
Untitled - IDUG
62
1
-
Upload
khangminh22 -
Category
Documents
-
view
5 -
download
0
Transcript of Untitled - IDUG

1

2

3

4

5
Appliance: optimized HW and SW for accelerating analytical queries running in DB2 for z/OS
Easy to deploy
Easy to operate
Load and Go
Hands-free-operation
Incredible performance out of the box
No indexes
No tuning
No Materialized query tables
Automated statistics and reorgs ->
Hybrid: combines best of both worlds
-Db2 for z/OS – the gold standard in transaction processing
- Netezza – industry leading price/performance with a massively parallel shared nothing architecture
Transparency
-Transparent to the application – still connects to DB2 for z/OS, no new userids, no new privileges, no new SQL dialect
Best of all: Incredible speed
Typical Factor 100x, sometimes up to 2000x over DB2

6
6
NZ 1000 has a revolutionary design based on principles that have allowed Netezza to provide the best price-performance in the market. The four key components that make up Nz 1000 are: SMP hosts; snippet blades (called S-Blades); disk enclosures and a network fabric (not shown in the diagram).
The disk enclosures contain high-density, high-performance disks that are RAID protected. Each disk contains a slice of the data in
the database table, along with a mirror of the data on another disk. The storage arrays are connected to the S-Blades via high-speed interconnects that allow all the disks to simultaneously stream data to the S-Blades at the fastest rate possible.
The SMP hosts are high-performance Linux servers that are set up in an active-passive configuration for high-availability. The active host presents a standardized interface to external tools and applications, such as BI and ETL tools and load utilities. It compiles SQL queries into executable code segments called snippets, creates optimized query plans and distributes the snippets to the S-Blades for execution.
S-Blades are intelligent processing nodes that make up the turbocharged MPP engine of the appliance. Each S-Blade is an independent server that contains powerful multi-core CPUs, Netezza's unique multi-engine FPGAs and gigabytes of RAM--all balanced and working concurrently to deliver peak performance. FPGAs are commodity chips that are designed to do process data streams at extremely fast rates. Netezza employs these chips to filter out extraneous data based on the SELECT and WHERE clauses in the SQL statement, as quickly as data can be streamed off the disk. The process of data filtering reduces the amount of data by 95-98%, freeing up downstream components from processing unnecessary amounts of data.
The S-Blades also execute an array of different database primitives such as sorts, joins and aggregations in the CPU cores. The CPU cores are designed with ample headroom to run embedded algorithms of arbitrary complexity against large data streams for
advanced analytics applications.
Network Fabric: All system components are connected via a high-speed network fabric. Netezza runs a customized IP-based protocol that fully utilizes the total cross-sectional bandwidth of the fabric and eliminates congestion even under sustained, bursty network traffic. The network is optimized to scale to more than a thousand nodes, while allowing each node to initiate large data transfers to every other node simultaneously.
All system components are redundant. While the hosts are active-passive, all other components in the appliance are hot-swappable.
User data is fully mirrored, enabling better than 99.99% availability.

7
7
What we see here is how we increased the scan speeds. Basically about each drive in the N2001 is capable of delivering about 130 megabytes per second of throughput (compared to approximately 120 MB/sec in the N1001).
What we had before with the 1 to 1 to 1 ratio, one drive to one FPGA core to one CPU core, the
speed of the drive was the limiting factor as far as how fast the FPGA core could process the
data - because the FPGA core could handle way more than that and the CPU core even more
than the FPGA core. So the speed of the drive was a limiting factor.
So we now have more than one drive per FPGA core and per CPU core. Using basic math, we
have about 2 1/2 drives per FPGA core and per CPU core. So that drives up the speed that data
can be scanned and delivered to the FPGA for processing up to about 325 megabytes per second.
If you add in the 4x compression that’s going to get up to around 1300 megabytes per second.
In the N2001 we now have faster FPGA cores that can process about 1000 megabytes per
second. So we are no longer I/O starved.
So we’re now delivering both 2 1/2 times as much data, you know, per second to the FPGA , to
the CPU core and that is how we fundamentally and how we increased the scan speed and how
we increase the performance of this system.

8
8
A single system for mixed OLTP and DW workloads
Workload optimized query execution
Combines the strengths of both System z and Netezza
Optimizer dynamically directs eligible queries to accelerator
Global default enabling or disabling of acceleration via QUERY_ACCELERATION subsystem parameter
User specified enabling or disabling of acceleration using special register QUERY ACCELERATION

9

10

11
Query Accelerator: specialized access path for data-intensive queries Storage Server: Sophisticated multi-temperature data and archiving
solution ELT Accelerator: accelerating in-databasetransformation Advanced Analytics: modeling, batch scoring, Hadoop, Streams integration Unified Store: consolidation and unification of transactional and analytical
data stores

12

13

14

15

16

17

18

19

Let’s start with the new Hardware.
In a short summary: the new hardware is more secure, faster and more
scalable with more models.
Why is it more secure:
The new models come with Self Encrypting Drives. These drives
encrypt all data at rest. The encryption is done in HW inside each disk
and thus has no performance impact.
So you get a fantastic new security feature without paying a price in
terms of performance. This should open the door in accounts like
healthcare that are currently blocked due to compliance rules.
The encryption HW features is enabled by new firmware and a new
NPS Kit – Version 7.2 of NPS. To support the new NPS version you
need a new version of the accelerator software – this is Version PTF 4.
The new IDAA refresh also provides a means to manage the disks‘
encryption key in the IDAA configuration console
Why is it faster:
The new models have been upgraded with the current generation of
Intel Chips, both on the host and the SPUs and we will have additional
details on the following slides.
20

Now if we look at the complete PDA family we have the existing Striper Models N2002 that are still available until we run out of stock for these models.
Then we have the new models N3001 with the new encrypting disks.
Both Striper generations provide price-performance optimized hardware so typically they are 10-100 times faster than custom systems. We continue to lead with time to market and simplicty – that means just load and go without tuning.
The new models provide the existing advantages plus
-these models come with additional Software licenses when sold as a standalone solution.
-They contain the self-encrypting disks
-They provide a wide range of models form partial rack to 8 rack
- and within a single installation you have flexible growth options to license a subcapacity of the HW installed
In addition we are announcing a low end model – the N3001-001:
This model does not come with its own rack but it can be mounted into a customer‘s existing rack. This model does not contain blades and also does not contain FPGAs.
Both are running as a virtual machine under a hypervisor on the two hosts.
Due to these limitations we do not plan to use this model in production as part of the IDAA solution, but the low-end for IDAA customers is the regular quarter-rack N3001-002. However, technically IDAA supports the model and it may be the right choice for limited deployments, for example for IBM development business partners that want to enable their software to work with IDAA but do not require the performance of a full rack. The N3001-001 has a specified capacity of 16 TB assuming 4x compression, but we have not yet tested the performance for IDAA.
And of course DB2 Analytics Accelerator for z/OS is also part of the PDA family and it immediately supports all new models N3001-x.
The big advantage here is that with IDAA you get a hybrid computing platform that integrates the Netezza technology with zEnterprise technology – so that you get the best of both worlds: fast transactional workloads running on DB2 for z/OS and complex queries running on the appliance.
It also directly benefits from the new, improved security of the self-encrypting disks and continues to accelerate complex queries up to 2000 times faster.
21

This slide shows the new top model of the N3001 series, the N3001-
080 8 rack system.
With over 2300 disks you get a huge capacity of 1.5 PB.
Imagine all these disks each scanning a piece of each table for every
query at incredible speed.
It contains 2 x3750M4 hosts with self encrypting disks and 56 HS23
blades plus 96 disk enclosures with 24 self-encrypting disks each.
22

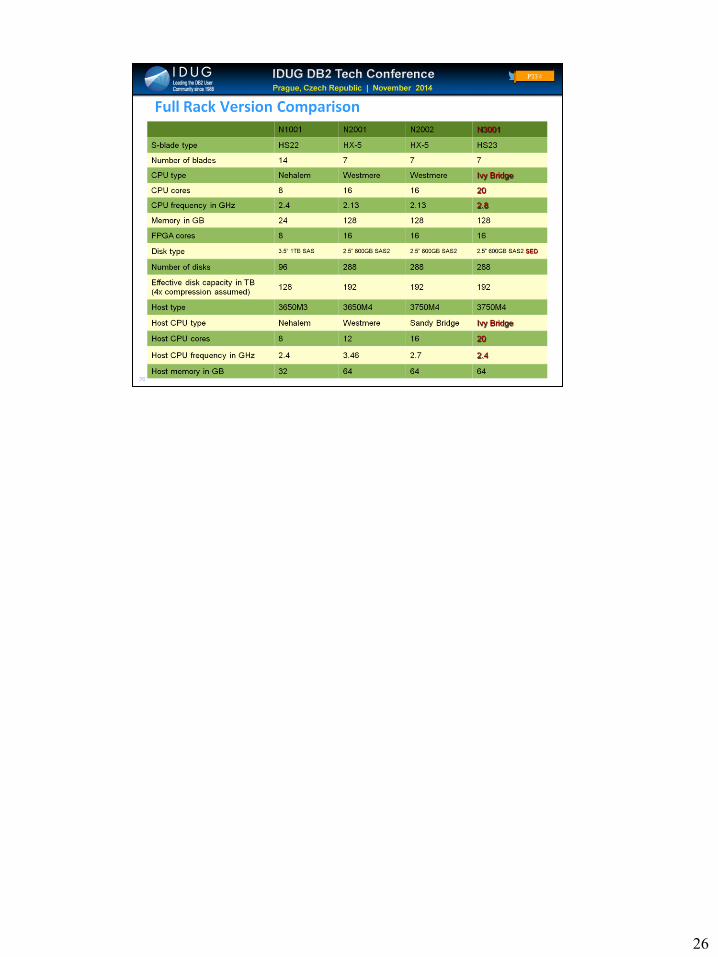
23 23
Now let us dive into what is different in terms of performance and
especially CPU performance in the new models.
This slide shows the HW configuration of the initial Striper models
N2001 that we introduced last year.
Basically we had 12 Disk enclosures with 24 disks each – giving a total
of 288 disks. This did not change in the new models, the only difference
is that the new N3001 models now contain self-encrypting disks, so
basically we still have the same scan speed of approx. 480 TB/hour
across all full rack models.
In the middle we see the CPU configuration of the hosts with 2 6-core
Intel Westmere CPUs.
And in the bottom we see the 7 Blades. Each blade comes with 2 8core
Intel chips and 2 8-engine FPGAs.
23

24 24
What we changed in the N2002 models that we introduced earlier this year is just a host replacement.
We used newer x3650 host models which come with a newer generation of Intel Processors, the Sandy Bridge CPUs.
Some of you may notice that the newer Intel chips on the host even had a lower nominal clock speed, but in terms of performance the N2001 and N2002 are absolutely at the same level.
So the N2002 was simply a refresh that was necessary because some x Series systems and Intel chips went out of stock and had to be replaced.
The biggest system available for N2002 is a 4 rack system, so it scales from a quarter rack to 4 racks.
24

25 25
In the newer models we get newer CPUs on both the host and the
blades and this also comes with a performance improvement for CPU-
intensive workloads.
For example on the host IDAA load and incremental update as well as
queries with lots of host-centric aggregation will benefit.
Also on the SPU complex queries that do lots of conversion or
computation will benefit.
In the hosts we get a new processor generation (Sandy Bridge -> Ivy
Bridge). The specint of the hosts has improved between 9 and 24 %
depending on model (better improvement for bigger models). As I said
this is good for loads and other work carried out on the hosts like
replication.
Q25+Q50: [email protected] Ghz -> [email protected]
Q100: [email protected] Ghz -> [email protected]
Q200+: [email protected] Ghz -> [email protected]
There is also a Blade refresh from the N2002 to N3001.
The blades also get new processor generation (Sandy Bridge -> Ivy
Bridge) with more cores (10 instead 8) and faster clock speed. This
more than doubles the speciInt rate for the blades. However FPGA and
memory on the blades remains the same and also Disk configuration
and Scan rate remains the same. 25
26

27

On this slide you get an overview of the capacity of all models that are
now available.
Including the rack-mountable N3001-001 that is not listed on the chart
the capacity now ranges from 16 TB to 1.5 PB with linear scalability.
So we have quarter rack – 002, half rack – 005, full rack 010, 2 rack
020 4 rack 040 and the top model the 8 rack system.
Starting with the two-rack system N3001-020 the host models come
with more CPU cores so if you want the ultimate load and incremental
update performance you should start with a model 20.
Note: Processing units refers to # FPGA cores, e.g. full rack (N3001-
010) has 7 x 2 x 8=112 FPGA cores but 7 x 2 x 10=140 processor cores
And of course from the software side we will continue to support Twinfin
models that are in the field, both with NPS engine updates and IDAA
software refreshs.
28

Support for DB2 11
Including first-day ESP support
Extending query routing eligibility to static SQL
Support for queries from local applications that use multi-row fetch
High Performance Storage Saver enhancements
Built-in restore
Better access control for archived partitions
Explicit protection for image copies created by archiving process
Loading from image copy
New RTS column: 'last-changed-at' timestamp
Explicitly used by stored procedure for detecting which tables/partitions need to be refreshed
Can be used when deciding which partitions are eligible for archiving by HPSS
Automatic workload balancing with multiple Accelerators
Incremental Update enhancements:
Supporting more DB2 systems connected to the same Accelerator
Better performance due to fewer log records that need to be processed by the Capture component (thanks to new DB2 IFI Filtering enhancement)
Improving performance for large result sets (thanks to new DRDA enhancements)
WLM support for local applications
Automated NZKit installation
Significantly reduced need for remote service access to System z and IDAA and on-site support
Richer monitoring at system, thread and statement level
Supporting EBCDIC and Unicode in the same DB2 system and Accelerator
Prospective CPU cost savings and elapsed time improvement(SMF)
Profile controlled special registers
Separation of duty for ACCEL_CONTROL_ACCELERATOR

Support for DB2 11
Including first-day ESP support
Extending query routing eligibility to static SQL
Support for queries from local applications that use multi-row fetch
High Performance Storage Saver enhancements
Built-in restore
Better access control for archived partitions
Explicit protection for image copies created by archiving process
Loading from image copy
New RTS column: 'last-changed-at' timestamp
Explicitly used by stored procedure for detecting which tables/partitions need to be refreshed
Can be used when deciding which partitions are eligible for archiving by HPSS
Automatic workload balancing with multiple Accelerators
Incremental Update enhancements:
Supporting more DB2 systems connected to the same Accelerator
Better performance due to fewer log records that need to be processed by the Capture component (thanks to new DB2 IFI Filtering enhancement)
Improving performance for large result sets (thanks to new DRDA enhancements)
WLM support for local applications
Automated NZKit installation
Significantly reduced need for remote service access to System z and IDAA and on-site support
Richer monitoring at system, thread and statement level
Supporting EBCDIC and Unicode in the same DB2 system and Accelerator
Prospective CPU cost savings and elapsed time improvement(SMF)
Profile controlled special registers
Separation of duty for ACCEL_CONTROL_ACCELERATOR

Support for DB2 11
Including first-day ESP support
Extending query routing eligibility to static SQL
Support for queries from local applications that use multi-row fetch
High Performance Storage Saver enhancements
Built-in restore
Better access control for archived partitions
Explicit protection for image copies created by archiving process
Loading from image copy
New RTS column: 'last-changed-at' timestamp
Explicitly used by stored procedure for detecting which tables/partitions need to be refreshed
Can be used when deciding which partitions are eligible for archiving by HPSS
Automatic workload balancing with multiple Accelerators
Incremental Update enhancements:
Supporting more DB2 systems connected to the same Accelerator
Better performance due to fewer log records that need to be processed by the Capture component (thanks to new DB2 IFI Filtering enhancement)
Improving performance for large result sets (thanks to new DRDA enhancements)
WLM support for local applications
Automated NZKit installation
Significantly reduced need for remote service access to System z and IDAA and on-site support
Richer monitoring at system, thread and statement level
Supporting EBCDIC and Unicode in the same DB2 system and Accelerator
Prospective CPU cost savings and elapsed time improvement(SMF)
Profile controlled special registers
Separation of duty for ACCEL_CONTROL_ACCELERATOR

Support for DB2 11
Including first-day ESP support
Extending query routing eligibility to static SQL
Support for queries from local applications that use multi-row fetch
High Performance Storage Saver enhancements
Built-in restore
Better access control for archived partitions
Explicit protection for image copies created by archiving process
Loading from image copy
New RTS column: 'last-changed-at' timestamp
Explicitly used by stored procedure for detecting which tables/partitions need to be refreshed
Can be used when deciding which partitions are eligible for archiving by HPSS
Automatic workload balancing with multiple Accelerators
Incremental Update enhancements:
Supporting more DB2 systems connected to the same Accelerator
Better performance due to fewer log records that need to be processed by the Capture component (thanks to new DB2 IFI Filtering enhancement)
Improving performance for large result sets (thanks to new DRDA enhancements)
WLM support for local applications
Automated NZKit installation
Significantly reduced need for remote service access to System z and IDAA and on-site support
Richer monitoring at system, thread and statement level
Supporting EBCDIC and Unicode in the same DB2 system and Accelerator
Prospective CPU cost savings and elapsed time improvement(SMF)
Profile controlled special registers
Separation of duty for ACCEL_CONTROL_ACCELERATOR

33
Self-encryting drives (SED, also called Hardware-based full disk encryption)
implement an encryption algorithm in hardware within the disk drive. All data that is
written is encrypted at full interface speed before writing it to media. Data is
decrypted before returned.
The disks in PDA models N300x use the symmetric cypher AES256. The symmetric
disk encryption key (DEK) is unique to each drive, stored in a secure tamper-proof
place on the drive and never leaves the drive.
The data on the drive is always encrypted using the DEK, however by default the SED
is in its unlocked state.
Unlocked Drive: A drive in a state where the SCSI session need not authenticate with
any AEK for the drive before any reads and writes can be performed. This is just like a
regular non-SED drive for all practical purposes though the drive stores the data
internally in an encrypted form using the DEK.
Secure cryptographic erasure: Because the drive is always encrypted, even in its
unlocked state you have a benefit. When you change the disk encryption key (DEK),
data that has been written and encrypted with the prior encryption key can no longer
be read. This capability is called Cryptographic erase. It allows to erase a full drive in
milliseconds (which would take hours or even days for a regular, unencrypted drive) -
for example before returning the drive to IBM service when a part is replaced. Since
the cryptographic erase can destroy valuable data, changing the DEK on the drive -
the cryptographic erasure function - requires to authenicate the request with a
Manufacturer’s Security Identifier (MSID). The MSID is unique for each drive and
supplied by the vendor of the drive.

34

The problem that we are solving with call home is to detect mainly
Hardware but also Software-failures and automatically inform IBM about
the failure, so that IBM can proactively send replacement parts to the
customer and send a field engineer to the customer for replacing the
part.
Previously IDAA has relied on failure event messages written to the
z/OS console log. The customer had to set up system automation to
detect such failures and manually open a problem ticket – a PMR.
This is now automatically done by the new call home feature.
Call home in IDAA is based on Netezza call home technology
introduced in NPS Kit 7.0.4.3P1
E-mails are generated in Netezza whenever certain events are
triggered
Events triggering a call home e-mail
Hardware problems (hardware errors, failed hard disks, …)
Software problems (Host failover, core dumps, …)
E-mails are relayed from the Accelerator to an IBM PMR gateway via
System z.
PMRs are automatically generated based on the information contained
in the e-mail
Information contains 35

36

37

38


40

41

42

43

44

45

46

47

48

49

50

51

52

53

In the group model, query processing continues to work as tody in IDAA
V4 using workload balancing:
Each accelerator in the group will tell the connected DB2 subsystem its
status, capacity and current utilization and DB2 distributes the query
workload accordingly among the participating accelerators.
54

55

56

57

58

59

Is the Accelerator being under/over utilized?
Can I improve on my utilization of the Accelerator?
How do I improve on my utilization of the Accelerator?
What queries are being routed to the Accelerator?
Can I improve on what gets routed to the Accelerator?
Can I make sure I have the “best” objects for consideration?
How do I determine which objects are best suited for query consideration?
How can I determine costs savings from Accelerator to report to management?
Can I populate the Accelerator with data from other platforms?
Is there a way I can manage the Accelerator from an ISPF screen?

Is the Accelerator being under/over utilized?
Can I improve on my utilization of the Accelerator?
How do I improve on my utilization of the Accelerator?
What queries are being routed to the Accelerator?
Can I improve on what gets routed to the Accelerator?
Can I make sure I have the “best” objects for consideration?
How do I determine which objects are best suited for query consideration?
How can I determine costs savings from Accelerator to report to management?
Can I populate the Accelerator with data from other platforms?
Is there a way I can manage the Accelerator from an ISPF screen?

62




















