
Speech-gesture driven multimodal interfaces for crisis management
28
Speech–Gesture Driven Multimodal Interfaces for Crisis Management RAJEEV SHARMA, MOHAMMED YEASIN, MEMBER, IEEE, NILS KRAHNSTOEVER, INGMAR RAUSCHERT, GUORAY CAI, MEMBER, IEEE, ISAAC BREWER, ALAN M. MACEACHREN, AND KUNTAL SENGUPTA Invited Paper Emergency response requires strategic assessment of risks, de- cisions, and communications that are time critical while requiring teams of individuals to have fast access to large volumes of com- plex information and technologies that enable tightly coordinated work. The access to this information by crisis management teams in emergency operations centers can be facilitated through var- ious human–computer interfaces. Unfortunately, these interfaces are hard to use, require extensive training, and often impede rather than support teamwork. Dialogue-enabled devices, based on nat- ural, multimodal interfaces, have the potential of making a variety of information technology tools accessible during crisis manage- Manuscript received November 30, 2002; revised March 17, 2003. This work is supported in part by the National Science Foundation under Grant 0113030, Grant IIS-97–33644, and Grant IIS-0081935, and in part by the U. S. Army Research Laboratory Cooperative Agreement DAAL01–96-2–0003. R. Sharma is with Advanced Interface Technologies, Inc., State College, PA 16801 USA and also with the Department of Computer Science and En- gineering, Pennsylvania State University, University Park, PA 16802 USA and also with the GeoVISTA Center, Pennsylvania State University, Univer- sity Park, PA 16802 USA (e-mail: [email protected]). M. Yeasin is with the Department of Computer Science and Engineering, Pennsylvania State University, University Park, PA 16802 USA and also with Advanced Interface Technologies, Inc., State College, PA 16801 USA (e-mail: [email protected]). N. Krahnstoever is with the the Department of Computer Science and En- gineering, Pennsylvania State University, University Park, PA 16802 USA (e-mail: [email protected]). I. Rauschert is with the Department of Computer Science and Engi- neering, Pennsylvania State University, University Park, PA 16802 USA and also with the GeoVISTA Center, Pennsylvania State University, University Park, PA 16802 USA (e-mail: [email protected]). G. Cai is with the School of Information Sciences and Technology, Penn- sylvania State University, University Park, PA 16802 USA and also with the GeoVISTA Center, Pennsylvania State University, University Park, PA 16802 USA (e-mail: [email protected]). I. Brewer is with the GeoVISTA Center,Pennsylvania State University, University Park, PA 16802 USA (e-mail: [email protected]). A. MacEachren is with the Department of Geography, Pennsylvania State University, University Park, PA 16802 USA and also with the GeoVISTA Center, Pennsylvania State University, University Park, PA 16802 USA (e-mail: [email protected]). K. Sengupta is with Advanced Interface Technologies, Inc., State College, PA 16801 USA. Digital Object Identifier 10.1109/JPROC.2003.817145 ment. This paper establishes the importance of multimodal inter- faces in various aspects of crisis management and explores many issues in realizing successful speech–gesture driven, dialogue-en- abled interfaces for crisis management. This paper is organized in five parts. The first part discusses the needs of crisis management that can be potentially met by the de- velopment of appropriate interfaces. The second part discusses the issues related to the design and development of multimodal inter- faces in the context of crisis management. The third part discusses the state of the art in both the theories and practices involving these human–computer interfaces. In particular, it describes the evolution and implementation details of two representative systems, Crisis Management (XISM) and Dialog Assisted Visual Environ- ment for Geoinformation (DAVE_G). The fourth part speculates on the short-term and long-term research directions that will help ad- dressing the outstanding challenges in interfaces that support dia- logue and collaboration. Finally, the fifth part concludes the paper. Keywords—Crisis management, dialogue design, gesture recog- nition, human–computer interaction (HCI), multimodal fusion, multimodal interface, speech recognition and usability study. I. THE NEED FOR MULTIMODAL INTERFACES IN CRISIS MANAGEMENT The need to develop information science and technology to support crisis management has never been more apparent. Crisis management scenarios (see Fig. 1 for an example scenario) considered in this paper include both strategic assessment (work to prepare for and possibly prevent po- tential crises) and emergency response (activities designed to minimize loss of life and property). Most crisis man- agement relies upon geospatial information (derived from location-based data) about the event itself, its causes, the people and infrastructure affected, the resources available to respond, and more. Geospatial information is essential for preevent assessment of risk and vulnerability as well as to response during events and subsequent recovery efforts. Emergency response requires strategic assessment of risks, decisions, and communications that are time critical while 0018-9219/03$17.00 © 2003 IEEE PROCEEDINGS OF THE IEEE, VOL. 91, NO. 9, SEPTEMBER 2003 1327
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Speech-gesture driven multimodal interfaces for crisis management

Speech–Gesture Driven Multimodal Interfacesfor Crisis Management
RAJEEV SHARMA, MOHAMMED YEASIN, MEMBER, IEEE, NILS KRAHNSTOEVER,INGMAR RAUSCHERT, GUORAY CAI, MEMBER, IEEE, ISAAC BREWER,ALAN M. MACEACHREN, AND KUNTAL SENGUPTA
Invited Paper
Emergency response requires strategic assessment of risks, de-cisions, and communications that are time critical while requiringteams of individuals to have fast access to large volumes of com-plex information and technologies that enable tightly coordinatedwork. The access to this information by crisis management teamsin emergency operations centers can be facilitated through var-ious human–computer interfaces. Unfortunately, these interfacesare hard to use, require extensive training, and often impede ratherthan support teamwork. Dialogue-enabled devices, based on nat-ural, multimodal interfaces, have the potential of making a varietyof information technology tools accessible during crisis manage-
Manuscript received November 30, 2002; revised March 17, 2003.This work is supported in part by the National Science Foundation underGrant 0113030, Grant IIS-97–33644, and Grant IIS-0081935, and inpart by the U. S. Army Research Laboratory Cooperative AgreementDAAL01–96-2–0003.
R. Sharma is with Advanced Interface Technologies, Inc., State College,PA 16801 USA and also with the Department of Computer Science and En-gineering, Pennsylvania State University, University Park, PA 16802 USAand also with the GeoVISTA Center, Pennsylvania State University, Univer-sity Park, PA 16802 USA (e-mail: [email protected]).
M. Yeasin is with the Department of Computer Science and Engineering,Pennsylvania State University, University Park, PA 16802 USA and alsowith Advanced Interface Technologies, Inc., State College, PA 16801 USA(e-mail: [email protected]).
N. Krahnstoever is with the the Department of Computer Science and En-gineering, Pennsylvania State University, University Park, PA 16802 USA(e-mail: [email protected]).
I. Rauschert is with the Department of Computer Science and Engi-neering, Pennsylvania State University, University Park, PA 16802 USAand also with the GeoVISTA Center, Pennsylvania State University,University Park, PA 16802 USA (e-mail: [email protected]).
G. Cai is with the School of Information Sciences and Technology, Penn-sylvania State University, University Park, PA 16802 USA and also withthe GeoVISTA Center, Pennsylvania State University, University Park, PA16802 USA (e-mail: [email protected]).
I. Brewer is with the GeoVISTA Center, Pennsylvania State University,University Park, PA 16802 USA (e-mail: [email protected]).
A. MacEachren is with the Department of Geography, Pennsylvania StateUniversity, University Park, PA 16802 USA and also with the GeoVISTACenter, Pennsylvania State University, University Park, PA 16802 USA(e-mail: [email protected]).
K. Sengupta is with Advanced Interface Technologies, Inc., State College,PA 16801 USA.
Digital Object Identifier 10.1109/JPROC.2003.817145
ment. This paper establishes the importance of multimodal inter-faces in various aspects of crisis management and explores manyissues in realizing successful speech–gesture driven, dialogue-en-abled interfaces for crisis management.
This paper is organized in five parts. The first part discusses theneeds of crisis management that can be potentially met by the de-velopment of appropriate interfaces. The second part discusses theissues related to the design and development of multimodal inter-faces in the context of crisis management. The third part discussesthe state of the art in both the theories and practices involvingthese human–computer interfaces. In particular, it describes theevolution and implementation details of two representative systems,Crisis Management (XISM) and Dialog Assisted Visual Environ-ment for Geoinformation (DAVE_G). The fourth part speculates onthe short-term and long-term research directions that will help ad-dressing the outstanding challenges in interfaces that support dia-logue and collaboration. Finally, the fifth part concludes the paper.
Keywords—Crisis management, dialogue design, gesture recog-nition, human–computer interaction (HCI), multimodal fusion,multimodal interface, speech recognition and usability study.
I. THE NEED FORMULTIMODAL INTERFACES INCRISIS
MANAGEMENT
The need to develop information science and technologyto support crisis management has never been more apparent.Crisis management scenarios (see Fig. 1 for an examplescenario) considered in this paper include both strategicassessment (work to prepare for and possibly prevent po-tential crises) and emergency response (activities designedto minimize loss of life and property). Most crisis man-agement relies upongeospatial information(derived fromlocation-based data) about the event itself, its causes, thepeople and infrastructure affected, the resources availableto respond, and more. Geospatial information is essentialfor preevent assessment of risk and vulnerability as well asto response during events and subsequent recovery efforts.Emergency response requires strategic assessment of risks,decisions, and communications that are time critical while
0018-9219/03$17.00 © 2003 IEEE
PROCEEDINGS OF THE IEEE, VOL. 91, NO. 9, SEPTEMBER 2003 1327

Fig. 1. A scenario of speech–gesture driven collaborative interfaces in the context of crisismanagement.
requiring teams of individuals to have fast access to largevolumes of complex information and technologies thatenable tightly coordinated work.
Crisis management also relies upon teams of people whoneed to collaboratively derive information from geospatialdata and to coordinate their subsequent activities. Currentgeospatial information technologies, however, have not beendesigned to support group work, and we have very littlescientific understanding of how groups (or multiple groups)work in crisis management using geospatial informationand the technologies for collecting, processing, and using it.Meeting the challenges of crisis management in a rapidlychanging world will require more research on fundamentalinformation science and technology. To have an impact, thatresearch must be linked directly with development, imple-mentation, and assessment of new technologies. Makinginformation technology easier to use for crisis managers and
related decision makers is expected to increase the efficiencyof coordination and control in strategic assessment and crisisresponse activities. To be useful and usable, the interfacetechnologies must be human centered, designed with inputfrom practicing crisis management personnel at all stages ofdevelopment.
We believe that dialogue-enabled devices based on nat-ural, multimodal interfaces have the potential of making avariety of information technology tools accessible duringcrisis management. Multimodal interfaces allow users tointeract via a combination of modalities such as speech,gesture, pen, touch screen, displays, keypads, pointingdevices, and tactile sensors. They offer the potential forconsiderable flexibility, broad utility, and use by a largerand more diverse population than ever before. A particularlyadvantageous feature of multimodal interface design isits ability to support superior error handling, compared to
1328 PROCEEDINGS OF THE IEEE, VOL. 91, NO. 9, SEPTEMBER 2003

unimodal recognition-based interfaces, in terms of botherror avoidance and graceful recovery from errors [1]–[3].However, the traditional human–computer interfaces do notsupport the collaborative decision making involved in crisismanagement.
The ability to develop a multimodal interface systemdepends on knowledge of the natural integration patternsthat typify people’s combined use of different input modes.Developing a multimodal interface for collaborative deci-sion making requires systematic attention to both humanand computational issues at all stages of the research. Thehuman issues range from analysis of the ways in whichhumans indicate elements of a geographic problem do-main (through speech and gesture) to the social aspects ofgroup work. The computational issues include developingrobust real-time algorithms for tracking multiple people,recognizing continuous gestures and understanding spokenwords, developing methods for syntactical and semanticanalysis of speech–gesture commands, and designing anefficient dialogue-based natural interface in the geospatialdomain for crisis management.
Given the complex nature of users’ multimodal interac-tion, a multidisciplinary approach is required to design amultimodal system that integrates complementary modali-ties to yield a highly synergistic blend. The main idea istoconsider each of the input modalities in terms of the others,rather than separately. The key to success is the integrationand synchronization requirements for combining differentmodes strategically into a whole system. A well-designedmultimodal architecture can supportmutual disambigua-tion of input signals [4]. Mutual disambiguation involvesrecovery from unimodal recognition errors within a multi-modal architecture. This is because semantic informationfrom each input mode supplies partial disambiguation ofthe other mode, thereby leading to more stable and robustoverall system performance. This integration is useful, bothin the disambiguation of the human input to the system andin the disambiguation of the system output.
This paper discusses the evolution and implementationof a dialogue-based speech–gesture driven multimodalinterface systems developed by group of researchers atPennsylvania State University, University Park, and Ad-vanced Interface Technologies (AIT), State College, PA.The main goal was to design natural human–computer inter-action (HCI) systems that will allow a team of individuals tocollaborate while interacting with complex geospatial infor-mation. The unified multimodal framework would includetwo or more people in front of a large display, agents in thefield with small displays, and mobile robotic agents. Such amultimodal, cross-platform collaborative framework couldbe an important element for rapid and effective responseto a wide range of crisis management activities, includinghomeland security emergencies. The objectives of this paperare as follows.
1) To outline how cutting-edge information technolo-gies—for example, a speech–gesture driven multi-modal interface—allow individuals and teams to
access essential information more quickly and nat-urally, thus improving decision making in crisissituations;
2) To discuss the challenges faced in designing such asystem, which may include:
a) to identify and respond to the critical needs ofcrisis mitigation and response;b) to provide the crisis management team a dis-tributed environment for training and testing in-cluding a virtual space for distant members to col-laborate in making the decision;
3) To discuss the state of the art of speech–gesturedriven collaborative systems and technological issuesinvolved in the design of speech–gesture based inter-faces. This includes speech and image analysis tasksfor sensing, multimodal fusion framework for useraction recognition, and dialogue design and semanticsissues in the domain of crisis management.
4) To report our progress to date by detailing the evolu-tion of two implemented systems, namely, XISM andDAVE_G.
5) To discuss the future challenges that must be overcometo realize natural and intuitive interfaces, for collabo-rative decision making in the context of crisis manage-ment.
A. A Crisis Management Scenario
Let us consider an example scenario that could helpin grounding the discussions on the role of multimodalinterfaces for collaborative work in crisis management (seeFig. 2 for a conceptual snapshot of the problem). Imaginethe crisis management center of a government organizationwith, Center Director Jane Smith and Paul Brown, chieflogistic and evacuation manager, in front of a large-screendisplay linked to the organization’s emergency managementsystem,Multimodal Interface for Collaborative EmergencyResponse(MICER).
An earthquake of magnitude 7.1 has hit San Diegoand many freeways and major roads are impassable.Buildings are severely damaged or collapsed, and firehas broken out in many places. Shortly before the quake,seismographs indicated a fault shift and triggered alarmsat emergency centers and local governments. A fewminutes later, emergency operation centers are occu-pied and prepared to respond to this situation…
They are assessing initially available information about theearthquake’s epicenter and its magnitude and preliminarydamage estimates. The crisis center is filled with responseprofessionals, each with different expertise, sitting in frontof displays showing information and reports from affectedsites. Assessing all available information and ensuring com-pleteness are critical tasks. Based on available information,immediate decisions have to be made about where to sendrescue teams, where to send resources, and how to prior-itize the response effort. They decide where and how they
SHARMA et al.: SPEECH–GESTURE DRIVEN MULTIMODAL INTERFACES FOR CRISIS MANAGEMENT 1329
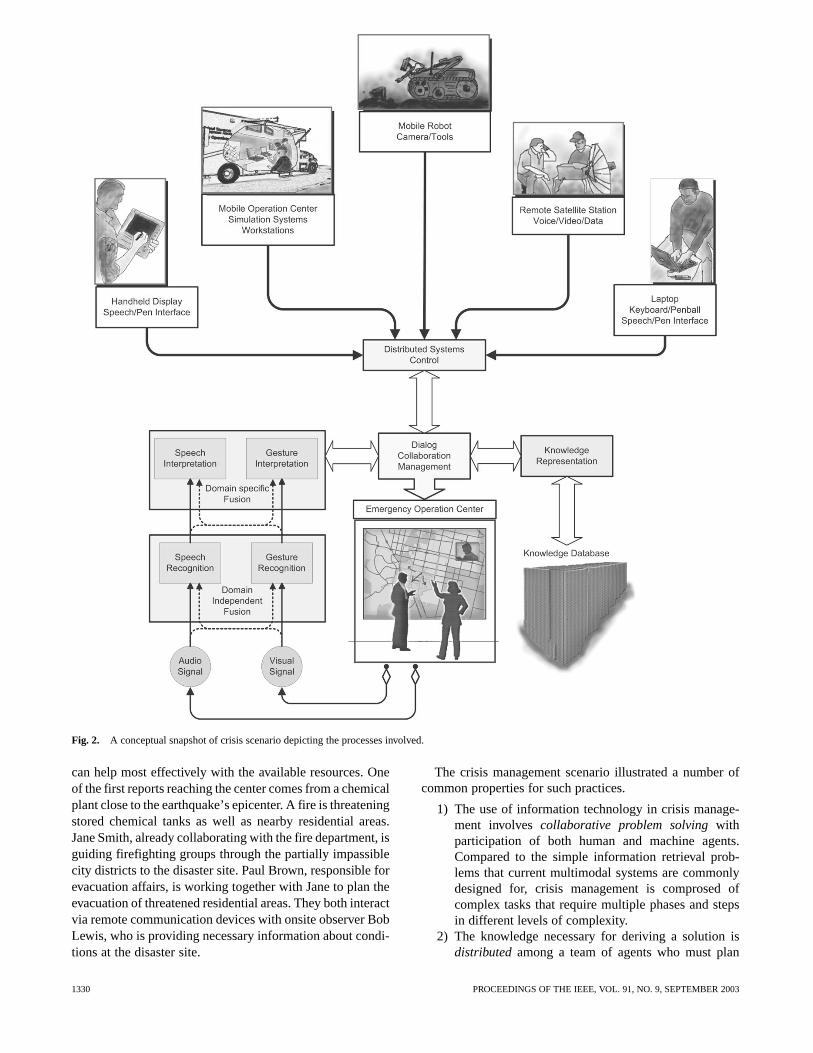
Fig. 2. A conceptual snapshot of crisis scenario depicting the processes involved.
can help most effectively with the available resources. Oneof the first reports reaching the center comes from a chemicalplant close to the earthquake’s epicenter. A fire is threateningstored chemical tanks as well as nearby residential areas.Jane Smith, already collaborating with the fire department, isguiding firefighting groups through the partially impassiblecity districts to the disaster site. Paul Brown, responsible forevacuation affairs, is working together with Jane to plan theevacuation of threatened residential areas. They both interactvia remote communication devices with onsite observer BobLewis, who is providing necessary information about condi-tions at the disaster site.
The crisis management scenario illustrated a number ofcommon properties for such practices.
1) The use of information technology in crisis manage-ment involvescollaborative problem solvingwithparticipation of both human and machine agents.Compared to the simple information retrieval prob-lems that current multimodal systems are commonlydesigned for, crisis management is comprosed ofcomplex tasks that require multiple phases and stepsin different levels of complexity.
2) The knowledge necessary for deriving a solution isdistributedamong a team of agents who must plan
1330 PROCEEDINGS OF THE IEEE, VOL. 91, NO. 9, SEPTEMBER 2003

and coordinate their actions through communication.(This raises serious challenges in knowledge manage-ment and planning functions of current multimodalsystems).
3) Users direct the operation of the system usingnaturalspoken language and free hand gesturesin ways sim-ilar to communicating with other humans. The contin-uous streams of speech and gesture signals must beanalyzed and interpreted to distill useful informationfrom noisy input.
4) Users’ information requests are expressed in theirtaskdomain vocabularyand are sometimeinseparablefrom their reasoning processabout their goals andmeans.
5) Information dialogues are neither system led nor userled. Instead, they aremixed-initiative, allowing boththe system and users to introduce new goals and toclarify with others.
6) Users’ information requests can be eitherexplicit orimplicit. Implicit requests are harder to recognize andrequire deep reasoning about users’ beliefs and goals.
II. I SSUES INDESIGNING SPEECH-GESTUREDRIVEN
MULTIMODAL INTERFACES
In this section, we outline both the scientific and en-gineering challenges in designing speech–gesture drivenmultimodal interfaces in the context ofcrisis manage-ment. Our main goal is to design a dialogue-enabled HCIsystem for collaborative decision making, command, andcontrol. While traditional interfaces support sequentialand unambiguous input from devices such as keyboardand conventional pointing devices (e.g., mouse, trackpad),speech–gesture driven dialogue-based multimodal interfacesrelax these constraints and typically incorporate a broaderrange of input devices (e.g., spoken language, eye andhead tracking, speech, gesture, pen, touch screen, displays,keypads, pointing devices, and tactile sensors). The abilityto develop a dialogue-based speech–gesture driven interfaceis motivated by the knowledge of the natural integrationpatterns that typify people’s combined use of differentmodalities for natural communications. Recent trends inmultimodal interfaces are inspired by goals to support moretransparent, flexible, efficient, and powerfully expressivemeans of HCI than ever before. Multimodal interfaces areexpected to support a wider range of diverse applications, tobe usable by a broader spectrum of the average population,and to function more reliably under realistic and challengingusage conditions. The mainchallengesrelated to the designof a speech–gesture driven multimodal interface for crisismanagement are:
1) domain and task analysis;2) acquisition of valid multimodal data;3) sensing technologies for multimodal data acquisition;4) detection/localization and tracking of users;5) recognizing users action (i.e., gesture recognition,
speech recognition, etc.);6) a framework to fuse gestures and spoken words;
7) dialogue design;8) semantics;9) usability studies and performance evaluation; and
10) interoperability of devices.We next discuss each of these challenges in some detail.
A. Domain and Task Analysis
Understanding the task domain is essential to makethe challenge of building a natural interface for crisismanagement (or other application domains) a tractableproblem. This is because multimodal signification (throughspeech, gesture, and other modalities) is context depen-dent. The crisis management context provides a particularchallenge for development of integrated speech–gestureinterfaces, since an important component of crisis manage-ment (response) is typically carried out under conditionsof considerable stress. Although there is a growing bodyof research on speech–gesture interfaces to geospatialinformation (usually presented via maps) [5]–[9], littleattention has been directed thus far to specific challengesof developing these interfaces to cope with interaction instressful situations. We believe that an integrated, multi-disciplinary approach is necessary to understanding theill-structured, highly dynamic, collaborative work domainof crisis management for the design of multimodal systems.Without such an approach, we could develop multimodalsystem that meets all usability design requirements and yethave constructed, in fact, the wrong system.
Analysis of thecrisis managementtask is of paramountimportance to develop a dialogue-based natural multimodalinterface system. By studying the work domain, researcherscan create realistic scenarios to conduct user studies withprototype systems. Crisis management often relies upongeospatial information and technologies (e.g., determiningevacuation routes, identifying locations of at-risk facilities,simulating the spread of a toxic gas released by HAZMATfacilities, and others), but only limited research has beendirected to understanding the use of geospatial informationand technologies for decision support [10]–[12]. In addition,traditional problems in usability engineering and HCIinvolve relatively well-defined user tasks. Thus, many ofthe methods developed for user task analysis in typicalHCI domains are inappropriate for task analysis in thecontext of crisis management, where the tasks are oftenill-defined [13]. As a result, analysis of tasks carried outin crisis management, particularly those involving use ofgeospatial information and technologies, requires adaptationof existing methods and development of new methods thatare applicable to analysis of ill-structured decision-makingtasks, often made under stress.
One context in which methods have been developedto address use and usability of technologies designed toenable decision making under crisis-like situations is thedesign of technologies to support military activities (e.g.,command and control, airplane cockpit controls, etc.).Within this context, cognitive systems engineering (CSE)has proven to be an effective methodology for understandingthe task domain and developing interface technologies to
SHARMA et al.: SPEECH–GESTURE DRIVEN MULTIMODAL INTERFACES FOR CRISIS MANAGEMENT 1331

support performance of tasks [14]–[16]. The theoreticalframeworks of distributed cognition [17], activity theory[18], and cognitive ergonomics [19] also have the potentialto help isolate and augment specific elements of the crisismanagement domain for multimodal system design. Weagree with Descortis [19] in that each approach producesspecific results based on the one instance of interpretation,and one should consider scale and needs before settling on asingle framework, making it important to consider a varietyof approaches in designing a collaborative multimodal crisismanagement system.
B. Acquisition of Valid Multimodal Data
An important feature of a natural interface would be theabsence of predefined speech and gesture commands. Theresulting multimodal “language” thus would have to beinterpreted by a computer. While some progress has beenmade in the natural language processing of speech, therehas been very little progress in the understanding of multi-modal HCI [20]. Although, most gestures are closely linkedto speech, they still present meaning in a fundamentallydifferent form from speech. Studies in human-to-humancommunication, psycholinguistics, and others have alreadygenerated a significant body of research on multimodalcommunication. However, they usually consider a differentgranularity of the problem. The patterns from face-to-facecommunication do not automatically transfer over to HCIdue to the “artificial” paradigms of information displays.Hence, the lack of multimodal data, which is required tolearn the multimodal pattern, prior the system buildingcreates so-called chicken-and-egg problem.
One of the solutions is to use Wizard-of-Oz style of experi-ments [21] in which the experimenter interprets user requestsand simulates system response. Zueet al. [22] pointed outthat while an experimenter-in-the-loop paradigm can provideimportant base information from which to build initial pro-totypes, once a prototype is developed, a system-in-the-loopparadigm (“Wizardless”) is preferable, one in which inter-action is with the system acting on its own. It is also im-portant to recognize that the lack of availablesensing tech-nologiesthat would allow sensing ofnatural user behavioris critical in speech–gesture driven multimodal HCI design.In addition, real HCI systems require the designer to viewthose levels from an interaction enabling perspective, e.g.,providing timely and adequate feedback. Use of statisticaltechniques is considered a preferred choice for building suchsystems. We believe that this problem can be solved by con-sidering analogous domain, such as weather narrators on aweather channel, to bootstrap the process. A weather channelprovides a virtually unlimited amount of bimodal data to cap-ture the “natural communication” to build speech–gestureenabled HCI systems. Additionally, this allows one to evolvethe design to develop methodologies for further disambigua-tion and error resolution.
C. Sensing
The role of sensing for multimodal interfaces is to under-stand a user’s queries and commands through speech and
gesture. Key challenges are acquisition and recognition ofspeech for understanding spoken commands in natural set-tings and the acquisition and recognition of gesture actions.
1) Speech Acquisition:Speech acquisition concernedwith capturing verbal commands and queries from the user.Because automatic speech recognition (ASR) systems todate are still very sensitive toward the quality of the capturedspeech signal, speech acquisition is both difficult and crucialfor multimodal interfaces. Three main conceptual approachesto capturing clean human speech signals in the presenceof background noise exist. One approach is to bring themicrophone as close to the speaker as possible. This approachis utilized by headset [23], throat, and lavalier microphones[24]. If this approach is not feasible, one has to either resortto physically directional microphones such as shotgun [25]or parabolic [26] microphones or resort to noise cancellationtechniques. Noise cancellation can be performed by havingone or several additional microphones capture mainly back-ground noise signals or, in an extreme approach, to use anarray of distributed microphones [27], [28].
In general, headset microphones tend to be the best choicein noisy environments but require a user to wear a dedicateddevice. Among long-range approaches, microphone domesseems to be better choice but have the disadvantages of sizeand that the user is in general constrained to interact witha system from a fixed location. In contrast, microphone ar-rays can adaptively capture localized sound signals from ar-bitrary locations in space but tend to have a lower signal-to-noise ratio (SNR), especially in reverberating indoor envi-ronments.
2) Gesture Acquisition:Gesture acquisition is concernedwith the capture of the hand/body motion information inorder to perform subsequent gesture recognition. Gesturesare in general defined as movement of the body or limbs thatexpresses or emphasizes ideas and concept. In the contextof multimodal systems, pen- and touch-based interfaces arealso commonly viewed to fall under the gesture recognitiondomain. However, while for pen- and touch-based systems,gesture acquisition is merely a marginal problem, it requiresconsiderable effort for most other approaches. Aside frompen- and touch-based systems [29], [30], the most commongesture acquisition methods are based on magnetic trackers,cyber-gloves and vision-based approaches. The suitability ofthe different approaches depends on the application domainand the platform. Pen-based approaches [30], [31] are themethod of choice for small mobile devices and are costeffective and reliable. Acquisition using magnetic trackers[21] and/or cyber gloves [32]–[34] is efficient and accuratebut suffers from the constraint of having to wear restrictivedevices. In contrast, vision-based approaches offer entirelycontact-free interaction and are flexible enough to operateon all platforms except the smallest mobile devices.
Using vision-based approaches, direct or indirect mea-surements of a person’s gesticulation have to be acquiredvisually by assuming a parameterized visual model ofthe gesturer [35]. The process by which the parametersof a given model are estimated from video sequences iscalled visual tracking. Tracking is commonly performed
1332 PROCEEDINGS OF THE IEEE, VOL. 91, NO. 9, SEPTEMBER 2003

incrementally by adjusting the model parameters for a givenvideo frame based on the parameters at earlier times, whichimproves the tracking accuracy and speed. However, forthis approach to be feasible, the tracker has to be initializedin a preliminary track initialization stage. Especially forhigh degree-of-freedom (DOF) articulated visual models,this step is inherently difficult to solve and, hence, oftenperformed manually. In the following, different trackingapproaches are discussed in more detail.
D. Detection, Localization, and Tracking of Users
Initialization of the vision component of a multimediasystem can be performed manually, but for convenience andreduced user training requirements, automatic approachesare desirable. Three main problems have to be addressed: 1)user detection; 2) user localization; and 3)track initializa-tion. A simple approach for detecting a user in the camera’sview is to perform foreground–background segmentationand subsequent silhouette analysis of the foreground. Themajor challenge for this approach is the modeling of thebackground in changing environments and the segmentationfor the case of coincidental foreground–background simi-larity. Motion-based approaches offer some improvement,but are computationally more demanding and often workonly under restricted conditions. Stereo systems, which canbe used to obtain depth maps of the environment, are attrac-tive solutions but require additional hardware and need to becarefully calibrated. Face detection algorithms have in recenttimes advanced both in speed and detection performancesuch that they can be utilized even in real-time systems forboth user detection and localization and additional taskssuch as head track verification and gaze estimation [36],[37]. After appropriate initialization one needs to track theperson/body parts over time to understand the gesture.
1) Visual Tracking: Visual tracking is one of the most ac-tively researched fields in computer vision. A thorough dis-cussion of human motion tracking methods is not possiblehere, and the reader is, hence, referred to a number of re-views on this subject [38], [39]. Rather, we will discuss inthis section the challenges that vision-based tracking algo-rithms encounter in the context of multimodal systems andto what degree standard approaches are suitable for differentapplication domains. For multimodal HCI systems, a visualtracking algorithm has to fulfill the following requirements.
1) Real time:A visual tracking algorithm in the HCI do-main has to be able to process incoming video infor-mation at a rate that yields sufficiently sampled motiondata. Rates of 30 frames/s are, in general, necessary.
2) Occlusion: Occlusion is an inherent problem forhuman motion tracking algorithms; for example,when people gesture, they hold their hand in front oftheir body and hands often occlude each other.
3) Visual distractions in background:In unconstrainedenvironments, it cannot be ensured that the user is theonly object or person in the view of the systems. Inaddition to the user, bystanders, furniture, or other ob-jects might be visible, which has to be handled by thetracker.
4) Target size:Visual sensors of an HCI system often cap-ture images of the entire user. The arms, hands, and fin-gers in the video might, therefore, only occupy a smallregion in the video images, making robust trackingchallenging.
5) Visual distractions in foreground:In addition to back-ground distractions, the user himself or herself can bea significant source of distraction to a tracking algo-rithm. For example, when the tracker is designed totrack a person’s hand based on skin color information,the user’s dressing style (short-sleeved shirts) can be asource of distraction.
6) Changing environmental conditions:Visual trackingsystems work best in environments that do not changeover time. For example, the natural diurnal cycle orchanging lighting environments can cause the trackerto fail if these changes are not handled appropriately.
7) Initialization: A visual tracker for HCI systems must,in general, be able to initialize automatically, to per-form its task independent of the person that is beingtracked. This means that no prior information, for ex-ample, about the size or height about a person, can beassumed.
2) Tracking Methods:Visual tracking methods haveunique advantages and disadvantages. In this section, wewill discuss a number of representative approaches andtheir suitability in the context of multimodal HCI. Themost complex target representations are those that involvedetailed models of the target in terms of articulated (skeletal)structure and volumetric shape descriptions of body parts[40]–[46]. These model-based representations are oftenparameterized by three-dimensional (3-D) locations andjoint angles with many DOFs. Model-based approaches areable to recover the 3-D location and pose of a gesticulatingsubject from monocular image sequences if the underlyingmodel is detailed enough. Unfortunately, the evaluation ofthese high DOF models is still prohibitively expensive forreal-time tracking systems.
Other visual tracking approaches assume much nar-rower and incomplete models of the gesticulating person.Feature-based approaches assume that the user’s gesturemovements give rise to image features that can be detectedand used for tracking. Common visual features used arecontours [47]–[49], points [50]–[52], color [53], and motion[54]. Finally, image content itself can directly serve asimage features [55], [56]. Contour-based approaches sufferfrom the requirement that they usually require some formof more detailed model of the target to be tracked. Thismakes the approaches often unsuitable because the inherentnonrigidity of human motion calls for nontrivial contourgenerators (except when shape can be approximated wellby, for example, ellipses, such as for head tracking [57]) andbecause of intraindividual shape variability. Point featuretrackers are able to detect and robustly track salient andstable image features over long periods. Unfortunately, theinteresting body parts of a gesticulating person often showa surprisingly small amount of salient features. Template-and exemplar-based approaches utilize typical snapshots or
SHARMA et al.: SPEECH–GESTURE DRIVEN MULTIMODAL INTERFACES FOR CRISIS MANAGEMENT 1333

representative descriptions of the target in combination withtemplate-to-image correlation to perform visual tracking.These approaches have proven to be good for applicationssuch as head, face, or whole person tracking but suffer ifthe appearance of the target changes over time or the targetis small in size. One of the most widely used approachesto hand tracking is based on color and motion cues. Thehuman skin color is an excellent feature that distinguishesthe human hand and face from other objects in an image. Ifcombined with additional cues such as motion information,robust trackers can be designed.
E. Recognizing User’s Action
The ability to develop a dialogue-based multimodal in-terface system is motivated by the knowledge of how hu-mans naturally integrate different input modes. Integrationof speech and gesture has tangible advantages in the con-text of HCI, especially when coping with the complexities ofspatial representations [58]. Hence, the requirements of thenatural interactive system would include the ability to un-derstand multiple modalities, i.e., speech and gesture whereinformation is somehow distributed across the modalities.
1) Gesture Recognition:Gesture recognition is theprocess of inferring gestures from captured motion data.In human-to-human communication, McNeill [59] dis-tinguishes four major types of gestures—deictic, iconic,metaphoric, and beats—by their relationship to the speech.Deictic gestures are used to direct a listener’s attention toa physical reference in course of a conversation. Iconicand metaphoric gestures are associated with abstract ideas,mostly peculiar to the subjective notions of an individual.Beats serve as gestural marks of speech pace. In a broadcastby a weather channel, the last three categories roughlyconstitute 20% of all the gestures exhibited by the narrators.Hence, when the discourse concerns geocentric data, theuse of deictic gestures is most common [60] and relativelyconsistent in coupling with speech.
The spatio-temporal evolution of different gestures per-formed by the same or two different people, will differ bothin spatial shape as well as temporal properties. Hence, a ges-ture can be viewed as a realization of a stochastic processand modeled appropriately. The stochastic nature of gesturesfoils attempts to perform direct comparisons of gesture tra-jectories, especially due to the time varying differences inspatial and temporal scale. Due to their stochastic nature, it isdifficult to manually find general and representative descrip-tions of spatio-temporal gesture motion patterns. Hence, theusual approach to gesture recognition is based on machinelearning methods. As with ASR, the two main approaches togesture recognition are based on neural networks (NNs) [61]and hidden Markov models (HMMs). The most common andsuccessful approach to dynamic gesture recognition is basedon HMMs [62]–[67]. HMMs model doubly stochastic pro-cesses with a state transition network. States in an HMMnetwork are associated with stochastic observation densities,and transitions are governed by probabilistic rules.
Stochastic observation streams such as gestures are thenviewed to arise from a realized path through the network and
from realized observations emitted at the visited states. Thetraditional state sequence approaches cannot be employed,as one has no easy method of detecting the beginning andend to the gestures embedded in the stream. There are twosolutions to this problem. One approach splits the gesturestream into chunks and applies the previously describedprocedure. However, this splitting operation can causethe gesture stream to be cut in the middle of a gesture.Overlapped splitting addresses this problem, but the fusionof ambiguous recognition results on overlapping segments ischallenging. Another approach operates the state estimationprocedure in a continuous mode by employing a simple yetpowerful approach called token passing [68]. Token passingoperates by maintaining a set of tokens that are copiedand passed around in the compound transition network.As tokens are passed around in the network, transitionsand observation incur costs as negative logarithm of thecorresponding probability values. At each time step, andfor each state, every token associated with the given stateare duplicated according to how many outgoing transitionsexists for the given state. The state transition history ofthe most probable (least cost) tokens is assumed to be thetrue sequence of performed gestures and can be determinedeasily at periodic intervals.
2) Speech Recognition:ASR systems build on threemajor components: a lexicon that contains mappings fromwords to phonemes, a language model that statisticallydescribes the likelihood of word sequences, and an acousticmodel that describes the probability of making certainfeature stream observations given a hypothesized wordsequence [69]. The language model is usually formulatedon the basis of HMMs [62]. These models reflect thedoubly stochastic processes underlying human speech.Using the lexicon, phoneme models are combined intoword models, which in turn are combined into sentencemodels by appropriately connecting HMMs into largerstate transition networks. Using this network representation,speech recognition is performed by determining the mostlikely state transition sequence through this network givenobserved speech features [70].
In commercial speech recognition systems, the end user iscommonly only confronted with the final most probable ut-terances; however, systems internally maintain a whole set ofpossible utterances defined as a confusion network. As thequality of the acquired speech signal deteriorates, obtainedconfusion networks will increase in size (i.e., the number ofparallel word sequences). The goal and advantage of mul-timodal HCI systems is that a plethora of additional infor-mation is available to further disambiguate these hypotheses.Speech recognition systems fall into two major classes: sys-tems that can recognize speech independent of the speakerand systems that are trained to recognize the voice of a spe-cific speaker (speaker dependent). Speaker dependent speechrecognition is much easier in general and hence associatedwith higher recognition rate. However, to make multimodalHCI systems operable under an unconstrained public envi-ronment, where user training is infeasible, speaker-depen-dent systems need to be employed.
1334 PROCEEDINGS OF THE IEEE, VOL. 91, NO. 9, SEPTEMBER 2003

Fig. 3. Architecture for speech–gesture fusion.
F. A Framework for Fusion of Gestures and Speech
The world around us offers continuously huge amountsof information, from which living organisms can elicit theknowledge and understanding they need for survival. By far,there is not a single theory that explains exactly how integra-tion takes place in the brain. Alternatively, instead of tryingto answer the questionhow the integration takes place, onecan arguewhythe integration takes place. There are varietiesof answers to this question. For example, integrating on-line,up-to-date information, which brings different levels of gen-erality and is sensed from a different scope, can give us a keyof how to adapt to the new situation and deal with it.
In Fig. 3, we illustrate the architecture of a possible fu-sion strategy. We believe that a probabilistic evaluation of allpossible speech–gesture combinations promises a better es-timation of users intent than either modality alone. The con-ditional probabilities of observing certain gestures given aspeech utterance will be based on several factors. Speech ut-terances will first have to be analyzed for keyword classessuch as typical deictic keywords (e.g., “this,” “that”). Thesekeywords can then be associated with corresponding deicticgestures. The association needs to take gesture and utterancecomponent classes into consideration and maintain the ap-propriate mapping between speech and gesture components.
Typically, a statistical method is employed for continuousrecognition (hypothesis search on the state transition networkusing token passing [68]), both the speech recognition andgesture recognition systems generate their recognition re-sults with time delays of typically 1 s. Verbal utterances fromthe speech recognition have to be associated with co-occur-ring gestures observed by the gesture recognition. The un-derstanding of the temporal alignment of speech and gestureis crucial in performing this association. While in pen-basedsystems [29], deictic gestures have been shown to occur be-fore the associated keywords, investigations from HCI andWeather Narration [71] showed that for large screen displaysystems, the deictic word occurred during or after the ges-ture in 97% of the cases. Hence, modality fusion should betriggered by the occurrence of verbal commands and, hence,
boils down to the problem of conditionally combining speechand gesture confusion networks.
Once data associations (or set of associations if several arepossible) have been determined, the co-occurrence modulecan determine a final match value between the utterance andthe gesture based on temporal co-occurrence statistics. Thedomain specific data can be used to perform the actual systemtraining to obtain optimal task specific co-occurrence rela-tions between speech and gesture.
G. Dialogue Design
Speech–gesture driven multimodal interfaces to crisismanagement information systems demand careful design ofinformation flow between users and those subsystems thatmanage various knowledge and data sources. The dialoguemanagement component of a crisis management systemtakes inputs from the output of speech and gesture recogni-tion subsystems and plans a strategy to mediate exchange ofmessages between the user and the information sources. Ifa user’s request is clearly stated and sufficient informationwas included, the process of dialogue handling could be“hard-coded” as a serially ordered steps including: 1) un-derstanding the user’s information request and constraints;2) determining whether sufficient information is included inthe request; 3) making requests to external applications; and4) communicating information (returned from an externalapplication) back to the user. However, handling natural,multimodal input from users is rarely so simple.
The hard-coded approach for processing multimodaldialogues may not be working for a number of reasons [72].First, the user’s multimodal input may be misinterpreted ormisunderstood. The system may have errors in recognizingand extracting speech and gesture input, or it may inferincorrectly on the user’s intended actions. Dialogue man-agement must provide adequate verification and groundingmechanism in order to allow misunderstandings to be com-municated and corrected. Second,the user’s input may beill-formed, incomplete, or even incorrect. Instead of simplyreporting these problems back to the user and requesting areformulation of the input, a dialogue manager should assistthe users by suggesting ways to correct or complete theirrequests. Third,there is a need to handle user inputs withflexibility. Flexibilities must be supported not only in thechoices of phrases and gestures, but also in the way theyare structured in an utterance or a dialogue. The dialoguemanager should accept the input in its natural form, andinitiate new dialogue to request any missing information, if itis necessary. Fourth,there is a need to support collaborativeplanning through dialogues. In the dynamic environment ofcrisis management, action plans often needs to be modified,extended, and negotiated by a group of participants in adialogue in response to changes in the state of the world(where and what threats, damages, priorities, resources) andin priorities. Such planning activities should be managed toallow participants of a dialogue to plan their actions throughcollaborative interactions.
To handle all these aspects of dialogues in crisis manage-ment, a dialogue management system must include: 1) more
SHARMA et al.: SPEECH–GESTURE DRIVEN MULTIMODAL INTERFACES FOR CRISIS MANAGEMENT 1335

Fig. 4. Dialogue management for multimodal crisis management systems—a conceptual view.
sophisticated methods for interpreting user’s multimodal in-puts; and 2) more flexible and cooperative dialogue controlstrategies so that sufficient repair, clarification, confirmation,and negotiation capabilities are supported. A high-level goalof dialogue design for crisis management is to support auser’s problem-solving process as it unfolds through the se-quence of communicative interactions.
Dialogue design for multimodal crisis management sys-tems is inherently a multifaceted problem. To facilitate laterdiscussions on various challenging issues of dialogue man-agement, Fig. 4 serves as a framework that lays out multipledesign dimensions and their relationships. It distinguishes anumber of processing tasks as well as the contexts requiredfor these tasks. Next, we will describe the desirable functionsfor each of the components of Fig. 4. Issues of contexts willbe separated and discussed in Section II-H, which focusesmore on the semantic aspects of multimodal system.
1) Understanding of Multimodal Input:As illustrated inFig. 4, the dialogue management system must first analyzethe recognized speech–gesture input and derive a meaning
representation of it. It normally starts with analyzing thesemantic content of each constituent (words, phrases, andgestures) in an input, and then constructing the meaning ofthe whole utterance by combining small semantic fragmentsinto larger chunks. If an input is grammatically correctand semantically self-complete, then the process of inputunderstanding can be handled by grammar-based semanticparsing techniques developed in computational linguistics[73]. However, full parsing of inputs in spontaneous dia-logues is often not possible. Instead, the goal of semanticparsing become the extraction of critical meaning fragmentsthat are to be further analyzed by other interpretation tech-niques, using perhaps high-level knowledge about discoursestructures, user’s focus of attentions, and pragmatics inthe domain. These knowledge sources are external to thecaptured gesture–speech input, and must be explicitlyrepresented in a form usable by the dialogue managementsystem. The input understanding component correspondsroughly to three of those boxes in Fig. 4: semantic parsing,discourse interpretation, and intention recognition.
1336 PROCEEDINGS OF THE IEEE, VOL. 91, NO. 9, SEPTEMBER 2003

a) Semantic Parsing:Semantic parsing takes therecognized words and detects the existence of meaningfulphrases. Common semantic parsing methods include afeature-based semantic grammar approach, robust parsingmethods, and more practical methods involving conceptspotting, each of which is further described later.
Semantic grammar approachesare based on the theoret-ical foundation of computational linguistics [73]. Normally,a feature-based description is used to represent the meaningof grammatical units (words, phrases, and sentence), and uni-fication grammar rules are used to compose meaning of anutterance from the meanings of its parts. This form of se-mantic analysis typically results in meaning represented infirst-order predicate calculus (FOPC). This approach can beinefficient and impractical to handle less well-formed inputdue to the difficulties of handling a large number of potentialdialogue features. For this reason, more robust parsing tech-niques have been developed.
Robust parsingaims at extracting semantic informationfrom ungrammatical input fragments without performing acomplete parse. Robust parsing does not attempt to under-stand every word or phrase—instead, it extracts only thosemeaningful items essential for the communication. This canbe accomplished by some form of feature-based bottom-upparser [73].Concept spottingattempts to extract critical con-cepts using some form of conceptual graph to represent fre-quently observed concept sequences. It has the advantage oflow computational cost, but it might not be able to handlemore complex cases where sophisticated grammatical anal-ysis is necessary to determine the interrelationships amongdisjoint constituents [74].
b) Discourse Interpretation:Some items in an inputare not interpretable out of the previous dialogue context.For example, pronouns (such asthey, it, etc.) and deicticexpressions (such asthese, the last one) usually refer tosome entities that were mentioned previously in the dia-logue; ellipses (clauses that are syntactically incomplete)and anaphors can only be interpreted when consideringsyntactic and semantic structures of previous clauses. Theseissues require that the system keep a record of previouslymentioned items and structures in order to assist interpreta-tion within the context of the previous discourse. A simpleapproach for representing discourse context is to maintain ahistory list of elements mentioned in the previous discourse.To update discourse context, the concepts ofcentering[75]andattentional state[76] are useful.
c) Intention and Belief Recognition:Interpretation ofthe user’s input may also be driven by a set of expectationson what the user will do or say next. One approach for gener-ating such expectations is to construct a model of the user’sintention and belief behind their communicative behavior. Innatural interactions, the system should recognize the reasonor intention that leads the user to make a request and subse-quently use that information to guide the response planningprocess. Recognition of the intention of an input includestwo components: 1) to identify the purpose of the input; and2) to identify how the purpose of this input relates to priorintentions.
2) Response Planning and Generation:The responseplanning and generation phase takes the interpreted inputand formulates proper response for this stage of the dialogue.We will discuss this part of dialogue management in fourcomponents: plan reasoning, information control, mixed-initiative dialogue control, and response content assembly.Although these subcomponents are commonly integrated asone functional component in practical dialogue systems, it isimportant to consider these as separate aspects of dialoguedesign. The separation of these subcomponents allows cleardesign of dialogue functionalities and is perhaps usefulas a guide for systems designed for better portability andextension in order to serve new domains and tasks [72], [77].
a) Plan Reasoning:The plan reasoning module has di-rect access to three knowledge sources: task knowledge (gen-eral ideas of how tasks should be done), user knowledge(what each user knows and works on), and world knowledge(world facts, processes, and events) (as indicated in Fig. 4).It serves two main purposes:
1) to establish the system’s intention and belief; and2) to elaborate the plan on the course of actions for the
task in focus.
When the plan reasoner collects enough information for thesystem to act on retrieving information, it will send an ac-tion item to the information controller with all the necessarydetails. This is represented as link of Fig. 4. Besides gen-erating action items for the dialogue controller and the infor-mation controller, the plan reasoner is also responsible formaintaining the dynamic context such as thetask states, theuser’s mental states, andcollaboration states.
If new obstacles (such as missing information) are discov-ered that require further communication with the user, it willnotify and prepare agenda items to be used by the dialoguecontroller (see link of Fig. 4). The system will also reasonon the set of beliefs held by users and the system and makesure they mesh well. When conflicting beliefs are detected,repair mechanisms will be suggested to the dialogue con-troller and new agenda items are added (see linkof Fig. 4).
b) Information Control: The information control com-ponent is needed to deal with ill-formed queries (to the ex-ternal information sources) that may result in no records ortoo many records being returned. The problem of no recordsreturned can be caused by any vocabulary differences dueto the problems of synonymy (multiple terms describing thesame object) and polyzemy (a single term carrying multiplemeanings) or conceptual differences that the ontology (howthings are categorized and related) imposed by the user onthe modeled world is incompatible with that of the system.Hence, the information control component should have ade-quate capability to report (to the dialogue controller) the rea-sons for why a query failure happens, possibly with sugges-tions on how to restate the query in the next round of userinput. In case that too many irrelevant results are returned to-gether with relevant ones, the system may suggest narrowerterms or add query constraints.
c) Mixed-Initiative Dialogue Control:Human interac-tions with crisis management systems, as exemplified by thescenario of Fig. 1, is inherently mixed-initiative dialogues,
SHARMA et al.: SPEECH–GESTURE DRIVEN MULTIMODAL INTERFACES FOR CRISIS MANAGEMENT 1337

which means that dialogue control is shared among humanand system agents. The user and the system are equally ca-pable of introducing new topics, and are equally responsibleto engage cooperative dialogue with the other participants.The commonly used dialogue control strategies includefi-nite-state-based, frame-based, plan-based, andagent-based(for recent review, see [72]). The choice of control strategyin a dialogue system depends on the complexity of the un-derlying task of a dialogue [77].
The finite-state-based method and the frame-basedmethod cannot support mixed-initiative dialogue due to theirfixed dialogue control structures. Artificial intelligence (AI)planning methods of dialogue management have sufficientmodels of complex task structures, but they require fullaccess to the user’s task schema, which may not be possiblein a group collaboration processes. An agent-based ap-proach uses advanced models of tasks advances, the user’sintentions and beliefs, and implements complex groundingmechanisms to manage the dynamics of collaboration. Thefull complexity of human–system–human interactions incrisis management requires the most powerful, agent-basedapproach to handle mixed-initiative, collaborative planningon complex tasks.
The dialogue control plays a central role in advancing theuser’s tasks while dealing with needs for dialogue repair anderror handling. To detect and correct recognition and under-standing errors, the system must provide adequate mecha-nisms for clarification, verification, and confirmation. Suchmechanisms give the user an opportunity to correct errors.The challenging issue for verification design is to verify suf-ficiently but not too much, since every verification processadds to the lengthy of the overall dialogue. The dialogue con-troller must also be able to buffer and synchronize responsecontents contributed by multiple components (such as the di-alogue controller and the information controller).
H. Semantics
Both the interpretation of multimodal input and thegeneration natural and consistent responses require accessto higher level knowledge. In general, semantics requiredby multimodal systems can be categorized along two di-mensions: general versus task/domain specific, and dynamicversus static, as shown in Table 1. They together provide thenecessary context for deep semantic analysis of multimodalinput, and for maintaining the context of dialogues betweenusers and the system as well as collaborations among mul-tiple users. Some of these semantics are included in Fig. 4as part of static and dynamic contexts.
1) Static Contexts:Static contexts include knowledgethat is manually compiled and stored in knowledge basesbefore an interaction session starts, and they usually donot change during the course of dialogue interactions.Linguistic/semantic knowledgeexists mostly in the formof feature-based grammars that support both syntactic andsemantic analysis of spoken input.Discourse knowledgeincludes knowledge about discourse structures and variousspeech acts.Task knowledgerefers to knowledge about thestructure of tasks in an application domain (e.g., hurricane
Table 1Types of Semantics
response). It should reflect the general problem-solvingmodel of the target domain. In particular, it could describeobjectives (goals, subgoals, and their constraints), solutions(courses of actions), resources (objects, space, and time),and situations (current world status) [77].User knowledgedescribes the general properties of the users in terms ofwhat they known and what they do.World knowledgeis astructured record of relevant entities, processes, and eventsthat have some effects on the dialogue system. Knowing thesituational information about the current world is often theprecondition for setting goals of task-domain actions, andspecial events in the world (flooding) can be used to initiatenew dialogues or interrupt ongoing dialogues.
2) Dynamic Contexts:In contrast to static contexts, dy-namic contexts are data structures that represent the currentstates of the interaction. They serve as a temporary store ofinformation about the task in focus, the user’s beliefs, and thestatus of collaboration. The contents of dynamic contexts aredirectly manipulated by various processing components. Inthe dynamic contexts of Fig. 4,discourse statesare records ofthe currently opened dialogue segments, a history list of men-tioned concepts, current dialogue focus, and current speechact.Task statesrepresent the planning status for the task infocus, and are used by intention recognition and reasoningcomponents.The user’s mental statesare models of the in-dividual user’s beliefs and intentions at any given moment.Collaboration statesare established and communicated be-liefs and commitments that are shared (intended to be shared)among all participants involved in collaboration.
I. Usability Studies and Performance Evaluation
Often, interface refinement and suggestions for im-provements result from feedback obtained during informaldemonstrations to potential users of the system. Shneiderman[78] recommends a more formalized approach for advancedsystem interface design in order to identify the range ofcritical usability concerns. However, a formalized approachfor a multimodal system does not yet exist; therefore, wemust piece together a elements from several approaches anddraw upon a suite of methods for addressing questions aboutindividual and collaborative human work with computersystems. A user-centered evaluation procedure modeled onthat proposed by Gabbardet al., [79] for the design of virtualenvironments has the potential to contribute to the creation ofa more formalized framework for the design of multimodal
1338 PROCEEDINGS OF THE IEEE, VOL. 91, NO. 9, SEPTEMBER 2003

systems. In [79], Gabbardet al.identify four steps including:1) user task analysis; 1) expert guidelines-based evaluation;3) formative user center evaluation; and 4) summative com-parative evaluation. This multistage process can help revealusability concerns early in the design process. In designinga multimodal system, the sooner that real users can interactwith the system and produce real usability data, the easier itwill be to identify key issues of usability.
In addition to a human centered usability testing approach,the CSE design approach can assist early in the develop-ment process by allowing designers to gain a deep under-standing of the underlying work domain. This approach canhelp focus development issues on more specific usabilitytasks within the crisis management work domain that are crit-ical for multimodal design. Crisis management is comprisedof multiple activities and actions that involve distributingand redistributing resources, identifying critical infrastruc-ture, and prioritizing traffic flow along evacuation routes,among others [80]. Here, we consider a simplified interac-tion task that would be used to complete any number of plan-ning, mitigation, response, or recovery activities: the selec-tion of areas on the screen by making a pointing gesture ac-companied by an activation action (e.g., “Select these facil-ities over here.”) This interaction is very similar to that per-formed using current devices; for example, the mouse is usedto move the cursor to where selection is desired, and usuallya mouse button is used to activate it.
One of the problems with multimodal performance evalu-ation studies is that the tasks used to evaluate selections havenot been consistent throughout different studies, making itvery difficult to compare them. The International StandardsOrganization (ISO) has published an emerging standard,ISO 9241, focused onErgonomic design for office workswith visual display terminals (VDT’s). Part 9 of the standard,Requirements for nonkeyboard input devices[81], addressesthe evaluation of performance, comfort and effort. Severalexperimental studies have adopted the recommendation ofthisstandardasabasis forusabilityassessment.Anexample isMacKenzie [82], who has used this strategy to evaluate mice,touch-pads, pens, gyro-pads, and several other input devices.These methods for evaluating performance are based on thework of Fitts [83], who conducted experiments to measure theinformation capacity of human articulations. One can drawupon methods developed to address scientific questions abouthuman perception and cognition, many of which have focusedon map-based displays that are common in crisis managementactivities (see [84]–[86]). Since the results of formativeuser-centered usability evaluation experiments will affectsome technology decisions, it is important to include themfrom the early phases of the system design and development.
Identification of key usability issues is important, but it isalso critical to develop a set of performance metrics to mea-sure the individual usability issues, as well the overall per-formance of the system. The performance metrics shall bedesigned to evaluate both the complete system as well as in-dividual components. At the system level, one can consider atleast two broad stages of evaluation:formativeandsumma-tive. At the formative level, one should consider a prototype
interface with lesser degree of cognitive load (less active, lessadaptive) to elicit more multimodal input from the user. It isalso possible to develop a metric to measure the performanceof a system by relating a grammatical model of multimodalconstructs (most likely in the form subject–action–object) tothe interaction time and errors. The relative subjective dura-tion (RSD) that provides a means for probing the difficultythat users have with performing tasks without requiring thequestioning of users about the difficulty can be another usefulmeasure of the performance of the system.
J. Interoperability of Devices
One of the key aspects of a crisis management system is itscollaborative framework. The system should be able to linkup several regions in the country (or world), and allow collab-orative tasks among people present at remote sites. The com-puting platforms, communication devices, and network con-nectivity vary from location to location. For example, the col-laborators at the crisis management center will be using pow-erful computer systems, large screen displays, and access tothe wealth of databases, like weather and other geographicinformation system (GIS) information, imagery, technical in-formation, on-scene video, digital photography, and other ex-pert information. As in the case of the Domestic EmergencyResponse Information Services (DERIS),1 these databaseswill be accessed by signing into a mission-critical Web-basedapplications with broadband network connectivity (usually,T1). As a sharp contrast, we will have the agents in the field,with low power computing and electronic devices, like per-sonal digital assistants (PDAs) and mobile phones. Theseagents will need to access the same databases, and commu-nicate with other sites through voice, text messaging, ande-mail. In some crisis management situations, it is essential toupload images and videos from the field, allowing the objectsof interest in the field to be viewed by the collaborators. Forexample, a helicopter hovering over the area of disaster mayrelay a video to the operations center. Or a camera mountedon the helmet of a member of a bomb squad should allowfor a real-time feed to the control center, so that they can ad-vise how to defuse the bomb. In Table 2, we illustrate thevariety of people and agents involved in a typical emergencyresponse situation, and the tools and devices that would beused in each of these.
The issue of interoperability across the wide range of de-vices is very critical for a seamless flow of information andcommunication. Hence, it is important to design aunifiedmultimedia applications system(UMAS) that supports mul-tiple devices and platforms (see Table 2). For example, audio,text, and images can be captured from the control centerand sent to the agent in the field operator who can retrievethe message from the Web-based messaging system usinga PDA. Images captured from the field can be sent back tothe control center, or to other platforms, for people to eval-uate the situation. The multimedia engine would enable theserver to handle requests from the entire spectrum of devices(from low-power mobile devices to supercomputers), by pro-cessing and filtering the GIS data set appropriately.
1http://www.niusr.org/XiiProject.htm
SHARMA et al.: SPEECH–GESTURE DRIVEN MULTIMODAL INTERFACES FOR CRISIS MANAGEMENT 1339

Table 2List of People and Agents Involved and the Tools/Devices to Be Used in a CrisisManagement Situation
Fig. 5. Evolution of speech–gesture driven dialogue-enabled HCI systems at Penn State and AIT.
III. EVOLUTION OF SYSTEMS AND IMPLEMENTATION
DETAILS
In this section, first we briefly discuss the state of the artin multimodal systems. Following this, we will discuss theresearch done at Pennsylvania State University and AIT thatled to a series of multimodal interfaces (see Fig. 5), especiallyfocused on free hand gestures and spoken commands.
Integration of speech and gesture has tangible advantagesin the context of HCI, especially when coping with the com-plexities of spatial representations [58]. Combining speech,gesture, and context understanding improves recognitionaccuracy. By integrating speech and gesture recognition,Bolt [21], [87] discovered that neither had to be perfect
provided they converged on the user’s intended meaning.In [88], speech, gesture, and graphics are integrated withan isolated 3-D computer-adided design package. A similarapproach is used in the NASA Virtual Environment Work-station. Another interface integrating speech and graphics isthe Boeing “Talk and Draw” project [89], an AWACS work-station that allows users to direct military air operations.The ALIVE interface developed by [90] is a gesture andfull-body recognition interface that allows users to interactwith autonomous agents in a virtual environment. Thesystem uses contextual information to simplify recognition.
Recently, hand-held computing devices have been gainingpopularity among the users. Their mobility along withusability augmented by pen-based “gestural” input was
1340 PROCEEDINGS OF THE IEEE, VOL. 91, NO. 9, SEPTEMBER 2003

found especially beneficial in interacting with spatiallypresented information, e.g., [91], [92]. Using state-of-the-artspeech recognition, Microsoft’s project MiPad has demon-strated successful combination of speech and pen inputfor interacting with a hand-held computer. Pen modalitywas also successfully applied to index audio recordings forlater retrieval [93]. Since the 1990s QuickSet collaborativesystem [94] that enabled users to create and position entitieson a map with both speech and pen-based gestures, thenew avenues for more effective hand-held HCI have beenopened. Since then, a number of pen-based and hand gestureinterfaces have been designed (cf. [20]). Distinct in theirfunctionality of input and multimodal architecture, all ofthem aimed to achieve easy and intuitive HCI. Because thereare large individual differences in ability and preferenceto use different modes of communication, a multimodalinterface permits the user to exercise selection and controlover how they interact with the computer [95]. In thisrespect, multimodal interfaces have the potential to accom-modate a broader range of users than traditional unimodalinterfaces. Those include different age groups, skill levels,cognitive styles, and temporary disabilities associated witha particular environment. With respect to the functionalityof multimodal input other known pen-based applications,e.g., IBM’s Human-Centric Word Processor [96] and NCR’sField Medic Information System [97] integrate spokenkeywords with the pen-based pointing events. In contrast,QuickSet [94] and Boeing’s Virtual Reality Aircraft Mainte-nance Training Prototype [98] process speech with a limitedvocabulary of symbolic gestures. Except for the Field MedicInformation System, which supports unimodal recognitiononly, these applications have parallel recognition of pen andspoken inputs. Multimodal integration of inputs is achievedlater by semantic-level fusion where keywords usuallyassociated with pen gestures.
The speech–gesture integration framework resulting fromour research is closer to the IBM VizSpace [99] prototypesystem, but differs in terms ofdesign and integration phi-losophyboth in the conceptual and implementation level. Incontrast, associated researchers from Penn State and AIT areaiming at developing multimodal systems that by strict de-sign are able to operate with moderate affordable off-the-shelf hardware. Other systems related to our work are theCompaq’s Smart Kiosk [100] that allows interaction usingvision (i.e., person detection) and touch. MIT has developeda range of prototype systems that combine aspects of visualsensing and speech recognition but in general rely on a largeamount of dedicated hardware and distributed computing onmultiple platforms. Along the same lines, Microsoft’s Ea-syLiving system [101] aims at turning peoples living spaceinto one large multimodal interface, with omnipresence in-teraction between users and their surroundings.
As discussed inSection II, valid multimodal data is oneof the basic design elements of multimodal interfaces. Toaddress this issue, it is of paramount importance to developa computational framework for the acquisition of nonprede-fined gestures. We sought a solution tobootstrapcontinuousgesture recognition (phonemes) through the use of an
analogous domain, which does not require predefinition ofgestures. We refer to it as theweather domain. The weatherdomain is derived from a weather channel on TV that showsa person gesticulating in front of the weather map whilenarrating the weather conditions. A similar set of gesturescan also be used for the display control problem. The naturalgestures in the weather domain were analyzed with the goalof applying the same recognition techniques to the design ofa gesture recognition system for our first system, callediMap[102]. It was developed in 1999 and received significantmedia attention as the first proof-of-concept speech–gestureinterface of its kind [66]. It required manual initializationand calibration and processing on four networked SGI O2workstations.iMap utilized an interactive campus map on alarge display that supported a variety of spatial informationbrowsing tasks using spoken words and free hand gestures.A second system, called Crisis Management (XISM), wascompleted in 2000 and simulated an urban emergencyresponse system for studying speech–gesture interactionunder stressful and time-constrained situations [102]. XISMextended theiMap framework to explore more a dynamicenvironment representative of stressful crisis situations.
The XISM system was the first natural multimodalspeech–gesture interface to run on a single processingplatform holistically addressing various aspects of thehuman computer interface design and development issues.The iMap and XISM systems were developed as part ofthe Federated Laboratory on “Advanced and InteractiveDisplays” funded by the U.S. Army. More recently, under agrant from the National Science Foundation, a system calledDialog Assisted Virtual Environment for Geoinformation(DAVE_G) is being developed for multimodal interactionwith a GIS. The goals of the research are to:
1) develop a cognitive framework for guiding the designof a multimodal collaborative system, with special em-phasis on context modeling, dialogue processing, anderror handling techniques;
2) design and implement robust computational tech-niques for inferring a user’s intent by fusing speech,communicative free hand gestures, pen gestures, gaze,and body movement using computer vision, speechrecognition, and other pattern recognition techniques;
3) produce a formal framework for doing user task anal-ysis in the context of geospatial information technolo-gies applied to crisis management;
4) conduct experimental evaluation to determine causalrelationships between multimodal interface character-istics and user performance and behavior; and
5) demonstrate using the experimental testbeds, to enablea team of participants to conduct a simulated emer-gency response exercise.
In the following sections, we will discuss the XISM andDAVE_G systems.
A. Crisis Management (XISM)—A Simulation Testbed
In this section, we provide an overview of the XISMsystem, which is a research testbed that was developed tostudy the suitability of advanced multimodal interfaces for
SHARMA et al.: SPEECH–GESTURE DRIVEN MULTIMODAL INTERFACES FOR CRISIS MANAGEMENT 1341

Fig. 6. XISM, a multimodal crisis management system.
typical crisis management tasks. The user takes the roleof an emergency center operator and is able to use speechand gesture commands to dispatch emergency vehicles tocrisis locations in a virtual city (see Fig. 6). The operatoris standing at a distance of about 5 ft from the displayin the view of a camera located on top of the unit. Theoperator’s speech commands are captured with a micro-phone-dome hanging from the ceiling above. The operatorhas a bird’s-eye view of the city but has the ability to zoomin on locations (in plan view) to get a more comprehensiveperspective. The goal of the operator is to acknowledgeand attend to incoming emergencies, indicated by animatedemergency symbols and accompanying audible alarmsignals. The speed at which each emergency is attended toultimately determines the final performance of the operator.
Emergencies are resolved by sending appropriate emer-gency vehicles to the crisis locations. For this, the operatorhas to decide which type of units to dispatch and from whichstation to dispatch them. Emergency stations (hospitals, po-lice, and fire stations) are spread throughout the city and havelimited dispatch capacities. The operator has to schedule thedispatch resources appropriately in order to avoid resourcedepletion. Units are dispatched through speech–gesture com-mands such as “Dispatch an ambulance from this station tothat location,” accompanied with an appropriate deictic con-tour gesture.
1) Simulation Parameters:The XISM system allows avariation of many different simulation parameters, whichmakes it possible to expose the operator to a variety ofscenarios. In particular, the task complexity can be increasedby adding resource constraints (more emergencies thanresources) as well as by changing the cognitive load level by
Fig. 7. Overview of the XISM framework.
varying the scale of the scenario (city size, urbanization den-sity, emergency rate) or duration of the simulation. When,due to the size of the city, the displayed information is toodense to perform accurate dispatch actions, the operator canuse speech–gesture commands of the form “Show this regionin more detail” or “ Zoom here” with an accompanying areaor pointing gesture to get a more detailed view.
2) System Components:To capture speech and gesturecommands, the XISM system utilizes a directional micro-phone and a single active camera. A large number of vision(face detection, hand detection, head and hand tracking) andspeech (command recognition, audio feedback) related com-ponents cooperate together under tight resource constraints.In order to minimize network communication overheads andhardware requirements, the system was developed to run ona single processing platform. From a system design perspec-tive smooth and automatic interaction initialization, robustreal-time visual processing and error recovery are very im-portant for the success of advanced interface approaches forcrisis management applications. The XISM system was builtusing a holistic approach, addressing all of the above issues(see Fig. 7) [103].
a) Vision Components:Since all systems are inte-grated onto a single standard PC, the allowable complexityof motion tracking methods is limited.
Face Detection:One of the most important and pow-erful components in the system is the face detector for robustuser detection and continuous head track status verification.The implementation [37] is based on neuronal networks andprovides a very low false positive rate of .
Hand Detection: With the proper camera placementand a suitable skin color model extracted from the faceregion, strong priors can be placed on the potential appear-ance and location of a user’s active hand in the view ofthe camera. The automatic hand detection operates basedon the assumption that the object to be detected is a smallskin colored blob-like region below and slightly off centerwith respect to the users head. In addition, the hand detector
1342 PROCEEDINGS OF THE IEEE, VOL. 91, NO. 9, SEPTEMBER 2003

Fig. 8. State transition model for deictic gestures.
favors but does not rely on the occurrence of motion at thelocation of the hand and integrates evidence over a sequenceof 60 frames. The (time varying) location of the hand is thengiven by the optimal (most probable) hypothesis-connectingpath through the set of frames under consideration. Theprobability of the path depends on the probability of eachhypothesis plus an additional cost associated with the spatialshift in location from one frame to the next. The optimalpath can be found efficiently using dynamic programmingusing the Viterbi algorithm [62].
Head and Hand Tracking:The algorithms for headand face tracking are based on similar but slightly differentapproaches. Both trackers are based on rectangular trackingwindows whose location is continuously adapted usingKalman filters [104] to follow the user’s head and hand.While the head tracker relies solely on skin color image cues,the hand tracker is a continuous version of the hand detectorand is geared toward skin-colored moving objects. Priorknowledge about the human body is utilized for avoidingand resolving conflicts and interference between the headand hand tracks. The tracking methods used are based onsimple imaging cues but are very efficient and require lessthan 15% processing time of a single CPU.
Continuous Gesture Recognition:The main visualinteraction modality is continuous gesture recognition. Weadopt Kendon’s framework [105] by organizing these into ahierarchical structure. He proposed a notion of gestural unit(phrase) that starts at the moment when a limb is lifted awayfrom the body and ends when the limb moves back to theresting position. After extensive analysis of gestures in theWeather domain andiMap [71], [106] we have selected thefollowing strokes:contour, point, andcircle.
Bootstrap and Evolve strategies were used to design thesystem. Based on our experience with examining weathernarration broadcasts, we modeled deictic gestures based ona set of fundamental gesture primitives that pose a min-imal and complete basis for the large-display interactiontasks considered by our applications. The statistical gesturemodel and continuous recognition is based on continuous
observation density HMMs [62] and is described in detailin [107].
The gesture acquisition system yields continuous streamsof observations. Hence, the traditional state sequence ap-proaches cannot be employed, as one has no easy method ofdetecting the beginning and end to the gestures embedded inthe stream. We have implemented the state estimation proce-dure in a continuous mode by employing a simple yet pow-erful approach called token passing [68]. Token passing oper-ates by maintaining a set of tokens that are copied and passedaround in the compound transition network. As tokens arepassed around in the network, transitions and observationincur costs as negative logarithm of the corresponding proba-bility values. At each time step and for each state, every tokenassociated with the given state are duplicated according tohow many outgoing transitions exist for the given state. Eachduplicate is passed along one outgoing transition and the costof this transition is added to the current cost associated withthe given token. In addition, the cost associated with the ob-servation available at this time step is obtained from the targetstate observation density and also added to the current cost ofthe token. Then, for every state, only a number of tokens withthe lowest cost are maintained, while all others are discarded.In addition to this procedure, the state transition history foreach token is maintained. Then, at periodic intervals, the setof tokens that share the most probable history up to a timelocated a certain interval in the past is determined. The statetransition history of these tokens is assumed to be the truesequence of performed gestures. The procedure is then con-tinued after discarding all but the offsprings associated withthis most probable history.
After bootstrapping, refinement of the HMM and therecognition network was performed by “pulling” desiredgestures from a user. The system extracted gesture andspeech data and automatically segmented the thus-obtainedgesture training data. To accommodate the incidental ges-ticulation and pauses in addition to meaningful gestures,garbage and rest models have been added to the compoundnetwork (see Fig. 8).
SHARMA et al.: SPEECH–GESTURE DRIVEN MULTIMODAL INTERFACES FOR CRISIS MANAGEMENT 1343

Fig. 9. Speech gesture modality fusion.
b) Speech Recognition:Speech recognition hasimproved tremendously in recent years and the robustincorporation of this technology in multimodal interfacesis becoming feasible. The XISM system utilizes a speakerdependent voice recognition engine (ViaVoice from IBM)that allows reliable speech acquisition. The set of all pos-sible utterances is defined in a context free grammar withembedded annotations. This allows constraining the nec-essary vocabulary that has to be understood by the systemwhile retaining flexibility in how speech commands can beformulated. The speech recognition module of the systemonly reports time-stamped annotations to the applicationfront end, which is responsible for the modality fusion andcontext maintenance.
3) Modality Fusion: In order to correctly interpret auser’s intent from his or her utterances and gestural motions,the two modalities have to be fused appropriately. Due tothe statistical method employed for continuous recognition,both the speech recognition and gesture recognition systemsemit their recognition results with time delays of typically1 s.
Verbal utterances such as “show methis region inmore detail” taken from a typical geocentric applicationhave to be associated with co-occurring gestures such as“ Preparation Area Gesture Stroke Retraction ”The understanding of the temporal alignment of speech andgesture is crucial in performing this association. While inpen-based systems [29], gesture have been shown to occurbefore the associated deictic word (“this”), our investigationsfrom HCI and Weather Narration [67] showed that for largescreen display systems, the deictic word occurred duringor after the gesture in 97% of the cases. Hence, modalityfusion can reliably be triggered by the occurrence of verbalcommands. The speech recognition system emits streams oftime stamped annotation embedded in the speech grammar;for the previous case one would obtain (see Fig. 9)
ZOOM LOCATION REGION
The annotation “LOCATION” occurring around the timecorresponds to the occurrence of the deictic
keyword “this.” Similarly, the gesture recognition mightreport
PREP AREA RETRACTION
indicating that an area gesture was recognized in the timeinterval [ ].
Using the time stamp of the deictic keyword, a windowedsearch in the gesture recognition result history is performed.
Each past gesture stroke is checked for co-occurrence withappropriate annotations. Given, for example, time stamps[ ] for a gesture stroke, association with a keyword thatoccurred at time is assumed if .Where and are constants determined from trainingdata. This approach allows the occurrence of the keyword ashort time before the gesture and a longer time delay afterthe gesture. Upon a successful association, the physicalcontent of the area gesture, namely, hand trajectory datafor the time interval [ ] is used to obtain the actualgesture conveyed components of the compound speechgesture command. For a detailed description of the systemcomponents, see [26]. The main system tasks were sepa-rated into a set of separate execution threads as shown inFig. 10. Since many of the components run on different timescales (especially the Speech Recognition, Face Detectorand Active Camera), the architecture was designed to takeadvantage of multithreaded parallel execution.
4) Usability Study: This XISM system has been and iscurrently being used for conducting cognitive load studiesin which different aspects of multimodal interaction can bemeasured accurately and compared to traditional and alterna-tive interaction methods under variable but controlled condi-tions. Informal user studies with the crisis management andrelated multimodal applications [108] have shown that 80%of users had successful interaction experiences. In addition,observations revealed that the system behaved according toits specifications in 95% of the cases. The acceptance of theXISM system was high with little or no difficulties in under-standing the “mechanics” of multimodal interaction. Formaluser studies are currently in progress.
B. DAVE_G
This section describes the subsequent HCI systemDAVE_G that takes XISM one step further to accommodatethe need for collaborative work on geospatial data in crisismanagement. Clear disadvantages of current emergencyoperations are the rather long and tedious, and also errorprone interactions with GIS specialists who work in thebackground to produce maps requested by the decisionmakers [109]. In order to overcome those problems, aneffective and natural-to-use interface to GIS is currentlybeing developed that allows the individuals participating incrisis management to utilize natural language and free handgestures as a means of querying GIS, where gestures providemore effective expression of spatial relations (see Fig. 11).
Compared to XISM that can only handle well-structuredcommands, the interface of DAVE_G broadens the spec-trum and complexity of expressible request and interaction
1344 PROCEEDINGS OF THE IEEE, VOL. 91, NO. 9, SEPTEMBER 2003

Fig. 10. Overview of the XISM system architecture. Each of the bold framed boxes constitutesa separate thread of execution.
Fig. 11. DAVE_G prototype: Interaction in the loop with naturalspeech, gesture, and dialogue interface.
patterns tremendously. Therefore, a form of dialogue man-agement is needed to process ill-structured, incomplete,and sometimes incorrect requests. The dialogue manager inDAVE_G is able to understand and guide the user throughthe querying process, and to verify and clarify with the userin case of missing information or recognition errors.
1) Evolution of DAVE_G From XISM:We are usingthe framework for speech–gesture based HCI XISM tobuild upon and extend the single-user interaction interfaceand achieve our goal of a dialogue-assisted, collaborativegroup-work-supporting interface to an intelligent GIS.This task poses several challenges to the existing HCIframework of XISM. One challenge is to extend XISM tosupport simultaneous interactions of multiple people withDAVE_G. Although the XISM framework supports severalcapture zones for multiple-user tracking, this approach hasdisadvantages in computational needs as well as restriction
of the users’ workspace and mobility. Therefore separateactive cameras are used for each user. Similar, instead ofusing only one microphone or a microphone array that isshared by all users, a separate microphone is used for eachuser. Thus, the identity of each user’s gesture and commandcan easily be tracked, which later will be useful in modelinga shared plan within DAVE_G’s dialogue management.
The integration of multiple user requests into one systemthat pursues a common goal raises further challenges to theinitial XISM, in which only one, relatively simple user com-mand had to be associated with one specific action that wasthen carried out by the system. DAVE_G, in contrast, at-tempts to leave behind such a command and control drivenenvironment and reaches for a more natural interface to querygeospatial information. Positioning DAVE_G, dialogues areneither user led nor system led, but rather a mixed initiativecontrolled by both the system and the users in a collabora-tive environment. It allows complex information needs to beincrementally specified by the user while the system can ini-tiate dialogues anytime to request missing information. Thisis important, since the specification of required spatial in-formation can be quite complex, and the input of multiplepeople in several steps might be needed to successfully com-plete a single GIS query. Therefore, the HCI can no longer re-quire the user to issue predefined commands, but needs to beflexible and intelligent enough to allow the user to specify re-quested information incompletely and in collaboration withother users and the system. A description of our initial proto-type version of DAVE_G is given in greater detail in [110].
Fig. 12 shows the system design for the current prototypeof DAVE_G that addresses some of the challenges discussedearlier in this paper. The prototype uses several instances ofspeech and gesture recognition modules from XISM. Thesemodules can be run on distributed systems or on one single
SHARMA et al.: SPEECH–GESTURE DRIVEN MULTIMODAL INTERFACES FOR CRISIS MANAGEMENT 1345

Fig. 12. Components and communication-flow of DAVE_G prototype.
machine as well. Each module recognizes, and interprets ona lower level, user actions and sends recognized phrases andgesture descriptions to an action integration unit, where di-rect feedback information (such as hand positions and rec-ognized utterances) are separated from actual GIS inquiries.While the former is used to give immediate feedback to theuser, the latter is sent to a dialogue management compo-nent that processes user requests, forms queries to the GIS,and engages in a collaborative dialogue with the users. Thedialogue manager is built using an agent-based frameworkthat uses semantic modeling and domain knowledge for col-laborative planning. The following section discuses selectedcomponents of DAVE_G in greater detail.
2) Interpreting User Actions and Designing a MeaningfulDialogue: In order to support such complex user inputsas depicted in the given scenarios at the beginning of thispaper, two challenges must be addressed. One is to achievesatisfactory recognition accuracy and robustness in speechrecognition, which has a direct impact on the overall systemperformance. Second, the semantic analysis and interpreta-tion of the recognized spoken and gestured user inputs hasto be powerful enough for such a broad and complex domainas crisis management. We started out with the speechrecognition engine IBM ViaVoice, which was also used inXISM. Here, the key to accurate performance is a finelytuned context-free grammar that defines syntactical andsemantic correct phrases and sentences that are to be usedin the spoken interaction. The following section describessome of the issues that have to be handled when natural HCIbeyond simple command and control environments makeuse of grammar-based speech recognition.
a) Speech Recognition:The first step in under-standing multimodal input is to recognize meaningfulphrases that help in discourse interpretation and intentionrecognition. Several methods for semantic parsing wasoutlined previously that differ in the degree of structuralconstraints that are posed on accepted input forms. Whilesemantic grammar parsingimposes many constrains onwell-formed input structures (e.g., it does not allow irregular
or spontaneous speech), it does improve overall speechrecognition accuracy compared to loose concept or keywordspotting from unconstrained speech.
Through insight gained from interviews and onsite visita-tions of emergency operations centers (see later), a commonrepresentative structure of most domain user actions couldbe identified. This was used to create an overall speech in-teraction corpus and to define a context-free grammar forDAVE_G. In general, the user might perform one of threeactions:request, reply, or inform. Requesting informationfrom the GIS (e.g., asking for a map) is the most frequentlyused interaction. In cases when the request is ambiguous orcannot completely be understood, the dialogue manager willrespond with a question that prompts the user to providemore information to resolve those ambiguities. A dialogue isachieved if the user replies and allows the dialogue managerto complete the initial request, thus helping to make progresson the current task. The third action a user might perform isto inform, in other words communicate with, the GIS aboutfacts and beliefs that are relevant to the task.
However, the required spectrum of request and commandutterances becomes very complex and modeling all possibleuser inputs is not possible. Based on scenario analysis,a subset of possible request-utterances was chosen. Themost commonly used request can be modeled as:– – – – . A
many times can directly be matched to a type orsequence of GIS queries (e.g., show a layer, select features).The action is applied to an that can be any featureon the map or an attribute of an entity. Each entity canfurther be described by a set of qualifiers like in “all cities”or “this area.” The most complex and challenging part ofthe grammar definition is the description of relations orprepositions that are possible between entities (e.g., “whichwill lay above”).
Since not all combinations of qualifiers, entities, andrelations are meaningful, they are further decomposed intosubclasses, which ideally would only occur together and,thus, preserve the inherent semantic meaning of defined
1346 PROCEEDINGS OF THE IEEE, VOL. 91, NO. 9, SEPTEMBER 2003

Fig. 13. Structural and semantic decomposition according to grammar.
sentences. In practice, however, overlapping, semantically,or even structurally incorrect sentences are still accepted bythe grammar and indeed produced by users. The dialoguemanagement will handle such incorrect phrases or sentencesin an intelligent way, and maintain a meaningful dialogue.
An example of the grammatically structured request lan-guage is depicted with the request “Dave, create a one-milebuffer around the current surge zone layer” in Fig. 13. Theheadings of the nonterminals (light boxes) represent thenonfinal stages and abstract definitions of their containingphrases. Headings of darker, final stage boxes (terminals)represent the actual semantic meaning of their containedwords or phrases. These tags help identifying semanticallyrelated phrases and structures in the interpretation and nat-ural language processing stage of the dialogue managementunit.
b) Semantic Interpretation:By using semantic knowl-edge about supported phrases and sentences directly withinthe speech recognition process, the interpretation of user ac-tions and their matching GIS queries becomes more feasible.The interpretation process of user actions can be hierarchi-cally divided into two levels. The lower level handles thefusion of all input streams and generates individual user re-quests as described in the previous section. The upper levelmakes use of task specific context and domain knowledge togenerate complete and meaningful queries to the GIS data-base, incorporating commands from all users. This level isembedded in a dialogue management unit that resolves am-biguous and conflicting requests and guides the user throughthe querying process.
A mixed-initiative dialogue control in an agent-based ap-proach is chosen that allows for complex communicationsduring problem-solving processes between users and a GIS[111], [112]. The distinctive feature of an agent-based systemis that it offers cooperative and helpful assistance to humansin accomplishing their intended tasks. A so-called GI agentreasons and supports each user’s intentions during collabo-rative work. A database of previous dialogue interaction (di-alogue history) is maintained within the knowledge base fordynamic domain context, in order to use it for the interpreta-
tion of subsequent user inputs. Additionally, the agent knowsabout spatial data availability and knows which proceduresfor data processing and display are valid (static domain con-text). The prototype of DAVE_G is more flexible than tra-ditional master–slave GIS interactions in several ways. First,the prototype allows users to provide partial interaction infor-mation without rejecting the command entirely. Second, thesystem accepts ambiguous commands. In case of unintelli-gible or incorrect commands, the system is able to questionthe user for further clarification. (For example: User: “Showpopulation density.” System: “Please indicate the area anddataset you want. There is population by block level and pop-ulation by county.”)
3) Error Resolution Using Multimodal Fusion:So far,only speech has been discussed as an input modality ofDAVE_G for interacting and communicating with a GIS.Another important source for conveying information (es-pecially geospatial information) are natural hand gestures.The HCI framework applied in XISM allows the recognitionof continuous hand gestures like pointing at a particularlocation and outlining an area of interest. As discussed inSection II, weaknesses of speech recognition can be partiallyresolved by incorporating complementary information formthe gesture cue and vice versa.
Currently, DAVE_G fuses speech and gesture informationon a timely and semantic level to resolve spatial references(e.g., “What is the capacity oftheseshelters?”) in a mannersimilar to that done in XISM. However, in a much richersemantic domain as needed for GIS-enabled collaborativecrisis management, the relation between a selecting gestureand a spoken reference “these” can no longer be resolved bysimple keyword spotting. The meaning of “these” dependson the actual context of discourse and domain. “these” mightrefer to shelters that were already selected in a previous re-quest (e.g., a previous request: “Dave, highlight all facilitiesin this area”) and thus, using discourse knowledge, DAVE_Gis able to make the correct inference about the specificationof “these shelters”. On the other hand, no shelters might havebeen specified earlier in the discourse and, thus, “these” rep-resents an unresolved reference. The system then has two
SHARMA et al.: SPEECH–GESTURE DRIVEN MULTIMODAL INTERFACES FOR CRISIS MANAGEMENT 1347

subsequent options for how to complete the query. It cansearch for available information in other cues (e.g., gestures)or prompt the user to specify missing pieces.
In the first case, DAVE_G has marked“these” as apotential spatial reference and the gesture cue is searched fortimely matching spatial descriptions that can complementthe missing information. Depending on the actual spatialreference, different gesture types are favored over others toclose the semantic gap of a given request. A second sourcefor retrieving missing information is to prompt the user toverbally specify missing information. (For example:“Thefollowing shelters are available: hospitals, schools andhurricane. Please specify which ones you want.”) Such adialogue is initiated if no other information resources areavailable to explain missing parameters for a correct dataquery. Dividing spatial references into such two categoriesis not all exhaustive because in part they also depend on thegiven context. However, it serves as an initial solution anduser studies have to be conducted in order to develop a morerealistic view of how to resolve spatial references outsideand within domain and discourse context.
4) Prototype Design and Usability:The utilization ofsuch a multimodal interface is likely to differ from thestandard mouse and keyboard interface we are used to.Therefore, special attention has to be applied to the designof such a new HCI to generate effective user interfacesfor multiuser applications in the emergency managementdomain. In designing the prototype, we have adopted a CSEapproach that involved incorporating domain experts intothe earliest stages of system design. See [113] and [114]for an overview on CSE and work domain analysis. Thisapproach involved conducting interviews and questionnairesas well as onsite visitations to emergency managementoperations centers.
First, a set of questionnaires was administrated for the do-main and task analysis. The questionnaire was sent out to 12emergency mangers in Florida; Washington, DC; and Penn-sylvania. The objective was to identify GIS-based responseactivities and operations on disaster events. The participantsindicated that a GIS-based emergency response would needto support zoom, pan, buffer, display, and spatial selection ofgeospatial data. The emergency tasks for which these opera-tions were used included transportation support, search andrescue, environmental protection, and firefighting. In a firststep, this allowed us to compile the required GIS function-ality into three categories: data query, viewing, and drawing.
Second, onsite visitations of emergency operations cen-ters helped to assess realistic scenarios, task distributions,and their interconnections [80]. This, in turn, helped to focusthe design of DAVE_G on realistic requirements. In partic-ular, a more specific set of gestures could be identified thatwould be most useful in gathering geospatial information, aswell as clusters of similar articulated actions that helped tobootstrap the dialogue design and the natural language pro-cessing modules.
The current multimodal prototype systems DAVE_G andXISM are still basic in nature and have been developed incontrolled laboratory conditions, with emphasis on the basic
research issues and theoretical foundations they imposeon natural HCI development. The main disadvantage ofthese systems is their limited robustness toward realisticenvironments in which considerable and unpredictablenoise in all input modalities makes their actual applicationimpracticable. Little error recovery has been applied toaccommodate for miss-recognition and interpretation.Whilethe results presented show excellent promise and can beleveraged forbootstrapping purposes, a fundamental changein research direction is neededDuring further developmentsof DAVE_G we will carry out constant validations thatwill guarantee the effectiveness and acceptance of this newinterface design for the emergency management domain. Inparticular, we will conduct usability studies for the currentprototype to gain insight of various interface propertiessuch as naturalness of request utterances, dialogue formand interaction feedback, information presentation andvisualization, ease of hand gestures as a form of spatial inputgeneration, and, last but not least, the overall effectivenesscompared to current interfaces to GIS. Further studies anddevelopments toward a realistic multimodal interface to GISwill be carried out on the basis of our findings in these initialstudies. Ongoing research and long-term research goalsfor DAVE_G as well as multimodal interfaces for crisismanagement in general will be discussed in the followingsection.
IV. FUTURE CHALLENGES
The lack of an integrated system in the real world, whichcan bring together all the agencies involved in emergencyresponse, verifies the technological challenges involved incrisis management. As discussed in the previous section,multimodal human computer interface technologies, per-vasive computing, device interoperability, etc., can addressthese limitations to some extent. In this section, we will dis-cuss our ongoing research efforts and the grand challengesthat need to be addressed to realize a practically feasiblecollaborative crisis management system. We discuss the sci-entific and engineering and practical challenges separatelyin the following sections.
A. Scientific Challenges
To develop a natural collaborative system for crisis man-agement, we believe that the following scientific challengesneed to be addressed in the system design:
1) development of cognitive and linguistic theories tosupport collaborative system design;
2) real-time sensing, automatic initialization, andtracking/management of multiple users;
3) multimodal fusion (i.e., to improve the recognition andto deal with inexact information);
4) semantic framework for multimodal and multiuser col-laboration; and
5) usability study as well as performance metrics.Next, we discuss each of them in detail.
1) Cognitive and Linguistic Theories:A few impor-tant steps in realizing a collaborative crisis management
1348 PROCEEDINGS OF THE IEEE, VOL. 91, NO. 9, SEPTEMBER 2003

system are the development of cognitive theories to guidemultimodal system design and the development of effec-tive natural language understanding, dialogue processing,and error handling techniques. Here, we believe an in-terdisciplinary approach (including, but not limited to,CSE, distributed cognition, activity theory, and cognitiveergonomics) to learning about the work domain will assistin the development of multimodal design guidelines. More-over, the use of realistic crisis management scenarios derivedfrom work domain analyses will be critical to designingbetter computer vision, gesture recognition and dialoguemanagement algorithms. Such scenarios can help assist inthe creation of usability standards and performance metricsfor multimodal systems.
2) Real-Time Sensing:Automatic initialization andtracking multiple people is a key challenge for collaborativeHCI system design. The most desirable properties of a visualhand and arm tracking system are robustness even in thepresence of rapid motion, the ability to track multiple handsor users simultaneously, and the ability to extract 3-D in-formation such as pointing direction while still maintainingreal-time performance and the initialization capability.When tracking multiple people robustly in an unconstrainedenvironment, data association and uncertainty is a majorproblem. Recently, we have been researching to developa framework using a multiple-hypotheses tracking (MHT)algorithm to track multiple people in real-world scenes(see [115] for details). We are also developing a statisticalframework to deal with data association and uncertaintyproblems associated with multiple people collaborating insame place.
3) A Framework for Multimodal Fusion:A generalframework for multimodal fusion is crucial in designinga robust collaborative HCI system. The key would betoconsider each of the input modalities in terms of the others,rather than separately. In this section, we outline futuredirections in gesture recognition and speech recognition
a) Speech Recognition:The speech recognition soft-ware currently used in our existing systems (e.g., XISM andDAVE_G) is IBM ViaVoice, which is speaker dependent andneeds to be trained for individual users. Hence, it would beuseful to experiment with other speech recognition products.One speaker independent product is Nuance, which supports26 different languages with dynamic language detection inreal time. Nuance reports a recognition accuracy of 96% ina clean environment. However, environments such as a crisismanagement usually involve variable noise levels, social in-terchange, multitasking and interruption of tasks,Lombardeffect, accent effects, etc. All these effects combined can leadto a 20%-50% drop in speech recognition accuracy. Thus, anaudiovisual fusion framework for signal enhancement usinggaze detection, blind source separation, and filtering will im-prove the quality of the speech signal significantly.
Two key issues in developing continuous speech recog-nition and automated speech understanding (ASU) systemsare thedisambiguationof word hypotheses and the abilityto segmentstreams of speech data into appropriate phrases.The incorporation of prosodic features in speech recognition
and ASU has led to significant improvements in recognitionaccuracy. Furthermore, prosodic information can also helpspeed up the recognition process, since with the incorpora-tion of prosodic cues one can significantly reduce the searchspace. We are researching to develop a new framework thatwill help to improve continuous speech recognition.
b) Gesture Recognition:The state of the art incontinuous gesture recognitionis still far from meeting“naturalness.” Despite recent advances in vision-basedgesture recognition its application remains largely limited topredefined gestures due to a low recognition rates for “nat-ural” gesticulation. It is widely perceived that multimodalcoanalysis of visual gesture and speech signals provide anattractive means of improving continuous gesture recogni-tion. We believe prosodic manifestations can be consideredas a basis for coanalyzing loosely coupled meaningful handmovement (phases of gesture) and speech signals. We areexploring a set of prosodic features for coanalysis of handkinematics and spoken prosody to improve recognition ofnatural spontaneous gesticulation. We consider coanalysisbased on both physiological and articulation phenomenaof gesture and speech production. Although it is difficultto formulate two different analyses that uniquely addresseach phenomenon, we assume that physiological con-straints of coverbal production are manifested when rawacoustic correlate of pitch ( ) is used for a feature-basedcoanalysis. In contrast, coarticulation analysis utilizesnotion of co-occurrence with prosodically prominent speechsegments.
4) Semantic Frameworks for Multimodal, MultiuserCollaboration: Collaborative problem solving in crisismanagement requires the fusion of gesture–speech inputsfrom multiple participants and maintain a semantic modelof collaboration in advancing tasks. Simple grammar-basedsemantic analysis is extremely inadequate. Plan-basedapproaches seem to be more appropriate modeling thedialogue phenomena in dynamic crisis management context.AI-planning methods use complex plan recognition andplan completion techniques to generate interactive systembehavior. However, traditional models based on single agentplans are not sufficient for modeling multiagent dialogues.A fruitful direction is to model collaborative dialoguesusingan agent-based approachwhere more explicit modelsof a user’s belief, a user’s task structure, related worldevents, and their interactions are maintained. In the currentDAVE_G system development, we are working on devel-oping a framework for dialogue management in multimodal,multiuser interactions with critical geospatial informationsources.
5) Usability Study and Performance Metric:Sophisti-cated methods for formal experimental evaluation are quitecrucial to determine causal relationships between interfacecharacteristic and user performance/ behavior. A seriouseffort is needed to measure the performance of speech–ges-ture driven multimodal crisis management systems. Whilesome researchers have focused on specific usability aspectsof multimodal design (e.g., [116]), researchers have not yetaddressed the range of issues important to the creation of a
SHARMA et al.: SPEECH–GESTURE DRIVEN MULTIMODAL INTERFACES FOR CRISIS MANAGEMENT 1349

working multimodal crisis management system. We believethat the traditional usability issues in interface design willneed to be expanded and adapted for multimodal systemdesign. Moreover, usability frameworks and performancemetrics for testing usability issues in multimodal systemsmust be established.
B. Engineering and Other Practical Challenges
Apart from the previously discussed scientific challenges,there are engineering issues that may help in system design.
1) Task-specific system:It is important to develop a fullyintegrated task-specific system that takes into accountthe multilevel users’ studies along with considerationof all possible aspects of a systems interaction cycleand integration issues (static and dynamic synchro-nization) to build innovative applications. Tools devel-oped in a task-specific system can be extended for gen-eral system design.
2) Framework for characterizing multimodal interaction:There should be a formal framework for characterizingand assessing various aspects of multimodal interac-tion, for example, the complementarities, assignment,redundancy, and equivalence that may occur betweenthe interaction techniques available in a multimodaluser interface.
3) Fusion and fission:Novel aspects of interactions mustbe considered, such as the fusion and fission of infor-mation, and the nature of temporal constraints on theinteractions. Fusion refers to the combination of sev-eral chunks of information to form new chunks, andfission refers to the decomposition phenomenon. Asfor fission, it may be the case that information comingfrom a single input channel or from a single contextneeds to be decomposed in order to be understood at ahigher level of abstraction.
4) Data Acquisition: During a crisis, the situation isalways in flux. A changing situation not only requirescontinuous reevaluation of rescue and response pri-orities, but also increases potential risk for rescueworkers. Hence, pervasive sensing technologies thatwould enable nonhuman monitoring of shifting,dangerous situations can play a key role. Such sensorscontinuously gather data with preplaced sensorscapable of wireless data transmission, eliminating theneed for humans to gather data.
5) Interoperability of devices:The issue of interoper-ability across the wide range of devices is very criticalfor a seamless flow of information and communica-tion. The wide range of devices, along with the specialneeds for the graphical user interface and the datahandling capability, as well as the bandwidth require-ments of these devices, creates a challenge for themultimedia engine in the interoperability architecture.
V. CONCLUSION
This paper discusses the potential role of multimodalspeech–gesture interfaces in addressing some of the crit-
ical needs in crisis management. Speech–gesture driveninterfaces can enable dialogue-assisted information access,easing the need for user training by hiding the complextechnologies underlying information systems used in crisismanagement. Further, such interfaces can support collabora-tive work that is a fundamental aspect of crisis management.However, there are many challenges that need to be ad-dressed before multimodal interfaces can be successfullyused for crisis management. This paper discusses both thechallenges as well as the progress to date. It describes theevolution of two implemented prototype systems, namely,XISM and DAVE_G, developed as a cooperative effort be-tween Penn State and Advanced Interface Technologies, Inc.Experiments with these systems reinforce the great potentialof speech–gesture driven systems for crisis management aswell as other collaborative work.
REFERENCES
[1] S. L. Oviatt, “Mutual disambiguation of recognition errors in a multi-modal architecture,” inProc. Conf. Human Factors Computing Sys-tems (CHI’99), 1999, pp. 576–583.
[2] S. L. Oviatt, J. Bernard, and G. Levow, “Linguistic adaptationduring error resolution with spoken and multimodal systems,”Lang. Speech, vol. 41, pp. 415–438, 1999.
[3] A. Rudnicky and A. Hauptmann, “Multimodal interactions in speechsystems,” inMultimedia Interface Design, M. Blattner and R. Dan-nenberg, Eds. New York: ACM, 1992, pp. 147–172.
[4] S. L. Oviatt, “Ten myths of multimodal interaction,”Commun. ACM,vol. 42, pp. 74–81, 1999.
[5] P. R. Cohen, M. Johnston, D. McGee, S. Oviatt, J. Pittman, I. Smith,L. Chen, and J. Clow, “Quickset: Multimodal interaction for dis-tributed applications,” inProc. 5th Int. Multimedia Conf. (Multi-media ’97), 1997, pp. 31–40.
[6] M. J. Egenhofer, “Query processing in spatial-query-by-sketch,”J.Vis. Lang. Comput., vol. 8, pp. 403–424, 1997.
[7] R. Sharma, V. I. Pavlovíc, T. S. Huang, Z. Lo, S. Chu, Y. Zhao, M.Zeller, J. C. Phillips, and K. Schulten, “Speech/gesture interface toa visual-computing environment,”IEEE Comput. Graph. Appl., vol.20, pp. 29–37, Mar.–Apr. 2000.
[8] G. Fischer, “Articulating the task at hand by making informationrelevant to it,”Human-Comput. Interact. (Special Issue on Context-Aware Computing), vol. 16, pp. 243–256, 2001.
[9] D. R. McGee, P. R. Cohen, R. M. Wesson, and S. Horman, “Com-paring paper and tangible, multimodal tools,” presented at theSIGCHI Conf. Human Factors in Computing Systems: Changingour World, Changing Ourselves, Minneapolis, MN, 2002.
[10] C. Davies and D. Medyckyj-Scott, “GIS users observed,”Int. J. Ge-ograph. Inf. Syst., vol. 10, pp. 363–384, 1996.
[11] B. Buttenfield, “Usability evaluation of digital libraries,”Sci.Technol. Libr., vol. 17, pp. 39–59, 1999.
[12] P. Jankowski and T. Nyerges, “GIS-supported collaborative deci-sion-making: Results of an experiment,”Ann. Assoc. Amer. Geog-raphers, vol. 91, pp. 48–70, 2001.
[13] M. P. Armstrong, “Requirements for the development of GIS-basedgroup decision-support systems,”J. Amer. Soc. Inf. Sci., vol. 45, pp.669–677, 1994.
[14] C. Stary and M. F. Peschl, “Representation still matters: Cognitiveengineering and user interface design,”Behav. Inf. Technology, vol.17, pp. 338–360, 1998.
[15] M. D. McNeese, “Discovering how cognitive systems should beengineered for aviation domains: A developmental look at work,research, and practice,” inCognitive Systems Engineering in Mil-itary Aviation Environments: Avoiding Cogminutia Fragmentosa,M. Vidulich, Ed. Wright-Patterson Air Force Base, OH: HSIACPress, 2001.
[16] M. D. McNeese and M. A. Vidulich,Cognitive Systems Engineeringin Military Aviation Environments: Avoiding Cogminutia Fragmen-tosa!. Wright-Patterson AFB, OH: Human Systems InformationAnalysis Center, 2002.
[17] E. Hutchins, “How a cockpit remembers its speeds,”Cogn. Sci., vol.19, pp. 265–288, 1995.
1350 PROCEEDINGS OF THE IEEE, VOL. 91, NO. 9, SEPTEMBER 2003

[18] B. A. Nardic, Context and Consciousness: Activity Theory andHuman Computer Interaction. Cambridge, MA: MIT Press, 1996.
[19] F. Descortis, S. Noirfalise, and B. Saudelli, “Activity theory, cogni-tive ergonomics and distributed cognition: Three views of a transportcompany,”Int. J. Human-Comput. Stud., vol. 53, pp. 5–33, 2000.
[20] R. Sharma, V. I. Pavlovic, and T. S. Huang, “Toward multimodalhuman-computer interface,”Proc. IEEE, vol. 86, pp. 853–869, May1998.
[21] R. Bolt, “Put-that-there: Voice and gesture at the graphics interface,”Comput. Graph., vol. 14, pp. 262–270, 1980.
[22] V. W. Zue and G. J. R. , “Conversational interfaces: Advances andchallenges,”Proc. IEEE, vol. 88, pp. 1166–1180, Aug. 2000.
[23] L. B. Larsen, M. D. Jensen, and W. K. Vodzi, “Multi modal userinteraction in an automatic pool trainer,” presented at the 4th Int.Conf. Multimodal Interfaces (ICMI), Pittsburgh, PA, 2002.
[24] B. Clarkson, N. Sawhney, and A. Pentland, “Auditory context aware-ness via wearable computing,” presented at the Workshops Percep-tual/Perceptive User Interfaces (PUI), Banff, AB, Canada, 1997.
[25] P. Kakumanu, R. Gutierrez-Osuna, A. Esposito, R. Bryll, A. Gosh-tasby, and O. N. Garcia, “Speech driven facial animation,” presentedat the Workshops Perceptual/Perceptive User Interfaces (PUI), Or-lando, FL, 2001.
[26] N. Krahnstoever, E. Schapira, S. Kettebekov, and R. Sharma, “Multi-modal human computer interaction for crisis management systems,”presented at the IEEE Workshop Applications Computer Vision, Or-lando, FL, 2002.
[27] K. Wilson, V. Rangarajan, N. Checka, and T. Darrell, “Audiovisualarrays for untethered spoken interfaces,” presented at the 4th Int.Conf. Multimodal Interfaces (ICMI), Pittsburgh, PA, 2002.
[28] H. F. Silverman, W. R. Patterson, and J. L. Flanagan, “The hugemicrophone array,”IEEE Concurrency, pp. 36–46, Oct.–Dec. 1998.
[29] S. L. Oviatt and R. vanGent, “Error resolution during multimodalhuman -computer interaction,” presented at the Int. Conf. SpokenLanguage Processing, Philadelphia, PA, 1996.
[30] S. Chatty and P. Lecoanet, “Pen computing for air traffic control,”presented at the Conf. Human Factors Computing Systems (CHI 96),Vancouver, BC, Canada, 1996.
[31] A. Meyer, “PEN COMPUTING—a technology overview and a vi-sion,” ACM SIGCHI Bull., vol. 27, no. 3, pp. 46–90, July 1995.
[32] K. Böhm, W. Broll, and M. Sokolewicz, “Dynamic gesture recog-nition using neural Networks; A fundament for advanced interac-tion construction,” presented at the IS&T/SPIE’s Symp. ElectronicImaging: Science & Technology 1994 (EI 94), San José, CA, 1994.
[33] D. L. Quam, “Gesture recognition with a DataGlove,”Proc. 1990IEEE National Aerospace and Electronics Conf., vol. 2.
[34] C. Wang and D. J. Cannon, “A virtual end-effector pointing systemin point-and-direct robotics for inspection of surface flaws using aneural network based skeleton transform,”Proc. IEEE Int. Conf.Robotics and Automation, vol. 3, pp. 784–789, 1993.
[35] V. I. Pavlovic, R. Sharma, and T. S. Huang, “Visual interpretationof hand gestures for human-computer interaction: A review,”IEEETrans. Pattern Anal. Machine Intell., vol. 19, pp. 677–695, July1997.
[36] Z. Zhang, L. Zhu, S. Z. Li, and H. Zhang, “Real-time multi-view facedetection,” presented at the Int. Conf. Automatic Face and GestureRecognition, Washington, DC, 2002.
[37] M. Yeasin and Y. Kuniyoshi, “Detecting and tracking human faceusing a space-varying sensor and an active head,” presented at theConf. Computer Vision and Pattern Recognition, Hilton Head, SC,2000.
[38] D. M. Gavrila, “The visual analysis of human movement: A survey,”Comput. Vis. Image Understand., vol. 73, pp. 82–98, 1999.
[39] T. B. Moeslund and E. Granum, “A survey of computer vision-basedhuman motion capture,”Comput. Vis. Image Understand., vol. 81,pp. 231–268, 2001.
[40] J. O’Rourke and B. U. Badler, “Model-based image analysis ofhuman motion using constraint propagation,”IEEE Trans. PatternAnal. Machine Intell., vol. PAMI-6, pp. 522–536, Nov. 1980.
[41] D. D. Morris and J. M. Rehg, “Singularity analysis for articulatedobject tracking,” presented at the IEEE Conf. Computer Vision andPattern Recognition, Santa Barbara, CA, 1998.
[42] C. Bregler and J. Malik, “Tracking people with twists and exponen-tial maps,” inProc. IEEE Conf. Computer Vision and Pattern Recog-nition, 1998, pp. 239–245.
[43] H. Sidenbladh and M. J. Black, “Learning image statistics forBayesian tracking,” inProc. IEEE Int. Conf. Computer Vision, vol.2, 2001, pp. 709–716.
[44] I. A. Kakadiaris and D. Metaxas, “Model-based estimation of 3Dhuman motion with occlusion based on active multi-viewpoint se-lection,” in Proc. IEEE Computer Vision and Pattern RecognitionConf., 1996, pp. 81–87.
[45] T. Drummond and R. Cipolla, “Real-time tracking of highlyarticulated structures in the presence of noisy measurements,”presented at the Int. Conf. Computer Vision, Vancouver, BC,Canada, 2001.
[46] N. R. Howe, M. E. Leventon, and W. T. Freeman, “Bayesian recon-struction of 3D human motion from a single-camera video,”Adv.Neural Inf. Process. Syst., vol. 12, Nov. 1999.
[47] M. Kass and A. Witkin, “Snakes: Active contour models,”Int. J.Comput. Vis., vol. 1, no. 4, pp. 321–331, 1987.
[48] A. Blake, B. Bascle, M. Isard, and J. MacCormick, “Statisticalmodels of visual shape and motion,” Phil. Trans. R. Soc. Lond. A,vol. 356, pp. 1283–1302, 1998, to be published.
[49] M. Isard and A. Blake, “CONDENSATION—conditional densitypropagation for visualtracking,”Int. J. Comput. Vis., vol. 29, pp.5–28, 1998.
[50] Q. Zheng and R. Chellappa, “Automatic feature point extraction andtracking in image sequences for arbitrary camera motion,”Int. J.Comput. Vis., vol. 15, pp. 31–76, 1995.
[51] C. Tomasi and T. Kanade, “Detection and tracking of point features,”School Comput. Sci., Carnegie Mellon Univ., Pittsburgh, PA, Tech.Rep. CMU-CS-91–132, 1991.
[52] H. Jin, P. Favaro, and S. Soatto, “Real-time feature tracking andoutlier rejection with changes in illumination,” presented at the Int.Conf. Computer Vision, Vancouver, BC, Canada, 2001.
[53] H. Stern and B. Efros, “Adaptive color space switching for facetracking in multi-colored lighting environments,” presented at theInt. Conf. Automatic Face and Gesture Recognition, Washington,DC, 2002.
[54] A. Wu, M. Sha, and N. d. V. Lobo, “A virtual 3D blackboard: 3Dfinger tracking using a single camera,” inProc. 4th IEEE Int. Conf.Automatic Face and Gesture Recognition, 2000, pp. 536–542.
[55] M. J. Black and A. Jepson, “Eigen tracking: Robust matching andtracking of an articulated objects using a view based representa-tion’,” presented at the 4th Eur. Conf. Computer Vision (ECCV’96),Part I, Cambridge, U.K., 1996.
[56] A. Lipton, H. Fujiyoshi, and R. Patil, “Moving target classificationand tracking from real-time video,” inProc. 4th IEEE Workshop Ap-plications Computer Vision (WACV ’98), 1998, pp. 8–14.
[57] S. Birchfield, “Elliptical head tracking using intensity gradients andcolor histograms,” inProc. IEEE Conf. Computer Vision and PatternRecognition, 1998, pp. 232–237.
[58] V. I. Pavlovic, R. Sharma, and T. S. Huang, “Visual interpretationof hand gestures for human-computer interaction: A review,”IEEETrans. Pattern Anal. Machine Intell., vol. 7, pp. 677–695 , July1997.
[59] D. McNeill, Hand and Mind. Chicago, IL: Univ. of Chicago Press,1992.
[60] S. Kettebekov and R. Sharma, “Understanding gestures in a multi-modal human computer interaction,”Int. J. Artif. Intell. Tools, vol.9, pp. 205–224, Sept. 2000.
[61] K. Murakami, H. Taguchi, S. P. Robertson, G. M. Olson, and J. S.Olson, “Gesture recognition using recurrent neural networks,”Proc.CHI, Human Factors in Computing Systems, Reaching ThroughTechnology, pp. 237–242, 1991.
[62] L. R. Rabiner, “A tutorial on hidden Markov models and selected ap-plications in speech recognition,”Proc. IEEE, vol. 77, pp. 257–286,Feb. 1989.
[63] T. E. Starner and A. Pentland, “Visual recognition of American signlanguage using hidden Markov models,” inInt. Workshop AutomaticFace and Gesture Recognition, 1995, pp. 189–194.
[64] M. Assan and K. Grobel, “Video based sign language recognitionusing hidden Markov models,” presented at the Gesture and SignLanguage in Human-Computer Interaction, Intl. Gesture Workshop,Bielfeld, Germany, 1997.
[65] A. Wilson and A. Bobick, “Parametric hidden Markov models forgesture recognition,”IEEE Trans. Pattern Anal. Machine Intell., vol.21, pp. 884–900, Sept. 1999.
SHARMA et al.: SPEECH–GESTURE DRIVEN MULTIMODAL INTERFACES FOR CRISIS MANAGEMENT 1351

[66] R. Sharma, I. Poddar, E. Ozyildiz, S. Kettebekov, H. Kim, and T. S.Huang, “Toward interpretation of natural speech/gesture for spatialplanning on a virtual map,” inProc. Advanced Display FederatedLaboratory Symposium, 1999, pp. 35–39.
[67] I. Poddar, Y. Sethi, E. Ozyildiz, and R. Sharma, “Toward naturalgesture/speech HCI: A case study of weather narration,” inProc.Workshop Perceptual User Interfaces (PUI98), 1998, pp. 1–6.
[68] S. J. Young, N. H. Rusell, and J. H. S. Thornton. (1989) Tokenpassing: A conceptual model for connected speech recognition. [On-line]. Available: ftp://svr-ftp.eng.cam.ac.uk
[69] M. Padmanabhan and M. Picheny, “Large-vocabulary speech recog-nition algorithms,”IEEE Computer, vol. 35, pp. 42–50, Apr. 2002.
[70] S. Young, J. Odell, D. Ollason, V. Valtchev, and P. Woodland,TheHTK Book, HTK Version 2.1 ed. Cambridge, U.K.: Entropic Ltd.,1995.
[71] R. Sharma, J. Cai, S. Chakravarthy, I. Poddar, and Y. Sethi, “Ex-ploiting speech/gesture co-occurrence for improving continuousgesture recognition in weather narration,” presented at the Int. Conf.Face and Gesture Recognition (FG’2000), Grenoble, France, 2000.
[72] M. F. McTear, “Spoken dialogue technology: Enabling the conver-sational user interface,”ACM Comput. Surv., vol. 34, pp. 90–169,2002.
[73] J. Allen, Natural Language Processing, 2nd ed. Redwood, CA:Benjamin Cummings, 1995.
[74] R. C. Moore, “Integration of speech and natural language under-standing,” inVoice Communication Between Humans and Machines,J. Wilpon, Ed. Washington, DC: National Academy Press, 1995,pp. 254–271.
[75] B. J. Grosz, A. K. Joshi, and S. Weinstein, “Providing a unifiedaccount of definite noun phrases in discourse,” presented at the 21stAnnu. Meeting Association Computational Linguistics, Boston,MA, 1983.
[76] B. J. Grosz and C. L. Sidner, “Attention, intentions, and the structureof discourse,”Comput. Linguist., vol. 12, pp. 175–204, 1986.
[77] J. Allen, D. Byron, M. Dzikovska, G. Ferguson, L. Galescu, andA. Stent, “Toward conversational human-computer interaction,”AIMag., vol. 22, pp. 27–37, 2001.
[78] B. Shneiderman,Designing the User Interface: Strategies for Ef-fective Human-Computer Interaction, 3rd ed. Reading, MA: Ad-dison-Wesley, 1998.
[79] J. L. Gabbard, D. Hix, and J. E. S. II, “User-centered design andevaluation of virtual environments,”IEEE Comput. Graph. Appl.,vol. 19, pp. 51–59, Nov./Dec. 1999.
[80] I. Brewer, “Cognitive systems engineering and GIscience: Lessonslearned from a work domain analysis for the design of a collabo-rative, multomodal emergency management GIS,” presented at theGIScience Conf., Boulder, CO, 2002.
[81] “Ergonomic requirements for office work with visual displayterminals (VDT’s), Part 9: Requirements for non-keyboard inputdevices (ISO 9241–9),” Int. Org. Standardization, Rep. ISO/TC159/SC4/WG3 N147, 1998.
[82] I. S. MacKenzie and A. Oniszczak, “A comparison of three selec-tion techniques for touchpads,” in ACM Conf. Human Factors Com-puting Systems (CHI ’98), 1998, pp. 336–343.
[83] P. M. Fitts, “The information capacity of human motor system incontrolling the amplitude of movement,”J. Exp. Psychol., vol. 47,pp. 381–391, 1954.
[84] T. A. Slocum, C. Blok, B. Jiang, A. Koussoulakou, D. R. Montello, S.Fuhrmann, and N. R. Hedley, “Cognitive and usability issues in geo-visualization,”Cartograph. Geograph. Inf. Sci., vol. 28, pp. 61–75,2001.
[85] A. M. MacEachren, “Cartography and GIS: Facilitating collabora-tion,” Prog. Human Geograph., vol. 24, pp. 445–456, 2000.
[86] , How Maps Work: Representation, Visualization and De-sign. New York: Guilford, 1995.
[87] R. A. Bolt, “Conversing with computers,” inHuman-Computer In-teraction: A Multidisciplinary Approach, R. M. Braeker and A. S.Buxton, Eds. San Mateo, CA: Morgan Kaufmann, 1987.
[88] D. Weimer and S. K. Ganapathy, “A synthetic visual environmentwith hand gesturing and voice input,” inProc. Human Factors Com-puting Systems (CHI’89), 1989, pp. 235–240.
[89] M. W. Salisbury, J. H. Hendrickson, T. L. Lammers, C. M. Fu, andS. A. , “Talk and draw: Bundling speech and grpahics,”Computer,vol. 23, pp. 59–65, 1990.
[90] P. Maes, T. Darrell, B. Blumberg, and A. Pentland, “The ALIVEsystem: Fullbody interaction with autonomous agents,” presented atthe Conf. Computer Animation ’95, Geneva, Switzerland, 1995.
[91] A. D. Angeli, W. Gerbino, G. Cassano, and D. Petrelli, “Visualdisplay: Pointing and natural language: The power of multimodalinteraction,” presented at the Conf. Advanced Visual Interfaces,L’Aquila, Italy, 1998.
[92] S. Oviatt, “Multimodal interfaces for dynamic interactive maps,” inProc. Conf. Human Factors Computing Systems (CHI’96), 1996, pp.95–102.
[93] L. Stifelman, B. Arouns, and C. Schmandt, “The audio notebook:Paper and pen interaction with structured speech,” inProc. SIG-CHIHuman Factors in Computing Systems, 2001, pp. 182–189.
[94] P. R. Cohen, M. Johnston, D.R. McGee, S. L. Oviatt, J. Pittman, I.Smith, L. Chen, and J. Clow, “Quickset: Multimodal interaction fordistributed applications,” inProc. 5th ACM Int. Multimedia Conf.(Multimedia ’97), 1997, pp. 31–40.
[95] H. Fell, H. Delta, R. Peterson, L. Ferrier, Z. Mooraj, and M. Valleau,“Using the baby-babble-blanket for infants with motor problems,”presented at the Conf. Assistive Technologies (ASSETS’94), Marinadel Rey, CA, 1994.
[96] K. A. Papineni, S. Roukos, and R. T. Ward, “Feature-based languageunderstanding,” presented at the 5th Eur. Conf. Speech Communi-cation and Technology, Rhodes, Greece, 1997.
[97] T. Holzman, “Computer-human interface solutions for emergencymedical care,”Interactions, vol. 6, pp. 13–24, 1999.
[98] L. Duncan, W. Brown, C. Eposito, H. Holmback, and P. Xue,“Enhancing virtual maintenance environments with speech under-standing,”Boeing M&CT TechNet, Mar. 1999.
[99] M. Lucente and A. George, “Visualization space: A testbed for de-viceless multimodal user interface,” presented at the Intelligent En-vironments Symp., AAAI Spring Symp. Series, Stanford, CA, 1997.
[100] J. M. Rehg, M. Loughlin, and K. Waters, “Vision for a smart kiosk,”in Proc. IEEE Conf. Computer Vision and Pattern Recognition, 1997,pp. 690–696.
[101] B. Brumitt, B. Meyers, J. Krumm, A. Kern, and S. Shafer, “Ea-syliving: Technologies for intelligent environments,” presented atthe 2nd Int. Symp. Handheld and Ubiquitous Computing (HUC),Bristol, U.K., 2000.
[102] S. Kettebekov, N. Krahnstoever, M. Leas, E. Polat, H. Raju, E.Schapira, and R. Sharma, “i2Map: Crisis management using amultimodal interface,” presented at the ARL Federated Laboratory4th Annu. Symp., College Park, MD, 2000.
[103] N. Krahnstoever, S. Kettebekov, M. Yeasin, and R. Sharma, “Areal-time framework for natural multimodal interaction with largescreen displays,” presented at the 4th IEEE Int. Conf. MultimodalInterfaces (ICMI 2002), Pittsburgh, PA, 2002.
[104] M. H. Hayes, Statistical Digital Signal Processing and Mod-eling. New York: Wiley, 1996.
[105] A. Kendon,Conducting Interaction. Cambridge, U.K.: CambridgeUniv. Press, 1990.
[106] S. Kettebekov and R. Sharma, “Toward natural gesture/speech con-trol of a large display,” inLecture Notes in Computer Science, Engi-neering for Human Computer Interaction, M. R. Little and L. Nigay,Eds. , : Springer-Verlag, 2001, vol. 2254.
[107] I. Poddar, “Continuous recognition of deictic gestures for multi-modal interfaces,” M.S. thesis, Pennsylvania State Univ., UniversityPark, 1999.
[108] N. Krahnstoever, S. Kettebekov, M. Yeasin, and R. Sharma, “Areal-time framework for natural multimodal interaction withlarge screen displays,” Dept. Comput. Sci. Eng., 220 Pond Lab,University Park, PA, Tech. Rep. CSE-02–010, 2002.
[109] I. Brewer, “Cognitive systems engineering and GIscience: Lessonslearned from a work domain analysis for the design of a collabo-rative, multimodal emergency management GIS,” presented at theGIScience Conf. 2002, Boulder, CO, 2002.
[110] I. Rauschert, P. Agrawal, S. Fuhrmann, I. Brewer, H. Wang,R. Sharma, G. Cai, and A. M. MacEachren, “Designing ahuman-centered, multimodal GIS interface to support emergencymanagement,” presented at the 10th ACM Int. Symp. AdvancesGeographic Information Systems, McLean, VA, 2002.
[111] N. Lesh, C. Rich, and C. L. Sidner, “Using Plan Recognition inHuman-Computer Collaboration,”Proc. 7th Int. Conf. User Mod-eling, pp. 23–32, 1999.
1352 PROCEEDINGS OF THE IEEE, VOL. 91, NO. 9, SEPTEMBER 2003

[112] I. Lokuge and S. Ishizaki, “Geospace: An interactive visualizationsystem for exploring complex information spaces,” presented at theCHI’95, Denver, CO, 1995.
[113] J. Rasmussen, A. M. Pejtersen, and L. P. Goodstein,Cognitive Sys-tems Engineering. New York: Wiley, 1994.
[114] K. J. Vicente,Cognitive Work Analysis: Toward Safe, Productive,and Healthy Computer-Based Work. Mahwah, NJ: Lawrence Erl-baum Assoc., 1999.
[115] E. Polat, M. Yeasin, and R. Sharma, “Tracking body parts of multiplepeople-A new approach,” presented at the IEEE Intl. Conf. Com-puter Vision, Vancouver, BC, Canada, 2001.
[116] S. Oviatt, A. D. Angeli, and K. Kuhn, “Integration and synchro-nization of input modes during multimodal human-computer interac-tion,” in Proc. Conf. Human Factors Computing Systems (CHI’97),1997, pp. 415–422.
Rajeev Sharmareceived the Ph.D. degree fromthe University of Maryland, College Park in 1993.
He was a Beckman Fellow at University ofIllinois, Urbana-Champaign. He is currently anAssociate Professor of Computer Science andEngineering at Pennsylvania State University,University Park. He is also helping in trans-ferring the results of the university researchto commercial applications through AdvancedInterface Technologies, Inc., State College,PA, in partnership with Penn State. Advanced
Interfaces has successfully deployed computer vision based “intelligence”products in the retail and other public environments and has developedinnovative human–computer interfaces for a variety of applications. Hismain research interests include the use of computer vision for human clas-sification, behavior analysis, and multimodal human–computer interfaces.His research has been funded through several grants from National ScienceFoundation and Department of Defense.
Dr. Sharma is an Associate Editor of IEEE TRANSACTIONS OFPATTERN
ANALYSIS AND MACHINE INTELLIGENCE.
Mohammed Yeasinreceived the Ph.D. degree inelectrical engineering (computer vision) from In-dian Institute of Technology, Bombay, India in1998 (deputed from Bangladesh Institute of Tech-nology, Chittagong).
From 1998 to 1999, he was a Center of Excel-lence Research Fellow at the Electro-TechnicalLaboratory, Tsukuba, Japan. From 1990 to 1998,he was a lecturer in the Electrical and ElectronicEngineering Department, Bangladesh Institute ofTechnology. In 1999, he was an Visiting Assis-
tant Professor at the University of West Florida, Pensacola, FL. He is cur-rently on the faculty of Pennsylvania State University (Penn State), Uni-versity Park. He also directs research and development at Advanced Inter-face Technologies, Inc., State College, PA, investigating robust computervision. Advanced Interfaces has used some of his research results (face de-tection, gender classification, etc.) for developing commercial products. Hisresearch interests include computer vision, image processing and advancedhuman–computer interaction (HCI). Major motivations of his work includedeveloping robust solution for human motion analysis, behavior analysis,classification and behavior-based biometrics; image analysis for biomedicalapplications; and multimodal human computer interfaces.
Nils Krahnstoever received the M.S. degree inphysics from the University of Kiel, Kiel, Ger-many, and is working toward the Ph.D. degree inthe Department of Computer Science and Engi-neering, Pennsylvania State University, Univer-sity Park, specializing in computer vision.
He has been a Student Intern and ContractDeveloper for Philips Research, Hamburg,Germany, and Director of Computer VisionResearch for Advanced Interface Technologies,Inc., State College, PA. His current research
interests include the vision-based analysis of human motion, especially inthe context of multimodal human computer interfaces, and surveillance.Other interests include large-scale computer vision system design, medicalimage processing, and visualization.
Ingmar Rauchert received the M.S. degree incomputer science from the Technical Universityof Munich, Munich, Germany, and is workingtoward the Ph.D. degree in the Departmentof Computer Science and Engineering, Penn-sylvania State University, University Park,specializing in computer vision.
His current research interests include vi-sion-based natural gesture recognition for HCI,gesture interpretation in geospatial context, HCIfor people with disabilities, usability measures
for HCI, and large-scale distributed system design.
Guoray Cai received the B.E and M.E. degreesin electrical engineering from Tianjin University,Tianjin, China, in 1983 and 1986 respectively,the M.A. degree in geography from WestVirginia University, Morgantown, in 1993, andthe Ph.D. degree in information sciences fromthe University of Pittsburgh, Pittsburgh, in 1999.
He joined Pennsylvania State University, Uni-versity Park, as the first group of faculty in theSchool of Information Sciences and Technology,and was subsequently appointed as an Affiliate
Faculty Member of geography as well as computer science and engineering.His main research interests include geographical information systems,spatial databases, geographical information retrieval, and multiagentapproaches for enabling human–computer and human–computer–humandialogues in collaborative spatial decision making. His recent researchefforts focus on the development of dialogue management systems forconversational and cooperative geographical information systems.
Isaac Breweris working toward the Ph.D. degreeat the GeoVISTA Center, Pennsylvania State Uni-versity, University Park, where he works underthe direction of Dr. MacEachren. His dissertationresearch is focused on the development of a cog-nitive systems engineering approach to guide de-sign of advanced interfaces that support collabo-rative interaction with a GIS in emergency man-agement situations.
His long-term research interests are in de-signing new interface technologies to geospatial
information and GIS that are modeled human’s cognitive processes andmaximize the visual system.
SHARMA et al.: SPEECH–GESTURE DRIVEN MULTIMODAL INTERFACES FOR CRISIS MANAGEMENT 1353

Alan M. MacEachren received the Ph.D. degreefrom the University of Kansas, Lawrence, in1979.
He has held faculty positions at VirginiaTech, Blacksburg, and the University of Col-orado, Boulder. He is currently a Professorof Geography and Director of the GeoVISTACenter (www.GeoVISTA.psu.edu) at Pennsyl-vania State University, University Park. He isAuthor of How Maps Work: Representation,Visualization and Design(New York: Guilford,
1995) and Coeditor of several additional books and journal special issues,including Research Challenges in Geovisualizationand a special issueof Cartography and Geographic Information Science, Vol. 28, no. 1,Jan. 2001, and an Associate Editor ofInformation Visualization. Hisresearch interests include geographic visualization, interfaces to geospatialinformation technologies, human spatial cognition as it relates to use ofthose technologies, human-centered systems, and user-centered design.Current research is supported by the National Science Foundation, theNational Institutes of Health, the National Imagery and Mapping Agency,the Advanced Research and Development Agency, and the U.S. FedStatsTask Force.
Dr. MacEachren is currently Chair of the International CartographicAssociation Commission on Visualization and Virtual Environments. Heis also a Member of the National Research Council Computer Scienceand Telecommunications Board Committee on the Intersections BetweenGeospatial Information and Information Technology.
Kuntal Sengupta received the B.Tech degreefrom the Indian Institute of Technology, Kanpur,in 1990, and the M.S and Ph.D degrees fromOhio State University, Columbus, in 1993 and1996, respectively.
From 1996 to 1998, he was a Researcher atthe Advanced Telecommunications ResearchLaboratories, Kyoto, Japan. From 1998 to 2002,he was with the Electrical and Computer Engi-neering Department of the National Universityof Singapore, Singapore. He is currently a Vision
Scientist with Advanced Interface Technologies, Inc., State College, PA.His research interests are in three-dimensional image analysis, dynamicthree-dimensional model compression, and multimodal signal analysis.
1354 PROCEEDINGS OF THE IEEE, VOL. 91, NO. 9, SEPTEMBER 2003




















