
Detection of Plagiarism in Programming Assignments
10
174 IEEE TRANSACTIONS ON EDUCATION, VOL. 51, NO. 2, MAY 2008 Detection of Plagiarism in Programming Assignments Francisco Rosales, Antonio García, Santiago Rodríguez, José L. Pedraza, Rafael Méndez, and Manuel M. Nieto Abstract—Laboratory work assignments are very important for computer science learning. Over the last 12 years many students have been involved in solving such assignments in the authors’ de- partment, having reached a figure of more than 400 students doing the same assignment in the same year. This number of students has required teachers to pay special attention to conceivable plagia- rism cases. A plagiarism detection tool has been developed as part of a full toolset for helping in the management of the laboratory work assignments. This tool defines and uses four similarity cri- teria to measure how similar two assignment implementations are. The paper describes the plagiarism detection tool and the experi- ence of using it over the last 12 years in four different programming assignments, from microprogramming a CPU to system program- ming in C. Index Terms—Computer engineering learning, mass courses management, software plagiarism detection, string similarity measurement. I. INTRODUCTION T HIS paper presents a specific tool for helping in the detec- tion of plagiarism cases in laboratory work assignments re- lated to computer engineering studies. The paper includes some figures referring to the use of the tool while managing several in- dependent laboratory work assignments, completed by students at the authors’ institution in the course of their curricula. The plagiarism detection assistant is part of a complete toolset de- veloped in the authors’ department for managing different lab- oratory work assignments completed by individual students or groups of up to four students. The toolset has been effectively in use for more than a decade now. A. The Plagiarism Problem Plagiarism is a universal problem, as shown by the pub- lication of this particular issue of IEEE TRANSACTIONS ON EDUCATION. However, plagiarism can be more frequent in some environments than in others (for instance in literature, scientific work, or technological work) or even in some geographical areas (the authors’ country, Spain, has some experience, and was even known for being a cradle of rogues, as described in the famous novel “Lazarillo de Tormes” [1]). Starting from this assertion, the degree of villainy of a particular group or society is extremely difficult to evaluate. The lack of comparative ele- ments, as well as differences among the academic environments of different educational systems make this evaluation difficult. The purpose of the figures included in this paper is to help Manuscript received December 19, 2006; revised July 26, 2007. The authors are with the Department of Computer System Architecture and Technology, Technical University of Madrid, 28660 Madrid, Spain (e-mail: frosal@fi.upm.es; dopico@fi.upm.es; srodri@fi.upm.es; pedraza@fi.upm.es; rmendez@fi.upm.es; mnieto@fi.upm.es). Digital Object Identifier 10.1109/TE.2007.906778 objectively to understand the kind of environment in which the tool is actually applied. Each case of plagiarism unquestionably represents a problem for the wealth of the academic system; students can become graduates without having met the minimum knowledge level. Other students will feel frustrated when they suspect or even know that someone else has passed by plagiarizing others’ work. Two problems are present when dealing with plagiarism: de- tection and sanctions. In the authors’ experience, the academic services of most of universities dictate norms about sanctioning students involved in plagiarism. However, they do not give any procedure or hint on how to detect plagiarism. Sanctions are usually heavy, such as expelling the student from the institution. However, getting to the point of applying such a sanction is re- ally difficult because of the lack of norms, human resources, or help tools for detecting a case. The tool described in this paper has been designed as a plagiarism detection aid in a specific but important field, namely, software development on several possible levels, from microprogramming to high level language programming. The tool does not determine plagiarism cases, but provides a list of group-pairs sorted by probability of potential plagiarism. Consequently, the tool has been named a detection aid or helper. Both the toolset, in general, and the plagiarism detec- tion assistant tool are easily configured to work with group and individual assignments without requiring any modification. B. Plagiarism in Software Development Focusing on the subject of software development where the tool has its application, programming is considered a creative task. In fact, programming consists in describing a particular be- havior (of a machine) in a very precise way by means of a specific programming language. A programming language has very few characteristic elements when compared to a natural language. From the point of view of plagiarism, this smaller size has some implications. A first observation is that to develop two identical, or at least very similar, program fragments is much easier than to write two identical or even very similar paragraphs when using natural language. At the same time, whether the cause of the sim- ilarity is plagiarism or whether such similarity is simply derived from an analogous working method based on the same theoret- ical knowledge is difficult to distinguish. The difficulty involved in determining the ultimate cause of similarity is one of the main reasons why the tool described in this paper is devoted to helping detect of plagiarism, not in determining positive cases. Students trying to pass a laboratory work assignment in a fraudulent way may make some small modifications to the code used to obstruct the plagiarism detection process. This behavior invites teachers to take some countermeasures which can de- pend on the specific programming language. A basic technique consists of simplifying some instructions or control structures to 0018-9359/$25.00 © 2008 IEEE
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Detection of Plagiarism in Programming Assignments

174 IEEE TRANSACTIONS ON EDUCATION, VOL. 51, NO. 2, MAY 2008
Detection of Plagiarism in Programming AssignmentsFrancisco Rosales, Antonio García, Santiago Rodríguez, José L. Pedraza, Rafael Méndez, and Manuel M. Nieto
Abstract—Laboratory work assignments are very important forcomputer science learning. Over the last 12 years many studentshave been involved in solving such assignments in the authors’ de-partment, having reached a figure of more than 400 students doingthe same assignment in the same year. This number of students hasrequired teachers to pay special attention to conceivable plagia-rism cases. A plagiarism detection tool has been developed as partof a full toolset for helping in the management of the laboratorywork assignments. This tool defines and uses four similarity cri-teria to measure how similar two assignment implementations are.The paper describes the plagiarism detection tool and the experi-ence of using it over the last 12 years in four different programmingassignments, from microprogramming a CPU to system program-ming in C.
Index Terms—Computer engineering learning, mass coursesmanagement, software plagiarism detection, string similaritymeasurement.
I. INTRODUCTION
THIS paper presents a specific tool for helping in the detec-tion of plagiarism cases in laboratory work assignments re-
lated to computer engineering studies. The paper includes somefigures referring to the use of the tool while managing several in-dependent laboratory work assignments, completed by studentsat the authors’ institution in the course of their curricula. Theplagiarism detection assistant is part of a complete toolset de-veloped in the authors’ department for managing different lab-oratory work assignments completed by individual students orgroups of up to four students. The toolset has been effectivelyin use for more than a decade now.
A. The Plagiarism Problem
Plagiarism is a universal problem, as shown by the pub-lication of this particular issue of IEEE TRANSACTIONS ON
EDUCATION. However, plagiarism can be more frequent in someenvironments than in others (for instance in literature, scientificwork, or technological work) or even in some geographicalareas (the authors’ country, Spain, has some experience, andwas even known for being a cradle of rogues, as described inthe famous novel “Lazarillo de Tormes” [1]). Starting from thisassertion, the degree of villainy of a particular group or societyis extremely difficult to evaluate. The lack of comparative ele-ments, as well as differences among the academic environmentsof different educational systems make this evaluation difficult.The purpose of the figures included in this paper is to help
Manuscript received December 19, 2006; revised July 26, 2007.The authors are with the Department of Computer System Architecture and
Technology, Technical University of Madrid, 28660 Madrid, Spain (e-mail:[email protected]; [email protected]; [email protected]; [email protected];[email protected]; [email protected]).
Digital Object Identifier 10.1109/TE.2007.906778
objectively to understand the kind of environment in which thetool is actually applied.
Each case of plagiarism unquestionably represents a problemfor the wealth of the academic system; students can becomegraduates without having met the minimum knowledge level.Other students will feel frustrated when they suspect or evenknow that someone else has passed by plagiarizing others’ work.Two problems are present when dealing with plagiarism: de-tection and sanctions. In the authors’ experience, the academicservices of most of universities dictate norms about sanctioningstudents involved in plagiarism. However, they do not give anyprocedure or hint on how to detect plagiarism. Sanctions areusually heavy, such as expelling the student from the institution.However, getting to the point of applying such a sanction is re-ally difficult because of the lack of norms, human resources, orhelp tools for detecting a case.
The tool described in this paper has been designed as aplagiarism detection aid in a specific but important field,namely, software development on several possible levels, frommicroprogramming to high level language programming. Thetool does not determine plagiarism cases, but provides a listof group-pairs sorted by probability of potential plagiarism.Consequently, the tool has been named a detection aid orhelper. Both the toolset, in general, and the plagiarism detec-tion assistant tool are easily configured to work with group andindividual assignments without requiring any modification.
B. Plagiarism in Software Development
Focusing on the subject of software development where thetool has its application, programming is considered a creativetask. In fact, programming consists in describing a particular be-havior (of a machine) in a very precise way by means of a specificprogramming language. A programming language has very fewcharacteristic elements when compared to a natural language.From the point of view of plagiarism, this smaller size has someimplications. A first observation is that to develop two identical,or at least very similar, program fragments is much easier than towrite two identical or even very similar paragraphs when usingnatural language. At the same time, whether the cause of the sim-ilarity is plagiarism or whether such similarity is simply derivedfrom an analogous working method based on the same theoret-ical knowledge is difficult to distinguish. The difficulty involvedin determining the ultimate cause of similarity is one of the mainreasons why the tool described in this paper is devoted to helpingdetect of plagiarism, not in determining positive cases.
Students trying to pass a laboratory work assignment in afraudulent way may make some small modifications to the codeused to obstruct the plagiarism detection process. This behaviorinvites teachers to take some countermeasures which can de-pend on the specific programming language. A basic techniqueconsists of simplifying some instructions or control structures to
0018-9359/$25.00 © 2008 IEEE

ROSALES et al.: DETECTION OF PLAGIARISM IN PROGRAMMING ASSIGNMENTS 175
obtain a canonical version of every original piece of code, thenproceed by labeling reserved words and, finally, comparing thecanonical versions instead of the original and probably alteredversions. Some of these simplification techniques are actuallybeing applied, and they are described in the examples sectionof some assignments. In any event, use of canonical code doesnot completely rule out the possibility of being deceived. Ac-cepting two implementations of laboratory work as different isstill possible, even when they come from the same original codewith some cosmetic retouching, applied to one or even both ofthem. However, another way of looking at this technique is thatfor two implementations to be considered different, they needto differ in such a number and depth of aspects that any studentcapable of conceiving and implementing the required modifica-tions could be considered qualified to pass.
The likelihood of detecting actual plagiarism varies de-pending on whether laboratory work assignments are specifiedin the form of small subroutines or specified as medium to largefunctions or routines, even if the total amount of work involvedis roughly the same. In the first case, plagiarism detectionwould be almost impossible because of the limited degree offreedom of the implementation. Consequently, a small-project(mini-project) model of the laboratory work assignments is inuse in the authors’ department. On the other hand, the authors’have not observed any considerable differences in the plagia-rism percentage regardless of whether or not the test battery tobe applied to the code was known to students in advance.
The plagiarism detection assistant tool, pk2,1 was specifi-cally developed for covering existing needs in the authors’ de-partment. The design was to make it flexible and easily adapt-able to operate with different low and high level programminglanguages. Consequently, since pk2 is a tool developed for asingle institution, one finds the tool difficult to compare withother documented tools. However, pk2 can be classified usingthe terminology mentioned by [2] as a local tool available underspecial arrangement, based on tokenization of student submis-sions. The pk2 tool is readily available for processing sub-missions written in programming languages with very differentcharacteristics, such as C, Motorola 88110 assembly language,and even a specific microcode previously transformed into mi-crooperation mnemonics. Adapting pk2 to other programminglanguages represents an easy task requiring a small effort. Thepk2 engine is similar to that described by [3], although pk2employs four different classification criteria, each treated on apar with the remaining criteria.
The next section describes the laboratory toolset used in theauthors’ department. The internal structure of the pk2 toolis then explained. Following the description of the tool aresome examples of actual laboratory assignments. They includeassignments aimed at practicing software development ondifferent abstraction levels, ranging from microprogrammingto high level language programming. Laboratory work assign-ments with very different characteristics are also considered;some of them change every year, while others are reused yearafter year. Finally, some results of the exploitation of the pla-giarism detection assistant tool are revealed and the conclusionsderived from the authors’ experience.
1When spelled in Spanish pk2 sounds like the word meaning “sins.”
II. APPLICATION ENVIRONMENT
The toolset described in this paper has been developed in theComputer Architecture Department of the Technical Universityof Madrid, Spain. The topics covered by this department handlemany concepts that allow the student to understand how a com-puter works. This objective is very difficult to achieve withoutstudents performing some practical work, i.e., some kind of soft-ware development (to be shown in detail later). The environmentdescribed in this section helps students to complete their labora-tory work. This environment also helps teachers to manage andassess the students’ assignments for subjects with up to 400 stu-dents per course.
The main objective of the teachers’ team is to provide highquality laboratory assignments that allow students to completemini-projects as similar as possible to real projects. The specificteaching objectives are as follows.
• Students have to be able to understand a specification doc-ument. Each laboratory assignment is presented to studentsin a small document containing the software specificationwhich the student has to follow when building the requiredcode.
• Students have to be able to find by themselves the neces-sary complementary information.
• Students have to be able to prove the correctness of theirown work, i.e., to develop a set of tests to debug their prac-tical work. They must ensure that their own test battery canguarantee that their practical assignments work properly.
• Teachers have to be able to measure the degree to whichthe assignments developed by the students meet the spec-ification. This problem is harder when many students aresolving the laboratory work.
These objectives are difficult to achieve if the laboratory workis proposed as a set of small exercises, because such cases do notrequire any specification document as in [4]–[6]. Furthermore,small exercises should be avoided because a subject has manyrelated concepts that the student must learn to apply. These ob-stacles and the objective to bring the student close to a real pro-gramming experience led instructors to establish small projectsas the basis of the laboratory work.
A. The Projects
Students are asked to develop small projects by using a speci-fication document that teachers have to produce. Since the spec-ification document is too complex to be personalized for eachstudent, each one has to solve the same exercise. The projectsapply to the following topics.
• System Programming in C. To develop a simple commandline interpreter with Unix. This assignment helps the stu-dent to understand the most important operating systemcalls and how to build the interface between the user andsystem.
• Assembly Language Programming. To develop a set of as-sembly subroutines in the actual language understood bythe computer. These subroutines are programmed on a re-duced instruction set computer (RISC) by using an emulatorof the MC88110 microprocessor. An exhaustive descriptionof this laboratory work and its features is given in [7].

176 IEEE TRANSACTIONS ON EDUCATION, VOL. 51, NO. 2, MAY 2008
Fig. 1. Application environment.
• Input/Output System. To develop a driver for a simple de-vice that operates by interrupts. The device and the com-puter allow a MC68000 emulator to use an automatic eval-uating environment. An extended description of this as-signment can be found in [8].
• Microprogramming. To design the control unit of a simpleprocessor. The student acquires an overview of the pro-cessor components and their connections and realizestheir complexity. References [9] and [10] describe similarprojects and contain many further references.
B. Management Environment
These projects have to be completed by every student whotakes the subject. Under the given circumstances teachers hadto build an automatic environment to check the correctness ofthe completed assignments. This environment (Fig. 1) was de-veloped entirely by the teaching staff in 1994 and has under-gone various updates since then. The environment is describedin more detail in [11] and consists of the following tools.
• Delivery agent. This application allows the students tosubmit their laboratory work to the automatic assessmentsystem to be checked. The system asks for a login-pass-word pair for previously registered students only. Thetool sends every file in the project, preventing studentsfrom forgetting to send any parts. The delivery agent alsoverifies that the delivered files are correct and contain allthe expected information. When the student assignmenthas been received, the files are stored in the system untilthe project evaluator is activated.
• Automatic project evaluator. This application executes aset of tests for each of the submitted assignments not yetchecked. This evaluator runs at specific times as publishedin the assignment document. For each test, the evaluatorbuilds the test code by using the student’s code and, if nec-essary, the test code provided by the teacher. The test resultis compared with the correct result that has been previouslystored in the system. If the result is not correct, a feedbackmessage is appended to the report describing the error thathas been found. This action is repeated for every test de-signed by the teaching staff. The final report file will con-tain the personalized description of the errors found in the
student’s assignment. This report can be retrieved by thestudent by using the delivery agent. To avoid students’ useof this evaluator as a debugging tool, teachers encouragestudents to build their own tests. Students are only allowedto use this tool for a limited number of evaluations.
• Plagiarism detection assistant. Sometimes students maytry to copy a valid solution from another student. Detec-tion of plagiarism is not possible without some kind ofautomatic or semiautomatic tool to assist in such a task.The large number of students led to developing pk2, a toolthat helps the teaching staff to detect plagiarism among stu-dents. Teachers run pk2 offline when the deadline for thelaboratory work has been met. This tool uses the students’database independently from the application environment.This tool and the authors’ experience in using it are de-scribed in the following sections.
III. PLAGIARISM DETECTION ASSISTANT
Any qualified teacher should be able to inspect a pair of pro-gramming projects and detect any plagiarism. However, becauseof the serious academic consequences, the most successful wayof making a final decision on a suspected case of plagiarism isthe consensual opinion of the whole group of teachers.
The actual problem of detecting plagiarism is choosing thepairs of projects which the teacher needs to check. A teacherwith ten projects to compare might remember them long enoughto find plagiarized cases without inspecting all the 45 possiblepairs. With one hundred students, or more, with thousands ofversions of the same programming project in a repository of pre-vious years’ projects, searching manually becomes worthless.
In looking for plagiarism among a given number of projects(A) and another set of similar projects from previous years (B),the total number of pairs to compare is
. Assuming symmetriccomparisons, that is, comparing X with Y gives the same resultsas comparing Y with X. For and , 6225 pairsare possible.
Obviously, the actual problem is the huge number of projectpairs to inspect. To solve it, a tool named pk2 has been de-veloped and maintained over the last ten years. The tool assiststeachers by analyzing any large set of projects and identifyingany pairs suspected of plagiarism. The tool compares each ofthe pairs of projects and sorts all pairs using the calcu-lated comparison measure.
A. Signature Strings
Today high level programming languages, such as Java, orlow level ones, such as Assembly, are more or less context free;text can be written with a high degree of freedom. In the caseof several similar large chunks of code, very few arguments areusually against the evidence.
Plagiarists are a little bit lazy or lack the knowledge, disci-pline, or motivation about the subject. Eventually, when studentscome under pressure, they may choose to cheat, as described in[12]. The answer to the question “How do plagiarists copy?” isby making the least possible effort. First, they obtain the sourcecode, presumably one that is a good solution to the programmingassignment. Then, they apply modifications until they think they

ROSALES et al.: DETECTION OF PLAGIARISM IN PROGRAMMING ASSIGNMENTS 177
can fool a casual inspection. They will usually try to change theoriginal source version in ways that do not noticeably affect itsbehavior, as explained in [13]. The source code of a good pro-grammer is supposed to be written to enhance readability, fol-lowing a logical order, using proper variable names, and com-menting and indenting the code properly. Plagiarists are peoplewho do not know enough to do the assignment on their own.They usually do aesthetic changes without significantly alteringthe underlying program structure, randomly changing identifiernames, comments, punctuation, and indentation, or moving in-dependent blocks of code.
The idea is to compare only those parts of the source codewhich are less prone to being altered by plagiarists, the partsnot so easily modified by these aesthetic changes. In this way,the focus will be on what makes the program work properly, itsunderlying structure. This way the pk2 tool opts for a structure-metric approach that, as many authors have stated [14]–[16], isgenerally better than attribute-counting approaches (based onlexicographic statistics). When comparing a programming lan-guage such as Java, only its reserved words and the most usedlibrary function names will be considered. No symbols, punctu-ation, separators, blanks, etc., will be used.
The same idea can be applied to most programming lan-guages (lisp style languages may be problematic), which iswhat pk2 does. This approach makes pk2 usable and easilyadaptable to several programming languages. The configura-tion consists of a different set of reserved words to be used,depending on the programming language selected.
For efficiency and generalization, once configured, pk2 willprocess each given project source file, transforming it into aninternal representation. This process substitutes the occurrenceof each reserved word by a corresponding internal symbol (usu-ally shown as a single character). Thus, a kind of signature stringwill reflect the set and order of the reserved words or predefinedpatterns appearing in each input source file (similar informationto that used in [17], but simpler to obtain). After this phase, thetool does not compare source files directly but rather their cor-responding signature strings. The tool will be comparing onlythe underlying program structure, less prone to being changed.As an example, the code segments of Fig. 2 are internally rep-resented by the signature strings.
B. Similarity Criteria
As programs are not objects in one dimensional space, thecomparison cannot be reduced to any single similarity measure.
Consider the equivalent problem of manually comparing agiven set of 2-D geometric figures for finding the most similarpair between them. No automatic solution is possible if the sim-ilarity concept is not defined in an absolute way. Is similarityrelated to shape, area, perimeter, color, weight, or some combi-nation of these and other measures? In any case, being an openproblem, the solution chosen by the authors is to produce not one
but several similarity measures. Ideally the measures should belinearly independent from each other but proportional to the ac-tual, absolute, and unknown similarity concept. These similaritymeasures can be used for ordering the search space in severaldifferent ways. Then the manual inspection of the first few pairsis accomplished by a person with the required knowledge.
Similarly when comparing two programs, instead of trying toreduce the comparison to a single number, pk2 computes foursimilarity measures. They were heuristically chosen becausethey are simple to understand, efficiently computable, mostlyindependent from one another, and proportional to the unknownsimilarity concept. Table I gives examples of signature stringsand corresponding evaluations of the four similarity criteria.
The first one is the length of the longest sequence of re-served words common to both files (the length of the longestcontiguous substring common to both signature strings—dif-ferent from the well-known longest common subsequence de-scribed in [18] and [19]). This simple criterion is based on amaximum measure and is absolute in the sense that it is nei-ther bound nor normalized. Intuitively, the longer the commonsubstring, the higher the probability of a global or partial literalcopy. But, quite obviously, one of the first things that a plagiaristdoes is to move blocks of code back and forth, thereby hashingthe original as much as possible. Another criterion is requiredwhich should be less sensitive to the hashing described.
The second criterion was defined as the cumulative valueof the length of the common sequences of reserved words. Inother words, the longest common substring of the two signaturestrings is located (the same as under the first criterion); its lengthis accumulated; and then the first character of each substring isdiscarded for further comparisons. This step is repeated until nocommon substring remains. In some way, the described proce-dure attempts to solve the observed hashing deficiency of thefirst criterion. This criterion is also based on a maximum (butthis time cumulative) measure, also absolute.
The third criterion is the normalized value of the second one.The plagiarist could try to introduce code not needed to hide thecopied material. This criterion tries to identify complete or par-tial inclusion of one string inside another. Since this measure isrelative to the full length of the compared signature strings, itsvalue is normalized to a maximum of 100%. A different rankingis offered, with the drawback of giving high values when com-paring a short file with larger ones, because the probability ofone being included in the other is high.
Finally, the fourth criterion is the percentage of the numberof reserved words common to both files, not depending on theposition of those reserved words. This criterion measures therelative size of the intersection of the histograms of the two sig-nature strings. Where the position of a reserved word occurs orwhat its relative position is does not matter. What matters is howmany of each kind are present. In fact, this criterion seems tobe very similar to an attribute counting metric, although it doesnot count lexicographic elements but structural ones. Becauseof its specific nature, this criterion is the fuzziest one. The valueproduced can be high for a pair of different original programs.On the other side, this criterion is the most difficult obstacle forcheaters. Too many changes need to be made on a plagiarizedprogram to lower the produced value.

178 IEEE TRANSACTIONS ON EDUCATION, VOL. 51, NO. 2, MAY 2008
Fig. 2. Evidences of digital plagiarism making visible (as a middle dot) the invisible space character.
TABLE IEXAMPLE OF SIGNATURE STRINGS AND SIMILARITY CRITERIA
Many other similarity criteria can be used. The classicaledit or Levenshtein distance is described in [20]. The muchmore modern and computationally demanding approximationto the theoretically perfect but not computable Kolmogorovcomplexity is described in [16]. The authors believe that almostany similarity proportional measure can be successfully usedbecause one important part of the analysis has already beencompleted, sieving the original data through the simplificationto the structural representation given by the signature strings.
C. Other Arguments
Thepk2 tool gives teachers hints about which pairs to inspectfor plagiarism, but the final decision in a case of plagiarism isvery difficult to make.
The presence of hidden watermarks can multiply the evidenceof plagiarism. Any language uses several invisible characters forspacing and separation, and their repeated use does not changethe program behavior. Because they are invisible, the plagiaristsdo not notice them and keep them as found in the original source.In [21], the initial source code given to each student was water-marked with a different code. Those watermarks which survivedthe source code modification phase were then used to detect pla-giarism and to distinguish the origin and target of each case.This method cannot be applied when a single initial source codeis given for all students. Hopefully, “spontaneous” watermarks(those blank spaces going unnoticed mixed with other tabula-tion characters) can still be used in a different way.
The companion tool dots is a simple inspection filter thatmakes the space characters visible. In some cases, this translationprovides the final proof for plagiarism, not only for having sharedthe idea but for having digitally copied the code. Fig. 2 shows anactual case of evidence of digital plagiarism on two code seg-ments as the result of using the dots filter over the source files.

ROSALES et al.: DETECTION OF PLAGIARISM IN PROGRAMMING ASSIGNMENTS 179
IV. PLAGIARISM DETECTION EXPERIENCES
A. System Programming in C
A command line interpreter, or shell in the Unix terminology,is a utility program to perform the tasks needed by users througha textual but powerful interface. The orders are internally de-veloped by intensive use of the operating system programminginterface. Thus, the developer of a shell should fully under-stand and correctly relate concepts from two abstraction levels:user and system spaces. For example, command execution withprocess creation and file execution, pipelines with process com-munication and input and output redirections with file descrip-tors and their inheritance.
In the authors’ department, as a fundamental part of the Oper-ating Systems course, the system programming interface of theUnix operating system is studied in detail. The development ofa small shell was found to be the most interesting and adequatepractical assignment for this course.
The Minishell project assignment is fully described in adocument equivalent to a classical Unix manual page aboutthe command (msh). Each of its features and capabilitiesis described in this document giving the specification of itsexpected behavior. No clues are given about how the featurescould be implemented. The command line parsing phase isgiven already solved, so that the students can concentrate theirefforts on launching the execution of the given sequence ofcommands. Additionally, several typical internal commandsmust be developed, too, such as: cd, umask, set, read, orlimit.
Since this practical project seemed very appropriate for thecourse, the same statement has been maintained year after year,differing only in the set of internal commands to develop. Thisstrategy has advantages and disadvantages.
The advantage for the teachers is that they have more timefor improving the quality of the assignment. A large set of fre-quently asked questions (known as the FAQ file) was compiled,and an automatic tester and assessment tool was developed. Thistool performs the role of an interactive Minishell user by en-tering one command after another into the shell. The right be-havior of each command is checked via its expected collateraleffects. The project is assessed by the first error found. The testerfollows the documentation given to the students, exhaustivelytesting the described expected behavior of every single featureand its combinations in two directions: what has to be done andwhat should not be done.
The advantage for the students is that they receive more assis-tance during the development. The tester tool was designed tobe self-explanatory; therefore, all its execution trace is loggedand later sent to the project author with the grade obtained. Byanalyzing this trace, students can reproduce the negative tests bythemselves and understand better the reasons for the failure. Incase of doubt, they may look for the answer in the FAQ file and,if any doubt remains, send the relevant question to the teacherby e-mail. Teachers can append significant answers to the FAQ,and accordingly, students can progress in the development oftheir projects to reach higher grades.
Obviously the main disadvantage of maintaining the samestatement year after year is that with each new course the
number of different implementations circulating grows, as wellas the probability of plagiarism. Indeed, this probability wasthe initial reason to develop a tool for detecting plagiarism.
At the end of each submission period, pk2 is applied to all thenew msh versions and all the previous ones kept in a repository.The configuration established uses of the C language reservedwords, plus the names of the standard library functions and thenames of the POSIX standard system calls.
After running pk2 on all the new projects and the entirerepository, the resultant pairs’ list is processed as follows. Onlythe top 20 or 30 pairs per criteria are extracted, and if any ap-pears more than once, the redundant cases are removed. Theresulting short list is ordered by the teacher’s preferred criteria,and the pairs are examined in order, looking for evidence of pla-giarism with the dots companion tool. Each pair is classifiedand labeled as positive or negative depending on whether evi-dence of plagiarism is present. Legitimate positive cases (samestudent project from previous year submissions) are labeled asredundant and are excluded from any further statistical analysis.When no positive cases have appeared for a while, the rest of thelist is reordered by the next preferred criteria and the study con-tinues. The procedure finishes when all the four criteria havebeen tried, and no positive cases seem to exist in the remainingentries of the list. The resulting classification is the starting pointfor approaching the students involved.
B. Assembly Language Programming
The specific laboratory work on assembly language program-ming is scheduled in the Computer Structure course as an im-portant goal that students must achieve. The assembly languageprogramming laboratory is specified as a relatively complexproblem in some significant subjects of computer engineering.The problem must be solved by developing a set of assemblylanguage routines. In the authors’ environment, the MotorolaMC88110 assembly language [22] is used. The main subgoalsof this assignment are as follows:
1) to know the characteristics and use of the instruction setand the addressing modes of an actual processor;
2) to know the possibilities of a conventional macro-assem-bler and how to use it;
3) to grasp some concepts already acquired in other parts ofthe Computer Structure course;
4) to develop the specific concepts of assembly language pro-gramming;
5) to work in small teams of, at least, two students.The problem to be solved is substantially modified every aca-
demic year, so that students who have not passed the subjectmust start from the beginning in the following year.
An example of these assignments, specified in 2005, was asimplified version of the FAT file system used in MS-DOS [23].Students had to develop and implement several file system op-erations, such as 1) creating—recursively, if needed—a new filespecified by its full path name; 2) removing a file located in aspecified folder; and 3) recursively, removing the files of a folderby making several calls to the previously described routine.
Two criteria were mainly used to help in the detection of pla-giarism cases in this assignment. They are the first two similaritycriteria explained in the pk2 section. Actual plagiarism cases

180 IEEE TRANSACTIONS ON EDUCATION, VOL. 51, NO. 2, MAY 2008
have been found in the full set of routines, in just one of theroutines, and in several fragments from several routines. Someof the students’ copy-modify-paste work may be applied witha certain degree of intelligence, so that several code fragmentscan seem different even when they come from the same originalcode, as follows:
1) using different instructions that do the same operation inmost cases, such as add (signed add) and addu (unsignedadd);
2) using different ways of getting the same result, such asinitializing a register to the null value, as in
3) expanding macro instructions or renaming macros that dothe same operations, as in
The student code is converted to a canonical form and is thenanalyzed with pk2 using all assembly mnemonics as reservedwords.
C. Input/Output System
Input/Output laboratory work is aimed at enabling studentsto implement a driver for a simple device. The input/outputassignment is scheduled in the Computer Architecture course(fifth semester). Students have to handle simultaneously twoserial lines operated by interrupts. They have to program sev-eral MC68000 assembly subroutines that allow sending and re-ceiving a buffer through a serial line. These operations are ex-ecuted by handling the interrupts that the device requests. Thisassignment is changed every year, but the essentials remain be-cause the range of operations with this simple device is limited.
The program pk2 has been used since 1999 to help findplagiarism in this laboratory assignment, and no case of plagia-rism has been found. The set of reserved words is composedof the MC68000 assembly language mnemonics. These tokensare reduced for each arithmetic and logic operation. Therefore,just one OR instruction is considered independently of ad-dressing modes, operand representation, and size as in previousassignments.
This laboratory work is completed after the microprogram-ming, assembly programming, and system programming labo-ratory assignments previously shown. As students have learnedfrom previous years, no plagiarism is found at this stage. Be-cause students already know that the department uses the pk2tool, they do not try to copy this assignment.
The second reason is that by its very nature this kind oflaboratory work does not offer teachers many possibilities ofchanging it completely. The laboratory work is reused withsmall changes year after year, because the only operationsavailable on a serial line are sending and receiving charactersby handling interrupts. These operations are not “code line”consuming, and the code tends to be very similar among stu-dents so that plagiarism is difficult to detect.
D. Microprogramming
Microprogramming is a very low level programming projectthat consists in implementing a reduced instruction set for asimple processor. The project is scheduled in the third semesteras a complementary practice in teaching processor structure. Itsmain objective is to provide students with an overall view ofcomputer operations where everything is clear and well known,and no black boxes hide any action performed by the processorwhile executing a program.
The project is based on a very simple processor resemblingthe Intel 8080 architecture, called P8080E [24], that is designedentirely with elementary logical components already known tothe students. P8080E has a microprogrammable control unit thatuses a ROM to store microinstructions; the microinstructionsspecify which microoperations are performed, where the resultsare stored, and which microinstructions sequence is required toperform the program instructions stored in the main memory.
The microinstructions stored in the ROM are grouped in mi-croroutines, each one corresponding to one instruction or de-voted to performing an auxiliary task, such as fetching the nextinstruction from the main memory. Each microinstruction is bi-nary coded and looks like , where
is its location in the ROM, and the remainder are 40 bitsthat will be spread to control the logic circuits of the processor.(An means indifferent.)
The assignment consists of an instruction set with several ad-dressing modes and some arithmetical operations. Also, the pro-gramming model provides two different execution levels and ex-ception processing.
With respect to plagiarism, the binary-coded microinstruc-tions are not suitable for use by pk2 and have to be translated toa common symbolic language called register transfer (RT) [25].RT uses predefined reserved words to specify the relevant micro-operations of each microinstruction. These reserved words werepreviously used to configure pk2. One of the characteristics ofthe microinstructions is that they are location independent, andthe students can easily hash the original without changing itsbehavior. To help pk2 in its job, the most complex instructionsubset is selected (as the others are so simple that they wouldgenerate false plagiarism candidates), and an intelligent disas-sembly is performed to generate all possible microinstructionflows for those instructions. Moreover, the address locations ofthe microinstructions are changed into symbolic labels, so thatthe possible hash is rearranged. The flow for one instruction isnamed itinerary, and one of its disassembled microinstructionswould look more or less as follows:
The files collecting the selected itineraries are submitted tobe compared by pk2. Finally, the most similar itinerary pairsaccording to the pk2 criteria and other textual information areeye-inspected to determine the existence of plagiarism.
V. RESULTS AND DISCUSSION
Fig. 3 summarizes the authors’ experience with using thepk2tool presented in this paper. The graph shows the percentage ofstudents found guilty of plagiarism after the investigation phase
ROSALES et al.: DETECTION OF PLAGIARISM IN PROGRAMMING ASSIGNMENTS 181
Fig. 3. Statistics of plagiarism in different practical projects.
Fig. 4. Minishell 1999: X–Y plot of analyzed cases.
[26] over the total number of students. A common pattern be-tween the projects cannot be identified clearly, because of itsparticular characteristics, although each project has its own pat-tern as explained in the following sections.
A. System Programming in C
The Minishell is a high level programming project of mediumto large size, which has been kept almost unchanged over theyears. From 1994 to 2005, all the students in the Operating Sys-tems courses were assigned this project; to date, the repositoryconsists of a total of 5,378 submissions. Using such a hugerepository and considering an average signature string of 210symbols in length, a sustained performance of about half a mil-lion processed pairs per hour can be reached.
In Fig. 3, a fairly constant rate of plagiarism, about 4.6%,can be observed in the msh practical project. This observationmeans that when original solutions are easy to obtain, some stu-dents will copy. No matter how tough the sanctions were, thispercentage of copy could not be reduced to zero. This pattern isa “falling into temptation” pathological behavior.
Fig. 4 shows an X–Y plot of the third and fourth similaritymeasures for every pair as produced by the tool. The actual
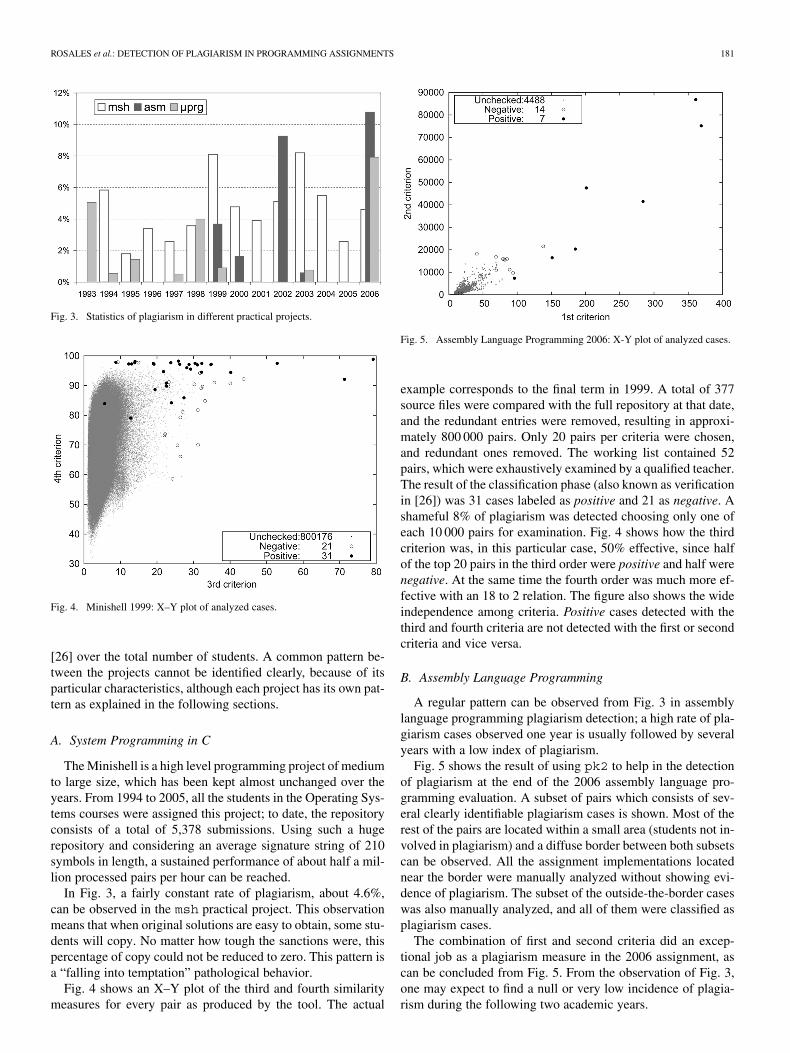
Fig. 5. Assembly Language Programming 2006: X-Y plot of analyzed cases.
example corresponds to the final term in 1999. A total of 377source files were compared with the full repository at that date,and the redundant entries were removed, resulting in approxi-mately 800 000 pairs. Only 20 pairs per criteria were chosen,and redundant ones removed. The working list contained 52pairs, which were exhaustively examined by a qualified teacher.The result of the classification phase (also known as verificationin [26]) was 31 cases labeled as positive and 21 as negative. Ashameful 8% of plagiarism was detected choosing only one ofeach 10 000 pairs for examination. Fig. 4 shows how the thirdcriterion was, in this particular case, 50% effective, since halfof the top 20 pairs in the third order were positive and half werenegative. At the same time the fourth order was much more ef-fective with an 18 to 2 relation. The figure also shows the wideindependence among criteria. Positive cases detected with thethird and fourth criteria are not detected with the first or secondcriteria and vice versa.
B. Assembly Language Programming
A regular pattern can be observed from Fig. 3 in assemblylanguage programming plagiarism detection; a high rate of pla-giarism cases observed one year is usually followed by severalyears with a low index of plagiarism.
Fig. 5 shows the result of using pk2 to help in the detectionof plagiarism at the end of the 2006 assembly language pro-gramming evaluation. A subset of pairs which consists of sev-eral clearly identifiable plagiarism cases is shown. Most of therest of the pairs are located within a small area (students not in-volved in plagiarism) and a diffuse border between both subsetscan be observed. All the assignment implementations locatednear the border were manually analyzed without showing evi-dence of plagiarism. The subset of the outside-the-border caseswas also manually analyzed, and all of them were classified asplagiarism cases.
The combination of first and second criteria did an excep-tional job as a plagiarism measure in the 2006 assignment, ascan be concluded from Fig. 5. From the observation of Fig. 3,one may expect to find a null or very low incidence of plagia-rism during the following two academic years.

182 IEEE TRANSACTIONS ON EDUCATION, VOL. 51, NO. 2, MAY 2008
C. Input/Output System
The objective of this project is that students can develop a lowlevel driver for a device in assembly language. This assignmentundergoes minor changes from one year to another. No plagia-rism case was found even though some assignments were verysimilar. The inspected assignments were rated with values be-tween 70 and 90 under the first criterion. These numbers meanthat the projects have common sequences of more than 70 re-served words, because of the lack of freedom in the assignment.For example, the interrupt handler developed by teachers hasabout 90 instructions, and this routine is very similar even whenthe developers are different people.
D. Microprogramming
Microprogramming projects were performed in two stages,each with different probabilities for detection of plagiarismby pk2. In the first one, the instruction set was relativelylarge and complex. The variability in the microprogrammingimplementations was very high, and the copies, either partialor total, stood out in several pk2 criteria. The first time theteaching staff performed a computer-based comparison ofmicroprogramming projects was in 1993. The program pk2was not available then; and the comparison was not very so-phisticated; however, 25 students were detected as involved inplagiarism since the copies were very simple. In the followingyears, the knowledge that plagiarism would be analyzed per-suaded students to do the work by themselves, and plagiarismcases dropped considerably (Fig. 3). The changes in the copiedprojects were more significant and intelligent, but pk2 wasstill able to reflect clearly such cases until 1998. That year,changes in the syllabus moved the project from the seventh andeight semesters to the third one, where students had much lessexperience, especially in low level programming.
The second stage of the project started in a similar way to thefirst one; the students had no references about plagiarism detec-tion; and the copies were again simple. The program pk2 wasvery efficient, and a high number of cases were detected. How-ever, the students learned how to make intelligent copies. Fur-ther cases did not appear so clearly differentiated by pk2, butmerged with other negative cases in the first positions. This ap-parent loss of efficiency appeared because the new assignmentswere much simpler and because the students received clear guid-ance in their work; a part was even supplied by the teaching staff.This fact and the plagiarists’ enhanced efforts made impossibleto certify certain cases as plagiarism. Fig. 3 reflects another in-teresting behavior. After some years without any plagiarism de-tection, the plagiarists relax, and new cases appear.
VI. CONCLUSION
A plagiarism detection assistant used in the Computer Archi-tecture Department of the Technical University of Madrid hasbeen presented. Teaching experience has confirmed that alwayssome students try to pass their assignments without doing theirwork, by copying from other students. This assistant, pk2, hasbeen in use for more than ten years to help teachers detect pla-giarism cases.
The program pk2 has proved to be good enough to detectmany cases of actual plagiarism in programming assignments,
even though some cases were quite well disguised. All thesource code parts prone to being disguised are removed, andthen the assignment pairs are ordered by similarity. The simi-larity criteria used are not relevant since pk2 works only withthe program structure.
This tool has proved to be flexible. It has been success-fully used to detect partial and total copies in very differentenvironments:
• assignments using very different abstraction levels. Forexample, high level programming, using C, low levelprogramming, assembly language, or even microprogram-ming, directly using binary code;
• assignments that change every year or that remain the sameyear after year;
• teachers who work with a small repository of assignments(less than one hundred) or with a large repository of assign-ments (more than five thousand).
The only situation that pk2 cannot detect is an assignmentcompounded by several very small fragments of source code.The scope of freedom within each fragment is too limited, andall the student solutions are too similar to distinguish the actualplagiarism cases from coincidental cases of similarity.
Teachers of this department have realized that students learnthat they cannot copy their assignments. They know they havea high probability of being detected even if they disguise theircopies or they copy only a fragment. Even the new studentsavoid copying assignments when a high number of cases of pla-giarism has recently been published, although the deterrent ef-fect is only temporary. Several semesters later, fresh studentsnaively start to copy again, thinking they are not going to be de-tected. Veteran students are rarely involved in plagiarism casesas they know they can be easily detected.
The authors’ department considers that this plagiarism detec-tion assistant has reached its main objective, to dissuade stu-dents from copying. The deterrence could even be more ef-fective if the sanctioning norms were stricter. In addition, theauthors are conscious that this tool can be easily adapted to anew laboratory work assignment, even if the laboratory work re-quires using a new programming language not previously used.Consequently, the department is planning to continue using, ex-tending, and improving pk2 over the following years.
A. Future Trends
The program pk2 could be improved in several ways, forexample, adding functionality to simplify the manual inspectiontask. A new tool, which would work only pair by pair, couldmark or highlight the common substrings found among theseassignment pairs. In this way, teachers could focus their effortson those fragments that are most probably copied.
Instead of comparing the source code files, the static part ofprograms, comparing the execution trace, i.e., examining thedynamic part of programs may be worthwhile. The only wayto change an execution trace is to change the program behavior,and plagiarists do not usually know enough to take this action.
Another interesting way to extend pk2 could be to adaptit to work with natural languages. Probably the best way toadapt pk2 to a natural language would be to consider as re-served words all the words occurring in the natural language.

ROSALES et al.: DETECTION OF PLAGIARISM IN PROGRAMMING ASSIGNMENTS 183
Gender and plural differences or verb conjugations would notbe considered. When copying several pages of natural languageone can disguise some paragraphs but not all of them withoutrewriting almost all the pages. Even if they try to disguise thecopy, common substrings of considerable length, dozens or hun-dreds of words without changes, will be found and would ex-pose the copy. Combined with the previously mentioned toolfor highlighting the common substrings, plagiarized paragraphscould easily be found.
REFERENCES
[1] La vida de Lazarillo de Tormes y de sus fortunas y adversidades.Medina del Campo, Valladolid, Spain: Mateo y Francisco del Canto,1554, Anonymous.
[2] T. Lancaster and F. Culwin, “A comparison of source code plagiarismdetection engines,” Comput. Sci. Educ., vol. 14, no. 2, pp. 101–117,2004.
[3] R. Irving, “Plagiarism detection: Experiences and issues,” presented atthe Joint Information Systems Committee 5th Information StrategiesConf., Focus on Access and Security, London, U.K., 2000.
[4] L. Malmi, A. Korhonen, and R. Saikkonen, “Experiences in automaticassessment on mass courses and issues for designing virtual courses,”in Proc. 7th Annu. SIGCSE/SIGCUE Conf. Innovation and Technologyin Computer Science Education, Aarhus, Denmark, Jun. 2002, pp.55–59.
[5] A. Korkohen et al., “Does it make a difference if students exercise onthe web or in the classroom?,” in Proc. 7th Annu. SIGCSE/SIGCUEConf. Innovation and Technology in Computer Science Education,Aarhus, Denmark, Jun. 2002, pp. 121–124.
[6] R. Saikkonen, L. Malmi, and A. Korkohen, “Fully automatic assess-ment of programming examples,” in Proc. 6th Annu. SIGCSE/SIGCUEConf. Innovation and Technology in Computer Science Education,Canterbury, UK, Jun. 2001, pp. 133–136.
[7] S. Rodríguez, J. L. Pedraza, A. G. Dopico, F. Rosales, and R. Méndez,“Computer-based management environment for an assembly languageprogramming laboratory,” Comput. Appl. Eng. Educ., vol. 15, no. 1, pp.41–54, Apr. 2007.
[8] S. Rodríguez, J. Zamorano, F. Rosales, A. García, and J. L. Pedraza,“A framework for lab work management in mass courses. Applicationto low level input/output without hardware,” Comput. Educ., vol. 48,no. 2, pp. 153–170, Feb. 2007.
[9] S. Robbins and K. Robbins, “A microprogramming animation,” IEEETrans. Educ., vol. 41, no. 4, pp. 293–300, Nov. 1998.
[10] J. Donaldson, “A microprogram simulator and compiler for anenhanced version of Tanenbaum’s MIC-1 machine,” in Proc. 26thSIGCSE Tech. Symp. Computer Science Education, New York, 1995,pp. 238–242.
[11] A. García, S. Rodríguez, F. Rosales, and J. L. Pedraza, “Automaticmanagement of laboratory work in mass computer engineeringcourses,” IEEE Trans. Educ., vol. 48, no. 1, pp. 89–98, Feb. 2005.
[12] S. Stevenson, S. Dench, A. Harestad, L. Harrison, D. Kaufman, M.Kimball, J. Perry, J. Shugarman, M. S. Denis, and M. Vance, “Final re-port of the task force on academic honesty and integrity,” Simon FraserUniv., Burnaby, BC, Canada, Tech. Rep., Feb. 2004.
[13] A. Parker and J. O. Hamblen, “Computer algorithms for plagiarismdetection,” IEEE Trans. Educ., vol. 32, no. 2, pp. 94–99, May 1989.
[14] K. L. Verco and M. J. Wise, “Software for detecting suspected plagia-rism: Comparing structure and attribute-counting systems,” in Proc. 1stSIGCSE Australasian Conf. Computer Science Education, J. Rosen-berg, Ed., New York, Jul. 1996, pp. 81–88.
[15] M. Joy and M. Luck, “Plagiarism in programming assignments,” IEEETrans. Educ., vol. 42, no. 2, pp. 129–133, May 1999.
[16] X. Chen, B. Francia, M. Li, B. McKinnon, and A. Seker, “Shared in-formation and program plagiarism detection,” IEEE Trans. Inf. Theory,vol. 50, no. 7, pp. 1545–1551, Jul. 2004.
[17] C. Liu, C. Chen, J. Han, and P. S. Yu, “Gplag: Detection of softwareplagiarism by program dependence graph analysis,” in Proc. 12th Int.Conf. Special Interest Group Knowledge Discovery and Data Mining,New York, 2006, pp. 872–881.
[18] A. Apostolico, “String editing and longest common subsequences,”in Handbook of Formal Languages, Volume 2 Linear Modeling:Background and Application. Berlin, Germany: Springer-Verlag,1997, pp. 361–398.
[19] L. Bergroth, H. Hakonen, and T. Raita, “A survey of longest commonsubsequence algorithms,” in Proc. 7th Int. Symp. String Processing In-formation Retrieval, Los Alamitos, CA, 2000, pp. 39–48.
[20] V. Levenshtein, “Binary codes capable of correcting deletions, inser-tions and reversals,” Sov. Phys.—Dokl., vol. 10, no. 8, pp. 707–710,1966.
[21] C. Daly and J. Horgan, “Patterns of plagiarism,” in Proc. 36th SIGCSETech. Symp. Computer Science Education, New York, 2005, pp.383–387.
[22] “MC88110: Second Generation RISC Microprocessor User’sManual,” Motorola Inc., Schaumburg, IL, 1991.
[23] A. S. Tanenbaum, Modern Operating Systems, 2nd ed. EngelewoodCliffs, NJ: Prentice-Hall, 2001.
[24] M. Córdoba and M. Nieto, Jul. 2007, Technical Univ. Madrid, Spain[Online]. Available: http://www.datsi.fi.upm.es/docencia/Estructura/U_Control
[25] C. Bell and A. Newell, Computer Structures: Readings and Examples.New York: McGraw-Hill, 1971.
[26] F. Culwin and T. Lancaster, 2001, Plagiarism, Prevention, Deterrenceand Detection [Online]. Available: http://www.ilt.ac.uk/resources/Culwin-Lancaster.htm
Francisco Rosales received the B.S. degree in computer engineering from theTechnical University of Madrid (UPM), Spain, in 1991.
He is currently an Assistant Professor in the Department of Computer Sys-tems Architecture and Technology at UPM. His teaching interests include op-erating systems, simulation, and system level programming.
Antonio García received the B.S. degree in computer engineering and the Ph.D.degree in computer science from the Technical University of Madrid (UPM),Spain, in 1993 and 2001, respectively.
He is currently an Associate Professor in the Department of Computer Sys-tems Architecture and Technology at UPM. His teaching interests include com-puter architecture, parallel and distributed systems, and hardware descriptionlanguages.
Santiago Rodríguez received the B.S. degree in computer engineering and thePh.D. degree in computer science from the Technical University of Madrid(UPM), Spain, in 1990 and 1996, respectively.
He is currently an Associate Professor in the Department of Computer Sys-tems Architecture and Technology at UPM. His teaching interests include com-puter architecture and fault tolerant computers.
José L. Pedraza received the B.S. degree in physics (electronics) and the Ph.D.degree in physics from the University of Salamanca, Spain, in 1981 and 1987,respectively.
He is currently an Associate Professor in the Department of ComputerSystem Architecture and Technology, Technical University of Madrid, Spain.His teaching interests include basic computer architecture, processor paral-lelism, and memory systems.
Rafael Méndez received the B.S. degree in aeronautic engineering and thePh.D. degree in computer science from the Technical University of Madrid(UPM), Spain, in 1980 and 1991, respectively.
He is currently is an Associate Professor in the Department of ComputerSystem Architecture and Technology at UPM. His teaching interests includecomputer architecture and fault-tolerant computer systems.
Manuel M. Nieto received the B.S. degree in computer engineering from theTechnical University of Madrid (UPM), Spain, in 1986.
He is currently an Assistant Professor in the Department of Computer Sys-tems Architecture and Technology at UPM. His teaching interests include com-puter architecture and microcontroller-based design.




















