
URD I The age of the table
33
Universal Relational Dimensional URD Universal Relational Dimensional I The age of the table Abstract Tables, hierarchies and lists dominates the way we organise data. In the field of computing, tables are the gold standard. These categories can be seen as more than data structures : They form the superstructure of our thoughts, the footprint of understanding. This viewpoint warrants a detailed study. Why do we use the table so much, and why is our understanding of these categories so limited? This paper presents how Category Theory can provide insights into the data structures we use to reason about our world, and draws limits to which categories are useful and why most are not.This new perspective means we are moving into the domain of semantics, logic, linguistics as well as database theory. Description Logic is a field of research concerned with creating predictive systems and Artificial Intelligence. The data structures and facilities for the expression of meaning are the building blocks DL. This paper discusses how reducing the expressiveness of a system changes how the system manifests under higher complexity, and present an alternate way of modelling the relationships than what is common in description logics. Audience : The audience for this paper is anyone interested in semantics, knowledge representation, artificial intelligence and expert systems. It will also be useful as an introduction to the overarching logic of the URD paradigm. If you are experienced in the fields of Category Theory and Description Logic, your feedback and suggestions for improvement is particularly useful.
-
Upload
independent -
Category
Documents
-
view
4 -
download
0
Transcript of URD I The age of the table

Universal Relational Dimensional
URD Universal Relational Dimensional
I
The age of the table
Abstract
Tables, hierarchies and lists dominates the way we organise data. In the field of computing, tables are the gold standard. These categories can be seen as more than data structures : They form the superstructure of our thoughts, the footprint of understanding. This viewpoint warrants a detailed study. Why do we use the table so much, and why is our understanding of these categories so limited?
This paper presents how Category Theory can provide insights into the data structures we use to reason about our world, and draws limits to which categories are useful and why most are not.This new perspective means we are moving into the domain of semantics, logic, linguistics as well as database theory. Description Logic is a field of research concerned with creating predictive systems and Artificial Intelligence. The data structures and facilities for the expression of meaning are the building blocks DL. This paper discusses how reducing the expressiveness of a system changes how the system manifests under higher complexity, and present an alternate way of modelling the relationships than what is common in description logics.
Audience : The audience for this paper is anyone interested in semantics, knowledge representation, artificial intelligence and expert systems. It will also be useful as an introduction to the overarching logic of the URD paradigm.
If you are experienced in the fields of Category Theory and Description Logic, your feedback and suggestions for improvement is particularly useful.

Universal Relational Dimensional
About The URD Stack
This paper is part of the URD stack, a series of documents exploring, at different levels of abstraction, the URD table-free database paradigm.Category theory provide a framework for studying the URD principles for database design.
The rest of the URD stack describe the following
URD I – The age of the table
URD II – A truly relational data model
URD III – Concept formation and AI
URD IV - A technical implementation
URD V – Performance enhancing techniques

Universal Relational Dimensional
Table of contentsChapter 1 – The age of the table...........................................................................................................4
The Grid...........................................................................................................................................4The universal language.................................................................................................................... 5
Chapter 2 : Categories.......................................................................................................................... 7The Category Perspective................................................................................................................ 7The Monoid......................................................................................................................................8Morphisms....................................................................................................................................... 8Ordered List..................................................................................................................................... 9Loop................................................................................................................................................. 9The Table....................................................................................................................................... 10The Cube and hypercube............................................................................................................... 11The Hierarchy................................................................................................................................ 11
Chapter 4 : Subsumption.................................................................................................................... 12Fundamental Categories................................................................................................................ 13The Path sequence......................................................................................................................... 14The Ladder sequence..................................................................................................................... 14The Hierarchy................................................................................................................................ 15
Chapter 5 - The fundamental relation.................................................................................................17Rejecting the key value dichotomy................................................................................................17Role fillers......................................................................................................................................17Rejecting IS-A and IS-PART......................................................................................................... 18The singular / plural equivalence...................................................................................................19
Chapter 6 – The Ortho functor........................................................................................................... 20Unbalanced Hierarchies ...............................................................................................................23What is the Ortho Functor exactly?............................................................................................... 25
Chapter 8 - The Universal Categories................................................................................................ 27Collapsing loops............................................................................................................................ 27Explaining the Metacategory......................................................................................................... 29List On List – The Table Category.................................................................................................29List on Hierarchy - The Dimension Category...............................................................................29Hierarchy on Hierarchy – The Pivot table category...................................................................... 30Completing the Metacategory........................................................................................................31
Chapter 7 – Other systems of reasoning ............................................................................................32URD as a Description Logic..................................................................................................... 32
Chapter 8 – End notes.........................................................................................................................33Is this a real problem?....................................................................................................................33Conclusion..................................................................................................................................... 33

Universal Relational Dimensional
Chapter 1 – The age of the table
A table, a chair, a bowl of fruit and a violin; what else does a man need to be happy?- Albert Einstein
When the history of the last part of the 20th century will be written, it may be called the computer age, or the age of data. But it might as well be called the age of the table. Throughout the known universe, all of the compiled human knowledge is stored in, exactly, tables. The table is so commonplace, so integral to the way we think about data, that few pause to consider a startling fact. The table itself, like our language, is an acquired category for understanding.It is no longer just a way for handling data, it has become the prototype of data.
Of all the database theory I have studies, I found one thing stand out. It is overly technical, and rarely address the human side of the equation : Our reliance on data structures for our reasoning. Human reasoning is integral to all computing, because the purpose of data management is ultimately informed desicion-making. The ability to make decisions on data is dependent on understanding what the data means. Effectively creating this understanding is the primary goal of any information system. The quality of an information system is its ability to align with the datastructures in your brain. The reality is that many business users are not using all the tools at their disposal. They have become overly reliant on one specific tool, Microsoft Excel, and it´s only data-structure, the table. A similar case can be made for all relational databases. Meanwhile, we are experiencing a techical revolution. In Memory computing is fundamentally a rejection of the table as the fundamental data structure for storing data. But this is only half the battle. The other part is rejecting the table as a feature of data itself, and begin looking at tables as communication tool, a means of spatially representing relations. The table is just a salient way of representing data for human consumption. It has nothing to do with data itself.
The GridOrganising data in a grid is an ubiquitous method for assigning relatedness and saving space. A grid is so common in use, that few realize it is actually a compression algorithm, using the geometric features of the grid structure to assign meaning to cell contents according to rules. The underlying logic is quite profound : Consider an Excel spreadsheet, with a list of people and their respective phone numbers.
Name Phone
John 6584 354 564
Anne 3544 345 645
Foo 3544 450 453
The first row is different from the remaining four as it contains the word "Name" and "Phone". We immediately understand how the other words and numbers are associated with each other. But this is actually an extraordinary advanced piece of cognition! John, Anne and Foo are all Names, simply

Universal Relational Dimensional
because they are stored in the same column as Name. The same goes for the numbers in the next column. We also know what number belongs to what Name. By the same two dimensional geometrical rules, we see that the names and the numbers correspond by row. Even if the name Foo is not a common name, its appearance in the same column as John and Anne makes us, at least in this particular context, treat "Foo" as a name. The grid structure, shown on a flat surface, is an integral part of the symbols used to convey this meaning.
Storing data this way is not the only way. In fact, for the computer has some serious disadvantages. Relationships can also be mapped by logical links inside the computer memory, instead of being physically close on the disk. However, the benefits of a fixed, spreadsheet style matrix has long outweighed the costs. Above all, it´s is the immediate understanding of the table that is so attractive. The table rests on the spatial faculty of our reasoning, more specifically, the ability to position sequences of something at 90 degrees angles to each other.
The table almost always acts as an intermediary when data and relations are presented for human consumption. In part because the table excel at this task. But also in part, because others structures are rarely used and poorly understood, so that the table prevails every time, even when it´s a poor choice. Becoming aware of the tables grip on your conceptualisation of data is the first major hurdle in rewiring your brain and escaping the influence of the grid.
The universal languageThe URD project relies on a technical architecture able to hold data. You ran read about in the remaining papers in the URD Stack. But that has no purpose without representation of the same for human consumption. This is another way of saying that the data must be «making sense». The vast majority of data is lexical, stored as sentences of words and numbers with some relation between them. Increasingly, data is stored in digital files, databases, spreadsheets and so on. These information systems assign metadata, or data about data. When the data volumes increase exponentially, the metadata is rapidly becoming more important than the data itself, because the actual data is too complex and come in too great amounts. The metadata, the structure of data, is what we have left when the data itself becomes intractable.
Human understanding revolves around words and sentences. Essentially, this «making sense» of data make it hard to avoid the connection to linguistics and semantic theories. After all, these are fields studying precisely how information, or meaning, can be transferred between humans through the use of symbols.
Experiments have shown that all languages have something in common. There is a template for language learning, that is invoked by our brains and allows us to acquire language as we grow.
Ronald Langacker, one of the most influential scholars in the field of linguistics spent most of his career developing a radically new system for semantic analysis called Cognitive Grammar. From this book Concept, Image and Symbol i quote :
What occupies the lowest level in conceptual hierarchies? I am neutral as to the possible existence of innately specified conceptual primitives. It is however necessary to posit a number of "basic domains", i.e. cognitively irreducible representational spaces or fields of conceptual potential. Among these basic domains are the experience of time and our capacity for dealing with two- and three-dimensional spatial configurations. [LANG]
The table itself is exactly this. What helps us to associate and understand the table is our «basic domain» of space. The table is the prototype of two dimensional space, where the capacities of the grid itself is used to assign meaning and relations to words, or concepts. In fact, the grid simply cannot exist independently of space, because a grid is two dimensional, and dimensionality, wether it is 2 or 3 or more dimensions, is space.

Universal Relational Dimensional
Tables are so widespread in everything from shopping lists to telephone catalogs, that the table as a symbol of data relatedness, and the table as a practical means of data storage, have been completely intertwined. To convey meaning effectively, tables are the gold standard and should not be abandoned. However, this cannot be a valid argument for storing the data this way, but merely an argument for presenting it this way. The relations themselves could exist without a two dimensional structure to hold them.
According to this view, the table is nothing more than a way of effectively mapping relationships in a visually pleasing manner. Understanding how the table as category of understanding affect or reasoning about facts and relatedness, is of great importance and has not been studied nearly enough.
Seeing the table merely as a presentation tool does not do justice to its usefulness. A more compelling argument is that the table is useful because it is predictable. As shown, everything is related to exactly two distinct identities, the rowID and the column header. There is exactly two relationships for each cell, one to the row, one to the column. This gives tables an arity of 2. A purpose of this paper is to show that all data structures, called categories, with an Arity of two are uniquely useful in structuring data. The table is merely one of them. Before we go so far, an introduction to Category Theory will be useful.

Universal Relational Dimensional
Chapter 2 : Categories
That whose existence is necessary must necessarily be one essence.– Avicenna
The Category PerspectiveCategory Theory was developed in the 1940 to address some shortcoming on the Zermelo Fraenkel Axiomatic Set theory, which is still the de facto building block of all mathematics. ZFC suffer from some problematic paradoxes, the most important being Russels Paradox, but on the whole, ZF is to a practical degree free from inconsistencies and have been used to prove a great number of theorems. So much in fact, that all mathematics as we know it rests on, and have their proofs and theorems formulated in Axiomatic Set Theory.
ZF Axiomatic Set theory deals largely with the structure of sets, and what these sets really are. Category theory on the other hand, are more concerned with the relations between objects, than with the objects themselves. Objects have relationships to other objects, and the category itself is defined not by the objects that partake in the category, but the relationships between the objects. In fact, the only concern for Category Theory is that the objects exist, otherwise they cannot have relations to other objects.
Category theory rapidly becomes a highly abstract and difficult subject. I do pretened to understand the intricacies of Category. What I do know is that the fundaments of Category theory can be understood by anyone, because of it´s unique simplicity. The elegance of the paradigm become clearer when we learn what the definition of an existing object is. An object exist in Category Theory, if it has the identity relationship, which is a relationships to itself. Existence is self reference.
Much like human existence is meaningless without a relationship to ourself, and to other humans, we must always remember that Category theory is not about objects at all, but only about relationships and their configurations relative to each other.
How this relates to information management will become clear by the end of this paper. For the time being, Category Theory provides a framework for defining basic structures, categories, and helps us reason about them. The only requirement is that each of the objects implicated in the category, has one identity relationship to itself.

Universal Relational Dimensional
The Monoid
The simplest category is the Monoid, identified by one object only, identified by its identity relationship, the relationship to itself.
One could say that the object has identity, or exists, because it relates to itself, because it is itself.
Showing the identity arrow for all objects may clutter up the graphs, so the identity relationship is usually implied, and omitted.
MorphismsAnother important thing to note is that the relationships, called morphisms, between the objects are directed, that is, they have direction from one object to another. An simple example is the Pinch category, directed inwards towards the centre. (You can see the direction of the morphism by the arrow head)
The opposite, or dual, of a category can be obtained by reversing the direction of the arrows. The dual of the Pinch Category for example, is an unordered hierarchy with only one level, also called the Unordered List.
Illustration 3: An unordered list categoryIllustration 4: The pinch category
Illustration 2: A monoid (identity arrow shown)Illustration 1: A monoid

Universal Relational Dimensional
All of these different Categories have their unique properties, and they can be separated from each other and have different names depending on those properties, and nothing else.
Ordered ListOne of the most important categories, is the ordered list. It is one dimensional, without loops.
The list is essentially only a special case of the hierachy, but because it implies some kind of equivalence of each level in the category, it has a special role and is mentioned independently.
LoopLoops are important structures and must be discussed because they change the rules, and increase complexity.
Like all Monoids, each of the objects (dots) in the Loop category have their identity relationships pointing back to themselves. But in addition, it relates back to itself through other objects. This rules out that the directed relationships (arrows) can represent that of subsumption. If one of the object is smaller than its parent, then the loop will result in a impossible category.
Because all objects in the category contain all other objects, the only remaining possibility for this category to make sense, is that all eeach of the concepts in the loop are in fact equivalent. But this creates another problem. If the concepts are equivalent, they express exactly the same. For them to be different identities, they must be distinguishable. Because they cannot both be equivalent and distinguishable at the same time, there is ample reason for considering the loop a nonsensical, or impossible category.
Another way of saying the same, is that the identity relationship itself can be seen as a loop, looping back to itself and constantly reaffirming its own existence. Another loop back to itself would add no extra meaning to the category. The additional relationships would do no other purpose than to confuse the human reader.
I have gone into greater detail about this in a separate paper, but for now suffice to say that Loops are prohibited because the are seen as invalid and nonsensical constructions that cannot exist, because they imply both equivalence and the existence of a selection rule at the same time. (See Axiom of Choice)
Illustration 6: A loop Category
Illustration 5: A list category

Universal Relational Dimensional
The TableThe table is an extremely important fundamental category, because it is so commonly used. A table is essentially is two lists acting together. Arity, the term denoting the number of required relationships to uniquely identify an object, is for tables always two.
Tables are very simple, and are characterised by each object having exactly two parent objects. This arity of two, the pairwise relationships for each object are fundamental features of the table, because each piece of data that exist is placed in a row and a column. This makes the table particularly useful for holding data of the same type.
When categories consist of objects with more than one parent, this inflicts on how to visualise the structure. As we know, the table is a two dimensional grid, with some values along the X axis (typically field names) and some values along the Y axis (typically unique keys). The characterising feature of a table is related to this, and in order to visualise it we require a visual representation using two dimensions. This requires our spatial faculty of reasoning to place the two lists at at 90 degree angles to each other.
However, our limited ability to visualise categories must be separated from the logical categories themselves. So far, we have only spoken about existence and relationship. Spatiality, as required for creating a 2D mapping for each of the two constituent lists in the table, is a way of reasoning about the datastructures. Although it can be hard hard to separate the semantic structure of the Table Category from the physical 2D representation we have grown so accustomed to, the Table Category and all other categories exists independently of both time and space, and is not contingent on our ability to visualise it to. Representing a table Category as a table, is simply the most practical way to visualise it.
Illustration 7: A table category

Universal Relational Dimensional
The Cube and hypercubeThe Cube is one step up from the table. Here is shown the minimal cube, with only one data object, and three subsumption relationships. As you can see, each object have arity of three.
The step up from cube, with arity 4 and more are called n-dimensional HyperCubes.
The picture shows a cube with exactly one cell, the minimal type of cube.
The Hierarchy
Hierarchies are the most important categories, because it is a naturally occurring category when subsuming concepts and assigning meaning. For this reason, the hiearchy will be treated in the next chapter.
Illustration 9: A hierarchy
Illustration 8: A cube category

Universal Relational Dimensional
Chapter 4 : Subsumption
A word or phrase whose semantic field is included within that of another word- Wikipedia
The directed nature of the morphism (arrow)has important consequences. The obvious reason is that a theory with only associative relationships (undirected) would be far less expressive, only able to describe equality, and therefore it would be uninteresting. Another reason for using directed arrows is that our language is built around the principle of subsumption, and if our language is, so should a data structure attempting to hold meaning. Subsumption is the assertion that the subject matter represented by an object is a subset of it´s parent. This means that the parent object subsumes the child object, and the direction of the arrow tells us which way the relationship is going. This is also common in other disciplines like Linguistics, and have analogs in Set theory, Computer science and Description Logic.
URD Computing Set Theory Description Logic Linguistics
Concept Parent (single) Including Subsumer Hypernym
Subdivision Concept
Child Included Subsumee Hyponym
In URD we generally use the word Subdivision Concept, a slightly more precise term, because it denotes not only subsumption by its parent, but also that is incongruent (separated) from it siblings. We say that a Concept (A hypernym) is subdivided into new concepts (each of the Hyponyms), conditioned on that each of Hyponyms do not have overlapping semantic fields.
Subsumption is a key feature of our language. As explained, the loop category violates the principle of subsumption, and is therefore considered nonsensical. Prohibiting and avoiding loops becomes a constraint on how you can build categories. This constraints alone limit the number of available Categories to only a handful. This reduction in the semantic expressiveness defines URD as a Decription Logic, very different from most existing DL.
The restrictions generalises the notion of Category in URD, and this has very important effects in reducing complexity. Descriptive Languages with more expressiveness certainly have its applications. Any system can be made sufficiently complex for human understanding of it to fail, but the fundamental complexity of a system defines how it evolves when more features are added.
The restriction on loops basically leaves URD with a short list of fundamental categories. This shortlist is nothing but randomly picked. In fact, one of the reasons I have spent a lot of time on this project is through trial and error, and finally arriving at using only a few important categories. Together they make the descriptive system able to do all the things that our language can do, databases can do, but not what poetry or art can do, which is entice us with ambiguity. It allows us to what all databases do today, but without running into the wilderness that truly open and free graphs can allow. A lattice model for example, or a network enable objects to link not only to themselves, but to other objects, and then indirectly to themselves. This creates cycles, or loops, and

Universal Relational Dimensional
these may be of arbitrary depth and complexity. Therefore, such cyclic structures (categories) are far more computationally difficult to model, predict and use than acyclic categories.
When the categories used here are properly understood, a vast opportunity for more descriptive systems can be found by introducing new categories. Most importantly, the effects of doing so, like the explosion of complexity that will occur in any Description Logic when increasing expressiveness, can be studied using category theory and, allowing deep insights before technical implementations begin.
Fundamental CategoriesBy fundamental categories, we refer to valid structures that does not violate subsumption. This means categories with loops are unequivocally banned. By restricting the structure of objects to acyclic categories, we can show consistent behaviour throughout the system that is predictable and easy to determine. In addition, it will not suffer from counting anomalies. (This will be explained in more detail in URD II. )
In Category theory, an object holds no information other than the analytical proof of its own existence. While it could be imagined that the value itself could hold an arbitrary amount of information, we generally consider such atomic data units as without any meaningful information on their own. It could be a phone number or an email address, or a measurement value. Without access to metadata (data about data), the data simply has no value. Monoids in URD therefore contain atomic information.
Please observe that we are now departing rom the domain of pure Category Theory, where objects simply exist, and that is all. We are now entering the domain of database theory, where objects are used to describe something.
URD theory uses a similar concept of identity and existence as in Category theory, where an object must reference itself (the identity relationship) in order to exist. For a concept to exist, it must be reachable through itself. This makes it possible to be subsumed by another concept as a subdivision concept, and access it by means of this relationship. A basic URD implementation does not separate between data types, so a concept, can be any string, or number. It is, by definition, on its own, and it therefore cannot hold any more meaning than the value that it is given. 1
This gives the Monoid an identity relationship, which means it exists. However, for that Object to be a Category, it must have relations to other objects.
1It has been noted that the Monoid category is cyclic, because it references itself. This is true, but it is of no importance. If this would make a graph cyclic, then all graphs are cyclic because all graphs consist of objects that reference themselves. Clearly, there must be some distinction between a cyclic identity relationship and a cyclic graph involving other, non-self objects, otherwise the distinction between cyclic and acyclic ceases to have any meaning for all graphs.
Illustration 10: The set of all strings

Universal Relational Dimensional
The fundamental building blocks of URD are
• The set of all Strings
• The fundamental morphism
• The Scope functor
• The Ortho functor
From these tools we are able to construct complex categories like tables, cubes and dimensions. In addition, when allowing the objects of a category to hold string values, the role and function of a category may vary depending on the actual values. Therefore, URD has some variants of fundamental categories.
The Path sequenceThe path sequence is a list category, but containing “concepts”, or words, that make sense to us. In order for a path sequence to be valid, it must follow the rules of subsumption, which means that the following sequence is meaningful
USA → California → San Francisco County → San Francisco
but the following is nonsensical :
California → USA → San Francisco → San Franciso County
We must distinguish between valid categories, and nonsensical categories. Both the sensical and nonsense categories shown above are equivalent, and valid. For the Path sequence to be meaningful however, its constituent concepts must go from general to specific within some domain of language that make sense to a human, so that each object in the list is subsumed by the one preceding it.
The Ladder sequenceA special case of the path sequence is that the concepts become more and more specific, but they remain strangely general. While Continent clearly is more general than City, it also remains the case that the Contintents refers to all of the Contintents in the world, and City refers to all Cities in the world. Although City seems more specific, it is actually not the case. City is in fact not a subsumption of Continent, but indicate an increasing granularity of the concepts that belong on this level. The Ladder sequence is a metadata structure that says something about some unknown structure, denoting what kind of entity that belongs on a given ladder. A conceptual analog can be found in database schemas, where the tables extending from a central table typically have names like this.
Continent → Country → County → City
Another often used example could be
Branch → Department → Employee
Illustration 11: A list category

Universal Relational Dimensional
As we can clearly see, these metadata structures are not particularly useful on their own. They are data about data, and is therefore the first example of a category that is relating to another category. While objects inside categories relate using morphisms, categories themselves relate to other categories using functors. In URD, the ladder Sequence relates to the Hierarchy using the orthogonal, or Ortho functor.
The HierarchyHierarchies, or trees are the most important structures within URD. The hierarchy in URD is similar to a rooted tree, and is a category branching off from exactly one root node. The tree is a subsumption graph, without loops or ambiguity. Each node (object) has only one parent, but may have many children.
Below is a simple hierarchy representing a geographic subsumption into smaller and smalle runits. Using JSON notation, a hierarhcy can be mapped like this.
{
Americas {
USA {
California {
San Francisco County {
San Francisco }
}
}
}
,
Europe {
Germany {
Bayern{
Múnich},
,
Schleswig Holstein {
Schwerin}
}
}
}
The tree data structure have many important applications in computer science. For instance, the folder structure of a computer is modelled as a tree, and many other important datastructures use the tree structure. Another word for tree is the directed, acyclic graph. These are the essential characteristics of a tree, separating it from other graphs. You may have noted that the branches of trees split, but the branches never fuse to create holes in the tree. This means, that for every leaf on every tree, there is only one path downwards to the trunk, and there can be no ambiguity as to how that leaf gets its nourishing sap. This unique path from leaf to root, is called the path sequence.
The tree has three important features that make it useful as a datastructure.
1. Trees are acyclic, which means loops cannot occur.
2. Trees are orthogonal, which means objects are fully enclosed in their parent concepts.
3. There are no such thing as an empty branch, it either does not exist, or it does exist.
Illustration 12: A hierarchy category

Universal Relational Dimensional
4. The tree consists of exactly the same number of distinct path sequences as there are bottom concepts, or concepts without relations extending away from them.
The difference between a hierarchy and a tree is formally only that a hierarchy has a defined single root, that is, it´s a rooted tree. If we define tree in the context of URD as a rooted tree with directed relationships, then there is no difference between a hierarchy and a tree. The shown hierarchy goes from general to specific. But note that there are no references to City, Country or Continent intermingled inside the graph. Doing so creates all manners of confusion, and we keep the tree as clean as possible.
The relationship between the Ladder sequence Category and the Hierarchy may now emerge, but there are some problems afoot which must be handled.

Universal Relational Dimensional
Chapter 5 - The fundamental relation
Awareness requires a rupture with the world we take for granted; then old categories of experience are called into question and revised.
Shoshana Zuboff
In the example above, the objects were given familiar names of Cities and other real words of the English language. The simple Monoids became embellished with the ability to carry a value, a member of the string of all srings. We left the world of Caegory Theory and entered the realm of Database theory, but we did it with some important baggage.
1. We have only one type of relationship, or morphism.
2. The morphism is directed.
3. All categories must be acyclic.
The first requirement is important, because it means we are separating from a large part of the traditional field of linguistics and database theory, which distinguishes between different kinds of relationships.
Rejecting the key value dichotomy
Most computer systems today revolve around an accepted truth that so far no one have really questioned. In their deep inquiry into relational databases, C.Date and Hugh Darwen l [DAT02], presents the following quote.
“Observe that there is a logical difference between an attribute value and its name.”
This seems to indicate that attributes are, by nature, ordered pairs, and, that an attribute of something is incomplete if it is only a value or only a name. This is not self-evident, because there also exist a complete system (dating back to Descartes) where attributes are single words.
That there is a logical difference between a name and a value per se is obvious. But the scope of this truth is not. A given string may be a value in one context, and a name in another. For example, colour is a valid value for the the attribute Attributes, but yellow is also valid value for the attribute colour. This seems to indicate that a Colour may be both a value and a name, but not at the same time. The question then becomes a matter of defining scope of the name/value relation we know to be true. By creating fundamental boundaries between keys and values, we are introducing a conceptual structure that we do not know how will affect the system under higher complexity. For this reason, for the reason of parsimony alone, we do not accept the notion of ordered pairs in URD.
Role fillersIn Description Logic, which studies logical languages for Knowledge Representation, there is an almost universal adoption of role fillers, relationships with an attached string value describing what is actually going on.
Some examples could be “Mary” IS-A Woman, “HasChild” William. The IS-A and HasChild are

Universal Relational Dimensional
values attached to the relationships describing what they contain. This models of triples, subject, object, predicate has been accepted by the W3C consortium and is (by 2013) a web standard. However powerful, this also has it´s drawbacks. The principal problem is that its role fillers will allows relationships to be directed both ways. For example, the role fillers “childOf” and “hasChild” are inherenltly duals (inversion). This creates a confusing mix of relationships that go both ways, but express the same thing. This gives freedom of expressing complex roles, but it also means the computer cannot infer anything from the direction of the relationships. This makes the directed nature of the relationship arrows untrustworthy.
In addition, the subject, object predicate model used in RDF has no facility for denoting the scope of the truth of a relation. The consequence is that we cannot rule out that a relation is true in some respects, but not in others. Because of this it cannot be used to enforce the rules that will make the category resistant to information entropy and eventual ambiguity
Once again, the focus shifts towards the actual relationships themselves, instead of the structure that the relationships preserve over the objects they affect. Some of the most cited Description Language scholar Brachman and Levesque have shown hat computational complexity of operations increase dramatically with increased complexity. [BRACH-LEVESQ_01]. That being said, RDF is a beautiful framework for many applications notably searching, but in its current form, it does not provide an alternative to relational databases.
Rejecting IS-A and IS-PARTThe most important relationships that are commonly used in both descripion logic and computer science are the following operators :
• ISA
• ISPART
• EQUALS
The ISA operator signifies type, that the current object is an instance of some class of objects. This implies some form of inheritance, that whatever attributes are relevant to the type, is also relevant to the instance of the type.
For example the statement "Joanna" ISA “Woman” implies inheritance of attributes from Woman to Joanna. ISPART on the other hand, indicates that the object is a lesser term, that specifies in more detail the attributes of a greater term. I.e. “Joanna” ISPART “Mothers”. Finally, EQUALS, only signifies that the two terms are the same, that they represent the same, that they are invariant.
By treating relationships as morphisms, URD does not separate between ISPART, ISA and EQUALS relationships, and does not allow custom specified relationships between objects. This is very different from most Description Logic system and databases, and this makes URD less expressive than most existing Description Logics. There are several reason for this important architectural choice:The first reason is that, such relations are not necessary to create a fully descriptive system. No matter how you choose to frame it, there is no absolute necessity to differentiate between ISA and ISPART relationships. Take for instance the the expression "Joanna" ISA Woman, ISPART "Mothers". This is equally well described through two distinct relationships. If we think of “Woman” as an attribute of “Joanna”, and other concepts “Mary”, “Anna” (but not “John”), share that attribute, we could easily group and access “Joanna”, “Hildegard” and “Mary” through their common reference to “Woman”.
If we think about concepts as groups, and are used to access members of the groups, it is easy to see

Universal Relational Dimensional
that “Joanna” ISPART “Woman” is not only is equally descriptive as "Joanna” ISA “Woman", but is actually the same thing. We can reduce the complexity of the descriptive system considerably by using only one fundamental morphism. For practical purposes, we discard ISA, ISPART and EQUALS, and use only the fundamental, directed morphism. For simplicity, we call it IN.
This creates statements like “Joanna” IN “Woman”, and “Mother” IN “Woman”.
This may be conflicting with how we intuitively may wish deal with terms in plural form. Since all of these concepts are acting as containers, Woman may equally well have been defined as "Women", in plural form. I believe that the reason so many feel they require both the ISA and the ISPART relationships is because it seems logical and is closer to our language. But this intuitive need to use both ISA and ISPART might be caused by the simple the fact that "Joanna" ISPART "Woman" sounds wrong, but “Joanna” ISA “Woman” sounds right. The problem is that from a philosophical perspective, going from one fundamental relation to two is tantamount to going from one to many, increasing the complexity of all future operations and fundamentally changing the way the system manifests itself under higher complexity. Avoiding this “role filler” relationship leaves us with a cleaner system .
The singular / plural equivalenceInstead of distinguishing between ISA and ISPART roles, we can achieve the same thing by supplying singular/plural neutral forms, or just remember that the mode of the subject is irrelevant, and use whatever seems more appropriate in each case. In such a case, "Woman" and "Women" are equal terms. With these modifications, see that the ISA and ISPART operators, for the purpose of grouping and accessing are exactly the same. This is precisely the reason for having only one type of relationships in URD, the directed morphism, IN.
Finally, ISA and ISPART has been used to distinguish between assertions such as “San Fransico IS-A City” and “San Francisco ISPART California”. This is understandable, because the two relationships are different. But expanding the relationship into a role filler is, as we shall see, not the only way to preserve the difference between being a city and being part of a state. We can also achieve this using categories and functors between the categories.

Universal Relational Dimensional
Chapter 6 – The Ortho functor
The orthogonal features, when combined, can explode into complexity.
- Yukihiro Matsumoto
This chapter is about Orthogonality, the idea that something can be combined without contradiction. From the perspective of visualisation, orthogonality means you can place something at 90 degrees angle to something else. To have a 90 degree angle requires the notion of space. But Category Theory itself exist independent of space, so this right-angledness is not the fundamental feature of orthogonality. Rather, the functor is a structure preserving map between a category and another. That means a functor is a rule that describes how relationships from one category should be created when the categories are combined using the functor.
Many functors can be imagined, but the most important is the ORTHO functor, which applies relationships between otherwise independent categories. In this example we will use the Ortho functor to map a metadata Ladder Sequence to a data holding a Hierarhcy. An important thing to note here is that the distinction between metadata and data categories is not features of the categories themselves, but the actual concept they reference.
Note : Most database theory introduce a clear distinction between metadata and data. I will argue that there is no need to do so. There is no difference on how data and metadata are stored in the human brain. It all depends on the context. The same fundamental logic applies in URD. Everything is concepts, even values, datatypes, fieldnames, even numbers and the categories themselves are referenced and accessed simply as atomic concepts.
Ortho functors can be used between all of the Universal Categories in URD, and the results are meaningful if the relationships that exist are correct. For more information on concept formation and Artificial Intelligence, see URD III – Concept formation and AI.
The Orthogonal functor was applied to the two Categories, and the resulting combined category has
Illustration 13: Distinct categories can be combined using functors
Universal Relational Dimensional
exactly twice the number of arrows, and therefore an arity of exactly 2.
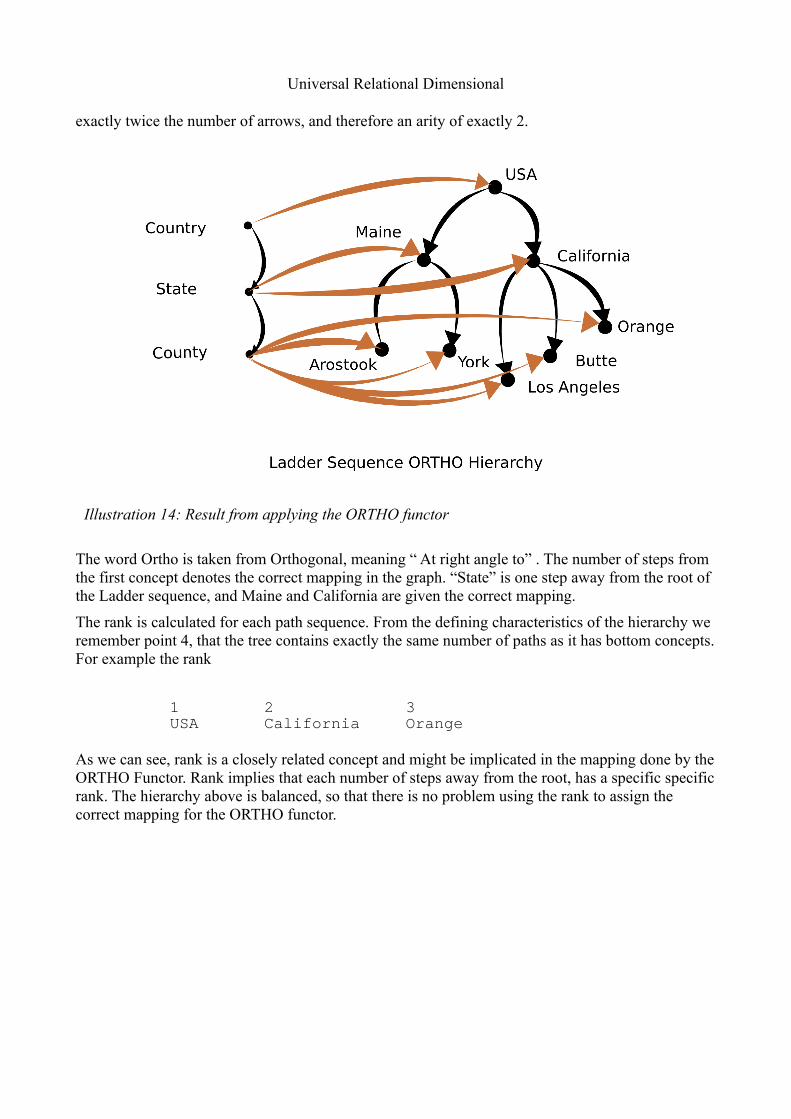
The word Ortho is taken from Orthogonal, meaning “ At right angle to” . The number of steps from the first concept denotes the correct mapping in the graph. “State” is one step away from the root of the Ladder sequence, and Maine and California are given the correct mapping.
The rank is calculated for each path sequence. From the defining characteristics of the hierarchy we remember point 4, that the tree contains exactly the same number of paths as it has bottom concepts. For example the rank
1 2 3USA � California � Orange
As we can see, rank is a closely related concept and might be implicated in the mapping done by the ORTHO Functor. Rank implies that each number of steps away from the root, has a specific specific rank. The hierarchy above is balanced, so that there is no problem using the rank to assign the correct mapping for the ORTHO functor.
Illustration 14: Result from applying the ORTHO functor
Universal Relational Dimensional
A more convenient illustration shows the exact same.
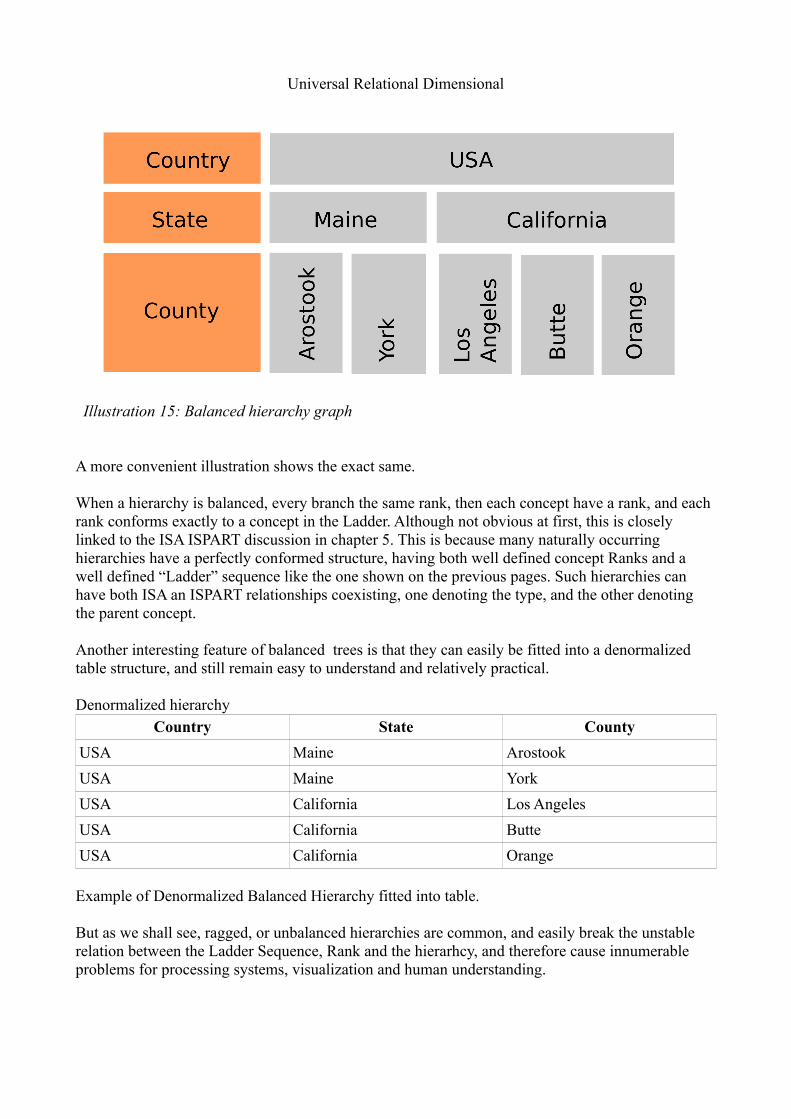
When a hierarchy is balanced, every branch the same rank, then each concept have a rank, and each rank conforms exactly to a concept in the Ladder. Although not obvious at first, this is closely linked to the ISA ISPART discussion in chapter 5. This is because many naturally occurring hierarchies have a perfectly conformed structure, having both well defined concept Ranks and a well defined “Ladder” sequence like the one shown on the previous pages. Such hierarchies can have both ISA an ISPART relationships coexisting, one denoting the type, and the other denoting the parent concept.
Another interesting feature of balanced trees is that they can easily be fitted into a denormalized table structure, and still remain easy to understand and relatively practical.
Denormalized hierarchyCountry State County
USA Maine Arostook
USA Maine York
USA California Los Angeles
USA California Butte
USA California Orange
Example of Denormalized Balanced Hierarchy fitted into table.
But as we shall see, ragged, or unbalanced hierarchies are common, and easily break the unstable relation between the Ladder Sequence, Rank and the hierarhcy, and therefore cause innumerable problems for processing systems, visualization and human understanding.
Illustration 15: Balanced hierarchy graph

Universal Relational Dimensional
Unbalanced Hierarchies In the real world, we have unbalanced hierarchies. Such trees have their bottom concept (the most specific concepts) at varying ranks. This should come as no surprise, as the balanced hierarchy is just a special case of the hierarchy.
As we can see on this rank, there is a difference in the number of subsumption levels. If we expect or assume that all concepts that share the same rank are the same type of concept, we will see that this hierarchy creates problems when we try to visualise it or squeeze it into a table. The results would be that California and Athens would end up in the same column, and then trying to find a name for that column would fail. If the string was serialized, then an import feature might cause the following table structure to appear.
Country State City
USA California Sacramento
Greece Sparta
Greece Athens
As we can see, NULL values have appeared signalling that the information about State is missing. The metadata suddenly suggest, that there actually are states in Greece, but the data is missing. The point of this observation is that trying to fit a structure into a table means coming up with valid column names, a very similar exercise to that we showed when applying the Ortho functor on the hierarchy. Failure to create well defined columns names using rank on an unbalanced hierarchy is going to fail. The process of denormalizing a data structure into a table is equivalent to applying the ORTHO functor with a list and a hierarchy. But where the denormalization will result in NULL values on unbalanced hierarchies, the ORTHO Functor works on every kind of combination of list
Illustrasjon 16: Ragged hierarchy - Same bottom concept at varying rank

Universal Relational Dimensional
and hierarchy, and will end in exactly four distinct types of categories. Learning to use these variations over the Hierarchy categories and understanding their properties, and developing visualisation processes for these related categories we can be able to handle complexity using better tools than the limiting ourselves to the table and the balanced hierarchy.
The addition of a metadata structure like the Ladder Sequence and using the ORTHO functor on a hierarchy, we end up with exactly four different types of Hierarchies, only one of which are the easy and problem free balanced hierarchy.
A balanced hierarchy – Whereboth rank and bottom concepts are well behaved.
A Ragged hierarchy – Where bottom concepts are well behaved (all the same) but may occur at varying rank.
Truncated hierarchy – A hierarchy that do not contradict the ladder sequence, but may have missing branches. (i.e. Not all of the bottom concepts are Cities, some incomplete branches may end with a Country.
A Ragged and Truncated hierarchy – A wild hierarchy where the rank may be variant for the relationships in the ORTHO functor, and several concepts may act as bottom concepts.
Illustrasjon 17: Skewed hierarchy

Universal Relational Dimensional
What is the Ortho Functor exactly?
By using the Ortho Functor on a Ladder sequence and a hierarchy, we can see how the complexity begins to develop. The result is exactly four different types of hierarchy. We all intuitively know that these four categories exist, and that we encounter them in our journey to categorise and understand the world. It is also apparent that this idea of combining categories into more expressive ones is salient. This is probably related to the fact that we, as humans, do this all the time. Applying the Ortho functor on information is a process that is similar to the way we as humans think.
In the process of applying the ORTHO functor in fusing two semantic structures, unbalanced and ragged hierarchies occur because we the world is ragged or unbalanced. Clinging to an idea of a hierarchy as a balanced hierarchy, isn´t going to help. Neither is forcing everything into a table. This leads to cognitive dissonance, attempting several different ways to encode the datastructures in your brain. 2
All the four hierarchies are equally true, and first class citizens. Even the least complacent of them, the Wild hierarchy, is still a very rigid and powerful structure compared to most other categories such as networks, lattices and loops. The wild hierarchy remain relatively easy to understand and visualise. This happens because all of these categories can be reverse engineered, including the table, can be decomposed into a combination of the fundamental building blocks and the ORTHO
2Who has not struggled to get reality to fit into Excel sheet, flipping back and forth between various strategies of visualisation, before finally giving up and settling with an approximation of what you had in mind, only to have the reader of the encoded information painstakingly rebuild the structure you so carefully disassembled whilst putting it behind the bars of Excel.
Illustrasjon 18: The four types of subsumption hierarchies

Universal Relational Dimensional
functor, and reversing this process makes the categories easy to comprehend.
Please note that this paper does not go in detail about how functors select the appropriate relationships and build the categories correctly. For simple hierarchies, rank can be used to map the relationships, but this would not be a foolproof design on ragged, truncated or wild hierarchies.
Rather, the Ortho functor uses a way of reasoning similar to that which you do when you are looking at a hierarchy, mapping Los Angles to City because you possess pre existing knowledege that LA is a City. Using a large repository of facts about the world, the ORTHO functor identifies candidate relationships and selects the single one of the highest fidelity, this way creating a new category from existing knowledge about concept subsumption. Information about how the Ortho Functor performs this computational task is the subject of the URD IV, Concept formation and AI.
It is something of a mystery that so many of us rely to such a great degree on the table when we seek to formalise or jot down data. We spend a lot of time attempting force all these categories into into a table structure for storage, presentation and so forth. The table structure has truly taken a massive hold on our minds. While there is nothing wrong with using the table, I am in fact doing in the above illustration, it is worthwhile to note that only the most well behaved of these four behaved in the family of hierarchies, on the upper left, will allow itself to be subjected to the confines of the table without protesting loudly.

Universal Relational Dimensional
Chapter 8 - The Universal Categories
Language is a part of our organism and no less complicated than it.
- Ludwig Wittgenstein
A category is a pattern of rules for structuring and reasoning about concepts. That makes a metacategory a category for structuring and reasoning about categories.
On the preceding pages we have shown examples of categories that arise from the combination of a bijective Ortho functor on the two appropriate fundamental categories, the list or the table, and attaching relationships between them according to common language baseline understanding of the concept relationships.
It is my firm belief that this class of categories, called Universal Categories, are particularly salient and easy to understand. They make sense to humans, are extremely useful in accessing and grouping data, because they can be reverse engineered to the fundamental categories, the basic building blocks of our understanding. The most prominent member of this group of categories is the table, but any combination of fundamental categories such as the list or hierarchy create a new, more powerful categories with its own set of properties and restrictions. It is my intent to show that any category that can be shown to belong in the ORTHO metacategory is useful and interesting. We should consider all of the members of this divine toolbox, and not be unnecessarily constrained to the table and poorly understood hierarchies.
There are three formal conditions to be met for a category to be a Universal Category
• It is orthogonal
◦ No loops
◦ Well defined arity
◦ Concept children are incongruent on siblings.
• Categories are sensical, they conform to our langauge
◦ Arrows correspond to subsumption
◦ Going from general to specific
Collapsing loops
As mentioned in Chapter 2, categories containing Loops are simply prohibited because they are difficult to make sense of. It could be argued, that Loops are self contradictory categories because they represent themselves via some other concept, and then, by necessity these objects may be aliases of the same identity. But there is in fact compelling arguments in favour of a this bold statement : That categories outside of the metatcategory simply cannot exist, they are either incomplete, impossible or may express nothing more than a single monoid.

Universal Relational Dimensional
I will argue that from the perspective of meaning, looping category would simply collapse into a single Monoid. Other, more complex categories involving more than one loop, the effects may be impossible to comprehend.
The category above, named the “Same-ish” category can be hard to understand. First of all, it has varying number of relationships, an arity of 1-2. Secondly, it involves two loops. The only way this category will commute, is if all relationships are equal, but this can be very hard to see.
In the case where all relationships signify equivalence, any other relationship could be constructed on the category and it would be the same category. So, the category is missing arrows.
Also, if the relationships signify equivalence, the concepts cannot be incongruent. It can be shown, that of all possible categories, only a small subset are both incongruent on siblings, and without loops. Other, far more complex categories can arise quickly from data if we are not careful, and when combining this category with another you will face unexpected and unpredictable results.
This category is not part of the Ortho Metacategory, on the grounds that it would require the Axiom of Choice to be able to create it. Because it is not part of the Ortho Metacategory, it´s not a valid ontology, Therefore it´s not fit for data management. For this reason it is not part of URD.
Illustrasjon 19: Loop and non-defined arity characterise this category

Universal Relational Dimensional
Explaining the Metacategory
The Metacategory shown above lists the categories arising from combining the primitive categories (Arity of 1) , non looping categories. All of the categories in the Ortho metacategory can be created using the two fundamental categories and mapping them to each other using the Ortho functor.
The third level in the hierarchy denotes which fundamental categories that are combined.
L on L (List on List)
L on H (List on Hierarchy)
H on H (Hierachy on Hierarchy)
List On List – The Table CategoryList on List simply ar combinations of two lists. It is fairly obvious that the result is a table. However, some tables have emtpy cells, or have members that only reference one parent, when they ought to be referencing two. One could say that the Complete table, where all members have an arity of 2 is a special case of the table.
However, visualizing incomplete tables is very different from visualising complete tables.
List on Hierarchy - The Dimension CategoryApplying the Ortho functor transforms into four different hierachies, and this was explained in the previous chapter. When we talk about hierarchies, we rarely consider only the free, fundamental hierarchy. The List on Hierarchy category is so common, that in URD it is given a specific name. The Dimension Category.
Illustrasjon 20: The 2D branch of the ORTHO Metacategory
Universal Relational Dimensional
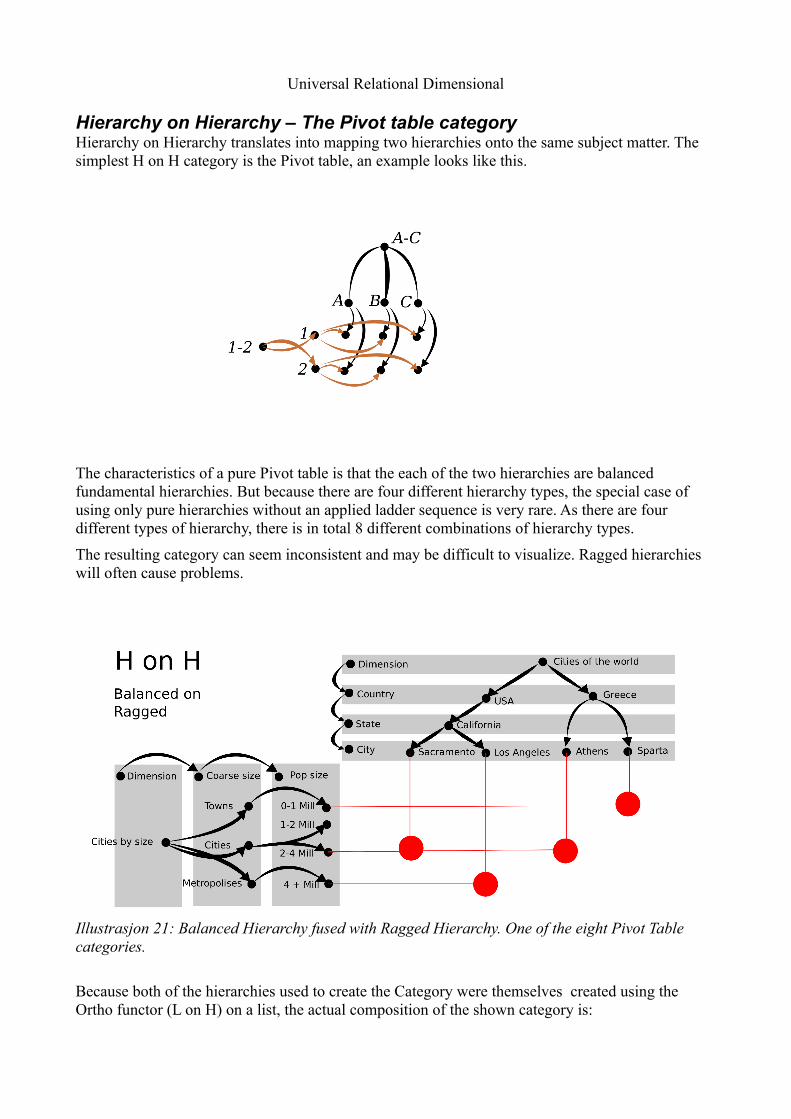
Hierarchy on Hierarchy – The Pivot table categoryHierarchy on Hierarchy translates into mapping two hierarchies onto the same subject matter. The simplest H on H category is the Pivot table, an example looks like this.
The characteristics of a pure Pivot table is that the each of the two hierarchies are balanced fundamental hierarchies. But because there are four different hierarchy types, the special case of using only pure hierarchies without an applied ladder sequence is very rare. As there are four different types of hierarchy, there is in total 8 different combinations of hierarchy types.
The resulting category can seem inconsistent and may be difficult to visualize. Ragged hierarchies will often cause problems.
Because both of the hierarchies used to create the Category were themselves created using the Ortho functor (L on H) on a list, the actual composition of the shown category is:
Illustrasjon 21: Balanced Hierarchy fused with Ragged Hierarchy. One of the eight Pivot Table categories.

Universal Relational Dimensional
(L on H) on (L on H)
Although part of the Ortho Metacategory, the various Pivot Tables are highly complex. Without the ability to reverse engineer these, the sheer amount of relationships might be hard to use for anything useful. The composition of the category is charaterized by the nested invocations of the Ortho Functor used to build the category. This tells us which members belong on each axis and is nescessary for us to know how to visualise the category for human consumption. Because visualisation is necessary to understand and extract meaning, information on how to visualise complex categories is of central importance.
Mapping the objects this way however enables a much greater degree of reuse. The shown Category C is the Orthogonal product of two other Categories (A and B). But there is absolutely nothing that prohibits the A and B categories to partake in other Categories at the same time. Cities of the world is a category, or dimension, that is free to structure completely different information. If there “Cities of the World” category needs to change, then this change will propagate to other Categories dependent on this.
We see that the model shown is comparatively simple. But we also remember that in URD we have severed the connection between the storage of data, and its representation. Implicit order during storage is not in any way used to denote relationships. The B and C categories are not stored within within the C category, and the Ortho functor does not permamently change them.
Completing the MetacategoryThe last branch of the Ortho Metacategory remain unexplored so far. This branch details with categories of arity of 3 and over. There is not much to be said about these categories. They are obviously more complex because they have more relationships. Apart from that they are really not different from arity of 2.
From a visualization standpoint, effectively presenting these higher level categories is extremely be challenging, requiring the use of 3D effects to illustrate the relationships that surpass the dimensional capacity for understanding we are given through the spatial faculty of our brains. Any category of arity of 3 or higher can be shown to be expressed by slicing and dicing, flipping through pieces of the category in a manner that allow us to understand relations criss crossing cubes and hypercubes. As usual, the key to success is to break the problem up into manageable parts. If we can rest assured that the internal logic of the semantic language, grouping and accessing are sound and consistent, we can in turn build powerful visualisation solution that lets us explore data.

Universal Relational Dimensional
Chapter 7 – Other systems of reasoning
There are three basic approaches to AI: Case-based, rule-based, and connectionist reasoning.- Marvin Minsky
URD as a Description Logic
In addition to being based on category theory, not First Order Logic, three things make URD different from most Description Logic.
URD is less expressive, and is ultimately distinguished by not having some of the most common facilities for denoting relationships used in Description Logic. To be specific URD does not have
• A distinction between key and value
• A distinction between type and instance
• Negation
• Role fillers
Without the distinction between a key and a value, having discarded the notion of “role filler” altogether, the system is far less expressive than most Description Logic Knowledge Bases. To be less expressive means much lower complexity, and that is perhaps the most important feature of a knowledge base. Solving the subsumption problem under higher complexity has been shown to be NP-Hard just by introducing simple ISA / ISPART relationships and negation.
Finding the right balance between expressiveness and complexity is one of the central points in the Study of Description Logic, and the algorithms working on solving subsumption problems will by necessity favour less complex data structures to work on.
The question remain wether URD is expressive enough to convey meaning effectively. The previous chater has shown that the introduction of the single ORTHO functor is sufficient to restore the the expressiveness of the system to a level where actual information can be presented, stored and reasoned about. In addition, the URD data structure is not created detached from the need to visualise for human consumption. These two things are completely intertwined and using only the symbols of logic to show these relationships seem to be an unnecessary constriction.
How the subsumption problem is solved is not in scope for this introduction. Please refer to the fourth paper in the URD Stack, URD IV – Concept formation and AI for detailed information.

Universal Relational Dimensional
Chapter 8 – End notes
Is this a real problem?The things I have shown so far may be seen as a presentation of obvious, self evident facts about the nature of data. What makes this perspective on data an improvement?First of all, In Memory Computing is rapidly changing how computers themselves deal with data. In order for these computers to interface with humans, they must continue to use tables like before.Part of this is necessity, the world still run on tables, and the shift towards another perspective will take time. Part of this is also lack of vision. The lure of the table goes all the way into the very heart of the most highly respected products that we use to run our world. It governs our research, it stores the data about our world, and it remains the workhorse category of our understanding. And yet, it is deeply flawed when used on things that are not table shaped.
ConclusionAbandoning the table in favour of other, more suitable categories like the various hierarchies require a deeper understanding of the merits and shortfalls of each category. It behooves us to take a step back and see these categories for what they truly are : Digital representations of our internal neural structures. The more similar the digital and the Neural structure is, the easier it is to extract meaning from the category. This does not happen isolated from the problem of effectively visualizing the increasing complexity of data. In linguistic, this characteristic is referred to as saliency, the ability to create a feeling of understanding. The Ortho functor is a case in point. It always translates into a 90 degree angle when shown on screen. This goes to show that these topics are not merely related, they are two sides of the same coin.
In Memory technology will replace the table based relational model of data in a few years. But it´s implementation will be slowed by resistance to changing aquired modes of thinking. From a human perspective, we cannot abandon the table before we have an alternative. This alternative can be found in category theory.
I also believe, that the reduction in expressiveness shown by URD will manifest itself in a new and particularly salient perspective on data management. In the remaining papers of the URD stack I will show how URD is able to represent any relational data, solve the subsumption problem and lend its unique facilities for reasoning to the Artificial Intelligence Research Community.
We need more categories order to make sense of this strange world. The world is not flat, it is ragged, skewed and wild. Our tools should reflect that.




















