TERMINOLOGY AND CONTENT DEVELOPMENT - CBS
437
TERMINOLOGY AND CONTENT DEVELOPMENT Edited by: Bodil Nistrup Madsen & Hanne Erdman Thomsen TKE 2005 7th International conference on Terminology and Knowledge Engineering ISBN: 87-91242-46-0 TERMINOLOGY AND CONTENT DEVELOPMENT Edited by: Bodil Nistrup Madsen & Hanne Erdman Thomsen TKE 2005 GTW-omslag 21/07/05 14:18 Side 1
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of TERMINOLOGY AND CONTENT DEVELOPMENT - CBS

TERMINOLOGY ANDCONTENT DEVELOPMENT
Edited by:Bodil Nistrup Madsen
& Hanne Erdman Thomsen
TKE 20057th International conference on
Terminology and Knowledge Engineering
ISBN: 87-91242-46-0
TERMINOLOGY AND CONTENT DEVELOPM
ENTEdited by: Bodil Nistrup M
adsen & Hanne Erdman Thom
sen
TKE 2005
GTW-omslag 21/07/05 14:18 Side 1

Terminology and Content Development © Association for Terminology and Knowledge Transfer (GTW) 2005
Udgivet af Litera - www.litera.dk
ISBN: 87-91242-46-0
Alle rettigheder forbeholdes. Elektronisk, fotografisk eller anden gengivelse af denne bog, eller dele deraf er forbudt uden forfatterens skriftlige tilladelse, ifølge gældende dansk lov om ophavsret. Undtaget herfra er korte citater til brug i anmeldelser.

Terminology and Content Development
Edited by
Bodil Nistrup Madsen & Hanne Erdman Thomsen
TKE 2005
7th International Conference on Terminology and Knowledge Engineering


Table of Contents
Preface................................................................................................................................ 9 Semantic Interoperability CHRISTIAN GALINSKI
Semantic Interoperability and Language Resources........................................... 11 KLAUS-DIRK SCHMITZ
Terminological Data Modelling for Software Localization ................................ 27 LEONARDO MEO-EVOLI & GILIOLA NEGRINI
Conceptualisation and Terminology for Knowledge Elicitation of Technologies and Production Processes................................................................ 37
CECILIA HEMMING
Compound Nouns in Swedish and French Technical Terms.............................. 51
Content Development SUE ELLEN WRIGHT
A Guide to Terminological Data Categories Extracting the Essentials from the Maze .................................................................. 63
LARS JOHNSEN Information Maps Meet Topic Maps From Structured Writing to Mergeable Knowledge Webs with XML....................... 77
GERHARD BUDIN Strategies for Integrated Multilingual Content Development and Terminological Knowledge Management in Academic E-Learning Environments...................................................................................... 91
KOEN KERREMANS, RITA TEMMERMAN & GANG ZHAO Terminology and Knowledge Engineering in Fraud Detection........................ 101
BARBARA DRAGSTED, INGE GORM HANSEN & HENRIK SELSØE SØRENSEN
TKE in Transnational Law Enforcement - a Case Study of Workflow and Terminology Management in the Production and Translation of Organised Crime Reports ..................................... 113
Concept Systems ANITA NUOPPONEN
Concept Relations An Update of a Concept Relation Classification .................................................... 127

Table of Contents
EKATERINA MHAANNA Comparing the Concept Relations and their Grouping in UMLS and in OntoQuery ................................................................................................. 139
LEE GILLAM & KHURSHID AHMAD Overcoming the Knowledge Acquisition Bottleneck? ....................................... 151
BODIL NISTRUP MADSEN, HANNE ERDMAN THOMSEN & CARL VIKNER
Multidimensionality in Terminological Concept Modelling ............................. 161 Ontologies ELENA PASLARU BONTAS & MALGORZATA MOCHOL
Towards a Reuse-Oriented Methodology for Ontology Engineering .............. 175 SAM H. MINELLI & ANDREA de POLO
From Taxonomy and Domain Ontology Building to Knowledge Representation for Semantic Multimedia Analysis of Cultural Heritage Contents ................................................................................................. 189
STEFFEN LEO HANSEN Ontological Semantics of Classical Music FYNBO – an Ontology-based IR System ................................................................ 199
HANNE ERDMAN THOMSEN & HENRIK BULSKOV Integration of a Formal Ontological Framework with a Linguistic Ontology ................................................................................... 211
VIKTOR SMITH Modeling the Semantics of Relocation For SugarTexts and Beyond.................................................................................... 225
Classification CHEN TAO, SUN MAOSONG & LU HUAMING
Automated Construction of Chinese Thesaurus Based on Self-Organizing Map ............................................................................ 237
PAWEŁ GARBACZ
Towards a Standard Taxonomy of Artifact Functions ..................................... 251
FULVIO MAZZOCCHI & PAOLO PLINI Thesaurus Classification and Relational Structure: the EARTh Experience......................................................................................... 265
ERIK VELLDAL A Fuzzy Clustering Approach to Word Sense Discrimination......................... 279

Table of Contents
Terminology Extraction ROBERTO BARTOLINI, DANIELA GIORGETTI, ALESSANDRO LENCI, SIMONETTA MONTEMAGNI & VITO PIRRELLI
Automatic Incremental Term Acquisition from Domain Corpora ..................... 293 VINCENT CLAVEAU & MARIE-CLAUDE L'HOMME
Automatic Incremental Term Acquisition from Domain Corpora Structuring Terminology using Analogy-Based Machine Learning ................ 301
ALEXANDRE PATRY & PHILIPPE LANGLAIS Corpus-Based Terminology Extraction .............................................................. 313
VALENTINA CEAUSU & SYLVIE DESPRES Towards a Text Mining Driven Approach for Terminology Construction .......................................................................................................... 323
K. ØVSTHUS, K. INNSELSET, M. BREKKE & M. KRISTIANSEN Developing Automatic Term Extraction Automatic Domain Specific Term Extraction for Norwegian................................. 337
PATRICK DROUIN & HEE SOOK BAE Korean Term Extraction in the Medical Domain using Corpus Comparison.................................................................................... 349
HANS FRIEDRICH WITSCHEL Terminology Extraction and Automatic Indexing Comparison and Qualitative Evaluation of Methods ............................................. 363
PÄIVI PASANEN A Term List or a Noise List? How Helpful is Term Extraction Software when Finnish Terms are Concerned? .............................................................................. 375
LONE BO SISSECK
Terminological Knowledge Extraction - and Machine Learning for Danish ....................................................................... 385
JAKOB HALSKOV
DiaSketching as a Filter in Web-Based Term Extraction Systems .................. 397 Information Extraction TROELS ANDREASEN, HENRIK BULSKOV & RASMUS KNAPPE
Modelling and Use of Domain-Specific Knowledge for Similarity and Visualization .......................................................................... 409

Table of Contents
BOLETTE SANDFORD PEDERSEN, COSTANZA NAVARRETTA & DORTE HALTRUP HANSEN
Anchoring Knowledge Organisation Systems to Language.............................. 419
ANDERS THURIN & SOFIA KNUBBE Automatic Identification of Reasons for Encounter Information Retrieval from Text in Swedish Patient Records using Methods from Language Technology ............................................................ 433

Semantic Interoperability and Language Resources
The Role of ISO/TC 37 Standards for Global Semantic
Interoperability
CHRISTIAN GALINSKI
Most users are interested not in the (hardware and software) tools, but in content. There are many kinds of content, including specialized content (representing domain specific knowledge in some way or other – including terminology). Terminology is often embedded in or combined with other kinds of content (mostly specialized texts). In order to make content development less expensive (because of its labour-intensiveness), we need new methods of content creation (and the respective workflow management): net-based, distributed, cooperative creation of structured content. In principle all Content items/units should be prepared and maintained in such a way that they fulfil the requirements of - single-sourcing uninhibited re-usability - resource-sharing (net-based distributed) cooperative content
development - universal accessibility incl. access by persons with special needs. This gives interoperability a new dimension – the fundamental requirement for achieving the aims of the semantic web (which is the generic concept in contrast to Tim Berners Lee’s Semantic Web). ISO/TC1 37 ”Terminology and other language and content resources” is gradually moving into this area, bringing in its competence and experience with the data modelling of terminological data and other language resources (LRs) from the point of view of domain experts’ ‘content’ complementary to the point of view of the ICT2 approaches.
1. a Technical Committee of ISO, the International Organization for Standardization 2. information and communication technology

Christian Galinski
1 Definitions eContent (i.e. digital content) in technical terms is defined as text (i.e. textual data, incl. all kinds of alpha-numeric data), sound (i.e. audio data), image (i.e. graphical data), video (i.e. audiovisual and multimedia data), which from a ‘semantic’ point of view is completely insufficient. Under a mobile content (mContent) perspective, today, content – including terminology – is from the outset:
• multilingual • multimodal • multimedia
and should be prepared in such a way that it meets multi-channel and universal accessibility requirements (comprising also the requirements of people with special needs). eContent thus should be prepared under a comprehensive content management perspective, based on a metadata approach and on unified data modelling principles and requirements in so that it is re-usable in all kinds of applications, especially the e-...s, such as:
• eLearning • eGovernment • eHealth • eBusiness • etc.
Sociolinguistics distinguishes between general purpose language (GPL – or common language in the generic sense) and special purpose language (SPL – or specialised language in the generic sense). One of the main characteristics of SPL is its high share of terminological units, which are indispensable for
• domain (or professional or subject-field) communication, • representation of domain (i.e. specialised or subject-field related)
knowledge, • access to specialised (i.e. subject-field related) information.
In this context we speak of the ‘specialised languages’ (SPLs) of the various subject-field/domain expert communities, who agree on their linguistic conventions (mostly geared towards the written form of their respective SPL) not necessarily always in conformance with GPL
12

Semantic Interoperability and Language Resources
conventions. Furthermore, quite some SPLs comprise – at least in their written form – many (and many different types of) non-linguistic representations, which also belong to content. 2 Content seen as Content Items To a large degree eContent – especially domain-specific content – takes the form of textual data (i.e. alphanumeric data of a textual nature), which, from a formal point of view, are composed of language resources (LRs – which comprise text corpora, speech corpora, grammar models, lexicographical and terminological data). 2.1 Representations of Concepts and Meaning Concepts in terminology are corresponding to (material and immaterial) objects in the real world (which comprises also human society and culture). Concepts are mental constructs functioning as ‘first order representation’, whereas the corresponding terms (or other kinds of concept representation) have the role of ‘second order representation’. Conceptual modelling thus has implications on higher levels of scientific-technical theory building. Under the aspect of semantic interoperability, which is indispensable, if present eContent and future mContent (comprising multilingual content in eBusiness, eLearning, eGovernment, eHealth and other e…s) shall really be effective, one soon recognises that there are different types of ‘mental constructs’, which can be called concepts in a wider sense. In terminology itself there are different types of terminologies (based on different sub-types of concepts), which can be subsumed under the respective concept systems such as:
• logical concept systems (which can be hierarchical, non-hierarchical or hybrid)
• ontological concept systems (which also can be hierarchical, non-hierarchical or hybrid)
• other kinds of concept systems (which again can be hierarchical, non-hierarchical or hybrid)
or which can be typologized among others as:
• regular scientific-technical terminologies (tending towards a hierarchical type of concept system)
• social-science and humanities oriented terminologies (tending towards a network type of concept system)
13

Christian Galinski
• nomenclature-type of terminology (following – ideally consistent and strict – specific naming rules for naming the nomenclature classes), etc.
In addition there are conceptual units, which can be called ‘terminology phraseology’, which often serve as a pre-stage in the terminologization of linguistic units to become terms (representing a distinct concept). Vice versa there are terminological units, which are de-terminologized and become lexical units of the general purpose language (GPL). In general GPL, too, there are different types of ‘mental constructs’ usually called meaning, represented by words and their morphological components, as well as collocations etc. There is a natural process of ‘terminologization’ of GPL units into terminology as well as ‘de-terminologization’ of terminological units into GPL usage. The human brain is highly productive in coping with any communicative situation because of the constant switching between different types of meaning and parallel ‘processing’ at different planes. Not to forget: all sorts of non-verbal communication may be decisive for the success of the communication efforts. This approach is quite ‘object-oriented’, as concepts correspond to objects. Every object – whether material or immaterial – is part of the whole universe and, therefore, ultimately is related to all information of the universe (which cannot – for the shear volume of this information – be processed by the human brain). Conceptual thinking – a ‘condition humaine’ of mankind – is absolutely necessary for the human brain to condense information and reduce information volume in such a way that it can be made instrumental for coping with everyday life. 2.2 Documentation Languages and Other Meta-Languages Given this immense volume of specialized information (i.e. scientific-technical or professional information), one or more meta-levels of condensation are necessary: for instance also documentation languages (i.e. indexing and retrieval languages) like classification schemes and thesauri. They are needed for several purposes, among others:
• subdividing volumes of information into ‘manageable’ portions • indexing of information for re-use • retrieval of indexed information
14

Semantic Interoperability and Language Resources
• browsing in information, etc. If there are many such documentation languages for different purposes, one further meta-level becomes necessary: umbrella classification schemes. For the sake of data processing of such documentation languages the respective metadata, datamodels and metamodels have to be defined. 2.3 Product Description and Classification In product description and classification (PDC) ‘object-related’ data are needed for each product (which can also be a service). Some types of product designations’ still belong to the traditional domain of terminology. But if it comes to series, models (and sub-models) and components as well as (mass-produced or individually produced) products, names of products or identifiers or barcodes can become ‘synonyms’. Some of the data distinguishing series, models, components, individual products, names (of makers, distributors …), etc. can be used as attributes, others as ‘traditional’ properties and characteristics. The relatively new field ‘ontology’ in data modelling tries to find solutions to structure this mass of information. However, ultimately only such methodological approaches are viable, which produce results that are ‘reproducible’ under same or similar conditions. 2.4 Terminology of the so-called e…s A simple overview on terminology usage shows an inconsistency in naming and defining elements such as class, attribute, property, characteristic, dictionary, etc. This calls for a clarification of basic concepts in eBusiness etc., in order to make content fully interoperable (including re-usability, single sourcing and resource-sharing) across all kinds of applications. If terminology belonging to same or similar ‘objects’ remains as fuzzy as it is today, the various expert communities for metadata approaches, ontology, eLearning and other e…s, content management, documentation, and last but not least terminology cannot communicate properly with each other. Competing, even contradicting methodological approaches would be conceived, in order to cope with problems in application fields. The very basic requirements of content management (in its broadest meaning), such as single-sourcing (in order to achieve optimal re-usability) and resource-sharing (in order to save human efforts in content development) could not be met in this case.
15

Christian Galinski
Within the framework of the Workshop CEN/ISSS/eCAT3 “Multilingual electronic catalogues and product classification” of the an attempt is made to clarify some or most of the conflicting terms concerning product description and classification so that communication across subject-fields becomes possible and terminologists could find a role in formulating basic principles and requirements for multilingual content development. 3 Standardization of e/mContent Related Aspects As already stated, all eContent items/units (based under a comprehensive content management perspective on the metadata approach and unified data modelling principles and requirements) in principle should be prepared and maintained in such a way that they fulfil the requirements of single-sourcing (resulting in uninhibited re-usability), resource-sharing (as a basis for [net-based distributed] cooperative content development) and universal accessibility (incl. access by persons with special needs). Thus for the sake of a broad re-usability we need more methodology standards than exist today. Such methodology standards can be sub-divided into:
• Standardization – Top-down including: • Harmonization of metadata (for all kinds of content
items/units), • Unification of principles and methods of data modelling, • Standardization of meta-models, • Standardization of workflow methodology (incl. that for net-
based distributed cooperative content development and maintenance);
• Standardization – Bottom-up including (for instance in eBusiness among others):
- product classification, - terminologies, - product identification, - other LRs, - e-catalogue data, - ontologies, etc.
By using net-based distributed cooperative working methods on the basis of methodology standards, some of which do not yet exist, content development will become much less expensive in the future than today through extensive net-based co-operation on the basis of standards.
3. Workshop of the Information Society Standardization System of the European
Committee for Standardization
16

Semantic Interoperability and Language Resources
Interoperability here acquires a new dimension. Among the hitherto identified
• Technical interoperability • Hardware-related • Software-related: software/network architectures,
components, tools, application programs, technical communication protocols, etc.
• Semantic interoperability • Organizational interoperability
semantic interoperability has to be further subdivided into
• Syntactic interoperability (ICT-approaches) (requiring:) basic principles and requirements }standards syntactic communication protocols }(maintenance) messages, interfaces }(maintenance) data dictionaries [1] }(maintenance) metamodels }maintenance agencies data modelling, XML schemas }registration authorities metadata/data categories }registration authorities certain data elements, data dictionaries [2] }registries basic principles and requirements }standards
• Conceptual / pragmatic interoperability (content point-of-view). In the field of terminology standardization ISO/TC 37SC 1, SC 2 and SC 3 take care of the standardization of terminological principles and methods applied to terminological data and other language and content resources as well as to the respective applications. The individual terminologies – as far as they are needed for the work of other TCs in ISO, IEC4 and other standards bodies – are standardized by these ‘vertical’ TCs. LR related principles, methods and certain applications are standardized by ISO/TC 37/SC 4 “Language resource management”; which was established in close cooperation with ELRA5. ISO/TC 37/SC 1 also takes care of the terminology of ISO/TC 37 itself. So there is a comprehensive ‘horizontal’ framework for standardization activities
4. International Electrotechnical Commission 5. European Language Resource Association
17

Christian Galinski
in the field of terminology and other language and content resources in place.
The semantic web (in the generic sense) is conceived as the global eContent infrastructure for eBusiness, eLearning, eHealth, eGovernment, eHealth, and other e…s, and – if it shall be efficient and effective – must provide rules and procedures as well as organizational frameworks to guarantee or at least support different kinds of interoperability, such as technical, operational and semantic interoperability:
• throughout the enterprise/organization, • between enterprises/organization, • within industry consortia, • between industry consortia (urgently needs open standards), • among different e…s, • between different language communities,
and also within the world of standards (which also needs further development and harmonization). ISO/TC 37 as a whole today has the competence and experience to intensify its engagement also with respect to semantic interoperability, and closely collaborate with other ISO groupings in this field. 4 ISO/TC 37 “Terminology and other Language and Content Resources” Over the years ISO/TC 37 has developed expertise for methodology standards for content (at conceptual level) in textual form as well as for the multilinguality and cultural diversity aspects of content management. The impact of TC 37 on harmonizing activities at international and European level is summarized in the document ISO/TC 37 N 496 endorsed by ISO/TC 37, CEN/ISSS/CDSG and CEN/ISSS itself. Thus the MoU/MG (Management Group of the “ISO/ IEC/ ITU/ UN-ECE Memorandum of Understanding concerning standardization in the field of eBusiness”) decided to put ISO/TC 37 related topics, such as
• terminology of product classification, • multilinguality and cultural diversity (MCD) with respect to
o multilingual product classification, o multilingual product catalogues, o multilingual content management at large,
in the field of eBusiness on the list of issues of primary concern to the MoU/MG under the general aspect of semantic interoperability.
18

Semantic Interoperability and Language Resources
ISO/TC 37 is represented in CEN/ISSS workshops, such as:
• CEN/ISSS/EBIF “Electronic Business Interoperability Forum”, • CEN/ISSS/LT “Language Technologies”, • CEN/ISSS/eCAT “Multilingual catalogue strategies for e-
commerce and e-business”, etc.
The activities of these workshops result in CEN Workshop Agreements6 and are promising with respect to identifying ‘horizontal’ topics related to terminology (in terms of methodology), multilinguality and cultural diversity, which could be taken up as a starting point for NWIs in TC 37.
Given this development ISO/TC 37 – renamed 2004 into “Terminology and other language and content resources” – decided on adapting its operational structure in 2004. Its scope now reads: “Standardization of principles, methods and applications relating to terminology and other language and content resources”. Its objective is to prepare standards specifying principles and methods for the preparation and management of terminology, language and other content resources (at the level of concepts) within the framework of standardization and related activities. Its technical work results in International Standards (and Technical Reports), which cover terminological principles and methods as well as various aspects of computer-assisted terminography. However, ISO/TC 37 is not responsible for the terminology standardizing activities of other ISO/TCs. ISO/TC 37’s mission is to provide standards and guidelines to standardization experts, language professionals in all institutions and organizations creating and handling terminology, language and other content resources (including ISO itself, other international organizations, national standards bodies, national government services, companies, non-governmental organizations, etc.) in order to enable them to prepare high-quality language resources and tools for a wide variety of applications in professional and scholarly information and communication, education, industry, trade, etc. Part of ISO/TC 37’s vision is that worldwide use of ISO/TC 37 standards will help
• to enhance the overall quality of terminologies and other language and content resources in all subject fields,
6. CWA – similar to ISO’s PAS – Publicly Available Specification
19

Christian Galinski
• to improve information management within various industrial, technical and scientific environments,
• to reduce its costs, and • to increase efficiency in technical standardization and
professional communication. Its secretariat being operated by Infoterm, the International Information Centre, on behalf of the Austrian Standards Institute (ON) ISO/TC 34 has made a tremendous progress over the last years (s. ISO/TC 37 N 499). 4.1 ISO/TC 37/SC 1 “Principles and Methods in Terminology and Knowledge Organization”7
ISO/TC 37/SC 1 started operation in 1980 (called “Principles of terminology”) in order to take care of the basic standards of ISO/TC 37, namely those related to terminology theory and methodology – including the vocabulary of terminology. Today its scope reads: “Standardization of principles and methods related to terminology, terminology policies and to knowledge organization in the multilingual information society”. The secretariat of ISO/TC 37 is operated by TNC, the Swedish Centre for Terminology, on behalf of the Swedish Standards Institute (SIS).
The objective of ISO/TC 37/SC 1 is to prepare standards laying down the basic principles for preparing, updating and harmonizing terminologies and other language and content resources on the one hand, and to standardize principles and methods related to terminology policies and knowledge organization in the multilingual information society.8
ISO/TC 37/SC 1’s mission is to provide standardization experts of national and international standards bodies and language professionals in international organizations, national government services, companies, non-governmental organizations, etc. with relevant standards and guidelines to assist them
- in creating high-quality terminologies and other language and content resources, and
7. The final wording of the title and scope of ISO/TC 37/SC 1 will be decides at the
ISO/TC 37 meetings in Warsaw in August 2005. 8. An overview on standards under the direct responsibility of ISO/TC 37/SC 1,
standards under preparation and planned new working items can be found in document ISO/TC 37/AG N 125.
20

Semantic Interoperability and Language Resources
- in formulating terminology policies and implementing knowledge organization.
4.2 ISO/TC 37/SC 2 “Terminographical and Lexicographical Working Methods”9
ISO/TC 37/SC 2 started operation in 1983 (then called “Layout of vocabularies”) in order to take care of standards of ISO/TC 37 related to terminography. Today its scope reads: “Standardization of terminological and lexicographical working methods, procedures, coding systems, workflows, and cultural diversity management, as well as related certification schemes”. The secretariat of ISO/TC 37/SC 2 is operated by PWGSC, Public Works and Government Services of Canada, on behalf of the Standards Council of Canada (SCC).
The objective of ISO/TC 37/SC 2 is to prepare practice-oriented standards for terminology work, terminography, lexicography, and reference coding.10 ISO/TC 37/SC 2 will pursue this objective by:
- identifying and targeting the client audience, and making the standards available on the market;
- identifying and meeting client needs. Its mission is to provide practical advice concerning activities covered by its scope through the publication of standards and the use of Internet in order to meet the needs of its client audience. 4.3 ISO/TC 37/SC 3 “Terminology Management Systems and Content Interoperability”11
ISO/TC 37/SC 3 started operation in 1985 (called “Computational aids in terminology”) in order to take care of standards of ISO/TC 37 concerning computerized terminography and related computer-applications. Today its scope reads: “Standardization of principles and requirements for semantic interoperability, terminology and content management systems, and knowledge ordering tools”. The Secretariat of ISO/TC 37/SC 3 is held by the German Institute for Standardization (DIN).
9. The final wording of the title and scope of ISO/TC 37/SC 2 will be decides at the
ISO/TC 37 meetings in Warsaw in August 2005. 10. An overview on standards under the direct responsibility of ISO/TC 37/SC 2,
standards under preparation and planned new working items can be found in document ISO/TC 37/AG N 125.
11. The final wording of the title and scope of ISO/TC 37/SC 3 will be decides at the ISO/TC 37 meetings in Warsaw in August 2005.
21

Christian Galinski
The objective of ISO/TC 37/SC 3 is to develop standards for the sake of semantic interoperability comprising specifications of terminology, language and content management, which cover data modelling, markup, data exchange, and evaluation of terminology management and knowledge ordering tools.12 The target groups of SC 3 are providers and users of terminology, language resource, content and knowledge management, including software companies active in this field. This also comprises the scientific community and educational institutions catering to those services. 4.4 ISO/TC 37/SC 4 “Language Resource Management” ISO/TC 37/SC 4 was established in 2002 after several years of negotiation with the European Language Resource Association (ELRA, with the pro-active support of the late Antonio Zampolli). The scope was defined as: “Standardization of specifications for computer-assisted language resource management”. Its secretariat is operated by KORTERM, the Terminology Research Center for Language and Knowledge Engineering, on behalf of the Korean Agency for Technology and Standards (KATS).
The objective of ISO/TC 37/SC 4 is to prepare various standards by specifying principles and methods for creating, coding, processing and managing language resources, such as written corpora, lexical corpora, speech corpora, dictionary compiling and classification schemes.13 These standards will also cover the information produced by natural language processing components in these various domains. They should particularly address the needs of industry and international trade as well as the global economy regarding multi-lingual information retrieval, across-cultural technical communication and information management. ISO/TC 37/SC 4’s goal is also to ensure that new developments in language engineering, knowledge management and information engineering comply with:
- development standards and related documents to maximize the applicability of language resources,
- international standards relating to the language resources of different kinds and their applications, and
12. An overview on standards under the direct responsibility of ISO/TC 37/SC 3,
standards under preparation and planned new working items can be found in document ISO/TC 37/AG N 125.
13. An overview on standards under the direct responsibility of ISO/TC 37/SC 4, standards under preparation and planned new working items can be found in document ISO/TC 37/AG N 125.
22

Semantic Interoperability and Language Resources
- standards and best practices enhancing the application of recognized methods and tools for language resources.
5 World-wide Content Updating and Maintenance Mechanisms Results of eContent related unification, standardization and harmonization efforts need to be regularly and constantly updated/maintained according to developments in science and technology, and even more so to the expectations of the users. As computers in the age of the Semantic Web have to communicate in seemingly natural language, which – contrary to true natural language – has to be more or less unambiguous, the emerging information society, will need many repositories of
- certain types of content items/units (data dictionaries [type 2: containing values/instances]), such as authority data, attributes, values, proper names (of persons, organizations, etc.), terminological data, etc.
- non-linguistic representations of knowledge (e.g. CAD/CAM symbols, etc.)
- certain data elements, metadata/data categories, etc. (data dictionaries [type 1: containing metadata])
- codes for names (of countries, currencies, languages, ...) - typologies, taxonomies, nomenclatures, ontologies, etc. - data structures, data models, XML schemas, interchange
formats, metamodels, etc. - interfaces, interface elements, etc. - (syntactic) communication protocols, messages, etc. - software components (of all kinds of complexity), etc.
supplementing the existing 5 Maintenance Agencies (MAs) and about 60 Registration Authorities (RAs) (figures according to the ISO portal). This will require a systematic approach to the establishment of
• maintenance agencies – whenever there is a need for a high degree of authority and high stability over time
• registration authorities – securing a high degree of consistency over time and more or less strict registration rules
• other registries for (the repositories of) codes, words (and word elements, terms, term elements, etc.) and for attributes, values, etc.
which have to take care of these repositories in a distributed, but well coordinated way. This calls for a policy of the standardization system,
23

Christian Galinski
how to deal with such maintenance agencies, registration authorities and other kinds of registries. Given the need for many more (and different types of) maintenance agencies, registration authorities and registries, this policy would lead to a coherent framework for
- the ‘objects’ to be taken care of by these MAs, RAs and repositories
- the degree of authoritativeness of each type of object - the objectives of standardized and non-standardized updating/
maintenance procedures - the terms of reference of these MAs, RAs and repositories - the work methodology as well as workflow management methods
to be used in the updating/maintenance process - business models for operating such MAs, RAs and repositories,
etc. Such a policy for a distributed, however well coordinated framework for all kinds of content items today only exists in a rudimentary form. The development may well end up in a network of distributed (federated) MAs, RAs and other kinds of registries becoming the backbone of the eContent infrastructures of the semantic web. Given the requirement for coherence of the objects taken care of in these MAs, RAs and repositories, the standards bodies not only will find new opportunities for standardization activities, but also have the societal responsibility to take the lead. 6 Copyright for Terminological Data and Other Kinds of Textual Content Concerning the content of the above-mentioned MAs, RAs and Registries, there is a copyright problem and a business model issue closely related to this problem. According to ISO/TC 37 standards a terminological entry consists of one (or more) entry term(s) (or abbreviation, symbol, etc.) and a definition. The term is representing a concept in a short ‘symbolic’ form, whereas the definition is representing the characteristics of the concept in a ‘descriptive’ form. If terminology is about representing concepts, then non-linguistic representations – be it graphical or other symbols or be it complex formulas or other kinds of non-linguistic representation of the characteristics of the concept in question – can equally represent concepts (and have to be acknowledged as equal to terms). As technological development increased the ways and means of concept representation, the share of non-linguistic representations of concepts is also increasing. Therefore, other kinds of IPRs on non-linguistic
24

Semantic Interoperability and Language Resources
representations are also at stake than just copyright on terms and definitions (being textual data).
Scientific/academic ethics should ‘morally’ prohibit to deprecate definitions in order to circumvent copyright, but strict enforcement of copyright might lead to this undesired consequence. In order to comply with the EU Directive for the protection of databases (or substantial parts hereof), one should try to obtain the written permission of the publisher, if one extracts a substantial part of a database/collection. Minor extracts can be considered as fair use. Beside, the proper citation of the source results in publicity for the data thus increasing its commercial value. Similar considerations can be made with respect to the contents of all kinds of MAs, RAs and Registries (for all kinds of repositories). 7 Outlook The “keep it simple, stupid!” principle in data modelling invariably results in very high costs (usually at the users’ expense, who do not get what they actually need – but more often than not cannot specify their needs). Given the complexity of the semantic interoperability requirements to be observed already today, experts from various quarters, such as
- terminology and other language resources (incl. the multilinguality and multimodality aspects);
- internationalization and localization (incl. cultural diversity and psychological aspects);
- information design (incl. accessibility aspects). should take the initiative and prepare fundamental basic standards cutting across all application fields with respect to multilinguality, multimodality, cultural diversity and related issues (covering also to some extent general cultural diversity, psychological and accessibility aspects). The application specific communities have to develop standards with the basic principles and requirements of the respective application field. New professional profiles for content development will have to be designed and implemented at educational institutions to provide the market with content developers able to cooperate with system designers and maintenance experts in developing also the most appropriate data models and metamodels conforming to – hopefully – international standards.
ISO/TC 37 standards in combination with the metadata approach and the respective JTC 1/SC 32/WG 2 standards as well as the registries for (the repositories of) all kinds of metadata, data types and other content
25

Christian Galinski
related matters will be among the cornerstones of future semantic interoperability – on a practical level. References Directive 96/9/EC of the European Parliament and of the Council of 11
March 1996 on the legal protection of databases ISO/TC 37 [ed.]. ISO/TC 37 “Terminology and other language and
content resources” 2005 (ISO/TC 37/AG N 125) ISO/TC 37 [ed.]. 50 Years ISO/TC 37 “Terminology and other language
resources” – A history of 65 years of standardization of terminological principles and methods (ISO/TC 37 N 499)
ISO/TC 37 [ed.]. (Draft) Business plan of ISO/TC 37 ‘Terminology and other language resources’ for 2005 – 2006
ISO/TC 37 [ed.]. Proposal for an MoU/MG statement concerning Semantic Interoperability and the need for a coherent policy for a framework of distributed, coordinated repositories for all kinds of content items on a world-wide scale (ISO/TC 37 N 496)
ISO/TC 37 [ed.]. Statement on eBusiness Standards and Cultural Diversity (ISO/TC 37 N 497)
Galinski, Christian; Semantic interoperability and language resources: Content development under the aspect of global semantic interoperability, in Maria A. Wimmer (eds.), E-Government 2005: Knowledge Transfer und Status. Tagungsband zu den e|Gov Days und Eastern European e|Gov Days 2005 des Forums e|Government in Wien und Budapest, Wien: Österreichische Computer Gesellschaft, 2005 (OCG Schriftenreihe Band 187).
26

Terminological Data Modelling for Software Localization
KLAUS-DIRK SCHMITZ Software Localization After an explosive growth of data processing and software since the beginning of the eighties and a strong orientation of the software industry in non US markets since the beginning of the nineties, we find today a global marketing of software in almost all regions of the world. Since software is no longer used by IT expert only, and since European and national regulations require user interfaces, manuals and documentation to be provided in the language of the customer, the market for software translation, i.e. for software localization, is the fastest growing market in the translation business.
Internationalization and localization comprise the whole of the effort involved in developing products for several regional markets. Internationalization concentrates on developing a software product in such a way that it will be easy to adapt it to other markets, i.e. other languages and cultures. The main goal of internationalization is to eliminate the need to reprogram or recompile the original program when localized for a specific regional market. Typical software development errors that are against the idea of internationalization are e.g.:
• text embedded in the program code • length limitations in the text (fields) • fixed formats for date, currency, units of measure, etc. • fixed formats for addresses • textual elements in graphics • country- and culture-specific icons and symbols
Localization can be defined as the whole process of adapting a software product to a local or regional market with the main goal to consider all appropriate linguistic and cultural aspects. The process of localization is performed by translators, localizers and language engineers and comprises the translation of the user interface, the online help, the documentation and all packing material including the adjustment of all addresses, examples, measures and screen shots.

Klaus-Dirk Schmitz
Internationalization and localization comprise the whole of the effort involved in developing products for several regional markets. While internationalization is “stuff” you have to do only once during the programming of a software, localization is “stuff” you have to do over and over again for each regional market. Therefore, the more stuff you push into internationalization out of localization, the less complicated and expensive the process becomes.
Types of Documents to be Localized The following figure shows the types of “documents” to be dealt with in software localization:
software product
documentation website software
paper online
help manual tutorial
program example
menu dialog message
Figure 1: Documents for software localization Software is handed over to the customer together with a set of printed documentation. This documentation will help the user to install the program, to learn how to use the program and to function as a reference manual if the user has to solve a specific problem. Installation instructions, manuals and reference guides are often completed by advertising material, guarantee and registration cards, packing material, floppy disk and CD-ROM labels etc. All these documents are subject to localization and have to be adapted to the regional markets.
Online help files and online learning programs (tutorials) are specific types of documentation. In contrast to printed material, these online documents are organized as hypertext documents and provided with clickable links from one topic to another. Online documents have to be translated and adapted during the localization process by preserving and – if necessary - modifying the hypertextual elements. The localization of web pages are also considered as part of the localization business. Although web pages are not always considered as part of the software (promotion material), they have to be localized
28

Terminological Data Modelling for Software Localization
using the same working method and they have to contain the same consistent terminology as all other documents related to a certain product. Since web pages are stored as HTML or XML files with clickable links (similar to most online help files) they have to be localized using specific editors.
A major and sometimes difficult part of the localization process is the localization of the software itself. The textual elements of the program’s user interface like menu items, list fields, dialog boxes, buttons and error messages are normally not so easy to access and modify. Specific localization tools support the localizer not only to translate the linguistic items but also to adjust the menus, boxes and buttons.
Tools used for Software Localization The localization of software and the documents belonging to it is not possible without the use of adequate electronic tools.
Printed documentation is normally localized with the help of word processing or desk-top-publishing programs, in most cases by over-typing the source language text with the translation in order to preserve the layout and formatting information. Sometimes it is necessary to convert files from a specific word processor or DTP-system format into a format that is recommended by the tools used at the localizing company. Online help files (with extension HLP) can be transformed into RTF and localized with standard word processors.
Modern help files as well as web pages have to be localized by using HTML or XML editors. So-called tag editors have similar functionality as word processors but they protect HTML, XML or other codes within the file against deletion or modification by the localizer.
Since documents typical for localization can be characterized by a high degree of internal and external repetition (within a document and between updates), translation memory systems can be applied very efficiently for this type of translation project. Translation memory tools operate either with a background database filled with previously translated segments or with parallel reference texts. In most cases, translation memory tools are designed as part of translators workbenches containing other necessary components like translation editors (word processing software) and terminology management systems. For the localization of the software itself specific localization software like Corel Catalyst or Passolo is used. These tools “extract”
29

Klaus-Dirk Schmitz
the linguistic items from the compiled program (e.g. from the EXE file) and allow the user to localize these items. Almost all localization tools also allows the resize menus, buttons and boxes if the target language term does not directly fit into the size of the original element.
Terminology management systems are used to store and access the terminology needed for the localization of all types of documents. Since normally several persons are involved in the localization of a product, the use of a terminology management system is a precondition for a consistent terminology through all types of documents (program, online help, documentation, web pages). Therefore the terminology management system must co-operate and interact with other tools needed for localization, like word processors, translation memories and specific localization tools.
Data Modelling for Terminological Data Collections The needs of the different user groups involved in elaborating and retrieving terminology as well as the organizational environment in which terminology management will take place have a strong impact on the conceptual design of a terminological database. It is very important to specify the types of data (terminological data categories) that should be managed, and to define the data model (terminological entry structure) that will form the basis of the termbase.
The selection and specification of terminological data categories should be based on ISO 12620 (1999) which lists and describes more than 200 data categories useful for terminology management. According to this standard and other publications dealing with terminology management, terminological data categories can be grouped under various headings, depending on whether they are concept-related or term-related or contain administrative data.
Concept-related terminological data categories comprise those data elements that refer to the concept underlying a terminological entry or describing the relationship between this concept and other concepts. Typically used concept-related data categories are:
• definition • subject field / domain • illustration / symbol / formula • classification / notation • superordinate concept • subordinate concept • co-ordinate concept
30

Terminological Data Modelling for Software Localization
Term-related terminological data categories contain those data elements that refer to one particular term representing the concept. The set of term-related data categories must be repeated for each term assigned to the concept both within one language (e.g. for synonyms) or for several languages (e.g. equivalents). Useful term-related data categories are:
• term (including synonyms, abbreviations,
orthographical variants) • term type • context / example • grammatical information (gender, part of speech,
number) • geographical restriction • linguistic restrictions • register • project code / company code
Administrative data categories refer to the entry as a whole or to individual concept-related or term-related data categories within this entry. Administrative data categories include:
• identification number (entry number) • date (creation / last update) • author (creator / checker / editor) • source • reliability • note / annotation / comment
The selection and specification of terminological data categories is a very important step in the design of a terminological database. Modifications and re-specifications of data categories are very labor and cost intensive when the database is already filled with data.
The next step in designing terminological data bases is the definition of the terminological entry structure, i.e., a systematically hierarchical arrangement of data categories. ISO 704 (2000), ISO 12200 (1999) and ISO 16642 (2003) provide good guidance for this data modeling process. Two major principles have to mentioned within this context.
Per definition, a terminological entry has to contain all terminological data related to one concept (ISO 1087-1, 2000). Therefore, the entry structure has to reflect the principle of concept orientation, thus allowing for the maintenance not only of all concept-related information
31

Klaus-Dirk Schmitz
but also of all terms in all languages with all term-related information within one terminological entry. Terminological entries designed according to the principle of term orientation, which we very often find in bilingual glossaries or dictionaries, are not appropriate for meticulous terminology management and will quickly lead very soon to inconsistent terminology collections that are not very useful, especially if multilingual terminology management is required.
The second important principle of terminological entry modeling is term autonomy. Term autonomy guarantees that all terms including synonyms, abbreviated forms and spelling variants can be documented with all necessary term-related data categories. This approach can be realized by designing the data model in such a way that allows the user to create an unlimited number of term sections or term blocks containing individual terms and all additional data categories describing the term and its use.
Data Modelling for Software Localization The terminological data categories specified in ISO 12620 (1999) as well as the three list of typical data categories mentioned in the previous chapter are very appropriate for most traditional application areas of terminology management systems, such as translation, technical writing, LSP dictionary compilation or terminology standardization. But are they sufficient for software localization?
The localization of printed documentation, web pages and online help is very similar to the translation of other text documents. Therefore, traditional terminological data categories and data modelling principles are suitable for these types of documents. But the management of user interface terminology requires additional data categories since terms and underlying concepts may have different meanings, definitions and translations depending on the part of the user interface they belong to. The same term can be used in the menu of a software, in a dialog box or in an error message, but representing different concepts. The following list shows a draft proposal for specific data categories needed for the management of user interface terminology:
• localization unit type (menu, dialog box, message etc.)
• menu type (menu bar, menu item etc.) • dialog box type (check button, radio button, push button
etc.) • message type (error message, status bar, tool tip etc.)
32

Terminological Data Modelling for Software Localization
• environment subset (e.g. Windows XP) • product subset (e.g. Notepad) • localization unit (ID number from localization tool) • etc.
The main principles of terminological data modelling such as concept orientation and term autonomy are also applicable for software localization. Term autonomy seems to be not so important since synonyms should be avoided within a specific software product. But for concept orientation we need a different and specific (theoretical) view. What makes up a concept in software localization? Are all elements of the software user interface concepts (of the same kind)?
Concepts are “cognitive representatives” (Felber & Budin, 1989) for objects, stand-ins, as it were, that arise out of the fact that humans recognize the common characteristics that exist in a majority of individual objects of the same type and then store these characteristics (e.g., remember them) and use them to impose order on the world of objects and in order to achieve mutual understanding when they communicate with other people. ISO 1087-1 (2000) defines a concept as a “units of knowledge created by a unique combination of characteristics”.
There is no doubt that user interface terms used in menus and dialog boxes like “file” or “options” are concepts in this traditional terminological view. But localization unit like “open file”, “save as …” or “insert table” represent also concepts of the user interface although they are traditionally classified as phrases. Similar problems arise with menu items like “templates and add-ins” or “spell check and grammar” that are not seen as single concepts but as combination of concepts. Very problematic are localization units used in error or system messages. The following list shows examples of this type of messages:
• paper jam • unexpected error in application program • not enough memory for display the graphic file • please check network configuration • file %f could not be opened
All these localization units are identified as individual items for the localization process by tools such as Catalyst or Passolo. They should be managed and documented as individual entries in terminology
33

Klaus-Dirk Schmitz
management systems and therefore understood as localization concepts. This requires a more specific and different view to the theoretical principles and methods of terminology science if this academic discipline will provide the theoretical foundation for software localization terminology management. More scientific investigation is needed to underpin this theoretical change in one of the basic concepts of terminology science.
Conclusion Software localization requires appropriate terminology management, but traditional approaches for designing and modelling terminology management solutions have to be adapted to the specific needs of user interface terminology. This will lead to a sophisticated terminological data modelling for software localization. As a consequence special localization tools like Catalyst and Passolo have to provide interfaces to supply terminology management systems with concept-oriented entries containing localization units that are documented with specific localization-related data categories. And exiting interchange formats such as TBX or XLIFF have to be adjusted to these particular needs.
References Esselink, Bert; A Practical Guide to Localization.
Amsterdam/Philadelphia: John Benjamins, 2000. Felber, Helmut & Gerhard Budin; Terminologie in Theorie und Praxis.
Tübingen: Narr, 1989. ISO 704; Terminology work – Principles and methods. Geneva: ISO,
2000. ISO 1087; Terminology work – Vocabulary – Part 1: Theory and
application. Geneva: ISO, 2000. ISO 12200; Computer applications in terminology – Machine-readable
terminology interchange format (MARTIF) – Negotiated Interchange. Geneva: ISO, 1999.
ISO 12620; Computer applications in terminology – Data categories. Geneva: ISO, 1999.
ISO 16642; Computer applications in terminology – Terminological markup framework (TMF). Geneva: ISO, 2004.
Mayer, Felix; Klaus-Dirk Schmitz & Jutta Zeumer (eds.); eTerminology - Professionelle Terminologiearbeit im Zeitalter des Internet. Akten des Symposions, Köln, 12.-13. April 2002. Köln: Deutscher Terminologie-Tag e.V., 2002.
34

Terminological Data Modelling for Software Localization
Reineke, Detlef; Datenmodellierung in der Softwarelokalisierung (Modelación de datos en la localización de software). Dissertation, Universidad de Las Palmas de Gran Canaria, 2003.
Reineke, Detlef & Klaus-Dirk Schmitz (eds.); Einführung in die Softwarelokalisierung. Tübingen: Narr, 2005.
Schmitz, Klaus-Dirk; Criteria for evaluating terminology database management programs, in Sue Ellen Wright & Gerhard Budin (eds.), Handbook of terminology management (Volume II), Amsterdam/Philadelphia: John Benjamins, 2001.
Schmitz, Klaus-Dirk; Terminologiearbeit, Terminologieverwaltung und Terminographie, in Karlfried Knapp et al. (eds.), Angewandte Linguistik. Ein Lehrbuch, Tübingen: Francke, 2004.
Schmitz, Klaus-Dirk & Kirsten Wahle (eds.); Softwarelokalisierung. Tübingen: Stauffenburg, 2000.
Wright, Sue Ellen & Gerhard Budin (eds.); Handbook of terminology management (Volume II). Amsterdam/Philadelphia: John Benjamins, 2001.
35


Conceptualisation and Terminology for Knowledge Elicitation of Technologies and Production
Processes
LEONARDO MEO-EVOLI & GILIOLA NEGRINI1
The paper introduces the KnowClass Model developed to represent fragments of reality and to retrieve terminology, information, knowledge and rules. The model enables identification, analysis and organisation of concepts embedded in terminology in that it integrates ontological, semantic and semiotic information in order to elicit knowledge and reveals the implicit components of the categorisation. The implicit categories governing the conceptualisation are of various types and lie at different levels of profundity. The paper describes the methodology adopted for the practical categorisation, presents some results and values, and shows the possible uses of the application in an interoperability context.
Introduction People live in a context where goods and services produced by the industrial system fit their needs, interests and activities. This interaction is termed the Man-Industry Value Chain (MI-VC) (ManuFuture, 2003), (Jovane, 2005), evolution of which depends on research and development activities to innovate goods, services, processes, and industries themselves. The interaction between research and industry is called the Research-Innovation Value Chain (RI-VC) (ManuFuture, 2003), (Jovane, Koren and Boër, 2003). In order to govern the evolution of society, it is necessary to describe and represent both of these Value Chains. Innovation introduced by the research system is necessary for the evolution of the industrial system. Innovation concerns produced/required technologies as well as production processes of
1. Istituto di Tecnologie Industriali e Automazione (ITIA), Consiglio Nazionale delle
Ricerche (CNR).

L. Meo-Evoli & G. Negrini
goods and services. Companies need to increase their output of high value-added products and technologies. By introducing innovation, research generates and transforms knowledge. The reorganization of the Consiglio Nazionale delle Ricerche (CNR: Italian National Research Council) currently in progress has designated a Department for Production Systems (SDP) whose objectives are the innovation and competitiveness of the industrial sector. The aim of our work is to provide the SDP with theoretical and applied support in relation to governance of the MI-VC and RI-VC. In particular, the intention is to represent and manage:
• The knowledge produced by innovation research. • Realised technologies. • The production of goods and services. • Italian research projects planning. • The information flow among the actors involved in innovation
research (i.e. researchers, industrialists, citizens, political and scientific governance bodies).
The Approach A model called the KnowClass Model has been developed to represent fragments of reality and to retrieve terminology, information, knowledge and rules. Its use is functional to the governance system which conceives studies, promotes, realises, and uses new technologies. The software system based on the KnowClass Model is termed the KnowClass Application, and it is used to identify, analyse and organise concepts embedded in terminology. The application comprises a multilingual terminological database. The knowledge base focuses on the reference entity represented by a term. The aim is to make explicit what the term implicitly expresses, as well as to furnish the most exhaustive information possible concerning the entity; information which consists of concepts extracted from both the term definitions and the reference context. The model adopts an ontological approach. Ontology is the theory of objects and the connections among them, and it provides criteria with which to distinguish among various types of objects - concrete and abstract, existent and non-existent, real and ideal, dependent and independent - and their relations, dependencies and ‘predications’ (Corazzon, 2004). Ontological criteria include categories like thing, process, matter, whole, part, i.e. pure categories which characterise
38

Conceptualisation and Terminology for Knowledge Elicitation
aspects or types of reality, as well as categories representing hierarchical structures or concept relations. Therefore ontology furnishes criteria and categories with which to organize and construct a ‘robust’ model. Materials, technologies enabling production processes, and produced artifacts should be described as objects with their own natures, forms, attributes, parts, uses. Production processes can be described in terms of their components, phases, evolutions and enabling elements. Relationships between objects and processes are identified by the knowledge base in order to represent fragments of reality. The KnowClass Model is based on Poli’s theory of semiotic, semantic, and ontological categorisation, (Poli, 2001), (Poli and Negrini, 2001). The theory integrates ontological, semantic and semiotic information in order to elicit the knowledge directly and indirectly embedded in the reference entity under examination. The approach brings out the implicit components of the categorisation. The implicit categories governing the conceptualisation are of various types, and they lie at different levels of profundity. A) Ontological aspect of the theory Theoretical analysis of a reference entity or item is concerned with its inner categories: that is, it identifies the item’s nature independently of roles, functions and use in context. These inner categories are called Metaroot, Root and Domain, and they constitute a hierarchical structure. The ontological theory adopted is discussed in detail by (Poli, 2001). Metaroot categories are not ‘a priori categories’; rather they are the result of empirical inquiry and consist of Tangible object, Intangible object, Stuff, Group, Process, Quality, Relation, Position (in space or time) and Language. All the Metaroots categories subsume an ontological definition which governs their behaviour. For example, Tangible object is defined as a "stationary, bounded event made of some material". The other categories can be similarly defined in ontological terms. This information enables construction of a first network of properties. The definition of a Tangible object yields the information that objects have a form (which can be articulated into shape and dimension) and that they have a material nature acquired from the material of which they are made. Root categories are of crucial importance for the segmentation of reality. The various categories are not mutually exclusive: for instance, Tangible object is distinguished into Natural object, Natural
39

L. Meo-Evoli & G. Negrini
phenomenon, Artifact, Fauna, Flora, Food and Human being. Each category has an intricate structure involving numerous Is_A hierarchies and other classifications. Domain categories yield information more closely connected with the functional characteristics of the item. Another dimension of investigation independent of the hierarchy of Metaroot, Root and Domain consists of the following categories, which constitute the core of the ontology: Particulars, Wholes, and their parts. B) Semiotic aspect of the theory Semiotic representation generally concerns the signs that represent items. Linguistic expression is the most important sign because it enables both the identification of a reference entity and communication between people. The knowledge base includes terms denoting a reference entity in several languages. Identification of the Preferred term between two synonyms is optional. The KnowClass Model allows the undifferentiated use of several terms representing the same item. It shows how a particular object traditionally hand-crafted in different regions can assume different denominations. This consolidation of local terms has a significant impact on the technical terminology of a national language. It also has an impact on automatic production where CAD (Computer Aided Design) and CAM (Computer Aided Manufacture) technologies require the unambiguous identification of an entity. Similar problems arise with English and American terms representing the same item. There is no difference between this national language problem and the plurality of languages denoting the same concept. For this reason several terms identifying the same ‘codified item’ may be present in the knowledge base. For the purpose of semiotic representation the model introduces the multimedia image of the item. The visual representation of the item is very important since the image contributes together with semantics to knowledge of the item. C) Semantic aspect of the theory Semantics is defined as the set of contents related to an item. These contents concern the nature, properties, matter, uses, type, etc of the item. Semantics requires specification of the context which gives social, historical and cultural information about the particular reference entity.
40

Conceptualisation and Terminology for Knowledge Elicitation
C.1) Contents and definitions The purpose of the knowledge database is to produce knowledge. The definition of a term representing an item is the statement of the term’s meaning. It expresses the contents of the item. We note following:
• A detailed definition produces more information than does a concise definition.
• Several definitions of the same term representing the same item should have the same meaning expressed in different ways.
• Several definitions of the same term representing the same item generally produce more information than does only one definition.
It may be inferred that a plurality of definitions is very important in order to acquire, by means of comparison, both correct contents and more information. However non-coincident contents as well as opposed contents should be carefully analysed. In order to acquire more information and to compare contents, the authors used general dictionaries, different dictionaries specialised in the same domain, and scientific/technical manuals. Our aim was to produce univocally logical, ontological and semantic relationships. These relations create the cognitive network, i.e. the structure of the knowledge system. In particular, we introduced a specific procedure which facilitates both item categorisation and concept systematisation. C.2) Knowledge platform construction The procedure consists in building a knowledge platform which integrates contents and represents the ‘raw material’ for knowledge acquisition and organisation. The three phases of the platform-building process are contents analysis, contents comparison, and concepts integration. We distinguish the following cases:
• Unicity of term definition: the definition itself constitutes the platform.
• Plurality of term definition: building a knowledge platform is necessary. This may be virtual or formal building.
The virtual platform is the ideal result of integrating concept elements which belong to several contents.
41

L. Meo-Evoli & G. Negrini
The formal platform is the material result of integrating concept elements which belong to several contents. Integration requires the following processes:
• Determining the objective in order to direct the contents choice.
• Considering the integration opportunity, estimating the advantage of building formally new contents.
• Making explicit what is unknown: for example, the meaning of a technical term included in the definition.
• Attaching the correct importance to different contents levels, avoiding the generalisation of particular aspects as well as the particularisation of general aspects.
• Fitting the contents to the objective. • Evaluating the rigour of a scientific-technical description. • Cohering all the elements for the purpose of integration.
The procedure yields important new knowledge resources for item categorisation using the ontological approach. From the Theory to the Application We now describe the theoretical constructs necessary to represent the fragment of reality under observation and to satisfy the aims of the Department for Production Systems. Theoretical constructs are transposed into the KnowClass Model and classified in three categories: Ontological, Semantic, Semiotic. The theoretical constructs2 introduced are:
• Concept, Concept name (an identifier) and Current name (a semiotic denotator depending on the set of Signs and the Preferred language chosen by the user in a multilingual environment).
• Sign or semiotic representation of a Concept, Type of sign (which may be Linguistic sign or Multimedia sign) and Preferred term (in the set of Linguistic signs of the same Language for the particular Concept); in what follows Linguistic signs are called Terms.
• Semantic Definition and related Source. 2. Adopted standard: in the paper Italicus strings denote elements of KnowClass
Model and ‘Quoted’ strings denote instances of the KnowClass Knowledge base.
42

Conceptualisation and Terminology for Knowledge Elicitation
• Hierarchy of Metaroots, Roots and Domains. • The Particular nature of an item (which may be Object,
Process, Stuff or Group). • Structure of an item (its composition) and its Whole type
(which may be Aggregate, Solidal composed or System). • Attribute of an item and its Value. • Logical relation between items (the Is_A relation plays a
particular role in the open set of types of Logical relations). • State of an item (which is changed by a Process). • Predecessor-Successor of an item in a structured Process and
the related Type of role (this may be Entity to be transformed, Social factor, Enabling factor, Transformed entity and Waste).
• Enabling technology: tools or resources enabling a Process. The above theoretical constructs are transposed into a conceptual database schema by means of the Entity-Relationship Diagram (ERD) (Chen, 1976). Formally, an ERD diagram is a connected graph of nodes and arcs. The authors define the sub-graph of the ERD graph connected to a single Concept as the Concept Knowledge Graph (CKG). The Concept used to denote a particular CKG is called the Centre of attention. The CKG represents all theoretical constructs and classes of an item. This information space may be very wide because it includes: terminology of an item, compositions, definitions, transition states, etc. The KnowClass Application adopts a human-computer interface comprising:
• The set of possible Views for specific item inspection/analysis (formally, Views are subsets of the Concept Knowledge Graph with the same Centre of attention).
• The manipulation primitives used to move the Centre of attention to an item included in the current CKG and to change the database content.
KnowClass Methodology The approach uses the ontological categories to make explicit the implicit knowledge of each reference entity. For example, the item denoted with the term Table is classified as:
43

L. Meo-Evoli & G. Negrini
• Root: Artifact3 • Structure with Whole type: Solidal composed • Particular: Object, where
• Object has Attribute ‘Dimension' • 'Dimension' has Value ‘Fixed’
The last two sentences are the elicitation of an implicit knowledge which is never expressed or confirmed. The existence of this implicit knowledge is focused upon when the item denoted by the term ‘Table’ is compared - for example - with the item denoted by the term ‘Extendable table’. In the case of ‘Extendable table’ the term itself qualifies the implicit category Dimension with the Value ‘Extendable’, which in this case is explicit. In other words, the procedures of linguistic denomination are governed by conceptual elements which are usually not explicitly named. KnowClass Methodology is the procedure adopted to use the KnowClass Model. This methodology analyses knowledge by means of four approaches: semantic approach, semiotic approach, ontological approach and interconnection approach. Items are introduced as Concepts with their identification (i.e. the Concept name). Concept name is like an anchor or a key necessary for the item identification. The semantic approach investigates concept definitions with their sources. On the basis of the knowledge platform built by the above-mentioned procedure, it captures concepts with their relationships. It furnishes concepts by integrating new elements into the CKG. The semiotic approach introduces the linguistic representation as well as the multimedia representation, if possible. Terms and their synonyms are introduced in different languages. One Concept may correspond to one or more Terms in the same language. One Term may correspond to one or more Concepts. The Term linked with the Concept Knowledge Graph acquires all CKG knowledge. The CKG creates a valuable knowledge source for the technical term. The ontological approach investigates the analysis of the concept in order to define ‘what’ an item is and to identify its properties: for example an Object (like ‘Shoe’), a Process (‘Cutting’), an Attribute (‘High’), a Structure (‘Clicking press’), a State (‘Verified’) and so on. The investigation must also specify the allocation in the hierarchy of Metaroots, Roots and Domains. The item classified as Structure must be investigated in terms of: 3. Artifact pertains to the Metaroot ‘Tangible object’.
44

Conceptualisation and Terminology for Knowledge Elicitation
• Component parts of Object and Process. • Cardinality of the component parts. • Different Structures of the same Object and Process by
different composition type. For example, the structure of the item ‘Cotton fibre’ could describe its chemical and morphological composition.4
The interconnection approach identifies the relations between the Concept and the elements of the universe under examination in terms of context, use, dependency, qualification of item sub-type. Example: ‘Extendable table’ is a sub-type of ‘Table’ and qualifies the Attribute ‘Dimension’ by the Value ‘Extendable’. In order to represent knowledge exhaustively, Logical relations are used to connect the Concept under investigation with a set of other Concepts, each of which performs a particular role; for example:
Logical relation (LR) Concept denoted by the Term
‘Mechanical footwear comfort’ item under investigation
LR-roles LR-arguments Is_A ‘Footwear comfort’dependent on ‘Balance’ dependent on ‘Shock absorption’dependent on ‘Footwear
flexibility’
connections with the universe under study
(N.B. all the LR-arguments are included in the CKG of the
reference entity) Table 1: Example of Logical relation Several Logical relations may exist for the same Concept; for example ‘Balance in gait’ 1) Is_A ‘Balance’ in ‘Gait cycle’ 2) Is_A ‘Dynamic balance’ since the knowledge base contains and defines two types of ‘Balance’ (‘Static balance’, ‘Dynamic balance’). The knowledge base includes the description of artifacts and technologies, i.e. tangible objects, as well as the description of intangible objects (‘Balance’, ‘Barycentre’, ‘Energy’, ‘Comfort’, etc.)
4. Chemically, ‘Cotton fibre’ is composed of ‘Lignin’, ‘Pectin’ and ‘Humidity’,
while its morphological composition is: ‘Cuticle’, ‘Primary wall’, ‘Lumen’ and ‘Secondary wall’.
45

L. Meo-Evoli & G. Negrini
belonging to Domains of physics, engineering, metrology, economics, and so on. Some Results At the moment the knowledge base contains about 2500 Concepts, 3900 Definitions and 4200 Terms in the following Domains: Anatomy, Manufacturing, Footwear industry, Furniture, Natural fibres. The purpose of the KnowClass Application is to describe technologies used to produce useful goods. Its knowledge base therefore represents the production process: that is, procedures, tools and machines. By ‘production process’ we mean ‘all the steps by which the production of one or more goods is conceived and realised’. We now present the results of specific analysis of the Concept denoted by the English Term ‘Cutting’. The semantic approach yields:
• Definition: ‘Make an opening, incision, or wound in (something) with a sharp-edged tool or object’.
• Source: The New Oxford Dictionary of English. The semiotic approach yields:
• Terms: ‘Cutting’ (English), ‘Schnitt’ (German), ‘Corte’ (Spanish), ‘Coupe’ (French), ‘Taglio’ (Italian), etc. Each of these Terms is a ‘denotator’.
The ontological approach yields:
• Domain: ‘Manufacturing’. • Particular: Process:
• Predecessors: ‘Material’ - State: ‘To be cut’ - Type of role: Entity to be transformed.
• Successor: ‘Material’ - State: ‘Cut’ - Type of role: Transformed entity.
• Enabling technology: ‘Sharp-edged tool’. The interconnection approach yields:
• Logical relations: • ‘Hand cutting’ Is_A ‘Cutting’ • ‘Mechanical cutting’ Is_A ‘Cutting’
46

Conceptualisation and Terminology for Knowledge Elicitation
• ‘Digital cutting’ Is_A ‘Cutting’ • ‘Upper parts cutting5‘ Name for ‘Cutting’ of ‘Upper
part’ For example, the previous Logical relation: ‘Mechanical cutting’ Is_A ‘Cutting’ triggers an inheritance mechanism from ‘Cutting’ to ‘Mechanical cutting’ giving all the properties of ‘Cutting’ to ‘Mechanical cutting’. In particular, the interesting properties inherited are:
• Predecessors and the related States and Type of role • Successors and the related States and Type of role • Enabling technologies
The following figure depicts the inherited knowledge in bold, while added or overridden information is underlined.
Predecessors States Type of roles ‘Material’ ‘ISO
Certified’Entity to be transformed
‘Cutter’ ‘Experienced’
Social factor
‘Energy’ ‘Fundamental’
Enabling factor
‘Mechanical cutting’ Components ‘Die creation’ ‘Die localisation’ ‘Incision’
Enabling technologies Successors States Type of roles
‘Sharp-edged tool’ = ‘Die’ ‘Material’ = ‘Cut piece’
‘Fundamental’
Transformed entity
‘Manual clicking press’ Figure1: Example of Process The Concepts included in the specific Process definition allow interesting navigation. By means of the connection with ‘Manual clicking press’, for instance, it is possible to move to its CKG, i.e.: Definitions, semiotic representation with Terms and multimedia image,
5. In the Domain of ‘Footwear industry’.
47

L. Meo-Evoli & G. Negrini
Structure and Logical Relations. We can thus arrive at the types of ‘Manual Clicking Press’: ‘Clicking press with turning arm’, ‘Cutting press with movable trolley’, ‘Beam press’ with their connected CKG, and so on. The chain of relations enables the user to investigate the knowledge base and to elicit non-explicit knowledge through the navigation. It is possible, for example, to show the typology of cutting systems with their properties and find ‘Digital cutting’ with its high-tech Enabling technology ‘Dieless cutting system’. KnowClass depicts both the evolution of enabling technologies and the requisite human capacities. Conclusions The KnowClass Application is still at the prototype stage. We intend to develop the management of concurrency on multiple access and an efficient inheritance mechanism between classes and sub-classes. Nevertheless, the current software version demonstrates the ‘robustness’ of both the model and the theory adopted. The ontological approach is essential for categorisation of an item and identification of its nature, properties, role, parts. Elicitation of these item categories enables links to be established with other items built by logical relations. The network of logical relations constitutes a wide and strong knowledge system. The ontological approach of the KnowClass Model and the KnowClass Methodology relates the item to a particular context. It can also be used to extend the investigation to other contexts. For example, the ‘Dieless cutting system’ may be initially investigated in the ‘Footwear industry’ context. In this case, the item performs the role of enabling technology. The same item may also be investigated in the ‘Capital goods’ context, where its role is product. The feature of integrating several context-views in the same concept enables communication among different skills and environments. For this reason, the KnowClass Application, once engineered, will be the interoperability tool for large multi-partners research projects. It will foster the flow of information among researchers, industrialists, citizens, political and scientific governance bodies, and actors in the research innovation process. References Chen, P.P.S.; The entity relationship model: toward a unifying view of
data, in ACM Trans. Database Systems, vol. 1, no. 1, 1976. Corazzon, R.; Ontology. A resource guide for philosophers, in
http://www.formalontology.it/, 2004.
48

Conceptualisation and Terminology for Knowledge Elicitation
Jovane, F.; Y. Koren & C.R. Boër; Present and Future of Flexible Automation: Towards New Paradigms, in CIRP Annals, 2003.
Jovane, F.; Research based Evolution of the Man-Industry Value Chain, ITIA series, Milano, ITIA-CNR, (in progress), 2005.
ManuFuture 2003 Conference; Working Document for the ManuFuture 2003 Conference, European Manufacturing of the future: Role of research and education for European leadership, Milano, 1st – 2nd, December 2003,
http://manufuture.itia.cnr.it/Manufuture%20document-final.doc Poli, R.; Alwis: ontology for knowledge engineers, PhD Thesis,
Utrecht, Utrecht University, 2001. Poli, R. & G. Negrini; Esplicitare l’informazione latente: il punto di
vista di Alvís, Roma, ISRDS-CNR, rapporto tecnico 6/2001, 2001.
49


Compound Nouns in Swedish and French Technical Terms
CECILIA HEMMING Introduction Terms in technical designations are rarely ambiguous. A common experience, however, shared by lexicographers, terminologists and technical translators is the comprehension problem of multi-word units and/or compounds (e.g. Bierwish 1989; Bourigault et al. 2001; Gawronska et al. 1994; Montero-Martinez et al. 2001). In Machine Translation (MT) and Machine Aided Human Translation (MAHT) stored knowledge from dictionaries, databases and translation memories can be reused when translating new texts, but what about the translation of an unknown term or complete new expressions (neologisms)? The study of technical word formation and equivalents in the source- (SL) and target languages (TL) can give valuable information when trying to predict a translation. This study aims at analysing Swedish and French binominal constructions used to designate technical items. Following e.g. (Johnston and Busa 1999) and (Bassac and Bouillon 2001), we will look into if it is possible to predict the French translations of some Swedish binominal compounds by taking the qualia structure, assumed in generative lexicon theory (Pustejovsky 1995), into consideration. The question is if an analysis of the Swedish compound’s qualia structure could give information about what preposition to use in a French equivalent term. The qualia structure would in this case be extracted from the SIMPLE database, a result of the ongoing SIMPLE project (SIMPLE Annual Report1999) aiming at adding a semantic layer to the existing morphological and syntactic layers of the joint European PAROLE project (Toporowska Gronostaj, M). 1.0 Compound Nouns in Technical Designation Technical word formation in both French and Swedish is frequently facilitated by compounding. In the following we will use the term compound or compound noun to designate juxtapositions of two nominals (as in the Swedish term kolvpump [piston pump]) as well as entities that contain a head-noun followed by a modifying prepositional

Cecilia Hemming phrase (as in the French term pompe à piston [piston pump]). Following (Kocourek 1991:139), we regard a French term of the form noun + preposition + noun as one entity, if no further modifiers can be placed between the constituents. In the study we are only considering bi-nominal constructions even if it is not unusual to see French terms in technical designation with four, five or even more constituents, e.g. moissonneuse-batteuse à barre de coupe frontale [front cut combine harvester] (Hemming 1998:19). There are morphological production patterns that seem to be language specific. In Swedish, a compound noun morphosyntactically consists of juxtaposed nominals where the head noun is placed at the end of the term, directly after the modifier, see example (1-a) below, e.g. avgaskanal [exhaust+pipe]. In French, however, a corresponding term is most often a post-modified prepositional compound where the head noun is followed by a preposition that in turn is followed by a nominal or verbal modifier, see (1-b), e.g. conduite d’échappement [exhaust + P(preposition) + pipe = “exhaust pipe”]. (1) a) Swedish: noun[modifier]+noun[head].
b) French: noun[head] + P + noun/verb[modifier] See the example terms in (2-a) and (2-b), where bränsle/carburant is the Swedish/French translation for “fuel”, kran/robinet corresponds to the English word “tap” and ledning/tube to “pipe”. (2) a) bränslekran — robinet de carburant [fuel tap].
b) bränsleledning — tube à carburant [fuel pipe]. It has been claimed that some French prepositions, like de and à are semantically underspecified or even lack meaning in that they seem interchangeable in some term patterns. This is what (Spang-Hansen 1963) calls les prépositions incolores [the uncoloured prepositions]. A more careful semantic analysis reveals, however, that there seems to be a semantic connection between the head noun and the preposition that introduces the modifying noun in a French bi-nominal composition. In a Swedish compound without preposition, the information about the semantic relation that holds between the head and the modifier is left unspecified, as in other Germanic languages (Johnston and Busa 1999).
52

Compound Nouns in Swedish and French Technical Terms
2.0 Relation between Head and Modifier in Binominal Compositions The relationship between the head and the modifier in a binominal compound can be ambiguous (Bassac and Bouillon 2001:1), such as in e.g. wine glass, see (3). It is thus important to have a semantic representation powerful enough to make the various interpretations explicit. There are different meanings about how to analyse term constituents and their relations but several researchers (e.g. Johnston and Busa 1999; Bassac and Bouillon 2001 and Soegaard 2004) claim that a model of compound interpretation in some way based on the the qualia structure can serve this purpose. According to (Pustejovsky 1995:76), the qualia structure specifies four essential aspects of a word’s meaning:
• FORMAL quale: distinguishes the word within a larger domain. • CONSTITUTIVE quale: the relation between an object and its constituents. • TELIC quale: the object’s purpose and function. • AGENTIVE quale: factors involved in the objects origin or “bringing it
about”(e.g. made-of).
2.1 Nominal Sense Alternations (Pustejovsky 1995:28) defines Logical Polysemy as a complementary ambiguity where the multiple senses of words have overlapping, dependent or shared meanings and where the word has the same lexical category in all senses. The analysis of the ambiguity in, for instance, Container/Containee alternations (e.g. the two senses of bottle in “to breake a bottle” and “to finish a bottle”) involves two senses that according to (Bassac and Bouillon 2001) could explain the different meanings conveyed by the French prepositions in terms like the following: (Bassac and Bouillon 2001) (3) a) verre de vin ”glass of wine” [glass of wine].
b) verre à vin ”glass for wine” [wine glass]. In our study we will concentrate the analysis on terms which denote a container-conductor concept. The question is if we can trace the use of French prepositions in a similar way.
Logical Polysemy can according to Pustejovsky (1995) be managed using Lexical Conceptual Paradigms (lcp), represented by dotted types (x·y). An lcp is a sort of constructor that allows for three different readings of the same locution: e.g. for the figure/ground reversal “pipe” there are the physical object, the aperture, and eventually the above
53

Cecilia Hemming mentioned dotted type physical-obj·aperture which encompasses both readings. Entries represented by means of lcp are thus underspecified representations in which lexical units share properties of two types, the appropriate reading depending on the context. We can illustrate this by looking at a semantic representation of the verre-à/de-vin-example from (Bassac and Bouillon 2001). The two terms refer to a container into which one can pour liquid, and their different readings are captured by the following two representations. (3-a) gives the reading: glass of wine λx%e’%y[verre - de - vin(x : artifact.y : wine) Λ holdF (x,y) Λ ◊λwλe[drinkT (e,w,y)...] Λ ...] (F= Formal and T=Telic) As the head is followed by a LIQUID modifier introduced by the preposition de, the liquid becomes the dot object which gives the reading: “a container containing wine”. Here, the compound as a whole has the same function as the modifier, i.e. to drink. In (3-b) the focus is instead on the container as such. The liquid in this case is not a dot object but instantiates instead the argument of the head noun’s telic role, which gives the reading “a container that may be used to contain wine”. It can be represented as follows: glass for wine λxλy%e’%v[verre-à-vin(x) Λ artifactF (x) Λ ◊λe%y[containT (e,x,y : wine)...] Λ ...] (F= Formal and T=Telic)
In contrast to what is the case for (3-a), the compound of (3-b) does not have the same function as its modifier (to drink): it is not possible to drink a verre à vin [wine glass]. As pointed out by e.g. (Bassac and Bouillon 2001), the prepositions à and de in French nominal compounds seem to indicate that modifiers specifiy relationships encoded by the different qualia roles. In this case the FORMAL role points to the fact that the compound refers to a container, while the TELIC role, which gives no information about the content as such, only focuses on the function of the object, see the example in (3-b). 3.0 Different Focus - Different Preposition When it comes to the distinction between different readings (Johnston and Busa 1999) show that for some English compounds the constitutive, agentive and telic interpretations all translate into different prepositional constructions in Italian. (Soegaard 2004) agrees that such translation patterns can be very consistent but points out that the different readings
54

Compound Nouns in Swedish and French Technical Terms
do not seem to arise from the constituents’ qualia and that Johnston and Busa ignore a lot of important phenomena. The aim of (Johnston and Busa 1999), though, is not to develop a complete analysis of compound terms but to handle the majority of equivalent compound patterns for English and Italian. This approach can be sufficient for a simple interlingual representation that maps translation equivalents from two different languages to each other. (Soegaard 2004) gives examples where the agentive and the telic interpretations of and English compound translate into Italian constructions with the preposition di and da respectively. See (4-a/5-a) for a simplistic representation of the agentive reading for plastic knife, “knife made of plastic”, and (4-b/5-b) for the telic reading “knife used for plastic”: English compound (plastic knife) (4) a. αβ = λx.λy.α’(x) Λ β’(y) Λ agentive(x,y)
b. αβ = λx.λy.α’(x) Λ β’(y) Λ telic(x,y) Italian equivalents (costello di plastica, costello da plastica) (5) a. α - di - β = λx.λy.α‘(x) Λ β ‘(y) Λ agentive(x,y)
b. α - da - β = λx.λy.α‘(x) Λ β ‘(y) Λ telic(x,y) 3.1 The Prepositions à and de in French Binominal Technical Terms The two Swedish compounds in (6) seem very similar on the surface, their French translations, though, are formed with different prepositions. Following the reasoning above, the question is if a simple analysis of the qualia structure of the constituents in a Swedish compound could give information about what the preposition in a French equivalent term hints to. (6) a. bränslerör — tube à carburant
[pipe P fuel: fuelpipe] b. bränsleledning — conduite de carburant
[pipe P fuel: fuelpipe] A possible interpretation of (6-a) would be that the preposition à puts focus on the FORMAL role, the physical object that encompasses the fuel, and that de in (6-b) instead focuses the CONSTITUTIVE role, the aperture, with the pass-through function, the TELIC role.
55
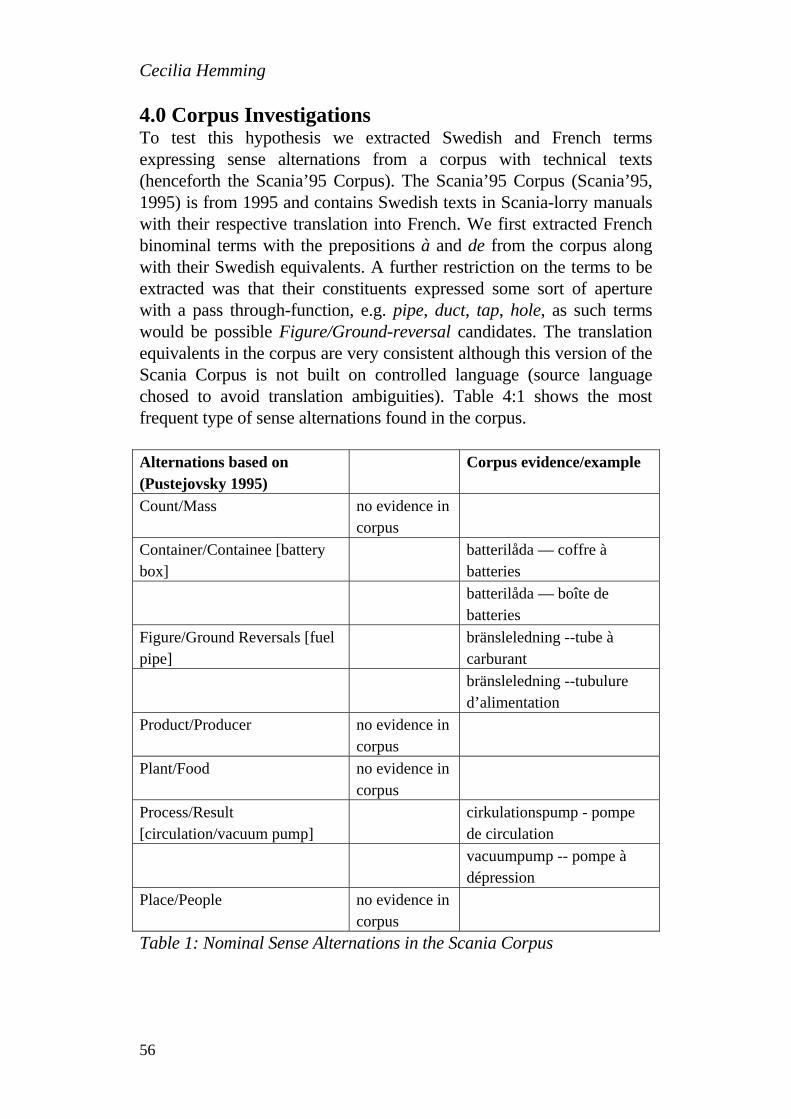
Cecilia Hemming 4.0 Corpus Investigations To test this hypothesis we extracted Swedish and French terms expressing sense alternations from a corpus with technical texts (henceforth the Scania’95 Corpus). The Scania’95 Corpus (Scania’95, 1995) is from 1995 and contains Swedish texts in Scania-lorry manuals with their respective translation into French. We first extracted French binominal terms with the prepositions à and de from the corpus along with their Swedish equivalents. A further restriction on the terms to be extracted was that their constituents expressed some sort of aperture with a pass through-function, e.g. pipe, duct, tap, hole, as such terms would be possible Figure/Ground-reversal candidates. The translation equivalents in the corpus are very consistent although this version of the Scania Corpus is not built on controlled language (source language chosed to avoid translation ambiguities). Table 4:1 shows the most frequent type of sense alternations found in the corpus. Alternations based on (Pustejovsky 1995)
Corpus evidence/example
Count/Mass no evidence in corpus
Container/Containee [battery box]
batterilåda — coffre à batteries
batterilåda — boîte de batteries
Figure/Ground Reversals [fuel pipe]
bränsleledning --tube à carburant
bränsleledning --tubulure d’alimentation
Product/Producer no evidence in corpus
Plant/Food no evidence in corpus
Process/Result [circulation/vacuum pump]
cirkulationspump - pompe de circulation
vacuumpump -- pompe à dépression
Place/People no evidence in corpus
Table 1: Nominal Sense Alternations in the Scania Corpus
56

Compound Nouns in Swedish and French Technical Terms
The extracted terms were divided into three different groups depending on the physical form of their Swedish referent, see Table 4:2, below. Group 1) Terms that combine a head-morpheme, denoting some
sort of a channel or pipe, and a modifier denoting its function or the substance supposed to pass through.
Group 2) Terms that combine a head-morpheme, denoting some
sort of tap or valve, and a modifier denoting its function or the substance supposed to pass through.
Group 3) Terms that combine a head-morpheme, denoting some
sort of hole/aperture, and a modifier denoting its function or the substance supposed to pass through.
Table 2: Head-Complement combinations In this way, we extracted a total number of 101 translation equivalents. 46 of these classified as Group1-terms, among them 44 with the preposition de and 2 (sic!) with the preposition à. The terms in Group 1, were translated into three different types of French terms: 1-1 HEAD(channel/pipe) + de + COMPL(function) [36 terms] avgaskanal — conduite d’échappement [exhaustpipe — pipe preposition exaust] sugledning — tube d’aspiration [suction pipe — pipe preposition suction] 1-2 HEAD(channel/pipe) + de + COMPL(substance) [8 terms] oljerör — tube d’huile [oil pipe — pipe preposition oil] bränsleledning — conduite de carburant [fuel pipe — pipe preposition fuel] 1-3 HEAD(channel/pipe) + à + COMPL(substance) [2 terms] oljekanal — canalisation à huile [oil duct — duct preposition oil] bränslerör — tube à carburant [fuel pipe — pipe preposition fuel]
57

Cecilia Hemming In Group 2, there are 38 terms in total, combining a head-morpheme like tap, valve or similar with a modifier denoting either the substance passing through or the function of the compound:
• HEAD(tap/valve) + de + COMPL(function) [34 terms] • HEAD(tap/valve) + de + COMPL(substance) [3 terms] • HEAD(tap/valve) + à + COMPL(substance) [1 terms]
In Group 3 there are 17 terms in total, the head-morpheme denotes a regular aperture/hole and the modifier specifies either the substance passing through or the function of the designated part. In this group there are two terms with a modifier that specify a regular or metaphorical substance (datautgång — sortie de données [data outlet]) passing through the aperture. The rest of the modifiers denote a function. All terms in this group are formed with the preposition de.
• HEAD(hole/aperture) + de + COMPL(function) [15 terms] • HEAD(hole/aperture) + de + COMPL(substance) [2 terms]
4.1 Results Bearing in mind that the number of examples in the analysed Scania Corpus is very low, we still conclude the following:
• Terms with a head-morpheme that designates some sort of channel, tap or aperture and a modifier expressing its function, are in the corpus exclusively formed with the preposition de.
• Terms with a head-morpheme that designates some sort of
channel, tap or aperture and a modifier that designate the substance passing through, are in the corpus formed with both prepositions à and de.
• In the Scania Corpus, the occurrence of terms according to point
1 are far more frequent than those according to point 2 (85 versus 16).
5.0 Web Investigations Due to the data sparseness in the small Scania Corpus, we also compared our corpus results with search hits on the Web. We used the Google search engine to search for six different French head-nouns, denoting some sort of channel, in combination with both prepositions à and de and a relevant modifier denoting either a substance or a function.
58

Compound Nouns in Swedish and French Technical Terms
This, in analogy with the terms found in our corpus. The use of the Google search engine was not supposed to give exact numbers of relevant term construction hits, but rather to give a hint of the frequency of different constructions. We are well aware of the fact that idioms, titles and other features are likely to bias such search. For the hit results, see table 3 below: tube tubulure tuyau tuyauterie canalisation conduite de à de à de à de à de à de à huile 179 1 3 - 61 6 26 - 140 - 153 1eau 173 123 4 - 785 127 251 3 6190 1 14200 10carburant 5 3 1 - 49 10 13 30 168 4 352 5air 245 219 43 2 1180 820 72 21 236 24 743 10échappement 230 - 333 - 6310 1 134 - 121 - 93 -évacuation 339 - 56 - 7230 - 125 - 610 - 644 -vidange 38 - 60 - 639 1 56 - 78 - 112 -aspiration 721 7 130 - 3370 1 414 - 93 1 336 -Table 3: Search hits using Google Regarding this Web study, we can conclude the following:
• More general French morphemes like eau [water] and air [air] seem to be used more frequently with the preposition à, especially in combination with the French words tube and tuyau [pipe].
• Only one term constructed with the preposition à, namely
tuyauterie à carburant scored higher in number of Google-hits than a correspondent term constructed with the preposition de, head and modifier unchanged (30 hits against 13).
6.0 Conclusions It is clear that the preposition de, in the sub-domain explored in this study, outperforms the preposition à. This is especially the case when the term modifier expresses the telic role of the compound. We found, in general, very few occurrences of head-noun/modifier-combinations formed with the preposition à. Due to data sparseness, we tried to extend our corpus evidences by using Google’s search engine on theWeb. In conclusion, we found similar results in the corpus and the Web-search. One exception, though, is for terms formed with the preposition à and the French modifiers eau [water] or air [air], which, as mentioned above, very well can be due to biased data with such general expressions. Some compounds of this form were nearly as frequently found as the correspondent term constructed with de. The results of this
59

Cecilia Hemming study were unambiguous and at least for us somewhat surprising, we had expected to find a more equal distribution of terms constructed with the two different prepositions, thus hinting at different interpretations of Figure/Ground-reversal candidates. References Bassac, C. & P. Bouillon; The telic relationship in compounds in french
and Turkish, in First International Workshop on Generative Approaches to the Lexicon, Genève, 2001.
Bierwisch, M.; Event-Nominalizations. Proposals and Problems. Motsch W. (eds.), Wort struktur und Satzstruktur. Berlin: VEB (=In Linguistische Studien, Reihe A 194), pp. 1 – 73, Berlin: Akademie Verlag, 1989.
Bourigault D.; C. Jacquemin, & M.-C. L'Homme (eds.), Recent Advances in Computational Terminology, John Benjamins Publishing Company, Amsterdam /Philadephia, 2001.
Gawronska, B.; C. Willners; A. Nordner & C. Johansson; Interpreting compounds for machine translation, in Proceedings of Coling-94. Kyoto, Japan, 1994.
Hemming, C.; Les termes du machinisme agricole. BA-thesis, Department of Languages, University of Skövde, 1998.
Johnston, M. & F. Busa; Qualia structure and the compositional interpretation of compounds, in Viegas, E. (eds.), Breadth and Depth of Semantics Lexicons, pp. 167 – 87, Kluwer Academic. Dordrecht, 1999.
Kocourek, R.; La langue française de la technique et de la science. Wiesbaden: Oscar Brandstetter Verlag, 2nd ed., 1991.
Montero-Martinez, S.; P.A. Fuertes-Olivera & M. Garcia de Quesada; The translator as ’language planner’: Syntactic calquing in an english-spanish technical translation of chemical engineering. Meta 46, 2001.
Pustejovsky, J.; The generative lexicon. MA: Cambridge, MIT Press, 1995. Scania’95; http://stp.ling.uu.se/~corpora/scania/#corpus, 2004-06-
23, 1995. SIMPLE Annual Report 1999,
http://www.ub.es/gilcub/SIMPLE/reports/ANNREP99.htm, 2005-01-01.
Soegaard, A.; A compound matrix. The 11th International Conference on Head-Driven Phrase Structure Grammar, Leuven, Belgium, 2004.
60

Compound Nouns in Swedish and French Technical Terms
Spang-Hansen, E.; Les prépositions incolores du français moderne. Copenhague: G.E.C. GADS Forlag, 1963.
Toporowska Gronostaj, M.; The Swedish PAROLE Lexicon. Göteborgs Universitet, Språkdata, 2005-01-01. http://www.ub.es/gilcub/SIMPLE/reports/parole/parole_swedish.
htm
61


A Guide to Terminological Data Categories
Extracting the Essentials from the Maze
SUE ELLEN WRIGHT
Introduction: Current trends Two major criticisms have been lodged against ISO 12620:1999, Computer Assisted Terminology—Data Categories: it is too large, with too many data categories, and the data categories that one needs for an “ordinary” terminology resources are potentially scattered throughout the voluminous list of options. The size of the original data category collection is a manifestation of the need to accommodate the huge variety of data category concepts that are utilized in the many different types of termbases maintained by official term banks, language planning organizations, major corporations, standards organizations, small and medium businesses, as well as individual terminologists, translators, and technical writers. Most of these resources each use a fairly modest number of data categories, at least compared to the hundreds of items contained in the standard, but many include a few specialized categories designed to meet their particular needs and objectives, which accounts for the fact that the entire set is so voluminous. Given the large number of items in the collection and divergent user requirements, it is highly desirable to provide termbase designers with clear guidance on application-specific use of the data categories. The 1999 document does provide some orientation by organizing categories into ten thematic sets, but the grouping principles used here reflect only one way of ordering the data categories. The standard does not propose any recommended sample sets that might be used in individual termbases, such as for translation-oriented terminology management or terminology planning. Thus the collection remains very opaque for newcomers to the standard because they need to select items from several different parts of the standard in order to meet their documentation needs. Furthermore, the structure used to present the data categories reflects assumptions regarding ideal data modeling approaches, which can

Sue Ellen Wright
nonetheless serve to obscure the location of some critical elements of information. This comment is not intended as a criticism of the approach taken, but simply emphasizes the need for user guidance. For instance, some common categories, such as synonym and abbreviation, are found as values of the closed data category termType. Finally, not everyone is happy with the systematic ordering of at least some of the data categories as they are presented in the standard. Indeed, one might assert that everyone is unhappy to some degree, but that the potential for any sort of consensus on a new ordering scheme is unfortunately limited.
Ironically, despite complaints about the size of the collection, current work in TC 37 with respect to data categories is moving in the direction of increased complexity rather than toward the kind of simplification that might appear to be desirable in light of the concerns expressed above. New applications and new venues for terminology management and related activities are necessitating the addition of new data categories. These areas of interest include hard copy dictionaries, machine-processable lexicographical resources, machine-translation lexicons, morpho-syntactic markup, NLP lexicons, and interoperability with thesauri and ontological resources, among others. These applications are of special interest to the relatively new TC 37/SC 4, Language Resource Management. The addition of new data categories accommodates a growing need for interaction and data leveraging among diverse, yet related, working environments. At the same time, experts are also identifying the widespread use of many of the same categories (e.g., term, word, definition, context, etc.), frequently accompanied by a slightly different focus and function, depending on the information management task involved.
At an intermediate stage when TC 37/SC 3 was contemplating the publication of a new hardcopy list of the data categories, the difficulties associated with trying to achieve consensus on a logical ordering system from among various options led to the decision to simply alphabetize entries, eliminating the subset-based categorization provided in the original 12620:1999. Subsequent expansion enriches the collection, but exacerbates the problem that new users can easily get lost in the maze. To make matters worse (or better, depending upon one’s perspective), TC 37 has begun creating a “Global Data Category Registry” (DCR) available on the Web to all potential experts. The system provides the capability of creating one’s own data category selection (DCS) based on the data category specifications found in the registry. This approach increases accessibility from a technical standpoint, in that the data
64

A Guide to Terminological Data Categories
categories, together with their definitions and other critical properties, are freely available in machine-readable form. But at the same time, the DCR in its current form still obscures retrievability issues because access to data categories is either by random look-up or from long alphabetical lists. Users are not currently presented with a comprehensive overview of the collection and there is no utility for exploring existing related items in any sort of structured way. Only those who already know what to look for will reap the maximum benefit from this resource (Wright, 2005; Ide and Romary, 2005). One possible solution to the question of “overviewability” (Übersichtlichkeit) may be to provide faceted subsets of data categories as a function of the DCR interface, which could be configured to present a variety of views on the collection.
Terminology Management Environments and Aims Although the original ISO 12620 was designed specifically for concept-oriented terminology management applications, it nonetheless targeted a broad audience of users with a variety of intentional aims. Potential creators of terminological resources include:
• national, regional, and local groups establishing databases and data banks to serve the public interest on a number of levels
• standardizers and other domain-specific experts • companies, enterprises, and governmental agencies • individual terminologists, translators, technical writers, and
students creating their own terminology resources
Other ways of classifying application-related criteria include whether the terminology resource being planned will be monolingual or multilingual and whether the originators of the database intend to design their own software tools or whether they intend to use existing, commercial off-the-shelf products. Data category selections and termbase models are quite naturally influenced by the needs and the points of view represented by these different user groups, and by the presence of legacy data that will be imported into the newly designed database. As a corollary to the organizational issues posed by the list of potential resource creators, it is also essential to consider the stakeholders who will elaborate, maintain, and use terminological resources. The selection of data categories depends on the constraints that prevail with regard to data input, storage, and retrieval, as well as
65

Sue Ellen Wright
the kinds of information output that will be required to achieve various intentional aims associated with the database. In addition to the major users already cited, other information professionals are turning to existing and developing terminology resources to supplement a variety of language resource environments, including technical writing, thesauri for information ordering and retrieval, rule-based ontologies and taxonomies for modern information management and processing, inventory and other object control systems, controlled language schemes, systematic map creation, etc. As noted, this proliferation of applications contributes to the expansion of the overall data category collection, as well as to both the diversity and sometimes apparent (but deceptive) redundancy of some of the data category names included in the Data Category Registry.
Criteria for a Guide to Terminological Data Categories Given all these factors, TC 37/SC 3 is embarking on the creation of a Guide to replace the earlier Technical Report, ISO/TR 12618:1994, Computer aids in terminology―Creation and use of terminological databases and text corpora. The report has been withdrawn because it is currently outdated, and reference to text corpora has been dropped. Among other topics, the new Guide will include a discussion of data categories for use in a variety of applications. Ideally this guide to data categories should start with an enumeration of the core data categories that are likely to be included in terminological resources, with an eye to coordination across the various language resources included in a multi-faceted approach. Because of the existence of ISO 12620:1999, it makes sense to start with the current list of data categories used in terminological entries. In this regard, however, about the only common item that appears in all terminological resources is the term itself. Variations then range from rudimentary glosses designed for representing bilingual translation equivalents to highly complex data structures having multiple intended uses, such as are encountered in comprehensive national term banks. Although ISO 12620 does not suggest master data models for any given application, there are two TC 37 standards that do provide an overview of data categories designed for specific purposes: ISO 10241:1992: Preparation and layout of international terminology standards, as well as ISO 12616:2002: Translation-oriented Terminography. These two documents present very similar recommendations:
66

A Guide to Terminological Data Categories
• terms (including all source-language synonyms and equivalents in other languages) - classification of term types (e.g., synonyms, variants, full
and abbreviated forms) - term-related information (grammar, etymology, register,
status) • descriptive information
- definitions, contexts - examples, notes, and graphic information
• administrative information - identifiers of various sorts - dates, responsibility - entry status - sources, distributed as needed with respect to terms
themselves, definitions, contexts, notes, and other pieces of information
Although the principles outlined in ISO 10241 are applicable in other situations, its focus is on standardized terminology and affords less flexibility than one might expect for translation-oriented terminology management. Given the relative freedom for innovation generally encountered in the translation community, it should be expected that the audience addressed by ISO 12616 will exercise a greater degree of flexibility than standardizers will, both in the selection of data categories to be included in terminology resources and in the structural approach to terminological entries. Interestingly, however, the standard presents a single, very traditional data model, based on the notion of a main entry term (presumably a preferred term), which is fully documented in the entry, and which is only associated with synonyms, abbreviations, and other related elements. There is at least an implication in the standard that multiple pieces of information might be included in individual data categories (e.g., different types of grammatical information, multiple synonyms, etc.). This strategy reflects in many respects a paper-based visualization of terminological data entries and fails to account for basic principles of terminological data modeling that underlie many existing electronic terminology management systems. With its focus on the main entry term, ISO 12616 actually veers in the direction of a quasi-lexicographical model, while at the same time espousing a concept-oriented approach.
In contrast, the data modeling philosophy underlying ISO 12620:1999 reflects the consideration of a number of data modeling principles, which include:
67

Sue Ellen Wright
• the concept orientation of terminological entries (each entry treats a single concept, together with all the terms associated with that concept)
• term autonomy (each term “has the right” to complete description and representation within the term entry, which means that all terms are “created equal” rather than simply being entered as synonyms without subsidiary term description; here deprecation is explicit rather than implied)
• appropriate data element granularity (specific data categories should be used to represent appropriate levels of detail, such as part of speech, grammatical number, etc., instead of, e.g., grammar, with multiple values in a single field)
• the elementarity of data categories (only one element of information can occupy a data field or data element; multiple data elements of the same category should be repeated if multiple values are present) (Schmitz 1998; Wright 2001)
With regards to term autonomy in particular, the issue of data modeling variance must be addressed. Although the DCR is based on the notion that each term will appear in its own term field, together with its own set of descriptive data categories, a Guide should provide advice for mapping data content along with an explanation that many term-related data categories are, as noted above, presented as items in a single data domain associated with the closed data category termType.
Any guide to the collection must address the problem of locating data categories within the global resource. In this regard, a comprehensive index associated with the major data categories treated in the standard should be compiled in order to facilitate finding data categories (including values specified as content for closed data categories) associated with different views of the collection. The inclusion of common, non-standardized synonymic data category names together with the appropriate cross-references should facilitate the search for appropriate items. Expanding the search and overview-related functions of the DCR would enhance the usability and accessibility of these data categories.
With respect to the original standard, it is important to account for the fact that although many of the core data categories are clustered near the beginning of the document, a certain subset of data categories that may be critical to the core set are positioned in the administrative data categories (inverted term, permuted term, homograph, homonym, homophone, and antonym), considerable “distance” from other more
68

A Guide to Terminological Data Categories
specifically term and concept-related data categories. Of course, in the DCR there is no such thing as presentational “distance” because the data categories are simply accessible as needed, or indeed, inaccessible if a user doesn’t know to look for them. Hence the presentation of a variety of possible data models and the alternate logical groupings of data categories can be highly useful.
Guidance for Application-Specific Data Category Selection Scattered through the collection are a number of data category sets that are the province of specific types of terminology management or that are pertinent to narrow domain specialties. Translation-specific data categories: As noted above, ISO 12616 provides a good model list of data categories used in translation-oriented terminology management, but consideration of a wider variety of data modeling approaches is recommended. Beyond these considerations, however, multilingual terminological entries that document translation equivalents can supply information on the degree of equivalence reflected in a particular matching pair, but the default view is to treat terms appearing in a single entry as equivalent, provided that their definitions do indeed match. Rather than simply indicating quasi-equivalence in problematic cases, it is desirable to specify detailed relationships by identifying false friends and by providing transfer comments indicating individual translation-related conditions affecting the use of partial equivalents. In multilingual terminology management, it may also on occasion be desirable to indicate directionality and to identify source and target languages with respect to a given term pair, especially in cases where conceptual references narrow (diversification) or expand (neutralization) across language boundaries. For instance, German Lack breaks into a variety of narrower concepts (lacquer, varnish, shellac, etc.) when any one of these concepts is paired with an English equivalent, while the individualized sub-concepts coalesce into a more neutralized semantic field moving from English into German. Standardization and language planning: The notion of term status is most frequently associated with the normative authorization assigned to a term, i.e., whether the term is preferred, admitted, or deprecated by an authoritative body or within the framework of a standardizing activity, such as in a private enterprise. Terms may also be identified as regulated terms, which are set down as legal definitions in formal legislation. By the same token, terms proposed for use in sociological terminology management are at best suggested, reflecting a disciplinary aversion to standardization. ISO 12620 also provides a
69

Sue Ellen Wright
series of qualifiers associated with language planning that can be used to characterize a terminological entry as it passes through the approval process. In this context, terms can be classified as recommended, nonstandardized, proposed, and new. The process status of terms with respect to workflow in terminology management is described for terminology planning as unprocessed, provisionally processed, and finalized, whereas the element working status (starter, working, consolidated) of an entry or an element in an entry applies to the completeness and approval status within a database as reflecting the stage of terminological work in general. Many of these items may not be transparent or easy to retrieve within the DCR itself, and some (for instance, term status and process status) can be easily confused if the mechanisms and working environments involved are not carefully explained. Data categories for materials management systems: Some data collections link to inventory control information such as sku (stock keeping unit) and part number, while entries in materials management databases document special values associated with a material-related concept, such as unit and range. Linkage and Language-Related Issues A number of issues or specific features associated with terminology management transcend domain or application-specific concerns. Concept systems and documentary languages (thesauri): It has long been highly recommended that terminological resources be created with reference to concept systems, which essentially place treated concepts within a network of parent and child relationships (superordinate and subordinate concepts). With the growing trend toward the creation of ontological resources in enterprises and in information management environments in general, it can be desirable to create links that point from terminologies to related ontologies and taxonomies. Concurrently, terminologies may evolve along side new or existing thesauri or other information classification and retrieval systems. The data categories that can be used to link these applications must be clarified to avoid confusion. A major concern in this regard is the presence of terminological systems that do not provide the access points needed for automatically linking terminological entries to ontological systems. This factor underscores the need for additional examination of the potential linkage points between the two resource types in order to facilitate automatic processing of terminological information (parsing of definitions, for instance) with an eye to extracting hypernymic and
70

A Guide to Terminological Data Categories
meronymic relations that can be used to automatically position terminological entries with respect to ontological systems. References to subject classification systems and approaches for dealing with legacy data from multiple classification systems should be addressed. Terminological resources do not always incorporate all the information contained in these resources, but it is important to identify the necessary contact points which will allow the user to traverse interfaces between types of information sources. Issues involving multilingual versions of originally monolingual classification or coding systems present special challenges related to differences in the way that the various linguistic and cultural communities order knowledge. Internal links: Terminology entries also feature special links pointing to other concept entries, such as antonym, entailed term, see, and see also references. Each of these items should be delineated, indicating its specific role in terminological collections. Potentially arcane items, such as entailed term (a designation identifying a term used in a definition, context, note, etc., that is defined elsewhere in the data collection), must be treated, together with an explanation of the differences between these various common links. Unfortunately, terminology management systems do not always make a distinction between the different kinds of links that can occur in termbases. Term links in interoperative environments: The interaction of data categories with text in conjunction with corpus management and between terminology collections and localization tools (translation memory or machine translation lexicons) has dictated the specification of additional information, such as the corpus trace link, which indicates the specific location of a terminological context within a text corpus. Term links (TBX link) represent a closely related data category introduced in the localization sector to connect terminological entries to related translation memory segments.1
Similar dynamic functions involve the use of concordancers as a function of the interaction between terminological databases and translation memory tools. Markup indicating term and word formation patterns and term boundaries can be critical in facilitating automatic
1. TBX Link is a namespace based XML notation that enables specific identified
terms within an XML document to be linked to a specific TBX - (TermBase eXchange (TBX) format) XML document. The purpose of the TBX Link specification is to provide a rigorous notation for linking embedded terms in an XML document to a their entries in a TBX document or a TBX database repository. http://www.lisa.org/oscar/tbxlink/
71

Sue Ellen Wright
term extraction during the pre-translation phase of localization. The markup of morphological structures may in the future play a more significant role in the automatic processing of terminological data, particularly with respect to term extraction or other sorts of information identification and extraction. Language and locale-related identifiers: The specification of xml:lang as the form for identifying working and object languages must be clearly explained, and the locale identifiers presented in the Common Locale Data Repository (CLDR) Project and Unicode’s Locale Data Markup Language (LDML) should be introduced (Unicode CLDR , UTS#35). Transcription, transliteration, Romanization, and source-language Unicode representation: The current standard already provides for the inclusion of transliterated, transcribed, and Romanized forms of terms where there is a need or desire to represent terms in non-native scripts. A new feature of some data resources (place names represented in geographical data repositories; GNS 2005) specifies the use of the Unicode representation of names and terms in the source language script as the unique identifying representation associated with a given geographic feature or conceptual reference. In the event that converted forms are used involving other scripts, it is essential that an indication be made concerning the specific conversion method used to arrive at these forms. Consensus must be reached within the TC 37 community concerning the data categories that are needed or can be added to terminological entries in order to facilitate reversibility of such conversions. Web-related issues: Data categories cited in the 1999 standard need to be reconsidered with an eye to current practice with respect to the standards of the World Wide Web Consortium (W3C), specifically with respect to the citation of URLs, URIs, and name-space identifiers. In light of the growing use of ontological resources within the framework of the Semantic Web, the interactive linkages described above will have a bearing on the ability to leverage terminological data for intelligent information retrieval and automatic problem solving in conjunction with axiom-enabled semantic resources. The potential afforded by these approaches provides incentives for termbase designers and implementers to expand their documentation of concept-oriented relationships within terminological resources.
72

A Guide to Terminological Data Categories
Shared Categories in the DCR The views on the data category collection described in the previous sections reflect the data category divisions presented by the current 12620:1999 and some of the criteria discussed in the past for alternate faceted arrangements of the data categories. They do not yet address procedures for harmonizing the use of identical or similar data categories across the various user groups in TC 37. This aspect of the evolving data category environment must be addressed in the various sub-groups of TC 37 in order to facilitate consensus on definitions and usage. Shared data categories include linguistic, that is, term and word-related information, such as part of speech, grammatical gender, etc., as well as typical dictionary-related information, such as definitions and usage notes. Some administrative data categories are also likely to fit into this group, although this information may not be critical in all applications involving interoperability. ISO 12620:1999 lists a wide range of data categories associated with different types and aspects of terminological transactions that are equally applicable in many other processing environments. The logical structure of this data should be the subject of discussion, specifically the identification of terminology transactions (origination, input, modification, check, and approval, withdrawal, standardization, exportation, and importation) and functions (date and responsibility) and the resulting combinations of elements that are used to document the history and provenance of a terminological entry or other language related data. Outlook Special consideration needs to be given to procedures for data category usage that will enable the sharing of important data content, such as the interchange of data between lexicographical and terminological systems, or, as noted above, the mapping of terminological entries to thesaurus or ontological and taxonomical structures. An understanding of the ways that the data categories are used in other resources will enable terminologists to better model their own data in order to ensure effective cohesion between systems using linguistic data. The primary challenge here requires the accommodation of different data models and the establishment of nodes for accessing information that can be shared across systems. Finally, the specification of data categories and their description within TC 37 should be viewed within the context of ISO 11179 for metadata registries. One unresolved conflict involves the insistence on
73

Sue Ellen Wright
the part of the terminologists that although data categories can be classified in terms of open and closed data categories together with their domain values, all of these elements comprise data element concepts. In contrast, closed data categories (such as grammatical gender, which has as its conceptual domain the values masculine, feminine, neuter) are construed by the framers of ISO 11179 (ISO/IEC Joint Technical Committee 32 for Metadata Registries) as having attributes, which are listed, but not further defined. It is consistent with standard terminological views that although one can of course categorize these values as “attributes”, they are concepts in their own right and require definition and specification within the framework of the DCR. References ISO Standards: Publisher: Geneva, International Organization for
Standardization. ISO 10241:1992. Preparation and layout of international terminology
standards. ISO 12616:2002. Translation-oriented Terminography. ISO/TR 12618:1994. Computer aids in terminology―Creation and
use of terminological databases and text corpora. (Withdrawn). ISO 12620:1999. Computer applications in terminology―Data
categories. ISO/IEC 11179-3:2003. Information technology — Metadata registries
(MDR) — Part 3: Registry metamodel and basic attributes Other Bibliography: GNS; GeoNet Names Server. US National Geospatial-Intelligence
Agancy, 2005. http://gnswww.nga.mil/geonames/GNS/index.jsp Ide, Nancy; Romary, Laurent; A registry of standard data categories
for linguistic annotation, in Proceedings of the IVth LREC International Conference on Language Resources and Evaluation, pp. 135 – 138 Lisboa, Portugal, 2004.
Schmitz, Klaus-Dirk; Über wichtige Aspekte bei der Einrichtung einer rechner-gestützten Terminologieverwaltung, in Rita Lundquist, Heribert Picht, & Jacques Qvistgaard (eds.), Proceedings of the 11th Eurpean Symposium on Languages for Special Purposes, pp. 383 – 390. Copenhagen: Handelshojskolen i Kobenhaven, 1998.
Unicode. Common locale data repository project. http://www.unicode.org/cldr/
Unicode. Unicode Technical Standard (UTS) # 35: Locale Data Markup Language (LDML). December 02, 2004.
http://www.unicode.org/reports/tr35/
74

A Guide to Terminological Data Categories
Wright, Sue Ellen; Data Categories for Terminology Management, in Handbook of Terminology Management. pp. 552 – 571, Amsterdam and Philadelphia: John Benjamins Publishing Company, 2001.
Wright, Sue Ellen; Terminology Management Entry Structures, in Handbook of Terminology Management. pp. 579 – 599, Amsterdam and Philadelphia: John Benjamins Publishing Company, 2001.
Wright, Sue Ellen; A global data category registry for interoperable language resources, in Proceedings of the IVth LREC International Conference on Language Resources and Evaluation. pp. 123 – 126, Lisboa, Portugal, 2004.
75


Information Maps Meet Topic Maps
From Structured Writing to Mergeable Knowledge Webs with XML
LARS JOHNSEN There is a growing interest in notions such as standardization and interoperability in many fields concerned with professional knowledge codification, management and dissemination (technical communication, e-learning, etc.). This interest is reflected in the development and use of a number of information models, most of them XML-based, for representing and interchanging document and data structures.
In this article it is discussed how two topic-oriented information models, namely Information Maps and Topic Maps, may be integrated and used for knowledge design in professional settings (technical documentation departments, educational institutions, etc.). More specifically, it is explored how an integration of the two models may lead to the creation of information architectures intended to be usable for people as well as for computers.
Thus, a case is made for an approach to professional content creation that seeks to combine the principles, methods and insights of user-oriented information and document design with the rigour of knowledge representation and especially knowledge representation for the Semantic Web. Information Maps Information maps are information modules designed and produced according to the principles of Structured Writing, a communication methodology devised and developed by R.E. Horn (see Horn 1989, 1993 and 1998). These principles provide guidelines for analyzing, organizing, presenting and sequencing information based on the communicative intent or instructional purpose of the information. Essential to Structured Writing is the idea that informational content should be chunked in manageable modules. The smallest unit in Structured Writing is the so-called information block, a content chunk with one central informational objective, while information maps are units consisting of a limited number of information blocks about the

Lars Johnsen
same topic. Information blocks and maps are always labelled to support such important human user activities as scanning, skimming or browsing content. A label may either indicate the contents of an information unit or its communicative function.
Further, information units may be classified on the basis of the primary communicative or instructional objective they are designed to fulfil. In Structured Writing, seven basic categories of content, or information types, are recognized:
• Concept (introducing and exemplifying concepts and ideas). • Procedure (telling the reader how to carry out specific tasks). • Process (communicating how a series of events develop over
time). • Structure (describing or illustrating objects and their
components and possibly the functions of these). • Fact (providing factual statements such as specifications,
results, measurements, etc.). • Principle (stating policies, rules, axioms and the like). • Classification (dividing domains into classes, subclasses and
instances). Another key principle of Structured Writing is that communicative or instructional goals should be consistently reflected in information or document design. This means that content items having the same purpose, definitions of concepts, say, or descriptions or illustrations of physical objects, must always follow identical design patterns or templates. Figure 1: Information maps
78

Information Maps Meet Topic Maps The appendix contains a simplified information map constructed for demonstration purposes only. It contains five blocks manifesting five different information types. The first block contains conceptual information, an introduction to a fictitious authoring tool; the second block lists the major modules of the tool (structure) and the third block contains factual information about its system requirements. In the fourth block procedural information specifies how the editor is to be installed while the last block contains rules concerning its use in the workplace (principle). A number of information design rules have been applied to ensure the consistency and navigability of the document: the position and design of block labels, the presence of horizontal rules to separate blocks as well as the use of a tabular format for procedural and structural information.
Information maps are highly modular and reusable and therefore conducive to efficient content management. For instance, information maps lend themselves to single sourcing, a document production methodology in which content is developed as self-contained objects and not assembled until publication (see Hackos, 2002 and Rockley, 2003). Likewise, information maps are versatile in that they can be used across different knowledge domains and across different presentation media.
Information maps are in principle independent of file formats, platforms, authoring tools and so on but tools do exist to help writers store their information maps in help files or Web formats such as HTML and XML. This is especially true if writers use Information Mapping®, a commercially available writing method employing and extending the principles of Structured Writing. With Information Mapping® comes for instance a schema called the Mapping Object Model (MOM) for constructing and marking up information maps and blocks in XML.
Albeit very useful for designing consistent user-oriented knowledge communication, information maps seem less ideal for more automated knowledge management tasks. There are at least two reasons for this. One is that information maps are typically stored in markup formats that reflect their presentational structure rather than their semantic content (HTML may be said to be the obvious example). Another reason lies in their inherently modular design which makes utilization or formal organization of more global knowledge structures somewhat difficult. At worst, information maps may become “information islands” where knowledge is either marooned, as it were, or only superficially connected to external knowledge sources through hyperlinks or the like.
79

Lars Johnsen
What seems to be needed, then, is some kind of mechanism which adds value to information maps by offering a way of representing knowledge structures reaching across, and beyond, map boundaries. Topic Maps This mechanism may well be Topic Maps. Topic Maps is an ISO standard and an XML syntax (known as XTM). It is sometimes characterized as a metadata model for creating mergeable electronic indexes but can in fact be used for organizing and classifying information in a wide range of structures (taxonomies, ontologies, etc.). In particular, the topic maps paradigm constitutes a model for superimposing a knowledge layer on top of distributed Web resources which may not only help users navigate more efficiently and effectively in a rapidly growing information space but also provide them with means of linking these resources in more meaningful ways.
Web resources
Topic map(s)
User interface
Figure 2: Topic maps Topic Maps is increasingly perceived as a key technology of the Semantic Web (see for instance Passin, 2004), something which is reinforced by the development of various supporting standards such as the Topic Map Query Language and the Topic Map Constraint Language.
A topic map is a collection of digital objects, every one of which represents a certain subject. A subject may be anything whatsoever we wish to discourse or store information about. Subjects may be addressable or non-addressable. Addressable subjects are information resources with a specific address which can be referenced (digital pictures, web pages, etc.) while non-addressable subjects are non-digital
80

Information Maps Meet Topic Maps entities in the real world (persons, events, products, etc.) or abstract concepts.
A topic, and the subject it represents, may belong to one or more classes and may be given one or more names. Topics may be assigned internal or external information resources, so-called occurrences, which may also be categorized. Last but not least topics may be related in what is known as associations and the role of individual topics in such associations may be specified. The name(s), occurrence(s) and role(s) of a topic are called its characteristics. The characteristics of a topic may be said to be valid in certain contexts or scopes. A scope is in itself a set of topics commonly referred to as themes. To create a topic is called reification. Anything may be reified in a topic map: occurrences, associations and even topic maps themselves. The subject of a topic may be made explicit in various ways. If the subject of a topic is addressable, the connection is made through a direct reference, a subject locator. If the subject is non-addressable, a subject identifier is used. A subject identifier is a pointer to a subject indicator, an information resource, usually a web page, which, directly or indirectly, explains or indicates what the subject is. For instance, the home page of the University of Southern Denmark might function as a subject indicator for the topic representing the University of Southern Denmark.
Topics having the same subject may be merged regardless of whether they occur in the same topic map or in different topic maps. The result of merging two (or more) topics is a union of the characteristics of the topics and the deletion of any duplicates. Topics are said to have the same subject if they refer to the same addressable subject; if they have the same subject identifier or if they share some other uniquely defined characteristic.
As should be clear, Topic Maps provides a relatively simple, yet flexible, topic-based model for organizing content items in the Semantic Web. There is nothing in the topic maps standard as such, however, to suggest just how topic-based material should be presented to users. Not surprisingly, this is of course where information maps may come in handy. Integrating Information Maps and Topic Maps At face value, information maps and topic maps seem to be fairly different things: information maps are stand-alone modules of content while topic maps are subject indexes over information sets. Still, terminology reveals some degree of affinity between the two models: it
81

Lars Johnsen
is no coincidence that both use the map as the central metaphor. In fact, Horn, in explaining the term, likens the information map to a geographical map that follows the contours of the terrain. Similarly, says Horn, an information map follows the underlying structure of its subject matter pointing out its most pertinent concepts, structures, processes, etc (Horn, 1989).
Juxtaposed in this way, both information maps and topic maps are about charting subject matters or knowledge domains. Arguably, the difference lies in the scopes, means and perspectives rather than the fundamental goals of the two models.
It is the assumption of this article that by integrating the two models in knowledge design we can have the best of both worlds: the flexibility and freedom of topic maps versus the guidance, or scaffolding, of information maps; the user-orientation of information maps versus the subject-centredness of topic maps; and the bird’s eye view of topic maps versus the focus of information maps.
Below, four different approaches to the integration of information maps and topic maps are proposed:
• Information maps to topic maps (IM2TM). • Topic maps to information maps (TM2IM). • Information maps for topic maps (IM4TM). • Topic maps for information maps (TM4IM).
In the two first approaches, a mapping from one model to another is envisaged while in the last two an attempt is made to combine the two models in one unified knowledge organization scheme. Information Maps to Topic Maps In this approach it is suggested that information maps may be used for content creation and information design and that automatic processes may be applied to harvest these information maps for salient information. The outcome of this harvesting process is stored in a number of individual topic maps. A further process is subsequently invoked to merge these topic maps into one big topic map which may be viewed, navigated, queried and visualized. The resultant topic map may be conceived of as a kind of global, unified chart of all the information maps and their contents. It may contain an index of term occurrences, a list of multimedia assets, a collection of link anchors and their destinations as well as more administrative metadata linking authors with groups of information maps and so on.
82

Information Maps Meet Topic Maps Figure 3: IM2TM It is hoped that transforming information maps into topic maps will not only create a more coherent view of the contents of the information maps, but also make it possible, at least in part, to merge these contents with content in other repositories. Metaphorically speaking, topic maps become the lingua franca with which information maps may communicate with the outside world.
One major issue in this approach is how well domain knowledge can be gleaned from information maps and captured in topic maps. It would appear that the markup capabilities of an XML vocabulary like MOM together with the writing and design rules laid down in Structured Writing provides an acceptable, but not perfect, basis for some domain knowledge extraction. Consider again the information map in the appendix. The tabular format of the second block combined with the linguistic structure and label of the first block, for example, might be used by a processing application to identify and capture a part-whole relationship in the domain (that is, between the modules listed in the table in the second block and the software package being introduced in the first block).
Another question which needs to be addressed in this approach is how content and metadata in information maps should be mapped onto topic maps categories. What content and metadata items should end up as topics and characteristics and what items are best represented as associations or scopes? Topic Maps to Information Maps Another method might be to use topic maps as the central starting point for knowledge organization. In this “domain oriented” approach, data about subjects are initially stored in topics, topic characteristics and associations but are transformed into, and displayed as, information maps at run, or production, time to accommodate user activities such as skimming, scanning and browsing.
83

Lars Johnsen
This procedure is knowledge-based in the sense that semantic structures are built up using a formal knowledge representation scheme: objects are created, named and related in ways that can be utilized by computer-based engines for querying, deduction or display purposes.
Figure 4: TM2IM
Adopting this approach entails two main lines of activities. One is designing and developing the underlying topic maps drawing upon some kind of ontological domain model and the other is formulating rules for mapping formal knowledge structures onto verbo-visual design. For instance, it must be resolved how specific types of semantic relations can be expressed by means of the visual design options allowed in Structured Writing. Also, rules need to be worked out to automate the generation of labels for information blocks and maps.
Information Maps for Topic Maps Integrating topic maps and information maps does not necessarily have to involve some kind of mapping or transformation. On the contrary, we can also think of designs in which the two models are meant to play complementing roles within one unified knowledge organization scheme.
In one approach topic maps may function as the basic information architecture into which information maps or blocks may be organized. One obvious way of adopting this strategy would be to create a conceptual space represented by topics, topic types and associations and then attach information maps and blocks as occurrences. Scopes might further be set to indicate the properties and metadata of the information
84

Information Maps Meet Topic Maps maps and blocks and the contexts in which they are intended to be valid (for example: language: English; level: beginner; area: programming, etc.).
Figure 5: IM4TM
Information maps assigned to topic maps would be appropriate in contexts where user-oriented materials are needed to clarify, explain or illustrate more formally expressed knowledge structures. E-learning environments might be a case in point (see below).
Populating topic maps with information blocks or maps can be done in two ways: chunks can either be represented as external occurrences referenced by the topic map or be embedded as native XML in the topic map, the latter apparently being an option in the next version of XTM (1.1).
Topic Maps for Information Maps Finally, one may consider a set-up in which the roles of information maps and topic maps are reversed. In this configuration information maps constitute the fundamental building blocks of the information architecture while topic maps are employed to enrich or augment that information space. For instance, clicking a term in an information map might send a user to a topic map letting him explore the conceptual networks in which the concept denoted by the term occurs.
85

Lars Johnsen
Figure 6: TM4IM Or topic maps could be superimposed information maps to indicate rhetorical relationships between content items in individual information maps. For instance, a topic map might highlight that one information map effectively provides a solution to a problem described in another or point out that content in one information map is summarized or elaborated upon in another. Used in this manner, topic maps could turn sets of modular information maps into a semantically cohesive online communication system such as an FAQ, a trouble shooting site or an e-learning architecture. Two Use Scenarios Now, how can these approaches actually are put to practical use in real world settings?
A mapping approach like IM2TM could, or perhaps should, be adopted in technical writing environments where Structured Writing in one form or another is often the chosen tool of the trade. Adopting this method would make it possible for technical writing teams to enrich their product information considerably while still retaining the writing methodology and markup system with which they are most familiar. For instance, it would enable them to semi-automatically create, on top of their user documentation, a conceptual network, which, in turn, could be transformed into a hyperlinked navigation system on a computer monitor or a menu-based access structure on a mobile device.
A non-mapping approach such as IM4TM or TM4IM might prove effective in educational settings supporting the production of digital libraries of e-learning materials. In such a scenario information maps (or blocks) may constitute learning objects, that is autonomous information resources with one central learning objective based on one of the seven information types (concept, procedure, process, structure, fact, principle
86

Information Maps Meet Topic Maps and classification), whereas topic maps may either represent subject-specific conceptual structures to which these learning objects can be attached or learning paths between the individual learning objects (or indeed both). Here teachers, being the subject-matter experts, can use topic maps to formally organize central domain concepts while employing information maps to provide user-centred learning materials about these concepts and their interrelations.
But teachers need not stop here. Since topics in topic maps can reify addressable as well as non-addressable subjects, they can also reify the information maps and blocks that function as learning objects. And once reified, information maps and blocks can be assigned all sorts of distributed information resources in a kind of layered e-learning architecture. For instance, an interactive test or a thread in a discussion forum in an e-learning management system may be attached to information maps effectively blurring the traditional distinction between static learning content and more dynamic and engaging learning resources.
One area where more integrated learning materials are needed is foreign language learning. Till now traditional resources such as dictionaries, grammars and handbooks have lived their own separate lives alongside more recent developments like multimedia products and web applications but there is no reason why these genres should not develop and converge into what we might call networked knowledge bases for language learning. New and innovative e-learning materials, however, will require new information architectures, and therefore, new information models. A combination of topic maps and information maps may prove useful in this respect exactly because it allows consistently designed instructional materials to be assigned to formally defined data structures and vice versa. This means, for example, that an explanation found in a grammar or a handbook can be attached, through a topic map, to a named relation between two entries in a dictionary. Concluding Remarks Although implementation issues are beyond the scope of this article, it is worth pointing out that most of what has been suggested above can be done using, or adapting, existing XML-aware technologies and tools, some of which are even freely available on the Internet. Relevant tools might include XSLT transformation sheets for harvesting and converting information maps to topic maps and vice versa; editors for creating and marking up information maps, topic maps and topic map
87

Lars Johnsen
ontologies; and browsing software for navigating, querying and visualizing topic maps. References Dichev, C.; D. Dicheva & L. Aroyo; Using Topic Maps for Web-
Based Education, Advanced Technology for Learning, vol. 1, no. 1, 2004.
Hackos, J.; Content Management for Dynamic Web Delivery. New York: John Wiley & Sons, Inc., 2002.
Horn, R.E.; Mapping Hypertext. Analysis, Linkage, and Display of Knowledge for the Next Generation of On-Line Text and Graphics. Lexington: The Lexington Institute, 1989.
Horn, R.E.; Structured Writing at Twenty-five. Performance and Instruction, 32, 1993.
Horn, R.E.; Structured Writing as a Paradigm, in A. Romiszowski & C. Dills (eds.), Instructional Development: State of the Art. Englewood Cliffs: Educational Technology Publications, 1998.
Park, J. & S. Hunting; XML Topic Maps. Creating and Using Topic Maps for the Web. Boston: Addison-Wesley, 2003.
Passin, T.B.; Explorer’s Guide to the Semantic Web. Greenwich: Manning Publications Co., 2004.
Rockley, A.; Managing Enterprise Content. A Unified Content Strategy. Indianapolis: New Riders, 2003.
88

Information Maps Meet Topic Maps
Appendix X-editor
Introduction
X-editor is a software package from X-company for producing andmarking up documents in various text formats.
Modules
In the table below the main modules of X-editor and their function are described:
Part Function
XML module Editor for producing documents in XML format
HTML module Editor for producing documents in HTML format
CSS module Editor for producing documents in CSS format
Platform X-editor is running under Windows 98 and XP.
Installation
Follow the procedure below if you wish to install X-editor:
Step Action
1 Insert the installation CD in the CD ROM drive.
2 Click on the Install X-editor icon.
3 Follow the instructions on the screen.
Policy
Questions concerning the use of the software package should beput to John Smith in the IT-department. Questions must be inwriting only.
89


Strategies for Integrated Multilingual Content Development and Terminological Knowledge Management in Academic E-Learning Environments
GERHARD BUDIN Introduction – Modelling Theory The purpose of this paper is to report on ongoing Research & Development work in designing E-Learning environments for multi-cultural learning communities at the University of Vienna.
The focus of this ongoing project is to develop a content strategy in the context of the organizational E-Learning strategy. In the following, the basic assumptions and hypotheses for the development of the strategy are explained. The core of the strategy is an integrated process model that integrates several components in an interactive way. Terminological knowledge management is one of these components with a key role in this process model.
A generic approach applied here is that of modelling. A General Theory of Modelling was developed by Herbert Stachowiak (in particular Stachowiak, 1973) in the epistemological paradigm of Neopragmatism. This General Theory of Modelling is obviously closely related to General Systems Theory and Cybernetics. By applying the generic principles of “modellism” (Stachowiak, 1973) to specific situations, methods such as user modelling, knowledge modelling, didactic modelling, process modelling, etc. have developed over time in different disciplines. For computational implementations many different (formal) modelling languages have been created. The strategy developed here is following this modellistic paradigm.
Didactic Design in E-Learning Environments Pedagogy shows a long history of didactic modelling. Flechsig traces this pedagogical paradigm back to Schwerdt and his “critical didactics” from 1933 (Flechsig, 1980: 74). In the 1970s Flechsig started a project collecting different didactic models in a model library in parallel to

Gerhard Budin
projects in the U.S. that developed typologies of didactic models (Joyce/Weil, 1972 “Models of Teaching” and an “Instructional Design Library” (Langdon, 1977).
In this modellistic paradigm didactic models are conceived as conceptual and symbolic reconstructions of instruction. A didactic model includes the epistemic conditions of knowledge acquisition as well as the intentions of the actors (learners and teachers). Didactic models may have either analytical functions (orientation, understanding, explanation, organization) or constructive functions (planning, developing, etc.) (Flechsig, 1980: 76). The main advantage of didactic models is their power to mediate between analytical and constructive functions in order to arrive at a coherent process model that can be directly implemented. The objects of didactic modelling may be elementary configurations of instructional or learning action, discourse patterns (questioning, answering, group discussion, etc.), instructional action patterns such as exercises, tests, exams, homework, etc. On a higher level of complexity didactic models may refer to types of courses (lectures, seminars, etc.) with proto-typical action patterns over the duration of the modelling unit (e.g. a semester course, a school year) (Flechsig ibidem based on Salzmann, 1972, for a recent compendium of didactic models see Flechsig, 1996).
In this tradition a process model of multimedia- and web-based didactics has been developed by Christian Swertz: it is a knowledge-oriented approach distinguishing different types of knowledge combined with a process model that includes different stages of dealing with knowledge in specific ways (e.g. de-contextualising and later re-contextualising scientific knowledge in the process of designing a web-based course in the spirit of hypertext) (Swertz, 2004). This approach focuses on the didactic organization of knowledge. Knowledge units are structured according to themes and relations between themes in a thesaurus structure. The didactic relations between knowledge units are dynamic in nature as they are re-created every time a course is designed and implemented in the practice of teaching-learning situations. In the model typology of didactic knowledge organization Swertz distinguishes on the levels of macro- and micro-models a range of models such as inductive models, deductive- or theory guided models, problem-based models, example-based models, role-based models, exploratory models, etc. For E-Learning didactics Swertz also distinguishes different media models where types of knowledge have to be related to the medium or media chosen to re-present knowledge units for subsequent knowledge acquisition processes on behalf of the learners. It is important to point
92

Terminological content development for E-Learning
out that all these models include the temporal dimension including sequencing and time allocation to each learning unit.
User modelling is an important process in software engineering in general and in educational technologies in particular. Learner-centered approaches focus on modelling learning patterns in empirical studies of real-life academic or school environments and on deriving generic design patterns from empirical data and the patterns emerging from statistical data interpretation (e.g. Derntl/Motschnig, 2003).
Knowledge construction processes in individual learners require targeted support by E-Learning environments. A contextual approach to the delivery of learning content to users is a crucial step into this direction. Learning contexts need to be modelled and linked to the semantic structures of learning content. The design and construction of so-called learning objects (knowledge units) need to become adaptive processes so that the learning objects themselves are adaptive to concrete contexts that are classified according to the context models. Schmidt and Winterhalter have proposed an integrative, ontology-based approach for user context-aware E-Learning aiming at contextualized learning object delivery (Schmidt/Winterhalter, 2002).
Learning Content Development and Knowledge Management The integration of E-Learning and knowledge management has become a major goal for many teams active in knowledge engineering and knowledge management communities as well as in E-Learning communities. The interaction between learning content modelled and packaged as learning objects and the individual knowledge acquisition processes is supported by ontology frameworks. With ontologies we include a semantic perspective that tailors modelling as a mediation process between the semantic content of learning objects and the semantic assignment of meaning to knowledge representations on behalf of the learner. Semantic Web approaches have produced a typology of ontologies (see Sowa, 2000 for such a typology). The KnowMore project (Abecker et al., 2000; Elst et al., 2001) has produced a typology of ontologies re-used by Schmidt/Winterhalter in the following way:
• Organizational ontologies (roles, departments) • Process ontologies (workflows) • Task ontologies • Knowledge area ontologies (Schmidt/Winterhalter, 2002).
93

Gerhard Budin
Such a typology of ontologies allows to create a framework in which different kinds of ontologies “communicate” to each other in the sense of meaning negotiation for specific learning contexts. The knowledge area or domain ontology provides the thematic concept system of the domain in question. The task ontology includes all possible tasks a learner may be assigned to by the teacher. Each task in itself is then modelled according to the goals to be achieved by the task, the way the fulfilment of the task will be controlled, and according to the methods to be used for fulfilling the task. Process ontologies provide models for the workflow in an E-Learning environment by sequencing tasks, assigning learning objects (that are organized according to the knowledge area ontology) to each task for a given stage in the learning workflow. The organizational ontology defines roles (including the roles of eTutors, learning communities, cooperation models among teachers, etc.). These roles are a pre-requisite for task ontologies to be used for assigning tasks to individuals who are assigned to pre-defined roles.
Context acquisition and modelling of concrete situations require role-based metadata that specify educational roles as well as possible situations and contexts. The results of such a research are “Situated models and metadata for learning management” (Allert/Richter/Nejdl, 2003).
Such approaches are very close to knowledge management practices that start from the perspective of knowledge that is available in employees of an organization or in members of a community of practice (distributed over several organizations or independent from any organization). This distributed personal knowledge needs to be “managed” in the sense of identifying it in each individual person, making this meta-knowledge (the knowledge that person x knows a fact y) available to the community in question and operationalize this meta-knowledge in business process management so that at end specific knowledge is made available at the right time in an appropriate form (knowledge representation) to the right person in order to enable this person to acquire this knowledge and to perform an assigned task in the context of identified workflows. The concept of organizational learning already represents this combined view: corporate E-Learning today is inseparable from corporate knowledge management and vice versa, since E-Learning in organizations is necessarily geared towards the instant enabling of persons assigned with a specific task to perform this task on the basis of targeted knowledge acquisition or learning processes. Obviously the types of knowledge typically stored in knowledge management systems, in addition to the previously mentioned meta-knowledge (“Who knows what in our organization”),
94

Terminological content development for E-Learning
have to be made available in appropriate ways, such as factual knowledge, procedural task-oriented knowledge, but also linguistic and terminological knowledge that enables users to communicate in competent ways in collaborative work processes. Typical process models developed for knowledge management present knowledge life cycles (or rather spirals), from the generation of knowledge to its explicitation, communication, and presentation, dissemination and use. Such life cycles can equally be applied to learning processes (Reinmann 2002).
Figure 1 is a roadmap for Semantic Web technology development in the area of E-Learning. The resulting term Semantic E-Learning covers a broad range of research challenges for developing web services for collaborative work and learning, for ontologies, content authoring, information flows and context modelling, community management, semantic interoperability, etc. (Naeve/Lytras/Nejdl/Balacheff/Hardin, 2005).
Figure 1: The Semantic E-Learning Roadmap (Naeve/Lytras/Nejdl/Balacheff/Hardin, 2005) This roadmap is obviously a long-range research programme since many of the issues listed in this figure are visions we are heading for, e.g. “ubiquitous learning”. At the same time, though, this figure is an excellent point of departure for policy development of large organizations.
95

Gerhard Budin
Terminological Knowledge Engineering for Creating Didactic Ontologies A more technical knowledge life cycle than the one that usually used in knowledge management is presented by Tao/Millard/Woukeu/Davis 2004 for Semantic Web engineering of E-Learning:
• Knowledge acquisition: collects knowledge from domain experts by building structured vocabularies
• Knowledge modelling: will then build ontologies with explicit conceptual relations between clearly defined classes
• Knowledge annotation: the ontology is tested in a domain. Knowledge resources are annotated with ontology metadata
• Knowledge reuse: the annotated resources are used, e.g. in E-Learning environments for creating learning objects or for designing new courses.
This model has made clear that terminologies and ontologies play a key role in E-Learning. Terminological logic (Hahn/Schnattinger/Markó, 2002) can be used for building knowledge-based text mining systems that support structured content development from large scale text resources. Conceptual hypotheses are constructed on the basis of initial text analysis by using terminological logic (applying hierarchical relations such as is-a, part-of, sequential relations, causal relations, etc. to build terminological axioms that are further used to build concept systems). These hypotheses are constantly tested against further text analysis so that the conceptual hypotheses are either corroborated, i.e. verified or they dismissed, i.e. falsified. The conceptual hypotheses are linked to each other. The concept system is constantly evolving and changing. The resulting text ontology can then be directly used for learning content development.
Given the fact that there are numerous terminological resources available it is feasible to expect the emergence of domain ontologies, as the example of medicine clearly shows: SNOMED and other structured medical vocabularies (thesauri, classification systems, list of subject headings) have been enriched with terminological logic and turned into an integrated medical ontology, i.e. the UMLS. These domain ontologies now need to be “didacticized”, i.e. adapted to their use in E-Learning environments as didactic ontologies that can be used not only to support semantic-based content annotation and content structuring, but also to
96

Terminological content development for E-Learning
create learner task ontologies, organizational ontologies for academic institutions or corporations, etc.
An Integrated Process Model for Content Development in Multilingual E-Learning Environments The integration of E-Learning, knowledge management, content management, and communication management has become a key process for research as well as for strategy development and concrete implementations. Due to globalization that has fundamentally changed our societies including academic learning, E-Learning today is more often than not a multilingual, cross-cultural process. Members of learning communities, teachers, tutors, etc. increasingly have different cultural and linguistic backgrounds. This aggravates communication problems caused by the specific teacher-learner situation by adding another dimension of cross-cultural communication and its countless pitfalls that most communication partners are not even aware of. Analyzing previous and ongoing E-Learning projects (e.g. Budin, 2004) as well as by looking at numerous other concrete projects it seems necessary to generalize from individual activities for formulating E-Learning strategies for content development.
The following generic requirements seem useful for the process of designing or improving E-Learning environments:
• Supporting multilingual co-operative work (including
computational translation systems) • Supporting cross-cultural and cross-disciplinary collaborative
work (group work with students from different countries) • Supporting the use of multilingual language resource corpora • Modelling different competence levels for curriculum design for
Bologna-type study programmes such as bachelor and master degrees
• Supporting search and navigation processes in learning content repositories
• Supporting learning resource assessment for quality and relevance
• Supporting usability of the E-Learning system. • Enhancing terminological coherence and consistency in all
learning content • Guaranteeing understandability and comprehensibility of
learning content based on user modelling • Supporting text mining with ontology building systems,
terminology extraction from language resource corpora
97

Gerhard Budin
• Supporting metadata harvesting from learning content • Supporting multimedia content management and content
repository management. The following process model is now proposed as the starting point for strategy development for E-Learning environments. The aspect of interactivity is seen as crucial for E-Learning in the future. Interaction design has become an important principle for learning design (interactive learning) and in fact for all modules of an E-Learning environment. Interactivity is also crucial for linking the four different dimensions of the model to each other. All four dimensions only make sense in an interactive model as part of the whole. Therefore it is mandatory that E-Learning environments show all these dimensions, none of them can be eliminated or simply “forgotten” as it frequently happens these days. The steering dimension is the left one, i.e. didactic design and learning management, this includes workflows of learning processes that are monitored, managed, and supported by teachers, also in exploratory autonomous learning situations. Knowledge management is an important aspect for E-Learning environments, but at the moment only few academic organizations have explicit knowledge management strategies. In that respect corporate E-Learning traditions are far more advanced by integrating knowledge management and E-Learning processes. Designing and using tools for hypermedia communication and for collaborative learning have become very important processes for supporting the social dimension of learning. The fourth dimension is obviously another crucial one, i.e. multilingual content development and content repository management. All four dimensions are linked to each other in dynamic ways, as figure 2 shows: Figure 2: An Integrated Process Model of Interactive E-Learning
98

Terminological content development for E-Learning
In concluding it seems that strategies for multilingual learning content development for E-Learning environments require a complex approach to modelling learning processes, didactic knowledge organization, ontology creation and multilingual resource support. References Abecker, Andreas; Ansgar Bernardi; Knut Hinkelmann; Otto Kühn &
Michael Sintek; Context-aware proactive delivery of task-specific information: The KnowMore Project, in International Journal on Information Systems Frontiers (ISF) 2 (314); Special Issue on Knowledge Management and Organizational Memory, pp. 139 – 162, Kluwer, 2000.
Allert, Heidrun; Christoph Richter & Wolfgang Nejdl; Learning objects on the Semantic Web – Explicitly modelling instructional theories and paradigms. 2003.
Allert, Heidrun; Christoph Richter & Wolfgang Nejdl; Situated Models and Metadata for Learning Management form an Organizational and Personal Perspective. 2002
Budin, Gerhard; Mehrsprachige Wissensorganisation für den Aufbau von E-Learning-Systemen für die Ökologie – Erfahrungsberichte zu den Projekten Logos Gaias und Media Nova Naturae, in G. Budin & Peter H. Ohly (eds.), Wissensorganisation in kooperativen Lern- und Arbeitsumgebungen, pp. 105 – 122, Würzburg: Ergon Verlag, 2004.
Derntl, Michael & Renate Motschnig; Employing patterns for web-based, person-centered learning: concepts and first experiences. Proceedings of the EdMedia Conference, 2003
Elst, Ludger van; Andreas Abecker & Heiko Maus; Exploiting user and process context for knowledge management systems, in DFKI. Workshop on User Modelling for Context-aware Applications at the 8th International Conference on User Modelling, Sonthofen, Germany, July 13-16, 2001.
http://orgwis.gmd.de/~gros/um2001/papers/elst.pdf
Flechsig, Karl-Heinz; Über didaktische Modelle und ihre Katalogisierung, in H. Stachowiak (eds.), Modelle und Modelldenken im Unterricht, pp. 74 – 91, Bad Heilbrunn: Julius Klinkhardt, 1980.
Flechsig, Karl-Heinz; Kleines Handbuch didaktischer Modelle. Eichenzell, 1996.
Hahn, Udo; Klemens Schnattinger & Kornél Markó; Wissensbasiertes Text Mining mit SynDICATe. Künstliche Intelligenz, heft 2, 2002.
99

Gerhard Budin
Joyce, B. & M. Weil; Models of Teaching. Englewood Cliffs, New Jersey: Prentice Hall, 1972.
Langdon, D.G.; The Instructional Design Library. Bryn Mawr: The American College, 1977.
Naeve, Ambjorn; Miltiadis Lytras; Wolfgang Nejdl; Nicolas Balacheff & Joseph Hardin; Advances of Semantic Web for E-Learning: Expanding learning frontiers. Call for papers for the British Journal of Educational Technology, 2005.
Reinmann-Rothmeier, Gabriele; Mediendidaktik und Wissens-management. Medienpädagogik, 2002. www.medienpaed.com/02-
2/reinmann1.pdf Salzmann, C.; Gedanken zur Bedeutung des Modellbegriffs in
Unterrichtsforschung und Unterrichtsplanung, Pädagogische Rundschau, pp. 468 – 485, 1972.
Schmidt, Andreas & Claudia Winterhalter; User Context Aware Delivery of E-Learning Material: Approach and Architecture. 2002.
Schwerdt, T.; Kritische Didaktik in klassischen Unterrichtsbeispielen. Paderborn: Schöningh, 1933.
Sowa, John; Knowledge Representation. Logical, Philosophical, and Computational Foundations. Brook/Cole, 2000.
Stachowiak, Herbert; Allgemeine Modelltheorie. Wien/New York: Springer, 1973.
Swertz, Christian; Didaktisches Design – Ein Leitfaden für den Aufbau hypermedialer Lernsysteme mit der Web-Didaktik. Bielefeld: Bertelsmann, 2004.
Tao, Feng; David Millard; Arouna Woukeu & Davis, Hugh; Semantic grid based E-Learning using the Knowledge Life Cycle. University of Southampton, 2004.
100

Terminology and Knowledge Engineering in Fraud Detection
KOEN KERREMANS, RITA TEMMERMAN & GANG ZHAO
1. Introduction Due to its huge volume of information and wide-spread access, the Internet becomes an attractive medium for fraudsters to reach a large number of potential victims in a short time. Moreover, its size and dynamics make it difficult to put the web contents under close legal surveillance. Consequently, most frauds on the Internet are discovered by accident and a large number of them go undetected (Davia, 2000). One of the aims of the FF POIROT project (IST-2001-38248), a European research project in the fifth framework is to develop formal and shareable knowledge repositories (i.e. ontologies) and terminological resources for applications detecting and intercepting e.g. securities fraud on the Internet. Securities fraud refers to the selling of overpriced or worthless shares, or other financial instuments to the general public (Zhao et al., 2004c). Within the framework of this research project, two approaches have been worked out to support the development of ontological repositories, on the one hand, and terminology bases, on the other hand. The integration of these resources in fraud detection systems, motivates the application-oriented views in both these methodologies: AKEM (for knowledge engineering) and Termontography (for terminology engineering). This article wants to show how the methods of AKEM and Termontography are interacting in the development process towards an innovative and technological solution for detecting and intercepting securities fraud. The development tracks will be outlined in section 2. Next, we will discuss the Termontography (section 3) and AKEM (section 4) approaches and explain how both approaches interact within the scope of the problem and knowledge space (section 5). In particular, we will show how principles of the AKEM methodology are integrated in Termontography and, vice versa, how Termontography contributes to the development of the formal and shareable knowledge repository. Finally, in section 6 we conclude.

K. Kerremans, R. Temmerman & G. Zhao
2. Development Tracks in FF POIROT' Figure 2:1 shows the development tracks in the FF POIROT project. The figure visualises how, within a problem and knowledge space, the development tracks of Termontography, AKEM and knowledge system development, lead towards an innovative and technological solution, whereby a system is developed which to identify and intercept fraudulent websites. Note that the dotted arrows indicate an interaction between terminology and knowledge engineering. On the one hand, terminology and knowledge rich contexts (Meyer, 2001) are extracted from stories created in AKEM. On the other hand, the terminology base contributes to the development of the ontology.
Figure 1: Terminology, knowledge and knowledge system development The problem determination implies a specification of the knowledge scope and system requirements. Sections 3 and 4 will be devoted to a general discussion of resp. Termontography and AKEM. The interaction between these two approaches with respect to the development of the ontological and terminological resources supporting the fraud detection system will be discussed in section 5. The knowledge system development track will not be discussed in detail as it goes beyond the scope of this article. The aim of this development track is to design and develop the knowledge processor by looking into its functional aspects derived from questions like how the knowledge system is going to be implemented and how the knowledge
102

Terminology and Knowledge Engineering in Fraud Detection
developed in the knowledge engineering track is going to be deployed. Figure 2:1 shows the main tasks in knowledge system development. The system requirements phase pertains to the performance requirements of the system, the analysis of the user perspective of the system behaviour as well as the functionality and system perspective of the processing tasks. System design seeks to identify the software components of knowledge processors and their interfaces. The system development stage builds and integrates components of knowledge processors and runtime knowledge repositories. It also takes the output of the knowledge deployment stage along the knowledge engineering track and makes it available to the knowledge processor via dedicated knowledge repositories. Finally, deployment refers to the evolution from Alfa to Beta testing of the intelligence and behaviour of the knowledge system.
3. Terminology Engineering in Termontography Termontography combines theories and methods of the sociocognitive analysis (Temmerman, 2000) with methods in ontology engineering. The motivation for combining terminography and ontology development derives from the view that existing methodologies in terminology compilation (Sager, 1990; Cabré, 1999; Temmerman, 2000) and (text-based, application- and/or task-driven) ontology development have significant commonalities (Kerremans et al., 2003). This will become clear in section 5 in which we will show how some of the methodical steps in the AKEM development cycle can be performed by terminographers following Termontography. In Termontography, six methodological phases are identified: analysis, information gathering, search, refinement, verification and validation (Kerremans et al., 2003). The resource resulting from this workflow is an ontologically-structured terminological knowledge repository. On the one hand, this resource serves in FF POIROT as knowledge input, supporting ontology development (see figure 2:1). On the other hand, it provides useful information to ontology-based natural language processing applications for detecting and intercepting financial fraud. A fundamental issue in Termontography is that terminographers need a solid reference framework to scope their terminology work. Scoping implies determining which linguistic words/patterns are considered relevant terms given the applications, users and purposes of the terminological resource. This insight was also at the basis of the OncoTerm project, in which the scope of the multilingual
103

K. Kerremans, R. Temmerman & G. Zhao
terminological database was determined by the knowledge specified on the conceptual level (Moreno & Pérez, 2001). In Termontography, requirements for terminology bases are therefore first translated into language-independent frameworks of interrelated categories which can provide, depending on their granularity level, detailed information with respect to the extraction of terms and knowledge rich contexts (Meyer, 2001) from a domain-specific corpus of texts (Kerremans, 2004).
4. Knowledge Engineering in AKEM AKEM, the Application Knowledge Engineering Methodology, (Zhao, 2004a; Zhao et al., 2004b) is based on the DOGMA ontology representation framework which defines an ontology as a set of lexons and their commitments in particular applications. Lexons represent relationship types between two object types and are constructed as follows: <Context, Term1, Role1, Term2, Role2> (Jarrar & Meersman, 2001). They capture the underlying concepts and relationships while commitments link them to a particular application or task requirement with specific constraints and instantiations (Deray & Verheyden, 2003). The AKEM methodology organises a geographically distributed, multi-disciplinary team of domain experts, knowledge analysts and engineers in a methodical traceable development cycle – shown in figure 2:1 – of knowledge scoping, knowledge analysis, ontology development and deployment, similar to RUP (Kruchten, 2000). In AKEM, knowledge scoping identifies that part of the universe of discourse, used for ontology modelling and development. Stories result from the knowledge scoping activity and are used to convey business cases and scenarios (see figure 2:1). From these stories, a constituent model is created during knowledge analysis to describe how the application semantics are decomposed and how each constituent is elaborated in the description of business logic. The ontology development activity refers to the process of creating ontologies to capture the meta knowledge. During deployment, certain concepts and relationships will be selected and constrained to form commitments or networks of application semantics in view of specific processing tasks (Zhao et al., 2004b). The conceptual model developed in FF POIROT and partly presented in section 5 has two purposes: 1) knowledge management of fraud investigative expertise and 2) automation of parts of monitoring or investigative procedures with knowledge-based applications. The ontology modelling perspective chosen for illustration, is the forensics modelled in view of official directives and laws. The resultant
104

Terminology and Knowledge Engineering in Fraud Detection
knowledge model can serve both the evidence recognition in detective work and argumentation in prosecution.
5. Termontography and AKEM in FF POIROT In section 5.1, we discuss knowledge scoping, an overlapping activity between Termontography and AKEM. Next, in section 5.2, we reflect on how Termontography contributes to ontology development in AKEM.
5.1 Knowledge Scoping In FF POIROT, the terminological and ontological resources are motivated by an overlapping knowledge scope, set up by a domain expert and derived from a common problem and knowledge space (see figure 2:1). In AKEM, the knowledge scope identifies that part of the universe of discourse, used for ontology modelling and development (section 4). In Termontography, the knowledge scope helps terminographers to identify relevant texts as knowledge resources (see figure 2:1) and, depending on the level of detail, to select those patterns which are considered relevant terms given the applications, users and purposes of the terminological resource (section 3). Figure 5.1:1 visualises the knowledge scope of fraud forensics from an ideational viewpoint. The knowledge scope is a semi-formal representation of knowledge involved in fraud detection and prevention. As such, it provides an onset towards the knowledge management and sharing among investigative professionals as well as the knowledge specification for intelligent system development to support fraud detection. Figure 2: The knowledge scope in FF POIROT
105

K. Kerremans, R. Temmerman & G. Zhao
From this knowledge scope, we derive that a certain process can be recognised as fraud when it matches a typical fraud scheme and when it contravenes the rules of law. Obviously, to each type of fraud, different legal rules apply. In FF POIROT, domain experts point terminographers and ontology modellers to the regulations and even the sections in regulations which apply to securities fraud. The regulations are added to the textual corpus from which terminographers extract terminology (see figure 2:1). Apart from law sections, also domain-specific texts related to securities fraud in particular and the financial and investment domains in general, are considered part of the corpus. Such texts provide substantial supplementary information about terms which are for instance mentioned, with very few additional information, in the definition of a term referring to a category encountered in a regulatory text. They allow us to capture a broader insight in certain concepts and are for that reason indispensible in the ontology development process.
With respect to the extraction of terms, it should be stressed that the different text types collected during the information gathering phase in Termontography (section 3), each time require a redefining of what should be considered a ‘term’. In law texts, any linguistic pattern which is used to express a category in a legal rule, will be considered a term. In domain-specific texts, linguistic patterns will be considered terminology if they a) denote core-concepts in fraud schemes; b) are essential for understanding terms denoting core-concepts in legal rules; c) denote core-concepts in fraud-related domains; d) are defined in the corpus. In the next section, we will discuss how the ontology is further developed from the knowledge scope onwards. We will point out that terminographers following the Termontography approach can contribute to certain activities in the development cycle of AKEM.
5.2 From Terminology to Ontology Development Determining the knowledge scope is not the only overlapping activity which implies an interaction between Termontography and AKEM (section 5.1). In the following paragraphs, the interaction between the two terminology and knowledge engineering approaches, will be explained by focussing on some of the key deliverables in AKEM (section 4). The AKEM developing steps allow knowledge modellers to extract, abstract and organise recurring knowledge elements and to establish reusable knowledge templates in order to account for semantic interoperability between various applications. Through the analysis of a particular case in securities fraud, called ExpertXChange, we will show
106

Terminology and Knowledge Engineering in Fraud Detection
how terminographers following the Termontography approach can contribute, and to some extent even take over, some of the tasks addressed in AKEM. ExpertXChange, a fictitious name for a real-life case in securities fraud, was provided by CONSOB (http://www.consob.it), the public authority and supervisory agency responsible for regulating the Italian securities market. ExpertXChange refers to the name of the company, registered in the British Virgin Islands, which offered to the public an unofficial 24-hour stock exchange service on the web. Investors were asked to become shareholders of the unofficial trade. The company targeted the Italian investment market and did so without registering to CONSOB’s prospectus of legal investment companies. In this sense, the company did not comply with the minimal disclosure rules on issues such as market access and pricing. Following the AKEM development cycle outlined in section 4, the case of ExpertXChange is first written down in a story, i.e. a structured use case which captures and communicates the theme and scope of attention (see also figure 2:1). From this story, knowledge constituents are extracted and mapped to a knowledge constituent model. These knowledge constituents are evidences and facts which are mapped to a legal framework of CONSOB rules, represented in an extended Wigmore chart (Wigmore, 1937). In this model, partly represented in figure 5.2:1, each knowledge constituent receives a unique identification code:
Figure 3: Example of an extended Wigmore chart
107

K. Kerremans, R. Temmerman & G. Zhao
From this model, knowledge is then elaborated into a decision tree or a set of production rules for intelligent processing. An example of such a rule is: IF 1.1 Organizer solicits investors on the WWW E1.1.1 Organizer manages a website that solicits investors E1.1.1.1 Website is managed/registered by organizer F1.1.1.1 Website states the name ‘ExpertXchange Ltd’ F1.1.1.2 Website registration details indicate ‘ExpertXchange Ltd’ as
registrant of website F1.1.1.3 URL = www.ExpertXchange.com1.2 AND no advance notice of solicitation to Consob E1.2.1 ExpertXchange did not give a notification to Consob regarding public
offer to purchase 1.3 AND no related prospectus filed with Consob E1.3.1 ExpertXchange Ltd did not draft or file a prospectus with Consob
regarding public offer to purchase F1.3.1 Consultation of Societa’ and Intermediari sections on Consob website
reveal that Consob did not receive any prospectus from ExpertXchange Ltd. THEN Public offer is unlawful The extraction and abstraction of knowledge constituents into production rules, allow knowledge modellers to identify and organise the abstract concepts and relations into an ontology (Zhao et al., 2004c). Since AKEM adopts principles of the DOGMA ontology engineering approach (Jarrar & Meersman, 2002), these relationships are represented as lexons in a lexon base (see table 5.2:1).
Context Term 1 Role 1 Role 2 Term 2 58.94.1 Offerer Make MadeBy PublicOffering 58.94.1 PublicOffering SubypeOf SuperTypeOf Offering 58.94.1 Offerer Give GivenBy AdvanceNotice 58.94.1 Regulator Receive ReceivedBy Notice 58.94.1 Notice Contain ContainedBy Prospectus 58.94.1 Authority Authorise AuthorisedBy Activity 58.94.1 Regulator SubtypeOf SupertypeOf Authority 58.94.1 Solicitation SubtypeOf SupertypeOf Activity 58.94.1 Solicitation Target TargetedBy Investor
Table 1: Example of a lexon base
108

Terminology and Knowledge Engineering in Fraud Detection
Termontography contributes to the process of ontology development by extracting terms from knowledge resources and directly classifying them according to the categories provided in the categorisation framework (section 3). The idea is to link each extracted term to a corresponding category in the framework and to create new categories if no direct correspondents can be found. Termontography is therefore not only concerned with the development of an ontologically-structured terminology resource but also contributes to the refinement of the conceptual model which initially started as knowledge scope. In this way, terminographers applying the Termontography approach can assist ontology modellers in the process of extraction and abstraction. For example, the lexons shown in table 5.2:1 are all derived from Title 2 (“Solicitation of public savings”), chapter 1 (“Public offerings”), article 94 (“Obligations of offerers”), rule 1 from the Legislative Decree 58/1998 on financial intermediation: “Persons who intend to make a public offering shall give advance notice thereof to Consob, attaching the prospectus to be published.” Through the analysis of this law section, the category of ‘Law’ in the initial knowledge scope (see figure 5.1:1), can be refined as follows: Law ⎣ relates to ⎯ Legislative Decree 58/1998 ⎣ has title ⎯ 2. Solicitation of public savings ⎣ has article ⎯ 94. Obligations of offerers ⎣ has rule ⎯ 1. […] Note that this is merely a semi-formal representation which still needs further abstraction. The same holds for the analysis of rule 94.1 from which terms like ‘Consob’, ‘notice’, ‘person’, ‘prospectus’ and ‘public offering’ are extracted and mapped to corresponding categories in the categorisation framework. New categories are created for terms which do not have corresponding categories in the framework. This results into the following semi-formal representation: … ⎯ Legislative Decree 58/1998 ⎣ has title ⎯ … ⎣ has categories ⎯ categories in Legislative Decree 58/1998 ⎣ Notice
109

K. Kerremans, R. Temmerman & G. Zhao
⎣ Offering ⎣ has a subtype ⎯ PublicOffering ⎣ Person ⎣ has a subtype ⎯ Offerer ⎣ Prospectus ⎣ RegulatoryAuthority ⎣ has a subtype ⎯ Consob Apart from this semi-formal framework, terminographers following the Termontography approach provide ontology modellers with semi-formal representations of relational statements derived from the knowledge rich contexts extracted in an earlier stage (see figure 2:1). For instance, from the co-text of rule 94.1 in the Legislative Decree 58/1998, the following relational statements can be derived: ‘offerer makes public offering’; ‘offerer gives notice (in advance) to Consob’; ‘notice contains prospectus’. Also definitions of terms like ‘offerer’ or ‘Consob’, extracted from other sources, are provided in natural language in order to support the formalisation process of the conceptual model. 6. Conclusion In this article, we have presented ongoing terminology and knowledge engineering work in the FF POIROT project, a European project in which ontological repositories and terminological resources are developed to assist applications in detecting and intercepting securities fraud. The overlapping activities between the terminology engineering approach of Termontography and the knowledge engineering approach of AKEM, have led to a development cycle in which both these methods closely interact. Starting from a common knowledge scope, we have shown how terminographers can support, or to some extent take over, the processes of extraction and abstraction, thereby contributing to the ontology development cycle. In order to account for semantic interoperability with other ontologies and standards, we will try to align the lexons derived from the ExpertXChange case with concepts and relations in the SUMO ontology base and domain ontologies (Pease et al., 2002). In order to better support the approach, a software tool will be developed which will allow the user to directly map the terminological analysis to the categorisation framework and see the results of this mapping in the terminological database (Kerremans et al., 2004). We also intend to investigate how multilingual terminological information may further improve multilingual conceptual models. For instance, it may be
110

Terminology and Knowledge Engineering in Fraud Detection
interesting to examine how the culture-specific differences between categories in fraud schemes that emerge from a multilingual terminological analysis, should be represented semi-formally in a terminology resource in order to provide feedback to the knowledge engineering development cycle in AKEM.
Acknowledgements The ideas in this paper have been worked out in FF POIROT (IST-2001-38248), a project supported by the European Commission under the 5th framework program. More info about this project can be found at: http://www.ffpoirot.org.
References Cabré, M.; Terminology: Theory, methods and applications.
Amsterdam/Philadelphia: John Benjamins, 1999. Davia, H.; Fraud 101 – Techniques and strategies for detection. New
York: John Wiley & Sons Inc., 2000. Deray, T. & P. Verheyden; Towards a Semantic Integration of Medical
Relational Databases by Using Ontologies: a Case Study, in R. Meersman et al. (eds.), On the Move to Meaningful Internet Systems 2003: CoopIS, DOA, and ODBASE, Berlin: Springer-Verlag, 2003.
Jarrar, M. & R. Meersman; Formal Ontology Engineering in the DOGMA Approach, in R. Meersman et al. (eds.), On the Move to Meaningful Internet Systems 2002: CoopIS, DOA, and ODBASE, Berlin: Springer-Verlag, 2002.
Kerremans, K.; Categorisation Frameworks in Termontography, in R. Temmerman & U. Knops (eds.), Linguistica Antverpiensia, new series (3-2004). The translation of domain-specific languages and multilingual terminology management, Antwerpen: s.n., 2004.
Kerremans, K.; R. Temmerman & J. Tummers; Representing Multilingual and Culture-Specific Knowledge in a VAT Regulatory Ontology: Support from the Termontography Approach, in R. Meersman et al. (eds.), On the Move to Meaningful Internet Systems 2003: CoopIS, DOA, and ODBASE, Berlin: Springer-Verlag, 2003.
Kruchten, P.; The Rational Unified Process: an Introduction. Boston: Addison Wesley, 2000.
Meyer, I.; Extracting knowledge-rich contexts for terminography: A conceptual and methodological framework, in D. Bourigault; C. Jacquemin & M.-C. L’Homme (eds.), Recent Advances in
111

K. Kerremans, R. Temmerman & G. Zhao
Computational Terminology, Amsterdam/Philadephia: John Benjamins, 2001.
Moreno, A. & C. Pérez; From Text to Ontology: Extraction and Representation of Conceptual Information, in M. Slodzian et al. (eds.), Proceedings of the Conférence TIA-2001, Nancy, 2001.
Pease, A.; I. Niles & J. Li; The Suggested Upper Merged Ontology: A Large Ontology for the Semantic Web and its Applications, in A. Pease, J. Hendler, & R. Fikes (eds.), Working Notes of the AAAI-2002 Workshop on Ontologies and the Semantic Web, Edmonton, 2002.
Sager, J.C.; A practical course in terminology processing. Amsterdam: John Benjamins, 1990.
Temmerman, R.; Towards New Ways of Terminology Description. The socio-cognitive approach. Amsterdam/Philadelphia: John Benjamins, 2000.
Temmerman, R. & K. Kerremans; Termontography: Ontology Building and the Sociocognitive Approach to Terminology Description, in E. Hajičová, A. Kotěšovcová & J. Mírovský (eds.), Proceedings of CIL17, Prague: Matfyzpress, 2003.
Wigmore, J.H.; The Science of Judicial Proof as given by Logic, Psychology and General Experience. Boston: Little Brown, 1937.
Zhao, G.; Application Semiotics Engineering Process, in S.K. Chang et al. (eds.), Proceedings of the International Conference of Software Engineering and Knowledge Engineering, Banff, 2004a.
Zhao, G.; Y. Gao & R. Meersman; An Ontology-based Approach to Business Modelling, in Ramos et al. (eds.), Proceedings of the International Conference of Knowledge Engineering and Decision Support, Porto, 2004b.
Zhao, G.; J. Kingston; K. Kerremans; R. Verlinden; F. Coppens; R. Temmerman & R. Meersman; Engineering an Ontology of Financial Securities Fraud, in R. Meersman (eds.), OTM 2004 Workshops: OTM Confederated International Workshops and Posters, GADA, JTRES, MIOS, WORM, WOSE, PhDS, and INTEROP 2004, Heidelberg: Springer Verlag, 2004c.
112

TKE in Transnational Law Enforcement
- a Case Study of Workflow and Terminology Management
in the Production and Translation of Organised Crime Reports
BARBARA DRAGSTED, INGE GORM HANSEN & HENRIK SELSØE SØRENSEN
Introduction The present study forms part of a TKE framework project, IntelliGET. In this paper, we will focus on an analysis of the problems related to the translation of Danish reports on organised crime (OC) into English and discuss methods for achieving quality enhancements. Danish OC reports together with similar translated or untranslated reports submitted by EU member states are merged into a common European Union Organised Crime Report prepared annually by the European Union law enforcement organisation, Europol. Considering this whole process as one cross-institutional and cross-border workflow involving different national concepts creates challenges in terms of terminology management and knowledge engineering. Examples will be given and solutions proposed. IntelliGET and Case Study IntelliGET is a terminology and knowledge engineering project carried out at the Copenhagen Business School (CBS). The project deals with multilingual communication in the domain of law enforcement and addresses the terminology and knowledge engineering requirements of law enforcement agencies (LEAs), security and intelligence services in Europe. Knowledge sharing and information retrieval are vital in cross-border law enforcement. With increased international co-operation among police officers and prosecutors and access to large-scale information systems, there is an urgent need for terminological resources supporting both law enforcement officers and translators across Europe.
The overall objective of the project is to develop a methodology for improving workflows in multilingual communication and to propose

B. Dragsted, I. G. Hansen & H. S. Sørensen
resource profiles to support specified user groups engaged in cross-border communication. IntelliGET aims to establish a method for collection, processing, storage, maintenance and distribution to specified police user groups and translators of relevant terminological data and related knowledge components.
IntelliGET will extend and capitalise on former projects, such as the LinguaNet project (1998) and the SENSUS project (2001). Both projects involved, among other things, data mining in law enforcement texts, including translations (Dragsted and Kjeldsen, 2004). The projects revealed a high degree of variation in term usage, reflecting major differences in legal systems and cultures. This was the motivation for carrying out the current case study analysing term usage in English translations of Danish texts in order to make observations on and suggestions for language policy and strategy in transnational professional police communication.
The study described here, which forms part of the IntelliGET project, is carried out as a case study based on a specific text type, one which is regularly translated, in this case into English, and used in an international context (by Europol). The aim of the case study is to describe and analyse the overall text production and translation workflow existing today, identify problem areas in the translation process and product, and make suggestions for how to improve the workflow and ensure a higher quality in the individual translation products and the joint Europol report.
At the more general level, our suggestions for changes in the present workflow may additionally contribute to an improvement of the efficiency of information retrieval because the project aims at ensuring a more consistent use of terminology in professional cross-border communication. The proposed workflow must of course allow for the wide variation in the definition of legal concepts across countries and cultures, the different national definitions of offences being a case in point. Still, in transnational police work, it is vital that different user groups have access to information deriving from other countries. If different terms are used to refer to the same phenomenon in different countries, this will strongly impede the search process. If, for instance, a Danish police officer is looking for information on high technology crime and searches for IT crime, which is the term used in the English translation of the Danish report, the search will result in no or very few examples of this type of crime in the Europol countries, because the term which seems to be preferred by Europol and the UK police authorities is high tech/hi-tech crime or cyber crime. Similarly, a search for information on narcotics smuggling (translation of the
114

TKE in Transnational Law Enforcement
Danish term “narkosmugling”) will yield very poor results in the area of drug trafficking.
Methods The study takes as its point of departure a concrete translation situation, viz. the translation of the Report on OC in Denmark published annually, both in Danish and in English, by the Danish National Police and submitted to Europol as the Danish contribution to the annual European Union OC Report. The English translation of the Danish text will be compared with the language and terminology of the final Europol report and reports from the UK. Texts The pilot study is based on EU Reports on OC (2001- 2004); Danish national OC reports (2001-2003) and the English translations submitted to Europol; UK Threat Assessment Reports on OC (2002, 2003) and One Step Ahead. A 21st Century Strategy to Defeat OC (2004) (IntelliGET text base, 2005). Wordsmith Tools Comparisons and analyses of the texts are carried out using frequency and concordance analyses produced with WordSmith Tools, an integrated set of corpus analysis tools. The analyses in WordSmith throw light on differences between the texts in the use of terms and phrases. Quantitative analyses in WordSmith serve to identify terminological variation and inconsistencies and other types of ‘weirdness’ in the English translation of the Danish text compared with UK and Europol reports. The words and phrases identified by WordSmith are subjected to qualitative analyses using cluster searches in Google (Sørensen, 2004), a method which also helps identifying equivalent or near-equivalent terms used internationally. User group involvement The project is based on input (oral and written) from the Serious Organised Crime Agency in Copenhagen and Europol, The Hague, including the Danish desk, as well as input from the Danish translators who were charged with translating the Danish reports into English.
115
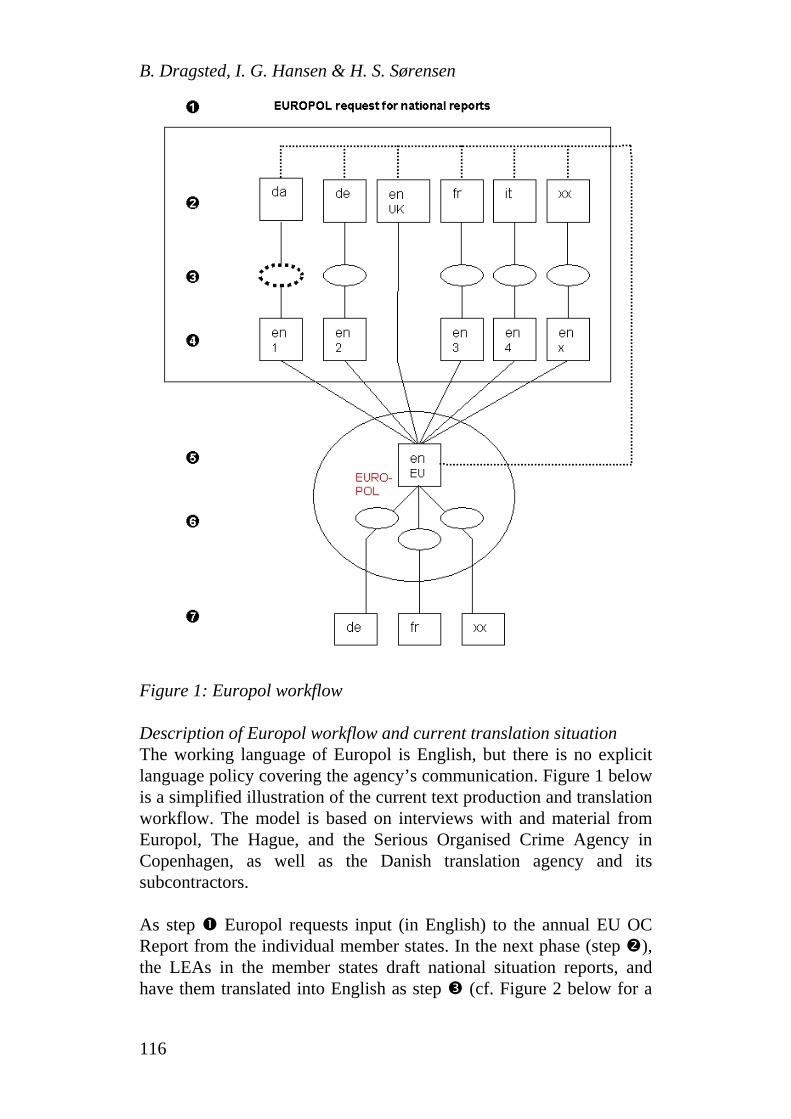
B. Dragsted, I. G. Hansen & H. S. Sørensen
Figure 1: Europol workflow Description of Europol workflow and current translation situation The working language of Europol is English, but there is no explicit language policy covering the agency’s communication. Figure 1 below is a simplified illustration of the current text production and translation workflow. The model is based on interviews with and material from Europol, The Hague, and the Serious Organised Crime Agency in Copenhagen, as well as the Danish translation agency and its subcontractors. As step Europol requests input (in English) to the annual EU OC Report from the individual member states. In the next phase (step ), the LEAs in the member states draft national situation reports, and have them translated into English as step (cf. Figure 2 below for a
116

TKE in Transnational Law Enforcement
detailed description of the Danish translation workflow in step ). As step , the translated versions of the national situation reports are submitted to the relevant Europol liaison officers and discussed at a joint meeting of liaison officers representing all countries contributing to the report, and finally Europol centre analysts assemble, edit and draft the final joint report, illustrated by step . The joint report is sent back to the member state LEAs for approval and then returned to the Europol centre, as illustrated by the dotted line. When the report has been approved by Europol/EU, the final English publication is submitted to the EU translation service for translation into German, French, Italian and Spanish (steps and ).
Figure 2 below zooms in on Step , illustrating the translation workflow for Denmark. The workflow may differ from one country to another, but similar procedures can be expected for the other member states.
Figure 2: Zoom in on translation workflow in Denmark The Danish LEA asks a Danish translation agency (TA) to translate the Danish report into English. The TA subcontracts the translation of the report to a UK-based TA, where it is translated by a freelance translator who is a native speaker of English. The translated report is sent back to the Danish TA for quality control and submitted to the Danish LEA.
Over the past 4 years, the same Danish TA has been in charge of the translations, using the same subcontractor. However, the texts have been translated by 3 different freelance translators over the 4 years. A definite weakness in the current workflow illustrated in Figure 1 is that it does not allow for involvement of and feedback to the translator/TA once the translation of the Danish text into English has been delivered. Thus there is no feedback to the translator/subcontractor or the Danish translation agency, and they are not part of the OC report approval process. Any changes made, for instance of terminology, at the subsequent stages of the workflow illustrated in Figure 1 above are not communicated to the TA.
117

B. Dragsted, I. G. Hansen & H. S. Sørensen
The UK-based subcontracting TA currently in charge of the translation translates the Danish text using the agency’s own translation memory (TM). The translators have compiled an internal document-specific TM, which has been used for two consecutive translations of the report. However, since the Danish LEA and Europol do not provide access to a common terminology database, other linguistic resources or guidelines, and provide no feedback on terminological changes etc., the TM is not updated regularly.
In the section on workflow strategies below, we will make suggestions for how to improve the existing workflow, including the local translation workflow. Quantitative Analyses in WordSmith The analyses in WordSmith Tools serve the purpose of comparing the Danish=>English translations with OC reports from Europol and the UK. Based on the analyses, we have identified terms and phrases which appear to be either overrepresented or underrepresented in the Danish=>English translation. Examples of such terms will be analysed qualitatively below, i.e. the analyses in WordSmith first of all aim to identify candidate terms for further investigation. The present analysis is based on single words. The results provide useful data for the purpose of the present study, but further analysis of multi-word units will be carried out at a later stage of the IntelliGET project to enhance the results. Examples illustrating the data elicited with WordSmith are given in the tables below, showing a comparison of the Danish=>English translation with the report from the UK. Significant overrepresentation of some 70 words was found in the Danish text. Examples are given below:
118

TKE in Transnational Law Enforcement
Key word1Freq. DK text
% DK text
Freq. UK text
% UK text Keyness2
NARCOTICS 60 0,23 0 0 106,13 SMUGGLING 111 0,42 48 0,13 52,74 PERSONS 34 0,13 3 0 42,49 BEINGS3 24 0,09 0 0 42,43 Table 1: Danish=>English vs. UK English – overrepresentation in the Danish=>English translation Approx. 25 words were found to be underrepresented in the Danish=>English translation compared with the UK report, for example:
Key word Freq. DK text
% DK text
Freq. UK text
% UK text Keyness
DRUG 6 0,02 48 0,13 -24,13 FRAUD 32 0,12 121 0,32 -28,71 FIREARMS 11 0,04 141 0,37 -91 CRIMINALS 12 0,05 302 0,8 -242,22 Table 2: Danish=>English vs. UK English – underrepresentation in the Danish=>English translation Similar analyses have been made to compare the Danish=>English translation with the Europol report. Again, the analyses showed significant over- and underrepresentation in the translated text of a number of words, several of which coincided with those found in the Danish=>English vs. UK English analysis. Notably, the same pattern was found with respect to NARCOTICS, SMUGGLING and DRUG. This confirms the hypothesis that the Danish=>English translation contains words and phrases which may not be entirely appropriate compared
1. A ‘key word’, in WordSmith terminology, is a word which occurs more often
than would be expected by chance in comparison with a reference text, in which case it can be said to be overrepresented, or which occurs less often than would be expected by chance, in which case it is underrepresented (Scott, 2004).
2. To compute the ‘keyness’ of a key word, i.e. the extent to which it is over- or underrepresented, the program computes its frequency in the text being analysed, the number of running words in the text being analysed, its frequency in the reference text and the number of running words in the reference text and cross-tabulates these (Scott, 2004).
3. Concordance analysis shows that all occurrences of BEINGS collocate with HUMAN (HUMAN BEINGS)
119

B. Dragsted, I. G. Hansen & H. S. Sørensen
with non-translated English texts and with the terminology preferred by Europol.
When, for example, NARCOTICS is strongly overrepresented in the Danish=>English translation compared with both other texts, whereas DRUG is strongly underrepresented, this indicates that the Danish=>English translation contains an instance of ‘weirdness’ with respect to the use of narcotics as a synonym for drugs. Although this claim calls for a further analysis of the actual use of these words in the texts, it seems to be a fairly straightforward example of less appropriate terminology use in the Danish=>English translation.
Another interesting observation which can be made on the basis of the WordSmith analyses, and which is considerably more complex than the example just mentioned, concerns the use of SMUGGLING vs. TRAFFICKING. As shown in the first table above, there is a preference in the Danish=>English translation for SMUGGLING. TRAFFICKING was found to be used less often in the Danish=>English translation compared with the Europol text. In the case of SMUGGLING vs. TRAFFICKING, it cannot immediately be established, however, whether one should be preferred over the other, since the two terms cover two different concepts. This complex case will be analysed in more detail in the next section. Qualitative Analyses of Term Usage The analyses in WordSmith gave an indication of differences in term usage when comparing the Danish=>English translation with UK English and Europol English respectively. However, as also mentioned above, further analysis is required to determine whether the apparent cases of ‘weirdness’ in the Danish=>English translation reflect actual mistranslations or whether they reflect a conscious strategy to imitate a particular variant of English used by a specific nationality or a specific international user community, such as the EU or the UN. In order to be able to relate terms and knowledge to different variants of English, we operate with working definitions of the variants most relevant to the workflow and texts we are analysing. At the same time, a distinction is made between different user communities with respect to preferences for specific language/terminology, cf. below. Variants of English There is much debate on how to classify different ’Englishes’ used in an international context, for instance global English, world English, international English, English as lingua franca (e.g. Phillipson, 2004; Phillipson, 2003; Crystal, 2003). For the purpose of the present study,
120

TKE in Transnational Law Enforcement
we will not take part in this discussion, but for practical purposes, in order to be able to classify texts and manage synonyms and quasi-synonyms and distribute them according to different user profiles, we operate with five different variants of English. In addition to standard definitions of British English (BrE) and American English (AmE), we operate with Global English (GE) as a functional language for communication between second-language users (Simpson, 2004; McArthur, 1998). Inspired by this definition, we suggest a working definition of Euro-English (EE) as a functional language for communication between second-language users characterised by significant usage of idioms and terminology with reference to concepts and phenomena defined in a European context, in particular the EU. Finally, we operate with Plain Bad English (PBE), defined as English language and terminology not complying with standards accepted (tacitly) by speakers of AmE, BrE, EE or GE. Usually PBE stems from speakers with insufficient language competence or from translators relying on creativity rather than documented equivalents. User communities It is important to determine if texts or terms are “controlled” by an organisation or a specific user community pursuing an explicit or implicit language policy. Terms from such sources should ideally be used for communication with the users in question.
In order to determine usage, we have used Google searches. The number of occurrences on the web combined with domain name, e.g. .gov, .us, .uk, etc. may give a preliminary indication of whether a given term should be marked as GE, AmE or BrE etc. For instance, the term ‘alien smuggling’ occurs over 36,000 times on the web, but less than 100 times on .uk servers, and when it occurs on .uk sites, it refers to American facts. In order to determine if a given user community prefers a particular term, subdomains, e.g. .cia.org or gov.uk are taken into consideration.
Term example: ‘People smuggling’ As an example of the proposed methodology, we have selected the concept of ‘people smuggling’ and different terms and synonyms used in the five variants of English.4 The first step is to identify a raw list of 4. The concept is defined by Interpol as: the procurement, in order to obtain,
directly or indirectly, a financial or other material benefit, of the illegal entry of a person into a State Party of which the person is not a national or a permanent resident (Interpol 2005).
121

B. Dragsted, I. G. Hansen & H. S. Sørensen
people smuggling (GE, BrE) 66,900 human smuggling (GE) 48,000 alien smuggling (AmE) 39,900 smuggling of migrants (GE) 20,100 migrant smuggling (AmE) 13,000 smuggling of human beings (PBE) 1,120 organised immigration crime (BrE) 1,040 smuggling of aliens (PBE) 901 aliens smuggling (PBE) 718 organised illegal immigration (EE) 252 facilitation of unauthorised entry and 167
residence (EE) facilitated illegal immigration (EE) 108
Table 3: Google search results candidate synonyms using Google and the cluster method. The resulting raw list has 12 terms (with the total number of Google occurrences given and sorted by frequency):
The candidates on the list must be analysed further taking into account different variants of English and usage by different user communities. To do this, a method based on subdomain-restricted Google searches is proposed, which allows us to conclude that ‘alien smuggling’ is the term preferred by CIA and FBI, whereas the United Nations prefer ‘smuggling of migrants’, and Europol prefers ‘organised illegal immigration’ (OC Report 2003), but there seems to be a change in preferred Europol terminology to ‘facilitation of unauthorised entry and residence’ (Types of Crime collected from the EU, 2005). The number of occurrences does not in itself allow us to draw any conclusions on usage: ‘organised illegal immigration’ is not very frequent and might be rejected by some, but since it is the only term used in Europol reports in the year 2003, it cannot be rejected.
‘People smuggling’ is far from being an exceptional case. Other examples of terminological inconsistencies and complicated patterns of usage are: ‘narcotics smuggling’ (PBE) vs. ‘drug trafficking’, ‘IT crime’ (PBE) vs. ‘high-tech/hi-tech crime’ and ‘cyber crime’. It takes more than just excellent language skills to choose the best strategy in cases like these. Intelligence and crime analysts, law makers, LEAs,
122

TKE in Transnational Law Enforcement
politicians and translators need to have access to term and knowledge bases5 enabling them to navigate in these muddy waters.
Suggested Workflow Strategies As illustrated by the Wordsmith analyses and the term examples, there are major inconsistencies in term usage in the OC reports. To address this problem, we have agreed with Europol to carry out an experiment testing a proactive workflow strategy for the 2005 report, where a selection of Europol’s preferred OC terminology is sent out to the member states in step in Figure 1 (Europol requests input to the OC report).
Together with the request for input, each member state will receive a ‘Term Kit’ of preferred English terms with brief ‘umbrella’ definitions. The ‘umbrella’ definitions are used for practical communication purposes and have to be broad enough to encompass the wide range of national legal definitions. In crime investigations or criminal intelligence operations carried out by Europol, offences are defined only by the law of the requesting state (Types of Crime collected from the EU, 2005).
When translating the national input for the OC report into English, each member state will be asked to use the preferred Europol terminology and add the corresponding term in their own language (e.g. Danish) to the Term Kit. In addition, they may add other English terms used for the same (national) concept. The Term Kit (sent to the Danish police) may contain, for example, the information shown in Table 4.
The Term Kit will accompany the text in its various stages shown in the workflow diagram (Figure 1), including both the Danish TA, the UK subcontractor and the freelance translator (step , cf. Figure 2). Feedback added to the Term Kit may derive from all preparatory stages.
The Term Kit is returned to Europol together with the national contribution to the EU OC report. The ideal scenario is that the Term Kits are evaluated at the meeting of liaison officers in step described above, in connection with the joint discussion of the national contributions. The Term Kits are updated and new terms added, where cases of inconsistencies and terms missing are identified in the evaluation of the contributions from the individual member states. The alternative English terms collected from the kits should ideally be
5. Eurodicautom, the European Commission's multilingual term bank, although
big in size does not at all provide details like the ones discussed here.
123
B. Dragsted, I. G. Hansen & H. S. Sørensen
processed like the list produced for people smuggling shown as Table 3, thus giving a comprehensive list of synonyms for a preferred term together with information on user community preferences. The updated Term Kits are circulated to all involved parties in the member states, including the translators. Europol preferred term
Europol umbrella definition
Preferred national term(s) in [Danish]
Alternative (previously used) English term(s) used by [Danish] LEAs
Comments
facilitation of unautho-rised entry and residence
Activities intended deliberately to facilitate, for financial gain, the entry into, residence or employment in the territory of the Member States of EU
menneske-smugling
People smuggling, smuggling of human beings
Suggestions for new concepts, questions etc. may be added here.
Table 4: Term Kit with one term example The workflow suggested here is very complex and requires a huge effort on the part of everybody involved, as well as allocation of human resources (terminologists). Considering the ingenuity of OC groups and the increasing international co-operation between LEAs to combat crime, OC terminology is a highly dynamic field. Term usage often changes from one year to the next, and new types of crime emerge (e.g. car jacking). The suggested workflow has to allow for these constant changes. To cater for the dynamics of the field, a concerted effort is required, ideally in the form of a common Europol term and knowledge base directly accessible by all parties involved in the workflow, including the translators, and perhaps even the general public. The case study experiment may be the first step towards creating such a database.
Conclusions The qualitative analysis has shown great variation in term usage across different variants of English and in different user communities. In our preliminary analyses, we have found no indications in the Danish=>English translation of stringent strategic choices of one specific variant over the other. Neither have we found any evidence of a workflow which supports consistent usage of institution-specific terminology, the most obvious choice in this case being Euro-English. Even though Europol seems to have a set of preferred terms, as illustrated in the examples with smuggling above, they do not provide
124

TKE in Transnational Law Enforcement
any guidelines to the national LEAs responsible for providing input to the Europol organised crime report. In the present paper, we have proposed ways to improve the quality and terminological consistency in translations, and suggested the formulation of a proactive workflow strategy which explicitly specifies preference for specific terms and definitions over others.
To ensure that mistranslations are not repeated from one year to the next, the suggested workflow includes feedback to all parties involved in the translation process in the form of a dynamic ‘loop process’. The ideal solution for knowledge and term sharing across institutions and member countries will be to merge input from the Term Kits and pool resources in a central and dynamic Europol term and knowledge base. References Biber, Douglas; Susan Conrad & Randi Reppen; Corpus Linguistics.
Investigating Language Structure and Use. Cambridge University Press, 1998.
Crystal, David; English as a global language. 2nd edition Cambridge University Press, 2003.
Dragsted, Barbara & Benjamin Kjeldsen; From raw data to knowledge representation: Methodologies for user-interactive acquisition and processing of multilingual terminology, in Hansen et al. (eds.), Claims, Changes and Challenges in Translation Studies. Selected contributions from the EST Congress, Copenhagen 2001, pp. 197 – 207, Amsterdam: Benjamins, 2004.
IntelliGET text base (2005): http://ezlearn.cbs.dk/hss/i/OCReports.htm
Interpol (2005): http://www.interpol.int/Public/THB/default.asp LinguaNet Project (1998): http://ezlearn.cbs.dk/hss/linguanet/ McArthur, Tom; The English Languages. Cambridge University
Press, 1998. Phillipson, Robert; ‘English-only Europe? Challenging language
policy. London: Routledge, 2003. Phillipson, Robert; Figuring out the Englishisation of Europe, to
appear in Proceedings of BAAL 2003, 2003. Scott, Mike; WordSmith Tools Help ©, 2004. SENSUS project (2001): http://ezlearn.cbs.dk/hss/sensus/ Simpson, John; The English Language: what happens when language
policy is not explicit? 2004. http://www.eurfedling.org/conf/files/Simpson-English.pdf
125

B. Dragsted, I. G. Hansen & H. S. Sørensen
Sørensen, Henrik Selsøe; The Bilingual Web Dictionary on Demand, in Maria Teresa Lino et al. (eds.), Proceedings of the Fourth International Conference on Language Resources and Evaluation, Lisbon, May 24 – 30, 2004: LREC Proceedings, vol. 4, pp. 1297 – 1300, 2004.
Types of Crime collected from the EU (2005): http://www.statewatch.org/news/2005/feb/13869.04.pdf
Zanettin, Federico; Bilingual Comparable Corpora and the Training of Translators, in META, 43: 4, pp. 616 – 630, 1998.
126

Concept Relations
An Update of a Concept Relation Classification
ANITA NUOPPONEN Ontologies, frames, scripts, semantic relations, semantic networks, semantic fields, taxonomies, library classifications, controlled vocabularies, thesauri, etc. have gotten new life in different projects developing ways of organising and finding knowledge in the Internet or in other information systems. For the terminological theories and methods this has also brought new application possibilities and challenges outside the traditional terminology work. In terminology work, however, mainly only few types of concept relations are being utilized according to the manuals and standards for terminological methods. These relationships are generic, partitive and associative. Generic relations refer to relations in abstraction hierarchies, typologies and taxonomies, while partitive relations are based on the relationships between wholes and parts. All other relations are mostly collected in the class of associative relations (e.g. temporal and causal relations). (See ISO 1087-1:2000.) Maybe this is enough for the traditional terminology work and term banks, but for more advanced terminology management systems, semantic web applications and concept modelling among others, these relation types are not enough.
In the mid of 1990's I developed an extensive classification of concept relations taking as starting point Eugen Wüster's otherwise forgotten classifications of concept relations and systems (Nuopponen, 1994 a). In the search for an extensive concept relation classification I applied terminological methods to get an overview of relation types instead of just trying to list all possible relations. Concept relation types described in terminological and related literature were analysed and a preliminary classification was created. This classification was utilized in the next phase when studying concept relations in their systematic context as parts of concept systems. Different types of concept systems were described and illustrated with examples. When the systems were seen as a whole, new types of relations between concept systems could be discovered and the classification refined.
The purpose was to develop a classification that would cover not only the most often used relations but to be a comprehensive set of relations

Anita Nuopponen
containing also more rare relation types. The classification has been criticized as being not realistic for practical terminology work (e.g. Madsen et. al. 2001: 7). The starting point was the needs of terminological analysis. However, the scope was purely descriptive, and not normative giving any recommendations for which relations should be used in terminology work Not every project needs all the relation types, and therefore, the relation classification could be seen as a menu where everyone can select those relations they need in their actual project, and develop them further to accommodate the concepts of the field to be targeted. The classification has over the years given ideas for terminology research and projects, as well as terminological data bases and data modelling (e.g. Hedin et al., 2000). My purpose is to develop the classification further, because much has happened after 1994, and it is time to revise the classification of concept relation types.
The purpose of this paper is to describe my earlier classification and reflect further on the changes on the basis of the latest research in terminology and findings of other fields interested in knowledge ordering. I find specially interesting the set of commonly used concept relations at the Copenhagen Business School and the hierarchy of semantic relations which has been used by Madsen et al.1 for instance for developing an ontology-based querying system. I will comment on some similarities and suggest additions and changes in my own classification on the basis of their classifications. 1. Basic Division of Concept Relations In my 1994 work I distinguished as the main categories of concept relations logical and ontological relations naming them in the line of Wüster's terminology (see Wüster 1971; 1974; 1985). The term 'logical (concept) relation' has always caused problems and there are several other term candidates (abstraction relation, categorial relation, genus-species relation, generic relation) for the relation based on the degree of abstraction of the concepts. Wüster (1974) motivates his choice of terms 'logical' and 'ontological' with that concept relations which he calls 'logical' originate in logic and logical reasoning in the same way as concept relations which are called 'ontological' have been borrowed from ontology. Today, however, the term 'generic relation' has become more popular. The main difference between logical and ontological concept relations is that logical concept relations are direct relations between concepts while ontological concept relations arise indirectly between 1. For the details of their classifications, see e.g. Madsen et al. 2001; 2002.
128

Concept Relations
concepts (Wüster, 1985). Today, very often the term 'ontology' is often used for a different concept as ten–twenty years ago, when the only definition to be found for it was "ontology a branch of philosophy concerned with the nature of being or existence" (Longman, 1984). In my classification, ontological concept relations were defined according to Wüster, who regarded them as simplifications of relations which are observed between individual objects in reality, i.e. ontical relations. Today's ontologies often cover also logical/generic concept relations.
2. Logical Concept Relations Logical concept relations were divided in two different ways combining thus alternative classifications presented in terminological literature (e.g. Wüster; Dahlberg, 1976; Arntz & Picht, 1982). On the one hand logical relations were divided according to the positions that the concepts have in the concept system when compared with each other (se Figure 1: 1.1–1.4). They can be on a higher, lower or the same level of abstraction. Superordination is the relation from superordinate concept to subordinate (personal computer – portable computer) one while subordination is its opposite (handheld computer – portable computer). Indirect super/subordination refers to the fact that there are one or more levels of abstraction between the concepts (computer – palmtop). In the case of indirect co-ordination concepts are on the same level of abstraction, but under different subdivision criteria of the same direct superordinate concept (e.g. portable computer – table top) or under different direct superordinate concepts. In addition to these relations, there are concepts in other positions in logical concept systems. They are diagonally related provided that they are on different abstraction levels (same indirect superordinate concept; e.g. minicomputer – palmtop).
Figure 1: Logical concept relations
129

Anita Nuopponen
Another criterion for the classification is the comparison of the concepts as to their intension and extension (see figure 1: 1.5–1.6). Both intension and extension of concepts can be handled quantitatively and thus we get the relations of identity, inclusion, overlapping, and disjunction. The concepts to be compared may thus have same characteristics or subordinate concepts (or refer to same objects), include each other either intensionally (subordinate concept) or extensionally (superordinate concept), overlap each other intensionally (co-ordinate concepts) or extensionally, or they do not have any common characteristics or objects of reference (disjunction).
These relations enable analysing and describing polydimensionality, when same concepts are divided into subconcepts according to several criteria on the same level of abstraction.
3. Ontological Concept Relations In terminology work and in concept analysis generally, logical concept relations alone are not sufficient. Concepts have also other dimensions apart from those expressed in logical concept relations and systems. The number and the quality of the dimensions depend on the particular concept category (e.g. entity, activity, process, method, and property concepts) and the subject field.
Figure 2: Ontological concept relations In my classification, ontological concept relations were divided into relations that are based on spatial or temporal contiguity (see figure 2: 2.1) and relations that have a causal component and which I call
130

Concept Relations
'concept relations of influence' or 'influence relations' (see figure 2: 2.2).2 The line between these two categories is not clear-cut.
3.1 Relations of Contiguity Concept relations of contiguity cover relations that are based on contact in space or time between concrete or abstract phenomena (see figure 3). All these relations may have several subtypes, but they are not all listed here. Partitive relations are often called 'whole-part relations', but this refers only to the super/subordination in partitive concept systems, whereas there are also co-ordinated concepts as well as diagonally related ones in them (cf. figure 1).
Figure 3: Concept relations of contiguity3
2. I use here mostly the shortened forms of the terms, e.g. 'causal relation' instead for
'causal concept relation'.
131

Anita Nuopponen
Partitive super- and subordination can be canonical or facultative, i.e. the entity needs the part (canonical superordination; e.g. car - tyre) or can exist also without the part (facultative superordination; e.g. hotel - restaurant), the part cannot exist without the whole (canonical subordination; e.g. finger - hand), or it does not need it necessarily (facultative subordination; e.g. tree - forest). Madsen et al. (2001: 7) divide partitive relations into sub-part relation (bicycle - wheel), partition relation (bread - slice), set-element relation (firm - employer) and material relation (book - paper). The first one represents the typical type of partitive relation, while the two following ones are special cases. They appear in my dissertation, but are not named or listed as different types. I have added them in figure 3, but call the first one 'compound relation' because the term 'sub-part relation' refers only to super/subordination. The third one I call 'set relation' for the same reason. Material relations will be discussed separately (see below). I make a distinction between several relations that are very near partitive relations and are thus often classified as belonging to them, e.g. material relation (Madsen et al. 2001: 7). In my classification there are several types of material relations, which however, are located in different classes. Only material component relation – based on an entity and a material that forms a "part" of it (e.g. olive - oil; egg – cholesterol) – is a contiguity relation. The others belong to relations of origin and development, and will be discussed later on. When analysing concepts that refer to abstract phenomena, no difference between partitive and material component relations cannot be necessarily made (e.g. friendship – trust). Enhancement relation is another relation type that is not always distinguishable from partitive relations, but sometimes it is useful to treat it separately. It refers to the relation between two entities, one of which can be attached to the other one without being an actual part of it (e.g. car – trailer; computer – CD-ROM). Ownership relation is not covered properly by any of my relation categories, and needs to be added. Locative relation is based on the relation between an object and a location, site, habitat, environment or container (e.g. fish – lake/water; passenger – airport terminal; tea – teapot). There are also other relations involving location. Madsen et al. (2001, 78; 2002, 23)
3. In the figures the relations in the 1994 year's version are marked with systematic
numbering while the additions with cursive font without numbering.
132

Concept Relations
distinguish between two main types of location relations, dynamic and static location, of which entity-static location relation corresponds with my locative relation; the rest of them I shall discuss below. Property relation is based on an entity and its properties (e.g. silicone – heat-resistant) while rank relation on evaluation and ordering objects according to a certain type of property (e.g. business class – tourist class). In concept systems with rank relations there appear both ordering and equivalence relations between the concepts. While the other contiguity relations could be characterised as "contact in space", temporal relations are based on contact in time and can be simultaneous or consequent. They can be divided into those that are based on division of a process, an event, or an action in its phases/stages and those based on a temporal order of persons or things that succeed one after another (succession relation; e.g. starters – main course). I have called the first ones 'event' or 'process relation' while Madsen et al. (2002, 18) call it 'phase relation'. As the second temporal relation they bring up development relation (frogs egg – tadpole), which I have treated belonging to a group of developmental relations (see below). 3.2 Causal and Developmental Concept Relations Rest of the ontological relations I classify in four influence relation types referring to the fact that there is some kind of causal element involved in the relation between the related entities, which one-sidedly or mutually affect each other (see figure 4). A distinction is thus made between causal and purely temporal concept relations (see above), and also between purely causal concept relations and other relations which include causal components (developmental relations, functional relations, and interactional relations). Figure 4: Influence relations
133

Anita Nuopponen
Causal relation is often seen as a relation between the concepts of cause and effect (causal sequence), but this is only the basis for a complex concept system that often is involved: there are different types of causes and effects (see figure 4: 2.2.1), several causal factors may occur together or alternatively (multicausality), there may also be several alternative or co-occurrent effects (multiple effect relation).4 Developmental relations are based on stages of a development process of an individual (ontogenetic relation; e.g. child – adult), a species (phylogenetic relation), a family (genealogic relation), or material (material development relation; e.g. water – ice). Role change relation that is based on changing or developing roles of the same individual has been included to this relation category (e.g. accused – guilty). Madsen et al. classify these relations as temporal relations, which is one possibility, but so far I have treated them separately. They have also role relations in their classification, but the equivalents for these are to be found in the next group of relations. 3.3 Functional Concept Relations Functional relations form the third type of influence relations. So far I have divided them into activity relations and origination relations, even though other possibilities exist and some relations can belong to both of them. Activity relations are based on a connection between an activity concept and phenomena involved in the activity (agent, object/patient, tool, and location). They are basically the same as in Madsen et al. (2001) with some exceptions. Their activity-static location relation corresponds here locational relation (activity - place of activity) while activity-source and activity-target relations belong to transfer relations in my classification. Activity-result relation is the same as resultative relation which I have classified as an origination relation, because I wanted to give each relation type only one position in the classification, even though some relation types could belong to several classes, e.g. resultative relation to activity relations. Activity relations have not yet included the relation between activity and purpose. It could be called teleological relation or purpose relation (see Madsen et al., 2001). Origination relations exist between a concept that refers to a concrete or abstract entity and concepts that refer to the origin of the object (e.g. original material, producer, instrument, manufacturing method, manufacturing process, place of origin, etc.). Also here purpose could
4. See more in Nuopponen 1994 b.
134

Concept Relations
be added, in this case the purpose for producing or creating the entity in question. This relation comes near causal relations.
Figure 5: Functional concept relations Instrumental relations (instrument -activity/object/result/user/location/ purpose/way of using ,etc.) could form a third group of functional relations. The agent-tool relation in Madsen et al. (2001) can be included in this group, and even their function relation (entity - way of working) could belong to this group. In addition to these, some relations between the concepts in functional concept systems are missing in the classification, e.g. agent - patient/object that appears also in transmission relations. For all relationships it is not necessary to create a new relation concept because some of them can be borrowed from other relation classes, e.g. instrument-location falls under locative relation (see 2.1.3 in figure 2). 3.4 Interactional Concept Relations Interactional conceptual relations are based on the interplay of referent phenomena. I divided them into concept relations of transmission, dependency, correlation and representation. The first one is based on the relation between agents in a process of transmission in which A gives/sends/transmits something to B (e.g. transmitter – receiver, coder – decoder). Relations that can be found in concept systems of transmission are e.g. source relation (sender/place – entity) and target relation (entity – receiver/ place). I have been using source and target relation not only to refer to sender and receiver, but also to the place of
135

Anita Nuopponen
departure and destination. However, it may be necessary to distinguish between these two sets of concept relation in some cases. When combined with temporal, developmental, and functional relations, as well as some other relations, transmission relations can be used to analyse e.g. processes.
Figure 6: Interactional concept relations
Dependency relations are based on various types of economic, legal and other similar relations which may exist between different parties (e.g. employer – employee). Correlation relation is a rare type of concept relation. It refers to a reciprocal relationship between entities (variables) with some kind of causal connection: when one changes, the other is likely to make a corresponding change (e.g. height – weight). Representational relation refers to the relation between an entity and its representative (e.g. concept – term, people – parliament).
4. Discussion In my earlier research I made an effort to create a concept system oriented classification of concept relations. The thoughts were derived in addition to Wüster (e.g. 1971, 1974) and other terminologists, from philosophy, theory of science, concept modelling, biology, and system theory. For this update I compared my original classification mainly with the classifications created by Madsen et al. One of the reasons why their classifications became the most interesting ones for me was that they share many features with my own. Several classifications are not paying much attention to the relations in their larger context as
136

Concept Relations
elements of concept systems, but list only the relations that are easiest to detect (e.g. part – whole) but ignore the relations between other concepts in same concept systems (e.g. part – part). In this article I have filled in some gaps in my earlier classification, but while doing this I have noticed some more gaps and alternative ways in organizing the classification, which, however have to wait for the version nr 3. References Arntz, R. & H. Picht; Einführung in die Übersetzungsbezogene
Terminologiearbeit. Hildesheim, Zürich, New York: Georg Olms Verlag, 1982.
Dahlberg, Ingetraut; Über Gegenstände, Begriffe, Definitionen, und Benennungen. Zur möglichen Neufassung von DIN 2330, in Muttersprache 2, 1976.
Hedin, A.; L. Jernberg; H.C. Lennér; T. Lundmark & S-B. Wallin; Att mena och mäta samma sak – en begreppsorienterad metod för terminologiskt arbete. Lund: Studentlitteratur, 2000.
ISO 1087-1:2000; Terminology work – Vocabulary – Part 1: Theory and application. International Organization for Standardization, 2000.
Longman Dictionary of the English Language. Harlow, Essex: Longman, 1984.
Madsen, B. Nistrup; H. Erdman Thomsen & C. Vikner; Data modelling and conceptual modelling in the domain of terminology, in Alan Melby (eds.), TKE 2002, Terminology and Knowledge Engineering. Proceedings, 6th International Conference 28th-30th August 2002. http://www.id.cbs.dk/~het/idterm/CTO/caos/modelTKE 02.pdf
Madsen, B. Nistrup; B. Sandford Pedersen & H. Erdman Thomsen; Semantic Relations in Content-based Querying Systems: a Research Presentation from the OntoQuery Project, in K. Simov & A. Kiryakov (eds.), Ontologies and Lexical Knowledge Bases. Proceedings of the 1st International Workshop, OntoLex 2000. Sofia: OntoText Lab., 2002.
Madsen, B. Nistrup; B. Sandford Pedersen & H. Erdman Thomsen; Defining semantic relations for OntoQuery, in A. Jensen & P. Skadhauge (eds.), Proceedings of the First International OntoQuery Workshop, Ontology-based interpretation of NP's. Kolding: Department of Business Communication and Information Science, University of Southern Denmark, 2001.
http://www.ontoquery.dk/publications/docs/Defining.doc
137

Anita Nuopponen
Nuopponen, Anita; Begreppssystem för terminologisk analys. [Concept systems for terminological analysis]. Vaasa: University of Vaasa, 1994a. [English version forthcoming].
Nuopponen, Anita; On Causality and Concept Relationships in J. Draskau & H. Picht (eds.), Terminology Science and Terminology Planning, IITF-Workshop on Theoretical Issues of Terminology Science. Vienna: TermNet, 1994b.
Wüster, Eugen; Österreichische Beiträge zur Überwindung der Klassifikationsprobleme, in J. Recla (eds.), Sportdokumentation im Durchbruch. Bad Honnef: Osang-Verlag, 1971.
Wüster, Eugen; Die allgemeine Terminologielehre – ein Grenzgebiet zwischen Sprachwissenschaft, Logik, Ontologie, Informatik und den Sachwissenschaften, in Linguistics 199, 1974.
Wüster, Eugen; Einführung in die Allgemeine Terminologielehre und Terminologische Lexikographie. Copenhagen: Fachsprachlichen Zentrum, Handelshochschule Kopenhagen, 1985.
138

Comparing the Concept Relations and their Grouping in UMLS1
and in OntoQuery2
EKATERINA MHAANNA 1. Introduction This paper concerns the work of the Danish National Board of Health on improving the existing Conceptual Model for Communication in Electronic Health Records (EHR). The concepts used in EHR are defined in the concept base (Begrebsbasen3), which is under development within the framework of the Concept Council (Begrebsrådet). All concepts in the concept base constitute the concept diagrams. While the number of concepts and concept relations in the concept base grows, it is becoming difficult to maintain the consistency in use of the relations. To make it easier to control the consistent use of the relations, it was suggested to group the relations and order the groups hierarchically, and to define the relations. The Danish National Board of Health used UMLS as a starting point in its work. The paper outlines the comparative analysis of the concept relations from UMLS and concept relations from OntoQuery, a cross-disciplinary project, working on methods for ontology based query systems. The conclusions of the analysis formed the basis of the improvements of the use of concept relations in the concept base. 2. Relations Defined in the OntoQuery Project In OntoQuery significant attention is paid to grouping concept relations into coherent classes and ordering them hierarchically as well as defining concept relations in accordance with their position in the hierarchy. The concept relations in OntoQuery are arranged into
1. Unified Medical Language System, see:
http://www.nlm.nih.gov/research/umls/META3_current_relations.html 2. Ontology-based Quering, see www.OntoQuery.dk 3. The official translation of the Danish expressions is being worked on by the
Danish National Board of Health.

Ekaterina Mhaanna
several part-hierarchies, among which the hierarchy of role relations is the most detailed one. Appendix 1 shows the general hierarchy of concept relations for OntoQuery project. The top concept in this general hierarchy is semantic relation. It has eight subgroups: generic4, partitive, temporal, property-characteristic and measurement relations, which are more common in terminology, plus such relations as location, activity and role relations, which are paid special attention in OntoQuery. There are five levels in the hierarchy. The lowest level represents the most specific role, activity and location relations. The names of the relation terms used in OntoQuery are combinations of noun phrases, for example: source – target relation, activity – patient relation or instrument – result relation. 3. Unified Medical Language System UMLS groups the relations into two super-ordinate types: isa and associated with (Appendix 2). There are four levels in the UMLS hierarchy, but there is no super-ordinate concept for the two relations. Associated with is subdivided into 5 groups: physically related to, spatially related to, functionally related to, temporally related to and conceptually related to. The relations themselves are expressed in natural language expressions by verbs (for example performs), verbal phrases (connected to) and prepositional phrases (branch of). 4. Comparison of UMLS and OntoQuery The Danish National Board of Health decided to investigate, whether the classifications of the relations in UMLS and in OntoQuery were compatible, i.e. whether it was possible to map the relations from UMLS to OntoQuery and vice versa. This investigation was to show, if there were any relations in the one system, which were not present in the other system. UMLS includes the relations, which are especially relevant for the health sector. Therefore it was quite possible that there were relations in OntoQuery, which were not present in UMLS. The OntoQuery classification has been worked out for the use in all fields. Therefore it was interesting to see, whether OntoQuery covered all UMLS relations. More precisely our investigation focused on the following points: • The analysis of the concept relations in UMLS and their grouping
in the UMLS hierarchy. Are the relations clear and distinct? Is the position of the relations in the hierarchy appropriate?
4. The relation terms in this paper are italicised.
140

Comparing the Concept Relations and their Grouping in UMLS and in OntoQuery
• The analysis of UMLS using the concept relations from OntoQuery. Can the OntoQuery relations be used to describe the relations from UMLS and by this to contribute to a better distinction of the UMLS relations? Do the OntoQuery relations cover all UMLS relations?
• Comparing of the concept relations and their grouping in UMLS with the concept relations and their categorisation in OntoQuery. Can we combine the two systems? Can the principles used in OntoQuery make UMLS more effective?
As a result of this comparison the Danish National Board of Health worked out some suggestions concerning the combination of the two systems (UMLS and OntoQuery) and the more effective use of the systems within the health domain.
In the paper I develop further our analysis of concept relations in UMLS and in OntoQuery5 that provided the basis for the decisions made by the Danish National Board of Health concerning the concept base. The further development of our analysis, which I outline and exemplify in this paper, can make the UMLS relations easier to understand and therefore easier to use in the concept diagrams of the concept base. Our research is also aiming at revealing the possible drawbacks of the UMLS hierarchy of concept relations, such as for example overlap among some of the UMLS relations. 5. Analysis of Some Concept Relations and their Grouping in UMLS 5.1 UMLS Relations conceptually related to and physically related to Conceptually related to is among the relations, subordinate to the associative relation in UMLS. It includes some relations, referring to the mental procedures, such as evaluation of, method of and others. The term for the relation – conceptually related to – sounds rather general, because all the relations in UMLS hierarchy are conceptual relations. Concept relation could be a top-concept in the UMLS hierarchy. Some of the relations, subordinate to conceptually related to, resemble the relations from different groupings in OntoQuery: 5. The subject of the paper is also a part of my research about concept relations in
OntoQuery.
141

Ekaterina Mhaanna
UMLS OntoQuery measurement of measurement relation measures measurement relation property of property-characteristic relation developmental form of development relation conceptual part of subpart relation
Table 1: Some resembling relations from UMLS and OntoQuery To add to this, not all the relations in for example physically related to (UMLS) are pure physical. Consider the sentence: Immunology is a branch of medicine. The relation branch of between immunology and medicine is more mental in nature, than it is physical. A solution can be to regroup the subtype relations of conceptually related to and physically related to using the OntoQuery groups, or find other expressions for the UMLS physically related to and conceptually related to. 5.2 Associative and Partitive Relations According to the classification6 of concept relations in the ISO7 standards for terminology work, all concept relations, other than generic and partitive relations, are associative relations (for example sequential, causal and the others), see ISO 1087-1 and ISO 704. associative concept relation
sequential concept relation
causal concept
hierarchical concept relation
partitive concept
generic concept
Figure 1: Classification of associative and partitive relations according to ISO 1087-1 In OntoQuery an associative relation is “other (unspecified) relation”, which is used when none of the other relations from the OntoQuery hierarchy apply, see Madsen et al. (2001)8.
6. Only the relations relevant for the section are presented in figures 1, 2 and 3. 7. International Standard Organisation 8. Associative relation is not in the draft diagram in Appendix 1, but it is presented in
the intermediate diagram in Madsen et al. (2001), fig.5.
142

Comparing the Concept Relations and their Grouping in UMLS and in OntoQuery
semantic relation associative
relation temporal relation role
relation activity relation
location relation
partitiv relation
generic relation
Figure 2: Classification of associative and partitive relations according to OntoQuery The subdivision in UMLS is rather different. Here associated with is at the first level of the hierarchy, co-ordinate to the isa (generic) relation. associated with isa
(generic relation) conceptually related to
temporally related to
functionally related to
spatially related to physically
related to
consists of contains branch of ingredient of part of
Figure 3: Classification of “associated with” and partitive relations according to UMLS Different types of partitive relation are included in the groups that are subordinate to associated with. For example in the subgroup physically related to we find the following relations, which could be classified as partitive9 relations: part of, consists of, contains, branch of, ingredient of. So if the more standard approach is to be followed, these UMLS relations should be grouped under the super-ordinate partitive relation and this group is to be placed at the same level as isa and associated with. It is the case in OntoQuery, where partitive relation is at the second level of the hierarchy, co-ordinate to the generic and some other relations. It is worth mentioning that the subtypes of physically related to from UMLS match the subtypes of the partitive relation from OntoQuery, for example: part of - subpart relation, consists of - subpart relation, contains - set-element relation, ingredient of - material relation. Grouping these relations in UMLS as partitive relations makes these relations more clear and distinct. The UMLS hierarchy can be by this 9. Some sources very conveniently call partitive relation “part-whole relation”.
143

Ekaterina Mhaanna
grouping organised in a more standard way, and the relations can gain a more appropriate position in the hierarchy. 5.3 The UMLS Relation surrounds The relation surrounds from the UMLS group spatially related to can in some cases be classified as partitive relation as well, if the entity that surrounds the object is at the same time a part of the object, as in the following examples10:
surrounds part of the outer membrane whichsurrounds the cell
outer membrane is a part of cell
the pericardium surrounds your heart
pericardium is a part of heart
a semi-permeable membrane that surrounds and protects the brain
semi-permeable membrane is a part of brain
Table 2: Correct phrases with “surrounds” as partitive relation The relation is different in the examples:
surrounds part of11
(cerebrospinal) fluid that surrounds the brain and spinal cord
*(cerebrospinal) fluid is a part of brain and spinal cord
cranium surrounds the brain *cranium is a part of brain amniotic fluid surrounds the growing fetus
*amniotic fluid is a part of growing fetus
Table 3: Incorrect phrases with “surrounds” as partitive relation Here the entity that surrounds is not a part of the other entity and the relation refers to the location of the object within the surrounding entity. The two kinds of surrounds are to be separated by naming them differently and placing them in different groups of the UMLS hierarchy: the first one – under partitive relation, while the other one
10. The example sentences with “” are from the Internet sites, linked to the UMLS
pages. The precise addresses are left out in this paper. 11. The incorrect phrases are marked by “*”.
144

Comparing the Concept Relations and their Grouping in UMLS and in OntoQuery
can stay under spatially related to. In OntoQuery a similar type of location relation is called entity-static location relation. 5.4 temporally related to in UMLS and temporal relation in OntoQuery Another interesting case is temporally related to from UMLS and temporal relation from OntoQuery. temporally related to (UMLS) has the subtypes co-occurs with and precedes. Temporal relation (OntoQuery) has subtypes phase relation and development relation. It would be logical to introduce the succeeds relation in UMLS. But precedes and succeeds are two sides of the same thing: if fatigue precedes migraine, then migraine succeeds fatigue. On the other hand there are relations in UMLS that are the inverse relations of other relations, for example part of-consists of and ingredient of-contains. And in the most developed part of the OntoQuery hierarchy (Appendix 1) the terms for the role, activity and location relations are combinations of noun phrases, referring to both sides of the relation (for example activity-patient). So precedes from UMLS in combination with succeeds provide a subtype for phase relation from OntoQuery: preceding phase-succeeding phase, referring to the relation between phases where the succeeding phase follows immediately after the preceding phase. For example: the process of cell nucleus division is a chain of several phases: prophase – metaphase – anaphase – telophase. So preceding phase-succeeding phase is the relation between prophase – metaphase, metaphase – anaphase and anaphase – telophase. But preceding phase – succeeding phase does not cover such relations as: cell nucleus division – metaphase (or the other phases); prophase – anaphase; prophase – telophase. These are the relations of some other types. The relation between cell nucleus division and metaphase (or the other phases) is the relation between the process and its phases as its parts. It can be characterised as a type of partitive relation. The relation between prophase and anaphase is a relation between parts of a process regardless of their sequence. The temporal aspect is of less importance in the last two cases, especially if compared to the relation between anaphase and telophase – the relation between the beginning and the end of cell nucleus division. Though it is also a relation between parts of a process, as between prophase and anaphase, the temporal aspect here (start phase-end phase) can in many cases be more significant for characterising the relation. Concluding the analysis of the example with cell nucleus division the following subtypes of phase relation in OntoQuery can be suggested:
145

Ekaterina Mhaanna
Example Suggestion for OntoQuery relation prophase – metaphase prophase – telophase
preceding phase-succeeding phase start phase-end phase
Table 4: Suggestions for subtypes of phase relation in OntoQuery The other subtype of temporally related to from UMLS is co-occurs with. Here are some examples from the Internet showing that co-occurs with does not fit as another subtype for the OntoQuery phase relation:
Example sentence UMLS relation
OntoQuery relation
Anxiety disorders precede onset of anorexia or bulimia
precedes phase relation – yes
Eating disorders co-exist with anxiety and depression
co-occurs
phase relation - no
Migraines may be preceded by visual disturbances and fatigue
precedes phase relation – yes
Table 5: “Co-occurs with” compared to “precedes” Being temporal in nature12 co-occurs can be introduced into OntoQuery as a subtype of temporal relation and co-ordinate with the phase relation and the development relation. 6. Concluding Remarks On the basis of the analysis, outlined in the paper, the following conclusions can be drawn (the numbers in brackets refer to the sections of the paper that illustrate the conclusion points13): • Some groups in UMLS hierarchy are (a) too general (5.1); (b) have
only one subtype. • Some UMLS relations (a) should be moved to another place in the
hierarchy in UMLS or in OntoQuery (5.1, 5.2); (b) match several groups in the hierarchies of UMLS or OntoQuery, and are to be clarified (5.3); (c) can have more co-ordinate relations (5.4).
12. A more precise description of the relation would require more examples and a
more detailed analysis than the size of the paragraph allows. 13. Not all of the conclusion points are exemplified in this paper.
146

Comparing the Concept Relations and their Grouping in UMLS and in OntoQuery
• The UMLS terms for the relations (a) can be more meaningful; (b) refer to the same relation.
• Some relations in OntoQuery are not present in UMLS and vice versa (5.4).
• In some cases UMLS relations correspond to OntoQuery relations (5.1, 5.2) or can be introduced in OntoQuery (5.4).
References ISO 1087-1 The International Standard ISO 1087-1; Terminology work
— Vocabulary — Part 1: Theory and application. ISO 2000. ISO 704 The International Standard ISO 704; Terminology work —
Principles and methods. ISO 2000. Madsen, Bodil Nistrup; Bolette Sandford Pedersen & Hanne
Erdman Thomsen; Defining Semantic Relations for OntoQuery, in P.A. Jensen & P. Skadhauge (eds.), Ontology-based Interpretation of Noun Phrases. Proceedings of the First International OntoQuery Workshop. Kolding: University of Southern Denmark, 2
147

Ekaterina Mhaanna
generic relation
subpart relation Appendix 1: The Hierarchy of Concept Relations in OntoQuery
location rel.
dynamic location relation
source rel.
target rel.activity-target rel.
activity-source rel.
source-target rel.
activity-static loc. rel.
entity-static loc. rel.
static location
semanticrelation
activity relation
role relation
activity-agent rel.
activity-patient rel.
activity-instrument rel.
activity-result rel.
agent-patient rel.
agent-instrument rel.
agent-result rel.
patient-instrument rel.
patient-result rel.
instrument-result rel.
result relation
instrument rel.
patient relation
agent relation
property-characteristic rel.
partition relation partitive r material relation elation
set-element rel.
temporal rel.
measurement rel.
phase relation
development rel.
148

Comparing the Concept Relations and their Grouping in UMLS and in OntoQuery
isa associated with physically related to part of consists of contains connected to interconnects branch of tributary of ingredient of spatially related to location of adjacent to surrounds traverses functionally related to affects manages treats disrupts complicates interacts with prevents brings about produces causes performs carries out exhibits practices occurs in process of uses manifestation of indicates result of temporally related to co-occurs with precedes [associated with] (continued) conceptually related to
149

Ekaterina Mhaanna
evaluation of degree of analyses assesses effect of measurement of measures diagnoses property of derivative of developmental form of method of conceptual part of issue in Appendix 2: The Hierarchy of Concept Relations in UMLS
150

Overcoming the Knowledge Acquisition Bottleneck?
LEE GILLAM & KHURSHID AHMAD Introduction This paper proposes a method for producing concept systems from corpora. Such a goal is not novel per se; however the combination of statistical measures, ISO standards, ontology markup languages, and ontology editors allows us to consider automated knowledge engineering from text, reprising ideas from previous work (Gillam and Ahmad 1996). This form of knowledge engineering suggests that it may become possible to overcome a principal hurdle in developing intelligent systems: the knowledge acquisition bottleneck.
The task of producing these concept systems is variously referred to as terminology structuring (Grabar and Zweigenbaum 2004) or ontology learning (Maedche 2002). Literature on ontology learning and terminology extraction, and on information extraction, enumerates three techniques: statistical (Salton 1971, Jing and Croft 1994); linguistic (Grefenstette 1994); and hybrid (Drouin 2003, Vivaldi and Rodriguez 2001). Statistical measures, such as log-likelihood and mutual information, are used to rank information extracted linguistically (for example Vivaldi and Rodriguez), but predominantly statistical approaches to this task are somewhat rare. Some authors augment linguistic approaches using TF/IDF, word clustering, and coded linguistic relationships (Maedche and Volz 2001). Hybrid techniques may include sophisticated classification systems (neural networks and other learning algorithms) and such methods rely on the frequency counts of linguistic units. Typically, approaches to ontology learning from text use syntactic parsing (Maedche and Volz 2001, Maedche and Staab 2003, Faure and Nédellec 1999; 1998, Mikheev and Finch 1995). The limitation of linguistic approaches is inherent in the accuracy and coverage of these resources: the prior linguistic knowledge. Such systems generally have to be trained in some way in order to produce accurate results. Arguably, the results depend in large part on this training phase.
The method presented differs from these approaches in being primarily statistical, though the results can be augmented subsequently

L. Gillam & K. Ahmad
using linguistic techniques. Furthermore, approaches to extraction of such concept systems are generally considered from the perspective of a single corpus. The work presented has been undertaken using several corpora from different specialisms with a goal to show that the approach is generalisable, albeit limited at present to specialist texts in English. Some of the analysis may be applicable to other languages, with specific modifications.
The notion being explored is that of “frequency correlating with acceptability” (Quirk 1995 p33). Frequency in specialisms should correlate with acceptability in the specialism, and contrast with a reference collection should provide an indication of the specialisation. This also provides a mechanism for quantifying the difference between LSP and LGP. We use the British National Corpus (BNC) (Aston and Burnard 1998) as a reference collection and consider some similarities between corpora using Zipf’s Law (Zipf 1949). This initial analysis suggests that a more general approach to specialist texts is possible. Subsequently, we combine a weirdness calculation (Ahmad and Davies 1994) adapted by smoothing (Gale and Church 1990), with a collocation extraction technique (Smadja 1993) to produce a candidate concept system.
This terminology structuring, or ontology learning, remind us of Minksy’s “thesaurus problem” (Minsky 1968, p27) of building and maintaining a thesaurus useful for a specific task or set of tasks, of learning to build thesauri, and of finding “new ways [to] make machines first to use them, then to modify them, and eventually to build for themselves new and better ones”. Building terminologies, or ontologies, provides an identical challenge. At the same time, distinctions between terminologies, thesauri and ontologies become increasingly difficult to make: a thesaurus has been described as “one type of ontology, one specialized to information retrieval” (Oard 1997), and sits on a “spectrum” of types of ontology (Lassila and McGuinness 2001) on which terminologies should may sit, depending on their construction. Extensively described terminologies, including strictly controlled inheritance relationships, inheritance of properties, and constraints on properties, become usable through ontology editors such as Protégé (Noy et al 2001), for the development of intelligent systems using, for example, expert system shells (Eriksson 2003). By reference to international standards (ISO) for terminology, and by automatically extracting candidate concept systems from text, and subsequently by extracting properties, and values for properties, and constraints on properties from text also, we can facilitate the construction of
152

Overcoming the Knowledge Acquisition Bottleneck?
terminological resources that have a potentially wider scope of use as ontologies. Such a terminology/ontology is suitable for validation by experts and use for the development of intelligent systems.
We have undertaken systematic analysis of five specialist text corpora of various sizes, stored at Surrey, to determine the efficacy of such an approach. Specific examples used are produced from one of these corpora – concerned with nanoscale science and design – but results from other specialist corpora show similar behaviour are the subject of ongoing expert evaluation. Our hypothesis is that if different specialisms use language in similar, productive, ways it becomes possible to systematically extract concepts from arbitrary collections of specialist text.
Method The first 100 most frequently occurring types in a text corpus comprise just under half the corpus, be it specialist or non-specialist (Ahmad 1999): the first 100 most frequent types within a text collection of around half a million words comprises between 30 and 40 open class words. This distinction between open-class and closed-class words requires human judgement and prior domain knowledge. To systematize our approach, we consider 5 specialist corpora and one general language corpus, with type and token counts as shown below (Table 1).
Breast Cancer
Automotive Nuclear Finance Nanoscale BNC
Tokens 166044 350920 393993 685037 1012096 100106029 Types 10036 14252 14937 28793 26861 669417
Table 1: Type and token counts for the 6 corpora in our analysis Zipf’s power-law function has been used to show that rank multiplied by frequency produces a constant that is a tenth the number of tokens in the corpus (e.g. for the Brown Corpus, Manning and Schütze 1999: pp26-27). Zipf’s law has been tested in analysis of large corpora of newswire texts (the Wall Street Journal for 1987, 1988 and 1989 of 19 million, 16 million and 6 million tokens approximately) and shows similar behaviour between these collections, with little deviation due to corpus size (Ha et al. 2002). Derivation from Zipf’s law for treating the hapax legomena shows some degree of consistency in use of low frequency words across our specialist corpora, with a key difference between specialist corpora and a general language corpus (Fig.1.).
153

L. Gillam & K. Ahmad
Figure 1: Difference between percentage of types (y-axis) in the specialist corpora and predicted values derived from Zipf’s law (0.00%) for frequencies between 1 and 10 (x-axis) for 5 specialist corpora. For frequency 1, specialisms have around 37-43% of types compared to expectation (50%) and BNC (53%).
Using these predicted values, 90% of words are estimated to occur with frequency of 10 or less in the hapax legomena. For BNC, this is 84.45%, while it is around 80% for the specialist corpora. Specialist corpora seem to follow a consistent pattern, deviating in a same manner from Zipf’s law. High frequency and low frequency words follow similar patterns of deviation from Zipf’s law that may be accounted for by the Zipf-Mandelbrot law. This analysis suggests that comparability to a general language corpus has a valid basis, and here we compare frequencies of words in the specialist corpora to frequencies found in general language using weirdness adapted to account for words not found in general language using “Add-one” smothing. For the specialist corpora, between 13% and 38% of types are not found in the BNC (Table 2), which suggests that such an approach is necessary for successful comparison.
Table 2: Words (types) in the specialist corpora that do not occur in the reference corpus.
Corpus Types Tokens Number of types not in BNC
% types not in BNC
Breast Cancer 10036 166044 1368 14% Automotive 14252 350920 1794 13% Nuclear 14937 393993 4190 28% Finance 28793 685037 4718 16% Nanoscale 26861 1012096 10231 38%
154
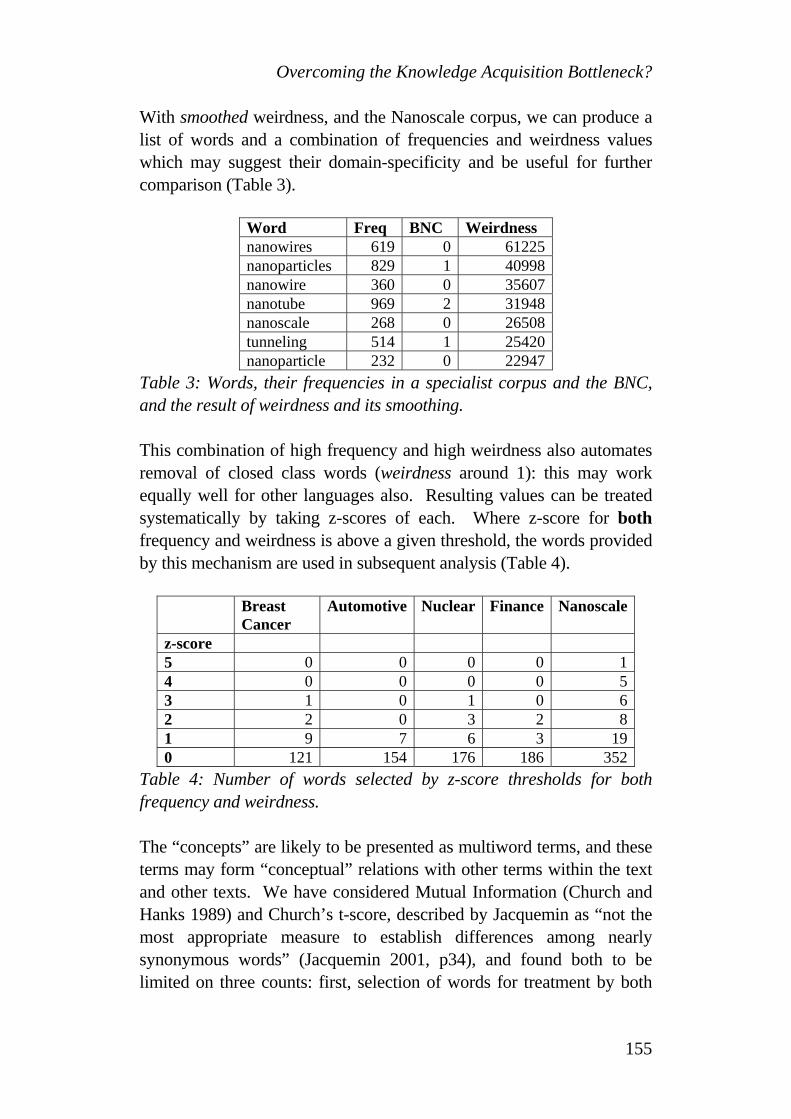
Overcoming the Knowledge Acquisition Bottleneck?
With smoothed weirdness, and the Nanoscale corpus, we can produce a list of words and a combination of frequencies and weirdness values which may suggest their domain-specificity and be useful for further comparison (Table 3).
Word Freq BNC Weirdness nanowires 619 0 61225nanoparticles 829 1 40998nanowire 360 0 35607nanotube 969 2 31948nanoscale 268 0 26508tunneling 514 1 25420nanoparticle 232 0 22947
Table 3: Words, their frequencies in a specialist corpus and the BNC, and the result of weirdness and its smoothing.
This combination of high frequency and high weirdness also automates removal of closed class words (weirdness around 1): this may work equally well for other languages also. Resulting values can be treated systematically by taking z-scores of each. Where z-score for both frequency and weirdness is above a given threshold, the words provided by this mechanism are used in subsequent analysis (Table 4).
Breast Cancer
Automotive Nuclear Finance Nanoscale
z-score 5 0 0 0 0 1 4 0 0 0 0 5 3 1 0 1 0 6 2 2 0 3 2 8 1 9 7 6 3 19 0 121 154 176 186 352
Table 4: Number of words selected by z-score thresholds for both frequency and weirdness. The “concepts” are likely to be presented as multiword terms, and these terms may form “conceptual” relations with other terms within the text and other texts. We have considered Mutual Information (Church and Hanks 1989) and Church’s t-score, described by Jacquemin as “not the most appropriate measure to establish differences among nearly synonymous words” (Jacquemin 2001, p34), and found both to be limited on three counts: first, selection of words for treatment by both
155

L. Gillam & K. Ahmad
seems to be arbitrary; second, neither considers the importance of the neighbourhood of the selected word(s); third, both metrics consider only two words. On the first issue, both metrics could be systematized using our weirdness-frequency combination; for the second, two words may appear important using these measures, but appear equi-frequently at all positions, hence there is no significant pattern; for the third, bigrams may form very meaningful patterns with additional words, but at lower frequencies. Smadja’s work on collocations can address these latter two to some extent (1993): we refer to the systematic extension of collocations as re-collocation, although we have to consider the validity of lower frequency with increasing length. The example collocation values in Table 5 are a selection of words collocating with carbon (frequency of 1506) in the Nanoscale corpus that satisfy Smadja’s constraints. Re-collocation with carbon nanotubes results in collocating words as shown in Table 6. Collocate Freq -5 -4 -3 -2 -1 1 2 3 4 5 nanotubes 690 8 8 9 2 0 647 6 0 7 3 nanotube 252 3 2 2 0 0 229 2 1 5 8 single-walled 77 0 0 1 1 75 0 0 0 0 0 aligned 94 1 1 3 5 74 0 1 1 3 5 multiwalled 70 1 1 2 0 59 0 0 1 5 1 amorphous 58 1 1 6 0 46 0 1 1 0 2 atoms 51 1 2 0 1 0 42 0 1 3 1 nanotips 44 0 2 1 1 0 39 0 0 1 0
Table 5: Collocations with carbon (frequency of 1506) in the Nanoscale science corpus.
Collocate Frequency -5 -4 -3 -2 1 1 2 3 4 5 single-walled 73 0 0 1 1 71 0 0 0 0 0 aligned 63 1 1 1 5 48 0 0 2 4 1 multiwalled 53 0 0 1 0 46 0 0 5 1 0 properties 60 1 4 15 32 0 0 0 6 2 0 multiwall 34 0 1 0 1 30 0 2 0 0 0 single-wall 26 0 0 1 0 24 0 0 0 1 0
Table 6: Collocations with carbon nanotubes (frequency of 647) in the Nanoscale science corpus.
The result from such analysis is a tree emanating from the originally selected list of words. We have shown elsewhere how this tree can be encoded in conformity with international standards for the production of terminology interchange formats using ISO 12620 and ISO 16642 and
156

Overcoming the Knowledge Acquisition Bottleneck?
for use with so-called ontology exchange languages (Gillam and Tariq 2004). A fragment of such a tree, resulting from the above analysis, and suitable for such encoding, is shown below (Fig. 2). The terminological status of such collocations still requires human validation.
nanotubes
1378
carbon nanotubes z nanotubes
647 24
aligned carbon nanotubes multiwalled carbon nanotubes single-wall carbon nanotubes multiwall carbon nanotubes
48 46 24 46
multiwalled carbon nanotubes mwnts single-wall carbon nanotubes swnts
13 4
vertically aligned carbon nanotubes vertically aligned carbon kai
15 15
Figure 2: Fragment of the resulting ontology from a corpus of Nanoscale science and design texts. Dotted outlines denote collocations deemed to be invalid. Discussion We have described a method for constructing ontologies, or terminologies, or perhaps thesauri, from text. Potential applications include: generating buy/sell signals in financial trading (Gillam 2002), health policy communication (Gillam and Ahmad 2002), digital heritage (Gillam, Ahmad and Salway 2002) and query expansion for multimedia information retrieval (Ahmad et al. 2003, Vrusias Tariq and Gillam 2004). The resulting ontology has been exported to a de facto standard ontology editor – Protégé - where it can be viewed and edited. Here it also becomes the basis for development of intelligent systems (Eriksson 2003). Initial discussions with domain experts have validated the first results with some degree of confidence, and we are studying the effects of increasing the length of multiword patterns being generated, against decrease in frequency. For example, at low frequencies, we have aligned single-walled carbon nanotubes (2) and large-diameter single-walled carbon nanotubes (2): maximum likelihood estimation suggests statistical validity to these patterns. Subsequent effort is considered for classify collocations into facets, whereby we begin to determine the properties and values of properties. In the examples presented, the types
157

L. Gillam & K. Ahmad
of carbon nanotubes appear to have “walledness” as a significant facet, and being aligned has importance also, though seems to be a value of a different facet. Determining this distinction currently requires expert input. properties is not a positionally valid collocation – though we can infer that properties of carbon nanotubes are described in this collection. We have considered use of linguistic patterns to augment these concept systems elsewhere (Gillam, Tariq and Ahmad 2005), and further work on these kinds of analysis is expected.
Results to date suggest the possibility to overcome a principal hurdle in developing intelligent systems: the knowledge acquisition bottleneck.
Acknowledgements This work was supported in part by the EU (SALT: IST-1999-10951, GIDA: IST-2000-31123, LIRICS: eContent-22236), EPSRC (SOCIS: GR/M89041/01) and ESRC (FINGRID: RES-149-25-0028). References Ahmad, K.; M. Tariq; B. Vrusias & C. Handy; Corpus-Based Thesaurus
Construction for Image Retrieval, in Specialist Domains, Lecture Notes in Computer Science (LNCS) 2633, pp. 502 – 510. Springer Verlag, Heidelberg, 2003.
Ahmad, K; Neologisms to Describe Neologisms: Philosophers of Science and Terminological Innovation, in P. Sandrini (eds.), TKE’99 Terminology and Knowledge Engineering, pp. 54 – 73, 1999.
Ahmad, K & A.E. Davies; Weirdness in Special-language Text: Welsh Radioactive Chemicals Texts as an Exemplar. Internationales Institut får Terminologieforschung Journal 5(2), pp. 22 – 52, 1994.
Aston, G. & L. Burnard; The BNC Handbook: Exploring the British National Corpus. Edinburgh: Edinburgh University Press, 1998.
Church, K.W. & P. Hanks; Word association norms, mutual information and lexicography, in Proceedings of the 27th Annual Conference of the Association of Computational Linguistics, pp. 76 – 82, 1989.
Drouin, P; Term extraction using non-technical corpora as a point of leverage. Terminology 9(1), pp. 99 – 115, John Benjamins, Amsterdam, 2003.
Eriksson, H; Using JessTab to Integrate Protégé and Jess. IEEE Intelligent Systems 18(2), pp. 43 – 50, 2003.
Faure, D. & C. Nédellec; Knowledge Acquisition of Predicate Argument Structures from Technical Texts Using Machine
158

Overcoming the Knowledge Acquisition Bottleneck?
Learning: The System ASIUM. Lecture Notes in Computer Science (LNCS) 1621. Springer Verlag, Heidelberg, 1999.
Faure, D. & C. Nédellec; ASIUM: Learning subcategorization frames and restrictions of selection, in Y. Kodratoff, (eds.), 10th Conference on Machine Learning (ECML 98), Workshop on Text Mining, Chemnitz, Germany, 1998.
Gale, W. & K.W. Church; What's wrong with adding one? IEEE Transactions on Acoustics, Speech and Signal Processing, 1990.
Gillam, L.; M. Tariq & K. Ahmad; Terminology and the Construction of Ontology. Terminology, John Benjamins, Amsterdam, (in Press), 2005.
Gillam, L. & M. Tariq; Ontology via Terminology? Proceedings of Workshop on Terminology, Ontology and Knowledge Representation (Termino) 2004, Lyon, 2004.
Gillam, L. (eds.); Terminology and Knowledge Engineering: making money in the financial services industry. Proceedings of workshop at 2002 conference on Terminology and Knowledge Engineering (TKE), LORIA, 2002.
Gillam, L. & K. Ahmad; Sharing the knowledge of experts. Fachsprache 24(1-2), pp. 2 – 19, 2002.
Gillam, L.; K. Ahmad & S. Salway; Digital Heritage and the use of Terminology. Proc. of 6th International Conference Terminology and Knowledge Engineering (TKE), LORIA, 2002.
Gillam, L. & K. Ahmad; Knowledge-Engineering Terminology (Data)Bases. Proc. of 4th International Congress on Terminology and Knowledge Engineering (TKE). INDEKS-Verlag, Frankfurt, pp. 205 – 214, 1996.
Grabar, N. & P. Zweigenbaum; Lexically-based terminology structuring. Terminology 10(1), John Benjamins, Amsterdam, pp. 23 – 53, 2004.
Grefenstette, G.; Explorations in Automatic Thesaurus Discovery. Kluwer Academic Publishers, Boston, USA, 1994.
Ha, L.Q.; E. Sicilia; J. Ming & F.J. Smith; Extension of Zipf's law to words and phrases. International Conference on Computational Linguistics (COLING 2002), pp. 315 – 320, Taipei, Taiwan, 2002.
Jacquemin, C; Spotting and Discovering Terms through Natural Language Processing. MIT Press, Cambridge, MA, 2001.
Jing, Y. & W.B. Croft; An Association Thesaurus for Information Retrieval, in F. Bretano & F. Seitz (eds.), Proceedings of RIAO’94, pp. 146 – 160, CIS-CASSIS, Paris, France, 1994.
159

L. Gillam & K. Ahmad
Lassila, O. & D.L. McGuinness; The Role of Frame-Based Representation on the Semantic Web. Knowledge Systems Laboratory Report KSL-01-02, Stanford University, 2001.
Maedche, A.; Ontology Learning for the Semantic Web. The Kluwer International Series in Engineering and Computer Science, vol. 665, 2002.
Maedche, A. & R. Volz; The Ontology Extraction and Maintenance Framework Text-To-Onto. Workshop on Integrating Data Mining and Knowledge Management. California, USA, 2001.
Maedche, A. & S. Staab; Ontology Learning, in S. Staab & R. Studer (eds.), Handbook on Ontologies in Information Systems. Springer-Verlag, Heidelberg, 2003.
Manning, C. & H. Schütze; Foundations of Statistical Natural Language Processing. MIT Press, Cambridge, MA, 1999.
Mikheev, A. & S.A. Finch; Workbench for Acquisition of Ontological Knowledge from Natural Text. Proceedings of the 7th conference of the European Chapter for Computational Linguistics (EACL'95), pp. 194 – 201, Dublin, Ireland, 1995.
Minsky, M.; Semantic Information Processing. MIT Press, 1968. Noy, N.F.; M. Sintek; S. Decker; M. Crubezy; R.W. Fergerson & M.A.
Musen; Creating Semantic Web contents with Protege-2000. IEEE Intelligent Systems 16 (2), pp. 60 – 71, 2001.
Oard, D.W.; Alternative approaches for cross-language text retrieval, in AAAI Symposium on Cross-Language Text and Speech Retrieval. American Association for Artificial Intelligence, 1997.
Quirk, R.; Grammatical and Lexical Variance in English. Longman, London & New York, 1995.
Salton, G.; Experiments in Automatic Thesauri Construction for Information Retrieval, in Proceedings of the IFIP Congress vol. TA-2, pp.43 – 49, Ljubljana, Yugoslavia, 1971.
Smadja, F.; Retrieving collocations from text: Xtract. Computational Linguistics, 19(1), pp. 143 – 178, Oxford University Press, 1993.
Vivaldi, J. & H. Rodríguez; Improving term extraction by combining different techniques. Terminology 7(1), pp. 31 – 47, John Benjamins, Amsterdam, 2001.
Vrusias, B.; M. Tariq & L. Gillam; Scene of Crime Information System: Playing at St Andrews. Lecture Notes in Computer Science (LNCS) 3237, pp. 631 – 645, Springer Verlag, Heidelberg, 2003.
Zipf, G.K.; Human Behavior and the Principle of Least Effort. Hafner, New York, 1949.
160

Multidimensionality in Terminological Concept Modelling
BODIL NISTRUP MADSEN, HANNE ERDMAN THOMSEN & CARL VIKNER1
In this paper, multidimensionality is seen as the use of multiple subdivision criteria in the description of the subconcepts of a given concept. We argue that the choice of subdivision criteria is subject to a number of constraints. The modelling of multidimensionality has been implemented in the UML-based system CAOS 22 and the paper will contain some illustrative examples generated by this system. 1 Multidimensionalities Multidimensionality has been used in a number of different ways in the terminology literature. In the following we present some representative views. 1.1 As Multiplication of Types of Characteristics In (Kageura, 1997: 120) multidimensionality is described as follows:
“Since the characteristics of a concept are frequently specified from different points of view or facets (function, material, shape, weight, etc.) a set of characteristics that constitutes a concept is normally multidimensional. From this point alone, we can expect a concept system to be multidimensional.”
This means that multidimensionality “corresponds basically to types of characteristics” (Kageura, 1997: 122).
1. Department of Computational Linguistics, Copenhagen Business School,
Bernhard Bangs Allé 17B, DK-2000 Frederiksberg, Denmark, {bnm, het, cv}[email protected].
2. CAOS - Computer-Aided Ontology Structuring - is a project whose aim is to develop a computer system designed to enable semi-automatic construction of concept systems. The system developed from 1998 to 2004 is called CAOS 1. See e.g. (Madsen, Thomsen, Vikner, 2004). In 2005 we have started the implementation of a new version, CAOS 2, which comprises a graphical user interface.

B. N. Madsen, H. E. Thomsen & C. Vikner
If characteristics are represented formally as feature specifications, i.e. pairs of attributes and values3, the type of the characteristics are encoded formally and can be read off directly from the attributes of the feature specifications. Multidimensionality in this sense means that a concept may be associated with a set of feature specifications such that several attributes are present in the set. Thus, the description we have given of impact printer and nonimpact printer (Madsen, Thomsen, Vikner, 2004:18) would qualify as multidimensional, because it describes impact printer by the following feature structure:
CHARACTER TRANSFER : impact NOISE: noisy COPY: multiple
However, the addition of the two last feature specifications do not contribute to distinguishing this concept from other concepts, because they are entailed by the sort of character transfer described by the first feature specification (Madsen, Thomsen, Vikner, 2004:18). This means that the multiplication of different types of characteristics may result in redundancy.4
Multidimensionality in this sense is therefore not in itself very important for the structuring of a concept system, and it will in fact be present in all but the most simple systems. 1.2 As Multiplication of Concept Relations Margaret Rogers introduces a “type of multidimensionality (...) in which two or more types of relation are combined, such as logical [i.e. type-of] with part-whole, or logical with temporal” (Rogers, 2004: 220). Now, it is evident that describing a concept by means of characteristics, e.g. ascribing to book the characteristic [HAS_PART: spine], or by means of relations to other concepts, e.g. a part-whole-relation linking book to the concept spine, are two equivalent ways of stating the same thing.5
3. Cf., for instance, (Thomsen, 1998, 1999) and (Madsen, 1998). 4. We are talking here about redundancy with respect to the delimitation of the
concepts, which does not mean that the information conveyed in such characteristics will be irrelevant to potential users of the concept system.
5. The related concept, i.e. spine in the example, is given a more prominent status in a “relational” description, where it is treated as a concept in its own right, that may itself receive an elaborated description in the form of feature specifications or
162

Multidimensionality in Terminological Concept Modelling
Therefore this second type of multidimensionality is equivalent to the first type mentioned in the previous section. 1.3 As Multiplication of Subdivision Criteria ISO 704 introduces a notion of “dimension” based on the notion “subdivision criterion” (which is unfortunately not further explained).
Subordinate concepts at the same level and having the same criterion of subdivision are called coordinate concepts. The coordinate concepts resulting from the application of the same criterion of subdivision to the superordinate concept constitute a dimension. A superordinate concept can have more than one dimension, in which case the concept system is said to be multidimensional.
(ISO 704, section 5.4.2.1)6
This notion of multidimensionality is different from the one mentioned in section 1.1 and 1.2 above, because what is crucial is not just the presence of more than one type of characteristic, but of more than one dimension, which means that there is also more than one subdivision criterion. If a concept system contains only delimiting characteristics, the multidimensionality notion of section 1.1 (and 1.2) becomes equivalent to the one of this section. 2 Implementation of Multidimensionality When multidimensionality is seen as multiplication of subdivision criteria, the crucial question is the definition and modelling of subdivision criteria. At this point we would like to introduce a notion of normal form. We will say that a concept system is in normal form if it satisfies the constraints concerning delimiting characteristics, subdivision criteria and definitions established in section 2.3 below. (Polyhierarchical
relations linking it to other concepts. In a description with only characteristics, the related concept is less prominent but may still be the object of independent description if the system allows complex values in feature specifications, where the element “spine” could then be associated with its own feature structure.
6. Cf. also: “In a generic relation, there may be several ways of subdividing a concept into subordinate concepts depending on the criteria or type of characteristic chosen. When more than one criterion are used in the construction of a generic concept system, it is considered multidimensional.” (ISO 704, section 5.4.2.2).
163

B. N. Madsen, H. E. Thomsen & C. Vikner
structures present deviations with respect to subdivision criteria, which we will leave for future investigations.) 2.1 Subdivision Criteria and Delimiting Characteristics We propose an approach to subdivision criteria based on the following considerations. The terminologists’ characteristics reflect shared properties of the entities belonging to the extension of the relevant concepts. There may be a large number of such properties. As our knowledge of a concept grows the more characteristics one can attach to it (Meyer, Eck, Skuce, 1997: 101). However it is clear that these characteristics will not all be equally important for the delimitation of the concept in question. Consequently, there is a need for some sort of ranking of the characteristics. (Bowker, 1997: 139, 142) considers the possibility of carrying out such a ranking in order of relative importance on the basis, for instance, of the frequency of occurrence in the documentation. Apparently, she assumes a ranking with a certain number of different ranks. ISO 704 proposes a ranking with three ranks: delimiting, essential and non-essential characteristics (ISO 704, section 5.3.3 and 5.3.4). We will propose to restrict the number of ranks to two, namely, delimiting characteristics and non-delimiting. We assume that a concept needs only one delimiting characteristic. That is, we hypothesize that a delimiting characteristic represents a necessary and sufficient condition for the delimitation of a concept (given the concept’s position in the concept system, i.e. its generic relations to superordinate concepts). If the terminologist considers it necessary to attach more than one delimiting characteristic to a concept (i.e. each of the characteristics are considered necessary, but none of them as sufficient in itself), this may indicate gaps in the concept system. In a concept system in normal form, such gaps may be filled by adding appropriate superordinate concepts somewhere in the system. As the delimiting characteristic of a concept is crucial for the delimitation of the concept, it should be used in the differentia specifica of the definition of the concept. Delimiting characteristics come in different types. Such a type of delimiting characteristic constitutes a subdivision criterion, and the presence of more than one subdivision criterion gives rise to multidimensionality. In traditional terminology subdivision criteria are depicted as shown in Figure 1 below.
164

Multidimensionality in Terminological Concept Modelling
Confusingly, the subdivision criterion, character transfer, appears as a node in the diagram and its position and notation do not differ much from the notation of a concept. Furthermore, it is a disadvantage that the characteristics of the concepts are not made explicit. ISO 1087-1 proposes another way of depicting subdivision criteria, which is shown in Figure 2 above. ISO’s diagram represents an improvement compared with the traditional one. The subdivision criterion is presented in a clearer way and cannot be mistaken for a concept. However, the characteristics of the concepts are still not made explicit. 2.2 Modelling of Subdivision Criteria Subdivision criteria are modelled in CAOS by means of formal dimensions, as shown in Figure 3 below. Characteristics are encoded as formal feature specifications consisting of an attribute and an associated value: [ATTRIBUTE: value], as mentioned in section 1.1. above. A dimension of a concept is an attribute occurring in a (non-inherited) feature specification of one of its subordinate concepts, i.e. an attribute whose possible values allow a distinction between some of the subconcepts of the concept in question. A dimension specification consists of a dimension and the values associated with the corresponding attribute in the feature specifications of the subordinate concepts: (DIMENSION : [value1, value2, ...]).7 This may perhaps seem to create a sort of unnecessary double dealing. We have introduced this representation firstly to be able to handle subdividing dimensions and secondly to be able to implement a 7. For more details, see e.g. (Madsen, Thomsen, Vikner, 2004:16).
1 printer
1.1 impact printer
1.2 nonimpact printer
(character transfer)
1 printer
character transfer
1.1 impact printer
1.2 nonimpact printer
Figure 1: Traditional concept system with subdivision criterion
Figure 2: Concept system according to ISO-1087-1
165

B. N. Madsen, H. E. Thomsen & C. Vikner
principle of uniqueness of dimensions, which contributes to maintaining consistency in ontologies.
feature specification
feature value
dimension specification
dimension
dimension specification dimension specification
dimension dimension dimension
NOISE COPY
CHARACTER TRANSFER: [impact, nonimpact] NOISE: [noisy, quiet] COPY: [multiple, single]
1 printer (201)
subdividing dimension CHARACTER TRANSFER
Figure 3: Concept system according to CAOS 1 One or more dimensions of a concept may be distinguished as subdividing dimensions, i.e dimensions that are used in the definitions of some of that concepts nearest subconcepts. A subdividing dimension represents a subdivision criterion. If one of the daughters of the concept associated with a subdividing dimension contains a feature specification that has the subdividing dimension as attribute, such a feature specification is called a delimiting feature specification. A delimiting feature specification represents a delimiting characteristic. 2.3 Graphic Representations of Subdivision Criteria
2.3.1 In UML Graphical tools based on UML (Unified Modeling Language), cf. (OMG 2003), have already for some years been used for concept modelling. The concept system in figure 3 may look as in figure 4 below, where the classes (boxes) of UML are used to model concepts. The generalization relation in UML corresponds to the relation which is called the generic relation in terminology.
delimiting feature specification
1.1 impact printer (202)
1.2 nonimpact printer (203)
CHARACTER TRANSFER: impact NOISE: noisy COPY: multiple
CHARACTER TRANSFER: nonimpact NOISE: quiet COPY: single
166

Multidimensionality in Terminological Concept Modelling
character transfer
impact printer
printer
nonimpact printer
discriminator
generalization
class
attributes
Reference
OralReference WrittenReference
ref = Integer pk type = String suppl = String
ref = Integer pk fk job: String name: String
ref = Integer pk fk year: String publisher: String author: String title: String
Figure 4: Concept system (concept model) in UML
Figure 5: Conceptual data model in UML
The discriminator of UML corresponds to the subdivision criterion in CAOS. However, in UML it is not possible to represent several dimensions, from which one may be chosen as the subdividing dimension, and there is no notation for the specification of dimension values, as is the case in CAOS. Furthermore, UML does not specify a notation for feature specifications. However, we will se that it is possible to use a facility of UML which comes close to a feature specification. When using UML for the elaboration of a conceptual data model for an IT system, it is possible to add attributes in a special compartment in the class, and it is possible to add to the attributes information about data types as well as information about primary key (pk) and foreign keys (fk), cf. figure 5 above. However, the attributes here serve another purpose than the feature specifications in the concept system, viz. to specify which kinds of information may be related to each class and consequently to each instance in the IT system. The values of the attributes will exist only in the IT system (e.g. in the database), and they will give information about instances. Cf. also (Madsen, Thomsen, Vikner, 2002). In (Gómez-Pérez, Fernández-López and Corcho 2004: 22) is given an example of a “travel ontology”, which actually is not an ontology, but rather a conceptual data model. Part of this model is found in figure 6. The attributes in this example specify which kinds of information may be related to each class. With one exception, which we will describe below, the attributes do not give information on the
167

B. N. Madsen, H. E. Thomsen & C. Vikner
characteristics of the classes. For example the specification of the attribute arrivalDate with the data type Date only tells that all instances of the class Travel have a specification of the date of arrival, the value of which will differ for each instance of the class. A given instance of the class Flight will inherit the date from the related instance of Travel. In fact one instance of Travel is related to one and only one instance of Flight, since there is a one-to-one relationship between a superclass and its subclass. However, the class Flight as such will inherit nothing from the class Travel. In the example in figure 6 the attribute transportMean is found in both the class Travel and in the class Flight. In the class Travel it is specified that it has the data type String, which gives no further characterization of the class Travel. But in the class Flight it is specified that at the time of creation of an instance the attribute transportMean has the initial value “plane”, which means that the value of this attribute of all instances of this class is “plane”. It could be argued that this attribute constraint is comparable to a feature specification characterizing the class Flight. Travel
arrivalDate: Date departureDate: Date companyName: String singleFare: Float transportMean: String
Figure 6, however, is misleading. In a UML model you will normally find the attribute corresponding to the discriminator (here transportMean) either in the superclass (Travel) or in the subclass (Flight). If the attribute transportMean is specified in the superclass Travel, the values attributed to the instances of Travel will vary according to the instances described (= “plane”, “ship”, “train”). If the attribute transportMean is specified in the subclass Flight, the value
Figure 6: Extract of the ”travel ontology” from (Gómez-Pérez et al. 2004)
Figure 7: Revised ”travel ontology” with the attribute transportMean only in the class
Travel
arrivalDate: Date departureDate: Date companyName: String singleFare: Float
Flight
flightNumber: String transportMean: “plane”
transportMean
Flight
flightNumber: String transportMean: “plane”
168

Multidimensionality in Terminological Concept Modelling
attributed to the instances of this class will not vary, i.e. the same value will be attributed to all instances of the class (= “plane”). In figure 7 we have changed the model from figure 6, so that the attribute transportMean is only found in the class Flight. It is possible to introduce a discriminator transportMean into this model, which is also done in figure 7. Another subclass could be ShipJourney in which the attribute transportMean could have the initial value “ship”. In the next section we will introduce some extensions to UML needed for terminological concept modelling and implemented in CAOS 2. 2.3.2 In CAOS 2 In CAOS 2 we use concept diagrams like the one shown in Figure 8 below. Our starting point was to use diagramming methods like the ones used in UML, and to add facilities which are – to our knowledge – not covered in UML systems. In CAOS 2, subdivision criteria (subdividing dimensions) are presented in a very clear way. It is possible to add several dimensions and to choose some of them as subdivision criteria. On the superconcepts are shown the dimension specifications, which specify the values associated with the corresponding attribute on the subconcepts.
Concepts belonging to the same subdividing dimension are grouped together and the subdividing dimension is shown on the links to the concepts, see, for example, the two concepts in position 1.1.1 and 1.1.2. The grouping in CAOS 2 is thus a function of the delimiting characteristics of the concepts in question. Thus the concept dot matrix printer could not be grouped together with the two concepts mentioned. In UML it is also possible to group concepts in a similar way, but the UML grouping is unprincipled, i.e. it is left to the user’s personal preferences, and nothing would prevent the grouping together of all three subconcepts of impact printer. Pursuing the analysis further would result in adding more concepts such that multiple subdividing criteria on one concept would be shown.
169

B. N. Madsen, H. E. Thomsen & C. Vikner
dimension specifications subdividing dimension
subdividing dimension
primary feature specificationinherited feature specifications
Figure 8: Concept system in CAOS 28
2.4 Constraints Related to Subdivision Criteria Evidently, the terminologist must take care to choose delimiting feature specifications (or subdividing dimensions) that reflect essential characteristics of the concept in question. But apart from this qualitative requirement, delimiting feature specifications and subdividing dimensions are subject to three formal constraints in normal form. Constraints on delimiting feature specifications and subdividing dimensions for concepts with only one mother concept in a concept system in normal form:
8. The two concepts in position 1.1.1 and 1.1.2 have not been associated with a
designation, because the documentation, so far, has only given information about their characteristics. The concept dot matrix printer in position 1.1.3 has not got a delimiting characteristic, because the terminologist, at this point of the investigation, has not found any appropriate information that could be used to determine a delimiting characteristic.
170

Multidimensionality in Terminological Concept Modelling
• A concept may contain at most one delimiting feature specification (i.e. a subdividing dimension may not overlap another one)
• A concept of level 2 or below9 must contain at least one
delimiting feature specification (i.e. the subdividing dimensions taken together must cover all daughter concepts)
• The definition of a concept must have the following form:
‘(Concept is) a SuperordinateConcept that has DelimitingCharacteristic’,
where DelimitingCharacteristic denotes the characteristic corresponding to the delimiting feature specification of the concept.
The basis for the first constraint is that multiplying delimiting characteristics in one concept may obscure the concept system by leaving out well-founded superordinate concepts, i.e. creating conceptual gaps. The basis for the third constraint is that this form of definition yields maximum simplicity and consistency. The basis for the second constraint is that it is not possible to make correct normal form definitions for a concept if the concept does not have a delimiting characteristic. In CAOS it is possible in a normalization phase to check a concept system for compliance with normal form, but the user has the possibility of overriding the normal form constraints if she wants to. 3 Conclusions We have proposed an extension of UML for terminological concept modelling as opposed to the use of UML for conceptual data modelling. An important rationale for this extension is that it makes it possible to model terminological principles concerning multidimen-sionality and inheritance of characteristics. We think that the version of multidimensionality we have proposed has a number of advantages:
9. The reason for the qualification concerning level 2 is the fact that in CAOS, for
technical reasons, the topmost concept place is always occupied by an empty concept named top (this is level 0). The topmost ‘real’ concept of the concept system is then inserted as a daughter of top (and constitutes level 1).
171

B. N. Madsen, H. E. Thomsen & C. Vikner
• It augments the simplicity, consistency and coherence of the description.
• It reduces the risk of omitting relevant concepts in the subject field (Bowker, 1997:138).
• It gives clear and consistent guidelines for formulating definitions.
• It gives a better overview of a concept system. References Bowker, Lynne; Multidimensional classification of concepts and
terms, in Sue Ellen Wright & Gerhard Budin (eds.), Handbook of Terminology Management, vol. 1, pp. 133 – 143, Amsterdam: Benjamins, 1997.
Gómez-Pérez, Asunción; Mariano Fernández-López & Oscar Corcho; Ontological engineering. Springer, 2004.
ISO 704. Terminology work — Principles and methods. Genève: ISO, 2000.
ISO 1087-1. Terminology work — Vocabulary — Part 1: Theory and applications. Genève: ISO, 2000.
Kageura, Kyo; Multifaceted/multidimensional concept systems, in Sue Ellen Wright & Gerhard Budin (eds.), Handbook of Terminology Management, vol. 1, pp. 119 – 132, Amsterdam: Benjamins, 1997.
Madsen, Bodil Nistrup; Typed Feature Structures for Terminology Work - Part I, in LSP - Identity and Interface - Research, Knowledge and Society. Proceedings of the 11th European Symposium on Language for Special Purposes. Copenhagen, August 1997, pp. 339 – 348, Copenhagen Business School, 1998.
Madsen, Bodil Nistrup; Hanne Erdman Thomsen & Carl Vikner; Data Modelling and Conceptual Modelling in the Domain of Terminology, in Alan Melby (eds.), Proceedings of TKE '02 - Terminology and Knowledge Engineering, pp. 83 – 88, Nancy: INRIA, 2002.
Madsen, Bodil Nistrup; Hanne Erdman Thomsen & Carl Vikner; Principles of a system for terminological concept modelling, in Proceedings of the 4th International Conference on Language Resources and Evaluation, vol. I, pp. 15 – 18, Lisbon, 2004.
Meyer, Ingrid; Karen Eck & Douglas Skuce; Systematic concept analysis within a knowledge-based approach to terminology, in Sue Ellen Wright & Gerhard Budin (eds.), Handbook of Terminology Management, vol. 1, pp. 98 – 118, Amsterdam: Benjamins, 1997.
172

Multidimensionality in Terminological Concept Modelling
OMG: Object Management Group; Unified Modeling Language Specification. Version 1.5, 2003. Downloaded from:
http://www.omg.org/technology/documents/formal/uml.htm.
Rogers, Margaret; Multidimensionality in concept systems. A bilingual textual perspective, Terminology vol. 10.2, pp. 215 – 240, 2004.
Thomsen, Hanne Erdman; Typed Feature Structures for Terminology Work - Part II, in LSP - Identity and Interface - Research, Knowledge and Society. Proceedings of the 11th European Symposium on Language for Special Purposes. Copenhagen, August 1997, pp. 349 – 359 Copenhagen Business School, 1998.
Thomsen, Hanne Erdman; Typed Feature Specifications for establishing Terminological Equivalence Relations, in World Knowledge and Natural Language Analysis. Copenhagen Studies of Language, vol. 23, pp. 39 – 55, Copenhagen: Samfundslitteratur, 1999.
173


Towards a Reuse-Oriented Methodology for Ontology
Engineering
ELENA PASLARU BONTAS &
MALGORZATA MOCHOL
Given the intrinsic meaning of the term “ontology” and the efforts required by ontology building, reuse and reusability are very important issues for a cost-effective and high-quality ontology engineering. While several methodologies describing the reuse process already emerged in the Semantic Web community, the implications of reuse in concrete application settings have not been examined to a satisfactory extent yet. In this paper we analyze the costs and benefits related to the reuse process on the basis of two case studies which attempt to build new ontologies in the domains of eRecruitment and medicine by means of ontological knowledge sources available on the Web.
Introduction Ontology engineering is already considered a mature discipline in the context of the Semantic Web. A variety of methodologies and tools to build, manage and merge ontologies emerged in the last decades (Lopez, 2002). Most of the currently available ontologies are, however, not aligned to a specific methodology. They are rather the result of some ad-hoc application- and domain-dependent engineering process. While it is generally accepted that building ontologies from scratch is a challenging, time-consuming and error-prone task, the development of new ontologies still does not tap the full potential of the knowledge sources available on the Web. Ontology reuse can be defined as the process in which existing (ontological) knowledge is used as input to generate new ontologies. Depending on the content of the knowledge sources and their overlapping one can distinguish between ontology merging and integration (Pinto and Martins, 2001). The limited reuse of ontologies currently available on the Web can be explained by the difficulties related to building reusable ontological sources which have to strike the balance between a rich conceptualization and application specificity

E. P. Bontas & M. Mochol
(Gruber, 1995), and by the fact that this issue has been poorly explored in existing engineering methodologies. A general explanation of the reuse process is given in (Uschold and King, 1995). (Pinto and Martins, 2001) offers a detailed methodology about how to perform ontology integration, leaving out methods to decide on the circumstances under which a reuse-oriented approach is profitable. Further on, as to the knowledge of the authors, none of the reuse methodologies provides tool support in order to allow an (at least partial) automation of the process.
In this paper we present our experiences in building domain ontologies on the basis of existing ontological knowledge (i.e. build by reuse). We adapt generic reuse methodologies to the current state of the art of the Semantic Web in order to be able to apply them efficiently to generate two ontologies in the e-Recruitment and the medical domain respectively. Finally we analyze the profitability of ontology reuse in the two use cases in terms of costs and benefits.
The remaining of this paper is organized as follows: we describe our reuse process model in Section “’Our Approach to Ontology Reuse” and present its application in two concrete Semantic Web projects in Sections “Case Study Human Resources” and “Case Study Medicine”. After a general description of the methodology employed to estimate and compare the costs and the benefits of reuse (Section “Costs and Benefits of Ontology Reuse”), we concretize these aspects in the context of the empirical studies. The limitations of our approach together with planed future work are subject of the Section “Conclusions and Future Work”.
Our Approach to Ontology Reuse Typically ontology reuse starts with the identification of potentially relevant knowledge sources. The presumed candidate ontologies usually differ in represented content and formality degree (thesauri, XML-Schemes, UML diagrams, etc.). Even when translation tools are available for some representation formats1, the resulting matching still requires human evaluation and refinement. Provided a common representation formalism the source ontologies have to be compared and eventually merged. For this purpose one needs a generic scheme-
1. In fact large amounts of domain knowledge are encoded in thesauri like Cyc,
UMLS (a medical ontology containing over 300,000 concepts) using proprietary formats or even natural language without any technical support for translation tools.
176

Towards a Reuse-Oriented Methodology for Ontology Engineering
matching algorithm which can deal with the heterogeneity of the incoming sources w.r.t. their structure, domain and application view upon the domain. Our approach copes with such limitations by proposing an incremental process which concentrates on the concepts represented in the input sources and subsequently takes into account additional information like semantic relationships and axioms depending on the application needs (see Figure 1). Our approach does not depend on any scheme-matching algorithm but merges the schemes depending on their degree of formality.
We start by considering the vocabulary of the sources (concepts, relations, and axioms) and compute a common vocabulary depending on the natural language in which the ontological primitives have been originally denominated. Categorizing the domain knowledge -- implicitly stored and managed in experts’ minds -- and representing it explicitly can be significantly simplified by generating a preliminary vocabulary of the domain, which is used as a start point for the domain experts for further refinements during the conceptualization.
Figure 1: The Reuse Process
177

E. P. Bontas & M. Mochol
The vocabulary contains several lists of potential ontological primitives: a list of concept names, a list of properties and a list of axioms. The generation of the candidate concepts is performed in the following steps. At the beginning we merge the source vocabularies, generate separate lists of ontological primitives according to the degree of formality of the considered models, and eliminate duplicates in order to avoid unnecessary computations. We compute syntactical similarities between concept names belonging to different source ontologies (Cohen et al., 2003). To improve the accuracy of the similarity computation we assume common naming conventions in ontology engineering2 to generate a bag of terms for each concept name in the source vocabularies. Word stemming and stop-word elimination are applied to improve precision and recall. As a result of this phase similar bags of words are aggregated to concept names.
We compute the ranking of the concepts by considering frequencies (concept names occurring in several source ontologies are ranked higher), source priority (relevance measure of the corresponding source to the target application domain) and application requirements.
After identifying relevant concepts, the user selects the relevant relationships, which can be added incrementally to the ontology until a certain level of complexity has been achieved. The presented methodology, though relatively straight forward and not tapping the full potential of the newest approaches in ontology matching/merging, has proved to be very useful and cost-saving in the application domains presented below, since it does not has to cope with the limitations related to the heterogeneity of the available source ontologies. Such heterogeneity issues currently make the automatic usage of matching techniques a tedious and error-prone process. A Cost Benefit Analysis of the Reuse Process As mentioned in the previous sections reusing existing knowledge for ontology engineering is today complicated by serious technical problems that should not be underestimated when deciding on how to build a specific application ontology (i.e. from scratch, by reuse, using ontology learning techniques or combinations of the three). Likewise software engineering, reusing an existing component implies costs for its discovery, comprehension, evaluation, adaptation and actualization. While most ontologies emerged in the last decades can be accessed on the Web (i.e. the costs for ontology discovery are 2. Ontological primitives are denominated by complex phrases, in which single
words are capitalized or delimited by space, underscore etc.
178

Towards a Reuse-Oriented Methodology for Ontology Engineering
relatively low) these ontologies show significant differences w.r.t. intrinsic and extrinsic features. In the first category we mention the representation language, the modeled domain, the view upon the domain, the granularity as well as the degree of formality. The second category contains features such as maturity, development stage or underlying methodology. This variety complicates severely the evaluation process and is therefore a major cost factor. The customization of the source ontologies with regard to a given set of requirements requires tools for their translation, comparison and merging. Existing tools though containing valuable ideas and techniques currently lack real-world practice and are usually confined to specific domains, representation languages or ontology types (e.g. taxonomies), thus not being able to deal with this heterogeneity (Do et al., 2002). The benefits of reuse have been alleviated in numerous engineering disciplines including ontology engineering. Besides implementation cost savings an important advantage in this case is interoperability. In terms of ontologies interoperability is achieved on the syntactic and the semantic level. While the former one can be provided by using commonly agreed interfaces, semantic interoperability assumes the usage of explicitly and formally defined domain models. Each of these aspects is relevant for the decision of the engineering team whether to newly build an ontology or generate it from existing sources. Ideally a cost benefit analysis should be supported by means to quantify and compare the mentioned factors. The costs involved by ontology building and the cost savings caused by ontology reuse can be estimated using appropriate cost models (see below). However the advantages achieved through an increased interoperability can hardly be expressed in a reliable quantitative manner. In the following we give a brief description of ONTOCOM (Paslaru and Mochol, 2005), a cost model that aims at predicting the costs (expressed in person months efforts or duration) involved in developing an ontology. ONTOCOM is applied for the cost benefit analysis of the case studies to estimate the presumed cost savings induced by reusing existing ontologies. A first step towards a cost estimation model for ontology engineering is the definition of an appropriate process model. After analyzing general-purpose cost estimation methodologies (Stewart, 1995; NASA, 2004) in terms of their suitability for ontology engineering we elaborated a methodology to realize a cost model for this field. In a first phase a top-down approach is applied to identify the cost-intensive sub-tasks of the project, in our case ontology building. Further on a parametric method similar to those adopted in related disciplines such as
179

E. P. Bontas & M. Mochol
software engineering (Boehm, 1997) is employed to define a cost calculation formula. The model is finally refined using the expert judgment method (the Delphi method (Linstone and Turoff, 1975)) which provides a fine-grained description on how the human-driven model validation and refinement should be performed. In the first step we identified three areas of ontology engineering for which the parametric cost calculation should be further defined:
• building3 which includes the efforts invested in requirements specification, conceptualization, implementation, instantiation and ontology evaluation,
• maintenance which involves costs related to analysis and updating the ontology, and
• reuse which relates to the costs for the acquisition and re-usage of available knowledge sources.
The overall effort (in person months PM) is calculated as the sum of the costs accruing in the three areas:
PM = PMB + PMB M + PMR (1)
PMB, PMB M and PMR represent the effort associated with building, maintenance and reuse of ontologies, respectively. In the effort estimation of these development phases different sets of cost drivers are relevant. Cost drivers have a rating level (from extra low to very high) that expresses their impact on the development effort. For the purpose of quantitative analysis, each rating level of each cost driver is associated to a weight (effort multiplier – EM). The average EM assigned to a cost driver is 1.0 (nominal weight). If a rating level causes more development effort, its corresponding EM is above 1.0. If the rating level reduces the effort then the corresponding EM is less than the nominal value. The values associated with each cost driver and effort multiplier are subject of further calibration on the basis of the statistical analysis of real-world project data (i.e. the real costs involved in ontology engineering projects). The costs caused by ontology building are calculated as:
PMB = A * SizeB BB
* ΠCDi (2)
3. See (Lopez, 2002) for a detailed description of ontology building and its sub-tasks.
180

Towards a Reuse-Oriented Methodology for Ontology Engineering
SizeB is the number of thousands of ontological primitives (e.g. for an ontology with 1000 primitives Size = 1). CD
B
i’s are the effort multipliers for the cost drivers. The constant A accounts for the multiplicative effects of efforts with increasing project size and is adapted from the COCOMO framework (Boehm et al., 1997). Ontology maintenance costs are estimated in a similar way:
PMM= A * SizeM * ΠCDi (3)
SizeM is the sum of the added and modified ontology fragments influenced by the appropriate cost factors. A different approach is applied for reuse processes:
PMR = A * SizeR * ΠCDi ,
(4) where
SizeR= Sizedir * (OU _ UNFM + OE) + (5)
Sizetrans * (OU _ UNFM + OE + OT) + Sizemod * (OU _ FM + OE + OM) + Sizetransmod * (OU _ UNFM + OE + OT + OM)
The reused size SizeR is divided into the size of the directly integrated (Sizedir), translated (Sizetrans) and/or modified (Sizemod, Sizetransmod) components with different cost drivers: the unfamiliarity of ontologists and domain experts (OUNF), ontology understanding (OU), evaluation (OE), modification (OM) and translation (OT). For a detailed explanation of the cost drivers see (Paslaru and Mochol, 2005).
We now turn to the presentation of the two case studies on ontology reuse from the domains of recruitment and medicine. Case Study Human Resources The “Knowledge Nets”4 project explores the potential of Semantic Web from a business and a technical viewpoint by means of pre-selected use scenarios. One of the scenarios analyzed the online job seeking and job procurement processes and the implications of Semantic Web technologies in this area (Mochol et al., 2004; Bizer et al., 2005). The first step towards the realization of the e-Recruitment scenario was the creation of a human resources ontology (HR-ontology). The requirements analysis revealed the necessity of aligning the resulting
4. http://nbi.inf.fu-berlin.de/research/wissensnetze
181

E. P. Bontas & M. Mochol
ontology with commonly used domain standards and classifications in order to maximize the integration of job seeker profiles and job postings.
First we identified the sub-domains of the application setting (skills, types of professions, etc.) and several useful knowledge sources covering them (approx. 25). As candidate ontologies we selected some of the most relevant classifications in the area, deployed by federal agencies or statistic organizations: Profession Reference Number Classification – BKZ (text file), Standard Occupational Classification – SOC5 (text file), Classification of Industrial Sector – WZ20036 (text file), North American Industry Classification System – NAISC7 (text file), Human Resources XML – HR-XML8 (XML scheme), HR-BA-XML (XML scheme) and KOWIEN Skill Ontology9 (DAML+OIL).
Depending on the language used in the knowledge sources (English/German) we generated lists of concept names. Except for the KOWIEN ontology, additional ontological primitives were not supported by the candidate sources. In order to reduce the computation effort required to compare and merge similar concept names we identified the sources which had to be completely integrated to the target ontology. For the remaining sources we identified several thematic clusters for further similarity computations. For instance the Profession Reference Classification and the Standard Occupational Classification System were directly integrated to the final ontology, while the KOWIEN skill ontology was subject of additional customization. To have an appropriate vocabulary for a core skill ontology we compiled a small conceptual vocabulary (15 concepts) from various job portals and job procurement Web sites and matched them against the comprehensive KOWIEN vocabulary. Next, the relationships extracted from KOWIEN and various job portals were evaluated by HR experts and inserted into the target skill sub-ontology. The resulting conceptual model was translated mostly manually to OWL (since except for KOWIEN the knowledge sources were not formalized using a Semantic Web representation language).
5. http://www.bls.gov/soc/ 6. http://www.destatis.de/allg/d/klassif/wz2003.htm 7. http://www.census.gov/epcd/www/naics.html 8. http://www.hr-xml.org 9. KOWIEN - Cooperative Knowledge Management in Engineering Networks; http://www.kowien.uni-essen.de/
182

Towards a Reuse-Oriented Methodology for Ontology Engineering
Case Study Medicine The project “A Semantic Web for Pathology”10 analyzes the impact of ontologies within a retrieval system for image and text data for the medical domain. The underlying ontology is used for concept-based search techniques and for the semantic annotation of medical data (i.e. medical reports in text form) (Paslaru et al., 2004).
In order to generate the ontology using available medical sources we applied the reuse-oriented methodology described in Section “A reuse-centered methodology for ontology engineering”. First, we identified and analyzed relevant knowledge sources, describing aspects of pathology-related knowledge and diagnosis procedures. However, the sources to be reused in this setting differ to a large extent in the content area and granularity, representation format and degree of formality: i). SNOMED11 and DigitalAnatomist12 describe the anatomy of the lung and typical diseases (database); ii). The UMLS Semantic Network13 contains generic and core medical concepts as part of UMLS (database format); iii). XML-HL7 is an XML-based format for the representation of patient data; and iv). Immunohistology Guidelines are a list of stains to be applied in diagnosis procedures in our partner healthcare organization (textual description).
After merging the vocabularies of the sources according to the language used in the documents (English/German) a preliminary vocabulary consisting of concepts and relations was selected. In the pre-processing phase we transformed complex concept names and computed similarities among the corresponding bags of terms. The concepts were ranked according to the application relevance, which was defined by a lexicon generated from the archive of medical documents. Candidate relationships were extracted from Digital Anatomist, SNOMED and UMLS Semantic Network. Approximately 50 relations were evaluated by domain experts, who finally inserted approximately 20 generic and medicine-specific core relations to the target ontology. The implementation of the target ontology was performed semi-automatically, by translating the corresponding database-stored data to OWL, while significant amounts of domain-specific knowledge were
10. http://nbi.inf.fu-
berlin.de/research/swpatho/deutsch/projektbeschreibung.htm 11. http://www.snomed.org 12. http://www.digitalanatomist.com/ 13. Unified Medical Language System, National Library of Medicine;
http://www.nlm.nih.gov/research/umls
183

E. P. Bontas & M. Mochol
encoded manually since not available in any of the knowledge sources in a structured form. Costs and Benefits of Reuse in the Case Studies The cost and benefit analysis of the presented case studies focused on the estimation of the presumed cost savings achieved by reuse. The real costs arisen in the two projects were compared with the predicted costs which would have been caused by building the corresponding ontologies from scratch. The costs induced by the second approach were calculated using ONTOCOM (Paslaru and Mochol, 2005). In the recruitment scenario we found several taxonomies for the description of skills, classification of job profiles and industrial sectors, which we wanted to reuse in our ontology. 15% of the total time was spent on gathering the relevant sources while about 35% were invested in their customization. Several ontologies have been fully integrated into the resulting ontology, while KOWIEN and the XML-based sources required additional customization. This part of the ontology building process produced over 40% of the total engineering costs. The last phase of the ontology building, refinement and evaluation, costs 10% of the overall resources. According to our experiences reusing existing knowledge source was profitable for the HR-domain and for our application setting. A cost estimation for a new implementation revealed that the reuse approach was more cost-effective (2,5 PM’s for the HR-ontology with reuse vs. 4 PM’s for development from scratch). In the same time re-using standard classifications is expected to considerably increase the usability of our e-Recruitment application. Nevertheless there is a need for reliable tools for translating between various representations and for ontology customization in order to further optimize reuse costs. The main challenge of the second scenario was the evaluation of existing sources. Medicine is one of the best examples of application domains where ontologies have already been deployed at large scale and have already demonstrated their utility (Gangemi et al., 1999). However most of the available ontologies in this domain are very comprehensive knowledge bases, which differ in the formalized domain, quality and appropriateness for certain application tasks. Additionally most of the available medical ontologies lack a “reuse-friendly” representation format. Since the retrieval system using the ontology is still under development, the product-oriented benefits of the reusing process can not be fully evaluated at this point. However we may say that, for this scenario, the efforts related to the customization of the source
184

Towards a Reuse-Oriented Methodology for Ontology Engineering
ontologies required over 45% of the time necessary to build the target ontology. Further 15% of the engineering time was spent on translating the input representation formalisms to OWL. The reuse oriented approach gave rise to considerable efforts to evaluate and extend the outcomes (approx. 40% of the total engineering time).
According to our experiences in this case study the benefits of reuse were outweighed by their costs, because of the difficulties related to the evaluation and (technical) management of large scale ontologies and because of the costs of the subsequent refinement phase. Using ONTOCOM we approximated the costs induced by semi-automatically building a similar ontology on the basis of a domain specific document corpus From a resource point of view, building the first ontology involved four times as many resources as a new implementation (5 person months for the UMLS based ontology with 1200 concepts vs. 1.25 person months for a manually developed ontology). In the same time the recall of the ontology w.r.t. the semantic annotation task would be consequently improved in the latter case because of the text-close nature of the generation method. Conclusions and Future Work In this paper we described two case studies on ontology reuse and a simple methodology underlying them. Further on we introduced a method to estimate the costs arisen in ontology building processes which was used to analyze the costs and the benefits of reuse in the mentioned case studies.
Ontology integration means not only the translation of the representation languages to a common format, but also the matching of the resulting schemes. Our experience during the presented case studies showed that due to scalability and heterogeneity issues both of these steps can not be performed efficiently using current techniques. This was the fundamental motivation for applying an eventually less technically-versed reuse methodology in the case studies. However exploiting incrementally the “lowest common denominator” of the source ontologies (i.e. their vocabulary) proved to be extremely useful in our reuse experiments.
We are working on further methods to optimize the costs and the quality of the reuse process. Currently a support tool for the described methodology is being developed in order to reduce the manual efforts invested in ontology reuse so far. In the same time the cost estimation methods presented here are subject of additional detailed empirical refinements.
185

E. P. Bontas & M. Mochol
Acknowledgements This work is a result of the cooperation within the Semantic Web PhD-Network Berlin-Brandenburg14 and has been partially supported by the KnowledgeWeb - Network of Excellence, by the project “A Semantic Web for Pathology” funded by the German Research Foundation DFG and by the “Knowledge Nets” project, which is part of the InterVal - Berlin Research Centre for the Internet Economy, funded by the German Ministry of Research BMBF. References Bizer, C. et al.; The Impact of Semantic Web Technologies on Job
Recruitment Processes. 7. Internationale Tagung Wirtschaftsinformatik (WI 2005), Bamberg, Germany, February 2005.
Boehm, B. et al.; COCOMO II Model Definition Manual. 1997, http://sunset.usc.edu/research/COCOMOII/Docs/modelman.pdf.
Cohen, W.W.; P. Ravikumar & S.E. Fienberg; A Comparison of String Distance Metrics for Name-Matching Tasks, in Proceedings of IIWEB Workshop at the IJCAI03, 2003.
Do, H.; S. Melnik & E. Rahm; Comparison of schema matching evaluations, in Proceedings of the 2nd International Workshop on Web Databases (German Informatics Society), 2002.
Gangemi, A.; D.M. Pisanelli & G. Steve; An Overview of the ONIONS Project: Applying Ontologies to the Integration of Medical Terminologies. Data Knowledge Engineering, 31(2), pp. 183 – 220, 1999.
Gruber, R.T.; Toward principles for the design of ontologies used for knowledge sharing. Int. J. Hum.-Comput. Stud., 43(5-6), pp. 907 – 928, 1995.
Grüninger, M. & M. Fox; Methodology for the Design and Evaluation of Ontologies, in Proceedings Workshop on Basic Ontological Issues in Knowledge Sharing, IJCAI95, 1995.
Linstone, H.A. & M. Turoff; The Delphi Method: Techniques and Application, Addison-Wesley, 1975.
Lopez, F. M.; Overview and analysis of methodologies for building ontologies, Knowledge Engineering Review, 17(2), 2002.
14. http://nbi.inf.fu-berlin.de/research/KnowledgeWeb/phd/phd.html
186

Towards a Reuse-Oriented Methodology for Ontology Engineering
Mochol, M.; R. Oldakowski & R. Heese; Ontology based Recruitment Process, in Proceedings Workshop Semantische Technologien für Informationsportale, INFORMATIK 2004, Ulm, Germany, 2004.
NASA, National Aeronautics and Space Administration; NASA Cost Estimating Handbook 2004, 2004, http://ceh.nasa.gov/.
Pinto, H.S. & J.P. Martins; A methodology for ontology integration, in K-CAP 2001: Proceedings of the international conference on Knowledge capture, ACM Press, 2001.
Paslaru Bontas, E. et al.; Generation and Management of a Medical Ontology in a Semantic Web Retrieval System, in Proceedings of the OTM Conferences, Larnaca, Cyprus, 2004.
Paslaru Bontas, E. & M. Mochol; A Cost Model for Ontology Engineering. Technical Report, TR-B-05-03, FU Berlin, 2005, ftp://ftp.inf.fu-berlin.de/pub/reports/tr-b-05-03.pdf.
Stewart, R.D.; R.M. Wyskida & J.D. Johannes; Cost Estimator’s Reference Manual. Wiley, 2nd edition, 1995.
Uschold M. & M. King; Towards a Methodology for Building Ontologies, in Proceedings Workshop on Basic Ontological Issues in Knowledge Sharing, IJCAI95, 1995.
187


From Taxonomy and Domain Ontology Building to Knowledge
Representation for Semantic Multimedia Analysis of Cultural
Heritage Contents
SAM H. MINELLI & ANDREA de POLO1
We aim to create advanced intelligent media content and retrieval agents; and the new content data is expected to become self-adaptable, self-annotating and easily reachable and usable. Alinari has built different domain ontologies and has started the knowledge representation for semantic multimedia data. This process deals with content retrieval and integrating knowledge and semantics for user-centred intelligent media services. The methodology takes advantage of the DOLCE high level ontology which enables automated information access for artificial intelligence. We have then started to extract visual descriptors as colour, shape and texture that could be used by knowledge assisted analysis of multimedia content. Our research activity has been supported by the European Community2.
Keywords: multimedia applications; content; user; network aware media engineering; domain ontology; semantic multimedia analysis; semantic web; user personalization; DOLCE core ontology; OntoEdit; OntoMat-VDE, MPEG-7 descriptors.
Introduction The Semantic Web (SW) is expected to give new access tools to cultural content repositories by means of automated agents and intelligent contents: the ontologies are the essential infrastructure for the SW.
1. Fratelli Alinari Photo Archives, R&D engineering unit, Largo Alinari, 15,
50123 Florence, Italy, E-mail: {sam, andrea}@alinari.it 2. This material is partially based upon work supported by the European Community
in the aceMedia project (FP6-001765), by the SCHEMA NoE (IST-2001-32795) and by eCHASE (e-Content 11262).

S. H. Minelli & A. de Polo
The ontologies should allow the cooperation of processes among various artificial agents.
Core ontologies are upper level conceptualisations that contain specifications which are domain independent: concepts and relations are based on formal principles derived from linguistics, mathematics, etc.
The aceMedia3 project partners have chosen the DOLCE4 ontology as a model for the building of the domain ontologies. This upper level ontology has a rich and consistent structure and axiomatization, it is modular and reusable, and it has explicit conceptualisation of qualities and spatio-temporal descriptions. Moreover, DOLCE has a declared cognitive scope by using the ontological categories and concepts underlying natural language and human commonsense. Taxonomy Considering Alinari’s taxonomy, each domain has a position in a rigid structured tree with a null node as root. In this model each keyword has a specific context, for example: “Person” in the domain of “Diet” has a different allocation from “Person” in the domain of “Justice” (see figure 1). The semantic path going from the leaf to the root is unique and different for each concept: each concept has a different allocation depending on its context. We guarantee that domains will be maintained distinguished and the position of each word depends on its position on the tree. Each concept can be appended along a tree path only if it belongs to the same context-path. When querying a domain concept, all the results are retrieved taking the tree-path elements of that specific context.
Figure 1: Hierarchic tree structure and an example referring to the concept “Person”. 3. http://www.acemedia.org 4. Descriptive Ontology for Linguistic and Cognitive Engineering
(http://www.loa-cnr.it/DOLCE.html)
190

From Taxonomy and Domain Ontology Building to Knowledge Representation Synonyms and related terms (as well as language translation mapping) have great consequences on the taxonomy, influencing the property of uniqueness and the retrieval methodology (see figure 2). Language translation mapping needs specific requirements due to the concepts association process which could be derived by statistical analysis of terms occurrence in corpora. A statistical process however, would not guarantee a well-structured conceptual system. The behaviour of a synonym should be an exact alias of the related term: navigating the tree by the key should have the same effect as navigating it by means of its alias (the properties of the active domain must be preserved).
Figure 2: The synonyms maintain the hierarchy of the term they refer to inside the tree.
The aceMedia domain ontologies have been constructed from the current taxonomy: we tried to maintain, where possible, the hierarchy of concepts and we reorganized the existing sets of concepts into aggregated sets which realized the new domains (such as “Sport-Motorcycle”, etc.). The rules, relations and documentations that govern the new ontology had to be created ad hoc according to both general-ontology and domain-specific.
Methodology The scope of the ontologies that have been built is related to the aceMedia project scenarios which identify both professional and non-professional user applications to which the project tries to give support. The ontological concepts should describe specific domains such as
191

S. H. Minelli & A. de Polo
“Family-Party” or “Sport-Motorcycle” by means of the constituent concepts and relations.
The domain ontologies have some classes of concepts in commune: the concept ‘Human-Face’ could compare in many domain ontologies. This would generate misleading results when querying for a ‘Human-Face’ in a specific context. It has therefore been necessary to create some classes of concepts to be shared by the different domains (an example of “Human-Body” is represented by figure 3, a portion of “Holiday-Beach” is represented by figure 4).
organism
Figure 3: The ’Human-Body’ class of concepts.
192

From Taxonomy and Domain Ontology Building to Knowledge Representation
Figure 4: portion of the ‘Holiday-Beach’ ontology used during the annotation process.
The granularity of the modelling depends on the scope of the ontology that is going to be built in the sense of sets and subsets of keywords. The ontologies required great changes to the conceptualization of the existing knowledge base used: new rules and relations were needed in comparison to the existing knowledge base. The knowledge representation for semantic contents is the actual focus of our activity. We built the ontologies using RDF(S) standard format which is supported by OntoMat-VDE tool. This tool has been used during the
193

S. H. Minelli & A. de Polo
visual description process for the extraction and ontology annotation by means of low-level multimedia features. The integration process required a domain ontology to be navigated and specific domain-concepts to be selected. This process generated the prototype instances of the domain concept and linked them to the extracted visual descriptors.
Tools We built the domain ontologies by using the OntoEdit tool: it supports representation-language neutral modelling for concepts, relations and axioms. OntoEdit is based on a plug-in framework open to third party extensions, and among the exporting formats it allows the RDF(S) file format.
To integrate the ontology knowledge with the content we used the OntoMat-VDE 0.512 tool for semi-automatic visual descriptor extraction and ontology annotation by means of low-level multimedia features. This tool supports the representations of the MPEG-7 visual descriptors using specific representation of visual features as texture, colour or shape that define the syntax and the semantics of a specific aspect of the feature as dominant colour, region shape, etc. (see figures 5 and 6).
Figure 5:on the left, the OntoMat-VDE tool interface with the ontology navigation on the left; on the image the hand selected region for ’Sailing-Boat’ concept is visible. On the right: the mask generated by OntoMat-VDE.
194

From Taxonomy and Domain Ontology Building to Knowledge Representation <rdf:RDF xml:base="http://www.acemedia.org/fact-statements/PROTOTYPES#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema" xmlns:vdo="http://www.acemedia.org/ontologies/VDO" xmlns:vdoext="http://www.acemedia.org/ontologies/VDO-EXT#">
<vdoext:Prototype rdf:ID="PROTO-INST-Bather3-instance-skin-dominant-colour"> <rdf:type rdf:resource="http://www.acemedia.org/ontologies/HOLIDAY-
BEACH#Bather"/> <vdoext:has-descriptor rdf:resource="VDE-INST-11085468067229698561"/> </vdoext:Prototype> </rdf:RDF>
Figure 6: A sample of XML output for the MPEG-7 dominant colour descriptor of the dominant skin colour of a bather.
The two tools help significantly with the setting up of the ontology and the annotation. An integrated tool would increase the speed of both activities. In fact, while building an ontology that is related to images and videos, the cataloguer would be helped by a visual support during the concepts generation and also during the relation linking. On the other hand, the visual descriptor would already be revealed and the association would be sped up. Issues During the ontology building process, one of the most important problems encountered is the impossibility of automatically importing the archive’s existing taxonomies: SW technologies do not yet allow importing functionalities due to the large number of differences among the existing taxonomies. The enlargement of the number of ontologies should reduce the discrepancy between the traditional and the new ontologies.
On the other hand, the improvements that would have a good impact on the knowledge representation are related to the following:
Ontology Browsing: a searching function for concepts would help the annotation when the ontology dimension is very large (some ontologies contain more than hundreds of concepts).
Visual Descriptor Extraction: more automatic tools are needed to fasten the annotation process. We foresee the usage of an image segmentation module to ‘suggest the selection’ of regions to be annotated; it would also improve the borders of the region selected (at this time the contour is drawn by hand by the cataloguer). Then, it would help to have some region operators to allow nearby regions to be added to aggregate sub-regions into one single concept-region (for example the human body parts into one single contour) or remove sub-
195

S. H. Minelli & A. de Polo
regions from a segmented one (for example a human body shape from objects which interrupt the body contour). Results The digital archive’s content is supposed to interact actively by means of intelligent agents and semantics with other contents. The creation of new ontologies for the aceMedia project has made new ways to aggregate contents information and intelligence evident. The domain ontologies created for the aceMedia project required a reconsideration of the original archive’s taxonomy and the creation of higher levels of content knowledge.
The visual descriptors annotation is part of the process of domain ontology building for the new tools of semantic multimedia analysis.
After extracting visual descriptors for sets of objects (i.e. for the Holiday-Beach ontology: ‘boat’, ‘sea’, etc.) we linked them by means of the described tools to the corresponding concepts. We also created special instances of the concepts (instantiation process) for the domain concepts and for the prototype concepts.
The instances of the domain are kept separated from the prototype instances which refer to regions of the image from which they have been generated. We have avoided linking concepts to each descriptor instance because it would have generated issues of meta-reasoning (which would imply ontological conflicts). The process of integrating the concepts prototypes to visual descriptors as prototype instances can be saved into separate RDF(S) files without changing the original ontology which remains at a separate level of abstraction.
A test set of instance prototypes has been generated and will be the starting set of low-level features for the domain ontologies. Conclusions and Future Work The integration of knowledge semantic and digital media technology will allow the development of new instruments for digital repositories navigation. The benefits of a digital content repository will apply to the cataloguing and to the retrieval of digital goods.
The annotation process is a slow process during this early stage as it has to be done semi automatically by drawing the region we want to identify. It is clear that if each image has, even at minimum, ten concept prototypes, then for a very large repository the process becomes too expensive. In fact, the ontology navigation is made of hundreds items the cataloguer must know or be very familiar with to be able to position correctly new concepts and relations.
196

From Taxonomy and Domain Ontology Building to Knowledge Representation Apart from these limits, which are already under improvement, the described process is the intermediate step to an automatic and fast annotation of the contents towards intelligent content.
Actual and future activity:
• improve the ontologies conceptualization • increase of relations and documentation • identify commune classes of concepts • create visual descriptor prototypes for all the generated
domains • generate feedback to the improvement of the annotation tool
Acknowledgment This material is partially based upon work supported by the European Community in the aceMedia project (FP6-001765), SCHEMA NoE (IST-2001-32795), eCHASE (e-Content 11262). References aceMedia project (FP6-001765), http://www.acemedia.orgBateman, J; The place of language within a foundational ontology.
University of Bremen, Germany. Gangemi, A.; N. Guarino; C. Masolo; A. Oltramari & L. Schneider;
Sweeting Ontologies with DOLCE. ISTC-CNR Rome/Padua, Italy. Gangemi, A.; N. Guarino; C. Masolo; A. Oltramari & L. Schneider,
Sweeting Ontologies with DOLCE. ISTC-CNR Rome/Padua, Italy. Kompatsiaris, Y.; Y. Avrithis; P. Hobson; T. May & J. Tromp;
Achieving Integration of Knowledge and Content Technologies: The aceMedia Project. London, UK, IEE EWIMT-2004 , 2004.
Lausen, H.; M. Stollberg; R.L. Hernández; Y. Ding; S. Han; & D. Fensel; Semantic Web Portals – State of the Art Survey.
Noy, N.F.; D.L. McGuinness; Ontology Development 101, Standford University, CA.
Ontoprise GmbH Amalienbadstraße 36 (Raumfabrik 29) 76227 Karlsruhe (Germany) http://www.ontoprise.de.
Petridis, K.; I. Kompatsiaris; M.G. Strintzis; S. Bloehdorn; S. Handschuh; S. Staab; N. Simou; V. Tzouvaras & Y. Avrithis; Knowledge Representation for Semantic Multimedia Content Analysis and Reasoning. London, UK , IEE EWIMT-2004, 2004.
RDF Vocabulary Description Language 1.0: RDF Schema http://www.w3.org/TR/rdf-schema/
197

S. H. Minelli & A. de Polo
RDF Vocabulary Description Language 1.0: RDF Schema http://www.w3.org/TR/rdf-schema/
Ren, K.; J. Bigham & E. Izquierdo; Image Annotation Aided by a Semantic Belief Network. London, UK, IEE EWIMT-2004 , 2004.
Stauder, J.; J. Sirot; H. Le Borgne; E. Cooke & N.E. O’Connor; Relating Visual and Semantic Image Descriptors. London, UK, IEE EWIMT-2004, 2004.
198

Ontological Semantics of Classical Music
FYNBO – an Ontology-based IR System
STEFFEN LEO HANSEN1
1 Introduction In this paper we shall present the IR system called FYNBO 2, a system developed to retrieve information about recordings of classical music requested by a user. The system is intended to supply the user with the kind of information about a specific recording available on the cover text normally accompanying a CD of classical music. Thus the user may want either all the information about one or more recordings of a work by a favourite composer or information about recordings of music performed by a specific soloist or orchestra, or interpreted by some explicitly named conductor. As an introduction to the way the system works and the kind of problems to be solved by the system, let us have a look at the following questions:3
(1) Jeg søger en indspilning af Carl Nielsen
I am looking for recordings of Carl Nielsen
(2) Jeg søger en indspilning af Tristan og Isolde
I am looking for a recording of Tristan and Isolde
(3) Jeg søger en indspilning med Leonard Bernstein
I am looking for recordings with Leonard Bernstein
1. Department of Computational Linguistics, Copenhagen Business School,
Bernhard Bangs Allé 17 B, DK – 2000 F., Denmark, [email protected] 2. The name is chosen to honour the Danish composer Carl Nielsen, born on the
island of FYN (Eng. Funen)

Steffen Leo Hansen
These are all quite simple queries, each of which, however, represents a specific challenge to the system4.
In order to answer the first query (1), the system needs to know that Carl Nielsen is a composer and that the phrase indspilning af Carl Nielsen means music composed by Carl Nielsen. The query (2) has a syntactic construction similar to the one in (1) and uses the same preposition: en indspilning af Tristan og Isolde. But this time the user wants to know about one or more recordings of the opera Tristan and Isolde by Richard Wagner. In (3) the user wants to know if there are any records with (Danish: med) Leonard Bernstein. In order to find an appropriate answer to this query, the system must have access to a lexicon containing the necessary information and world knowledge to find out that the person mentioned in this case is either the composer, the conductor or the soloist Leonard Bernstein.
In order to find out which kind of information the user is looking for and to find that information, FYNBO applies semantic parsing to the input representing the user’s query, uses a domain-specific ontology of music to verify the ontological types presented in the input and, finally, a database of actual recordings to retrieve the relevant information 5. In this paper we will mainly be concerned with the modules responsible for the ontological semantics of the system: the parser and the ontology 6.
In the remainder of this paper we present the central components of the system FYNBO and the way in which each of them contribute to producing the relevant answers. In section 2 we present the semantic parser, the lexicon it applies to parse the input and the structure and content of the semantic representation generated as output. Section 3 introduces the lexicon of world knowledge, the enumeration of composers, artists and ensembles involved in classical music, the kind of information it contains and the structure and format of the lexicon. In section 4 we present and discuss the ontology used by the system, the designing principles and structure of the ontology and the way the representation delivered by the semantic parser is evaluated and used as
3. Please don’t forget that FYNBO speaks Danish. The present version of the parser
is not tuned to deal with imperatives (Show me…) or questions (Do you have…) as input.
4. In this version of FYNBO we neglect the Danish genitive corresponding to phrases like recordings of the violin concerto by Carl Nielsen and recordings of Wagner’s opera Tristan and Isolde
5. A presentation of how this information is produced and stored is found in (Nelson and Hansen 2002).
6. All components and modules in FYNBO are encoded in Prolog.
200

Ontological Semantics of Classical Music
a basis to generate an answer to the user. Finally, in section 5, we shall conclude, sketching some problems and challenges of future work.
2 Communicating with FYNBO 2.1 Semantic parsing If you are interested in classical music, then you may go online and use one of the many IR systems on the Internet designed to inspect, download or even buy recordings of the piece of music you are looking for. In most cases, the means of navigating until you reach the goal, consists in selecting predefined categories like composer, performer, instruments or compositions 7. Most of these systems are well structured and perform very well. In the case of FYNBO we decided to drop the clicking and keyword-based retrieval and replace it by a natural language interface allowing the user to communicate with the system in a familiar language using a familiar terminology. As an implication of this decision, the main focus of communication and interaction within the system changes from that of navigating to a quite different one of terminology and of lexical and ontological semantics.
Semantic parsing is the central point in processing the queries to the system. The parser implemented in the interface of FYNBO guarantees that the input sentence is not only syntactically, but also semantically well-formed, i.e. conforming to the semantics applied by the lexicon used by the parser and in accordance with the conceptual types defined in the ontology. By semantic parsing, then, we understand the process of checking the terminology and semantic relations in the input including semantic roles as presented in (Ruus 1979) and the argument structure (cf. Pustejovsky 1995, Pustejovsky 1996) of the verb to be sure that it is consistent with respect to the lexical semantics and the ontology defining the domain of classical music.
2.2 Lexical semantics Consider the lexical entry for the verb søger (Eng. look for)8 and the lexical information defining the meaning of this verb:
7. http://www.arkivmusic.com/classical/main.jsp http://www.classicalarchives.com/live/ http://www.imusic.dk/ 8. cf. the input in (1): jeg søger en indspilning af Carl Nielsen
201

Steffen Leo Hansen
(4) vt_leks([lexeme:søger, argType:AGENT:human, argType:TEMA:musik, argType:SOURCE:kunstner] )
This entry tells us that søger is associated with three arguments or argTypes to be represented in the input in the order stated in the entry. The first argType is the AGENT of the event denoted by søger, the person looking for something, of ontological type human. The second argument is the TEMA (Eng. theme), the thing we are looking for, of ontological type musik (Eng. music), and the third argument, finally, is the SOURCE of type kunstner (Eng. artist) denoting the origin or producer of what we are looking for 9. For an input sentence using the Danish verb søger to be semantically well-formed, it must necessarily contain three arguments conforming to the conditions defined in the lexical entry presented in (4).
All the lexical entries for Danish nouns have the following canonical structure:
(5) n_leks([lexeme:WordForm, cat:POS, køn:Gender, ontoType:Type])
This is illustrated in (6) below for the word indspilning (Eng. recording). The first position in the structure is the word-form of the lexical unit in question followed by information about part-of-speech, gender and, finally, the category ontoType associating the lexical unit with an ontological type:
(6) n_leks([lexeme:indspilning, cat:sb, køn:fk, ontoType:komposition])
From this entry we learn that indspilning is a noun sb of common gender fk (Da. fælleskøn) and that its ontological type is komposition (Eng. composition). Of special interest and importance in the process of parsing are the prepositions. We consider prepositions to be lexical units with a
9. Notice that the structure represented in the lexical entry implies that phrases like
recordings by/of NN are analysed as a combination of two separate constituents.
202

Ontological Semantics of Classical Music
semantics of their own (cf. Jensen and Fischer Nilsson 2003 and the research project OntoQuery 10), in the present framework denoting a semantic relation holding between arguments represented in the argument structure defined by the verb. A crucial part of the parsing, therefore, is to find and resolve the appropriate relation in the context considered. This makes prepositional semantics especially important as a means of disambiguating phrases like indspilninger af Carl Nielsen compared to en indspilning af Tristan og Isolde.
Consider the lexical entries for the Danish prepostion af as illustrated below:
(7) p_leks([lexeme:af,sem_relation:komponere, domain:komponist, range:musik]) p_leks([lexeme:af,sem_relation:opføre, domain:musik, range:komposition])
In the first case it says that af denotes a semantic relation called komponere (Eng. compose) between an argument (the domain) of ontological type komponist (Eng. composer) and an argument (the range) of type musik (Eng. music). This reading of af corresponds to the English preposition by and the final retrieval of recordings will look for some piece of music by the composer mentioned. In the second case, the semantic relation is labelled opføre (Eng.perform) holding between an argument of type musik (Eng. music) and an argument of type komposition (Eng. composition). The corresponding reading and retrieval will look for recordings of an explicitly mentioned composition.
For the input to be semantically correct, the arguments and ontological types associated with each lexical entry must all be compatible. This check of compatibility is performed by the parser consulting a traditional ‘is_a’ hierarchical representation of the ontology11. Since the types discussed so far are all compatible, the input is considered semantically well-formed.
10. See: http://www.ontoquery.dk/ 11. cf. section 4.2
203

Steffen Leo Hansen
3 World Knowledge in FYNBO12
The knowledge base or lexicon of names13 reflects the necessary world knowledge of the system. This knowledge is used to relate names of people, orchestras, compositions etc. to the conceptual world represented in the ontology. There are three different kinds of information associated with a name: the name itself, a definition of the entry and an ontological type relating the entry to the domain specific ontology. This can be illustrated by the entries describing the names introduced so far:
(8) the composer Carl Nielsen kb(lexeme('Carl_Nielsen'), encyclopedia('Dansk komponist, 1865-1931'), ontoType(komponist) ). (9) the opera Tristan and Isolde by Richard Wagner kb(lexeme('Tristan_og_Isolde'), encyclopedia('Opera af Richard Wagner, komponeret 1865'), ontoType(opera) ). (10) the composer, conductor and pianist Leonard Bernstein kb(lexeme(‚Leonard Bernstein’),
encyclopedia(’Amerikansk komponist, dirigent og pianist, 1918-1990’),
ontoType:kunstner) ).
This information together with the information from the ontology is used to generate the final answer.
12. The Knowledge Base is based on the information found in: The Encyclopedia of
Music, Collins 5, 1989. 13. On the idea to use a lexicon of names, an Onomasticon, see (Ortiz et al. 2002).
204

Ontological Semantics of Classical Music
4 The FYNBO Ontology When you are going to design and build an ontology, there are different ways of modelling and different methodologies and criteria to chose among (cf. Thompson 2004, Ngoy et al. 2002). In the case of FYNBO, we have decided that the expected questions from the user should define ‘the competency of the ontology’ (Grüninger et al. 1995) in specifying the domain and range of problems the ontology must be able to deal with. The result, we think, will be an ontology ‘… which corresponds to reality as it exists beyond our concepts.’ (Smith 2004: 76). 4.1 The Structure of the Ontology The idea behind FYNBO is to design and construct a user-oriented information system. Further, we assume that any user of the system is looking for information about either some piece of music or trying to find specific artists or groups of musicians. This gives us an ontology with *FYNBO* as the top node and MUSIC, ARTISTS and ENSEMBLES as subclasses 14.
The ontology is a traditional subsumption hierarchy of generic relations between super- and subclasses. The designing principle behind the ontology has been to reflect the intuition and the terminology of both the user and the cover text accompanying and describing the recordings accessible for retrieval. Thus the subclasses of MUSIC are COMPOSITION, instrumental and vocal music, and RECORDING. ARTIST subsumes musicians of any kind like conductors, soloist, composers and other not specified performers. ENSEMBLE is the superclass of orchestras, choirs and other groups like a wind or string quartet. The main emphasis in constructing the ontology has been to make it intuitively correct, flat and tractable. The top of the ontology, then, looks like the following:
(11)
1 Music 1.1 Composition
1.1.1 Instrumental music 1.1.2 Symphony 1.1.3 Vocal music
1.1.3.1 Opera 1.1.3.2 Lieder
14. For the sake of presentation, we use the English terminology to discuss the
ontology
205

Steffen Leo Hansen
1.1.3.3 … 1.2 Recording
1.2.1 CD 1.2.2 …
2 Artist 2.1 Composer 2.2 Conductor 2.3 Soloist 2.4 …
3 Ensemble 3.1 Orchestra 3.2 Choir 3.3 Chamber Ensemble
3.3.1 String quartet 3.3.2 Wind quartet
…
4.2 The Implementation of the Ontology Each type occurring in the ontology is implemented by means of an information structure based on the categories ontoType and definition introducing the thing we are talking about, the category onto_position declaring the position in the ontology in terms of a superclass and one or more subclass(es) 15 as well as the category onto_relation, the semantic relations in which the specific type may participate. To illustrate the idea behind this design, consider the following ontological entry for artist: (12)
ontology([ontoType:artist, definition([‘A professional performer such as a musician or composer’]),
onto_position( superclass:*fynbo*, subclass:[composer,conductor,soloist]), onto_relation([ is_a:artist, composer_of:composition, performer_of:music]) ])
15. This information is re-used in the aforementioned is_a hierarchy consulted by the
parser (cf. section 2.2 i.f.)
206

Ontological Semantics of Classical Music
Now, recall the result of looking up Leonard Bernstein in the lexicon of names. The ontoType associated with this name was artist (Da. kunstner). As a final step of generating an appropriate structure that can be used for the retrieval of recordings with Leonard Bernstein, the system will look up in the ontology to find out what it means to be an artist. The subclasses listed here will be used to produce a list of recordings with Leonard Bernstein as either composer, conductor or as the soloist of one or more retrieved performances.
4.3 Ontology-based Information Retrieval To fully understand how the final result and answer to a query is generated, it is important to remember that every cover text of a CD has been marked up and stored as an XML document and that FYNBO has access to a database of RDF descriptions of each of these XML documents. The scope of the final retrieval will be this database of RDF descriptions each of which are based on a set of tags denoting the composer, the composition, the performers and the conductor of the recording
Keeping this in mind, we shall once again turn to the queries presented in the introduction and repeated below as:
(13) Jeg søger en indspilning af Carl Nielsen (14) Jeg søger en indspilning af Tristan og Isolde (15) Jeg søger en indspilning med Leonard Bernstein
As the first step in the overall process, it turns out that all the input sentences are semantically well-formed. As the second step, all proper nouns found in the input have been checked with the lexicon of names and assigned the ontological type prescribed. The third and next step then is to find the types in the ontology corresponding to the types generated by the parser. The query in (13), consequently, will trigger a retrieval of one or more compositions by the composer Carl Nielsen from the database of RDF descriptions, the query in (14) will cause a retrieval of a recording of the opera Tristan and Isolde, and, finally, the query in (15) will lead to a list of recordings with the composer or the conductor or the soloist Leonard Bernstein.
The answer presented to the user will be a URL found in the RDF database pointing to the corresponding XML documents and a possible output of one or more answers like:
207

Steffen Leo Hansen
Carl Nielsen Symphony no. 2
Thomas Jensen Danish National Orchestra
5 Conclusions In this paper, we have presented the IR system called FYNBO. We have discussed the main components providing the foundations of ontology-based semantic parsing and information retrieval. Many interesting aspects and problems have been left out and will be central parts of future work. First of all, the final retrieval of recordings in the database of RDF descriptions based on ontological types and the presentation of the findings must be further developed. As for the communication, the parser must be able to deal with imperatives and questions like: ‘Please show me…’ or ‘Do you have any recordings…’as well as Danish genitive phrases of the form: ‘Har du nogle indspilninger af Carl Nielsens violinkoncert med…’.
Finally, prepositional semantics deserves much more investigation and consideration. In our opinion, it seems to be one of the key issues in building a robust and well functioning ontology-based IR system. References Grüninger, Michael & Mark S. Fox; Methodology for the Design and
Evaluation of Ontologies, Workshop on Basic Ontological Issues in Knowledge Sharing, IJCAL-95. Motreal: TOVE Ontology Project, 1995, at:
http://www.eil.utoronto.ca/enterprise-modelling/papers/index.html. Jensen, Per Anker & Jørgen Fischer Nilsson; Ontology-Based
Semantics for Prepositions, ACM-SIGSEM Workshop on the Linguistic Dimension of Prepositions and their use in Computational Linguistics. Toulouse: September 4-6, 2003. To be republished in extended version Kluwer, 2004.
Kalinichenko, Leonid; Michell Missikoff; Ferica Schiappelli & Nikolay Skvortsov; Ontological Modelling, in Proceedings of the 5th Russian Conference on Digital Libraries RCDL2003. St. Petersburg, 2003. at:
http://synthesis.ipi.ac.ru/synthesis/publications/ontomodeling/ontomodeling.pdf
Noy, Natalya F. & Deborah L. McGuinness; Ontology Development 101: A Guide to Creating Your First Ontology, SMI Technical Report SMI-2002-0880. Stanford University, 2001.
208

Ontological Semantics of Classical Music
Nelson, Mette & Steffen Leo Hansen: XMLizing CDs, in XML Scandinavia 2001, Building Bridges, proceedings, pp. 89 – 101, Copenhagen, 2002.
Ortiz, Antonio M.; Victor Raskin & Sergei Nirenburg; New Developments in Ontological Semantics, in Proceedings of the LREC 2002. Spain, 2002. visited at:
http://ilit.umbc.edu/SergeiPub/ Pustejovsky, James; The syntax of event structure, in James
Pustejovsky & Branimir Boguraev (eds.), Lexical Semantics, pp. 47 – 81, Clarendon Press, 1996.
Pustejovsky, James; The Generativ Lexicon. MIT press, 1995. Ruus, Hanne; Sproglig betydningsanalyse – semantiske roller i tekster,
in Nydanske studier & Almen Kommunikationsteori 10-11, pp. 82 – 99, Akademisk Forlag, 1979.
Smith, Barry; Beyond Concepts: Ontology as Reality Representation, in Formal Ontology in Information Systems, proceedings of the Third International Conference (FOIS-2004), pp. 73 – 84, IOS Press, 2004.
Thomasson, Amie L.; Methods of Categorization, in Formal Ontology in Information Systems, Proceedings of the Third International Conference (FOIS-2004), pp. 3 – 17, IOS Press, 2004.
Sites on Classical Music http://www.arkivmusic.com/classical/main.jsp
http://www.classicalarchives.com/live/
http://www.imusic.dk/
209


Integration of a Formal Ontological Framework with a Linguistic
Ontology
HANNE ERDMAN THOMSEN1 & HENRIK BULSKOV2
1. Introduction A number of large linguistic ontologies have been developed over the last decades, e.g. WordNet (Miller, 1990; Fellbaum, 1998), EuroWordNet (Vossen, 1998) and SIMPLE 3. These resources contain large amounts of data and are potentially useful for ontology-based approaches in diverse fields, such as information retrieval and natural language processing. Being developed primarily as linguistic resources, they are ontologically relatively informal and not always consistently coded. In this paper we will propose a method to integrate a large linguistic ontology into a formal ontological framework. The work described is based primarily on experience from using the Danish linguistic ontology, SIMPLE, for ontology-based NL analysis and for content-based information retrieval, both within a lattice-based formal ontology framework in the OntoQuery project. 2. Background The paper describes work within the OntoQuery project, a project on ontology-based querying of text databases4 (Andreasen et al., 2004). The project aims at developing theories and methods for content-based information retrieval by devising a description language, OntoLog, whose expressive power covers not only the purely linguistic analysis of texts, but also the descripton of a concept ontology and the analysis of queries. The theoretical results are exploited in the development of a
1. Dept. of Computational Linguistics, Copenhagen Business School. [email protected] 2. Computer Science, Roskilde University, Denmark. [email protected] 3. http://www.ub.es/gilcub/SIMPLE/simple2.html 4. Partners in the project are the following Danish research institutions: Copenhagen
Business School, the Danish Technical University, Roskilde University and the University of Copenhagen. The project is funded by the Danish Research Agency under the Information Technology Programme.

H. E. Thomsen & H. Bulskov
prototype system, where queries in natural language (Danish) are answered by returning relevant sentences from (Danish) texts in the text database. Answers are ranked according to their distance from the query in an ontology. In the current prototype, the ontology is that of the Danish SIMPLE lexicon5, which is also used for analyzing texts and queries (Pedersen & Paggio, 2002). One of the main challenges in the project is the integration of this comprehensive semantic lexicon with the generative ontology framework which is central in the project. The present paper is an attempt to look closer at this challenge. 2.1 Formal Ontological Framework In the generative ontology framework of OntoQuery, described in e.g. (Andreasen & Fischer Nilsson, 2004) and (Jensen & Fischer Nilsson, 2003, 2004), an Ontological Grammar describes ontologically admissible concepts in the ontology and, as the lexicon is related to the ontology, this grammar simultaneously describes ontologically admissible noun phrases. This is done by giving rules for legal combinations of concept descriptors, making use of a fixed set of semantic relations, most of them originating in Fillmore’s case roles.6
In the logical description language, OntoLog, concept descriptors can be either simple (atomic) or complex. Complex descriptors consist of a simple descriptor plus one or more relations to other concept descriptors (simple or complex). Examples are
• vitamin • vitaminD • lack [WRT: vitamin] • lack [WRT: vitamin][TMP: winter] • disease [CBY: lack [WRT: vitamin]]
5. The Danish SIMPLE lexicon, which contains 10.000 lexical entries, has been
developed at the Centre for Language Technology, University of Copenhagen, see Pedersen & Keson (1999) and Pedersen & Nimb (2000).
6. The following relations are used in the current version of OntoLog: TMP: temporal; LOC: location; PRP: purpose; WRT: with respect to; CHR: characteristic; MNR: manner; CUM: cum, accompanying; BMO: by means of; CBY: caused by; CMP: comprising; AGT: agent; PNT: patient; SRC: source; DST: destination; QUA: according to; DE: possession
212

Integration of a Formal Ontological Framework with a Linguistic Ontology
Taxonomic relations between simple descriptors are recorded in a knowledge base. Furthermore the following rules of specialization hold:
• A [Rel: B] is a specialization of A • A [Rel: B1] is a specialization of A [Rel: B2] if B1 is a
specialization of B2
The first rule implies that ‘lack [WRT: vitamin]’ IS-A ‘lack’, whereas it follows from the second rule that ‘lack [WRT: vitaminD]’ IS-A ‘lack [WRT: vitamin]’since vitaminD IS-A vitamin. These rules make it possible to estimate the distance between concepts, and in the ontology-based search they are essential for evaluating to what extent a given text matches a query, see e.g. (Andreasen et al., 2003). 2.2 Linguistic Ontology in the Prototype: SIMPLE The SIMPLE lexicon contains entries for natural language word meanings, and as such it can be classified as a linguistic ontology c.f. (Gómez-Pérez et al., 2004). Each entry corresponds to a linguistic sign, i.e. the combination of a word string and one of its meanings. The entries contain a.o. ontological information concerning taxonomic and other relations among linguistic signs7, and has therefore been adopted as lexicon and ontology for prototype work in the project. At the top of the purely linguistic (lexcical) ontology, SIMPLE has a top-level ontology to which the lexical entries are anchored. 2.3 The Challenge Currently the theoretical part of the project and the prototype are two very separate things: On the one hand we have the generative Ontological Grammar and OntoLog, and on the other the static SIMPLE lexicon. We can construct complex descriptors from NPs occurring in natural language text, be it texts in the text database, or NL queries to the database. An example is the above mentioned
lack [WRT: vitamin] rendered by the analysis of mangel på vitamin (‘lack of vitamin’). Unfortunately, however, descriptors are not always mapped to concepts in the ontology contained in SIMPLE, since each lexical entry in SIMPLE has only been supplemented with a simple descriptor identical with the lemma, i.e. the descriptor of vitaminmangel (‘vitamin lack’), is ‘vitaminmangel’, whereas the complex descriptor above is not found in the static lexical part of the ontology.
7. In SIMPLE, 42 different semantic relations are used.
213

H. E. Thomsen & H. Bulskov
Therefore, OntoLog and SIMPLE have to be merged, so that the specialization rules above can actually be used for reasoning about ontological distance, and also in order to retrieve the same set of answers when using any one of a set of synonymous expressions (e.g. diabetes / sukkersyge or vitaminmangel ‘vitamin lack’ / mangel på vitamin ‘lack of vitamin’). Because of the linguistic and relatively informal nature of linguistic ontologies such as SIMPLE, various problems are encountered when switching to the formal framework. Similar problems are encountered by other projects, see e.g. (Haav & Lubi, 2001) and (Goerz et al., 2003). One group of problems concern inconsistencies in the coding of relations to other concepts (e.g. circularity in the taxonomy, synonyms with different mothers, or inheritance of inconsistent features). Other problems are due to incomplete data, e.g. lack of differentiating features on most concepts, temporary dummy concepts, i.e. concepts entered with a minimum of information, because their presence is needed in order to complete the relations of another concept, and never completed. These concepts are typically not correctly located in the taxonomy. In SIMPLE, 2.500 of the entries are “dummies” which have (temporarily) been located right below the top-ontology. A third group of problems concern violation of ontological principles, as described in e.g. (Gangemi et al. 2003a, 2003b). These problems are not handled in the present paper, as our concern is to find a way to extract the information encoded in the lexicon, and render it as formal OntoLog descriptors, in order to exploit it for text search despite inconsistencies and ontological ‘untidiness’. If the ontology is to be used for more refined inference purposes, an OntoCleaning process would certainly be needed. 3 Extraction of OntoLog Descriptors from SIMPLE In this section we will present a method for generating complex OntoLog descriptors for the concepts in SIMPLE automatically from the contents in the lexical entries, especially the relations contained in each lexical entry. 3.1 Basic Principle An OntoLog descriptor should describe the meaning of a concept, much as a definition in a dictionary or termbase does by means of the immediately superordinate concept and the delimiting characteristics. As mentioned, SIMPLE entries contain information about taxonomic
214

Integration of a Formal Ontological Framework with a Linguistic Ontology
and other relations between concepts. The taxonomic relations render the immediate superordinate concept, whereas the other relations should provide further characteristics. For a presentation and discussion of the relations used see (Madsen et al., 2002a). Ideally, the SIMPLE entry for diabetes should contain the following information concerning semantic relations to other concepts (relations and concepts are highlighted for convenience): <RWeightValSemU semr="SRIsa"
target="USEM_N_sygdom_DIS_1"
weight="PROTOTYPICAL">
<RWeightValSemU semr="SRCausedBy"
target="USEM_N_insulinmangel_STATE_
1"
weight="PROTOTYPICAL">
This means that diabetes is a sygdom (‘illness’) caused by insulinmangel (‘lack of insulin’), and therefore the following OntoLog descriptor for diabetes can be derived: sygdom [CBY: insulinmangel] Likewise we can derive the descriptor for insulinmangel (‘lack of insulin’): mangel [WRT: insulin] and combine the two to get a more complex descriptor for diabetes: sygdom [CBY: mangel [WRT: insulin]]8
Using this descriptor, texts containing any of the following NL phrases will be retrieved as answers to a query concerning diabetes: diabetes sukkersyge (assuming it has a SIMPLE entry identical to that of diabetes) sygdom forårsaget af insulinmangel (’illness caused by lack of insulin’) sygdom forårsaget af mangel på insulin (’illness caused by …’)
3.2 Inheritance of Features Turning to types of bread in the Danish SIMPLE lexicon, and moving up the taxonomy, descriptors can be created for the bread concepts and all of their superconcepts, by taking the immediate superconcept and all of the relations specified. This gives the taxonomy in Figure 1,
8. In these examples, the relations found in SIMPLE have been translated to
OntoLog relations. In the rest of the paper SIMPLE relations are maintained.
215

H. E. Thomsen & H. Bulskov
ending at the lowest concept in the top ontology (for convenience descriptors contain only English glosses).
substans ‘substance’ entity []
stof ‘stuff’ substance []
næring ‘nourishment’ stuff [OBJ_ACTIVITY: consumption]
mad ‘food’ nourishment [OBJ_ACTIVITY: eat]
brød ‘bread’ food [CREATED_BY: bake OBJ_ACTIVITY: eat MADE_OF: flour]
hvedebrød ‘white bread’ bread [CREATED_BY: bake
OBJ_ACTIVITY: eat MADE_OF: flour [MADE_OF: wheat]]
rugbrød ‘brown rye bread’ bread [CREATED_BY: bake
OBJ_ACTIVITY: eat MADE_OF: flour [MADE_OF: rye]]
ENTITY
entitet ‘entity’ ENTITY []
Figure 1: Ontology of bread types These descriptors can be simplified thanks to the inheritance of features included in the formal ontological framework. Hence, relations or features on the lowest level can be eliminated as they are already encoded higher in the hierarchy, e.g. the feature
216

Integration of a Formal Ontological Framework with a Linguistic Ontology
[OBJ_ACTIVITY: eat] on brød (‘bread’) and its subconcepts, and the feature [CREATED_BY: bake] on the two subconcepts. The feature MADE_OF, on the other hand, should be left as it is, since its value gets more specific as we move down the hierarchy. This illustrates the second OntoLog specialization rule given above. Rugbrød (‘brown rye bread’) thus has the descriptor:
bread [MADE_OF: flour [MADE_OF: rye]] and brød (‘bread’) the descriptor:
food [CREATED_BY: bake MADE_OF: flour]
3.3 Atomic Descriptors In order to get the head concept of the descriptors, we have just moved up to the nearest superordinate concept. But we might go further up the hierarchy, substituting the simple descriptors with the entire descriptor of the superconcept as we go along. So in the descriptor for rugbrød (‘brown rye bread’) above, ‘bread’ can be substituted with the descriptor for the concept brød (‘bread’) (except for the feature MADE_OF c.f. above) rendering the descriptor:
food [CREATED_BY: bake MADE_OF: flour [MADE_OF: rye]]
This, of course, could be done all the way up to the topmost concept of the ontology, thus describing all concepts in the ontology with the topmost concept as origin. This leads to the question of where this substitution should stop. There are three innate possibilities:
1. The immediately superordinate concept Has as consequence that it would be difficult to get to texts containing rugbrød (‘brown rye bread’ = bread [MADE_OF: flour [MADE_OF: rye]]) from a query concerning mad bagt af rugmel (‘food baked with rye flour’ = food [CREATED_BY: bake, MADE_OF: flour[MADE_OF: rye]])
2. The first superordinate where no new features are added This would allow us to extract all the refined information available in the SIMPLE lexicon.
3. The first concept encountered in the top-ontology This choice is equivalent to using the concepts from the top-ontology as atomic descriptors, i.e. rugbrød will get the descriptor: ENTITY [OBJ_ACTIVITY: eat, CREATED_BY:
217

H. E. Thomsen & H. Bulskov
bake, MADE_OF: flour [MADE_OF: rye]]9. It has the disadvantage that a rather large number of concepts would get identical descriptors, e.g. substans and stof above, as they are subconcepts of the same top level concept and have no further features to discriminate between them.
For a first approach we choose the first option, i.e. the complex descriptors for each concept in the linguistic ontology are constructed from the immediate superordinate concept. We have chosen this because in the current OntoQuery prototype complex noun phrases will not get an analysis more refined than this. Furthermore, going higher in the ontology, the descriptor will contain a higher number of atomic parts, and it becomes more and more unlikely that they can all be found within the limits of one sentence. 3.4 The Problem of Identical Descriptors As mentioned above, differentiating features have not been encoded systematically, and therefore the content coded for some concepts is identical to that of their superconcepts, leaving not only sister concepts with identical descriptors, but also mother and daughter. An example of this is constituted by the concepts substans and stof in the above hierarchy, but also concepts with several extra relations may be identical. This problem can be resolved by letting each concept have one more descriptor, namely the original lemma-identical one. In the above example the pair of descriptors generated for stof now differs from that generated for substans: stof: (stuff, substance) substans: (substance, entity) Likewise, sister concepts such as substans and genstand (‘object’), will differ from each other in containing their own lemma-descriptor in their set of descriptors. substans: (substance, entity) genstand: (object, entity) In the case of complex descriptors, each of the component concepts will thus have more than one representation, and therefore each
9. with the atoms eat, bake, flour and rye further substituted.
218

Integration of a Formal Ontological Framework with a Linguistic Ontology
concept in the ontology must have a set of descriptors, rather than just a pair, as shown below.
næring ‘nourishment’: {nourishment, stuff [OBJ_ACTIVITY: consumption], stuff [OBJ_ACTIVITY: RELATIONAL_ACT] }
3.5 Synonyms Finally, in order to ensure that synonyms have identical sets of descriptors, the synonymy relation is used to add the lemma descriptors of synonyms to each descriptor-set in the synonymy relation. This means that the sets of descriptors for the words sukkersyge and diabetes should all contain (a.o.) the descriptors: {diabetes, sukkersyge, …..} In cases where synonyms are inconsistently coded, i.e. have different superconcepts or other relations, the problems can be remedied by using the union of the descriptor sets declared synonymous in the lexicon, in order to give them identical semantic content. Ontologically and linguistically this is not a very satisfying approach, but as the goal is to retrieve the same set of texts for two synonymous expressions rather than the correct semantic representation, the approximation is acceptable.
4 An Example In the current OntoQuery prototype queries are expanded with similar concepts from the ontology (Andreasen et al., 2003). This is done by expanding each concept in the query to a fuzzy set of similar concepts, where the grade of membership defines the similarity between concepts in the ontology. Instead of searching for objects including only the concepts defined by the user, the query evaluation also include similar concepts from the ontology. The result of the query evaluation could therefore be a set of objects with more or less relevance to the original query, depending on which concepts in the fuzzy set caused the match. The measure of similarity between concepts is then used to rank the result, with the best match first, which of course would be the objects matching the original query, if any. Taking the ontology in figure 1 as basis, the query {rugbrød (‘brown rye bread’)} could, for instance, be expanded to {1.00/rugbrød (‘brown rye bread’) + 0.50/brød (‘bread’) + 0.25/mad (‘food’)}. The values {1.00, 0.50, 0.25} used here to express distance in the ontology,
219

H. E. Thomsen & H. Bulskov
are chosen as an example, and express that the distance from rugbrød (‘brown rye bread’) to mad (‘food’) is larger than the distance from rugbrød (‘brown rye bread’) to bread (‘bread’). Text objects containing the concept bread (‘bread’) would therefore be a better match than objects with the concept mad (‘food’) on the query {rugbrød (‘brown rye bread’)}. The evaluation of the above expanded query on the three sentences 1 Brød lavet af rug. (’Bread made of rye.’) 2 Hævet rugbrød fremstilles
med surdej. (‘Raised brown rye bread is made with leaven.’)
3 Brød lavet af hvede (‘Bread made of wheat.’) would give the following result ranked by relevance to the query:
1.00 Hævet rugbrød fremstilles med surdej.0.50 Brød lavet af rug. 0.50 Brød lavet af hvede.
This ranking is due to the fact that the first sentence matches the concept rugbrød (‘brown rye bread’) to the degree 1.00, and the second and third sentences match the concept brød (‘bread’) to the degree 0.50. From the ontology we know that rugbrød (‘brown rye bread’) and bread[MADE_OF: rug] (‘bread’[MADE_OF: ‘rye’]) are two paraphrases meaning the same thing. If we extend the expansion of the above query with the complex descriptor of the immediately superordinate concept as suggested in section 3.2, we get the expansion {1.00/“rugbrød” (‘brown rye bread’) + 1.00/brød[MADE_OF: rug] (‘bread’[MADE_OF: ‘rye’]) + 0.50/brød (‘bread’) + 0.25/mad (‘food’)}, and the evaluation would give the result:
1.00 Hævet rugbrød fremstilles med surdej.1.00 Brød lavet af rug. 0.50 Brød lavet af hvede.
assuming that the analysis of sentences recognizes the MADE_OF relation. The phrase “Brød lavet af rug” (‘bread made of rye’) can be transformed into the expression brød[MADE_OF: rug] (‘bread’[MADE_OF: ‘rye’], and due to the expansion with the
220

Integration of a Formal Ontological Framework with a Linguistic Ontology
complex descriptor of the immediately superordinate concept, it matches the query with the relevance 1.00 instead of the previous 0.50. 5 Concluding Remarks In the paper we have shown how a link between the generative ontology framework in the OntoQuery project and the static lexical database can be created by enriching the lexical entries with sets of descriptors that can be located in the dynamic ontology. We see no problems in adopting the proposed method for other linguistic ontologies with a top-ontology, as well as for other formal frameworks. The set of descriptors for a given entry consists of
1. A simple descriptor orthographically identical to the lemma.
2. Descriptors created by combining the lemma of the immediately subsuming concept with the supplementary relations coded in the linguistic ontology..
3. In the case of synonyms, the union of the descriptor sets cf. 1 & 2 of all synonyms is used.
Incompleteness in the linguistic ontology concerning lack of delimiting features is remedied by 1 above. Inconsistencies concerning the location of synonyms in the ontology, are handled by 3 above.Finally we have shown how this approach could give more satisfactory results when used for querying a text database. Future research will address how to overcome other problems of inconsistent and incomplete data, and whether moving higher up the ontology will prove worthwile. 6. References Andreasen, T; H. Bulskov & R. Knappe; From Ontology over
Similarity to Query Evaluation, 2nd CoLogNET-ElsNET Symposium, Questions and Answers: Theoretical and Applied Perspectives, to appear in Journal of Applied Logic, ELSEVIER, 2003.
Andreasen, Troels; Per Anker Jensen; Jørgen Fischer Nilsson; Patrizia Paggio; Bolette Sandford Pedersen & Hanne Erdman Thomsen; ‘Content-based text querying with ontological descriptors’, in P. Johannesson (eds.), Applications of Natural Language to Information Systems (NLDB) 2002, Special issue of: Data & Knowledge Engineering, Esevier, 2004.
221

H. E. Thomsen & H. Bulskov
Andreasen, Troels & Jørgen Fischer Nilsson; ‘Grammatical Specification of Domain Ontologies’, Data & Knowledge Engineering, 48(2), pp. 221 – 230, 2004.
Fellbaum, Christiane (eds.), WordNet - An Electronic Lexical Database. Bradford Books, 1998.
Gangemi, Aldo; Roberto Navigli & Paola Velardi; ‘The OntoWordNet Project: Extension and Axiomatization of Conceptual Relations in WordNet’, in On The Move to Meaningful Internet Systems 2003: CoopIS, DOA, and ODBASE, pp. 820 – 838 Springer Verlag, 2003a.
Gangemi, Aldo; Nicola Guarino; Claudio Masolo & Alessandro Oltramari; Sweetening WORDNET with DOLCE. AI Magazine 24(3), pp. 13 – 24, 2003b.
Gómez-Pérez, Asunción; Mariano Fernández-López & Oscar Corcho; Ontological Engineering – with examples from the areas of Knowledge Management, e-Commerce and the Semantic Web, Springer Verlag, London Limited, 2004.
Goerz, Günther; Kerstin Bücher; Bernd Ludwig; Frank-Peter Schweinberger & Iman Thabet; ‘Combining a Lexical Taxonomy with Domain Ontologies in the Erlangen Dialogue System’, in Barry Smith (eds.), KI - 2003 Workshop 11 - Reference Ontologies vs. Applications Ontologies, Proceedings, 2003.
Haav, Hele-Mai & Tanel-Lauri Lubi; ‘A Survey of Concept-based Information Retrieval Tools on the Web’, in A. Caplinkas & J. Eder (eds), Advances in Databases and Information Systems, Proc. of 5th East-European Conference ADBIS*2001, vol 2, pp. 29 – 41, Vilnius "Technika", 2001.
Jensen, Per Anker & Jørgen Fischer Nilsson; ‘Ontology-based Semantics for Prepositions’ at ACM-SIGSEM Workshop on the Linguistic Dimension of Prepositions and their use in Computational Linguistics, Institut de Recherce en Informatique de Toulouse, Toulouse, September 4-6, 2003.
Jensen, Per Anker & Jørgen Fischer Nilsson; Ontology-based Semantics for Prepositions, a revised and extended version of (Jensen & Nilsson, 2003), forthcoming, Kluwer, 2004.
Madsen, Bodil Nistrup; Bolette Sandford Pedersen & Hanne Erdman Thomsen ; ”Semantic Relations in Content-based Querying Systems: a Research Presentation from the OntoQuery Project”, in K. Simov & A. Kiryakov (eds.), Ontologies and Lexical Knowledge Bases. Proceedings of the 1st International Workshop, OntoLex 2000, pp. 72 – 82, Sofia: OntoText Lab., 2002a.
222

Integration of a Formal Ontological Framework with a Linguistic Ontology
Miller, George; WordNet: An On-line Lexical Database, International Journal of Lexiography, vol. 3, no. 4, 1990.
Pedersen, B.S. & B. Keson; ‘SIMPLE: Semantic Information for Multifunctional Plurilingual Lexicons: Some Examples of Danish Concrete Nouns’, in SIGLEX 99: Standardisaing Lexical Resources, ACL Workshop, pp. 46 – 51, University of Maryland, USA, 1999.
Pedersen, B.S., & S. Nimb; ‘Semantic Encoding of Danish Verbs in SIMPLE Adapting a verb-framed model to a satellite-framed language’, in Proceedings from 2nd Internal Conference on Language Resources and Evaluation, pp. 1405 – 1412, Athens, Greece, 2000.
Pedersen, B. & Patrizia Paggio; ”Semantic Lexical Resources Applied to Content-based Querying – the OntoQuery Project”, in Third International Conference on Language Resource and Evaluation 2002 pp. 1753 – 1759, Las Palmas, Gran Canaria, 2002.
Vossen, P. (eds.); EuroWordNet: A Multilingual Database with Lexical Semantic Networks. Dordrecht: Kluwer Academic Publishers, 1998.
223


Modeling the Semantics of Relocation
For SugarTexts and Beyond
VIKTOR SMITH 1. Dealing with Relocation in a TKE Context This paper deals with the apparently universal cognitive mechanisms which underlie humans’ perception and conceptualization of what we will here call relocation processes and events, i.e. the enterprise of moving – or being moved – from one place (Loc1) to another (Loc2), and the very different ways in which these mental representations can be conveyed linguistically in different languages and language types. In a Terminology & Knowledge Engineering (TKE) context, two questions impose themselves. First, what does this have to do with terminology? The linguistic expressions naturally in focus here are verbs, and most of them are indeed quite “ordinary” verbs the use of which is by no means restricted to professional communication. So they do not really qualify as “terms” in any prototypical sense. Still, they convey a type of real-world information which is crucial to many kinds of professional activities, one self-explanatory example being the planning and understanding of technological processes. In verbal descriptions of such processes, the nouns (mostly qualifying as terms in a quite classic sense) will denote the participants of the situations of interest, i.e. process media, machinery, etc., whereas verbs are used for “setting the scene” for the situations themselves and their stepwise progression. When modeling the underlying knowledge structures, it therefore seems reasonable to address the two aspects in combination. Second, what kind of “modeling” does the title suggest? In a knowledge engineering context, one might perhaps expect some ready-made format for handling the type of knowledge in question in a computer based knowledge managing system. However, the theoretical basis for such an (obvious) next step seems to need some further refinement first. What this paper might contribute is thus a few elements for a “pre-operational” ontology, i.e. a system of concepts and variables which may provide a better basis for capturing the

Viktor Smith
interplay between cognitive universals and linguistic specifics at issue here than do the alternatives presently available. In doing so, we continue an ongoing discussion in the fields of language psychology and cognitive linguistics which has however not yet been extended to professional communication and knowledge engineering. I think it should be. For a more extensive discussion of the integration of cognitive approaches into knowledge representation system, see e.g. Evermann (2005). 2. Background and Scope Beginning with an influential study by Talmy (1985; see 1991 and 2000: 25ff. for further developments), several authors have supported a sharp typological distinction which divides the world’s languages – or rather, the majority of those considered so far – into two distinct categories according to their preferred way of lexicalizing the cognitive domain under consideration (e.g. Slobin, 2004, 1996a, 1996b; Berthele, 2004; Mora Gutiérrez, 2001; Gennari et al., 2002; Papafragou et al., 2002; Herslund & Baron, 2003): (a) MANNER languages (and/or satellite-framed languages), e.g. Danish, Swedish, English, German, Russian, Chinese, where the MANNER of motion is obligatorily lexicalized in the verb roots, while the direction or PATH of motion can be explicated when required through the addition of a satellite in the shape of a particle (preposition/adverb) or a prefix, thus forming a complex (as for particles: a phrasal) lexeme e.g. English: roll, fly, walk + down, off, etc., and (b) PATH languages (and/or verb-framed languages), e.g. French, Italian, Spanish, Modern Greek, Turkish, Japanese, where the verb roots lexicalize either MANNER or PATH, e.g. French: courir vs. entrer, but only the PATH verbs convey the core meaning of relocation in the sense indicated above, leaving MANNER to be explicated elsewhere in the sentence structure, e.g. à pied, en avion, if at all.
This difference complicates the transfer of information between the two prototypes of languages in various ways, most obviously in the course of translation, including LSP translation as in the case of e.g. process descriptions. Yet much remains to be discovered. For one thing, not all languages fit equally well into the binary typology just outlined and many languages have not been sufficiently examined in this respect. For example, in a language like Russian, the two lexicalization strategies appear to be complementary rather than mutually exclusive, which means that Russian speakers may (and must) make certain choices that are never at issue in a full-fledged
226

Modeling the Semantics of Relocation
MANNER language like Danish or a full-fledged PATH language like French (see Smith, 2003 and 2005; Ozol, 2004). Also, the influence of pragmatic factors on speakers’ actual utilization of the options offered by any given language-system in various communicative settings – say, that of a fairytale vs. that of a technical process description – deserves more systematic examination. And the alleged influence of the typological differences in question on translation and other forms of crosslinguistic communication – and perhaps also on nonverbal thinking and problem solving (see Papafragou et al., 2002; Gennari et al., 2001) – needs to be tested against more extensive and diversified empirical evidence.
One possible way of providing such evidence is presently being tested in the framework of the Copenhagen Business School (CBS) research project SugarTexts which was initiated in the spring of 2004 by Lita Lundquist, Svetlana Ozol and myself. Continuing the idea underlying the well-known Frog Story studies (Berman & Slobin, 1994; Strömqvist & Verhoeven, 2004), the present project builds on a multilingual corpus containing spontaneous verbalizations of uniform extralinguistic scenarios involving a wide variety of relocation processes and events. Only, in our case these verbalizations have not come about on the experimenter’s initiative in the course of interviews. They have been produced quite “voluntarily” by specialists and/or technical writers simply doing their job: telling the SugarStory. That is, presenting the consecutive steps through which sugar beets eventually turn into fine sugar crystals in a beet sugar factory. The resultant SugarTexts – as found in textbooks, research reports, information folders, sales material, on websites, etc. – provide an excellent basis for quantitative and qualitative analyses of cognitive and linguistic variables of potential interest. By April 2005 the corpus contained a total of 59 SugarTexts in Danish, French, English, and Russian, but the number of texts and the selection of object languages are expected to increase significantly during this and the coming year. Next languages in line are Italian, Spanish, and German.
However, in this paper I will not go into any detail on findings already made or plans for future investigations as regards the typological description of particular languages and their possible intra- and extralinguistic implications. Instead, I will present another preliminary result which grew out of simple necessity: the demand for a more precise and unambiguous metalanguage for comparing the semantic variables of interest within and across languages. Thus, several authors have pointed out the need for:
227

Viktor Smith
(a) A more explicit and consistent theoretical basis for distinguishing motion in general from going somewhere (i.e. from Loc1 to Loc2) – a distinction that obviously underlies most of the existing work on the subject though it has not yet been too unambiguously defined or, indeed, lexicalized. The latter form of motion, which is the one that concerns us here, is most commonly referred to as “motion events” or “directed (or translational) motion”, while the verbs lexicalizing it are called “directed motion verbs”, “change-of-location verbs”, etc. In this paper, a case for the terms relocation and relocation verbs will be made as an integral part of the theorizing to follow. (b) A further specification and differentiation of the intuitively attractive, but vaguely defined parameters of MANNER and PATH. It seems so obvious that things can “move in different ways” and/or “go different places” and that these are the key variables that can be lexicalized by the verb expressions under consideration – which apparently keeps many authors from going into any further analysis of these “primitives”. Nevertheless, a number of possible variations of both parameters must eventually be accounted for if larger amounts of data from different spatial domains and different languages are to be compared in a meaningful way. A more concise metalanguage for these purposes is therefore required. For more detailed reviews of existing approaches, see e.g. Mora Gutierrez (2001) and Slobin (2004). A different angle is taken by Tenny (1995). The next section presents the core elements of a conceptual framework which definitely needs further development (indeed, a lot), but which even at this stage allows us to address the issues just outlined in a more coherent way than has been the case so far.
3. A Semantics for Relocation: Basic Ingredients The present approach is based on the cross-linguistic principles of verb classification suggested by Durst-Andersen (1992, 2000, 2002; Durst-Andersen & Herslund, 1996). The framework was originally developed as a basis for analyzing the category of aspect in Russian, English, and other languages, but it also contributes to verb semantics in general by incorporating certain basic insights on humans’ pre-linguistic perception and conceptualization of situations – which are considered the standard referents of verbs, just as nouns refer to “things” in a broad, but still readily recognizable sense. The point of departure is visual cognition, but the cognitive principles described below seem to have been generalized so that they have come to underlie verb semantics in general.
228

Modeling the Semantics of Relocation
3.1 States, Activities, Actions According to Durst-Andersen (e.g. 2000: 60ff.), all humans, regardless of what language they speak, routinely distinguish between two kinds of real-world phenomena (situations) that can potentially be referred to by means of verbs, the mental representations of which can be described in terms of figure-ground relationships, namely:
(a) States which are perceived as a stable figure on a stable ground thus constituting a stable picture. In their own right, such situations are referred to by means of state verbs, e.g. English: lie, stand, resemble, etc. (b) Activities which are perceived as either an unstable figure on a stable ground or a stable figure on an unstable ground thus constituting an unstable picture. In their own right, such situations are referred to by means of activity verbs, e.g. English: dance, shiver, carry, etc.
Only these two kinds of situations can be identified through direct observation. However, our world knowledge tells us that some activities, if sufficient, can bring about certain states, and that some states have been brought about by certain activities. This allows us to also identify (c) Actions which are mental constructs linking together a certain activity and a certain state. When perceived and referred to as elements of an action, activities are further classified as processes and states are further classified as events. The corresponding propositional interpretations are denoted p and q, respectively. The directed relationship between the two situations as such is described in terms of telicity. Actions (as represented by processes and/or events) are referred to by means of action verbs, e.g. English: put, arrive, kill, show, etc. The principle is illustrated by Durst-Andersen’s verb model of actions, a variant of which is shown in Figure 1.
Figure 1: The semantics of putting
229

Viktor Smith
In actual communication, an action verb will usually be referring to either an activity (presenting it as a process), e.g. ”She is just putting the cake on the table”, where p is asserted and q is treated as a standard implicature, or a (change of) state (presenting it as an event), e.g. “Who put that cake on my table?”, where q is asserted and p is presupposed (for further details on the metalanguage, see Durst-Andersen, 1992: 60-63 and 100f.). If the change of state in question is definable in terms of spatial relationships (location) alone, the corresponding verb is called a location-based action verb or as one might put it more compactly: a relocation verb – the alternative categories being possession-based, experience-based, and qualification-based action verbs (Durst-Andersen, 1992: 61 and 2002: 60ff) which will be touched upon very briefly in section 5. Thus, what differentiates relocation verbs from simple motion verbs – i.e. pure activity verbs – is that the change of location is not just a possible inference, but an integral part of the verb’s semantics. A similar point has been underlying the “classic” tradition of motion event typology mentioned in section 2 all along, but Durst-Andersen’s framework allows us to state that point in less ambiguous terms, providing a firmer basis for further theoretical developments.
3.2 Specifying the MANNER/PATH Distinction The present framework also allows us to further specify the PATH/MANNER distinction. MANNER verbs are activity-oriented (whether or not the activity is seen as part of an action, i.e. as a process) specifying certain properties of either the figure, the ground and/or the interrelations between them. For example, a ball can bounce on a hard floor, but water cannot really bounce on a piece of fluffy cotton – though it may well soak through it. For transitive verbs, the agent’s interaction with the figure and/or ground, given these properties, can also be part of the semantics. Thus, one may throw a ball, but not a handful of air.
PATH verbs are (change of) state, i.e. event, oriented in that they specify certain properties of either the initial location (Loc1), the consequent location (Loc2), and/or the interrelations between them (the figure here being a variable only in terms of its presence/absence on these locations, i.e. grounds). This makes PATH verbs action verbs and relocation verbs by nature. For example, a verb like arrive presents Loc1 as distant and Loc2 as close.
230

Modeling the Semantics of Relocation
4. Applying the Framework: French vs. Danish As already indicated, we assume that the cognitive principles just outlined are universal and that all languages therefore have some classes of expressions “tailored” for referring to activities, states and actions, respectively. However, the default patterns according to which these cognitive universals are conveyed linguistically display profound crosslinguistic differences, in particular with regard to what is lexicalized (and how)1 and what can merely be inferred or explicated by means of free syntactic constructions. Let us now return to the distinction between MANNER (and/or satellite-framed) languages and PATH (and/or verb-framed) languages introduced in section 2 and see how the present framework can be used for pinpointing he difference between a (proto)typical PATH language, French, and a (proto)typical MANNER language, Danish (expanding upon Herslund’s exemplification in 1998: 8-9).
In French we find one group of verbs which specify the PATH of motion without saying anything about the MANNER: the objects in question may be walking, crawling, flying, etc. These verbs are action verbs, and hence relocation verbs, by their very nature. The MANNER of motion is specified by a different group of verbs in French which however say nothing about the PATH. The standard function of these verbs seems to be to characterize a motion in its own capacity without relating it directly to the change of state (in terms of location) that may or may not result from it. In other words, these verbs normally function as pure activity verbs with no potential for presenting the activity as part of an action, i.e. as a process. These verbs certainly refer to motion, but not to relocation. French: PATH MANNER
aller [≈ go] marcher [≈ walk]
entrer [≈ enter] courir [≈ run]
venir [≈ come] flâner [≈ stroll]
sortir [≈ exit] ramper [≈ crawl]
etc. etc.
1. The relevance of distinguishing between the what-aspect and the how-aspect of
lexicalization is further discussed in Smith (2000:20ff).
231

Viktor Smith
Danish also has a very large and diversified group of verbs that specify the MANNER of motion, a few of which are given below. Danish: MANNER (+ PATHsatellite)
gå [≈ walk] løbe [≈ run] ind [≈ in], ud [≈ out],
spadsere [≈ stroll] op [≈ up], ned [≈ down], etc.
kravle [≈ crawl] etc.
Like the French ones, they are all activity verbs, at least to start with. However, the standard way of referring to PATH in Danish is completely different from the French one in that it involves the present type of verbs as well. Danish does have a few “genuine” PATH verbs, but the standard procedure is to take a suitable MANNER verb and extend it with a PATH-specifying satellite (most commonly in the shape of a preposition/adverb) which merges with the initial verb into a phrasal lexeme. This transforms the initial activity verb (e.g. løbe [≈ run]) into an action verb (e.g. løbe ind [≈ run inside]) and hence a relocation verb. The fundamental difference, then, is that the MANNER of motion has to “go along” with the PATH in Danish, whereas speakers of French may well omit the MANNER-related information if they do not feel like specifying it. (And when they do, they are forced to insert an additional MANNER verb somewhere in the sentence structure, e.g. en courant, or rely on other lexical means such as à pied, en avion, etc.). There is no space to go into the various communicative implications of this in the present context. But it should be clear that you simply cannot tell e.g. the story of beet sugar production in French in a way that can be reproduced in Danish in a word-by-word fashion, or vice versa. The underlying cognitive principles are the same – one advantage of the present framework being its potential for modeling them in their own right as well – but as soon as the interface between knowledge and natural language enters the picture (like when KE has a T in front of it), the typological differences just sketched become part of the picture too.
5. Further Perspectives Several aspects of the suggested framework call for further development.
232

Modeling the Semantics of Relocation
As for the language-typological aspect, one problem is the exact line of demarcation between (phrasal) lexemes and genuinely free syntactic constructions in satellite-framed (i.e. MANNER) languages. Thus, in languages like Danish and English, several satellites are often combined with one main verb in the same clause, and they cannot all be seen as part of one lexeme, e.g. “She ran out of the kitchen up to the bedroom... etc.” However, the “satellite number one” seems to play the decisive role in the shift from (what we have just called) activity to action verb and hence merges semantically with the initial verb in a way that the rest do not, or rather: do not have to. This line of reasoning finds support in other satellite-framed languages. In German the corresponding satellite would be a prefix, at least in the infinitive, in casu: hinauslaufen, and in Russian this would be the case in all forms, in casu: выбежать (⇒ выбежала, etc.). As for Russian, these prefixes furthermore play the dual role of both PATH and aspect markers. The two facts that (a) the prefix turns an activity verb into an action (and relocation) verb and that (b) only action verbs form aspect pairs in Russian, where the perfective member is coined through simple prefixation, while the imperfective member is coined through additional suffixation, can hardly be coincidental or irrelevant to understanding the mechanisms in play in typologically related languages as those mentioned. Also, the framework might be applied to explain the semantics of such verbs that combine the reference to relocation with other types of information. One category might be called positioning verbs. For example, in English you can put both a bottle and a book on a table, but in Danish you have to say “stille flasken på bordet” and “lægge bogen på bordet”. That is, in addition to the figure’s relocation from Loc1 to Loc2, these verbs lexicalize the position of the figure on Loc2: Danish: stille means EXIST VERTICALLY ON LOC2 and Danish: lægge means EXIST HORISONTALLY ON LOC2. A further step would be to consider verbs which operate on some of the alternative categories briefly mentioned in 3.1, i.e. possession, experience, and qualification, in combination with location (plus/minus position). For example, a verb like English: steal is bound to refer to a relocation process or event, but it will also qualify the existence of y on Loc2 in a certain way: as illegal. Finally, it should be mentioned once again that verb semantics and language typology are not the only areas where theorizing along these lines might prove to be of some relevance. We build on the assumption that the cognitive variables on which the analyses are based remain the same, no matter how they end up being lexicalized and verbalized in particular languages. So it would be quite natural to test the
233

Viktor Smith
explanatory power and potential usefulness of the framework in other areas of research, including knowledge engineering. Yet if any modeling that might result from this should also be conveyable in linguistic form, the lexical and typological dimensions must be dealt with here as well. References Berman, Ruth A. & Dan I. Slobin (eds.); Relating events in narratives.
Hillsdale, NJ: Lawrence Erlbaum Associates, 1994. Berthele, Raphael; The typology of motion and posture verbs: A
variationist account, in B. Kortmann, (eds.), Dialectology meets typology. Dialect grammar from a cross-linguistic perspective. Berlin & New York, 2004.
Durst-Andersen, Per; Russian and English as two distinct subtypes of accusative languages, Scando-Slavica Tomus 48, 2002.
Durst-Andersen, Per; The English progressive as picture description, Acta Linguistica Hafniensia 32, 2000.
Durst-Andersen, Per; Mental grammar. Russian aspect and related issues. Columbus, Ohio: Slavica Publishers, 1992.
Durst-Andersen, Per & Michael Herslund; The syntax of Danish verbs. Lexical and syntactic transitivity, in E. Engberg-Pedersen et al. (eds.), Content, expression, and structure. Studies in Danish functional grammar, Amsterdam/Philadelphia: John Benjamins, 1996.
Evermann, Joerg; Towards a cognitive foundation for knowledge representation, Information Systems Journal 15 (2), 2005.
Gennari, Silvia P.; Steven A. Sloman.; Barbara C. Malt & William T. Fitch; Motion events in language and cognition, Cognition 83, 2002.
Herslund, Michael; Typologi, leksikalisering og oversættelse. [Typology, lexicalization, and translation]. Lingvistisk oversættelse, Copenhagen Working Papers in LSP 3, 1998.
Herslund, Michael & Irene Baron; Language as world view. Endocentric and exocentric representations of reality, in I. Baron (eds.), Language and culture, Copenhagen Studies in Languages 29, 2003.
Mora Gutiérrez & Juan P; Directed motion in English and Spanish, Estudios de Lingüística Española 11, 2001.
Ozol, Svetlana. Fra sukkerroe til sukkerskål: Onomasiologisk undersøgelse af danske og russiske relokationsverber baseret på SugarTexts. [From sugar beet to sugar pot: An onomasiological study of Danish and Russian relocation verbs based on SugarTexts.] Unpublished Master’s Thesis, Copenhagen Business School, 2004.
234

Modeling the Semantics of Relocation
Papafragou, Anna; Christine Massey & Lila Gleitman; Shake, rattle ‘n’ roll: The representation of motion in language and cognition, Cognition 84, pp. 189 – 219, 2002.
Slobin, Dan; The many ways to search for a frog: Linguistic typology and the expression of motion events, in S. Strömquist & L. Verhoeven (eds.), Relating events in narrative: Typological contextual perspectives. Mahwah, NJ: Lawrence Erlbaum Associates, 2004.
Slobin, Dan; Two ways to travel: Verbs of motion in English and Spanish, in M. Shibatani & S. Tompson (eds.), Grammatical constructions: Their form and meaning, Oxford: Oxford University Press, 1996a.
Slobin, Dan; From “thought and language” to “thinking for speaking”, in J. J. Gumperz & S.C. Levinson (eds.), Rethinking linguistic relativity, Cambridge: Cambridge University Press, 1996b.
Smith, Viktor; Motion at the sugar factory: Is Russian a genuine MANNER language? in K. Ahmad & M. Rogers (eds.), Proceedings of the 14th European symposium on language for special purposes. Communication, culture, knowledge. Surrey: University of Surrey, 2005.
Smith, Viktor; Talking about motion in Danish, French, and Russian: Some implications for LSP in theory and practice, in LSP & Professional Communication 2, 2003.
Smith, Viktor; On the contrastive study of lexicalization patterns for translation purposes: Some reflections on the levels of analysis, in I. Korzen & C. Marello (eds.), Argomenti per una linguistica della traduzione. Notes pour une linguistique de la traducion. On linguistic aspects of translation. Gli argomenti umani 4. Alessandria: Edizioni dell'Orso, 2000.
Strömqvist, Sven. & Ludo Verhoeven (eds.); Relating events in narrative: Typological and contextual perspectives. Mahwah, NJ: Lawrence Erlbaum Associates, 2004.
Talmy, Leonard; Towards a cognitive semantics: Volume 2: Typology and process in concept structuring. Cambridge, MA:MIT Press, 2000.
Talmy, Leonard; Path to realization: A typology of event conflation, in Proceedings of the Berkeley Linguistic Society 17, 1991.
Talmy, Leonard; Lexicalization patterns: semantic structure in lexical forms, in T. Shopen (eds.), Language typology and syntactic description, vol. III, Grammatical categories and the lexicon, Cambridge: University Press, 1985.
235

Viktor Smith
Tenny, Carol; How motion verbs are special: The interaction of semantic and pragmatic information in aspectual verb meaning, Pragmatics & Cognition 3 (1), 1995.
236

Automated Construction of Chinese Thesaurus Based on
Self-Organizing Map
CHEN TAO, SUN MAOSONG & LU HUAMING Thesauri are vital for many NLP applications, for example, query expansion in information retrieval, estimation of semantic similarities between example sentences in machine translation, and smoothing for handling data sparseness problems in language computing. They also play important roles in content-oriented knowledge management systems, such as the design and construction of ontologies, either linguistic or engineering, in sementic web.
There are two ways for building thesaurus. The first one is manual manipulation by human experts, such as The Merriam Webster Thesaurus and Roget’s International Thesaurus for English, and TongYiCiCilin (Mei et al., 1983) for Chinese. Its advantage is obvious, but the main drawback is it cannot catch up with the rapid development of application domains synchronously. The second one is automated generation using clustering techniques. It avoids the main drawback of manual manipulation, but the quality of clustering is often not so satisfactory. The focus of this chapter is on the latter.
Self-Organizing Map (SOM for short) is a kind of widely used neural network, in the category of unsupervised learning (Kohonen, 1997). It features in self-organization of large-scale data, capable of presenting the results of clustering in a two-dimensional lattice while the input can be high-dimensional (Kohonen, 1998; Kohonen, 2000). Some scholars began to apply SOM to automated construction of Chinese thesaurus. Typical works are (Ma et al., 2001a, 2001b; Zhang et al., 2001). However, they only used 85 common nouns as the target (Figure 1). The research here will be in the line with their work, with major expansions on (1) targeting at much more common words in Chinese (in fact 4,638 high frequent content words); and (2) further improving the related scheme by experimental studies.

Chen Tao, Sun Maosong & Lu Huaming
238
Key Factors in the Scheme A number of key factors need to be figured out in our scheme from the following perspectives.
Figure 1: Results of automatically constructed Chinese thesaurus by (Ma et al., 2001a, 2001b; Zhang et al., 2001) The Setting of SOM SOM consists of two neuron layers, the input layer and the output layer. The number of neurons in the input layer is equal to the dimentinality of iput vectors. The density of the two-dimensional lattice, say, the number of neurons in the output layer, M= mm× , is designed according to the task. We concern the setting of SOM here. Suppose that the input vector is x in the iteration t, the winning neuron in t is c, for any neuron i within a neighboring square area of c, the connecting weight iy of i and x in the iteration t+1 is calculated by:
))()(()()1( tyxthtyty iciii −+=+ (1)
)(thci is a neighboring fucntion:
))(2
exp()()( 2
2
ttth ci
ci σα Δ
−×= (2)
where: ciΔ represents the distance between c and i in the two-dimentional lattice,σ is the radius of the neighboring square area, and α is the learning rate.
The radius will decrease with the increasing of t:

Automated Construction of Chinese Thesaurus based on SOM
239
1))1()1)((()1( +−×−=+TttINTt σσ (3)
T is the total number of iterations. The learning rate will also decreae with the increasing of t:
Ttt )0()()1( ααα −=+ (4)
)0(α is the initial learning rate. The Context Vector of a Word As is widely supposed, the semantics of a word can be reflected to some extent by its context, or, surrounding words. If the contexts of two words are similar, they are likely to have similar semantic properties. This is a fundamental assumption of our approach throughout this chapter.
Let Q be a set of q words to be clustered, L be a Chinese wordlist with l word types, CTC be a manually word-segmented and POS-tagged Chinese corpus. Then for any word Q
iw ∈Q (i=1,…,q), a context vector of Q
iw with dimension l, )( QiwCXT , can be obtained by collecting the
frequency of each word Ljw ∈L (j=1,…,l), say ),( L
jQi wwf , within the
context of Qiw over CTC:
]),(),([)( 1Ll
Qi
LQi
Qi wwfwwfwCXT L= (5)
)( QiwCXT can be reduced from dimension l to 1l by eliminating every
Ljw with ),( L
jQi wwf being equal to 0 or less than a threshold θ for i =
1,…,q. Obviosuly, we have ll <<1 . The remainning words are called feature words of Q, denoted L1 with 1l word types. (Ma et al., 2001a, 2001b) and (Zhang et al., 2001) regarded the left adjacent word (nouns or adjectives) of Q
iw as its context. We believe it is not enough. The syntactic property of a word is closely associated with its adjacent left word (POS bigrams in part-of-speech tagging, for example), but the semantic property of it requires much larger context. This factor needs to be determined experimentally. It is also worth pointing out that we expand the object of contexts to nouns, adjectives and verbs. We herein use another term, the context window, to specify the scope of the context of a word.
The Weight of Positions in the Context Window The position of a feature word of Q
iw is indexed by ± j, if it is j words away from Q
iw (a negative number indicates it is on the left of Qiw and
a positive number indicates it is on the right). Should the different

Chen Tao, Sun Maosong & Lu Huaming
240
positions in the context window be treated equally or differently? We shall try three strategies: (1) all positions are assigned identical weights; (2) the location ± j is assigned a weight 1.0-(j-1)*0.1 if j
10≤ otherwise 0; and (3) the location ± j is assigned a weight 1/j. Dimension Reduction by Feature Selection The dimension of context vectors, 1l , is still very high, resulting in both high cost and high noise in SOM training. Feature selection is thus needed. The feature selection method used in (Ma et al., 2001a, 2001b; Zhang et al., 2001) is too simple to capture the saliency of features effectively. We use a totally different approach as follows. For any ∈1L
jw L1 (j=1,…, 1l ), its saliency is estimated by:
)()(log)( 110
1* Lj
Qj
Lj wIGnwIG ×= (6)
where Qjn is the number of words in Q co-occurring with 1L
jw within the contexts, )( 1L
jwIG is the information gain of 1Ljw with respect to Q:
)|()()( 11 Lj
Lj wQHQHwIG −= (7)
)(QH is the entropy of words to be clustered:
∑=
×−=q
i
Qi
Qi wpwpQH
12 ))(log)(()( (8)
and )|( 1LjwQH is the conditional entropy of words to be clustered
given 1Ljw :
))|(log)|(()|(1
12
11 ∑=
×−=q
i
Lj
Qi
Lj
Qi
Lj wwwwpwQH (9)
The set of feature words, L1, can be further reduced to L2 (with 2l word types) by eliminating all 1L
jw with )( 1* LjwIG being lower than a
threshold δ , resulting in a reduced context vector. Generally, we have 12 ll << .
Feature weighting
(Ma et al., 2001a, 2001b) and (Zhang et al., 2001) compared several methods for feature weighting, and claimed that the traditonal TF*IDF method in IR is preferred. We thus simply adopt TF*IDF here.
For any Qiw ∈Q (i=1,…,q) and ∈2L
jw L2 (j=1,…, 2l ), the weight of the feature 2L
jw of Qiw is given by:

Automated Construction of Chinese Thesaurus based on SOM
241
∑=
×
×=
2
1
22
2
22
2
))/(log),((
)/(log),(),(
l
j
Qj
Lj
Qi
Qj
Lj
QiL
jQi
nqwwf
nqwwfwwwt (10)
Consequently, the reduced context vector is transformed into a feature vector that will serve as the input to SOM:
]),(),([)( 221 2
Ll
Qi
LQi
Qi wwwtwwwtwWT L= (11)
The complexity of SOM training is )( 22 lmqTO ××× .
Fixing the Key Factors In this section, we use the 85 common nouns adopted in (Ma et al., 2001a, 2001b; Zhang et al., 2001) to fix the related factors in our scheme. The evaluation criterion will follow theirs. The lattice of the output layer is set at 13*13, the initial learning rate at 0.1, same as theirs too. The total number of iterations (T) we used to train SOM each time is 20,000. The context vectors of those 85 words are derived from BF-PD980106, a manually word-segmented and POS-tagged Chinese news corpus (the whole collection of People’s Daily from January to June 1998) with 28 million Chinese characters, developed by the Institute of Computational Linguistics of Peking University.
Determine the size of the context window
The number of feature words regarding the size of the context window is given in Table 1.
The size of the context window
Number of words within the context window
initially
Number of feature words (θ is set at 5)
2 11,382 3,408 4 16,597 4,009 6 18,668 4,379 8 19,814 4,658
Full sentence 20,852 5,483 Table 1: Number of feature words vs. the size of the context window
To simplify the situation here, we set the number of feature words at 2,000 (also refer to Table 3). SOM gives the results as in Table 2:

Chen Tao, Sun Maosong & Lu Huaming
242
The size of the context window
Precision Recall F-measure
2 0.769 0.728 0.748 4 0.778 0.754 0.766 6 0.829 0.805 0.817 8 0.850 0.803 0.825
Full sentence 0.852 0.819 0.835
Table 2: The effect of the context window to clsutering (under the condition of 2,000 feature words and identical position weights)
Thus, the context window is chosen as the full sentence throughout the remaining part of the chapter.
Determine the number of feature words by feature selection
In the condition of ‘the full sentence as the context window’, a series of experiments are performed to determine the number of feature words most appropriate for our task, as shown in Table 3.
Number of feature words
Precision Recall F-measure
600 0.666 0.651 0.658 800 0.519 0.604 0.559 1,000 0.626 0.678 0.651 1,200 0.602 0.650 0.625 1,400 0.777 0.743 0.760 1,600 0.776 0.792 0.784 1,800 0.813 0.824 0.818 2,000 0.852 0.819 0.835 2,200 0.832 0.817 0.824 2,400 0.801 0.794 0.797 2,600 0.821 0.813 0.817 2,800 0.778 0.774 0.776 3,000 0.763 0.752 0.757
Table 3: Number of feature words vs. the size of the context window (under the condition of ‘the full sentence as the context window’ and identical position weights)

Automated Construction of Chinese Thesaurus based on SOM
243
SOM obtains the highest F-measure as the number of feature words (that is, the dimension of feature vectors) is set at 2,000. Determine the weight of positions in the context window As shown in Table 4, the strategy ‘identical weights’ obtains the highest F-measure, though the result is a bit surprising.
Strategy Precision Recall F-measure identical weights 0.852 0.819 0.835 1.0-(j-1)*0.1 if j
10≤ otherwise 0 0.788 0.737 0.762
1/j 0.756 0.699 0.726
Table 4: The effect of three strategies of position weighting to clustering (under the condition of ‘the full sentence as the context window’ and 2,000 feature words)
Comparisons of our scheme with others
We have made two comparisons. Comparison 1: SOM vs. the method of (Ma et al., 2001a, 2001b) and (Zhang et al., 2001).
Clustering method Precision Recall F-measure SOM 0.852 0.819 0.835
Method of (Ma et al., 2001a, 2001b) and (Zhang et al., 2001)
0.689 0.687 0.688
Table 5: Comparison of SOM (under the condition of ‘the full sentence as the context window’, 2,000 feature words, and identical position weights ) and the method of (Ma et al., 2001a, 2001b) and (Zhang et al., 2001)
As can be seen in Table 5, SOM here significantly outperforms its counterpart. Comparison 2: SOM vs. ‘K-means clustering + Genetic algorithms’ To further observe the effectiveness of SOM, we use another classic scheme to do clustering on the same data: ‘K-means clustering + Genetic algorithms’. The purpose of using Genetic algorithms is trying to jump out of the local minimum of K-means clustering. The setting for Genetic algorithms used here is: real number encoding, fitness fucntion defined as the sum of distances among clusters over the sum of

Chen Tao, Sun Maosong & Lu Huaming
244
distances within clusters, population=100, crossover rate=0.9, mutation rate=0.1, generation=500.
Clustering method Precision Recall F-measure SOM 0.852 0.819 0.835
K-means clustering + Genetic algorithms
0.661 0.739 0.698
Table 6: Comparison of SOM (under the condition of ‘the full sentence as the context window’, 2,000 feature words, and identical position weights ) and ‘K-means clustering + Genetic algorithms’
Again, SOM significantly outperforms its counterpart.
Experiments on Large-Scale Data We apply the SOM scheme, as determined in the preceding section, to a large data set. We extract the top 4,638 frequent nouns, adjectives and verbs from BF-PD980106 (with frequency greater than 100) as our target. The setting of our scheme is: the full sentence as the context window, 2,000 feature words, identical position weights, the initial learning rate of SOM 0.1, and the total number of iterations 1,000 (the computation will not be feasible if T is set too large, in case that the scale of problems increases almost two orders of magnitude). The lattice of the output layer will be discussed later. Unlike the case in the preceding section, we do not have correct answers to evaluate the clustering result of these 4,638 words directly. Instead, we make use of perplexity to evaluate the effectiveness of clustering indirectly (Dagan et al, 1999). The perplexity of words in a language with respect to a corpus, in terms of word bigrams, is defined as:
)1|(
12log1
2−
=− ∑
=iwiwp
N
iNWPP (12)
where N is the size of the tranning corpus. For the purpose here, we use the clusters 1−ic and ic of 1−iw and iw as an approximation of (12):
)|()|()|( 11 −− ×= iiiiii ccpcwpwwp (13)
In general, the smaller the perplexity, the more adequate the result of clustering.

Automated Construction of Chinese Thesaurus based on SOM
245
The change of perplexities of these 4,638 words after clustering over BF-PD980106, with lattice 10*10, 20*20, 30*30, and 40*40 respectively, is illustrated in Figure 2.
Number of i t er at i ons0
200
400
600
800
1000
1200
Perp
lexi
ty
Lat t i ce10*10
Lat t i ce20*20
Lat t i ce30*30Lat t i ce40*40
Figure 2: Perplexity vs. number of iterations in different setting of the lattice
Two statements hold from Figure 2: (1) The perplexities decrease significantly as the number of iterations increases, showing the effectiveness of SOM; and (2) The more subtle the lattice, the smaller the perplexity will be obtained at last. However, the computation cost will increase dramatically, so eventually we use 40*40 without further refining the lattice. SOM obtains 641, 424, 332 and 98 clusters respectively with lattice 10*10, 20*20, 30*30, and 40*40. For the sake of comparison, K-Means and ‘K-means + Genetic algorithms’ (no change in setting except generation=100 here) is explored to group the 4,638 words into 641, 424, 332 and 98 clusters accordingly. Then, we compare the corresponded perplexities obtained, as given in Table 7.

Chen Tao, Sun Maosong & Lu Huaming
246
Number of clusters Perplexity (C-Means)
Perplexity (C-Means +
Genetic algorithms)
Perplexity (SOM)
641 353.68 337.27 247.37 424 445.24 433.17 382.88 332 580.71 511.94 551.25 98 813.19 807.21 802.90
Table 7: Comparison of three clustering methods in terms of perplexity Table 7 shows SOM outperforms the other two methods remarkably in most cases. Detailed observations on the clusters obtained by SOM, as illustrated in Table 8, indicate that the results are reasonable from human’s point of view – the clusters do capture semantic similarities among words in some degree and thus can be regarded as a sort of thesaurus, though there exist some errors in the results.

Automated Construction of Chinese Thesaurus based on SOM
247
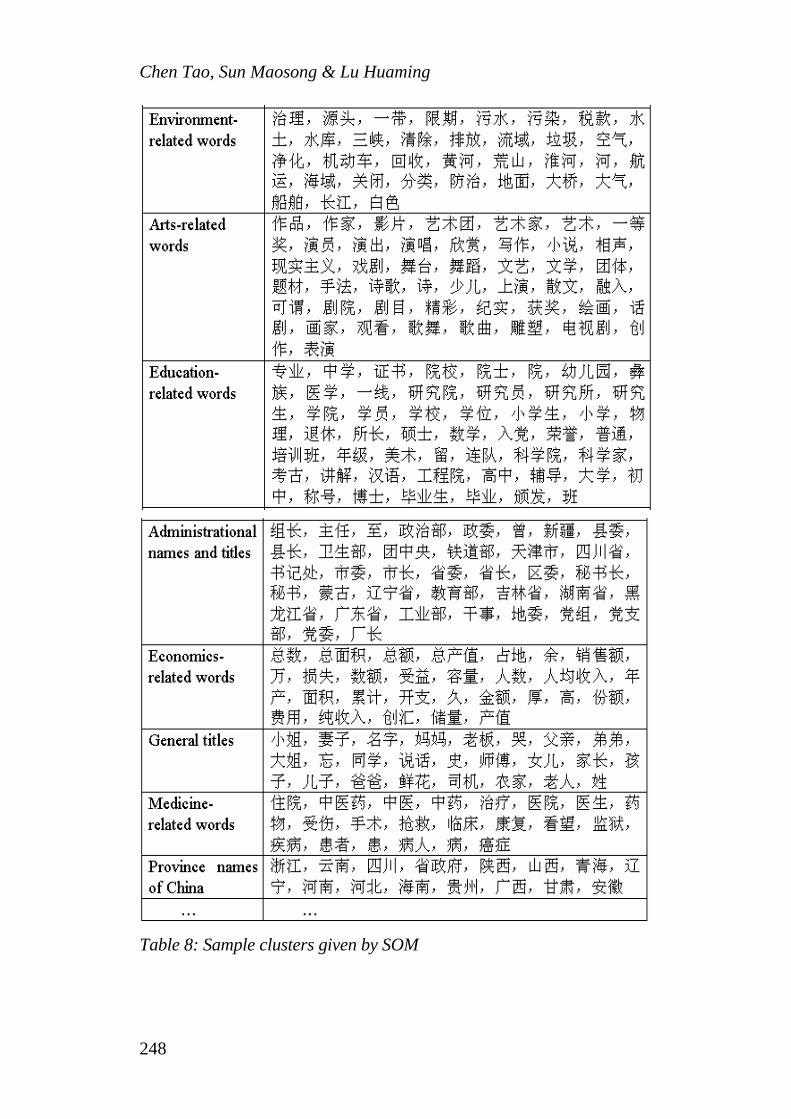
Chen Tao, Sun Maosong & Lu Huaming
248
Table 8: Sample clusters given by SOM

Automated Construction of Chinese Thesaurus based on SOM
249
Conclusion In this chapter, a SOM-based approach to automated generation of thesaurus is presented. Preliminary experimental results are promising. The proposed scheme is in fact language independent, though the work is done with Chinese words.
Acknowledgements This research is supported by the National Natural Science Foundation of China under grant number 60321002 and the National 863 Project of China under grant number 2001AA114210-03. References Dagan, Ido et al.; Similarity-based models of word co-occurrence
probabilities, Machine Learning, 34, pp. 43 – 69, 1999. Kohonen, T.; Self organization of a massive document collection, IEEE
Transactions on Neural Networks, 11(3), 2000. Kohonen, T.; Self-organization of very large document collections:
State of the art, in Proceedings of ICANN’98, pp. 65 – 74, London, 1998.
Kohonen, T.; Self-organizing maps. Spring Publisher, 2nd edition, 1997. Ma, Q. et al.; Self-organization of Chinese semantic maps using TFIDF
term weighting, in Proceedings of NLPNN’01, Tokyo, 2001a. Ma, Q. et al.; Emergence of Chinese semantic maps from self-
organization, in Proceedings of ICONIP’01, pp. 681 – 686, Shanghai, 2001b.
Mei, Jiaju et al.; TongYiCiCiLin (A dictionary of Chinese thesaurus). Shanghai: Shanghai Dictionary Publisher, 1983.
Zhang, M. et al.; Optimizing feature encoding for self-organizing Chinese semantic map, in Proceedings of NLPNN’01, Tokyo, 2001.


Towards a Standard Taxonomy of Artifact Functions
PAWEŁ GARBACZ If one pretends to have an adequate knowledge about a technical artifact, then one needs to represent somehow the function(s) of the artifact. Such functional representations are of crucial importance in the design process; in particular the so-called conceptual design focuses almost entirely on functions. If a designer (or a manufacturer, buyer, etc.) wants to share her functional knowledge with other designers and her sharing involves artificial systems of information processing, then some standards of function representations might turn out to be beneficial for her efforts. The benefits of information standardisation concern the efficiency, reliability, translation expendit-ures, etc. of the process of information exchange.
One of the means of such standardisation is an abstract representation of a standardised domain. It has been argued that an adequate representation of artifact functions should contain a tax-onomy of functions (Szykman [1999]). There are at least three reasons for this claim:
• Taxonomy decreases ambiguity at the linguistic level.
Referring to it we may recognise different terms that denote the same function and identify terms denoting different functions.
• Taxonomy also decreases ambiguity at the conceptual level since it limits the number of concepts in a given functional model. Consequently, the model becomes simpler and more usable.
• Taxonomy increases the uniformity of information within a given functional model. This will facilitate the exchange of information.
It seems that a taxonomy must satisfy the standard logical conditions imposed on partitions (i.e. exclusiveness, exhaustiveness, and homogeneity) in order to achieve these aims.

Paweł Garbacz
Reconciled Functional Basis The Reconciled Functional Basis (from now on RFB) is one of the recent efforts towards establishing a standard taxonomy of artifact function (see Hirtz et al. [2001]). RFB is the result of reconciliation of two previous taxonomies: the NIST taxonomy (cf. Szykman [1999]) and the older versions of Functional Basis developed in Little et al. [1997], Stone et al. [1998], [1999] and McAdams et al. [1999]. Each of these taxonomies is a result of empirical generalisation of engineering specifications of products. RFB follows the classic paradigm of Pahl and Beitz (cf. Pahl and Beitz [1996]) in defining artifact functions by means of flows. Strictly speaking, Pahl and Beitz define a function as a r e l a t i o n between an input and an output of an artifact, but they also claim that functions are derived from flows. A flow is either a con-version of material (e.g. a chunk of clay is converted in a vase), or a conversion of energy (e.g. electrical energy is converted into heat), or a conversion of signal (e.g. a safety buzz indicates the high pressure of vapour). Unfortunately, we are not informed what it means that functions are derived from flows. One of the examples of functions Pahl and Beitz give is the function denoted by the expression „transfer torque”, which clearly is a flow of a torque.
The RFB classification of flows is claimed to refine the taxonomy of Pahl and Beitz. This means, among other things, that the most general division of flows distinguishes between material, energy, and signal flows. However, RFB modifies the meaning of the term ‘flow’ since here ‘flow’ does not mean ‘a process of flowing’ (e.g. removing a debris), but ‘a thing that flows’ (e.g. a debris). This shift in meaning is, to be sure, justifiable since it is hard to see how one might differentiate between a flow and a function given the conception of Pahl and Beitz.
The RFB taxonomy of flows is flawed in at least three respects: • Some submembers of the classification of flows are called
‘flows’ themselves. • The classification is not exclusive, e.g. the ‘flow’ flow, which
is a submember of the classification is defined in such a way that the definition is satisfied by other submembers.
• There are members that contain entities from different ontological categories.
RFB also contains a three-layer classification of functions. All func-tions are divided on the first layer into eight primary types. Then, some primary functions are divided into the secondary functions. Finally,
252

Towards a Standard Taxonomy of Artifact Functions
some secondary functions are divided on the third layer into the ter-tiary functions. The whole taxonomy is depicted in table 1.
Primary functions Secondary functions Tertiary functions Distribute
Divide Extract
Branch Separate
Remove Import
Export
Transport Transfer Transmit Translate
Rotate
Channel
Guide
Allow degree(s) of free-dom
Mix Join
Connect Couple
Link Actuate
Increase Regulate Decrease Increment Decrement
Shape
Change
Condition Prevent
Control Magnitude
Stop Inhibit
Convert Supply
Contain
Store Collect Detect Sense
Measure Track Indicate
Display
Signal
Process Stabilise Secure
Support
Position Table 1: Reconciled Functional Basis
253

Paweł Garbacz
The first (respectively, second and third) layer will be called the primary (secondary and tertiary) division. Any logical division from the second (third) layer will be called a secondary (tertiary) division. A member of the primary (secondary, tertiary) division will be called a primary (secondary, tertiary) member.
A closer look at the whole taxonomy reveals the following shortcomings.
• RFB does not provide with any explicit principles of any of its
(sub)divisions. • There seems to be no principle of the primary division. • There is no principle of the secondary division of the ‘Channel’
member. • Some divisions do not correspond to the definitions of their
members. • There are some ambiguities in the definitions and examples. • Some subdivisions are not exhaustive.
Some of these defects may be important only for a philosophically conscious researcher, but others pose a serious threat to the whole rationale behind the enterprise of standardisation of function taxonomies.
It seems that at least some of these shortcomings might be mitigated by a careful ontological analysis of artifact functions. My proposal of such analysis consists of two components. First, I will argue that the most adequate ontological category of artifact functions is the category of states of affairs. Secondly, I will show how to improve the RFB by means of the ontological taxonomy of DOLCE. DOLCE belongs to the (small) family of formal ontologies intended to provide abstract models of very general domains. Due to its philosophical content and formal outlook DOLCE is hoped to remedy at least some of the afore-mentioned shortcomings. In particular, the ambiguity threat is diminished in DOLCE by a number of formal definitions and axioms that establish the meanings of the terms used therein.
Functions as States of Affairs The central thesis of this section has it that despite appearances, artifact functions are states of affairs, i.e. the extra-lingustic counterparts of sentences. First let me briefly clarify the category of states of affairs I have here in mind. Assume that you have manufactured a glass prism that produces a rainbow. Then there exist
254

Towards a Standard Taxonomy of Artifact Functions
two different entities: some object, namely your glass prism, and some property, namely the property of producing rainbow. Furthermore, these two entities are somehow connected, namely the object has the property (or in another terminology, the property inheres in the object). It is this connection that is called here a state of affairs (from now on a soa). Analogously, if an object participates in a process (or an event), the connection of the object and the process (the event) is a soa. Usually we refer to a soa by means of a sentence: the sentence „The glass prism produces rainbow” refers to the soa that the glass prism produces rainbow.
Although the standard forms of functional expressions are ‘The function of x is to ϕ (e.g. to produce light)’, ‘The function of x is ϕ-ing’, or ‘x is for ϕ-ing’, artifact functions are not properties, relations, processes or events. It is meaningless to say that the function of some artifact is a property ϕ. To put it more tentatively, if one claims a function of an artifact is a property ϕ, then her claim refers to the fact that some object (possibly different from the artifact itself) has ϕ. Similarly, when one claims that the function of some artifact is a process of ϕ-ing (e.g. producing light), her claim refers to the fact that the artifact causes ϕ-ing or to the fact that some object (possibly different from the artifact itself) takes part in ϕ-ing. If you need one umbrella concept for all such cases, it seems that your best choice is the category of soas. The claim that artifact functions are soas is supported by the RFB itself: e v e r y example of a function within the RFB taxonomy is introduced by means of sentence, e.g. the sentence ‘A handle on the blender pitcher imports a human hand’ introduces the example of the tertiary function type ‘Import’.
If artifact functions are soas, an ontology-based taxonomy of artifact functions depends on the taxonomy of entities within an accepted ontology. In what follows I will attempt to clean, so to speak, the RFB taxonomies with the help of the ontological taxonomy developed within the DOLCE project. DOLCE DOLCE (Descriptive Ontology for Linguistic and Cognitive Engineering) (cf. Masolo et al. [2003]) is the first module of the WonderWeb Foundational Ontology Library. The WonderWeb project is aimed at developing language architecture for representing ontologies in the Semantic Web. Within this library DOLCE plays the role of a reference module to be adopted as a starting point of
255

Paweł Garbacz
comparing and elucidating the relationships with other modules in the library.
DOLCE is a first-order axiomatic theory. Its axioms and definitions establish, among other things, the taxonomy of particular entities. The taxonomy is depicted in table 2. Notice that some subdivisions are not exhaustive; the missing entires are indicated by the ellipsis mark ‘...’.
Amount of matter
Feature Physical endurant
Physical Object
Endurant
Non-physical endurant Achievement Eventive perdurant
Accomplishment State
Perdurant
Stative perdurant Process
Temporal location Temporal quality ...
Spatial location Topol.
connectedness
Physical Quality
...
Quality
Abstract quality ... Quale Abstract entity
...
Table 2: DOLCE taxonomy
An endurant is defined as an entity whose all (essential) parts are present at any time at which the entity is present. A perdurant is defined as an entity whose some parts are not present at some time at which the entity is present. A shaft is an example of an endurant and a rotation of the shaft is an example of a perdurant. A quality is an entity that inheres in another entity. The weight of a shaft is an example of a quality. In what follows I will restrict the intended domain of qualities to the so-called direct qualities, i.e. to such qualities that are not themselves qualities of other qualities. An abstract entity is an entity that does not have any spatial or temporal qualities and that is not a quality itself. In DOLCE we distinguish between qualities and quales. The weight of a shaft is a quality of the shaft and the actual weight is a quale. A quale is an abstract entity which is a part of a quality region. The colour quales, for instance, compose the colour space.
256

Towards a Standard Taxonomy of Artifact Functions
The first level of DOLCE taxonomy is not a homogeneous division. In order to obtain a homogeneous taxonomy, I suggest the following modification. First, let the most general division divide all entities into carriers of qualities and qualities. Then, on the second level, the domain of carriers of qualities is further divided into concrete (i.e. non-abstract) and abstract entities. Finally, let a concrete carrier of qualities be either an endurant or a perdurant. The modified taxonomy is depict-ed in table 3.
Amount of matter Feature
Physical endurant
Physical object
Endurant
Non-physical endurant
....
Achievement Eventive perdurant Accomplishment
State
Concrete entity
Perdurant
Stative perdurant Process
Quale
Carrier of
qualities
Abstract entity ...
Temporal location Temporal quality ...
Spatial location Topol.
connectedness
Physical quality
...
Quality
Abstract quality
...
Table 3: Modified DOLCE taxonomy The domain of endurants is related to the domain of perdurants by the relation of participation: an endurant participates in a perdurant (in a time interval). The domain of qualities is related to the domain of carriers of qualities by the relation of inherence: a quality inheres in a carrier of qualities, or equivalently, a carrier of qualities has a quality. The domain of qualities is related to the domain of quales by the relation of having a value: a quality has a value (in a time interval) which is a quale region. DOLCE advances the constraint to the effect
257

Paweł Garbacz
that the relation of inherence is atemporal. This means that a quality inheres in an entity during the whole time interval in which the entity exists.
A physical endurant is an endurant that has some spatial qualities. A non-physical endurant does not have any spatial qualities. The category of physical endurants is divided into subcategories by means of the notion of whole. Roughly speaking, an entity x is a whole under a relation R iff x is a maximal (under the relation of mereological parthood) mereological sum of entities that belong to the domain of R and are related to each other by R (cf. Gangemi et al. [2001]). An amount of matter is a physical endurant that is not a whole. A physical object is a physical endurant that is a whole under some unifying relation, but different kinds of objects are wholes under different unifying relations. Since Masolo et al. [2003] does not provide with any definition of the notion of feature, I also leave it undefined.
If the (mereological) sum of any two perdurants of a kind ϕ is a perdurant of the kind ϕ, then all perdurants of this kind are stative; otherwise they are eventive. If all (mereological) parts of a stative perdurant of a kind ϕ are of the kind ϕ, then the perdurant is a state; otherwise the perdurant is a process. If an eventive perdurant has no proper parts, then it is called an achievement; otherwise we call it an accomplishment. Conferences, ascents, and performances are examples of accomplishments. Acts of reaching (e.g. a reaching of the summit of K2), departures, and deaths are examples of achievements.
A quality is temporal if it inheres in a perdurant. One of the most crucial examples of temporal qualities is a temporal location of a perdurant. A quality is physical if it inheres in a physical endurant. One of the most crucial examples of physical qualities is a spatial location of an endurant. Moreover, it seems that at least some topological qualities (e.g. topological connectedness) also belong to this category although they are not explicitly mentioned in DOLCE. A quality is abstract if it inheres in a non-physical endurant.
An Ontologically Clean Version of RFB Now I attempt to do the ontological cleaning of RFB with the help of DOLCE. The new taxonomy will be called the ontologically clean Functional Basis, OntoRFB for short.
If we follow the approach of Pahl and Beitz, first we should modify a taxonomy of flows. DOLCE ontology makes room for a more comprehensive taxonomy of flows than the standard account, e.g. besides energy DOLCE acknowledges other physical qualities such as
258

Towards a Standard Taxonomy of Artifact Functions
weight, stiffness, etc. The resulting taxonomy is depicted in table 4. It is easy to notice that this taxonomy is more fine-grained than the ternary taxonomy of Pahl and Beitz.
Material flow Feature flow
Flow of physical endurant Flow of
physical object
Flow of endurant
Flow of non-physical
endurant
...
Flow of achievement
Eventive flow
Flow of accomplishment
Flow of state
Carrier flow
Concrete flow
Flow of perdurant
Stative flowFlow of process
Flow of temporal location
Flow of temporal quality ...
Flow of spatial location Flow of topol. connectedness
Qualitative flow
Flow of physical quality
...
Table 4: OntoRFB taxonomy of flows
The OntoRFB taxonomy strictly follows the DOLCE taxonomy of entities, i.e. it acknowledges concrete flows, qualitative flows, etc., except for the abstract entity member and the abstract quality member, which seemingly do not correspond to any flow.
Notice that the DOLCE division of physical endurants leads to the division of materials into amounts of matter (e.g. chunks of clay), features (e.g. surfaces), and physical objects (e.g. coins). Similarly, the division of perdurants yields the division of signals into achievements (e.g. a switch), accomplishments (e.g. a temperature rise), states (e.g. a tactile signal), and processes (e.g. a repeating auditory signal). Following the technologically based RFB distinctions we may divide further the categories of amounts of matter, features, physical objects, energy, and signal.
259

Paweł Garbacz
The DOLCE taxonomy leads to three basic types of soas. If an entity has a quality, then I will say that the respective state affairs (i.e. that the entity has the quality) is of the inherence type (for short, of the i-type). If an endurant participates in a perdurant, then I will say that the respective state affairs (i.e. that the endurant participates in the perdu-rant) is of the participation type (of the p-type). If a quality has a value which is a quale region, then I will say that the respective state affairs (i.e. that the quality has a value which is the quale) is of the value type (of the v-type).
Given that artifact functions are soas, the OntoRFB taxonomy of artifact functions should copy the foregoing taxonomy of soas. However there is one important exception: due to the DOLCE notion of atemporal inherence, no soa of the i-type is an artifact function. Thus, we divide artifact functions into the participation functions (p-functions), i.e. those functions which are soas of the p-type, and the value functions (v-functions), i.e. those functions which are soas of the v-type. Then we divide both kinds of functions with respect to the kind of entities involved in the respective soas.1 If a physical endurant participates in an achievement (respectively in an accomplishment, state, or process), then the soa that the endurant participates in the achievement (accomplishment, state, or process) is a function of the Achieve (Accomplish, Maintain, or Process) type, provided that this soa is a function at all. If a quality of spatial location (respectively, of a topological connectedness, topological disconnectedness, energy, temporal location quality) has a value which is a quale region, then the soa is a function of the Locate (Connect, Branch, Energate, or Temporate) type. The resulting subtaxonomies are depicted in the tables 6 and 7.
Physical endurant Achievement Achieve Eventive
perdurant Accomplishment Accomplish State Maintain Stative
perdurant Process Process Table 6: Taxonomy of p-functions
1. As in the RFB taxonomy, the names of functions are partially stipulative. Due to
the lack of appropriate English expressions in some cases OntoRFB introduces neologisms. The meaning of any function term is always determined by the respective definition. In order to avoid ambiguity the names of the OntoRFB functions will be rendered in the Arial face.
260

Towards a Standard Taxonomy of Artifact Functions
Quality
Physical quality Temporal quality
Spatial location
Topol. connect.
Topol. disconnect.
Energy ... Temporal location
...
Quale region
Locate Connect Branch Energate … Temporate ...
Table 7: Taxonomy of v-functions As it stands, the OntoRFB taxonomy of functions is both richer (in one respect) and poorer (in another respect) than the RFB taxonomy. As for the former, we have now the Temporate category, which contains those functions that fix the temporal characteristic of some perdurant. Apparently, such functions are not recognised by RFB. As for the latter, such categories as Achieve, Accomplish, Maintain, and Process are far more general than the RFB categories.
OntoRFB may be developed in several directions. One possibility is to divide the four categories of the p-type soas. To this end I annotate every soa of the p-type with a pair of (possibly identical) v-type soas: the initial soa and the terminal soa. Both of these soa involve the qualities that are changed in the soa of the p-type. Any quality of this kind will be called a quality associated with the soa (of the p-type). The initial soa corresponds to the initial values of these qualities and the terminal soa corresponds to the terminal values. Take, for example, the soa that a coffee maker transports water from its reservoir through its cheating chamber to the filter basket. The quality associated with this soa (of the p-type) is the spatial location of water. The initial soa (of the v-type) is that the spatial location of water has the quale of the spatial location of the reservoir of the coffee maker. The terminal state of affairs (of the v-type) is that the spatial location of water has the quale of the spatial location of the filter basket of the coffee maker. Apparently, for any eventive perdurant, the initial soa is different from the terminal soa and for any stative perdurant, these states are identical. Now a soa of the p-type may be classified with respect of a quality associated with it. The resulting taxonomy of functions is depicted in table 8. The rows contain the perdurants involved in the soas of the p-type and the columns contain the qualities associated with these soas. For instance, assume that some endurant achieves a certain spatial location. Then the respective soa is of the p-type and the physical
261

Paweł Garbacz
quality of spatial location is associated with this soa. Consequently, if this soa is a function of some artifact, this function may be classified as a function of the ‘Reach’ type. Since in general there may be more than one quality associated with a state of affairs, this taxonomy is not exclusive. However, if we restrict the domain of perdurants to the so-called basic quality changes (cf. Lehmann et. al. [2004]), i.e. to such perdurants with which only one quality is associated, then our taxonomy becomes exclusive. Another solution might be a ‘multi-plication’ of the base functions displayed in table 8. For example, a ‘multiplied’ function: Reach and Load would be the state of affairs (of the p-type) in which some endurant both achieves some spatial location and accomplishes some energy. The ‘multiplied’ taxonomy would be an exclusive logical division.
Spatial
location Topol.
connect. Topol.
disconnect.Energy ...
Achievement Reach Touch Split Switch ...Accomplishment Channel Attach Disjoin Load ...
State Moor Join Cleave Conserve ...Process Move Process_Topology Energise ...
Table 8: Extended taxonomy of p-functions Conclusions This paper exemplifies the results of cleaning engineering taxonomies of artifact functions with the help of formal ontologies. It turned out that despite their empirical origin and technological applicability, the existing taxonomies of functions are unsatisfactory even on their own terms. We also saw that the existing formal ontologies need further substantial developments in order to serve as ‘ontological brooms’ in modelling of engineering knowledge. In particular, the formal ontologists should pay more attention to the formalisation of such en-tities as energies, fields, velocities, etc. References Gangemi, A.; N. Guarino; C. Masolo & A. Oltramari; Understanding
top-level ontological distinctions, in A. Gomez-Peres et al., Proceedings of IJCAI 2001 workshop on Ontologies and Information Sharing, Seattle, 2001.
Hirtz, J.; R. Stone; D. McAdams; S. Szykman & K.´Wood; A Functional Basis for Engineering Design: Reconciling and
262

Towards a Standard Taxonomy of Artifact Functions
Evolving Previous Efforts. Research in Engineering Design, 13, 2001.
Lehmann, J.; S. Borgo; C. Masolo & A. Gangemi; Causality and Causation in DOLCE, in A. Varzi & L. Vieu (eds.), Formal Ontology in Information Systems, Proceedings of the International Conference FOIS 2004, Torino: IOS Press Amsterdam, 2004.
Little, A.; K. Wood & D. McAdams; ‘Functional Analysis: A Fundamental Empirical Study for Reverse Engineering, Benchmarking and Redesign. Proceedings of the ASME Design Theory and Methodology Conference, Sacramento (California), 1997.
Masolo, C.; S. Borgo; A. Gangemi,; N. Guarino & A. Oltramari; WonderWeb Deliverable D18. Ontology Library, Technical Report, National Research Council – Institute of Cognitive Science and Technology 2003, http://wonderweb.semanticweb.org.
McAdams, D.; R. Stone & K. Wood; Functional Interdependence and Product Similarity Based on Customer Needs. The Journal of Research in Engineering Design, 11, 1999.
Pahl, G. & W. Beitz; Engineering Design. A Systematic Approach. London: Springer 1996.
Stone, R.; K. Wood & R. Crawford; A Heuristic Method to Identify Modules from a Functional Description of a Product. Proceedings of DETC98 (DETC98/DTM-5642), Atlanta (GA), 1998.
Stone, R. & K. Wood; Development of a Functional Basis for Design. Proceedings of DETC99 (DETC99/DTM-8765), Las Vegas (NV), 1999.
Szykman, S.; J. Racz & R. Sriram; 1999, ‘The Representation of Function in Computer-based Design’, Proceedings of the 1999 ASME Design Engineering Technical Conferences (DETC99/DTM-8742),Las Vegas (NV), 1999.
263


Thesaurus Classification and Relational Structure:
the EARTh Experience
FULVIO MAZZOCCHI & PAOLO PLINI
Introduction The present work is based on the assumption that many of the present issues in the field of knowledge organisation and information management can be traced back to meaning representation and delimitation.
While representing the semantics of a term we have to choose which types of characteristics and how many of them need to be considered and included in the representation.
Different theoretical models of meaning representation are available but an overall distinction can be made between approaches that conceive meaning as an entity that can be defined in a clear and univocal way, and others proposing, with different scales, a more fuzzy theory of meaning.
In our approach we have considered that on one hand there is the necessity to share a common and stable meaning of the terms in order to guarantee communication within a community. Nevertheless, openness to a further exploration of meaning should also be ensured so as not to impoverish its richness and complexity.
In the semantic tradition many attempts have been made in order to distinguish between constitutive and non-constitutive elements of the meaning. For example, (Bierwisch & Kiefer, 1970) have proposed a distinction between core elements -they include the semantic specifications that determine the meaning of the word by specifying its place within the system of lexical entries- and periphery elements -which do not determine but contribute to the meaning. Comparable distinctions have also been proposed by other authors, which differentiate between semantic marker and distinguisher (Katz & Fodor, 1963), or between essential and non-essential properties (Wierzbicka, 1985) or among necessary, centrality and typical conditions (Jackendoff, 1983).

F. Mazzocchi & P. Plini
Is it then possible to define a hierarchy of semantic properties where a nucleus of them can also be identified -at least from an operative point of view- as “essential”, without restraining the analysis of lexical meaning? (Violi, 1997).
An example should help to better clarify this point. In how many ways “benzene” could be defined? An environmental planner may consider it as a pollutant that could enter biogeochemical cycles creating potential damage to the environment. A biologist may consider its toxicity and the different routes through which it can enter an organism. An engineer would consider it as a fuel for a combustion engine. A chemist may see it as the precursor of a class of chemical compounds, etc. (Fugmann, 1993).
Benzene can be defined in several different ways depending on the context in which it is considered. However we should also underline that all these definitions share a common premise: benzene is first of all a substance (that may have toxic effects, usable as a fuel, causing pollution, etc.). In the current historical-cultural context of the Western tradition, this semantic trait cannot be cancelled, unless we want to incur in a complete reformulation of the meaning of the term (Violi, 1997).1
Lexical meaning can be considered as a compound and structured set of diversified traits. Each term is viewed as a unitas multiplex, forming a unity that aggregates multiple traits organised according to a hierarchy. Different semantic traits have a different weight in signification and their different status depends on their cancellability degree (Violi, 1997).
We think that these considerations could be brought in the field of knowledge organisation and also used to design semantic control tools. Highly structured and refined, but flexible tools are in fact needed in order to deal with issues such as information management on the web or to satisfy the growing demand of semantic interoperability.
1. A New Format of Environmental Thesaurus: the EARTh Project The goal of our project is the development of a thesaurus that could include the above assumptions aiming to become an advanced tool to be applied in environmental information management. The need of systems able to rationalise environmental information management is a much-
1. Of course, to obtain a full definition is not enough to say that benzene is a
substance, but we have also to include the conceptual differences that characterize it among other substances.
266

The EARTh Experience
debated topic. In fact, in order to sustain environmental policy and research, not only access to- but also high-level quality of information is required. To achieve this result, however, systems capable of dealing with the specific features of the environmental sector are needed. The incompleteness of the terminology collections often depends, in fact, on the kind of approach that is utilised. The environment is analysed mainly with a static and sectorial approach, reflecting a vision pertaining to classic science and to environmental policy that transforms its paradigms in operational terms. This implies limited openings, for example, to the development of contemporary science (i.e., chaos theory and complex thinking), even if it has played a prominent role in offering renewed approaches and methods to analyse the environmental issues.
Starting from this premise, we have tried to adopt a more inclusive approach concerning both conceptual coverage and semantic organisation. Taking also into considerations suggestions arising from the development of applied ontologies, we are working on an environmental thesaurus format that contains some innovative elements.
2. The EARTh Semantic Model
2.1 The Tree Classification Structure EARTh (Environmental Application Reference Thesaurus) is based on a multidimensional classificatory and semantic model. The “vertical structure” of the Thesaurus is the fundamental constituent of such a model. This structure is basically mono-hierarchical. It has been developed according to a tree semantic model and is founded on a system of categories. It is organised in a framework composed of different levels and classification knots and comprises hierarchical relationships.
The use of the term “category” requires some further clarification. The notion “category” has taken on different meanings in the history of Western thinking. From an ontological and logical point of view it has been interpreted as the foundation essential to distinguish things and to construct speech on a logical basis; in linguistics a correspondence between categorical and grammatical figures has been investigated. Categories in a kantian sense are judgement forms; in semiotics they are mainly viewed as metalinguistic operative models; they are studied in psychology as mental tools capable of creating order in data coming from experiences. The notion “category” was, finally, extrapolated from philosophy to the classification science where categories have also been considered as the foundation (not always visible) of knowledge
267

F. Mazzocchi & P. Plini
organisation systems and are utilised for different purposes (Barite, 2000).
In the context of the present work, categories are conceived in their primitive Aristotelian form as the most general genera or the logical progenitors under which every single terms can be placed.
The first two levels of the classification correspond to the system of categories. The first level includes four “supercategories”: ENTITIES, ATTRIBUTES, DYNAMIC ASPECTS and DIMENSIONS.2 ENTITIES constitutes “things”. ATTRIBUTES defines character of “things”, at least in their static aspects. DYNAMIC ASPECTS relates to transformations and operations connected to “things”. DIMENSIONS identifies the spatio-temporal circumstances where all this is manifested.
In the subsequent level of the classification, the supercategory ENTITIES is divided into Material entities and Immaterial entities. ATTRIBUTES includes three different categories: Properties; Structure and Morphology; Composition. DYNAMIC ASPECTS comprehends: Processes; Conditions; Activities. DIMENSIONS refers to Space and Time.
As already said, the semantic model is based on a system of categories. First of all the semantics of the terms is, in fact, described by the categories where they are located.3 The vertical structure analyses the meaning of the terms according to a logical perspective. It can be considered as an operative tool that – by providing the categorial interpretation of the meaning of the terms and by placing them in the classificatory-hierarchical tree – aims to orientate the users towards the most “essential” characteristics of their semantics.
2. Dahlberg considers these supercategories as Ur-categories and she adopted them
to classify the ten Aristotle’s categories (Dahlberg, 1994). According to this point of view the Ur-categories represent the ultimate logical foundation. But the adoption of a perspective like this opens up many questions. For example, do the categories have an ontological character? Is it then possible to conceive universal categories in the sense that, by navigating within whatever semantic structure developed in the context of different cultures and languages the final destination is always the same? What is the mediation role of the language that is still necessary to express the categorial system?
3. Following a bottom-up perspective, terms could be analysed according to a progressive hierarchical scale. In that scale conceptual features are progressively discarded following an intensional perspective (while in an extensional perspective the number of things associated to that intension is increased). The maximum level of generality is thus reached. Categories represent the top of this vertical structure (Fugmann, 1993).
268

The EARTh Experience
Nevertheless it does not limit the conceptual analysis of terms to a static and univocal view. Awareness of the semantic complexity associated with each term is maintained. Different layers of meaning have to be explored, even if there is a hierarchy of semantic traits and each one of them contributes to lexical signification with a different specific weight.
2.2 The Thematic Classification The model envisages the possibility to develop additional arrangements of the terminology. For example, a thematic organisation of terms could be elaborated. A theme or a subject is here conceived as a sector of interest that reassembles the terms related to it (while a tree or faceted structure tends to scatter them under their referral logical category). The system of themes, as it was conceived, should be developed according to the specific needs of the applicative context.
In our project, we have developed a demo/draft version of a thematic classification that has been utilised to classify the terms and that could also be used for the management of information in the field of environmental policy.
From a semiotic point of view, this model should allow meaning representation according to different “second order” perspectives and acceptations. The possibility to apply additional classification models would ensure, in fact, openness and flexibility to the model.
Coming back to the above example, the benzene will be classified in the vertical structure as an ENTITY (supercategory), that is material (material entities is the second level category), non living (non living entities is the third level), till to its placing - going down in the classificatory-hierarchical tree - as an aromatic organic substance.
Other views of “benzene” as toxic substance, pollutant or fuel could emerge, instead, according to the additional classifications that reflect the perspective of the specific subject.4
The topic of semantics of terms is more complex that it would appear. It is sufficient to say at the moment that the proposed semantic model has been developed for operational purposes and is based on a regulating principle which feasibility needs to be further evaluated.
4. At another level, also RTs and other semantic relations can, of course, help in
expressing additional semantic traits.
269

F. Mazzocchi & P. Plini
Figure 1: Classification of benzene according to the vertical structure and the systems of themes
In the vertical structure, for example, the lower down the semantic hierarchy the more the tree becomes affected, at a general level, by historical and cultural contingencies and, more specifically, by operational choices and by the characteristics of the domain of knowledge. Let’s clarify at least the first point; that benzene is a substance or that the whale is an animal – we are considering here only the semiotic aspects and not including ontological considerations – is a strongly consolidated notion in our culture. However that benzene is an aromatic organic substance (benzene formula has been discovered in 1865 by Kekulé) or that the whale is a mammal (and not a fish as it was believed in the past), as well as the fact that these two semantic specifications are more essential than others, appears historically a more modifiable condition. 3. EARTh Relational Structure The usefulness of a well-structured domain-specific thesaurus for the management of information – also on the Internet – is rather acknowledged. However there is a widespread opinion that the traditional thesaurus format doesn’t completely fit the current needs. One of the main problems posed by thesauri seems to be the fact that
270

The EARTh Experience
they provide a poorly differentiated set of relationships between terms, distinguishing only among hierarchical relationships, associative relationships and equivalence relationships. It has been also said that since thesaurus relationships are characterised by semantic vagueness, they are not applied consistently. This causes ambiguity in the interpretation and can result in unpredictable semantic structures (Soergel, 2004). Moreover thesauri are expected to be developed on the basis of a more fully concept-oriented model -while a term-oriented model, according to this viewpoint, may promote ambiguity and incompatibility- where concepts are considered to be independent and precede their designations.
One of the solutions that is commonly proposed to overcome these limitations and to enable more powerful searching and intelligent information processing entails a reengineering of the traditional KOSs into systems containing domain concepts linked through an extended network of well-defined relationships and a rich set of terms identifying these concepts (Soergel, 2004). An identifier can then be assigned to each concept, irrespective of the lexicalisation that are utilised to represent it, facilitating a better interoperability among different systems (Soergel, 2004).
In our project we are trying to incorporate to a certain extent these assumptions. For this reason, the implementation of a more refined set of semantic relationships is at present under way. Standard relationships will be arranged into richer subtypes, whose semantic content is specified. Linguistic structures will express semantic relations. The augmentation of thesaurus relationships will ensure a stronger semantic control -also because different relationships can hold each other in check (Fisher, 1998)- and open up new possibilities for information retrieval applications (Tudhope, 2001). The enrichment of the relations and their increased semantic clarification could enable, for example, a better semantic description of Web resources and guide a user in meaningful information discovery on the Web (Soergel, 2004). Besides, it will increase the possibility of using them also for artificial intelligence applications. Traditional thesauri, in fact, were not designed for- and their semantic structure supports limitedly automated information processing (Soergel, 2004).
Nevertheless from another point of view we hold the awareness of the intrinsic complexity of contemporary lexicons that are systems very rich of polysemies, redundancies and so on. We have to provide tools able to ensure a stronger semantic control as much as possible. But we have also to use great care in avoiding an excess of “compulsory way” or
271

F. Mazzocchi & P. Plini
artificially compressed meanings. While applying a highly elaborated net of semantic relationships unwanted effects of this kind could, in fact, be generated. It seems instead reasonable to adopt a hermeneutical attitude open to “accept”, to a certain extent the weak nature of lexicons.
Regarding the term vs. concept-oriented model, we would also like to mention what has been proposed by Cabrè to reconcile these two dimensions. In her approach, terminological units are characterised by a multidimensional nature that include three viewpoints: the cognitive (the concept), the linguistic (the term) and the communicative (the contextual situation). These thee aspects according to Cabrè are inseparable in the terminological units and allow access to the objects (Cabrè, 2000).
Finally we also believe that ensuring a high modularity of these systems is another important requisite to be achieved. This should enable also other kinds of utilisation by users that may not need or make such a fine distinction of the thesaurus relations (Milstead, 2003) -in this case it could even become a problem more than a solution- and that are interested in using a simpler and more traditional version of the thesaurus relational structure.
3.1 Hierarchical Relationship Thesaurus standards and the scientific literature include three kinds of hierarchical relations: “generic”, “partitive” and “instance”, which are conflated into one generic ”hierarchical relationship”. Perhaps this is the most misused relation. Many existent thesauri provide relations that are labelled as BT/NT but they could be better interpreted as associative relations. They are, in fact, based on a document-retrieval definition of ‘broader-narrower’ that is of pragmatic nature and oriented towards the function of the search process (Fisher, 1998).5 In EARTh only hierarchies that are logically based will be included. Moreover we will differentiate the three types of relations and as far as the generic and the partitive relations are concerned, subtypes will be identified.
3.1.1 Generic Relation This is the classical inclusion where the relations between a genus and its species have to be established. In our system, its polydimensionality as well as the formation of intrahierarchical semantically homogeneous clusters will be ensured by the simultaneous application of different 5. “Concept A is broader that concept B whenever the following holds: in any
inclusive search for A all items dealing with B should be found. Conversely B is narrower than A” (Soergel in Fisher, 1998).
272

The EARTh Experience
subdivision criteria. Node labels will show different characteristics of subdivision. On the basis of this work we are also evaluating if it is possible to distinguish conceptual taxonomical relationships from hierarchies where the added conceptual differences don’t seem to be of the same importance as those allowing the creation of genus/species pairs sensu stricto. In some cases this distinction seems to be achievable. In the biological field, for example, -where there is a consolidated taxonomical tradition- we can quite easily distinguish the relationship between “animals” and “insects” from the relationship between “animals” and “aquatic animals”. But in other sectors, things are historically less definable.
3.1.2 Partitive Relation We are also working to differentiate the part-whole relationship. We have started our work considering the past researches in this field, taking as main references the work done by the SAC Subcommittee on Subject Relationships/Reference Structures of the American Library Association (Greenberg et al., 1997) and the Winston, Chaffin & Herrmann’s Taxonomy of Part-Whole Relations which distinguishes the following subtypes: integral object-component; collection-member; mass-portion; stuff-object; activity-feature; area-place (Winston et al., 1987). We are also considering how the part-whole relationship takes form when it is viewed according to the different categories – i.e., material entities may have material parts; processes or activities can be compound of different phases or steps; etc. Finally, we are also evaluating the feasibility to distinguish the relations that connect a whole and its parts from the whole-complex relations.
The partitive relation is considered to be hierarchical by most of the systems but for others it is a type of associative relation (Greenberg et al., 1997). A distinction that has been made is to consider as hierarchical only the whole-part relation that is exclusive to a pair of terms. When the part can belong to multiple wholes an associative relation rather than a hierarchical one should be established.
3.2 Associative Relationship The associative relation is quite difficult to describe because it covers a heterogeneous and undifferentiated set of relations. ISO 704 defines it as a relation that “exists when a thematic connection can be established between concepts by virtue of experience”. It can express many kinds of association between terms that are not hierarchically based. Such links should be made explicit in a thesaurus since they suggest additional terms that can be used in indexing or retrieval.
273

F. Mazzocchi & P. Plini
In our work we will try to specify the nature of the relations and to differentiate RTs in subtypes (i.e., “cause/effect”, “raw material/product”, “discipline/practitioner”, etc.). We will also try to extend the range of useful RTs types although they probably constitute a series that is intrinsically open and their making topical is strongly connected with the characteristics of the operative context.
In this way, by strengthening the transversal relational structure –which is based on associative relations – a knowledge representation model that is net-like structured will be actually developed. It will emphasize the system of interrelations, the “connecting” ties that limit the degree of separation of a conceptual field and cannot be represented by the taxonomic-hierarchic tree-like model (Trigari, 2003). In our case this is very important also to obtain a system able to deal with the environment, which is a domain where the complexity of the systems as well as the web of interlinking plays a key role. And it will also be useful to deal with the networked and barely hierarchical information and knowledge management on the Internet and to better reflect the emerging mental maps of the information searcher (Trigari, 2003).
To better represent and visualize this transversal structure, we are also thinking to the possibility of designing additional ways of browsing the thesaurus based on the RTs and showing different microworlds of connected concepts and terms (Trigari, 2003).
3.3 Equivalence Relationship Equivalence relationship covers at least the following basic types: synonyms, lexical variants and near-synonymy. Synonymy refers to meaning similarity. It has also been defined as interchangeability between terms, although it’s very difficult to think about the existence of an absolute or perfect synonymy where there is interchangeability in all contexts (Violi, 1997). In this sense, it is interesting the notions of contextual synonymy (Greenberg et al., 1997) -where the key factor is the range of contexts where interchangeability is possible- as well as of cognitive synonymy, for which terms can have the same cognitive meaning but not necessarily the same connotations (there could be, for example, emotive distinctions) (Greenberg et al., 1997). Classes of synonyms include, for example, dialectal variants, popular and technical term pairs, generic and trade name pairs, different linguistic origin variants, variant names for emergent concepts, slang or jargon synonyms and so on (Greenberg et al., 1997). Lexical variants are different word forms for the same expression and derive from morphological and grammatical variations (i.e., orthographic and syntactic variants). For synonyms as well as for lexical variants we will
274

The EARTh Experience
try to identify different subtypes. The category of near-synonyms as such won’t be included at this stage in the system.6
4. Multilingualism and Cultural Diversity Issues Semantic and structural divergences that may concern multilingual thesauri -here we are referring to regional diversities that occur in the context of a common general culture, as the Western culture- will be taken into account. Developing a multilingual version of the thesaurus could mean to produce a non-symmetrical system in which a full correspondence between semantic relations in different languages may not be achieved and the number of descriptors is not necessarily the same (Hudon, 1997).
Moreover problems posed by cultures that are epistemologically far removed from the Western one, will also be considered. Nowadays connection at planetary level is strongly increased. Different cultures and knowledge forms meet on global platforms. We bring the awareness that different cultures hold different visions of the world and this is reflected in the way they organise knowledge too. We will evaluate in which way the future development of the Thesaurus could integrate a multicultural perspective.
5. EARTh Possible Applications
5.1 Interoperability Issues The Thesaurus could be utilised for different purposes. It could be interesting to evaluate the use of EARTh -having in mind the structure of its semantic model- to deal with interoperability issues and as a tool for mapping among different environment-related thesauri. Nowadays networked information access to heterogeneous data sources requires interoperability of controlled vocabularies. Technology allows, in fact, shared access but incompatibilities in the vocabularies have to be solved so that they can interoperate for the purpose of information retrieval. Thesauri are created with different points of view, their development reflects different scopes and can be based on different ways of conceptualisation. They may differ in structure and in selection of concepts and terms. Tools able to create dynamic and semantically
6. Near-synonymy is characterised by an inderminate nature. Its definition is usually
based on pragmatic assumptions. Although the meaning of terms interpreted as near-synonyms is different – there is, of course, a certain degree of overlapping – such terms are considered as synonyms for indexing and retrieval purposes. Near-synonyms are then regarded as interchangeable only in some operative contexts.
275

F. Mazzocchi & P. Plini
based correspondences among different vocabularies are then urgently needed.
5.2 EARTh as Environmental Semantic Map Current research also indicates new roles of thesauri. They are increasingly seen as maps of subject domains or semantic networks, knowledge representation and organisation systems, patterns of knowledge (Kosovac, 1998). Disciplines as applied linguistics, cognitive science and artificial intelligence can view and study them as models of conceptualisation reflecting our Weltanschauung and employed to structure knowledge domains according to logical and semantic criteria. A thesaurus that, like EARTh, is expected to have a refined semantic structure seems to be highly suitable for this scope and could allow domain-specific navigation on a semantic basis.
Conclusion In the field of thesaurus theory and construction a transition phase has been probably reached. It’s clear that something should be changed in order to better reflect the present needs. This is also confirmed by initiatives concerning the development of new Standards,7 that are trying to incorporate new key issues as interoperability or problems posed by multilingualism.
In this paper a project has been presented where the possibility to develop a thesaurus with a more refined structure is explored. The goal was to provide a more powerful tool for semantic control and knowledge organisation. We have also tried to strengthen the role of the thesaurus as “semantic connector” and to elaborate a model that maintains semiotic openness.
Having this in mind, we have made an explicit reference to a theory about meaning representation that aims at reconciling what concurs in ensuring semantic stability with what gives rise to variability and complexity. We believe that exploring the possibility to reconcile at different level these two dimensions is indeed a key factor and could also offer many potential insights in knowledge organisation issues.
7. NISO is revising the standard for thesaurus construction: ANSI/NISO Z39.19,
Guidelines for the Construction, Format, and Management of Monolingual Thesauri. A revision and extension of the British standards for monolingual and multilingual thesauri is in under way as well (BS 8723: Structured vocabularies for information retrieval - Guide). Another initiative is the IFLA Working Group on Guidelines for Multilingual Thesauri that has recently presented a document as a draft for world-wide review.
276

The EARTh Experience
References Barite, M.G.; The Notion of ‘Category’. Its Implications in Subject
Analysis and in the Construction and Evaluation of Indexing Languages, Knowledge Organization, vol. 27, no. 2, 2000.
Bierwisch, M. & F. Kiefer; Remarks on Definitions in Natural Language, in F. Kiefer (eds.), Studies in Syntax and Semantics, Dordrecht: Mouton, 1970.
Cabrè, M.T.; Elements of a theory of terminology. Towards an alternative paradigm, Terminology, 6.1, 2000.
Dahlberg, I.; Conceptual Structures and Systematization, in Categorie, oggetti e strutture della conoscenza. Rome: CNR-ISRDS, 1995.
Fisher, D.H.; From Thesauri towards Ontologies? Advances in Knowledge Organization, vol. 6, 1998. Fugmann, Robert; Subject Analysis and Indexing. Frankfurt: INDEKS
Verlag, 1993. Greenberg, J. et al.; Final Report to the ALCTS/CCS Subject Analysis
Committee, American Library Association Report, 1997. www.ala.org/ala/alctscontent/catalogingsection/catcommitees/subjectan
alysis/subjectrelations/finalreport.htm
Hudon, M.; Multilingual thesaurus construction: Integrating the view of different cultures in one gateway to knowledge and concepts, Knowledge Organization, vol. 24, no. 2, 1997.
Jackendoff, Ray; Semantics and Cognition. Cambridge, Mass: MITT Press, 1983.
Katz, J.J. & J.A. Fodor; The structure of a semantic theory, Language, 39, 1963.
Kosovac, B.; Internet/Intranet and Thesauri, Project report - BELCAM "Roofing Thesaurus". NRC Canada, Institute for Research in Construction, 1998.
International Organization for Standardization (ISO); ISO 704: Terminology work – Principles and methods, 2nd edition, Geneva: ISO, 2000, http://irc.nrccnrc.gc.ca/thesaurus/roofing/report_b.html.
Milstead, J.; Thesaurus Development: What Have We Learned? in Multites Conference, London, September 29–30, 2003,
www.multites.com/conference03.htm. Schmitz-Esser, W.; Thesaurus and Beyond: An Advanced Formula for
Linguistic Engineering and Information Retrieval, Knowledge Organization, vol. 26, no. 1, 1999.
Soergel, D. et al.; Reengineering Thesauri for New Applications: the AGROVOC Example, Journal of Digital Information, vol. 4, issue 4, article no. 257, 2004,
277

F. Mazzocchi & P. Plini
http://jodi.ecs.soton.ac.uk/Articles/v04/i04/Soergel/. Trigari, M.; Old problems in a new environment. The impact of the
Internet on multilingual thesauri as research interfaces, in Multites Conference, London, September 29–30, 2003,
www.multites.com/conference03.htm. Tudhope, D.; H. Alani & C. Jones; Augmenting thesauri relationships:
Possibilities for Retrieval, Journal of Digital Information, vol. 1, issue 8, article no. 41, 2001,
http://jodi.ecs.soton.ac.uk/Articles/v01/i08/Tudhope/.
Violi, Patrizia; Significato ed esperienza. Bompiani: Milano, 1997. Wierzbicka, Anna; Lexicography and Conceptual Analysis. Ann Arbor:
Karoma Publishers, 1985. Winston, M.E.; R. Chaffin & D. Herrmann; A Taxonomy of Part-Whole
Relations, Cognitive Science, 11, 1987.
278

A Fuzzy Clustering Approach to Word Sense Discrimination
ERIK VELLDAL This paper describes a novel approach to automatically categorize (i.e. cluster) a set of words in order to reflect their various senses and their relations of semantic similarity. We report on experiments on a set of Norwegian nouns that are represented by their co-occurrence profiles over various lexico-grammatical contexts extracted from corpora. With the purpose of capturing a notion of typicality the clusters themselves are construed as fuzzy sets, and the words are assigned varying degrees of membership with respect to the various classes. The membership functions are based on the distance between the context vectors that represent the words and the prototype vectors that represent the classes. The goal is to automatically uncover soft semantic classes, where the various memberships of a given word can be used to characterize its various senses.
Fuzzy clustering techniques have predominantly been used in such application areas of pattern recognition as image processing and computer vision. However, we argue that fuzzy clustering methods may be useful in modeling conceptual classes and word senses as well, by virtue of allowing for multiple and graded memberships (without being probabilistically constrained). This is in contrast to the hard classes and crisp memberships of conventional clustering methods that have often been used for deriving classes of (distributionally) similar words. It also contrasts with probabilistic approaches where the membership of a given word in a given class is relative and constrained with respect to its other membership values.
The categorization process has four main steps: i) Extracting local context features for words from corpora, ii) computing association scores for the word–context co-occurrences, iii) clustering the resulting association vectors to form a set of tight initial clusters (containing only a subset of all the words) and finally iv) assigning fuzzy membership values for words across the various clusters based on similarity towards class prototypes. In the next section we first briefly review the notion of fuzzy sets and describe how we will represent the semantic clusters. We

Erik Velldal
then step through the different stages of the process before finally showing examples of what the resulting soft word classes look like. Fuzzy Sets and Semantic Classes We want the clusters that are formed to represent meanings in some sense, with words categorized according to their semantic content. As words are frequently seen to be homonymic, polysemous or vague, any attempt to pin down some aspect of word meaning should take these possibilities of ambiguity into account. For example, by the fact that words may have multiple meanings, our clustering model should allow objects to have multiple memberships across clusters. Moreover, different words can represent more or less typical instances of a given concept. Some words may represent clear-cut instances of a given category, while others represent peripheral or border-line cases. Correspondingly, the boundaries of conceptual categories are often fleeting and not precisely determined.
In order to represent the semantic categories and the associated memberships of words, we will adopt the notion of fuzzy sets. This construct was introduced by (Zadeh, 1965) for the purpose of describing classes that lack precisely defined criteria for membership. In contrast to classical sets, objects may “belong” to a fuzzy set with varying degrees of membership. We furthermore adopt a similarity based interpretation (Ruspini and Francesc, 1998) of fuzziness, where we let a membership value represent the degree of typicality or compatibility that a word holds toward the concept a class expresses.
A fuzzy set ζ on X is characterized by a membership function uζ that maps each xj∈X to a real number in the unit interval [0,1] (Zadeh, 1965). The value of uζ(xj) = uζj represents the grade of membership that xj holds in ζ, where unity corresponds to the highest degree of membership (Zadeh, 1965). By contrast, for an ordinary crisp set the two-valued characteristic function is restricted to either 1 or 0, corresponding to whether the object does or does not belong to the set. Note also that we do not impose the so-called Ruspini condition that would require the membership values for a given word to sum to 1.
To ease notation, we let uζ denote both the characteristic function and the set itself. Furthermore, a set of c fuzzy clusters on the set of k association vectors X is represented by a c×k partition matrix U where a component uij gives the strength of membership for xj in the i-th class. A class ui will itself actually be represented by a prototype vector vi formed on the basis of a tight set of initial members. These prototypes may be seen to resemble the notion of committee based centers
280

A Fuzzy Clustering Approach to Word Sense Discrimination
employed by (Pantel and Lin, 2002), and we will get back to the details of how these representations are construed later on. The spatial metaphor underlying the vector space representations of the distributional profiles facilitates an intuitive approach to specifying the memberships as a function of the distance d(xj, vi) between a word vector xj and a class prototype vi. Many empirical and psychological studies of concept formation have also advocated that similarity should be modeled as an exponentially decaying function of distance in the representational space (see e.g. Gärdenfors, 2000). The membership function that we later describe is defined in line with this, computing the similarity-based fuzzy memberships based on distance towards cluster prototypes. Local Context Features Most work on distributional characterization of word similarity has been based on co-occurrences within n-grams, broad context windows, or even documents, without incorporating much linguistic information. However, the previous work of, among others, (Hindle, 1990), (Pereira et al., 1993), and (Pantel and Lin, 2002), clearly demonstrate the plausibility of deriving classes of semantically similar words on the basis of more “local” contextual information in the form of grammatical and syntactic relations. The set of 3000 nouns that we analyze for this paper are characterized by way of their co-occurrences with other (lemmatized) words in various grammatical and syntactic constructions. These contexts are based on relations such as adjectival modification, prepositional modification, noun–noun modification, noun–noun conjunction, possessive modification, and various verb–argument relations. The features are extracted by an ad hoc shallow processing tool, Spartan1
(Velldal, 2003), that works on top of the morpho-syntactical annotations of the Oslo-Bergen Tagger (Hagen et al., 2000). The tagged Norwegian texts that we use comprise 18.5 million words from The Oslo Corpus and 4 million words from a corpus which is still under development at the Section for Norwegian Lexicography and Dialectology at the University of Oslo (UiO). As an example of what the extracted contextual features may look like, the contexts recorded for the sentence in Example 1 are shown in Table 1.
1. Shallow PARsing of TAgged Norwegian text (Velldal, 2003)
281

Erik Velldal
Table 1: Context features of nouns in Example 1
Target noun Feature kunde (customer) SUBJ_OF bestille (order) vin (wine) OBJ_OF bestille (order) vin (wine) ADJ_MOD_BY eksklusiv (exclusive) vin (wine) PP_MOD_BY meny (menu) meny (menu) PP_MOD_OF vin (wine)
Example 1: Kunden bestilte den mest eksklusive vinen på menyen. (The customer ordered the most exclusive wine on the menu.) Each noun ti∈T is represented by an n-dimensional feature vector fi = <fi1,…,fin>. We will use F = {f1,…,fk} to denote the set of k feature vectors that represent the nouns in T. The value of an element fij is the observed co-occurrence frequency for ti and the jth contextual feature of a set C = {c1,…,cn}, where C consists of the n most frequent contextual features resulting from the shallow processing step (with n = 1000 for the results reported here). We did not implement any additional feature selection other than this simple frequency-based approach, but this also seems like a more acute problem when using more broadly defined and crude contexts such as windows, than when dealing with these localized linguistic contexts. Intuitively, the property of occurring somewhere within a 100 words distance from the word-form drink is a lot less semantically focused than the property of occurring as the direct object of the verb with the same form
Association Weighting Since raw frequency alone is not normally regarded a good indicator of relevance, co-occurrence counts are usually weighted with some measure of association strength, typically in the form of a statistical test of dependence. Let A be such a weighting function that maps each element fij of the feature vectors in F to a real value. We will use X to denote the resulting set of association vectors where each xi = <A(fi1),…, A(fin)>. In other words, the salience score of the contextual feature cj for the noun represented by fi is then given by xij = A(fij).
In this paper we take A to be based on the log odds ratio, log θ, as used in the semantic space experiments of (Lowe and McDonald, 2000). The odds ratio θ gives the ratio of the odds for some event to occur, where the odds themselves are also a ratio. Given a local context c, the odds of finding t rather than some other noun can be stated as P(c,t) ⁄ P(c,¬t) (where P is the maximum likelihood estimate based on the relative frequencies in F). Given any other context than c instead, the
282

A Fuzzy Clustering Approach to Word Sense Discrimination
chance of seeing t rather than some other noun, is P(¬c,t) ⁄ P(¬c,¬t). Finally, the ratio of these two odds indicates how much the chance of seeing t increases in the event of c being present:
P P(1)
P P¬ ¬ ¬
= =¬ ¬ ¬ ¬ ¬( ) ( , ) F( , )F( , )
( , ) ( , ) F( , )F( , )c,t c t c t c tc t c t c t c t
θ
Taking the natural logarithm of the odds ratio makes the score symmetric around 0, with 0 being the neutral value that indicates independence (Lowe and McDonald, 2000). If log θ(c,t) > 0, then the probability of seeing t increases when c is present. Note that we here assume all unobserved or negatively correlated co-occurrence pairs (c,t) to have zero association, both because this relation is of less interest for the task at hand and because of the problem of getting reliable estimates from the sparse corpus data. Clustering the Nouns The simple clustering scheme that we apply to the noun data consists of the following four stages: We first define a set of (hard) initial clusters B through a phase of standard bottom-up (agglomerative) clustering using the within-groups average method (WGAC), using what we call the singletons ratio to define a stopping condition. The resulting partition tree is then pruned before we compute a set of association weighted prototypes Vʹ for the resulting set of hard clusters B defined on a subset of X. In the final pass we compute the partition matrix U where each uij is given by a function of the distance between the word vector xj and the corresponding cluster center v'i. This final step can be seen as a “fuzzified” version of a simple nearest prototype classifier. Instead of doing a crisp 1-NP classification, we let the soft classification of each xj∈X be a function of its distance to each class prototype v'j∈V'.
Agglomerative Clustering A pseudo-code outline of the general agglomerative algorithm is given in Table 2. One of the defining properties of different instances of this general algorithm is the way one chooses to compute the similarity between collections of objects (i.e. the clusters). When plugging in the WGAC method, the similarity of two clusters bh and bi is computed as the average pairwise similarities within their union. The within-group average similarity of a cluster bj ⊆ X is defined as:
( )1(2) W s
1=
−∑ ∑( ) ( )jb y
b b ∈ ≠ ∈j jj jy b y z b
, z
283

Erik Velldal
With respect to the general procedure shown in Table 2, sim(bh, bi) is computed as W(bh ∪ bi). We furthermore use the cosine measure to compute the similarity between the individual cluster members s(y,z) (which for the length normalized association vectors in X simply is the dot product). In order to secure good initial prototypes we apply the WGAC method to the entire noun set X, but with a cut-off for the ratio of objects merged, or, equivalently, a threshold for the number of singleton root nodes. With respect to the general outline in Table 2, we use a termination condition Λ that indicates if the ratio of singleton clusters in B is above a specified threshold ρ ∈ [0,1]. Given a function singletons defined as { }singletons( ) | 1= ∈ ∧ =B b b B b , and a threshold ρ, we define our stopping criterion Λ for the agglomerative algorithm in Table 2 as
, if singletons( )
(3) Λ( ), otherwise
T BB
Fkρ≥⎧
= ⎨⎩
this means that we only need to perform a maximum of (k ρ)₋1 mergers and a minimum of (k ρ) ⁄ 2. The greedy WGAC method is guaranteed to produce a monotonic sequence of partitions, and the rationale behind the singleton ratio criterion is to ensure that only the objects that show the strongest degree of similarity are clustered. When forming the initial prototypes we thereby only rely on the most confident merging decisions. This is in contrast to the often-used Buckshot strategy that relies on a random sample of size ( )ck , clustered until B c= (Cutting et al., 1992). Note also that the singleton ratio does not specify the number of classes c directly, as we do not know a priori the branching structure of the partition tree. This means that although a cut-off is employed, the number of clusters c is not specified in advance. The final number of clusters, however, is also determined by the pruning of the resulting partition tree. For the noun clustering we used ρ = 0.5.
284

A Fuzzy Clustering Approach to Word Sense Discrimination
{ }1
: Λ
: ( ) ( )
, ,
( ) ( )
Parameters:
simstopping criterionpruning function →
=
× → ℜ
L k
P X P X
X x x
P X P X
prune
{ }{ }
{ }
1
( , )
for 1 to do
, ,1
while Λ( ) do( , ) arg max sim( , )
∈ ×
=←
←
← +
←
←
←
K
Um n
i i
k
m nih b b B B
j ih
i kb x
B b bj k
Bb b b b
b b b
B B
{ } { },
1
( )
return
⎛ ⎞⎜ ⎟⎝ ⎠
← +
←
Ui jhb b b
j j
B prune B
B
Table 2: Agglomerative Clustering Pruning the Partition Tree In order to further secure the distinctiveness of the prototypes, a pruning procedure is applied to the noun clusters B resulting from the bottom-up run. After first discarding all singletons, the prune function then recursively merges all clusters that are reciprocal nearest neighbors (RNN) with a within-groups average similarity greater than a specified threshold δ. The purpose of this merging step is similar in spirit to the way committees are defined in (Pantel and Lin, 2002), and is an attempt to ensure that the remaining clusters B are well scattered in the space, and to reduce the chances of discovering duplicate senses. In the final step of the pruning, we discard all remaining groups b∈B for which |b| < σ, as these smallest clusters are less likely to yield good and representative prototypes. Note that the elements of the discarded groups are not reassigned to other clusters during the pruning, since this would dilute the final prototypes. After the initial clustering of the 3000 nouns, this merging and trimming (with δ = 0.35 and σ = 3) leaves us
285

Erik Velldal
with a set of c = 167 hard clusters BB = {b1,…,bc} that includes roughly one third of the words in the initial data set. Computing the Prototypes and the Partition Matrix Based on the set of tight initial clusters obtained so far, we now compute the association-weighted prototypes in order to finally define the membership matrix U. As shown in Table 3, the first step of computing the class prototypes is to compute a set of class–context co‐occurrence vectors V, analogous to the feature vectors in F for individual words.
Each vector vi ∈V is the sum of the frequency vectors fj∈F that correspond to the elements xj ∈ bi. This effectively means that each corpus occurrence of one of the clustered words is counted as an occurrence of the corresponding cluster type. The next natural step then is to perform the same association weighting as we did for word vectors above. A set of association vectors Vʹ is constructed by applying the weight function A (based on log θ) to each element of the class co-occurrence vectors. If desired we can now easily also check what it is that ties the members of a
given cluster together, by simply inspecting the context features sorted according to their association scores (see (Velldal, 2003) for examples). Note also that, although the possible effects of differences in occurrence frequencies are reduced by the association-weighting, we also normalize the vectors to have unit length.
{ }1n n
, ,
Parameters:Frequency vectors Association measure Clusters Distance function : Sensitivity weight
× →
=ℜ ℜ ℜ
K cb b
FA
Bdw
{ }
{ }1
1
1
' ( ), , ( )
'
' 1 '
for all do
, ,for all do
' , , 'ensure '
∈
∈
∈←
= ∀ ∈
←
←
←
∑
L
K
K
j i
i
jx b
i
ni
i
i
c
c
i
b Bf
v
v Vv A v A v
v
v V
v
V v
V vv
2
( , )
for all do
exp
return ( , ')
⎛ ⎞⎜ ⎟⎜ ⎟⎝ ⎠
∈
−←
ij
j iij
U
d x vw
u
u
U V
Table 3: Fuzzy Prototype Classification
286

A Fuzzy Clustering Approach to Word Sense Discrimination
The final step of the categorization process is to assign the fuzzy membership values of all the words across the clusters. The memberships function itself is defined in Equation 4.
2
(4)⎛ ⎞
= −⎜ ⎟⎝ ⎠
d( , )u ( ) exp j ii j
x vx
w Decreasing the weight parameter w results in a more rapid decay of the function. Using this membership function we perform a single-pass assignment of word memberships computing a 167 × 3000 partition matrix U (see the procedural outline in Table 3). Results and Discussion We have described a fuzzy clustering approach to unsupervised acquisition of soft semantic classes with the purpose of modeling senses for a set of Norwegian nouns. Words and classes are represented on the basis of their lexical-syntactic environment in text, and a fuzzy clustering method assigns multiple and graded memberships to words across the constructed classes. Some examples of clusters are shown in Tables 6 to 8 (with English translations in parenthesis). Each example shows a target noun and the four clusters in which it has its strongest degree of membership. The clusters themselves are represented by their ten most “typical” members (which might or might not include the target word) together with the associated membership values. Many of the strongest clusters for the various target words seem very encouraging, and many of the classes themselves appear to be highly coherent. Unfortunately, however, we are not able to include any systematic quantitative evaluation in this paper. In order to assess the quality of automatically derived word classes, one needs to compare the results against some sort of gold standard, but no broad-coverage repository of semantic information for Norwegian exists as yet. Moreover, some important unresolved issues also remain, such as the possibility of delineating the number of senses for each word on an individual basis and by a more principled means than just relying on a globally specified similarity threshold. If our aim was a crisp clustering, we would simply assign every word uniquely to the class in which it holds the strongest degree of membership, thus obliterating the need for any threshold. When dealing with a fully fuzzy partition, on the other
287

Erik Velldal
hand, we might need to determine (for some practical purposes at least) to what degree a given word must be associated with a given class ui, in order for ui to be included among its senses. We soon run into trouble if we define a single such threshold to apply for all words and classes. To illustrate the problem, consider the two highest ranking clusters for the nouns hest (horse) and gris (pig) shown in Tables 4 and 5 below.
The two most salient clusters for hest (horse):
Cluster 154, membership: 0.5746
bil (car)
bile (?, Def Sg/Pl = bil)
buss (bus)
busse (?, Def Sg/Pl = buss)
båt (boat)
tog (train)
drosje (taxi)
fly (airplane)
hest (horse)
trikk (tram)
0.9711
0.9611
0.7988
0.7617
0.7248
0.6735
0.6212
0.6152
0.5746
0.5635
Cluster 62, membership: 0.4791
fugl (bird)
hund (dog)
katt (cat)
katte (cat)
slange (snake)
slang (slang, Def Sg = slange)
mann (man)
dame (woman)
dyr (animal)
gutt (boy)
0.8558
0.8330
0.7990
0.7660
0.6261
0.6039
0.5556
0.5293
0.4998
0.4810
Table 4: Cluster memberships of hest (horse)
The two most salient clusters for gris (pig):
Cluster 62, membership: 0.2507
fugl (bird)
hund (dog)
katt (cat)
katte (cat)
slange (snake)
slang (slang, Def Sg/Pl = slange)
mann (man)
dame (woman)
dyr (animal)
gutt (boy)
0.8558
0.8330
0.7990
0.7660
0.6261
0.6039
0.5556
0.5293
0.4998
0.4810
Cluster 116, membership: 0.2433
fisk (fish)
brød (bread)
kjøtt (meat)
kak (?)
kake (cake)
pølse (sausage)
bolle (bun, bread roll, bowl)
melk (milk)
mat (food)
vin (wine)
0.8008
0.7990
0.7939
0.6599
0.6429
0.5663
0.5413
0.5153
0.4821
0.4648
Table 5: Cluster memberships of gris (pig)
The two highest ranked sense classes for the noun hest (horse) (i.e. clusters 154 and 62), seem quite appropriate and can be seen to correspond to its vehicle and animal sense respectively. However,
288

A Fuzzy Clustering Approach to Word Sense Discrimination
classes with a lower rank than these two, that have associated memberships less than u(62)(horse) = 0.48, seem a lot less appropriate. A reasonable threshold in the case of hest (horse) then might be 0.45, blocking every sense class with a membership value that falls below this limit. However, with this cut-off, none of the 2 nearest prototypes of the noun gris (pig) (clusters 62 and 116, see Table 5), would pass through, rendering the target “senseless”, so to speak. Of course, lowering the threshold to, say, 0.2, in order to accomodate the animal and food senses for gris (pig), would mean that too many clusters are included for hest (horse). Instead of settling on some global criterion common to all words, the final sense assignments should be based on individually learned thresholds. The four most salient clusters for sjel (soul): Cluster 93, membership: 0.8428 ånd (spirit) sjel (soul) ånde (breath), Def Sg/Pl = ånd gud (god) dyr (animal) følelse (feeling) vesen (being) kropp (body) menneske (human) natur (nature)
0.9136 0.8428 0.8226 0.4058 0.3934 0.3788 0.3704 0.3697 0.3686 0.3489
Cluster 55, membership: 0.3558 hånd (hand) hand (hand) ansikt (face) arm (arm) hode (head) finger (finger) skulder (shoulder) kropp (body) fot (foot) ben (leg, bone)
0.9350 0.8933 0.7918 0.7872 0.7571 0.7292 0.6846 0.6817 0.6689 0.6628
Cluster 10, membership: 0.3392 tanke (thought) tank (tank, Def Sg/Pl = tanke) følelse (feeling) tanker (? tanker, Pl = tanke) kjærlighet (love) opplevelse (experience) glede (pleasure, happiness) sorg (sorrow, grief) smerte (pain, ache) lengsel (yearning, longing)
0.8885 0.8806 0.8378 0.7318 0.6250 0.6239 0.5888 0.5748 0.5710 0.5476
Cluster 62, membership: 0.2907 fugl (bird) hund (dog) katt (cat) katte (cat) slange (snake) slang (slang, Def Sg = slange) mann (man) dame (woman) dyr (animal) gutt (boy)
0.8558 0.8330 0.7990 0.7660 0.6261 0.6039 0.5556 0.5293 0.4998 0.4810
Table 6: Cluster memberships of sjel (soul)
One inherent limitation of the approach described in this paper is that it is only suitable for words of the higher frequency stratas for which we can observe sufficient syntactical co-occurence information.
289

Erik Velldal
(Grefenstette, 1993) compares classical windowing techniques to methods using lexical-syntactic relations for the task of extracting similarity relations from corpora, and finds that local context information provides very precise sense indicators when available, but that a window based approach seems more viable when dealing with infrequent and rare words. However, one type of representation does not exclude the other, and when using distributional data one might actually benefit from a division of labor between different types of contextual representations. In addition to the local context features that we used in this paper, distributional profiles based on more broadly defined “topical” contexts could also be associated with the words and the classes. The core members of the classes could consist of high-frequency words clustered on the basis of reliable features of the local context. When words of less frequent appearance are to be categorized or compared, one could then fall back on a representation of a broader contextual distribution. (Velldal, 2003) also describes other variations over the hybrid approach presented in this paper, where the result of the bottom-up pass is used to initialize further clustering with the fuzzy c-means (Bezdek, 1981) and possibilistic c-means (Krishnapuram and Keller, 1993) methods. The literature on fuzzy computing contains a well of other clustering methods that can be applied in order to automatically elicit fuzzy membership functions directly from data. Undoubtedly, many of these methods might also profitably be applied to the task of inferring semantic word classes directly from distributional language data.
The four most salient clusters for språk (language): Cluster 54, membership: 0.9157 kultur (culture) språk (language) tradisjon (tradition) litteratur (literature) religion (religion) kunst (art) identitet (identity) samfunn (community, society) miljø (environment) tenkning (thought, thinking)
0.9332 0.9157 0.6337 0.5628 0.5507 0.5101 0.4562 0.4475 0.4153 0.3910
Cluster 132, membership: 0.4432 norsk (Norwegian) engelsk (English) tysk (German) fransk (French) samisk (Lapp) språk (language) morsmål (mother tongue) matematikk (mathematics) ord (word) fag (subject)
0.9761 0.7895 0.6423 0.6351 0.4804 0.4432 0.3445 0.3347 0.3200 0.3085
290

A Fuzzy Clustering Approach to Word Sense Discrimination
Cluster 86, membership: 0.2957 ord (word) ting (thing) navn (name) sang (song) musikk (music) lyd (sound) vers (verse) melodi (melody) tekst (text) dikt (poem)
0.9143 0.8142 0.7963 0.5780 0.5779 0.4898 0.4785 0.4768 0.4598 0.4138
Cluster 29, membership: 0.2403 uttrykk (expression) begrep (notion, conception) setning (sentence) ytring (statement, utterance) utsagn (statement, assertion) ord (word) tekst (text) fortelling (story) tegn (sign) formulering (formulation)
0.9127 0.7510 0.6710 0.6690 0.4715 0.4498 0.4084 0.3868 0.3727 0.3614
Table 7: Cluster memberships of språk (language)
The four most salient clusters for reaksjon (reaction): Cluster 10, membership: 0.3834 tanke (thought) tank (tank, Def Sg/Pl = tanke) følelse (feeling) tanker (? tanker, Pl = tanke) kjærlighet (love) opplevelse (experience) glede (pleasure, happiness) sorg (sorrow, grief) smerte (pain, ache) lengsel (yearning, longing)
0.8885 0.8806 0.8378 0.7318 0.6250 0.6239 0.5888 0.5748 0.5710 0.5476
Cluster 105, membership: 0.3427 kritikk (criticism, review) anklage (accusation) beskyldning (accusation, charge) angrep (attack, charge) innvending (objection) spark (kick) protest (protest) oppfordring (invitation, appeal) press (pressure, stress) reaksjon (reaction)
0.9933 0.6776 0.6768 0.3921 0.3904 0.3858 0.3665 0.3654 0.3600 0.3427
Cluster 49, membership: 0.3181 faktor (factor) egenskap (quality, property) trekk (feature, move) element (element) kjennetegn (mark, characteristic) aspekt (aspect) forutsetning ((pre) komponent (component) svakhet (weakness) holdning (attitude)
0.8494 0.8112 0.7797 0.7651 0.6440 0.5010 0.4325 0.4258 0.4214 0.4125
Cluster 152, membership: 0.3145 virkning (effect) konsekvens (consequence) betydning (meaning, consequence) effekt (effect) utslag (outcome, result) skadevirkning (harmful effect) sammenheng (connection) årsak (cause) problem (problem) forskjell (difference)
0.8708 0.8607 0.8236 0.7783 0.4903 0.4700 0.4596 0.4340 0.3975 0.3948
Table 8: Cluster memberships of reaksjon (reaction)
291

Erik Velldal
References Bezdek, J.C; Pattern Recognition with Fuzzy Objective Function
Algorithms, Advanced Applications in Pattern Recognition. Plenum Press, 1981.
Cutting, D.R.; D. Karger; J. Pedersen & J.W. Tukey; Scatter/Gather: A cluster-based approach to browsing large document collections. Proceedings of SIGIR-92, Copenhagen, Denmark, 1992.
Gärdenfors, P.; Conceptual spaces: the geometry of thought. MIT Press, Cambridge, 2000.
Grefenstette, G.; Evaluation techniques for automatic semantic extraction: Comparing syntactic and window based approaches, Proceedings of the ACL SIGLEX Workshop on Lexical Acquisition. Columbus, Ohio, 1993.
Hagen, K.; J.B. Johannessen & A. Nøklestad; A constraint-based tagger for Norwegian, Proceedings of the 17th Scandinavian Conference of Linguistics, 2000.
Krishnapuram, R. & J.M. Keller; A possibilistic approach to clustering, IEEE Transactions On Fuzzy Systems 1(2), 1993.
Lowe, W. & S. McDonald; The direct route: Mediated priming in semantic space (Informatics Research Report EDI-INF-RR-0017). Division of Informatics, University of Edinburgh, 2000.
Pantel, P. & D. Lin; Discovering word senses from text, Proceedings of ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2002.
Pereira, F.; N. Tishby, & L. Lee; Distributional clustering of english words, Proceedings of the 31st Annual Meeting of the Association for Computational Linguistics, 1993.
Ruspini, E.H. & E. Francesc; Interpretations of Fuzzy Sets, Handbook of Fuzzy Computation (Chapter B2.3), Institute of Physics Publishing, 1998.
Velldal, E.; Modeling word senses with fuzzy clustering (Cand.philol. thesis). University of Oslo, 2003.
Zadeh, L.A.; Fuzzy sets, Information and Control 8, pp. 338 – 353, 1965.
292

Automatic Incremental Term Acquisition from Domain Corpora
ROBERTO BARTOLINI1, DANIELA GIORGETTI1, ALESSANDRO LENCI2, SIMONETTA MONTEMAGNI1 & VITO PIRRELLI1
1Istituto di Linguistica Computazionale – CNR
Via Moruzzi 1 – 56100 Pisa ITALY
2Dipartimento di Linguistica – Università di Pisa Via Santa Maria 36 – 56100 Pisa ITALY
We describe a technique for the acquisition of terms from Italian domain text corpora, which relies both on sophisticated linguistic analysis and on statistical measures applied to linguistically processed text rather than to raw text as it is usually the case. The main advantage of this technique is that minimal a priori knowledge of term structure is required, thus allowing to explore and discover terms in a given domain without imposing a strict pattern matching structure on them, and also to easily extend it to different domains.
The approach we present in this paper is incremental as it may be iterated to discover terms of increasing complexity built on top of terms discovered in the previous iteration. The reason why it is convenient to adopt such an incremental approach is that it allows to “clean” data from noise in the first step, elicitating the constituent terms, and then to refine term acquisition on “skimmed” term data.
Introduction The increasing amount of unstructured text data available from the Internet and from intranets requires efficient approaches for eliciting relevant information both for human users and software agents. We designed and developed Text-2-Knowledge (T2K), a modular flexible system for the automatic creation of thesauri from raw text consisting of three different incremental steps:
• Terminology acquisition • Taxonomy creation

R. Bartolini, D. Giorgetti, A. Lenci, S. Montemagni & V. Pirrelli
• Semantic net clustering.
In this paper we are going to concentrate on the original aspects characterizing the first step, where we extract a list of terms from the corpus relying on automatic tools for linguistic analysis to identify candidate terms and on statistic modules to rank and filter the previously identified candidate terms. There are two kinds of extracted terms in T2K: simple terms and multi-word terms. Multi-word terms are incrementally extracted iterating the extraction and ranking process in order to obtain more complex terms from simpler terms.
There are several advantages in the T2K approach: the a priori knowledge required to apply the linguistic analysis modules is minimal, thus setting up a real discovery mechanism, the statistical measures are not directly applied on raw (or just POS tagged) text as it is usually the case, as that can lead to hardly detectable noise, and the iterative process makes use of “cleaner” results produced by the previous iterations. Background and Related Work The computational terminology field (Bourigault et al., 2001) is multi-faceted, as terms, which can be seen as linguistic labels of concepts (Jacquemin & Bourigault, 2002), may be used for different purposes going from pure thesaurus creation, directly useful for human users, to text indexing for applications such as information retrieval, text summarization, question answering, automated translation, ontology building, semantic indexing and annotation, etc.
Term recognition is a complex task due to term ambiguity and term variation (Nenadic et al., 2004). There exist linguistic (Bourigault et al., 1996), statistical (Dunning, 1993) and hybrid (Daille, 1996, Frantzi et al. 2000) approaches to extract terminology from text. Different methods may be adopted to filter out terms, ranging from the pure term frequency statistics to more complex ones, which are based on statistical association measures either from the statistics literature or new ad hoc designed ones. In (Frantzi et al. 2000) the C-value/NC-value method is used to filter multi-word terms. The C-value ranks candidate terms, extracted from POS tagged corpora, weighing not only the frequency of occurrence of terms but also the length of a term and its frequency as a nested term. The NC-value incorporates context information to the C-value method to re-rank candidate terms. Daille’s (Daille, 1996) approach is maybe the most similar to ours, adopting the log-likelihood ratio for ranking bigram terms, but, differently from ours, the extraction
294

Automatic Incremental Term Acquisition from Domain Corpora
of candidate terms is from POS tagged corpora and requires a set of strict rules to extract them.
The T2K approach belongs to the hybrid category, but it differs from other hybrid approaches both on the linguistic and the statistic side. There is the possibility of selecting different incremental levels of linguistic analysis (from POS tagging, to chunking, to syntactic parsing), and as the deepness of linguistic analysis increases, a lower degree of a priori knowledge is imposed on candidate terms. For example a term may consist of a noun chunk and a prepositional chunk, but there is no hypothesis on whether the prepositional chunk contains just a noun or a noun and an adjective etc., so that it makes it possible to extract multi-word terms like “Ministero dell’Innovazione Tecnologica” without pre-imposing on POS tagged text a fine grained structure. Another characterizing aspect of our approach is the possibility of extracting iteratively more and more complex terms. The difference from other approaches which use association measures for scoring terms is that we use these association measures in an unusual fashion, applying them to abstract linguistic structures (i.e. chunk sequences) rather than to plain words or word patterns.
Term Extraction There are several reasons for using NLP tools in order to extract (and also to cluster) terms, an important one is that terms stand for concepts, and concepts may be expressed in synctactically complex forms, which cannot be identified using just pattern matching or frequency measures or simple stemming algorithms.
Extraction of candidate terms is achieved through a suite of linguistic tools for text processing of Italian documents (Bartolini et al., 2004), which accomplish the following tasks:
• Tokenization • Lexical analysis • Chunking • Syntactic parsing
In Figure 1 we show the sequential pipeline of the linguistic processing modules. The tokenization module divides (ASCII or HTML) text into “atomic” units including words, dates, numbers, abbreviations, punctuation marks. The module may be customized according to domain or application needs. The lexical analyzer requires a tokenized input and returns an output containing all the tokenized words with their
295

R. Bartolini, D. Giorgetti, A. Lenci, S. Montemagni & V. Pirrelli
possible lemmas and corresponding part of speech and morpho-syntactic role. The module relies on a lexical base containing about 100,000 lemmas, which can be dynamically extended for the domain or application needs. Unknown words are dealt with using ad hoc heuristics.
The chunking module takes as input a morpho-syntactically analysed text, and after tagging it (i.e., it performs a morpho-syntactic disambiguation), it segments the text into an unstructured sequence of syntactically organized text units called chunks. Chunks consist of contiguous word tokens related through dependencies (for example determiner, auxiliary, etc.) to the lexical head, which is the “potential governor” of the chunk, roughly corresponding to its semantic head and usually the word which can combine syntactically to neighboring chunks in a lexical relationship. Finally, the syntactic parser is able to identify general functional inter-chunk dependencies, such as subject, object, modifier, complement etc., and to reduce ambiguities by applying a set of constraints to the identified functional dependencies. The syntactic parser relies on grammar rules defined on chunks which test some of the information contained in chunks, e.g., the number and gender agreement. The parsing approach allows to identify grammatical relations in context by progressively reducing under-specification in synctactic representations.
INPUT .txt documents
tokenization (Token-IT)
morphological analysis (MAGIC)
chunking (Chunk-IT)
deep parsing (IDEAL)
syntactic lexicon
tokenized text
morphologically analyzed text
syntactically chunked text
grammatical functions (subj, obj, ecc.) identification
Figure 1: Italian NLP pipeline
296

Automatic Incremental Term Acquisition from Domain Corpora
For the task of term extraction we defined a minimal, simple and general set of rules (for example, a rule that extracts a nominal chunk followed by a prepositional chunk) for the parser. This way of operating, as already pointed out, is quite different from other approaches, as it is able to abstract from the exact linguistic appearance of the term. Term Selection Once candidate terms have been extracted from text we rank them with statistical measures.
Simple frequency works quite well for plain terms, which are first selected excluding stop-words and collapsing morphological variants to the most frequent occurrence form in domain text. Another viable solution to establish the domain relevance of a term might be using a contrastive corpora, and comparing its normalized frequency in the domain with its normalized frequency in a different general corpus.
Complex (or multi-words) terms are ranked (using the NSP package (Banerjee and Pedersen, 2003)) according to the log-likelihood ratio association measure (Dunning, 1993), which computes the likelihood for two words of occurring together more often than they would “by chance”, relying on their joint frequency and their disjoint frequencies. The reason why we preferred log-likelihood ratio to other association measures such as mutual information, chi square etc., is that it performed better in some empirical tests, and moreover this measure is less prone to data sparsness (i.e., it doesn’t rank high rare co-occurrences of words). Log-likelihood ratio in NLP is usually adopted for discovering collocations, i.e., idiomatic phrases; we assume that domain terms are close to the notion of “idiomatic phrase”. However, we applied the log-likelihood ratio in a somewhat unusual fashion; instead of measuring the association strength in a word context window, we measure the association strength between syntactic structures represented by the semantic head of chunks.
The advantage of applying association measures to such syntactic structures rather than to word context windows is that many “false terms” (i.e. frequent co-occurrences of words which cannot be considered terms) have already been discarded by the previously performed linguistic analysis.
Ranked plain and complex terms are finally selected setting thresholds, which can be interactively chosen by users or set to a default by the system.
297

R. Bartolini, D. Giorgetti, A. Lenci, S. Montemagni & V. Pirrelli
Incremental Term Acquisition A major aspect of the T2K approach is that the chunking and parsing steps may be iterated in order to discover more complex (i.e. longer) terms. As a matter of fact terms extracted and ranked in the i_th iteration may be mapped back on chunked text as they were simple atomic units, and then parsing rules may be applied again to this new chunked format extracting new candidate terms formed by at least a previously extracted term. For example, if the system had found out during its first iteration that “controllo a campione” (lit. sample check) is a term, a second iteration involving the reprojection of this term on the chunked text, may find out that the longer expression “controllo a campione di operazioni” (lit. sample check of operations) is a term too.
The set of rules introduced in the first iteration may be changed or extended in subsequent iterations. We experimented for example, that introducing coordination rules (rules which discover chunks linked through conjunctions) in the first iteration leads to a noisy output, due to the intrinsic complexity and ambiguity of coordination structures, where many unrelevant candidate terms are extracted, while introducing coordination rules in the second iteration entails that at least one of the two coordinated chunks has already been identified as a term, and so there is better warranty of relevance of the new candidate term (however, relevance in our approach is assessed by statistical measures). Experiments and First Evaluations We tested the T2K system within the framework of the project Traguardi, sponsored by the Italian Government. The goal of the project was to develop an advanced document management system for Italian Regional Administrations. T2K has been integrated within the Traguardi system for the automatic creation of linguistic ontologies and the semantic indexing and mark-up of documents, in order to allow a “concept-based” search in documents rather than a pure keyword search. We tested T2K on a corpus of 252 documents from the Italian Public Administration consisting of about 785,000 words, coming from the Traguardi document base. The corpus, originally consisting of documents in several different formats such as Adobe pdf, Microsoft Word, Microsoft PowerPoint etc., was first converted to ASCII format, and then passed on to the T2K modules.
Evaluation of the obtained terms is by no means a trivial issue, and the typical way for evaluating how good automatically extracted terms are, is to ask some domain expert to evaluate them. In our case the corpus we experimented on had no pre-existing term dictionaries to
298

Automatic Incremental Term Acquisition from Domain Corpora
compare with. However, as an encouraging first signal, we found out that our term glossary extends a pre-existing term glossary manually built, without meaningful losses. For example, while in the glossary created by domain experts we have the term rischio inerente, in the glossary created by our modules not only have we the term rischio inerente but also terms like rischio complessivo, rischi gestionali, rischi industriali, rischio legale, rischio residente, which enrich the variety of terms and may provide with a basis for developing horizontal (synonym-like) and vertical (hyperonym-hyponym like) taxonomies. Conclusion We present a technique to dynamically acquire terminology from domain documents, where terms are represented by single- and multi-words dynamically extracted from raw text and selected by means of statistical measures which “weigh” their relevance to the domain.
The T2K system is based on a minimal set of linguistic rules as the only a priori knowledge; further more, statistical measures are adapted in order to rank linguistically processed text. The aim of our technique is on one hand not to impose a too strict pre-defined schema on candidate terms, on the other hand to use statistical measures trying to reduce drawbacks coming from their application to linguistically unprocessed text. References Banerjee, S. & T. Pedersen; The Design, Implementation and Use of the
Ngram Statistics Package, Proceedings of the Fourth International Conference on Intelligent Text Processing and Computational Linguistics, Mexico City, 2003.
Bartolini, R.; A. Lenci; S. Montemagni & V. Pirrelli; Hybrid Constrains for Robust Parsing: First Experiments and Evaluation, Proceedings of LREC 2004, Lisbon, 2004.
Bourigault, D.; I. Gonzalez-Mullier & C. Gros; LEXTER, a Natural Lnaguage Processing Tool for Terminology Extraction, Proceedings of the 7th EURALEX International Congress, Göteborg, 1996.
Bourigault, D.; C. Jacquemin & M.-C. L'Homme (eds.); Recent Advances in Computational Terminology. Amsterdam/Philadelphia: John Benjamins Publishing Company, 2001.
Daille, B.; Study and Implementation of Combined Techniques for Automatic Extraction of Terminology, in P. Resnik & J. Klavans (eds.), The Balancing Act: Combining Symbolic and Statistical Approaches to Language, MIT Press, 1996.
299

R. Bartolini, D. Giorgetti, A. Lenci, S. Montemagni & V. Pirrelli
Dias, G.; S. Guilloré; J-C. Bassano & J.G. Pereira Lopes; Combining Linguistics with Statistics for Multiword Term Extraction: A Fruitful Association? Proceedings of Recherche d'Informations Assistee par Ordinateur (RIAO 2000), 2000.
Dunning, T.; Accurate Methods for the Statistics of Surprise and Coincidence, Computational Linguistics, 19(1), 1993.
Frantzi K.T.; S. Ananiadou & H. Mima; Automatic Recognition of Multi-word Terms: the C-value/NC-value Method, International Journal on Digital Libraries, 3(2), 2000.
Jacquemin, C. & D. Bourigault; Term extraction and automatic indexing, in R. Mitkov (eds.) Handbook of Computational Linguistics. Oxford: Oxford University Press, 2002.
Nenadic, G.; S. Ananiadou & J. McNaught; Enhancing Automatic Term Recognition through Recognition of Variation, Proceedings of COLING 2004, Geneva, Switzerland, 2004.
300

Structuring Terminology using Analogy-Based Machine Learning
VINCENT CLAVEAU & MARIE-CLAUDE L'HOMME1
I – Introduction In the field of computational terminology, in addition to work on term extraction, more and more research highlights the importance of structuring terminology, that is, finding and labeling the links between terminological units. Retrieving such relations between terms is usually undertaken using either “external” or “internal” methods (see Daille et al. (2004) for an overview). External methods rely on the (automatic) analysis of corpora to see what kind of words can be associated with a term in context (e.g. Claveau & L'Homme, 2004). Internal methods rely only on the form of the terms to make such associations. Some of this research relies heavily on the use of external knowledge resources (Namer & Zweigenbaum, 2004; Daille, 2003), which implies a lot of human intervention if the technique is defined for another domain or language. Others add little information and make the most of existing data, such as thesauri (Zweigenbaum & Grabar, 2000) or corpora (Zweigenbaum & Grabar, 2003) but aim to identify morphological families without distinguishing the semantic roles of the individual members. This paper explores the way a simple machine learning technique together with a terminological extraction system can be used to find whether a term is related to another. Our work bears a number of similarities with that developed by Zweigenbaum & Grabar (2003), but it also aims at precisely predicting the semantic link between the two terms. This work relies on two main hypotheses:
1. specialized corpora contain regular morphological relationships coupled with a regular semantic relation;
2. such morphological links may be “exclusive” to the studied domain.
1. OLST, University of Montreal,C.P. 6128 succ Centre-Ville, Montréal, QC, H3C
3J7, Canada. {vincent.claveau,mc.lhomme}@umontreal.ca

V. Claveau & M.-C. L’Homme
The machine learning technique based on analogy we propose allows us to take into account the particularities of this classification task and does not need any external morphology knowledge in order to comply with our second hypothesis. The whole technique is evaluated in the domain of computer science and applied on a French corpus. We first present the framework of this research, and in particular the way we describe and encode the semantic links between morphologically related terms. Then we present the supervised, analogy-based machine-learning technique developed for this task, as well as the terminological extraction system it relies on. Last, we describe the methodology used for the evaluation of our technique and the results obtained.
II – Framework The work is undertaken in order to assist terminologists in the enrichment of a French specialized dictionary of computing. The dictionary is compiled using a lexico-semantic approach to the analysis of terminology (L’Homme, 2004) and relies heavily on lexical functions, hereafter LFs (Mel’čuk et al., 1984-1999) to represent semantic relations between terms. (Entries can be accessed at: http://olst.ling.umontreal.ca/dicoinfo.)
Lexical functions are viewed as a means to capture terminological relationships by an increasing number of researchers. Their completeness and systematicity make them relevant and suitable for several terminological tasks: encoding relationships in dictionaries (Jousse & Bouveret, 2003), structuring terms (Daille, 2003), and classifying specialized collocations (Wanner, 2005, forthcoming). Various semantic links are encoded in our dictionary of computing. First, users will find syntagmatic links, i.e. those expressed by collocates; e.g. enregistrer (Eng. to save), défragmenter (Eng. to defragment) and externe (Eng. external) for disque dur (Eng. hard disk). Secondly, entries also cover paradigmatic relations, such as hyperonymy, synonymy, antonymy, and actantial relationships. LFs are used to explain in a uniform and systematic manner the meanings of collocates or the relationships between a given key term and another semantically related term. The work reported in this article is concerned with a subset of semantic relationships. They can be syntagmatic or paradigmatic but they all involve pairs of terms that are morphologically related. Examples of such links are listed below with their corresponding LFs.
302

Structuring Terminology using Analogy-Based Machine Learning
S0(formater) = formatage (Eng. to format – formatting); noun which has the same sense as key word Sagent(programme) = programmeur (Eng. program – programmer); typical agent of the key word Sinstr(éditer) = éditeur (Eng. to edit – editor); typical instrument of the key word Sres(programmer) = programme (Eng. to program – program); typical result of the key word Anti(installer) = désinstaller (Eng. to install – to uninstall); antonymy Able1(interagir) = interactif (Eng. to interact – interactive); the agent can + sense of the key word Able2(programmer) = programmable (Eng. program – programmable); the key word can be verb-ed A1(résider) = résident (Eng. to reside – resident); the agent has or is + the sense of the key word A2(infecter) = infecté (Eng. to infect – infected); the patient is + the sense of the key word De_nouveau(compiler) = recompiler (Eng. to compile - to recompile); once again Fact1(pirate) = pirater (Eng. hacker – to hack); the key word performs an action on the patient Labreal12(navigateur) = naviguer (Eng. browser – to browse); the agent uses the key word to act on the patient Caus1Func0(imprimé) = imprimer (Eng. printout - to print); the agent creates the key word Caus1Oper2(partition) = partitionner (Eng. partition – to partition); the agent causes that the patient has a key word CausPred(valide) = valider (Eng. valid – to validate); something or somebody renders + key word
It is important to point out that LFs are designed to represent semantic relationships regardless of formal similarity (morphological resemblance is considered as accidental in this framework). However, in this work, according to our first hypothesis, it is assumed that formal resemblance is likely to be indicative of a strong semantic link.
Other work has shown that morphological proximity – even if it does not reveal the entire terminological structure of a domain – can shed light on important terminological relations in many domains:
• Medicine (Zweigenbaum & Grabar, 2000) : acide, acido,
acidité, acidurie, acidémie, acidophile, acidocitose. • Agri-food industry (Daille, 2003): solubilisation micellaire =>
insolubilisation micellaire, plume de canard => plumard de canard, filetage de saumon => filet de saumon.
303

V. Claveau & M.-C. L’Homme
• Business (Binon et al., 2000): promotion, promo, promoteur, promotrice, promouvoir, promotionner.
III – Machine Learning Technique 1 – Learning by Analogy The learning method underlying our approach is based on analogy. Analogy can be formally represented as A : B :: C : D which means “A is to B what C is to D” (Lepage, 2003). Learning by analogy has already been used in some NLP applications (Lepage, 2004).
It is particularly suited for our task, in which such analogies can be drawn from our morphologically related pairs. For example we have analogies like the following one: connecteur : connecter :: éditeur : éditer (Eng. connector : to connect :: editor : to edit); knowing that Sinstr(connecter) = connecteur, we can guess that the same link (i.e. the same LF) is valid for describing éditeur and éditer, that is Sinstr(éditer) = éditeur. From a machine learning point of view, this approach using learning by analogy has several interesting particularities. First, it is “inherently” a supervised method, being a special case of case-based learning (Kolodner, 1993) in which an instance is a pair of word; thus, we do need examples of related pairs along with their LF. Secondly, the number of classes considered, that is the different LFs describing our derivational links, is quite large and dependent on the set of examples. Last, a given pair of morphologically related words can be (correctly) tagged by several LFs. These properties make it impossible to use many other existing machine learning techniques in which multiple classes cannot be assigned to a given instance.
2 – Preparing the Training Data In order to identify morphological analogies, we need examples of morphologically related terms along with their LF. To gather them, we use the existing entries in the dictionary we are planning to enrich. They are automatically extracted from it by searching, within all the encoded links between terms, for the ones such that the two linked terms are “close” in terms of edit distance or longest common substring.
Thus, even if our learning method is supervised, our technique finally does not require any human intervention; the whole process is actually semi-supervised. In the experiments reported below, about 900 examples are gathered this way and then used to draw the analogies with the test set pairs.
304

Structuring Terminology using Analogy-Based Machine Learning
3 – Analogy between Morphologically Related Pairs The most important feature in learning by analogy is of course the notion of similarity which is used to determine that two pairs of propositions – in our case, two pairs of lemmas – are analogous. The similarity notion we use, hereafter Sim, is quite simple but well adapted to French (as well as many other languages), in which derivation in mainly obtained by prefixation and suffixation.
Let us note LCSS(X,Y) the longest common substring shared by two strings X and Y, X +suf Y being the concatenation of the suffix Y to X, X -suf Y being the subtraction of the suffix Y of X, X +pre Y being the concatenation of the prefix Y to X, and X -pre Y being the subtraction of the prefix Y of X. The similarity notion Sim works as follows (an example is given below): if we have two pairs of words W1-W2, W3-W4,
W1 = LCSS(W1, W2) +pre Pre1 +suf Suf1,
and Sim(W1-W2, W3-W4) = 1 if W2 = LCSS(W1, W2) +pre Pre2 +suf Suf2, and
W3 = LCSS(W3, W4) +pre Pre1 +suf Suf1, and
W4 = LCSS(W3, W4) +pre Pre2 +suf Suf2
otherwise Sim(W1-W2, W3-W4) = 0.
Prei and Sufi are any character strings. Intuitively, Sim checks that the same “path” of deprefixation, prefixation, desuffixation and suffixation is needed to go from W1 to W2 as to go from W3 to W4. If Sim(W1-W2, W3-W4) = 1, the analogy W1 : W2 :: W3 : W4 stands and, if the LF between W1 and W2 is known, the same one certainly holds between W3 and W4. Our morphological tagging process involves checking if an unknown pair is in analogy with one or several of our examples. If so, the unknown pair is tagged with the same LF (or possibly several LFs) as the examples. Practically, we learn from our examples the way Sim is computed, that is, the path of operations needed to go from a word to another in terms of Prei and Sufi, and assigns the LF to this path. For instance, if V0(programmation) = programmer (Eng. programming, to program) is an example, the following path is learned:
V0(W1) = W2 if W1 -suf “ation” +suf “er” = W2
Any new pair following this path will be annotated with the V0 LF. Conversely, since we also know that S0(programmer) = programmation, we also have a rule:
S0(W1) = W2 if W1 -suf “er” +suf “ation” = W2
305

V. Claveau & M.-C. L’Homme
Similarly, from the example Able2Anti(activer) = désactivable (Eng. activate – deactivatable), the following rule is built:
AntiAble2(W1) = W2 if W1 -suf “er” +suf “able” +pre “dés” = W2
In all, 402 morphological rules are obtained from our examples, allowing us to identify 67 different LFs. Any pair of words that complies with one of these rules is therefore in analogy with one of our 900 example pairs and can be annotated by the same LF as in this example. 4 – Use of the Term Extraction System TermoStat In addition to the learning process described above, we use a corpus-based term-extraction system called TermoStat (Drouin, 2003). This system, contrary to many other term-extraction techniques, is able to retrieve single-word terms. To perform this extraction, TermoStat computes the “specificities” of words occurring in a specialized corpus by comparing their frequency in the corpus and in a general-language corpus. Basically, the higher the specificity of a word, the more likely it is to be a term of the domain. Conversely, a word with a negative specificity coefficient certainly belongs to the general language.
The French domain-specific corpus used in our experiments is composed of several articles from books or web sites specialized in computer science; all of them were published between 1996 and 2004. It covers different computer science sub-domains (networking, managing Unix computers, webcams...) and comprises about 1,000,000 words. This corpus is thus compared to the French general corpus Le Monde, composed of newspaper articles (Lemay et al., 2005).
In our experiments, TermoStat, by providing us with words likely to be domain-specific terms, is used to filter out non-related pairs within the domain framework. Indeed, we can avoid wrong associations like architecture-architectural (Eng. architecture (of a system or network)-architectural) (in which architectural is morphologically related to architecture from a diachronic point of view, but not semantically related in the computer science domain), since architectural does not have a high specificity coefficient. Thus, to retrieve domain-relevant morphologically related terms and annotate them with their LFs, the 402 learned rules are applied to each possible pair of words having a specificity coefficient higher than a certain threshold.
It is interesting to note that the use of TermoStat allows us not only to focus on terms of the domain, but also to reduce the time complexity of our algorithm. Indeed, detecting analogies implies to test every possible pair of lemmas supplied by the corpus with our rules; thus, the
306

Structuring Terminology using Analogy-Based Machine Learning
complexity of our approach is O(n2) with n the number of lemmas in the corpus. Focusing on lemmas with specificities higher than a certain threshold keeps n at a lower level and reduces the computing cost of the analogy search. IV - Evaluation This section is devoted to describing the evaluation of the technique presented above. We first present the test set used, and then we describe the measures chosen to precisely evaluate our system and the results obtained. 1 – Building the Test Set In order to evaluate the completeness and the precision of the results obtained by our technique, we built a test set containing morphologically related terms along with their LFs. The first step of this process involves randomly selecting more than 220 words from the lemma list of the computer science corpus. Then, for each of these 220 test words, we constitute pairs by manually retrieving in the corpus all the morphologically related lemmas, but only if the two words composing the pair are terms sharing an actual semantic link in the computer science domain. This means that pairs like découvrir – découverte (Eng. to discover-discovery) are not considered as relevant since neither of the words are terms and that the pair référentiel – référencer (Eng. referential – to reference) is not considered as relevant since there is no semantic link in the computer-science domain. Finally, each pair of related words is given all its possible LFs. In the case of polysemous words, a pair can receive several LFs describing all the relations between the two terms); conversely, some of the words do not have any morphologically related word in the corpus.
Table 1 gives some statistics on this test set. Note that to prevent any bias in the results, none of these terms were used as examples during the learning step; they were removed from the example set.
Total number of different test words 222 Total number of pairs 469 Number of different links (LFs) 50
Table 1: Statistics on the Test Set
2 – Results In order to evaluate our results, we are interested in two questions: do we find all the existing links between two units? do we find only valid
307

V. Claveau & M.-C. L’Homme
links? To answer these two questions, we use the standard recall/precision approach. The global quality of the system is measured with the help of a single rate, the f-measure (harmonic mean of R and P), defined as: f = 2PR/(P+R).
The evaluation process is the following: we apply the learned rules to each possible pair of words in the corpus having a specificity coefficient higher than a certain threshold and containing one of the 220 test words. A pair matched by one of the rules is in analogy with one of the example and thus receives the same LF. The list of annotated pairs obtained is compared to the one built manually in order to compute R, P and f. This evaluation process is repeated for different specificity thresholds in order to evaluate the influence of this parameter. Figure 1 presents the variation of R, P and f with respect to the specificity threshold. The threshold value that maximizes the f-measure is 0; with this value, we have: f = 0.6848 with R = 71.77% and P = 65.48%
Figure 1: Variation of the Recall and Precision rates and f-measure according to the specificity threshold
Given the simplicity of our approach, these results are surprisingly good in terms of both recall and precision. As expected, focusing on the positive specificities ensures that we obtain more precise results, leading to a better recall/precision compromise than if the method had been applied on the whole list of words in the corpus. Moreover, the optimal threshold is 0, meaning that our results are coherent with the way TermoStat retrieves term candidates; and no good relations are found in words with a specificity coefficient lower than -5.
308

Structuring Terminology using Analogy-Based Machine Learning
Basically, errors produced by our method can be classified into two different groups. First, it can detect an erroneous semantic relation in a pair (this type of error is called a false positive). False positives are mainly generated by:
• The detection of pairs in which at least one word is not a term
of the domain: e.g. démasquer-masquer (Eng. reveal-mask). • The detection of pairs in which terms do not share a relevant
relationship in the field: e.g., table-tablette (Engl. table-shelf). • Detection of valid pairs but with a wrong LF:
o Many errors in this category are due to morphemes that convey different meanings. Nouns ending in -eur can be instruments, like éditeur, or agents, like programmeur, of the related verb). We can also mention nominalizations of verbs (nouns ending in –ation, - age, -ment, etc.) most of which can convey two different meanings, that of result and that of activity. However, in some cases, the noun only conveys one of those meanings: e.g., in balayage-balayer (Engl. analysis, to analyze), balayage only conveys a meaning of activity.
o Some morphological configurations are frequently associated with a given relationship but can be confused, in a few rare cases, with an invalid relationship: e.g. re- used almost exclusively in terms that mean “once again” as in configurer-reconfigurer (Eng. configure-reconfigure). Our system wrongly labeled a pair that shares a different relationship: e.g. chercher-rechercher (Eng. search). Incidently, rechercher cannot be decomposed into a base meaning “chercher” and a morpheme meaning “once again” and the terms in this case are synonyms.
The second kind of error is due the failure of our method to detect valid pairs (called false negatives). These are mainly due to the following errors:
• The absence of one of the terms in the list of specificities: e.g.,
in aide-aider (Engl. help-to help), the noun was part of the specificities, but not the verb.
• Rare morphological configurations that do not appear in our examples: e.g. S0Inter(connecter) = interconnexion (Eng. to connect-interconnection).
309

V. Claveau & M.-C. L’Homme
• Morphological configurations for which we do have some examples, but no example with the valid semantic link: e.g. brancher-branchement (Eng. to connect-connection) was identified but the semantic relationship was wrong.
Finally, results can be presented to the terminographer in the form of graphs such as the one shown in Figure 2. Note that in this case two wrong LFs were detected: Sres between compiler-compilation and recompiler-recompilation.
Figure 2: Resulting graph for the “compilation” morphological family
V – Conclusion This paper presents a simple method for automatically retrieving and identifying a semantic relation, expressed with the help of Lexical Functions, between morphologically related terms of a domain. This technique uses a special kind of machine learning approach based on analogies and the results of a term-extraction system. The relative simplicity of the technique is actually one of its most important advantages. Indeed, it does not rely on predefined classes of relations or LFs, nor on external knowledge or language. Moreover, results obtained, measured through an evaluation in the field of computer science, are very good, both in terms of completeness and precision of the semantic relations found.
310

Structuring Terminology using Analogy-Based Machine Learning
With these experiments, we have also confirmed the first hypothesis underlying this work: morphological proximity generally indicates semantic proximity, which can be encoded by LFs. To verify our second hypothesis, that is, that these morphological links have to be learned for each domain, it is necessary to conduct experiments on other domains. However, similar experiments drawing analogies from general language examples (Claveau & L’Homme, 2005) and close experiments in the biomedical domain (Zweigenbaum & Grabar, 2000) tend to confirm it. Future work is planned to solve some frequent errors, such as the ones reported in Section IV.2, by using other approaches that incorporate an analysis of syntagmatic relationships (Claveau & L’Homme, 2004). From an application point of view, we are planning to use the same technique on a computer-science corpus in English. VI – Acknowledgements The authors would like to thank Léonie Demers-Dion for her help in the test set construction and Elizabeth Marshman for her comments on a previous version of this article. VII – References Binon, J.; S. Verlinde; J. Van Dyck & A. Bertels; Dictionnaire
d'apprentissage du français des affaires. Paris: Didier, 2000. Claveau, V. & M.-C. L’Homme; Discovering Specific Semantic
Relationships between Nouns and Verb in a Specialized French Corpus, in Proceedings of the 3rd International Workshop on Computational Terminology (CompuTerm'04), Geneva, Switzerland, 2004.
Claveau, V. & M.-C. L’Homme; Apprentissage par analogie pour la structuration de terminologie - Utilisation comparée de ressources endogènes et exogènes, Actes de la conférence Terminologie et Intelligence Artificielle (TIA’05), Rouen, France, 2005.
Daille B.; Conceptual Structuring through Term Variation, Workshop on Multiword Expressions. Analysis, Acquisition and Treatment. Proceedings of ACL 2003, Sapporo, Japan, 2003.
Daille, B.; K. Kageura; H. Nakagawa & L.-F. Chien (eds.); Terminology. Special Issue on Recent Trends in Computational Terminology, 10(1), 2004.
Drouin, P.; Term-extraction using Non-technical Corpora as Point of Leverage, Terminology, 9(1), 2003.
Kolodner, J. (eds.); Machine Learning, Special Issue on Case-Based Reasoning, 10(3), 1993.
311

V. Claveau & M.-C. L’Homme
Jousse, A.L. & M. Bouveret; Lexical Functions to Represent Derivational Relations in Specialized Dictionaries, Terminology, 9(1), pp. 71 – 98, 2003.
Lemay C.; M.-C. L’Homme & P. Drouin; Two Methods for Extracting Specific Single-word Terms from Specialized Corpora: Experimentation and Evaluation, International Journal of Corpus Linguistics, 10(2), 2005.
Lepage, Y.; De l'analogie; rendant compte de la communication en linguistique. Grenoble, France, 2003.
Lepage, Y.; Lower and Higher Estimates of the Number of ”True Analogies” between Sentences Contained in a Large Multilingual Corpus, Proceedings of the 20th International Conference on Computational Linguistics, COLING'04, Geneva, Switzerland, 2004.
L’Homme, M.-C.; A Lexico-Semantic Approach to the Structuring of Terminology, Proceedings of the 3rd Workshop on Computational Terminology, CompuTerm'04, Geneva, Switzerland, 2004.
Mel’čuk, I. et al.; Dictionnaire explicatif et combinatoire du français contemporain. Recherches lexico-sémantiques I-IV, Montréal: Les Presses de l’Université de Montréal, 1984 – 1999.
Namer, F. & P. Zweigenbaum; Acquiring Meaning for French Medical Terminology: Contribution of Morpho-semantics, Conference Medinfo 2004. San Francisco, USA, 2004.
Wanner, L. et al.; The First Step towards the Automatic Compilation of Specialized Dictionaries, Terminology, 11(1), forthcoming, 2005.
Zweigenbaum, P. & N. Grabar; A Contribution of Medical Terminology to Medical Language Processing Resources: Experiments in Morphological Knowledge Acquisition from Thesauri, Conference on Natural Language Processing and Medical Concept Representation, Phoenix, USA, 1999.
Zweigenbaum, P. & N. Grabar; Liens morphologiques et structuration de terminologie, Ingénierie des connaissances, IC 2000, pp. 325 – 334, 2000.
Zweigenbaum, P. & N. Grabar; Learning Medical Words from Medical Corpora, Conference on Artificial Intelligence in Medecine, AIME'03, Protaras, Cyprus, 2003.
312

Corpus-Based Terminology Extraction
ALEXANDRE PATRY & PHILIPPE LANGLAIS Terminology management is a key component of many natural language processing activities such as machine translation (Langlais and Carl, 2004), text summarization and text indexation. With the rapid development of science and technology continuously increasing the number of technical terms, terminology management is certain to become of the utmost importance in more and more content-based applications.
While the automatic identification of terms from texts has been the focus of past studies (Jacquemin, 2001) (Castellví et al, 2001), the current trend in Terminology Management (TM) has shifted to the issue of term networking (Kageura et al, 2004). A possible explanation of this shifting may lie in the fact that Terminology Extraction (TE), although being a noisy activity, encompasses well established techniques that seem difficult to improve significantly upon.
Despite this shift, we do believe that better extraction of terms could carry over subsequent steps of TM. A traditional TE system usually involves a subtle mixture of linguistic rules and statistical metrics in order to identify a list of candidate terms where it is hoped that terms are ranked first.
We distinguish our approach to TE from traditional ones in two different ways. First, we give back to the user an active role in the extraction process. That is, instead of encoding a static definition of what might or might not be a term, we let the user specify his own. We do so by asking him to set up a training corpus (a corpus where the terms have been identified by a human) from which our extractor will learn how to define a term. Second, our approach is completely automatic and is readily adapted to the tools (part-of-speech tagger, lemmatizer) and metrics of the user.
One might object that requiring a training corpus is asking the user to do a part of the job the machine is supposed to do, but we see it in a different way. We consider that a little help from the user could pay back in flexibility.

A. Patry & P. Langlais
The structure of our paper outlines the three steps involved in our approach. In the following section, we describe our algorithm to identify candidate terms. In the third section, we introduce the different metrics we compute to score them. The fourth section explains how we applied AdaBoost (Freund and Schapire, 1999), a machine learning algorithm, to rank and identify a list of terms. We then evaluate our approach on a corpus which was set up by the Office québécois de la langue française to evaluate commercially available term extractors. We show that our classifier outperforms the individual metrics used in this study. Finally, we discuss some limitations of our approach and propose future works to be done. Extraction of Candidate Terms It is a common practice to extract candidate terms using a part-of-speech (POS) tagger and an automaton (a program extracting word sequences corresponding to predefined POS patterns). Usually, those patterns are manually handcrafted and target noun phrases, since most of the terms of interest are noun phrases (Justeson and Katz, 1995). Typical examples of such patterns can be found in (Jacquemin, 2001).
As pointed out in (Justeson and Katz, 1995), relying on a POS tagger and legitimate pattern recognition is error prone, since taggers are not perfect. This might be especially true for very domain specific texts where a tagger is likely to be more erratic. To overcome this problem without giving up the use of POS patterns (since they are easy to design and to use), we propose a way to use a training corpus in order to automate the creation of an automaton.
There are many potential advantages with this approach. First, the POS tagger and the tagging errors, to the extent that they are consistent, will be automatically assimilated by the automaton. Second, this gives to the user the opportunity to specify the terms that are of interest for him. If many terms involving verbs are found in the training corpus, the automaton will reflect that interest as well. We also observed in informal experiments that wide spread patterns often fails to extract many terms found in our training corpus.
Several approaches can be applied when generating an automaton from sequences of POS encountered in a training corpus. A straightforward approach is to memorize all the sequences seen in the training corpus. A sequence of words is thus a candidate term only if its sequence of POS tags has been seen before. This approach is simple but naive. It cannot generate new patterns that are slight variations of the ones seen at training time, and an isolated tagging error can lead to a bad pattern.
314

Corpus-Based Terminology Extraction
To avoid those problems, we propose to generate the patterns using a language model trained on the POS tags of the terms found in the training corpus. A language model is a function computing the probability that a sequence of words has been generated by a certain language. In our case, the words are POS tags and the language is the one recognizing the sequences of tags corresponding to terms. Our language model can be described as follow:
∏=
=n
iii
n HwPwP1
1 )|()(
where is a sequence of POS tags and is called the history which summarizes the information of the
nw1 iH1−i previous tags. To build an
automaton, we only have to set a threshold and generate all the patterns whose probability is higher than it. An excerpt of such an automaton is given in Figure 1.
Probability Pattern 0.538 NomC AdjQ 0.293 NomC Prep NomC 0.032 NomC Dete-dart-ddef NomC 0.0311 NomC Verb-ParPas 0.0311 NomC Prep Dete-dart-ddef NomC …
Figure 1: Excerpt of an automatically generated automaton. Another advantage of such an automaton is that all patterns are associated with a probability, giving more information than a binary value (legitimate or not). Indeed, the POS pattern probability is one of the numerous metrics that we feed our classifier with.
Scoring the Candidate Terms In the previous section, we showed a way to generate an automaton that extracts a set of candidate terms that we now want to rank and/or filter. Following many other works on term extraction, we score each candidate using various metrics. Many different ones have been identified in (Daille, 1994) and (Castellví et al, 2001). We do not believe that a single metric is sufficient, but instead think that it is more fruitful to use several of them and train a classifier to learn how to take benefit of each of them.
Because we think they are interesting for the task, we retained the following metrics: the frequency, the length, the log-likelyhood, the
315

A. Patry & P. Langlais
entropy, tf·idf and the POS pattern probabilities discussed in the previous section. Recall however that our approach is not restricted to these metrics, but instead can benefit from any other one that can be computed automatically.
Alone, the frequency is not a robust metric to assess the terminological property of a candidate, but it does carry useful information, as does also the length of terms.
In (Dunning, 1993), Dunning advocates the use of log-likelyhood to measure whether two events that occur together do so as a coincidence or not. In our case, we want to measure the cohesion of a complex candidate term (a candidate term composed of two words or more) by verifying if its words occur together as a coincidence or not. The log-likelyhood ratio of two adjacent words ( and v) can be computed with the following formula (Daille, 1994):
u
)log()()log()()log()()log()(loglogloglogloglog
bdbddcdcbabacaca
NNddccbbaauv
++−++−++−++−++++=−
where is the number of times appears in the document, the number of times appears not followed by v , the number of times v appears not preceded by ,
a uv bu c
u N the corpus size and the number of candidate terms that does not involve or v . Following (Russell, 1998), to compute log-likelyhood on candidate terms involving more than two words, we keep the minimum value among the log-likelyhood of each possible split in the candidate term.
du
With the intuition that terms are coherent units that can appear surrounded by various different words, we use as well the entropy to rate a candidate term. The entropy of a candidate is computed by averaging its left and right entropy:
( ){ }∑∈
=
+=
Cusus
usleft
nright
nleftn
hse
wewewe
:
111
)(
2)()(
)(
( ){ }
xxxh
hseCsuu
ssu
right
log)(
)(:
=
= ∑∈
where is the candidate term and w1
n C is the corpus from which we are extracting the terms.
Finally, to weight the salience of a candidate term, we also use tf·idf. This metric is based on the idea that terms describing a document
316

Corpus-Based Terminology Extraction
should appear often in it but should not appear in many other documents. It is computed by dividing the frequency of a candidate term by the number of documents in an out-of-domain corpus that contains it. Because tf·idf is usually computed on one word, when we evaluated complex candidate terms, we computed tf·idf on each of its words and kept five values: the first, the last, the minimum, the maximum and the average. In our experiments, the out-of-domain corpus was composed of texts taken from the French Canadian parliamentary debates (the so-called Hansard), totalizing 1.4 million sentences.
Identifying Terms among Candidates
cide which ones should
nd and Schapire, 1999) to
Experiments lacks a common benchmark on which we could
Once each candidate terms is scored, we must definally be elected a term. To accomplish this task, we train a binary classifier (a function which qualifies a candidate as a term or not) on the face of the scores we computed for a candidate.
We use the AdaBoost learning algorithm (Freu build this classifier. AdaBoost is a simple but efficient learning
technique that combines many weak classifiers (a weak classifier must be right more than half of the time) into a stronger one. To achieve this, it trains them successively, each time focusing on examples that have been hard to classify correctly by the previous weak classifiers. In our experiments, the weak classifiers were binary stumps (binary classifiers that compare one of the score to a given threshold to classify a candidate term) and we limited their number to 50. An example of such a classifier is presented in Figure 2.
Our community compare our result with others. In this work, we applied our approach to a corpus called EAU. It is composed of six texts dealing with water supply. Its complex terms have been listed by some members or the Office québécois de la langue française for a project called ATTRAIT (Atelier de Travail Informatisé du Terminologue) whose main objective was to evaluate existing software solutions for the terminologist1.
1. See http://www.rint.org for more details on this project.
317

A. Patry & P. Langlais
nput: A scored candidate term c I
β = 0 if entropy(c) > 1.6 then β = β + 0.26 else β = β - 0.26 if length(c) > 1.6 then β = β + 0.08 else β = β - 0.08 … if β > 0 then return term else return not-term
igure A Adaboost
In our experiments, we kept the preprocessing stage as simple as
ready identified, it is str
-validation. This m
o not co
omaton has a high recall but a lo
F 2: n excert from a classifier generated by thelearning algorithm.
possible. The corpus and the list of terms were automatically tokenized, lemmatized and had their POS tagged with an in-house package (Foster, 1991). Once preprocessed, the EAU corpus is composed 12 492 words and 208 terms. Of these 208 terms, 186 appear without syntactic variation (as they were listed) a total of 400 times.
Since the terms of our evaluation corpus are alaightforward to compute the precision and the recall of our system.
Precision (resp. recall) is the ratio of terms correctly identified by the system over the total number of terms identified as such (resp. over the total number of terms manually identified in the list).
We evaluated our system using five fold crosseans that the corpus was partitioned into five subsets and that five
experiments were run each time testing with a different subset and training the automaton and the classifier with the four others. Each training set (resp. testing set) was composed of about 12 000 (resp. 3000) words containing an average of about 150 (resp. 50) terms.
Because only complex terms are listed and because we dnsider term variations, our results only consider complex terms that
appear without variation. Also, after informal experiments, we set the minimum probability of a pattern to be accepted by our automaton to 0.005. The performance of our system, averaged on the five fold of the cross-validation, can be found in Table 1.
From the results, we can see that the autw precision, which was to be expected. Indeed, the automaton is only
a rough filter that eliminates easy to eliminate word sequences, but keep as much terms as possible. On the other hand, the selection did not perform as well as we expected. Its low recall and precision could be explained by the metrics that are not as expressive as we though and by the fact that 75% of the terms in our test corpora appears only one time. When a term appears only one time, its frequency and entropy become
318

Corpus-Based Terminology Extraction
useless. The results presented in Table 2 seem to confirm our hypothesis.
Part μ σ
Precision 0. 0.05 14Extraction
n Identification
Overall system
Recall 0.94 0.03
Precisio 0.45 0.19 Recall 0.41 0.20
Precision 0.43 0.18 Recall 0.38 0.18
Table 1: Mean ( μ ) and standard deviation (σ ) of the precision and
Because we wanted to compare our system with the individual metrics
recall of the different parts of our system.
that it uses, we had to modify it such that it ranks the candidate terms instead of simply accepting or rejecting them. To do so, we made our system return β instead of term or not term (see Figure 2). We then sorted the candidate terms in decreasing order of their β value.
A common practice when comparing ranking algorithms is to build th
Discussion and Future Works ch to automatically generate an
e can easily extend th
eir ROC (receiving operator curve), which shows the ratio of good identifications (y axis) against the ratio of bad identification (x axis) for all the acceptation thresholds. The best curve will augment in y faster than in x, so will have a greater area under it. We can see in Figure 3 that our system performs better than entropy or log-likelyhood alone. This leads us to believe that different scores carry different information and that combining them, as we did it, is fruitful.
In this paper, we presented an approaend-to-end term extractor from a training corpus. We also proposed a way to combine many statistical scores in order to extract terms more efficiently than when each score is used in isolation.
Because of the nature of the training algorithm, we set of metrics we considered here. Even a priori knowledge could
be integrated by specifying keywords before the extraction and setting a score to one when a candidate term contains a keyword or zero otherwise. The same flexibility is achieved when the automaton is created. By generating it directly from the output of the POS tagger, our solution does not depend of a particular tagger and is tolerant to consistent tagging errors.
319

A. Patry & P. Langlais
μ σ Criteria Precision 0.39 0.16 Candidates appearing o
n Candidates appearing at least two times
ne time Recall 0.33 0.22
Precisio 0.73 0.14 Recall 0.85 0.09
Table 2: Comparison of the performance of the term identificat
Figure 3: The ROC of our system (AdaBoost) against two other score
A shortcoming of this work is that we did not treat term variations.
complex terms. Because some sc
ion part for candidates appearing with different frequencies.
when we trained our system on one half of our corpus and tested on theother. A greater area under the curve is better.
Terminology variation is a well-known phenomenon, whose amount is estimated according to (Kageura et al., 2004) from 15% to 35%. We think that the best way to deal with them in our framework would be to introduce a preprocessing stage where variations are normalized to a canonical form. Term variations have been extensively studied in (Jacquemin, 2001) and (Daille, 2003).
In our experiments, we focused on ores do not apply to simple terms (e.g. log-likelyhood and length), we
think that the best way to extract simple terms would be to train a dedicated classifier.
320

Corpus-Based Terminology Extraction
Acknowledgements ugo Larochelle who found the corpus we used
eferences eresa Cabré; Bagot; Rosa Estopà; Palastresi; & Jordi
Daille, Béatrice; Study and Implementation of Combined Techniques
Daille, Béatrice; Conceptual structuring through term variations, in
Du tistics of Surprise and
Fos tical lexical disambiguation, Master Thesis.
Fre duction to Boosting, in Journal
Jac hrough Natural
Jus nical Terminology: Some
Kag Hiroshi & Lee-Feng Chien;
Langlais, Philippe & Michael Carl; General-purpose statistical
We would like to thank Hin our experiments and Elliott Macklovitch who made some useful comments on the first draft of this document. This work has been subsidized by NSERC and FQRNT. RCastellví, M; T
Vivaldi; Automatic Term Detection: A Review of Current Systems, in Recent advances in computational terminology, John Benjamin, 2001.
for Automatic Extraction of Terminology, in The Balancing Act: Combining Symbolic and Statistical Approaches to Language, New Mexico State University, Las Cruces, 1994.
Proceedings of the ACL Workshop on Multiword Expressions: Analysis, Acquisition and Treatment, 2003.
nning, Ted; Accurate Methods for the StaCoincidence. 1993. ter, George; StatisMcGill University, Montreal, 1991. und, Y.; R.E. Schapire; A Short Introof Japanese Society for Artificial Intelligence, 1999. quemin, Christian; Spotting and Discovering Terms tLanguage Processing, MIT Press, 2001. teson, John; S. Katz & M. Slava; TechLinguistic Properties and an Algorithm for Identification in Text, in Natural Language Engineering, 1995. eura, Kyo; Daille Béatrice; NakagawaRecent Trends in Computational Terminology, in Terminology, John Benjamin, 2004.
translation engine and domain specific texts: Would it work? in Terminology, John Benjamin, 2004.
321


Towards a Text Mining Driven Approach for Terminology
Construction
VALENTINA CEAUSU & SYLVIE DESPRES
In this paper we investigate the contribution of text mining techniques to a methodology of terminology construction from natural language corpora. The application area of our experimentation is accidentology. In this context, the results of text mining techniques are used in order to guide the construction of a terminology of road accidents from a collection of accident reports. A model of our field, an ontology of accidentology, is used that allows us to carry out the text mining process. The Terminae methodology and the tool supporting it offer the general frame for the resource construction. Further on we shall present our employed text mining techniques and the integration of the results we obtained into different phases of the construction process. Suggestions for further research to improve our techniques are also presented in this study. Keywords: terminology, text mining, association rules, ontology. 1. Introduction In this paper we investigate the contribution of text mining techniques to a methodology of terminology construction from natural language corpora. We propose an approach for terminological resources construction based on Terminae (Biébow, Szulman, 2000) methodology with a number of adaptations. The application area of our experimentation is accidentology. An ontology of accidentology exists which was created from experts’ knowledge (Després, 2002). We focus here on the construction of a terminology of accidentology from a collection of accident reports written by policemen. The two resources (ontology and terminology) will be exploited in a case based reasoning system, having cases created from heterogeneous natural language sources. The larger the corpora, the more difficult the construction process, and guiding information is then needed. We employed text mining techniques in order to extract this information: (a)a pattern recognition algorithm that generates a set of nominal and

V. Ceausu & S. Despres
verbal syntagms; (b)Apriori algorithm in order to refine the set of nominal syntagms; and (c) an approach using the ontology of road accidents to refine the set of verbal syntagms.
The outline of the paper is as follows: section 2 introduces natural language corpora used later in the paper and knowledge extraction from corpora; section 3 describes the solutions adopted in order to validate the knowledge extracted previously; section 4 briefly introduces the Terminae methodology for terminological resource construction and focuses on how this process is guided by text mining results; related approaches in the field of ontological engineering or machine learning are presented in section 5; different suggestions for further research and improvements of the techniques are presented in the conclusion (section 6). 2. Knowledge Extraction for Terminology Construction A terminology is created by structuring specific terms of a given field. Terms represent linguistic manifestations of concepts and provide valuable indication about knowledge inside documents (Ville-Ometz et al., 2004). Terminology is related to a task and the underlying model is specific to the task. The main purpose of our work is to build a terminology from text corpora by adopting a mixed approach: Terminae methodology and tool, and text mining techniques the results of which guide the construction process. Corpora description We used a corpora composed of 250 reports of accidents which occurred in and around Lille. The PACTOL tool (Centre d’Etudes Techniques de l’Equipement de Rouen) made the reports anonymous. Accident reports are created by the police and include variables describing the actors of the accident as well as natural language paragraphs explaining what happened in the accident. The terminology is created from natural language paragraphs of accident reports. Tools for annotating text with lexical information, namely TreeTagger or Cordial, were used in the treatment of the paragraphs. Generating word regroupings – patterns recognition algorithm A module for knowledge extraction was developed which identifies terms of accidentology and relations between the identified terms. This module realises two treatments: it generates sets of word regroupings and it provides approaches to refine the extracted sets.
Word regroupings are generated according to linguistic patterns. A linguistic pattern is a set of lexical categories: (Noun, Noun) or (Verb,
324

Towards a Text Mining Driven Approach for Terminology Construction
Preposition, Noun). Terms of domain or conceptual relations can be recognized as sequences of words which respect defined linguistic patterns. The module takes as input results of text annotating tools, Cordial or TreeTagger. The annotation allows us to assign to each word of the corpus its lexical category: noun, adjective, verb, preposition, etc.
The module implements a pattern recognition algorithm (Fig.1) and automatically generates sets of word regroupings corresponding to defined patterns. For each sentence of the corpora : (1)eliminate elements of context (proper names) and references (pronouns); (2) For each word of the sentence :Test whether its lexical category can generate a pattern with the lexical categories of its neighbours ;if so, create a regrouping ;If not, analyze the next word; (3)Insert created regroupings into regrouping set; Figure I: Pattern recognition algorithm
For this study, we have defined two categories of patterns: nominal patterns having a noun as first term and verbal patterns the first term of which is a verb. The conceptual relations associated with the nominal patterns can be hyponymy relations (Hearst, 1992 ; Morin, 1999 ; Kietz et al., 2000);verbal patterns highlight properties between the concepts which will be translated as roles. A pattern recognition algorithm identifies instances of already defined patterns inside each sentence. Two sets of word regroupings corresponding to each pattern category are generated as result (Fig. 2). Each regrouping can represent: a verbal construction {(venir de -- come from);( tourner sur droite -- turn to right)} ; terms of the domain {( ceinture de sécurité – seat belt);( priorité du passage – give way)}; a relation between terms of domain {(propriétaire, véhicule -- owner, vehicle);(passager, véhicule -- passenger, vehicle) . We also obtained regroupings without semantic contents which represent noise {(c, véhicule --c, vehicle) ; (venir de 3o6 – come from 306)}.
325

V. Ceausu & S. Despres
Patterns Corresponding word regroupings Noun, Noun : accident , agent (accident, policeman) Noun, Preposition, Noun : usager de route (road user) Noun, Preposition, Noun : groupe de piéton ( group of pedestrians) Noun, Preposition, Adjective : trottoir de droite (right side pavement) Verb, Preposition, Noun : diriger vers place (direct to square) Verb, Preposition, Adjective : virer à gauche (turn left)Figure 2:Examples of patterns and corresponding regroupings
At this stage, the number of word regroupings is important (44000) and refining is needed to make the extracted knowledge exploitable. Refining processing is specific to each category of regroupings. The refining of the nominal syntagm set is realised by applying the APRIORI algorithm. The set of verbal syntagms is refined with the help of the accidentology ontology. 3. Refining the Extracted Knowledge Association rules extraction from the set of nominal syntagms Association rules are employed in data mining and constitute good indicators to identify regularities in large volumes of data. In text mining, extracted rules can be interpreted as co-occurrences of terms in texts and consequently are able to reflect semantic relations between terms. In ontological engineering (Maedche et Staab, 2000 ; Kietz et al., 2000) association rules were used to discover non-taxonomic relations between concepts by using a hierarchy of concepts as basic knowledge. CLOSE (Pasquier et al., 1999) and APRIORI (Agrawal & Srikant, 1993) algorithms allow the implementation of rules extraction process. Quality measures are defined to identify, in the set of rules, those which are considered to be useful for the terminology modeling and to eliminate the inconsequential ones.
APRIORI algorithm, as used by (Maedche and Staab, 2000), is adapted to our problem. It contributes to eliminate accidental regroupings and produces a set of regroupings containing domain terms {(usager de route – road user)} and relations between domain terms {(conducteur, véhicule -- driver, vehicle) }. The generation of nominal syntagms set is an integral part of APRIORI algorithm. First, regroupings are extracted from sentences according to patterns previously defined. The basic association rule algorithm is provided with a set of transactions:
The basic association rule algorithm is provided with a set of transactions:
326

Towards a Text Mining Driven Approach for Terminology Construction
{ }1 2 pT = t , t , . . . , t where each transaction i consists of a set of items and each item is made of one or more words
t{ }1 2 kM m , m , ..., m= .
In this case, a transaction is a sentence of corpora. The available corpora represents the set of transactions. We define an association rule by a relation R : (X=>Y), where X (premise of rule) and Y(conclusion of rule) are word regroupings: { }1 2 p iX = x ,x , . . . , x |x M∈ ; { }1 2 n iY = ,y , . . . , y |y My ∈ . The meaning of a rule R is that sentences containing the word regrouping X tend to contain the word regrouping Y with some probability. We used two restricted forms of association rules: -the R1 form restricted to two words, having 1 word in premise and 1 word as conclusion. (X Y⇒ ) where: { }|X x x M= ∈ , { }|Y y y M= ∈ (R1) -the R2 form restricted to three words, having 1 word as premise and a regrouping of two words as conclusion. (X Y⇒ ) where : { }|X x x M= ∈ , { }1 2 1 2, | ,Y y y y y M= ∈ (R2) Patterns previously defined help in the construction of associations corresponding to the two forms. A pattern (Noun, Noun) generates associations having the (R1) form {X = conducteur (driver), Y = véhicule (vehicle)}; a pattern (Noun, Preposition, Noun) creates an association of (R2) form {X = chaussée (road), Y = de gauche (left side)}. The (R1) form makes it possible to identify relations between terms. Extracted relations could be structural (IS-A relation) or functional {véhicule (vehicle), propriétaire (owner)}. Accidentology terms can be found according to (R2) form. Two measures of quality, support and confidence are used to rank extracted rules. The support of R ( )X Y⇒ represents the percentage of sentences containing the terms of ( )X Y∪ :
( )( ){ }
{ }i i
i
t X Y tS u p p o r t X Y
t
∪ ∈⇒ =
Confidence is the percentage of sentences containing Y, when X appears in the sentence.
327

V. Ceausu & S. Despres
( )( ){ }{ }|
|i i
i i
t X Y tC onfidence X Y
t X t
∪ ∈⇒ =
⊂
It measures the validity degree of a rule. When the confidence value is worth 1, the rule is known as total, otherwise it is known as partial.
Thresholds are defined for these quality measures: minsup for minimal support and minconf for minimal confidence. The minsup threshold defines the value above which a regrouping is regarded as frequent. Values of support lower than minsup correspond to rare associations which we consider as accidental (noise).Values v of the support such as minsup < v <1 generally indicates generic concepts of domain. The minconf threshold makes it possible to generate only rules the confidence of which is between minconf and 1. Hence, the steps of APRIORI algorithm are : (1)Generate the association set(according to patterns); (2)For each association calculate support and confidence; (3)Eliminate associations having confidence and support below minsup and minconf thresholds. Adaptations of APRIORI as presented by (Maedche and Staab, 2000) concern step 1, in which associations are generated according to patterns, and step 3, in which associations are eliminated with respect to both thresholds. In a first version of algorithm implementation, arbitrary values were assigned to minsup and minconf thresholds. The second version of implementation makes it possible for an expert to select suitable values for the two thresholds among the values of support and confidence. In this approach, support and confidence are the only quality measures considered because generating the set of regroupings according to defined pattern already represents a validation.
Other quality measures based on knowledge models such as the index of interest, innovation or satisfaction - (Cherfi and Al, 2003) are currently under study and will be considered in future work to improve the results obtained.
Among association rules retained at the end of this refining stage, composite terms of domain are observed and various types of relations (Fig.3) are highlighted. The extracted relations are unnamed and express the fact that two terms are more or less strongly related, although the exact nature of the relationship is unknown. Functional
328

Towards a Text Mining Driven Approach for Terminology Construction
relations will be labelled by verbs by using the ontology of road accidents.
Extracted relations Relation type (name) véhicule ,automobile ( vehicle, car)
Is-a
volant, véhicule (steering wheel ,vehicle)
Part-of
conducteur, véhicule (driver, vehicle)
functional
conducteur, camion (driver, van) conducteur, cyclomoteur (driver, motorbike )
particular cases of previous relation as van and motorbike are both vehicles
Figure 3: Conceptual relations discovered Using a domain model to refine the set of verbal syntagms Refining the set of verbal syntagms is realised in two steps: first, classes of verbs are identified in the set of verbal syntagms, and, secondly, the ontology of accidentology is used to improve identified classes.
A class of verbs represents the set of regroupings generated by the same verb. Each class of verbs contains two categories of associations (Fig.4): two-term associations corresponding to a pattern "verb, preposition" (diriger vers—direct to) and three-term associations generated by a pattern "verb, preposition, syntagm"( diriger vers bretelle – direct to slip road). The three-term associations are obtained by adding to two-term associations an extension corresponding to the grammatical function of “complement”.
diriger vers ( direct to);diriger vers lieu ( direct to place ) ;diriger vers usine (direct to factory) ; diriger vers parc(direct to park); tourner à (turn to ); tourner à droite (turn right); tourner sur gauche (turn left) ; Figure 4: Extracts from "diriger (direct)” class and “tourner (turn)” class The results we obtained reveal inside each class a reduced number of two-term associations to which correspond a rather significant number of possible extensions which in turn lead to three-term associations. However, the vast number of three-term associations and their extremely fine level of granularity make them not easily exploitable. In
329

V. Ceausu & S. Despres
order to reduce the number of three-terms associations inside a verb class, we have recourse to the ontology of accidentology. Thus, extensions of three-term associations are organized in homogeneous lists (Fig. 4). Then, a manual intervention is realized that associates each list to a concept of ontology. Concept of ontology List of terms direction (direction) :droite (right), gauche (left), devant (in front of) ; lieu (place) :usine (factory), parc (park), domicile (home), école (school) Figure 5: Lists of terms associated to concepts of ontology
Using the ontology reduces the number of three-term associations (Fig.5). It also eliminates noise by removing associations in which parasitic terms appear, such as « diriger vers 12 (direct to 12) » or associations such as « diriger par sapeur (directed by fireman) » which are of no interest in the studied context: “diriger (direct)” having the meaning of command is not the usual sense in accidentology. However, if this approach reduces the number of three-term associations, it is also likely to eliminate valid syntagms if our lists are incomplete. Diriger à direction (direct to direction) ; Diriger par humain (directed by someone) Diriger vers lieu(direct to place) ;Diriger vers direction ( direct to direction) Diriger vers infrastructure (direct to infrastructure) ; Diriger vers immeuble (direct to building ) Figure 6: Class "diriger (direct)" refined by ontology The results of previously described processing are exploited in order to build the terminological resource.
4. Driving the Terminology Construction Process TERMINAE is a methodology for terminological resources construction from natural language corpora. A tool having the same name implements this methodology. For a specific application, TERMINAE uses texts of domain and assists the user in his resource modeling task, from term identification to concept formalisation.
In order to clarify further presentation, the phases of TERMINAE methodology are presented:(a) browsing terms extracted by the term
330

Towards a Text Mining Driven Approach for Terminology Construction
extractor Syntex (Bourigault &Fabre, 2000) in order to select the relevant ones; (b) analysing the term occurrences and their lexico-syntactic relations. Lexico-syntactic relations are analysed by a Terminae integrated module, called Linguae, which is able to scan a textual corpus previously labelled with lexical-syntactic markers to find relationships between terms. (c) elaborating of a terminological profile for each term where the various meanings of the term are defined; (d) then considering and standardizing each meaning of term with respect to corpora, the considered application and the selected point of view; this standardization defines a terminological concept;(e) constructing a formal ontology which could be validated.
In (a), the selection of relevant terms is directed by association rules results. The list of composite terms validated by APRIORI algorithm constitutes a help for the selection of terms extracted by Syntex and makes it possible to eliminate those which are not relevant to our task. In (b), relations identified by APRIORI algorithm facilitate the study of term occurrences in the corpora. They also improve the use of LINGUAE module. In (d), terminological concepts are completed by integrating terms discovered by APRIORI (Fig.6).
Some of the terms identified by SYNTEX contain information specific to particular contexts. The module of regrouping generation eliminates context specific information and provide generic results, having a better level of abstraction :se diriger vers la Commune de Wahagnies (Direct to Wahagnies village )--Syntex result vs. diriger vers lieu (direct to place)--our extraction module .The (e) phase requires modeling of concepts and roles at the formal level. Concepts resulting from (d) are used as a basis to create formal concepts.
Figure 7: Enrichment of "Infrastructure" concept
331

V. Ceausu & S. Despres
Roles describe relations between concepts. Verbal syntagms constitute good indicators to model them. SYNTEX identifies verbs representative of domain, but the number of corresponding instances of a verb remains limited. This limitation proves to be a factor that influences modeling of relations between concepts. Thus, some relations could not be highlighted because of a reduced number of associated instances of verbs. In order to eliminate this insufficiency, we use the classes of verbs identified by text mining algorithms. The classes identified by those algorithms are used in the last phase of Terminae methodology to model relations within the terminological resource. Roles are created from verb classes and the structure of the terminological resource is refined by integrating relations provided by the processing of nominal syntagm set.
5. Related Approaches Approaches proposed in ontological engineering and in machine learning field are at the origin of presented work.
In ontological engineering, (Maedche & Staab, 2000) proposes a general solution allowing the construction of ontology from a natural language corpora. The proposed framework allows the automatic extraction of knowledge whereas modeling of knowledge discovered is realised by a semi-automatic module. Syntactic patterns (predicate - complement) and heuristics specific to sources are used in order to identify associations between words. This approach integrates generic resources and offers several methods of text pre-processing.
Our approach presents a reduced number of pre-processing methods and sources provided by Cordial or TreeTagger which only allow treatment at sentence level. Integrating the previously created ontology of road accidents constitutes an advantage. The two approaches offer solutions specific to the task and the resources used and have the advantage of taking into account the non-taxonomic relations identified using the same algorithm.
Several machine learning works related to verbs and discovery of semantic relations are also in relation with the present work. Among them, (Faure & Nedellec, 1998) uses hierarchical classification and grammatical relations in order to extract so-called diagrams of sub categorization describing a specific term in its context.
The work of (Wiemer-Hastings & all, 1998) concerns the identification of significance of the unknown verbs using the context of occurrence of the verb. The system CAMILLE uses WordNet as background knowledge and generates assumptions concerning the
332

Towards a Text Mining Driven Approach for Terminology Construction
meaning of verbs. The assumptions are formulated according to linguistic criteria’s.
The solution suggested by (Byrd & Ravin, 1999) identifies relations according to particular syntactic pattern and assigns names to them.
The Prométhée (Morin, 1999) system offers a solution for structuring terminological units. In his training phase, Prométhée extracts lexico-syntactic pattern specific to a semantic relation. The patterns thus identified are used in the structuring phase in order to identify relations between terminological units. In our approach, the relations correspond to patterns defined in a general way and are validated and named by an expert. The system uses a set of predefined patterns that will not be enriched.
The solutions directed by the verbs present the disadvantage of identifying the relations characterized by verbs only. Our contribution relates to the additional relations obtained using associations rules. 6. Conclusion and Future Work From a practical point of view, our approach facilitates the construction of a terminological resource by automating some of the text treatments. The results we obtained (extraction of domain terms, construction of verbs classes and emergence of generic and functional relations) support the terminology construction. Those results direct the term selection and represent good indicators of associations between the selected terms. The model of terminological concepts in the normalisation phase is enriched using the ontology of accidentology which also allowed us to eliminate some irrelevant word regroupings.
In future, the definition of syntactic patterns, able to generate more relevant regroupings is possible. Algorithms generating regroupings on more complex levels such as paragraphs will be integrated. In order to validate the set of nominal syntagms, quality measures such as the index of interest, innovation or satisfaction (Cherfi & all, 2003) could be used. An automatic solution could be proposed to associate lists of terms to concepts of ontology. Employing text mining techniques to identify structural and functional properties of terms is also a possible prospect of this study. References Biébow, B. & S. Szulman; TERMINAE : A linguistic-based tool for
the building of a domain ontology, in Proceedings of the 11th European Workshop, Knowledge Acquisition, Modeling and
333

V. Ceausu & S. Despres
Management (EKAW' 99), pp. 49 – 66, Dagstuhl Castle, Germany, 1999.
Byrd, R.J. & Y. Ravin; Identifying and Extracting Relations in Text. Proceedings of NLDB 99, Klagenfurt, Austria, 1999.
Bourigault, D. & C. Fabre; Approche linguistique pour l'analyse syntaxique de corpus. Cahiers de Grammaires, n° 25, Université Toulouse - Le Mirail, 2000.
Cherfi, H. & Y. Toussaint; Adéquation d’indices statistiques à l’interprétation de règles d’association, in Actes JADT : 6èmes journées internationales d’Analyse statistique des Données Textuelles, St. Malo, France, 2002.
Cherfi, H.; A. Napoli & Y. Toussaint; Vers une méthodologie de fouille de textes s’appuyant sur l’extraction de motifs fréquents et de règles d’association. Conférence d’apprentissage, Laval, France, 2003.
Després, S.; Contribution à la conception de méthodes et d’outils pour la gestion des connaissances. Habilitation à Diriger des Recherches en Informatique, Université René Descartes, Paris 2002.
Faure, D. & C. Nedellec; A corpus-based conceptual clustering method for verb frames and ontologies acquisition. LREC workshop on adapting lexical and corpus resources to sublanguages and applications, Granada, Spain, 1998.
Feldman, R.; M. Fresko; Y. Kinar; Y. Lindell; O. Liphstat; M. Rajman, Y. Schler & O. Zamir; Text Mining at the term level. LNAI: Principle of Data Mining and Knowledge Discovery, 1510(1), pp. 65 – 73, 1998.
Hahn, U. & K. Schnattinger; Towards text knowledge engineering. Proc. of AAAI, pp. 129 – 144, Madison, Wisconsin, 1998.
Hearst, M.A.; Automatic acquisition of hyponyms from large text corpora, in Proceedings of the 14th International Conference on Computational Linguistics, Nantes, France, 1992.
Kodratoff, Y.; Knowledge Discovery in Texts: A definition, and Applications, in LNAI. Proc.of the 11th Int’l Symp.ISM’99, vol. 1609, pp. 16 – 29, Warsaw, Poland, 1998.
Maedche, A. & S. Staab; Mining ontologies from text, in Knowledge Acquisition, Modeling and Management, 12th International Conference, EKAW 2000, pp. 189 – 202, Juan-les-Pins, France, 2000.
Morin, E.; Automatic acquisition of semantic relations between terms from technical corpora, in Proceedings of the Fifth International
334

Towards a Text Mining Driven Approach for Terminology Construction
Congress on Terminology and Knowledge Engineering - TKE’99, Innsbruck, Austria, 1999.
Séguéla P.; Adaptation semi-automatique d’une base de marqueurs de relations sémantiques sur des corpus specialises, in Actes de TIA’99 (Terminologie et Intelligence Artificielle), Nantes, Terminologies Nouvelles, n°19, pp. 52 – 60, Nantes, France, 1999.
Srikant, R. & R. Agrawal; Mining generalized association rules, in Future Generation Computer Systems, pp. 161 – 180, 1997.
Toussaint Y.; A. Simon & H. Cherfi; Apport de la fouille de données textuelles pour l’analyse de l’information, in Actes de la conférence IC’2000, Ingénierie des connaissances, pp. 335 – 344, Toulouse, France, 2000.
Ville-Ometz, F.; J. Royauté & A. Zasadzinski; Filtrage semi-automatique des variantes de terms dans un processus d’indexation contrôlée, in Actes de Colloque International sur la Fouille des Textes, La Rochelle, France, 2004.
Wiemer-Hastings, P.; A. Graesser & K. Wiemer-Hastings; Inferring the meaning of verbs from context. Proceedings of the Twentieth Annual Conference of the Cognitive Science Society, Mahwah, NJ: Lawrence Erlbaum Associates, 1998.
335


Developing Automatic Term Extraction
Automatic Domain Specific Term
Extraction for Norwegian
K. ØVSTHUS, K. INNSELSET, M. BREKKE & M. KRISTIANSEN Introduction Knowledge-Bank of Norway (KB-N) is a 3-year project at the Department of Professional and Intercultural Communication, Norwegian School of Economics and Business Administration (NHH), with the aim of establishing a knowledge-bank for economic-administrative domains. The KB-N database comprises a text database and a term database. Building a term database from a text database on this scale requires an automatic term extraction module for Norwegian, but no adequate tool for this purpose exists today. A preliminary version is under development as part of the KB-N software suite and was demonstrated at LREC 2004 (Brekke, 2004).
The further development and refinement of this tool is a great challenge facing the KB-N project team. For this purpose a pilot study was carried out where we performed term extraction from a given text by using two different methods: a) Term extraction by using the preliminary automatic term extraction module and b) Manual term excerption by a domain expert and an experienced terminologist. Manual term excerption, while superior to an automatic extraction algorithm, will simply not cope with the amount of text envisaged for the KB-N corpus. A list of term candidates based on the excerption performed by a domain specialist and a terminologist can therefore be considered a gold standard for the purpose of refining the algorithms for automatic extraction, yielding interesting recall and precision figures. On this empirical basis we should then be able to identify possibilities for further enhancement of the existing extraction algorithm, such as additional NP-structures which should be included in the linguistic filter, as well as additional items which should be excluded by stop lists for the linguistic filter.

K. Øvsthus, K. Innselset, M. Brekke & M. Kristiansen
Currently the term extraction using the two methods has been completed and part of the analysis carried out. In the following we will describe the functioning of the preliminary version of the automatic term extraction module, the methods applied for manual term excerption as well as analysis of the results. Finally we will present some preliminary results of the analysis, and areas for further investigation. The Automatic Term Extraction Module The term extraction module in its present form extracts NP term candidates from texts in the text database according to set criteria, mainly linguistic and statistical, based on the texts being automatically POS-tagged prior to term extraction. A preliminary filter for term extraction has been established. In its basic form it has three components:
• Linguistic filter which only accepts a. (adjectives in the positive form)* + noun (except the genitive form) b. adjective + “og/eller” + adjective + noun c. noun + “-“ + “og/eller” + noun As an extension of the linguistic filter a preliminary stop list for adjectives (pure and participial) has been established. It contains adjectives which we assume will seldom or never occur as modifying part of multiword terms within the economic-administrative domain. The empirical basis for the list was a study of two-word term candidates with premodifying adjectives extracted from a representative sample of the corpus by an earlier version of the automatic extraction module. Adjectives co-occurring with a large number of nouns where all combinations could be rejected offhand as potential terms by domain experts, were included in the stop list. At the time of the pilot study the list contained approximately 300 adjectives (examples include adjectives like “øvrige”, “viss”, “dårlig”, “presentert” and the categories ordinals and nationality adjectives).
• Named entity recognition which will, according to set criteria, accept structures otherwise suppressed by the linguistic filter, e.g. NPs expressing organization names beginning with a definite article and containing adjectives included in the stop list mentioned above. The named entity recognition formalism underlying the KB-N approach is further described at:
338

Developing Automatic Term Extraction
http://scrooge.spraakdata.gu.se/nn/Material/ Janne_B_J_MONS-01,_vansk.navn,_PPT.ppt.
• Significance ratio (“weirdness filter”) which suppresses strings which occur more frequently in an LGP corpus than in the LSP text under consideration, but which otherwise satisfy the structural criteria of the linguistic filter. As reference corpus we use a Norwegian newspaper corpus of approximately 350 million words, compiled and administered by Knut Hofland, Aksis, University of Bergen.
Method for Manual Term Excerption As textual basis for the pilot study we selected Finansregnskap - Teori og metode (Havstein and Moen, 2004). This is a text from the economic-administrative domain, more specifically the sub-domain of accounting, and contains 36,000 words. Being a recognized textbook on financial accounting at a fairly introductory level, we expected it would contain a good selection of the most important terminology of this sub-domain. Furthermore, this text was available in electronic form. On registration in the database all texts are XML-coded. In addition to the elements for structure-coding an element <term> has been established, for marking the term candidates manually in the file.
Before we, the terminologist and the domain expert, commenced our work, two separate copies of the file were made. We agreed upon certain basic criteria for excerption, and apart from these we would work separately and only compare our results afterwards. The basic criteria we agreed upon were the following:
• We would excerpt term candidates from all economic-
administrative domains, not only from accounting, since term candidates from other sub-domains would be of potential interest for the KB-N database later. Also the automatic extraction module would extract term candidates from all economic-administrative domains, as it does not distinguish between the different sub-domains.
• We would accept that relevant concepts can, in principle, be realized in many different linguistic forms, not only the most common ones like pure root nouns, compounds and the combination adjective/participle + noun, structures which for that very reason have been included as acceptable structures in the preliminary linguistic filter of the extraction module. The excerption process should therefore concentrate on concepts irrespective of form. Prior knowledge of accepted or common
339

K. Øvsthus, K. Innselset, M. Brekke & M. Kristiansen
term structures realizing concepts, like those mentioned above, should not prevent us from excerpting any string of any form with potential terminological value. Thus we approached the excerption task quite unprejudiced as to “acceptable” term structure, fully aware of the fact that looking only for concept realizations conforming to predetermined “canonical” linguistic structures would be more a source of error than guidance.
• We would excerpt coordinating NP structures typically representing more than one concept with a hyphen postfixed to the noun preceding the conjunction or a hyphen prefixed to the noun following it, for later splitting into two or more separate terms (actually some strings of this form represent terms in their own right, e.g. “lønns- og trekkoppgave”, which coordinates “lønnsoppgave” and “trekkoppgave”). This for the obvious reason that the relevant concepts may be represented solely by such structures in the text at hand. The same procedure would apply to NPs with coordinated premodifying adjectives. Most of this is also catered for by the preliminary linguistic filter. Acceptance of the coordinating structure with prefixed hyphen is yet to be implemented.
• For fear of missing relevant concepts we decided on a wide interpretation allowing us to include any string where we had the slightest suspicion that it might represent a relevant concept.
These ground rules having been agreed on, term candidates were intuitively excerpted from the text. We then compared and combined the results of the separate excerption processes carried out by the terminologist and the domain expert, respectively. In the course of the process we came to realize that the units identified in the study would remain term candidates and not necessarily be recognized as terms. To decide on the final term status of all the term candidates based on consistent criteria is a major task in itself, which eventually will be undertaken. Thus far we have grouped the manually excerpted term candidates not covered by the automatic extraction algorithm according to linguistic structure. Method for Analysis of the Results The results from automatic term extraction and manual excerption were organized in a table with all the term candidates listed in the leftmost column (Table 1). Then a number of other columns were established to enable us to add various kinds of information about the term candidates, and which would be used as sorting criteria in the
340

Developing Automatic Term Extraction
process of analyzing the results. Most word processors (in casu Microsoft Word) offer the opportunity to sort the columns in different orders, to provide different perspectives for the analysis of the term candidates.
The second column in Table 1 indicates whether the term candidate in question has been selected by the automatic extraction module, the manual team or both.
The third column names the type of structure that has been excerpted, and which will be considered for inclusion in the linguistic filter. Blank cells represent structures already permitted by the linguistic filter. This column is therefore relevant for candidates excerpted manually only.
In the fourth column the prepositions used in the prepositional phrases in question are listed.
In the fifth column the term candidates have been assigned to different sub-domains within the economic-administrative domain. As stated in the criteria for the manual excerption, candidates from all economic-administrative sub-domains would be considered. For our purpose three labels suffice: RR, ØK and NIL. They represent accounting term candidates, general/unspecified economic-administrative term candidates, and rejected candidates respectively. At this stage of the investigation rejection procedures have only been carried out for automatically extracted candidates, as evidenced from Table 1 where the two NIL items also carry the label AUTO in the second column. Both rejected candidates are compound nouns (recognized as a perfectly legitimate candidate structure by the linguistic filter) which have escaped suppression by the weirdness filter, but have failed the test of terminological relevance by manual scrutiny.
In the rightmost column there is an alphanumeric code for candidates which have “packed” or “unpacked” equivalents elsewhere in the candidate list (Andersen, 1998). This means that, for example, for the term candidate “bruker av regnskapet” with the code “18U”, there is also an equivalent “regnskapsbruker” elsewhere in the table (not shown in this sample table extract) marked by the code “18P”. The authors’ choice between the “packed” and “unpacked” version of the term is seemingly random, but it could be discussed if the extended use of unpacked versions at the expense of packed in this text is due to the fact that this is an elementary textbook on the subject of accounting, and the unpacked version tends to give away more information about the concept. Table 1 provides a fragment of the master table alphabetically sorted.
341

K. Øvsthus, K. Innselset, M. Brekke & M. Kristiansen
Term candidate Selected Structure Prep Dom P/U ajourholdsfrist AUTO/MAN ØK 27P avdrag og renter MAN NP+konj.+NP RR behandlingsprosess AUTO NIL bileksempel AUTO NIL bokføre MAN V RR bokføring AUTO/MAN RR bokføring av korreksjoner
MAN NP+PP Av RR
bokføring på konto MAN NP+PP På RR bokføring til debet MAN NP+PP Til RR bokføringsfeil AUTO/MAN RR bokført salg AUTO/MAN RR bokført utgift AUTO/MAN RR bransje MAN ØK bruker av regnskapet MAN NP+PP Av RR 18Uetterskuddsvis MAN A ØK forskudd leie MAN NP+NP RR forskuddsvis MAN A ØK godskrevet MAN PSP RR konto for forskuddsbetalt leie
MAN NP+PP For RR
kreditert MAN PSP RR solgte varers anskaffelseskost
MAN NPgen.+NP RR
årets resultat MAN NPgen.+NP RR Table 1: Term candidates sorted alphabetically The main purpose of the pilot study was to develop a basis on which additional/enhanced criteria for the automatic extraction module could be built. As a consequence the main focus of the analysis would be on the term candidates that were excerpted in the manual process, but missed in the automatic extraction process.
The “missing” candidates can only be explained with reference to the three-component automatic extraction filter.
The first component, the linguistic filter, suppresses all formal linguistic structures which it has not been explicitly instructed to accept. Therefore, at the structure type level, all discrepancies between the manually and automatically extracted candidate lists originating in structural features can be ascribed to manual excerption of term candidates with a structure not (yet) implemented as a recognized term
342

Developing Automatic Term Extraction
structure in the linguistic filter. This is just as it should be; deviations on this point would indicate faulty programming of the underlying algorithm, or what sometimes actually happens, but is beyond our immediate control, that the otherwise reliable POS-tagger fails to interpret a lexicon-external compound correctly. Alternatively it may be the case that the shallow syntax annotation is insufficient to prevent breakdown of constituent structure.
A term candidate can also be missing from the automatic extraction list for non-structural reasons. This relates to the third component of the extraction module, the weirdness filter. From the point of view of the extraction module a string satisfying structural criteria does not become a term candidate before it has been tested for its frequency in the LSP text at hand compared to its frequency in the LGP reference corpus. The required excess frequency is expressed as a value indicating the threshold level for acceptance as a term candidate. If a high number of undisputed terms are suppressed by the weirdness filter, the threshold level should be adjusted. This is ultimately a question of balancing precision and recall.
We shall illustrate some of the points mentioned above with reference to Table 2 below and hopefully in the process also demonstrate the usefulness of tables for research purposes of this kind.
Table 2 contains exactly the same information as Table 1, only the sorting order is different. Table 2 is sorted in the column order 2, 3, 4.
For ease of reference we shall focus on column 2, the primary sorting order. As we can see, the term candidates in the two topmost rows originate solely from the automatic extraction list. For lack of terminological relevance they have both been rejected by the domain expert (as indicated by NIL in column 5). This should come as no surprise; we would expect any string with potential terminological value also to be represented in the manual excerption list. So why bother with the AUTO candidates at all? The answer is threefold:
For structurally legitimate candidates (predefined structures accepted by the linguistic filter) the AUTO list enables us to: a) pick up undisputed term candidates that we simply have overlooked in the manual excerption process (which we in fact did in a few cases), and b) to evaluate the appropriateness of the current threshold level of the weirdness component. A study of the number and semantics of AUTO candidates supplements the study of undisputed, but missing candidates from the AUTO list (= MAN candidates with predefined acceptable structures) and provides a clue for threshold adjustment.
For structurally illegitimate candidates (none included in Table 2) the AUTO list provides feedback to the programmer which can be
343

K. Øvsthus, K. Innselset, M. Brekke & M. Kristiansen
used not only to refine or correct the programmed algorithm for the linguistic filter, but also to refine the POS-tagger and the lexicon.
Now back to table 2. What follows in column 2 are five instances of AUTO/MAN, i.e. term candidates which have been extracted/excerpted both automatically and manually. The number of such cases is, together with the number of missing undisputed candidates and extracted undisputed non-candidates from the AUTO list, a measure of success for the extraction module in terms of precision and recall within the limits set by the term extraction filter.
The remaining rows in the table represent candidates which have been excerpted manually only. The first row with MAN in column 2 stands out as the only MAN candidate with no structure description in the adjacent column. The reason for this is that its structure (in casu root noun) is already implemented in the linguistic filter, and we are of course only interested in describing additional structures for future inclusion in the filter. All the same, the empty cell signals that this term would also have been extracted automatically unless the weirdness filter, with the present threshold level, had suppressed it.
The remaining MAN candidates all represent structures not defined in the linguistic filter algorithm and have consequently been provided with a structural description (the various structures are described in Table 3). The structures are grouped in alphabetical order for the MAN candidates since the third column was selected as the second priority sorting order. Internal grouping of the structures is according to the alphabetical order of the entries in column 4, the third priority sorting order. Column four is only relevant for the structure NP+PP. It contains the prepositions used in the individual NP+PP structures.
As our main goal is to enhance the automatic term extraction module, and then in particular the linguistic filter component, we shall naturally focus on the MAN candidates whose structure is currently not included in the linguistic filter, and which therefore have been provided with a structural description. All the facts we need are readily available in our master table when sorted in the column order 2, 3, 4 as in Table 2, which is a sample extract from this master table. A survey of the frequency of the various structures is, shown by the entries in column 3, easily obtained by a mere count. The result of such a count for the entire master table is presented in the section “Preliminary results”.
344

Developing Automatic Term Extraction
Term candidate Selected Structure Prep Dom P/UBehandlingsprosess AUTO NIL Bileksempel AUTO NIL ajourholdsfrist AUTO/MAN ØK 27P bokføring AUTO/MAN RR bokføringsfeil AUTO/MAN RR bokført salg AUTO/MAN RR bokført utgift AUTO/MAN RR bransje MAN ØK etterskuddsvis MAN A ØK forskuddsvis MAN A ØK avdrag og renter MAN NP+konj.+NP RR forskudd leie MAN NP+NP RR bokføring av korreksjoner
MAN NP+PP Av RR
bruker av regnskapet MAN NP+PP Av RR 18Ukonto for forskuddsbetalt leie
MAN NP+PP For RR
bokføring på konto MAN NP+PP På RR bokføring til debet MAN NP+PP Til RR solgte varers anskaffelseskost
MAN NPgen.+NP RR
årets resultat MAN NPgen.+NP RR godskrevet MAN PSP RR kreditert MAN PSP RR bokføre MAN V RR
Table 2: Term candidates sorted by selection method and structural pattern Preliminary Results We shall now turn our attention to Table 3. Column 1 shows the observed types of manually excerpted structures so far not included in the linguistic filter. Column 3 indicates the observed frequencies.
Note that some of the low-frequent “structures” are not term candidates as they stand, but rather strings combining two candidates in the relationship ‘preferred term/abbreviation’ or ‘preferred term/shortened form’. Such strings should if possible be extracted by the automatic extraction module for subsequent manual treatment, as they explicitly link relevant information which otherwise would have had to be sought and combined separately.
345
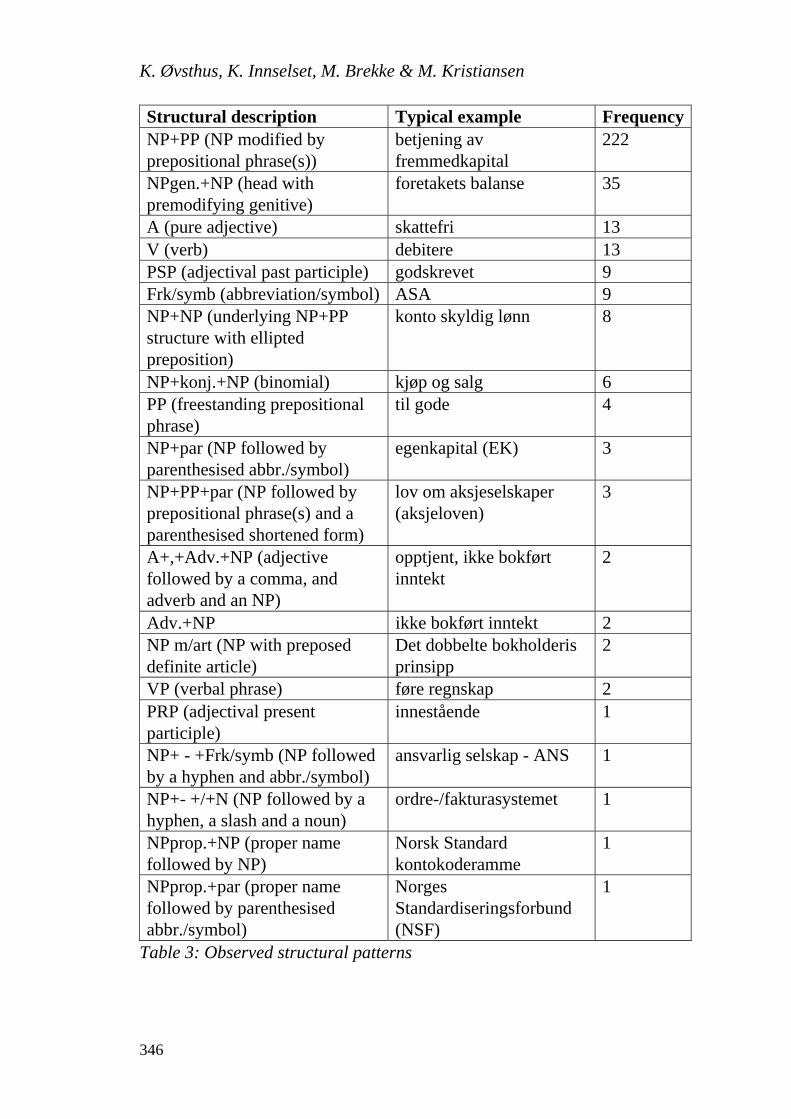
K. Øvsthus, K. Innselset, M. Brekke & M. Kristiansen
Structural description Typical example FrequencyNP+PP (NP modified by prepositional phrase(s))
betjening av fremmedkapital
222
NPgen.+NP (head with premodifying genitive)
foretakets balanse 35
A (pure adjective) skattefri 13 V (verb) debitere 13 PSP (adjectival past participle) godskrevet 9 Frk/symb (abbreviation/symbol) ASA 9 NP+NP (underlying NP+PP structure with ellipted preposition)
konto skyldig lønn 8
NP+konj.+NP (binomial) kjøp og salg 6 PP (freestanding prepositional phrase)
til gode 4
NP+par (NP followed by parenthesised abbr./symbol)
egenkapital (EK) 3
NP+PP+par (NP followed by prepositional phrase(s) and a parenthesised shortened form)
lov om aksjeselskaper (aksjeloven)
3
A+,+Adv.+NP (adjective followed by a comma, and adverb and an NP)
opptjent, ikke bokført inntekt
2
Adv.+NP ikke bokført inntekt 2 NP m/art (NP with preposed definite article)
Det dobbelte bokholderis prinsipp
2
VP (verbal phrase) føre regnskap 2 PRP (adjectival present participle)
innestående 1
NP+ - +Frk/symb (NP followed by a hyphen and abbr./symbol)
ansvarlig selskap - ANS 1
NP+- +/+N (NP followed by a hyphen, a slash and a noun)
ordre-/fakturasystemet 1
NPprop.+NP (proper name followed by NP)
Norsk Standard kontokoderamme
1
NPprop.+par (proper name followed by parenthesised abbr./symbol)
Norges Standardiseringsforbund (NSF)
1
Table 3: Observed structural patterns
346

Developing Automatic Term Extraction
We see that structures with the description ‘NP+PP’ constitute by far the largest category, about twice the sum of the rest. This is an indication that many important concepts in the accounting sub-domain can be represented by this type of structure, and that it should be worth considering whether criteria could be developed for the automatic extraction module that would improve recall without adversely influencing precision.
Of the total number of manually excerpted term candidates (1300), the 222 NP+PP structures amount to roughly 17% of the candidates. Whether this is typical for the sub-domain accounting to the exclusion of other economic-administrative domains, remains to be seen. A study undertaken for a completely unrelated domain such as the oil and gas industry as represented by the operating manuals for the Gullfaks A platform, reveals an almost equal percentage for this structure, 15.5% (Myking, 1987).
The prepositions ”av” and ”for” are by far the most frequent prepositions in our NP+PP structure term candidates. “Av” is used in 96 cases, amounting to roughly 43% of these candidates. “For” occurs 56 times, and accounts for 25% of the candidates. These prepositions are also the two most frequent in the Gullfaks A material, but in the reverse order. “For” amounts to almost 75%, “av” to only 7% (Myking, 1987).
We have found the use of tables very effective when carrying out our analyses. Tables allow a large amount of information to be presented in a limited space, and the sorting function makes it possible to consider the information from different viewpoints. Plans for Further Analysis Because of its relative importance we will concentrate our further analysis on the structural type ‘NP + PP’. Plans for further analysis include: • Performing a semantic case-type classification of the structures in
question, using categories such as the noun modifier relationship labels proposed by Ken Barker and Stan Szpakowicz (Barker and Szpakowicz, 1998). These are shown in Table 4 below.
• Discussing deverbal nouns and the potential effect on the term status of the structures in which they appear
• Studying prepositional phrases with respect to their relationship with the corresponding “packed versions”
347

K. Øvsthus, K. Innselset, M. Brekke & M. Kristiansen
Agent (agt) Material (matr) Beneficiary (benf) Object (obj) Cause (caus) Possessor (poss) Container (ctn) Product (prod) Content (cont) Property (prop) Destination (dest) Purpose (purp) Equative (equa) Result (resu) Instrument (inst) Source (src) Located (led) Time (time) Location (loc) Topic (top)
Table 4: Noun modifier relationship labels The objective of the analysis is to make the criteria for the enhancement of the automatic extraction module as specific as possible, so as to gain on recall without losing on precision.
We believe the method could be a small contribution to the further development of automatic domain-specific term extraction for Norwegian, and hence automatic term extraction in general.
References Andersen, Øivin; Argumentstruktur og nominalisering. LexicoNordica
5/98. Oslo: Nordisk Forening for leksikografi, 1998. Barker, Ken & Stan Szpakowicz; Semi-automatic recognition of noun
modifier relationships, in Proc. of the 36th Annual Meeting of the ACL and 17th International Conference on Computational Linguistics (COLING/ACL-98), pp. 96 – 102, Montreal, Canada, 1998.
Brekke, Magnar; KB-N: Computerized extraction, representation and dissemination of special terminology. Computational and Computer-assisted Terminology. Lisboa: European Language Resources Association, Paris, 2004.
Havstein, Bjørgunn & Tove-Gunn Moen; Finansregnskap - Teori og metode. Bergen: Fagbokforlaget, 2004.
Myking, Johan; Complex noun phrases as a problem of terminological practice, in Småskrifter 15/87, Bergen: Norsk termbank, University of Bergen, 1987.
348

Korean Term Extraction in the Medical Domain using Corpus
Comparison
PATRICK DROUIN & HEE SOOK BAE1
Abstract This paper describes an automatic terminology recognition (ATR) experiment on a corpus of medical documents in Korean that aims at retrieving high precision results in order for them to be useful in day to day terminography work. The tool used for our ATR study compares the behavior of lexical units in the medical corpus to their behavior in a large general corpus. We first analyze a precompiled list of terms from the medical domain to gather information about the surface structures of Korean terms. The structures are then implemented in TermoStat, an ATR tool (Drouin 2003). The quality of results obtained is manually evaluated and presented.
1. Introduction Recently, corpus comparison has been used by a number of researchers for extracting single-word terms (SWT) from specialized corpora. It is viewed as a means to supplement multi-word term (MWT) extraction, the focus of which is on noun phrases. However, little is known about the value of this technique in a terminological setting. This paper presents a method for finding both SWT and MWT in a corpus of Korean medical documents. 2. Related Work Corpus comparison techniques have been used by Ahmad et al. (1994) and Chung (2003) on English corpora of medicine. Both of these experiments used methods that exploited word raw or normalized word frequencies. Drouin (2003) devised a statistical method that locates
1. Observatoire de linguistique Sens-Texte, Université de Montréal, C.P. 6128,
succursale Centre ville, Montréal (Québec), H3C 3J7. [email protected] & [email protected]

P. Drouin & H. S. Bae
specific adjectives and nouns in an English corpus of telecommunications and then uses them to access SWTs and MWTs. This method was also applied to French in the fields of computer sciences by Lemay et al. (2005) Other researchers have been interested in finding lexical units that would not normally be considered as true terminological units but use similar methods: Nelson (2000), for instance, isolates the English vocabulary of business.
Early work on ATR in Korean was done by Oh and Choi (1999) who put forward a method aimed at identifying transliterated foreign words (these are often terms) using statistical techniques. Fujii et al. (2004) pursued a similar objective and also extracted foreign words based on phonetical similarities of Korean words to Japanese Katakana words. Building on their previous work on transliterated foreign words, Oh and Choi (2000) presented an ATR method that also used statistical information and dictionaries. In their experiment, term are identified using linguistic filters that describe the surface structures of terms using the following pattern: Noun+((jcm|xsn)?Noun+)2.
Recently, Ryu and Choi (2004) proposed a method in order to determine the specificity of terms based on information retrieval (IR) measure. In their experiment, they do not proceed to term extraction but rather use data from the MeSH thesaurus3 in order to quantify domain specificity.
3. Methodology The method proposed in this paper differs from previous work as it uses a corpus comparison method based on a statistical measure and not raw or normalized frequencies (Ahmad et al. 1994; Chung (2003)) that aims at identifying both specific SWT and MWT. This goes further than the work presented in Drouin (2003) where only specific SWT were identified in order to gain access to MWT without an evaluation of the specificity of these last items. We also expand the surface structures used in previous experiments (Oh and Choi 2000) for ATR in order to achieve better coverage. We also advocate a knowledge poor technique that does not rely on external dictionaries (Oh and Choi 2000) and that uses the corpora as the sole source of information for ATR.
2. In this patterm jcm is a case particle modifier while xsn is a subjective derivational
suffix. No information is given as to what part of speech was considered to be a noun.
3. http://www.nlm.nih.gov/mesh/meshhome.html
350

Korean Term Extraction
3.1 Corpus In this study, we used two corpora: a domain specific corpus and a general corpus. The sizes of the corpora are about 3,100,000 eojeols4 (±72Mb of text) and 42,000,000 eojeols (±880Mb of text) for the medical corpus and the general corpus respectively. Both corpora were analyzed using the KAIST (Korea Advanced Institute of Science and Technology) part-of-speech tagger. This tagger, dedicated to the Korean language, relies on a tag set of 54 tags (Yoon and Choi 1999).
The general corpus is made of documents dealing with various subjects: literature, health, social facts, culture, etc., but most of the corpus is composed of literary documents. The general corpus was built by KORTERM / KAIST as the results of a project described in Choi (2001). The medical corpus used was created during the Sejong project supported by Ministry of Culture and Tourism of Korea (see Choi 2003).
3.2 Gathering Term Structures In order to come up with surface description of medical terms that can be implemented into TermoStat, we used a bilingual list (English - Korean) of about 15,000 terms that was built by KORTERM as a result of the 21st Sejong Project. Based on this list, Seo (2003) produces an analysis of term structures; he described the elements that make up the terms covering their grammatical properties, their linguistic origin (Native Korean, Sino Korean, and English), etc.
From the original list of 15,974 terms included in the list described above, we were able to manually isolate 255 different term structures. Table 1 shows examples of the most frequent structures that we identified. We noted that the 22 most frequent term structures allowed coverage of 92% of the terms included in Seo’s report. This basically means that by providing a term extraction tool with these most frequent structures, one could easily reach significant coverage.
The first column in Table 1 shows the frequency of the term structure in the second column, the last column contains examples as well as their English translation. With respect to Seo (2003) work, the term structures are described using the YONSEI tag set which includes 26 tags.
The conversion of the term structure list to the KAIST tag set allowed us to come up with simplified list of 194 term structures. In order to
4. An eojeol is a Korean linguistic unit separated by blank or punctuation. It
basically consists of a content word and functional words.
351
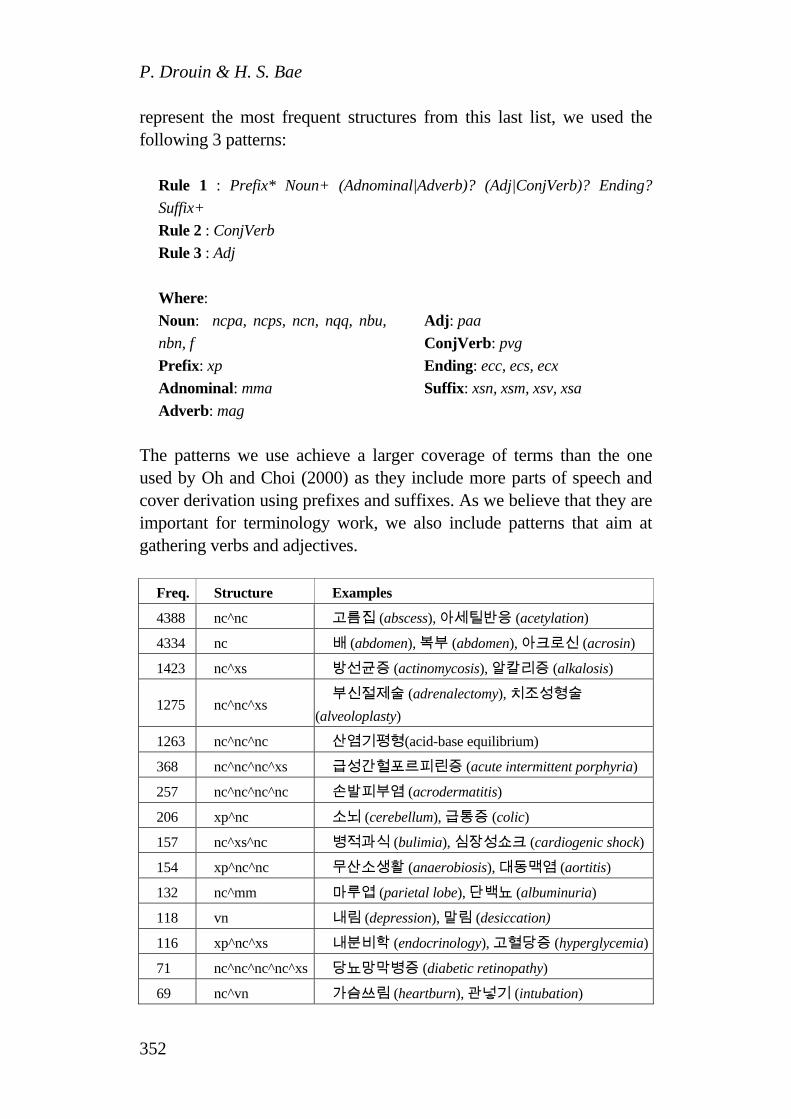
P. Drouin & H. S. Bae
represent the most frequent structures from this last list, we used the following 3 patterns:
Rule 1 : Prefix* Noun+ (Adnominal|Adverb)? (Adj|ConjVerb)? Ending? Suffix+ Rule 2 : ConjVerb Rule 3 : Adj
Where: Noun: ncpa, ncps, ncn, nqq, nbu, nbn, f Prefix: xp Adnominal: mma Adverb: mag
Adj: paa ConjVerb: pvg Ending: ecc, ecs, ecx Suffix: xsn, xsm, xsv, xsa
The patterns we use achieve a larger coverage of terms than the one used by Oh and Choi (2000) as they include more parts of speech and cover derivation using prefixes and suffixes. As we believe that they are important for terminology work, we also include patterns that aim at gathering verbs and adjectives.
Freq. Structure Examples
4388 nc^nc 고름집 (abscess), 아세틸반응 (acetylation)
4334 nc 배 (abdomen), 복부 (abdomen), 아크로신 (acrosin)
1423 nc^xs 방선균증 (actinomycosis), 알칼리증 (alkalosis)
1275 nc^nc^xs 부신절제술 (adrenalectomy), 치조성형술
(alveoloplasty)
1263 nc^nc^nc 산염기평형(acid-base equilibrium)
368 nc^nc^nc^xs 급성간헐포르피린증 (acute intermittent porphyria)
257 nc^nc^nc^nc 손발피부염 (acrodermatitis)
206 xp^nc 소뇌 (cerebellum), 급통증 (colic)
157 nc^xs^nc 병적과식 (bulimia), 심장성쇼크 (cardiogenic shock)
154 xp^nc^nc 무산소생활 (anaerobiosis), 대동맥염 (aortitis)
132 nc^mm 마루엽 (parietal lobe), 단백뇨 (albuminuria)
118 vn 내림 (depression), 말림 (desiccation)
116 xp^nc^xs 내분비학 (endocrinology), 고혈당증 (hyperglycemia)
71 nc^nc^nc^nc^xs 당뇨망막병증 (diabetic retinopathy)
69 nc^vn 가슴쓰림 (heartburn), 관넣기 (intubation)
352

Korean Term Extraction
67 va^nc 느린맥 (bradycardia), 넓은인대 (broad ligament)
66 nc^vn^xs 젖흐름증 (galactorrhea), 콩팥굳음증
(nephrosclerosis)
59 mm^nc 깨물근 (masseter muscle), 편두통 (migraine)
52 nc^nb^nc 경막외마취 (peridural anesthesia), 세포내이입
(endocytosis)
49 nc^mm^nc 가로잘룩창자 (transverse colon), 포자모세포
(sporoblast)
47 nc^nc^vn^xs 배벽갈림증 (gastroschisis), 척주앞굽음증 (lordosis)
41 nc^nc^mm 가슴막오목 (pleural recess), 직장요도루
(rectourethral fistula)
Table 1: The most frequent term structures as described by Seo (2003)
3.3 TermoStat The method used for terminology acquisition relies on TermoStat, a piece of software that relies on a corpora comparison technique in order to identify terms in a corpus. The term extraction technique used is based on the one described in Drouin (2003) and Drouin (2004). Since then, the system has been modified in order to make it as much as possible language independent and POS tagger independent. The term acquisition method is based on a three stage process: pattern matching, corpora comparison and candidate term ranking and filtering. 3.3.2 Pattern Matching As mentioned earlier, TermoStat uses normalized set of tags so that pattern matching can be made POS tagger independent. So far, broad POS categories are used and have been sufficient to replicate high level POS information and to obtain desired results: common noun, proper noun, adjective, adverb, preposition, past participle, coordinating conjunctions, determiners, conjugated verbs and infinitive verbs. This set can be easily modified, expanded and maintained by any user who understands Perl. Patterns for term extraction are stored in a text file and passed to the system on the command line. The patterns are described using regular expressions. TermoStat contains a set of predefined tags to represent the before mentioned broad categories but users can also write their own patterns in order to match on specific lexical items instead of parts of speech.
Pattern matching using parts of speech can sometimes lead to noisy
353

P. Drouin & H. S. Bae
results. In order to address this problem, users can influence the pattern matching algorithm and stop some tokens from being taken into account when building the original list of candidate terms. One can use this mechanism to prevent lexical units whose presence in candidate terms prove to lead to noisy results like “suivant/Adjective” and “quelconque/Adjective” in French, “above/Adjective” and “same/Adjective” in English or, in the case of Korean 대개 (most) and 개개(each) as common nouns.
Such a technique can also be helpful in fixing part of speech tagging errors that would lead to noise in the list of candidate terms. Of course, this blocking mechanism needs to be used very carefully in order not to exclude interesting candidates from the results. The exclusion list is also maintained in a text file and passed to the software on the command line. Users can thus maintain it easily. The following list shows the filtering used for the current experiment.
대개 n. (most) 대부분 n. (major) 개개 n. (each) 각각 n. (each) 것 n. (that) 경우 n. (case) 사실 n. (fact) 이번 n. (this time) 그때 n. (the moment) 그곳 n. (the place)
일부 n. (a part) 그림 n. (figure) 표 n. (table) 곳 n. (place) 듯 n. (as like) 아래 n. (below) 순간 n. (moment) 때 n. (moment that) 들 suffix. (plural marker)
However, the technique cannot be applied to all words (후/after, 등/etc., 수/possible, etc.) because they can appear as part of a term’s element but as different forms and different parts of speech. In Korean, the use of space in order to separate words is not systematic. Even if the word is autonomous and independent, it can be used without space as like a part of a term. For example, 등/nbn (etc.) is a homonym of 등/ncn (back) or 등/ncn (light) and the tagger used tends to identify it as 등/ncn (etc.) in most cases. In addition, this form can appear inside a term: 등척수축 (isometric contraction), 등통증 (back pain), 가슴등신경 (thoracodorsal nerve), 등선량곡선 (isodose curve), 섹극등현미경 (slit lamp microscope), etc.
354

Korean Term Extraction 3.3.3 Corpus Comparison The software used for term extraction in the current experiment relies on a comparison of the frequencies of the lexical items in two corpora: a reference corpus (RC) and an analysis corpus (AC). In order to compare frequencies in the corpora, we will be using a 2x2 contingency table representing the possible scenarios.
Corpus RC AC Total
Frequency of word a b a+b Frequency of other words c d c+d Total a+c b+d N=a+b+c+d
Table 2: Basic contingency table
TermoStat can compare frequencies using various statistical tests; a first test is the specificity test described by Lafon (1980), another test is X2 as used by Rayson et al. (1997) and Kilgariff (2001); the last one is the log-likelihood test originally proposed by Dunning (1993) and used by Rayson and Garside (2000) in order to compare corpora. This last test was used to extract candidate terms for the current study; it can be computed as follow:
E1 = ((a+c)(a+b))/((a+c)(b+d)) E2 = ((b+d)(a+b))/((a+c)(b+d)) LL = 2*((a*ln(a/E1)) + (b*ln(b/E2)))
The software can also be used without a statistical test and will then simply proceed with the extraction of all structures described using the patterns presented in section 3.3.2. 3.3.4 Ranking and Filtering The last step performed by the software is to filter out the candidate terms which have a frequency in the analysis corpus which is not significantly different from the frequency observed in the RC. The filters used by TermoStat only select candidates that have a frequency that corresponds to a probability smaller or equal to 1/1,000 based on the frequency seen in the general corpus. The candidates are then ranked according to their specificity score as computed during the previous step. The software also allows user to choose not to use a cut-off threshold if desired; in such a case, results are just ranked according to
355

P. Drouin & H. S. Bae the specificity. The technique described here is somewhat different from the one used by Ryu and Choi (2004) who ranked terms according to their domain specificity. Their ranking, based on the one proposed earlier by Frantzi and Ananiadou (1999) used several source of information about the candidates while ours solely uses the frequency comparison in order to valuate corpus specificity. Our algorithm is also significantly different as the specificity is computed on uniterms and on multiterms.
4. Performance Evaluation To select medical terms among the candidates, we relied on semantic lexical criteria put forward by L’Homme (2004) based on Mel’cuk et al. (1995). We first determined whether the candidate contains a meaning related to the domain of medecine and if its arguments (if the term is predicative) are also medical terms. The morphology and the semantic relation between candidates were also taken into account for the selection of terms. English words included in the Korean corpus such as bleomycin, cobalamin and tetracycline, as well as abbreviations like TIA, FSH and RSV were considered to be terms when their meaning was domain related. On the other hand, units like mg, kg and mm, etc. were not selected since they are not closely related to the domain.
5. Results 5.1 Precision The term extraction process led to a list of about 77,000 candidate terms. In order to evaluate precision, we built a smaller sample (8,491 candidates) by randomly selected about 1 candidate out of 10 throughout the ranked list. Figure 1 shows the precision of the results as we go down the ranked list of candidate terms gathered by the software. The overall level of precision obtained by TermoStat on this sample is somehow surprising as it reaches slightly over 90 %. One interesting fact is that the level of the precision slightly increases as we go down the list. This seems to indicate that the ranking of the results according to the score computed using the log-likelihood does not allow for the intended ranking. On the other hand, we can see that the same test does lead to the selection of highly interesting candidates by TermoStat.
356

Korean Term Extraction
Figure 1: Precision evaluated over the ranked list of candidate terms.
The precision levels obtained in our experiment are lower than the ones presented by Oh and Choi (2000) but in this case their experiment was using specialised dictionaries as an external source of knowledge. On the other hand, the precision presented in the same paper decreased significantly when looking at candidates raked lower by the system, this is not the case with our results.
In many cases of the words wrongly selected, a dependent noun was included in the term candidate while it should not have been, here are some examples:
• 압통/ncn (pressure pain) 등/nbn (etc.); • 회/nbn (times) 경구투여하다/pvg (give madication
orally); • 뒤/nbn (after) 급성인두염/ncn” (acute pharyngitis).
In 1), 압통 is a medical term while 등 is not. In the last two examples, 회 and 뒤 are dependent nouns always related to the precedent noun and should not have been concatenated to 경구투여하다 and 급성인두염 by TermoStat. This type of error could be avoided with slight modifications of the patterns used. In this research, we considered both dependent nouns and nouns while only the last type should have been included. This type of error is repeated in the list of candidates and has a significant effect on precision.
Preprocessing of the corpora used could also have increased precision since XML-like encoding tags, structuring elements (headings such as
357

P. Drouin & H. S. Bae 장/chapter and 참조/reference) and caption (그림/figure and 표/table) also show up in the list. These are sometimes parts of the specialized discourse features and TermoStat tends to extract them as they do not appear as often in general corpora.
In order to evaluate the impact of the filtering process, we proceeded to the evaluation of the precision on candidates that had not reached the p>=0,001 threshold. TermoStat identified over 280,000 candidates that matched the patterns used for our study that did not satisfy the cut off threshold. We randomly selected 4,109 (roughly a little below 1/50) for evaluation. Figure 2 shows the precision level measured on this second list of discarded items.
Figure 2: Precision evaluated over the list of candidate terms discarded by TermoStat. The precision level displayed in the figure above reach 72% for the items ranked between 77,000 and 280,000. This is surprisingly high for candidates that were ignored by the software. This seems to indicate that the items in this list would have been interesting for terminological processing. This high level of precision on the list of candidates retrieved without filtering indicates that approximately 7 words out of 10 in the corpus of medecine that matched our patterns could be considered as terms. This is quite surprising. Potential explanations are the level of technicality of the documents that make up the corpus or some particularities of the Korean language.
358

Korean Term Extraction 6. Conclusion and Future Work Since we deliberately left out some of the surface structures described by Seo (2003) because they did not correspond to high frequency patterns in his corpus, the patterns used for the current study could be refined in order to boost coverage and increase recall. This first step could be done by using the descriptions put together by Seo (2003) and by looking at other corpora/domain. One key point that needs to be validated is the fact that the structures described in Seo (2003) and in our paper are not domain dependant and would lead to equally good results on other domains.
Although we were able to achieve a significantly high level of precision on our corpus, we believe that our technique should be tested on other domains or corpora. This would allow us to verify if the performance obtained should be solely attributed to method used or if the characteristics of the discourse found in our corpora of medicine.
Looking at what has been discarded by the filtering technique showed that a significant number of valid terms were put aside when using a cut-off threshold based on a statistical filter. This, of course, has an impact on recall which should be evaluated with users of the software, the terminologists.
Acknowledgements We would like to thank KORTERM (Prof. Key-Sun Choi) and the National Institute of the Korean language for providing us with the corpus and detailed list of term in the medical domain and their thorough analysis. Without their cooperation, we would not have been able to achieve the current research. References Ahmad, K.A. et al.; What’s in a Term? The Semi-automatic Extraction
of Terms from Text, in Snell-Hornby; M.F. Pochhacker & K. Kaindl (eds.), Translation Studies, An Inter-discipline, Amsterdam/ Philadephia: John Benjamins, 1994.
Choi, K.S.; KAIST Language resources, Ministry of Science & Technology Software Project results 1995-2000
(http://kibs.kaist.ac.kr), 2001. Choi, K.S.; Terminology, Ministry of Culture and Tourism of Korea The
21 Century Sejong Project results, 2003, st
(http://www.sejong.or.kr/sejong_kr/ index.html).
359

P. Drouin & H. S. Bae Chung, T.M.; A Corpus Comparison Approach for Terminology
Extraction, Terminology, 9(2), 2003. Drouin, P.; Term Extraction Using Non-technical Corpora as a Point of
Leverage, Terminology, 9(1), 2003. Drouin, P.; Spécificités lexicales et acquisition de la terminologie, Actes
des 7e Journées internationales d'analyse statistique des données textuelles (JADT-2004), Belgique: Louvain-la-Neuve, 2004.
Dunning, T.; Accurate Methods for the Statistics of Surprise and Coincidence, Computational Linguistics, 19(1), 1993.
Frantzi, K. & S. Ananiadou; The C-value / NC-value domain independent method for multi-word term extraction, Journal of Natural Language Processing, 6(3), 1999.
Fujii, A.; T. Ishikawa & J.H. Lee; Term Extraction from Korean Corpora via Japanese, Proceedings of the 3rd International Workshop on Computational Terminology (CompuTerm 2004), 2004.
Jang, S.J.; Korean, John Benjamins Publishing Company, Amsterdam/ Philadelphia, 1996.
Kilgarriff, A.; Comparing corpora. International Journal of Corpus Linguistics, 6(1), 2001.
L’Homme, M.C.; La terminologie : principes et methodes, Montréal: Presses de l'Université de Montréal, 2004.
Lemay, C.; M.C. L’Homme & P. Drouin; Two Methods for Extracting "Specific" Single-word Terms from Specialized Corpora: Experimentation and Evaluation, International Journal of Corpus Linguistics, 10(2), forthcoming.
Lafon, P.; Sur la variabilité de la fréquence des formes dans un corpus, MOTS, 1, 1980.
Mel’cuk, I. et al.; Introduction a la lexicologie explicative et combinatoire, Paris: Duculot, 1995.
Nelson, M.; A Corpus-based Study of Business English and Business English Teaching Materials, Manchester: Unpublished PhD Thesis at University of Manchester, 2000.
Oh, Jong-Hoon & Key-Sun Choi; Automatic Terminology Recognition: Using the Lexical Resource of the Specific Fields. Second International Conference on Language Resources and Evaluation (LREC 2000), Terminology Resource and Computation Workshop (WTRC), 2000.
Oh, J.H. & K.S. Choi.; Automatic extraction of a transliterated foreign word using hidden markov model, Proceedings of the 11th Korean and Processing of Korean Conference, 1999.
360

Korean Term Extraction Rayson, P. & R. Garside; Comparing corpora using frequency profiling,
Proceedings of the workshop on Comparing Corpora, 38th annual meeting of the Association for Computational Linguistics (ACL 2000), 2000.
Rayson, P. et al.; Social differentiation in the use of English vocabulary: some analyses of the conversational component of the British National Corpus, International Journal of Corpus Linguistics, 2(1), 1997.
Ryu, P.M. & K.S. Choi; Determining the specificity of terms based on information theoric measures, Proceedings of the 3rd International Workshop on Computational Terminology (CompuTerm 2004), 2004.
Seo, S.K.; Korean linguistic research on the terminology (Medical domain), Ministry of Culture and Tourism of Korea The 21 Century Sejong Project results:
st
(http://www.sejong.or.kr/sejong_kr/index.html), 2003. Santorini, B.; Part-of-speech tagging guidelines for the Penn Treebank
Project, Technical report MS-CIS-90-47, Department of Computer and Information Science, University of Pennsylvania, 1990.
Yoon, J.T. & K.S. Choi; 한국어 품사부착 말뭉치에 대한고찰 (Study on Korean POS tagged corpus, in Knowledge, 1999.
361


Terminology Extraction and Automatic Indexing
Comparison and Qualitative Evaluation of Methods
HANS FRIEDRICH WITSCHEL Introduction Many terminology engineering processes involve the task of automatic terminology extraction: before the terminology of a given domain can be modelled, organised or standardised, important concepts (or terms) of this domain have to be identified and fed into terminological databases. These serve in further steps as a starting point for compiling dictionaries, thesauri or maybe even terminological ontologies for the domain. For the extraction of the initial concepts, extraction methods are needed that operate on specialised language texts.
On the other hand, many machine learning or information retrieval applications require automatic indexing techniques. In Machine Learning applications concerned with the automatic clustering or classification of texts, often feature vectors are needed that describe the contents of a given text briefly but meaningfully. These feature vectors typically consist of a fairly small set of index terms together with weights indicating their importance. Short but meaningful descriptions of document contents as provided by good index terms are also useful to humans: some knowledge management applications (e.g. topic maps) use them as a set of basic concepts (topics).
The author believes that the tasks of terminology extraction and automatic indexing have much in common and can thus benefit from the same set of basic algorithms. It is the goal of this paper to outline some methods that may be used in both contexts, but also to find the discriminating factors between the two tasks that call for the variation of parameters or application of different techniques. The discussion of these methods will be based on statistical, syntactical and especially morphological properties of (index) terms. The paper is concluded by the presentation of some qualitative and quantitative results comparing statistical and morphological methods.

Hans Friedrich Witschel
Some definitions The notion of terminology is defined by ISO 1087 as
”Set of terms representing the system of concepts of a particular subject field.”
This means that terminology is above all associated to subject fields. There is no direct relation between terminological units and the texts they appear in. However, we will later see that they can be distinguished by their characteristic occurrence in specialised texts. A definition for “index term” is given by (Knorz, 1991):
“Wort, das den Inhalt eines Dokumentes kennzeichnet.” (”Word which describes the contents of a document.”)
A very similar definition can be found in (Sparck-Jones 1999) who defines an index term as ”a content-bearing key”. This indicates that index terms are used for representing contents of specific documents – they are not used beyond this scope. An index term should also help to distinguish a document from others. In many cases, though, the terms that best describe the contents of a document are at the same time terminological units of the text’s domain. This is why the same algorithms can be applied to the extraction of both technical terms and index terms from specialised texts. Statistics The most important approach to automatic indexing is based on word frequencies: words that are repeated frequently within a document are likely to be good descriptors of its content. On the other hand, terms that appear in many documents (like “the”, “about” or “believe”) do not help to distinguish one document from another. Based on these intuitions, (Salton et al., 1975) introduced the TF/IDF measure which is still widely used. It can be computed for a given term by multiplying its frequency in the current document (TF = term frequency) with its inverse document frequency (IDF) – a measure that yields large values for terms that appear only in very few documents of the given document collection. Words with high TF/IDF ranking are then selected as index terms. Similarly, technical terms tend to occur more often in specialised text of their respective domain than in everyday language. As proposed by (Ahmad et al., 1992) or (Damerau, 1993), terminological units can be identified by comparing a word’s relative frequency in a given specialised text T to its relative frequency in a large, well-balanced corpus R covering many aspects of everyday language (which will be
364

Terminology Extraction and Automatic Indexing
called “reference corpus” from now on). Words that occur significantly more often in T than we would expect when looking at its relative frequency in R should be extracted as terminology. Details and a comparison of statistical tests that can be applied in this field can be found in (Witschel, 2004). There is no reason why the same methodology shouldn’t work for automatic indexing: the idea of extracting terms that appear often in the specialised text T (≈ high TF), but only rarely in the reference corpus (≈ high IDF) corresponds quite precisely to calculating TF/IDF. There is also a small advantage of using a reference corpus: documents will be assigned the same index terms regardless of the collection they are part of (provided the reference corpus stays the same) and they can even be indexed in a stand-alone fashion, i.e. with no other documents present. It is important to realise that parameters may vary for the two tasks: for the purpose of terminology extraction, we may be interested in low-frequent terms (e.g. “background terms” that are only mentioned once or twice) that are not representative of the document’s topic but statistically significant. For automatic indexing, on the other hand, a certain frequency threshold may be needed (i.e. a minimum TF) to ensure that index terms are good descriptors of the text’s content. Syntax Many terminological units consist of more than one word. More precisely, technical terms are often noun phrases. As (Arppe, 1995) points out, there is a very limited number of part-of-speech (POS) patterns used in terminological phrases: when searching for the patterns “N N” (noun noun), “A N” (adjective noun”) or “N”, Arppe was able to retrieve 60% of all terminological noun phrases contained in his test corpus. This suggests the use of regular expressions over POS tags or possibly some other – more sophisticated – form of syntax parsing in order to find the desired noun phrases. However, using these patterns, we will also find units that became neighbours only accidentally. As (Bourigault, 1992) puts it:
”It is possible to devise an extraction program solely based on syntactic data [...] It is not possible to expect this program to
extract terminological units and nothing else.“ This means that we are actually looking for phrases that are either collocational in some way or compounds. The parts of these units tend
365

Hans Friedrich Witschel
to occur together, i.e. the probability of observing them in the same sentence strongly deviates from statistical independence. A variety of statistical filters on POS patterns have been proposed that are based on this insight. They range from raw frequency counts up to highly sophisticated co-occurrence analyses using statistical significance measures. Strikingly, (Daille et al., 1994) found the pure frequency of a multiword unit (MWU) to be the best criterion for its term status. (Justeson and Katz, 1995) justify this by arguing that terminological phrases are lexical, i.e. that their meaning cannot be inferred completely from their parts (therefore they need to be lexicalised). This is why – as opposed to accidentally neighboured words – they tend to occur unvaried and repeatedly. Based on these findings, I propose the use of regular expressions over POS tags to find noun phrases, combined with a frequency filter. It should be mentioned that some approaches (cf. Frantzi and Ananiadou, 1996) do not use syntactical analysis at all, i.e. they only extract words that co-occur frequently. Other approaches use much more sophisticated syntactical methods than pure POS patterns (cf. (Salton, 1988) and (Evans and Lefferts, 1995)) which are, however, quite expensive both computationally and as far as resources like dictionaries etc. are concerned. The proposed combination has proved to be a good solution for the purpose of terminology extraction. But it has been discussed quite controversially (cf. for instance (Sparck-Jones, 1999)) whether or not the use of phrases as index terms really enhances information retrieval or machine learning. There seems to be little gain in effectiveness provided by phrases; they are often redundant because their constituents have already been selected as index terms which seems to be sufficient for most applications. On the other hand, phrases have never shown to have a negative impact. Morphology The use of morphological knowledge for (index) term selection is not a standard method – neither in automatic indexing nor in terminology extraction. Work like that of (Cohen, 1995) or (Heid, 1998) has shown, however, that the internal structure of words can give important clues with respect to their term status. The two papers mentioned point in different directions: while Cohen proposes a statistical analysis of arbitrary n-grams of characters, Heid restricts his search to morphemes. More precisely, in a first step, Cohen extracts n-grams of characters the frequency of which is significantly higher in a given text T than in
366

Terminology Extraction and Automatic Indexing
a reference corpus R – i.e. he applies exactly the same methods as suggested in the section on “Statistics” above. In a second step, scores for words (or word groups) are computed by adding up the significance values of the n-grams they contain. Words with scores above a certain threshold are then selected as index terms. This is especially effective for domains that employ technical terms from foreign languages (e.g. Greek or Latin), as for instance medicine: a term that contains the n-gram “-itis” is very probably a medical technical term and “-itis” will be highly statistically significant when compared to everyday language. Heid, on the other hand, performs a morphological analysis on nouns and compound adjectives and participles, yielding both lexical and derivational morphemes. By counting lexical morphemes (i.e. those that are neither inflectional nor derivational) and selecting the ones that occur frequently, a list of so-called “domain-specific morphemes” can be acquired. Note that “frequency” has a different meaning in this context: the frequency of a lexical morpheme is defined as the number of different words or compounds that contain it. Heid proposes to restrict the morphological analysis to words that have previously been extracted by statistical methods as described above (section “Statistics”). He uses regular expressions over domain-specific morphemes to produce lists of term candidates: words that contain domain-specific morphemes at certain positions are extracted as terms. The difference between the two approaches is small at first glance: both identify small domain-specific units (namely character n-grams or morphemes) and then select words that contain them. This can be used for both automatic indexing and terminology extraction and has shown to produce good results (cf. (Witschel, 2004)). Terminology extraction can benefit from using domain-specific units because background terms with low frequency can be found: even if they occur only once or twice in the given text, they will be extracted if they contain domain-specific units. For automatic indexing, the extraction of words containing domain-specific units should again be combined with a frequency threshold to guarantee that index terms are good representatives of the text’s contents. However, there is an important difference between the two approaches. Morphemes – unlike character n-grams – bear a well-defined meaning and many lexical morphemes are free, i.e. they can occur as single words within a text. That means that domain-specific morphemes may themselves be selected as index terms.
367

Hans Friedrich Witschel
Intuitively, the parts of a compound (especially its head) have a more general meaning than the whole compound: “Saft” (juice) is more general than “Orangensaft” (orange juice). We will see in the next section that domain-specific (free) morphemes acquired by morphological analysis of compounds tend to be quite general. They do, in fact, describe the contents of a text in quite a general way which is why they are very well suited for automatic indexing. On the other hand, they are usually much too broad (in meaning) to be considered technical terms. Experimental Setup In this section, some quantitative and qualitative results of morphological analysis and its application to acquiring index terms will be given. These results will be compared to terms extracted by statistical methods. There are two main hypotheses to be verified:
1. Morphemes are more general in meaning than other descriptors. This should result in high overlap between index terms extracted from different documents of the same domain.
2. Morphemes are good features for clustering and classifying documents, i.e. besides their generality, they also serve to discriminate documents of different semantic classes.
The experiments conducted were based on a German newspaper corpus of 991 texts from 10 categories. The number of documents was approximately balanced across the categories, i.e. there were about 100 documents in each category. As a first step, documents were assigned feature vectors using four different indexing techniques:
• Statistical analysis: uses a reference corpus and extracts terms with high statistical significance and a minimum frequency of 2. This approach uses a likelihood ratio test (cf. Dunning, 1993).
• TF/IDF: extracts terms with high TF/IDF values (a list of stop words is used additionally).
• Frequent nouns: as nouns are often thought of as content-bearing keys, this method uses POS information to extract nouns that occur frequently within the given text. This can be considered a sort of baseline for all indexing methods using linguistic knowledge.
368

Terminology Extraction and Automatic Indexing
• Morphemes: extracts morphemes that occur in many compounds throughout the text. This method relies on compound analysis and only operates on morphemes that are part of a compound.
Each of these methods can be used to produce term rankings: the first two approaches yield a measure of goodness (significance value and TF/IDF, respectively), in the last two cases, the frequency of the nouns or morphemes can be used for ranking them. The actual feature vectors were formed out of these ranked lists: each document was assigned the X best features from the list, with varying X, thus producing feature vectors of varying size. When doing text categorization, this is not a standard approach to feature selection. Normally, an index vocabulary is built by measuring the discriminatory power of features: terms that occur in documents from many different categories should be eliminated (cf. Yang and Pedersen, 1997). In our case, however, we are interested in studying discriminatory power and generality of index terms by themselves, i.e. without further intervention. The use of indexing vocabularies is therefore omitted which accounts for the relatively bad categorization results given below. Having obtained different sorts of feature vectors for all documents, the field of text categorization was used to evaluate the quality of the features. The vectors were fed into the Weka package (cf. www.cs.waikato.ac.nz/~ml/weka) which was applied to perform multinomial naïve Bayes with ten-fold cross-validation on the whole set of documents. Results A good way to measure the generality of features is to assess the total number of (different) features produced by the algorithms: a low number of features indicates that there is substantial overlap between different documents. This tends to occur when index terms are very general. Figure 1 depicts the total number of features as a function of the vector size.
369

Hans Friedrich Witschel
Figure 1: Total number of features as a function of vector size It can be seen that the statistical methods produce many features (i.e. small overlap) whereas the linguistically chosen features tend to be more general which yields good overlap. Morphemes are the “winners” of this contest with 3000 features when using a vector size of 10 (which means that there are 9910 feature tokens but only 3000 types). The actual categorization accuracy obtained with these vectors is shown in Figure 2.
Figure 2: Categorization accuracy as a function of vector size
370

Terminology Extraction and Automatic Indexing
Unsurprisingly, precision increases as more features are used. More strikingly, statistical analysis yields results which are better than TF/IDF figures but still significantly worse than those obtained by linguistic methods. This suggests that terms obtained by statistical methods tend to be very special and rarely content-bearing. Another interesting observation that can be made is the fact that the linguistic baseline (i.e. frequent nouns) outperforms all other methods when using five or more features per document. Although morphemes yield the best results for very low dimensions (< 5 features), this indicates that nouns have a higher potential for discriminating between categories. However, the difference is not significant which leads us to the conclusion that morphemes are good document descriptors for text categorization and clustering, especially when working with few dimensions: because of their high generality, only very few features are required to describe the contents of a text. Finally, I would like to illustrate this generality by presenting some qualitative data. Text topic Terms found by
statistical analysis Domain-specific morphemes
Civil rights schwarz, Rassentrennung, Schule, weiß, Gerichtshof (black, racial segregation, school, white, court)
Recht, Verfassung, Bürger, Krieg, Rasse (law, constitution, citizen, war, race)
Solar energy Energie, Schottky, Photovoltaik, Solarzelle, Sonne (energy, Schottky, photovoltaics, solar cell, sun)
Energie, Sonne, Welt, Raum, Land, Kraft, Rakete, Jahr, Selen, Licht, Strom (energy, sun, world, space, land, power, rocket, year, selen, light, electricity)
Skiing holiday Vail, Skifahrer, Berg, Ski, Colorado (Vail, skier, mountain, ski, Colorado)
Ski, Schnee, Berg, Lift, tief, Sport, Hotel, Winter, Piste (ski, snow, mountain, lift, deep, sport, hotel, winter, slope)
Nervous system
Synapse, Membran, Transmitter, synaptisch, Axon (synapse, membrane, transmitter, synaptic, axon)
Nerv, Rezeptor, Information, Übertragung, Potential, Zelle (nerve, receptor, information, transfer, potential, cell)
Table 1: Comparison of terms found by statistical analysis and domain-specific morphemes
371

Hans Friedrich Witschel
Table 1 shows terms that have been extracted from four documents that cover different topics. Terms in the middle column were found by using statistical methods, the ones in the rightmost column originate in morphological analysis. English translation of terms is given in brackets underneath. The lists of statistically extracted terms consists of the five highest ranked words (with respect to statistical significance), the terms retrieved by morphological analysis comprise all words that appeared in more than three different compounds. There is a number of things that can be observed from this data:
• Statistical analysis sometimes produces proper names (e.g. “Schottky”, “Colorado”). This never happens with morphological analysis.
• As we suspected, terms in the rightmost column are more general than in the middle column.
• This effect can be seen most clearly in the last example where the statistical analysis retrieves a number of very specific technical terms whereas domain-specific morphemes are much more general. This last text is the most specialised one: the greater the distance between the document’s topic and everyday language, the clearer the difference between the two methods.
All in all, acquiring domain-specific morphemes really seems to yield good and fairly general index terms. Conclusions The primary goal of this article is to give an overview over techniques that may be used both for terminology extraction and for automatic indexing. It was revealed that a variety of statistical, syntactical and morphological methods are suitable for both problems: relative frequency comparisons, identification of multiword units by using regular expressions over POS tags and identification of small domain-specific units were proposed. The main difference between both tasks is the fact that automatic indexing needs to assure that selected index terms are representative of the text’s content, which is, however, of no relevance to terminology extraction. In most cases though, this problem can be solved by introducing additional frequency thresholds for automatic indexing. Finally, there was a focus on morphological analysis of compound nouns. The results of compound splitting and subsequent identification of domain-specific lexical morphemes was suggested as a means to
372

Terminology Extraction and Automatic Indexing
retrieve a general description of a document’s contents. The results that were presented in this context seem to be quite promising for automatic indexing purposes. Unfortunately, this kind of analysis can only be used in languages that use (one-word) compounding like German or Danish (Korean, Japanese, Dutch…). In general, linguistic knowledge seems to be somewhat valuable in the context of feature selection for text categorization: frequent nouns behave very well as far as generality and discriminatory power are concerned which suggests that even working with very shallow linguistic knowledge can significantly outperform purely statistical methods in this context. References Ahmad, K.; A. Davies; H. Fulford & M. Rogers; What is a term? The
semi-automatic extraction of terms from text, in M. Snell-Hornby & F. Pöchhacker & K. Kaindl (eds.), Translation Studies: An Interdiscipline, Amsterdam: John Benjamins Publishing Company, 1994.
Arppe, A.; Term extraction from unrestricted text. NODALIDA-95, Helsinki, 1995,
http://www.lingsoft.fi/doc/nptool/term-extraction.html
Bourigault, D.; Surface Grammatical Analysis for the Extraction of Terminological Noun Phrases. Proceedings of Coling 92, pp. 977 – 981, 1992.
Cohen, J.D.; Highlights: language and domain independent automatic indexing terms for abstracting. Journal of the American Society for Information Science, 46(3), pp. 162 – 174, 1995.
Daille, B.; E. Gaussier & J. Langé; Towards Automatic Extraction of Monolingual and Bilingual Terminology. Proceedings of COLING 94, pp. 515 – 521, 1994.
Damerau, F.J.; Evaluating domain-oriented multiword terms from texts. Information Processing and Management, 29(4), pp. 433 –
447, 1993. Dunning, T.; Accurate Methods for the Statistics of Surprise and
Coincidence. Computational Linguistics, 19(1), pp. 61 – 74, 1993. Evans, D.A. & R.G. Lefferts; CLARIT-TREC Experiments.
Information Processing and Management, 31(3), pp. 385 – 395, 1995.
Frantzi, K.T. & S. Ananiadou; Extracting nested collocations. Proceedings of COLING 96, pp. 41 – 46, 1996.
Heid, U.; A linguistic bootstrapping approach to the extraction of term candidates from German text. Terminology, 5(2), pp. 161 – 181, 1998.
373

Hans Friedrich Witschel
Justeson, J.S. & S.M. Katz; Technical terminology: some linguistic properties and an algorithm for identification in text. Natural Language Engineering, 1(1), pp. 9 – 27, 1995.
Knorz, G.; Indexieren, Klassieren, Extrahieren, in M. Buder, W. Rehfeld & T. Seeger (eds.), Grundlagen der praktischen Information und Dokumentation. München: K.G. Saur, 1991.
Salton, G.; A. Wong & C.S. Yang; A Vector Space Model for Automatic Indexing. Communications of the ACM, 18(11), pp. 613 – 620, 1975.
Salton, G.; Syntactic Approaches to Automatic Book Indexing. Proc. of the 26th Annual Meeting of the Association for Computational Linguistics, pp. 204 – 210, 1988.
Sparck-Jones, K; What Is The Role for NLP in text retrieval? in T. Strzalkowski (eds.), Natural Language Information Retrieval. Dordrecht: Kluwer, 1999.
Witschel, H.F.; Terminologie-Extraktion – Möglichkeiten der Kombination statistischer und musterbasierter Verfahren. Würzburg: Ergon Verlag, 2004.
Yang, Y. & J.O. Pedersen; A Comparative Study on Feature Selection in Text Categorization, ACM Computing Surveys, 34(1), pp. 1 – 47, 1997.
374

A Term List or a Noise List?
How Helpful is Term Extraction Software when Finnish Terms are Concerned?
PÄIVI PASANEN
The growth of specialised text production has resulted in a need for the development of automated methods for the extraction of terminological information from texts, for example, a terminologist or a translator might wish to compile his or her own vocabularies using term extraction software. Thanks to modern information technology, semiautomatic methods are available.
In this paper, the results of a term extraction project are presented. In the project, Finnish maritime terms were extracted from a text manually by one domain expert and automatically using two commercial term extraction tools: one of which mainly utilizes a statistical and the other one chiefly puts to use a hybrid method.
The aim of the experiment was to test the performance of commercial term extraction tools. With this aim in mind, the term list produced manually and candidate term lists produced automatically were compared.
The Main Features of Term Extraction Methods The manual extraction of terms from a text is a highly reliable method when conducted by a skilled domain expert. However, experience shows that manual term recognition is dependent on individual choices even if the test subjects have the same education (cf. Soininen, 1998; Pasanen, 2004). The influence of the individuality factor in term recognition can be diminished by group work. In this case, the term recognition task is conducted by a number of individuals and only widely accepted candidate terms are validated. This method, however, is too complicated to be used excluding research purposes. Another way to diminish the influence of the individuality factor is to use automated methods.
Since 1980’s, the efforts of engineers and linguists have produced a great selection of term extraction tools. They mainly utilize methods

Päivi Pasanen
which are based on either statistical or linguistic parameters of terms in texts. Statistical methods are based on counting the frequencies of words and word sequences. These methods are language independent and detect also one word terms. Linguistic methods are based on recognition of term patterns in texts. These methods are language dependent. A combination of statistical and linguistic methods, called a hybrid method, is also widely used. In hybrid methods two basically different methods are combined. Therefore, these methods have given better results than pure statistical or linguistic methods.
Term extraction tools can be evaluated by counting the precision and the recall of the term candidate lists produced by the software. Normally, the precision varies between 30 and 70 percent. This means that on an average just half of the extracted candidate terms are valid terms. Still, (Soininen, 1999), for example, says that precision of up to 90 percent can be reached. In spite of encouraging results, semiautomatic methods have not been able to completely replace manual work, since a computer cannot recognise meanings.
Knowing the problems related to term recognition and admitting that there is no such thing as the only correct choice in term recognition, I have asked one Finnish maritime expert to compile a term list from a Finnish source text (Wihuri, 2002) with 2366 words. In addition, candidate term lists were produced automatically with two commercial term extraction tools.
Description of Tools used in the Term Extraction Project In the term extraction project, two commercial tools were employed. The NaviTerm 2.0 term extraction tool utilizes the hybrid method of term detection. Besides statistical counts, it uses morphological and syntactic methods of text analysis. The tool detects nominal phrases with the ideal length of 1 to 3 words. Due to linguistic analysis, NaviTerm 2.0 is language dependent. At the moment, the choice can be made between English and Finnish. The NaviTerm 2.0 software algorithm is reported in detail in (Lahtinen, 2000).
The other tool, MultiTerm Extract, was the latest version of Trados term extraction tools at the time of the project. The user’s manual does not give any information about the method used in term extraction, but on the basis of the candidate term list, I would suggest that mainly statistical method is utilized. This assumption is partly based on the fact that candidate terms are unlemmatized. Therefore, more than one inflected forms having the same base form may be included in the candidate term list. For example, the basic form alueellinen ‘regional’ is
376

A Term List or a Noise List?
followed by the genitive form alueellisen and the plural partitive form alueellisia.
Both term extraction tools allow refining the search depending on the preferences. Since high recall usually results in low precision and vice versa, the choice has to be made in favour of either recall or precision. The aim was to produce a candidate term list with maximally high recall. This means that the number of detected valid terms divided by the number of all terms in the text should be as close to 1 as possible. With this aim in mind and based on my previous tests with NaviTerm 2.0, the default settings were used. With MultiTerm Extract, the candidate term lists were produced with default settings except that the noise ratio was set at 75 percent. In the following sections the main results of the term extraction project are reported.
Comparison of Automatically Produced Candidate Term Lists and the Expert’s Term List The term extraction project was based on the assumption that a domain expert makes his or her choice relying on his or her world and domain knowledge and the text context. Computer software counts word frequencies and recognizes linguistic patterns (e.g. Adjective + Noun).
The Finnish maritime expert recognized 220 terms from the Finnish source text with 2366 words. From the same source text, NaviTerm 2.0 compiled a list with 694 candidate terms with default settings. MultiTerm Extract produced a list with 306 unlemmatized candidate terms with the noise ratio settled to 75 percent.
The results of the automated term extraction were then compared with the results of the manual term recognition. Term and term candidate frequencies, lengths measured with number of words, and term patterns were studied. Comparison of Term and Candidate Term Frequencies When term frequencies in the source text are concerned, it must be noted that almost 70 percent of terms chosen by the Finnish domain expert occurred only once in the source text. Therefore, the majority of terms stand unnoticed, if the term extracting software has been programmed to extract terms occurring at least twice in the source text as is often the case. The number of low frequency terms might depend on text length, but the high percentage of low frequency terms in the source text suggests that it’s not wise to ignore words or phrases, which occur only once. In this project, the NaviTerm 2.0 detected 147 out of 220 terms extracted by the domain expert. This gives recall of 67
377

Päivi Pasanen
percent which is quite good. The MultiTerm Extract term extraction tool had severe problems to detect terms which occur only once in the source text. Only 50 out of 220 terms were detected. Therefore, recall is as low as 23 percent. Precision is quite low in both cases. The NaviTerm 2.0 gets poor precision due to the high number of “noisy” term candidates, 147 candidates out of 694 are valid terms. This gives precision of 21 percent. The MultiTerm Extract candidate term list is shorter but so is the list of valid terms. 50 valid terms out of 306 candidates gives a precision rate of 16 percent.
When the terms occurring only once in the source text are ignored, both recall and precision are a lot higher. In the Finnish expert’s term list, there are 68 terms out of 220, which occur at least twice in the source text. Out of these 68 terms, NaviTerm 2.0 was able to extract 57, which gives recall of 84 percent. Since the software extracted 161 candidate terms with two or more occurrences in the source text, precision is 35 percent. MultiTerm Extract produced 184 term candidates with the occurrence of two or more. 39 of these were valid terms. This gives recall of 57 percent and precision of 21 percent. That means that both tools produce a great amount of high frequency words or phrases, which are not terms. In the NaviTerm 2.0 candidate term list these are mainly general language nouns, which match the common term pattern N (e.g. alue ‘region’; järjestelmä ‘system’). In the MultiTerm Extract candidate term list all parts of speech are represented (e.g. komitea ‘committee’; taloudellisia ‘economical’; päättää ‘decide’ kuitenkin ‘however’).
Comparison of Term and Candidate Term Lengths When the term length measured with number of words is considered, there is no significant difference between Finnish expert’s terms and candidate terms produced by NaviTerm 2.0. However, when the candidate terms produced by MultiTerm Extract are compared with the terms chosen by the Finnish expert, the difference is remarkable. MultiTerm Extract tends to extract shorter candidate terms than the expert. Especially notable is the small portion of terms which consist of two or three words (see Table 5:1).
378

A Term List or a Noise List?
Word count Expert % (f)
NaviTerm 2.0 % (f)
MultiTerm Extract % (f)
1 62.3% (137) 60.7% (421) 87.6% (268)
2 29.1% (64) 26.7% (185) 8.5% (26)
3 5.9% (13) 10.9% (76) 2.6% (8)
4 2.3% (5) 1.4% (10) 1.0% (3)
5 or more 0.4% (1) 0.3% (2) 0.3% (1)
Total 100% (220) 100% (694) 100% (306)
Table 1: Word count in a term and a term candidate
On the basis of the expert’s term list more than 60 percent of Finnish terms have the length of one word only. This is due to the agglutinative nature of the Finnish language. Therefore, the common notion that majority of terms have the length of two words does not hold true for Finnish terms. This fact is a serious problem for automatic term extraction, because without domain knowledge it is difficult to decide whether a word is a term or a general language word. As a result, both candidate term lists include a great number of “noisy” general language words with a high frequency in the source text (e.g. alue ‘region, field’; järjestelmä ‘system’; kehitys ‘development’; määritelmä ‘definition’; tieto ‘information’; toiminta ‘operation’; yhteistyö ‘coordination’).
Comparison of Term and Candidate Term Patterns In this study, term patterns of the candidate terms extracted with term extraction tools were compared with the patterns of the terms recognized by the domain expert. The most common term patterns in the term list of the Finnish domain expert are single-word compound nouns (Nc; e.g. informaatiopalvelu ‘information service’), single-word simple nouns (N; e.g. satama ‘port’), and phrases consisting of an abbreviation and a simple or compound noun (Abb N(c); e.g. VTS operaattori ‘VTS operator’). More than 60 percent of the terms match with these term patterns. Phrases consisting of an adjective and a simple or a compound noun (A N(c); e.g. kansainvälinen merenkulkujärjestö
379

Päivi Pasanen
‘international maritime organization’), phrases consisting of two nouns (N(c) N(c); e.g. laivaliikenteen ohjauspalvelu ‘Vessel Traffic Service’), where each noun may be a compound word, and abbreviations (Abb; e.g. VTS) comprise about 25 percent of the terms.
Expert % (f) Navi-Term
% (f) Multi-Term
% (f)
Nc 30% (65) N 32% (221) N 29% (89)
N 18% (40) Nc 21% (143) V 18% (55)
Abb N(c) 15% (33) N(c) N(c)
11% (80) A 11% (35)
N(c) N(c)
12% (27) A N(c) 9% (65) Nc 10% (29)
A N(c) 8% (17) en 5% (34) Adv 8% (25)
Abb 6% (14) Abb N(c)
4% (28) Abb 6% (17)
N(c) C N(c)
2% (4) Abb 2% (15) Pron 3% (9)
Total 91% (200)
Total 84% (586) Total 85% (259)
Table 2: The most common term patterns A=Adjective; Abb=Abbreviation; Adv=Adverb; C=copula;
c=compound; en=English word; N=Noun; Pron=Pronoun; V=verb
In the NaviTerm 2.0 candidate term list, the most common term patterns are almost the same as in the expert’s term list as can be seen in the Table 5:2. Still, a candidate term matching the term pattern might not be a term. In contrast, in the MultiTerm Extract candidate term list the difference in term patterns is striking. Patterns of complex terms are missing as could be expected on the basis of term length analysis.
380

A Term List or a Noise List?
Instead, many single-word terms are verbs, adjectives or adverbs which are not represented in the expert’s list of most common term patterns (see Table 5:2).
Characteristics of Undergenerated Candidate Terms When comparing the NaviTerm 2.0 candidate term list with the Finnish expert’s term list, it can be noted that undergenerated terms are mainly one or two word terms with low frequency in the source text. The higher the frequency of a valid term the better is the chance to be extracted. The critical limit seems to be two occurrences in the source text. For NaviTerm 2.0 undergeneration or silence, as it is usually called in terminological literature, is not the real problem, although one third of valid terms were undetected.
About 50 percent of two word candidate terms detected by MultiTerm Extract really are terms. Still, 52 two word terms out of 64 are missing. When frequencies are concerned, the MultiTerm Extract term extraction tool performs well, if the frequency is 3 or higher. If a term occurs twice in the text, the tool has certain difficulties in detection resulting in both undergeneration (21 terms out of 31) and overgeneration (108 “noisy” candidate terms). If a term occurs only once in the source text, the tool tends to undergenerate heavily. The tool was able to detect only 12 out of 152 terms having the occurrence of one in the source text.
In conclusion, undergeneration is a crucial problem with the MultiTerm Extract term extraction tool. Although it is possible to increase the noise ratio hoping to reduce silence, my previous tests show that increased noise does not result in silence decrease. The noise problem could be partly solved by lemmatization and stop list elaboration, but the silence problem seems to be difficult to handle with statistical methods only. Characteristics of Overgenerated Candidate Terms In the NaviTerm 2.0 candidate term list, the overgenerated candidate terms tend to be nouns or one word compound nouns as well as phrases comprising of two nouns, an adjective and a noun or two nouns connected with the copula ja ‘and’. It is interesting to notice that although there are complex terms with the copula ja both in the expert’s list (e.g. etsintä ja pelastus ‘search and rescue’) and in the NaviTerm 2.0 candidate term list (e.g. järjestelmä ja tietokanta ‘system and database’), none of the detected candidate terms having this structure are valid terms.
381

Päivi Pasanen
Overgeneration is a problem for NaviTerm 2.0, since 547 candidate terms out of 694 are not valid terms. Therefore, a lot of manual work is needed to clean the candidate term list from non-valid candidates. The noise ratio is highest when the term or candidate term occurs only once in the source text. When term length is concerned the NaviTerm 2.0 tends to overgenerate two-word (155 “noisy” candidates out of 185 candidates) and one-word (306 “noisy” candidates out of 421 candidates) terms.
Weeding out single-word candidate terms with low frequency from the NaviTerm 2.0 candidate term list would partly solve the noise problem, but at the same time many valid terms would be lost.
In the MultiTerm Extract candidate term list, a great majority of overgenerated candidate terms are single word candidates. The tool clearly tends to overgenerate single word candidate terms. Still, 101 single word terms out of 137 are missing in the candidate term list.
Conclusions It has been argued that nominal phrases having the length of two words comprise the majority of special language term reserves. Also, it is a general assumption that terms occur in the source text more than once. However, the results of this study show that in Finnish special language, the majority of terms have the length of one word only. Still, one third of terms have the length of two words. Most of the terms occurred in the source text only once. The results of this study support the common claim that adjectives, verbs and adverbs alone hardly ever are terms. High frequency together with pattern match seems to be a good term indicator. The term extraction software tested here produces candidate term lists which can be useful but only after some manual work. The NaviTerm 2.0 term extraction tool is useful with Finnish source texts and gives results which are comparable with the results of the most advanced term extraction software in the world when measured with recall and precision.
The MultiTerm Extract tool may work well with Germanic languages like English or German, which were not included in this study, but with Finnish the software algorithm certainly needs adjustment, if it is meant to lighten terminologists’ or translators’ work load. First of all, a terminologist or a translator would expect automatic lemmatizing of the candidate terms. In this study, the candidate term list was full of surprises, which are difficult to explain, for example, the abbreviated term VTS is missing although it has a frequency of 55 in the source text.
382

A Term List or a Noise List?
The two big issues are still waiting for a satisfactory solution: undergeneration and overgeneration or silence and noise as they are also known. Although it might be impossible to produce a perfect term list automatically since it is impossible to produce one even manually due to the vagueness of the concept term itself, modern information technology might help to come as close as possible. At the moment, a term extraction project generally starts from scratch and cannot exploit the information collected during previous projects. It can be expected that in the future term extraction tools could be part of a system which automatically uses the information collected in the system memory. References Lahtinen, Timo; Automatic indexing: an approach using an index term
corpus and combining linguistic and statistical methods. Helsinki: University of Helsinki, 2000.
Pasanen, Päivi; “Roskaisia”, sanoi terminologi koneella poimituista termeistä, in Merja Koskela & Nina Pilke (eds.), Erikoiskielet ja käännösteoria, Vakki-symposiumi XXIV, Vaasa 7.–8.2.2004, Vaasa: Vaasan yliopisto, 2004.
Soininen, Pirjo; Terminhaun automatisointi. 1998. Available at: http://www.ling.helsinki.fi/~psoinine/lp.html.(cited February 13,
2002). ---------------; Sanastotyön tietotekniset apuvälineet. Pro gradu thesis.
Helsinki: Helsingin yliopisto, 1999. Wihuri, Paavo; Meriliikenteen ohjausjärjestelmät VTS ja VTMIS. A
seminar paper presented in Uusikaupunki September 23, 2002.
383

Päivi Pasanen
APPENDIX A Sample of the Terms and Term Candidates Terms beginning with the letter h in the Finnish expert’s term list (n=4) HAZMAT-direktiivi hinauspalvelu horisontaalinen integraatio huono näkyvyys Term candidates beginning with the letter h in the NaviTerm 2.0 term candidate list (n=20) haaste hakumuoto hallinta hallinto Hampuri Hampurin satama harkinta HAZMAT-direktiivi henkilöstö hinauspalvelu horisontaalinen integraatio horisontaalinen tietojenvaihto huomattava edistysaskel huomio huono näkyvyys huono näkyvyysolosuhde hylly hyvä kokemus hyväksyntä häiriö Term candidates beginning with the letter h in the MultiTerm Extract term candidate list (n=7) horisontaalinen huolimatta huomattavana huomattavasti huonoissa näkyvyysolosuhteissa hyväksyttiin hyötyä
384

Terminological Knowledge Extraction
- and Machine Learning for Danish
LONE BO SISSECK1
1 Introduction Some words, which are very often verbs, can indicate a semantic relation between concepts in a text. They are, among others, known as linguistic signals (Pearson, 1998). Linguistic signals can be supportive in a system aiming at automatically relating concepts in the process of constructing ontologies. Where particularly English, French and Spanish researchers2 have identified linguistic signals for their languages and classified them by relation type, Danish research is limited within this area3. In this paper, I will describe an investigation of some Danish linguistic signals that can indicate the generic-specific relation. In addition I will propose a method of identifying the semantic value connected to these words based syntactic rules learned from machine learning.
2 Concept Analysis The terminologist’s most prominent task is to perform concept analysis within a specific domain. Concept analysis implies that the terminologist needs to identify the domain-specific terms and to understand the concepts behind the terms. Within the field of terminology it is crucial to determine the domain-specific concepts and their designations (terms), and to construct domain-specific concept systems in order to model the subject field.
Concepts do not exist as isolated units of thought but always in relation to each other. Our thought processes constantly create and refine the relations between concepts, whether these relations are formally acknowledged or not (ISO, 2000)p.4.
1. Department of Computational Linguistics, Copenhagen Business School. 2. E.g. (Ahmad, 1993), (Marshman, 2002) and (Feliu, 2002). 3. Lotte Weilgaard has done research within this field by investigating Danish so-
called definitorial verbs (Weilgard, 2002).

Lone Bo Sisseck
To model a concept system, at least one of the following relations should be used (ISO, 2000):
• hierarchical relations - generic-specific relations - partitive relations
• associative relations
The most common relation type is the generic-specific relation. A generic-specific relation exists between two concepts when the intension of the subordinate concept includes the intension of the superordinate concept plus at least one additional delimiting characteristic (ISO, 2000)p.5.
The generic-specific relationship identifies concepts as belonging to the same category in which there is a broader (generic-specific) concept which is said to be superordinate to the narrower (specific), subordinated concept or concepts. The generic-specific relationship is the most common type of semantic relationship and can be expressed by one of the following formulas (Sager, 1990):
• X is a type of A. • or X, Y and Z are types of A • or A has the specific concepts X, Y and Z. • or A has the subtype X
3 Linguistic Signals Initially the focus of (semi-)automatic terminological extraction has been on automatic term recognition and extraction, and this is still an area of great interest both from a linguistic and a statistical point of view. During the last decade there has been a great interest in extracting, not only domain-specific terms from text, but also in extracting knowledge about the terms. Researchers in artificial intelligence (AI) use conceptual patterns and/or statistics on for example collocation patterns for the automatic extraction of related concepts for ontology construction (Hearst, 1992, Kawtrakul, 2004, Navigli, 2004). For terminology researchers, there has been a focus on how to semi-automatically extract related concepts and the surrounding context on the basis of conceptual patterns in the text (Ahmad, 1993, Condamines, 2002 & 2001, Feliu, 2002, Marshman, 2002, Meyer, 2001, Weilgaard, 2002).
386

Terminological Knowledge Extraction
A corpus can be useful for providing conceptual information. Sometimes the context surrounding a particular term contains a definition, explanation or description of some of the characteristics of the concept designated by that term (Bowker, 2002)p.38.
The identification of linguistic signals, as an aid to automatically extract terminological information from documents, is a relatively new research topic that has emerged through the nineties along with the growing access to electronic corpora. For English, the prototypical patterns for the generic-specific relation are is a, type of and form of and for the part-whole relation they are consists of, part of and includes (Marshman, 2002). Linguistic signals, also called knowledge probes (Ahmad, 1993) or knowledge patterns (Meyer, 2001), provide the means for the automatic recognition of knowledge-rich contexts (Meyer, 2001) and these are gradually being incorporated into current knowledge-extraction tools. They are based on the premise that conceptual relations sometimes will be expressed by recurring patterns in text. Even with only a simple understanding of a text, people without domain knowledge can infer useful information about domain-specific concepts from domain-specific text because of the linguistic signals between the concepts (Hearst, 1992). 4 Case Study In an earlier investigation of a Danish corpus on nutrition4 Danish linguistic signals that can indicate the generic-specific relation (Sisseck, 2004) has been identified. The manually build ontology in the OntoQuery Project (2001-2005) has functioned as a Gold Standard in that investigation. A sample of concepts that were semantically related by the generic-specific relation, so that one of the concepts was a superordinate concept of the other(s), were manually identified. The linguistic signals that “glued” the concepts together are outlined in Table 2. 4. This corpus consists of the articles on nutrition in a Danish encyclopaedia (Den
store Danske Encyclopædi, 1994-2003). The size is aprox. 20.000 words. It has been used as the knowledge background for the manually build ontology used for ontology based search in (The OntoQuery Project, 2001-2005)
387

Lone Bo Sisseck
Expression aR(b,…,n) where R =
Collocation example
at være (to be)
er (is) Chrom er et sporstof (chromium is a tracer)
colon : : …vitaminer: B1, ,…,n (vitamins: B1,…,n) parenthesis ( ) ( ) …organisk jern (hæmoglobin, myoglobin)
…(organic iron (haemoglobin, myoglobin)) fx (e.g) fx (e.g.) …spormetaller, fx selen og kobber
(…trace metals e.g. selenium and cobber) omfatte (to include)
omfatter (include(s))
…næringsstoffer omfatter vitaminer og mineraler (…nutrients include vitamins and minerals)
Table 2: Linguistic “glue” patterns
These patterns were then applied to the whole corpus using a corpus tool (WordSmith) in order to find out if it was possible to locate semantic relations throughout the whole corpus by using the manually found linguistic signals as search patterns. Since the nutrition corpus is very small, around 20.000 words, it was possible to go through every occurrence manually in order to determine whether there was a generic-specific relation present in the sentence construction or not. The list was “cleaned” first by the condition that two or more domain-specific concepts should be involved in the collocation pattern and second by the recognition of a genuine5 generic-specific relation. The results of this analysis are summarized in Table 3.
Expression aR(b,…,n) where R = Occurences
#
Candidatefor the generic-specific relation
#
Genuine generic-specific relation
#
Genuine generic-specific relation %
at være (to be) er (is) 447 65 45 70 % colon : : 70 37 29 78 % parenthesis ( ) ( ) 11 9 8 88 % fx (e.g) fx (e.g.) 10 9 9 100
% omfatte (to include)
omfatter (include(s)) 4 4 2 50 %
Total 124 93 75 % Table 3: The generic-specific relation pattern statistics
5. By genuine I mean as genuine as it could be when not having pure domain
knowledge. But since the corpus is from an encyclopedia, the language is meant to be understood by non-experts.
388

Terminological Knowledge Extraction
Out of 124 sentences where the linguistic signal is a candidate linguistic pattern for the generic-specific relation between concepts, meaning that two or more domain-specific concepts were present in the sentence construction, 93 occurrences were recognized as a genuine generic-specific relation between two or more concepts, that is 75 % of the total. The concepts that were manually extracted using the linguistic signal er(is) were subsequently manually mapped into a concept system. In order to see, if there was any reason in trying to relate concepts solely on the basis of the linguistic pattern, the ontology was compared to similar fragments from the manually built ontology in the OntoQuery project (OntoQuery, 2001-2005). This comparison showed that the ontology based on the linguistic pattern er(is) tends to be more general than the OntoQuery domain ontology (Sisseck, 2004). For example, steroid and glutahion are directly subordinate concepts to substance on the same level as bilirubin and ubiquinon, and there is no indication that glutahion and bilirubin are hormones, whereas in the OntoQuery ontology there is an extra dimension, namely the “hormon”-level between the superordinate concept substance and the two subordinate concepts steroid and glutahion.
Ubiquinon (ubiquinon)
bilirubin (bilirubin)
Stof (substance)
Hormon (hormones)
Glutathion (glutathio
Steorid (steorid)
Ontology fragment based on the linguistic “glue” signal er/is Ontology fragment from the OntoQuery ontology
Figure 1: Example from the comparison of ontology fragments (Sisseck, 2004). This comparison showed that the linguistic signals, which were identified as representatives of the generic-specific relation, were able to express an acceptable knowledge structure of the domain.
389

Lone Bo Sisseck
4.1 Machine Learning In order to explore the possibility of using machine learning techniques to automatically induce rules for disambiguating the generic-specific relation sense of er(is) (from now on called the ISA sense) from the non-ISA sense, I chose to experiment with the Brill Tagger (Brill, 1995). Brill tagging is also called transformation-based learning because the output is an ordered list of transformation rules that constitute a tagging procedure applied to a new corpus (Jurafsky, 2000). The Brill Tagger was trained on the manually tagged Parole corpus (LE-PAROLE) to recognize the Danish part of speech tags6.
The Brill Tagger learns by first tagging words in raw text with their most frequent tag. The system searches among transformations that instantiate different transformation templates and produces transformation rules on the basis of a window of, for instance, three words before and after the “search word”. Learning proceeds iteratively by trying every instantiation of the transformations templates, and by finding the transformation that result in the greatest error reduction (Brill, 1995).
First 92 sentences from the nutrition corpus were randomly selected for the training corpus. All of them contain the Danish verb at være/to be in the present tense er/is. Some of the er-instances indicate the generic-specific relation between two or more concepts and some do not. This file was formatted and POS tagged by the Danish version of the Brill Tagger. All the domain-specific terms in were then tagged T (for term). As I mentioned earlier, the identification of a semantic relation is conditional on the presence of two or more related concepts. In principle, it is therefore very important to identify the terms in the corpus that represent the corresponding concepts. Due to the complexity of concepts, this is actually not a straightforward matter, but for this small pilot project, I decided upon the following rules for “termhood”.
TERM = N (Noun) where the N is domain-specific. In some cases the N is not domain-specific but refers to a domain-specific noun in the same or in another sentence e.g. kilder/sources refers to A-vitaminkilder/sources of vitamin A7
6. The Danish Parole tag set consists of 151 distinct tags, containing information
such as syntactic category, number, gender, case, tense and so on. 7. The noun kilder (source) may belong to concepts that themselves are relations
(Sager, 1990)p.26. Here this will not be taken into consideration, and kilder is treated as a concept referring to e.g. A-vitaminkilder (sources of vitamin A).
390

Terminological Knowledge Extraction
TERM = ADJ (adjective) N (noun) but only in the cases where my intuition told me that the two words belong together and form a term, for example, frie radikaler (free radicals).
TERM = N (noun) P (preposition) N (noun) when it is possible to convert the phrase into a one word term, e.g. mangel på A-vitamin (lack of vitamin A) = A-vitaminmangel (*Vitamin A lack).
After manually changing the tag sets of the above structures into the tag T, the file was copied, and the er/V_PRES occurrences of the generic-specific relation were changed into er/V_PRES_ISA in the copied version. In total, 34 occurrences were changed in this way. So one file contains the training corpus/truth (with the ISA relations), the other contains the test corpus /dummy (without the ISA-relations).
The system learned the following rules:
• (1) V_PRES V_PRES_ISA NEXT1OR2OR3TAG T • (2) V_PRES_ISA V_PRES NEXT1OR2TAG PRÆP • (3) V_PRES_ISA V_PRES NEXT1OR2TAG
V_PARTC_PAST • (4) V_PRES_ISA V_PRES NEXTBIGRAM T ADJ • (5) V_PRES_ISA V_PRES NEXT1OR2WD ikke
Rule no1 specifies that V_PRES should be changed into V_PRES_ISA when one of the next three tags is T. Since the whole nutrition corpus has not yet been TERM tagged, it has not been possible to test this rule so far. It seems correct, however, to say that one of the related terms always will be placed after the verb whereas all related terms will never be placed in front of the verb.
Rule no 2 specifies that V_PRES_ISA should be changed into V_PRES when one of the next two tags is a preposition (PRÆP). 124 occurrences in the nutrition corpus were found containing a preposition at one or two places after er/is. Only 10 of these contain potential conceptual relations. In most of these cases the preposition is part of an NP and is therefore a potential domain-specific term. With a more thorough identification and tagging of domain-specific terms in the whole corpus, these conceptual relations could be “captured” by another rule.
Example 1 (non ISA sense): Vitaminer er kendt for at forebygge mangelsygdomme. (Vitamins are known for preventing illnesses.)
Example 2 (potential ISA sense):[ …] mens symptomer på udtalt mangel(på vitaminet riboflamin) er revnedannelse i mundvige og på
391

Lone Bo Sisseck
læber[…]. ([…] while symptoms of noticeable lack(of the vitamine riboflavin) are chaps in the corner of the mouth and on the lips[…].)
Rule no 3 specifies that V_PRES_ISA should be changed into V_PRES when one of the next two tags is a V_PARTC_PAST. 56 occurrences in the nutrition corpus were found to contain a past participle of a verb one or two positions after er/is. In all of them er/is performs as an auxillary verb. 14 of the occurrences overlap with rule no 2, leaving us with 42 disambiguated er/is examples.
Example: I biologien er antioxidanter defineret som enhver substans […]. (Within biology antioxidants have been defined as any substance […].)
Rule no 4 specifies that V_PRES_ISA should be changed into V_PRES when the next two tags are T ADJ. 5 occurrences in the nutrition corpus were found where a potential term is modified by an adjective. None of them indicate a conceptual relation and therefore all 5 occurrences are disambiguated by this rule.
Example: Uden behandling med protein, fx mælkepulver, er sygdommen dødelig. (Without treatment with e.g. milk powder, the illness is fatal.)
Rule no 5 specifies that V_PRES_ISA should be changed into V_PRES when the next one or two words is ikke (not). 13 occurrences in the nutrition corpus were found containing either er ikke/is not or er * ikke/is * not. None of them had the ISA sense, so 13 out of the occurrences of er/is are disambiguated.
Example: Hos mennesker er mangelsymptomer ikke karakteristiske og […]. (Symptoms of lack (of vitamins) are not characteristic for humans.)
Conclusion on the machine learning experiment 198 (44%) out of 447 of the er/is occurrences were present in one of the syntactic constructions. 87% (174 occurrences) of them were correctly disambiguated by the rules. These were all non-ISA senses and in the remaining 13 % the linguistic signal er/is potentially has the ISA sense. When taking the total of 447 occurrences of er/is in the Danish corpus on nutrition into consideration, it means that 39% non-ISA senses have been disambiguated by the rules so far. In future I hope to improve this result further by enlarging the corpus on which the rules are learned. In addition, I anticipate that the system will learn rules that are also able to disambiguate the ISA sense more directly. Only the first rule does that but since the whole nutrition corpus has not yet been tagged with domain-specific terms, it has not been possible so far to test this rule.
392

Terminological Knowledge Extraction
5 Conclusion and Future Research The use of linguistic signals as a means for terminological knowledge acquisition is very likely to become obligatory in future knowledge extraction tools. For the terminologist, who is not an expert, it is very time consuming to manually extract terms and term related information from domain-specific documentation. The growing access to specialized electronic corpora as a knowledge resource has indeed increased the need for these kinds of knowledge acquisition tools.
The potential for automatic extraction of terminological knowledge is exemplified by the case study. Based on a small set of data, it has been possible to construct a useful ontology based on the identified linguistic signals (Sisseck, 2004). Looking at the complexity of sentences, it is interesting that useful rules can be produced from such a small context, which in this case was three words before and after the “search term”. With more data it is therefore likely that more useful rules can be produced for the sense disambiguation task of semantic relations. When one takes the limited corpus size into consideration, the rules produced by the Brill Tagger are very effective and are able to sense disambiguate 39 % of the total occurrences of the linguistic pattern er/is.
The fact that it was the non-ISA senses of er/is that were disambiguated may seem like a curiosity at first. But Ahmad (1992) actually introduced the possibility of identifying negative knowledge probes which are words or phrases that never seem to indicate the presence of a semantic relation. For example, kind of could indicate a semantic relation whereas kind of you never would. This means that kind of would be identified as a linguistic signal provided that it does not take part in the phrase kind of you.
In this article, I have not treated the question of how to determine, in the process of investigating the linguistic signals, when to accept a conceptual structure as being “legal”. The answer to may exists in the borderline between terminology theory and formal ontology theory. With regard to the machine learning experiment, it will in the near future be expanded with more data in order to, hopefully, produce more and even better syntactic rules.
References Ahmad, K. & H. Fulford; Semantic Relations and their Use in
Elaborating Terminology. Knowledge Processing Report 4. University of Surrey, 1992.
393

Lone Bo Sisseck
Bowker, L. & J. Pearson; Working with Specialized Language. London: Routledge, (2002).
Brill, Eric; Transformation-Based Error-Driven Learning and Natural Language Processing: A Case Study in Part of Speech Tagging. Computational Linguistics, Dec. ’95, 1995.
Condamines, Anne; Corpus analysis and conceptual relation patterns. Terminology 8:1, pp. 141 – 162, 2002.
Condamines, A. & J. Rebeyrolle; Searching for and Identifying Conceptual Relationships via a Corpus-based Approach to a Terminological Knowledge Base (CTKB): Method and Results, in D. Bourigault; C. Jacquemin & M.C. L’Homme (eds.), Recent Advances in Computational Terminology, pp. 127 – 148, Amsterdam / Philadelphia: John Benjamins, 2001.
Den Store Danske Encyclopædi (1994-2003). Gyldendal. Danmark. Feliu, Judit; Conceptual relations in specialized texts: new typology
and an extraction system proposal, in TKE ’02. Sixth International Congress on Terminology and Knowledge Engineering. pp. 45 – 49, August, 2002.
Jurafsky, D. & J.H. Martin; Speech and Language Processing. Prentice-Hall, Inc. Pearson Higher Education, New Jersey, 2000.
Hearst, Marti A.; Automatic Acquisition of Hyponyms from Large Text Corpora. The 14th International Conference on Computational Linguistics. Nantes, July, 1992.
ISO 704; Terminology work — Principles and methods, 2000. Kawtrakul, Asanee; Automatic Thai Ontology Construction and
Maintenance System. LREC 2004. Fourth International Conference on Language resources and Evaluation, OntoLex 2004, pp. 68 – 74, Workshop, Lisboa, May, 2004.
LE-PAROLE; Website: http://www.tei-c.org/Applications/apps-le02.html
(last visited 2005-04-07) Marshman, Elizabeth; French patterns for expressing concept relations.
Terminology, 8:1, pp. 1 – 29, 2002. Meyer, Ingrid; Extracting Knowledge-Rich Contexts for
Terminography: A Conceptual and Methodological Framework, in D. Bourigault; C. Jacquemin & M.C. L’Homme (eds.), Recent Advances in Computational Terminology, pp. 279 – 302, Amsterdam/Philadelphia: John Benjamins, (2001).
Navigli, R. & P. Velardi; Learning Domain Ontologies from Document Warehouses and Dedicated Websites, Computational Linguistics (30-2), MIT Press, June, 2004.
394

Terminological Knowledge Extraction
OntoQuery Project, (2001-2005). Information on website: www.ontoquery.dk (last visited 2005-04-07) Pearson, Jennifer; Terms in Context. Amsterdam/Philadelphia: John
Benjamins, 1998. Sager, Juan; A Practical Course in Terminology Processing.
Amsterdam/Philadelphia: John Benjamins, 1990. Sisseck, Lone; Semantic Relations between Concepts in Danish
Domain Specific Texts, in Proceedings of the Fourth International Conference on Language Resources and Evaluation, LREC, Workshop Computational and Computer-assisted Terminology, Lisbon, May 24-30, 2004.
Weilgaard, Lotte; På datafangst – hvad repræsenterer verber som ’kalde’, ’karakterisere’ og andre?, in Viden om Viden. Del 2 – Forskning, pp. 47 – 88, 2002 DANTERM-centret, København, 2002.
WordSmith: www.liv.ac.uk/~ms2928/
395


DiaSketching as a Filter in Web-Based Term Extraction
Systems
JAKOB HALSKOV Abstract The article describes how identifying recurrent usage patterns of terms in non-specialized contexts (determinologized usage) can act as a filtering device and increase the precision of WEXTER, a system for Web-based Extraction of Terms. It outlines an implementation of a WEXTER component called the DiaSketch (Diachronic wordSketch), which detects co-occurrence patterns of mother terms in general language diachronic corpora. Finally, some linguistic properties of determinologized usage are revealed through a case study of DiaSketches for a term from the domain of Information Technology (IT).
Introduction Using the Internet as a specialized corpus in a term extraction system has a number of obvious advantages. Keeping termbases up-to-date is an arduous task, especially for domains like Information Technology (IT), which are characterized by rapid term growth. As has been demonstrated in Baroni (2004) bootstrapping specialized corpora and terms from the Internet is a speedy means of achieving this goal. The web, however, is a very dirty and multifarious collection of texts, and termhood assumptions, which hold for neat corpora of highly specialized discourse, are not always true for web corpora. While one-off cases of creative or fuzzy usage of terms are easily ignored by standard term extraction systems (cf. the statistical filter in table 1), it is a different story when large numbers of non-specialists use terms from a domain, forming strong collocations, which, formally speaking, may resemble terminological neologisms, while not functioning as such. This paper stresses the importance of adding a functional perspective to terminology in line with Pearson (1998), Temmerman (1999), Cabré (2000) and Kageura (2002) and describes a statistico-

Jakob Halskov
grammatical method for detecting determinologized usage patterns of a given term in a given corpus. The implementation, which is called DiaSketch (Diachronic wordSketch), is inspired by Adam Kilgarriff's SketchEngine (Kilgarriff, 2004), but is new in the sense that it introduces a longitudinal and a terminological aspect. The patterns identified by DiaSketching will constitute a filter in WEXTER, a system for Web-based Extraction of Terminology, the architecture of which is outlined in table 1.
Step 1 Retrieval of comparable web corpora (English and Danish) Step 2 Statistical score of terminess Step 3 Contextual score of terminess Step 4 Fuzzy matching score of terminess Step 5 Linguistic filter (optional) Step 6 "Determinologization" filter Step 7 Repeat from step 1 with highest ranking candidates as query
Table 1: WEXTER system architecture Comparable specialized corpora are bootstrapped from the web using the Google API in an iterative fashion inspired by Baroni (2004). While the statistical scores of terminess are computed by means of log-odds ratios, a measure not unlike the so-called weirdness coefficient (Ahmad, 1993), the contextual scores are based on the average number of context terms in a given window of the candidate1. If the Levenshtein edit distance between a Danish candidate and an English candidate (possibly a multiword unit) is below a specified threshold value, this can be an additional indicator of terminess. Following an optional linguistic filter, the final step of the algorithm is then a "determinologization" filter, which is the topic of the rest of the paper. What is Determinologization? It is not surprising that conceptual fuzziness tends to occur when non-specialists use terminology in non-specialized communicative contexts. It seems intuitive that what is a term (representing a clear-cut concept) to one person may be a (possibly unknown) word representing a fuzzy category to another person who lacks the required specialist knowledge to decode the term fully and correctly. It also seems probable that traces of this conceptual fuzziness can be registered in linguistic usage.
1. This approach is inspired by Maynard and Ananiadou (2000)
398

Probing the Properties of Determinologization - The DiaSketch
Scholars have defined determinologization as “the ways in which terminological usage and meaning can 'loosen' when a term captures the interest of the general public” (Meyer and Mackintosh 2000a: 12). The seman- tic/pragmatic changes caused by determinologization have been grouped into two types:
• Maintien des aspects fondamentaux du sens terminologique • Dilution du sens terminologique d'origine (Meyer and
Mackintosh, 2000b: 202) The distinction between preservation and dilution of a terminological concept largely corresponds to the distinction between sense modulation and sense selection in lexical semantics (Cruse, 1986). Examples of the former type of determinologization include collocations of a term with semantically vague, general language adjectives like large server or powerful server. Although it is unclear whether the modifier, large, refers to the physical size of the head, server, or to its storage capacity, clock frequency or data transmission rate, the conceptual reference of the head itself seems to be preserved. In the sentence The Internet business model needs a reboot2, however, the term reboot no longer refers to the original domain specific concept of shutting down and restarting an operating system, but is being used in the more general sense of starting something afresh. Why Should Determinologization be Studied? As a result of the knowledge-based society and economy, more and more non-specialists encounter and are forced to use terminology from a number of specialized domains both in their private and professional lives. A linguistic consequence of this is that determinologization takes place at an unprecedented pace. Whether we like it or not, the phenomenon is likely to affect more and more domains, and as determinologized usage spreads it will become a challenge that terminologists and standardization bodies will have to deal with. While determinologization is an important field of research in Socioterminology (Gaudin, 1993), it also has important implications for the optimization of term extraction algorithms. The extensive usage of terminology from a domain like IT by vast numbers of non-experts in a variety of communicative settings complicates the automatic extraction task. While determinologized usage can be avoided by using corpora, which have been manually compiled and are known to 2. New York Times, 1999
399

Jakob Halskov
represent specialized communication between experts, such corpora are expensive to come by and age swiftly (especially in a domain like IT). Thus using the Internet as a dynamic and inexhaustible treasure trove of terms is becoming increasingly appealing to computational terminologists, but doing so exacerbates the problem of automatically assessing termhood or rather, degree of terminess. While the linguistic nature of determinologized usage cannot be fully described through statistical analysis of terminological usage in large general language corpora, such an approach seems likely to give us a better understanding of important notions like termhood and domain. How Can Determinologization be Studied? The definition of determinologization in Meyer and Mackintosh (2000b: 202) can be operationalized by means of lexical profiling techniques (Kilgarriff, 2001) and co-occurrence statistics (Evert, 2004). In a quantitative framework determinologized usage can be identified as relational co-occurrence patterns of a term, which resemble those of comparable lexical units from the general vocabulary. Comparing word sketches (Kilgarriff, 2001) of a term in successive time slices of specialized and non-specialized corpora will provide a DiaSketch (Diachronic wordSketch) with which prominent patterns of determinologized usage can be identified. Methodology and Issues A corpus-based description of how domain specific terms are used in general language is faced with two obvious problems:
• Since terms are specific to a domain we must expect their frequency of occurrence to be relatively low outside the domain in question.
• When lexical units, which function as terms in specialized discourse (e.g. bus, server, driver), occur in non-specialized contexts, the most frequent senses are likely to be the non-specialized ones.
The first problem can be (partially) overcome by using large corpora like the Gigaword from the Linguistic Data Consortium, but the second problem is trickier. While the context of the domain allows us to presume monosemy, language outside the domain wall is rife with
400

Probing the Properties of Determinologization - The DiaSketch
polysemy, and terms thus need to be disambiguated (sense tagged) before any reliable DiaSketches can be produced. Since supervised approaches to word sense disambiguation (WSD) presuppose a large, manually annotated corpus, subcorpora from Gigaword (containing terms in context) will be processed by an implementation of a Yarowsky-style algorithm for unsupervised WSD (Yarowsky, 1995). As evidenced by the case study at the end of this paper, however, even DiaSketches of terms, which have not been semantically disambiguated, may yield interesting results. Corpus Compilation and Annotation The corpora listed in table 2 represent communication between experts (Computer Journal published by Oxford University Press), between experts and advanced users (the British computer magazine PcPlus published by Future Publishing) and between non-experts (Gigaword newspaper corpus). Computer
Journal PcPlus LDC
Gigaword Tokens 4.5M 6M 1.7Bn Time frame 1997-2004 2000-
2004 1994-2002
Assumed degree of determinologization
none low high
Table 2: Specialized and non-specialized corpora In order to identify relational co-occurrences the corpora are PoS tagged (penn tagset) and lemmatized with the TreeTagger3 and subsequently phrase chunked with Yamcha4. An example of an annotated corpus slice can be seen in table 3 where B- indicates the beginning of a phrase and I- indicates a non-boundary. The corpora are finally converted into a special indexed format used by Corpus WorkBench (Schulze, 1994). CWB allows sophisticated and fast corpus queries using regular expressions over combinations of positional and/or structural attributes. In the case of the DiaSketch implementation the four positional attributes token, POS, lemma and chunk are used.
3. http://www.ims.uni-stuttgart.de/projekte/corplex/TreeTagger 4. http://chasen.org/~taku/software/yamcha
401

Jakob Halskov
Relational Co-Occurrence
Token PoS Lemma ChunkHe PP he B-NP reckons VVZ reckon B-VP the DT the B-NP current JJ current I-NP account NN account I-NP deficit NN deficit I-NP will MD will B-VP
Table 3: Annotated corpus slice The benefits and pitfalls of a number of statistical association measures are described and implemented by (Evert, 2004) in the UCS5 toolkit. The main advantage of relational co-occurrence over simple positional co-occurrence is that the former reduces noise from grammatically unrelated n-grams and leads to more meaningful results. The UCS tables generated by Evert's perl scripts are called frequency signatures and contain the four values, joint frequency (O11), marginal frequencies (O12, O21) and sample size (N). This corresponds to a classical four-celled contingency table like table 4, where O11 is the number of times partition and server co-occur in the sample (of size N) of all noun bigrams in the corpus, O12 is the number of times partition occurs with another noun in this sample and O21 the number of times server occurs with another noun. Comparing the observed with the expected frequencies (E11-E22) provides a measure of the strength of association between the two lemmas.
v=server v≠server u=partition O11 O12u≠partition O21 O22u=partition E11 = (R1*C1)/N E12 = (R1*C2)/N u≠partition E21 = (R2*C1)/N E22 = (R2*C2)/N
Table 4: Contingency table This association measure can be based on a number of statistical models, but the DiaSketch uses Evert's implementation of Fisher's exact test because it provides p-values, which are not approximations, 5. Utilities for Co-occurrence Statistics (http://www.collocations.de)
402

Probing the Properties of Determinologization - The DiaSketch
and it "is now generally accepted as the most appropriate test for independence in a 2-by-2 contingency table"6. A cut-off level of significance of p<10-6 and a O11/O21 threshold of at least 2% are enforced to avoid DiaSketches cluttered with collocates. Implementing the DiaSketch The present implementation of the DiaSketch accepts only nouns as input and identifies significant co-occurrences, which are modifiers of the node or predicates which subcategorize for the node as subject or object. In the case of the SUBJ_OF relation, a CQL (Corpus Query Language) query like [pos="NN.*"][pos="WDT"]?[chunk=".*- VP"]*[pos="VV[ZPDG]?"]7 retrieves (virtually) all these relations in the given corpus slice. By setting the matching strategy to longest, we make sure that we get the main verb of complex VPs like to help convince (cf. table 5). If longer relative clauses intervene, however, the pattern will simply match the first main verb. This can only be avoided by carrying out a computationally expensive full parsing. Piping the results of this CQL query into UCS yields the N value needed in the contingency table (table 4). agency/NN/I-NP has/VHZ/B-VP been/VBN/I-VP recruited/VVN/I-VP to/TO/I-VP help/VV/I-
VP convince/VV/I-VP model/NN/I-NP that/WDT/B-NP made/VVD/B-VP
schools/NNS/I-NP serving/VVG/B-VP industry/NN/I-NP might/MD/B-VP not/RB/I-VP exist/VV/I-VP
Table 5: SUBJ_OF examples from New York Times In case we want a sketch of the term server, the general query is simply transformed to a specific query by substituting [lemma="server"] for [pos="NN.*"]. Such a query will then provide all the observed frequencies needed to complete the contingency table, compute the association scores and retrieve salient collocates of the term in this grammatical relation. The following section will give an example of two DiaSketches for this term. 6. Evert, 2004 - http://www.collocations.de/AM/ 7. A noun in plural or singular possibly followed by a relative pronoun, any number
of VP chunk elements and finally a mandatory full verb which is not a past participle.
403

Jakob Halskov
Case Study: Server According to Collins Cobuild English Dictionary (1995) the lexical unit server has three senses:
• the player whose turn it is to hit the ball • something that is used for serving food • part of a computer network which does a particular task
Judging by the collocations in the general language DiaSketch for server (figure 2), the non-IT senses seem to be virtually absent (except for the collocation altar server). So in this case semantic tagging proved not to be a critical issue. Defining a reasonable cut-off point can be difficult, but as mentioned before this case study only includes those co-occurrences which defeat the Null Hypothesis at a significance level of p < 0.000001 (or –log(p) > 6) and where the number of co-occurrences (O11) exceeds 2% of the marginal frequency of the term in question (O21). While the absolute number of occurrences of the lemma server are approximately the same in the two corpora (some 800 per time slice), the relative frequencies of course differ tremendously. While figure 1 charts the most significant modifiers of the term server through time in a 6M word slice (2000-2003) of the British computer magazine PcPlus, figure 2 lists significant modifiers of the same term in a 915M word slice (1994-2002) of the New York Times (NYT) corpus. Strength of association, as measured in negative logarithmic p-values, is indicated along the y-axis and the collocation candidates are listed along the x-axis. A striking difference between the two figures is that the three noun modifiers network, Internet and computer are prominent collocations in the newspaper corpus (throughout the timeframe) but do not occur in the Dia-Sketch for the corpus of computer magazines. Internet server is a colloquial variant and network server is an infrequent8 variant of the term web server (which is highly salient in both corpora), but computer server is a case of determinologized usage. In this compound the noun modifier is used as a kind of domain label to distinguish the IT sense of the head noun from other senses possible outside this domain (for example the altar server). The expression is no more fuzzy than server on its own, but the modifier would be
8. http://google.scholar.com: network server (3,800 hits), Internet server
(3,300 hits), computer server (683 hits), web server (62,800 hits) - April 28th, 2005
404
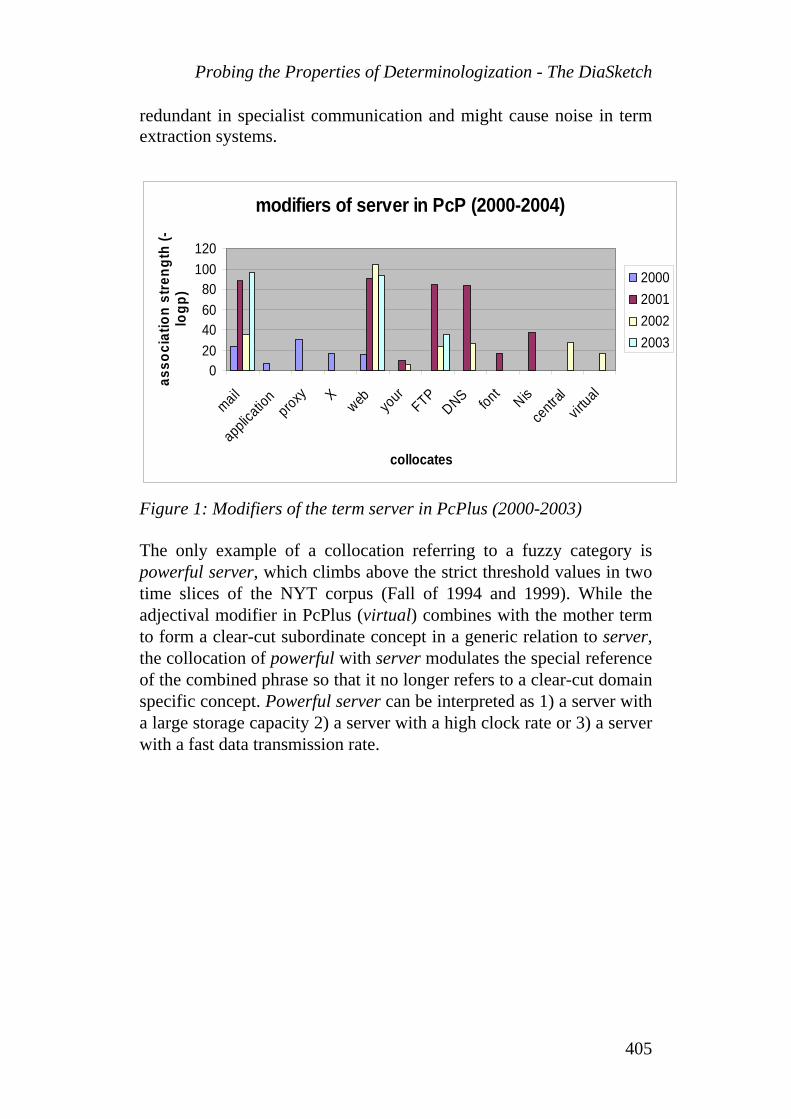
Probing the Properties of Determinologization - The DiaSketch
redundant in specialist communication and might cause noise in term extraction systems.
modifiers of server in PcP (2000-2004)
020406080
100120
applica
tion
proxy X
web your
FTPDNS font
Nis
centra
lvir
tual
collocates
asso
ciat
ion
stre
ngth
(-lo
gp)
2000200120022003
Figure 1: Modifiers of the term server in PcPlus (2000-2003) The only example of a collocation referring to a fuzzy category is powerful server, which climbs above the strict threshold values in two time slices of the NYT corpus (Fall of 1994 and 1999). While the adjectival modifier in PcPlus (virtual) combines with the mother term to form a clear-cut subordinate concept in a generic relation to server, the collocation of powerful with server modulates the special reference of the combined phrase so that it no longer refers to a clear-cut domain specific concept. Powerful server can be interpreted as 1) a server with a large storage capacity 2) a server with a high clock rate or 3) a server with a fast data transmission rate.
405

Jakob Halskov
Figure 2: Modifiers of the term server in New York Times (1994-2002)
406

Probing the Properties of Determinologization - The DiaSketch
Further Work and Perspectives The DiaSketch of server in a corpus representing communication between non-experts revealed two linguistic properties of determinologized usage, namely
• redundant domain labels (computer server) and • semantically vague adjectival modifiers (powerful server).
It also identified the two most prominent subordinate concepts of server in non-specialized discourse, namely (E-)mail server and web server. Not surprisingly, most people these days will be familiar with these two concepts. In order to test whether the tendencies from the case of server can be generalized, usage patterns of a wider range of (sense tagged) terms need to be analyzed, however. If recurrent patterns can indeed be identified, this knowledge will make it possible to improve the precision of term extraction systems, like WEXTER, which use the Internet as a corpus. A list of semantically vague or redundant modifiers typically used with mother terms in non-specialized discourse could for example be used in document classification. While extending the analysis to include grammatical relations like SUBJ_OF or OBJ_of might yield further insights into the linguistic properties of determinologized usage, such analyses are likely to be severely restricted by data sparseness issues. When the results of further DiaSketching have been analyzed and implemented in the form of a determinologization filter, the contribution of such a filter towards improving the overall precision of the WEXTER system needs to be evaluated. References Ahmad, Khurshid; Pragmatics of Specialist Terms: The Acquisition
and Representation of Terminology, in Machine Translation and the Lexicon, 3rd int. EAMT Workshop proceedings, Heidelberg, Germany, 1993.
Baroni, Marco; BootCat: Bootstrapping Corpora and terms from the web, in Proceedings of LREC, 2004.
Cabré, Castellví & María Teresa; Elements for a theory of terminology: Towards an alternative paradigm, in Terminology 6:1, pp. 35 – 57, Amsterdam: John Benjamins, 2000.
Cruse, D.A.; Lexical Semantics. Cambridge University Press, 1986.
407

Jakob Halskov
Evert, Stefan & Brigitte Krenn; "Computational approaches to collocations" Introductory course at the European Summer School on Logic, Language and Information (ESSLLI), 2003.
Evert, Stefan; The Statistics of Word Cooccurrences: Word Pairs and Collocations. Ph.D. dissertation, University of Stuttgart, 2004.
Gaudin, François; Socioterminologie: du signe au sens, construction d’un champ, in Meta, 38(2), pp. 293 – 301, Les Presses de l'Université de Montréal, 1993.
Kageura, Kyo; The Dynamics of Terminology - a descriptive theory of term formation and terminological growth. Amsterdam: John Benjamins, 2002.
Kilgarriff, Adam & David Tugwell; WORD SKETCH: Extraction and Display of Significant Collocations for Lexicography, in Proceedings of ACL 2001, pp. 32 – 38, Toulouse, France, 2001.
Kilgarriff, Adam; Pavel Rychly; Pavel Smrz & David Tugwell; The Sketch Engine, in Proceedings of the 11th EuraLex International Congress Lorient, France, 2004.
Maynard, Diana & Sophia Ananiadou; Identifying Terms by their Family and Friends, in Proceedings of the 17th conference on Computational linguistics, pp. 530 – 536, Saarbrücken, 2000.
Meyer, Ingrid & Kristen Mackintosh; When terms move into our everyday lives: An overview of determinologization, in Terminology, vol. 6(1), pp. 111 – 138, 2000a.
Meyer, Ingrid & Kristen Mackintosh; L'étirement du sens terminologique: apercu du phénomène de la déterminologisation, in Le Sens en Terminologie, pp. 198 – 217, Lyon, 2000b.
Pearson, Jennifer; Terms in Context. Amsterdam: John Benjamins, 1998.
Schulze, Bruno Maximilian; Entwurf und Implementierung eines Anfragesystems für Textcorpora Diplomarbeit Nr. 1059 Institut für maschinelle Sprachverarbeitung (IMS), Universität Stuttgart, 1994.
Temmerman, Rita; Why traditional terminology theory impedes a realistic description of categories and terms in the life sciences, in Terminology 5:1, pp. 77 – 92, Amsterdam: John Benjamins, 1999.
Yarowsky, David; Unsupervised Word Sense Disambiguation Rivaling Supervised Methods, in Proceedings of ACL 33, pp. 189 – 196, 1995.
408

Modelling and Use of Domain-Specific Knowledge
for Similarity and Visualization
TROELS ANDREASEN, HENRIK BULSKOV & RASMUS KNAPPE1
1. Introduction The use of ontologies can contribute significantly to the organization of concepts, structure and relations within a knowledge domain. Incorporation of ontologies in tools for information access provides foundation for enhanced, knowledge-based approaches to surveying, indexing and querying of document collections.
We introduce in this paper the notion of an instantiated ontology as a subontology derived from a general ontology and restricted by the set of instantiated concepts in a target document collection. This instantiated ontology represents a conceptual organization reflecting the document collection, and reveals domain knowledge, for instance about the thematic areas of the domain which in turn facilitates means for a topic-based navigation and visualization of the structure within the domain.
Modeling and use of ontologies is the major focus in this paper. We introduce, in section 2, to a formalism for representation of ontologies. Section 3 describes the modeling of general and instantiated ontologies respectively. In section 4 it is discussed how to establish a measure of domain-specific similarity from a so-called domain-specific ontology. Section 5 introduces the use of an instantiated ontology for domain and query visualization. Concept expressions, that are the key to modelling and use of ontologies, are explained in more detail below, we refer, however, to (Andreasen et al., 2004b) for a discussion of general principles behind parsing for concepts.
1. Department of Computer Science, Roskilde University, P.O. Box 260, DK-4000
Roskilde, Denmark {troels,bulskov,knappe}@ruc.dk

T. Andreasen, H. Bulskov & R. Knappe
2. Representation of Ontologies The purpose of the ontology, in this context, is to define and relate concepts that may appear in the document collection or in queries to this. We define a generative ontology framework where a basis ontology situates a set of atomic term concepts A in a concept inclusion lattice. A concept language (description language) defines a set of well-formed concepts, including both atomic and compound term concepts. The concept language used here, Ontolog (Nilsson 2001), defines a set of semantic relations R that can be used for “attribution” (feature-attachment) of concepts to form compound concepts. The set of available relations may vary with different domains and applications. We may choose R = {WRT,CHR,CBY,TMP,LOC,...}, for with respect to, characterized by, caused by, temporal, location, respectively.
Expressions in Ontolog are concepts situated in the ontology formed by an algebraic lattice with concept inclusion (ISA) as the ordering relation. Attribution of concepts can be written as feature structures. Simple attribution of a concept with relation r and a concept c is denoted . 1 2 1 2
Given atomic concepts A and relations R, the set of well-formed terms L of the Ontolog language is defined as follows.
c [ : ]c r c
1 1
- if then L- if L, R and L, 1,...,
then [ : ,..., : ] Li i
n n
x xx r y i
x r y r y
∈Α ∈∈ ∈ ∈ =
∈
n It appears that compound terms can be built from nesting, for instance,
1 1 2 2 3 and from multiple attribution as in . The attributes of a term with multiple attributes 1 1
[ : [ : ]]c r c r c 1 1 2 2 3[ : , : ]c r c r c[ : ,..., : ]n nT x r y r y= are
considered as a set, thus we can rewrite T with any permutation of . 1 1{ : ,..., : }n nr y r y
3. Modeling Ontologies One objective in ontology modeling, is for the domain expert or knowledge engineer to construct a knowledge base ontology over atomic or multi-word concepts.
Ontology modeling in the present information retrieval context consists of two parts. The inclusion of knowledge from available knowledge sources into a general ontology and a restriction to the part of the general ontology covering the instantiated concepts in the document collection. The first part involves modeling of concepts in a generative ontology and the second part the so-called domain-specific ontology is retrieved as a subontology of the general ontology. The restriction to this subontology is build based on the set of concepts that appears (is instantiated) in the document collection and the result is called an instantiated ontology.
410

Modelling and Use of Domain-Specific Knowledge
3.1 The General Ontology Sources for knowledge base ontologies may have various forms. Typically a taxonomy can be provided with supplements, e.g. word and term lists as well as dictionaries for definition of vocabularies and for handling of morphology. We will not go into details on the modeling here but just assume the presence of a taxonomy in the form of a simple taxonomic concept inclusion relation ISAKB over the set of atomic concepts A. ISAKB and A expresses the domain and world knowledge provided. ISAKB is assumed to be explicitly specified – e.g. by domain experts – and would most typically not be transitively closed.
Based on TRANIS the transitive closure of ISAA KB, we can generalize into a relation over all well-formed terms of the language L by the following:
TRAN- if ISA then
-if [...] [...] then also[..., : ] [...],and[..., : ] [..., : ],
-if then also[..., : ] [..., : ]
x y xx yx r z y
y
x r z y r zx yz r x z r y
≤≤
≤≤
≤≤
where repeated ... in each inequality denote zero or more attributes of the form . :i ir w
The general ontology O = (L,≤,R) thus encompasses a set of well-formed expressions L derived in the concept language from a set of atomic concepts A, an inclusion relation generalized from an expert provided relation ISAKB and a supplementary set of semantic relations R, where for R we obviously have that
r∈[ : ]x r y x≤ and that [ : ]x r y is in relation r to y. Observe
that L is infinite and that O thus is generative.
3.2 The Domain-Specific Ontology Apart from the general ontology O, the target document collection contributes to the construction of the domain ontology. We assume a processing of the target document collection, where an indexing, formed by sets of concepts from L, of text in documents is attached. In broad terms the domain ontology is a restriction of the general ontology to the concepts appearing in this indexing.
More specifically the generative ontology is, by means of concept occurrence analysis over the document collection, transformed into a domain specific ontology restricted to include only the concepts instantiated in the documents covering that particular domain.
411

T. Andreasen, H. Bulskov & R. Knappe
(The final paper will contain a formal definition of the instantiated ontology, as well as examples showing the modelling of an example instantiated ontology, based on figure 1) anything
animal
ISAkb
color
ISAkb
ISAkb
noise
cat
ISAkb
dog
ISAkb
bird
ISAkb
black
ISAkb
brown
ISAkb
ISAkb
red
Figure 1: An example knowledge base ontology ISAKB 4. Deriving Similarity The domain-specific ontology may provide an excellent means to survey and give perspective to the collection. However as far as access to documents is concerned ontology reasoning is not the most obvious evaluation strategy and it may well entail scaling problems. Applying measures of similarity derived from the ontology is a way to replace reasoning with simple computation still influenced by the ontology. A well-known and straightforward approach to this is the shortest path approach (Bulskov et al. 2002, Rada et al. 1989), where closeness between two concepts in the ontology implies high similarity. A problem with this approach is that multiple connections are ignored. In the ontology in figure 2 we thus have that the shortest path similarity between cat and dog would be equal to or greater than the similarity between cat[CHR:black] and dog[CHR:black] (depending on whether CHR-edges are included or not), while intuitively the former should be less than the latter because we have two concepts that meet in animal AND share the black-property. To differentiate here an option is to consider all paths rather than only the shortest path. A “shared nodes” approach that reflects multiple paths, but still avoids the obvious complexity of full computation of all paths is presented in (Andreasen et al. 2004a). In this approach the basis for the similarity between two concepts 1c and 2 is the set of “upwards reachable” concepts (nodes) shared between and . This is, with
c1c 2c ( ) ( ( ))x xα ω τ= , the intersection
( ) ( )x yα α∩ .
412

Modelling and Use of Domain-Specific Knowledge
anything
animal
ISA
color
ISA
noise
ISA
cat
ISA
dog
ISA
black
ISA
brown
ISA
noise[CBY:dog]
ISA
cat[CHR:black]
ISA
dog[CHR:black]
ISA
dog[CHR:brown]
ISA
noise[CBY:dog[CHR:black]]
CBY
CHR CHR CHR
ISA
Figure 2: An example instantiated ontology
Similarity can be defined in various ways, one option being, as described in (Andreasen et al., 2003), a weighted average, where [0,1]ρ ∈ determines the degree of influence of the nodes reachable from x respectively y. | ( ) ( ) | | ( ) ( ) |( , ) (1 ) (1)
| ( ) | | ( ) |x y x ysim x y
x yα α α αρ ρ
α α∩ ∩
= + − As it appears the upwards expansion ( )cα includes not only all subsuming concepts but also concepts that appears as attributes to c or to any subsuming concept of attributes. The latter must be included if we want to cope with multiple connections and want to consider for instance two concepts more similar if they bear the same color. However, a further refinement seems appropriate here. If we want two concepts to be more similar if they have an immediate subsuming concept (e.g. cat[CHR:black] and cat[CHR:brown] due to the subsuming cat) than if they only share an attribute (e.g. black shared by cat[CHR:black] and dog[CHR:black] we must
ISA{ | }ic c c
413

T. Andreasen, H. Bulskov & R. Knappe
differentiate and cannot just define ( )cα as a crisp set. The following is a generalization to fuzzy set based similarity.
First of all notice that ( )cα can be derived as follows. Let the triple ( , , )x y r be the edge of type r from concept x to concept y, E be the set of all edges in the ontology, and T be the top concept. Then we have:
( , , )
( ) { }( ) { } ( ( ))
ic c r E i
T Tc c c
αα α∈
== ∪ U
A simple modification that generalizes ( )cα to a fuzzy set is obtained through a function that attaches a weight to each relation type r. With this function we can generalize to:
( )weight r
( , , )
( , , ) ( ) / ( )
( ) {1/ }( ) { } ( ( ) ( ))
{ } ( ( ) ( ) / )i
i ij ij i
c c r E i
c c r E c c c ij ij
T Tc c weight r c
c weight r c cμ α
αα α
μ∈
∈ ∈
== ∪
= ∪ ∑U
U
( )cα is thus the fuzzy set of nodes reachable from the concept c and modified
by weights of relations . For instance from the instantiated ontology in figure 2 and assuming relation weights
( )weight rISA( )weight 1= ,
and CHR( ) 0.weight = 5
5CBY( ) 0.weight = we have: ( [CBY : [CHR: ]])
1/ [CBY: [CHR: ] 1/ 0.5 / [CHR: ] 0.5 / 0.5 / 0.25 / 0.25 / 1/
noise dog blacknoise dog black noise
dog black dog animal blackcolor anything
α =+ +
+ + ++
+
For concept similarity we can still use the parameterized expression (1) above, applying minimum for fuzzy intersection and sum for fuzzy cardinality:
( [CHR: ]) ( [CHR: ]) 0.5 / 0.5 / 1/ 1/
| ( [CHR: ]) ( [CHR: ]) | 3.0
cat black dog blackblack color animal anything
cat black dog black
α α
α α
∩ =+ + +
∩ =
The similarities between dog[CHR:black] and other concepts in the ontology are, when collected in a fuzzy subset of similar concepts (with
) and ( ) ( , ) /similar x sim x y y= 45ρ = the following:
( [CHR: ]) 1.00 / [CHR: ]
0.68 / 0,6 / [CHR: ] 0.6 / [CBY: [CHR: ] 0,52 / 0, 45 /
0, 45 / 0,39 / 0,36 / 0,34 / 0.26 /
similar dog black dog blackdog cat black
noise dog black animal blackcat color anything brown noise
= ++ +
+ ++ + + + +
414

Modelling and Use of Domain-Specific Knowledge
5. Applications As the instantiated ontology is a restriction of a general ontology with respect to a set of concepts, it can be used for providing structured descriptions. The restriction could be with respect to the sets of concepts in a particular target document collection, as described earlier, but it could also comprise the set of concept of a query, the set of concept in a complete search result, or part of the search result as in relevance feedback, or any set of concept selected by the user or the querying system.
The notion of instantiated ontologies has as such applications with respect to navigation and surveying of the topics covered by the domain in question, where the domain could be the instantiated ontology of any of the suggested restrictions above, not only a particular target document collection. 5.1 A Simple Prototype System The examples are constructed using a prototype system based on a general ontology constructed from the WordNet lexicon (Miller 1990, Miller 1995), the Suggested Upper Merged Ontology (SUMO) (Niles 2001), and the mid-level ontology (MILO) (Niles 2001) designed to bridge the high-level ontology SUMO and WordNet. The knowledge base ontology contains approximately 100.000 concepts (synsets). The ontology relation ISAKB is based on the hypernym relation individually from WordNet, MILO, and SUMO and the three relations, equivalence, subsumed by, and instance of, from the mapping between WordNet and MILO/SUMO. 5.2 Navigating and Surveying One of the difficulties users have to overcome when querying information systems, concerns the transformation of their need of information into descriptions used by the system. As the concepts instantiated in the document collection expresses the information available, the instantiated ontology therefore provides a structuring of this information. Consider the example in figure 2, where we have a document collection with the following four instantiated concepts, I = {palisade, stockade[CHR:old], rampart[CHR:old], church[CHR:old]}. The instantiated ontology reveals two different aspects covered by the document collection, 1) different kinds of fortifications and 2) a place of worship. On a more general level the instantiated ontology describes buildings and the abstract notion of something dated back in time.
As the size and complexity of the instantiated ontology increases, it can be difficult for the user to form a general view – mainly due to the complexity and volume of the ontology.
415

T. Andreasen, H. Bulskov & R. Knappe
Entity
past
old
isa
church[chr: old]
chr
rampart[chr: old]
chr
stockade[chr: old]
chr
Artifact
Building
isa
structure
isa
Abstract
Quantity
isa
time
isa
Object
isa
Physical
isa
TimeMeasure
isa
building
place_of_worship
isa
church
isa
isa
defensive_structure
fortification
isa
palisade
isa
rampart
isa
stockade
isaisa
isa
isa
isa
isaisa
isa isa
Figure 3: A simple instantiated ontology, based on WordNet, SUMO and MILO and the four concepts stocade[chr:old], rampart[chr:old], church[chr:old], palisade One possibility in the direction of overcoming this challenge is the remove the concepts which do not contribute with significant information and have minor influence on the overall structure. As one can see in figure 2, there are concepts present in the instantiated ontology that are either very abstract or are not part of a everyday vocabulary. These kinds of concepts could possibly contribute to confusion and could therefore be candidates for exclusion from the visualization. By utilizing the notion of familiarity as described in (Beckwith and Miller), these concepts can be selected. Familiarity is defined using the correlation there exist between frequency of occurrence and polysemy. Associated with every word
416

Modelling and Use of Domain-Specific Knowledge
form in the lexicon, there is an integer that represents a count, using the Collins Dictionary of the English Language, of the number of senses that word form has when it is used as a noun, verb, adjective, or adverb (Beckwith and Miller). One very simple way to utilize familiarity is to eliminate all concepts from the visualization of the instantiated ontology, having a familiarity lower than a certain threshold. 5.3 Visualizing Queries Another use of instantiated ontologies is for visualizing user queries. When users pose queries to the system using polysemous concepts, the instantiated ontology constructed from the query can be used to visualize the different senses known to the system. If for example a user poses a query Q={bank,huge}, then the system cannot use the concept huge to disambiguate bank , since huge can be used in connection many different senses of bank.
One possible way to incorporate the knowledge visualized is to ask the user to identify the correct senses of the concepts used in the query, and use the disambiguated concept in the query evaluation.
6. Conclusion Firstly, we have introduced the notion of a domain-specific ontology as a restriction of a general ontology to the concepts instantiated in a document collection, and we have demonstrated its applications with respect to navigation and surveying of a target document collection.
Finally, we have presented a methodology for deriving similarity using the domain-specific ontology by means of weighted shared nodes. The proposed measure incorporates multiple aspects when calculating overall similarity between concepts, but also respects the structure and relations of the ontology.
References Andreasen, T.; H. Bulskov & R. Knappe; On Querying Ontologies and
Databases, Flexible Query Answering Systems, in 6th International Conference, FQAS 2004, Lyon, France, June 24-26, 2004.
Andreasen, T.; P. Anker Jensen; J. Fischer Nilsson; P. Paggio; B.S. Pedersen & H. Erdman Thomsen; Content-based Text Querying with Ontological Descriptors, in Data & Knowledge Engineering 48, pp. 199 – 219, Elsevier, 2004.
Andreasen, T.; H. Bulskov, & R. Knappe; Similarity from Conceptual Relations, in Ellen Walker (eds.), 22nd International Conference of the
417

T. Andreasen, H. Bulskov & R. Knappe
North American Fuzzy Information Processing Society, NAFIPS 2003, pp. 179 – 184, Chicago, Illinois, USA, July 24-26, 2003.
Beckwith, R.; G.A. Miller & R. Tengi (eds.); Design and implementation of the WordNet lexical database and searching software.
http://www.cogsci.princeton.edu/ wn/5papers.ps.
Bulskov, H.; R. Knappe, & T. Andreasen; On Measuring Similarity for Conceptual Querying, LNAI 2522, in T. Andreasen; A. Motro, H. Christiansen & H.L. Larsen (eds.), Flexible Query Answering Systems 5th International Conference, FQAS 2002, pp. 100 – 111, Copenhagen, Denmark, October 27-29, 2002.
Miller, George: WordNet; An On-line Lexical Database, International Journal of Lexiography, vol. 3, no. 4, 1990.
Miller, George; WordNet: An Lexical Database for English, Communication of the ACM, vol. 38, no. 11, pp. 39 – 41, 1995.
Niles, I. & A. Pease; Towards a Standard Upper Ontology, in Chris Welty & Barry Smith (eds.), Proceedings of the 2nd International Conference on Formal Ontology in Information Systems (FOIS-2001), Ogunquit, Maine, October 17-19, 2001.
Nilsson, J. Fischer; A Logico-algebraic Framework for Ontologies – ONTOLOG, in Jensen & Skadhauge (eds.): Proceedings of the First International OntoQuery Workshop – Ontology-based interpretation of NP’s, Department of Business Communication and Information Science, University of Southern Denmark, Kolding, 2001.
Rada, Roy; Hafedh Mili; Ellen Bicknell; & Maria Blettner; Development and Application of a Metric on Semantic Nets, IEEE Transactions on Systems, Man, and Cybernetics, vol. 19, no. 1, pp. 17 – 30, 1989.
418

Anchoring Knowledge Organisation Systems to Language
BOLETTE SANDFORD PEDERSEN, COSTANZA NAVARRETTA & DORTE HALTRUP HANSEN,
Center for Language Technology, University of Copenhagen
1. Introduction: From Texts to Knowledge Organisation Systems and vice versa The establishment of knowledge organisation systems to cover company and domain specific knowledge is becoming more and more common in business and public administration. Several Danish business companies and public organisations are now realising the need for knowledge organisation systems in order to be able to efficiently accumulate - and navigate in - the increasing amount of available information within specific domains and subject areas. A number of products are on the market today with the aim of guiding the organisation of such systems. However, two important aspects seem to be glaringly missing in most Danish scenarios: (i) semi-automatic tools for efficient and time-saving mapping between the knowledge system and the text material to be dealt with, and (ii) high-quality language customisation. In Denmark, a few small companies are beginning now to develop language tools for Danish and combine these with search engines and indexing systems, two of these being Ankiro and Navigo Systems A/S1. In this paper, we report from the Danish research project, VID (VIden og Dokumenthåndtering med Sprogteknologi – Knowledge and Document Handling with Language Technology) which Center for Language Technology has carried through in 2003-2005 together with five Danish companies, among others the above mentioned companies, Ankiro and Navigo Systems. A central aim of the project is to focus on language technology techniques as a way of anchoring knowledge
1. Also Corporum developed in Norway by CognIt (www.cognit.no) deals with
corpus-based ontology building, text summarisation and content-based search. Corporum is implemented for a number of languages, including Norwegian and Swedish, but not for Danish.

B.S. Pedersen, C. Navarretta & D.H. Hansen
organisation systems to Danish text material. As will be seen, language technology can play an important role both in the pre-process of building the knowledge system and in the phase of using it. The subject areas that we deal with in this paper relate to intellectual property rights (IPR), more precisely the patent- and trademark domains. The experiments described all have their background in specific challenges raised by the participating companies, either by the technology providers or by the IPR company which acts as our user. First we look at some of the pre-processes for building knowledge organisation systems in terms of term acquisition, ontology building and automatic indexing. Thereafter we look at language-based techniques for search and query expansion. Finally, we describe the VID prototype working on the IPR domain; an implementation which includes a search engine encompassing many of the aspects described in the preceding sections. 2 Semi-Automatic, Language-Based Pre-Processes 2.1 Automatic Term Acquisition Term identification constitutes the backbone in the building of most knowledge organisation systems. For large, already established domains, electronic term lists and/or thesauruses are usually already available to a certain extent. In such cases the task of further term acquisition can be seen as an enrichment phase where corpora are mapped up against existing vocabularies in order to extend the term lists in a dynamic way (cf. Jaquemin 2001). However, in smaller, practical environments where we are dealing with medium-sized enterprises handling Danish text material on smaller domains, existing reliable vocabularies are only available to a very limited extent. In such cases, more fragile techniques depending basically on a computational lexicon of general language, can be brought into play. After POS-tagging, it proved most reliable – since Danish is a more inflective language than English – to conflate morphologically related words from the texts through lemmatisation and not through the more frequently applied stemming techniques. The lemmatiser was developed (Jongejan & Haltrup 2001) as a set of flexion rules produced by training on the Danish computational lexicon, STO (Braasch & Olsen 2004). Content words were extracted and mapped up against the general vocabulary in STO, with an approach similar to that proposed by Jørgensen et al. (2003), and words that did not appear in the general
420

Anchoring Knowledge Organisation Systems to Language vocabulary list (60,000 lemmas) were proposed as term candidates. The last step consisted of an automatic recuperation phase with the aim of ‘repairing’ on the domain-relevant grey-zone terms that occurred in the general vocabulary list and had therefore been discarded. For several of these domain-relevant grey-zone words, it proved to be the case that they occurred also in a specialised form as lexical heads of a compound term, as gebyr (fee) in ekspeditionsgebyr (dispatch fee) and rettighed (right) in patentrettighed (patent right) and were automatically reintroduced on the term candidate list. The candidate lists were evaluated by term experts in the company. Precision, i.e. the proportion of identified terms that were relevant, was 71,14%. Recall, i.e. the proportion of relevant terms that were identified, was 77,24 %. These figures include the calculation of terms that were not in the texts, but which the term experts anyhow had found relevant to the domain. We also realized afterwards that a prior text normalization could probably have improved precision, since tagger errors due to unforeseen text types gave rise to several errors (for more details cf. Navarretta el al. 2004). 2.2 Linguistic Aspects in Ontology Building Traditionally, ontologies are built on the basis of expert knowledge, but recently attempts are being made in order to develop and evaluate ontologies also by applying large document collections (see among many others Buitelar et al. 2004 and Pedersen et al. 2004). There are several advantages of applying text corpora for this task. First of all corpora can support human introspection and improve the consistency and the quality of the developed ontologies. Secondly, ontology building can become less expensive and time-consuming since automatic procedures are introduced. Finally, the texts resemble the actual use of the domain language. To specify this use is particularly important when building ontologies for text oriented applications. Thus, the backbone of the VID ontology on patent and trademark (cf. Pedersen et al. 2004) is constituted by the acquired terms, which have been clustered semi-automatically at the lowest level in cases where compound terms share a common lexical head (cf. –ansøgning (application) in figure 2). We have also experimented with statistically based techniques for non-hierarchical clustering, using the CMU-Cambridge Statistical Language Modeling Toolkit (http://lib.stat.cmu.edu/) and the Lnknet-system developed at MIT Lincoln Laboratory (http://www.ll.mit.edu/IST/lnknet/). However,
421

B.S. Pedersen, C. Navarretta & D.H. Hansen
our domain corpus proved too small for statistical manipulation to be really powerful in the specific context. Nevertheless, a first meaningful grouping of some of the most frequently used concepts was proposed automatically by the system (see Navarretta 2005). Examples of some of the best clusters extracted are:
• patentansøgning, grundansøgning, ansøgning, oversættelse, patent (patent application, basic application, application, translation, patent)
• gebyr, afgift, årsafgift, årsgebyr, fornyelsesafgift, kravgebyr (fee, fee, annual fee, annual fee, renewal fee, demand fee)
The top-level of the ontology is linguistically motivated in the sense that it is based on the SIMPLE top-ontology which provides linguistic tests for each established top-ontological category (Lenci et al. 2001, Pedersen & Paggio 2004). These tests are used as a guide for the ontology builder and ensure some degree of consistency and ontological soundness. Like in other formal ontologies (SUMO, DOLCE, BFO and others), inclusion defines the basic skeleton of the ontology, however, in contrast to these, the characterisation of the categories relies on the tests and not on a formal characterisation based on axioms. The middle layer is mainly based on extra-linguistic expert knowledge, and besides in this part of the ontology specific system requirements play the most important role (i.e. what kind of inference and how much query expansion should be performed on the ontology etc.). Figure 1 shows an excerpt of the ontology generated in OWL via the tool Protégé-2000 and the corresponding OWL plugin, both developed at Stanford University (http://protege.stanford.edu/).
422

Anchoring Knowledge Organisation Systems to Language
Figure 1: Excerpt of patent ontology with the subclasses of ansøgning (application) 2.3 Automatic Indexing Automatic indexing is a more specialised task than term acquisition since the aim is not only to acquire terms but to assign the words to a text or text chunk which best represents its content. This means that word importance must be calculated in terms of a weighting algorithm where relative frequency proves to be a central factor. We perform free indexing in the terms of Jaquemin (2001:15) since we do not make reference to the specific terminological vocabulary. On our approach, we extract all nouns instead of using stop lists, and we calculate their frequency relatively to their frequency in the other texts in the text collection. In this way a word with low frequency in a given text can be
423

B.S. Pedersen, C. Navarretta & D.H. Hansen
Indexhave not
exompoun
considered important for the text if it does not occur in any of the other texts in the collection. We have further refined the technique by decomposing compounds and focusing in particular on the non-head of the compound, which in many cases tends to envelope important information about the text. This refinement improves the results considerably especially when dealing with highly specialised texts, see figure 2.
words where compounds been decomposed
Indc
words consisting of frequent d non-heads
ansøgnin patent (patent) g (application) trin (s ansøg n) tep) ning (applicatioskrive indlevlse (letter) ering (delivery) opfind else (invention) indlev ering (delivery) ansøg er (applicant) modta gelse (reception) besva relse (answer) rappo rtering (reporting) ansøg t) ningstekst (application tex
Figure 2: Index words calculated automatically from an instruction text regarding the treatment of patent applications
right column of Figure 1 lso occur in the left column, the right column more precisely denotes
technology
ith the aim of providing language technology for more flexible and language customized search engines, we have examined the linguistic
Note that even if two of the index words in theathe content of the text. The first right column word, patent, actually most accurately tells what the text is about, namely patents. Our indexing technique was evaluated on another domain (job descriptions) provided by one of the participating providers, Navigo Systems A/S. We compared our technique with their approach which consists in stemming of the text and removal of stop words. This list is then subsequently refined on a purely manual basis – a method which is relatively time-consuming. The comparison showed that on our approach, we find fewer and much more precise keywords automatically than what can be found from the much simpler automatic method currently applied by the company. 3. Query expansion and search W
424

Anchoring Knowledge Organisation Systems to Language
n the line of Voorhees 1994,
• wider semantic relations working horizontally (an example is rizontal relation (AgentIs) is g (application) and ansøger
Expansi
whereas expansion to synonymous phrases proves much more complex nd requires more linguistic information about the context. Phrases are
es? • can we on the basis of syntax information automatically
In order tup into th earched for in the corpus. The hits
ax. 200 hits per compound) were further tagged with information on
aspects relating to query expansion (iAndreassen et al. 2004, and Pedersen et al. 2004), such as:
• synonymous words and phrases • hyponymy (vertical expansion)
seen in figure 2 where a hoestablished between ansøgnin(applicant)).
on to synonymous words is treated via a lexical database
ahighly productive and cannot easily be listed in a synonymy list. We have focused on one aspect, namely on phrases synonymous to compounds, since this phenomenon proves both frequent and highly problematic to our users (cf. Dalianos 2005 and Chen & Gey 2003 for similar problems in Swedish). For instance, when searching for varemærkeansøgning (trademark application), it might be the case that a relevant text contains the synonymous phrase ansøgning om varemærke (application on trademark), and this hit can only be found by expanding the original query. The questions are:
• can we decide which kinds of compounds have frequent synonymous counterparts in terms of phras
delimit the often seen disadvantages of query expansion, namely too much noise?
o find answers to these questions, 100 compounds were split eir two components and s
(mwhether the two words occurred within the same noun phrase; our hypothesis being that this criterion might filter out bad hits where the two words just accidentally appeared in the same context without being synonymous to the compound. By using an NP-recognizer built in the CASS formalism, cf. Haltrup (2000) and automatically discarding hits where the two query words were not in the same noun phrase (achieving a weight below the threshold of 10), we achieved an average precision of 90 % and an average recall of 70 % for expanded compounds with valency-bearing heads. The valency information was
425

B.S. Pedersen, C. Navarretta & D.H. Hansen
extracted from STO. Figure 3 illustrates the tagging and weighting mechanism applied on two hits where the search engine has expanded on the compound værdigodkendelse (value approval). weight <WORD>værdigodkendelse
godkendelse værdi</WORD><COUNT>200</COUNT>
19.0
I [NP2 [NP1 [NP [N forbindelse]] [PRÆP med] [NP [N _PAST forhøjede]
<T9>værdier</T9>]]] skal det fastlægges , hvor ofte der skal udtages <T9>godkendelse</T9>]]] [PRÆP af] [NP [V_PARTC[Nprøver til kontrol af , at dispensationen ikke overskrides .
9.0
[N begrænsning]]
3 dele : Beløbsmæssig begrænsning , begrænsning af den kreds af foreninger mv . , der kan opnå [NP [N <T9>godkendelse</T9>]] til at modtage fradragsberettigede ydelser , samt [NP2 [NP1 [NP [PRÆP af] [NP [PRON_DEMO den] [ADJ skattemæssige] [N <T9>værdi</T9>]]] [PRÆP af] [NP [N fradraget]]] . Af bevismæssige grunde må det , for at der kan gives fradrag , kræves
3: Two hits including godkendelse (approval) and værdi prioritized on the basis of a linguistic analys
Figure (value) is: weight higher than the threshold of 10 is assigned hen both search words occur in
ous complex noun phrases, and
at by applying the noun phrase principle as our threshold criterion,
.1 A Search Engine Tuned for the IPR Domain to evaluate to which extent linguistic and
emantic knowledge of the kind described in the preceding sections, can ID users acted as a
wthe same noun phrase. In conclusion, we found that compounds with valent lexical head werehighly productive regarding synonymthgood hits could be selected automatically. For compounds with non-valent heads (i.e. lånevaluta (loan currency)), in contrast, synonymous phrases did not appear to the same extent. And in cases where expansion on these did result in relevant hits, the applied noun phrase principle proved less decisive resulting therefore in a lower recall (see also Pedersen et al. 2005 for more details). For expansion on hyponymy and wider semantic relations, we applied the information described in section 2.2; this aspect is further described in section 4. 4. The VID Prototype 4The aim of the prototype is sactually improve information retrieval. One of our V
426

Anchoring Knowledge Organisation Systems to Language
words and morphologic and
:Identifier contains a link to the original Word document on
mption of applications (genoptagelse af
case-study, namely the Nordic consultancy company dealing with intellectual property rights (IPR). The company wants to systematise and automate their document production and is therefore developing a knowledge organisation system for semiautomatic saving and production of their standard documents. An important requirement in this scenario is a content-based search engine where information can be retrieved in a flexible way, more or less independently of the actual linguistic expressions found in the texts. The prototype was developed together with Ankiro. Ankiro provided a search engine and a lexical database, containing general language words. We encoded the domain-specificsemantic information about these. Semantic information mainly consists of semantic relations, such as synonymy, hyponymy, and wider or more unspecified similarity relations. We have also encoded information about the different components of a compound, eg. patentansøgning (patent application) is related to ansøgning (application) by an hyponymy relation, while it is related to patent via a less strong horizontal relation. In the prototype there is no information about valency of words. The search engine, working exclusively on content words, expands on all the encoded information, but each information source is weighted differently. Weights span from 10% to 99%. The highest weights are assigned to the results obtained by expanding on the inflectional paradigms, a bit lower to those obtained on the basis of strict semantic relations (synonymy, hyponymy), lowest to the results obtained by expanding on wider horizontal or unspecified similarity relations. The patent documents from the IPR company were automatically marked with Dublin Core metadata encoded with XML-syntax. The element dcthe internet/intranet, whereas dc:Subject contains a list of relevant index words automatically extracted from the texts with a subset of the techniques described in 2.3. The subject metadata give the user a way to restrict search with general index words. Free text search is possible via the metadata field Body. In figure 4 the prototype internet interface (Netscape) is shown. In the example the user asks for all Danish documents written in 2003 with information about resuansøgninger). No documents from 2003 contained all the content words searched for. The best result has a weight of 71.7% and returns a document containing one search word ansøgningen in another inflectional form than in the search string, while the search engine has
427
B.S. Pedersen, C. Navarretta & D.H. Hansen
expanded from the noun genoptagelse (resumption) to the related verb genoptage. In the second search result (weight 46.8%) none of the original query words matches the text, but the system has expanded on the hyperonym of the lexical head (ansøgning - designansøgninger) and has expanded via the relation which connects the noun genoptagelse (revision) to the noun fornyelse (renewal).
Figure 4: The prototype search engine 4.1 Evaluation
ueries which were provided by e company and by us. We have only evaluated results of searches on
e text) where expansion takes places. The results of the
We tested the system with a set of 75 qththe body-field (thsearches were in a few cases reviewed by a representative of the company, while in the remaining cases they were reviewed by us. We have calculated precision and recall for the returned documents with
428

Anchoring Knowledge Organisation Systems to Language
age technology techniques can prove and scale-up the customisation of knowledge organisation
l. In the VID experiment we have had
n the basis of Danish lexical data
c
scores over 90% and for the overall set of returned documents (all scores) in order to compare the results obtained by expansion on morphological information with the results obtained by expanding on both morphology and semantic relations. Precision and recall for results with scores over 90% are respectively 98.8% and 79.2%. The precision and recall scores for all returned texts are 89.2% and 95.1% respectively. In these scores we did not include missing results when the users had incorrect spellings in the queries, because spelling corrections have not yet been added to the prototype. In two cases (queries provided by us) we got no results because the words searched for were neither in the thesaurus nor in the texts. It is unclear whether these words would actually be used by the company’s employees. However these types of error indicate that it is difficult to decide with certainty how restrictive over the acceptable vocabulary such an application should be. The obtained results also indicate that the recall of the prototype is much higher than the recall that can be obtained with a search engine based on simple string recognition or morphological expansion, and that the corresponding fall in precision is not as serious. However it must be investigated in future work to which extent relations such as similarity and vertical relations have an unwanted influence on precision in domains that are not as restricted as the present one. We must also compare the results we have obtained for Danish with those obtained by similar applications for other languages. 5. Concluding Remarks In this paper we have shown how languimsystems to Danish text materiathe chance to look into a series of specific problems that the involved companies encounter when getting from documents to a knowledge organisation system and vice versa. We have focussed on some of the linguistic phenomena where Danish differs substantially from a language like English; for instance, we have shown how lemmatisation oas well as the understanding of the internal structure of Danish compounds can improve both term acquisition, indexing and search. We have also looked into more semantically oriented techniques such as query expansion via semantic relations. The achieved results indicate that recall improves substantially by expanding on semantirelations and that precision is still good (near 90%) when working in restricted domains. Much more work has to be done in this field in
429

B.S. Pedersen, C. Navarretta & D.H. Hansen
; P. Paggio; B.S. Pedersen & H.E. Thomsen; Content-based text querying with ontological
, in: Database and Knowledge Engineering Journal, no.
Bui
clef.iei.pi.cnr.it/2003/WN_web/05.pdf, 2003.
-21, 2005. y Technical
Jongejan, B. & Dorte Haltrup; The CST Lemmatiser, Technical Report,
tational lexicon, in Corpus Linguistics 2003 Proceedings,
Len
E – A General Framework for the Development of
order to estimate to which extent semantic networks and ontologies can really improve information retrieval in broader domains. Also in this case, however, language-specific resources at a large scale are a prerequisite for high-quality results. One of these resources is just currently under construction for Danish, namely the Danish DanNet lexical database (cf. www.wordnet.dk). References Andreasen, T.; P.A. Jensen; J.F. Nilsson
descriptiors48: pp. 199 – 219, Elsevier Science B.V., Holland, 2004. telar, P.; D. Olejnik; M. Hutanu; A. Schutz; T. Declerck & M. Sintek; Towards ontology engineering based on linguistic analysis, in Proceedings of LREC-2004, Lisboa, pp. 7 – 10, 2004.
Braasch, A. & S. Olsen: STO: A Danish Lexicon Resource - Ready for Applications, in Proceedings of LREC-2004, 4:1079 – 1082, Lisboa, 2004.
Chen, A. & F. Gey; Combining Query Translation and Document Translation in Cross Language Retrieval CLEF 2003, http://
Dalianis, H.; Improving search engine retrieval using a compound splitter for Swedish. Nodalida, Joensuu, Finland, May 20
Haltrup Hansen, D; NP-genkendelse i Ontoquery, OntoQuerReport, Center for Langauge Technology, University of Copenhagen. 2000.
Jacquemin, C; Spotting and Discovering Terms through National Language Processing. MIT Press, Cambridge, Massachusetts, 2001.
STO, Center for Langauge Technology, University of Copenhagen. 2001.
Jørgensen, S.W.; C. Hansen; J. Drost; D. Haltrup; A. Braasch & S. Olsen; Domain specific corpus building and lemma selection in a compuLancaster, 2003. ci, A.; N. Bel; F. Busa; N. Calzolari; E. Gola; M. Monachini; A. Ogonowski; I. Peters; W. Peters; N. Ruimy; M. Villages & A. Zampolli; SIMPLMultilingual Lexicons, in T. Fontenelle (eds.), International Journal of Lexicography, vol. 13, pp. 249 – 263, Oxford University Press, 2001.
430

Anchoring Knowledge Organisation Systems to Language Nav
ge Technology Elements in a Knowledge Organisation
Navontologier. VID Technical report no. 7, Center for
PedThe VID
Pedl of
Ped Technical Report no. 6,
Vo
arretta, C.; B. Sandford Pedersen & D. Haltrup Hansen; Human LanguaSystem -The VID project, in Proceedings of LREC-2004, 1:75 – 78, Lisboa. 2004. arretta, C.; Statistiske metoder der kan understøtte opbygning af tekstbaserede Langauge Technology, University of Copenhagen, 2005. ersen, B.S.; C. Navarretta & L. Henriksen; Building Business Ontologies with Language Technology Techniques – project. OntoLex 2004 Proceedings, pp. 30 – 35, Lisboa, 2004. ersen, B. & P. Paggio; The Danish SIMPLE Lexicon and its Application in Content-based Querying, in Nordic JournaLinguistics, vol. 27:1, pp. 97 – 127, 2004. ersen, B.; C. Navarretta & D. Haltrup Hansen; Ontologibaseret teksthåndtering – med sprogteknologi. VIDCenter for Langauge Technology, University of Copenhagen, 2005.
orhees, E; Query expansion using lexical-semantic relations, in W. Bruce; Proceedings of the 17th Annual ACM SIGIR Conference onResearch and Development Information Retrieval, Pittsburg, pp. 171 – 180, 1994.
431


Automatic Identification of Reasons for Encounter
Information Retrieval from Text in Swedish Patient Records
using Methods from Language Technology
ANDERS THURIN & SOFIA KNUBBE Purpose A majority of the patients treated at our hospital are non-planned and initially admitted through the emergency ward. When a patient is discharged the final diagnosis is reported for national statistics, but there is no statistical analysis of the initial reasons why the patients visit the hospital. The panorama of patients at the emergency ward is of crucial importance to the workload and direction of activities at the hospital. Manual coding of patients' reasons for encounter is time consuming, and no optimal coding system is available. The aim of this study was to explore whether relevant information about the reasons for encounter can be extracted from the existing medical records using methods from language technology. Data extracted this way could be aggregated to describe the case mix of actual patients, and help in planning the work and activities at the hospital. We were also interested in whether patterns of reasons for encounter could be found in a selected group of patients, and therefore separately analysed patients where anticoagulant treatment with warfarin was discussed. The hypothesis here was that conditions related to bleeding would be more common in this group. Material We used text from the database of Melior, the patient record system used in our hospital, provided by Siemens Health Solutions. All records from the department of surgery, Östra Sjukhuset, Sahlgrenska University Hospital, Göteborg, Sweden, were analysed. The database has been in use since 1994 and medical records from Melior since that time have been used as text material in this project. We have no access to the database tables containing patient identity, which helps preserve patient integrity. The method of data collection has been approved by the local ethics committee and responsible for security at the hospital.

A. Thurin & S. Knubbe
Text in the patient record is sorted in the database under different record headings, and for this study only text under the heading besöksorsak (reason for encounter) was analysed. This text can consist of a single word, like buksmärtor (abdominal pains), or it can be made up of anything from a few words to several sentences, like patienten söker på grund av illamående och buksmärtor (the patient seeks help because of nausea and abdominal pains). In addition to the reason for encounter text under this heading often describes other conditions of patients' admission, such as from where patient is referred (other hospital, GP, other clinic), or how patient comes to the emergency ward (by ambulance/brought in by police…). SQL-queries were constructed to obtain such text paragraphs from the database. This resulted in a relatively homogeneous set of lines of text where usually a reason for encounter can be found on each line. The average length of each text line was 38.3 characters. The longest text string was 1444 characters and the shortest 1 character. The result set was saved in a text file consisting of 49918 lines with text from one medical record on each line. A similar text file was produced with the additional criterion that the medical record somewhere contained the string “Waran”, the trade name for Warfarin in Sweden. This file has 1035 lines of text. Methods A concordance (a list of all the words in the text presented with their closest context) was created from the larger text file using Concordance 3.01. This software also counts the number of instances of every unique word, and concordance list can be sorted by the context that appears around the word - by the word before or after, by two words before or after, and so on. Sorting the words by number of appearances made it possible to see which reasons for encounter were the most common. By looking at the concordance of a common reason for encounter with the context sorted in different ways it was easy to see in which surroundings the word often appears. Patterns in the text that were often associated with a reason for encounter were determined by manual analysis of concordances, and guided by these identified patterns, customized scripts were written in the Perl2 programming language to automatically identify and count the reasons for encounter according to the patterns determined in the concordance analysis. The method of 1. R.J.C Watts. http://www.concordancesoftware.co.uk/ 2. ActivePerl 5.8 http://www.activestate.com
434

Automatic Identification of Reasons for Encounter
doing this is divided into two steps. In the first step, a Perl script reads through the text file one line at a time, trying to match each line with a reason for encounter pattern. If the text line is matched to a pattern, the line or a part of it (the probable reason for encounter) is saved in a hash table, indexed by the string describing reason for encounter, and a counter is increased each time this string is found, thus counting number of occurrences of the reasons for encounter. If a line does not match any of the patterns it is saved in another text file to be reviewed later. Some examples of common patterns for matching in step 1 are:
• One single word, like buksmärtor (abdominal pains) or skalltrauma (head trauma).
• Two or a few words, or comma separated lists of such word groups, like commotio cerebri or svårighet att gå, buksmärtor (difficulties to walk, abdominal pains) .
• Comma separated lists of single words, like buksmärta, illamående, diarreer (abdominal pains, nausea, diarrhea) or hematemes, melena samt buksmärtor (hematemes, melena and abdominal pains).
• Longer text strings where keywords or keyphrases indicate the reason for encounter, like ...frågeställning om appendicit (suspected appendicitis) or ...söker pga högersidig buksmärta, illamående och kräkningar (seeking care due to abdominal pain, nausea and vomiting). In these cases only the rest of the sentence after the keyphrase (here frågeställning om and söker pga) is regarded as the reason for encounter, even if there is more text after that sentence.
In the second step another perl-script reads through the hashtable to further divide and analyze the reasons for encounter identified in step 1. This is necessary because the patterns in step 1 sometimes identify very long strings of text or lists of words separated by commas as the reason for encounter. Step 2 is also accomplished by pattern matching and the reasons for encounter are counted. Some examples of the most common patterns that are handled in step 2 are:
• Words in lists and enumerations separated by commas, full stops and conjunctions are regarded as separate reasons for encounter, like buksmärta, illamående, diarreer (abdominal pain, nausea, diarrhea) which result in three reasons for encounter.
435

A. Thurin & S. Knubbe
• Lists or enumerations of word groups consisting of a few words separated by commas, full stops and conjuctions are regarded as separate reasons for encounter, like svårighet att gå, högersidiga buksmärtor (difficulties to walk, abdominal pains on the right side). Here svårighet att gå is one reason for encounter, högersidiga buksmärtor is another.
Results The Perl scripts were able to identify a reason for encounter according to the patterns in 42961 of the 49918 lines in the total material text file (86.1 %). In all, 50093 occurrences of any of 10459 different reasons for encounter were found. 406 reasons for encounter were identified 10 times or more, accounting for 35934 occurrences (72% of all). 8283 reasons for encounter only appear once (16% of occurrences, 79% of types) some of which may be e.g. spelling errors or in need of further processing. The most common reasons for encounter consist of one or two words, like illamående (nausea) or trauma skalle (head trauma). 3387 (32% of types) of the reasons for encounter consist of one or two words, and most of these are probably correct and relevant.
Table 1: Reasons for encounter, their occurrences and frequencies in the total material and in the Waran text file.
Total material Waran material
Reason for encounter Occurrences Frequency
(‰) Reason for encounter Occurrences Frequency
(‰)
buksmärtor abdominal pains 9036 180,4 buksmärtor abdominal pains 158 147,4
buksmärta abdominal pain 4224 84,3 buksmärta abdominal pain 58 54,1 kräkningar vomiting 1455 29,0 melena melena 27 25,2 misshandel abuse 953 19,0 falltrauma fall 25 23,3 sårskada wound 834 16,6 illamående nausea 23 21,5 illamående nausea 813 16,2 kräkningar vomiting 23 21,5 feber fever 712 14,2 hematemes hematemesis 19 17,7 falltrauma fall 609 12,2 feber fever 18 16,8 trafikolycka traffic accident 585 11,7 hematuri hematuria 14 13,1 diarreer diarrhea 512 10,2 gastrointestinal blödning GI bleeding 13 12,1 skalltrauma head injury 412 8,2 rektalblödning rectal bleeding 12 11,2 melena melena 409 8,2 svart avföring black stools 10 9,3 hematemes hematemesis 402 8,0 sårskada wound 10 9,3 trauma skalle head trauma 383 7,6 diarre diarrhea 10 9,3 diarre diarrhea 344 6,9 urinstämma urinary obstruction 9 8,4 förstoppning obstipation 268 5,4 ikterus icterus 8 7,5 obstipation obstipation 264 5,3 trauma skalle head trauma 8 7,5 epigastralgier epigastralgia 257 5,1 anemi anemia 8 7,5
urinstämma urinary obstruction 209 4,2 blödning per rektum rectal bleeding 7 6,5
trauma thorax thorax trauma 181 3,6 trötthet tiredness 7 6,5
In the Waran text file a preliminary reason for encounter was identified in 883 of the 1035 lines (85.3 %). 1072 occurrences of 502 different reasons for encounter were found. 411 of the reasons for encounter were only found once (38% of occurrences, 82% of types) and 264 consist of one or two words.
436

Automatic Identification of Reasons for Encounter
The most common reason for encounter in both the total material and the Waran text file is buksmärtor (abdominal pains). The most common reasons for encounter in each file is shown in table 1. A calculation of the ratio of frequencies of reason for encounter between the two patient groups was made to evaluate whether e.g. different types of bleeding is common in relation to Waran mention. The result was sorted by the size of the quotient, the larger the quotient the more common the reason for encounter is in the Waran text file. It is quite clear that reasons for encounter related to some kind of bleeding are much more common among the Waran patients than in the whole patient group (table 2).
Reason for encounter Frequency (‰) Ratio
sv en Total Waran Waran/Total
hematuri hematuria 2,73 13,06 4,78
gastrointestinal blödning GI bleeding 2,66 12,13 4,57
svart avföring melena 2,20 9,33 4,25
rektalblödning rectal bleeding 3,35 11,19 3,34
blödning per rektum rectal bleeding 2,10 6,53 3,12
melena melena 8,16 25,19 3,08
subileus subileus 1,02 2,80 2,75
rektal blödning rectal bleeding 2,38 6,53 2,75
makroskopisk hematuri macroscopic hematuria 1,04 2,80 2,70
nedsatt at general malaise 1,80 4,66 2,60
ikterus icterus 2,91 7,46 2,56
trötthet tiredness 2,69 6,53 2,42
anemi anemia 3,25 7,46 2,29
hematemes hematemesis 8,03 17,72 2,21
nedsatt allmäntillstånd general malaise 1,28 2,80 2,19
urinstämma urinary obstruction 4,17 8,40 2,01
blodiga kräkningar hematemesis 1,46 2,80 1,92
falltrauma fall 12,16 23,32 1,92
urinretention urinary retention 2,04 3,73 1,83
smärtor under höger arcus pain upper right abdomen 1,04 1,87 1,80
Table 2: Ratio of frequencies of selected reasons for encounter in Waran-cases compared to total material. Discussion We have developed methods to identify, extract, sort and group reasons for encounter from plain text in patient records from a department of general surgery at a teaching hospital. We find a reason for encounter in about 86 % of the records, suggesting that the method could be useful for example in statistical calculations and studies of patient groups. As a separate group we considered patients where "Waran" is mentioned. This is the trade name of warfarin in Sweden, the only currently existing oral anticoagulant. Mention in the text does
437

A. Thurin & S. Knubbe
not necessarily imply that the patient is treated with Warfarin before hospital admission, and this is a weakness in the design, but at least it suggests that patient has some condition where warfarin is discussed. Methods to ascertain whether current treatment includes warfarin would be very interesting, but this adds a lot of complexity to the information retrieval strategy. Experience from other authors suggest that general negation-detecting methods (Chapman et al. 2005) can be used to distinguish "Waran" from "not Waran" which seems hopeful. The possibilities of text data mining is getting a lot of recent attention within biomedicine, but most of the work is done in the domain of identifying genes and biochemical entities in published literature, much less work is focused on patient data e.g. (Pakhomov, Ruggieri and Chute 2002). Also coding of "chief complaint" has been attempted (Mikosz et al. 2004), (Shapiro 2004), (Chapman et al. 2005). However, in our setting where all patient records are written in Swedish, we also need to adapt all methods to our language, and we are not aware of any similar work done in Swedish. Many of the reasons for encounter identified with this method are only found once and consist of long text strings. These reasons for encounter often result from a string matching where the rest of the sentence after words like inkommer för (comes because of?) is saved. Some of these lines and the lines where no reason for encounter was found need to be further analyzed and perhaps handled in a different way to make it possible to decide which the actual reasons for encounter are. The result of the study could probably be improved by adding more patterns to the string matching scripts and by improving the already existing patterns. Analyzing the lines where a reason for encounter have not been found might help in doing this. A thorough analysis of the identified reasons for encounter is also needed to see what kinds of mistakes are made during identification, and what can be done to improve the precision and remove incorrect reasons. A larger text material would probably make the numbers and calculations more accurate and would also be a way of further improving the results. Many of the reasons for encounter are different morphological forms of the same word and should be considered synonyms, like buksmärtor and buksmärta (abdominal pain/pains). Natural language processing techniques, like part-of-speech tagging and stemming, can be applied to the material to help joining morphological forms. Work to accomplish this improvement has begun. Grouping and categorizing the reasons for encounter could be
438

Automatic Identification of Reasons for Encounter
achieved by looking for certain indicators of for example location, laterality or time. These indicators can then be used to search for reasons for encounter that are synonymous but not variants of the same word, like hematemes and blodiga kräkningar which refer to the same health condition. It would be interesting to apply this method to different kinds of medical text and some work on this has already been started. The initial tests show that some modifications of the method are needed, and the pattern matching algorithm might have to be changed according to the text at hand. Acknowledgements Funding for the project has been provided by the European Commission within the SemanticMining Network of Excellence, and the Center for Health Systems Analysis (CHSA). References Chapman, W.W.; L.M. Christensen; M.M. Wagner; P.J. Haug; O.
Ivanov; J.N. Dowling & R.T. Olszewski; Classifying free-text triage chief complaints into syndromic categories with natural language processing. Artificial Intelligence in Medicine, 33, pp. 31 – 40, 2005.
Mikosz, C.A.; J. Silva; S. Black; G. Gibbs & I. Cardenas; Comparison of two major emergency department-based free-text chief-complaint coding systems. MMWR. Morbidity and Mortality Weekly Report, 53 Suppl, pp. 101 – 105, 2004.
Pakhomov, S.V.; A. Ruggieri & C.G. Chute; Maximum entropy modeling for mining patient medication status from free text. Proceedings / AMIA Symposium. Annual Symposium, pp. 587 – 591, 2002.
Shapiro, A.R; Taming variability in free text: application to health surveillance. MMWR. Morbidity and Mortality Weekly Report, 53 Suppl, pp. 95 – 100, 2004.
439