
University learning with anti-plagiarism systems
22
Full Terms & Conditions of access and use can be found at https://www.tandfonline.com/action/journalInformation?journalCode=gacr20 Accountability in Research Policies and Quality Assurance ISSN: (Print) (Online) Journal homepage: https://www.tandfonline.com/loi/gacr20 University learning with anti-plagiarism systems Manjur Kolhar & Abdalla Alameen To cite this article: Manjur Kolhar & Abdalla Alameen (2020): University learning with anti- plagiarism systems, Accountability in Research, DOI: 10.1080/08989621.2020.1822171 To link to this article: https://doi.org/10.1080/08989621.2020.1822171 Accepted author version posted online: 09 Sep 2020. Published online: 23 Sep 2020. Submit your article to this journal Article views: 30 View related articles View Crossmark data
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of University learning with anti-plagiarism systems
Full Terms & Conditions of access and use can be found athttps://www.tandfonline.com/action/journalInformation?journalCode=gacr20
Accountability in ResearchPolicies and Quality Assurance
ISSN: (Print) (Online) Journal homepage: https://www.tandfonline.com/loi/gacr20
University learning with anti-plagiarism systems
Manjur Kolhar & Abdalla Alameen
To cite this article: Manjur Kolhar & Abdalla Alameen (2020): University learning with anti-plagiarism systems, Accountability in Research, DOI: 10.1080/08989621.2020.1822171
To link to this article: https://doi.org/10.1080/08989621.2020.1822171
Accepted author version posted online: 09Sep 2020.Published online: 23 Sep 2020.
Submit your article to this journal
Article views: 30
View related articles
View Crossmark data

University learning with anti-plagiarism systemsManjur Kolhar and Abdalla Alameen
Department of Computer Science, College of Arts and Science, Prince Sattam Bin Abdulaziz University, Al-Kharj, Saudi Arabia
ABSTRACTWe have designed an anti-plagiarism software to detect plagi-arism in students’ assignments, especially written assignments, homework, and research reports, which will hereinafter be collectively referred to as student work. We used our university network to gather student work to detect plagiarism. . To collect data, we used a domain name system to store the student work data based on the respective location, time, and the subject on which each student was assigned work. Once the student work data were collected, they were sent to an extraction module to remove unwanted data. The remain-ing data were then fed to a similarity index module, which produced similarity values based on comparisons between the collected data and the student work. This module uses math-ematical equations that are built using semantic and syntactic similarity reports. Furthermore, in this study, we recommended procedures that can be applied to avoid plagiarism using the programming approach. This approach can raise awareness of plagiarism among students and encourage them to generate innovative ideas instead of plagiarizing. To attract faculty members to use the software, promotional materials can be customized based on the actual control factors that directly affect their adoption of the software. For example, the cam-paign should provide information highlighting the ease of implementation of the software for senior faculty members.
ARTICLE HISTORYIntegra12 September 2020
KEYWORDSBackhaul services; learning and teaching method; plagiarism; software; win32 programming
Introduction
Gipp, Meuschke, and Breitinger (2014) highlighted that plagiarized papers hinder the scientific research process. The plagiarized content and wrong findings can adversely impact the future research direction as well as practical applications (Alsallal et al. 2013). Such as in medicines and pharmacology, the plagiarized researches can skew the meta-studies, which cause a detrimental effect on the patient’s safety and puts patients’ safety in jeopardy. A number of colleges and universities add to their formal honor codes, enact strong enforce-ment policies, install anti-plagiarism software, and promote greater awareness
CONTACT Manjur Kolhar [email protected] Department of Computer Science, College of Arts and Science, Prince Sattam Bin Abdulaziz University, Al-Kharj 119900, Saudi Arabia
ACCOUNTABILITY IN RESEARCH, 2020https://doi.org/10.1080/08989621.2020.1822171
© 2020 Informa UK Limited, trading as Taylor & Francis Group

programs for overcoming with the epidemic of Internet plagiarism (Amin, Yaseen, and Mohammadkarimi 2019). A pertinent and effective method is provided by systematic detection via anti-plagiarism software of these counter-measures (Popescu, Laszlo, and Naaji 2017). On the contrary, anti-plagiarism software has been adopted by comparatively few faculty members. This study sought to demonstrate the large gap between faculty members’ concern regard-ing the use of Internet plagiarism and their minimal implementation of pre-ventative software (Kale 2020). Some speculation recommends they might be unwilling for adopting anti-plagiarism software, but evidence has yet to recog-nize the enablers and facilitators of decisions of faculty members to adopt (Pradhan 2020). Previously, studies have majorly emphasized on the motivation of students for committing Internet plagiarism, not on the role of faculty in order to fight and educate students regarding the topic (Nikam and Mahadevaswamy 2018). Additionally, studies have treated protective systems as similar to productivity-improving technologies and utilize generic IT adop-tion theories for addressing their adoption.
Previous studies have provided a critical overview of anti-plagiarism models. For instance, Culwin and Lancaster (2000) have indicated that Plagiarism.org is effective while Integriguard is usually unsatisfactory for majority of academic institutions. They further noted that Copycatch was the easiest to use and EVE generated the least convincing outcomes. Another study has used key phrase searching for trying and locating text sources in other papers (Satterwhite and Gerein 2001). Their results have indicated a surprising divergence in outcomes, with some apparently sophisticated and expensive automated detection services offering little better as compared to a simple search engine phrase search. Paper bin or How original were amongst the services, which were specifically ineffec-tive as they catch recurrent phrases or single words to check. McKeever (2006) has revealed that Turnitin disappointed in detecting the see-mingly random nature of the passage checking where a clear association was observed. Comparative reviews of functionality were similarly com-plicated to find as compared to their performance.
Despite all these potential disadvantages, there are many advantages in using plagiarism detection. In this day of mass student numbers, the most noteworthy is that of time saving. A previous study has explained a series of cases in which the alleged plagiarism was examined regardless of the assistance of an automated detected service from the conventional sources (Larkham 2003). The Internet means causing this massive infor-mation elevation has now been exploded to encompass a vast range of web-based materials, to which students might have been expected to confine themselves in specific subjects. If handled judiciously, online detection can be employed as an influential educational tool to enable a tutor for evaluating the plagiarism scale in merely punitive fashion,
2 M. KOLHAR AND A. ALAMEEN

and then to work with students for dealing with it in a constructive approach, specifically with some detection services providing self-test and rewrite facilities.
The underlying argument in educational institutes is that plagiarism leads to the use of ideas, innovations, and writings, etc., of others and reuse of them (completely or partially) regardless of appropriate references or cita-tions to the source. For educators, the ability to identify plagiarism is challenged by the quality, functionality, and accessibility of the different tools and resources supported by institutional platforms. In particular, much of the research on plagiarism is relied on reducing and identifying intention, a qualitative factor that has restricted adaptability in analytical tools.
For students, the decision to plagiarism is majorly classified to one of seven different conditions, which include poor writing/referencing/ research practice, saving time or effort, getting higher marks, belief that one’s work is inappropriate, lack of understanding about plagiarism, cultural factors, and belief that majority of people plagiarize. The out-come of plagiarism on an institutional scale has been directly classified to the degradation of institutional reputations. The need for exemplary plagiarism monitoring and detection has become unprecedented in today’s globally connected and information-rich scholastic community.
Study objectives and contribution
The purpose of this research is to develop anti-plagiarism software proce-dures and study the level of awareness about plagiarism amongst university students. The study also help developers and university administrators to exploit software’s effectiveness in the plagiarism and existence of university policies to manage it.
Related work
Ataman et al. (2016) showed that artificial publication inflation counts through the plagiarism can cause adverse outcomes. Such as studies in plagiarized content were often cited similar to that in the original content, which increases the citation counts, affecting the research performance and causing problems in funding and hiring.
Harris Salleh (2011) has undertaken the overview of effective plagiarism detection tools for assisting the users in their research work by comparing different software tools. According to Harris Salleh (2011), there is no such software that can prove 100% plagiarized document as each software and tool possess advantages and barriers based on their performance and features. Patil (2015) has emphasized that different software tools handle plagiarism,
ACCOUNTABILITY IN RESEARCH 3

help students and teachers to validate text, and guide researchers. The study has also discussed the attributes and limitations of different plagiarism soft-ware including Anti-Plagiarism Dupli Checker, Viper, Paper Rater, Turnitin iThenticate (as shown in Fig 1.), Urkund, Plagium, Plagtracker, and Plagscan. Chowdhury and Bhattacharyya (2018) have emphasized on a few methods for detecting plagiarism on the basis of machine learning techniques along with advantages and limitations, and concerns and challenges of such meth-ods. The study has also emphasized on several methods available for detect-ing the plagiarism such as vector-based methods, syntax-based methods, semantic-based methods, character-based methods, grammar semantics, methods for cross-lingual plagiarism detection, classification, cluster-based methods, citation-based methods, and hybrid plagiarism detection methods.
Kunschak (2018) has assessed the use of Turnitin and offered an overview of the different measures adopted by the students, teachers, and tutors for making the vital use of different functions of the software for investigating writing. The results have indicated that a preference was expressed by students to continue access to Turnitin for other classes. The capacity of Turnitin allows to raise consciousness with respect to digital literacy and critical media which are of significant importance with the current net- generation. In addition, several opportunities are presented by Turnitin for peer-collaboration via its peer-review function, honing important editing and self-editing skills for their additional university life. Additional support is provided by Turnitin in facilitating teachers to set up different stages in the writing process, ensuring several drafts, and in turn an enhanced central argument.
Halgamuge (2017) has examined the effectiveness of the Turnitin software as a tool for helping in writing. A total of 3173 samples were collected from 14 university students. The findings have offered an overview in order to avoid different plagiarism levels through Turnitin. The study has further concluded that there is a significant advantage in using Turnitin as an educational writing tool as compared to a punitive tool. The use of Turnitin encourages student learning findings with considerably enhanced academic skills.
Dodigovic and Jiaotong (2013) have claimed that Turnitin could be uti-lized as a learning tool for assisting the students in order to enhance their skills for quoting and purchasing adequately with the assistance of instruc-tions formulated for this objective. The findings have indicated that Turnitin used as a learning tool for making essential adjustments and effective para-phrasing. Turnitin can be used for uploading the final assignment drafts only, all assignment drafts and for improving paraphrasing skills.
Previously, several studies have been undertaken by the authors for asses-sing the effectiveness of Turnitin in the academic realm. Biggam and McCann (2010) have identified Turnitin as a mechanism to reduce the
4 M. KOLHAR AND A. ALAMEEN

occurrences of plagiarism. They have concluded that Turnitin reports were beneficial for supervisors as they can be used for discussing writing styles of students and the sources referenced. Supervisors were also alerted on the slow rate of student submissions of poor time management of students.
Thompsett and Ahluwalia (2010) have recommended that students did not find anti-plagiarism software user-friendly neither did they emphasize on its usefulness in academics. The study has concluded that the alternative way is preferred by majority of the students in detecting plagiarism and collusion. Educators can be assisted in understanding these perspectives and developing new strategies when experiencing collusion and plagiarism in final year undergraduate biosciences.
Cortes-Vera, Garcia, and Machin-Mastromatteo (2018) have identified a non-comprehensive list of advantages and challenges that emerged from using the Turnitin software. Rashid and Rashid (2018) have suggested the ways for adequate use of the Turnitin software for supporting the training of researchers so that they can develop the effectiveness of the tool in standard writing. The study has used Turnitin for reinforcing and justifying its use for detecting questions, queries, comments, and suggestions attended and responded in a timely fashion.
Brabazon (2015) has studied how anti-plagiarism software solved the crisis in universities. Patel, Bakhtiyari, and Taghavi (2011) have emphasized on the repercussions of anti-plagiarism services in order to detect the plagiarism activities in scholarly work. Bailey and Challen (2014) have monitored the utilization of the software and further invited the students for expressing their observations on Turnitin and its value as a learning tool. Ali and Holi (2013) have examined and evaluated the experiences of the faculty and assessed the strength and limitations of the anti-plagiarism software.
Butakov et al. (2019) have proposed architecture to emphasize on light-weight integration with LMS and the probability for the universities to adjust the amount of information being transferred to plagiarism detection services on the basis of intellectual property rules implemented by the university. Javaid, Sultan, and Ehrich (2020) have conducted Rasch analysis to optimize the measurement qualities of its scale. No significant changes were indicated in the attitude and behavior of the students, which remained very soft and lenient toward plagiarism in spite of the strict policies of the higher educa-tion commission as well as the university. These findings indicate that the students lacked understanding and awareness of what comprises as plagiar-ism, and requires the development of anti-plagiarism services for reducing academic misconduct. Amin and Karimi () have indicated that Turnitin could be an influential deterrent against plagiarism. One of the major limitations noted was the lack of appropriate feedback from supervisors to students before submitting their works based on the outcomes of Turnitin,
ACCOUNTABILITY IN RESEARCH 5

specifically for undergraduate and Master students. The study has also indicated that the services of Turnitin was not applicable when detecting quotations in the text. Perkins, Gezgin, and Roe (2020) have identified the costs needed for developing anti-plagiarism services (Turnitin) in the English for Academic Purposes (EAP) program in British University Vietnam. It was identified that such costs may pose a barrier to entry for majority of the institutions, which cannot be ignored by universities, given the increasing focus on academic integrity.
Mphahlele and McKenna (2019) have revealed that technology is an important aspect in the attempts of universities toward the occurrences of plagiarism, and that Turnitin is the most preferred text-matching tool. On the contrary, the software is wrongly used as a plagiarism detected tool for policing objectives and ignoring its educational capacity for student devel-opment. Students might develop their academic writing if Turnitin is pri-marily used as a policing tool, but its misuse can also alter behavior of students in undesirable ways. Kumar, Prabhakar, and Dahiya (2019) have reviewed and identified that Turnitin is a very effective and dominant detection tool. However, its services are available on payment basis and compares the data of uploaded documents with the online data. The simi-larity of text is only detected by Turnitin or any other plagiarism detection tools in the uploaded documents rather than plagiarism but similarity does not show the significant form of plagiarism.
Previously developed models such as Zhang and Chow, Evolutionary Plagiarism Probability (EPP), semantic analysis model and etc. failed to capture the source document and sentence, where the predominant focus was on the Internet search (; Zhang and Chow 2011). This led to their generation of inaccurate or redundant matching results. However, the study framework started a collection as soon as students start working on assignments and laboratory reports. Hence, it avoided searching for source text sentences on the Internet. Studies have shown that undetected cases of plagiarism can cause severe negative outcomes. Such as Foltýnek, Meuschke, and Gipp (2019) reported that the plagiarist could receive the research funds or the career advancement based on their plagiarized idea recognition by a funding agency.
Proposed system
The proposed system architecture is presented in Figure 2. It contains a plagiarized material collector and constitutes two modules; one runs at the client machine, and the other is the server. During online submission of laboratory reports or college assignments, students were required to complete and submit their respective assignments in college itself. While the students were completing their assignments using mouse and keyboards, the reports
6 M. KOLHAR AND A. ALAMEEN
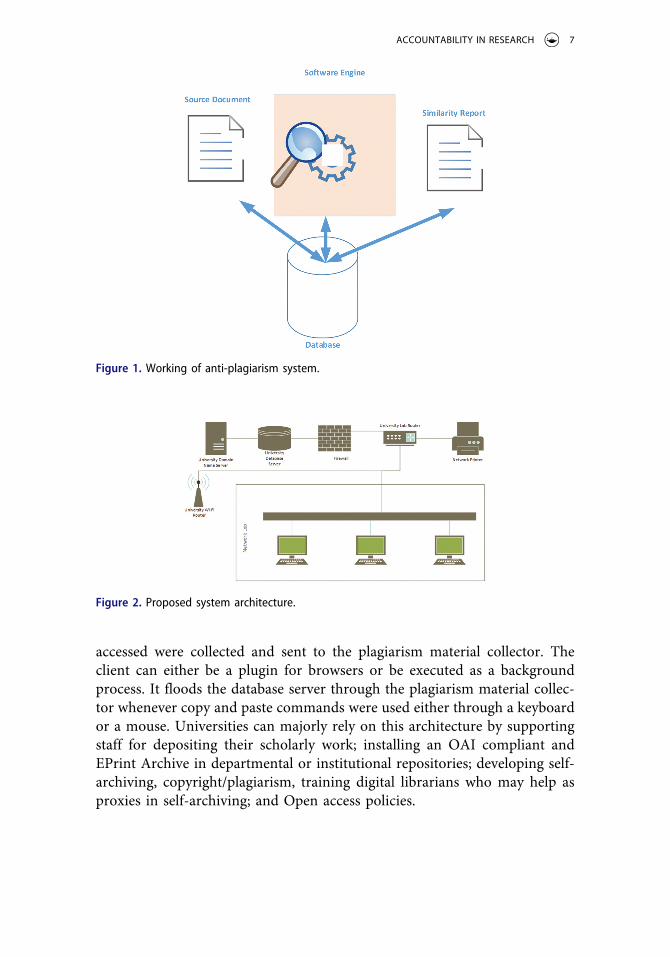
accessed were collected and sent to the plagiarism material collector. The client can either be a plugin for browsers or be executed as a background process. It floods the database server through the plagiarism material collec-tor whenever copy and paste commands were used either through a keyboard or a mouse. Universities can majorly rely on this architecture by supporting staff for depositing their scholarly work; installing an OAI compliant and EPrint Archive in departmental or institutional repositories; developing self- archiving, copyright/plagiarism, training digital librarians who may help as proxies in self-archiving; and Open access policies.
Figure 2. Proposed system architecture.
Figure 1. Working of anti-plagiarism system.
ACCOUNTABILITY IN RESEARCH 7

Client module
It does not require students to input any details because it runs as a background program on the students’ computer. It collects data while the student works on laboratory reports or assignments. Win32 programming was used for collecting data. The collected data were categorized into two: data collected from the local drive, called local data, and data from sources such as browsers and drives (Google or OneDrive, etc.), called foreign data.
Figure 3 shows client communication, wherein as soon as users or students log in with their Internet protocol address, name, and academic number, all credential data were transferred to the server. For capturing mouse and keyboard movements, some hooks (wind32 application programming inter-face [API]) from the NET library from Windows were used. Furthermore, the GetLastInputInfo API was used to obtain the last input (from the mouse or keyboard). This API provides useful information such as the date and time of the last input from the mouse or keyboard.
In case a student copies information from the source, the client module would obtain its URL and send it to the server. Request.Url.AbsoluteUri API was used to obtain the information of the browser. This API will procure the URL of the current page using C#. The final step was executed when data (local and foreign data) were used in the client module. The study client module uses socket programming to transfer the data to the server.
The main concern related to capturing data from various clients or students was the creation and management of accounts for students. When accounts are created, only a specific client can send local and foreign data. Presently, the study proposed framework was in the testing phase, where maintaining student accounts were difficult as students can perform outside
Figure 3. Client-server communication module.
8 M. KOLHAR AND A. ALAMEEN

the university campus. The developed and proposed framework supports two categories of student management, namely centralized and distributed, where each category has certain advantages and disadvantages.
In the centralized student management (CSM) module, a student’s account can be created under the teachers’ account. The teacher can give specific access privileges to each student or their group. The teacher can use CSM with Administrator login privileges for creating student’s assignment groups. Nonetheless, with the above access privilege, once a group was created, and then they were restricted to work on university campuses only. By contrast, the CSM approach enhances teacher role and control over student activities. Subsequently, the teacher can easily watch, verify, and grade the assignments.
Whereas the CSM module lacks in preparing students assignments outside the university campus cannot be submitted as, and they do not have any privileges. In the distributed student management module, students create their accounts using their college credentials, such as their academic num-bers. Hence, students can work on their assignments from home or on campus. Lastly, instructors have no control over students’ activities, and students cannot share activity space among themselves (typically, student’s exhibit nonuniform submission or nonuniform activities).
In the proposed framework, the focus was on designing the web database management systems that were consistent with overall work requirements. The related and unrelated data were measured for determining the success of the firm project. For instance, the information from the related and unrelated student data was accessed along with the quantity of the transferred data, following optimized data distribution and control data explosion. No valida-tion system was required for the remote stored data as these techniques were likely to be supplemented through different database management systems, including database fragmentation, distribution, caching, scalability, and clus-tering. The large database transaction cost, as well as relevant parameters, can be reduced using the stated techniques (Teh and Paull 2013). In this parti-cular study, a normal database was used to record the students’ activities related to laboratory reports and assignments. Currently, the study system was hosted by 25 students. When the system was being implemented on the entire university, any technique can be opted.
Server
To build the documents database, several documents over the network and recorded client programs were used. The client program was executed as a background process. The database server saves these documents and for-wards it to the teacher who has assigned the task. The database server contains five fields: student ID, password, e-mail address, academic ID,
ACCOUNTABILITY IN RESEARCH 9

local document, and URL information (access date and time). Also, the details of their job (assignment name and laboratory session report number) were required.
After students’ successful login to the server, their respective systems can be used to work on their assignments or laboratory reports. For this purpose, they will have to choose a name and password and should type the required information before log in to the server. The client notes students searched keywords and texts on the Internet or locally saved documents. If copy or paste commands were not detected while using a browser, the client does not forward data to the server. However, the client can also send its collected data even if no activities related to the copy and paste commands were detected.
This database can produce temporary data because of the repeated execu-tion of structured query language (SQL) queries. Hence, the proposed frame-work holds certain temporary data, including objects such as tables, table variables, and data results from data-intensive operations such as storing and retrieving local and foreign data. The size of the temporary memory needed to execute the query was crucial. If a query requires more than the available temporary memory, spills-to-disk queries were executed for each database.
If a query requires considerable memory for execution, then the database can be split into the data to file (temporary file). Microsoft SQL and Oracle RDBMS both use temporary tables. Hence, a special database such as TempDB from Microsoft SQL Server can spill such temporary data, whereas Oracle used Tablespaces. These services were incorporated into research to enhance the performance of queries.
Data gathering
To learn about the students’ activities in lab sessions, the browsed data were collected from the website www.psau.edu.sa. a platform that enables students, faculties, and departmental heads to attend online exams. Our network labs are equipped with a thin client server architecture, which enables us to collect data from the university network domain during student work sessions. The university network is optimized for remote connections with the university server environment. The university server does most of the work, such as running a backhand server and storing student data.
Classification of data
In the proposed framework, the student’s data convey different types of plagiarism, which were classified into three aspects such as completely copied, partially copied and acknowledged. Student selects one or more types of plagiarism for their task. The data will also be checked from the articles available in the PDF format.
10 M. KOLHAR AND A. ALAMEEN

In the completely copied category, students completely copy their work, and never acknowledged it. The proposed framework was responsible for identifying such jobs and asking concern authorities to take steps to elim-inate the problems and guiding the students to an acceptable standard. Partially copied, such categories were still considered as plagiarism because they fail to acknowledge others’ work. In academics, such cases were also dealt with severely, and students were expected to rectify their assignments and lab works.
Data pre-processing
To identify plagiarism in student’s work, the module has been divided into three submodules, such as sentence module, stop word removal module, and stemming. In sentence module, source document (data were gathered from the website, when categorized based on student name, IP address, etc.) and student documents are split sentence wise. However, the sentence splitting and tokenizing require software tools for different languages. Hence, the project has used text to sentence split using the heuristic algorithm by Philipp Koehn and Josh Schroeder, which was available in the form of python libraries. For removing stop words, Natural Language Toolkit, python has a list of stop words available in 16 different languages. Table 1 and Table 2 shows the list of available stop words.
Table 1. A list of stop words derived from python shell.{“ourselves”, “hers”, “between”, “yourself”, “but”, “again”, “there”, “about”, “once”, “during”, “out”, “very”,
“having”, “with”, “they”, “own”, “an”, “be”, “some”, “for”, “do”, “its”, “yours”, “such”, “into”, “of”, “most”, “itself”, “other”, “off”, “is”, “s”, “am”, “or”, “who”, “as”, “from”, “him”, “each”, “the”, “themselves”, “until”, “below”, “are”, “we”, “these”, “your”, “his”, “through”, “don”, “nor”, “me”, “were”, “her”, “more”, “himself”, “this”, “down”, “should”, “our”, “their”, “while”, “above”, “both”, “up”, “to”, “ours”, “had”, “she”, “all”, “no”, “when”, “at”, “any”, “before”, “them”, “same”, “and”, “been”, “have”, “in”, “will”, “on”, “does”, “yourselves”, “then”, “that”, “because”, “what”, “over”, “why”, “so”, “can”, “did”, “not”, “now”, “under”, “he”, “you”, “herself”, “has”, “just”, “where”, “too”, “only”, “myself”, “which”, “those”, “i”, “after”, “few”, “whom”, “t”, “being”, “if”, “theirs”, “my”, “against”, “a”, “by”, “doing”, “it”, “how”, “further”, “was”, “here”, “than”}
*The programmer can further comprehend this list as required.
Table 2. Performance comparison between PAN-PC-11systems.{“ourselves”, “hers”, “between”, “yourself”, “but”, “again”, “there”, “about”, “once”, “during”, “out”, “very”,
“having”, “with”, “they”, “own”, “an”, “be”, “some”, “for”, “do”, “its”, “yours”, “such”, “into”, “of”, “most”, “itself”, “other”, “off”, “is”, “s”, “am”, “or”, “who”, “as”, “from”, “him”, “each”, “the”, “themselves”, “until”, “below”, “are”, “we”, “these”, “your”, “his”, “through”, “don”, “nor”, “me”, “were”, “her”, “more”, “himself”, “this”, “down”, “should”, “our”, “their”, “while”, “above”, “both”, “up”, “to”, “ours”, “had”, “she”, “all”, “no”, “when”, “at”, “any”, “before”, “them”, “same”, “and”, “been”, “have”, “in”, “will”, “on”, “does”, “yourselves”, “then”, “that”, “because”, “what”, “over”, “why”, “so”, “can”, “did”, “not”, “now”, “under”, “he”, “you”, “herself”, “has”, “just”, “where”, “too”, “only”, “myself”, “which”, “those”, “i”, “after”, “few”, “whom”, “t”, “being”, “if”, “theirs”, “my”, “against”, “a”, “by”, “doing”, “it”, “how”, “further”, “was”, “here”, “than”}
*The programmer can further comprehend this list as required.
ACCOUNTABILITY IN RESEARCH 11

Stemming wordsStemming reduces word to its stem form. It helps to recognize words that belong to the same stem, such as am, are, and is belong to be. Hence, stemming it gives root words by using WordNet. WordNet is a lexical dataset and comprises nouns, verbs, adjectives, and adverbs, which were grouped into sets of cognitive synonyms (synsets), each expressing a distinct concept. This library has 121,962 words, 99,642 synsets, and 173,941 sense of words.
Student’s job in the form doc (student work) was compared with the student data, and then collected during their assignment or LAB session. Both document SW and document SD were compared in terms of sentences. Following steps were followed while comparing the two documents.
● Tokenization of sentence and words● Wordnet● Create a bag of words● Term Frequency – Inverse Document Frequency● Create a Similarity measure object
In the tokenization of words module, a text document was divided into smaller entities called tokens. In natural language processing, it was used for developing applications such as text classification, chatbots, analysis for review system, language translation, etc. Hence, tokenization is a major module in the aforementioned techniques. Further, tokenization was used for finding text patterns before applying for stemming.
In this proposal, aforementioned technique word tokenizer was applied to split a sentence present in the original document and student job into words. Out of this process was an input to the cleaning process, such as stemming. Hence, the ML engine can use numerical data for both training and prediction. However, apart from these benefits, tokenization address specific challenges such as words contain parentheses, handling abbreviations, end of the line, true hyper, and hyphens, especially when dealing with biomedical documents.
To create a word vector for each word appearing in both the documents, following steps were followed.
(1) Input the documents.(2) Read the documents line by line(3) Tokenize the line(4) Stem the words(5) Word order vector(6) Repeat step 2 to step 5 until it is to the end of the document.
12 M. KOLHAR AND A. ALAMEEN

Afterword vector, Bags of Words (BoW) for each sentence was con-structed. Once word vector was built, BoW was developed using a pair of words using a bi-gram and 2 g because it was easy to represent words in 1 g.
Term-frequency-inverse document frequency (TF-IDF) was yet another technique to measure the topic of an article by the words it contains. TF-IDF allows the researcher to measure weight TF-IDF importance, not how many times a word appears. That is, word counts were replaced with TF-IDF scores for a particular document.
Initially, the study counted the number of times given the words for both documents. However, the appearance of some words such as “and” and “the” was discarded because they appeared frequently.
wi;j ¼ tfi;j � logNdfi
� �
where tfi,j is the occurrence of the word i in j, dfi is the number of documents containing i,
N= total number of documents.
Similarity reportThe most important components of any given student work are the sentences and words that comprise a complete document. We develop an arrangement to compare two documents (the student work and the data collected during student work sessions). We use the WordNet library to report a similarity index based on semantic and syntactic arrangements throughout documents. Such databases are called lexical databases, and they yield synsets, which are lists of synonyms. For the purpose of comparison, we use the following equations, which are given by (Abdi et al. 2015), to iterate through the WordNet lexical database and find the least common subsume.
IC wð Þ ¼ 1 �log synset wð Þ þ 1ð Þ
log maximumwð Þ
similarity w1;w2ð Þ ¼2�IC LCS w1;w2ð Þð Þ
IC w1w2ð Þ
Experiment
The experiments on datasets collected were conducted for over more than 2 years. To measure the performance of the proposed method, different eva-luation metrics were used such as precision, recall, F-measure, and granularity.
ACCOUNTABILITY IN RESEARCH 13

It is suggested to use the following equation to detect plagiarism (Abdi et al. 2015).
prec S;Rð Þ ¼1Rj j
X
r2R
[s2S S\rð Þj j
rj j
Rec S;Rð Þ ¼X
s2S
[r2R S\rð Þj j
sj j
where
S\r ¼s\r
;
�
if r detects s and otherwise ;This study proposed framework outperform PAN-PC-11systems propo-
sals. Different evaluation metrics such as recall, precision, and F-measure were used for experiment.
Tables 3 and 4 list entries of state of the art of proposals wherein the formula below was applied to calculate the percentage of improvement for the PAN-PC-11 dataset.
impr in% ¼our Proposed method � state of the art research
state of the art research
� �
%100
The documents used in the framework were derived from the student portal. Every document in the framework serves one of two objectives: it is either used as a document suspicious of plagiarism or as a source for
Table 3. Document statistics of the PAN-PC-11.Document Purpose Percentage
Source documents 60%Suspicious documentsWith plagiarism 20%Without plagiarism 20%
Intended algorithmsExternal detection 60%Internal detection 40%
Plagiarism per documentEntirely 10%Extreme 30%Medium 50%Low 10%
Document lengthShort 60%Medium 35%Long 5%
14 M. KOLHAR AND A. ALAMEEN

plagiarism. The suspicious documents were divided into documents that actually comprise of plagiarism and documents that do not. The documents without plagiarism facilitate in determining whether or not a detector can differentiate plagiarism cases from overlaps that happen naturally between random documents. The intrinsic plagiarism detection and external plagiar-ism detection were the two paradigms in which the framework was divided. The source documents used were omitted for generating the plagiarism cases.
Main advantages of the proposed framework
This framework provides access to compare multi-lingual texts, which require language detection, machine translation, and a determination of word position in the translated and original text as possible. Furthermore, transformation of text enables the detection of matches throughout a specific part of text. Based on short sub-sequences, detection of plagiarized text passages is merely possible to detect the matching parts of appropriate representations of source and suspicious text. The number of subtext char-acters can be defined by overlapping N-grams, which is currently popular and backed by tests. This framework is also able to detect similar passages in source and suspicious files based on heuristics, defining the minimum number of consecutive positive representation matches or the minimum extent of matches throughout the passage.
Extraction of appropriate passages in source and suspicious files is often the most difficult stage as it requires the merging of passages from a phrase and division and exclusion. This is either done by segmentation methods or heuristic methods, which can be illustrated in a 2D plane. Certain typical patterns are showed from the visualizations of non-plagiarized, obfuscated or non-obfuscated source and suspicious passages.
Finally, the student’s problem with a laboratory slot was not an issue as students can work on their assignments from anywhere and at any time.
Table 4. Plagiarism case statistics over PAN-PC-11system.Topic Match Percentage
Intra-topic cases 70%Inter-topic cases 30%
ObfuscationNone 35%ArtificialLow obfuscation 25%High obfuscation 25%Simulated 6%Translated 9%
ACCOUNTABILITY IN RESEARCH 15

Strengths and limitations of proposed framework
To avoid such situations, information on plagiarism was disseminated as well as its consequences. This improved course learning outcomes.
Some written comments were also received in which students stated the use of the developed framework for preparing laboratory reports and assign-ments. This is highly inspiring from two perspectives, i.e., knowledge about plagiarism and gaining skills, particularly writing skills, for research publication.
This plagiarism evaluation framework measures for plagiarism detection and laboratory reports and assignments. The features presented in this algorithm were based on different types of plagiarism cases such as high-lighting the similarity index and the source, plugging into anti-plagiarism software and other evaluation metrics including F-measure, recall, and pre-cision. An evaluation of the laboratory reports and assignments in relation to previous assignments indicate a high degree of maturity. Until now, more than seven plagiarism detectors have been compared via evaluation frame-work. This number of systems has been accomplished on the basis of two benchmarking workshops in which the framework was developed and imple-mented, such as PAN’ 09 and PAN’ 10.
This study offers technical information to software developers and uni-versity management and administrative departments to discuss both the efficacy of anti-plagiarism software and the risk of Internet plagiarism. The adoption of anti-plagiarism software is affected by both threat and coping appraisals for addressing plagiarized content. Additional emphasis on threat appraisals could encourage the implementation of anti-plagiarism software rigorously.
All academics are encouraged to continuously explore anti-plagiarism measures with a perspective to find any assignments or text posted there and collecting the essential evidence for informing any other academics whose assignments may be involved. The lack of any technical examination at offshore operation made it impossible for identifying the students involved. The proposed model had the initial tip-off from the academic overseas with the evidence of the laboratory reports and assignment posted, and conducted an exhaustive and extensive technical examination in acces-sing the IThenticate services for a solution. An ideal scenario might be to have IThenticate services monitored on a frequent basis for detecting the presence of laboratory reports and assignments posted by students. Such postings are accessible to registered users, where registration is open to anyone. Therefore, this study implies that a collegiate approach could lead to an inter-varsity approach to address the plagiarism issues.
A plagiarism policy should be adopted in academic institutions as well as strict actions should be taken against defaulters on plagiarism, which make
16 M. KOLHAR AND A. ALAMEEN

the students aware of the methods for avoiding plagiarism, and lastly, a program should be organized at the national level for promoting academic integrity. It is also vital for promoting the use of anti-plagiarism software as a learning tool for detecting the duplication of research effort and research content as compared to a controlling device or policing. Additionally, the software must be anticipated as an assistance to a positive and coherent educational approach to academic honesty as compared to quick shortcut for stopping plagiarism or cheating or unintentional or intentional copying. It is essential to explore at the reports analytically as compared to depending on merely mechanically generated and screened the similarity score alone for all of these reasons. The role of librarians and library as facilitators, educa-tors, counselors, and monitors of usage is huge as they are already successful and experienced in order to handle the electronic resources on campuses.
Conclusion
In this study, a student-targeted anti-plagiarism architecture was proposed. These phases of plagiarism monitoring, subversion, and detection are merely a first stage in the analytical protocols that must be implemented at the core of any university. The possibility to reduce plagiarism is minimal through any singular strategy with students continuing to engage in more subversive behavior. On the contrary, it is postulated that the prevalence of plagiarism will commence to reduce over time, by widening the scope of evaluation, improving the depth of analysis, and re-emphasizing current protocols on a complicated spectrum of dimensions.
Implications and recommendations
This study has evaluated the breadth of plagiarism monitoring and detection resources that are presently being implemented in higher education institu-tions across the developing world. A much more definitive stance against plagiarism and its multiple iterations are required with an instantly evolving phenomenon, the scope of student ethics and value systems, and globalized scholasticism. In this regard, a continuum of student-oriented adaptations has been revealed through this framework, which are rapidly changing the scope of detection and monitoring platforms.
One of the major challenges addressed through this framework is the textual and conceptual copying, which are two different elements in student writing. The capability to detect such offenses is reduced by the depth of analysis throughout the system itself while a student might avoid and sum-marize a specific idea or concept. On the contrary, a published insight should be copied by student to convey a robust concept or idea regardless of any attribution. The challenge for educators is to determine what comprises
ACCOUNTABILITY IN RESEARCH 17

plagiarism and how can these standards be implemented universally. This gray area contradiction may consequently emphasize in a formal and inten-sified rigidity, which erroneously effects upon the educational experience of ethically superior, honest students.
Acknowledgments
We would like to thank The Deanship of Scientific Research at Prince Sattam Bin Abdulaziz University for the resources.
Disclosure statement
No potential conflict of interest was reported by the authors.
Funding
This project was supported by the Deanship of Scientific Research at Prince Sattam Bin Abdulaziz University under the research project #2019/01/10440.
References
Abdi, A., N. Idris, R. M. Alguliyev, and R. M. Aliguliyev. 2015. “PDLK: Plagiarism Detection Using Linguistic Knowledge.” Expert Systems with Applications 42 (22): 8936–8946. doi:10.1016/j.eswa.2015.07.048.
Ali, H., and I. Holi. 2013. “Minimizing Cyber-plagiarism through Turnitin: Faculty’s & Students’ Perspectives.” International Journal of Applied Linguistics and English Literature 2 (2): 33–42. doi:10.7575/aiac.ijalel.v.2n.2p.33.
Alsallal, M., R. Iqbal, S. Amin, and A. James. 2013. “Intrinsic Plagiarism Detection Using Latent Semantic Indexing and Stylometry.” In 2013 Sixth International Conference on Developments in eSystems Engineering, 145–150. IEEE. doi:10.1109/DeSE.2013.34.
Amin, M., M. Yaseen, and E. Mohammadkarimi. 2019. “ELT Students’ Attitudes toward the Effectiveness the Anti-plagiarism Software, Turniti.” Applied Linguistics Research Journal 3 (5): 63–75.
Ataman, D., J. G. C. De Souza, M. Turchi, and M. Negri. 2016. “FBK HLT-MT at SemEval-2016 Task 1: Cross-lingual Semantic Similarity Measurement Using Quality Estimation Features and Compositional Bilingual Word Embeddings.” In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), 570–576.
Bailey, C., and R. Challen. 2014. “Student Perceptions of the Value of Turnitin Text-matching Software as a Learning Tool.” Practitioner Research in Higher Education 9 (1): 38–51.
Baydik, O. D., and A. Y. Gasparyan. 2016. “How to Act When Research Misconduct Is Not Detected by Software but Revealed by the Author of the Plagiarized Article.” Journal of Korean Medical Science 31 (10): 1508–1510. doi:10.3346/jkms.2016.31.10.1508.
Biggam, J., and M. McCann. 2010. “A Study of Turnitin as an Educational Tool in Student Dissertations.” Interactive Technology and Smart Education 7 (1): 44–54. doi:10.1108/ 17415651011031644.
Brabazon, T. 2015. “Turnitin? Turnitoff: The Deskilling of Information Literacy.” Turkish Online Journal of Distance Education 16 (3): 13–32.
18 M. KOLHAR AND A. ALAMEEN

Butakov, S., V. Shcherbinin, V. Diagilev, and A. Tskhay. 2019. “Embedding Plagiarism Detection Mechanisms into Learning Management Systems.” In Scholarly Ethics and Publishing: Breakthroughs in Research and Practice, 216–231. IGI Global.
Chowdhury, H. A., and D. K. Bhattacharyya. 2018. “Plagiarism: Taxonomy, Tools and Detection Techniques.” arXiv preprint arXiv:1801.06323.
Conway, J. 1972. “Unpredictable Iterations.” 49–52.Cooke, N., L. Gillam, P. Wrobel, H. Cooke, and F. Al-Obaidli. 2011. “A High-performance
Plagiarism Detection System.” In PLEF 2011 Notebook papers.Cortes-Vera, J., T. J. Garcia, and J. D. Machin-Mastromatteo. 2018. “A Mexican Strategy to
Promote Greater Ethics in Academic Communications through Nation-wide Access to Turnitin.” Information Development 34 (4): 422–427. doi:10.1177/0266666918785849.
Culwin, F., and T. Lancaster. 2000. “A Review of Electronic Services for Plagiarism Detection in Student Submissions.” In LTSN-ICS 1st Annual Conference, 23–25.
Dahl, S. 2007. “Turnitin®: The Student Perspective on Using Plagiarism Detection Software.” Active Learning in Higher Education 8 (2): 173–191. doi:10.1177/1469787407074110.
Dodigovic, M., and X. Jiaotong. 2013. “The Role of Anti-plagiarism Software in Learning to Paraphrase Effectively.” 23–37.
Ehsan, N., F. W. Tompa, and A. Shakery. 2016. “Using a Dictionary and N-gram Alignment to Improve Fine-grained Cross-language Plagiarism Detection.” In Proceedings of the 2016 ACM Symposium on Document Engineering, 59–68. doi:10.1145/2960811.2960817.
Ekbal, A., S. Saha, and G. Choudhary. 2012. “Plagiarism Detection in Text Using Vector Space Model.” In 2012 12th International Conference on Hybrid Intelligent Systems (HIS), 366–371. IEEE. doi:10.1109/his.2012.6421362.
Foltýnek, T., N. Meuschke, and B. Gipp. 2019. “Academic Plagiarism Detection: A Systematic Literature Review.” ACM Computing Surveys (CSUR) 52 (6): 1–42. doi:10.1145/3345317.
Franco-Salvador, M., P. Gupta, P. Rosso, and R. E. Banchs. 2016a. “Cross-language Plagiarism Detection over Continuous-space-and Knowledge Graph-based Representations of Language.” Knowledge-based Systems 111: 87–99. doi:10.1016/j.knosys.2016.08.004.
Franco-Salvador, M., P. Rosso, and M. Montes-y-Gómez. 2016b. “A Systematic Study of Knowledge Graph Analysis for Cross-language Plagiarism Detection.” Information Processing & Management 52 (4): 550–570. doi:10.1145/3345317.
Gipp, B., N. Meuschke, and C. Breitinger. 2014. “Citation-based Plagiarism Detection: Practicability on a Large-scale Scientific Corpus.” Journal of the Association for Information Science and Technology 65 (8): 1527–1540. doi:10.1007/978-3-658-06394-8_4.
Grman, J., and R. Ravas. 2011. “Improved Implementation for Finding Text Similarities in Large Collections of Data.” In Notebook Papers of CLEF 2011 LABs and Workshops.
Grozea, C., C. Gehl, and M. Popescu. 2009. “ENCOPLOT: Pairwise Sequence Matching in Linear Time Applied to Plagiarism Detection.” In 3rd PAN Workshop. Uncovering Plagiarism, Authorship and Social Software Misuse, 10.
Hababeh, I., I. Khalil, and A. Khreishah. 2014. “Designing High Performance Web-based Computing Services to Promote Telemedicine Database Management System.” IEEE Transactions on Services Computing 8 (1): 47–64. doi:10.1109/tsc.2014.2300499.
Halgamuge, M. N. 2017. “The Use and Analysis of Anti-plagiarism Software: Turnitin Tool for Formative Assessment and Feedback.” Computer Applications in Engineering Education 25 (6): 895–909. doi:10.1002/cae.21842.
Harris Salleh, M. 2011. “Academic Dishonesty: Factor That’s Contribute Plagiarism in A Technical College in Malaysia.” Kolokium Pembentangan Penyelidikan POLIMAS.
Javaid, S. T., S. Sultan, and J. F. Ehrich. 2020. “Contrasting First and Final Year Undergraduate Students’ Plagiarism Perceptions to Investigate Anti-plagiarism
ACCOUNTABILITY IN RESEARCH 19

Measures.” Journal of Applied Research in Higher Education. doi:10.1108/JARHE-04-2020- 0080.
Jharotia, A. K. 2018. Plagiarism Detection through Software in Digital World.Jiffriya, M. A. C., M. A. C. Akmal Jahan, R. G. Ragel, and S. Deegalla. 2013. “AntiPlag:
Plagiarism Detection on Electronic Submissions of Text-based Assignments.” In 2013 IEEE 8th International Conference on Industrial and Information Systems, 376–380. IEEE.
Kale, S. T. 2020. “Use of Turnitin and Urkund Anti-plagiarism Software Tools for Plagiarism Detection/similarity Checks to the Doctoral Theses: Indian Experience.” Cadernos BAD 1: 95–99.
Kasprzak, J., M. Brandejs, and M. Kripac. 2009. “Finding Plagiarism by Evaluating Document Similarities.” Proceeding of the SEPLN 9 (4): pp. 24–28.
Kleerekoper, A., and A. Schofield. 2019. “The False-Positive Rate of Automated Plagiarism Detection for SQL Assessments.” In Proceedings of the 1st UK & Ireland Computing Education Research Conference, 1–6.
Kumar, N., P. Prabhakar, and S. Dahiya. 2019. “Plagiarism and Deterrence Tools: A Fight against Academic Dishonesty.” Library Progress (International) 39 (2): 414–423. doi:10.5958/2320-317X.2019.00044.8.
Kunschak, C. 2018. “Multiple Uses of Anti-plagiarism Software.” The Asian Journal of Applied Linguistics 5 (1): 60–69.
Lagarias, J. C., ed.. 2010. The Ultimate Challenge: The 3x+ 1 Problem. American Mathematical Society. doi:10.1090/mbk/078.
Larkham, P. J. 2003. Exploring and Dealing with Plagiarism: Traditional Approaches.Luo, L., J. Ming, D. Wu, P. Liu, and S. Zhu. 2014. “Semantics-based Obfuscation-resilient
Binary Code Similarity Comparison with Applications to Software Plagiarism Detection.” In Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering, 389–400. doi:10.1145/2635868.2635900.
McKeever, L. 2006. “Online Plagiarism Detection Services—saviour or Scourge?” Assessment & Evaluation in Higher Education 31 (2): 155–165. doi:10.1080/02602930500262460.
Mphahlele, A., and S. McKenna. 2019. “The Use of Turnitin in the Higher Education Sector: Decoding the Myth.” Assessment & Evaluation in Higher Education 44 (7): 1079–1089. doi:10.1080/02602938.2019.1573971.
Nikam, K., and M. Mahadevaswamy. 2018. “Attitudes and Perceptions of the Research Scholars Towards the Use of Anti-Plagiarism Software for Quality Research Output: A Study.” Journal of Advancements in Library Sciences 2 (3): 7–17. doi:10.37591/joals. v2i3.367.
Oberreuter, G., and J. D. VeláSquez. 2013. “Text Mining Applied to Plagiarism Detection: The Use of Words for Detecting Deviations in the Writing Style.” Expert Systems with Applications 40 (9): 3756–3763. doi:10.1016/j.eswa.2012.12.082.
Önaçan, M., B. Kağan, M. Uluağ, T. Önel, and T. D. Medeni. 2019. “Selection of Plagiarism Detection Software and Its Integration into Moodle for Universities: An Example of Open Source Software Use in Developing Countries.” In Scholarly Ethics and Publishing: Breakthroughs in Research and Practice, 200–215. IGI Global. doi:10.4018/978-1-5225- 8057-7.ch009.
Patel, A., K. Bakhtiyari, and M. Taghavi. 2011. “Evaluation of Cheating Detection Methods in Academic Writings.” Library Hi Tech 29 (4): 623–640. doi:10.1108/07378831111189732.
Patil, A. V. 2015. “Plagiarism Software’s Useful to Researchers: Analysis of Few Softwares.” Asian Journal of Multidisciplinary Studies 3 (12): 86–91.
Perkins, M., U. B. Gezgin, and J. Roe. 2020. “Reducing Plagiarism through Academic Misconduct Education.” International Journal for Educational Integrity 16: 1–15. doi:10.1007/s40979-020-00052-8.
20 M. KOLHAR AND A. ALAMEEN

Popescu, M., C. Laszlo, and A. Naaji. 2017. “Software for Assessing the Performance of Anti-plagiarism Programs.” In MATEC Web of Conferences. Vol. 125, 04005. EDP Sciences. doi:10.1051/matecconf/201712504005.
Pradhan, B. 2020. “Anti-Plagiarism Software and Academic Integrity of Research Ethics: A Need of the Hour in Higher Education.” Tathapi with 2320-0693 Is an UGC CARE Journal 19 (6): 211–219.
Rao, S., P. Gupta, K. Singhal, and P. Majumder. 2011. External & Intrinsic Plagiarism Detection: VSM & Discourse Markers-based Approach Notebook for PAN at CLEF 2011.
Rashid, A., and A. Rashid. 2018. “Academic Policing via Top-Down Implementation of Turnitin in Pakistan: Students’ Perspective and Way Forward.” Pakistaniaat: A Journal of Pakistan Studies 6.
Rodríguez-Torrejón, D. A., and J. M. Martín-Ramos. 2010. “CoReMo System (Contextual Reference Monotony) a Fast, Low Cost and High Performance Plagiarism Analyzer System: Lab Report for PAN at CLEF 2010.” In Notebook Papers of CLEF.
Satterwhite, R., and M. Gerein. 2001. Downloading Detectives: Searching for Online Plagiarism.
Schleimer, S., D. S. Wilkerson, and A. Aiken. 2003. “Winnowing: Local Algorithms for Document Fingerprinting.” In Proceedings of the 2003 ACM SIGMOD international con-ference on Management of data, 76–85. doi:10.1145/872757.872770.
Schmidt, A., and S. Bühler. 2015. “On the Detection of Nontrivial and Cross Language Plagiarisms.” DBKDA 50.
Schneider, J., A. Bernstein, J. V. Brocke, K. Damevski, and D. C. Shepherd. 2018. “Detecting Plagiarism Based on the Creation Process.” IEEE Transactions on Learning Technologies 11 (3): 348–361. doi:10.1109/tlt.2017.2720171.
Selemani, A., W. D. Chawinga, and G. Dube. 2018. “Why Do Postgraduate Students Commit Plagiarism? An Empirical Study.” International Journal for Educational Integrity 14 (1): 1–15. doi:10.1007/s40979-018-0029-6.
Singh, B. P. 2016. “Preventing the Plagiarism in Digital Age with Special Reference to Indian Universities.” International Journal of Information Dissemination and Technology 6 (4): 281–287.
Smart, P., and T. Gaston. 2019. “How Prevalent are Plagiarized Submissions? Global Survey of Editors.” Learned Publishing 32 (1): 47–56. doi:10.1002/leap.1218.
Šprajc, P., M. Urh, J. Jerebic, D. Trivan, and E. Jereb. 2017. “Reasons for Plagiarism in Higher Education.” Organizacija 50 (1): 33–45. doi:10.1515/orga-2017-0002.
Stacey, A. 2019. “Reframing Plagiarism in Academia 4.0.” In 18th European Conference on Research Methodology for Business and Management Studies, 305. doi:10.34190/rm.19.068.
Teh, E. C., and M. Paull. 2013. “Reducing the Prevalence of Plagiarism: A Model for Staff, Students and Universities.” Issues in Educational Research 23 (2): 283–298.
Thompsett, A., and J. Ahluwalia. 2010. “Students Turned off by Turnitin? Perception of Plagiarism and Collusion by Undergraduate Bioscience Students.” Bioscience Education 16 (1): 1–15. doi:10.3108/beej.16.3.
Wang, S., H. Qi, L. Kong, and C. Nu. 2013. “Combination of VSM and Jaccard Coefficient for External Plagiarism Detection.” In 2013 International Conference on Machine Learning and Cybernetics, 1880–1885. IEEE 4. doi:10.1109/icmlc.2013.6890902.
Yusuf, A., A. Isiaka, M. Abubakar, H. O. Aminulai, A. Abdullahi, and T. A. Alayande. 2019. “Development of an Android Based Mobile Application for the Design and Detailing of Isolated Pad Foundations according to Eurocode 2.” I-manager’s Journal on Mobile Applications and Technologies 6 (1): 21. doi:10.26634/jmt.6.1.15702.
Zhang, H., and T. W. S. Chow. 2011. “A Coarse-to-fine Framework to Efficiently Thwart Plagiarism.” Pattern Recognition 44 (2): 471–487. doi:10.1016/j.patcog.2010.08.023.
ACCOUNTABILITY IN RESEARCH 21




















