СТРУКТУРИЗАЦИЯ ТЕКСТА В КОМПЬЮТЕРНОЙ СИСТЕМЕ "ЛИНДА"...
18
18Ч,\ 0X03-2400 Структурная и прикладная лингвистика
Transcript of СТРУКТУРИЗАЦИЯ ТЕКСТА В КОМПЬЮТЕРНОЙ СИСТЕМЕ "ЛИНДА"...

18Ч,\ 0X03-2400
Структурная и прикладнаялингвистика

С.ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
Издается с 1987 г.
СТРУКТУРНАЯИ ПРИКЛАДНАЯ ЛИНГВИСТИКА
Межвузовский сборник
В ы п у с к 4
Под редакцией А. С. Герда
САНКТ-ПЕТЕРБУРГИЗДАТЕЛЬСТВО С.-ПЕТЕРБУРГСКОГО УНИВЕРСИТЕТА
1993

ББК 81Д С87
Сборник (адп.З вышел в 1987 г . ) содержит статьи, охватывающие широкий круг проблем современной теоретической и прикладной лингвистики. Рассматриваются актуальные вопросы семантики и синтаксиса, применения математических методов в языкознании, разработки лингвистических основ автоматической обработки текстов.
Для специалистов по прикладной и Математической лингвистике .
Р е д а к ц и о н н а я к о л л е г и я : д-р филол.наук В.В.Богданов, д-р филол. наук Л.З.Бондарко, д-р филол. наук А.С.Герд (отв. редактор), д-р филол. наук Б.Ю.Городецкий.
Р е ц е н з е н т : д-р филол. наук Л.Н.Беляева (Рос.гос. пед. ун-т)
Печатается по постановлению Редакционно-издательского совета
С.-Петербургского университета
п 1403000000 - 088 лт а? 076(02) - 93
(р) Издательство ^ С.-Петербургского
университета, I 993

0 . Н. Г р и н б а у м, Г .Я . М а р т ы н е н к о
СТРУКТУРИЗАЦИЯ ТЕКСТА Й КОМПЬЮТЕРНОЙ СИСТЕМЕ "ЛИНДА"
1. Компьютерные системы в фило логических из следованиях. Машинный фонд русского языка и аналогичные ему компьютерные системы ориентированы на решение филологических проблем, которые в целом ряде аспектов отличаются от проблем чисто лингвистических. * * Остановимся на тех особенностях филологического подхода к языку, которые с предельной ясностью должны сознаваться как создателями,- так и пользователями компьютерных систем.
Исходной реальностью, из которой черпается и на шторой строится филологическая мысль, является текст во всей совокупности своих внутренних аспектов и внешних связей. При этом текст в филологии рассматривается как памятник, как средствор Яфиксации "памяти мира", "памяти культуры", т .е . как культурно-историческая категория. Существенно также и то, что язык в тексте выступает в письменной форме со-всей внешней "атрибутикой" такой формы (фиксации речевого произведения.
© О.Н.Гринбаум, Г.Я.Мартыненко, 1993
* Е л ь ы с л е в Л. Пролегомены к теории языка / / Новое ь лингвистике. М., 1960. Вып.4. С .-264-389; З в е г и н ц е в В>А. Язык и лингвистическая теория, М., 1973.
I,' о л ь А. Социодинамика культуры. М., 1973.
0 Л о т м а н Ю.М. К современному понятии текста / / ш - КиАаиса.Тарту, 1986, Вып.786. С .104-108.
171

Филологические задачи, при решении которых используются сведения о языке, имеют, , как правило, четкую прикладную направленность,. язык и стиль текста в такой ситуации является не целью исследования, а средством решения внелингвистических проблем. Важным является также и то, что решение конкретной филологической задачи (например, проблемы спорного авторства) обычно не ограничивается жесткими рамками какой-либо одной методики исследования, а ведется с использованием методов и фактов, относящихся к самым разнообразным областям знания и практической деятельности. Филологический анализ всегда требует интегрального, комплексного подхода. Это предполагает и внутритекстовый анализ, и анализ условий создания текста, и изучение взаимоотношений данного текста с другими текстами. Заключение филолога часто субъективны, ибо строятся на здравом смысле, догадке, интуиции, житейской мудрости и редко претендуют на безусловную научную строгость и окончательность выводов.
В компьютерной филологии текст, так ке как и в филологии традиционной, остается исходной эмпирической данностью; Однако в компьютерной среде филологическое восприятие текста смещается в сторону большей объективности, методической строгости и максимальной формализованноети. Видение текста становится предельно "вещным", "производственно-технологическим"; с помощью компьютерных программ исследователь общается с текстом как с непосредственно осязаемым материальным образованием, построенным по конкретным лингво-полиграфическим "законам". В компьютерной филологии утрачивается (по крайней мере в ее нынешнем состоянии) комплексность традиционного филологического подхода, теряется бесконечное богатство ассоциаций, возникающих при общении с текстом и его окружением. И в то ке время приобретаются практически неограниченные возможности для единообразной и быстрой обработки больших массивов данных, извлекаемых из печатного текста. Эффективность работы ЭВМ особенно велика там, где используются сложные процедуры многомерного анализа текста: дистрибутивно-статистический метод,^ алгоритмы лингвистической
^ Ш а й к е в и ч А.Я. Дистрибутивно-статистический анализ текстов: Авторе:;, дяо. . . . докт. филол. наук. М„, {982.
*72

дешифровки, 5 методы квантитативной типологии® и таксономии^О
текстов, алгоритмы стилистической диагностики, стилеметрические методы.^
Все сложные алгоритмические процедуры автоматической обработки текста являются разновидностями диагностической работы, связанной с упорядочиванием и систематизацией текстов, частей текста и единиц текста. Отличительной чертой диагностических классификаций является то, что все они основаны на использовании поверхностных симптоматических признаков, образующих диагностический синдром, на основании которого делаются заключения о глубинных, латентных характеристиках структурной организациитекста. Не случайно многие исследователи называют диагностиче-
дОские алгоритмы асемантическими, поскольку в них в качестве исходных используются лишь те данные, которые содержатся во внешней структуре печатного текста.
2. Автоматическая структуризация текста. Важным этапом диагностической работы компьютерной филологии является выделение единиц текста, его членение. Ориентация на машинную обработку диктует необходимость обращения к объемно-композиционному расположению речевого материала в тексте, эксплицитно выраженному в правилах и нормах графического представления и пространственного размещения единиц и частей текста. В лингво-по-
е:С у х о т и н Б.В. Алгоритмы лингвистической деиийров-
ки / / Проблемы структурной лингвистики. М., 1983. С.75-102.
^ А л е к с е е в П.М. О квантитативной типологии текста / / Труды по лингвостатистике. Тарту, 1981. Выл.991. С.В-13.
^ 1 а 1 к е в и ч А.Я. Гипотезы о естественных классах и возможность количественной таксономии в лингвистике / / Гипотеза в современной лингвистике. М., 1989. С.319-351.
^ М а р у с е н к о М.А. Отбор информативных параметров в задачах стилистической диагностики / / Структурная и прикладная лингвистика. Л., 1987. С.84-93.
^ М а р т ы н е н к о Г.Я. Основы сТилеметрии. Л., 1988.
А н д р е е в Н.Д. Статистико-комбинаторные методы в теоретическом и прикладном языкознании. Л., 1967.
** Г а л ь п е р и н И.Р. Текст как объект лингвистического исследования. М., 1981.
173

лиграфической структуре текста помимо чисто внешних примет(шрифт, формат, строкоделение, длина абзацного отступа, способы оформления заголовков и т . п . ) преломляются стилистические (функциональные, жанровые, авторские и д р .) особенности текота.
Компьютерную, экспликацию лингво-полиграфического членения текста будем называть структуризацией. Этот термин связан с ассоциативным рядом "компьютер-компьютеризация", "автомат-автоматизация" и подчеркивает компьютерный, формальный аспект процесса членения текста. Структуризация основывается на трех принципах: формальности, однородности и лингво-стилистической надежности. П р и н ц и п ф о р м а л ь н о с т и означает, что процесс членения текста опирается на элементы графического 1 оформления текста с учетом правил русской пунктуации и пространственного расположения материала на страницах печатных изданий. Использование словарной информации допускается лишь как вспомогательное средство, например, при анализе стандартных сокращений, анализе сочетаний, эквивалентных слову,*8 разрешении омонимии "дефис-перенос" .* ,+ П р и н ц и п о д н о р о д н о - с т и ч л е н е н и я предполагает автоматическое отнесение единиц текста к одному из структурно-функциональных типов речи в пределах конкретного нанра. Например, в пределах художественной прозы автоматически выделяются и группируются подмножества единиц, относящиеся к разным типам письменной речи (речи автора, чужой речи) о последующим разбиением подмножества единиц чужой речи на три однородные совокупности: прямую (диалогическую) речь, смешанную речь и вложенную прямую речь. П р и н ц и п л и н г в о - с т и л и с т и ч е с к о й н а- ц е н н о с т и предполагает отказ от гарантированного результата как итога работы абсолютно безошибочного алгоритма чле-
^ В и н о г р а д о в В,В. О языке художественной литературы. М., 1969; А к и м о в а Г.Н. Новые явления в синтаксическом строе современного русского языка. Л ., 1982.
^ Р о г ж н н к о в а Р.П. Словах,ь сочетаний, эквивалентных слову. М,, 1983.
^ 2 а р к о « И.В., Г р и к б а у и О.Н., Н а р т ы- я в н о Г.Я. Алгоритм восстановления цельности словоформы в системах автоматической обработки текста / / Научно-техническая кв.'ориацпя. Сер.2. 1988. .V I . С .И '.
1?<*

нения текста. При необходимости ошибки структуризации устраняются филологом-исследователем в диалоге с компьютерной системой.
Практическая целесообразность структуризации текста хорошо прослеживается на примере создания машинного фонда лексических единиц.4,5 Применяемое ныне правило определения контекста как определенного числа символов вправо и влево .от ключевого слоьа4ь не может считаться безупречным и используется только потому, что текст, хранимый в памяти ЭВМ для получения карточек-цитат, не структурирован. При наличии структурно-фрагментированного текста понятие к о н т е к о т имеет неформальное (смысловое) значение даже з формальных (компьютерных) системах, а сам контекст по желанна исследователя шжет строиться из произвольного числа единиц различных уровней: словоупотреблений, предложений, абзацев.
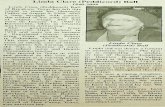
.3. База лингвистических данных системы "ЛИНДА". Лингво-полиграфический подход к членению текстов и разработанный на его основе (формально-пунктуационный метод структуризации получили свое-практическое воплощение в диалоговой системе "1Л88коте" , результатом работы которой (точнее, лингвиста.в диалоге в ’ЧЯЗЗ- коте" ) явлнются массивы структурированных текстов, которые водят в состав лингвистической базы данных системы "ЛИНДА" _ (см. схему).47
Компьютерная система "ЛИНДА" - это один из вариантов построения текстового фонда Машинного фонда русского языка. Она задумана и проектируется, как многоцелевая лингвистическая система, в которой должнп решаться задачи по следующим направления/! :
г5Р о г о к н и к о в а Р.1Г. Машинный фонд русского язы
ка и словарное дело / / Вопросы языкознания. И ., 4985. Ш А.С. 5А- 60. ,
15 А з а р о в а И.В., Г о р о х о в а С.И., Г р и г о р ь е в Г .Г ., К у з н е ц о в а Е.А. Разработка автоматических словоуказателей и конкордансов для художественных текстов / / Структурная и прикладная лингвистика. Л.. 4983. Вып.2.С. 487-190.
тпГ р и н б а у м О.Н. М а р т ы н е н к о Г.Я ., Ф и-
т и я л о в С.Я. Проект "ЛИНДА" - автоматизированная система обработки лингвостатистических данных / / Прикладная лингвистика и автоматический анализ текста: Тез. докл. Тарту, 4988. С. 91— 23 - 475
а) первичная обработка лингвистических данных (построениерядов распределения, вычисление статистик, статистических оценок, проверка статистических гипотез и д р .) ,
Основные компоненты базы данных системы "ЛИНДА".
б) лексигогре,ическая обработка текстовых данных с учетом однородности/ньоднородности: создание частотных и алфавит-
.о -частотных словарей, словарей-конкордансов, словоуказателей, обратных словарей, словарей писателей и т .п .;
з) информационно-поисковые задачи:- поиск текстовых единиц, обладающих определенным.набором
качественных и количественных характеристик для решения стилистических и грамматических проблем;
- автоматический поиск текстов (авторский, г.анровый, историко-хронологический, библиографический и д р .);
176

г) систематико-таксономические задачи:- обработка многомерных данных с использованием стандарт
ных алгоритмических процедур (факторного, дискриминантного, кластерного и других методов анализа статистических данных);
- обработка лингвистических данных с помощью специальных лингвистических методов (дешифровочных алгоритмов, дистрибутивно-статистического метода, методов датировки, атрибуции, диагностики и типологии текстов и д р .);
д) теоретические исследования: изучение количественных закономерностей в символьных последовательностях, изучение проблемы устойчивости и вариативности лингвостатистических чисел, проблемы однородности текстов, условий действия законов больших чисел, оптимизация выборочных исследований и др.
Система "ЛИНДА" проектируется с учетом, концепции экспертных систем,*8 поэтому в ее макроструктуру уже на начальной стадии работ закладывается возможность, с одной стороны, самостоятельного функционирования лингвистической базы данных, а с другой - совместная работа трех подсистем, включаемых в общий контур управления по мере их создания: классов и отношений (базы данных), правил и управляющей структуры.
Классы и отношения есть не что иное, как база данных в ее классическом понимании: это именованная совокупность (см.рисунок) лингвистических данных, отображающая состояние объектов и их отношений в области филологических исследований.
В базе данных системы "ЛИНДА" накапливаются декларативные значения об исследуемых лингвистических объектах:
а) текстах и их основных, в том числе библиографических, характеристиках;
б) единицах текстов с приписанными им (автоматически иЛши вручную) маркерами и словарными признаками (категориями).
В основе построения базы данных лежит принцип пересекающихся множеств описаний данных при уникальности компьютерного представления самих лингвистических данных. Именно эти описания связей между информационными массивами используются проце-
*8 Э л т и Дж., К у м б с М. Экспертные системы: концепции и примеры. М., 1987; П о п о в Э.В. Экспертные системы: решение неформализованных задач в диалоге с ЭВМ. г.!., 1987.
177
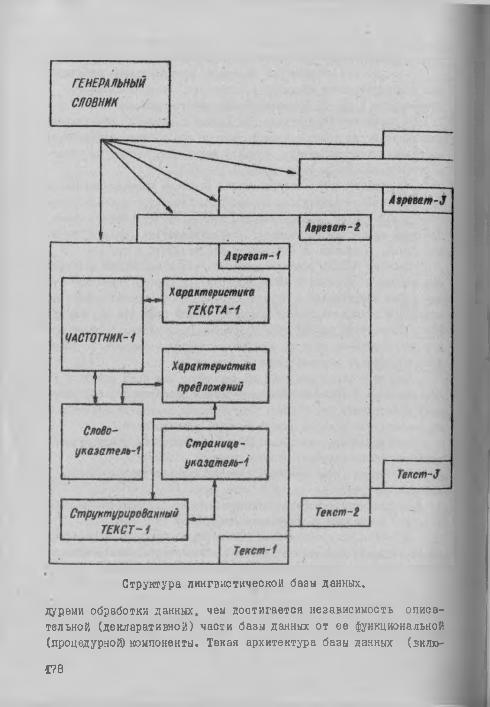
Структура лингвистической базы данных.
дурами обработки данных, чем достигается независимость описательной (декларативной) части базы данных от ее функциональной (процедурной) компоненты. Такая архитектура базы данных (вклю-
Г?8

чая управляющие структуры и средства поддержки диалога человек- ЭВМ) позволяет успешно решать самые сложные и логически хорошо формализуемые задачи, но интерпретацию полученных результатов оставляет человеку.
В лингвистической базе данных системы "ЛИНДА" основными информационными массивами (см. рисунок) являш са:
генеральный словник; массивы структурированных текстов; массивы характеристик текстов (справки по текстам); массивы словоуказателей; массивы страницеуказателей; массивы характеристик предложений; массивы частотных словарей (частотники).Все массивы лингвистических данных, аа. исключением гене
рального словника, агрегируются по своей принадлежности к исходному произведению (ТЕКСТ-1, ТЕКСТ-2, ТЕКСТ-8 и т . д . ). Генеральный словник связан через ключевое ноле с каждым агрегатом данных и дополняется (корректируется, изменяется) в процессе работы над каждым вновь включаемым в лингзистичеокую базу источником (текстом). Подобные изменения автоматически выполняются прикладными программами при обработке текстовой информации. Специальные наборы данных хранят сведения о состоянии каждого ив агрегатов и выполненных над его элементами (массивами) операциями с тем, чтобы исключить дублирование работ и несанкционированный доступ к информационным массивам.
Массивы лингвистических данных содержат*® следующую информацию: '•
а) массив "Характеристика текста": автор, название, год издания, библиографические данные, интерпретация полей "Частот- ника";
б) массив "Характеристика предложения": номер предложения, тип (маркер) предложения, длина, синтаксические меры сложности (ширина, длина, густота дерева, степень разрывности, однородности, гнездования, перечислительности, мощнооть уровня);
*® Представленные здесь основные поля маосивов лингвистических данных не исчерпывают все возможные варианты и поэтому не являются окончательно сформированными.
Г79

в) массив "Структурированный текст": номер предложения и текст самого предложения;
г) массив "Страницеукэзатель": номер страницы исходного текста и номер последнего предложения на этой странице;
д) массив "Словоуказатель": номер слова (словоупотребления) по "Генеральному словнику" и список номеров предложений, в которых это слово встречается для данного текста;
е) массив "Частотник": номер слова (словоупотребления) по "Генеральному словнику" и частоты (абсолютные) встречаемости этого слова по данному тексту в зависимости от объема выборки;
ж) массив "Генеральный словник": номер слова, слово (словоупотребление), характеристики слова (длина, род, число, падеж, одушевленность, разряд, переходность и д р .).
Основным ключевым элементом (связующим звеном) является слово (словоупотребление), однако не само символьное его изображение, а номер по Генеральному словнику. Внутренние агрегатные связи осуществляются по таким полям, как "номер предложения" и "номер слова (словоупотребления)", т .е . "номер слова" является глобальной (межагрегатной) и локальной связующей единицей лингвистической базы данных.
Прикладные программы - это прежде всего процедуры обработки лингвистических данных по основным направлениям исследований: первичной и лексикографической обработки, информационного поиска и систематико-таксономических задач, теоретических исследований. Сюда включаются стандартные пакеты прикладных программ (например, многомерного статистического анализа^0 ), апробированные в условиях работы с лингвистическими единицами, а также оригинальное программное обеспечение, созданное для проведения .специальных лингвистических исследований.
Концепция баз данных^* позволяет наиболее экономным способом хранить и обрабатывать большие массивы информации, одна-
рос Е н ю к о в И.С. Методы, алгоритмы, программы многомерного статистического анализа: Пакет ППСА. М., 1936. Д а й - и т б а т о в Д.М., К а л м ы к о в а О.В., Ч е р е п а н о в А.И. Программное обеспечение статистической обработки данных. М., 1984.
^ М а р т и н Дк. Организация баз данных в вычислительных системах. М., 1980.180

ко. (подчернем это еще раз) главную задачу любого исследования - оценку полученных результатов - оставляет за человеком.
В отличие от традиционных систем баз данных экспертные системы оперируют не только данными, но и знаниями (декларативными и процедуральными), в которых формализован коллективный опыт специалистов некоторой предметной области. Нередко эти знания постепенно' пополняют, надстраивают систему баз данных более высокими уровнями организации (знаниями) и управления (метапроцедурами).
Именно в этом направлении постепенной интеллектуальной эволюции, расширения диалоговых и исследовательских возможностей системы, включения в нее моделей филологического знания, усвоения и обучения, т .е . создания в конечном счете базы филологических знаний, так же как и базы управляющей знаний,мы видим магистральный путь развития системы "ЛИНДА", как, впрочем, и любой другой компьютерной лингвистической системы.
*
181

О Г Л А В Л Е Н И Е
М а т е м а т и ч е с к а я и прикладная лингвистикав С.-Петербургском университете ................................. ^
Б о г д а н о в В.В. Деятельность в вербальном общении(С.Петербургский у н -т ) ..................................................... 14
Т е л е г и н а Г .В . Семантика и прагматика модусныхпредикатов: мнения и проблемы (Тюменский у н -т) . . . 22
Д и к а р е в а С.С. Инициатива в диалоге (Симферопольский у н -т ) .............................................. 30
З у б к о в а Т.И. О роли предлогов 6 предложении (На материале исследований детской речи и нарушений речи при афазии ) (С.-Петербургский у н -т ) ................... 39
Т а б а н а к о в а В.Д. Прагматический аспект логического анализа текста словарного определения (Тюменский у н -т) . . . . .......... ......................................................... 45
Л у б и н и н а Т.А. Семантическая структура предложений с инфинитивом в функции подлежащего (на' материале английского языка) (С.-Петербургский у н - т ) . . 50
К л и м о н о в В.Л. О ноизоморфизме маркированности всклонении русских существительных (АН Германии)... 59
А л е к с е е в П.М. О некоторых квантитативно-лингвистических оппозициях (Рос. пед, у н -т) ....................... 66
Г е р д А,С. К вопросу о роли низкочастотных фактов влингвистическом исследовании (С.-Петербургский ун-т) 75
М а н а с я н Н.С. О двух статистических способах различения типов текста (Ереванский политех.. ин-т) . . 98
Б у т о р о в В.Л. , Ш е р е м е т ь е в а С.О. Частотные характеристики семантико-синтаксических признаков предикатной лексики в текстах формулы изобрете пя (С.-Петербургский у н -т )................................ ЮЗ
Р у с к о а а М.П. Статистические параметры имен существительных мужского рода множественного числа в болгарском языке ХУШ в. (С.-Петербургский у н -т) . . 134
22А

м а р у с е н к о М.А. Алгоритмизация проверки литературно-критической атрибуционной гипотезы (С.-Петербургский ун-т) .................................. . . .................................... 1*5
Г а й ш т у т К.М. Особенности номинаций и семантического развития в терминосистеме наименований видов деловых текстов (Тверской ун-т) ....................................... 160
Г р и н б а у м О.Н., М а р т , ы н е н к о Г.Я. Структуризация текста в компьютерной системе "ЛИНДА" (С.- Петербургский у н - т ) ......... . ..................................................... 171
О т к у п щ и к о в а М.И., К р е м н е в а Н.Д.,К и р и ч е н к о Н.Л., З а м б р ж и ц к и й В Х Функционально-семантическая информация в словарных процедурах для анализа текстов узкой предметной области (С.-Петербургский ун-т) ............................................ 181
В о I с к у н с к и й В. Г ., З а х а р о в В.П. Диалоговый отладочный комплекс (С.-Петербургский центр научно-техн. информации) ......................... 197
П а р т ы к о З.В. Комбинаторный метод автоматизациипроцессов корректуры (Львовский полиграф, ин-т) . . . 211

C O N T E N T
M a t h e m a t l c a l linguistics at S.-PetersburgUniversity.... ............................. 3
B o g d a n o v V.V. Activities in verbal communication (S.-Petersburg Univ.) ................ ........ 14
T e l e g i n a G.V. Semantics and pragmatics of moduspredicates 1 opinions and problems (Tyumen Univ.) 22
D i k a r e v a S.S. Initiative in dialogue (Simferopol Univ.) ........................... ........... 30
Z u b k o v a T.I. On the role of prepositions in asentence (S.-Petersburg Univ.) ................. 39
T a b a n a k o v a V.D. A pragmatic aspect of the logical analysis of a dictionary definition (Tyumen Univ.) ........................................ 43
D u b i n i n s T.A. The semantic structure of sentences containing an infinitive subject (in English sentences) (S.-Petersburg Univ.) ................. 50
K l i m o n o v V.D. On non-isomorphism of markednessin Russian noun declension (Academy of science. Germany) ............ •.......................... 51,
A l e k s e y e v P.M. On some quantitative linguisticoppositions (Ped. Univ.) ......................... 66
H e a r d A.S. On the problem of the role of low frequency facts in linguistic investigations (S.-Petersburg Univ.) ................................ 75
M a n a s y a n N.S. On two statistic ways of text typedifferentiation (Yerevan Polytechnical Institute) 98
B u t 0 r o v V.D., S h e r e m e t e v a S.O. Frequency characteristics of semantico-syntactic features of predicate words in invention formula texts (S.-Petersburg Univ.) .......... ................. 103
K u s k o v a M.P. Statistic parameters of masculinenouns in the plural in the Bulgarian language of the XVIII century (S.-Petersburg Univ.) ......... 134
226

M a r u s e n k o M.A. Compiling algorithms for check- . ing literary c r itic attribution hypothesis (S.-Peters burg Univ.) ............ .................................... 145
G a i s h t u t K.M. Some characteristic features of nomination and semantic development in the term system of business text names (Tver. Univ.) . . . . . . 160
G r i n b a u m O.N., M a r t y n e n k o G.Ya. Struc- turalysation of text in a computer system "LINDA”(S. -Peters burg Univ.) ............ ................................ 171
O t k u p s h c h i k o v a M.I., K r e m n e v a N.D.K i r i c h e n k o N.L., Z a m b r z h i t s - k y V.L. Functional semantic information in dictionary procedures for narrow subject fie ld text analysis (S.-Petersburg Univ.) ................. ............ 181
V o y s k u n s k i V.G.; Z a k h a r o v V.P. Interactive debugging complex (S.-Petersburg Centre of Sci.-Tech. In f.) .......... . 197
P a r t y k o Z.V. Combinatorial method of proof-reading automation (Lvov Bolygr. Inst.) ...................... 211