
The Internal Consistencies of the 1987 SEI Maturity Questionnaire and the SPICE Capability Dimension
23
Empirical Software Engineering, 3, 179–201 (1997) c 1997 Kluwer Academic Publishers, Boston. Manufactured in The Netherlands. The Internal Consistencies of the 1987 SEI Maturity Questionnaire and the SPICE Capability Dimension PIERFRANCESCO FUSARO AND KHALED EL EMAM Fraunhofer Institute for Experimental Software Engineering, Sauerwiesen 6, D-67661 Kaiserslautern, Germany BOB SMITH European Software Institute, Parque Tecnologico de Zamudio #204, E-48170 Bilbao, Spain Abstract. This paper presents the results of an empirical evaluation of the reliability of two commonly used assessment instruments: the 1987 SEI Maturity Questionnaire and the SPICE v1 capability dimension. The type of reliability that was evaluated is internal consistency. A study of the internal consistency of the 1987 questionnaire was only briefly mentioned in a 1991 article, and the internal consistency of the SPICE v1 capability dimension has not been evaluated thus far. We used two different data sets to evaluate the internal consistency of each instrument. Our results indicate that both assessment instruments are very reliable and also have similar reliability levels. The results are encouraging for users of assessment instruments, and provide a baseline with which to compare subsequent versions of these instruments. Keywords: process assessment, measurement reliability, internal consistency, organizational maturity, process capability 1. Introduction One of the recently developed class of decision making tools for software engineering management is the software process assessment. The scores from such assessments are being applied in focusing and tracking self-improvement efforts, and as part of the contract award decision making process. While we are not aware of a published systematic survey of the prevalence of assessments in software engineering practice worldwide, results from software process assessments are becoming important ingredients of software process im- provement and procurement efforts. This is evidenced, for example, by the stipulations of large software acquirers. For instance, attaining a maturity level 3 on the SEI’s maturity scale (i.e., the CMM for software) is encouraged for potential contractors of the US Air Force (Saiedian, 1995; Coffman, 1997). In addition, there is an on-going effort to develop an international standard for software process assessment (El Emam, 1998). When ratings are assigned to measure the maturity of organizations or the capability of processes, during or as a consequence of an assessment, then an assessment can be considered as a measurement procedure. Furthermore, because assessment ratings depend upon the judgment of assessors, they are a subjective measurement procedure. Given the importance of the decisions made by organizations based on assessment scores, the issue of the reliability of assessments is very critical. Reliability is defined in general as the extent to which the same measurement procedure will yield the same results on repeated trials (Carmines and Zeller, 1979). Lack of reliability is caused by random measurement error. For subjective measurements, there are many potential sources of random measure-
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of The Internal Consistencies of the 1987 SEI Maturity Questionnaire and the SPICE Capability Dimension

Empirical Software Engineering, 3, 179–201 (1997)c© 1997 Kluwer Academic Publishers, Boston. Manufactured in The Netherlands.
The Internal Consistencies of the 1987 SEI MaturityQuestionnaire and the SPICE Capability Dimension
PIERFRANCESCO FUSARO AND KHALED EL EMAMFraunhofer Institute for Experimental Software Engineering, Sauerwiesen 6, D-67661 Kaiserslautern, Germany
BOB SMITHEuropean Software Institute, Parque Tecnologico de Zamudio #204, E-48170 Bilbao, Spain
Abstract. This paper presents the results of an empirical evaluation of the reliability of two commonly usedassessment instruments: the 1987 SEI Maturity Questionnaire and the SPICE v1 capability dimension. Thetype of reliability that was evaluated is internal consistency. A study of the internal consistency of the 1987questionnaire was only briefly mentioned in a 1991 article, and the internal consistency of the SPICE v1 capabilitydimension has not been evaluated thus far. We used two different data sets to evaluate the internal consistencyof each instrument. Our results indicate that both assessment instruments are very reliable and also have similarreliability levels. The results are encouraging for users of assessment instruments, and provide a baseline withwhich to compare subsequent versions of these instruments.
Keywords: process assessment, measurement reliability, internal consistency, organizational maturity, processcapability
1. Introduction
One of the recently developed class of decision making tools for software engineeringmanagement is the software process assessment. The scores from such assessments arebeing applied in focusing and tracking self-improvement efforts, and as part of the contractaward decision making process. While we are not aware of a published systematic surveyof the prevalence of assessments in software engineering practice worldwide, results fromsoftware process assessments are becoming important ingredients of software process im-provement and procurement efforts. This is evidenced, for example, by the stipulations oflarge software acquirers. For instance, attaining a maturity level 3 on the SEI’s maturityscale (i.e., the CMM for software) is encouraged for potential contractors of the US AirForce (Saiedian, 1995; Coffman, 1997). In addition, there is an on-going effort to developan international standard for software process assessment (El Emam, 1998).
When ratings are assigned to measure the maturity of organizations or the capabilityof processes, during or as a consequence of an assessment, then an assessment can beconsidered as a measurement procedure. Furthermore, because assessment ratings dependupon the judgment of assessors, they are a subjective measurement procedure.
Given the importance of the decisions made by organizations based on assessment scores,the issue of the reliability of assessments is very critical. Reliability is defined in general asthe extent to which the same measurement procedure will yield the same results on repeatedtrials (Carmines and Zeller, 1979). Lack of reliability is caused by random measurementerror. For subjective measurements, there are many potential sources of random measure-

180 FUSARO, EL EMAM AND SMITH
ment error. In the context of process assessment, some potential sources of error have beendescribed in El Emam and Goldenson (1995).
A lack of reliability in assessments may lead to erroneous decisions when one comparesassessment scores. For example, comparisons occur when tracking ratings over time tomonitor process improvement progress, when comparing the ratings of potential suppliers,or when deciding which is the weakest process to invest resources in.
The objective of this paper is to report on a study of the reliability of two assessment in-struments: the 1987 SEI Maturity Questionnaire, and the SPICE capability dimension. Themethod of evaluating reliability uses an internal consistency coefficient (called Cronbachalpha), the same as the one reported by Humphrey and Curtis (1991) and used in an earlierstudy of the reliability of measuring organizational maturity (El Emam and Madhavji, 1995).
One of the earliest assessment instruments was the maturity questionnaire developed atthe SEI (Humphrey and Sweet, 1987). Initial assessments used this questionnaire in theprocess of scoring the software engineering practices of organizations (Olson et al., 1989).More recently the CBA-IPI (Dunaway and Masters, 1996) and the Interim Profile (Whitneyet al., 1994) assessment methods were developed. In the context of source selection, theassessment1 method used is known as the Software Capability Evaluation (Barbour, 1996).
While the SEI has released a new maturity questionnaire in 1994 (Zubrow et al., 1994), it isof scientific and practical utility to evaluate the reliability of the 1987 Maturity Questionnairefor the following three reasons:
• it is a scientific necessity to replicate and confirm the results obtained by other re-searchers (Lamal, 1991), and ours can be considered a confirmatory study of the onementioned in (Humphrey and Curtis, 1991) where the internal consistency of the 1987questionnaire is briefly mentioned.2
• evaluation of the 1987 Maturity Questionnaire serves as a baseline for comparing sub-sequent improvements to the questionnaire; if there is no baseline, then future studies ofthe reliability of the 1994 Maturity Questionnaire would not be able to indicate whetherit was an improvement or deterioration;
• the 1987 Maturity Questionnaire is still being used; for example, it was used for asurvey conducted in Singapore on the maturity of organizations (Tan and Yap, 1995)and up until the November 1996 issue of the maturity profile of the software industry(SEI, 1996), data collected since 1987 using the 1987 Maturity Questionnaire was stillbeing presented and included in the profile;3 therefore data using the 1987 MaturityQuestionnaire is still being applied in characterizing the maturity status of the softwareindustry in the US and internationally.
An international standard for software process assessment,ISO/IEC 15504—InformationTechnology—Software Process Assessment, is currently under development (El Emam etal., 1998; Rout, 1995). The initial version of the 15504 document set was developed bythe SPICE (Software Process Improvement and Capability dEtermination) Project. Whilenow the document set is evolving under the auspices of a joint ISO/IEC committee, theterm SPICE still enjoys widespread use. As part of the original mandate of the SPICEProject, and its current primary mandate, there are a set of empirical trials (Maclennan

INTERNAL CONSISTENCIES 181
and Ostrolenk, 1995). During the trials, data has been collected from early users of theassessment framework. Our focus in this paper is on the first version of the document set,known asSPICE v1.
Briefly, our results indicate that the reliability (calculated using an internal consistencymethod described later in the paper) of both the 1987 Maturity Questionnaire and theSPICE v1 capability dimension is very high. Furthermore, both have similar values. Theseresults are encouraging for users of software process assessments. They also establish abaseline which can be used in the evaluation of future versions of the questionnaire and thecapability dimension, and for comparison with other contemporary assessment instruments.
In this paper we first review the two instruments that we evaluate, basic reliability concepts,and previous work on the reliability of assessments. We then describe the data sets usedin this study, and we explain the data analysis method that we followed. In section 4 wepresent the results of the evaluation of the internal consistency of the 1987 version of theSEI Maturity Questionnaire and the SPICE v1 capability dimension, and discuss the resultsachieved in comparison with those obtained in Humphrey and Curtis (1991). Section 5concludes the paper with a summary and directions for future research.
2. Background
2.1. The Assessment Instruments
The reliabilities of two assessment instruments4 were evaluated. These two instrumentsmeasure different things: one measures organizational maturity and the other measuresprocess capability. The difference between these two general approaches used in processassessments is explained in Paulk and Konrad (1994). Below we give only an overview ofthe rating schemes employed by the two approaches.
The 1987 Maturity Questionnaire
The first, the 1987 SEI Maturity Questionnaire consists of 85 dichotomous questions cov-ering software engineering practices and 16 technology questions. The questionnaire mea-sures the maturity of organizations. As noted in Bollinger and McGowan (1991), thetechnology questions are not graded to determine the maturity of an organization. Organi-zational maturity is measured on a five point scale indicating extent of maturity. The gradingalgorithm to get from the responses to the 85 questions to a score on the 5-point maturityscale is described in Bollinger and McGowan (1991) and Humphrey and Sweet (1987).
The Maturity Questionnaire is used in two contexts. It is used as an orientation tool duringan assessment. Also, it has been used as a stand-alone tool for estimating the maturity oforganizations.
When used as an orientation tool, the questionnaire is filled during the preparation phaseof the assessment and on the first day of the assessment phase (Olson et al., 1989). Anexample of this kind of application is given in Rugg (1993) where the questionnaire waspart of a request for proposal in a source selection situation.

182 FUSARO, EL EMAM AND SMITH
The purpose of using the questionnaire as a stand-alone tool has commonly been to pro-duce a profile of the maturity of organizations. Such a profile can be used for benchmarkingpurposes (e.g., see Coffman and Thompson, 1997). Data is collected from a sample that isassumed to be representative of a larger population.
It has been recommended, however, that the Maturity Questionnaire not be used as a stand-alone assessment tool, but rather as an orientation tool during an assessment, and to establishan initial maturity level (Olson et al., 1989). Nevertheless, stand-alone applications are notuncommon. An example is the study conducted by Humphrey et al. (1991) on the maturity ofJapanese software companies. The bulk of this data was collected from large meetings whereprofessionals rate their own organizations (similar to assessment tutorials). Another morerecent example is the survey conducted to characterize the maturity of software organizationsin Singapore (Tan and Yap, 1995).
The reliability of the Maturity Questionnaire is an important issue in both contexts de-scribed above. A low reliability questionnaire can lead to incorrect initial maturity scores,which may cause inefficient assessments due to misorientation. It may also produce an erro-neous characterization of organizational maturity and consequent erroneous benchmarkingresults that use such a characterization.
The SPICE v1 Capability Dimension
The unit of analysis in the SPICE framework (ISO/IEC, 1995) is a process instance. A pro-cess instance is defined as “a singular instantiation of a process that is uniquely identifiableand about which information can be gathered in a repeatable manner” (ISO/IEC, 1995).The capability of process instances is rated during assessments. The SPICE architecture hastwo dimensions: a capability dimension and a process dimension. The capability of pro-cesses is evaluated using 26 generic practices that span 6 capability levels. Each successivelevel indicates a higher process capability. More details of the general SPICE architectureare given in Appendix A.
Ratings in a SPICE-based assessment are usually made on a form. The exact natureof this form is not stipulated in the SPICE documents. However, the definitions of thegeneric practices against which one does the ratings, the processes that are rated, and therating scheme are explicitly defined in the documents. Therefore, an instrument in thiscase consists of the generic practices and the rating scheme that are defined in the SPICEdocuments.
2.2. The Reliability of Assessments
The two approaches for evaluating reliability that have been studied in a process assess-ment context are the internal consistency of assessment instruments (e.g., see El Emam andMadhavji, 1995; Humphrey and Curtis, 1991) and interrater agreement (e.g., see El Emamet al., 1996; El Emam et al., 1997). Internal consistency measures the extent to which thecomponents of an instrument have been constructed to the same or to consistent contentspecifications of what the instrument is supposed to measure. It is also affected by am-

INTERNAL CONSISTENCIES 183
biguities in wording and inconsistencies in interpretation by respondents. This approachaccounts for consistency within the set of rating scales as a source of measurement error.Interrater agreement measures the extent to which independent assessors produce the sameratings when presented with the same evidence. This approach accounts for the differentassessors as a source of measurement error. In the current study we are only concernedwith internal consistency.
2.3. Basic Concepts
A basic concept for comprehending the reliability of measurement is that of aconstruct.A construct refers to a meaningful conceptual object. A construct is neither directly mea-surable nor observable. However, the quantity or value of a construct is presumed to causea set of observations to take on a certain value. An observation can be considered as aquestion in a maturity questionnaire (this is also referred to as anitem). Thus, the constructcan be indirectly measured by considering the values of those items.
For example, organizational maturity is a construct. Thus, the value of an item measuring“ the extent to which projects follow a written organizational policy for managing systemrequirements allocated to software” is presumed to be caused by the true value of organiza-tional maturity. Also, the value of an item measuring “the extent to which projects follow awritten organizational policy for planning software projects” is presumed to be caused bythe true value of organizational maturity. Such a relationship is depicted in the path diagramin Figure 1. Since organizational maturity is not directly measurable, the above two itemsare intended to estimate the actual magnitude or true score of organizational maturity.
Since reliability is concerned with random measurement error, error must be considered inany theory of reliability. The classic theory (see Allen and Yen, 1979) states that an observedscore consists of two components, a true score and an error score:X = T + E. Thus,X isthe score obtained in a maturity assessment,T is the mean of the theoretical distribution ofX scores that would be found in repeated assessments of the same organization using thesame maturity assessment procedure, andE is the error component.
The true score is considered to be a perfect measure of maturity. In practice, however,the true score can never be really known since it is generally not possible to obtain a largenumber of repeated assessments of the same organization. True scores are therefore onlyhypothetical quantities, but useful nevertheless.
2.4. Estimating Reliability
The most commonly used estimate of internal consistency is the Cronbach alpha coefficient(Cronbach, 1951). This is the same coefficient that has been used by Humphrey and Curtis(1991) in their note about the internal consistency of the 1987 Maturity Questionnaire,and in a recent study of the internal consistency of an organizational maturity instrument(El Emam and Madhavji, 1995). Below we describe the logic behind this coefficient. Weuse organizational maturity as the construct being measured for ease of presentation, butthe explanations are equally valid for the process capability construct.

184 FUSARO, EL EMAM AND SMITH
Figure 1. Path diagram depicting the organizational maturity construct and example items for its measurement.
The type of scale used in the most common assessment instruments is a summative one.This means that the individual scores for each item are summed up to produce an overallscore. One property of the covariance matrix for a summative scale that is important forthe following formulation is that the sum of all the elements in the matrix give exactly thevariance of the scale as a whole.
One can think of the variability in a set of item scores as being due to one of two things:(a) actual variation across the organizations in maturity (i.e., true variation in the constructbeing measured) and this can be considered as the signal component of the variance, and(b) error which can be considered as the noise component of the variance. Computing theCronbach alpha coefficient involves partitioning the total variance into signal and noise.The proportion of total variation that is signal equals alpha.
The signal component of variance is considered to be attributable to a common source,presumably the true score of the construct underlying the items. When maturity variesacross the different organizations, scores on all the items will vary with it because it is acause of these scores. The error terms are the source of unique variation that each itempossesses. Whereas all items share variability due to maturity, no two items are consideredto share any variation from the same error source.
Unique variation is the sum of the elements in the diagonal of the covariance matrix:6σ 2i
(wherei = 1 . . . N items). Common variation is the difference between total variation andunique variation: σ 2
y − 6σ 2i , where the first term is the variation of the whole scale.
Therefore, the proportion of common variance can be expressed as:(σ 2y − 6σ 2
i )/σ2y . To
express this in relative terms, the number of elements in the matrix must be considered.The total number of elements isN2, and the total number of elements that are communalareN2− N. Thus the corrected equation for coefficient alpha becomes:
α = N
(N − 1)
[1−
∑σ 2
i /σ2y
]The Cronbach alpha coefficient varies between 0 and 1. If there is no true score but onlyerror in the items, then the variance of the sum will be the same as the sum of variances of

INTERNAL CONSISTENCIES 185
the individual items. Therefore, coefficient alpha will be equal to zero (i.e., the proportionof true scores in the scale is zero percent). If all items are perfectly reliable and measurethe same thing, then coefficient alpha is equal to one (i.e., the proportion of true score inthe scale is 100 percent).
To illustrate the calculation of Cronbach s alpha through an example, let us assume thatwe have an instrument with five items. Also, let the variances of each of these items be4.32, 3.86, 2.62, 2.55, and 2.46. The sum of the variances,6σ 2
i , is 15.81. For this five iteminstrument, the variance of the sum of the 5 items,σ 2
y , was say 53.95. Then the Cronbachalpha coefficient would be 1.25(1− (15.81/53.95)) = 0.88. The values for the samplevariances can be computed as(
∑(xj − x̄)2)/NOBS−1, where thexj ’s are the actual values
for each observationj ( j = 1 . . .NOBS), andx̄ is the mean of all observations, and NOBSis the total number of observations.
Cronbach’s alpha is a generalization of a coefficient introduced by Kuder and Richardsonto estimate the reliability of scales composed of dichotomously scored items. Dichotomousitems are scored one or zero depending on whether the respondent does or does not endorsethe particular characteristic under investigation. To determine the reliability of scales com-posed of dichotomously scored items, the Kuder-Richardson formula (symbolized KR20)is Allen and Yen (1979):
K R20= N
(N − 1)
[1−
∑pi qi /σ
2y
]whereN is the number of dichotomous items;pi is the proportion responding positivelyto thei th item;qi is equal to 1− pi ; andσ 2
y is equal to the variance of the total composite.Since KR20 is simply a special case of alpha, it has the same interpretation as alpha.
2.5. Predicting Reliability for a Different Length Instrument
When one is not able to collect data on all of the items of an assessment instrument,5 it isstill possible to evaluate the reliability for all of the questions in the instrument. A wellknown formulation for doing so is the Spearman-Brown prophecy formula:
SB= k× K R20
1+ ((k− 1)× K R20), or SB= k× α
1+ ((k− 1)× α)
wherek is the number of times the instrument must be larger or smaller than the currentone. For example, for an instrument twice the current size,k = 2. Usually, reliabilityincreases when new questions are added. However, as also noted in Humphrey and Curtis(1991), adding new questions may actually reduce reliability if the new questions correlatepoorly with the other already existing questions.
The Spearman-Brown formula can be used to facilitate comparisons between instruments.As noted in Allen and Yen (1979) when comparing two instruments the longer instrumentwill in general have a higher reliability because it is longer. Therefore, it would be appro-priate to make the instruments being compared of equal length.

186 FUSARO, EL EMAM AND SMITH
If differences are found when comparing instruments’ internal consistency, it may notbe reasonable to change the assessment instrument lengths as a means for adjusting inter-nal consistency from a practical perspective. Reducing the length of an instrument couldnegatively impact its validity (e.g., the extent to which an instrument is measuring organiza-tional maturity). Similarly, it would not be practical to increase the length of an instrumentbecause that could dramatically increase the cost of conducting assessments; one shouldalways be considerate of the economic impact of changing instrument length. Therefore,it would be more appropriate to explore the underlying content, structure, and applicationmethod as reasons for such a difference.
2.6. Interpreting Reliability Coefficients
There are two approaches that can be used to determine whether an internal consistencyvalue is good or bad. The first is by reference to some commonly accepted threshold.Since internal consistency thresholds have not been established in software engineering,we can resort to using general guidelines from other disciplines, namely psychometrics.The second is by reference to values obtained in other studies of assessment instrumentsconducted in the software engineering domain.
What a satisfactory level of reliability is depends on how a measure is being used. Inthe early stages of the research on assessment instruments, reliabilities of 0.7 or higher areconsidered sufficient. For basic research, a value of 0.8 is acceptable. However, in appliedsettings where important decisions are made with respect to assessment scores, a reliabilityof 0.9 is the minimum that would be acceptable (Nunnally, 1978).
To our knowledge, only two studies have been published in the past that evaluate theinternal consistency of instruments used in assessing the maturity of organizations or thecapability of software processes. These are presented below.
In their 1991 critique of the SEI’s Software Capability Evaluations, Bollinger and Mc-Gowan (1991) question the ‘statistical reliability’ of the algorithm used to calculate thematurity of organization. In their reply, Humphrey and Curtis note that some reliabilitystudies of this questionnaire were conducted using “data gathered from SEI assessments”and quote a figure of 0.9 for the level 2 and level 3 questions (Humphrey and Curtis, 1991).Levels 2 and 3 contain 65 questions. If we use the Spearman-Brown formula above, wecan estimate that the full 85 question Maturity Questionnaire has a reliability of 0.92. Thisis larger then the commonly accepted minimal threshold value of 0.9 for applied settings(Nunnally, 1978).
The second study in El Emam and Madhavji (1995) evaluated the internal consistencyof a questionnaire that covered four generic dimensions of organizational maturity: stan-dardization, project management, tools, and organization. The overall internal consistencyvalue for the composite of the 4 dimensions was approximately 0.95, a value sufficientlyhigh for applied settings (Nunnally, 1978).
Therefore, in general, an absolute minimum value of internal consistency that would beacceptable is 0.8. However, an achievable value that is more desirable for applied settingswould be 0.9. Since in our study, the Maturity Questionnaire and the SPICE capability

INTERNAL CONSISTENCIES 187
dimension are both being used in making important decisions, the minimal tolerable valueof internal consistency for these instruments should be set at 0.9.
3. Research Method
In this section we present the data sets that we used and the analysis method. In total we hadfour data sets, two using the Maturity Questionnaire, and two using the SPICE capabilitydimension.
3.1. Maturity Questionnaire Data Sources
We used two Maturity Questionnaire data sets each representing the responses of twosamples of practicing maintainers. This is the same data set used in Drehmer and Dekleva,1993). The first sample consisted of forty surviving respondents from an original base ofsixty-two who were members of a third-round Delphi panel in a large study conducted byDekleva (1993). The second sample of subjects consisted of thirty nine respondents whocompleted a mail survey designed specifically for measuring maturity.
Each subject was an experienced software maintainer with an average of 15 years ininformation systems of which 11 years were spent in software maintenance or managementof maintenance and therefore was qualified as an appropriate subject. The first sample weresolicited from persons who attended the 1990 and 1991 Software Management Associationprofessional conferences and the second sample were attendees of the 1992 meeting ofthe same conference. Respondents to the questionnaire were rating the practices in theirInformation Systems departments.
The first data set consisted of the responses of 40 subjects to 25 maturity-related questions(i.e., 12 items associated with “repeatable, level 2” , and 13 items associated with “defined,level 3” ). The second data set consisted of the responses of 39 subjects to 56 maturity-related questions (i.e., 21 items associated with “repeatable, level 2” , 23 items associatedwith “defined, level 3” , and 12 items associated with “managed, level 4” ). More detailsof these questions are given in Appendix B.
3.2. SPICE Capability Dimension Data Sources
We used two separate SPICE data sets for this study. Each is described below.The first data set was obtained from three assessments conducted within Europe during
1996. In total, 50 process instances in 14 projects were assessed. Five of the projects weremaintenance and the remainder new development. We analyzed the generic practices forlevels 2 and 3.
The method used for the three assessments was as follows. First, there was a half daypre-assessment meeting between the assessors and the organizational unit personnel forintroductions and scoping of the assessment. The first half day of the actual assessmentconsisted of an introduction to SPICE and to the assessment for all of the assessment
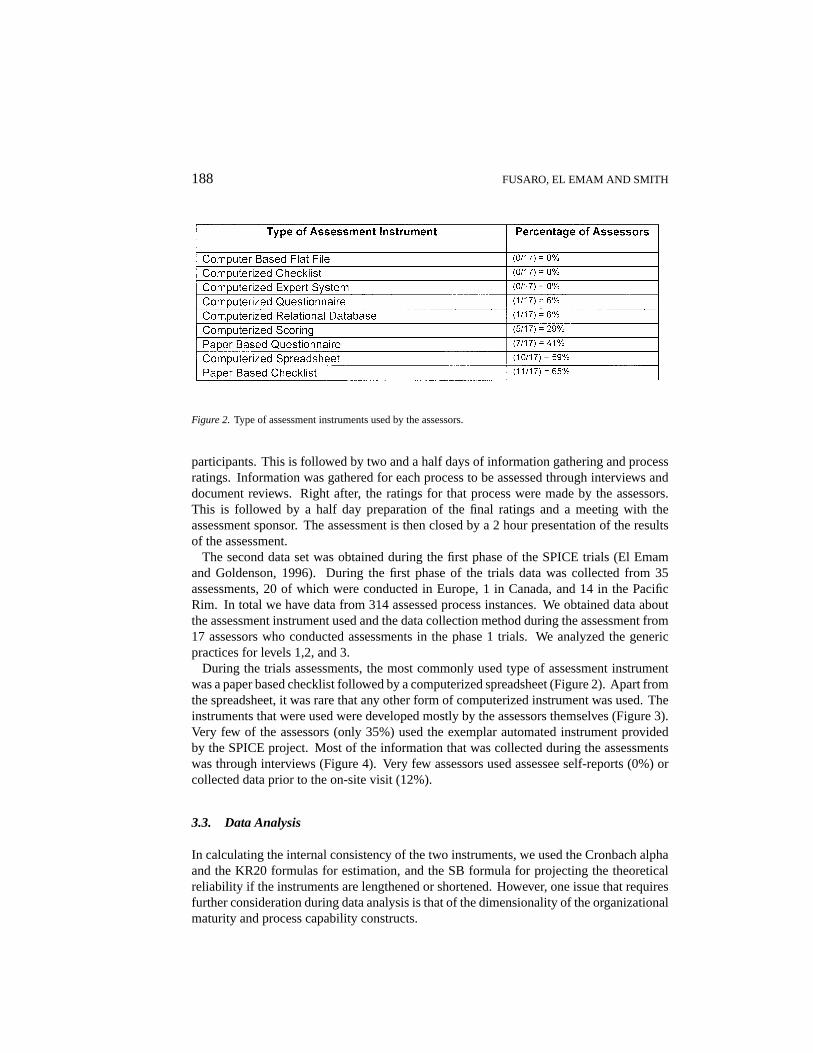
188 FUSARO, EL EMAM AND SMITH
Figure 2. Type of assessment instruments used by the assessors.
participants. This is followed by two and a half days of information gathering and processratings. Information was gathered for each process to be assessed through interviews anddocument reviews. Right after, the ratings for that process were made by the assessors.This is followed by a half day preparation of the final ratings and a meeting with theassessment sponsor. The assessment is then closed by a 2 hour presentation of the resultsof the assessment.
The second data set was obtained during the first phase of the SPICE trials (El Emamand Goldenson, 1996). During the first phase of the trials data was collected from 35assessments, 20 of which were conducted in Europe, 1 in Canada, and 14 in the PacificRim. In total we have data from 314 assessed process instances. We obtained data aboutthe assessment instrument used and the data collection method during the assessment from17 assessors who conducted assessments in the phase 1 trials. We analyzed the genericpractices for levels 1,2, and 3.
During the trials assessments, the most commonly used type of assessment instrumentwas a paper based checklist followed by a computerized spreadsheet (Figure 2). Apart fromthe spreadsheet, it was rare that any other form of computerized instrument was used. Theinstruments that were used were developed mostly by the assessors themselves (Figure 3).Very few of the assessors (only 35%) used the exemplar automated instrument providedby the SPICE project. Most of the information that was collected during the assessmentswas through interviews (Figure 4). Very few assessors used assessee self-reports (0%) orcollected data prior to the on-site visit (12%).
3.3. Data Analysis
In calculating the internal consistency of the two instruments, we used the Cronbach alphaand the KR20 formulas for estimation, and the SB formula for projecting the theoreticalreliability if the instruments are lengthened or shortened. However, one issue that requiresfurther consideration during data analysis is that of the dimensionality of the organizationalmaturity and process capability constructs.

INTERNAL CONSISTENCIES 189
Figure 3. The developer(s) of the assessment instruments that were used.
Figure 4. The method(s) that the assessors used to collect information during the assessment.
The coefficients of internal consistency that we use assume that the construct beingmeasured is unidimensional (Allen and Yen, 1979). There are a number of assumptionsthat one can make about the dimensionality of the organizational maturity and processcapability constructs to satisfy this requirement. It is not clear which assumption was madein Humphrey and Curtis (1991) however.
The first assumption that can be made is that organizational maturity itself is a unidimen-sional construct, and therefore all of the questions in a maturity questionnaire are measuringthis single construct (this is the assumption made in Figure 1). The alternative assumption isthat organizational maturity is a multidimensional construct. This assumption has receivedsome support from the point of view that treating maturity as a single dimension is an over-simplification of the factors that affect software development (Topper and Jorgensen) andtherefore represents a rather coarse measure of the implementation of software engineeringpractices (El Emam and Madhavji, 1996).
If we assume that organizational maturity is a multidimensional construct, then there arealternative ways that one can conceptually differentiate amongst the subdimensions. Oneapproach would be to treat each maturity level as a subdimension. Therefore, for example,there would be a subdimension “level 2 practices” that covers practices differentiatingbetween theInitial level and theRepeatablelevel, and a subdimension “level 3 practices”that differentiates between theRepeatablelevel and theDefinedlevel, and so on. However,this dimensional structure has not been empirically evaluated. Another approach is toempirically derive the subdimensions of maturity using an exploratory factor analysis, asdone in Curtis (1996).
In our analysis, we calculate the internal consistency of the maturity questionnaire as-suming that maturity is a unidimensional construct. The primary reason for this is that,

190 FUSARO, EL EMAM AND SMITH
while the dimensionality of the maturity and capability constructs has been acknowledged,no systematic investigations of this dimensionality have been conducted thus far. Thesame reasoning applies for the SPICE capability dimension, where we assume that it is aunidimensional construct.
The consequence of this assumption is that we obtaindeflatedinternal consistency esti-mates for instruments of equal length if indeed maturity and capability are multidimensionalconstructs. The reason is that internal consistency is a function of interitem correlations(Carmines and Zeller, 1979). If, for example, organizational maturity is a multidimensionalconstruct and we treat it as a unidimensional construct, then this heterogeneity of items willcause the interitem correlations to be lower. Consequently, the internal consistency esti-mate would be lower. If the construct is treated as multidimensional, then the items ineach dimension would be more homogeneous and hence the interitem correlations wouldincrease, increasing the internal consistency estimate.
4. Results
4.1. The 1987 SEI Maturity Questionnaire
Assuming that maturity is a unidimensional construct, we calculated coefficient KR20 foreach of the two data sets. The results are presented in Figure 5. These results show quitelarge reliability values. We would expect the value from data set 1 to be lower than thevalue from data set two because of the smaller number of items in data set 1.
Our data set does not include all of the questions that are in the original 1987 questionnaire.We can plot the number of questions against the reliability, given that reliability will varywith questionnaire length. This is shown in Figure 6. As can be seen, the minimal value ofa reliability of 0.9 is passed at 45 items for both data sets. This is a remarkably consistentresult obtained from our two data sets. For the total questionnaire size of 85 items the valuewould be approximately 0.94 for both data sets.
It would be expected that an empirically estimated reliability of the questionnaire fromdata collected during assessment tutorials or actual assessments would be higher than froma survey because in the former contexts the respondents have the opportunity to clarifyany ambiguities. However, our results do not confirm this expectation. Compared tothe estimated value of an 85 item questionnaire from the results in Humphrey and Curtis(1991)—which are stated to be based on SEI assessments (see Section 2.6)—of 0.92, ourobtained value from a survey is slightly larger.
4.2. The SPICE v1 Capability Dimension
We calculated the internal consistency of the SPICE capability dimension. The results aresummarized in Figure 7. As can be seen, the values of Cronbach alpha are very large andhigher than the minimal threshold stipulated earlier. The same results hold for both datasets that we used.

INTERNAL CONSISTENCIES 191
Figure 5. Results from the internal consistency analysis for the 1987 SEI maturity questionnaire.
Figure 6. Reliability values of different questionnaire lengths for the two data sets.6
The total number of generic practices on the capability dimension is 26. The graph inFigure 8 shows the estimated reliability for different instrument lengths. It is clear that thereliability would increase to approximately 0.94 for the first data set and 0.97 for the seconddata set with a 26 item instrument. In general, these two values are consistent with eachother.
4.3. Comparison
A comparison of the SPICE results with the Maturity Questionnaire results that we ob-tained here can be informative to the extent that it highlights potential areas for improvingassessment instruments. Two types of differences between the two instruments that canpotentially explain differences in their internal consistency are:

192 FUSARO, EL EMAM AND SMITH
Figure 7. Results from the internal consistency analysis for the SPICE v1 capability dimension.
Figure 8. Reliability against the number of generic practices.
Differences in Instruments
• Unit of Rating: with the SEI Maturity Questionnaire the unit of rating is the organiza-tion, whereas in the SPICE framework, the unit of rating is the process instance; and
• Scale Used:the scale used in the SEI Maturity Questionnaire is a 2-point scale, whereasthe SPICE measurement framework stipulates a 4-point scale.
Differences in Application Context
• Ratings on the Maturity Questionnaire when used as either an orientation tool or astand-alone tool are not based on information collected over an extended period andon the examination of evidence. Conversely, a SPICE-based assessment involves thecollection of detailed information over an extended period. This information is thenused to assign capability ratings. Therefore, differences in internal consistency maybe attributable to the differences in the amount and collection rigor of information thatinstrument ratings are based upon. However, a priori, since it was noted above that the

INTERNAL CONSISTENCIES 193
Figure 9. Comparisons of results.
internal consistency of the 1987 Maturity Questionnaire using a survey was slightlyhigher than that obtained in Humphrey and Curtis (1991), the application context maynot provide such a strong explanation.
Our results are tabulated together with those from Humphrey and Curtis (1991) in Figure 9.We used the Spearman-Brown formula to make all of the reliability estimates applicable toinstruments of equal lengths. The two values chosen were 85 and 26 items, to match thefull length instruments of the 1987 Maturity Questionnaire and the SPICE v1 capabilitydimension respectively.
Two points can be noted from Figure 9. First, that all of the internal consistency valuesfor full length instruments are above the 0.9 minimal threshold. Therefore, both full lengthinstruments can be considered internally consistent for practical purposes. Second, thatthe SPICE capability dimension tends to beslightly more internally consistent than the1987 Maturity Questionnaire, whichever instrument length is chosen. Even though bothinstruments are usable as they are defined, from a research perspective, it would be beneficialto understandwhy differences in internal consistency exist, and make changes to futureinstrument structure, content, and application context accordingly. A candidate explanationis the unit of rating. In an assessment based on SPICE, the unit of rating is the processinstance. This is potentially more conducive to higher reliability as opposed to the moreheterogeneous “organization” unit of rating (i.e., usually multiple process instances) usingthe 1987 Maturity Questionnaire. This deserves further careful investigation in the future.
5. Conclusions
In this paper we evaluated the internal consistency of the 1987 SEI Maturity Questionnaireand the v1 SPICE capability dimension. We found that the two assessment instruments asthey are constructed have very high internal consistency values. We found the results to beconsistent across two samples for each instrument. This gives us some initial confidence inthe usage of these instruments.
Further research ought to focus on two issues. For the first, estimation of other types ofreliability using other methods is necessary. For example, interrater agreement coefficients.Different types of reliability estimation take into account different sources of error. Whilethere have been some studies of the interrater agreement in SPICE-based assessments (e.g.,El Emam et al., 1996; El Emam et al., 1997), no published reports of interrater agreement

194 FUSARO, EL EMAM AND SMITH
studies of SEI assessment models and methods are known to the authors. Secondly, nowthat we have established a baseline, it would be prudent to compare the internal consis-tency of the new version of the Maturity Questionnaire and the new version of the SPICEcapability dimension to these baselines. It is then that we will know whether, at least interms of internal consistency, the new instruments are an improvement over the previousversions.
Acknowledgments
The authors wish to thank Sasa Dekleva for providing us with his maturity data. We also wishto thank the assessors and sponsoring organizations who took part in the SPICE assessments,and to all participants in Phase 1 of the SPICE Trials. The authors also thank Sasa Dekleva,Dennis Goldenson, and Janne Jarvinen for their comments on an earlier version of thispaper. The comments of the anonymous reviewers of the Empirical Software Engineeringjournal have also resulted in important improvements to the paper, and we wish to thankthem for their thoughtful feedback.
7. Appendix A
The SPICE architecture is two dimensional.7 Each dimension represents a different perspec-tive on software process management. One dimension consists ofprocesses. Each processcontains a number ofbase practices. A base practice is defined as a software engineeringor management activity that addresses the purpose of a particular process. Processes aregrouped intoProcess Categories. An example of a process isDevelop System Requirementsand Design. Base practices that belong to this process include:Specify System Require-ments, Describe System Architecture, andDetermine Release Strategy. An overview of theprocess categories is given in Figure 10.
The other dimension consists ofgeneric practices. A generic practice is an imple-mentation or institutionalization practice that enhances the capability to perform a pro-cess. Generic practices are grouped intoCommon Features, which in turn are groupedinto Capability Levels. An example of a Common Feature isDisciplined Performance.A generic practice that belongs to this Common Feature stipulates that data on perfor-mance of the process must be recorded. An overview of the Capability Levels is given inFigure 11.
Ratings are made against the capability dimension. Each generic practice is rated basedon its implementation in the process. This rating utilizes a four-point adequacy scale. Thefour discrete values are summarized in Figure 12. The four values are also designated asF , L, P, andN.

INTERNAL CONSISTENCIES 195
Figure 10.Brief description of the Process Categories.
Figure 11.Brief description of the capability levels.
Figure 12.Description of the rating scheme for generic practices.

196 FUSARO, EL EMAM AND SMITH
8. Appendix B
This appendix contains the exact text of the questions that were used to evaluate the 1987SEI Maturity Questionnaire. This information is included here to save the reader fromgoing back to the original report (Humphrey and Sweet, 1987). Respondents answered Yesor No to each question. We indicate in the tables whether a question was included in thefirst and second data sets. The numbers in the first column reference the question numbersin Humphrey and Sweet (1987).

INTERNAL CONSISTENCIES 197

198 FUSARO, EL EMAM AND SMITH
9. Appendix C
This appendix gives the name of each of the SPICE processes that were assessed for eachof our two data sets, as well as the number of process instances that were assessed for eachprocess.
Notes
1. In the SEI’s terminology, the SCE is referred to specifically as an “evaluation method” rather than an “assess-ment method,” and when the objective is process improvement, the term “assessment method” is used. Weuse the term “assessment method” in a generic sense in this paper to cover both objectives: source selectionand process improvement.

INTERNAL CONSISTENCIES 199
2. In Humphrey and Curtis (1991) only a note of the results of evaluating the internal consistency of the SEI1987 Maturity Questionnaire is given. The study’s details and assumptions are not presented.
3. The maturity profile is being used by organizations for benchmarking. For example, the US Air Force hasused the profile for benchmarking their progress with process improvement (Coffman and Thompson, 1997).
4. In this paper we use the term instrument to mean a questionnaire or any other form of data collection mechanismthat allows rating of software engineering practices against an assessment model. For example, this can beachieved using automated tools.
5. Or alternatively when one wishes to estimate the reliability after increasing/reducing the size of an existinginstrument.
6. While not obvious, this figure shows the curves for both data sets. The strong similarity in KR20 between thetwo data sets can be seen by putting the values in Figure 5 into the Spearman-Brown prophecy formula. Forexample, with ak value of(56/25) 2.24 and a KR20 value of 0.84, KR20 for the 56 item instrument is 0.92,which is the empirically calculated value for the 56 item instrument in Figure 5.
7. Elements of the SPICE architecture have recently been revised and restructured. The basic two dimensionalarchitecture remains however. In this study, we used the first version of the SPICE documents only.
References
Allen, M., and Yen, W. 1979.Introduction to Measurement Theory. Brooks/Cole Publishing Company.Barbour, R. 1996. Software capability evaluation version 3.0: Implementation guide for supplier selection.
Technical Report CMU/SEI-95-TR-012, Software Engineering Institute.Bollinger, T., and McGowan, C. 1991. A critical look at software capability evaluations.IEEE Software, pages
25–41.Carmines, E. G., and Zeller, R. A. 1979.Reliability and Validity Assessment. Beverly Hills: Sage Publications.Coffman, A., and Thompson, K. 1997. Air force software process improvement report.Crosstalk, pages 25–27.Cronbach, L. 1951. Coefficient alpha and the internal structure of tests.Psychomterika16(3): 297–334.Curtis, B. 1996 The factor structure of the CMM and other latent issues. Paper presented at the Empirical Studies
of Programmers: Sixth Workshop, Washington DC.Dekleva, S. 1992. Delphi study of software maintenance problems.Proceedings of the International Conference
on Software Maintenance, 10–17.Drehmer, D., and Dekleva, S. 1993. Measuring software engineering maturity: A Rasch calibration.Proceedings
of the International Conference on Information Systems, 191–202.Dunaway, D., and Masters, S. 1996. CMM-based appraisal for internal process improvement (CBA IPI): Method
description. Technical Report CMU/SEI-96-TR-7, Software Engineering Institute.El Emam, K., and Goldenson, D. R. 1995. SPICE: An empiricist’s perspective.Proceedings of the Second IEEE
International Software Engineering Standards Symposium, August, 84–97.El Emam, K., and Madhavji, N. H. 1995. The reliability of measuring organizational maturity.Software Process
Improvement and Practice1(1): 3–25.El Emam, K., and Goldenson, D. R. 1996. An empirical evaluation of the prospective international SPICE
standard.Software Process Improvement and Practice2(2): 123–148.El Emam, K., Goldenson, D. R., Briand, L., and Marshall, P. 1996. Interrater agreement in SPICE-based assess-
ments: Some preliminary results.Proceedings of the Fourth International Conference on the Software Process,149–156.
El Emam, K., and Madhavji, N. H. 1996. Does organizational maturity improve quality?IEEE Software, pages109–110.
El Emam, K., and Goldenson, D. R. 1996. Description and evaluation of the SPICE Phase one trials assessments.Proceedings of the International Software Consulting Network Conference (ISCN’96).
El Emam, K., Briand, L., and Smith, R. 1997. Assessor agreement in rating SPICE processes.Software ProcessImprovement and Practice2(4): 291–306.
El Emam, K., Drouin, J-N, and Melo, W. (eds.) 1998.SPICE: The Theory and Practice of Software ProcessImprovement and Capability Determination. IEEE CS Press.
Humphrey, W., and Sweet, W. 1987. A method for assessing the software engineering capability of contractors.Technical Report CMU/SEI-87-TR-23, Software Engineering Institute.
Humphrey, W., and Curtis, B. 1991. Comments on a ‘A Critical Look.’IEEE Software, pages 42–46.

200 FUSARO, EL EMAM AND SMITH
Humphrey, W., Kitson, D., and Gale, J. 1991. A comparison of US and Japanese software process maturity.Proceedings of the 13th International Conference on Software Engineering, 38–49.
ISO/IEC. 1995.Software Process Assessment—Part 2: A Model for Process Management, Working Draft 1.00.ISO/IEC. 1995.Software Process Assessment—Part 4: Guide to Conducting Assessments, Working Draft 1.00.Lamal, P. 1991. On the importance of replication. In J. Neuliep (ed.),Replication Research in the Social Sciences.
Sage Publications.Maclennan, F., and Ostrolenk, G. 1995. The SPICE trials: Validating the framework.Proceedings of the 2nd
International SPICE Symposium, Brisbane, Australia.Nunnally, J. C. 1978.Psychometric Theory. New York: McGraw-Hill.Olson, T., Humphrey, W., and Kitson, D. 1989. Conducting SEI-assisted software process assessments. Technical
Report CMU/SEI-89-TR-7, Software Engineering Institute.Paulk, M., and Konrad, M. 1994. Measuring process capability versus organizational maturity.Proceedings of
the 4th International Conference on Software Quality.Rout, T. 1995. SPICE: A framework for software process assessment.Software Process Improvement and
Practice, Pilot Issue, 57–66.Rugg, D. 1993. Using a capability evaluation to select a contractor.IEEE Software, pages 36–45.Saiedian, H., and Kuzara, R. 1995. SEI capability maturity model’s impact on contractors.Computer28(1):
16–26.SEI. 1996. Process maturity profile of the software community: 1996 update. Software Engineering Institute.Tan, M., and Yap, C. 1995. Impact of organizational maturity on software quality. In M. Lee, B-Z Barta, and
P. Juliff (eds.),Software Quality and Productivity: Theory, Practice, Education and Training. Chapman & Hall.Topper, A., and Jorgensen, P. More than one way to measure process maturity.IEEE Software, pages 9–10.Whitney, R., Nawrocki, E., Hayes, W., and Siegel, J. 1994. Interim profile: Development and trial of a method
to rapidly measure software engineering maturity status. Technical Report CMU/SEI-94-TR-4, Software Engi-neering Institute.
Zubrow, D., Hayes, W., Siegel, J., and Goldenson, D. 1994. Maturity questionnaire. Technical Report CMU/SEI-94-SR-7, Software Engineering Institute.
Pierfrancesco Fusaroreceived his Laurea degree from the University of Bari, Italy, in 1995. He is currently aresearcher of the Quality and Process Engineering at the Fraunhofer Institute for Experimental Software Engi-neering (IESE) an industry-oriented research centre located in Kaiserslautern, Germany. His research interestsinclude goal-oriented measurement based on the Goal-Question-Metric approach, experimentation, evaluationand improvement of the reliability and validity of software process assessments. He is also a joint researcher ofthe SER Lab (Software Engineering Research Laboratory) of the Computer Science Department, University ofBari.

INTERNAL CONSISTENCIES 201
Khaled El Emam is currently the head of the Quantitative Methods Group at the Fraunhofer Institute for Ex-perimental Software Engineering in Germany. Dr. El Emam is also the founding and current editor of the IEEETCSE Software Process Newsletter, the current International Trials Coordinator for the SPICE Trials, which isempirically evaluating the emerging ISO/IEC 15504 international standard world-wide, co-editor of ISO’s projectto develop an international standard defining the software measurement process, and current chairman of the QAIboard to develop a certification scheme for software process improvement professionals. He is also editor of twobooks on software process assessment and improvement. Previously, he worked in both small and large softwareresearch and development projects for organizations such as Toshiba International Company, Yokogawa Electric,and Honeywell Control Systems. Khaled El Emam obtained his Ph.D. from the Department of Electrical andElectronics Engineering, King’s College, the University of London (UK) in 1994. He was previously a researchscientist at the Centre de recherche informatique de Montreal (CRIM) in Canada.
Bob Smith is the Technical Manager at the European Software Institute in Bilbao, Spain. He is responsible formanaging the technical program aimed at providing techniques and services to European industry for continuousprocess improvement in areas of software development; systems engineering; product-line based reuse; processmeasurement; and best practice adoption. He has 15 years of experience in software with a specific background inthe management and development of safety critical systems in the avionics industry. He was the International TrialsCoordinator of the SPICE Project from 1995–1997 and continues to support the trials of the new InternationalStandard ISO15504 on Software Process Assessment. He is an SEI-qualified instructor of the Introduction toCMM and is also an instructor of the ESI Introduction to SPICE course. He has a degree in Computer Sciencefrom Strathclyde University, Glasgow and is a Chartered Engineer through membership of the British ComputerSociety.




















