
TOPIC MODELING AND SPAM DETECTION ... - OhioLINK ETD
75
TOPIC MODELING AND SPAM DETECTION FOR SHORT TEXT SEGMENTS IN WEB FORUMS by YINGCHENG SUN Submitted in partial fulfillment of the requirements For the degree of Doctor of Philosophy Department of Computer and Data Sciences CASE WESTERN RESERVE UNIVERSITY January, 2020
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of TOPIC MODELING AND SPAM DETECTION ... - OhioLINK ETD

TOPIC MODELING AND SPAM DETECTION FOR SHORT TEXT
SEGMENTS IN WEB FORUMS
by
YINGCHENG SUN
Submitted in partial fulfillment of the requirements
For the degree of Doctor of Philosophy
Department of Computer and Data Sciences
CASE WESTERN RESERVE UNIVERSITY
January, 2020

Topic Modeling and Spam Detection for Short Text Segments in Web
Forums
Case Western Reserve University
Case School of Graduate Studies
We hereby approve the thesis1 of
YINGCHENG SUN
for the degree of
Doctor of Philosophy
Dr. Kenneth Loparo
Committee Member, Adviser 11/20/2019Department of Electrical, Computer, and Systems Engineering
Dr. An Wang
Committee Member 11/20/2019Department of Computer and Data Sciences
Dr. Erman Ayday
Committee Member 11/20/2019Department of Computer and Data Sciences
Dr. Xusheng Xiao
Committee Chair 11/20/2019Department of Computer and Data Sciences
1We certify that written approval has been obtained for any proprietary material contained therein.

Dedicated to all the people helped me during my PhD study andmy parents

Table of Contents
List of Tables vi
List of Figures vii
Acknowledgements ix
Abstract x
Chapter 1. Introduction 1
Motivation 1
Scope and Organization of the Dissertation 3
Chapter 2. Conversational Structure Aware Topic Model for Online Discussions 5
Introduction 5
Related Research 8
Conversational Structure Aware Topic Model 11
Experiment 18
Case Study 27
Conclusion 29
Chapter 3. Opinion Spam Detection Based on Heterogeneous Information
Network 30
Introduction 30
Related Work 32
The Skynet Framework 36
Data Sets 45
Evaluation 47
iv

Conclusion 50
Chapter 4. Suggested Future Research 52
Dynamic topic modeling 52
Adaptive spam detection 52
Downstream Applications 53
Complete References 55
v

List of Tables
2.1 The number of discussion threads (Disc) picked from 30 different
subreddits (SubR) 19
2.2 Averaged coherence, measured by 6 different methods. The top two
results are in boldface and italic respectively 25
3.1 Compatibility potentials used by SkyNet for “User – Review” and
“Review- Product” relation 42
3.2 Compatibility potentials for “User – User” relation 43
3.3 Compatibility potentials for “Review – Review” relation, (+) represents
support, (-) represents oppose 43
3.4 Review Datasets Used In This Work 46
3.5 Photo Distribution. (“Rec” is short for “Recommended”) 46
3.6 Social Network and Votes Distribution. (“Rec” is short for
“Recommended”) 47
3.7 Precision@K Of Compared Methods On (From Top To Bottom) Yelpzip. 49
3.8 Precision@K Of Compared Methods On Yelp1k 50
vi

List of Figures
2.1 Large Array Cassegrain Optical Concentrators 7
2.2 (a) Example of a discussion tree with 4 levels (b) Subtrees used for
calculating popularity scores of nodes 2 to 9. Shade of color represents
topic “influence” of the root, the deeper the stronger the influence 13
2.3 Distributions of popularity scores calculated by arithmetic, geometric
and harmonic progressions on the same datasets. 15
2.4 Topic assignment using the topic “transitivity” property in a discussion
tree, determining the topic distribution of node 8. The shades of
color represent topic dependency, the deeper the color the greater the
dependency, with white representing no dependency. 17
2.5 An example of topic annotation interface of Tagtog. 20
2.6 Word frequency distribution of the dataset. In the bar graph, the X-axis
lists the words, and the Y-axis represents their frequency. The pie graph
shows the percentage distribution of word frequency. 22
2.7 Accuracy of topic assignments to comments 26
2.8 Caption for LOF 28
3.1 SkyNet collectively utilizes metadata and the relational data under a
Heterogeneous Information Network to rank all of users, reviews, and
shops/products by spamicity. 37
3.2 The review about a Chinese restaurant with photos attached. 38
vii

3.3 Examples of benign users (left) and spammers (right) detected by
Yelp.com. It is clear to see that the number of friends is different
between benign users and spammers. 39
3.4 a) A review discussion thread for the food “Wisconsin Ginseng Slice”.
Users argue on whether the original review is fake. b) An example of
review and how it is evaluated by other users.” 40
3.5 Average Precision of Compared Methods on Two Dataset.” 48
3.6 AUC performance of compared methods on two datasets. 49
3.7 Precision@k of SkyNet for review ranking on the Yelp1K with varying %
of labeled data. 50
viii

Acknowledgements
I would like to give my sincerest gratitude to Prof. Kenneth Loparo, my advisor,
whose encouragement and insightful advices have been indispensable during my Ph.D.
study journey. Most of the work presented herein comes from intellectual discussions
I have with him over the last few years. As an outstanding researcher and advisor, Prof.
Loparo have helped me to learn not only how to conduct research but also lifelong
lessons.
I would also like to acknowledge Dr. Xusheng Xiao for serving as my dissertation
committee chair and Dr. An Wang and Dr. Erman Ayday for serving as my dissertation
committee members, and for their great help during my Ph.D. study and defense.
I would like to extend my thanks to all professors and my colleagues I worked with
who provide me with encouraging research environment, their friendship and collab-
orations. I would like to specially acknowledge prof. Guoqiang Zhang, Dr. Richard
Kolacinski, Dr. Farhad Kaffashi, Dr. Chika Emeka-Nweze, Dr. Benjamin Vandendriess-
che, Bianka Marlen Hubert, Dr. Fei Guo, Dr. Fan Zhang, Dr. James McDonald, Nicolas
Coucke, Annabel Descamps, my best friend Rong Bai and all the students in NEST group
in Olin 703, for countless valuable discussions and all the good times we have had.
Finally, I owe a special debt of gratitude to my family who have made enormous
sacrifices for me and have always been there when I needed them the most. I owe all of
my accomplishments to them.
ix

Abstract
Topic Modeling and Spam Detection for Short Text Segments in Web
Forums
Abstract
by
YINGCHENG SUN
In the era of the Social Web, there has been explosive growth of user-generated con-
tent published on various online web forums. Segments of short texts have become a
fashionable writing format because they are convenient to post and respond. Examples
include comments, tweets, reviews, questions/answers, to name a few. Given the large
volume of short texts that are available online, quick comprehension and filtering have
become a challenging problem. In this dissertation, we explore two questions related on
short texts: what are they talking about and can you trust the source?
To answer the first question, an effective and efficient approach is to discover latent
topics from large text datasets. Because of the text sparseness of text in online discus-
sions, traditional topic models have had limited success when directly applied to the
topic mining tasks. Short texts do not provide sufficient term co-occurrence information
for the reliable discovery of topics. To overcome that limitation, we use (1) the discus-
sion thread tree structure and propose a “popularity” metric to quantify the number of
replies to a given comment and extend the frequency of word occurrences, and (2) the
x

“transitivity” concept to characterize topic dependency among nodes in a nested dis-
cussion thread. We then build a Conversational Structure Aware Topic Model (CSATM)
based on popularity and transitivity to infer topics and their assignments to comments.
For the second question, the users of business review forums are generally con-
cerned with whether the reviews of products or services are genuine, because fake re-
views (also called opinion spams) have become a widespread problem in online discus-
sion forums. Existing approaches have gained success in detecting opinion spams by
utilizing various features. However, spammers are sophisticated and adaptable to game
the system with fast evolving content and network patterns, and it is challenging for
the anti-spamming systems that only use old features. In this dissertation, we proposed
three novel features based on the photos that are provided in reviews, user social net-
work and the evaluation of reviews, and discussed a new approach called SkyNet that
uses clues extracted from associated heterogeneous data including metadata (e.g. text,
photos within reviews, etc.) as well as relational data (e.g. social and review networks),
to detect suspicious users and reviews within a unified computational framework.
The proposed CSATM topic model is used on forum datasets exported from Red-
dit.com and the computational experiments demonstrate improved performance for
topic extraction based on six different measurements of coherence , and impressive ac-
curacy for topic assignments. To evaluate the proposed SkyNet framework we use busi-
ness review data from Yelp.com to run computational experiments assuming “recom-
mended” reviews are genuine and “not recommended” reviews are fake to show that the
proposed SkyNet framework outperforms several baselines and state-of-the-art opinion
detection methods.
xi

1
1 Introduction
1.1 Motivation
Web forums are online portals for open comments on specific issues or topics. In news
or content discussion forums like Reddit, Quora and Hackernews, people participate in
threaded discussions to exchange knowledge and ask questions. For each thread, a user
makes an initial post and others express their opinions by replying to the responses. In
business or product review forums like Yelp, TripAdvisor or E-commerce websites such
as Amazon, where users can submit reviews of products or services. Millions of com-
ments or reviews are generated every day, and with the vast amount of data including
in these online forums, users are challenged with sorting through and processing this
data to attract useful information while browsing the web forums1. The requirements
for automatically summarizing each discussion thread and extracting the main topics
are becoming more and more important if this vast source of data is to effectively mined
and used in meaningful ways2. In other discussion thread web forums where users can
comment on products and services, there is a strong need to identify and filter fake re-
views or opinion spam that has become a widespread problem3.

Introduction 2
’Topic’ is a certain distribution of words in a document, and "topic model" is a type of
statistical model for discovering the abstract "topics" that occur in a collection of doc-
uments. Traditional topic modeling and text classification methods do not work well
because most of the comments, reviews or posts in web forums are segments of short
text that generally do not provide sufficient term co-occurrence information and tra-
ditional topic models like Latent Semantic Analysis (pLSA)4 and Latent Dirichlet Allo-
cation (LDA)5 have several limitations when directly applied to this type mining task.
Further, fake reviews are well written and methods based on textual features can easily
fail because spammers may imitate the writing pattern of regular users to provide fake
reviews that are difficult to identify as having suspicious content6.
Based on results from the existing literature, there is a need for additional work that
specifically addresses problems with using short text segments for topic modeling or
spam detection. In this dissertation, we investigate an extended LDA topic model based
on the occurrence of topic dependencies in online discussions. A thread is a type of
asynchronous conversation that is based on temporal topic dependencies among posts
and replies. When one thread participant A replies to a post from author B, we consider
that a topic dependency has been built from user B to user A, and it is believed that reply
relations among posts dominate the topic dependencies7. Although this appears to be a
logical and a reasonable approach to topic assignment, simply replying or commenting
on a post does not necessarily guarantee that the main topic in the reply is consistent
with the main topic in the post! What often happens is that a to pic in a post will ini-
tiate a reply that introduces a new topic, causing a topic shift in the discussion thread.
Others users may then reply to that post, while others in the same thread may reply to
the topic in the original post. Our approach to address this important problem is to

Introduction 3
develop a Conversational Structure Aware Topic Model (CSATM) that can be applied to
online discussions. The basic idea is to follow a conversational thread, even has topics
are changed, and use the analysis of this conversational thread to analyze the topics.
For the detection of opinion spams and spammers, we explore the underlying charac-
teristics of opinion spam and spammers in a web forum to obtain some insights. These
insights include whether there are photos embedded in a review, the social network of
author associated with review, and feedback from other users, and other traditional fea-
tures. To maximize the effectiveness of the spam detection, we use information derived
from all of the metadata (text, timestamps, ratings) as well as relational data (e.g. the re-
view network), and integrate the information under a unified framework to detect spam
users, fake reviews, as well as products that have been targeted by fake reviews. We eval-
uate the proposed models using data from real web forum datasets including Reddit and
Yelp, and the results of our testing and evaluations provide evidence of the effectiveness
and efficiency of models for topic extraction and spam detection tasks.
1.2 Scope and Organization of the Dissertation
The first goal of this dissertation is to develop an efficient and effective topic model for
short text segments from online discussions. Related work on topic modeling methods
is discussed in Section 2.2. In section 2.3, we propose the CSATM model and its inference
steps. In section 2.4, we introduce the online discussion dataset and discuss the steps
that we prepossess the data and how to use the proposed model, and then we show
the experiment results. Finally we conclude the topic modeling aspects of this work in
section 2.5.

Introduction 4
The second goal of this dissertation is to develop an unsupervised opinion spam
framework that can be used to detect fake reviews and suspicious users, and identify
products and businesses that have been targeted by the fake reviews. To this end, we
present related work in section 3.2. We introduce the SkyNet opinion spam framework
and discuss the details of proposed features and its representations in section 3.3. In
section 3.4, we describe the datasets that we used for the experiments and show the
experimental results. We conclude opinion spam aspects of this work in section 3.5.

5
2 Conversational Structure Aware TopicModel for Online Discussions
2.1 Introduction
With the prevalence of content sharing platforms, such as online forums, microblogs,
social networks, photo and video sharing websites, people are more and more accus-
tomed to expressing and sharing their opinions on the Internet. Modern news websites
provide commenting facilities for their readers to freely post and reply. The increasing
popularity of such platforms results in huge amounts of online discussions each day.
For example, the number of comments generated by users on Reddit is 1,075 per month
in 2005 December, but that number rises to 91,558,594 in 2018 January 1. Automatically
modeling topics from massive texts can help people better understand the main clues
and semantic structures, and can also be useful to downstream applications such as dis-
cussion summarization8, stance detection9, event tracking10, and so on.
Conventional topic models, like probabilistic Latent Semantic Analysis (pLSA)4 and
Latent Dirichlet Allocation (LDA)5 assume that the word distribution in documents is
Gaussian Mixture Distribution that can be split into multiple components with each one
of them representing a topic. Documents with latent semantic structure (“topics”) can
1https://www.reddit.com

Conversational Structure Aware Topic Model for Online Discussions 6
be inferred from word–document co-occurrences. They have achieved great success in
modeling long text documents over the past decades, but may not work well when di-
rectly applied to short texts that dominate online discussions for two reasons about the
data: 1) Sparse: The occurrences of words in short documents have a diminished dis-
criminative role compared to lengthy documents where the model has sufficient word
counts to determine how words are related.11 2) Noisy: Comment threads often contain
unproductive banter, insults, and cursing, with users often “shouting” over each other12,
and people sometimes publish “unserious” response posts that are unrelated to the dis-
cussion topics13. Noisy comments perhaps could be used for sentiment analysis, but
are significant disturbances when extracting topics from discussion threads.
To address the issues discussed above, in this chapter, we use the tree structure that
each discussion thread inherently exhibits based on the relationship between postings
and replies to enrich the background information of each comment. Fig. 2.1 illustrates
a typical discussion thread of user comments on a submitted question and its corre-
sponding tree structure.
In Fig. 2.1, the word distribution shows that the occurrence frequency of each word
in the possible topic “concept of ‘how all roads work’ completely blows your mind”
equals to or even less than those “non-topical” words, making it very difficult to be
modeled using conventional topic models. However, we can see that different com-
ment nodes have different numbers of replies, and nodes (node 0 and 1) leading the
topics have more replies than others, and those nodes are also in relatively “higher” po-
sitions in the discussion tree, above their topic “following” nodes as shown in the right
part of 2.1. Motivated by this observation, we propose “popularity” metric to measure
2https://www.reddit.com/r/AskReddit/comments/3dtyke/what_concept_completely_blows_your_mind

Conversational Structure Aware Topic Model for Online Discussions 7
What concept completely blows your mind?[–]JaguarGator9 1975 points 3 years ago How all of the roads work in terms of everything being connected up.
[–]Antithesys 1429 points 3 years ago To put it another way, that there is a continuous line of asphalt from Anchorage to Miami that wasn't there even sixty years ago. You can walk across the United States without touching a blade of grass.
[–]ratsock 1047 points 3 years ago
Anchorage to Miami is nothing... Try South Africa to Sweden to
Singapore...
[–]Antithesys 808 points 3 years ago
I will, thanks. Is it paved the whole way?
[–]SigmundFrog 1070 points 3 years ago
Bring trail mix
[–]WhuddaWhat 352 points 3 years ago
And like, at least a gallon of water. Maybe even two.
[–]socxc9 26 points 3 years ago
and six gasolines
[–]CowboyNinjaAstronaut 20 points 3 years ago
And my axe!
[–]thekefentse 1 point 3 years ago
:O
[–]yakkafoobmog 1 point 3 years ago
For some reason Vinny came to mind while reading that.
0
1
2
3
4
5
6
7
8
9
10
1
0
2
3
4
5
6
7 8
9
10
00.5
11.5
22.5
Figure 2.1. An example thread of user comments on the posted question:”the concept completely blows your mind” 2with the original nested dis-cussion on the left and its corresponding Tree structure on the right.i: thei-th comment. The figure on the bottom shows the word distribution thatis closed to uniform.
the number of replies to a comment as an extension to the frequency of word occur-
rence. We also observe that the topic distribution of a node is dependent on its parent
because comments in reply to the content of their parents form a conversational thread.
We use this “transitivity” characteristic as context information to reduce the inaccuracy
of topic assignments to comments, especially for those “noisy” ones, like comment 9
in Fig. 2.1. Based on the above two characteristics, we build a Conversational Structure

Conversational Structure Aware Topic Model for Online Discussions 8
Aware Topic Model (CSATM) that makes the topics modeled meaningful and usable, and
robust to noisy comments.
The rest of this chapter is organized as follows. In Section 2.2, we present related
work. In Section 2.3, we propose the CSATM model and explain the inference method
for the model. In Section 2.4, we introduce the datasets, comparison methods and eval-
uation metrics, as well as the experimental results. In Section 2.5, we analyze the appli-
cation CSATM to a specific example. We conclude our work in Section 2.6.
2.2 Related Research
Topic models aim to discover latent semantic information, i.e., topics, from texts and
have been extensively studied. Latent Dirichlet Allocation5 is a widely used topic model
that represents a document as a mixture of latent topics to be inferred, where a topic
is modeled as a multinomial distribution of words. Nevertheless, prior research has
demonstrated that topic models only focusing on word–document co-occurrences are
not suitable for short and informal texts like Tweets, reviews, and online comments due
to data sparsity and noise14. Therefore, three main strategies are proposed by recent
researchers to tackle these problems and we provide a brief overview of them.
2.2.1 Merging Shorts Texts into Long Pseudo Documents
The idea of this strategy is merging related short texts together and applying standard
topic modeling techniques on the pooled documents. Auxiliary contextual information
is used during the merging process, like authors, time, locations, hashtags, conversa-
tions, and etc. For example, Weng et al.15, Hong and Davison11, and Zhao et al.16 heuris-
tically aggregate messages posted by the same user or that share the same words before

Conversational Structure Aware Topic Model for Online Discussions 9
conventional topic models are applied. Alvarez-Melis and Saveski17 group tweets to-
gether occurring in the same user-to-user conversation. Ramage, Dumais, and Liebling18
and Mehrotra et al.19 employ hashtags as labels to train supervised topic models. The
performance of these models can be compromised when facing unseen topics that are
irrelevant to any hashtag in the training data.
In practice, auxiliary information is not always available or just too costly for de-
ployment, so models without using auxiliary information have been put forward, like
Self-Aggregation-based Topic Model (SATM)20, Pseudo-document-based Topic Model
(PTM)21, and etc. However, those models still could not deal with the case when the data
is extremely sparse and noisy like the example Fig. 2.1 shows, and no prior knowledge is
given to ensure the quality of text aggregation, that will further affect the performance
of topic inference.
2.2.2 Building Internal Relationships of Words
This strategy uses the internal semantic relationships of words to overcome the prob-
lem of lacking word co-occurrence, and the semantic information of words has been ef-
fectively captured by deep-neural network-based word embedding techniques. Several
attempts22 23 have been made to discover topics for short texts by leveraging semantic
information of words from existing sources. These topic models rely on a meaningful
embedding of words obtained through training on a large-scale high-quality external
corpus, which should be both in the same domain and language as the data used for
topic modeling.
However, such external resources are not always available. The SeaNMF14 model
learns the semantic relationship between words and their context from a skip-gram view

Conversational Structure Aware Topic Model for Online Discussions 10
of the corpus. The Biterm Topic Model (BTM)24 and the RNN-IDF-based Biterm Short-
text Topic Model (RIBSTM)25 model biterm co-occurrences in the entire corpus to en-
hance topic discovery. Latent Feature LDA (LFTM)26 incorporates latent feature vector
representations of words. The relational BTM model (R-BTM)27, links short texts using
a similarity list of words computed using an embedding of the words. However, be-
cause social media content and network structures influence each other, only focusing
on content is insufficient.
2.2.3 Leveraging Discussion Tree Structure as Prior
The third line of research focuses on enriching prior knowledge when training the topic
model. LeadLDA7 distinguishes reply nodes into “leaders” and “followers” in the con-
versation tree, and models the distribution of topical and non-topical words from “lead-
ers” and “followers”, respectively. To detect “leaders” and “followers” in the tree struc-
ture, the first step is to extract all root-to-leaf paths and then classifying nodes in each
path using a supervised learning model after labeling, and then combing all paths28.
Extracting and combing paths is time consuming and labeling is labor intensive, so
LeadLDA may not be suitable for large online discussion datasets. Li et al.29 exploits dis-
course in conversations and joins conversational discourse and latent topics together
for topic modeling. This model also organizes microblog posts as a conversation tree
structure, but does not consider topic hierarchies and model robustness issue like our
proposed model.
Hierarchical Dirichlet Process (HDP)30 and Nested Hierarchical Dirichlet Process
(nHDP)31can build hierarchical topic models with nonparametric Bayesian networks,
but they model the hierarchical structure of topics, not the documents. In online dis-
cussions, if we treat each comment as a document, the comment it replies to and its

Conversational Structure Aware Topic Model for Online Discussions 11
following replies all provide plentiful clues for its topic inference, which is not discussed
in HDP or nHDP. In this chapter, we will introduce a model that uses the conversational
structure of a discussion thread inherently has to improve the topic modeling perfor-
mance for short texts within online discussions32.
2.3 Conversational Structure Aware Topic Model
Our model extends the LDA model by adding the structural relationships among nodes
in a discussion tree as context information for each online comment. With the conversa-
tional structure, we observe the “popularity” and “transitivity” characteristics of topics
in online discussions. We will introduce the intuitions on “popularity” and “transitivity”
and how we use them in our model to make extracted topics meaningful and usable..
2.3.1 Topic Generation with Popularity
In online discussions, users can easily participate by submitting comments or writing
replies to those that draw their attention. In writing a reply, a user reads the initial post
or headline, browses the comments and selects one for a reply. By writing a reply, a
user explicitly expresses their interest in the topic(s) in the discussion thread, thereby
increasing their popularity and enlarging the discussion tree by adding leaf nodes. The
main topics of a reply may not be closely related to comments located at a distance in the
discussion thread, but will definitely be responsive to the comment it is directly replying
to. A topic is a matter dealt with in a text, discourse, or conversation; a subject, according
to the definition in Oxford Dictionary, so it needs to be discussed and popular. We thus
design our model based on two intuitions:

Conversational Structure Aware Topic Model for Online Discussions 12
1) The popularity of topics discussed in a comment node is positively related to
the number of replies.
2) The topic distribution of a node is dependent on its ancestors, and the depen-
dency is negatively related to the distance from the node to its ancestor.
For intuition 1), the word “popularity” is commonly used as the state or condition of
a person or item being liked by the people. The popularity of an item usually depends
on the number of people that support it. As the readers to a book and the audience to
a movie, the popularity of a topic can be measured by the number of people that are
involved in its discussions. There may be various reasons that a topic becomes popular
like its creation time, the celebrity of its author or the topic itself, but the reasons are not
what we are going to discuss in this chapter. We are more interested in finding the most
popular and influential topics in an online discussion thread, and we also believe that
such kind of topics should be extracted by topic models. As the discussion tree example
Fig. 2.2a shows, root node 1 may put forward a main topic with three replies: nodes
2, 3, and 4. If we assume these three nodes discuss three “sub-topics”, then the sub-
topic in node 3 is the most popular because it receives the most responses and should
be assigned with higher possibility.
Following intuition 1), the “popularity” pi of node i depends on all replies in its sub-
trees, and replies in different level have different weights but the same weight in the
same level; so pi can be written as:
pi =∑
i
∑nl
wl ∗node =∑di
wl ∗p j (2.1)
where nl is the number of nodes in level l , and wl is the weight for nodes in level l .
We can also write the popularity score of a node as the sum of its children’s popularity

Conversational Structure Aware Topic Model for Online Discussions 13
1
2
5
3
6
4
7
8 9
level 1
level 2
level 3
level 4
2
5
3
6
4
7
8 9
5 67
8 9
8 9
(a)
(b)
Figure 2.2. (a) Example of a discussion tree with 4 levels (b) Subtrees usedfor calculating popularity scores of nodes 2 to 9. Shade of color representstopic “influence” of the root, the deeper the stronger the influence
scores by iterative accumulation, and di is the degree of node i . We need to be careful
that all counts should be taken in node i ’s subtree. As Fig. 2.2b shows, node 2’s popu-
larity is calculated only on node 5 and 8, not on any other node. Also, we set the initial
popularity of any node as 1 in this chapter, so the popularity value of a node without any
reply is 1 that is its initial value, like node 4, 6, 8 and 9 in Fig. 2.2. For nodes with replies,
like node 1, 2, 3 ,5 and 7, their popularity values are the sum of the initial popularity and
the popularity of replies. According to intuition 2), the popularity of replies in different
levels does not have the same weight.
For intuition 2), let’s assume there is a comment node i in the discussion tree t. Users
can choose any comment to reply in t, but if i is chosen, it indicates that the topics in
comment node i attract the users more than other nodes. The newly added child node
to i continue the topics discussed in i, making topic transitive from i to its children, but

Conversational Structure Aware Topic Model for Online Discussions 14
it is found that 64% to 72% of all comments are shifted from their original topics33, and
that topic shift34 or the topic drift35 phenomenon make the transitivity process with
some “loss”, so the “topic influence” of a root decreases when the discussion thread gets
longer. In Fig. 2.2a, the topic introduced in node 1 spreads across the entire tree, but
its influence will weaken from level 1 to level 4 because of the topic transitivity loss. We
thus use a decreasing sequence to model the weight wl in equation (1) and we assume
that nodes in level l of the subtree have the same weight. We list three different options
as the decreasing sequence:
a) arithmetic progression
wal = c − (l −1)d ;
b) geometric progression
wg l = cr l−1;
c) harmonic progression with “gravity” power
whl = (c + (l −1)b)−G
where c is a constant, d is the common difference for arithmetic progression, l is
the number of the level, and r is the common ratio for the geometric sequence. G is
the “gravity” power controlling the fall rate of weights for harmonic progression, and
the weight decreases faster the larger G is. If G = 1, it becomes general harmonic series,
where c and b are real numbers. From arithmetic progression to harmonic progression,
the weigh distribution curve will become smoother. Fig. 2.3 shows their differences.
The distribution of popularity score computed by arithmetic progression is sharper,
meaning that nodes leading a discussion with a large number of descendants will be

Conversational Structure Aware Topic Model for Online Discussions 15
Figure 2.3. Distributions of popularity scores calculated by arithmetic,geometric and harmonic progressions on the same datasets.
given more weights than the other two, so if the dataset is very sparse or topical words are
corrupted by noises, the arithmetic progression will be a better choice. From arithmetic
progression to harmonic progression, the weight distribution curve becomes smoother
and smoother. The choice of sequence is based on the word distribution of datasets, and
other sequence can also be used if it fits the modeling requirements.
2.3.2 Model Inference
CSATM extends the LDA model by integrating the popularity property for each online
comment. The latent variables of interest are the topic assignments for word tokens z,
the comment level topic distribution θ and the topic – word distributionφ. The multino-
mial distribution θ and φ can be efficiently marginalized due to the conjugate Dirichlet-
multinomial design, we thus only need to sample the topic assignments z. It is com-
putationally intractable to compute the exact posterior distribution using Gibbs sam-
pling for approximating inference. To perform Gibbs sampling, we first choose initial

Conversational Structure Aware Topic Model for Online Discussions 16
states for the Markov chain randomly. Then we calculate the conditional distribution
p(zi = k|z−i , w, pc ,α,β) for each word, where the superscript ‘−i ’ signifies leaving the
i th token out of the calculation, w is the global word set, and pc is the popularity score
for comment c. By applying the chain rule on the joint probability of the data, we can
obtain the conditional probability as:
p(zi = k|z−i , w, pc ,α,β) ∝ (n−ik,cλpc +αk )
n−ik,wλpc +βw∑
w n−ik,wλpc +βw
where nk,c is the number of words in comment c that are assigned to topic k, and
nk,w is the number of times that topic k is assigned to word term w , both of which are
scaled by the popularity score, and λ is the scaling ratio. Following the conventions of
LDA, here we use symmetric Dirichlet priors α and β. Based on the topic assignments
of word occurrences, we can estimate the topic-word distributions φ and global topic
distributions θ as:
φk,w = βw +nk,wλpc
βw +∑w nk,wλpc
;
θk,c =αw +nk,cλpc
αw +∑k nk,cλpc
2.3.3 Topic Assignment with Transitivity
After discovering usable topics from the corpus, we want the correspondence of topic
assignments to documents to be meaningful. Conventional topic assignment meth-
ods do not consider the document context information, because for most of the corpus,
documents are not dependent. However, comments in online discussions demonstrate
clear topic dependency through their nested reply relationships, so we propose a new

Conversational Structure Aware Topic Model for Online Discussions 17
topic assignment strategy. With CSATM, we obtain the topic distribution for each given
comment, and then work out new topic assignments for the comments using the topic
transitivity property:
t ′i =∑li
j=1 wli− j+1t ji∑li
j=1 wli− j+1
, i = 1...N
where ti ’ is the new topic assignment compared to the original assignment t ji for
comment i , and j is the relative order in the path from comment node i to the root, and
li is the level where node i is located, and w is the weight of level li used for calculating
the popularity score.
1
2
5
3
6
4
7
8 9
level 1
level 2
level 3
level 4
t4,w1
t3,w2
t2,w3
t1,w4
Figure 2.4. Topic assignment using the topic “transitivity” property in adiscussion tree, determining the topic distribution of node 8. The shadesof color represent topic dependency, the deeper the color the greater thedependency, with white representing no dependency.
In Fig. 2.4, the topic distribution of node 8 depends on that of nodes in its path
to the root, which are nodes 5, 2 and 1, and does not depend on any node out of the
path to the root in terms of the topic distribution. The dependency weakens as the level
increases because comments indicate stronger interests in their parent nodes they reply
to in upper level than nodes in other levels as discussed intuition 2). By using this new
strategy, we can reduce the inaccuracy and uncertainty when assigning topics to noisy
comments.

Conversational Structure Aware Topic Model for Online Discussions 18
2.4 Experiment
In this section, we evaluate the proposed CSATM against LDA and several state-of-the-
art baseline methods on two real world datasets. We report the performance in terms of
six different coherence measures, and compare the accuracy for topic assignments.
2.4.1 Datasets, Compared Models, and Parameter Settings
In the experiment, we use the Reddit dataset. Reddit is an online discussion website.3
Registered members can submit content to the site such as links, text posts, or images,
and write comments or reply other comments. Posts are organized by subject into user-
created boards called "subreddits", which cover a variety of topics. The dataset is ob-
tained from a data collection forum containing 1.7 billion messages (221 million con-
versations) from December 2005 to March 2018 4.
After prepossessing, we find that there are 42% posts without any comments and
35% posts with less than or equal to 5 comments. Most of these discussions only focus
on one rather than multiple topics and do not have the topic shift phenomenon, so their
topics are easy to be modeled accurately, or we can just use the title of each discussion
thread as its topic. In order to prove the effectiveness of our proposed model, we thus
filter the posts with the number of replies less than 100, and then randomly picked 200
discussions from 30 different “subreddits”. Table 2.1 lists the details.
No category information is available for this dataset, so three annotators were asked
to label each conversation with the topics, and labels agreed by at least two annotators
are used as the ground truth, with a total of 810 topics labeled in this manner. We use
3https://www.reddit.com/4https://files.pushshift.io/reddit/

Conversational Structure Aware Topic Model for Online Discussions 19
Table 2.1. The number of discussion threads (Disc) picked from 30 differ-ent subreddits (SubR)
SubR Disc SubR Disc SubR DiscAskReddit 7 movies 7 LifeProTip 6funny 7 Music 5 mildlyinte 6todayilear 7 aww 7 DIY 6pics 5 gifs 6 Showerthou 6worldnews 7 news 8 sports 6IAmA 7 explainlik 8 space 6announceme 7 askscience 8 tifu 6videos 9 EarthPorn 7 Jokes 6gaming 7 books 7 InternetIs 6blog 7 television 7 food 6
a web-based text annotation tool called Tagtog 5 to annotate the topics for each discus-
sion, as Fig. 2.5 shows.
During the annotation process, the number of topics needs to be set first, and topic
assignment of each comment needs to labeled, but the topic set is automatically gen-
erated and updated as the labeling work goes on. In addition, the annotation tool will
find all the same words across the document and label them, so annotators only need
to focus on the words that have not been labeled. In Fig. 2.5, the labeled words are
marked different colors by topics. To simplify the labeling and topic modeling process,
each comment is assigned only 1 topic, and the discussion thread is labeled 4 topics on
average to avoid too detailed topic assignment.
We evaluate the performance of the following models, using all their original imple-
mentations.
5https://www.tagtog.net

Conversational Structure Aware Topic Model for Online Discussions 20
Figure 2.5. An example of topic annotation interface of Tagtog.
• LDA: The classic Latent Dirichlet Allocation (LDA) model is used as the baseline
model. For every dataset, the LDA model is used by setting the hyper parame-
ters α = 0.1 and β= 0.01, and the number of topics = 70.6
• PTM: Pseudo document based Topic Model21 aggregates short texts against
data sparsity. The original implementation with the number of pseudo doc-
uments = 1000 and λ = 0.1.7
• BTM: Biterm Topic Model24 directly models topics of all word pairs (biterms)
in each post and explicitly models the word co-occurrence patterns to enhance
topic learning. Following the original paper, α = 50/K and β = 0.01.8
6Python library: gensim.models.LdaModel7http://ipv6.nlsde.buaa.edu.cn/zuoyuan/8https://github.com/xiaohuiyan/BTM

Conversational Structure Aware Topic Model for Online Discussions 21
• LeadLDA: Generates words according to topic dependencies derived from con-
versation trees7. A classifier trained to differentiate leader and follower mes-
sages is required before using LeadLDA28, labelled leader and follower mes-
sages and CRF are used to obtain the probability distribution of leaders and
followers.9
• LFTM: Latent Feature LDA26 incorporates latent feature vector representations
of words trained on very large corpora to improve the word-topic mapping learnt
on a smaller corpus. Following the paper, the hyper-parameter α = 0.1.10 .
• SATM: Self-Aggregation-Based Topic Model20 aggregates documents and infers
topics simultaneously. Following7, the pseudo-document number is chosen
from 100 to 1000 in all evaluations, and the best scores are reported.11
• CSATM: We need to select a decreasing sequence to model the weights of the
levels used for calculating the popularity score. In this experiment, we use the
arithmetic progression with the “sharper” weight distribution because the word
distribution of the dataset is pretty sparse and 74% of words show up only once.
Fig. 2.6 shows the bar and pie charts of the word distribution.
2.4.2 Coherence Evaluation
Topic model evaluation is inherently difficult. In previous work, perplexity is a popular
metric to evaluate the predictive abilities of topic models using a held-out dataset with
unseen words5. However, Chang et al.36 have domonstrated that the method does not
translate to the actual human interpretability of topics, so the coherence score is widely
used to measure the quality of topics20, assuming that words represnting a coherent
9https://github.com/girlgunner/leadlda10https://github.com/datquocnguyen/LFTM11https://github.com/WHUIR/SATM

Conversational Structure Aware Topic Model for Online Discussions 22
1 2 3… … NWord ID
Fre
qu
en
cy
Figure 2.6. Word frequency distribution of the dataset. In the bar graph,the X-axis lists the words, and the Y-axis represents their frequency. Thepie graph shows the percentage distribution of word frequency.
topic are likely to co-occur within the same document21. To reduce the impact of low
frequency counts in word co-occurreces, we employ the topic coherence metric called
normalized PMI (NPMI)37. Given the T most probable words in a topic k, N P M I is
computed by:
N P M I (k) = 2
T (T −1)
∑1≤i≤ j≤T
l ogp(wi ,w j )
p(wi )p(w j )
−l og p(wi , w j ))
where p(wi ) and p(wi , w j ) are the probabilities that word wi occurs, and that the
word pair (wi , w j ) co-occurred estimated by the reference corpus, respectively. T is set
to 10 in our experiments. We also use five other confirmation measures to futher en-
hance the comparisons across models.

Conversational Structure Aware Topic Model for Online Discussions 23
CUC I is a coherence that is based on a sliding window and the pointwise mutual
information (PMI) of all word pairs of the given top words38. The word co-occurrence
counts are derived using a sliding window with the size 10. For every word pair the PMI
is calculated. The arithmetic mean of the PMI values is the result of this coherence.
CUC I = 2
T (T −1)
N−1∑i=1
N∑j=i+1
logp(wi , w j )
p(wi )p(w j )
CU M ass is based on document co-occurrence counts, a one-preceding segmentation
and a logarithmic conditional probability as confirmation measure39. The main idea of
this coherence is that the occurrence of every top word should be supported by every top
preceding top word. Thus, the probability of a top word to occur should be higher if a
document already contains a higher order top word of the same topic. Therefore, for ev-
ery word the logarithm of its conditional probability is calculated using every other top
word that has a higher order in the ranking of top words as condition. The probabilities
are derived using document co-occurrence counts. The single conditional probabilities
are summarized using the arithmetic mean.
CU M ass = 2
T (T −1)
N∑i=2
i−1∑j=1
l ogp(wi , w j )
p(w j )
CV is based on a sliding window, a one-set segmentation of the top words and an in-
direct confirmation measure that uses normalized pointwise mutual information (NPMI)
and the cosinus similarity40.This coherence measure retrieves co-occurrence counts for
the given words using a sliding window and the window size 110. The counts are used
to calculated the NPMI of every top word to every other top word, thus, resulting in a set
of vectors—one for every top word. The one-set segmentation of the top words leads to
the calculation of the similarity between every top word vector and the sum of all top

Conversational Structure Aware Topic Model for Online Discussions 24
word vectors. As similarity measure the cosinus is used. The coherence is the arithmetic
mean of these similarities.
CV = 2
T (T −1)
N−1∑i=1
N∑j=i+1
Si mcos(wi , w j ))
C A is based on a context window, a pairwise comparison of the top words and an in-
direct confirmation measure that uses normalized pointwise mutual information (NPMI)
and the cosinus similarity40. This coherence measure retrieves co-occurrence counts
for the given words using a context window with the window size 5. The counts are used
to calculated the NPMI of every top word to every other top word, thus, resulting in a
single vector for every top word. After that the cosinus similarity between all word pairs
is calculated. The coherence is the arithmetic mean of these similarities.
CP is a based on a sliding window, a one-preceding segmentation of the top words
and the confirmation measure of Fitelson’s coherence41. Word co-occurrence counts
for the given top words are derived using a sliding window and the window size 70. For
every top word, the confirmation to its preceding top word is calculated using the con-
firmation measure of Fitelson’s coherence. The coherence is the arithmetic mean of the
confirmation measure results.
Instead of using the collection itself to measure word association — which could
reinforce noise or unusual word statistics42 — we use a large external text data source:
an English Wikipedia reference corpus of 8 million documents, and all experiments are
conducted on Palmetto platform 12. The experimental results are given in Table 2.2.
From the results we observe that that the traditional modeling method (LDA) cannot
improve the performance of short text topic model. Additionally, we observe that PTM,
12http://aksw.org/Projects/Palmetto.html

Conversational Structure Aware Topic Model for Online Discussions 25
Table 2.2. Averaged coherence, measured by 6 different methods. The toptwo results are in boldface and italic respectively
Measure Cv Cp Cuci Cumass NPMI Ca
LDA 0.370 -0.014 -1.455 -4.186 -0.037 0.137PTM 0.367 0.077 -0.958 -2.783 -0.023 0.091BTM 0.372 0.015 -1.123 -3.008 -0.022 0.151leadLDA 0.396 0.054 -1.095 -2.962 0.018 0.153LFTM 0.359 0.044 -2.012 -3.038 0.008 0.089SATM 0.368 0.032 -1.086 -3.164 0.007 0.111CSATM 0.390 0.079 -0.915 -2.826 0.021 0.166
BTM, LFTM and SATM are almost at the same level. The performance gap among the
four is slightly behind LeadLDA and not significant. Recall, LeadLAD uses labelled mes-
sages to help identify potential topical words. CSATM outperforms all baseline models
in most cases. More importantly, CSATM is competitive against LeadLDA, but doesn’t
require model training with labelled comments, which saves time and effort.
2.4.3 Topic Assignment Evaluation
After extracting high-quality topics from the corpus, the assignments of topics to com-
ments should have reasonable accuracy; sometimes it is important to know the “targets”
each comment discusses in some downstream applications like stance detection, opin-
ion mining, and so on. In our experiment, we labelled the topic assignments to the top
100 comments in each discussion thread, and compared the performance on CSATM to
other models in terms of the accuracy of topic assignment, and the results are given in
Fig. 2.7.
We observe that CSATM achieves much higher accuracy than other models. That’s
because conventional models cannot deal with noisy comments like emojis, pictures,
cursing, and so on in online discussions. CSATM has the ability to find the correct topic
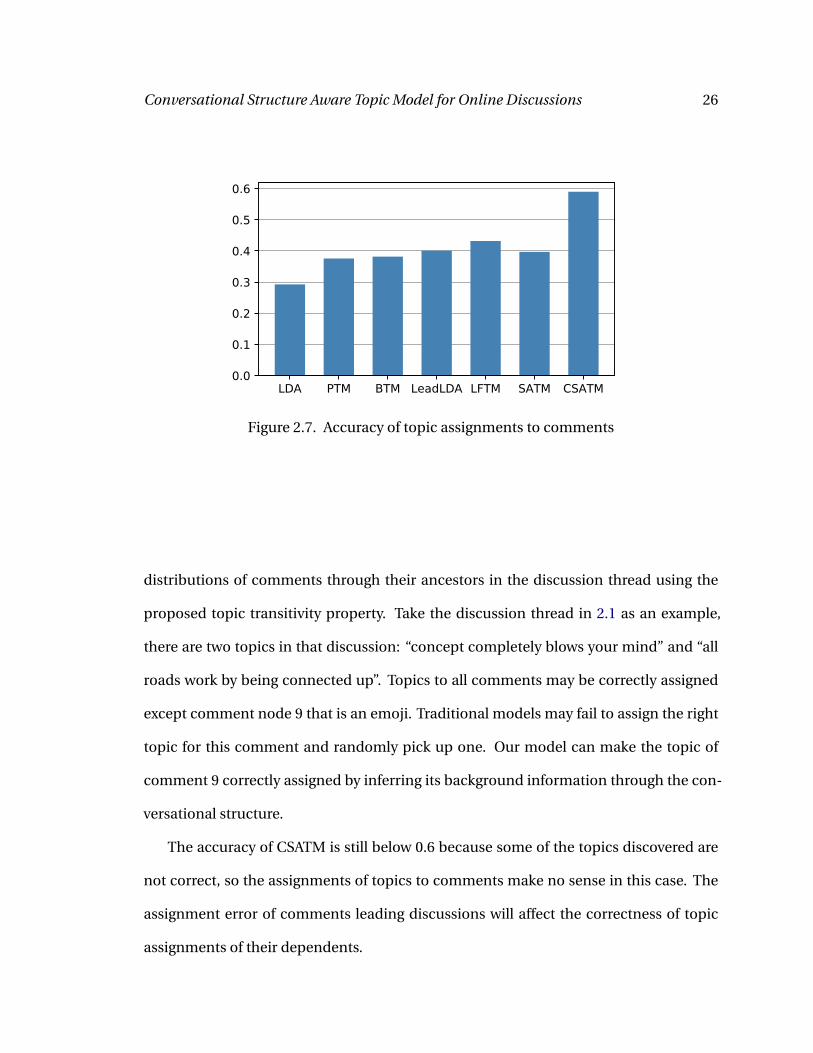
Conversational Structure Aware Topic Model for Online Discussions 26
Figure 2.7. Accuracy of topic assignments to comments
distributions of comments through their ancestors in the discussion thread using the
proposed topic transitivity property. Take the discussion thread in 2.1 as an example,
there are two topics in that discussion: “concept completely blows your mind” and “all
roads work by being connected up”. Topics to all comments may be correctly assigned
except comment node 9 that is an emoji. Traditional models may fail to assign the right
topic for this comment and randomly pick up one. Our model can make the topic of
comment 9 correctly assigned by inferring its background information through the con-
versational structure.
The accuracy of CSATM is still below 0.6 because some of the topics discovered are
not correct, so the assignments of topics to comments make no sense in this case. The
assignment error of comments leading discussions will affect the correctness of topic
assignments of their dependents.

Conversational Structure Aware Topic Model for Online Discussions 27
2.5 Case Study
In this section, we use a real case as demo to show the effectiveness of our model. The
left box in Fig. 2.8 is a snippet of an online discussion on the news “Texas serial bomber
made video confession before blowing himself up”. Topics are bolded and marked by
different colors. We can see there are basically three topics discussed in this thread:
1. the news title, 2. chance to see the video, 3. Browns win the Super Bowl. This is a
very typical and special case, because the topical words are very sparse, and one topic
(browns win super bowl) shifts from the main discussion thread.
We set the number as three and use four different topic models to extract the top-
ics: LDA, PTM, BTM and CSATM. We can see that LDA extracted topic 2 and 3, but they
are mixed together. PTM extracted topic 2 and 3, but did not capture enough topical
words for topic 3. BTM only extracted topic 2. All the three models failed to extract topic
1. Compared to the above three models, CSATM shows great performance by success-
fully extracted all the three topics with enough topical words. For topics that lead the
discussions but their topical words are not repeatedly occurred in the comments and
replies, conventional topic models based on word occurrence may not extract such kind
of topics successfully, but our proposed model CSATM could deal with this issue. Of
course, when the data is not sparse and topic word occurrence is high enough for mod-
eling, CSATM can also achieve good performance by setting the difference of the weight
sequence in equation (1) to a smaller to value until 1.
13https://www.reddit.com/r/news/comments/867njq/texas_serial_bomber_made_video_confession_before/?st=jw0idbj9&sh=fe12e994

Conversational Structure Aware Topic Model for Online Discussions 28
Texas serial bomber made video confession before blowing himself up
What are the chances we ever see the video?
About the same as the chances of the Browns winning the Super Bowl.
I take the browns to the super bowl every morning.
I have to applaud your regularity.
I thought at first you meant he posts that comment regularly. But now I get it. Healthy colon.
Consistency is the key.
Pshh I'm taking the browns to the super bowl as we speak
Seriously. Well done.
Notice no one here shit talking how the Browns are going all the way this year?
All the way to the #1 overall pick. Again.
To be fair, with that roster they should at least be a 6 game winning team this year.
The guy you replied to is definitely shit talking about the Browns going to the Superbowl.
Same chance that we’re allowed to talk about fight club
Zero, videos like this are locked down and used for training purposes. The bittaker and david
parker ray tapes come to mind. Transcript of one of the tapes found here
Holy fuck, here I am thinking "just transcripts? How bad can it be" Bad, guys. Very fucking bad.
So is this a video of someone else reading the transcript of the tape made by this guy?
Yeah but if you prefer you can read this transcript instead.
LDA• btk people got made guy like play going they're brown
• read transcript reading like i'm need brown it evil want
• guy like brown one crime they'll think say get chance
• like, brown, read, think, people, going, get, really, want, i'm
• guy, need, it., see, go, one, made, something, btk
• transcript, tape, crime, they'll, would, got, they're, ever, can't, chancePTM
• guy like get people actually think them, fucked them. transcript
• tape life bittaker reading killer need made transcript read crime
• they'll drug homeless like something get i've gang got crime
• confession video tape blowing made need texas bomber serial evil
• super brown bowl winning chance like morning every take something
• see ever chance video read need training purposes life evil
BTM
CSATM
Figure 2.8. An example thread of user comments on the news: " Texasserial bomber made video confession before blowing himself up" 13Threetopics are bolded and marked by different colors

Conversational Structure Aware Topic Model for Online Discussions 29
2.6 Conclusion
In this chapter, we have proposed the topic “popularity” and “transitivity” intuitions
and presented a novel topic model CSATM for online discussions. Conventional works
considering only plain text streams is not sufficient enough to summarize noisy discus-
sion trees. CSATM captures the conversational structure as context for topic modelling
and topic assignment to each comment, leading to better performance in terms of topic
coherence and assignment accuracy. By comparing our proposed model with a num-
ber of state-of – the –art baseline models on real word datasets, we have demonstrated
competitive results, and the effectiveness of using conversational discourse structure to
help in identifying topical content embedded in short and colloquial online discussions.
Weight sequence selection may be a little confusing, but that is due to the inherent sub-
jectivity of topic modeling and there are no uniform standards for measure a topic good
or not even its coherence score is high enough. In future work, we will explore and ex-
plain this part more.

30
3 Opinion Spam Detection Basedon Heterogeneous Information Net-work
3.1 Introduction
Consumers rely increasingly on user-generated online reviews to make, or reverse pur-
chase decisions, and opinion spam has been a long existing problem within Internet
applications, especially in e-commerce websites, review websites, or APP stores. Since
the financial incentives are associated with reviews, some users fabricate fake reviews to
either unjustly hype (for promotion) or defame (under competition) a product or busi-
ness, and the activities are called opinion spam3. This problem is surprisingly prevalent:
it is estimated that one-third of all consumer reviews on the Internet are fake43. Opin-
ion Spammers are hired to write fake reviews, and such "reputation management" ser-
vices are easy to be found online. Several high-profile cases have been reported in the
news44, even big companies like Samsung hired posters to promote its own products
and denounce its rivals on web forums45
While widespread, opinion spam detection is a hard and mostly open problem. In
the past few years, several supervised methods for detecting review spams or review
spammers have been proposed. Unlike other forms of spamming, it is difficult to collect

Opinion Spam Detection Based on Heterogeneous Information Network 31
a large amount of gold-standard labels for reviews by means of manual effort. Thus,
most of these methods46 just rely on the ad-hoc or pseudo fake or non-fake labels for
model training, such as the labels annotated by the Amazon anonymous online workers,
but neither of them can generate good ground truth by now. This renders supervised
methods inadmissible to a large extent, and thus unsupervised methods47–49 have been
proposed to detect the individual review spammer and review spammer groups.
Since the seminal work of Jindal et al. on opinion spam3, a variety of approaches
have been proposed. At a high level, those can be categorized as linguistic approaches50–52
that utilize the linguistic patterns of spam vs. benign users for psycholinguistic clues of
deception, behavioral approaches53,54 that analyze the reviewers’ behaviors such as rat-
ing behaviors, temporal or spatial patterns, and graph-based methods that leverage the
relational ties between users, reviews, and products to detect individual spammer or
group of spammers55–57.
These have made considerable progress in understanding and spotting opinion spam,
however the problem remains far from fully solved. Spammers continually change their
spamming content patterns to avoid being detected, so we need to use new features and
approaches to detect them58. In this paper, we list three new features for the classifica-
tion of benign and spam reviews: the number of images, social network of users, and the
controversy in review discussions. By incorporating these features, we propose an unsu-
pervised framework called SkyNet, that makes full use of heterogeneous data including
metadata and relational data, and harness them collectively under a unified framework
to spot spam users, fake reviews, as well as targeted products or shops. Moreover, SkyNet
can seamlessly integrate labels on any subset of objects (user, review, and/or product)

Opinion Spam Detection Based on Heterogeneous Information Network 32
when available to become a semi-supervised method, which yields a higher accuracy.
We summarize the contributions of this work as follows.
• The number of photos attached to a review is proposed as a feature because it
is a valuable clue to distinguish between spam and genuine reviews.
• Social network is introduced into the classification framework to detect spam
and spammers since spammers usually show different social behavior with be-
nign users.
• The evaluation of review is used for opinion spam detection. The feedback from
other users such as comments or votes can help to evaluate the quality of review
and its authenticity to an extent, so the evaluation of review is considered to be
a feature.
We evaluate our method on two real-world datasets, both of which are acquired from
Yelp.com with “not recommended” (spam) and recommended (genuine) reviews. The
filtering algorithm of Yelp is not perfect, but it has been found to produce accurate re-
sults and used widely in research6,59. The experiment results show that SkyNet outper-
forms several baselines and state-of-the-art techniques.
The rest of this paper is organized as follows. In Section 3.2, we present related work.
In Section 3.3, we propose the SkyNet framework, and discuss the algorithm and pro-
posed features. In Section 3.4, we introduce the dataset and show the experiment re-
sults. We conclude our work in Section 3.5.
3.2 Related Work
This section motivates our work by briefly describing related work in opinion spam de-
tection Opinion spam. After briefly introducing the possible ways to obtain ground

Opinion Spam Detection Based on Heterogeneous Information Network 33
truth, we organize the various approaches to opinion spam problem into three groups:
linguistic-, behavior- and graph-based.
3.2.1 Ground Truth Obtaining
Opinion spam detection is a ‘Truth Or Dare’ game, so there are only two ways to gain
ground truth: one is that spammers tell us whether they are spamming; the other is that
people manually label the genuine and fake reviews. For the first way, Ott et al.60 used
Amazon Mechanical Turk (AMT) to crowdsource anonymous online workers to write
fake hotel reviews to portray some hotels and used linguistic features to get a high (90
%) detection accuracy, but experiments on the Yelp data yielded a maximum accuracy of
68.1% using the same features and classification method. The reason is that the ‘Turkers’
did not do a good job at faking, maybe they had little gain in doing so or it is not a real-life
environment where you need to cheat commercial websites. Yu-Ren et al.61 used leaked
spreadsheets which keep the histories of the opinion spam posts in the case “Samsung
probed in Taiwan over ‘fake web reviews’,” as ground truth, but that dataset is not large
enough. For the second way, human readers usually cannot detect this kind of opin-
ion spam because most opinion spam is carefully designed to avoid being identified by
users or review content providers, so manual labeling of reviews is extremely difficult by
merely reading them, where humans are only slightly better than random60. Therefore,
all the training or testing data obtained now are near-ground-truth, but they still can be
used skillfully for our research. Recently, a new method to collect spam reviews from
low moderation crowdsourcing sites like RapidWorkers, ShortTask, and Microworkers,
where attacks on review sites can be launched by malicious paymasters. By tracking

Opinion Spam Detection Based on Heterogeneous Information Network 34
these workers from the crowdsourcing platform to a target review site like Amazon, de-
ceptive review manipulators can be identified62, but this method usually fails to collect
large number of spam reviews.
3.2.2 Linguistic-based approaches
This approach extract linguistic-based features to find spam reviews. Methods in this
category focus on the characteristics of language that the opinion spammers use and
how it differs from the language used in genuine reviews. The spam detection task can
be viewed as a text categorization problem63,64. Ott et al.60 applied psychological and
linguistic clues such as bag-of-n-grams to identify review spam. Changge et al.65 in-
troduce two types of deep level linguistic features. The first type of features is derived
from a shallow discourse parser trained on Penn Discourse Treebank, which can cap-
ture inter-sentence information. The second type is based on the relationship between
sentiment analysis and spam detection. Linguistic features need not take much time
to form, but Mukherjee et al.6 have proved that the linguistic features are not effective
enough in detecting real-life fake reviews from the commercial website after analyzing
the effectiveness of linguistic clues on a Yelp dataset with filtered and recommended re-
views. They found that the most effective traditional linguistic features cannot detect
the review spam effectively in the cold start task.
3.2.3 Behavior-based approaches
Behavior-based approaches often use features based on metadata and not the review
text itself. Jindal and Liu3 crawled dataset from amazon.com and use the review rating
and review feedbacks as the behavior features to identify suspicious reviews. Li et al.66
proposed a two-view semi-supervised co-training method based on behavioral features

Opinion Spam Detection Based on Heterogeneous Information Network 35
to spot fake reviews. Huayi et al.67 worked with Dianping which is the largest online
search and review service website in China, and proposed temporal and spatial features
which demonstrate fundamental differences between spammers and non-spammers.
Xie et al.68 find that the normal reviewers’ arrival pattern is stable and uncorrelated to
their rating pattern temporally. In contrast, spam attacks are usually bursty and either
positively or negatively correlated to the rating. They thus propose to detect such attacks
via unusually correlated temporal patterns. Besides detecting individual spammers, the
group spammers’ behavioral features are studied by Mukherjee et al.69 and Xu et al.70.
3.2.4 Graph-based approaches
A few graph-based approaches have also been proposed. Wang et al.71 proposed a het-
erogeneous graph model with three different types of nodes (i.e., reviewers, reviews, and
businesses) to detect opinion spams through analyzing relationships among the three
types of nodes. Rayana et al.59 proposed a unified spam detection framework, SpEagle,
to utilizes both the metadata such as texts and the relational data. Akoglu et al. pro-
posed a spam detection framework, FraudEagle, exploiting the network effect among
reviewers and businesses based on Markov Random Field (MRF)72. Li et al.73 construct
a user-IP-review graph to relate reviews that are written by the same users and from the
same IPs. All of these approaches model the fake review(er) detection problem as a col-
lective classification task on these networks, and employ algorithms such as Loopy Be-
lief Propagation (LBP)74, Iterative Classification Algorithm (ICA)75, meta search76–79 or
context aware learning algorithms80–83. A related direction is in detecting dense blocks
in a review-rating matrix84. Extraordinary dense blocks correspond to groups of users
with lockstep behaviors85. Moreover, this method has been lately extended from ma-
trix to tensor representation to incorporate more dimensions (e.g., temporal aspects)86.

Opinion Spam Detection Based on Heterogeneous Information Network 36
However, these approaches may have difficulty in detecting subtle attacks where there
are not such clearly defined dense block characteristics. Bitarafan and Dadkha extract
candidate groups using spammer behaviors and their relations based on Heterogeneous
Information Network (HIN)87, and converts the spammer group identification problem
to into a HIN classification problem.
These research have showed effectiveness in detecting spam reviews and users, how-
ever the spam users will crack the detection mechanism and use new tricks to camou-
flage themselves and polish their reviews, so the problem remains far from fully solved
and we need new features to identify the opinion spam, like the images, social network
and review evaluation. We mentioned the these features in our previous research88, and
will discuss more details in this dissertation.
3.3 The Skynet Framework
As mentioned above, the best method for opinion spam detection by now is a graph-
based approach. The intuition behind this is that graph-based approach can use more
information (clues) than traditional machine learning methods, so we formulate the
spam detection problem as a network classification task on the user-review-product
Heterogeneous Information Network (HIN).
3.3.1 Proposed Framework SkyNet
SkyNet harnesses heterogeneous data including metadata (text, timestamp, photos, rat-
ing, and etc.) and relational data (social network and review network), collectively under
a unified framework to spot spam users, fake reviews, as well as targeted products, as Fig.
3.1 shows.

Opinion Spam Detection Based on Heterogeneous Information Network 37
————————
————————
————————
————————
————————
————————
SKYNET FRAMEWORK
————————
————————
FEATURE MATRIX
Text
Features
Behavior
Features
Photo
Pictures
Labels
(if
have)Extract
SOCIAL NETWORK REVIEW NETWORK SHOP/ PRODUCT
Benign
User Spammer Review Spam Untarget Target
Figure 3.1. SkyNet collectively utilizes metadata and the relational dataunder a Heterogeneous Information Network to rank all of users, reviews,and shops/products by spamicity.
SkyNet leverages the metadata to estimate initial class probabilities for users, prod-
ucts, and reviews as prior class probabilities. After obtaining the prior knowledge, it uses
relational data to construct a Markov Random Field network to infer the class probabil-
ities of each node. Besides traditional features like textual contents, the ratio of positive
votes, burstiness and etc., we introduce three new features in SkyNet.
The first one is whether there is any photo attached to a review. With the wide use
of mobile devices, it is very convenient for people to take pictures or videos to record
the food, product or services they have purchased, and upload them together with their
writings, like the example shown in Fig. 3.2. Photos are more and more popular since

Opinion Spam Detection Based on Heterogeneous Information Network 38
Pretty good food. I came here at around 9:00 in the evening. It
is almost full. The lamb is delicious. The fried leek dumpling is
a little salty. The beef rolls are great. I did not know it is such a
large plate of food. I think it might fit four or five people. Just
too much for one person.
Figure 3.2. The review about a Chinese restaurant with photos attached.
they are more intuitive than plain text. We find that the number of photos embedded in
opinion spams are much less than that genuine reviews. It might cost too much labor
for spammers to make fake reviews with fake photos. We also find that it is more dis-
criminating between zero and non-zero photos than the other pairs of numbers such as
two and three photos for the review classification, so we use the binary value 0 and 1 to
represent a review with or without photos as the feature.
Secondly, the social network of users is introduced as part of relational data. A lot
of e-commerce websites and review forums like Yelp allow users to make friends. Ac-
cording to the news and report43–45, benign users and spammers show different social
behaviors. For example, most of spammer’s friends are spammers, or they do not have
friends, see the examples showed in Fig. 3.3. To take control of the sentiment for a
product or shop, a group of spammers sometimes work together writing fake reviews to
promote or demote a set of target products or shops.

Opinion Spam Detection Based on Heterogeneous Information Network 39
Figure 3.3. Examples of benign users (left) and spammers (right) detectedby Yelp.com. It is clear to see that the number of friends is different be-tween benign users and spammers.
Finally, the evaluation of a review by other users is an important feature. More and
more e-commerce websites or web forums allow users to give social feedback such as
comment or vote others’ reviews. Since such comments are also talking about the same
product or shop with the “root review”, we consider them are all reviews. The relation-
ship between reviews can be classified into two classes: support and opposition. If a
review is supported by a large number of benign users, there is a high probability that
such a review is not a spam; otherwise it may be a spam. Fig. 3.4a shows such an exam-
ple where the review and its comment have conflict, so it is possible that one of them
is spam. We can analyze the sentiment variance of the review discussion thread and
use the difference between the average of positive sentiments and average of negative
sentiments as the feature value. Fig. 3.4b shows an example that a review is voted by
other users. The number of positive or negative votes can also be used as the metric of
evaluation to the review. In this work we only consider the number of positive votes as
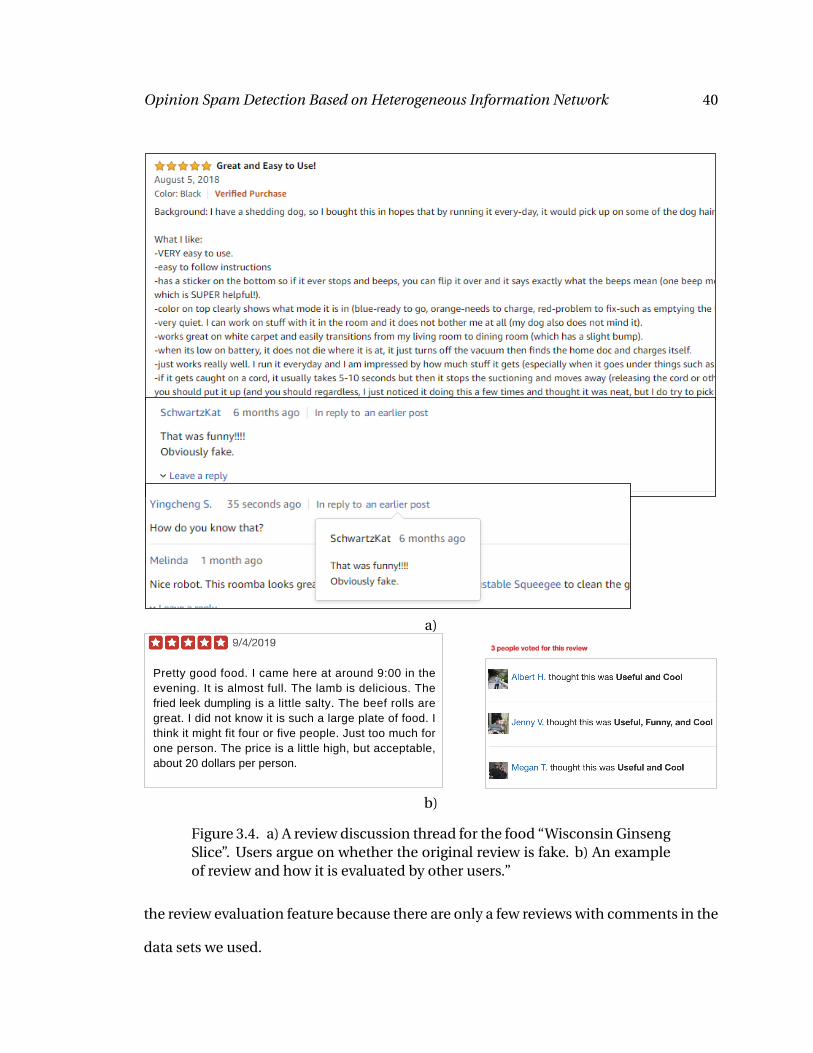
Opinion Spam Detection Based on Heterogeneous Information Network 40
a)
Pretty good food. I came here at around 9:00 in the
evening. It is almost full. The lamb is delicious. The
fried leek dumpling is a little salty. The beef rolls are
great. I did not know it is such a large plate of food. I
think it might fit four or five people. Just too much for
one person. The price is a little high, but acceptable,
about 20 dollars per person.
b)
Figure 3.4. a) A review discussion thread for the food “Wisconsin GinsengSlice”. Users argue on whether the original review is fake. b) An exampleof review and how it is evaluated by other users.”
the review evaluation feature because there are only a few reviews with comments in the
data sets we used.

Opinion Spam Detection Based on Heterogeneous Information Network 41
For the online review systems without the functions of “social network” or “comment
to reviews”, SkyNet is flexible enough to classify reviews in a relative high accuracy with
other features based on the user–review-product graph. In this work, we used three
other features proposed and verified by previous researchers: burstiness (spammers are
often short term members of the site)89, extremity of rating54 and the average content
similarity—pairwise cosine similarity among user’s (product’s) reviews, where a review
is represented as a bag-of-bigrams90
3.3.2 The Algorithm
To implement the SkyNet framework represented as Markov Random Field (MRF), we
use the Loopy Belief Propagation (LBP) algorithm to infer the hidden variables in the
model. Belief Propagation is an efficient inference algorithm in graphical models, but
there is no closed-form solution and it is not guaranteed to converge unless the graph
has no loops. Nevertheless, LBP works well in practice for performing inference on
graphical models, and it has been shown to perform extremely well for a wide variety
of applications in the real world91.
Given the user–review–product graph G = (V, E), review metadata (ratings, times-
tamps, text, and etc.) and labeled node set L, our aim is to obtain class probabilities for
each node i ∈ V \ L using LBP. First we need to define the domain of class labels. The
user–review–product graph G contains M user nodes U = {u1, ...,uM }, N review nodes
R = {r1, ...,rN }, and W product nodes that need to be reviewed, such as restaurant, bar or
product, etc. P = {p1, ..., pW }. The domain of class labels is LU = {beni g n, spammer }
for users, LR = {g enui ne, f ake} for products and LP = {non− t ar g et , t ar g et } for prod-
ucts. Second, to formally define the classification problem, the network is represented as
a pairwise Markov Random Field, so the joint probability of labels is written as a product

Opinion Spam Detection Based on Heterogeneous Information Network 42
Table 3.1. Compatibility potentials used by SkyNet for “User – Review”and “Review- Product” relation
User(ψs=′wr i te ′) Product(ψs=′bel ong ′)
Review benign spammer non-target targetgenuine 1 0 1- ε ε
fake 0 1 ε 1- ε
of individual and pairwise factors, parameterized over the nodes and the edges, respec-
tively on a factor graph:
P (y) = 1
Z
∏Yi εV
φi (yi )∏
(Yi ,Y j ,s)∈E∓ψs
i j (yi , y j ) (3.1)
where y denotes an assignment of labels to all nodes, yi refers to node i ’s assigned
label, and Z is the normalization constant. The individual factors φ : Ł → R+are called
prior (or node) potentials, and represent initial class probabilities for each node, often
initialized based on prior knowledge. The pairwise factorsψs : LU ∗LP → R+ are called
compatibility (or edge) potentials, and capture the likelihood of a node with label yi to
be connected to a node with label y j through an edge with sign s. We estimate the prior
potentials φi from metadata for all three types of nodes and initialize the compatibility
potentials ψsi j for all relations in network. Table 3.1 lists the settings of SkyNet for “user-
review” and “review- product” relations.
We assume that all the reviews written by spammers (benign users) are fake (gen-
uine), and that with high probability fake (genuine) reviews belong to targeted (non-
targeted) products; although with some probability fake reviews may also belong to
non-targeted products as part of camouflage, and similarly genuine reviews may co-
exist along with fake reviews for targeted products. The variable stands for a small value
as discussed in72, and it is similar for λ in Table 3.2 and δ in Table 3.3. Table II lists

Opinion Spam Detection Based on Heterogeneous Information Network 43
Table 3.2. Compatibility potentials for “User – User” relation
User(ψs=′know ′)
User benign spammerbenign 1-λ λ
spammer λ 1- λ
Table 3.3. Compatibility potentials for “Review – Review” relation, (+)represents support, (-) represents oppose
(+)Review (-)ReviewReview genuine fake genunine fakegenunie 1- δ δ δ 1- δfake δ 1- δ 1- δ δ
the settings for “user-user” relation SkyNet uses. We assume that benign users (spam-
mers) have high probability to make friends with benign users (spammers), although
with some probability spammers may also have friends of benign users. Similar to the
assumption in Table I, we assume that the majority of the benign users would not like to
make friend with spammers.
For “review-review” relation, we need to distinguish between supporting and oppo-
sition, as lists in Table 3.3. If the main point of a review supports another review, we
assume that with high probability fake (genuine) reviews support to fake (genuine) re-
views. Otherwise, if there are conflicts of points among the reviews, we assume that
with high probability genuine (fake) reviews oppose to fake (genuine) reviews, although
with some probability a benign user may also disagree with other benign users and write
comments against the reviews.
Third, to estimate the prior potentials, we extracted indicative features of spam from
available metadata (ratings, timestamps, review text) and then convert them to prior
class probabilities. Most of our features have been used several times in previous work
on opinion spam detection, except for the “photo feature” which is proposed by us.

Opinion Spam Detection Based on Heterogeneous Information Network 44
The features, however, may have different scales and varying distributions. To unify
them into a comparable scale and interpretation, we leverage the cumulative distribu-
tion function. In particular, when we design the features, we have an understanding of
whether a high (H) or a low (L) value is more suspicious for each feature. More formally,
for each feature l , 1 ≤ l ≤ F , and its corresponding value xli , we compute
f (xli ) =
1−P (Xl ≤ xli ), i f hi g h i s suspi ci ous
P (Xl ≤ xli ), other wi se(3.2)
where Xl denotes a real-valued random variable associated with feature l with proba-
bility distribution P . To compute f (u), we use the empirical probability distribution of
each feature over all the nodes of the given type. Overall, the features with suspiciously
low or high values all receive low f values. Finally we combine these f values to compute
the spam score of a node i as follows.
Si = 1−√∑F
l=1 f (xli )2
F(3.3)
When a set of labeled nodes are given, we simply initiate the priors as {ε,1− ε} for
those that are associated with spam (i.e., fake, spammer, or target), and {1− ε,ε} other-
wise. The priors of unlabeled nodes are estimated from metadata as given in equation
above.
Finally, we follow the main steps of the LBP algorithm. The inference algorithm ap-
plied on SkyNet can be concisely expressed as the following equations:
mi→ j (y j ) =α1∑
(yi∈LU )
(ψΘi , j (yi , y j )ψUi (yi )
∏Yk∈Ni
⋂yP \Y j
mk→i (yi )) (3.4)

Opinion Spam Detection Based on Heterogeneous Information Network 45
bi (yi ) =α2ψUi (yi )
∏Y j∈Ni
⋂yP
m j→i (yi ) (3.5)
where mi→ j is a message sent by user yi to review y j (a similar equation can be
written for messages from reviews to products, users to users and reviews to reviews),
and bi (yi ) denotes the belief of user i having label yi (again, a similar equation can be
written for beliefs of reviews or products). α1 and α2 are the normalization constants,
which respectively ensure that each message and each set of marginal probabilities sum
to 1.
The algorithm proceeds by making each set of yi ∈ T , where T ∈ {U ,R,P } alternately
communicate messages with its neighbors in an iterative fashion until the messages sta-
bilize, i.e. convergence. After they stabilize, we calculate the marginal probabilities. For
classification, one can assign labels based on maxyi bi (yi ). For ranking, we sort by the
probability values bi (yi ) where yi = spammer and yi = f ake respectively for users and
reviews.
3.4 Data Sets
Obtaining large ground truth dataset for the opinion spam detection problem is a great
challenge. First, spammers will not tell others that they are lying. Second, manual anno-
tation of reviews by humans is close to random60. Third, the Amazon Mechanical Turk
workers cannot write fake reviews with “high quality”60, and the “professional” reputa-
tion marketing services cost too much. In most of the previous work, Yelp.com is thus
used to create the near-ground-truth dataset59.
Yelp marks each review as “recommended” or “not recommended”, and make them
public. People can argue with Yelp if their reviews are put on the “not recommended”

Opinion Spam Detection Based on Heterogeneous Information Network 46
Table 3.4. Review Datasets Used In This Work
Dataset #Reviews (filtered %) #Reviews (filtered %) #Products (rest.&hotel)YelpZip 608, 598 (13.22%) 260,277 (23.91%) 5,044Yelp1K 44, 479 (23.8%) 36, 222 (31%) 1,000
Table 3.5. Photo Distribution. (“Rec” is short for “Recommended”)
Dataset#Photos/ Products(Not Rec)
#Photos/ Reviews(Not Rec)
Review with photos/ Reviews(Not Rec)
YelpZip 16.5 (1.9) 0.386 (0.06) 0.241 (0.01)Yelp1K 19.9 (2.5) 0.473 (0.03) 0.404 (0.034)Average 18.2 (2.2) 0.47 (0.045) 0.327 (0.022)
list. While the Yelp filtering algorithm is not perfect and the “not recommended” reviews
do not mean they are fake, such labeled reviews with full metadata is the still cheapest
and largest real-world dataset available, and it has been found accurate enough for our
research topic92. “Yelp challenge” offers a large dataset but it does not include the “not
recommended” reviews, so we make a dataset called “Yelp1K” by scraping reviews from
1000 randomly picked business pages on Yelp. We also obtain the “YelpZip” dataset of-
fered by Rayana59. The original “YelpZip” dataset does not have the attributes of photos,
user social network and review evaluation. We extend the original dataset by adding the
above attributes and values to construct the corresponding feature vectors. The sum-
mary statistics of the two datasets is given in Table 3.4.
We acquired the number of photos attached to each review for the two datasets. Ta-
ble 3.4 lists the photo distribution. The average number of photos taken by users to a
product is 16 in “recommended” reviews, which is much higher than that in “not rec-
ommended” reviews (2.2). The value gap is also big for the average number of photos
per review has and the percentage of review with photos to all reviews.

Opinion Spam Detection Based on Heterogeneous Information Network 47
Table 3.6. Social Network and Votes Distribution. (“Rec” is short for “Rec-ommended”)
Dataset#Friends(Not Rec)
#Friends/Users(Not Rec)
#Votes(Not Rec)
#Votes(Not Rec)
YelpZip1, 215, 737, 955
(58,676,207)46.7(2.0)
398, 156(1010)
1.03(0.01)
Yelp1K59, 848, 506(3,378,600)
43.4(2.2)
23, 578(467)
0.92(0.02)
We build the social network given the all the users and their friendship information.
In Yelp, there are three types of voting to a review: ‘useful’, ‘funny’ and ‘cool’. Since they
are all positive feedback, we combine them together and make the sum of these evalu-
ations as the total votes to a review. Table 3.6 lists the basic statistics of social network
and voting information. From the table we can see that the distribution of friends and
votes are both discriminating for “Recommended” and “Not Recommended”reviews.
3.5 Evaluation
We use three different ranking based metrics for our performance evaluation on the two
datasets. We obtain the (i) precision-recall (PR) as well as (ii) ROC (true positive rate
vs. FPR) curves, where the points on a curve are obtained by varying the classification
threshold. We compute the area under the curve, respectively denoted as AP (average
precision) and AUC. For spam detection problem, often the quality at the top of the
ranking results are more important. Therefore, we also inspect (iii) precision@k, for k =
100, 200, . . . , 1000, where it captures the ratio of spam in top k positions.
As Fig. 3.5 and Fig. 3.6 shown, we compare the performance of SkyNet to SpEagle59
as well as to the graph-based approach proposed Wang et al.71. We also consider Prior,

Opinion Spam Detection Based on Heterogeneous Information Network 48
0
0.1
0.2
0.3
0.4
0.5
Random Prior Wang et al . SpEagle SkyNet
Ave
rage
Pre
cisio
n
Y'1K Y'ZIP
Figure 3.5. Average Precision of Compared Methods on Two Dataset.”
where we use the spam scores (for users and reviews) computed solely based on meta-
data. Prior does not use the network information, and hence corresponds to SkyNet
without LBP. We find that SkyNet outperforms all other methods on both AP and AUC.
The performance of SkyNet running on Yelp1K is a little bit better than YelpZip. That’s
because the reviews in YelpZip are acquired five years ago and the photos in reviews at
that time are not so common as nowadays, and most reviews in Yelp1K are fresh reviews.
Next we inspect precision@k, for k = 100, 200, . . . , 1000. From Table 3.7 and Table
3.8 we can see that the superiority of SkyNet’s ranking becomes more evident when the
top of the ranking results are considered by precision@k.
Next we investigate how much the detection performance can be improved by semi-
supervision; i.e., providing SkyNet with a subset of the review labels. We analyze per-
formance for varying amount of labeled data. Fig. 3.7 shows the corresponding pre-
cision@k values for review ranking (user ranking performance is similar, omitted for
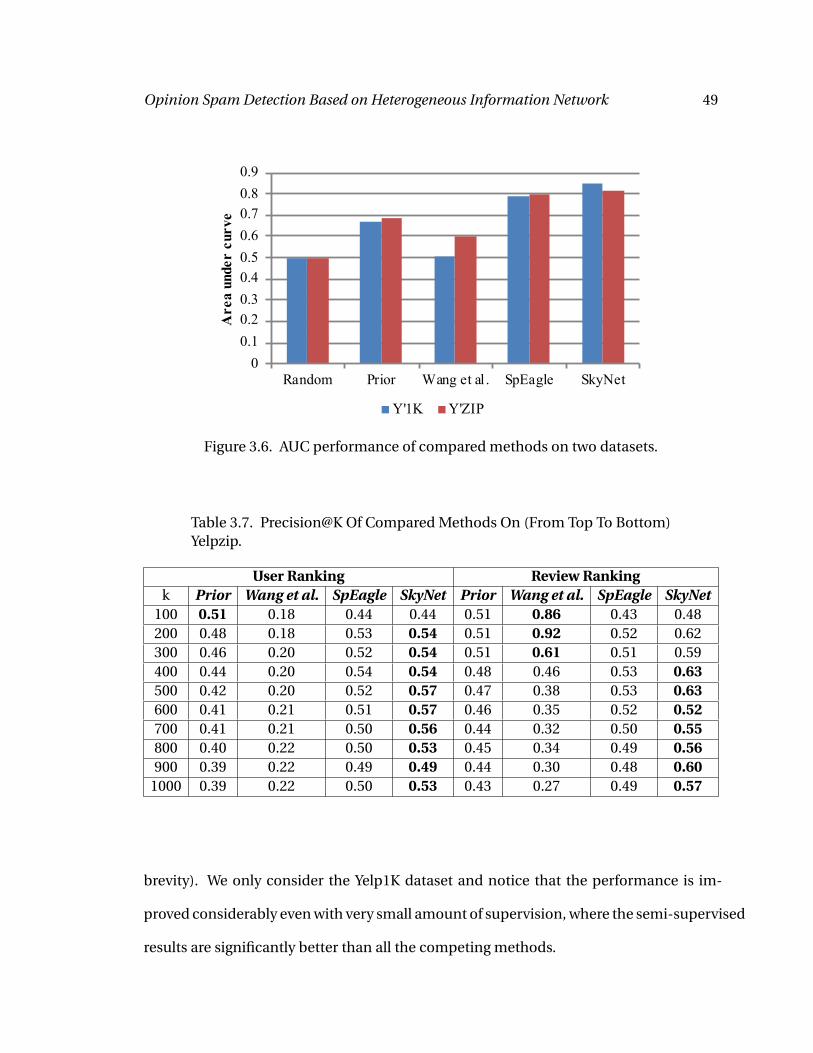
Opinion Spam Detection Based on Heterogeneous Information Network 49
00.10.20.30.40.50.60.70.80.9
Random Prior Wang et al . SpEagle SkyNet
Are
a un
der
curv
e
Y'1K Y'ZIP
Figure 3.6. AUC performance of compared methods on two datasets.
Table 3.7. Precision@K Of Compared Methods On (From Top To Bottom)Yelpzip.
User Ranking Review Rankingk Prior Wang et al. SpEagle SkyNet Prior Wang et al. SpEagle SkyNet
100 0.51 0.18 0.44 0.44 0.51 0.86 0.43 0.48200 0.48 0.18 0.53 0.54 0.51 0.92 0.52 0.62300 0.46 0.20 0.52 0.54 0.51 0.61 0.51 0.59400 0.44 0.20 0.54 0.54 0.48 0.46 0.53 0.63500 0.42 0.20 0.52 0.57 0.47 0.38 0.53 0.63600 0.41 0.21 0.51 0.57 0.46 0.35 0.52 0.52700 0.41 0.21 0.50 0.56 0.44 0.32 0.50 0.55800 0.40 0.22 0.50 0.53 0.45 0.34 0.49 0.56900 0.39 0.22 0.49 0.49 0.44 0.30 0.48 0.60
1000 0.39 0.22 0.50 0.53 0.43 0.27 0.49 0.57
brevity). We only consider the Yelp1K dataset and notice that the performance is im-
proved considerably even with very small amount of supervision, where the semi-supervised
results are significantly better than all the competing methods.
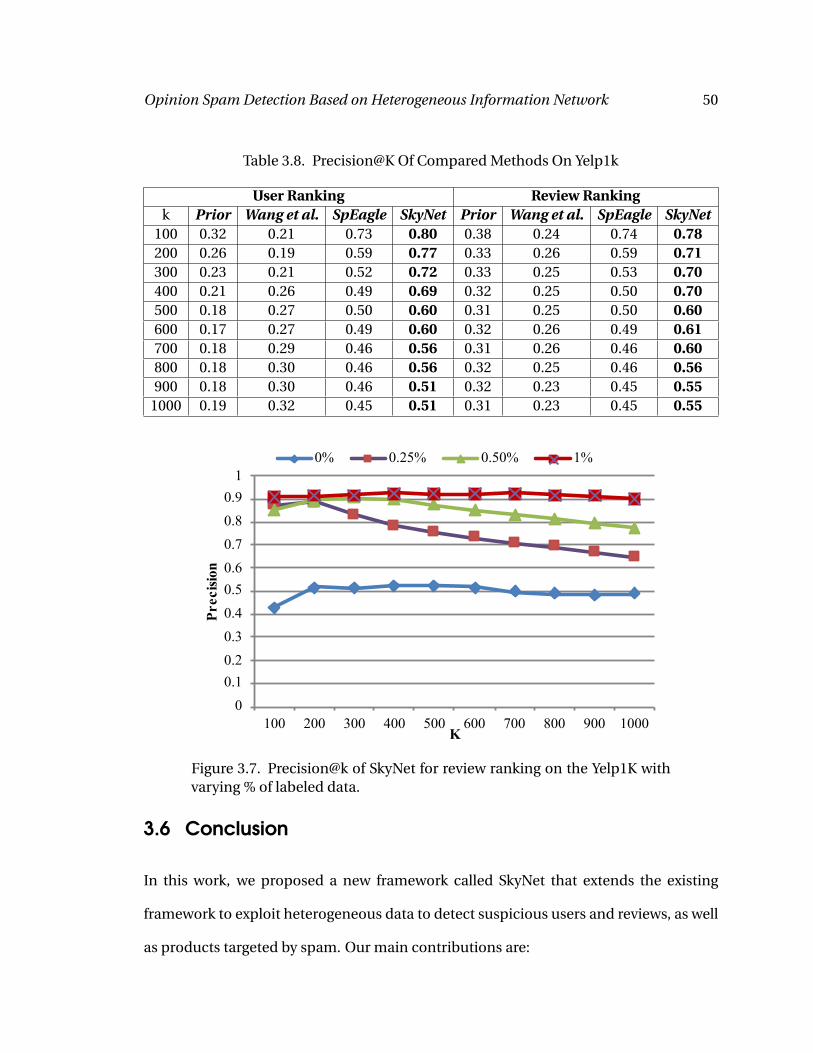
Opinion Spam Detection Based on Heterogeneous Information Network 50
Table 3.8. Precision@K Of Compared Methods On Yelp1k
User Ranking Review Rankingk Prior Wang et al. SpEagle SkyNet Prior Wang et al. SpEagle SkyNet
100 0.32 0.21 0.73 0.80 0.38 0.24 0.74 0.78200 0.26 0.19 0.59 0.77 0.33 0.26 0.59 0.71300 0.23 0.21 0.52 0.72 0.33 0.25 0.53 0.70400 0.21 0.26 0.49 0.69 0.32 0.25 0.50 0.70500 0.18 0.27 0.50 0.60 0.31 0.25 0.50 0.60600 0.17 0.27 0.49 0.60 0.32 0.26 0.49 0.61700 0.18 0.29 0.46 0.56 0.31 0.26 0.46 0.60800 0.18 0.30 0.46 0.56 0.32 0.25 0.46 0.56900 0.18 0.30 0.46 0.51 0.32 0.23 0.45 0.55
1000 0.19 0.32 0.45 0.51 0.31 0.23 0.45 0.55
00.10.20.30.40.50.60.70.80.91
100 200 300 400 500 600 700 800 900 1000
Precision
K
0% 0.25% 0.50% 1%
Figure 3.7. Precision@k of SkyNet for review ranking on the Yelp1K withvarying % of labeled data.
3.6 Conclusion
In this work, we proposed a new framework called SkyNet that extends the existing
framework to exploit heterogeneous data to detect suspicious users and reviews, as well
as products targeted by spam. Our main contributions are:

Opinion Spam Detection Based on Heterogeneous Information Network 51
• The number of photo attached to reviews is first time proposed as a feature, and
SkyNet is such an approach for the opinion spam detection problem, which
makes full use of relational data with metadata, i.e., it utilizes all of heteroge-
neous information collectively.
• Social network is introduced into the classification framework in our project to
detect possible group spammers, who might work together writing fake reviews
to promote or demote a set of target products.
• Review evaluation is used as a clue to increase the spam detection accuracy.
The comments or votes by other user both provide useful feedback evidence to
spam detection.
We evaluated our method on a real-world datasets with labeled reviews (recom-
mended vs. not recommended), as collected from Yelp.com. The experiment results
show that our proposed framework SkyNet has competitive effectiveness in filtering
opinion spams and spammers.

52
4 Suggested Future Research
4.1 Dynamic topic modeling
The content of online discussions evolve over time, since users keep adding comments
or replies to the discussion thread, especially for those discussions with "hot" topics. It
is of interest to explicitly model the dynamics of the underlying topics for short text seg-
ment collections. Such kind of models can not only capture the newly emerging topics
but also keep track of the topic trends of discussion threads. For example, Derek and
James are interested in extracting latent thematic patterns in political speeches by de-
veloping a dynamic topic model to investigate how the plenary agenda of the European
Parliament has changed over the past terms93. Daniel et al. seek to uncover the broad
trends and facts from social sentences in social networking sites94. It might be an inter-
esting research direction to develop dynamic topic models for online discussions with
conversational structures.
4.2 Adaptive spam detection
After being filtered by the opinion spam detection systems, spammers will update their
spamming methods and evolve themselves. More camouflage skills will be used by
spammers to avoid being detected. In this case, the opinion spam detection system

Suggested Future Research 53
also needs to update and adaptively catch new features. In email spam identification
field, adaptive spam detection approaches have been explored before95,96, but there are
seldom discussed in the methods of adaptively detecting opinion spams and spammers
For the work introduced in this dissertation, there are several interesting research topics
for future research. For example, the photo of one’s profile can also be used as an impor-
tant feature since spammer usually would not like to expose themselves. With the time
constrained, we did not do experiments on other datasets, more datasets can be used to
make the experiment conclusions strong enough.
4.3 Downstream Applications
There are plentiful downstream applications of our proposed model. For example, it
can assistant users to browse a long discussion thread quickly by summarizing the pos-
sible topics. Oftentimes, a popular news article or interesting post can easily accumu-
late thousands of comments within a short period of time, which makes it difficult for
interested users to access and digest information in such data. Therefore, modeling the
user-generated comments with respect to different topics and automatically gaining the
insight of readers’ opinions and attention on the news event will save users’ a lot of time.
It will also very helpful for sentiment analysis or stance detection. The massive
amount of online discussions provide us with valuable resources for studying and un-
derstanding public opinions on fundamental societal issues, e.g., abortion or gun rights.
Automatically predicting user stance and identifying corresponding arguments are im-
portant tasks for improving policy-making process and public deliberation. Traditional
stance detection methods assume that there is only one topic in a discussion and try
to classify the stance into positive and negative. However,there are sometimes multiple

Suggested Future Research 54
topics within one discussion thread, such as the post "What is a long term solution to
illegal immigration in the US?"

Bibliography 55
Complete References
[1] Yingcheng Sun, Richard Kolacinski, and Kenneth Loparo. Eliminating search in-tent bias in learning to rank. In 2019 first IEEE International conference onConversational Data and Knowledge Engineering (CDKE), volume 1. IEEE, 2019.
[2] Zhaochun Ren, Jun Ma, Shuaiqiang Wang, and Yang Liu. Summarizing web forumthreads based on a latent topic propagation process. In Proceedings of the 20thACM international conference on Information and knowledge management, pages879–884. ACM, 2011.
[3] Nitin Jindal and Bing Liu. Opinion spam and analysis. In Proceedings of the 2008international conference on web search and data mining, pages 219–230. ACM,2008.
[4] Thomas Hofmann. Probabilistic latent semantic analysis. In Proceedings of theFifteenth conference on Uncertainty in artificial intelligence, pages 289–296. Mor-gan Kaufmann Publishers Inc., 1999.
[5] David M Blei, Andrew Y Ng, and Michael I Jordan. Latent dirichlet allocation.Journal of machine Learning research, 3(Jan):993–1022, 2003.
[6] Arjun Mukherjee, Vivek Venkataraman, Bing Liu, and Natalie Glance. What yelpfake review filter might be doing? In Seventh international AAAI conference onweblogs and social media, 2013.
[7] Jing Li, Ming Liao, Wei Gao, Yulan He, and Kam-Fai Wong. Topic extraction frommicroblog posts using conversation structures. In ACL (1). World Scientific, 2016.
[8] Jun Hatori, Akiko Murakami, and Jun’ichi Tsujii. Multi-topical discussion summa-rization using structured lexical chains and cue words. In International conferenceon intelligent text processing and computational linguistics, pages 313–327.Springer, 2011.
[9] Rui Dong, Yizhou Sun, Lu Wang, Yupeng Gu, and Yuan Zhong. Weakly-guideduser stance prediction via joint modeling of content and social interaction. InProceedings of the 2017 ACM on Conference on Information and KnowledgeManagement, pages 1249–1258. ACM, 2017.
[10] Adrien Guille and Cécile Favre. Event detection, tracking, and visualization in twit-ter: a mention-anomaly-based approach. Social Network Analysis and Mining,5(1):18, 2015.

Bibliography 56
[11] Liangjie Hong and Brian D Davison. Empirical study of topic modeling in twitter.In Proceedings of the first workshop on social media analytics, pages 80–88. acm,2010.
[12] Courtney Napoles, Aasish Pappu, and Joel Tetreault. Automatically identifyinggood conversations online (yes, they do exist!). In Eleventh International AAAIConference on Web and Social Media, 2017.
[13] Chaotao Chen and Jiangtao Ren. Forum latent dirichlet allocation for user interestdiscovery. Knowledge-Based Systems, 126:1–7, 2017.
[14] Tian Shi, Kyeongpil Kang, Jaegul Choo, and Chandan K Reddy. Short-text topicmodeling via non-negative matrix factorization enriched with local word-contextcorrelations. In Proceedings of the 2018 World Wide Web Conference on WorldWide Web, pages 1105–1114. International World Wide Web Conferences SteeringCommittee, 2018.
[15] Jianshu Weng, Ee-Peng Lim, Jing Jiang, and Qi He. Twitterrank: finding topic-sensitive influential twitterers. In Proceedings of the third ACM internationalconference on Web search and data mining, pages 261–270. ACM, 2010.
[16] Wayne Xin Zhao, Jing Jiang, Jianshu Weng, Jing He, Ee-Peng Lim, Hongfei Yan,and Xiaoming Li. Comparing twitter and traditional media using topic models. InEuropean conference on information retrieval, pages 338–349. Springer, 2011.
[17] David Alvarez-Melis and Martin Saveski. Topic modeling in twitter: Aggregatingtweets by conversations. In Tenth International AAAI Conference on Web and SocialMedia, 2016.
[18] Daniel Ramage, Susan Dumais, and Dan Liebling. Characterizing microblogs withtopic models. In Fourth International AAAI Conference on Weblogs and SocialMedia, 2010.
[19] Rishabh Mehrotra, Scott Sanner, Wray Buntine, and Lexing Xie. Improving lda topicmodels for microblogs via tweet pooling and automatic labeling. In Proceedingsof the 36th international ACM SIGIR conference on Research and development ininformation retrieval, pages 889–892. ACM, 2013.
[20] Xiaojun Quan, Chunyu Kit, Yong Ge, and Sinno Jialin Pan. Short and sparsetext topic modeling via self-aggregation. In Twenty-Fourth International JointConference on Artificial Intelligence, 2015.
[21] Yuan Zuo, Junjie Wu, Hui Zhang, Hao Lin, Fei Wang, Ke Xu, and Hui Xiong. Topicmodeling of short texts: A pseudo-document view. In Proceedings of the 22nd ACM

Bibliography 57
SIGKDD international conference on knowledge discovery and data mining, pages2105–2114. ACM, 2016.
[22] Guangxu Xun, Yaliang Li, Wayne Xin Zhao, Jing Gao, and Aidong Zhang. A corre-lated topic model using word embeddings. In IJCAI, pages 4207–4213, 2017.
[23] Bei Shi, Wai Lam, Shoaib Jameel, Steven Schockaert, and Kwun Ping Lai.Jointly learning word embeddings and latent topics. In Proceedings of the40th International ACM SIGIR Conference on Research and Development inInformation Retrieval, pages 375–384. ACM, 2017.
[24] Xiaohui Yan, Jiafeng Guo, Yanyan Lan, and Xueqi Cheng. A biterm topic model forshort texts. In Proceedings of the 22nd international conference on World WideWeb, pages 1445–1456. ACM, 2013.
[25] Heng-Yang Lu, Lu-Yao Xie, Ning Kang, Chong-Jun Wang, and Jun-Yuan Xie. Don’tforget the quantifiable relationship between words: Using recurrent neural net-work for short text topic discovery. In Thirty-First AAAI Conference on ArtificialIntelligence, 2017.
[26] Dat Quoc Nguyen, Richard Billingsley, Lan Du, and Mark Johnson. Improving topicmodels with latent feature word representations. Transactions of the Associationfor Computational Linguistics, 3:299–313, 2015.
[27] Ximing Li, Ang Zhang, Changchun Li, Lantian Guo, Wenting Wang, and JihongOuyang. Relational biterm topic model: Short-text topic modeling using word em-beddings. The Computer Journal, 62(3):359–372, 2018.
[28] Jing Li, Wei Gao, Zhongyu Wei, Baolin Peng, and Kam-Fai Wong. Using content-level structures for summarizing microblog repost trees. In EMNLP, pages 2168–2178. World Scientific, 2015.
[29] Jing Li, Yan Song, Zhongyu Wei, and Kam-Fai Wong. A joint model of conversationaldiscourse and latent topics on microblogs. Computational Linguistics, 44(4):719–754, 2018.
[30] Yee Whye Teh, Michael I Jordan, Matthew J Beal, and David M Blei. Hierarchicaldirichlet processes. Journal of the American Statistical Association, 101(476):1566–1581, 2006.
[31] John Paisley, Chong Wang, David M Blei, and Michael I Jordan. Nested hierar-chical dirichlet processes. IEEE Transactions on Pattern Analysis and MachineIntelligence, 37(2):256–270, 2014.

Bibliography 58
[32] Yingcheng Sun, Kenneth Loparo, and Richard Kolacinski. Conversational structureaware and context sensitive topic model for online discussions. In 2019 14th IEEEInternational conference on semantic computing, volume 1. IEEE, 2019.
[33] Kamil Topal, Mehmet Koyuturk, and Gultekin Ozsoyoglu. Emotion-and area-driventopic shift analysis in social media discussions. In 2016 IEEE/ACM InternationalConference on Advances in Social Networks Analysis and Mining (ASONAM), pages510–518. IEEE, 2016.
[34] CS Lifna and M Vijayalakshmi. Identifying concept-drift in twitter streams.Procedia Computer Science, 45:86–94, 2015.
[35] Albert Park, Andrea L Hartzler, Jina Huh, Gary Hsieh, David W McDonald, andWanda Pratt. “how did we get here?”: topic drift in online health discussions.Journal of medical Internet research, 18(11):e284, 2016.
[36] Jonathan Chang, Sean Gerrish, Chong Wang, Jordan L Boyd-Graber, and David MBlei. Reading tea leaves: How humans interpret topic models. In Advances in neuralinformation processing systems, pages 288–296, 2009.
[37] Gerlof Bouma. Normalized (pointwise) mutual information in collocation extrac-tion. Proceedings of GSCL, pages 31–40, 2009.
[38] D Newman, JH Lau, K Grieser, and T Baldwin. Automatic evaluation of topic coher-ence. inhuman language technologies: The 2010 annual conference of the northamerican chapter of the association for computational linguistics, hlt’10, 2010.
[39] David Mimno, Hanna M Wallach, Edmund Talley, Miriam Leenders, and AndrewMcCallum. Optimizing semantic coherence in topic models. In Proceedings of theconference on empirical methods in natural language processing, pages 262–272.Association for Computational Linguistics, 2011.
[40] Michael Röder, Andreas Both, and Alexander Hinneburg. Exploring the spaceof topic coherence measures. In Proceedings of the eighth ACM internationalconference on Web search and data mining, pages 399–408. ACM, 2015.
[41] Branden Fitelson. A probabilistic theory of coherence. Analysis, 63(3):194–199,2003.
[42] David Newman, Youn Noh, Edmund Talley, Sarvnaz Karimi, and Timothy Baldwin.Evaluating topic models for digital libraries. In Proceedings of the 10th annual jointconference on Digital libraries, pages 215–224. ACM, 2010.
[43] David Streitfeld. The best book reviews money can buy. The New York Times,25(08), 2012.

Bibliography 59
[44] David Streitfeld. Buy reviews on yelp, get black mark. New York Times. http://www.nytimes. com/2012/10/18/technology/yelp-tries-to-halt-deceptive-reviews. html,2012.
[45] David Streitfeld. Samsung probed in taiwan over ’fake web reviews’. BBC News.,2013.
[46] Junting Ye and Leman Akoglu. Discovering opinion spammer groups by networkfootprints. In Joint European Conference on Machine Learning and KnowledgeDiscovery in Databases, pages 267–282. Springer, 2015.
[47] Cennet Merve Yilmaz and Ahmet Onur Durahim. Spr2ep: a semi-supervisedspam review detection framework. In 2018 IEEE/ACM International Conference onAdvances in Social Networks Analysis and Mining (ASONAM), pages 306–313. IEEE,2018.
[48] Yinqing Xu, Bei Shi, Wentao Tian, and Wai Lam. A unified model for unsuper-vised opinion spamming detection incorporating text generality. In Twenty-FourthInternational Joint Conference on Artificial Intelligence, 2015.
[49] Ziyu Guo, Liqiang Wang, Yafang Wang, Guohua Zeng, Shijun Liu, and GerardDe Melo. Public opinion spamming: A model for content and users on sina weibo.In Proceedings of the 10th ACM Conference on Web Science, pages 210–214. ACM,2018.
[50] Huayi Li, Geli Fei, Shuai Wang, Bing Liu, Weixiang Shao, Arjun Mukherjee, andJidong Shao. Bimodal distribution and co-bursting in review spam detection. InProceedings of the 26th International Conference on World Wide Web, pages 1063–1072. International World Wide Web Conferences Steering Committee, 2017.
[51] Santosh KC and Arjun Mukherjee. On the temporal dynamics of opinion spam-ming: Case studies on yelp. In Proceedings of the 25th International Conferenceon World Wide Web, pages 369–379. International World Wide Web ConferencesSteering Committee, 2016.
[52] Song Feng, Ritwik Banerjee, and Yejin Choi. Syntactic stylometry for deceptiondetection. In Proceedings of the 50th Annual Meeting of the Association forComputational Linguistics: Short Papers-Volume 2, pages 171–175. Association forComputational Linguistics, 2012.
[53] Euijin Choo. Analyzing opinion spammers’ network behavior in online review sys-tems. In 2018 IEEE Fourth International Conference on Big Data Computing Serviceand Applications (BigDataService), pages 270–275. IEEE, 2018.

Bibliography 60
[54] Arjun Mukherjee, Abhinav Kumar, Bing Liu, Junhui Wang, Meichun Hsu, MaluCastellanos, and Riddhiman Ghosh. Spotting opinion spammers using behavioralfootprints. In Proceedings of the 19th ACM SIGKDD international conference onKnowledge discovery and data mining, pages 632–640. ACM, 2013.
[55] Bimal Viswanath, Muhammad Ahmad Bashir, Muhammad Bilal Zafar, SimonBouget, Saikat Guha, Krishna P Gummadi, Aniket Kate, and Alan Mislove. Strengthin numbers: Robust tamper detection in crowd computations. In Proceedings ofthe 2015 ACM on Conference on Online Social Networks, pages 113–124. ACM,2015.
[56] Zhenni You, Tieyun Qian, and Bing Liu. An attribute enhanced domain adap-tive model for cold-start spam review detection. In Proceedings of the 27thInternational Conference on Computational Linguistics, pages 1884–1895, 2018.
[57] Yafeng Ren and Donghong Ji. Neural networks for deceptive opinion spam detec-tion: An empirical study. Information Sciences, 385:213–224, 2017.
[58] Yingcheng Sun, Xiaoshu Cai, and Kenneth Loparo. Learning-based adapta-tion framework for elastic software systems. In Proceedings of the 31st IEEEInternational Conference on Software Engineering and Knowledge Engineering,pages 281–286. IEEE, 2019.
[59] Shebuti Rayana and Leman Akoglu. Collective opinion spam detection: Bridgingreview networks and metadata. In Proceedings of the 21th acm sigkdd internationalconference on knowledge discovery and data mining, pages 985–994. ACM, 2015.
[60] Myle Ott, Yejin Choi, Claire Cardie, and Jeffrey T Hancock. Finding deceptiveopinion spam by any stretch of the imagination. In Proceedings of the 49thannual meeting of the association for computational linguistics: Human languagetechnologies-volume 1, pages 309–319. Association for Computational Linguistics,2011.
[61] Yu-Ren Chen and Hsin-Hsi Chen. Opinion spam detection in web forum: a realcase study. In Proceedings of the 24th International Conference on World WideWeb, pages 173–183. International World Wide Web Conferences Steering Commit-tee, 2015.
[62] Parisa Kaghazgaran, James Caverlee, and Anna Squicciarini. Combating crowd-sourced review manipulators: A neighborhood-based approach. In Proceedings ofthe Eleventh ACM International Conference on Web Search and Data Mining, pages306–314. ACM, 2018.

Bibliography 61
[63] Qingshan Li, Yingcheng Sun, and Baoye Xue. Complex query recognition basedon dynamic learning mechanism. Journal of Computational Information Systems,8(20):1–8, 2012.
[64] Yingcheng Sun and Kenneth Loparo. Information extraction from free text in clin-ical trials with knowledge-based distant supervision. In 2019 IEEE 43rd AnnualComputer Software and Applications Conference (COMPSAC), volume 1, pages954–955. IEEE, 2019.
[65] Changge Chen, Hai Zhao, and Yang Yang. Deceptive opinion spam detection us-ing deep level linguistic features. In Natural Language Processing and ChineseComputing, pages 465–474. Springer, 2015.
[66] Fangtao Huang Li, Minlie Huang, Yi Yang, and Xiaoyan Zhu. Learning to iden-tify review spam. In Twenty-second international joint conference on artificialintelligence, 2011.
[67] Huayi Li, Zhiyuan Chen, Arjun Mukherjee, Bing Liu, and Jidong Shao. Analyzingand detecting opinion spam on a large-scale dataset via temporal and spatial pat-terns. In ninth international AAAI conference on web and social Media, 2015.
[68] Sihong Xie, Guan Wang, Shuyang Lin, and Philip S Yu. Review spam detection viatemporal pattern discovery. In Proceedings of the 18th ACM SIGKDD internationalconference on Knowledge discovery and data mining, pages 823–831. ACM, 2012.
[69] Arjun Mukherjee, Bing Liu, and Natalie Glance. Spotting fake reviewer groups inconsumer reviews. In Proceedings of the 21st international conference on WorldWide Web, pages 191–200. ACM, 2012.
[70] Chang Xu, Jie Zhang, Kuiyu Chang, and Chong Long. Uncovering collusive spam-mers in chinese review websites. In Proceedings of the 22nd ACM internationalconference on Conference on information & knowledge management, pages 979–988. ACM, 2013.
[71] Guan Wang, Sihong Xie, Bing Liu, and S Yu Philip. Review graph based online storereview spammer detection. In 2011 IEEE 11th International Conference on DataMining, pages 1242–1247. IEEE, 2011.
[72] Leman Akoglu, Rishi Chandy, and Christos Faloutsos. Opinion fraud detection inonline reviews by network effects. In Seventh international AAAI conference onweblogs and social media, 2013.
[73] Huayi Li, Zhiyuan Chen, Bing Liu, Xiaokai Wei, and Jidong Shao. Spotting fakereviews via collective positive-unlabeled learning. In 2014 IEEE InternationalConference on Data Mining, pages 899–904. IEEE, 2014.

Bibliography 62
[74] Jonathan S Yedidia, William T Freeman, and Yair Weiss. Understanding beliefpropagation and its generalizations. Exploring artificial intelligence in the newmillennium, 8:236–239, 2003.
[75] Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, andTina Eliassi-Rad. Collective classification in network data. AI magazine, 29(3):93–93, 2008.
[76] Qingshan Li and Yingcheng Sun. An agent based intelligent meta search engine. InInternational Conference on Web Information Systems and Mining, pages 572–579.Springer, 2012.
[77] Qing-shan Li, Yan-xin Zou, and Ying-cheng Sun. Ontology based user personaliza-tion mechanism in meta search engine. In 2012 2nd International Conference onUncertainty Reasoning and Knowledge Engineering, pages 230–234. IEEE, 2012.
[78] Ying-cheng Sun and Qing-shan Li. The research situation and prospect analy-sis of meta-search engines. In 2012 2nd International Conference on UncertaintyReasoning and Knowledge Engineering, pages 224–229. IEEE, 2012.
[79] Qingshan Li, Yanxin Zou, and Yingcheng Sun. User personalization mechanism inagent-based meta search engine. Journal of Computational Information Systems,8(20):1–8, 2012.
[80] Yingcheng Sun and Kenneth Loparo. Topic shift detection in online discus-sions using structural context. In 2019 IEEE 43rd Annual Computer Software andApplications Conference (COMPSAC), volume 1, pages 948–949. IEEE, 2019.
[81] Yingcheng Sun and Kenneth Loparo. A clicked-url feature for transactional queryidentification. In 2019 IEEE 43rd Annual Computer Software and ApplicationsConference (COMPSAC), volume 1, pages 950–951. IEEE, 2019.
[82] Yingcheng Sun and Kenneth Loparo. Context aware image annotation in activelearning with batch mode. In 2019 IEEE 43rd Annual Computer Software andApplications Conference (COMPSAC), volume 1, pages 952–953. IEEE, 2019.
[83] Yingcheng Sun, Kenneth Loparo, and Richard Kolacinski. Characterizing usersearch intent diversity into click models in learning to rank. In 2019 14th IEEEInternational conference on semantic computing, volume 1. IEEE, 2019.
[84] Bryan Hooi, Hyun Ah Song, Alex Beutel, Neil Shah, Kijung Shin, and ChristosFaloutsos. Fraudar: Bounding graph fraud in the face of camouflage. In Proceedingsof the 22nd ACM SIGKDD International Conference on Knowledge Discovery andData Mining, pages 895–904. ACM, 2016.

Bibliography 63
[85] Kijung Shin, Bryan Hooi, and Christos Faloutsos. M-zoom: Fast dense-block detec-tion in tensors with quality guarantees. In Joint European Conference on MachineLearning and Knowledge Discovery in Databases, pages 264–280. Springer, 2016.
[86] Kijung Shin, Bryan Hooi, Jisu Kim, and Christos Faloutsos. D-cube: Dense-blockdetection in terabyte-scale tensors. In Proceedings of the Tenth ACM InternationalConference on Web Search and Data Mining, pages 681–689. ACM, 2017.
[87] Alireza Bitarafan and Chitra Dadkhah. Spgd_hin: Spammer group detection basedon heterogeneous information network. In 2019 5th International Conference onWeb Research (ICWR), pages 228–233. IEEE, 2019.
[88] Yingcheng Sun and Kenneth Loparo. Opinion spam detection based on heteroge-neous information network. In 2019 IEEE 31st International Conference on Toolswith Artificial Intelligence (ICTAI), volume 1. IEEE, 2019.
[89] Geli Fei, Arjun Mukherjee, Bing Liu, Meichun Hsu, Malu Castellanos, and Rid-dhiman Ghosh. Exploiting burstiness in reviews for review spammer detection. InSeventh international AAAI conference on weblogs and social media, 2013.
[90] Ee-Peng Lim, Viet-An Nguyen, Nitin Jindal, Bing Liu, and Hady Wirawan Lauw. De-tecting product review spammers using rating behaviors. In Proceedings of the 19thACM international conference on Information and knowledge management, pages939–948. ACM, 2010.
[91] Dhivya Eswaran, Stephan Günnemann, Christos Faloutsos, Disha Makhija, andMohit Kumar. Zoobp: Belief propagation for heterogeneous networks. Proceedingsof the VLDB Endowment, 10(5):625–636, 2017.
[92] Karen Weise. A lie detector test for online reviewers. Bloomberg Business Week,2011.
[93] Derek Greene and James P Cross. Exploring the political agenda of the europeanparliament using a dynamic topic modeling approach. Political Analysis, 25(1):77–94, 2017.
[94] Daniel Ramage, Evan Rosen, Jason Chuang, Christopher D Manning, and Daniel AMcFarland. Topic modeling for the social sciences. In NIPS 2009 workshop onapplications for topic models: text and beyond, volume 5, page 27, 2009.
[95] Yan Zhou, Madhuri S Mulekar, and Praveen Nerellapalli. Adaptive spam filteringusing dynamic feature spaces. International Journal on Artificial Intelligence Tools,16(04):627–646, 2007.

Bibliography 64
[96] Congfu Xu, Baojun Su, Yunbiao Cheng, Weike Pan, and Li Chen. An adaptive fusionalgorithm for spam detection. IEEE Intelligent Systems, 29(4):2–8, 2013.




















