
The protein data bank: A computer-based archival file for macromolecular structures
108
Proposed WIDE PROTEIN DATA BANK (WPDB) Format Strawman Version 0.0.1 14 July 2005 rev 20 July 2005 Frances C. Bernstein 1 and Herbert J. Bernstein 2 Work funded in part by the Office of Science (BER), U.S. Department of Energy Grant No. DE-FG02-03ER63601 Based in part on PROTEIN DATA BANK ATOMIC COORDINATE AND BIBLIOGRAPHIC ENTRY FORMAT DESCRIPTION February 1992 Protein Data Bank, Brookhaven National Laboratory and Protein Data Bank Contents Guide: Atomic Coordinate Entry Format Description Version 2.1 (draft), October 25, 1996 and Version 2.2 20 December 1996 Protein Data Bank, Brookhaven National Laboratory This is a strawman draft put forward to solicit comments and is subject to significant change. Based on whatever comments are received, we will either put forward a revised strawman draft or move on to a tinman draft. One should avoid significant investments in software prior to the tinman draft. Send comments to: [email protected] [email protected] 1 Bernstein + Sons, Bellport, NY, USA 2 Dowling College, Oakdale, NY, USA
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of The protein data bank: A computer-based archival file for macromolecular structures

ProposedWIDE PROTEIN DATA BANK (WPDB) Format
Strawman Version 0.0.114 July 2005
rev 20 July 2005
Frances C. Bernstein1 and Herbert J. Bernstein2
Work funded in part by the Office of Science (BER), U.S. Department of EnergyGrant No. DE-FG02-03ER63601
Based in part onPROTEIN DATA BANK
ATOMIC COORDINATE AND BIBLIOGRAPHIC ENTRY FORMAT DESCRIPTIONFebruary 1992
Protein Data Bank, Brookhaven National Laboratoryand
Protein Data Bank Contents Guide:Atomic Coordinate Entry Format Description
Version 2.1 (draft), October 25, 1996and
Version 2.2 20 December 1996Protein Data Bank, Brookhaven National Laboratory
This is a strawman draft put forward to solicit comments and is subject to significant change. Basedon whatever comments are received, we will either put forward a revised strawman draft or
move on to a tinman draft. One should avoid significant investments in software prior to thetinman draft.
Send comments to:[email protected]
1 Bernstein + Sons, Bellport, NY, USA2 Dowling College, Oakdale, NY, USA

ii
TABLE OF CONTENTS
SUMMARY OF RECORD TYPES AND THEIR SEQUENCE ...................................................1Continuation .............................................................................................................................2Record identification fields .......................................................................................................3Left-justified fields....................................................................................................................3Right-justified fields .................................................................................................................4Preformatted fields....................................................................................................................41. LEADER ..........................................................................................................................52. OBSLTE ...........................................................................................................................66. SOURCE ..........................................................................................................................97. KEYWDS .......................................................................................................................118. EXPDTA ........................................................................................................................129. AUTHOR........................................................................................................................1310. REVDAT ....................................................................................................................1411. SPRSDE......................................................................................................................1512. JRNL...........................................................................................................................15
JRNL AUTH subtype........................................................................................................16JRNL TITL subtype ............................................................................................................16JRNL REF subtype .............................................................................................................17JRNL PUBL subtype...........................................................................................................19JRNL REFN subtype...........................................................................................................20
13. REMARK ...................................................................................................................21REMARK 1 ........................................................................................................................22REMARK 1 BLANK RECORD .........................................................................................22REMARK 1 REFERNCE RECORD...................................................................................22REMARK 1 AUTH subtype................................................................................................23REMARK 1 TITL subtype..................................................................................................23REMARK 1 REF subtype ...................................................................................................23REMARK 1 PUBL subtype ................................................................................................24REMARK 1 REFN subtype ................................................................................................24REMARK 2 ........................................................................................................................25REMARK 3 ........................................................................................................................26REMARK 4 ........................................................................................................................32REMARK 5 ........................................................................................................................32REMARK 6 - 99 .................................................................................................................33REMARK 100 – 199..........................................................................................................33REMARK 200-250 .............................................................................................................35REMARK 200 ....................................................................................................................35REMARK 205 ....................................................................................................................36REMARK 210 and 215 .......................................................................................................36REMARK 220 and REMARK 225......................................................................................37REMARK 230 ....................................................................................................................37REMARK 240 ....................................................................................................................38REMARK 250 ....................................................................................................................38REMARK 280 ....................................................................................................................38

iii
REMARK 285 ....................................................................................................................38REMARK 290 ....................................................................................................................39REMARK 295 ....................................................................................................................39REMARK 300 ....................................................................................................................40REMARK 350 ....................................................................................................................40REMARK 375 ....................................................................................................................41REMARK 400 ....................................................................................................................42REMARK 450 ....................................................................................................................42REMARK 460 ....................................................................................................................42REMARK 470 ....................................................................................................................42REMARK 500 ....................................................................................................................43REMARK 525 ....................................................................................................................45REMARK 550 ....................................................................................................................45REMARK 600 ....................................................................................................................45REMARK 650 ....................................................................................................................46REMARK 700 ....................................................................................................................46REMARK 800 ....................................................................................................................48REMARK 900 ...................................................................................................................49REMARK 999 ...................................................................................................................50
14. DBREF .......................................................................................................................5115. SEQADV ....................................................................................................................53
SEQADV Location Record .................................................................................................53SEQADV Conflict Comment Record ..................................................................................54
16. SEQRES .....................................................................................................................5517. SEQALN.....................................................................................................................5718. MODRES....................................................................................................................5819. FTNOTE .....................................................................................................................5920. HET ............................................................................................................................6021. HETNAM ...................................................................................................................6122. HETSYN.....................................................................................................................6223. FORMUL....................................................................................................................6224. HELIX ........................................................................................................................6425. SHEET........................................................................................................................65
SHEET Strand Definition Record........................................................................................65SHEET Strand Registration Record, Current Strand ............................................................66SHEET Strand Registration Record, Previous Strand ..........................................................67
26. TURN .........................................................................................................................6827. SSBOND.....................................................................................................................6928. LINK...........................................................................................................................7029. HYDBND ...................................................................................................................7230. SLTBRG .....................................................................................................................7331. CISPEP .......................................................................................................................7432. SITE............................................................................................................................7533. CRYST1 .....................................................................................................................7634. ORIGX........................................................................................................................7735. SCALE........................................................................................................................7836. MTRIX .......................................................................................................................7937. TVECT .......................................................................................................................80

iv
38. MODEL ......................................................................................................................8139. ATOM ........................................................................................................................8140. HETATM....................................................................................................................8141. SIGATM .....................................................................................................................8242. ANISOU .....................................................................................................................8343. SIGUIJ ........................................................................................................................8444. TER.............................................................................................................................8445. ENDMDL ...................................................................................................................8546. CONECT ....................................................................................................................8547. MASTER ....................................................................................................................8748. END............................................................................................................................87
APPENDIX A - COORDINATE SYSTEMS AND TRANSFORMATIONS ..............................88APPENDIX B - ATOM NAMES................................................................................................90
A. Amino Acids ......................................................................................................................90ATOM NAMES, REMOTENESS CODES, AND ORDER INDICATORS ........................92FOR THE COMMON AMINO ACIDS. .............................................................................92
B. Nucleic Acids .....................................................................................................................93C. Non-Standard (HET) Groups ..............................................................................................93
ATOM NAMES AND ORDER INDICATORS FOR THE COMMONRIBONUCLEOTIDES........................................................................................................94
APPENDIX C - STANDARD RESIDUE NAMES AND ABBREVIATIONS............................98A. Amino Acids ......................................................................................................................98B. Nucleic Acids .....................................................................................................................99C. Miscellaneous.....................................................................................................................99
APPENDIX D - PROTEIN DATA BANK CONVENTIONS ...................................................100APPENDIX E - FORMULAS AND MOLECULAR WEIGHTS FOR STANDARD RESIDUES.................................................................................................................................................101

1
SUMMARY OF RECORD TYPES AND THEIR SEQUENCE
For each atomic coordinate and bibliographic entry, the file consists of records each of up to 132characters. Most record types permit continuation.
The record sequence is as follows:
1. LEADER Date entered into Data Bank; identification code2. OBSLTE Identifies an entry that has been replaced3. TITLE Title for the experiment or analysis4. CAVEAT Warning of severe errors5. COMPND Name of molecule and identifying information6. SOURCE Species, organ, tissue, and mutant from which the molecule has been
obtained, where applicable7. KEYWDS Terms relevant to the entry8. EXPDTA Experimental technique of structure determination9. AUTHOR Names of contributors10. REVDAT Revision date; identifies current modification level11. SPRSDE Identifies and entry that has replaced others12. JRNL Literature citation that defines coordinate set13. REMARK General remarks14. DBREF Database references15. SEQADV Sequence discrepancies16. SEQRES Residue sequence17. SEQALN Sequence alignment to atom list18. MODRES Residue modifications19. FTNOTE Footnotes relating to specific atoms or residues20. HET Identification of non-standard groups or residues (heterogens)21. HETNAM Chemical names for heterogens22. HETSYN Synomyms for chemical names of heterogens23. FORMUL Chemical formulas of non-standard groups24. HELIX Identification of helical substructures25. SHEET Identification of sheet substructures26. TURN Identification of hairpin turns27. SSBOND Identification of disulfide bonds28. LINK Specification of connectivity29. HYDBND Specification of hydrogen bonds30. SLTBRG Specification of ionic bonds31. CISPEP Identification of peptides in cis configuration32. SITE Identification of groups comprising the various sites33. CRYST1 Unit cell parameters, space group designation34. ORIGX Transformation from orthogonal Å coordinates to submitted coordinates35. SCALE Transformation from orthogonal Å coordinates to fractional
crystallographic coordinates36. MTRIX Transformations expressing non-crystallographic symmetry37. TVECT Translation vector for infinite covalently connected structures38. MODEL Specification of model number for multiple structure models in a single
data entry

2
39. ATOM Atomic coordinate records for "standard" groups40. HETATM Atomic coordinate records for "non-standard" groups41. SIGATM Standard deviations of atomic parameters42. ANISOU Anisotropic temperature factors43. SIGUIJ Standard deviations of anisotropic temperature factors44. TER Chain terminator45. ENDMDL End-of-model flag for multiple structure models in a single data entry46. CONECT Connectivity records47. MASTER Master control record with checksums of total number of records in the file,
for selected record types48. END End-of-entry record
Note: A record type for translation of fields in still under discussion and is not included in this draft.The record type under consideration is called XLATE and would appear between CONECTand MASTER, rather than earlier in the entry.
In describing record formats it will be convenient to use the punched-card analogy and refer tocolumn numbers. Records are present in each entry in the order specified above with thefollowing exceptions:
(i) ATOM and HETATM records appear in the order appropriate to the structure.
(ii) TER records may appear among ATOM or HETATM records as appropriate.
(iii) SIGATM, ANISOU and SIGUIJ records, when present, directly follow the correspondingATOM (or HETATM) record in the order SIGATM, ANISOU, SIGUIJ.
(iv) A MODEL record precedes, and an ENDMDL record follows, the set of ATOM, HETATM,and TER records for each model among a series of multiple structure models in a single dataentry. MODEL and ENDMDL records generally are employed only for NMR entries, buthave been used for non-NMR entries.
Note: The WPDB format will evolve. It is very important to check the WPDB revision level on theLEADER record to determine the format of the remaining records.
Continuation
Most WPDB record types permit records to be continued. Such records have a continuation field incolumns 19 through 21. When writing a WPDB entry, the original record should contain blanks incolumns 19 –21, the first continuation record should have a right-justified “2” in columns 19 – 21,the next continuation record should contain a right-justified “3” in columns 19– 21, etc. All recordtype identification fields should be repeated on each continuation record.
The information on WPDB continuation records is handled field by field. Whatever fields aredefined on the original record are defined on the continuation record. Each field other than thecontinuation field may be designated as a “record type identification field”, “a left-justified field”, a“right-justified field”, or a “pre-formatted field”.

3
An alternative to field-by-field continuation is simple repetition of a record of as given type withoutuse of the continuation field. This technique is used for most REMARKS.
Record identification fields
If a field is intended to be repeated verbatim on each continuation record it is designated as a “recordidentification field” (RIF). Columns 1 – 6 are record identification fields on all records. Somerecord types, such as JRNL and REMARK 1, have additional RIFs to identify record subtypes. Theatom serial number on ATOM and HETATM records is another example of an RIF. Because of thehandling of continuation in WPDB format, it is important not to repeat any data from the fields ofthe original record which have not been designated as RIFs in continuation records, since thatinformation would be concatenated, changing the meaning.
Left-justified fields
If a field is intended to hold an ordinary string of blank or comma-separated text tokens, it isdesignated as “left-justified” and the information in the field on the original record consists of theleft-most characters of a larger combined text string. In interpreting the combined character string,the reverse solidus (or backslash), “\”, is used to indicate special handling of the text. In thefollowing discussion, in order to help distinguish between the character sequence reverse solidusfollowed by “n “and the special character newline used to represent a line break, we write the actualnewline character as a boldface “\n”.
The field on the first continuation record contains the text characters intended to be concatenatedimmediately to the right of the initial portion of the character string, etc. As each field isconcatenated with the prior fields:
1. any trailing white space is removed2. if the continuation field begins with a blank, a newline (“\n”) is inserted between the
prior fields and the continuation field3. if the continuation field does not begin with a blank a single blank (and no newline)
is inserted between the prior fields and the continuation field.
As the combined character string is scanned left to right:
1. “\\” (reverse solidus, reverse solidus) is interpreted as a single reverse solidus andthe scan moves to the next character (the resulting reverse solidus is notreprocessed),
2. “\ “ (reverse solidus, blank) is omitted.3. “\\n” (reverse solidus, newline) is omitted,4. “\n” (reverse solidus, “n”) is interpreted as a newline (“\n”)
This means that a left justified field that ends with an unescaped reverse solidus, possibly followedby whitespace, is always concatenated with a following continuation field, even if the continuationfield begins with a blank.

4
Right-justified fields
If a field holds numeric data or a character string for which the most important data is at the rightend, it is designated as “right-justified” and the information in the field on the original recordconsists of the right-most characters of the larger combined character string. The field on the firstcontinuation record contains text characters intended to be concatenated immediately to the left ofthe initial portion of the text string, etc. For right-justified fields there is no stripping of white spaceand no blanks or newlines are inserted between continuation fields. The same interpretation of thereverse solidus in the combined character strings as is used for left-justified fields is used for right-justified fields.
Preformatted fields
If a field is intended to hold a multi-line string that is not to be reflowed, it is designated as“preformatted”. The information in the field on original record is the first line of the multi-linestring. The field on the first continuation record contains the second line of the multi-line string, etc.As each field is concatenated with the prior fields, any trailing white space is removed and a newline(“\n”) is inserted between continuation fields, whether or not the continuation field begins with ablank. The same interpretation of the reverse solidus in the combined character strings as is usedfor left-justified fields is used for pre-formatted fields.

5
RECORD FORMATS
The WPDB record format is similar to the PDB format, but is presented in a longer 132 characterline rather than in the 80 character line used in the PDB format. Most WPDB records permitcontinuation records to extend all fields to up to 999 times their size on a single record. Each suchfield is designated as “left-justified”, “right-justified” or “pre-formatted” (see above). For a left-justified field, the fields from continuation records are appended to the right of the field on the firstrecord. For a right-justified field, the fields from continuation records are prepended to the left ofthe field on the first record. Pre-formatted fields are similar to left-justified fields, but each fieldalways begins on a new line. In practice, because of the use of wider fields in a 132 character line,continuation of right-justified fields is not expected to be required very often, but the capability isprovided to make it less likely that the format will need to be extended again in the near future.
Fields that should be repeated verbatim on each continuation record are marked “(RIF)” for “recordidentification field”.
1. LEADER
The LEADER record is the WPDB equivalent of the PDB HEADER record, and is used todistinguish WPDB entries from PDB entries. The LEADER uniquely identifies a WPDB entrythrough the identification code field. This record also provides a classification for the entry andcontains the date the coordinates were deposited at the PDB.
Columns Contents1 – 6 “LEADER” (RIF)14 – 17 WPDB format identifier in as a right-justified integer.19 – 21 Continuation field (this field will be blank for the first LEADER record in each entry and
numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer (i).23 – 82 Functional classification of macromolecule, left-justified (ii)84 – 94 Date of creation or of deposition into the Protein Data Bank in the format dd-mmm-yyyy
(e.g. December 1, 1983 is given as 01-DEC-1983) (iii).96 – 110 Identification code, right-justified
FORMAT (A6,7X,I4,1X,I3,1X,A60,1X,A11,1X,A15)
Note:
(i) Unlike the PDB HEADER record, the WPDB LEADER record permits continuation. Eachfield in the LEADER continuation records extends the corresponding fields in the firstLEADER record.
(ii) As a left-justified text field, the initial 60 characters of the functional classification are on thefirst LEADER record. The second block of 60 characters are on the first continuationLEADER record, etc.

6
2. OBSLTE
OBSLTE appears in entries which have been withdrawn from distribution.
This record acts as a flag in an entry which has been withdrawn from the PDB's full release. Itindicates which, if any, new entries have replaced the withdrawn entry.
The format allows for the case of multiple new entries replacing one existing entry.
Columns Contents1 – 6 “OBSLTE” (RIF)14 – 17 OBSLTE record serial number, right-justified (ii)19 – 21 Continuation field (this field will be blank for the first OBSLTE record in each entry and
numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer (i)23 – 33 Date this entry was replaced35 – 49 Identification code of this entry which is now obsolete, right-justified51 – 65 Identification code of a new entry which has replaced this old entry, right-justified67 – 81 Identification code of a new entry which has replaced this old entry, right-justified83 – 97 Identification code of a new entry which has replaced this old entry, right-justified99 –113 Identification code of a new entry which has replaced this old entry, right-justified115-129 Identification code of a new entry which has replaced this old entry, right-justified
FORMAT (A6,7X,I4,1X,I3,1X,A11,6(1X,A15))
Note: This record will be inserted only in archived entries that are no longer distributed in the usualway.
(i) The OBSLTE record may be continued to extend each of the fields. The continuationrecords will have the same OBSLTE record serial number.
(ii) More than 6 identification codes may be given by using multiple OBSLTE records withdistinct monotone increasing OBSLTE record serial numbers,
3. TITLE
The TITLE record contains a title for the experiment or analysis that is represented in the entry. Itshould identify an entry in the PDB in the same way that a title identifies a paper.
Columns Contents1 – 6 “TITLE”, left-justified (RIF)19 – 21 Continuation field (this field will be blank for the first TITLE record in each entry and
numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer (i)23 - 132 Title of the experiment, left-justified (ii)
FORMAT (A6,12X,I3,1X,A110)
Note:

7
(i) The TITLE record permits continuation.(ii) As a left-justified text field, the initial 110 characters of the title are on the first TITLE
record. The second block of 110 characters is on the first continuation TITLE record, etc.(iii) The title of the entry is free text and should describe the contents of the entry and any
procedures or conditions that distinguish this entry from similar entries. It presents anopportunity for the depositor to emphasize the underlying purpose of this particularexperiment.
(iv) Some items that may be included in TITLE are:a. Experiment type.b. Description of the mutation.c. The fact that only alpha carbon coordinates have been provided in the entry.
4. CAVEAT
CAVEAT warns of severe errors in an entry. Use caution when using an entry containing this record.
Columns Contents1 – 6 “CAVEAT” (RIF)19 – 21 Continuation field (this field will be blank for the first CAVEAT record in each entry and
numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer (i)23 - 37 Identification code of this entry39 –132 Reason for the caveat, left-justified(ii)
FORMAT (A6,12X,I3,1X,A94)
Note:
(i) The CAVEAT record permits continuation.(ii) As a left-justified text field, the initial 94 characters of the caveat text are on the first
CAVEAT record. The second block of 94 characters is on the first continuation CAVEATrecord, etc.
5. COMPND
The COMPND record describes the macromolecular contents of an entry. Each macromoleculefound in the entry is described by a set of token:value pairs, and is referred to as a COMPND recordcomponent.
For each macromolecular component, the molecule name, synonyms, number assigned by theEnzyme Commission (EC), and other relevant details are specified.
Columns Contents1 – 6 “COMPND” (RIF)19 – 21 Continuation field (this field will be blank for the first COMPND record in each entry
and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer (i)23 - 132 Description of the macromolecular components, left-justified (ii)

8
FORMAT (A6,12X,I3,1X,A110)
Note:
(i) The COMPND record permits continuation.(ii) As a left-justified text field, the initial 110 characters of the compound are on the first
COMPND record. The second block of 110 characters is on the first continuation COMPNDrecord, etc.
(iii) The COMPND record is a specification list. The specifications, or tokens, that may be usedare listed below:
TOKEN VALUE DEFINITIONMOL_ID Numbers each component; also used in SOURCE to associate the
information.MOLECULE Name of the macromolecule.CHAIN Comma-separated list of chain identifier(s). “NULL” is used to indicate a
blank chain identifier.FRAGMENT Specifies a domain or region of the molecule.SYNONYM Comma-separated list of synonyms for MOLECULE.EC The Enzyme Commission number associated with the molecule. If there is
more than one EC number, they are presented as a comma-separated list.For enzymes the E.C. number is given in the form (E.C.n.n.n.n) with nointernal blanks and without splitting over two lines. If an enzyme has nothad an E.C. number assigned, the string (E.C. NUMBER NOTASSIGNED) will be used. The Enzyme Commission numbers are obtainedfrom the International Union of Biochemistry on-line.
ENGINEERED Indicates that the molecule was produced using recombinant technology orby purely chemical synthesis.
MUTATION Describes mutations from the wild type molecule.BIOLOGICAL_UNIT If the MOLECULE functions as part of a larger biological unit, the entire
functional unit may be described.OTHER_DETAILS Additional comments.(ii) In the general case the PDB tends to reflect the biological/functional view of the molecule.
For example, the hetero-tetramer hemoglobin molecule is treated as a discrete component inCOMPND.
(iii) In the case of synthetic molecules, e. g., hybrids, the description will be provided by thedepositor.
(iv) No specific rules apply to the ordering of the tokens, except that the occurrence of MOL_IDor FRAGMENT indicates that the subsequent tokens are related to that specific molecule orfragment of the molecule.
(v) Physical layout of these items may be altered by PDB staff to improve human readability ofthe COMPND record.
(vi) Asterisks in nucleic acid names (in MOLECULE) are for ease of reading.(vii) When insertion codes are given as part of the residue name, they must be given within square
brackets, i.e., H57[A]N. This might occur when listing residues in FRAGMENT,MUTATION, or OTHER_DETAILS.

9
(viii) For multi-chain molecules, e.g., the hemoglobin tetramer, a comma-separated list of CHAINidentifiers is used.
(ix) When non-blank chain identifiers occur in the entry, they must be specified.(x) NULL is used to indicate blank chain identifiers. E.g., CHAIN: NULL, CHAIN: NULL, B,
C.(xi) ENGINEERED is followed either by "YES" or by a comment.(xii) For the token MUTATION, the following set of examples illustrate the conventions used by
PDB to represent various types of mutations.
MUTATIONTYPE
DESCRIPTION FORM
Simplesubstitution
His 57 replaced by Asn H57N
His 57A replaced by Asn, in chain C only Chain C, H57[A]NInsertion His and Pro inserted before Lys 48
Leu and Val inserted after Ala 200INS(HP-K48)INS(A200-LV)
Deletion Arg 141 of chains A and C deleted, not deleted inchain B
Chain A, C, DEL(R141)
His 23 through ARG 26 deleted DEL(23-26)His 23C and Arg 26 deleted from chain B only Chain B,
DEL(H23[C],R26)(xiii) When there are more than ten mutations:
• All the mutations are listed in the SEQADV record.• Some mutations may be listed in MUTATION in COMPND to highlight the most
important ones, at the depositor's discretion.
6. SOURCE
The SOURCE record specifies the biological and/or chemical source of each biological molecule inthe entry. Sources are described by both the common name and the scientific name, e.g., genus andspecies. Strain and/or cell-line for immortalized cells are given when they help to uniquely identifythe biological entity studied.
Columns Contents1 – 6 “SOURCE” (RIF)19 – 21 Continuation field (this field will be blank for the first SOURCE record in each entry and
numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer (i)23 - 132 Description of the source of the macromolecule, left-justified (ii) (iii)
FORMAT (A6,12X,I3,1X,A110)
Note:
(i) The SOURCE record permits continuation.(ii) As a left-justified text field, the initial 110 characters of the source are on the first SOURCE
record. The second block of 110 characters is on the first continuation SOURCE record, etc.(iii) The description is given as a “token: value list” using the following tokens

10
TOKEN VALUE DEFINITIONMOL_ID Numbers each molecule. Same as appears in COMPND.SYNTHETIC Indicates a chemically-synthesized source.FRAGMENT A domain or fragment of the molecule may be specified.ORGANISM_SCIENTIFIC Scientific name of the organism.ORGANISM_COMMON Common name of the organism.STRAIN Identifies the strain.VARIANT Identifies the variant.CELL_LINE The specific line of cells used in the experiment.ATCC American Type Culture Collection tissue culture number.ORGAN Organized group of tissues that carries on a specialized
function.TISSUE Organized group of cells with a common function and structure.CELL Identifies the particular cell type.ORGANELLE Organized structure within a cell.SECRETION Identifies the secretion, such as saliva, urine, or venom, from
which the molecule was isolated.CELLULAR_LOCATION Identifies the location inside (or outside) the cell.PLASMID Identifies the plasmid containing the gene.GENE Identifies the gene.EXPRESSION_SYSTEM System used to express recombinant macromolecules.EXPRESSION_SYSTEM_STRAIN Strain of the organism in which the molecule was expressed.EXPRESSION_SYSTEM_VARIANT Variant of the organism used as the expression system.EXPRESSION_SYSTEM_CELL_LINE The specific line of cells used as the expression system.EXPRESSION_SYSTEM_ATCC_NUMBER Identifies the ATCC number of the expression systemEXPRESSION_SYSTEM_ORGAN Specific organ which expressed the molecule.EXPRESSION_SYSTEM_TISSUE Specific tissue which expressed the molecule.EXPRESSION_SYSTEM_CELL Specific cell type which expressed the molecule.EXPRESSION_SYSTEM_ORGANELLE Specific organelle which expressed the molecule.EXPRESSION_SYSTEM_CELLULAR_LOCATION Identifies the location inside or outside the cell which expressed
the molecule.EXPRESSION_SYSTEM_VECTOR_TYPE Identifies the type of vector used, i.e., plasmid, virus, or
cosmid.EXPRESSION_SYSTEM_VECTOR Identifies the vector used.EXPRESSION_SYSTEM_PLASMID Plasmid used in the recombinant experiment.EXPRESSION_SYSTEM_GENE Name of the gene used in recombinant experiment.OTHER_DETAILS Used to present information on the source which is not given
elsewhere.
(iv) As in COMPND, the order is not specified except that MOL_ID or FRAGMENT indicatessubsequent specifications are related to that molecule or fragment of the molecule.
(v) Physical layout of these items may be altered by PDB staff to improve human readability ofthe SOURCE record.
(vi) Only the relevant tokens need to appear in an entry.(vii) Molecules prepared by purely chemical synthetic methods are described by the specification
SYNTHETIC followed by "YES" or an optional value, such as NON-BIOLOGICALSOURCE or BASED ON THE NATURAL SEQUENCE. ENGINEERED must appear in theCOMPND record.
(viii) In the case of a chemically synthesized molecule using a biologically functional sequence(nucleic or amino acid), SOURCE reflects the biological origin of the sequence andCOMPND reflects its synthetic nature by inclusion of the token ENGINEERED. The tokenSYNTHETIC appears in SOURCE.
(ix) If made from a synthetic gene, ENGINEERED appears in COMPND and the expression

11
system is described in SOURCE (SYNTHETIC does NOT appear in SOURCE).(x) If the molecule was made using recombinant techniques, ENGINEERED appears in
COMPND and the system is described in SOURCE.(xi) When multiple macromolecules appear in the entry, each MOL_ID, as given in the
COMPND record, must be repeated in the SOURCE record along with the sourceinformation for the corresponding molecule.
(xii) Hybrid molecules prepared by fusion of genes are treated as multi-molecular systems for thepurpose of specifying the source. The token FRAGMENT is used to associate the sourcewith its corresponding fragment.• When necessary to fully describe hybrid molecules, tokens may appear more than
once for a given MOL_ID.• All relevant token:value pairs that taken together fully describe each fragment are
grouped following the appropriate FRAGMENT.• Descriptors relative to the full system appear before the FRAGMENT (see Example 3
below).(xiii) ORGANISM_SCIENTIFIC provides the Latin genus and species. Virus names are listed as
the scientific name.(xiv) Cellular origin is described by giving cellular compartment, organelle, cell, tissue, organ, or
body part from which the molecule was isolated.(xv) CELLULAR_LOCATION may be used to indicate where in the organism the compound was
found. Examples are: extracellular, periplasmic, cytosol.(xvi) Entries containing molecules prepared by recombinant techniques are described as follows:
• The expression system is described• The organism and cell location given are for the source of the gene used in the
cloning experiment.• Transgenic organisms, such as mouse producing human proteins, are treated as
expression systems.(xvii) For a theoretical modeling experiment, SOURCE describes the modeled compound just as
though it were an experimental study.
7. KEYWDS
The KEYWDS record contains a set of terms relevant to the entry. Terms in the KEYWDS recordprovide a simple means of categorizing entries and may be used to generate index files. Thisrecord addresses some of the limitations found in the classification field of the HEADERrecord. It provides the opportunity to add further annotation to the entry in a concise andcomputer-searchable fashion.
Columns Contents1 – 6 “KEYWDS” (RIF)19 – 21 Continuation field (this field will be blank for the first KEYWDS record in each entry
and numbered 2, 3, etc. for continuation records) as a three-digit right-justifiedinteger (i)
23 - 132 Keywords, left-justified (ii) (iii)
FORMAT (A6,12X,I3,1X,A110)

12
Note:(i) The KEYWDS record permits continuation.(ii) As a left-justified text field, the initial 110 characters of the experimental technique are on
the first KEYWDS record. The second block of 110 characters is on the first continuationKEYWDS record, etc.
(iii) The KEYWDS record contains a list of terms relevant to the entry, similar to that found injournal articles. A phrase may be used if it presents a single concept (e.g., reaction center).Terms provided in this record may include those that describe the following:• Functional classification.• Metabolic role.• Known biological or chemical activity.• Structural classification
(iv) Other classifying terms may be used. No ordering is required for these terms. A number ofPDB entries contain complexes of macromolecules. In these cases, all terms applicable toeach molecule should be provided.
(v) Note that the terms in the KEYWDS record duplicate those found in the classification fieldof the HEADER record. Terms abbreviated in the HEADER record are unabbreviated inKEYWDS, and the parentheses used in HEADER are optional in KEYWDS.
8. EXPDTA
The EXPDTA record presents information about the experiment.
The EXPDTA record identifies the experimental technique used. This may refer to the type ofradiation and sample, or include the spectroscopic or modeling technique.
Permitted values include:
ELECTRON DIFFRACTIONFIBER DIFFRACTIONFLUORESCENCE TRANSFERNEUTRON DIFFRACTIONNMRTHEORETICAL MODELX-RAY DIFFRACTION
Columns Contents1 – 6 “EXPDTA” (RIF)19 – 21 Continuation field (this field will be blank for the first EXPDTA record in each entry and
numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer (i)23 - 132 Experimental technique, left-justified (ii) (iii)
FORMAT (A6,12X,I3,1X,A110)
Note:(i) The EXPDTA record permits continuation.

13
(ii) As a left-justified text field, the initial 110 characters of the experimental technique are onthe first EXPDTA record. The second block of 110 characters is on the first continuationEXPDTA record, etc.
(iii) The technique must match one of the permitted values. See above.(iv) If more than one model appears in the entry, the number of models included must be stated.(v) If only one model appears in the entry, its significance must be stated, such as it being a
minimized average or regularized mean structure.(vi) If more than one technique was used for the structure determination and is being represented
in the entry, EXPDTA presents the techniques as a semi-colon separated list. Each techniquemay have a comment, which appears before the semi-colon.
9. AUTHOR
The AUTHOR record contains the names of the people responsible for the contents of the entry.
Columns Contents1 – 6 “AUTHOR” (RIF)19 – 21 Continuation field (this field will be blank for the first AUTHOR record in each entry and
numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer (i)23 - 132 List of author names, left-justified (ii) (iii)
FORMAT (A6,12X,I3,1X,A110)
Note:• The AUTHOR record permits continuation.• As a left-justified text field, the initial 110 characters of the author list are on the first
AUTHOR record. The second block of 110 characters is on the first continuation AUTHORrecord, etc.
• The author list field lists author names separated by commas with no subsequent spaces.• Representation of personal names:
• First and middle names are indicated by initials, each followed by a period, andprecede the surname.
• Only the surname (family or last name) of the author is given in full.• Hyphens can be used if they are part of the author's name.• Apostrophes are allowed in surnames.• The word Junior is not abbreviated.• Umlauts and other character modifiers are not given.
• Structure of personal names:• There is no space after any initial and its following period.• Blank spaces are used in a name only if properly part of the surname (e.g., J.VAN
DORN), or between surname and Junior, II, or III.• Abbreviations that are part of a surname, such as St. or Ste., are followed by a period
and a space before the next part of the surname.• Representation of corporate names:
• Group names used for one or all of the authors should be spelled out in full.• The name of the larger group comes before the name of a subdivision, e.g., University
of Somewhere Department of Chemistry.

14
• Structure of list:• Line breaks between multiple lines in the author list occur only after a comma, if
possible• Personal names are not split across two lines.
• Special cases:• Names are given in English if there is an accepted English version; otherwise in the
native language, transliterated if necessary.• "ET AL." may be used when all authors are not individually listed.
• Unlike the PDB AUTHOR record, the WPDB AUTHOR record does not begin with a space.
10. REVDAT
Columns Contents1 – 6 “REVDAT” (RIF)19 – 21 Continuation field (this field will be blank for the first REVDAT record for each
modification number and numbered 2, 3, etc. for continuation records) as a three-digitright-justified integer (i)
23 – 31 Modification number (ii)33 – 43 Date(iii)45 – 54 Identification name used for the correction56 Modification type (iv)58 – 127 Blank separated list of record types that were corrected, left-justified (iv).
FORMAT (A6,12X,I3,1X,I9,1X,A11,1X,A10,1X,I1,1X,A70)
Notes:
(i) The REVDAT permits continuation for each modification number.(ii) Each revision will be given a modification number assigned in increasing numerical order
but inserted in the entry in decreasing numerical order. New entries will be assigned themodification number 1.
(iii) (iii) For new entries this date will be the date when the entry was released for distributionrather than the date of deposition which appears in the HEADER record. A four-digit year isused.
(iv) The following integer values will be used to identify the modification type:• 0 Initial released entry.• 1 Miscellaneous - mostly typographical.• 2 Modification of a CONECT record.• 3 Modification to coordinates or transformations.• 4 - 9 Not defined.
(In case of revisions with more than one possible type, the highest value applicable will be assigned).

15
11. SPRSDE
The SPRSDE records contain a list of the ID codes of entries that were made obsolete by the givencoordinate entry and withdrawn from the PDB release set. One entry may replace many.
Columns Contents1 – 6 “SPRSDE” (RIF)19 – 21 Continuation field (this field will be blank for the first SPRSDE record in each entry and
numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer23 – 26 SPRSDE record serial number, right-justified28 – 38 Date that this entry superseded an older one40 – 54 Identification code of this entry which is replacing an older one55 – 69 Identification code of an entry which is being replaced by this entry, right justified70 – 84 Identification code of an entry which is being replaced by this entry, right justified85 – 99 Identification code of an entry which is being replaced by this entry, right justified100 –114 Identification code of an entry which is being replaced by this entry, right justified115 –129 Identification code of an entry which is being replaced by this entry, right justified
FORMAT (A6,12X,I3,1X,I4,1X,A11,1X,6A15)
Note:
(i) The SPRSDE record may be continued to extend each of the fields. The continuation recordswill have the same SPRSDE record serial number.
(ii) More than 6 identification codes may be given by using multiple SPRSDE records withdistinct monotone increasing SPRSDE record serial numbers.
12. JRNL
The JRNL records contains the primary literature citation that describes the experiment that resultedin the deposited coordinate set. There is at most one JRNL reference per entry. If there is no primaryreference, then there is no JRNL reference. Other references are given in REMARK 1 (see below).
A subtype is given in columns 23 – 26. The valid JRNL subtypes “AUTH”, “TITL”, “EDIT”,“REF“, “PUBL” or “REFN”.
The JRNL records begin with the AUTH record subtype. This is followed by TITL, EDIT, REF,PUBL, and REFN record subtypes. REF and REFN are mandatory in JRNL. EDIT and PUBLshould appear only if the reference is to a non-journal.
Columns Contents1 – 6 “JRNL”, left-justified (RIF)19 – 21 Continuation field (this field will be blank for the first JRNL record of each JRNL
subtype and numbered 2, 3, etc. for continuation records) as a three-digit right-justifiedinteger
23 – 26 JRNL record subtype: “AUTH”, “TITL”, “EDIT”, “REF”, “PUBL” or “REFN”, leftjustified (RIF)

16
justified (RIF)28 –127 Subtype-specific fields
JRNL AUTH subtype
Columns Contents1 – 6 “JRNL”, left-justified (RIF)19 – 21 Continuation field (this field will be blank for the first JRNL record of each JRNL AUTH
subtype and numbered 2, 3, etc. for continuation records) as a three-digit right-justifiedinteger
23 – 26 “AUTH”, left justified (RIF)28 –127 List of authors, left justified (i) (ii) (iii) (iv)
FORMAT (A6,12X,I3,1X,A4,1X,A100)Notes:(i) The AUTH record subtype contains the list of authors associated with the cited article or
contribution to a larger work (i.e., AUTH is not used for the editor of a book).(ii) The author list is formatted similarly to the AUTHOR record. It is a comma-separated list of
names. Spaces at the end of a sub-record are not significant; all other spaces are significant.See the AUTHOR record for full details.
(iii) Continuation records of the AUTH subtype should not have a blank in column 28.(iv) An individual author's name, consisting of the initials and family name, should not be split
across two lines. If there are continuation sub-records, then all but the last sub-record mustend in a comma.
JRNL TITL subtype
Columns Contents1 – 6 “JRNL”, left-justified (RIF)19 – 21 Continuation field (this field will be blank for the first JRNL record of each JRNL TITL
subtype and numbered 2, 3, etc. for continuation records) as a three-digit right-justifiedinteger
23 – 26 “TITL”, left justified (RIF)28 –127 Title of the article (i) (ii) (iii) (iv)
FORMAT (A6,12X,I3,1X,A4,1X,A100)
Notes:
(i) The TITL record subtype specifies the title of the reference. This is used for the title of ajournal article, chapter, or part of a book. The TITL line is omitted if the author(s) listed inthe list of authors (in the corresponding AUTH record subtype) wrote the entire book (orother work) listed in the corresponding REF record subtype and no specific section of thebook is being cited.
(ii) If an article is in a language other than English and is printed with an alternate title in

17
English, the English language title is given, followed by a space and then the name of thelanguage (in its English form, in square brackets) in which the article is written.
(iii) If the title of an article is in a non-Roman alphabet the title is transliterated.(iv) A line cannot end with a hyphen. A compound term (two elements connected by a hyphen)
or chemical names which include a hyphen must appear on a single line, unless they are toolong to fit on one line, in which case the split is made at a normally-occurring hyphen. Anindividual word cannot be hyphenated at the end of a line and put on two lines. An exceptionis when there is a repeating compound term where the second element is omitted, e.g.,"DOUBLE- AND TRIPLE-RESONANCE". In such a case the non-completed word"DOUBLE-" could end a line and not alter reconstruction of the title.
JRNL REF subtype
Columns Contents1 – 6 “JRNL”, left-justified (RIF)19 – 21 Continuation field (this field will be blank for the first JRNL record of each
JRNL REF subtype and numbered 2, 3, etc. for continuation records) as athree-digit right-justified integer
23 – 26 “REF”, left justified (RIF)28 – 101 Publication name (left justified) or “TO BE PUBLISHED” (ii) (iii) (iv) (v)103 –104 “V.” or blank106 –111 Volume number (right justified) or blank (vi)113 –121 Page number (right justified) or blank (vi)123 –127 Year of publication (right justified) or blank (vi)
FORMAT(A6,12X,I3,1X,A4,1X,A74,1X,A2,1X,I6,1X,I9,1X,I5)
Notes:
(i) The REF subtype is a group of fields that contain either the publication status or the name ofthe publication (and any supplement and/or report information), volume, page, and year.
(ii) Publication name:• The publication name or the string “TO BE PUBLISHED” should be given.• If the publication is a serial (i.e., a journal, an annual, or other non-book or non-
monograph item issued in parts and intended to be continued indefinitely), use theabbreviated name of the publication as listed in American Chemical Society (A.C.S.)publications such as CAS Source Index (CASSI) or Chemical Abstracts. (The A.C.S.abbreviation is based on the International Standards Organization's standard ISO 4-1984[E].) If the A.C.S. has not yet established an abbreviation for the publication, thename is given in full.
• If the publication is a book, monograph, or other non-serial item, use its full nameaccording to the Anglo-American Cataloging Rules, 2nd Ed., 1988 revision(AACR2R). (Non-serial items include theses, videos, computer programs, andanything that is complete in one or a finite number of parts.) If there is a sub-title, andthe item is verified in an online catalog, it will be included using the samepunctuation as in the source of verification. Preference will be given to verification

18
using cataloging of the Library of Congress, the National Library of Medicine, andthe British Library, in that order.
• If a book is part of a monograph series: the full name of the book (according toAACR2R) is listed first, followed by the name of the series in which it was published.The series information is given within parentheses and the series name is preceded by"IN:" and a space. If the series has an A.C.S. abbreviation, that abbreviation shouldbe used; otherwise the series name should be listed in full. If applicable, the seriesname should be followed, after a comma and a space, by a volume (V.) and/ornumber (NO.) and/or part (PT.) indicator and the relevant characters to indicate itsnumber and/or letter in the series.
(iii) Supplement (follows publication name in the publication name field):• If a reference is in a supplement to the volume listed, or if information about a "part"
is needed to distinguish multiple parts with the same page numbering, suchinformation should be put in the REF sub-record.
• A supplement indication should follow the name of the publication and should bepreceded by a comma and a space. Supplement should be abbreviated as "SUPPL." Ifthere is a supplement number or letter, it should follow "SUPPL." without anintervening space. A part indication should also follow the name of the publicationand be preceded by a comma and a space. A part should be abbreviated as "PT.", andthe number or letter should follow without an intervening space.
• If there is both a supplement and a part, their order should reflect the order printed onthe work itself.
(iv) Report (follows publication name and any supplement or part information in the publicationname field):• If a book has a report designation, the report information should follow the title and
precede series information. The name and number of the report is given inparentheses, and the name is preceded by "REPORT:" and a space.
(v) Reconstruction of publication name:• The name of the publication is reconstructed by removing any trailing blanks in the
publication name field, and concatenating all of the publication name fields from thecontinuation lines with intervening space. There are two conditions where nointervening space is added between lines: when the publication name field on a lineends with a hyphen or a period, or when the line ends with a hyphen (-). When theline ends with a period (.), add a space if this is the only period in the entirepublication name field; do not add a space if there are two or more periods throughoutthe publication name field, excluding any periods after the designations "SUPPL","V", "NO", or "PT".
(vi) Volume, page, and year (volume, page, year fields respectively):• The REF sub-record type group also contains information about volume, page, and
year when applicable.• In the case of a monograph with multiple volumes that is also in a numbered series,
the number in the volume field represents the volume number of the book, not theseries. (The volume number of the series is in parentheses with the name of the series,as described above under publication name.)

19
JRNL PUBL subtype
Columns Contents1 – 6 “JRNL”, left-justified (RIF)19 – 21 Continuation field (this field will be blank for the first JRNL record of each JRNL PUBL
subtype and numbered 2, 3, etc. for continuation records) as a three-digit right-justifiedinteger
23 – 26 “PUBL”, left justified (RIF)28 –127 Publisher (left-justified) (i) (ii) (iii) (iv) (v) (vi)
FORMAT (A6,12X,I3,1X,A4,1X,A100)
Notes:
(i) The PUBL subtype contains the name of the publisher and place of publication if thereference is to a book or other non-journal publication. If the item has not yet been publishedor released, this sub-record is absent.
(ii) The place of publication is listed first, followed by a space, a colon, another space, and thenthe name of the publisher/issuer. This arrangement is based on the ISBD(M) InternationalStandard Bibliographic Description for Monographic Publications (Rev.Ed., 1987) andAACR2R and is used in public online catalogs in libraries. Details on the contents of PUBLare given below.
(iii) Place of publication:• Give the place of publication. If the name of the country, state, province, etc. is
considered necessary to distinguish the place of publication from others of the samename, or for identification, then follow the city with a comma, a space, and the nameof the larger geographic area.
• If there is more than one place of publication, only the first listed will be used. If anonline catalog record is used to verify the item, the first place listed there will beused, omitting any brackets. Preference will be given to the cataloging done by theLibrary of Congress, the National Library of Medicine, and the British Library, in thatorder.
(iv) Publisher's name (or name of other issuing entity):• Give the name of the publisher in the shortest form in which it can be understood and
identified internationally, according to AACR2R rule 1.4D.• If there is more than one publisher listed in the publication, only the first is used. If an
online catalog record is used to verify the item, the first place listed there will be usedfor the name of the publisher. Preference will be given to the cataloging of theLibrary of Congress, the National Library of Medicine, and the British Library, in thatorder.
(v) Ph.D. and other theses:• Theses are presented in the PUBL record if the degree has been granted and the thesis

20
made available for public consultation by the degree-granting institution.• The name of the degree-granting institution (the issuing agency) is followed by a
space and "(THESIS)".
(vi) Reconstruction of place and publisher:• The PUBL sub-record type can be reconstructed by removing all trailing blanks in the
pub field and concatenating all of the pub fields from the continuation lines with anintervening space. Continued lines do not begin with a space.
JRNL REFN subtype
Columns Contents1 – 6 “JRNL”, left-justified (RIF)19 – 21 Continuation field (this field will be blank for the first JRNL record of each
JRNL REFN subtype and numbered 2, 3, etc. for continuation records) as athree-digit right-justified integer
23 – 26 “REFN”, left justified (RIF)28 – 31 “ASTM” or blank33 – 38 ASTM coden (right justified) or blank (ii)40 – 41 Country code or blank (iii)43 – 46 “ISSN” or “ISBN” or blank (iv)48 – 72 ISSN or ISBN (left-justified) or blank74 – 79 CCDC/PDB coden (right-justified) or “0353” for unpublished (v)
FORMAT(A6,12X,I3,1X,A4,1X,A4,1X,A6,1X,A2,1X,A4,1X,A25,1X,I6)
(i) The REFN subtype is a group of fields that contain encoded references to the citation. Nocontinuation is normally needed. Each piece of coded information has a designated field.
(ii) The American Society for Testing and Materials (ASTM) number is an encoded reference tothe journal title. New ASTM codens are assigned by the Chemical Abstracts Service andappear in CASSI and its supplements.
(iii) The country field is blank if the reference was published in more than one country.
(iv) If more than one ISBN is known, select one that matches the individual volume cited (e.g. ifit happens to be in a set that also has an ISBN for the set). If the reason for multiple ISBNs isthat the publication is issued in more than one country, use the ISBN for the country of thefirst listed place of publication. If there are hardcover and paperback ISBN numbers, use theISBN for the hardbound version.
(v) Because some publications do not have an ASTM coden, an ISSN number, or an ISBNnumber, each publication is assigned a number. This list of numbers, or codens, wasestablished by the Cambridge Crystallographic Data Center (CCDC) and new numbers areassigned by both CCDC and PDB as new publications are added to their respectivedatabases.

21
Example 1 1 1 1 1 2 3 4 5 6 7 8 9 0 1 2 3123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012JRNL AUTH M.L.Raves,M.Harel,Y.-P.Pang,I.Silman,A.P.Kozikowski,J.L.SussmanJRNL TITL 3D STRUCTURE OF ACETYLCHOLINESTERASE COMPLEXED WITH THE NOOTROPIC ALKALOID, (-)-HUPERZINE AJRNL REF TO BE PUBLISHEDJRNL REFN 0353
13. REMARK
REMARK records present experimental details, annotations, comments, and information notincluded in other records. In a number of cases, REMARKs are used to expand the contents of otherrecord types. The type of each remark is identified by a REMARK number ranging from 1 through9999 in columns 8 – 11. Gaps and repetitions are permitted, but the remarks should be presented inincreasing order of REMARK number.
When a REMARK is repeated (e.g. for REMARK 1 when there are multiple references), aREMARK sub-serial number is given in columns 13 – 17. This field may be blank.
REMARK 1 is used for references.
For any REMARK a subtype may be given in columns 23 – 26. The valid subtypes are “ ” (theblank subtype), “AUTH”, “TITL”, “EDIT”, “REF”, “PUBL” or “REFN”. For REMARKs otherthan REMARK 1, only the blank subtype is used. The other subtypes are used for REMARK 1with the same meanings as when they are used in the JRNL record type (see above). All REMARKrecords of the blank subtype have blank continuation fields. For those REMARKS continuation isimplicit from the sequence of REMARK records. The first REMARK record of a given REMARKnumber, given sub-serial number and given subtype other than the blank subtype has a blankcontinuation field in columns 19 – 21. The next REMARK record of the same REMARK number,sub-serial number and subtype has “ 2” in the continuation field, etc.
REMARKS 1, 2, 3, 4 and 5 have special formatting. For all REMARK numbers greater than 5 andless than 100, columns 28 – 127 are a left-justified text field. REMARKs 100 – 106, 200, 205, 210,215, 220, 225, 230, 240, 250, 280, 285, 290, 295, 300, 350, 375, 400, 450, 460, 470, 500, 525, 550,600, 650, 700, 750, 800, 850, 860, 900, 999 and 9600 have special formatting. For all REMARKnumbers greater than 99, columns 28 – 127 are a pre-formatted text field.
Every REMARK with a given REMARK number and REMARK sub-serial number begins with arecord with a blank subtype, blank continuation field and blanks in columns 28 – 127. ForREMARK 1 this blank subtype is continued with a second blank subtype record with “ 2” in thecontinuation field and “REFERENCE nnnnn” (where nnnnn is the sub-serial number) left justified incolumns 28 – 127. These two initial records for REMARK 1 are followed by the AUTH recordsubtype. This is followed by TITL, EDIT, REF, PUBL, and REFN record subtypes. REF and REFNare mandatory in REMARK 1. EDIT and PUBL appear only if the reference is to a not from ajournal.

22
Columns Contents1 – 6 “REMARK” (RIF)8 – 11 “ 1” right justified (RIF)13 – 17 REMARK sub-serial number, right justified, allows for repeated use of the same
REMARK number (RIF)19 – 21 Continuation field (this field will be blank for the first REMARK record of each given
REMARK number, REMARK sub-serial-number and subtype and numbered 2, 3, etc. forcontinuation records) as a three-digit right-justified integer. This field is always blank forthe blank REMARK record subtype.
23 – 26 REMARK record subtype: “ ”, “AUTH”, “TITL”, “EDIT”, “REF“, “PUBL” or“REFN”, left justified, used only for REMARK number = 1 (RIF)
28 –127 Fields specific to a given REMARK number and subtype
REMARK 1
REMARK 1 is organized in blocks. Each block is identified by a reference number in the REMARKsub-serial number field, starting with reference number 1. Each block begins with two records of theblank subtype: a REMARK 1 blank record and a REMARK 1 REFERENCE record that help tocaption the block. The remainder of the block has the same structure as the JRNL record type.
REMARK 1 BLANK RECORD
Columns Contents1 – 6 REMARK (RIF)8 – 11 “ 1” right justified (RIF)13 – 17 REMARK sub-serial number, right justified, allows for repeated use of the same
REMARK number (RIF)19 – 21 blank28 –127 blank
REMARK 1 REFERNCE RECORD
Columns Contents1 – 6 REMARK (RIF)8 – 11 “ 1” right justified (RIF)13 – 17 REMARK sub-serial number, right justified, allows for repeated use of the same
REMARK number (RIF)19 – 21 blank28 –36 “REFERENCE”, left justified38 – 42 REMARK sub-serial number from columns 13 – 17

23
REMARK 1 AUTH subtype
Columns Contents1 – 6 REMARK (RIF)8 – 11 “ 1” right justified (RIF)13 – 17 REMARK sub-serial number, right justified, giving the reference number, starting from
1 for the first reference, not counting the JRNL record (RIF)19 – 21 Continuation field (this field will be blank for the first REMARK record of each given
REMARK number, REMARK sub-serial-number AUTH subtype and numbered 2, 3, etc.for continuation records) as a three-digit right-justified integer
23 – 26 “AUTH”, left justified (RIF)28 –127 List of authors, left justified
FORMAT (A6,1X,I4,1X,I5,1X,I3,1X,A4,1X,A100)
REMARK 1 TITL subtype
Columns Contents1 – 6 REMARK (RIF)8 – 11 “ 1” right justified (RIF)13 – 17 REMARK sub-serial number, right justified, allows for repeated use of the same
REMARK number (RIF)19 – 21 Continuation field (this field will be blank for the first REMARK record of each given
REMARK number, REMARK sub-serial-number and REMARK TITL subtype andnumbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 26 “TITL”, left justified (RIF)28 –127 Title of the article
FORMAT (A6,1X,I4,1X,I5,1X,I3,1X,A4,1X,A100)
REMARK 1 REF subtype
Columns Contents1 – 6 REMARK (RIF)8 – 11 “ 1” right justified (RIF)13 – 17 REMARK sub-serial number, right justified, allows for repeated use of the same
REMARK number (RIF)19 – 21 Continuation field (this field will be blank for the first REMARK record of each given
REMARK number, REMARK sub-serial-number and REMARK REF subtype andnumbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 26 “REF”, left justified (RIF)28 – 101 Publication name (left justified) or “TO BE PUBLISHED”

24
103 –104 “V.” or blank106 –111 Volume number (right justified) or blank113 –121 Page number (right justified) or blank123 –127 Year of publication (right justified) or blank
FORMAT(A6,1X,I4,1X,I5,1X,I3,1X,A4,1X,A74,1X,A2,1X,I6,1X,I9,1X,I5)
REMARK 1 PUBL subtype
Columns Contents1 – 6 REMARK (RIF)8 – 11 “ 1” right justified (RIF)13 – 17 REMARK sub-serial number, right justified, allows for repeated use of the same
REMARK number (RIF)19 – 21 Continuation field (this field will be blank for the first REMARK record of each given
REMARK number, REMARK sub-serial-number and REMARK PUBL subtype andnumbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 26 “PUBL”, left justified (RIF)28 –127 Publisher (left-justified)
FORMAT (A6,1X,I4,1X,I5,1X,I3,1X,A4,1X,A100)
REMARK 1 REFN subtype
Columns Contents1 – 6 REMARK (RIF)8 – 11 “ 1” right justified (RIF)13 – 17 REMARK sub-serial number, right justified, allows for repeated use of the same
REMARK number (RIF)19 – 21 Continuation field (this field will be blank for the first REMARK record of each given
REMARK number, REMARK sub-serial-number and REMARK REFN subtype andnumbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 26 “REFN”, left justified (RIF)28 – 31 “ASTM” or blank33 – 38 ASTM coden (right justified) or blank (ii)40 – 41 Country code or blank (iii)43 – 46 “ISSN” or “ISBN” or blank (iv)48 – 72 ISSN or ISBN (left-justified) or blank74 – 79 CCDC/PDB coden (right-justified) or “0353” for unpublished (v)
FORMAT(A6,1X,I4,1X,I5,1X,I3,1X,A4,1X,A4,1X,A6,1X,A2,1X,A4,1X,A25,1X,I6)

25
Example 1 1 1 1 1 2 3 4 5 6 7 8 9 0 1 2 3123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012REMARK 1 1REMARK 1 1 REFERENCE 1REMARK 1 1 AUTH G.Bucht,K.HjalmarssonREMARK 1 1 TITL RESIDUES IN TORPEDO CALIFORNICA ACETYLCHOLINESTERASE NECESSARY FOR PROCESSING TO A GLYCOSYLREMARK 1 1 2 TITL PHOSPHATIDYLINOSITOL-ANCHORED FORMREMARK 1 1 REF BIOCHIM.BIOPHYS.ACTA V. 1292 223 1996REMARK 1 1 REFN ASTM BBACAQ NE ISSN 0006-3002 0113REMARK 1 2REMARK 1 2 REFERENCE 2REMARK 1 2 AUTH P.H.Axelsen,M.Harel,I.Silman,J.L.SussmanREMARK 1 2 TITL STRUCTURE AND DYNAMICS OF THE ACTIVE SITE GORGE OF ACETYLCHOLINESTERASE: SYNERGISTIC USE OFREMARK 1 2 2 TITL MOLECULAR DYNAMICS SIMULATION AND X-RAY CRYSTALLOGRAPHYREMARK 1 2 REF PROTEIN SCI. V. 3 188 1994REMARK 1 2 REFN ASTM PRCIEI US ISSN 0961-8368 0795
REMARK 2
REMARK 2 states the highest resolution, in Ångstroms, that was used in building the model. Aswith all the remarks, the first REMARK 2 record is empty and is used as a spacer. The secondREMARK 2 record has one of two formats. The first is used for diffraction studies, the second forother types of experiments in which resolution is not relevant, e.g., NMR and theoretical modeling.Additional explanatory text may be included in the REMARK 2 record. For example, depositorsmay wish to qualify the resolution value provided due to unusual experimental conditions.
Columns Contents1 – 6 REMARK (RIF)8 – 11 “ 2” right justified (RIF)13 – 17 REMARK sub-serial number, right justified, allows for repeated use of the same
REMARK number (RIF), normally blank for REMARK 219 – 21 Continuation field (this field will be blank for the first REMARK record of each given
REMARK number, REMARK sub-serial-number and REMARK REFN subtype andnumbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
28 – 38 “RESOLUTION.” left justified39 – 33 Resolution right justified45 – 54 “ÅNGSTROMS.”56 – 127 comments, left justified
or

26
Columns Contents1 – 6 REMARK (RIF)8 – 11 “ 2” right justified (record type identification field_13 – 17 REMARK sub-serial number, right justified, allows for repeated use of the same
REMARK number (RIF), normally blank for REMARK 219 – 21 Continuation field (this field will be blank for the first REMARK record of each given
REMARK number, REMARK sub-serial-number and REMARK REFN subtype andnumbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
28 – 54 “RESOLUTION. NOT APPLICABLE.” left justified56 – 127 comments, left justified
REMARK 3
REMARK 3 presents information on refinement program(s) used and the related statistics. For non-diffraction studies, REMARK 3 is used to describe any refinement done, but its format in those casesis mostly free text.
If more than one refinement package was used, they may be named in "OTHER REFINEMENTREMARKS". However, Remark 3 statistics are given for the final refinement run.
Instead of providing record format table, each template is given as it appears in WPDB entries.
Details
The value “NULL” is given when there is no data available for a particular token.
Refinement using X-PLOR
This remark will be output by X-PLOR(online) in the very similar PDB format. The differencesbetween the format in this document and the format produced by XPLOR is that the WPDB recordshave an extra blank before the REMARK number and the text is shifted further to the right to start incolumn 28. Structures done using earlier versions of X-PLOR will contain the same PDB template,but with many of the data items containing “NULL” .
Template 1 1 1 1 1 2 3 4 5 6 7 8 9 0 1 2 3123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012REMARK 3REMARK 3 REFINEMENT.REMARK 3 PROGRAM : X-PLORREMARK 3 AUTHORS : BRUNGERREMARK 3REMARK 3 DATA USED IN REFINEMENT.REMARK 3 RESOLUTION RANGE HIGH (ÅNGSTROMS) :REMARK 3 RESOLUTION RANGE LOW (ÅNGSTROMS) :REMARK 3 DATA CUTOFF (SIGMA(F)) :REMARK 3 DATA CUTOFF HIGH (ABS(F)) :REMARK 3 DATA CUTOFF LOW (ABS(F)) :REMARK 3 COMPLETENESS (WORKING+TEST) (%) :REMARK 3 NUMBER OF REFLECTIONS :REMARK 3REMARK 3 FIT TO DATA USED IN REFINEMENT.REMARK 3 CROSS-VALIDATION METHOD :

27
REMARK 3 FREE R VALUE TEST SET SELECTION :REMARK 3 R VALUE (WORKING SET) :REMARK 3 FREE R VALUE :REMARK 3 FREE R VALUE TEST SET SIZE (%) :REMARK 3 FREE R VALUE TEST SET COUNT :REMARK 3 ESTIMATED ERROR OF FREE R VALUE :REMARK 3REMARK 3 FIT IN THE HIGHEST RESOLUTION BIN.REMARK 3 TOTAL NUMBER OF BINS USED :REMARK 3 BIN RESOLUTION RANGE HIGH (A) :REMARK 3 BIN RESOLUTION RANGE LOW (A) :REMARK 3 BIN COMPLETENESS (WORKING+TEST) (%) :REMARK 3 REFLECTIONS IN BIN (WORKING SET) :REMARK 3 BIN R VALUE (WORKING SET) :REMARK 3 BIN FREE R VALUE :REMARK 3 BIN FREE R VALUE TEST SET SIZE (%) :REMARK 3 BIN FREE R VALUE TEST SET COUNT :REMARK 3 ESTIMATED ERROR OF BIN FREE R VALUE :REMARK 3REMARK 3 NUMBER OF NON-HYDROGEN ATOMS USED IN REFINEMENT.REMARK 3 PROTEIN ATOMS :REMARK 3 NUCLEIC ACID ATOMS :REMARK 3 HETEROGEN ATOMS :REMARK 3 SOLVENT ATOMS :REMARK 3REMARK 3 B VALUES.REMARK 3 FROM WILSON PLOT (A**2) :REMARK 3 MEAN B VALUE (OVERALL, A**2) :REMARK 3 OVERALL ANISOTROPIC B VALUE.REMARK 3 B11 (A**2) :REMARK 3 B22 (A**2) :REMARK 3 B33 (A**2) :REMARK 3 B12 (A**2) :REMARK 3 B13 (A**2) :REMARK 3 B23 (A**2) :REMARK 3REMARK 3 ESTIMATED COORDINATE ERROR.REMARK 3 ESD FROM LUZZATI PLOT (A) :REMARK 3 ESD FROM SIGMAA (A) :REMARK 3 LOW RESOLUTION CUTOFF (A) :REMARK 3REMARK 3 CROSS-VALIDATED ESTIMATED COORDINATE ERROR.REMARK 3 ESD FROM C-V LUZZATI PLOT (A) :REMARK 3 ESD FROM C-V SIGMAA (A) :REMARK 3REMARK 3 RMS DEVIATIONS FROM IDEAL VALUES.REMARK 3 BOND LENGTHS (A) :REMARK 3 BOND ANGLES (DEGREES) :REMARK 3 DIHEDRAL ANGLES (DEGREES) :REMARK 3 IMPROPER ANGLES (DEGREES) :REMARK 3REMARK 3 ISOTROPIC THERMAL MODEL :REMARK 3REMARK 3 ISOTROPIC THERMAL FACTOR RESTRAINTS. RMS SIGMAREMARK 3 MAIN-CHAIN BOND (A**2) : ;REMARK 3 MAIN-CHAIN ANGLE (A**2) : ;REMARK 3 SIDE-CHAIN BOND (A**2) : ;REMARK 3 SIDE-CHAIN ANGLE (A**2) : ;REMARK 3REMARK 3 NCS MODEL :REMARK 3REMARK 3 NCS RESTRAINTS. RMS SIGMA/WEIGHTREMARK 3 GROUP 1 POSITIONAL (A) : ;REMARK 3 GROUP 1 B-FACTOR (A**2) : ;REMARK 3 GROUP 2 POSITIONAL (A) : ;REMARK 3 GROUP 2 B-FACTOR (A**2) : ;REMARK 3 GROUP 3 POSITIONAL (A) : ;REMARK 3 GROUP 3 B-FACTOR (A**2) : ;REMARK 3 GROUP 4 POSITIONAL (A) : ;REMARK 3 GROUP 4 B-FACTOR (A**2) : ;REMARK 3REMARK 3 PARAMETER FILE 1 :REMARK 3 PARAMETER FILE 2 :REMARK 3 PARAMETER FILE 3 :REMARK 3 PARAMETER FILE 4 :REMARK 3 PARAMETER FILE 5 :REMARK 3 PARAMETER FILE 6 :REMARK 3 TOPOLOGY FILE 1 :REMARK 3 TOPOLOGY FILE 2 :REMARK 3 TOPOLOGY FILE 3 :REMARK 3 TOPOLOGY FILE 4 :REMARK 3 TOPOLOGY FILE 5 :REMARK 3 TOPOLOGY FILE 6 :

28
REMARK 3REMARK 3 OTHER REFINEMENT REMARKS:
Refinement using NUCLSQ
Template 1 1 1 1 1 2 3 4 5 6 7 8 9 0 1 2 3123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012
REMARK 3REMARK 3 REFINEMENT.REMARK 3 PROGRAM : NUCLSQREMARK 3 AUTHORS : WESTHOF,DUMAS,MORASREMARK 3REMARK 3 DATA USED IN REFINEMENT.REMARK 3 RESOLUTION RANGE HIGH (ÅNGSTROMS) :REMARK 3 RESOLUTION RANGE LOW (ÅNGSTROMS) :REMARK 3 DATA CUTOFF (SIGMA(F)) :REMARK 3 COMPLETENESS FOR RANGE (%) :REMARK 3 NUMBER OF REFLECTIONS :REMARK 3REMARK 3 FIT TO DATA USED IN REFINEMENT.REMARK 3 CROSS-VALIDATION METHOD :REMARK 3 FREE R VALUE TEST SET SELECTION :REMARK 3 R VALUE (WORKING + TEST SET) :REMARK 3 R VALUE (WORKING SET) :REMARK 3 FREE R VALUE :REMARK 3 FREE R VALUE TEST SET SIZE (%) :REMARK 3 FREE R VALUE TEST SET COUNT :REMARK 3REMARK 3 FIT/AGREEMENT OF MODEL WITH ALL DATA.REMARK 3 R VALUE (WORKING + TEST SET, NO CUTOFF) :REMARK 3 R VALUE (WORKING SET, NO CUTOFF) :REMARK 3 FREE R VALUE (NO CUTOFF) :REMARK 3 FREE R VALUE TEST SET SIZE (%, NO CUTOFF) :REMARK 3 FREE R VALUE TEST SET COUNT (NO CUTOFF) :REMARK 3 TOTAL NUMBER OF REFLECTIONS (NO CUTOFF) :REMARK 3REMARK 3 NUMBER OF NON-HYDROGEN ATOMS USED IN REFINEMENT.REMARK 3 PROTEIN ATOMS :REMARK 3 NUCLEIC ACID ATOMS :REMARK 3 HETEROGEN ATOMS :REMARK 3 SOLVENT ATOMS :REMARK 3REMARK 3 B VALUES.REMARK 3 FROM WILSON PLOT (A**2) :REMARK 3 MEAN B VALUE (OVERALL, A**2) :REMARK 3 OVERALL ANISOTROPIC B VALUE.REMARK 3 B11 (A**2) :REMARK 3 B22 (A**2) :REMARK 3 B33 (A**2) :REMARK 3 B12 (A**2) :REMARK 3 B13 (A**2) :REMARK 3 B23 (A**2) :REMARK 3REMARK 3 ESTIMATED COORDINATE ERROR.REMARK 3 ESD FROM LUZZATI PLOT (A) :REMARK 3 ESD FROM SIGMAA (A) :REMARK 3 LOW RESOLUTION CUTOFF (A) :REMARK 3REMARK 3 RMS DEVIATIONS FROM IDEAL VALUES.REMARK 3 DISTANCE RESTRAINTS. RMS SIGMAREMARK 3 SUGAR-BASE BOND DISTANCE (A) : ;REMARK 3 SUGAR-BASE BOND ANGLE DISTANCE (A) : ;REMARK 3 PHOSPHATE BONDS DISTANCE (A) : ;REMARK 3 PHOSPHATE BOND ANGLE, H-BOND (A) : ;REMARK 3REMARK 3 PLANE RESTRAINT (A) : ;REMARK 3 CHIRAL-CENTER RESTRAINT (A**3) : ;REMARK 3REMARK 3 NON-BONDED CONTACT RESTRAINTS.REMARK 3 SINGLE TORSION CONTACT (A) : ;REMARK 3 MULTIPLE TORSION CONTACT (A) : ;REMARK 3REMARK 3 ISOTROPIC THERMAL FACTOR RESTRAINTS. RMS SIGMAREMARK 3 SUGAR-BASE BONDS (A**2) : ;REMARK 3 SUGAR-BASE ANGLES (A**2) : ;REMARK 3 PHOSPHATE BONDS (A**2) : ;

29
REMARK 3 PHOSPHATE BOND ANGLE, H-BOND (A**2) : ;REMARK 3REMARK 3 OTHER REFINEMENT REMARKS:
Refinement using PROLSQ, CCP4, PROFFT, GPRLSA, and related programs
Template 1 1 1 1 1 2 3 4 5 6 7 8 9 0 1 2 3123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012
REMARK 3REMARK 3 REFINEMENT.REMARK 3 PROGRAM :REMARK 3 AUTHORS :REMARK 3REMARK 3 DATA USED IN REFINEMENT.REMARK 3 RESOLUTION RANGE HIGH (ÅNGSTROMS) :REMARK 3 RESOLUTION RANGE LOW (ÅNGSTROMS) :REMARK 3 DATA CUTOFF (SIGMA(F)) :REMARK 3 COMPLETENESS FOR RANGE (%) :REMARK 3 NUMBER OF REFLECTIONS :REMARK 3REMARK 3 FIT TO DATA USED IN REFINEMENT.REMARK 3 CROSS-VALIDATION METHOD :REMARK 3 FREE R VALUE TEST SET SELECTION :REMARK 3 R VALUE (WORKING + TEST SET) :REMARK 3 R VALUE (WORKING SET) :REMARK 3 FREE R VALUE :REMARK 3 FREE R VALUE TEST SET SIZE (%) :REMARK 3 FREE R VALUE TEST SET COUNT :REMARK 3REMARK 3 FIT/AGREEMENT OF MODEL WITH ALL DATA.REMARK 3 R VALUE (WORKING + TEST SET, NO CUTOFF) :REMARK 3 R VALUE (WORKING SET, NO CUTOFF) :REMARK 3 FREE R VALUE (NO CUTOFF) :REMARK 3 FREE R VALUE TEST SET SIZE (%, NO CUTOFF) :REMARK 3 FREE R VALUE TEST SET COUNT (NO CUTOFF) :REMARK 3 TOTAL NUMBER OF REFLECTIONS (NO CUTOFF) :REMARK 3REMARK 3 NUMBER OF NON-HYDROGEN ATOMS USED IN REFINEMENT.REMARK 3 PROTEIN ATOMS :REMARK 3 NUCLEIC ACID ATOMS :REMARK 3 HETEROGEN ATOMS :REMARK 3 SOLVENT ATOMS :REMARK 3REMARK 3 B VALUES.REMARK 3 FROM WILSON PLOT (A**2) :REMARK 3 MEAN B VALUE (OVERALL, A**2) :REMARK 3 OVERALL ANISOTROPIC B VALUE.REMARK 3 B11 (A**2) :REMARK 3 B22 (A**2) :REMARK 3 B33 (A**2) :REMARK 3 B12 (A**2) :REMARK 3 B13 (A**2) :REMARK 3 B23 (A**2) :REMARK 3REMARK 3 ESTIMATED COORDINATE ERROR.REMARK 3 ESD FROM LUZZATI PLOT (A) :REMARK 3 ESD FROM SIGMAA (A) :REMARK 3 LOW RESOLUTION CUTOFF (A) :REMARK 3REMARK 3 RMS DEVIATIONS FROM IDEAL VALUES.REMARK 3 DISTANCE RESTRAINTS. RMS SIGMAREMARK 3 BOND LENGTH (A) : ;REMARK 3 ANGLE DISTANCE (A) : ;REMARK 3 INTRAPLANAR 1-4 DISTANCE (A) : ;REMARK 3 H-BOND OR METAL COORDINATION (A) : ;REMARK 3REMARK 3 PLANE RESTRAINT (A) : ;REMARK 3 CHIRAL-CENTER RESTRAINT (A**3) : ;REMARK 3REMARK 3 NON-BONDED CONTACT RESTRAINTS.REMARK 3 SINGLE TORSION (A) : ;REMARK 3 MULTIPLE TORSION (A) : ;REMARK 3 H-BOND (X...Y) (A) : ;REMARK 3 H-BOND (X-H...Y) (A) : ;REMARK 3REMARK 3 CONFORMATIONAL TORSION ANGLE RESTRAINTS.REMARK 3 SPECIFIED (DEGREES) : ;

30
REMARK 3 PLANAR (DEGREES) : ;REMARK 3 STAGGERED (DEGREES) : ;REMARK 3 TRANSVERSE (DEGREES) : ;REMARK 3REMARK 3 ISOTROPIC THERMAL FACTOR RESTRAINTS. RMS SIGMAREMARK 3 MAIN-CHAIN BOND (A**2) : ;REMARK 3 MAIN-CHAIN ANGLE (A**2) : ;REMARK 3 SIDE-CHAIN BOND (A**2) : ;REMARK 3 SIDE-CHAIN ANGLE (A**2) : ;REMARK 3REMARK 3 OTHER REFINEMENT REMARKS:
Refinement using SHELXLThis remark will be output by SHELXL-96 for direct submission to PDB. Structures done usingearlier versions of SHELX will use the same template, but with many of the data items containing“NULL” .
Template 1 1 1 1 1 2 3 4 5 6 7 8 9 0 1 2 3123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012
REMARK 3REMARK 3 REFINEMENT.REMARK 3 PROGRAM : SHELXLREMARK 3 AUTHORS : G.M.SHELDRICKREMARK 3REMARK 3 DATA USED IN REFINEMENT.REMARK 3 RESOLUTION RANGE HIGH (ÅNGSTROMS) :REMARK 3 RESOLUTION RANGE LOW (ÅNGSTROMS) :REMARK 3 DATA CUTOFF (SIGMA(F)) :REMARK 3 COMPLETENESS FOR RANGE (%) :REMARK 3 CROSS-VALIDATION METHOD :REMARK 3 FREE R VALUE TEST SET SELECTION :REMARK 3REMARK 3 FIT TO DATA USED IN REFINEMENT (NO CUTOFF).REMARK 3 R VALUE (WORKING + TEST SET, NO CUTOFF) :REMARK 3 R VALUE (WORKING SET, NO CUTOFF) :REMARK 3 FREE R VALUE (NO CUTOFF) :REMARK 3 FREE R VALUE TEST SET SIZE (%, NO CUTOFF) :REMARK 3 FREE R VALUE TEST SET COUNT (NO CUTOFF) :REMARK 3 TOTAL NUMBER OF REFLECTIONS (NO CUTOFF) :REMARK 3REMARK 3 FIT/AGREEMENT OF MODEL FOR DATA WITH F>4SIG(F).REMARK 3 R VALUE (WORKING + TEST SET, F>4SIG(F)) :REMARK 3 R VALUE (WORKING SET, F>4SIG(F)) :REMARK 3 FREE R VALUE (F>4SIG(F)) :REMARK 3 FREE R VALUE TEST SET SIZE (%, F>4SIG(F)) :REMARK 3 FREE R VALUE TEST SET COUNT (F>4SIG(F)) :REMARK 3 TOTAL NUMBER OF REFLECTIONS (F>4SIG(F)) :REMARK 3REMARK 3 NUMBER OF NON-HYDROGEN ATOMS USED IN REFINEMENT.REMARK 3 PROTEIN ATOMS :REMARK 3 NUCLEIC ACID ATOMS :REMARK 3 HETEROGEN ATOMS :REMARK 3 SOLVENT ATOMS :REMARK 3REMARK 3 MODEL REFINEMENT.REMARK 3 OCCUPANCY SUM OF NON-HYDROGEN ATOMS :REMARK 3 OCCUPANCY SUM OF HYDROGEN ATOMS :REMARK 3 NUMBER OF DISCRETELY DISORDERED RESIDUES :REMARK 3 NUMBER OF LEAST-SQUARES PARAMETERS :REMARK 3 NUMBER OF RESTRAINTS :REMARK 3REMARK 3 RMS DEVIATIONS FROM RESTRAINT TARGET VALUES.REMARK 3 BOND LENGTHS (A) :REMARK 3 ANGLE DISTANCES (A) :REMARK 3 SIMILAR DISTANCES (NO TARGET VALUES) (A) :REMARK 3 DISTANCES FROM RESTRAINT PLANES (A) :REMARK 3 ZERO CHIRAL VOLUMES (A**3) :REMARK 3 NON-ZERO CHIRAL VOLUMES (A**3) :REMARK 3 ANTI-BUMPING DISTANCE RESTRAINTS (A) :REMARK 3 RIGID-BOND ADP COMPONENTS (A**2) :REMARK 3 SIMILAR ADP COMPONENTS (A**2) :REMARK 3 APPROXIMATELY ISOTROPIC ADPS (A**2) :REMARK 3REMARK 3 BULK SOLVENT MODELING.REMARK 3 METHOD USED:

31
REMARK 3REMARK 3 STEREOCHEMISTRY TARGET VALUES :REMARK 3 SPECIAL CASE:REMARK 3REMARK 3 OTHER REFINEMENT REMARKS:
Refinement using TNT
Template 1 1 1 1 1 2 3 4 5 6 7 8 9 0 1 2 3123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012REMARK 3REMARK 3 REFINEMENT.REMARK 3 PROGRAM : TNTREMARK 3 AUTHORS : TRONRUD,TEN EYCK,MATTHEWSREMARK 3REMARK 3 DATA USED IN REFINEMENT.REMARK 3 RESOLUTION RANGE HIGH (ÅNGSTROMS) :REMARK 3 RESOLUTION RANGE LOW (ÅNGSTROMS) :REMARK 3 DATA CUTOFF (SIGMA(F)) :REMARK 3 COMPLETENESS FOR RANGE (%) :REMARK 3 NUMBER OF REFLECTIONS :REMARK 3REMARK 3 USING DATA ABOVE SIGMA CUTOFF.REMARK 3 CROSS-VALIDATION METHOD :REMARK 3 FREE R VALUE TEST SET SELECTION :REMARK 3 R VALUE (WORKING + TEST SET) :REMARK 3 R VALUE (WORKING SET) :REMARK 3 FREE R VALUE :REMARK 3 FREE R VALUE TEST SET SIZE (%) :REMARK 3 FREE R VALUE TEST SET COUNT :REMARK 3REMARK 3 USING ALL DATA, NO SIGMA CUTOFF.REMARK 3 R VALUE (WORKING + TEST SET, NO CUTOFF) :REMARK 3 R VALUE (WORKING SET, NO CUTOFF) :REMARK 3 FREE R VALUE (NO CUTOFF) :REMARK 3 FREE R VALUE TEST SET SIZE (%, NO CUTOFF) :REMARK 3 FREE R VALUE TEST SET COUNT (NO CUTOFF) :REMARK 3 TOTAL NUMBER OF REFLECTIONS (NO CUTOFF) :REMARK 3REMARK 3 NUMBER OF NON-HYDROGEN ATOMS USED IN REFINEMENT.REMARK 3 PROTEIN ATOMS :REMARK 3 NUCLEIC ACID ATOMS :REMARK 3 OTHER ATOMS :REMARK 3REMARK 3 WILSON B VALUE (FROM FCALC, A**2) :REMARK 3REMARK 3 RMS DEVIATIONS FROM IDEAL VALUES. RMS WEIGHT COUNTREMARK 3 BOND LENGTHS (A) : ; ;REMARK 3 BOND ANGLES (DEGREES) : ; ;REMARK 3 TORSION ANGLES (DEGREES) : ; ;REMARK 3 PSEUDOROTATION ANGLES (DEGREES) : ; ;REMARK 3 TRIGONAL CARBON PLANES (A) : ; ;REMARK 3 GENERAL PLANES (A) : ; ;REMARK 3 ISOTROPIC THERMAL FACTORS (A**2) : ; ;REMARK 3 NON-BONDED CONTACTS (A) : ; ;REMARK 3REMARK 3 INCORRECT CHIRAL-CENTERS (COUNT) :REMARK 3REMARK 3 BULK SOLVENT MODELING.REMARK 3 METHOD USED :REMARK 3 KSOL :REMARK 3 BSOL :REMARK 3REMARK 3 RESTRAINT LIBRARIES.REMARK 3 STEREOCHEMISTRY :REMARK 3 ISOTROPIC THERMAL FACTOR RESTRAINTS :REMARK 3REMARK 3 OTHER REFINEMENT REMARKS:
Non-diffraction studiesUntil standard refinement remarks are adopted for non-diffraction studies, their refinement detailsare given in REMARK 3, but its format will consist totally of free text beginning on the sixth line ofthe remark.

32
Template 1 1 1 1 1 2 3 4 5 6 7 8 9 0 1 2 3123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012REMARK 3REMARK 3 REFINEMENT.REMARK 3 PROGRAM :REMARK 3 AUTHORS :REMARK 3REMARK 3 FREE TEXT
REMARK 4
Remark 4 appears in PDB entries released after April 15, 1996 and identifies the version of the PDBContents Guide to which the PDB format entry conforms. For completeness, the information fromREMARK 4 may appear in a WPDB entry, but the appearance of this remark does not imply use ofthe PDB format in a WPDB entry. The specification conformance of a WPDB entry is given by thecontents of columns 14 – 17 of the LEADER record.
Template 1 1 1 1 1 2 3 4 5 6 7 8 9 0 1 2 3123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012REMARK 4REMARK 4 XXXX COMPLIES WITH FORMAT V. 2.2, 16-DEC-1996
• XXXX refers to the ID code of the entry.• N.M refers to the version number.• DD-MMM-YYYY refers to the release date of that version of the format. DD is a
number 01 through 31, MMM is a 3 letter abbreviation for the month, and YYYY isthe year.
Example 1 1 1 1 1 2 3 4 5 6 7 8 9 0 1 2 3123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012REMARK 4REMARK 4 1ABC COMPLIES WITH FORMAT V. 2.1, 25-OCT-1996
REMARK 5
Remark 5 repeats information presented on the CAVEAT record, which warns of severe errors in anentry. It also presents depositors' remarks of a cautionary nature, such as noting regions of poorlydefined density.
Template 1 1 1 1 1 2 3 4 5 6 7 8 9 0 1 2 3123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012REMARK 5REMARK 5 WARNINGREMARK 5 XXXX: FREE TEXT GOES HERE.

33
XXXX refers to the ID code of the entry.
Example 1 2 3 4 5 6 7 812345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 5REMARK 5 WARNINGREMARK 5 1ABC: THE CRYSTAL TRANSFORMATION IS IN ERROR BUT ISREMARK 5 UNCORRECTABLE AT THIS TIME.
REMARK 6 - 99Non-standard remark annotations, or those with no clearly defined topic or assigned remark numberappear with remark number 6 or greater, but less than remark number 100. For these remarks,columns 28 – 127 as a left-justified text field.
REMARK 100 – 199
These remarks are used in nucleic acid structures processed by the Nucleic Acid Database.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 100REMARK 100 THIS ENTRY HAS BEEN PROCESSED BY THE NUCLEIC ACID DATABASEREMARK 100 ON DD-MMM-YYYY.REMARK 100 THE NDB ID CODE IS NNNNNN.
For modified residues
REMARK 101 is mandatory if substituted nucleic acid residues exist.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 101REMARK 101 RESIDUE X Y N HAS XXX BONDED TO AB.REMARK 101 RESIDUE X Y N HAS XXX BONDED TO AB.
X is the modified residue name, Y is the chain identifier, N is the sequence number, XXX is thename of the modifier, A is the atom name and B the sequence number of the atom carrying themodifier.
Example 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 101REMARK 101 RESIDUE G A 4 HAS CH3 BONDED TO O6.REMARK 101 RESIDUE G B 16 HAS CH3 BONDED TO O6.
For base mispairings
REMARK 102 is mandatory if mispaired bases exist and Watson-Crick H-bonding is present.
Template 1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 102REMARK 102 BASES A B NN AND X Y ZZ ARE MISPAIRED.REMARK 102 BASES A B NN AND X Y ZZ ARE MISPAIRED.REMARK 102 ALL OTHER HYDROGEN BONDS BETWEEN BASE PAIRS IN THIS ENTRY

34
REMARK 102 FOLLOW THE CONVENTIONAL WATSON-CRICK HYDROGEN BONDINGREMARK 102 PATTERN AND THEY HAVE NOT BEEN PRESENTED ON *CONECT*REMARK 102 RECORDS IN THIS ENTRY.
A is the residue name, B the chain identifier, and NN the sequence number of first base, X is theresidue name, Y the chain id, and ZZ the sequence number of the second base.
For structures containing inosine
Inosine is treated like a standard residue, however, entries containing inosine also include remarks103 and 104.
REMARK 103 is mandatory if non-Watson-Crick H-bonding is present for specific interactions.
Template 1 2 3 4 5 6 7 812345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 103REMARK 103 THERE ARE NON-WATSON-CRICK HYDROGEN BONDS BETWEEN THEREMARK 103 FOLLOWING ATOMS:REMARK 103 AB I X N AND AB Z X NNREMARK 103 AB I X N AND AB Z X NNREMARK 103 ALL OTHER HYDROGEN BONDS BETWEEN BASE PAIRS IN THIS ENTRYREMARK 103 FOLLOW THE CONVENTIONAL WATSON-CRICK HYDROGEN BONDINGREMARK 103 PATTERN AND THEY HAVE NOT BEEN PRESENTED ON *CONECT*REMARK 103 RECORDS IN THIS ENTRY.
AB is the atom name, I the residue name inosine, X the chain identifier, and N the sequence numberof inosine, and AB is the atom name, Z the residue name, X the chain identifier, and NN thesequence number of the base which is paired with inosine.
REMARK 104 is mandatory if inosine exists.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 104REMARK 104 RESIDUE I X N IS INOSINE.REMARK 104 RESIDUE I X N IS INOSINE.
X is the chain identifier and N the sequence number.
Example 1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 103REMARK 103 THERE ARE NON-WATSON-CRICK HYDROGEN BONDS BETWEEN THEREMARK 103 FOLLOWING ATOMS:REMARK 103 N1 I A 1 AND N3 C B 16REMARK 103 O6 I A 1 AND N4 C B 16REMARK 103 N1 I A 3 AND N3 C B 14REMARK 103 O6 I A 3 AND N4 C B 14REMARK 103 ALL OTHER HYDROGEN BONDS BETWEEN BASE PAIRS IN THIS ENTRYREMARK 103 FOLLOW THE CONVENTIONAL WATSON-CRICK HYDROGEN BONDINGREMARK 103 PATTERN AND THEY HAVE NOT BEEN PRESENTED ON CONECTREMARK 103 RECORDS IN THIS ENTRY.REMARK 104REMARK 104 RESIDUE I A 1 IS INOSINE.REMARK 104 RESIDUE I A 3 IS INOSINE.
For nucleic acid entries
REMARK 105 is mandatory if nucleic acids exist in an entry.

35
Template 1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 105REMARK 105 THE PROTEIN DATA BANK HAS ADOPTED THE SACCHARIDE CHEMISTSREMARK 105 NOMENCLATURE FOR ATOMS OF THE DEOXYRIBOSE/RIBOSE MOIETYREMARK 105 RATHER THAN THAT OF THE NUCLEOSIDE CHEMISTS. THE RINGREMARK 105 OXYGEN ATOM IS LABELLED O4* INSTEAD OF O1*.
For non-mismatched structures
REMARK 106 is mandatory if hydrogen bonding is Watson-Crick.
Template 1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 106REMARK 106 THE HYDROGEN BONDS BETWEEN BASE PAIRS IN THIS ENTRY FOLLOWREMARK 106 THE CONVENTIONAL WATSON-CRICK HYDROGEN BONDING PATTERN.REMARK 106 THEY HAVE NOT BEEN PRESENTED ON *CONECT* RECORDS IN THISREMARK 106 ENTRY.
REMARK 200-250
Remarks in this range present the data collection details for the data which resulted in the refinementstatistics of REMARK 3. They provide information on the structure determination experiment,which may have been done by diffraction, NMR, theoretical modeling, or some other technique.
The “NULL” value will be used if the data for a token is not supplied by the depositor.
REMARK 200
To be used for single crystal, fiber, or polycrystalline X-ray diffraction experiments.REMARK 200 is should always appear for an entry based on X-ray diffraction.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 200REMARK 200 EXPERIMENTAL DETAILSREMARK 200 EXPERIMENT TYPE : X-RAY DIFFRACTIONREMARK 200 DATE OF DATA COLLECTION :REMARK 200 TEMPERATURE (KELVIN) :REMARK 200 PH :REMARK 200 NUMBER OF CRYSTALS USED :REMARK 200REMARK 200 SYNCHROTRON (Y/N) :REMARK 200 RADIATION SOURCE :REMARK 200 BEAMLINE :REMARK 200 X-RAY GENERATOR MODEL :REMARK 200 MONOCHROMATIC OR LAUE (M/L) :REMARK 200 WAVELENGTH OR RANGE (A) :REMARK 200 MONOCHROMATOR :REMARK 200 OPTICS :REMARK 200REMARK 200 DETECTOR TYPE :REMARK 200 DETECTOR MANUFACTURER :REMARK 200 INTENSITY-INTEGRATION SOFTWARE :REMARK 200 DATA SCALING SOFTWARE :REMARK 200REMARK 200 NUMBER OF UNIQUE REFLECTIONS :REMARK 200 RESOLUTION RANGE HIGH (A) :REMARK 200 RESOLUTION RANGE LOW (A) :REMARK 200 REJECTION CRITERIA (SIGMA(I)) :REMARK 200

36
REMARK 200 OVERALL.REMARK 200 COMPLETENESS FOR RANGE (%) :REMARK 200 DATA REDUNDANCY :REMARK 200 R MERGE (I) :REMARK 200 R SYM (I) :REMARK 200 <I/SIGMA(I)> FOR THE DATA SET :REMARK 200REMARK 200 IN THE HIGHEST RESOLUTION SHELL.REMARK 200 HIGHEST RESOLUTION SHELL, RANGE HIGH (A) :REMARK 200 HIGHEST RESOLUTION SHELL, RANGE LOW (A) :REMARK 200 COMPLETENESS FOR SHELL (%) :REMARK 200 DATA REDUNDANCY IN SHELL :REMARK 200 R MERGE FOR SHELL (I) :REMARK 200 R SYM FOR SHELL (I) :REMARK 200 <I/SIGMA(I)> FOR SHELL :REMARK 200REMARK 200 METHOD USED TO DETERMINE THE STRUCTURE:REMARK 200 SOFTWARE USED:REMARK 200 STARTING MODEL:REMARK 200REMARK 200 REMARK:
REMARK 205
REMARK 205 should appear in an entry based on fiber diffraction with a non-crystalline sample.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 205REMARK 205 THESE COORDINATES WERE GENERATED FROM FIBER DIFFRACTIONREMARK 205 DATA. PROTEIN DATA BANK CONVENTIONS REQUIRE THAT CRYST1REMARK 205 AND SCALE RECORDS BE INCLUDED, BUT THE VALUES OF THESEREMARK 205 RECORDS ARE MEANINGLESS.
REMARK 210 and 215
REMARKs 210 and 215 should appear if the entry is based on an NMR study. REMARK 217should appear if an entry is based on a solid-state NMR study.
Templates 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 210REMARK 210 EXPERIMENTAL DETAILSREMARK 210 EXPERIMENT TYPE : NMRREMARK 210 TEMPERATURE (KELVIN) :REMARK 210 PH :REMARK 210REMARK 210 NMR EXPERIMENTS CONDUCTED :REMARK 210 SPECTROMETER FIELD STRENGTH :REMARK 210 SPECTROMETER MODEL :REMARK 210 SPECTROMETER MANUFACTURER :REMARK 210REMARK 210 STRUCTURE DETERMINATION.REMARK 210 SOFTWARE USED :REMARK 210 METHOD USED :REMARK 210REMARK 210 CONFORMERS, NUMBER CALCULATED :REMARK 210 CONFORMERS, NUMBER SUBMITTED :REMARK 210 CONFORMERS, SELECTION CRITERIA :REMARK 210REMARK 210 REMARK:
1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 215REMARK 215 NMR STUDYREMARK 215 THE COORDINATES IN THIS ENTRY WERE GENERATED FROM SOLUTIONREMARK 215 NMR DATA. PROTEIN DATA BANK CONVENTIONS REQUIRE THATREMARK 215 CRYST1 AND SCALE RECORDS BE INCLUDED, BUT THE VALUES ONREMARK 215 THESE RECORDS ARE MEANINGLESS.

37
1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 217REMARK 217 SOLID STATE NMR STUDYREMARK 217 THE COORDINATES IN THIS ENTRY WERE GENERATED FROM SOLIDREMARK 217 STATE NMR DATA. PROTEIN DATA BANK CONVENTIONS REQUIRE THATREMARK 217 CRYST1 AND SCALE RECORDS BE INCLUDED, BUT THE VALUES ONREMARK 217 THESE RECORDS ARE MEANINGLESS.
REMARK 220 and REMARK 225
REMARKs 220 and 225 should appear if the entry is based on a theoretical model.
Templates 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 220REMARK 220 EXPERIMENTAL DETAILSREMARK 220 EXPERIMENT TYPE : THEORETICAL MODELINGREMARK 220REMARK 220 REMARK:
1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 225REMARK 225 THEORETICAL MODELREMARK 225 THE COORDINATES IN THIS ENTRY REPRESENT A MODEL STRUCTURE.REMARK 225 PROTEIN DATA BANK CONVENTIONS REQUIRE THAT CRYST1 ANDREMARK 225 SCALE RECORDS BE INCLUDED, BUT THE VALUES ON THESEREMARK 225 RECORDS ARE MEANINGLESS.
REMARK 230
REMARK 230 should appear if the entry is based on a neutron diffraction study.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 230REMARK 230 EXPERIMENTAL DETAILSREMARK 230 EXPERIMENT TYPE : NEUTRON DIFFRACTIONREMARK 230 DATE OF DATA COLLECTION :REMARK 230 TEMPERATURE (KELVIN) :REMARK 230 PH :REMARK 230 NUMBER OF CRYSTALS USED :REMARK 230REMARK 230 NEUTRON SOURCE :REMARK 230 BEAMLINE :REMARK 230 WAVELENGTH OR RANGE (A) :REMARK 230 MONOCHROMATOR :REMARK 230 OPTICS :REMARK 230REMARK 230 DETECTOR TYPE :REMARK 230 DETECTOR MANUFACTURER :REMARK 230 INTENSITY-INTEGRATION SOFTWARE :REMARK 230 DATA SCALING SOFTWARE :REMARK 230REMARK 230 NUMBER OF UNIQUE REFLECTIONS :REMARK 230 RESOLUTION RANGE HIGH (A) :REMARK 230 RESOLUTION RANGE LOW (A) :REMARK 230 REJECTION CRITERIA (SIGMA(I)) :REMARK 230REMARK 230 OVERALL.REMARK 230 COMPLETENESS FOR RANGE (%) :REMARK 230 DATA REDUNDANCY :REMARK 230 R MERGE (I) :REMARK 230 R SYM (I) :REMARK 230 <I/SIGMA(I)> FOR THE DATA SET :

38
REMARK 230REMARK 230 IN THE HIGHEST RESOLUTION SHELL.REMARK 230 HIGHEST RESOLUTION SHELL, RANGE HIGH (A) :REMARK 230 HIGHEST RESOLUTION SHELL, RANGE LOW (A) :REMARK 230 COMPLETENESS FOR SHELL (%) :REMARK 230 DATA REDUNDANCY IN SHELL :REMARK 230 R MERGE FOR SHELL (I) :REMARK 230 R SYM FOR SHELL (I) :REMARK 230 <I/SIGMA(I)> FOR SHELL :REMARK 230REMARK 230 METHOD USED TO DETERMINE THE STRUCTURE:REMARK 230 SOFTWARE USED :REMARK 230 STARTING MODEL:REMARK 230REMARK 230 REMARK:
REMARK 240
REMARK 240 should appear if the entry is based in an electron diffraction study.
Template 1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 240REMARK 240 EXPERIMENTAL DETAILSREMARK 240 EXPERIMENT TYPE : ELECTRON DIFFRACTIONREMARK 240 DATE OF DATA COLLECTION :REMARK 240REMARK 240 REMARK:
REMARK 250
REMARK 250 should appear if the entry is based on a study than x-ray, NMR, theoretical model,neutron, or electron study.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 250REMARK 250 EXPERIMENTAL DETAILSREMARK 250 EXPERIMENT TYPE :REMARK 250 DATE OF DATA COLLECTION :REMARK 250REMARK 250 REMARK:
REMARK 280
REMARK 280 presents information on the crystal. It should appear in any entry based on a singlecrystal study. The solvent content and Matthews coefficient are provided for protein andpolypeptide crystals. Crystallization conditions are free text.
Template 1 2 3 4 5 6 7 812345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 280REMARK 280 CRYSTALREMARK 280 SOLVENT CONTENT, VS (%):REMARK 280 MATTHEWS COEFFICIENT, VM (ÅNGSTROMS**3/DA):REMARK 280REMARK 280 CRYSTALLIZATION CONDITIONS: FREE TEXT GOES HERE.
REMARK 285
REMARK 285 presents information on the unit cell.

39
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 285REMARK 285 CRYST1REMARK 285 FREE TEXT GOES HERE.
Example 1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 285REMARK 285 CRYST1REMARK 285 TEXT TO EXPLAIN UNUSUAL UNIT-CELL DATA: THE DATA WASREMARK 285 COLLECTED ON TWO-DIMENSIONAL CRYSTALS AND HENCE THEREMARK 285 C-AXIS REPEAT DOES NOT CORRESPOND TO A REAL REPEAT, BUTREMARK 285 INSTEAD REFERS TO THE SAMPLING THAT IS USED TO DESCRIBEREMARK 285 THE CONTINUOUS TRANSFORM. THE C VALUE OF 100.9 ISREMARK 285 THEREFORE THE VALUE WHICH SHOULD BE USED INREMARK 285 INTERPRETING THE MEANING OF THE L INDEX.
REMARK 290
REMARK 290 presents information on symmetry operators for crystallographic studies
Template 1 2 3 4 5 6 7 812345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 290REMARK 290 CRYSTALLOGRAPHIC SYMMETRYREMARK 290 SYMMETRY OPERATORS FOR SPACE GROUP: P 21 21 21REMARK 290REMARK 290 SYMOP SYMMETRYREMARK 290 NNNMMM OPERATORREMARK 290 1555 X,Y,ZREMARK 290 2555 1/2-X,-Y,1/2+ZREMARK 290 3555 -X,1/2+Y,1/2-ZREMARK 290 4555 1/2+X,1/2-Y,-ZREMARK 290REMARK 290 WHERE NNN -> OPERATOR NUMBERREMARK 290 MMM -> TRANSLATION VECTORREMARK 290REMARK 290 CRYSTALLOGRAPHIC SYMMETRY TRANSFORMATIONSREMARK 290 THE FOLLOWING TRANSFORMATIONS OPERATE ON THE ATOM/HETATMREMARK 290 RECORDS IN THIS ENTRY TO PRODUCE CRYSTALLOGRAPHICALLYREMARK 290 RELATED MOLECULES.REMARK 290 SMTRY1 1 1.000000 0.000000 0.000000 0.00000REMARK 290 SMTRY2 1 0.000000 1.000000 0.000000 0.00000REMARK 290 SMTRY3 1 0.000000 0.000000 1.000000 0.00000REMARK 290 SMTRY1 2 -1.000000 0.000000 0.000000 36.30027REMARK 290 SMTRY2 2 0.000000 -1.000000 0.000000 0.00000REMARK 290 SMTRY3 2 0.000000 0.000000 1.000000 59.50256REMARK 290 SMTRY1 3 -1.000000 0.000000 0.000000 0.00000REMARK 290 SMTRY2 3 0.000000 1.000000 0.000000 46.45545REMARK 290 SMTRY3 3 0.000000 0.000000 -1.000000 59.50256REMARK 290 SMTRY1 4 1.000000 0.000000 0.000000 36.30027REMARK 290 SMTRY2 4 0.000000 -1.000000 0.000000 46.45545REMARK 290 SMTRY3 4 0.000000 0.000000 -1.000000 0.00000REMARK 290REMARK 290 REMARK:
REMARK 295
REMARK 295 provides a description of non-crystallographic symmetry. It should be present whenMTRIX records are given.

40
Template 1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 295REMARK 295 NON-CRYSTALLOGRAPHIC SYMMETRYREMARK 295 THE TRANSFORMATIONS PRESENTED ON THE MTRIX RECORDS BELOWREMARK 295 DESCRIBE NON-CRYSTALLOGRAPHIC RELATIONSHIPS AMONG ATOMSREMARK 295 IN THIS ENTRY. APPLYING THE APPROPRIATE MTRIXREMARK 295 TRANSFORMATION TO THE RESIDUES LISTED FIRST WILL YIELDREMARK 295 APPROXIMATE COORDINATES FOR THE RESIDUES LISTED SECOND.REMARK 295 CHAIN IDENTIFIERS GIVEN AS "?" REFER TO CHAINS FOR WHICHREMARK 295 ATOMS ARE NOT FOUND IN THIS ENTRY.REMARK 295REMARK 295 APPLIED TO TRANSFORMED TOREMARK 295 TRANSFORM CHAIN RESIDUES CHAIN RESIDUES RMSDREMARK 295 SSS ? ? .. ? ? ? .. ? ?REMARK 295REMARK 295 WHERE SSS -> COLUMNS 8-10 OF MTRIX RECORDSREMARK 295REMARK 295 REMARK:
Example 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 295REMARK 295 NON-CRYSTALLOGRAPHIC SYMMETRYREMARK 295 THE TRANSFORMATIONS PRESENTED ON THE MTRIX RECORDS BELOWREMARK 295 DESCRIBE NON-CRYSTALLOGRAPHIC RELATIONSHIPS AMONG ATOMSREMARK 295 IN THIS ENTRY. APPLYING THE APPROPRIATE MTRIXREMARK 295 TRANSFORMATION TO THE RESIDUES LISTED FIRST WILL YIELDREMARK 295 APPROXIMATE COORDINATES FOR THE RESIDUES LISTED SECOND.REMARK 295 CHAIN IDENTIFIERS GIVEN AS "?" REFER TO CHAINS FOR WHICHREMARK 295 ATOMS ARE NOT FOUND IN THIS ENTRY.REMARK 295REMARK 295 APPLIED TO TRANSFORMED TOREMARK 295 TRANSFORM CHAIN RESIDUES CHAIN RESIDUES RMSDREMARK 295 SSSREMARK 295 M 1 A 1 .. 374 C 1 .. 374 0.010REMARK 295 M 2 B 1 .. 374 D 1 .. 374 0.010REMARK 295REMARK 295 WHERE SSS -> COLUMNS 8-10 OF MTRIX RECORDSREMARK 295REMARK 295 REMARK:
REMARK 300
REMARK 300 provides a description of the biologically functional molecule (biomolecule) in freetext. REMARK 300 should be present if REMARK 350 is given.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 300REMARK 300 BIOMOLECULEREMARK 300 FREE TEXT DESCRIPTION OF THE BIOLOGICALLY FUNCTIONALREMARK 300 MOLECULE.
REMARK 350
REMARK 350 presents all transformations, both crystallographic and non-crystallographic, neededto generate the biomolecule. These transformations operate on the coordinates in orthogonalÅngstroms in the entry. REMARK 350 should be present if REMARK 300 is given.

41
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 350REMARK 350 GENERATING THE BIOMOLECULEREMARK 350 COORDINATES FOR A COMPLETE MULTIMER REPRESENTING THE KNOWNREMARK 350 BIOLOGICALLY SIGNIFICANT OLIGOMERIZATION STATE OF THEREMARK 350 MOLECULE CAN BE GENERATED BY APPLYING BIOMT TRANSFORMATIONSREMARK 350 GIVEN BELOW. BOTH NON-CRYSTALLOGRAPHIC ANDREMARK 350 CRYSTALLOGRAPHIC OPERATIONS ARE GIVEN.REMARK 350REMARK 350 APPLY THE FOLLOWING TO CHAINS: ?, ?...REMARK 350 BIOMT1 N N.NNNNNN N.NNNNNN N.NNNNNN N.NNNNNREMARK 350 BIOMT2 N N.NNNNNN N.NNNNNN N.NNNNNN N.NNNNNREMARK 350 BIOMT3 N N.NNNNNN N.NNNNNN N.NNNNNN N.NNNNN
Example 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 350REMARK 350 GENERATING THE BIOMOLECULEREMARK 350 COORDINATES FOR A COMPLETE MULTIMER REPRESENTING THE KNOWNREMARK 350 BIOLOGICALLY SIGNIFICANT OLIGOMERIZATION STATE OF THEREMARK 350 MOLECULE CAN BE GENERATED BY APPLYING BIOMT TRANSFORMATIONSREMARK 350 GIVEN BELOW. BOTH NON-CRYSTALLOGRAPHIC ANDREMARK 350 CRYSTALLOGRAPHIC OPERATIONS ARE GIVEN.REMARK 350REMARK 350 APPLY THE FOLLOWING TO CHAINS: A, B, CREMARK 350 BIOMT1 1 1.000000 0.000000 0.000000 0.00000REMARK 350 BIOMT2 1 0.000000 1.000000 0.000000 60.00000REMARK 350 BIOMT3 1 0.000000 0.000000 1.000000 0.00000REMARK 350 BIOMT1 2 -1.000000 0.000000 0.000000 0.00000REMARK 350 BIOMT2 2 0.000000 1.000000 0.000000 -120.00000REMARK 350 BIOMT3 2 0.000000 0.000000 -1.000000 0.00000REMARK 350 APPLY THE FOLLOWING TO CHAINS: D, E, FREMARK 350 BIOMT1 3 1.000000 0.000000 0.000000 0.00000REMARK 350 BIOMT2 3 0.000000 -1.000000 0.000000 60.00000REMARK 350 BIOMT3 3 0.000000 0.000000 1.000000 0.00000REMARK 350 BIOMT1 4 -1.000000 0.000000 0.000000 0.00000REMARK 350 BIOMT2 4 0.000000 -1.000000 0.000000 -120.00000REMARK 350 BIOMT3 4 0.000000 0.000000 1.000000 0.00000
REMARK 350REMARK 350 GENERATING THE BIOMOLECULEREMARK 350 COORDINATES FOR A COMPLETE MULTIMER REPRESENTING THE KNOWNREMARK 350 BIOLOGICALLY SIGNIFICANT OLIGOMERIZATION STATE OF THEREMARK 350 MOLECULE CAN BE GENERATED BY APPLYING BIOMT TRANSFORMATIONSREMARK 350 GIVEN BELOW. BOTH NON-CRYSTALLOGRAPHIC ANDREMARK 350 CRYSTALLOGRAPHIC OPERATIONS ARE GIVEN.REMARK 350REMARK 350 APPLY THE FOLLOWING TO CHAINS: A, B, C, D, E, F, G, HREMARK 350 APPLY THE FOLLOWING TO CHAINS: I, J, K, LREMARK 350 BIOMT1 1 -0.500000 -0.865983 0.000000 0.00000REMARK 350 BIOMT2 1 0.866068 -0.500000 0.000000 0.00000REMARK 350 BIOMT3 1 0.000000 0.000000 1.000000 0.00000
REMARK 375
REMARK 375 specifies atoms that are known to lie a special position, i.e. a location in the cellwhich is mapped into itself by one of the symmetry operations of the space group other than theidentity.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 375REMARK 375 SPECIAL POSITIONREMARK 375 FREE TEXT GOES HERE.

42
Example 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 375REMARK 375 SPECIAL POSITIONREMARK 375 HOH 301 LIES ON A SPECIAL POSITION.REMARK 375 HOH 77 LIES ON A SPECIAL POSITION.
REMARK 375REMARK 375 SPECIAL POSITIONREMARK 375 MG MO4 A 10 LIES ON A SPECIAL POSITION.REMARK 375 HOH A 13 LIES ON A SPECIAL POSITION.REMARK 375 HOH A 28 LIES ON A SPECIAL POSITION.REMARK 375 HOH A 36 LIES ON A SPECIAL POSITION.
REMARK 400
REMARK 400 provides further details on the macromolecular contents of the entry, supplementingthe information on the COMPND record.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 400REMARK 400 COMPOUNDREMARK 400 FREE TEXT GOES HERE.
REMARK 450
REMARK 450 provides further details on the biological source of the macromolecular contents ofthe entry, supplementing the information in the SOURCE record.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 450REMARK 450 SOURCEREMARK 450 FREE TEXT GOES HERE.
REMARK 460
REMARK 460 is used to provide detailed information when IUPAC-IUB rules are not strictlyfollowed in naming side-chain atoms.
Template 1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 460REMARK 460 NON-IUPACREMARK 460 BY REQUEST OF THE DEPOSITOR, THE PROTEIN DATA BANK HAS NOTREMARK 460 APPLIED THE IUPAC-IUB RECOMMENDATIONS REGARDING THEREMARK 460 DESIGNATION OF BRANCHES 1 AND 2 OF SIDE-CHAIN ATOMS INREMARK 460 RESIDUES ARG, ASP, GLU, LEU, PHE, TYR, AND VAL TO THISREMARK 460 ENTRY.
REMARK 470
REMARK 470 is used to report the detail about non-hydrogen atoms of standard residues that aremissing from the coordinates. Missing HETATMS are not listed here.

43
Template 1 2 3 4 5 6 7 8 912345678901234567890123456789012345678901234567890123456789012345678901234567890123457890REMARK 470REMARK 470 MISSING ATOMREMARK 470 THE FOLLOWING RESIDUES HAVE MISSING ATOMS (M=MODEL NUMBER;REMARK 470 RES=RESIDUE NAME; C=CHAIN IDENTIFIER; SSEQ=SEQUENCE NUMBER;REMARK 470 I=INSERTION CODE):REMARK 470 M RES CSSEQI ATOMS
Example 1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 470REMARK 470 MISSING ATOMREMARK 470 THE FOLLOWING RESIDUES HAVE MISSING ATOMS (M=MODEL NUMBER;REMARK 470 RES=RESIDUE NAME; C=CHAIN IDENTIFIER; SSEQ=SEQUENCE NUMBER;REMARK 470 I=INSERTION CODE):REMARK 470 M RES CSSEQI ATOMSREMARK 470 ARG A 412 CG CD NE CZ NH1 NH2REMARK 470 ARG A 456 CG CD NE CZ NH1 NH2REMARK 470 GLU A 486 CG CD OE1 OE2REMARK 470 GLU A 547 CG CD OE1 OE2REMARK 470 GLU A 548 CG CD OE1 OE2REMARK 470 LYS A 606 CG CD CE NZREMARK 470 ARG B 456 CG CD NE CZ NH1 NH2REMARK 470 ASP B 484 CG OD1 OD2REMARK 470 GLN B 485 CG CD OE1 NE2REMARK 470 GLU B 486 CG CD OE1 OE2REMARK 470 ARG B 490 CG CD NE CZ NH1 NH2REMARK 470 GLU B 522 CG CD OE1 OE2REMARK 470 ARG B 576 CG CD NE CZ NH1 NH2REMARK 470 ASP B 599 CG OD1 OD2
REMARK 500
REMARK 500 provides further details on the stereochemistry of the structure.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 500REMARK 500 GEOMETRY AND STEREOCHEMISTRYREMARK 500 SUBTOPIC:REMARK 500REMARK 500 FREE TEXT GOES HERE.
Example (close contacts)
1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 500REMARK 500 GEOMETRY AND STEREOCHEMISTRYREMARK 500 SUBTOPIC: CLOSE CONTACTSREMARK 500REMARK 500 THE FOLLOWING ATOMS THAT ARE RELATED BY CRYSTALLOGRAPHICREMARK 500 SYMMETRY ARE IN CLOSE CONTACT. SOME OF THESE MAY BE ATOMSREMARK 500 LOCATED ON SPECIAL POSITIONS IN THE CELL.REMARK 500REMARK 500 DISTANCE CUTOFF: 2.2 ÅNGSTROMSREMARK 500 2.2 ÅNGSTROMS FOR CONTACTS NOT INVOLVING HYDROGEN ATOMSREMARK 500 1.6 ÅNGSTROMS FOR CONTACTS INVOLVING HYDROGEN ATOMSREMARK 500REMARK 500 ATM1 RES C SSEQI ATM2 RES C SSEQI SSYMOP DISTANCEREMARK 500 CB LEU D 68 - CE LYS E 76 1656 2.10REMARK 500 CB THR D 173 - O HOH 1151 4455 1.73REMARK 500 O HOH 1151 - CB THR D 173 4566 1.73REMARK 500 CZ ARG D 64 - O HOH 1422 3656 1.75
REMARK 500REMARK 500 GEOMETRY AND STEREOCHEMISTRYREMARK 500 SUBTOPIC: CLOSE CONTACTS IN SAME ASYMMETRIC UNITREMARK 500

44
REMARK 500 THE FOLLOWING ATOMS ARE IN CLOSE CONTACT.REMARK 500REMARK 500 ATM1 RES C SSEQI ATM2 RES C SSEQI DISTANCEREMARK 500 O HOH 761 - O ARG 17 1.89REMARK 500 O HOH 806 - N ARG 88 1.46
Example (non-CIS, non-trans) 1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 500REMARK 500 GEOMETRY AND STEREOCHEMISTRYREMARK 500 SUBTOPIC: NON-CIS, NON-TRANSREMARK 500REMARK 500 THE FOLLOWING PEPTIDE BONDS DEVIATE SIGNIFICANTLY FROM BOTHREMARK 500 CIS AND TRANS CONFORMATION. CIS BONDS, IF ANY, ARE LISTEDREMARK 500 ON CISPEP RECORDS. TRANS IS DEFINED AS 180 +/- 30 ANDREMARK 500 CIS IS DEFINED AS 0 +/- 30 DEGREES.REMARK 500 MODEL OMEGAREMARK 500 VAL A 123 GLN A 124 0 221.48REMARK 500 VAL B 123 GLN B 124 0 222.43
Example (chiral centers) 1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 500REMARK 500 GEOMETRY AND STEREOCHEMISTRYREMARK 500 SUBTOPIC: CHIRAL CENTERSREMARK 500REMARK 500 UNEXPECTED CONFIGURATION OF THE FOLLOWING CHIRALREMARK 500 CENTER(S) (M=MODEL NUMBER; RES=RESIDUE NAME; C=CHAINREMARK 500 IDENTIFIER; SSEQ=SEQUENCE NUMBER; I=INSERTION CODE).REMARK 500REMARK 500 STANDARD TABLE:REMARK 500 FORMAT: (10X,I3,1X,A3,1X,A1,I4,A1,6X,A12)REMARK 500REMARK 500 M RES CSSEQIREMARK 500 0 GLU 1 ALPHA-CARBONREMARK 500 0 GLU 1 SIDE-CHAINREMARK 500 0 GLU 1 ALPHA-CARBON
Example (covalent bond angles) 1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 500REMARK 500 GEOMETRY AND STEREOCHEMISTRYREMARK 500 SUBTOPIC: COVALENT BOND ANGLESREMARK 500REMARK 500 THE STEREOCHEMICAL PARAMETERS OF THE FOLLOWING RESIDUESREMARK 500 HAVE VALUES WHICH DEVIATE FROM EXPECTED VALUES BY MOREREMARK 500 THAN 4*RMSD (M=MODEL NUMBER; RES=RESIDUE NAME; C=CHAINREMARK 500 IDENTIFIER; SSEQ=SEQUENCE NUMBER; I=INSERTION CODE).REMARK 500REMARK 500 STANDARD TABLE:REMARK 500 FORMAT: (10X,I3,1X,A3,1X,A1,I4,A1,3(2X,A4,17X,F5.1)REMARK 500REMARK 500 EXPECTED VALUES: ENGH AND HUBER, 1991REMARK 500REMARK 500 M RES CSSEQI ATM1 ATM2 ATM3REMARK 500 0 ASP 3 C-1 - N - CA ANGL. DEV. = 21.7 DEGREES
Example (torsion angles) 1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 500REMARK 500 GEOMETRY AND STEREOCHEMISTRYREMARK 500 SUBTOPIC: TORSION ANGLESREMARK 500REMARK 500 TORSION ANGLES OUTSIDE THE EXPECTED RAMACHANDRAN REGIONS:REMARK 500 (M=MODEL NUMBER; RES=RESIDUE NAME; C=CHAIN IDENTIFIER;REMARK 500 SSEQ=SEQUENCE NUMBER; I=INSERTION CODE).REMARK 500REMARK 500 STANDARD TABLE:REMARK 500 FORMAT:(10X,I3,1X,A3,1X,A1,I4,A1,4X,F7.2,3X,F7.2)REMARK 500REMARK 500 M RES CSSEQI PSI PHIREMARK 500 0 VAL 26 -174.85 -134.80REMARK 500 0 MET 61 46.11 -176.53

45
REMARK 525
REMARK 525 provided information about the solvent molecules of the entry.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 525REMARK 525 SOLVENTREMARK 525 FREE TEXT GOES HERE.
Example 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 525REMARK 525 SOLVENTREMARK 525 MANY OF THE WATER MOLECULES APPEAR TO BE ASSOCIATED WITHREMARK 525 A SYMMETRY-RELATED MOLECULE.
REMARK 525REMARK 525 SOLVENTREMARK 525 THE FOLLOWING SOLVENT MOLECULES LIE FARTHER THAN EXPECTEDREMARK 525 FROM THE PROTEIN OR NUCLEIC ACID MOLECULE AND MAY BEREMARK 525 ASSOCIATED WITH A SYMMETRY RELATED MOLECULE (M=MODELREMARK 525 NUMBER; RES=RESIDUE NAME; C=CHAIN IDENTIFIER; SSEQ=SEQUENCEREMARK 525 NUMBER; I=INSERTION CODE):REMARK 525REMARK 525 M RES CSSEQIREMARK 525 0 HOH 561 DISTANCE = 5.07 ÅNGSTROMSREMARK 525 0 HOH 791 DISTANCE = 5.08 ÅNGSTROMS
REMARK 550
REMARK 550 provides descriptions of the segment identifiers used in ATOM/HETATM.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 550REMARK 550 SEGIDREMARK 550 FREE TEXT GOES HERE.
Example 1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 550REMARK 550 SEGIDREMARK 550 RESIDUES 1-55, SEGID VH1 ARE THE HEAVY CHAIN, VARIABLEREMARK 550 REGION 1. RESIDUES 56-100, SEGID VH2 ARE THE HEAVY CHAIN,REMARK 550 VARIABLE REGION 2,AND RESIDUES 101-150., SEGID VH3 ARE THEREMARK 550 HEAVY CHAIN.
REMARK 600
REAMRK 600 provides details on the heterogens in the entry.

46
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 600REMARK 600 HETEROGENREMARK 600 FREE TEXT GOES HERE.
Example 1 2 3 4 5 6 7 812345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 600REMARK 600 HETEROGENREMARK 600 HET GROUP TRIVIAL NAME: PHOSPHOTYROSINEREMARK 600 EMPIRICAL FORMULA : C9 O6 N PREMARK 600REMARK 600 OREMARK 600 / _REMARK 600 O = C C = C OREMARK 600 \ / \ / _REMARK 600 C - C - C C - O - P - OREMARK 600 / \\ // \\REMARK 600 N C - C OREMARK 600REMARK 600REMARK 600 NUMBER OF ATOMS IN GROUP: 17 (EXCLUDING HYDROGENS)
REMARK 650
REMARK 650 provides further details on the helix contents of the entry.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 650REMARK 650 HELIXREMARK 650 FREE TEXT GOES HERE.
Example 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 650REMARK 650 HELIXREMARK 650 DETERMINATION METHOD: KDSSPREMARK 650 THE MAJOR DOMAINS ARE: "N" FOR N-TERMINAL DOMAIN, "B" FORREMARK 650 BETA-BARREL DOMAIN, AND "C" FOR C-TERMINAL DOMAIN. "F"REMARK 650 REFERS TO THE ACTIVE SITE FLAP. ALPHA HELICES ARE NAMEDREMARK 650 WITH TWO CHARACTERS, THE FIRST REFERRING TO THE DOMAINREMARK 650 IN WHICH THEY OCCUR.
REMARK 700
REMARK 700 provides further details on the sheet contents of the structure. Several standardtemplates are included here.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 700REMARK 700 SHEETREMARK 700 FREE TEXT GOES HERE.
REMARK 700REMARK 700 SHEETREMARK 700 DETERMINATION METHOD:REMARK 700 THE SHEET STRUCTURE OF THIS MOLECULE IS BIFURCATED. INREMARK 700 ORDER TO REPRESENT THIS FEATURE IN THE SHEET RECORDS BELOW,REMARK 700 TWO SHEETS ARE DEFINED. STRANDS N1, N2, N3 AND N4 OF SHEETREMARK 700 XXX AND XXX ARE IDENTICAL.
REMARK 700

47
REMARK 700 SHEETREMARK 700 DETERMINATION METHOD:REMARK 700 THE SHEET PRESENTED AS XXX ON SHEET RECORDS BELOW ISREMARK 700 ACTUALLY AN N-STRANDED BETA-BARREL. THIS ISREMARK 700 REPRESENTED BY A N+1-STRANDED SHEET IN WHICH THE FIRST ANDREMARK 700 LAST STRANDS ARE IDENTICAL.
REMARK 700REMARK 700 SHEETREMARK 700 DETERMINATION METHOD:REMARK 700 THERE ARE SEVERAL BIFURCATED SHEETS IN THIS STRUCTURE.REMARK 700 EACH IS REPRESENTED BY TWO SHEETS WHICH HAVE ONE OR MOREREMARK 700 IDENTICAL STRANDS.REMARK 700 SHEETS XXX AND XXX REPRESENT ONE BIFURCATED SHEET.REMARK 700 SHEETS XXX AND XXX REPRESENT ONE BIFURCATED SHEET.
N1, N2, N3 and N4 represent strand numbers, and XXX represents sheet identifiers.
When the remark for several bifurcated sheets is used, its last line is repeated for the appropriatenumber of bifurcated sheets, as shown in the last template above.
Example 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 700REMARK 700 SHEETREMARK 700 THE SHEET STRUCTURE OF THIS MOLECULE IS BIFURCATED. INREMARK 700 ORDER TO REPRESENT THIS FEATURE IN THE SHEET RECORDS BELOW,REMARK 700 TWO SHEETS are defined. STRANDS 3, 4, AND 5REMARK 700 OF SHEET *B2A* AND *B2B* ARE IDENTICAL. STRANDS 3, 4, ANDREMARK 700 5 OF SHEET *B2C* AND *B2D* ARE IDENTICAL.
REMARK 700REMARK 700 SHEETREMARK 700 STRANDS 1 TO 4 OF THE BETA-SHEET HAVE GREEK-KEY TOPOLOGY.REMARK 700 THE SHEET FORMS A FIVE-STRANDED BETA-BARREL WITH BULGES INREMARK 700 STRANDS 3 AND 5. IN ORDER TO REPRESENT THIS FEATURE IN THEREMARK 700 SHEET RECORDS BELOW, TWO SHEETS ARE DEFINED.
REMARK 700REMARK 700 SHEETREMARK 700 THE SHEET PRESENTED AS S5 ON SHEET RECORDS BELOW ISREMARK 700 ACTUALLY A 6-STRANDED BETA-BARREL. THIS ISREMARK 700 REPRESENTED BY A 7-STRANDED SHEET IN WHICH THE FIRST ANDREMARK 700 LAST STRANDS ARE IDENTICAL.
REMARK 750
REMARK 750 provides further details on the turns.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 750REMARK 750 TURNREMARK 750 FREE TEXT GOES HERE.
Example 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 750REMARK 750 TURNREMARK 750 TURN_ID: T4, TYPE I (ONE OR MORE OF THE PHI, PSI ANGLESREMARK 750 DEVIATE BY MORE THAN PLUS,MINUS 45 DEGREES FROM THE IDEALREMARK 750 VALUES USED BY WILMOT & THORNTON(1989)).REMARK 750REMARK 750 TURN_ID: T10, TYPE I (ONE OR MORE OF THE PHI, PSI ANGLESREMARK 750 DEVIATE BY MORE THAN PLUS,MINUS 45 DEGREES FROM THE IDEALREMARK 750 VALUES USED BY WILMOT & THORNTON(1989)).REMARK 750REMARK 750 TURN_ID: T16, TYPE VIII (ONE OR MORE OF THE PHI, PSIREMARK 750 ANGLES DEVIATE BY MORE THAN PLUS,MINUS 45 DEGREES FROM

48
REMARK 750 THE IDEAL VALUES USED BY WILMOT & THORNTON(1989)).
REMARK 800
REMARK 800 provides further details on the contents of the SITE records of the entry.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 800REMARK 800 SITEREMARK 800 SITE_IDENTIFIER: FREE TEXT GOES HERE.REMARK 800 SITE_DESCRIPTION: FREE TEXT GOES HERE.
Example 1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 800REMARK 800 SITEREMARK 800 SITE_IDENTIFIER: RCAREMARK 800 SITE_DESCRIPTION: DESIGNATED RECOGNITION REGION IN PRIMARYREMARK 800 REFERENCE. PROPOSED TO AFFECT SUBSTRATE SPECIFICITY.REMARK 800REMARK 800 SITE_IDENTIFIER: RCBREMARK 800 SITE_DESCRIPTION: DESIGNATED RECOGNITION REGION IN PRIMARYREMARK 800 REFERENCE. PROPOSED TO AFFECT SUBSTRATE SPECIFICITY.
REMARK 850, Revisions to Deposited Coordinates, Before Release
REMARK 850 provides information on revisions made to deposited coordinates before release.The PDB uses this REMARK in entries in PDB format to track revisions to deposited coordinatesbefore release. The REMARK contents are carried in WPDB format.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 850REMARK 850 CORRECTION BEFORE RELEASEREMARK 850 ORIGINAL DEPOSITION REVISED PRIOR TO RELEASEREMARK 850 DATE REVISED: DD-MMM-YYYY TRACKING NUMBER: T?
DD is a number 01 through 31, MMM is a 3 letter abbreviation for the month, and YYYY is theyear.
Example 1 2 3 4 5 6 7 812345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 850REMARK 850 CORRECTION BEFORE RELEASEREMARK 850 ORIGINAL DEPOSITION REVISED PRIOR TO RELEASEREMARK 850 DATE REVISED: 13-FEB-1996 TRACKING NUMBER: T7770REMARK 850 DATE REVISED: 10-APR-1996 TRACKING NUMBER: T8125
REMARK 860
REMARK 860 provides further details on corrections that have been made to the entry, as referredto in the REVDAT record. The PDB templates used two-digit years. For WPDB, four-digit years

49
are used.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 860REMARK 860 CORRECTION AFTER RELEASEREMARK 860 FREE TEXT GOES HERE.
Example 1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 860REMARK 860 CORRECTIONREMARK 860 CORRECT RESIDUE IDENTIFICATION ON SITE RECORDS. ADDREMARK 860 RESIDUE TO SITE RECORDS. 15-JUL-1981.REMARK 860REMARK 860 CORRECT DATES IN REMARKS 7 AND 16. 15-JAN-1982.REMARK 860REMARK 860 CORRECT ATOM NAME FOR ATOM 6 FROM CG2 TO CG1. 07-MAR-1983.REMARK 860REMARK 860 CHANGE RESIDUE 122 FROM ASN TO ASP. ADD REFERENCE.REMARK 860 12-MAY-1983.REMARK 860REMARK 860 INSERT REVDAT RECORDS. 30-SEP-1983.REMARK 860REMARK 860 CORRECT CODEN FOR REFERENCE 1. 27-OCT-1983.
REMARK 900
REMARK 900 gives ID codes of PDB files related to the entry. These may include coordinateentries deposited as a related set, the structure factor or NMR restraint file related to the entry, or thefile containing the biologically functional molecule ("biomolecule") generated by the PDB fromsymmetry records.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 900REMARK 900 RELATED ENTRIESREMARK 900 FREE TEXT GOES HERE.
Example 1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 900REMARK 900 RELATED ENTRIESREMARK 900 THE BIOMOLECULE RELATED TO THIS ENTRY HAS BEEN GENERATEDREMARK 900 AND IS AVAILABLE AS PDB FILE BIO1ABC.PDB
REMARK 900REMARK 900 RELATED ENTRIESREMARK 900 THE STRUCTURE FACTORS FOR THIS EXPERIMENT ARE AVAILABLE ASREMARK 900 PDB FILE R1ABCSF.ENT
REMARK 900REMARK 900 RELATED ENTRIESREMARK 900 THE LIST OF EXPERIMENTAL RESTRAINTS IS AVAILABLE AS PDBREMARK 900 FILE 1ABC.MR
REMARK 900REMARK 900 RELATED ENTRIESREMARK 900 THE BIOMOLECULE IS AVAILABLE AS PDB FILE BIO1ABC.PDB

50
REMARK 999
REMARK 999 provides further details on the sequence.
For cases where there are gaps in the structure as reflected in missing ATOM records missing N-terminus and C-terminus residues are delineated in REMARK 999 records, whereas internalstructural gaps are represented in SEQADV records. Several cases must be considered whenevaluating these REMARK 999 records:
• The missing N-terminus atoms are not found in the ATOM record as they representprecursor sequence and are not found in the mature protein.
• The missing N-terminus residues were not found in the density map. According to thePDB Contents Guide, the PDB will attempt to flag these as SEQADV records; the PDBdoes not guarantee that they will always be handled uniformly. The primary reason forthis inconsistency is that, in a number of cases, neither PDB nor the depositors are certainwhere chains start and end.
Template 1 2 3 4 5 6 71234567890123456789012345678901234567890123456789012345678901234567890REMARK 999REMARK 999 SEQUENCEREMARK 999 FREE TEXT GOES HERE.
Example 1 2 3 4 5 6 7 8 9123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890REMARK 999REMARK 999 SEQUENCEREMARK 999 1ARL SWS P00730 1 - 110 NOT IN ATOMS LISTREMARK 999 1ARL SWS P00730 418 - 419 NOT IN ATOMS LISTREMARK 999REMARK 999 REFERENCEREMARK 999 REFERENCE: PETRA, ET AL., (1971) BIOCHEMISTRY 10, PPREMARK 999 4023-4025.REMARK 999REMARK 999 SHOHAM, G., NECHUSHTAI, R., STEPPUN, J.,NELSON, H.,REMARK 999 NELSON N., UNPUBLISHED RESULTS.REMARK 999REMARK 999 LE HUEROU,I., GUILLOTEAU P., TOULLEC, R., PUIGSERVER, A.,REMARK 999 WICKER,C., (1991) BIOCHEMICAL, BIOPHYSICAL RESEARCHREMARK 999 COMM., 175, PP 110 - 116.REMARK 999REMARK 999 THE SEQUENCE USED IS THAT PROVIDED BY THE CDNA, WHICHREMARK 999 CORRECTS SEVERAL ASP/ASN AND GLU/GLN MISASSIGNMENTS.
REMARK 999REMARK 999 SEQUENCEREMARK 999 MET A 1 - MET A 1 - MISSING FROM SWS P10599REMARK 999 1CQG B SWS P27695 1 - 57 NOT IN ATOMS LISTREMARK 999 1CQG B SWS P27695 71 - 317 NOT IN ATOMS LISTREMARK 999REMARK 999 THR AT POSITION 74 WAS FOUND BY WOLMAN ET AL., JOURNAL OFREMARK 999 BIOCHEMISTRY 263, 15506 (1988).
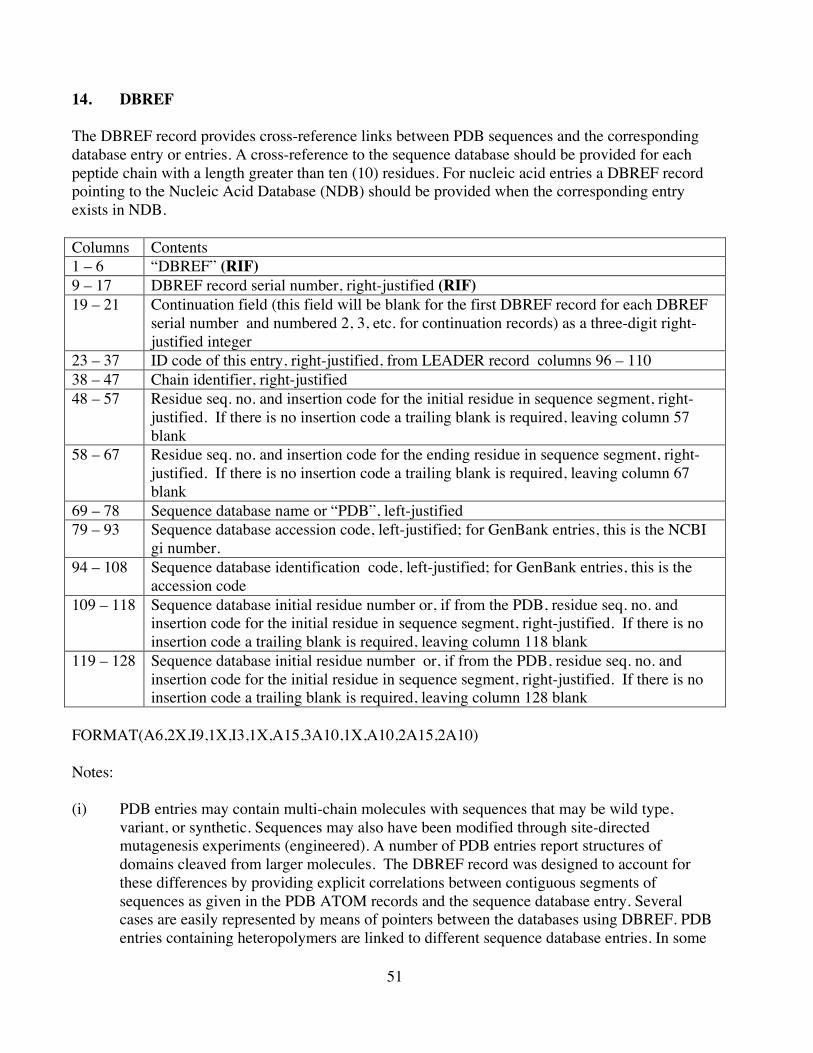
51
14. DBREF
The DBREF record provides cross-reference links between PDB sequences and the correspondingdatabase entry or entries. A cross-reference to the sequence database should be provided for eachpeptide chain with a length greater than ten (10) residues. For nucleic acid entries a DBREF recordpointing to the Nucleic Acid Database (NDB) should be provided when the corresponding entryexists in NDB.
Columns Contents1 – 6 “DBREF” (RIF)9 – 17 DBREF record serial number, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first DBREF record for each DBREF
serial number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 37 ID code of this entry, right-justified, from LEADER record columns 96 – 11038 – 47 Chain identifier, right-justified48 – 57 Residue seq. no. and insertion code for the initial residue in sequence segment, right-
justified. If there is no insertion code a trailing blank is required, leaving column 57blank
58 – 67 Residue seq. no. and insertion code for the ending residue in sequence segment, right-justified. If there is no insertion code a trailing blank is required, leaving column 67blank
69 – 78 Sequence database name or “PDB”, left-justified79 – 93 Sequence database accession code, left-justified; for GenBank entries, this is the NCBI
gi number.94 – 108 Sequence database identification code, left-justified; for GenBank entries, this is the
accession code109 – 118 Sequence database initial residue number or, if from the PDB, residue seq. no. and
insertion code for the initial residue in sequence segment, right-justified. If there is noinsertion code a trailing blank is required, leaving column 118 blank
119 – 128 Sequence database initial residue number or, if from the PDB, residue seq. no. andinsertion code for the initial residue in sequence segment, right-justified. If there is noinsertion code a trailing blank is required, leaving column 128 blank
FORMAT(A6,2X,I9,1X,I3,1X,A15,3A10,1X,A10,2A15,2A10)
Notes:
(i) PDB entries may contain multi-chain molecules with sequences that may be wild type,variant, or synthetic. Sequences may also have been modified through site-directedmutagenesis experiments (engineered). A number of PDB entries report structures ofdomains cleaved from larger molecules. The DBREF record was designed to account forthese differences by providing explicit correlations between contiguous segments ofsequences as given in the PDB ATOM records and the sequence database entry. Severalcases are easily represented by means of pointers between the databases using DBREF. PDBentries containing heteropolymers are linked to different sequence database entries. In some

52
cases, such as those PDB entries containing immunoglobulin Fab fragments, each chain islinked to two different SWISS-PROT, PIR, and/or GenBank entries. This facility is neededbecause these databases represent sequences for the various immunoglobulin domains asseparate entries. DBREF also is able to represent molecules engineered by altering the gene(fusing genes, altering sequences, creating chimeras, or circularly permuting sequences). Thisdesign has the additional advantage that it will be possible to construct pointers to otherrelevant databases such as the Nucleic Acid Database, BioMagResBank, and databasesdescribing sequence motifs (e.g., PROSITE, BLOCKS).
(ii) Database names and their abbreviations as used on DBREF records:
Database name database (code in columns 61 – 70)BioMagResBank BMRBBLOCKS BLOCKSEuropean Molecular Biology Laboratory EMBLGenBank GBGenome Data Base GDBNucleic Acid Database NDBPROSITE PROSITProtein Data Bank PDBProtein Identification Resource PIRSWISS-PROT SWSTREMBL TREMBL
(iii) When no sequence numbers are given in columns 48 – 67 and 109 - 128, then the mapping isbetween database entries rather than segments within an entry. For example, this is normallyused to point to the related NDB entry.
(iv) DBREF records present sequence correlations between PDB ATOM records andcorresponding PIR, GenBank, or SWISS-PROT, etc. entries.
(v) All possible references to the listed databases might not be provided. In most cases, only onereference to a sequence database will be provided.
(vi) PDB entries containing chains for which residues are missing primarily due to disorder mayhave several DBREF records, each linking an observed sequence segment to a sequencedatabase entry.
(vii) If no reference is found to the sequence databases, then the entry itself is given as thereference.
Example 1 2 3 4 5 6 7 8 9 0 1 2 3123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012DBREF 1 1ABC B 1B 36 PDB 1ABC 1ABC 1B 36
DBREF 1 3AKY 3 220 SWS P07170 KAD1_YEAST 5 222
DBREF 1 1HAN 2 288 GB 397884 X66122 1 287

53
DBREF 1 3HSV A 1 92 SWS P22121 HSF_KLULA 193 284DBREF 2 3HSV B 1 92 SWS P22121 HSF_KLULA 193 284
DBREF 1 1ARL 1 307 SWS P00730 CBPA_BOVIN 111 417
DBREF 1 249D A 1 12 NDB BDL070 BDL070 1 12DBREF 2 249D B 13 24 NDB BDL070 BDL070 13 24DBREF 3 249D C 26 36 NDB BDL070 BDL070 26 36DBREF 4 249D D 37 48 NDB BDL070 BDL070 37 48
15. SEQADV
The SEQADV record identifies conflicts between sequence information in the ATOM records of thePDB entry and the sequence database entry given on DBREF. Please note that these records weredesigned to identify differences and not errors. No assumption is made as to which database containsthe correct data. PDB may include REMARK records in the entry that reflect the depositor's view ofwhich database has the correct sequence. Each conflict is presented as a pair of records, the firstrecord having an “L” in column 7, giving the location of the conflict, the second record having a “C”in column 7, giving the conflict comment. The two records of each pair will have the sameSEQADV record serial number.
SEQADV Location Record
Columns Contents1 – 6 “SEQADV” (RIF)7 “L” (RIF)9 – 17 SEQADV record serial number, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first SEQADVL record for each
SEQADV serial number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 37 ID code of this entry, right-justified, from LEADER record columns 96 – 11038 – 47 Residue name of PDB residue in conflict, right-justified48 – 57 Chain identifier for the PDB residue in conflict, right-justified58 – 67 Residue seq. no. and insertion code for the PDB residue in conflict, right-justified. If
there is no insertion code a trailing blank is required, leaving column 67 blank69 – 78 Sequence database name or “PDB”, left-justified79 – 93 Sequence database accession code, left-justified; for GenBank entries, this is the NCBI
gi number.94 – 108 Sequence database identification code, left-justified; for GenBank entries, this is the
accession code109 – 118 Sequence database residue name, right justified119 – 128 Sequence database initial residue number or, if from the PDB, residue seq. no. and
insertion code for the initial residue in sequence segment, right-justified. If there is noinsertion code a trailing blank is required, leaving column 128 blank
FORMAT(A6,A1,1X,I9,1X,I3,1X,A15,3A10,1X,A10,2A15,2A10)

54
SEQADV Conflict Comment Record
Columns Contents1 – 6 “SEQADV” (RIF)7 “C” (RIF)9 – 17 SEQADV record serial number, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first SEQADVC record for each
SEQADV serial number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 37 ID code of this entry, right-justified, from LEADER record columns 96 – 11039 – 132 Conflict comment, left-justified
FORMAT(A6,A1,1X,I9,1X,I3,1X,A15,1X,A94)
Notes:
(i) For cases where there are gaps in the structure as reflected in missing ATOM records,SEQADV records are produced which reflect the lack of correlation between the chain andthe sequence database entry. (Several DBREF records are also produced.) Note that internalstructural gaps are represented in SEQADV records, whereas missing N-terminus and C-terminus residues are delineated in REMARK 999 records
(ii) If the missing N-terminus residues were not found in the density map, the PDB will attemptto flag these as SEQADV records. However, we cannot guarantee that they will always behandled uniformly since, in a number of cases, neither PDB nor the depositors are certainwhere chains start and end.
(iii) In a number of cases, conflicts between the sequences found in PDB entries and in PIR orSWISS-PROT entries have been noted. There are several possible reasons for these conflicts,including natural variants or engineered sequences (mutants), polymorphic sequences, orambiguous or conflicting experimental results. These discrepancies, which were previouslydescribed in REMARK records, are now reported in SEQADV.
(iv) SEQADV describes conflicts between residue sequences given by PDB ATOM/HETATMrecords and those in the appropriate sequence database entry, such as residues missing due todisorder.
(v) This record will give a description of the differences between the sequence database entriesand complete chains. If a chain is referenced by more than one sequence database entry, as inthe case of fused genes, then SEQADV will describe the relationship between each chainsegment.
(vi) Some of the possible conflict comments:Cloning artifactConflictEngineered

55
DisorderedGap in PDB entryMissing from [database name]VariantInsertionDeletionMicroheterogeneityD-configuration
(vii) When conflicts arise which are not classifiable by these terms, a reference to either apublished paper, a PDB entry, or a REMARK within the entry is given. References are givenin the form YY-VOL-PAGE-CODEN where YY is year of publication, VOL is the journalvolume number, PAGE is the starting page and CODEN is the four-digit code assigned tojournals by PDB and the Cambridge Crystallographic Data Centre (CCDC).
(viii) When reference is made to a PDB entry, then the form is PDB: 1ABC, where 1ABC is therelevant entry ID code.
(ix) Finally, the comment "SEE REMARK 999" is included in the PDB format when theexplanation for the conflict is too long to fit the SEQADV record. For WPDB format entries,this is not necessary, since the conflict comment can be continued.
(x) Microheterogeneity is to be represented as a variant with one of the possible residues in thesite being selected (arbitrarily) as the primary residue, in which case a SEQADV record mustbe provided for the alternate residue. Also see the WPDB SEQALN record type.
16. SEQRES
SEQRES records contain the amino acid or nucleic acid sequence of residues in each chain of theparticular macromolecule or complex that was studied. No cognizance is taken here of homologousmolecules on which the residue sequence identifiers may be based. In general, if the macromoleculeis composed of two or more chains which are commonly conceptualized as being logicallyseparable, e.g., ribonuclease S, or papain with an oligopeptide inhibitor, then separate sets ofSEQRES records are provided for each of these chains. If, however, these chains are usually thoughtof as comprising an integral unit (e.g., the three chains of α-chymotrypsin) a single set of SEQRESrecords is given.
Columns Contents1 – 6 “SEQRES” (RIF)9 – 17 Serial number of SEQRES record for current chain, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first SEQRES record for each
SEQRES serial number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 32 Chain identifier, right-justified33 – 41 Number of residues in this chain, right-justified43 – 52 Residue name, right-justified53 – 62 Residue name, right-justified

56
63 – 72 Residue name, right-justified73 – 82 Residue name, right-justified83 – 92 Residue name, right-justified93 – 102 Residue name, right-justified103 –112 Residue name, right-justified113 –122 Residue name, right-justified123 –132 Residue name, right-justified
FORMAT (A6,2X,I9,1X,I3,1X,A10,I9,1X,9A10)
Notes:
(i) PDB entries use the three-letter abbreviation for amino acid names and the one letter code fornucleic acids.
(ii) The continuation field is to allow for handling of residue names of more than 10 characters orSEQRES serial numbers of more than 9 digits, not to handle additional residue namesAdditional SEQRES records, with the same chain identifier in cols. 20 – 29 and monotoneincreasing SEQRES serial numbers, are used as needed.
(iii) In the case of non-standard groups, a heterogen identifier is used. Common HET namesappear in the HET dictionary. The heterogen identifiers from the PDB are limited to 3alphanumeric characters. The WPDB format permits longer identifiers. Up to 10 charactersmay be used before continuation records are needed.
(iv) Each covalently contiguous sequence of residues (connected via the "backbone" atoms) isrepresented as an individual chain.
(v) Heterogens which are integrated into the backbone of the chain are listed as being part of thechain and are included in the SEQRES records for that chain.
(vi) Each set of SEQRES records and each HET group is assigned a component number. Thecomponent number is assigned serially beginning with 1 for the first set of SEQRES records.This number is given explicitly in the FORMUL record, but only implicitly in the SEQRESrecord.
(vii) The SEQRES records must list residues present in the molecule studied, even if thecoordinates are not present, but residues removed from the chain terminii (e.g., during anactivation process) are not included. Residues excised from the chain (not at the terminii,e.g., in α-chymotrypsin) are represented by EXC in the SEQRES records.
(viii) N- and C-terminal residues for which no coordinates are provided due to disorder must belisted on SEQRES.
(ix) All occurrences of standard amino or nucleic acid residues (ATOM records) must be listedon a SEQRES record. This implies that a number of residues of 1 is valid.
(x) No distinction is made between ribo- and deoxyribonucleotides in the SEQRES records.These residues are identified with the same residue name (i.e., A, C, G, T, U, I).
(xi) If the entire residue sequence is unknown, the serial number in columns 11 – 19 is "0", thenumber of residues thought to comprise the molecule is entered as number of residues incolumns 30 – 38, and residue name in columns 39 – 48 is "UNK".
(xii) In case of microheterogeneity, only one of the sequences is presented. A REMARK isgenerated to explain this and a SEQADV is also generated. The heterogeneity may bedescribed in detail in the SEQALN records

57
17. SEQALN
The SEQALN record provides information about the alignment between the sequence specified inthe SEQRES records and the sequence of residues in the ATOM/HETATM list. Each residue listedin the SEQRES records for a given chain is implicitly associated with its ordinal in that chain,starting with 1 for the first residue. For each chain the corresponding SEQALN records list thoseordinals with the residue name and residue sequence numbers (and codes for insertion, if given)from the ATOM/HETATM list.
Columns Contents1 – 6 “SEQALN” (RIF)9 – 17 Serial number of SEQALN record for current chain, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first SEQRES record for each
SEQRES serial number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 32 Chain identifier, right-justified33 – 41 Number of residues in this chain from SEQRES, right-justified42 – 50 SEQRES residue ordinal, right-justified52 – 61 ATOM/HETATM list residue name, right-justified62 – 71 Residue seq. no. and insertion code for the PDB residue name used in this entry, right-
justified. If there is no insertion code a trailing blank is required, leaving column 71blank
73 – 81 SEQRES residue ordinal, right-justified82 – 91 ATOM/HETATM list residue name, right-justified92 – 101 Residue seq. no. and insertion code for the PDB residue name used in this entry, right-
justified. If there is no insertion code a trailing blank is required, leaving column 100blank
103 – 112 SEQRES residue ordinal, right-justified113 – 122 ATOM/HETATM list residue name, right-justified123 – 132 Residue seq. no. and insertion code for the PDB residue name used in this entry, right-
justified. If there is no insertion code a trailing blank is required, leaving column 130blank
FORMAT(A6,2X,I9,1X,I3,1X,A10,2I9,2A10,1X,I9,2A10,1X,I9,2A10)
Notes:
(i) Gaps in the ATOM/HETATM list are shown by giving a blank for the ATOM/HETATMresidue sequence number.
(ii) Microheterogeneity is shown by listing the corresponding SEQRES residue ordinals morethan once. Normally the SEQRES records should completely and accurately represent thesubstance being studied in the experiment. Therefore, normally, there should be a SEQRESsequence ordinal for each residue from the ATOM/HETATM list. However, it isconceivable that a microheterogenity of, for example, a long loop in solution, might give riseto the case there are more residues in one of the microhetergenens than there are in the

58
corresponding section of SEQRES records. In such a rare case, a blank should be used forthe SEQRES residue ordinals corresponding to the insertion. If a corresponding SEQRESresidue ordinal is blank (because of such an insertion), the sequence of residues from theATOM/HETATM list should be extended forward and/or backwards sufficiently to provideSEQRES residue ordinals for alignment, even if this takes the run past the microherogenityor past the beginning or end of the SEQRES chain. Because of this rule, the same alignmentsmay occur more than once in SEQALN. If it is necessary to run past the beginning of theSEQRES chain, zero and negative numbers and numbers greater than the number of residuesin the SEQRES chain may be used.
18. MODRES
The MODRES record provides descriptions of modifications (e.g., chemical or post-translational) toprotein and nucleic acid residues. Included are a mapping between residue names given in a PDBentry and standard residues.
Columns Contents1 – 6 “MODRES” (RIF)9 – 17 MODRES record serial number, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first MODRES record for each
MODRES serial number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 37 ID code of this entry, right-justified, from LEADER record columns 96 – 11038 – 47 Residue name as used in this entry, right-justified48 – 57 Chain identifier, right-justified58 – 67 Residue seq. no. and insertion code for the PDB residue name used in this entry, right-
justified. If there is no insertion code a trailing blank is required, leaving column 67blank
69 – 78 Standard residue name, right-justified80 – 132 Description of the residue modification.
FORMAT(A6,2X,I9,1X,I3,1X,A15,3A10,1X,A10,1X,A53)
Notes:
(i) Residues modified post-translationally, enzymatically, or by design are described inMODRES records. In those cases where PDB has opted to use a non-standard residue namefor the residue, MODRES also provides a mapping to the precursor standard residue name.
(ii) MODRES is should always appear when modified standard residues exist in the entry.
(iii) Examples of some modification descriptions:Glycosylation sitePost-translational modificationDesigned chemical modificationPhosphorylation siteBlocked N-terminus

59
Aminated C-terminusD-configurationReduced peptide bond
(iv) MODRES is not required if coordinate records are not provided for the modified residue.
(v) D-amino acids are given their own resName , i.e., DAL for D-alanine. This resName appearsin the SEQRES records, and has the associated SEQADV, MODRES, HET, and FORMULrecords. The coordinates are given as HETATMs within the ATOM records and occur in thecorrect order within the chain.
(vi) When a standard residue name is used to describe a modified site, the PDB residue name(columns 38 – 47) and the standard residue name (columns 69 – 78) contain the same value.
19. FTNOTE
The FTNOTE record type supports the footnotes used in older PDB entries.
Columns Contents1 – 6 “FTNOTE” (RIF)12 – 17 Footnote number, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first FTNOTE record for each
FTNOTE number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 132 Footnote text, left justified
FORMAT (A6,5X,I6,1X,I3,1X,A110)
Note:
FTNOTE records are used to describe details which are specific to certain atoms or residues.These footnotes are keyed to particular atoms by the footnote number here and in cols. 117-122 of the ATOM/HETATM record. Any individual footnote may run over several FTNOTErecords (each with the same footnote number). A maximum of 999,999 footnotes areallowed.

60
20. HET
HET records are used to describe non-standard residues, such as prosthetic groups, inhibitors,solvent molecules, and ions for which coordinates are supplied. Groups are considered HETif they are:
• not one of the standard amino acids, and• not one of the nucleic acids (C, G, A, T, U, and I), and• not one of the modified versions of nucleic acids (+C, +G, +A, +T, +U, and +I), and• not an unknown amino acid or nucleic acid where UNK is used to indicate the
unknown residue name.
Het records also describe heterogens for which the chemical identity is unknown, in which case thegroup is assigned the heterogen identifier “UNK”.
Columns Contents1 – 6 “HET” left-justified (RIF)9 – 17 HET record serial number, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first HET record for each HET record
serial number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 32 Heterogen identifier, right-justified33 – 42 Chain identifier, right-justified43 – 52 Residue seq. no. and insertion code for the residue in the current strand, right-justified. If
there is no insertion code a trailing blank is required, leaving column 52 blank54 – 62 Number of HETATM records for the heterogen present in the entry, right justifies64 – 132 Text describing the heterogen, left-justified (v)
FORMAT(A6,2X,I9,1X,I3,1X,3A10,1X,I9,1X,A69)
Notes:
(i) Each heterogen (HET group) is assigned a heterogen identifier. No more than threealphanumeric characters are used for heterogen identifiers from PDB entries. The sequencenumber, chain identifier, insertion code, and number of coordinate records are given for eachoccurrence of the HET group in the entry. The chemical name of the HET group is given inthe HETNAM record and synonyms for the chemical name are given in the HETSYNrecords.
(ii) There is a separate HET record for each occurrence of the HET group in an entry.
(iii) A particular HET group is represented in the PDB archives with a unique heterogenidentifier.
(iv) PDB entries do not have HET records for water molecules.
(v) The Text field is for descriptive material. The token PART_OF followed by a value may beused to indicate that the HET group is part of a larger group which has been represented by

61
its separate components (e.g., PART_OF: actinomycin). Segment identifiers, columns 124 –127 of ATOM/HETATM records, may also be used to relate individual components of alarge HET group.
(vi) Unknown atoms or ions will be represented as UNX with the chemical formula X1.
21. HETNAM
The HETNAM record gives the chemical name of the compound with the given component number.
Columns Contents1 – 6 “HETNAM” (RIF)9 – 17 HETNAM record serial number, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first HETNAM record for each
HETNAM record serial number and numbered 2, 3, etc. for continuation records) as athree-digit right-justified integer
23 – 32 Heterogen identifier, right-justified34 – 132 Chemical name, left justified
FORMAT(A6,2X,I9,1X,I3,1X,A10,1X,A99)
Notes:
(i) Each heterogen component is assigned a unique chemical name for the HETNAM record.
(ii) Other names for the group are given on HETSYN records.
(iii) PDB follows IUPAC/IUB naming conventions to describe groups systematically.
(iv) Continuation of chemical names onto subsequent records is allowed.
(v) Only one HETNAM record is included for a given heterogen identifier, even if the sameheterogen identifier appears on more than one HET record.

62
22. HETSYN
This record provides synonyms, if any, for the compound in the corresponding (i.e., same hetID)HETNAM record. This is to allow greater flexibility in searching for HET groups.
Columns Contents1 – 6 “HETSYN” (RIF)9 – 17 HETSYN record serial number, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first HETSYN record for each
HETSYN record serial number and numbered 2, 3, etc. for continuation records) as athree-digit right-justified integer
23 – 32 Heterogen identifier, right justified34 – 132 Semi-colon separated list of synonyms, left justified
FORMAT(A6,2X,I9,1X,I3,1X,A10,1X,A99)
Notes:
This is not guaranteed to be a complete list of possible synonyms, but is uniform across thePDB. New synonyms may be added. The list can be continued onto additional HETSYNrecords. Even if the same heterogen identifier appears on more than one HET record, onlyone set of HETSYN records is included for the heterogen identifier.
23. FORMUL
The FORMUL record presents the chemical formula and charge of a non-standard group. (Theformulas for the standard residues are given in Appendix 5.)
Columns Contents1 – 6 “FORMUL” (RIF)7 “*” for water or blank9 – 17 FORMUL record serial number, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first FORMUL record for each
FORMUL component number and numbered 2, 3, etc. for continuation records) as athree-digit right-justified integer
23 – 31 Component number33 – 42 Heterogen identifier, right justified44 – 132 Chemical formula, left justified
FORMAT(A6,A1,1X,I9,1X,I3,1X,I9,1X,A10,1X,A89)
Notes:
(i) The elements of the chemical formula are given in the order C, H, N, and O, with otherelements following in alphabetical order, each separated by a single blank.
(ii) The number of each atom type present immediately follows its chemical symbol with no

63
intervening blank.
(iii) Each set of SEQRES records and each HET group is assigned a component number in anentry. These numbers are assigned serially, beginning with 1 for the first set of SEQRESrecords. In addition:• If a HET group is presented on a SEQRES record its FORMUL is assigned the
component number of the chain in which it appears.• If the HET group occurs more than once and is not presented on SEQRES records, the
component number of its first occurrence is used.
(iv) All occurrences of the HET group within a chain are grouped together with a multiplier. Theremaining occurrences are also grouped with a multiplier. The sum of the multipliers is thenumber equaling the number of times that that HET group appears in the entry.
(v) The "*" in column 7 is used if the HET group is water or UNX, indicating that it should beexcluded from the molecular weight calculation.
(vi) A continuation field is provided in the event that more space is needed for the formula.

64
24. HELIX
HELIX records are used to identify the position of helices in the molecule. Helices are both namedand numbered. The residues where the helix begins and ends are noted, as well as the total length.
Columns Contents1 – 6 “HELIX” left-justified (RIF)9 – 17 HELIX serial number, right-justified (RIF) (ii)19 – 21 Continuation field (this field will be blank for the first HELIX record for each HELIX
serial number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 32 Helix identifier, right justified (ii)34 – 43 Residue name for the initial residue in the helix, right justified44 – 53 Chain identifier for the initial residue, right-justified54 – 63 Residue seq. no. and insertion code for the initial residue, right-justified. If there is no
insertion code a trailing blank is required, leaving column 63 blank65 – 74 Residue name for the terminal residue in the helix, right justified75 – 84 Chain identifier for the terminal residue, right-justified85 – 94 Residue seq. no. and insertion code for the terminal residue, right-justified. If there is
no insertion code a trailing blank is required, leaving column 94 blank96 – 97 Helix class (see below). (iii)99 –104 Length of this helix106 – 132 Associated comment
FORMAT(A6,2X,I9,1X,I3,1X,A10,1X,3A10,1X,3A10,1X,I2,1X,I6,1X,A27)
Notes:
(i) Additional HELIX records with different serial numbers and identifiers occur if more thanone helix is present.
(ii) The initial residue is the N-terminal residue of the helix.
(iii) Helices are classified as follows:
TYPE OF HELIX CLASS NUMBER (COLUMNS 96 - 97)Right-handed alpha (default) 1Right-handed omega 2Right-handed pi 3Right-handed gamma 4Right-handed 310 5Left-handed 6Left-handed omega 7Left-handed gamma 827 ribbon/helix 9Polyproline 10

65
25. SHEET
SHEET records are used to identify the position of sheets in the molecule. Sheets are both namedand numbered. The residues where the sheet begins and ends are noted. Sheet records are providedin groups. A supplemental identifier is provided in column 7. When that identifier is an “S”, thefields in the rest of the record define a strand. When the identifier is a “C” or a “P”, the recordsoccur in SHEETC – SHEETP pairs. The fields in the rest of the “SHEETC” (current) record definea residue that is hydrogen bonded to the residue defined by the fields in the corresponding“SHEETP” (previous) record with the same registration record serial number. All the records for asingle sheet should be presented in a group with the same SHEET serial number, grouped bySTRAND serial number, starting each group with the SHEETS record to define the a strand, andthen followed by pairs of SHEETC and SHEETP records for which the same strand serial number iscontained in columns 34 – 42 of the SHEETC record and columns 85 – 93 of the SHEETP record.Thus for a simple unbifurcated sheet the records would be in SHEETS – SHEETC – SHEETPtriples, with each triple corresponding to one PDB format SHEET record.
SHEET Strand Definition Record
Columns Contents1 – 6 “SHEET” left-justified (RIF)7 “S” (RIF)9 – 17 STRAND serial number, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first SHEET record for each
STRAND serial number and SHEET serial number and numbered 2, 3, etc. forcontinuation records) as a three-digit right-justified integer
24 – 32 SHEET serial number, right justified (RIF)34 – 43 Residue name for the initial residue in the strand, right justified44 – 53 Chain identifier for the initial residue, right-justified54 – 63 Residue seq. no. and insertion code for the initial residue, right-justified. If there is no
insertion code a trailing blank is required, leaving column 63 blank65 – 74 Residue name for the terminal residue in the strand, right justified75 – 84 Chain identifier for the terminal residue, right-justified85 – 94 Residue seq. no. and insertion code for the terminal residue, right-justified. If there is
no insertion code a trailing blank is required, leaving column 94 blank96 –104 Number of strands in the sheet106 – 115 Sheet identifier, right justified
FORMAT(A6,A1,1X,I9,1X,I3,2X,I9,1X,3A10,1X,3A10,1X,I9,1X,A10)

66
SHEET Strand Registration Record, Current Strand
Columns Contents1 – 6 “SHEET” left-justified (RIF)7 “C” (RIF)9 – 17 Registration record serial number, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first SHEETC record for each
SHEET registration record serial number and SHEET serial number and numbered 2, 3,etc. for continuation records) as a three-digit right-justified integer
24 – 32 SHEET serial number, right justified (RIF)34 – 42 Current strand serial number44 – 53 Atom name in current strand54 – 63 Residue name for the residue in the current strand, right justified64 – 73 Chain identifier for the residue in the current strand, right-justified74 – 83 Residue seq. no. and insertion code for the residue in the current strand, right-justified.
If there is no insertion code a trailing blank is required, leaving column 83 blank85 – 93 Previous strand serial number95 – 96 Sense of current strand relative to the previous strand: 0 if the current strand is the first
strand, “ 1” if the current strand is parallel to the previous strand and “-1” if the currentstrand is anti-parallel to the previous strand
106 – 115 Sheet identifier, right justified
FORMAT(A6,A1,1X,I9,1X,I3,2X,I9,1X,I9,1X,4A10,1X,I9,1X,I2,9X,A10)

67
SHEET Strand Registration Record, Previous Strand
Columns Contents1 – 6 “SHEET” left-justified (RIF)7 “P” (RIF)9 – 17 Registration record serial number, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first SHEETP record for each SHEET
registration record serial number and SHEET serial number and numbered 2, 3, etc. forcontinuation records) as a three-digit right-justified integer
24 – 32 SHEET serial number, right justified (RIF)34 – 42 Previous strand serial number44 – 53 Atom name in previousstrand54 – 63 Residue name for the residue in the previous strand, right justified64 – 73 Chain identifier for the residue in the previous strand, right-justified74 – 83 Residue seq. no. and insertion code for the residue in the previous strand, right-justified.
If there is no insertion code a trailing blank is required, leaving column 83 blank85 – 93 Current strand serial number95 – 96 Sense of current strand relative to the previous strand: 0 if the current strand is the first
strand, “ 1” if the current strand is parallel to the previous strand and “-1” if the currentstrand is anti-parallel to the previous strand
106 – 115 Sheet identifier, right justified
FORMAT(A6,A1,1X,I9,1X,I3,2X,I9,1X,I9,1X,4A10,1X,I9,1X,I2,9X,A10)
Notes:
(i) The initial residue for a strand is the one closer to itsN-terminus. Normally strands are listedstarting with one edge of the sheet and continuing with the spatially adjacent strand.
(ii) The registration between two strands may be specified by one hydrogen bond between eachsuch pair of strands, and at least one such SHEETC – SHEETR pair of registration recordsshould be provided for each pair of adjacent strands in a sheet. No registration informationshould be provided for the first strand, except in a barrel.
(iii) Split strands, or strands with two or more runs of residues from discontinuous parts of theamino acid sequence, are explicitly listed. Provide a description to be included in theREMARK section.
(iv) If the sheet is bifurcated, the practice in PDB entries has been to define two distinct sheets,because the SHEET records in PDB format only permitted the strictly sequential registrationof strands. In addition, for a barrel, the first strand had to be defined twice, once at thebeginning of the set of SHEET records and once at the end of the set of SHEET records. Inorder to maintain consistency between REMARKS and SHEET records in WPDB entriesmade from entries in PDB format, the same practices may be followed in creating a WPDBformat entry. Unlike the PDB format, WPDB format permits registration of strands in anyorder. Therefore, in creating a WPDB entry ab-initio or from a data format that supports fullstrand-based sheet definitions, it is a better practice to define a bifurcated sheet in a single

68
group of SHEET records, and to use appropriate registration records to align the multiplestrands involved in a bifurcation or to close a barrel.
26. TURN
The TURN records identify turns and other short loop turns which normally connect other secondarystructure segments, e.g. hairpin turns (β-turns and γ-bends) in the structure which do not occur inhelices.
Columns Contents1 – 6 “TURN” left-justified (RIF)9 – 17 TURN serial number, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first TURN record for each TURN
serial number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 32 Turn identifier, right justified34 – 43 Residue name for the initial residue in the turn, right justified44 – 53 Chain identifier for the initial residue, right-justified54 – 63 Residue seq. no. and insertion code for the initial residue, right-justified. If there is no
insertion code a trailing blank is required, leaving column 63 blank65 – 74 Residue name for the terminal residue in the turn, right justified75 – 84 Chain identifier for the terminal residue, right-justified85 – 94 Residue seq. no. and insertion code for the terminal residue, right-justified. If there is
no insertion code a trailing blank is required, leaving column 94 blank106 – 132 Associated comment
FORMAT(A6,2X,I9,1X,I3,1X,A10,1X,3A10,1X,3A10,11X,A27)
Notes:
(i) Turns include those sets of residues which form β turns, i.e., have a hydrogen bond linking(C-O)i to (N-H)i+3. Turns which link residue i to i+2 (γ-bends) may also be included. Othersmay be also be classified as turns.
(ii) The initial residue is the one closer to N-terminus.

69
27. SSBOND
The SSBOND record identifies each disulfide bond in protein and polypeptide structures byidentifying the two residues involved in the bond.
Columns Contents1 – 6 “SSBOND” left-justified (RIF)9 – 17 SSBOND serial number, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first SSBOND record for each
SSBOND serial number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 32 Atom name for the first Sγ sulfur atom, right justified33 – 35 Alternate location indicator, right justified36 – 45 Residue name for the first residue involved, right justified (normally “CYS”)46 – 55 Chain identifier for the first residue involved, right-justified56 – 65 Residue seq. no. and insertion code for the first residue involved, right-justified. If
there is no insertion code a trailing blank is required, leaving column 65 blank67 – 76 Atom name for the second Sγ sulfur atom, right justified77 – 79 Alternate location indicator, right justified80 – 89 Residue name for the second residue involved, right justified (normally “CYS”)90 – 99 Chain identifier for the second residue involved, right-justified100 – 109 Residue seq. no. and insertion code for the second residue involved, right-justified. If
there is no insertion code a trailing blank is required, leaving column 109 blank111 – 116 Symmetry operation for first sulfur atom, right justified or blank (iii)117 – 122 Symmetry operation for second sulfur atom, right justified or blank (iii)124 – 132 Model number or blank, right justified (iv)
FORMAT(A6,2X,I9,1X,I3,1X,A10,A3,3A10,1X, A10,A3,3A10,1X,2A6,1X,I9)
Notes:
(i) Bond distances between the sulfur atoms must be close to expected values.
(ii) The cysteine closer to the N-terminal is listed first in each intra-chain pair. The cysteinewhich occurs first in the coordinate entry is listed first for inter-chain pairs.
(iii) The symmetry operations are given as blank when the identity operator (and no celltranslation) is to be applied to the atom. If non-blank, each operation is given in the formmmmnnn, where mmm is the operation number in REMARK 290, and nnn is an encoding ofthe translations, with “555” for no translation.
(iv) If the model number is blank, the SSBOND applies to all models. If a model number isspecified, the SSBOND applies only to the model number given.
(v) CONECT records are generated for the disulfide bonds when SG atoms of both cysteines arepresent in the coordinate records.

70
28. LINK
The LINK record specifies connectivity between residues that is not implied by the primarystructure. Connectivity is expressed in terms of the atom names. This record supplementsinformation given in CONECT records.
Columns Contents1 – 6 “LINK” left-justified (RIF)9 – 17 LINK serial number, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first LINK record for each LINK
serial number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 32 Atom name for the first bonded atom, right justified33 – 35 Alternate location indicator, right justified36 – 45 Residue name for the first residue involved, right justified46 – 55 Chain identifier for the first residue involved, right-justified56 – 65 Residue seq. no. and insertion code for the first residue involved, right-justified. If
there is no insertion code a trailing blank is required, leaving column 65 blank67 – 76 Atom name for the second bonded atom, right justified77 – 79 Alternate location indicator, right justified80 – 89 Residue name for the second residue involved, right justified90 – 99 Chain identifier for the second residue involved, right-justified100 – 109 Residue seq. no. and insertion code for the second residue involved, right-justified. If
there is no insertion code a trailing blank is required, leaving column 109 blank111 – 116 Symmetry operation for first sulfur atom, right justified or blank (vi)117 – 122 Symmetry operation for second sulfur atom, right justified or blank (vi)124 – 132 Model number or blank, right justified (vii)
FORMAT(A6,2X,I9,1X,I3,1X,A10,A3,3A10,1X, A10,A3,3A10,1X,2A6,1X,I9)
Notes:
(i) The atoms involved in bonds between HET groups or between a HET group and standardresidue are listed.
(ii) Interresidue linkages not implied by the primary structure are listed (e.g., reduced peptidebond).
(iii) Non-standard linkages between residues, e.g., side-chain to side-chain, are listed.
(iv) Each LINK record specifies one linkage.
(v) These records do not specify connectivity within a HET group (see CONECT), hydrogenbonds (see HYDBND), or disulfide bridges (see SSBOND).
(vi) Hydrogen bonds and salt bridges are described on HYDBND and SLTBRG records,respectively.

71
(vii) The symmetry operations are given as blank when the identity operator (and no celltranslation) is to be applied to the atom. If non-blank, each operation is given in the formmmmnnn, where mmm is the operation number in REMARK 290, and nnn is an encoding ofthe translations, with “555” for no translation.
(viii) If the model number is blank, the LINK applies to all models. If a model number isspecified, the LINK applies only to the model number given
(ix) Link records may include atoms not present in the atom list, but when both atoms are presentin the entry, the CONECT records showing the bond should be included.

72
29. HYDBND
The HYDBND record shows the hydrogen bonds in the entry. When the hydrogen is not specified,one HYDBND record is given for each hydrogen bond. When a hydrogen is known, the HYDBNDrecords are given in pairs, with the two non-hydrogen atoms on the first record of the pair and thehydrogen on the second record of the pair. The second HYDBND record of such a pair has an “H”in column 7.
Columns Contents1 – 6 “HYDBND” left-justified (RIF)7 Hydrogen flag “H” or blank (RIF)9 – 17 HYDBND serial number, right-justified (RIF) (i)19 – 21 Continuation field (this field will be blank for the first HYDBND record for each
HYDBND serial number and Hydrogen flag and numbered 2, 3, etc. for continuationrecords) as a three-digit right-justified integer
23 – 32 Atom name for the first hydrogen-bonded atom or, if the hydrogen flag is set to “H”,the atom name of the mediating hysdrogen, right justified
33 – 35 Alternate location indicator, right justified36 – 45 Residue name for the first residue involved, right justified46 – 55 Chain identifier for the first residue involved, right-justified56 – 65 Residue seq. no. and insertion code for the first residue involved, right-justified. If
there is no insertion code a trailing blank is required, leaving column 65 blank67 – 76 Atom name for the second bonded atom right-justified or, if the hydrogen flag is set to
“H”, blank77 – 79 Alternate location indicator, right justified or blank80 – 89 Residue name for the second residue involved, right justified or blank90 – 99 Chain identifier for the second residue involved, right-justified or blank100 – 109 Residue seq. no. and insertion code for the second residue involved, right-justified. If
there is no insertion code a trailing blank is required, leaving column 109 blank111 – 116 Symmetry operation for the atom specified in columns 23 – 65, right justified or blank
(iv)117 – 122 Symmetry operation for atom, if any, specified in columns 67 – 109, right justified or
blank (iv)124 – 132 Model number or blank, right justified (v)
FORMAT(A6,A1,1X,I9,1X,I3,1X,A10,A3,3A10,1X, A10,A3,3A10,1X,2A6,1X,I9)
Notes:
(i) If a hydrogen atom is specified, the same HYDBND serial number will be used on theHYDBND record for the hydrogen of the hydrogen bond as was used on the HYDBND,record for the two non-hydrogen atoms.
(ii) The hydrogen bonds listed normally are those supplied by the depositor.
(iii) For nucleic acids, Watson-Crick hydrogen bonds between bases may be listed, but this isoptional.

73
(iv) The symmetry operations are given as blank when the identity operator (and no celltranslation) is to be applied to the atom. If non-blank, each operation is given in the formmmmnnn, where mmm is the operation number in REMARK 290, and nnn is an encoding ofthe translations, with “555” for no translation. For a hydrogen atom, use the symmetryoperation for the non-hydrogen to which it is bonded.
(v) If the model number is blank, the HYDBND applies to all models. If a model number isspecified, the HYDBND applies only to the model number given. The model number shouldbe repeated on both HYDBND records of a hydrogen bond that include a hydrogen
(vi) HYDBND records may include atoms not present in the atom list, but when both non-hydrogen atoms are present in the entry, the CONECT records showing the bond should beincluded.
30. SLTBRG
The SLTBRG records specify salt bridges in the entry in terms of atom names, residue numbers andchain identifiers, rather than in terms of atom serial numbers,supplementing the information inCONECT records.
Columns Contents1 – 6 “SLTBRG” left-justified (RIF)9 – 17 SLTBRG serial number, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first SLTBRG record for each
SLTBRG serial number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 32 Atom name for the first atom in the salt bridge, right justified33 – 35 Alternate location indicator, right justified36 – 45 Residue name for the first residue involved, right justified46 – 55 Chain identifier for the first residue involved, right-justified56 – 65 Residue seq. no. and insertion code for the first residue involved, right-justified. If
there is no insertion code a trailing blank is required, leaving column 65 blank67 – 76 Atom name for the second atom in the salt bridge, right justified77 – 79 Alternate location indicator, right justified80 – 89 Residue name for the second residue involved, right justified90 – 99 Chain identifier for the second residue involved, right-justified100 – 109 Residue seq. no. and insertion code for the second residue involved, right-justified. If
there is no insertion code a trailing blank is required, leaving column 109 blank111 – 116 Symmetry operation for first atom, right justified or blank (iv)117 – 122 Symmetry operation for second atom, right justified or blank (iv)124 – 132 Model number or blank, right justified (v)
FORMAT(A6,2X,I9,1X,I3,1X,A10,A3,3A10,1X, A10,A3,3A10,1X,2A6,1X,I9)

74
Notes:
(i) Salt bridges listed normally are those provided by the depositor.
(ii) The two atoms forming the salt bridge through their electrostatic interactions are specified.
(iii) No distinction is made as to which atom has excess positive or negative charge.
(iv) The symmetry operations are given as blank when the identity operator (and no celltranslation) is to be applied to the atom. If non-blank, each operation is given in the formmmmnnn, where mmm is the operation number in REMARK 290, and nnn is an encoding ofthe translations, with “555” for no translation.
(v) If the model number is blank, the salt bridge applies to all models. If a model number isspecified, the salt bridges apply only to the model number given.
31. CISPEP
CISPEP records specify the prolines and other peptides found to be in the cis conformation. Fornewer PDB entries, the CISPEP record has replaced the use of FTNOTE records to list cis peptides.
Columns Contents1 – 6 “CISPEP” left-justified (RIF)9 – 17 CISPEP serial number, right-justified (RIF) (iii)19 – 21 Continuation field (this field will be blank for the first CISPEP record for each CISPEP
serial number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 32 Residue name for the first residue involved, right justified34 – 43 Chain identifier for the first residue involved, right-justified45 – 54 Residue seq. no. and insertion code for the first residue involved, right-justified. If
there is no insertion code a trailing blank is required, leaving column 54 blank56 – 65 Residue name for the second residue involved, right justified67 – 76 Chain identifier for the second residue involved, right-justified78 – 87 Residue seq. no. and insertion code for the second residue involved, right-justified. If
there is no insertion code a trailing blank is required, leaving column 87 blank89 – 97 Model number or blank99 – 111 Measure of the omega dihedral angle between the two residues (i) (ii)
FORMAT(A6,2X,I9,1X,I3,6(1X,A10),1X,I9,1X,F13.5)
Notes:
(i) The omega angle between two residues is the dihedral angle formed formed by the Cα-C-Nplane of the first residue and the C-N-Cα plane of the second residue.
(ii) Cis peptides are those with omega angles of 0°±30°. Deviations larger than 30° are listed inREMARK 500.

75
(iii) Each cis peptide is listed on a separate line, with an incrementally ascending sequencenumber.
32. SITE
The SITE records supply the identification of groups comprising important sites in themacromolecule.
Columns Contents1 – 6 “SITE left-justified (RIF)9 – 17 Site serial number, right-justified (RIF) (ii) (iv)19 – 21 Continuation field (this field will be blank for the first SITE record for each site serial
number and numbered 2, 3, etc. for continuation records) as a three-digit right-justifiedinteger
23 – 32 Site name, right-justified (RIF)34 – 42 Number of residues comprising site, right justified43 – 52 Residue name for the first residue comprising the site, right justified53 – 62 Chain identifier for the first residue comprising the site, right-justified63 – 72 Residue seq. no. and insertion code for the first residue comprising the site, right-
justified. If there is no insertion code a trailing blank is required, leaving column 72blank
73 – 82 Residue name for the second residue comprising the site, right justified83 – 92 Chain identifier for the second residue comprising the site, right-justified93 – 102 Residue seq. no. and insertion code for the second residue comprising the site, right-
justified. If there is no insertion code a trailing blank is required, leaving column 75blank
103 – 112 Residue name for the third residue comprising the site, right justified113 – 122 Chain identifier for the third residue comprising the site, right-justified123 – 132 Residue seq. no. and insertion code for the third residue comprising the site, right-
justified. If there is no insertion code a trailing blank is required, leaving column 75blank
FORMAT (A6,2X,I9,1X,I3,1X,A10,1X,I9,9A10)
Notes:
(i) Site records specify residues comprising catalytic, cofactor, anticodon, regulatory or otherimportant sites.
(ii) The site serial number (columns 9 – 17) is reset to 1 for each new site.
(iii) SITE names (columns 23 - 32) should be explained in REMARK 800.
(iv) If a site is comprised of more than three residues, these may be specified on additional

76
records bearing the same site name. The site serial number is incremented by 1 for eachadditional record.
(v) SITE records can include HET groups.
33. CRYST1
The CRYST1 record presents the unit cell parameters, space group, and Z value. If the structure wasnot determined by crystallographic means, CRYST1 simply defines a unit cube. The unit cellconstants of the native crystals are given here unless explicitly stated otherwise. Native in thiscontext means "underivatized" but if a derivative structure is solved as the native, e.g., tosyl elastase,then the cell constants of this pseudo-native macromolecule are given.
Columns Contents1 – 6 “CRYST1” (RIF)19 – 21 Continuation field (this field will be blank for the first CRYST1 record and numbered
2, 3, etc. for continuation records) as a three-digit right-justified integer23 – 35 Cell edge length a in Ångstroms, right-justified37 – 49 Cell edge length b in Ångstroms, right-justified51 – 63 Cell edge length c in Ångstroms, right-justified65 – 73 Cell angle α in degrees, right-justified75 – 83 Cell angle β in degrees, right-justified85 – 93 Cell angle γ in degrees, right-justified95 – 107 Space group symbol, left-justified (ii)109 – 113 Z value, right-justified (iii)
FORMAT(A6,12X,I3,3(1X,F13.6),3(1X,F9.5),1X,A13,1X,I5)
Notes:
(i) If the entry describes a structure determined by a technique other than crystallography,CRYST1 will contain unit cell edge lengths, a = b = c = 1.0, orthogonal cell angles α = β = γ= 90°; the space group symbol field will contain “P 1” and Z=1.
(ii) The space group symbol field contains the Hermann-Mauguin space group The symbol isgiven without parenthesis, e.g., P 43 21 2. A screw axis is described as a two digit number.The full international Hermann-Mauguin symbol is used, e.g., P 1 21 1 instead of P 21. For arhombohedral space group in the hexagonal setting, the lattice type symbol used is H.
(iii) The Z value is the number of polymeric chains in a unit cell. In the case of heteropolymers, Zis the number of occurrences of the most populous chain. As an example, given two chainsA and B, each with a different sequence, and the space group P 2 that has two equipoints inthe standard unit cell, the following table gives the correct Z value.
ASU Content Full CellContent
Number ofCopies of A
Number ofCopies of B
Z value
A AA 2 0 2

77
AA AAAA 4 0 4AB ABAB 2 2 2AAB AABAAB 4 2 4AABB AABBAABB 4 4 4
(iv) In the case of a polycrystalline fiber diffraction study, CRYST1 and SCALE contain thenormal unit cell data.
34. ORIGX
Columns Contents1 – 6 “ORIGX1” or “ORIGX2” or “ORIGX3”, (ORIGXn) left-justified (RIF)19 – 21 Continuation field (this field will be blank for the first ORIGXn record and numbered 2,
3, etc. for continuation records) as a three-digit right-justified integer23 – 35 On,1 component of ORIGXn, right-justified37 – 49 On,2 component of ORIGXn, right-justified51 – 63 On,3 component of ORIGXn, right-justified65 – 77 Tn component of ORIGXn, right justified
FORMAT (A6,12X,I3,3(1X,3F13.6),1X,F13.5)
Notes:
Let the original submitted coordinates be xsub, ysub, zsub and the orthogonal Å coordinatescontained in the data entry be x, y, z. Then
€
xsubysubzsub
=
O1,1x +O1,2y +O1,3z + T1O2,1x +O2,2y +O2,3z + T2O3,1x +O3,2y +O3,3z + T3
Even if this is an identity transformation (unit matrix, null vector) it is supplied. See below underSCALE for a definition of the default coordinate system in orthogonal Ångstroms. Appendix Adetails the derivation of the ORIGX coordinate transformation.

78
35. SCALE
Columns Contents1 – 6 “SCALE1” or “SCALE2” or “SCALE3”, (SCALEn) left-justified (RIF) (i) (ii)19 – 21 Continuation field (this field will be blank for the first SCALEn record and numbered 2,
3, etc. for continuation records) as a three-digit right-justified integer23 – 35 Sn,1 component of SCALEn, right-justified (ii)37 – 49 Sn,2 component of SCALEn, right-justified (ii)51 – 63 Sn,3 component of SCALEn, right-justified (ii)65 – 77 Un component of SCALEn, right justified (ii)
FORMAT (A6,12X,I3,3(1X,3F13.6),1X,F13.5)
Notes:
(i) Let the coordinates in orthogonal Ångstroms be x, y, z. Let the fractional cell coordinates bexfrac, yfrac, zfrac. Then:
€
x fracy fracz frac
=
S1,1x + S1,2y + S1,3z +U1
S2,1x + S2,2y + S2,3z +U2
S3,1x + S3,2y + S3,3z +U3
(ii) The SCALE transformation provides a means of generating fractional coordinates from theorthogonal Å coordinates contained in the data entry. The standard orthogonal Å coordinatesystem is related to the axial system of the unit cell supplied (CRYST1 record) by thedefinition below. (Non-standard coordinate systems are generally explained in theREMARKs.)
(iii) If
€
r a ,r b , r c are vectors describing the crystallographic cell edges and
€
r A ,
r B ,
r C are unit basis
vectors describing the default coordinate system in orthogonal Ångstroms, then
•
€
r A ,
r B ,
r C and
€
r a ,r b , r c have the same origin.
•
€
r A is parallel to
€
r a .•
€
r B is parallel to
€
r C ×
r A
•
€
r C is parallel to
€
r a ×r b , i.e. c*
(iv) For NMR, fiber diffraction - fiber sample, and theoretical model entries, SCALE is given asan identity matrix with no translation.
(v) Appendix A details the derivation of the SCALE coordinate transformation.

79
36. MTRIX
Columns Contents1 – 6 “MTRIX1” or “MTRIX2” or “MTRIX3”, (MTRIXn) left-justified (RIF) (i) (ii)9 – 17 Matrix serial number, right-justified (RIF) (i)19 – 21 Continuation field (this field will be blank for the first MTRIXn record for each matrix
serial number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 35 Mn,1 component of MTRIXn, right-justified (ii)37 – 49 Mn,2 component of MTRIXn, right-justified (ii)51 – 63 Mn,3 component of MTRIXn, right-justified (ii)65 – 77 Vn component of MTRIXn, right justified (ii)79 – 81 IGIVEN, right justified (iii)
FORMAT (A6,2X,I9,1X,I3,3(1X,3F13.6),1X,F13.5,1X,I3)
Notes:
(i) One trio of MTRIX records (MTRIX1, MTRIX2, MTRIX3) with a constant serial number isgiven for each non-crystallographic symmetry operation that is defined, given as a matrix Mand a vector V:
€
M =
M1,1 M1,2 M1,3
M2,1 M2,2 M2,3
M3,1 M3,2 M3,3
V =
V1
V2
V3
A corresponding REMARK 295 should be given in the entry to describe the transformation.
(ii) The MTRIX transformations operate on the stored coordinates to yield equivalentrepresentations of the molecule in the same space:
€
x 'y 'z'
new
= Mxyz
+V
See Appendix A for more information.
(iii) If coordinates for the representations which are approximately related by thetransformation in question are contained in the file, the quantity IGIVEN isset to 1. Otherwise this field will be blank.

80
37. TVECT
The TVECT records present the translation vector for infinite covalently connected structures.
Columns Contents1 – 6 “TVECT”, left-justified (RIF)9 – 17 Translation vector serial number, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first TVECT record for each
translation vector serial number and numbered 2, 3, etc. for continuation records) as athree-digit right-justified integer
23 – 35 X component of translation vector in orthogonal Å, right-justified37 – 49 Y component of translation vector in orthogonal Å, right-justified51 – 63 Z component of translation vector in orthogonal Å, right-justified65 – 132 Comment, left-justified
FORMAT (A6,2X,I9,1X,I3,3(1X,F13.5),1X,A68)
Note:
For structures not comprised of discrete molecules (e.g., infinite polysaccharide chains) theentry will contain a fragment which can be built into the full structure by the simpletranslation vectors of TVECT records.

81
38. MODEL
Columns Contents1 – 6 “MODEL”, left-justified (RIF)9 – 17 Model serial number(i), right justified19 – 21 Continuation field (this field will be blank for the first MODEL record for each MODEL
serial number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
FORMAT (A6,2X,I9,1X,I3)
Note:
ATOM, HETATM, SIGATM, ANISOU, SIGUIJ, and TER records for each structure model,as appropriate, will occur between MODEL and ENDMDL records.
39. ATOM40. HETATM
ATOM records give atomic coordinates for "standard" groups. HETATM records give atomiccoordinates for "non-standard" groups. The orthogonal Ångstrom coordinates stored are either thosespecified by the depositor or defined with respect to the default set of orthogonal axes (Appendix A).In the case that the stored coordinates are in orthogonal Ångstroms but not with respect to the defaultaxial system, then this is explained in a REMARK.
Columns Contents1 – 6 “ATOM” OR “HETATM”, left-justified (RIF)9 – 17 Atom serial number, right-justified (RIF) (i)19 – 21 Continuation field (this field will be blank for the first ATOM record for each atom
serial number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 32 Atom name, left-justified (ii)33 – 35 Alternate location indicator, left-justified (iii)36 – 45 Residue name, right-justified (iv,v)46 – 55 Chain identifier, e.g., A for hemoglobin A chain, right-justified56 – 65 Residue seq. no. and code for insertions of residues, e.g., 66A, 66B, etc., right-justified.
If there is no insertion code a trailing blank is required, leaving column 65 blank66 – 78 X coordinate in orthogonal Å, right-justified79 – 91 Y coordinate in orthogonal Å, right-justified92 – 104 Z coordinate in orthogonal Å, right-justified105 –110 Occupancy, right-justified (vi)111 –116 Temperature factor, right-justified (vi) (vii)117 –122 Footnote number, right-justified124 –127 Segment ID, left-justified129 –132 Element symbol (viii)

82
FORMAT(A6,2X,I9,1X,I3,1X,A10,A3,3A10,3F13.5,2F6.2,I6,2(1X,A4))
Notes:
(i) Residues occur starting from the N-terminal residue for proteins and the 5'-terminal residuefor nucleic acids. Within each residue the atoms are ordered as indicated in Appendix B. Insome old entries, if the residue sequence is known, certain atom serial numbers may beomitted to allow for future insertion of any missing atoms. If the sequence is not reliablyknown, these serial numbers are simply ordinals.
(ii) See Appendix B.(iii) Alternate locations for atoms may be denoted here by A, B, C, etc.(iv) Standard residue names are given in Appendix C; other components are defined in HET
records.(v) HETATM records are used for water molecules and atoms contained in HET groups.(vi) The occupancy and temperature factor fields will contain the default values 1.0 and 0.0 if
these parameters were not deposited. Otherwise these fields will contain the suppliedquantities in their original form, i.e., as fractional occupancy/isotropic thermal parameter (B)or electron count/atomic-radius form.
(vii) Normally, the isotropic B value appears here. However, if anisotropic temperature factorshave been provided, the temperature factor field of the corresponding ATOM or HETATMrecord will contain the equivalent U-isotropic [U(eq)] which is calculated byU(eq) = 1/3[U(1,1) + U(2,2) + U(3,3)]*10-4.
(viii) The element symbol per se uses the first two characters of this 4-character field, right-justified. The second two characters may be used for a charge indicator consisting of a singledigit and a sign (+ or -).
(ix) If an atom is found in two or more locations (i.e., disordered) the records carrying thedifferent coordinates for the atom in question occur together.
(x) In HETATM records, in order to avoid problems associated with the special characters “'”(apostophe) and “''” (double quote), which are often employed for saccharide atomicnomenclature, the more standard characters “*” (asterisk) and “$” (dollar sign) wereemployed in their place in entries released through January 1992.
(xi) A uniform nomenclature and ordering (this may not be the same as that employed by thedepositor) for the atoms of all non-standard groups is assigned. This nomenclature isillustrated for some commonly-occurring non-standard groups in Appendix B.
41. SIGATM
Columns Contents1 – 6 “SIGATM” (RIF)9 – 17 Atom serial number, right-justified (RIF) (i)19 – 21 Continuation field (this field will be blank for the first ATOM record for each atom
serial number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 32 Atom name, left-justified33 – 35 Alternate location indicator, left-justified36 – 45 Residue name, right-justified

83
46 – 55 Chain identifier, e.g., A for hemoglobin A chain, right-justified56 – 65 Residue seq. no. and code for insertions of residues, e.g., 66A, 66B, etc., right-justified.
If there is no insertion code a trailing blank is required, leaving column 63 blank66 – 78 Standard deviation of X coordinate in orthogonal Å, right-justified79 – 91 Standard deviation of Y coordinate in orthogonal Å, right-justified92 – 104 Standard deviation of Z coordinate in orthogonal Å, right-justified105 –110 Standard deviation of occupancy, right-justified111 –116 Standard deviation of temperature factor, right-justified117 –122 Footnote number, right-justified124 –127 Segment ID, left-justified129 –132 Element symbol
FORMAT(A6,2X,I9,1X,I3,1X,A10,A3,3A10,3F13.5,2F6.2,I6,2(1X,A4))
42. ANISOU
Columns Contents1 – 6 “ANISOU” (RIF)9 – 17 Atom serial number, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first ANISOU record for each atom
serial number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 32 Atom name33 – 35 Alternate location indicator36 – 45 Residue name46 – 55 Chain identifier, e.g., A for hemoglobin A chain, right-justified56 – 65 Residue seq. no. and code for insertions of residues, e.g., 66A, 66B, etc., right-
justified. If there is no insertion code a trailing blank is required, leaving column 63blank
68 – 73 Anisotropic temperature factor U(1,1) in 104Å2, right-justified (i,ii)76 – 81 Anisotropic temperature factor U(2,2) in 104Å2, right-justified (i,ii)84 – 89 Anisotropic temperature factor U(3,3) in 104Å2, right-justified (i,ii)92 – 97 Anisotropic temperature factor U(1,2) in 104Å2, right-justified (i,ii)100 – 105 Anisotropic temperature factor U(1,3) in 104Å2, right-justified (i,ii)108 – 113 Anisotropic temperature factor U(2,3) in 104Å2, right-justified (i,ii)124 – 127 Segment ID, left-justified129 – 132 Element symbol
FORMAT(A6,2X,I9,1X,I3,1X,A10,A3,3A10,6(2X,I6),10X,A4,1X,A4)
Notes:(i) If anisotropic temperature factors have been provided, the temperature factor field of the
corresponding ATOM or HETATM record will contain the equivalent U - isotropic [U(eq)]which is calculated by U(eq) = 1/3[U(1,1) + U(2,2) + U(3,3)]*10-4
(ii) The anisotropic temperature factors will be stored in the same coordinate frame as the atomiccoordinate records.

84
43. SIGUIJ
Columns Contents1 – 6 “SIGUIJ” (RIF)9 – 17 Atom serial number, right-justified (RIF)19 – 21 Continuation field (this field will be blank for the first SIGUIJ record for each atom
serial number and numbered 2, 3, etc. for continuation records) as a three-digit right-justified integer
23 – 32 Atom name33 – 35 Alternate location indicator36 – 45 Residue name46 – 55 Chain identifier, e.g., A for hemoglobin A chain, right-justified56 – 65 Residue seq. no. and code for insertions of residues, e.g., 66A, 66B, etc., right-justified.
If there is no insertion code a trailing blank is required, leaving column 63 blank68 – 73 Standard deviation of U(1,1) in 104Å2, right-justified (i,ii)76 – 81 Standard deviation of U(2,2) in 104Å2, right-justified (i,ii)84 – 89 Standard deviation of U(3,3) in 104Å2, right-justified (i,ii)92 – 97 Standard deviation of U(1,2) in 104Å2, right-justified (i,ii)100 – 105 Standard deviation of U(1,3) in 104Å2, right-justified (i,ii)108 – 113 Standard deviation of U(2,3) in 104Å2, right-justified (i,ii)124 – 127 Segment ID, left-justified129 – 132 Element symbol
FORMAT(A6,2X,I9,1X,I3,1X,A10,A3,3A10,6(2X,I6),10X,A4,1X,A4)
44. TER
These records are inserted after the carboxy-terminal (3'-terminal) residue of each polypeptide(nucleotide) chain if the terminal residue is represented in the data set. TER cards are also insertedto denote the ends of inhibitors or pseudo-substrates that are obtained by condensing like structuralunits present (e.g., peptides, oligonucleotides, oligosaccharides, etc.).
Columns Contents1 – 6 “TER”, left-justified (RIF)9 – 17 Atom serial number, right-justified (RIF) (i)19 – 21 Continuation field (this field will be blank for the first TER record for each atom serial
number and numbered 2, 3, etc. for continuation records) as a three-digit right-justifiedinteger
23 – 32 Atom name(ii)33 – 35 Alternate location indicator(iii)36 – 45 Residue name(iv,v)46 – 55 Chain identifier, e.g., A for hemoglobin A chain, right-justified56 – 65 Residue seq. no. and code for insertions of residues, e.g., 66A, 66B, etc., right-justified.
If there is no insertion code a trailing blank is required, leaving column 68 blank124 –127 Segment ID, left-justified

85
FORMAT(A6,2X,I9,1X,I3,1X,A10,A3,3A10,48X,A4)
Note: TER records occur among the ATOM records, and are placed after the terminal atom of eachchain. For a protein the residue defined on these TER records is the carboxy-terminal residueof the chain in question. For a nucleic acid it is the 3'-terminal residue.
45. ENDMDL
Columns Contents1 – 6 “ENDMDL”
FORMAT (A6)
Note:ENDMDL records follow ATOM, HETATM, SIGATM, ANISOU, SIGUIJ and TER recordsfor each structure model, for data entries with multiple structure models. Generally employedonly for NMR structures.
46. CONECT
These records may be used to specify all linkages not implied by the primary structure. Bonds fromthe polymeric chain to any non-standard groups present are given here as are all covalent bondswithin such groups. Cross-links between polymeric chains (e.g., disulfide bonds) are specified asare any other important linkages deemed worthy of inclusion by the depositor.
Columns Contents1 – 6 “CONECT” (RIF)9 – 17 CONECT record serial number, right-justified (RIF) (i)19 – 21 Continuation field (this field will be blank for the first CONECT record for each
CONECT record serial number and numbered 2, 3, etc. for continuation records) as athree-digit right-justified integer (ii)
23 – 31 Atom serial number to which bonds are made, right-justified33 – 41 Atom serial number of covalently bonded atom, right-justified43 – 51 Atom serial number of covalently bonded atom, right-justified53 – 61 Atom serial number of covalently bonded atom, right-justified63 – 71 Atom serial number of covalently bonded atom, right-justified73 – 81 Atom serial number of hydrogen bonded acceptor atom, right-justified (v)83 – 91 Atom serial number of hydrogen bonded acceptor atom, right-justified (v)93 – 101 Atom serial number of salt bridge bonded cation atom, right-justified (vi)103 – 111 Atom serial number of hydrogen bonded donor atom, right-justified (v)113 – 121 Atom serial number of hydrogen bonded donot atom, right-justified (v)123 – 131 Atom serial number of salt bridge bonded anion atom, right-justified (vi)
FORMAT (A6,2X,I9,1X,I3,10(1X,I9))
Notes:

86
(i) Atom serial numbers are identical to those in cols. 11 – 19 of the appropriateATOM/HETATM records, and connectivity entries correspond to these serial numbers.
(ii) The continuation field is to allow for handling of atom serial numbers of more than ninedigits, not to handle additional bonds. Additional CONECT records, with the same atomserial number in cols. 23 – 31, are used if necessary. Either all or none of the covalentconnectivity of an atom must be specified, and if hydrogen bonding is specified the covalentconnectivity is included also. In some older entries, the occurrence of a negative atom serialnumber on a CONECT record denotes that a translationally equivalent copy (see TVECTrecords) of the target atom specified is linked to the origin atom of the record.
(iii) Disulfide bridges specified in the SSBOND records have corresponding CONECT records.(iv) Hydrogen bonds and salt bridges have CONECT records.(v) In older PDB entries, a distinction is made between hydrogen bond donors and acceptors. If
the atom specified in columns 23 – 31 is the donor, the acceptors are listed in columns 73 –81 and 83 – 91. If the atom specified in columns 23 – 31 is the acceptor, the donors are listedin columns 103 – 111 and 113 – 121. In newer PDB entries, no differentiation is madebetween donor and acceptor for hydrogen bonds, and all four fields may be used.
(vi) In older PDB entries, a distinction is made between cations (positively charged ions) andanions (negatively charged ions) in salt bridges (ionic bonds). In newer PDB entries, nodifferentiation is made between atoms with excess negative or positive charge.
(vii) CONECT records occur in increasing order of the atom serial numbers they carry in columns23 – 31. The target-atom serial numbers carried on these records also occur in increasingorder.
(viii) The connectivity list given here is redundant in that each bond indicated is given twice, oncewith each of the two atoms involved specified in columns 23 – 31.
(ix) For nucleic acids, Watson-Crick hydrogen bonds between bases may be listed, but this isoptional.
(x) For hydrogen bonds, when the hydrogen atom is present in the coordinates, PDB generates aCONECT record between the hydrogen atom and its acceptor atom.
(xi) For older PDB NMR entries, CONECT records for all models are generated. Newer PDBNMR entries recycle the same atom serial numbers for each model, making it impossible toadhere to this convention. WPDB entries have unique atom serial numbers for all atoms, soCONECT records for all models are generated.

87
47. MASTER
Columns Contents1 – 6 “MASTER” (RIF)19 – 21 Continuation field (this field will be blank for the first MASTER record and numbered
2, 3, etc. for continuation records) as a three-digit right-justified integer (ii)23 – 31 Number of REMARK records, right-justified32 – 40 Number of FTNOTE records, right-justified41 – 49 Number of HET records, right-justified50 – 58 Number of HELIX records, right-justified59 – 67 Number of SHEET records, right-justified68 – 76 Number of TURN records, right-justified77 – 85 Number of SITE records, right-justified86 – 94 Number of coordinate transformation records (ORIGX + SCALE + MTRIX), right-
justified95 – 103 Number of atomic coordinate records (ATOM + HETATM), right-justified104 – 112 Number of TER records, right-justified113 – 121 Number of CONECT records, right-justified122 –130 Number of SEQRES records, right-justified
FORMAT (A6,13X,I3,12I9)
Note: The MASTER record provides data for validation of the number of records in the data entryfor selected record types.
48. END
Each entry ends with this record.
Columns Contents1 – 6 “END”, left-justified
FORMAT (A6)

88
APPENDIX A - COORDINATE SYSTEMS AND TRANSFORMATIONS
The coordinates stored in the Protein Data Bank give the atomic positions measured in Ångstromsalong three orthogonal directions. Unless otherwise specified, the default axial system (detailedbelow) will be assumed.
If
€
r a ,r b , r c are vectors describing the crystallographic cell edges and
€
r A ,
r B ,
r C are unit basis vectors
describing the default coordinate system in orthogonal Ångstroms, then
•
€
r A ,
r B ,
r C and
€
r a ,r b , r c have the same origin.
•
€
r A is parallel to
€
r a .•
€
r B is parallel to
€
r C ×
r A
•
€
r C is parallel to
€
r a ×r b , i.e. c*
The matrix which premultiplies the column vector of fractional crystallographic coordinates (xfrac,yfrac, zfrac) to yield coordinates in the
€
r A ,
r B ,
r C system is
€
M =
a bcos(γ) c cos(β)0 bsin(γ) c(cos(α) − cos(β)cos(γ)) /sin(γ))0 0 V /(absin(γ))
where
€
V = abc(1− cos(α)2 − cos(β)2 − cos(γ)2 + 2cos(α)cos(β)cos(γ))1/ 2so that
€
xyz
= Mx fracy fracz frac
If the submitted coordinates are either fractions of the unit cell edges or are given in Ångstroms withrespect to the default orthogonal system, the ORIGX and SCALE transformations will be givendefault values.
In general the depositor will have supplied:
(i) The original submitted coordinates
€
r x sub = (xsub ,ysub ,zsub )(ii) A transformation from
€
r x sub to the orthogonal Ångstrom coordinates stored in the ProteinData Bank ,
€
r x = Osubr x sub +
r T sub
(iii) A transformation from
€
r x sub to fractional crystallographic coordinates
€
r x frac = Ssubr x sub +
r U sub
(iv) A set of transformations expressing any approximate or exact non-crystallographicsymmetry elements in the structure
€
r x sub' = Msub
r x sub +r
V sub
Since it is desirable for the stored ORIGX, SCALE and MTRIX transformations to operate on thestored rather than the submitted coordinates, some manipulation of the supplied quantities is

89
performed in order to obtain the stored quantities.The stored quantities are:
(i) The coordinates in orthogonal Ångstroms
€
r x = Osubr x sub +
r T sub
(ii) The ORIGX transformation from stored to original coordinates
€
(O,r T ).
From above
€
r x = Osubr x sub +
r T sub
Whence
€
Osubr x sub =
r x −r T sub
∴r x sub = (Osub )
−1 r x + (−(Osub )−1
r T sub )
Thus
€
O = (Osub )−1
and
€
r T = −(Osub )
−1r T sub
(iii) The SCALE transformation from stored to fractional coordinates
€
(S,r
U ),From above
€
r x frac = Ssubr x sub +
r U sub
but
€
r x sub = (Osub )−1 r x + (−(Osub )
−1r T sub )
∴r x frac = Ssub ((Osub )
−1 r x + (−(Osub )−1
r T sub ))+
r U sub
i.e.
€
r x frac = Ssub (Osub )−1 r x + (−Ssub (Osub )
−1r T sub )) +
r U sub
Thus
€
O = Ssub (Osub )−1
and
€
r U = −Ssub (Osub )
−1r T sub +
r U sub
(iv) The MTRIX transformation(s) expressing non-crystallographic symmetry in the space of thestored coordinates
€
(M,r V )
€
r x sub' = Msub
r x sub +r V sub
r x ' = Osubr x sub' +
r T sub = Osub (Msub
r x sub +r
V sub ) +r T sub
but
€
r x sub = (Osub )−1 r x + (−(Osub )
−1r T sub )
∴r x ' = Osub (Msub ((Osub )
−1 r x + (−(Osub )−1
r T sub )) +
r V sub ) +
r T sub
and
€
M = Osub Msub (Osub )−1
r V = −Osub Msub (Osub )
−1r T sub + Osub
r V sub +
r T sub
In summary the stored coordinates and transformations are:
€
r x (ATOM, HETATM records)
€
(O,r T ) (ORIGX records)
€
(S,r
U ) (SCALE records)
€
(M,r V ) (MTRIX records)

90
APPENDIX B - ATOM NAMES
A. Amino AcidsThese atom names follow the IUPAC-IUB rules3 except:
(i) Greek letter remoteness codes are transliterated as follows: α-A, β-B, γ-G, δ-D, ε-E,ζ- Z, η-H
(ii) Atoms for which some ambiguity exists in the crystallographic results are designatedA. This will usually apply only to the terminal atoms of asparagine and glutamine andto the ring atoms of histidine.
(iii) Within each residue the atoms occur in the order specified by the superscripts (see thefigures below).
(iv) The extra oxygen atom of the carboxy terminal amino acid is designated OXT.(v) The atom name fields on WPDB records are 10 characters wide, and longer names
can be handled by using continuation records, but atom names taken from PDBentries are only 4 characters long. The PDB atom naming convention is as follows:
Columns Meaning1 – 2 Chemical symbol - right-justified3 Remoteness indicator (alphabetic)4 Branch designator (numeric)
For protein coordinate sets containing hydrogen atoms, the IUPAC-IUB rules havebeen followed by the PDB, except that rule number 4.4 has been modified as follows:
When more than one hydrogen atom is bonded to a single non-hydrogen atom,the hydrogen atom number designation is given as the first character of theatom name rather than as the last character (e.g. Hβ1 is denoted as 1HB).
The wrapping of multi-digit branch designators in the PDB format is not used in theWPDB format, in which up to 10 characters are available:
Columns Meaning1 – 2 Chemical symbol - right-justified3 Remoteness indicator (alphabetic)4 – 5 Branch designator (numeric) left-justified
Except when the PDB format for hydrogen atoms with two-digit branch designators isused, in both PDB and WPDB format, when the chemical symbol is a singlecharacter, a blank is given in the first character position of the atom name field.
(v) In large het groups it sometimes is not possible to follow the convention of having thefirst two characters be the chemical symbol and still use atom names that aremeaningful to users. A example is nicotinamide adenine dinucleotide, atom namesbegin with an A or N, depending on which portion of the molecule they appear in,e.g., AC6 or NC6, AN1 or NN1. The element symbol is available in columns 129 –132 of ATOM/HETATM recorrds.
3 IUPAC-IUB Commission on Biochemical Nomenclature. "Abbreviations and Symbols for theDescription of the Conformation of Polypeptide Chains. Tentative Rules (1969)", J. Biol. Chem.245, 6489 (1970). The 1974 recommendations on the "Nomenclature of a-Amino Acids(Biochemistry, 14, 449 (1975)) provides a scheme based on normal rules for organic compounds, butthis scheme is not, in general, used in PDB entries.

91
(vi) In some newer PDB entries,instead of wrapping the two digit branch designator for,say, Hγ11 to make 1HG1, the atom name was shifted to the left and presented asHG11. This is not done in WPDB format.
Exceptions to these rules may occur in certain entries. Any such exceptions should be delineatedclearly in FTNOTE and/or REMARK records.
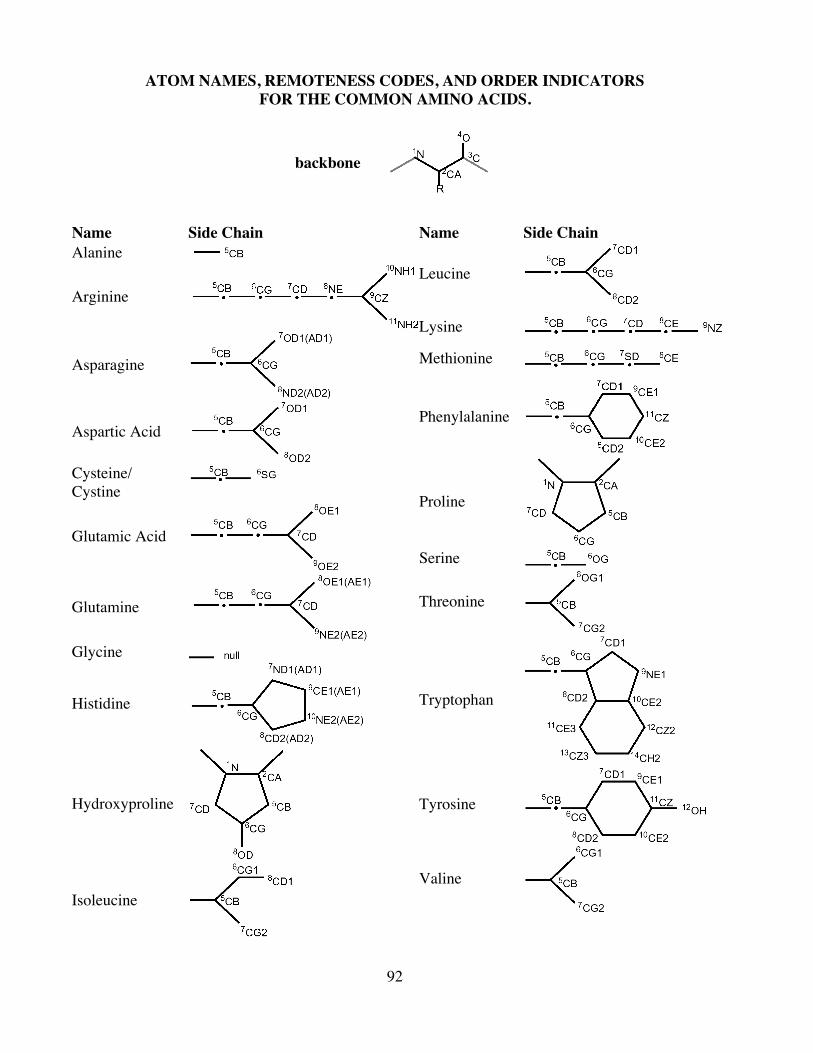
92
ATOM NAMES, REMOTENESS CODES, AND ORDER INDICATORSFOR THE COMMON AMINO ACIDS.
backbone
Name Side ChainAlanine
Arginine
Asparagine
Aspartic Acid
Cysteine/Cystine
Glutamic Acid
Glutamine
Glycine
Histidine
Hydroxyproline
Isoleucine
Name Side Chain
Leucine
Lysine
Methionine
Phenylalanine
Proline
Serine
Threonine
Tryptophan
Tyrosine
Valine

93
B. Nucleic Acids
Atom names employed for polynucleotides generally follow the precedents set for mononucleotides.The following points are worthy of note.
(i) The prime character (') commonly used to denote atoms of the ribose originally wasavoided because of non-uniformity of its external representation. An asterisk(“*”)therefore was used in its place, in entries released through January 1992.
(ii) As with the amino acids, the leftmost two characters of the atom name are reservedfor the chemical symbol (right-justified) and the remaining two denote the atom'sposition.
(iii) Atoms exocyclic to the ring systems have the same position identifier as the atom towhich they are bonded except if this would result in identical atom names. In this casean alphabetic character is used to avoid ambiguity.
(iv) The ring-oxygen atom of the ribose is denoted O4 rather than O1.(v) The extra oxygen atom at the free 5' phosphate terminus is designated OXT. This
atom will be placed first in the coordinate set.For nucleotides which are simple derivatives (e.g., methyl or acetyl) of the parent nucleotide themodifying atoms or groups occur immediately after the atom to which they are bonded. In the caseof an acetyl modifier, the three atoms are ordered carbonyl carbon, carbonyl oxygen, methyl carbon.
C. Non-Standard (HET) Groups
Because of the repeated occurrence of certain cofactors, prosthetic groups, etc., the almost completelack of uniformity in the nomenclature assigned by depositors, and in the absence of anyauthoritative precedent, the Protein Data Bank assigned a standard nomenclature and ordering of theatoms in some of these groups. These assignments appear below for the following groups: ATP,Coenzyme A, Flavin mononucleotide (FMN), Heme, Methotrexate, NAD

94
ATOM NAMES AND ORDER INDICATORS FOR THE COMMON RIBONUCLEOTIDES(Order indicators are given as preceding superscripts.)
backbone
bases (names according to nucleoside)
Adenosine
Cytidine
Guanosine
Uridine

PROTEIN DATA BANK STANDARD NOMENCLATURE FOR ADENOSINETRIPHOSPHATE (ATP)
C10 H12 N5 O13 P3(Order indicators are given as preceding superscripts.)

94
PROTEIN DATA BANK STANDARD NOMENCLATURE FOR COENZYME AC21 H36 N7 O16 P3 S
(Order indicators are given as preceding superscripts.)
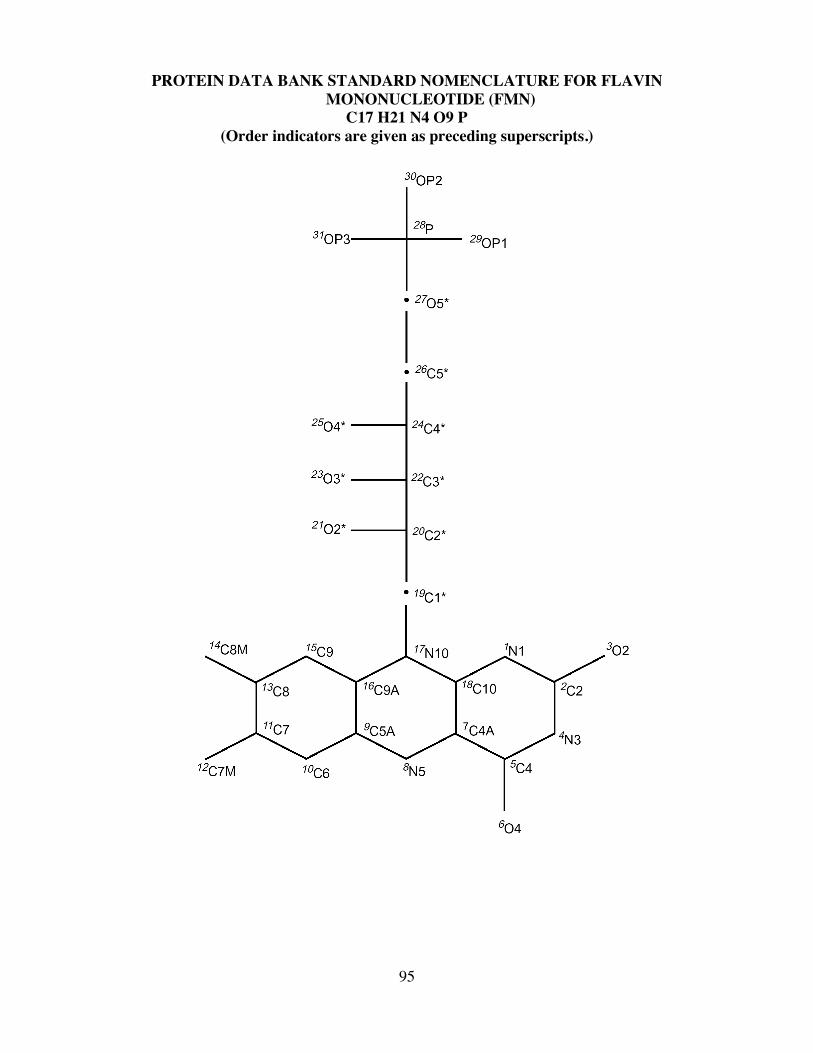
95
PROTEIN DATA BANK STANDARD NOMENCLATURE FOR FLAVINMONONUCLEOTIDE (FMN)
C17 H21 N4 O9 P(Order indicators are given as preceding superscripts.)

96
PROTEIN DATA BANK STANDARD NOMENCLATURE FOR A HEME GROUPC34 H32 N4 O4 FE
(Order indicators are given as preceding superscripts. Non-protein ligandsof the iron atom are listed after those atoms given below.)

97
PROTEIN DATA BANK STANDARD NOMENCLATURE FOR METHOTREXATEC20 H22 N8 05
(Order indicators are given as preceding superscripts.)
PROTEIN DATA BANK STANDARD NOMENCLATURE FOR NICOTINAMIDE ADENINEDINUCLEOTIDE (NAD)
C21 H28 N7 O14 P2(Order indicators are given as preceding superscripts. For an NADP molecule
the atoms of the extra phosphate group will be listed after those above.)
*

98
APPENDIX C - STANDARD RESIDUE NAMES AND ABBREVIATIONS
A. Amino AcidsResidue Abbr. Synonymγ−Aminobutyric acid ABUAcidic unknown ACDAlanine ALA Aβ-Alanine ALBAliphatic unknown ALIArginine ARG RAromatic unknown ARØAsparagine ASN NAspartic acid ASP DASP/ASN ambiguous ASX BBasic unknown BASCysteine CYS C,CYH,CSHCystine CYS C,CSS,CYXGlutamine GLN QGlutamic acid GLU EGLU/GLN ambiguous GLX ZGlycine GLY GHistidine HIS HHydroxyproline HYPIsoleucine ILE I,ILULeucine LEU LLysine LYS KMethionine MET MPyrrolidone carboxylic acid(pyroglutamate)
PCA PGA
Phenylalanine PHE FProline PRØ P,PR0,PRZSarcosine SARSerine SER SThreonine THR TTryptophan TRP W,TRYTyrosine TYR YValine VAL V
Notes:(i) Standard residue abbreviations conform to the IUPAC-IUB rules in J. Biol. Chem. 241, 527,
2491 (1966).(ii) Recognizable synonyms, such as those above, will be changed to the standard abbreviation.(iii) Non-standard residues (metals, prosthetic groups, etc.) are given a three-character designation
which is defined in a special HET record.(iv) To avoid confusion here within residue abbreviations, the alphabetic character is written"Ø" and
the numeric "0". This convention is not observed elsewhere throughout these specifications.

99
B. Nucleic Acids
Abbreviations conform to the IUPAC-IUB recommendations (J. Biol. Chem. 245, 5171 (1970)) fornucleosides with some extensions to cover the modified nucleosides and alterations because ofcharacter-set limitations. Currently, the following abbreviations are in use for the indicated residues.
Residue AbbreviationAdenosine A1-Methyladenosine 1MACytidine C5-Methylcytidine 5MC2'-Ø-Methylcytidine ØMCGuanosine G1-Methylguanosine 1MGN(2)-Methylguanosine 2MGN(2)-Dimethylguanosine M2G7-Methylguanosine 7MG2'-Ø-Methylguanosine ØMGWybutosine YGInosine IThymidine TUridine UModified Uridine +UDihydrouridine H2URibosylthymidine 5MUPseudouridine PSU
Note:To avoid confusion here within residue abbreviations, the alphabetic character is written "Ø" andthe numeric "0". This convention is not observed elsewhere throughout these specifications.
C. Miscellaneous
The following residue names are used to identify other commonly occurring groups.
Residue Abbr. SynonymAcetyl ACEFormyl FØRWater HØH H2Ø,WAT,ØH2Unknown UNK
Note:To avoid confusion here within residue abbreviations, the alphabetic character is written "Ø" andthe numeric "0". This convention is not observed elsewhere throughout these specifications.

100
APPENDIX D - PROTEIN DATA BANK CONVENTIONS
For certain older PDB entries, special typesetting codes were used to represent upper and lower casewhile using only the upper case characters:
(i) Typesetting codes were kept to a minimum by a judicious choice of default conventions.In the text strings of COMPND, SOURCE, REF, TITL and PUBL records, all letters arelowercase unless preceded by one of the following characters: blank, comma, period, leftparenthesis, or asterisk. The occurrence of a slash forces all succeeding letters to beuppercase until the end of the text field is reached or either a dollar sign or a hyphen(minus sign) is encountered.
(ii) Superscripts are initiated and terminated by double equal signs, e.g., S==2+==.(iii) Subscripts are initiated and terminated by single equals signs, e.g., F=c=.(iv) For author lists all characters are lowercase unless they are adjacent to a period, a
comma, or preceded by an asterisk (*). A dollar sign ($) is used to separate a lowercasecharacter from a period or comma which otherwise would force uppercase.
In generating text fields the following general rules apply:(i) No word is to be hyphenated and split over two records.(ii) Only the surname of an author or editor is given in full; other names are indicated by initials
only, e.g., A.B.Cooper.(iii) Blanks and hyphens are used in author lists only if they are properly part of a name (e.g., C.-
I.Branden, C.J.Birkett-Clews, L.Riva di Sansaverino).(iv) The word Junior is written out in full.

101
APPENDIX E - FORMULAS AND MOLECULAR WEIGHTS FOR STANDARD RESIDUES
Note that these weights and formulas correspond to the unpolymerized state of the component. Theelements of one water molecule are eliminated for each two components joined.
Name Code Formula Mol. Wt.Amino Acids
Alanine ALA C3 H7 N1 Ø2 89.09Arginine ARG C6 H14 N4 Ø2 174.20Asparagine ASN C4 H8 N2 Ø3 132.12Aspartic acid ASP C4 H7 N1 Ø4 133.10ASP/ASN ambiguous ASX C4 H71/2 N11/2 Ø31/2 132.61Cysteine CYS C3 H7 N1 Ø2 S1 121.15Glutamine GLN C5 H10 N2 Ø3 146.15Glutamic acid GLU C5 H9 N1 Ø4 147.13GLU/GLN ambiguous GLX C5 H91/2 N11/2 Ø31/2 146.64Glycine GLY C2 H5 N1 Ø2 75.07Histidine HIS C6 H9 N3 Ø2 155.16Isoleucine ILE C6 H13 N1 Ø2 131.17Leucine LEU C6 H13 N1 Ø2 131.17Lysine LYS C6 H14 N2 Ø2 146.19Methionine MET C5 H11 N1 Ø2 S1 149.21Phenylalanine PHE C9 H11 N1 Ø2 165.19Proline PRØ C5 H9 N1 Ø2 115.13Serine SER C3 H7 N1 Ø3 105.09Threonine THR C4 H9 N1 Ø3 119.12Tryptophan TRP C11 H12 N2 Ø2 204.23Tyrosine TYR C9 H11 N1 Ø3 181.19Valine VAL C5 H11 N1 Ø2 117.15Undetermined UNK C5 H6 N1 Ø3 128.16
NucleotidesAdenosine A C10 H14 N5 Ø7 P1 347.221-Methyladenosine 1MA C11 H16 N5 Ø7 P1 361.25Cytidine C C9 H14 N3 Ø8 P1 323.205-Methylcytidine 5MC C10 H16 N3 Ø8 P1 337.232’-Ø-Methylcytidine ØMC C10 H17 N3 Ø8 P1 338.23Guanosine G C10 H14 N5 Ø8 P1 363.221-Methylguanosine 1MG C11 H16 N5 Ø8 P1 377.25N(2)-Methylguanosine 2MG C11 H16 N5 Ø8 P1 377.25N(2)-Dimethylguanosine M2G C12 H18 N5 Ø8 P1 391.287-Methylguanosine 7MG C11 H10 N5 Ø8 P1 377.252’-Ø-Methylguanosine ØMG C11 H16 N5 Ø8 P1 377.25Wybutosine YG C21 H26 N6 Ø11 P1 587.48Inosine I C10 H13 N4 Ø8 P1 348.21Thymidine T C10 H15 N2 Ø8 P1 322.21Uridine U C9 H13 N2 Ø9 P1 324.18
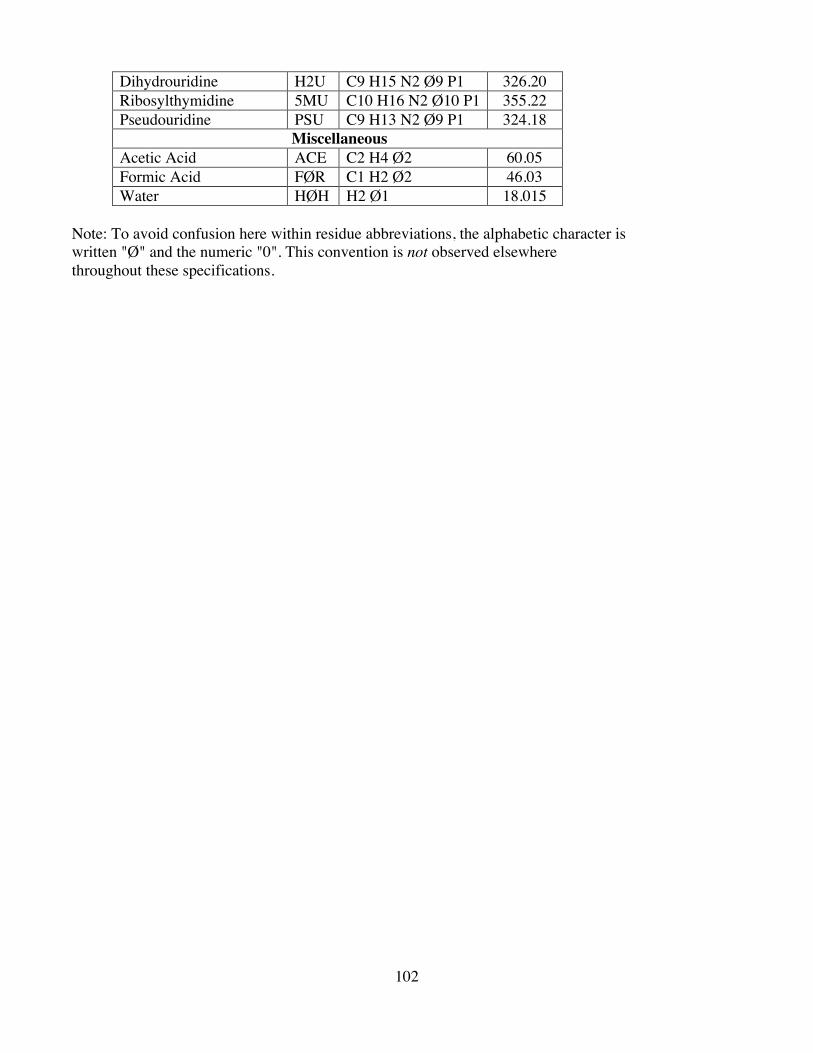
102
Dihydrouridine H2U C9 H15 N2 Ø9 P1 326.20Ribosylthymidine 5MU C10 H16 N2 Ø10 P1 355.22Pseudouridine PSU C9 H13 N2 Ø9 P1 324.18
MiscellaneousAcetic Acid ACE C2 H4 Ø2 60.05Formic Acid FØR C1 H2 Ø2 46.03Water HØH H2 Ø1 18.015
Note: To avoid confusion here within residue abbreviations, the alphabetic character iswritten "Ø" and the numeric "0". This convention is not observed elsewherethroughout these specifications.




















