. observed a similar but non-linear reduction
effect [162]; however, Aviv et al. observed that the inference accuracy does not even change when
the sampling frequency is reduced from 50Hz to 20Hz [159].
To quantify the effect of reducing sampling frequency on inference accuracy, we extract, from
our original motion sensor dataset (60Hz), the first of every two, three, four, five, and six data
points to derive five new low-frequency datasets with the sampling frequencies of 30Hz, 20Hz,
160

15Hz, 12Hz, and 10Hz, respectively. For each low-frequency dataset and each participant, we
train a classifier without performing the training data screening and fine-grained data filtering, and
perform 5 rounds of 10-fold cross validation. The inference accuracy results obtained from these
five datasets can now be fairly compared with the inference accuracy results for the baseline (i.e.,
blue bars) presented in Figure 6.5.
Figure 6.16(a) compares the inference accuracy results from all these six datasets on the letter
charset for each participant. Overall, as the sampling frequency decreases from 60Hz to 10Hz,
the inference accuracy decreases as well in a linear proportional manner. At 10Hz, the inference
accuracy is below 20% for all the 20 participants. We observed a similar trend in reduction (based
on reducing the sampling frequency) for the inference on digit and mixed charsets, and for the
segmentation of motion sensor data.
6.5.2 Data Perturbation by Adding Noises
Adding noises to the motion sensor data is another intuitive approach that may reduce the
accuracy of input inference attacks, but this approach has not been formally studied in existing
research [159, 162, 173, 184].
To quantify the effect of adding noises on inference accuracy, we add to each data point a
random noise within a certain ratio of the maximum amplitude observed in a session. Based on
our original motion sensor dataset and five noise amplitude ratio values from 0.2 to 1.0, we derive
five new polluted datasets. Similar to what we did for the five low-frequency datasets, we train
classifiers, and obtain the inference accuracy results that can be fairly compared with the inference
accuracy results for the baseline.
Figure 6.16(b) compares the inference accuracy results from all these six datasets on the letter
charset for each participant. Overall, as the noise amplitude ratio value increases from 0% to
100%, the inference accuracy decreases quickly and then flattens out. When the noise amplitude
ratio is 100% (i.e., the amplitude of the random noise is not greater than the maximum amplitude
observed from the original motion sensor data), the inference accuracy is below 10% for all the 20
161
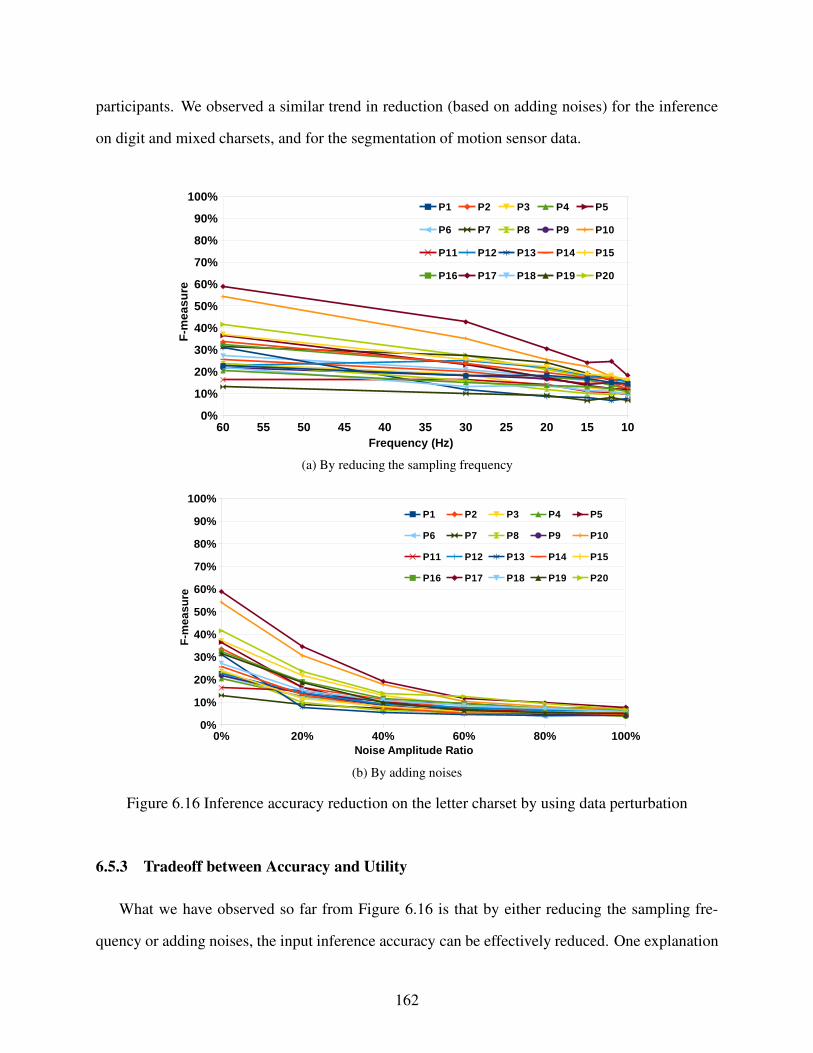
participants. We observed a similar trend in reduction (based on adding noises) for the inference
on digit and mixed charsets, and for the segmentation of motion sensor data.
(a) By reducing the sampling frequency
(b) By adding noises
Figure 6.16 Inference accuracy reduction on the letter charset by using data perturbation
6.5.3 Tradeoff between Accuracy and Utility
What we have observed so far from Figure 6.16 is that by either reducing the sampling fre-
quency or adding noises, the input inference accuracy can be effectively reduced. One explanation
162

is that from either the low-frequency data or the polluted data, the extracted features cannot fur-
ther well capture the characteristics of individual keystrokes. However, an important question is
that: while positively reducing the inference accuracy, whether these two data perturbation tech-
niques also negatively compromise the utility of motion sensor data and affect the functionality of
legitimate Web or mobile applications.
This question has not yet been answered in existing research efforts on input inference at-
tacks [159, 162, 173, 184], but it should be answered because a good defense solution must not
sacrifice the utility of motion sensor data too much for the sake of achieving better security protec-
tion. It is indeed difficult to answer this question due to two main reasons. One is that legitimate
Web and mobile applications often have different purposes, and they use motion sensor data in
many different ways; therefore, the utility of low-frequency or polluted motion sensor data de-
pends on all these different factors, and is specific to individual applications. The other reason
is that those different purposes and ways of using motion sensor data cannot be easily measured,
especially when the data are simply sent to the server-side for processing and analysis.
We tentatively answer this question by considering two application scenarios, and by visually
inspecting the low-frequency data and the polluted data given that they will reduce the inference
accuracy to the same level. In one scenario, applications are only interested in detecting if some
tapping-like activities are performed in a certain period of time; in the other scenario, applications
are interested in quantifying the number of tappings performed in a certain period of time.
Assuming the security protection goal is to reduce the input inference accuracy to 20% for
all the 20 participants, we can see from Figure 6.16(a) that the sampling frequency needs to be
at 10Hz, or from Figure 6.16(b) that the noise amplitude ratio needs to be at 40%. Figure 6.17
illustrates a representative example of perturbing z axis acceleration force data of some letter inputs
in 15 seconds; the three subfigures show the original data, the low-frequency data (at 10Hz), and
the polluted data (with the noise amplitude ratio at 40%), respectively. We can visually estimate
that the utility of the low-frequency data and the polluted data is still preserved to a large extent
for the first application scenario because tapping-like activities are still obvious, but it has been
163
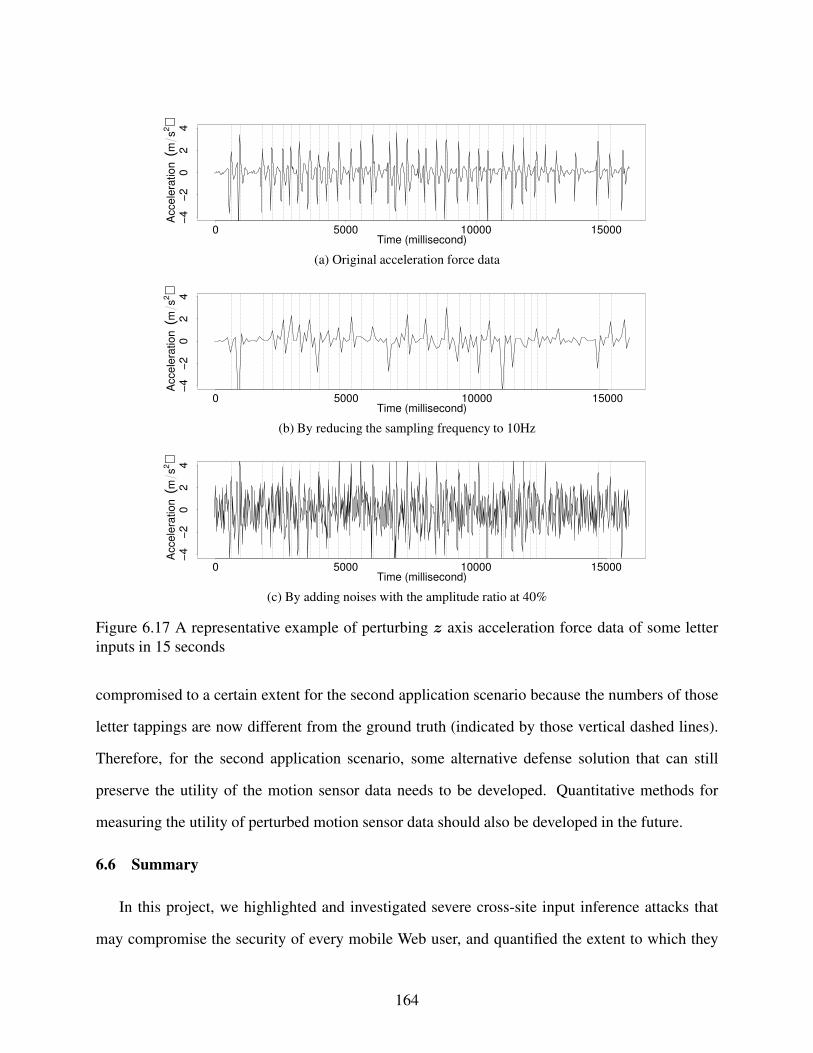
0 5000 10000 15000
−4
−2
02
4
Time (millisecond)
Accele
ration
(ms
2)
(a) Original acceleration force data
0 5000 10000 15000
−4
−2
02
4
Time (millisecond)
Accele
ration
(ms
2)
(b) By reducing the sampling frequency to 10Hz
0 5000 10000 15000
−4
−2
02
4
Time (millisecond)
Accele
ration
(ms
2)
(c) By adding noises with the amplitude ratio at 40%
Figure 6.17 A representative example of perturbing z axis acceleration force data of some letter
inputs in 15 seconds
compromised to a certain extent for the second application scenario because the numbers of those
letter tappings are now different from the ground truth (indicated by those vertical dashed lines).
Therefore, for the second application scenario, some alternative defense solution that can still
preserve the utility of the motion sensor data needs to be developed. Quantitative methods for
measuring the utility of perturbed motion sensor data should also be developed in the future.
6.6 Summary
In this project, we highlighted and investigated severe cross-site input inference attacks that
may compromise the security of every mobile Web user, and quantified the extent to which they
164

can be effective. We formulated our attacks as a typical multi-class classification problem, and
built an inference framework that trains a classifier in the training phase and predicts a user’s new
inputs in the attacking phase. We addressed the data quality and data segmentation challenges in
our attacks by designing and experimenting with three unique techniques: training data screening,
fine-grained data filtering, and key down timestamp detection and adjustment. We intensively
evaluated the effectiveness of our attacks, and provided an in-depth analysis on the evaluation
results. On average, our attacks achieved 38.83%, 50.79%, and 31.36% inference accuracy on
three charsets, respectively. We also performed experiments to evaluate the effect of using data
perturbation defense techniques on decreasing the accuracy of our input inference attacks.
Our results demonstrate that researchers, smartphone vendors, and app developers should pay
serious attention to the severe cross-site input inference attacks that can be pervasively performed,
and start to design and deploy defense techniques. In the future, we plan to explore ways such as
using different parameters to optimize our classifiers, experiment with the inference of other keys
such as caps lock key and keyboard switching key, and investigate effective and usable defense
techniques.
165

CHAPTER 7
THE HIGHLY INSIDIOUS EXTREME PHISHING ATTACKS
7.1 Introduction
One of the most severe and challenging threats to Internet security is phishing, which uses
spoofed websites to steal users’ passwords and online identities. To defend against phishing at-
tacks, researchers have proposed various blacklist-based, heuristics-based, and whitelist-based so-
lutions (Section 7.6), organizations and communities such as APWG [7] and PhishTank [185]
have provided phishing reporting and verification services; many vendors have also provided se-
cure browsing systems such as Google Safe Browsing, Microsoft SmartScreen Filter, McAfee
SiteAdvisor, and Norton Safe Web. However, phishing attacks have also been quickly evolving
to evade the detection and defense [186], and the battle between phishers and defenders will be
long-standing.
Phishers mainly use spoofed emails or instant messages to lure users to the phishing websites.
A spoofed email or instant message provides the first-layer context (e.g., asking for account ver-
ification or update) to entice users to click on a phishing URL, and the phishing website further
provides the second-layer context with the look and feel similar to a targeted legitimate website
to lure users to submit their login credentials [46]. In terms of the first-layer context, the success
of phishing is mainly limited by two constraints [46]. One is that if phishing emails or instant
messages are suspicious, users would not click on phishing URLs and visit the phishing web-
sites [187, 188]. The other is that phishing emails captured by spam filters [189] cannot even reach
users in the first place. In terms of the second-layer context, the success of phishing is mainly
limited by two other constraints [46]. One is that phishing websites will trigger warnings if they
are detected by browsers, thus security-conscious users would not visit them and submit creden-
tials [190]. The other is that if the look and feel of the undetected phishing websites are suspicious,
security-conscious users would not submit their credentials [19, 187, 191–193].
166

In this project, we focus on the second-layer context to explore the extreme of phishing attacks.
In other words, we explore the feasibility of creating extreme phishing attacks that have the almost
identical look and feel as those of the targeted legitimate websites, and evaluate the effectiveness
of such phishing attacks.
In particular, we design and implement a phishing toolkit that can support both the traditional
phishing and the newly emergent Web Single Sign-On (SSO) phishing [46]. In terms of the tra-
ditional phishing, our toolkit can automatically construct unlimited levels of phishing webpages
in real time based on user interactions; in terms of the Web SSO phishing, our toolkit can allow
attackers to easily construct spoofed Web SSO login “windows” for Gmail, Facebook, and Yahoo.
The constructed phishing webpages and Web SSO login “windows” are almost identical to their le-
gitimate counterparts, potentially making it very difficult for users to identify if they are interacting
with real or spoofed websites.
The toolkit can be used by attackers to easily construct and deploy extreme phishing attacks;
it can also be used by researchers to easily construct testbeds for performing phishing related user
studies and exploring new phishing defense mechanisms. In particular, we design and perform a
user study to evaluate the effectiveness of the phishing attacks constructed from this toolkit. The
user study results based on 94 participants demonstrate that extreme phishing attacks constructed
by our toolkit are indeed highly effective, i.e., insidious. The questionnaire results show that 87
(92.6%) of the 94 participants were actually not suspicious about the extreme phishing websites
that they visited, and the observation results show that 91 (96.8%) of the 94 participants submitted
their credentials to the extreme phishing websites; meanwhile, most of those “victims” were aware
of phishing before participating in this study or had been susceptible to some phishing attacks in
the past. Therefore, it is reasonable to assume that extreme phishing attacks will be widely adopted
and deployed in the future, and we call for a collective effort to effectively defend against them.
The main contributions of this project include: (1) we define and explore extreme phishing
attacks and investigate the techniques for constructing them (Section 7.3), (2) we design and im-
plement a concrete toolkit that can be feasibly and easily used by attackers to construct and deploy
167

such attacks (Section 7.4), (3) we design and perform a user study with 94 participants to demon-
strate the effectiveness of such attacks (Section 7.5), and (4) we discuss the impacts of extreme
phishing on existing phishing defense mechanisms and provide suggestions to researchers and
users for them to better defend against such attacks (Section 7.6).
7.2 Related Work
We review the related work on phishing toolkits and testbeds in this section, and defer the
discussion of the related phishing detection and defense techniques to Section 7.6.
Attackers often use phishing toolkits to construct their phishing websites [191]. Cova et al. an-
alyzed a large collection of free underground phishing toolkits [194], and found that those toolkits
target not only users but also inexperienced phishers (through backdoors) as victims. They also
found that most of those toolkits target only one organization, and include the related resources
(e.g., HTML, JavaScript, CSS, image, and PHP files) with a limited page depth for replicating a
portion of a targeted legitimate website; meanwhile, the links in the replicated webpages are often
unchanged and still point to the targeted website, thus the phishing website may easily lose the con-
trol of visitors and fail to collect their login credentials. In contrast, our toolkit can replicate many
targeted organizations by automatically constructing unlimited levels of phishing webpages in real
time based on user interactions; meanwhile, all the links in the replicated webpages are modified to
keep holding visitors on the corresponding phishing website and maximize the chances of collect-
ing their login credentials. In addition, Cova et al. [194] did not report the existence of Web Single
Sign-On (SSO) phishing [46] in those toolkits; while our toolkit supports Web SSO phishing as
well as the traditional phishing.
Existing phishing susceptibility studies [19, 187, 192, 193, 195–197] often use some specific,
not very realistic, and non-sharable testbeds with a limited webpage depth. For example, in [19],
participants were informed of the real purpose of the study (i.e., identifying spoofed websites)
in advance; in [187], participants were given a test account to role play; in [195], two specific
domains (ebay-login.net and amazonaccounts.net) were registered to spoof Amazon and eBay;
168

in [196], credentials of university students were the targets of a spear phishing test; in [197], one
single bank website was used to evaluate the effectiveness of security indicators; in [193], a role-
play survey was answered by participants recruited through Amazon’s Mechanical Turk. In [192],
Jackson et al. used a reverse proxy as the phishing website to intervene between the participants’
computer and the legitimate websites; their testbed was designed to study the effectiveness of the
extended validation certificate mechanism and the picture-in-picture phishing attacks; their partic-
ipants were informed of the real purpose of the study in advance similar to [19]. However, our
toolkit can be used by researchers to easily construct testbeds for performing various phishing
related user studies. The constructed testbeds will be comprehensive and realistic because they
support both the traditional phishing and the newly emergent Web SSO phishing, support all the
popular browsers and allow participants to use their real login credentials to perform real browsing
activities; meanwhile, they will not expose participants to any anticipated risk if properly config-
ured (Section 7.5.1).
7.3 Extreme Phishing and Our Goal
As introduced in Section 7.1, the success of phishing depends on two layers of contexts [46].
The first-layer context, i.e., an email or instant message, is critical to entice users to click on a
phishing URL [187, 193, 196], and the second-layer context, i.e., a phishing website itself, is
critical to lure users to submit their login credentials [19, 187, 191–193].
Focusing on the second-layer context, we classify phishing attacks into three levels as shown
in Figure 7.1, simple phishing, advanced phishing, and extreme phishing, based on the extent to
which their look and feel are similar to their targeted legitimate websites. Intuitively, the more a
phishing website is similar to the targeted legitimate website, the more likely it will be effective;
researchers indeed found that, users often (1) identify phishing websites based on their suspicious
look and feel [19, 191–193], (2) do not understand security indicators [19, 187, 193, 195, 198],
and (3) disregard the absence of security indicators [29].
169

7.3.1 Metrics for Look and Feel
We define the look and feel of a phishing website using four metrics: its appearance, page
depth, support to dynamic user interaction, and phishing types. The three levels of phishing attacks
differ in their look and feel based on these four metrics.
Figure 7.1 The classification of phishing attacks based on the second-layer context
The appearance including page layouts, text contents, images, and styles of a phishing website
gives visitors the first impression. Phishing webpages with low visual similarity to the corre-
sponding legitimate webpages could be easily detected as fake by users [19]. The appearance of
simple phishing websites is only somewhat similar to that of corresponding legitimate websites,
the appearance of advanced phishing websites is mostly similar to that of corresponding legiti-
mate websites, and the appearance of extreme phishing websites is similar in every way to that of
corresponding legitimate websites.
The page depth of a phishing website is the levels of webpages that are organized and linked
together on the phishing website. Users often visit several linked pages on a website. Phishing
webpages with missing or invalid links can potentially reduce the trust from visitors and fail to
lure them to submit login credentials, while phishing webpages with valid but unmodified links
(i.e., linking to the targeted or other legitimate websites) will lose the control of visitors and fail to
attack them. The page depth of simple phishing websites is one and the links on the webpage are
170

partially modified, the page depth of advanced phishing websites is limited to a certain number and
the links on the webpages are partially modified, and the page depth of extreme phishing websites
is unlimited and the links on the webpages are completely modified to gain the maximum control
of visitors.
The support to dynamic user interaction of a phishing website means that user interactions such
as clicking, searching, and form submission as well as the triggered JavaScript executions such as
dynamic URL or other DOM element creation can all be supported by the phishing website. A
phishing website with better support to dynamic user interaction can potentially deceive visitors
in a more effective manner. The support to dynamic user interaction is often missing in simple
phishing and advanced phishing websites, while it is provided in extreme phishing websites.
The phishing types of a phishing website include traditional phishing and Web Single Sign-On
(SSO) phishing. Traditional phishing aims to steal visitors’ accounts that are created specifically
for a website such as a shopping or banking website; Web SSO phishing aims to steal visitors’
identity provider accounts such as Gmail, Facebook, and Yahoo accounts, each of which can allow
a user to log into multiple relying party websites (Section 7.4.3). The simple phishing websites only
support traditional phishing, the advanced phishing websites can support both traditional phishing
and low-quality Web SSO phishing, and the extreme phishing websites can support both traditional
phishing and high-quality Web SSO phishing.
7.3.2 Existing Phishing Websites
With a careful measurement and inspection of 471 live phishing websites reported on Phish-
Tank [185] in 2015, we found that the majority of existing phishing websites are at the level of
simple phishing because they have the corresponding properties of all the four metrics, only a
handful of existing phishing websites are at the level of advanced phishing because they have the
corresponding properties of some of those four metrics, and none of the existing phishing websites
is at the level of extreme phishing because none of them has the corresponding properties of any
of those four metrics.
171

Among those 471 phishing websites, 449 (95%) of them only contain a single phishing web-
page which does not link to any other webpage on the same site. Meanwhile, among the landing
pages of those 471 phishing websites, 30% of them do not contain any link, 22% of them con-
tain invalid links that do not respond to users’ click actions, 17.6% of them contain links to the
targeted legitimate websites, and 26.4% of them contain links to other websites. By further man-
ually examining 100 (out of 471) randomly selected phishing websites, we found that 69 of them
are only somewhat similar to their targeted legitimate websites, only support traditional phishing,
and do not support dynamic user interaction; two Yahoo, eleven Paypal, and three Gmail phishing
websites are mostly similar to their corresponding legitimate websites in terms of the appearance;
two Paypal phishing websites contain over two levels of webpages; ten phishing websites support
low-quality Web SSO phishing.
7.3.3 Our Goal
The technical challenges in constructing those three levels of phishing attacks are different. For
simple phishing, attackers only need to copy a single login webpage; for advanced phishing, attack-
ers need to copy and link several webpages, and construct low-quality spoofed login “windows”
if they want to perform Web SSO phishing. The webpages in these two levels of phishing at-
tacks can be statically constructed and then deployed to a phishing website. For extreme phishing,
attackers need to dynamically generate unlimited levels of webpages based on user interactions,
accurately replace links on the generated webpages, and properly construct high-quality spoofed
login “windows” if they want to perform Web SSO phishing; however, it is very challenging to
meet these requirements because essentially the HTML elements, Cascading Style Sheets (CSS),
and JavaScript on the legitimate websites must be accurately replicated to phishing websites and
then rendered or executed on users’ browsers in real time.
Correspondingly, the overall complexity and effort in constructing those three levels of phish-
ing attacks also increase from simple to advanced and finally to extreme phishing. These factors
can, to certain extent, explain why the majority of existing phishing websites are at the level of sim-
172

ple phishing and only a handful of existing phishing websites are at the level of advanced phishing.
However, the success rate of existing phishing attacks in terms of the second-layer context is about
10% as reported in previous measurement studies [188, 199].
Therefore, our goal in this project is to explore the feasibility of creating extreme phishing
attacks that have the almost identical look and feel as those of the targeted legitimate websites,
and evaluate the effectiveness of such extreme phishing attacks by performing a user study. It is
reasonable to assume that if extreme phishing attacks can be more effective (i.e., insidious) than
existing phishing attacks and can be easily constructed by using some toolkits, they will be widely
adopted and deployed by phishers in the future.
7.4 Design and Implementation
We now present our design and implementation of a toolkit for extreme phishing. This toolkit
has the properties of all the four metrics of extreme phishing illustrated in Figure 7.1.
7.4.1 Overview
A toolkit for extreme phishing needs to automatically construct unlimited levels of phishing
webpages in real time based on user interactions. Meanwhile, in general phishers cannot deploy
any toolkit on either a user’s computer or a legitimate website because they do not have such
capabilities in the threat model for phishing attacks. Therefore, it is very appropriate for us to take
a proxy-based approach to design a toolkit for extreme phishing.
Figure 7.2 illustrates the high level design of the toolkit. It is deployed on a phishing website,
works together with the phishing Web server, and acts as a proxy between a visitor and legitimate
websites. It consists of four components: webpage generation, temporary webpage repository,
link substitution, and Web SSO library. The webpage generation component intercepts the in-
coming/outgoing requests/responses to/from the phishing Web server for creating and delivering
phishing webpages. The temporary webpage repository component temporarily saves the initially
created and the finally modified phishing webpages. The link substitution component locally per-
forms static link substitution and further enables dynamic link substitution on a user’s browser
173

by injecting JavaScript. The Web SSO library component constructs spoofed login “windows”
based on different Web browsers and Web SSO identity providers. Only with a little configuration
and customization effort, phishers can use this toolkit to construct and perform extreme phishing
attacks. It is worth mentioning that this toolkit can support the replication of multiple targeted
legitimate websites at the same time.
Figure 7.2 High level design of the toolkit
The workflow of the deployed extreme phishing attacks is as follows. Once a visitor clicks on a
link to visit a phishing webpage, the corresponding request is sent to the phishing Web server. The
webpage generation component of the toolkit intercepts the request, constructs a corresponding
request to the legitimate website, saves the retrieved legitimate webpage as a file to the tempo-
rary webpage repository, and lets the Web server return the correspondingly constructed phishing
webpage to the visitor’s browser. Note that our toolkit serves phishing webpages via http (not
https) and does not self-sign or forge SSL certificates [200], thus both avoiding triggering SSL
warnings in visitors’ browsers and reducing the effort for constructing the attacks; in other words,
our proxy-based approach is more similar to SSL stripping than to SSL man-in-the-middle. Using
files in the temporary webpage repository is an easy and reliable way to enable the inter-process
communication between an independent toolkit and an unmodified Web server for them to com-
plete the process. Once a visitor submits either a traditional or a Web SSO login form, the extreme
174

phishing website redirects the visitor’s browser to the corresponding legitimate website and does
not need to further keep controlling the visitor.
7.4.2 Link Substitution
To keep holding visitors on a phishing website and maximize the chances of collecting their
login credentials, our toolkit needs to ensure that all the links (including the hypertext references
for elements such as anchors, buttons, and images) on each phishing webpage will be modified
to point to the phishing website. There are two types of links: static links and dynamic links.
Static links are contained in a webpage and they do not change after the webpage is delivered to a
browser, while dynamic links are created or modified by JavaScript after the webpage is delivered
to a browser. Accurate substitution of links especially dynamic links is critical to the success of
extreme phishing, but it is also very challenging due to the dynamics of JavaScript. To address
such challenges, our toolkit first performs accurate static link substitution on a phishing website,
and then injects cleverly crafted JavaScript for performing accurate dynamic link substitution on a
visitor’s browser.
7.4.2.1 Static Link Substitution
The substitution for static links is relatively straightforward, but some details should be care-
fully considered. For each link element on a given webpage, if its “href” attribute uses an absolute
path, (1) the legitimate domain name will be changed to the phishing domain name, and (2) the
HTTPS scheme will be changed to the HTTP scheme. Later, once a visitor clicks on any link to
a phishing website, a backward domain name replacement (i.e., from phishing to legitimate) will
be performed by the toolkit to construct the corresponding request to the legitimate website. Such
forward and backward domain name replacement operations will continue while a visitor is still
browsing the phishing website.
This substitution cannot replace those static links that are contained in special elements such as
<head> and <script>, for which special substitution operations will be performed by the toolkit.
For instance, Yahoo extensively uses the window.location.replace method to perform the redirec-
175

tion on a JavaScript-enabled browser, and uses the http-equiv=“refresh” attribute in <meta> to
perform the redirection on a JavaScript-disabled browser. Our toolkit uses a set of customizable
rules to replace the corresponding URLs in these and other special cases.
7.4.2.2 Dynamic Link Substitution
Unlike static links, dynamic links are created or modified by JavaScript after a webpage is
delivered to a browser. Our toolkit injects cleverly crafted JavaScript for performing accurate
dynamic link substitution on a visitor’s browser. The injected JavaScript intercepts the dynamic
link generation and modification events, and changes the legitimate domain name to the phishing
domain name for each link.
The rendering of a webpage consists of two phases: loading and event driven. In these two
phases, although many types of events can trigger the generation of dynamic links, eventually
DOM (Document Object Model) insertion and modification events (i.e., DOMNodeInserted and
DOMAttrModified) are directly related to the dynamic link generation. Correspondingly, our in-
jected JavaScript code focuses on listening to these two types of events for dynamic link substi-
tution. However, these two types of events often occur frequently in the webpage loading phase,
thus intercepting and processing them in this phase will incur high performance overhead to the
browser. Therefore, in our design, the injected JavaScript code first intercepts the Load event for
the window object (which indicates the completion of the loading phase) and replaces all the links
that are dynamically generated in the loading phase in batch, and then intercepts the DOMNodeIn-
serted and DOMAttrModified events only in the event driven phase. To ultimately ensure that the
legitimate domain names in links are replaced by the phishing domain names, out toolkit further
injects JavaScript code to monitor the clicked links on a visitor’s browser and modify them if
needed.
7.4.3 Web SSO Login Window Generation
Web Single Sign-On (SSO) systems allow users to log into multiple relying party (RP) web-
sites such as foxnews.com and sears.com using one single identity provider (IdP) account such
176

as a Google, Facebook, or Yahoo account, thus relieving users from the huge burden of creating
and remembering many online credentials. In recent years, open Web SSO standards such as the
OpenID authentication framework and the OAuth authorization framework have been rapidly and
widely adopted by IdPs and RPs [201, 202]. Major IdPs such as Facebook, Google, Microsoft, and
Twitter have also re-purposed OAuth for user authentication [168].
Researchers have identified the logic and implementation vulnerabilities of many deployed
Web SSO systems [44, 45, 168], and have also highlighted the serious threat and consequence of
Web SSO phishing attacks [46]. In comparison with traditional phishing, Web SSO phishing is
more profitable and insidious because the value of IdP accounts is highly concentrated, the attack
surface area is highly enlarged, and the difficulty of phishing detection by either algorithms or
users is highly increased [46].
Web SSO phishing was proposed and manually constructed for a specific RP website by Yue
in [46]. Our toolkit extends [46] and achieves the automatic and dynamic construction as well
as inclusion of Web SSO phishing login windows. A Web SSO phishing site contains at least a
base webpage for displaying the spoofed Web SSO login windows. Our toolkit aims to make the
look and feel of the spoofed Web SSO login windows as close as possible to those of the legitimate
ones, and make the inclusion of the spoofed Web SSO login windows as easy as possible. On a
legitimate RP website, an Web SSO login window is a real browser window with the HTTPS URL
address of an IdP (e.g., Google) login webpage; the same-origin policy in Web browsers ensures
that a user’s login credential submitted on an Web SSO login window cannot be accessed by any
RP website. Therefore, the base webpage on a Web SSO phishing site cannot use a real window
with an IdP’s URL address to steal a visitor’s login credentials.
In our design, we use <div> elements to create spoofed Web SSO login “windows” on the base
webpage. Our toolkit provides a JavaScript library for populating each <div> element with the
corresponding content and style of a real Web SSO login window. This populated <div> element
emulates the address bar and buttons of a real browser window using images, emulates the identical
HTTPS URL of an IdP and the corresponding security lock icon using images, and emulates the
177

identical content and style of a real Web SSO login page; it also supports all the relevant actions for
the spoofed login “window” (e.g., minimize, maximize, close, resize, and drag), the security lock
icon (e.g., click for viewing the certificate), and the login form (e.g., submit the login credentials).
The appearance of legitimate Web SSO login windows varies on different OSes, browsers, and
IdPs. For example, the window icon, the security lock icon, and the certificate viewing interface
are different on different browsers, while the window title, the URL address, and the login page
content depend on the IdPs. All these differences are properly considered in our JavaScript library.
To support Web SSO phishing, attackers only need to embed a few lines of HTML and JavaScript
code into the base webpage of their phishing site. The look and feel of our spoofed “window”
are identical to those of the real window; it is almost impossible for users to differentiate them as
demonstrated in our user study (Section 7.5).
7.4.4 Implementation
We implemented our toolkit in Perl and JavaScript. The toolkit runs on an Apache Web server
as an external filter [203], and supports the five most popular Web browsers (i.e., Google Chrome,
Firefox, Opera, Safari, and Internet Explorer) on visitors’ computers. The toolkit allows attackers
to easily construct and deploy phishing attacks against different legitimate websites even including
very complex ones such as Amazon, Sears, Yahoo, and AOL. It processes requests and responses
efficiently, and delivers phishing webpages to visitors’ browsers in real time.
7.5 User Study
To evaluate the effectiveness of extreme phishing, we set up a testbed and conducted a user
study with the IRB (Institutional Review Board) approval.
7.5.1 Testbed
We used our toolkit to construct a testbed with four extreme phishing websites Amazon, Yahoo,
Sears, and AOL, hosted via http on a Web server. The legitimate Amazon website only supports tra-
ditional sign-on, the legitimate Yahoo website supports both traditional sign-on and Web SSO (us-
178

ing Google and Facebook accounts, from 2011 to 2014), the legitimate Sears website supports both
traditional sign-on and Web SSO (using Google, Facebook, and Yahoo accounts), and the legiti-
mate AOL website supports both traditional sign-on and Web SSO (using Google, Facebook, Ya-
hoo, and Twitter accounts). The four phishing websites emulate the corresponding sign-on features
of the four legitimate websites, respectively. We assigned domain names www.amazon.jigdee.com,
www.yahoo.ibancu.com, www.sears.leuxfo.com, and www.aol.keirtu.com to the four phishing web-
sites; this type of phishing domain name composition trick has been used in real phishing attacks
as analyzed in [204]. At the client-side, we provided a computer for all the participants. On this
computer, we modified the DNS entries in the hosts file to have the phishing domain names point
to the IP address of our phishing Web server. We also installed the five most popular browsers and
configured them to clear the history and cookies for each session. This testbed provides a real-
istic environment for our study because it allows participants to use their real login credentials to
perform real browsing activities. Meanwhile, this testbed with our configuration does not expose
participants to any anticipated risk – when a participant submits any login form on our phishing
websites, client-side JavaScript code will immediately redirect the participant’s browser to the cor-
responding legitimate website, thus no login credential of any participant will be recorded by our
testbed.
7.5.2 Participants
We recruited 94 adults (57 younger and 37 older, 62 female and 32 male) from our campus and
the local community to participate in this study. The age range of younger participants is from 18 to
38 years, while the age range of older participants is from 50 to 88 years. All the participants ranged
in education from 12 to 20 years. 29 participants are/were majoring in psychology, medical, or
nursing related fields; 21 participants are/were majoring in education, business, communication, or
art related fields; 20 participants are/were majoring in engineering related fields; 24 participants did
not provide their major information. All the participants were prescreened for the study eligibility
that excludes who had a brain injury or concussion in the last three months, had been diagnosed
179

with a mental disorder that may disrupt cognition, were currently taking any medications that
interfered with thinking ability, or had been diagnosed with any cognitive or neurological disorder.
Participants who do not routinely use Internet (at least once per month) or do not have enough
accounts for this study were also excluded. Older adults received $15 compensation for their
participation, and younger adults received either psychology course credits or $15 compensation
for their participation.
7.5.3 Procedure
At the beginning of the procedure, participants were administered the informed consent, in
which they were told that the study examines computer usage patterns in younger and older adults.
No mention of phishing was included in the study’s introduction. This deception was used so
that any observed participant behavior on the websites could be attributed to aspects of the sites
themselves and the participants’ ability to evaluate them as they typically would. We also provided
handout instructions to the participants on using Web SSO, and encouraged them to ask questions
if needed.
We then asked each participant to perform four tasks by browsing four different websites,
according to his or her list of personal accounts. Of the four websites presented, two were extreme
phishing websites, one through traditional sign-on and one through Web SSO; the other two were
legitimate websites, similarly, one through traditional sign-on and one through Web SSO. The links
to the homepages of the four websites are provided on a task webpage; they were customized and
their sequence was randomized for each participant. All the participants were allowed to use any of
their favorite browsers and to leave the study at any time without penalty if they felt uncomfortable.
In each task, a participant was provided with an instruction to browse the corresponding website
as he or she usually does (e.g., click on links and submit forms) for a few minutes, log into it using
the specified traditional or Web SSO sign-on method sometime during the browsing, and finally
sign out. The experimenters left the room before a participant started to perform the set of Web
browsing tasks.
180

The Internet browsing portion of the study was followed by a questionnaire about Internet
safety, security practices, and aspects of the websites just visited. All the participants were de-
briefed regarding the true nature of the study and their questions were answered before they left.
7.5.4 Data Collection
We collected data through behavioral observation and questionnaire. The observation of Web
browsing tasks occurred in a separate room, where a second computer was linked to the computer
used by a participant via a screen sharing program, TeamViewer. For each participant on each
website, experimenters observed and noted the website name, sign-on type (traditional or Web
SSO), and user interactions. Experimenters also noted whether a participant exhibited any of a
series of behaviors that would indicate his or her suspicion about a website, for example, clicking
on the security lock icon, typing the website URL in another tab, searching the website URL or
name via a search engine, or refusing to log into the website. After the participant completed
the Web browsing tasks, a questionnaire was administered. This questionnaire included questions
specific to the participant’s behaviors and experience on the Web browsing tasks as well as his or
her attitudes, beliefs, and practices regarding Internet security and phishing in general.
7.5.5 Results
We present the user study results in terms of the main questionnaire results, the observed &
questionnaire results correlation, the Web SSO related questionnaire results, and other question-
naire results. Due to the contribution of our collaborators to the presentation of evaluation results,
here we only report the overall results regarding the effectiveness of our extreme phishing attacks.
For more details, please refer to our published conference paper [205].
The questionnaire results show that 87 (92.6%) of the 94 participants were actually not sus-
picious about the extreme phishing websites that they visited, and the observation results show
that 91 (96.8%) of the 94 participants submitted their login credentials to the extreme phishing
websites; meanwhile, most of those “victims” were aware of phishing before participating in this
study or had been susceptible to some phishing attacks in the past.
181

Recall that in Section 7.3.3, we reviewed that the success rate of existing phishing attacks
in terms of the second-layer context is about 10% as reported in previous measurement stud-
ies [188, 199], thus existing phishing attacks do not work sufficiently well. In addition, we allowed
participants to browse extreme phishing websites for minutes, while this type of realistic environ-
ment was not observed in existing phishing susceptibility studies that we reviewed in Section 7.2.
Therefore, overall, we conclude that extreme phishing attacks are indeed very effective, i.e., highly
insidious.
Note that it is not really possible to replicate the exact setup of those previous studies [188, 199]
to have a direct comparison between the extreme phishing and existing simple phishing attacks.
Also note that an extreme phishing website can use any of its webpages as the landing webpage
and does not further control the visitor once the login form is submitted, while a simple phishing
website often uses a single login webpage. Therefore, it is not really possible to design a new study
to directly and fairly compare extreme phishing with simple phishing attacks because there will
be no difference between them if a login webpage is used as the landing webpage for an extreme
phishing website. This is also the main reason why we only measured the effectiveness of the
extreme phishing attacks in our study.
7.6 Discussion
The extreme phishing attacks that we explored are highly insidious - they can effectively de-
ceive visitors as demonstrated in Section 7.5, and can also effectively weaken many existing phish-
ing defense mechanisms especially heuristics-based detection solutions. In this section, we discuss
such impacts and provide suggestions to researchers and users for them to better defend against
the extreme phishing attacks.
To detect phishing attacks, researchers have proposed various blacklist-based, heuristics-based,
and whitelist-based solutions [206]. Blacklist-based solutions can achieve near-zero false posi-
tives [207, 208], but they do not protect against zero-day phishing attacks [206, 209] because black-
lists are updated only periodically and their coverage is often incomplete [208]; moreover, they
182

have been challenged by the “rock phish gang”, that uses phishing toolkits to create a large num-
ber of unique phishing URLs [209, 210]. As a result, many heuristics-based solutions have been
proposed to detect phishing attacks using machine learning techniques with features extracted from
URLs [189, 199, 207, 211, 212] and visual or non-visual elements on webpages [189, 207, 212–
214]. Heuristics-based solutions can be used at the client-side to perform phishing detection in real
time, and also at the servers-side to detect and supply phishing URLs for serving blacklist-based
solutions; they need to achieve low false positives in order to be really usable and useful [206].
Whitelist-based solutions [29, 84] have also been proposed to complement the blacklist-based and
heuristics-based solutions. In addition, hashing-based solutions [39, 215] have been proposed to
protect against (rather than detect) phishing attacks.
Extreme phishing attacks will directly affect the effectiveness of many existing heuristics-based
solutions, will indirectly affect the effectiveness of the existing blacklist-based solutions, but may
not affect the effectiveness of the existing whitelist-based and hashing-based solutions.
Any heuristics-based solution that only uses features extracted from visual or non-visual el-
ements on webpages may fail to accurately detect extreme phishing attacks that serve webpages
with identical look and feel as those of the legitimate webpages. For example, most solutions
heavily rely on the content including text, forms, scripts, and links of a webpage to detect anoma-
lies [189, 207, 212, 213], and some solutions also use images to detect anomalies [213, 214].
Unfortunately, extreme phishing webpages will not produce obvious anomalies to them. Any
heuristics-based solution that uses features extracted from URLs may become either inaccurate or
incorrect on the detection of our Web SSO phishing attacks. Phishers can simply host the base
webpages for Web SSO phishing attacks on their own RP websites or some legitimate websites
such as Web forums and blogs, while the spoofed Web SSO login “windows” do not correspond
to real URL addresses; therefore, no suspicious URL will be exposed to heuristics-based solu-
tions [189, 199, 207, 211, 212] for performing the detection.
While blacklist-based solutions are not directly affected by extreme phishing attacks, they will
be indirectly affected if the construction of their blacklists relies on heuristics-based techniques
183

or anti-phishing communities. For example, the phishing blacklists used in Google Chrome and
Mozilla Firefox are constructed and periodically updated by Google’s large-scale automatic phish-
ing classification infrastructure [189], which heavily uses heuristics-based techniques. In addi-
tion, blacklists often include phishing URLs verified by anti-phishing communities such as Phish-
Tank [185]; it is very difficult for regular users to identify extreme phishing attacks as demonstrated
in Section 7.5, and for them to further submit phishing URLs to communities in a timely manner.
So far, whitelist-based solutions [29, 84] and hashing-based solutions [39, 215] are more robust
against extreme phishing because they mainly rely on domain names to perform form filling or
password derivation operations. However, users may need to pay more attention to properly use
those solutions (such as pressing special keys for triggering password protection [39, 215]), while
without being tricked by the look and feel of extreme phishing in the first place.
We suggest that researchers should seriously consider extreme phishing in their heuristics-
based phishing detection solutions. For one example, anomalies in webpages alone can no longer
serve as an effective metric in phishing detection; instead, URL analysis and webpage analysis
should be combined together. For another example, identifying the intention (i.e., the intended
website) of a user becomes indispensable in detecting extreme phishing, and existing solutions
such as [29, 209, 214] are some good examples. Furthermore, researchers should also explore
Web SSO phishing detection techniques. For example, the intention of a click action (i.e., the
intended Web SSO IdP) on the base webpage could be leveraged to detect if a corresponding real
login window or a <div> element for a spoofed login “window” is displayed. However, automatic
detection of extreme phishing attacks will still not be easier than automatic detection of simple
phishing attacks especially because many phishing websites are short-lived [194, 207] and may
not even be crawled in the first place; in addition, intention-based solutions (such as [209]) are
already very effective in detecting simple phishing, and the space for them to further improve on
detecting extreme phishing is very limited.
We suggest that Web users should be trained to (1) be aware of extreme phishing, (2) pay more
attention to the domain name of a URL displayed in the address bar rather than just the look and
184

feel of webpages, and (3) differentiate the spoofed Web SSO login “windows” from real ones. For
example, one technique for detecting a spoofed Web SSO login “window” is to maximize, drag,
or resize it because a spoofed “window” can never reach out of the webpage content area. In addi-
tion, it could be helpful for users to use some tools such as browser extensions to obtain intuitive
information about the domain name in real time, thus potentially making informed decisions.
7.7 Summary
In this project, we explored the extreme phishing attacks and investigated the techniques for
constructing them. We designed and implemented a concrete toolkit that can be feasibly and easily
used by attackers to construct and deploy such attacks. Our toolkit can support both the traditional
phishing and the newly emergent Web Single Sign-On phishing, and can automatically construct
unlimited levels of phishing webpages in real time based on user interactions. We designed and
performed a user study with 94 participants and demonstrated that extreme phishing attacks con-
structed by our toolkit are indeed highly effective, i.e., insidious. Finally, we discussed the impacts
of extreme phishing on existing phishing defense mechanisms and provided suggestions to re-
searchers and users for them to better defend against such attacks. It is reasonable to assume that
attackers will adopt and widely deploy extreme phishing attacks using some similar toolkits in the
future. Therefore, we urge the research community to pay serious attention to extreme phishing
attacks, and we call for a collective effort to effectively defend against such attacks.
185

CHAPTER 8
CONCLUSION
Using different end-user applications on personal computers and mobile devices has become
an integral part of our daily lives. However, users’ sensitive data may not be properly protected in
those applications and can be leaked to attackers resulting in severe consequences. Therefore, it is
in great need and important to explore potential vulnerabilities and protect sensitive data in end-
user applications. In this dissertation, we explore the vulnerabilities in both end-user applications
and end users by conducting six projects; we expect to advance the scientific and technological un-
derstanding on protecting users’ sensitive data in applications, and make users’ online experience
more secure and enjoyable.
In terms of end-user applications, we focus on Web browsers, browser extensions, stand-alone
applications, and mobile applications by manually or automatically exploring their vulnerabilities
and by proposing new data protection mechanisms. Specifically,
1. We uncovered the vulnerabilities of password managers in the five most popular Web browsers,
and proposed a novel Cloud-based Storage-Free BPM (CSF-BPM) design to achieve a high
level of security with the desired confidentiality, integrity, and availability. Our evaluation
results and analysis demonstrated that CSF-BPM can be efficiently and conveniently used to
manage online passwords.
2. We analyzed the security design of two commercial browser extension and cloud based pass-
word managers (BCPMs). We identified several critical, high, and medium risk level vul-
nerabilities, and provided some general suggestions to help improve the security design of
BCPMs.
3. We presented a framework , LvDetector, that combines static and dynamic program anal-
ysis techniques for automatic detection of information leakage vulnerabilities in legitimate
186

browser extensions. We evaluated LvDetector on 28 popular Firefox and Google Chrome ex-
tensions. The evaluation results and the feedback to our responsible disclosure demonstrated
that LvDetector is useful and effective.
4. We took a middleware approach and designed SafeSky, a secure cloud storage middleware
that can immediately enable either legacy or new end-user applications to have the secure
cloud storage capability without requiring any code modification or recompilation to them.
We evaluated the correctness and performance of SafeSky by using real-world applications,
and analyzed its security. Our evaluation and analysis results demonstrated that SafeSky is a
feasible and practical approach.
5. We highlighted and investigated severe cross-site input inference attacks that may compro-
mise the security of every mobile Web user, and quantified the extent to which they can be
effective. We addressed the data quality and data segmentation challenges in our attacks
by designing and experimenting with three unique techniques: training data screening, fine-
grained data filtering, and key down timestamp detection and adjustment. We intensively
evaluated the effectiveness of our attacks, and provided an in-depth analysis on the evalua-
tion results.
In terms of end users, we focus on phishing attacks by investigating users’ susceptibility to
both traditional phishing and Single Sign-On phishing. Specifically,
6. We explored the extreme phishing attacks and investigated the techniques for construct-
ing them. We designed and implemented a concrete toolkit that can be feasibly and easily
used by attackers to construct and deploy such attacks. We designed and performed a user
study with 94 participants and demonstrated that extreme phishing attacks constructed by
our toolkit are indeed highly effective, i.e., insidious.
187

REFERENCES CITED
[1] CNN. Yahoo Says 500 Million Accounts Stolen. http://money.cnn.com/2016/
09/22/technology/yahoo-data-breach/, 2014.
[2] CNN. Hackers Selling 117 Million LinkedIn Passwords. http://money.cnn.com/
2016/05/19/technology/linkedin-hack/, 2016.
[3] Forbes. The Dyn DDOS Attack And The Changing Balance Of Online Cyber Power.
http://www.forbes.com/sites/kalevleetaru/2016/10/31/the-dyn
-ddos-attack-and-the-changing-balance-of-online-cyber-power
/#49912191e230, 2016.
[4] Zakir Durumeric, James Kasten, David Adrian, J. Alex Halderman, Michael Bailey, Frank
Li, Nicolas Weaver, Johanna Amann, Jethro Beekman, Mathias Payer, and Vern Paxson.
The matter of heartbleed. In Proceedings of the Conference on Internet Measurement
Conference, pages 475–488, 2014.
[5] Zdnet. Mirai DDoS botnet powers up, infects Sierra Wireless gateways. http://www.
zdnet.com/article/mirai-ddos-botnet-powers-up-infects-sierra
-wireless-gateways/, 2016.
[6] Manuel Egele, David Brumley, Yanick Fratantonio, and Christopher Kruegel. An empirical
study of cryptographic misuse in android applications. In Proceedings of the ACM SIGSAC
Conference on Computer & Communications Security (CCS), pages 73–84, 2013.
[7] APWG. Anti-Phishing Working Group. http://www.antiphishing.org, 2016.
[8] Yahoo. Snapchats Phishing Attack Could Have Been Much Worse. http://finance.
yahoo.com/news/snapchat-phishing-attack-could-much
-194819518.html, 2016.
[9] CNBC. Tax-refund fraud to hit $21 billion, and there’s little the IRS can do. http://
www.cnbc.com/2015/02/11/tax-refund-fraud-to-hit-21-billion
-and-theres-little-the-irs-can-do.html, 2016.
[10] Joseph Bonneau, Cormac Herley, Paul C. van Oorschot, and Frank Stajano. The quest to
replace passwords: A framework for comparative evaluation of web authentication
schemes. In Proceedings of the IEEE Symposium on Security and Privacy, pages 553–567,
2012.
188

[11] Cormac Herley and Paul C. van Oorschot. A research agenda acknowledging the
persistence of passwords. IEEE Security & Privacy, 10(1):28–36, 2012.
[12] Cormac Herley, Paul C. van Oorschot, and Andrew S. Patrick. Passwords: If we’re so
smart, why are we still using them? In Proceedings of the Financial Cryptography, pages
230–237, 2009.
[13] Anne Adams and Martina Angela Sasse. Users are not the enemy. Commun. ACM, 42(12):
40–46, 1999.
[14] David C. Feldmeier and Philip R. Karn. Unix password security – ten years later. In
Proceedings of the Annual International Cryptology Conference (CRYPTO), pages 44–63,
1989.
[15] Saranga Komanduri, Richard Shay, Patrick Gage Kelley, Michelle L. Mazurek, Lujo Bauer,
Nicolas Christin, Lorrie Faith Cranor, and Serge Egelman. Of passwords and people:
Measuring the effect of password-composition policies. In Proceedings of the SIGCHI
conference on Human Factors in Computing Systems (CHI), pages 2595–2604, 2011.
[16] Robert Morris and Ken Thompson. Password security: a case history. Commun. ACM, 22
(11):594–597, 1979.
[17] Jeff Yan, Alan Blackwell, Ross Anderson, and Alasdair Grant. Password memorability and
security: Empirical results. IEEE Security and Privacy, 2(5):25–31, 2004.
[18] Markus Jakobsson and Steven Myers. Phishing and Countermeasures: Understanding the
Increasing Problem of Electronic Identity Theft. Wiley-Interscience, ISBN 0-471-78245-9,
2006. ISBN 0471782459.
[19] Rachna Dhamija and J.D.Tygar and Marti Hearst. Why phishing works. In Proceedings of
the SIGCHI conference on Human Factors in Computing Systems (CHI), pages 581–590,
2006.
[20] Dinei Florencio and Cormac Herley. A large-scale study of web password habits. In
Proceedings of the International Conference on World Wide Web (WWW), pages 657–666,
2007.
[21] Brett Stone-Gross, Marco Cova, Lorenzo Cavallaro, Bob Gilbert, Martin Szydlowski,
Richard A. Kemmerer, Christopher Kruegel, and Giovanni Vigna. Your botnet is my
botnet: analysis of a botnet takeover. In Proceedings of the ACM Conference on Computer
and Communications Security (CCS), pages 635–647, 2009.
189

[22] Alysson Bessani, Miguel Correia, Bruno Quaresma, Fernando Andre, and Paulo Sousa.
Depsky: dependable and secure storage in a cloud-of-clouds. In Proceedings of The
European Conference on Computer Systems (EuroSys), 2011.
[23] Kevin D. Bowers, Ari Juels, and Alina Oprea. Hail: a high-availability and integrity layer
for cloud storage. In Proceedings of the ACM Conference on Computer and
Communications Security (CCS), pages 187–198, 2009.
[24] Prince Mahajan, Srinath Setty, Sangmin Lee, Allen Clement, Lorenzo Alvisi, Mike Dahlin,
and Michael Walfish. Depot: Cloud storage with minimal trust. ACM Trans. Comput. Syst.,
29(4), 2011.
[25] Raluca Ada Popa, Jay Lorch, David Molnar, Helen J. Wang, and Li Zhuang. Enabling
security in cloud storage slas with cloudproof. In Proceedings of the USENIX Annual
Technical Conference, 2011.
[26] Cong Wang, Qian Wang, Kui Ren, Ning Cao, and Wenjing Lou. Toward secure and
dependable storage services in cloud computing. IEEE Trans. Serv. Comput., 5(2):
220–232, 2012.
[27] Windows Azure Storage Team. Windows azure storage: a highly available cloud storage
service with strong consistency. In Proceedings of the ACM Symposium on Operating
Systems Principles (SOSP), 2011.
[28] Adi Shamir. How to share a secret. Commun. ACM, 22(11):612–613, 1979.
[29] Min Wu, Robert C. Miller, and Greg Little. Web wallet: preventing phishing attacks by
revealing user intentions. In Proceedings of the Symposium on Usable Privacy and
Security (SOUPS), pages 102–113, 2006.
[30] Agilebits. 1Password. https://agilebits.com/onepassword, 2016.
[31] RoboForm. RoboForm Password Manager. http://www.roboform.com/, 2016.
[32] David P. Kormann and Aviel D. Rubin. Risks of the passport single signon protocol.
Comput. Networks, 33(1-6):51–58, 2000.
[33] San-Tsai Sun, Yazan Boshmaf, Kirstie Hawkey, and Konstantin Beznosov. A billion keys,
but few locks: the crisis of web single sign-on. In Proceedings of the New security
Paradigms Workshop (NSPW), pages 61–72, 2010.
[34] OpenID. OpenID 2.0. http://openid.net/specs/openid-authentication
-2_0.html, 2016.
190

[35] IETF. The OAuth 2.0 Authorization Framework. http://tools.ietf.org/html/
rfc6749, 2012.
[36] Darren Davis, Fabian Monrose, and Michael K. Reiter. On user choice in graphical
password schemes. In Proceedings of the USENIX Security Symposium, pages 151–164,
2004.
[37] Julie Thorpe and P.C. van Oorschot. Human-seeded attacks and exploiting hot-spots in
graphical passwords. In Proceedings of the USENIX Security Symposium, pages 103–118,
2007.
[38] Julie Thorpe and Paul C. van Oorschot. Towards secure design choices for implementing
graphical passwords. In Proceedings of the Annual Computer Security Applications
Conference (ACSAC), pages 50–60, 2004.
[39] J. Alex Halderman, Brent Waters, and Edward W. Felten. A convenient method for
securely managing passwords. In Proceedings of the International Conference on World
Wide Web (WWW), pages 471–479, 2005.
[40] Blake Ross, Collin Jackson, Nick Miyake, Dan Boneh, and John C. Mitchell. Stronger
password authentication using browser extensions. In Proceedings of the USENIX Security
Symposium, pages 17–32, 2005.
[41] Ka-Ping Yee and Kragen Sitaker. Passpet: convenient password management and phishing
protection. In Proceedings of the Symposium on Usable Privacy and Security (SOUPS),
pages 32–43, 2006.
[42] LastPass. LastPass Password Manager. https://lastpass.com/, 2016.
[43] Rui Zhao, Chuan Yue, and Kun Sun. Vulnerability and risk analysis of two commercial
browser and cloud based password managers. ASE Science Journal, 1(4):1–15, 2013.
[44] San-Tsai Sun and Konstantin Beznosov. The devil is in the (implementation) details: an
empirical analysis of oauth sso systems. In Proceedings of the ACM Conference on
Computer and Communications Security (CCS), 2012.
[45] Rui Wang, Shuo Chen, and XiaoFeng Wang. Signing me onto your accounts through
facebook and google: A traffic-guided security study of commercially deployed
single-sign-on web services. In Proceedings of the IEEE Symposium on Security and
Privacy, 2012.
[46] Chuan Yue. The Devil is Phishing: Rethinking Web Single Sign-On Systems Security. In
Proceedings of the USENIX Workshop on Large-Scale Exploits and Emergent Threats
(LEET), 2013.
191

[47] Sonia Chiasson, P. C. van Oorschot, and Robert Biddle. A usability study and critique of
two password managers. In Proceedings of the USENIX Security Symposium, pages 1–16,
2006.
[48] Rui Zhao and Chuan Yue. All Your Browser-saved Passwords Could Belong to Us: A
Security Analysis and A Cloud-based New Design (short paper). In Proceedings of the
ACM Conference on Data and Application Security and Privacy (CODASPY), 2013.
[49] Pauline Bowen, Joan Hash, and Mark Wilson. Information Security Handbook: A Guide
for Managers. In NIST Special Publication 800-100, 2007. http://csrc.nist.gov/
publications/nistpubs/800-100/SP800-100-Mar07-2007.pdf.
[50] Marco Cova, Christopher Kruegel, and Giovanni Vigna. Detection and analysis of
drive-by-download attacks and malicious javascript code. In Proceedings of the
International Conference on World Wide Web (WWW), pages 281–290, 2010.
[51] Long Lu, Vinod Yegneswaran, Phillip Porras, and Wenke Lee. Blade: an attack-agnostic
approach for preventing drive-by malware infections. In Proceedings of the ACM
Conference on Computer and Communications Security (CCS), 2010.
[52] Alex Moshchuk, Tanya Bragin, Steven D. Gribble, and Henry M. Levy. A crawler-based
study of spyware in the web. In Proceedings of the Annual Network & Distributed System
Security Symposium (NDSS), 2006.
[53] Niels Provos, Panayiotis Mavrommatis, Moheeb Abu Rajab, and Fabian Monrose. All your
iframes point to us. In Proceedings of the USENIX Security Symposium, pages 1–15, 2008.
[54] Yi-Min Wang, Doug Beck, Xuxian Jiang, Roussi Roussev, Chad Verbowski, Shuo Chen,
and Samuel T. King. Automated web patrol with strider honeymonkeys: Finding web sites
that exploit browser vulnerabilities. In Proceedings of the Annual Network & Distributed
System Security Symposium (NDSS), 2006.
[55] Mike Ter Louw, Jin Soon Lim, and V. N. Venkatakrishnan. Enhancing web browser
security against malware extensions. Journal in Computer Virology, 4(3):179–195, 2008.
[56] J. Alex Halderman, Seth D. Schoen, Nadia Heninger, William Clarkson, William Paul,
Joseph A. Calandrino, Ariel J. Feldman, Jacob Appelbaum, and Edward W. Felten. Lest
we remember: Cold boot attacks on encryption keys. In Proceedings of USENIX Security
Symposium, 2008.
[57] Francis Hsu, Hao Chen, Thomas Ristenpart, Jason Li, and Zhendong Su. Back to the
future: A framework for automatic malware removal and system repair. In Proceedings of
the Annual Computer Security Applications Conference (ACSAC), pages 257–268, 2006.
192

[58] Eric Grosse and Mayank Upadhyay. Authentication at scale. IEEE Security and Privacy,
11:15–22, 2013.
[59] SQLite. SQLite Home Page. http://www.sqlite.org, 2016.
[60] Microsoft. Windows CryptProtectData function. http://msdn.microsoft.com/
en-us/library/windows/desktop/aa380261(v=vs.85).aspx, 2016.
[61] Microsoft. Windows CryptUnprotectData function. http://msdn.microsoft.com/
en-us/library/windows/desktop/aa380882(v=vs.85).aspx, 2016.
[62] Cristian Bravo-Lillo, Lorrie Cranor, Julie Downs, Saranga Komanduri, Stuart Schechter,
and Manya Sleeper. Operating system framed in case of mistaken identity: measuring the
success of web-based spoofing attacks on os password-entry dialogs. In Proceedings of the
ACM Conference on Computer and Communications Security (CCS), pages 365–377,
2012.
[63] William E. Burr, Donna F. Dodson, Elaine M. Newton, Ray A. Perlner, W. Timothy Polk,
Sarbari Gupta, and Emad A. Nabbus. Electronic Authentication Guideline. In NIST
Special Publication 800-63-1, 2011. http://csrc.nist.gov/publications/
nistpubs/800-63-1/SP-800-63-1.pdf.
[64] Luke St. Clair, Lisa Johansen, William Enck, Matthew Pirretti, Patrick Traynor, Patrick
McDaniel, and Trent Jaeger. Password exhaustion: predicting the end of password
usefulness. In Proceedings of the International Conference on Information Systems
Security, pages 37–55, 2006.
[65] Matt Bishop and Daniel V. Klein. Improving system security via proactive password
checking. Computers & Security, 14(3):233–249, 1995.
[66] Patrick Gage Kelley, Saranga Komanduri, Michelle L. Mazurek, Richard Shay, Timothy
Vidas, Lujo Bauer, Nicolas Christin, Lorrie Faith Cranor, and Julio Lopez. Guess again
(and again and again): Measuring password strength by simulating password-cracking
algorithms. In Proceedings of the IEEE Symposium on Security and Privacy, pages
523–537, 2012.
[67] Jianxin Jeff Yan. A note on proactive password checking. In Proceedings of the New
security Paradigms Workshop (NSPW), pages 127–135, 2001.
[68] Cormac Herley and Stuart Schechter. Breaking our password hash habit – why the sharing
of users’ password choices for defensive analysis is an underprovisioned social good, and
what we can do to encourage it. In Proceedings of the Workshop on the Economics of
Information Security (WEIS), 2013.
193

[69] Ben Laurie. Nigori: Storing Secrets in the Cloud. http://www.links.org/files/
nigori-overview.pdf, 2010.
[70] Burt Kaliski. RFC 2898, PKCS5: Password-Based Cryptography Specification Version
2.0. http://www.ietf.org/rfc/rfc2898.txt, 1999.
[71] Advanced Encryption Standard (AES). In NIST FIPS 197, 2001. http://csrc.nist.
gov/publications/fips/fips197/fips-197.pdf.
[72] Morris Dworkin. Recommendation for Block Cipher Modes of Operation: The CCM
Mode for Authentication and Confidentiality. In NIST Special Publication 800-38C, 2004.
http://csrc.nist.gov/publications/nistpubs/800-38C/
SP800-38C.pdf.
[73] Xavier Boyen. Halting password puzzles: hard-to-break encryption from
human-memorable keys. In Proceedings of the USENIX Security Symposium, pages
119–134, 2007.
[74] William Stallings. Cryptography and Network Security: Principles and Practice. Prentice
Hall Press, 5th edition, 2010. ISBN 0136097049, 9780136097044.
[75] NIST. NIST: Secure Hashing. http://csrc.nist.gov/groups/ST/toolkit/
secure_hashing.html, 2016.
[76] Firefox. Firefox Sync Service. https://wiki.mozilla.org/Services/Sync,
2016.
[77] Thomas Wu. The secure remote password protocol. In Proceedings of the Annual Network
& Distributed System Security Symposium (NDSS), 1998.
[78] Firefox. XPCOM: Cross Platform Component Object Model. https://developer.
mozilla.org/en/XPCOM, 2016.
[79] Emily Stark, Michael Hamburg, and Dan Boneh. Symmetric cryptography in javascript. In
Proceedings of the Annual Computer Security Applications Conference (ACSAC), pages
373–381, 2009.
[80] Ran Canetti, Shai Halevi, and Michael Steiner. Mitigating dictionary attacks on
password-protected local storage. In Proceedings of the Annual International Cryptology
Conference (CRYPTO), pages 160–179, 2006.
[81] Alma Whitten and J. D. Tygar. Why Johnny can’t encrypt: a usability evaluation of PGP
5.0. In Proceedings of the USENIX Security Symposium, 1999.
194

[82] Likert scale. http://en.wikipedia.org/wiki/Likert_scale.
[83] Chuan Yue and Haining Wang. BogusBiter: A Transparent Protection Against Phishing
Attacks. ACM Transactions on Internet Technology (TOIT), 10(2):1–31, 2010.
[84] Chuan Yue. Preventing the Revealing of Online Passwords to Inappropriate Websites with
LoginInspector. In Proceedings of USENIX Large Installation System Administration
(LISA) Conference, 2012.
[85] Microsoft. Windows Live ID. http://msdn.microsoft.com/en-us/library/
bb288408.aspx, 2007.
[86] San-Tsai Sun, Kirstie Hawkey, and Konstantin Beznosov. Systematically breaking and
fixing openid security: Formal analysis, semi-automated empirical evaluation, and practical
countermeasures. Computers & Security, 31(4):465–483, 2012.
[87] PCWorld. LastPass, Online Password Manager, May Have Been Hacked. http://www.
pcworld.com/article/227223/LastPass_Online_Password_Manager_
May_Have_Been_Hacked.html, 2011.
[88] Karthikeyan Bhargavan and Antoine Delignat-Lavaud. Web-based attacks on host-proof
encrypted storage. In Proceedings of the USENIX Workshop on Offensive Technologies
(WOOT), 2012.
[89] Mozilla. Mozilla’s JavaScript Debugger. https://developer.mozilla.org/
en-US/docs/Venkman, 2012.
[90] IEInspector. HTTP Analyzer. http://www.ieinspector.com/httpanalyzer/
index.html, 2012.
[91] IEInspector. OWASP Risk Rating Methodology. https://www.owasp.org/
index.php/OWASP_Risk_Rating_Methodology, 2016.
[92] Sruthi Bandhakavi, Samuel T King, Parthasarathy Madhusudan, and Marianne Winslett.
Vex: Vetting browser extensions for security vulnerabilities. In Proceedings of USENIX
Security Symposium, pages 339–354, 2010.
[93] Adam Barth, Adrienne Porter Felt, Prateek Saxena, and Aaron Boodman. Protecting
browsers from extension vulnerabilities. In Proceedings of the Annual Network and
Distributed Security Symposium (NDSS), 2010.
[94] Nicholas Carlini, Adrienne Porter Felt, and David Wagner. An evaluation of the google
chrome extension security architecture. In Proceedings of USENIX Security Symposium,
2012.
195

[95] Wentao Chang and Songqing Chen. Defeat information leakage from browser extensions
via data obfuscation. In Proceedings of the International Conference on Information and
Communications Security (ICICS), pages 33–48, 2013.
[96] Mohan Dhawan and Vinod Ganapathy. Analyzing information flow in javascript-based
browser extensions. In Proceedings of the Annual Computer Security Applications
Conference (ACSAC), pages 382–391, 2009.
[97] Arjun Guha, Matthew Fredrikson, Benjamin Livshits, and Nikhil Swamy. Verified security
for browser extensions. In Proceedings of the IEEE Symposium on Security and Privacy,
pages 115–130, 2011.
[98] Vineeth Kashyap and Ben Hardekopf. Security signature inference for javascript-based
browser addons. In Proceedings of Annual IEEE/ACM International Symposium on Code
Generation and Optimization (CGO), pages 219–229, 2014.
[99] Lei Liu, Xinwen Zhang, Guanhua Yan, and Songqing Chen. Chrome extensions: Threat
analysis and countermeasures. In Proceedings of the Annual Network and Distributed
Security Symposium (NDSS), 2012.
[100] Nick Nikiforakis, Luca Invernizzi, Alexandros Kapravelos, Steven Van Acker, Wouter
Joosen, Christopher Kruegel, Frank Piessens, and Giovanni Vigna. You are what you
include: Large-scale evaluation of remote javascript inclusions. In Proceedings of the ACM
Conference on Computer and Communications Security (CCS), pages 736–747, 2012.
[101] Gregor Richards, Christian Hammer, Brian Burg, and Jan Vitek. The eval that men do - a
large-scale study of the use of eval in javascript applications. In Proceedings of the
European Conference on Object-Oriented Programming (ECOOP), pages 52–78, 2011.
[102] Gregor Richards, Sylvain Lebresne, Brian Burg, and Jan Vitek. An analysis of the dynamic
behavior of javascript programs. In Proceedings of the ACM SIGPLAN Conference on
Programming Language Design and Implementation (PLDI), pages 1–12, 2010.
[103] Chuan Yue and Haining Wang. A measurement study of insecure javascript practices on
the web. ACM Transactions on the Web, 7(2):7:1–7:39, 2013.
[104] Ravi Chugh, Jeffrey A. Meister, Ranjit Jhala, and Sorin Lerner. Staged information flow
for javascript. In Proceedings of the ACM SIGPLAN Conference on Programming
Language Design and Implementation (PLDI), pages 50–62. ACM, 2009.
[105] Seth Just, Alan Cleary, Brandon Shirley, and Christian Hammer. Information flow analysis
for javascript. In Proceedings of the ACM SIGPLAN International Workshop on
Programming Language and Systems Technologies for Internet Clients (PLASTIC), pages
9–18, 2011.
196

[106] Magnus Madsen, Benjamin Livshits, and Michael Fanning. Practical static analysis of
javascript applications in the presence of frameworks and libraries. In Proceedings of the
Joint Meeting on Foundations of Software Engineering (FSE), pages 499–509, 2013.
[107] Mozilla. Firefox Extensions. https://addons.mozilla.org/, 2016.
[108] Google. Google Chrome Extensions. https://chrome.google.com/
extensions/, 2016.
[109] Ron Cytron, Jeanne Ferrante, Barry K. Rosen, Mark N. Wegman, and F. Kenneth Zadeck.
Efficiently computing static single assignment form and the control dependence graph.
ACM Trans. Program. Lang. Syst., 13(4):451–490, 10 1991.
[110] Andrei Sabelfeld and Andrew C Myers. Language-based information-flow security. IEEE
JSAC, 21(1):5–19, 2003.
[111] Philipp Vogt, Florian Nentwich, Nenad Jovanovic, Engin Kirda, Christopher Kruegel, and
Giovanni Vigna. Cross site scripting prevention with dynamic data tainting and static
analysis. In Proceedings of the Annual Network & Distributed System Security Symposium
(NDSS), 2007.
[112] Salvatore Guarnieri and Benjamin Livshits. Gatekeeper: Mostly static enforcement of
security and reliability policies for javascript code. In Proceedings of USENIX Security
Symposium, pages 151–168, 2009.
[113] Benjamin Livshits, Manu Sridharan, Yannis Smaragdakis, Ondrej Lhotak, J. Nelson
Amaral, Bor-Yuh Evan Chang, Samuel Z. Guyer, Uday P. Khedker, Anders Møller, and
Dimitrios Vardoulakis. In defense of soundiness: A manifesto. Commun. ACM, 58(2):
44–46, 2015.
[114] David Grove, Greg DeFouw, Jeffrey Dean, and Craig Chambers. Call graph construction in
object-oriented languages. In Proceedings of the ACM SIGPLAN conference on
Object-oriented programming, systems, languages, and applications (OOPSLA), year =
1997, pages = 108–124.
[115] William E. Weihl. Interprocedural data flow analysis in the presence of pointers, procedure
variables, and label variables. In Proceedings of the ACM SIGPLAN-SIGACT symposium
on Principles of programming languages (POPL), pages 83–94, 1980.
[116] Google. Closure Compiler. https://developers.google.com/closure/
compiler/, 2013.
[117] IBM. WALA Compiler. http://wala.sourceforge.net/wiki/index.php,
2013.
197

[118] Qing Yi, Vikram Adve, and Ken Kennedy. Transforming loops to recursion for multi-level
memory hierarchies. In Proceedings of the ACM SIGPLAN Conference on Programming
Language Design and Implementation (PLDI), pages 169–181, 2000.
[119] Mark Weiser. Program slicing. In Proceedings of ICSE, pages 439–449, 1981.
[120] Manuel Egele, David Brumley, Yanick Fratantonio, and Christopher Kruegel. An empirical
study of cryptographic misuse in android applications. In Proceedings of the ACM
Conference on Computer and Communications Security (CCS), pages 73–84, 2013.
[121] Clemens Kolbitsch, Benjamin Livshits, Benjamin Zorn, and Christian Seifert. Rozzle:
De-cloaking internet malware. In Proceedings of the IEEE Symposium on Security and
Privacy, pages 443–457, 2012.
[122] Prateek Saxena, Devdatta Akhawe, Steve Hanna, Feng Mao, Stephen McCamant, and
Dawn Song. A symbolic execution framework for javascript. In Proceedings of the IEEE
Symposium on Security and Privacy, pages 513–528, 2010.
[123] Vladan Djeric and Ashvin Goel. Securing script-based extensibility in web browsers. In
Proceedings of USENIX Security Symposium, 2010.
[124] Charlie Curtsinger, Benjamin Livshits, Benjamin G Zorn, and Christian Seifert. Zozzle:
Fast and precise in-browser javascript malware detection. In Proceedings of USENIX
Security Symposium, pages 33–48, 2011.
[125] Salvatore Guarnieri, Marco Pistoia, Omer Tripp, Julian Dolby, Stephen Teilhet, and Ryan
Berg. Saving the world wide web from vulnerable javascript. In Proceedings of the
International Symposium on Software Testing and Analysis (ISSTA), pages 177–187, 2011.
[126] Ankur Taly, Ulfar Erlingsson, John C. Mitchell, Mark S. Miller, and Jasvir Nagra.
Automated Analysis of Security-Critical JavaScript APIs. In Proceedings of the IEEE
Symposium on Security and Privacy, pages 363–378, 2011.
[127] Daniel Hedin and Andrei Sabelfeld. Information-flow security for a core of javascript. In
Proceedings of the IEEE Computer Security Foundations Symposium (CSF), pages 3–18,
2012.
[128] Dongseok Jang, Ranjit Jhala, Sorin Lerner, and Hovav Shacham. An empirical study of
privacy-violating information flows in javascript web applications. In Proceedings of the
ACM Conference on Computer and Communications Security (CCS), pages 270–283,
2010.
198

[129] Omer Tripp, Pietro Ferrara, and Marco Pistoia. Hybrid security analysis of web javascript
code via dynamic partial evaluation. In Proceedings of the International Symposium on
Software Testing and Analysis (ISSTA), pages 49–59, 2014.
[130] Shiyi Wei and Barbara G. Ryder. Practical blended taint analysis for javascript. In
Proceedings of the International Symposium on Software Testing and Analysis (ISSTA),
pages 336–346, 2013.
[131] Chuan Yue. Toward Secure and Convenient Browsing Data Management in the Cloud. In
Proceedings of the USENIX Workshop on Hot Topics in Cloud Computing (HotCloud),
2013.
[132] Gary Anthes. Security in the cloud. Commun. ACM, 53(11):16–18, 2010.
[133] Michael Armbrust, Armando Fox, Rean Griffith, Anthony D. Joseph, Randy Katz, Andy
Konwinski, Gunho Lee, David Patterson, Ariel Rabkin, Ion Stoica, and Matei Zaharia. A
view of cloud computing. Commun. ACM, 53(4):50–58, 2010.
[134] Hassan Takabi, James B. D. Joshi, and Gail-Joon Ahn. Security and Privacy Challenges in
Cloud Computing Environments. IEEE Security and Privacy, 8(6):24–31, 2010.
[135] Wenliang Du, Karthick Jayaraman, Xi Tan, Tongbo Luo, and Steve Chapin. Position Paper:
Why Are There So Many Vulnerabilities in Web Applications? In Proceedings of the New
Security Paradigms Workshop (NSPW), 2011.
[136] Nadia Heninger, Zakir Durumeric, Eric Wustrow, and J. Alex Halderman. Mining Your Ps
and Qs: Detection of Widespread Weak Keys in Network Devices. In Proceedings of the
USENIX Security Symposium, 2012.
[137] Rui Zhao, Chuan Yue, and Qing Yi. Automatic detection of information leakage
vulnerabilities in browser extensions. In Proceedings of the International Conference on
World Wide Web (WWW), pages 1384–1394, 2015.
[138] Hussam Abu-Libdeh, Lonnie Princehouse, and Hakim Weatherspoon. RACS: a case for
cloud storage diversity. In Proceedings of the ACM symposium on Cloud Computing
(SoCC), pages 229–240, 2010.
[139] Seny Kamara and Kristin Lauter. Cryptographic cloud storage. In Proceedings of the
Financial Cryptography (FC), pages 136–149, 2010.
[140] Michael Vrable, Stefan Savage, and Geoffrey M. Voelker. BlueSky: A Cloud-backed File
System for the Enterprise. In Proceedings of the USENIX Conference on File and Storage
Technologies (FAST), 2012.
199

[141] Amazon. Amazon Cloud Drive. http://www.amazon.com/gp/feature.html?
ie=UTF8&docId=1000828861, 2016.
[142] Box. Box Cloud Storage. https://www.box.com/, 2016.
[143] Dropbox. Dropbox Cloud Storage. https://www.dropbox.com/, 2016.
[144] Google. Google Drive. https://drive.google.com/, 2016.
[145] HP. HP Cloud Object Storage. https://www.hpcloud.com/products/
object-storage, 2016.
[146] Apple. iCloud. http://www.apple.com/icloud/, 2016.
[147] Microsoft. Microsoft OneDrive. http://windows.microsoft.com/en-us/
onedrive/skydrive-to-onedrive, 2016.
[148] Roy T. Fielding and Richard N. Taylor. Principled design of the modern Web architecture.
ACM Transactions on Internet Technology (TOIT), 2(2):115–150, 2002.
[149] Cesare Pautasso, Olaf Zimmermann, and Frank Leymann. Restful web services vs. “big”
web services: making the right architectural decision. In Proceedings of the International
Conference on World Wide Web (WWW), 2008.
[150] OpenStack. Swift - OpenStack. https://wiki.openstack.org/wiki/Swift,
2016.
[151] Forbes. iCloud Data Breach. http://www.forbes.com/sites/davelewis/
2014/09/02/icloud-data-breach-hacking-and-nude-celebrity
-photos/, 2014.
[152] Matt Blaze. A cryptographic file system for unix. In Proceedings of the ACM Conference
on Computer and Communications Security (CCS), pages 9–16, 1993.
[153] Charles P. Wright, Michael C. Martino, and Erez Zadok. Ncryptfs: A secure and
convenient cryptographic file system. In Proceedings of the Annual USENIX Technical
Conference, pages 197–210, 2003.
[154] Philip A. Bernstein. Getting consensus for data replication: Technical perspective.
Commun. ACM, 57(8):92–92, 2014.
[155] Robert H. Thomas. A majority consensus approach to concurrency control for multiple
copy databases. ACM Transactions on Database Systems (TODS), 4(2):180–209, 1979.
200

[156] GNU. The GNU C Library. http://www.gnu.org/software/libc/libc.
html, 2016.
[157] Homebank. HomeBank. http://homebank.free.fr, 2014.
[158] Scintilla. SciTE: a SCIntilla based Text Editor. http://scintilla.org/SciTE.
html, 2014.
[159] Adam J Aviv, Benjamin Sapp, Matt Blaze, and Jonathan M Smith. Practicality of
accelerometer side channels on smartphones. In Proceedings of the Annual Computer
Security Applications Conference (ACSAC), pages 41–50, 2012.
[160] Liang Cai and Hao Chen. Touchlogger: Inferring keystrokes on touch screen from
smartphone motion. In Proceedings of the USENIX conference on Hot Topics in Security,
2011.
[161] Liang Cai and Hao Chen. On the practicality of motion based keystroke inference attack.
In Proceedings of the International Conference on Trust and Trustworthy Computing,
pages 273–290, 2012.
[162] Emmanuel Owusu, Jun Han, Sauvik Das, Adrian Perrig, and Joy Zhang. Accessory:
password inference using accelerometers on smartphones. In Proceedings of the Workshop
on Mobile Computing Systems & Applications, 2012.
[163] Zhi Xu, Kun Bai, and Sencun Zhu. Taplogger: Inferring user inputs on smartphone
touchscreens using on-board motion sensors. In Proceedings of the ACM conference on
Security and Privacy in Wireless and Mobile Networks, pages 113–124, 2012.
[164] Maryam Mehrnezhad, Ehsan Toreini, Siamak F. Shahandashti, and Feng Hao.
Touchsignatures: Identification of user touch actions and PINs based on mobile sensor data
via javascript. Journal of Information Security and Applications, 26:23 – 38, 2016.
[165] Android. WebView on Android. https://developer.android.com/
reference/android/webkit/WebView.html, 2016.
[166] Apple. WebView on iOS. https://developer.apple.com/reference/
uikit/uiwebview, 2016.
[167] W3C. Same Origin Policy. https://www.w3.org/Security/wiki/Same_
Origin_Policy, 2016.
[168] Eric Y. Chen, Yutong Pei, Shuo Chen, Yuan Tian, Robert Kotcher, and Patrick Tague.
Oauth demystified for mobile application developers. In Proceedings of the ACM
Conference on Computer and Communications Security (CCS), 2014.
201

[169] Zhou Li, Kehuan Zhang, Yinglian Xie, Fang Yu, and XiaoFeng Wang. Knowing your
enemy: Understanding and detecting malicious web advertising. In Proceedings of the
ACM Conference on Computer and Communications Security (CCS), pages 674–686,
2012.
[170] Apostolis Zarras, Alexandros Kapravelos, Gianluca Stringhini, Thorsten Holz, Christopher
Kruegel, and Giovanni Vigna. The dark alleys of madison avenue: Understanding
malicious advertisements. In Proceedings of the Conference on Internet Measurement
Conference, pages 373–380, 2014.
[171] Hristo Bojinov, Yan Michalevsky, Gabi Nakibly, and Dan Boneh. Mobile device
identification via sensor fingerprinting. CoRR, abs/1408.1416, 2014.
[172] Anupam Das, Nikita Borisov, and Matthew Caesar. Tracking mobile web users through
motion sensors: Attacks and defenses. In Proceedings of the Annual Network and
Distributed System Security Symposium (NDSS), 2016.
[173] Emiliano Miluzzo, Alexander Varshavsky, Suhrid Balakrishnan, and Romit Roy
Choudhury. Tapprints: your finger taps have fingerprints. In Proceedings of the
International conference on Mobile systems, applications, and services, pages 323–336,
2012.
[174] W3C. DeviceOrientation Event Specification: 4.4 devicemotion Event. https://www.
w3.org/TR/orientation-event/, 2016.
[175] W3C. Document Object Model (DOM). http://www.w3.org/DOM/, 2016.
[176] Xiangyu Liu, Zhe Zhou, Wenrui Diao, Zhou Li, and Kehuan Zhang. When good becomes
evil: Keystroke inference with smartwatch. In Proceedings of the ACM Conference on
Computer and Communications Security (CCS), pages 1273–1285, 2015.
[177] Chen Wang, Xiaonan Guo, Yan Wang, Yingying Chen, and Bo Liu. Friend or foe?: Your
wearable devices reveal your personal pin. In Proceedings of the ACM on Asia Conference
on Computer and Communications Security (AsiaCCS), pages 189–200, 2016.
[178] Sophocles J Orfanidis. Introduction to signal processing. Prentice-Hall, Inc., 1995.
[179] Steven W Smith. The scientist and engineer’s guide to digital signal processing. 1997.
[180] Machine Learning Group at the University of Waikato. Weka 3: Data Mining Software in
Java. http://www.cs.waikato.ac.nz/ml/weka/, 2016.
[181] John Platt. Sequential minimal optimization: A fast algorithm for training support vector
machines. Technical report, 1998.
202

[182] R Project. The R Project for Statistical Computing. https://www.r-project.org,
2016.
[183] Xingquan Zhu. Knowledge Discovery and Data Mining: Challenges and Realities:
Challenges and Realities. Igi Global, 2007.
[184] Chuan Yue. Sensor-based mobile web fingerprinting and cross-site input inference attacks.
In Proceedings of the IEEE Workshop on Mobile Security Technologies (MoST), 2016.
[185] PhishTank. PhishTank. http://www.phishtank.com/, 2016.
[186] Symantec. Symantec Internet Security Threat Report. http://www.symantec.com/
security_response/publications/threatreport.jsp, 2015.
[187] Julie S. Downs, Mandy B. Holbrook, and Lorrie Faith Cranor. Decision strategies and
susceptibility to phishing. In Proceedings of the Symposium on Usable Privacy and
Security (SOUPS), pages 79–90, 2006.
[188] Markus Jakobsson and Jacob Ratkiewicz. Designing Ethical Phishing Experiments: A
Study of (ROT13) rOnl Query Features. In Proceedings of the International Conference on
World Wide Web (WWW), 2006.
[189] Colin Whittaker, Brian Ryner, and Marria Nazif. Large-scale automatic classification of
phishing pages. In Proceedings of the Annual Network & Distributed System Security
Symposium (NDSS), 2010.
[190] Devdatta Akhawe and Adrienne Porter Felt. Alice in warningland: A large-scale field
study of browser security warning effectiveness. In Proceedings of the USENIX Security
Symposium, pages 257–272, 2013.
[191] Jason Hong. The state of phishing attacks. Communications of the ACM, 55(1):74–81,
2012.
[192] Collin Jackson, Daniel R Simon, Desney S Tan, and Adam Barth. An evaluation of
extended validation and picture-in-picture phishing attacks. In Financial Cryptography
and Data Security, volume 4886, pages 281–293. 2007.
[193] Steve Sheng, Mandy Holbrook, Ponnurangam Kumaraguru, Lorrie Faith Cranor, and Julie
Downs. Who falls for phish?: A demographic analysis of phishing susceptibility and
effectiveness of interventions. In Proceedings of the SIGCHI Conference on Human
Factors in Computing Systems (CHI), 2010.
203

[194] Marco Cova, Christopher Kruegel, and Giovanni Vigna. There is no free phish: An
analysis of “free” and live phishing kits. In Proceedings of the USENIX Workshop on
Offensive Technologies (WOOT), 2008.
[195] Serge Egelman, Lorrie Faith Cranor, and Jason Hong. You’ve been warned: An empirical
study of the effectiveness of web browser phishing warnings. In Proceedings of the
SIGCHI conference on Human Factors in Computing Systems (CHI), pages 1065–1074,
2008.
[196] Tom N. Jagatic, Nathaniel A. Johnson, Markus Jakobsson, and Filippo Menczer. Social
phishing. Communications of the ACM, 50(10):94–100, 2007.
[197] Stuart E. Schechter, Rachna Dhamija, Andy Ozment, and Ian Fischer. The emperor’s new
security indicators: An evaluation of website authentication and the effect of role playing
on usability studies. In Proceedings of the IEEE Symposium on Security and Privacy,
pages 51–65, 2007.
[198] Rachna Dhamija and J.D.Tygar. The battle against phishing: Dynamic security skins. In
Proceedings of the Symposium on Usable Privacy and Security (SOUPS), pages 77–88,
2005.
[199] Sujata Garera, Niels Provos, Monica Chew, and Aviel D. Rubin. A framework for
detection and measurement of phishing attacks. In Proceedings of the ACM Workshop on
Recurring Malcode, pages 1–8, 2007.
[200] Lin Shung Huang, Alex Rice, Erling Ellingsen, and Collin Jackson. Analyzing forged ssl
certificates in the wild. In Proceedings of the IEEE Symposium on Security and Privacy,
pages 83–97, 2014.
[201] OAuth. OAuth 2.0. http://oauth.net/about/, 2016.
[202] OpenID. What is OpenID? http://openid.net/get-an-openid/what-is
-openid, 2016.
[203] Apache. Apache External Filters. http://httpd.apache.org/docs/2.2/mod/
mod_ext_filter.html, 2016.
[204] D. Kevin McGrath and Minaxi Gupta. Behind phishing: An examination of phisher modi
operandi. In Proceedings of the Usenix Workshop on Large-Scale Exploits and Emergent
Threats (LEET), 2008.
[205] R. Zhao, S. John, S. Karas, C. Bussell, J. Roberts, D. Six, B. Gavett, and C. Yue. The
highly insidious extreme phishing attacks. In 2016 25th International Conference on
Computer Communication and Networks (ICCCN), pages 1–10, 2016.
204

[206] Chuan Yue and Haining Wang. Bogusbiter: A transparent protection against phishing
attacks. ACM Transactions on Internet Technology (TOIT), 10(2):6, 2010.
[207] Christian Ludl, Sean Mcallister, Engin Kirda, and Christopher Kruegel. On the
effectiveness of techniques to detect phishing sites. In Proceedings of the International
Conference on Detection of Intrusions and Malware, and Vulnerability Assessment
(DIMVA), pages 20–39, 2007.
[208] Steve Sheng, Brad Wardman, Gary Warner, Lorrie Cranor, Jason Hong, and Chengshan
Zhang. An empirical analysis of phishing blacklists. In Proceedings of the Conference on
Email and Anti-Spam (CEAS), 2009.
[209] Guang Xiang, Jason Hong, Carolyn P. Rose, and Lorrie Cranor. Cantina+: A feature-rich
machine learning framework for detecting phishing web sites. ACM Transactions on
Information and System Security (TISSEC), 14(2):21:1–21:28, 2011.
[210] Guang Xiang, Bryan A Pendleton, Jason Hong, and Carolyn P Rose. A hierarchical
adaptive probabilistic approach for zero hour phish detection. In Proceedings of the
European Symposium on Research in Computer Security (ESORICS), pages 268–285.
2010.
[211] Justin Ma, Lawrence K. Saul, Stefan Savage, and Geoffrey M. Voelker. Beyond blacklists:
Learning to detect malicious web sites from suspicious urls. In Proceedings of the ACM
SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD),
pages 1245–1254, 2009.
[212] Ying Pan and Xuhua Ding. Anomaly based web phishing page detection. In Proceedings
of the Annual Computer Security Applications Conference (ACSAC), pages 381–392, 2006.
[213] Neil Chou, Robert Ledesma, Yuka Teraguchi, and John C. Mitchell. Client-side defense
against web-based identity theft. In Proceedings of the Annual Network & Distributed
System Security Symposium (NDSS), 2004.
[214] Eric Medvet, Engin Kirda, and Christopher Kruegel. Visual-similarity-based phishing
detection. In Proceedings of the International Conference on Security and Privacy in
Communication Netowrks (SecureComm), pages 22:1–22:6, 2008.
[215] Blake Ross, Collin Jackson, Nick Miyake, Dan Boneh, and John C. Mitchell. Stronger
password authentication using browser extensions. In Proceedings of the USENIX Security
Symposium, 2005.
205

APPENDIX A - KEYBOARDS
(a) Letter keyboard layout
(b) Digit keyboard layout
Figure A.1 Google Keyboard layouts
206
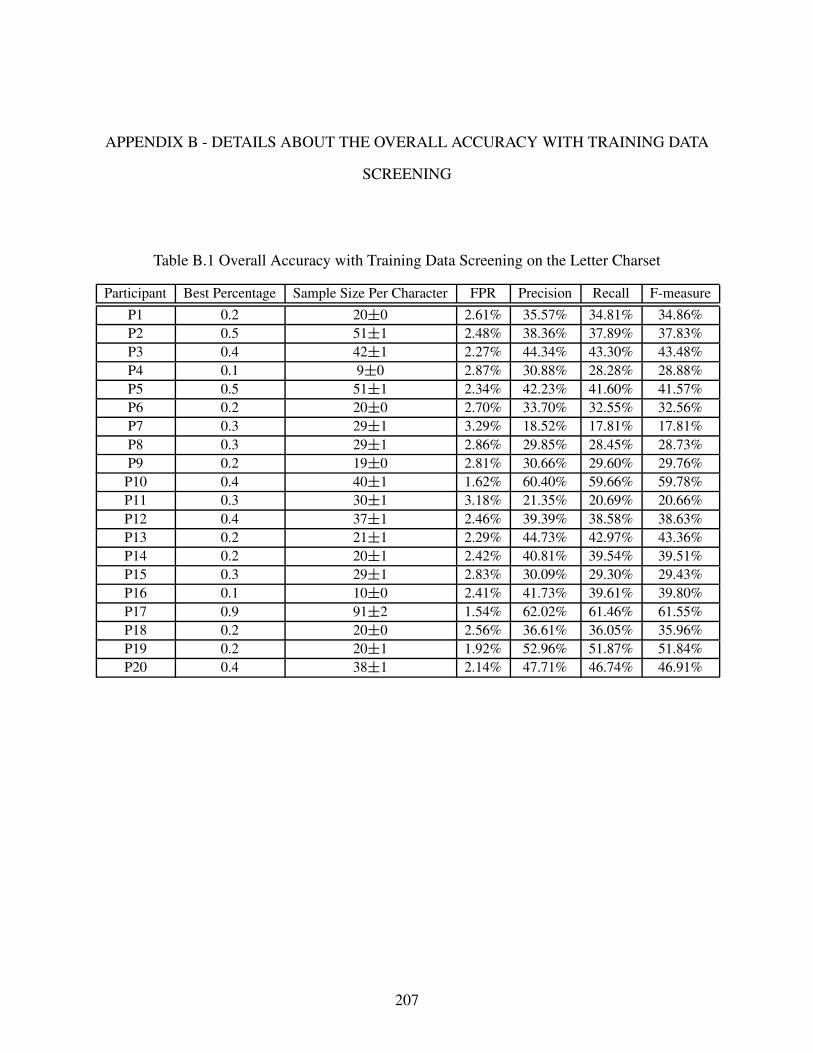
APPENDIX B - DETAILS ABOUT THE OVERALL ACCURACY WITH TRAINING DATA
SCREENING
Table B.1 Overall Accuracy with Training Data Screening on the Letter Charset
Participant Best Percentage Sample Size Per Character FPR Precision Recall F-measure
P1 0.2 20±0 2.61% 35.57% 34.81% 34.86%
P2 0.5 51±1 2.48% 38.36% 37.89% 37.83%
P3 0.4 42±1 2.27% 44.34% 43.30% 43.48%
P4 0.1 9±0 2.87% 30.88% 28.28% 28.88%
P5 0.5 51±1 2.34% 42.23% 41.60% 41.57%
P6 0.2 20±0 2.70% 33.70% 32.55% 32.56%
P7 0.3 29±1 3.29% 18.52% 17.81% 17.81%
P8 0.3 29±1 2.86% 29.85% 28.45% 28.73%
P9 0.2 19±0 2.81% 30.66% 29.60% 29.76%
P10 0.4 40±1 1.62% 60.40% 59.66% 59.78%
P11 0.3 30±1 3.18% 21.35% 20.69% 20.66%
P12 0.4 37±1 2.46% 39.39% 38.58% 38.63%
P13 0.2 21±1 2.29% 44.73% 42.97% 43.36%
P14 0.2 20±1 2.42% 40.81% 39.54% 39.51%
P15 0.3 29±1 2.83% 30.09% 29.30% 29.43%
P16 0.1 10±0 2.41% 41.73% 39.61% 39.80%
P17 0.9 91±2 1.54% 62.02% 61.46% 61.55%
P18 0.2 20±0 2.56% 36.61% 36.05% 35.96%
P19 0.2 20±1 1.92% 52.96% 51.87% 51.84%
P20 0.4 38±1 2.14% 47.71% 46.74% 46.91%
207
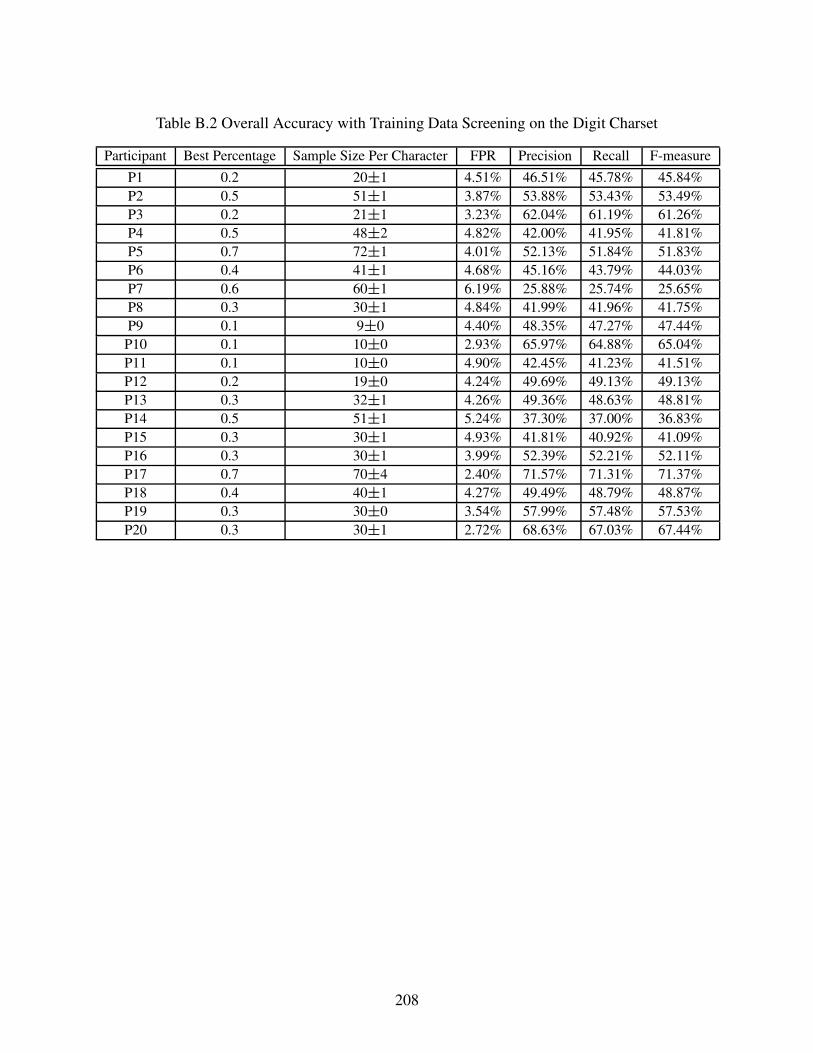
Table B.2 Overall Accuracy with Training Data Screening on the Digit Charset
Participant Best Percentage Sample Size Per Character FPR Precision Recall F-measure
P1 0.2 20±1 4.51% 46.51% 45.78% 45.84%
P2 0.5 51±1 3.87% 53.88% 53.43% 53.49%
P3 0.2 21±1 3.23% 62.04% 61.19% 61.26%
P4 0.5 48±2 4.82% 42.00% 41.95% 41.81%
P5 0.7 72±1 4.01% 52.13% 51.84% 51.83%
P6 0.4 41±1 4.68% 45.16% 43.79% 44.03%
P7 0.6 60±1 6.19% 25.88% 25.74% 25.65%
P8 0.3 30±1 4.84% 41.99% 41.96% 41.75%
P9 0.1 9±0 4.40% 48.35% 47.27% 47.44%
P10 0.1 10±0 2.93% 65.97% 64.88% 65.04%
P11 0.1 10±0 4.90% 42.45% 41.23% 41.51%
P12 0.2 19±0 4.24% 49.69% 49.13% 49.13%
P13 0.3 32±1 4.26% 49.36% 48.63% 48.81%
P14 0.5 51±1 5.24% 37.30% 37.00% 36.83%
P15 0.3 30±1 4.93% 41.81% 40.92% 41.09%
P16 0.3 30±1 3.99% 52.39% 52.21% 52.11%
P17 0.7 70±4 2.40% 71.57% 71.31% 71.37%
P18 0.4 40±1 4.27% 49.49% 48.79% 48.87%
P19 0.3 30±0 3.54% 57.99% 57.48% 57.53%
P20 0.3 30±1 2.72% 68.63% 67.03% 67.44%
208
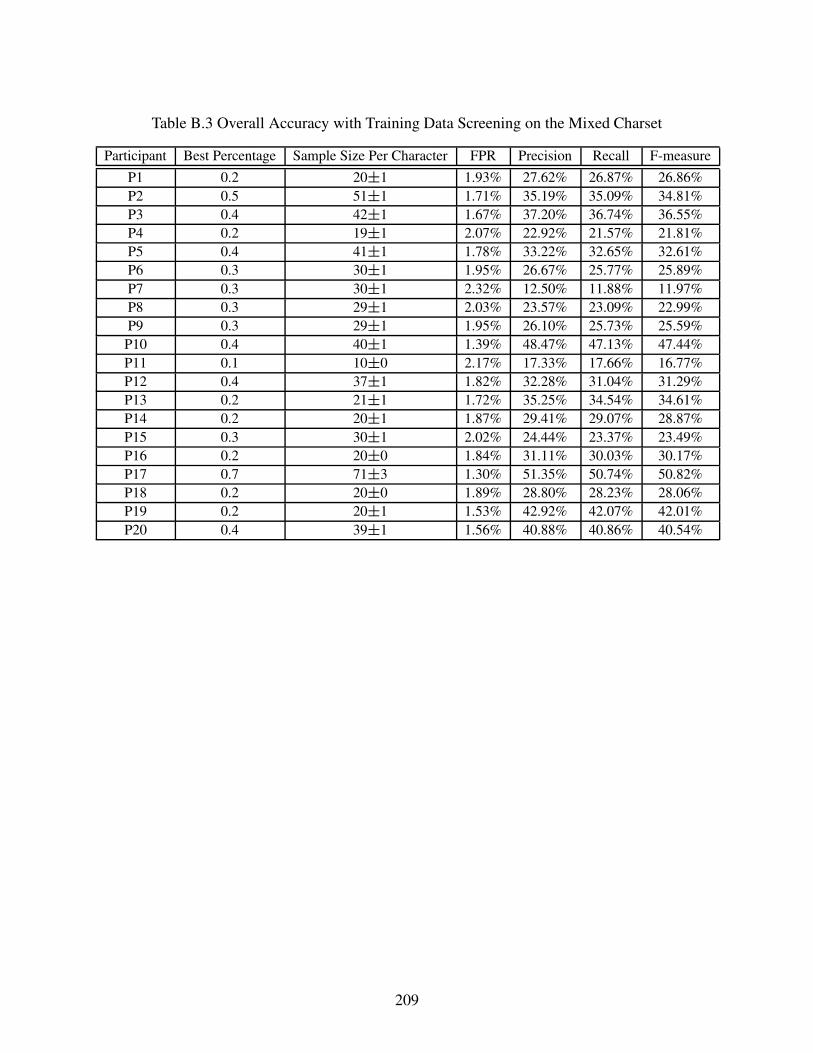
Table B.3 Overall Accuracy with Training Data Screening on the Mixed Charset
Participant Best Percentage Sample Size Per Character FPR Precision Recall F-measure
P1 0.2 20±1 1.93% 27.62% 26.87% 26.86%
P2 0.5 51±1 1.71% 35.19% 35.09% 34.81%
P3 0.4 42±1 1.67% 37.20% 36.74% 36.55%
P4 0.2 19±1 2.07% 22.92% 21.57% 21.81%
P5 0.4 41±1 1.78% 33.22% 32.65% 32.61%
P6 0.3 30±1 1.95% 26.67% 25.77% 25.89%
P7 0.3 30±1 2.32% 12.50% 11.88% 11.97%
P8 0.3 29±1 2.03% 23.57% 23.09% 22.99%
P9 0.3 29±1 1.95% 26.10% 25.73% 25.59%
P10 0.4 40±1 1.39% 48.47% 47.13% 47.44%
P11 0.1 10±0 2.17% 17.33% 17.66% 16.77%
P12 0.4 37±1 1.82% 32.28% 31.04% 31.29%
P13 0.2 21±1 1.72% 35.25% 34.54% 34.61%
P14 0.2 20±1 1.87% 29.41% 29.07% 28.87%
P15 0.3 30±1 2.02% 24.44% 23.37% 23.49%
P16 0.2 20±0 1.84% 31.11% 30.03% 30.17%
P17 0.7 71±3 1.30% 51.35% 50.74% 50.82%
P18 0.2 20±0 1.89% 28.80% 28.23% 28.06%
P19 0.2 20±1 1.53% 42.92% 42.07% 42.01%
P20 0.4 39±1 1.56% 40.88% 40.86% 40.54%
209
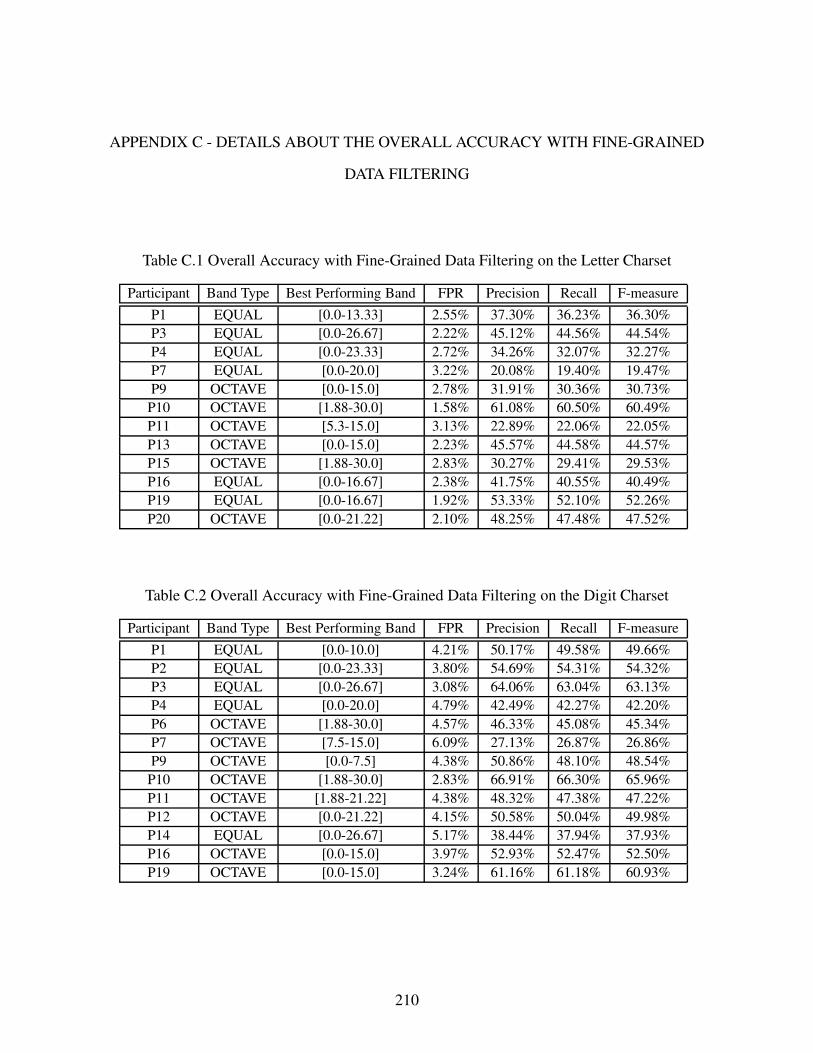
APPENDIX C - DETAILS ABOUT THE OVERALL ACCURACY WITH FINE-GRAINED
DATA FILTERING
Table C.1 Overall Accuracy with Fine-Grained Data Filtering on the Letter Charset
Participant Band Type Best Performing Band FPR Precision Recall F-measure
P1 EQUAL [0.0-13.33] 2.55% 37.30% 36.23% 36.30%
P3 EQUAL [0.0-26.67] 2.22% 45.12% 44.56% 44.54%
P4 EQUAL [0.0-23.33] 2.72% 34.26% 32.07% 32.27%
P7 EQUAL [0.0-20.0] 3.22% 20.08% 19.40% 19.47%
P9 OCTAVE [0.0-15.0] 2.78% 31.91% 30.36% 30.73%
P10 OCTAVE [1.88-30.0] 1.58% 61.08% 60.50% 60.49%
P11 OCTAVE [5.3-15.0] 3.13% 22.89% 22.06% 22.05%
P13 OCTAVE [0.0-15.0] 2.23% 45.57% 44.58% 44.57%
P15 OCTAVE [1.88-30.0] 2.83% 30.27% 29.41% 29.53%
P16 EQUAL [0.0-16.67] 2.38% 41.75% 40.55% 40.49%
P19 EQUAL [0.0-16.67] 1.92% 53.33% 52.10% 52.26%
P20 OCTAVE [0.0-21.22] 2.10% 48.25% 47.48% 47.52%
Table C.2 Overall Accuracy with Fine-Grained Data Filtering on the Digit Charset
Participant Band Type Best Performing Band FPR Precision Recall F-measure
P1 EQUAL [0.0-10.0] 4.21% 50.17% 49.58% 49.66%
P2 EQUAL [0.0-23.33] 3.80% 54.69% 54.31% 54.32%
P3 EQUAL [0.0-26.67] 3.08% 64.06% 63.04% 63.13%
P4 EQUAL [0.0-20.0] 4.79% 42.49% 42.27% 42.20%
P6 OCTAVE [1.88-30.0] 4.57% 46.33% 45.08% 45.34%
P7 OCTAVE [7.5-15.0] 6.09% 27.13% 26.87% 26.86%
P9 OCTAVE [0.0-7.5] 4.38% 50.86% 48.10% 48.54%
P10 OCTAVE [1.88-30.0] 2.83% 66.91% 66.30% 65.96%
P11 OCTAVE [1.88-21.22] 4.38% 48.32% 47.38% 47.22%
P12 OCTAVE [0.0-21.22] 4.15% 50.58% 50.04% 49.98%
P14 EQUAL [0.0-26.67] 5.17% 38.44% 37.94% 37.93%
P16 OCTAVE [0.0-15.0] 3.97% 52.93% 52.47% 52.50%
P19 OCTAVE [0.0-15.0] 3.24% 61.16% 61.18% 60.93%
210
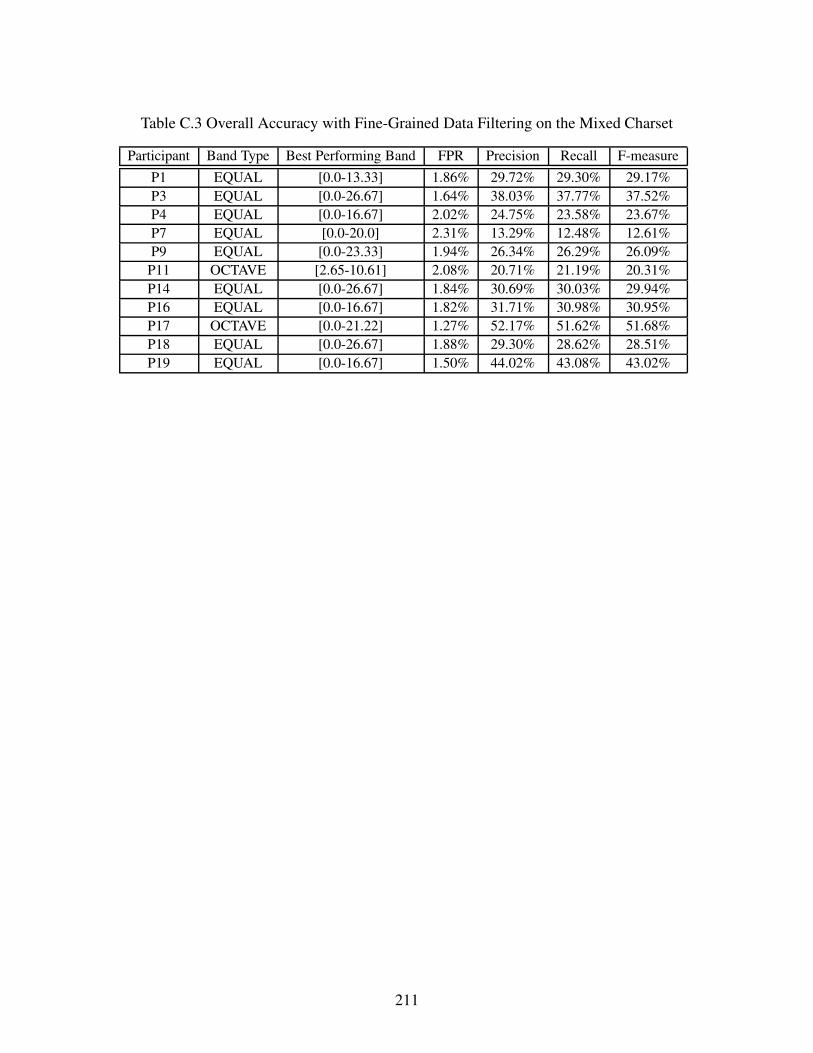
Table C.3 Overall Accuracy with Fine-Grained Data Filtering on the Mixed Charset
Participant Band Type Best Performing Band FPR Precision Recall F-measure
P1 EQUAL [0.0-13.33] 1.86% 29.72% 29.30% 29.17%
P3 EQUAL [0.0-26.67] 1.64% 38.03% 37.77% 37.52%
P4 EQUAL [0.0-16.67] 2.02% 24.75% 23.58% 23.67%
P7 EQUAL [0.0-20.0] 2.31% 13.29% 12.48% 12.61%
P9 EQUAL [0.0-23.33] 1.94% 26.34% 26.29% 26.09%
P11 OCTAVE [2.65-10.61] 2.08% 20.71% 21.19% 20.31%
P14 EQUAL [0.0-26.67] 1.84% 30.69% 30.03% 29.94%
P16 EQUAL [0.0-16.67] 1.82% 31.71% 30.98% 30.95%
P17 OCTAVE [0.0-21.22] 1.27% 52.17% 51.62% 51.68%
P18 EQUAL [0.0-26.67] 1.88% 29.30% 28.62% 28.51%
P19 EQUAL [0.0-16.67] 1.50% 44.02% 43.08% 43.02%
211
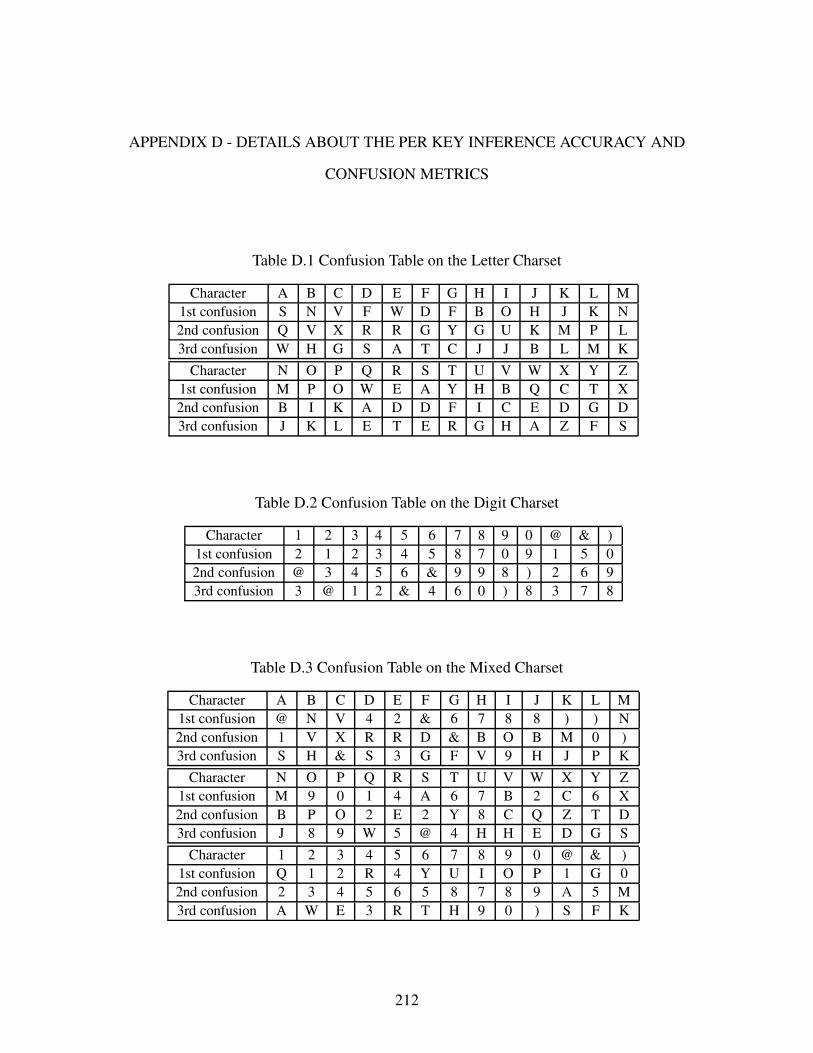
APPENDIX D - DETAILS ABOUT THE PER KEY INFERENCE ACCURACY AND
CONFUSION METRICS
Table D.1 Confusion Table on the Letter Charset
Character A B C D E F G H I J K L M
1st confusion S N V F W D F B O H J K N
2nd confusion Q V X R R G Y G U K M P L
3rd confusion W H G S A T C J J B L M K
Character N O P Q R S T U V W X Y Z
1st confusion M P O W E A Y H B Q C T X
2nd confusion B I K A D D F I C E D G D
3rd confusion J K L E T E R G H A Z F S
Table D.2 Confusion Table on the Digit Charset
Character 1 2 3 4 5 6 7 8 9 0 @ & )
1st confusion 2 1 2 3 4 5 8 7 0 9 1 5 0
2nd confusion @ 3 4 5 6 & 9 9 8 ) 2 6 9
3rd confusion 3 @ 1 2 & 4 6 0 ) 8 3 7 8
Table D.3 Confusion Table on the Mixed Charset
Character A B C D E F G H I J K L M
1st confusion @ N V 4 2 & 6 7 8 8 ) ) N
2nd confusion 1 V X R R D & B O B M 0 )
3rd confusion S H & S 3 G F V 9 H J P K
Character N O P Q R S T U V W X Y Z
1st confusion M 9 0 1 4 A 6 7 B 2 C 6 X
2nd confusion B P O 2 E 2 Y 8 C Q Z T D
3rd confusion J 8 9 W 5 @ 4 H H E D G S
Character 1 2 3 4 5 6 7 8 9 0 @ & )
1st confusion Q 1 2 R 4 Y U I O P 1 G 0
2nd confusion 2 3 4 5 6 5 8 7 8 9 A 5 M
3rd confusion A W E 3 R T H 9 0 ) S F K
212
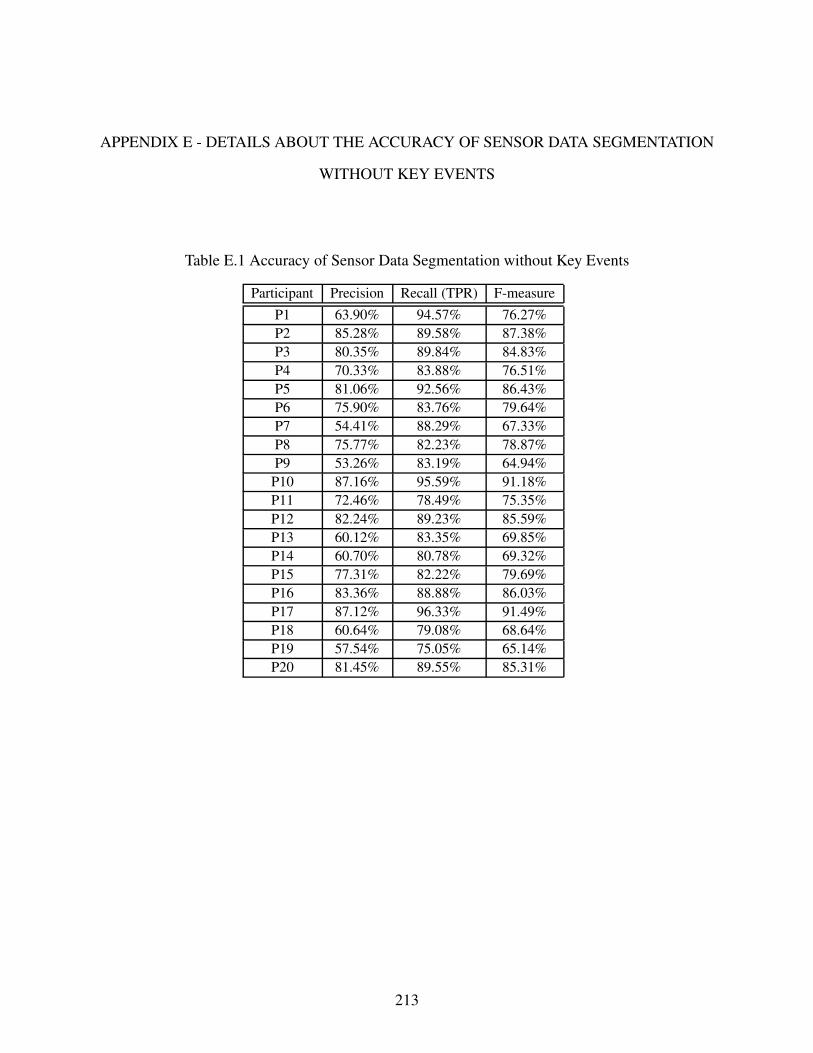
APPENDIX E - DETAILS ABOUT THE ACCURACY OF SENSOR DATA SEGMENTATION
WITHOUT KEY EVENTS
Table E.1 Accuracy of Sensor Data Segmentation without Key Events
Participant Precision Recall (TPR) F-measure
P1 63.90% 94.57% 76.27%
P2 85.28% 89.58% 87.38%
P3 80.35% 89.84% 84.83%
P4 70.33% 83.88% 76.51%
P5 81.06% 92.56% 86.43%
P6 75.90% 83.76% 79.64%
P7 54.41% 88.29% 67.33%
P8 75.77% 82.23% 78.87%
P9 53.26% 83.19% 64.94%
P10 87.16% 95.59% 91.18%
P11 72.46% 78.49% 75.35%
P12 82.24% 89.23% 85.59%
P13 60.12% 83.35% 69.85%
P14 60.70% 80.78% 69.32%
P15 77.31% 82.22% 79.69%
P16 83.36% 88.88% 86.03%
P17 87.12% 96.33% 91.49%
P18 60.64% 79.08% 68.64%
P19 57.54% 75.05% 65.14%
P20 81.45% 89.55% 85.31%
213




















